Изобретение относится к области криптографии, а более конкретно - к способам защиты различных форм информации, обеспечивающим соблюдение авторских прав и обеспечение конфиденциальности информации.
Одним из наиболее известных в настоящее время способов защиты цифровых данных является внедрение невидимых "водяных" знаков или сообщений на носитель защищаемой информации, например изображение, аудио- или видеопоток. Однако не менее востребованными являются способы применения подобных цифровых маркирующих подходов для аналоговых носителей информации, таких как, например, напечатанный на бумаге документ. Область применения таких подходов может включать в себя предотвращение подделки или несанкционированной модификации печатных документов, используемых для целей идентификации, безопасности или отслеживания транзакций.
Из уровня техники известны многочисленные методы защиты печатных документов, например использование бумаги с водяными знакам, защитных волокон, голограмм или специальных чернил. Препятствием к использованию подобных приемов является их довольно высокая стоимость и необходимость применения специального оборудования. Дополнительно следует отметить, что существует немало ситуаций, когда необходимо с помощью маркирования напечатанного документа незаметно передать дополнительную цифровую информацию, позволяющую облегчить процесс подтверждения подлинности документа. Поэтому незначительная модификация документа, позволяющая внедрить в этот документ незаметное для невооруженного глаза скрытое уникальное цифровое сообщение, может привести к созданию полезного и экономически выгодного механизма для последующего установления подлинности документа.
Следует отметить, что значительное число технических решений было разработано для осуществления защиты от копирования, регулирования копирования документов и установления подлинности посредством внедрения некоторой защищающей информации в документ. Однако большинство известных методов ориентировано на внедрение скрытой информации в мультимедийные документы или цифровые изображения, и эти методы не могут быть непосредственно применены к напечатанным документам из-за сложно формализируемых процессов печати, растрирования, сканирования и т.п.
В частности, изобретение, описанное в выложенной патентной заявке США 20090021795 [1], основано на внедрении идентификационных меток в псевдослучайные позиции документа. Метки представляют собой кластер из черных или белых точек для белых или черных областей документа соответственно. Предполагается, что созданные подобным методом метки устойчивы к изменению контраста изображения и процессу растеризации, являющемуся результатом передачи документа по факсу. Однако предложенные идентификационные метки могут быть заметны для наблюдателя и визуально ухудшают качество напечатанного документа.
В патенте США 6983056 [2] рассматривается способ внедрения водяных знаков в напечатанный документ за счет модификации символов. На первом этапе выполняют обнаружение текстовых строк, которые далее разделяются на подблоки. Подблоки, в свою очередь, разбиваются на подгруппы. Информация внедряется в документ за счет модификации признаков символов. В качестве одного из таких признаков используют толщину линий символов. Извлечение скрытого сообщения выполняется с помощью вычисления указанных признаков и их сравнения между собой. Недостатком этого способа является его высокая вычислительная сложность и необходимость наличия текстовых строк в исходном документе.
Выложенная патентная заявка США 20080292129 [3] предлагает способ добавления дополнительной информации в печатный документ за счет внедрения специальных информационных меток в предопределенные позиции. Метки, состоящие из набора точек, ставят на свободные области документа. После этого изображение преобразовывается для печати и печатается. Недостатком раскрытого в заявке изобретения является очевидная заметность внедряемой информации для стороннего наблюдателя.
С точки зрения особенностей зрительного восприятия человека эффективным решением для маскирования скрытого сообщения в текстовом документе является внедрение группы меленьких белых точек в сплошные области черного цвета относительно небольшой площади, соответствующих, например, текстовым символам типичных размеров (от 10 до 14 пунктов). Такой подход позволяет осуществлять практически невидимые для невооруженного глаза деформации в документе, устойчивые к печати и сканированию. Другие общепринятые способы внедрения скрытой информации, основанные на внедрении черных точек в области белого цвета или белых точек в достаточно широкие области черного цвета, заметны для глаза, а для малых размеров точек неустойчивы к печати и сканированию.
Заявляемое изобретение решает задачу передачи скрытых цифровых данных посредством использования печатного документа как носителя информации.
При этом заявляемый способ добавления незаметной цифровой информации в печатаемый текстовый документ основывается на внедрении меток, состоящих из нескольких белых точек, в тонкие протяженные черные области, соответствующие фрагментам символов или геометрических примитивов.
Технический результат достигается за счет внедрения скрытого цифрового сообщения в печатаемые документы и извлечения сообщения, посредством выполнения следующих операций (этапов):
• этап внедрения скрытого цифрового сообщения в печатаемый документ, включающий в себя следующие действия:
- растрируют исходное изображение для печати;
- детектируют области в составляющей черного цвета растрированного изображения, пригодные для внедрения информационных меток;
- вычисляют точные позиции для внедрения информационных меток;
- вычисляют объем информации, который может быть внедрен в данное изображение;
- внедряют сообщение в составляющую черного цвета растрированного изображения;
- печатают растрированное изображение.
• этап извлечения скрытого сообщения из печатного документа, включающий в себя следующие действия:
- сканируют напечатанный документ и сохраняют сканированное изображение в памяти;
- улучшают контраст сканированного изображения;
- получают из сканированного изображения бинарное изображение путем пороговой обработки;
- фильтруют бинарное изображение;
- определяют области на бинарном изображении, в которых предположительно могут находиться внедренные метки;
- повышают на сканированном изображении контраст маленьких светлых пятен на темном фоне в пределах определенных на предыдущем этапе областей;
- детектируют положение и распознают внедренные метки;
- восстанавливают структуру извлекаемого сообщения.
Структура внедряемого сообщения имеет строгую упорядоченность, обеспечивающую высокую устойчивость к шуму и скосу (наклону) документа при сканировании.
В качестве исходного изображения в описываемом варианте реализации заявляемого изобретения используется бинарное растрированное изображение. Изобретение включает в себя два этапа: внедрение скрытой информации на первом этапе и извлечение скрытой информации на втором этапе.
Иными словами, заявляемое изобретение описывает процедуры внедрения скрытого сообщения в текстовый документ на этапе печати и извлечения скрытого сообщения на этапе сканирования.
Первый этап заявляемого изобретения основывается на модификации бинарного растрированного изображения перед печатью за счет вставки группы белых точек маленького размера, образующих информационную метку, в сплошные области черного цвета с относительно небольшой шириной, соизмеримой с размером метки. Такой подход обеспечивает незаметные для невооруженного глаза изменения исходного документа с высокой устойчивостью к печати и сканированию. Первый этап способа включает в себя следующие последовательные действия:
- входное растрированное изображение или последовательность полос исходного растрированного изображения помещают в промежуточный буфер памяти;
- детектируют области изображения, пригодные для внедрения меток;
- устанавливают точные координаты для внедрения меток;
- определяют структуру внедряемого сообщения в соответствии с определенными в процессе детектирования местоположениями меток и предустановленными правилами;
- отклоняют координаты для меток, не соответствующие применяемой структуре сообщения, и в дальнейшем их не используют;
- вычисляют возможную емкость внедряемого сообщения на основе числа меток, которые могут быть внедрены в данный документ;
- определяют содержимое внедряемого сообщения в соответствии с его возможной емкостью;
- внедряют сообщение путем проставления меток на входном изображении в предопределенных позициях. Тип метки для каждой позиции определяется содержимым сообщения.
Второй этап основан на обработке сканированного анализируемого документа для извлечения скрытого сообщения. Этап включает в себя следующие операции:
- входное сканированное полутоновое (серое) изображение или последовательность полос изображения помещаются в промежуточный буфер для обработки;
- выполняют улучшение входного полутонового изображения и его бинаризацию;
- выполняют фильтрацию бинарного изображения;
- детектируют области, пригодные для размещения в них меток;
- выполняют детектирование и распознавание внедренных меток на исходном сканированном полутоновом изображении с учетом областей, определенных на предыдущем этапе;
- восстанавливают структуру внедренного сообщения, игнорируют ложные результаты детектирования, не соответствующие этой структуре;
- распознают содержимое сообщения в соответствии с распознанной структурой и результатами детектирования.
Далее существо заявляемого изобретения поясняется в деталях с привлечением графических материалов.
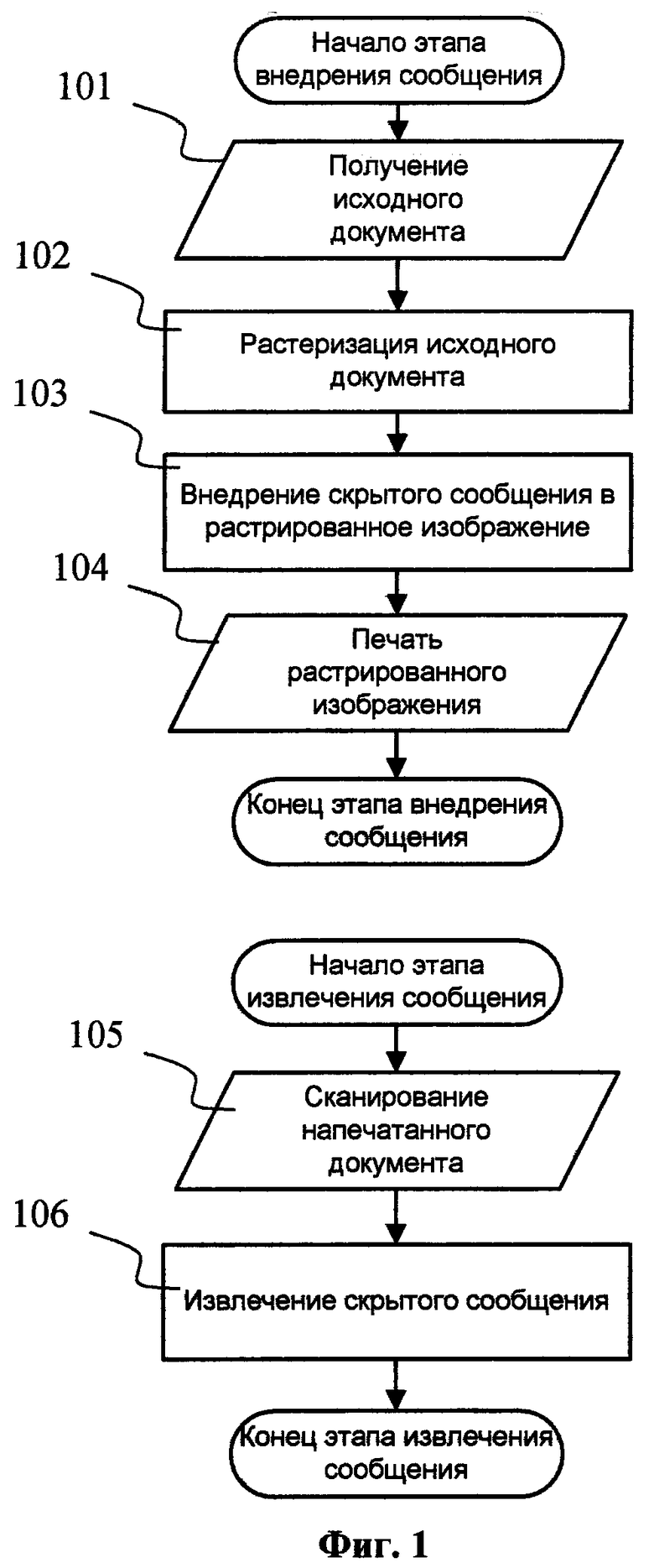
Фиг.1. Упрощенная схема внедрения и извлечения скрытого сообщения.
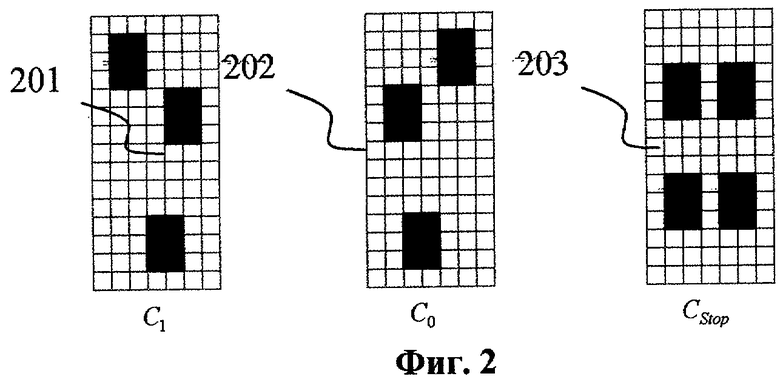
Фиг.2. Примеры конфигурации меток.
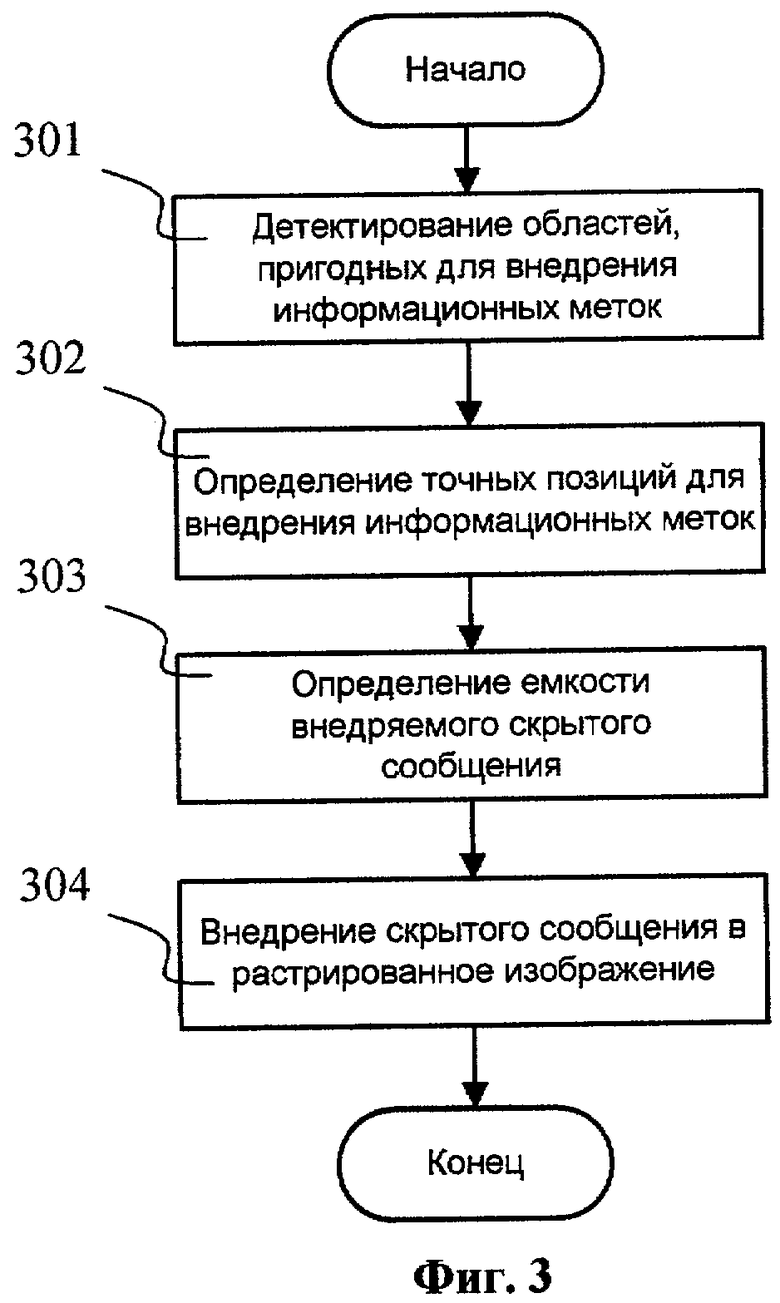
Фиг.3. Обобщенная блок-схема этапа внедрения скрытого сообщения.
Фиг.4. Пример результата детектирования областей, пригодных для внедрения метки.
Фиг.5. Пример определения местоположений меток для внедрения сообщения.
Фиг.6. Пример структуры сообщения для внедрения двух байт. Фрагмент изображения с внедренными данными.
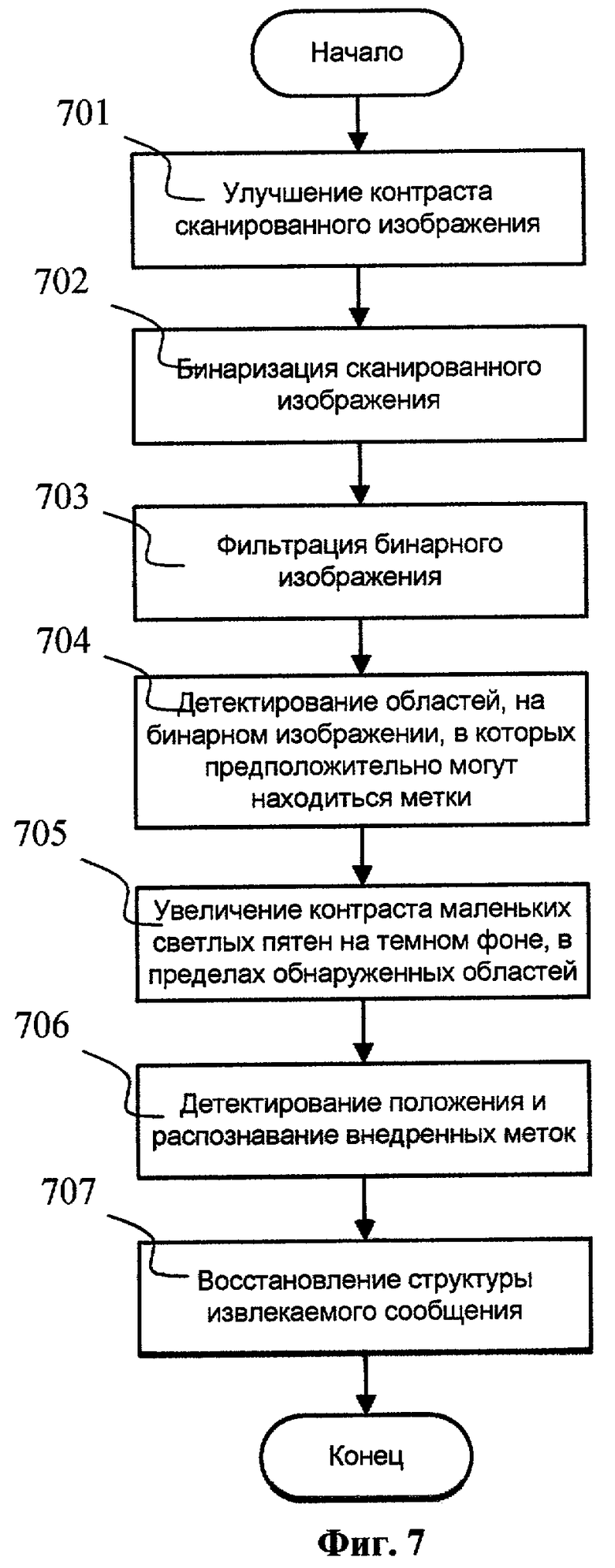
Фиг.7. Блок-схема этапа извлечения скрытого сообщения.
Фиг.8. Пример результата детектирования областей с предполагаемыми метками на сканированном изображении.
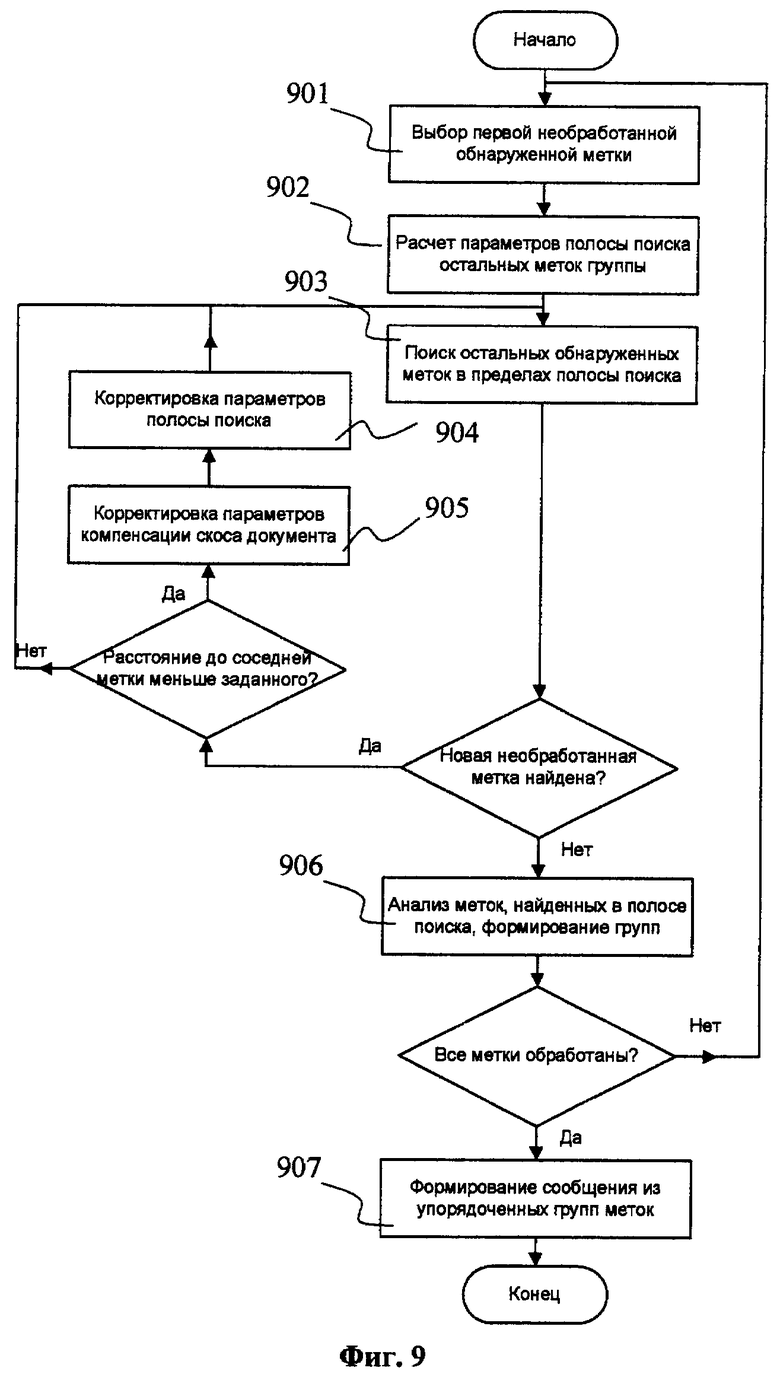
Фиг.9. Блок-схема восстановления сообщения в пределах одной полосы поиска.
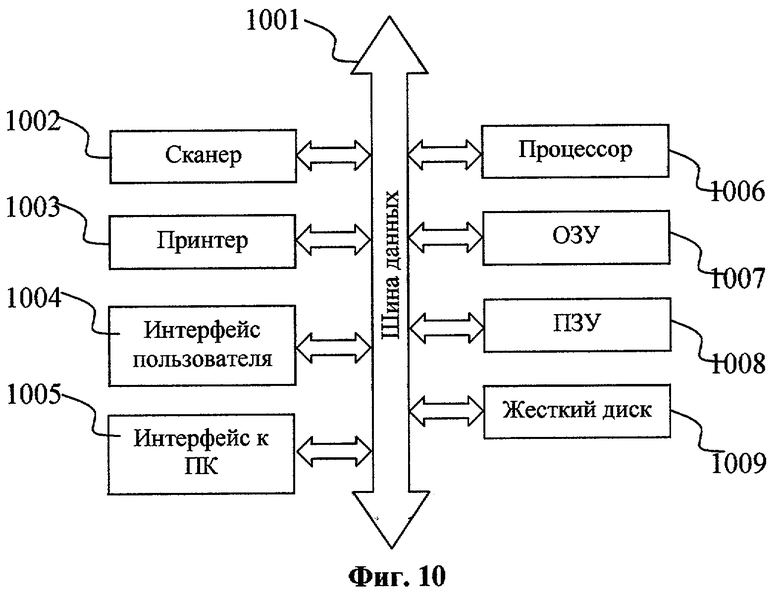
Фиг.10. Схема системы для реализации способа.
На Фиг.1 представлена блок-схема заявляемого способа, включающая в себя основные компоненты, реализующие изобретение. Исходный документ, предназначенный для печати, загружается в буфер памяти на шаге 101. Соответственно специфике печатного процесса документ конвертируется из исходного формата, как, например, PDF, DOC, PS и т.д., в бинарное изображение путем растеризации на шаге 102. Растеризация документа осуществляется встроенным в печатающее устройство RIP-процессором, представляющим собой средство преобразования векторной графики и текста в растровое изображение. В рассматриваемом варианте реализации изобретения внедрение скрытого сообщения осуществляется только для составляющей черного цвета растрированного изображения, но само растрированное изображение может иметь и другие цветовые каналы.
Далее результирующее растрированное изображение служит в качестве носителя информации для передачи скрытого цифрового сообщения, внедряемом на шаге 103. Более подробно этот шаг будет рассмотрен далее. На шаге 104 печатается измененное растрированное изображение. В результате получается бумажный, напечатанный вариант исходного документа со встроенным скрытым сообщением. На этом шаге заканчивается первый этап внедрения скрытого сообщения в напечатанный документ. Последующий этап извлечения скрытого сообщения начинается со сканирования напечатанного бумажного документа на шаге 105. Далее, на шаге 106 сканированное изображение анализируется для извлечения скрытого сообщения. Более подробно этот шаг будет изложен ниже. Извлеченное сообщение может быть использовано для идентификации текущего документа и установления его подлинности. В простейшем случае извлеченное сообщение может визуализироваться для просмотра пользователем или сравниваться с учетной записью в базе данных. Для специалиста в данной области очевидно, что возможны и иные варианты применения изобретения. позволяющего сохранять небольшие объемы цифровой информации в печатных документах. Например, это может быть дополнительная метаинформация, цифровая подпись, идентификационный номер, дата печати, имя автора документа и т.д. Последовательные шаги 104, 105 описывают основные трансформации исходного документа при передаче скрытого сообщения.
На Фиг.2 продемонстрированы предпочтительные варианты конфигурации информационных меток, используемых для записи скрытого сообщения в напечатанный документ. В представленном варианте реализации данного изображения используются три метки с размерами 7×15 аппаратных пикселей для разрешения печати 600 точек на дюйм. Такой размер метки позволяет использовать символы размером от 10 пунктов для внедрения скрытой информации предложенным методом. Метки состоят из нескольких белых точек с размерами 3×2 или 2×3 пикселей. Предполагается, что точки отстоят друг от друга и от границ метки. Это позволяет избежать видимых разрывов внутри и по краям областей, используемых для внедрения меток. Как было выявлено в ходе экспериментального тестирования, такая конфигурация точек обладает высокой устойчивостью к печати на различных устройствах печати. Очевидно, что большие размеры точек имеют лучшую устойчивость при печати и надежнее могут быть распознаны после сканирования, но в этом случае вставленные метки могут быть заметны для стороннего наблюдателя, что демаскирует наличие скрытой записи в документе. В соответствии с Фиг.2 метки C1 (201) и Cn (202) используются для обозначения информационных бит - 1 и 0 соответственно. Одна служебная метка CStop (203) предназначается для упорядочивания структуры сообщения и в большинстве случаев используется как разделяющий бит. С помощью метки CStop последовательность бит преобразуется в набор логических элементов, например байтов. Кроме того, метка CStop используется для обозначения границ групп логических элементов. Для специалиста в данной области очевидно, что возможны иные варианты конфигураций меток и их количество в зависимости от разрешения печати и иных ограничений, накладываемых на допустимые размеры меток.
На Фиг.3 представлена обобщенная блок-схема шага 103, реализующего внедрение скрытого идентифицирующего сообщения в исходное растрированное изображение. Предполагается, что исходное регистрированное изображение находится в буфере памяти (шаг 102). В зависимости от ресурсов памяти и способа реализации предложенного изобретения изображение может загружаться целиком или частично в виде горизонтальных полос. Основные шаги этапа внедрения идентифицирующего сообщения могут быть обозначены следующими действиями. Шаг 301 заключается в обнаружении областей на растрированием изображении, пригодных для внедрения меток. Последующий шаг 302 заключается в вычислении точных позиций для внедрения каждой метки, результатом выполнения которого является массив будущих местоположений меток с упорядоченной структурой. На шаге 303 вычисляется максимальный возможный размер внедряемого сообщения, который, очевидно, ограничивается наполненностью документа текстовой информацией. Тем не менее изменение конфигураций меток может служить необходимым инструментом для регулирования потенциальной информационной емкости изображения документа. Далее определяется содержимое внедряемого сообщения в соответствии с его максимально возможным размером и вставляется в исходный растрированный документ на шаге 304. После модифицирования полученное растрированное изображение печатается на шаге 104.
Рассмотрим более подробно основные элементы блок-схемы. На шаге 301 вычисляется карта тех областей на растрированием изображении Xmap, которые подходят для внедрения меток. При детектировании таких областей в предложенном варианте изобретения используются два структурирующих элемента: Bmax и Bmin, размером 12×29 и 7×29 аппаратных точек соответственно. Конфигурация структурирующих элементов введена для используемого размера метки 7×15 точек. В общем случае, элементы Bmax, Bmin ограничивают возможный размер обнаруженных областей и могут различаться по размеру и форме для других возможных реализаций изобретения. На этом шаге используются морфологические операции для выделения областей Xmap:
Xmap=(X-XoBmax)oBmin;
где 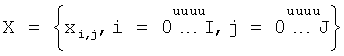 - исходное бинарное растрированное изображение, о - морфологическая операция «открытия» (opening). В данной реализации изобретения координаты изображения i и j соответствуют осям абсцисс и ординат, где I и J - ширина и высота. Точка с координатами (i=0, j=0) находится в левом верхнем углу изображения, ось i направлена вправо, а ось j вниз.
- исходное бинарное растрированное изображение, о - морфологическая операция «открытия» (opening). В данной реализации изобретения координаты изображения i и j соответствуют осям абсцисс и ординат, где I и J - ширина и высота. Точка с координатами (i=0, j=0) находится в левом верхнем углу изображения, ось i направлена вправо, а ось j вниз.
Как следует из выражения, из исходного изображения X удаляются все объекты, чьи размеры превышают структурирующий элемент Bmax (операция (X-XoBmax)). Далее выделяются области, соответствующие структурирующему элементу Bmin. В предпочтительном варианте реализации изобретения быстродействие оптимизируется за счет кэширования повторяющихся вычислений, что позволяет использовать их повторно без дополнительных вычислительных затрат.
В качестве примера на Фиг.4 представлен фрагмент текстового документа, состоящий из белого фона, символов 401 черного цвета и обнаруженных областей 402, помеченных серым цветом. Можно видеть, что символ 401 распознан алгоритмом как слишком большой для того, чтобы в него можно было незаметно поставить метку.
Фиг.5 иллюстрирует шаг 302, на котором осуществляется точное определение позиций внедряемых меток 503 внутри предварительно обнаруженных областей 502. Позиции меток расставляются в пределах горизонтально ориентированной узкой структурирующей полосы 501. Вертикальная верхняя координата начала структурирующей полосы определяется по первой (сверху вниз) обнаруженной области в карте областей Xmap. Последующие соседние горизонтальные полосы разделены друг от друга параллельными линиями 501 с шириной в одну аппаратную точку. Ширина используемых структурирующих полос соответствует высоте используемых информационных меток с запасом в три аппаратных точки. Следовательно, для текущего размера метки в 15 точек, ширина полосы равняется 18 аппаратным точкам. Отсюда следует, что информационные метки позиционируются вдоль горизонтальных прямых линий с небольшими отклонениями, ограниченными структурирующей полосой. Благодаря предложенному подходу внедряемые метки позиционируются с высокой регулярностью, что дает дополнительные преимущества при восстановлении сообщения. Для специалиста в данной области очевидно, что возможны и иные варианты реализации изобретения, и что возможно использование структурирующих полос и соответственно разделяющих линий другого размера, ориентации и формы.
Кроме того, шаг 302 включает в себя несколько ограничений, определяющих, какие именно позиции для внедрения меток, выявленные внутри структурирующих полос, будут использоваться. Для этого вычисленные позиции предполагаемых меток, находящихся в пределах одной полосы, объединяются в компактную последовательность (группу) определенной конфигурации. Первое ограничение устанавливает минимальное расстояние между соседними позициями меток внутри одной группы, которое должно составлять не менее 500 аппаратных точек. Более того, для первой (сверху вниз) группы позиций меток в документе налагается дополнительное более жесткое ограничение - расстояние между текущей и одной из соседних позиций меток внутри одной группы должно быть менее 150 аппаратных точек. Это условие обеспечивает устойчивость алгоритма извлечения сообщения к скосам документа при сканировании, поскольку предварительное оценивание параметров скоса далее будет определяться по результатам детектирования первых обнаруженных информационных меток. В одной структурирующей полосе может быть выделено несколько групп меток, если расстояние между крайними метками в группах превышает требуемое.
Следующее ограничение касается числа меток в одной группе. Структура группы задана так, что при потере нескольких информационных меток на этапе извлечения сообщения не происходит повреждения всего сообщения из-за смещения битовой последовательности. Для этого применяется сервисная метка CStop. Сервисная метка обеспечивает разделение групп меток бит на логические элементы, например байты и обозначение начала и конца группы. Очевидно, что группа меток может включать в себя только целое число логических элементов, в данном случае байтов.
На Фиг.6.1 приводится схематичное изображение группы меток, состоящей из двух байт. На практике количество логических элементов в группе ограничено только емкостью текстовой строки. Таким образом, в предпочтительном варианте реализации изобретения структура группы включает в себя обозначение начала (603) и конца (606) группы, определяемых трехкратным повторением сервисной метки (601). Каждый логический элемент (604) в данной реализации изобретения включает в себя восемь последовательных бит (602) и отделяется от соседнего одной разделяющей сервисной меткой (605). Следовательно, для реализации текущего варианта изобретения, количество меток N в одной группе должно определяться следующим выражением:
N=5+K·9,
где K - количество байт. Соответственно, если всего в группе может быть расположено N* меток, они могут быть разбиты на K=(N*-5)/9 байт. Значение K должно быть округлено в меньшую сторону. Таким образом, общее количество меток N* уменьшается до N, которое определяется вышеприведенным выражением. Оставшиеся неиспользованные позиции для внедрения меток игнорируются. Также игнорируются позиции меток, число которых меньше 14 в сформированной группе. Для иллюстрации структуры внедренного сообщения на Фиг.6.2 представлен фрагмент бинарного растрированного изображения с уже внедренными метками. На фрагменте изображения присутствует левый край информационных групп, начало которых обозначено тремя сервисными метками.
Этап извлечения скрытого сообщения на шаге 106 из сканированного изображения печатного документа (105) представлен блок-схемой, изображенной на Фиг.7. Оба этапа внедрения и исключения скрытых идентифицирующих сообщений жестко взаимосвязаны и используют одинаковую конфигурацию меток и их групп. В текущем варианте реализации изобретения предполагается сканирование с разрешением 600 точек на дюйм, и все приводимые численные значения параметров предназначены для обработки изображений, сканированных с таким разрешением. Этап включает в себя следующие основные действия. Выполняется улучшение контраста (шаг 701) с последующей бинаризацией (шаг 702) сканированного изображения. Далее полученное бинарное изображение фильтруется на шаге 703. Результат используется для выделения областей на шаге 704, в которых возможно присутствие внедренных меток. На шаге 705 выполняется усиление контраста маленьких светлых пятен в пределах обнаруженных областей, обеспечивающее эффективное обнаружение меток в дальнейшем. На шаге 706 осуществляется детектирование местоположения внедренных меток в выделенных областях и их распознавание. Шаг 707 используется для восстановления структуры извлекаемого сообщения, в процессе которого выполняется упорядочивание данных и отбрасывание ложных результатов детектирования. Результатом действия на шаге 707 является преобразование обнаруженных групп меток в последовательность логических элементов (байт), составляющих сообщение. Указанные операции рассматриваются более подробно ниже.
Для компенсации изменения яркости изображения в процессе печати и сканирования используется процедура улучшения контраста на шаге 701 за счет растяжения гистограммы изображения с отсечением ее левого и правого краев, включающих в себя 3% от общей площади гистограммы (1,5% для каждой границы). На шаге 702 выполняется бинаризация полученного изображения путем сравнения с порогом в соответствии со следующим выражением:

где 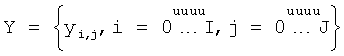 - сканированное изображение с улучшенным контрастом;
- сканированное изображение с улучшенным контрастом; 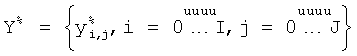 - результирующее бинарное изображение.
- результирующее бинарное изображение.
Значения, не превышающие порог, соответствуют уровню черного цвета в результирующем бинарном изображении, остальные значения соответствуют уровню белого. Значение порога указано для полутонового изображения с диапазоном яркости от 0 до 255.
Следующим действием является шумоподавляющая фильтрация, выполняемая на шаге 703. Часто, для разных печатающих устройств, результат печати может значительно различаться на детальном уровне. Этот эффект обуславливается многими факторами, такими как изношенность устройства, наполненность картриджа, качество тонера, отличающиеся методы печати и т.д. Все это приводит к непостоянству формы и яркости формы напечатанных точек для разных принтеров. Такой нежелательный эффект приводит к пропускам областей с внедренной информацией. Для обхода таких ситуаций выполняется процедура масочной фильтрации с размером маски 3×3 элемента, описываемая следующим выражением:
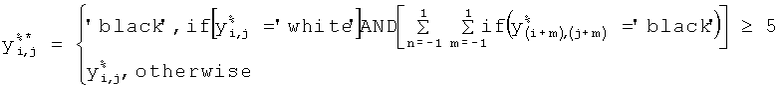
где 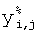 - значение точки бинарного результирующего изображения Y% после пороговой обработки,
- значение точки бинарного результирующего изображения Y% после пороговой обработки, 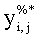 - значение точки результата фильтрации (изображение Y%*). Как следует из приведенного выше выражения, обрабатываются только белые пиксели ('white'). Текущая анализируемая белая ('white') точка заменяется на черную ('black'), если количество всех соседних точек черных ('black') точек больше или равно пяти.
- значение точки результата фильтрации (изображение Y%*). Как следует из приведенного выше выражения, обрабатываются только белые пиксели ('white'). Текущая анализируемая белая ('white') точка заменяется на черную ('black'), если количество всех соседних точек черных ('black') точек больше или равно пяти.
На шаге 704 определяются области, в которых наиболее вероятно могут присутствовать внедренные метки. Массив таких обнаруженных областей описывается картой Ymap, которая, по аналогии с Xmap, вычисляется следующим образом:
Ymap=(Y%*-Y%*oDmax)oDmin,
где структурирующие элементы Dmax и Dmin в рассматриваемом варианте изобретения для разрешения сканирования 600 точек на дюйм имеют прямоугольную форму и размеры 17×29 и 7×29 точек соответственно. Структурирующий элемент Dmax шире, чем для Bmax для учета деформации символов в результате печати и сканирования.
На Фиг.8 иллюстрируется результат обнаружения областей с возможной внедренной информацией, помеченных на чертеже серым цветом 802.
Далее (шаг 705) в пределах выделенных областей Y∈Ymap осуществляется усиление информационных точек, образующих метки. Усиление выполняется за счет свертки с оператором Лапласа, описываемой следующим выражением:
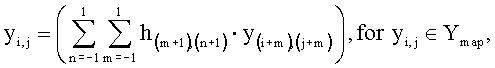
где 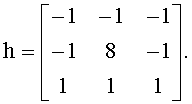
На шаге 706 применяется серия согласованных фильтров, используемых для обнаружения и распознавания внедренных меток. Ядра фильтров задаются в соответствии с используемыми конфигурациями меток C0, C1 и CStop. Обозначим F[yi,j,С], процедуру фильтрации одной точки yi,j с использованием ядра С:
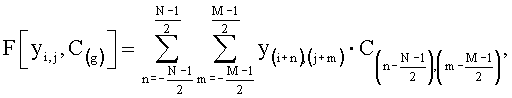
где С(g) - обозначает в данном случае используемое ядро свертки.
Соответственно результат фильтрации определяется как максимальный отклик среди трех фильтров, вычисляемый в пределах выделенных областей Ymap:
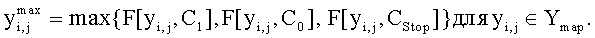
Для повышения быстродействия фильтрации используются только точки, для которых отклик фильтра превышает или равен предустановленному порогу. В предпочтительном варианте реализации изобретения порог устанавливается равным пятнадцати. Сопоставление с пороговым значением не является обязательным, но позволяет увеличить быстродействие процедуры детектирования. Информационная метка считается обнаруженной, если в ее пределах присутствует только один пик отклика согласованных фильтров. При этом пик соответствует середине метки.
Необходимо подчеркнуть, что внедренное сообщение имеет позиционно-зависимую структуру и местонахождение каждой метки в составе группы имеет существенное значение при извлечении сообщения. По этой причине часть усилий направлена на восстановление структуры внедренного сообщения, реализуемой на шаге 707. Указанный шаг направлен на упорядочивание результатов детектирования и отсеивание ложных обнаружений.
Более подробная блок-схема действий, выполняемых в ходе реализации шага 707, представлена на Фиг.9. На шаге 901 выбирается отклик согласованного фильтра среди еще необработанных откликов, который имеет минимальное значение координаты j. Направление анализа документа предполагается сверху вниз (j), слева направо (i). Затем, начиная с выбранной позиции предполагаемой метки, на шаге 902 рассчитываются параметры горизонтальной полосы поиска, в пределах которого будут анализироваться другие отклики согласованного фильтра. Расчет сводится к вычислению параметров параллельных прямых, ограничивающих эту полосу. Высота полосы поиска равняется высоте меток, которая в предпочтительном варианте реализации изобретения составляет пятнадцать точек. Для самых первых анализируемых меток параметры компенсации скоса документа неизвестны, поэтому считается, что скос отсутствует. Последующие полосы для поиска новых меток формируются с учетом компенсации скоса. Поиск ближайших соседних позиций обнаруженных меток на шаге 903 осуществляется в пределах полосы для обоих горизонтальных направлений, начиная от текущей, стартовой позиции. Поиск продолжается до тех пор, пока не будет найдена новая неучтенная обнаруженная метка, для которой затем оцениваются параметры компенсации скоса документа на шаге 905. Далее корректируется полоса поиска меток на шаге 904 с учетом компенсации скоса. Существует отличие функционирования шага 904 для самой первой полосы поиска в документе и для последующих полос. Оно заключается в том, что для первой полосы поиска используются только параметры компенсации скоса, полученные на шаге 905, а для последующих используются усредненные значения параметров, учитывающие оценки по ранее обработанным полосам. Более того, для учета влияния различного рода помех, оценки параметров компенсации для уже обработанных полос берутся с большими весами при усреднении, чем текущая оценка. Подобный подход позволяет компенсировать скос документа при сканировании в пределах 1,5-2 градусов, что превышает диапазон случайных наклонов документа формата А4 при сканировании. В случае, если обнаруженная метка отстоит на расстояние больше 500 точек от соседней, то такая метка не участвует в оценивании параметров компенсации скоса документа.
По мере завершения поиска в пределах текущей полосы поиска, последовательности результатов детектирования для обоих направлений объединяются в одну. Затем все обнаруженные позиции предполагаемых меток в текущей полосе поиска анализируются на шаге 906 для проверки достоверности меток и выделения их групп. В предпочтительном варианте реализации изобретения шаг 906 включает в себя пять основных условий, которые тесно взаимосвязаны с используемыми предпосылками на этапе внедрения сообщения. Первое условие ограничивает расстояние между позициями соседних обнаруженных меток, как не превышающее пятьсот пикселей. Второе условие предписывает необходимость расположения обнаруженных меток вдоль одной прямой, возможное отклонение от этой прямой до анализируемой позиции метки не должно превышать пяти пикселей. В большей степени это условие реализуется при выборе обнаруженных меток только в пределах полосы поиска на шаге 903. Согласно третьему условию в начале и в конце каждой группы меток не должно быть обнаружено менее двух сервисных меток. Четвертое условие определяет минимальное количество обнаруженных меток внутри одной группы как не менее десяти. Пятое условие ограничивает отличие оценок параметров компенсации скоса для текущей полосы поиска от предыдущих оценок, которое не должно превышать 20%. Для самой первой анализируемой полосы поиска накладывается дополнительное ограничение, касающееся минимального расстояния от текущего до одного из соседних позиций. Оно должно быть менее ста пятидесяти точек.
Позиции обнаруженных меток и формируемые из них группы. удовлетворяющие приведенным выше условиям, предполагаются действительными. Метки, не удовлетворяющие указанным условиям, отбрасываются и не используются в дальнейшей обработке. Далее формируется результирующая последовательность информационных бит, упорядоченная слева направо в соответствии с обнаруженными обозначениями начала и конца группы меток. Результатом шага 906 является разделение существующих групп меток. Распознанные логические элементы (байты) последовательности, содержащие количество бит, не соответствующее заданному, помечаются как поврежденные. Благодаря использованию разделяющих меток пропуск одного бита не приводит к повреждению всего сообщения, в этом случае повреждается только один логический элемент (байт) символьной последовательности. Использование избыточного кодирования позволит значительно повысить надежность извлечения идентифицирующего сообщения.
Описанная на Фиг.9 процедура повторяется для обнаружения каждой горизонтальной группы меток до тех пор, пока все обнаруженные метки не будут обработаны. После этого на шаге 907 осуществляется сортировка всех групп меток в порядке возрастания их координаты i. Этот шаг необходим при существенных скосах документа. Далее, из упорядоченных групп обнаруженных меток извлекаются фрагменты логической последовательности сообщения, которые затем объединяются в результирующее сообщение.
Система для реализации предлагаемого способа показана на Фиг.10. Подобная система соответствует устройству современных много функциональных периферийных устройств (МФП) и цифровых копиров. Центральный процессор 1006 управляет работой всех модулей системы. На этапе внедрения скрытого сообщения исходный документ растрируется и модифицируется с помощью процессора 1006. Процессор выполняет поиск областей, пригодных для вставления информационных меток, и вставку меток путем выполнения программы, хранящейся в постоянной памяти 1008 (ПЗУ). Далее сгенерированное изображение помещается в оперативную память 1007 (ОЗУ) и печатается на принтере 1003. Включение или выключение опции внедрения скрытого сообщения может быть реализовано с помощью модуля 1004 интерфейса пользователя. Существует несколько вариантов для реализации модуля интерфейса пользователя, например, он может быть выполнен в виде сенсорного дисплея. Жесткий диск 1009 используется для сохранения файлов со страницами результирующего растрированного изображения. Обмен данными в системе осуществляется по шине 1001 данных.
На этапе извлечения сообщения страница анализируемого документа сканируется сканером 1002, и изображение помещается в оперативную память 1006 (ОЗУ). Далее в зависимости от варианта реализации изобретения сканированное изображение может обрабатываться с помощью собственных ресурсов устройства или передаваться по шине 1001 данных к внешнему вычислительному устройству через интерфейс 1005.
Способ внедрения скрытого цифрового сообщения в печатаемые документы и извлечения сообщения предназначен для реализации в печатающих устройствах. Этап внедрения скрытого цифрового сообщения в печатный документ может быть реализован в устройстве печати или в драйвере печатающего устройства. Этап извлечения скрытого сообщения может быть реализован в качестве программного продукта, поставляемого вместе со сканирующим устройством или МФУ.
Следует отметить, что рассмотренный выше вариант выполнения изобретения был изложен лишь с целью иллюстрации, поэтому специалистам должно быть ясно, что возможны разные модификации, добавления и замены, не выходящие за рамки объема и смысла заявляемого изобретения, раскрытого в описании и прилагаемой формуле изобретения.



Изобретение относится к способам защиты печатных документов. Технический результат заключается в повышении степени защиты документов от копирования за счет внедрения в документ скрытого уникального цифрового сообщения. Способ содержит этап внедрения скрытого цифрового сообщения, в котором растрируют исходное изображение для печати, детектируют области в составляющей черного цвета растрированного изображения, пригодные для внедрения информационных меток, вычисляют точные позиции для внедрения информационных меток, вычисляют объем информации, который может быть внедрен в данное изображение, внедряют сообщение в составляющую черного цвета растрированного изображения, печатают растрированное изображение, и этап извлечения скрытого сообщения, в котором сканируют напечатанный документ и сохраняют сканированное изображение в памяти, улучшают контраст сканированного изображения, получают из сканированного изображения бинарное изображение путем пороговой обработки, фильтруют бинарное изображение, определяют области на бинарном изображении, в которых предположительно могут находиться внедренные метки, повышают на сканированном изображении контраст маленьких светлых пятен на темном фоне в пределах определенных на предыдущем этапе областей, детектируют положение и распознают внедренные метки, восстанавливают структуру извлекаемого сообщения. 9 з.п. ф-лы, 10 ил.
1. Способ внедрения скрытого цифрового сообщения в печатаемые документы и извлечения сообщения, заключающийся в выполнении следующих этапов:
- этап внедрения скрытого цифрового сообщения в печатаемый документ, включающий в себя следующие действия:
- растрируют исходное изображение для печати;
- детектируют области в составляющей черного цвета растрированного изображения, пригодные для внедрения информационных меток;
- вычисляют точные позиции для внедрения информационных меток;
- вычисляют объем информации, который может быть внедрен в данное изображение:
внедряют сообщение в составляющую черного цвета растрированного изображения;
- печатают растрированное изображение;
- этап извлечения скрытого сообщения из печатного документа, включающий в себя следующие действия:
- сканируют напечатанный документ и сохраняют сканированное изображение в памяти;
- улучшают контраст сканированного изображения;
- получают из сканированного изображения бинарное изображение путем пороговой обработки;
- фильтруют бинарное изображение;
- определяют области на бинарном изображении, в которых предположительно могут находиться внедренные метки;
- повышают на сканированном изображении контраст маленьких светлых пятен на темном фоне в пределах определенных на предыдущем этапе областей;
- детектируют положение и распознают внедренные метки;
- восстанавливают структуру извлекаемого сообщения.
2. Способ по п.1, отличающийся тем, что модификацию исходного документа осуществляют за счет вставки меток предопределенной конфигурации в область текста или геометрических примитивов с участками сплошной заливки черного цвета.
3. Способ по п.1, отличающийся тем, что вставляемые метки формируют из набора белых точек минимального диаметра, обеспечивающего возможность распознавания меток на этапе извлечения сообщения.
4. Способ по п.1, отличающийся тем, что набор возможных меток включает в себя как минимум одну сервисную метку, служащую для структурирования внедряемого сообщения.
5. Способ по п.1, отличающийся тем, что детектирование областей в составляющей черного цвета растрированного изображения, пригодных для внедрения информационных меток, выполняют путем выделения областей черного цвета, причем размер и форму таких областей ограничивают двумя заданными структурирующими элементами.
6. Способ по п.1, отличающийся тем, что вычисление точных позиций для внедрения информационных меток выполняют за счет последовательности действий, включающих в себя следующие шаги:
- ограничивают размещение информационных меток пределами определенных в процессе детектирования областей, пригодных для внедрения меток;
- позиционируют информационные метки вдоль горизонтальных прямых линий с заданными возможными отклонениями;
- ограничивают расстояние между соседними информационными метками в пределах одной горизонтальной группы - предопределенным значением;
- формируют из меток группы предопределенной конфигурации, начало и конец которых ограничен с помощью сервисных меток;
- разделяют метки внутри каждой группы с помощью сервисных меток на логические последовательности;
- ограничивают используемое количество меток внутри одной группы.
7. Способ по п.1, отличающийся тем, что фильтрацию бинарного изображения осуществляют путем применения масочного фильтра размером 3×3, выполненного с возможностью замены точки белого цвета на черный цвет, в случае если
- больше половины соседних точек черного цвета;
- белые области меньше заданного размера.
8. Способ по п.1, отличающийся тем, что детектирование положения и распознавание внедренных меток выполняют за счет анализа максимального отклика набора согласованных фильтров с ядрами, соответствующими конфигурациям используемых меток.
9. Способ по п.1, отличающийся тем, что восстановление структуры извлекаемого сообщения для каждой группы меток осуществляют за счет проверки на соответствие структуре внедренного сообщения, причем проверка включает в себя следующие операции:
- ищут первую необработанную ранее обнаруженную метку;
- формируют горизонтальную полосу поиска остальных обнаруженных меток группы, ориентированную с учетом оценки скоса документа, если таковая производилась на предыдущих шагах;
- ограничивают минимальное расстояние между соседними обнаруженными метками с помощью предопределенного значения;
- корректируют оценку скоса документа для каждой новой обнаруженной метки в пределах полосы поиска;
- ищут остальные обнаруженные метки текущей группы в пределах полосы поиска;
- формируют найденные обнаруженные метки в логические группы, являющиеся частью извлеченного сообщения;
- переходят к оставшимся необработанным обнаруженным меткам или прекращают цикл, если все метки обработаны;
- формируют результирующее сообщение из упорядоченных логических элементов.
10. Способ по п.9, отличающийся тем, что формирование найденных обнаруженных меток в логические группы, являющихся частью извлеченного сообщения, осуществляют за счет выполнения следующих действий:
- выполняют поиск обозначения границ каждой логической группы обнаруженных меток, обозначенных комбинацией сервисных меток;
- разделяют каждую группу на логические элементы с помощью поиска сервисных разделяющих меток внутри групп;
- проверяют соответствие количества обнаруженных меток в пределах каждого логического элемента на соответствие предопределенному значению.
| Устройство для преобразования угловых координат | 1986 |
|
SU1372334A1 |
| WO 2006087351 А2, 24.08.2006 | |||
| ПРОГРАММНО-РЕАЛИЗУЕМЫЙ ЦИФРОВОЙ СПОСОБ ЗАЩИТЫ ОТ ПОДДЕЛОК И УСТРОЙСТВО ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 1996 |
|
RU2176823C2 |
| US 20090021795 A1, 22.01.2009 | |||
| WO 9407326 A1, 31.03.1994 | |||
| RU 2008147670, 01.06.2007. | |||

