Область техники, к которой относится изобретение
Настоящее изобретение относится к анализу структуры web-страницы. Более конкретно, данное изобретение относится к способу для определения информации о web-сайте посредством анализа структуры web-страницы, который может анализировать структуры web-страниц по мере того как программа слежения, предварительно установленная на клиентах и серверах, генерирует конкретное сообщение каждый раз, когда осуществляется доступ к web-странице и ее перемещение. Этот способ может определять доступ к конкретной web-странице и пути web-навигации пользователей, которые используют систему клиент - сервер, и затем создает, используя результаты, базу данных, определяя таким образом информацию, такую как информация о состоянии доступа к web-сайтам, полях, представляющих интерес для пользователей, и улучшая управление взаимоотношениями с потребителями (CRM) и управление отношениями с целевыми потребителями.
Предшествующий уровень техники
В последние годы для обнаружения информации широко использовался анализ журнала регистрации, такой как анализ состояния доступа пользователей к конкретной web-странице. Анализ журнала регистрации обеспечивает информацию для определения состояния web-сайта на основе анализа информации, такой как количество посетителей, количество просмотров страницы, значения из куки-файлов и т.д.
Анализ журнала регистрации подразделяется на (1) способ введения журнала регистрации, в ходе которого напрямую вводят журнал регистрации в web-сервер, управляющий конкретной web-страницей, генерируют сигналы, такие как сигналы доступа в журнал регистрации, формируют данные на основе этих сигналов и анализируют эти данные, (2) способ введения кода, в ходе которого вводят сценарии и/или коды в web-сайт, формируют данные на основе значения этого кода и анализируют эти данные, и (3) способ косвенного анализа журнала регистрации, в ходе которого анализируют внешние статистические данные.
Способ введения журнала регистрации невыгоден тем, что когда количество пользователей (которые осуществляют доступ к серверу) увеличивается, количество данных журнала регистрации становится настолько большим, что эта работа должна быть поручена специализированной анализирующей структуре. Способ введения кода подходит для web-сайта, к которому обращается относительно небольшое количество посетителей, но он невыгоден тем, что если к такому web-сайту обращается больше чем заданное количество посетителей, то объем работы становится намного больше, чем по сравнению со способом введения журнала регистрации.
Поскольку анализ журнала регистрации выполняется таким образом, что коды и/или журналы регистрации должны вводиться в web-сайт, то он может быть использован администратором web-сайта только для того, чтобы проверять состояние использования этого web-сайта, которым он или она управляет. Таким образом, при традиционном анализе журнала регистрации может выполняться только ограниченный сосредоточенный вокруг администратора анализ.
Когда администратор хочет в стратегических целях определить состояния использования web-сайтов конкурента, так же как и его/ее собственного web-сайта, для того, чтобы определить, какие web-сайты пользуются популярностью и к каким из web-сайтов и web-страниц пользователи имеют более высокий интерес, какие web-сайты спонсируются рекламодателями, и проанализировать управление взаимоотношениями с потребителями посредством циклов web-навигации пользователей, этот администратор должен определить состояния доступа к web-сайтам, отличным от собственного web-сайта администратора. Однако традиционный анализ журнала регистрации, который обеспечивает сосредоточенный вокруг администратора анализ, не дает информацию о состоянии использования других web-сайтов или информацию о предпочитаемых потребителями web-сайтах и т.д.
В то время как web-маркетинг быстро развивался, традиционный анализ журнала регистрации дает возможность администратору web-сайта определять состояние доступа только к web-сайту, которым он или она управляет, но не позволяет администратору создавать усовершенствованные по сравнению с конкурентами маркетинговые стратегии. Кроме того, традиционный анализ журнала регистрации не предполагает способа для быстрой обработки запросов пользователей. Следовательно, для анализа web-сайтов требуется новый способ.
В ответ на эту потребность был предложен, например, способ для определения состояния web-навигации и путей web-навигации в том, что касается пользователей, а не администратора, управляющего web-сайтом. То есть этот способ может извлекать информацию о доступе к web-сайту, основываясь на некоторой конкретной группе пользователей.
Для того чтобы определить осуществлял ли конкретный пользователь доступ к конкретному web-сайту и определить путь web-навигации пользователя, должны быть выполнены предшествующие этому процессы: должна быть проанализирована структура конкретной web-страницы web-сайта, к которому осуществлялся доступ пользователя; и должен быть сгенерирован сигнал доступа, соответствующий структуре проанализированной web-страницы, и все сигналы должны также быть обработаны.
Вообще, web-страница проектируется как одинарная страница или как сложная страница, которая использует теги, задающие фреймы и/или внутфреймовые теги.
Одинарная страница представляет собой тип web-страницы, связанной с единственным web-сервером, использующим только один URL-адрес (унифицированный указатель информационного ресурса). Таким образом, одинарная страница имеет наиболее общую структуру и представляет собой html-страницу (страницу на языке гипертекстовой разметки), которая не использует такие теги, как теги, задающие фреймы, и внутрифреймовые теги. Сложная страница представляет собой тип web-страницы, связанной с одним web-сервером и/или множеством web-серверов, использующих различные URL-адреса. Сложная страница представляет собой web-страницу, использующую такие теги, как теги, задающие фреймы, и внутрифреймовые теги. Сложная страница содержит основную страницу и подстраницы. Основная страница характеризует постраничную навигацию и относится к странице, соответствующей URL-адресу в адресной строке. Подстраницы создаются тегами, задающими фреймы, и/или внутрифреймовыми тегами на основной странице.
Web-сайты в Интернете все состоят из одинарной web-страницы и/или сложной web-страницы. Эти web-страницы связаны с соответствующими web-сайтами, так что пользователи могут перемещаться между web-сайтами. Пользователи могут перемещаться от одной web-страницы к другой во время загрузки web-страниц. Пользователь может также перемещаться от одной web-страницы к другой при прерывании одной web-страницы прежде чем она будет полностью загружена.
Для того чтобы проанализировать структуру web-страницы, традиционный способ должен сначала решить следующие задачи:
1) структуры web-страниц должны быть точно проанализированы в соответствии с типами web-страниц, так как web-страницы спроектированы в виде одинарной web -страницы и/или сложной web-страницы, и эти web-страницы неоднократно перемещаются в соответствии с web-навигацией пользователя;
2) в сложной странице должны быть распознаны подстраницы, поскольку сложная страница содержит подстраницы, и все страницы могут быть полностью загружены только в том случае, если полностью загружены подстраницы;
3) когда web-страницы не перемещаются, но обновляются, то изменяется только содержимое страниц. Следовательно, при обновлении web-страниц должно быть определено, идентично ли их содержание предшествующему содержанию;
4) когда в web-страницах изменяются только фреймы, то определяется, выбраны ли и изменены ли фреймы произвольно пользователем или они изменены в соответствии с некоторой периодической операцией;
5) поскольку одинарная страница не имеет никаких дополнительных подстраниц, то следует прибегнуть к способу определения того, обновлена ли одинарная страница, причем этот способ представляет собой способ, отличный от способа, проверяющего имеется ли подстраница.
Следовательно, имеет место случай, при котором администратору нужно проверять состояние перемещения сосредотачивающихся у пользователя web-страниц для того чтобы определить состояния использования разнообразных web-сайтов, которыми этот администратор не управляет. В этом случае для того чтобы более точно определять состояние перемещения пользователя между web-страницами, требуется способ для точного анализа структуры web-страницы и для определения разнообразных моделей перемещения, таких как загрузка всех web-документов, соответствующих web-страницам, к которым осуществляет доступ пользователь, обновление web-страниц, нестандартное перемещение и т.д.
Сущность изобретения
Техническая задача
Настоящее изобретение решает вышеупомянутые задачи и предусматривает способ, который не вводит журнал или сценарий регистрации в web-сервер, но обрабатывает и анализирует информацию о состоянии использования пользователем web-сайтов для того, чтобы определить состояния использования разнообразных web-сайтов, которыми не управляет данный администратор, которые не включают в себя web-сайт под управлением конкретного администратора, и генерирует и обрабатывает сообщения о перемещении web-страниц для соответствующих web-страниц при перемещении web-страниц для того, чтобы отслеживать путь перемещения пользователя по web-страницам, при этом предполагается, что должна быть получена информация о состоянии использования web-сайтов и о том, каким образом пользователь их использует.
Настоящее изобретение, кроме того, предусматривает способ, который подразделяет сообщение о перемещении web-страницы в соответствии с временной последовательностью и управляет подразделенными сообщениями согласно соответствующим стилям перемещения web-страниц для того, чтобы получить высокий уровень информации о перемещении web-страниц, который идентичен уровням других web-страниц, которые установлены другими структурами, такими как web-страницы с сигналом и/или сложные web-страницы.
Настоящее изобретение, кроме того, предусматривает способ, который определяет перемещение одинарной web-страницы согласно тому, изменяется ли при обновлении web-страницы заголовок браузера, и определяет перемещение сложной страницы согласно тому, изменяется ли при обновлении web-страницы подстраница.
Настоящее изобретение, кроме того, предусматривает способ для получения разнообразной информации при совместном использовании информации об использовании web-страницы, такой как пути перемещения web-страниц между пользователями, которые используют программы слежения, отслеживающие пути перемещения пользователя, где программы слежения установлены на клиентах и серверах, которые поддерживают связь друг с другом.
Настоящее изобретение, кроме того, предусматривает способ для передачи информации, полученной в соответствии с программами слежения, на дополнительный сервер управления и для анализа путей перемещения пользователя по web-страницам, выполняемого соответствующим образом и систематически так, чтобы эта информация могла использоваться в качестве разнообразных данных для web-маркетинга.
Настоящее изобретение, кроме того, предусматривает способ для воспроизведения точного местонахождения указателя, присоединенного к web-страницам, записи информации о воспроизведенном местонахождении и т.д. на сервере управления, и управления ими в соответствии с программой исполнения указателя.
Техническое решение
В соответствии с приводимым в качестве примера вариантом реализации настоящего изобретения настоящее изобретение предусматривает способ для определения информации о web-сайте посредством анализа структуры web-страниц, включающий в себя этапы, на которых генерируют, когда web-страница начинает перемещаться, сообщение о начале перемещения, которое содержит идентификаторы, выданные для того, чтобы идентифицировать соответствующие web-страницы; генерируют, когда web-страница начинает перемещаться, сообщение о завершении перемещения, которое содержит информацию URL-адреса по соответствующей web-странице и информацию для определения, выполняемого посредством идентификатора, того, является ли соответствующая web-страница основной страницей или подстраницей; генерируют, когда все web-страницы загружены, сообщение о завершении документа, содержащее информацию, которая анализирует то, какая из web-страниц была перемещена; собирают эти сообщения и генерируют базу данных с сообщениями; и определяют, основываясь на анализе базы данных с сообщениями, информацию о web-сайте, относящуюся к состоянию посещения конкретным пользователем и состояниям доступа к web-сайту.
Полезные результаты
Как было описано выше, способ для определения информации о web-сайте посредством анализа структуры web-страницы согласно настоящему изобретению имеет нижеследующие преимущества:
1) поскольку информации о web-сайте и структуре web-сайта определяется путем анализа пути web-навигации пользователя, она не требует введения журнала или сценария регистрации в web-сервер и может определять все состояния использования web-сайтов, управляемых другими администраторами, так же как состояние использования web-сайта, управляемого конкретным администратором;
2) этот способ может узнавать структуру web-сайта и получать информацию о нем и относительно высокий уровень информации о перемещении web-страниц, где этот уровень идентичен для любых web-страниц, таких как одинарная web-страница и/или сложная web-страница, которые отличаются друг от друга по своей структуре;
3) этот способ дает возможность программам для анализа web-страниц поддерживать между собой связь так, чтобы пользователи, использующие эти программы, могли совместно друг с другом использовать информацию о web-страницах, такую как информация о пути перемещения web-страниц и т.д., и таким образом могли получать разнообразную информацию;
4) этот способ может определить подробным образом обновлена ли одинарная страница/сложная страница и изменена ли часть подстраницы; и
5) этот способ может выполнить точное воспроизведение указателя, присоединенного к web-странице, что было трудновыполнимым в традиционной структуре браузере вследствие ассоциативной связи с указателем; может позволить точную реализацию указателя в web-сети; и может позволить получать специализированную и разнообразную информацию о рекламных объявлениях для целевых пользователей и данные для управления взаимоотношениями с потребителями.
Краткое описание чертежей
Признаки и преимущества настоящего изобретения будут более очевидны из нижеследующего подробного описания, рассматриваемого в сочетании с прилагаемыми чертежами, на которых:
фиг.1 представляет собой структурную схему, иллюстрирующую систему, приспособленную к способу для определения информации о web-сайте посредством анализа структуры web-страницы, соответствующему настоящему изобретению;
фиг.2 представляет собой web-страницу, к которой присоединен указатель;
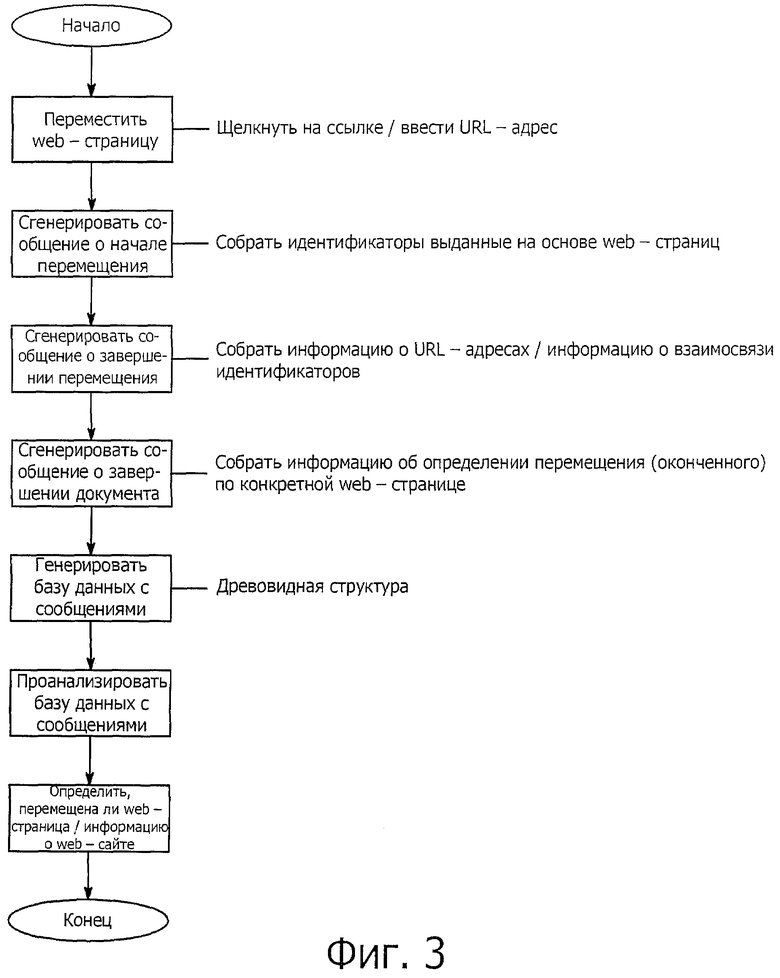
фиг.3 представляет собой блок-схему алгоритма, описывающую способ для определения информации о web-сайте посредством анализа структуры web-страницы, соответствующий настоящему изобретению;
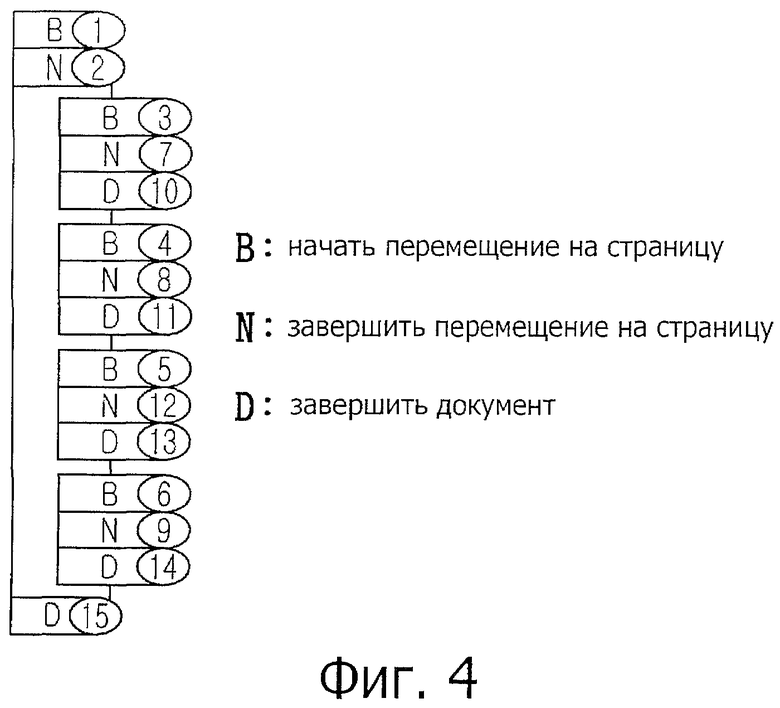
фиг.4 представляет собой изображение, описывающее последовательность сообщений, генерируемых при перемещении web-страниц, соответствующее настоящему изобретению;
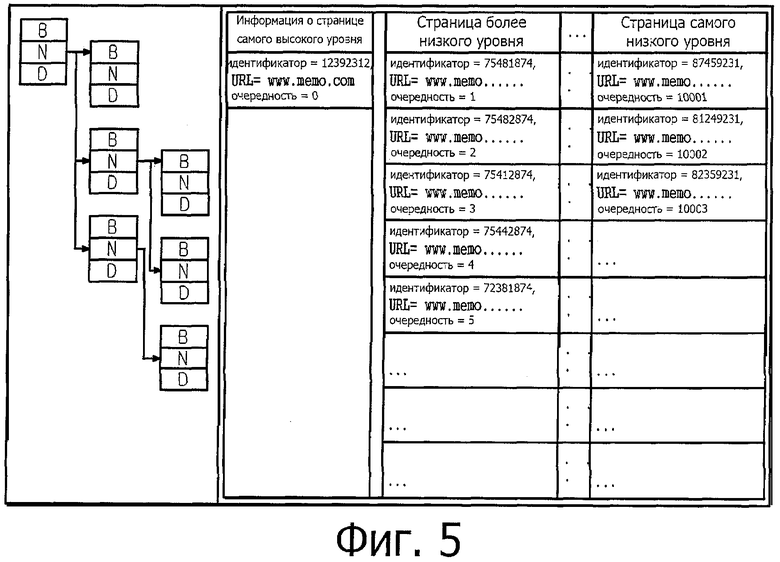
фиг.5 представляет собой изображение, описывающее древовидную структуру web-страниц, генерируемую посредством сообщений о перемещении, соответствующее настоящему изобретению;
фиг.6 представляет собой изображение, описывающее процесс для выяснения того, завершены ли страницы;
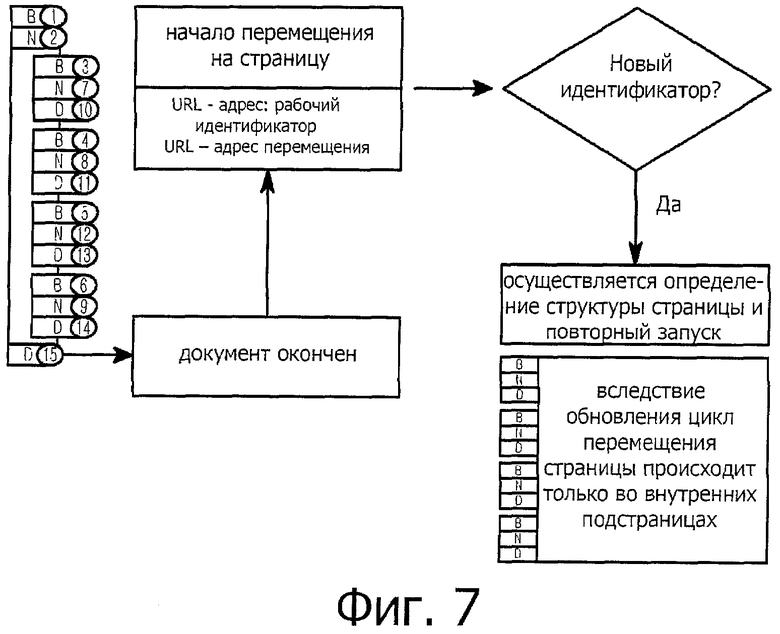
фиг.7 представляет собой изображение, описывающее процесс для определения того, перемещена ли страница в случае, когда обновляется сложная страница;
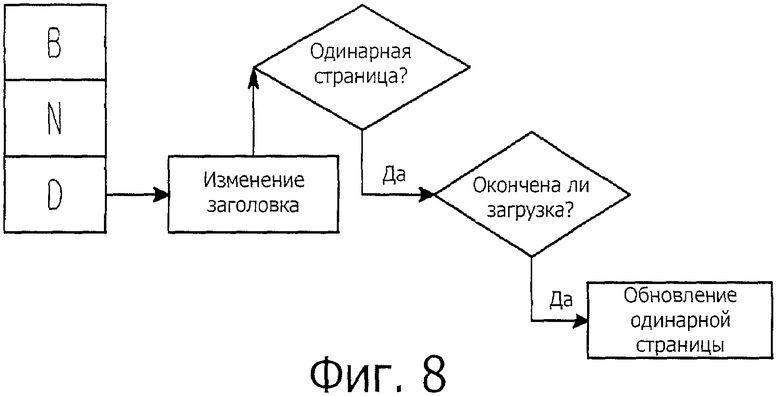
фиг.8 представляет собой изображение, описывающее процесс для определения того, перемещена ли страница в случае, когда обновляется одинарная страница; и
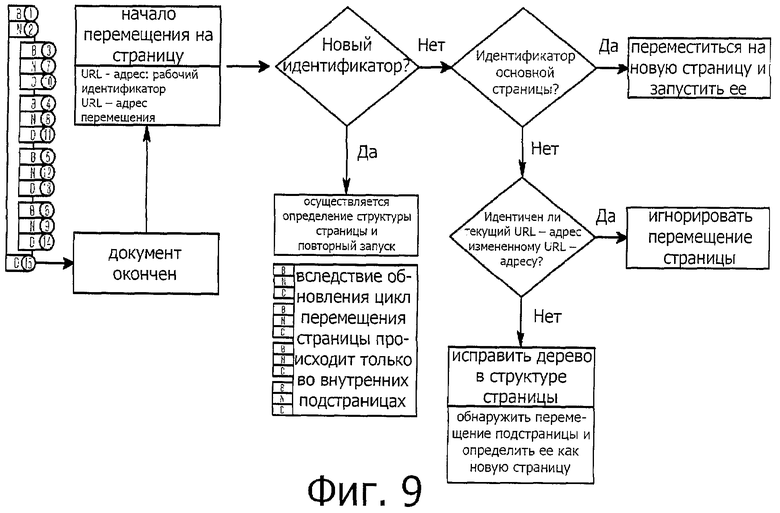
фиг.9 представляет собой изображение, описывающее процесс для определения того, перемещена ли web-страница в случае, когда изменяется подстраница, и соответственно изменяется только цикл перемещения подстраницы.
Краткое описание символов на чертежах:
100: указатель,
200: программа слежения,
210: модуль генерирования сообщений,
220: модуль хранения сообщений,
230: модуль генерирования указателей,
240: модуль проверки указателей,
300: сервер управления,
310: модуль анализа сообщений.
Наилучший способ осуществления изобретения
Настоящее изобретение предусматривает способ для определения информации о web-сайте посредством анализа структуры web-страниц, включающий в себя этапы, на которых генерируют, когда web-страница начинает перемещаться, сообщение о начале перемещения, которое содержит идентификаторы, выданные для того, чтобы идентифицировать соответствующие web-страницы; генерируют, когда web-страница начинает перемещаться, сообщение о завершении перемещения, которое содержит информацию URL-адреса по соответствующей web-странице и информацию для определения, выполняемого посредством идентификатора, того, является ли соответствующая web-страница основной страницей или подстраницей; генерируют, когда все web-страницы загружены, сообщение о завершении документа, содержащее информацию, которая анализирует то, какая из web-страниц была перемещена; собирают эти сообщения и генерируют базу данных с сообщениями; и определяют, основываясь на анализе базы данных с сообщениями, информацию о web-сайте, относящуюся к состоянию посещения конкретным пользователем и состояниям доступа к web-сайту.
Способ осуществления изобретения
Ниже, со ссылкой на прилагаемые чертежи подробно описываются варианты реализации настоящего изобретения. На чертежах одинаковые или аналогичные элементы обозначены одними и теми же ссылочными позициями даже притом, что они изображены на различных чертежах.
Фиг.1 представляет собой структурную схему, иллюстрирующую систему, приспособленную к способу для определения информации о web-сайте посредством анализа структуры web-страницы, соответствующему настоящему изобретению.
Термин «web-страница» в настоящей заявке также именуется «страницей». Термин «рабочий идентификатор» также именуется как «идентификатор потока» или «идентификатор».
Настоящее изобретение предусматривает технологии для получения информации об использовании web-сайта и результата анализа журнала регистрации путем анализа структуры web-страницы и определения пути перемещения пользователя по web-страницам. С этой целью на клиентах и серверах, которые позволяют пользователям осуществлять доступ в Интернет, должна быть установлена программа для анализа путей перемещения пользователя по web-страницам, которая в настоящем изобретении называется программой (200) слежения.
Программа (200) слежения может быть установлена на клиенты и серверы без ведома пользователя.
Эта программа (200) слежения может быть установлена на клиенты и серверы для достижения разнообразных стратегий. Например, в корейском патенте № 705474, принадлежащем заявителю по настоящему изобретению и озаглавленному СИСТЕМА ДЛЯ ОТОБРАЖЕНИЯ И УПРАВЛЕНИЯ ИНФОРМАЦИЕЙ НА WEB-СТРАНИЦАХ С ИСПОЛЬЗОВАНИЕМ УКАЗАТЕЛЯ, были раскрыты указатель (100), модуль (230) исполнения указателя и программа (200) слежения. В этом раскрытом изобретении поскольку модуль (230) исполнения указателя, реализованный для использования указателя (100), установлен в программе (200) слежения, то программа (200) слежения может быть естественным образом установлена на клиентах и серверах вместе с модулем (230) исполнения указателя. Здесь указатель (100) относится к окну отображения информации, которое собирает разнообразную информацию таким образом, чтобы эта информация могла быть сгруппирована вокруг конкретного содержания web-страниц и использована пользователями.
Фиг.2 представляет собой web-страницу, к которой присоединен указатель (100).
Указатель (100) согласно настоящему изобретению относится к части, которая корреспондирует документам, записанным в web-страницах, картинкам, движущимся изображениям и т.д. Например, этот указатель (100) играет роль самоклеящегося листочка для записей (post-it note), выпускаемого подразделением Art Fry (Художественные мелочи) компании 3М, каковой листочек временно прикрепляется к портативным компьютерам, стенам, доскам и т.д. Таким образом, указатель (100) представляет собой функционирующую в режиме онлайн памятную записку.
Указатель (100) представляет собой прямоугольное пространство определенного размера, в которое могут быть добавлены комментарий, дополнительное объяснение, меморандум и т.д., относящиеся к содержанию соответствующей web-страницы. Указатель (100) может быть загружен тогда, когда этого требуют обстоятельства. Во время отображения указателя (100) могут быть также активированы и web-страницы.
Указатель (100) включает в себя такую информацию, как содержание, местонахождение, связанное с web-страницей, URL-адрес web-страницы, к которой присоединен указатель (100) и т.д. Связанная с указателем информация сохраняется в модуле (230) исполнения указателя и передается на сервер (300) управления.
Сервер (300) управления сортирует информацию из указателя, такую как информацию о наличии/местонахождении/содержании, сохраняет ее как базу данных и управляет ею. Эта сохраненная в базе данных информация указателя позволяет определять точное местонахождение указателя, присоединенного к web-странице, извлекать конкретную информацию о пользователях, которые используют указатель, и использовать эту информацию в качестве рекламы на целевых пользователей и данных управления взаимоотношениями с потребителями. Напротив, традиционный браузер сталкивается с трудностью при определении web-документа, соответствующего web-странице, к которой дополнительно присоединен указатель.
Когда пользователь узнает об установке программы (200) слежения, функция поиска перемещения пользователя по web-страницам, которая находится в главном фокусе настоящего изобретения, может быть произвольным образом ограничена для защиты конфиденциальности пользователя.
Согласно фиг.1 система информации о web-сайтах, использующая анализ структуры web-страницы, включает в себя сервер (300) управления, включающий в себя в себя модуль (310) анализа сообщений, который управляет базой (222) данных с сообщениями, анализирует ее; и программы (200) слежения, которые установлены на клиентах и серверах для того, чтобы отслеживать путь web-навигации пользователя, подготавливают данные для проведения анализа структуры web-страниц, и включают в себя модуль (230) исполнения указателя и модуль (240) проверки указателя.
Программы (200) слежения служат для того, чтобы определять путь перемещения web-страниц, что является основной идеей настоящего изобретения. Программы (200) слежения включают в себя модуль (210) генерирования сообщений, модуль (220) сохранения сообщений, модуль (230) исполнения указателя и модуль (240) проверки указателя.
Модуль (210) генерирования сообщений служит для того, чтобы генерировать три сообщения о перемещении web-страницы, основанные на процессах перемещения, которые будут описаны ниже. Модуль (220) сохранения сообщений служит для того, чтобы сохранять сообщения о перемещении web-страницы, располагать их в виде базы данных, как база (222) данных с сообщениями, и передавать их на сервер (300) управления. Модуль (230) исполнения указателя служит для того, чтобы генерировать и исполнять указатель (100) и собирать информацию об указателе (100). Модуль (240) проверки указателя служит для того, чтобы определять, имеется ли в перемещенной web-странице указатель (100).
Сервер (300) управления принимает сообщения из базы (222) данных с сообщениями и сохраняет их и управляет ими. Сервер (300) управления анализирует базу (222) данных с сообщениями посредством модуля (310) анализа сообщений, анализируя структуру web-страницы и структуру web-сайта, включающего в себя эту web-страницу. Сервер (300) управления вычисляет разнообразные статистические данные доступа, основываясь на пользователях и web-страницах. Сервер (300) управления принимает информацию указателя от модуля (240) проверки указателя и собирает и управляет информацией, такой как информация о наличии и местонахождении указателя (100), присоединенного к web-странице
Фиг.3 представляет собой блок-схему алгоритма, описывающую способ для определения информации о web-сайте посредством анализа структуры web-страницы, соответствующий настоящему изобретению.
Как показано на фиг.3, способ последовательно генерирует три сообщения о перемещении страницы от начала перемещения web-страницы до завершения этого перемещения.
Сообщения о перемещении web-страницы относятся к следующим сообщениям, которые являются частью сообщений, непрерывно генерируемых от того момента, когда пользователь исполняет браузер до тех пор, пока браузер не остановлен:
1) сообщение о начале перемещения страниц, относящееся к сообщению, которое генерируется в модуле (210) генерирования сообщений, когда пользователь непосредственно вводит URL-адрес в адресную строку URL или щелкает на ссылке на web-страницу, и соответственно web-страница начинает перемещаться. Это сообщение о начале перемещения страниц позволяет получить один идентификатор потока (который в дальнейшем именуется идентификатором или рабочим идентификатором) для всех web-страниц. Если web-браузер первоначально связан с конкретной web-страницей, то может быть получен новый идентификатор потока, который будет подробно описан ниже;
2) сообщение о завершении перемещения страниц, относящееся к сообщению, которое генерируется непосредственно перед отображением web-страницы на мониторе после того, как принята информация обо всех перемещенных web-страницах. Это сообщение о завершении перемещения страниц включает в себя информацию о URL-адресе, информацию об идентификаторе и т.д;
3) сообщение о завершении документа, относящееся к сообщению, которое генерируется после того, как завершена вся работа с использованием web-страниц. Сообщение о завершении документа генерируется каждый раз, когда завершается один поток. Сообщение о завершении документа требуется для определения завершения подстраницы, завершения всех потоков и т.д.
Это сообщение используется для определения случая, при котором пользователь распознает страницу как другую страницу, потому что эта страница была перемещена и затем только частично изменена внутрифреймовыми тегами или тегами, задающими фрейм и т.д. Здесь перемещение страницы может быть завершено, поскольку поток самого высокого уровня генерируется последним.
В дополнение к этому на этапе генерирования сообщения о завершении документа определяется, имеется ли указатель.
Поскольку эти три сообщения о перемещении web-страницы генерируются в соответствии с процессом перемещения web-страницы (при котором последовательность перемещения страницы отличается в зависимости от того, является ли эта web-страница одинарной страницей или сложной страницей, что будет описано ниже), они используются для определения структуры web-страницы.
Здесь термин "рабочий идентификатор" (идентификатор потока или идентификатор) относится к идентификационному номеру web-страницы, который используется для того, чтобы распознавать точный источник подстраниц, когда сообщение о завершении страниц/документа генерируется случайным образом в каждой подстранице.
Для того чтобы получить генерирующее сообщение браузера, должна быть использована функция запуска сообщений модели компонентных объектов. Браузер генерирует один поток на URL-адрес и независимо выполняет соответствующие перемещения страницы. Следовательно, перемещение web-страниц выполняется не способом последовательного перемещения, а способом параллельного перемещения, который будет описан подробно со ссылкой на чертежи. Поэтому при генерировании всех сообщений о перемещении, имеющих целью определить структуру web-страницы, должно быть определено, к какому потоку (или идентификатору самого высокого уровня) принадлежит каждое сообщение о перемещении и к какому состоянию принадлежит каждое сообщение о перемещении, то есть конкретный идентификатор.
Для того чтобы определить эти состояния, способ согласно настоящему изобретению генерирует сообщения о перемещении, предназначенные для генерирования и извлечения разнообразной информации о web-страницах. Последовательность генерирования сообщений о перемещении подробно описывается ниже.
Когда web-страница начинает перемещаться, генерируется сообщение о начале перемещения страницы и может быть получен идентификатор потока (идентификатор или рабочий идентификатор) для соответствующего URL-адреса и другая дополнительная информация. Если это сообщение о начале перемещения страницы первоначально генерируется после того, как был запущен браузер, то может быть получен самый высокий рабочий идентификатор, который может отличать перемещение web-страницы.
После того как информация о соответствующей странице была принята, генерируется сообщение о завершении перемещения. При этом определяется поток, которому соответствует это сообщение. Если описать это более конкретно, то через посредство идентификатора, сгенерированного на этапе генерирования сообщения о начале перемещения страницы, выполняется проверяющий процесс, анализирующий, к какому идентификатору основной страницы и/или страницы самого высокого уровня относится перемещаемая в настоящий момент web-страница.
Кроме того, на этапе генерирования сообщения о завершении перемещения страницы может быть получен точный URL-адрес посредством извлечения соответствующего URL-адреса. Причина, по которой URL-адрес не извлекается в начале перемещения страницы, заключается в том, что информация о URL-адресе, генерируемая в начале перемещения страницы, может включать в себя неправильный URL-адрес вследствие операции ввода пользователем или вследствие того, что связанная с URL-адресацией система web-сервера, который управляет соответствующим web-сайтом, может произвольно изменить информацию. Вследствие этих причин URL-адрес извлекается тогда, когда страница уже перемещена, то есть после того, как информация web-страницы найдена и затем принята.
В то время как генерируются эти два сообщения, использующие информацию об идентификаторе каждого перемещения, URL-адресе, последовательности генерирования идентификатора и т.д., осуществляется анализ структуры страницы путем генерирования базы данных с сообщениями, анализируемой в виде древовидной структуры.
Когда генерируется сообщение о завершении документа, в базе данных с сообщениями, составленной из древовидной структуры web-страницы, которая была предварительно определена, определяется, по какой из web-страниц работа завершена (если первым осуществлялось посещение web-сайта, то древовидные структуры для web-сайтов, посещенных после операции проверки, будут сгенерированы заново). Обработка web-страницы, завершающей работу, проводится в случае, когда осуществляется завершение внутренней страницы, или способом для проверки того, завершен ли самый высокий уровень работы.
После этого эти три сообщения о перемещении для соответствующих web-страниц генерируются в виде базы данных с сообщениями, и эта база данных с сообщениями передается на сервер управления. Посредством базы данных с сообщениями сервер управления может анализировать структуру web-сайта, собирать статистические данные о посещении основной страницы и посещении подстраниц, использовать информацию о состояниях доступа к web-сайту, таких как время посещения, и использовать данные управления взаимоотношениями с потребителями и данные управления потребителем, которые получаются посредством анализа состояния посещения web-сайта пользователем. Кроме того, посредством этих процессов сервер управления может получать данные для выполнения целевой рекламы на пользователей, которые используют указатель.
Фиг.4 представляет собой изображение, описывающее последовательность сообщений, генерируемых при перемещении web-страниц, соответствующую настоящему изобретению.
Перед описанием фиг.4 рассмотрим структуру web-страницы, образующую web-сайт.
Термин "структура web-страницы" относится к структуре страницы, отображаемой на экране клиента, и подразделяется на структуру одинарной страницы, составленную из одного URL-адреса, и структуру сложной страницы, составленной из множества URL адресов. Структура сложной страницы подразделяется на основную страницу (страницу самого высокого уровня) и подстраницу. Основная страница представляет собой страницу, соответствующую URL-адресу, который может отличить перемещения страницы и отображается в адресной строке. Подстраница создается в основной странице с использованием внутфреймовых тегов или тегов, задающих фреймы.
Термин "основная страница" относится к странице, которая может распознавать изменение страницы. Страница, не использующая фрейм, имеет только одну страницу, соответствующую одному URL-адресу. Основная страница, использующая теги, задающие фреймы, составлена только из тегов фрейма, которые составлены из URL-адреса внутренней страницы, и все содержимое, отображаемое на экране клиента, обрабатывается во внутреннем фрейме. Согласно хорошо известному способу, в сложной странице, притом что базовое изменение страниц может быть проверено по изменению основных страниц, невозможно проверять изменение внутренней страницы или функцию обновления и т.д.
Термин "подстраница" относится ко всем страницам, содержащимся под основной страницей. Распознавание перемещения страницы не может быть определено только по подстранице. Однако подстраница может быть использована как косвенный метод, который определяет распознавание перемещения страницы. Например, посредством информации о перемещении/изменении подстраницы можно проверять, обновлена ли сложная страница или изменена внутренняя страница.
Следовательно, для сложной страницы важно, изменена ли подстраница. Способ согласно настоящему изобретению генерирует три типа сообщений о перемещении для подстраницы и обнаруживает связь между основной страницей и подстраницей, тем самым точно определяя всю структуру web-сайта.
Как показано на фиг.4, когда страница перемещается в сложную страницу, сначала генерируется сообщение о начале перемещения страницы для основной страницы, и затем во время загрузки внутреннего содержимого генерируется сообщение о завершении перемещения страницы. При этом когда страница содержит другие подстраницы, генерируются сообщения о начале перемещения страниц/сообщения о завершении перемещения страниц/сообщения о завершении документов для подстраниц. Сообщения о начале перемещения страниц генерируются последовательно. Другие сообщения о завершении перемещения/сообщения о завершении документа генерируются в произвольном порядке.
Это объясняется тем, что в каждой странице генерируется один поток и тем, что перемещение страниц выполняется одновременно, так что последовательность генерирования сообщений не ждет до тех пор, пока будет загружено внутреннее содержимое. Если описать это более конкретно, то в состоянии, включающем в себя этап выдачи идентификатора в момент времени, когда только начинается перемещение страницы, когда ей выделяется поток, сообщения о начале перемещения страницы генерируются последовательно для того, чтобы обеспечить идентификатор, а затем другие сообщения генерируются в соответствии с установкой кодов подстраниц и временем загрузки. После этого когда сообщения о завершении документа для основной страницы наконец сгенерированы, выясняется, что перемещение соответствующей страницы завершено и она анализируется на предмет того, является ли она основной страницей и/или подстраницей, для чего используется структура web-страницы, то есть информация URL-адреса, и связь идентификаторов, исходящих от других web-страниц.
Фиг.5 представляет собой изображение, описывающее древовидную структуру web-страниц, генерируемую посредством сообщений о перемещении, соответствующую настоящему изобретению.
Древовидная структура web-страницы представляет собой информацию из базы данных с сообщениями, иерархически организованной на основе web-страниц. Таким образом, web-страница иерархически представлена структурой "ветвь дерева", так что информация основной страницы и информация подстраниц могут быть организованы в виде ветвящейся структуры. Причем эта структура простирается в формате ветвей дерева от страницы самого высокого уровня (основной страницы) до страницы более низкого уровня (подстраницы).
Когда база данных с сообщениями подготовлена в виде древовидной структуры и анализируется web-страница, количество рабочего времени может быть уменьшено, и положения и информация основной страницы и подстраниц могут также быть с легкостью определены. Кроме того, просто определять изменения в страницах, такие как добавление новой страницы, удаления страницы и т.д. К тому же, что касается web-сайта, к которому уже осуществлен доступ, то его структура, то есть древовидная структура также сохранена в памяти. Следовательно, способ согласно настоящему изобретению может быстро обрабатывать информацию, сравнивая эту информацию с такого рода сохраненной древовидной структурой.
Для того чтобы выводить структуру web-страницы из сообщений о перемещении страниц, на этапе генерирования сообщения о начале перемещения страницы выдаются идентификаторы для различения страниц. Эти идентификаторы хранятся в древовидной структуре страниц.
Если конкретная web-страница перемещается на первую страницу, то рабочий идентификатор, сгенерированный на этапе генерирования сообщения о начале перемещения, сохраняется до тех пор, пока не завершена работа браузера по перемещению, благодаря чему обеспечивается идентификация для работы по перемещению.
Рабочие идентификаторы страниц, отличные от идентификатора, сгенерированного при первом перемещении, все генерируются в произвольном порядке. Рабочие идентификаторы генерируются вновь при перемещении страницы и при обновлении страницы.
Следовательно, сервер управления сравнивает эти идентификаторы и определяет, согласуется ли информация URL-адреса существующего идентификатора с этой информацией для нового идентификатора, так что может быть определено количество доступов к конкретной web-странице и определено, перемещена ли web-страница.
Однако когда изменяется только часть сложной страницы, рабочий идентификатор не выдается.
Согласно этому принципу при изменении web-страницы определяется, изменяется ли страница при общем перемещении. В дополнение к этому при изменении части страницы определяется, должна ли эта страница быть признана новой страницей.
Для того чтобы анализировать структуру web-страницы, генерируются и записываются данные, формирующие базу данных с сообщениями. Эти данные могут представлять собой идентификатор, информацию URL-адреса, информацию о последовательности генерирования сообщений о перемещения и т.д. и подробно описаны в том, что касается цели их использования.
Когда сообщение о начале перемещения страницы сгенерировано, производится проверка того, был ли ранее по соответствующей странице сохранен идентификатор страницы самого высокого уровня, что делается для того, чтобы проанализировать, соответствует ли эта страница новому состоянию доступа. Если идентификатор страницы самого высокого уровня не хранится, то это означает, что браузер запускается впервые, и соответственно первоначальный рабочий идентификатор не выдан. Следовательно, выдается новый идентификатор страницы самого высокого уровня.
Если идентификатор страницы самого высокого уровня уже выдан, то имеют место два случая.
Когда первоначальный идентификатор генерируется вновь, то определяется, что начинается новое перемещение web-страницы. Напротив, когда генерируется другой идентификатор, отличный от первоначального идентификатора, то определяется, что запускается подстраница в сложной странице, но страница не перемещается.
Что касается одинарной страницы, то поскольку цикл перемещения страницы выполняется только один раз и, таким образом информация подстраницы не существует, структура web-страницы может быть проанализирована с использованием только информации идентификатора. При этом в качестве дополнительной информации может быть использован URL-адрес этой одинарной страницы.
Что касается сложной страницы, то трудно, используя только идентификатор страницы, определить, обновлена ли страница или изменена часть страницы. Следовательно, необходимо генерировать и записывать отличную от идентификатора информацию, такую как URL-адрес страницы, последовательность генерирования страницы.
Таким образом, поскольку в сложной странице существуют подстраницы основной страницы, то в древовидную структуру страницы записывают и управляют информацией, такой как рабочий идентификатор подстраницы, URL-адрес подстраницы, последовательность генерирования подстраниц и т.д., отличной от информации идентификатора об основной странице. После сравнения идентификаторов, сравнения URL-адресов, и анализа информации о последовательности генерирования подстраниц, может быть определено, перемещена ли сложная страница, и/или может быть определена структура сложной страницы. Следовательно, для сложной страницы требуется информацию о URL-адресах и информация о последовательности генерирования подстраниц.
Нижеследующее описание раскрывает процедуры для проверки перемещений одинарной страницы и сложной страницы.
Фиг.6 представляет собой изображение, описывающее процесс для выяснения того, завершены ли страницы.
В случае одинарной страницы поскольку цикл перемещения одинарной страницы генерируется один раз и одинарная страница не включает в себя никакой подстраницы, определение того, завершена ли страница, производится по генерированию трех типов сообщений о перемещении без записи дополнительной древовидной структуры.
В случае сложной страницы поскольку в цикле перемещения основной страницы имеется множество циклов перемещения подстраниц, основная страница и подстраница должны быть различены друг от друга. Если описать это более конкретно, то когда сгенерировано сообщение о начале перемещения основной страницы, сгенерированы сообщения о перемещении подстраниц в произвольном порядке, в соответствии с последовательностью загрузки и завершен процесс перемещения всех подстраниц, генерируется сообщение о завершении документа для цикла перемещения основной страницы.
В ходе этого процесса завершение перемещения сложной страницы может быть определено в соответствии с тем, существует ли сообщение о завершении документа основной страницы.
Фиг.7 представляет собой изображение, описывающее процесс для определения того, перемещена ли страница в случае, когда обновляется сложная страница.
Когда точно подготовлена древовидная структура страницы, которая показана на фиг.5, и затем осуществляется посещение соответствующей web-страницы, то можно с легкостью определить структуру всей web-страницы.
В частности, поскольку сложная страница имеет в себе множество подстраниц, то для того чтобы выполнить операцию управления, такую как обновление и т.д., требуется записать информацию о подстраницах подробно в древовидную структуру страницы.
Согласно фиг.7, когда функция обновления выполняется в сложной странице, все подстраницы, за исключением основной страницы, перезагружаются. В этом случае заново генерируются идентификаторы цикла перемещения страницы. Вновь сгенерированные идентификаторы отличаются от рабочих идентификаторов предшествующих страниц.
Следовательно, если генерируется сообщение о завершении документа и затем вновь генерируются сообщения о начала перемещения страниц, то производится проверка того, содержится ли рабочий идентификатор в ранее подготовленной древовидной структуре страницы, и того, является ли рабочий идентификатор идентификатором основной страницы. Если рабочий идентификатор не содержится в ранее подготовленной древовидной структуре страницы и не является идентификатором основной страницы, то определяется, что сложная страница обновляется.
Фиг.8 представляет собой изображение, описывающее процесс для определения того, перемещена ли страница в случае, когда обновляется одинарная страница.
Одинарная страница сама не содержит никакой подстраницы. Следовательно, в отличие от сложной страницы невозможно определить, обновляется ли одинарная страница по генерированию сообщения подстраницы. Для того чтобы решить эту проблему, используются следующие два сообщения:
Как описано в приведенной выше таблице 1, сообщение об изменении заголовка генерируется в случае, когда изменяется заголовок браузера, а сообщение о завершении загрузки генерируется в случае, когда загружено все содержимое страницы.
Другими словами, при обновлении одинарной страницы сначала генерируется сообщение об изменении заголовка. Когда генерируется сообщение об изменении заголовка, в состоянии, при котором сообщение о начале перемещения страницы не сгенерировано после того, как перемещение страницы было завершено, и когда структура страницы также представляет собой одинарную страницу, предполагается, что существует ситуация, при которой может происходить обновление страницы. Таким образом, поскольку обновление является операцией, которая выполняется после того, как web-страница была уже загружена, состояние обновления определяется в соответствии с тем, генерируется ли после установления того, что web-страница является одинарной страницей, последующее сообщение, и в соответствии с типом этого последующего сообщения.
Состояние обновления одинарной страницы может быть определено в соответствии с сообщением об изменении заголовка или сообщением о завершении загрузки, указывающим на решение завершить документ, без генерирования дополнительного сообщения о начала перемещения после генерирования сообщения о завершении документа.
Причем состояние, при котором генерируется сообщение об изменении заголовка, не определено как обновление страницы, но только предполагается являющимся обновлением страницы. Это объясняется тем, что сообщение об изменении заголовка может быть сгенерировано на странице при исправлении сценария и т.д. Следовательно, изменение заголовка используется для распознавания только математического ожидания начала перемещения страницы. Когда генерируется сообщение об изменении заголовка и затем генерируется сообщение о завершении загрузки, то это распознается как обновление страницы.
Фиг.9 представляет собой изображение, описывающее процесс для определения того, перемещена ли web-страница, в случае, когда изменяется подстраница, и соответственно изменяется только цикл перемещения подстраницы.
Web-сайты могут быть спроектированы так, чтобы функционировать следующим образом: web-сайт проектируется таким образом, что информация web-сайта отображается там, где выполнена панель (web-страницы) с внутренней рамкой, так что можно менять только эту внутреннюю панель, не изменяя при этом основную страницу; и web-сайт проектируется таким образом, что рекламные объявления на странице выполнены с рамками, так что их можно заменить другими по истечении определенного промежутка времени.
В этих двух способах внутренние страницы генерируют цикл перемещения страницы. Однако пользователь распознает тот факт, что страница изменена на другую, в момент времени между до и после того, как изменится первая панель. Напротив, хотя рекламные объявления изменяются, пользователь не распознает тот факт, что страница изменилась на новую страницу. Следовательно, когда перемещается подстраница, необходимо распознавать тот факт, является ли подстраница новой страницей или перемещение игнорируется.
Когда изменяется только подстраница, рабочий идентификатор подстранице не выдается, но вместо этого используется предшествующий рабочий идентификатор. Этот рабочий идентификатор используется для того, чтобы найти, какой странице в древовидной структуре страниц соответствует эта подстраница. Когда новый URL-адрес отличается от ранее сохраненного URL-адреса, то распознается тот факт, что страница была изменена. Напротив, когда новый URL-адрес идентичен ранее сохраненному URL-адресу, то изменение страницы игнорируется.
Когда новый URL-адрес отличается от ранее сохраненного URL-адреса, то подстраница может быть туда добавлена в соответствии с новым URL-адресом. В этом случае добавляемая подстраница должна быть добавлена в древовидную структуру страницы.
Посредством этих процессов может быть определен путь перемещения конкретного пользователя по web-страницам. Другими словами, когда база данных с сообщениями, которая записывает данные, генерируемые посредством сбора информации о пути перемещения при web-навигации конкретного пользователя, передается на сервер управления, она анализируется с целью обеспечения статистических данных, таких как состояние доступа к соответствующим web-сайтам, анализ пути доступа конкретного пользователя и т.д.
Кроме того, когда к web-странице присоединен указатель, сервер управления собирает информацию об указателе и определяет данные указателя и информацию указателя о месте его присоединения и т.д.
Если описать это более конкретно, то на этапе генерирования сообщения о завершении документа определяется, имеет ли указатель информацию, подлежащую передаче. Когда установлено, что указатель имеет информацию, подлежащую передаче, то информация о том, что соответствующий указатель существует, передается на сервер управления вместе с сообщением о завершении документа. Сервер управления позволяет информации о том, что соответствующий указатель существует, быть включенной в базу данных с сообщениями.
При генерировании сообщения о завершении документа информация документа передается на сервер управления; производится поиск и повторная передача указателя, существующего в соответствующем документе, и указатель включается в состав web-страницы и затем отображается.
Традиционный браузер сталкивается с трудностями, определяя информацию о местонахождении и/или существовании указателя, используя только его структуру. Однако способ по настоящему изобретению может воспроизводить информацию о точном местонахождении указателя, присоединенного к конкретной web-странице, посредством имеющейся информации об указателе, и собирать эту информацию для того, чтобы записывать ее/управлять ею/сохранять ее в сервере управления таким образом, что целевая реклама может быть предъявлена пользователям, которые используют указатели, и может быть собрана информация, которая не может быть получена при традиционном анализе журнала регистрации.
Хотя в иллюстративных целях были раскрыты предпочтительные варианты реализации настоящего изобретения, специалисты в данной области техники должны понимать, что возможны различные изменения, дополнения и замены, что не выходит за рамки объема и сущности изобретения, раскрытых в прилагаемой формуле изобретения.
Промышленная применимость
Как было сказано выше, в описании и прилагаемых чертежах описано содержание и функционирование СПОСОБА ДЛЯ ОПРЕДЕЛЕНИЯ ИНФОРМАЦИИ О WEB-САЙТЕ ПОСРЕДСТВОМ АНАЛИЗА СТРУКТУРЫ WEB-СТРАНИЦЫ согласно настоящему изобретению, но вышеприведенное описание и прилагаемые чертежи является только иллюстрацией предпочтительных вариантов реализации изобретения, не ограничивая его, и в проиллюстрированные варианты реализации изобретения могут быть внесены модификации и изменения, что не выходит за рамки сущности настоящего изобретения.


Изобретение относится к способам анализа структуры web-страницы. Техническим результатом является повышение достоверности информации предоставляемой веб-страницами. В способе для определения информации о web-сайте посредством анализа структуры web-страниц генерируют сообщение о начале перемещения страницы, которое содержит идентификаторы, выданные для того чтобы идентифицировать соответствующие web-страницы, генерируют сообщение о завершении перемещения web-страницы, которое содержит информацию URL-адреса по соответствующей web-странице и информацию для определения, выполняемого посредством идентификатора, является ли соответствующая web-страница основной страницей или полстраницей, генерируют сообщение о завершении документа, когда все web-страницы загружены, при этом в информации указано, какая из web-страниц была перемещена, собирают эти сообщения и генерируют базу данных с сообщениями, и определяют, основываясь на анализе базы данных с сообщениями, информацию о web-сайте, относящуюся к состоянию посещения конкретным пользователем и состояниям доступа к web-сайту. 8 з.п. ф-лы, 9 ил., 1 табл.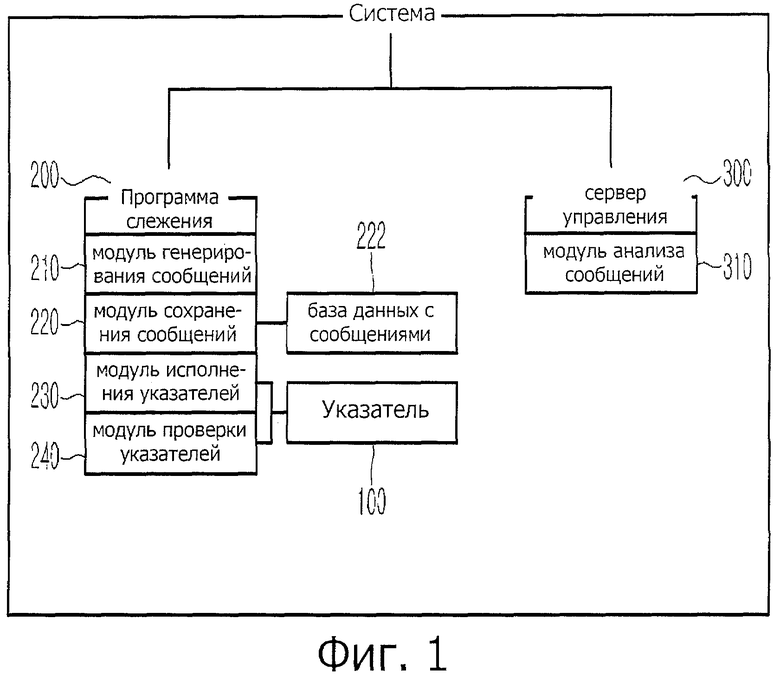
1. Способ для определения информации о web-сайте посредством анализа структуры web-страниц, содержащий этапы, на которых:
генерируют, когда web-страница начинает перемещаться, сообщение о начале перемещения, которое содержит идентификатор, выданный для того, чтобы идентифицировать соответствующие web-страницы;
генерируют, когда web-страница начинает перемещаться, сообщение о завершении перемещения, которое содержит информацию URL-адреса по соответствующей web-странице и информацию для определения, выполняемого посредством идентификатора, того, является ли соответствующая web-страница основной страницей или полстраницей;
генерируют, когда все web-страницы загружены, сообщение о завершении документа, содержащее информацию, которая анализирует то, какая из web-страниц была перемещена;
собирают эти сообщения и генерируют базу данных с сообщениями; и определяют, основываясь на анализе базы данных с сообщениями, информацию о web-сайте, относящуюся к состоянию посещения конкретным пользователем и состояниям доступа к web-сайту.
2. Способ по п.1, в котором, когда перемещается множество web-страниц, сообщения о начале перемещения генерируют последовательно, основываясь на web-страницах, а сообщения о завершении документа генерируются в произвольном порядке, согласно последовательности загрузки; и
информация, собранная в отношении последовательности генерирования сообщений, сохраняется в базе данных с сообщениями.
3. Способ по п.1, в котором этап, на котором генерируют базу данных с сообщениями, содержит этап, на котором:
генерируют базу данных с сообщениями, где множество web-страниц конкретного web-сайта определены, посредством соответствующих сообщений, в виде древовидной структуры, от основной страницы до подстраницы.
4. Способ по п.1, в котором этап, на котором генерируют сообщение о начале перемещения, содержит этап, на котором:
для того чтобы определить, посещается ли соответствующая web-страница в первый раз, проверяют, хранится ли информация идентификатора по соответствующей web-странице в базе данных с сообщениями.
5. Способ по п.1 в случае, когда web-страница выполняет функцию обновления, соответствующую сложной странице, дополнительно содержащий этапы, на которых
сравнивают идентификатор, выданный полстранице, с существующим идентификатором;
выполняют анализ этого сравнения; и
определяют, обновляется ли сложная страница.
6. Способ по п.1 в случае, когда web-страница выполняет функцию обновления, соответствующую одинарной странице, дополнительно содержащий этапы, на которых:
генерируют сообщение об изменении заголовка; и
генерируют дополнительное сообщение о завершении загрузки, когда загружено внутреннее содержание web-страницы,
при этом состояние обновления одинарной страницы определяется в соответствии с сообщением об изменении заголовка или сообщением о завершении загрузки.
7. Способ по п.1 в случае, когда в сложной странице изменяется только подстраница, дополнительно содержащий этапы, на которых:
поддерживают рабочий идентификатор полстраницы;
осуществляют поиск местонахождения соответствующей web-страницы, исходя из базы данных с сообщениями посредством этого поддерживаемого рабочего идентификатора; и распознают тот факт, что web-страница изменена, когда информация текущего URL-адреса отличается от информации URL-адреса web-странице, по которой осуществлялся поиск.
8. Способ по п.1, в котором этап, на котором генерируют сообщение о завершении документа, содержит этапы, на которых:
проверяют, присоединен ли дополнительно к соответствующей web-странице указатель; и
генерируют в случае, когда к соответствующей web-странице присоединен указатель, существующую информацию об указателе.
9. Способ по п.8, в котором:
существующая информация об указателе содержит информацию о местонахождении указателя и информацию о содержании указателя; и
эта существующая информация сохраняется в дополнительной базе данных.
| СПОСОБ ПОИСКА, РАЗМЕТКИ И ОТОБРАЖЕНИЯ ИНФОРМАЦИИ И СИСТЕМА ПОИСКА, РАЗМЕТКИ И ОТОБРАЖЕНИЯ ИНФОРМАЦИИ | 2005 |
|
RU2292078C1 |
| US 6014638 A, 11.01.2000 | |||
| JP 11345202 A, 14.12.1999 | |||
| KR 1020030040263 A, 22.05.2003. | |||

