ОБЛАСТЬ ТЕХНИКИ
Изобретение имеет отношение к кодированию и декодированию аудиообъектов и, в частности, но не исключительно, к кодированию и/или декодированию аудиообъектов, совместимых со стандартом SAOC (пространственное кодирование аудиообъектов) MPEG.
УРОВЕНЬ ТЕХНИКИ
Многоканальное аудио широко распространено и стало популярным для многих различных приложений, в том числе для домашнего кино и многоканальных музыкальных систем. Аудиокодирование часто используется для формирования потоков данных, которые обеспечивают эффективное представление данных аудиосигналов. Такое аудиокодирование дает возможность эффективного хранения и распространения аудиосигналов. Много различных стандартов аудиокодирования было разработано для кодирования и декодирования как традиционных монофонических и стереофонических аудиосигналов, так и для кодирования и декодирования многоканальных аудиосигналов. Термин "многоканальный" в дальнейшем используется для обозначения более чем двух каналов. Использование специализированных аудиостандартов дает возможность взаимодействия и совместимости между многими различными системами, устройствами и приложениями, и поэтому важно придерживаться эффективных стандартов. Однако существенная проблема возникает, когда разрабатываются новые стандарты или изменяются существующие стандарты. В частности, модификации стандартов могут быть не только трудоемкими и громоздкими для выполнения, но также могут привести к тому, что существующее оборудование становится непригодным для новых или даже для существующих стандартов. Чтобы обеспечить возможность введения новых стандартов или модификаций стандартов, желательно, чтобы они требовали как можно меньше модификаций существующих стандартов. В некоторых случаях даже возможно сделать модификации, которые являются полностью совместимыми с существующими стандартами, то есть модификации могут быть применены без какого-либо изменения существующей спецификации стандарта. Примером этого является создание «водяных знаков» битового потока. При создании водяных знаков битового потока конкретные элементы битового потока модифицируются совместимым образом, вследствие чего битовый поток по-прежнему может быть декодирован в соответствии со спецификацией стандарта. Хотя выходная информация изменилась, различие в качестве обычно не заметно.
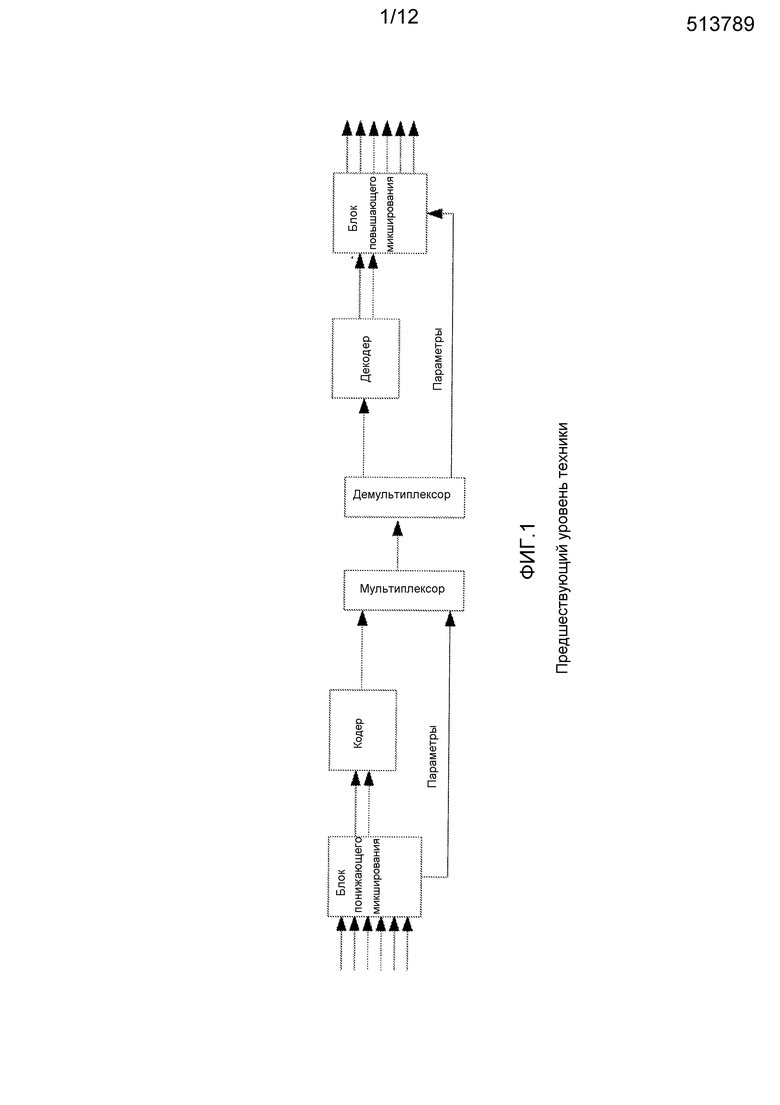
Технология MPEG Surround является одним из главных усовершенствований в многоканальном аудиокодировании недавно была стандартизирована экспертной группой по движущимся изображениям в ISO/IEC 23003-1. Технология MPEG Surround представляет собой инструмент многоканального аудиокодирования, который позволяет расширить существующие основанные на монофонических или стереофонических сигналах службы на многоканальные приложения. Фиг. 1 показывает блок-схему базового стереофонического кодера, расширенного с помощью MPEG Surround. Сначала кодер MPEG Surround создает стереофоническое понижающее микширование из многоканального входного сигнала. Затем оцениваются пространственные параметры из многоканального входного сигнала. Эти параметры кодируются в битовый поток MPEG Surround. Стереофоническое понижающее микширование кодируется в битовый поток с использованием базового кодера, например, HE-AAC. Полученный в результате битовый поток базового кодера и пространственный битовый поток объединяются для создания полного битового потока. Обычно пространственный битовый поток содержится во вспомогательных данных или в секции пользовательских данных битового потока базового кодера. На стороне декодера базовый и пространственный битовые потоки разделяются. Стереофонический базовый битовый поток декодируется для воспроизведения стереофонического понижающего микширования. Это понижающее микширование вместе с пространственным битовым потоком вводится в декодер MPEG Surround. Пространственный битовый поток декодируется для обеспечения пространственных параметров. Затем пространственные параметры используются для повышающего микширования из стереофонического понижающего микширования, чтобы получить многоканальный выходной сигнал.
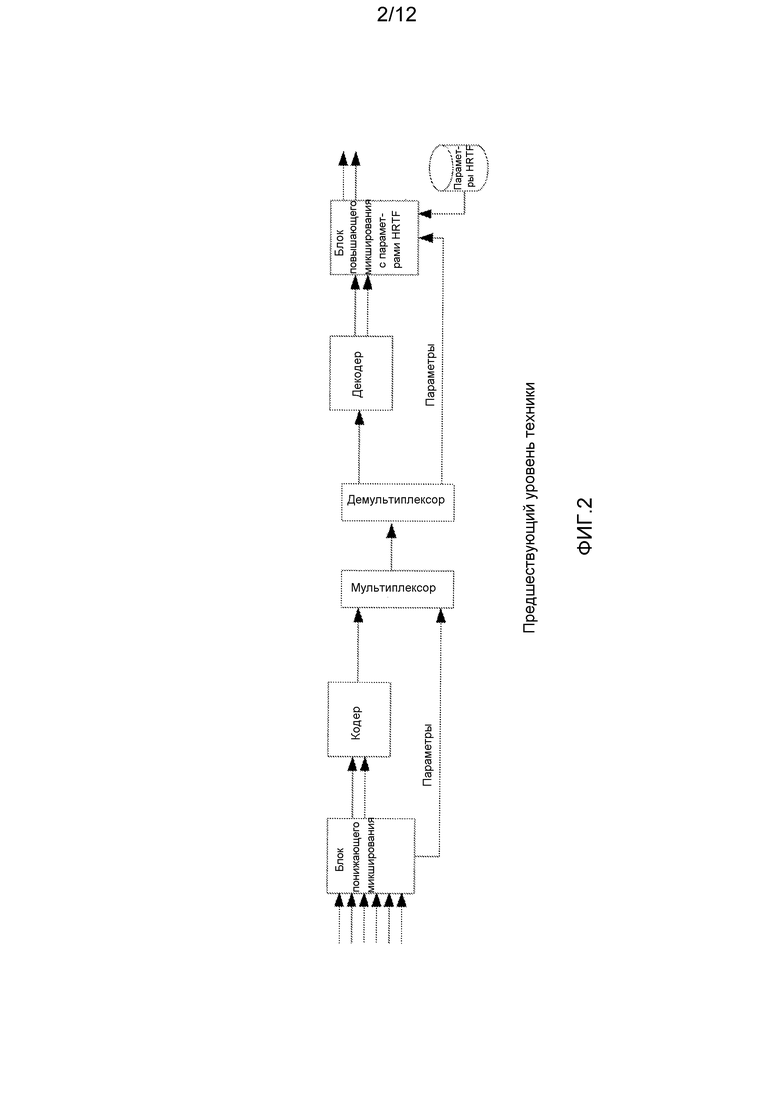
Поскольку пространственный образ многоканального входного сигнала параметризован, технология MPEG Surround дает возможность декодирования того же самого многоканального битового потока на устройствах воспроизведения, отличающихся от многоканальной установки динамиков. Примером является воспроизведение виртуального окружающего звука в наушниках, которое называется процессом бинаурального декодирования MPEG Surround. В этом режиме реалистическое окружающее звучание может быть обеспечено с использованием обычных наушников. Фиг. 2 показывает блок-схему стереофонического базового кодека, расширенного с помощью MPEG Surround, в которой выходной сигнал декодируется в бинауральный. Процесс кодера идентичен показанному на фиг. 1. В системе пространственные параметры объединяются с функцией моделирования восприятия звука (HRTF), и результат используется для получения так называемого бинаурального выходного сигнала.
Основываясь на концепции MPEG Surround, группа MPEG стандартизировала систему для кодирования отдельных аудиообъектов. Этот стандарт известен как "Пространственное кодирование аудиообъектов" (MPEG-D SAOC) ISO/IEC 23003-2. С точки зрения высокого уровня SAOC эффективно кодирует звуковые объекты вместо аудиоканалов, причем каждый звуковой объект обычно может соответствовать единственному источнику звука в звуковом образе. В MPEG Surround каждый канал динамика может рассматриваться как происходящий из отдельного микширования звуковых объектов, тогда как в SAOC данные предоставлены для отдельных звуковых объектов. Аналогично технологии MPEG Surround монофоническое или стереофоническое понижающее микширование также создается в SAOC. Более определенно, SAOC также формирует монофоническое или стереофоническое понижающее микширование, которое кодируется с использованием стандартного кодера микширования, такого как HE-AAC. Таким образом, унаследованные устройства воспроизведения будут игнорировать параметрические данные и воспроизводить монофоническое или стереофоническое понижающее микширование, тогда как декодеры SAOC могут выполнять повышающее микширование сигнала для извлечения первоначальных звуковых объектов или позволять их воспроизведение в желаемой выходной конфигурации. Параметры объектов и понижающего микширования встроены в секцию вспомогательных данных закодированного битового потока понижающего микширования, чтобы обеспечить информацию относительного уровня и усиления для индивидуальных объектов SAOC, обычно отражающую их понижающее микширование в стереофоническое/монофоническое понижающее микширование. На стороне декодера пользователь может управлять различными признаками отдельных объектов (такими как пространственная позиция, усиление и частотная коррекция) посредством манипуляции этими параметрами, или пользователь может применить эффекты, такие как реверберация, к отдельным объектам.
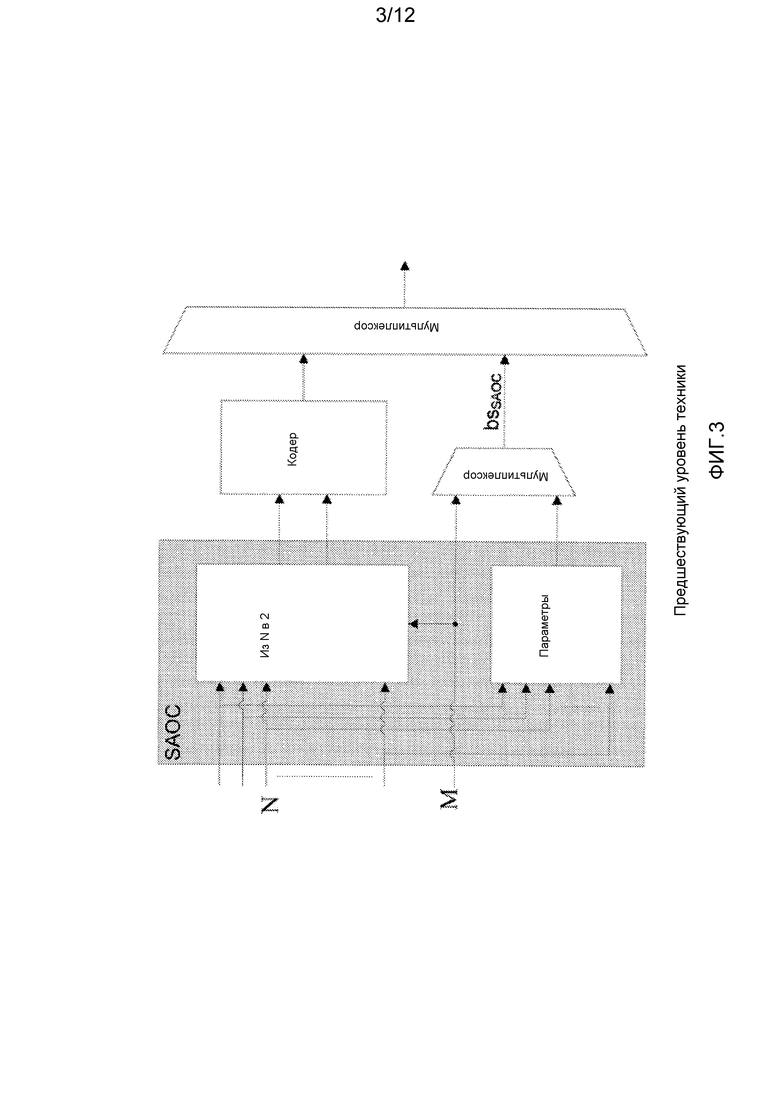
Фиг. 3 показывает блок-схему для регулярного кодирования SAOC. Кодер SAOC может рассматриваться как модуль предварительной обработки, расположенный перед традиционным монофоническим или стереофоническим кодером. Предварительная обработка состоит из формирования стереофонического (или монофонического) понижающего микширования из N объектных сигналов. Дополнительно параметры объектов извлекаются и сохраняются в битовом потоке SAOC вместе с информацией о матрице M понижающего микширования. Информация понижающего микширования SAOC кодируется в параметрах двух типов. Сначала параметр DMG (коэффициент усиления понижающего микширования) указывает коэффициент усиления, примененный к объекту. Параметр DCLD (разность уровня канала понижающего микширования) сообщает распределение объекта по двум каналам в стереофоническом понижающем микшировании. Оба эти параметры заданы для каждого объекта.
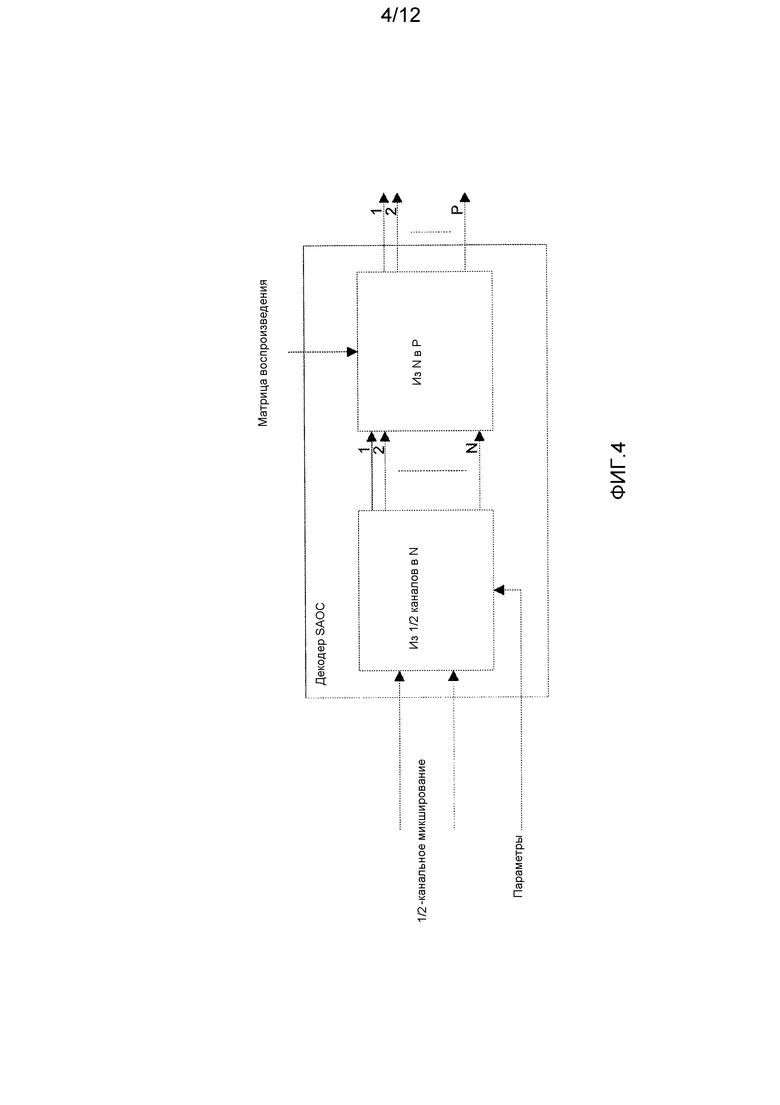
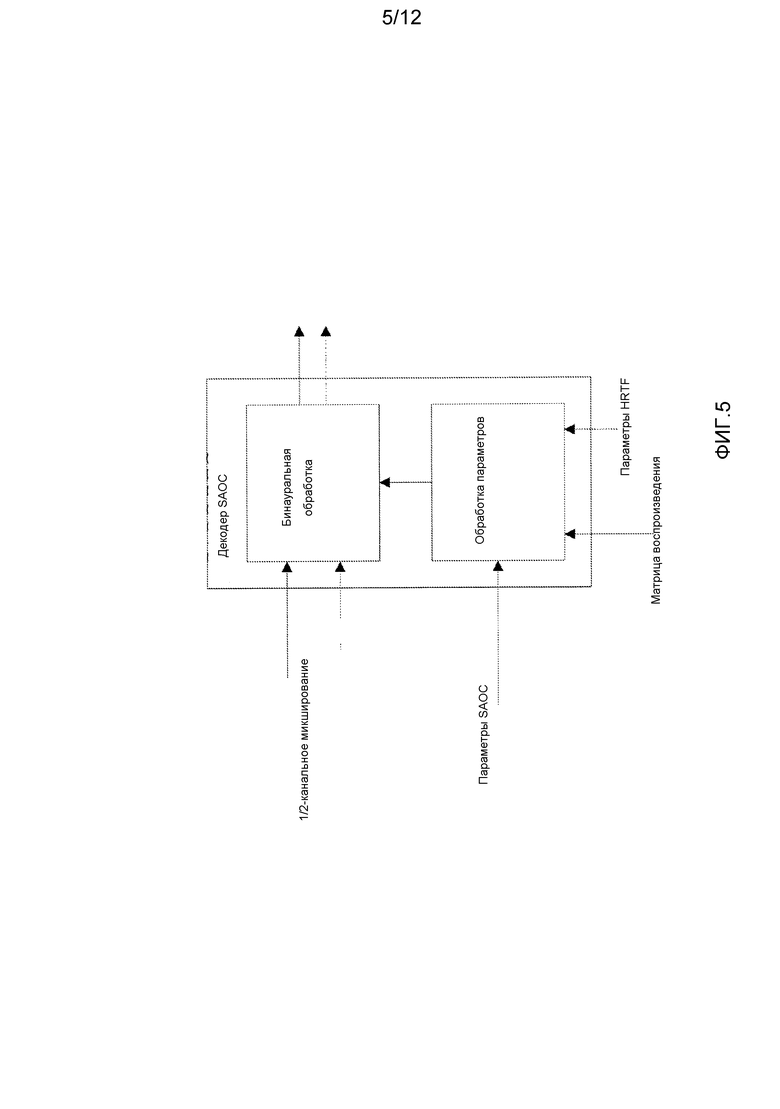
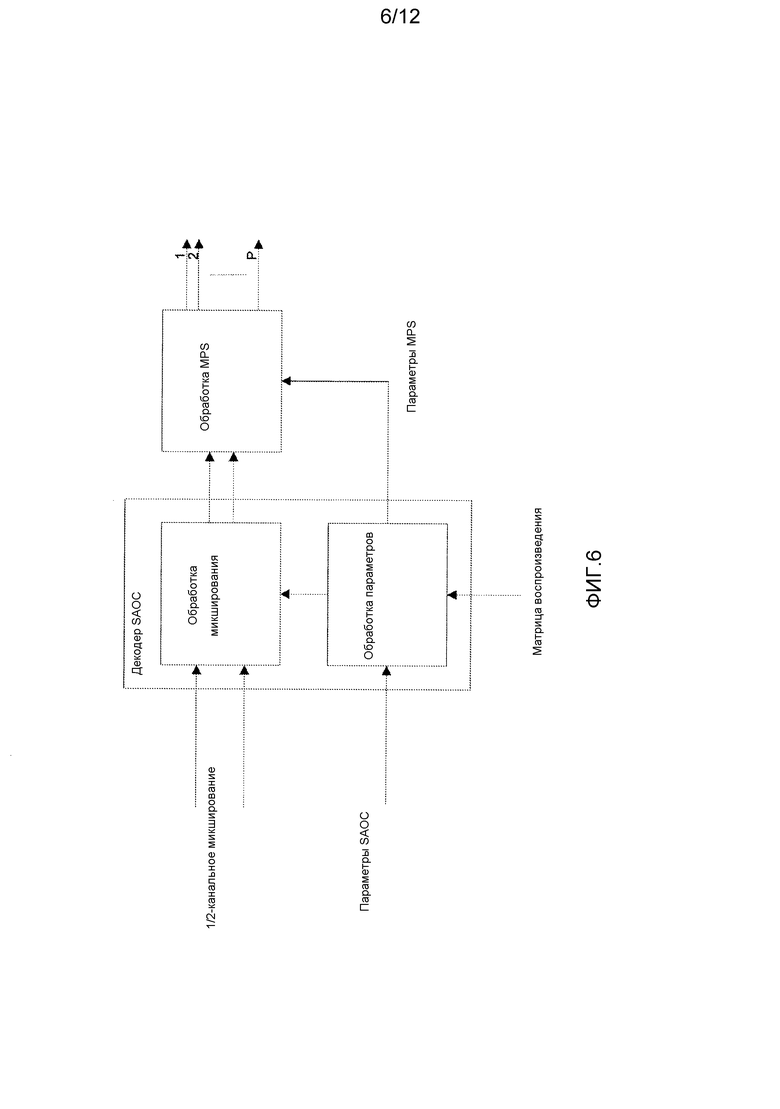
Декодер SAOC может выполнить противоположную операцию. Принятое монофоническое или стереофоническое понижающее микширование может быть декодировано и микшировано с повышением для желаемой выходной конфигурации. Операция повышающего микширования включает в себя объединенную операцию повышающего микширования монофонического или стереофонического понижающего микширования для формирования аудиообъектов, за которыми следует их отображение на требуемую выходную конфигурацию на основе матрицы воспроизведения, как проиллюстрировано на фиг. 4, где входное монофоническое или стереофоническое понижающее микширование сначала подвергается повышающему микшированию до N аудиообъектов на основе параметров SAOC. Полученные в результате N аудиообъектов затем микшируются с понижением в P выходных каналов с использованием матрицы воcпроизведения, определяющей, где расположены индивидуальные объекты. Фиг. 4 иллюстрирует концептуальное декодирование SAOC. Однако обычно матрица повышающего микширования и матрица воспроизведения объединяются в единую матрицу, и формирование выходных каналов из монофонического или стереофонического понижающего микширования выполняется как одна операция. Пример этого показан на фиг. 5, где показан конкретный пример, в котором P равно одному или двум, и в котором специально для P=2 вывод может представлять собой бинауральный пространственный выходной канал. Таким образом, два выходных канала формируются с использованием параметров HRTF, примененным к индивидуальным объектам, для формирования желаемого бинаурального пространственного образа. Фиг. 6 иллюстрирует пример, в котором P>2, и декодирование/обработка MPEG Surround (MPS) используется для формирования P выходных каналов.
Однако проблема, связанная с SAOC, заключается в том, что спецификация поддерживает только монофоническое и стереофоническое понижающее микширование, тогда как имеется много приложений и примеров использования, в которых используются или иногда даже требуются многоканальные микширования, например DVD и Blu-Ray. Поэтому желательно, чтобы кодирование SAOC поддерживало такие многоканальные приложения, то есть многоканальное понижающее микширование, но это потребует существенных поправок к стандартной спецификации SAOC, что было бы громоздким, непрактичным увеличением сложности и привело бы к сокращению обратной совместимости.
В частности, было бы полезно, если бы существующие алгоритмы, функциональные блоки, специализированные аппаратные средства и т.д., разработанные для кодирования и декодирования SAOC, могли бы быть использованы с возможностью улучшенной поддержки многоканального аудио.
Следовательно, будет полезен улучшенный подход для кодирования и/или декодирования объектов (такого как, например, кодирование/декодирование SAOC), и, в частности, будут полезны подходы, дающие возможность увеличения гибкости, уменьшения воздействия на стандартизированные подходы, увеличения или обеспечения обратной совместимости, увеличения повторного использования функциональности кодирования и/или декодирования, обеспечения возможности реализации многоканальной поддержки при кодировании объектов и/или увеличения производительности.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В соответствии с этим изобретение стремится предпочтительно смягчить, облегчить или устранить один или несколько упомянутых выше недостатков отдельно или в любой комбинации.
В соответствии с аспектом изобретения обеспечен кодер аудиообъектов, содержащий: приемник для приема N аудиообъектов; микшер для микширования N аудиообъектов в M аудиоканалов; схему каналов для получения K аудиоканалов из M аудиоканалов, где K=1 или 2, и K<M; схему параметров, формирующую параметры повышающего микширования аудиообъектов по меньшей мере для части из каждого из N аудиообъектов относительно K аудиоканалов; выходную схему для формирования потока выходных данных, содержащего параметры повышающего микширования аудиообъектов и M аудиоканалов.
Изобретение может дать возможность аудиокодирования, которое может обеспечить улучшенную производительность для систем многоканального воспроизведения при поддержке кодирования аудиообъектов. Система может в некоторых сценариях дать возможность улучшенного многоканального воспроизведения и может в некоторых сценариях дать возможность улучшенной функциональности аудиообъектов. Низкий темп передачи данных может быть достигнут посредством объединения M аудиоканалов с параметрами повышающего микширования аудиообъектов, относящимися к K звуковым каналам, вследствие чего нет необходимости включать закодированные данные для K аудиоканалов в поток выходных данных.
Изобретение может дать возможность многоканальной поддержки (более чем с двумя каналами) в системах кодирования аудиообъектов, обеспечивающих кодирование (и/или декодирование) аудиообъектов на основе только монофонических и стереофонических сигналов. Кодирование может формировать поток выходных данных, в котором многоканальный сигнал обеспечивается вместе с соответствующими данными аудиообъектов, которые, однако, определены не относительно многоканального сигнала, а относительно монофонического или стереофонического сигнала, который может быть получен из многоканального сигнала.
Во многих приложениях изобретение может дать возможность улучшенного повторного использования и/или обратной совместимости с существующей функциональностью кодирования и/или декодирования аудиообъектов.
Аудиообъект может представлять собой компонент аудиосигнала, соответствующий единственному источнику звука в аудиосреде. Более определенно, аудиообъект может включать в себя аудиоинформацию только от одной позиции в аудиосреде. Аудиообъект может иметь соответствующую позицию, но не соответствовать какой-либо конкретной конфигурации воспроизведения источника звука, и, в частности, может не соответствовать какой-либо конкретной конфигурации громкоговорителей.
Поток выходных данных может не включать в себя данные кодирования K аудиоканалов. В некоторых вариантах осуществления один, несколько или все из N аудиообъектов формируются из K аудиоканалов.
Получение K каналов может быть выполнено в каждом сегменте, и конкретное получение может изменяться динамически, например, между сегментами. Во многих вариантах осуществления и/или сценариях M может быть меньше N.
В соответствии с дополнительным признаком изобретения, схема каналов выполнена с возможностью получать K каналов посредством понижающего микширования M аудиоканалов.
Это может обеспечить особенно выгодную систему во многих сценариях и приложениях. В частности, это может дать возможность повторного использования функциональности и может дать возможность эффективного кодирования и декодирования аудиообъектов. Более определенно, подход может дать возможность сформированному понижающему микшированию обеспечивать подходящие компоненты в K аудиоканалов для всех аудиообъектов, также представленных в M аудиоканалах.
В некоторых вариантах осуществления понижающее микширование может быть таким, что каждый из M аудиоканалов представлен по меньшей мере в одном из K каналов, и в некоторых вариантах осуществления во всех из K каналов.
В соответствии с дополнительным признаком изобретения схема каналов выполнена с возможностью получать K каналов посредством выбора K-канального подмножества из M аудиоканалов.
Это может обеспечить особенно выгодную систему во многих сценариях и приложениях. В частности, это может дать возможность повторного использования функциональности и может дать возможность эффективного кодирования и декодирования аудиообъектов. Во многих вариантах осуществления это может уменьшить сложность и/или увеличить гибкость. Выбор K каналов может динамически варьироваться, что дает возможность выбора разных K каналов в разных сегментах времени.
В соответствии с дополнительным признаком изобретения поток выходных данных содержит поток многоканальных закодированных данных для M аудиоканалов, и параметры повышающего микширования аудиообъектов содержатся в части потока многоканальных закодированных данных.
Это может обеспечить особенно выгодный поток выходных данных во многих вариантах осуществления. В частности, это может дать возможность объединенного потока данных, который поддерживает как многоканальное аудио непосредственно, так и кодирование аудиообъектов на основе монофонических и/или стереофонических сигналов, тем самым обеспечивая обратную совместимость. Таким образом, может быть обеспечен поток многоканальных закодированных данных, который содержит многоканальный сигнал и параметры повышающего микширования аудиообъектов, которые не обеспечены относительно кодируемого многоканального сообщения, но которые тем не менее позволяют декодировать объект на основе закодированного многоканального сигнала.
В соответствии с дополнительным признаком изобретения выходная схема выполнена с возможностью включать данные микширования, представляющие микширование N аудиообъектов в M аудиоканалов, в поток выходных данных.
Это может дать возможность улучшенной производительности во многих вариантах осуществления, и, в частности, во многих вариантах осуществления может дать возможность обеспечить улучшенное декодирование аудиообъектов и функциональность в декодере. Данные микширования, например, могут быть заданы в частотно-временной области.
В соответствии с аспектом изобретения, имеется декодер аудиообъектов, содержащий: приемник для приема потока данных, содержащего аудиоданные для микширования M каналов из N аудиообъектов и параметры повышающего микширования аудиообъектов для N аудиообъектов относительно K аудиоканалов, где K=1 или 2, и K<M; схему каналов, получающую K аудиоканалов из микширования M каналов; и декодер объектов для формирования P аудиосигналов из N аудиообъектов, по меньшей мере частично сформированных посредством повышающего микширования из K аудиоканалов на основе параметров повышающего микширования аудиообъектов.
Изобретение может дать возможность декодирования аудиообъектов и, в частности, может дать возможность эффективного декодирования аудиообъектов на основе сигнала, который непосредственно поддерживает системы многоканального воспроизведения. Декодер аудиообъектов может формировать P аудиосигналов без приема каких-либо данных аудиокодирования для K аудиоканалов.
Во многих приложениях изобретение может дать возможность улучшенного повторного использования и/или обратной совместимости с существующей функциональностью кодирования и/или декодирования аудиообъектов.
Декодер объектов может быть выполнен с возможностью формировать P аудиосигналов посредством повышающего микширования из K каналов N аудиообъектов и затем отображения N аудиообъектов на P аудиоканалов. Отображение может быть представлено матрицей воспроизведения. Повышающее микширование из K каналов N аудиообъектов и отображение N аудиообъектов на P выходных каналов могут быть выполнены как единая интегрированная операция. Более определенно, матрица повышающего микширования из K в N может быть объединена с матрицей из N в P для формирования матрицы из K в P, которая непосредственно применяется к K каналам для формирования P выходных сигналов. Таким образом, декодер объектов может быть выполнен с возможностью формировать P выходных каналов на основе параметров повышающего микширования аудиообъектов для N аудиообъектов и матрицы воспроизведения для P выходных каналов. В некоторых вариантах осуществления могут быть явно сформированы N аудиообъектов, и особенно каждый из P аудиосигналов может соответствовать единственному аудиообъекту из N аудиообъектов. В некоторых сценариях N может быть равно P.
В соответствии с дополнительным признаком изобретения, схема каналов выполнена с возможностью получать K каналов посредством понижающего микширования M аудиоканалов.
Это может обеспечить особенно выгодную систему во многих сценариях и приложениях. В частности, это может дать возможность эффективного кодирования и декодирования аудиообъектов. Более определенно, подход может дать возможность сформированному понижающему микшированию обеспечивать подходящие компоненты в K аудиоканалах для всех аудиообъектов, также представленных в M аудиоканалах. В некоторых вариантах осуществления декодер объектов может быть выполнен с возможностью формировать каждый из N аудиообъектов посредством повышающего микширования из K аудиоканалов на основе параметров повышающего микширования аудиообъектов.
В некоторых вариантах осуществления понижающее микширование может быть таким, что каждый из M аудиоканалов представлен по меньшей мере в одном из K каналов, и в некоторых вариантах осуществления во всех из K каналов.
В соответствии с дополнительным признаком изобретения поток данных дополнительно содержит данные понижающего микширования, являющиеся показателем понижающего микширования кодера из M в K каналов, причем схема каналов выполнена с возможностью адаптировать понижающее микширование в ответ на данные понижающего микширования.
Это может дать возможность увеличенной гибкости и/или улучшенной производительности во многих вариантах осуществления. Например, это может дать возможность адаптации понижающего микширования к конкретным характеристикам сигнала и может, например, дать возможность адаптировать понижающее микширование к N аудиообъектам для обеспечения подходящих компонентов сигнала всех N аудиообъектов, чтобы обеспечить формирование объектов в декодере.
В некоторых вариантах осуществления в кодере и декодере может использоваться фиксированное или предопределенное понижающее микширование M каналов в K каналов. Это может уменьшить сложность и может, в частности, устранить необходимость включать данные, являющиеся показателем понижающего микширования, в поток данных, тем самым потенциально позволяя уменьшить темп передачи данных.
В соответствии с дополнительным признаком изобретения схема каналов выполнена с возможностью получать K каналов посредством выбора K-канального подмножества из M аудиоканалов.
Это может дать возможность улучшения и/или обеспечения кодирования аудиообъектов во многих вариантах осуществления. Во многих вариантах осуществления это может дать возможность уменьшения сложности.
В соответствии с дополнительным аспектом изобретения поток данных дополнительно содержит дополнительные параметры повышающего микширования аудиообъектов для N аудиообъектов относительно L аудиоканалов, где L=1 или 2, и L<M, и L аудиоканалов и K аудиоканалов являются разными подмножествами из M аудиоканалов, причем декодер объектов дополнительно выполнен с возможностью формировать P каналов из N аудиообъектов, по меньшей мере частично формированных посредством повышающего микширования из L аудиоканалов на основе дополнительных параметров повышающего микширования аудиообъектов.
Это может дать возможность улучшенного декодирования аудиообъектов во многих вариантах осуществления. В частности, это может дать возможность использовать компоненты сигнала каждого звукового объекта в более чем K (и, в частности, во всех M) аудиоканалах при формировании аудиообъекта.
Подмножества могут быть непересекающимися. В некоторых вариантах осуществления повышающее микширование дополнительно может быть основано на одном или нескольких дополнительных подмножествах аудиоканалов с соответствующими параметрами повышающего микширования аудиообъектов. В некоторых вариантах осуществления комбинация подмножеств может включать в себя все M аудиоканалов.
В соответствии с дополнительным признаком изобретения по меньшей мере один из P каналов формируется посредством объединения вкладов как от повышающего микширования из K аудиоканалов на основе параметров восстановления аудиообъектов, так и от повышающего микширования из L аудиоканалов на основе дополнительных параметров повышающего микширования аудиообъектов.
Это может дать возможность улучшенного декодирования аудиообъектов во многих вариантах осуществления. В частности, это может дать возможность использовать компоненты сигнала каждого аудиообъекта в более чем K (и, в частности, во всех M) аудиоканалах при формировании аудиообъекта.
В соответствии с дополнительным признаком изобретения поток данных содержит данные микширования, представляющие микширование N аудиообъектов в M аудиоканалов, причем декодер объектов выполнен с возможностью формировать разностные данные по меньшей мере для подмножества из N аудиообъектов в ответ на данные микширования и параметры повышающего микширования аудиообъектов и формировать P аудиосигналов в ответ на разностные данные.
Это может обеспечить улучшенное качество одного, некоторых или всех декодированных аудиообъектов во многих вариантах осуществления. Во многих вариантах осуществления это может дать возможность совместимости со стандартизированными алгоритмами декодирования аудиообъектов, которые могут принимать разностные данные, такими как, например, стандарт SAOC. Разностные данные, в частности, могут являться показателем разности между аудиообъектом, сформированным из K каналов и параметров повышающего микширования аудиообъектов, и соответствующим аудиообъектом, сформированным на основе M аудиоканалов данных понижающего микширования.
В соответствии с аспектом изобретения обеспечен способ кодирования аудиообъектов, содержащий этапы, на которых: принимают N аудиообъектов; микшируют N аудиообъектов в M аудиоканалов; получают K аудиоканалов из M аудиоканалов, где K=1 или 2, и K<M; формируют параметры повышающего микширования аудиообъектов по меньшей мере для части из каждого из N аудиообъектов относительно K аудиоканалов; и формируют поток выходных данных, содержащий параметры повышающего микширования аудиообъектов и M аудиоканалов.
В соответствии с дополнительным аспектом изобретения обеспечен способ декодирования аудиообъектов, содержащий этапы, на которых: принимают поток данных, содержащий аудиоданные для микширования M каналов из N аудиообъектов и параметры повышающего микширования аудиообъектов для N аудиообъектов относительно K аудиоканалов, где K=1 или 2, и K<M; получают K аудиоканалов из микширования M каналов; и формируют P аудиосигналов из N аудиообъектов, по меньшей мере частично сформированных посредством повышающего микширования из K аудиоканалов на основе параметров повышающего микширования аудиообъектов.
Эти и другие аспекты, отличительные признаки и преимущества изобретения будут понятны и разъяснены со ссылкой на варианты осуществления, описанные далее.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления изобретения будут описаны только в качестве примера со ссылкой на чертежи.
Фиг. 1 - иллюстрация системы MPEG Surround в соответствии с предшествующим уровнем техники;
Фиг. 2 - иллюстрация системы MPEG Binaural Surround в соответствии с предшествующим уровнем техники;
Фиг. 3 - иллюстрация кодера SAOC MPEG в соответствии с предшествующим уровнем техники;
Фиг. 4-6 иллюстрируют примеры декодеров SAOC MPEG в соответствии с предшествующим уровнем техники;
Фиг. 7 иллюстрирует пример элементов кодера аудиообъектов в соответствии с некоторыми вариантами осуществления изобретения;
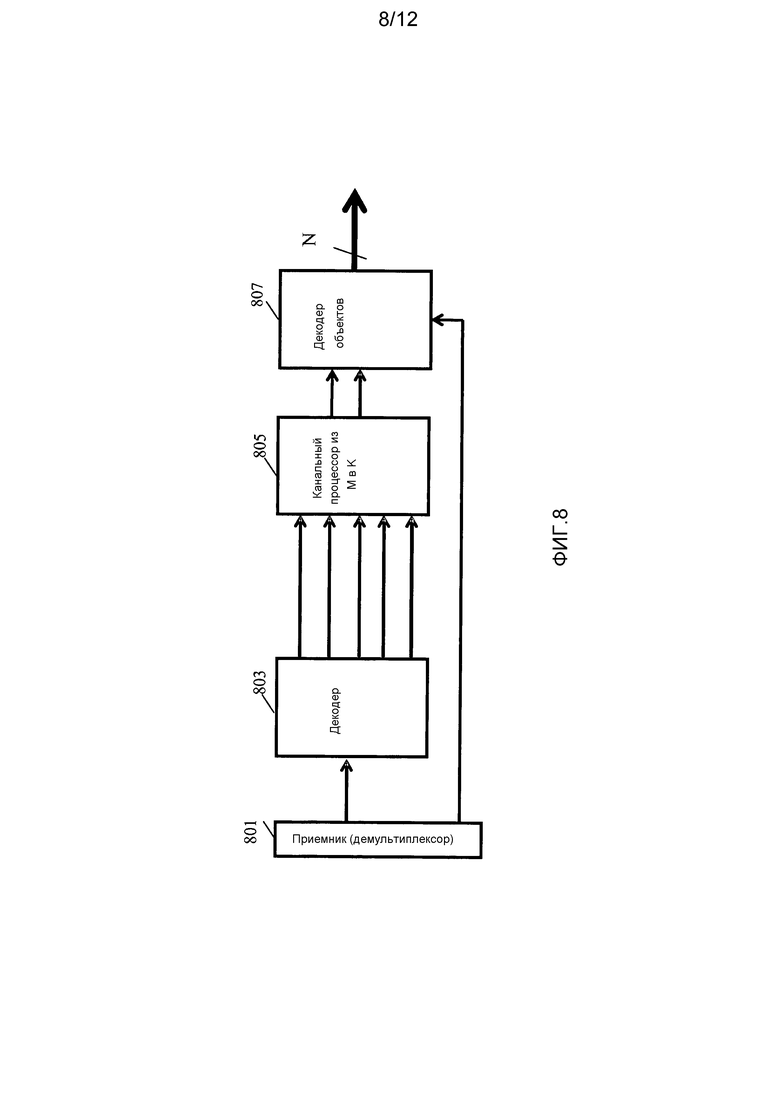
Фиг. 8 иллюстрирует пример элементов декодера аудиообъектов в соответствии с некоторыми вариантами осуществления изобретения;
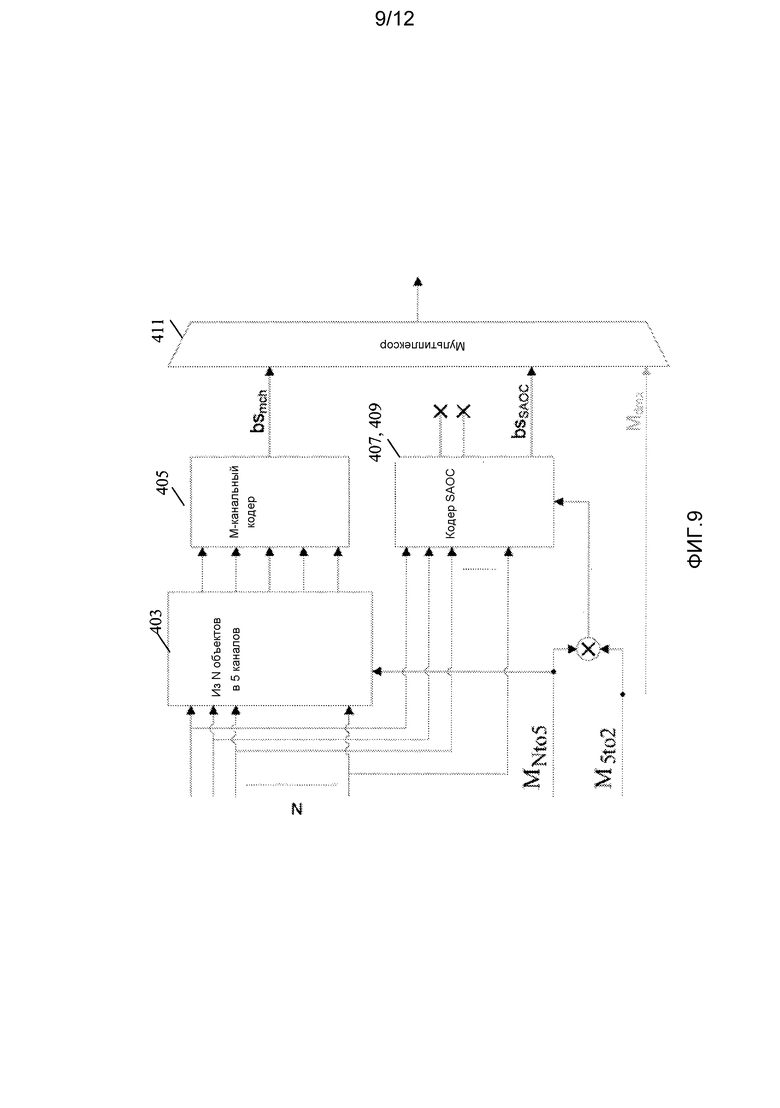
Фиг. 9 иллюстрирует пример элементов кодера аудиообъектов в соответствии с некоторыми вариантами осуществления изобретения;
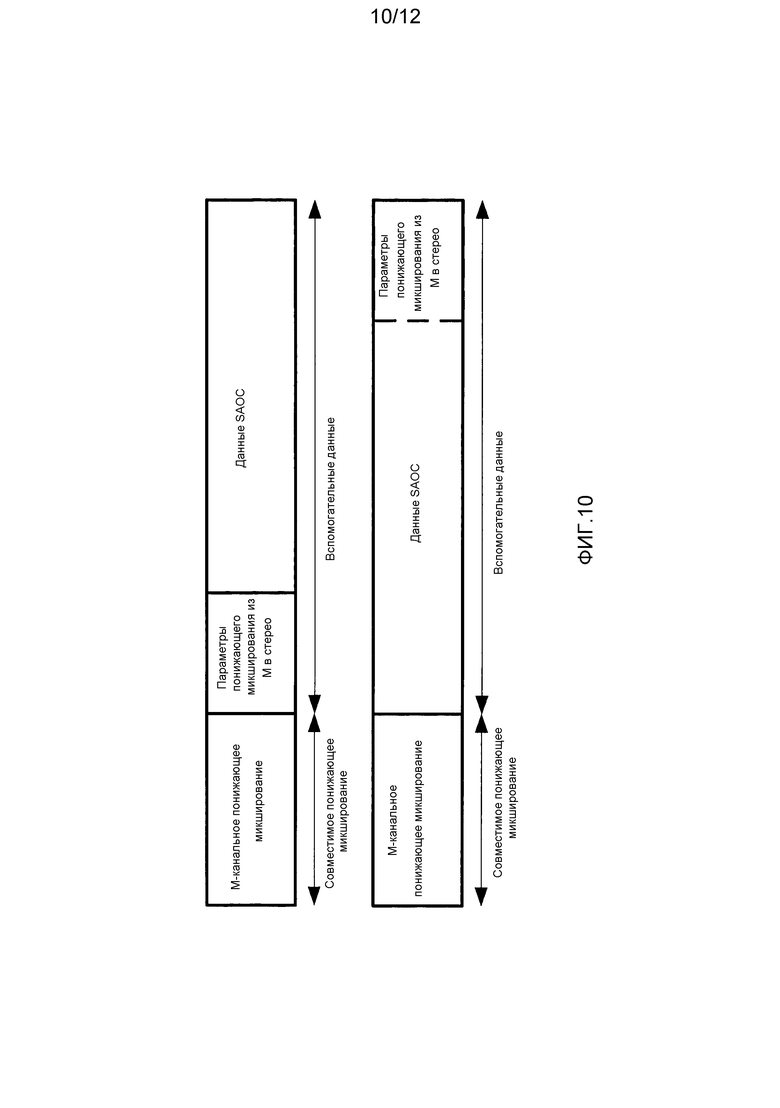
Фиг. 10 иллюстрирует пример потока выходных данных кодера в соответствии с некоторыми вариантами осуществления изобретения;
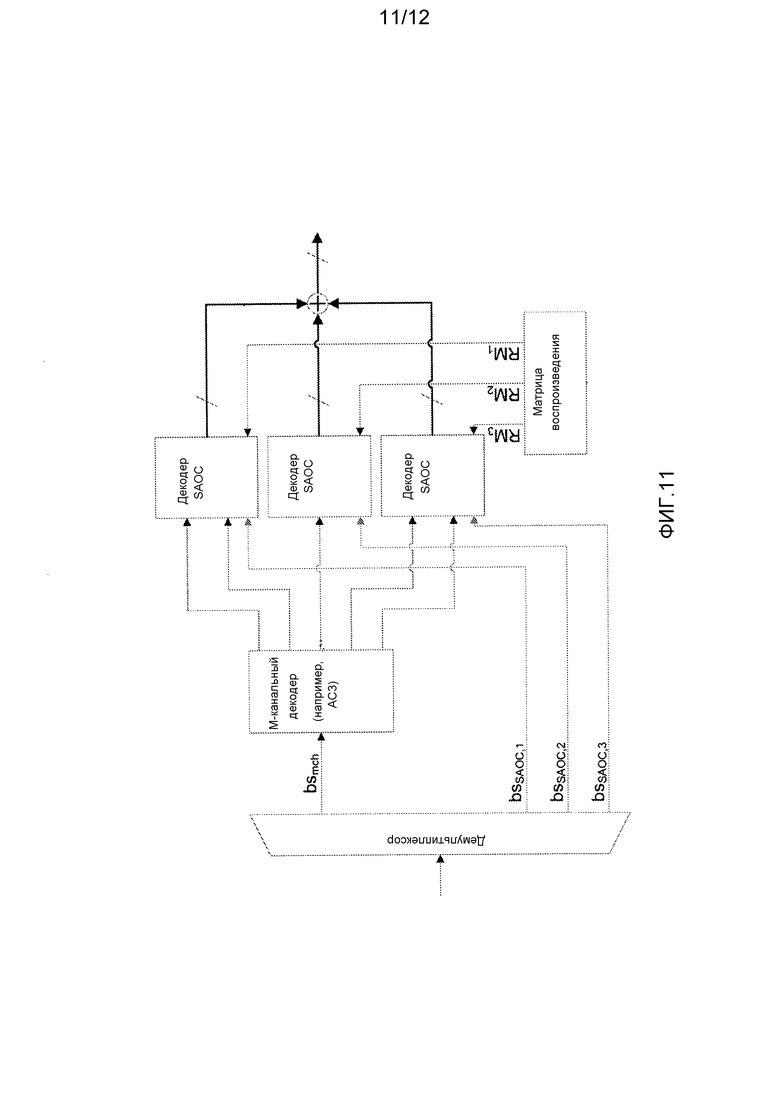
Фиг. 11 иллюстрирует пример элементов декодера аудиообъектов в соответствии с некоторыми вариантами осуществления изобретения; и
Фиг. 12 иллюстрирует пример элементов декодера аудиообъектов в соответствии с некоторыми вариантами осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ НЕКОТОРЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Следующее описание сосредоточено на системе кодера и декодера объекта, в которой N аудиообъектов сводятся (подвергаются понижающему микшированию) в M аудиоканалов, причем M<N. Однако, будет понятно, что может использоваться другое микширование, и что в некоторых вариантах осуществления и сценариях M может быть равным или больше чем N.
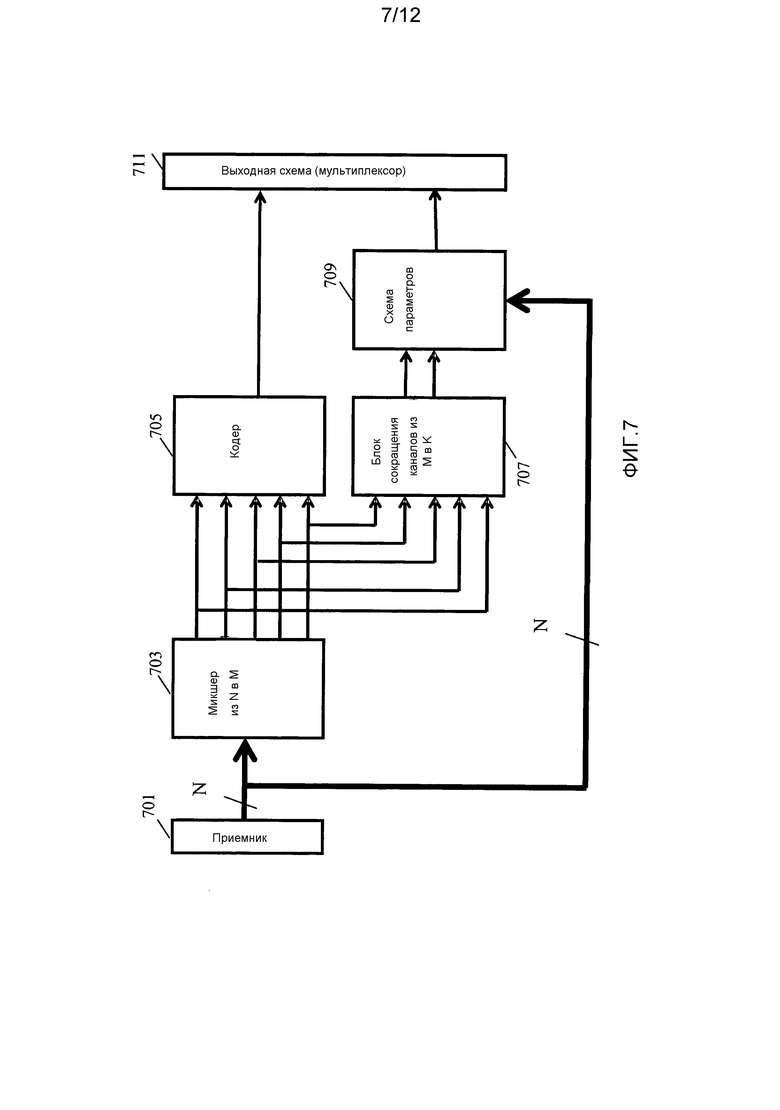
Фиг. 7 иллюстрирует элементы кодера аудиообъекта в соответствии с некоторыми вариантами осуществления изобретения.
Кодер содержит приемник 701, который принимает N аудиообъектов. Каждый аудиообъект обычно соответствует одному источнику звука. Таким образом, в отличие от аудиоканалов и, в частности, аудиоканалах традиционного пространственного многоканального сигнала, аудиообъекты не содержат компоненты от множества источников звука, которые могут иметь в значительной степени разные позиции. Аналогичным образом, каждый аудиообъект обеспечивает полное представление источника звука, и каждый аудиообъект, таким образом, соответствует данным пространственной позиции только для одного источника звука. Более определенно, каждый аудиообъект может рассматриваться как единственное и полное представление источника звука и может соответствовать единственной пространственной позиции.
Кроме того, аудиообъекты не соответствуют какой-либо конкретной конфигурации воспроизведения и, в частности, не соответствуют какой-либо конкретной пространственной конфигурации звуковых преобразователей. Таким образом, в отличие от традиционных пространственных аудиоканалов, которые обычно соответствуют конкретной пространственной установке динамиков, например, в частности, установке окружающего звука, аудиообъекты не определены относительно какой-либо конкретной пространственной конфигурации воспроизведения.
N аудиообъектов подаются в понижающий микшер 703 из N в M, который микширует с понижением N аудиообъектов в M аудиоканалов. В примере M<N, но будет понятно, что в некоторых сценариях N может быть равным или даже меньшим чем M. В конкретном примере на фиг. 7 M равно 5, но будет понятно, что в других вариантах осуществления могут использоваться другие количества каналов, в том числе, например, M=7 или M=9.
Таким образом, понижающий микшер 703 из N в M формирует M-канальный многоканальный сигнал, в котором аудиообъекты распределены по каналам. В отличие от N аудиообъектов M аудиоканалов представляют собой традиционные аудиоканалы, которые обычно содержат данные от множества аудиообъектов и, таким образом, от множества источников звука с разными позициями. Кроме того, отдельные аудиообъекты обычно распределены по M аудиоканалам, и часто каждый из M аудиоканалов содержит компонент от заданного аудиообъекта, хотя в некоторых сценариях некоторые аудиообъекты могут быть представлены только в подмножестве M аудиоканалов.
Понижающий микшер 703 из N в M формирует многоканальный сигнал (в дальнейшем используется для обозначения сигнала, обеспеченного M аудиоканалами), который может быть непосредственно воспроизведен как многоканальный сигнал. Более определенно, многоканальный сигнал, сформированный M аудиоканалами, может представлять собой сигнал пространственного окружающего звука, и в конкретном примере M аудиоканалов могут представлять собой соответственно передний левый, передний правый, центральный, окружающий левый и окружающий правый каналы из пятиканальной системы (и, соответственно, M=5). Таким образом, многоканальный сигнал, сформированный M аудиоканалами, соответствует конкретной конфигурации воспроизведения, и, в частности, каждый аудиоканал является аудиоканалом, соответствующим позиции воспроизведения.
Понижающий микшер 703 из N в M может выполнить понижающее микширование таким образом, что отдельные аудиообъекты располагаются по желанию в окружающем звуковом образе, обеспечиваемом M аудиоканалами. Например, один аудиообъект может быть расположен непосредственно спереди, другой объект может быть расположен слева от номинальной позиции слушателя и т.д. Понижающее микширование из N в M, в частности, может управляться вручную, чтобы получающийся в результате сигнал окружающего звука M аудиоканалов обеспечивал желаемое пространственное распределение, когда многоканальный сигнал непосредственно воспроизводится. Понижающее микширование из N в M, в частности, может быть основано на матрице понижающего микширования из N в M, которая сформирована вручную человеком для обеспечения желаемого сигнала окружающего звука от M аудиоканалов.
M аудиоканалов подаются на M-канальный кодер 705, который затем кодирует M аудиоканалов в соответствии с любым подходящим алгоритмом кодирования. M-канальный кодер 705 обычно использует традиционную схему многоканального кодирования для обеспечения эффективного представления соответствующего сигнала окружающего звука.
Будет понятно, что кодирование M аудиоканалов обычно предпочтительно, но не является необходимым во всех вариантах осуществления. Например, понижающий микшер 703 из N в M может непосредственно сформировать представление в частотной области или во временной области сигналов, которые могут использоваться непосредственно. Например, возможно отправить M аудиоканалов в декодер объектов с использованием незакодированных данных PCM. Однако эффективное кодирование может в значительной степени уменьшить скорость передачи данных и поэтому обычно используется.
Закодированный многоканальный сигнал может, в частности, соответствовать традиционному многоканальному сигналу, и традиционное аудиоустройство, принимающее многоканальный сигнал, может соответствующим образом воспроизвести многоканальный сигнал непосредственно.
Кодер, показанный на фиг. 7, кроме того, содержит функциональность для обеспечения параметров повышающего микширования аудиообъектов, которые позволяют восстановить первоначальные N аудиообъектов в подходящим образом оборудованном устройстве декодирования объектов. Однако параметры повышающего микширования аудиообъектов обеспечиваются не относительно M аудиоканалов, а вместо этого обеспечиваются относительно K аудиоканалов, где K равно одному или двум. Таким образом, кодер формирует параметры повышающего микширования аудиообъектов относительно монофонического или стереофонического сигнала. Это дает возможность совместимости со стандартами, позволяющими кодирование и декодирование объектов только на основе монофонических или стереофонических сигналов понижающего микширования из первоначальных аудиообъектов. Во многих сценариях это может позволить повторно использовать стандартную функциональность кодера или декодера аудиообъектов для монофонических или стереофонических сигналов в случаях с многоканальной поддержкой. Например, подход может использоваться, чтобы дать возможность улучшенной совместимости с кодированием SAOC.
Кодер содержит блок 707 сокращения каналов из M в K, который принимает M аудиоканалов от понижающего микшера 703 из N в M и затем получает K аудиоканалов из M аудиоканалов, где K равно 1 или 2.
Блок 707 сокращения каналов из M в K соединен со схемой 709 параметров, которая также принимает первоначальные N аудиообъектов от приемника. Блок 707 сокращения каналов из M в K выполнен с возможностью формировать параметры повышающего микширования аудиообъектов по меньшей мере для части каждого из N аудиообъектов относительно K аудиоканалов. Таким образом, формируются параметры повышающего микширования аудиообъектов, которые описывают, каким образом часть из N аудиообъектов или все N аудиообъектов могут быть сформированы из монофонического или стереофонического сигнала, принятого от блока 707 сокращения каналов из M в K.
М-канальный кодер 705 и схема 709 параметров соединены с выходной схемой 711, которая формирует поток выходных данных, содержащий параметры повышающего микширования аудиообъектов, принятые от схемы 709 параметров, и закодированные M аудиоканалов, принятые от M-канального кодера 705. Однако поток выходных данных не включает в себя данные K аудиоканалов (закодированные или не закодированные). Таким образом, формируется поток выходных данных, который содержит закодированный многоканальный сигнал, который может быть воспроизведен непосредственно унаследованными многоканальными устройствами, даже если они не способны к декодированию или обработке аудиообъектов. Кроме того, обеспечиваются параметры повышающего микширования аудиообъектов, которые могут позволить восстановить первоначальные N аудиообъектов на стороне декодера. Однако параметры повышающего микширования аудиообъектов обеспечиваются не относительно сигнала, включенного в поток данных, а вместо этого относительно монофонического или стереофонического сигнала, который не включен в поток выходных данных. Это дает совместимость операции с подходами кодирования и декодирования аудиообъектов, которые ограничены монофоническими и стереофоническими сигналами. Например, существующее блоки кодирования и декодирования SAOC могут быть повторно использованы, давая возможность многоканальной поддержки.
Кроме того, хотя K аудиоканалов не включены в поток выходных данных, они могут быть получены декодером из многоканального сигнала. В соответствии с этим подходящим образом оборудованный декодер может получить K аудиоканалов и затем сформировать N аудиообъектов на основе параметров повышающего микширования аудиообъектов. Это, в частности, может быть сделано с использованием существующей функциональности повышающего микширования на основе лежащего в основе стереофонического или монофонического сигнала. Таким образом, этот подход может позволить единственному потоку выходных данных обеспечивать многоканальный сигнал, который может быть воспроизведен непосредственно многоканальными устройствами, и данные аудиообъекта, относящиеся к монофоническому или стереофоническому сигналу, не включенные в поток выходных данных, позволяя однако сформировать первоначальные аудиообъекты.
Поток выходных данных может, в частности, содержать поток многоканальных закодированных данных для M аудиоканалов, причем поток многоканальных закодированных данных также включает в себя параметры повышающего микширования аудиообъектов. Таким образом, может быть обеспечен поток многоканальных закодированных данных, который содержит непосредственно многоканальный сигнал плюс данные для формирования индивидуальных аудиообъектов, содержащихся в многоканальном сигнале, но причем эти данные связаны не непосредственно с многоканальным сигналом, а с монофоническим или стереофоническим сигналом, который не включен в поток многоканальных закодированных данных. Параметры повышающего микширования аудиообъектов, в частности, могут быть включены в поле вспомогательных или опциональных данных потока многоканальных закодированных данных.
Фиг. 8 иллюстрирует пример декодера в соответствии с некоторыми вариантами осуществления изобретения.
Декодер содержит приемник 801 для приема потока выходных данных от кодера, показанного на фиг. 7. Таким образом, приемник принимает поток данных, содержащий аудиоданные для понижающего микширования M каналов из N аудиообъектов вместе с параметрами повышающего микширования аудиообъектов для N аудиообъектов относительно K аудиоканалов, где K=1 или 2, и K<M. В примере аудиоданные для понижающего микширования M каналов являются закодированными аудиоданными.
Закодированные аудиоданные для понижающего микширования M каналов подаются многоканальному декодеру 803, который формирует M аудиоканалов из закодированных аудиоданных. M аудиоканалов подаются канальному процессору 805 из M в K, который получает K аудиоканалов из M аудиоканалов. Канальный процессор 805 из M в K, в частности, выполняет ту же самую операцию, что и блок 707 сокращения каналов из M в K из кодера, показанного на фиг. 7. Полученные в результате K аудиоканалов подаются декодеру 807 объектов, который формирует N аудиообъектов посредством повышающего микширования из K аудиоканалов на основе параметров повышающего микширования аудиообъектов. Декодер 807 объектов, в частности, выполняет обратную операцию схемы 709 параметров, показанной на фиг. 7.
Будет понятно, что в примере на фиг. 8 декодер 807 объектов восстанавливает N аудиообъектов, которые затем могут быть индивидуально обработаны и/или отображены на конкретную конфигурацию динамиков. Таким образом, в примере формируются P выходных сигналов, где P=N, и каждый выходной сигнал соответствуют одному из аудиообъектов N.
В некоторых вариантах осуществления отображение на заданную конфигурацию динамиков может быть объединено с повышающим микшированием декодера 807 объектов, например, посредством применения единого матричного умножения, причем матричные коэффициенты отражают объединенное матричное умножение отображения K аудиоканалов на N аудиообъектов и матричное умножение отображения N аудиообъектов на каналы конфигурации динамиков.
В частности, может быть сформировано P аудиосигналов, где каждый из Р аудиосигналов может соответствовать пространственному выходному каналу заданной P-канальной конфигурации воспроизведения. Это может быть достигнуто посредством применения декодером 807 объектов матрицы воспроизведения, которая отображает N аудиообъектов на P аудиосигналов. Как правило, матрица повышающего микширования объектов, формирующая N аудиообъектов из K аудиоканалов, объединяется с матрицей воспроизведения, отображающей N аудиообъектов на P аудиосигналов. Таким образом, единая объединенная матрица повышающего микширования объектов и воспроизведения применяется к K звуковым каналам для формирования P аудиосигналов. Объединенная матрица повышающего микширования объектов и воспроизведения, в частности, может быть сформирована посредством умножения матрицы повышающего микширования объектов и матрицы воспроизведения.
В некоторых вариантах осуществления канальный процессор 805 из M в K и блок 707 сокращения каналов из M в K могут быть выполнены с возможностью формировать K каналов посредством понижающего микширования M аудиоканалов. В частности, понижающее микширование может быть сформировано таким образом, что все аудиообъекты имеют существенные компоненты сигнала в понижающем микшировании, что тем самым дает возможность повышающего микширования на основе K каналов, достаточного для всех N аудиообъектов.
Пример этого подхода проиллюстрирован на фиг. 9. В конкретном примере кодирование объектов является совместимым со стандартом SAOC, и, таким образом, используется кодер SAOC. В конкретном примере M=5 и K=2.
Кроме того, следует отметить, что в примере на фиг. 9 формирование K аудиоканалов выполняется посредством объединения операции, которая формирует M аудиоканалов из N аудиообъектов, и операции, которая формирует K аудиоканалов из M аудиообъектов, в единую операцию.
Более определенно, M аудиоканалов могут быть сформированы посредством применения матрицы MNto5 воспроизведения кодера к N аудиообъектам для обеспечения M аудиоканалов (матричное умножение может быть выполнено для каждого частотно-временного элемента, как известно специалистам в области техники). Аналогичным образом, K аудиоканалов может быть сформированы посредством применения матрицы M5to2 воспроизведения к M аудиоканалам для обеспечения K аудиоканалов (матричное умножение может быть выполнено для каждого частотно-временного элемента, как известно специалисту в области техники). Последовательная операция этих двух матричных операций может быть заменена единой матричной операцией, выполняющей объединенную операцию. Более определенно, единое матричное умножение на матрицу
MNto2=M5to2·MNto5
может быть применено непосредственно к N аудиообъектам, поскольку это идентично применению матрицы M5to2 к M (в конкретном примере к 5) аудиоканалам, сформированным понижающим микшером 703 из N в M посредством применения матрицы MNto5. Таким образом, в декодере K каналов формируются просто посредством умножения M (в конкретном примере 5) аудиоканалов и матрицы M5to2 понижающего микширования.
Будет понятно, что может использоваться любой подходящий подход или способ для выбора или определения матрицы MNto5 воспроизведения. Как правило, матрица формируется (полу)вручную для обеспечения требуемого звукового образа.
Аналогичным образом, будет понятно, что может использоваться любой подходящий подход или способ для выбора или определения матрицы M5to2 понижающего микширования. В некоторых вариантах осуществления может использоваться фиксированная или предопределенная матрица M5to2 понижающего микширования. Эта предопределенная матрица может быть известна в декодере, который может соответствующим образом применит ее к M аудиоканалам для формирования стереофонического сигнала, желаемого для формирования аудиообъекта.
В других вариантах осуществления матрица M5to2 понижающего микширования может быть переменной матрицей, которая адаптируется или оптимизируется в кодере в зависимости от конкретных характеристик. Например, матрица M5to2 понижающего микширования может быть определена таким образом, что она гарантирует, что все аудиообъекты представлены желаемым образом в полученном в результате стереофоническом сигнале. В таких вариантах осуществления информация о матрице M5to2 понижающего микширования, используемой в кодере, может быть включена в поток выходных данных. Тогда декодер может извлечь матрицу M5to2 понижающего микширования и применить ее к декодированным M аудиоканалам, вследствие чего формируются K аудиоканалов, к которым могут быть применены параметры SAOC.
При предоставлении возможности адаптивного понижающего микширования многоканального сигнала в стереофонический сигнал данные могут быть переданы с использованием вспомогательной структуры данных в синтаксисе многоканального битового потока, например, аналогично передаче данных SAOC. Это проиллюстрировано на фиг. 10, которая показывает два различных варианта:
параметры понижающего микширования передаются в отдельном контейнере до (или после) контейнера SAOC; и
параметры понижающего микширования передаются в контейнере SAOC как новый элемент в поле SAOCExtensionConfig().
В некоторых вариантах осуществления получение K каналов из M аудиоканалов выполняется посредством выбора подмножества из M аудиоканалов.
Например, кодирование SAOC может быть выполнено в ответ на только два аудиоканала, такие как передний левый и передний правый каналы из пятиканального сигнала окружающего звука, сформированного M аудиоканалами.
Однако во многих сценариях такой подход может привести к субоптимально декодируемым объектам из-за того, что выбранные каналы подмножества потенциально не включают в себя какие-либо компоненты сигнала от заданного аудиообъекта (в отличие от микшированных с понижением каналов, когда M аудиоканалов могут быть микшированы с понижением в K аудиоканалов таким образом, что вклады от всех M аудиоканалов и, таким образом, от всех N аудиообъектов включены в микшированные с понижением K каналов).
Такие проблемы, вероятно, могут быть решены посредством формирования декодером части или всех из некоторых из N аудиообъектов c использованием других параллельных подходов. Например, с использованием SAOC функциональности интерфейса эффектов передачи, определяющей эффекты передачи для введения сформированного вклада в качестве эффекта передачи. Эффект передачи может быть определен таким образом, что он может обеспечить вклад для аудиообъектов, которые не могут быть сформированы с достаточным качеством из выбранных K аудиоканалов.
В некоторых вариантах осуществления вклады от аудиообъектов могут быть сформированы из множества подмножеств из M аудиоканалов, причем каждое подмножество снабжается подходящими параметрами повышающего микширования аудиообъектов. В некоторых вариантах осуществления каждый аудиообъект может быть сформирован из единственного подмножества из M аудиоканалов, причем разные аудиообъекты формируются из разных подмножеств в зависимости от того, каким образом объекты были микшированы с понижением в M аудиоканалов. Однако обычно N объектов будут распределены по более чем K каналам из M аудиоканалов, и поэтому аудиообъекты могут быть сформированы посредством объединения вкладов от повышающего микширования разных подмножеств из M аудиоканалов.
Таким образом, кодер может иметь параллельные блоки оценки параметров, которым подаются разные подмножества из N аудиообъектов. В качестве альтернативы, все N объектов подаются каждому из параллельных блоков оценки параметров. Матрица MNto5 воспроизведения разбивается и используется в качестве матрицы понижающего микширования в каждом блоке оценки параметров таким образом, что выходные сигналы блоков оценки параметров образуют M-канальное микширование. Например, один блок оценки параметров может произвести K аудиоканалов из M аудиоканалов, и другой блок оценки параметров может произвести L аудиоканалов из M аудиоканалов. Например, один блок оценки параметров формирует передние левый и правый каналы, и другой блок оценки формирует центральный канал. Блоки оценки параметров дополнительно формируют параметры повышающего микширования аудиообъектов для соответствующих каналов. Параметры повышающего микширования аудиообъектов для каждого индивидуального блока оценки параметров включаются в поток выходных данных как отдельное множество параметров повышающего микширования аудиообъектов, например, как отдельный поток данных параметров SAOC.
Таким образом, кодер может сформировать множество параллельных совместимых с SAOC потоков данных, каждый из которых соответствует стереофоническому или монофоническому подмножеству из M аудиоканалов. Тогда соответствующий декодер может индивидуально декодировать каждый из этих совместимых с SAOC потоков данных с использованием стандартной настройки декодера SAOC. Затем полученные в результате декодированные компоненты аудиообъекта объединяются в полные аудиообъекты (или непосредственно в выходные каналы, соответствующие желаемой выходной конфигурации динамиков). Таким образом, подход может дать возможность, чтобы все сигнальные компоненты в M аудиоканалах могли быть использованы при формировании индивидуального аудиообъекта. Более определенно, подмножества могут быть выбраны таким образом, что они вместе содержат все M аудиоканалов, при этом каждый аудиоканал включен только в одно подмножество. Таким образом, подмножества могут быть непересекающимися и включать в себя все M аудиоканалов.
В качестве конкретного примера, несколько потоков SAOC могут быть включены/переданы с помощью понижающего микширования M аудиоканалов таким образом, что каждый поток работает на монофоническом или стереофоническом подмножестве многоканального понижающего микширования. С объектами, возможно присутствующими либо в конкретном потоке, либо в нескольких потоках, матрица воспроизведения, используемая на стороне декодера для распределения аудиообъектов желаемой выходной конфигурации (динамиков) может быть выполнена с возможностью объединять индивидуальные вклады в индивидуальные аудиообъекты. Подход может обеспечить особенно высокое качество воссоздания.
По сравнению с вариантом осуществления на фиг. 9, матрица из N в 5 в таком конкретном примере не объединяется с матрицей понижающего микширования из 5 в 2 для обеспечения K-канального понижающего микширования пяти аудиоканалов. Вместо этого матрица из N в 5 рассекается и посылается в три параллельных кодера SAOC, все битовые потоки из которых мультиплексируются в битовый поток.
Например, матрица
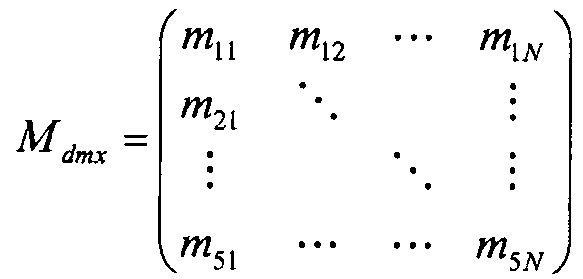
может быть разделена на матрицы
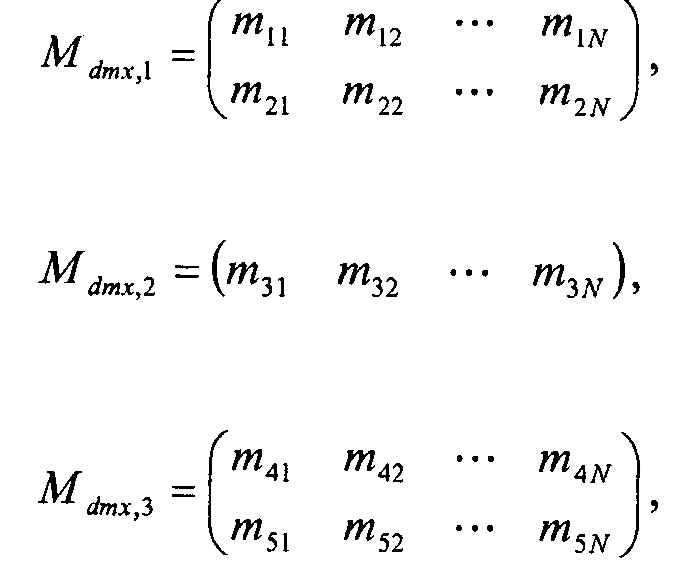
чтобы обеспечить три параллельных потока SAOC, которые обычно хорошо работают для обычных пяти каналов {Lf, Rf, C, Ls, Rs}, где L обозначает левый, R обозначает правый, C обозначает центральный, нижний индекс f обозначает передний, и нижний индекс s обозначает окружающий.
Фиг. 11 показывает пример декодера для такого подхода.
В некоторых вариантах осуществления кодер может быть дополнительно выполнен с возможностью включать данные понижающего микширования, представляющие понижающее микширование N аудиообъектов в M аудиоканалов, в поток выходных данных. Например, матрица воспроизведения кодера, описывающая понижающее микширование N аудиообъектов в N аудиоканалов, может быть включена в поток выходных данных (то есть, в конкретном примере на фиг. 9, может быть включена матрица MNto5).
Дополнительная информация может по-разному использоваться в разных вариантах осуществления.
Более определенно, в некоторых вариантах осуществления данные понижающего микширования могут использоваться для формирования подмножества аудиообъектов на основе M аудиоканалов. Поскольку имеется больше информации, доступной в M аудиоканалах, чем в K аудиоканалах, это может позволить формировать аудиообъекты с улучшенным качеством. Однако обработка может не быть совместимой с соответствующим стандартом кодирования/декодирования аудиообъектов и, таким образом, может потребовать дополнительной функциональности. Кроме того, вычислительные требования обычно будут выше, чем для стандартного (и обычно в большой степени оптимизированного) декодирования объектов на основе K сигналов. Таким образом, декодирование аудиосигнала на основе M аудиоканалов и данных понижающего микширования может быть ограничено только подмножеством аудиообъектов и обычно только очень небольшим количеством наиболее доминирующих аудиообъектов. Оставшиеся аудиообъекты могут быть сформированы с использованием стандартизированного декодера на основе K каналов. Это декодирование часто может быть в значительной степени более эффективным, например, посредством использования специализированных и стандартизированных аппаратных средств.
Кроме того, некоторые стандарты кодирования, такие как SAOC, способны принимать разностные данные от кодера, при этом закодированные данные отражают разность между первоначальным аудиообъектом и тем, что будет сформировано декодером на основе низведения и параметров повышающего микширования аудиообъектов. Более определенно, SAOC поддерживает функцию, известную как усовершенствованные аудиообъекты (EAO), которая позволяет обеспечивать разностные данные для вплоть до четырех аудиообъектов.
В некоторых вариантах осуществления данные понижающего микширования, представляющие понижающее микширование N аудиообъектов в M аудиоканалов, могут использоваться для формирования разностных данных в декодере. Более определенно, декодер может вычислить конкретный аудиообъект на основе данных понижающего микширования, M аудиоканалов и параметров повышающего микширования аудиообъектов. Кроме того, этот же объект может быть декодирован на основе K аудиоканалов и параметров повышающего микширования аудиообъектов. Разностные данные могут быть сформированы как показатель относительно разности между ними. Эти разностные данные могут затем использоваться при декодировании N аудиообъектов. Это декодирование может использовать стандартизированный подход для стандарта декодирования объектов, который основан на K каналах, и который дает возможность обеспечить разностные данные из кодера.
В таком подходе дополнительная информация, обеспеченная данными понижающего микширования и M аудиоканалами, таким образом, используется для формирования информации разностных данных в декодере, а не в кодере. Таким образом, разностные данные не требуется передавать. Будет понятно, что объект, сформированный из данных понижающего микширования и M аудиоканалов, может не являться идентичным соответствующему аудиообъекту до кодирования, но дополнительная информация обычно будет обеспечивать улучшение по сравнению с соответствующим аудиообъектом, формированным из K аудиоканалов.
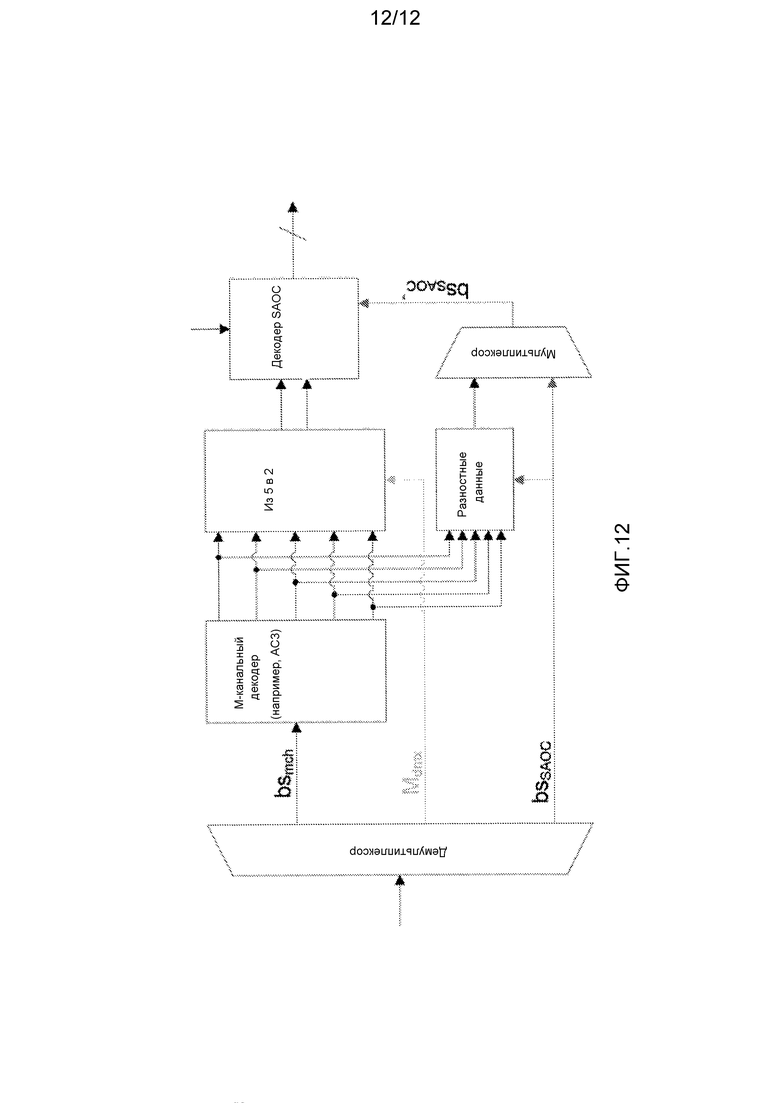
В качестве конкретного примера, стандартный декодер SAOC может быть снабжен препроцессором, который формирует разностные данные, которые подаются декодеру SAOC, как если бы они являлись разностные данные, сформированными в кодере. Таким образом, декодер SAOC может работать полностью в соответствии со стандартом SAOC относительно EAO. Пример такого декодера проиллюстрирован на фиг. 12.
Препроцессор может, в частности, вычислить аудиообъект с использованием матрицы MNto5. Например, аудиообъект может быть сформирован из понижающего микширования 5 каналов с использованием следующего уравнения:
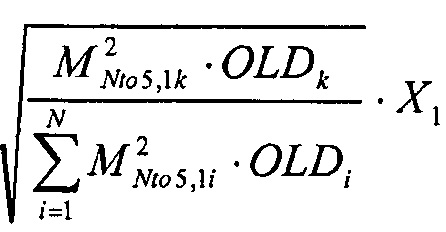
которое воссоздает объект k из канала X1 понижающего микширования, где OLD - линейное представление параметра OLD (разность уровней объектов) в битовом потоке SAOC. Это уравнение может быть применено к каждому частотно-временному элементу канала X1 с использованием соответствующих параметров SAOC.
Приведенное выше воссоздание подразумевает некоррелированные объекты. Посредством включения параметров IOC SAOC возможно принять во внимание корреляцию между объектами, например, посредством использования уравнения:
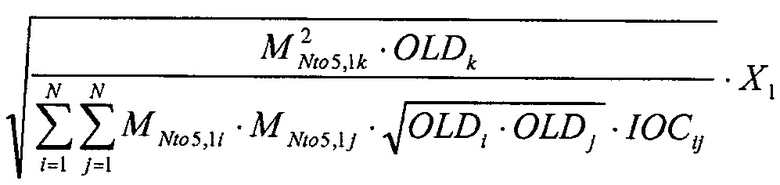
Это воссоздание взвешено с помощью коэффициента усиления объекта k в канале 1 понижающего микширования (MNto5,1k).
Объединение аналогичных воссозданий из всех 5 каналов дает воссоздание объекта, которое взвешено в соответствии с коэффициентами усиления для объекта k, то есть канал, в котором объект k имеет самый большой коэффициент усиления, обеспечивает самый большой вклад в объединенное воссоздание 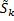 объекта k:
объекта k:
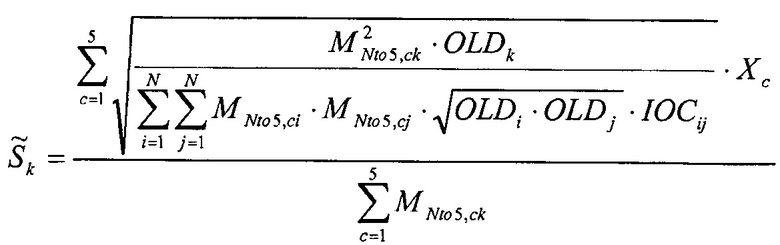
где 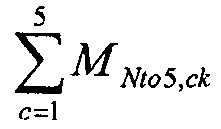 нормализует воссоздание до корректного уровня.
нормализует воссоздание до корректного уровня.
В качестве другого примера, альтернативное взвешенное воссоздание может стремиться к "изолированности" объекта в канале понижающего микширования.
Определим:
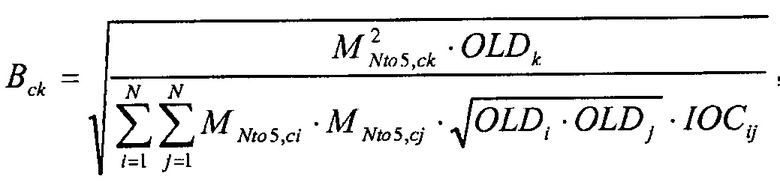
тогда альтернативное воссоздание
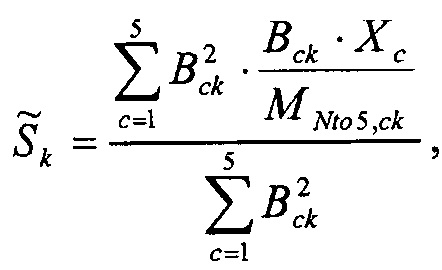
взвешивает каждое нормализованное под-воссоздание (Bck·Xc) объекта k с помощью его относительного вклада в соответствующий канал понижающего микширования.
Будет понятно, что в других вариантах осуществления могут использоваться другие подходы для формирования звукового объекта из аудиоканалов и понижающего микширования из M в N.
В кодере SAOC, в котором кодируются усовершенствованные аудиообъекты (EAO), соответствующие разностные сигналы вычисляются как разность между первоначальным сигналом объекта и воссозданием на основе монофонического или стереофонического понижающего микширования SAOC. Таким образом, эти усовершенствованные объекты (Xeao) обрабатываются отдельно от регулярных объектов (Xreg).
Регулярные объекты сводятся в соответствии с субматрицей (Dreg) матрицы (D) понижающего микширования размером K×N, где D=(Dreg, Deao), когда X=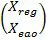 . Результатом является K-канальное понижающее микширование:
. Результатом является K-канальное понижающее микширование:
Yreg=Dreg·Xreg
Объекты EAO также подвергаются понижающему микшированию с использованием соответствующей субматрицы Deao, и результирующее понижающее микширование объединяется с понижающим микшированием регулярных объектов (Yreg) в понижающее микширование SAOC.
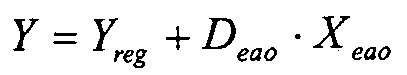
Это понижающее микширование ожидается на входе декодера SAOC.
С использованием понижающего микширования Yreg и объектов EAO в качестве входных сигналов вычисляются промежуточные вспомогательные сигналы с использованием матрицы Daux размером Neao×(K+Neao), где Neao=N-Nreg - количество объектов EAO.
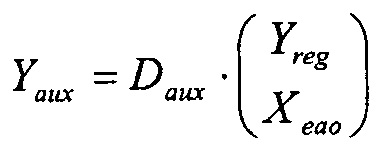
Формирование понижающего микширования Y и вспомогательных сигналов Yaux может быть объединено в одно матричное уравнение:
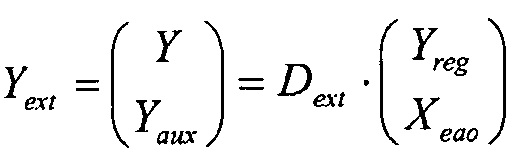
Где
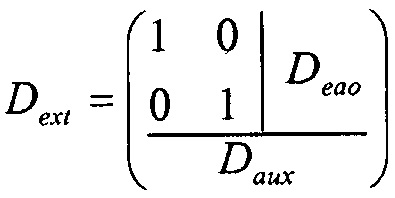
Матрица Daux выбирается таким образом, что матрица Dext является невырожденной, и отделение EAO от понижающего микширования оптимизировано. Элементы Daux определены в стандарте SAOC и, таким образом, доступны в декодере. В декодере SAOC, с использованием инверсии матрицы Dext, EAO (Xeao) могут быть отделены от регулярных объектов (Yreg) с использованием понижающего микширования (Y) и вспомогательных сигналов (Yaux) в качестве ввода.
Чтобы улучшить эффективность кодирования, вспомогательные сигналы предсказываются из сигналов понижающего микширования с коэффициентами предсказания, которые получены из данных, уже доступных в декодере.
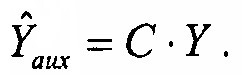
Погрешность предсказания 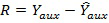 может быть эффективно закодирована с использованием механизма разностного кодирования стандарта SAOC.
может быть эффективно закодирована с использованием механизма разностного кодирования стандарта SAOC.
Разности в этом варианте осуществления могут быть сформированы таким же образом, как описано выше с использованием М-канального воссоздания 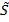 объекта как объектов EAO (=Xeao). Поскольку отдельные объекты уже микшированы, эти этапы могут быть опущены. Таким образом, определим
объекта как объектов EAO (=Xeao). Поскольку отдельные объекты уже микшированы, эти этапы могут быть опущены. Таким образом, определим
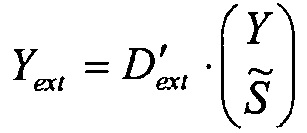 ,
,
при этом
 ,
,
И
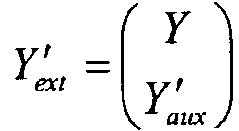 .
.
В случае четырех EAO:

Тогда разности вычисляются как
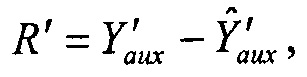
при этом
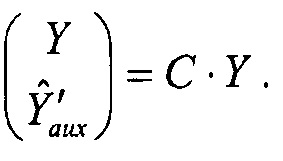
Полученные в результате разности (R') затем могут быть вставлены в битовый поток SAOC, в котором объекты, для которых вычислены разности, идентифицированы как EAO. Тогда стандартный декодер SAOC может продолжить выполнять стандартное декодирование EAO SAOC для формирования N аудиоканалов.
Это может обеспечить улучшенное качество декодированных аудиообъектов во многих вариантах осуществления. Во многих вариантах осуществления это может дать возможность совместимости со стандартизированными алгоритмами декодирования аудиообъектов, способными принимать разностные данные, такими как, например, стандарт SAOC. Разностные данные, в частности, могут являться показателем разности между аудиообъектом, сформированным из K каналов и параметров повышающего микширования аудиообъектов, и соответствующим аудиообъектом, сформированным на основе M аудиоканалов и данных понижающего микширования.
Будет понятно, что приведенное выше описание для ясности описало варианты осуществления изобретения в отношении различных функциональных схем, блоков и процессоров. Однако будет понятно, что любое подходящее распределение функциональности между различными функциональными схемами, блоками или процессорами может использоваться без отступления от изобретения. Например, функциональность, иллюстрированная как выполняемая отдельными процессорами или контроллерами, может быть выполнена одним и тем же процессором или контроллерами. Следовательно, ссылки на конкретные функциональные блоки или схемы предназначены только для того, чтобы они рассматривались как ссылки на подходящие средства для обеспечения описанной функциональности, а не являлись показателем строгой логической или физической структуры или организации.
Изобретение может быть реализовано в любой подходящей форме, в том числе в виде аппаратных средств, программного обеспечения, программируемого оборудования или любой их комбинации. Изобретение факультативно может быть реализовано по меньшей мере частично как программное обеспечение, работающее на одном или более процессорах и/или процессорах цифровых сигналов. Элементы и компоненты варианта осуществления изобретения могут быть физически, функционально и логически реализованы любым подходящим способом. Действительно, функциональность может быть реализована в единственном блоке, во множестве блоков или как часть других функциональных блоков. Таким образом, изобретение может быть реализовано в единственном блоке или может быть физически и функционально распределено между различными блоками, схемами и процессорами.
Хотя настоящее изобретение было описано в связи с некоторыми вариантами осуществления, не предусматривается, чтобы оно было ограничено конкретной изложенной здесь формой. Объем настоящего изобретения ограничен только сопровождающей формулой изобретения. Дополнительно, хотя может показаться, что отличительные признаки описаны в связи с конкретными вариантами осуществления, специалист в области техники поймет, что различные отличительные признаки описанных вариантов осуществления могут сочетаться в соответствии с изобретением. В формуле изобретения термин "содержит" не исключает присутствие других элементов или этапов.
Кроме того, хотя множество средств, элементов, схем или этапов способов перечисляются индивидуально, они могут быть реализованы, например, посредством единственной схемы, блока или процессора. Дополнительно, хотя отдельные отличительные признаки могут быть включены в разные пункты формулы изобретения, они могут быть успешно объединены, и включение в разные пункты формулы изобретения не подразумевает, что комбинация отличительных признаков не выполнима и/или не выгодна. Кроме того, включение отличительного признака в одну категорию пунктов формулы изобретения не подразумевает ограничение для этой категории, а скорее указывает, что отличительный признак при необходимости одинаково применим к другим категориям пунктов формулы изобретения. Кроме того, порядок отличительных признаков в пунктах формулы изобретения не подразумевает какого-либо заданного порядка, в котором должны разрабатываться отличительные признаки, и, в частности, порядок отдельных этапов в пункте формулы изобретения, описывающем способ, не подразумевает того, что этапы должны быть выполнены в этом порядке. Вместо этого этапы могут быть выполнены в любом подходящем порядке. Кроме того, упоминания в единственном числе не исключают множество. Таким образом, единственное число, "первый", "второй" и т.д. не предотвращают множество. Ссылочные позиции в пунктах формулы изобретения представлены просто в качестве разъяснительного примера, который не должен рассматриваться как какое-либо ограничение объема формулы изобретения.
Изобретение относится к средствам кодирования и декодирования аудиообъектов. Технический результат заключается в повышении эффективности кодирования и декодирования аудиообъектов. Кодер аудиообъектов содержит приемник, который принимает N аудиообъектов. Микшер микширует N аудиообъектов в M аудиоканалов, и схема каналов получает K аудиоканалов из M аудиоканалов, K=1, 2, и K<M. Схема параметров формирует параметры повышающего микширования аудиообъектов по меньшей мере для части из каждого из N аудиообъектов относительно K аудиоканалов, и выходная схема формирует поток выходных данных, содержащий параметры повышающего микширования аудиообъектов и M аудиоканалов. Декодер аудиообъектов принимает поток данных и включает в себя схему каналов, получающую K аудиоканалов из понижающего микширования M каналов; и декодер объектов для формирования по меньшей мере части из каждого из N аудиообъектов посредством повышающего микширования из K аудиоканалов на основе параметров повышающего микширования аудиообъектов. 4 н. и 10 з.п. ф-лы, 12 ил.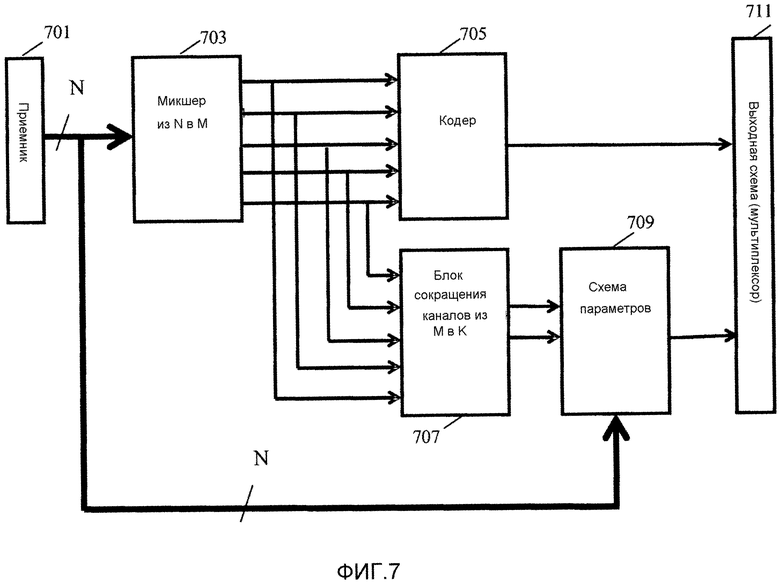
1. Кодер аудиообъектов, содержащий:
приемник (701) для приема N аудиообъектов;
микшер (703) для микширования N аудиообъектов в М аудиоканалов;
схему (707) каналов для получения K аудиоканалов из М аудиоканалов, где K=1 или 2, и K<М;
схему (709) параметров, формирующую параметры повышающего микширования аудиообъектов по меньшей мере для части из каждого из N аудиообъектов относительно K аудиоканалов;
выходную схему (705, 711) для формирования потока выходных данных, содержащего параметры повышающего микширования аудиообъектов и М аудиоканалов.
2. Кодер аудиообъектов по п. 1, в котором схема (707) каналов выполнена с возможностью получать K каналов посредством понижающего микширования М аудиоканалов.
3. Кодер аудиообъектов по п. 1, в котором схема (707) каналов выполнена с возможностью получать K каналов посредством выбора К-канального подмножества из М аудиоканалов.
4. Кодер аудиообъектов по п. 1, в котором поток выходных данных содержит поток многоканальных закодированных данных для М аудиоканалов, и параметры повышающего микширования аудиообъектов содержатся в части потока многоканальных закодированных данных.
5. Кодер аудиообъектов по п. 1, в котором выходная схема (705, 711) выполнена с возможностью включать в себя данные микширования, представляющие микширование N аудиообъектов в М аудиоканалов, в поток выходных данных.
6. Декодер аудиообъектов, содержащий:
приемник (801, 803) для приема потока данных, содержащего аудиоданные для микширования М каналов из N аудиообъектов и параметры повышающего микширования аудиообъектов для N аудиообъектов относительно K аудиоканалов, где K=1 или 2, и K<М;
схему (805) каналов, получающую K аудиоканалов из микширования М каналов; и
декодер (807) объектов для формирования Р аудиосигналов из N аудиообъектов, по меньшей мере частично формированных посредством повышающего микширования из K аудиоканалов на основе параметров повышающего микширования аудиообъектов.
7. Декодер аудиообъектов по п. 6, в котором схема (805) каналов выполнена с возможностью получать K каналов посредством понижающего микширования М аудиоканалов.
8. Декодер аудиообъектов по п. 7, в котором поток данных дополнительно содержит данные понижающего микширования, являющиеся показателем понижающего микширования кодером из М в K каналов, причем схема (805) каналов выполнена с возможностью адаптировать понижающее микширование в ответ на данные понижающего микширования.
9. Декодер аудиообъектов по п. 7, в котором схема (805) каналов выполнена с возможностью получать K каналов посредством выбора K-канального подмножества из М аудиоканалов.
10. Декодер аудиообъектов по п. 9, в котором поток данных дополнительно содержит дополнительные параметры повышающего микширования аудиообъектов для N аудиообъектов относительно L аудиоканалов, где L=1 или 2, и L<M, и L аудиоканалов и K аудиоканалов являются разными подмножествами из М аудиоканалов, причем декодер (807) объектов дополнительно выполнен с возможностью формировать Р каналов из N аудиообъектов, по меньшей мере частично сформированных посредством повышающего микширования из L аудиоканалов на основе дополнительных параметров повышающего микширования аудиообъектов.
11. Декодер аудиообъектов по п. 10, в котором по меньшей мере один из Р каналов формирован посредством объединения вкладов от повышающего микширования из K аудиоканалов на основе параметров повышающего микширования аудиообъектов и от повышающего микширования из L аудиоканалов на основе дополнительных параметров повышающего микширования аудиообъектов.
12. Декодер аудиообъектов по п. 6, в котором поток данных содержит данные микширования, представляющие микширование N аудиообъектов в N аудиоканалов, причем декодер (807) объектов выполнен с возможностью формировать разностные данные по меньшей мере для подмножества из N аудиообъектов в ответ на данные микширования и параметры повышающего микширования аудиообъектов и формировать Р аудиосигналов в ответ на разностные данные.
13. Способ кодирования аудиообъектов, содержащий этапы, на которых:
принимают N аудиообъектов;
микшируют N аудиообъектов в М аудиоканалов;
получают K аудиоканалов из М аудиоканалов, где K=1 или 2, и K<М;
формируют параметры повышающего микширования аудиообъектов по меньшей мере для части из каждого из N аудиообъектов относительно K аудиоканалов; и
формируют поток выходных данных, содержащий параметры повышающего микширования аудиообъектов и М аудиоканалов.
14. Способ декодирования аудиообъектов, содержащий этапы, на которых:
принимают поток данных, содержащий аудиоданные для микширования М каналов из N аудиообъектов и параметры повышающего микширования аудиообъектов для N аудиообъектов относительно K аудиоканалов, где K=1 или 2, и K<М;
получают K аудиоканалов из микширования М каналов; и
формируют Р аудиосигналов из N аудиообъектов, по меньшей мере частично формированных посредством повышающего микширования из K аудиоканалов на основе параметров повышающего микширования аудиообъектов.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| EP 1913578 A1, 23.04.2008 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СПОСОБ ПРОИЗВОДСТВА ОБОГАЩЕННОЙ СОЛЕНОЙ РЫБОПРОДУКЦИИ | 1992 |
|
RU2054875C1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СПОСОБЫ УЛУЧШЕНИЯ ХАРАКТЕРИСТИК МНОГОКАНАЛЬНОЙ РЕКОНСТРУКЦИИ НА ОСНОВЕ ПРОГНОЗИРОВАНИЯ | 2005 |
|
RU2369917C2 |

