Настоящее изобретение относится к кодированию аудиосигналов, обработке и декодированию, и, в частности, к декодеру, кодеру и способу информированной оценки громкости в системах основывающегося на объектах кодирования аудио.
В последнее время, параметрические способы для эффективных в отношении битовой скорости передачи/хранения аудиосцен, содержащих множество сигналов аудиообъектов, были предложены в области кодирования аудио [BCC, JSC, SAOC, SAOC1, SAOC2] и информированного разделения источников [ISS1, ISS2, ISS3, ISS4, ISS5, ISS6]. Эти способы направлены на восстановление требуемой выходной аудиосцены или объекта аудиоисточника на основе дополнительной вспомогательной информации, описывающей переданную/сохраненную аудиосцену и/или объекты источников в аудиосцене. Это восстановление происходит в декодере с использованием схемы информированного разделения источников. Восстановленные объекты могут комбинироваться, чтобы вырабатывать выходную аудиосцену. В зависимости от способа, с помощью которого объекты комбинируются, воспринимаемая громкость выходной сцены может изменяться.
В телевизионном и радиовещании, уровни звука аудиодорожек различных программ могут нормализовываться на основе различных аспектов, таких как пиковый уровень сигнала или уровень громкости. В зависимости от динамических свойств сигналов, два сигнала с одним и тем же пиковым уровнем могут иметь широко различающийся уровень воспринимаемой громкости. Теперь при переключении между программами или каналами различия в громкости сигнала являются очень раздражающими и являются главным источником жалоб конечных пользователей в широковещании.
В предшествующем уровне техники, было предложено нормализовывать все программы на всех каналах аналогично общему опорному уровню с использованием меры на основе воспринимаемой громкости сигнала. Одной такой рекомендацией в Европе является Рекомендация EBU R128 [EBU] (ниже упоминаемая как R128).
Рекомендация говорит, что "громкость программы", например, средняя громкость по одной программе (или одному рекламному ролику, или некоторой другой имеющей смысл программной сущности) должна равняться определенному уровню (с малыми разрешенными отклонениями). Когда больше и больше вещательных компаний находятся в соответствии с этой рекомендацией и требуемой нормализацией, различия в средней громкости между программами и каналами должны минимизироваться.
Оценка громкости может выполняться несколькими способами. Существует несколько математических моделей для оценки воспринимаемой громкости аудиосигнала. Рекомендация EBU R128 полагается на модель, представленную в ITU-R BS.1770 (ниже упоминаемую как BS.1770) (см. [ITU]) для оценки громкости.
Как указывалось ранее, например, согласно рекомендации EBU R128, громкость программы, например, средняя громкость по одной программе, должна равняться определенному уровню с малыми разрешенными отклонениями. Однако это ведет к значительным проблемам, когда выполняется воспроизведение аудио, нерешенным до сих пор в предшествующем уровне техники. Выполнение воспроизведения аудио на стороне декодера имеет значительное влияние на общую/полную громкость принятого входного аудиосигнала. Однако, несмотря на выполнение воспроизведения сцены, полная громкость принятого аудиосигнала должна оставаться одной и той же.
В текущее время, для этой проблемы никакого конкретного решения стороны декодера не существует.
EP 2 146 522 A1 ([EP]), относится к концепциям для генерирования выходных аудиосигналов с использованием основывающихся на объектах метаданных. Генерируется, по меньшей мере, один выходной аудиосигнал, представляющий суперпозицию, по меньшей мере, двух разных сигналов аудиообъектов, но не обеспечивает решение для этой проблемы.
WO 2008/035275 A2 ([BRE]) описывает аудиосистему, содержащую кодер, который кодирует аудиообъекты в блоке кодирования, который генерирует микшированный с понижением аудиосигнал и параметрические данные, представляющие множество аудиообъектов. Микшированный с понижением аудиосигнал и параметрические данные передаются в декодер, который содержит блок декодирования, который генерирует приблизительные дубликаты аудиообъектов, и блок воспроизведения, который генерирует выходной сигнал из аудиообъектов. Декодер дополнительно содержит процессор для генерирования данных модификации кодирования, которые посылаются в кодер. Кодер затем модифицирует кодирование аудиообъектов, и, в частности, модифицирует параметрические данные, в ответ на данные модификации кодирования. Подход обеспечивает возможность манипулирования аудиообъектами, подлежащими управлению посредством декодера, но выполняемого полностью или частично посредством кодера. Таким образом, манипулирование может выполняться над фактическими независимыми аудиообъектами, нежели над приблизительными дубликатами, тем самым, обеспечивая улучшенную производительность.
EP 2 146 522 A1 ([SCH]) раскрывает устройство для генерирования, по меньшей мере, одного выходного аудиосигнала, представляющего суперпозицию, по меньшей мере, двух разных аудиообъектов, содержащее процессор для обработки входного аудиосигнала, чтобы обеспечивать объектное представление входного аудиосигнала, где это объектное представление может генерироваться посредством параметрически направляемого приближения исходных объектов с использованием микшированного с понижением сигнала объектов. Модуль манипулирования объектами индивидуально манипулирует объектами с использованием основывающихся на аудиообъектах метаданных, ссылающихся на индивидуальные аудиообъекты, чтобы получать подвергнутые манипулированию аудиообъекты. Подвергнутые манипулированию аудиообъекты микшируются с использованием модуля микширования объектов для окончательного получения выходного аудиосигнала, имеющего один или несколько канальных сигналов в зависимости от конкретной настройки воспроизведения.
WO 2008/046531 A1 ([ENG]) описывает кодер аудиообъектов для генерирования кодированного сигнала объектов с использованием множества аудиообъектов, включающий в себя генератор информации понижающего микширования для генерирования информации понижающего микширования, указывающей распределение множества аудиообъектов в, по меньшей мере, двух каналах понижающего микширования, генератор параметров аудиообъектов для генерирования параметров объектов для аудиообъектов, и интерфейс вывода для генерирования импортированного выходного аудиосигнала с использованием информации понижающего микширования и параметров объектов. Синтезатор аудио использует информацию понижающего микширования для генерирования выходных данных, используемых для создания множества выходных каналов предварительно определенной выходной конфигурации аудио.
Было бы желательным иметь точную оценку выходной средней громкости или изменения в средней громкости без задержки, и когда программа не изменяется или сцена воспроизведения не изменяется, оценка средней громкости также должна оставаться статической.
Цель настоящего изобретения состоит в том, чтобы обеспечить улучшенные концепции кодирования, обработки и декодирования аудиосигналов. Цель настоящего изобретения решается посредством декодера согласно пункту 1 формулы изобретения, посредством кодера согласно пункту 15 формулы изобретения, посредством системы согласно пункту 18 формулы изобретения, посредством способа согласно пункту 19 формулы изобретения, посредством способа согласно пункту 20 формулы изобретения и посредством компьютерной программы согласно пункту 21 формулы изобретения.
Обеспечивается информированный способ оценки громкости вывода в системе основывающегося на объектах кодирования аудио. Обеспеченные концепции полагаются на информацию о громкости объектов в результате микширования аудио, подлежащем обеспечению в декодер. Декодер использует эту информацию вместе с информацией воспроизведения для оценки громкости выходного сигнала. Это обеспечивает возможность затем, например, оценивать различие громкости между устанавливаемым по умолчанию микшированным с понижением и воспроизводимым выводом. Тогда является возможным компенсировать различие, чтобы получать приблизительно постоянную громкость на выходе независимо от информации воспроизведения. Оценка громкости в декодере выполняется полностью параметрическим способом, и является вычислительно очень легкой и точной по сравнению с концепциями основывающейся на сигналах оценки громкости.
Обеспечиваются концепции для получения информации о громкости конкретной выходной сцены с использованием чисто параметрических концепций, которые затем обеспечивают возможность для обработки громкости без явной основывающейся на сигналах оценки громкости в декодере. Более того, описывается конкретная технология пространственного кодирования аудиообъектов (SAOC), стандартизированная посредством MPEG [SAOC], но обеспеченные концепции могут использоваться в соединении с другими технологиями кодирования аудиообъектов, также.
Обеспечивается декодер для генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов. Декодер содержит интерфейс приема для приема входного аудиосигнала, содержащего множество сигналов аудиообъектов, для приема информации громкости о сигналах аудиообъектов, и для приема информации воспроизведения, указывающей, должен ли один или более из сигналов аудиообъектов усиливаться или ослабляться. Более того, декодер содержит сигнальный процессор для генерирования упомянутых одного или более выходных аудиоканалов выходного аудиосигнала. Сигнальный процессор сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения. Дополнительно, сигнальный процессор сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости.
Согласно одному варианту осуществления, сигнальный процессор может быть сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости, так что громкость выходного аудиосигнала равняется громкости входного аудиосигнала, или так что громкость выходного аудиосигнала является более близкой к громкости входного аудиосигнала, чем громкость модифицированного аудиосигнала, который бы проистекал из модификации входного аудиосигнала посредством усиления или ослабления сигналов аудиообъектов входного аудиосигнала согласно информации воспроизведения.
Согласно другому варианту осуществления, каждый из сигналов аудиообъектов входного аудиосигнала может назначаться в точности одной группе из двух или более групп, при этом каждая из упомянутых двух или более групп может содержать один или более из сигналов аудиообъектов входного аудиосигнала. В таком варианте осуществления, интерфейс приема может быть сконфигурирован с возможностью принимать значение громкости для каждой группы из упомянутых двух или более групп в качестве информации громкости, при этом упомянутое значение громкости указывает исходную полную громкость упомянутых одного или более сигналов аудиообъектов из упомянутой группы. Дополнительно, интерфейс приема может быть сконфигурирован с возможностью принимать информацию воспроизведения, указывающую для, по меньшей мере, одной группы из упомянутых двух или более групп, должны ли упомянутые один или более сигналов аудиообъектов из упомянутой группы усиливаться или ослабляться, посредством указания модифицированной полной громкости упомянутых одного или более сигналов аудиообъектов из упомянутой группы. Более того, в таком варианте осуществления, сигнальный процессор может быть сконфигурирован с возможностью определять значение компенсации громкости в зависимости от модифицированной полной громкости каждой из упомянутой, по меньшей мере, одной группы из упомянутых двух или более групп и в зависимости от исходной полной громкости каждой из упомянутых двух или более групп. Дополнительно, сигнальный процессор может быть сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от модифицированной полной громкости каждой из упомянутой, по меньшей мере, одной группы из упомянутых двух или более групп и в зависимости от значения компенсации громкости.
В конкретных вариантах осуществления, по меньшей мере, одна группа из упомянутых двух или более групп может содержать два или более из сигналов аудиообъектов.
Более того, обеспечивается кодер. Кодер содержит блок основывающегося на объектах кодирования для кодирования множества сигналов аудиообъектов, чтобы получать кодированный аудиосигнал, содержащий множество сигналов аудиообъектов. Дополнительно, кодер содержит блок кодирования громкости объектов для кодирования информации громкости о сигналах аудиообъектов. Информация громкости содержит одно или более значений громкости, при этом каждое из упомянутых одного или более значений громкости зависит от одного или более из сигналов аудиообъектов.
Согласно одному варианту осуществления, каждый из сигналов аудиообъектов из кодированного аудиосигнала может назначаться в точности одной группе из двух или более групп, при этом каждая из упомянутых двух или более групп содержит один или более из сигналов аудиообъектов из кодированного аудиосигнала. Блок кодирования громкости объектов может быть сконфигурирован с возможностью определять упомянутые одно или более значений громкости из информации громкости посредством определения значения громкости для каждой группы из упомянутых двух или более групп, при этом упомянутое значение громкости упомянутой группы указывает исходную полную громкость упомянутых одного или более сигналов аудиообъектов из упомянутой группы.
Дополнительно, обеспечивается система. Система содержит кодер согласно одному из вышеописанных вариантов осуществления для кодирования множества сигналов аудиообъектов, чтобы получать кодированный аудиосигнал, содержащий множество сигналов аудиообъектов, и для кодирования информации громкости о сигналах аудиообъектов. Дополнительно, система содержит декодер согласно одному из вышеописанных вариантов осуществления для генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов. Декодер сконфигурирован с возможностью принимать кодированный аудиосигнал в качестве входного аудиосигнала и информацию громкости. Более того, декодер сконфигурирован с возможностью дополнительно принимать информацию воспроизведения. Дополнительно, декодер сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения. Более того, декодер сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости.
Более того, обеспечивается способ генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов. Способ содержит:
- Прием входного аудиосигнала, содержащего множество сигналов аудиообъектов.
- Прием информации громкости о сигналах аудиообъектов.
- Прием информации воспроизведения, указывающей, должен ли один или более из сигналов аудиообъектов усиливаться или ослабляться.
- Определение значения компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения. Кроме того:
- Генерирование упомянутых одного или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости.
Дополнительно, обеспечивается способ кодирования. Способ содержит:
- Кодирование входного аудиосигнала, содержащего множество сигналов аудиообъектов. Кроме того:
- Кодирование информации громкости о сигналах аудиообъектов, при этом информация громкости содержит одно или более значений громкости, при этом каждое из упомянутых одного или более значений громкости зависит от одного или более из сигналов аудиообъектов.
Более того, обеспечивается компьютерная программа для осуществления вышеописанного способа при исполнении на компьютере или сигнальном процессоре.
Предпочтительные варианты осуществления обеспечиваются в зависимых пунктах формулы изобретения.
В последующем, варианты осуществления настоящего изобретения описываются более подробно со ссылкой на фигуры, на которых:
Фиг.1 иллюстрирует декодер для генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов согласно одному варианту осуществления,
Фиг.2 иллюстрирует кодер согласно одному варианту осуществления,
Фиг.3 иллюстрирует систему согласно одному варианту осуществления,
Фиг.4 иллюстрирует систему пространственного кодирования аудиообъектов, содержащую кодер SAOC и декодер SAOC,
Фиг.5 иллюстрирует декодер SAOC, содержащий декодер вспомогательной информации, разделитель объектов и модуль воспроизведения,
Фиг.6 иллюстрирует поведение оценок громкости выходного сигнала при изменении громкости,
фиг.7 изображает информированную оценку громкости согласно одному варианту осуществления, иллюстрируя компоненты кодера и декодера согласно одному варианту осуществления,
Фиг.8 иллюстрирует кодер согласно другому варианту осуществления,
Фиг.9 иллюстрирует кодер и декодер согласно одному варианту осуществления, относящемуся к улучшению диалогов SAOC, который содержит обходные каналы,
Фиг.10 изображает первую иллюстрацию измеренного изменения громкости и результата использования обеспеченных концепций для оценки изменения в громкости параметрическим способом,
Фиг.11 изображает вторую иллюстрацию измеренного изменения громкости и результат использования обеспеченных концепций для оценки изменения в громкости параметрическим способом, и
Фиг.12 иллюстрирует другой вариант осуществления для выполнения компенсации громкости.
Перед подробным описанием предпочтительных вариантов осуществления, описываются оценка громкости, пространственное кодирование аудиообъектов (SAOC) и улучшение диалогов (DE).
Сначала, описывается оценка громкости.
Как уже указывалось ранее, рекомендация EBU R128 полагается на модель, представленную в ITU-R BS.1770, для оценки громкости. Эта мера будет использоваться в качестве примера, но описанные концепции ниже могут применяться также для других мер громкости.
Операция оценки громкости согласно BS.1770 является относительно простой и она основывается на следующих основных этапах [ITU]:
- Входной сигнал xi (или сигналы в случае многоканального сигнала) фильтруется с помощью K-фильтра (комбинации полочного и высокочастотного фильтров), чтобы получать сигнал (сигналы) yi.
- Вычисляется среднеквадратичная энергия zi сигнала yi.
- В случае многоканального сигнала, применяется Gi взвешивание по каналам, и взвешенные сигналы складываются. Громкость сигнала затем определяется как

где постоянное значение c=-0,691. Вывод затем выражается в единицах "LKFS" (громкость, K - взвешенная, по отношению к полной шкале), что является шкалой, аналогичной шкале в децибелах.
В вышеописанной формуле, Gi может, например, равняться 1 для некоторых из каналов, в то время как Gi может, например, равняться 1,41 для некоторых других каналов. Например, если рассматривается левый канал, правый канал, центральный канал, левый канал объемного звука и правый канал объемного звука, соответствующие веса Gi могут, например, равняться 1 для левого, правого и центрального канала, и могут, например, равняться 1,41 для левого канала объемного звука и правого канала объемного звука, см. [ITU].
Можно видеть, что значение громкости L близко связано с логарифмом энергии сигнала.
В последующем, описывается пространственное кодирование аудиообъектов.
Концепции основывающегося на объектах кодирования аудио обеспечивают возможность для большой гибкости на стороне декодера цепи. Примером концепции основывающегося на объектах кодирования аудио является пространственное кодирование аудиообъектов (SAOC).
Фиг.4 иллюстрирует систему пространственного кодирования аудиообъектов (SAOC), содержащую кодер 410 SAOC и декодер 420 SAOC.
Кодер 410 SAOC принимает N сигналов аудиообъектов 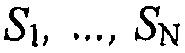 в качестве ввода. Более того, кодер 410 SAOC дополнительно принимает инструкции "Информация микширования D" в отношении того, как эти объекты должны комбинироваться, чтобы получать микшированный с понижением сигнал, содержащий M каналов понижающего микширования
в качестве ввода. Более того, кодер 410 SAOC дополнительно принимает инструкции "Информация микширования D" в отношении того, как эти объекты должны комбинироваться, чтобы получать микшированный с понижением сигнал, содержащий M каналов понижающего микширования  . Кодер 410 SAOC извлекает некоторую вспомогательную информацию из объектов и из обработки понижающего микширования, и эта вспомогательная информация передается и/или сохраняется вместе с микшированными с понижением сигналами.
. Кодер 410 SAOC извлекает некоторую вспомогательную информацию из объектов и из обработки понижающего микширования, и эта вспомогательная информация передается и/или сохраняется вместе с микшированными с понижением сигналами.
Главное свойство системы SAOC состоит в том, что микшированный с понижением сигнал X, содержащий каналы понижающего микширования  , формирует семантически содержательный сигнал. Другими словами, является возможным прослушивать микшированный с понижением сигнал. Если, например, приемник не имеет функциональной возможности декодера SAOC, приемник может несмотря ни на что всегда обеспечивать микшированный с понижением сигнал в качестве вывода.
, формирует семантически содержательный сигнал. Другими словами, является возможным прослушивать микшированный с понижением сигнал. Если, например, приемник не имеет функциональной возможности декодера SAOC, приемник может несмотря ни на что всегда обеспечивать микшированный с понижением сигнал в качестве вывода.
Фиг.5 иллюстрирует декодер SAOC, содержащий декодер 510 вспомогательной информации, разделитель 520 объектов и модуль 530 воспроизведения. Декодер SAOC, проиллюстрированный посредством фиг.5, принимает, например, от кодера SAOC, микшированный с понижением сигнал и вспомогательную информацию. Микшированный с понижением сигнал может рассматриваться в качестве входного аудиосигнала, содержащего сигналы аудиообъектов, так как сигналы аудиообъектов микшированы внутри микшированного с понижением сигнала (сигналы аудиообъектов микшированы внутри упомянутых одного или более каналов понижающего микширования микшированного с понижением сигнала).
Декодер SAOC может, например, затем пытаться (виртуально) восстановить исходные объекты, например, посредством использования разделителя 520 объектов, например, с использованием декодированной вспомогательной информации. Эти (виртуальные) восстановления объектов  , например, восстановленные сигналы аудиообъектов, затем комбинируются на основе информации воспроизведения, например, матрицы воспроизведения R, чтобы вырабатывать K выходных аудиоканалов
, например, восстановленные сигналы аудиообъектов, затем комбинируются на основе информации воспроизведения, например, матрицы воспроизведения R, чтобы вырабатывать K выходных аудиоканалов 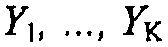 выходного аудиосигнала Y.
выходного аудиосигнала Y.
В SAOC, часто, сигналы аудиообъектов, например, восстанавливаются, например, посредством использования ковариационной информации, например, ковариационной матрицы сигналов E, которая передается от кодера SAOC в декодер SAOC.
Например, может использоваться следующая формула, чтобы восстанавливать сигналы аудиообъектов на стороне декодера:
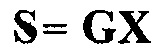 , где
, где 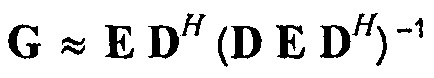 ,
,
где
N количество сигналов аудиообъектов,
Nsamples количество рассматриваемых выборок сигнала аудиообъекта
M количество каналов понижающего микширования,
X микшированный с понижением аудиосигнал, размер M×NSamples,
D матрица понижающего микширования, размер M×N
E ковариационная матрица сигналов, размер N×N, определяется как 
S параметрически восстановленные N сигналов аудиообъектов, размер N×NSamples
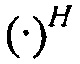 самосопряженный (эрмитов) оператор, который представляет сопряженное транспонирование для
самосопряженный (эрмитов) оператор, который представляет сопряженное транспонирование для 
Тогда, матрица воспроизведения R может применяться на восстановленных сигналах аудиообъектов S, чтобы получать выходные аудиоканалы выходного аудиосигнала Y, например, согласно формуле:
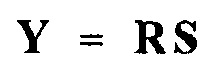 ,
,
где
K количество выходных аудиоканалов  выходного аудиосигнала Y.
выходного аудиосигнала Y.
R матрица воспроизведения размера K×N
Y выходной аудиосигнал, содержащий K выходных аудиоканалов, размер K×NSamples
На фиг.5, обработка восстановления объектов, например, выполняемая посредством разделителя 520 объектов, упоминается с использованием признака "виртуальная", или "необязательная", так как она может не быть обязательно необходимой, чтобы выполняться, но требуемая функциональная возможность может получаться посредством комбинирования этапов восстановления и воспроизведения в параметрической области (то есть комбинирования уравнений).
Другими словами, вместо сначала восстановления сигналов аудиообъектов с использованием информации микширования D и ковариационной информации E, и затем применения информации воспроизведения R на восстановленных сигналах аудиообъектов, чтобы получать выходные аудиоканалы 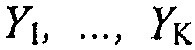 , оба этапа могут выполняться в одиночном этапе, так что выходные аудиоканалы
, оба этапа могут выполняться в одиночном этапе, так что выходные аудиоканалы 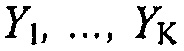 напрямую генерируются из каналов понижающего микширования.
напрямую генерируются из каналов понижающего микширования.
Например, может использоваться следующая формула:
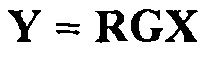 , где
, где 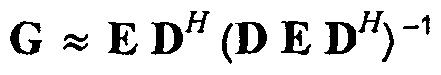 .
.
В принципе, информация воспроизведения R может запрашивать любую комбинацию исходных сигналов аудиообъектов. На практике, однако, восстановления объектов могут содержать ошибки восстановления и запрошенная выходная сцена может не необходимо достигаться. Как грубое общее правило, охватывающее много практических случаев, чем больше запрошенная выходная сцена отличается от микшированного с понижением сигнала, тем больше будет слышимых ошибок восстановления.
В последующем, описывается улучшение диалогов (DE). Технология SAOC может, например, использоваться, чтобы реализовывать сценарий. Следует отметить, что даже хотя название "Улучшение диалогов" подсказывает сосредоточение на ориентированных на диалоги сигналах, тот же принцип может использоваться с другими типами сигналов, также.
В сценарии DE, степени свободы в системе ограничены от общего случая.
Например, сигналы аудиообъектов 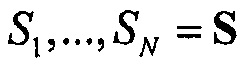 группируются (и возможно микшируются) в два метаобъекта из объекта переднего плана (FGO) SFGO и объекта заднего плана (BGO) SBGO.
группируются (и возможно микшируются) в два метаобъекта из объекта переднего плана (FGO) SFGO и объекта заднего плана (BGO) SBGO.
Более того, выходная сцена 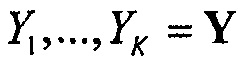 имеет сходство с микшированным с понижением сигналом
имеет сходство с микшированным с понижением сигналом 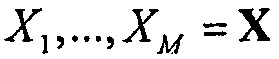 . Более конкретно, оба сигнала имеют одни и те же размерности, то есть K=M, и конечный пользователь может управлять только относительными уровнями микширования упомянутых двух метаобъектов FGO и BGO. Чтобы быть более точными, микшированный с понижением сигнал получается посредством микширования FGO и BGO с некоторыми скалярными весами
. Более конкретно, оба сигнала имеют одни и те же размерности, то есть K=M, и конечный пользователь может управлять только относительными уровнями микширования упомянутых двух метаобъектов FGO и BGO. Чтобы быть более точными, микшированный с понижением сигнал получается посредством микширования FGO и BGO с некоторыми скалярными весами

и выходная сцена получается аналогично с некоторым скалярным взвешиванием FGO и BGO:

В зависимости от относительных значений весов микширования, баланс между FGO и BGO может изменяться. Например, с помощью установки
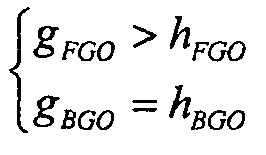
является возможным увеличивать относительный уровень FGO в результате микширования. Если FGO является диалогом, эта установка обеспечивает функциональную возможность улучшения диалога.
В качестве примера случая использования, BGO может быть шумами стадиона и другим звуком заднего плана в течение события спортивных состязаний и FGO является речью комментатора. Функциональная возможность DE обеспечивает возможность конечному пользователю усиливать или ослаблять уровень комментатора по отношению к заднему плану.
Варианты осуществления основываются на обнаружении того, что использование технологии SAOC (или аналогичной) в сценарии широковещания обеспечивает возможность обеспечения конечного пользователя функциональной возможностью расширенного манипулирования сигналами. Обеспечивается больше функциональных возможностей, чем только изменение канала и регулировка уровня громкости проигрывания.
Одна возможность использовать технологию DE кратко описана выше. Если широковещательный сигнал, который является микшированным с понижением сигналом для SAOC, нормализован по уровню, например, согласно R128, разные программы имеют сходную среднюю громкость, когда никакая (SAOC-)обработка не применяется (или описание воспроизведения является таким же как описание понижающего микширования). Однако, когда некоторая (SAOC-)обработка применяется, выходной сигнал отличается от устанавливаемого по умолчанию микшированного с понижением сигнала и громкость выходного сигнала может отличаться от громкости устанавливаемого по умолчанию микшированного с понижением сигнала. С точки зрения конечного пользователя, это может вести к ситуации, в которой громкость выходного сигнала между каналами или программами может снова иметь нежелательные скачки или различия. Другими словами, преимущества нормализации, применяемой вещательной компанией, частично теряются.
Эта проблема не является специфичной только для SAOC или для сценария DE, но может возникать также с другими концепциями кодирования аудио, которые обеспечивают возможность конечному пользователю взаимодействовать с контентом. Однако во многих случаях это не причиняет какого-либо вреда, если выходной сигнал имеет другую громкость, нежели устанавливаемое по умолчанию понижающее микширование.
Как указывалось ранее, полная громкость программы входного аудиосигнала должна равняться определенному уровню с малыми разрешенными отклонениями. Однако как уже очерчено, это ведет к значительным проблемам, когда выполняется воспроизведение аудио, так как воспроизведение может иметь значительное влияние на общую/полную громкость принятого входного аудиосигнала. Однако, несмотря на выполнение воспроизведения сцены, полная громкость принятого аудиосигнала должна оставаться одной и той же.
Одним подходом будет оценивать громкость сигнала пока он проигрывается, и с соответствующей концепцией временной интеграции, оценка может сходиться к истинной средней громкости после некоторого времени. Время, требуемое для сходимости, является, однако, проблематичным с точки зрения конечного пользователя. Когда оценка громкости изменяется, даже когда никакие изменения не применяются на сигнале, компенсация изменения громкости должна также реагировать и изменять свое поведение. Это ведет к выходному сигналу с изменяющейся по времени средней громкостью, которая может восприниматься как достаточно раздражающая.
Фиг.6 иллюстрирует поведение оценок громкости выходного сигнала при изменении громкости. Среди прочего, изображена основывающаяся на сигналах оценка громкости выходного сигнала, которая иллюстрирует эффект решения, как только что описано. Оценка приближается к корректной оценке достаточно медленно. Вместо основывающейся на сигналах оценки громкости выходного сигнала, была бы предпочтительной информированная оценка громкости выходного сигнала, которая немедленно корректно определяет громкость выходного сигнала.
В частности, на фиг.6, пользовательский ввод, например, уровень объекта диалога, изменяется в момент времени T посредством увеличения в значении. Истинный уровень выходного сигнала, и соответствующим образом громкость, изменяется в один и тот же момент времени. Когда оценка громкости выходного сигнала выполняется из выходного сигнала с некоторым временем временной интеграции, оценка изменяется постепенно и достигает корректного значения после некоторой задержки. В течение этой задержки, значения оценки изменяются и не могут надежно использоваться для дополнительной обработки выходного сигнала, например, для коррекции уровня громкости.
Как уже указывалось, было бы желательным иметь точную оценку выходной средней громкости или изменения в средней громкости без задержки, и когда программа не изменяется или сцена воспроизведения не изменяется, оценка средней громкости также должна оставаться статической. Другими словами, когда применяется некоторая компенсация изменения громкости, параметр компенсации должен изменяться, только когда либо изменяется программа, либо имеется некоторое взаимодействие с пользователем.
Требуемое поведение проиллюстрировано на самой нижней иллюстрации из фиг.6 (информированная оценка громкости выходного сигнала). Оценка громкости выходного сигнала должна изменяться немедленно, когда пользовательский ввод изменяется.
Фиг.2 иллюстрирует кодер согласно одному варианту осуществления.
Кодер содержит блок 210 основывающегося на объектах кодирования для кодирования множества сигналов аудиообъектов, чтобы получать кодированный аудиосигнал, содержащий множество сигналов аудиообъектов.
Дополнительно, кодер содержит блок 220 кодирования громкости объектов для кодирования информации громкости о сигналах аудиообъектов. Информация громкости содержит одно или более значений громкости, при этом каждое из упомянутых одного или более значений громкости зависит от одного или более из сигналов аудиообъектов.
Согласно одному варианту осуществления, каждый из сигналов аудиообъектов из кодированного аудиосигнала назначается в точности одной группе из двух или более групп, при этом каждая из упомянутых двух или более групп содержит один или более из сигналов аудиообъектов из кодированного аудиосигнала. Блок 220 кодирования громкости объектов сконфигурирован с возможностью определять упомянутые одно или более значений громкости из информации громкости посредством определения значения громкости для каждой группы из упомянутых двух или более групп, при этом упомянутое значение громкости упомянутой группы указывает исходную полную громкость упомянутых одного или более сигналов аудиообъектов из упомянутой группы.
Фиг.1 иллюстрирует декодер для генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов согласно одному варианту осуществления.
Декодер содержит интерфейс 110 приема для приема входного аудиосигнала, содержащего множество сигналов аудиообъектов, для приема информации громкости о сигналах аудиообъектов, и для приема информации воспроизведения, указывающей, должен ли один или более из сигналов аудиообъектов усиливаться или ослабляться.
Более того, декодер содержит сигнальный процессор 120 для генерирования упомянутых одного или более выходных аудиоканалов выходного аудиосигнала. Сигнальный процессор 120 сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения. Дополнительно, сигнальный процессор 120 сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости.
Согласно одному варианту осуществления, сигнальный процессор 110 сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости, так что громкость выходного аудиосигнала равняется громкости входного аудиосигнала, или так что громкость выходного аудиосигнала является более близкой к громкости входного аудиосигнала, чем громкость модифицированного аудиосигнала, который бы проистекал из модификации входного аудиосигнала посредством усиления или ослабления сигналов аудиообъектов входного аудиосигнала согласно информации воспроизведения.
Согласно другому варианту осуществления, каждый из сигналов аудиообъектов входного аудиосигнала назначается в точности одной группе из двух или более групп, при этом каждая из упомянутых двух или более групп содержит один или более из сигналов аудиообъектов входного аудиосигнала.
В таком варианте осуществления, интерфейс 110 приема сконфигурирован с возможностью принимать значение громкости для каждой группы из упомянутых двух или более групп в качестве информации громкости, при этом упомянутое значение громкости указывает исходную полную громкость упомянутых одного или более сигналов аудиообъектов из упомянутой группы. Дополнительно, интерфейс 110 приема сконфигурирован с возможностью принимать информацию воспроизведения, указывающую для, по меньшей мере, одной группы из упомянутых двух или более групп, должны ли упомянутые один или более сигналов аудиообъектов из упомянутой группы усиливаться или ослабляться, посредством указания модифицированной полной громкости упомянутых одного или более сигналов аудиообъектов из упомянутой группы. Более того, в таком варианте осуществления, сигнальный процессор 120 сконфигурирован с возможностью определять значение компенсации громкости в зависимости от модифицированной полной громкости каждой из упомянутой, по меньшей мере, одной группы из упомянутых двух или более групп и в зависимости от исходной полной громкости каждой из упомянутых двух или более групп. Дополнительно, сигнальный процессор 120 сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от модифицированной полной громкости каждой из упомянутой, по меньшей мере, одной группы из упомянутых двух или более групп и в зависимости от значения компенсации громкости.
В конкретных вариантах осуществления, по меньшей мере, одна группа из упомянутых двух или более групп содержит два или более из сигналов аудиообъектов.
Существует прямое отношение между энергией 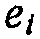 сигнала аудиообъекта i и громкостью
сигнала аудиообъекта i и громкостью 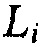 сигнала аудиообъекта i согласно формулам:
сигнала аудиообъекта i согласно формулам:
 ,
,
где c является постоянным значением.
Варианты осуществления основываются на следующих обнаружениях: Разные сигналы аудиообъектов входного аудиосигнала могут иметь разную громкость и, таким образом, разную энергию. Если, например, пользователь хочет увеличить громкость одного из сигналов аудиообъектов, информация воспроизведения может соответствующим образом регулироваться, и увеличение громкости этого сигнала аудиообъекта увеличивает энергию этого аудиообъекта. Это ведет к увеличенной громкости выходного аудиосигнала. Чтобы удерживать полную громкость постоянной, должна выполняться компенсация громкости. Другими словами, модифицированный аудиосигнал, который бы проистекал из применения информации воспроизведения на входном аудиосигнале, должен регулироваться. Однако точное влияние усиления одного из сигналов аудиообъектов на полную громкость модифицированного аудиосигнала зависит от исходной громкости усиленного сигнала аудиообъекта, например, сигнала аудиообъекта, громкость которого увеличивается. Если исходная громкость этого объекта соответствует энергии, которая была достаточно низкой, влияние на полную громкость входного аудиосигнала будет незначительным. Если, однако, исходная громкость этого объекта соответствует энергии, которая была достаточно высокой, влияние на полную громкость входного аудиосигнала будет значительным.
Можно рассмотреть два примера. В обоих примерах, входной аудиосигнал содержит два сигнала аудиообъектов, и в обоих примерах, посредством применения информации воспроизведения, энергия первого одного из сигналов аудиообъектов увеличивается на 50%.
В первом примере, первый сигнал аудиообъекта вносит 20% и второй сигнал аудиообъекта вносит 80% в полную энергию входного аудиосигнала. Однако во втором примере, первый аудиообъект, первый сигнал аудиообъекта вносит 40% и второй сигнал аудиообъекта вносит 60% в полную энергию входного аудиосигнала. В обоих примерах эти вклады могут получаться из информации громкости о сигналах аудиообъектов, так как существует прямое отношение между громкостью и энергией.
В первом примере, увеличение, равное 50% энергии первого аудиообъекта, дает результатом то, что модифицированный аудиосигнал, который генерируется посредством применения информации воспроизведения на входном аудиосигнале, имеет полную энергию 1,5×20%+80%=110% энергии входного аудиосигнала.
Во втором примере, увеличение, равное 50% энергии первого аудиообъекта, дает результатом то, что модифицированный аудиосигнал, который генерируется посредством применения информации воспроизведения на входном аудиосигнале, имеет полную энергию 1,5×40%+60%=120% энергии входного аудиосигнала.
Таким образом, после применения информации воспроизведения на входном аудиосигнале, в первом примере, полная энергия модифицированного аудиосигнала должна уменьшаться только на 9% (10/110), чтобы получать равную энергию и во входном аудиосигнале, и в выходном аудиосигнале, в то время как во втором примере, полная энергия модифицированного аудиосигнала должна уменьшаться на 17% (20/120). Для этой цели, может вычисляться значение компенсации громкости.
Например, значение компенсации громкости может быть скаляром, который применяется на всех выходных аудиоканалах выходного аудиосигнала.
Согласно одному варианту осуществления, сигнальный процессор сконфигурирован с возможностью генерировать модифицированный аудиосигнал посредством модификации входного аудиосигнала посредством усиления или ослабления сигналов аудиообъектов входного аудиосигнала согласно информации воспроизведения. Более того, сигнальный процессор сконфигурирован с возможностью генерировать выходной аудиосигнал посредством применения значения компенсации громкости на модифицированном аудиосигнале, так что громкость выходного аудиосигнала равняется громкости входного аудиосигнала, или так что громкость выходного аудиосигнала является более близкой к громкости входного аудиосигнала, чем громкость модифицированного аудиосигнала.
Например, в первом примере выше, значение компенсации громкости lcv, может, например, устанавливаться на значение lcv=10/11, и коэффициент умножения, равный 10/11, может применяться на всех каналах, которые проистекают из воспроизведения входных аудиоканалов согласно информации воспроизведения.
Соответственно, например, во втором примере выше, значение компенсации громкости lcv, может, например, устанавливаться на значение lcv=10/12=5/6, и коэффициент умножения, равный 5/6, может применяться на всех каналах, которые проистекают из воспроизведения входных аудиоканалов согласно информации воспроизведения.
В других вариантах осуществления, каждый из сигналов аудиообъектов может назначаться одной из множества групп, и для каждой из групп может передаваться значение громкости, указывающее значение полной громкости сигналов аудиообъектов из упомянутой группы. Если информация воспроизведения определяет то, что энергия одной из групп ослабляется или усиливается, например, усиливается на 50%, как показано выше, увеличение полной энергии может вычисляться и значение компенсации громкости может определяться, как описано выше.
Например, согласно одному варианту осуществления, каждый из сигналов аудиообъектов входного аудиосигнала назначается в точности одной группе из в точности двух групп как упомянутые две или более группы. Каждый из сигналов аудиообъектов входного аудиосигнала назначается либо группе объектов переднего плана из упомянутых в точности двух групп, либо группе объектов заднего плана из упомянутых в точности двух групп. Интерфейс 110 приема сконфигурирован с возможностью принимать исходную полную громкость упомянутых одного или более сигналов аудиообъектов из группы объектов переднего плана. Более того, интерфейс 110 приема сконфигурирован с возможностью принимать исходную полную громкость упомянутых одного или более сигналов аудиообъектов из группы объектов заднего плана. Дополнительно, интерфейс 110 приема сконфигурирован с возможностью принимать информацию воспроизведения, указывающую для, по меньшей мере, одной группы из упомянутых в точности двух групп, должны ли упомянутые один или более сигналов аудиообъектов из каждой из упомянутой, по меньшей мере, одной группы усиливаться или ослабляться, посредством указания модифицированной полной громкости упомянутых одного или более сигналов аудиообъектов из упомянутой группы.
В таком варианте осуществления, сигнальный процессор 120 сконфигурирован с возможностью определять значение компенсации громкости в зависимости от модифицированной полной громкости каждой из упомянутой, по меньшей мере, одной группы, в зависимости от исходной полной громкости упомянутых одного или более сигналов аудиообъектов из группы объектов переднего плана, и в зависимости от исходной полной громкости упомянутых одного или более сигналов аудиообъектов из группы объектов заднего плана. Более того, сигнальный процессор 120 сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от модифицированной полной громкости каждой из упомянутой, по меньшей мере, одной группы и в зависимости от значения компенсации громкости.
Согласно некоторым вариантам осуществления, каждый из сигналов аудиообъектов назначается одной из трех или более групп, и интерфейс приема может быть сконфигурирован с возможностью принимать значение громкости для каждой из упомянутых трех или более групп, указывающих полную громкость сигналов аудиообъектов из упомянутой группы.
Согласно одному варианту осуществления, чтобы определять значение полной громкости двух или более сигналов аудиообъектов, например, определяется значение энергии, соответствующее значению громкости, для каждого сигнала аудиообъекта, значения энергии всех значений громкости складываются, чтобы получить сумму энергий, и значение громкости, соответствующее сумме энергий, определяется как значение полной громкости упомянутых двух или более сигналов аудиообъектов. Например, может использоваться формула
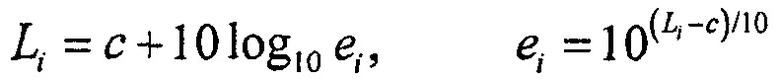 .
.
В некоторых вариантах осуществления, значения громкости передаются для каждого из сигналов аудиообъектов, или каждый из сигналов аудиообъектов назначается одной или двум или более группам, при этом для каждой из групп, передается значение громкости.
Однако в некоторых вариантах осуществления, для одного или более сигналов аудиообъектов или для одной или более из групп, содержащих сигналы аудиообъектов, никакое значение громкости не передается. Вместо этого, декодер может, например, предполагать, что эти сигналы аудиообъектов или группы сигналов аудиообъектов, для которых никакое значение громкости не передается, имеют предварительно определенное значение громкости. Декодер может, например, основывать все дополнительные определения на этом предварительно определенном значении громкости.
Согласно одному варианту осуществления, интерфейс 110 приема сконфигурирован с возможностью принимать микшированный с понижением сигнал, содержащий один или более каналов понижающего микширования, в качестве входного аудиосигнала, при этом упомянутые один или более каналов понижающего микширования содержат сигналы аудиообъектов, и при этом количество сигналов аудиообъектов меньше, чем количество упомянутых одного или более каналов понижающего микширования. Интерфейс 110 приема сконфигурирован с возможностью принимать информацию понижающего микширования, указывающую то, как сигналы аудиообъектов микшированы внутри упомянутых одного или более каналов понижающего микширования. Более того, сигнальный процессор 120 сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации понижающего микширования, в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости. В одном конкретном варианте осуществления, сигнальный процессор 120 может, например, быть сконфигурирован с возможностью вычислять значение компенсации громкости в зависимости от информации понижающего микширования.
Например, информация понижающего микширования может быть матрицей понижающего микширования. В вариантах осуществления, декодер может быть декодером SAOC. В таких вариантах осуществления, интерфейс 110 приема может, например, быть дополнительно сконфигурирован с возможностью принимать ковариационную информацию, например, ковариационную матрицу, как описано выше.
По отношению к информации воспроизведения, указывающей, должен ли один или более из сигналов аудиообъектов усиливаться или ослабляться, следует отметить, что, например, информация, которая указывает то, как один или более из сигналов аудиообъектов должны усиливаться или ослабляться, является информацией воспроизведения. Например, матрица воспроизведения R, например, матрица воспроизведения из SAOC, является информацией воспроизведения.
Фиг.3 иллюстрирует систему согласно одному варианту осуществления.
Система содержит кодер 310 согласно одному из вышеописанных вариантов осуществления для кодирования множества сигналов аудиообъектов, чтобы получать кодированный аудиосигнал, содержащий множество сигналов аудиообъектов.
Дополнительно, система содержит декодер 320 согласно одному из вышеописанных вариантов осуществления для генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов. Декодер сконфигурирован с возможностью принимать кодированный аудиосигнал в качестве входного аудиосигнала и информацию громкости. Более того, декодер 320 сконфигурирован с возможностью дополнительно принимать информацию воспроизведения. Дополнительно, декодер 320 сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения. Более того, декодер 320 сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости.
Фиг.7 иллюстрирует информированную оценку громкости согласно одному варианту осуществления. На левой стороне транспортного потока 730, проиллюстрированы компоненты кодера основывающегося на объектах кодирования аудио. В частности, проиллюстрированы блок 710 основывающегося на объектах кодирования ("основывающийся на объектах аудиокодер") и блок 720 кодирования громкости объектов ("модуль оценки громкости объектов").
Сам транспортный поток 730 содержит информацию громкости L, информацию понижающего микширования D и вывод основывающегося на объектах аудиокодера 710 B.
На правой стороне транспортного потока 730, проиллюстрированы компоненты сигнального процессора декодера основывающегося на объектах кодирования аудио. Интерфейс приема декодера не проиллюстрирован. Изображены модуль 740 оценки выходной громкости и блок 750 основывающегося на объектах декодирования аудио. Модуль 740 оценки выходной громкости может быть сконфигурирован с возможностью определять значение компенсации громкости. Блок 750 основывающегося на объектах декодирования аудио может быть сконфигурирован с возможностью определять модифицированный аудиосигнал из аудиосигнала, который вводится в декодер, посредством применения информации воспроизведения R. Применение значения компенсации громкости на модифицированном аудиосигнале, чтобы компенсировать изменение полной громкости, вызываемое воспроизведением, на фиг.7 не показано.
Ввод в кодер состоит из входных объектов S как минимум. Система оценивает громкость каждого объекта (или некоторую другую относящуюся к громкости информацию, такую как энергия объектов), например, посредством блока 720 кодирования громкости объектов, и эта информация L передается и/или сохраняется. (Является также возможным, что громкость объектов обеспечивается в качестве ввода в систему, и этап оценки внутри системы может пропускаться).
В варианте осуществления из фиг.7, декодер принимает, по меньшей мере, информацию громкости объектов и, например, информацию воспроизведения R, описывающую микширование объектов в выходной сигнал. На основе этого, например, модуль 740 оценки выходной громкости, оценивает громкость выходного сигнала и обеспечивает эту информацию в качестве своего вывода.
Информация понижающего микширования D может обеспечиваться в качестве информации воспроизведения, в этом случае оценка громкости обеспечивает оценку громкости микшированного с понижением сигнала. Является также возможным обеспечивать информацию понижающего микширования в качестве ввода в модуль оценки громкости объектов, и передавать и/или сохранять ее вместе с информацией громкости объектов. Модель оценки выходной громкости может затем оценивать одновременно громкость микшированного с понижением сигнала и воспроизводимого вывода и обеспечивать эти два значения или их разность в качестве выходной информации громкости. Значение разности (или его обратное) описывает требуемую компенсацию, которая должна применяться на воспроизводимом выходном сигнале, чтобы делать его громкость аналогичной громкости микшированного с понижением сигнала. Информация громкости объектов может дополнительно включать в себя информацию относительно коэффициентов корреляции между различными объектами и эта корреляционная информация может использоваться в оценке выходной громкости для более точной оценки.
В последующем, описывается один предпочтительный вариант осуществления для применения улучшения диалогов.
В применении улучшения диалогов, как описано выше, входные сигналы аудиообъектов группируются и частично микшируются с понижением, чтобы формировать два метаобъекта, FGO и BGO, которые могут затем тривиально суммироваться для получения окончательного микшированного с понижением сигнала.
Следуя описанию SAOC [SAOC], N входных сигналов объектов представляются как матрица S размера N×NSamples, и информация понижающего микширования как матрица D размера M×N. Микшированные с понижением сигналы могут затем получаться как 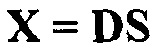 .
.
Информация понижающего микширования D может теперь разделяться на две части
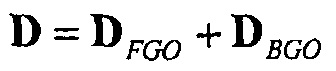
для метаобъектов.
Так как каждый столбец матрицы D соответствует исходному сигналу аудиообъекта, упомянутые две составляющие матрицы понижающего микширования могут получаться посредством установки столбцов, которые соответствуют другому метаобъекту, на ноль (при предположении, что никакой исходный объект не может присутствовать в обоих метаобъектах). Другими словами, столбцы, соответствующие метаобъекту BGO устанавливаются на ноль в DFGO, и наоборот.
Эти новые матрицы понижающего микширования описывают способ, с помощью которого упомянутые два метаобъекта могут получаться из входных объектов, именно:
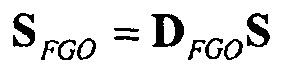 и
и  ,
,
и фактическое понижающее микширование упрощается до
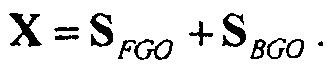
Также может рассматриваться, что декодер объектов (например, SAOC) пытается восстанавливать метаобъекты:
 и
и  ,
,
и специфичное для DE воспроизведение может быть записано как комбинация этих двух восстановлений метаобъектов:
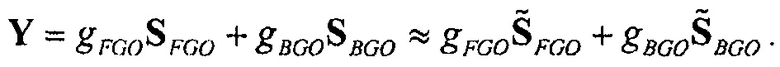
Модуль оценки громкости объектов принимает упомянутые два метаобъекта  и
и  в качестве ввода и оценивает громкость каждого из них:
в качестве ввода и оценивает громкость каждого из них: 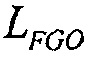 является (полной/общей) громкостью для
является (полной/общей) громкостью для  , и
, и 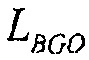 является (полной/общей) громкостью для
является (полной/общей) громкостью для 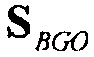 . Эти значения громкости передаются и/или сохраняются.
. Эти значения громкости передаются и/или сохраняются.
В качестве альтернативы, с использованием одного из метаобъектов, например, FGO, в качестве эталона, является возможным вычислять различие громкости этих двух объектов, например, как
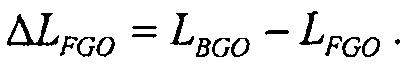
Это одиночное значение затем передается и/или сохраняется.
Фиг.8 иллюстрирует кодер согласно другому варианту осуществления. Кодер из фиг.8 содержит модуль 811 понижающего микширования объектов и модуль 812 оценки вспомогательной информации объектов. Дополнительно, кодер из фиг.8 дополнительно содержит блок 820 кодирования громкости объектов. Более того, кодер из фиг.8 содержит модуль 805 микширования метааудиообъектов.
Кодер из фиг.8 использует промежуточные аудиометаобъекты в качестве ввода в модуль оценки громкости объектов. В вариантах осуществления, кодер из фиг.8 может быть сконфигурирован с возможностью генерировать два аудиометаобъекта. В других вариантах осуществления, кодер из фиг.8 может быть сконфигурирован с возможностью генерировать три или более аудиометаобъектов.
Среди прочего, обеспеченные концепции обеспечивают новую функциональную возможность, состоящую в том, что кодер может, например, оценивать среднюю громкость всех входных объектов. Объекты могут, например, микшироваться в микшированный с понижением сигнал, который передается. Обеспеченные концепции, более того, обеспечивают новую функциональную возможность, состоящую в том, что громкость объектов и информация понижающего микширования может, например, включаться во вспомогательную информацию кодирования объектов, которая передается.
Декодер может, например, использовать вспомогательную информацию кодирования объектов для (виртуального) разделения объектов и заново комбинирует объекты с использованием информации воспроизведения.
Дополнительно, обеспеченные концепции обеспечивают новую функциональную возможность, состоящую в том, что также информация понижающего микширования может использоваться, чтобы оценивать громкость устанавливаемого по умолчанию микшированного с понижением сигнала, информация воспроизведения и принятая громкость объектов могут использоваться для оценки средней громкости выходного сигнала, и/или изменение громкости может оцениваться из этих двух значений. Или, может использоваться информация понижающего микширования и воспроизведения, чтобы оценивать изменение громкости из устанавливаемого по умолчанию понижающего микширования, другая новая функциональная возможность обеспеченных концепций.
Дополнительно, обеспеченные концепции обеспечивают новую функциональную возможность, состоящую в том, что вывод декодера может модифицироваться, чтобы компенсировать изменение в громкости, так что средняя громкость модифицированного сигнала соответствует средней громкости устанавливаемого по умолчанию понижающего микширования.
Конкретный вариант осуществления, относящийся к SAOC-DE, проиллюстрирован на фиг.9. Система принимает входные сигналы аудиообъектов, информацию понижающего микширования, и информацию группирования объектов в метаобъекты. На основе этого, модуль 905 микширования метааудиообъектов формирует упомянутые два метаобъекта  и
и  . Является возможным, что часть сигнала, который обрабатывается с помощью SAOC, не составляет весь сигнал. Например, в конфигурации каналов 5.1, SAOC может развертываться на поднаборе каналов, как, например, на фронтальном канале (левом, правом, и центральном), в то время как другие каналы (левый объемного звука, правый объемного звука, и низкочастотных эффектов) маршрутизируются в обход, (посредством обхода) SAOC и доставляются как таковые. Эти каналы, не обрабатываемые посредством SAOC, обозначаются с помощью
. Является возможным, что часть сигнала, который обрабатывается с помощью SAOC, не составляет весь сигнал. Например, в конфигурации каналов 5.1, SAOC может развертываться на поднаборе каналов, как, например, на фронтальном канале (левом, правом, и центральном), в то время как другие каналы (левый объемного звука, правый объемного звука, и низкочастотных эффектов) маршрутизируются в обход, (посредством обхода) SAOC и доставляются как таковые. Эти каналы, не обрабатываемые посредством SAOC, обозначаются с помощью 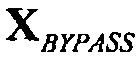 . Возможные обходные каналы должны обеспечиваться для кодера для более точной оценки информации громкости.
. Возможные обходные каналы должны обеспечиваться для кодера для более точной оценки информации громкости.
Обходные каналы могут обрабатываться различными способами.
Например, обходные каналы могут, например, формировать независимый метаобъект. Это обеспечивает возможность определения воспроизведения так, что все три метаобъекта масштабируются независимо.
Или, например, обходные каналы могут, например, комбинироваться с одним из других двух метаобъектов. Настройки воспроизведения этого метаобъекта управляют также частью обходного канала. Например, в сценарии улучшения диалогов, может иметь смысл комбинировать обходные каналы с метаобъектом заднего плана:  .
.
Или, например, обходные каналы могут, например, игнорироваться.
Согласно вариантам осуществления, блок 210 основывающегося на объектах кодирования кодера сконфигурирован с возможностью принимать сигналы аудиообъектов, при этом каждый из сигналов аудиообъектов назначается в точности одной из в точности двух групп, при этом каждая из упомянутых в точности двух групп содержит один или более из сигналов аудиообъектов. Более того, блок 210 основывающегося на объектах кодирования сконфигурирован с возможностью микшировать с понижением сигналы аудиообъектов, которые содержатся в упомянутых в точности двух группах, чтобы получать микшированный с понижением сигнал, содержащий один или более аудиоканалов понижающего микширования в качестве кодированного аудиосигнала, при этом количество упомянутых одного или более каналов понижающего микширования меньше, чем количество сигналов аудиообъектов, которые содержатся в упомянутых в точности двух группах. Блок 220 кодирования громкости объектов предназначен, чтобы принимать один или более дополнительных обходных сигналов аудиообъектов, при этом каждый из упомянутых одного или более дополнительных обходных сигналов аудиообъектов назначается третьей группе, при этом каждый из упомянутых одного или более дополнительных обходных сигналов аудиообъектов не содержится в первой группе и не содержится во второй группе, при этом блок 210 основывающегося на объектах кодирования сконфигурирован с возможностью не микшировать с понижением упомянутые один или более дополнительные обходные сигналы аудиообъектов внутри микшированного с понижением сигнала.
В одном варианте осуществления, блок 220 кодирования громкости объектов сконфигурирован с возможностью определять первое значение громкости, второе значение громкости и третье значение громкости из информации громкости, при этом первое значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из первой группы, при этом второе значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из второй группы, и при этом третье значение громкости указывает полную громкость упомянутых одного или более дополнительных обходных сигналов аудиообъектов из третьей группы. В одном другом варианте осуществления, блок 220 кодирования громкости объектов сконфигурирован с возможностью определять первое значение громкости и второе значение громкости из информации громкости, при этом первое значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из первой группы, и при этом второе значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из второй группы и упомянутых одного или более дополнительных обходных сигналов аудиообъектов из третьей группы.
Согласно одному варианту осуществления, интерфейс 110 приема декодера сконфигурирован с возможностью принимать микшированный с понижением сигнал. Более того, интерфейс 110 приема сконфигурирован с возможностью принимать один или более дополнительных обходных сигналов аудиообъектов, при этом упомянутые один или более дополнительных обходных сигналов аудиообъектов не микшированы внутри микшированного с понижением сигнала. Дополнительно, интерфейс 110 приема сконфигурирован с возможностью принимать информацию громкости, указывающую информацию о громкости сигналов аудиообъектов, которые микшированы внутри микшированного с понижением сигнала, и указывающую информацию о громкости упомянутых одного или более дополнительных обходных сигналов аудиообъектов, которые не микшированы внутри микшированного с понижением сигнала. Более того, сигнальный процессор 120 сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации о громкости сигналов аудиообъектов, которые микшированы внутри микшированного с понижением сигнала, и в зависимости от информации о громкости упомянутых одного или более дополнительных обходных сигналов аудиообъектов, которые не микшированы внутри микшированного с понижением сигнала.
Фиг.9 иллюстрирует кодер и декодер согласно одному варианту осуществления, относящемуся к SAOC-DE, который содержит обходные каналы. Среди прочего, кодер из фиг.9 содержит кодер 902 SAOC.
В варианте осуществления из фиг.9, возможное комбинирование обходных каналов с другими метаобъектами происходит в двух блоках 913, 914 "добавления обходных сигналов", вырабатывающих метаобъекты 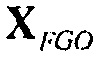 и
и  с включением туда определенных частей из обходных каналов.
с включением туда определенных частей из обходных каналов.
Воспринимаемая громкость  ,
,  , и
, и  обоих из этих метаобъектов оцениваются в блоках 921, 922, 923 оценки громкости. Эта информация громкости затем преобразуется в соответствующее кодирование в модуле 925 оценки информации громкости метаобъектов и затем передается и/или сохраняется.
обоих из этих метаобъектов оцениваются в блоках 921, 922, 923 оценки громкости. Эта информация громкости затем преобразуется в соответствующее кодирование в модуле 925 оценки информации громкости метаобъектов и затем передается и/или сохраняется.
Фактические кодер и декодер SAOC работают как ожидаемое извлечение вспомогательной информации объектов из объектов, создание микшированного с понижением сигнала X, и передача и/или сохранение информации в декодере. Возможные обходные каналы передаются и/или сохраняются вместе с другой информацией в декодере.
Декодер 945 SAOC-DE принимает значение усиления "Усиление диалога" в качестве пользовательского ввода. На основе этого ввода и принятой информации понижающего микширования, декодер 945 SAOC определяет информацию воспроизведения. Декодер 945 SAOC затем вырабатывает воспроизводимую выходную сцену как сигнал Y. В дополнение к этому, он вырабатывает коэффициент усиления (и значение задержки), который должен применяться на возможных обходных сигналах XBYPASS.
Блок 955 "добавления обходных сигналов" принимает эту информацию вместе с воспроизводимой выходной сценой и обходными сигналами и создает полный выходной сигнал сцены. Декодер 945 SAOC вырабатывает также набор значений усилений метаобъектов, при этом их количество зависит от группирования метаобъектов и требуемой формы информации громкости.
Значения усиления обеспечиваются в модуль 960 оценки громкости результата микширования, который также принимает информацию громкости метаобъектов от кодера.
Модуль 960 оценки громкости результата микширования затем способен определять требуемую информацию громкости, которая может включать в себя, но не ограничена этим, громкость микшированного с понижением сигнала, громкость воспроизводимой выходной сцены, и/или различие в громкости между микшированным с понижением сигналом и воспроизводимой выходной сценой.
В некоторых вариантах осуществления, информация громкости сама является достаточной, в то время как в других вариантах осуществления, является желательным обрабатывать полный вывод в зависимости от определенной информации громкости. Эта обработка может, например, быть компенсацией любого возможного различия в громкости между микшированным с понижением сигналом и воспроизводимой выходной сценой. Такая обработка, например, посредством блока 970 обработки громкости, будет иметь смысл в сценарии широковещания, так как она будет уменьшать изменения в воспринимаемой громкости сигнала независимо от взаимодействия с пользователем (установки введенного "усиления диалога").
Относящаяся к громкости обработка в этом конкретном варианте осуществления содержит множество новых функциональных возможностей. Среди прочего, FGO, BGO, и возможные обходные каналы подвергаются предварительному микшированию в окончательную конфигурацию каналов, так что понижающее микширование может осуществляться посредством простого сложения упомянутых двух подвергнутых предварительному микшированию сигналов вместе (например, коэффициентов матриц понижающего микширования, равных 1), что составляет новую функциональную возможность. Более того, в качестве дополнительной новой функциональной возможности, оцениваются средние громкости FGO и BGO, и вычисляется разность. Дополнительно, объекты микшируются в микшированный с понижением сигнал, который передается. Более того, в качестве дополнительной новой функциональной возможности, информация различия в громкости включается во вспомогательную информацию, которая передается. (новое) Дополнительно, декодер использует вспомогательную информацию для (виртуального) разделения объектов и заново комбинирует объекты с использованием информации воспроизведения, которая основывается на информации понижающего микширования и усилении модификации пользовательского ввода. Более того, в качестве другой новой функциональной возможности, декодер использует усиление модификации и переданную информацию громкости для оценки изменения в средней громкости вывода системы по сравнению с устанавливаемым по умолчанию понижающим микшированием.
В последующем, обеспечивается формальное описание вариантов осуществления.
При предположении, что значения громкости объектов ведут себя аналогично логарифму значений энергии, когда объекты суммируются, то есть значения громкости должны преобразовываться в линейную область, складываться там, и в заключение преобразовываться назад в логарифмическую область. Теперь будет представлена мотивация этого через определение BS.1770 меры громкости (для простоты, количество каналов устанавливается равным единице, но такой же принцип может применяться на многоканальных сигналах с подходящим суммированием по каналам).
Громкость i-ого K-фильтрованного сигнала zi со среднеквадратичной энергией ei определяется как
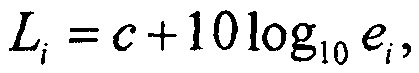
где c является константой смещения. Например, c может быть -0,691. Из этого следует, что энергия сигнала может определяться из громкости с помощью
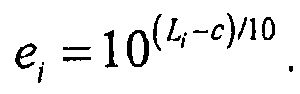
Энергия суммы N некоррелированных сигналов 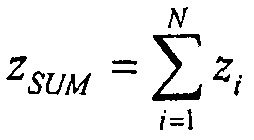 тогда
тогда
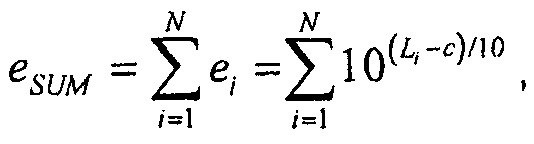
и громкость этого сигнала суммы тогда
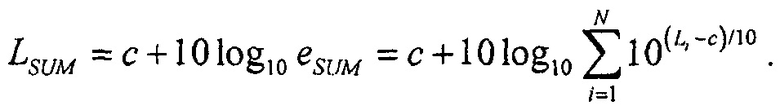
Если сигналы не являются некоррелироваными, коэффициенты корреляции Ci,j должны учитываться при приближении энергии сигнала суммы как

где взаимная энергия ei,j между i-ым и j-ым объектами определяется как
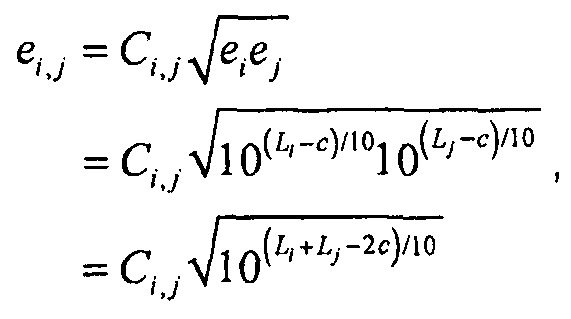 ,
,
где  является коэффициентом корреляции между упомянутыми двумя объектами i и j. Когда два объекта являются некоррелированными, коэффициент корреляции равняется 0, и когда упомянутые два объекта являются идентичными, коэффициент корреляции равняется 1.
является коэффициентом корреляции между упомянутыми двумя объектами i и j. Когда два объекта являются некоррелированными, коэффициент корреляции равняется 0, и когда упомянутые два объекта являются идентичными, коэффициент корреляции равняется 1.
При дополнительном расширении модели с помощью весов микширования gi, подлежащих применению на сигналах в обработке микширования, то есть  , энергия сигнала суммы будет
, энергия сигнала суммы будет
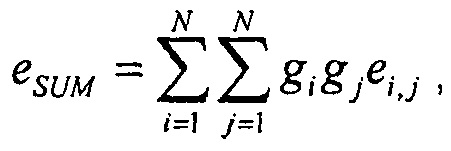
и громкость сигнала результата микширования может получаться из этого, как ранее, с помощью
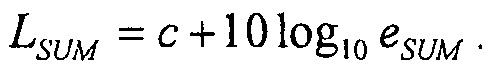
Различие между громкостью двух сигналов может оцениваться как
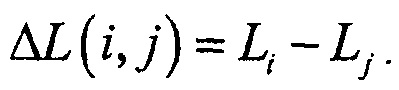
Если определение громкости теперь используется как ранее, это может быть записано как

что может рассматриваться как функция энергий сигналов. Если теперь требуется оценить различие громкости между двумя результатами микширования
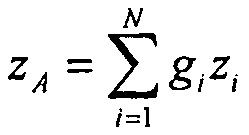 и
и 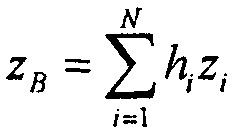
с возможно отличающимися весами микширования gi и hi, это может оцениваться с помощью

В случае, когда объекты являются некоррелированными ( и
и 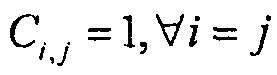 ), оценка различия становится
), оценка различия становится
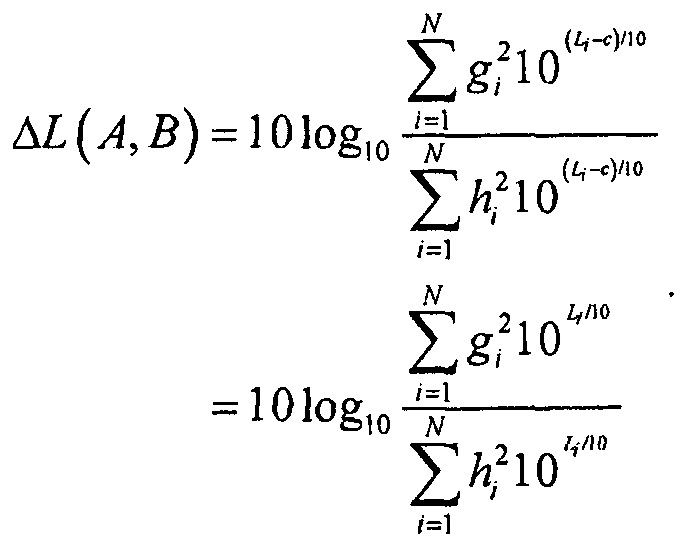
В последующем, рассматривается дифференциальное кодирование.
Является возможным кодировать значения громкости в расчете на объект как отличия от громкости выбранного опорного объекта:
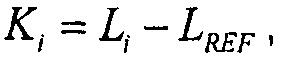
где LREF является громкостью опорного объекта. Это кодирование является предпочтительным, если никакие значения абсолютной громкости не нужны как результат, так как теперь необходимо передавать на одно значение меньше, и оценка различия громкости может быть записана как
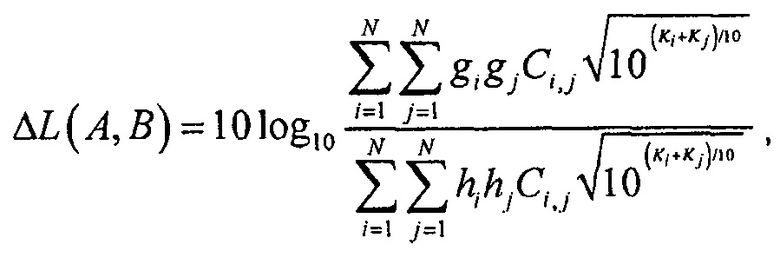
или в случае некоррелированных объектов
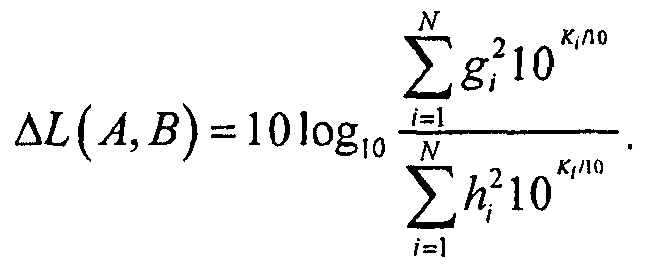
В последующем, рассматривается сценарий улучшения диалогов.
Рассмотрим снова сценарий применения улучшения диалогов. Свобода определения информации воспроизведения в декодере ограничена только изменением уровней упомянутых двух метаобъектов. Пусть дополнительно предполагается, что упомянутые два метаобъекта являются некоррелированными, то есть 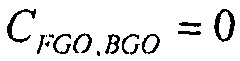 . Если веса понижающего микширования метаобъектов являются
. Если веса понижающего микширования метаобъектов являются 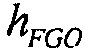 и
и 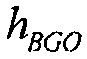 , и они воспроизводятся с усилениями
, и они воспроизводятся с усилениями 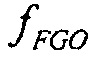 и
и 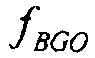 , громкость вывода по отношению к устанавливаемому по умолчанию понижающему микшированию равняется
, громкость вывода по отношению к устанавливаемому по умолчанию понижающему микшированию равняется

Это является тогда также требуемой компенсацией, если требуется иметь такую же громкость на выходе как в устанавливаемом по умолчанию понижающем микшировании.
 может рассматриваться как значение компенсации громкости, которое может передаваться сигнальным процессором 120 декодера.
может рассматриваться как значение компенсации громкости, которое может передаваться сигнальным процессором 120 декодера. 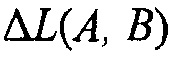 может также называться как значение изменения громкости и, таким образом, фактическое значение компенсации может быть обратным значением. Или является ли правильным использовать название "коэффициент компенсации громкости" для него, тоже? Таким образом, значение компенсации громкости lcv, упомянутое ранее в этом документе, будет соответствовать значению gDelta ниже.
может также называться как значение изменения громкости и, таким образом, фактическое значение компенсации может быть обратным значением. Или является ли правильным использовать название "коэффициент компенсации громкости" для него, тоже? Таким образом, значение компенсации громкости lcv, упомянутое ранее в этом документе, будет соответствовать значению gDelta ниже.
Например, 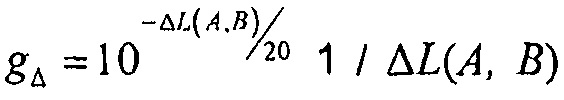 может применяться как коэффициент умножения на каждом канале модифицированного аудиосигнала, что проистекает из применения информации воспроизведения на входном аудиосигнале. Это уравнение для gDelta работает в линейной области. В логарифмической области, уравнение будет другим, как, например,
может применяться как коэффициент умножения на каждом канале модифицированного аудиосигнала, что проистекает из применения информации воспроизведения на входном аудиосигнале. Это уравнение для gDelta работает в линейной области. В логарифмической области, уравнение будет другим, как, например,  , и применяться соответственно.
, и применяться соответственно.
Если обработка понижающего микширования упрощается так, что упомянутые два метаобъекта могут микшироваться с единичными весами для получения микшированного с понижением сигнала, то есть 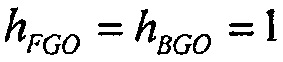 , и теперь усиления воспроизведения для этих двух объектов обозначаются с помощью
, и теперь усиления воспроизведения для этих двух объектов обозначаются с помощью 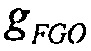 и
и 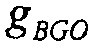 . Это упрощает уравнение для изменения громкости в
. Это упрощает уравнение для изменения громкости в
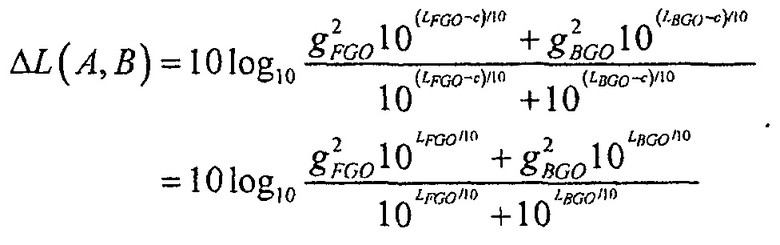
Снова, 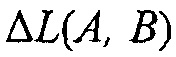 может рассматриваться как значение компенсации громкости, которое определяется сигнальным процессором 120.
может рассматриваться как значение компенсации громкости, которое определяется сигнальным процессором 120.
В общем,  может рассматриваться как усиление воспроизведения для объекта переднего плана FGO (группы объектов переднего плана), и
может рассматриваться как усиление воспроизведения для объекта переднего плана FGO (группы объектов переднего плана), и  может рассматриваться как усиление воспроизведения для объекта заднего плана EGO (группы объектов заднего плана).
может рассматриваться как усиление воспроизведения для объекта заднего плана EGO (группы объектов заднего плана).
Как упоминалось ранее, является возможным передавать различия громкости вместо абсолютной громкости. Пусть определяется опорная громкость как громкость метаобъекта FGO 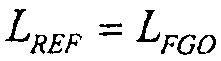 , то есть
, то есть 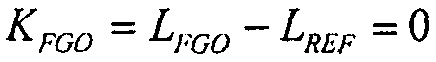 и
и 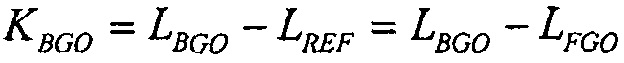 . Теперь, изменение громкости является
. Теперь, изменение громкости является
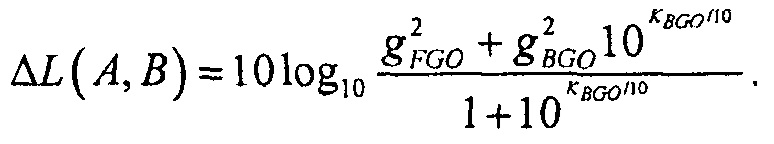
Также может быть, как имеет место в SAOC-DE, что два метаобъекта не имеют индивидуальных коэффициентов масштабирования, но один из объектов остается немодифицированным, в то время как другой ослабляется, чтобы получать корректное отношение микширования между объектами. В этой настройке воспроизведения, вывод будет более низким по громкости, чем устанавливаемый по умолчанию результат микширования, и изменение в громкости является
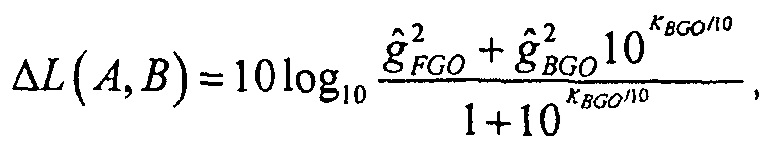
где
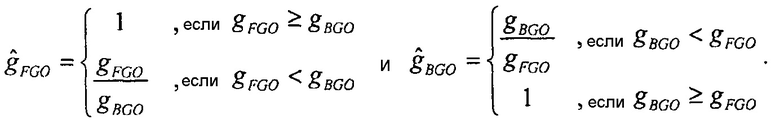
Эта форма является уже достаточно простой, и является достаточно агностической относительно используемой меры громкости. Единственное реальное требование состоит в том, что значения громкости должны складываться в экспоненциальной области. Является возможным передавать/сохранять значения энергий сигналов вместо значений громкости, так как упомянутые два имеют близкую связь.
В каждой из вышеописанных формул, 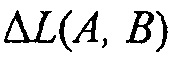 может рассматриваться как значение компенсации громкости, которое может передаваться сигнальным процессором 120 декодера.
может рассматриваться как значение компенсации громкости, которое может передаваться сигнальным процессором 120 декодера.
В последующем, рассматриваются иллюстративные случаи. Точность обеспеченных концепций иллюстрируется посредством двух иллюстративных сигналов. Оба сигнала имеют понижающее микширование 5.1 с каналами объемного звука и LFE, обходимыми в обработке SAOC.
Используются два основных подхода: один ("3-членный") с тремя метаобъектами: FGO, BGO, и обходными каналами, например,
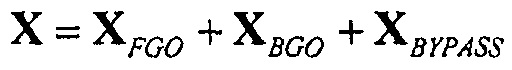 ,
,
и другой ("2-членный") с двумя метаобъектами, например:
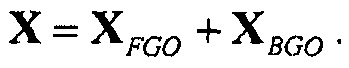
В 2-членном подходе, обходные каналы могут, например, микшироваться вместе с BGO для оценки громкости метаобъектов. Громкость обоих (или всех трех) объектов также как громкость микшированного с понижением сигнала оцениваются, и значения сохраняются.
Инструкции воспроизведения имеют форму
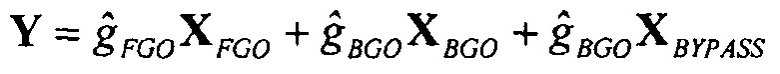
и
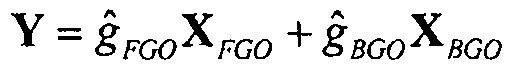
для упомянутых двух подходов соответственно.
Значения усиления, например, определяются согласно:
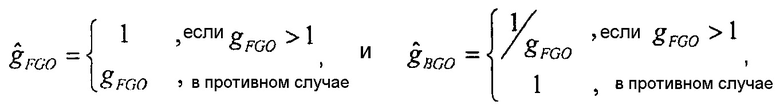 ,
,
где усиление FGO  изменяется между -24 и +24 дБ.
изменяется между -24 и +24 дБ.
Выходной сценарий воспроизводится, громкость измеряется, и вычисляется ослабление из громкости микшированного с понижением сигнала.
Этот результат изображен на фиг.10 и фиг.11 с помощью синей линии с круговым маркерами. Фиг.10 изображает первую иллюстрацию и фиг.11 изображает вторую иллюстрацию измеренного изменения громкости и результат использования обеспеченных концепций для оценки изменения в громкости чисто параметрическим способом.
Далее, ослабление от понижающего микширования параметрически оценивается с использованием сохраненных значений громкости метаобъектов и информации понижающего микширования и воспроизведения. Оценка с использованием громкости трех метаобъектов проиллюстрирована с помощью зеленой линии с квадратными маркерами, и оценка с использованием громкости двух метаобъектов проиллюстрирована с помощью красной линии, помеченной маркерами со звездочками.
Можно видеть из фигур, что 2- и 3-членный подходы обеспечивают практически идентичные результаты, и они оба приближают измеренное значение достаточно хорошо.
Обеспеченные концепции демонстрируют множество преимуществ. Например, обеспеченные концепции обеспечивают возможность оценки громкости сигнала результата микширования из громкости составляющих сигналов, формирующих результат микширования. Преимущество этого состоит в том, что громкость составляющего сигнала может оцениваться один раз, и оценка громкости сигнала результата микширования может получаться параметрически для любого результата микширования без необходимости фактической основывающейся на сигналах оценки громкости. Это обеспечивает значительное улучшение в вычислительной эффективности всей системы, в которой необходима оценка громкости различных результатов микширования. Например, когда конечный пользователь изменяет настройки воспроизведения, оценка громкости вывода является немедленно доступной.
В некоторых применениях, как, например, при обеспечении соответствия с рекомендацией EBU R128, средняя громкость по полной программе является важной. Если оценка громкости в приемнике, например, в сценарии широковещания, осуществляется на основе принятого сигнала, оценка сходится к средней громкости только после того, как вся программа была принята. Из-за этого, любая компенсация громкости будет иметь ошибки или демонстрировать временные изменения. При оценке громкости составляющих объектов, как предложено, и передаче информации громкости, является возможным оценивать среднюю громкость результата микширования в приемнике без задержки.
Если требуется, чтобы средняя громкость выходного сигнала оставалась (приблизительно) постоянной независимо от изменений в информации воспроизведения, обеспеченные концепции обеспечивают возможность определения коэффициента компенсации по этой причине. Вычисления, необходимые для этого в декодере, являются из-за их вычислительной сложности незначительными, и, таким образом, можно добавлять упомянутую функциональную возможность к любому декодеру.
Имеются случаи, в которых уровень абсолютной громкости вывода не является важным, но важность лежит в определении изменения в громкости от опорной сцены. В таких случаях абсолютные уровни объектов не являются важными, но являются важными их относительные уровни. Это обеспечивает возможность определения одного из объектов в качестве опорного объекта и представления громкости других объектов по отношению к громкости этого опорного объекта. Это имеет некоторые преимущества при принятии во внимание транспортировки и/или сохранения информации громкости.
Прежде всего, не является необходимым транспортировать уровень опорной громкости. В случае применения двух метаобъектов, это делит пополам количество данных, подлежащих передаче. Второе преимущество относится к возможному квантованию и представлению значений громкости. Так как абсолютные уровни объектов могут быть почти всем, чем угодно, значения абсолютной громкости также могут быть почти всем, чем угодно. С другой стороны, предполагается, что относительные значения громкости имеют 0 среднее и достаточно хорошо сформированное распределение около среднего. Различие между представлениями обеспечивает возможность определения сетки квантования относительного представления способом с потенциально более большой точностью с одним и тем же количеством битов, используемых для квантованного представления.
Фиг.12 иллюстрирует другой вариант осуществления для выполнения компенсации громкости. На фиг.12, компенсация громкости может выполняться, например, чтобы компенсировать потерю в громкости. Для этой цели, например, могут использоваться значения DE_loudness_diff_dialogue (= KFGO) и DE_loudness_diff_background (= KBGO) из DE_control_info. Здесь, DE_control_info может определять информацию управления "улучшения диалогов" (DE) усовершенствованного очищенного аудио.
Компенсация громкости достигается посредством применения значения усиления "g" на выходном сигнале SAOC-DE и обходных каналах (в случае многоканального сигнала).
В варианте осуществления из фиг.12, это делается следующим образом:
Используется ограниченное значение усиления модификации диалога 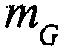 , чтобы определять эффективные усиления для объекта переднего плана (FGO, например, диалога) и для объекта заднего плана (BGO, например, окружения). Это делается посредством блока 1220 "Преобразования усиления", который вырабатывает значения усиления
, чтобы определять эффективные усиления для объекта переднего плана (FGO, например, диалога) и для объекта заднего плана (BGO, например, окружения). Это делается посредством блока 1220 "Преобразования усиления", который вырабатывает значения усиления 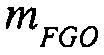 и
и 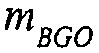 .
.
Блок 1230 "модуля оценки выходной громкости" использует информацию громкости 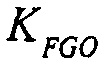 и
и 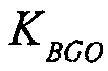 , и эффективные значения усиления
, и эффективные значения усиления 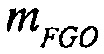 и
и 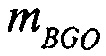 , чтобы оценивать это возможное изменение в громкости по сравнению со случаем устанавливаемого по умолчанию понижающего микширования. Изменение затем преобразуется в "коэффициент компенсации громкости", который применяется на выходных каналах для выработки окончательных "выходных сигналов".
, чтобы оценивать это возможное изменение в громкости по сравнению со случаем устанавливаемого по умолчанию понижающего микширования. Изменение затем преобразуется в "коэффициент компенсации громкости", который применяется на выходных каналах для выработки окончательных "выходных сигналов".
Для компенсации громкости применяются следующие этапы:
- Прием ограниченного значения усиления 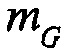 от декодера SAOC-DE (как определено в пункте 12.8 "Modification range control for SAOC-DE" [DE]), и определение применяемых усилений FGO/BGO:
от декодера SAOC-DE (как определено в пункте 12.8 "Modification range control for SAOC-DE" [DE]), и определение применяемых усилений FGO/BGO:
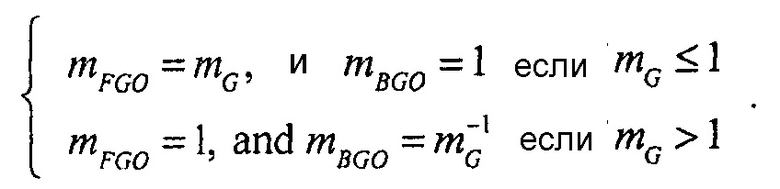
- Получение информации громкости метаобъектов  и
и  .
.
- Вычисление изменения в выходной громкости по сравнению с устанавливаемым по умолчанию понижающим микшированием с помощью

- Вычисление усиления компенсации громкости 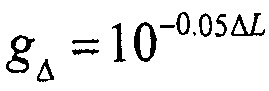 .
.
- Вычисление коэффициентов масштабирования 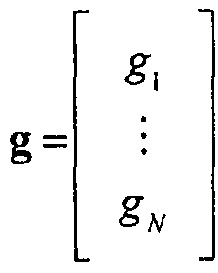 , где
, где
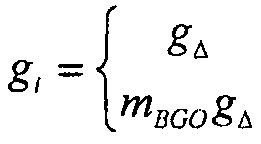
и N является полным количеством выходных каналов. На фиг.12, регулировка усиления разделена на два этапа: усиление возможных "обходных каналов" регулируется с помощью  до комбинирования их с "выходными каналами SAOC-DE", и затем общее усиление
до комбинирования их с "выходными каналами SAOC-DE", и затем общее усиление  затем применяется на всех комбинированных каналах. Это является только возможным переупорядочиванием операций регулировки усиления, в то время как
затем применяется на всех комбинированных каналах. Это является только возможным переупорядочиванием операций регулировки усиления, в то время как  здесь комбинирует оба этапа регулировки усиления в одну регулировку усиления.
здесь комбинирует оба этапа регулировки усиления в одну регулировку усиления.
- Применение значений масштабирования  на аудиоканалах YFULL, состоящих из "выходных каналов SAOC-DE" YSAOC и возможных выровненных по времени "обходных каналов" YBYPASS:
на аудиоканалах YFULL, состоящих из "выходных каналов SAOC-DE" YSAOC и возможных выровненных по времени "обходных каналов" YBYPASS: 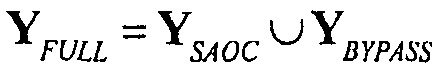 .
.
Применение значений масштабирования g на аудиоканалах YFULL выполняется посредством блока 1240 регулировки усиления.
 , как вычисляется выше, может рассматриваться как значение компенсации громкости. В общем,
, как вычисляется выше, может рассматриваться как значение компенсации громкости. В общем,  указывает усиление воспроизведения для объекта переднего плана FGO (группы объектов переднего плана), и
указывает усиление воспроизведения для объекта переднего плана FGO (группы объектов переднего плана), и 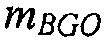 указывает усиление воспроизведения для объекта заднего плана BGO (группы объектов заднего плана).
указывает усиление воспроизведения для объекта заднего плана BGO (группы объектов заднего плана).
Хотя некоторые аспекты были описаны в контексте устройства, должно быть ясным, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства.
Новый разложенный сигнал может сохраняться в цифровом запоминающем носителе или может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, такая как сеть Интернет.
В зависимости от некоторых требований реализации, варианты осуществления изобретения могут осуществляться в аппаратном обеспечении или в программном обеспечении. Вариант осуществления может выполняться с использованием цифрового запоминающего носителя, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего электронно-читаемые сигналы управления, сохраненные на нем, которые работают вместе (или способны работать вместе) с программируемой компьютерной системой, так что соответствующий способ выполняется.
Некоторые варианты осуществления согласно изобретению содержат нетранзиторный носитель данных, имеющий электронно-читаемые сигналы управления, которые являются способными работать вместе с программируемой компьютерной системой, так что выполняется один из способов, здесь описанных.
В общем, варианты осуществления настоящего изобретения могут осуществляться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью для выполнения одного из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код может, например, быть сохраненным в машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, здесь описанных, сохраненную в машиночитаемом носителе.
Другими словами, один вариант осуществления нового способа является, поэтому, компьютерной программой, имеющей программный код для выполнения одного из способов, здесь описанных, когда компьютерная программа исполняется на компьютере.
Один дополнительный вариант осуществления новых способов является, поэтому, носителем данных (или цифровым запоминающим носителем, или машиночитаемым носителем), содержащим, записанную на нем, компьютерную программу для выполнения одного из способов, здесь описанных.
Один дополнительный вариант осуществления нового способа является, поэтому, потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из способов, здесь описанных. Поток данных или последовательность сигналов может, например, быть сконфигурирован с возможностью передаваться посредством соединения передачи данных, например, посредством сети Интернет.
Один дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, сконфигурированное с возможностью или выполненное с возможностью выполнять один из способов, здесь описанных.
Один дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, здесь описанных.
В некоторых вариантах осуществления, может использоваться программируемое логическое устройство (например, программируемая пользователем вентильная матрица), чтобы выполнять некоторые или все из функциональных возможностей способов, здесь описанных. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может работать вместе с микропроцессором, чтобы выполнять один из способов, здесь описанных. В общем, способы предпочтительно выполняются посредством любого устройства аппаратного обеспечения.
Вышеописанные варианты осуществления являются всего лишь иллюстративными для принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и деталей, здесь описанных, должны быть ясными другим специалистам в данной области техники. Предполагается, поэтому, что ограничение обеспечивается только посредством объема приложенной патентной формулы изобретения и не посредством конкретных деталей, представленных путем описания и объяснения вариантов осуществления отсюда.
Ссылочные источники
[BCC] C. Faller and F. Baumgarte, "Binaural Cue Coding - Part II: Schemes and applications", IEEE Trans. on Speech and Audio Proc., vol. 11, no. 6, Nov. 2003.
[EBU] EBU Recommendation R 128 "Loudness normalization and permitted maximum level of audio signals", Geneva, 2011.
[JSC] C. Faller, "Parametric Joint-Coding of Audio Sources", 120th AES Convention, Paris, 2006.
[ISS1] M. Parvaix and L. Girin: "Informed Source Separation of underdetermined instantaneous Stereo Mixtures using Source Index Embedding", IEEE ICASSP, 2010.
[ISS2] M. Parvaix, L. Girin, J.-M. Brossier: "A watermarking-based method for informed source separation of audio signals with a single sensor", IEEE Transactions on Audio, Speech and Language Processing, 2010.
[ISS3] A. Liutkus and J. Pinel and R. Badeau and L. Girin and G. Richard: "Informed source separation through spectrogram coding and data embedding", Signal Processing Journal, 2011.
[ISS4] A. Ozerov, A. Liutkus, R. Badeau, G. Richard: "Informed source separation: source coding meets source separation", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2011.
[ISS5] S. Zhang and L. Girin: "An Informed Source Separation System for Speech Signals", INTERSPEECH, 2011.
[ISS6] L. Girin and J. Pinel: "Informed Audio Source Separation from Compressed Linear Stereo Mixtures", AES 42nd International Conference: Semantic Audio, 2011.
[ITU] International Telecommunication Union: "Recommendation ITU-R BS.1770-3 - Algorithms to measure audio programme loudness and true-peak audio level", Geneva, 2012.
[SAOC1] J. Herre, S. Disch, J. Hilpert, O. Hellmuth: "From SAC To SAOC - Recent Developments in Parametric Coding of Spatial Audio", 22nd Regional UK AES Conference, Cambridge, UK, April 2007.
[SAOC2] J. Engdegård, B. Resch, C. Falch, O. Hellmuth, J. Hilpert, A. Hölzer, L. Terentiev, J. Breebaart, J. Koppens, E. Schuijers and W. Oomen: "Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric Object Based Audio Coding", 124th AES Convention, Amsterdam 2008.
[SAOC] ISO/IEC, "MPEG audio technologies - Part 2: Spatial Audio Object Coding (SAOC)", ISO/IEC JTC1/SC29/WG11 (MPEG) International Standard 23003-2.
[EP] EP 2146522 A1: S. Schreiner, W. Fiesel, M. Neusinger, O. Hellmuth, R. Sperschneider, "Apparatus and method for generating audio output signals using object based metadata", 2010.
[DE] ISO/IEC, "MPEG audio technologies - Part 2: Spatial Audio Object Coding (SAOC) - Amendment 3, Dialogue Enhancement", ISO/IEC 23003-2:2010/DAM 3, Dialogue Enhancement.
[BRE] WO 2008/035275 A2.
[SCH] EP 2 146 522 A1.
[ENG] WO 2008/046531 A1.

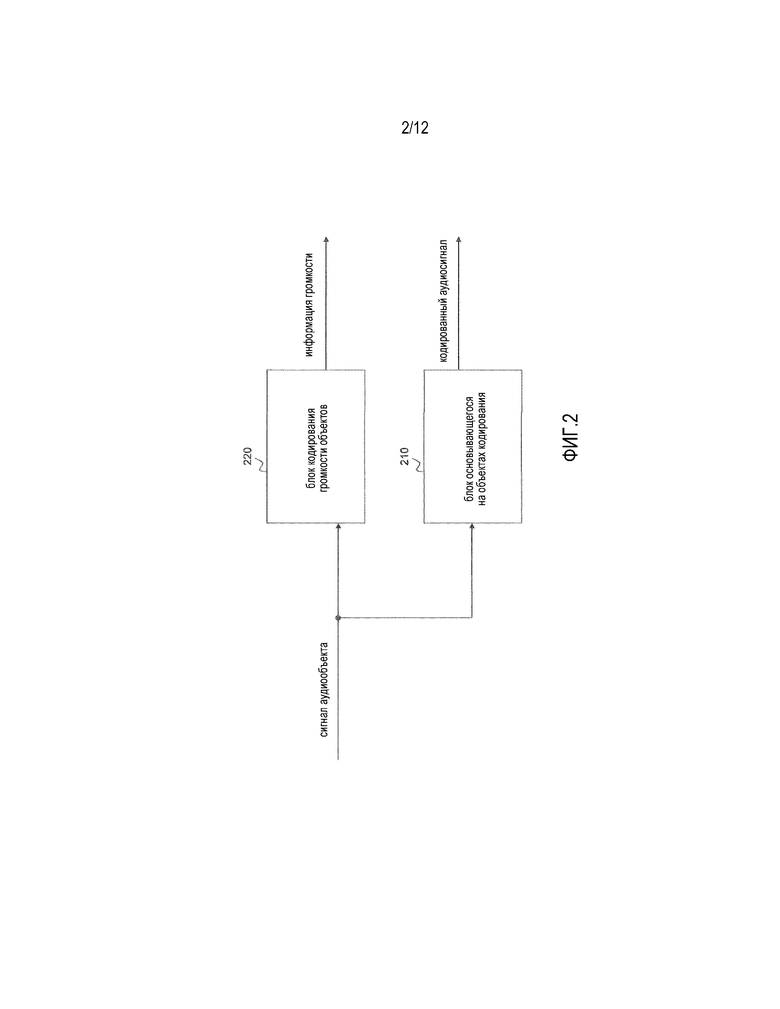

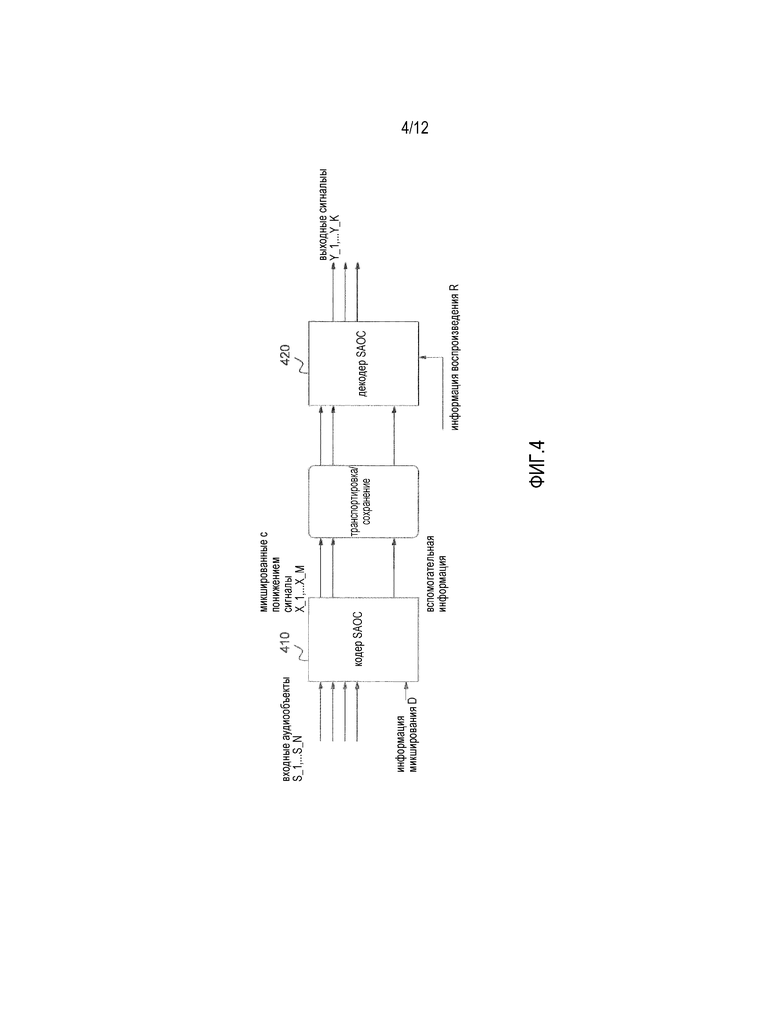
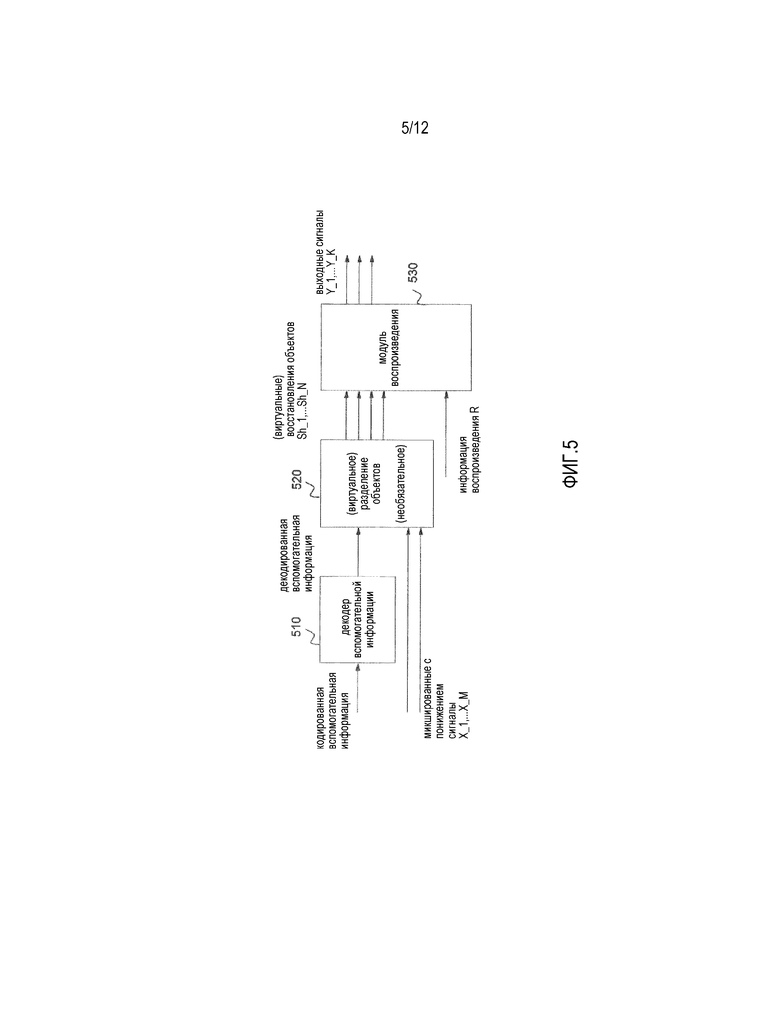

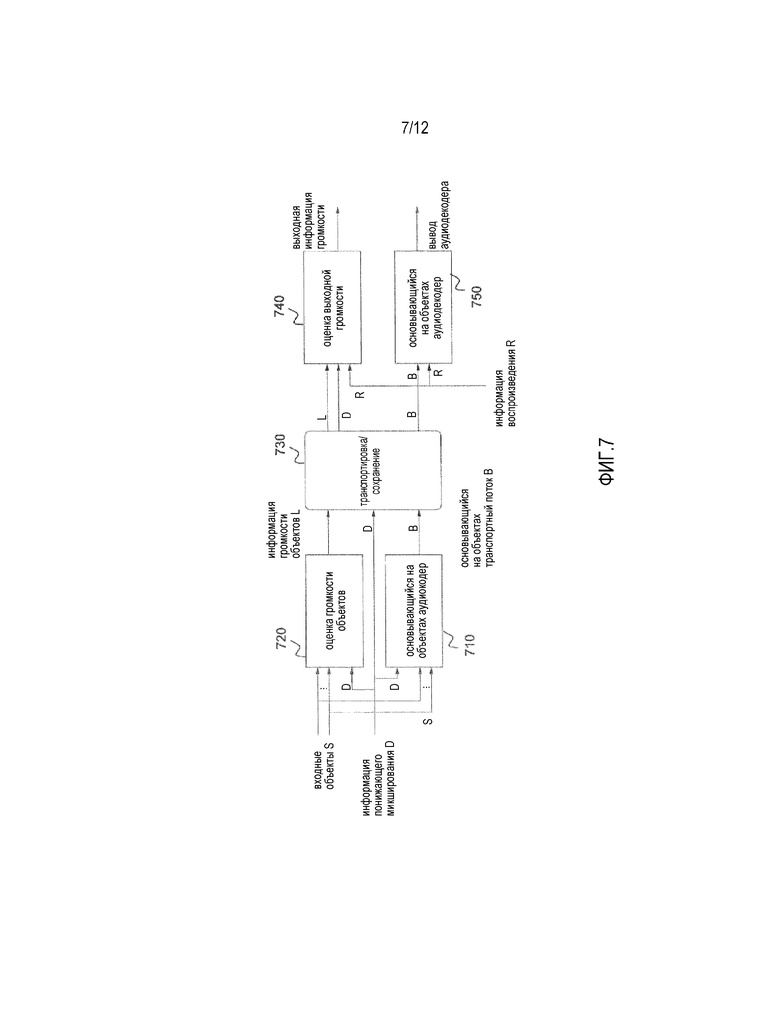

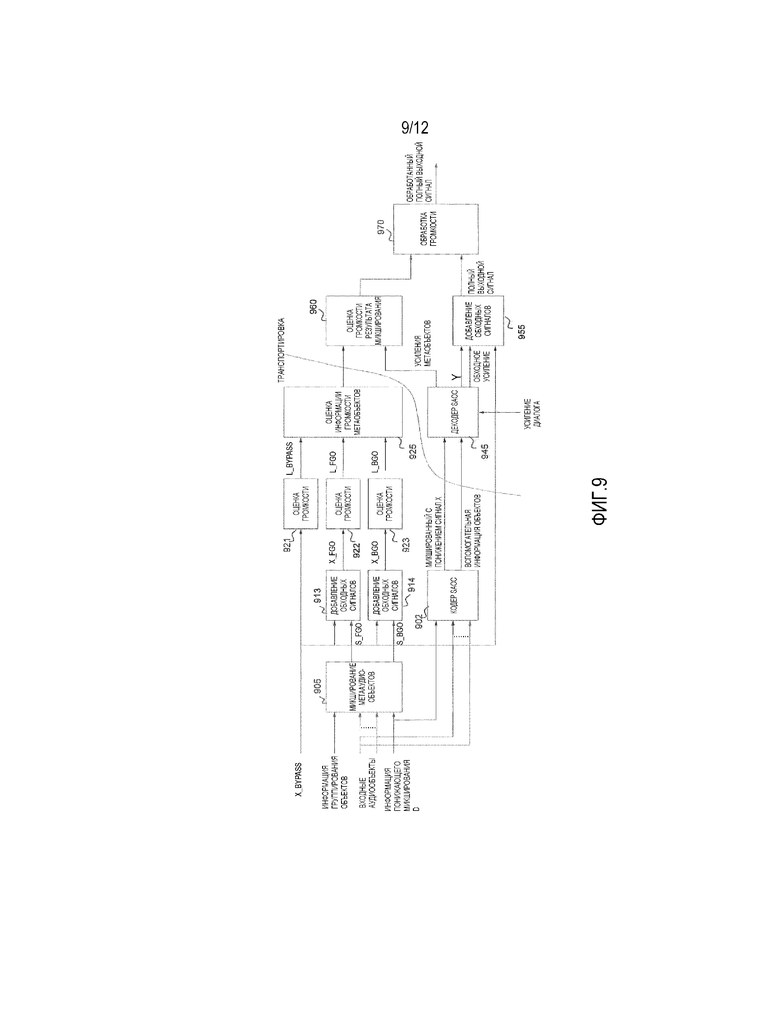
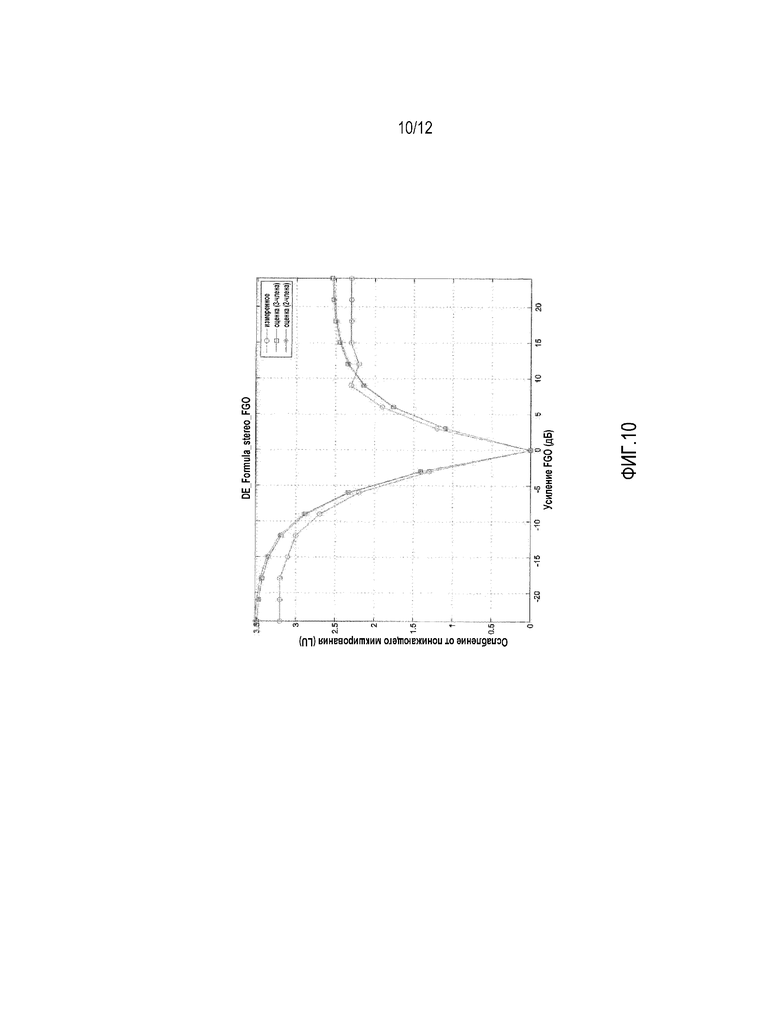

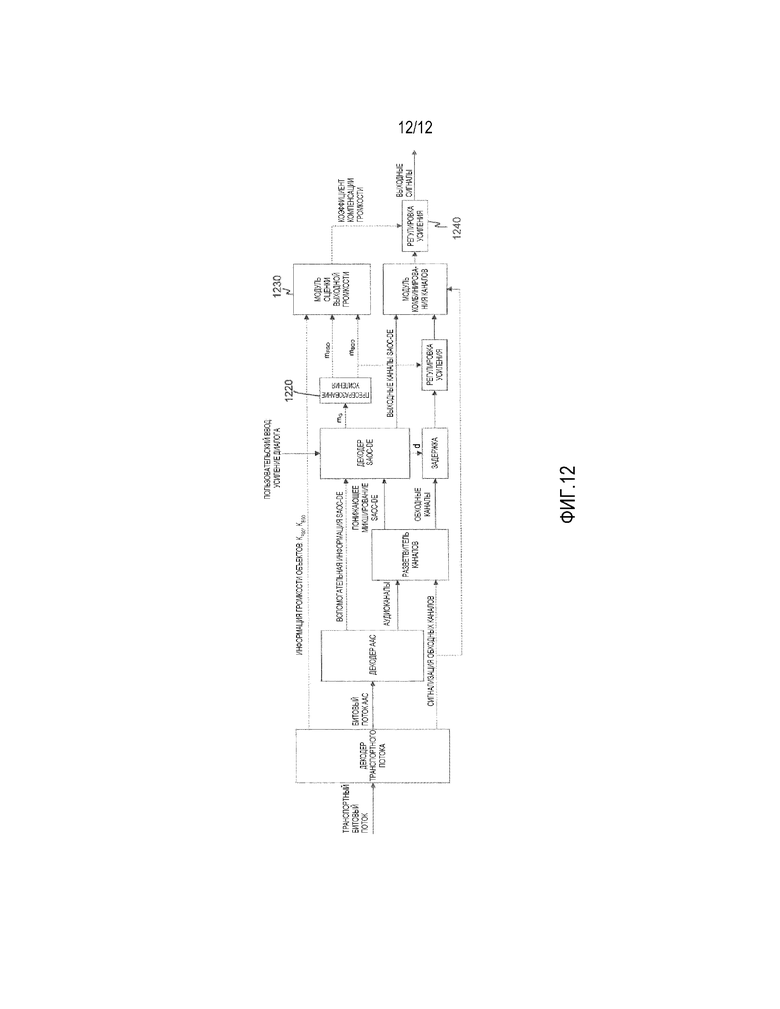
Изобретение относится к способу кодирования аудиосигналов. Технический результат заключается в повышении эффективности кодирования, обработки и декодирования аудиосигналов. Технический результат достигается посредством декодера для генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов, при этом декодер содержит: интерфейс приема для приема входного аудиосигнала; сигнальный процессор для генерирования выходных аудиоканалов, выходного аудиосигнала, сконфигурированный с возможностью определять значение компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения, генерировать один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости, так что громкость выходного аудиосигнала равняется громкости входного аудиосигнала, или так что громкость выходного аудиосигнала является более близкой к громкости входного аудиосигнала, чем громкость модифицированного аудиосигнала. 13 н. и 12 з.п. ф-лы, 12 ил.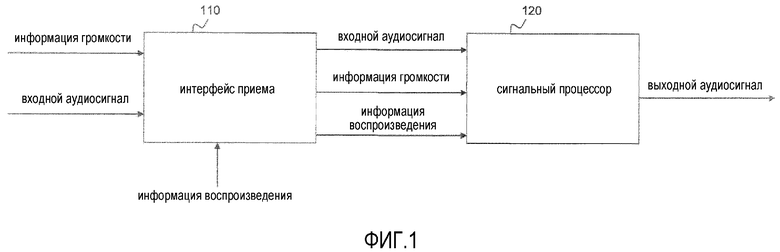
1. Декодер для генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов, при этом декодер содержит:
интерфейс (110) приема для приема входного аудиосигнала, содержащего множество сигналов аудиообъектов, для приема информации громкости о сигналах аудиообъектов, и для приема информации воспроизведения, указывающей то, как один или более из сигналов аудиообъектов должны усиливаться или ослабляться, и
сигнальный процессор (120) для генерирования упомянутых одного или более выходных аудиоканалов выходного аудиосигнала,
при этом сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения, и
при этом сигнальный процессор (120) сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости,
при этом сигнальный процессор (120) сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости, так что громкость выходного аудиосигнала равняется громкости входного аудиосигнала, или так что громкость выходного аудиосигнала является более близкой к громкости входного аудиосигнала, чем громкость модифицированного аудиосигнала, который бы проистекал из модификации входного аудиосигнала посредством усиления или ослабления сигналов аудиообъектов входного аудиосигнала согласно информации воспроизведения.
2. Декодер по п.1,
в котором сигнальный процессор (120) сконфигурирован с возможностью генерировать модифицированный аудиосигнал посредством модификации входного аудиосигнала посредством усиления или ослабления сигналов аудиообъектов входного аудиосигнала согласно информации воспроизведения, и
в котором сигнальный процессор (120) сконфигурирован с возможностью генерировать выходной аудиосигнал посредством применения значения компенсации громкости в отношении модифицированного аудиосигнала, так что громкость выходного аудиосигнала равняется громкости входного аудиосигнала, или так что громкость выходного аудиосигнала является более близкой к громкости входного аудиосигнала, чем громкость модифицированного аудиосигнала.
3. Декодер по п.1,
в котором каждый из сигналов аудиообъектов входного аудиосигнала назначается в точности одной группе из двух или более групп, при этом каждая из упомянутых двух или более групп содержит один или более из сигналов аудиообъектов входного аудиосигнала,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать значение громкости для каждой группы из упомянутых двух или более групп в качестве информации громкости,
при этом сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости в зависимости от значения громкости каждой из упомянутых двух или более групп, и
при этом сигнальный процессор (120) сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от значения компенсации громкости.
4. Декодер по п.3, в котором, по меньшей мере, одна группа из упомянутых двух или более групп содержит два или более из сигналов аудиообъектов.
5. Декодер по п.1,
в котором каждый из сигналов аудиообъектов входного аудиосигнала назначается в точности одной группе из более чем двух групп, при этом каждая из упомянутых более чем двух групп содержит один или более из сигналов аудиообъектов входного аудиосигнала,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать значение громкости для каждой группы из упомянутых более чем двух групп в качестве информации громкости,
при этом сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости в зависимости от значения громкости каждой из упомянутых более чем двух групп, и
при этом сигнальный процессор (120) сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от значения компенсации громкости.
6. Декодер по п.5, в котором, по меньшей мере, одна группа из упомянутых более чем двух групп содержит два или более из сигналов аудиообъектов.
7. Декодер по п.3,
в котором сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости согласно формуле
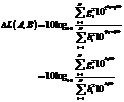
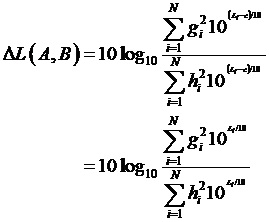
или согласно формуле
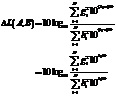

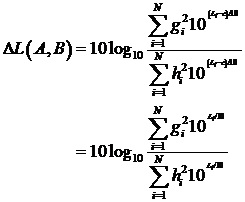
где ΔL является значением компенсации громкости,
где i указывает i-й сигнал аудиообъекта из сигналов аудиообъектов,
где Li является громкостью i-го сигнала аудиообъекта,
где gi является первым весом микширования для i-го сигнала аудиообъекта,
где hi является вторым весом микширования для i-го сигнала аудиообъекта,
где c является постоянным значением, и
где N является количеством.
8. Декодер по п.3,
в котором сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости согласно формуле


где ΔL является значением компенсации громкости,
где i указывает i-й сигнал аудиообъекта из сигналов аудиообъектов,
где gi является первым весом микширования для i-го сигнала аудиообъекта,
где hi является вторым весом микширования для i-го сигнала аудиообъекта,
где N является количеством, и
где Ki определяется согласно

где Li является громкостью i-го сигнала аудиообъекта, и
где 
9. Декодер по п.3,
в котором каждый из сигналов аудиообъектов входного аудиосигнала назначается в точности одной группе из в точности двух групп как упомянутые две или более группы,
при этом каждый из сигналов аудиообъектов входного аудиосигнала назначается либо группе объектов переднего плана из упомянутых в точности двух групп, либо группе объектов заднего плана из упомянутых в точности двух групп,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать значение громкости группы объектов переднего плана,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать значение громкости группы объектов заднего плана,
при этом сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости в зависимости от значения громкости группы объектов переднего плана, и в зависимости от значения громкости группы объектов заднего плана, и
при этом сигнальный процессор (120) сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от значения компенсации громкости.
10. Декодер по п.9,
в котором сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости согласно формуле
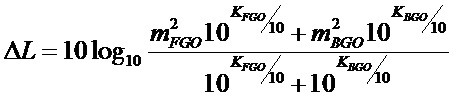
где ΔL является значением компенсации громкости,
где KFGO указывает значение громкости группы объектов переднего плана,
где KBGO указывает значение громкости группы объектов заднего плана,
где  указывает усиление воспроизведения группы объектов переднего плана, и
указывает усиление воспроизведения группы объектов переднего плана, и
где 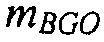 указывает усиление воспроизведения группы объектов заднего плана.
указывает усиление воспроизведения группы объектов заднего плана.
11. Декодер по п.9,
в котором сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости согласно формуле
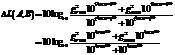
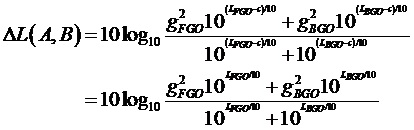
где ΔL является значением компенсации громкости,
где 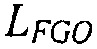 указывает значение громкости группы объектов переднего плана,
указывает значение громкости группы объектов переднего плана,
где 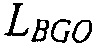 указывает значение громкости группы объектов заднего плана,
указывает значение громкости группы объектов заднего плана,
где 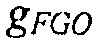 указывает усиление воспроизведения группы объектов переднего плана, и
указывает усиление воспроизведения группы объектов переднего плана, и
где 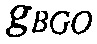 указывает усиление воспроизведения группы объектов заднего плана.
указывает усиление воспроизведения группы объектов заднего плана.
12. Декодер по п.1,
в котором интерфейс (110) приема сконфигурирован с возможностью принимать микшированный с понижением сигнал, содержащий один или более каналов понижающего микширования, в качестве входного аудиосигнала, при этом упомянутые один или более каналов понижающего микширования содержат сигналы аудиообъектов, и при этом количество упомянутых одного или более каналов понижающего микширования меньше, чем количество сигналов аудиообъектов,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать информацию понижающего микширования, указывающую то, как сигналы аудиообъектов микшированы внутри упомянутых одного или более каналов понижающего микширования, и
при этом сигнальный процессор (120) сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации понижающего микширования, в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости.
13. Декодер по п.12,
в котором интерфейс (110) приема сконфигурирован с возможностью принимать один или более дополнительных обходных сигналов аудиообъектов, при этом упомянутые один или более дополнительных обходных сигналов аудиообъектов не микшированы внутри микшированного с понижением сигнала,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать информацию громкости, указывающую информацию о громкости сигналов аудиообъектов, которые микшированы внутри микшированного с понижением сигнала, и указывающую информацию о громкости упомянутых одного или более дополнительных обходных сигналов аудиообъектов, которые не микшированы внутри микшированного с понижением сигнала, и
при этом сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации о громкости сигналов аудиообъектов, которые микшированы внутри микшированного с понижением сигнала, и в зависимости от информации о громкости упомянутых одного или более дополнительных обходных сигналов аудиообъектов, которые не микшированы внутри микшированного с понижением сигнала.
14. Декодер для генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов, при этом декодер содержит:
интерфейс (110) приема для приема входного аудиосигнала, содержащего множество сигналов аудиообъектов, для приема информации громкости о сигналах аудиообъектов, и для приема информации воспроизведения, указывающей, должен ли один или более из сигналов аудиообъектов усиливаться или ослабляться, и
сигнальный процессор (120) для генерирования упомянутых одного или более выходных аудиоканалов выходного аудиосигнала,
при этом сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения, и
при этом сигнальный процессор (120) сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать микшированный с понижением сигнал, содержащий один или более каналов понижающего микширования, в качестве входного аудиосигнала, при этом упомянутые один или более каналов понижающего микширования содержат сигналы аудиообъектов, и при этом количество упомянутых одного или более каналов понижающего микширования меньше, чем количество сигналов аудиообъектов,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать информацию понижающего микширования, указывающую то, как сигналы аудиообъектов микшированы внутри упомянутых одного или более каналов понижающего микширования, и
при этом сигнальный процессор (120) сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации понижающего микширования, в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать один или более дополнительных обходных сигналов аудиообъектов, при этом упомянутые один или более дополнительных обходных сигналов аудиообъектов не микшированы внутри микшированного с понижением сигнала,
при этом интерфейс (110) приема сконфигурирован с возможностью принимать информацию громкости, указывающую информацию о громкости сигналов аудиообъектов, которые микшированы внутри микшированного с понижением сигнала, и указывающую информацию о громкости упомянутых одного или более дополнительных обходных сигналов аудиообъектов, которые не микшированы внутри микшированного с понижением сигнала, и
при этом сигнальный процессор (120) сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации о громкости сигналов аудиообъектов, которые микшированы внутри микшированного с понижением сигнала, и в зависимости от информации о громкости упомянутых одного или более дополнительных обходных сигналов аудиообъектов, которые не микшированы внутри микшированного с понижением сигнала.
15. Кодер для кодирования множества сигналов аудиообъектов, содержащий:
блок (210; 710) основывающегося на объектах кодирования для кодирования упомянутого множества сигналов аудиообъектов, чтобы получать кодированный аудиосигнал, содержащий множество сигналов аудиообъектов, и
блок (220; 720; 820) кодирования громкости объектов для кодирования информации громкости о сигналах аудиообъектов,
при этом информация громкости содержит одно или более значений громкости, при этом каждое из упомянутых одного или более значений громкости зависит от одного или более из сигналов аудиообъектов,
при этом каждый из сигналов аудиообъектов из кодированного аудиосигнала назначается в точности одной группе из двух или более групп, при этом каждая из упомянутых двух или более групп содержит один или более из сигналов аудиообъектов из кодированного аудиосигнала, при этом, по меньшей мере, одна группа из упомянутых двух или более групп содержит два или более из сигналов аудиообъектов,
при этом блок (220; 720; 820) кодирования громкости объектов сконфигурирован с возможностью определять упомянутые одно или более значений громкости из информации громкости посредством определения значения громкости для каждой группы из упомянутых двух или более групп, при этом упомянутое значение громкости упомянутой группы указывает полную громкость упомянутых одного или более сигналов аудиообъектов из упомянутой группы.
16. Кодер для кодирования множества сигналов аудиообъектов, содержащий:
блок (210; 710) основывающегося на объектах кодирования для кодирования упомянутого множества сигналов аудиообъектов, чтобы получать кодированный аудиосигнал, содержащий множество сигналов аудиообъектов, и
блок (220; 720; 820) кодирования громкости объектов для кодирования информации громкости о сигналах аудиообъектов,
при этом информация громкости содержит одно или более значений громкости, при этом каждое из упомянутых одного или более значений громкости зависит от одного или более из сигналов аудиообъектов,
при этом блок (210; 710) основывающегося на объектах кодирования сконфигурирован с возможностью принимать сигналы аудиообъектов, при этом каждый из сигналов аудиообъектов назначается в точности одной из в точности двух групп, при этом каждая из упомянутых в точности двух групп содержит один или более из сигналов аудиообъектов, при этом, по меньшей мере, одна группа из упомянутых в точности двух групп содержит два или более из сигналов аудиообъектов,
при этом блок (210; 710) основывающегося на объектах кодирования сконфигурирован с возможностью микшировать с понижением сигналы аудиообъектов, которые содержатся в упомянутых в точности двух группах, чтобы получать микшированный с понижением сигнал, содержащий один или более аудиоканалов понижающего микширования в качестве кодированного аудиосигнала, при этом количество упомянутых одного или более каналов понижающего микширования меньше, чем количество сигналов аудиообъектов, которые содержатся в упомянутых в точности двух группах,
при этом блок (220; 720; 820) кодирования громкости объектов сконфигурирован с возможностью принимать один или более дополнительных обходных сигналов аудиообъектов, при этом каждый из упомянутых одного или более дополнительных обходных сигналов аудиообъектов назначается третьей группе, при этом каждый из упомянутых одного или более дополнительных обходных сигналов аудиообъектов не содержится в первой группе и не содержится во второй группе, при этом блок (210; 710) основывающегося на объектах кодирования сконфигурирован с возможностью не микшировать с понижением упомянутые один или более дополнительные обходные сигналы аудиообъектов внутри микшированного с понижением сигнала, и
при этом блок (220; 720; 820) кодирования громкости объектов сконфигурирован с возможностью определять первое значение громкости, второе значение громкости и третье значение громкости из информации громкости, при этом первое значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из первой группы, при этом второе значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из второй группы, и при этом третье значение громкости указывает полную громкость упомянутых одного или более дополнительных обходных сигналов аудиообъектов из третьей группы, или сконфигурирован с возможностью определять первое значение громкости и второе значение громкости из информации громкости, при этом первое значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из первой группы, и при этом второе значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из второй группы и упомянутых одного или более дополнительных обходных сигналов аудиообъектов из третьей группы.
17. Система для генерирования выходного аудиосигнала, содержащая:
кодер (310), содержащий:
блок (210; 710) основывающегося на объектах кодирования для кодирования множества сигналов аудиообъектов, чтобы получать кодированный аудиосигнал, содержащий множество сигналов аудиообъектов, и
блок (220; 720; 820) кодирования громкости объектов для кодирования информации громкости о сигналах аудиообъектов,
при этом информация громкости содержит одно или более значений громкости, при этом каждое из упомянутых одного или более значений громкости зависит от одного или более из сигналов аудиообъектов,
декодер (320) по одному из пп.1-14 для генерирования упомянутого выходного аудиосигнала, содержащего один или более выходных аудиоканалов,
при этом декодер (320) сконфигурирован с возможностью принимать кодированный аудиосигнал в качестве входного аудиосигнала и принимать информацию громкости,
при этом декодер (320) сконфигурирован с возможностью дополнительно принимать информацию воспроизведения,
при этом декодер (320) сконфигурирован с возможностью определять значение компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения, и
при этом декодер (320) сконфигурирован с возможностью генерировать упомянутые один или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости.
18. Способ генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов, при этом способ содержит:
прием входного аудиосигнала, содержащего множество сигналов аудиообъектов,
прием информации громкости о сигналах аудиообъектов,
прием информации воспроизведения, указывающей то, как один или более из сигналов аудиообъектов должны усиливаться или ослабляться,
определение значения компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения, и
генерирование упомянутых одного или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости,
при этом генерирование упомянутых одного или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала выполняется в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости, так что громкость выходного аудиосигнала равняется громкости входного аудиосигнала, или так что громкость выходного аудиосигнала является более близкой к громкости входного аудиосигнала, чем громкость модифицированного аудиосигнала, который бы проистекал из модификации входного аудиосигнала посредством усиления или ослабления сигналов аудиообъектов входного аудиосигнала согласно информации воспроизведения.
19. Способ генерирования выходного аудиосигнала, содержащего один или более выходных аудиоканалов, при этом способ содержит:
прием входного аудиосигнала, содержащего множество сигналов аудиообъектов, при этом прием входного аудиосигнала выполняется посредством приема микшированного с понижением сигнала, содержащего один или более каналов понижающего микширования, в качестве входного аудиосигнала, при этом упомянутые один или более каналов понижающего микширования содержат сигналы аудиообъектов, и при этом количество упомянутых одного или более каналов понижающего микширования меньше, чем количество сигналов аудиообъектов,
прием информации воспроизведения, указывающей, должен ли один или более из сигналов аудиообъектов усиливаться или ослабляться,
прием информации понижающего микширования, указывающей то, как сигналы аудиообъектов микшированы внутри упомянутых одного или более каналов понижающего микширования,
прием одного или более дополнительных обходных сигналов аудиообъектов, при этом упомянутые один или более дополнительных обходных сигналов аудиообъектов не микшированы внутри микшированного с понижением сигнала,
прием информации громкости о сигналах аудиообъектов, при этом информация громкости указывает информацию о громкости сигналов аудиообъектов, которые микшированы внутри микшированного с понижением сигнала, и указывает информацию о громкости упомянутых одного или более дополнительных обходных сигналов аудиообъектов, которые не микшированы внутри микшированного с понижением сигнала, и
определение значения компенсации громкости в зависимости от информации громкости и в зависимости от информации воспроизведения, при этом определение значения компенсации громкости выполняется в зависимости от информации о громкости сигналов аудиообъектов, которые микшированы внутри микшированного с понижением сигнала, и в зависимости от информации о громкости упомянутых одного или более дополнительных обходных сигналов аудиообъектов, которые не микшированы внутри микшированного с понижением сигнала, и
генерирование упомянутых одного или более выходных аудиоканалов выходного аудиосигнала из входного аудиосигнала в зависимости от информации понижающего микширования, в зависимости от информации воспроизведения и в зависимости от значения компенсации громкости.
20. Способ кодирования множества сигналов аудиообъектов, содержащий:
кодирование упомянутого множества сигналов аудиообъектов, чтобы получать кодированный аудиосигнал, содержащий множество сигналов аудиообъектов, и
определение информации громкости о сигналах аудиообъектов, при этом информация громкости содержит одно или более значений громкости, при этом каждое из упомянутых одного или более значений громкости зависит от одного или более из сигналов аудиообъектов,
при этом определение упомянутых одного или более значений громкости из информации громкости выполняется посредством определения значения громкости для каждой группы из упомянутых двух или более групп, при этом упомянутое значение громкости упомянутой группы указывает полную громкость упомянутых одного или более сигналов аудиообъектов из упомянутой группы,
кодирование информации громкости о сигналах аудиообъектов,
при этом каждый из сигналов аудиообъектов из кодированного аудиосигнала назначается в точности одной группе из двух или более групп, при этом каждая из упомянутых двух или более групп содержит один или более из сигналов аудиообъектов из кодированного аудиосигнала, при этом, по меньшей мере, одна группа из упомянутых двух или более групп содержит два или более из сигналов аудиообъектов.
21. Способ кодирования множества сигналов аудиообъектов, содержащий:
прием упомянутого множества сигналов аудиообъектов, при этом каждый из сигналов аудиообъектов назначается в точности одной из в точности двух групп, при этом каждая из упомянутых в точности двух групп содержит один или более из сигналов аудиообъектов, при этом, по меньшей мере, одна группа из упомянутых в точности двух групп содержит два или более из сигналов аудиообъектов,
кодирование множества сигналов аудиообъектов, чтобы получать кодированный аудиосигнал, содержащий множество сигналов аудиообъектов, посредством микширования с понижением сигналов аудиообъектов, которые содержатся в упомянутых в точности двух группах, чтобы получать микшированный с понижением сигнал, содержащий один или более аудиоканалов понижающего микширования в качестве кодированного аудиосигнала, при этом количество упомянутых одного или более каналов понижающего микширования меньше, чем количество сигналов аудиообъектов, которые содержатся в упомянутых в точности двух группах,
определение информации громкости о сигналах аудиообъектов, при этом информация громкости содержит одно или более значений громкости, при этом каждое из упомянутых одного или более значений громкости зависит от одного или более из сигналов аудиообъектов,
посредством определения первого значения громкости, второго значения громкости и третьего значения громкости из информации громкости, при этом первое значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из первой группы, при этом второе значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из второй группы, и при этом третье значение громкости указывает полную громкость упомянутых одного или более дополнительных обходных сигналов аудиообъектов из третьей группы, или
посредством определения первого значения громкости и второго значения громкости из информации громкости, при этом первое значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из первой группы, и при этом второе значение громкости указывает полную громкость упомянутых одного или более сигналов аудиообъектов из второй группы и упомянутых одного или более дополнительных обходных сигналов аудиообъектов из третьей группы,
кодирование информации громкости о сигналах аудиообъектов,
прием одного или более дополнительных обходных сигналов аудиообъектов, при этом каждый из упомянутых одного или более дополнительных обходных сигналов аудиообъектов назначается третьей группе, при этом каждый из упомянутых одного или более дополнительных обходных сигналов аудиообъектов не содержится в первой группе и не содержится во второй группе, и
отсутствие микширования с понижением упомянутых одного или более дополнительных обходных сигналов аудиообъектов внутри микшированного с понижением сигнала.
22. Машиночитаемый носитель, содержащий компьютерную программу для осуществления способа по п. 18 при исполнении на компьютере или сигнальном процессоре.
23. Машиночитаемый носитель, содержащий компьютерную программу для осуществления способа по п. 19 при исполнении на компьютере или сигнальном процессоре.
24. Машиночитаемый носитель, содержащий компьютерную программу для осуществления способа по п. 20 при исполнении на компьютере или сигнальном процессоре.
25. Машиночитаемый носитель, содержащий компьютерную программу для осуществления способа по п. 21 при исполнении на компьютере или сигнальном процессоре.
| Колосоуборка | 1923 |
|
SU2009A1 |
| ФАРМАЦЕВТИЧЕСКИЙ ПРЕПАРАТ | 1994 |
|
RU2146522C1 |
| US 7415120 B1, 19.08.2008 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| УСОВЕРШЕНСТВОВАННЫЙ МЕТОД КОДИРОВАНИЯ И ПАРАМЕТРИЧЕСКОГО ПРЕДСТАВЛЕНИЯ КОДИРОВАНИЯ МНОГОКАНАЛЬНОГО ОБЪЕКТА ПОСЛЕ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ | 2007 |
|
RU2430430C2 |

