Уровень техники
Известны функции ранжирования, которые ранжируют документы согласно их релевантности для данного поискового запроса. В данной области техники прилагаются усилия к тому, чтобы разработать функции ранжирования, которые предоставляют лучшие результаты поиска для данного поискового запроса в сравнении с результатами поиска, формируемыми посредством поисковых механизмов с использованием известных функций ранжирования.
Сущность изобретения
В данном документе описываются помимо других вещей различные технологии для определения показателя релевантности документов для данного документа в сети. Показатель релевантности документа формируется посредством функции ранжирования, которая содержит один или более независимых от запроса компонентов, при этом, по меньшей мере, один независимый от запроса компонент включает в себя параметр смещенного расстояния, измеряемого количеством последовательных переходов, который учитывает значения смещенного расстояния, измеряемого количеством последовательных переходов, для нескольких документов в сети. Функции ранжирования могут быть использованы посредством поискового механизма для того, чтобы ранжировать несколько документов по порядку (в типичном варианте в порядке убывания) на основе показателей релевантности для нескольких документов.
Данный раздел "Сущность изобретения" предусмотрен для того, чтобы в общем представить читателю в упрощенной форме одну или более выбираемых идей, которые дополнительно описываются ниже в разделе "Подробное описание изобретения". Этот раздел "Сущность изобретения" не предназначен для того, чтобы идентифицировать ключевые и/или обязательные признаки заявляемой сущности изобретения.
Краткое описание чертежей
Фиг. 1 представляет примерную логическую блок-схему последовательности операций, иллюстрирующую примерные этапы способа создания ранжированных результатов поиска в ответ на поисковый запрос, введенный пользователем.
Фиг. 2 - это блок-схема некоторых основных компонентов примерного операционного окружения для реализации способов и процессов, раскрытых в данном документе.
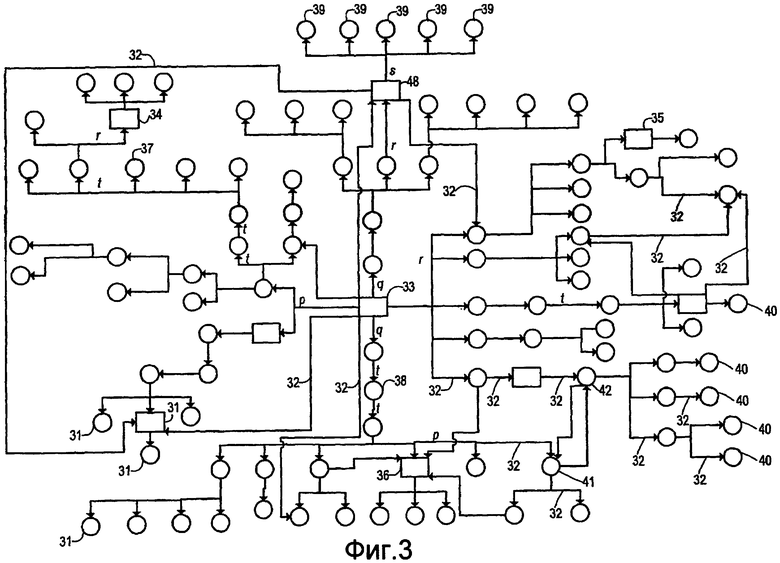
Фиг. 3 иллюстрирует примерный веб-граф, идентифицирующий документы в сетевом пространстве, ссылки между документами, авторитетные узлы, имеющие присвоенное значение смещенного расстояния, измеряемого количеством последовательных переходов, и неавторитетные узлы, имеющие вычисленное значение смещенного расстояния, измеряемого количеством последовательных переходов.
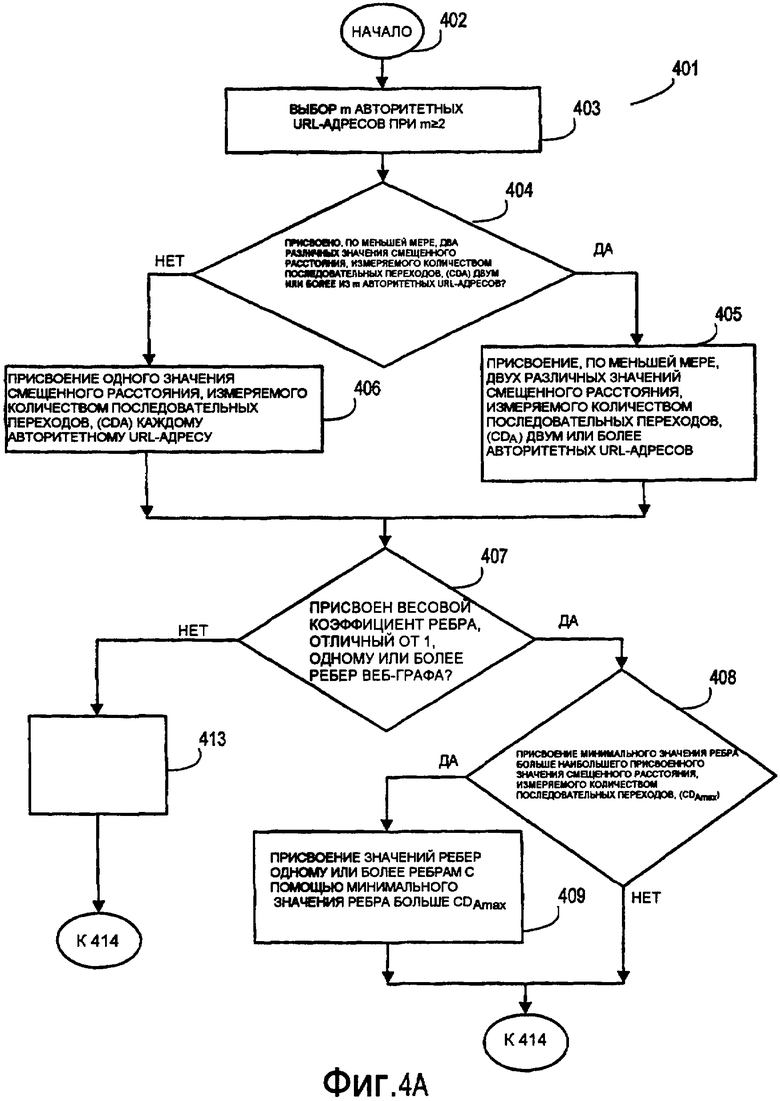
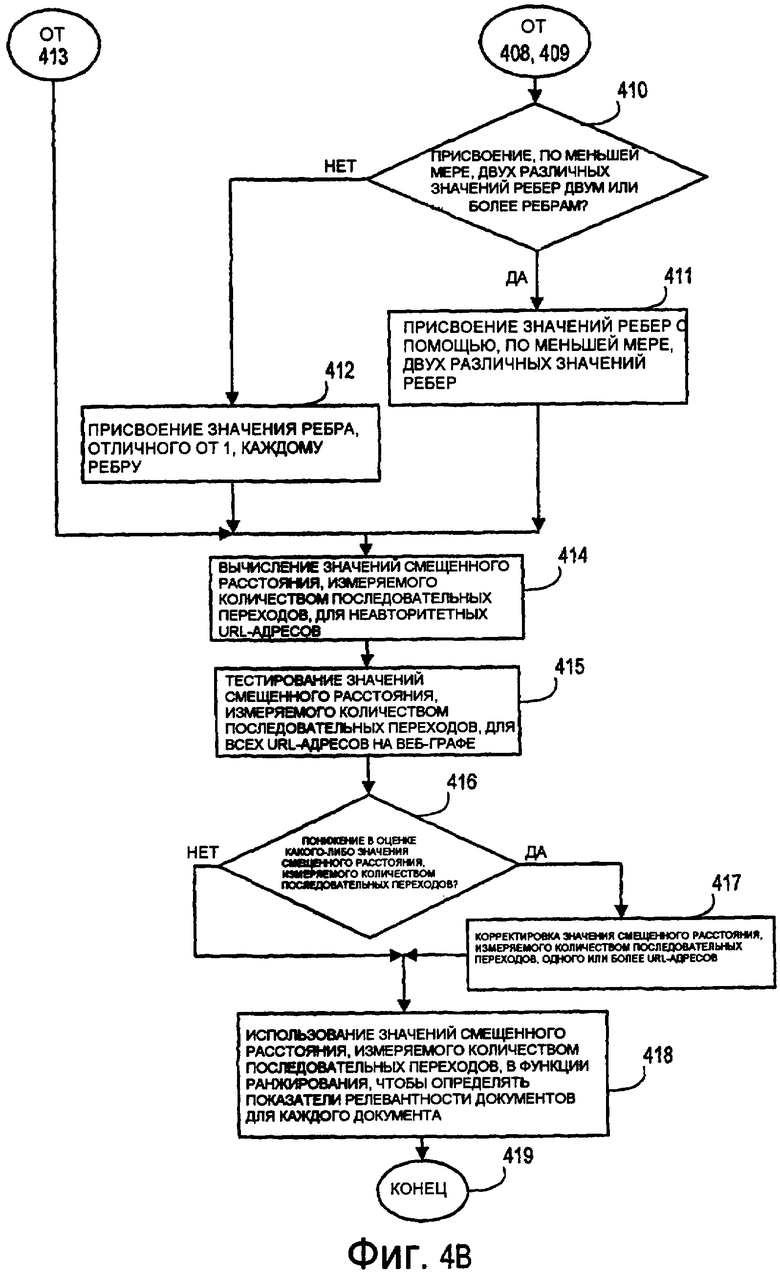
Фиг. 4A-4B представляют логическую блок-схему последовательности операций, иллюстрирующую примерные этапы способа присвоения и формирования значений смещенного расстояния, измеряемого количеством последовательных переходов, для узлов на веб-графе.
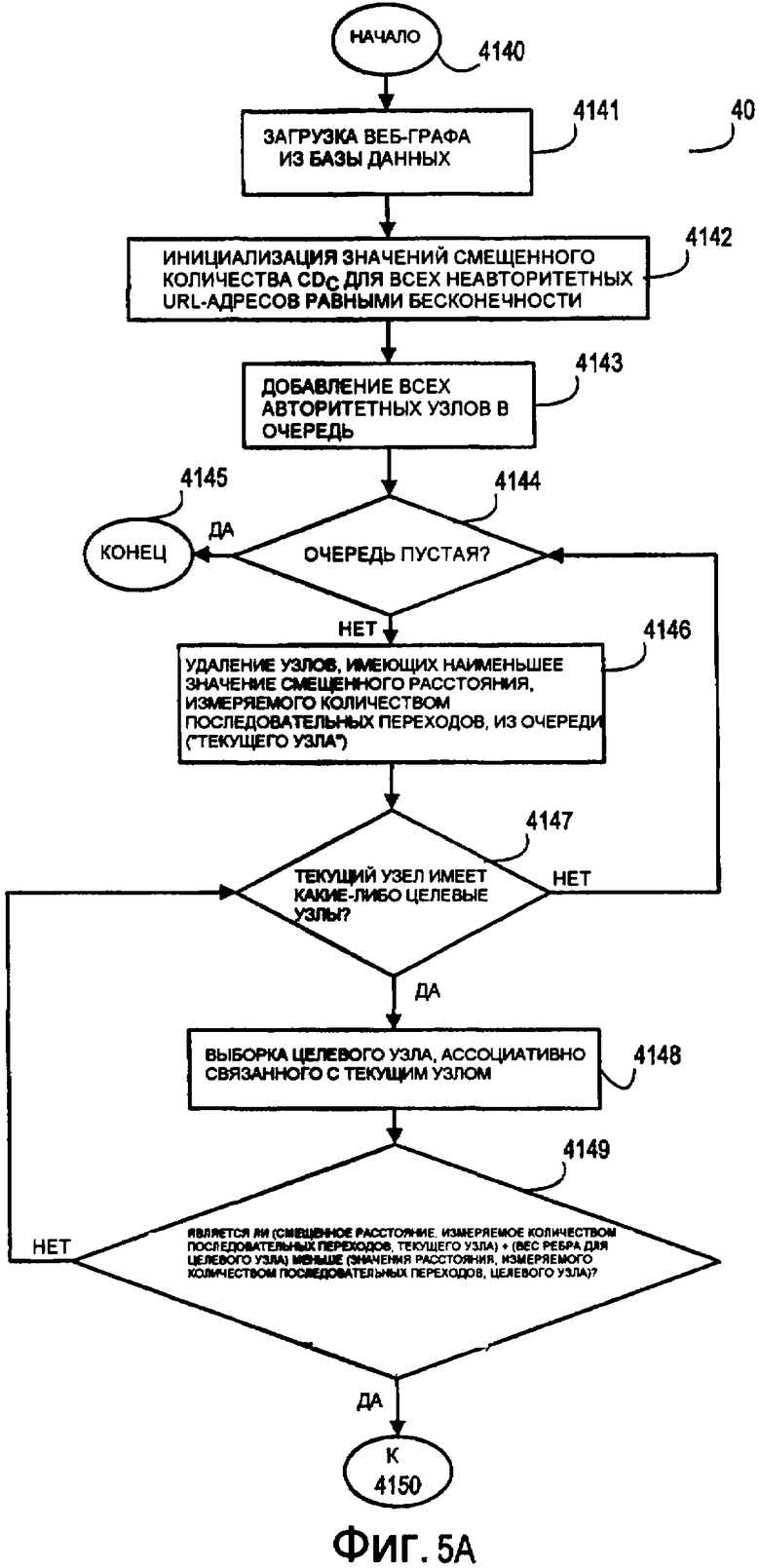
Фиг. 5A-5B представляют логическую блок-схему последовательности операций, иллюстрирующую примерные этапы способа формирования значений смещенного расстояния, измеряемого количеством последовательных переходов, для неавторитетных узлов на веб-графе.
Фиг. 6 представляет логическую блок-схему последовательности операций, иллюстрирующую примерные этапы способа ранжирования результатов поиска, сформированных с помощью функции ранжирования, содержащей параметр значения смещенного расстояния, измеряемого количеством последовательных переходов.
Подробное описание изобретения
Чтобы способствовать пониманию принципов способов и процессов, раскрываемых в данном документе, далее приводится описание конкретных вариантов осуществления и для того, чтобы описать конкретные варианты осуществления, используется специальный язык. Тем не менее, следует понимать, что ограничение на область применения раскрытых способов и процессов не налагается посредством использования специального языка. Изменения, дополнительные модификации и аналогичные дополнительные варианты применения поясненных раскрытых способов и устройств предполагаются, как должно быть обычно очевидным специалистам в данной области техники, к которым относятся раскрытые способы и процессы.
Раскрываются способы определения показателя релевантности документов для документов в сети. Каждый показатель релевантности документов вычисляется с помощью функции ранжирования, которая содержит один или более зависимых от запроса компонентов (к примеру, функциональный компонент, который зависит от специфики данного поискового запроса или условия поискового запроса), а также один или более независимых от запроса компонентов (к примеру, функциональный компонент, который не зависит от данного поискового запроса или условия поискового запроса). Показатели релевантности документов, определенные посредством функции ранжирования, могут быть использованы для того, чтобы ранжировать документы внутри сетевого пространства (к примеру, пространства корпоративной сети интранет) согласно показателю релевантности каждого документа. Примерный процесс поиска, в котором могут быть использованы раскрытые способы, показан как примерный процесс 10 на фиг. 1.
Фиг. 1 иллюстрирует примерный процесс 10 поиска, который начинается с этапа 80 процесса, на котором пользователь вводит поисковый запрос. От этапа 80 примерный процесс 10 поиска переходит к этапу 200, на котором поисковый механизм находит все документы в сетевом пространстве по одному или более условиям поискового запроса. От этапа 200 примерный процесс 10 поиска переходит к этапу 300, на котором функция ранжирования поискового механизма сортирует документы в сетевом пространстве на основе показателя релевантности каждого документа, при этом показатель релевантности документа основан на одном или более зависимых от запроса компонентов и одном или более независимых от запроса компонентов. От этапа 300 примерный процесс 10 поиска переходит к этапу 400, на котором отсортированные результаты поиска представляются пользователю, в типичном варианте в порядке убывания релевантности, идентифицируя документы в сетевом пространстве, которые наиболее релевантны к поисковому запросу.
Как подробнее описано ниже, в некоторых примерных способах определения показателя релевантности документов, по меньшей мере, один независимый компонент функции ранжирования, используемой для того, чтобы определять показатель релевантности документов, учитывает "смещенное расстояние, измеряемое количеством последовательных переходов (кликов)" каждого документа в сетевом пространстве. Смещенному расстоянию, измеряемому количеством последовательных переходов, для определенных документов, упоминаемых в данном описании как "авторитетные документы" в сети или "авторитетные узлы" на веб-графе, может быть присвоено начальное значение расстояния, измеряемого количеством последовательных переходов, чтобы идентифицировать эти документы как имеющие различную степень значимости относительно друг друга и, возможно, более высокую степень значимости относительно остальных документов в сети. Остальные документы, упоминаемые в данном документе как "неавторитетные документы" в сети или "неавторитетные узлы" на веб-графе, имеют значение смещенного расстояния, измеряемого количеством последовательных переходов, которое вычисляется на основе их позиции относительно ближайшего авторитетного документа в сетевом пространстве (или ближайшего авторитетного узла на веб-графе), приводящие в результате к смещению значений расстояния, измеряемого количеством последовательных переходов, относительно авторитетных узлов.
В одном примерном варианте осуществления значение смещенного расстояния, измеряемого количеством последовательных переходов, может быть присвоено m авторитетным документам в сети, содержащей всего N документов, при этом m больше или равно 2 и меньше N. В этом примерном варианте осуществления системный администратор вручную выбирает либо программный код в поисковой системе автоматически идентифицирует m авторитетных документов в данном сетевом пространстве, которые имеют определенную степень значимости в сетевом пространстве. Например, один из m авторитетных документов может быть домашней страницей веб-узла или другой страницей, ссылающейся непосредственно на домашнюю страницу веб-узла.
В другом примерном варианте осуществления, по меньшей мере, два значения смещенного расстояния, измеряемого количеством последовательных переходов, присвоенные m авторитетным документам, отличаются друг от друга. В этом варианте осуществления различные числовые значения могут быть присвоены двум или более m авторитетным документам, чтобы дополнительно количественно задать значимость одного авторитетного документа для другого авторитетного документа. Например, значимость данного авторитетного документа может быть указана посредством небольшого значения смещенного расстояния, измеряемого количеством последовательных переходов. В этом примере авторитетные документы, имеющие значение смещенного расстояния, измеряемого количеством последовательных переходов, равным 0, рассматриваются как более значимые, чем авторитетные документы, имеющие значение смещенного расстояния, измеряемого количеством последовательных переходов, больше 0.
Раскрытые способы определения показателя релевантности документов дополнительно могут использовать функцию ранжирования, которая содержит, по меньшей мере, один независимый от запроса компонент, который включает в себя параметр значения ребра, который учитывает значения ребер, присвоенные каждому ребру сети, при этом каждое ребро соединяет один документ с другим документом в рамках структуры гиперссылок сети (или один узел с другим узлом на веб-графе). Присвоение значений ребер одному или более ребрам, соединяющим документы друг с другом в сети, предоставляет дополнительный способ влияния на показатель релевантности документов в сети. Например, в примере, раскрытом выше, в котором низкое значение смещенного расстояния, измеряемого количеством последовательных переходов, указывает значимость данного документа, увеличение значения ребра между двумя документами, такими как первый документ и второй документ, связанный с первым документом, дополнительно снижает значимость второго документа (т.е. связанного документа) относительно первого документа. В отличие от этого посредством присвоения низкого значения ребра ребру между первым документом и вторым документом значимость второго документа становится больше относительно первого документа.
В примерном варианте осуществления двум или более ребрам, связывающим документы в сетевом пространстве, могут быть присвоены значения ребер, которые отличаются друг от друга. В этом примерном варианте осуществления различные числовые значения могут быть присвоены двум или более ребрам, чтобы дополнительно количественно задать значимость одного документа для другого в сетевом пространстве. В других примерных вариантах осуществления всем ребрам, связывающим документы в сетевом пространстве, присваивается одно значение ребра, при этом присвоенное значение ребра равно 1 или какому-либо другому положительному числу. В еще одном другом варианте осуществления значения ребер равны друг другу и равны или превышают наибольшее значение смещенного расстояния, измеряемого количеством последовательных переходов, первоначально присвоенное одному или более авторитетным документам.
В еще одном дополнительном примерном варианте осуществления раскрытые способы определения показателя релевантности документов используют функцию ранжирования, которая содержит, по меньшей мере, один независимый от запроса компонент, который включает в себя и вышеописанный параметр смещенного расстояния, измеряемого количеством последовательных переходов, и вышеописанный параметр значения ребра.
Показатель релевантности документов может быть использован для того, чтобы ранжировать документы в сетевом пространстве. Например, способ ранжирования документов в сети может содержать этапы определения показателя релевантности документов для каждого документа в сети с помощью вышеописанного способа; и ранжирования документов в требуемом порядке (в типичном варианте в порядке убывания) на основе показателей релевантности для каждого документа.
Показатель релевантности документов также может быть использован для того, чтобы ранжировать результаты поиска для поискового запроса. Например, способ ранжирования результатов поиска для поискового запроса может содержать этапы определения показателя релевантности документов для каждого документа в результатах поиска для поискового запроса с помощью вышеописанного способа; и ранжирования документов в требуемом порядке (в типичном варианте в порядке убывания) на основе показателей релевантности для каждого документа.
Прикладные программы, использующие способы, раскрытые в данном документе, могут быть загружены и приведены в исполнение для множества вычислительных систем, содержащих множество аппаратных компонентов. Примерная вычислительная система и примерное операционное окружение для применения на практике способов, раскрытых в данном документе, описаны ниже.
Примерное операционное окружение
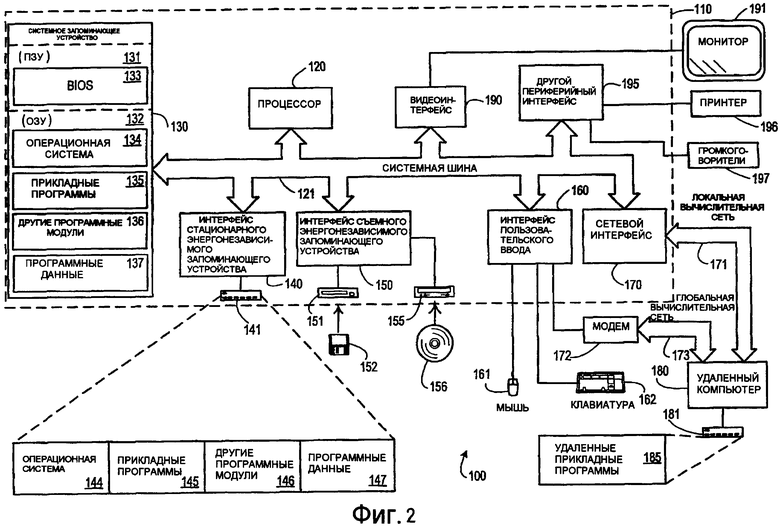
Фиг. 2 иллюстрирует пример подходящего окружения 100 вычислительной системы, в котором способы, раскрытые в данном документе, могут быть реализованы. Окружение 100 вычислительной системы является только одним примером подходящего вычислительного окружения и не имеет намерением мотивировать какое-либо ограничение в качестве границ использования или функциональности способов, раскрытых в данном документе. Также вычислительное окружение 100 не должно быть интерпретировано в качестве имеющего какую бы то ни было зависимость или требование, относящееся к любому одному или сочетанию из компонентов, проиллюстрированных в примерном операционном окружении 100.
Способы, раскрытые в данном документе, являются работоспособными с многочисленными другими конфигурациям или средами вычислительных систем общего применения или специального назначения. Примеры хорошо известных вычислительных систем, сред и/или конфигураций, которые могут быть пригодными для использования со способами, раскрытыми в данном документе, включают в себя, но не в качестве ограничения, персональные компьютеры, серверные компьютеры, «карманные» или «дорожные» устройства, многопроцессорные системы, основанные на микропроцессорах системы, компьютерные приставки к телевизору, программируемую бытовую электронную аппаратуру, сетевые ПК (персональные компьютеры, PC), миникомпьютеры, универсальные вычислительные машины, распределенные вычислительные среды, которые включают в себя любые из вышеприведенных систем или устройств, и тому подобное.
Способы и процессы, раскрытые в данном документе, могут быть описаны в общем контексте машинно-исполняемых инструкций, к примеру, программных модулей, являющихся исполняемыми компьютером. Программные модули, в общем, включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.д., которые выполняют отдельные задачи или реализуют отдельные абстрактные типы данных. Способы и процессы, раскрытые в данном документе, могут быть также осуществлены на практике в распределенной вычислительной среде, где задачи выполняются удаленными обрабатывающими устройствами, которые связаны через сеть передачи данных. В распределенном вычислительном окружении программные модули могут быть расположены в носителе хранения и локального, и удаленного компьютера, включающего в себя запоминающие устройства памяти.
Относительно фиг. 2 примерная система для реализации способов и процессов, раскрытых в данном документе, включает в себя вычислительное устройство общего назначения в виде компьютера 110. Компоненты компьютера 110 могут включать в себя, но не только, процессор 120, системную память 130 и системную шину 121, которая соединяет различные компоненты системы, включая, но не ограничивая, системную память 130 с процессором 120. Системная шина 121 может быть любой из некоторых типов шинных структур, включающих в себя шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из многообразия шинных архитектур. В качестве примера, но не ограничения, такие архитектуры включают в себя шину стандартной архитектуры для промышленного применения (ISA), шину микроканальной архитектуры (MCA), шину расширенной ISA (EISA), шину стандарта (VESA) локальной видеошины для ПК и шину соединения периферийных компонентов (PCI), также известную как мезонинная шина.
Компьютер 110 в типичном варианте включает в себя многообразие машиночитаемых носителей. Машиночитаемыми носителями могут быть любые имеющиеся в распоряжении носители, доступ к которым может быть осуществлен компьютером 110 и которые могут быть как энергозависимыми или энергонезависимыми, так и съемными или несъемными. В качестве примера, но не ограничения, машиночитаемые носители могут содержать компьютерные запоминающие носители и среду передачи данных. Носитель хранения компьютера включает в себя энергозависимый и энергонезависимый, сменный и стационарный носитель, реализованный по любому способу или технологии хранения такой информации, как машиночитаемые команды, структуры данных, программные модули и другие данные. Компьютерные запоминающие носители включают в себя, но не в качестве ограничения, ОЗУ (оперативное запоминающее устройство, RAM), ПЗУ (постоянное запоминающее устройство, ROM), ЭСППЗУ (электрически стираемое и программируемое ПЗУ, EEPROM), флэш-память или другую технологию памяти, CD-ROM (ПЗУ на компакт-диске), цифровой универсальный диск (DVD) или другое оптическое дисковое запоминающее устройство, магнитные кассеты, магнитную ленту, магнитный дисковый накопитель или другие магнитные запоминающие устройства или любой другой носитель, который может быть использован, чтобы хранить желаемую информацию, и к которому может быть осуществлен доступ компьютером 110. Среда передачи данных обычно воплощает машиночитаемые инструкции, структуры данных, программные модули или другие данные в модулированном информационном сигнале, таком как несущая, или другом транспортном механизме и включает в себя любую среду доставки информации. Термин "модулированный информационный сигнал" означает сигнал, который обладает одной или несколькими характеристиками, заданными или измененными таким способом, как кодирование информации в сигнале. В качестве примера, но не ограничения, среда передачи данных включает в себя проводную среду, такую как проводная сеть, или непосредственное проводное соединение, и беспроводную среду, такую как акустическая, RF, инфракрасная и другие беспроводные среды. Сочетания любого из вышеперечисленного также следует включить в число машиночитаемого носителя как используемого в настоящем документе.
Системная память 130 включает в себя компьютерную среду хранения в виде энергозависимого и/или энергонезависимого запоминающего устройства, такого как постоянное запоминающее устройство 131 (ПЗУ) и оперативное запоминающее устройство 132 (ОЗУ). Базовая система 133 ввода/вывода (BIOS), содержащая в себе базовые процедуры, которые помогают передавать информацию между элементами в пределах компьютера 110, к примеру, во время запуска, типично сохранена в ПЗУ 131. ОЗУ 132 типично содержит в себе данные и/или программные модули, которые непосредственно доступны и/или являются собственно выполняемыми процессором 120. В качестве примера, но не ограничения, фиг. 2 иллюстрирует операционную систему 134, прикладные программы 135, другие программные модули 136 и программные данные 137.
Компьютер 110 может также включать в себя другие съемные/несъемные энергозависимые/энергонезависимые компьютерные запоминающие носители. Исключительно в качестве примера, фиг. 2 иллюстрирует накопитель 140 на жестком диске, который выполняет считывание с или запись на несъемные энергонезависимые носители, магнитный дисковод 151, который выполняет считывание с или запись на съемный энергонезависимый магнитный диск 152, а также оптический дисковод 155, который выполняет считывание с или запись на съемный энергонезависимый оптический диск 156, такой как CD-ROM или другие оптические носители. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные запоминающие носители, которые могут быть использованы в примерной рабочей среде, включают в себя, но не в качестве ограничения, кассеты магнитной ленты, карты флэш-памяти, цифровые многофункциональные диски, цифровую видеоленту, твердотельное ОЗУ, твердотельное ПЗУ и тому подобное. Накопитель 141 на жестком диске типично подключен к системной шине 121 через интерфейс несъемной памяти, такой как интерфейс 140, а привод 151 магнитного диска и привод 155 оптического диска типично подключены к системной шине 121 посредством интерфейса съемной памяти, такого как интерфейс 150.
Накопители и ассоциативно связанный с ним носитель хранения вычислительной машины, обсужденные выше и проиллюстрированные на фиг. 2, предоставляют хранение машиночитаемых инструкций, структур данных, программных модулей и других данных для вычислительной машины 110. На фиг. 2, например, накопитель 141 на жестких дисках проиллюстрирован в качестве сохраняющего операционную систему 144, прикладные программы 145, другие программные модули 146 и программные данные 147. Заметим, что эти компоненты могут либо быть такими же как или отличными от операционной системы 134, прикладных программ 135, других программных модулей 136 и программных данных 137. Операционная система 144, прикладные программы 145, другие программные модули 146 и программные данные 147 даны в настоящем документе с разными номерами, чтобы проиллюстрировать, что, как минимум, они являются различными другими копиями.
Пользователь может вводить команды и информацию в компьютер 110 через устройства ввода, такие как клавиатура 162 и указательное устройство 161, обычно упоминаемое как мышь, шаровой манипулятор (трекбол) или сенсорная панель. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую панель, спутниковую антенну, сканер или тому подобное. Эти и другие устройства ввода часто подключены к процессору 120 через пользовательский интерфейс 160 ввода, который соединен с системной шиной 121, но могут не быть подключены посредством других интерфейсов и шинных структур, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 191 или другой тип устройства отображения также подключен к системной шине 121 посредством такого интерфейса, как видеоинтерфейс 190. Помимо монитора 191 компьютер 110 может также включать в себя другие периферийные устройства вывода, например динамики 197 и принтер 196, которые могут быть подключены средствами периферийного интерфейса 195 вывода.
Компьютер 110 может работать в сетевом окружении, использующем логические соединения с одним или более удаленными компьютерами, такими как удаленный компьютер 180. Удаленный компьютер 180 может быть персональным компьютером, сервером, маршрутизатором, сетевым персональным ПК, одноранговым устройством или другим общим узлом сети, и он типично включает в себя многие или все элементы, описанные выше относительно компьютера 110, хотя на фиг. 2 проиллюстрировано только запоминающее устройство 181 хранения. Логические соединения, показанные на фиг. 2, включают в себя локальную вычислительную сеть (LAN) 171 и глобальную сеть (WAN) 173, но могут также включать в себя другие сети. Такие сетевые среды являются обычными в офисах, корпоративных компьютерных сетях, сетях интранет (локальных сетях, основанных на технологиях Интернет) и Интернете.
Когда используется в сетевом окружении LAN, компьютер 110 подключен к LAN 171 через сетевой интерфейс или адаптер 170. Когда используется в сетевом окружении WAN, компьютер 110 типично включает в себя модем 172 или другое средство для установления связи по WAN 173, такой как Интернет. Модем 172, который может быть внутренним или внешним, может быть подключен к системной шине 121 через интерфейс 160 пользовательского ввода или с использованием другого подходящего устройства. В сетевом окружении программные модули, изображенные относительно компьютера 110, или их части могут быть сохранены в удаленном запоминающем устройстве памяти. В качестве примера, а не ограничения, фиг. 2 иллюстрирует удаленные прикладные программы 185 как находящиеся на запоминающем устройстве 181 хранения. Должно быть очевидно, что показанные сетевые соединения являются примерными и может быть использовано другое средство установления линии связи между вычислительными машинами.
Способы и процессы, раскрытые в данном документе, могут быть реализованы с помощью одной или нескольких прикладных программ, включающих в себя, но не ограниченных, приложение поиска и ранжирования результатов, которые могут быть одним из числа прикладных программ, указанных как прикладные программы 135, прикладные программы 145 и удаленные прикладные программы 185 в примерной системе 100.
Как упомянуто выше, специалисты в данной области техники поймут, что раскрытые способы формирования показателя релевантности документа для данного документа могут быть реализованы в других конфигурациях вычислительных систем, включающих в себя портативные устройства, многопроцессорные системы, основанную на микропроцессорах или программируемую бытовую электронную аппаратуру, сетевые персональные компьютеры, мини-ЭВМ, мейнфреймы и т.п. Раскрытые способы формирования показателя релевантности документа для данного документа могут быть также осуществлены на практике в распределенной вычислительной среде, где задачи выполняются удаленными обрабатывающими устройствами, которые связаны через сеть передачи данных. В распределенном вычислительном окружении программные модули могут быть размещены на локальных и удаленных устройствах хранения данных.
Реализация примерных вариантов осуществления
Как описано выше, предусмотрены способы определения показателя релевантности документов для документа в сети. Раскрытые способы позволяют ранжировать документ в сети с помощью (i) функции ранжирования, которая учитывает значение смещенного расстояния, измеряемого количеством последовательных переходов, каждого документа в сети, (ii) функции ранжирования, которая учитывает одно или более значений ребер, присвоенных ребрам (или связям) между документами в сети, или (iii) и (i), и (ii).
Раскрытые способы определения показателя релевантности документа в сети могут содержать ряд этапов. В одном примерном варианте осуществления способ определения показателя релевантности документа в сети содержит этапы сохранения информации документа и связи для документов в сети; формирования представления сети из информации документа и связей, при этом представление сети включает в себя узлы, которые представляют документы, и ребра, которые представляют связи; присвоения значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD A), по меньшей мере, двум узлам в сети, при этом узлы, которым присвоено значение смещенного расстояния, измеряемого количеством последовательных переходов, являются авторитетными узлами; вычисление смещенного расстояния, измеряемого количеством последовательных переходов, для каждого из неавторитетных узлов в представлении сети, при этом смещенное расстояние, измеряемое количеством последовательных переходов, для данного неавторитетного узла измеряется от данного неавторитетного узла до авторитетного узла, ближайшего к данному неавторитетному узлу, причем этап вычисления приводит к вычисленному значению смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) для каждого неавторитетного документа, и использования значения смещенного расстояния, измеряемого количеством последовательных переходов, (т.е. CD A или CD C) для каждого документа, чтобы определить показатель релевантности данного документа в сети.
Этап сохранения информации документов и ссылок для документов в сети может быть выполнен посредством программного кода индексации, как правило, используемого в вычислительных системах. Программный код индексации формирует представление сети из информации документов и связей, при этом представление сети включает в себя узлы, которые представляют документы, и ребра, которые представляют связи. Это представление сети, в общем, упоминается как "веб-граф". Один примерный способ формирования веб-графа содержит использование данных, собираемых посредством процесса, при котором информация связей и текста привязки собирается и приписывается конкретным целевым документам привязки. Этот процесс и понятие текста привязки более полно описаны в Патентной заявке (США) серийный номер 10/955462, озаглавленной "SYSTEM AND METHOD FOR INCORPORATING ANCHOR TEXT INTO RANKING SEARCH RESULTS", поданной 30 августа 2004 года, предмет которой полностью содержится в данной заявке по ссылке.
Фиг. 3 иллюстрирует примерный веб-граф, идентифицирующий документы в сетевом пространстве и связи между документами. Как показано на фиг. 3, примерный веб-граф 30 содержит узлы 31, которые представляют каждый документ в данном сетевом пространстве (к примеру, в корпоративной сети интранет), и ребра 32, которые представляют связи между документами в данном сетевом пространстве. Следует понимать, что примерный веб-граф 30 является сильно упрощенным представлением данного сетевого пространства. В типичном варианте данное сетевое пространство может содержать сотни, тысячи или миллионы документов и сотни, тысячи или миллионы связей, соединяющих документы друг с другом. Дополнительно, хотя примерный веб-граф 30 иллюстрирует до восьми связей, соединенных с данным узлом (к примеру, центральным узлом 33), следует понимать, что при фактических сетевых настройках данный узел может иметь сотни ссылок, соединяющих узел (к примеру, документ) с сотнями других документов в сети (к примеру, домашняя страница сети может быть связана со всеми страницами в сети).
Помимо этого примерный веб-граф 30 иллюстрирует небольшое количество циклов (к примеру, первый узел, связанный со вторым узлом, который может связываться с дополнительными узлами, при этом второй узел или один из дополнительных узлов связывается обратно с первым узлом). Один такой цикл представлен посредством узлов 41 и 42 на фиг. 3. Другие циклы могут быть представлены, если любой из конечных узлов 40 связан обратно с любым другим узлом, показанным на фиг. 3, таким как центральный узел 33. Вне зависимости от простоты или сложности данного веб-графа раскрытые способы формирования показателя релевантности документов могут быть использованы в любом веб-графе, в том числе и в содержащем циклы.
После того как веб-граф сформирован, одна или более методик могут быть использованы для того, чтобы повлиять на относительную значимость одного или более документов в сетевом пространстве, представленных посредством узлов веб-графа. Как описано выше и ниже, эти методики включают в себя, но не только, (i) указание двух или более узлов как авторитетных узлов; (ii) присвоение каждому из авторитетных узлов значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD A), (iii) необязательно, присвоение двух или более значений смещенного расстояния, измеряемого количеством последовательных переходов, (CD A), которые отличаются друг от друга; (iv) присвоение значения ребра каждому ребру веб-графа; (v) необязательно, присвоение минимального значения ребра каждому ребру веб-графа, при этом минимальное значение ребра больше максимальных или наибольших присвоенных значений смещенного расстояния, измеряемого количеством последовательных переходов, (CD Amax); (vi) необязательно, присвоение одного или более значений ребер, которые отличаются друг от друга; (vii) вычисление значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) для каждого неавторитетного узла; и (viii) необязательно, понижение в оценке значений смещенного расстояния, измеряемого количеством последовательных переходов, (CD A или CD C) при необходимости, если тестовые запросы с помощью значений смещенного расстояния, измеряемого количеством последовательных переходов, формируют нерелевантные результаты поиска. Некоторые из вышеописанных примерных методик оказания влияния на значение смещенного расстояния, измеряемого количеством последовательных переходов, одного или более документов в сети, представленных посредством примерного веб-графа 30, показаны на фиг. 3.
В примерном веб-графе узлы 31, имеющие квадратную форму, используются для того, чтобы идентифицировать авторитетные узлы в сети, при этом узлы 31, имеющие круглую форму, используются для того, чтобы идентифицировать неавторитетные узлы. Следует понимать, что любое число узлов в данном веб-графе может быть указано в качестве авторитетных узлов в зависимости от числа факторов, включающих в себя, но не только, общее число документов в сетевом пространстве, и число значимых документов, которые находятся в сетевом пространстве. В примерном веб-графе 30, 9 из 104 узлов указаны как авторитетные узлы (т.е. представляют 9 из 104 документов как имеющие особую значимость).
Дополнительно, хотя не показано на примерном веб-графе 30, каждое ребро 32 между каждой парой узлов 31 имеет весовой коэффициент ребра, ассоциативно связанный с ним. В типичном варианте, каждое ребро 32 имеет весовой коэффициент ребра по умолчанию, равный 1; тем не менее, как описано выше, каждому ребру 32 может быть присвоен весовой коэффициент ребра, отличный от 1. Дополнительно, в некоторых вариантах осуществления два или более различных весовых коэффициента ребер могут быть присвоены ребрам в одном веб-графе. На фиг. 3 буквы p, q, r, s и t, показанные в примерном веб-графе 30, используются для того, чтобы указывать значения некоторых ребер 32. Как описано выше, значения p, q, r, s и t ребер могут иметь значение 1, значение, отличное от 1, и/или значения, которые отличаются друг от друга, чтобы дополнительно влиять на значения смещенного расстояния, измеряемого количеством последовательных переходов, узлов 31 в примерном веб-графе 30. В типичном варианте, значения ребер для p, q, r, s и t, а также для других ребер в примерном веб-графе 30 являются одинаковым числом и в типичном варианте равны или больше 1. В некоторых вариантах осуществления значения ребер для p, q, r, s и t, а также для других ребер в примерном веб-графе 30 являются одинаковым числом и в типичном варианте равны или больше наибольшего значения смещенного расстояния, измеряемого количеством последовательных переходов, присвоенного авторитетному узлу.
Одна или более методик, используемых для того, чтобы модифицировать веб-граф, чтобы влиять на значения смещенного расстояния, измеряемого количеством последовательных переходов, для документов в сети, могут быть инициированы вручную или выполнены системным администратором. Системный администратор может просматривать данный веб-граф и редактировать веб-граф, как требуется для того, чтобы повысить и/или уменьшить относительную значимость одного или более документов в сетевом пространстве, как описано выше. Программный код, например программный код в вычислительной системе, допускающей осуществление поискового запроса, может автоматически формировать смещение на веб-графе с помощью одной или более вышеописанных методик (к примеру, вычисления на основе значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) для каждого неавторитетного узла).
Фиг. 4A-4B представляют логическую блок-схему последовательности операций, иллюстрирующую примерные этапы примерного способа присвоения и формирования значений смещенного расстояния, измеряемого количеством последовательных переходов, для узлов на веб-графе, после которого выполняется необязательная процедура понижения в оценке системным администратором. Как показано на фиг. 4A, примерный способ 401 начинается на этапе 402 и переходит к этапу 403. На этапе 403 определенное число авторитетных узлов (или URL-адресов) выбирается из общего числа N узлов (или URL-адресов) в сетевом пространстве. В примерном способе 401 m авторитетных узлов (или URL-адресов) выбирается, при этом m больше или равно 2. После того как авторитетные узлы (или URL-адресы) выбраны, примерный способ 401 переходит к этапу 404 принятия решения.
На этапе 404 принятия решения выполняется определение системным администратором того, следует ли присваивать, по меньшей мере, два различных значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD A) двум или более из m авторитетным узлам (или URL-адресам). Если принято решение присвоить, по меньшей мере, два различных значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD A) двум или более из m авторитетных узлов (или URL-адресов), примерный способ 401 переходит к этапу 405, на котором, по меньшей мере, два различных значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD A) присваиваются двум или более из m авторитетных узлов (или URL-адресов). Например, ссылаясь на примерный веб-граф 30, показанный на фиг. 3, авторитетным узлам 33 и 34 может быть присвоено значение смещенного расстояния, измеряемого количеством последовательных переходов, в 0, авторитетным узлам 35 и 36 может быть присвоено значение смещенного расстояния, измеряемого количеством последовательных переходов, в +3, а авторитетному узлу 48 может быть присвоено значение смещенного расстояния, измеряемого количеством последовательных переходов, в +2. От этапа 405 примерный способ 401 переходит к этапу 407 принятия решения.
Возвращаясь к этапу 404 принятия решения, если принято решение присвоить, по меньшей мере, два различных значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD A) двум или более из m авторитетных узлов (или URL-адресов), примерный способ 401 переходит к этапу 406, на котором одинаковое значение смещенного расстояния, измеряемого количеством последовательных переходов, (CD A) присваивается двум или более из m авторитетных узлов (или URL-адресов). Например, снова ссылаясь на примерный веб-граф 30 по фиг. 3, каждому из авторитетных узлов может быть присвоено значение смещенного расстояния, измеряемого количеством последовательных переходов, такое как 0, +2 или +5. От этапа 406 примерный способ 401 переходит к этапу 407 принятия решения.
На этапе 407 принятия решения выполняется определение системным администратором или программного кода в отношении того, следует ли присваивать весовой коэффициент ребра, отличный от 1, одному или более реберам веб-графа. Если принято решение присвоить весовой коэффициент ребра, отличный от 1, одному или более ребрам веб-графа, примерный способ 401 переходит к этапу 408 принятия решения. На этапе 408 принятия решения выполняется определение системным администратором того, чтобы присвоить минимальное значение ребра ребрам веб-графа, при этом минимальное значение ребра больше максимального присвоенного значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD Amax). Если принято решение о том, чтобы присвоить минимальное значение ребра ребрам веб-графа, при этом минимальное значение ребра больше наибольшего присвоенного значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD Amax), примерный способ 401 переходит к этапу 409, на котором минимальное значение ребра, большее наибольшего присвоенного значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD Amax), присваивается всем ребрам веб-графа. Например, ссылаясь на примерный веб-граф 30, показанный на фиг. 3, если авторитетному узлу 33 присвоено наибольшее значение смещенного расстояния, измеряемого количеством последовательных переходов, (CD Amax), и CD Amax равно +3, минимальное значение ребра больше +3 присваивается каждому ребру, показанному на фиг. 3.
В некоторых вариантах осуществления применение минимального значения ребра, которое больше наибольшего присвоенного значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD Amax), каждому ребру веб-графа может иметь некоторые преимущества. В этом варианте осуществления такая методика гарантирует то, что присвоенное значение смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) каждого авторитетного узла (или документа, или URL-адреса) меньше вычисленного значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) каждого неавторитетного узла (или документа, или URL-адреса) на веб-графе. Когда значимость документа базируется на меньшем значении смещенного расстояния, измеряемого количеством последовательных переходов, эта методика дает возможность всем авторитетным узлам (или документам, или URL-адресам) считаться более значимыми, чем неавторитетные узлы (или документы, или URL-адреса) на веб-графе.
От этапа 409 примерный способ 401 переходит к этапу 410 принятия решения, показанному на фиг. 4B и описанному ниже. Возвращаясь к этапу 408 принятия решения, если принято решение не присваивать минимальное значение ребра каждому ребру, где минимальное значение ребра больше наибольшего присвоенного значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD Amax), примерный способ 401 переходит непосредственно к этапу 410 принятия решения, показанному на фиг. 4B и описанному ниже. В этом варианте осуществления возможно неавторитетному узлу иметь значение смещенного расстояния, измеряемого количеством последовательных переходов, меньше, чем авторитетному узлу (т.е. считаться более значимым, чем авторитетный узел, при этом значимость документа базируется на меньшем значении смещенного расстояния, измеряемого количеством последовательных переходов,). Например, ссылаясь на примерный граф 30 по фиг. 3, если авторитетному узлу 34 присвоено значение смещенного расстояния, измеряемого количеством последовательных переходов, в +3, авторитетному узлу 48 присваивается значение смещенного расстояния, измеряемого количеством последовательных переходов, в 0, а значение ребра s равно +1, неавторитетные узлы 39 имеют вычисленное значение смещенного расстояния, измеряемого количеством последовательных переходов, в +1 (т.е. сумму присвоенного значения смещенного расстояния, измеряемого количеством последовательных переходов, ближайшего авторитетного узла 48, 0, и значения ребра s, +1).
На этапе 410 принятия решения, показанном на фиг. 4B, выполняется определение системным администратором того, следует ли присваивать, по меньшей мере, два различных значения ребер двум или более ребрам веб-графа. Если принято решение присвоить, по меньшей мере, два различных значения ребер двум или более ребрам веб-графа, примерный способ 401 переходит к этапу 411, на котором, по меньшей мере, два различных значения ребер присвоены двум или более ребрам веб-графа. Например, ссылаясь на примерный веб-граф 30, показанный на фиг. 3, любым двум из значений ребер p, q, r, s и t могут быть присвоены, по меньшей мере, два различных числа. От этапа 411 примерный способ 401 переходит к этапу 414, описанному ниже.
Возвращаясь к этапу 410 принятия решения, если принято решение не присваивать, по меньшей мере, два различных значения ребер двум или более ребрам веб-графа, примерный способ 401 переходит к этапу 412, на котором одно значение ребра присваивается каждому ребру веб-графа, и значение ребра имеет значение, отличное от 1. Например, ссылаясь на примерный веб-граф 30, показанный на фиг. 3, каждому из значений ребер p, q, r, s и t присваивается одинаковое число и число, отличное от 1. От этапа 412 примерный способ 401 переходит к этапу 414, описанному ниже.
Возвращаясь к этапу 407 принятия решения, показанному на фиг. 4A, если принято решение не присваивать весовой коэффициент ребра одному или более ребрам веб-графа, примерный способ 401 переходит к этапу 413, на котором значение ребра по умолчанию (к примеру, +1) используется для каждого ребра веб-графа, с тем, чтобы ребра веб-графа имели минимальное влияние на вычисленные значения смещенного расстояния, измеряемого количеством последовательных переходов. В этом варианте осуществления такие факторы, как число и размещение авторитетных узлов, имеют большее влияние на вычисленные значения смещенного расстояния, измеряемого количеством последовательных переходов, чем значения ребер по умолчанию. От этапа 413 примерный способ 401 переходит к этапу 414, показанному на фиг. 4B.
На этапе 414 значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) для неавторитетных узлов (или документов, или URL-адресов) вычисляются. Как подробнее описывается ниже, значение смещенного расстояния, измеряемого количеством последовательных переходов, для данного целевого узла (т.е. неавторитетного узла) (CD Ctarget), связанного непосредственно с авторитетным узлом, может быть вычислено с помощью формулы:
CD Ctarget = min(CD Aclosest + EdgeWeight),
где CD Aclosest представляет присвоенное значение смещенного расстояния, измеряемого количеством последовательных переходов, для авторитетного узла, ближайшего к целевому узлу; а EdgeWeight (также упоминаемый в данном документе как EdgeValue) представляет значение весового коэффициента ребра, присвоенное ребру, соединяющему ближайший авторитетный узел, целевому узлу. Функция min(x) используется для того, чтобы указывать то, что минимальное значение смещенного расстояния, измеряемого количеством последовательных переходов, используется для данного узла, например, если узел связан непосредственно с двумя авторитетными узлами. Значение смещенного расстояния, измеряемого количеством последовательных переходов, для данного целевого узла (т.е. неавторитетного узла) (CD Ctarget), отличного от связанных непосредственно с авторитетным узлом, может быть вычислено с помощью формулы:
CD Ctarget = min(CD Cmin + EdgeWeight),
где CD Cmin представляет вычисленное значение смещенного расстояния, измеряемого количеством последовательных переходов, соседнего узла, имеющего наименьшее вычисленное значение смещенного расстояния, измеряемого количеством последовательных переходов, а EdgeWeight представляет значение ребра или весовой коэффициент ребра, присвоенный ребру, связывающему соседний узел, имеющий наименьшее вычисленное значение смещенного расстояния, измеряемого количеством последовательных переходов, и целевой узел. От этапа 414 примерный способ 401 переходит к этапу 415. На этапе 415 результирующие значения смещенного расстояния, измеряемого количеством последовательных переходов, присвоенные (CD A) и вычисленные (CD C), проверяются системным администратором. В типичном варианте, системный администратор тестирует систему посредством приведения в исполнение одного или более поисковых запросов с помощью результирующих значений смещенного расстояния, измеряемого количеством последовательных переходов, (присвоенного (CD A) и вычисленного (CD C)). Если системный администратор замечает очевидно нерелевантное содержимое, возвращающееся обратно, системный администратор может использовать вышеописанные средства/методики смещения, чтобы понизить один или более узлов, например архивных папок или веб-узлов, формирующих нерелевантное содержимое. Вышеописанный тест позволяет системному администратору оценивать значения смещенного расстояния, измеряемого количеством последовательных переходов, для возможных несовместимостей между (i) фактической значимостью данного документа в сетевом пространстве и (ii) значимостью документа, указанное посредством значения смещенного расстояния, измеряемого количеством последовательных переходов. От этапа 415 примерный способ 401 переходит к этапу 416 принятия решения.
На этапе 416 принятия решения выполняется определение системным администратором того, следует ли понизить какие-либо значения смещенного расстояния, измеряемого количеством последовательных переходов, чтобы более тщательно представить значимость данного документа в сетевом пространстве. Если принято решение понизить одно или более значений смещенного расстояния, измеряемого количеством последовательных переходов, чтобы более тщательно представить значимость одного или более документов в сетевом пространстве, примерный способ 401 переходит к этапу 417, на котором значения смещенного расстояния, измеряемого количеством последовательных переходов, одного или более документов (или URL-адресов) корректируются в отрицательную или положительную сторону. От этапа 417 примерный способ 401 переходит к этапу 418.
Возвращаясь к этапу 416 принятия решения, если принято решение не понижать одно или более значений смещенного расстояния, измеряемого количеством последовательных переходов, чтобы более тщательно представить значимость одного или более документов в сетевом пространстве, примерный способ 401 переходит непосредственно к этапу 418. На этапе 418 значения смещенного расстояния, измеряемого количеством последовательных переходов, присвоенные авторитетным узлам и вычисленные для неавторитетных узлов, используются в функции ранжирования для того, чтобы определить общий показатель релевантности для каждого документа в сетевом пространстве. От этапа 418 примерный способ 401 переходит к конечному этапу 419.
Как описано выше, значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) для неавторитетных узлов (или URL-адресов) на веб-графе вычисляются на основе кратчайшего расстояния между данным неавторитетным узлом (или URL-адресом), также упоминаемым как "целевой узел", и ближайшим авторитетным узлом (или URL-адресом). Один примерный процесс вычисления значений смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) для неавторитетных URL-адресов в сетевом пространстве проиллюстрирован на фиг. 5A-5B.
Фиг. 5A-5B иллюстрируют логическую блок-схему последовательности операций примерного процесса 40 вычисления смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) для неавторитетных узлов (или URL-адресов) в сетевом пространстве. Примерный процесс 40 начинается на этапе 4140 и переходит к этапу 4141, на котором веб-граф, содержащий (i) авторитетные узлы с присвоенными значениями смещенного расстояния, измеряемого количеством последовательных переходов, (CD A), (ii) неавторитетные узлы, (iii) связи между узлами и (iv) значения ребер для каждой связи, загружаются из базы данных в запоминающее устройство. (См., например, примерный веб-граф 30 на фиг. 3.) Веб-граф может быть ранее сформирован с помощью процедуры индексирования, описанной выше. От этапа 4141 примерный процесс 40 переходит к этапу 4142.
На этапе 4142 значения смещенного расстояния, измеряемого количеством последовательных переходов, (CD C) для неавторитетных узлов инициализируются равными максимальному значению смещенного расстояния, измеряемого количеством последовательных переходов, например, бесконечности. Присвоение максимального значения смещенного расстояния, измеряемого количеством последовательных переходов, например, бесконечности неавторитетным узлам идентифицирует узлы, для которых должно быть вычислено значение смещенного расстояния, измеряемого количеством последовательных переходов, (CD C). После того как инициализация максимального значения смещенного расстояния, измеряемого количеством последовательных переходов, выполнена, примерный процесс 40 переходит к этапу 4143.
На этапе 4143 m авторитетных узлов вставляются в очередь. M авторитетных узлов, вставляемых в очередь, соответствуют m самых авторитетных узлов сетевого пространства, как заранее определено системным администратором или каким-либо другим системным средством определения. После того как m авторитетных узлов добавлено в очередь, примерный процесс 40 переходит к этапу 4144 принятия решения.
На этапе 4144 принятия решения выполняется определение посредством программного кода в отношении того, является ли очередь пустой. Пустая очередь означает, что все узлы веб-графа либо (i) получили присвоенное значение смещенного расстояния, измеряемого количеством последовательных переходов, (CD A), либо (ii) вычислили свое значение смещенного расстояния, измеряемого количеством последовательных переходов, (CD C). Если очередь пустая, примерный процесс 40 переходит к конечному этапу 4145, на котором примерный процесс 40 завершается. Тем не менее, если очередь не пустая, примерный процесс 40 переходит к этапу 4146.
На этапе 4146 узел, имеющий наименьшее значение смещенного расстояния, измеряемого количеством последовательных переходов, (т.е. CD A или CD C), удаляется из очереди. Этот узел упоминается в данном документе как "текущий узел". В ходе первой итерации примерного процесса 40 авторитетный узел, имеющий наименьшее присвоенное значение смещенного расстояния, измеряемого количеством последовательных переходов, (т.е. CD Amin), является текущим узлом. В ходе последующих итераций примерного процесса 40 узел, имеющий наименьшее значение смещенного расстояния, измеряемого количеством последовательных переходов, может быть авторитетным узлом или неавторитетным узлом. В ходе последней итерации примерного процесса 40 узел, имеющий наименьшее присвоенное значение смещенного расстояния, измеряемого количеством последовательных переходов, в типичном варианте является неавторитетным узлом. После того как узел, имеющий наименьшее значение смещенного расстояния, измеряемого количеством последовательных переходов, (т.е. CD A или CD C), удаляется из очереди, примерный процесс 40 переходит к этапу 4147 принятия решения.
На этапе 4147 принятия решения выполняется определение посредством программного кода в отношении того, имеет ли текущий узел какие-либо целевые узлы. При использовании в данном документе термин "целевой узел" или "целевые узлы" означает один или более узлов, связанных с текущим узлом. Если текущий узел не имеет каких-либо целевых узлов, примерный процесс 40 возвращается к этапу 4144 принятия решения, чтобы повторно определить то, является ли очередь пустой, а затем продолжается так, как описано выше. Тем не менее, если текущий узел имеет один или более целевых узлов, примерный процесс 40 переходит к этапу 4148.
На этапе 4148 целевой узел, ассоциативно связанный с текущим узлом, извлекается из веб-графа и оценивается. Например, ссылаясь на примерный веб-граф 30 по фиг. 3, если авторитетный узел 48 - это текущий узел (т.е. узел, имеющий наименьшее значение смещенного расстояния, измеряемого количеством последовательных переходов), любой из неавторитетных узлов 39 может быть целевым узлом (т.е. узлом, связанным с авторитетным узлом 48 и имеющим первоначальное значение смещенного расстояния, измеряемого количеством последовательных переходов, равным бесконечности). После того как текущий узел и целевой узел выбраны, примерный процесс 40 переходит к этапу 4149 принятия решения.
На этапе 4149 принятия решения выполняется определение посредством программного кода в отношении того, превышает ли расстояние, измеряемое количеством последовательных переходов, ассоциативно связанное со значением смещенного расстояния, измеряемого количеством последовательных переходов, целевого узла, значение смещенного расстояния, измеряемого количеством последовательных переходов, текущего узла плюс значение весового коэффициента ребра для ребра, соединяющего текущий узел и целевой узел. Если выполнено определение того, что значение смещенного расстояния, измеряемого количеством последовательных переходов, целевого узла больше значения смещенного расстояния, измеряемого количеством последовательных переходов, текущего узла плюс значение весового коэффициента ребра для ребра, соединяющего текущий узел с целевым узлом, примерный процесс 40 переходит к этапу 4150 (показанному на фиг. 5B), на котором значение смещенного расстояния, измеряемого количеством последовательных переходов, целевого узла обновляется до равенства значению смещенного расстояния, измеряемого количеством последовательных переходов, текущего узла плюс значение весового коэффициента ребра для ребра, соединяющего текущий узел с целевым узлом.
В ходе первой итерации примерного процесса 40 все целевые узлы имеют начальное значение смещенного расстояния, измеряемого количеством последовательных переходов, целевого узла равным бесконечности. Следовательно, примерный процесс 40 переходит к этапу 4150, на котором значение смещенного расстояния, измеряемого количеством последовательных переходов, целевого узла обновляется так, как описано выше. Тем не менее, при последующих итерациях примерного процесса 40 выбранный целевой узел, например, может иметь начальное значение смещенного расстояния, измеряемого количеством последовательных переходов, целевого узла равным бесконечности (примерный процесс 40 переходит к этапу 4150) или может иметь значение смещенного расстояния, измеряемого количеством последовательных переходов, заранее сконфигурированное системным администратором (к примеру, целевой узел является авторитетным узлом). От этапа 4150 примерный процесс 40 переходит к этапу 4151.
На этапе 4151 текущий узел и целевой узел с обновленным значением смещенного расстояния, измеряемого количеством последовательных переходов, целевого узла добавляются в очередь. От этапа 4150, примерный процесс 40 возвращается к этапу 4146 принятия решения (показанному на фиг. 5A) и продолжается так, как описано выше.
Возвращаясь к этапу 4149 принятия решения (показанному на фиг. 5A), если выполнено определение того, что значение смещенного расстояния, измеряемого количеством последовательных переходов, целевого узла не больше значения смещенного расстояния, измеряемого количеством последовательных переходов, текущего узла плюс значения весового коэффициента ребра для ребра, соединяющего текущий узел с целевым узлом, (i) целевой узел сохраняет вычисленное значение смещенного расстояния, измеряемого количеством последовательных переходов, целевого узла, (ii) целевой узел остается вне очереди, и (iii) примерный процесс 40 возвращается к этапу 4147 принятия решения (показанному на фиг. 5A), где выполняется определение того, имеет ли текущий узел другие целевые узлы. Если выполнено определение того, что текущий узел не имеет другого целевого узла, примерный процесс 40 возвращается к этапу 4144 принятия решения и продолжается так, как описано выше. Если выполнено определение того, что текущий узел имеет другой целевой узел, примерный процесс 40 переходит к этапу 4148 принятия решения и продолжается так, как описано выше.
Когда примерный процесс 40 возвращается к этапу 4148, другой целевой узел, ассоциативно связанный с текущим узлом, выбирается и оценивается так, как описано выше. Если выбранный целевой узел не выбран до этого, целевой узел должен иметь начальное значение смещенного расстояния, измеряемого количеством последовательных переходов, равным бесконечности, и примерный процесс 40 должен перейти к этапу 4150, как описано выше.
Вышеописанный примерный способ предоставления значения смещенного расстояния, измеряемого количеством последовательных переходов, для всех узлов на веб-графе предотвращает изменение значения смещенного расстояния, измеряемого количеством последовательных переходов, данного целевого узла, если значение смещенного расстояния, измеряемого количеством последовательных переходов, ниже суммы значения смещенного расстояния, измеряемого количеством последовательных переходов, текущего узла плюс значения ребра узла, соединяющего целевой узел с текущим узлом.
После того как все узлы данного веб-графа определены и необязательно понижены в оценке (или необязательно повышены в оценке) при необходимости, значения смещенного расстояния, измеряемого количеством последовательных переходов, для каждого документа могут быть использованы в качестве параметра в функции ранжирования, чтобы предоставить показатель релевантности для каждого документа. Этот показатель релевантности документов также может быть использован для того, чтобы ранжировать результаты поиска для поискового запроса. Примерный способ ранжирования результатов поиска, сформированных с помощью функции ранжирования, содержащей параметр смещенного расстояния, измеряемого количеством последовательных переходов, показан на фиг. 6. Фиг. 6 представляет логическую блок-схему последовательности операций, иллюстрирующую примерные этапы примерного способа 20, при этом примерный способ 20 содержит способ ранжирования результатов поиска, сформированных с помощью функции ранжирования, содержащей параметр смещенного расстояния, измеряемого количеством последовательных переходов. Как показано на фиг. 6, примерный способ 20 начинается на этапе 201 и переходит к этапу 202. На этапе 202 пользователь запрашивает поиск посредством ввода поискового запроса. Перед этапом 202 заранее вычислены значения смещенного расстояния, измеряемого количеством последовательных переходов, для каждого из документов в сети. От этапа 202 примерный способ 20 переходит к этапу 203.
На этапе 203 значение смещенного расстояния, измеряемого количеством последовательных переходов, для каждого документа в сети объединяется со всей статистикой документа (к примеру, независимой от запроса статистикой) для каждого документа, сохраненного в индексе. Объединение значений смещенного расстояния, измеряемого количеством последовательных переходов, с другой статистикой документа предоставляет возможность уменьшения времени ответа на запрос, поскольку вся информация, связанная с запросом, собрана вместе. Соответственно, каждый документ, перечисленный в индексе, имеет ассоциативно связанное значение смещенного расстояния, измеряемого количеством последовательных переходов, после объединения. После того как объединение выполнено, примерный способ 20 переходит к этапу 204.
На этапе 204 независимая от запроса статистика по данному документу, в том числе значение смещенного расстояния, измеряемого количеством последовательных переходов, предоставляется как компонент функции ранжирования. Зависимые от запроса данные также предоставляются для данного документа, в типичном варианте как отдельный компонент функции ранжирования. Зависимые от запроса данные или связанная с содержимым часть функции ранжирования зависит от фактических условий поиска и содержимого данного документа.
В одном варианте осуществления функция ранжирования содержит сумму, по меньшей мере, одного зависимого от запроса (QD) компонента и, по меньшей мере, одного независимого от запроса (QID) компонента, например:
Score = QD(doc, query) + QID(doc).
QD-компонент может быть любой функцией вычисления для документа. В одном варианте осуществления QD-компонент соответствует взвешенной по полям функции вычисления, описанной в Патентной заявке (США) серийный номер 10/804326, озаглавленной "FIELD WEIGHTING IN TEXT DOCUMENT SEARCHING", зарегистрированной 18 марта 2004 года, предмет которой полностью содержится в данной заявке по ссылке. Как предусмотрено в Патентной заявке (США) серийный номер 10/804326, одно уравнение, которое может быть использовано в качестве представления взвешенной по полям функции вычисления, следующее:
www.example.com\dl\d2\d3\d4.htmwww.example.com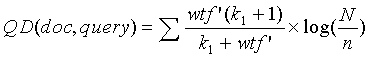
где:
wtf' представляет взвешенную частоту терминов или сумму частот терминов для данных терминов в поисковом запросе, умноженную на весовые коэффициенты в полях (к примеру, заголовок, тело и т.д. документа) и нормализованную по длине каждого поля и соответствующей средней длине,
N представляет число документов в сети,
n представляет число документов, содержащих условие запроса, и
k 1 - это корректируемая константа.
Вышеуказанные условия и уравнение дополнительно подробно описаны в Патентной заявке (США) серийный номер 10/804326, предмет которой полностью содержится в данной заявке по ссылке.
QID-компонент может быть любым преобразованием значения смещенного расстояния, измеряемого количеством последовательных переходов, и другой статистикой по документу (такой, как глубина URL-адреса) для данного документа. В одном варианте осуществления QID-компонент содержит следующую функцию:
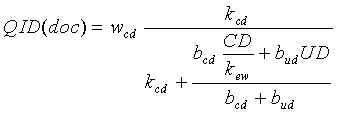
где:
w cd представляет весовой коэффициент независимого от запроса компонента, такого как компонент, содержащий параметр смещенного расстояния, измеряемого количеством последовательных переходов,
b cd представляет весовой коэффициент смещенного расстояния, измеряемого количеством последовательных переходов, относительно глубины URL-адреса,
b ud представляет весовой коэффициент глубины URL-адреса,
CD представляет вычисленное расстояние, измеряемое количеством последовательных переходов, или присвоенное смещенное расстояние, измеряемое количеством последовательных переходов, для документа,
k ew представляет константу настройки, которая определяется посредством оптимизации точности функции ранжирования, аналогично другим параметрам настройки (т.е. k ew может представлять значение весового коэффициента ребра, когда все ребра имеют одинаковое значение весового коэффициента ребра, или k ew может представлять среднее или усредненное значение весового коэффициента ребра, когда значения весового коэффициента ребра отличаются друг от друга),
UD представляет глубину URL-адреса, и
k cd - это константа насыщения смещенного расстояния, измеряемого количеством последовательных переходов.
Взвешенные члены (w cd, b cd и b ud) помогают в задании значимости каждого из своих связанных членов (т.е. компонента, содержащего параметр смещенного расстояния, измеряемого количеством последовательных переходов, значение смещенного расстояния, измеряемого количеством последовательных переходов, для данного документа и глубину URL-адреса данного документа соответственно) и, в завершение, в результате функций вычисления.
Глубина URL-адреса (UD) - это необязательное дополнение к вышеупомянутому независимому от запроса компоненту, чтобы сглаживать эффект, который значение смещенного расстояния, измеряемого количеством последовательных переходов, может иметь на функцию вычисления. Например, в некоторых случаях документ, который не очень значим (т.е. имеет большую глубину URL-адреса), может иметь небольшое значение смещенного расстояния, измеряемого количеством последовательных переходов. Глубина URL-адреса представляется посредством числа косых черт в URL-адресе документа. Например, включает в себя четыре косые черты и, следовательно, имеет глубину URL-адреса 4. Тем не менее, документ может иметь ссылку непосредственно с главной страницы, придавая ей относительно небольшое значение смещенного расстояния, измеряемого количеством последовательных переходов. Включение члена глубины URL-адреса в вышеуказанную функцию и взвешивание члена глубины URL-адреса касательно значения смещенного расстояния, измеряемого количеством последовательных переходов, компенсирует относительно высокое значение смещенного расстояния, измеряемого количеством последовательных переходов, чтобы более точно отразить значимость документа в сети. В зависимости от сети глубина URL-адреса в 3 и более может считаться глубокой ссылкой.
В одном варианте осуществления функция ранжирования, используемая для того, чтобы определить показатель релевантности данного документа, содержит следующую функцию:
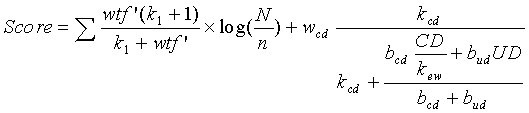
члены которой такие, как описано выше.
В других вариантах осуществления глубина URL-адреса может быть удалена из функции ранжирования или другие компоненты могут быть добавлены в функцию ранжирования, чтобы повысить точность зависимого от запроса компонента, независимого от запроса компонента или и того, и другого. Более того, вышеописанный зависимый от запроса компонент, содержащий параметр смещенного расстояния, измеряемого количеством последовательных переходов, может быть включен в другие функции ранжирования (не показаны), чтобы улучшить ранжирование результатов поиска.
После того как статистика по данному документу предоставлена в функцию ранжирования на этапе 204, примерный способ 20 переходит к этапу 205. На этапе 205 показатель релевантности определяется для данного документа, сохраняется в запоминающем устройстве и ассоциативно связывается с данным документом. От этапа 205 примерный способ 20 переходит к этапу 206 принятия решения.
На этапе 206 принятия решения выполняется определение посредством программного кода того, вычислен ли показатель релевантности документа для каждого документа в сети. Если выполнено определение того, что показатель релевантности не вычислен для каждого документа в сети, примерный способ 20 возвращается к этапу 204 и продолжается так, как описано выше. Если выполнено определение того, что показатель релевантности вычислен для каждого документа в сети, примерный способ 20 переходит к этапу 207.
На этапе 207 результаты поиска запроса, содержащие множество документов, ранжируются согласно ассоциативно связанным показателям релевантности документов. Результирующие показатели релевантности документов учитывают значение смещенного расстояния, измеряемого количеством последовательных переходов, каждого из документов в сети. После того как результаты поиска ранжированы, примерный способ 20 переходит к этапу 208, на котором результаты ранжирования отображаются пользователю. От этапа 208 примерный способ 20 переходит к этапу 209, на котором результаты с наивысшим рангом выбираются и просматриваются пользователем. От этапа 209 примерный способ 20 переходит к этапу 210, на котором примерный способ 20 завершается.
Помимо вышеописанных способов формирования показателя релевантности документов для документов в сети и использования показателей релевантности документов для того, чтобы ранжировать результаты поиска по поисковому запросу, в данном документе также раскрывается машиночитаемый носитель, имеющий сохраненные машиноисполняемые инструкции для выполнения вышеописанных способов.
Также в данном документе раскрываются вычислительные системы. Примерная вычислительная система содержит, по меньшей мере, один прикладной модуль, используемый в вычислительной системе, при этом, по меньшей мере, один прикладной модуль содержит программный код, загруженный в него, причем программный код осуществляет способ формирования показателя релевантности для документов в сети. Программный код может быть загружен в вычислительную систему с помощью любого из вышеописанных машиночитаемых носителей, имеющих машиноисполняемые инструкции для формирования показателя релевантности для документов в сети и использования показателя релевантности документов для того, чтобы ранжировать результаты поиска по поисковому запросу, как описано выше.
Хотя данное подробное описание изобретения приведено относительно его конкретных вариантов осуществления, следует принимать во внимание, что специалисты в данной области техники после достижения понимания вышеописанного могут легко представить себе изменения, вариации и эквиваленты этих вариантов осуществления. Соответственно, область применения раскрытых способов, машиночитаемого носителя и вычислительных систем должна определяться как область применения прилагаемой формулы изобретения и всех ее эквивалентов.
| название | год | авторы | номер документа |
|---|---|---|---|
| ФУНКЦИИ РАНЖИРОВАНИЯ, ИСПОЛЬЗУЮЩИЕ СТАТИСТИЧЕСКИЕ ДАННЫЕ ИСПОЛЬЗУЕМОСТИ ДОКУМЕНТА | 2006 |
|
RU2419861C2 |
| ДЛИНА ДОКУМЕНТА В КАЧЕСТВЕ СТАТИЧЕСКОГО ПРИЗНАКА РЕЛЕВАНТНОСТИ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2009 |
|
RU2517271C2 |
| ПОСТРОЕНИЕ И ПРИМЕНЕНИЕ ВЕБ-КАТАЛОГОВ ДЛЯ ФОКУСИРОВАННОГО ПОИСКА | 2005 |
|
RU2382400C2 |
| СБОР ДАННЫХ О ПОЛЬЗОВАТЕЛЬСКОМ ПОВЕДЕНИИ ПРИ ВЕБ-ПОИСКЕ ДЛЯ ПОВЫШЕНИЯ РЕЛЕВАНТНОСТИ ВЕБ-ПОИСКА | 2007 |
|
RU2435212C2 |
| СПОСОБ И ПОИСКОВАЯ СИСТЕМА ПРЕДОСТАВЛЕНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ НА МНОЖЕСТВО КЛИЕНТСКИХ УСТРОЙСТВ | 2015 |
|
RU2632423C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| СИСТЕМА И СПОСОБ ВЫПОЛНЕНИЯ ПОИСКА | 2014 |
|
RU2597476C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ АНОМАЛЬНЫХ ПОСЕЩЕНИЙ ВЕБ-САЙТОВ | 2019 |
|
RU2775824C2 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ ОБЪЕКТОВ НА ОСНОВЕ ОТНОШЕНИЙ ВНУТРИ ТИПА И МЕЖДУ ТИПАМИ | 2005 |
|
RU2387005C2 |
Изобретение относится к устройствам и способам определения показателя релевантности документов для документов в сети. Технический результат заключается в обеспечении достоверности результатов поиска. Сохраняют информацию документа в запоминающем устройстве, информация документа идентифицирует множество документов в сети, причем множество документов включает в себя авторитетные документы и неавторитетные документы. Сохраняют информацию связи в запоминающем устройстве, причем информация связи идентифицирует связи между множеством документов. Вычисляют значения расстояния, измеряемого количеством последовательных переходов для каждого из неавторитетных документов к авторитетным документам. Вычисляют смещенное значение расстояния, измеряемого количеством последовательных переходов, для каждого из неавторитетных документов в сети к авторитетным документам. Исполняют поисковый запрос для формирования списка множества документов, который включает в себя, по меньшей мере, одно условие поиска. Осуществляют ранжирование списка множества документов, который включает в себя, по меньшей мере, одно условие поиска с использованием функции ранжирования, которая содержит один или более независимых от запроса компонентов. Выводят ранжированные результаты поиска в соответствии с ранжированием. 3 н. и 11 з.п. ф-лы, 8 ил.
1. Машиночитаемый носитель, имеющий сохраненные на нем машиноисполняемые инструкции для ранжирования множества документов в сети, при этом упомянутые машиноисполняемые инструкции при исполнении компьютером выполняют способ формирования результатов поиска в ответ на поисковый запрос, причем способ заключается в том, что
сохраняют информацию документа в запоминающем устройстве, информация документа идентифицирует множество документов в сети, причем множество документов включает в себя авторитетные документы и неавторитетные документы, причем авторитетные документы включают в себя, по меньшей мере, первый авторитетный документ и второй авторитетный документ, и неавторитетный документ включает в себя, по меньшей мере, первый неавторитетный документ;
сохраняют информацию связи в запоминающем устройстве, причем информация связи идентифицирует связи между множеством документов;
вычисляют значения расстояния, измеряемого количеством последовательных переходов для каждого из неавторитетных документов к авторитетным документам, причем значение расстояния, измеряемого количеством последовательных переходов включает в себя, по меньшей мере, первое значение расстояния, измеряемого количеством последовательных переходов, которое является функцией количества связей, которым необходимо следовать, чтобы создать маршрут от первого неавторитетного документа к первому авторитетному документу, и второе значение расстояния, измеряемого количеством последовательных переходов, которое является функцией количества связей, которым необходимо следовать, чтобы создать маршрут от первого неавторитетного документа ко второму авторитетному документу;
вычисляют смещенное значение расстояния, измеряемого количеством последовательных переходов, для каждого из неавторитетных документов в сети к авторитетным документам, причем смещенное значение расстояния, измеряемого количеством последовательных переходов, включает в себя, по меньшей мере, первое смещенное значение расстояния, измеряемого количеством последовательных переходов, которое является функцией меньшего из значений первого и второго расстояний, измеряемых количеством последовательных переходов;
принимают поисковый запрос, включающий в себя, по меньшей мере, условия поиска;
исполняют поисковый запрос для формирования списка множества документов, который включает в себя, по меньшей мере, одно условие поиска, причем список множества документов включает в себя идентификатор первого неавторитетного документа;
осуществляют ранжирование списка множества документов, который включает в себя, по меньшей мере одно условие поиска с использованием функции ранжирования, которая содержит один или более независимых от запроса компонентов, причем, по меньшей мере, один независимый от запроса компонент включает в себя параметр смещенного расстояния, измеряемого количеством последовательных переходов, который учитывает значение смещенного расстояния, измеряемого количеством последовательных переходов, включающего в себя первое смещенное значение расстояния, измеряемого количеством последовательных переходов,
выводят ранжированные результаты поиска в соответствии с ранжированием.
2. Машиночитаемый носитель по п.1, в котором в способе дополнительно присваивают присвоенное значение смещенного расстояния, измеряемого количеством последовательных переходов, авторитетным документам.
3. Машиночитаемый носитель по п.2, в котором, по меньшей мере, два присвоенных смещенных расстояния, измеряемых количеством последовательных переходов, отличаются друг от друга.
4. Машиночитаемый носитель по п.1, в котором функция ранжирования дополнительно содержит, по меньшей мере, второй независимый от запроса компонент, который включает в себя параметр значения ребра, который учитывает значения ребер каждого ребра в сети, при этом одно или более значений ребер - это число, отличное от 1.
5. Машиночитаемый носитель по п.4, в котором значения ребер равны друг другу и равны числу, отличному от 1.
6. Машиночитаемый носитель по п.4, в котором значения ребер равны друг другу и равны или превышают наибольшее значение смещенного расстояния, измеряемого количеством последовательных переходов, первоначально присвоенное одному или более авторитетным документам.
7. Машиночитаемый носитель по п.1, дополнительно содержащий машиноисполняемые инструкции для присвоения показателя, сформированного посредством функции ранжирования, каждому документу в сети, при этом упомянутый показатель используется для того, чтобы ранжировать документы в порядке убывания.
8. Машиночитаемый носитель по п.7, в котором показатель для каждого документа формируется с помощью формулы
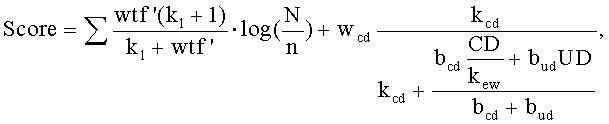
где wtf' представляет взвешенную частоту терминов,
N представляет число документов в сети,
n представляет число документов, содержащих условие запроса,
wcd представляет весовой коэффициент независимого от запроса компонента,
bcd представляет весовой коэффициент расстояния, измеряемого количеством последовательных переходов,
bud представляет весовой коэффициент глубины URL-адреса,
CD представляет вычисленное расстояние, измеряемое количеством последовательных переходов, или присвоенное смещенное расстояние, измеряемое количеством последовательных переходов, для документа,
kew представляет константу настройки, связанную с весами ребер,
UD представляет глубину URL-адреса,
kcd и k1 - константы.
9. Способ определения показателей релевантности документов в сети, содержащий этапы, на которых
сохраняют информацию документа и информацию связей для документов в сети;
формируют представление сети из информации документов и информацию связей, при этом представление сети включает в себя узлы, которые представляют документы, и ребра, которые представляют связи;
присваивают смещенное значение расстояния, измеряемого количеством последовательных переходов, по меньшей мере, двум авторитетным узлам в сети, при этом два авторитетных узла включают в себя, по меньшей мере, первый авторитетный узел, имеющий первое присвоенное смещенное расстояние, измеряемое количеством последовательных переходов, и второй авторитетный узел, имеющий второе присвоенное смещенное расстояние, измеряемое количеством последовательных переходов;
вычисляют смещенные расстояния, измеряемые количеством последовательных переходов, для каждого неавторитетного узла в представлении сети к, по меньшей мере, двум авторитетным узлам, причем расстояния, измеряемые количеством последовательных переходов, включают в себя первое расстояние, измеряемое количеством последовательных переходов, и второе расстояние, измеряемое количеством последовательных переходов, причем первое расстояние, измеряемое количеством последовательных переходов, является функцией количества связей, которым необходимо следовать, чтобы создать маршрут от первого неавторитетного узла к первому авторитетному узлу, и второе расстояние, измеряемое количеством последовательных переходов, которое является функцией количества связей, которым необходимо следовать, чтобы создать маршрут от первого неавторитетного узла ко второму авторитетному узлу;
вычисляют смещенные значения расстояний, измеряемых количеством последовательных переходов, для каждого из неавторитетных документов, причем смещенные значения расстояний, измеряемых количеством последовательных переходов, включают в себя, по меньшей мере, первое смещенное значение расстояния, измеряемого количеством последовательных переходов, которое является функцией меньшего из значений первого и второго расстояний, измеряемых количеством последовательных переходов;
используют смещенные значения расстояния, измеряемого количеством последовательных переходов, чтобы определить показатели релевантности для каждого из документов в сети.
10. Способ по п.9, в котором, первое присвоенное смещенное расстояние, измеряемое количеством последовательных переходов, и второе присвоенное смещенное расстояние, измеряемое количеством последовательных переходов, отличаются друг от друга.
11. Способ по п.9, дополнительно содержащий этап, на котором присваивают каждому ребру в представлении сети значение ребра, при этом значения ребер равны или больше 1.
12. Способ по п.11, в котором каждое значение ребра больше наибольшего значения смещенного расстояния, измеряемого количеством последовательных переходов, присвоенного какому-либо из авторитетных узлов.
13. Способ по п.9, в котором показатель релевантности для каждого документа в сети формируется с помощью формулы
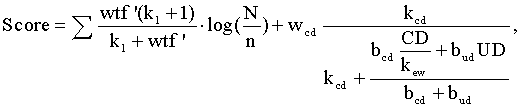
где wtf' представляет взвешенную частоту терминов,
N представляет число документов в сети,
n представляет число документов, содержащих условие запроса,
Wcd представляет весовой коэффициент независимого от запроса компонента,
bcd представляет весовой коэффициент расстояния, измеряемого количеством последовательных переходов,
bud представляет весовой коэффициент глубины URL-адреса,
CD представляет вычисленное расстояние, измеряемое количеством последовательных переходов, или присвоенное смещенное расстояние, измеряемое количеством последовательных переходов, для документа,
kew представляет константу настройки, связанную с весами ребер,
UD представляет глубину URL-адреса,
kcd и k1 - константы.
14. Вычислительная система, содержащая процессор и запоминающее устройство с сохраненными на нем машиноисполняемыми инструкциями, которые при исполнении процессором выполняют способ определения показателей релевантности документа для узлов в сети, причем способ заключается в том, что присваивают значения смещенного расстояния, измеряемого количеством последовательных переходов, по меньшей мере, двум авторитетным узлам в представлении сети, при этом, по меньшей мере, два авторитетных узла включают в себя, по меньшей мере, первый авторитетный узел, имеющий первое присвоенное смещенное расстояние, измеряемое количеством последовательных переходов, и второй авторитетный узел, имеющий второе присвоенное смещенное расстояние, измеряемое количеством последовательных переходов; вычисляют расстояния, измеряемые количеством последовательных переходов, для каждого неавторитетного узла в представлении сети к, по меньшей мере, двум авторитетным узлам, причем расстояния, измеряемые количеством последовательных переходов, включают в себя первое расстояние, измеряемое количеством последовательных переходов, и второе расстояние, измеряемое количеством последовательных переходов, причем первое расстояние, измеряемое количеством последовательных переходов, является функцией количества связей, которым необходимо следовать, чтобы создать маршрут от первого неавторитетного узла к первому авторитетному узлу, и второе расстояние, измеряемое количеством последовательных переходов, которое является функцией количества связей, которым необходимо следовать, чтобы создать маршрут от первого неавторитетного узла ко второму авторитетному узлу; вычисляют смещенные значения расстояний, измеряемых количеством последовательных переходов, для неавторитетных узлов, причем смещенные расстояния, измеряемые количеством последовательных переходов, включают в себя, по меньшей мере, первое смещенное значение расстояния, измеряемого количеством последовательных переходов, которое является функцией меньшего из значений первого и второго расстояний, измеряемых количеством последовательных переходов; используют значения смещенного расстояния, измеряемого количеством последовательных переходов, чтобы определить показатели релевантности для каждого из узлов в сети.
| US 6285999 B1, 04.09.2001 | |||
| US 6718365 B1, 06.04.2004 | |||
| US 6041323 A, 21.03.2000 | |||
| ТОРМОЗ МЕХАНИЧЕСКОГО ПРЕССА | 0 |
|
SU282060A1 |
| EP 1557770 A1, 27.07.2005 | |||
| СИСТЕМА ПОИСКА ИНФОРМАЦИИ В КОМПЬЮТЕРНОЙ СЕТИ | 1998 |
|
RU2138076C1 |

