Область техники
Изобретение относится к обработке аудиосигналов. Более конкретно оно относится к получению компонент сигналов окружения из аудиосигналов источника, получению компонент матрично-декодированных сигналов из аудиосигналов источника и управляемому объединению компонент сигналов окружения с компонентами матрично-декодируемых сигналов.
Включение посредством ссылки
Следующие ссылки включаются сюда посредством ссылки, каждая в полном объеме.
[1] C. Avendano and Jean-Marc Jot, "Frequency Domain Techniques for Stereo to Multichannel Upmix", AES 22<nd> Int. Conf. on Virtual, Synthetic Entertainment Audio.
[2] E. Zwicker, H. Fasti, "Psycho-acoustics", Second Edition, Springer, 1990, Germany.
[3] B. Crockett, "Improved Transient Pie-Noise Performance of Low Bit Rate Audio Coders Using Time Scaling Synthesis", Paper No. 6184, 117th AES Conference, San Francisco, Oct. 2004.
[4] Заявка на американский патент за номером № 10/478,538, PCT, поданная 26 февраля 2002 г., опубликованная как US 2004/0165730 A1 26 августа 2004 г., «Segmenting Audio Signals into Auditory Events», Brett G. Crockett.
[5] A. Seefeldt, M. Vinton, C. Robinson, "New Techniques in Spatial Audio Coding", Paper No. 6587, 119th AES Conference, New York, Oct 2005.
[6] Заявка на американский патент за номером № 10/474,387, PCT, поданная 12 февраля 2002 г., опубликованная как US 2004/0122662 A1 24 июня 2004 г., «High Quality Time-Scaling and Pitch-Scaling of Audio Signals», Brett Graham Crockett.
[7] Заявка на американский патент за номером № 10/476,347, PCT, поданная April 25, 2002, опубликованная как US 2004/0133423 A1 8 июля 2004 г., «Transient Performance of Low Bit Rate Audio Coding Systems by Reducing Pre-Noise», Brett Graham Crockett.
[8] Заявка на американский патент за номером № 10/478,397, PCT, поданная February 22, 2002, опубликованная как US 2004/0172240 A1 8 июля 2004 г., «Comparing Audio Using Characterizations Based on Auditory Events», Brett G. Crockett et al.
[9] Заявка на американский патент за номером № 10/478,398, PCT, поданная February 25, 2002, опубликованная как US 2004/0148159 A1 29 июля 2004 г., «Method for Time Aligning Audio Signals Using Characterizations Based on Auditory Events», Brett G. Crockett et al.
[10] Заявка на американский патент за номером № 10/91 1,404, PCT, поданная 3 августа 2004 г., опубликованная как US 2006/0029239 A1 9 февраля 2006 г., «Method for Combining Audio Signals Using Auditory Scene Analysis», Michael John Smithers.
[11] Международная заявка, опубликованная по Договору о патентной кооперации, PCT/US2006/020882, дата международной подачи 26 мая 2006 г., назначенная Соединенными Штатами, опубликованная как WO 2006/132857 A2 and A3 14 декабря 2006 г., «Channel Reconfiguration With Side Information», Alan Jeffrey Seefeldt, et al.
[12] Международная заявка, опубликованная по Договору о патентной кооперации, PCT/US2006/028874, дата международной подачи 24 июля 2006 г., назначенная Соединенными Штатами, опубликованная как WO 2007/016107 A2 8 февраля 2007 г., «Controlling Spatial Audio Coding Parameters as a Function of Auditory Events», Alan Jeffrey Seefeldt, et al.
[13] Международная заявка, опубликованная по Договору о патентной кооперации, PCT/US2007/004904, дата международной подачи 22 февраля 2007, назначенная Соединенными Штатами, опубликованная как WO 2007/106234 A1 20 сентября 2007 г., "Rendering Center Channel Audio", Mark Stuart Vinton.
[14] Международная заявка, опубликованная по Договору о патентной кооперации, PCT/US2007/008313, дата международной подачи 30 марта 2007 г., назначенная Соединенными Штатами, опубликованная как WO 2007/127023 8 ноября 2007 г., "Audio Gain Control Using Specific Loudness-Based Auditory Event Detection", Brett G. Crockett, et al.
Уровень техники
Создание многоканального аудиоматериала или стандартного матрично-кодированного двухканального стереофонического материала (в котором каналы часто обозначаются как «Lt» и «Rt») или нематрично-кодированного двухканального стереофонического материала (в котором каналы часто обозначаются «Lo» и «Ro») усиливается посредством извлечений объемных каналов. Однако роль объемных каналов для каждого типа сигналов (матрично- и нематрично-кодированного материала) полностью различается. Для нематрично-кодированного материала использование объемных каналов для подчеркивания окружения начального материала часто создает приятно слышимые результаты. Однако для матрично-кодированного материала желательно восстанавливать или аппроксимировать панорамированные звуковые изображения начальных объемных каналов. Кроме того, желательно обеспечить структуру, которая автоматически обрабатывает объемные каналы большинством соответствующих способов, не смотря на входной тип (или нематрично- или матрично-кодированный), без необходимости слушателю выбирать режим декодирования.
В настоящее время есть много методов повышающего микширования двух каналов во множество каналов. Такие методы классифицируются от просто фиксированных или пассивных матричных декодеров до активных матричных декодеров, а также методов выделения окружения для извлечения объемных каналов. Позднее методы выделения окружения частотной области для извлечения объемных каналов (см., например, ссылку [1]) показали перспективу создания приятных многоканальных опытов. Однако такие методы не воспроизводят повторно изображения объемных каналов из матрично-декодированного (LtRt) материала, так как они изначально предназначены для нематрично-декодированного (LoRo) материала. Альтернативно, пассивные и активные матричные декодеры делают достаточно хорошую работу изоляции объемно-панорамированных изображений для матрично-кодированного материала. Однако методы выделения окружения обеспечивают лучшую производительность для нематрично-кодированного материала, чем делает матричное декодирование.
С текущим формированием восходящих микшеров слушателю часто требуется переключение системы восходящего микширования для выбора одного, который наилучше соответствует входному аудиоматериалу. Поэтому объектом настоящего изобретения является создание сигналов объемных каналов, которые являются приятно слышимыми как для матрично-, так и нематрично-кодированного материала без какой-либо необходимости для пользователя переключать между режимами декодирования работы.
Сущность изобретения
В соответствии с аспектами настоящего изобретения способ получения двух аудиоканалов объемного звука из двух входных аудиосигналов, при этом аудиосигналы могут включать в себя компоненты, сформированные матричным кодированием, содержит получение компонент сигналов окружения из аудиосигналов, получение компонент матрично-декодированных сигналов из аудиосигналов и управляемое объединение компонент сигналов окружения и компонент матрично-декодированных сигналов для обеспечения аудиоканалов объемного звука. Получение компонент сигналов окружения может включать в себя применение масштабного коэффициента усиления компонент динамически изменяемых сигналов окружения. Масштабный коэффициент усиления компонент сигналов окружения может быть функцией величины кросс-корреляции входных аудиосигналов, в которой, например, масштабный коэффициент усиления компонент сигналов окружения увеличивается по мере того, как степень кросс-корреляции увеличивается, и наоборот. Величина кросс-корреляции может временно выравниваться и, например, величина кросс-корреляции может временно выравниваться посредством использования зависимого от сигнала квазиинтегратора или, альтернативно, посредством использования скользящего среднего. Временное выравнивание может быть сигнально-адаптивным, например временное выравнивание адаптируется в ответ на изменения в спектральном распределении.
В соответствии с аспектами настоящего изобретения получение компонент сигналов окружения может включать в себя применение, по меньшей мере, одной последовательности фильтра декорреляции. Одна и та же последовательность фильтра декорреляции может применяться к каждому из входных аудиосигналов или, альтернативно, разная последовательность фильтра декорреляции может применяться к каждому из входных аудиосигналов.
В соответствии с другими аспектами настоящего изобретения получение компонент матрично-декодированных сигналов может включать в себя применение матричного декодирования для входных аудиосигналов, при этом матричное декодирование адаптируется для обеспечения первого и второго аудиосигналов, каждый из которых связан с задним направлением объемного звука.
Управляемое объединение может включать в себя применение масштабных коэффициентов усиления. Масштабные коэффициенты усиления могут включать в себя масштабный коэффициент усиления компонент динамически изменяемых сигналов окружения, примененный для получения компонент сигналов окружения. Масштабные коэффициенты усиления могут также включать в себя масштабный коэффициент усиления компонент динамически изменяемых матрично-декодированных сигналов, примененный к каждому из первого и второго аудиосигналов, связанных с задним направлением объемного звука. Масштабный коэффициент усиления компонент матрично-декодированных сигналов может быть функцией величины кросс-корреляции входных аудиосигналов, при этом, например, масштабный коэффициент усиления компонент динамически изменяемых матрично-декодированных сигналов увеличивается по мере того, как степень кросс-корреляции увеличивается, и уменьшается по мере того, как степень кросс-корреляции уменьшается. Масштабный коэффициент усиления компонент динамически изменяемых матрично-декодированных сигналов и масштабный коэффициент усиления компонент динамически изменяемых сигналов окружения могут увеличиваться и уменьшаться по отношению друг к другу таким образом, что сберегается объединенная энергия компонент матрично-декодированных сигналов и компонент сигналов окружения. Масштабные коэффициенты усиления могут дополнительно включать в себя масштабный коэффициент усиления динамически изменяемых аудиоканалов объемного звука для дополнительного управления усилением аудиоканалов объемного звука. Масштабный коэффициент усиления аудиоканалов объемного звука может быть функцией величины кросс-корреляции входных аудиосигналов, в которой, например, функция побуждает масштабный коэффициент усиления аудиоканалов объемного звука увеличиваться по мере того, как величина кросс-корреляции уменьшается до значения, ниже которого масштабный коэффициент усиления аудиоканалов объемного звука уменьшается.
Различные аспекты настоящего изобретения могут выполняться в частотно-временной области, при этом, например, аспекты изобретения могут выполняться в одном или более частотных диапазонах в частотно-временной области.
Повышающее микширование или матрично-кодированного двухканального аудиоматериала, или нематрично-кодированного двухканального материала обычно требует формирование объемных каналов. Хорошо известные системы матричного декодирования работают хорошо для матрично-кодированного материала, хотя методы «выделения» окружения также работают хорошо для нематрично-кодированного материала. Для избегания необходимости слушателю переключаться между двумя режимами повышающего микширования аспекты настоящего изобретения переменно смешиваются между матричным декодированием и выделением окружения для автоматического обеспечения соответствующего повышающего микширования для данного типа входных сигналов. Для этого достижения величина кросс-корреляции между начальными входными каналами управляет частью компонент прямых сигналов из отдельного матричного декодера («отдельный» в том смысле, что матричный декодер только необходим для декодирования объемных каналов) и компонент сигналов окружения. Если два входных канала сильно коррелированы, то больше компонент прямых сигналов, чем компонент сигналов окружения, применяются к каналам объемных каналов. С другой стороны, если два входных канала декоррелируются, тогда больше компонент сигналов окружения, чем компонент прямого сигнала, применяются к каналам объемных каналов.
Методы выделения окружения, которые описаны в ссылке [1], удаляют аудиокомпоненты окружения из начальных передних каналов и панорамируют их к объемным каналам, которые могут усиливать ширину передних каналов и улучшать восприятие окружения. Однако методы выделения окружения не панорамируют дискретные изображения к объемным каналам. С другой стороны, методы матричного декодирования делают относительно хорошую работу панорамирования прямых изображений («прямой» в смысле звук, имеющий прямой путь от источника к местоположению слушателя, в противоположность отражающему или окружающему звуку, который отражается, или «непрямой») к объемным каналам и, следовательно, способны восстанавливать матрично-декодированный материал более точно. Для получения преимущества от эффективности как систем декодирования гибрид выделения окружения и матричного декодирования является аспектом настоящего изобретения.
Задачей изобретения является создание приятно слышимого многоканального сигнала из двухканального сигнала, который или матрично кодируется, или нематрично кодируется без необходимости слушателю переключать режимы. Для ясности изобретение описывается в контексте четырехканальной системы, использующей левый, правый, левый объемный и правый объемный каналы. Изобретение, однако, может предполагаться для пяти каналов или более. Хотя любой из разных известных методов для обеспечения центрального канала, а также пяти каналов может использоваться, особенно полезен метод, который описывается в международной заявке, опубликованной по Договору о патентной кооперации, WO 2007/106324, поданной 22 февраля 2007 г. и опубликованной 20 сентября 2007 г., названной «Rendering Center Channel Audio», автор Mark Stuart Viniton. Упомянутая публикация WO 2007/106324 A1 включена сюда посредством ссылки полностью.
Описание чертежей
Фиг.1 показывает схематичную функциональную блок-схему устройства и процесса извлечения двух аудиоканалов объемного звука из двух входных аудиосигналов в соответствии с аспектами настоящего изобретения.
Фиг.2 показывает схематичную функциональную блок-схему повышающего аудиомикшера или процесса, повышающего микширование, в соответствии с аспектами настоящего изобретения, в котором обработка выполняется в частотно-временной области. Часть структуры фиг.2 включает в себя вариант осуществления частотно-временной области устройства или процесса на фиг.1.
Фиг.3 изображает соответствующую пару окон анализа/синтеза для временных блоков двух последовательных кратковременных дискретных преобразований (STDFT) Фурье, используемых в частотно-временном преобразовании, которое может использоваться в конкретных аспектах настоящего изобретения.
Фиг.4 показывает график центральной частоты каждого диапазона в герцах для эталонной скорости в 44100 Гц, которая может использоваться в конкретных аспектах настоящего изобретения, в котором масштабные коэффициенты усиления применяются к соответствующим коэффициентам в спектральных диапазонах, каждый из которых равен приблизительно половине ширины критического диапазона.
Фиг.5 показывает график Коэффициента Выравнивания (вертикальная ось) в зависимости от номера преобразования Блока (горизонтальная ось), примерный отклик альфа-параметра, зависимого от сигнала квазиинтегратора, который может использоваться в качестве блока оценки, используемого для уменьшения временного изменения величины кросс-корреляции в конкретных аспектах настоящего изобретения. Наличие границы события аудитории показывается в виде резкого понижения Коэффициента Выравнивания на границе блока только до Блока 20.
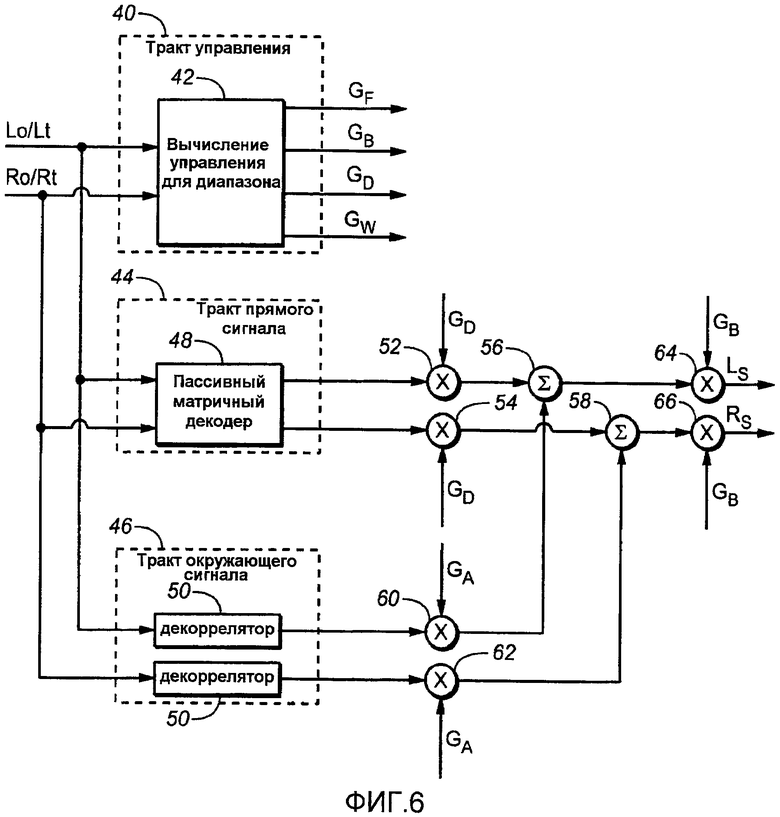
Фиг.6 показывает схематичную функциональную блок-схему части получения объемного звука повышающего аудиомикшера или процесса повышающего микширования на фиг.2 в соответствии с аспектами настоящего изобретения. Для ясности представления фиг.6 показывает схематично поток сигналов в одном из множества частотных диапазонов, что делает понятным, что объединенные действия во всех множествах частотных диапазонах создают аудиоканалы LS и RS объемного звука.
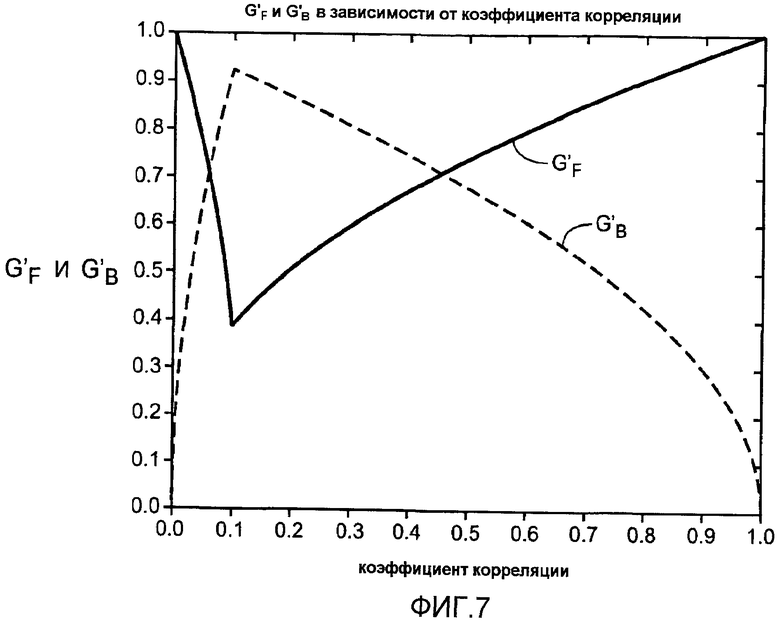
Фиг.7 показывает график масштабных коэффициентов 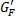 и
и 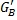 усиления (вертикальная ось) в зависимости от коэффициента корреляции (p
LR
(m,b)) (горизонтальная ось).
усиления (вертикальная ось) в зависимости от коэффициента корреляции (p
LR
(m,b)) (горизонтальная ось).
Наилучший вариант выполнения изобретения
Фиг.1 показывает схематичную функциональную блок-схему устройства или процесса извлечения двух аудиоканалов объемного звука из двух входных аудиосигналов в соответствии с аспектами настоящего изобретения. Входные аудиосигналы могут включать в себя компоненты, сформированные матричным кодированием. Входные аудиосигналы могут быть двумя стереофоническими аудиоканалами, обычно представляющими левое и правое направления звука. Как указано выше, для стандартного матрично-кодированного двухканального стереофонического материала каналы часто обозначаются «Lt» и «Rt» и для нематрично-кодированного двухканального стереофонического материала каналы часто обозначаются «Lo» и «Ro». Таким образом, для указания, что входные аудиосигналы могут матрично кодироваться в одно время и нематрично кодироваться в другое время, входы обозначаются «Lo/Lt» и «Ro/Rt» на фиг.1.
Оба входных аудиосигнала в примере на фиг.1 применяются к отдельному матричному декодеру или функции декодирования («Отдельный Матричный Декодер») 2, который формирует компоненты матрично-декодированных сигналов в ответ на пару входных аудиосигналов. Компоненты матрично-декодированных сигналов получаются из двух входных аудиосигналов. В частности, Отдельный Матричный Декодер 2 выполнен с возможностью обеспечения первого и второго аудиосигналов, каждый из которых связан с задним направлением объемного звука (таким как левое объемное и правое объемное). Таким образом, например, Отдельный Матричный Декодер 2 может реализовываться как часть объемных каналов в 2:4 матричном декодере или функции декодирования (т.е. «отдельный» матричный декодер или функция декодирования). Матричный декодер может быть пассивным или активным. Отдельный Матричный Декодер 2 может характеризоваться как «тракт прямого сигнала (или тракты)» (где «прямой» используется в смысле, объясненном выше) (см. фиг.6, описанную ниже).
На фиг.1 оба входа также применяются к Окружению 4, которое может быть любым разнообразием хорошо известных устройств или функций, формирующих, извлекающих или выделяющих окружение, которые функционируют в ответ на один или два входных аудиосигнала для обеспечения одного или двух выходов компонент сигналов окружения. Компоненты сигналов окружения получаются из двух входных аудиосигналов. Окружение 4 может включать в себя устройства и функции [1], в которых окружение может характеризоваться как «выделенное» из входного сигнала(ов) (как, например, из устройства выделения окружения Хафлерра 1950, в котором один или более разные сигналы (L-R, R-L) извлекаются из Левого и Правого стереофонических сигналов, или современного устройства выделения окружения частотно-временной области, как в ссылках [1] и [2], в которых окружение может характеризоваться как «добавленное» к или «сформированное» в ответ на входной сигнал(ы) (как, например, из цифрового (линия задержки, конвольвер и т.д.) или аналогового (камера, плата, ключ, линия задержка и т.д.) отражателя).
В современных устройствах выделения окружения частотной области выделение окружения может достигаться посредством контроля кросс-корреляции между входными каналами и выделения компонент сигнала во времени и/или частоты, которые декоррелируют (имеют небольшой коэффициент корреляции, близкий к нулю). Для дополнительного увеличения выделения окружения декорреляция может применяться в тракте сигнала окружения для улучшения восприятия переднего/обратного отделения. Такая декорреляция не будет смешиваться с компонентами выделенных декоррелирующих сигналов, или процессов, или устройств, используемых для выделения их. Целью такой декорреляции является уменьшение любой остаточной корреляции между передними каналами и полученными объемными каналами. Смотри заголовок ниже «Декорреляторы для объемных каналов».
В случае одного входного аудиосигнала и двух выходных сигналов окружения, два входных аудиосигнала могут объединяться или только один из них используется. В случае двух входов и одного выхода, один выход может использоваться для обоих выходов сигналов окружения. В случае двух входов и двух выходов, устройство или функция могут функционировать независимо от каждого входа так, что каждый выход сигнала окружения может реагировать только на один конкретный вход или, альтернативно, два выхода могут реагировать и зависеть от обоих входов. Окружение 4 может характеризоваться как «тракт сигнала окружения (или тракты)».
На примере фиг.1 компоненты сигналов окружения и компоненты матрично-декодированных сигналов управляемо объединяются для обеспечения двух аудиоканалов объемного звука. Это может сопровождаться, таким образом, как показано на фиг.1, или аналогичным образом. На примере фиг.1 масштабный коэффициент усиления компонент динамически изменяемых матрично-декодированных сигналов применяется к обоим выходам Отдельного Матричного Декодера 2. Это показывается как применение одного масштабного коэффициента «Усиления Прямого Тракта» к каждым двум умножителям 6 и 8, каждый в выходном тракте Отдельного Матричного Декодера 2. Масштабный коэффициент усиления компонент динамически изменяемых сигналов окружения применяется к обоим выходам Окружения 4. Это показывается как применение одного масштабного коэффициента «Усиления Окружающего Тракта» к каждому из двух умножителей 10 и 12, каждый в выходе Окружения 4. Выход матричного декодера с динамически регулируемым усилением умножителя 6 суммируется с выходом окружения с динамически регулируемым усилением умножителя 10 в аддитивном объединителе 14 (показан как символ ∑ суммирования) для создания одного из выходов объемного звука. Выход матричного декодера с динамически регулируемым усилением умножителя 8 суммируется с выходом окружения с динамически регулируемым усилением умножителя 12 в аддитивном объединителе 16 (показано как символ ∑ суммирования) для создания другого одного из выходов объемного звука. Для обеспечения левого объемного (LS) выхода из объединителя 14 сигнал отдельного матричного декодера с регулируемым усилением из умножителя 6 будет получаться из левого объемного выхода Отдельного Матричного Декодера 2, и сигнал окружения с регулируемым усилением из умножителя 10 будет получаться из выхода Окружения 4, заданного для левого объемного выхода. Аналогично для обеспечения правого объемного (RS) выхода из объединителя 16 сигнал отдельного матричного декодера с регулируемым усилением из умножителя 8 будет получаться из правого объемного выхода Отдельного Матричного Декодера 2, и сигнал окружения с регулируемым усилением из умножителя 12 будет получаться из выхода Окружения 4, предназначенного для правого объемного выхода.
Применение масштабных коэффициентов с динамически изменяемым усилением к сигналу, который подает выход объемного звука, может характеризоваться как «панорамирование» этого сигнала в и из такого выхода объемного звука.
Тракт прямого сигнала и тракт сигнала окружения регулируются с усилением для обеспечения соответствующего количества прямого аудиосигнала и аудиосигнала окружения на основе входящего сигнала. Если входные сигналы хорошо коррелируются, то большая часть тракта прямого сигнала будет представляться в конечных сигналах объемных каналов. Альтернативно, если входные сигналы существенно декоррелируются, то большая часть тракта сигнала окружения будет представляться в конечных сигналах объемных каналов.
Так как некоторые из звуковой энергии входных сигналов проходят по объемным каналам, может быть желательно, кроме того, регулировать усиления передних каналов с тем, чтобы давление конечного воспроизведенного звука существенно не менялось. Смотрите пример на фиг.2.
Следует отметить, что, когда используются методы выделения окружения частотно-временной области, как в ссылке 1, выделение окружения может сопровождаться применением соответствующего масштабного коэффициента усиления компонент динамически изменяемых сигналов окружения к каждому входному аудиосигналу. В этом случае блок Окружения 4 может рассматриваться для включения умножителей 10 и 12 таким образом, что масштабный коэффициент Усиления Окружающих Трактов применяется к каждому из входных аудиосигналов Lo/Lt и Ro/Rt независимо.
В этих широких аспектах изобретение, которое охарактеризовано в примере на фиг.1, может реализоваться (1) в частотно-временной области или частотной области, (2) на широкополосной или диапазонной основе (ссылка на частотные диапазоны) и (3) в аналоговом, цифровом или смешанном аналого/цифровом способе.
Хотя метод кросс-смешивания отдельного матричного декодируемого аудиоматериала с сигналами окружения для создания объемных каналов можно сделать широкополосным способом, производительность может быть улучшена посредством вычисления желаемых объемных каналов в каждом из множества частотных диапазонов. Один возможный способ извлечения желаемых объемных каналов в частотных диапазонах использует перекрывающее кратковременное дискретное преобразование Фурье как для анализа начальных двухканальных сигналов, так и конечного синтеза многоканального сигнала. Однако имеется много хорошо известных методов, которые позволяют сегментацию сигнала как по времени и частоте для анализа, так и синтеза (например, фильтр-банки, квадратурные зеркальные фильтры и т.д.).
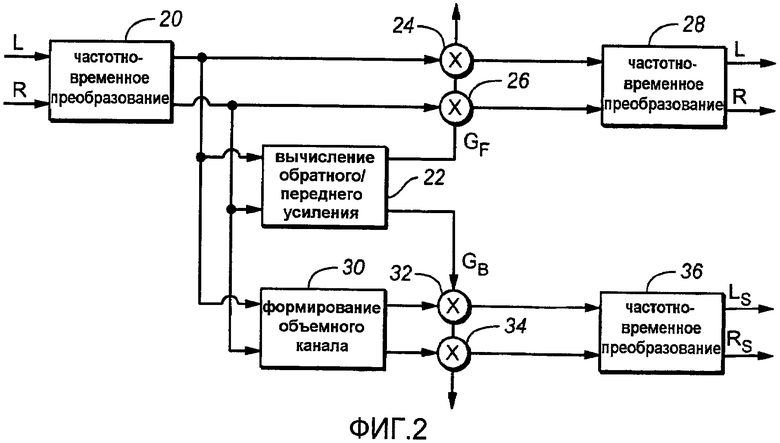
Фиг.2 показывает схематичную функциональную блок-схему повышающего аудиомикшера или процесса, повышающего микширование, в соответствии с аспектами настоящего изобретения, в котором обработка выполняется в частотно-временной области. Часть структуры фиг.2 включает в себя вариант осуществления частотно-временной области устройства или процесса на фиг.1. Пара стереофонических входных сигналов Lo/Lt и Ro/Rt используется в восходящем микшере или процессе восходящего микширования. В примере фиг.2 и других примерах здесь, в которых обработка выполняется в частотно-временной области, масштабные коэффициенты усиления могут динамически обновляться каждый раз по скорости блока преобразования или по скорости выровненного по времени блока.
Хотя, в принципе, аспекты изобретения могут использоваться аналоговыми, цифровыми или гибридными аналого/цифровыми вариантами осуществления, пример на фиг.2 и другие примеры, обсужденные ниже, являются цифровыми вариантами осуществления. Таким образом, входные сигналы могут быть временными отсчетами, которые могут быть извлечены из аналоговых аудиосигналов. Временные отсчеты могут кодироваться в качестве сигналов линейной импульсно-кодовой модуляции (PCM). Каждый входной аудиосигнал линейной PCM может обрабатываться функцией фильтр-банка или устройства, имеющего как синфазный, так и квадратурный выход, такой как 2048 контактов, обрабатывающий методом окна кратковременное дискретное преобразование Фурье (STDFT).
Таким образом, двухканальные стереофонические входные сигналы могут преобразовываться в частотную область, используя устройство или процесс кратковременного дискретного преобразования Фурье (STDFT) («Частотно-временное Преобразование) 20, и группируются в диапазоны (группирование не показано). Каждый диапазон может обрабатываться независимо. Тракт управления вычисляет в устройстве или функции («Вычисление Обратного/Переднего Усиления») 22 отношения передних/обратных масштабных коэффициентов усиления (G F и G B) (см. Уравнения 12 и 13 и фиг.7 и их описание ниже). Для четырехканальной системы два входных сигнала могут умножаться на масштабный коэффициент G F усиления (показан как символы 24 и 26 умножителя) и проходить через обратное преобразование или процесс преобразования («Частотно-Временное Преобразование») 28 для обеспечения левого и правого выходных каналов L'o/L't и R'o/R't, которые могут отличаться по уровню от входных сигналов из-за масштабирования усиления G F. Сигналы LS и RS объемных каналов, полученные из варианта частотно-временной области устройства или процесса на фиг.1 («Формирование Объемного Канала») 30, который представляет переменное смешивание аудиокомпонент окружения и матрично-декодированных аудиокомпонент, умножаются на обратный масштабный коэффициент G B усиления (показано как символы 32 и 34 умножителя) до инверсного преобразования или процесса преобразования («Частотно-временное Преобразование») 36.
Частотно-временное преобразование 20
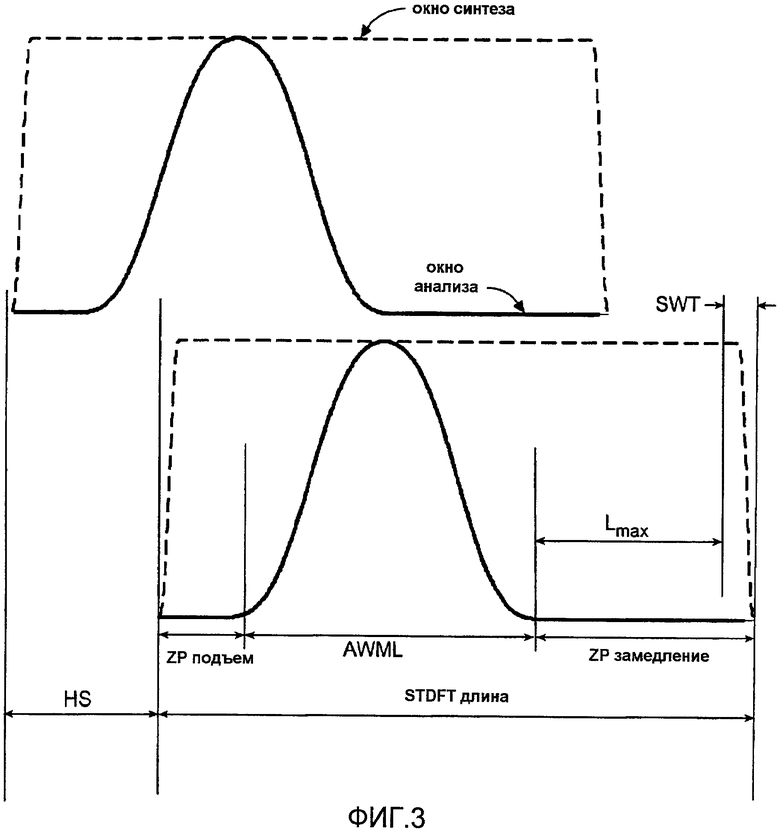
Частотно-Временное Преобразование 20, используемое для формирования двух объемных каналов из входных двухканальных сигналов, может основываться на хорошо известном кратковременном дискретном преобразовании Фурье (STDFT). Для минимизации эффектов циклической свертки 75% перекрытие может использоваться как для анализа, так и синтеза. С подходящим выбором окон анализа и синтеза перекрывающееся STDFT может использоваться для минимизации слышимых эффектов циклической свертки, несмотря на обеспечение способности применения величины и фазовых модификаций к спектру. Хотя пара отдельных окон не является критической, фиг.3 изображает подходящую пару окон анализа/синтеза для двух соответствующих временных блоков STDFT.
Окно анализа назначается так, чтобы сумма перекрытых окон анализа равнялась целому числу для выбранного перекрывающего интервала. Площадь Кайзер-Базель-Извлеченного (KBD) окна может использоваться, хотя использование этого отдельного окна не является существенным для изобретения. С таким окном анализа может прекрасно синтезироваться анализированный сигнал с несинтезированным окном, если модификации были сделаны для перекрывающихся STDFT. Однако в зависимости от примененных изменений величин и последовательностей декорреляции, используемых в этом примерном варианте осуществления, желательно сузить окно синтеза для предотвращения слышимых разрывов блоков. Параметры окон, используемые в примерной системе пространственного аудиокодирования, перечисляются ниже.
STDFT Длина: 2048
Длина Основной Доли Окна Анализа (AWML): 1024
Размер скачка (HS): 512
Ведущее дополнение нулями (ZPlead): 256
Отстающее дополнение нулями (ZPlag): 768
Сужение Окна Синтеза (SWT): 128
Полосовое сжатие
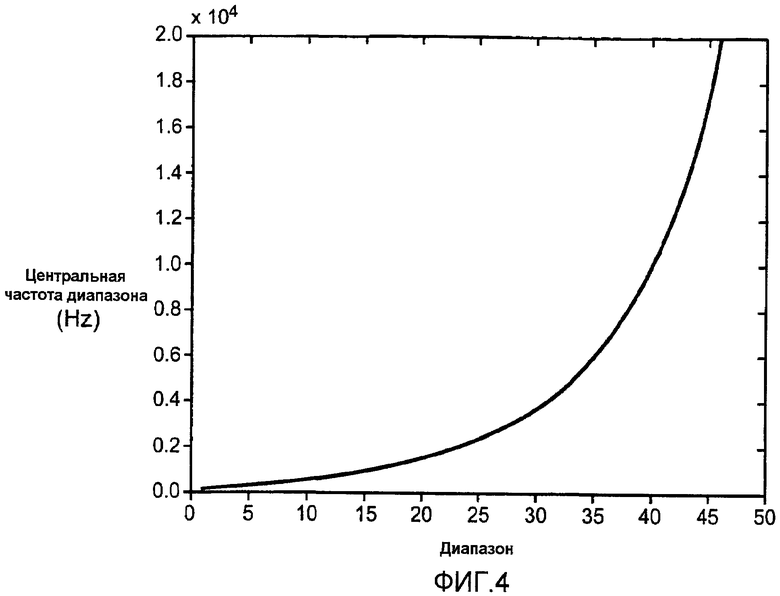
Примерный вариант осуществления повышающего микширования в соответствии с аспектами настоящего изобретения вычисляет и применяет масштабные коэффициенты усиления к соответствующим коэффициентам в спектральных диапазонах с приблизительно половинной шириной критического диапазона (см., например, ссылку [2]). Фиг.4 показывает график центральной частоты каждого диапазона в герцах для эталонной скорости в 44100 Гц, и таблица дает центральную частоту для каждого диапазона для эталонной скорости в 44100 Гц.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
65
129
221
289
356
409
488
553
618
684
749
835
922
1008
1083
1203
1311
1407
1515
1655
1794
1955
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
2288
2492
2728
2985
3253
3575
3939
4348
4798
5301
5859
6514
7190
7963
8820
9807
10900
12162
13616
15315
17331
19957
Сигнальный Адаптивный Квазиинтегратор
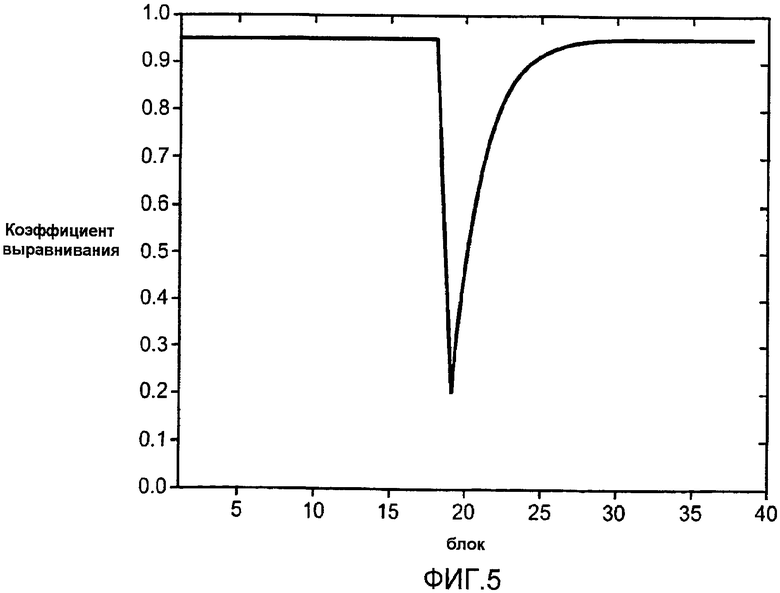
В примерной структуре повышающего микширования в соответствии с аспектами изобретения каждая статистика и переменная сначала вычисляется по спектральному диапазону и затем выравнивается по времени. Временное выравнивание каждой переменной сначала легко упорядочивается IIR, как показано в Уравнении 1. Однако альфа-параметр предпочтительно адаптируется по времени. Если детектируется событие аудитории (см., например, ссылку [3] или ссылку [4]), альфа-параметр уменьшается до нижнего значения и затем он восстанавливается до верхнего значения по времени. Таким образом, система обновляется более быстро во время изменений в аудио.
Событие аудитории может определяться как мгновенное изменение в аудиосигнале, например изменение сигнала инструмента или появление голоса говорящего. Таким образом, создается восприятие повышающего микширования для быстрого изменения его статистических оценок около точки детектирования события. Кроме того, система человеческой аудитории менее чувствительна во время возникновения переходных режимов/событий, так что моменты в аудиосегменте могут использоваться для скрытия отсутствия системных оценок статистических отсчетов. Событие может детектироваться посредством изменений в спектральном распределении между двумя смежными блоками по времени.
Фиг.5 показывает примерный отклик альфа-параметра (см. Уравнение 1, только ниже) в диапазоне, когда детектируется появление события аудитории (граница события аудитории только до блока 20 преобразования в примере на фиг.5). Уравнение 1 описывает зависимый от сигнала квазиинтегратор, который может использоваться в качестве блока оценки, используемого для уменьшения временного изменения величины кросс-корреляции (см. также обсуждение Уравнения 4 ниже).
C'(n,b)=αC'(n-1,b)+(1-α)C(n,b), (1)
где C(n,b) - переменная, вычисленная по спектральному диапазону b в блоке n, и C'(n,b) - переменная после временного выравнивания в блоке n.
Вычисления Объемных Каналов
Фиг.6 показывает более подробно схематичную функциональную блок-схему части получения объемного звука повышающего аудиомикшера или процесса, повышающего микширование, на фиг.2 в соответствии с аспектами настоящего изобретения. Для простоты представления фиг.6 показывает схематично поток сигналов в одном из множества частотных диапазонов, будет понятно, что объединенные действия во всех диапазонах множества частот создают аудиоканалы LS и RS объемного звука.
Как показано на фиг.6, каждый из входных сигналов (Lo/Lt и Ro/Rt) разделяется на три тракта. Первый тракт является «Трактом Управления» 40, который, в этом примере, вычисляет масштабные коэффициенты (G F и G B) усиления переднего/обратного отношения и масштабные коэффициенты (G D и G A) усиления прямого/окружающего отношения в компьютере или функции вычисления («Вычисление Управления для Диапазона») 42, который включает в себя устройство или процесс (не показано) для обеспечения величины кросс-корреляции входных сигналов. Другие два тракта являются «Трактом Прямого Сигнала» 44 и Трактом 46 Сигнала Окружения, выходы которых управляемо смешиваются совместно под управлением масштабных коэффициентов усиления G D и G A для обеспечения пары сигналов LS и RS объемных каналов. Тракт прямого сигнала включает в себя пассивный матричный декодер или процесс декодирования («Пассивный Матричный Декодер») 48. Альтернативно, активный матричный декодер может использоваться взамен пассивного матричного декодера для улучшения разделения объемных каналов под определенными условиями сигналов. Многие такие активные и пассивные матричные декодеры и функции декодирования хорошо известны из уровня техники, и использование любого такого конкретного одного устройства или процесса не является существенным для изобретения.
Необязательно для дополнительного улучшения эффекта разработки, созданного посредством панорамирования компонент окружающих сигналов для объемных каналов посредством применения масштабного коэффициента усиления G A, компоненты сигналов окружения из левого и правого входных сигналов могут применяться к соответствующему декоррелятору или умножаться на соответствующую последовательность фильтра декорреляции («Декоррелятор») 50 до смешивания с аудиокомпонентами прямого изображения из матричного декодера 48. Хотя декорреляторы 50 могут быть идентичными друг другу, некоторые слушатели могут предпочитать производительность, обеспеченную, когда они не являются идентичными. Хотя любой из множества типов декорреляторов может использоваться для тракта сигнала окружения, должна применяться осторожность для минимизации эффектов слышимого объединенного фильтра, которые могут вызывать микширование декоррелирующего аудиоматериала с недекоррелирующим сигналом. Конкретно эффективный декоррелятор описывается ниже, хотя его использование не существенно для изобретения.
Тракт 44 Прямого Сигнала может характеризоваться как включающий в себя соответствующие умножители 52 и 54, в которых масштабные коэффициенты G D усиления компонент прямого сигнала применяются к соответствующим левым объемным и правым объемным компонентам матрично-декодированных сигналов, выходы которых, в свою очередь, применяются к соответствующим аддитивным объединителям 56 и 58 (каждый показан как символ ∑ суммирования). Альтернативно, масштабные коэффициенты G D усиления компонент прямого сигнала могут применяться к входам Тракта 44 Прямого Сигнала. Обратный масштабный коэффициент G B усиления может затем применяться к выходу каждого объединителя 56 и 58 в умножителях 64 и 66 для создания левого и правого объемных выходов LS и RS. Альтернативно, масштабные коэффициенты G B и G D усиления могут умножаться вместе и затем применяться к соответствующим левым объемным и правым объемным компонентам матрично-декодированных сигналов до применения результатов к объединителям 56 и 58.
Тракт окружающих сигналов может характеризоваться путем включения соответствующих умножителей 60 и 62, в которых масштабные коэффициенты G A усиления компонент сигналов окружения применяются к соответствующим входным правым и левым сигналам, сигналы которых могут применяться к необязательным декорреляторам 50. Альтернативно, масштабные коэффициенты G A усиления компонент окружающих сигналов могут применяться к входам Тракта 46 Окружающих Сигналов. Применение масштабных коэффициентов G A усиления компонент динамически изменяемых сигналов окружения приводит к выделению компонент сигналов окружения из левого и правого входных сигналов независимо от того, используется ли декоррелятор 50. Такие компоненты сигналов левого и правого окружений затем применяются к соответствующим аддитивным объединителям 56 и 58. Если затем не применяются объединители 56 и 58, масштабный коэффициент усиления G B может умножаться на масштабный коэффициент G A усиления и применяться к компонентам сигналов левого и правого окружения до применения результата к объединителям 56 и 58.
Вычисления каналов объемного звука, которые могут требоваться в примере на фиг.6, могут характеризоваться следующими этапами и подэтапами.
Этап 1
Группирование каждого из входных сигналов в диапазонах
Как показано на фиг.6, тракт управления формирует масштабные коэффициенты G F, G B, G D и G A усиления - эти масштабные коэффициенты усиления вычисляются и применяются к каждому из частотных диапазонов. Отметим, что масштабный коэффициент усиления G F не используется в получении каналов объемного звука - он может применяться к передним каналам (см. фиг.2). Первым этапом в вычислении масштабных коэффициентов усиления является группирование каждого из входных сигналов в диапазонах, как показано в Уравнениях 2 и 3.
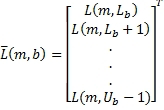 , (2)
, (2)
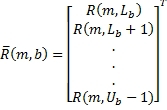 , (3)
, (3)
где m - индекс времени, b - индекс диапазона, L(m,k) - k-й спектральный отсчет левого канала за время m, R(m,k) - k-й спектральный отсчет правого канала за время m, 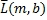 - столбцовая матрица, содержащая спектральные отсчеты левого канала для диапазона b,
- столбцовая матрица, содержащая спектральные отсчеты левого канала для диапазона b, 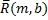 - столбцовая матрица, содержащая спектральные отсчеты правого канала для диапазона b, L
b - нижняя граница диапазона b и U
b - верхняя граница диапазона b.
- столбцовая матрица, содержащая спектральные отсчеты правого канала для диапазона b, L
b - нижняя граница диапазона b и U
b - верхняя граница диапазона b.
Этап 2
Вычисление величины кросс-корреляции между двумя входными сигналами в каждом диапазоне
Следующим этапом является вычисление величины межканальной корреляции между двумя входными сигналами (т.е. «кросс-корреляция») в каждом диапазоне. В этом примере это сопровождается тремя подэтапами.
Подэтап 2а
Вычисление величины уменьшенной временной дисперсии (выровненной по времени) кросс-корреляции
Сначала, как показано в Уравнении 4, вычисляют величину уменьшенной временной дисперсии межканальной корреляции. В Уравнении 4 и других уравнениях здесь E - оператор блока оценки. В этом примере блок оценки представляет уравнение зависимого от сигнала квазиинтегратора (такое как Уравнение 1). Есть множество других методов, которые могут использоваться в качестве блока оценки для уменьшения временной дисперсии измеренных параметров (например, простое скользящее временное среднее), и использование любого конкретного блока оценки не существенно для изобретения.
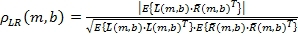 (4)
(4)
где T - транспонированный оператор Эрмита, ρ
LR
(m,b) - оценка коэффициента корреляции между левым и правым каналами в диапазоне b во время m. ρ
LR
(m,b) может иметь значение в диапазоне от нуля до одного. Транспонированный оператор Эрмита является как транспонированным оператором, так и сопряжением комплексных терминов. В Уравнении 4, например, 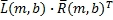 получает комплексный скаляр, в котором и - комплексные векторы строк, которые определены в Уравнениях 1 и 2.
получает комплексный скаляр, в котором и - комплексные векторы строк, которые определены в Уравнениях 1 и 2.
Подэтап 2b
Создание смещенной величины кросс-корреляции
Коэффициент корреляции может использоваться для управления количеством окружающего и прямого сигнала, который панорамируется из объемных каналов. Однако если левые и правые сигналы полностью отличаются, например два разных инструмента панорамируются для левого и правого каналов соответственно, то кросс-корреляция равна нулю, и строго панорамированные инструменты будут панорамироваться для объемных каналов, если используется подход, такой как подэтап 2а. Для достижения такого результата смещенная величина кросс-корреляции левого и правого входных сигналов может создаваться так, как показано в Уравнении 5.
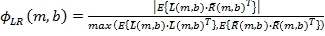 , (5)
, (5)
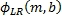 может иметь значение в диапазоне от нуля до единицы.
может иметь значение в диапазоне от нуля до единицы.
где - сдвинутая оценка коэффициента корреляции между левым и правым каналами.
Оператор «max» в знаменателе Уравнения 5 приводит в знаменателе к максимуму или 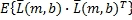 или
или 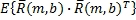 . В результате кросс-корреляция нормализируется или по энергии в левом сигнале, или по энергии в правом сигнале вместо геометрического значения, как в Уравнении 4. Если мощности левого и правого сигналов отличаются, то смещенная оценка коэффициента корреляции в Уравнении 5 приводит к меньшим значениям, чем те, которые сформированы коэффициентом ρ
LR
(m,b) корреляции в Уравнении 4. Таким образом, смещенная оценка может использоваться для уменьшения степени панорамирования в объемных каналах инструментов, которые являются строго панорамированными левыми и правыми.
. В результате кросс-корреляция нормализируется или по энергии в левом сигнале, или по энергии в правом сигнале вместо геометрического значения, как в Уравнении 4. Если мощности левого и правого сигналов отличаются, то смещенная оценка коэффициента корреляции в Уравнении 5 приводит к меньшим значениям, чем те, которые сформированы коэффициентом ρ
LR
(m,b) корреляции в Уравнении 4. Таким образом, смещенная оценка может использоваться для уменьшения степени панорамирования в объемных каналах инструментов, которые являются строго панорамированными левыми и правыми.
Подэтап 2c
Объединение несмещенных и смещенных величин кросс-корреляции
Далее, объединение несмещенной оценки кросс-корреляции, данной в Уравнении 4, со смещенной оценкой, данной в Уравнении 5, дает конечную величину межканальной корреляции, которая может использоваться для управления сигналом окружения и прямым сигналом, панорамированным для объемных каналов. Объединение может выражаться в качестве Уравнения 6, которое показывает, что межканальная связь равна коэффициенту корреляции, если смещенная оценка коэффициента корреляции (Уравнение 5) выше порога; иначе межканальная связь линейно приближается к целому. Целью Уравнения 6 является гарантия, что инструменты, которые являются строго панорамированными левыми и правыми во входных сигналах, не панорамируются для объемных каналов. Уравнение 6 является только одним возможным способом из множества для достижения такой цели.
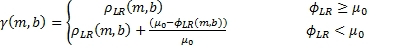 (6)
(6)
где µ0 - заранее заданный порог. Порог µ0 будет малым, насколько это возможно, но предпочтительно не нулем. Он может быть приблизительно равен дисперсии оценки смещенного коэффициента корреляции.
Этап 3
Вычисление переднего и обратного масштабных коэффициентов G F и G B усиления
Далее вычисляют передний и обратный масштабные коэффициенты G F и G B усиления. В этом примере это сопровождается тремя подэтапами. Подэтапы 3а и 3b могут выполняться или последовательно, или одновременно.
Подэтап 3а
Вычисление переднего и обратного масштабных коэффициентов 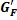 и
и 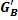 усиления благодаря только сигналам окружения
усиления благодаря только сигналам окружения
Далее вычисляют первый промежуточный набор переднего/обратного панорамирующих масштабных коэффициентов ( и ) усиления, как показано в Уравнениях 7 и 8 соответственно. Они представляют желаемое количество обратного/переднего панорамирования благодаря детектированию только сигналов окружения; конечные передний/обратный панорамированные масштабные коэффициенты усиления, которые описаны ниже, учитывают как панорамирование окружения, так и панорамирование объемного изображения.
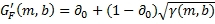 , (7)
, (7)
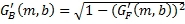 , (8)
, (8)
где 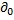 - заранее заданный порог и управляет максимальным количеством энергии, которая может панорамироваться в объемных каналах из области переднего звука. Порог может выбираться пользователем для управления количеством окружающего контента, посланного в объемных каналах.
- заранее заданный порог и управляет максимальным количеством энергии, которая может панорамироваться в объемных каналах из области переднего звука. Порог может выбираться пользователем для управления количеством окружающего контента, посланного в объемных каналах.
Хотя выражения для и в Уравнениях 7 и 8 являются подходящими и сберегают мощность, они не являются существенными для изобретения. Другие отношения, в которых и обычно являются инверсными друг для друга, могут использоваться.
Фиг.7 показывает график масштабных коэффициентов и усиления в зависимости от коэффициента (ρ
LR
(m,b)) корреляции. Отметим, что по мере того, как коэффициент корреляции уменьшается, больше энергии панорамируется в объемных каналах. Однако когда коэффициент корреляции падает ниже определенной точки, порог µ0, сигнал обратно панорамируется в передних каналах. Это предохраняет строго панорамированные изолированные инструменты в начальном левом и правом каналах от панорамирования в объемных каналах. Фиг.7 показывает только ситуацию, в которой энергии левого и правого сигналов равны; если левая и правая энергии различны, сигналы обратно панорамируются в передних каналах при более высоком значении коэффициента корреляции. Более конкретно, точка возврата, порог µ0, появляется при большем значении коэффициента корреляции.
Подэтап 3b
Вычисление переднего и обратного масштабных коэффициентов 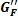 и
и 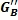 усиления благодаря только матрично-декодированным прямым сигналам
усиления благодаря только матрично-декодированным прямым сигналам
До настоящего момента было определено, сколько энергии прибавлено к объемным каналам, благодаря детектированию окружающего аудиоматериала; следующим этапом является вычисление желаемого уровня объемного канала благодаря только матрично-декодированным дискретным изображениям. Для вычисления количества энергии в объемных каналах благодаря таким дискретным изображениям первая оценка действительной части коэффициента корреляции Уравнения 4 показывается в Уравнении 9.
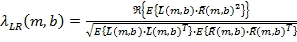 (9)
(9)
Благодаря 90% фазовому сдвигу во время процесса матричного кодирования (понижающее микширование), действительная часть коэффициента корреляции плавно переходит от 0 к -1, а также изображения в начальном многоканальном сигнале, перед понижающим микшированием, переходят из передних каналов в объемные каналы. Здесь может создаваться дополнительный промежуточный набор переднего/обратного панорамируемых масштабных коэффициентов усиления, как показано в Уравнениях 10 и 11.
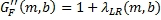 (10)
(10)
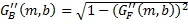 (11)
(11)
где 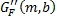 и
и 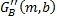 являются передним и обратным масштабными коэффициентами усиления для матрично-декодированного прямого сигнала соответственно для диапазона b за время m.
являются передним и обратным масштабными коэффициентами усиления для матрично-декодированного прямого сигнала соответственно для диапазона b за время m.
Хотя выражения для и в Уравнениях 10 и 11 являются подходящими и сберегают энергию, они не являются существенными для изобретения. Другие отношения, в которых и обычно являются инверсными друг к другу, могут использоваться.
Подэтап 3c
Используя результаты подэтапов 3а и 3b, вычисляют конечный набор переднего и обратного масштабных коэффициентов и усиления.
Теперь вычисляем конечный набор переднего и обратного масштабных коэффициентов усиления, которые получены в Уравнениях 12 и 13.
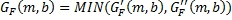 (12)
(12)
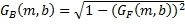 (13)
(13)
где MIN означает, что конечный передний масштабный коэффициент G
F
(m,b) усиления равен 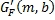 , если меньше, чем , иначе G
F
(m,b) равен .
, если меньше, чем , иначе G
F
(m,b) равен .
Хотя выражения для G F и G B в Уравнениях 10 и 11 являются подходящими и сберегают энергию, они не являются существенными для изобретения. Другие отношения, в которых G F и G B обычно являются инверсными друг к другу, могут использоваться.
Этап 4
Вычисление окружающих и матрично-декодированных прямых масштабных коэффициентов G D и G A усиления
В этой точке количество энергии, которое отправляется в объемные каналы, благодаря как детектированию сигналов окружения, так и детектированию матрично-декодированных прямых сигналов, было определено. Однако теперь требуется управление количеством каждого типа сигналов, который представлен в объемных каналах. Для вычисления масштабных коэффициентов усиления, которые управляют кросс-смешиванием между прямым сигналом и сигналами (G D и G A) окружения, может использоваться коэффициент ρ LR (m,b) корреляции из Уравнения 4. Если левый и правый входные сигналы являются относительно некоррелированными, то больше компонент сигналов окружения, чем компонент прямого сигнала, будет представлено в объемных каналах; если входные сигналы являются хорошо коррелирированными, то больше компонент прямых сигналов, чем компонент сигналов окружения, может быть представлено в объемных каналах. Здесь могут получаться масштабные коэффициенты усиления для прямого/окружающего отношения, как показано в Уравнении 14.
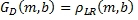
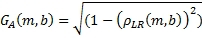 (14)
(14)
Хотя выражения для G D и G A в Уравнении 14 являются подходящими и сберегают энергию, они не являются существенными в изобретении. Другие отношения, в которых G D и G A обычно являются инверсными друг к другу, могут использоваться.
Этап 5
Создание компонент матрично-декодированных сигналов и сигналов окружения
Далее создают компоненты матрично-декодированных сигналов и сигналов окружения. Это может сопровождаться двумя подэтапами, которые могут выполняться или последовательно, или одновременно.
Подэтап 5а
Создание компонент матрично-декодированных сигналов для диапазона b
Создают компоненты матрично-декодированных сигналов для диапазона b, как показано, например, в Уравнении 15.
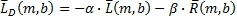
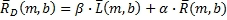 (15)
(15)
где 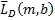 - компоненты матрично-декодированных сигналов из матричного декодера для левого объемного канала в диапазоне b за время m и
- компоненты матрично-декодированных сигналов из матричного декодера для левого объемного канала в диапазоне b за время m и 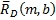 - компоненты матрично-декодированных сигналов из матричного декодера для правого объемного канала в диапазоне b за время m.
- компоненты матрично-декодированных сигналов из матричного декодера для правого объемного канала в диапазоне b за время m.
Этап 5b
Создание компонент окружающих сигналов для диапазона b
Применение масштабного коэффициента G A усиления, который динамически изменяется от скорости блока преобразования, выровненного по времени, выполняется для извлечения компонент сигналов окружения (см., например, ссылку [1]). Динамически изменяющийся масштабный коэффициента G A усиления может применяться до или после тракта 46 окружающих сигналов (фиг.6). Извлеченные компоненты сигналов окружения могут дополнительно увеличиваться посредством умножения всего спектра начального левого и правого сигналов на представление спектральной области в декорреляторе. Здесь для диапазона b и времени m даны сигналы окружения для левого и правого объемных сигналов, например, посредством Уравнений 16 и 17.
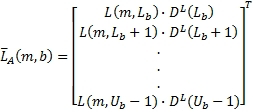 (16)
(16)
где 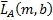 - сигнал окружения для левого объемного канала в диапазоне b во время m и D
L
(k) - представление спектральной области декоррелятором левого канала в столбце k.
- сигнал окружения для левого объемного канала в диапазоне b во время m и D
L
(k) - представление спектральной области декоррелятором левого канала в столбце k.
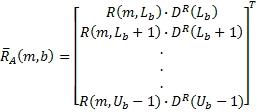 (17)
(17)
где 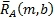 - сигнал окружения для правого объемного канала в диапазоне b во время m и D
R
(k) - представление спектральной области в декорреляторе правого канала в столбце k.
- сигнал окружения для правого объемного канала в диапазоне b во время m и D
R
(k) - представление спектральной области в декорреляторе правого канала в столбце k.
Этап 6
Применение масштабных коэффициентов G B , G D , G A усиления для получения сигналов объемных каналов
Наличие извлеченных коэффициентов G B , G D , G A усиления сигналов управления (этапы 3 и 4) и компонент матрично-декодированных и окружающих сигналов (этап 5) может применяться, как показано на фиг.6, для получения конечных сигналов объемных каналов в каждом диапазоне. Конечные выходные левый и правый объемные сигналы могут теперь получаться Уравнением 18.
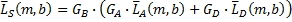
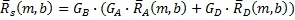 (18)
(18)
где 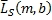 и
и 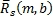 являются конечными левым и правым сигналами объемных каналов в диапазоне b за время m.
являются конечными левым и правым сигналами объемных каналов в диапазоне b за время m.
Как отмечено выше в связи с этапом 5b, будет очевидно, что применение масштабного коэффициента G A усиления, который динамически изменяется при скорости блока преобразования, выровненного по времени, может рассматриваться для извлечения компонент сигналов окружения.
Вычисления каналов объемного звука могут суммироваться, как указано далее.
1. Группируют каждый из входных сигналов в диапазоны (Уравнения 2 и 3).
2. Вычисляют величину кросс-корреляции между двумя входными сигналами в каждом диапазоне.
а. Вычисляют величину дисперсии, уменьшенной по времени (выровненной по времени) кросс-корреляции (Уравнение 4).
b. Создают смещенную величину кросс-корреляции (Уравнение 5).
с. Объединяют несмещенные и смещенные величины кросс-корреляции (Уравнение 6).
3. Вычисляют передний и обратный масштабные коэффициенты G F и G B усиления.
а. Вычисляют передний и обратный масштабные коэффициенты и усиления благодаря только окружающим сигналам (Уравнения 7, 8).
b. Вычисляют передний и обратный масштабные коэффициенты 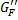 и
и 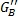 усиления благодаря только матрично-декодированным прямым сигналам (Уравнения 10, 11).
усиления благодаря только матрично-декодированным прямым сигналам (Уравнения 10, 11).
с. Используя результаты подэтапов 3а и 3b, вычисляют конечный набор передних и обратных масштабных коэффициентов G F и G B усиления (Уравнения 12, 13).
4. Вычисляют окружающие и матрично-декодированные прямые масштабные коэффициенты G D и G A усиления (Уравнение 14).
5. Создают компоненты матрично-декодированных и окружающих сигналов.
а. Создают компоненты матрично-декодированных сигналов для диапазона b (Уравнение 15).
b. Создают компоненты окружающих сигналов для диапазона b (Уравнения 16, 17, применение G A).
6. Применяют масштабные коэффициенты G B, G D, G A усиления к созданным компонентам сигналов для получения сигналов объемных каналов (Уравнение 18).
Альтернативы
Одна соответствующая реализация аспектов настоящего изобретения использует этапы обработки или устройства, которые реализуют соответствующие этапы обработки и функционально связаны, как указано выше. Хотя этапы, перечисленные выше, могут каждый выполняться последовательностями компьютерных программных команд, действующими в порядке этапов, перечисленных выше, будет понятно, что эквивалентные и аналогичные результаты могут получаться этапами, упорядоченными другими способами, учитывая, что определенное количество извлекается из указанного ранее. Например, последовательности многопотоковых компьютерных программных команд могут использоваться с тем, чтобы определенные последовательности этапов выполнялись параллельно. В качестве другого примера, порядок определенных этапов в указанном выше примере является произвольным и может изменяться без влияния на результаты - например, подэтапы 3а и 3b могут меняться и подэтапы 5а и 5b могут меняться. Также будет очевидно из просмотра Уравнения 18, что масштабный коэффициент G B усиления не требует отдельного вычисления от вычисления масштабных коэффициентов G A и G D усиления - единственный масштабный коэффициент G B G A усиления и единственный масштабный коэффициент G B G D усиления могут вычисляться и использоваться в модифицированной форме Уравнения 18, в которой масштабный коэффициент G B усиления вводится в скобки. Альтернативно, описанные этапы могут реализоваться в качестве устройств, которые выполняют описанные функции, при этом разные устройства имеют функциональные взаимоотношения, как описано выше.
Декорреляторы для Объемных Каналов
Для улучшения разделения между передними каналами и объемными каналами (или для усиления охвата начального аудиоматериала) может применяться декорреляция к объемным каналам. Декорреляция, как далее описано, может быть аналогична тем, которые представлены в ссылке [5]. Хотя был найден соответствующий декоррелятор, описанный далее, его использование не является существенным для изобретения и другие методы декорреляции могут использоваться.
Импульсная характеристика каждого фильтра может конкретизироваться как синусоидальная последовательность конечной длины, чья мгновенная частота уменьшается монотонно от 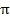 до нуля в течение продолжительности последовательности:
до нуля в течение продолжительности последовательности:
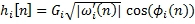 , n=0 … Li
, n=0 … Li
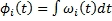 , (19)
, (19)
где ω
i
(t) - функция монотонно уменьшающейся мгновенной частоты, 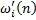 - первая производная мгновенной частоты, ф
i
(t) - мгновенная фаза, полученная интегралом мгновенной частоты, и L
i - длина фильтра. Множитель
- первая производная мгновенной частоты, ф
i
(t) - мгновенная фаза, полученная интегралом мгновенной частоты, и L
i - длина фильтра. Множитель 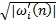 требуется для создания частотного отклика h
i
[n] аппроксимированной плоскости, пересекающей все частоты, и коэффициент G
i усиления вычисляется как:
требуется для создания частотного отклика h
i
[n] аппроксимированной плоскости, пересекающей все частоты, и коэффициент G
i усиления вычисляется как:
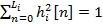 (20)
(20)
Конкретный импульсный отклик имеет форму последовательности типа импульса с линейной частотной модуляцией, и, как результат, фильтрование аудиосигналов с таким фильтром может иногда получать слышимые «импульсные линейные частотные модуляции» артефакты в местах импульсных помех. Этот эффект может уменьшаться посредством добавления шума к мгновенной фазе отклика фильтра:
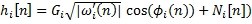 (21)
(21)
Создание этой шумовой последовательности N
i
[n], равной белому Гауссовому шуму с дисперсией, которая является малой частью 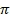 , достаточно для создания более шумного импульсного ответного звука, чем импульс с линейной частотной модуляцией, хотя желаемое отношение между частотой и задержкой, определяемой ω
i
(i), еще в большей мере поддерживается.
, достаточно для создания более шумного импульсного ответного звука, чем импульс с линейной частотной модуляцией, хотя желаемое отношение между частотой и задержкой, определяемой ω
i
(i), еще в большей мере поддерживается.
При очень низких частотах задержка, созданная последовательностью импульса с линейной частотной модуляцией, очень большая, что приводит к слышимым вырезкам, когда микшированный с повышением аудиоматериал микшируется с понижением для двух каналов. Для уменьшения этого артефакта последовательность импульса с линейной частотной модуляцией может заменяться на 90-ступенчатое фазовое переключение при частоте ниже 2,5 кГц. Фаза переключается между положительными и отрицательными 90 ступенями с переключением, возникающим с логарифмическим интервалом.
Так как система микширования с повышением использует STDFT с достаточным дополнением нулями (описано выше), фильтры декорреляции, данные Уравнением 21, могут применяться путем использования умножения в спектральной области.
Реализация
Изобретение может реализовываться аппаратно или программно или в комбинации (например, программируемые логические матрицы). Без другой конкретизации алгоритмы или процессы, включенные как часть изобретения, несущественно относятся к любым конкретным компьютерам или устройствам. В частности, различные машины общего назначения могут использоваться с программами, записанными в соответствии с идеей, описанной здесь, или может быть более подходящим создание более специализированных устройств (например, интегральные схемы) для выполнения требуемых этапов способа. Таким образом, изобретение может реализовываться в одной или более компьютерных программах, выполняемых на одной или более программируемых компьютерных системах, каждая содержащая, по меньшей мере, один процессор, по меньшей мере одну систему хранения данных (включая энергозависимую и энергонезависимую память и/или запоминающие элементы), по меньшей мере, одно устройство ввода или порт и, по меньшей мере, одно устройство вывода или порт. Программный код применяется к входным данным для выполнения функций, описанных здесь, и формирует выходную информацию. Выходная информация применяется к одному или более устройствам вывода известным образом.
Каждая такая программа может реализовываться на любом желаемом компьютерном языке (включая машинный, ассемблированный или процедурный высокого уровня, логический или объектно-ориентированные языки программирования) для связи с компьютерной системой. В любом случае язык может быть компилированным или интерпретированным языком.
Каждая такая компьютерная программа предпочтительно сохраняется на или загружается в запоминающий носитель или устройство (например, твердотельная память или носитель или магнитный или оптический носитель), считывается компьютером, программированным для обычной или специальной цели, для конфигурирования и функционирования компьютера, когда запоминающий носитель или устройство считывается компьютерной системой для выполнения процедур, описанных здесь. Изобретение может также создаваться для реализации в качестве считываемого компьютером носителя данных, конфигурируемого с компьютерной программой, где такой сконфигурированный носитель данных побуждает компьютерную систему функционировать конкретным и заранее определенным способом для выполнения функций, описанных здесь.
Ряд вариантов осуществления изобретений описан здесь. Однако будет понятно, что различные модификации могут быть сделаны без отхода от сущности и объема изобретения. Например, что также предполагается выше, некоторые этапы, описанные здесь, могут упорядочиваться независимо и, таким образом, могут выполняться в ином порядке от того, который описан.
Изобретение относится к обработке аудиосигналов, в частности к получению компонент сигналов окружения из аудиосигналов источника, получению компонент матрично-декодированных сигналов из аудиосигналов источника и управляемому объединению компонент сигналов окружения с компонентами матрично-декодируемых сигналов. Техническим результатом является создание приятно слышимого многоканального сигнала из двухканального сигнала, который или матрично кодируется, или нематрично кодируется без необходимости слушателю переключать режимы. Указанный технический результат достигается тем, что способ получения двух аудиоканалов объемного звука из двух входных аудиосигналов, при этом аудиосигналы могут включать в себя компоненты, сформированные матричным кодированием, содержит этапы, на которых получают компоненты сигналов окружения из упомянутых аудиосигналов, получают компоненты матрично-декодированных сигналов из аудиосигналов и управляемо объединяют компоненты сигналов окружения и компоненты матрично-декодированных сигналов для обеспечения аудиоканалов объемного звука, при этом управляемое объединение включает в себя применение масштабных коэффициентов усиления. 3 н. и 20 з.п. ф-лы, 7 ил., 1 табл.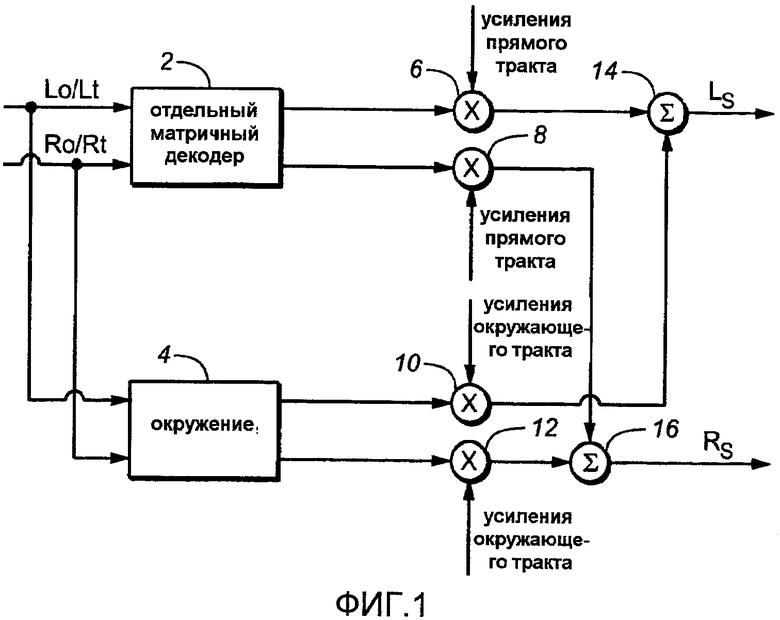
1. Способ получения двух аудиоканалов объемного звука из двух входных аудиосигналов, при этом упомянутые аудиосигналы могут включать в себя компоненты, сформированные матричным кодированием, содержащий этапы на которых:
получают компоненты сигналов окружения из упомянутых аудиосигналов,
получают компоненты матрично-декодированных сигналов из упомянутых аудиосигналов, и
управляемо объединяют компоненты сигналов окружения и компоненты матрично-декодированных сигналов для обеспечения упомянутых аудиоканалов объемного звука, при этом упомянутое управляемое объединение включает в себя применение масштабных коэффициентов усиления.
2. Способ по п.1, в котором получение компонент сигналов окружения включает в себя применение масштабного коэффициента усиления компонент динамически изменяемых сигналов окружения к входному аудиосигналу, и при этом упомянутые масштабные коэффициенты усиления включают в себя масштабный коэффициент усиления компонент динамически изменяемых сигналов окружения, примененный для получения компонент сигналов окружения.
3. Способ по п.2, в котором получение компонент матрично-декодированных сигналов включает в себя применение матричного декодирования к упомянутым входным аудиосигналам, матричное декодирование которых адаптируется для обеспечения первого и второго аудиосигналов, каждый из которых связан с задним направлением объемного звука, и при этом упомянутые масштабные коэффициенты усиления дополнительно включают в себя масштабный коэффициент усиления компонент динамически изменяемых матрично-декодированных сигналов, примененный к каждому из первого и второго аудиосигналов, связанных с задним направлением объемного звука.
4. Способ по п.3, в котором упомянутый масштабный коэффициент усиления компонент матрично-декодированных сигналов является функцией величины кросс-корреляции упомянутых входных аудиосигналов.
5. Способ по п.4, в котором масштабный коэффициент усиления компонент динамически изменяемых матрично-декодируемых сигналов увеличивается по мере того, как степень кросс-корреляции увеличивается, и уменьшается по мере того, как степень кросс-корреляции уменьшается.
6. Способ по п.5, в котором масштабный коэффициент усиления компонент динамически изменяемых матрично-декодированных сигналов и масштабный коэффициент усиления компонент динамически изменяемых сигналов окружения увеличиваются и уменьшаются по отношению друг к другу таким образом, что сохраняется объединенная энергия компонент матрично-декодированных сигналов и компонент сигналов окружения.
7. Способ по п.5, в котором упомянутые масштабные коэффициенты усиления дополнительно включают в себя масштабный коэффициент усиления динамически изменяемых аудиоканалов объемного звука для дополнительного управления усилением аудиоканалов объемного звука.
8. Способ по п.7, в котором масштабный коэффициент усиления аудиоканалов объемного звука является функцией величины кросс-корреляции упомянутых входных аудиосигналов.
9. Способ по п.8, в котором функция побуждает масштабный коэффициент усиления аудиоканалов объемного звука увеличиваться по мере того, как величина кросс-корреляции уменьшается до значения, ниже которого уменьшается масштабный коэффициент усиления аудиоканалов объемного звука.
10. Способ по п.9, в котором способ выполняется в частотно-временной области.
11. Способ по п.10, в котором способ выполняется в одном или более частотных диапазонах в частотно-временной области.
12. Способ по п.2, в котором упомянутый масштабный коэффициент усиления компонент сигналов окружения является функцией величины кросс-корреляции упомянутых входных аудиосигналов.
13. Способ по п.12, в котором масштабный коэффициент усиления компонент сигналов окружения уменьшается по мере того, как степень кросс-корреляции увеличивается, и наоборот.
14. Способ по п.12, в котором упомянутая величина кросс-корреляции временно выравнивается.
15. Способ по п.14, в котором величина кросс-корреляции временно выравнивается посредством использования зависимого от сигнала квазиинтегратора.
16. Способ по п.14, в котором величина кросс-корреляции временно выравнивается посредством использования скользящего среднего.
17. Способ по п.14, в котором временное выравнивание является сигнально-адаптивным.
18. Способ по п.17, в котором временное выравнивание адаптируется в ответ на изменения в спектральном распределении.
19. Способ по п.1, в котором получение компонент сигналов окружения включает в себя применение, по меньшей мере, одной последовательности фильтра декорреляции.
20. Способ по п.19, в котором одна и та же последовательность фильтра декорреляции применяется к каждому из упомянутых входных аудиосигналов.
21. Способ по п.19, в котором разная последовательность фильтра декорреляции применяется к каждому из упомянутых входных аудиосигналов.
22. Устройство для получения двух аудиоканалов объемного звука из двух входных аудиосигналов, выполненное с возможностью выполнения способа по п.1.
23. Считываемый компьютером носитель данных, содержащий сохраненную на нем компьютерную программу для побуждения компьютера выполнять способ по п.1.
| US 2006262936 А1, 23.11.2006 | |||
| US 7107211 В2, 12.09.2006 | |||
| US 7003467 В1, 21.02.2006 | |||
| WO 2005002278 А2, 06.01.2005 | |||
| KR 20030038786 А, 16.05.2003 | |||
| WO 9526083 A1, 28.09.1995 | |||
| ПОСТУСИЛИТЕЛЬНАЯ СХЕМА ДЕКОДИРОВАНИЯ СТЕРЕОФОНИЧЕСКОГО ЗВУКА В ОКРУЖАЮЩИЙ ЗВУК | 1997 |
|
RU2193827C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПЕРЕДАЧИ ХАРАКТЕРИСТИК ВИРТУАЛЬНОГО АКУСТИЧЕСКОГО ОКРУЖАЮЩЕГО ПРОСТРАНСТВА | 1998 |
|
RU2234819C2 |

