Описание
Область техники, к которой относится изобретение
Настоящее изобретение имеет дело с обработкой данных.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Локализацией является процесс модификации продуктов или услуг, чтобы принять во внимание различия на отдельных рынках. Самый общий пример локализации встречается, когда приложение создается на исходном языке и выдвигается на рынок, который использует целевой язык, отличный от оригинального. Например, если приложение было создано на английском языке, а затем ввезено в Китай, оно должно быть локализовано посредством перевода различных англоязычных строк и элементов (меню, иконок и т.п.) UI (пользовательского интерфейса), программных компонентов и поддержки пользователя в приложении на китайский язык. Компоновка и стиль UI (в том числе, тип шрифта, размер, управляющие позиции и т.д.), вероятно, также будут изменены, чтобы соответствовать целевому языку. Разумеется, понятие локализации является более широким, чем просто трансформирование языка. Рынки, которые используют один и тот же язык, могут быть непохожими по другим причинам. Например, программное приложение может быть «локализовано» для разных возрастных групп. Оно может иметь один набор языка и внешнего вида для взрослых людей и другой - для детей или юношей. Таким образом, локализация, в качестве иллюстрации, осуществляет согласование с широким многообразием различий на обособленных рынках.
Несмотря на то что, как описано выше, локализация затрагивает гораздо больше вещей, чем просто перевод строк; чтобы облегчить чтение документа, мы сосредоточим описание на таком сценарии. Подобным образом, большинство примеров взяты из области техники локализации программного обеспечения, но изобретение не ограничено локализацией программного обеспечения. Аналогичным образом, в то время как большая часть настоящего всестороннего исследования фокусируется на локализации продукта, изобретение не является ограниченным до такой степени и с тем же успехом применимо к услугам, и, таким образом, термин «продукт» включает в себя «услуги» в целях этого описания. В прошлом, не было попыток системного уровня обеспечить локализацию, но взамен, локализация выполнялась с использованием индивидуальных компонентов для решения индивидуальных задач. Например, локализатор может быть усилен некоторыми технологиями машинного перевода, чтобы повысить скорость, точность и непротиворечивость локализации. Однако разные локализаторы могут использовать именно системы переводческой памяти для того, чтобы повысить коэффициент повторного использования посредством повторного использования предыдущих переводов, тем самым предоставляя более согласованный результат при более высокой скорости, чем они обеспечили бы без инструментальных средств.
К тому же все это делалось традиционно автономным образом. Другими словами, автор создает полное приложение или большую часть компонента, а такой компонент или приложение предоставляется локализатору для локализации. Обычно процесс таков, что взаимодействие локализатора с исходным автором является минимальным или несуществующим. Это делает затруднительным внесение изменений в контент (содержимое) оригинала, что могло бы облегчить его локализацию. Фактически, во многих случаях, локализация не выполняется до тех пор, пока значительно позже не будет разработан полный продукт и не будет принято стратегическое маркетинговое решение распространять такой продукт на другой рынок, который использует другой язык или является обособленным в некотором другом роде. Во всех из этих случаев, типично, очень небольшая предварительная работа выполняется при разработке приложения с точки зрения локализации или даже оптимизации для локализации. Подобным образом, на стадии разработки/создания имеет место весьма небольшая поддержка для разработки приложения или другого продукта/услуги, которые будут относительно легкими для локализации, хотя создание продукта или услуги, которые легко локализуемы, является не более затруднительным, чем создание таковых, которые нелегки для локализации.
Следовательно, продукты, услуги и приложения традиционно переводились на разные языки или локализовались иным образом посредством сложной, ручной и трудоемкой работы. Цена этой локализации программных продуктов и перевод имеющего отношение к продукту контента представляет значительное препятствие, которое должно быть преодолено для того, чтобы проникнуть на новые рынки. Это особенно верно для от малых до средних независимых поставщиков программного обеспечения или авторов контента.
Проблема локализации также масштабируется в зависимости от конкретного места, в котором разрабатывается программное обеспечение. Для разработчиков, которые создают программное обеспечение в местах, где имеются большие рынки, локализация программного обеспечения для других (и вероятно, меньших) рынков является менее необходимой. Однако, если разработчики создают в месте (и с использованием языка), которое имеет относительно небольшой рынок, вся жизнеспособность продукта может зависеть от возможности локализовать такой продукт на языках, используемых на больших рынках. Это требует от производителей расходовать чрезмерно большой объем ресурсов на локализацию. Это зачастую уменьшает ресурсы, имеющиеся в распоряжении для разработки.
Другая проблема, ассоциативно связанная с усилиями для предварительной локализации, состоит в том, что не было в распоряжении удобного способа заимствовать работу многообразия других источников локализации. Например, широкое многообразие поставщиков локализуют свои продукты для различных рынков. Подобные приложения, разработанные разными поставщиками, вероятно, могут быть локализацией идентичных, или очень похожих, строк или программного обеспечения для одних и тех же рынков. Однако в настоящий момент нет подходящего способа касательно этих двух, чтобы заимствовать или совместно использовать усилия друг друга. Поэтому имеют место большой объем в точности повторяющейся работы при локализации продуктов.
Более того, есть много разных моделей программирования (таких как Win32 (32-разрядный интерфейс прикладного программирования для Windows), CLR (общеязыковая среда исполнения) и создание WEB-сценариев) с разными типами администраторов ресурсов, форматов ресурсов и информационных хранилищ. Они требуют разных анализаторов и комплектов инструментальных средств, чтобы справляться с локализацией, что имеет результатом сложные и дорогостоящие процессы, и несоответствия качества локализации.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение предоставляет систему для обработки данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 - один из иллюстративных вариантов осуществления среды, в которой настоящее изобретение может быть использовано.
Фиг. 2 - более детализированная структурная схема среды исполнения, применяющей аспекты настоящего изобретения.
Фиг. 3 - блок-схема последовательности операций способа, иллюстрирующая полную работу платформы (или системы), показанной на фиг. 2, в которой перевода нет в наличии.
Фиг. 4 - блок-схема последовательности операций способа, иллюстрирующая работу компонента сопоставления, показанного на фиг. 2.
Фиг. 5 - более детализированная структурная схема платформы (или системы) локализации, показанной на фиг. 2, которая используется во время разработки приложения или другого контента.
Фиг. 6 - блок-схема последовательности операций способа, иллюстрирующая каким образом продукт может быть разработан с реализацией технологий, которые способствуют дальнейшей локализации, в соответствии с одним из вариантов осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ИЛЛЮСТРАТИВНЫХ
ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Настоящее изобретение предоставляет операционную систему с интегрированной платформой локализации или платформу локализации, которая содержит компоненты, тесно работающие с операционной системой, хотя и не интегрированные полностью. Настоящая платформа локализации также может быть предоставлена в качестве службы, которая запрашивается операционной системой. Настоящее изобретение использует платформу локализации, чтобы локализовать контент (содержимое) и программное обеспечение. Настоящее изобретение также может быть использовано во время разработки продуктов или услуг, реализующих инструкции, которые дают возможность более быстрой и более эффективной локализации продукта или службы. Настоящее обсуждение будет продолжаться касательно перевода во время процесса локализации, но изобретение не ограничено до такой степени, а локализация также включает в себя широкое многообразие других приспособлений для обособленных рынков. Перед более подробным описанием настоящего изобретения будет описан вариант осуществления среды, в которой настоящее изобретение может быть использовано.
Фиг. 1 иллюстрирует пример подходящей среды 100 вычислительной системы, в которой изобретение может быть реализовано. Среда 100 вычислительной системы является только одним из примеров подходящей вычислительной среды и не имеет намерением предлагать какое бы то ни было ограничение объема использования или функциональных возможностей изобретения. Вычислительная среда 100 также не должна быть истолкована как имеющая какую бы то ни было зависимость или требование, относящиеся к любому одному или сочетанию компонентов, проиллюстрированных в примерной рабочей среде 100.
Изобретение работоспособно с многочисленными другими конфигурациями или средами вычислительных систем общего применения или специального назначения. Примеры хорошо известных вычислительных систем, сред и/или конфигураций, которые могут быть пригодными для использования с изобретением, включают в себя, но не в качестве ограничения, персональные компьютеры, серверные компьютеры, «карманные» или «дорожные» устройства, многопроцессорные системы, основанные на микропроцессорах системы, компьютерные приставки к телевизору, программируемую бытовую электронную аппаратуру, сетевые ПК (персональные компьютеры, PC), миникомпьютеры, универсальные вычислительные машины, телефонные системы, распределенные вычислительные среды, которые включают в себя любые из вышеприведенных систем или устройств, и тому подобное.
Изобретение может быть описано в общем контексте машинно-исполняемых инструкций, к примеру, программных модулей, являющихся исполняемыми компьютером. Как правило, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и так далее, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Изобретение к тому же может быть осуществлено на практике в распределенной вычислительной среде, где задачи выполняются удаленными обрабатывающими устройствами, которые связаны через сеть передачи данных. В распределенной вычислительной среде программные модули расположены как на локальных, так и удаленных компьютерных запоминающих носителях, в том числе запоминающих устройствах памяти.
Со ссылкой на фиг. 1, примерная система для реализации изобретения включает в себя вычислительное устройство общего применения в виде компьютера 110. Компоненты компьютера 110 могут включать в себя, но не в качестве ограничения, процессор 120, системную память 130 и системную шину 121, которая соединяет различные системные компоненты, в том числе системную память, с процессором 120. Системная шина 121 может быть любой из некоторых типов шинных структур, в том числе шиной памяти или контроллером памяти, периферийной шиной и локальной шиной, использующей любую из многообразия шинных архитектур. В качестве примера, а не ограничения, такие архитектуры включают в себя шину архитектуры промышленного стандарта (ISA), шину микроканальной архитектуры (MCA), шину расширенной ISA (EISA), локальную шину ассоциации по стандартизации в области видеотехники (VESA) и шину соединения периферийных компонентов (PCI), также известную как мезонинная (Mezzanine) шина.
Компьютер 110 типично включает в себя многообразие машиночитаемых носителей. Машиночитаемые носители могут быть любыми доступными носителями, к которым может быть осуществлен доступ компьютером 110, и включают в себя как энергозависимые и энергонезависимые носители, так и съемные и несъемные носители. В качестве примера, а не ограничения, машиночитаемые носители могут содержать компьютерные запоминающие носители и среду передачи данных. Компьютерные запоминающие носители включают в себя как энергозависимые и энергонезависимые, так и съемные и несъемные носители, реализованные по любому способу или технологии для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Компьютерные запоминающие носители включают в себя, но не в качестве ограничения, ОЗУ (оперативное запоминающее устройство, RAM), ПЗУ (постоянное запоминающее устройство, ROM), ЭСППЗУ (электрически стираемое и программируемое ПЗУ, EEPROM), флэш-память или другую технологию памяти, CD-ROM, цифровой многофункциональный диск (DVD) или другие оптические дисковые запоминающие устройства, магнитные кассеты, магнитную ленту, магнитные запоминающие диски или другие магнитные запоминающие устройства, либо любой другой носитель, который может быть использован для хранения требуемой информации и к которому может быть осуществлен доступ компьютером 110. Среда передачи данных типично воплощает машиночитаемые инструкции, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как сигнал несущей или другой транспортный механизм, и включает в себя любую среду доставки информации. Термин «модулированный сигнал данных» означает сигнал, который имеет одну или более его характеристик, установленных или изменяемых таким образом, чтобы кодировать информацию в сигнале. В качестве примера, а не ограничения, среда передачи данных включают в себя проводную среду, такую как проводная сеть или непосредственное проводное соединение, и беспроводную среду, такую как акустическую, РЧ (радиочастотную, RF), инфракрасную и другую беспроводную среду. Сочетания любых из вышеприведенных также должны быть включены в пределы объема машиночитаемых носителей.
Системная память 130 включает в себя компьютерные запоминающие носители в виде энергозависимой и/или энергонезависимой памяти, такой как постоянное запоминающее устройство (ПЗУ) 131 и оперативное запоминающее устройство (ОЗУ) 132. Базовая система 133 ввода/вывода (BIOS), содержащая базовые процедуры, которые помогают передавать информацию между элементами в пределах компьютера 110, к примеру, во время запуска, типично хранится в ПЗУ 131. ОЗУ 132 типично содержит модули данных и/или программ, которые доступны непосредственно и/или, собственно, являются управляемыми процессором 120. В качестве примера, а не ограничения, фиг. 1 иллюстрирует операционную систему 134, прикладные программы 135, другие программные модули 136 и данные 137 программ.
Компьютер 110 также может включать в себя другие съемные/несъемные энергозависимые/энергонезависимые компьютерные запоминающие носители. Исключительно в качестве примера, фиг. 1 иллюстрирует накопитель 141 на жестком диске, который выполняет считывание с или запись на несъемные энергонезависимые магнитные носители, магнитный дисковод 151, который выполняет считывание с или запись на съемный энергонезависимый магнитный диск 152, и оптический дисковод 155, который выполняет считывание с или запись на съемный энергонезависимый оптический диск 156, такой как CD-ROM или другие оптические носители. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные запоминающие носители, которые могут быть использованы в примерной рабочей среде, включают в себя, но не в качестве ограничения, кассеты магнитной ленты, карты флэш-памяти, цифровые многофункциональные диски, цифровую видеоленту, твердотельное ОЗУ, твердотельное ПЗУ и тому подобное. Накопитель 141 на жестком диске типично соединен с системной шиной 121 через интерфейс несъемной памяти, такой как интерфейс 140, а дисковод 151 для магнитного диска и дисковод 155 для оптического диска типично соединены с системной шиной 121 посредством интерфейса съемной памяти, такого как интерфейс 150.
Накопитель и дисководы и их ассоциированные компьютерные запоминающие носители, обсужденные выше и проиллюстрированные на фиг. 1, обеспечивают хранение машиночитаемых инструкций, структур данных, программных модулей и других данных для компьютера 110. На фиг. 1, например, накопитель 141 на жестком диске проиллюстрирован в качестве хранящего операционную систему 144, прикладные программы 145, другие программные модули 146 и данные 147 программ. Заметим, что эти компоненты могут быть либо такими же как, либо отличными от операционной системы 134, прикладных программ 135, других программных модулей 136 и данных 137 программ. Операционная система 144, прикладные программы 145, другие программные модули 146 и данные 147 программ здесь снабжены другими номерами, чтобы проиллюстрировать, что они, как минимум, являются другими копиями.
Пользователь может вводить команды и информацию в компьютер 110 через устройства ввода, такие как клавиатура 162, микрофон 163 и координатно-указательное устройство 161, такое как мышь, шаровой манипулятор или сенсорная панель. Другие устройства ввода (не показаны) могут включать в себя джойстик, игровую панель, спутниковую антенну, сканер или подобное. Эти и другие устройства ввода часто соединены с процессором 120 через пользовательский интерфейс 160 ввода, который соединен с системной шиной, но могут быть соединены посредством других интерфейсов и шинных структур, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 191, или другой вид устройства визуального отображения, также соединен с системной шиной 121 через интерфейс, такой как видеоинтерфейс 190. В дополнение к монитору, компьютеры также могут включать в себя другие периферийные устройства вывода, такие как динамики 197 и принтер 196, которые могут быть подключены через интерфейс 195 периферийного вывода.
Компьютер 110 работает в сетевой среде с использованием логических соединений с одним или более удаленных компьютеров, таких как удаленный компьютер 180. Удаленный компьютер 180 может быть персональным компьютером, карманным устройством, сервером, маршрутизатором, сетевым ПК, одноранговым устройством или другим общим узлом сети и типично включает в себя многие или все из элементов, описанных выше относительно компьютера 110. Изображенные на фиг. 1 логические соединения включают в себя локальную сеть (LAN) 171 и глобальную сеть (WAN) 173, но также могут включать в себя другие сети. Такие сетевые среды являются обычными в офисах, корпоративных компьютерных сетях, сетях интранет (локальных сетях, основанных на технологиях Интернет) и сети Интернет.
Когда используется в сетевой среде LAN, компьютер 110 подключен к LAN 171 через сетевой интерфейс или адаптер 170. При использовании в сетевой среде WAN, персональный компьютер 110 типично включает в себя модем 172 или другое средство для установления соединений через WAN 173, такую как сеть Интернет. Модем 172, который может быть внутренним или внешним, может быть соединен с системной шиной 121 через интерфейс 160 пользовательского ввода, или другой подходящий механизм. В сетевой среде программные модули, изображенные относительно компьютера 110, или их части, могут быть сохранены в удаленном запоминающем устройстве памяти. В качестве примера, а не ограничения, фиг. 1 иллюстрирует удаленные прикладные программы 185 в качестве находящихся на удаленном компьютере 180. Будет принято во внимание, что показанные сетевые соединения являются примерными, и может быть использовано другое средство установления линии связи между компьютерами.
Фиг. 2 иллюстрирует платформу (или систему) 200 локализации, которая интегрирована в операционную систему 134, показанную на фиг. 1. Платформа 200 локализации показана с некоторым количеством различных хранилищ памяти, и будет понятно, что эти хранилища памяти могут быть воплощены в любом из многообразия запоминающих устройств, показанных на фиг. 1, или в других запоминающих устройствах. Система 200 показана интерактивно скомпонованной с приложением 202, которое будет подвергаться локализации, и многообразием источников 204 входных данных, которые вводят различные переводы в информационные хранилища в системе 200 через компонент 205 сбора данных.
Система 200, сама по себе, включает в себя администратор 206 ресурсов, подсистему 208 компоновки, блок 210 поиска соответствий переводческой памяти (ТМ), администратор 212 загрузки, информационную службу 214 переводческой памяти (TM), систему 216 машинного перевода (MT), фильтры 218, систему 220 сертификатов и множество разных информационных хранилищ. Информационные хранилища, показанные на фиг. 2, содержат информационное хранилище 222 прикладных правил, локальное и приватное (частное) хранилища 224 и 226 соответственно, информационное хранилище 228 терминологической базы и информационное хранилище 230 перевода терминологической базы, онтологическое хранилище 232, переводческую память 234 и информационное хранилище 236 общих элементов UI. Вообще, прикладные правила используются в ресурсах, чтобы указывать имеющие отношение к приложению ценные данные, в то время как фильтры используются для того, чтобы гарантировать, что объекты (или источники 204 входных данных), вносящие вклад в данные, способны модифицировать только данные, которые они внесли, и что все добавленные данные отфильтрованы на основании некоторых правил. Конечно, информационные хранилища могут быть по-разному сгруппированы, объединены или разделены любым желательным образом. Подробное функционирование системы 200 описано позже в описании изобретения относительно фиг. 2-6. Однако далее будет предпринято краткое обсуждение работы системы 200 и элементов, показанных на фиг. 2.
Во время выполнения, администратор 206 ресурсов загружает ресурсы, ассоциативно связанные с приложением 202, в кэш-память 207 (подобные сценарии могут быть созданы для контента (содержимого) и другого типа локализуемых данных). Администратор 206 ресурсов также принимает вызовы от приложения 202 касательно ресурсов. В ответ администратор 206 ресурсов сначала загружает строку на языке, который ассоциирован с национальными настройками, выбранными в настоящий момент посредством платформы 200. Администратор 206 ресурсов решает, какую версию ресурса следует загружать, на основании многообразия критериев, таких как доступность, уровень доверия, пользовательские установки и т. п. Администратор 206 ресурсов может решить задействовать блок 210 поиска соответствий ТМ. Чтобы поступить таким образом, администратор 206 ресурсов вызывает блок 210 поиска соответствий ТМ, чтобы получить перевод (или локализацию) заданного ресурса. Блок 210 поиска соответствий ТМ также может иметь предварительно пополненные данные ресурса, чтобы избежать задержек во время исполнения при загрузке ресурса; предварительно заполненная информация будет помечена релевантной информацией, такой как, поступила ли она от МТ-системы 216 или блока 210 поиска соответствий ТМ, ее доверительный источник, и т. п. Это обсуждено более подробно ниже. Если блок 210 поиска соответствий ТМ не возвращает соответствие для ресурса, администратор 206 ресурсов последовательно проходит через резервы ресурса для того, чтобы перевод мог быть предоставлен на другом резервном языке. Это также более подробно описано ниже. К тому же в одном из вариантов осуществления, оба, администратор 206 ресурсов и блок 210 поиска соответствий ТМ, имеют резервы. Они могут быть отличными один от другого и, хотя результаты блока 210 поиска соответствий ТМ могут влиять на администратор 206 ресурсов, администратор 206 ресурсов может решить перейти на резерв без вызова блока 210 поиска соответствий ТМ.
Не является необычным, что изменения, произведенные локализацией по строкам, требуют изменения элементов отображения, содержащих такие строки. Распространенные примеры включают в себя потребность в большем пространстве (более длинные строки), изменениях в протекании диалога (языковые конструкции с записью справа налево против языковых конструкций с записью слева направо) и т. д. Процесс настройки может происходить во время локализации, во время визуализации или во время обоих. Наиболее общий случай состоит в том, что при диалоге требуется перегруппировка и изменение размера элементов, и этот процесс упоминается как автоматическая компоновка. Количество и корректность информации, предоставляемой во время процесса авторской разработки, будет влиять на результаты, получаемые во время выполнения.
Блок 210 поиска соответствий ТМ расположен между различными источниками переводов и администратором 206 ресурсов, который запрашивает контент, подлежащий сопоставлению (или переводу на другой язык или локализации иным образом). Блок 210 поиска соответствий ТМ просматривает доступные источники (и те источники, которые сделаны доверительным приложением 202), чтобы найти перевод, который имеет наивысшую оценку доверия, ассоциативно связанную с ним.
Кроме того, более подробное обсуждение работы блока 210 поиска соответствий ТМ изложено ниже относительно фиг. 4. Тем не менее, вкратце, блок 210 поиска соответствий ТМ обращается к правилам, ассоциативно связанным с приложением или контентом 202, в информационном хранилище 222 прикладных правил, чтобы гарантировать, что какая бы то ни было локализация, которая предоставляется администратору 206 ресурсов, не послужит причиной неправильной работы приложения 202. Блок 210 поиска соответствий ТМ сначала просматривает локальное информационное хранилище 224 и приватное (частное) информационное хранилище 226, чтобы посмотреть, существует ли уже локализация. Локальное информационное хранилище 224 хранит переводы или другие локализации ресурсов, которые уже были локализованы, в случае, когда запрос, произведенный администратором 206 ресурсов, является запросом, который был сделан прежде.
Блок 210 поиска соответствий ТМ также задействует информационную ТМ-службу 214. Информационная ТМ-служба 214 обращается к переводческой памяти 234, которая содержит переводы или другие локализации широкого многообразия различных вещей, таких как общие элементы пользовательского интерфейса (UI), сохраненные в хранилище 236, а также определенные термины, сохраненные в базе 228 терминов, а онтологическое хранилище 232 предоставляет контекстную информацию для приложения 202 и ассоциативно связанной области знаний.
Если пока нет никаких локализаций, как локально, в хранилище 224 или 226, так и удаленно, в хранилище 234, блок 210 поиска соответствий ТМ может обращаться к необязательно доступной системе 216 машинного перевода (МТ) (или одной из множества доступных МТ-систем), чтобы выполнить машинный перевод контента, подлежащего локализации. Решение блока 210 поиска соответствий ТМ задействовать МТ-систему 216 может быть основано на пользовательских предпочтениях, наличии перевода, качестве доступных и предоставляемых MT-системой переводов и т. д. В одном из вариантов осуществления, система 216 машинного перевода является любой доступной для приобретения МТ-системой и только в целях иллюстрации используется для переводов, если не было найдено соответствий с более высоким доверительным уровнем из любого из других источников памяти (таких как информационная ТМ-служба 214, а также локальное и приватное информационные хранилища 224 и 226). Тот факт, что МТ-система 216 может быть, по существу, любой МТ-системой, или любой системой, способной к использованию данных в разных хранилищах (например, предыдущих переводах), чтобы производить переводы, значительно улучшает расширяемость системы, так как новые или отличные МТ-системы могут быть легко использованы блоком 210 поиска соответствий ТМ.
Конечно, расширяемость МТ-системой не является единственной расширяемостью в системе, а является только одним из примеров. Некоторые другие примеры расширяемости системы включают в себя редакторы создания контента, анализаторы языка, системы переводческой памяти сторонних производителей, общие редакторы, среды авторской разработки, соединения с веб-службами и т.д. Расширяемость в этих и других областях поддерживается API (программными интерфейсами приложения) в платформе 200.
В любом случае, каждый из переводческих ресурсов, вызываемый блоком 210 поиска соответствий ТМ, будет, в качестве иллюстрации, снабжать блок 210 поиска соответствий ТМ оценкой доверия (или классом перевода, коэффициентом повторного использования, или другой подобной мерой), показывающей степень доверия или повторного использования, ассоциативно связанную с локализацией, являющейся запрашиваемой. Блок 210 поиска соответствий ТМ затем может выбирать локализацию или перевод из доверительного источника, который предоставляет перевод, ассоциированный с наивысшей оценкой. Затем переводы загружаются администратором 212 загрузки в локальное хранилище 224, если они там еще не хранятся.
В одном из иллюстративных вариантов осуществления, широкое многообразие источников 204 входных данных могут поставлять переводческие входные данные в различные запоминающие устройства в системе 200. Например, поставщики или производители программного обеспечения, которые разрабатывают операционные системы, которые включают в себя платформу 200 локализации, будут, в качестве иллюстрации, предоставлять выверенные термины в различную память. Однако, в одном из вариантов осуществления, источники 204 входных данных могут включать в себя общность (сообщество) в общем смысле и общность (сообщество) разработки. Общность в общем смысле дает возможность всякому, кто выполняет услуги локализации с использованием системы 200, возможность предоставлять предполагаемую локализацию части контента для соответствующего запоминающего устройства через компонент 205 сбора данных. Источники 204 входных данных также могут включать в себя общность разработки, которая будет (в противоположность общности в общем смысле) сохранять переводы, предоставленные только разработчиками, официально распознаваемые в качестве таковых. Таким образом, можно видеть, что платформа 200 позволяет процесс локализации сделать открытым для задействования общества в очень большом масштабе, а также настроенным на гранулярном уровне (например, пользователь решает, чему доверять, а чему нет), чтобы удовлетворять пользовательским потребностям и ожиданиям.
Кроме того, компонент сбора данных может динамически (во время установки, выполнения, конфигурирования и т. д.) периодически собирать новые данные из многообразия источников 204 входных данных. Новые данные, конечно, могут быть данными нового ресурса, а также предварительно локализованными данными или данными переводческой памяти для поддержки новых приложений, новых областей знаний, и для выполнения самообращения работающей операционной системы. Это заключает в себе адаптируемость и точность системы.
Однако конкретный разработчик приложений, системный администратор или пользователь может пожелать, чтобы только определенный контент локализации был доверительным. Разработчик, например, может не пожелать доверять контенту локализации из общности в общем смысле или общности разработки, а только от поставщиков и производителей ОС (операционных систем, OS). Это позволяет разработчику или пользователю устанавливать предел, до которого платформа 200 открывает задачи локализации разным источникам. Это может быть установлено даже на построчной основе.
В одном из таких вариантов осуществления, система 200 включает в себя систему 220 сертификатов, которая прикрепляет сертификаты к контенту, предоставляемому определенными источниками. В таком случае, разработчик приложения 202 может пожелать, чтобы доверительным был контент локализации только с прикрепленным сертификатом. Например, разработчики и другие соавторы могли бы быть способны получить право подписывать свой контент, который является относящимся к тому уровню, на котором они находятся, относительно их приложения. Это означает, что сертификат разработчика приложения ставит такого разработчика на уровень разработчиков для этого конкретного приложения, а все остальные соавторы находятся одним уровнем ниже в «других ISV» (других независимых поставщиках программного обеспечения), уровне общности или пользователя. Сертификаты могут быть сделаны доверительными по отношению к уровню соавтора. Например, данный производитель всегда мог бы иметь наивысший уровень, но с этого уровня и ниже пользователь может определять доверительный уровень, а в пределах уровня - доверительные источники. Указание в отношении того, какой контент локализации должен быть сделан доверительным любым заданным приложением 202 или каким-либо пользователем, может быть сохранено в информационном хранилище 222 прикладных правил. Сертификаты помогают установить систему доверий для переводов.
Пользователь или разработчик также может выбирать иерархические доверительные источники. Например, на основании происхождения контента локализации пользователь может определять, доверять ли только производителю ОС, а если никаких нет в распоряжении, то доверять ли переводам независимых поставщиков программных продуктов, а если таковых нет в распоряжении, то доверять только общности разработки, и так далее. В одном из иллюстративных вариантов осуществления, эта иерархия устанавливается по умолчанию, но пользователь может просто принять или подменить ее своими персональными установочными параметрами. Такие установочные параметры могут быть реализованы в прикладных правилах, связанных с каждым приложением или с отдельной машиной, выполняющей приложение.
Также должно быть отмечено, что приватное (частное) хранилище 226 подобно локальному хранилищу 224 тем, что оно находится в пользовательском информационном хранилище. Однако локальное хранилище 224, в качестве иллюстрации, является обширным системным хранилищем, тогда как приватное хранилище 226 является хранилищем, которое может быть использовано, чтобы указывать доверительный контент локализации, соответствующий отдельному пользователю, в том числе, данные, введенные пользователем для его собственного приватного (частного) использования. Следовательно, каждый отдельный пользователь может идентифицировать разный доверительный контент локализации. Этот контент идентифицирован для такого конкретного пользователя в приватном хранилище 226. Это предоставляет отдельному пользователю настраивать по специальным требованиям процесс локализации даже сверх того, что ассоциируется с отдельным приложением. Например, пользователь может производить изменения в его или ее собственных приложениях, как требуется и разрешается приложением. Пользователь также может распространять локальное или приватное хранилища обратно в общность.
В дополнение, некоторые переводы могут быть заблокированы для того, чтобы они не модифицировались. Это может быть критически важным для избежания потенциально возможных выполненных со злым умыслом переводов. Например, один из источников входных данных может предоставить совершенный со злым умыслом перевод, который мог бы перевести выражение «Щелкните кнопкой мыши здесь, чтобы отформатировать ваш жесткий диск» как «Щелкните кнопкой мыши здесь, чтобы продолжить».
Как только блок 210 поиска соответствий ТМ получает требуемую локализацию для запроса от администратора 206 ресурсов, он применяет фильтры 218 и прикладные правила из хранилища 222. Фильтры, в качестве иллюстрации, определяют термины, которые не должны размещаться в каком бы то ни было контенте локализации на любом заданном языке. Например, некоторые пользователи могут пожелать фильтровать непристойные термины или любой другой спорный контент. Поэтому фильтры 218 применяются перед использованием локализованного контента, запрошенного администратором 206 ресурсов. Будет отмечено, что применение фильтров (также как и любого другого вида проверки правильности данных) является одним из этапов при локализации и может быть применено на многих этапах процесса таких как редактирование, загрузка, использование и т. д.
Например, проверка правильности данных вообще, совершается всякий раз, когда два компонента обмениваются данными, за исключением ситуации, когда компоненты полностью доверяют один другому, и используемый канал для обмена информацией также является доверительным (к примеру, по отношению к пиратской деятельности). Поэтому, например, если ресурсы загружаются из доверительного источника, и ресурсы заключают в себе действительную цифровую подпись, никакой другой проверки правильности (отличной от проверки правильности подписи) делать не требуется. Если источник является доверительным, но файл не подписан, то канал, используемый для передачи информации, оценивается, чтобы определить, является ли он также доверительным. Например, неподписанный файл, который был загружен из сети Интернет, будет подделан более вероятно, нежели неподписанный файл, который пользователь скопировал из другой папки на том же компьютере. В зависимости от некоторых факторов, он может решить предпринять быструю функциональную проверку правильности, или может быть проведена некоторая дополнительная проверка правильности контента, такая как проверка на агрессивные слова, или чтобы убедиться, что термины из исходного ресурса присутствуют на целевом ресурсе (например, что «меню» не переводится как «папка»).
Компонент 240 установки/конфигурации приложения используется во время установки и конфигурации после установки. Во время установки приложение 202 регистрирует свои ресурсы с помощью локального хранилища 224 ресурсов. Компонент 240, в качестве иллюстрации, открывает для воздействия пользовательский интерфейс, который предоставляет пользователю возможность локализовать приложение на целевой язык, поддерживаемый платформой, если оно еще не было локализовано. Пользовательский интерфейс может предоставлять пользователю возможность выбрать целевой язык явным образом. Компонент 241 локализации, по требованию, пересылает эти запросы администратору 206 ресурсов, а также, возможно, блоку 210 поиска соответствий ТМ.
Унаследованное приложение 242 представляет приложения, которые были разработаны и не осведомлены о платформе 200. Уровень 243 совместимости поддерживает существующие интерфейсы ресурсов, используемые приложением 242, и перенаправляет вызовы администратору 206 ресурсов.
Фиг. 3 - блок-схема последовательности операций способа, которая иллюстрирует работу платформы 200 более подробно, в соответствии с одним из вариантов осуществления настоящего изобретения. Во время выполнения, пользователь сначала выбирает или запускает приложение 202. Это указано этапом 300 на фиг. 3. Затем в этом варианте осуществления, администратор 206 ресурсов загружает требуемые ресурсы, связанные с приложением 202, в кэш-память 207 (или в другое запоминающее устройство, все из которых будут в материалах настоящей заявки упоминаться как «кэш», в этом контексте). Это показано этапом 302.
В фоновом режиме, операционная система (и, в частности, платформа 200 локализации) начинает перевод ресурсов в кэше 207, на требуемый язык. При действии таким образом платформа 200 реализует прикладные правила 222, связанные с приложением 202, и модель доверий (т. е. доверительные источники локализации), связанную с приложением 202 или пользователем (кто бы не применял). Администратор 206 ресурсов задействует блок 210 поиска соответствий ТМ для ресурсов, сохраненных в кэше 207, чтобы получить их локализованное значение. Локализация ресурсов, загруженных в кэш 207 в фоновом режиме, показана этапом 304 на фиг. 3.
Должно быть отмечено, что пополнение локализованных ресурсов для приложения не нуждается в ожидании до времени исполнения. Взамен оно может быть сделано во время установки или в другое время. В дополнение, некоторые части локализации могут быть запущены во время выполнения, тогда как другие могут быть произведены при установке или в другое время. Например, некоторые из более ресурсозатратных или затратных по времени задач могут выполняться в фоновом режиме, во время установки или в другое время, тогда как более быстрые задачи могут выполняться во время исполнения. В другом варианте осуществления, задачам может быть назначено (пользователем) выполняться в любое заданное время, а также может быть отображен статус этих задач.
Так как ресурсы локализуются в фоновом режиме, локализованные значения сохраняются не только в кэше 207, но они также размещаются в локальном хранилище 224. Следовательно, в следующий раз, когда будет запущено приложение 202, процесс локализации будет более быстрым, поскольку все значения ресурса, которые были локализованы, уже будут размещены в локальном хранилище 224. Таким образом, блоку 210 поиска соответствий ТМ не требуется отыскивать информационную ТМ-службу 214 или иметь в распоряжении значения, переведенные с использованием системы 216 машинного перевода, так как локализации будут вспомнены системой. Взамен они могут быть просто извлечены из локального хранилища 224. Сохранение переводов в локальном хранилище 224 указано этапом 306 на фиг. 3. К тому же, по требованию, целостные переводы могут быть загружены в локальное хранилище 224 с использованием администратора 212 загрузки.
Конечно, настоящая система также может производить проверки на обновление. Например, первоначально может быть выбран неидеальный перевод, так как ни один лучший не может быть определен. Позже, однако, может быть загружен более хороший перевод в одну из памяти одним из источников 204. Ресурс затем может периодически обновляться, чтобы согласовать это.
Подобным образом, обновления кода могут сделать ранее локализованные ресурсы недействительными. Поэтому в одном из вариантов осуществления изменения кода инициируют переопределение некоторых или всех ресурсов.
Так как выполняются переводы ресурсов, механизм 208 компоновки идентифицирует определенного рода переводы, которые потребуют модификаций компоновки визуального отображения для приложения. В дополнение, шрифты, используемые на исходном языке в приложении, отображаются шрифты на целевом языке. Это может быть сделано подсистемой 208 компоновки или другими компонентами во время выполнения или в предшествующее время. Отображение компоновки и шрифта показано этапом 308 на фиг. 3.
Таким образом, платформа 200 локализации в операционной системе продолжает локализовывать ресурсы, связанные с приложением 202 и сохраненные в кэше 207. Может случаться, однако, что приложение делает запрос на ресурс, который еще не был локализован в фоновом режиме. Такой запрос показан этапом 310 на фиг. 3. Администратор 206 ресурсов сначала определяет, был ли запрошенный ресурс уже локализован и сохранен в кэше 207. Это показано этапом 312 на фиг. 3. Если так, локализация запрошенного ресурса просто возвращается из кэш-памяти 207 в приложение 202. Это показано этапом 314.
Однако, если ресурс еще не был локализован в фоновом режиме и сохранен в кэше 207, то администратор 206 ресурсов запрашивает локализацию ресурса у блока 210 поиска соответствий ТМ. Затем блок 210 поиска соответствий ТМ запрашивает локализацию ресурса из различных источников, к которым он имеет доступ, и возвращает локализацию запрошенного ресурса. Задействование блока 210 поиска соответствий ТМ показано этапом 316 на фиг. 3. Работа блока 210 поиска соответствий ТМ более подробно описана касательно фиг. 4.
Посредством локализации ресурсов в кэше 207 в фоновом режиме, платформа 200 локализации значительно отходит от предшествующих систем. Предшествующие системы загружают кэш ресурсами. Однако это ведет к значительным недостаткам при локализации. Если платформа локализации ожидает, чтобы приложение запросило ресурс для того, чтобы локализовать его налету, посредством задействования МТ, это, вероятно, ведет к нежелательной задержке в работе приложения 202, или результаты будут ограничены набором алгоритмов, которые могут использоваться в такой ограниченной среде (требования производительности могут ограничивать точность). Современная технология машинного перевода требует, приблизительно половину секунды, чтобы перевести предложение. Несмотря на то что перевод налету и другая локализация безусловно предусмотрены настоящим изобретением, перевод всех ресурсов налету, с использованием системы 216 машинного перевода, вероятно, приводит к чрезмерной задержке в работе приложения. Конечно, если прежде было локализовано достаточное количество ресурсов и они хранятся в локальном хранилище 224 или приватном хранилище 226, или если они были сохранены в переводческой памяти 234, и только относительно малую часть ресурсов необходимо перевести МТ-системой 216, то локализация кэша 207 в фоновом режиме является не так важной для избежания дискредитации работы приложения 202.
В любом случае, блок 210 поиска соответствий ТМ продолжает локализовывать значения в кэше 207, либо в фоновом режиме и/или налету. Блок 210 поиска соответствий ТМ продолжает до тех пор, пока все ресурсы не будут локализованы.
Вообще, блок 210 поиска соответствий ТМ может работать с одним или более информационных хранилищ. Он может по выбору объединяться с другими подсистемами повторного использования (такими как блоки поиска соответствий ТМ или МТ-системы). Он, необязательно, может иметь преимущество терминологий наряду с их переводами и отношениями (онтологиями). Он может использовать метаданные, чтобы решать, какие части данных в хранилищах предполагаются для учреждения пространства поиска (такого как область знаний, автор, статус утверждения, или другие метаданные). Он может проверять ограничения (прикладные правила/фильтры) по самой строке и воспользоваться таковыми, чтобы производить более точное сравнение или сравнение, которое будет более легко проверяться на правильность. Конечно, все эти особенности являются необязательными и, более того, могут быть дополнены, или, по желанию, они могут быть изменены или удалены из работы блока 210 поиска соответствий ТМ.
Фиг. 4 - блок-схема последовательности операций способа, иллюстрирующая один из вариантов осуществления работы блока 210 поиска соответствий ТМ более подробно, только в целях примера. Администратор 206 ресурсов сначала снабжает блок 210 поиска соответствий ТМ запросом на локализацию. Это показано этапом 350 на фиг. 4. Затем блок 210 поиска соответствий ТМ получает информацию модели доверий для текущего контекста. В одном из вариантов осуществления, информация модели доверий сохраняется вместе с самими данными, но также может быть сохранена в приватном хранилище 226 или в любом другом источнике, который идентифицирует любые другие элементы контекста, по которым должны определяться доверительные источники локализации, обусловленные настоящим контекстом. Информация модели доверия может содержать указание того, какие источники являются доверительными, или перечень требований, которые должны быть удовлетворены для того, чтобы локализованный элемент был правильным и обоснованным. Это также оказывает содействие при сценариях обновления. Обновления в коде могут изменять набор ограничений, которым должны удовлетворять ресурсы. Такие изменения потребуют повторной проверки правильности ранее допущенных действительных ресурсов. Это показано этапом 352 на фиг. 4.
Затем блок 210 поиска соответствий ТМ, в качестве иллюстрации, запрашивает локализации ресурса изо всех доверительных источников локализации, но может действовать таким образом в заданном порядке. Порядок и количество проверенных источников, в качестве иллюстрации, изменяется в зависимости от обстоятельств (таких как, имеет ли место локализация во время выполнения, во время установки, пакетной обработки, и т. д.). Это показано этапом 354. Другими словами, в одном из вариантов осуществления, блок 210 поиска соответствий ТМ даже не запрашивает перевод из недоверительных источников. В таком случае, допустим, что пользователь не желает доверять переводам из общности в общем смысле или из общности разработки в источниках 204 входных данных. Блок 210 поиска соответствий ТМ запрашивает только локализацию контента, который исходит из доверительных источников, и тем самым будет исключать все из локализованного контента, предоставленного общностью в общем смысле и общностью разработки. Конечно, блок 210 поиска соответствий ТМ будет модифицировать источники, из которых запрошены результаты локализации, основываясь на доверительных источниках, обусловленных настоящим контекстом.
В ответ на запрос от блока 210 поиска соответствий ТМ, различные источники, которые были запрошены для контента локализации, возвращают ассоциативно связанные с ними оценки доверия. Например, для результатов перевода является наиболее общепринятым иметь ассоциированный уровень доверия, указывающий, насколько вероятно, что перевод является корректным, при условии входных данных на исходном языке. Для целей настоящего изобретения неважно, какая конкретная мера используется, чтобы указать доверие, ассоциативно связанное с переводом или другой локализацией. В иллюстративном варианте осуществления, оценки из всех источников используют или одну и ту же меру, или меры, которые коррелируются друг с другом так, что блок 210 поиска соответствий ТМ может определить относительную величину этих оценок. Возврат оценок доверия, ассоциативно связанных с переводами (или контентом локализации), показан этапом 356 на фиг. 4.
Затем блок 210 поиска соответствий ТМ получает локализованный контент (например, перевод) из доверительного источника с наивысшей оценкой. Это показано этапом 358. Также блок 210 поиска соответствий ТМ может выбирать локализованный контент на основании другого или дополнительного критерия, такого как время, требуемое для получения локализованного контента, насколько близок локализованный контент к целевому рынку, критерия проверки правильности или другого критерия или любого сочетания критериев. В дополнение, блок поиска соответствий ТМ может извлекать контент локализации из множества источников и комбинировать их.
Как только перевод принят, блок 210 поиска соответствий ТМ применяет фильтры 218 и другую проверку правильности для того, чтобы гарантировать, что контент локализации (или перевод) соответствует данному приложению и контексту, и любым фильтрам или критериям правильности, требуемым пользователем. Применение фильтров и другой проверки правильности показано этапом 360 на фиг. 4. Также блок 210 поиска соответствий ТМ, в качестве иллюстрации, применяет прикладные правила так, что контент локализации, извлеченный для данного ресурса, не будет задерживать работу приложения или вызывать неправильную работу или иным образом приводить к отказу приложения. Также должно быть отмечено, что некоторые из операций фильтрации и проверки правильности могут быть обработаны заранее, вместо ожидания выполнения всех необходимых этапов в этой точке в последовательности операций.
Как только это сделано, блок 210 поиска соответствий ТМ возвращает результат администратору 206 ресурсов. Это показано этапом 362. Будет принято во внимание, что этот процесс будет выполняться всякий раз, когда блок 210 поиска соответствий ТМ задействуется администратором 206 ресурсов. Таким образом, процесс будет выполняться, когда ресурсы в кэше 207 являются локализуемыми в фоновом режиме, и он будет выполняться, когда приложение 202 производит вызов несуществующего или еще не локализованного ресурса.
В обоих случаях, блок 210 поиска соответствий ТМ может обнаружить, что перевода на желаемом языке нет, или возвращенные оценки доверия находятся ниже заданного порога, но что перевод должен быть предпринят с использованием системы 216 машинного перевода. В этот момент, в одном из вариантов осуществления, администратор 206 ресурсов уведомляется, и он может запросить у блока 210 поиска соответствий ТМ поиск перевода на резервном языке. Например, если целевым языком является каталонский, приложение 202 может запросить перевод ресурса, но перевода в каталонском языке может не быть. Тем не менее администратор 206 ресурсов может быть сконфигурирован так, что испанский язык является первым резервным языком для каталонского языка. В этом случае, блок 210 поиска соответствий ТМ отвечает администратору 206 ресурсов, указывая, что перевода на каталонском языке нет и что должна быть задействована система 216 машинного перевода, чтобы получить такой перевод (в качестве альтернативы, МТ-система 216 может быть вызвана блоком 210 поиска соответствий ТМ при первом вызове). Администратор 206 ресурсов, взамен ухудшения производительности, связанной машинным переводом налету, может просто запросить у блока 210 поиска соответствий ТМ возврат перевода запрошенного ресурса на испанский язык. Если перевод доступен, он возвращается блоком 210 поиска соответствий ТМ.
Несомненно, как показано выше, резервные национальные настройки/языки могут быть иерархически каскадированы до любого желаемого уровня так, что различные национальные настройки являются резервными для других различных национальных настроек, окончательным резервом которых может быть язык источника. Так, если вместо предоставления перевода запрошенного ресурса достигнут окончательный резерв, администратор 206 ресурсов просто возвращает приложению 202 запрошенный ресурс в окончательном резерве, который обеспечивается платформой так, что приложение не будет нарушать или терять точку взаимодействия с пользователем из-за платформы.
В качестве иллюстрации, пользователь может также задавать, как работает иерархия резервов. Например, пользователь может указать, что визуальное отображение группы ресурсов совместно (например, диалога с несколькими строками) может показывать части диалога на одном языке (или локализованными для одного рынка), а части - на другом (например, на резервном). Другие пользователи могут указать, что визуально отображаемая группа ресурсов должна быть вся на одном языке (или локализованной для одного и того же рынка).
Также должно быть отмечено, что пользователю не требуется запускать приложение, чтобы получить его перевод посредством платформы 200. Пользователь может просто выбрать приложение или другой программный компонент для локализации, а платформа 200 может локализовать его в фоновом режиме. Например, в одном из вариантов осуществления, пользователь щелкает правой кнопкой мыши на приложении и из меню выбирает «Локализовать». Платформа 200 затем начинает локализацию приложения в фоновом режиме, сохраняя локализованный контент в локальном хранилище. Контент также может быть локализован в фоновом режиме. В одном из вариантов осуществления пользователь щелкает правой кнопкой мыши на документе, который сохранен в файловой системе или на сервере и выбирает «Локализовать». Платформа локализации локализует документ в фоновом режиме. То же самое применяется к документам, загруженным из сети Интернет.
В дополнение, когда приложение инсталлируется (или в более позднее время), пользователь может выбирать множество различных языков для инсталляции. Эти языки затем загружаются в локальное информационное хранилище 224. Переводы могут быть сохранены на компакт-диске продукта или на другом носителе.
Фиг. 5 - структурная схема, иллюстрирующая компоненты платформы 200 в контексте разработки. Большинство элементов подобны показанным на фиг. 2 и пронумерованы подобным образом.
Фиг. 5 показывает вспомогательную платформу 380 и компонент 382 разработки. Компонент 382 разработки может быть любым желательным компонентом разработки, таким как Visual Studio, доступный для приобретения у корпорации Microsoft из Редмонда, Вашингтон, или любым другим желаемым компонентом разработки для авторского создания программного обеспечения. Вспомогательная платформа 380 помогает при авторской разработке контента посредством взаимодействия с одним или более компонентами платформы 200, такими как платформа 381 перевода, чтобы предоставить разработчику возможность разрабатывать продукт, который имеет высокий коэффициент повторного использования и, соответственно, весьма сниженную стоимость для локализации на разных языках. Оба, компонент 382 разработки и вспомогательная платформа 380, пользуются службами, предоставленными платформой 200. При действии таким образом компонент 382 разработки и вспомогательная платформа 380 в соединении с другими компонентами встраивают некоторые инструкции в предварительном процессе разработки/авторского создания интерфейсной части, которые, вероятно, чрезвычайно улучшат возможность продукта быть локализованным, чтобы проникнуть на разнообразные другие рынки и, таким образом, значительно увеличить рентабельность инвестиций в разработку.
Компонент 384 построения использует информацию, предоставленную платформой локализации и/или вспомогательной платформой 380 или любым другим инструментальным средством авторского создания контента, которое может осуществлять доступ к платформе локализации через API-интерфейсы и прикладные правила в информационном хранилище 222, и создает приложение 202, а также документы контента.
Также следует заметить, что настоящее обсуждение (фиг. 5) большей частью происходит касательно разработки приложения разработчиком или создания контента автором. Однако система может быть использована для многообразия вещей, безотносительно к типу контента или программного обеспечения, которое разрабатывает разработчик или создает автор.
В соответствии с одним из вариантов осуществления настоящего изобретения, есть два способа для разработчика или автора, соответственно, использовать компонент 382 разработки, чтобы разрабатывать программное обеспечение или использовать вспомогательную платформу 380, чтобы разрабатывать контент. Первый заключается в том, чтобы использовать свойство ее среды разработки/создания, т.е. когда посредством программного интерфейса приложения (API) платформы или другого подобного механизма определяется, был ли уже разработан какой бы то ни было подобный контент или программное обеспечение, и сохранен в какой-либо из памяти в платформе 200. Второй способ предназначен для разработчика, чтобы просто разрабатывать программное обеспечение или контент (исходный или нет). В последнем случае, платформа 200 просто действует, чтобы снабдить разработчика обратной связью в отношении коэффициента повторного использования (например, количестве контента/программного обеспечения, которое может быть переведено на разные языки в платформе 200, задавшись прежними переводами) контента/программного обеспечения и чтобы предложить инструкции, которые, вероятно, будут увеличивать коэффициент повторного использования, а также предложить инструкции, которые будут предохранять приложение от неправильной работы после локализации.
В соответствии с первым вариантом осуществления, автор контента предоставляет входные данные через вспомогательную платформу 380, а вспомогательная платформа 380 вызывает API или другой подобный механизм для создания ресурса. Это показано этапом 500 на фиг. 6. Затем вспомогательная платформа 380 задействует блок 210 поиска соответствий ТМ, чтобы осуществить доступ к локальному хранилищу 224, и возвращает все типы ресурсов, которые уже имеют переводы. Это показано этапом 502 на фиг. 6. Например, платформа разработчика может задействовать API с указанием, что разработчик контента желает создать ресурс. В ответ платформа 380 возвращает указание всех различных классов ресурсов, которые содержатся в платформе 200 и которые уже имеют переводы на многообразие разных языков. Допустим, например, что результатом из платформы и представленным пользователю платформой разработчика являются классы «меню» и «сообщения об ошибках».
Через открытые для воздействия функциональные возможности в API разработчик может выбирать классы «сообщений об ошибках», а вспомогательная платформа 380 запрашивает эту информацию платформы 200 (она может быть сохранена в любой памяти), затем возвращает все разные классы сообщений об ошибках, которые содержатся в платформе 200. Затем разработчик выбирает один из классов сообщений об ошибках, а платформа 380 возвращает все из конкретных сообщений об ошибках, ассоциативно связанных с таким классом. Затем пользователь может просто выбирать одно из сообщений об ошибках, которое уже было создано и для которого локализация уже будет высокоэффективной (например, потому, что оно уже было переведено на многообразие разных языков или локализовано иным образом). Выбор разработчиком типа, класса и конкретного ресурса, если имеется в распоряжении, показан этапом 504 на фиг. 6.
Также, конечно, будет принято во внимание, что конкретное, точное сообщение, которое разработчик желает создать, может еще не быть доступным. В таком случае, пользователь может выбрать очень близкое по смыслу сообщение и модифицировать его. Модифицированное сообщение, во многих случаях, вероятно, будет способно быть локализованным вполне эффективно, так как большая часть его уже присутствовала в платформе 200 локализации. В любом случае, выбор подобного неидентичного сообщения будет приводить к ухудшению доверия. Модифицирование выбранного ресурса показано этапом 506 на фиг. 6.
Этот тип повторного использования снабжает автора высокой степенью гибкости, по отношению к локализации предшествующего уровня техники, которая происходит после разработки. Например, автор может изменять количество знакомест в программной строке, тогда как традиционный локализатор значительно более ограничен. Также автор может заменить исходное предложение полностью (с допущением, что ключевые термины сохраняются), в то время как традиционный локализатор может не иметь такой способности. Рассмотрим предложение для сообщения об ошибке: «файл {0} не существует.» Автор может заменить это на «файл {0} на приводе {1} не может быть найден.», тогда как традиционный локализатор не может использовать перевод первого предложения в качестве перевода для второго, так как без доступа к коду традиционный локализатор не способен изменять лежащие в основе допуска кода касательно количества знакомест. Повторное использование может выполняться не только по отношению к тексту, найденному в сообщениях, но также может выполняться по отношению к общим элементам UI в информационном хранилище 236. Повторное использование прежних элементов UI также совершенствует коэффициент повторного использования и локализацию продукта.
Во время разработки, разработчик также может пожелать предоставить хранилище 232 онтологии относительно онтологии. Онтология является описанием на концептуальном уровне и описывает отношения между терминами, которые предоставляют возможность семантического кодирования контента и строк. Один из вариантов осуществления онтологии изложен в патентах США № 6253170 и № 6098033. Другое описание онтологии изложено в Gruber, A TRANSLATION APPROACH TO PORTABLE ONTOLOGIES, Knowledge Acquisition, 5(2):199-220 (1993) (Грубер, ПЕРЕВОДЧЕСКИЙ ПОДХОД К ПЕРЕНОСИМЫМ ОНТОЛОГИЯМ, Приобретение знаний, 5(2):199-220 (1993)).
Вообще, слова переводятся по-разному в зависимости от контекста. Более точно, слова или термины могут быть переведены по-разному в зависимости от прикладного контекста при локализации программного обеспечения. Платформа 200 локализации имеет доступ к семантическим данным, находящимся в виде онтологического информационного хранилища 282, которые описывают отношения между терминами. Онтологии могут быть сформированы вручную, посредством ввода семантической информации вместе со словом или термином, или автоматически, посредством применения алгоритмов, которые способны определять семантический контекст по близости слов или терминов к другим словам или терминам. Информационное хранилище 282, в качестве иллюстрации, заполняется структурами и прикладным контекстом, выведенным из формата ресурса. Тип семантического кодирования в онтологическом хранилище 282 предоставляет платформе 200 возможность разрешать неоднозначности семантики для ресурсов, которые должны быть переведены, к тому же, наряду с обеспечением мощных возможностей поиска, так как он также предусматривает разрешение неоднозначности запроса. Платформа 381 перевода определяет, требуется ли разрешение неоднозначности на этапе 508 по фиг. 6. Если так, к онтологическому хранилищу 232 может быть осуществлен доступ, чтобы получить разрешающую неоднозначность семантическую информацию, или вспомогательная платформа 380 может запросить разрешающую неоднозначность семантическую информацию у автора, таким же образом компонент 382 разработки может делать то же самое для разработчика. Это показано этапом 510 на фиг. 6.
Так как разработчик продолжает разработку продукта, каждый из разработанных ресурсов подвергается оценке степени локализации платформой 381 перевода в платформе 200. При оценивании степени локализации созданных ресурсов, платформа 381 перевода идентифицирует долю тех ресурсов, которые уже были переведены (или локализованы иным образом) и которые находятся где-либо в платформе 200. Платформа 381 перевода к тому же учитывает требование подвергнуть ресурсы машинному переводу посредством системы 216, а также принимает во внимание оценки доверия, ассоциированные с каждым из переводов, находящихся в платформе 200. Эти элементы комбинируются, чтобы обеспечить коэффициент повторного использования, который является мерой того, насколько создаваемый продукт будет легко локализован на рынках, работающих на других языках. Предоставление текущего, суммарного коэффициента повторного использования показано этапом 512 на фиг. 6.
Следует отметить, что коэффициент повторного использования может быть использован в широком многообразии разных способов. Например, если разработчик разрабатывает лишь компонент целой системы, от компонента может потребоваться удовлетворять некоторому пороговому значению коэффициента повторного использования, перед тем как ему будет дана возможность быть зарегистрированным. Подобным образом, коэффициент повторного использования действительно может быть показателем ценности продукта, обусловленным тем, насколько вероятно, что продукт будет выведен на другие рынки. Конечно, этот коэффициент повторного использования также может использоваться в широком многообразии других способов.
Также должно быть отмечено, что система может подсчитывать коэффициент повторного использования для кода, который не разрабатывался на этой платформе. Код может просто поставляться в платформу 200, а блок 210 поиска соответствий ТМ может подсчитывать коэффициент повторного использования для этого кода, как результат, и возвращать его, по желанию. Это может быть использовано при принятии решения, развертывать ли продукт на новых рынках или даже приобретать ли права на продукт.
Далее обсуждение продолжается относительно варианта осуществления, в котором разработчик не выбирает уже существующие ресурсы. Допуская, что разработчик не желает выбирать из предварительно созданных ресурсов, разработчик может создавать исходные ресурсы или контент. Это показано этапом 514 на фиг. 6. В таком случае, разработчик просто создает часть контента, а вспомогательная платформа 380 вызывает блок 210 поиска соответствий ТМ, чтобы определить коэффициент повторного использования для созданного контента. Это показано этапом 516 на фиг. 6. Затем блок 210 поиска соответствий ТМ осуществляет доступ к источникам локализации и возвращает коэффициент повторного использования для вновь созданного ресурса или контента. Это показано этапом 518 на фиг. 6.
На этой стадии, платформа 200 также может быть использована, чтобы уведомлять автора в отношении инструкций, которые могут помочь автору улучшить коэффициент повторного использования продукта, находящегося в разработке, или чтобы предупредить автора касательно некоторых вариантов воплощения, которые могут стать причиной неисправной работы приложения после его локализации. Возвращение этих подсказок показано этапом 520 на фиг. 6. В одном из вариантов осуществления эти подсказки предоставляются, даже если источник продукта является повторно используемым. Тот факт, что он является повторно используемым, конечно, может означать, что некоторые из проверок уже были выполнены.
Некоторые примеры инструкций, которые могут повлиять на коэффициент повторного использования или работу приложения, включают в себя, например, написание длинных строк. Длинные строки являются не только более трудными для понимания, они также являются более трудными для перевода. В дополнение, программное обеспечение представляет риск переполнения буфера, что может привести к сбою приложения. Другие инструкции, которые могут повлиять на коэффициент повторного использования или работу приложения, включают в себя использование специальных символов или использование неподходящей, или неформальной грамматики. Использование правильных грамматических конструкций приводит к значительному увеличению возможности перевести текст. Таким образом, блок 210 поиска соответствий ТМ обеспечивает обратную связь в реальном времени в отношении коэффициента повторного использования кода и подсказок инструкций.
К тому же платформа 200 может предпринимать определенные действия, чтобы уменьшить негативное влияние этих проблемных областей в анализируемом контенте. Эти действия будут уменьшать вероятность того, что в приложении произойдет сбой после претерпевания локализации. Платформа 200 может предупредить пользователя, что эти исправляющие действия будут предприняты.
Некоторое количество других элементов должно быть отмечено касательно настоящего изобретения. Прежде всего, оно, в качестве иллюстрации, обеспечивает автоматическую обработку «горячих» клавиш. Платформа 381 перевода, в качестве иллюстрации, отслеживает «горячие» клавиши, которые визуально отображены на любом данном элементе UI, чтобы избежать двух функций, являющихся назначенными на одну и ту же «горячую» клавишу на данном элементе UI. Платформа 381 перевода может быть задействована, чтобы автоматически выбирать «горячую» клавишу или она просто может быть задействована для проверки, чтобы гарантировать, что не предпринимается никакого дублирования «горячей» клавиши по данному элементу UI. Для того чтобы быть способной выбирать или предлагать «горячую» клавишу пользователю, платформе требуется информация касательно того, какие элементы одновременно доступны пользователю так, что платформа может избежать повторений. Эта информация тесно связана с требуемой для того, чтобы визуализировать информацию на пользовательском компьютере.
Настоящее изобретение также может обеспечивать проверку правильности и моделирование среды исполнения. Как только разработчик создал компонент, разработчик может задействовать API в платформе 382 разработки, а платформа 200 будет моделировать среду исполнения, под которую требуется локализация. Моделирование исполнения предоставляет разработчику возможность физически видеть отображение на экране дисплея, после того как оно было локализовано. Это предоставляет возможность разработчику высматривать ошибки, оценивать эстетическую привлекательность отображений и производить изменения, что желательно.
Настоящее изобретение таким образом повышает способность разработчика повторно использовать уже разработанный контент. Это значительно улучшает коэффициент повторного использования и локализацию продукта.
Кроме того, настоящее изобретение предоставляет систему, которая интеллектуально комбинирует локализованный контент из операционной системы, приложений, общности и от сторонних производителей, и из машинного перевода. Администратор ресурсов загружает ресурсы приложения, возвращая запрошенные ресурсы в соответствии с необходимым языком или другими культурными или рыночными критериями из многообразия источников или хранилищ данных (также упоминаемых как компоненты контента локализации).
В дополнение, платформа локализации может быть использована, чтобы предоставлять локализованные данные широкому многообразию запрашивающих объектов, таких как приложения, браузеры, поисковые машины, загрузчики ресурсов, авторский инструментарий и т. п.
К тому же, посредством предоставления общности (обществу) и общности (обществу) в широком смысле возможности предлагать альтернативные варианты локализации, настоящее изобретение позволяет локализации стандарта общности быть определенной и иногда дает возможность локализации для некоторых очень небольших рынков. Например, настоящее изобретение предоставляет пользователю возможность локализовать англоязычное приложение для суахили. Пользователь может предоставить эту локализацию обратно платформе 200 в качестве предложенного перевода различных ресурсов в приложении. Другие южноафриканские пользователи могут предпочесть доверять этому локализованному контенту и загрузить его на суахили, или локализовать его самим, либо модифицировать локализацию и предоставить их собственную локализацию обратно платформе 200. В таком направлении, приложение может быть локализовано и исправлено и сделано доступным на рынке, где оно в противном случае могло бы и не быть из-за небольшого размера рынка.
В одном из вариантов осуществления, когда источник 204 входных данных предоставляет данные, компонент 205 сбора данных также записывает метаданные, такие как происхождение, использование, информация контекста (к примеру, контроль версий ресурса), уровень доверия, атрибуты, подсказки машинного перевода и т. д. Другие данные также могут быть собраны и отсортированы. К тому же в одном из вариантов осуществления, только источник 204 входных данных, который предоставлял данные может изменять такие данные.
Настоящее изобретение обеспечивает не только загрузку переводов из общности, но также загрузку переводов в общности. В дополнение, подобным образом могут быть загружены в обоих направлениях строки источника.
Также следует заметить, что сторонние компании и сообщества могут добавлять новый источник и переводческие памяти к платформе 200. В одном из иллюстративных вариантов осуществления, платформа 200 предоставляет веб-страницу или веб-службу, которая дает возможность добавления термина нового источника и его метаданных. Пользователи, в качестве иллюстрации, будут аутентифицированы таким образом, что платформа 200 может определять источник каждого вновь добавленного элемента.
В дополнение, платформа 200 будет, в качестве иллюстрации, работать согласно опубликованной схеме (такой как XML-схема), которая дает пользователям возможность загружать в главную систему несколько строк одновременно. С другой стороны, источник каждой строки известен, когда каждая операция требует аутентификации. Такие исходные строки, в качестве иллюстрации, могут быть дополнены одним или более переводами. Платформа 200 работает подобным образом касательно терминов в терминологической базе данных.
К тому же, в соответствии с одним из вариантов осуществления, общности способны предоставлять переводы для исходных строк в платформе 200. При редактировании переводов, метаданные, представленные в источнике, в качестве иллюстрации, доступны «переводчику», а метаданные принудительно применяются до допущения перевода. Это может быть сделано через простой веб-интерфейс. Эти переводы могут быть использованы другими людьми, если пользователь предпочитает совместно использовать его или ее переводы с обществом.
Настоящее изобретение, в качестве иллюстрации, предоставляет возможность обществу просматривать переводы, которые уже существуют в платформе 200. Это предоставляет источнику переводов возможность определять, сколько раз его или ее переводы были избраны другими пользователями. Это будет давать возможность источникам входных данных в общности создавать имя для них самих на основании качества работы, а это подталкивает источники входных данных делать работу лучше, с тем чтобы стать более высоко оцененным в обществе.
В соответствии с еще одним другим вариантом осуществления настоящего изобретения, когда разработчик загружает приложение в основную систему для перевода, разработчик обеспечивается благоприятной возможностью позволить конечным пользователям загружать их собственную локализованную версию продукта. Если такой вариант задействован, пользователь может зайти в систему платформы 200 и выбрать, какой язык, подсистемы и переводы использовать для того, чтобы сформировать персональную версию продукта.
Например, пользователь может потребовать версию «xyz» продукта наряду с заданием только точных соответствий машин перевода с использованием систем переводческой памяти, которые одобрило общество (или отдельный пользователь). Этот процесс может периодически повторяться, чтобы получать более высокий процент перевода ресурса. Платформа 200 также может предусматривать уведомления пользователей посредством электронной почты или других служб предупреждения, когда доступны новые переводы.
В соответствии с еще одним вариантом осуществления, третья сторона может добавлять к платформе 200 новую подсистему проверки (или перевода) источника. Как обсуждено выше, разработчик может представлять на рассмотрение платформе 200 приложение, чтобы определить, является ли приложение благоприятно локализуемым. Третьи стороны могут написать новые подсистемы для поддержки этого. Когда третья сторона разрабатывает подсистему, которая удовлетворяет критериям для выполнения проверки источника (например, когда она реализует требуемый интерфейс), то третья сторона может загрузить ее в платформу 200 и возложить обратно на пользователя обязанность загружать подсистему. Как с другими частями процессов, описанных относительно настоящего изобретения, подписывание (электронной подписью) и аутентификация, в качестве иллюстрации, используются, чтобы гарантировать, что источник подсистемы известен, а пользователь решил доверять такому источнику.
Подсистемы перевода могут быть добавлены подобным образом, но могут, в качестве иллюстрации, работать на сервере, реализующем платформу 200 с этапами, предпринятыми, чтобы гарантировать, что подсистема перевода не портит какие бы то ни было уже существующие данные перевода. В дополнение, настоящее изобретение выполняет глобализацию и лингвистическую проверку, чтобы содействовать авторам. Настоящее изобретение также предоставляет обществу возможность помогать автору. Например, у общества может быть запрошена исходная строка в диалоговом окне в некоторой области знаний, где исходная строка может быть легко локализована. Это содействует автору в начинании по созданию благоприятно локализуемого контента.
Также должно быть отмечено, что, несмотря на то, что определенные функции назначены определенным компонентам в описанном варианте осуществления, в таковом нет необходимости. Функции могли бы выполняться разными компонентами, а значит, некоторые компоненты могли бы быть удалены, модифицированы или добавлены, полностью в пределах объема настоящего изобретения.
Таким образом, можно видеть, что настоящее изобретение консолидирует данные для локализации из прошлых локализаций широкого многообразия продуктов и широкого многообразия источников входных данных. Взамен каждого приложения или продукта, обладающего своей собственной памятью переводов, которая не доступна другим продуктам, платформа 200 делает эту информацию доступной, по желанию разработчика или пользователя, для последующей локализации разных продуктов. Она также изменяет процесс локализации так, что конечные пользователи имеют доступ к более обширному спектру опций для переделывания (локализации) их компьютерного опыта. Она также дает возможность участия общества в этом процессе. Как следствие, сама задача локализации становится независимой от продукта, и связанной с продуктом только через контекст приложения. Другие приложения могут осуществлять доступ к локализованным строкам в любое время, если модель доверий и контекст приложения предусматривают это.
Несмотря на то что настоящее изобретение было описано со ссылками на конкретные варианты осуществления, специалисты в данной области техники будут осознавать, что могут быть сделаны изменения по форме и содержанию, не отступая от сущности и объема изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СОЗДАНИЕ РЕСУРСА С ИСПОЛЬЗОВАНИЕМ ОНТОЛОГИЙ | 2006 |
|
RU2422890C2 |
| КОНЕЧНЫЙ АВТОМАТ УНИФИЦИРОВАННОГО ОБМЕНА СООБЩЕНИЯМИ | 2008 |
|
RU2470364C2 |
| МЕХАНИЗМ КООРДИНАЦИИ ДЛЯ ВЫБОРА ОБЛАКА | 2012 |
|
RU2628902C2 |
| ПЕРЕВОДЧЕСКИЙ СЕРВИС НА БАЗЕ ЭЛЕКТРОННОГО СООБЩЕСТВА | 2015 |
|
RU2604984C1 |
| ВЕБ-КАНАЛ, БАЗИРУЕМЫЙ НА ЯЗЫКЕ XML, ДЛЯ ВЕБ-ДОСТУПА УДАЛЕННЫХ ИСТОЧНИКОВ | 2009 |
|
RU2503056C2 |
| ГИБКИЙ ПЕРЕВОД ОТОБРАЖЕНИЯ | 2006 |
|
RU2436146C2 |
| СИСТЕМЫ И СПОСОБЫ СОПРЯЖЕНИЯ ПРИКЛАДНЫХ ПРОГРАММ С ПЛАТФОРМОЙ ХРАНЕНИЯ НА ОСНОВЕ СТАТЕЙ | 2003 |
|
RU2412461C2 |
| JAVA-МОДЕЛЬ ЖИЗНЕННОГО ЦИКЛА ДЛЯ BD-ДИСКОВ | 2004 |
|
RU2369898C2 |
| ГЛУБИННЫЕ ССЫЛКИ ДЛЯ НАТИВНЫХ ПРИЛОЖЕНИЙ | 2015 |
|
RU2774319C2 |
| СЕГМЕНТ ДАННЫХ О ПЕРЕВОДЕ | 2002 |
|
RU2295150C2 |
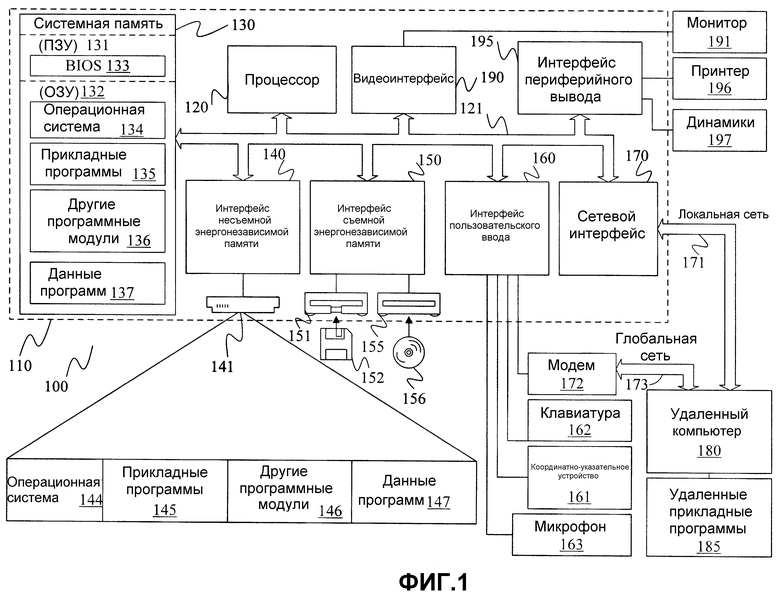
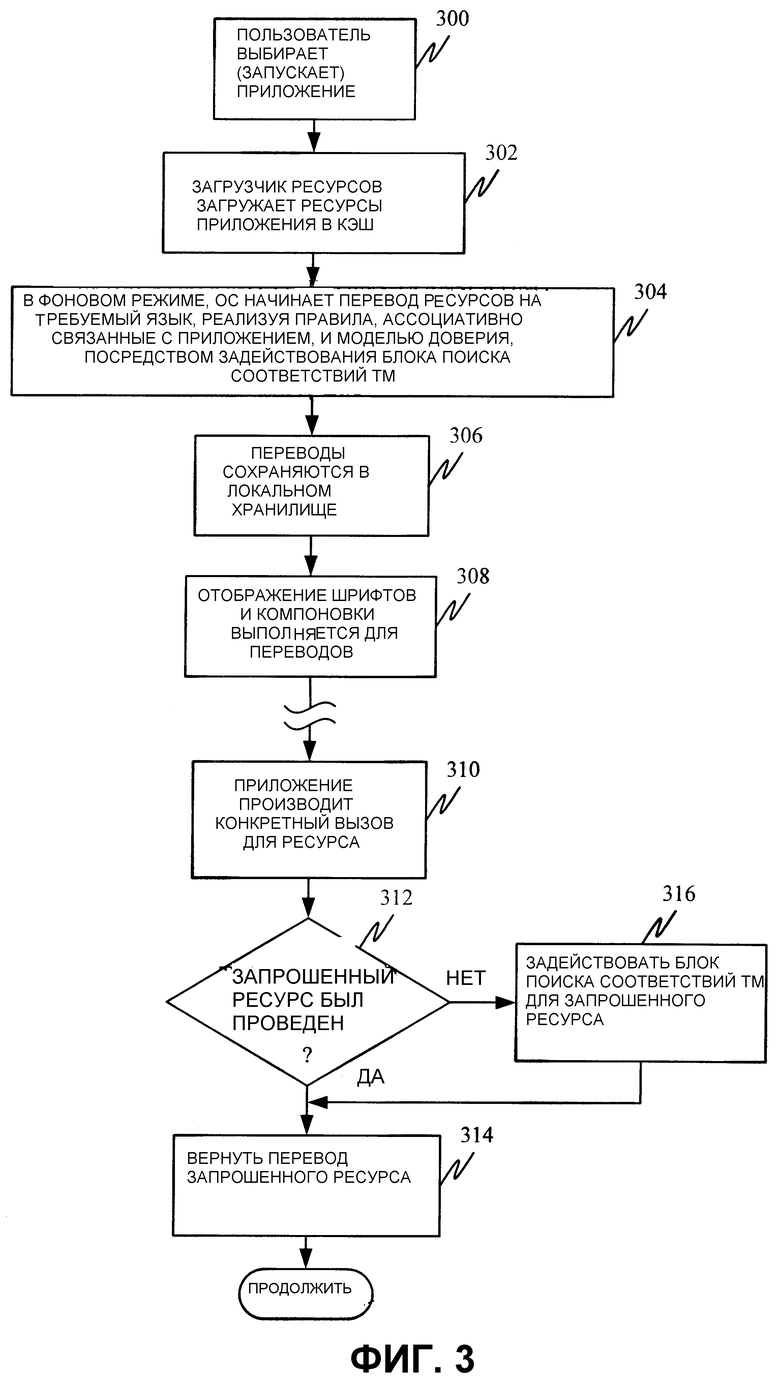
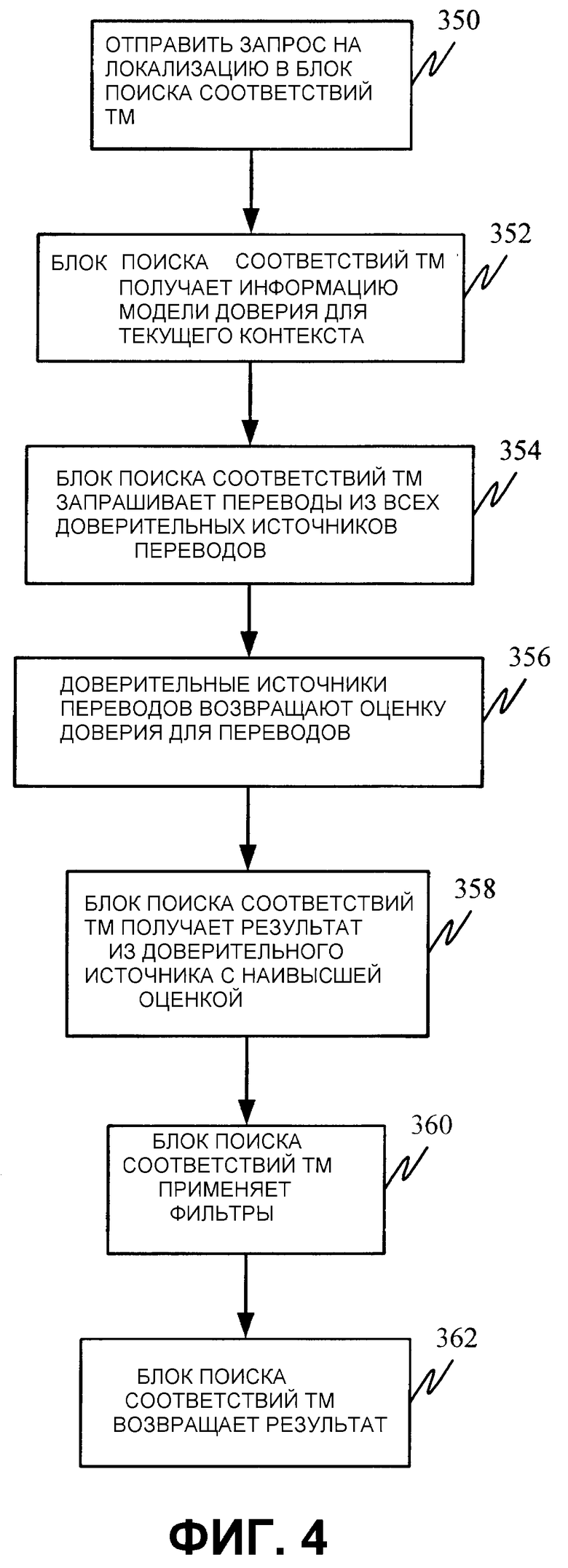
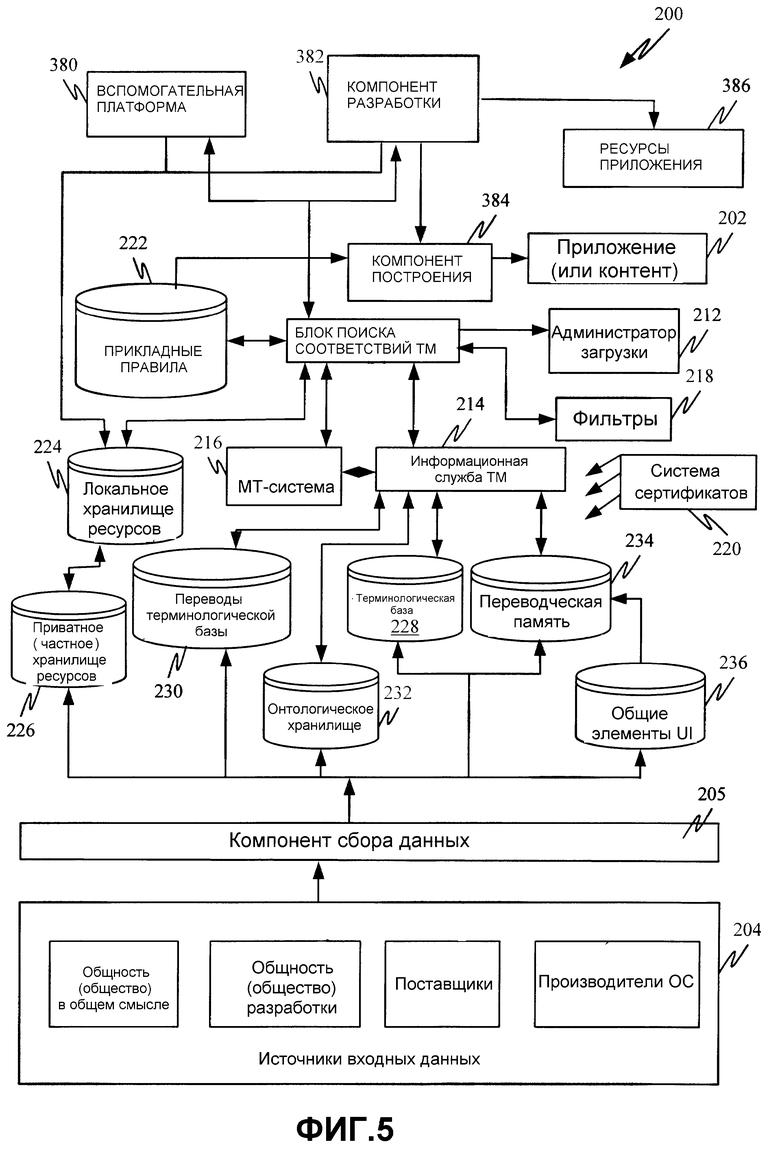
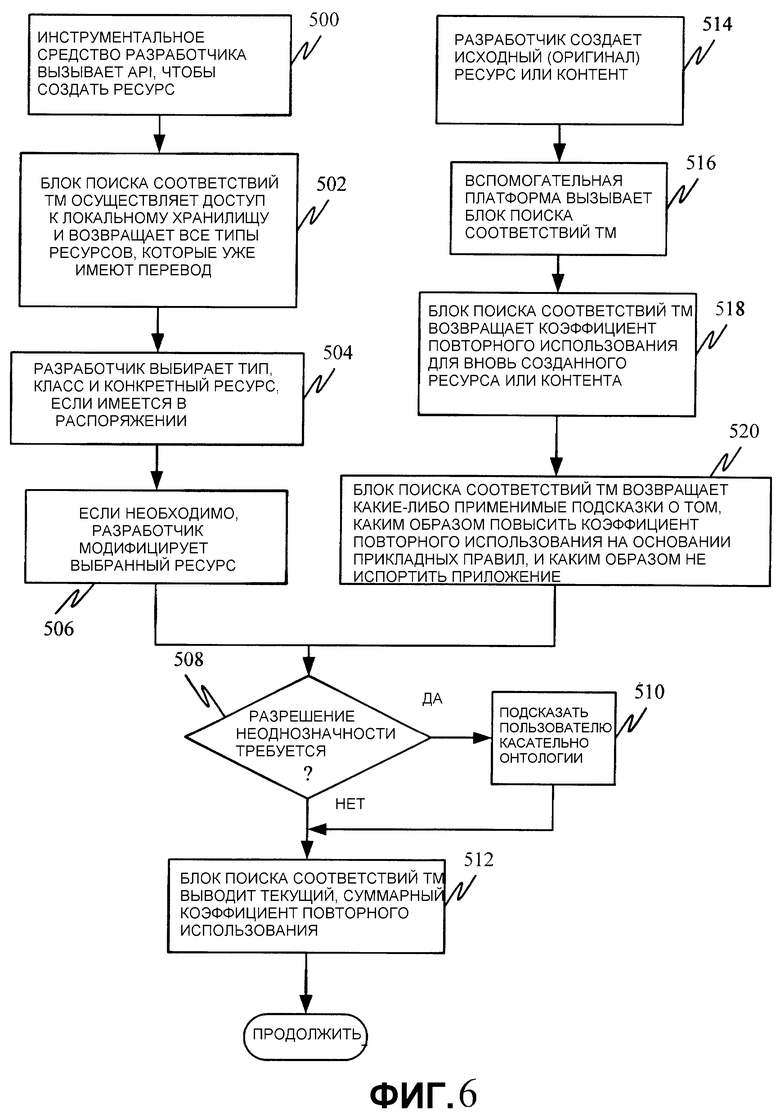
Изобретение относится к системам локализации контента и программного обеспечения. Техническим результатом является упрощение локализации контента и программного обеспечения. Система включает: платформу локализации, компонент поиска соответствий; множество компонентов контента локализации, при этом платформа локализации содержит: администратор ресурсов, компонент сбора данных, причем контент локализации содержит ресурсы, локализованные посредством по меньшей мере одного источника входных данных, предоставляющего их, и метаданные, и контекстную информацию, идентифицирующие каждый источник входных данных и ассоциированный локализованный контент, который он предоставил, причем компонент сбора данных сохраняет контент локализации в компонентах контента локализации, при этом компонент сбора данных разрешает источнику входных данных модифицировать только тот контент локализации, который предоставлен через этот компонент сбора данных этим источником входных данных, на основании метаданных, ассоциированных с модифицируемым контентом локализации. 2 н. и 16 з.п. ф-лы, 6 ил.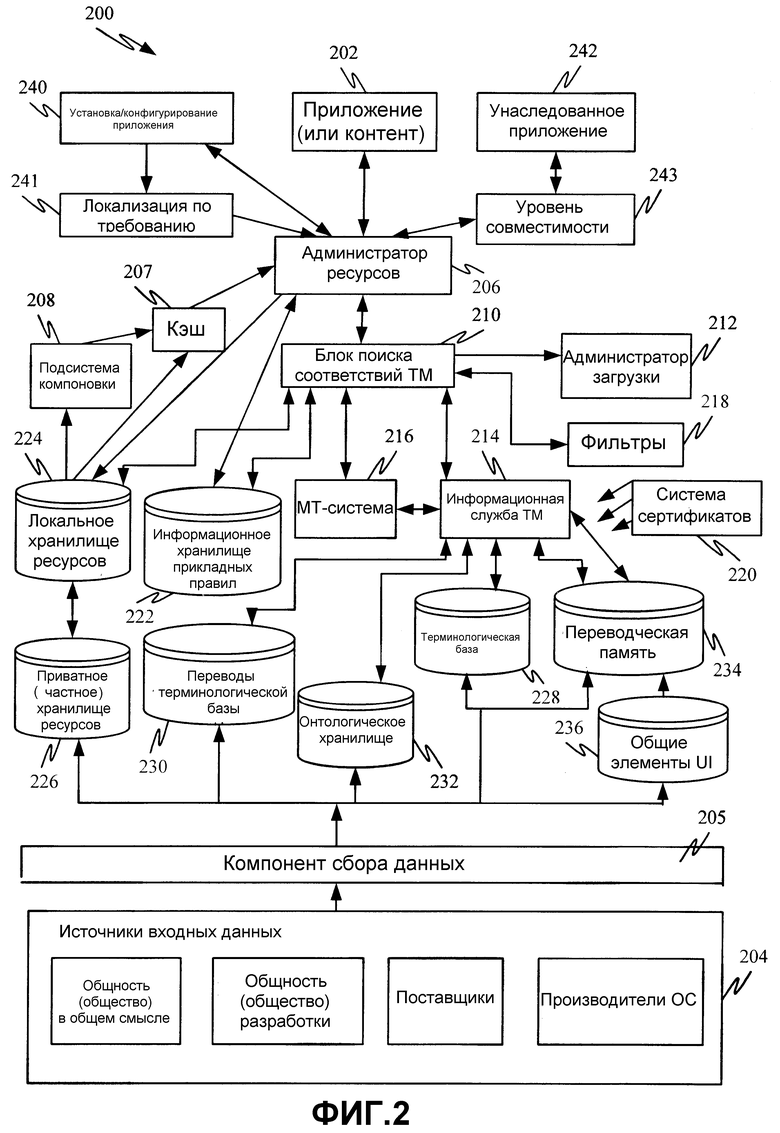
1. Реализованная компьютером система для локализации контента и программного обеспечения, содержащая:
платформу локализации, включающую в себя администратор ресурсов, выполненный с возможностью загрузки ресурсов, запрошенных приложением, в компонент памяти, и ответа на запросы ресурсов от приложения посредством возвращения приложению запрошенных ресурсов;
компонент поиска соответствий;
множество компонентов контента локализации, каждый из которых выдает локализованный контент после приема запроса, при этом компонент поиска соответствий выполнен с возможностью приема запроса локализации от администратора ресурсов, запроса у множества компонентов контента локализации и получения локализованного контента, соответствующего запросу локализации, из одного или более из множества компонентов контента локализации на основе запроса множества компонентов контента локализации, причем процессор компьютера активируется администратором ресурсов и компонентом поиска соответствий для облегчения загрузки запрошенных ресурсов и получения локализованного контента, и при этом платформа локализации содержит:
компонент сбора данных, выполненный с возможностью приема контента локализации из по меньшей мере одного источника входных данных, внешних относительно платформы локализации, причем контент локализации содержит ресурсы, локализованные посредством упомянутого по меньшей мере одного источника входных данных, предоставляющего их, и метаданные и контекстную информацию, идентифицирующие каждый источник входных данных и ассоциированный локализованный контент, который он предоставил, причем компонент сбора данных сохраняет контент локализации в компонентах контента локализации, при этом компонент сбора данных разрешает источнику входных данных модифицировать только тот контент локализации, который предоставлен через этот компонент сбора данных этим источником входных данных, на основании метаданных, ассоциированных с модифицируемым контентом локализации.
2. Система по п.1, в которой компоненты контента локализации содержат:
локальное информационное хранилище, локальное для администратора ресурсов, хранящее ранее локализованный контент; и
удаленное информационное хранилище, удаленное от администратора ресурсов, хранящее ранее локализованный контент.
3. Система по п.1, в которой компоненты контента локализации содержат:
информационную службу переводческой памяти, оперативно соединенную с компонентом поиска соответствий и множеством информационных хранилищ контента локализации, причем информационная служба переводческой памяти выполнена с возможностью поиска контента локализации в информационных хранилищах контента локализации.
4. Система по п.3, в которой информационное хранилище контента локализации включает в себя по меньшей мере одно из терминологической базы и одной или более переводческих памятей, сохраняющих переводы терминов или общих элементов UI (пользовательского интерфейса), или обоих.
5. Система по п.1, в которой компоненты контента локализации содержат:
систему машинного перевода, предоставляющую перевод в ответ на запрос компонента поиска соответствий.
6. Система по п.1, в которой компонент сбора данных выполнен с возможностью приема контента локализации из множества источников входных данных через интерфейс веб-страницы или веб-службу.
7. Система по п.1, в которой компонент сбора данных выполнен с возможностью приема приложений из источников входных данных для локализации платформой локализации.
8. Система по п.1, в которой платформа локализации выполнена с возможностью локализации по меньшей мере частей приложения в фоновых операциях.
9. Система по п.1, в которой платформа локализации выполнена с возможностью локализации по меньшей мере частей приложения во время установки или конфигурирования приложения.
10. Система по п.1, в которой платформа локализации выполнена с возможностью локализации по меньшей мере частей приложения во время исполнения.
11. Система по п.1, в которой по меньшей мере один источник входных данных, внешний к платформе локализации, включает в себя сообщество источников входных данных, причем упомянутое сообщество содержит множество источников входных данных, внешних для платформы локализации.
12. Платформа локализации, содержащая:
множество компонентов локализации, выполненных с возможностью предоставления данных, которые локализованы для одного или более обособленных рынков; и
компонент поиска соответствий, выполненный с возможностью приема входных данных, подлежащих локализации для заранее определенного рынка, осуществления доступа к множеству компонентов локализации и возвращения локализованных данных, соответствующих входным данным на основании осуществления доступа к множеству компонентов локализации,
компонент сбора данных, выполненный с возможностью приема данных, локализованных для одного или более рынков, от по меньшей мере одного источника входных данных, внешних для платформы локализации, через интерфейс Web-страницы, и сохранения принятых данных в качестве дополнительного компонента локализации, доступного для компонента поиска соответствий, в дополнение к множеству компонентов локализации, и
процессор компьютера, активизируемый компонентом поиска соответствий для возврата локализованных данных.
13. Платформа локализации по п.12, в которой множество компонентов локализации и компонент поиска соответствий интегрированы в операционную систему.
14. Платформа локализации по п.12, в которой множество компонентов локализации и компонент поиска соответствий выполнены с возможностью предоставления локализованных данных в качестве услуги в ответ на вызов от внешнего компонента, содержащего одно из приложения и операционной системы.
15. Платформа локализации по п.12, в которой компоненты локализации содержат:
компонент информационной службы, доступ к которому может осуществлять компонент поиска соответствий; и
множество информационных хранилищ локализации, доступ к которым может осуществлять компонент информационной службы, хранящих данные, локализованные для одного или более обособленных рынков, причем компонент информационной службы осуществляет поиск в множестве информационных хранилищ локализации для возвращения локализованных данных на основании запроса от компонента поиска соответствий.
16. Платформа локализации по п.15, в которой компоненты локализации содержат:
по меньше мере одну систему машинного перевода, доступную для компонента поиска соответствий и выполненную с возможностью осуществления доступа к компоненту информационной службы для перевода данных, подлежащих локализации.
17. Платформа локализации по п.12, в которой данные, подлежащие локализации, содержат приложение.
18. Платформа локализации по п.12, в которой по меньшей мере один источник входных данных содержит множество различных источников входных данных.
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 5477451 A, 19.12.1995. | |||

