Изобретение относится к вычислительной технике, в частности к способу компрессии многомерных данных для хранения, поиска и анализа информации в системе управления базами данных и устройству для его осуществления, и может быть использовано для увеличения объема записи и надежного хранения и поиска различной информации в системе управления базами данных (СУБД), для поддержки информационных хранилищ, а также в других случаях ненормализованного хранения информации.
За последние десятилетия в связи с развитием вычислительной техники и использованием компьютерных технологий, все более актуальной является задача хранения большого объема различной информации, проведения быстрого поиска и анализа востребованной информации, а также управление базами данных, в которых эта информация хранится. Большинство производителей баз данных ориентированы на поддержку продуктов такого класса. Одним из направлений развития является обработка и хранение большого объема различной информации (текстовой, числовой, тип даты и т.д.) в целях анализа. Используются различные подходы к организации процесса анализа, которые позволяют использовать для анализа вычислительную технику с достаточно небольшими требованиями к ресурсам. Это становится возможным благодаря появлению механизмов компрессии и специальных способов для обработки информации в сжатом виде.
Известно техническое решение [патент РФ №2270528 «Способ сжатия и восстановления цифровых данных и устройство для его осуществления», H04N 1/417], которое заключается в том, что для увеличения объема записи на DVD (digital video disc цифровой видеодиск (компакт-диск большой емкости, обеспечивающий качественное воспроизведение видео- и аудиоинформации, записанной на нем в кодированной (цифровой) форме) или CD (compact disk) осуществляют сжатие цифровых данных, для чего формируют плавающий коэффициент сжатия от 2 до 255 при записи путем сравнения значений кодов потока по величине, подсчета числа равных по величине и следующих друг за другом кодов, формирование двоичного кода этого числа и введение его в поток за первым кодом своей последовательности с исключением из нее подсчитанных кодов. При восстановлении производится определение в потоке кода числа равных кодов, дешифрирование его и формирование числа сигналов выдачи первого кода, равного числу изъятых кодов при сжатии.
Изобретение по патенту РФ №2270528 невозможно использовать для анализа в СУБД, хранящих очень большой объем различной информации (текстовой, числовой, тип даты и т.д.).
Известно изобретение по патенту [США 6317867 В1 11/2001 «Method and system for clustering instructions within executable code for compression», в котором компрессия для исполняемых файлов, ориентирована на поиске битовых шаблонов.
Изобретение по патенту США №6317867 невозможно использовать для анализа в СУБД, хранящих большой объем различной информации (текстовой, числовой, тип даты и т.д.).
Наиболее близким техническим решением к заявляемому изобретению является изобретение [патент США №6122628 «Multidimensional data clustering and dimensional reduction for indexing and searching]. Способ-прототип предназначен для сжатия многомерных данных, каждый элемент которых представлен в виде числового n-мерного вектора, что следует из использования матричной алгебры для преобразования векторов. Структурная схема устройства, на котором осуществляют способ-прототип, выполнено на фиг.1 описания к патенту США №6122628, а фиг.6 описания к патенту иллюстрирует алгоритм блока компрессии.
Для сравнения заявляемого изобретения и прототипа к материалам данной заявки прилагается описание и чертежи к патенту США №6122628.
Рассмотрим подробнее способ-прототип, который заключается в следующем:
- исходный набор векторов разбивают на кластеры (используя известные методы, и на основании знаний о природе данных, например, может использовать метрику Евклида для определения расстояния);
- для каждого кластера запоминают его характеристики, в частности границы;
- для каждого кластера вычисляют матрицу собственных значений и матрицу преобразований для сингулярного разложения;
- набор собственных векторов сортируют по убыванию абсолютных значений;
- удаляют размерности, которые соответствуют собственным векторам с наименьшими собственными значениями и тестируют точность выполнения запросов на случайной выборке;
- осуществляют преобразование исходных элементов кластера путем умножения матриц и выведения из рассмотрения координат, соответствующих удаленным измерениям (здесь очевидно сжатие, так как хранятся не все компоненты каждого вектора). При этом допускается погрешность в представлении вектора в индексе в рамках, достаточных для корректного выполнения операций поиска;
- результат преобразования, матрица преобразования и собственные вектора сохраняют в текущем узле для обратного преобразования при поиске;
- к элементам кластера процедура кластеризации и уменьшения размерности применяется рекурсивно;
- процесс кластеризации останавливают, когда ошибка становится выше пороговой на очередном этапе уменьшения размерности;
- выполняют запросы на поиск вектора на равенство и поиск по условию «в диапазоне» для компонент векторов. Для этого выполняют рекурсивный поиск по дереву индекса с отсечением ветвей, которые априори не содержат искомой информации на основании анализа границ кластера, который соответствует ветви.
На фиг.1 описания к патенту США №6122628 выполнена структурная схема устройства, на котором осуществляют способ-прототип. Устройство-прототип содержит:
блок генерации запросов пользователей (101) для генерации запросов пользователей,
сеть (102), посредством которой осуществляется связь (взаимодействие) блока генерации запросов пользователей с блоком обработки данных и блоком управления системой баз данных,
блок аналитической обработки запросов пользователей (103),
блок обработки реляционных запросов пользователей (104),
блоки хранения данных (105),
блок обработки множества индексов (107),
блок генерации индексов (110),
блок хранения индексов (108),
блок формирования информации о кластере данных (111),
блок компрессии (112).
Алгоритм работы устройства заключается в следующем:
- пользователи через блок генерации запросов пользователей (101) формируют запрос;
- сформированный запрос передается через сеть (102) в блок аналитической обработки запросов пользователей (103) или в блок обработки реляционных запросов пользователей (104) в зависимости от типа запроса;
- блок аналитической обработки запросов пользователей (103) выполняет запрос с помощью блока обработки реляционных запросов (104);
- блок обработки реляционных запросов пользователей осуществляет доступ к данным посредством блоков хранения данных (105);
- блок обработки реляционных запросов осуществляет доступ к индексам посредством блока обработки множества индексов (107);
- блок обработки множества индексов (107) использует блок хранения индексов (108);
- блок хранения индексов (108) хранит индексы, полученные в результате обработки данных блоком генерации индексов (110);
- блок генерации индексов (110) формирует индексы с помощью блока хранения индексов (108), блока формирование информации о кластере данных (111), блока компрессии (112);
- блок формирования информации о кластере (111) использует блок хранения индексов (108) для хранения информации о кластерах;
- блок компрессии (112) использует блок хранения индексов (108) для хранения информации об уменьшении размерности (компрессии).
Недостатком описанного изобретения по патенту США №6122628 является то, что:
- способ и устройство-прототип неприменимы для текстовой информации;
- позволяют сжимать только разработанные ими индексы, а не данные, но в индексах данные могут быть представлены с погрешностью;
- не позволяют сжимать повторяющиеся части текстовых полей;
- используют сложный алгоритм вычисления сингулярного разложения;
- используют несколько проходов для обработки информации (для кластеризации на каждом уровне), что также характеризует как сложный алгоритм в реализации;
- большое время на распаковку и упаковку, т.к. выполняется умножение матриц;
- не оптимизируют запросы с агрегируемыми функциями (сумма, среднее, минимум, максимум, количество), т.е. направлены только на равенство или нечеткий поиск.
Все перечисленные недостатки изобретения по патенту США №6122628 не позволяют его использовать в современных системах универсальных баз данных (СУБД) для увеличения объема записей и надежного хранения и поиска различной информации (в том числе текстовой информации), для поддержки информационных хранилищ, а также в других случаях ненормализованного хранения информации.
Задача заявляемого изобретения - повышение степени компрессии (сжатия) многомерных данных без потери их полезной функции, увеличение объема хранения информации и повышение надежности хранения и поиска различной информации в базах данных (БД).
Поставленная задача решается заявляемым способом компрессии многомерных данных для хранения и поиска информации в системе управления базами данных, заключающемся в том, что
каждый входной поток многомерных данных, состоящий из элементов одинаковой структуры, где каждый элемент представлен набором полей с заданными значениями, а совокупность значений одного и того же поля в разных элементах образует столбец значений, разбивают на строки, каждая из которых представляет структурированный набор столбцов, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, причем каждый тип данных представлен соответствующей последовательностью байтов или последовательностью битов,
определяют для каждого столбца его функциональное назначение, формируя, таким образом, по меньшей мере, три группы данных:
поисковую, агрегируемую и информационную,
в поисковую группу данных определяют те столбцы, которые служат для ограничения выборки данных,
в агрегируемую группу данных формируют столбцы, которые представляют числовой показатель и используются в условиях отбора данных при поиске,
в информационную группу данных определяют столбцы с длинными текстовыми полями, которые не участвуют в условиях отбора при поиске и не представляют числовой показатель,
запоминают информацию о сформированных группах данных,
анализируют данные (информацию) в сформированных группах данных и по результатам анализа выполняют компрессию сформированных групп данных, для чего:
для столбцов поисковой группы данных формируют групповой словарь, при этом каждый элемент группового словаря состоит из значений, которые принадлежат входному потоку многомерных данных,
используя сформированный групповой словарь, анализируют данные, содержащиеся в столбцах поисковой группы данных, таким образом, что для каждого входного элемента потока данных добавляют элемент в групповой словарь, если такой элемент уже имеется, то увеличивают количество повторений элемента, если элемент отсутствует в групповом словаре, то добавляют элемент, соответствующий входному элементу потока данных,
при переполнении группового словаря осуществляют подсчет различных значений для каждого столбца, значения которого входят в элемент группового словаря,
удаляют из группового словаря столбец, имеющий наибольшее количество различных значений без повторений,
групповой словарь перестраивают путем объединения элементов, которые отличаются значениями полей удаленного столбца, выполняя, таким образом, компрессию группового словаря,
для столбцов поисковой группы данных, элементы которых не вошли в групповой словарь, формируют словарь уникальных значений, в котором каждое значение встречается один раз и имеет свой номер,
для каждого набора уникальных значений формируют два типа шаблонов, первый из которых формируют для типа данных, в которых семантические части значения представлены последовательностью байт, второй шаблон - для типа данных, значения которых представлены последовательностью бит,
первый шаблон представляет собой общий вид всех значений в рамках столбцов для типа данных, в которых семантические части значений представлены записью с полями, размер которых кратен байту,
второй шаблон представляет собой общий вид всех значений в рамках столбцов для типа данных, в которых семантические части значений представлены записью с полями, размер которых кратен биту,
причем выделяют шаблон путем сравнения изменений соответственно значений байта или бита,
используя сформированные шаблоны, выполняют компрессию столбцов данных таким образом, что при компрессии сохраняют только те части, которые не являются частью шаблона, и удаляют части значений столбца, соответствующих шаблону.
осуществляют компрессию столбцов информационной группы путем преобразования значений столбцов этой группы, представленных последовательностью байтов, в последовательность, представленную меньшим количеством байтов, за счет преобразования подряд идущих одинаковых значений байтов,
сохраняют информацию об использованных процедурах выполненной компрессии информационной, агрегируемой и поисковой групп данных и данных в них,
для выполнения процедуры поиска формируют индексы в зависимости от типа столбцов и количества различных значений в словаре уникальных значений таким образом, что
для столбцов поисковой группы данных формируют такие индексы, которые при поиске позволяют вычислять отношения среди значений данного столбца, в случае, если количество различных значений в столбце не превышает заданное пороговое значение, которое определяют в зависимости от конфигурации системы,
для столбцов агрегируемой группы данных формируют такие индексы, которые при поиске в зависимости от запроса пользователем требуемой информации позволяют вычислять отношение значений среди значений данного столбца, или суммировать значения столбцов или находить минимальное или максимальное значения среди значений данного столбца, или количество значений или среднее значение среди значений данного столбца,
сохраняют сформированные индексы,
осуществляют динамическую генерацию библиотеки декомпрессии для каждого входного потока многомерных данных:
для чего выполняют генерацию стандартных точек входа для исходного кода библиотеки декомпрессии, при этом генерируют исходный код на языке программирования для распаковки значений столбцов, вошедших в групповой словарь,
для каждого столбца, не вошедшего в групповой словарь, генерируют исходный код на языке программирования для распаковки значений столбцов, не вошедших в групповой словарь,
запускают компилятор для создания библиотеки декомпрессии на основании исходного кода,
запоминают библиотеку декомпрессии,
регистрируют библиотеку декомпрессии для входного потока многомерных данных,
завершают генерацию библиотеки декомпрессии,
по запросу пользователя, который содержит информацию о выбираемых столбцах потока данных, или условиях, ограничивающих выбираемый набор строк, или функции агрегирования осуществляют восстановление запомненных данных, для чего
распознают команду пользователя путем трансляции - лексического и семантического анализа и преобразование его во внутреннее представление (форму), используя которое определяют те столбцы данных, которые должны быть переданы пользователю,
определяют набор поисковых столбцов, используя которые осуществляют фильтрацию данных, и соответствующие им индексы,
определяют набор столбцов, для которых вызывают агрегируемые функции, и соответствующие им индексы,
определяют порядок извлечения и процедуру декомпрессии данных, вычисляют результат запроса пользователя, используя определенные порядок извлечения и процедуру декомпрессии данных, для чего:
при использовании индексов, для столбцов поисковой группы данных определяют результаты операций отношений в виде номеров элементов исходного потока данных,
при использовании индексов для столбцов агрегируемой группы определяют результаты операции агрегирования,
выполняют поиск сохраненных данных и библиотеки декомпрессии и осуществляют декомпрессию необходимых для выполнения запроса элементов данных путем вызова библиотеки декомпрессии через стандартные точки входа, восстанавливая, таким образом, входной поток многомерных данных, удовлетворяющих условиям поиска, который передают пользователю.
При этом столбцы поисковой группы данных представлены, например, последовательностью байтов или последовательностью битов.
Столбцы агрегируемой группы данных представлены, например, последовательностью байтов или последовательностью битов.
Столбцы информационной группы данных представлены последовательностью байтов.
В качестве группового словаря, например, используют хэш-таблицу, количество элементов в которой не превышает мощности машинного слова, а каждый элемент состоит из совокупности элементов всех колонок, кроме колонок информационной группы данных.
Компрессию столбцов информационной группы данных, представленных последовательностью байтов, осуществляют путем замены последовательности подряд идущих одинаковых значений байтов на последовательность из двух элементов - количество и само значение, осуществляя, таким образом, преобразование в последовательность, представленную меньшим количеством байтов.
Для столбцов поисковой группы формируют Bitmap индексы, которые представляют собой структуру из нескольких последовательностей битов, каждый из которых соответствует уникальному значению столбца, для которого строится индекс.
Для столбцов агрегируемой группы формируют индексы кусочно-битовые Bit-sliced, представляющие собой последовательности битов, причем каждая последовательность образована конкатенацией i-го бита каждого значения столбца, при этом количество последовательностей определяется количеством битов, необходимых для представления каждого значения.
Если установлено, что для выполнения процедуры поиска для столбцов поисковой группы возможно применить Bitmap индексы, то поиск запрошенных пользователем данных осуществляют, используя Bitmap индексы.
Если установлено, что для выполнения процедуры поиска для столбцов агрегируемой группы возможно применить индексы кусочно-битовые Bit-sliced, то поиск запрошенных пользователем данных осуществляют, используя кусочно-битовые индексы Bit-sliced.
Поставленная задача решается также заявляемым устройством компрессии многомерных данных для хранения и поиска информации в системе управления базами данных, содержащим
блок генерации запросов пользователей,
первую сеть,
блок обработки многомерных запросов,
блок оптимизации и выполнения запросов пользователей,
блок хранения компрессированных данных,
блок хранения компрессированных индексов,
блок компрессии многомерных данных и индексов,
блок управления загрузкой многомерных данных,
вторую сеть,
блок оперативного хранения многомерных данных,
блок обработки ответов пользователям,
при этом вход блока генерации запросов пользователей является первым входом устройства - сигнальным входом, выход блока генерации запросов пользователей через первую сеть соединен с первым входом блока обработки многомерных запросов, первый выход которого соединен с первым входом блока оптимизации и выполнения запросов пользователей, выход которого соединен со вторым входом блока обработки многомерных запросов, второй вход блока оптимизации и выполнения запросов пользователей соединен с выходом блока хранения компрессированных данных, третий вход блока оптимизации и выполнения запросов пользователей соединен с выходом блока хранения компрессированных индексов, вход которого соединен с первым выходом блока компрессии многомерных данных и индексов, вход блока оперативного хранения данных является вторым входом устройства - информационным входом, второй выход блока обработки многомерных запросов соединен через первую сеть с входом блока обработки ответов пользователям, выход которого является выходом устройства,
причем блок компрессии многомерных данных и индексов содержит формирователь индексов,
согласно изобретению:
выход блока оперативного хранения данных через вторую сеть соединен с входом блока управления загрузкой многомерных данных, выход которого соединен с входом блока компрессии многомерных данных и индексов, второй выход которого соединен с входом блока хранения компрессированных данных,
блок компрессии многомерных данных и индексов содержит:
узел разделения входного потока многомерных данных,
формирователь поисковой группы данных с элементом памяти,
формирователь агрегируемой группы данных с элементом памяти,
формирователь информационной группы данных с элементом памяти,
формирователь группового словаря,
формирователь уникального словаря,
узел компрессии столбцов информационной группы данных,
формирователь первого шаблона,
формирователь второго шаблона,
узел компрессии данных и индексов,
узел компрессии группового словаря,
первый узел компрессии столбцов данных,
второй узел компрессии столбцов данных,
узел формирования библиотеки декомпрессии,
при этом вход узла разделения входного потока многомерных данных является входом блока компрессии многомерных данных и индексов, первый выход узла разделения входного потока многомерных данных соединен с входом формирователя поисковой группы данных с элементом памяти, второй его выход соединен с входом формирователя агрегируемой группы данных с элементом памяти, а третий выход - с входом формирователя информационной группы данных с элементом памяти,
первый выход формирователя поисковой группы данных с элементом памяти соединен с входом формирователя группового словаря, второй выход формирователя поисковой группы данных с элементом памяти соединен с входом формирователя уникального словаря, третий выход - с первым входом формирователя индексов, второй вход которого соединен с выходом формирователя агрегируемой группы данных с элементом памяти,
выход формирователя группового словаря соединен с первым входом узла компрессии группового словаря, первый выход и второй вход которого соединены соответственно с первыми входом и выходом узла формирования библиотеки декомпрессии,
первый и второй выходы формирователя уникального словаря соединены соответственно с входами формирователя первого шаблона и формирователя второго шаблона,
выход формирователя первого шаблона соединен с первым входом первого узла компрессии столбцов данных, первый выход и второй вход которого соединены соответственно со вторыми входом и выходом узла формирования библиотеки декомпрессии,
выход формирователя второго шаблона соединен с первым входом второго узла компрессии столбцов данных, первый выход и второй вход которого соединены соответственно с третьими входом и выходом узла формирования библиотеки декомпрессии,
четвертые вход и выход узла формирования библиотеки декомпрессии соединены соответственно с первым выходом и вторым входом узла компрессии данных и индексов, первый вход которого соединен с выходом формирователя индексов,
пятые вход и выход узла формирования библиотеки декомпрессии соединены соответственно с первым выходом и вторым входом узла компрессии столбцов информационной группы данных, первый вход которого соединен с выходом формирователя информационной группы данных с элементом памяти,
вторые выходы узла компрессии столбцов информационной группы данных, первого и второго узлов компрессии столбцов данных и узла компрессии группового словаря образуют по шине второй выход блока компрессии многомерных данных и индексов,
второй выход узла компрессии данных и индексов является первым выходом блока компрессии многомерных данных и индексов.
Сопоставительный анализ заявляемого изобретения (способа и устройства) с известным уровнем техники и наиболее близким из них прототипом показывает, что заявляемое изобретение в результате предложенной последовательности действий процедуры компрессии многомерных данных для хранения и поиска информации в системе управления базами данных позволяет получить лучший технический эффект, а именно:
универсальность, т.к. применим для любого типа загружаемой информации (текстовой, числовой, тип даты и т.д.), что достигается путем анализа внутреннего представления значений, основанного либо на байтовой, либо на битовой последовательности;
позволяет сжимать не только индексы, но и данные, что достигается предлагаемой процедурой компрессии;
позволяет сжимать повторяющиеся части элементов, используя сформированный групповой словарь;
позволяет сжимать повторяющиеся части текстовых строк, дат и других типов данных, используя байтовый и битовый шаблоны;
позволяет сжимать повторяющиеся значения в пределах одного столбца, используя сформированный словарь уникальных значений;
алгоритм обеспечивает эффективную распаковку элементов входного потока на этапе анализа и динамическую генерацию кода для библиотек распаковки;
позволяет оптимизировать запросы с агрегируемыми функциями (сумма, среднее, минимум, максимум, количество), что достигается за счет использования индексов, например Bit-sliced индексов.
Рассмотрим подробнее признаки, общие с прототипом и отличительные от него, при этом для наглядности будем использовать фиг.9 и 10 заявляемого устройства и фиг.1 (описание к патенту США №6122628).
Так, например, блок генерации запросов пользователей 1, сеть 2 и блок управления загрузкой многомерных данных 8 заявляемого устройства (фиг.9) эквивалентны по общему функциональному назначению соответственно блокам 101, 102 и 103 прототипа (описание к патенту США №6122628). Блок обработки многомерных запросов 2, блок оптимизации и выполнения запроса пользователей 4 и блок обработки ответов пользователям 10 эквивалентны по функциональному назначению соответственно блоку 104 прототипа (описание к патенту США №6122628). Поэтому эти блоки (по общему функциональному назначению) отнесены в ограничительную часть формулы изобретения на устройство.
Блок хранения компрессированных данных 5 и блок оперативного хранения данных (сервер) 9 также имеются в прототипе - блоки под номером 105, только сгруппированы блоки 5 и 9 заявляемого устройства по другому и имеют другие, отличные от прототипа связи, поэтому блоки по своему общему функциональному назначению отнесены в ограничительную часть формулы, а соответственно новые связи вошли в отличительную часть формулы (второй выход блока компрессии многомерных данных и индексов 7 соединен с входом блока хранения компрессированных данных 5, а вход блока компрессии многомерных данных и индексов 7 соединен с выходом блока управления загрузкой многомерных данных 8 (в прототипе аналогичный блок под номером 103 соединен с блоками хранения данных через блок 104).
Поскольку блоки под номерами 107, 108, 110, 111 и 112 (в прототипе) обеспечивают формирование, обработку индексов, их хранение и кластеризацию данных посредством индексов, то соответственно блок хранения компрессированных индексов 6 и формирователь индексов 11, а также связь - первый выход блока компрессии 7 соединен с входом блока хранения компрессированных индексов 6, отнесены в ограничительную часть формулы по общему функциональному назначению. Хотя заявляемое устройство (в этой части) работает по другому алгоритму и позволяет эффективно использовать любые известные индексы для компрессии многомерных данных (в отличие от прототипа, который позволяет сжимать только разработанные ими индексы, а не данные, но в индексах данные могут быть представлены с погрешностью).
Главным отличительным признаком заявляемого устройства является предлагаемая структурная схема блока компрессии многомерных данных и индексов, которая обеспечивает в совокупности с другими блоками и связями между ними в устройстве реализацию всех признаков заявляемого способа и обеспечивает выполнение поставленной задачи по повышению степени компрессии (сжатия) многомерных данных без потери их полезной функции, увеличению объема хранения информации и повышению надежности хранения и поиска различной информации в базах данных.
Все перечисленные преимущества позволяют использовать заявляемый способ в системах управления универсальными базами данных с высокой степенью надежности и оперативности.
Далее описание заявляемого изобретения поясняется примерами выполнения и чертежами.
Фиг.1 иллюстрирует алгоритм компрессии многомерных данных (в общем виде) согласно заявляемому изобретению.
На фиг.2 показана процедура разбиения входного потока многомерных данных.
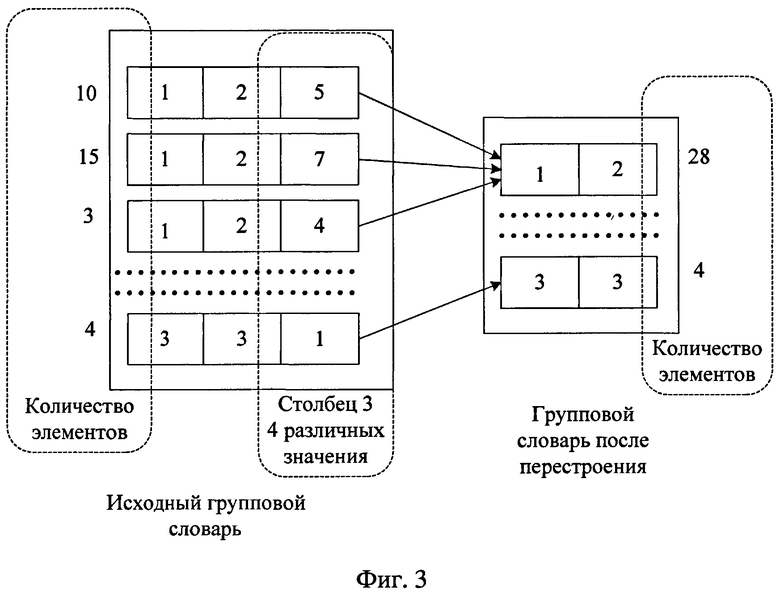
На фиг.3 - процедура формирования группового словаря и его компрессия.
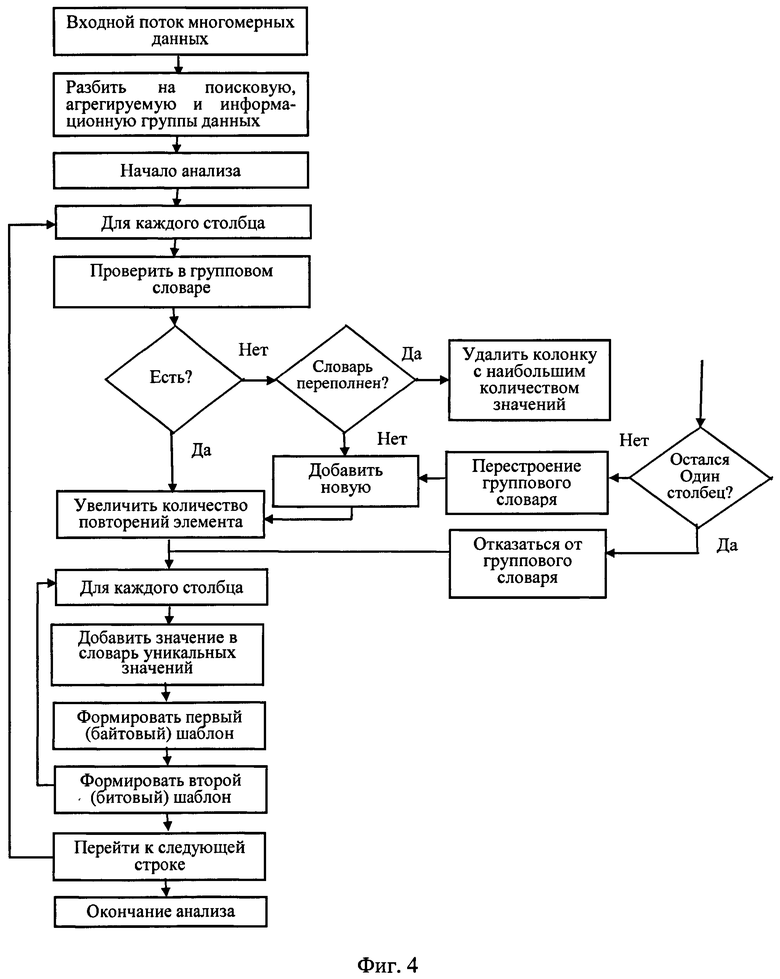
Фиг.4 иллюстрирует алгоритм анализирования данных в сформированных группах данных.
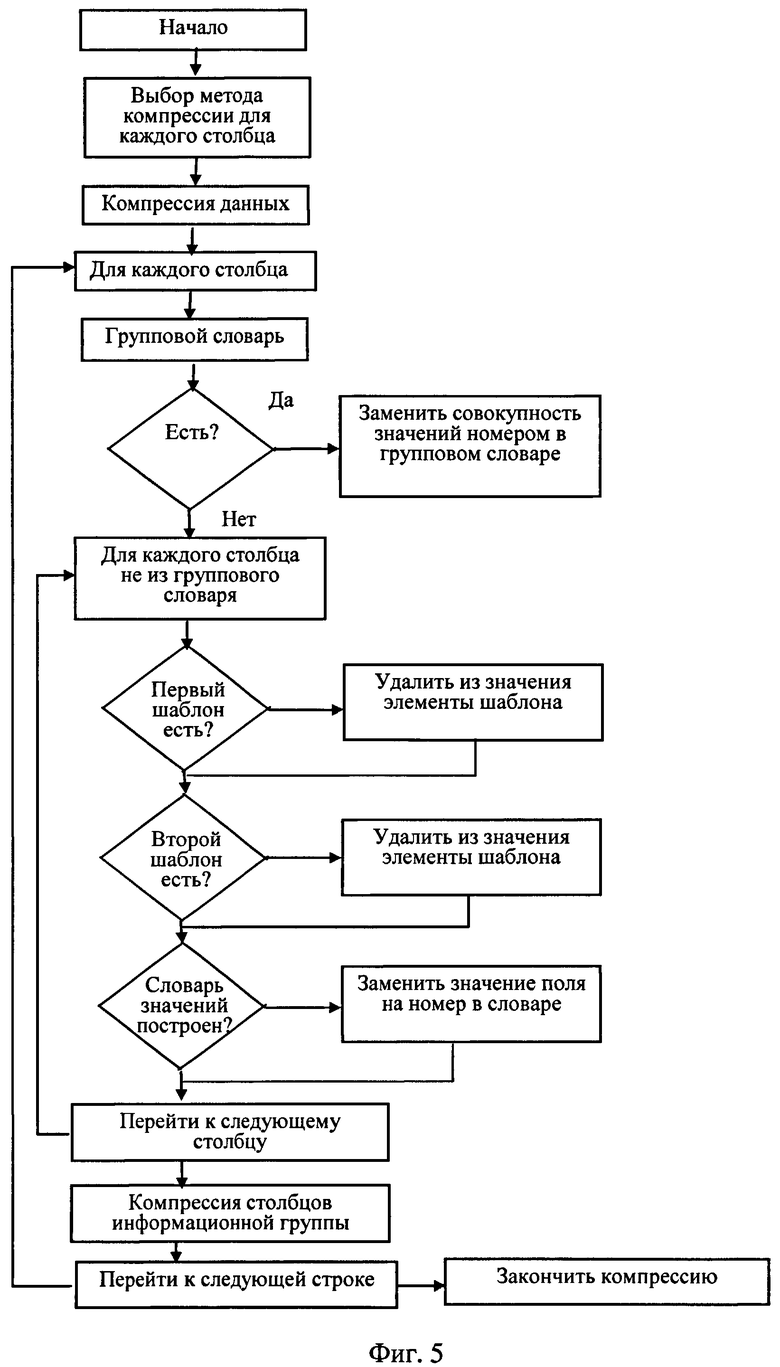
Фиг.5 - алгоритм процедуры компрессии.
Фиг.6 - алгоритм построения индексов для процедуры поиска пользователем информации.
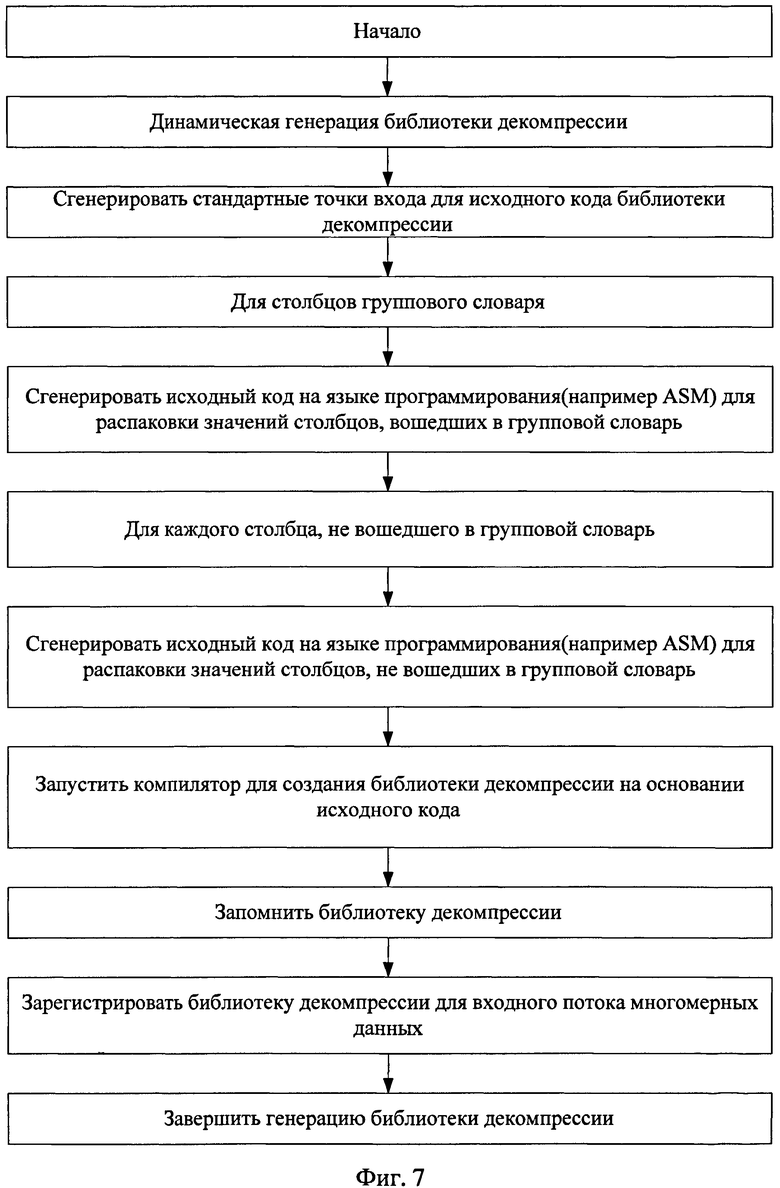
Фиг.7 - алгоритм динамической генерации библиотеки декомпрессии.
Фиг.8 иллюстрирует общую схему использования изобретения, когда пользователь обратился к системе с запросом на поиск затребованной информации.
На фиг.9 выполнена структурная схема заявляемого устройства.
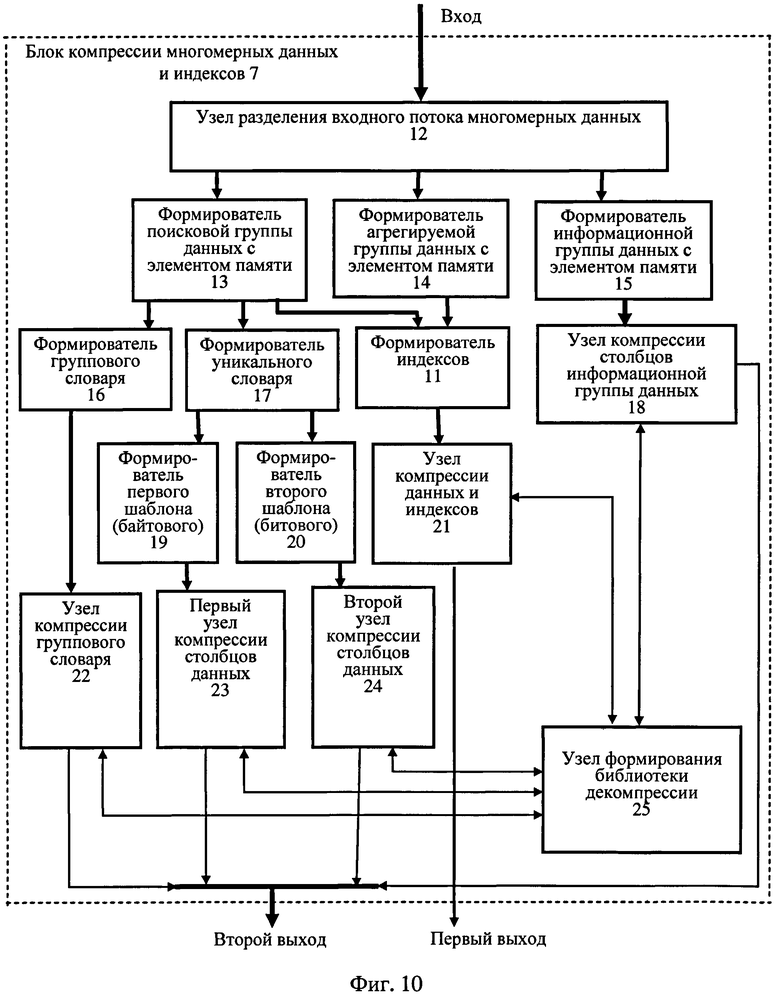
На фиг.10 - структурная схема блока компрессии многомерных данных и индексов.
Заявляемое устройство компрессии многомерных данных для хранения и поиска информации в системе управления базами данных (фиг.9 и 10) содержит:
1 - блок генерации запросов пользователей,
21 - первую сеть,
22 - вторую сеть,
3 - блок обработки многомерных запросов,
4 - блок оптимизации и выполнения запросов пользователей,
5 - блок хранения компрессированных данных,
6 - блок хранения компрессированных индексов,
7 - блок компрессии многомерных данных и индексов,
8 - блок управления загрузкой многомерных данных,
9 - блок оперативного хранения данных,
10 - блок обработки ответов пользователям,
при этом вход блока генерации запросов пользователей 1 является первым входом устройства - сигнальным входом, выход блока генерации запросов пользователей 1 соединен через первую сеть 21 с первым входом блока обработки многомерных запросов 3, первый выход которого соединен с первым входом блока оптимизации и выполнения запросов пользователей 4, выход которого соединен со вторым входом блока обработки многомерных запросов 3, второй вход блока оптимизации и выполнения запросов пользователей 4 соединен с выходом блока хранения компрессированных данных 5, третий вход блока оптимизации и выполнения запросов пользователей 4 соединен с выходом блока хранения компрессированных индексов 6, вход которого соединен с первым выходом блока компрессии многомерных данных и индексов 7, вход блока оперативного хранения данных 9 является вторым входом устройства - информационным входом, второй выход блока обработки многомерных запросов 3 соединен через первую сеть 21 с входом блока обработки ответов пользователям 10, выход которого является выходом устройства,
причем блок компрессии многомерных данных и индексов 7 содержит формирователь индексов 11,
согласно изобретению:
выход блока оперативного хранения данных 9 соединен через вторую сеть 22 с входом блока управления загрузкой многомерных данных 8, выход которого соединен с входом блока компрессии многомерных данных и индексов 7, второй выход которого соединен с входом блока хранения компрессированных данных 5,
блок компрессии многомерных данных и индексов 7 содержит:
12 - узел разделения входного потока многомерных данных,
13 - формирователь поисковой группы данных с элементом памяти,
14 - формирователь агрегируемой группы данных с элементом памяти,
15 - формирователь информационной группы данных с элементом памяти,
16 - формирователь группового словаря,
17 - формирователь уникального словаря,
18 - узел компрессии столбцов информационной группы данных,
19 - формирователь первого шаблона,
20 - формирователь второго шаблона,
21 - узел компрессии данных и индексов,
22 - узел компрессии группового словаря,
23 - первый узел компрессии столбцов данных,
24 - второй узел компрессии столбцов данных,
25 - узел формирования библиотеки декомпрессии,
при этом вход узла разделения входного потока многомерных данных 12 является входом блока компрессии многомерных данных и индексов 7, первый выход узла разделения входного потока многомерных данных 12 соединен с входом формирователя поисковой группы данных с элементом памяти 13, второй его выход соединен с входом формирователя агрегируемой группы данных с элементом памяти 14, а третий выход - с входом формирователя информационной группы данных с элементом памяти 15,
первый выход формирователя поисковой группы данных с элементом памяти 13 соединен с входом формирователя группового словаря 16, второй выход формирователя поисковой группы данных с элементом памяти 13 соединен с входом формирователя уникального словаря 17, третий выход - с первым входом формирователя индексов 11, второй вход которого соединен с выходом формирователя агрегируемой группы данных с элементом памяти 14,
выход формирователя группового словаря 16 соединен с первым входом узла компрессии группового словаря 22, первый выход и второй вход которого соединены соответственно с первыми входом и выходом узла формирования библиотеки декомпрессии 25,
первый и второй выходы формирователя уникального словаря 17 соединены соответственно со входами формирователя первого шаблона 19 и формирователя второго 20 шаблона,
выход формирователя первого шаблона 19 соединен с первым входом первого узла компрессии столбцов данных 23, первый выход и второй вход которого соединены соответственно со вторыми входом и выходом узла формирования библиотеки декомпрессии 25,
выход формирователя второго шаблона 20 соединен с первым входом второго узла компрессии столбцов данных 24, первый выход и второй вход которого соединены соответственно с третьими входом и выходом узла формирования библиотеки декомпрессии 25,
четвертые вход и выход узла формирования библиотеки декомпрессии 25 соединены соответственно с первым выходом и вторым входом узла компрессии данных и индексов 21, первый вход которого соединен с выходом формирователя индексов 11,
пятые вход и выход узла формирования библиотеки декомпрессии 25 соединены соответственно с первым выходом и вторым входом узла компрессии столбцов информационной группы данных 18, первый вход которого соединен с выходом формирователя информационной группы данных с элементом памяти 15,
вторые выходы узла компрессии столбцов информационной группы данных 18, первого 23 и второго 24 узлов компрессии столбцов данных и узла компрессии группового словаря 22 образуют по шине второй выход блока компрессии многомерных данных и индексов 7,
второй выход узла компрессии данных и индексов 21 является первым выходом блока компрессии многомерных данных и индексов 7.
Далее рассмотрим примеры осуществления изобретения со ссылкой на чертежи и иллюстрации.
Рассмотрим фиг.1-7, которые подробно иллюстрируют заявляемый способ компрессии многомерных данных, при этом фиг.1 иллюстрирует алгоритм компрессии многомерных данных (в общем виде), на фиг.2 показана процедура разбиения входного потока многомерных данных, на фиг.3 показана процедура формирования группового словаря и его компрессия, на фиг.4 - алгоритм анализа данных, на фиг.5 - алгоритм процедуры компрессии, на фиг.6 - алгоритм построения индексов для процедуры поиска пользователем информации, на фиг.7 - алгоритм динамической генерации библиотеки декомпрессии.
Рассмотрим сначала фиг.1, которая иллюстрирует алгоритм компрессии многомерных данных в общем виде.
1. Каждый входной поток многомерных данных разбивают на строки, каждая из которых представляет структурированный набор столбцов, каждый из которых имеет свой тип данных.
2. Определяют для каждого столбца его функциональное назначение, формируя, таким образом, по меньшей мере, три группы данных: поисковую, агрегируемую и информационную.
3. Анализируют данные в сформированных группах и по результатам анализа выполняют компрессию, для чего:
- для столбцов поисковой группы данных формируют групповой словарь, каждый элемент которого состоит из значений, которые принадлежат входному потоку многомерных данных;
- выполняют компрессию группового словаря;
- для столбцов поисковой группы данных, элементы которых не вошли в групповой словарь, формируют словарь уникальных значений, в котором каждое значение встречается один раз и имеет свой номер, для чего формируют два типа шаблонов, используя которые выполняют компрессию столбцов,
- для столбцов поисковой и агрегируемой групп данных формируют кусочно-битовые индексы, используя которые осуществляют компрессию,
- осуществляют компрессию столбцов информационной группы данных.
4. Осуществляют динамическую генерацию библиотеки декомпрессии.
5. Сохраняют компрессированные данные.
Для лучшего понимания заявляемого способа рассмотрим фиг.2-7.
Каждый входной поток многомерных данных, состоящий из элементов одинаковой структуры, где каждый элемент представлен набором полей с заданными значениями, а совокупность значений одного и того же поля в разных элементах образует столбец значений, разбивают на строки (фиг.2 и 4), каждая из которых представляет структурированный набор столбцов, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, причем каждый тип данных представлен соответствующей последовательностью, например, N байтов, и/или последовательностью, например, М битов. Образуя, таким образом, как показано на фиг.2, М строк и N столбцов.
Причем столбцы поисковой группы данных представлены, например, последовательностью байтов или последовательностью битов. Столбцы агрегируемой группы данных - последовательностью байтов или последовательностью битов. Столбцы информационной группы данных представлены, например, последовательностью байтов.
Определяют для каждого столбца его функциональное назначение, формируя, таким образом, по меньшей мере, три группы данных: поисковую, агрегируемую и информационную.
В поисковую группу данных определяют те столбцы, которые служат для ограничения выборки данных. Столбцы поисковой группы данных представляют собой набор столбцов, который используется для отбора данных (информации), необходимой для анализа.
В агрегируемую группу данных формируют столбцы, которые представляют числовой показатель и используются в условиях отбора данных при поиске. Т.е. столбцы агрегируемой группы данных представляют числовые характеристики, для которых выполняются функции агрегирования. Использование этих данных происходит как на верхнем уровне оператора SELECT, так и во вложенных подзапросах. При больших объемах данных к таким операциям предъявляются высокие требования по скорости (особенности для аналитических систем).
В информационную группу данных определяют столбцы с длинными текстовыми полями, которые не участвуют в условиях отбора при поиске и не представляют числовой показатель. К информационной группе данных относят столбцы, информация о которых не используется как условие отбора или как количественный показатель для агрегируемых функций. Как правило, такие столбцы используются лишь на верхнем уровне оператора SELECT языка SQL.
Запоминают информацию о сформированных группах данных.
Анализируют данные (информацию) в сформированных группах данных (фиг.4) и по результатам анализа выполняют компрессию сформированных групп данных (фиг.5).
Для чего для столбцов поисковой группы данных формируют групповой словарь. Пример формирования группового словаря и его компрессия показаны на фиг.3. Каждый элемент группового словаря состоит из значений, которые принадлежат входному потоку многомерных данных. При этом в качестве группового словаря можно, например, использовать хэш-таблицу, количество элементов в которой не превышает мощности машинного слова, а каждый элемент состоит из совокупности элементов всех колонок, кроме колонок информационной группы данных. Алгоритмы работы с хэш-таблицей являются общеизвестными, например [Кнут Д.Э. Искусство программирования. Т.3: Сортировка и поиск: Пер. с англ. Изд. 2, М.: Вильямс, 2004. - 832 с., глава 6.4] или [М.Сибул и Ямамото "Алгоритмы обработки данных", М., Мир, 1995, 218 стр.], или [Гектор Гарсиа-Молина, Джеффри Ульман, Дженнифер Уидом "Системы баз данных. Полный курс" М.: Вильямс, 2003. - 1088 с., глава 13.4].
Используя сформированный групповой словарь (фиг.3 и 4), анализируют данные, содержащиеся в столбцах, которые относятся к поисковой системе данных, таким образом, что для каждого входного элемента потока данных добавляют элемент в групповой словарь, если такой элемент уже имеется, то увеличивают количество повторений элемента, если элемент отсутствует в групповом словаре, то добавляют элемент, соответствующий входному элементу потока данных.
При переполнении группового словаря осуществляют подсчет различных значений для каждого столбца, значения которого входят в элемент группового словаря.
Удаляют из группового словаря столбец, имеющий наибольшее количество различных значений без повторений (фиг.4).
Групповой словарь перестраивают путем объединения элементов, которые отличаются значениями полей удаленного столбца, выполняя, таким образом, компрессию группового словаря (как показано на фиг.3).
Для столбцов поисковой группы данных, элементы которых не вошли в групповой словарь, формируют словарь уникальных значений (фиг.4), в котором каждое значение встречается один раз и имеет свой номер. Для чего формируют два типа шаблонов, первый из которых формируют для типов данных, в которых семантические части значения представлены последовательностью байт, второй тип шаблонов - для типа данных, значения которых представлены последовательностью бит.
Первый шаблон представляет собой общий вид всех значений в рамках столбцов для типа данных, в которых семантические части значений представлены записью с полями, размер которых кратен байту.
Второй шаблон представляет собой общий вид всех значений в рамках столбцов для типа данных, в которых семантические части значений представлены записью с полями, размер которых кратен биту.
Причем выделяют шаблон путем сравнения изменений соответственно значений байта или бита.
Используя сформированные шаблоны, выполняют компрессию столбцов данных (фиг.5) таким образом, что при компрессии сохраняют только те части, которые не являются частью шаблона, и удаляют часть значения, соответствующую шаблону.
Осуществляют компрессию столбцов информационной группы путем преобразования значений столбцов этой группы, представленных последовательностью байтов, в последовательность, представленную меньшим количеством байтов, за счет преобразования подряд идущих одинаковых значений байтов. Так как большинство столбцов информационной группы данных представлены текстовой информацией, которая востребована только на верхнем уровне запросов SELECT, требуется лишь однократная декомпрессия данных. Поэтому компрессию данных можно осуществлять без дальнейшей индексации данных столбцов. Единственным условием является высокая компрессия текстовой информации, поэтому можно использовать такие известные методы компрессии, или RLE (Run Length Encoding), или метод кодирования Хаффмана, или LZW (Lempel-Ziv-Welch), или другие, например, компрессию столбцов информационной группы данных, представленных последовательностью N байтов, можно осуществить путем замены последовательности подряд идущих одинаковых значений байтов на последовательность из двух элементов - количество и само значение (метод RLE). Более детально о способах компрессии можно прочитать [Д.Сэлмон "Сжатие данных, изображений и звука", М.: Техносфера, 2004. - 368 с, LZW - с.97, Хаффман - с.30].
Сохраняют информацию об использованных процедурах выполненной компрессии поисковой, агрегируемой и информационной групп данных и данных в них.
Для выполнения процедуры поиска формируют индексы в зависимости от типа столбцов и количества различных значений в словаре уникальных значений (фиг.6).
Для столбцов поисковой группы данных формируют такие индексы, которые при поиске позволяют вычислять отношения среди значений данного столбца, в случае, если количество различных значений в столбце не превышает заданное пороговое значение, которое определяют в зависимости от конфигурации системы. При этом, например, для столбцов поисковой группы формируют Bitmap индексы, которые представляют собой структуру из нескольких последовательностей битов, каждый из которых соответствует уникальному значению столбца, для которого строится индекс, установленный в значение «1» бит в n-й позиции последовательности означает, что строка в указанном столбце содержит значение соответствующей последовательности.
Для столбцов агрегируемой группы данных формируют такие индексы, которые при поиске в зависимости от запроса пользователем требуемой информации позволяют вычислять отношение значений среди значений данного столбца, или суммировать значения столбцов, или находить минимальное или максимальное значения среди значений данного столбца, или количество значений или среднее значение среди значений данного столбца. При этом, например, для столбцов агрегируемой группы формируют кусочно-битовые индексы Bit-sliced, представляющие собой последовательности битов, причем каждая последовательность образована конкатенацией i-го бита каждого значения столбца, при этом количество последовательностей определяется количеством битов, необходимых для представления каждого значения.
Сохраняют сформированные индексы.
Осуществляют динамическую генерацию библиотеки декомпрессии для каждого входного потока многомерных данных (фиг.7), для чего
выполняют генерацию стандартных точек входа для исходного кода библиотеки декомпрессии,
для столбцов группового словаря выполняют генерацию исходного кода на языке программирования (например, ASM) для распаковки значений столбцов, вошедших в групповой словарь,
для каждого столбца, не вошедшего в групповой словарь, генерируют исходный код на языке программирования (например, ASM) для распаковки значений столбцов, не вошедших в групповой словарь,
запускают компилятор для создания библиотеки декомпрессии на основании исходного кода,
запоминают библиотеку декомпрессии,
регистрируют библиотеку декомпрессии для входного потока многомерных данных,
завершают генерацию библиотеки декомпрессии.
По запросу пользователя (фиг.8), который содержит информацию о выбираемых столбцах потока данных или условиях, ограничивающих выбираемый набор строк, или функции агрегирования, осуществляют восстановление запомненных данных, для чего
распознают команду пользователя путем трансляции - лексического и семантического анализа и преобразование его во внутреннее представление (форму), используя которое определяют те столбцы данных, которые должны быть переданы пользователю, известные алгоритмы такой процедуры описаны, например, [Ахо "Компиляторы. Принципы, технология, инструменты" М.: Вильямс, 2003. - 768 с.];
определяют набор поисковых столбцов, используя которые осуществляют фильтрацию данных;
определяют набор столбцов, для которых вызывают агрегируемые функции;
определяют набор индексов для использования операций поиска и агрегирования в зависимости от операций, указанных в запросе, если при вычислении запроса используются функции агрегирования, то выбирается Bit-sliced индекс для соответствующих столбцов, для вычисления операций отношений над столбцами выбирают В-tree или Bitmap индексы, в зависимости от их наличия;
определяют порядок извлечения и процедуру декомпрессии данных, вычисляют результат запроса пользователя, используя определенные порядок извлечения и процедуру декомпрессии данных, для чего
1. при использовании индексов, для столбцов поисковой группы данных определяют результаты операций отношений в виде номеров элементов исходного потока данных, например так, как описано [Гектор Гарсиа-Молина, Джеффри Ульман, Дженнифер Уидом "Системы баз данных. Полный курс" М.: Вильямс, 2003. - 1088 с., главы 15, 16];
при использовании индексов для столбцов агрегируемой группы определяют результаты операции агрегирования, например, так, как описано [Р.O'Neil, D.Quass, Improved Query Performance with Variant Indexes. Proc. ACM SIGMOD Int. Conf. on Management of Data, c.38-49, 1997];
выполняют поиск сохраненных данных и библиотеки декомпрессии и осуществляют декомпрессию необходимых элементов данных путем вызова библиотеки декомпрессии через стандартные точки входа, восстанавливая, таким образом, входной поток многомерных данных, удовлетворяющих условиям поиска, который передают пользователю.
Рассмотрим реализацию заявляемого способа на устройстве, структурная схема которого выполнена на фиг.9 и 10.
По выходному сигналу блока управления загрузкой многомерных данных 8 (фиг.9), который поступает на вход блока компрессии многомерных данных и индексов 7, загружается через вторую сеть 22 каждый входной поток многомерных данных с блока оперативного хранения данных 9, на вход которого со второго (информационного) входа устройства поступает сигнал записи данных (информации).
С входа блока компрессии многомерных данных и индексов 7 каждый входной поток многомерных данных поступает на вход узла разделения входного потока многомерных данных 12 (фиг.10), который разбивает его на строки, каждая из которых представляет структурированный набор столбцов, каждый из которых имеет свой тип данных, и определяет для каждого столбца его функциональное назначение. Таким образом, с первого, второго и третьего выходов узла разделения входного потока многомерных данных 12 структурированные наборы столбцов по функциональному назначению поступают соответственно на входы формирователя поисковой группы данных с элементом памяти 13, формирователя агрегируемой группы данных с элементом памяти 14 и формирователя информационной группы данных с элементом памяти 15.
Формирователи 13, 14 и 15 формируют соответственно три группы данных: поисковую, агрегируемую и информационную, запоминают информацию о сформированных группах данных и данных в них.
Анализируют данные в сформированных группах и по результатам анализа выполняют компрессию, для чего
- для столбцов поисковой группы данных в формирователе группового словаря 16 формируют групповой словарь, каждый элемент которого состоит из значений, которые принадлежат входному потоку многомерных данных;
- в узле компрессии группового словаря 22 выполняют компрессию группового словаря;
- для столбцов поисковой группы данных, элементы которых не вошли в групповой словарь, в формирователе уникального словаря 17 формируют словарь уникальных значений, в котором каждое значение встречается один раз и имеет свой номер, для чего в первом 19 и втором 20 формирователях шаблонов формируют два типа шаблонов (соответственно байтовый шаблон и битовый шаблон), используя которые соответственно в первом 23 и втором 24 узлах компрессии столбцов данных выполняют компрессию;
- для столбцов поисковой и агрегируемой групп данных формируют кусочно-битовые индексы, используя для этого формирователь индексов 11; используя сформированные индексы, осуществляют компрессию в узле компрессии данных и индексов 21;
- осуществляют компрессию столбцов информационной группы данных в узле компрессии столбцов для информационной группы данных 18;
- сохраняют компрессированные данные и индексы.
Компрессированные данные со вторых выходов узлов 22, 23, 24 и 18 поступают на второй выход блока компрессии многомерных данных и индексов 7, а на первый выход - компрессированные индексы со второго выхода узла 21.
Для процедуры поиска информации осуществляют динамическую генерацию библиотеки декомпрессии в узле формирования библиотеки декомпрессии 25, для чего
выполняют генерацию стандартных точек входа для исходного кода библиотеки декомпрессии,
для столбцов группового словаря выполняют генерацию исходного кода на языке программирования (например, ASM) для распаковки значений столбцов, вошедших в групповой словарь,
для каждого столбца, не вошедшего в групповой словарь, генерируют исходный код на языке программирования (например, ASM) для распаковки значений столбцов, не вошедших в групповой словарь,
запускают компилятор для создания библиотеки декомпрессии на основании исходного кода,
запоминают библиотеку декомпрессии,
регистрируют библиотеку декомпрессии для входного потока многомерных данных,
завершают генерацию библиотеки декомпрессии.
По запросу пользователя, поступающему на вход блока генерации запросов пользователей 1 (фиг.9), который содержит информацию о выбираемых столбцах потока данных или условиях, ограничивающих выбираемый набор строк, или функции агрегирования, осуществляют восстановление запомненных данных, для чего
в блоке обработки многомерных запросов 3:
- распознают команду пользователя путем трансляции - лексического и семантического анализа и преобразование его во внутреннее представление (форму), используя которое определяют те столбцы данных, которые должны быть переданы пользователю;
- определяют набор поисковых столбцов, используя которые осуществляют фильтрацию данных;
- определяют набор столбцов, для которых вызывают агрегируемые функции;
- определяют набор индексов для использования операций поиска и агрегирования в зависимости от операций, указанных в запросе, если при вычислении запроса используются функции агрегирования, то выбирается Bit-sliced индекс для соответствующих столбцов, для вычисления операции отношений над столбцами выбирают В-tree или Bitmap индексы, в зависимости от их наличия в блоке 4.
В блоке оптимизации и выполнения запросов пользователей 4 определяют порядок извлечения и процедуру декомпрессии данных, вычисляют результат запроса пользователя, используя определенные порядок извлечения и процедуру декомпрессии данных, для чего
при использовании индексов для столбцов поисковой группы данных определяют результаты операций отношений в виде номеров элементов исходного потока данных с использованием информации из блока хранения компрессированных индексов 6;
при использовании индексов для столбцов агрегируемой группы определяют результаты операции агрегирования с использованием информации из блока хранения компрессированных индексов 6;
выполняют поиск сохраненных данных и библиотеки декомпрессии в узле 25 (фиг.10) и осуществляют декомпрессию необходимых элементов данных путем вызова библиотеки декомпрессии через стандартные точки входа блоком хранения компрессированных данных 5 (фиг.9), восстанавливая, таким образом, входной поток многомерных данных, удовлетворяющих условиям поиска, который передают пользователю с блока обработки ответов 10.
Заявляемое устройство может быть реализовано как на микро ЭВМ, так и в аппаратурной реализации.
Таким образом, заявляемое изобретение позволяет получить лучший технический эффект по сравнению с известными техническими решениями в данной области техники, а именно:
универсальность, т.к. способ применим для любого типа загружаемой информации (текстовой, числовой, тип даты и т.д.), что достигается путем анализа внутреннего представления значений, основанного либо на байтовой, либо на битовой последовательности;
позволяет сжимать не только индексы, но и данные, что достигается предлагаемой процедурой компрессии;
позволяет сжимать повторяющиеся части элементов, используя сформированный групповой словарь;
позволяет сжимать повторяющиеся части текстовых строк, дат и других типов данных, используя байтовый и битовый шаблоны;
позволяет сжимать повторяющиеся значения в пределах одного столбца, используя сформированный словарь уникальных значений;
алгоритм обеспечивает эффективную распаковку элементов входного потока на этапе анализа и динамическую генерацию кода для библиотек распаковки;
позволяет оптимизировать запросы с агрегируемыми функциями (сумма, среднее, минимум, максимум, количество), что достигается за счет использования индексов, например Bit-sliced индексов.
Что позволяет повысить степень компрессии (сжатия) многомерных данных без потери их полезной функции, увеличить объем хранения информации и повысить надежность хранения и поиска различной информации в базах данных.
Все перечисленные преимущества позволяют использовать заявляемый способ в системах управления универсальными базами данных с высокой степенью надежности и оперативности.




Изобретение относится к вычислительной технике, в частности к способу компрессии многомерных данных для хранения, поиска и анализа информации в системе управления базами данных и устройству для его осуществления. Техническим результатом является увеличение объема хранения и повышение надежности информации в базе данных. Заявляемый способ применим для любого типа загружаемой информации, в том числе текстовой и числовой, и позволяет сжимать индексы, данные, повторяющиеся части элементов, используя сформированный групповой словарь, а также позволяет сжимать повторяющиеся части текстовых строк, дат и других типов данных, используя байтовый и битовый шаблоны. При сжатии повторяющихся значений в пределах одного столбца используют сформированный словарь уникальных значений, алгоритм обеспечивает эффективную распаковку элементов входного потока на этапе анализа и динамическую генерацию кода для библиотек распаковки. При этом оптимизируют запросы с агрегируемыми функциями (сумма, среднее, минимум, максимум, количество), что достигается за счет использования индексов. 2 н. и 9 з.п. ф-лы, 10 ил.
1. Способ компрессии многомерных данных для хранения и поиска информации в системе управления базами данных, заключающийся в том, что каждый входной поток многомерных данных, состоящий из элементов одинаковой структуры, где каждый элемент представлен набором полей с заданными значениями, а совокупность значений одного и того же поля в разных элементах образует столбец значений, разбивают на строки, каждая из которых представляет структурированный набор столбцов, каждый из которых имеет свой тип данных: текстовый или числовой, или тип даты, причем каждый тип данных представлен соответствующей последовательностью байтов, или последовательностью битов, определяют для каждого столбца его функциональное назначение, формируя, таким образом, по меньшей мере, три группы данных: поисковую, агрегируемую и информационную, в поисковую группу данных определяют те столбцы, которые служат для ограничения выборки данных, в агрегируемую группу данных формируют столбцы, которые представляют числовой показатель и используются в условиях отбора данных при поиске, в информационную группу данных определяют столбцы с длинными текстовыми полями, которые не участвуют в условиях отбора при поиске и не представляют числовой показатель, запоминают информацию о сформированных группах данных, анализируют данные (информацию) в сформированных группах данных и по результатам анализа выполняют компрессию сформированных групп данных, для чего для столбцов поисковой группы данных формируют групповой словарь, при этом каждый элемент группового словаря состоит из значений, которые принадлежат входному потоку многомерных данных, используя сформированный групповой словарь, анализируют данные, содержащиеся в столбцах поисковой группы данных, таким образом, что для каждого входного элемента потока данных добавляют элемент в групповой словарь, если такой элемент уже имеется, то увеличивают количество повторений элемента, если элемент отсутствует в групповом словаре, то добавляют элемент, соответствующий входному элементу потока данных, при переполнении группового словаря осуществляют подсчет различных значений для каждого столбца, значения которого входят в элемент группового словаря, удаляют из группового словаря столбец, имеющий наибольшее количество различных значений без повторений, групповой словарь перестраивают путем объединения элементов, которые отличаются значениями полей удаленного столбца, выполняя таким образом, компрессию группового словаря, для столбцов поисковой группы данных, элементы которых не вошли в групповой словарь, формируют словарь уникальных значений, в котором каждое значение встречается один раз и имеет свой номер, для каждого набора уникальных значений формируют два типа шаблонов, первый из которых формируют для типа данных, в которых семантические части значения представлены последовательностью байт, второй шаблон - для типа данных, значения которых представлены последовательностью бит, первый шаблон представляет собой общий вид всех значений в рамках столбцов для типа данных, в которых семантические части значений представлены записью с полями, размер которых кратен байту, второй шаблон представляет собой общий вид всех значений в рамках столбцов для типа данных, в которых семантические части значений представлены записью с полями, размер которых кратен биту, причем выделяют шаблон путем сравнения изменений соответственно значений байта или бита, используя сформированные шаблоны, выполняют компрессию столбцов данных таким образом, что при компрессии сохраняют только те части, которые не являются частью шаблона, и удаляют части значений столбца, соответствующих шаблону, осуществляют компрессию столбцов информационной группы путем преобразования значений столбцов этой группы, представленных последовательностью байтов, в последовательность, представленную меньшим количеством байтов, за счет преобразования подряд идущих одинаковых значений байтов, сохраняют информацию об использованных процедурах выполненной компрессии информационной, агрегируемой и поисковой групп данных и данных в них, для выполнения процедуры поиска формируют индексы в зависимости от типа столбцов и количества различных значений в словаре уникальных значений таким образом, что для столбцов поисковой группы данных формируют такие индексы, которые при поиске позволяют вычислять отношения среди значений данного столбца, в случае, если количество различных значений в столбце не превышает заданное пороговое значение, которое определяют в зависимости от конфигурации системы, для столбцов агрегируемой группы данных формируют такие индексы, которые при поиске в зависимости от запроса пользователем требуемой информации позволяют вычислять отношение значений среди значений данного столбца, или суммировать значения столбцов, или находить минимальное или максимальное значения среди значений данного столбца, или количество значений или среднее значение среди значений данного столбца, сохраняют сформированные индексы, осуществляют динамическую генерацию библиотеки декомпрессии для каждого входного потока многомерных данных, для чего выполняют генерацию стандартных точек входа для исходного кода библиотеки декомпрессии, при этом генерируют исходный код на языке программирования для распаковки значений столбцов, вошедших в групповой словарь, для каждого столбца, не вошедшего в групповой словарь, генерируют исходный код на языке программирования для распаковки значений столбцов, не вошедших в групповой словарь, запускают компилятор для создания библиотеки декомпрессии на основании исходного кода, запоминают библиотеку декомпрессии, регистрируют библиотеку декомпрессии для входного потока многомерных данных, завершают генерацию библиотеки декомпрессии, по запросу пользователя, который содержит информацию о выбираемых столбцах потока данных, или условиях, ограничивающих выбираемый набор строк, или функции агрегирования, осуществляют восстановление запомненных данных, для чего распознают команду пользователя путем трансляции - лексического и семантического анализа и преобразование его во внутреннее представление - форму, используя которое определяют те столбцы данных, которые должны быть переданы пользователю, определяют набор поисковых столбцов, используя которые осуществляют фильтрацию данных, и соответствующие им индексы, определяют набор столбцов, для которых вызывают агрегируемые функции, и соответствующие им индексы, определяют порядок извлечения и процедуру декомпрессии данных, вычисляют результат запроса пользователя, используя определенные порядок извлечения и процедуру декомпрессии данных, для чего при использовании индексов для столбцов поисковой группы данных определяют результаты операций отношений в виде номеров элементов исходного потока данных, при использовании индексов для столбцов агрегируемой группы, определяют результаты операции агрегирования, выполняют поиск сохраненных данных и библиотеки декомпрессии и осуществляют декомпрессию необходимых элементов данных путем вызова библиотеки декомпрессии через стандартные точки входа, восстанавливая, таким образом, входной поток многомерных данных, удовлетворяющих условиям поиска, который передают пользователю.
2. Способ по п.1, отличающийся тем, что столбцы поисковой группы данных представлены последовательностью байтов или последовательностью битов.
3. Способ по п.1, отличающийся тем, что столбцы агрегируемой группы данных представлены последовательностью байтов или последовательностью битов.
4. Способ по п.1, отличающийся тем, что столбцы информационной группы данных представлены последовательностью байтов.
5. Способ по п.1, отличающийся тем, что в качестве группового словаря используют хэш-таблицу, количество элементов в которой не превышает мощности машинного слова, а каждый элемент состоит из совокупности элементов всех колонок, кроме колонок информационной группы данных.
6. Способ по п.1, отличающийся тем, что компрессию столбцов информационной группы данных, представленных последовательностью байтов, осуществляют путем замены последовательности подряд идущих одинаковых значений байтов на последовательность из двух элементов - количество и само значение, осуществляя таким образом преобразование в последовательность, представленную меньшим количеством байтов.
7. Способ по п.1, отличающийся тем, что для столбцов поисковой группы формируют Bitmap индексы, которые представляют собой структуру из нескольких последовательностей битов, каждый из которых соответствует уникальному значению столбца, для которого строится индекс.
8. Способ по п.1, отличающийся тем, что для столбцов агрегируемой группы формируют индексы кусочно-битовые Bit-sliced, представляющие собой последовательности битов, причем каждая последовательность образована конкатенацией i-го бита каждого значения столбца, при этом количество последовательностей определяется количеством битов, необходимых для представления каждого значения.
9. Способ по п.1, отличающийся тем, что если определено, что для выполнения процедуры поиска для столбцов поисковой группы возможно применить Bitmap индексы, то поиск запрошенных пользователем данных осуществляют, используя Bitmap индексы.
10. Способ по п.1, отличающийся тем, что если определено, что для выполнения процедуры поиска для столбцов агрегируемой группы возможно применить индексы кусочно-битовые Bit-sliced, то поиск запрошенных пользователем данных осуществляют, используя индексы кусочно-битовые Bit-sliced.
11. Устройство компрессии многомерных данных для хранения и поиска информации в системе управления базами данных, содержащее блок генерации запросов пользователей, первую сеть, блок обработки многомерных запросов, блок оптимизации и выполнения запросов пользователей, блок хранения компрессированных данных, блок хранения компрессированных индексов, блок компрессии многомерных данных, блок управления загрузкой многомерных данных, вторую сеть, блок оперативного хранения многомерных данных, блок обработки ответов пользователям, при этом вход блока генерации запросов пользователей является первым входом устройства - сигнальным входом, выход блока генерации запросов пользователей через первую сеть соединен с первым входом блока обработки многомерных запросов, первый выход которого соединен с первым входом блока оптимизации и выполнения запросов пользователей, выход которого соединен со вторым входом блока обработки многомерных запросов, второй вход блока оптимизации и выполнения запросов пользователей соединен с выходом блока хранения компрессированных данных, третий вход блока оптимизации и выполнения запросов пользователей соединен с выходом блока хранения компрессированных индексов, вход которого соединен с первым выходом блока компрессии многомерных данных и индексов, вход блока оперативного хранения данных является вторым входом устройства - информационным входом, второй выход блока обработки многомерных запросов соединен через первую сеть с входом блока обработки ответов пользователям, выход которого является выходом устройства, причем блок компрессии многомерных данных и индексов содержит формирователь индексов, отличающееся тем, что выход блока оперативного хранения данных через вторую сеть соединен с входом блока управления загрузкой многомерных данных, выход которого соединен с входом блока компрессии многомерных данных и индексов, второй выход которого соединен с входом блока хранения компрессированных данных, блок компрессии многомерных данных и индексов содержит узел разделения входного потока многомерных данных, формирователь поисковой группы данных с элементом памяти, формирователь агрегируемой группы данных с элементом памяти, формирователь информационной группы данных с элементом памяти, формирователь группового словаря, формирователь уникального словаря, узел компрессии столбцов информационной группы данных, формирователь первого шаблона, формирователь второго шаблона, узел компрессии данных и индексов, узел компрессии группового словаря, первый узел компрессии столбцов данных, второй узел компрессии столбцов данных, узел формирования библиотеки декомпрессии, при этом вход узла разделения входного потока многомерных данных является входом блока компрессии многомерных данных и индексов, первый выход узла разделения входного потока многомерных данных соединен с входом формирователя поисковой группы данных с элементом памяти, второй его выход соединен с входом формирователя агрегируемой группы данных с элементом памяти, а третий выход - с входом формирователя информационной группы данных с элементом памяти, первый выход формирователя поисковой группы данных с элементом памяти соединен с входом формирователя группового словаря, второй выход формирователя поисковой группы данных с элементом памяти соединен с входом формирователя уникального словаря, третий выход - с первым входом формирователя индексов, второй вход которого соединен с выходом формирователя агрегируемой группы данных с элементом памяти, выход формирователя группового словаря соединен с первым входом узла компрессии группового словаря, первый выход и второй вход которого соединены соответственно с первыми входом и выходом узла формирования библиотеки декомпрессии, первый и второй выходы формирователя уникального словаря соединены соответственно со входами формирователя первого шаблона и формирователя второго шаблона, выход формирователя первого шаблона соединен с первым входом первого узла компрессии столбцов данных, первый выход и второй вход которого соединены соответственно со вторыми входом и выходом узла формирования библиотеки декомпрессии, выход формирователя второго шаблона соединен с первым входом второго узла компрессии столбцов данных, первый выход и второй вход которого соединены соответственно с третьими входом и выходом узла формирования библиотеки декомпрессии, четвертые вход и выход узла формирования библиотеки декомпрессии соединены соответственно с первым выходом и вторым входом узла компрессии данных и индексов, первый вход которого соединен с выходом формирователя индексов, пятые вход и выход узла формирования библиотеки декомпрессии соединены соответственно с первым выходом и вторым входом узла компрессии столбцов информационной группы данных, первый вход которого соединен с выходом формирователя информационной группы данных с элементом памяти, вторые выходы узла компрессии столбцов информационной группы данных, первого и второго узлов компрессии столбцов данных и узла компрессии группового словаря образуют по шине второй выход блока компрессии многомерных данных и индексов, второй выход узла компрессии данных и индексов является первым выходом блока компрессии многомерных данных и индексов.
| МНОГОМЕРНАЯ БАЗА ДАННЫХ И СПОСОБ ДОСТУПА К МНОГОМЕРНОЙ БАЗЕ ДАННЫХ | 2006 |
|
RU2325690C1 |
| ХРАНИЛИЩЕ ДАННЫХ ДЛЯ ОСНОВАННОЙ НА ЗНАНИЯХ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ДАННЫХ | 2003 |
|
RU2297665C2 |
| US 6122628 A, 19.09.2000 | |||
| US 6317867 B1, 13.11.2001 | |||
| СПОСОБ СЖАТИЯ И ВОССТАНОВЛЕНИЯ ЦИФРОВЫХ ДАННЫХ И УСТРОЙСТВО ЕГО ОСУЩЕСТВЛЕНИЯ | 2004 |
|
RU2270528C1 |

