Изобретение относится к области информационных технологий, в частности к способам поиска информации в больших документальных базах данных (БД).
Известен способ [RU, 2167450 С1, класс G06F 17/30, 2001.05.20] идентификации объектов по их описаниям, заключающийся в том, что преобразуют тексты естественного языка в заданных областях знаний в сигналы, пригодные для машинной обработки, формируют соответствующие тезаурусы текста путем машинной обработки сигналов, преобразованных из каждого упомянутого текста, в системе хранения и обработки информации, осуществляют статистическую обработку слов в тезаурусах каждого текста, объединяют тезаурусы текстов в соответствующие базы данных в системе хранения и обработки информации, при идентификации конкретного объекта в упомянутых областях знаний формируют запрос к выбранной базе данных путем указания выборки желательных слов, характеризующих упомянутый конкретный объект, сравнивают упомянутую выборку слов из сформированного запроса с тезаурусами текстов в выбранной базе данных, по результатам этого сравнения принимают решение об идентификации упомянутого конкретного объекта, при этом в процессе формирования тезаурусов каждого текста осуществляют лингвистическую сортировку всех слов этого текста по заранее заданным кластерам, упомянутую статистическую обработку слов осуществляют для каждого кластера данного текста, осуществляют лингвистическую сортировку всех слов из выборки слов сформированного запроса, аналогичную лингвистической сортировке слов при формировании тезаурусов текстов, в процессе упомянутого сравнения вычисляют статистическую меру совпадения тезаурусов для выборки слов из сформированного запроса и текстов из выбранной базы данных, решение об идентификации упомянутого конкретного объекта принимают на основе сопоставления вычисленных статистических мер совпадения для различных текстов.
Недостатком указанного способа является то, что тезаурусы требуют частого обновления.
Наиболее близким к заявляемому способу поиска информации является способ [RU №2266560 С1, класс G06F 17/30, 2005.12.20] поиска информации в политематических массивах неструктурированных текстов, заключающийся в том, что терминам вектора запроса присваивают порядковые номера, затем поиск осуществляют с занесением в память компьютера номеров документов, в которых присутствует хотя бы один термин вектора запроса, затем заносят в память компьютера количество совпавших терминов с терминами запроса и порядковые номера совпавших терминов, затем в памяти компьютера документы сортируют по классам с равным количеством совпавших терминов, при этом внутри каждого класса формируют подклассы индекса i класса индекса j, характеризующиеся полным совпадением номеров терминов, затем определяют количество документов (nij) в подклассе индекса i класса индекса j, затем определяют количество документов (nj) класса j, затем определяют вероятность принадлежности документа к подклассу i при условии его принадлежности к классу j, затем определяют критерий выдачи для каждого класса и далее расширяют запрос, если в документах класса содержатся новые термины, которые относятся к тематике поиска.
Недостатком этого способа является его низкое быстродействие, так как осуществляется деление найденных документов на классы и подклассы и определение вероятности принадлежности документа к подклассу i, при условии его принадлежности к классу j.
Техническим результатом является сокращение времени поиска, так как не осуществляется деление найденных документов на классы и подклассы, а выдача документа производится по критерию максимального количества совпадений терминов в его заголовке с терминами из базы терминов по определенной тематике.
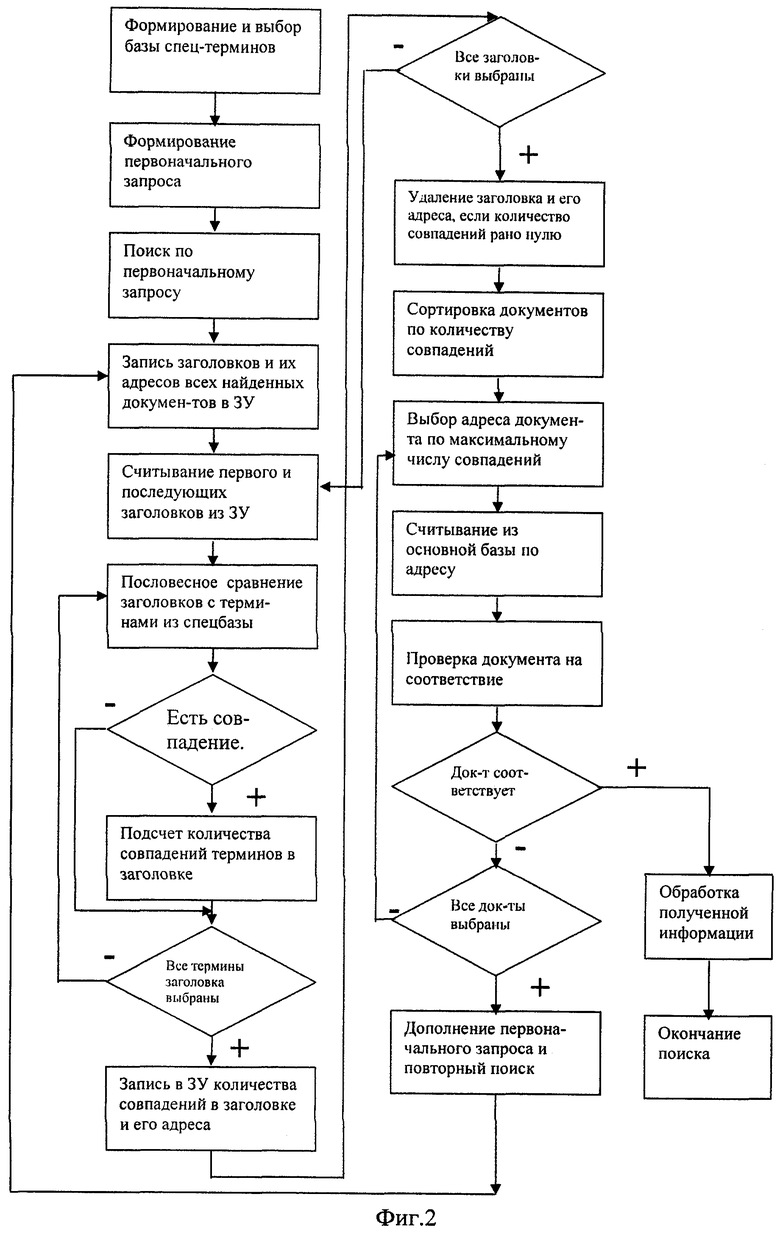
Технический результат достигается тем, что в способе поиска информации в политематических массивах неструктурированных текстов поиск осуществляют с занесением в память компьютера номеров документов, заносят в память компьютера количество совпавших терминов, в памяти компьютера документы сортируют, определяют критерий выдачи и расширяют запрос, дополнительно сначала формируют базу терминов по определенной тематике, после чего формируют на компьютере первоначальный запрос и осуществляют по нему поиск в основной базе, затем при нахождении каждого документа заносят в память компьютера его заголовок и адрес, после занесения в память компьютера заголовков и адресов всех найденных документов, отдельно для каждого из них осуществляют пословесное сравнение заголовков с терминами из базы терминов по определенной тематике, суммирование количества совпавших терминов и занесение в память компьютера полученного количества совпавших терминов соответственно для каждого документа и его адреса, затем проверяют наличие документов, для которых количество совпавших терминов равно нулю, и удаляют их заголовок и адрес из памяти компьютера, затем осуществляют сортировку заголовков и адресов оставшихся документов в соответствии с количеством совпавших терминов, затем производят выбор адреса документа по определенному критерию и выдачу на экран монитора компьютера документа, соответствующего этому адресу, затем осуществляют проверку выданного документа на соответствие первоначальному запросу, причем основных баз и баз терминов по определенной тематике может быть несколько, причем сортировку найденных заголовков и адресов документов осуществляют путем ранжирования по убыванию количества совпавших терминов, соответствующего каждому документу, причем критерием выбора адреса документа является соответствующее ему максимальное значение количества совпавших терминов, причем в информационно-поисковую систему загружаются документы, представленные на естественном языке.
Введение указанных дополнительных действий и последовательности их выполнения позволяет сократить время поиска, так как не осуществляется деление найденных документов на классы и подклассы, а выдача документа производится по критерию максимального количества совпадений терминов в его заголовке с терминами из базы терминов по определенной тематике. В других известных технических решениях отсутствуют подобные признаки в их совокупности, что приводит к положительному эффекту, так как исключая любое из действий или нарушая порядок их выполнения, невозможно достичь указанного технического результата.
На фиг.1 представлен пример функциональной схемы системы поиска информации.
На фиг.2 представлен порядок выполнения действий в виде блок-схемы алгоритма.
Так как в способе действия выполняются над материальными объектами, то система поиска может быть представлена следующим образом (фиг.1). Она содержит блок 1 формирования запроса, выход которого соединен с входом блока 2 памяти заголовков и адресов выбранных документов, выход которого соединен с первым входом блока 3 сравнения терминов заголовков с специальными терминами, выдаваемыми на его второй вход с выхода базы терминов 4 по определенной тематике, выход блока 3 сравнения терминов заголовков с специальными терминами соединен с входом счетчика 5, выход которого соединен с входом блока 6 памяти и сортировки количества совпавших терминов, выход которого соединен с входом блока 7 выбора документов, выход которого через соответствующие шины данных 12 и шины управления 13 соединен с процессором 8, блоком воспроизведения 9, основной базой 10 и контроллером 11.
Блок 1 формирования запроса может представлять собой стандартный блок ввода-вывода данных с клавиатурой и мышью, с возможностью отображения вводимой информации на экране блока воспроизведения 9, т.е. это может быть дисплей, экран монитора и т.п. В то же время блок формирования запроса 1 может быть выполнен в виде формирователя сообщения о выборе базы данных для проведения поиска, которое передается в контроллер 11 для запуска программы поиска в основной базе 10. Блок 2 памяти заголовков и адресов выбранных документов представляет собой отдельный блок или часть запоминающего устройства компьютера. Блок 3 сравнения терминов заголовков с специальными терминами и счетчик 5 могут быть выполнены как аппаратно, так и программно. Блок 6 памяти и сортировки количества совпавших терминов может быть выполнен как аппаратно, так и программно-аппаратно. Блок 7 выбора документов, процессор 8, блок воспроизведения 9 и контроллер 11 представляют собой единую компьютерную систему.
Поиск осуществляется следующим образом (фиг.1, фиг.2).
При включении системы пользователю с помощью блока воспроизведения 9 предлагается меню, которое отображается на экране монитора, на котором, в частности, представлен перечень названий имеющихся баз данных системы 10 и баз терминов 4 по определенной тематике. Далее с помощью блока формирования запроса 1 пользователь формирует первоначальный запрос, сообщение об этом сразу попадает в контроллер.
Далее пользователю системы предлагаются заголовки документов, выданные из основной базы по первоначальному запросу, которые отображаются на экране монитора. Одновременно заголовки документов и их адреса системой в автоматическом режиме записываются в блок 2 памяти. После окончания записи всех выданных по первоначальному запросу документов и их адресов осуществляется их поочередное считывание из блока 2 памяти и сравнение заголовков с терминами, выбранными из базы терминов 4 по определенной тематике. Каждое совпадение с терминами подсчитывается счетчиком 5. После того как будет выполнено сравнение всех терминов и суммирование количества совпадений для очередного заголовка, общее количество совпавших терминов записывается в блок 6 памяти и сортировки количества совпавших терминов. Затем системой будет выбран заголовок очередного документа и будет осуществляться сравнение с терминами, выбранными из базы терминов 4 по определенной тематике, подсчет количества совпавших терминов и их запись в блок 6 памяти и сортировки количества совпавших терминов. После того как будет выполнено сравнение и суммирование терминов заголовков всех предложенных документов, в блоке 6 памяти и сортировки количества совпавших терминов производится проверка наличия адресов документов, количество совпавших терминов которых равно нулю (нет ни одного термина заголовка документа, совпавшего с терминами, выбранными из базы терминов 4 по определенной тематике). Вся информация о таких документах удаляется из памяти компьютера. Затем в блоке 6 памяти и сортировки количества совпавших терминов производится сортировка найденных адресов документов путем ранжирования по убыванию количества совпавших терминов, соответствующих каждому документу (при этом предполагается, что документ, которому соответствует максимальное значение количества совпавших терминов, наиболее вероятно соответствует запросу). Затем с помощью блока 7 выбора документов производится выбор из основной базы 10 документа, количество совпавших терминов которого максимально. Выбранный документ отображается на экране монитора блока воспроизведения 9. Оператор производит анализ выбранного документа и, если выданный документ не соответствует первоначальному запросу, то всю информацию о нем удаляют и осуществляют выдачу на экран монитора следующего документа из оставшихся, количество совпавших терминов которого максимально, и осуществляют проверку выданного документа на соответствие первоначальному запросу. Как только очередной документ будет соответствовать первоначальному запросу, то поиск путем прерывания заканчивают. Если же все выданные документы не соответствует первоначальному запросу, то расширяют первоначальный запрос путем добавления дополнительных терминов и повторяют процесс поиска.
Таким образом, способ позволяет сократить время поиска, так как не осуществляется деление найденных документов на классы и подклассы, а выдача документа производится по критерию максимального количества совпадений терминов в его заголовке с терминами из базы терминов по определенной тематике.
Изобретение относится к области информационных технологий, в частности к способам поиска информации в больших документальных базах данных (БД). Техническим результатом является сокращение времени поиска. В способе формируют базу терминов по определенной тематике, запрос и при поиске по запросу и нахождении каждого документа заносят в память компьютера его заголовок и адрес, пословесно сравнивают заголовки с терминами из базы терминов по определенной тематике и заносят в память количество совпавших терминов для каждого документа и его адреса, проверяют наличие документов, для которых количество совпавших терминов равно нулю, и удаляют их заголовок и адрес из памяти компьютера, сортируют заголовки и адреса оставшихся документов по количеству совпавших терминов, осуществляют проверку выданного документа на соответствие первоначальному запросу, если выданный документ не соответствует первоначальному запросу, то всю информацию о нем удаляют и осуществляют выдачу на экран монитора следующего по критерию документа. 4 з.п. ф-лы, 2 ил.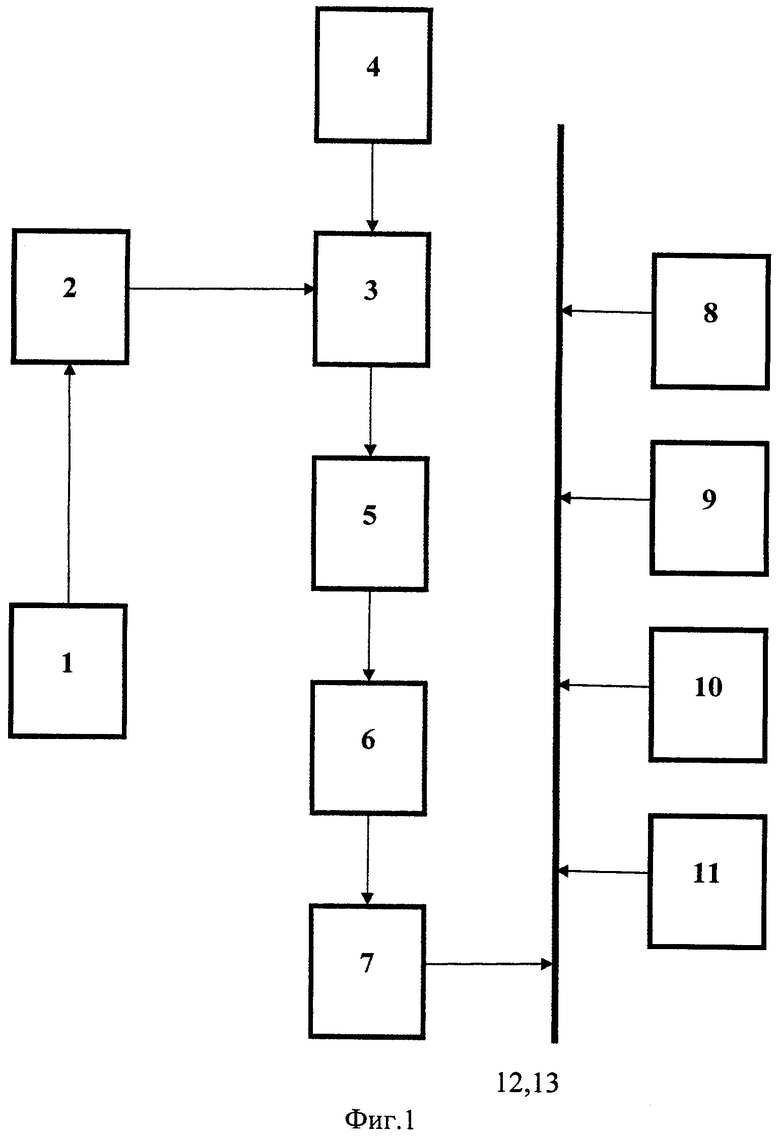
1. Способ поиска информации в политематических массивах неструктурированных текстов, заключающийся в том, что поиск осуществляют с занесением в память компьютера номеров документов, заносят в память компьютера количество совпавших терминов, в памяти компьютера документы сортируют, определяют критерий выдачи и расширяют запрос, отличающийся тем, что сначала формируют базу терминов по определенной тематике, после чего формируют на компьютере первоначальный запрос и осуществляют по нему поиск в основной базе, затем при нахождении каждого документа заносят в память компьютера его заголовок и адрес, после занесения в память компьютера заголовков и адресов всех найденных документов отдельно для каждого из них осуществляют пословесное сравнение заголовков с терминами из базы терминов по определенной тематике, суммирование количества совпавших терминов и занесение в память компьютера полученного количества совпавших терминов соответственно для каждого документа и его адреса, затем проверяют наличие документов, для которых количество совпавших терминов равно нулю и удаляют их заголовок и адрес из памяти компьютера, затем осуществляют сортировку заголовков и адресов оставшихся документов в соответствии с количеством совпавших терминов, затем производят выбор адреса документа по определенному критерию и выдачу на экран монитора компьютера документа, соответствующего этому адресу, затем осуществляют проверку выданного документа на соответствие первоначальному запросу.
2. Способ по п.1, отличающийся тем, что основных баз и баз терминов по определенной тематике может быть несколько.
3. Способ по п.1, отличающийся тем, что сортировку найденных заголовков и адресов документов осуществляют путем ранжирования по убыванию количества совпавших терминов, соответствующих каждому документу.
4. Способ по п.1, отличающийся тем, что критерием выбора адреса документа является соответствующее ему максимальное значение количества совпавших терминов.
5. Способ по п.1, отличающийся тем, что в информационно-поисковую систему загружаются документы, представленные на естественном языке.
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В ПОЛИТЕМАТИЧЕСКИХ МАССИВАХ НЕСТРУКТУРИРОВАННЫХ ТЕКСТОВ | 2004 |
|
RU2266560C1 |
| СИСТЕМА ПОИСКА ИНФОРМАЦИИ В КОМПЬЮТЕРНОЙ СЕТИ | 1998 |
|
RU2138076C1 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ | 2006 |
|
RU2320005C1 |
| US 5748954 А, 05.05.1998 | |||
| CN 101080711 A, 28.11.2007. | |||

