Настоящее изобретение относится к способу и устройству для защиты и аутентификации документов, в особенности к распознаванию копий документов, упаковок, готовых изделий, литых изделий и карт, например идентификационных или банковских. Термин "документ" означает любой носитель информации. Визуальным представлением информации на поверхности, которое может быть считано машиной, является штрихкод. Вначале штрихкоды представляли информацию в виде ширины параллельных линий и ширины промежутков между линиями, что ограничивало количество информации на единицу площади. Поэтому указанные штрихкоды называют одномерными, или "1D", штрихкодами. Для увеличения количества информации штрихкоды эволюционировали и превратились в узоры из концентрических окружностей или точек. Штрихкоды широко используются для быстрой и надежной автоматической идентификации захваченного изображения путем автоматической обработки. Штрихкоды могут считываться портативными оптическими считывающими устройствами или сканерами, оборудованными соответствующим программным обеспечением.
Двумерные матричные штрихкоды, называемые 2D штрихкодами, являются носителями информации, которые большей частью состоят из квадратных элементов, расположенных внутри заданного периметра, причем каждый элемент или каждая ячейка принимают один из двух заранее определенных цветов, например черный или белый в соответствии со значением двоичного символа, описанного в данной ячейке. Кроме того, двумерный штрихкод позволяет представить на одной и той же площади гораздо большее количество информации, чем одномерный.
Таким образом, двумерный штрихкод является более предпочтительным по сравнению с одномерным, хотя считывающие системы для него являются более сложными и дорогостоящими, а относительно взаимного положения считывающего устройства и штрихкода в большинстве случаев обеспечивают менее гибкое считывание.
Двумерные штрихкоды широко используются для хранения или передачи информации на пассивных объектах, например на бумаге, идентификационных картах, наклейках, металле, стекле или пластмассе.
Система, формирующая двумерные штрихкоды, в качестве информации на входе, как правило, получает последовательность символов заданного алфавита, например 128-символьного ASCII алфавита, 36-символьного буквенно-цифрового алфавита или двоичного алфавита.
На выходе система выдает цифровое изображение, которое затем печатают на объект, согласно настоящему изобретению называемый «документом». Для считывания штрихкодов и реконструкции информации, содержащейся в двумерных штрихкодах, обычно используют систему, захватывающую изображение и подсоединенную к процессору.
Штрихкод, одномерный или двумерный, используется для передачи информации от отправителя к получателю. Во многих областях применения указанный способ передачи информации должен быть исполнен безопасным способом, что влечет за собой обеспечение следующих свойств защиты:
1) сохранение конфиденциальности передаваемого сообщения (нежелательно прочтение ее третьими лицами), 2) аутентичности сообщения (уверенность в его происхождении), 3) целостность сообщения может быть проверена (уверенность, что сообщение не было изменено или подделано), 4) отправитель не может отрекаться от сообщения (желательно избежать ситуации, в которой автор передаваемой информации отрицает его отправление). Указанные различные степени защиты информации могут быть достигнуты путем шифрования или кодирования сообщения шифровальным ключом, известным только уполномоченным лицам или организациям. Для получения нескольких вышеуказанных свойств защиты информации обычно комбинируют способы шифрования открытым ключом или индивидуальным ключом.
При шифровании сообщения 2D штрихкод обеспечивает физический документ свойствами защиты, которые изначально были предназначены для защиты цифровой информации и цифровых документов. Таким образом, 2D штрихкод помогает избежать подделки документов или обнаружить ее. Например, текстовая информация, напечатанная на документе в нешифрованном виде, может быть легко изменена, например даты истечения срока действия или срока годности документа, или персональные данные идентификационной карты, в то время как те же данные, закодированные в 2D штрихкоде, не могут быть изменены легко и согласовано с изменением текстовой информации. Таким образом, 2D штрихкод обеспечивает возможность обнаружения изменения текстовой информации.
Кроме того, 2D штрихкод может использоваться для отслеживания документов. Происхождение, назначение и/или маршрут распространения документа могут быть зашифрованы в 2D штрихкоде, напечатанном на данном документе, что позволяет удостовериться, что документ находится в законном месте согласно маршруту его распространения. Шифрование указанной информации в указанных случаях является необходимым, поскольку в противном случае информация может быть фальсифицирована или даже не иметь никакого отношения к подлинной.
Благодаря использованию штрихкодов цифровые криптографические способы могут быть использованы для защиты аналоговых документов (представляющих собой реальные объекты) и пассивных документов (не способных отзываться на сигнал). Таким образом, указанным документам могут быть приданы свойства защиты, эквивалентные свойствам защиты цифровой информации или цифровых документов.
Однако 2D штрихкоды не обеспечивают защиты от точного, так называемого слепого копирования. Обычно каждая ячейка 2D штрихкода может быть идентифицирована и считана с большой точностью, вследствие чего может быть легко изготовлена точная копия каждого штрихкода. Поэтому двумерный штрихкод не дает полного решения главной проблемы распознания подлинности источника (происхождения) документа, так как зашифрованный 2D штрихкод не позволяет ответить на вопрос, является ли содержащий его документ оригиналом или его репродукцией.
Кроме того, правообладатели интеллектуальной собственности, в особенности товарных знаков, и организации, выпускающие официальные документы, которые для решения проблем, связанных с подделками, внедрили зашифрованные 2D штрихкоды или другие носители информации, например электронные этикетки RFID (сокращение от Radio Frequence Identification - радиочастотная идентификация), тем не менее, для избежания или обнаружения слепого копирования вынуждены использовать совершенно другие методы аутентификации («аутентификаторы»), например голограммы, защитные краски, микротексты или так называемые «гильоширные» узоры (тонкие кривые линии, интерферирующие с системами цифрового воспроизведения, например, благодаря эффекту водяного знака).
Тем не менее, указанные средства имеют свои ограничения, которые становятся более заметными по мере ускорения распространения технологий, позволяющих изготовителям подделок все лучше и быстрее копировать указанные аутентификаторы. Таким образом, голограммы копируются изготовителями подделок все лучше и лучше, а конечные пользователи не имеют ни возможностей, ни мотивации для их проверки. Защитные краски, так называемые «гильоширные» узоры и микротексты, нерентабельны, трудно включаемы в производственные процессы компаний или информационные каналы, а также не обеспечивают требуемый в большинстве случаев уровень защиты. Кроме того, они могут оказаться сложными для идентификации и не обеспечивают реальных гарантий защиты от изготовителей подделок.
Для определения подлинности документа считываемую информацию по возможности используют в комбинации с базой данных. Таким образом, вы можете, например, косвенно обнаружить подделку, если ранее или в другом месте был обнаружен другой документ, содержащий точно такую же информацию. Следует отметить, что в этом случае предполагается, что отдельный документ содержит уникальную информацию, что не всегда осуществимо всеми средствами изготовления документа, в особенности средствами офсетной печати. Однако осуществление подобных решений является дорогостоящим, а быстрый доступ к базе данных может быть невозможен, в особенности если считывающее устройство является портативным. Наконец, даже доступ к базе данных не решает проблему распознавания, какой из двух на вид идентичных документов является подделкой.
Узоры для распознавания копий представляют собой разновидность видимых аутентификационных узоров, которые обычно образуют некий фон и которые создают с применением ключа псевдослучайным способом. Указанные узоры главным образом используют для распознавания оригинальных печатных документов и печатных документов, скопированных с них, например фотокопированием или с использованием сканера и принтера. Для этого сравнивают захваченное изображение аналогового, т.е. реального, узора для распознавания копии с исходным цифровым представлением данного узора для измерения степени расхождения между ними. Вследствие искажения изображения при копировании более высока степень расхождения такого захваченного изображения узора, которое не было получено с использованием исходного аналогового узора.
Для того чтобы псевдослучайное изображение содержало информацию, его разрезают на блоки, а цвета пикселей каждого блока, представляющего одно из двоичных значений, инвертируют, оставляя неизменными пиксели каждого блока, представляющего другое двоичное значение. Кроме того, может быть использовано другое кодирование двоичного значения блока. На практике блоки должны быть достаточно большими с тем, чтобы указанное двоичное значение надежно считывалось, так что количество информации, которую несет изображение, ограничено.
Однако указанная технология имеет недостатки. В частности, она является оптимальной для распознавания копий, но не позволяет нести большое количество информации на заданной площади, тогда как во многих областях применения документы несут большое количество защищенной информации и при этом имеют большие ограничения (эстетика, доступная площадь, изображение торговой марки и т.д.), ограничивающие площадь, доступную для распознавания копий. Использование указанной технологии требует сравнения двух изображений и масштабирования захваченного узора, для чего необходим большой объем. Кроме того, указанное масштабирование может привести к искажению модифицированного изображения, которое при определенных обстоятельствах может привести к ограничению способности к распознаванию копий. Кроме того, считывающее устройство должно воспроизводить и сохранять в памяти узор для распознавания копии на этапе сравнения изображений, что одновременно является дорогостоящей и потенциально опасной операцией, поскольку злоумышленник может "считать" память, что может позволить ему точно воспроизвести узор для распознавания копии.
Целью настоящего изобретения является устранение как недостатков 2D штрихкодов, так и недостатков узоров для распознавания копий. В особенности, целью настоящего изобретения является создание средств и способа создания информационной матрицы, обеспечивающей распознавание копий или поддельных документов.
Первым аспектом настоящего изобретения предложено создание способа защиты документа, содержащего:
- этап определения условий печати указанного документа,
- этап определения физических характеристик ячеек по меньшей мере одной конфигурации в соответствии с указанными условиями печати, например доля ячеек, напечатанных с ошибкой печати, возникающей исключительно вследствие непредвиденных переменных, больше, чем заданное первое значение, и меньше, чем заданное второе значение,
- этап представления единицы информации путем изменения внешнего вида ячеек, представляющих указанные физические характеристики, и
- этап печати указанной конфигурации с использованием указанных условий печати, причем указанная конфигурация выполнена с обеспечением возможности распознавания копии, модифицирующей внешний вид множества указанных ячеек.
В настоящем описании "ошибкой печати" называют изменение внешнего вида ячейки, модифицирующее представление информации, которую несет данная ячейка, при анализе, позволяющем избежать ошибок чтения или захвата, например, под микроскопом. Следует отметить, что если изначально ячейки часто имеют двоичные значения, то захваченные изображения часто содержат оттенки серого, и, следовательно, с ячейкой ассоциируется значение, которое не является двоичным и которое может быть интерпретировано, например, как вероятность того, что ячейка будет иметь исходное двоичное значение.
Авторами настоящего изобретения обнаружено, что, если доля ошибок печати превышает заданное значение, копирование конфигурации, выполненное с применением тех же средств печати, что и оригинальный оттиск, или аналогичных средств, обязательно вызывает появление дополнительной доли ошибок, дающей возможность распознавания указанной копии. Кроме того, авторами настоящего изобретения обнаружено, что в зависимости от заданных ограничений (например, ограничения количества или физического размера ячеек защищенной информационной матрицы) существует доля ошибок печати, оптимальная для обеспечения возможности распознавания копии. Указанная оптимальная доля ошибок печати соответствует заданному размеру ячейки или разрешению печати и зависит от средств печати.
Таким образом, вопреки сложившемуся мнению, наивысшее разрешение печати необязательно, и даже редко, является разрешением, обеспечивающим наилучший результат для обеспечения возможности распознавания копий.
В этом случае следует различать собственное разрешение средств печати и разрешение печати ячеек, каждая из которых обычно состоит из множества точек типографской краски, каждая из которых соответствует собственному разрешению печати. Очевидно, разрешение печати защищенной информационной матрицы не может варьироваться. На самом деле, большинство средств печати печатают в двоичном коде (точка типографской краски присутствует или отсутствует) с фиксированным разрешением, уровни серого или других цветов воспроизводят с использованием различных методов растрирования. В случае офсетной печати указанное "собственное" разрешение определяется разрешением печатной формы, которое составляет, например, 2400 точек на дюйм (2400 dpi). Таким образом, изображение по шкале серого, предназначенное для печати с разрешением 300 пикселей на дюйм (300 ppi), на практике печатается в двоичном коде с разрешением 2400 точек на дюйм (2400 dpi), причем каждый пиксель соответствует приблизительно 8×8 точек растра.
Несмотря на то что, как правило, разрешение печати не может быть изменено, с другой стороны, можно изменить размер ячеек защищенной информационной матрицы в пикселях с тем, чтобы одна ячейка была представлена несколькими печатными точками. Таким образом, вы можете, например, представить ячейку квадратным блоком размером 1×1, 2×2, 3×3, 4×4 или 5×5 пикселей (также возможны блоки неквадратной формы), соответствующим разрешению 2400, 1200, 800, 600 и 480 ячеек на дюйм соответственно.
Согласно отличительным признакам изобретения, на этапе определения физических характеристик ячеек определяют размеры ячеек, предназначенных для печати.
Согласно отличительным признакам изобретения, на этапе определения физических характеристик ячеек определяют часть ячейки, имеющую постоянную форму и изменяющийся цвет для представления различных значений единицы информации, причем указанная часть, безусловно, меньше, чем указанная ячейка.
Согласно отличительным признакам изобретения, первое заданное значение составляет более 5%.
Согласно отличительным признакам изобретения, первое заданное значение составляет более 10%.
Согласно отличительным признакам изобретения, первое заданное значение составляет более 15%.
Согласно отличительным признакам изобретения, первое заданное значение составляет более 20%.
Согласно отличительным признакам изобретения, второе заданное значение составляет менее 25%.
Согласно отличительным признакам изобретения, второе заданное значение составляет менее 30%.
Согласно отличительным признакам изобретения, на этапе печати используется собственное разрешение средств печати, осуществляющих указанную печать.
Согласно отличительным признакам изобретения, способ защиты документа, краткое описание которого приведено выше, дополнительно содержит этап создания конфигурации в цифровой информационной матрице, представляющей сообщение, содержащее избыточность.
На самом деле, авторами настоящего изобретения обнаружено, что любая копия или любой оттиск единицы напечатанной информационной матрицы, имеющей небольшой размер, воспроизводит количество ошибок, возрастающее с повышением качества печати, а вставка в матрицу избыточной информации, например кодов коррекции ошибок, позволяет определить, данный документ является копией или оригиналом: вставка избыточной информации позволяет прочитать сообщение по зашумленному каналу и/или измерить количество ошибок зашифрованного сообщения, таким образом обеспечивая возможность определить, является данный документ копией или оригиналом.
Необходимо отметить, что искажения, возникающие при печати или копировании, зависят от многих факторов, например от качества печати, разрешения подложки и изображения, используемого во время захвата изображения или на этапе нанесения меток, осуществляемого с целью изготовления копии.
Согласно отличительным признакам изобретения, на этапе создания конфигурации имеется достаточная доля избыточности, позволяющая скорректировать долю ошибок большую, чем указанное первое заданное значение.
Согласно отличительным признакам изобретения, на этапе создания конфигурации указанная избыточность содержит коды коррекции ошибок.
Благодаря указанным средствам содержимое метки дает возможность скорректировать ошибки на этапе нанесения меток и воспроизвести оригинальное сообщение.
Согласно отличительным признакам изобретения, на этапе создания конфигурации указанная избыточность содержит коды коррекции ошибок.
Благодаря каждому из указанных средств количество ошибок, искажающих метку, может быть определено и использовано в качестве базы для распознавания копии указанной метки.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы указанная информационная матрица на уровне каждой элементарной ячейки и независимо от соседних элементарных ячеек представляет сообщение, содержащее избыточность.
Таким образом, количество информации, которую несет метка, увеличивается по отношению к представлению значений блоками точек.
Согласно отличительным признакам изобретения, на этапе нанесения меток делается по меньшей мере пять процентов несвязанных ошибок, а использование избыточности позволяет их подсчитать.
Авторами настоящего изобретения обнаружено, что проще использовать высокий коэффициент ошибок, сделанных на этапе нанесения меток, для отличения копии от метки, причем коэффициент ошибок копии зависит от коэффициента ошибок исходной метки.
Согласно отличительным признакам изобретения, на стадии генерации информационной матрицы избыточность создается для обеспечения возможности распознавания в метке несвязанных ошибок, сделанных на этапе нанесения меток.
Согласно отличительным признакам изобретения, на этапе нанесения меток к метке информационной матрицы добавляют дополнительную надежную метку, несущую сообщение.
Благодаря указанным средствам сообщение, которое несет дополнительная метка, является более устойчивым к искажениям, вызванным копированием, и, следовательно, будет считано, даже если указанные искажения являются значительными, например после нескольких последовательных копий. Согласно отличительным признакам изобретения на этапе генерации информационной матрицы представление указанного сообщения шифруют с помощью шифровального ключа.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы представление указанного сообщения кодируют для создания указанной избыточности.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы представление указанного сообщения воспроизводят с целью создания нескольких идентичных копий.
Таким образом, очень простым способом создается избыточность, обеспечивающая обнаружение ошибок в процессе считывания метки.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы позиции элементов представления указанного сообщения меняют местами в соответствии с секретным ключом.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы позиции элементов представления указанного сообщения частично меняют местами в соответствии с секретным ключом, отличающимся от ключа первой перестановки.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы функцию замещения значения, зависящую, с одной стороны, от значения элемента, а с другой стороны, от значения элемента секретного ключа, применяют по меньшей мере к одной части элементов представления указанного сообщения.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы функцию частичного замещения значений, зависящую, с одной стороны, от значения элемента, а с другой стороны, от значения элемента секретного ключа, который отличается от секретного ключа первой замещающей функции, применяют по меньшей мере к одной части элементов представления указанного сообщения.
Согласно отличительным признакам изобретения, указанная функция замещения попарно замещает значения, связанные с соседними ячейками в указанной конфигурации.
Благодаря каждому из указанных средств указанное сообщение обеспечивается свойствами защиты от чтения неуполномоченными третьими лицами.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы используют по меньшей мере один ключ, причем это не тот связанный ключ, который необходим для воспроизведения информации, а другой ключ.
Таким образом, ключ для определения аутентичности документа или продукта, содержащего метку, представляющую указанную информационную матрицу, не может быть использован для создания другой информационной матрицы, содержащей другое сообщение.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы генерируется цифровая информационная матрица, представляющая по меньшей мере два сообщения, оснащенных различными средствами защиты.
Благодаря указанным средствам различные люди или компьютерные системы могут иметь различные полномочия и средства считывания, например, с целью разграничения функций аутентификации и определения происхождения подделок.
Согласно отличительным признакам изобретения, одно из указанных сообщений представляет собой информацию, требуемую при чтении информационной матрицы для определения другого сообщения и/или обнаружения ошибок в нем. Согласно отличительным признакам изобретения, одно из указанных сообщений представляет собой по меньшей мере один ключ, требуемый для чтения другого сообщения.
Согласно отличительным признакам изобретения, на этапе генерации информационной матрицы к представлению указанного сообщения добавляют его хеш-значение.
Вторым аспектом настоящего изобретения предложено создание устройства для обеспечения защиты документа, содержащего:
- средства определения условий печати указанного документа,
- средства определения физических характеристик ячеек по меньшей мере одной конфигурации в соответствии с указанными условиями печати, например доля ячеек, напечатанных с ошибкой печати, возникающей исключительно вследствие непредвиденных переменных, больше, чем заданное первое значение, и меньше, чем заданное второе значение,
- средства представления единицы информации путем изменения внешнего вида ячеек, представляющих указанные физические характеристики, и
- средства печати указанной конфигурации с использованием указанных условий печати, причем указанная конфигурация выполнена с обеспечением возможности распознавания копии, модифицирующей внешний вид множества указанных ячеек.
Поскольку преимущества, цели и отличительные признаки указанного устройства, создание которого предложено вторым аспектом настоящего изобретения, те же самые, что и для способа, создание которого предложено первым аспектом настоящего изобретения, здесь они повторно не приводятся. Третьим аспектом настоящего изобретения предложено создание компьютерной программы, содержащей инструкции, которые могут быть прочитаны компьютером, и внедрение способа, краткое описание которого приведено выше.
Четвертым аспектом настоящего изобретения предложено создание носителя информации, читаемого компьютером и содержащего инструкции, читаемые компьютером, и применение способа, краткое описание которого приведено выше.
Кроме того, настоящее изобретение относится к способу и устройству защиты документов и продуктов, основанному на усовершенствованных защищенных информационных матрицах, в особенности к идентификации и аутентификации документов и продуктов. Изобретение используют, в частности, для однозначной идентификации, аутентификации оригиналов и распознавания копий документов, упаковок, промышленных изделий, литых изделий и карт, идентификационных или банковских.
Существует много способов защиты документов с использованием или дорогостоящих средств (голограмм, защитных красок и т.д.), поскольку они требуют расходных материалов, или цифровых средств, которые в большинстве случаев являются более экономичными. Цифровые средства дают дополнительное преимущество, так как хорошо приспособлены к цифровой обработке данных. Таким образом, могут быть использованы не очень дорогие детекторы, содержащие, главным образом, процессор, подсоединенный к устройству для захвата изображений или сигналов (сканеру и т.д.), и интерфейс с оператором.
Для защиты документа цифровыми средствами вы можете обратиться к использованию цифровых аутентификационных кодов. Например, вы можете напечатать на нем защищенную информационную матрицу или узор для распознавания копий. Кроме того, цифровые аутентификационные коды обеспечивают возможность содержать в себе зашифрованную информацию и, таким образом, отслеживать передвижение документов или продуктов.
Цифровой аутентификационный код - это цифровое изображение, которое, во-первых, печатается на документе, во-вторых, обеспечивает возможность его отслеживания, и в то же время распознавания копии документа. В отличие от двумерного штрихкода, который является просто носителем информации, который может быть идентично скопирован, любая копия цифровых аутентификационных кодов влечет за собой ее искажение. Указанное искажение может быть измерено компьютерными средствами из захваченного изображения и позволяет считывающему устройству определить, является цифровой аутентификационный код оригиналом или копией. Более того, информация, содержащаяся в цифровом аутентификационном коде, как правило, зашифрована и/или скремблирована.
Цифровые аутентификационные коды могут быть невидимыми или, по меньшей мере, визуально трудноразличимыми, такими, например, как чувствительный к копированию цифровой водяной знак, выполненный за одно целое с изображением, или узор из точек с псевдослучайным распределением, также известный как "AMSM". Цифровые аутентификационные коды подобного рода обычно расположены на большой площади и имеют низкую плотность информации. Однако цифровые аутентификационные коды могут иметь и высокую плотность информации и быть сосредоточены на небольшой площади, например защищенные информационные матрицы и узоры для распознавания копий. Защищенные информационные матрицы и узоры для распознавания копий часто включают в цифровой файл документа или продукта и печатают одновременно с ним.
Узоры для распознавания копий являются фоновыми узорами, генерированными псевдослучайным образом с использованием криптографического ключа. Копии распознают путем сравнения и измерения сходства между оригинальным цифровым изображением и захваченным изображением. Кроме того, узор для распознавания копий может содержать небольшое количество информации. Защищенные информационные матрицы представляют собой информационные матрицы, предназначенные для содержания большого количества информации в зашифрованном виде, причем при считывании указанная информация является устойчивой к высокому коэффициенту ошибок. Копии распознаются измерением коэффициента ошибок сообщения.
Защищенные информационные матрицы и узоры для распознавания копий часто состоят наполовину из "черных" (или цветных) пикселей и наполовину из "белых", или непечатаемых, пикселей. Однако для некоторых типов печати, типов бумаги или настроек печатных машин напечатанная информационная матрица может быть с избытком залита краской. Избыточный уровень заполнения краской в защищенной информационной матрице может значительно уменьшить ее читаемость и даже способность быть отличенной от одной из ее копий. Следовательно, исключительно важно избежать избыточного уровня краски, однако, на практике это не всегда достижимо, поскольку уровень краски редко является величиной, полностью контролируемой печатником, а в некоторых случаях он является величиной, задаваемой печатнику клиентом. Таким образом, является более предпочтительным создание защищенных информационных матриц, свойства которых являются менее чувствительными к уровню краски, нанесенному на бумагу.
Оказывается, что защищенные информационные матрицы обычно более чувствительны к повышенному уровню краски, чем к пониженному. На самом деле, если уровень краски понижен, черные или содержащие цвет ячейки обычно печатаются и, следовательно, мало влияют на считывание матрицы. Если уровень краски повышен, краска стремится переполнить подложку, и белые участки до некоторой степени "затопляются" краской из соседних черных участков. Сходный эффект наблюдается при нанесении меток контактной печатью, лазерной гравировкой и т.д.
Теоретически, защищенные информационные матрицы создают в соответствии с заданным разрешением печати, например 600 точек на дюйм (600 ppi). Однако оказывается, что в зависимости от условий печати оптимальное разрешение печати, или разрешение, обеспечивающее наилучшее распознавание оригиналов и копий, варьируется: чем выше качество печати, тем более высоким должно быть разрешение печати матрицы или соответственно должен уменьшаться размер ее ячеек.
Задачей пятого и шестого аспектов настоящего изобретения является устранение указанных недостатков.
Для этого согласно пятому аспекту настоящего изобретения предложено создание способа защиты документов, согласно которому печатают конфигурацию, содержащую ячейки, которые представляют единицу информации и внешний вид каждой из которых изменяется в соответствии с информацией, которую она представляет, причем указанная конфигурация выполнена с обеспечением возможности распознавания копии, модифицирующей внешний вид указанных ячеек, отличающегося тем, что он содержит:
этап определения части ячеек, которая имеет постоянную форму и изменяющийся цвет для представления различных значений единицы информации и которая, безусловно, меньше, чем указанная ячейка, и
этап представления в указанной конфигурации единицы информации путем изменения внешнего вида частей ячеек.
Благодаря указанным средствам, даже если во время печати присутствует повышенный уровень краски, поскольку только ограниченная часть ячеек заполнена краской, снижается риск затопления другой ячейки и изменения ее внешнего вида, а способность к распознаванию копии повышается.
Таким образом, для того чтобы защищенные информационные матрицы гарантированно могли обеспечить распознавание копий при любых условиях печати, используют такие защищенные информационные матрицы, в которых по меньшей мере одна часть соответствует условиям печати, при которых уровень заполнения краски повышенный. Таким образом, свойства защищенной информационной матрицы, обеспечивающие защиту от копирования, становятся малочувствительными к уровню заполнения краской, используемому при печати. Следует заметить, что выбор части в каждой ячейке, подлежащей печати, предпочтительно объединяется с выбором размера ячеек, описание которого приведено в другом месте, с целью получения доли ошибок, лучше всего способствующей распознаванию копий.
Согласно отличительным признакам изобретения, способ, краткое описание которого представлено выше, содержит этап определения нескольких конфигураций, не наложенных один на другой, причем размеры ячеек по меньшей мере двух различных конфигураций отличаются.
Благодаря указанным средствам одна и та же защищенная информационная матрица может быть напечатана на различных носителях различными печатными средствами, не имеющими одинакового разрешения, и, тем не менее, сохранять свои свойства распознавания копии.
Согласно отличительным признакам изобретения, способ, краткое описание которого представлено выше, содержит этап определения нескольких конфигураций, не наложенных один на другой, и на этапе определения части указанная часть отличается по меньшей мере для двух различных конфигураций. Благодаря указанным средствам получают защищенные информационные матрицы, устойчивые к широкому диапазону уровней заполнения краской, поскольку несколько частей указанной защищенной информационной матрицы, соответствующих вышеуказанным конфигурациям, приспособлены к различным уровням заполнения краской. Таким образом, защищенная информационная матрица может содержать несколько участков, на которых плотность ячеек, т.е. отношение площади части к площади ячеек варьируется с тем, чтобы по меньшей мере одно из значений плотности ячеек соответствовало используемому при печати уровню заполнения краской. В этом случае считывание может быть выполнено с использованием участков, имеющих наиболее подходящий уровень заполнения краской.
Согласно отличительным признакам изобретения, каждая ячейка квадратная, и указанная часть ячейки тоже квадратная.
Например, если размер ячейки составляет 4×4 пикселя, можно выбрать для печати квадратную часть размером 3×3 пикселя или 2×2 пикселя. Следовательно, заполнение краской снижается в отношении 9/16 и 1/4 соответственно (следует отметить, что белые ячейки не затрагиваются). В другом примере, если ячейка составляет 3×3 пикселя, можно выбрать для печати квадратную часть размером 2×2 пикселя или 1×1 пикселя.
Согласно отличительным признакам изобретения, указанная часть имеет форму креста. Например, указанный крест сформирован из пяти напечатанных пикселей из девяти.
Согласно отличительным признакам изобретения, способ, который является предметом настоящего изобретения, краткое описание которого приведено выше, содержит этап определения размеров ячеек по меньшей мере одной конфигурации, подлежащих для печати в соответствии с условиями печати с тем, чтобы доля ячеек, напечатанных с ошибкой печати, возникающей исключительно вследствие непредвиденных переменных, была больше, чем заданное первое значение, и меньше, чем заданное второе значение.
Поскольку отличительные признаки способа, который предложен первым аспектом настоящего изобретения, также являются отличительными признаками способа, предложенного пятым аспектом настоящего изобретения, они здесь не повторяются.
Шестым аспектом настоящего изобретения предложено создание напечатанной конфигурации, содержащей ячейки, которые представляют единицу информации и внешний вид каждой из которых изменяется в соответствии с информацией, представляемой указанной ячейкой, причем указанная конфигурация выполнена с обеспечением возможности распознавания копии, модифицирующей внешний вид указанных ячеек, отличающегося тем, что ячейки содержат часть, которая имеет постоянную форму и изменяющийся цвет, представляя различные значения единицы информации, и которая, безусловно, меньше указанной ячейки, при этом внешний вид частей ячеек представляет указанную информацию.
Седьмым аспектом настоящего изобретения предложено создание устройства для защиты документов, содержащего устройство для печати конфигурации, образованной ячейками, которые представляют единицу информации и внешний вид каждой из которых изменяется в соответствии с информацией, представленной указанной ячейкой, причем указанная конфигурация выполнена с обеспечением возможности распознавания копии, модифицирующей внешний вид указанных ячеек, отличающегося тем, что он содержит:
- средства определения части ячеек, имеющей постоянную форму и изменяющийся цвет для представления различных значений единицы информации, причем указанная часть, безусловно, меньше указанной ячейки, и
- средства представления единицы информации путем изменения внешнего вида частей ячеек.
Поскольку преимущества, цели и отличительные признаки указанной напечатанной конфигурации, создание которой предложено шестым аспектом настоящего изобретения, и устройства, создание которого предложено седьмым аспектом настоящего изобретения, те же самые, что в пятом аспекте настоящего изобретения, они здесь не повторяются.
Для принятия решения о подлинности документа в зависимости от ошибок, которые несут ячейки конфигурации, может быть декодировано сообщение, содержащееся в конфигурации, или может быть восстановлено изображение указанной конфигурации. Тем не менее, во втором случае необходимо обеспечить в устройстве распознавания копии средства восстановления оригинальной цифровой конфигурации, что является весьма слабым местом с точки зрения защиты информации, поскольку изготовитель подделок, который завладеет данным устройством, может без ошибок генерировать оригинальные конфигурации. Если в первом случае нанесение меток ведет к существенному искажению сообщения, в особенности копий, или если сообщение несет большое количество информации, оно может быть нечитаемым, в этом случае коэффициент ошибок не может быть измерен. Кроме того, считывание сообщения, которое несет конфигурация, с использованием устройства для распознавания копий, является еще одним слабым местом с точки зрения защиты информации, поскольку изготовитель подделок, завладевший данным устройством, может воспользоваться указанным сообщением.
Кроме того, определение подлинности конфигурации влечет за собой интенсивное использование ресурсов памяти, обработки данных и/или средств связи с удаленным сервером аутентификации.
Восьмой аспект настоящего изобретения нацелен на устранение указанных недостатков.
Для этого восьмой аспект настоящего изобретения предлагает создание способа определения подлинности конфигурации, напечатанной на документе, содержащего:
- этап определения множеств ячеек указанной напечатанной конфигурации, причем ячейки каждого множества ячеек соответствуют одной и той же единице информации,
- этап захвата изображения указанной конфигурации,
- этап определения доли ячеек каждого множества ячеек указанной конфигурации, которые представляют информационное значение, отличное от информационного значения в других ячейках указанного множества, и
- этап определения подлинности указанной конфигурации в соответствии с указанной долей ячеек, по меньшей мере, указанного множества ячеек.
Таким образом, благодаря использованию способа согласно восьмой особенности настоящего изобретения не требуется ни восстановления оригинального воспроизведенного сообщения, ни даже декодирования сообщения, и не требуется, чтобы сообщение что-либо означало, т.к. информация может быть случайной. В действительности, количество ошибок сообщения измеряют с использованием некоторых свойств самого сообщения в момент оценивания кодированного сообщения.
Однако следует отметить, что должны быть известны группировки ячеек, представляющих информационное значение, обычно двоичное. Согласно отличительным признакам изобретения, на этапе определения доли ячеек определяют среднее информационное значение, которое несут разные ячейки одного и того же множества ячеек.
Согласно отличительным признакам изобретения, на этапе определения доли ячеек указанное среднее значение определяют путем взвешивания информационного значения, которое несет каждая ячейка, в соответствии с внешним видом указанной ячейки.
Таким образом, с каждой ячейкой ассоциируют вес или коэффициент, показывающий вероятность того, что оценка каждого бита закодированного сообщения выполнена правильно. Указанный вес используется для взвешивания вкладов каждой ячейки в соответствии с вероятностью, с которой ассоциированный бит корректно оценен. Простота реализации данного способа состоит в том, что значения, читаемые в каждой ячейке из множества ячеек, не преобразуются в двоичную форму.
Согласно отличительным признакам изобретения, способ, краткое описание которого приведено выше, содержит этап определения среднего по всей конфигурации значения из значений, представленных ячейками, и этап компенсации разницы между указанным средним значением и ожидаемым средним значением.
Следует отметить, что чем более зашумленным является сообщение, тем выше риск, что оцененный бит закодированной информации является ошибочным. Это вызывает систематическую ошибку, заключающуюся в том, что при измерении количества ошибок недооценивается реальное количество ошибок. Указанная систематическая ошибка оценивается статистически и корректируется в процессе измерения количества ошибок.
Согласно отличительным признакам изобретения, на этапе определения доли ячеек указанного множества ячеек, представляющих информационное значение, отличающееся от информационного значения в других ячейках указанного множества, с целью получения информационного значения в указанной ячейке используется криптографический ключ, изменяющий информационное значение, представленное по меньшей мере одной ячейкой изображения конфигурации.
Согласно отличительным признакам изобретения, на этапе определения доли ячеек указанного множества ячеек, представляющих информационное значение, отличающееся от информационного значения в других ячейках указанного множества, используют вероятность наличия значения точки изображения по меньшей мере для одной точки изображения конфигурации.
Считывание DAC требует точного установления его положения в захваченном изображении так, чтобы значение в каждой из составляющих его ячеек было восстановлено с максимально возможной точностью с учетом искажений сигнала в результате печати и, возможно, захвата. Однако захваченные изображения часто содержат символы, которые могут интерферировать на этапе установления положения.
Установление положения защищенной информационной матрицы может быть затруднено условиями захвата (плохое освещение, размывание границ и т.д.), а также произвольным углом установки положения в диапазоне 360 градусов.
В отличие от других символов двумерного штрихкода, которые относительно мало изменяются в зависимости от различных типов печати, характеристики DAC, например текстура изображения, сильно изменяются. Таким образом, известные способы, например раскрытый в US 6775409, являются неприемлемыми. В действительности, указанный способ основан на направленности градиента яркости, т.е. на его варьировании в соответствии с направлением его положения для обнаружения кодов. Однако градиент яркости защищенной информационной матрицы не имеет особой направленности.
Некоторые способы установления положения DAC могут использовать тот факт, что они имеют квадратную или прямоугольную форму, что вызывает заметный контраст с непрерывными сегментами, которые могут быть обнаружены и обработаны стандартными способами обработки изображений. Однако в некоторых случаях указанные способы безуспешные, а с другой стороны, желательно иметь возможность использования DAC, которые не обязательно представляют собой квадрат или прямоугольник (или не обязательно являются вписанными в них).
Вообще говоря, площадь, на которой напечатан DAC, отличается повышенной плотностью краски. Однако, хотя использование измерений плотности краски является полезным, но оно не может быть единственным критерием. На самом деле, Datamatrixes (зарегистрированная торговая марка) или другие штрихкоды, которые могут быть смежными с DAC, обладают еще более высокой плотностью краски. Следовательно, недостаточно использовать только указанный критерий.
В патенте ЕР 1801692 с целью определения участков изображения, принадлежащих к узорам для распознавания копий, предложено использовать повышенную энтропию таких узоров. Однако хотя эти узоры перед печатью действительно обладают повышенной энтропией, последняя может сильно измениться в процессе печати, захвата или измерения. Например, простое измерение энтропии, основанное на гистограмме разброса значений пикселей каждого участка, может иногда привести к повышенным показателям на участках, не очень наполненных по содержанию, которые теоретически должны обладать низкой энтропией, например это может происходить в результате появления артефактов при сжатии в формате JPEG, из-за текстуры бумаги, проявляющейся в захваченном изображении, или в результате эффектов отражения от подложки. Таким образом, ясно, что критерий энтропии также является недостаточным.
Вообще говоря, способы измерения или определения характеристик текстур представляются более подходящими для того, чтобы характеризовать одновременно интенсивность или пространственные связи, специфические для текстур DAC. Например, Харалик в работе "Статистические и структурные подходы к текстуре" (Haralick, "Statistical and structural approaches to texture") описывает множество измерений характеристики текстур, которые могут быть комбинированы таким образом, чтобы они однозначно описывали большое количество текстур.
Однако DAC могут иметь текстуры, которые сильно изменяются в зависимости от типа печати или захвата, и в большинстве случаев это невозможно или, по меньшей мере, непрактично обеспечить характеристики текстуры для способа размещения DAC, главным образом потому, что они должны быть отрегулированы в зависимости от специфических воздействий средств захвата при измерении текстуры.
Задачей девятого аспекта настоящего изобретения является устранение указанных недостатков.
Для этого девятым аспектом настоящего изобретения предложено создание способа определения положения конфигурации, содержащего:
- этап разделения изображения конфигурации на участки так, чтобы площадь конфигурации соответствовала количеству участков, большему, чем заданное значение,
- этап измерения показателя текстуры каждого участка,
- этап определения порога обнаружения части конфигурации,
- этап определения участков, принадлежащих указанной конфигурации, путем сравнения показателя текстуры участка с соответствующим порогом обнаружения,
- этап определения непрерывных групп участков, принадлежащих указанной конфигурации,
- этап определения контура по меньшей мере одной группы участков и
- этап сопоставления контура по меньшей мере одной группы с контуром указанной конфигурации.
Таким образом, для надежного определения положения конфигурации в настоящем изобретении используется множество критериев.
Согласно отличительным признакам изобретения, показатель текстуры характеризует плотность краски для печати конфигурации.
Согласно отличительным признакам изобретения, показатель текстуры характеризует локальную динамику. Следует отметить, что локальная динамика может включать в себя различные физические параметры, например частоту или пропорцию локального изменения или, например, сумму градиентов.
Согласно отличительным признакам изобретения, на этапе определения порога обнаружения указанный порог варьируется в зависимости от положения участка в изображении.
Согласно отличительным признакам изобретения, на этапе определения участков, принадлежащих к указанной конфигурации, используют по меньшей мере одну операцию растягивания и/или размывания изображения.
Согласно отличительным признакам изобретения, указанная конфигурация является прямоугольной, а на этапе сопоставления определяют две пары точек, сформированные наиболее удаленными друг от друга точками, и определяют, лежит ли отношение длин отрезков прямых, образованных указанными парами точек, в заданном интервале значений.
Согласно отличительным признакам изобретения, указанная конфигурация является прямоугольной, а на этапе сопоставления определяют две пары точек, сформированные наиболее удаленными друг от друга точками, и определяют, лежит ли угол между отрезками прямых, образованных указанными парами точек, в заданном интервале значений.
Согласно отличительным признакам изобретения, указанная конфигурация является прямоугольной, а на этапе сопоставления используют преобразование Хафа (Hough).
Десятым аспектом настоящего изобретения предложено создание устройства для определения положения конфигурации, содержащего:
- средство разделения изображения конфигурации на участки так, чтобы площадь конфигурации соответствовала количеству участков, большему, чем заданное значение,
- средство измерения показателя текстуры каждого участка,
- средство определения порога обнаружения части конфигурации,
- средство определения участков, принадлежащих указанной конфигурации, путем сравнения показателя текстуры участка с соответствующим порогом обнаружения,
- средство определения непрерывных групп участков, принадлежащих указанной конфигурации,
- средство определения контура по меньшей мере одной группы участков и средство сопоставления контура по меньшей мере одной группы в соответствии с контуром указанной конфигурации.
Поскольку преимущества, цели и отличительные признаки указанного устройства, создание которого предложено десятым аспектом настоящего изобретения, те же самые, что и в девятом аспекте настоящего изобретения, они здесь не повторяются.
Одиннадцатым аспектом настоящего изобретения предложено создание способа генерации конфигурации, предназначенной для защиты от копирования, содержащего:
- этап определения по меньшей мере одного параметра печати указанной конфигурации,
- этап включения в состав указанной конфигурации сообщения, представляющего указанный параметр печати,
- этап печати указанной конфигурации с применением указанного параметра печати.
Авторами настоящего изобретения обнаружено, что если параметры печати, в том числе устройство печати, используемая подложка и другие параметры печати (в том числе размер растра при офсетной печати), являются известными, они могут быть полезными при использовании конфигурации, предназначенной для защиты от копирования, в особенности для его аутентификации.
Согласно отличительным признакам изобретения, по меньшей мере один из указанных параметров печати представляет собой характеристику типа подложки, на которой напечатана указанная конфигурация.
Например, особо указывается, что представляет собой подложка: бумагу, картон, алюминий, ПВХ, стекло и т.д.
Согласно отличительным признакам изобретения, по меньшей мере один из указанных параметров печати представляет собой характеристику устройства, используемого для печати.
Например, специально указывается, являются ли средства печати средствами офсетной, высокой, трафаретной, глубокой печати и т.д.
Согласно отличительным признакам изобретения, по меньшей мере один из указанных параметров печати представляет собой характеристику плотности уровня краски, использованного в процессе печати.
Согласно отличительным признакам изобретения на этапе определения по меньшей мере одного параметра печати производят захват изображения узора, напечатанного с использованием средств печати, использованных на этапе печати, и автоматически определяют значение указанного параметра путем обработки указанного изображения.
Двенадцатым аспектом настоящего изобретения предложено создание способа определения подлинности напечатанной конфигурации, предназначенного для защиты от копирования, содержащего:
- этап захвата изображения напечатанной конфигурации, предназначенного для защиты от копирования,
- этап считывания из указанного изображения единицы информации, представляющей по меньшей мере один параметр печати указанной конфигурации и
- этап определения подлинности напечатанной конфигурации, предназначенной для защиты от копирования, с использованием указанной информации, представляющей по меньшей мере один параметр печати указанной конфигурации.
Тринадцатым аспектом настоящего изобретения предложено создание устройства для генерации конфигурации, предназначенной для защиты от копирования, содержащего:
- средства определения по меньшей мере одного параметра печати указанной конфигурации,
- средства включения в состав указанной конфигурации сообщения, представляющего указанный параметр печати, и
- средства печати указанной конфигурации с применением указанного параметра печати.
Четырнадцатым аспектом настоящего изобретения предложено создание устройства для определения подлинности напечатанной конфигурации, предназначенного для защиты от копирования, содержащего:
- средства захвата изображения напечатанной конфигурации, предназначенной для защиты от копирования,
- средства считывания из указанного изображения единицы информации, представляющей по меньшей мере один параметр печати указанной конфигурации и
- средства определения подлинности напечатанной конфигурации, предназначенной для защиты от копирования, с использованием указанной информации, представляющей по меньшей мере один параметр печати указанной конфигурации.
Поскольку преимущества, цели и отличительные признаки указанного способа, создание которого предложено двенадцатым аспектом настоящего изобретения, и устройств, создание которых предложено тринадцатым и четырнадцатым аспектами настоящего изобретения, те же самые, что и в одиннадцатом аспекте настоящего изобретения, они здесь не повторяются.
Важнейшие или отличительные признаки каждого аспекта настоящего изобретения являются отличительными признаками других аспектов настоящего изобретения с целью создания системы обеспечения защиты документов, обладающей преимуществами всех аспектов настоящего изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Ниже приведено подробное описание в форме примера, которое не ограничивает объема изобретения и в котором для лучшего понимания других преимуществ, целей и отличительных признаков настоящего изобретения даны ссылки на прилагаемые чертежи.
на фиг.1 схематически в виде логической схемы проиллюстрированы этапы обнаружения, печати и захвата информации для оригинала и копии указанного оригинала,
на фиг.2 схематически в виде логической схемы проиллюстрированы этапы, используемые для нанесения меток на документы или продукты с целью обеспечения возможности их дальнейшей аутентификации,
на фиг.3 схематически в виде логической схемы проиллюстрированы этапы, используемые для аутентификации документов или продуктов с меткой, нанесенной использованием этапов, проиллюстрированных на фиг.2,
на фиг.4А и 4В показаны информационные матрицы, предназначенные для нанесения метки на объект,
на фиг.5А и 5В показаны захваченное изображение подлинной метки информационной матрицы и скопированной метки указанной информационной матрицы соответственно,
на фиг.6 показана информационная матрица, напечатанная со слишком высоким уровнем заполнения краской,
на фиг.7 показана информационная матрица, содержащая в центральной части матрицу точек с переменными характеристиками,
на фиг.8 показана информационная матрица, окруженная матрицей точек с переменными характеристиками,
на фиг.9 показана информационная матрица, содержащая полностью заполненный краской участок,
на фиг.10 показана информационная матрица, содержащая заполненный краской соседний участок,
на фиг.11 показаны, с одной стороны, вверху информационная матрица и, с другой стороны, внизу та же самая информационная матрица, модулированная ячейка за ячейкой, с использованием воспроизведенного сообщения,
на фиг.12 показаны различные информационные матрицы, в которых только ограниченная часть ячеек имеет переменный внешний вид и является черной или белой,
на фиг.13 показаны информационные матрицы, в которых использованы различные части ячеек с переменным внешним видом, и в конце – матрица (13с), покрытая (или замощенная) второй (13b),
на фиг.14 показана информационная матрица, захваченная под углом примерно 30° и при разрешении примерно 2000 точек на дюйм (2000 dpi),
на фиг.15 представлен результат измерения комбинированного показателя текстуры (106×85) изображения, показанного на фиг.14,
на фиг.16 показано изображение, показанное на фиг.15, после сравнения с пороговым значением,
на фиг.17 показано изображение, показанное на фиг.16, после применения по меньшей мере одной операции растягивания и одной операции размывания,
на фиг.18 показан контур информационной матрицы, определенный путем обработки изображения, показанного на фиг.17,
на фиг.19 показаны углы контура, показанного на фиг.18, определенные путем обработки изображения, показанного на фиг.18,
на фиг.20 представлены графики, показывающие доли ошибок в соответствии с размерами ячеек информационной матрицы, и
на фиг.21 приведена итоговая схема.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Перед подробным описанием некоторых вариантов осуществления настоящего изобретения ниже приведены определения используемых терминов. "Информационной матрицей" называется машиночитаемое физическое представление сообщения, обычно наносимое на твердую поверхность (в отличие от водяных знаков или стеганографических изображений, которые обычно модифицируют значения пикселей предназначенного для печати рисунка). Определение информационной матрицы охватывает, например, двумерные штрихкоды, одномерные штрихкоды и другие менее интрузивные средства представления информации, например Dataglyphs (маркировка информации).
"Ячейкой" называется элемент информационной матрицы, представляющий единицу информации.
"Документом" называется любой объект (вещественный), содержащий информационную матрицу.
"Нанесением меток" или "печатью" называется любой процесс, с помощью которого осуществляется переход от цифрового изображения (в том числе информационной матрицы, документа и др.) к его представлению в реальном мире, причем указанное представление обычно выполняется на поверхности, например струйная, лазерная, офсетная, термическая печать, а также тиснение, лазерное гравирование, формирование голограмм. Кроме того, это включает более сложные процессы, например литье, при котором цифровое изображение вначале гравируют на форме и затем формируют на каждом объекте (следует отметить, что "литое" изображение можно рассматривать как трехмерное в физическом мире, даже если его цифровое представление двумерное). Следует также отметить, что некоторые из упомянутых способов включают несколько преобразований, например стандартная офсетная печать (в противоположность офсетной печати по технологии "компьютер-печатная форма") включает создание пленки, изготовление печатной формы при помощи указанной пленки и печать с использованием указанной печатной формы. Другие способы также позволяют печатать единицу информации в невидимой области или с использованием частот за пределами видимого спектра или нанесением информации внутрь поверхности и т.д.
"Захватом" называется любой процесс, с помощью которого получают цифровое представление реального мира, в том числе цифровое представление физического документа, содержащего информационную матрицу.
На всем протяжении нижеследующего описания используются квадратные конфигурации. Однако настоящее изобретение не ограничивается данным типом конфигурации, а, напротив, распространяется на все конфигурации, которые могут быть напечатаны. Например, возможно использование конфигураций, состоящих из защищенных информационных матриц, имеющих различные разрешения и различный уровень заполнения краской, согласно настоящему изобретению, преимуществом которых является, в особенности то, что по меньшей мере одна из этих матриц соответствует оптимальному разрешению и оптимальной плотности чернил.
На протяжении настоящего описания используется заполнение напечатанной конфигурации, которое может быть представлено матрицей ячеек. Однако настоящее изобретение не ограничивается указанным типом конфигурации, а, напротив, распространяется на все виды заполнения ячейками одинаковых или различных форм или размеров.
В качестве введения в описание вариантов осуществления способа и устройства согласно настоящему изобретению, следует заметить, что результатом искажения информационной матрицы является то, что некоторые ячейки не могут быть корректно декодированы.
На каждом этапе создания информационной матрицы поставлена цель, чтобы оригинальное сообщение было считано без ошибок, даже если исходное считывание информационной матрицы нарушено ошибками. В особенности, одной из целей создания указанной информационной матрицы является использование количества или коэффициента ошибок кодированных, воспроизведенных, переставленных или скремблированных сообщений с целью определения подлинности метки информационной матрицы и, следовательно, содержащего ее документа.
В действительности, коэффициент указанного искажения может быть подобран в соответствии с параметрами печати, поскольку изготовление копии ведет к дополнительным ошибкам, в результате чего коэффициент ошибок в среднем выше при считывании копии, чем при считывании оригинала.
Для понимания, почему измерение коэффициента ошибок в сообщении может быть достаточным для определения, является документ оригиналом и копией, может быть полезной аналогия с системами связи. На самом деле, переход кодированного скремблированного сообщения в информационную матрицу представляет не что иное, как модуляцию сообщения, которая определяется как процесс, посредством которого сообщение преобразуется из первоначального вида в вид, пригодный для передачи по каналам связи. Указанный канал связи, а именно средства передачи сообщения, соединяющие источник с получателем и обеспечивающие передачу сообщения, отличаются в зависимости от того, оригинальной или скопированной является захваченная информационная матрица. Канал связи может изменяться: канал связи «оригинала» и канал связи «копии» отличаются. Указанное расхождение может быть измерено на основе отношения сигнал/шум, которое меньше для захваченной скопированной информационной матрицы.
Кодированное сообщение, извлеченное из захваченной копии информационной матрицы, будет содержать больше ошибок, чем кодированное сообщение, извлеченное из захваченного оригинала информационной матрицы. В соответствии с некоторыми особенностями настоящего изобретения количество или коэффициент обнаруженных ошибок используют для того, чтобы отличить копию от оригинала.
Канал связи оригинала и канал связи копии преимущественно описываются на основе содержащихся в них подканалов, причем указанные подканалы в двух указанных случаях частично различаются. Согласно изложенному ниже, каждый подканал канала передачи сигнала, т.е. информационной матрицы, представляет собой аналого-цифровое или цифроаналоговое преобразование.
На фиг.1 показаны каналы связи для захваченной оригинальной информационной матрицы и захваченной копии информационной матрицы. Первый канал содержит подканал 105, преобразующий сгенерированную в цифровом виде информационную матрицу в фактическую информационную матрицу, т.е. в аналоговую, метку на документе, защиту которого требуется обеспечить, т.е. на оригинальном документе, и второй подканал 110, соответствующий считыванию указанной метки. В случае копии, дополнительно к указанным первым двум каналам используются третий подканал 115, используемый для воспроизведения метки из считанной метки в реальном мире, и четвертый подканал 120, используемый для считывания указанного отпечатка для определения подлинности.
Следует отметить, что, как вариант, возможно изготовление второй копии на основе первой чисто аналоговым путем (например, с использованием аналогового фотокопирования или аналоговой фотографии), однако пятый аналогово-аналоговый подканал 125 обычно отличается большим искажением сигнала, превышающим искажение вследствие считывания с использованием датчика изображения с высоким разрешением.
Третий, четвертый и/или пятый подканалы накладывают дополнительное искажение сообщения, позволяющее отличить оригинал, например изображение 505, показанное на фиг.5А, от копии, например изображение 510, соответствующее той же самой информационной матрице, что и изображение 505, представленное на фиг.5В. Как видно из сравнения изображений 505 и 510, копия обладает меньшей четкостью деталей, искажение указанных изображений соответствует ошибкам, воспроизводимым меткой оригинальной информационной матрицы.
Поскольку изготовители подделок стремятся свести к минимуму издержки производства, подканалы, используемые для изготовления копии, и в особенности подканалы, приводящие к аналоговому отпечатку, в данном случае третий и пятый каналы, иногда выполняются с низким качеством нанесения меток или печати. Следовательно, сообщения, содержащиеся в копиях, изготовленных таким способом, имеют значительно более низкое отношение сигнал/шум, что обеспечивает возможность распознавания указанных копий, даже более простым способом. Однако следует отметить, что в случаях, когда изготовитель подделок использует средства печати, сходные или даже превосходящие по качеству средства печати, используемые при изготовлении оригинальных документов, обычно не возникает особых проблем. В действительности, изготовитель подделок не может полностью избежать наложения шума, что при печати копии приводит к дополнительным ошибкам в процессе демодуляции информационной матрицы. Таким образом, данная операция приведет к уменьшению отношения сигнал/шум. В большинстве случаев разница отношений сигнал/шум будет достаточной для того, чтобы отличить захваченные оригинальные информационные матрицы от захваченных копий информационных матриц.
Предпочтительно информационная матрица, и в особенности четкость ее деталей, такова, чтобы оттиск, характеристики которого заблаговременно известны, был таким, что напечатанная информационная матрица была искаженной. Кроме того, кодированное сообщение содержит ошибки при считывании в значительном, но не чрезмерном количестве. Таким образом, при печати копии изготовитель подделок не сможет избежать дополнительного искажения. Как указано, искажение в процессе печати оригинала должно быть естественным и случайным, т.е. быть вызванным физическим явлением локально непредсказуемого характера, дисперсией краски в бумаге, естественной нестабильностью печатной машины и т.д., т.е. таким, которое нельзя отследить. Поскольку потеря информации будет по сути необратимой, указанное искажение таково, что изготовитель подделок не будет иметь возможности ни скорректировать ошибки, ни избежать дополнительных ошибок, причем при печати копии будет иметь место то же самое физическое явление. В целях повышения защиты против изготовления подделок создание информационной матрицы является зависимым по меньшей мере от одного параметра, удерживаемого в секрете, называемого секретным ключом или секретными ключами. Следовательно, в случае, если предыдущий ключ был раскрыт третьими лицами, требуется только сменить секретный ключ для того, чтобы вернуть первоначальную степень защиты. Для упрощения описания речь обычно будет идти об одном секретном ключе, подразумевается, что указанный ключ может сам состоять из нескольких секретных ключей.
Секретный ключ используется для шифрования исходного сообщения перед его кодированием. Поскольку указанный тип шифрования может использовать лавинный эффект, и при этом ошибки, возникающие в процессе демодуляции или считывания матрицы в большинстве случаев устраняются кодом коррекции ошибок, две сгенерированные из одного и того же ключа информационные матрицы, содержащие сообщения, которые отличаются только на один бит, т.е. на минимально возможное расхождение между двумя сообщениями, покажутся совершенно различными.
То же самое верно для двух информационных матриц, содержащих идентичные сообщения, но сгенерированных из различных ключей. Первое из указанных свойств является особенно преимущественным, поскольку изготовитель подделок не сможет распознать периодически повторяющийся узор, который может быть использован для изготовления подделок, путем анализа информационных матриц, созданных с использованием одного и того же ключа, но содержащих различные сообщения. Следует отметить, что также является возможным добавление к сообщению случайного числа с тем, чтобы две информационные матрицы, сгенерированные с использованием одного и того же ключа и одного и того же сообщения, но содержащие различные случайные числа, добавленные к сообщению, также казались совершенно различными.
Информационная матрица может быть рассмотрена как результат модуляции сообщения, представленного символами алфавита, например двоичного. В некоторых вариантах выполнения изобретения на уровне сообщения добавляются символы синхронизации, выравнивания или определения положения, или на уровне информационной матрицы производится вставка узоров для определения местоположения.
На фиг.2 со ссылкой на этапы итоговой схемы фиг.21 в виде логической схемы проиллюстрированы этапы генерации информационной матрицы и нанесения меток на документ в соответствии с некоторыми особенностями способа согласно настоящему изобретению. После начала процесса (этап 185) на этапе 190 получают или измеряют по меньшей мере один параметр нанесения меток или печати, например тип печати, тип среды, вид используемой краски. Затем на этапе 195 определяют, является ли площадь участка защищенной информационной матрицы или количество ее ячеек фиксированным для данной области применения или для данного клиента. На этапе 200 определяют плотность краски, соответствующую определенным параметрам нанесения меток/печати, например, прочтением в базе данных или в справочной таблице плотности, соответствующей параметрам печати. На этапе 205 определяют размер ячеек защищенной информационной матрицы, например, прочтением в базе данных или в справочной таблице размера ячеек, соответствующих параметрам печати. Следует отметить, что соответствия, хранимые в базах данных или в справочных таблицах, определяются согласно изложенному ниже, в частности по отношению к фиг.20. Указанные соответствия направлены на достижение хорошего качества печати и доли ошибок при печати, находящейся между первым и вторым заданными значениями, например 5%, 10%, 15% или 20% для первого заданного значения и 25% или 30% для второго заданного значения.
Затем, на этапе 210, получают сообщение, предназначенное для передачи с использованием документа и главным образом зависящее от идентификатора документа, а на этапе 215 получают по меньшей мере один секретный ключ шифрования и/или скремблирования.
Оригинальное сообщение представляет собой, например, наименование документа, одного или нескольких правообладателей присоединенных прав интеллектуальной собственности, номер заказа на изготовление, адресат документа, данные изготовителя. Указанное сообщение составляют с использованием известных способов. Оригинальное сообщение представлено заданным алфавитом, например алфавитно-цифровым.
Для создания зашифрованного сообщения на этапе 215 сообщение зашифровывают с использованием симметричного ключа или предпочтительно асимметричного ключа, например пары ключей типа PKI (сокращение для «Рublic key infrastructure" - инфраструктура открытого ключа). Таким образом, с целью повышения степени защиты сообщения, его зашифровывают таким образом, чтобы изменение одной единицы двоичной информации сообщения на входе шифрования вызывало изменение большого объема двоичной информации на выходе процесса шифрования.
Шифрование, как правило, выполняют на блоках битов фиксированной длины, например 64 бит или 128 бит. Могут быть использованы следующие алгоритмы шифрования: DES (сокращение для "data encryption standard" - стандарт шифрования данных) с ключом длиной 56 бит и блоком сообщения длиной 64 бит, трехкратное шифрование DES с ключом длиной 168 бит и блоком сообщения длиной 64 бит и AES (сокращение для "advanced encryption standard" - передовой стандарт шифрования) с ключами длиной 128, 192 и 256 бит и блоком сообщения длиной 128 бит, поскольку они широко распространены и признаны устойчивыми к атакам. Однако также возможно использование многих других алгоритмов шифрования, поблочных или последовательных. Следует отметить, что теоретически при использовании поблочных алгоритмов шифрования получаются зашифрованные сообщения той же самой длины, что и первоначальное сообщение, в той мере, насколько оно является кратной длине блока.
Считается, что стандарт AES обладает наивысшим уровнем защиты, однако следует отметить, что он работает с блоками сообщения минимальной длины 128 бит. В случае если длина передаваемого сообщения является кратной 64 битам, следует использовать алгоритм, подобный трехкратному шифрованию DES. Наконец, является возможным создание нового алгоритма шифрования, в особенности если вы ограничены очень небольшим размером сообщения, например 32 бит. Однако следует заметить, что безопасность указанных алгоритмов будет ограниченной вследствие небольшого количества различных зашифрованных сообщений.
Однако следует также заметить, что теоретически криптографические атаки, имеющие целью поиск ключа, не могут быть использованы, по меньшей мере, в их стандартном виде, известном в криптографии. На самом деле, изготовитель подделок теоретически имеет доступ только к захваченному изображению напечатанной оригинальной информационной матрицы, и для начала криптографической атаки ему требуется, по меньшей мере, иметь доступ к расшифрованному сообщению. Однако сообщение может быть расшифровано только в том случае, если оно предварительно дескремблировано, для этого требуется поиск ключа скремблирования.
Указанные способы шифрования называются "симметричными", т.е. при расшифровании используется тот же самый ключ. Передача ключей в модуль распознавания и их хранение должны осуществляться очень хорошо защищенным способом, поскольку изготовитель подделок, завладевший указанным ключом, будет способен создавать зашифрованные сообщения, которые не будут выглядеть поддельными. Однако указанные риски могут быть снижены использованием асимметричных способов шифрования, в которых ключ расшифровки отличается от ключа шифрования. На самом деле, поскольку ключ расшифровки не позволяет шифровать сообщения, изготовитель подделок, получивший указанный ключ, не сможет создавать ни новые действительные сообщения, ни, как следствие, информационные матрицы, несущие другое сообщение.
На этапе 220 зашифрованное сообщение кодируют с целью получения закодированного зашифрованного сообщения. Предпочтительно при кодировании используют сверточное кодирование, которое производится очень быстро, причем декодирование также происходит быстро, например с использованием широко известного способа, разработанного Витерби (Viterbi). Если при сверточном кодировании используется полиномиальная образующая девятой степени, а кодовая скорость составляет два бита на выходе на один бит на входе, получим увеличение кода 7 дБ по отношению к тому же сообщению, подвергнутому простому воспроизведению, как следствие, при декодировании риск ошибки значительно снижается. Если предназначенное для кодирования сообщение содержит 128 бит, с использованием вышеуказанного сверточного кода получают кодированное сообщение длиной 272 бит (на выходе для каждого из 128 бит кода получится два бита, еще восемь бит отводятся памятью кодировщика для полиномиальной образующей девятой степени). Однако следует отметить, что возможно использование многих других видов кодирования (арифметического кодирования, турбокодов и т.д.), использующих тот же самый принцип.
Предпочтительно, далее указанное кодированное зашифрованное сообщение записывают в двоичном алфавите, т.е. оно содержит «0» и «1».
На этапе 225 кодированное зашифрованное сообщение воспроизводят и вставляют в список доступных ячеек в информационной матрице, недоступные участки которой содержат символы синхронизации, выравнивания или определения положения или узоры для определения местоположения, которые, согласно вариантам изобретения, определяют с использованием секретного ключа. Узоры для выравнивания представляют собой, например, матрицы размером 9×9 пикселей, периодически распределенные в информационной матрице. Таким образом, кодированное шифрованное сообщение воспроизводят или повторяют, чтобы каждая единица двоичной информации была представлена несколько раз в соответствии с количеством доступных ячеек информационной матрицы. Указанное воспроизведение, зависимое от кодирования повторения или избыточности, позволяет существенно снизить коэффициент ошибок кодированного сообщения, которое поступит на вход алгоритма декодирования сверточного кода. Ошибки, не исправленные путем повторений, в большинстве случаев исправляются сверточным кодом.
На этапах 235 и 240 воспроизведенное кодированное зашифрованное сообщение подвергают шифрованию путем перестановки (так называемому «скремблированию») с целью получения скремблированного кодированного зашифрованного сообщения.
Предпочтительно, функция скремблирования воспроизведенного кодированного зашифрованного сообщения состоит в последовательном использовании перестановки двоичных значений сообщения на этапе 235 и замещения на этапе 240, причем оба этапа с использованием второго секретного ключа, возможно, идентичного первому секретному ключу. Предпочтительно, замещение выполняется с использованием функции "исключающее ИЛИ" и псевдослучайной последовательности.
Таким образом, скремблирование кодированного зашифрованного сообщения выполняют нетривиальным способом с использованием секретного ключа, который может быть идентичным ключу, используемому для шифрования сообщения, или отличным от него. Следует отметить, что если согласно отличительным признакам изобретения, используется другой ключ, он может быть вычислен из функции ключа, используемого для шифрования.
Использование секретного ключа как для шифрования сообщения, а также для скремблирования закодированного сообщения обеспечивает повышенный уровень защиты от подделок. Для сравнения следует упомянуть, так как существующие способы создания 2D штрихкодов, в которых кодированное сообщение не скремблируется. Изготовитель подделок может легко воспроизвести оригинальную информационную матрицу после декодирования сообщения захваченной информационной матрицы. Даже если декодированное сообщение зашифровано, для точного воспроизведения информационной матрицы ему не нужно расшифровывать это сообщение.
Предпочтительно, скремблирование в данном случае заключается в комбинации перестановки на стадии 235 и применении функции "исключающее ИЛИ", или функции XOR, на стадии 240, таблица которой имеет следующий вид:
По сути, указанный вид скремблирования позволяет избежать увеличения количества ошибок (здесь отсутствует так называемый "лавинный эффект": ошибка в одном элементе скремблированного сообщения приводит к одной и только одной ошибке в дескремблированном сообщении). Лавинный эффект является нежелательным, поскольку он затрудняет считывание информационной матрицы, когда в скремблированном сообщении присутствует одна единственная ошибка. Однако как было показано, ошибки играют важную роль в использовании настоящего изобретения.
Перестановка (этап 235) проводится в соответствии с алгоритмом перестановки с использованием ключа, обеспечивающего выполнение всех перестановок псевдослучайным способом. На этапе 240 применяется функция "исключающее ИЛИ" к последовательности, содержащей перестановки (длина которой соответствует количеству доступных ячеек) и к двоичной последовательности той же длины, также генерируемой из ключа. Следует отметить, что если сообщение не представлено в двоичном виде (ячейки способны представить более двух возможных значений), перестановка может быть выполнена тем же способом, а функция "исключающее ИЛИ" может быть заменена на функцию, выполняющую суммирование по модулю числа возможных значений сообщения со сгенерированной псевдослучайным образом последовательностью, содержащей то же число возможных значений, что и скремблированное сообщение.
Много перестановок зависит от существующего секретного ключа. Простой алгоритм заключается в циклическом выполнении цикла по возрастающему нижнему индексу i= от 0 до длины сообщения N-1 и для каждого индекса i генерации псевдослучайного целого числа j= от 0 до N-1 с последующей перестановкой значений сообщения в положении индексов i и j.
Псевдослучайные числа могут быть сгенерированы с использованием в цепном режиме алгоритмов шифрования, например вышеуказанных, или алгоритма хеширования, например, SHA-1 (вторая версия "Secure Hash Algorithm", который является частью американского государственного стандарта). Для инициализации алгоритма используется ключ, который повторно инициализируется на каждом новом этапе из чисел, сгенерированных на предыдущем этапе.
После того как на этапе 235 двоичные данные сообщения подвергают перестановке, битовые значения на этапе 240 пропускают через фильтр "исключающее ИЛИ", или "хоr", вместе с последовательностью псевдослучайных значений бита, имеющей ту же длину, что и сообщение. Согласно варианту изобретения, этап 240 выполняют перед этапом 235 перестановки.
Таким образом, каждое из двоичных данных скремблированного воспроизведенного кодированного зашифрованного сообщения модулируют в ячейке информационной матрицы путем присвоения одного из двух цветов, например черного и белого, двоичному значению "0" и второго из них - двоичному значению "1", причем соответствие может варьировать по поверхности изображения.
В зависимости от способа печати на этапе 245 может быть напечатан только один из двух цветов, причем второй цвет соответствует исходному цвету подложки или предварительно печатается в качестве "фона". Для способов печати, которые создают физический рельеф, например для тиснения или лазерного гравирования, выбирают один из двух цветов, связанных с определенным двоичным значением, например, случайным образом.
Вообще говоря, размер изображения в пикселях определяется площадью доступной поверхности документа и разрешением печати. Если, например площадь доступной поверхности составляет 5 мм × 5 мм, а разрешение печати матрицы составляет 600 пикселей на дюйм (данную величину часто выражают в британской системе измерений), специалист может вычислить, что площадь доступной поверхности в пикселях равна 118×118 пикселей. Если предположить, что с каждой стороны матрицы добавляют черную окантовку 4 пикселя, размер матрицы в пикселях составит 110×110 пикселей, всего 12100 пикселей. Если предположить, что размер каждой ячейки составляет один пиксель, информационная матрица будет содержать 12100 пикселей.
В матрицу могут быть включены блоки выравнивания, имеющие известное или определяемое детектором значение. Указанные блоки, например, размером 10×10 пикселей могут быть вставлены с постоянными интервалами от левого верхнего угла матрицы, например, через каждые 25 пикселей. Следовательно, следует отметить, что матрица будет насчитывать 5×5=25 блоков выравнивания, каждый размером 100 пикселей, всего 25×100=2 500 пикселей выравнивания, или 2500 ячеек сообщения. Таким образом, количество ячеек, доступных для воспроизведения кодированного сообщения, равно 12100-2500=9600. Согласно вышеуказанному, кодированное сообщение содержит 272 бита и может быть воспроизведено полностью 35 раз и частично 36-й раз (80 первых битов кодированного сообщения). Следует отметить, что указанные 35 повторений позволяют увеличить отношение сигнал/шум кодированного сигнала более чем на 15 дБ, что обеспечивает очень небольшой риск ошибки при считывании сообщения.
Два примера представлений информационной матрицы, полученной согласно способу обеспечения защиты документа, проиллюстрированному на фиг.2, представлены на фиг.4А, показана матрица 405 без видимых блоков выравнивания, и на фиг.4В показана матрица 410 с видимыми блоками выравнивания 415. На последнем чертеже вследствие регулярного расположения хорошо заметны блоки выравнивания 415, образованные черными крестами на белом фоне. Согласно другим вариантам изобретения, как показано на фиг.4А, указанные блоки имеют точно такой же внешний вид, как и остальная часть изображения. Наконец, как показано на фиг.4А и 4В, со всех сторон сообщения и возможных блоков выравнивания может быть добавлена черная окантовка 420.
Следует отметить, что, кроме окантовки и блоков выравнивания, которые могут быть псевдослучайными, двоичные значения "0" и "1" предпочтительно являются равновероятными.
Согласно одному варианту изобретения, окантовку информационной матрицы составляют из ячеек, имеющих больший размер, чем ячейки остальной части области нанесения меток с тем, чтобы представить в них более устойчивое сообщение. Например, чтобы построить квадратную ячейку окантовки, соединяют четыре периферийные ячейки информационной матрицы и в указанной окантовке представляют скремблированное кодированное зашифрованное сообщение. Таким способом содержимое окантовки будет очень устойчивым к последующим искажениям метки, в особенности к захвату ее изображения или копированию на другой документ.
Согласно другим вариантам изобретения, в дополнение к сообщению, которое несет информационная матрица, сообщение также несет документ, например, на электронной этикетке или двумерном штрихкоде. Как указано ниже, это дополнительное сообщение может представлять собой исходное сообщение или сообщение, используемое в процессе аутентификации документа, например ключи, использованные при генерации информационной матрицы, данные, связанные с указанными ключами и хранящиеся в удаленной памяти, порог количества ошибок, используемый для принятия решения о подлинности документа.
Согласно вариантам изобретения, после этапов 235 и 240 выполняют частичное скремблирование скремблированного воспроизведенного кодированного зашифрованного сообщения с применением третьего секретного ключа. Следовательно, скремблированное воспроизведенное кодированное зашифрованное сообщение может быть само частично скремблировано с применением ключа, отличающегося от ключа или ключей, используемых на предыдущих этапах. Например, указанное дополнительное частичное скремблирование затрагивает приблизительно от 10 до 20% ячеек (обычно количество фиксированное). Ячейки, подвергаемые указанному дополнительному скремблированию, выбирают псевдослучайным образом с помощью ключа дополнительного скремблирования. Значения в выбранных ячейках могут систематически модифицироваться, например, для двоичных значений путем замены "1" на "0" и "0" на "1". В одном варианте изобретения выбранные ячейки могут быть пропущены через фильтр "исключающее ИЛИ", сгенерированный из ключа дополнительного скремблирования и, следовательно, имеют вероятность модификации 50%.
Цель указанного дополнительного скремблирования состоит в том, чтобы детектор, не снабженный ключом дополнительного скремблирования, тем не менее, мог бы корректно извлекать сообщение и распознавать копии. Однако подобный детектор при попадании в руки неуполномоченных лиц, содержит не всю информацию или не все ключи, необходимые для воспроизведения оригинала. В самом деле, не имея ключа дополнительного скремблирования, злоумышленник сможет сгенерировать и напечатать информационную матрицу, которая будет распознана детектором, оборудованным ключом дополнительного скремблирования, как копия. Вообще говоря, детекторы, рассматриваемые как менее надежные, не будут оборудованы ключом дополнительного скремблирования.
Ниже будут рассмотрены другие варианты, реализованные с применением указанного принципа, заключающиеся в непредоставлении всех ключей или параметров, использованных для создания информационной матрицы.
На этапе 245 на документ наносят метки с информационной матрицей, например посредством печати или гравировки, с таким разрешением метки, при котором представление информационной матрицы содержит ошибки, возникающие благодаря указанному этапу нанесения меток таким способом, чтобы любое считывание указанной информационной матрицы показывало ненулевой коэффициент ошибок. На этапе нанесения меток формируется метка, содержащая вследствие физических условий нанесения меток, по меньшей мере, частично являющиеся случайными или непредвиденными локальные ошибки, т.е. ошибки, также влияющие на представления ячеек информационной матрицы.
Физические условия нанесения меток включают в себя, в особенности физические допуски средств нанесения меток, носителя (изображения) и, в особенности, состояние его поверхности и материала, например, возможно, нанесенной краски.
Термин "непредвиденный" означает, что до физического осуществления нанесения метки на документ невозможно определить, какие ячейки информационной матрицы будут корректно представлены с помощью метки, а какие будут ошибочные.
Для каждого из использованных секретных ключей, в случае если ключ предшествующего уровня оказался раскрытым третьими лицами, чтобы вернуть первоначальный уровень защиты, достаточно изменить секретный ключ.
Следует отметить, что кодирование и, возможно, воспроизведение дают возможность, с одной стороны, значительно повысить устойчивость сообщения к искажениям, а с другой стороны, возможность аутентификации документа посредством оценки или измерения количества или коэффициента ошибок, обнаруживаемых при считывании метки информационной матрицы.
Следует отметить, что этапы кодирования, шифрования, скремблирования, дополнительного скремблирования и воспроизведения являются обратимыми при условии, что секретный ключ или секретные ключи являются известными.
При проверке оригинальных информационных матриц, захваченных и напечатанных с разрешением 1200 точек на дюйм и содержащих ячейки размером 8×8, 4×4, 2×2 и 1×1 пикселей, замечено, что чтение при высоком разрешении двоичного значения, представленного каждой ячейкой:
- при размере ячеек 8×8 пикселей практически не приводит к ошибкам,
- при размере ячеек 4×4 пикселя приводит к небольшому количеству ошибок,
- при размере ячеек 2×2 пикселя воспроизводит много ошибок и
- при размере ячеек 1×1 пикселя коэффициент ошибок приближается к максимуму, равному 50%, что коррекция ошибок наверно будет неэффективной, а ухудшение качества из-за копирования становится незаметным, поскольку невозможно изменить коэффициент ошибок.
Оптимум находится между крайними размерами ячеек, и в представленной здесь ограниченной выборке оптимальным является один из случаев, когда размер ячеек составляет 4×4 или 2×2 пикселей. Ниже предложен способ определения указанного оптимума.
Как показано на фиг.3, согласно отличительным признакам изобретения, способ аутентификации документа после этапа инициализации 305 содержит:
- этап 310 получения по меньшей мере одного секретного ключа, этап 315 захвата изображения метки информационной матрицы на указанном документе, предпочтительно при помощи массива датчиков изображения, например видеокамеры,
- этап 320 определения местоположения метки информационной матрицы, этап 325 перебора узоров для выравнивания и определения места ячеек информационной матрицы в указанной метке,
- этапы 330 и 335 дескремблирования элементов сообщения с использованием секретного ключа с целью получения воспроизведенного кодированного зашифрованного сообщения для выполнения замещения, этап 330, и перестановки, этап 335,
- этап 340 накопления повторов воспроизведенного кодированного зашифрованного сообщения для получения кодированного зашифрованного сообщения,
- этап 345 декодирования кодированного зашифрованного сообщения для получения зашифрованного сообщения, необязательный этап 350 расшифровки зашифрованного сообщения с использованием секретного ключа,
- этап 355 определения количества ошибок, влияющих на зашифрованное сообщение, с использованием избыточности, ассоциированной с сообщением на этапе кодирования и
- этап 360 принятия решения о том, является ли документ с нанесенной меткой информационной матрицы копией или оригиналом.
Каждый секретный ключ предпочтительно является случайным или псевдослучайным.
Таким образом, способ аутентификации необязательно содержит этап расшифровки первоначального сообщения с использованием симметричного или асимметричного ключа шифрования. В зависимости от вида шифрования, т.е. с использованием симметричного или асимметричного ключей, ключ расшифровки является идентичным ключу шифрования или отличается от него. Идентичные ключи используются при симметричном шифровании, тогда как различные - при асимметричном. Важным преимуществом асимметричного шифрования является то, что ключ расшифровки не позволяет генерировать действительное зашифрованное сообщение. Таким образом, третьи лица, имеющие доступ к детектору и сумевшие получить ключ расшифровки, не смогут использовать его для генерации нового действительного сообщения.
С целью воспроизвести метку, сформированную на документе, во-первых, ее захватывают датчиком изображения, обычно массивом датчиков изображения фотокамеры, например монохромной. Оцифрованное захваченное изображение имеет формат, например матрицы точек (формат, известный под названием "bitmap" - битовая карта).
На фиг.5 показан пример оцифрованного захваченного изображения размером 640×480 пикселей, содержащего восемь двоичных данных на пиксель (т.е. шкала из 256 уровней серого). Ниже представлено подробное описание последовательно используемых функций при считывании.
Во-первых, применяют к полученному изображению функцию перебора для каждого из 25 узоров для выравнивания. Выходной результат указанной функции содержит 50 целых чисел значений вертикального и горизонтального положений 25 узоров для выравнивания. Указанная функция выполняется в два этапа:
- этап определения положения информационной матрицы в целом в оцифрованном захваченном изображении и этап, на котором проводится локальный перебор (перебор на части изображения) каждого из узоров для выравнивания с целью определения их положений.
Для выполнения первого этапа специалист может использовать известный способ, например раскрытый в патенте США №5296690. Другой простой и быстрый алгоритм заключается в разграничении участка оцифрованного захваченного изображения, содержащего информационную матрицу, путем внимательного изучения резких переходов оттенков серого строка за строкой и столбец за столбцом, или после выполнения, во-первых, суммирования всех строк и, во-вторых, суммирования всех столбцов с целью создания одной строки и одного столбца, в которых осуществляется поиск. Например, уровни оттенков серого, обладающие наивысшими абсолютными значениями, соответствуют краям информационной матрицы, и таким образом может быть выполнена грубая оценка положения четырех ее углов.
Для осуществления второго этапа оцененные положения четырех углов информационной матрицы используют для оценки положения узоров для выравнивания известными геометрическими методами.
Для определения сдвига, масштабирования и угла поворота информационной матрицы в изображении, захваченном датчиком изображений, могут быть использованы стандартные геометрические методы. Аналогично, указанные сдвиг, масштаб и угол поворота могут быть использованы для определения положений углов информационной матрицы. Таким образом, последовательное приближение может быть выполнено повторением указанных двух этапов.
Вообще говоря, получают ожидаемое положение каждого узора выравнивания с точностью приблизительно X пикселей по горизонтальной и вертикальной оси. Указанное значение X зависит от условий применения, в частности от отношения между разрешением захвата и разрешением печати, максимального допустимого угла чтения и точности ожидаемых положений четырех углов информационной матрицы. Приемлемым значением X является 10 пикселей, в этом случае область поиска имеет размер 21×21 пикселей. Осуществляют свертывание между узором выравнивания и блоком выравнивания, указанный блок выравнивания, возможно, масштабируется, если отношение разрешения захвата к разрешению печати отличается от единицы. Положение результирующей матрицы свертки с максимальным значением соответствует исходному положению блока выравнивания.
Положения 25 узоров выравнивания сохраняют в памяти. Указанный набор данных используют на этапе демодуляции для определения положения каждой ячейки информационной матрицы в захваченном изображении с максимальной точностью.
Для каждого двоичного значения используют ближайший узор выравнивания соответствующей ячейки в качестве начальной точки для ожидаемого положения ячейки в единицах пикселей захваченного изображения. С использованием ожидаемых поворота и масштабирования и известного относительного положения ячейки в цифровой информационной матрице рассчитывают центральное положение ячейки в захваченной информационной матрице с использованием известных геометрических способов.
Применение функции дескремблирования, обратной функции скремблирования, применяемой при создании исходной информационной матрицы, позволяет восстановить исходное воспроизведенное сообщение, поврежденное ошибками. Если индикаторы сохраняются, получают действительные или целые числа, которые могут быть положительными или отрицательными и непосредственно к которым функция «исключающее ИЛИ» не может быть применена. Таким образом, для получения ожидаемого дескремблированного сообщения из индикаторов требуется умножить индикатор на -1, если значение фильтра «исключающее ИЛИ» равно 0, и на +1, если его значение равно 1. Следует отметить, что перестановка выполняется одинаковым способом для различных типов индикаторов (двоичного, целого и действительного).
Далее следует этап оценки значения каждого бита кодированного сообщения в соответствии с анализом захваченных значений ячеек дескремблированной информационной матрицы. Для этого следующий этап содержит определение индикатора двоичного значения, присвоенного ячейке, полагая, что черный имеет двоичное значение «0» и белый «1» (или наоборот). Указанный индикатор может быть, например, средней яркостью (или средним значением по шкале серого цвета) небольшой смежной области, окружающей центр ячейки (и больше всего соответствующей площади ячейки), или наиболее высоким значением указанной небольшой окружающей области, или наименьшим значением яркости в указанной смежной области. Полезным может оказаться подход, заключающийся в определении двух смежных областей, небольшой области, окружающей центр ячейки, и большей области, окружающей и исключающей указанную меньшую смежную область. Таким образом, индикатор может быть основан на сравнении значений яркости в наружной смежной области и в меньшей смежной области, называемой внутренней областью. Измерение методом сравнения может быть разницей между средней яркостью во внутренней смежной области и средней яркостью в большей смежной области.
После того как был определен индикатор двоичного значения для каждой ячейки информационной матрицы, полезно выполнить дополнительную обработку указанных индикаторов. В зависимости от изменений, которые испытывает информационная матрица, от цифровой информационной матрицы до захваченной информационной матрицы, индикаторы могут представлять отклонение. Простая дополнительная обработка с целью уменьшить указанное отклонение заключается в вычитании среднего значения или значения индикатора, занимающего срединное положение, и, возможно, в нормализации указанных индикаторов в диапазоне значений от -1 до +1. Указанные нормализованные индикаторы могут быть использованы для определения наиболее вероятных двоичных значений посредством сравнения их с пороговым значением, например «0», более высоким значениям присвоено значение «1» и более низким значениям присвоено «0», что приводит к тому же самому числу двоичных значений «0» и «1».
Согласно предпочтительному варианту изобретения, для каждого искомого двоичного значения выполняется суммирование значений индикаторов по всем представлениям и затем сравнивается с пороговым значением. Указанная обработка, с более интенсивным использованием ресурсов, в сущности, дает большую надежность на данном этапе.
Возвращаясь к вышеуказанному примеру, информационная матрица содержит 35 раз закодированное сообщение длиной 272 двоичных значений, 80 из которых воспроизводятся 36-й раз. Следовательно, для каждого значения закодированного сообщения существует 35 или 36 индикаторов. Концентрация или накопление приводит к сохранению только одного конечного значения (двоичного, действительного или целого), зависящего от указанного множества представлений одного и того же первоначального двоичного значения. Например, выполняется усреднение 35 или 36 индикаторов, при этом положительное среднее значение расшифровывается как "1", а отрицательное - как "0". Таким образом, средние значения индикаторов можно сравнивать с нулевым пороговым значением.
Согласно вариантам изобретения, к индикаторам применяются более сложные методы статистической обработки, что в некоторых случаях требует обучающего этапа. Например, с целью расчета вероятности соответствующего первоначального двоичного значения «0» или «1» соответственно над средними значениями индикаторов могут быть выполнены нелинейные операции. В действительности, оценочная вероятность может обеспечить уточнение результата декодера.
В конце этапа накопления получают кодированное сообщение, содержащее избыточность, предназначенную для обеспечения возможности коррекции или, по меньшей мере, обнаружения ошибок.
Декодер, принцип действия которого в случае сверточного кода предпочтительно основывается на методе Витерби (Viterbi), на выходе выдает зашифрованное сообщение, длина которого в настоящем примере составляет 128 бит. Затем декодированное зашифрованное сообщение расшифровывают с использованием алгоритма, использованного для шифрования, предпочтительно AES для блоков длиной 128 бит, в обратном порядке.
Следует напомнить, что часть сообщения может быть зарезервирована для хранения математической функции остальной части сообщения, например хеш-функции. В вышеуказанном примере 16 бит являются зарезервированными для хранения математической функции остальных 112 битов сообщения. К оставшимся 112 битам сообщения добавляют незначащие биты и вычисляют хеш-значение или дайджест типа SHA-1 сообщения, к которому добавлены незначащие биты и для создания которого использован тот же самый секретный ключ. Если первые 16 бит полученного хеш-значения соответствуют 16 зарезервированным битам, достоверность информации подтверждается, и процесс считывания может перейти к следующему этапу. В противном случае 112-битное сообщение считается недействительным. Причины указанной недействительности могут быть разные: некорректное считывание, сообщение сгенерировано неправильным путем и т.д. Точную причину проблемы можно определить путем более подробного анализа, возможно, при вмешательстве человека.
Расшифрованное 112-битное сообщение интерпретируется так, чтобы на выходе обеспечить пользователя значимой информацией. Указанное сообщение само по себе может предоставить пользователю важную информацию о характере документа или носителя, содержащего информационную матрицу: о сроке использования продукта, маршруте распространения или согласовании с другой информацией из того же документа и т.д. Кроме того, указанная информация может быть использована для отправки запроса в базу данных, которая может предоставить новую информацию, подтвердить действительность, проверить происхождение документа или распознать копию и т.д.
Однако, как указано выше, чтение и анализ передаваемого сообщения не дают точного ответа на вопрос, "является ли рассматриваемый документ оригиналом или копией". В действительности, высококачественная копия оригинального документа будет содержать читаемое сообщение, содержащее информацию, которая, в принципе, является действительной. Даже если информация, извлеченная из копии, считается недействительной, например если копия документа передана по сети распространения, которая не соответствует информации, извлеченной из информационной матрицы, важно знать точную причину фальсификации и распознать, подлинный или поддельный продукт прошел через несанкционированный канал? Далее представлено описание различных способов определения источника документа (оригинал или копия).
Существует много декодеров, обеспечивающих измерение коэффициента ошибок в кодированном сообщении. Например, для сверточного кода детектор Витерби вычисляет на основе заданной метрики, в пространстве состояний декодера, самый короткий маршрут, ведущий к рассматриваемому кодированному сообщению.
Выбор метрики зависит от представления кодированных данных, поступающих в декодер. Если указанные данные являются двоичными, метрика основывается на расстоянии Хэмминга (Hamming distance), а именно на числе положений или различных битовых значений между кодом, поступающим на вход декодера, и кодом, соответствующим кратчайшему маршруту в пространстве состояний. Если данные являются не двоичными, а имеют более точное измерение или являются целым или действительным числом, используют соответствующую метрику.
Независимо от того, какая именно метрика используется для измерения коэффициента ошибок в сообщении, указанный коэффициент ошибок теоретически будет выше для захваченной копии информационной матрицы, чем для захваченной оригинальной информационной матрицы. Для определения типа информационной матрицы (оригинал или копия) требуется порог принятия решения. Например, можно использовать следующий способ вычисления указанного порога:
- генерируют характерный образец приложения, например 100 различных оригинальных информационных матриц, каждая из которых захватывается три раза в условиях применения для получения всего 300 захваченных изображений,
- для каждого из 300 захваченных изображений измеряют коэффициент ошибок,
- вычисляют измеренные среднее значение и разброс коэффициентов ошибок образца, например среднее арифметическое и среднеквадратичное отклонение образца,
- в соответствии с измерениями среднего значения и разброса определяют порог принятия решения о коэффициенте ошибок, выше которого информационная матрица будет рассматриваться как копия. Указанный порог принятия решения может быть равен, например, среднему значению +4 * среднеквадратичное отклонение,
- с целью обнаружения возможных отклонений при печати оригинальных информационных матриц можно задать нижний порог принятия решения, равный, например, среднему значению - 3 * среднеквадратичное отклонение, ниже которого пользователь получает предупреждение об особенно низком коэффициенте ошибок в образце.
Если условия захвата информационных матриц неподходящие настолько, что вследствие плохих условий захвата это приводит к слишком высокому коэффициенту ошибок, можно также задать интервал, в котором невозможно с уверенностью определить источник информационной матрицы, тогда выполняется запрос на повторный захват изображения. Указанный интервал может располагаться, например, между средним значением +2 * среднеквадратичное отклонение и порогом принятия решения (в данном примере равным среднему значению +4 * среднеквадратичное отклонение).
Измерение коэффициента ошибок, полученных на этапе декодирования, теоретически вычисляется непосредственно на этапе декодирования, поэтому его использование очень практично. Как указано выше, указанный коэффициент ошибок кодированного сообщения основан на накоплении, в нашем примере 35 или 36 индикаторов для каждого бита закодированной информации. Однако в некоторых случаях желательно проводить более глубокий анализ коэффициента ошибок, основанный непосредственно на значениях индикаторов, а не на накопленных значениях указанных индикаторов. В действительности, более глубокий анализ коэффициента ошибок может обеспечить возможность лучшего распознавания копий информационных матриц.
Для этого необходимо определить позиции ошибок по каждому из указанных индикаторов. Для этого, прежде всего, определяют оригинальное кодированное сообщение, которое может быть предоставлено декодером. В противном случае его можно вычислить кодированием декодированного сообщения. Следует отметить, что указанный этап кодирования является особенно выгодным при использовании сверточного кода. Затем кодированное сообщение воспроизводят для получения оригинального воспроизведенного сообщения. Оригинальное воспроизведенное сообщение может быть сравнено с полученным ранее оригинальным воспроизведенным сообщением, поврежденным ошибками, и в подходящей метрике может быть рассчитано измерение коэффициента ошибок. Если воспроизведенное сообщение, поврежденное ошибками, представлено в двоичных значениях, может быть непосредственно посчитано число ошибок (эквивалент расстоянию Хемминга) и нормализовано разделением его на длину воспроизведенного сообщения. Если сохраняются значения индикаторов, воспроизведенное сообщение, поврежденное ошибками, представляют в целых или действительных числах. В этом случае воспроизведенное сообщение может быть уподоблено вектору, и может быть выбрана метрика, обеспечивающая возможность рассчитать расстояние между указанными векторами. Например, широко используется линейный коэффициент корреляции между двумя векторами, изменяющийся от -1 до +1, для измерения подобия между векторами. Следует отметить, что расстояние между векторами может быть вычислено простым изменением знака измерения подобия, в данном случае изменением знака указанного линейного коэффициента корреляции.
Очевидно, что могут быть использованы многие другие способы измерения расстояния, при сохранении сущности метода. Измерение расстояния воспроизведенного сообщения обеспечивает более глубокий анализ, на уровне элементарных единиц сообщения, представленных ячейками матрицы. Может потребоваться провести анализ на дополнительном уровне точности, отдельно рассматривая различные географические участки матрицы. Например, может потребоваться анализ и определение коэффициента ошибок на определенном участке, например в верхнем левом углу матрицы. Указанная возможность представляет особый интерес в случае, например, если информационная матрица была локально повреждена (царапина, загиб, истирание, пятно и т.д.) или если она была неровно захвачена (слишком темные или слишком светлые участки, или не сфокусированные).
В действительности, требуется избегать указанных искажений, которые могут повредить оригинальные информационные матрицы, имеющие следствием высокий коэффициент ошибок для указанных матриц. Следовательно, анализ локальных элементов может предоставить возможность пренебрегать или придавать заниженное весовое значение поврежденным участкам, имеющим повышенный коэффициент ошибок.
Указанная задача может быть решена рассматриванием сообщения с переставленными битами или скремблированного сообщения вместо воспроизведенного. В действительности, информационная матрица сгенерирована фиксированным способом (независимо от ключа) из скремблированного сообщения и блоков выравнивания, следовательно, легко извлечь части сообщения с переставленными битами или скремблированного сообщения, соответствующие точным географическим участкам. Следует заметить, что, если вместо скремблированного сообщения используют сообщение с переставленными битами, это позволяет избежать этапа наложения фильтра «исключающее ИЛИ» для получения скремблированного оригинального сообщения.
Для произвольного географического участка можно применить вышеуказанные измерения расстояния между оригинальным сообщением с переставленными битами или скремблированным оригинальным сообщением и сообщением с переставленными битами или скремблированным сообщением, поврежденным ошибками. Во всех случаях можно включать в анализ блоки выравнивания.
Возможно использование множества алгоритмов, регулирующих использование различных географических участков. Кроме того, в некоторых случаях возможно участие человека-оператора, который, возможно, будет способен определить причину искажений (случайное, намеренное, систематическое и т.д.) Однако часто анализ должен быть выполнен автоматически и генерировать особенный результат: оригинал, копия, ошибка чтения и т.д. Таким образом, общий подход включает в себя разделение информационной матрицы на особенные участки одинакового размера, например на 25 участков размером 22×22 пикселей для матрицы 110×110 пикселей из вышеуказанного примера. Следовательно, вычисляется 25 значений расстояния между оригинальным сообщением и сообщением, поврежденным ошибками, соответствующих указанным отдельным географическим участкам. Затем извлекают восемь наивысших значений расстояния, соответствующих восьми наименее поврежденным участкам. Наконец, рассчитывают средний коэффициент ошибок по указанным восьми географическим участкам. Таким образом, предпочтение отдается участкам информационной матрицы, вероятность которых быть правильно прочитанными является наивысшей.
Следует отметить, что, так как несколько индикаторов коэффициента ошибок могут быть вычислены в соответствии с кодированным, воспроизведенным, с переставленными битами или скремблированным сообщением, так и в соответствии с различными географическими участками можно сгруппировать различные измеренные коэффициенты ошибок, чтобы произвести глобальное измерение коэффициента ошибок.
Исходя из двоичных значений сообщения длиной 255 двоичных значений декодер определяет декодированное сообщение и количество или коэффициент ошибок. В случае использования декодеров, не определяющих количество или коэффициент ошибок, заново кодируют декодированное сообщение и сравнивают его с сообщением, полученным из захваченной информационной матрицы.
Из двоичных значений согласно количеству обнаруженных ошибок определяют, является ли захваченная аналоговая информационная матрица оригиналом или копией.
В случае если сообщение может быть декодировано и могут быть определены позиции ошибок, на выходе этапа декодирования получают список из 255 двоичных значений, равных "1" для ошибок и "0" в случае отсутствия ошибки в соответствующем двоичном значении декодированного сообщения.
Следует отметить, что количество ошибок, которые могут быть декодированы, ограничено до тех пор, пока не определено декодированное сообщение, известно, что количество ошибок больше, чем указанный предел обнаружения. Когда сообщение декодировано, его расшифровывают с использованием секретного ключа. Следует заметить, что использование асимметричных ключей делает возможным повысить безопасность указанного этапа.
Согласно опыту авторов изобретения, параметры печати, как результат физических допусков используемых средств нанесения меток, состояния поверхности документа и, возможно, нанесенного покрытия, генерирующие по меньшей мере 5 процентов и предпочтительно от 10 до 35 процентов, и даже более предпочтительно от 20 до 25 процентов некорректно напечатанных символов, обеспечивают хороший уровень возможности распознавания копий. Для достижения указанного коэффициента ошибок варьируют параметры печати, влияющие на ухудшение качества напечатанного сообщения. Ниже следует более подробное описание, как концепция защищенной информационной матрицы оптимизирована в соответствии с условиями печати.
Далее оптимизация создания защищенных информационных матриц в зависимости от условий печати описана более подробно.
Следует отметить, что еще не напечатанная защищенная информационная матрица в цифровом виде не содержит ошибок. В действительности, случайная, предумышленная или «искусственная» генерация ошибок отсутствует. Кроме того, указанные случаи не являются ошибками печати согласно настоящему изобретению, т.к. "ошибка печати" относится к изменению внешнего вида ячейки, модифицирующего представление информации, которую несет данная ячейка, при анализе, позволяющем избежать ошибок чтения или захвата, например под микроскопом. Следует отметить, что если изначально ячейки часто имеют двоичные значения, то захваченные изображения часто содержат оттенки серого, и, следовательно, с ячейкой ассоциируется значение, которое не является двоичным и которое может быть интерпретировано, например, как вероятность того, что ячейка будет иметь исходное двоичное значение.
Таким образом, ошибки содержит напечатанный вариант защищенной информационной матрицы. Рассматриваемые ошибки, используемые в настоящем изобретении, не являются причиненными искусственно, они возникают естественно. В действительности, рассматриваемые ошибки возникают случайным и естественным путем на стадии нанесения меток при печати защищенной информационной матрицы с достаточно высоким разрешением.
Указанные ошибки являются необходимыми, даже если они образуют сложную комбинацию. В действительности, если информационная матрица нанесена без ошибок (или с очень низким коэффициентом ошибок), то копия той же информационной матрицы, изготовленная при сравнимых условиях печати, не будет содержать большего количества ошибок. Таким образом, очевидно, что информационная матрица, напечатанная «практически совершенно», может быть с точностью скопирована с использованием аналогичного средства нанесения меток. Напротив, если информационная матрица нанесена со слишком большим количеством ошибок, насколько можно ожидать, только меньшая часть ячеек может быть скопирована с дополнительным ошибками. Следовательно, требуется избегать слишком высокого разрешения при нанесении меток, поскольку из-за этого снижается возможность отличать оригиналы от копий. Очевидно, разрешение печати защищенной информационной матрицы не может варьироваться. В действительности, большинство средств печати печатают в двоичном коде (точка типографской краски присутствует или отсутствует) с фиксированным разрешением, оттенки серого или других цветов копируют с использованием различных методов растрирования. В случае офсетной печати указанное "собственное" разрешение определяется разрешением печатной формы, которое составляет, например, 2400 точек на дюйм (2400 dpi). Таким образом, изображение в оттенках серого, предназначенное для печати с разрешением 300 пикселей на дюйм (300 ppi), на практике печатается в двоичном коде с разрешением 2400 точек на дюйм (2400 dpi), причем каждый пиксель соответствует приблизительно 8×8 точек растра.
Несмотря на то что вообще разрешение печати не может варьироваться, с другой стороны, можно изменить размер ячеек защищенной информационной матрицы в пикселях с тем, чтобы одна ячейка была представлена несколькими печатными точками и, согласно вариантам изобретения, часть каждой ячейки, внешний вид которой в двоичных информационных матрицах способен варьироваться, т.е. быть напечатанной в белом или черном цвете. Таким образом, можно, например, представить ячейку квадратным блоком размером 1×1, 2×2, 3×3, 4×4 или 5×5 пикселей (также возможны блоки неквадратной формы), соответствующим разрешению 2400, 1200, 800, 600 и 480 ячеек на дюйм соответственно.
В соответствии с некоторыми особенностями настоящего изобретения, определяют количество пикселей в ячейке, которое приводит к естественному ухудшению качества печати, что позволяет увеличить до предела расхождение между оригиналами и копиями.
Следующая модель позволяет получить ответ по указанному определению, даже если она и является следствием упрощения используемого процесса. Предположим, что цифровая защищенная информационная матрица состоит из n двоичных ячеек и что существует вероятность р того, что каждая ячейка напечатана с ошибкой (например, "1" будет прочитана как "0" и наоборот).
Далее предположим, что копия будет изготовлена с использованием эквивалентных средств печати, что выражается с той же вероятностью р ошибки в ячейках в процессе копирования. Следует отметить, что вероятность р ошибки больше, чем 0,5, в контексте указанной модели не имеет смысла, поскольку в этом случае корреляция между напечатанной информационной матрицей и цифровой информационной матрицей нулевая (следовательно, значение 0,5 соответствует максимальному искажению).
Основываясь на захваченном изображении, детектор подсчитывает количество ошибок (количество ячеек, не соответствующих начальному двоичному значению) и на основании указанного количества ошибок принимает решение о происхождении защищенной информационной матрицы (оригинал или копия). Установлено, что на практике захваченное изображение в большинстве случаев состоит из оттенков по шкале серого, таким образом, для получения двоичных значений требуется сравнивать значения ячеек с пороговым значением.
Для того чтобы на этапе сравнения с пороговым значением не происходило потерь информации, значения, представленные в оттенках по шкале серого, могут быть интерпретированы как вероятности двоичных значений. Однако далее рассматривается, каким образом из полученного изображения устанавливают двоичные значения ячеек защищенной информационной матрицы.
Для измерения надежности распознавания копий в соответствии с вероятностью р ошибки в каждой ячейке используют индикатор I, который равен разности между средним количеством ошибок для копий и для оригиналов, нормированной на среднеквадратичное отклонение количества ошибок в оригинале. Таким образом, получаем следующую формулу:
I=(Ес-Ео)/So,
где Ео - среднее количество ошибок в оригиналах,
Еc - среднее количество ошибок в копиях,
So - среднеквадратичное отклонение количества ошибок в оригиналах.
Следует отметить, что по причине простоты модели среднеквадратичным отклонением для копий пренебрегают. Поскольку в указанной модели существует вероятность р того, что каждая ячейка напечатана с ошибкой, можно применять формулы для среднего и среднеквадратичного отклонения биноминального распределения. Следовательно, находим значения Ео, Ес и So в соответствии с р и n:
Ео=n⋅р
Ес=2⋅n⋅р⋅(1-р)
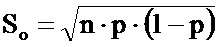
Следовательно, значение индикатора I равно:
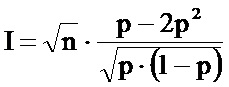
На фиг.20 сплошной линией 700 показано значение индикатора I в соответствии с р для р от 0 до 0,5, нормированное на интервале от 0 до 1. Таким образом, можно отметить следующее: для р=0 и р=0,5, т.е. для минимального и максимального коэффициентов ошибок, значение индикатора равно нулю, следствием чего является отсутствие расхождений между оригиналами и копиями. В действительности, при отсутствии каких-либо искажений ячеек при печати нет возможности отличить оригиналы от копий, и, напротив, если искажение является очень сильным (т.е. близко к 0,5), практически не остается ячеек, доступных для искажений, и, как следствие, снижается возможность отличить оригиналы от копий. Следовательно, является нормальным, что индикатор проходит через оптимум, который соответствует значению 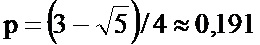
Авторами изобретения обнаружен оптимум искажения, не зависящий от количества n доступных ячеек. Кроме того, обнаружено, что индикатор I возрастает в соответствии с n: следовательно, необходимо, чтобы n был как можно большим. Однако относительно часто случается так, что доступной для печати защищенной информационной матрицы является фиксированная площадь, например 0,5×0,5 см. Таким образом, матрица из 50×50 ячеек размером по 8×8 пикселей занимает такую же площадь, как и матрица из 100×100 ячеек размером по 4×4 пикселя. В последнем случае ячеек в четыре раза больше, но очень возможно, что вероятность р ошибки будет выше. Таким образом, определение оптимального значения р должно проводиться с учетом того, что для более высокого разрешения используется большее количество ячеек. Если сделать предположение, согласно которому вероятность р обратно пропорциональна площади, доступной для ячейки, то 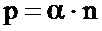
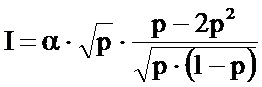
Как показано на фиг.20 на кривой пунктирной линией 705, с учетом изменения р в зависимости от n индикатор проходит через максимум при значении р, равном 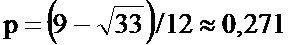
Таким образом, использование коэффициента ошибок, лежащего в интервале от 20 до 25%, является предпочтительным, так как данный интервал находится между вышеуказанными оптимумами, равными 19,1% и 27,1%. Оптимум 19,1% соответствует случаю, в котором количество ячеек является фиксированным, например, когда методика считывания позволяет считывать только информационные матрицы с фиксированным количеством ячеек, тогда как оптимум 27,1% соответствует случаю, в котором количество ячеек не является ограниченным, тогда как физический размер информационной матрицы ограниченный.
Ниже указаны варианты или усовершенствования использования некоторых особенностей настоящего изобретения.
1) Использование недвоичных информационных матриц. Осуществление информационных матриц не ограничивается двоичными информационными матрицами. На всех этапах для перехода от первоначального сообщения к информационной матрице элементы сообщения могут иметь более двух различных значений. Рассмотрим случай, когда ячейки информационной матрицы могут принимать 256 различных значений, что соответствует печати изображений в оттенках серого, принимающих значение между 0 и 255. Скремблированное и кодированное сообщение также будет принимать 256 значений. Для выделения скремблированного и кодированного сообщения из кодированной информации функция перестановки может остаться той же самой, тогда как функция "исключающее ИЛИ" может быть заменена на суммирование 255 по модулю, а псевдослучайная последовательность, используемая для указанного суммирования 256 по модулю, также будет содержать значения, лежащие между 0 и 255.
Исходное сообщение и часть кодировки, соответствующая применению кода коррекции ошибок, также могут быть представлены (но не обязательно представлены) двоичными значениями. Однако на подэтапе воспроизведения придется преобразовывать двоичное кодированное сообщение в воспроизведенное, содержащее значения, например, от 0 до 255 (8 бит). Для этого в одном из вариантов группируют двоичное кодированное сообщение в единицы по 8 последовательных битов с последующим представлением указанных единиц по шкале от 0 до 255.
2) Определение копий, основанное на результате декодирования, без расчета коэффициента ошибок. Согласно вариантам реализации изобретения, со ссылками на прилагаемые чертежи, коэффициент ошибок используется для определения происхождения захваченной информационной матрицы (оригинал или копия). Кроме того, как указано выше, коэффициент ошибок может быть измерен только в том случае, если захваченное кодированное сообщение информационной матрицы может быть декодировано. В описании раскрыты необходимые этапы для обеспечения возможности декодирования сообщения, в большинстве случаев вплоть до требуемого коэффициента ошибок. Таким образом, можно убедиться в том, что в большинстве случаев коэффициент ошибок можно измерить и для копий при условии, что они содержат достаточное количество ошибок.
В некоторых случаях не полагаются единственно на коэффициент ошибок для того, чтобы определить, является ли информационная матрица копией. Это происходит, в особенности в случае, когда объем информации, вставляемый в информационную матрицу, слишком велик по сравнению с доступной площадью или с доступным количеством пикселей, вследствие чего кодированное сообщение не может быть многократно воспроизведено (в нашем примере кодированное сообщение воспроизводят 35 или 36 раз). Таким образом, стремятся удостовериться в том, что оригинальные информационные матрицы читаются корректно, и наоборот, копии информационных матриц в большинстве случаев читаются некорректно. Корректное чтение позволяет удостовериться в том, что информационная матрица является оригиналом, напротив, некорректное чтение не обязательно является гарантией того, что информационная матрица является копией.
Объем информации является высоким, если сообщение зашифровано асимметричным ключом, например с использованием алгоритма шифрования RSA с открытым ключом с длиной шифруемого сообщения 1024 бит, или в случае симметричного шифрования фотографии владельца идентификационной карты (от 2000 до 5000 бит). Если размер информационной матрицы ограничен (например, менее 1 кв. см), многократное воспроизведение кодированного сообщения невозможно, и в данном случае в зависимости от качества печати сообщение копии, вероятно, будет нечитаемым.
3) Использование информационных матриц, содержащих несколько сообщений. Возможно создание информационных матриц, содержащих несколько сообщений, использующих различные ключи, рекурсивным методом. В особенности это полезно для областей применения, в которых различным средствам верификации или различным пользователям присваиваются различные уровни полномочий. Кроме того, это полезно для обеспечения нескольких уровней защиты: если открытый ключ раскрыт третьими лицами, может быть подделана только часть информационной матрицы.
Для упрощения выделения указанных вариантов реализации изобретения рассмотрим два сообщения (сообщения 1 и 2). Сообщения 1 и 2 могут быть сгруппированы на нескольких уровнях, например:
- последовательно соединяют сообщения 1 и 2, раздельно зашифрованные ключами 1 и 2. Ключ 1 (или группу ключей 1) используют на этапах перестановки, скремблирования и т.д. Сообщение 2 может быть расшифровано только теми считывающими устройствами, которые оснащены ключом 2. Аутентификация с целью определения, является ли информационная матрица оригиналом или копией, может быть выполнена по матрице целиком с использованием ключа 1. Указанный подход обеспечивает преимущества, если изображение захвачено портативным устройством, соединенным с удаленным сервером, оснащенным ключом 2, и при этом связь является дорогостоящей, длительной и трудной для установления соединения: в результате объем передаваемых данных не очень важен,
- скремблированное сообщение 1 и скремблированное сообщение 2 последовательно соединяют и информационную матрицу формируют из последовательно соединенных скремблированных сообщений 1 и 2. Следует отметить, что в информационной матрице два указанных сообщения физически разделены,
- скремблированное сообщение 1 и скремблированное сообщение 2 последовательно соединяют и последовательно соединенное сообщение подвергают перестановке и скремблированию с использованием ключа 1. Следует отметить, что позиции скремблированного сообщения 2 зависят от обоих ключей 1 и 2, вследствие чего для чтения сообщения 2 требуются оба ключа.
Использование нескольких защищенных сообщений с различными ключами делает возможным контролировать различные уровни полномочий различных пользователей модуля верификации. Например, одни подразделения уполномочены прочитать и удостоверить подлинность первого сообщения, другие могут только удостоверить подлинность первого сообщения. Автономный модуль верификации, не имеющий доступа к серверу для верификации, в общем случае не способен ни к прочтению, ни к аутентификации второго сообщения. Очевидно, что также возможны многие другие варианты. Следует отметить, что приведенные выше соображения могут быть распространены на информационные матрицы, содержащие более двух сообщений.
4) Вставка кода обнаружения ошибок или подделок. Чем выше коэффициент ошибок, тем выше риск, что сообщение некорректно декодировано. Желательно иметь механизм распознавания некорректно декодированных сообщений. Иногда это может быть выполнено на прикладном уровне: некорректно декодированное сообщение не является согласованным. Однако невозможно использование значения декодированного сообщения для проверки его действительности. Другой подход заключается в оценке риска, что сообщение некорректно декодировано, с использованием измерения отношения сигнал/шум кодированного сообщения относительно типа используемого кода и декодирования. Существуют графики, в особенности в книге «Помехозащитное кодирование», Второе издание, Лин и Костелло ("Error Control Coding", Second Edition, Lin and Costello). Например, на стр.555 указанной книги показано, что для сверточного кода с памятью 8 и коэффициентом ½, с программным декодированием с непрерывным вводом данных, коэффициент ошибок на кодированный бит составляет 10-5 для отношения сигнал/шум 6 дБ.
Другой подход, который может дополнять предыдущий, заключается в добавлении к зашифрованному сообщению хеш-значения этого сообщения. Например, можно использовать хэш-функцию SHA-1 для вычисления количества хеш-битов в зашифрованном сообщении. Указанные хеш-биты добавляют в конец зашифрованного сообщения. При обнаружении хеш-биты зашифрованного сообщения сравнивают с присоединенными хеш-битами. Если они совпадают, можно сделать заключение с большой вероятностью, что сообщение корректно декодировано. Следует отметить, что при наличии 16 хеш-битов существует один шанс из 216, что ошибка не обнаружена. Возможно увеличить количество хеш-битов, но за счет количества ячеек, доступных для воспроизведения зашифрованного сообщения.
5) Хеширование может быть использовано с целью добавления уровня безопасности. В действительности, предположим, что используется симметричное шифрование и что третьим лицам удается завладеть ключом шифрования. Указанный злоумышленник может сгенерировать неограниченное количество действительных информационных матриц. Однако следует отметить, что если изначально был использован ключ дополнительного скремблирования и он не стал объектом владения третьих лиц, то информационные матрицы, сгенерированные третьими лицами, будут распознаны как копии детектором, оборудованным указанным ключом дополнительного скремблирования. Однако к зашифрованному сообщению могут быть последовательно присоединено хеш-значение необработанного или зашифрованного сообщения, находящееся в зависимости от ключа, теоретически не сохраняемого в детекторах, потенциально доступных третьим лицам. Верификация хеш-значения, возможно на защищенных считывающих устройствах, дает возможность удостовериться, что сгенерировано действительное сообщение. Таким образом, третьи лица, оснащенные ключом шифрования, но не имеющие ключа хеширования, не способны к вычислению дествительного хеш-значения сообщения. Кроме того, указанное действительное хеш-значение дает возможность в целом обеспечить целостность информации, содержащейся в сообщении.
6) Использование информационных матриц в системе серверов. Обработка полностью осуществляется сервером, удаленным от средств захвата изображений, или в случае аутентификации автономным считывающим устройством, возможно содержащим набор секретных ключей.
Согласно предпочтительному варианту изобретения, сервер обеспечивает чтение сообщения, а портативное считывающее устройство обеспечивает распознавание копий.
Предпочтительно, часть этапов 320-350 алгоритма воспроизведения оригинальной информации выполняется считывающим устройством на месте захвата изображения информационной матрицы, а другая часть этапа воспроизведения осуществляется компьютерной системой, например сервером, удаленным от места захвата изображения информационной матрицы. Таким образом, данные, относящиеся к созданию и считыванию информационных матриц (ключи и ассоциированные параметры), могут храниться в одном месте или на одном сервере со строгим режимом защиты. Уполномоченные пользователи могут соединяться с сервером после аутентификации с целью заказа некоторого количества информационных матриц, которые будут нанесены на документы, которые должны быть защищенные и/или отслеживаемые. Указанные информационные матрицы генерируются сервером, используемые ключи хранятся на сервере. Они передаются пользователю или непосредственно на печатную машину защищенным способом (например, с использованием средств шифрования).
С целью осуществления технического контроля непосредственно на производственной линии модули захвата (датчик + программное обеспечение для обработки + средства передачи информации) позволяют оператору захватывать изображения напечатанных информационных матриц, которые автоматически передаются на сервер. Сервер определяет ключи и соответствующие параметры, осуществляет считывание и аутентификацию захваченных информационных матриц и возвращает результат оператору. Следует отметить, что указанный способ, кроме того, может быть автоматизирован при помощи промышленных видеокамер, автоматически захватывающих изображение каждой напечатанной информационной матрицы, пропускаемой на производственной линии.
Если портативные устройства захвата на местах могут соединиться с сервером, сходный способ может быть использован для считывания и/или аутентификации. Однако не всегда желательно или возможно указанное соединение, в этих случаях некоторые из ключей должны храниться в устройстве аутентификации. Таким образом, особенно преимущественным является использование ключа частичного скремблирования, поскольку если он не хранится в портативном считывающем устройстве, то указанное считывающее устройство не имеет достаточной информации для создания оригинальной информационной матрицы. Аналогично, если выполняется шифрование асимметричным способом, ключ расшифрования, хранящийся в портативном считывающем устройстве, не способен к шифрованию и, следовательно, к генерации информационной матрицы, содержащей иное сообщение, которое было бы действительным.
В некоторых областях применения сервер распространения и удостоверения информационных матриц должен справляться с большим количеством различных "профилей" (профилем называется однозначно определяемая пара ключ - параметр). В частности, это имеет место в случае, когда система используется различными компаниями или учреждениями, желающими обеспечить защиту своих документов, продуктов и т.д. Можно увидеть преимущество в том, что разные пользователи обладают разными ключами: обычно информация, содержащаяся в информационной матрице, имеет конфиденциальный характер. Следовательно, система может иметь большое количество ключей для управления. Кроме того, как известно в криптографии, предпочтительно обновлять ключи через равные промежутки времени. Мультиплицирование ключей должно быть четко рассмотрено с точки зрения верификации: в действительности, если модуль верификации заранее не знает, который из ключей был использован для генерации матрицы, нет другого выхода, кроме проверки один за другим всех ключей, способных к этому. В этом примере использования изобретения преимущественным является включение двух сообщений в информационную матрицу, используя для каждого различные ключи. Следовательно, можно использовать закрепленный ключ для первого сообщения так, что модуль верификации может непосредственно считывать и/или аутентифицировать первое сообщение. Для считывания второго сообщения первое сообщение содержит, например, индикатор, который позволяет модулю верификации запросить защищенную базу данных, которая способна обеспечить его ключами для считывания и/или аутентификации второго сообщения. В общем, первое сообщение содержит информацию общего характера, в то время как второе сообщение содержит конфиденциальную информацию, которая может быть персонализирована.
7) Порог обнаружения/Параметры печати. В целях облегчения автономной аутентификации информационной матрицы порог принятия решения или пороги принятия решений или другие параметры, относящиеся к печати, могут быть сохранены в сообщении или сообщениях, включенных в информационную матрицу. Таким образом, не требуется запрашивать указанные параметры в базе данных и хранить их в автономных модулях верификации. Кроме того, это дает возможность управлять приложениями или информационными матрицами, имеющими одинаковую природу с точки зрения области применения, но напечатанными различными способами. Например, информационные матрицы, нанесенные на одном и том же виде документа, но напечатанные на различных машинах, могли использовать одинаковый ключ или одинаковые ключи. Они могут содержать параметры печати, сохраняемые в соответствующих сообщениях.
8) Вышеуказанная перестановка воспроизведенного сообщения может быть дорогостоящей. В действительности, для перестановки должно быть сгенерировано максимальное число псевдослучайных чисел. Кроме того, в процессе распознавания в некоторых областях применения из захваченного изображения может быть вычислено множество скремблированных сообщений, так что вычисляется на этом множестве скремблированных сообщений наименьший измеренный коэффициент ошибок. Кроме того, каждое из указанных скремблированных сообщений должно быть подвергнуто обратной перестановке, что будет стоить еще дороже, поскольку приходится иметь дело с большим количеством скремблированных сообщений.
Стоимость указанной перестановки можно снизить группированием некоторого числа соседних единиц воспроизведенного сообщения с последующей перестановкой указанных сгруппированных единиц. Например, если воспроизведенное сообщение содержит двоичные значения и состоит из 10000 элементов и если указанные единицы сгруппированы парами, получим 5000 групп, каждая из которых способна принимать четыре различных значения (в четвертичном представлении). 5000 групп подвергают перестановке, затем четвертичные значения представляют двумя битами перед применением функции "исключающее ИЛИ" и/или модуляции. Согласно вариантам изобретения, функция "исключающее ИЛИ" заменяется на суммирование по модулю (как раскрыто в патенте на изобретение MIS 1), затем значения заново переводятся в битовое представление.
Для кодированных сообщений длиной, кратной двум, количество сгруппированных единиц может быть нечетным числом, например 3, для того чтобы избежать того, что два соседних бита кодированного сообщения всегда были соседними в защищенной информационной матрице. Это повышает защиту сообщения.
В процессе чтения выполняют обратную перестановку групп значений или этих значений, накопленных на единственном объекте, так чтобы обеспечить их последовательное разделение.
Далее описывается способ оптимизации параметров печати цифровых водяных знаков. В качестве примера рассмотрены пространственные цифровые водяные знаки.
Цифровые водяные знаки используют маскирующие модели для прогнозирования количества возможных видоизменений в изображении, которые будут незаметными или по меньшей мере приемлемыми с точки зрения приложения. Таким образом, указанные видоизменения будут установленными в соответствии с содержимым изображения и, следовательно, типично будут больше на текстурированных или светлых участках, поскольку человеческий глаз «маскирует» различия в большей степени на указанных участках. Следует отметить, что цифровые изображения, предназначенные для печати, могут быть изменены таким образом, чтобы видоизменения оказывались видимыми и искажающими цифровое изображение, но становились невидимыми или менее искажающими изображение после печати. Следовательно, предположим, что для цифрового изображения в оттенках по шкале серого или в цвете, состоящего из N пикселей, маскирующая модель дает возможность вычислить количество, с помощью которого оттенок серого или цвет в каждом пикселе могут быть изменены допустимым для данной области применения образом. Отмечено, что частотная маскирующая модель специалистом может быть легко приспособлена для выводимых пространственных маскирующих значений. Кроме того, предположим, что пространственная модель цифрового водяного знака, в которой изображение разделено на блоки пикселей одинакового размера и вставлен в него элемент сообщения, например один бит водяного знака в каждый блок с помощью увеличения или уменьшения значения серого или цвета в каждом пикселе до допустимого максимума или минимума, увеличение или уменьшение создаются в соответствии с вставляемым битом. Следует отметить, что биты водяного знака могут, например, быть эквивалентными скремблированному сообщению защищенной информационной матрицы.
Для того чтобы определить, является ли захваченное изображение оригиналом или копией, на основании коэффициента ошибок в сообщении, измеренного по количеству некорректно обнаруженных элементов сообщения. Следует отметить, что для этого необходимо, чтобы сообщение было считано корректно, что предполагает вставку достаточного объема избыточности.
Известно много способов измерения значения бита, хранящегося в блоке изображения, в которых используется, например, фильтр низких частот или полосовой фильтр, нормализация значений по всей поверхности изображения или по участку. Обычно получают недвоичное значение, непрерывное, положительное или даже отрицательное. Указанное значение можно сравнить с пороговым для определения наиболее вероятного бита, а коэффициент ошибок может быть измерен путем сравнения с вставленным битом. Кроме того, можно сохранить значения и измерить коэффициент корреляции, из которого, как указано выше, выведен коэффициент ошибок.
Следует также отметить, что коэффициент ошибок сообщения может быть измерен косвенным путем с использованием способа распознавания копий без считывания сообщения, как указано в другом месте.
Для специалиста очевидно, что чем больше размер блоков в пикселях, тем ниже коэффициент ошибок в сообщении. С другой стороны, избыточность сообщения будет ниже. В зависимости от качества и разрешения печати специалист определит размер блока, позволяющий получить наилучший компромисс между коэффициентом ошибок сообщения и избыточностью, для того чтобы довести до максимума вероятность того, что сообщение будет корректно декодировано. С другой стороны, в уровне техники не решена задача подбора размера ячеек с целью оптимизации распознавания копий. Указанная задача решена благодаря некоторым особенностям настоящего изобретения.
Здесь может быть использована теоретическая модель, использованная выше для определения оптимального коэффициента ошибок цифрового аутентификационного кода. В действительности, можно рассматривать каждый блок как ячейку, имеющую вероятность р быть ухудшенной, и можно искать оптимум р в случае, когда имеется фиксированный физический размер ячеек (в действительности, предназначенное для печати изображение имеет фиксированные размер в пикселях и разрешение). Более того, можно приблизительно предположить, что вероятность р обратно пропорциональна площади, доступной для ячейки. Более того, установлено, что индикатор I является максимальным при р=27%. Возможны другие модели, которые приводят к другому оптимуму.
Для определения размера блока, оптимального для распознавания копии, можно использовать следующие этапы:
- получают по меньшей мере одно изображение, характеризующее изображение, используемое в данном приложении,
- с использованием маскирующей модели вычисляют для каждого пикселя каждого изображения максимальное расхождение, которое может быть внесено,
- для различных размеров испытываемых блоков, например 1×1, 2×2, ……, до 16×16 пикселей, генерируют по меньшей мере одно сообщение, размер которого соответствует количеству блоков изображения,
- в каждое изображение вставляют каждое из сообщений, соответствующих каждому размеру блоков, для получения изображений с нанесенной меткой,
- по меньшей мере один раз печатают каждое из изображений с меткой, нанесенной в условиях печати приложения,
- по меньшей мере один раз захватывают каждое из изображений с нанесенной меткой,
- считывают водяной знак и определяют коэффициент ошибок для каждого из захваченных изображений, группируют измеренные коэффициенты ошибок по размерам блоков и вычисляют средний коэффициент ошибок для каждого размера блока и
- определяют размер блока, средний коэффициент ошибок которого является ближайшим к целевому значению, например 27%.
Ниже описывается способ оптимизации параметров печати AMSM.
AMSM состоят из точек, распределенных псевдослучайным образом с некоторой плотностью, которая является достаточно низкой для того, чтобы обнаружение точного местонахождения было затруднительным, например с плотностью 1%. Показатель, соответствующий максимуму взаимной корреляции между исходным и захваченным AMSM, соответствует энергетическому уровню сигнала и теоретически будет более низким для копий. Следует уточнить, что если копия является «рабской», например фотокопией, велика вероятность того, что большое количество точек, уже ослабленных первой распечаткой, в процессе печати копии полностью исчезнет, следовательно, в этом случае будет очень легко распознать копию, энергетический уровень сигнала которой гораздо слабее. С другой стороны, если перед печатью копии наносят программируемое изображение, предназначенное для идентификации точек и восстановления их до исходного энергетического уровня, такая копия будет обладать существенно более высокими энергетическим уровнем и показателем. Для уменьшения указанного риска и обеспечения максимального расхождения в показателе между копиями и оригиналами они должны быть напечатаны с разрешением или размером точек, которые разницу энергетических уровней доводят до максимума. Однако из уровня техники неизвестны решения указанной задачи, a AMSM часто создаются мало оптимальным способом в отношении к распознаванию копий.
Простое рассуждение позволяет сделать вывод, что в идеале точки AMSM должны иметь такой размер, чтобы примерно 50% указанных точек "исчезали" в процессе исходной печати. Термин "исчезать", используемый в настоящем описании, означает, что алгоритм, пытающийся локализовать и восстановить точки, сможет корректно обнаружить только 50% исходных точек.
В действительности, предположим, что при печати оригинала исчезает в среднем р процентов точек. Если копия изготавливается при тех же условиях печати, также исчезнет р процентов оставшихся точек, вследствие чего процент исчезнувших точек составит р+р * (1-р).
Используя вышеуказанный критерий, согласно которому стремятся сделать максимальным расхождение между оригиналами и копиями, нормированное на стандартное отклонение оригиналов, равное р* (1-р), доводят указанный ниже критерий С до максимума в зависимости от р:
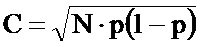
где N - фиксированное количество точек в AMSM.
Установлено, что максимальное значение С соответствует р=0,5.
Вышеуказанная модель применяется в случаях, когда фиксированным является количество точек. С другой стороны, если требуется, чтобы фиксированной была плотность пикселей, например 1% пикселей с нанесенной меткой, и если точки содержат несколько пикселей, можно использовать большее количество N точек на заданную плотность.
Если определить плотность d и количество пикселей на точку m, получим отношение:
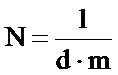
Сделав предположение, что вероятность того, что точка исчезнет, может быть приближенно выражена как обратно пропорциональная размеру точки в пикселях, получим:

где а - постоянная.
В зависимости от р, d, а и m С выражается следующим образом:
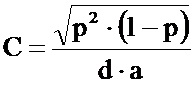
Установлено, что, если d и а для данной области применения являются постоянными, максимальное значение С соответствует р=2/3, или 66,6%.
Для реализации изобретения можно использовать следующие этапы:
- при фиксированной плотности (черных пикселей) печатают AMSM узоры, содержащие точки различного размера, например 1×1, 1×2, 2×2 и т.д.,
- захватывают по меньшей мере одно изображение каждого из различных узоров AMSM,
- для каждого AMSM определяют количество корректно идентифицированных точек и измеряют коэффициент ошибок и
- выбирают параметры, соответствующие узору AMSM, имеющему коэффициент ошибок, наиболее близкий к оптимальному для выбранного критерия, например 50% или 66%.
Следует отметить, что если AMSM содержит сообщение, коды коррекции ошибок должны быть скорректированы с учетом указанного максимального коэффициента ошибок. Кроме того, следует отметить, что если детектор принимает за основу предельный энергетический уровень, показатель копии может быть искусственно завышен путем печати корректно определенных точек таким образом, чтобы они вносили максимальный вклад в измерение энергетического уровня сигнала. Наконец, возможны другие критерии определения оптимума, учитывающие, например, плотность точек, количество пикселей, имеющих отклонения положения, формы или размера, количество корректно окрашенных пикселей в каждой ячейке и т.д.
Следует отметить, что сходным образом может быть осуществлена обработка VCDP (сокращение от Variable Characteristic Dot Pattern- узор из точек с переменными характеристиками), при этом подразумевается, что ячейки, поврежденные ошибками печати или копирования, не обязательно изменяют внешний вид от наличия до отсутствия, но указанные ошибки могут модифицировать их позиции, размеры или формы, изменяемые в соответствии с представляемой информацией.
VCDP (узор из точек с переменными характеристиками) производят генерацией такого распределения точек, в котором:
- по меньшей мере половина точек указанного распределения не соприкасаются с четырьмя другими точками указанного распределения точек и
- по меньшей мере один размер по меньшей мере одной части точек указанного распределения точек имеет тот же порядок амплитуды, что и среднее значение для абсолютного значения указанного случайного отклонения.
Таким образом, это дает возможность использования индивидуальных геометрических характеристик нанесенных точек и измерения отклонений характеристик указанных точек, так чтобы интегрировать их в метрику (т.е. определять, удовлетворяют ли они по меньшей мере одному критерию, применяемому при измерении), позволяя отличить оригиналы от копий или подделок.
Предпочтительно, более половины точек в распределении точек не касаются никакой другой точки указанного распределения. Таким образом, в противоположность защищенным информационным матрицам и узорам для распознавания копий и аналогично AMSM и цифровым водяным знакам, узоры из точек с переменными характеристиками обеспечивают вставку невидимых или малозаметных меток. Кроме того, указанные метки легче интегрируются, чем цифровые водяные знаки или AMSM. Они обеспечивают более надежный способ распознавания копий, чем цифровые водяные знаки, и они могут быть индивидуально охарактеризованы в процессе статической печати, что обеспечивает возможность однозначной идентификации каждого документа.
Согласно вариантам реализации изобретения, создаются точки, по меньшей мере одна из характеристик которых является переменной, причем геометрическая амплитуда сгенерированного отклонения имеет тот же разряд числа, что и средний размер по меньшей мере части точек. Следовательно, это дает возможность генерировать и оптимальным образом использовать изображения узоров из точек с переменными характеристиками, также называемых "VCDP", разработанных с тем, чтобы сделать более трудным и даже невозможным копирование путем точного воспроизведения.
Согласно вариантам реализации изобретения, сгенерированное отклонение соответствует:
- отклонению позиций точек по меньшей мере в одном направлении по отношению к положению, в котором центры точек являются выровненными по параллельным линиям, перпендикулярным указанному направлению, и отделенными друг от друга в указанном направлении на расстояние, равное по меньшей мере одному размеру указанных точек. Таким образом, это дает возможность использовать точные характеристики положения точек и измерить очень небольшие изменения точного положения точек, так чтобы внести их в метрику, обеспечивая возможность отличать оригиналы от копий,
- отклонению по меньшей мере одного размера точек по меньшей мере в одном направлении по отношению к среднему размеру указанных точек в данном направлении,
- отклонению формы точек по отношению к средней форме точек в указанном направлении.
Распределение точек может быть представлением кодированной единицы информации, тем самым позволяя хранить или передавать информацию в распределении точек с переменными характеристиками. При одинаковом объеме содержащейся информации распределения точек могут занимать существенно меньшую площадь, чем AMSM, например несколько квадратных миллиметров, что позволяет захватывать их портативными устройствами с высоким разрешением, и, следовательно, обеспечивается высокая точность считывания.
Ниже описано, каким образом измерением количества ошибок в сообщении можно принять решение о подлинности документа в соответствии с указанным количеством ошибок. Для этого теоретически необходимо декодировать указанное сообщение, поскольку если оно является нечитаемым, невозможно определить ошибки, повреждающие его. Однако если нанесение меток существенно ухудшило качество сообщения, в особенности копий, или если передается большой объем информации, возможно, что сообщение будет нечитаемым, и в этом случае невозможно измерить коэффициент ошибок. Желательно было бы иметь возможность измерения количества ошибок без декодирования указанного сообщения.
Во-вторых, на стадии декодирования информации используются алгоритмы, которые могут оказаться дорогостоящими. Если требуется только аутентификация сообщения, без его прочтения, операция декодирования производится только с целью измерения коэффициента ошибок, предпочтительнее было бы исключить данный этап. Кроме того, если требуется более глубокий анализ коэффициента ошибок, необходимо восстановить воспроизведенное сообщение.
Восстановление воспроизведенного оригинального сообщения может оказаться дорогостоящим, предпочтительнее было бы избегать этого.
Однако согласно одной из особенностей настоящего изобретения было обнаружено, что для измерения количества ошибок не требуется, и это парадоксально, ни восстановление воспроизведенного оригинального сообщения, ни даже его декодирование. В действительности, количество ошибок в сообщении может быть измерено с использованием некоторых свойств самого сообщения при оценивании кодированного сообщения.
Рассмотрим случай двоичного сообщения. Кодированное сообщение состоит из последовательности битов, которые дублированы, затем скремблированы, и скремблированное сообщение используется для создания защищенной информационной матрицы. Скремблирование, как правило, содержит перестановку и, по выбору, применение функции "исключающее ИЛИ" и в общем зависит по меньшей мере от одного ключа. Таким образом, каждый бит сообщения может быть несколько раз представлен в матрице. Как показано на примере на фиг. с 1 до 5В, один бит повторяется 35 или 36 раз. На этапе накопления шифрованного сообщения все показатели значения каждого бита или элемента сообщения накапливаются.
Благодаря указанной операции обычно существенно снижается статистическая погрешность значения бита. Следовательно, указанная оценка, рассматриваемая как истинное значение бита, может быть использована в целях измерения количества ошибок. В действительности, если нанесенная матрица содержит относительно мало ошибок, все указанные ошибки в основном исправляются на этапе суммирования, и поэтому не требуется восстановление кодированного сообщения, поскольку не содержащий ошибок вариант уже имеется. Кроме того, если некоторые биты кодированного сообщения были неверно оценены, обычно они оказывают уменьшенное влияние на измерение количества ошибок.
Ниже приведен алгоритм измерения количества ошибок для двоичных данных без декодирования сообщения:
- для каждого бита кодированного сообщения суммируют значения показателей,
- путем сравнения с пороговым значением определяют наиболее вероятное значение бита ("1" или "0"), получают наиболее вероятную оценку кодированного сообщения и
- подсчитывают количество показателей, соответствующих оценке бита соответствующего зашифрованного сообщения (для отдельной ячейки это может быть плотность или нормированное значение яркости). Таким образом можно измерить целое число ошибок или коэффициент или долю поврежденных ошибками битов.
В качестве альтернативы последнему указанному этапу можно сохранять в памяти значение показателя и измерить общий коэффициент сходства между значениями показателей и соответствующими оценочными битами кодированного сообщения. Коэффициентом сходства может служить, например, коэффициент корреляции.
Согласно одному из вариантов изобретения, можно установить соответствие с весовым коэффициентом, указывающим вероятность того, что каждый оцененный бит кодированного сообщения оценен корректно. Указанный весовой коэффициент используется для взвешивания вкладов отдельных показателей в соответствии с вероятностью, с которой корректно оценен ассоциированный бит. Простота реализации данного подхода заключается в том, что накопленные значения, соответствующие каждому биту кодированного сообщения, не сравниваются с пороговым значением.
Следует отметить, что чем более зашумлено сообщение, тем выше риск, что оцененный бит зашифрованного сообщения является ошибочным. Это ведет к возникновению систематической ошибки, заключающейся в том, что при измерении количества ошибок истинное количество ошибок недооценено. Указанная систематическая ошибка может быть оценена статистическими методами и скорректирована, когда измерено количество ошибок.
Интересно отметить, что с использованием указанного нового подхода к измерению количества ошибок защищенная информационная матрица может быть аутентифицирована без необходимости в распознавании прямым или косвенным образом сообщений, необходимых для ее создания. Просто должны быть известны группы ячеек, обладающие общими свойствами.
Согласно вариантам изобретения, получают несколько наборов показателей, соответствующих различным способам предварительной обработки, применяемым к изображению, например преобразование гистограммы, или считывание защищенной информационной матрицы в различных положениях, для каждого набора показателей вычисляют количество ошибок и наименьший коэффициент ошибок сохраняют в памяти. Для ускорения расчетов оценка кодированного сообщения может быть выполнена только один раз (низкая вероятность того, что указанная оценка изменяется для каждого набора показателей).
Можно считать, что генерируются изображения (или матрицы), части которых обладают общими свойствами. В самом простом случае части ячеек или пиксели имеют то же самое значение, и они распределены в изображении псевдослучайным образом в соответствии с ключом. Рассматриваемое свойство не обязательно должно быть известным. При чтении знать это свойство необязательно, поскольку его можно оценить. Таким образом, измерение показателя, служащее признаком подлинности, не требует ни обращения к оригинальному изображению, ни определения сообщения. Следовательно, согласно вариантам изобретения, для аутентификации документа используются следующие этапы:
- получения набора подгрупп элементов изображения, например значений пикселей, причем каждая подгруппа элементов изображения использует одну и ту же характеристику, указанные характеристики не обязательно являются известными,
- захвата изображения,
- измерения характеристик каждого элемента изображения,
- оценки характеристик, общих для каждой подгруппы элементов изображения,
- измерения соответствия между указанными оценками характеристик, общих для каждой подгруппы, и указанными измеренными характеристиками каждого из элементов изображения и
- принятия решения о подлинности в соответствии с указанным измерением соответствия.
Согласно другим вариантам изобретения, описание которых представлено ниже, для аутентификации цифрового аутентификационного кода нет необходимости ни знать или воспроизвести оригинальное изображение, ни декодировать сообщение, которое он несет. В действительности, при создании достаточно создать изображение, содержащее подгруппы пикселей, имеющих одно и то же значение. При распознавании просто требуется знать позиции пикселей, принадлежащих к каждой из подгрупп. Свойство, например значение пикселей, принадлежащих к одной подгруппе, не должно быть известно: оно может быть найдено в процессе считывания без необходимости в декодировании сообщения. Даже если указанное свойство не было корректно определено, цифровые аутентификационные коды все еще могут быть аутентифицированы. Далее данный новый тип цифровых аутентификационных кодов называется "случайным аутентификационным узором" ("RAP"). Слово "случайный" означает, что внутри RAP может принимать любое из заданного набора возможных значений, причем после создания изображения данное значение не сохраняется.
Например, предположим, что имеется цифровой аутентификационный код, состоящий из 12100 пикселей, т.е. квадрат размером 110×110 пикселей. Указанные 12100 пикселей можно разделить на 110 подгрупп размером 110 пикселей каждая, так чтобы каждый пиксель находился строго в одной подгруппе. Разделение пикселей на подгруппы производится псевдослучайным образом, предпочтительно с помощью криптографического ключа, так чтобы без ключа невозможно было узнать позиции различных пикселей, принадлежащих подгруппе.
После того как определены 110 подгрупп, пикселям каждой подгруппы присваивают случайное или псевдослучайное значение. Например, для двоичных значений пикселей можно присвоить значение "1" или "0", всего 110 значений. В случае определения значений случайным образом при помощи генератора случайных чисел генерируют 110 бит, которые затем можно как сохранить, так и не сохранить. Следует отметить, что для данного разделения на подгруппы существует 2110 возможных случайных аутентификационных узоров (RAP). В случае псевдослучайной генерации значений используют генератор псевдослучайных чисел, оснащенный криптографическим ключом, который затем обычно сохраняют. Следует отметить, что для подобного генератора, основанного на хеш-функции SHA-1, длина ключа составляет 160 бит, тогда как в рассматриваемом примере необходимо сгенерировать только 110 бит. Таким образом, указанный генератор может иметь ограниченное применение.
Зная значение каждого пикселя, затем можно собрать изображение, в рассматриваемом случае размером 110×110 пикселей. Изображение может представлять собой обычный квадрат с присоединением черной окантовки, облегчающей его обнаружение, или иметь произвольную форму, содержать микротекст и т.д. Также возможно использование групп пикселей с известными значениями, служащих для точного выравнивания изображения.
Изображение наносят таким способом, чтобы оптимизировать степень его искажения, в соответствии с качеством нанесения меток, которое, в свою очередь, зависит от качества подложки, точности машины нанесения меток и ее настроек. Ниже представлены способы реализации указанного процесса.
Распознавание из захваченного изображения случайного аутентификационного узора (RAP) выполняют следующим образом. Для точного определения положения узора в захваченном изображении применяют известные способы обработки и распознавания изображений. Затем измеряют значения каждого пикселя RAP (часто по шкале 256 уровней серого). Для удобства и единообразия расчетов указанные значения могут быть нормированы, например, в промежутке от -1 до +1. Затем значения группируют в подгруппы, в рассматриваемом примере размером по 110 пикселей.
Таким образом, для подгруппы пикселей, изначально имеющих заданное значение, получим 110 значений. Если значение исходных пикселей (в двоичной системе) было "0", должны преобладать отрицательные значения (в промежутке от -1 до +1), тогда как должны преобладать положительные значения, если значение было "1". Следовательно, для каждой из 110 подгрупп 110 пикселям можно присвоить значения "1" или "0".
Для каждого из 12100 пикселей получим измеренное значение в изображении, возможно нормированное, и оцененное исходное значение. Таким образом, может быть измерено количество ошибок, например, вычислением количества пикселей, которое совпадает с их оцененным значением (т.е. если значения нормированы в промежутке от -1 до +1, отрицательное значение соответствует "0", а положительное соответствует "1"). Таким образом, можно измерить коэффициент корреляции и т.д.
Найденный показатель ("показатель" означает коэффициент ошибок или сходство) затем сравнивают с пороговым значением с целью определения, соответствует ли захваченное изображение оригиналу или копии. Для определения указанного порогового значения могут быть использованы стандартные статистические методы.
Следует отметить, что для определения показателя описанная процедура не использует данные за пределами изображения, за исключением состава подгрупп. Таким образом, вычисление количества ошибок может быть выражено следующим образом.
Количество ошибок равно сумме по всем подгруппам
(Sum(Sign(zij)==f(zi1, …, ziM))),
где zij - значение i-ro пикселя j-й подгруппы, содержащей М элементов, возможно нормированное, и
f - функция, оценивающая значение пикселя для подгруппы, например f(zi1,…,ziM)=Sign(zi1+…+ziM).
Возможны несколько вариантов:
- для скремблирования значений пикселей одной и той же подгруппы применяется криптографический ключ так, чтобы не все они имели одно и то же значение. Функция скремблирования может быть функцией "исключающее ИЛИ",
- функция вычисления показателя может оценивать и определять вероятность того, что значение пикселя равно "1" и "0" соответственно (для двоичных значений пикселей),
- указанный способ может применяться к другим типам цифровых аутентификационных кодов, если их структура подходит для этого, в особенности к защищенным информационным матрицам, обладающим вышеуказанными преимуществами,
- указанный способ может быть распространен на недвоичные значения пикселей и/или
- значения пикселей подгруппы могут быть определены так, чтобы они передавали сообщение (без необходимости его декодирования при считывании).
Считывание цифрового аутентификационного кода (DAC) требует точного определения его положения в захваченном изображении так, чтобы значение каждой из составляющих его ячеек было восстановлено с наибольшей возможной точностью с учетом искажений, вызванных печатью и, возможно, захватом. Однако захваченные изображения часто содержат символы, которые могут интерферировать на этапе установления положения. Очевидно, что чем меньше площадь, занимаемая защищенной информационной матрицей, тем выше вероятность того, что на этапе установления положения другие символы или узоры будут интерферировать. Например, входные данные в виде страницы формата А4, например папка, содержащая защищенную информационную матрицу, будет содержать большое количество других элементов. Однако даже захваченные изображения относительно небольшого размера, например 1,5 см на 1,1 см, могут содержать символы, которые можно спутать с защищенной информационной матрицей, например черный квадрат, DataMatrix и т.д., как показано на фиг.6.
Установление положения защищенной информационной матрицы может быть затруднено условиями захвата (плохое освещение, размыванием границ и т.д.), а также произвольной ориентацией изображения в диапазоне 360 градусов.
В отличие от других типов символов двумерных штрихкодов, которые относительно мало изменяются при различных типах печати, характеристики цифровых аутентификационных кодов (DAC), например текстура, исключительно изменчивые. Таким образом, известные способы, например, описанный в патенте US 6775409, являются неприменимыми. В действительности, указанный способ обнаружения кодов основан на направленности градиента яркости, однако в случае с защищенной информационной матрицей градиент не имеет определенного направления.
Некоторые способы установления положения цифровых аутентификационных кодов (DAC) получают преимущество из того, что DAC имеют квадратную или прямоугольную форму, что обуславливает заметный контраст с непрерывными сегментами, которые могут быть обнаружены и использованы с помощью стандартных способов обработки изображений. Однако в некоторых случаях указанные способы оказываются неуспешными, и, с другой стороны, требуется иметь возможность использования DAC, которые не обязательно представляют собой квадрат или прямоугольник (или не обязательно являются вписанными в них).
Вообще говоря, площадь, на которой напечатан цифровой аутентификационный код (DAC), имеет повышенную плотность краски. Однако, хотя использование измерений плотности краски является полезным, оно не может являться единственным критерием: в действительности, Datamatrix или другие штрихкоды, часто смежные с DAC, обладают еще более высокой плотностью краски. Следовательно, недостаточно использовать только данный критерий.
Для определения участков изображения, принадлежащих CDP, в патенте ЕР 1,801,692 предложено использование повышенной энтропии. Однако хотя еще не напечатанные узоры для распознавания копий действительно обладают повышенной энтропией, последняя может сильно измениться в процессе печати, захвата или измерения. Например, простое измерение энтропии, основанное на гистограмме разброса значений пикселей каждого участка, может иногда приводить к получению более высоких значений на участках, не очень наполненных по содержанию, которые теоретически должны обладать низкой энтропией, например, это может происходить в результате появления артефактов при сжатии в формате JPEG, или из-за текстуры бумаги, проявляющейся в захваченном изображении, или в результате эффектов отражения от подложки. Таким образом, ясно, что критерий энтропии также является недостаточным.
Вообще говоря, способы измерения или определения характеристик текстур представляются более подходящими для того, чтобы характеризовать одновременно интенсивность или пространственные связи, специфические для текстур DAC. Например, Харалик в работе "Статистические и структурные подходы к текстуре" (Haralick, "Statistical and structural approaches to texture"), ссылка на которую здесь включена в качестве справки, описывает множество способов измерения характеристики текстур, которые могут быть комбинированы таким образом, чтобы они однозначно описывали большое количество текстур.
Однако цифровые аутентификационные коды (DAC) могут иметь текстуры, которые сильно изменяются в зависимости от типа печати или захвата, и в большинстве случаев невозможно или по меньшей мере непрактично обеспечить характеристики текстуры для способа размещения DAC, главным образом потому, что они должны быть отрегулированы в зависимости от специфических эффектов средств захвата при измерении текстуры.
Таким образом, очевидно, что для надежного определения положения DAC должно интегрироваться множество критериев нежестким способом, в особенности подходят следующие критерии:
- текстура цифрового аутентификационного кода (DAC): DAC обычно имеют более высокий уровень краски и более сильный контраст с их окружением. Следует отметить, что сам по себе указанный критерий может не быть характерным в достаточной мере: например, может не быть сильного контраста для некоторых DAC, переполненных краской,
- DAC имеют сильный контраст по краям: обычно DAC окружен зоной молчания, которая не содержит метку и которая сама может быть окружена окантовкой для получения максимального контраста (следует отметить, что некоторые DAC не имеют окантовку или имеют только частичную окантовку),
- DAC часто имеют особенную форму (квадратную, прямоугольную, круглую или другую), которая может быть использована для определения положения, и
- DAC в своей внутренней структуре часто содержат фиксированные группы данных, конечно, при условии владения криптографическим ключом или ключами, использованным или использованными для их генерации, обычно служащим или служащими для точной синхронизации. Если указанные группы данных не обнаруживаются, это означает или то, что положение защищенной информационной матрицы корректно не установлено, или что неизвестна синхронизация групп данных.
Указанные четыре критерия, представляющие собой общие характеристики текстуры DAC, характеристики по краям DAC, общую форму и внутреннюю структуру, если они комбинированы подходящим образом, могут обеспечить с высокой надежностью определение положения DAC в так называемых "неблагоприятных" условиях (в присутствии других двумерных кодов, при плохом качестве захвата, локально изменчивых характеристиках изображения и т.д.).
В целях установления положения DAC в настоящем изобретении предложен следующий способ. Очевидно, что возможно много вариантов способа, которые не выходят за пределы его сущности. Способ, который применяется к квадратным или прямоугольным DAC, но также может быть распространен и на другие формы, согласно которому:
- разделяют изображение на участки одного и того же размера так, чтобы площадь DAC соответствовала достаточному количеству участков,
- измеряют показатель текстуры для каждого участка. Показатель может быть многомерным, и предпочтительно содержать количество, показывающее уровень наполнения краской, и количество, показывающее локальную динамику,
- возможно, для каждого участка вычисляют общий показатель текстуры, например в форме взвешенной суммы каждого показателя, измеренного для участка,
- определяют по меньшей мере один порог обнаружения в зависимости от того, в памяти сохраняются один или несколько показателей на участок. Вообще говоря, значение больше, чем пороговое значение, наводит на мысль, что соответствующий участок формирует часть DAC. Для изображений, представляющих отклонения освещенности, может быть использовано переменное пороговое значение. Когда в памяти сохраняют несколько показателей, может потребоваться, чтобы все показатели были больше, чем их соответствующие пороговые значения для участков, которые рассматриваются как формирующие часть DAC, или только один из показателей был больше, чем его соответствующее пороговое значение,
- определяют участки, которые являются частью DAC, называемые «положительными зонами» (и наоборот - «отрицательными зонами»). Получено двоичное изображение. Как вариант, использование очистки с использованием последовательно растяжения и размытия, например, с использованием способов, раскрытых в главе 9 в книге «Обработка цифрового изображения с использованием Matlab», Гонзалес, Вудс и Эддин ("Digital Image Processing using Matlab" by Gonzales, Woods and Eddin),
- определяют непрерывные группы положительных зон размером более чем минимальный участок. Если не обнаружена непрерывная группа, возвращаются обратно ко второму этапу указанного алгоритма и уменьшают пороговое значение до тех пор, пока не будет обнаружена по меньшей мере одна непрерывная группа минимального размера. Как вариант, изменяют выбор критерия участков, если каждый участок имеет несколько показателей текстуры. Определяют участки, отслеживая контур группы, которые расположены по границе DAC, отличающиеся тем, что они имеют по меньшей мере одну соседнюю отрицательную зону,
- для обнаружения квадрата определяют две пары точек, сформированные наиболее удаленными друг от друга точками. Если два соответствующих отрезка имеют одну длину и если они образуют угол 90°, то делают вывод, что они формируют квадрат. Как вариант, применяют преобразование Хафа,
- как вариант, используют ограничивающий фильтр обнаружения к оригинальному изображению или его сокращенному варианту (в главе 10 указанной книги показаны примеры фильтров) и
- определяют пороговое значение, затем позиции пикселей, имеющих отклик на фильтр больший, чем пороговое значение. Указанные пиксели показывают границы объекта, в особенности границы участка защищенной информационной матрицы. Убеждаются в том, что участки, находящиеся с четырех краев цифрового аутентификационного кода, содержат минимальное количество пикселей, что указывает на границы объекта.
Относительно этапа разделения изображения на участки следует указать, что размер участков может оказывать существенное влияние на результат определения положения. Если участки слишком маленькие, измеренные показатели будут неточными и/или сильно зашумленными, что затруднит обнаружение участков, принадлежащих к DAC. С другой стороны, если они слишком большие, определение положения DAC будет неточным и будет трудно определить, что форма предполагаемого DAC соответствует искомой форме (например, квадрату). Кроме того, размеры участков должны быть подобраны в соответствии с площадью DAC в захваченном изображении, которая может быть, но не обязательно является известной. Для некоторых средств захвата изображения будут иметь фиксированный размер, например часто встречающийся формат 640×480 пикселей. Следовательно, теоретически разрешение захвата не будет очень изменчивым. Некоторые средства захвата способны к поддерживанию более одного формата изображений, например 640×480 и 1280×1024. Следовательно, размер участка требуется подобрать в соответствии с разрешением. Например, для средства захвата, производящего изображения форматом 640×480 с разрешением захвата, равным 1200 dpi (точек на дюйм), изображение можно разделить на участки размером по 10×10 пикселей, всего 64×48 участков. Если то же средство захвата также поддерживает формат 1280×1024, вследствие чего удваивается разрешение захвата до 2400 dpi, размер участка также следует удвоить до 20×20 пикселей (пиксели по краям, не формирующие целого участка, могут быть оставлены с одной стороны). Для изображений, полученных из сканера, разрешение которых не всегда известно, можно предположить, что разрешение захвата равно 1200 dpi, или определить его на основании метаданных.
Следует отметить, что возможно использование участков размером в один пиксель при условии устранения или контроля на последующих этапах рисков, связанных с наибольшим зашумлением.
Относительно измерения показателя текстуры, как указано выше, текстура DAC может сильно изменяться, и не существует идеального измерения показателя текстуры. Однако DAC обычно отличаются высоким уровнем заполнения краски и/или его сильными изменениями. Если используемая краска черная или темная и если значения пикселей находятся в диапазоне от 0 до 255, для значения i-го пикселя участка можно принять yi=255-xi. Следовательно, показатель уровня заполнения краски участка равен среднему значению у. Однако можно также принять среднее, наименьшее значение или процентиль выборки значений (положение/значение на гистограмме, соответствующее заданному проценту выборки). Такие значения от выборки значений могут быть более стабильными или более характерными, чем просто средняя величина.
В качестве показателя изменений можно измерить градиент в каждой точке и сохранить его абсолютное значение.
В качестве комбинированного показателя текстуры можно сложить в равной или неравной пропорции показатель заполнения уровня краски и показатель изменений. Поскольку указанные показатели не приведены к единой шкале, вначале вычисляют показатели заполнения уровня краски и изменений для всех участков изображения, нормируют их с тем, чтобы каждый показатель имел одинаковые максимумы/минимумы, и затем суммируют их с получением комбинированных показателей текстуры.
Относительно определения порога обнаружения следует отметить, что он является очень ненадежным. В действительности, если порог слишком высокий, много участков, принадлежащих к DAC, по существу, не обнаруживаются. С другой стороны, слишком низкий порог приводит к ошибочному обнаружению значительного количества участков, не принадлежащих к DAC.
На фиг.14 показана информационная матрица 665, захваченная под углом примерно 30° с разрешением примерно 2000 dpi. На фиг.15 показан результат измерения 670 комбинированного показателя текстуры (106×85), выполненного для изображения, показанного на фиг.14. На фиг.16 показано то же изображение, что и на фиг.15, после сравнения с пороговым значением, изображение обозначено позицией 680. На фиг.17 показано то же изображение, что и на фиг.16, после применения по меньшей мере одной операции растяжения и одного размытия; изображение обозначено позицией 685. На фиг.18 показан контур 690 информационной матрицы, определенный путем обработки изображения, представленного на фиг.17. На фиг.19 показаны углы 695 контура, показанного на фиг.18, определенные путем обработки изображения, показанного на фиг.18.
Определение порога затрудняет тот факт, что свойства изображений существенно изменяются. Кроме того, свойства текстуры изображений могут претерпевать локальные изменения. Например, вследствие условий освещения правая сторона изображения может оказаться более темной, чем его левая сторона, и применение одного и того же порогового значения к двум сторонам приведет ко многим ошибкам обнаружения.
Следующий алгоритм придает определенную устойчивость изменениям текстуры, согласно которому разделяют изображения на четыре участка и применяют к ним четыре порога обнаружения:
- определяют десятый и девяностый процентиль (или первый и последний дециль) показателя для всего изображения, например 44 и 176,
- определяют первый порог как среднее из двух указанных порогов: (176+44)/2=110,
- матрицу участков разделяют на четыре участка одинакового размера, например 32×24 при размере участка 64×48, и вычисляют десятый процентиль для каждого из четырех участков, например 42, 46, 43 и 57.
Ниже описан способ локального сегментирования, или "адаптивное определение пороговой величины". Некоторые захваченные DAC имеют слабый контраст на границах или проявляют изменения освещенности, которая может быть такой, что некоторые части DAC могут быть более светлыми, чем фон (чего теоретически быть не может для DAC, напечатанного черным на белом фоне). В этом случае просто не существует общего порогового значения, которое обеспечивает возможность корректного сегментирования, или по меньшей мере указанное значение невозможно определить стандартными способами.
Для решения указанной задачи прибегают к следующему алгоритму, который дает возможность определения участков, представляющих заданную равномерность показателя. Например, определяют участок, который подлежит сегментированию, начиная с начальной точки (или начального участка), затем последовательно выбирают все смежные участки, удовлетворяющие критерию сходства. Указанную начальную точку часто выбирают такой, чтобы она содержала экстремальное значение, например самый низкий показатель для изображения. Например, если начальная точка содержит (минимальный) показатель X и если критерий сходства заключается в том, что все участки, находящиеся в промежутке от X до Х+А, где А - заранее вычисленное положительное значение, например, соответствуют измерениям динамики изображения, последовательно выбирают группу смежных ячеек, удовлетворяющих указанному критерию.
Если данный способ не удовлетворяет, применяют альтернативный способ, заключающийся в определении участков, в которых отсутствует резкий переход. Кроме того, способ заключается в обнаружении начальной точки с показателем X, затем выбирают смежную точку Ра, если ее показатель Y меньше, чем Х+В (В также является заданной величиной). Затем в случае выбора указанной смежной точки Ра критерий отбора для точек, смежных с Ра, заменяют на Y+B.
Следует отметить, что указанные алгоритмы можно применять к изображению несколько раз, например, на каждой операции принимая различные точки за начальные точки. Таким образом можно получить несколько кандидатур на участки, некоторые из которых могут частично совпадать.
Относительно классификации участков в соответствии с вычисленным пороговым значением следует указать, что для определения общего порогового значения могут быть использованы подобные методы, например итеративный метод, описанный на стр.405-407 книги «Обработка цифрового изображения с использованием Matlab», Гонзалес, Вудс и Эддин ("Digital Image Processing using Matlab" by Gonzales, Woods and Eddin).
Относительно определения участков, принадлежащих к DAC, следует указать, что зоны окантовки могут быть определены подбором участков, для которых по меньшей мере один из смежных участков не удовлетворяет критерию для участков (показатель текстуры превосходит порог обнаружения).
Однако после определения по меньшей мере одной кандидатуры на участок следует также определить, имеют ли данные участки форму, соответствующую искомой. Например, большое количество DAC имеют квадратную, но также они могут быть прямоугольными, круглыми и т.д. В таком случае можно определить "сигнатуру" (характерный признак) искомой формы посредством определения центра тяжести оригинальной формы с последующим вычислением расстояния от центра тяжести до наиболее удаленного от него края формы для каждого градуса угла от 0 до 360°. Таким образом, сигнатура соответствует кривой, представляющей собой нормированное по углу расстояние. Указанная кривая постоянная для круга, а для квадрата содержит четыре одинаковых экстремума, и т.д.
Для кандидатуры на участок также вычисляют сигнатуру. Затем указанную сигнатуру сравнивают с оригинальной сигнатурой, например, измерением максимума автокорреляционной функции (с целью учета возможного поворота). Кроме того, может потребоваться повторно произвести отбор оригинальной или вычисленной сигнатуры.
Если вычисленное значение сходства больше, чем заданное пороговое значение, участок сохраняют в памяти, в противном случае его отбрасывают. Если проводится поиск участков, содержащих экстремальные значения, например квадрата, впоследствии может оказаться полезным определение углов квадрата из точек, связанных с указанными экстремумами.
Могут быть использованы следующие этапы:
- получают оригинальную сигнатуру и представление данных, характеризующее кандидатуру на участок,
- вычисляют сигнатуру кандидатуры на участок,
- измеряют максимум сходства между сигнатурой кандидатуры на участок и оригинальной сигнатурой и
- сохраняют в памяти кандидатуру на участок, если указанное значение сходства выше, чем пороговое значение, и факультативно определяют точки, соответствующие экстремумам сигнатуры кандидатуры.
Далее следует описание способа для защищенной информационной матрицы, не очень чувствительной к уровню заполнения краски. Как указано выше, избыточный уровень заполнения краски защищенной информационной матрицы может существенно снизить ее читаемость и даже способность быть отличенной от одной из ее копий. Однако, несмотря на то, что существуют средства, способные, насколько возможно, контролировать уровень заполнения краски при печати, их использование может быть затруднительным или даже невозможным. Предпочтительным является создание защищенной информационной матрицы, устойчивой к широкому диапазону уровней заполнения краски.
Оказывается, что защищенные информационные матрицы обычно являются более чувствительными к повышенному уровню заполнения краски, чем к пониженному. В действительности, если уровень заполнения краски является низким, черные, или содержащие цвет, ячейки обычно всегда печатаются, следовательно, мало влияют на считывание защищенной информационной матрицы. Напротив, как показано на фиг.6, изображение 515, если уровень заполнения краски является слишком высоким, краска стремится переполнить подложку, и белые участки в некоторой степени "затопляются" краской из окружающих черных участков. Сходный эффект может наблюдаться при нанесении отметок контактной печатью, лазерной гравировкой и т.д.
Асимметрия между негативным влиянием избыточного уровня краски и недостаточного уровня краски приводит к выводу, что защищенные информационные матрицы, содержащие меньшую долю маркированных пикселей, будут более устойчивыми к изменениям уровня заполнения краски. Однако значения ячеек обычно являются равновероятными, что вызвано алгоритмами шифрования и скремблирования, создающими максимальную энтропию матрицы. Для двоичных матриц, содержащих черные или белые ячейки, всегда можно уменьшить количество черных пикселей, формирующих черные ячейки. Например, если размер ячейки составляет 4×4 пикселя, можно выбрать для печати квадратную часть размером 3×3 пикселя или 2×2 пикселя. Следовательно, уровень заполнения краской снижается в отношении 9/16 и 1/4 соответственно (следует отметить, что белые ячейки не затрагиваются). Возможны и другие конфигурации, например, показанные на фиг.12. На фиг.12 показано:
- защищенная информационная матрица 585 с размером ячеек 4×4 пикселя, и размер напечатанного участка каждой ячейки составляет 4×4 пикселя, окружающая VCDP 575 и окруженная микротекстом 580,
- защищенная информационная матрица 600 с размером ячеек 4×4 пикселя, и размер напечатанного участка каждой ячейки составляет 3×3 пикселя, окружающая VCDP 590 и окруженная микротекстом 595,
- защищенная информационная матрица 615 с размером ячеек 3×3 пикселя, и размер напечатанного участка каждой ячейки составляет 3×3 пикселя, окружающая VCDP 605 покруженная микротекстом 610,
- защищенная информационная матрица 630 с размером ячеек 3×3 пикселя, и напечатанный участок каждой ячейки формирует крест из 5 пикселей, окружающая VCDP 620 и окруженная микротекстом 625, и
- защищенная информационная матрица 645 с размером ячеек 3×3 пикселя, и размер напечатанного участка каждой ячейки составляет 2×2 пикселя, окружающая VCDP 635 и окруженная микротекстом 640.
Кроме того, например, можно напечатать участки размером 2×2 пикселя или 1×1 пиксель в ячейках размером, например, 4 или 2 пикселя. Очевидно, также возможны асимметричные или изменяемые конфигурации, в которых изменчивость может выполнять такие функции, как сохранение сообщения или ссылки для целей аутентификации, как показано ниже на фиг.11.
В последнем указанном случае добавленное сообщение может быть защищенным от ошибок и защищенным способом, сходным с защитой других сообщений, вставленных в защищенную информационную матрицу. Будет отличаться только модуляция. Рассмотрим на примере: защищенная информационная матрица, содержащая 10000 ячеек, содержащая сообщение, в среднем будет содержать 5000 черных ячеек. Однако точное число их будет отличаться для каждого сообщения или для каждого ключа шифрования и скремблирования. Следовательно, во-первых, требуется сгенерировать защищенную информационную матрицу аналогично случаю с заполненными целиком ячейками с целью определения точного количества доступных пикселей (следует напомнить, что это количество напрямую влияет на применяемую операцию перестановки). Таким образом, предположим, что в данном случае защищенная информационная матрица содержит 4980 черных ячеек. Если размер ячейки составляет 4×4 пикселя, в наличии имеется 4980*16=79680 пикселей. Если требуется вставка сообщения длиной 8 байт, длина которого после преобразования в сверточный код 2-й степени с памятью 8 составит 176 бит, сообщение может быть воспроизведено 452 раза (и частично 453-й раз). Воспроизведенное сообщение скремблируют, т.е. выполняют операцию перестановки и применяют функцию "исключающее ИЛИ". Ниже представлен способ минимизации затрат на перестановку. Скремблированное сообщение модулируют в черных ячейках защищенной информационной матрицы.
На фиг.11 внизу показан пример результата 570 такой модуляции в сравнении с показанной сверху защищенной информационной матрицей 565 с «наполненными целиком» черными ячейками.
Следует отметить, что благодаря использованию указанного способа статистически 50% пикселей черных ячеек будут покрыты краской, следовательно, наполовину снижается уровень заполнения краской. Можно легко изменить указанную степень снижения уровня заполнения краской, например, с помощью резервирования определенного количества пикселей ячеек, которые получают заданное значение, черное или белое. При минимальном количестве пикселей, имеющих черный цвет, удается избежать того, что случайным образом в "черной" ячейке нет черных пикселей.
Указанный второй уровень сообщения обеспечивает большие преимущества. Благодаря более высокому разрешению сообщение содержит большее количество ошибок, которое, однако, компенсируется более высокой избыточностью, которая в 8 раз выше для ячеек размером 4x4 пикселя. Такое сообщение гораздо труднее скопировать, поскольку оно имеет очень высокое разрешение и даже само его присутствие может и не быть обнаружено. Содержащееся сообщение или содержащиеся сообщения могут быть зашифрованными и скремблированными с помощью различных ключей, благодаря чему может быть обеспечено большее число уровней защиты.
Возможны и многие другие варианты, например разделение ячейки размером 4×4 пикселя на четыре участка размером 2×2 пикселя: уровень заполнения краской статистически будет таким же, а разрешение будет ниже, и сообщение будет содержать меньше ошибок, но также будет содержать меньший уровень избыточности.
Кроме того, защищенная информационная матрица может содержать несколько участков, плотность ячеек которых изменяется так, чтобы по меньшей мере одно из значений плотности ячеек соответствовало уровню заполнения краской, используемому при печати. В этом случае считывание может быть выполнено с помощью участков, имеющих наиболее подходящий уровень заполнения краской.
Ниже описан комбинированный способ оптимизации размера ячеек и плотности уровня заполнения краской для ячеек: тестируют несколько пар размер/уровень заполнения краской, выбирают, например, те, что находятся в диапазоне количества ошибок 19-27%. Если выбрано несколько пар, выбирают те, что имеют наибольшее разрешение.
Относительно коэффициента, или доли, ошибок следует указать, что его значение можно определить как = (1-corr)/2, где corr - измерение, соответствующее корреляции между полученным сообщением и оригинальным сообщением в промежутке от -1 до +1 (на практике отрицательные значения маловероятны). Таким образом, для corr=0,75 коэффициент ошибок будет равен 0,125% или 12,5%. Следует отметить, что термин "корреляция" означает «имеющий то же самое значение». Следует также отметить, что использованный в настоящем описании термин "ошибка" относится к ошибкам печати, ошибкам, возникшим вследствие искажения информационной матрицы в течение жизни документа, к ошибкам чтения значения ячеек матрицы и к ошибкам копирования соответственно. С целью минимизации третьей составляющей (ошибок чтения) предпочтительно выполняют несколько последовательных операций считывания и сохраняют в памяти операцию с наименьшим коэффициентом ошибок.
В противном случае, с целью измерения коэффициента ошибок, изображение можно сравнить с пороговым значением адаптивным способом, значения больше/меньше пороговой величины определяются как белые/черные. Адаптивное определение пороговой величины позволяет защитить больше информации, причем изображение, полученное адаптивным сравнением с пороговым значением, обычно представляет большую изменчивость, чем изображение, полученное путем общего сравнения с пороговым значением. Для применения адаптивного определения пороговой величины, например, можно вычислить среднюю величину порога для изображения и применить локальную систематическую ошибку, соответствующую средней освещенности блока данных размером 10×10 пикселей. Альтернативно, для внешнего эффекта к изображению можно применить высокочастотный фильтр, затем глобальный фильтр. Для определения коэффициента ошибок в случае сравнения изображения с пороговым значением просто подсчитывают количество ячеек, значение которых после сравнения с пороговым значением не соответствует ожидаемому.
В случае, когда генерация, печать и/или считывание выполнены с учетом уровней серого, каждая ячейка имеет индивидуальный коэффициент ошибок, и корреляция использует указанный индивидуальный коэффициент ошибок ячеек.
Следует напомнить, чтобы максимизировать вероятность распознавания копий защищенной информационной матрицы, должны быть напечатаны с разрешением печати, по возможности самым близким к оптимуму искажения. Однако указанный оптимум варьируется в зависимости от того, какое ограничение используют в модели, фиксированный физический размер или фиксированное количество ячеек. Кроме того, для заданного размера ячеек, или разрешения, плотность ячеек может оказывать сильное влияние на величину искажения. Таким образом, предпочтение отдается плотности ячейки, обеспечивающей самый низкий коэффициент ошибок для заданного размера ячейки, даже если он приближается к оптимуму. В действительности, относительно плотности заполнения краской, предпочтительны условия печати, обеспечивающие наилучшее качество печати, так чтобы, если изготовители подделок использовали ту же самую процедуру печати, они не смогли бы напечатать копии лучшего качества, чем оригиналы.
В следующем примере созданы шесть защищенных информационных матриц с одинаковым количеством ячеек, следовательно, с различными физическими размерами и с шестью наборами значений размер ячейки/плотность. Матрицы напечатаны офсетным способом с разрешением печатной формы 2400 ppi, затем считаны с помощью планшетного сканера с разрешением 2400 dpi с получением изображения хорошего качества с целью сведения к минимуму ошибок чтения, вызванных захватом изображения. Нижеследующая таблица подытоживает средние коэффициенты ошибок, полученные для различных параметров, минимальный коэффициент ошибок (MIN) получен для каждого размера ячеек, соответствующая плотность DMIN, и разность DIFF между указанным значением MIN и теоретическим оптимальным коэффициентом ошибок 19% для фиксированного количества ячеек. Следует отметить, что незаполненные графы таблицы соответствуют невозможным комбинациям параметров, а именно плотности, превышающей размер ячейки. Кроме того, следует отметить, что плотность "1", т.е. значение, при котором в каждой ячейке печатается только один пиксель, не тестировали, даже несмотря на то, что это иногда может давать хорошие результаты.
Результаты испытаний приведены в следующей таблице, причем цифры, указанные в строках и столбцах, означают размеры ячейки (столбцы) и квадратных участков внутри ячеек, заполненных краской (строки), таким образом, пересечение строки 3 со столбцом 4 соответствует случаю, в котором печатается исключительно квадрат размером 3×3 пикселя в ячейке размером 4×4, предназначенной для заполнения краской.
Как видно из таблицы, размер ячейки 3 (столбец 3) с плотностью 2 (строка 2) дает значение коэффициента ошибок, наиболее близкое к оптимуму 19%. Как указано, коэффициент ошибок для плотности 4 и размера ячеек 4 равен 3% от оптимума. Однако, поскольку при плотности 2 и 3 получают существенно более низкие коэффициенты ошибок, как показано в таблице на пересечении строк 2, 3 и столбца 4, не рекомендуется выбирать эти параметры печати.
Могут быть использованы следующие этапы:
- для каждой пары размер ячеек/плотность кандидатуры создают одну защищенную информационную матрицу,
- печатают каждую созданную защищенную информационную матрицу по меньшей мере один раз в условиях печати, которые впоследствии будут использованы для печати документа, например три раза,
- выполняют по меньшей мере один захват по меньшей мере одного оттиска каждой созданной защищенной информационной матрицы, например три захвата,
- вычисляют средний коэффициент ошибок, полученный для каждой захваченной защищенной информационной матрицы,
- определяют минимальный средний коэффициент ошибок, полученный MIN для различных защищенных информационных матриц, созданных в соответствии с размером ячеек, и выбирают соответствующую плотность DMIN,
- для каждого значения MIN вычисляют разность DIFF между абсолютным значением и оптимумом и
- выбирают размер Т ячеек, обеспечивающий наименьшее значение DIFF, и соответствующую плотность DMIN.
Согласно вариантам реализации, если при фиксированном размере ячеек может изменяться плотность или при фиксированной плотности ячейки может изменяться размер, можно использовать тот же самый алгоритм, что делает его проще.
Предпочтительно, параметры печати, например средства печати, используемая подложка и другие параметры печати, например размер растра в офсетной печати (если они известны), включены в сообщение, которое несет защищенная информационная матрица. Указанная информация может быть использована для автоматической интерпретации или интерпретации человеком.
Например, для указания, является ли подложка бумагой, картоном, алюминием, ПВХ, стеклом и т.д., обычно бывает достаточно нескольких битов. Аналогично, обычно бывает достаточно нескольких битов для указания, являются ли средства печати средствами офсетной, высокой, трафаретной, глубокой печати и т.д. Таким образом, если средства печати являются средствами глубокой печати на алюминии, указанная информация хранится в защищенной информационной матрице. Если высококачественная копия напечатана на хорошей бумаге средствами офсетной печати, так что благодаря высокому качеству печати копия может быть принята за оригинал, оператор, информированный об ожидаемой подложке, при считывании защищенной информационной матрицы может определить, что подложка не соответствует ожидаемой.
Существуют способы автоматического определения типа печати, например офсетная или лазерная печать оставляют специфические следы, которые могут облегчить автоматическое определение типа печати на основе захвата и обработки изображения или изображений. Результат применения подобного способа может автоматически сравниваться с сохраненными в защищенной информационной матрице параметрами печати, и результат может быть интегрирован в процесс принятия решения о подлинности документа.
Ниже следует описание этапов генерации и чтения или использования рассматриваемой информации, причем "параметры печати" могут включать измерение уровня заполнения краской или плотность ячеек защищенной информационной матрицы (указанные этапы применяют ко всем типам DAC):
- автоматически измеряют параметры печати для DAC или индикаторного участка, как показано на фиг.9 и 10, путем обработки изображения или, например, с использованием выходного сигнала с помощью денсиметра, или, как вариант, с помощью ввода параметров оператором,
- получают параметры печати DAC,
- кодируют параметры печати, например, в двоичном или алфавитно-цифровом формате,
- вставляют кодированные параметры в сообщение DAC и/или в микротекст и
- генерируют DAC в соответствии с известным алгоритмом.
Для использования параметров печати:
- автоматически измеряют параметры печати для DAC или индикаторного участка, как показано на фиг.9 и 10, путем обработки изображения или, например, с использованием выходного сигнала с помощью денсиметра, или, как вариант, с помощью ввода параметров оператором,
- получают параметры печати DAC,
- считывают DAC,
- извлекают параметры печати из сообщения, содержащегося в считываемом DAC, и
- сравнивают извлеченные и полученные параметры и на основании данного сравнения принимают решение о происхождении документа.
Согласно варианту осуществления, вышеуказанный алгоритм применяется только в том случае, если DAC уже определен как оригинал, или автоматически, или вручную.
Относительно измерения других параметров печати, кроме уровня заполнения краской, они обычно средствами печати не изменяются. Следовательно, измерение может быть выполнено с помощью показателей, не присоединенных к документу, но используемых на этапе тестирования и поверки средств печати.
На фиг.13а показана защищенная информационная матрица 650, содержащая 21×21 ячеек, представляющая сообщение. На фиг.13b показана защищенная информационная матрица 655, содержащая 21×21 ячеек, представляющая то же самое сообщение. На фиг.13с показана защищенная информационная матрица, покрытая четыре раза (или замощенная) матрицей из фиг.13b для формирования защищенной информационной матрицы 660.
Далее следует описание предпочтительного варианта создания информационных матриц, в которые включают указание на плотность заполнения краской. Для измерений плотности или уровня заполнения краской печатники обычно используют денситометр. Денситометр обычно применяют к базовым прямоугольникам, содержащим максимальное количество краски, расположенным на краях отпечатанных листов и отбрасываемым при нарезке листов на документы. Часто для документа (или продукта, упаковки и т.д.), предназначенного для печати, печатник получает предельные значения плотности краски: оттиски, значение плотности краски для которых лежит за пределами допуска, не являются действительными, и печатник теоретически должен напечатать их заново. Если этого не происходит, т.е. если печатник напечатал документы, не соблюдая предел допусков плотности заполнения краской для всех конфигураций, крайне желательно иметь возможность обнаружить это на документах, находящихся в обращении: в действительности, считывание может быть искаженным, например оригинал может быть распознанным как копия, если плотность заполнения краской слишком высокая или слишком низкая, и в этом случае необходимо уведомить правообладателя, что существуют проблемы с плотностью заполнения краской, которые, возможно, являются причиной указанного ошибочного считывания. Следовательно, это позволит избежать вредных последствий неверного распознавания и может дать возможность привлечь печатника, не соблюдающего параметры печати, к ответственности. Однако, как указано выше, базовые прямоугольники, главным образом, удаляются при резке.
Для соответствующего измерения плотности заполнения краской обычно требуется участок площадью приблизительно 4 мм2, поскольку диаметр захвата денситометра составляет примерно 1,5 мм2. Полезно прикрепить участок указанной площади внутри защищенной информационной матрицы, напечатанной цветом, используемым для нее, или рядом с ней, так чтобы иметь возможность проверить, достаточна ли плотность краски в том случае, когда считывание защищенной информационной матрицы может не дать ожидаемый результат (например, копия). На фиг.9 показана защищенная информационная матрица 550, объединенная с полностью заполненным краской участком 545, расположенным в ней. На фиг.10 показана защищенная информационная матрица 555, объединенная с заполненным краской участком 560, расположенным рядом с ней.
Для считывания можно использовать следующие этапы, на которых:
- получают нижний и верхний пределы плотности краски, при необходимости указанные границы преобразуют в соответствующие уровни по шкале серого для заданных условий захвата,
- вводят плотность краски изображения базового участка,
- по изображению определяют значение уровня указанного участка по шкале серого и
- проверяют, находится ли указанное значение внутри указанных пределов: если да, возвращают положительное сообщение, в противном случае - отрицательное сообщение.
Далее следует описание способа генерации информационных матриц, содержащих геометрические узоры, в данном случае окружности. Генерируется изображение, содержащее различные геометрические узоры, предпочтительно с использованием ключа и, возможно, сообщения. Геометрические узоры и их параметры определяются с использованием ключа.
Для создания информационных матриц с геометрическими узорами можно использовать следующие этапы:
- с помощью ключа генерируют последовательность псевдослучайных чисел,
- генерируют пустое изображение,
- в зависимости от сгенерированных чисел определяют множество геометрических фигур и связанных с ними параметров,
- для каждой из определенных геометрических фигур вставляют геометрические фигуры в пустое изображение.
Для обнаружения геометрических параметров можно использовать следующие этапы:
- с помощью ключа генерируют последовательность псевдослучайных чисел,
- в зависимости от сгенерированных чисел определяют множество геометрических фигур и связанных с ними параметров, называемых «исходными параметрами»,
- для каждой из определенных геометрических фигур оценивают параметры фигуры в изображении и
- в заданной метрике измеряют расстояние между ожидаемыми параметрами и исходными параметрами фигуры.
Далее следует описание способа присоединения узора из точек с переменными характеристиками.
Как указано выше, узоры из точек с переменными характеристиками (VCDP) могут быть использованы для распознавания копий, хранения информации, а также для однозначной идентификации изображения-первоисточника. В особенности они предлагают преимущественные и дополнительные средства защиты документов. На фиг.7 показана защищенная информационная матрица 520, содержащая центральный участок, в котором помещен VCDP 535, содержащий геометрические фигуры, в данном случае окружности и микротексты 530. На фиг.8 показана защищенная информационная матрица 535, окруженная VCDP 540. Следует отметить, что в данном случае элементы, позволяющие определить местонахождение DAC, например его углы, могут быть использованы для определения местоположения и определения приблизительных позиций точек VCDP. На фиг.12 показаны соединенные VCDP и защищенная информационная матрица.
Кроме того, благодаря интеграции VCDP в защищенную информационную матрицу можно повысить степень защиты, поскольку изготовитель подделок должен преодолевать барьеры защиты от копирования одновременно VCDP и защищенной информационной матрицы. VCDP и защищенная информационная матрица могут быть созданы с использованием различных криптографических ключей, поэтому рассекречивание одного из ключей является недостаточным для рассекречивания всего изображения. С другой стороны, содержащаяся информация может быть скоррелирована так, чтобы VCDP и защищенная информационная матрица, по существу, были связаны между собой. Далее представлен возможный алгоритм:
- получают сообщение, криптографический ключ А для VCDP и ключ В для защищенной информационной матрицы,
- из сообщения и ключа А создают защищенную информационную матрицу, резервируя заданное пространство для VCDP,
- выделяют второе сообщение из полученного сообщения, например из его части,
- из второго сообщения и ключа В создают VCDP и
- вставляют созданный VCDP в защищенную информационную матрицу.
Согласно варианту реализации настоящего изобретения, в котором печатают не всю поверхность участка ячеек, например на основании плотности заполнения краской, как это описано в другом месте, положение заполненной краской части в ячейке модулируют в соответствии с сообщением, возможно, случайным образом, также как с VCDP. Например, заполненный краской участок, представленный квадратом размером 3×3 пикселя в ячейке размером 4×4 пикселя, может принимать четыре различные позиции. Таким образом, можно повысить способность к распознаванию копий и/или вкладывать дополнительную информацию в матрицу.
Далее следует описание использования информационной матрицы для однозначной идентификации с помощью анализа материала. Способы идентификации и аутентификации документов, основанные на получении характеристик материала, предлагают высокую степень защиты. Однако данные способы могут быть трудными для использования, поскольку без меток, указывающих на участок документа, использовавшийся для создания оттиска, может оказаться затруднительным правильное размещение считывающего устройства с тем, чтобы была захвачена соответствующая часть документа. Однако защищенные информационные матрицы создают легко идентифицируемый ориентир для установки положения считывающего устройства. Таким образом, для создания оттиска материала может быть использован расположенный в центре защищенной информационной матрицы участок, положение которого благодаря эталонным конфигурациям защищенной информационной матрицы может быть известно с высокой точностью. Это может быть выполнено, несмотря на резервирование указанного участка для вставки VCDP.
Далее следует описание интеграции в информационную матрицу микротекста или текста. Микротекст обычно представляют в векторной форме. Однако защищенные информационные матрицы представляют собой растровые изображения. Как следствие, для вставки в защищенную информационную матрицу микротекст должен быть растровым. Для сохранения точности текста по мере возможностей предпочтительно представлять защищенную информационную матрицу с максимально возможным разрешением. Например, защищенная информационная матрица размером 110×110 пикселей, предназначенная для печати с разрешением 600 точек на дюйм (600 ppi), должна быть увеличена в четыре раза (440×440 пикселей) для того, чтобы ее можно было напечатать с разрешением 2400 точек на дюйм (2400 ppi), если это позволяют средства печати.
Защищенная информационная матрица часто содержит рамку, имеющую черный цвет или создающую контраст с непосредственным окружением матрицы, что облегчает ее обнаружение в захваченном изображении. Однако оказывается, что, хотя углы рамки на практике являются очень полезными (определение положений каждого из углов обеспечивает возможность точной установки положения защищенной информационной матрицы), центральные части рамки не очень полезны. Преимущественно заменить их на микротекст. Например, если окантовка составляет 3 пикселя для печати с разрешением 600 точек на дюйм (600 ppi) и, следовательно, 12 пикселей для печати с разрешением 2400 точек на дюйм (2400 ppi), микротекст может составлять до 11 пикселей в высоту (предпочтительно оставлять один пиксель для внутреннего края матрицы).
В случае квадратной или прямоугольной защищенной информационной матрицы и если с четырех сторон вписан идентичный микротекст, например имя правообладателя, наименование продукта и т.д., может быть преимущественным ориентировать текст таким образом, чтобы при любой ориентации, при которой наблюдается или захватывается защищенная информационная матрица, считывание текста было нормальным. Подобная матрица показана на фиг.7 и 12.
Кроме того, для вставки микротекста также могут быть зарезервированы участки внутри матрицы. В этом случае для того, чтобы настроить модуляцию и демодуляцию сообщения или сообщений соответствующим образом, устройства создания и считывания должны быть информированы о содержащих микротекст участках.
В случае, если оттиск воспроизводит изображение и, следовательно, напечатанная защищенная информационная матрица должна изменяться на каждом отпечатке, что в особенности вероятно для средств цифровой печати, микротекст может быть видоизменен на каждом отпечатке. В этом случае микротекст может, например, содержать идентификатор, серийный номер, уникальный номер или любой другой текст, в особенности текст, обеспечивающий связь защищенной информационной матрицы с остальной частью документа. Если документ является идентификационной картой, микротекст может содержать, например, имя держателя. Если документ является упаковкой, микротекст может содержать срок годности, номер партии, торговую марку, наименование продукта и т.д.
Ниже представлены этапы интеграции изменяемого микротекста в защищенной информационной матрице:
- получают сообщение, криптографический ключ, возможно шрифт, участки, зарезервированные для микротекста с соответствующей ориентацией текста,
- создают изображение защищенной информационной матрицы в соответствии с полученным сообщением и ключом, зарезервированными участками,
- в соответствии с полученным сообщением генерируют изображение микротекста и
- вставляют изображение, содержащее микротекст, в каждый зарезервированный участок, возможно, с поворотом на угол, кратный 90°, в соответствии с ориентацией текста.
Согласно варианту реализации, сообщение, использованное для микротекста, является частью полученного сообщения. Согласно другому варианту, сообщение шифруют с использованием ключа, полученного до генерации микротекста.
Следует отметить, как вариант, что содержимое микротекста при печати является функцией содержания информационной матрицы или, наоборот, содержание информационной матрицы может быть функцией содержимого микротекста. Рассматриваемые функции могут быть, например, криптографическими функциями. Например, содержимое микротекста может при считывании служить криптографическим ключом для определения содержания информационной матрицы.
Теоретически, микротекст предназначен для чтения и интерпретации человеком, однако микротекст также может быть прочитан автоматически с помощью средств захвата изображений и программного обеспечения оптического считывающего устройства. В данном случае указанное программное обеспечение может предоставить результат в виде текста, который может автоматически сравниваться с другими типами предоставленной информации: данными, извлеченными из защищенной информационной матрицы, или с другими символами, нанесенными на документ, и т.д.
Ниже следует описание вставки информационных матриц в штрихкоды. Подобно вставке сообщения, распределенного по всем ячейкам защищенной информационной матрицы, сама она может быть вставленной в ячейки двумерного штрихкода, например Datamatrix (зарегистрированный товарный знак). Так как защищенные информационные матрицы имеют высокий уровень заполнения краской, теоретически они не будут интерферировать при считывании двумерного штрихкода.
Согласно предпочтительному варианту реализации, каждая черная ячейка штрихкода Datamatrix содержит защищенную информационную матрицу. Если ограничительные условия приложения позволяют, каждая защищенная информационная матрица содержит свое сообщение, в котором, например, одна часть является фиксированной, а другая часть содержит указатель, который может быть связан с позицией ячейки в коде Datamatrix.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЗАЩИТЫ И АУТЕНТИФИКАЦИИ ДОКУМЕНТОВ | 2007 |
|
RU2458395C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ ЗАЩИТЫ ДОКУМЕНТОВ | 2008 |
|
RU2452014C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ПЕЧАТНОЙ ФОРМЫ ДОКУМЕНТА И УСТРОЙСТВО ДЛЯ ЭТОЙ ЦЕЛИ | 2009 |
|
RU2511616C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ БЕЗОПАСНОСТИ ДОКУМЕНТОВ | 2007 |
|
RU2477522C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ БЕЗОПАСНОСТИ ДОКУМЕНТОВ | 2012 |
|
RU2628119C2 |
| ДВУХМЕРНЫЙ ШТРИХКОД И СПОСОБ АУТЕНТИФИКАЦИИ ШТРИХКОДА | 2014 |
|
RU2681696C2 |
| Способ модификации и идентификации копии документа для установления канала несанкционированного распространения | 2016 |
|
RU2646341C1 |
| ФОРМИРОВАНИЕ, ФИКСАЦИЯ И ИСПОЛЬЗОВАНИЕ МЕТОК ВИЗУАЛЬНОЙ ИДЕНТИФИКАЦИИ ДЛЯ ДВИЖУЩИХСЯ ОБЪЕКТОВ | 2011 |
|
RU2596997C2 |
| Способ кодирования цифровой информации в виде многомерного нанобар-кода | 2020 |
|
RU2777708C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ АУТЕНТИФИКАЦИИ ГЕОМЕТРИЧЕСКОГО КОДА | 2009 |
|
RU2520432C2 |
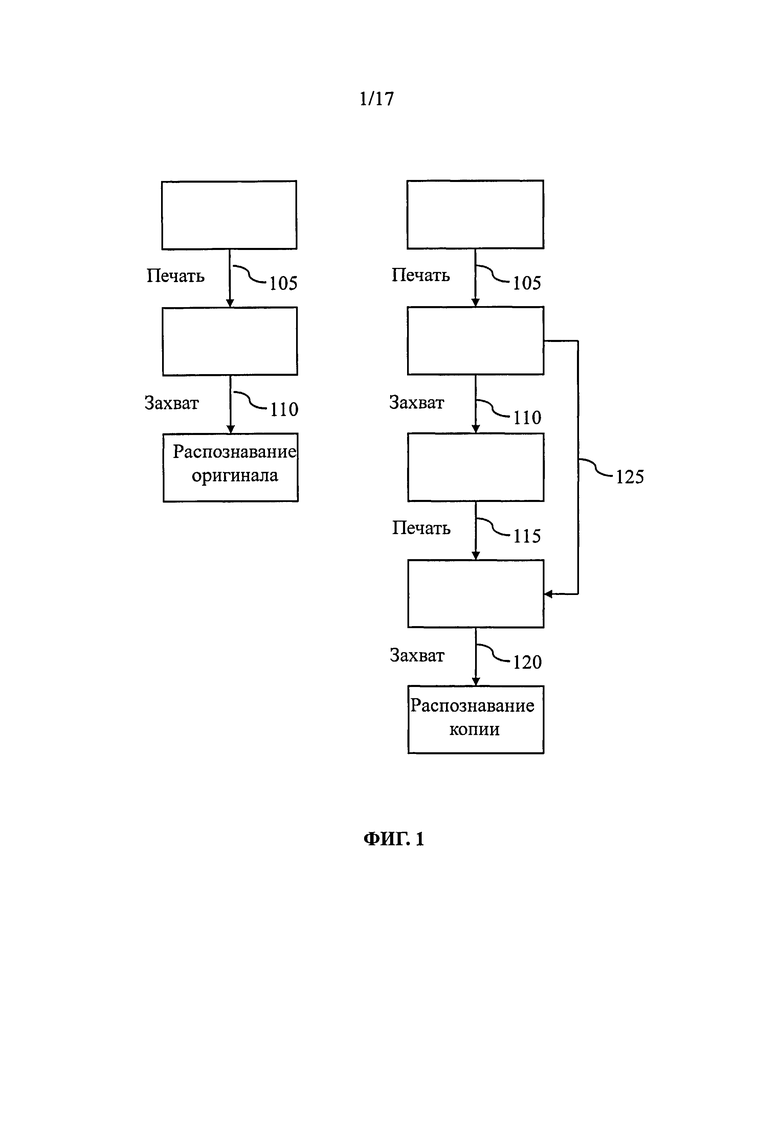
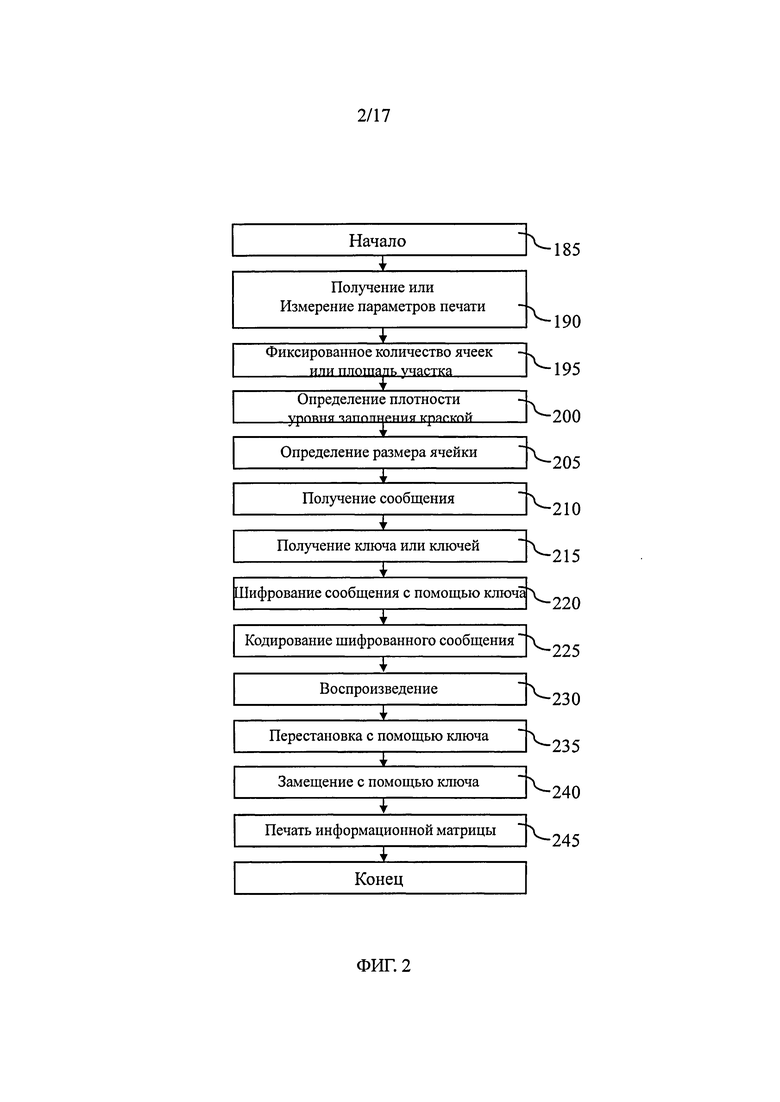
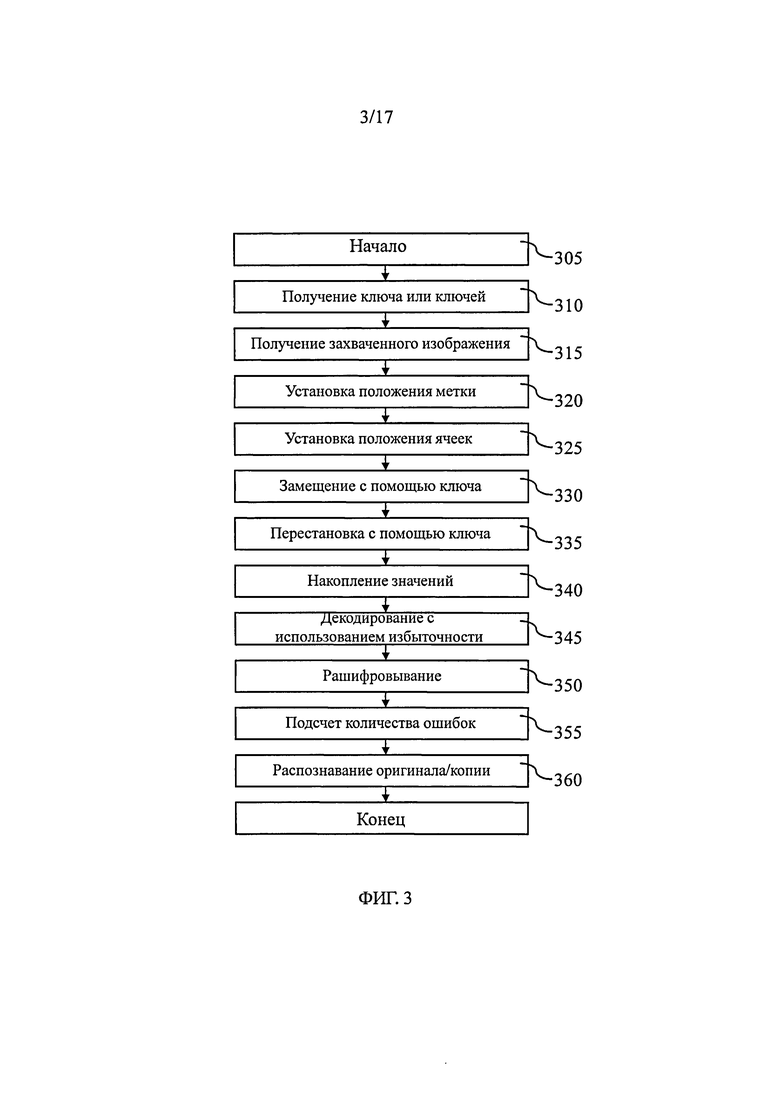
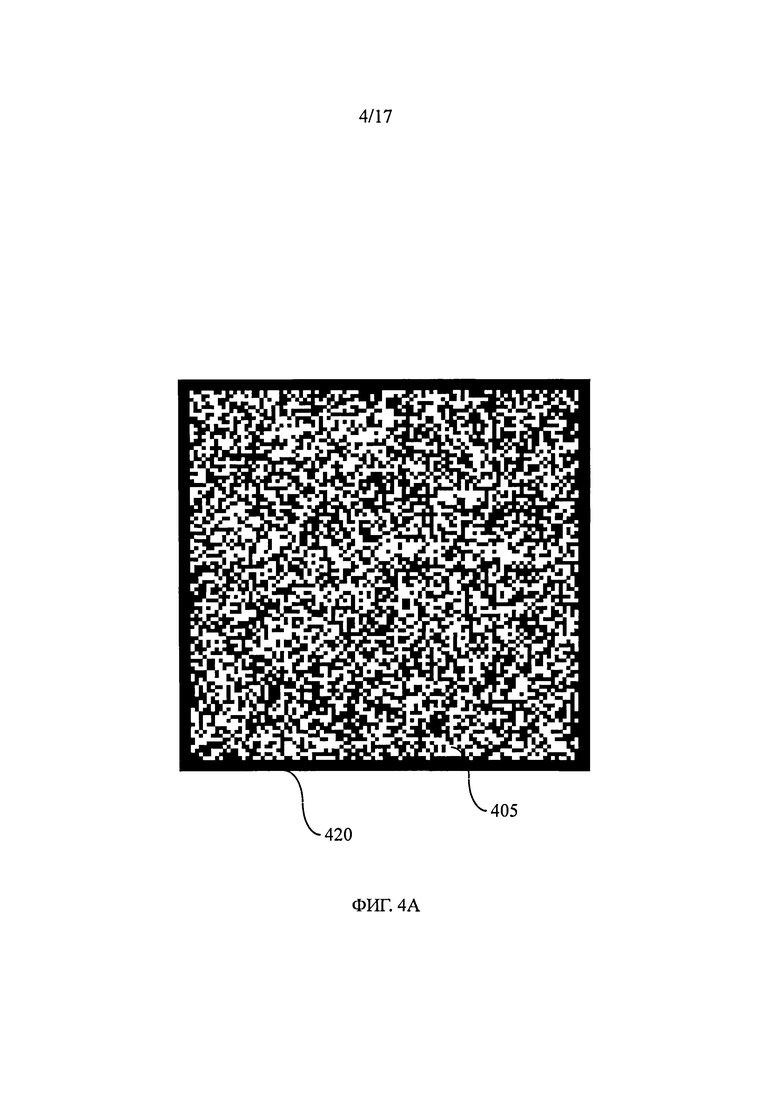
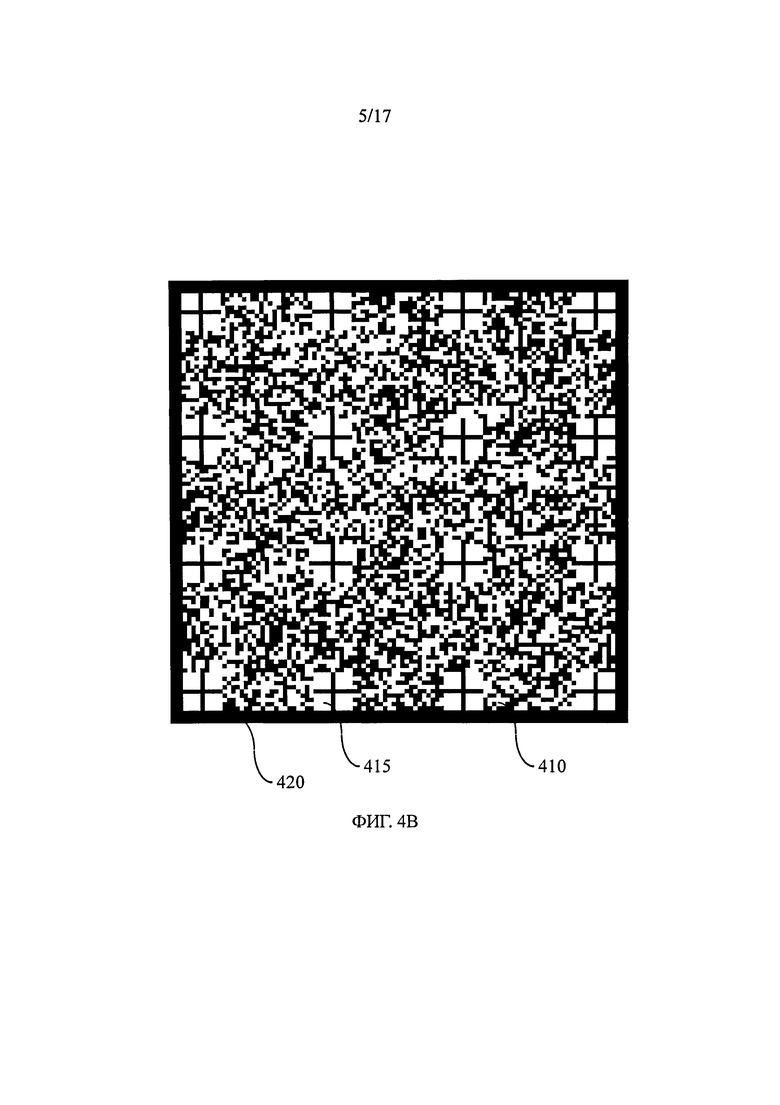


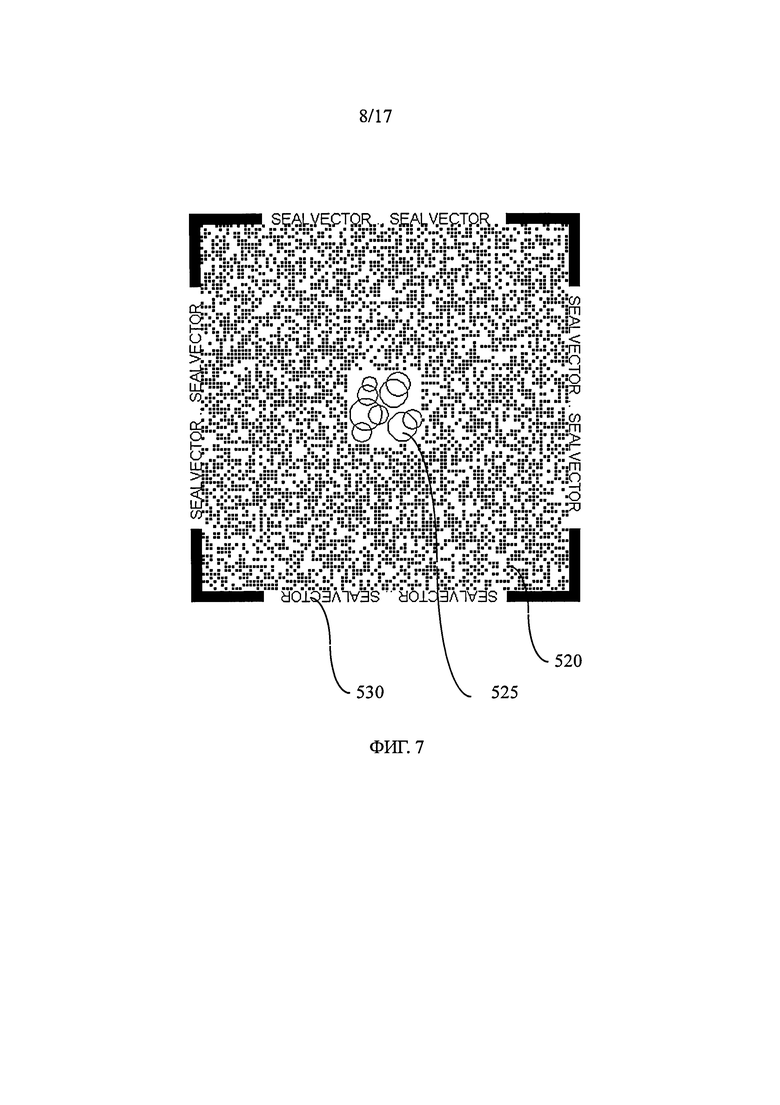

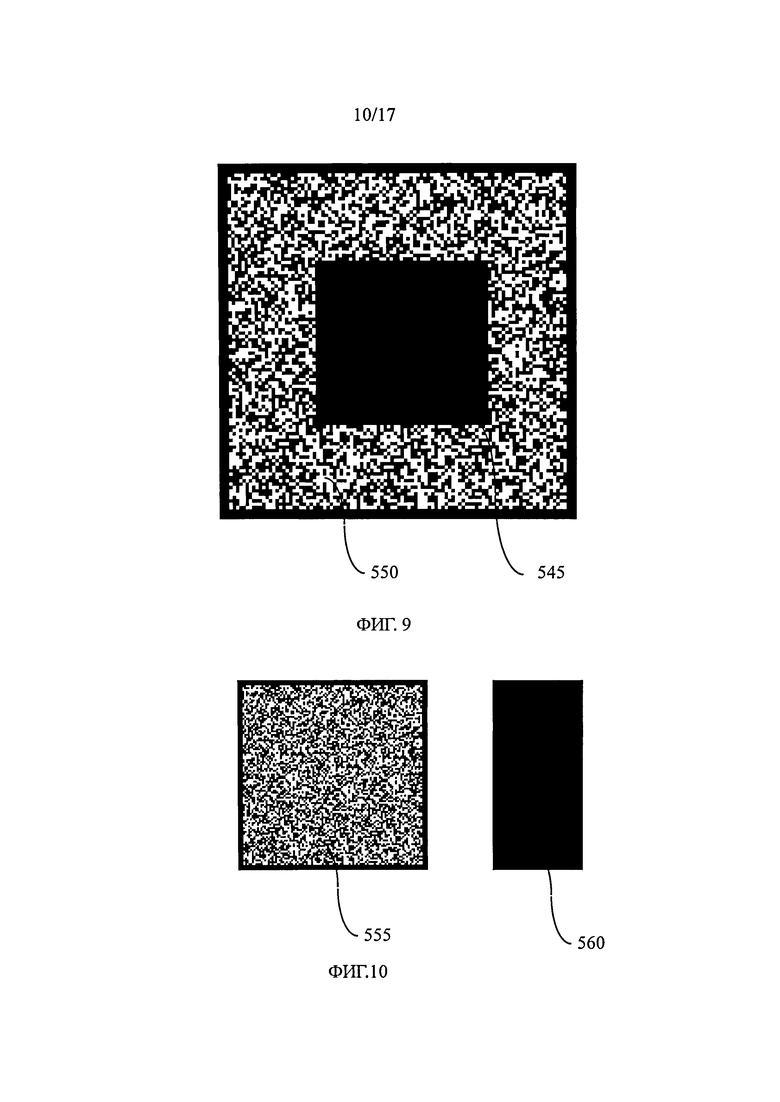


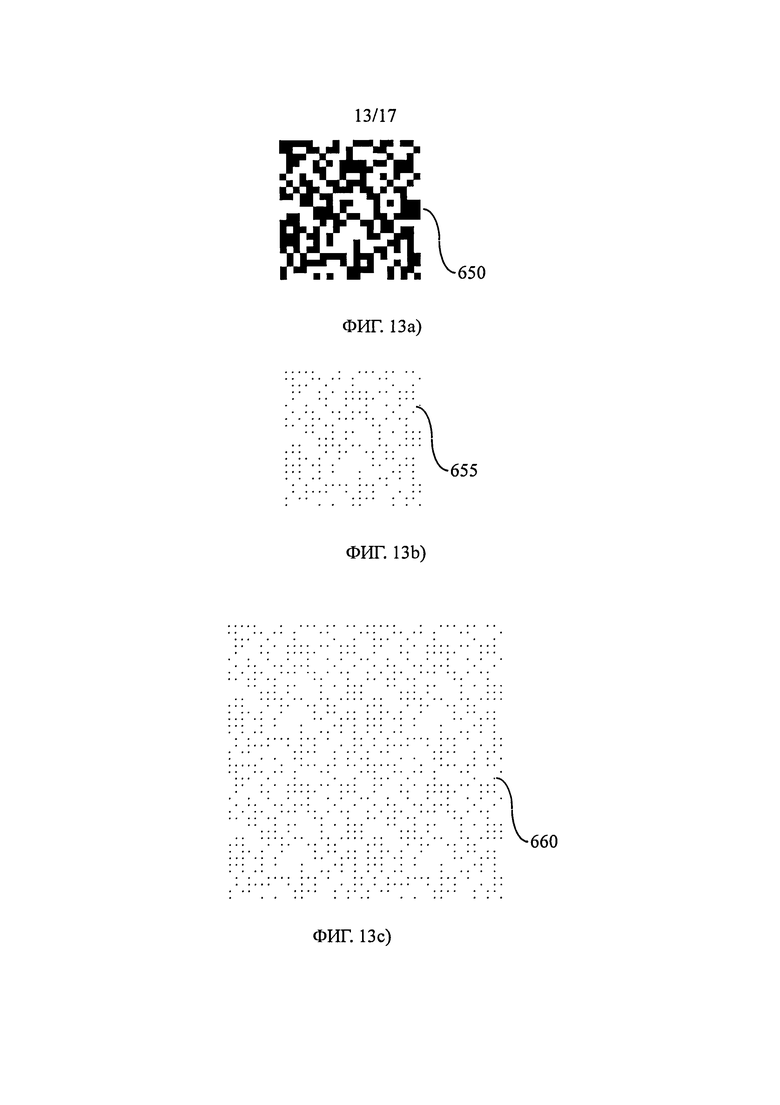
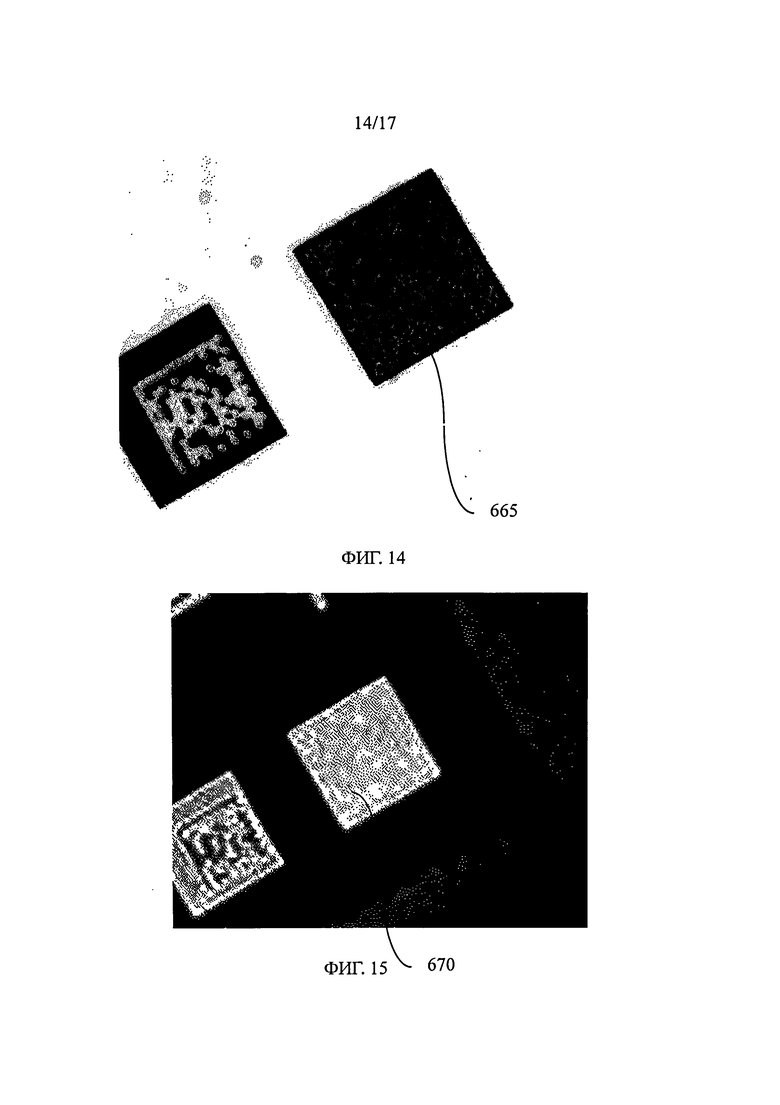
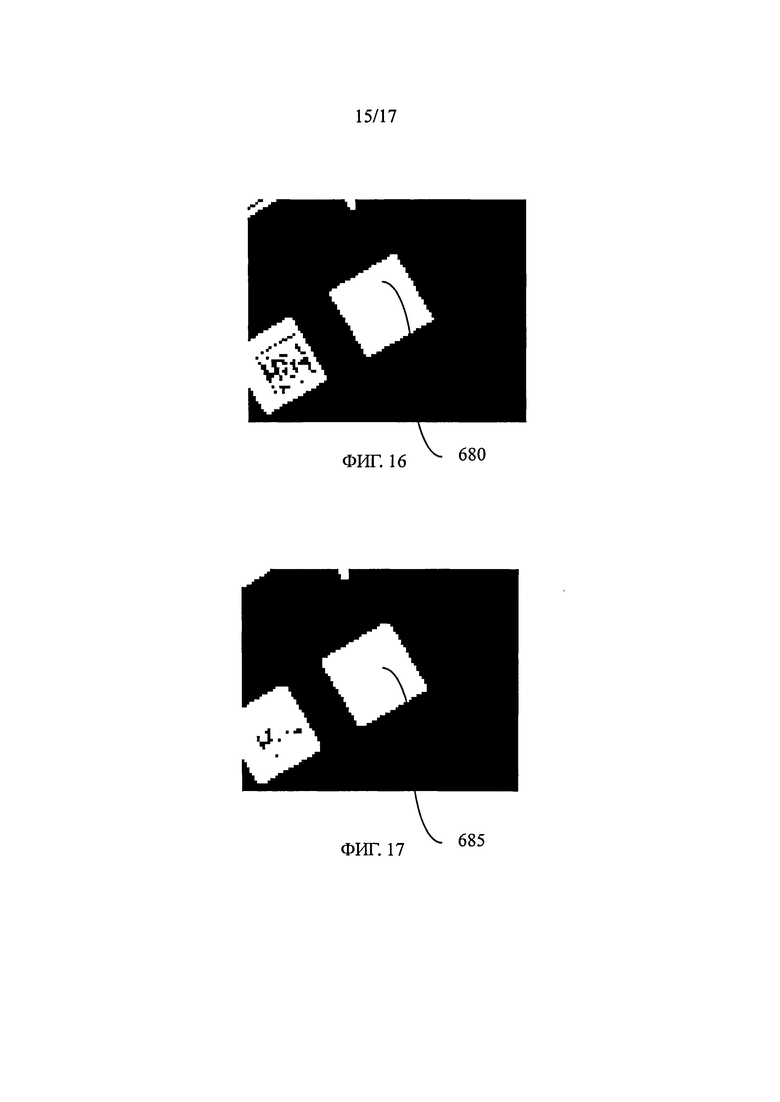
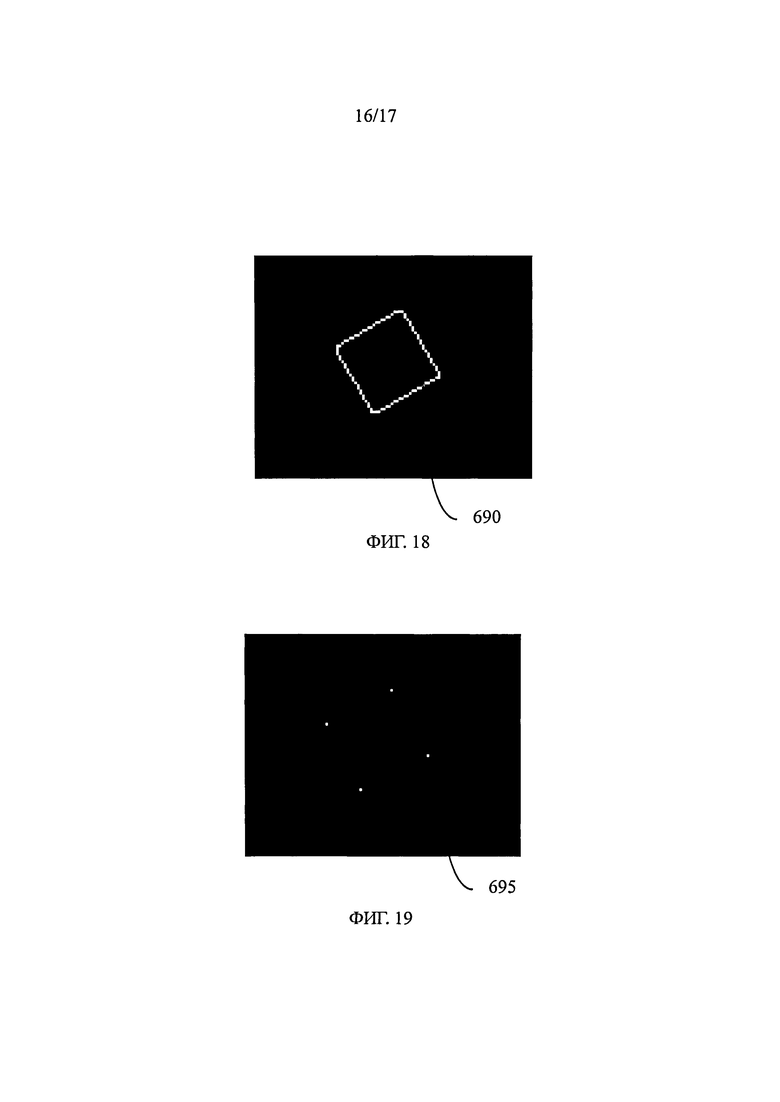
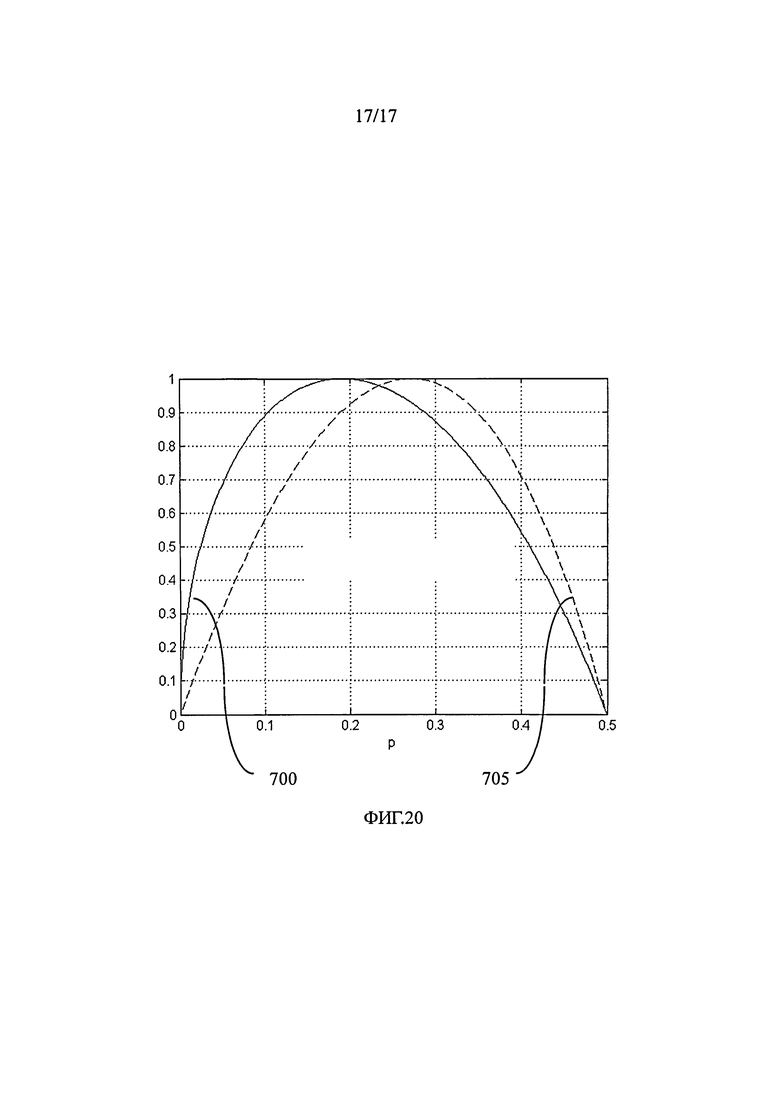
Изобретение относится к средствам защиты и аутентификации документов. Технический результат заключается в повышении надежности защиты. В способе защиты документа осуществляют этап кодирования сообщения для обеспечения избыточности, этап генерирования цифровой информационной матрицы ячеек, представляющей кодированное сообщение, путем изменения внешнего вида ячеек матрицы, причем кодированное сообщение содержит избыточность, этап печати матрицы на документе, этап захвата единиц информации напечатанной матрицы, этап измерения коэффициента ошибок в напечатанном кодированном сообщении посредством декодирования захваченных единиц информации путем использования избыточности в кодированном сообщении и этап определения порога принятия решения о коэффициенте ошибок в соответствии с измеренным коэффициентом ошибок такой, что документ, имеющий напечатанную информационную матрицу, представляющую сообщение, с коэффициентом ошибок выше, чем порог принятия решения о коэффициенте ошибок, будет рассмотрен как копия. 2 н. и 22 з.п. ф-лы, 25 ил.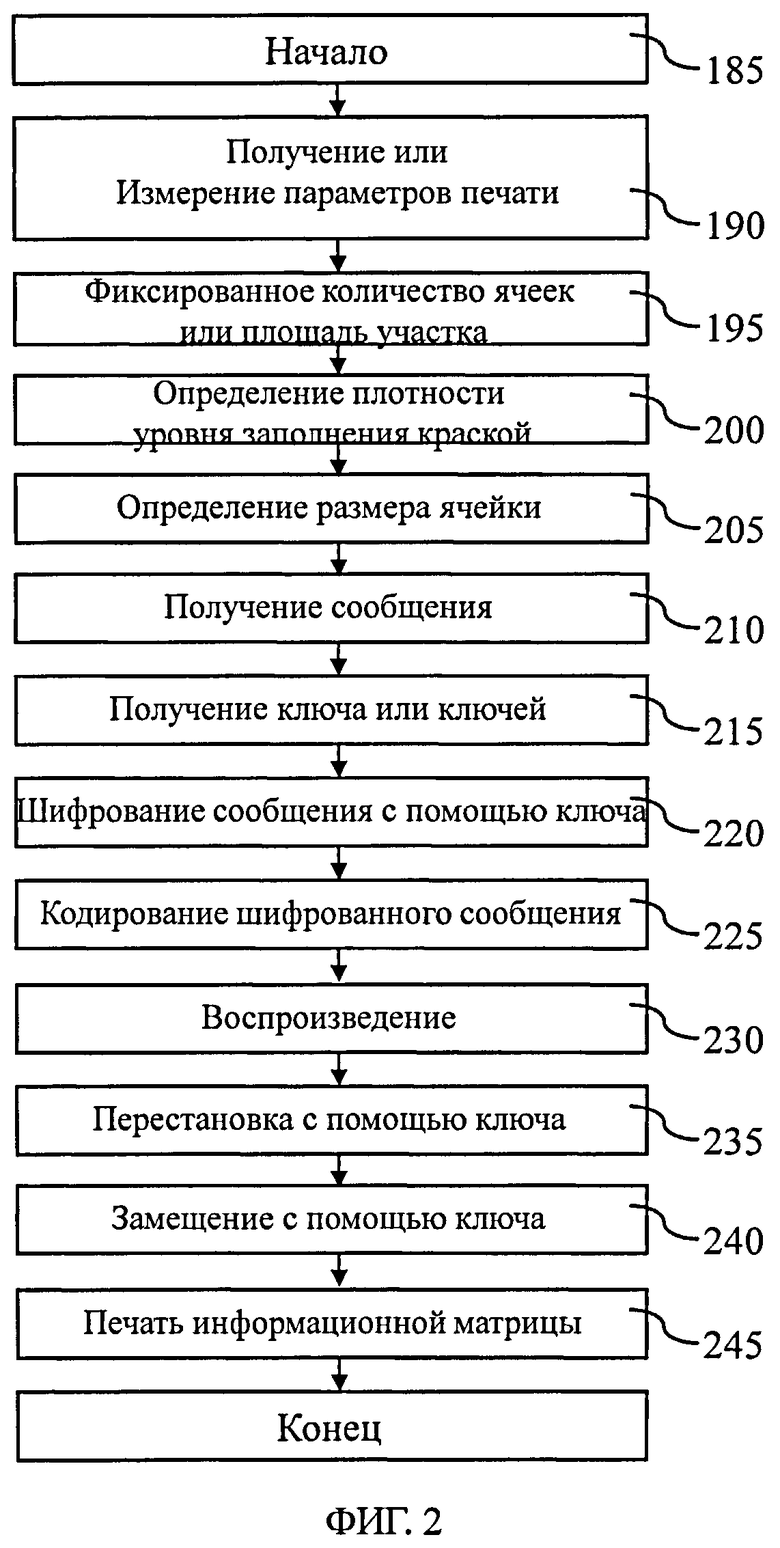
1. Способ защиты документа, содержащий:
- этап кодирования сообщения для обеспечения избыточности,
- этап генерирования цифровой информационной матрицы ячеек, представляющей кодированное сообщение, путем изменения внешнего вида ячеек матрицы, причем кодированное сообщение содержит избыточность,
- этап печати матрицы на документе,
- этап захвата единиц информации напечатанной матрицы,
- этап измерения коэффициента ошибок в напечатанном кодированном сообщении и
- этап определения порога принятия решения о коэффициенте ошибок в соответствии с измеренным коэффициентом ошибок такой, что документ, имеющий напечатанную информационную матрицу, представляющую сообщение, с коэффициентом ошибок выше, чем порог принятия решения о коэффициенте ошибок, будет рассмотрен как копия,
- этап измерения на печатном документе, подлежащем аутентификации, содержащем информационную матрицу, включающую кодированное сообщение, содержащее избыточность, коэффициента ошибок посредством декодирования информационной матрицы с использованием избыточности кодированного сообщения,
- этап принятия решения, является ли указанный документ аутентичным или нет, на основании сравнения коэффициента ошибок печатного документа, подлежащего аутентификации, и порога принятия решения о коэффициенте ошибок.
2. Способ по п. 1, согласно которому на этапе кодирования сообщения обеспечена достаточная доля избыточности, позволяющая скорректировать долю ошибок большую, чем коэффициент ошибок, сгенерированный этапом печати.
3. Способ по п. 1 или 2, согласно которому на этапе генерирования избыточность содержит коды обнаружения ошибок.
4. Способ по п. 3, согласно которому на этапе кодирования избыточность содержит коды коррекции ошибок.
5. Способ по п. 4, согласно которому на этапе кодирования используют сверхточное кодирование.
6. Способ по п. 5, согласно которому на этапе кодирования используют кодировщик Витерби.
7. Способ по любому из пп. 1, 2, 4-6, согласно которому на этапе генерирования информационной матрицы эта матрица на уровне каждой элементарной ячейки и независимо от соседних элементарных ячеек представляет сообщение, содержащее избыточность.
8. Способ по любому из пп. 1, 2, 4-6, согласно которому на этапе генерирования информационной матрицы избыточность выполняют такой, чтобы обеспечить возможность распознавания в метке несвязанных ошибок, сделанных на этапе нанесения меток.
9. Способ по любому из пп. 1, 2, 4-6, содержащий:
- этап определения условий печати указанного документа,
- этап определения коэффициента избыточности в кодированном сообщении согласно условиям печати, причем на этапе кодирования используют определенный коэффициент избыточности для кодирования сообщения.
10. Способ по п. 9, согласно которому на этапе определения коэффициента избыточности коэффициент избыточности определяют так, что отношение доли ячеек, напечатанных с ошибкой печати, возникающей исключительно вследствие непредвиденных переменных на этапе печати, больше, чем заданное первое значение, и меньше, чем заданное второе значение.
11. Способ по п. 10, согласно которому заданное первое значение составляет по меньшей мере 5%, а заданное второе значение составляет по большей мере 35%.
12. Способ по любому из пп. 1, 2, 4-6, 10 или 11, согласно которому на этапе печати к метке информационной матрицы добавляют дополнительную надежную метку, содержащую сообщение.
13. Способ по любому из пп. 1, 2, 4-6, 10 или 11, согласно которому на этапе кодирования сообщения представление указанного сообщения шифруют с помощью шифровального ключа.
14. Способ по любому из пп. 1, 2, 4-6, 10 или 11, согласно которому на этапе кодирования сообщения представление указанного сообщения воспроизводят с целью создания нескольких идентичных копий.
15. Способ по любому из пп. 1, 2, 4-6, 10 или 11, согласно которому на этапе кодирования сообщения позиции элементов представления указанного сообщения меняют местами в соответствии с секретным ключом.
16. Способ по любому из пп. 1, 2, 4-6, 10 или 11, согласно которому на этапе кодирования сообщения функцию замещения значения, зависящую, с одной стороны, от значения элемента и в то же время от значения элемента секретного ключа, применяют по меньшей мере к одной части элементов представления указанного сообщения.
17. Способ по любому из пп. 1, 2, 4-6, 10 или 11, согласно которому на этапе кодирования сообщения функцию частичного замещения значений, зависящую, с одной стороны, от значения элемента и в то же время от значения элемента секретного ключа, который отличается от секретного ключа первой замещающей функции, применяют по меньшей мере к одной части элементов представления указанного сообщения.
18. Способ п. 16, согласно которому указанная функция замещения попарно замещает значения, связанные с соседними ячейками в указанной конфигурации.
19. Способ по любому из пп. 1, 2, 4-6, 10, 11 или 18, согласно которому на этапе кодирования сообщения используют по меньшей мере один ключ, причем связанный ключ, который необходим для воспроизведения сообщения, является другим.
20. Способ по любому из пп. 1, 2, 4-6, 10, 11 или 18, согласно которому на этапе кодирования сообщения кодированное сообщение представляет по меньшей мере два сообщения, оснащенных различными средствами защиты.
21. Способ по п. 20, согласно которому одно из указанных сообщений представляет собой информацию, требуемую при чтении информационной матрицы для определения другого сообщения и/или обнаружения ошибок в нем.
22. Способ по п. 21, согласно которому одно из указанных сообщений представляет собой по меньшей мере один ключ, требуемый для чтения другого сообщения.
23. Способ по любому из пп. 1, 2, 4-6, 10, 11, 18, 21 или 22, согласно которому на этапе кодирования сообщения к представлению сообщения добавляют его хеш-значение.
24. Устройство для защиты документа, содержащее:
- средства кодирования сообщения для обеспечения избыточности,
- средства генерирования цифровой информационной матрицы ячеек, представляющей кодированное сообщение, путем изменения внешнего вида ячеек матрицы, причем кодированное сообщение содержит избыточность,
- средства печати матрицы на документе,
- средства захвата единиц информации напечатанной матрицы,
- средства измерения коэффициента ошибок в напечатанном кодированном сообщении и
- средства определения порога принятия решения о коэффициенте ошибок в соответствии с измеренным коэффициентом ошибок такие, что документ, имеющий напечатанную информационную матрицу, представляющую сообщение, с коэффициентом ошибок выше, чем порог принятия решения о коэффициенте ошибок, будет рассмотрен как копия,
- декодер для измерения на печатном документе, подлежащем аутентификации, содержащем информационную матрицу, включающую кодированное сообщение, содержащее избыточность, коэффициента ошибок посредством декодирования информационной матрицы путем использования избыточности в кодированном сообщении,
- детектор для принятия решения, является ли указанный документ аутентичным или нет, на основании сравнения коэффициента ошибок печатного документа, подлежащего аутентификации, и порога принятия решения о коэффициенте ошибок.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| СПОСОБ ПРОВЕРКИ ПОДЛИННОСТИ ДЕНЕЖНОГО ИЛИ ГАРАНТИЙНОГО ДОКУМЕНТА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ (ВАРИАНТЫ) | 1992 |
|
RU2089938C1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

