Область техники, к которой относится изобретение
Настоящее изобретение относится к области информационных технологий, а именно к способу автоматизированной семантической индексации текста на естественном языке.
Уровень техники
В настоящее время известны различные способы автоматизированной индексации текстов на естественных языках.
Например, в патенте РФ №2268488 (опубл. 20.01.2006), описан способ, в котором кодируют слова, фразы, идиомы, предложения для последующей числовой обработки. В патенте РФ №2273879 (опубл. 10.04.2006) раскрыт способ проведения морфологического и синтаксического анализа текста с последующей индексацией. Патент ЕАПВ №002016 (опубл. 22.01.2001) раскрывает способ, в котором во фрагментах текста определяют уникальные блоки информации и используют их для последующей обработки и поиска. Способ по патенту США №6871174 (опубл. 22.03.2005) позволяет определить сходство текстов по текстовым фрагментам. В патенте США №6189002 (опубл. 13.02.2001) раскрыт способ, в котором текст разбивают на абзацы и слова, которые преобразуют в векторы упорядоченных элементов. Каждый элемент вектора соответствует абзацу, найденному применением заданной функции к числу появлений в этом абзаце слова, соответствующего этому элементу. Текстовый вектор рассматривается как семантический профиль документа. Однако все эти способы не учитывают семантической неоднозначности слов и выражений естественного языка.
Учет семантической неоднозначности осуществляется во многих известных способах. Например, в патенте РФ №2242048 (опубл. 10.12.2004), в патентах США №№6871199 (опубл. 22.03.2005), 7024407 (опубл. 04.04.2006) и 7383169 (опубл. 03.06.2008), в заявках на патент США №№2007/0005343 и 2007/0005344 (обе опубл. 04.01.2007), 2008/0097951 (опубл. 24.04.2008), в выложенных заявках Японии №№05-128149 (опубл. 25.05.1993), 06-195374 (опубл. 15.07.1994), 10-171806 (опубл. 26.06.1998) и 2005-182438 (опубл. 07.07.2005), в заявке ЕПВ №0853286 (опубл. 15.07.1998) описаны способы, обеспечивающие тем или иным образом устранение неоднозначности встречающихся в текстах слов и (или) выражений. Однако все эти способы имеют лишь частное применение и не затрагивают полноценной семантической индексации текста.
В заявке на патент США №2007/0073533 (опубл. 29.03.2007) охарактеризован способ, в котором в сегментированном тексте выделяют из каждого участка текста такие признаки, как: именованная сущность, тождество по референту, лексическая статья, семантико-структурное отношение, атрибутивная и меронимическая информация. Далее определяют для каждого участка текста его конституентную структуру в виде перечня конституентов и их порядка следования. Определяют функциональную структуру для каждого участка текста и, на основе функциональной структуры, находят предикатные тройки применением линеаризационных правил переноса значений. Объединяют конституентную структуру участка текста, перечень канонизированных предикатных троек и выявленные признаки, для формирования канонизированного представления участка текста, из которых и формируют индекс всего текста. Этот способ ограничен вследствие того, что для формирования индекса используются только предикатные тройки, остальные аргументы расширенной предикатной структуры остаются неиспользованными, что ухудшает точность семантического анализа.
Наиболее близкий к заявленной группе изобретений способ автоматизированной семантической индексации текста на естественном языке раскрыт в патенте РФ №2399959 (опубл. 20.09.2010). В этом способе текст в цифровой форме сегментируют на элементарные единицы первого уровня (слова); формируют для каждой элементарной единицы первого уровня (слова) элементарную единицу второго уровня (нормализованную словоформу); сегментируют текст в цифровой форме на предложения, соответствующие участкам индексируемого текста; выявляют в тексте, в процессе лингвистического анализа, элементарные единицы третьего уровня (устойчивые словосочетания); в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, выявляют в каждом из сформированных предложений элементарные единицы четвертого уровня (семантически значимый объект и его атрибут) и семантически значимые отношения между выявленными семантически значимыми объектами, а также между семантически значимыми объектами и атрибутами; формируют в пределах данного текста для каждого из выявленных семантически значимых отношений множество элементарных единиц пятого уровня (триад); индексируют на множестве сформированных триад все связанные семантически значимыми отношениями семантически значимые объекты, а также атрибуты, по отдельности, и все триады вида «семантически значимый объект - семантически значимое отношение - семантически значимый объект», а также все триады вида «семантически значимый объект - семантически значимое отношение - атрибут»; сохраняют в базе данных сформированные триады и полученные индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады.
Недостатком данного способа является отсутствие ранжирования сформированных элементарных единиц второго, третьего и четвертого уровней, что приводит к неоправданно большому объему вычислений, связанному с необходимостью использовать для дальнейшей обработки весь сформированный индекс.
Раскрытие изобретения
Цель настоящего изобретения состоит в расширении арсенала способов индексации текстов на естественных языках за счет использования методов их автоматизированного лингвистического анализа и последующего использования его результатов для построения семантических индексов.
Достижение этой цели и получение указанного технического результата обеспечиваются в настоящем изобретении посредством способа автоматизированной семантической индексации текста на естественном языке, заключающемся в том, что: представляют индексируемый текст в цифровой форме для последующей автоматической и (или) автоматизированной обработки; сегментируют текст в цифровой форме на элементарные единицы первого уровня, включающие в себя, по меньшей мере, слова; сегментируют по графематическим правилам текст в цифровой форме на предложения; формируют на основе морфологического анализа для каждой элементарной единицы первого уровня, представляющей собой слово, элементарную единицу второго уровня, включающую в себя нормализованную словоформу, именуемую далее леммой; подсчитывают частоту встречаемости каждой элементарной единицы первого уровня для двух и более соседних единиц первого уровня в данном тексте и объединяют среди элементарных единиц первого уровня последовательности слов, следующих друг за другом в данном тексте, в элементарные единицы третьего уровня, представляющие собой устойчивые сочетания слов, в случае, если для каждых двух и более следующих друг за другом слов в данном тексте разности подсчитанных частот встречаемости этих слов для первого появления данной последовательности слов и для нескольких последующих их появлений для каждой пары слов последовательности остаются неизменными; выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимый объект и его атрибут, являющиеся единицами четвертого уровня; сохраняют в памяти каждый семантически значимый объект и атрибут; выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимые отношения между выявленными единицами четвертого уровня - семантически значимыми объектами, а также, между семантически значимыми объектами и атрибутами; присваивают каждому семантически значимому отношению соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится индексируемый текст; сохраняют в памяти каждое семантически значимое отношение вместе с присвоенным ему типом; выявляют частоты встречаемости элементарных единиц четвертого уровня на всем тексте; формируют в пределах данного текста для каждого из выявленных семантически значимых отношений, связывающих как соответствующие семантически значимые объекты, так и семантически значимый объект и его атрибут, множество триад, которые являются элементарными единицами пятого уровня; индексируют на множестве сформированных триад по отдельности все связанные семантически значимыми отношениями семантически значимые объекты с их частотами встречаемости, все атрибуты с их частотами встречаемости и все сформированные триады; сохраняют в базе данных сформированные элементарные единицы второго, третьего, четвертого и пятого уровней с их частотами встречаемости, а также полученные индексы вместе со ссылками на конкретные предложения данного текста.
Особенность способа по настоящему изобретению состоит в том, что для каждой единицы четвертого уровня могут фиксировать тождество по референции между соответствующим семантически значимым объектом, а также атрибутом, и соответствующей анафорической ссылкой при ее наличии в индексируемом тексте, заменяя каждую анафорическую ссылку на соответствующий ей антецедент.
Еще одна особенность способа по настоящему изобретению состоит в том, что из упомянутых триад могут формировать семантическую сеть таким образом, что первая элементарная единица второго или третьего уровня последующей триады связывается с такой же второй элементарной единицей второго или третьего уровня предыдущей триады. При этом перед сохранением в базе данных сформированных триад и полученных индексов осуществляют, в процессе итеративной процедуры, перенормировку частот встречаемости в смысловой вес элементарных единиц второго и третьего уровней, являющихся вершинами семантической сети, таким образом, что элементарные единицы второго и третьего уровней, связанные в сети с большим числом элементарных единиц второго и третьего уровней с большой частотой встречаемости, увеличивают свой смысловой вес, а другие элементарные единицы второго и третьего уровней его равномерно теряют.
Еще одна особенность способа по настоящему изобретению состоит в том, что могут ранжировать сформированные элементарные единицы второго и третьего уровней по смысловому весу путем сравнения их смыслового веса с заранее заданным пороговым значением.
Наконец, еще одна особенность способа по настоящему изобретению состоит в том, что могут удалять триады, в которых элементарные единицы второго и третьего уровней имеют смысловой вес ниже порогового.
Краткое описание чертежей
Настоящее изобретение поясняется далее описанием конкретного примера его осуществления и прилагаемыми чертежами.
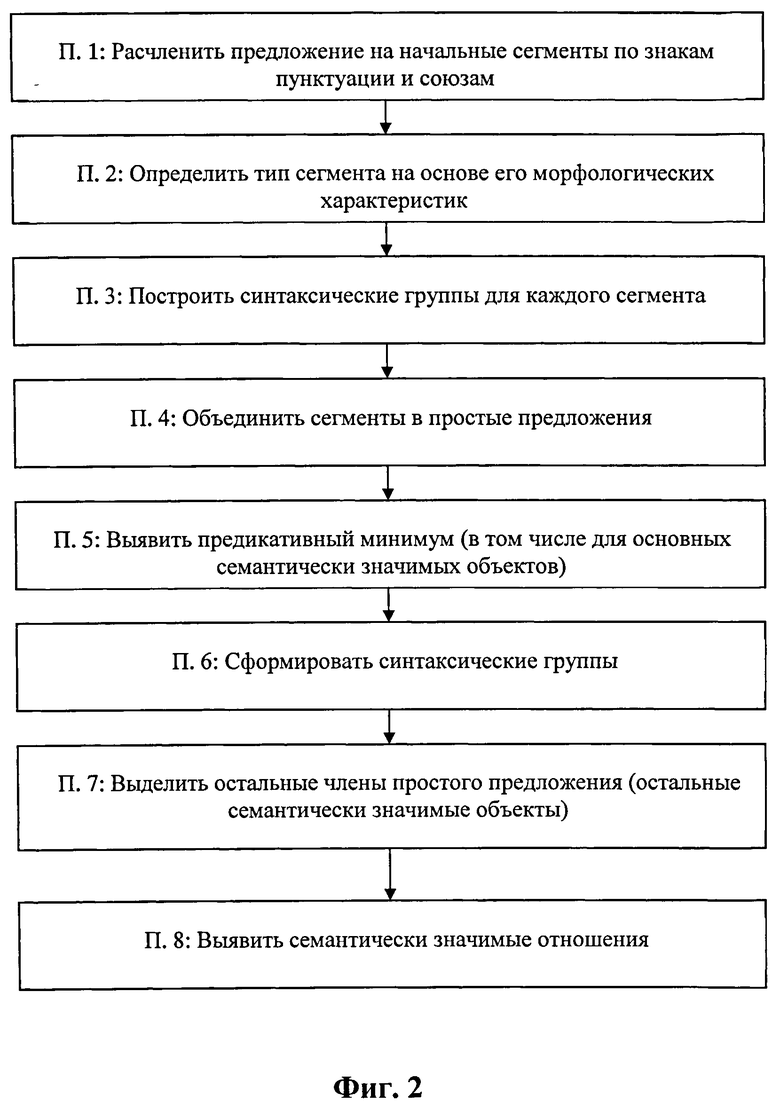
На Фиг.1 приведена условная блок-схема, поясняющая заявленный способ.
На Фиг.2 приведена схема обработки текста на основе многоступенчатого семантико-синтаксического анализа для выявления семантически значимых объектов, атрибутов и семантически значимых отношений.
Подробное описание изобретения
Способ по настоящему изобретению может быть реализован практически в любой вычислительной среде, к примеру, на персональном компьютере, подключенном к внешним базам данных. Этапы осуществления способа иллюстрируются на Фиг.1.
Все дальнейшие пояснения даются в применении к русскому языку, который является одним из самых высокофлективных языков, хотя предложенный способ применим к семантической индексации текстов на любых естественных языках.
Прежде всего, подлежащий индексации текст необходимо представить в электронной форме для последующей автоматизированной обработки. Этот этап на Фиг.1 условно обозначен ссылочной позицией 1 и может быть выполнен любым известным способом, например, сканированием текста с последующим распознаванием с помощью общеизвестных средств типа ABBYY FineReader. Если же текст поступает на индексацию из электронной сети, к примеру, из Интернета, то этап его представления в электронной форме выполняется заранее, до размещения этого текста в сети.
Специалистам должно быть понятно, что операции этого и последующих этапов осуществляются с запоминанием промежуточных результатов, например, в оперативном запоминающем устройстве (ОЗУ).
Преобразованный в электронную форму текст поступает на обработку, в процессе которой сначала этот текст сегментируется на элементарные единицы первого уровня, включающие в себя, по меньшей мере, слова. В упомянутом патенте РФ №2399959 эти элементарные единицы первого уровня именуются токенами (token). Токеном может быть любой текстовый объект из следующего множества: слова, состоящие каждое из последовательности букв и, возможно, дефисов; последовательность пробелов; знаки препинания; числа. Иногда сюда же относят такие последовательности символов, как А300, i150b и т.п. Выделение токенов всегда осуществляется по достаточно простым правилам, например, как в упомянутом патенте РФ №2399959. На Фиг.1 этот этап условно обозначен ссылочной позицией 2.
Вслед за этим, на этапе 3 (Фиг.1) сегментируют индексируемый текст в цифровой форме на предложения, соответствующие участкам данного текста. Такую сегментацию проводят по графематическим правилам. К примеру, самым простым правилом для выделения предложений является: «Предложением является последовательность токенов, начинающаяся с заглавной буквы и заканчивающаяся точкой».
Далее для каждой элементарной единицы первого уровня (для каждого токена), представляющей собой слово, на основе морфологического анализа формируют соответствующую элементарную единицу второго уровня, представляющую собой нормализованную словоформу, именуемую далее леммой. К примеру, для слова «иду» нормализованной словоформой будет «идти», для слова «красивого» нормализованной словоформой будет «красивый», а для слова «стеной» нормализованная словоформа - «стена». Кроме того, для каждой словоформы указывается часть речи, к которой относится данное слово, и его морфологические характеристики. Естественно, что для разных частей речи эти характеристики различны. К примеру, для существительных и прилагательных это род (мужской - женский - средний), число (единственное - множественное), падеж; для глаголов это вид (совершенный - несовершенный), лицо, число (единственное - множественное) и т.д. Таким образом, для заданного слова его нормализованная словоформа (лемма) + морфологические характеристики, в том числе часть речи, являются его морфом. Одно и то же слово может иметь несколько морфов. Например, слово «стекло» имеет два морфа - один для существительного среднего рода и один для глагола в прошедшем времени. Этот этап условно обозначен на Фиг.1 ссылочной позицией 4.
Следующий этап, условно обозначенный на Фиг.1 ссылочной позицией 5, состоит в том, что для каждой из упомянутых элементарных единиц первого уровня в упомянутом тексте подсчитывают частоту встречаемости. Иначе говоря, определяют, сколько раз каждое слово встречается в обрабатываемом тексте. Эту операцию осуществляют автоматически, например, простым подсчетом частоты встречаемости каждого токена, либо так, как это описано в патенте РФ №2167450 (опубл. 20.05.2001), либо в упомянутом патенте США №6189002. Одновременно с подсчетом частоты встречаемости находят для каждых двух и более следующих друг за другом слов в данном тексте разности подсчитанных частот встречаемости этих слов в первое появление этой последовательности слов и в последующие их появления. Если эти разности для первого появления данной последовательности слов и для нескольких последующих их появлений остаются неизменными, такую последовательность слов, следующих друг за другом в данном тексте (т.е. элементарных единиц второго уровня), объединяют в элементарные единицы третьего уровня, представляющие собой устойчивые словосочетания.
Далее, на следующем этапе, обозначенном на Фиг.1 ссылочной позицией 6, с целью выявления семантически значимых объектов и атрибутов, выполняют многоступенчатый семантико-синтаксический анализ. Такой многоступенчатый семантико-синтаксический анализ выполняют путем обращения к сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде. Такой средой может быть, например, лингвистическая среда, упомянутая в вышеуказанной заявке на патент США №2007/0073533, либо в вышеуказанных патентах РФ №2242048 и РФ №2399959, либо любая иная лингвистическая среда, определяющая соответствующие правила, которые позволяют устранять синтаксические и семантические неоднозначности слов и выражений реального текста. Лингвистические и эвристические правила в выбранной среде именуются далее правилами.
Выявление семантически значимых объектов и атрибутов, которые считаются элементарными единицами четвертого уровня, производится в предложении на множестве элементарных единиц первого, второго и (или) третьего уровней.
Для каждого семантически значимого объекта и атрибута, т.е. элементарной единицы четвертого уровня, с присвоенным ему типом находят соответствующую ему анафорическую ссылку (если она есть). Например, в предложении «Механика - часть физики, которая изучает закономерности механического движения и причины, вызывающие или изменяющие это движение» анафорической ссылкой к слову «механика» будет местоимение «которая», тогда как слово «механика» будет антецедентом для этой анафоры, и еще, анафорической ссылкой к слову «механическое» будет местоимение «это», тогда как слово «механическое» будет антецедентом для этой анафоры. Этот этап нахождения анафорической ссылки условно обозначен на Фиг.1 ссылочной позицией 7. Каждую анафорическую ссылку заменяют на соответствующий ей антецедент. После этого каждый выявленный семантически значимый объект и атрибут сохраняют в соответствующей памяти.
На следующем этапе, обозначенном на Фиг.1 ссылочной позицией 8, выполняют многоступенчатый семантико-синтаксический анализ, с помощью которого на основе элементарных единиц первого, второго, третьего и четвертого уровней находят с помощью упомянутых правил семантически значимые отношения между семантически значимыми объектами, а также между семантически значимыми объектами и атрибутами.
На этапе, обозначенном на Фиг.1 ссылочной позицией 9, каждому семантически значимому отношению присваивают соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится индексируемый текст. После этого каждое семантически значимое отношение сохраняют в соответствующей памяти вместе с присвоенным ему типом и найденными для него морфологическими и семантическими атрибутами.
После этого на этапе, обозначенном на Фиг.1 ссылочной позицией 10, выявляют частоты встречаемости семантически значимых объектов и атрибутов, на всем данном тексте. Эту операцию выполняют практически так же, как на этапе 4 для элементарных единиц второго уровня.
На этапе, обозначенном на Фиг.1 ссылочной позицией 11, сохраненные семантически значимые объекты, а также атрибуты, и семантически значимые отношения используют для формирования триад. При этом в пределах индексируемого текста для каждого из выявленных семантически значимых отношений, связывающих определенные семантически значимые объекты, формируют множество триад двух типов. Каждая из множества триад первого типа включает семантически значимое отношение и два семантически значимых объекта, которые связываются этим семантически значимым отношением. Каждая из множества триад второго типа включает семантически значимое отношение, один семантически значимый объект, а также его атрибут, которые связываются этим семантически значимым отношением. Если обозначить два семантически значимых объекта через Oi и Oj, а связывающее их семантически значимое отношение через Rij, то каждую из триад первого типа можно условно представить (изобразить) как Oi→Rij→Oj. Каждая из триад второго типа может быть представлена как Oi→Am, где Am являются соответствующими атрибутами. В этих записях индексы i, j, m представляют собой целые числа.
Затем, на этапе, обозначенном на Фиг.1 ссылочной позицией 12, выполняют индексацию текста. При этом индексируют по отдельности на множестве сформированных триад все связанные семантически значимыми отношениями семантически значимые объекты с их частотами встречаемости, все атрибуты с их частотами встречаемости и все сформированные триады.
Для этого на множестве сформированных триад индексируют все семантически значимый объект и его атрибут по отдельности, с их частотами встречаемости, и все триады вида «семантически значимый объект - семантически значимое отношение - семантически значимый объект», а также все триады вида «семантически значимый объект - семантически значимое отношение - атрибут». Сформированные на этапе 11 триады и полученные на этапе 12 индексы вместе со ссылкой на конкретные предложения исходного текста, из которого сформированы эти триады, сохраняют в базе данных (этап 13 на Фиг.1).
Для специалистов очевидно, что упоминавшиеся на отдельных этапах запоминающие устройства могут на деле быть как разными устройствами, так и одним запоминающим устройством достаточного объема. Точно так же отдельные базы данных, упоминавшиеся на соответствующих этапах, могут быть не только физически раздельными базами данных, но и единственной базой данных. Более того, упомянутые запоминающие устройства (памяти) могут быть выполнены на той же самой единственной базе данных, либо объединяться с одной из упомянутых баз данных. Специалистам также понятно, что заявленные в настоящем изобретении способы выполняются в соответствующей вычислительной среде под управлением соответствующих программ, которые записаны на машиночитаемых носителях, предназначенных для непосредственного участия в работе компьютера.
Особенность способа по настоящему изобретению состоит в том, что из упомянутых триад могут формировать семантическую сеть таким образом, что первый семантически значимый объект последующей триады связывается с таким же вторым семантически значимым объектом предыдущей триады. При этом перед сохранением в базе данных сформированных триад и полученных индексов осуществляется, в процессе итеративной процедуры, перенормировка частот встречаемости семантически значимых объектов и атрибутов в смысловой вес семантически значимых объектов и атрибутов, являющихся вершинами семантической сети, таким образом, что семантически значимые объект и атрибут, связанные в сети с большим числом семантически значимых объектов и атрибутов с большой частотой встречаемости, увеличивают свой смысловой вес, а другие семантически значимый объект и его атрибут его равномерно теряют (этап 14 на Фиг.1).
Еще одна особенность способа по настоящему изобретению состоит в том, что сформированные семантически значимый объект и его атрибут могут ранжироваться по смысловому весу путем сравнения их смыслового веса с заранее заданным пороговым значением (этап 15 на Фиг.1).
Наконец, еще одна особенность способа по настоящему изобретению состоит в том, что могут удалять триады, в которых семантически значимый объект и его атрибут имеют смысловой вес ниже порогового (этап 16 на Фиг.1).
Пример
Для иллюстрации осуществления заявленного способа автоматизированной семантической индексации текста на естественном языке рассмотрим следующий пример. Пусть имеется некоторый русскоязычный текст по курсу физики, представленный на Интернет-сайте http://www.kodges.ru/. Таким образом, можно считать, что преобразование текстов в электронную форму, обозначенное на Фиг.1 ссылочной позицией 1, уже выполнено.
Типичным примером такого текста является следующий фрагмент из учебника Т.И.Трофимовой «Курс физики», Москва, «Высшая школа», 2001: «Механика - часть физики, которая изучает закономерности механического движения и причины, вызывающие или изменяющие это движение. Механическое движение - это изменение с течением времени взаимного расположения тел или их частей.…»
В соответствии с заявленным способом автоматизированной семантической индексации текста на естественном языке используют предварительно созданную базу синтаксических правил и словарей, в рамках которых будет осуществляться обработка текста и построение семантического индекса. Подобные базы готовятся экспертами-лингвистами, которые на основании своего опыта и знаний определяют последовательность и состав синтаксической обработки текста, характерные для конкретного языка.
Экспертами-лингвистами предварительно строится множество графематических и синтаксических правил, которые позволяют с помощью использования также предварительно построенных экспертами-лингвистами соответствующих лингвистических словарей, в дальнейшем в обрабатываемых текстах автоматически выявлять конкретные сведения, соответствующие семантически значимым объектам и атрибутам и семантически значимым отношениям, которые могут иметь место в каждой паре семантически значимых объектов или в каждой паре из семантически значимого объекта и его атрибута.
Кроме спецификации предметной области и правил в соответствии с изложенными выше способами используются словари общей и специальной лексики.
В соответствии с заявленным способом автоматизированной семантической индексации текста на естественном языке сначала осуществляют сегментацию текста на элементарные единицы - токены (ссылочная позиция 2 на Фиг.1) и морфологический анализ токенов, представляющих собой слова (ссылочная позиция 3 на Фиг.1). В результате выполнения этого этапа исходный текст трансформируется во множество токенов и морфов, которые представлены в Таблице 1 и Таблице 2, соответственно.
Далее после сегментации текста на токены и морфологического анализа токенов - слов осуществляют выделение устойчивых словосочетаний (ссылочная позиция 4 на Фиг.1). Для этого подсчитывают частоту встречаемости слов в последовательностях из двух и более слов в тексте. Затем сравнивают разности частот встречаемости слов в последовательности для первого появления данной последовательности слов и для нескольких последующих их появлений.
Частоты встречаемости слов при первом появлении последовательности и при ее последующем появлении, а также разности этих частот представлены в Таблице 3.
В результате выполнения этого этапа исходный текст, кроме элементарных единиц первого и второго уровней, дополняется множеством единиц третьего уровня - устойчивыми словосочетаниями. Словосочетания для нашего примера представлены в Таблице 4.
После выполнения вышеуказанных этапов осуществляют фрагментацию обрабатываемого текста на предложения (ссылочная позиция 5 на Фиг.1). В результате выполнения этого этапа сформированные выше множества дополняются множеством предложений, представленным в Таблице 5.
Таким образом, после выполнения всех рассмотренных выше этапов обрабатываемый текст будет сегментирован на предложения, каждое из которых размечено множествами аннотаций элементарных единиц первого, второго и третьего уровней.
Вслед за этим, в соответствии с заявленным способом осуществляют выявление семантически значимых объектов и атрибутов (элементарных единиц четвертого уровня) (ссылочная позиция 6 на Фиг.1). Оно производится в каждом предложении на множестве элементарных единиц первого, второго и (или) третьего уровней путем применения упомянутого заранее сформированного множества лингвистических и эвристических правил с использованием заранее же сформированных соответствующих лингвистических словарей.
Так, например, в предложении «Механика - часть физики, которая изучает закономерности механического движения и причины, вызывающие или изменяющие это движение» рассматриваемого текста с помощью множества правил, соответствующая которому схема обработки сигналов представлена на Фиг.2 (пункты обработки 1-7), а используемые в этом правиле словари представлены в Таблицах 6-16, выделяются семантически значимый объект «механика». Другие семантически значимый объект и его атрибут выделяются с помощью того же самого множества правил. В результате в исходном тексте выделяют семантически значимый объект и его атрибут. Множество таких семантически значимых объектов и атрибутов для рассматриваемого примера представлено в Таблице 17.
Далее осуществляется построение простых синтаксических групп, соответствующих атрибутивному уровню описания (Таблицы 7 и 8): признак объекта/субъекта/действия + объект/субъект/действие, мера признака объекта/субъекта/действия + объект/субъект/действие.
Далее в предложениях текста выявляются и раскрываются анафорические ссылки (если они имеются в индексируемом тексте). Для этого в пределах всего обрабатываемого текста в процессе выполнения этапа, обозначенного на Фиг.1 ссылочной позицией 7, находят местоимения, которые могут быть анафорическими ссылками на соответствующие слова, и для местоимений, которые действительно таковыми являются, фиксируют тождество по референции между соответствующим семантически значимым объектом и его анафорической ссылкой. Так в предложении «Механика - часть физики, которая изучает закономерности механического движения и причины, вызывающие или изменяющие это движение» местоимение «это» заменяется на слово «механическое»: «Механика - часть физики, которая изучает закономерности механического движения и причины, вызывающие или изменяющие механическое движение».
После этого объединяют фрагменты в простые предложения, в том числе с помощью подчинительных союзов (Таблица 10).
Далее осуществляется выявление предикативного минимума (в том числе, основных семантически значимых объектов) предложения путем сравнения его структуры со словарем шаблонов минимальных структурных схем предложений (Таблица 11). Результат для нашего примера приведен в Таблице 12.
Далее осуществляется построение синтаксических групп внутри полученных простых предложений, в которых актанты предикатов - главные слова, с помощью синтаксических правил, выявляющих синтаксические связи между словами. Построенные группы приведены в Таблице 13.
Выделение остальных членов простого предложения (остальных семантически значимых объектов и атрибутов) и семантически значимых связей осуществляется последовательным сравнением слов предложения с актантной структурой глагола из словаря валентностей глаголов.
Фрагмент используемого словаря валентности глаголов для глаголов «являться» и «изучать» приведен в Таблице 14. Жирными буквами выделены варианты, подходящие для текста примера.
Заполненные валентные гнезда для предикатов текста примера приведены в Таблице 15.
Таким образом, выявляется множество семантически значимых объектов и атрибутов. Для указанного примера они сведены в Таблицу 16.
После выполнения предыдущих этапов на множестве выделенных элементарных единиц первого, второго, третьего и четвертого уровней с помощью упомянутых правил находят семантически значимые отношения между семантически значимыми объектами (этап 8 на Фиг.1). Так, например, в предложении «Механика - часть физики, которая изучает закономерности механического движения и причины, вызывающие или изменяющие это движение» рассматриваемого текста с помощью множества правил, соответствующая которому схема обработки сигналов представлена на Фиг.2 (пункты обработки 1-8), а используемые в этом правиле словари представлены в Таблицах 6-15, выделяется семантически значимое отношение «есть». Другие семантически значимые отношения выделяются с помощью того же самого множества правил. Семантически значимым отношениям присваивается их тип. В результате в исходном тексте выделяют семантически значимые отношения. Множество таких семантически значимых отношений с присвоенным им типом для рассматриваемого примера представлено в Таблице 17.
Таким образом, после выполнения всех рассмотренных выше этапов обработки исходный текст будет размечен множеством аннотаций, соответствующих семантически значимым объектам, их атрибутам и семантически значимым отношениям между семантически значимыми объектами, а также между семантически значимыми объектами и атрибутами.
После этого на этапе, обозначенном на Фиг.1 ссылочной позицией 9, выявляют частоты встречаемости семантически значимых объектов и атрибутов на всем данном тексте. Эту операцию выполняют практически так же, как на этапе 4 для элементарных единиц второго уровня. Фрагмент такого частотного словаря для нашего примера представлен в Таблице 18.
На следующем этапе, обозначенном на Фиг.1 ссылочной позицией 10, выполняется формирование триад, соответствующих сохраненным семантически значимым объектам и семантически значимым отношениям. Так для исходного текста, содержащего предложения «Механика - часть физики, которая изучает закономерности механического движения и причины, вызывающие или изменяющие это движение»,…, «Механическое движение - это изменение с течением времени взаимного расположения тел или их частей»,… фрагмент множества таких триад для нашего примера представлен в Таблице 19. По сути дела, сформированное множество триад составляет исходные данные для построения семантического индекса, обработанного на предыдущих этапах текста.
На этапе, обозначенном на Фиг.1 ссылочной позицией 11, строят семантический индекс следующим образом: сначала из множества триад, полученных на предыдущем этапе, формируют подмножества триад, каждое из которых соответствует одному семантически значимому объекту с его атрибутами, и каждое полученное подмножество триад используют как вход для одного из стандартных индексаторов, например, широко известного свободно распространяемого индексатора Lucene, индексатора поисковой машины Яндекс, индексатора Google или любого другого индексатора, с выхода которого получают уникальный для заданного подмножества триад индекс. Аналогичную последовательность действий выполняют для всех подмножеств триад вида «семантически значимый объект - семантически значимое отношение - семантически значимый объект» и триад вида «семантически значимый объект - семантически значимое отношение - атрибут», получая множество соответствующих уникальных индексов, которые в совокупности и составляют семантический индекс текста.
Сформированные на этапе 10 триады и полученные на этапе 11 индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады, сохраняют в базе данных (этап 16 на Фиг.1).
В соответствии с заявленным способом - до сохранения в базе данных - из упомянутых триад могут формировать семантическую сеть так, что первый семантически значимый объект или атрибут последующей триады связывается с таким же вторым семантически значимым объектом или атрибутом предыдущей триады (этап 12 на Фиг.1). Пример фрагмента такой семантической сети приведен в Таблице 20.
При этом перед сохранением в базе данных сформированных триад и полученных индексов осуществляют, в процессе итеративной процедуры, перенормировку частот встречаемости семантически значимых объектов в смысловой вес семантически значимых объектов, являющихся вершинами семантической сети, таким образом, что семантически значимый объект и его атрибут, связанные в сети с большим числом семантически значимых объектов и атрибутов с большой частотой встречаемости, увеличивают свой смысловой вес, а другие семантически значимый объект и его атрибут его равномерно теряют (этап 13 на Фиг.1). Пример перенормированных в смысловые веса численных значений весовых коэффициентов понятий семантической сети приведен в Таблице 21.
Далее, сформированные семантически значимый объект и его атрибут ранжируют по смысловому весу путем сравнения их смыслового веса с заранее заданным пороговым значением (этап 14 на Фиг.1). Пример сохраненных отранжированных семантически значимых объектов и атрибутов представлен в Таблице 22.
Наконец (Таблица 23), удаляют семантически значимый объект и его атрибут, которые имеют смысловой вес ниже порогового (порог, например, равен 50). Этому действию соответствует этап 15 на Фиг.1.
Следует отметить, что три последние процедуры (этапы 13-15 на Фиг.1) являются опциональными, но предпочтительными, поскольку позволяют уменьшить объем вычислений и повысить удобство для пользователя при визуализации результатов анализа (семантической сети).
Таким образом, настоящее изобретение обеспечивает более точное построение индексов текстов на естественных языках за счет удаления из него семантически мало значимых (в данном тексте) объектов и атрибутов (которые имеют смысловой вес ниже порогового). Основное отличие этого способа от известных способов индексации состоит в том, что подсчитываются частоты встречаемости семантически значимых объектов и атрибутов с последующей их итеративной перенормировкой в смысловые веса. Объединение триад, построенных из семантически значимых объектов и их атрибутов с помощью семантически значимых отношений в семантическую сеть, необходимую для итеративной перенормировки частот встречаемости в смысловой вес, обеспечивает ассоциативную навигацию по документам и коллекциям документов, а также высокоточный и быстрый поиск релевантных информационным потребностям пользователя фактов и документов, особенно в применении к текстам на высокофлективных языках.
ция
ческий класс
Пояснения к таблице:
цифровые индексы в столбце «Валентные гнезда» указывают на необходимое заполнение определенных валентно обусловленных ячеек (1 - левосторонний актант, или субъект действия; 2, 3, 4, 5, 6, 7 - правосторонние актанты и, соответственно: объект, адресат, инструмент, исходный, конечный, промежуточный локативы);
звездочка при цифровом индексе в столбце «Валентность» указывает на необязательное заполнение данной валентно обусловленной ячейки предиката;
10 - надстрочный символ «0» при цифре указывает на нулевое заполнение ячейки субъекта;
(о), (в) (на) - буквенные символы между N и цифровым индексом, обозначающим падеж имени существительного, называет предлог, с которым возможно заполнение данной ячейки;
N - имя существительное;
N1 - цифровой индекс при N обозначает номер падежа в парадигме по порядку (N1 N2 N3 N4 N5 N6);
Adj - имя прилагательное;
Adv - наречие;
Vf - спрягаемая форма глагола;
Inf - неопределенная форма глагола (инфинитив);
Vpl3 - форма множественного числа третьего лица глагола;
2(ся) - буквенный символ при цифровом символе 2 в столбце «Валентность» указывает на то, что заполнение данной ячейки валентности (с семантикой объекта) происходит в рамках слова и не требует дополнительного формального выражения.
Изобретение относится к области информационных технологий, а именно к индексации текста. Техническим результатом является повышение точности построения индексов текстов на естественных языках. В способе автоматизированной семантической индексации текста на естественном языке сегментируют текст на элементарные единицы первого уровня (слова) и на предложения. Формируют единицы второго уровня (нормализованные словоформы). Подсчитывают частоту встречаемости каждой единицы первого уровня для соседних единиц первого уровня и объединяют последовательности слов в единицы третьего уровня (устойчивые сочетания слов). Выявляют в каждом предложении семантически значимый объект и его атрибут (единицы четвертого уровня). Выявляют в каждом предложении семантически значимые отношения между семантически значимыми объектами, а также между семантически значимыми объектами и атрибутами. Выявляют частоты встречаемости единиц второго и третьего уровней. Формируют для каждого семантически значимого отношения множество триад (единицы пятого уровня). Индексируют на множестве сформированных триад по отдельности все связанные семантически значимыми отношениями семантически значимые объекты с их частотами встречаемости, все атрибуты с их частотами встречаемости и все сформированные триады. 5 з.п. ф-лы, 2 ил., 23 табл.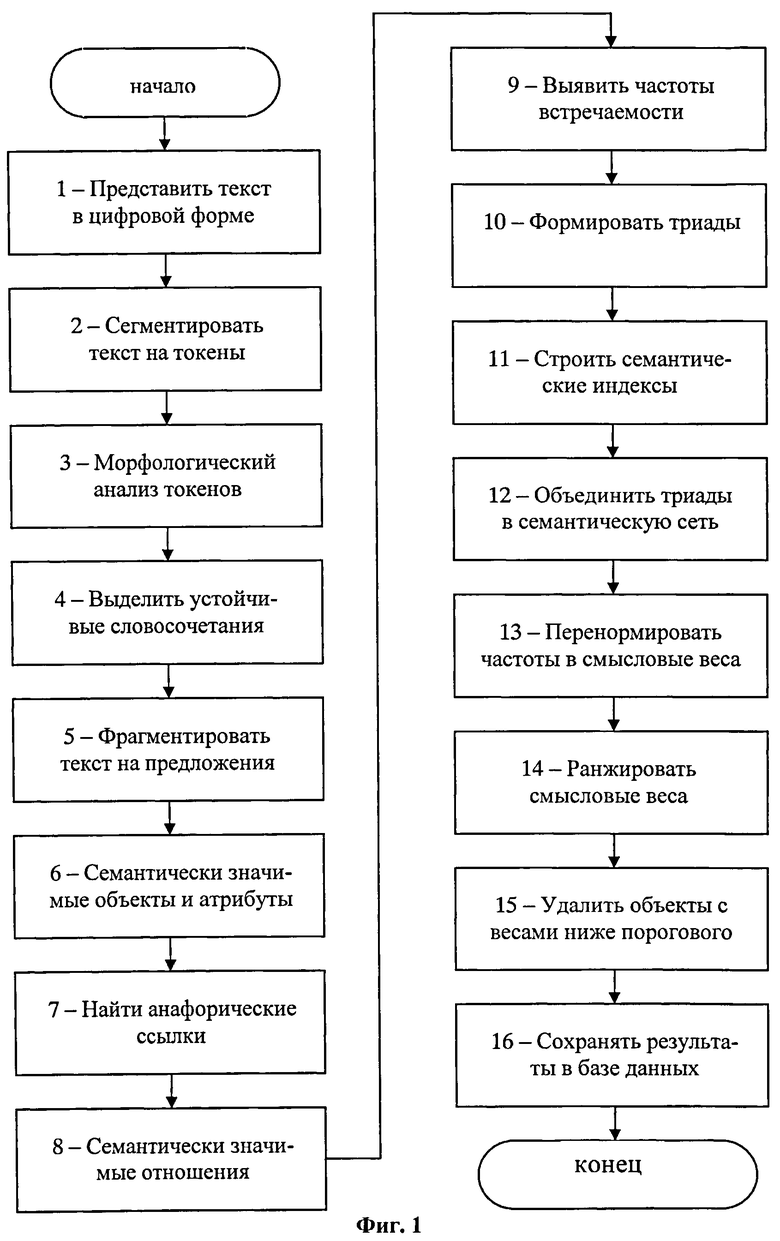
1. Способ автоматизированной семантической индексации текста на естественном языке, заключающийся в том, что:
- представляют индексируемый текст в цифровой форме для последующей автоматической и (или) автоматизированной обработки;
- сегментируют текст в цифровой форме на элементарные единицы первого уровня, включающие в себя, по меньшей мере, слова;
- сегментируют по графематическим правилам текст в цифровой форме на предложения;
- формируют для каждой элементарной единицы первого уровня, представляющей собой слово, на основе морфологического анализа элементарные единицы второго уровня, включающие в себя нормализованную словоформу;
- подсчитывают частоту встречаемости каждой элементарной единицы первого уровня для двух и более соседних единиц первого уровня в данном тексте и объединяют среди упомянутых элементарных единиц первого уровня последовательности слов, следующих друг за другом в данном тексте, в элементарные единицы третьего уровня, представляющие собой устойчивые сочетания слов, в случае, если для каждых двух и более следующих друг за другом слов в данном тексте разности подсчитанных частот встречаемости этих слов для первого появления данной последовательности слов и для нескольких последующих их появлений для каждой пары слов последовательности остаются неизменными;
- выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимый объект и его атрибут - единицы четвертого уровня;
- сохраняют в памяти каждый семантически значимый объект и атрибут;
- выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимые отношения между выявленными единицами четвертого уровня - семантически значимыми объектами, а также между семантически значимыми объектами и атрибутами;
- присваивают каждому семантически значимому отношению соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится индексируемый текст; сохраняют в памяти каждое семантически значимое отношение вместе с присвоенным ему типом;
- выявляют частоты встречаемости элементарных единиц четвертого уровня на всем тексте;
- формируют в пределах данного текста для каждого из выявленных семантически значимых отношений, связывающих как соответствующие семантически значимые объекты, так и семантически значимый объект и его атрибут, множество триад, которые являются элементарными единицами пятого уровня;
- индексируют на множестве сформированных триад по отдельности все связанные семантически значимыми отношениями семантически значимые объекты с их частотами встречаемости, все атрибуты с их частотами встречаемости и все сформированные триады;
- сохраняют в базе данных сформированные элементарные единицы второго, третьего, четвертого и пятого уровней с их частотами встречаемости, а также полученные индексы вместе со ссылками на конкретные предложения данного текста.
2. Способ по п.1, в котором для каждой единицы четвертого уровня фиксируют тождество по референции между соответствующим семантически значимым объектом, а также атрибутом и соответствующей анафорической ссылкой при ее наличии в индексируемом тексте, заменяя каждую анафорическую ссылку на соответствующий ей антецедент.
3. Способ по п.1, в котором формируют из упомянутых триад семантическую сеть таким образом, что первая элементарная единица второго или третьего уровня последующей триады связывается с такой же второй элементарной единицей второго или третьего уровня предыдущей триады.
4. Способ по п.3, в котором после сохранения в базе данных сформированных триад и полученных индексов осуществляют, в процессе итеративной процедуры, перенормировку частот встречаемости в смысловой вес элементарных единиц второго и третьего уровней, являющихся вершинами семантической сети, таким образом, что элементарные единицы второго и третьего уровней, связанные в сети с большим числом элементарных единиц второго и третьего уровней с большой частотой встречаемости, увеличивают свой смысловой вес, а другие элементарные единицы второго и третьего уровней его равномерно теряют.
5. Способ по п.1, в котором ранжируют по смысловому весу сформированные элементарные единицы второго и третьего уровней сравнением их смыслового веса с заранее заданным пороговым значением.
6. Способ по п.1, в котором удаляют триады, в которых элементарные единицы второго и третьего уровней имеют смысловой вес ниже порогового значения.
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ЕГО СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ, СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ КОЛЛЕКЦИИ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ИХ СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ И МАШИНОЧИТАЕМЫЕ НОСИТЕЛИ | 2008 |
|
RU2399959C2 |
| US 7171349 B1, 30.01.2007 | |||
| US 7383169 B1, 03.06.2008 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

