Область техники
[01] Настоящее техническое решение относится к способам предоставления поисковой системой поисковых результатов множеству клиентских устройств.
Уровень техники
[02] На текущий момент интернет предоставляет доступ к огромному количеству информации. В общем случае, пользователь может получить доступ к ресурсу в сети передачи данных двумя основными способами. Пользователь может получить доступ к конкретному ресурсу напрямую, введя адрес ресурса (обычно URL - единый указатель ресурса, например, http://www.webpage.com), или же выбрав ссылку в электронном сообщении или на другом веб-ресурсе. В другом случае пользователь может выполнить поиск с помощью поисковой системы для нахождения желаемого ресурса. Последнее особенно подходит для тех случаев, когда пользователю известна интересующая его тематика, но неизвестен конкретный адрес интересующего ресурса.
[03] Существует множество доступных пользователю поисковых систем. Некоторые из них считаются универсальными поисковыми системами (такие как Яндекс (Yandex™), Google™, Yahoo™ и подобные им). Другие считаются вертикальными поисковыми системами - например, поисковые системы, нацеленные на определенную тему поиска - такие как Momondo™, поисковая система для поиска авиаперелетов.
[04] Вне зависимости от того, какая поисковая система используется, в данной области техники известно, что поисковая система обычно выполнена с возможностью получать от пользователя поисковый запрос, включающий в себя единственный поисковый термин или множество поисковых терминов, с разных клиентских устройств (настольный компьютер, портативный компьютер, ноутбук, смартфон, планшет и т.д.), на котором может быть запущено множество приложений. Поисковая система затем осуществляет поиск и идентифицирует множество документов, соответствующих одному или нескольким поисковым терминам.
[05] Обычно поисковая система предоставляет поисковые результаты пользователя на странице результатов поиска (SERP), созданной поисковой системой. Поисковые результаты организованы на странице конкретным образом, определенным поисковой системой. Обычно поисковые результаты, в общем случае, расположены в вертикальном списке, в котором наиболее релевантные поисковые результаты находятся в начале (т.е. сверху на SERP), а за ними идут следующие по релевантности результаты (т.е. сразу под наиболее релевантными поисковыми результатами) и так далее. Общее описание типичной SERP может совпадать с тем, что опубликовано Google Inc. на http://www.googleguide.com/results_page.html, и оно полностью включено в настоящую заявку посредством ссылки.
[06] Для определения последовательности, в которой поисковые результаты появятся на SERP, поисковая система ранжирует поисковые результаты по их релевантности с использованием алгоритма ранжирования, который может учитывать различные факторы, указывающие на релевантность. В данной области техники это известно как «зависимое от запроса ранжирование» ("query-specific ranking", здесь и далее упоминаемое как "QSR"). Более полное описание подходов и операций ранжирования поисковыми системами может быть найдено в международной патентной заявке No. WO 2015/004607 А2, опубликованной 15 января 2015 года и озаглавленной «Компьютерный способ и система для поиска инвертированного индекса с множеством списков словопозиций» (далее «заявка 607»), которая полностью включена здесь посредством ссылки. Как описано в заявке 607, один из способов, по которым поисковая система извлекает зависимое от запроса ранжирование - с помощью информации, например, данных основанных на щелчках (кликах), описанных в заявке, относящихся к пользовательским взаимодействиям с поисковыми результатами, предоставленными в отношении конкретных поисковых запросов. Данные, основанные на щелчках, - не единственный тип информации, относящийся к пользовательским взаимодействиям с поисковыми результатами, доступный поисковым системам для улучшения извлечения QSR. Другая информация, например, относящаяся к движениям курсора пользователя и отслеживанию направления взгляда пользователя, также обычно доступна для поисковых систем с этой целью.
[07] Хотя обычные способы организации поисковых результатов на SERP в соответствии с их QSR и способы извлечения самого QSR находятся на надлежащем уровне, возможны дальнейшие улучшения, которые могут быть полезны в определенных обстоятельствах.
Раскрытие
[08] Таким образом, объектом настоящего технического решения является улучшение поиска, проводимого поисковыми системами.
[09] Типичная визуальная конфигурация поисковых результатов на SERP (как описано выше) считается оптимальной, так как основана на предпосылке, что именно таким образом пользователи обычно взаимодействуют с поисковыми результатами. Т.е., предполагается, что, когда пользователям предоставили SERP, они сначала смотрят на первый в списке поисковый результат, думая, что он наиболее релевантный. А если он не наиболее релевантен, пользователь переходит по странице ниже, сверху вниз, последовательно рассматривая каждый перечисленный поисковый результат, пока не найдет тот поисковый результат, который наиболее соответствует искомой информации.
[10] Было обнаружено, что на самом деле так происходит не всегда. Пользователи не всегда взаимодействуют с SERP таким образом. Например, существуют обстоятельства, при которых пользователь начинает рассматривать самый первый поисковый результат в списке, расположенный в самом верху SERP, а затем рассматривает поисковые результаты в случайном порядке. В более конкретном примере, данный набор поисковых результатов является списком из 6 элементов, показанных на SERP в порядке QSR (или, реже, в порядке QIR - в любом случае, упоминаемом здесь и далее как «порядок ранжирования по релевантности»), и пользователь, которому предоставили поисковые результаты, может сначала посмотреть на первый в списке поисковый результат, расположенный на SERP сверху. Если этот первый в списке поисковый результат не предоставил пользователю искомую информацию, пользователь затем (неожиданно) может перейти к пятому по счету поисковому результату от верха страницы. Если этот пятый в списке поисковый результат не предоставил пользователю искомую информацию, пользователь затем может вернуться обратно ко второму по счету поисковому результату от верха страницы, и так далее в любом конкретном случае. (Это описание служит только примером объясняемой методологии, а не описанием того, что на самом деле происходит для каждой (любой) данной SERP.)
[11] Кроме того, не всегда случается, что пользователь начинает просмотр с самого верха страницы. В конкретном примере, не ограничивающем объем настоящего технического решения, данного набора поисковых результатов, которые являются списком из шести элементов, показанных на SERP в порядке QSR, пользователь может начать с четвертого по счету поискового результата от верха страницы. Если этот четвертый в списке поисковый результат не предоставил пользователю искомую информацию, пользователь затем может перейти к шестому по счету поисковому результату от верха страницы. Если этот шестой в списке поисковый результат не предоставил пользователю искомую информацию, пользователь затем может вернуться ко второму по счету поисковому результату от верха страницы, и так далее в любом конкретном случае. (Это описание также служит только примером объясняемой методологии, а не описанием того, что на самом деле происходит для каждой (любой) данной SERP.)
[12] Кроме того, при некоторых обстоятельствах пользовательское поведение на SERP может распространяться не только на вертикальный список. Например, в примере, аналогичном тому, что описан выше, пользователь может сначала просмотреть первый в списке поисковый результат на верху SERP, а затем перейти к уточненному результату справа от SERP, а дальше просмотреть пятый в списке поисковый результат в середине SERP, а затем вернуться ко второму в списке поисковому результату ближе к началу SERP.
[13] Обычно пользовательские взаимодействия с SERP такого типа, описанные в примерах выше, учитываются при определении QSR для аналогичных поисковых запросов в будущем. Это основано на предположении, что пользователь быстро просматривает список поисковых результатов, определяет, какой из перечисленных поисковых результатов является наиболее релевантным для искомой информации, и начинает просматривать его. Если этот поисковый результат из списка не предоставляет пользователю искомой информации, он возвращается обратно к списку поисковых результатов и переходит к тому результату, который, как ему кажется, предоставит искомую информацию. И так далее, и тому подобное, пока он не найдет искомую информацию. Таким образом поисковая система собирает данные о том, какие результаты из списка поисковых результатов сочтены пользователями системы релевантными поисковому запросу, и в каком порядке ранжировать эти результаты. Цель заключается в том, чтобы поисковые результаты располагались в идеальном порядке QSR. В чрезвычайно упрощенном примере (который используется только в иллюстративных целях), в следующий раз, когда пользователь введет именно этот конкретный поисковый запрос, позиция поисковых результатов может поменять свое индивидуальное положение, чтобы новый порядок (начиная с самого верха SERP), совпадал с тем, что был определен как наиболее релевантный на основе предыдущих пользовательских взаимодействий с SERP, как было описано выше.
[14] В вышеупомянутых примерах тот факт, что пользователь «начинает» с конкретного поискового результата в списке, не обязательно означает, что пользователь «щелкает» на этот поисковый результат (хотя он может и щелкнуть), это значит, что пользователь рассматривает информацию, представленную на SERP, об этом конкретном поисковом результате в списке, чтобы определить, предоставлена ли ему релевантная информация. Обычно на известном уровне техники это определяется отслеживанием движений пользовательского курсора или направления взгляда пользователя, а также пользовательских переходов по ссылкам и возвращений на SERP.
[15] Обнаружилось, что при некоторых обстоятельствах упомянутое выше предположение неверно. При некоторых обстоятельствах, вопреки очевидному, пользователи начинают с поискового результата из списка, который ранжирован ниже, чем самый высокоранжированный поисковый результат, не по причине того, что они думают, будто тот поисковый результат, с которого они начинают, наиболее релевантен из всех предоставленных поисковых результатов. Без попыток выдвинуть какую-то конкретную теорию, предположим, что причина, по которой пользователь так действует, связана с тем, как он получает доступ к поисковой системе. Например, если доступ к поисковой системе осуществляется из веб-браузера настольного компьютера, поисковые результаты будут предоставлены в совершенно другом визуальном формате, чем в случае, если доступ к поисковой системе осуществляется с помощью специализированного приложения на смартфоне. В первом случае обычно предоставляются результаты вместе с другой информацией в формате с большим количеством графики (причем этот формат может сильно различаться, как будет описано здесь ниже). Во втором случае результаты обычно предоставляются как простой список текстовых элементов, без графики.
[16] Например, современные SERP во многих случаях не представляют собой простую единственную колонку с текстовым списком поисковых результатов, снабженных гиперссылкой на URL интернет-источника (который является поисковым результатом) с текстовым информационным фрагментом (сниппетом), предоставляющим информацию, которая может быть найдена на этом ресурсе. Например, на Фиг. 1 показана типичная SERP 10 поисковой системы Google™ (управляется Google Inc.) для поискового запроса «эйфелева башня»; к странице был совершен доступ из браузера настольного компьютера. Как можно видеть на Фиг. 1, SERP в общем случае делится на два столбца 12, 14. В левом столбце 12 представлен список URL, которые поисковая система считает релевантными конкретному запросу «эйфелева башня», причем список приведен в порядке QSR, вместе с текстовыми фрагментами информации (сниппетами), которую можно обнаружить по этим URL, 161, 162, 163, 164, 165, 166, 167. В центре столбца 12, под третьим в списке поисковым результатом 163, и над четвертым в списке поисковым результатом 164, находится раздел 18 поисковых результатов для новостей и раздел 20 поисковых результатов для изображений. Раздел 18 поисковых результатов для новостей предоставляет список новостных элементов, релевантных поисковому запросу «эйфелева башня». Раздел 20 поисковых результатов для изображений предоставляет набор картинок, релевантных поисковому запросу «эйфелева башня». В правом столбце 16 находится «карточка 22 объекта» для объекта «эйфелева башня». «Карточка 22 объекта» предоставляет картографический фрагмент 24, показывающий положение Эйфелевой башни в Париже, Франция, а также изображение 26 Эйфелевой башни в Париже, Франция. (Эйфелева башня в Париже, Франция является наиболее вероятным объектом, который искали посредством поискового запроса «эйфелева башня»). Кроме того, «карточка объекта» включает в себя (i) фрагмент 28 информации из статьи в Википедии об Эйфелевой башне в Париже, Франция; (ii) информацию 30, относящуюся к самому популярному расписанию посещения Эйфелевой башни в Париже, Франция (источник неизвестен); (iii) отзывы 32 об Эйфелевой башне, Париж, Франция (из Google™ Reviews) и (iv) указание 34 некоторых других запросов, которые вводили люди, искавшие информацию по запросу «эйфелева башня».
[17] Визуальный эффект от SERP, показанной на Фиг. 1, сильно отличается от более традиционной SERP, показанной на Фиг. 2. SERP, показанная на Фиг. 2, является типичной SERP 40 поисковой системы DuckDuckGo™ (управляется DuckDuckGo, Inc.) для поискового запроса «эйфелева башня»; к странице был совершен доступ из браузера настолько компьютера. Как можно видеть на Фиг. 2, SERP 40 в общем случае имеет единственный столбец. В начале SERP 40 находится простая карточка 42 объекта. Под карточкой 42 объекта находятся два простых, расположенных друг за другом текстовых рекламных объявления 441, 442. Под двумя рекламными объявлениями 441, 442 представлен список URL, которые поисковая система считает релевантными конкретному запросу «эйфелева башня», причем список приведен в порядке QSR, вместе с текстовыми фрагментами информации (сниппетами), которую можно обнаружить по этим URL, 461, 462, 463, 464.
[18] Визуальный эффект от SERP, показанной на Фиг. 3, сильно отличается тех SERP, что показаны на Фиг. 1 и 2. SERP, показанная на Фиг. 3, является типичной SERP 50 поисковой системы Яндекс (Yandex™) (управляется ООО Яндекс) для поискового запроса «эйфелева башня»; к странице был совершен доступ со специализированного приложения, запущенного на смартфоне iPhone™, произведенном Apple Inc. и работающем на iOS. Как можно видеть на Фиг. 3, SERP 50 включает в себя один столбец и предоставляет простой текстовый список URL, которые поисковая система считает релевантными конкретному запросу «эйфелева башня», причем список приведен в порядке QSR, вместе с текстовыми фрагментами информации (сниппетами), которую можно обнаружить по этим URL, 521, 522, 523. На SERP 50 не предоставляется другой информации.
[19] В более показательном примере, когда к поисковой системе совершается голосовой доступ с помощью персонального помощника (т.е. Сири (Siri™), разработанная Apple Inc., или Кортана (Cortana™), разработанная Microsoft Inc.), результаты будут представлять собой произнесенные вслух слова. Поисковый результат, предоставленный пользователю первым, в общем случае будет выбран самой поисковой системой, без начального предоставления выбора пользователю. В этом случае визуальное представление сводится к минимуму или и вовсе не присутствует, и пользователю не предоставляется SERP, чтобы использовать ее для выбора из различных результатов поиска.
[20] Учитывая это, но опять же без попыток выдвинуть какую-то конкретную теорию, получается, что способ представления поисковых результатов влияет на пользовательское взаимодействие с поисковыми результатами. Сложность, которая представлена этим сценарием, заключается в том, что QSR поисковых результатов должно быть в общем случае одинаковым, вне зависимости от того как пользователь взаимодействует с поисковой системой (хотя QSR может и различаться у разных поисковых систем). Таким образом, для данного идентичного (во всех смыслах) поискового запроса, вне зависимости от того, как был получен доступ к поисковой системе, поисковые результаты должны быть одинаковы. Однако в общем случае, из-за того, что пользовательские взаимодействия с поисковыми результатами используются при определении QSR для будущих аналогичных поисковых запросов, в этом отношении поисковой системой собираются неверные данные. Это приводит к неверным QSR для будущих аналогичных поисковых запросов. Для пользователей неверные QSR часто являются всего лишь незначительным неудобством, поскольку искомая информация обычно все равно оказывается в пределах самых высоко ранжированных поисковых результатов, пусть даже эти поисковые результаты и могут быть ранжированы не в том порядке. Для поисковой системы, однако, неверные QSR приводят к значительным потерям ресурсов. Чтобы рассмотреть эту ситуацию в контексте, следует понимать, что современная поисковая система может проводить 50000 поисков в секунду, каждую секунду каждого дня месяца. И это число не остается постоянным, а повышается. Поисковые системы должны отслеживать пользовательские взаимодействия с поисковыми результатами по многим причинам. Одна из причин упоминалась выше - это сбор обратной связи для улучшения будущих поисков. Но это не единственная причина. Чем больше взаимодействия осуществит пользователь с SERP, чтобы найти искомую информацию, тем больше ресурсов требуется от поисковой системы по отношению к этому единственному поиску. Этот недостаток увеличивается с каждым поиском, и потеря поисковой системой ресурсов становится огромной. Настоящее техническое решение было разработано благодаря пониманию этих процессов и желанию улучшить эффективность поисковой системы.
[21] Таким образом, одним объектом настоящего технического решения является способ предоставления поисковой системой поисковых результатов на множество клиентских устройств, причем поисковая система включает в себя:
- по меньшей мере один сервер;
- первую базу данных с множеством списков словопозиций, выполненную с возможностью электронного обмена данными по меньшей мере с одним сервером,
- вторую базу данных с информацией, относящейся к предыдущим пользовательским взаимодействиям с поисковыми результатами, предоставленными системой, причем система выполнена с возможностью электронного обмена данными по меньшей мере с одним сервером,
- сеть передачи данных выполнена с возможностью обеспечения электронного обмена данными по меньшей мере между одним сервером и множеством клиентских устройств,
способ включает в себя осуществление по меньшей мере одним сервером:
- получения поискового запроса от одного из множества клиентских устройств по сети передачи данных, причем поисковый запрос включает в себя информацию, указывающую на принадлежность приложения, запущенного на клиентском устройстве, от которого был получен поисковой запрос;
- осуществления поиска по меньшей через первую базу данных для определения поисковых результатов, отвечающих на поисковый запрос, причем поисковые результаты ранжированы по релевантности;
- определения вероятной последовательности пользовательских взаимодействий с поисковыми результатами на основе информации во второй базе данных и на основе информации, указывающей на принадлежность приложения, запущенного на одном из клиентских устройств, от которого был получен поисковой запрос, причем вероятная последовательность пользовательских взаимодействий с поисковыми результатами отличается от порядка ранжирования поисковых результатов по релевантности;
- отправки поисковых результатов на одно из клиентских устройств по сети передачи данных, причем поисковые результаты включают в себя информацию, предоставляющую возможность визуальной конфигурации поисковых результатов, предоставленных пользователю приложением, от которого был получен поисковой запрос, в соответствии вероятной последовательностью пользовательских взаимодействий с поисковыми результатами, поддерживая при этом порядок ранжирования поисковых результатов по релевантности.
[22] Настоящее техническое решение является попыткой улучшить текущий уровень техники с помощью отслеживания поисковой системой пользовательских взаимодействий с поисковыми результатами для того, чтобы иметь возможность предоставлять визуальную конфигурацию поисковых результатов, принимая во внимание принадлежность (или принадлежности) приложения (запущенного на клиентском устройстве), с которого осуществляется доступ к поисковой системе, при модификации порядка (т.е. QSR) ранжирования поисковых результатов по релевантности.
[23] Таким образом, настоящее техническое решение может предоставить возможность (в зависимости от обстоятельств) различной визуальной конфигурации поисковых результатов в различных обстоятельствах, без влияния на порядок ранжирования по релевантности.
[24] Таким образом, в некоторых вариантах осуществления настоящего технического решения клиентскому устройству предоставляются инструкции на отображение поисковых результатов не в порядке ранжирования по релевантности (поддерживая при этом порядок).
[25] В некоторых вариантах осуществления настоящего технического решения клиентскому устройству предоставляются инструкции на отображение поисковых результатов в порядке, который не является линейно-вертикальным.
[26] В некоторых вариантах осуществления настоящего технического решения клиентскому устройству предоставляются инструкции на отображение поисковых результатов в порядке, который не является линейно-горизонтальным.
[27] В некоторых вариантах осуществления настоящего технического решения клиентскому устройству предоставляются инструкции на отображение по меньшей мере одного поискового результата по-другому по сравнению с другими поисковыми результатами. В некоторых вариантах осуществления настоящего технического решения по меньшей мере один поисковый результат обладает по меньшей мере одним отличительным признаком по сравнению с остальными поисковыми результатами: другой шрифт, или другой размер шрифта, или другой цвет, или другой стиль шрифта, или другое подчеркивание шрифта, или другой шрифтовой эффект.
[28] В некоторых вариантах осуществления настоящего технического решения клиентскому устройству предоставляются инструкции на отображение поисковых результатов исключительно изображений, связанных с одним из поисковых результатов, рядом с этим одним поисковым результатом.
[29] В некоторых вариантах осуществления настоящего технического решения принадлежность приложения, запущенного на клиентском устройстве, от которого был получен поисковой запрос, заключается в том, что это приложение является веб-браузером для настольного компьютера.
[30] В некоторых вариантах осуществления настоящего технического решения клиентскому устройству предоставляются инструкции на отображение поисковых результатов; инструкции находятся в информации, относящейся к предыдущим пользовательским взаимодействиям с поисковыми результатами, предоставленными системой; эта информация является результатом использования алгоритма машинного обучения.
[31] В некоторых вариантах осуществления настоящего технического решения способ дополнительно включает в себя:
- получение от одного из множества клиентских устройств по сети передачи данных информации, связанной с текущим пользовательским взаимодействием с результатами; и
- обновление информации во второй базе данных, информации связанной с предыдущими пользовательскими взаимодействиями, теми поисковыми результатами, которые были предоставлены системой, без обновления в системе информации, относящейся к порядку ранжирования по релевантности.
[32] Другим объектом настоящего технического решения является поисковая система, включающая в себя:
- по меньшей мере один сервер, выполненный с возможностью предоставления поисковой системой поисковых результатов на множество клиентских устройств, в соответствии со способом, описанным здесь;
- первую базу данных со множеством списков словопозиций, выполненную с возможностью электронного обмена данными по меньшей мере с одним сервером;
- вторую базу данных с информацией, относящейся к предыдущим пользовательским взаимодействиям с поисковыми результатами, полученным системой, причем система выполнена с возможностью электронного обмена данными по меньшей мере с одним сервером; и
- сеть передачи данных выполнена с возможностью обеспечения электронного обмена данными по меньшей мере между одним сервером и множеством клиентских устройств.
[33] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для настоящего технического решения. В контексте настоящего технического решения использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами; оба варианта включены в выражение «по меньшей мере один сервер».
[34] В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами клиентских устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как клиентское устройство в настоящем контексте, может вести себя как сервер по отношению к другим клиентским устройствам. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного способа.
[35] В контексте настоящего описания «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, на котором хранится или используется информация, хранящаяся в базе данных, или же база данных может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
[36] В контексте настоящего описания «информация» включает в себя информацию любого рода или типа, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[37] В контексте настоящего описания «компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[38] В контексте настоящего описания «используемый компьютером носитель компьютерной информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[39] В контексте настоящего описания слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной связи между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий «второй сервер» обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[40] Каждый вариант осуществления настоящего технического решения преследует по меньшей мере одну из вышеупомянутых целей и/или объектов. Следует иметь в виду, что некоторые объекты настоящего технического решения, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять и другим целям, отдельно не указанным здесь.
[41] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
Краткое описание чертежей
[42] Для лучшего понимания настоящего технического решения, а также других его аспектов и характерных черт, сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[43] На Фиг. 1, Фиг. 2, Фиг. 3 показан известный уровень техники настоящего технического решения.
На Фиг. 4, Фиг. 5, Фиг. 6 показана схема различных сетевых компьютерных систем, подходящих для осуществления настоящего технического решения.
На Фиг. 7, Фиг. 8, и Фиг. 9 показан наглядный пример осуществления настоящего технического решения в поисковой системе Яндекс для поискового запроса «тренажеры», введенного в поисковое приложение Яндекс под iOS,
На Фиг. 10 показан наглядный пример осуществления настоящего технического решения в поисковой системе Яндекс для поискового запроса «тренажеры», введенного в браузер для настольного компьютера по URL www.yandex.com,
Осуществление
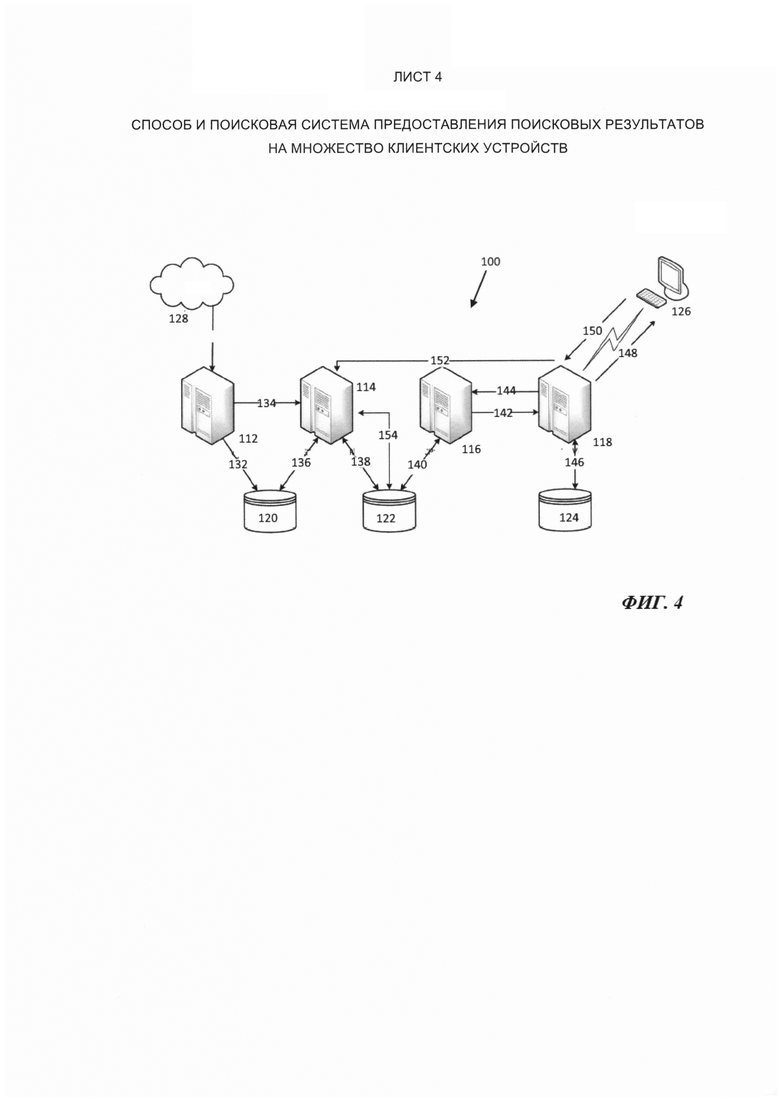
[44] На Фиг. 4 показана схема различных сетевых компьютерных систем, обменивающихся друг с другом данным по сети передачи данных, и включающих в себя поисковую систему 100. Следует понимать, что различные компьютерные системы являются только некоторыми вариантами осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание показательного примера настоящего технического решения. Это описание не предназначено для определения объема или установления границ настоящего технического решения. Некоторые полезные примеры модификаций компьютерной систем также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящего технического решения. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящего технического решения. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что компьютерные системы представляют собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящего технического решения, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящего технического решения будут обладать гораздо большей сложностью.
Поисковые системы - общее описание
[45] Обычно при формировании системы управления набором данных с возможностью поиска элементы данных индексируются в соответствии с некоторыми или всеми возможными поисковыми терминами, которые могут быть включены в поисковые запросы. Таким образом, системой создается, сохраняется и обновляется «инвертированный индекс». Инвертированный индекс включает в себя большое число «списков словопозиций», необходимых для просмотра во время выполнения поискового запроса. Каждый список словопозиций соответствует потенциальному поисковому термину и включает в себя «словопозиции», которые являются ссылками на элементы данных в наборе данных, включающем в себя данный поисковый термин (или иным образом удовлетворяющем некоторым иным условиям, которые выражаются поисковым термином). Например, если элементы данных являются текстовыми документами, что часто встречается в работе поисковых интернет- (или «веб-») систем, то поисковые термины являются индивидуальными словами (и/или некоторыми наиболее часто используемыми их комбинациями), а инвертированный индекс включает в себя один список словопозиций для каждого слова, которое встретилось по меньшей мере в одном документе.
[46] Поисковые запросы обычно выглядят как простой список из одного или нескольких слов, которые являются «поисковыми терминами» поискового запроса. Каждый такой поисковый запрос может пониматься как запрос поисковой системе на обнаружение каждого элемента данных в наборе данных, включающем в себя все поисковые термины, указанные в поисковом запросе. Обработка поискового запроса будет включать в себя поиск в одном или нескольких списках словопозиций инвертированного индекса. Как было описано выше, обычно каждому поисковому термину в поисковом запросе будет соответствовать список словопозиций. Поиск производится в списках словопозиций потому, что они могут легко сохраняться и управляться из быстродействующей памяти, в отличие от самих элементов данных (элементы данных обычно хранятся в более медленнодействующей памяти). Это, в общем случае, позволяет осуществлять поисковые запросы с гораздо более высокой скоростью.
QIR и QSR
[47] Обычно каждый элемент данных в наборе данных пронумерован. Элементы данных в наборе данных упорядочены не хронологически, географически или в алфавитном порядке, а обычно упорядочены (и пронумерованы) в порядке убывания их «независимой от запроса релевантности» ("query-independent relevance QIR"), как известно в данной области техники. Независимая от запроса релевантность QIR является эвристическим параметром, определяемым системой таким образом, что элементы данных с более высоким QIR статистически более вероятно окажутся сочтены релевантными инициаторами любого поискового запроса. Элементы данных в наборе данных будут упорядочены таким образом, что при завершении поиска элементы с более высоким значением QIR будут расположены сначала. Они, таким образом, в общем случае появятся в начале (или близко к началу) списка поисковых результатов (который обычно отображается на различных страницах, причем те результаты, что расположены в начале списка поисковых результатов, отображаются на первой странице). Таким образом, каждый список словопозиций в инвертированном индексе будет включать в себя словопозиции, список ссылок на элементы данных, включающий в себя термины, с которыми этот список словопозиций связан, при этом словопозиции расположены в порядке убывания значения QIR.
[48] Однако, должно быть очевидно, что такой эвристический параметр как QIR, может не давать оптимального расположения поисковых результатов в отношении любого данного конкретного запроса, поскольку понятно, что элемент данных, который обычно релевантен во многих поисках (и, получается, имеет высокое значение QIR), может не быть особенно релевантным в любом конкретном случае. Кроме того, релевантность любого конкретного элемента данных будет различаться в разных поисках. Из-за этого обычные поисковые системы применяют различные способы фильтрования, ранжирования и/или реорганизации поисковых результатов, чтобы предоставить их в таком порядке, который представляется релевантным для конкретного создания поисковых результатов для поискового запроса. В данной области техники это известно как «зависимая от запроса релевантность» ("query-specific relevance", здесь и далее упоминаемая как "QSR"). При определении QSR обычно принимается во внимание множество параметров. Такие параметры включают в себя: различные характеристики поискового запроса; поискового параметра; элементов данных для ранжирования; данных, собранных во время прошлых сходных поисковых запросов (или, более широко, определенных «сведений», полученных из прошлых сходных поисковых запросов).
[49] Таким образом, в общем процессе выполнения поискового запроса может быть выделено два основных различных этапа: Первый этап, на котором все поисковые результаты собираются на основе (частично) их значений QIR, сгруппированных и организованных в порядке убывания QIR; и второй этап, на котором по меньшей мере некоторые поисковые результаты перегруппировываются в соответствии с их QSR. После этого создается и отправляется автору запроса новый список поисковых результатов, упорядоченных по их QSR. Список поисковых результатов обычно отправляется частями, начиная с той части, которая включает в себя поисковые результаты с наиболее высоким QSR.
[50] Обычно на первом этапе сбор поисковых результатов прекращается после достижения определенного заранее максимального числа результатов или определенного заранее минимального порогового значения QIR. В данной области техники это называется «прюнинг» (от англ. "pruning" - обрезка); причем при удовлетворении прюнинг-условия весьма вероятно, что релевантные элементы данных уже были обнаружены.
[51] Обычно на втором этапе создается более короткий список (который является подгруппой поисковых результатов с первого этапа), упорядоченный по QSR. Это происходит потому, что интернет-поисковые системы при проведении поиска элемента данных, удовлетворяющего данному поисковому запросу, по своему набору данных (который включает в себя несколько миллиардов элементов данных), могут легко создавать список десятка тысяч поисковых результатов (в некоторых случаях даже более). Очевидно, что автору запроса не нужно предоставлять такое количество поисковых результатов. Отсюда понятно огромное значение уменьшения количества поисковых результатов, в итоге предоставляемых автору запроса, до нескольких десятков, которые потенциально имеют высокую релевантность для автора запроса.
Данные, основанные на щелчках
[52] Одним из способов, которым пользуется система для сужения количества поисковых результатов, является использование «знаний», полученных из прошлых аналогичных поисков. Одним из очень важных типов такой информации, полученной из предыдущих поисковых запросов, являются так называемые «данные, основанные на щелчках» («данные по переходам»). В конце выполнения поиска по поисковому запросу, пользователю, запросившему поиск, обычно выдается страница результатов поиска ("SERP"), которая показывает поисковые результаты. На SERP каждый элемент данных, который является поисковым результатом, обычно показывается с заголовком, гиперссылкой на расположение элемента данных в Интернете, и с информационным фрагментом («сниппетом» - короткой цитатой из основной части элемента данных, обычно включающей в себя некоторые или все поисковые термины поискового запроса). Информация, показанная на SERP, может быть использована пользователем, сделавшим запрос, для выбора элементов данных, которые наиболее его интересуют, для дальнейшего просмотра. Обычно пользователь, сделавший запрос, выбирает несколько элементов данных, щелкая на их гиперссылки, чтобы открыть их для дальнейшего чтения. Таким образом, много других данных остается без внимания. Хотя не каждый элемент данных, по которому пользователь, сделавший запрос, щелкнул («перешел»), будет рассмотрен как интересующий элемент данных, эти элементы данных, по которым «перешли», тем не менее, могут рассматриваться в среднем как группа элементов, представляющая больший интерес для пользователя, сделавшего запрос, чем те элементы данных, по которым пользователь не щелкнул (не «перешел»). Такие элементы данных, по которым щелкнули, могут, таким образом, быть рассмотрены как элементы с более высоким QSR по отношению к поисковому запросу, чем те элементы, по которым не щелкнули.
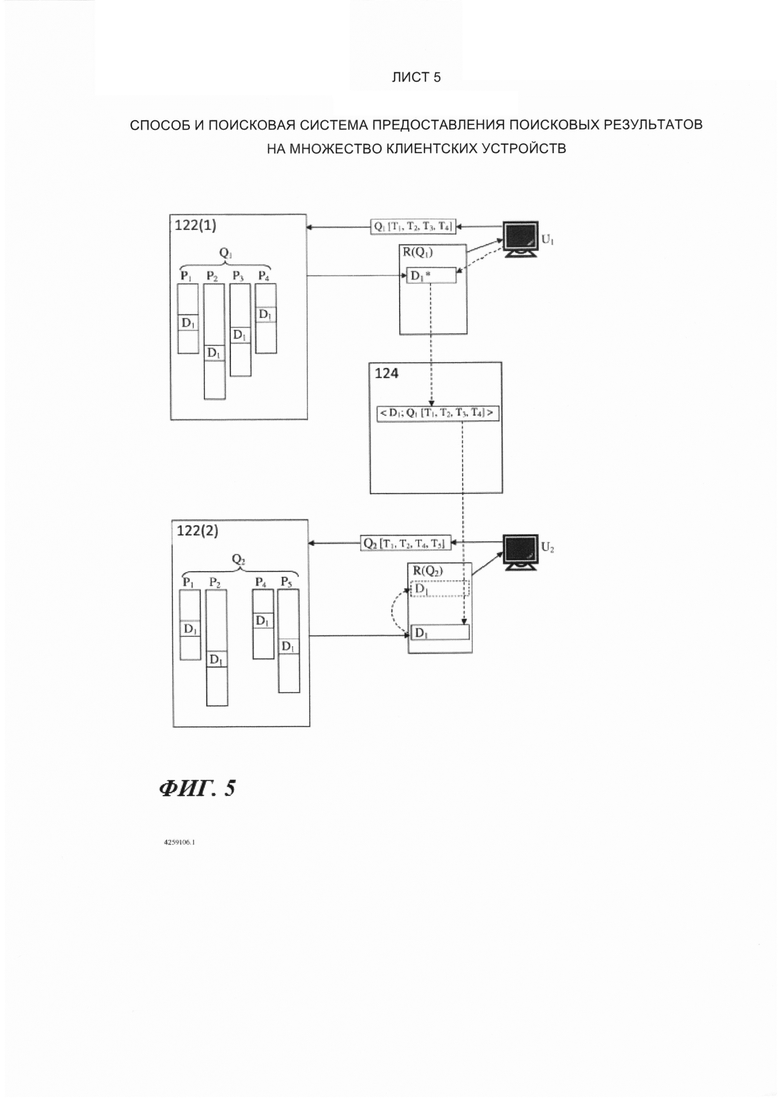
[53] Такие данные, основанные на щелчках, обычно хранятся в базе(ах) данных поисковой системы. Эта информация может быть полезной для будущих аналогичных поисковых запросов, поскольку может быть использована позже для улучшения ранжирования поисковых результатов по QSR (для будущих поисковых результатов с такими же или в основном такими же поисковыми терминами). При ранжировании поисковых результатов таких будущих поисковых запросов данные, основанные на щелках, из прошлых аналогичных запросов могут быть использованы для назначения элементу данных, по которому щелкнули, более высокого QSR. Таким образом, такие элементы данных могут быть показаны текущему пользователю, сделавшему запрос, прежде других элементов данных, которые были обнаружены во время этапа сбора результатов (первый этап) для текущего поискового запроса, но по которым не щелкнули в предыдущих поисках по аналогичным поисковых запросам.
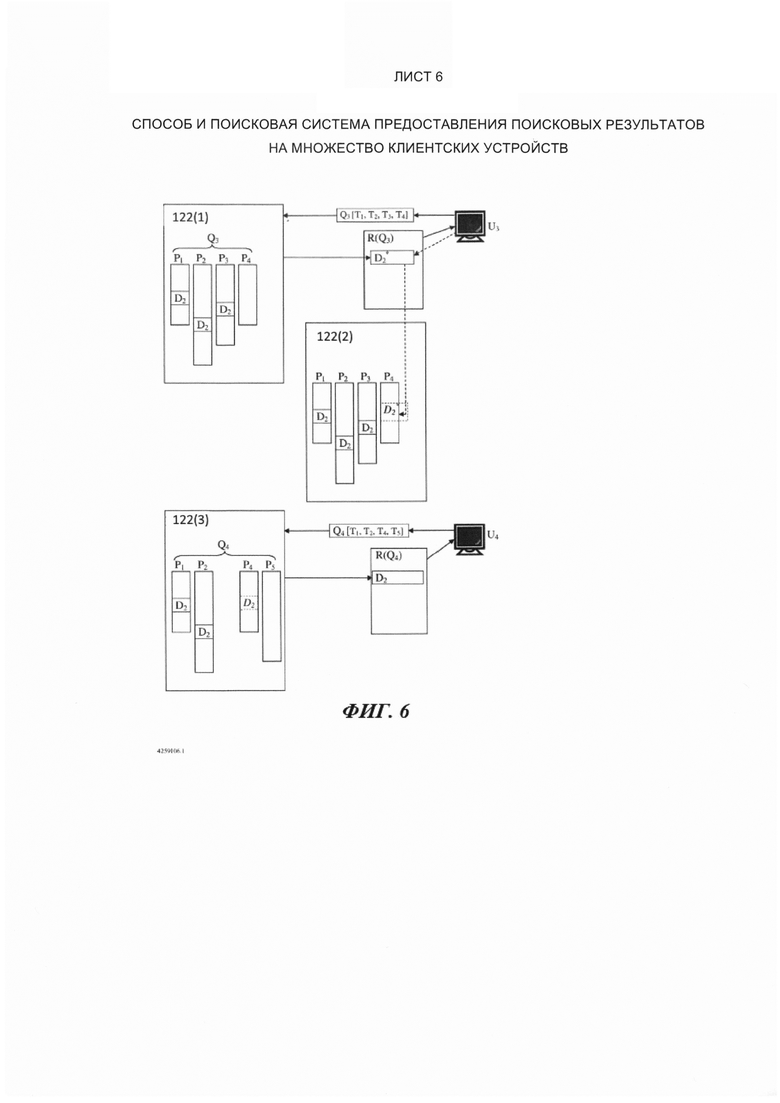
Поисковые системы - типы серверов и функциональность
[54] На Фиг. 4, в одном варианте осуществления настоящего технического решения поисковая интернет-система 100 включает в себя четыре различных типа серверов (или групп серверов), показанных на Фиг. 4 как сервер 112 «поисковый робот», сервер 114 «индексирования», сервер 116 «поиска» и сервер 118 «запросов», отдельно описанные ниже.
[55] Сервер 112 «поисковый робот» воплощен как «поисковый интернет-робот», чьей функцией является розыск и сбор копий веб-страниц из всемирной паутины (указанной как «сеть» 128 на Фиг. 4), а также сохранение этих страниц как «элементов данных» в базе данных 120 «элементов данных». Для каждого элемента данных сервер 112 «поисковый робот» определяет и сохраняет в базе данных 120 элементов данных значение «независимой от запроса релевантности» ("query-independent relevance QIR"). (В некоторых других системах такая функциональность может быть выполнена отдельным сервером, который является независимым от сервера 112 «поискового робота».
[56] Сервер 114 индексирования является сервером индексирования, который (пере)присваивает номера элементам данных в базе данных 120 элементов данных. (Сервер 114 индексирования таким образом получает значение QIR для каждого элемента данных от сервера 112 «поискового робота». Сервер 114 индексирования также создает, сохраняет и поддерживает инвертированный индекс элементов данных в базе данных 122 «инвертированных индексов». Таким образом, сервер 114 индексирования отвечает за просмотр каждого элемента данных и определение того, какие ключевые слова находятся в элементе данных, и затем вставку словопозиции в релевантные списки словопозиций по отношению к этому элементу данных.
[57] Сервер 116 поиска является сервером поиска, который получает поисковые запросы от сервера 118 запросов (см. ниже), осуществляет поиск таких поисковых запросов по инвертированным индексам, хранящимся в базе данных 122 «инвертированных индексов», и создает список поисковых результатов по порядку независимой от запроса релевантности.
[58] Сервер 118 запросов является сервером запросов, который получает и анализирует поисковые запросы от пользователей, сделавших запрос (представленных иконкой 126 персонального компьютера); и для каждого полученного поискового запроса сервер 118 поисковых запросов инициирует поисковую процедуру с помощью сервера 116 поиска. Сервер 118 запросов получает «список поисковых результатов» по порядку независимой от запроса релевантности от сервера 116 поиска. Сервер 118 запросов определяет по меньшей мере для некоторых элементов данных список поисковых результатов по порядку зависимой от запроса релевантности ("query-specific relevance QSR") и формирует список поисковых результатов по порядку зависимой от запроса релевантности для данного поиска. Сервер 118 запросов также формирует визуальное представление для поискового списка. Сервер 118 запросов извлекает «заголовок» и зависящий от запроса «фрагмент информации» («сниппет») из базы данных 120 (конкретно не показана на фигурах) элементов данных для каждого элемента данных в списке поисковых результатов. Сервер 118 запросов предоставляет инициатору 126 поиска части списка поисковых результатов по порядку зависимой от запроса релевантности вместе с их заголовками и информационными фрагментами, и визуальным представлением. Сервер 118 запросов также записывает щелчки перехода инициатора поиска на некоторые элементы данных, показанные как часть поисковых результатов, и сохраняет подходящие данные относительно таких щелчков («переходов») в своей базе данных 124 запросов. Сервер 118 запросов также ищет информацию относительно прошлых поисков в базе данных 124 запросов при подготовке поисковых результатов для текущего поиска и определяет зависимую от запроса релевантность по меньшей мере для некоторых поисковых результатов как функцию информации, найденной в базе данных 124 запросов перед предоставлением поисковых результатов инициатору поиска.
Поисковые системы - серверные процедуры
[59] После описания общих функций каждого из серверов 112, 114, 116 и 118 будут описаны некоторые конкретные процедуры серверов 112, 114, 116 и 118. В связи с этим сервер 112 «поисковый робот» выполнен как поисковый робот, который (постоянно или периодически - в зависимости от обстоятельств) просматривает всемирную паутину в поисках новых (или недавно обновленных) веб-страниц (канал 130 передачи данных). Для каждой такой найденной веб-страницы создается элемент данных в базе данных 120 элементов данных (канал 132 передачи данных). Каждый элемент данных из базы данных 120 элементов данных включает в себя локальную копию соответствующей веб-страницы в интернете, гиперссылку на оригинальную веб-страницу в интернете (также называемый веб-адрес) и набор признаков элементов данных, которые были назначены элементам данных во время их обработки поисковой системой 100.
[60] Первой проведенной процедурой с любым новым элементом данных является определение значения независимой от запроса релевантности QIR. Поскольку значения независимой от запроса релевантности QIR используются для группирования элементов данных, они обычно реализуются как числовые (хотя не обязательно целочисленные) характеристики элемента данных. Значение независимой от запроса релевантности QIR определяется поисковой системой 100 с использованием множества разнообразных признаков самого элемента данных (включая, среди прочего, его заголовок, дату создания, оригинальное местоположение веб-страницы и так далее) и числа и характеристики ссылок на этот элемент данных на других веб-страницах, и, с большой вероятностью, с использованием некоторых данных истории, которые были получены системой 100 из прежде введенных в систему элементов данных, осуществленных ранее поисковых запросов и другой общеизвестной используемой информации. В этой связи существует несколько способов определения значения независимой от запроса релевантности, которые общеизвестны в данной области техники и могут использоваться подходящим образом. В большинстве поисковых интернет-системах определение значения независимой от запроса релевантности для каждого нового элемента данных осуществляется с помощью сервера 112 «поискового робота»; однако в некоторых других оно осуществляется другими серверами, например, сервером 114 индексирования или специализированным сервером QIR.
[61] Каждый элемент данных, хранящийся в базе данных 120 элементов данных, определяется в рамках системы 100 по своему назначенному системой уникальному идентификатору, который обычно является порядковым номером. Обычно весь набор элементов данных управляется настолько большой поисковой интернет-системой, что она не может содержаться на одном сервере баз данных, и обычно делится на несколько «сегментов» баз данных. В этом случае у каждого сегмента обычно есть своя собственная схема присвоения номеров элементам данных и свой собственный алгоритм выполнения поиска в своей части базы данных документов. При исполнении поискового запроса каждый посегментный частичный список поисковых результатов после создания совмещается в один общий список по независимой от запроса релевантности, который затем сортируется по зависимой от запроса релевантности.
[62] Элементы данных нумеруются системой 100 в порядке убывания их независимой от запроса релевантности, а не в порядке их получения сервером 112 («поисковым роботом»). Элементы данных с одинаковой независимой от запроса релевантностью могут быть пронумерованы в любом порядке, например, в инвертированном хронологическом (последним элементам данных присваиваются меньшие порядковые номера, чтобы найти их раньше тех, что были обнаружены ранее). Поэтому при наличии у полученного нового элемента данных D значения независимой от запроса релевантности меньшего, чем у существующего элемента данных (допустим, №999), но большего, чем значение независимой от запроса релевантности следующего элемента данных (№1000) или равного ему, элементу данных D присваивается номер №1000, в то время как бывший №1000 становится №1001 и так далее. Поэтому и номера элементов данных, и контент инвертированного индекса (см. ниже) постоянно и периодически обновляются. Обычно процедура (пере)присваивания номеров элементам данных осуществляется сервером 114 индексирования, но это не является обязательным.
[63] После получения элемента данных (например, D) сервером 112 («поисковым роботом»), сохранения в базе данных 120 элементов данных, назначения значения независимой от запроса релевантности, назначения номера элемента данных (например, №1000), он переходит на сервер 114 индексирования (информационный канал 134 на Фиг. 4) для дальнейшей обработки (двунаправленный канал 136 передачи данных). Сервер 114 индексирования управляет своими базами данных 122 (двунаправленный канал 138 передачи данных), которые в основном включают в себя инвертированный индекс набора элементов данных, содержащегося в базе данных 120 элементов данных.
Словопозиции и списки словопозиций
[64] Как было описано выше, инвертированный индекс обычно включает в себя ряд списков словопозиций. Сервер 114 индексирования исследует новый элемент данных №1000, определяет различные «термины, доступные для поиска», и для каждого доступного для поиска термина в элементе данных создает новую запись в подходящем списке словопозиций.
[65] Запись в списке словопозиций обычно включает в себя номер элемента данных (или другую информацию, достаточную для определения номера элемента данных) и опционально включает в себя некоторые дополнительные данные. Каждый список словопозиций соответствует соответствующему доступному для поиска термину и включает в себя серии записей, ссылающиеся на каждый из тех элементов данных в базе данных 120 элементов данных, которые включают в себя по меньшей мере одно появление доступного для поиска термина.
[66] Дополнительные данные также могут быть обнаружены в записи; например, число появления данного доступного для поиска термина появляется в заголовке элемента данных, и так далее. Эта дополнительная информация может отличаться в разных поисковых системах.
[67] Доступные для поиска термины обычно (но не обязательно) представляют собой слова или другие последовательности символов. Обычная поисковая интернет-система, как правило, работает практически с каждым словом ряда различных языков, а также с именами собственными, числами, символами и так далее. Также в этот список могут быть включены «слова» с распространенными опечатками. В данном описании любой подобный доступный для поиска термин может быть отнесен к «слову» или «термину». Сервер 114 индексирования обновляет соответствующий список словопозиций каждым доступным для поиска термином, который был обнаружен по меньшей мере в одном элементе данных, или же создает новый список (если термин встретился впервые). Поэтому общее число списков словопозиций может достигать нескольких миллионов. Длина данного списка словопозиций зависит от того, как часто используется соответствующее слово в совокупности элементов данных (например, в интернете). У очень распространенного слова может быть список словопозиций с миллиардом записей (или даже больше - размер неограничен). (На практике при разделении базы данных 120 элементов данных на несколько «сегментов», каждый «сегмент» включает в себя собственный инвертированный индекс 122, и поэтому длина списка словопозиций каждого сегмента значительно уменьшается.)
[68] В каждом списке словопозиций записи элементов данных располагаются по убыванию номеров элемента данных, т.е. по убыванию их независимой от запроса релевантности. Следовательно, процесс индексирования нового элемента данных D не сводится к добавлению номера элемента данных D, допустим, №1000 в список словопозиций каждого слова Ti, которое возникает в D. Напротив, при назначении D уже существующего номера элемента данных 1000, должна быть обновлена (в данном случае, увеличена на 1) каждая существующая запись в каждом списке словопозиций с номером, равным или превышающим 1000. В действительности, поисковые системы обычно выполняют эту процедуру обновления периодически с сериями элементов данных, причем эти элементы данных получены с прошлого обновления базы данных 122 инвертированных индексов.
Осуществление поискового запроса
[69] Затем может быть осуществлен поиск элементов данных, причем элементы данных хранятся в базе данных 120 элементов данных и проиндексированы в базе данных 122 инвертированных индексов. На Фиг. 4 видно, что пользователи («инициаторы поискового запроса», которые на Фиг. 1 объединены изображением персонального компьютера 126) делают поисковые запросы, а сервер 118 запросов получает их (канал 150 передачи данных на Фиг. 4). Сервер 118 запросов разбивает каждый полученный поисковый запрос на различные поисковые термины, которые входят в его состав (причем сервер 118 запросов опционально может не учитывать вспомогательные слова, такие как предлоги и союзы, которые не будут включены в поиск из-за того, что встречаются повсеместно), и может осуществлять некоторые другие общеизвестные действия. Например, поисковый запрос Q1, полученный в момент времени t0, может включать в себя четыре поисковых термина T1, Т2, Т3, Т4, которые могут быть записаны как Q1[T1, T2, T3, T4].
[70] Запрос Q1 затем передается сервером 118 запросов серверу 116 поиска (канал 144 передачи данных). Сервер 116 поиска обычно работает с базой данных 122 инвертированных индексов, т.е. с инвертированным индексом и его многочисленными списками словопозиций. В этом примере поисковый процесс, или выполнение поискового запроса, включает в себя определение номеров элемента данных всех тех элементов данных, которые включают в себя появление каждого поискового термина, определенного в поисковом запросе (как было описано выше, это самая простая форма поискового процесса; в следующем примере, описанном ниже, будет приведен принцип кворума). Обычно это осуществляется параллельным исследованием каждого списка словопозиций, соответствующего поисковым терминам запроса, начиная с начала каждого списка словопозиций. В настоящем примере поисковым терминам T1, Т2, Т3, Т4 соответствуют списки словопозиций P1, Р2, Р3, Р4, соответственно. (Более широко - список словопозиций, соответствующий термину Tn обозначается в этом описании как Pn). Элемент данных, номер которого встречается в каждом списке словопозиций, релевантном поисковому запросу, считается поисковым результатом (иногда он также называется «хитом») и расположен в списке поисковых результатов как следующий элемент (т.е. после хитов, которые уже были размещены в списке результатов). Таким образом, список поисковых результатов поискового запроса представляет собой номера элементов данных в возрастающем порядке, т.е. в убывающем порядке значений независимой от запроса релевантности.
[71] Процедура определения следующих поисковых результатов останавливается либо при достижении конца одного из списков словопозиций, либо при удовлетворении некоторым «прюнинг-условиям» («условиям обрезки»), как было указано выше. В разнообразных примерах прюнинг-условия могут, например, быть определены сервером 118 запросов на основании каждого отдельного запроса и предоставлены с каждым запросом Q сервером 118 серверу 116 запроса; альтернативно прюнинг-условия могут быть настроены относительно системы и являться одинаковыми для всех запросов. В любом случае, прюнинг-условия могут быть выражены, например, как максимальное число элементов данных в списке поисковых результатов или как минимальное значение независимой от запроса релевантности для элемента данных для включения в список поисковых результатов, или с помощью других общеизвестных способов. В любом случае, применение прюнинг-условий должно «выбирать» лучшие результаты в терминах их независимой от запроса релевантности.
[72] Список поисковых результатов готовится сервером 116 поиска для данного запроса, например, для Q1, и затем направляется назад сервером 116 поиска серверу 118 запроса (канал 142 передачи данных). (В следующем описании список поисковых результатов для запроса Qm обозначается "R(Qm)", а каждая индивидуальная позиция в списке R(Qm) обозначается Ry(Qm)). В терминах двухэтапного запроса, описанного выше, первый этап - сбор поисковых результатов - теперь завершается, и начинается второй этап, этап ранжирования, или перестановки списка поисковых результатов. На этом этапе сервер 118 запросов перед предоставлением результатов инициатору поиска перестанавливает их предположительно наиболее подходящим для этого конкретного данного запроса образом, размещая на самых верхних позициях списка те поисковые результаты (элементы данных), которые имеют наиболее высокую зависимую от запроса релевантность (QSR) для этого конкретного запроса. Такое ранжирование и перестановка по зависимой от запроса релевантности изначально ранжированных по независимой от запроса релевантности поисковых результатов, вероятно, наиболее сложная процедура, осуществляемая поисковой веб-системой, и эта процедура одна их тех, что наиболее сильно затрагивают удовлетворенность конечного пользователя (т.е. инициатора запроса).
[73] Для определения наилучшего ранжирования по зависимой от запроса релевантности QSR для данного конкретного запроса может быть одновременно принята во внимание информация из многих различных источников. Часть информации, используемой для оценки зависимой от запроса релевантности элемента данных, может быть найдена в самом элементе данных; например, общее число появлений в элементе данных каждого поискового термина данного поискового запроса; появления двух или нескольких поисковых терминов, находящихся в ближайшем соседстве друг с другом (например, в одной фразе), или, что еще более важно, следующих друг за другом в таком же порядке, как и в поисковом запросе; поисковые термины, обнаруженные в заголовке документа и так далее. Однако, все эти критерии, носящие ограниченный характер по охватываемому объему, не обязательно могут отражать уровень «удовлетворенности пользователя» данным элементом данных в контексте конкретного запроса.
[74] Поисковые веб-системы используют информацию из истории, причем эта информация собрана с помощью большого количества выполненных ранее поисковых запросов, и сохранена в базе данных. Эта «база данных запросов» показана на Фиг. 4 в связи со ссылкой на номер 124, и она доступна для сервера 118 запросов по двустороннему каналу 146 передачи данных. Из каждого запроса может быть извлечена, сохранена, обработана и использована для улучшения ранжирования результатов следующего запроса по зависимой от запроса релевантности разнородная информация. В контексте настоящего примера считаются релевантными только данные, основанные на щелчках, как было кратко описано выше. Поэтому пользователь U1 Фиг. 5, сделав поисковой запрос, допустим, Q1[T1, Т2, Т3, Т4], получает от сервера 118 запросов список поисковых результатов, найденных для запроса сервером 116 поиска и ранжированных сервером 118 запросов (как было описано выше). Часто список является очень длинным, поэтому он отправляется пользователю по частям (или «постранично»), например, по 120 записей в каждой части. Каждая запись является «доступной для щелчка», то есть, при щелчке на нее пользователем с помощью мыши или другого указательного устройства, инициирует открытие элемента данных, например, в другом окне или другой вкладке браузерного приложения на компьютере пользователя. Для пользователя с большой вероятностью является предпочтительным иметь возможность просматривать каждый поисковый результат перед тем, как его открыть, чтобы не терять свое время на открытие одного за другим элементов данных в поисках нужного. Поэтому сервер 118 запросов обычно предоставляет пользователю «фрагмент информации» («сниппет»), короткую выдержку (или несколько объединенных более коротких фрагментов) из элемента данных, в котором запрошенные поисковые термины появляются, предположительно, в очевидном контексте. После просмотра фрагмента информации (а также другой предоставленной информации) пользователь может решить, открывать элемент данных (посредством щелчка («перехода») на него) или нет.
Пример использования данных, основанных на щелчках
[75] Прежде, чем открывать элемент данных, пользователь может более внимательно исследовать его и решить, точно ли тот представляет для него интерес. Хотя поисковая система никоим образом не может точно «знать», представляет ли элемент данных интерес для пользователя, поисковая система может, по крайней мере, записать тот факт, что пользователь перешел на данный элемент данных, появившийся на странице результатов поиска. Это происходит потому, что страница результатов поиска обычно предоставляется пользователю поисковой системой в веб-приложении, которое обычно запрограммировано на то, что каждое действие «перехода» на странице сначала отправляется обратно поисковой системе (в настоящем примере серверу 118 запросов системы 100). Сервер 118 запросов затем перенаправляет пользователя на веб-страницу запрошенного элемента данных (или, альтернативно, показывает ему копию элемента данных, сохраненного в базе данных 120 элементов данных). Таким образом, сервер 118 запросов может записывать все действия «перехода», осуществленные пользователями на предоставленной им странице результатов поиска.
[76] Было статистически подтверждено, что среди поисковых результатов запроса, которые были успешно показаны инициаторам запроса, те, на которые инициаторы щелкнули, были в среднем более интересны, чем те, на которые они не щелкнули. Более того, последний элемент данных, на который был осуществлен переход, т.е. тот, после которого пользователь прекратил дальнейшее исследование списка и не стал переходить на другие элементы данных, оказался в среднем еще более интересным пользователю, чем те документы, на которые переход был осуществлен ранее. Эти статистические особенности и «история переходов» используются для наилучшего ранжирования списка поисковых результатов для каждого следующего поискового запроса, с помощью использования «истории переходов» из прошлых поисковых запросов.
[77] База данных 124 запросов сохраняет данные, основанные на щелчках, из прошлых запросов в виде записей <Dk; Qm[T1, Т2, Т3, … Tn]>, указывая, что инициатор запроса Qm[T1, Т2, Т3, … Tn] перешел на документ Dk, когда он/она просматривал(а) результаты поиска по этому запросу. Опционально могут также быть записаны (и затем использованы позже) данные, относящиеся к инициатору запроса (например, IP-адрес), ко времени выполнения запроса и так далее. Приведенный выше набор записей представляет базу данных, которая может быть классифицирована по документам, на которые щелкнули, или по некоторым или всем поисковым терминам, используемым в запросах, или иначе.
[78] На Фиг. 5, например, пользователь U1 сделал запрос Q1[T1, Т2, Т3, Т4], который выполнен сервером 116 поиска с помощью исследования списка словопозиций P1, Р2, Р3, Р4 поисковых терминов T1, Т2, Т3, Т4 (соответственно) поискового запроса Q1. Как пример, элемент данных D1 (более конкретно, запись (т.е. ссылка на D1) находится в каждом из этих списков словопозиций; поэтому D1 включен в список поисковых результатов R(Q1) для запроса Q1. Список поисковых результатов, после некоторых перестановок по QSR, представляется пользователю U1. Пользователь U1, щелкая на запись, соответствующую элементу данных D1 в списке, решает, что он может быть интересен. (Переход на элемент данных схематически указан на Фиг. 5 и Фиг. 6 звездочкой "*".) Эта информация сохраняется в базе данных 124 запросов в виде записи <D1; Q1[T1, Т2, Т3, Т4]>.
[79] Позже, с помощью сравнения запросов с «почти такими же» поисковыми терминами и/или с «в основном, такими же» списками поисковых результатов, особенно тех, у которых «в основном, такие же» подгруппы результатов, по которым щелкнули, система 100 (а именно, сервер 118 запросов) может установить определенную «степень сходства» среди прошлых запросов, а также между следующим запросом, например, Q2, и некоторыми прошлыми запросами, например, Q0. Это происходит по сложной и общеизвестной схеме, поэтому ее детали не будут описываться здесь; для настоящих целей важно понимать то, как информация из прошлых запросов, сходная с текущим запросом Q2, обычно используется для того, чтобы облегчать поисковой системе предоставление более подходящих результатов текущему инициатору запроса.
[80] В связи с этим, при аналогичности текущего запроса, например, Q2, какому-либо предыдущему запросу, например, Q1, и при наличии среди поисковых результатов для Q2 элемента данных D1, для которого существует запись <D1; Q1[…]> в базе данных 124 запросов, обозначающая, что документ D1 был среди результатов для запроса Q1 и, более того, на него щелкнул предыдущий инициатор запроса Q1, элемент данных D1 рассматривается как имеющий более высокую зависимую от запроса релевантность для Q2, чем иные результаты для Q2 с такими же или сходными другими характеристиками. Другими словами, указанный выше критерий «был щелкнут в одном или нескольких прошлых сходных запросах», хотя и не является решающим, используется как один из критериев, которые способны повысить зависимую от запроса релевантность D1 для Q2, и, следовательно, поднять D1 выше в ранжированном списке поисковых результатов для запроса Q2. Таким образом, D1 будет показан инициатору поискового запроса в списке поисковых результатов раньше, чем в случае, если бы на D1 ранее не щелкнули.
[81] Это иллюстративно показано на Фиг. 5. Пользователь U2 (который может быть тем же пользователем, что и U1, или иным) делает поисковой запрос Q2[T1, Т2, Т4, Т5], который отличается от рассмотренного ранее поискового запроса Q1[T1, Т2, Т3, Т4] тем, что не включает в себя поискового термина Т3, а вместо него включает в себя другой поисковой термин Т5. Сервер 116 поиска просматривает списки словопозиций, соответствующие поисковым терминам, на этот раз, списки словопозиций P1, Р2, Р4, Р5 соответствующие поисковым терминам T1, Т2, Т4, Т5 запроса Q2. (На Фиг. 2 это изображено на втором изображении базы данных 122 индексирования, отмеченной как 122(2).) Как пример, тот же самый документ D1 снова обнаруживается в каждом из этих списков словопозиций; поэтому D1 включается в список поисковых результатов R(Q2) для запроса Q2. Однако на этот раз список результатов R(Q2) включает в себя слишком много других документов, предположительно, с более высокой релевантностью для пользователя U2, чтобы вообще показывать документ D1 пользователю. Это схематически изображено на на Фиг. 5 с помощью размещения D1 ниже в списке R(Q2).
[82] В соответствии с обычным использованием данных по переходам сервер 118 (не показано на Фиг. 5) запросов перед представлением списка результатов R(Q2) пользователю U2, просматривает базу данных 124 запросов и находит там (среди, вероятно, иной информации) ранее сохраненную запись <D1; Q1[T1, T2, T3, T4]>, показывающую, что по документу D1 щелкнули в одном из нескольких предыдущих запросов, а именно в запросе Q1[T1, Т2, Т3, Т4], который отличается от данного запроса Q2[T1, Т2, Т4, Т5] по одному из своих четырех поисковых терминов. Принятие во внимание того факта, что по этому документу ранее щелкали, придает некоторую дополнительную ценность документу D1, поэтому сервер 118 запросов поднимает его выше в списке R(Q2), как показано пунктирными стрелками на Фиг. 5; таким образом, D1 будет представлен пользователю U2.
[83] На Фиг. 7, 8, и 9 показана SERP 2001 поисковой системы Яндекс для поискового запроса «тренажеры», введенного в поисковое приложение Яндекс под iOS, запущенное на смартфоне Apple™ iPhone™. SERP 2001 была создана в соответствии с процедурой, описанной выше, и здесь, с целью краткости, эта процедура не будет описана повторно. Поисковые результаты перечислены в порядке QSR, и сервер 118 запросов определил (с помощью информации, сохраненной в базе данных 124 запросов), что, из-за того, что доступ к поисковым результатам осуществлялся с помощью приложения для смартфона, вероятная последовательность пользовательских взаимодействий с поисковыми результатами - QSR.
[84] Таким образом, начиная сверху SERP 2001, первый поисковый результат 2011 в списке - URL stronglifts.com/home-gym equipment… 211, с заголовком ресурса, который находится на URL 211, и текстовым фрагментом информации, предоставляемой ресурсом. Второй поисковый результат 2021 в списке - URL home-gym-bodybuilding.com/my-home… 212, с заголовком ресурса, который находится на URL 212, и текстовым фрагментом информации, предоставляемой ресурсом. Третий поисковый результат 2031 в списке - URL www.reddit.com/r/homegym/ 213, с заголовком ресурса, который находится на URL 213, и текстовым фрагментом информации, предоставляемой ресурсом. Четвертый поисковый результат 2041 является виджетом 214 выбора изображения. Пятый поисковый результат 2051 в списке - URL decoist.com/2013-11-30/home-gym…215, с заголовком ресурса, который находится на URL 215, и текстовым фрагментом информации, предоставляемой ресурсом. Шестой поисковый результат 2061 в списке - URL homedesignlover.com/…cool-home-gym…216, с заголовком ресурса, который находится на URL 216, и текстовым фрагментом информации, предоставляемой ресурсом. Седьмой поисковый результат 2071 является виджетом 217 выбора видео. Восьмой поисковый результат 2081 в списке - URL www.t-nation.com/…home-gym, с заголовком ресурса, который находится на URL 218, и текстовым фрагментом информации, предоставляемой ресурсом. Девятый поисковый результат 2091 в списке - URL www.facebook.com/…, с заголовком ресурса, который находится на URL 219, и текстовым фрагментом информации, предоставляемой ресурсом.
[85] На Фиг. 10, напротив, показана SERP 2002 поисковой системы Яндекс для поискового запроса «тренажеры», введенного в браузер для настольного компьютера по URL www.yandex.com. SERP 2002 была создана в соответствии с процедурой, описанной выше, и здесь, с целью краткости, эта процедура также не будет описана повторно. Разница между SERP 2002 и SERP 2001 для идентичных поисковых терминов заключается в том, что сервер 118 запросов определил (с помощью информации, сохраненной в базе данных 124 запросов), что, из-за того, что доступ к поисковым результатам осуществлялся с помощью браузера для настольного компьютера, вероятная последовательность пользовательских взаимодействий с поисковыми результатами не является порядком QSR. Следовательно, сервер 118 запросов предоставил инструкции на отображение поисковых результатов не в соответствии с их QSR, а в соответствии с вероятной последовательностью пользовательских взаимодействий с поисковыми результатами. Эти результаты на SERP 2002 визуально конфигурированы по-иному, чем на SERP 2001.
[86] Начиная сверху SERP 2002, первый поисковый результат 2012 в списке - URL home-gym-bodybuilding.com/my-home… 212, с заголовком ресурса, который находится на URL 212, и текстовым фрагментом информации, предоставляемой ресурсом. Как видно на Фиг. 7, 8, 9, однако, URL 212 на самом деле является вторым поисковым результатом по QSR.
[87] Второй поисковый результат 2022 в списке - URL stronglifts.com/home-gym equipment… 211, с заголовком ресурса, который находится на URL 211, и текстовым фрагментом информации, предоставляемой ресурсом. Как видно на Фиг. 7, 8, 9, однако, URL 211 на самом деле является первым поисковым результатом по QSR.
[88] Третий поисковый результат 2032 в списке - URL www.reddit.com/r/homegym/ 213, с заголовком ресурса, который находится на URL 213, и текстовым фрагментом информации, предоставляемой ресурсом. Как видно на Фиг. 7, 8, 9, URL 213 также является третьим поисковым результатом по QSR.
[89] Четвертый поисковый результат 2042 является виджетом 214 выбора изображения. Как видно на Фиг. 7, 8, 9, виджет 214 выбора изображения также является четвертым поисковым результатом по QSR.
[90] Пятый поисковый результат 2052 является виджетом 217 выбора видео. Как видно на Фиг. 7, 8, 9, однако, виджет 217 выбора видео на самом деле является седьмым поисковым результатом по QSR.
[91] Шестой поисковый результат 2062 в списке - URL decoist.com/2013-11-30/home-gym…215, с заголовком ресурса, который находится на URL 215, и текстовым фрагментом информации, предоставляемой ресурсом.
[92] Седьмой поисковый результат 2072 в списке - URL homedesignlover.com/…cool-home-gym… 216, с заголовком ресурса, который находится на URL 216, и текстовым фрагментом информации, предоставляемой ресурсом. Как видно на Фиг. 7, 8, 9, однако, URL 216 на самом деле является шестым поисковым результатом по QSR.
[93] Восьмой поисковый результат 2082 в списке - URL www.t-nation.com/…home-gym, с заголовком ресурса, который находится на URL 218, и текстовым фрагментом информации, предоставляемой ресурсом. Как видно на Фиг. 7, 8, 9, URL 218 также является восьмым поисковым результатом по QSR.
[94] Девятый поисковый результат 2092 в списке - URL www.facebook.com/…, с заголовком ресурса, который находится на URL 219, и текстовым фрагментом информации, предоставляемой ресурсом. Как видно на Фиг. 7, 8, 9, URL 219 также является девятым поисковым результатом по QSR.
[95] Таким образом, сервер 118 запросов определил на основе предыдущих пользовательских взаимодействий с поисковыми результатами, что вероятная последовательность пользовательских взаимодействий с SERP 2002 такова: сначала просмотр второго в списке поискового результата 2022, затем просмотр первого в списке поискового результата 2012, затем просмотр третьего в списке поискового результата 2032, затем просмотр четвертого в списке поискового результата 2042, затем просмотр шестого в списке поискового результата 2062, затем просмотр седьмого в списке поискового результата 2072, затем просмотр пятого в списке поискового результата 2052, затем просмотр восьмого в списке поискового результата 2082, и наконец просмотр девятого в списке поискового результата 2092. Таким образом, поисковые результаты по QSR на самом деле визуально конфигурированы на странице по их вероятной последовательности пользовательских взаимодействий.
[96] Модификации и улучшения вышеописанных вариантов осуществления настоящего технического решения будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИСПОЛНЯЕМЫЙ НА КОМПЬЮТЕРЕ СПОСОБ И СИСТЕМА ДЛЯ ПОИСКА В ИНВЕРТИРОВАННОМ ИНДЕКСЕ, ОБЛАДАЮЩЕМ МНОЖЕСТВОМ СПИСКОВ СЛОВОПОЗИЦИЙ | 2014 |
|
RU2718435C2 |
| Способ и система для рекомендации свежих саджестов поисковых запросов в поисковой системе | 2018 |
|
RU2692045C1 |
| СПОСОБ СОЗДАНИЯ АННОТИРОВАННОГО ПОИСКОВОГО ИНДЕКСА И СЕРВЕР, ИСПОЛЬЗУЕМЫЙ В НЕМ | 2015 |
|
RU2606309C2 |
| СПОСОБ И СЕРВЕР ОБРАБОТКИ ПОИСКОВОГО ПРЕДЛОЖЕНИЯ | 2015 |
|
RU2609079C2 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2015 |
|
RU2632148C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ПОДСКАЗОК ПО РАСШИРЕНИЮ ПОИСКОВЫХ ЗАПРОСОВ В ПОИСКОВОЙ СИСТЕМЕ | 2019 |
|
RU2744111C2 |
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА | 2015 |
|
RU2640639C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| СПОСОБ ПРЕДСТАВЛЕНИЯ РЕЗУЛЬТАТОВ ПОИСКА В СООТВЕТСТВИИ С ПОИСКОВЫМ ЗАПРОСОМ В СЕТИ ИНТЕРНЕТ | 2014 |
|
RU2598789C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБНОВЛЕНИЯ БАЗЫ ДАННЫХ ПОИСКОВОГО ИНДЕКСА | 2018 |
|
RU2733482C2 |







Изобретение относится к представлению поисковой системой поисковых результатов. Технический результат – улучшение поиска, проводимого поисковыми системами. Поисковая система для предоставления поисковых результатов на множество клиентских устройств, включающая в себя по меньшей мере один сервер, первую базу данных с множеством списков словопозиций, вторую базу данных с информацией, относящейся к предыдущим пользовательским взаимодействиям с поисковыми результатами, сеть передачи данных. 2 н. и 9 з.п. ф-лы, 10 ил.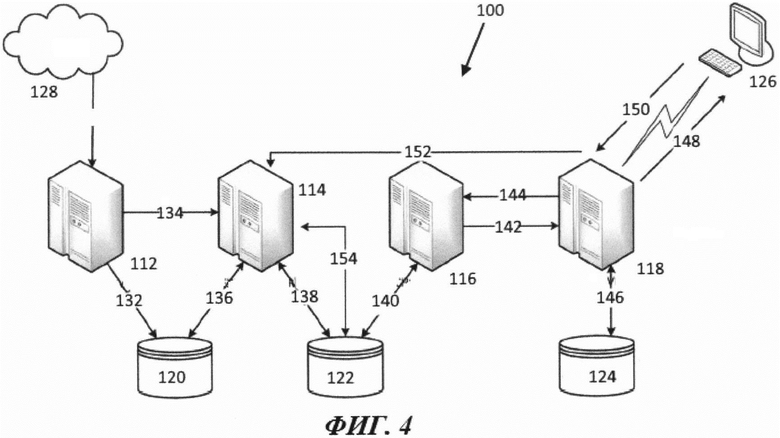
1. Способ предоставления поисковой системой поисковых результатов на множество клиентских устройств, причем поисковая система включает в себя:
по меньшей мере один сервер;
первую базу данных с множеством списков словопозиций, выполненную с возможностью электронного обмена данными по меньшей мере с одним сервером,
вторую базу данных с информацией, относящейся к предыдущим пользовательским взаимодействиям с поисковыми результатами, предоставленными системой, причем система выполнена с возможностью электронного обмена данными по меньшей мере с одним сервером,
сеть передачи данных выполнена с возможностью обеспечивать электронный обмен данными по меньшей мере между одним сервером и множеством клиентских устройств,
способ включает в себя осуществление по меньшей мере одним сервером:
получения поискового запроса от одного из множества клиентских устройств по сети передачи данных, причем поисковый запрос включает в себя информацию, указывающую на принадлежность приложения, запущенного на клиентском устройстве, от которого был получен поисковой запрос;
осуществления поиска по меньшей через первую базу данных для определения поисковых результатов, отвечающих на поисковый запрос, причем поисковые результаты ранжированы по релевантности;
определения вероятной последовательности пользовательских взаимодействий с поисковыми результатами на основе информации во второй базе данных и на основе информации, указывающей на принадлежность приложения, запущенного на одном из клиентских устройств, от которого был получен поисковой запрос, причем вероятная последовательность пользовательских взаимодействий с поисковыми результатами отличается от порядка ранжирования поисковых результатов по релевантности;
отправки поисковых результатов на одно из клиентских устройств по сети передачи данных, причем поисковые результаты включают в себя информацию, предоставляющую возможность визуальной конфигурации поисковых результатов, предоставленных пользователю приложением, от которого был получен поисковой запрос, в соответствии вероятной последовательностью пользовательских взаимодействий с поисковыми результатами, поддерживая при этом порядок ранжирования поисковых результатов по релевантности.
2. Способ по п. 1, в котором информация, предоставляющая возможность визуальной конфигурации поисковых результатов, включает в себя инструкции на отображение поисковых результатов в порядке, отличном от ранжирования по релевантности.
3. Способ по п. 1, в котором информация, предоставляющая возможность визуальной конфигурации поисковых результатов, включает в себя инструкции на отображение поисковых результатов в порядке, отличном от линейно-вертикального порядка.
4. Способ по п. 1, в котором информация, предоставляющая возможность визуальной конфигурации поисковых результатов, включает в себя инструкции на отображение поисковых результатов в порядке, который является отличным от линейно-горизонтального порядка.
5. Способ по п. 1, в котором информация, предоставляющая возможность визуальной конфигурации поисковых результатов, включает в себя инструкции на отображение по меньшей мере одного поискового результата по-другому по сравнению с другими поисковыми результатами.
6. Способ по п. 5, в котором по меньшей мере один поисковый результат обладает по сравнению с остальными поисковыми результатами по меньшей мере одним отличительным признаком из: другой шрифт, или другой размер шрифта, или другой цвет, или другой стиль шрифта, или другое подчеркивание шрифта, или другой шрифтовой эффект.
7. Способ по п. 1, в котором информация, предоставляющая возможность визуальной конфигурации поисковых результатов, включает в себя инструкции на отображение поисковых результатов исключительно изображений, связанных с одним из поисковых результатов, рядом с этим одним поисковым результатом.
8. Способ по п. 1, в котором принадлежность приложения, запущенного на клиентском устройстве, от которого был получен поисковой запрос, заключается в том, что это приложение является веб-браузером для настольного компьютера.
9. Способ по п. 1, в котором информация, относящаяся к предыдущим пользовательским взаимодействиям с поисковыми результатами, предоставленными системой, является результатом использования алгоритма машинного обучения.
10. Способ по любому из пп. 1-9, в котором дополнительно выполняют:
получение от одного из множества клиентских устройств по сети передачи данных информации, связанной с текущим пользовательским взаимодействием с результатами; и
обновление информации во второй базе данных, информации, связанной с предыдущими пользовательскими взаимодействиями, теми поисковыми результатами, которые были предоставлены системой, без обновления в системе информации, связанной с порядком ранжирования по релевантности.
11. Поисковая система для предоставления поисковых результатов на множество клиентских устройств, включающая в себя:
по меньшей мере один сервер, выполненный с возможностью предоставления поисковой системой поисковых результатов на множество клиентских устройств, в соответствии со способом по любому из пп. 1-10;
первую базу данных с множеством списков словопозиций, выполненную с возможностью электронного обмена данными по меньшей мере с одним сервером;
вторую базу данных с информацией, относящейся к предыдущим пользовательским взаимодействиям с поисковыми результатами, предоставленными системой, причем система выполнена с возможностью электронного обмена данными по меньшей мере с одним сервером; и
сеть передачи данных, выполненную с возможностью обеспечения электронного обмена данными по меньшей мере между одним сервером и множеством клиентских устройств.
| ОТНОСИТЕЛЬНЫЕ РЕЗУЛЬТАТЫ ПОИСКА НА ОСНОВЕ ПОЛЬЗОВАТЕЛЬСКОГО ВЗАИМОДЕЙСТВИЯ | 2006 |
|
RU2419860C2 |
| СБОР ДАННЫХ О ПОЛЬЗОВАТЕЛЬСКОМ ПОВЕДЕНИИ ПРИ ВЕБ-ПОИСКЕ ДЛЯ ПОВЫШЕНИЯ РЕЛЕВАНТНОСТИ ВЕБ-ПОИСКА | 2007 |
|
RU2435212C2 |
| СПОСОБ ОТБОРА ЭФФЕКТИВНЫХ ВАРИАНТОВ В ПОИСКОВЫХ И РЕКОМЕНДАТЕЛЬНЫХ СИСТЕМАХ (ВАРИАНТЫ) | 2013 |
|
RU2543315C2 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |

