Изобретение касается обработки цифровых аудиосигналов (в частности, речевых сигналов).
Оно применяется в системе кодирования/декодирования, выполненной с возможностью передачи/приема таких сигналов. В частности настоящее изобретение касается обработки при передаче и позволяет повысить качество декодированных сигналов при потере блоков данных.
Для преобразования в цифровом виде и для сжатия цифрового аудиосигнала существуют разные технологии. Наиболее распространенными из них являются:
- способы кодирования по форме волны, такие как кодирование ИКМ («Импульсно-кодовая модуляция») и АДИКМ («Адаптивная дифференциальная импульсно-кодовая модуляция»), называемые также "РСМ" и "ADPCM" на английском языке,
- способы параметрического кодирования путем анализа-синтеза, такие как кодирование CELP (от "Code Excited Linear Prediction") и,
- способы перцептуального субполосного кодирования или кодирования по трансформанте.
Эти технологии предусматривают последовательную обработку входного сигнала от одной выборки к другой (ИКМ или АДИКМ) или по блокам выборок, называемым «фреймами» (CELP и кодирование по трансформанте).
Можно вкратце напомнить, что речевой сигнал может быть предсказан на основании его непосредственного прошлого (например, 8-12 выборок при 8 кГц) при помощи параметров, определяемых в коротких окнах (в данном примере от 10 до 20 мс). Эти параметры краткосрочного предсказания, характеризующие функцию передачи голосового канала (например, при произнесении согласных), получают при помощи методов анализа LPC (от "Linear Prediction Coding" или «кодирование с линейным предсказанием»). Существует также более долговременная корреляция, связанная с квазипериодичностью речи (например, тональные звуки, такие как гласные), которая проявляется в результате вибрации голосовых связок. Таким образом, речь идет об определении, по меньшей мере, основной частоты тонального сигнала, которая обычно меняется от 60 Гц (низкий голос) до 600 Гц (высокий голос) в зависимости от говорящих. При этом при помощи анализа LTP (от "Long Term Prediction" или «долговременное предсказание») определяют параметры LTP долговременного предиктора и, в частности, противоположность основной частоты, часто называемую «питч-периодом». При этом определяют число выборок в питч-периоде при помощи соотношения Fe/F0 (или его целой части), где:
- Fe - частота дискретизации, и
- F0 - основная частота.
Таким образом, можно отметить, что параметры долговременного предсказания LTP, в том числе питч-период, характеризуют основную вибрацию речевого сигнала (если он является тональным), тогда как параметры кратковременного предсказания LPC характеризуют спектральную оболочку этого сигнала.
В некоторых кодерах все эти параметры LPC и LTP, проявляющиеся в результате речевого кодирования, могут быть переданы в виде блоков в соответствующий декодер через одну или несколько телекоммуникационных сетей для последующего восстановления первоначального речевого сигнала.
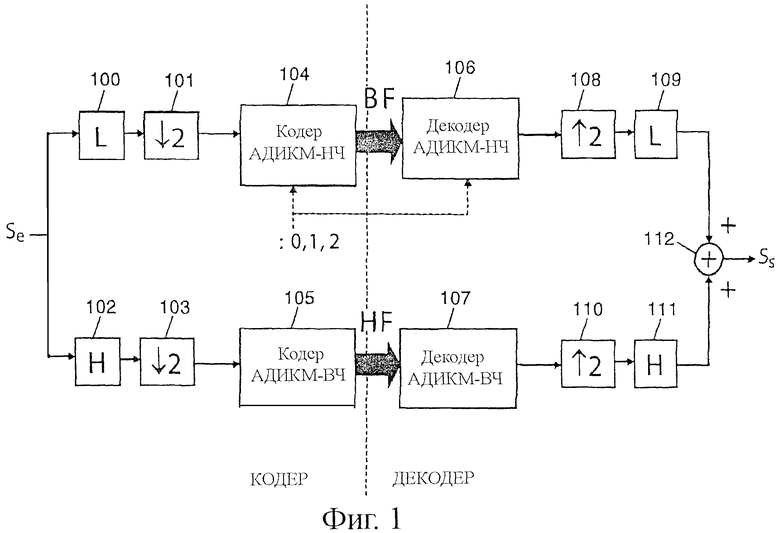
Однако в дальнейшем будет рассматриваться (в качестве примера) система кодирования G.722 на 48,56 и 64 бит, стандартизированная UIT-T для передачи речевых сигналов в расширенной полосе (которые дискретизируются на 16 кГц). Кодер G.722 содержит схему кодирования АДИКМ по двум субполосам, получаемым при помощи набора фильтров QMF (от "Quadrature Mirror Filter"). Для более подробной информации можно обратиться к тексту технического описания G.722.
На фиг.1 показано известное техническое решение со структурой кодирования и декодирования согласно техническому описанию G.722. Блоками 101-103 показан передающий набор фильтров QMF (спектральное разделение на высокие 102 и низкие 100 частоты и субдискретизация 101 и 103), применяемый для входного сигнала Se. Следующие блоки 104 и 105 соответствуют кодерам АДИКМ в полосе низких частот и высоких частот. Пропускная способность низкочастотного кодера АДИКМ определяется режимом 0, 1 или 2, соответствующим пропускной способности 6,5 или 4 бит на выборку, тогда как пропускная способность высокочастотного кодера АДИКМ является фиксированной (два бита на выборку). Декодер содержит эквивалентные блоки декодирования АДИКМ (блоки 106 и 107), выходы которых скомбинированы в принимающем наборе фильтров QMF (супердискретизация 108 и 110, обратные фильтры 109, 111 и объединение полос высоких и низких частот 112) для генерирования синтезированного сигнала Ss.
Рассматриваемой в данном случае общей задачей является коррекция потерь блоков при декодировании. Действительно, получаемый при кодировании поток битов, как правило, сформатирован в виде строк битов для передачи через самые разные типы сетей. Например, говорят о «IP-пакетах» (от "Internet Protocol") для блоков, передаваемых через Интернет-сеть, о «фреймах» для блоков, передаваемых через сети ATM (от "Asynchronous Transfer Mode") и т.д. Блоки, передаваемые после кодирования, могут быть утеряны по разным причинам:
- если маршрутизатор сети насыщен и производит очистку очереди,
- если блок получен с задержкой (следовательно, не учтен) во время декодирования с непрерывным потоком и в режиме реального времени,
- если нарушена достоверность принятого блока (например, если не проверяется его паритетный код CRC).
При потере одного или нескольких последовательных блоков декодер может реконструировать сигнал, не имея информации об утерянных или дефектных блоках. Он опирается на информацию, декодированную ранее на основании полученных нормальных блоков. Эта задача, называемая «коррекцией потерянных блоков» (или еще в дальнейшем называемая «коррекцией стертых фреймов»), по сути дела является более общей, чем простая экстраполяция недостающей информации, так как потеря фреймов часто приводит к потере синхронизации между кодером и декодером, в частности, если они являются предикативными, а также к проблемам непрерывности между экстраполированной информацией и декодированной информацией после потери. Таким образом, коррекция стертых фреймов охватывает также технологии восстановления состояний, реконвергенции и т.д.
В приложении I к техническому описанию UIT-T G.711 описана коррекция стертых фреймов, адаптированная для кодирования ИКМ. Поскольку кодирование ИКМ не является предикативным, коррекция потерь фреймов сводится к простой экстраполяции недостающей информации и в обеспечении непрерывности между воссозданным фреймом и принятыми в надлежащем виде фреймами после потери. Экстраполяцию осуществляют путем повторения прошлого сигнала синхронно с основной частотой (или, наоборот, с «питч-периодом»). Непрерывность обеспечивается при помощи сглаживания (или «плавного перехода» от английского термина "cross-fading") между принятыми выборками и экстраполированными выборками.
В документе:
"A packet Loss Concealment Method using Pitch Waveform Repetition and Internal State Update on the Decoded Speech for the Sub-band ADPCM Wideband Speech Codec", M-Serizawa and Y.Nozava, IEEE Speech Coding Workshop, стр.68-70 (2002)
была предложена коррекция стертых фреймов для кодера/декодера стандарта G.722 путем экстраполяции потерянного фрейма при помощи алгоритма повторения питч-периодов (при этом повторение может быть аналогичным повторению, описанному в приложении I к техническому описанию G.711). Для обновления состояний кодера G.722 (память фильтров и память адаптации шага) экстраполированный таким образом фрейм делят на две субполосы, которые опять кодируют при помощи кодирования АДИКМ.
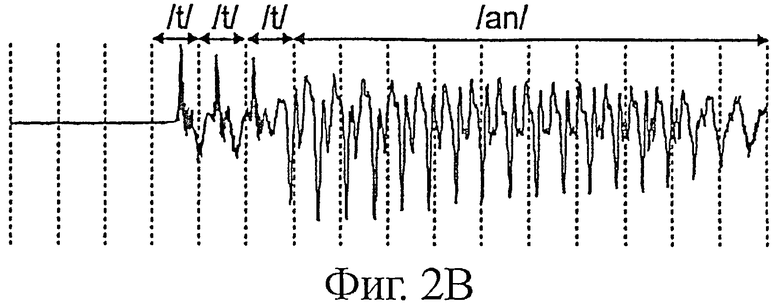
Однако такие технологии коррекции потерь фреймов путем повторения питч-периодов могут нормально работать только в случае, если прошедший сигнал является стационарным или, по меньшей мере, циклично-стационарным. Таким образом, они отталкиваются от неочевидного предположения, что сигнал, связанный с потерянным фреймом (который необходимо экстраполировать), является «подобным» декодированному сигналу до потери фрейма. В случае речевого сигнала это предположение о стационарности строго подтверждается только для таких звуков, как повторяемая часть гласных. Например, гласную «а» можно повторить несколько раз (что дает «аааа...» без какого-либо дискомфорта при прослушивании). Однако речевой сигнал содержит так называемые «переходные» звуки (нестационарные звуки, обычно включающие в себя начало гласных, и звуки, называемые «плозивными», которые соответствуют коротким согласным, таким как "р", "b", "d", "t", "k"). Таким образом, если, например, фрейм пропал сразу после звука "t", то коррекция потери фрейма путем простого повторения создаст очень неприятную на слух последовательность "t" (которая на французском языке будет звучать как "teu-teu-teu-teu-teu") в виде автоматной очереди при потере нескольких последовательных фреймов (например, пять последовательных потерь).
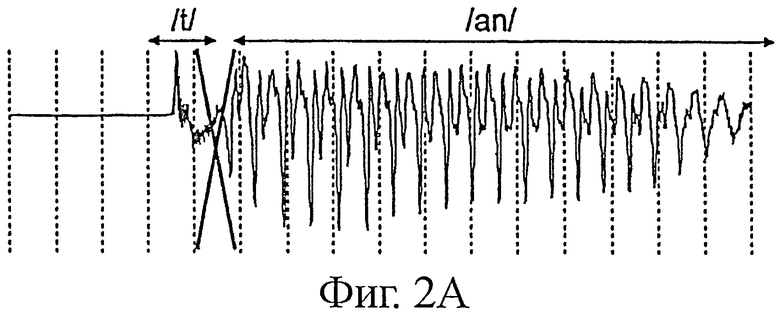
На фиг.2А и 2B показан этот акустический эффект в случае широкополосного сигнала, закодированного кодером согласно техническому описанию G.722. В частности, на фиг.2А показан речевой сигнал, декодированный на идеальном канале (без потери фрейма). В представленном примере этот сигнал соответствует французскому слову "temps", разделенному на две фонемы: /t/ и /an/. Вертикальные пунктирные линии показывают границы между фреймами. В данном случае рассматривается случай фреймов длиной порядка 10 мс. На фиг.2B показан сигнал, декодированный по технологии, аналогичной описанной в вышеуказанном известном документе Serozava et al, когда потеря фрейма происходит сразу после фонемы /t/. На этой фиг.2B хорошо видна проблема повторения прошлого сигнала. Отмечается, что фонема /t/ повторяется в экстраполированном фрейме. Она присутствует также в следующем или в следующих фреймах, так как в представленном примере экстраполяцию слегка продлевают после потери, чтобы реализовать плавный переход к декодированию в нормальных условиях (то есть при наличии полезных данных в принятом сигнале).
В известных до настоящего времени документах проблема повторения плозивных звуков никогда не рассматривалась.
Настоящее изобретение призвано восполнить этот недостаток.
В этой связи изобретением предлагается способ синтеза цифрового аудиосигнала, представленного в виде последовательных блоков выборок, в котором после получения такого сигнала, чтобы заменить, по меньшей мере, один дефектный блок, на основании выборок, по меньшей мере, одного нормального блока генерируют заменяющий блок.
В целом способ содержит следующие этапы:
а) определяют период повторения сигнала, по меньшей мере, в одном нормальном блоке, и
б) выборки периода повторения копируют, по меньшей мере, в один заменяющий блок.
В соответствии с настоящим изобретением в способе:
- на этапе а) определяют последний период повторения, по меньшей мере, в одном нормальном блоке, непосредственно предшествующем дефектному блоку, и
- на этапе б) выборки последнего периода повторения корректируют в зависимости от выборок предыдущего периода повторения, причем таким образом, чтобы ограничить амплитуду возможного переходного сигнала, который может присутствовать в последнем периоде повторения.
После этого скорректированные таким образом выборки копируют в заменяющий блок.
Предпочтительно способ в соответствии с настоящим изобретением применяется для обработки речевого сигнала как в случае тонального сигнала, так и в случае нетонального сигнала. Так, если сигнал является тональным, период повторения представляет собой просто питч-период, и на этапе а) способа определяют, в частности, питч-период (обычно представляющий собой противоположность основной частоты) тона сигнала (например, тон голоса в речевом сигнале), по меньшей мере, в одном нормальном блоке, предшествующем потере.
Если принятый нормальный сигнал не является тональным, то реально не существует детектируемого питч-периода. В этом случае можно предусмотреть данное произвольное число выборок, которое будет считаться длиной питч-периода (который можно произвольно назвать «периодом повторения»), и реализовать способ в соответствии с настоящим изобретением на основании этого периода повторения. Например, можно выбрать максимально длинный питч-период, обычно 20 мс (соответствующий 50 Гц очень низкого голоса), то есть 160 выборок с частотой дискретизации 8 кГц. Можно также взять значение, соответствующее максимуму функции корреляции, ограничив поиск в интервале значения (например, от МАХ_Р1ТСН/2 до МАХ_Р1ТСН, где MAX_PITCH является максимальным значением в поиске питч-периода).
Предпочтительно, если при приеме необходимо заменить несколько дефектных блоков и если эти блоки укладываются, по меньшей мере, в один период повторения, этап коррекции выборок б) применяют для всех выборок последнего периода повторения, принимаемых одна за другой в качестве текущей выборки.
Кроме того, если дефектные блоки занимают несколько периодов повторения, то скорректированный таким образом на этапе б) период повторения копируют несколько раз для формирования заменяющих блоков.
В частном варианте выполнения для вышеуказанной коррекции выборок, которую осуществляют на этапе б), можно действовать следующим образом. Для текущей выборки из последнего периода повторения сравнивают:
- амплитуду этой выборки по абсолютной величине,
- с амплитудой по абсолютной величине, по меньшей мере, одной выборки, временно позиционированной по существу в один период повторения перед текущей выборкой,
и текущей выборке придают наименьшую амплитуду по абсолютной величине из этих двух амплитуд, присвоив ей также, разумеется, знак ее первоначальной амплитуды.
В данном случае под выражением «позиционировать по существу» следует понимать то, что предыдущем периоде повторения ищут окружение, которое следует связать с текущей выборкой. Так, предпочтительно, для текущей выборки последнего периода повторения:
- определяют набор выборок в окружении, сосредоточенном вокруг выборки, временно позиционированной в периоде повторения перед текущей выборкой,
- определяют амплитуду, выбираемую из амплитуд выборок указанного окружения, взятых по абсолютной величине,
- и эту выбранную амплитуду сравнивают с амплитудой текущей выборки по абсолютной величине для придания текущей выборке наименьшей амплитуды по абсолютной величине среди выбранной амплитуды и амплитуды текущей выборки.
Предпочтительно эта амплитуда, выбранная среди амплитуд выборок указанного окружения, является максимальной амплитудой по абсолютной величине.
Кроме того, обычно применяют затухание (постепенное ослабление) амплитуды выборок в заменяющих блоках. В данном случае предпочтительно детектируют переходный характер сигнала перед потерей блоков и, в случае необходимости, применяют более быстрое ослабление, чем для стационарного (непереходного) сигнала.
Дополнительно или в варианте можно также осуществить обновление (RAZ) памяти последующих фильтров в обработке синтеза, специально адаптированное для переходных звуков, чтобы избежать проявления влияния таких переходных звуков при обработке последующих нормальных блоков.
Предпочтительно детектирование переходного сигнала, предшествующего потере блока, осуществляют следующим образом:
- для нескольких текущих выборок последнего периода повторения измеряют отношение по абсолютной величине амплитуды этой выборки к вышеуказанной выбранной амплитуде (определенной в окружении, как было указано выше),
- затем подсчитывают число проявлений для текущих выборок, при которых вышеуказанное соотношение превышает первый заранее определенный порог (например, значение, близкое к 4, что будет рассмотрено ниже), и
- детектируют присутствие переходного сигнала, если число проявлений превышает второй заранее определенный порог (например, если имеется более одного проявления, что будет рассмотрено ниже).
Эти этапы можно применять также для запуска этапа коррекции б) в соответствии с настоящим изобретением в случае обнаружения переходного звука в периоде повторения, непосредственно предшествующем потере блока.
Вместе с тем, чтобы принять решение о применении или не применении этапа коррекции б) способа в соответствии с настоящим изобретением, действуют следующим образом. Если цифровой аудиосигнал является речевым сигналом, то предпочтительно детектируют степень тональности в речевом сигнале и этап коррекции б) не применяют, если речевой сигнал сильно тонирован (что проявляется в виде коэффициента корреляции, близкого к «I», при поиске питч-периода). Иначе говоря, эту коррекцию применяют, только если сигнал не тонирован или является слабо тонированным.
Таким образом, избегают применения коррекции этапа б) и нецелесообразного ослабления сигнала в заменяющих блоках, если принятый сигнал является сильно тонированным (то есть стационарным), что в реальности соответствует произнесению устойчивой гласной (например, «аааа»).
Таким образом, если резюмировать, настоящее изобретение касается изменения сигнала перед повторением периода повторения (или «питча» для тонального речевого сигнала) для синтеза потерянных блоков при декодировании цифровых аудиосигналов. Эффектов повторения переходных сигналов избегают, сравнивая выборки питч-периода с выборками предыдущего питч-периода. Предпочтительно сигнал изменяют, выбирая наименьшее значение между текущей выборкой и, по меньшей мере, одной выборкой по существу в том же положении в предыдущем питч-периоде.
В контексте декодирования при наличии потерь блоков изобретение имеет несколько преимуществ. В частности, оно позволяет избежать появления артефактов в результате ошибочного повторения переходных звуков (когда используют простое повторение питч-периода). Кроме того, оно позволяет осуществлять детектирование переходных звуков, которое позволяет адаптировать контроль энергии экстраполированного сигнала (через переменное затухание).
Другие преимущества и отличительные признаки настоящего изобретения будут более очевидны из нижеследующего подробного описания, представленного в качестве примера, со ссылками на прилагаемые чертежи, на которых, кроме уже представленных выше фиг.2А и 2B:
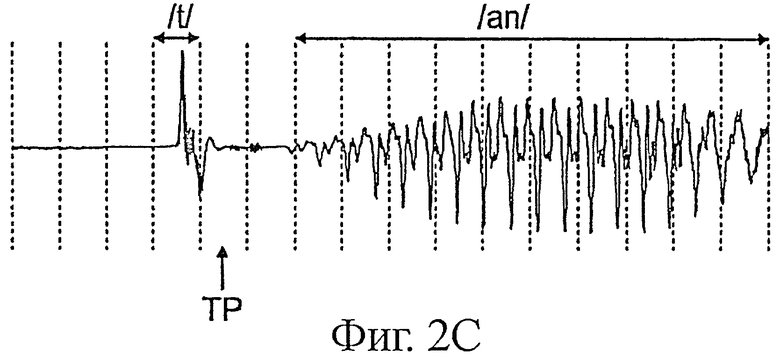
Фиг.2С иллюстрирует для сравнения эффект обработки в соответствии с настоящим изобретением на том же сигнале, что и показанный на фиг.2А и 2B, в случае которого произошла потеря фрейма ТР;
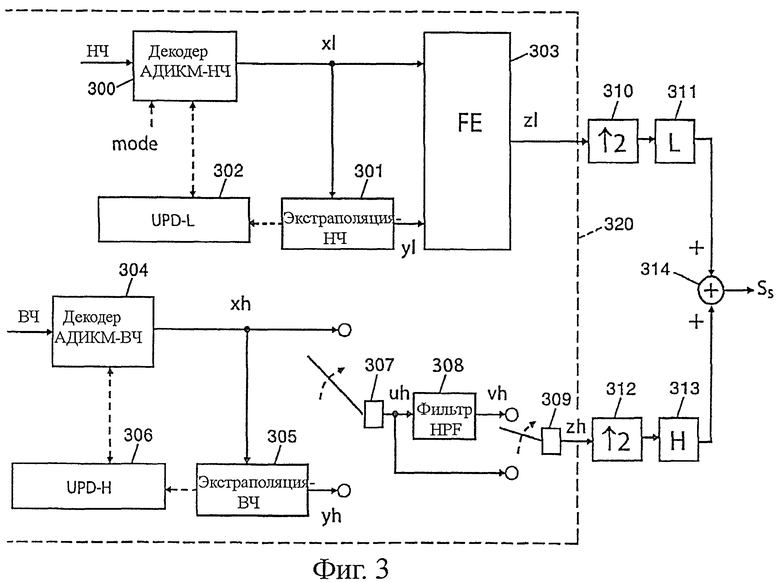
Фиг.3 - декодер согласно техническому описанию G.722, но модифицированный путем интегрирования устройства коррекции стертых фреймов в соответствии с настоящим изобретением;
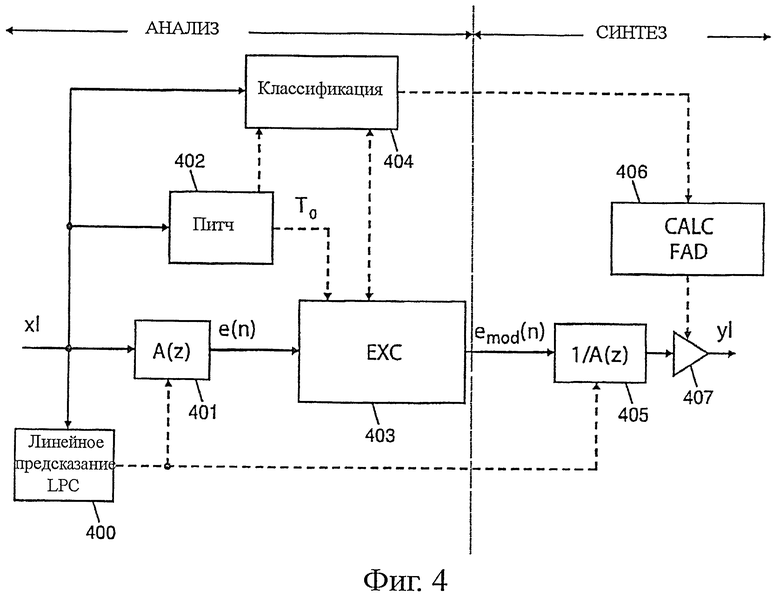
Фиг.4 - принцип экстраполяции низкочастотной полосы;
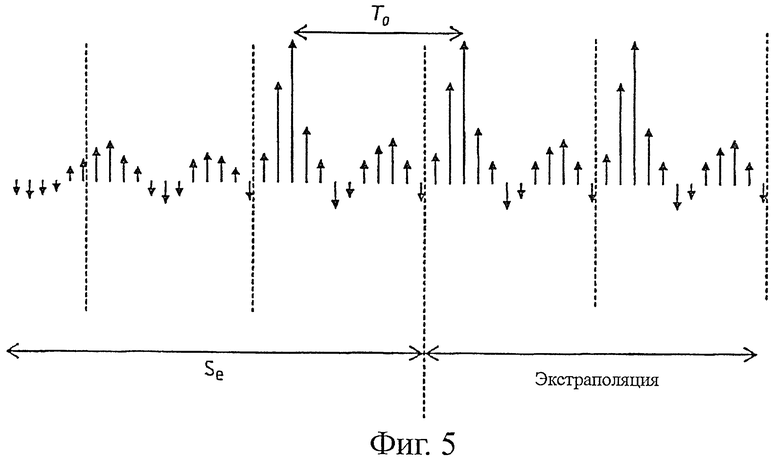
Фиг.5 - принцип повторения питча (в области возбуждения);
Фиг.6 - изменение сигнала возбуждения в соответствии с настоящим изобретением с последующим повторением питча;
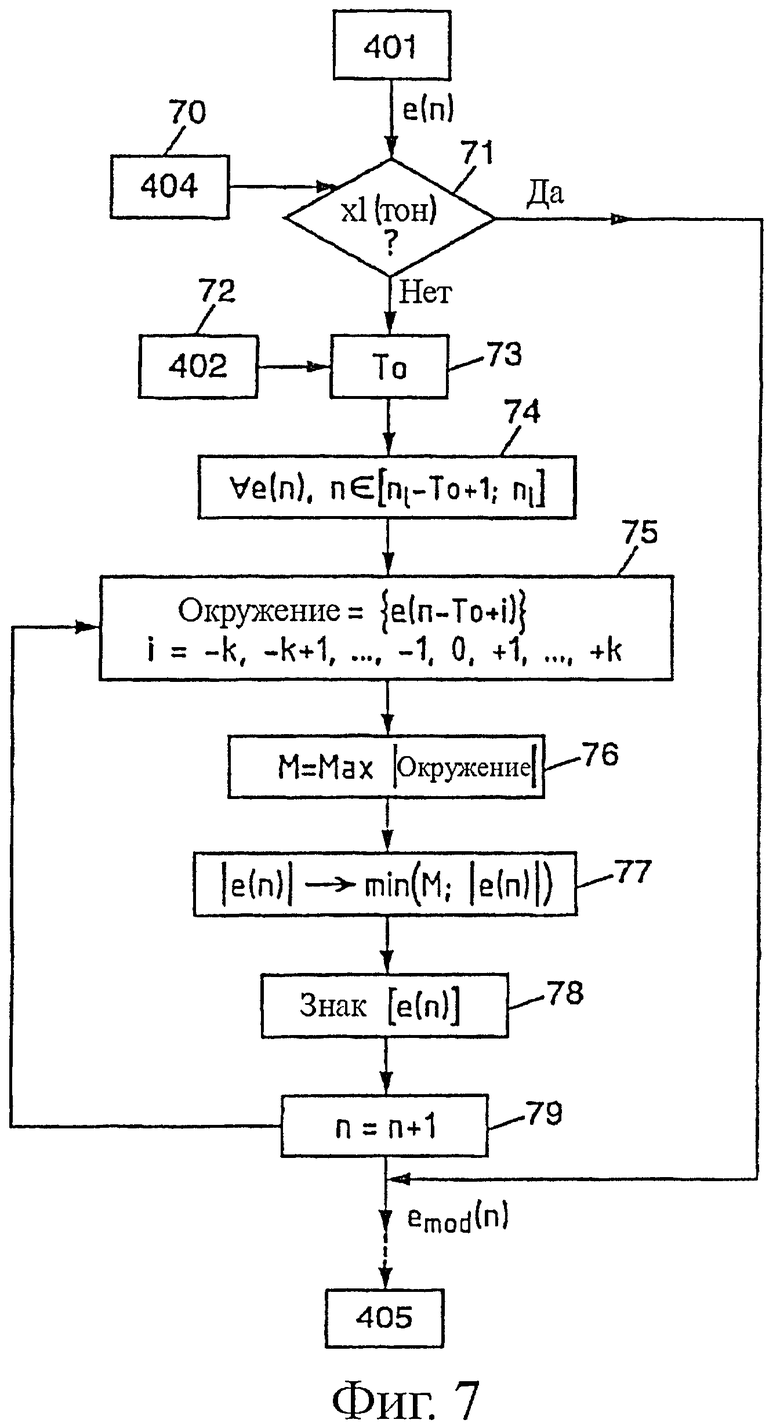
Фиг.7 - этапы способа в соответствии с настоящим изобретением согласно частному варианту выполнения;
Фиг.8 - схема устройства синтеза для применения способа в соответствии с настоящим изобретением;
Фиг.8А - общая структура квадратурного набора двухканальных фильтров (QMF);
Фиг.8B - спектры сигналов x(n), xl(n), xh(n), показанных на фиг.8А, при идеальных фильтрах L(z) и H(z) (то есть f'e=2fe).
Ниже представлено описание варианта реализации изобретения, основанного на примере системы кодирования согласно техническому описанию G.722. Описание кодера G.722 опускается (он был описан со ссылками на фиг.1). Ограничимся лишь описанием модифицированного декодера G.722, в который интегрирован корректор питч-периодов, воспроизводимых в случае потери фреймов.
Показанный на фиг.3 декодер в соответствии с настоящим изобретением (в данном случае согласно техническому описанию G.722) тоже имеет архитектуру с двумя субполосами с наборами фильтров приема QMF (блоки 310-314). По сравнению с декодером, показанным на фиг.1, декодер на фиг.3 дополнительно содержит устройство 320 коррекции стертых фреймов.
Декодер G.722 генерирует выходной сигнал Ss, дискретизированный по 16 кГц и разбитый на временные фреймы (или блоки выборок) по 10, 20 или 40 мс. Его работа различается в зависимости от наличия или отсутствия потери фреймов.
При полном отсутствии потери фреймов (то есть, если все фреймы приняты и являются нормальными) битовый поток низкочастотной полосы BF декодируется блоком 300 устройства 320 в соответствии с настоящим изобретением, при этом не происходит никакого плавного перехода (блок 303), и воспроизводимый сигнал представляет собой просто zl=xl. Точно так же битовый поток высокочастотной полосы HF декодируется блоком 304. Переключатель 307 выбирает канал uh=xh, а переключатель 309 выбирает канал zh=uh=xh.
Однако в случае потери одного или нескольких фреймов в полосе низких частот стертый фрейм экстраполируется в блоке 301 на основании прошлого сигнала xl (в частности, копирование питча), и состояния декодера АДИКМ обновляются в блоке 302. Стертый фрейм восстанавливается в виде zl=у1. Этот процесс повторяется все время, пока обнаруживают потерю фреймов. Необходимо отметить, что блок экстраполяции 301 не ограничивается только генерированием экстраполированного сигнала на текущем (потерянном) фрейме: он генерирует также 10 мс сигнала для следующего фрейма, чтобы осуществить плавный переход в блоке 303.
Затем после приема нормального фрейма его декодируют в блоке 300 и осуществляют плавный переход 303 в течение первых 10 миллисекунд между нормальным фреймом xl и ранее экстраполированным фреймом у1.
В полосе высоких частот HF стертый фрейм экстраполируется в блоке 305 на основании прошлого сигнала xh, и состояния декодера АДИКМ обновляются в блоке 306. В предпочтительном варианте выполнения экстраполяция yh является простым повторением последнего периода прошлого сигнала xh. Переключатель 307 выбирает канал uh=yh.
Предпочтительно этот сигнал uh фильтруют для получения сигнала vh. Действительно, кодирование G.722 представляет собой рекурсивную предикативную схему кодирования (типа "backword"). В каждой субполосе она использует предсказание типа ARMA (от "Auto-Regressive Moving Average" - авторегрессивный фильтр с подвижным средним значением) и процедуру адаптации шага квантования и адаптации фильтра ARMA, одинаковыми для кодера и для декодера. Предсказание и адаптация шага опираются на декодированные данные (погрешность предсказания, воссозданный сигнал).
Ошибки передачи, в частности потери фреймов, приводят к нарушению синхронизации между переменными величинами декодера и кодера. В этом случае процедуры адаптации шага и предсказания оказываются ошибочными и искаженными в течение большого периода времени (до 300-500 мс). В полосе высоких частот это искажение, кроме проявления других артефактов, может привести к появлению постоянной составляющей очень слабой амплитуды (порядка+/-10 для сигнала максимальной динамики +/-32767). При этом после прохождения через набор фильтров QMF синтеза эта постоянная составляющая оказывается в виде синусоиды на 8 кГц, ощущаемой и очень дискомфортной на слух.
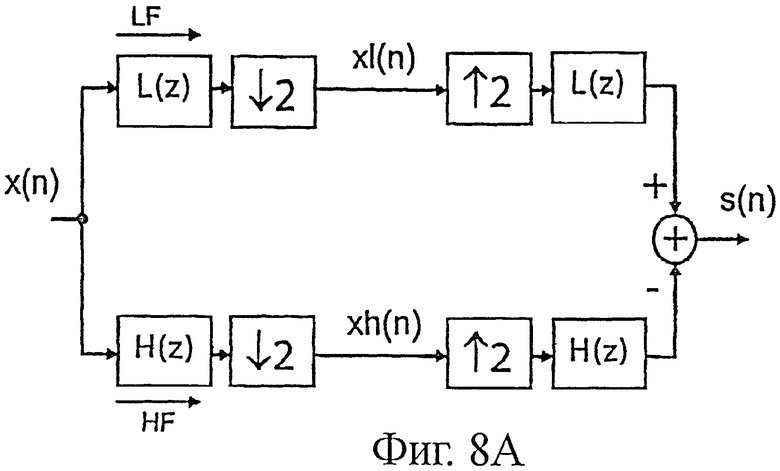
Преобразование постоянной составляющей (или «составляющей DC») в синусоиду 8 кГц будет пояснено ниже. На фиг.8А показан квадратурный набор двухканальных фильтров (QMF). Сигнал х(n) разбивается на две субполосы при помощи набора фильтров анализа. Таким образом получают полосу низких частот х1(n) и полосу высоких частот xh(n). Эти сигналы определяются своей трансформантой в z:
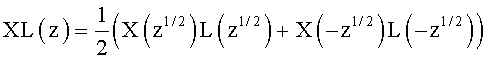
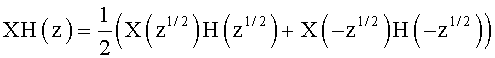
Поскольку фильтры низких частот L(z) и высоких частот H(z) построены по схеме квадратуры, то H(z)=L(-z).
Если L(z) идеально отвечает условиям восстановления, сигнал, получаемый после набора фильтров синтеза, идентичен сигналу х(n) с учетом смещения.
Таким образом, если частотой дискретизации сигнала х(n) является fe', сигналы х1(n) и xh(n) дискретизируют на частоте fe=fe'/2. Обычно fe'=16 кГц, то есть fe'=8 кГц. Кроме того, следует отметить, что фильтры L(z) и H(z) могут быть, например, фильтрами QMF на 24 коэффициента, указанными в техническом описании UIT-T G.722.
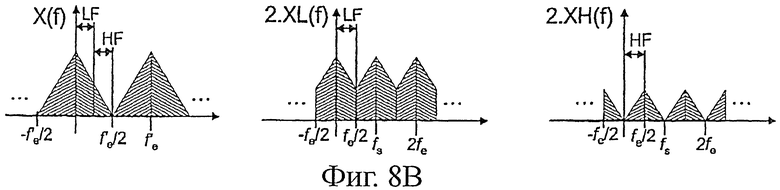
На фиг.8B показан спектр сигналов х(n), х1(n) и xh(n) в случае, когда фильтры L(z) и H(z) являются идеальными полуполосными фильтрами. В идеальном случае частотная характеристика L(z) в интервале [-fe/2, +fe'/2] представляет собой:
|L(f)|=1, если |f|≤fe'/4, и =0 в других случаях.
Отмечается, что спектр xh(n) соответствует свернутой полосе высоких частот. Это свойство свертывания (или "folding на английском языке), хорошо известное специалистам, можно пояснить визуально или при помощи вышеуказанного уравнения, определяющего XH(z). Свертывание высокочастотной полосы претерпевает «инверсию» от набора фильтров синтеза, которые восстанавливают спектр высокочастотной полосы в естественном порядке частот.
Однако на практике фильтры L(z) и H(z) не являются идеальными. Вследствие этого появляется составляющая спектрального свертывания, которая устраняется синтезирующим набором. Вместе с тем полоса высоких частот остается в состоянии инверсии.
В этом случае блок 308 осуществляет фильтрование высоких частот (HPF от "high pass filter"), которое устраняет постоянную составляющую ("DC remove" на английском языке). Использование такого фильтра является предпочтительным, в том числе за рамками коррекции питч-периода в полосе низких частот в соответствии с настоящим изобретением.
Кроме того, использование такого фильтра HPF (блок 308), устраняющего постоянную составляющую в полосе высоких частот, могло бы быть объектом отдельной правовой защиты в общем контексте потери фреймов при декодировании. В целом понятно, что в контексте декодирования принятого сигнала с разделением этого сигнала на полосу высоких частот и полосу низких частот, то есть, по меньшей мере, на два канала, как в декодировании по стандарту G.722, когда происходит потеря сигнала с последующим синтезом заменяющего сигнала, как правило, в канале высоких частот декодера, это может привести к появлению постоянной составляющей в заменяющем сигнале. Эффект этой постоянной составляющей может продолжаться также в декодированном сигнале в течение некоторого времени, когда принимаемый кодированный сигнал опять становится нормальным, по причине нарушения синхронизации между кодером и декодером и с учетом размера памяти фильтров.
Предпочтительно фильтр высоких частот 308 предусматривают на высокочастотном канале. Предпочтительно этот фильтр высоких частот 308 предусматривают, например, на входе набора фильтров QMF этого высокочастотного канала декодера G.722. Такое расположение позволяет избежать свертывания постоянной составляющей на 8 кГц (значение, взятое из частоты дискретизации f'e), когда его применяют для набора фильтров QMF. В более широком смысле, когда в декодере применяют набор фильтров для обработки на высокочастотном канале, предпочтительно на входе этого набора фильтров предусматривают фильтр высоких частот QMF.
Таким образом, если вернуться к фиг.3, переключатель 309 выбирает канал uh=xh до тех пор, пока существует потеря фреймов.
Затем, как только принимают нормальный фрейм, его декодируют при помощи блока 304, и коммутатор 307 выбирает канал uh=xh. В течение нескольких следующих моментов (например, спустя четыре секунды) переключатель 309 выбирает еще канал zh=vh, но по истечении этих нескольких секунд возвращаются к «нормальной» работе, когда переключатель 309 опять выбирает канал zh=uh, обходя блок 308, то есть без применения фильтра высоких частот 308.
В целом понятно, что предпочтительно этот фильтр высоких частот 308 применяют временно (например, несколько секунд) во время или после потери блоков, даже если опять возобновляется прием нормальных блоков. Фильтр 308 можно было бы использовать непрерывно. Однако его активируют только в случае потерь фреймов, так как возмущение, связанное с постоянной составляющей, происходит только в этом случае, поэтому выход модифицированного декодера G.722 (включающего механизм коррекции потерь) идентичен выходу декодера UIT-T G.722 при отсутствии потерь фреймов. Этот фильтр 308 применяют только во время коррекции потерь фреймов и в течение нескольких секунд, следующих за потерей. Действительно, в случае потери происходит нарушение синхронизации между декодером G.722 и кодером в течение периода от 100 до 500 мс после потери и, как правило, постоянная составляющая в полосе высоких частот присутствует только в течение 1-2 секунд. Действие фильтра 308 сохраняют немного дольше для обеспечения запаса надежности (например, четыре секунды).
Более подробно описывать декодер, показанный на фиг.3, не имеет смысла, так как изобретение применяется, в частности, в блоке 301 экстраполяции полосы низких частот. Этот блок 301 детально представлен на фиг.4.
Как показано на фиг.4, экстраполяция полосы низких частот основана на анализе прошлого сигнала х1 (часть фиг.4, обозначенная ANALYS) с последующим синтезом предназначенного для выдачи сигнала у1 (часть фиг.4, обозначенная SYNTH). Блок 400 производит анализ путем линейного предсказания (LPC) на прошлом сигнале х1. Этот анализ аналогичен анализу, осуществляемому, в частности, в кодере стандарта G.729. Он состоит в ограничении сигнала окном, в вычислении автокорреляции и в нахождении коэффициентов линейного предсказания при помощи алгоритма Левинсона-Дурбина. Предпочтительно используют только 10 последних секунд и порядок LPC устанавливают на 8. Таким образом, получают девять коэффициентов LPC (в дальнейшем обозначаемых а0,а1,…ар)в виде:
A(z)=а0+a1 z-1+…+ap z-p при р=8 и а0=1.
После анализа LPC при помощи блока 401 производят вычисление прошлого сигнала возбуждения.. Прошлый сигнал возбуждения обозначается е(n) при n=-М,…, -1, где М соответствует числу прошлых и внесенных в память выборок.
Блок 402 осуществляет оценку основной частоты или ее противоположности: питч-периода Т0. Эту оценку производят, например, аналогично анализу питча (называемому «анализу в открытом контуре», в частности, как в стандартном кодере G.729).
Определенный таким образом питч Т0 используется блоком 402 для экстраполяции возбуждения текущего фрейма.
Кроме того, прошлый сигнал х1 классифицируют в блоке 404. В данном случае можно вести поиск наличия переходных звуков, например, наличия плозивного звука для применения коррекции питч-периода в соответствии с настоящим изобретением, однако в предпочтительном варианте стремятся определить, является ли сигнал Se сильно тонированным (например, когда корреляция по отношению к питч-периоду очень близка к 1). Если сигнал является сильно тонированным (что соответствует произнесению устойчивой гласной, например, «аааа…»), то в этом случае сигнал Se не содержит переходных звуков, и коррекцию питч-периода в соответствии с настоящим изобретением не применяют. Если нет, то во всех других случаях предпочтительно применяют коррекцию питч-периода в соответствии с настоящим изобретением.
Подробности детектирования степени тональности опускаются, так как оно само по себе известно и не входит в рамки настоящего изобретения.
Как показано на фиг.4, синтез SYNTH следует хорошо известной модели, называемой «фильтром-источником». Он состоит в фильтровании экстраполированного возбуждения при помощи фильтра LPC. В данном случае экстраполированное возбуждение е(n) (или, сохраняя n=0,…, L-1, где L является длиной экстраполируемого фрейма) фильтруют при помощи обратного фильтра 1/A(z) (блок 405). После этого полученный сигнал ослабляется блоком 407 в зависимости от ослабления, вычисленного в блоке 406, и в конечном счете выдается в у1.
Собственно изобретение реализуется блоком 403, показанным на фиг.4, все функции которого описаны ниже.
На фиг.5 в качестве примера представлен принцип простого повторения возбуждения, соответствующий известным техническим решениям. Возбуждение можно экстраполировать, просто повторив последний питч-период Т0, то есть копируя последовательность последних выборок прошлого возбуждения, при этом число выборок в этой последней последовательности соответствует числу выборок, которые содержит питч-период Т0.
Как показано на фиг.6, перед повторением последнего питч-периода Т0 его изменяют в соответствии с настоящим изобретением следующим образом.
Для каждой выборки n=-Т0,…, -1 выборку е(n) изменяют на emod(n) согласно формуле типа:
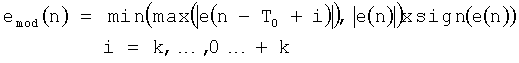
Как было указано выше, предпочтительно это изменение сигнала не применяют,
если сигнал х1 (и, следовательно, входной сигнал Se) является сильно тонированным. Действительно, в случае сильно тонированного сигнала простое повторение последнего питч-периода без изменения может дать лучший результат, тогда как изменение последнего питч-периода и его повторение могут привести к небольшому ухудшению качества.
На фиг.7 в виде блок-схемы показана обработка, соответствующая применению этой формулы, для иллюстрации этапов способа согласно варианту выполнения изобретения. В данном случае начинают с прошлого сигнала е(n), который поступает из блока 401. На этапе 70 получают информацию о том, является ли сигнал х1 сильно тонированным или нет, при помощи модуля 404, определяющего степень тональности. Если сигнал является сильно тонированным (стрелка О на выходе теста 71), последний питч-период нормальных блоков копируют без изменения в блок 403, показанный на фиг.4, и после этого обработку продолжают путем простого применения обратного фильтрования 1/A(z) при помощи модуля 405.
Если же, наоборот, сигнал х1 не является сильно тонированным (стрелка N на выходе теста 71), то стремятся изменить последние выборки сигнала возбуждения е(n), соответствующие последним принятым нормальным блокам, причем эти выборки располагаются по всему питч-периоду Т0 (этап 73), полученному при помощи модуля 402, показанному на фиг.4 (на этапе 72). В варианте выполнения, показанном на фиг.7, стараются изменить все выборки е(n) по всему питч-периоду Т0, при этом е(n) находится между nl - Т0+1 и nl, при этом e(nl) соответствует, таким образом, последней принятой нормальной выборке (этап 74). С учетом этих положений понятно, что выборка е(n), где n находится между nl - Т0+1 и nl, просто принадлежит к последнему нормально принятому питч-периоду.
На этапе 75 с каждой выборкой е(n) последнего питч-периода приводят в соответствие окружение NEIGH в предыдущем питч-периоде, то есть в предпоследнем питч-периоде. Эта мера является предпочтительной, но ни в коем случае не обязательной. Ее преимущество будет описано ниже. Сейчас просто отметим, что в описанном примере окружение содержит нечетное число выборок 2k+1. Разумеется, в варианте это число может быть четным. Кроме того, в примере, показанном на фиг.6, k=1. Действительно, рассматривая фиг.6, можно отметить, что выбрана (этап 74) третья выборка третьего питч-периода, обозначенная е(3), и связанные с ней выборки окружения NEIGH в предпоследнем питч-периоде (этап 75) показаны жирными линиями: е(2-Т0), е(3-Т0) и е(4-Т0). Таким образом, они сосредоточены вокруг е(3-Т0).
На этапе 76 из выборок окружения NEIGH выбирают максимальную выборку по абсолютной величине (то есть выборку е(2-Т0) в примере, показанном на фиг.6). Этот отличительный признак является предпочтительным, но не обязательным. Его преимущество будет показано ниже. Обычно, в варианте, можно отдать предпочтение определению, например, средней выборки из окружения NEIGH.
На этапе 77 определяют минимум по абсолютной величине между значением текущей выборки е(n) и значением максимума М, найденного в окружении NEIGH на этапе 76. В примере, показанном на фиг.6, этот минимум между е(3) и е(2-Т0) и является выборкой предпоследнего питч-периода е(2-Т0). На этом же этапе 77 амплитуду текущей выборки е(n) заменяют этим минимумом. На фиг.6 амплитуда выборки е(3) становится равной амплитуде выборки е(2-Т0). Эту же процедуру применяют для всех выборок последнего периода от е(1) до е(12). На фиг.6 скорректированные выборки показаны пунктирной линией. Выборки экстраполированных питч-периодов Tj+1, Tj+2, скорректированные в соответствии с настоящим изобретением, показаны закрытыми стрелками.
Таким образом, понятно, что благодаря предпочтительному применению этого этапа 77, если в последнем питч-периоде Tj присутствует плозив (высокая интенсивность сигнала по абсолютной величине, как показано на фиг.6), то определяют минимум между этой интенсивностью плозивного звука и интенсивностью выборок по существу в такой же временной позиции в предыдущем питч-периоде (термин «по существу» в данном случае значит «с учетом окружения ±k», в чем и состоит преимущество этапа 75), и, в случае необходимости, интенсивность плозивного звука заменяют более низкой интенсивностью, принадлежащей к предпоследнему питч-периоду Tj-1. Если же интенсивность выборок последнего питч-периода Tj меньше интенсивности предпоследнего периода Tj-1, то, выбирая минимум между текущей выборкой е(3) и значением интенсивности е(2-Т0) в предпоследнем питч-периоде Tj-1, последний период не изменяют и, таким образом, избегают риска копирования плозивного звука (высокой интенсивности) из предпоследнего питч-периода Tj-1.
Таким образом, на этапе 76 определяют максимум М по абсолютной величине из выборок окружения (а не другой параметр, например, такой как среднее значение в этом окружении), компенсируя тем самым эффект выбора минимума на этапе 77 осуществления замены значения е(n). Эта мера позволяет, таким образом, не слишком ограничивать амплитуду питч-периодов замены Tj+1, Tj+2 (фиг.6).
Кроме того, предпочтительно применяют этап 75 определения окружения, так как питч-период не всегда является регулярным, и, если выборка е(n) имеет максимальную интенсивность в питч-периоде е(n+Т0), то это не всегда происходит с выборкой е(n+Т0) в следующем питч-периоде. Кроме того, питч-период может продолжаться до временной позиции, попадающей между двумя выборками (на данной частоте дискретизации). При этом говорят о «дробном питче». Поэтому всегда предпочтительно брать окружение вокруг выборки е(n-Т0), если эту выборку е(n-Т0) необходимо связать с выборкой е(n), позиционированной в следующем питч-периоде.
Наконец, поскольку обработка на этапах 75-77 ведется в основном по абсолютным значениям выборок, то на этапе 78 измененной выборке emod(n) просто опять присваивают знак исходной выборки е(n).
Этапы 75-78 повторяют для следующей выборки е(n) (n перед n+1 на этапе 79) до завершения питч-периода Т0 (то есть до прихода к последней нормальной выборке e(nl)).
Таким образом, для продолжения декодирования на обратный фильтр 1/A(z) (на фиг.4 обозначен позицией 405) выдают измененный сигнал emod(n).
Вместе с тем, следует отметить также еще два возможных варианта выполнения.
Так, можно корректировать последний питч-период Tj, применить эту коррекцию Tj' к этому последнему питч-периоду Tj и копировать коррекцию для следующих питч-периодов, то есть: Tj=Tj+1=Tj+2=Tj '.
В варианте последний питч-период Tj не трогают, но зато его коррекцию Tj' копируют в следующие питч-периоды Tj+1 и Tj+2.
При сравнении фиг.5 и 6 видно преимущество производимого таким образом изменения возбуждения. Таким образом, в случае, когда в последнем питч-периоде присутствует плозив, то этот период автоматически удаляют перед повторением питча, так как он не будет иметь эквивалента в предпоследнем питч-периоде. Таким образом, этот вариант выполнения позволяет устранить один из наиболее нежелательных артефактов повторения питча, состоящий в повторении плозивных звуков.
Кроме того, предпочтительно предусматривают более быстрое ослабление синтезированного и повторяемого сигнала, если в последнем питч-периоде обнаружен плозив. Пример осуществления обнаружения переходного звука, как правило, может
состоять в подсчете числа появлений следующего условия:
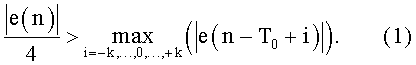
Если это условие проверяется, например, более одного раза на текущем фрейме, значит прошлый сигнал х1 содержит переходный звук (например, плозив), что позволяет произвести быстрое ослабление при помощи блока 406 на сигнале синтеза у1 (например, ослабление на 10 мс).
На фиг.2С показан декодированный сигнал при применении настоящего изобретения в сравнении с фиг.2А и 2B, на которых фрейм, содержащий плозив /t/ потерян. Благодаря изобретению, можно избежать повторения фонемы /t/. Отличия, которые отмечаются после потери фрейма, не связаны собственно с детектированием плозивов. На самом деле ослабление сигнала после потери фрейма на фиг.2 объясняется тем, что в этом случае повторно инициализируют декодер G.722 (полное обновление состояний в блоке 302, показанном на фиг.3), тогда как в случае фиг.2B декодер G.722 повторно не инициализируют. При этом понятно, что изобретение касается детектирования плозивов для экстраполяции стертого фрейма и не рассматривает проблему повторного запуска после потери фрейма. Вместе с тем, при прослушивании сигнал, показанный на фиг.2С, является более качественным, чем сигнал, показанный на фиг.2B.
Объектом настоящего изобретения является также компьютерная программа, предназначенная для хранения в памяти устройства синтеза цифрового аудиосигнала. Эта программа содержит команды для осуществления способа в соответствии с настоящим изобретением, когда его выполняют при помощи процессора такого устройства синтеза. Кроме того, описанная выше фиг.7 может иллюстрировать блок-схему такой компьютерной программы.
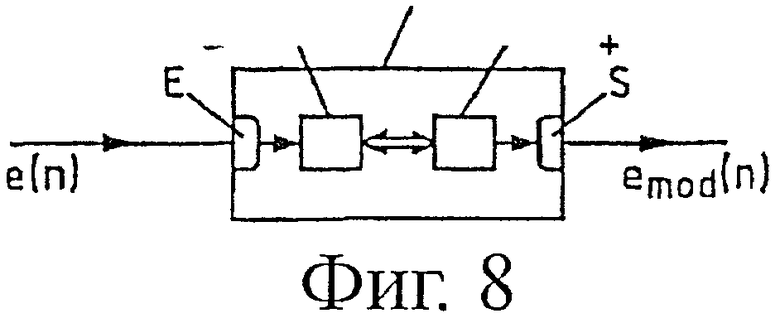
Кроме того, объектом настоящего изобретения является также устройство синтеза цифрового аудиосигнала, состоящего из множества блоков. Это устройство может содержать память, в которую записывают вышеуказанную компьютерную программу, и может представлять собой блок 403, показанный на фиг.4, с описанными выше функциональными возможностями. Как показано на фиг.8, это устройство SYN содержит:
- вход Е для приема блоков сигнала е(n), предшествующих, по меньшей мере, одному текущему блоку, предназначенному для синтеза, и
- выход S для выдачи синтезированного сигнала emod(n), содержащего, по меньшей мере, один синтезированный текущий блок.
Устройство синтеза SYN в соответствии с настоящим изобретением содержит такие средства, как рабочая память MEM (или память для хранения вышеуказанной компьютерной программы) и процессор PROC, взаимодействующий с этой памятью MEM, для осуществления способа в соответствии с настоящим изобретением и для синтеза текущего блока на основании, по меньшей мере, одного из предыдущих блоков сигнала е(n).
Объектом настоящего изобретения является также декодер цифрового аудиосигнала, состоящего из последовательности блоков, при этом декодер содержит устройство 403 в соответствии с настоящим изобретением для синтеза дефектных блоков.
Настоящее изобретение не ограничивается описанными выше и представленными в качестве примеров вариантами выполнения и охватывает другие варианты.
В вариантах выполнения параметрами коррекции питч-периода и/или детектирования переходных звуков могут быть следующие параметры. Можно рассматривать интервал, содержащий число выборок в предпоследнем питч-периоде, отличное от трех. Можно взять, например, k=2, чтобы получить всего пять рассматриваемых блоков. Точно так же можно адаптировать пороговое значение для детектирования переходного звука (1/4 в примере вышеуказанного условия (1)). Кроме того, сигнал можно считать переходным, если условие детектирования не проверяется, по меньшей мере, m раз, при m≥. 1.
Кроме того, изобретение можно применять в другом контексте, отличном от описанного выше.
Например, детектирование и изменение сигнала можно осуществлять в области сигнала (а не в области возбуждения). Обычно для коррекции потерь фреймов в декодере CELP (который работает по модели фильтра-источника) возбуждение экстраполируют путем повторения питча и, в случае необходимости, добавления произвольного элемента и это возбуждение фильтруют при помощи фильтра типа 1/A(z), где A(z) является производным последнего правильно принятого предикативного фильтра.
Естественно, изобретение можно применять также для декодера согласно стандарту G.711.
Разумеется, простое копирование предпоследнего питч-периода Tj-1 для получения новых синтезированных периодов Tj+1, Tj+2 уже само по себе позволяет решить проблему повторения плозивов, если, кроме всего прочего, производить детектирование плозивов в предпоследнем питч-периоде (например, используя условие типа вышеуказанного условия (1)). Этот вариант выполнения входит в рамки изобретения.
Кроме того, для большей ясности изложения была описана коррекция выборок на этапе б) с последующим копированием скорректированных выборок в заменяющий(ие) блок(и). Разумеется, можно технически строго эквивалентно сначала копировать выборки последнего периода повторения и затем корректировать все эти выборки в заменяющем(их) блоке(ах). Таким образом, коррекция выборок и копирование могут быть этапами, которые можно осуществлять в любом порядке и, в частности, можно менять местами.
Изобретение касается изменения сигнала перед повторением питч-периода для синтеза блоков, потерянных при декодировании цифровых аудиосигналов. Влияния повторения переходных звуков, таких как плозивных звуки речевого сигнала, избегают, сравнивая выборки питч-периода с выборками предыдущего питч-периода. Предпочтительно сигнал изменяют, выбирая минимум между текущей выборкой (е(3)) последнего питч-периода (Тj) и, по меньшей мере, одной выборкой (е(2-Т0)) по существу в том же положении в предыдущем питч-периоде (Tj-1). Технический результат - повышение качества декодирования при потере блоков данных. 3 н. и 9 з.п. ф-лы, 12 ил.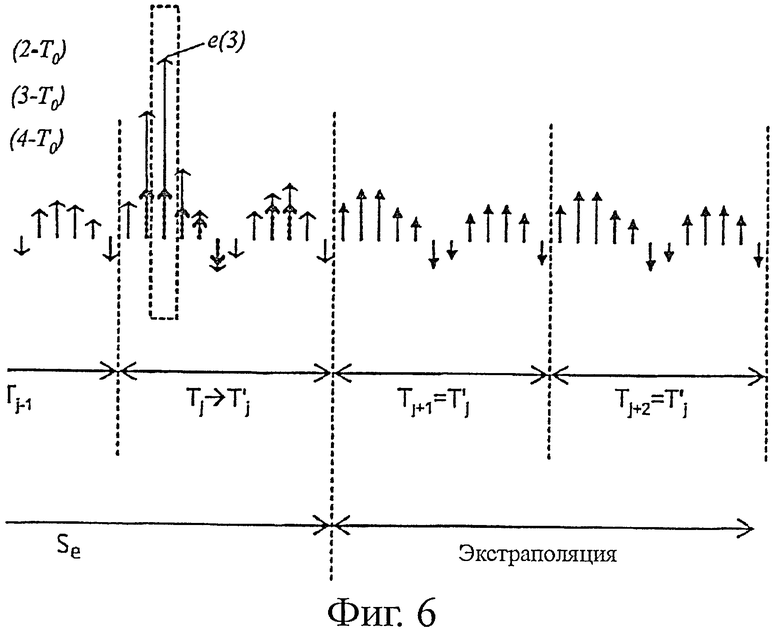
1. Способ синтеза цифрового аудиосигнала, представленного в виде последовательных блоков выборок, в котором после получения такого сигнала, чтобы заменить, по меньшей мере, один дефектный блок, на основании выборок, по меньшей мере, одного нормального блока генерируют заменяющий блок,
при этом способ содержит следующие этапы:
а) определяют (402) период повторения сигнала, по меньшей мере, в одном нормальном блоке, и
б) выборки периода повторения копируют (403), по меньшей мере, в один заменяющий блок,
отличающийся тем, что:
на этапе а) определяют последний период повторения (Tj), по меньшей мере, в одном нормальном блоке, непосредственно предшествующем дефектному блоку, и
на этапе б) выборки (е(3)) указанного последнего периода повторения (Тj) корректируют в зависимости от выборок (е(2-Т0), е(3-Т0), е(4-Т0)) периода повторения (Тj-1), предшествующего указанному последнему периоду повторения, таким образом, чтобы ограничить амплитуду возможного переходного сигнала в указанном последнем периоде повторения, и скорректированные таким образом выборки копируют в указанный заменяющий блок (Tj+1, Tj+2).
2. Способ по п.1, в котором сигнал является тональным, отличающийся тем, что период повторения является питч-периодом, соответствующим противоположности основной частоты сигнала.
3. Способ по п.1, отличающийся тем, что на этапе б) корректируют текущую выборку (е(3)) последнего периода повторения, сравнивая:
амплитуду этой текущей выборки по абсолютной величине,
с амплитудой по абсолютной величине, по меньшей мере, одной выборки (е(2-Т0)), временно позиционированной, по существу, в один период повторения перед текущей выборкой, и текущей выборке придают наименьшую амплитуду по абсолютной величине из этих двух амплитуд.
4. Способ по п.3, отличающийся тем, что для текущей выборки (е(3)) последнего периода повторения:
определяют набор выборок (75) в окружении, сосредоточенном вокруг выборки (е(3-Т0)), временно позиционированной в периоде повторения перед текущей выборкой,
определяют амплитуду, выбираемую (76) из амплитуд выборок указанного окружения, взятых по абсолютной величине,
и эту выбранную амплитуду сравнивают с амплитудой текущей выборки по абсолютной величине для придания (77) текущей выборке (е(3)) наименьшей амплитуды по абсолютной величине среди выбранной амплитуды и амплитуды текущей выборки.
5. Способ по п.4, отличающийся тем, что амплитуда, выбранная среди амплитуд выборок указанного окружения, является максимальной амплитудой по абсолютной величине (М).
6. Способ по п.1, в котором цифровой аудиосигнал является речевым сигналом, отличающийся тем, что детектируют степень тональности в речевом сигнале (71), и тем, что этапы а) и б) применяют, если речевой сигнал не тонирован или слабо тонирован.
7. Способ по п.1, в котором применяют ослабление амплитуды выборок в указанном заменяющем блоке, отличающийся тем, что детектируют возможный переходный характер сигнала в последнем периоде повторения и, в случае необходимости, применяют более быстрое ослабление, чем для стационарного сигнала.
8. Способ по п.7, в котором на этапе б) корректируют текущую выборку последнего периода повторения, сравнивая:
амплитуду этой текущей выборки по абсолютной величине,
с амплитудой по абсолютной величине, по меньшей мере, одной выборки, временно позиционированной, по существу, в один период повторения перед текущей выборкой,
и текущей выборке придают наименьшую амплитуду по абсолютной величине из этих двух амплитуд, отличающийся тем, что:
для нескольких текущих выборок последнего периода повторения измеряют отношение по абсолютной величине амплитуды текущей выборки к указанной выбранной амплитуде, и
подсчитывают число проявлений для указанных текущих выборок, при которых указанное отношение превышает первый заранее определенный порог, и
детектируют присутствие переходного характера, если число проявлений превышает второй заранее определенный порог.
9. Способ по п.1, отличающийся тем, что в случае приема нескольких последовательных дефектных блоков, укладывающихся, по меньшей мере, в один период повторения, этап коррекции выборок б) применяют для всех выборок последнего периода повторения, рассматриваемых одна за другой в качестве текущей выборки.
10. Способ по п.9, отличающийся тем, что в случае приема нескольких последовательных дефектных блоков, распределенных в нескольких периодах повторения, для замены указанных нескольких дефектных блоков копируют несколько раз период повторения, скорректированньй на этапе б), для формирования заменяющих блоков.
11. Устройство синтеза цифрового аудиосигнала, состоящего из множества блоков, содержащее:
вход (Е) для приема блоков сигнала (е(n)), предшествующих, по меньшей мере, одному текущему блоку, предназначенному для синтеза, и
выход (S) для выдачи синтезированного сигнала (emod(n)), содержащего, по меньшей мере, указанный текущий блок,
отличающееся тем, что содержит средства: рабочая память (MEM) и процессор (PROC) для осуществления способа по одному из пп.1-10 для синтеза текущего блока на основании, по меньшей мере, одного из указанных предыдущих блоков.
12. Декодер цифрового аудиосигнала, состоящего из последовательности блоков, отличающийся тем, что дополнительно содержит устройство (403) по п.11 для синтеза дефектных блоков.
| US 6597961 B1, 2003.07.22 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| RU 2004138286 A, 2005.06.10 | |||
| US 5740187 A, 1998.04.14 | |||
| УСТРОЙСТВО И СПОСОБ МАСКИРОВАНИЯ ПОСЛЕДСТВИЙ ПОТЕРИ КАДРОВ | 1994 |
|
RU2120141C1 |
| US 5805469 A, 1998.09.08. | |||

