РОДСТВЕННЫЕ ЗАЯВКИ
Данная патентная заявка испрашивает приоритет следующих одновременно рассматриваемых Предварительных патентных заявок США:
• предварительной патентной заявки США № 60/844806 «Method of Separately Controlling Dialogue Volume», поданной 14 сентября 2006, номер дела поверенного № 19819-047P01;
• предварительной патентной заявки США № 60/884594 «Separate Dialogue Volume (SDV)», поданной 11 января 2007, номер дела поверенного № 19819-120P01;
• предварительной патентной заявки США № 60/943268 «Enhancing Stereo Audio with Remix Capability and Separate Dialogue», поданной 11 июня 2007, номер дела поверенного № 19819-160P01.
Каждая из этих предварительных патентных заявок включена во всей своей полноте в настоящий документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
Объект изобретения данной патентной заявки в общем случае относится к обработке сигналов.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Методы улучшения качества аудио часто используются в домашних развлекательных системах, стереосистемах и других электронных потребительских устройствах для усиления низких звуковых частот и моделирования различных окружающих условий прослушивания (например, концертных залов). Некоторые методы направлены на то, чтобы сделать диалоги в кино более отчетливыми, добавляя, например, больше высоких частот. Ни один из этих методов, однако, не обращается к улучшению качества диалогов по отношению к внешней среде и сигналам других компонент.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Многоканальный аудиосигнал (например, стерео аудио) обрабатывается для изменения усиления (например, громкости) сигнала речевой компоненты (например, диалогов актеров в кино) относительно сигнала компоненты внешней среды (например, отраженного звука) или сигналов других компонент. В одном из аспектов сигнал речевой компоненты идентифицируют и изменяют. В одном из аспектов сигнал речевой компоненты идентифицируют, предполагая, что источник речи (например, говорящий в настоящее время актер) находится в центре аудиограммы стереофонического многоканального аудиосигнала, и с учетом спектрального состава сигнала речевой компоненты.
Раскрыты другие варианты осуществления, которые включают в себя варианты осуществления, направленные на способы, системы и машиночитаемые носители.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 является структурной схемой модели смешивания для методов улучшения качества диалогов.
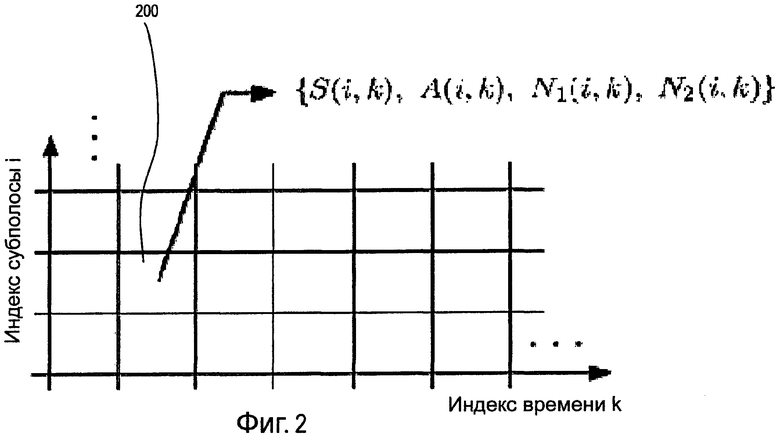
Фиг.2 является графиком, показывающим разложение стереофонических сигналов, используя элементы частота/время.
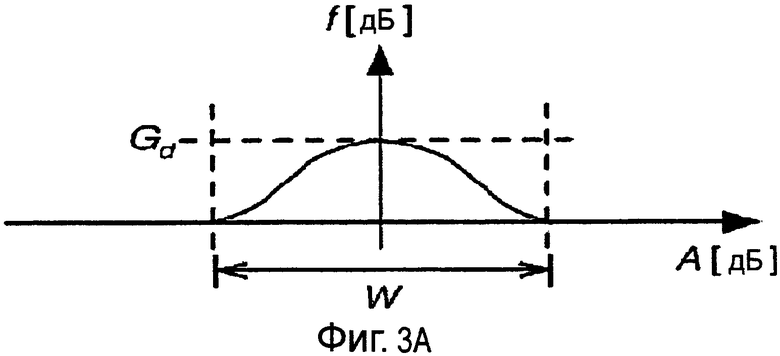
Фиг.3A является графиком функции для вычисления усиления как функции от коэффициента усиления разложения для диалога, который расположен в центре аудиограммы.
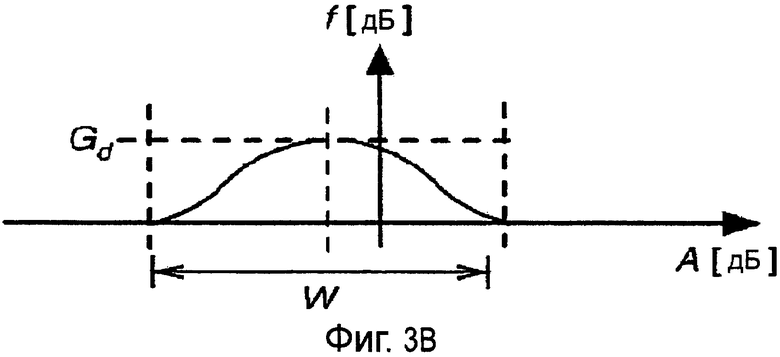
Фиг.3B является графиком функции для вычисления усиления как функции от коэффициента усиления разложения для диалога, который не расположен в центре.
Фиг.4 является структурной схемой примерной системы улучшения диалогов.
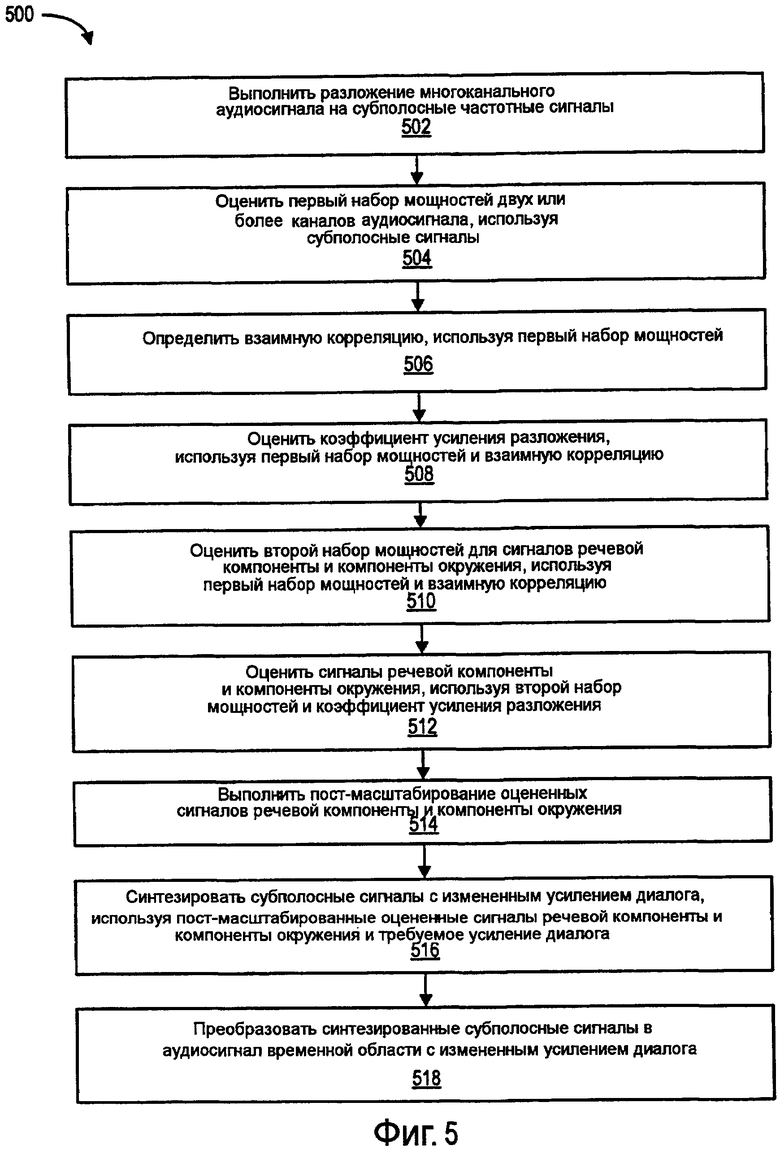
Фиг.5 является последовательностью операций примерного процесса улучшения диалогов.
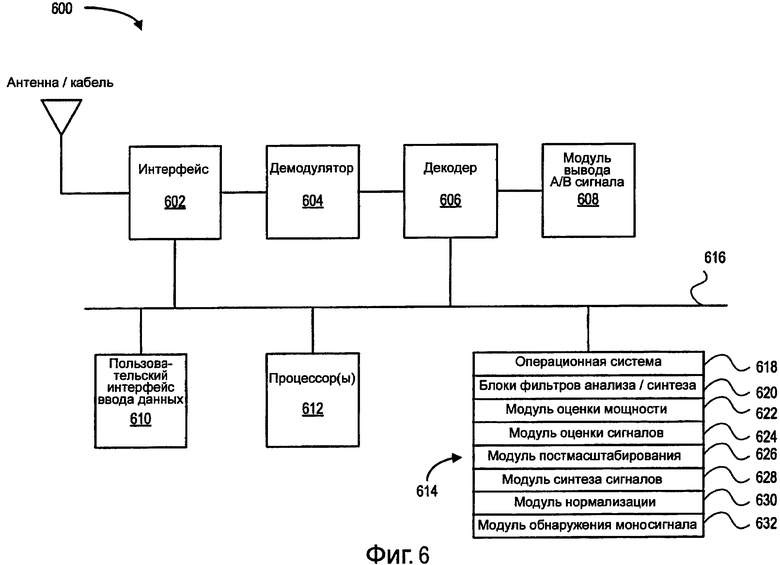
Фиг.6 является структурной схемой цифровой телевизионной системы для осуществления признаков и процессов, описанных со ссылкой на фиг.1-5.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Методы улучшения диалогов
Фиг.1 является структурной схемой модели 100 смешивания для методов улучшения диалогов. В модели 100 слушатель принимает аудио сигналы от левого и правого каналов. Аудиосигнал s соответствует локализованному звуку от направления, определяемого коэффициентом a. Независимые аудиосигналы n1 и n2, которые соответствуют отраженному звуку, часто называют звуком окружающей среды или окружением. Стереофонические сигналы можно записывать или смешивать таким образом, чтобы для заданного источника аудио исходный аудиосигнал направлялся когерентно в левый и правый каналы аудиосигнала с определенными метками направлений (например, различием уровней, разницей во времени), а отраженные независимые сигналы n1 и n2 направлялись в каналы, определяя метки ширины акустического действия и окружения слушателя. Модель 100 может быть представлена математически как основанное на восприятии разложение стереофонического сигнала с одним источником аудио, из нее получают локализацию источника аудио и окружения.
x1(n) = s(n) + n1(n)
x2(n) = as(n) + n2(n) [1]
[1]
Для получения разложения, которое эффективно при изменяющихся сценариях со множеством одновременно активных источников аудио, разложение [1] может выполняться независимо на ряд частотных полос и адаптивно во времени
X1(i,k) = S(i,k) + N1(i,k)
X2(i,k) = A(i,k)S(i,k) + N2(i,k),
 [2]
[2]
где i - индекс субполосы, и k - индекс времени субполосы.
Фиг.2 является графиком, показывающим разложение стереофонического сигнала, используя элементы частота/время. В каждом элементе 200 частота/время с индексами i и k сигналы S, N1, N2 и коэффициент A усиления результата разложения можно оценивать независимо. Для краткости записи индексы i и k субполос и времени в последующем описании опускаются.
При использовании субполосного разложения с основанным на восприятии определением ширины частотных субполос ширину частотных субполос можно выбирать так, чтобы она была равна одной критической полосе. Оценку S, N1, N2 и A можно выполнять приблизительно каждые t миллисекунд (например, 20 мс) в каждой субполосе. Для уменьшения сложности вычислений можно использовать кратковременное преобразование Фурье (STFT) для осуществления быстрого преобразования Фурье (FFT). При заданных стереофонических субполосных сигналах X1 и X2 можно выполнять оценку S, A, N1, N2. Кратковременную оценку мощности X1 можно обозначать как
PX1(i,k) = E{X1 2 (i,k)},
 [3]
[3]
где E{.} - операция кратковременного усреднения. Для других сигналов может использоваться то же самое соглашение, т.е. PX2, PS и PN = PN1 = PN2 - соответствующие кратковременные оценки мощности. Предполагается, что мощности N1 и N2 одинаковые, т.е. предполагается, что величина бокового независимого звука одинакова для левого и правого каналов.
Оценка PS, A и PN
При заданном субполосном представлении стереофонических сигналов можно определять мощность (PX1, PX2) и нормализованную взаимную корреляцию. Нормализованная взаимная корреляция между левым и правым каналами равна
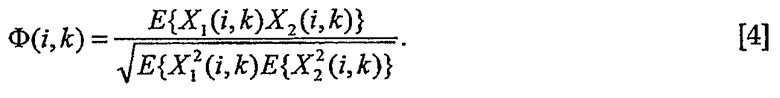
A, PS, PN можно вычислять как функцию от оценок PX1, PX2 и Φ. Три уравнения, которые определяют соотношения между известными и неизвестными переменными, являются следующими:

Уравнения [5] можно решать для A, PS и PN для получения

причем
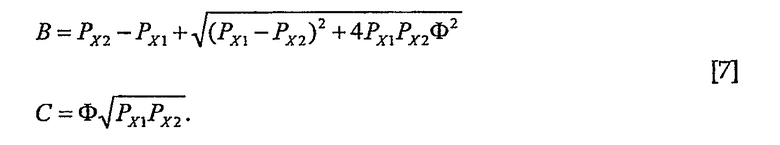
Оценка S, N1 и N2 по методу наименьших квадратов
Затем выполняют оценку S, N1 и N2 по методу наименьших квадратов как функцию от A, PS и PN. Для каждого i и k оценку сигнала S можно выполнять как
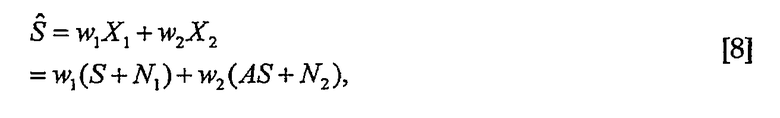
где w1 и w2 являются действительными весовыми коэффициентами. Погрешность оценки равна
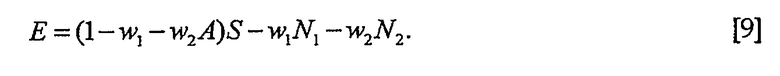
Весовые коэффициенты w1 и w2 оптимальны по отношению к наименьшим квадратам, когда погрешность E ортогональна к X1 и X2 [6], т.е.
E{EX1} = 0
E{EX2} = 0, [10]
[10]
что приводит к двум уравнениям
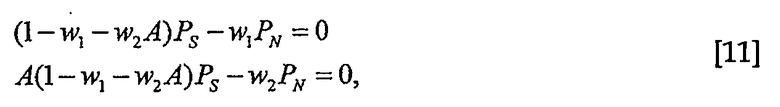
из которых вычисляют весовые коэффициенты
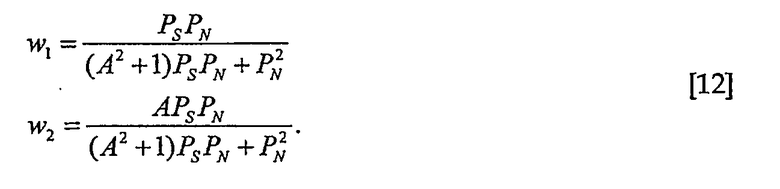
Оценку N1 можно выполнять следующим образом
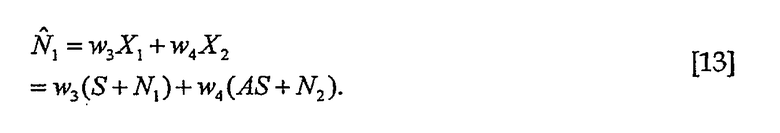
Погрешность оценки равна
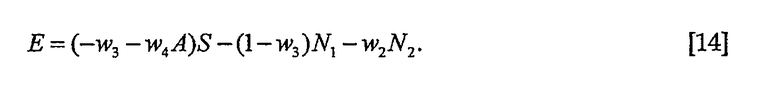
Весовые коэффициенты опять вычисляют таким образом, чтобы погрешность оценки была ортогональна к X1 и X2, что приводит к
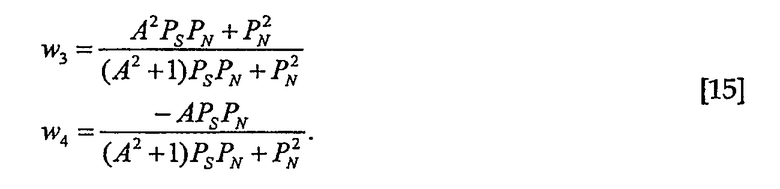
Весовые коэффициенты для вычисления оценки по методу наименьших квадратов N2
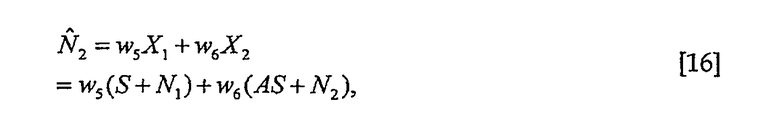
равны
Постмасштабирование
В некоторых вариантах осуществления оценки по методу наименьших квадратов можно постмасштабировать таким образом, чтобы мощность оценок была равна PS и PN = PN1 = PN2. Мощность 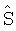 равна
равна
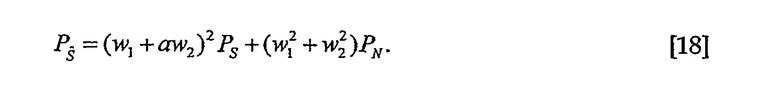
Таким образом, для получения оценки S с помощью мощности PS,  масштабируют
масштабируют
По аналогичным причинам  и
и 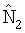 масштабируют следующим образом
масштабируют следующим образом
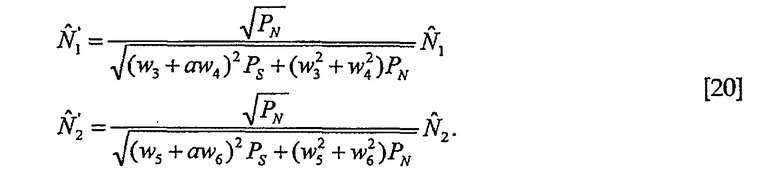
Синтез стереофонического сигнала
Учитывая ранее описанное разложение сигнала, сигнал, который подобен исходному стереофоническому сигналу, можно получать применением [2] в каждый момент времени и для каждой субполосы и преобразованием данных субполос обратно во временную область.
Для генерации сигнала с измененным усилением диалога субполосы вычисляют как
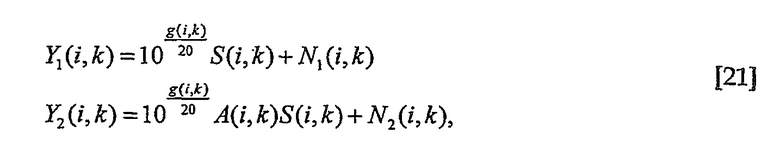
где g(i,k) является коэффициентом усиления в децибелах (дБ), который вычисляют таким образом, чтобы усиление диалога изменялось, когда это требуется.
Существуют несколько наблюдений, которые обосновывают, как следует вычислять g(i,k).
• Обычно диалог находится в центре аудиограммы, т.е. сигнал компоненты, принадлежащий диалогу в момент времени k и на частоте i, будет иметь соответствующий коэффициент усиления разложения A(i,k), близкий к единице (0 дБ).
• Речевые сигналы содержат большую часть энергии до 4 кГц. Выше 8 кГц речь фактически не содержит энергии.
• Речь обычно также не содержит очень низких частот (например, ниже приблизительно 70 Гц).
Эти наблюдения подразумевают, что g(i,k) устанавливается в 0 дБ на очень низких частотах и выше 8 кГц для того, чтобы потенциально изменять стереофонический сигнал как можно меньше. На других частотах g(i,k) управляется как функция требуемого коэффициента усиления диалога Gd и A(i,k):

Пример подходящей функции f показан на фиг.3A. Следует отметить, что на фиг.3A соотношение между f и A(i,k) изображено с использованием логарифмического (дБ) масштаба, но A(i,k) и f в других случаях определяют в линейном масштабе. Конкретный пример для f:
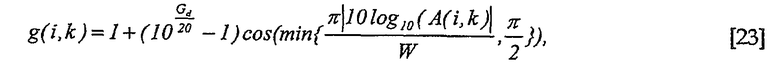
где W определяет ширину зоны усиления функции f, которая показана на фиг.3A. Константа W относится к чувствительности по направлению усиления диалога. Значение W = 6 дБ, например, дает хорошие результаты для большинства сигналов. Но следует отметить, что для различных сигналов могут быть оптимальными различные W.
Из-за плохой калибровки оборудования передачи или приема (например, различных коэффициентов усиления для левого и правого каналов) может случиться так, что диалог оказывается не точно в центре. В этом случае функцию f можно сдвигать таким образом, чтобы ее центр соответствовал расположению диалога. Пример сдвинутой функции f показан на фиг.3B.
Альтернативные варианты осуществления и обобщения
Идентификация сигнала речевой компоненты, основанная на предположении о расположении в центре (или в общем случае на предположении о расположении в определенной позиции) и на спектральном интервале речи, является простой и работает хорошо во многих случаях. Идентификацию диалога, однако, можно изменять и потенциально улучшать. Одной из возможностей является исследование большего количества особенностей речи, таких как форманты, гармоническая структура, переходные процессы, для обнаружения сигнала речевой компоненты.
Как отмечено, для различного аудиоматериала может быть оптимальной различная форма функции усиления (например, фиг.3A и 3B). Таким образом, можно использовать настраиваемую функцию усиления сигнала.
Управление усилением диалога можно также осуществлять для систем домашнего кинотеатра с окружающим звуком. Одним из важных аспектов управления усилением диалога является обнаружение, находится ли диалог в центральном канале или нет. Одним из способов выполнения этого является обнаружение, имеет ли центральный канал достаточно энергии сигнала, так чтобы было вероятно, что диалог находится в центральном канале. Если диалог находится в центральном канале, то можно увеличивать усиление центрального канала для управления громкостью диалога. Если диалог не находится в центральном канале (например, если система окружающего звука воспроизводит стереофоническую информацию), то можно применять управление усилением диалога с двумя каналами, как ранее описано со ссылкой на фиг.1-3.
В некоторых вариантах осуществления раскрытые методы улучшения диалогов можно осуществлять с помощью ослабления сигналов других компонент, кроме сигнала речевой компоненты. Например, многоканальный аудиосигнал может включать в себя сигнал речевой компоненты (например, сигнал диалога) и сигналы других компонент (например, отраженного звука). Сигналы других компонент можно изменять (например, уменьшать), основываясь на расположении сигнала речевой компоненты на аудиограмме многоканального аудиосигнала, а сигнал речевой компоненты можно оставлять неизменным.
Система улучшения диалогов
Фиг.4 является структурной схемой примерной системы 400 улучшения диалогов. В некоторых вариантах осуществления система 400 включает в себя блок 402 фильтров анализа, модуль 404 оценки мощности, модуль 406 оценки сигналов, модуль 408 постмасштабирования, модуль 410 синтеза сигналов и блок 412 фильтров синтеза. Хотя компоненты 402-412 системы 400 показаны как отдельные процессы, процессы двух или большего количества компонентов можно объединять в один компонент.
В каждый момент времени k многоканальный сигнал с помощью блока 402 фильтров анализа преобразуется в субполосные сигналы i. В показанном примере разложение левого и правого каналов x1(n), x2(n) стереофонического сигнала выполняется с помощью блока 402 фильтров анализа на субполосы X1(i,k), X2(i,k). Модуль 404 оценки мощности генерирует оценки мощности 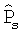 ,
, 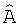 и
и  , которые были ранее описаны со ссылкой к фиг.1 и 2. Модуль 406 оценки сигналов генерирует оценки сигналов
, которые были ранее описаны со ссылкой к фиг.1 и 2. Модуль 406 оценки сигналов генерирует оценки сигналов 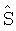 ,
, 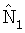 и
и  из оценок мощности. Модуль 408 постмасштабирования масштабирует оценки сигналов для обеспечения
из оценок мощности. Модуль 408 постмасштабирования масштабирует оценки сигналов для обеспечения 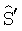 ,
, 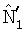 и
и 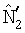 . Модуль 410 синтеза сигналов принимает постмасштабированные оценки сигналов и коэффициент A усиления разложения, константу W и требуемый коэффициент Gd усиления диалога и синтезирует оценки левого и правого субполосных сигналов
. Модуль 410 синтеза сигналов принимает постмасштабированные оценки сигналов и коэффициент A усиления разложения, константу W и требуемый коэффициент Gd усиления диалога и синтезирует оценки левого и правого субполосных сигналов 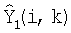 и
и 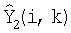 , которые вводят в блок 412 фильтров синтеза для обеспечения левого и правого сигналов во временной области
, которые вводят в блок 412 фильтров синтеза для обеспечения левого и правого сигналов во временной области 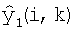 и
и 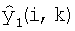 с измененным усилением диалога, основанным на Gd.
с измененным усилением диалога, основанным на Gd.
Процесс улучшения диалогов
Фиг.5 является последовательностью операций примерного процесса 500 улучшения диалогов. В некоторых вариантах осуществления процесс 500 начинается выполнением разложения многоканального аудиосигнала на субполосные частотные сигналы (502). Разложение может выполняться с помощью блока фильтров, используя различные известные преобразования, которые включают в себя преобразования с помощью многофазного блока фильтров, квадратурного зеркального блока фильтров (QMF), гибридного блока фильтров, дискретное преобразование Фурье (DFT) и модифицированное дискретное косинусное преобразование (MDCT), но не ограничены ими.
Первый набор мощностей двух или более каналов аудиосигнала оценивается (504) с использованием субполосных сигналов. Взаимная корреляция определяется (506) с использованием первого набора мощностей. Коэффициент усиления разложения оценивается (508) с использованием первого набора мощностей и взаимной корреляции. Коэффициент усиления разложения обеспечивает метку расположения источника диалога на аудиограмме. Второй набор мощностей для сигнала речевой компоненты и сигнала компоненты окружения оценивается (510) с использованием первого набора мощностей и взаимной корреляции. Сигналы речевой компоненты и компоненты окружения оцениваются (512) с использованием второго набора мощностей и коэффициента усиления разложения. Оценки сигналов речевой компоненты и компоненты окружения постмасштабируются (514). Субполосные сигналы синтезируются с помощью измененного коэффициента усиления диалога с использованием постмасштабированных оценок сигналов речевой компоненты и компоненты окружения и требуемого усиления диалога (516). Требуемое усиление диалога можно устанавливать автоматически, или его может определять пользователь. Синтезированные субполосные сигналы преобразуются (512) в аудио сигнал во временной области с измененным усилением диалога с использованием, например, блока фильтров синтеза.
Нормализация выхода для подавления фона
В некоторых вариантах осуществления требуется подавлять аудио фоновых сцен вместо увеличения громкости сигнала диалога. Этого можно достигать с помощью нормализации выходного сигнала с увеличенной с помощью усиления диалога громкостью диалога. Нормализацию можно выполнять, по меньшей мере, двумя различными способами. В одном из примеров выходной сигнал и можно нормализовать с помощью коэффициента нормализации gnorm:

В другом примере влияние увеличения громкости диалога компенсируют с помощью нормализации, используя весовые коэффициенты w1 - w6 с gnorm. Коэффициент нормализации gnorm может иметь то же самое значение, что измененный коэффициент усиление диалога 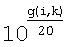 .
.
Для того чтобы сделать максимальным качество восприятия, gnorm можно изменять. Нормализацию можно выполнять и в частотной области, и во временной области. При выполнении в частотной области нормализацию можно выполнять для диапазона частот, где применяется коэффициент усиления диалога, например между 70 Гц и 8 кГц.
Альтернативно подобный результат можно обеспечивать, когда уменьшают N1(i,k) и N2(i,k), не применяя усиления к S(i,k). Эта концепция может быть описана с помощью следующих уравнений:

Использование отдельной громкости диалога, основанной на монофоническом обнаружении
Когда входные сигналы X1(i,k) и X2(i,k) по существу подобны, например входной сигнал подобен монофоническому сигналу, почти каждую часть входного сигнала можно расценивать как S, и когда пользователь обеспечивает требуемое усиление диалога, это требуемое усиление диалога увеличивает громкость сигнала. Для предотвращения этого пользователю необходимо использовать метод отдельной громкости диалога (SVD) для соблюдения характеристик входных сигналов.
В формуле [4] вычисляют нормализованную взаимную корреляцию стереофонических сигналов. Нормализованная взаимная корреляция может использоваться в качестве показателя для обнаружения монофонического сигнала. Когда «фи» в [4] превышает заданное пороговое значение, входной сигнал можно расценивать как монофонический сигнал и отдельную громкость диалогов можно автоматически выключать. В отличие от этого, когда «фи» меньше заданного порогового значения, входной сигнал можно расценивать как стереофонический сигнал и можно автоматически включать отдельную громкость диалогов. Усиление диалога может работать в качестве алгоритмического переключателя для отдельной громкости диалогов как:

Кроме того, когда φ находится между Thrmono и Thrstereo, g(i,k) можно представлять как функцию от φ:
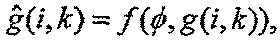 для
для 
Одним из примеров является применение взвешивания для 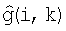 в обратной пропорции к φ как
в обратной пропорции к φ как
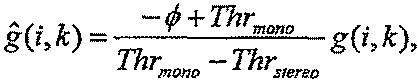 для
для 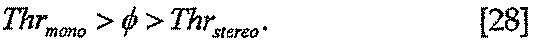
Для предотвращения резкого изменения 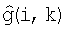 , для получения можно использовать методы сглаживания во времени.
, для получения можно использовать методы сглаживания во времени.
Пример цифровой телевизионной системы
Фиг.6 является структурной схемой примерной цифровой телевизионной системы 600 для осуществления признаков и процессов, описанных со ссылкой на фиг.1-5. Цифровое телевидение (ЦТВ) является телекоммуникационной системой для передачи и приема киноизображений и звука посредством цифровых сигналов. ЦТВ использует цифровые модулированные данные, которые сжаты в цифровой форме и требуют декодирования с помощью специально разработанного телевизионного приемника, или стандартного приемника с абонентским устройством, или ПК (персонального компьютера), в который установлена телевизионная плата. Хотя система на фиг.6 является системой ЦТВ, раскрытые варианты осуществления для улучшения диалогов можно также применять к аналоговым телевизионным системам или к любым другим системам, в которых можно улучшать диалоги.
В некоторых вариантах осуществления система 600 может включать в себя интерфейс 602, демодулятор 604, декодер 606 и модуль 608 вывода аудио/видео (А/В) сигнала, пользовательский интерфейс 610 ввода данных, один или большее количество процессоров 612 (например, процессоров Intel®) и один или большее количество машиночитаемых носителей 614 (например, ОП (оперативную память), ПЗУ (постоянное запоминающее устройство), синхронное динамическое оперативное запоминающее устройство (SDRAM), жесткий диск, оптический диск, флэш-память, СХД (сеть хранения данных) и т.д.). Каждый из этих компонентов связан с одним или большим количеством каналов 616 связи (например, шин). В некоторых вариантах осуществления интерфейс 602 включает в себя различные каналы для получения аудиосигнала или объединенного аудио/видео сигнала. Например, в аналоговой телевизионной системе интерфейс может включать в себя электронику антенны, блок настройки или смеситель, радиочастотный (РЧ) усилитель, локальный генератор, усилитель промежуточной частоты (ПЧ), один или большее количество фильтров, демодулятор, аудио усилитель и т.д. Возможны другие варианты осуществления системы 600, которые включают в себя варианты осуществления с большим или меньшим количеством компонентов.
Блок 602 настройки может быть блоком настройки ЦТВ для приема цифрового телевизионного сигнала, который включает в себя видео и аудиоинформацию. Демодулятор 604 извлекает видео и аудио сигналы из цифрового телевизионного сигнала. Если видео и аудио сигналы кодированы (например, кодированы с помощью MPEG (стандарта экспертной группы по кинематографии), то декодер 606 декодирует эти сигналы. Модуль вывода А/В сигнала может быть любым устройством, которое может отображать видеоинформацию и воспроизводить аудио (например, телевизионным дисплеем, компьютерным монитором, LCD (жидкокристаллическим дисплеем), динамиками, аудиосистемами).
В некоторых вариантах осуществления уровень громкости диалога можно отображать пользователю, используя устройство отображения, например, на удаленном контроллере или на экранном меню (OSD). Можно устанавливать соответствие уровня громкости диалога с уровнем основной громкости. Один или большее количество графических объектов могут использоваться для отображения уровня громкости диалога и уровня громкости диалога относительно основной громкости. Например, первый графический объект (например, изображенный штрихами) может отображаться для указания основной громкости, а второй графический объект (например, изображенный линиями) может отображаться вместе или с помощью наложения на первый графический объект для указания уровня громкости диалога.
В некоторых вариантах осуществления пользовательский интерфейс ввода данных может включать в себя схему (например, беспроводной или инфракрасный приемник) и/или программное обеспечение для приема и декодирования инфракрасных или беспроводных сигналов, сгенерированных с помощью удаленного контроллера. Удаленный контроллер может включать в себя отдельную клавишу или кнопку управления громкостью диалога или отдельную клавишу выбора регулировки громкости диалога для изменения состояния клавиши или кнопки управления основной громкостью, так чтобы кнопка регулировки основной громкости могла использоваться для управления или основной громкостью, или отдельной громкостью диалога. В некоторых вариантах осуществления клавиша управления громкостью диалога или основной громкостью может изменять свой видимый внешний вид для указания своей функции.
Пример контроллера и пользовательского интерфейса описаны в патентной заявке США № _____ «Controller and User Interface For Dialogue Enhancement Techniques», поданной 14 сентября 2007, номер дела поверенного № 19819-160001, данная патентная заявка включена во всей своей полноте в данный документ посредством ссылки.
В некоторых вариантах осуществления один или большее количество процессоров могут выполнять код, хранящийся на машиночитаемом носителе 614, для осуществления особенностей и операций 618, 620, 622, 624, 626, 628, 630 и 632, которые описаны со ссылкой на фиг.1-5.
Машиночитаемый носитель дополнительно включает в себя операционную систему 618, блоки 620 фильтров анализа/синтеза, модуль 622 оценки мощности, модуль 624 оценки сигналов, модуль 626 постмасштабирования и модуль 628 синтеза сигналов. Термин «машиночитаемый носитель» относится к любым носителям, которые участвуют в обеспечении команд на процессор 612 для выполнения, которые включают в себя без ограничения энергонезависимые носители (например, оптические или магнитные диски), энергозависимые носители (например, память) и средства связи. Средства связи включают в себя без ограничения коаксиальные кабели, медный кабель и волоконную оптику. Средства связи могут также принимать форму акустических, световых или радиочастотных волн.
Операционная система 618 может быть многопользовательской, многопроцессорной, многозадачной, многопоточной, реального времени и т.д. Операционная система 618 выполняет основные задачи, которые включают в себя, но не ограничены ими: распознавание вводимой информации от пользовательского интерфейса 610 ввода данных; отслеживание и обработку файлов и каталогов на машиночитаемом носителе 614 (например, в памяти или на запоминающем устройстве); управление периферийными устройствами и управление трафиком в одном или большем количестве каналов 616 связи.
Описанные признаки можно воплощать преимущественно в одной или большем количестве компьютерных программ, которые можно выполнять на программируемой системе, включающей в себя по меньшей мере один программируемый процессор, соединенный с системой хранения данных для приема и передачи данных и команд, по меньшей мере одно устройство ввода данных и по меньшей мере одно устройство вывода данных. Компьютерная программа является набором команд, которые могут использоваться прямо или косвенно в компьютере для выполнения определенной деятельности или получения определенного результата. Компьютерная программа может быть написана на языках программирования любого вида (например, Objective-C, Java), которые включают в себя компилируемые или интерпретируемые языки, и ее можно размещать в любой форме, которая включает в себя как автономную программу или как модуль компонент, подпрограмму или другой блок, подходящий для использования в вычислительной среде.
Подходящие процессоры для выполнения программы из команд включают в себя, например, и общие, и специальные микропроцессоры, и единственный процессор или один из множества процессоров или ядер компьютера любого типа. В общем случае процессор принимает команды и данные от постоянного запоминающего устройства или оперативной памяти или от них обоих. Основными элементами компьютера являются процессор, предназначенный для выполнения команд, и одно или большее количество запоминающих устройств, предназначенных для хранения команд и данных. В общем случае компьютер также включает в себя или функционально связан для осуществления связи с одним или большим количеством запоминающих устройств большой емкости для хранения файлов данных; такие устройства включают в себя магнитные диски, такие как внутренние жесткие и сменные диски; магнитооптические диски и оптические диски. Запоминающие устройства, подходящие для материального воплощения команд компьютерной программы и данных, включают в себя все формы энергонезависимой памяти, включающей в себя посредством примера устройства полупроводниковой памяти, такие как стираемое программируемое ПЗУ, электрически стираемое программируемое ПЗУ и устройство флэш-памяти; магнитные диски, такие как внутренние жесткие и сменные диски; магнитооптические диски и диски CD-ROM и DVD-ROM. Процессор и память можно дополнять с помощью специализированных интегральных схем (СпИС) или внедрять в них.
Для обеспечения взаимодействия с пользователем данные признаки можно воплощать в компьютере, имеющем устройство отображения, такое как монитор CRT (с электронно-лучевой трубкой) или LCD (жидкокристаллический дисплей) для отображения информации пользователю, и клавиатуру и устройство позиционирования, такое как мышь или «трекбол», с помощью которого пользователь может обеспечивать ввод информации в компьютер.
Данные признаки можно воплощать в компьютерной системе, которая включает в себя внутренний компонент, такой как сервер данных, или которая включает в себя компонент промежуточного программного обеспечения, такой как сервер приложений или Интернет-сервер, или она включает в себя подсистему первичной обработки данных, такую как клиентский компьютер, имеющий графический пользовательский интерфейс или Интернет-браузер, или любую их комбинацию. Компоненты системы можно соединять с помощью среды передачи цифровых данных любого типа, например с помощью сети связи. Примеры сетей связи включают в себя, например, ЛС (локальную сеть), ГС (глобальную сеть) и компьютеры и сети, формирующие Интернет.
Компьютерная система может включать в себя клиенты и серверы. Клиент и сервер в общем случае удалены друг от друга и обычно взаимодействуют через сеть. Взаимодействие клиента и сервера возникает на основе компьютерных программ, работающих на соответствующих компьютерах и имеющих клиент-серверные взаимоотношения друг с другом.
Были описаны многие варианты осуществления. Однако подразумевается, что можно выполнять различные их модификации. Например, элементы одного или большего количества вариантов осуществления можно объединять, удалять, изменять или дополнять для формирования дополнительных вариантов осуществлений. В качестве другого примера, последовательности выполнения этапов способов, изображенные на чертежах, не требуют определенного показанного порядка выполнения или последовательного порядка для достижения необходимых результатов. Кроме того, можно обеспечивать другие этапы, или некоторые этапы можно удалять из описанных последовательностей выполнения, и другие компоненты можно добавлять или удалять из описанных систем. Соответственно другие варианты осуществления находятся в рамках следующей далее формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ КОМПЕНСАЦИИ ПОТЕРИ СЛУХА В ТЕЛЕФОННОЙ СИСТЕМЕ И В МОБИЛЬНОМ ТЕЛЕФОННОМ АППАРАТЕ | 2013 |
|
RU2568281C2 |
| СИСТЕМА ОБРАБОТКИ АУДИО | 2014 |
|
RU2625444C2 |
| ПРИКЛАДНОЕ ИСПОЛЬЗОВАНИЕ СИСТЕМЫ ГОЛОС/ЗВУКОВОЕ СОПРОВОЖДЕНИЕ (Г/ЗС) | 2001 |
|
RU2257676C2 |
| ВЫДЕЛЕНИЕ АУДИООБЪЕКТА ИЗ СИГНАЛА МИКШИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ХАРАКТЕРНЫХ ДЛЯ ОБЪЕКТА ВРЕМЕННО-ЧАСТОТНЫХ РАЗРЕШЕНИЙ | 2014 |
|
RU2646375C2 |
| АППАРАТ И СПОСОБ УЛУЧШЕНИЯ АУДИОСИГНАЛА, СИСТЕМА УЛУЧШЕНИЯ ЗВУКА | 2015 |
|
RU2666316C2 |
| ПАРАМЕТРИЧЕСКОЕ СОВМЕСТНОЕ КОДИРОВАНИЕ АУДИОИСТОЧНИКОВ | 2006 |
|
RU2376654C2 |
| СПОСОБ ПОВЫШЕНИЯ РАЗБОРЧИВОСТИ И ИНФОРМАТИВНОСТИ ЗВУКОВЫХ СИГНАЛОВ В ШУМОВОЙ ОБСТАНОВКЕ | 2014 |
|
RU2589298C1 |
| ДЕКОДЕР, КОДЕР И СПОСОБ ИНФОРМИРОВАННОЙ ОЦЕНКИ ГРОМКОСТИ С ИСПОЛЬЗОВАНИЕМ ОБХОДНЫХ СИГНАЛОВ АУДИООБЪЕКТОВ В СИСТЕМАХ ОСНОВЫВАЮЩЕГОСЯ НА ОБЪЕКТАХ КОДИРОВАНИЯ АУДИО | 2014 |
|
RU2651211C2 |
| ДЕКОДЕР, КОДЕР И СПОСОБ ИНФОРМИРОВАННОЙ ОЦЕНКИ ГРОМКОСТИ В СИСТЕМАХ ОСНОВЫВАЮЩЕГОСЯ НА ОБЪЕКТАХ КОДИРОВАНИЯ АУДИО | 2014 |
|
RU2672174C2 |
| УСОВЕРШЕНСТВОВАНИЕ ЗВУКОВОГО СИГНАЛА ВОЗМОЖНОСТЬЮ ПОВТОРНОГО МИКШИРОВАНИЯ | 2007 |
|
RU2414095C2 |

Изобретение относится к способам обработки сигналов, в частности к методам улучшения качества многоканальных аудиосигналов. Техническим результатом является улучшение качества диалогов по отношению к внешней среде и сигналам других компонент. Указанный технический результат достигается тем, что многоканальный аудиосигнал (в частности, стереофонический аудиосигнал) обрабатывают для изменения усиления (громкости) сигнала речевой компоненты относительно сигнала компоненты окружения (например, отраженного звука) или сигналов других компонент. Способ обработки аудиосигнала заключается в получении многоканального аудиосигнала, включающего сигнал речевой компоненты и сигнал другой компоненты, определении взаимной корреляции между двумя каналами аудиосигнала, определении пространственного расположения сигнала речевой компоненты с использованием взаимной корреляции и значения усиления для управления уровнем каждого канала аудиосигнала, идентифицировании сигнала речевой компоненты на основе пространственного расположения сигнала речевой компоненты, изменении сигнала речевой компоненты посредством применения усиления к сигналу речевой компоненты и формировании измененного аудиосигнала, включающего в себя измененный сигнал речевой компоненты. 4 н. и 19 з.п. ф-лы, 7 ил.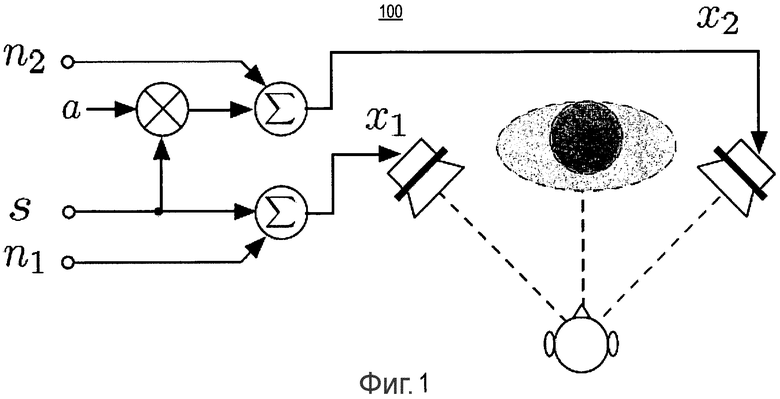
1. Способ обработки аудиосигнала, содержащий этапы, на которых:
получают многоканальный аудиосигнал, включающий в себя сигнал речевой компоненты и сигнал другой компоненты;
определяют взаимную корреляцию между двумя каналами аудиосигнала;
определяют пространственное расположение сигнала речевой компоненты, используя, по меньшей мере, одно из взаимной корреляции и значений усиления для управления уровнем каждого канала аудиосигнала;
идентифицируют сигнал речевой компоненты, основываясь на пространственном расположении сигнала речевой компоненты;
изменяют сигнал речевой компоненты посредством применения усиления к сигналу речевой компоненты; и
формируют измененный аудиосигнал, включающий в себя измененный сигнал речевой компоненты.
2. Способ по п.1, в котором изменение дополнительно содержит этап, на котором:
идентифицируют сигнал речевой компоненты, основываясь на спектральном диапазоне сигнала речевой компоненты.
3. Способ по п.2, в котором усиление является функцией расположения сигнала речевой компоненты и требуемого усиления для сигнала речевой компоненты.
4. Способ по п.3, в котором функция является зависящей от сигнала функцией усиления, имеющей область усиления, которая связана с чувствительностью по направлению коэффициента усиления.
5. Способ по п.1, в котором изменение дополнительно содержит этап, на котором:
нормализуют многоканальный аудиосигнал с помощью коэффициента, нормализации во временной области или в частотной области.
6. Способ по п.1, дополнительно содержащий этапы, на которых:
сравнивают взаимную корреляцию с одним или более пороговыми значениями;
определяют, является ли аудиосигнал, по существу, монофоническим;
и изменяют сигнал речевой компоненты, когда аудиосигнал не является, по существу, монофоническим.
7. Способ по п.1, в котором изменение дополнительно содержит этапы, на которых:
выполняют разложение аудиосигнала на множество субполосных частотных сигналов;
оценивают первый набор мощностей для двух или более каналов многоканального аудиосигнала, используя субполосные сигналы;
определяют взаимную корреляцию, используя первый набор оцененных мощностей;
оценивают коэффициент усиления разложения, используя первый набор оцененных мощностей и взаимную корреляцию.
8. Способ по п.1, в котором диапазон частот по меньшей мере одной субполосы выбирают так, чтобы он был равен одному критическому диапазону слуховой системы человека.
9. Способ по п.6, дополнительно содержащий этап, на котором:
оценивают второй набор мощностей для сигнала речевой компоненты и сигнала компоненты окружения из первого набора мощностей и взаимной корреляции.
10. Способ по п.9, дополнительно содержащий этап, на котором:
оценивают сигнал речевой компоненты и сигнал компоненты окружения, используя второй набор мощностей и коэффициент усиления разложения.
11. Способ по п.10, в котором оцененные сигналы речевой компоненты и компоненты окружения определяются с использованием оценки наименьших квадратов.
12. Способ по п.10, в котором взаимную корреляцию нормализуют.
13. Способ по п.11 или 12, в котором оцененные сигналы речевой компоненты и компоненты окружения подвергают постмасштабированию.
14. Способ по п.9, дополнительно содержащий этап, на котором:
синтезируют субполосные сигналы, используя оцененные вторые мощности и определенное пользователем усиление.
15. Способ по п.14, дополнительно содержащий этап, на котором:
преобразуют синтезированные субполосные сигналы в аудиосигнал во временной области, имеющий сигнал речевой компоненты, который изменен с помощью определенного пользователем усиления.
16. Устройство обработки аудиосигнала, содержащее:
интерфейс, конфигурируемый для получения аудиосигнала; и
процессор, соединенный с интерфейсом и конфигурируемый для получения пользовательского ввода, определяющего изменение сигнала первой компоненты аудиосигнала, и изменения сигнала первой компоненты, основываясь на вводе и метке расположения сигнала первой компоненты на аудиограмме аудиосигнала;
причем метка расположения основывается, по меньшей мере, на одном из взаимной корреляции между двумя каналами аудиосигнала и значений усиления для управления уровнем каждого канала аудиосигнала.
17. Устройство по п.16, в котором изменение дополнительно содержит: применение коэффициента усиления к сигналу первой компоненты.
18. Устройство по п.17, в котором коэффициент усиления является функцией метки расположения и требуемого усиления для сигнала первой компоненты.
19. Устройство по п.18, в котором функция имеет зону усиления, которая связана с чувствительностью по направлению коэффициента усиления.
20. Устройство по любому из пп.16-19, в котором изменение дополнительно содержит:
нормализацию аудиосигнала с помощью коэффициента нормализации во временной области или в частотной области.
21. Устройство по п.16, в котором изменение дополнительно содержит:
выполнение разложения аудиосигнала на множество субполосных частотных сигналов;
оценивание первого набора мощностей для двух или более каналов аудиосигнала, используя субполосные сигналы;
определение взаимной корреляции, используя первый набор мощностей;
оценивание коэффициента усиления разложения, используя первый набор мощностей и взаимную корреляцию;
оценивание второго набора мощностей для сигнала первой компоненты и сигнала второй компоненты из первого набора мощностей и взаимной корреляции;
оценивание сигнала первой компоненты и сигнала второй компоненты, используя второй набор мощностей и коэффициент усиления разложения;
синтез субполосных сигналов, используя оцененные сигналы первой и второй компонент и ввод; и
преобразование синтезированных субполосных сигналов в аудиосигнал временной области, имеющий измененный сигнал первой компоненты.
22. Система обработки аудиосигнала, содержащая:
интерфейс, конфигурируемый для получения многоканального аудиосигнала, включающего в себя сигнал речевой компоненты и сигнал другой компоненты; и
процессор, соединенный с интерфейсом и конфигурируемый для определения взаимной корреляции между двумя каналами аудиосигнала, определения пространственного расположения сигнала речевой компоненты, используя, по меньшей мере, одно из взаимной корреляции и значений усиления для управления уровнем каждого канала аудиосигнала, идентификации сигнала речевой компоненты, основываясь на пространственном расположении сигнала речевой компоненты, изменения сигнала речевой компоненты посредством применения усиления к сигналу речевой компоненты, и формирования измененного аудиосигнала, включающего в себя измененный сигнал речевой компоненты.
23. Устройство обработки аудиосигнала, содержащее:
интерфейс, конфигурируемый для получения многоканального аудиосигнала, включающего в себя сигнал речевой компоненты и сигнал другой компоненты; и
процессор, соединенный с интерфейсом и конфигурируемый для изменения сигнала другой компоненты, основываясь на расположении сигнала речевой компоненты на аудиограмме многоканального аудиосигнала,
причем расположение сигнала речевой компоненты основывается, по меньшей мере, на одном из взаимной корреляции между двумя каналами аудиосигнала и значений усиления для управления уровнем каждого канала аудиосигнала.
| US 2005117761 А1, 02.06.2005 | |||
| Устройство для выращивания растений | 1980 |
|
SU865227A1 |
| US 6990205 В1, 24.01.2006 | |||
| WO 9904498 А2, 28.01.1999 | |||
| RU 98121130 А, 20.09.2000. | |||

