ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к системам и методам создания корпусов текстов для различных исследовательских и других целей. Корпуса текстов, полученные из различных источников и содержащие различную лексику, в том числе, например, региональную или стратифицированную по возрастным или профессиональным категориям представляют интерес для машинного обучения, задач прикладной, коммуникативной и генеративной лингвистики. Однако не существует таких целостных источников, из которых можно было бы получить "живой" разговорный язык в достаточном объеме. Единственным источником такого рода могут быть интернет-форумы, социальные сети и др. социальные медиа. Однако они требуют предварительной обработки по выделению собственно сообщения и удалению лишней информации.
УРОВЕНЬ ТЕХНИКИ
Для наполнения корпуса терабайтного объема требуется значительное количество естественных текстов, размещенных на публично доступных интернет-ресурсах. Форумы содержат лексику, необходимую для создания корпуса, сбалансированного по коммуникативным целям.
При извлечении текста из форумов сложность заключается в том, что значительная часть текста естественного языка находится в коротких сообщениях - обычном обсуждении или же комментариях под статьей. Стандартные методы удаления обвязки могут выделить текст, но при этом точность отделения текстов пользователей от остального контента не гарантируется. Форумные тексты, как правило, могут быть соединены с сопутствующей информацией из профиля пользователя или сведений, сообщаемых им о себе и размещенных непосредственно в сообщении, что позволяет, при сохранении такой метаразметки, группировать тексты корпуса по значению некоторого атрибута и использовать полученный корпус в задачах машинного обучения.
Для работы с веб-страницами, в том числе и парсинга, удобство и унифицируемость представляют следующие две технологии:
1) DOM (Document Object Model) - не зависящий от платформы и языка программный интерфейс, позволяющий программам и скриптам получить доступ к содержимому HTML, XHTML и XML-документов, а также изменять содержимое, структуру и оформление таких документов.
2) XPath (XML Path Language) - язык запросов к элементам XML-документа, использующийся для указания точного пути к вершине в DOM-дереве.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 иллюстрирует приблизительную последовательность этапов метода настоящего изобретения.
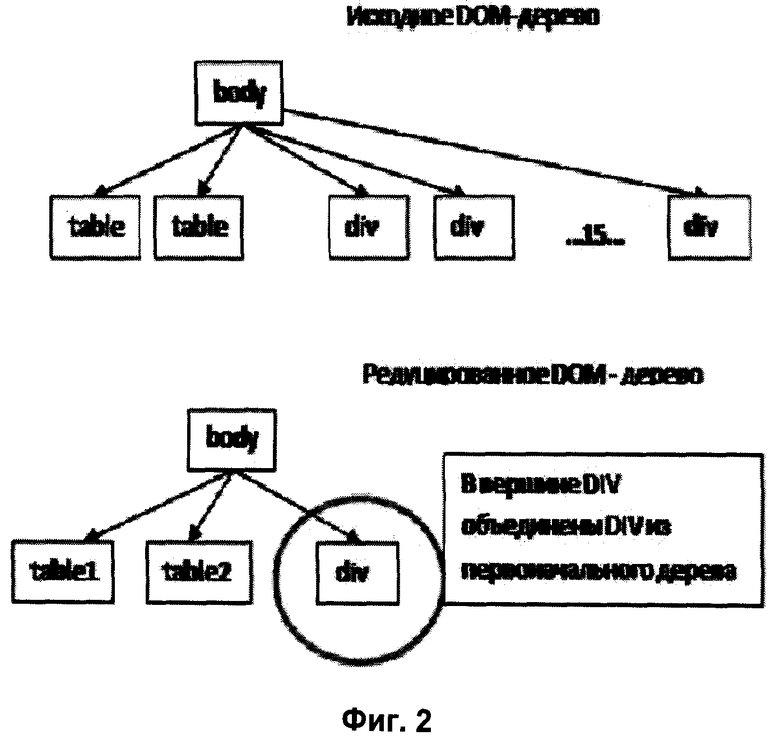
Фиг. 2 иллюстрирует этап слияния вершин в соответствии с методом настоящего изобретения.
На Фиг. 3 приведен возможный пример вычислительного средства, которое может быть использовано для внедрения настоящего изобретения.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Заявленные способ, носитель информации и система служат для автоматизации построения корпусов текстов, предназначенных, главным образом, для исследовательских целей, на основе разнообразных social media, например форумов в интернете. Форумы содержат лексику, необходимую для создания корпуса, сбалансированного по коммуникативным целям.
Так, заявленный способ построения корпусов текстов на основе интернет-форумов заключается в том, что, по меньшей мере, один раз производят следующую последовательность действий:
- построение объектной модели документа в виде древовидной DOM-структуры данных;
- выделение групп однотипных вершин в дереве объектной модели документа;
- удаление необязательных элементов оформления со страниц;
- слияние нелистовых вершин с одинаковыми именами в дереве объектной модели;
- объединение листовых вершин с одинаковыми свойствами;
- оценка вершин;
- фильтрация групп;
- построение, по крайней мере, одного выражения ХРАТН;
- применение полученных выражений ХРАТН к набору файлов, содержащих все документы с выбранного форума.
Предпочтительные, но не обязательные варианты реализации способа предполагают также, в частности, применение полученных выражений ХРАТН к набору файлов, содержащих все документы с выбранного форума.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Заявленные способ, носитель информации и система служат для автоматизации построения корпусов текстов, предназначенных, главным образом, для исследовательских целей, на основе разнообразных social media, например форумов в интернете. Форумы содержат лексику, необходимую для создания корпуса, сбалансированного по коммуникативным целям.
Есть две основных стадии работы метода. Первая стадия состоит в получении выражений ХРАТН, представляющих обобщенный (то есть, пригодный для адресации любых однотипных элементов) путь в DOM-дереве к информационным элементам, представляющим интерес. Этот шаг применяется независимо к одной произвольно выбранной типичной странице выбранного форума. Разработанный метод автоматического выделения ХРАТН классифицирует пути на абсолютные и относительные. Абсолютный путь рассчитывается от корневого элемента DOM-дерева. Такой путь задает регулярную структуру сообщений на интернет-форуме, описывает путь к визуальным элементам-контейнерам, содержащих свойства отдельного сообщения. Примером такого элемента может служить рамка вокруг одного сообщения. Относительные пути позволяют адресовать подчиненные элементы по отношению к одному конкретному элементу, выбранного путем примения абсолютного ХРАТН.
При этом каждому относительному ХРАТН сопоставляется еще идентификатор типа извлекаемой информации. Тип определяется в соответствии с эвристиками, позволяющими подсчитывать значение весовой функции для каждого типа - кандидата. В качестве наиболее правдоподобного идентификатора типа выбирается тот, на котором достигается максимальное значение весовой функции.
Вторая стадия состоит в применении полученных выражений ХРАТН к набору файлов, содержащих все документы с выбранного форума. Методика состоит в построении DOM-модели для каждого из входных документов, применении абсолютного и относительного путей полученной DOM-модели. Извлеченная информация записывается в выходной XML файл, при этом каждое сообщение помещается в отдельный элемент - "конверт", позволяющий отделить информационные сущности различных сообщений. Для произвольного форума может использоваться неизвестное или нераспространенное программное обеспечение, однако при автоматизированном сборе информации в сети интернет пути для извлечения очищенных текстов и их атрибутов невозможно вручную подбирать выражение ХРАТН для каждого конкретного форума.
Блок-схема метода (100) настоящего изобретения представлена на Фиг. 1. Первоначально, на этапе 111, необходимо получить исходную объектную модель документа (110) - DOM, которая представляет собой формальное описание древовидной структуры, соответствующей структуре документа: она содержит иерархию блоков, атрибутов и т.п. Построение объектной модели документов может производиться, например, при помощи пакета org.w3c.dom для языка программирования Java. Форумы отличаются тем, что множество сообщений выглядит, как правило, как некоторая древовидная структура. Порции текста, извлекаемые из сообщений форумов, должны быть структурированы и соответствующим образом атрибутированы - должны быть распознаны основные атрибуты сообщения, например, ник автора, дата, время, заголовок и т.п. Одновременно создается дерево стилей, которое используется в методе настоящего изобретения для объединения свойств одинаковых вершин, но могут быть использованы и для объединения множеств одинаковых вершин одного уровня.
Как показывает детальное рассмотрение страниц большинства форумов, все множество сообщений, имен авторов и сопутствующей информации об авторах и сообщениях может быть получено при помощи фильтрации с помощью довольно простых выражений XPath. Метод данного изобретения включает автоматическое выделение группы однотипных вершин DOM-дерева (этап 112), содержащих необходимую информацию, и построения для этой группы вершин выражения XPath, которым можно было бы воспользоваться для извлечения информации для подобных страниц этого же форума.
На этапе 113 решается задача удаления обвязки (boilerpate) с web-страниц, с целью избавления от элементов, не несущих полезной информации. Принципиально подходы для удаления обвязки можно разделить на два класса - методы страничного уровня и методы уровня сайта. Страничные методы обрабатывают каждую страницу по отдельности, не используя информацию об остальных страницах сайта. Методы уровня сайта для удаления обвязки собирают информацию со всех страниц сайта или с репрезентативного подмножества его страниц. Постраничный анализ применяется, когда нет возможности получить некоторое достаточное подмножество страниц сайта перед обработкой.
Задача удаления элементов оформления со страниц является более общей по сравнению с выделением авторов и их сообщений на страницах форумов. Ключевым является факт того, что форумы имеют регулярную, периодическую структуру DOM и каждая страница содержит несколько (обычно не меньше 10) сообщений от различных пользователей. Чтобы воспользоваться данным преимуществом, было решено модифицировать метод обхода деревьев стилей следующим нижеописанным образом, адаптировав его для работы с отдельными страницами, а не с сайтом в целом. Дерево стилей, получаемое в результате объединения вершин, мы будем ниже называть редуцированным DOM-деревом. Одной из задач является нахождение имени автора на странице.
Был совершен ручной анализ популярных русскоязычных форумов, таких как: rsdn.ru, 4pda.ru, gamedev.ru, sql.ru и др. На основании полученной информации и известных фактах об устройстве веб-страниц и DOM-деревьев были получены следующие важные выводы, которые, могут быть применимы к большинству страниц форумов.
1) Вся информация о пользователе, включая его тексты, как правило, хранится в листовых вершинах DOM-дерева.
2) Имена пользователей отображаются на странице форума в виде гиперссылок на страницу профиля автора.
3) Пользователи либо самостоятельно предпочитают, либо вынуждены из-за ограничений форума использовать псевдонимы, содержащие только буквы английского алфавита и цифры.
4) Длина имен пользователей варьируется и довольно небольшая со средним выборочным значением 8 и малой дисперсией.
5) За редким исключением, на одной странице содержится более 10 сообщений. Страницами, содержащими меньшее количество сообщений, можно пренебречь.
6) После некоторого уровня в DOM-дереве можно выделить вершину, наследниками которой будут являться идентичные по структуре поддеревья, содержащие сообщения авторов, информацию из профилей, онлайн статус, присвоенный «ранг» и т.п. В любом форуме можно выделить элемент, который регулярно повторяется и содержит внутри все атрибуты отдельного сообщения или комментария: имя пользователя, дата сообщения, текст, подпись, ссылка на картинку - аватар и т.д. Таким образом, выше данного элемента в DOM-дереве будут вершины, определяющие форматирование, внешний вид целой группы сообщений, а ниже - детали одного конкретного сообщения. Предлагаемый способ призван выделить общий вид элементов для всех страниц некоторого форума, весь дочерний контент которых имеет отношение к одному сообщению. То есть, иными словами, отсылку на общую среди всех форумных страниц вершину дерева, которая отображает рамку вокруг отдельного сообщения.
7) Число различных элементов, которые повторяются в различных сообщениях, должно быть значительное число, например в каждом сообщении будет имя автора, ссылка на его профиль, его рейтинг, статус на форуме и прочие, и каждый такой элемент должен повторяться одинаковое количество раз, так как такие элементы входят в каждое сообщение.
8) Множество псевдонимов авторов не может содержать только один элемент и не может содержать все различные - должен соблюдаться баланс между ситуацией, когда человек беседует только сам с собой, и ситуацией, когда на странице отсутствует дискуссия, каждый отметился по разу.
Идея модификации деревьев стилей, реализованная в методе настоящего изобретения заключается в следующем: сливать в одну вершину нелистовые вершины с одинаковым именем (этап 114), а листовые вершины объединять в именные (листовые) группы (этап 115). При этом вершина может содержать несколько дочерних элементов с одинаковыми именами, которые могут являться различными элементами оформления и поэтому их не стоит объединять в одной вершине.
Для отсеивания последнего случая применяется следующая эвристика: метод параметризуется значением нижнего порога количества сообщений на странице, далее происходит предобработка DOM-дерева при помощи метода обхода в ширину:
1) Для текущей обрабатываемой вершины производится подсчет дочерних вершин с одинаковыми именами.
2) Для каждой группы дочерних вершин с одинаковым именем производится оценка: если количество вершин ниже порогового (нижний порог количества сообщений на странице), то вершины переименуются в соответствии с их порядком следования.
Важно отметить, что данная методика будет работать только для случаев, когда поддеревья, содержащие непосредственно сообщения, имеют одинаковую линейную структуру для каждой вершины. Имеется в виду, что внутри каждой вершины содержащее форумное сообщение, порядок внутренних элементов всегда один и тот же: например, сначала аватар, затем никнейм, кол-во сообщений и дата регистрации, затем сам текст. Так как сообщения генерируются программой, порядок обычно сохраняется такой же, как в шаблоне.
Пример предобработки изображен на Фиг. 2. У вершины body только 2 дочерних элемента с именем table, и они будут переименованы, а дочерних элементов с именем div больше порогового, и они не будут переименованы.
После описанной выше предобработки следует этап слияния похожих вершин (этап 114). В отличие от оригинального метода style-tree, будут сливаться не все вершины оригинального DOM-дерева, а только те, что содержатся в родительской вершине в количестве, большем порогового.
Слияние на произвольном шаге происходит следующим образом:
1) Если вершина с таким именем не встречалась среди уже рассмотренных подвершин рассматриваемой вершины, то мы выбираем ее в качестве базовой и создаем ее копию в редуцированном DOM-дереве.
2) Если вершина с таким именем уже встречалась - находится базовая вершина в редуцированном DOM-дереве, которой передаются все потомки текущей вершины.
3) Если вершина является листовой (то есть содержит текст), то листовая вершина прикрепляется к именованной группе вершин как дочерняя вершина. Именованная группа вершин выбирается таким образом, чтобы однотипные тексты, находящиеся в оригинальном DOM-дереве в разных вершинах, но на одних и тех же позициях, оказались объединены под одной вершиной.
После слияния получено редуцированное DOM-дерево, каждая вершина в котором оценивается (этап 116) на то, не содержат ли они тексты, похожие на псевдонимы пользователей. Для этого необходимо проанализировать полученные листовые группы. Пользуясь предположением 7), интересующую нас информацию следует искать только в тех группах, которые встречаются ровно столько же раз, как и другие группы. Для этого необходимо построить гистограмму, где каждый столбец отображает количество групп с одинаковым размером, нам необходимо выбрать самый высокий столбец. Это отражает ситуацию, что вершина, представляющая сообщение в целом, содержит больше всего однотипных подвершин, повторяющихся в каждом сообщении, к примеру никнеймы повторяются столько же раз, сколько встречаются даты сообщений, ранг участника форума, текст сообщения, его аватарка.
После выбора набора групп с одинаковым размером все группы, кроме тех, что объединяют под собой текстовые вершины, фильтруются (также на этапе 116). Дальнейший отбор стоит проводить с помощью простых правил и системы штрафов. Например, для отбора группы, содержащей имена авторов, стоит применить оценки, исходящие из того, что, скорее всего, родителем в DOM-дереве каждой вершины будет являться гиперссылка, будут содержаться преимущественно символы английского алфавита и конечно длина: порядка 5-10 символов.
Для каждого необходимого атрибута сообщения можно выделить свои наборы правил, выделяющие его главные характеристики. Для выделения текста автора можно сформулировать эвристики, сходные с теми, что применяются для автора: различие всех сообщений, средняя длина теста составляет 20-30 слов, и некоторые другие. На выходе (этап 117) имеем ХРАТН, представляющий группу вершин, обладающих сходными свойствами и имеющих одно назначение. После этого шага полученные выражения ХРАТН применяются к набору файлов, содержащих все документы с выбранного форума. Извлеченная информация записывается в выходной XML файл, при этом каждое сообщение помещается в элемент - конверт, позволяющий отделить информационные сущности различных сообщений.
Метод настоящего изобретения прошел тестирование. Для тестирования были выбраны следующие форумы: 4pda.ru, gamedev.ru, forums.goha.ru, sql.ru, forum.asus.ru. B качестве объекта извлекаемой метаинформации было выбрано имя автора сообщения. Для отбора лучшей группы были применены следующие правила:
1) группа набирает очко, если ее элемент длиннее 5 символов;
2) группа набирает очко, если ее элемент короче 10 символов.
Два первых правила рассчитываются для всех элементов группы, и полученные очки усредняются на длину группы;
3) чем больше различных элементов набирается в группе, тем больше очков она набирает.
Под «группой» понимается группа именно листовых вершин редуцированного дерева, а под лучшей группой понимается та, что содержит искомую группу вершин.
Набор из трех простых правил дает значительный результат: на форумах gamedev.ru, forums.goha.ru, sql.ru, forum.asus.ru на страницах, где заведомо было больше 10 сообщений, метод выбирал правильную группу вершин. На сайте 4pda.ru вместо псевдонимов пользователей были выделены модели телефонов, указанные в профилях пользователей. Стоит учесть, что метод отработает одинаково на всех страницах сайта: либо найдет всех авторов, либо не найдет ни одного.
Как показало тестирование - даже использование таких простых эвристик на этапе фильтрации вершин дает хороший результат. Для дальнейшего развития стоит выделить больше правил и возможно применить методы машинного обучения для подбора параметров правил.
Новизна предлагаемого метода заключается в предлагаемом методе построения редуцированного дерева стилей, который позволяет выделять элементы, повторяющиеся на странице, и последующего выделения пути, описывающего положение в DOM-дереве для всех этих вершин, а также в используемом наборе эвристик, позволяющих некоторую группу схожих вершин относить к определенному типу.
Технический результат предлагаемого метода заключается в повышении точности отделения текстов пользователей от остального контента веб-страниц при автоматическом построении корпуса текстов.
На Фиг. 3 приведен возможный пример вычислительного средства 300, которое может быть использовано для внедрения настоящего изобретения, осуществленного так, как было описано выше. Вычислительное средство 300 включает в себя, по крайней мере, один процессор 302, соединенный с памятью 304. Процессор 302 может представлять собой один или более процессоров, может содержать одно, два или более вычислительных ядер. Память 304 может представлять собой оперативную память (ОЗУ), а также содержать любые другие типы и виды памяти, в частности устройства энергонезависимой памяти (например, флэш-накопители) и постоянные запоминающие устройства, например жесткие диски и т.д. Кроме того, может считаться, что память 304 включает в себя аппаратные средства хранения информации, физически размещенные где-либо еще в составе вычислительного средства 300, например кэш-память в процессоре 302, память, используемую в качестве виртуальной и хранимую на внешнем либо внутреннем постоянном запоминающем устройстве 310.
Вычислительное средство 300 также обычно имеет некоторое количество входов и выходов для передачи информации вовне и получения информации извне. Для взаимодействия с пользователем вычислительное средство 300 может содержать одно или более устройств ввода (например, клавиатура, мышь, сканер и т.д.) и устройство отображения 308 (например, жидкокристаллический дисплей). Вычислительное средство 300 также может иметь одно или более постоянных запоминающих устройств 310, например привод оптических дисков (CD, DVD или другой), жесткий диск, ленточный накопитель. Кроме того, вычислительное средство 300 может иметь интерфейс с одной или более сетями 312, обеспечивающими соединение с другими сетями и вычислительными устройствами. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, соединенные со всемирной сетью Интернет или нет. Подразумевается, что вычислительное средство 300 включает подходящие аналоговые и/или цифровые интерфейсы между процессором 302 и каждым из компонентов 304, 306, 308, 310 и 312.
Вычислительное средство 300 работает под управлением операционной системы 314 и выполняет различные приложения, компоненты, программы, объекты, модули и т.д., указанные обобщенно цифрой 316.
Вообще программы, исполняемые для реализации способов, соответствующих данному изобретению, могут являться частью операционной системы или представлять собой обособленное приложение, компоненту, программу, динамическую библиотеку, модуль, скрипт, либо их комбинацию.
Настоящее описание излагает основной изобретательский замысел авторов, который не может быть ограничен теми аппаратными устройствами, которые упоминались выше. Следует отметить, что аппаратные устройства, прежде всего, предназначены для решения узкой задачи. С течением времени и с развитием технического прогресса такая задача усложняется или эволюционирует. Появляются новые средства, которые способны выполнить новые требования. В этом смысле следует рассматривать данные аппаратные устройства с точки зрения класса решаемых ими технических задач, а не чисто технической реализации на некой элементной базе.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОПТИМИЗАЦИЯ ВЫПОЛНЕНИЯ ВРЕМЕННОЙ РАЗМЕТКИ HD-DVD | 2007 |
|
RU2460157C2 |
| УСТРОЙСТВО И СПОСОБ ОБРАБОТКИ СОДЕРЖИМОГО ВЕБ-РЕСУРСА В БРАУЗЕРЕ | 2014 |
|
RU2595524C2 |
| МЕТОД ПРОСМОТРА WEB-СТРАНИЦ, ПЛАТФОРМА WEBAPP, МЕТОД И УСТРОЙСТВО ДЛЯ ИСПОЛНЕНИЯ JAVASCRIPT ДЛЯ МОБИЛЬНЫХ ТЕРМИНАЛОВ | 2013 |
|
RU2604326C2 |
| СПОСОБЫ И СИСТЕМЫ ОБРАБОТКИ ОБЪЕКТНЫХ МОДЕЛЕЙ ДОКУМЕНТОВ (DOM) ДЛЯ ОБРАБОТКИ ВИДЕОКОНТЕНТА | 2010 |
|
RU2475832C1 |
| Способ и система для модификации текста в документе | 2015 |
|
RU2610585C2 |
| ПРОГРАММИРУЕМОСТЬ ДЛЯ ХРАНИЛИЩА XML ДАННЫХ ДЛЯ ДОКУМЕНТОВ | 2006 |
|
RU2417420C2 |
| МЕТОД АНАЛИЗА ТОНАЛЬНОСТИ ТЕКСТОВЫХ ДАННЫХ | 2014 |
|
RU2571373C2 |
| Система и способ формирования классификатора для обнаружения фишинговых сайтов при помощи хешей объектов DOM | 2023 |
|
RU2811375C1 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2371758C2 |
| Способ обнаружения фишинговых сайтов и система его реализующая | 2023 |
|
RU2813242C1 |

Изобретение относится к системам и методам создания корпусов текстов для различных исследовательских и других целей. Техническим результатом является повышение точности отделения текстов пользователей от остального контента веб-страниц при автоматическом построении корпуса текстов. В способе построения корпуса текстов на основе интернет-форумов для компьютерной системы строят объектную модель документа в виде древовидной DOM-структуры данных. Выделяют группу однотипных вершин в дереве объектной модели документа. Удаляют необязательные элементы оформления со страниц. Осуществляют слияние нелистовых вершин с одинаковыми именами в дереве объектной модели и объединение листовых вершин с одинаковыми свойствами. Выполняют оценку вершин и фильтрации групп. Строят выражения ХРАТН и применяют полученные выражения ХРАТН к набору файлов, содержащих все документы с выбранного форума. 3 н. и 7 з.п. ф-лы, 3 ил.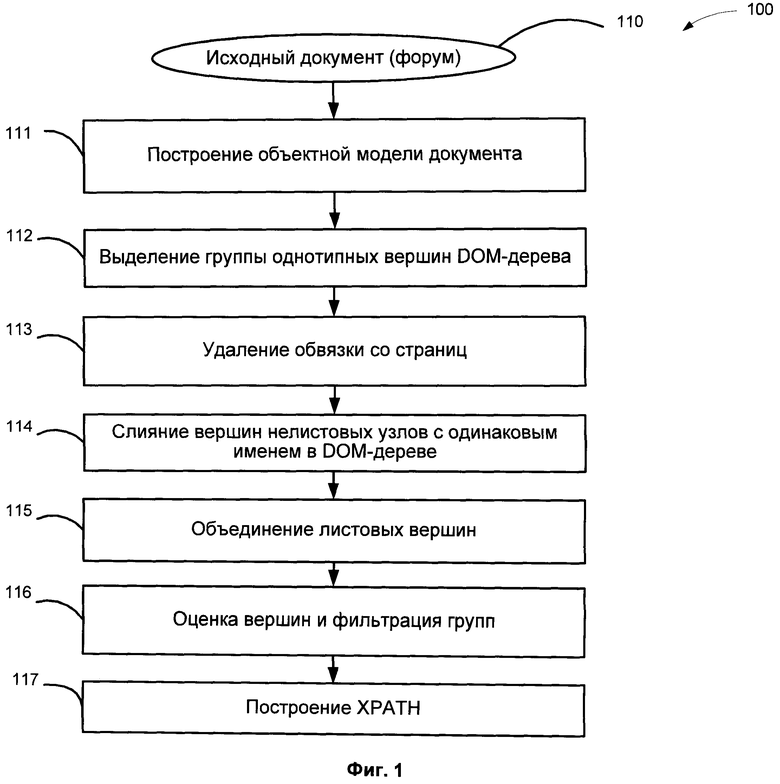
1. Способ построения корпуса текстов на основе интернет-форумов для компьютерной системы, заключающийся в том, что, по меньшей мере, один раз производят следующую последовательность действий:
- построение объектной модели документа в виде древовидной DOM-структуры данных;
- выделение групп однотипных вершин в дереве объектной модели документа;
- удаление необязательных элементов оформления со страниц;
- слияние нелистовых вершин с одинаковыми именами в дереве объектной модели;
- объединение листовых вершин с одинаковыми свойствами;
- оценка вершин;
- фильтрация групп;
- построение, по крайней мере, одного выражения ХРАТН;
- применение полученных выражений ХРАТН к набору файлов, содержащих все документы с выбранного форума.
2. Способ по п. 1, который дополнительно включает применение полученных выражений ХРАТН к набору файлов, содержащих все документы с выбранного форума.
3. Способ по п. 1, где каждому относительному ХРАТН сопоставляется идентификатор типа извлекаемой информации.
4. Способ по п. 3, где тип извлекаемой информации определяется с учетом значения весовой функции для каждого типа - кандидата, и в качестве идентификатора типа выбирается тот, на котором достигается максимальное значение весовой функции.
5. Способ по п. 2, где извлеченная информация записывается в выходной XML файл, при этом каждое сообщение помещается в отдельный элемент.
6. Способ по п. 1, где при слиянии вершин в дереве объектной модели происходит объединение свойств одинаковых вершин.
7. Способ по п. 6, где при слиянии вершин узлов с одинаковыми именами дополнительно устанавливают значение нижнего порога количества сообщений на странице, и для текущей обрабатываемой вершины производится подсчет дочерних вершин с одинаковыми именами.
8. Способ по п. 7, где для каждой группы дочерних вершин с одинаковым именем производится оценка: если количество вершин ниже порогового, то вершины переименовываются в соответствии с порядком их следования.
9. Система для построения корпуса текстов на основе интернет-форумов, включающая: один или более процессоров, одно или более устройств памяти, программные инструкции для вычислительного устройства, записанные в одно или более устройств памяти, которые при выполнении на одном или более процессорах управляют системой для:
- построения объектной модели документа в виде древовидной DOM-структуры данных;
- выделения групп однотипных вершин в дереве объектной модели документа;
- удаления необязательных элементов оформления со страниц;
- слияния нелистовых вершин с одинаковыми именами в дереве объектной модели;
- объединения листовых вершин с одинаковыми свойствами;
- оценки вершин;
- фильтрации групп;
- построения, по крайней мере, одного выражения ХРАТН;
- применения полученных выражений ХРАТН к набору файлов, содержащих все документы с выбранного форума.
10. Машиночитаемый носитель информации, несущий исполняемые компьютером инструкции для обеспечения возможности:
- построения объектной модели документа в виде древовидной DOM-структуры данных;
- выделения групп однотипных вершин в дереве объектной модели документа;
- удаления необязательных элементов оформления со страниц;
- слияния нелистовых вершин с одинаковыми именами в дереве объектной модели;
- объединения листовых вершин с одинаковыми свойствами;
- оценки вершин;
- фильтрации групп;
- построения, по крайней мере, одного выражения ХРАТН;
- применения полученных выражений ХРАТН к набору файлов, содержащих все документы с выбранного форума.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ЕГО СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ, СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ КОЛЛЕКЦИИ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ИХ СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ И МАШИНОЧИТАЕМЫЕ НОСИТЕЛИ | 2008 |
|
RU2399959C2 |
| УСОВЕРШЕНСТВОВАННЫЕ СИСТЕМЫ И СПОСОБЫ РАНЖИРОВАНИЯ ДОКУМЕНТОВ НА ОСНОВАНИИ СТРУКТУРНО ВЗАИМОСВЯЗАННОЙ ИНФОРМАЦИИ | 2004 |
|
RU2367997C2 |

