Изобретение относится к обработке цифровых аудиосигналов, таких как речевые сигналы в области телекоммуникации, в частности к декодированию таких сигналов.
Можно вкратце напомнить, что речевой сигнал может быть предсказан на основании его непосредственного прошлого (например, 8-12 выборок при 8 кГц) при помощи параметров, определяемых в коротких окнах (в данном примере от 10 до 20 мс). Эти параметры краткосрочного предсказания, характеризующие функцию передачи голосового канала (например, при произнесении согласных), получают при помощи методов анализа LPC (от «Linear Prediction Coding» или «кодирование с линейным предсказанием»). Применяют также более долговременную корреляцию для определения периодичности тональных звуков (например, гласных), связанной с вибрацией голосовых связок. Таким образом, речь идет об определении, по меньшей мере, основной частоты тонального сигнала, которая обычно меняется от 60 Гц (низкий голос) до 600 Гц (высокий голос) в зависимости от говорящих. При этом при помощи анализа LTP (от «Long Term Prediction» или «долговременное предсказание») определяют параметры LTP долговременного предиктора и, в частности, противоположность основной частоты, часто называемую «питч-периодом». При этом определяют число выборок в питч-периоде при помощи соотношения Fe/F0 (или его целой части), где:
- Fe - частота дискретизации,
- F0 - основная частота.
Таким образом, можно отметить, что параметры долговременного предсказания LTP, в том числе питч-период, характеризуют основную вибрацию речевого сигнала (если он является тональным), тогда как параметры краткосрочного предсказания LPC характеризуют спектральную оболочку этого сигнала.
Все эти параметры LPC и LTP, проявляющиеся в результате речевого кодирования, передаются в виде блоков в соответствующий декодер через одну или несколько телекоммуникационных сетей для последующего восстановления первоначального речевого сигнала.
В рамках поблочной передачи таких сигналов может произойти потеря одного или нескольких последовательных блоков. Под термином «блок» следует понимать последовательность данных сигнала, которая может быть фреймом в мобильной радиосвязи или пакетом, например, при передаче на IP («Internet Protocol») и т.д.
В области мобильной радиосвязи, например, большинство технологий кодирования путем предикативного синтеза и, в частности, кодирование типа CELP (от «Code Excited Linear Predictive») предлагают решения для восстановления стертых фреймов. В декодер поступает информация о появлении стертого фрейма, например, путем передачи информации о стирании фрейма, поступающей от канального кодера. Задачей восстановления стертых фреймов является экстраполяция параметров стертого фрейма на основании одного или нескольких предыдущих фреймов, которые считаются нормальными. Некоторые параметры, которыми манипулируют или которые кодируют предикативные кодеры, характеризуются сильной корреляцией между фреймами. Обычно речь идет о параметрах долговременного предсказания LTP, например, для тональных звуков и о параметрах краткосрочного предсказания LPC. С учетом этой корреляции более предпочтительным является повторное использование параметров последнего нормального фрейма, чем использование случайных и даже ошибочных параметров.
Классически при генерировании возбуждения CELP параметры стертого фрейма получают следующим образом.
Параметры LPC восстанавливаемого фрейма получают на основании параметров LPC последнего нормального фрейма путем простого копирования параметров или с дополнительным применением определенного ослабления (технология, применяемая, например, в кодере стандарта G723.1). После этого детектируют тональность или ее отсутствие в речевом сигнале для определения степени гармоничности сигнала на уровне стертого фрейма.
Если сигнал не является тональным, то сигнал возбуждения может быть генерирован произвольно (путем копирования кодового слова прошлого возбуждения, путем легкого уменьшения коэффициента усиления прошлого возбуждения, путем произвольного выбора в прошлом возбуждении или путем использования переданных кодов, которые могут быть полностью ошибочными).
Если сигнал является тональным, то питч-периодом (называемым также «задержкой LTP»), как правило, является период, рассчитанный для предыдущего фрейма, в случае необходимости с легким «дрожанием» (увеличение значения задержки LTP для фреймов последовательной ошибки, при этом коэффициент усиления LTP берут близким к 1 или равным 1). Таким образом, сигнал возбуждения ограничивается долговременным предсказанием, осуществляемым на основании прошлого возбуждения.
Средства маскирования стертых фреймов при декодировании, как правило, тесно связаны с конструкцией декодера и могут быть общими для модулей этого декодера, как, например, модуль синтеза сигнала. Эти средства используют также промежуточные сигналы, имеющиеся в наличии внутри декодера, например прошлый сигнал возбуждения, сохраненный в памяти во время обработки нормальных фреймов, предшествующих стертым фреймам.
В некоторых технологиях, применяемых для маскирования ошибок, производимых пакетами, потерянными во время передачи данных, закодированных путем кодирования временного типа, часто используют способы замены формы волн. Такие технологии призваны восстанавливать сигнал путем выбора порций сигнала, декодированного до момента потери, и не прибегают к моделям синтеза. Применяют также технологии сглаживания, чтобы избежать артефактов, проявляющихся при конкатенации различных сигналов.
В случае декодеров, работающих на сигналах, кодированных при помощи кодирования трансформантой, технологии восстановления стертых фреймов, как правило, опираются на применяемую структуру кодирования. Некоторые технологии предназначены для регенерации потерянных трансформированных коэффициентов на основании значений, которые эти коэффициенты принимали до стирания.
Одновременно с канальным кодированием были разработаны технологии маскирования стертых фреймов. Они используют данные, поставляемые канальным декодером, например данные, связанные со степенью надежности принятых параметров. В нашем случае следует отметить, что объект настоящего изобретения не предполагает наличия канального кодера.
В документе Combescure et al.: "А 16,24,32 kbit/s Wideband Speech Codec Based on ATCELP", P.Combescure, J.Schnitzler, K.Ficher, R.Kirchherr, C.Lamblin, A.Le Guyader, D.Massaloux, C.Quinquis, J.Stegmann, P.Vary, Proceedings Conference ICASSP (1998), было предложено использовать метод маскирования стертых фреймов, эквивалентный методу, используемому в кодерах CELP для кодирования трансформантой.
Недостатком этого метода было введение ощущаемых на слух спектральных искажений («синтетический» голос, паразитные резонансы и т.д.). Эти недостатки были связаны, в частности, с использованием плохо контролируемых фильтров долговременного синтеза (единая гармоничная составляющая по тональным звукам, использование части остаточного прошлого сигнала в виде не тональных звуков). Кроме того, в данном случае контроль энергии происходит на уровне сигнала возбуждения, и энергетическую мишень этого сигнала сохраняют постоянной во время всей продолжительности стирания, что тоже приводит к появлению ощущаемых на слух дискомфортных артефактов.
В документе FR-2,813,722 была предложена технология маскирования стертых фреймов, не генерирующая искажений при более высоких коэффициентах ошибок и/или для более длинных стертых интервалов. Эта технология позволяет избежать избытка периодичности для тональных звуков и лучше контролировать генерирование не тонального возбуждения. Для этого сигнал возбуждения (если он является тональным) рассматривают как сумму двух сигналов:
- сильно гармоническая составляющая, ограниченная по полосе низких частот общего спектра, и
- другая, менее гармоническая, составляющая, ограниченная более высокими частотами.
Сильно гармоническую составляющую получают путем фильтрования LTP. Вторую составляющую тоже получают фильтрованием LTP, которое делают не периодическим путем случайного изменения его основного периода.
Главная проблема технологий маскирования ошибок, использовавшихся до сих пор в кодерах CELP, кроется в генерировании тонального возбуждения, которое при потере нескольких последовательных фреймов может создать эффект чрезмерной тональности, связанный с повторением одного и того же питч-периода на нескольких фреймах.
Настоящее изобретение призвано устранить этот недостаток.
В этой связи изобретением предлагается способ синтеза цифрового аудиосигнала, состоящего из последовательных блоков выборок, в котором при получении такого сигнала, чтобы заменить, по меньшей мере, один дефектный блок, генерируют заменяющий блок на основании выборок, по меньшей мере, одного нормального блока, предшествующего дефектному блоку.
Способ в соответствии с настоящим изобретением содержит следующие этапы:
а) выбирают определенное число выборок, образующих последовательность, по меньшей мере, в последнем нормальном блоке, предшествующем дефектному блоку,
б) последовательность выборок разбивают на группы выборок и, по меньшей мере, в одной группе выборок производят инверсию выборок согласно заранее определенным правилам,
в) группы, по меньшей мере, в некоторых из которых выборки были инвертированы на этапе б), опять объединяют для формирования, по меньшей мере, части заменяющего блока, и
г) если указанная часть, полученная на этапе в), не заполняет заменяющий блок полностью, указанную часть копируют в заменяющий блок и для указанной скопированной части опять применяют этапы а), б), в).
Целью этой инверсии выборок, которая представляет собой очень простое и недорогое манипулирование с точки зрения расчетов и средств обработки, является «ослабление» чрезмерной гармоничности, которая могла бы иметь место, если бы применяли простое копирование питч-периода.
Таким образом, одним из преимуществ настоящего изобретения является дешевизна и простота вычисления при его применении.
Предпочтительно изобретение применяют в случае, когда цифровой аудиосигнал является тональным сигналом и, в частности, слабо тонированным сигналом, так как в этом случае простое копирование питч-периода не дает ощутимых результатов. Таким образом, согласно предпочтительному отличительному признаку, в речевом сигнале детектируют степень тональности и применяют этапы а)-г) если сигнал является, по меньшей мере, слабо тонированным.
Предпочтительно настоящее изобретение отталкивается от основной частоты цифрового аудиосигнала для формирования групп на этапе б). Так, предпочтительно на этапе а):
a1) детектируют тон в цифровом аудиосигнале,
а2) указанное определенное число выборок, выбранных на этапе а), соответствует числу выборок, которое содержит период, соответствующий противоположности основной частоты детектированного тона.
Разумеется, в случае речевого сигнала операция a1) может состоять в детектировании тональности и операция а2, если сигнал является тонированным, может состоять в выборе числа выборок, которые расположены по всему питч-периоду (противоположности основной частоту тона голоса). Однако следует отметить, что этот вариант выполнения может также касаться сигнала, отличного от речевого сигнала, в частности музыкального сигнала, если в нем можно детектировать основную частоту, характерную для общего тона музыки.
В варианте выполнения разбивку на этапе б) осуществляют группами по две выборки и производят инверсию положений выборок между собой в одной группе.
Однако в этом варианте выполнения следует выделить случай, когда питч-период (или в целом обратный период основной частоты) содержит четное или нечетное число выборок. В частности, если число выборок, которые содержит период детектированного тона, является четным, предпочтительно в этот период добавляют или из него удаляют нечетное число выборок (предпочтительно только одну выборку) для формирования выбора на этапе а).
Следует также уточнить, что понимают под «заранее определенными правилами инверсии». Эти правила, которые можно выбирать в зависимости от характеристик принятого сигнала, предусматривают, в частности, число выборок по группам на этапе б) и способ инверсии выборок в группе. В вышеуказанном варианте выполнения предусматривают группы из двух выборок и простую инверсию соответствующих положений этих двух выборок. Вместе с тем, возможны и другие конфигурации (группы, содержащие более двух выборок, и перестановка всех выборок в таких группах). Кроме того, правила инверсии могут также фиксировать число групп, в которых производится инверсия. Частный вариант выполнения предусматривает случайность появлений инверсии выборок в каждой группе и фиксирование порога вероятности, чтобы производить или не производить инверсию выборок группы. Этот порог вероятности может иметь фиксированное значение или переменное значение и предпочтительно может зависеть от функции корреляции, касающейся питч-периода. В этом случае формальное определение питч-периода само по себе не является обязательным. Кроме того, в целом обработку в соответствии с настоящим изобретением можно также осуществлять, если принятый нормальный сигнал просто не является тональным, и в этом случае реально не существует детектируемого периода. В этом случае можно предусмотреть произвольное данное число выборок (например, двести выборок) и осуществлять обработку в соответствии с настоящим изобретением на этом числе выборок. Можно также взять значение, соответствующее максимуму функции корреляции, ограничив поиск в интервале значения (например, между MAX_PITCH/2 и MAX_PITCH, где MAX_PITCH является максимальным значением в поиске питч-периода).
Настоящее изобретение, предлагающее ослабление чрезмерной тональности, имеет следующие преимущества:
- речь, синтезированная при потере блока, практически не содержит явления чрезмерной гармоничности или чрезмерной тональности,
- для генерирования тонального возбуждения требуется очень низкая степень сложности, что будет показано ниже в подробном описании примера выполнения.
Другие преимущества и отличительные признаки настоящего изобретения будут более очевидны из нижеследующего подробного описания, представленного в качестве примера, со ссылками на прилагаемые чертежи, на которых:
фиг.1 - принцип генерирования возбуждения, позволяющего ослабить эффект чрезмерной тональности, с применением произвольной инверсии выборок на блоках из двух выборок и с вероятностью 50% в представленном примере по всему питч-периоду;
фиг.2 - принцип генерирования возбуждения с применением инверсии выборок, в данном случае систематической, на блоках из двух выборок в представленном примере и по всему питч-периоду;
фиг.3a - применение систематической инверсии, показанной на фиг.2, на сигнале, в котором произвели оценку питч-периода, содержащего нечетное число выборок;
фиг.3b - иллюстрация применения систематической инверсии, показанной на фиг.2, на сигнале, в котором произвели оценку питч-периода, содержащего четное число выборок;
фиг.3c - применение систематической инверсии, показанной на фиг.2, в данном случае с коррекцией путем добавления выборки к продолжительности, соответствующей питч-периоду, чтобы сделать эту продолжительность нечетной с точки зрения числа содержащихся в ней выборок;
фиг.4 - схема основных этапов способа в соответствии с настоящим изобретением при декодировании;
фиг.5 - очень схематичный вид конструкции прибора для приема цифрового аудиосигнала, содержащего устройство синтеза для осуществления способа в соответствии с настоящим изобретением.
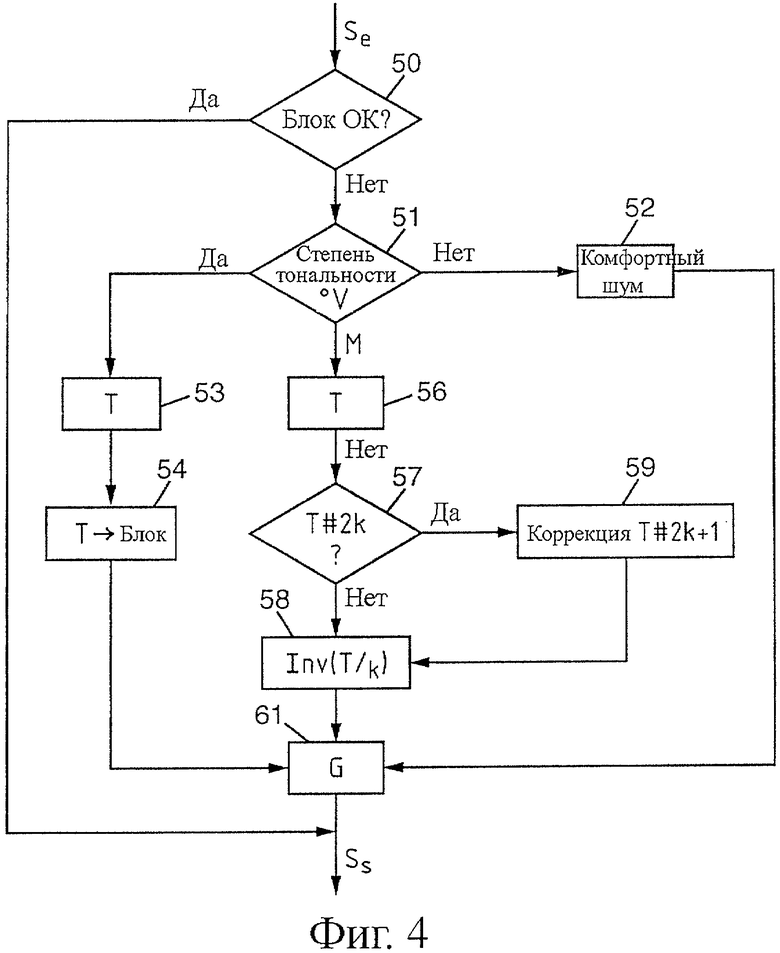
Для иллюстрации контекста применения настоящего изобретения обратимся сначала к фиг.4. При приеме входного сигнала Se во время декодирования детектируют (тест 50) потерю одного или нескольких последовательных блоков. Если не отмечается потери блока (стрелка Да на выходе теста 50), никаких проблем не возникает и обработка, показанная на фиг.4, завершается.
Если же обнаруживается потеря одного или нескольких последовательных блоков (стрелка Нет на выходе теста 50), то в этом случае детектируют степень тональности (тест 51) сигнала.
Если сигнал не является тональным (стрелка Нет на выходе теста 51), потерянные блоки заменяют, например, воспринимаемым на слух «белым» шумом, называемым «комфортным шумом» 52, и корректируют коэффициент усиления 61 восстановленных таким образом выборок блоков. Например, можно осуществлять контроль энергии восстановленного сигнала Ss с адаптацией закона изменения и/или изменять параметры модели в сторону сигнала покоя, такого как комфортный шум 52.
В варианте настоящего изобретения рассматриваются только два класса сигналов: с одной стороны, тональные сигналы и, с другой стороны, слабо тонированные или не тональные сигналы. Преимущество этого варианта заключается в том, что генерирование не тонального сигнала идентично синтезу слабо тонированного сигнала. Как было указано выше, «питч-период», используемый для не тональных сигналов, представляет собой произвольное значение, предпочтительно достаточно большое (например, двести выборок). В не тональном блоке предыдущий сигнал является не гармоничным, и, применяя обработку в соответствии с настоящим изобретением для достаточно большого периода, обеспечивают сохранение негармоничности генерированного таким образом сигнала. Предпочтительно природа сигнала сохраняется, чего не происходит в случае использования произвольно генерированного сигнала (например, белого шума).
Если сигнал является сильно тонированным (стрелка Да на выходе теста 51), потерянные блоки заменяют путем копирования питч-периода Т. Следовательно, определяют питч-период Т, идентифицированный в остающейся нормальной последней части принятого сигнала Se (при помощи любой известной технологии 53). Затем выборки этого питч-периода Т копируют в потерянные блоки (позиция 54). После этого применяют соответствующий коэффициент усиления 61 для замененных таким образом выборок (например, для осуществления ослабления или "fading").
В описанном примере, если сигнал является умеренно тональным (или в менее сложном, но более общем варианте, если сигнал просто является тональным), применяют способ в соответствии с настоящим изобретением (стрелка М на выходе теста 51 на степень тональности).
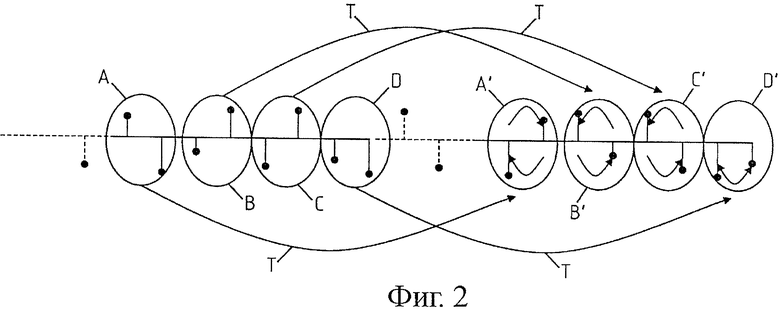
Показанный на фиг.1 и 2 принцип изобретения состоит в объединении выборок последних принятых нормальных блоков в группы, по меньшей мере, из двух выборок. В примере, показанном на фиг.1 и 2, действительно, эти выборки сгруппированы по две в группе. Вместе с тем, их можно группировать более чем по две выборки, и в этом случае следует слегка адаптировать подробно описанные ниже правила инверсии выборок по группам и учета паритетности по числу выборок питч-периода Т.
В частности, показанные на фиг.2 группы A, B, C, D из двух выборок в последних принятых нормальных блоках скопированы и связаны с последними принятыми выборками. Однако в этих скопированных группах, обозначенных A', B', C', D', была произведена инверсия значений двух выборок в каждой группе (или их значение сохранено и произведена инверсия их соответствующих положений). Так, группа A становится группой A' с ее двумя выборками, инвертированными по отношению к группе A (в соответствии с двумя стрелками группы A' на фиг.2). Группа В становится группой B' с ее двумя выборками, инвертированными по отношению к группе B, и так далее. Предпочтительно копирование и конкатенацию групп A', B', C', D' осуществляют с соблюдением питч-периода Т. Так, группа A', состоящая из инвертированных выборок группы A, отделена от группы А на число выборок, соответствующее продолжительности питч-периода Т. Точно так же группа B' отделена от группы В продолжительностью, соответствующей питч-периоду Т, и так далее.
Показанная на фиг.2 инверсия выборок по группам является систематической. В варианте, показанном на фиг.1, проявление этой инверсии можно сделать случайным. Можно даже предусмотреть фиксированный порог p вероятности, чтобы производить или не производить инверсию группы. В примере, показанном на фиг.1, порог p фиксируют на 50% таким образом, чтобы только две группы B', C' из четырех содержали инвертированные выборки. Можно также сделать порог p вероятности переменным, в частности, чтобы он зависел от функции корреляции, касающейся питч-периода Т, что будет показано ниже.
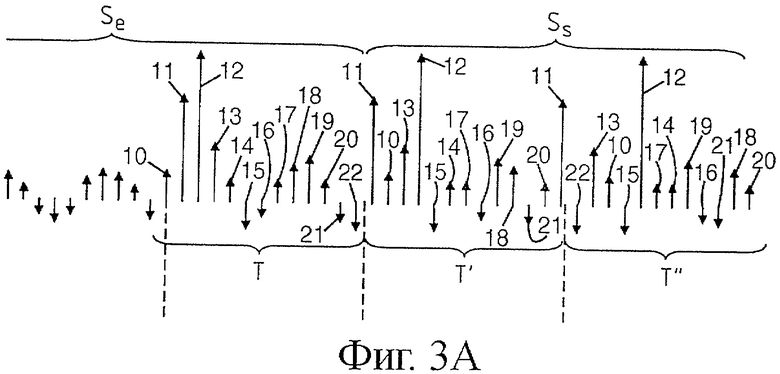
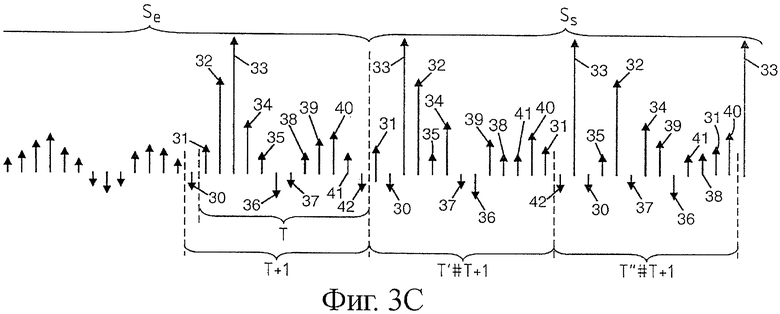
Возвращаясь к варианту выполнения, показанному на фиг.2, где применяют систематическую инверсию выборок по группам, получают показанную на фиг.3 новую последовательность выборок T' продолжительностью, соответствующей питч-периоду T, но с инверсией выборок по парам. На фиг.3a показаны последние выборки последних принятых нормальных блоков в сигнале Se, которые были сохранены в памяти декодера. В данном случае, поскольку инверсия является систематической, а не случайной и с оценкой корреляции, определяют питч-период Т тонального сигнала (при помощи любого известного средства) и собирают последние выборки 10, 11,…,22 сигнала Se, которые располагаются по продолжительности питч-периода Т. Две первые выборки 10 и 11 инвертируют в восстанавливаемом сигнале, обозначенном Ss. Третью и четвертую выборки 12 и 13 тоже инвертируют и так далее. В результате получают последовательность Т' выборок 11, 10, 13, 12,…, которая расположена по той же продолжительности, что и питч-период. Если при декодировании не достает нескольких блоков, расположенных на разных питч-периодах, то восстановление сигнала Ss продолжают, используя последовательность Т' и возобновляя инверсию выборок по парам в последовательности T', чтобы получить новую последовательность T", и так далее.
В случае, представленном на фиг.3a, число выборок по периодам Т, Т', Т" равно одинаковому нечетному числу (в представленном примере тринадцать выборок), что позволяет получить постепенное смешивание выборок по мере восстановления сигнала Ss и, следовательно, эффективное ослабление чрезмерной гармоничности (или, иначе говоря, чрезмерной тональности восстановленного сигнала).
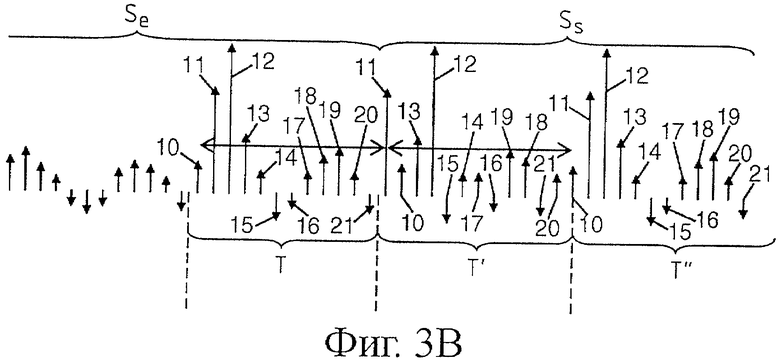
Что же касается случая, представленного на фиг.3b, где число выборок по периодам T, T', T" является четным числом (в представленном примере двенадцать выборок), то, осуществляя дважды инверсию (от периода T к периоду T', затем от периода T' к периоду T") выборок питч-периода T, взятых попарно, получили точно такую же последовательность, что и питч-период T в последовательности T", в результате чего генерируется чрезмерная гармоничность.
Эту проблему можно преодолеть, изменяя число инвертируемых выборок в группе (и взять, например, нечетное число выборок в группе).
Вместе с тем, на фиг.3c показан другой вариант выполнения. Если питч-период содержит четное число выборок и если инверсия касается четных чисел выборок на группу, то этот вариант выполнения просто состоит в добавлении нечетного числа выборок к питч-периоду восстанавливаемого сигнала. На фиг.3c последний детектированный питч-период Т содержит двенадцать выборок 31, 32,…,42. В этом случае к питч-периоду добавляют одну выборку и получают период T+1, содержащий нечетное число выборок. Таким образом, в примере, показанном на фиг.3c, выборка 30 становится первой выборкой памяти, на основании которой применяют инверсию выборок по парам, как показано на фиг.2 (или на фиг.3a). Получают период T' восстановленного сигнала Ss, содержащий нечетное число выборок, к которому применяют инверсию выборок по парам для получения периода T", тоже содержащего нечетное число выборок, и так далее. При этом следует отметить, что последовательность выборок 33, 30, 35, 32, 34,… периода T" на этот раз отличается от последовательности выборок 30, 31, 32, 33,… исходного питч-периода T.
Вернемся к фиг.4, где в представленном примере показано применение варианта выполнения, показанного на фиг.2, 3a и 3c, когда сигнал Se является умеренно тональным (стрелка М на выходе теста 51), и определяют питч-период Т на последних выборках нормально принятого сигнала Se (при помощи технологии 56, которая сама по себе может быть известной). При детектировании определяют, является ли число выборок в питч-периоде T четным или нечетным. Если это число является нечетным (стрелка Нет на выходе теста 57), то непосредственно применяют инверсию выборок по парам (этап 58), как было описано выше со ссылками на фиг.3a. Если число выборок в питч-периоде T является четным (стрелка Да на выходе теста 57), к питч-периоду T добавляют одну выборку (этап 59) и после этого применяют инверсию выборок по парам (этап 58) при помощи обработки, описанной выше со ссылками на фиг.3c. После этого в случае необходимости применяют выбранный коэффициент усиления 61 для полученной таким образом последовательности выборок, чтобы сформировать окончательно восстановленный сигнал Ss.
Как было указано выше со ссылками на фиг.4, питч-период сначала вычисляют на основании одного или нескольких предыдущих фреймов. После этого генерируют возбуждение с пониженной гармоничностью, как показано на фиг.2, с применением систематической инверсии. Вместе с тем, в варианте, показанном на фиг.1, его можно генерировать с произвольной инверсией. Эта неравномерная инверсия выборок тонального возбуждения предпочтительно позволяет ослабить чрезмерную тональность. Далее следует подробное описание этого предпочтительного варианта выполнения.
Обычно при простом копировании питч-периода тональное возбуждение вычисляют в формуле типа:
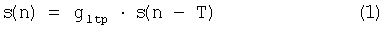
где T - расчетный питч-период, a gltp - выбранный коэффициент усиления LTP.
В варианте выполнения изобретения тональное возбуждение вычисляют для группы из двух выборок и с произвольной инверсией при помощи описанной ниже обработки.
Прежде всего генерируют произвольное число x в интервале [0; 1]. Затем в зависимости от значения x:
- если x<p, то s(n) и s(n+1) вычисляют при помощи уравнения (1),
- если x≥p, то s(n) и s(n+1) вычисляют при помощи следующих уравнений (2) и (3):
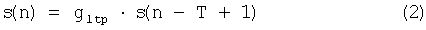
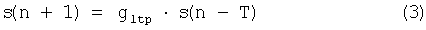
Значение p характеризует вероятность инверсии двух выборок s(n) и s(n+1). Например, можно установить фиксированное значение p=50%.
В предпочтительном варианте можно также выбрать переменную вероятность, например, в виде:
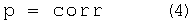
где переменная corr соответствует максимальному значению функции корреляции на питч-периоде, обозначенной Corr(T). Для питч-периода T функцию корреляции Corr(T) вычисляют, используя только 2*Tm выборок в конце сохраненного в памяти сигнала, и:
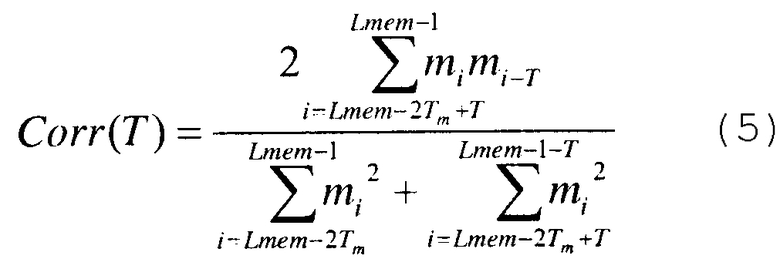
где m0…mLmem-1 - последние выборки ранее декодированного сигнала, которые сохранились в памяти декодера.
Из этой формулы понятно, что объем этой памяти Lmem (по числу сохраненных выборок) должен быть равен, по меньшей мере, двукратному максимальному значению продолжительности питч-периода (по числу выборок). Чтобы учитывать самые низкие тоны (более низкая основная частота порядка 50 Гц), число сохраняемых в памяти выборок может достигать 300 при низкой частоте дискретизации в узкой полосе и превышать 300 при более высоких частотах дискретизации.
Функция корреляции corr(T), полученная при помощи формулы (5), достигает максимального значения, если переменная T соответствует питч-периоду T0, и это максимальное значение указывает на степень тональности. Обычно, если это максимальное значение очень близко к 1, то сигнал является сильно тонированным. Если оно близко к 0, сигнал не является тональным.
Таким образом, понятно, что в этом варианте выполнения предварительное определение питч-периода не является обязательным для построения групп выборок, предназначенных для инверсии. В частности, определение питч-периода Т0 можно осуществлять одновременно с образованием групп в соответствии с настоящим изобретением путем применения вышеуказанной формулы (5).
Если сигнал является сильно тонированным, то вероятность р будет очень высокой, и тональность будет сохраняться согласно расчету по формуле (1). Если же наоборот, тональность сигнала Se не является ярко выраженной, вероятность p будет ниже, и в этом случае предпочтительно используют уравнения (2) и (3).
Разумеется, можно использовать и другие вычисления корреляций.
Например, можно вычислять гармоническое возбуждение в зависимости от заранее определенных классов. Для сильно тонированных классов предпочтительно использовать формулу (1). Для умеренно или слабо тонированных классов отдают предпочтение формулам (2) и (3). Для не тональных классов не происходит генерирования гармонического возбуждения, и возбуждение в этом случае можно генерировать на основании белого шума. Однако в ранее описанном варианте используют также уравнения (2) и (3) с достаточно большим произвольным питч-периодом.
В целом настоящее изобретение не ограничивается описанными вариантами выполнения, представленными в качестве примеров; оно охватывает и другие варианты.
В рамках реализации подробно описанного выше изобретения генерирование возбуждения при кодировании путем предикативного синтеза CELP должно позволять избежать чрезмерной тональности в контексте маскирования ошибок при передаче фреймов. Однако принципы настоящего изобретения можно применять для расширения полосы. В этом случае можно использовать генерирование возбуждения в расширенной полосе в системе расширения полосы (с передачей или без передачи информации), основанной на модели типа CELP (или субполосы CELP). Возбуждение полосы высоких частот можно в этом случае вычислить, как было описано выше, что позволяет ограничить чрезмерную гармоничность этого возбуждения.
Кроме того, настоящее изобретение можно применять для передачи в сетях фреймами или же пакетами, например пакетами «IP-тонов» (от «Internet Protocol»), таким образом, чтобы обеспечивать приемлемое качество во время потери таких пакетов в IP и в то же время сохранять ограниченную сложность.
Разумеется, инверсию выборок можно производить по группам выборок размером более двух выборок.
Кроме того, выше было описано генерирование блока, заменяющего дефектный блок, на основании выборок нормального блока, предшествующего дефектному блоку. В варианте можно отталкиваться от нормального блока, следующего за дефектным блоком, для осуществления синтеза дефектного блока (пост-синтез). Этот вариант выполнения является предпочтительным, в частности, для синтеза нескольких последовательных дефектных блоков и, в частности, для синтеза:
- дефектных блоков, следующих непосредственно за предыдущими нормальными блоками, на основании этих предыдущих блоков,
- затем дефектных блоков, непосредственно предшествующих следующим нормальным блокам, на основании этих следующих блоков.
Объектом настоящего изобретения является также компьютерная программа, предназначенная для хранения в памяти устройства синтеза цифрового аудиосигнала. Эта программа содержит команды для осуществления способа в соответствии с настоящим изобретением, когда его выполняют при помощи процессора такого устройства синтеза. Кроме того, описанная выше фиг.4 может иллюстрировать блок-схему такой компьютерной программы.
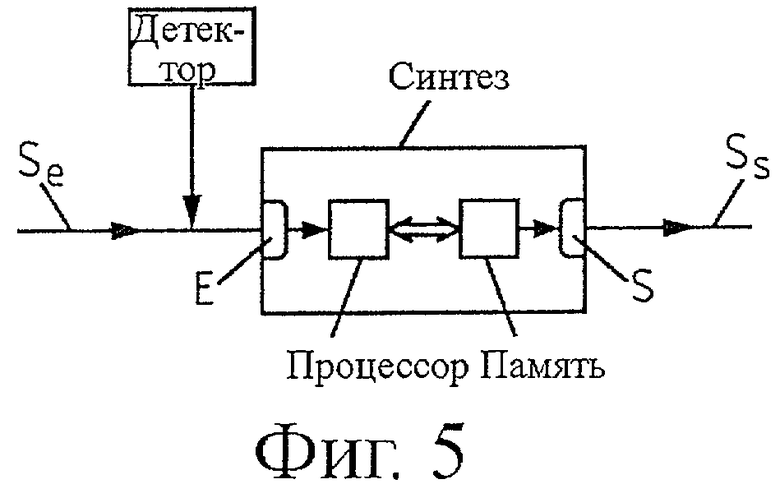
Кроме того, объектом настоящего изобретения является также устройство синтеза цифрового аудиосигнала, состоящего из последовательности блоков. Это устройство может содержать память, в которую записывают вышеуказанную компьютерную программу. Как показано на фиг.5, это устройство SYN содержит:
- вход E для приема блоков сигнала Se, предшествующих, по меньшей мере, одному текущему блоку, предназначенному для синтеза, и
- выход S для выдачи синтезированного сигнала Ss, содержащего, по меньшей мере, этот предназначенный для синтеза текущий блок.
Устройство синтеза SYN в соответствии с настоящим изобретением содержит такие средства, как рабочая память MEM (или память для хранения вышеуказанной компьютерной программы) и процессор PROC, взаимодействующий с этой памятью MEM, для осуществления способа в соответствии с настоящим изобретением и для синтеза текущего блока на основании, по меньшей мере, одного из предыдущих блоков сигнала Se.
Объектом настоящего изобретения является также прибор для приема цифрового аудиосигнала, состоящего из последовательности блоков, такой, например, как декодер этого сигнала. Как показано на фиг.5, этот прибор предпочтительно может содержать детектор дефектных блоков DET, а также устройство SYN в соответствии с настоящим изобретением для синтеза дефектных блоков, обнаруженных детектором DET.
Изобретение касается синтеза сигнала, состоящего из последовательных блоков. В частности, предлагается во время приема такого сигнала заменять при помощи синтеза потерянные или ошибочные блоки этого сигнала. Для этого предлагается ослаблять чрезмерную тональность во время генерирования синтезированного сигнала. В частности, генерируют тональное возбуждение на основании питч-периода (Т), вычисленного или переданного в предыдущий блок, в случае необходимости путем применения коррекции плюс или минус одной выборки продолжительности этого периода (рассчитываемой по числу выборок), путем образования групп (А, В, С, D), по меньшей мере, из двух выборок и путем произвольной (В', С') или фиксированной инверсии положений выборок в группах. Технический результат - ослабляют чрезмерную гармоничность в генерируемом возбуждении и, следовательно, ослабляют эффект чрезмерной тональности в синтезе генерированного сигнала. 3 н. и 8 з.п. ф-лы, 7 ил.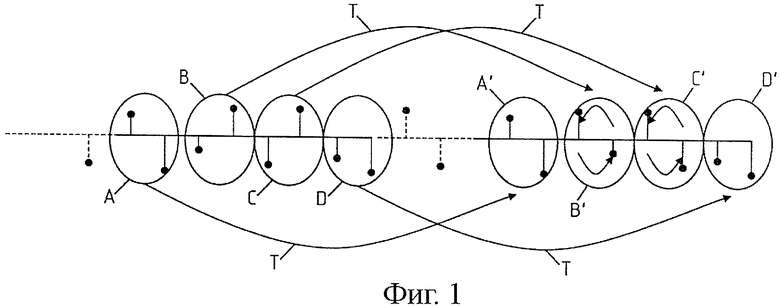
1. Способ синтеза цифрового аудиосигнала, состоящего из последовательных блоков выборок, в котором при получении такого сигнала, чтобы заменить, по меньшей мере, один дефектный блок, генерируют заменяющий блок на основании выборок, по меньшей мере, одного нормального блока, предшествующего дефектному блоку,
отличающийся тем, что содержит следующие этапы:
а) выбирают определенное число (Т) выборок, образующих последовательность, по меньшей мере, в последнем нормальном блоке, предшествующем дефектному блоку,
б) последовательность выборок разбивают на группы выборок (А, В, С, D) и, по меньшей мере, в одной группе выборок производят инверсию выборок согласно заранее определенным правилам,
в) группы (А', В', С', D'), по меньшей мере, в некоторых из которых выборки были инвертированы на этапе б), подвергают повторной конкатенации для формирования, по меньшей мере, части (Т') заменяющего блока, и
г) если указанная часть, полученная на этапе в), не заполняет заменяющий блок полностью, указанную часть (Т') копируют в заменяющий блок и для указанной скопированной части опять применяют этапы а), б), в).
2. Способ по п.1, в котором цифровой аудиосигнал является речевым сигналом, отличающийся тем, что в речевом сигнале детектируют степень тональности (51) и применяют этапы а)-г), если сигнал является, по меньшей мере, слабо тонированным.
3. Способ по п.1, в котором цифровой аудиосигнал является речевым сигналом, отличающийся тем, что в речевом сигнале детектируют степень тональности (51) и применяют этапы а)-г), если сигнал является слабо тонированным или не является тональным.
4. Способ по п.1, отличающийся тем, что при осуществлении этапа а):
а1) детектируют тон в цифровом аудиосигнале (56), и
а2) указанное определенное число выборок, выбранных на этапе а), соответствует числу выборок, которое содержит период (Т), соответствующий противоположности основной частоты детектированного тона.
5. Способ по п.1, отличающийся тем, что разбивку на этапе б) осуществляют группами по две выборки и производят инверсию положений выборок между собой в одной группе (В', С').
6. Способ по п.5, в котором при осуществлении этапа а):
а1) детектируют тон в цифровом аудиосигнале (56), и
а2) указанное определенное число выборок, выбранных на этапе а), соответствует числу выборок, которое содержит период (Т), соответствующий противоположности основной частоты детектированного тона, отличающийся тем,
что если число выборок, которые содержит период (Т) детектированного тона, является четным числом, в указанный период (Т) добавляют или из него удаляют нечетное число выборок для формирования выбора на этапе а).
7. Способ по п.1, отличающийся тем, что заранее определенные правила предусматривают случайность появлений инверсии выборок в каждой группе и фиксируют порог вероятности (р), чтобы производить или не производить инверсию выборок группы.
8. Способ по п.7, в котором при осуществлении этапа а):
а1) детектируют тон в цифровом аудиосигнале (56), и
а2) указанное определенное число выборок, выбранных на этапе а), соответствует числу выборок, которое содержит период (Т), соответствующий противоположности основной частоты детектированного тона, отличающийся тем,
что порог вероятности (р) является переменным и зависит от функции корреляции, касающейся указанного периода (Т).
9. Устройство синтеза цифрового аудиосигнала, состоящего из последовательности блоков, содержащее:
вход для приема блоков сигнала (Se), предшествующих, по меньшей мере, одному текущему блоку, предназначенному для синтеза, и
выход для выдачи синтезированного сигнала (Ss), содержащего, по меньшей мере, указанный текущий блок,
отличающееся тем, что содержит средства: рабочую память (MEM) и процессор (PROC) для осуществления способа по одному из пп.1-8 для синтеза текущего блока на основании, по меньшей мере, одного из предыдущих блоков.
10. Прибор для приема цифрового аудиосигнала, состоящего из последовательности блоков, содержащий детектор (DET) дефектных блоков, отличающийся тем, что дополнительно содержит устройство синтеза цифрового аудиосигнала (SYN) по п.9 для синтеза дефектных блоков.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| RU 2004138286 A, 10.06.2005 | |||
| US 2006173687 А1, 03.08.2006 | |||
| Устройство для контроля кода "1 из 5 | 1985 |
|
SU1288916A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Способ получения нового производного на основе аминокислоты и ингибитор ацетилхолинэстеразы (AChE) на его основе | 2021 |
|
RU2774827C1 |
| US 5884010 A, 16.03.1999. | |||

