Настоящее изобретение относится к кодированию, обработке и декодированию звукового сигнала, и в частности - к устройству и способу для улучшенного плавного изменения сигнала для систем с переключаемым кодированием звука во время маскирования ошибок.
В последующем описано современное состояние по отношению к плавному изменению во время маскирования потери пакетов (PLC) для речевых и звуковых кодеков. Объяснения по отношению к современному состоянию начинаются с кодеков ITU-T G-серии (G.718, G.719, G.722, G.722.1, G.729. G.729.1), за ними следуют 3GPP кодеки (AMR, AMR-WB, AMR-WB+) и один кодек IETF (OPUS), и заканчиваются двумя кодеками MPEG (HE-AAC, HILN) (ITU=международный союз по телекоммуникациям; 3GPP=проект партнерства 3-го поколения; AMR=адаптивное кодирование с переменной скоростью; WB=широкополосное; IETF=целевая группа разработки Интернет). Впоследствии анализируется современное состояние по отношению к отслеживанию уровня фонового шума, за которым следует итоговая информация, которая обеспечивает краткий обзор.
Сначала рассматривают G.718. G.718 - узкополосный и широкополосный кодек для речевых сигналов, который поддерживает DTX/CNG (DTX=системы цифрового театра; CNG=генерация комфортного шума). Поскольку варианты осуществления, в частности, относятся к коду с низкой задержкой, версия режима с низкой задержкой будет описана более подробно в данной работе.
Рассматривая ACELP (уровень 1) (ACELP=линейное предсказание с алгебраическим кодовым возбуждением), ITU-T рекомендует для G.718 [ITU08a, раздел 7.11] адаптивное плавное изменение в области линейного предсказания для управления скоростью плавного изменения. В общем случае маскирование следует этому принципу:
Согласно G.718, в случае стираний кадра стратегия маскирования может обобщаться как сходимость энергии сигнала и спектральной огибающей к оцененным параметрам фонового шума. Периодичность сигнала сходится к нулю. Скорость сходимости зависит от параметров последнего правильно принятого кадра и количества последовательных стертых кадров, и управляется с помощью коэффициента ослабления α. Коэффициент ослабления α дополнительно зависит от стабильности θ фильтра LP (LP=линейное предсказание) для «невокализованных» кадров. В общем случае сходимость является медленной, если последний хороший принятый кадр находится в устойчивом сегменте, и быстрой, если кадр находится в сегменте перехода.
Коэффициент ослабления α зависит от класса речевого сигнала, который извлекается с помощью классификации сигнала, описанной в [ITU08a, раздел 6.8.1.3.1 и 7.1 1.1.1]. Коэффициент стабильности θ вычисляется, основываясь на измерении расстояния между смежными фильтрами ISF (спектральной частоты иммитанса) [ITU08a, раздел 7.1.2.4.2].
Таблица 1 показывает схему вычисления α:
> 3
0,4
= 2
> 2
0,6
0,4
Значения коэффициента ослабления α, значение θ является коэффициентом стабильности, вычисленным из измерения расстояния между смежными фильтрами LP. [ITU08a, раздел 7.1.2.4.2].
Кроме того, G.718 обеспечивает способ плавного изменения для изменения спектральной огибающей. Общей идеей является выполнение схождения параметров последней ISF к адаптивному вектору средних значений ISF. Сначала усредненный вектор ISF вычисляется из последних 3 известных векторов ISF. Затем усредненный вектор ISF снова усредняется с автономно подготовленным долгосрочным вектором ISF (который является постоянным вектором) [ITU08a, раздел 7.1 1.1.2].
Кроме того, G.718 обеспечивает способ плавного изменения для управления долгосрочным режимом работы и таким образом - для взаимодействия с фоновым шумом, где энергия тонального возбуждения (и таким образом периодичность возбуждения) сходится к 0, в то время как случайная энергия возбуждения сходится к энергии возбуждения CNG [ITU08a, раздел 7.1 1.1.6]. Ослабление инновационного усиления вычисляется как
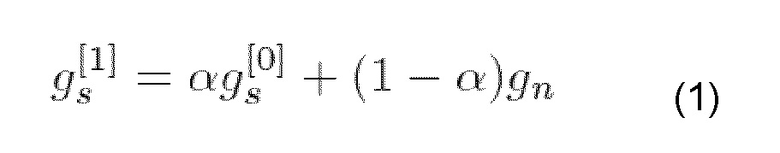
где gs[1] является инновационным усилением в начале следующего кадра, gs[0] является инновационным усилением в начале текущего кадра, gn является усилением возбуждения, используемыми во время генерации комфортного шума и коэффициенте ослабления α.
Аналогично периодическому ослаблению возбуждения, усиление ослабляется линейно по всему кадру на основе «выборка за выборкой», начиная с gs[0] и достигая gs[1] в начале следующего кадра.
Фиг. 2 схематично представляет структуру декодера G.718. В частности, фиг. 2 показывает высокоуровневую структуру декодера G.718 для PLC, показывая высокочастотный фильтр.
С помощью вышеописанного подхода G.718 инновационное усиление gs сходится к усилению, используемому во время генерации комфортного шума gn для потерь длинных пачек пакетов. Как описано в [ITU08a, раздел 6.12.3], усиление gn комфортного шума задается как квадратный корень из энергии Ẽ. Условия обновления Ẽ не описаны подробно. Следуя эталонному воплощению (C-код с плавающей запятой, stat_noise_uv_mod.c), Ẽ извлекают следующим образом:

причем unvoiced_vad охватывает обнаружение активности речи, причем unv_cnt охватывает количество расположенных подряд невокализованных кадров, причем lp_gainc охватывает низкочастотное усиление фиксированной кодовой книги, и причем lp_ener охватывает низкочастотную CNG оценку энергии Ẽ, она инициализируется в 0.
К тому же G.718 обеспечивает высокочастотный фильтр, введенный в тракт передачи сигналов невокализованного возбуждения, если сигнал последнего хорошего кадра был классифицирован отличающимся от «невокализованного», см. фиг. 2, также см. [ITU08a, раздел 7.1 1.1.6). Этот фильтр имеет характеристику «низкой полки» с частотной характеристикой по DC, расположенной приблизительно на 5 дБ ниже, чем частота Найквиста.
Кроме того, G.718 предлагает разъединенный цикл обратной связи LTP (LTP=долгосрочное предсказание): хотя во время обычного функционирования цикл обратной связи для адаптивной кодовой книги обновляется по субкадрам ([ITU08a, раздел 7.1.2.1.4]), основываясь на полном возбуждении. Во время маскирования этот цикл обратной связи обновляется по кадрам (см. [ITU08a, раздел 7.11.1.4, 7.1 1.2.4, 7.1 1.1.6, 7.1 1.2.6; dec_GV_exc@dec_gen_voic.c и syn_bfi_post@syn_bfi_pre_post.c]), основываясь только на вокализованном возбуждении. С этим подходом адаптивная кодовая книга не «засоряется» шумом, возникающим в случайно выбранном инновационном возбуждении.
Рассматривая уровни (3-5) улучшения кодирования с преобразованием из G.718, во время маскирования декодер ведет себя по отношению к верхнему уровню декодирования аналогично обычному функционированию, только спектр MDCT устанавливают в нуль. Никакой специальный режим плавного изменения не применяется во время маскирования.
По отношению к CNG, в G.718 синтез CNG выполняется в следующем порядке. Сначала декодируются параметры кадра комфортного шума. Затем синтезируется кадр комфортного шума. Впоследствии сбрасывается буфер основных тонов. Затем сохраняется классификация синтеза для FER (устранения ошибок кадра). Впоследствии проводится компенсация предыскажений спектра. Затем проводится низкочастотное постфильтрование. Затем обновляются переменные CNG.
В случае маскирования выполняется точно то же самое, кроме того, что параметры CNG не декодируются из битового потока. Это означает, что параметры не обновляются во время потери кадра, а используются декодированные параметры из последнего хорошего кадра SID (описателя вставки тишины).
Теперь рассматривают G.719. G.719, который основан на Siren 22, является основанным на преобразовании звуковым кодеком полного диапазона. ITU-T рекомендует для G.719 плавное изменение с повторением кадра в спектральной области [ITU08b, раздел 8.6]. Согласно G.719, механизм маскирования стирания кадра внедряется в декодер. Когда кадр правильно принимается, восстановленные коэффициенты преобразования сохраняются в буфере. Если декодеру сообщают, что кадр потерян или что кадр поврежден, то коэффициенты преобразования, восстановленные в последнем принятом кадре масштабируются в сторону уменьшения с коэффициентом 0,5 и затем используются в качестве восстановленных коэффициентов преобразования для текущего кадра. Декодер действует с помощью преобразования их во временную область и выполнения операции «кадрированного перекрытия с суммированием».
В последующем описан G.722. G.722 является системой кодирования 50-7000 Гц, которая использует адаптивную дифференциальную импульсно-кодовую модуляцию поддиапазона (SB-ADPCM) в пределах скорости передачи битов до 64 кбит/сек. Сигнал делится на верхний и нижний поддиапазоны, используя анализ QMF (QMF=квадратурный зеркальный фильтр). Два полученных в результате диапазона кодируются с помощью ADPCM (ADPCM=адаптивная дифференциальная импульсно-кодовая модуляция).
Для G.722 алгоритм с высокой сложностью для маскирования потери пакетов определен в приложении III [ITU06a], а алгоритм с низкой сложностью для маскирования потери пакетов определен в приложении IV [ITU07]. G.722 - приложение III ([ITU06a, раздел III.5]) предлагает выполнение постепенного заглушения, которое начинается после 20 мс потери кадров и которое заканчивается после 60 мс потери кадров. Кроме того, G.722 - приложение IV предлагает методику плавного изменения, которая применяет «к каждой выборке коэффициент усиления, который вычисляется и адаптируется «выборка за выборкой»» [ITU07, раздел IV.6.1.2.7].
В G.722 процесс заглушения происходит в области поддиапазона непосредственно перед синтезом QMF и как последний этап модуля PLC. Вычисление коэффициента заглушения выполняется, используя информацию о классе от классификатора сигнала, который также является частью модуля PLC. Различие делается между классами TRANSIENT, UV_TRANSITION и другими. К тому же различие сделано между одиночными потерями кадров 10 мс и другими случаями (множественными потерями кадров 10 мс и одиночными/множественными потерями кадров 20 мс).
Это показано на фиг. 3. В частности, фиг. 3 изображает сценарий, где коэффициент плавного изменения G.722 зависит от информации о классе, и в котором 80 выборок эквивалентны 10 мс.
Согласно G.722, модуль PLC создает сигнал для недостающего кадра и некоторый дополнительный сигнал (10 мс), который, как предполагается, плавно переходит в следующий хороший кадр. Заглушение для этого дополнительного сигнала придерживается тех же самых правил. При маскировании высокочастотного диапазона G.722 плавный переход не происходит.
В последующем рассматривают G.722.1. G.722.1, который основан на Siren 7, является основанным на преобразовании звуковым кодеком широкого диапазона с режимом расширения на сверхширокий диапазон, называемым G.722.1C.G. 722.1C основан на Siren 14. ITU-T рекомендует для G.722.1 повторение кадра с последующим заглушением [ITU05, раздел 4.7]. Если декодеру сообщают, посредством внешнего механизма сигнализации, не определенного в данной рекомендации, что кадр потерян или поврежден, то он повторяет декодированные коэффициенты MLT (модулированного задержанного преобразования) предыдущего кадра. Он действует с помощью выполнения их преобразования во временную область и выполнения операции перекрытия с суммированием декодированной информации предыдущего и последующего кадров. Если предыдущий кадр был также потерян или поврежден, то декодер устанавливает все коэффициенты MLT текущего кадра в ноль.
Теперь рассматривают G.729. G.729 является алгоритмом сжатия звуковых данных для голоса, который сжимает цифровой голос в пакетах продолжительностью 10 миллисекунд. Это официально описано как кодирование речи со скоростью 8 кбит/сек, используя речевое кодирование с линейным предсказанием с кодовым возбуждением (CS-ACELP) [ITU12].
Как описано в [CPK08], G.729 рекомендует плавное изменение в области LP. Алгоритм PLC, используемый в стандарте G.729, восстанавливает речевой сигнал для текущего кадра, основываясь на принятой ранее речевой информации. Другими словами, алгоритм PLC заменяет недостающее возбуждение эквивалентной характеристикой ранее принятого кадра, хотя энергия возбуждения постепенно затухает в конечном счете, усиление адаптивной и фиксированной кодовых книг ослабляется с постоянным коэффициентом.
Ослабленное усиление фиксированной кодовой книги задают с помощью:
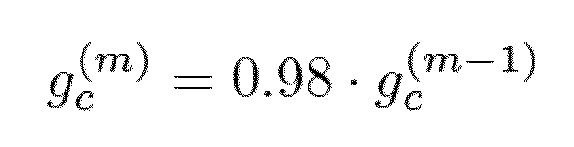
где m является индексом субкадра.
Усиление адаптивной кодовой книги основано на ослабленной версии предыдущего усиления адаптивной кодовой книги:
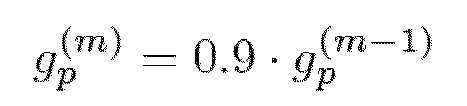 , ограничено с помощью
, ограничено с помощью 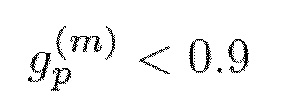
Nam in Park и др. предлагают для G.729 контроль за амплитудой сигнала, используя предсказание посредством линейной регрессии [CPK08, PKJ+11]. Оно адресовано потере пачки пакетов и использует линейную регрессию в качестве основной методики. Линейная регрессия основана на линейной модели следующим образом
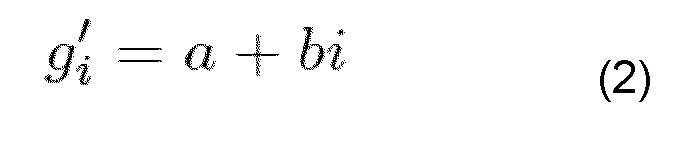
где gi’ - вновь предсказанная текущая амплитуда, a и b - коэффициенты для линейной функции первого порядка, и i - индекс кадра. Чтобы найти оптимизированные коэффициенты a* и b*, суммирование квадратичной ошибки предсказания минимизируется:
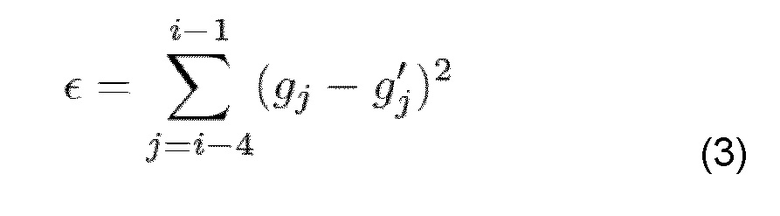
ε - квадратичная ошибка, gj - оригинал предыдущей j-й амплитуды. Для минимизации этой ошибки производная, относящаяся к a и b, просто устанавливается в ноль. При использовании оптимизированных параметров a* и b* оценка каждого gi* обозначается с помощью
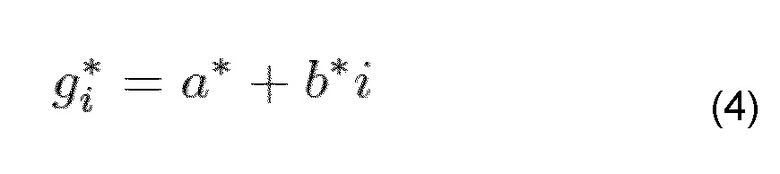
Фиг. 4 показывает предсказание амплитуды, в частности предсказание амплитуды gi*, при использовании линейной регрессии.
Для получения амплитуды Ai’ потерянного пакета i, отношение σi
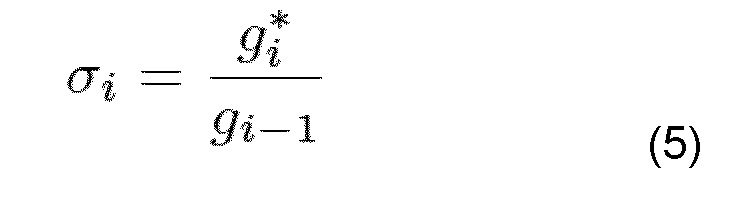
умножают на коэффициент Si масштабирования:

причем коэффициент Si масштабирования зависит от количества последовательных маскируемых кадров l(i):
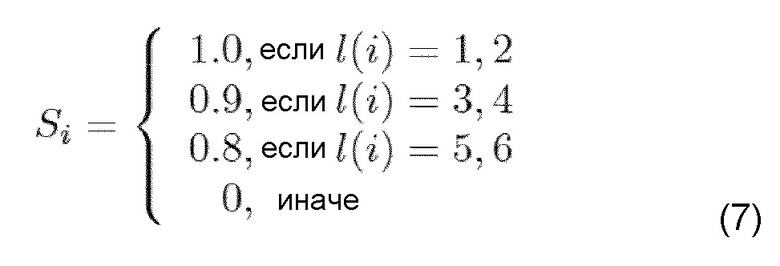
В [PKJ+11] предложено немного отличающееся масштабирование.
Согласно G.729, впоследствии Ai’ будет сглаживаться для предотвращения дискретного ослабления на границах кадра. Окончательная сглаженная амплитуда Ai(n) умножается на возбуждение, полученное из предыдущих компонент PLC.
В последующем рассматривают G.729.1. G.729.1 является основанным на G.729 внедренным кодером с переменной скоростью передачи битов: масштабируемым широкополосным кодером битового потока на 8-32 кбит/сек, совместимым с G.729 [ITU06b].
Согласно G.729.1, как в G.718 (см. выше), предложено адаптивное плавное изменение, которое зависит от стабильности характеристик сигнала ([ITU06b, раздел 7.6.1]). Во время маскирования сигнал обычно ослабляется, основываясь на коэффициенте ослабления, который зависит от параметров класса последнего хорошего принятого кадра и количества последовательно стертых кадров. Коэффициент ослабления дополнительно зависит от стабильности LP фильтров для «невокализованных» кадров. В общем случае ослабление является медленным, если последний хороший принятый кадр находится в устойчивом сегменте, и быстрым, если кадр находится в сегменте перехода.
К тому же коэффициент α ослабления зависит от среднего значения усиления основного тона за субкадр 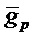 ([ITU06b, eq. 163, 164]):
([ITU06b, eq. 163, 164]):
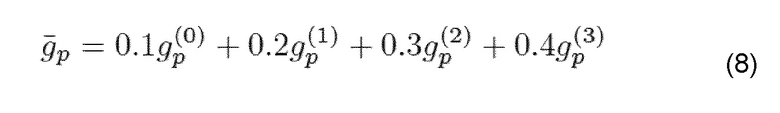
где gp(i) - усиление основного тона в субкадре i.
Таблица 2 показывает схему вычисления α, где
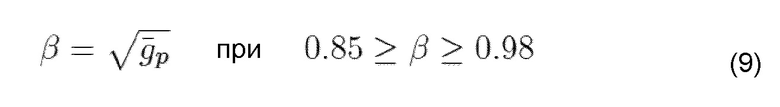
Во время процесса маскирования α используется в следующих средствах маскирования:
2,3
> 3
0,4
2,3
> 3
0,4
2,3
> 3
0,4
> 2
0,2
2,3
> 3
0,6 θ+0,4
0,4
Значения коэффициента ослабления α, значение θ является коэффициентом стабильности, вычисляемым из измерения расстояния между смежными фильтрами LP. [ITU06b, раздел 7.6.1].
Согласно G.729.1, относительно повторной синхронизации глоттального импульса, поскольку последний импульс возбуждения предыдущего кадра используется для создания периодической части, ее усиление является приблизительно правильным в начале маскируемого кадра и может устанавливаться в 1. Усиление затем линейно ослабляется по всему кадру на основе «выборка за выборкой» для достижения значения α в конце кадра. Формирование энергии вокализованных сегментов экстраполируется при использовании значений усиления тонального возбуждения каждого субкадра последнего хорошего кадра. В общем случае, если эти усиления больше 1, то энергия сигнала увеличивается, если они ниже 1, то энергия уменьшается. α таким образом устанавливается в β=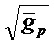 , как описано выше, см. [ITU06b, eq. 163, 164]. Значение β обрезается между 0,98 и 0,85, чтобы избежать сильных увеличений и уменьшений энергии, см. [ITU06b, раздел 7.6.4].
, как описано выше, см. [ITU06b, eq. 163, 164]. Значение β обрезается между 0,98 и 0,85, чтобы избежать сильных увеличений и уменьшений энергии, см. [ITU06b, раздел 7.6.4].
Рассматривая создание случайной части возбуждения, согласно G.729.1 в начале стертого блока инновационное усиление gs инициализируется при использовании инновационного усиления возбуждения каждого субкадра последнего хорошего кадра:
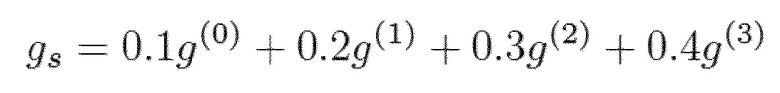
причем g(0), g(1), g(2) и g(3) являются усилениями фиксированной кодовой книги, или инновационными усилениями, четырех субкадров последнего правильно принятого кадра. Ослабление инновационного усиления выполняется следующим образом:
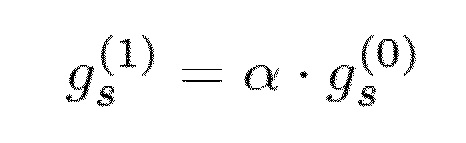
причем gs(1) является инновационным усилением в начале следующего кадра, gs(0) является инновационным усилением в начале текущего кадра, и α является тем, что определено выше в таблице 2. Аналогично периодическому ослаблению возбуждения, усиление таким образом линейно ослабляется по всему кадру на основе «выборка за выборкой», начиная с gs(0) и доходя до значения gs(1), которое будет достигнуто в начале следующего кадра.
Соответственно, для G.729.1, если последний хороший кадр является «невокализованным», то используется только инновационное возбуждение, и оно дополнительно ослабляется с коэффициентом 0,8. В этом случае предыдущий буфер возбуждения обновляется инновационным возбуждением, поскольку периодическая часть возбуждения не доступна, см. [ITU06b, раздел 7.6.6].
В последующем рассматривают AMR. 3GPP AMR [3GP12b] является кодеком для разговорных сигналов, использующим алгоритм ACELP. AMR имеет возможность кодировать речь с частотой дискретизации 8000 выборок в секунду и скоростью передачи битов между 4,75 и 12,2 кбит/сек и поддерживает сигнализацию кадров описания тишины (DTX/CNG).
В AMR, во время маскирования ошибок (см. [3GP12a]), различают между собой кадры, которые подвергаются ошибкам (битовым ошибкам), и кадры, которые полностью потеряны (вообще нет данных).
Для маскирования ACELP AMR представляет конечный автомат, который оценивает качество канала: чем больше значение счетчика состояний, тем хуже качество канала. Система начинает работу в состоянии 0. Каждый раз, когда обнаруживается плохой кадр, счетчик состояний увеличивается на единицу и насыщается, когда он достигает 6. Каждый раз, когда обнаруживается хороший речевой кадр, счетчик состояний возвращается в ноль, кроме тех случаев, когда состояние равно 6, в этом случае счетчик состояний устанавливается в 5. Поток команд управления конечным автоматом может описываться с помощью следующего C-кода (BFI - индикатор плохого кадра, State - переменная состояния):
if(BFI != 0 ) {
State=State+1;
}
else if(State == 6) {
State=5;
}
else {
State=0;
}
if(State > 6 ) {
State=6;
}
В дополнение к этому конечному автомату, в AMR проверяются флажки плохого кадра из текущего и предыдущего кадров (prevBFI).
Возможны три различные комбинации:
Первая из этих трех комбинаций - BFI=0, prevBFI=0, состояние=0: ошибки не обнаружены в принятом или в предыдущем принятом речевом кадре. Принятые речевые параметры используются обычным способом при синтезе речи. Текущий кадр речевых параметров сохраняется.
Вторая из этих трех комбинаций - BFI=0, prevBFI=1, состояние=0 или 5: ошибки не обнаружены в принятом речевом кадре, но предыдущий принятый речевой кадр был плохим. Усиление LTP и усиление фиксированной кодовой книги ограничиваются ниже значений, используемых для последнего принятого хорошего субкадра:
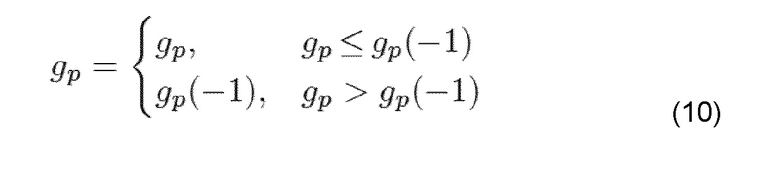
где gp=текущее декодированное усиление LTP, gp (-1)=усиление LTP, используемое для последнего хорошего субкадра (BFI=0), и
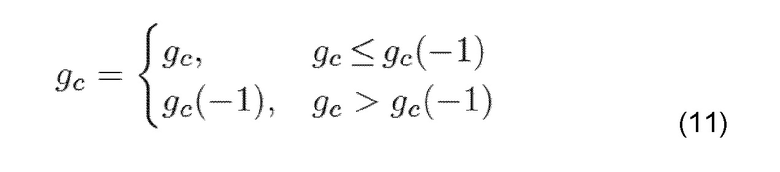
где gc=текущее декодированное усиление фиксированной кодовой книги, и gc (-1)=усиление фиксированной кодовой книги, используемое для последнего хорошего субкадра (BFI=0).
Остальная часть принятых речевых параметров обычно используется при синтезе речи. Текущий кадр речевых параметров сохраняется.
Третья из этих трех комбинаций - BFI=1, prevBFI=0 или 1, состояние=1... 6: ошибка обнаружена в принятом речевом кадре, и начинается процедура замены и заглушения. Усиление LTP и усиление фиксированной кодовой книги заменяются ослабленными значениями из предыдущих субкадров:
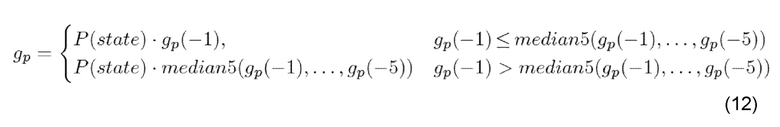
где gp обозначает текущее декодированное усиление LTP и gp(-1),..., gp(-n) обозначают усиление LTP, используемое для последних n субкадров, и median5() обозначает операцию усреднения по 5 точкам и
P(state)=коэффициент ослабления,
где (P(1)=0,98, P(2)=0,98, P(3)=0,8, P(4)=0,3, P(5)=0,2, P(6)=0,2) и state=количество состояний, и
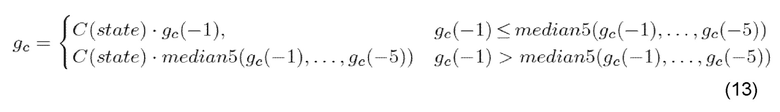
где gc обозначает текущее декодированное усиление фиксированной кодовой книги и gc(-1),..., gc(-n) обозначают усиление фиксированной кодовой книги, используемое для последних n субкадров, и median5() обозначает операцию усреднения по 5 точкам и C(state)=коэффициент ослабления, где (C(1)=0,98, C(2)=0,98, C(3)=0,98, C(4)=0,98, C(5)=0,98, C(6)=0,7) и state=количество состояний.
В AMR значения LTP-отставания (LTP=долгосрочное предсказание) заменяются предыдущим значением из 4-го субкадра предыдущего кадра (режим 12,2) или немного модифицированными значениями, основываясь на последнем правильно принятом значении (все другие режимы).
Согласно AMR, принятые импульсы инновационной фиксированной кодовой книги из ошибочного кадра используются в том состоянии, в котором они были приняты, когда принимаются поврежденные данные. В случае, когда никакие данные не были приняты, должны использоваться случайные индексы фиксированной кодовой книги.
Рассматривая CNG в AMR, согласно [3GP12a, раздел 6.4] каждый первый потерянный кадр SID заменяют при использовании информации SID из ранее принятых действительных кадров SID, и данная процедура применяется для действительных кадров SID. Для последующих потерянных кадров SID методика ослабления применяется к комфортному шуму, уровень которого будет плавно изменяться на выходе. Поэтому проверяется, выполняется или нет условие, что последнее обновление SID больше 50 кадров (= 1 с) назад, если да, то выходной сигнал будет заглушаться (ослабление уровня -6/8 дБ за кадр [3GP12d, dtx_dec{}@sp_dec.c], что приводит к 37,5 дБ в секунду). Следует отметить, что плавное изменение, относящееся к CNG, выполняется в области LP.
В последующем рассматривают AMR-WB. Адаптивное кодирование с переменной скоростью - WB [ITU03, 3GP09c] является кодеком для разговорных сигналов ACELP, основанным на AMR (см. раздел 1.8). Он использует параметрическое расширение полосы пропускания и также поддерживает DTX/CNG. В описании стандарта [3GP12g] приведены примерные решения маскирования, которые являются такими же, как для AMR [3GP12a] с незначительными отклонениями. Поэтому, только различия с AMR описаны в данной работе. Для описания стандарта см. приведенное выше описание.
Рассматривая ACELP, в AMR-WB плавное изменение ACELP выполняется, основываясь на эталонном исходном коде [3GP12c] с помощью модификации усиления gp основного тона (для вышеприведенного AMR называется усилением LTP), и с помощью модификации кодового усиления gp.
В случае потерянного кадра усиление gp основного тона для первого субкадра является тем же самым, как в последнем хорошем кадре, за исключением того, что оно ограничено между 0,95 и 0,5. Для второго, третьего и последующих субкадров усиление gp основного тона уменьшается с коэффициентом 0,95 и снова ограничивается.
AMR-WB предлагает, чтобы в маскируемом кадре gc было основано на последнем gc:
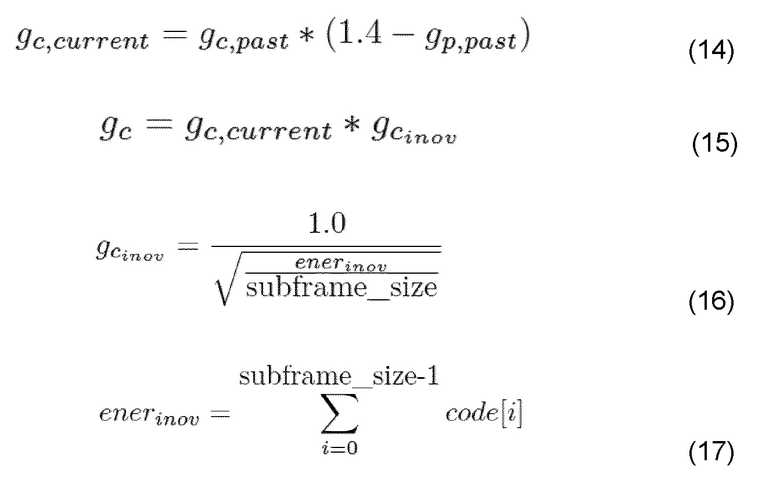
Для маскирования LTP-отставания в AMR-WB хронология пяти прошлых хороших LTP-отставаний и LTP-усилений используется для поиска наилучшего способа обновления в случае потери кадра. В случае, если кадр принимается с ошибками в символе, выполняется предсказание, пригодно или нет принятое отставание LTP для использования [3GP12g].
Рассматривая CNG, в AMR-WB, если последним правильно принятым кадром был кадр SID и кадр классифицирован как потерянный, то он должен быть заменен информацией последнего действительного кадра SID и должна применяться процедура для действительных кадров SID.
Для последовательно потерянных кадров SID AMR-WB предлагает применять методику ослабления к комфортному шуму, которая будет постепенно уменьшать уровень на выходе. Поэтому проверяется, выполняется или нет условие, что последнее обновление SID было больше чем 50 кадров (= 1 с) назад, если да, то выходной сигнал будет заглушаться (ослабление уровня -3/8 дБ за кадр [3GP12f, dtx_dec {} @dtx.c], что приводит к 18,75 дБ в секунду). Следует отметить, что плавное изменение, относящееся к CNG, выполняется в области LP.
Теперь рассматривают AMR-WB+. Адаптивное кодирование с переменной скоростью - WB+ [3GP09a] является переключаемым кодеком, использующим ACELP и TCX (TCX=преобразование кодированного возбуждения) в качестве основных кодеков. Он использует параметрическое расширение полосы пропускания и также поддерживает DTX/CNG.
В AMR-WB+ применяется логика экстраполяции режима для экстраполяции режимов потерянных кадров в пределах искаженного суперкадра. Эта экстраполяция режима основана на том факте, что существует избыточность в определении индикаторов режима. Логика решения (заданная в [3GP09a, фиг. 18]), предложенная AMR-WB+, является следующей:
- Определяется векторный режим (m−1, m0, m1, m2, m3), где m−1 указывает режим последнего кадра предыдущего суперкадра и m0, m1, m2, m3 указывают режимы кадров в текущем суперкадре (декодированном из битового потока), где mk=-1, 0, 1, 2 или 3 (-1: потерянный, 0: ACELP, 1: TCX20, 2: TCX40, 3: TCX80), и где количество потерянных кадров nloss может быть между 0 и 4.
- Если m−1=3 и два из индикаторов режима кадров 0-3 будут равны трем, то все индикаторы будут установлены в три, потому что наверняка, что один кадр TCX80 указан в пределах суперкадра.
- Если только один индикатор кадров 0-3 равен трем (и количество потерянных кадров nloss равно трем), то режим будет установлен в (1, 1, 1, 1), потому что в таком случае 3/4 целевого спектра TCX80 потеряно, и вероятно, что глобальное усиление TCX потеряно.
- Если режим укажет (x, 2, -1, x, x) или (x, -1, 2, x, x), то он будет экстраполироваться к (x, 2, 2, x, x), указывая кадр TCX40. Если режим укажет (x, x, x, 2, -1) или (x, x, -1, 2), то он будет экстраполироваться к (x, x, x, 2, 2), также указывая кадр TCX40. Нужно отметить, что (x, [0, 1], 2, 2, [0, 1]) являются недействительными конфигурациями.
- После этого для каждого кадра, который потерян (режим=-1), режим устанавливается в ACELP (режим=0), если предыдущим кадром был ACELP, и режим устанавливается в TCX20 (режим=1) для всех других случаев.
Рассматривая ACELP, согласно AMR-WB+, если режим потерянных кадров приводит к mk=0 после экстраполяции режима, тот же самый подход как в [3GP12g] применяется для этого кадра (см. выше).
В AMR-WB+, в зависимости от количества потерянных кадров и экстраполируемого режима, соотнесенные подходы маскирования следующего TCX отличаются (TCX=преобразование кодированного возбуждения):
- Если весь кадр потерян, то применяется аналогичное ACELP маскирование: последнее возбуждение повторяется и маскируемые коэффициенты ISF (немного сдвинутые к их адаптивному среднему значению) используются для синтеза сигнала во временной области. Дополнительно, коэффициент плавного изменения, равный 0,7 за кадр (20 мс) [3GP09b, dec_tcx.c], умножается в области линейного предсказания непосредственно перед синтезом LPC (кодирования с линейным предсказанием).
- Если последним режимом был TCX80, а так же режимом экстраполируемого (частично потерянного) суперкадра является TCX80 (nloss=[1, 2], режим=(3, 3, 3, 3, 3)), то маскирование выполняется в области FFT, используя экстраполяцию фазы и амплитуды, учитывая последний правильно принятый кадр. Подход экстраполяции информации фазы не имеет никакого интереса в данной работе (никакого отношения к стратегии плавного изменения) и поэтому не описан. Для дополнительных подробностей см. [3GP09a, раздел 6.5.1.2.4]. По отношению к модификации амплитуды A-WB+, подход, выполняемый для маскирования TCX, состоит из следующих этапов [3GP09a, раздел 6.5.1.2.3]:
- Вычисляется спектр значения предыдущего кадра:
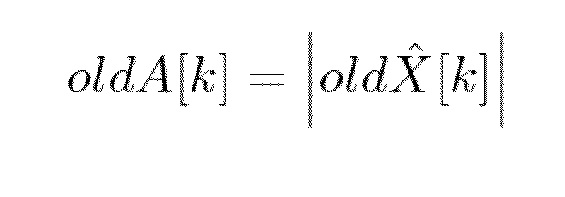
- Вычисляется спектр значения текущего кадра:
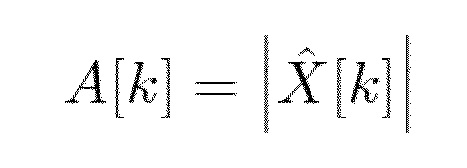
- Вычисляется разница усиления энергии непотерянных спектральных коэффициентов между предыдущим и текущим кадром:
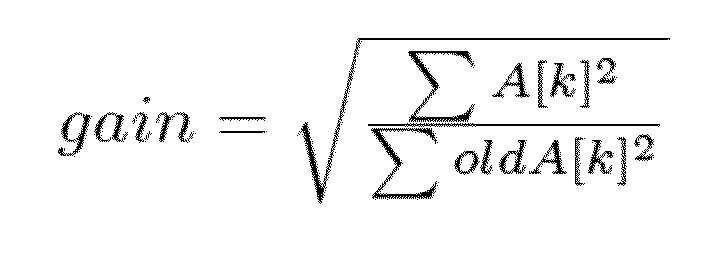
- Экстраполируется амплитуда недостающих спектральных коэффициентов, используя:
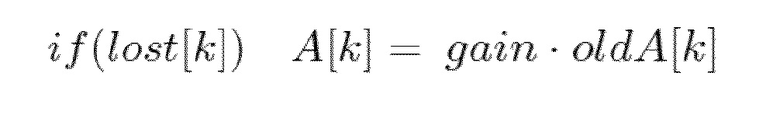
- В любом другом случае потерянного кадра с mk=[2, 3], целевой TCX (обратное FFT декодированного спектра плюс заполнение шумом (используя уровень шума, декодированный из битового потока)) синтезируется, используя всю доступную информацию (включающую в себя глобальное усиление TCX). Плавное изменение в этом случае не применяется.
Рассматривая CNG, в AMR-WB+ используется тот же самый подход, как в AMR-WB (см. выше).
В последующем рассматривают OPUS. OPUS [IET12] внедряет технологию из двух кодеков: ориентированного на речь SILK (известного как кодек Skype) и с низким временем ожидания CELT (CELT=перекрывающееся преобразование с ограниченной энергией). OPUS может беспроблемно адаптироваться между высокой и низкой скоростями передачи битов, и внутренне он переключается между кодеком линейного предсказания в более низкими скоростями передачи битов (SILK) и кодеком преобразования в более высокими скоростями передачи битов (CELT), так же как гибрид для короткого перекрытия.
Рассматривая сжатие и распаковку звуковых данных SILK, в OPUS существует несколько параметров, которые ослабляются во время маскирования в подпрограмме декодера SILK. Параметр усиления LTP ослабляется с помощью умножения всех коэффициентов LPC или на 0,99, 0,95 или на 0,90 за кадр, в зависимости от количества последовательных потерянных кадров, причем возбуждение создается с помощью использования последнего цикла основного тона из возбуждения предыдущего кадра. Параметр отставания основного тона очень медленно увеличивается во время последовательных потерь. Для одиночных потерь он сохраняется постоянным по сравнению с последним кадром. Кроме того, параметр усиления возбуждения по экспоненте уменьшается с 0,99lostcnt за кадр, так, чтобы параметр усиления возбуждения был равен 0,99 для первого параметра усиления возбуждения, так, чтобы параметр усиления возбуждения был равен 0,992 для второго параметра усиления возбуждения, и так далее. Возбуждение генерируется, используя генератор случайных чисел, который генерирует белый шум с помощью переменного переполнения. К тому же коэффициенты LPC экстраполируются/усредняются, основываясь на последнем правильно принятом наборе коэффициентов. После генерации ослабленного вектора возбуждения маскируемые коэффициенты LPC используются в OPUS для синтеза выходного сигнала во временной области.
Теперь рассматривают CELT в контексте OPUS. CELT является основанным на преобразовании кодеком. Маскирование CELT показывает подход PLC, основанного на основном тоне, который применяется к до пяти последовательно потерянных кадров. Начиная с 6-го кадра применяется подход шумоподобного маскирования, который генерирует фоновый шум, характеристики которого, как предполагается, звучат как предшествующий фоновый шум.
Фиг. 5 показывает режим работы CELT при потере пачки. В частности, фиг. 5 изображает спектрограмму (ось X: время; ось у: частота) маскируемого с помощью CELT речевого сегмента. Светло-серый квадрат указывает первые 5 последовательно потерянных кадров, где применяется основанный на основном тоне подход PLC. Кроме того, показано шумоподобное маскирование. Нужно отметить, что переключение выполняется немедленно, переход не происходит постепенно.
Рассматривая маскирование на основе основном тона, в OPUS маскирование на основе основном тона состоит из обнаружения периодичности в декодированном сигнале с помощью автокорреляции и повторения кадрированного колебательного сигнала (в области возбуждения, используя анализ и синтез LPC), используя смещение основном тона (отставание основном тона). Кадрированный колебательный сигнал перекрывается таким образом, чтобы сохранить маскирование наложения спектров во временной области с предыдущим кадром и следующим кадром [IET12]. Дополнительно коэффициент плавного изменения извлекается и применяется с помощью следующего кода:


В этом коде exc содержит сигнал возбуждения до выборок MAX_PERIOD перед потерей.
Сигнал возбуждения позже умножается на ослабление, затем синтезируется и выводится через синтез LPC.
Алгоритм плавного изменения для подхода во временной области может быть получен в итоге в таком виде:
- Находят равновесную энергию основном тона последнего цикла основного тона перед потерей.
- Находят равновесную энергию основном тона второго последнего цикла основного тона перед потерей.
- Если энергия увеличивается, то ее ограничивают так, чтобы она оставалась постоянной: ослабление=1.
- Если энергия уменьшается, то продолжают то же самое ослабление во время маскирования.
Рассматривая шумоподобное маскирование, согласно OPUS для 6-ого и последующих последовательных потерянных кадров подход замены шумом в области MDCT выполняется для моделирования фонового комфортного шума.
Рассматривая отслеживание уровня и формы фонового шума, в OPUS оценка фонового шума выполняется следующим образом: после анализа MDCT квадратный корень энергий диапазона MDCT вычисляется для диапазона частот, где группирование элементов MDCT выполняется в соответствии со шкалой барков согласно [IET12, таблица 55]. Затем квадратный корень энергий преобразовывается в область log2 с помощью:
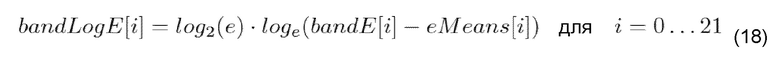
причем e - число Юлера, bandE - квадратный корень из диапазона MDCT, и eMeans - вектор констант (необходимый для получения результирующего нулевого среднего значения, которое приводит к усовершенствованному усилению кодирования).
В OPUS фоновый шум регистрируется на стороне декодера следующим образом [IET12, amp2Log2 и log2Amp@quant_bands.c]:
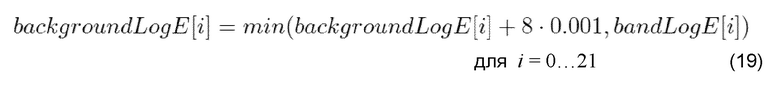
Отслеживаемая минимальная энергия в основном определяется с помощью квадратного корня из энергии диапазона текущего кадра, но увеличение от одного кадра к следующему ограничено 0,05 дБ.
Рассматривая применение уровня и формы фонового шума, согласно OPUS, если применяется шумоподобное PLC, то backgroundLogE, который извлекается в последнем хорошем кадре, используется и преобразовывается обратно в линейную область:
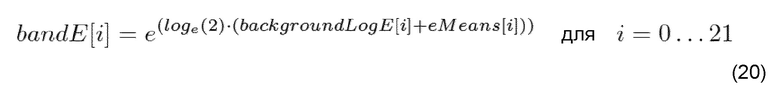
где e - число Юлера, и eMeans - тот же самый вектор констант, как для преобразования из «линейной в логарифмическую область».
Текущей процедурой маскирования является заполнение кадра MDCT белым шумом, произведенным с помощью генератора случайных чисел, и масштабирование этого белого шума таким способом, чтобы он соответствовал в диапазоне энергии bandE. Впоследствии применяется обратное MDCT, что приводит к сигналу во временной области. После перекрытия со сложением и компенсации предыскажений (как при обычном декодировании) он выводится.
В последующем рассматривают MPEG-4 HE-AAC (MPEG=экспертная группа по кинематографии; HE-AAC=высокоэффективное усовершенствованное кодирование звука). Высокоэффективное усовершенствованное кодирование звука состоит из основанного на преобразовании звукового кодека (AAC), дополненного параметрическим расширением полосы пропускания (SBR).
Рассматривая AAC (AAC=перспективное кодирование звука), консорциум DAB определяет для AAC в DAB+ плавное изменение к нулю в частотной области [EBU10, раздел A1.2] (DAB - цифровое радиовещание). Характер плавного изменения, например, пилообразный сигнал ослабления, может устанавливаться или корректироваться пользователем. Спектральные коэффициенты из последнего AU (AU=блок доступа) ослабляются с помощью коэффициента, соответствующего характеристикам плавного изменения, и затем передаются к сопоставлению «частота/время». В зависимости от пилообразного сигнала ослабления маскирование переключается на заглушение после множества последовательных недействительных AU, что означает, что весь спектр будет установлен в 0.
Консорциум DRM (DRM=цифровое управление правами) определяет для AAC в DRM плавное изменение в частотной области [EBU12, раздел 5.3.3]. Маскирование воздействует на спектральные данные непосредственно перед окончательным преобразованием «частота/время». Если множество кадров повреждены, то маскирование сначала воплощает плавное изменение, основываясь на немного модифицированных спектральных значениях из последнего действительного кадра. Кроме того, аналогично DAB+, характер плавного изменения, например, пилообразный сигнал ослабления, может устанавливаться или корректироваться пользователем. Спектральные коэффициенты из последнего кадра ослабляются с помощью коэффициента, соответствующего характеристикам плавного изменения, и затем передаются к сопоставлению «частота/время». В зависимости от пилообразного сигнала ослабления маскирование переключается на заглушение после множества последовательных недействительных кадров, что означает, что весь спектр будет установлен в 0.
3GPP представляет для AAC в усовершенствованном aacPlus плавное изменение в частотной области, аналогичное DRM [3GP12e, раздел 5.1]. Маскирование воздействует на спектральные данные непосредственно перед окончательным преобразованием «частота/время». Если множество кадров повреждены, то маскирование сначала воплощает постепенное изменение, основываясь на немного модифицированных спектральных значениях из последнего хорошего кадра. Полное плавное изменение использует 5 кадров. Спектральные коэффициенты из последнего хорошего кадра копируются и ослабляются с коэффициентом:
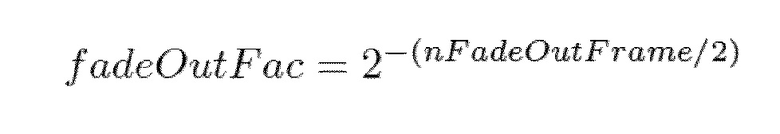
с nFadeOutFrame в качестве счетчика кадров с последнего хорошего кадра. После пяти кадров плавного изменения маскирование переключается к заглушению, что означает, что весь спектр будет установлен в 0.
Lauber и Sperschneider представляют для AAC покадровое плавное изменение спектра MDCT, основываясь на экстраполяции энергии [LS01, раздел 4.4]. Формы энергии предыдущего спектра могут использоваться для экстраполяции формы оцененного спектра. Экстраполяция энергии может выполняться независимо от методик маскирования в качестве вида последующего маскирования.
Рассматривая AAC, вычисление энергии выполняется на основе диапазона коэффициента масштабирования для того, чтобы быть близко к критическим диапазонам человеческой слуховой системы. Отдельные значения энергии уменьшаются на основе «кадр за кадром» для постепенного уменьшения громкости, например, для плавного изменения сигнала. Это становится необходимым, поскольку вероятность того, что оцененные значения представляют текущий сигнал, уменьшается быстро с течением времени.
Для генерации спектра, который будет выводиться, предлагают повторение кадра или замену шумом [LS01, разделы 3.2 и 3.3].
Quackenbusch и Driesen предлагают для AAC экспоненциальное покадровое плавное изменение к нулю [QD03]. Предлагается повторение смежного набора коэффициентов времени/частоты, причем каждое повторение имеет экспоненциально увеличивающееся ослабление, таким образом постепенно выполняя плавное изменение к заглушению в случае длительных перерывов в работе.
Рассматривая SBR (SBR=репликация спектральной полосы) в MPEG-4 HE-AAC, 3GPP предлагает для SBR в усовершенствованном aacPlus буферизовать декодированные данные огибающей и, в случае потери кадра, многократно использовать буферизированные энергии переданных данных огибающей и уменьшать их с помощью постоянного показателя, равного 3 дБ для каждого маскируемого кадра. Результат подается в обычный процесс декодирования, где корректировка огибающей использует его для вычисления усиления, используемого для коррекции исправленных высокочастотных диапазонов, созданных с помощью генератора ВЧ. Декодирование SBR затем происходит как обычно. Кроме того, дельта-кодированный уровень шума и значения уровня гармонических перегрузок удаляются. Поскольку нет никакого отличия от предыдущей информации, декодированный уровень шума и уровни гармонических перегрузок остаются пропорциональными энергии сгенерированного сигнала ВЧ [3GP12e, раздел 5.2].
Консорциум DRM определил для SBR вместе с AAC ту же самую методику, как 3GPP [EBU12, раздел 5.6.3.1]. Кроме того, консорциум DAB определяет для SBR в DAB+ ту же самую методику, как 3GPP [EBU10, раздел A2].
В последующем MPEG-4 CELP и MPEG-4 рассматривают HVXC (HVXC=гармоническое кодирование с векторным возбуждением). Консорциум DRM определяет для SBR вместе с CELP и HVXC [EBU12, раздел 5.6.3.2], что минимальное требуемое маскирование для SBR для кодеков для разговорных сигналов должно применять предопределенный набор значений данных всякий раз, когда обнаруживается поврежденный кадр SBR. Эти значения приводят к статической спектральной огибающей высокочастотного диапазона на относительно низком уровне воспроизведения, показывая спад к высоким частотам. Цель состоит просто в обеспечении того, чтобы никакие потенциально громкие пачки звуков с плохими характеристиками не достигали ушей слушателя посредством вставки «комфортного шума» (в противоположность строгому заглушению). Фактически это не является реальным плавным изменением, а скорее переходом к конкретному уровню энергии для вставки некоторого комфортного шума.
Впоследствии упоминается альтернативный вариант [EBU12, раздел 5.6.3.2], который многократно использует последние правильно декодированные данные и медленное плавное изменение уровней (L) к 0, аналогично случаю AAC+SBR.
Теперь рассматривают MPEG-4 HILN (HILN=гармоники и одиночные линии плюс шум). Meine и др. представляют плавное изменение для параметрического кодека MPEG-4 HILN [ISO09] в параметрической области [MEP01]. Для длительных гармонических компонент хорошим заданным по умолчанию режимом работы для замены поврежденных дифференцированно кодированных параметров является сохранение частоты постоянной для уменьшения амплитуды с коэффициентом ослабления (например, -6 дБ), и предоставление возможности спектральной огибающей сходиться к амплитуде усредненной низкочастотной характеристики. Альтернативно, спектральная огибающая должна сохраняться неизменной. Рассматривая амплитуды и спектральные огибающие, компоненты шума могут обрабатываться тем же самым образом, как гармонические компоненты.
В последующем рассматривают отслеживание уровня фонового шума в предшествующем уровне техники. Rangachari и Loizou [RL06] обеспечивают хороший краткий обзор нескольких способов и обсуждают некоторые из их ограничений. Способами для отслеживания уровня фонового шума являются, например, процедура отслеживания минимума [RL06] [Coh03] [SFB00] [Dob95], основанная на VAD (VAD=обнаружение речевой активности); фильтр Калмана, [Gan05] [BJH06], декомпозиция подпространства [BP06] [HJHOSj; мягкое решение [SS98] [MPC89] [HE95] и статистическая информация о минимумах.
Подход статистической информации о минимумах выбран для использования в рамках USAC-2 (USAC=объединенное кодирование речи и звука) и впоследствии изложен более подробно.
Оценка спектральной плотности мощности шума, основанная на оптимальном сглаживании и статистической информации о минимумах [Mar01], представляет оценочную функцию шума, которая имеет возможность работать независимо от сигнала, являющегося активным речевым или фоновым шумом. В отличие от других способов, алгоритм статистической информации о минимумах не использует явного порогового значения, чтобы различать речевую активность и паузу в речи, и поэтому более близко соотносится со способами мягкого решения, чем с традиционными способами распознавания активности речи. Аналогично способам мягкого решения, может также обновляться PSD (спектральная плотность мощности) оцененного шума во время речевой активности.
Способ статистической информации о минимумах базируется на двух наблюдениях, а именно, что речь и шум обычно статистически независимы и что мощность шумного речевого сигнала часто уменьшается к уровню мощности шума. Поэтому можно извлекать точную оценку PSD (PSD=спектральная плотность мощности) шума с помощью отслеживания минимума PSD сигнала шума. Так как минимум меньше (или в других случаях равен) среднего значения, то способ отслеживания минимума требует компенсации смещения.
Смещение является функцией дисперсии сглаженного сигнала PSD и как таковое зависит от параметра сглаживания оценочной функции PSD. В отличие от ранее разработанного отслеживания минимума, которое использует постоянный параметр сглаживания и постоянную коррекцию смещения минимума, используется зависящее от времени и частоты сглаживание PSD, которое также требует зависящей от времени и частоты компенсации смещения.
Использование отслеживания минимума обеспечивает грубую оценку мощности шума. Однако существуют некоторые недостатки. Сглаживание с фиксированным параметром сглаживания расширяет пики речевой активности сглаженной оценки PSD. Это приведет к неточным оценкам шума, поскольку подвижное окно для поиска минимума может смещаться в широкие максимумы. Поэтому близкие к единице параметры сглаживания не могут использоваться, и, как следствие, у оценки шума будет относительно большая дисперсия. Кроме того, оценка шума смещается к нижним значениям. К тому же в случае увеличения мощности шума отслеживание минимумов отстает.
Основанное на MMSE отслеживание PSD шума с низкой сложностью [HHJ10], представляет подход PSD фонового шума, использующий поиск MMSE, используемый на спектре DFT (дискретного преобразования Фурье). Алгоритм состоит из следующих этапов обработки:
- Вычисляется оценочная функция максимальной вероятности, основываясь на PSD шума предыдущего кадра.
- Вычисляется минимальная среднеквадратическая оценочная функция.
- Оценивается оценочная функция максимальной вероятности, используя направленный на решение подход [EM84].
- Вычисляется обратный коэффициент смещения, предполагая, что речевые и шумовые коэффициенты DFT имеют распределение Гаусса.
- Сглаживается оцененная спектральная плотность мощности шума.
Также существует подход системы обеспечения безопасности, применяемый для того, чтобы избежать полной блокировки алгоритма.
Отслеживание нестационарного шума, основанное на управляемой данными рекурсивной оценке мощности шума [EH08], представляет способ оценки дисперсии спектра шума из речевых сигналов, засоренных источниками в значительной мере нестационарного шума. Этот способ также использует сглаживание в направлении времени/частоты.
Алгоритм оценки шума с низкой сложностью, основанный на сглаживании оценки мощности шума и коррекции смещения оценки [Yu09], расширяет подход, представленный в [EH08]. Основным отличием является то, что спектральная функция усиления для оценки мощности шума находится с помощью итерационного управляемого данными способа.
Статистические способы улучшения шумной речи [Mar03] комбинируют подход статистической информации о минимумах, приведенный в [Mar01], с модификацией усиления с помощью мягкого решения [MCA99], с оценкой априорного SNR [MCA99], с адаптивным ограничением усиления [MC99] и со средством оценки логарифма спектральной амплитуды MMSE [EM85].
Плавное изменение особенно интересно для множества речевых и звуковых кодеков, в частности, для AMR (см. [3GP12b]) (включающего в себя ACELP и CNG), AMR-WB (см. [3GP09c]) (включающего в себя ACELP и CNG), AMR-WB+ (см. [3GP09a]) (включающего в себя ACELP, TCX и CNG), G.718 (см. [ITU08a]), G.719 (см. [ITU08b]), G.722 (см. [ITU07]), G.722.1 (см. [ITU05]), G.729 (см. [ITU12, CPK08, PKJ+11]), MPEG-4 HE-AAC/усовершенствованного aacPlus (см. [EBU10, EBU12, 3GP126, LS01, QD03]) (включающего в себя AAC и SBR), MPEG-4 HILN (см. [ISO09, MEP01]), и OPUS (см. [IET12]) (включающего в себя SILK и CELT).
В зависимости от кодека плавное изменение выполняется в различных областях:
Для кодеков, которые используют LPC, постепенное изменение выполняется в области линейного предсказания (также известной, как область возбуждения). Это сохраняется для кодеков, которые основаны на ACELP, например, для AMR, AMR-WB, ядра ACELP AMR-WB+, G.718, G.729, G.729.1, ядра SILK в OPUS; кодеков, которые дополнительно обрабатывают сигнал возбуждения, используя частотно-временное преобразование, например, для ядра TCX AMR-WB+, ядра CELT в OPUS; и для схем генерации комфортного шума (CNG), которые работают в области линейного предсказания, например, для CNG в AMR, CNG в AMR-WB, CNG в AMR-WB+.
Для кодеков, которые непосредственно преобразовывают временной сигнал в частотную область, плавное изменение выполняется в спектральной области/области поддиапазонов. Это остается правильным для кодеков, которые основаны на MDCT или аналогичном преобразовании, таких как AAC в MPEG-4 HE-AAC, G.719, G.722 (в области поддиапазонов) и G.722.1.
Для параметрических кодеков плавное изменение применяется в параметрической области. Это остается правильным для MPEG-4 HILN.
Рассматривая скорость плавного изменения и кривую плавного изменения, плавное изменение обычно реализуется с помощью применения коэффициента ослабления, который применяется к представлению сигнала в соответствующей области. Размер коэффициента ослабления управляет скоростью плавного изменения и кривой плавного изменения. В большинстве случаев коэффициент ослабления применяется по кадрам, но также используется и применение «по выборкам», см., например, G.718 и G.722.
Коэффициент ослабления для конкретного сегмента сигнала может обеспечиваться двумя способами, абсолютным и относительным.
В случае, когда коэффициент ослабления обеспечивается абсолютно, эталонным уровнем всегда является уровень последнего принятого кадра. Абсолютные коэффициенты ослабления обычно начинаются со значения, которое близко к 1, для сегмента сигнала непосредственно после последнего хорошего кадра, и затем снижаются быстрее или медленнее к 0. Кривая плавного изменения непосредственно зависит от этих коэффициентов. Это, например, случай маскирования, описанного в приложении IV G.722 (см., в частности [ITU07, фиг. IV.7]), где кривые возможного плавного изменения линейны или фракционно линейны. Учитывая коэффициент усиления g(n), где g(0) представляет коэффициент усиления последнего хорошего кадра, коэффициент αabs(n) абсолютного ослабления, коэффициент усиления любого последующего потерянного кадра, может извлекаться следующим образом
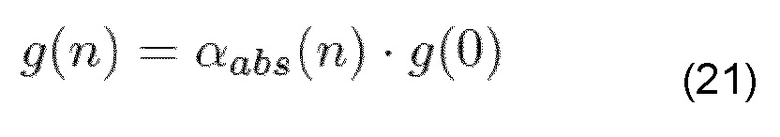
В случае, когда коэффициент ослабления обеспечивается относительно, эталонным уровнем является уровень из предыдущего кадра. У этого есть преимущество в случае процедуры рекурсивного маскирования, например, если уже ослабленный сигнал дополнительно повторно обрабатывается и ослабляется.
Если коэффициент ослабления применяется рекурсивно, то он может быть постоянным значением, независимым из количества последовательно потерянных кадров, например, 0,5 для G.719 (см. выше); постоянным значением по отношению к количеству последовательно потерянных кадров, например, как предложено для G.729 в [CPK08]: 1,0 для первых двух кадров, 0,9 для следующих двух кадров, 0,8 для кадров 5 и 6, и 0 для всех последующих кадров (см. выше); или значением, которое соотносится с количеством последовательно потерянных кадров и которое зависит от характеристик сигнала, например, более быстрым плавным изменением для неустойчивого сигнала и более медленным плавным изменением для устойчивого сигнала, например, G.718 (см. вышеуказанный раздел и [ITU08a, таблица 44]);
Принимая, что относительный коэффициент постепенного изменения 0 ≤ arel(n) ≤ 1, тогда как n является количеством потерянных кадров (n ≥ 1); коэффициент усиления любого последующего кадра может извлекаться следующим образом
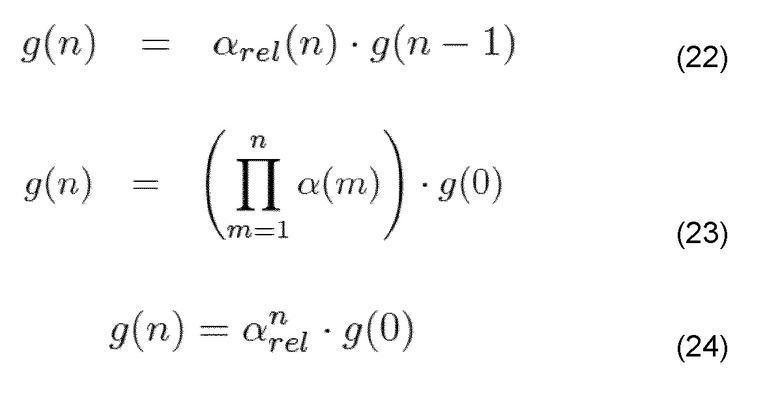
что приводит к экспоненциальному плавному изменению.
Рассматривая процедуру плавного изменения, обычно определяется коэффициент ослабления, но в некоторых стандартах применения (DRM, DAB+) его оставляют на усмотрение изготовителя.
Если различные части сигнала плавно изменяются отдельно, то различные коэффициенты ослабления могут применяться, например, для плавного изменения тональных компонент с конкретной скоростью, а шумоподобных компонент - с другой скоростью (например, AMR, SILK).
Обычно, конкретное усиление применяется к целому кадру. Когда плавное изменение выполняется в спектральной области, это - единственный возможный путь. Однако, если плавное изменение выполняется во временной области или в области линейного предсказания, то возможно более детализированное плавное изменение. Такое более детализированное плавное изменение применяется в G.718, где отдельные коэффициенты усиления извлекаются для каждой выборки с помощью линейной интерполяции между коэффициентом усиления последнего кадра и коэффициентом усиления текущего кадра.
Для кодеков с переменной продолжительностью кадра постоянный коэффициент относительного ослабления приводит к отличающейся скорости плавного изменения в зависимости от продолжительности кадра. Это, например, случай AAC, где продолжительность кадра зависит от частоты дискретизации.
Для применения применяемой плавно изменяющейся кривой к временной форме последнего принятого сигнала, (статические) коэффициенты плавного изменения могут дополнительно корректироваться. Такая дополнительная динамическая корректировка, например, применяется для AMR, где учитывается среднее значение предыдущих пяти коэффициентов усиления (см. [3GP12b] и раздел 1.8.1). Прежде, чем выполняется какое-либо ослабление, текущее усиление устанавливается в среднее значение, если данное среднее значение меньше последнего усиления, иначе используется последнее усиление. Кроме того, такая дополнительная динамическая корректировка, например, применяется для G729, где амплитуда предсказывается с помощью использования линейной регрессии предыдущих коэффициентов усиления (см. [CPK08, PKJ+11] и раздел 1.6). В этом случае результирующий коэффициент усиления для первых маскированных кадров может превышать коэффициент усиления последнего принятого кадра.
Рассматривая целевой уровень плавного изменения, за исключением G.718 и CELT, целевой уровень 0 для всех проанализированных кодеков включает в себя генерацию комфортного шума этих кодеков (CNG).
В G.718 плавное изменение тонального возбуждения (представляющего тональные компоненты) и плавное изменение случайного возбуждения (представляющего шумоподобные компоненты) выполняются отдельно. Хотя коэффициент усиления основного тона плавно изменяется к нулю, инновационный коэффициент усиления плавно изменяется к энергии возбуждения CNG.
Предполагая, что коэффициенты относительного ослабления заданы, это приводит - основываясь на формуле (23) - к следующему коэффициенту абсолютного ослабления:
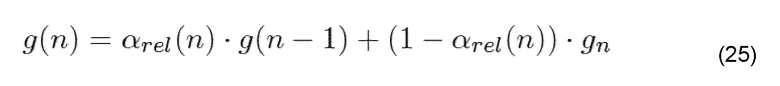
с gn, являющимся усилением возбуждения, используемым во время генерации комфортного шума. Эта формула соответствует формуле (23), когда gn=0.
G.718 не выполняет плавного изменения в случае DTX/CNG.
В CELT нет никакого плавного изменения к целевому уровню, но после 5 кадров тонального маскирования (включающего в себя плавное изменение), уровень немедленно переключается к целевому уровню в 6-ом последовательно потерянном кадре. Уровень извлекается по диапазонам, используя формулу (19).
Рассматривая целевую форму спектра плавного изменения, все проанализированные кодеки, основанные на чистом преобразовании (AAC, G.719, G.722, G.722.1), так же как SBR просто продлевают форму спектра последнего хорошего кадра во время плавного изменения.
Различные кодеки для разговорных сигналов плавно изменяют форму спектра к среднему значению, используя синтез LPC. Среднее значение может быть статичным (AMR) или адаптивным (AMR-WB, AMR-WB+, G.718), тогда как последнее извлекают из статического среднего значения и краткосрочного среднего значения (извлекаемого с помощью усреднения последних n наборов коэффициентов LP) (LP=линейное предсказание).
Все модули CNG в обсуждаемых кодеках AMR, AMR-WB, AMR-WB+, G.718 продлевает форму спектра последнего хорошего кадра во время плавного изменения.
Рассматривая отслеживания уровня фонового шума, существует пять разных подходов, известных из литературы:
- основанный на детекторе голосовой активности: основан на SNR/VAD, но его очень сложно настраивать и тяжело использовать для речи с низким SNR.
- схема мягкого решения: подход мягкого решения учитывает вероятность присутствия речи [SS98] [MPC89] [HE95].
- статистическая информация о минимумах: минимум PSD отслеживается, удерживая некоторое количество значений в течение времени в буфере, таким образом предоставляя возможность найти минимальный шум из прошлых выборок [Mar01] [HHJ10] [EH08] [Yu09].
- фильтрование Калмана: алгоритм использует последовательность измерений, наблюдаемых в течение времени, содержащих шум (случайные колебания), и производит оценки PSD шума, которые имеют тенденцию быть более точными, чем основанные только на одном единственном измерении. Фильтр Калмана воздействует рекурсивно на потоки шумных входных данных для создания статистически оптимальной оценки состояния системы [Gan05] [BJH06].
- декомпозиция подпространства: этот подход пытается выполнить декомпозицию шумоподобного сигнала на чистый речевой сигнал и шумовую часть, используя, например, KLT (преобразование Карунена-Лоэва, также известное как анализ главных компонент) и/или DFT (дискретное преобразование Фурье). Затем собственные векторы/собственные значения могут отслеживаться, используя произвольный алгоритм сглаживания [BP06] [HJH08].
Задачей настоящего изобретения является обеспечение улучшенных концепций для систем кодирования звука. Задача настоящего изобретения решается с помощью устройства по п. 1, способа по п. 14 и компьютерной программы по п. 15.
Обеспечено устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала. Данное устройство содержит интерфейс приема для приема множества кадров, буфер задержки для сохранения выборок звукового сигнала для декодированного звукового сигнала, блок выбора выборок для выбора множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере задержки, и процессор выборок для обработки выбранных выборок звукового сигнала для получения восстановленных выборок звукового сигнала для восстановленного звукового сигнала. Блок выбора выборок конфигурируется для выбора, если текущий кадр принимается с помощью интерфейса приема и если текущий кадр, принимаемый с помощью интерфейса приема, не поврежден, множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере задержки, в зависимости от информации отставания основного тона, содержащейся в текущем кадре. Кроме того, блок выбора выборок конфигурируется для выбора, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр, принимаемый с помощью интерфейса приема, поврежден, множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере задержки, в зависимости от информации отставания основного тона, содержащейся в другом кадре, принимаемом ранее с помощью интерфейса приема.
Согласно варианту осуществления процессор выборок может, например, конфигурироваться для получения восстановленных выборок звукового сигнала, если текущий кадр принимается с помощью интерфейса приема и если текущий кадр, принимаемый с помощью интерфейса приема, не поврежден, с помощью повторного масштабирования выбранных выборок звукового сигнала в зависимости от информации усиления, содержащейся в текущем кадре. Кроме того, блок выбора выборок может, например, конфигурироваться для получения восстановленных выборок звукового сигнала, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр, принимаемый с помощью интерфейса приема, поврежден, с помощью повторного масштабирования выбранных выборок звукового сигнала в зависимости от информации усиления, содержащейся в указанном другом кадре, принимаемом ранее с помощью интерфейса приема.
В варианте осуществления процессор выборок может, например, конфигурироваться для получения восстановленных выборок звукового сигнала, если текущий кадр принимается с помощью интерфейса приема и если текущий кадр, принимаемый с помощью интерфейса приема, не поврежден, с помощью умножения выбранных выборок звукового сигнала и значения, зависящего от информации усиления, содержащейся в текущем кадре. Кроме того, блок выбора выборок конфигурируется для получения восстановленных выборок звукового сигнала, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр, принимаемый с помощью интерфейса приема, поврежден, с помощью умножения выбранных выборок звукового сигнала и значения, зависящего от информации усиления, содержащейся в указанном другом кадре, принимаемом ранее с помощью интерфейса приема.
Согласно варианту осуществления процессор выборок может, например, конфигурироваться для сохранения восстановленных выборок звукового сигнала в буфере задержки.
В варианте осуществления процессор выборок может, например, конфигурироваться для сохранения восстановленных выборок звукового сигнала в буфере задержки перед тем, как дополнительный кадр будет принят с помощью интерфейса приема.
Согласно варианту осуществления процессор выборок может, например, конфигурироваться для сохранения восстановленных выборок звукового сигнала в буфере задержки после того, как дополнительный кадр будет принят с помощью интерфейса приема.
В варианте осуществления процессор выборок может, например, конфигурироваться для повторного масштабирования выбранных выборок звукового сигнала в зависимости от информации усиления для получения повторно масштабированных выборок звукового сигнала и объединения повторно масштабированных выборок звукового сигнала с входными выборками звукового сигнала для получения обработанных выборок звукового сигнала.
Согласно варианту осуществления процессор выборок может, например, конфигурироваться для сохранения обработанных выборок звукового сигнала, указывающих комбинацию повторно масштабированных выборок звукового сигнала и входных выборок звукового сигнала, в буфере задержки, и не выполнения сохранения повторно масштабированных выборок звукового сигнала в буфере задержки, если текущий кадр принимается с помощью интерфейса приема и если текущий кадр, принимаемый с помощью интерфейса приема, не поврежден. Кроме того, процессор выборок конфигурируется для сохранения повторно масштабированных выборок звукового сигнала в буфере задержки и не выполнения сохранения обработанных выборок звукового сигнала в буфере задержки, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр, принимаемый с помощью интерфейса приема, поврежден.
Согласно другому варианту осуществления процессор выборок может, например, конфигурироваться для сохранения обработанных выборок звукового сигнала в буфере задержки, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр, принимаемый с помощью интерфейса приема, поврежден.
В варианте осуществления блок выбора выборок может, например, конфигурироваться для получения восстановленных выборок звукового сигнала с помощью повторного масштабирования выбранных выборок звукового сигнала в зависимости от модифицированного усиления, причем модифицированное усиление определяется согласно формуле:
gain=gain_past * damping;
в которой gain является модифицированным усилением, в которой блок выбора выборок может, например, конфигурироваться для установки gain_past в gain после того, как значение gain вычислено, и которой damping является действительной величиной.
Согласно варианту осуществления блок выбора выборок может, например, конфигурироваться для вычисления модифицированного усиления.
В варианте осуществления damping может, например, определяться согласно: 0 ≤ damping ≤ 1.
Согласно варианту осуществления модифицированное усиление gain может, например, устанавливаться в нуль, если по меньшей мере предопределенное количество кадров не принято с помощью интерфейса приема после того, как кадр последний раз принят с помощью интерфейса приема.
Кроме того, обеспечен способ декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала. Данный способ содержит этапы, на которых:
- Принимают множество кадров.
- Сохраняют выборки звукового сигнала для декодированного звукового сигнала.
- Выбирают множество выборок для выбранного звукового сигнала из выборок звукового сигнала, сохраненных в буфере задержки. И:
- Обрабатывают выборки выбранного звукового сигнала для получения восстановленных выборок звукового сигнала для восстановленного звукового сигнала.
Если текущий кадр принимается и если текущий принимаемый кадр не поврежден, то этап выбора множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере задержки, проводится в зависимости от информации отставания основного тона, содержащейся в текущем кадре. Кроме того, если текущий кадр не принимается или если текущий принимаемый кадр поврежден, то этап выбора множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере задержки, проводится в зависимости от информации отставания основного тона, содержащейся в другом кадре, принимаемом ранее с помощью интерфейса приема.
Кроме того, обеспечена компьютерная программа для реализации вышеописанного способа, когда она выполняется на компьютере или процессоре обработки сигнала.
Варианты осуществления используют TCX LTP (TXC LTP=долгосрочное предсказание с возбуждением, управляемым кодовым преобразованием). Во время обычного функционирования TCX LTP память обновляется с помощью синтезируемого сигнала, содержащего шум и восстановленные тональные компоненты.
Вместо того, чтобы блокировать TCX LTP во время маскирования, его обычное функционирование может быть продолжено во время маскирования с параметрами, принятыми в последнем хорошем кадре. Это сохраняет форму спектра сигнала, особенно те тональные компоненты, которые моделируются с помощью фильтра LTP.
Кроме того, варианты осуществления разъединяют цикл обратной связи TCX LTP. Простое продолжение обычной работы TCX LTP представляет дополнительный шум, поскольку с каждым этапом обновления дополнительно представляется случайно генерируемый шум от возбуждения LTP. Тональные компоненты следовательно искажаются все больше со временем с помощью добавленного шума.
Чтобы преодолеть это, только обновленный буфер TCX LTP может подаваться обратно (без добавления шума) для того, чтобы не засорять тональную информацию нежелательным случайным шумом.
К тому же согласно вариантам осуществления усиление TCX LTP плавно изменяется к нулю.
Эти варианты осуществления основаны на обнаружении, что продолжение TCX LTP помогает сохранять характеристики сигнала в течение короткого срока, но имеет недостатки в течение длительного срока: сигнал, воспроизводимый во время маскирования, будет включать в себя голосовую/тональную информацию, которая присутствовала перед потерей. Особенно для чистой речи или речи с фоновым шумом крайне маловероятно, что тон или гармоническое колебание будут снижаться очень медленно за очень продолжительное время. С помощью продолжения работы TCX LTP во время маскирования, особенно если обновление памяти LTP разъединено (только тональные компоненты подаются назад, а не часть со скремблированным знаком), голосовая/тональная информация останется присутствовать в маскируемом сигнале для всей потери, будучи ослабленной только с помощью полного плавного изменения к уровню комфортного шума. Кроме того, невозможно достичь огибающую комфортного шума во время потерь пачки пакетов, если TCX LTP применяется во время потери пачки без ослабления в течение времени, потому что сигнал будет в таком случае всегда внедрять голосовую информацию LTP.
Поэтому усиление TCX LTP плавно изменяется к нулю, так что тональные компоненты, представленные с помощью LTP, будут плавно изменяться к нулю, в то же самое время сигнал плавно изменяется к уровню и форме фонового сигнала, и таким образом, чтобы плавное изменение достигло необходимую огибающую спектра фона (комфортного шума) без внедрения нежелательных тональных компонент.
В вариантах осуществления та же самая скорость плавного изменения используется для плавного изменения усиления LTP, как и для плавного изменения белого шума.
Напротив, в предшествующем уровне техники нет никакого известного кодека преобразования, который использует LTP во время маскирования. Для MPEG-4 LTP [ISO09] никакие подходы маскирования не существуют в предшествующем уровне техники. Другим основанным на MDCT кодеком предшествующего уровня техники, который использует LTP, является CELT, но этот кодек использует аналогичное ACELP маскирование для первых пяти кадров, а для всех последующих кадров генерируется фоновый шум, который не использует LTP. Недостатком предшествующего уровня техники при не использовании TCX LTP является то, что все тональные компоненты, моделируемые с LTP, резко исчезают. Кроме того, в основанных на ACELP кодеках предшествующего уровня техники операция LTP продлевается во время маскирования, и усиление адаптивной кодовой книги плавно изменяется к нулю. Что касается работы цикла обратной связи, предшествующий уровень техники использует два подхода, или все возбуждение, например, сумма инновационного и адаптивного возбуждения, подается назад (AMR-WB); или только обновленное адаптивное возбуждение, например, тональные части сигнала, подаются назад (G.718). Вышеупомянутые варианты осуществления преодолевают недостатки предшествующего уровня техники.
Кроме того, обеспечено устройство для декодирования звукового сигнала.
Данное устройство содержит интерфейс приема. Интерфейс приема конфигурируется для приема множества кадров, причем интерфейс приема конфигурируется для приема первого кадра из множества кадров, указанный первый кадр содержит первую часть звукового сигнала, указанная первая часть звукового сигнала представлена в первой области, и причем интерфейс приема конфигурируется для приема второго кадра из множества кадров, указанный второй кадр содержит вторую часть звукового сигнала.
Кроме того, устройство содержит блок преобразования для преобразования второй части звукового сигнала или значения или сигнала, извлеченного из второй части звукового сигнала, из второй области в область отслеживания для получения информации второй части сигнала, причем вторая область отличается от первой области, причем область отслеживания отличается от второй области, и причем область отслеживания равна или отличается от первой области.
К тому же устройство содержит блок отслеживания уровня шума, причем блок отслеживания уровня шума конфигурируется для приема информации первой части сигнала, представленной в области отслеживания, причем информация первой части сигнала зависит от первой части звукового сигнала. Блок отслеживания уровня шума конфигурируется для приема второй части сигнала, представленной в области отслеживания, и причем блок отслеживания уровня шума конфигурируется для определения информации уровня шума в зависимости от информации первой части сигнала, представленной в области отслеживания, и в зависимости от информации второй части сигнала, представленной в области отслеживания.
Кроме того, устройство содержит блок восстановления для восстановления третьей части звукового сигнала в зависимости от информации уровня шума, если третий кадр из множества кадров не принимается с помощью интерфейса приема, но он поврежден.
Звуковой сигнал может, например, быть речевым сигналом, или музыкальным сигналом, или сигналом, который содержит речь и музыку, и т.д.
Утверждение, что информация первой части сигнала зависит от первой части звукового сигнала, подразумевает, что информация первой части сигнала или является первой частью звукового сигнала, или что информация первой части сигнала получена/сгенерирована в зависимости от первой части звукового сигнала или другим способом зависит от первой части звукового сигнала. Например, первая часть звукового сигнала, возможно, была преобразована из одной области в другую область для получения информации первой части сигнала.
Аналогично, утверждение, что информация второй части сигнала зависит от второй части звукового сигнала, подразумевает, что информация второй части сигнала или является второй частью звукового сигнала, или что информация второй части сигнала получена/сгенерирована в зависимости от второй части звукового сигнала или другим способом зависит от второй части звукового сигнала. Например, вторая часть звукового сигнала, возможно, была преобразована из одной области в другую область для получения информации второй части сигнала.
В варианте осуществления первая часть звукового сигнала может, например, быть представлена во временной области в качестве первой области. Кроме того, блок преобразования, может, например, конфигурироваться для преобразования второй части звукового сигнала или значения, извлеченного из второй части звукового сигнала, из области возбуждения, являющейся второй областью, во временную область, являющуюся областью отслеживания. К тому же блок отслеживания уровня шума может, например, конфигурироваться для приема информации первой части сигнала, представленной во временной области в качестве области отслеживания. Кроме того, блок отслеживания уровня шума может, например, конфигурироваться для приема второй части сигнала, представленной во временной области в качестве области отслеживания.
Согласно варианту осуществления первая часть звукового сигнала может, например, быть представлена в области возбуждения в качестве первой области. Кроме того, блок преобразования может, например, конфигурироваться для преобразования второй части звукового сигнала или значения, извлеченного из второй части звукового сигнала, из временной области, являющейся второй областью, в область возбуждения, являющуюся областью отслеживания. К тому же блок отслеживания уровня шума может, например, конфигурироваться для приема информации первой части сигнала, представленной в области возбуждения в качестве области отслеживания. Кроме того, блок отслеживания уровня шума может, например, конфигурироваться для приема второй части сигнала, представленной в области возбуждения в качестве области отслеживания.
В варианте осуществления первая часть звукового сигнала может, например, быть представлена в области возбуждения в качестве первой области, причем блок отслеживания уровня шума может, например, конфигурироваться для приема информации первой части сигнала, причем указанная информация первой части сигнала представлена в области FFT, которая является областью отслеживания, и причем указанная информация первой части сигнала зависит от указанной первой части звукового сигнала, представленной в области возбуждения, причем блок преобразования может, например, конфигурироваться для преобразования второй части звукового сигнала или значения, извлеченного из второй части звукового сигнала, из временной области, являющейся второй областью, в область FFT, являющуюся областью отслеживания, и причем блок отслеживания уровня шума может, например, конфигурироваться для приема второй части звукового сигнала, представленной в области FFT.
В варианте осуществления устройство может, например, дополнительно содержать первый блок объединения для определения первого объединенного значения в зависимости от первой части звукового сигнала. Кроме того, устройство может, например, дополнительно содержать второй блок объединения для определения, в зависимости от второй части звукового сигнала, второго объединенного значения в качестве значения, извлеченного из второй части звукового сигнала. К тому же блок отслеживания уровня шума может, например, конфигурироваться для приема первого объединенного значения в качестве информации первой части сигнала, представленной в области отслеживания, причем блок отслеживания уровня шума может, например, конфигурироваться для приема второго объединенного значения в качестве информации второй части сигнала, представленной в области отслеживания, и причем блок отслеживания уровня шума может, например, конфигурироваться для определения информации уровня шума в зависимости от первого объединенного значения, представленного в области отслеживания, и в зависимости от второго объединенного значения, представленного в области отслеживания.
Согласно варианту осуществления первый блок объединения может, например, конфигурироваться для определения первого объединенного значения таким образом, чтобы первое объединенное значение указывало среднеквадратическое значение первой части звукового сигнала или сигнала, извлеченного из первой части звукового сигнала. Кроме того, второй блок объединения может, например, конфигурироваться для определения второго объединенного значения таким образом, чтобы второе объединенное значение указывало среднеквадратическое значение второй части звукового сигнала или сигнала, извлеченного из второй части звукового сигнала.
В варианте осуществления блок преобразования может, например, конфигурироваться для преобразования значения, извлеченного из второй части звукового сигнала, из второй области в область отслеживания с помощью применения значения усиления к значению, извлеченному из второй части звукового сигнала.
Согласно вариантам осуществления значение усиления может, например, указывать усиление, представленное с помощью синтеза кодирования с линейным предсказанием, или значение усиления может, например, указывать усиление, представленное с помощью синтеза кодирования с линейным предсказанием и компенсации предыскажений.
В варианте осуществления блок отслеживания уровня шума может, например, конфигурироваться для определения информации уровня шума с помощью применения подхода статистической информации о минимумах.
Согласно варианту осуществления блок отслеживания уровня шума может, например, конфигурироваться для определения уровня комфортного шума в качестве информации уровня шума. Блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала в зависимости от информации уровня шума, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
В варианте осуществления блок отслеживания уровня шума может, например, конфигурироваться для определения уровня комфортного шума в качестве информации уровня шума, извлеченной из спектра уровня шума, причем указанный спектр уровня шума получается с помощью применения подхода статистической информации о минимумах. Блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала в зависимости от множества коэффициентов линейного предсказания, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
Согласно другому варианту осуществления блок отслеживания уровня шума может, например, конфигурироваться для определения множества коэффициентов линейного предсказания, указывающих уровень комфортного шума в качестве информации уровня шума, и блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала в зависимости от множества коэффициентов линейного предсказания.
В варианте осуществления блок отслеживания уровня шума конфигурируется для определения множества коэффициентов FFT, указывающих уровень комфортного шума в качестве информации уровня шума, и первый блок восстановления конфигурируется для восстановления третьей части звукового сигнала в зависимости от уровня комфортного шума, извлеченного из указанных коэффициентов FFT, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
В варианте осуществления блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала в зависимости от информации уровня шума и в зависимости от первой части звукового сигнала, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
Согласно варианту осуществления блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала с помощью ослабления или усиления сигнала, извлеченного из первой или второй части звукового сигнала.
В варианте осуществления устройство может, например, дополнительно содержать блок долгосрочного предсказания, содержащий буфер задержки. Кроме того, блок долгосрочного предсказания может, например, конфигурироваться для генерации обработанного сигнала в зависимости от первой или второй части звукового сигнала, в зависимости от вводимой в буфер задержки информации, сохраняемой в буфере задержки, и в зависимости от усиления долгосрочного предсказания. К тому же блок долгосрочного предсказания может, например, конфигурироваться для плавного изменения усиления долгосрочного предсказания к нулю, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
Согласно варианту осуществления блок долгосрочного предсказания может, например, конфигурироваться для плавного изменения усиления долгосрочного предсказания к нулю, причем скорость, с которой усиление долгосрочного предсказания плавно изменяется к нулю, зависит от коэффициента плавного изменения.
В варианте осуществления блок долгосрочного предсказания может, например, конфигурироваться для обновления вводимой в буфер задержки информации с помощью сохранения сгенерированного обработанного сигнала в буфере задержки, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
Согласно варианту осуществления блок преобразования может, например, быть первым блоком преобразования, а блок восстановления - первым блоком восстановления. Устройство дополнительно содержит второй блок преобразования и второй блок восстановления. Второй блок преобразования может, например, конфигурироваться для преобразования информации уровня шума из области отслеживания во вторую область, если четвертый кадр из множества кадров не принимается с помощью интерфейса приема, или если указанный четвертый кадр принимается с помощью интерфейса приема, но он поврежден. Кроме того, второй блок восстановления может, например, конфигурироваться для восстановления четвертой части звукового сигнала в зависимости от информации уровня шума, представленной во второй области, если указанный четвертый кадр из множества кадров не принимается с помощью интерфейса приема, или если указанный четвертый кадр принимается с помощью интерфейса приема, но он поврежден.
В варианте осуществления второй блок восстановления может, например, конфигурироваться для восстановления четвертой части звукового сигнала в зависимости от информации уровня шума и в зависимости от второй части звукового сигнала.
Согласно варианту осуществления второй блок восстановления может, например, конфигурироваться для восстановления четвертой части звукового сигнала с помощью ослабления или усиления сигнала, извлеченного с помощью первой или второй части звукового сигнала.
Кроме того, обеспечен способ декодирования звукового сигнала.
Данный способ содержит этапы, на которых:
- Принимают первый кадр из множества кадров, указанный первый кадр содержит первую часть звукового сигнала, указанная первая часть звукового сигнала представлена в первой области.
- Принимают второй кадр из множества кадров, указанный второй кадр содержит вторую часть звукового сигнала.
- Преобразовывают вторую часть звукового сигнала или значение или сигнал, извлеченный из второй части звукового сигнала, из второй области в область отслеживания для получения информации второй части сигнала, причем вторая область отличается от первой области, причем область отслеживания отличается от второй области, и причем область отслеживания равна или отличается от первой области.
- Определяют информацию уровня шума в зависимости от информации первой части сигнала, которая представлена в области отслеживания, и в зависимости от информации второй части сигнала, представленной в области отслеживания, причем информация первой части сигнала зависит от первой части звукового сигнала. И:
- Восстанавливают третью часть звукового сигнала в зависимости от информации уровня шума, представленной в области отслеживания, если третий кадр из множества кадров не принимается или если указанный третий кадр принимается, но он поврежден.
К тому же обеспечена компьютерная программа для реализации вышеописанного способа, когда она выполняется на компьютере или процессоре обработки сигналов.
Некоторые из вариантов осуществления настоящего изобретения обеспечивают изменяющийся во времени параметр сглаживания таким образом, чтобы возможности отслеживания сглаженного графика спектральной функции и его дисперсия были лучше сбалансированы для разработки алгоритма для компенсации смещения и ускорения отслеживания шума в общем случае.
Варианты осуществления настоящего изобретения основаны на обнаружении, что по отношению к плавному изменению следующие параметры представляют интерес: область плавного изменения; скорость плавного изменения, или, более обобщенно, кривая плавного изменения; целевой уровень плавного изменения; целевая форма спектра плавного изменения; и/или отслеживание уровня фонового шума. В этом контексте варианты осуществления основаны на обнаружении, что предшествующий уровень техники имеет существенные недостатки.
Обеспечены устройство и способ для улучшенного плавного изменения сигнала для переключаемых систем кодирования звука во время маскирования ошибок.
Кроме того, обеспечена компьютерная программа для реализации вышеописанного способа, когда она выполняется на компьютере или процессоре обработки сигналов.
Варианты осуществления реализуют плавное изменение к комфортному уровня шума. Согласно вариантам осуществления реализовано общее отслеживание уровня комфортного шума в области возбуждения. Уровень комфортного шума, который является целью во время потери пачки пакетов, будет одинаковым, независимо от используемого основного кодера (ACELP/TCX), и он всегда будет актуальным. Нет никакого известного предшествующего уровня техники, где общее отслеживание уровня шума необходимо. Варианты осуществления обеспечивают плавное изменение переключаемого кодека к комфортному шумоподобному сигналу во время потери пачки пакетов.
Кроме того, варианты осуществления реализуют то, что полная сложность будет ниже по сравнению с наличием двух независимых модулей отслеживания уровня шума, так как функции (ППЗУ) и память могут совместно использоваться.
В вариантах осуществления извлечение уровня в области возбуждения (по сравнению с извлечением уровня во временной области) обеспечивает больше минимумов во время активной речи, так как часть речевой информации охватывается коэффициентами LP.
В случае ACELP, согласно вариантам осуществления извлечение уровня происходит в области возбуждения. В случае TCX, в вариантах осуществления уровень извлекается во временной области, и усиление синтеза LPC и компенсации предыскажений применяется в качестве коэффициента коррекции для моделирования уровня энергии в области возбуждения. Отслеживание уровня в области возбуждения, например, перед FDNS, теоретически также возможно, но компенсация уровня между областью возбуждения TCX и областью возбуждения ACELP, как считают, является довольно сложной.
Никакой предшествующий уровень техники не внедряет такое общее отслеживание уровня фона в различных областях. Методики предшествующего уровня техники не имеют такого общего отслеживания уровня комфортного шума, например, в области возбуждения, в системе переключаемого кодека. Поэтому варианты осуществления предпочтительны по сравнению с предшествующим уровнем техники, поскольку для методик предшествующего уровня техники уровень комфортного шума, который является целевым во время потерь пачки пакетов, может быть различным, в зависимости от предыдущего режима кодирования (ACELP/TCX), где отслеживается уровень; как в предшествующем уровне техники, отслеживание, которое выполняется отдельно для каждого режима кодирования, вызывает ненужную служебную информацию и дополнительную вычислительную сложность; и как в предшествующем уровне техники, возможно, что никакой актуальный уровень комфортного шума не будет доступен ни в одном ядре из-за недавнего переключения к этому ядру.
Согласно некоторым вариантам осуществления отслеживание уровня проводится в области возбуждения, но плавное изменение TCX проводится во временной области. С помощью плавного изменения во временной области предотвращают отказы TDAC, которые бы вызвали наложение спектров. Это становится особенно интересным, когда маскируются тональные компоненты сигнала. Кроме того, предотвращают преобразование уровня между областью возбуждения ACELP и спектральной областью MDCT и таким образом, например, экономятся вычислительные ресурсы. Из-за переключения между областью возбуждения и временной областью требуются корректировки уровня между областью возбуждения и временной областью. Это решается с помощью извлечения усиления, которое представлено с помощью синтеза LPC и компенсации предыскажений, и использования этого усиления в качестве коэффициента коррекции для преобразования уровня между этими двумя областями.
Напротив, методики предшествующего уровня техники не проводят отслеживание уровня в области возбуждения и плавное изменение TCX во временной области. Рассматривая современное состояние основанных на преобразовании кодеков, коэффициент ослабления применяется или в области возбуждения (для подходов маскирования во временной области/аналогично ACELP, см. [3GP09a]), или в частотной области (для подходов частотной области, таких, как повторение кадра или замена шумом, см. [LS01]). Недостаток подхода предшествующего уровня техники для применения коэффициента ослабления в частотной области состоит в том, что это будет приводить к наложению спектров в зоне перекрытия с суммированием во временной области. Это будет происходить для смежных кадров, к которым применяются различные коэффициенты ослабления, потому что процедура плавного изменения приводит к тому, что TDAC (компенсация наложения спектров во временной области) заканчивается неудачно. Это в частности рассматривается, когда маскируются тональные компоненты сигнала. Вышеупомянутые варианты осуществления поэтому являются предпочтительными по сравнению с предшествующим уровнем техники.
Варианты осуществления компенсируют влияние высокочастотного фильтра на усиление синтеза LPC. Согласно вариантам осуществления для компенсации нежелательного изменения усиления из-за анализа LPC и предыскажений, вызванных фильтрованным с помощью высокочастотного фильтра невокализованного возбуждения, извлекают коэффициент корректировки. Этот коэффициент корректировки учитывает это нежелательное изменение усиления и изменяет целевой уровень комфортного шума в области возбуждения таким образом, чтобы правильный целевой уровень был достигнут во временной области.
Напротив, предшествующий уровень техники, например, G.718 [ITU08a], вводит высокочастотный фильтр в тракт передачи сигналов невокализованного возбуждения, как изображено на фиг. 2, если сигнал последнего хорошего кадра не классифицирован в качестве «невокализованного». С помощью этого методики предшествующего уровня техники вызывают нежелательные побочные эффекты, так как усиление последующего синтеза LPC зависит от характеристик сигнала, которые изменяются с помощью этого высокочастотного фильтра. Так как фоновый уровень отслеживается и применяется в области возбуждения, алгоритм основывается на усилении синтеза LPC, которое в свою очередь снова зависит от характеристик сигнала возбуждения. Другими словами: модификация характеристик сигнала возбуждения из-за высокочастотного фильтрования, которое проводится в предшествующем уровне техники, может привести к модифицированному (обычно уменьшенному) усилению синтеза LPC. Это приводит к неправильному уровню на выходе даже при том, что уровень возбуждения является правильным.
Варианты осуществления преодолевают эти недостатки предшествующего уровня техники.
В частности варианты осуществления реализуют адаптивную форму спектра комфортного шума. В отличие от G.718, с помощью отслеживания формы спектра фонового шума и применения (плавного изменения к ней) этой формы во время потерь пачки пакетов, характеристики шума предшествующего фонового шума будут приведены в соответствие, что приведет к благоприятной шумовой характеристики комфортного шума. Это предотвращает выдающиеся несоответствия в форме спектра, которая может быть представлена при использовании спектральной огибающей, которая извлекается с помощью автономной подготовки, и/или формы спектра последних принятых кадров.
Кроме того, обеспечено устройство для декодирования звукового сигнала. Данное устройство содержит интерфейс приема, причем интерфейс приема конфигурируется для приема первого кадра, содержащего первую часть звукового сигнала, и причем интерфейс приема конфигурируется для приема второго кадра, содержащего вторую часть звукового сигнала.
Кроме того, устройство содержит блок отслеживания уровня шума, причем блок отслеживания уровня шума конфигурируется для определения информации уровня шума в зависимости по меньшей мере от одной из первой части звукового сигнала и второй части звукового сигнала (это означает: в зависимости от первой части звукового сигнала и/или второй части звукового сигнала), причем информация уровня шума представлена в области отслеживания.
К тому же устройство содержит первый блок восстановления для восстановления в первой области восстановления третьей части звукового сигнала в зависимости от информации уровня шума, если третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден, причем первая область восстановления отличается или равна области отслеживания.
Кроме того, устройство содержит блок преобразования для преобразования информации уровня шума из области отслеживания во вторую область восстановления, если четвертый кадр из множества кадров не принимается с помощью интерфейса приема, или если указанный четвертый кадр принимается с помощью интерфейса приема, но он поврежден, причем вторая область восстановления отличается от области отслеживания, и причем вторая область восстановления отличается от первой области восстановления.
К тому же устройство содержит второй блок восстановления для восстановления во второй области восстановления четвертой части звукового сигнала в зависимости от информации уровня шума, представленной во второй области восстановления, если указанный четвертый кадр из множества кадров не принимается с помощью интерфейса приема, или если указанный четвертый кадр принимается с помощью интерфейса приема, но он поврежден.
Согласно некоторым вариантам осуществления область отслеживания может, например, быть временной областью, спектральной областью, областью FFT, областью MDCT или областью возбуждения. Первая область восстановления может, например, быть временной областью, спектральной областью, областью FFT, областью MDCT или областью возбуждения. Вторая область восстановления может, например, быть временной областью, спектральной областью, областью FFT, областью MDCT или областью возбуждения.
В варианте осуществления область отслеживания может, например, быть областью FFT, первая область восстановления может, например, быть временной областью, а вторая область восстановления может, например, быть областью возбуждения.
В другом варианте осуществления область отслеживания может, например, быть временной областью, первая область восстановления может, например, быть временной областью, а вторая область восстановления может, например, быть областью возбуждения.
Согласно варианту осуществления указанная первая часть звукового сигнала может, например, быть представлена в первой входной области, а указанная вторая часть звукового сигнала может, например, быть представлена во второй входной области. Блок преобразования может, например, быть вторым блоком преобразования. Устройство может, например, дополнительно содержать первый блок преобразования для преобразования второй части звукового сигнала или значения или сигнала, извлеченного из второй части звукового сигнала, из второй входной области в область отслеживания, для получения информации второй части сигнала. Блок отслеживания уровня шума может, например, конфигурироваться для приема информации первой части сигнала, представленной в области отслеживания, причем информация первой части сигнала зависит от первой части звукового сигнала, причем блок отслеживания уровня шума конфигурируется для приема второй части сигнала, представленной в области отслеживания, и причем блок отслеживания уровня шума конфигурируется для определения информации уровня шума в зависимости от информации первой части сигнала, представленной в области отслеживания, и в зависимости от информации второй части сигнала, представленной в области отслеживания.
Согласно варианту осуществления первая входная область может, например, быть областью возбуждения, а вторая входная область может, например, быть областью MDCT.
В другом варианте осуществления первая входная область может, например, быть областью MDCT, и причем вторая входная область может, например, быть областью MDCT.
Согласно варианту осуществления первый блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала с помощью проведения первого плавного изменения к шумоподобному спектру. Второй блок восстановления может, например, конфигурироваться для восстановления четвертой части звукового сигнала с помощью проведения второго плавного изменения к шумоподобному спектру и/или второго плавного изменения усиления LTP. Кроме того, первый блок восстановления и второй блок восстановления могут, например, конфигурироваться для проведения первого плавного изменения и второго плавного изменения к шумоподобному спектру и/или второго плавного изменения усиления LTP с той же самой скоростью плавного изменения.
В варианте осуществления устройство может, например, дополнительно содержать первый блок объединения для определения первого объединенного значения в зависимости от первой части звукового сигнала. Кроме того, устройство дополнительно может, например, содержать второй блок объединения для определения, в зависимости от второй части звукового сигнала, второго объединенного значения в качестве значения, извлеченного из второй части звукового сигнала. Блок отслеживания уровня шума может, например, конфигурироваться для приема первого объединенного значения в качестве информации первой части сигнала, представленной в области отслеживания, причем блок отслеживания уровня шума может, например, конфигурироваться для приема второго объединенного значения в качестве информации второй части сигнала, представленной в области отслеживания, и причем блок отслеживания уровня шума конфигурируется для определения информации уровня шума в зависимости от первого объединенного значения, представленного в области отслеживания, и в зависимости от второго объединенного значения, представленного в области отслеживания.
Согласно варианту осуществления первый блок объединения может, например, конфигурироваться для определения первого объединенного значения таким образом, чтобы первое объединенное значение указывало среднеквадратическое значение первой части звукового сигнала или сигнала, извлеченного из первой части звукового сигнала. Второй блок объединения конфигурируется для определения второго объединенного значения таким образом, чтобы второе объединенное значение указывало среднеквадратическое значение второй части звукового сигнала или сигнала, извлеченного из второй части звукового сигнала.
В варианте осуществления первый блок преобразования может, например, конфигурироваться для преобразования значения, извлеченного из второй части звукового сигнала, из второй входной области в область отслеживания с помощью применения значения усиления к значению, извлеченному из второй части звукового сигнала.
Согласно варианту осуществления значение усиления может, например, указывать усиление, представленное с помощью синтеза кодирования с линейным предсказанием, или в котором значение усиления указывает усиление, представленное с помощью синтеза кодирования с линейным предсказанием и компенсации предыскажений.
В варианте осуществления блок отслеживания уровня шума может, например, конфигурироваться для определения информации уровня шума с помощью применения подхода статистической информации о минимумах.
Согласно варианту осуществления блок отслеживания уровня шума может, например, конфигурироваться для определения уровня комфортного шума в качестве информации уровня шума. Блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала в зависимости от информации уровня шума, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
В варианте осуществления блок отслеживания уровня шума может, например, конфигурироваться для определения уровня комфортного шума в качестве информации уровня шума, извлеченной из спектра уровня шума, причем указанный спектр уровня шума получается с помощью применения подхода статистической информации о минимумах. Блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала в зависимости от множества коэффициентов линейного предсказания, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
Согласно варианту осуществления первый блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала в зависимости от информации уровня шума и в зависимости от первой части звукового сигнала, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
В варианте осуществления первый блок восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала с помощью ослабления или усиления первой части звукового сигнала.
Согласно варианту осуществления второй блок восстановления может, например, конфигурироваться для восстановления четвертой части звукового сигнала в зависимости от информации уровня шума и в зависимости от второй части звукового сигнала.
В варианте осуществления второй блок восстановления может, например, конфигурироваться для восстановления четвертой части звукового сигнала с помощью ослабления или усиления второй части звукового сигнала.
Согласно варианту осуществления устройство может, например, дополнительно содержать блок долгосрочного предсказания, содержащий буфер задержки, причем блок долгосрочного предсказания может, например, конфигурироваться для генерации обработанного сигнала в зависимости от первой или второй части звукового сигнала, в зависимости от вводимой в буфер задержки информации, сохраняемой в буфере задержки, и в зависимости от усиления долгосрочного предсказания, и причем блок долгосрочного предсказания конфигурируется для плавного изменения усиления долгосрочного предсказания к нулю, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
В варианте осуществления блок долгосрочного предсказания может, например, конфигурироваться для плавного изменения усиления долгосрочного предсказания к нулю, причем скорость, с которой усиление долгосрочного предсказания плавно изменяется к нулю, зависит от коэффициента плавного изменения.
В варианте осуществления блок долгосрочного предсказания может, например, конфигурироваться для обновления вводимой в буфер задержки информации с помощью сохранения сгенерированного обработанного сигнала в буфере задержки, если указанный третий кадр из множества кадров не принимается с помощью интерфейса приема или если указанный третий кадр принимается с помощью интерфейса приема, но он поврежден.
Кроме того, обеспечен способ декодирования звукового сигнала. Данный способ содержит этапы, на которых:
- Принимают первый кадр, содержащий первую часть звукового сигнала, и принимают второй кадр, содержащий вторую часть звукового сигнала.
- Определяют информацию уровня шума в зависимости по меньшей мере от одной из первой части звукового сигнала и второй части звукового сигнала, причем информация уровня шума представлена в области отслеживания.
- Восстанавливают в первой области восстановления третью часть звукового сигнала в зависимости от информации уровня шума, если третий кадр из множества кадров не принимается или если указанный третий кадр принимается, но он поврежден, причем первая область восстановления отличается или равна области отслеживания.
- Преобразовывают информацию уровня шума из области отслеживания во вторую область восстановления, если четвертый кадр из множества кадров не принимается или если указанный четвертый кадр принимается, но он поврежден, причем вторая область восстановления отличается от области отслеживания, и причем вторая область восстановления отличается от первой области восстановления. И:
- Восстанавливают во второй области восстановления четвертую часть звукового сигнала в зависимости от информации уровня шума, представленной во второй области восстановления, если указанный четвертый кадр из множества кадров не принимается, или если указанный четвертый кадр принимается, но он поврежден.
Кроме того, обеспечена компьютерная программа для реализации вышеописанного способа, когда она выполняется на компьютере или процессоре обработки сигналов.
Кроме того, обеспечено устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала. Данное устройство содержит интерфейс приема для приема одного или большего количества кадров, генератор коэффициентов и средство восстановления сигнала. Генератор коэффициентов конфигурируется для определения, если текущий кадр из одного или большего количества кадров принимается с помощью интерфейса приема и если текущий кадр, принимаемый с помощью интерфейса приема, не поврежден, одного или большего количества коэффициентов первого звукового сигнала, содержащихся в текущем кадре, причем указанный один или большее количество коэффициентов первого звукового сигнала указывают характеристику кодированного звукового сигнала, и один или большее количество коэффициентов шума указывают фоновый шум кодированного звукового сигнала. Кроме того, генератор коэффициентов конфигурируется для генерации одного или большего количества коэффициентов второго звукового сигнала, в зависимости от одного или большего количества коэффициентов первого звукового сигнала и в зависимости от одного или большего количества коэффициентов шума, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр, принимаемый с помощью интерфейса приема, поврежден. Средство восстановления звукового сигнала конфигурируется для восстановления первой части восстановленного звукового сигнала в зависимости от одного или большего количества коэффициентов первого звукового сигнала, если текущий кадр принимается с помощью интерфейса приема и если текущий кадр, принимаемый с помощью интерфейса приема, не поврежден. Кроме того, средство восстановления звукового сигнала конфигурируется для восстановления второй части восстановленного звукового сигнала в зависимости от одного или большего количества коэффициентов второго звукового сигнала, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр, принимаемый с помощью интерфейса приема, поврежден.
В некоторых вариантах осуществления один или большее количество первых коэффициентов звукового сигнала могут, например, быть одним или большим количеством коэффициентов фильтра линейного предсказания кодированного звукового сигнала. В некоторых вариантах осуществления один или большее количество коэффициентов первого звукового сигнала могут, например, быть одним или большим количеством коэффициентов фильтра линейного предсказания кодированного звукового сигнала.
Согласно варианту осуществления один или большее количество коэффициентов шума могут, например, быть одним или большим количеством коэффициентов фильтра линейного предсказания, указывающими фоновый шум кодированного звукового сигнала. В варианте осуществления один или большее количество коэффициентов фильтра линейного предсказания могут, например, представлять форму спектра фонового шума.
В варианте осуществления генератор коэффициентов может, например, конфигурироваться для определения одной или большего количества вторых частей звукового сигнала таким образом, чтобы одна или большее количество вторых частей звукового сигнала была одним или большим количеством коэффициентов фильтра линейного предсказания восстановленного звукового сигнала, или таким образом, чтобы один или большее количество коэффициентов первого звукового сигнала был одной или большим количеством спектральных пар иммитанса восстановленного звукового сигнала.
Согласно варианту осуществления генератор коэффициентов может, например, конфигурироваться для генерации одного или большего количества коэффициентов второго звукового сигнала с помощью применения формулы:
fcurrent[i]=α∙flast[i]+(1 - α) - ptmean[i]
в которой fcurrent[i] обозначает один из одного или большего количества коэффициентов второго звукового сигнала, в которой flast[i] обозначает один из одного или большего количества коэффициентов первого звукового сигнала, в которой ptmean[i] является одним из одного или большего количества коэффициентов шума, в которой α является действительным числом при 0 ≤ α ≤ 1, и в которой i является индексом. В варианте осуществления 0 < α < 1.
Согласно варианту осуществления flast[i] обозначает коэффициент фильтра линейного предсказания кодированного звукового сигнала и причем fcurrent[i] обозначает коэффициент фильтра линейного предсказания восстановленного звукового сигнала.
В варианте осуществления ptmean[i] может, например, обозначать фоновый шум кодированного звукового сигнала.
В варианте осуществления генератор коэффициентов может, например, конфигурироваться для определения, если текущий кадр из одного или большего количества кадров принимается с помощью интерфейса приема и если текущий кадр, принимаемый с помощью интерфейса приема, не поврежден, одного или большего количества коэффициентов шума с помощью определения спектра шума кодированного звукового сигнала.
Согласно варианту осуществления генератор коэффициентов может, например, конфигурироваться для определения коэффициентов LPC, представляющих фоновый шум, с помощью использования подхода статистической информации о минимумах к спектру сигнала для определения спектра фонового шума и вычисления коэффициентов LPC, представляющих форму фонового шума, из спектра фонового шума.
Кроме того обеспечен способ декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала. Данный способ содержит этапы, на которых:
- Принимают один или большее количество кадров.
- Определяют, если текущий кадр из одного или большего количества кадров принимается и если текущий принимаемый кадр не поврежден, один или большее количество коэффициентов первого звукового сигнала, содержащихся в текущем кадре, причем указанный один или большее количество коэффициентов первого звукового сигнала указывает характеристику кодированного звукового сигнала, и один или большее количество коэффициентов шума указывает фоновый шум кодированного звукового сигнала.
- Генерируют один или большее количество коэффициентов второго звукового сигнала в зависимости от одного или большего количества коэффициентов первого звукового сигнала и в зависимости от одного или большего количества коэффициентов шума, если текущий кадр не принимается или если текущий принимаемый кадр поврежден.
- Восстанавливают первую часть восстановленного звукового сигнала в зависимости от одного или большего количества коэффициентов первого звукового сигнала, если текущий кадр принимается и если текущий принимаемый кадр не поврежден. И:
- Восстанавливают вторую часть восстановленного звукового сигнала в зависимости от одного или большего количества коэффициентов второго звукового сигнала, если текущий кадр не принимается или если текущий принимаемый кадр поврежден.
Кроме того, обеспечена компьютерная программа для реализации вышеописанного способа, когда она выполняется на компьютере или процессоре обработки сигналов.
Наличие общего средства отслеживания и применения формы спектра комфортного шума во время плавного изменения имеет несколько преимуществ. С помощью отслеживания и применения формы спектра таким образом, чтобы это можно было сделать аналогично для обоих основных кодеков, предоставляется возможность простого общего подхода. CELT предлагает отслеживание энергий только по диапазонам в спектральной области и формирование по диапазонам формы спектра в спектральной области, что невозможно для ядра CELP.
Напротив, в предшествующем уровне техники форма спектра комфортного шума, представленного во время потерь пачки, или полностью статична, или частично статична и частично адаптивна к краткосрочному среднему значению формы спектра (как реализовано в G.718 [ITU08a]), и не будет обычно соответствовать фоновому шуму в сигнале перед потерей пакета. Это несовпадение характеристик комфортного шума может вызывать беспокойство. Согласно предшествующему уровню техники может использоваться автономно подготовленная (статическая) форма фонового шума, который может звучать приятно для конкретных сигналов, но менее приятно для других, например, автомобильный шум звучит полностью отличающимся образом от офисного шума.
Кроме того, в предшествующем уровне техники может использоваться адаптация к краткосрочному среднему значению формы спектра ранее принятых кадров, которая может приближать характеристику сигнала к сигналу, принятому раньше, но не обязательно к характеристикам фонового шума. В предшествующем уровне техники отслеживание формы спектра по диапазонам в спектральной области (как реализовано в CELT [IET12]) не применяется для переключаемого кодека, используя не только основанное на области MDCT ядро (TCX), но также и основанное на ACELP ядро. Вышеупомянутые варианты осуществления таким образом предпочтительны по сравнению с предшествующим уровнем техники.
Кроме того, обеспечено устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала. Данное устройство содержит интерфейс приема для приема одного или большего количества кадров, содержащих информацию о множестве выборок звукового сигнала из спектра звукового сигнала для кодированного звукового сигнала, и процессор для генерации восстановленного звукового сигнала. Процессор конфигурируется для генерации восстановленного звукового сигнала с помощью плавного изменения модифицированного спектра к целевому спектру, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр принимается с помощью интерфейса приема, но он поврежден, причем модифицированный спектр содержит множество модифицированных выборок сигнала, причем для каждой из модифицированных выборок сигнала из модифицированного спектра абсолютная величина указанной модифицированной выборки сигнала равна абсолютной величине одной из выборок звукового сигнала из спектра звукового сигнала. Кроме того, процессор конфигурируется для того, чтобы не выполнять плавное изменение модифицированного спектра к целевому спектру, если текущий кадр из одного или большего количества кадров принимается с помощью интерфейса приема и если текущий кадр, принимаемый с помощью интерфейса приема, не поврежден.
Согласно варианту осуществления целевой спектр может, например, быть шумоподобным спектром.
В варианте осуществления шумоподобный спектр может, например, представлять белый шум.
Согласно варианту осуществления шумоподобный спектр может, например, иметь конкретную форму.
В варианте осуществления форма шумоподобного спектра может, например, зависеть от спектра звукового сигнала ранее принятого сигнала.
Согласно варианту осуществления шумоподобный спектр может, например, формироваться в зависимости от формы спектра звукового сигнала.
В варианте осуществления процессор может, например, использовать коэффициент наклона для формирования шумоподобного спектра.
Согласно варианту осуществления процессор может, например, использовать формулу
shaped_noise[i]=noise * power (tilt_factor, i/N)
в которой N обозначает количество выборок, в которой i является индексом, в которой 0 <= i < N при tilt_factor > 0, и в которой power является степенной функцией.
power (x, y) обозначает 
power (tilt_factor, i/N) обозначает 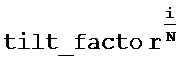
Если tilt_factor меньше 1, то это означает ослабление с увеличением i. Если tilt_factor больше 1, то это означает усиление с увеличением i.
Согласно другому варианту осуществления процессор может, например, использовать формулу
shaped_noise[i]=noise * (1+i/(n-1) * (tilt_factor-1))
в которой N обозначает количество выборок, в которой i является индексом, в которой 0 <= i < N при tilt_factor > 0.
Если tilt_factor меньше 1, то это означает ослабление с увеличением i. Если tilt_factor больше 1, то это означает усиление с увеличением i.
Согласно варианту осуществления процессор может, например, конфигурироваться для генерации модифицированного спектра с помощью изменения знака одной или большего количества выборок звукового сигнала из спектра звукового сигнала, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр, принимаемый с помощью интерфейса приема, поврежден.
В варианте осуществления каждая из выборок звукового сигнала из спектра звукового сигнала может, например, быть представлена действительным числом, а не мнимым числом.
Согласно варианту осуществления выборки звукового сигнала из спектра звукового сигнала могут, например, быть представлены в области модифицированного дискретного косинусного преобразования.
В другом варианте осуществления выборки звукового сигнала из спектра звукового сигнала могут, например, быть представлены в области модифицированного дискретного синусного преобразования.
Согласно варианту осуществления процессор может, например, конфигурироваться для генерации модифицированного спектра с помощью использования функции случайного знака, которая случайно или псевдослучайно выводит или первое, или второе значение.
В варианте осуществления процессор может, например, конфигурироваться для плавного изменения модифицированного спектра к целевому спектру с помощью последовательного уменьшения коэффициента ослабления.
Согласно варианту осуществления процессор может, например, конфигурироваться для плавного изменения модифицированного спектра к целевому спектру с помощью последовательного увеличения коэффициента ослабления.
В варианте осуществления, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр, принимаемый с помощью интерфейса приема, поврежден, процессор может, например, конфигурироваться для генерации восстановленного звукового сигнала, используя формулу:
x[i]=(1-cum_damping) * noise[i]+cum_damping * random_sign() * x_old[i]
в которой i является индексом, в которой x[i] обозначает выборку восстановленного звукового сигнала, в которой cum_damping является коэффициентом ослабления, в которой x_old[i] обозначает одну из выборок звукового сигнала из спектра звукового сигнала для кодированного звукового сигнала, в которой random_sign() возвращает 1 или -1, и в которой noise является случайным вектором, указывающим целевой спектр.
В варианте осуществления указанный случайный вектор noise может, например, масштабироваться таким образом, чтобы его среднеквадратическое значение было аналогично среднеквадратическому значению спектра кодированного звукового сигнала, содержащегося в одном из кадров, принятых последними с помощью интерфейса приема.
Согласно общему варианту осуществления процессор может, например, конфигурироваться для генерации восстановленного звукового сигнала с помощью использования случайного вектора, который масштабируется таким образом, чтобы его среднеквадратическое значение было аналогично среднеквадратическому значению спектра кодированного звукового сигнала, содержащегося в одном из кадров, принятых последними с помощью интерфейса приема.
Кроме того, обеспечен способ декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала. Данный способ содержит этапы, на которых:
- Принимают один или большее количество кадров, содержащих информацию о множестве выборок звукового сигнала из спектра звукового сигнала для кодированного звукового сигнала. И:
- Генерируют восстановленный звуковой сигнал.
Генерация восстановленного звукового сигнала проводится с помощью плавного изменения модифицированного спектра к целевому спектру, если текущий кадр не принимается или если текущий кадр принимается, но он поврежден, причем модифицированный спектр содержит множество модифицированных выборок сигнала, причем для каждой из модифицированных выборок сигнала из модифицированного спектра абсолютная величина указанной модифицированной выборки сигнала равна абсолютной величине одной из выборок звукового сигнала из спектра звукового сигнала. Плавное изменение модифицированного спектра к спектру белого шума не выполняется, если текущий кадр из одного или большего количества кадров принимается и если текущий принимаемый кадр не поврежден.
Кроме того, обеспечена компьютерная программа для реализации вышеописанного способа, когда она выполняется на компьютере или процессоре обработки сигналов.
Варианты осуществления реализуют плавное изменение спектра MDCT к белому шуму перед применением FDNS (FDNS=замена шумом в частотной области).
Согласно предшествующему уровню техники в основанных на кодировании и линейном предсказании кодеках инновационная кодовая книга заменяется случайным вектором (например, шумом). В вариантах осуществления подход кодирования и линейного предсказания, который состоит из замены инновационной кодовой книги случайным вектором (например, шумом), применяется к структуре декодера TCX. В данном случае эквивалентом инновационной кодовой книги является спектр MDCT, обычно принимаемый в пределах битового потока и подаваемый в FDNS.
Классическим подходом маскирования MDCT является простое повторение данного спектра «как есть» или применение конкретного процесса рандомизации, который в основном продлевает форму спектра последнего принятого кадра [LS01]. У этого подхода есть недостаток, что продлевается форма краткосрочного спектра, что часто приводит к повторяющемуся металлическому звуку, который не похож на фоновый шум, и поэтому не может использоваться в качестве комфортного шума.
Используя предложенный способ, формирование краткосрочного спектра выполняется с помощью FDNS и TCX LTP, формирование спектра в течение длительного времени выполняется только с помощью FDNS. Формирование FDNS плавно изменяется от формы краткосрочного спектра к отслеживаемой форме долгосрочного спектра фонового шума, и TCX LTP плавно изменяется к нулю.
Плавное изменение коэффициентов FDNS к отслеживаемым коэффициентам фонового шума приводит к наличию постепенного перехода между последней хорошей спектральной огибающей и спектральной огибающей фона, которая должна быть целью в конечном счете для достижения приятного фонового шума в случае потерь длительной пачки кадров.
Напротив, согласно современному состоянию для основанных на преобразовании кодеков шумоподобное маскирование проводится с помощью повторения кадра или замены шумом в частотной области [LS01]. В предшествующем уровне техники замена шумом обычно выполняется с помощью скремблирования знака спектральных элементов. Если в предшествующем уровне техники скремблирование знака в TCX (в частотной области) используется во время маскирования, то последние принятые коэффициенты MDCT повторно используются, и каждый знак рандомизируется перед тем, как спектр обратно преобразовывается во временную область. Недостатком этой процедуры предшествующего уровня техники является то, что для последовательных потерянных кадров тот же самый спектр неоднократно используется, только с различной рандомизацией знака и глобальным ослаблением. Когда смотрят на спектральную огибающую во времени на крупной временной сетке, можно заметить, что огибающая является приблизительно постоянной во время потери последовательных кадров, потому что энергии диапазона сохраняются постоянными друг относительно друга в пределах кадра и только глобально ослабляются. В используемой системе кодирования согласно предшествующему уровню техники спектральные значения обрабатываются, используя FDNS, для восстановления исходного спектра. Это означает, что если хотят плавно изменить спектр MDCT к конкретной спектральной огибающей (используя коэффициенты FDNS, например, описывающие текущий фоновый шум), то результат зависит не только от коэффициентов FDNS, но также зависит от ранее декодированного спектра, для которого выполнялось скремблирование знака. Вышеупомянутые варианты осуществления преодолевают эти недостатки предшествующего уровня техники.
Варианты осуществления основаны на обнаружении, что необходимо плавно изменять спектр, используемый для скремблирования знака белого шума перед подачей его на обработку FDNS. Иначе выводимый спектр никогда не будет соответствовать целевой огибающей, используемой для обработки FDNS.
В вариантах осуществления та же самая скорость плавного изменения используется для плавного изменения усиления LTP, как и для плавного изменения белого шума.
В последующем варианты осуществления настоящего изобретения описаны более подробно со ссылкой на фигуры, на которых:
фиг. 1a показывает устройство для декодирования звукового сигнала согласно варианту осуществления,
фиг. 1b показывает устройство для декодирования звукового сигнала согласно другому варианту осуществления,
фиг. 1c показывает устройство для декодирования звукового сигнала согласно другому варианту осуществления, в котором данное устройство дополнительно содержит первый и второй блоки объединения,
фиг. 1d показывает устройство для декодирования звукового сигнала согласно дополнительному варианту осуществления, в котором данное устройство кроме того содержит блок долгосрочного предсказания, содержащий буфер задержки,
фиг. 2 показывает структуру декодера G.718,
фиг. 3 изображает сценарий, где коэффициент плавного изменения G.722 зависит от информации о классе,
фиг. 4 показывает подход для предсказания амплитуды, используя линейную регрессию,
фиг. 5 показывает режим работы перекрывающегося преобразования с ограниченной энергией (CELT) при потере пачки,
фиг. 6 показывает отслеживание уровня фонового шума согласно варианту осуществления в декодере во время безошибочного рабочего режима,
фиг. 7 показывает извлечение усиления синтеза LPC и компенсации предыскажений согласно варианту осуществления,
фиг. 8 изображает применение уровня комфортного шума во время потери пакета согласно варианту осуществления,
фиг. 9 показывает улучшенную компенсацию высокочастотного усиления во время маскирования ACELP согласно варианту осуществления,
фиг. 10 изображает разъединение цикла обратной связи LTP во время маскирования согласно варианту осуществления,
фиг. 11 показывает устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала согласно варианту осуществления,
фиг. 12 показывает устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала согласно другому варианту осуществления, и
фиг. 13 показывает устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала дополнительного варианта осуществления, и
фиг. 14 показывает устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала другого варианта осуществления.
Фиг. 1a показывает устройство для декодирования звукового сигнала согласно варианту осуществления.
Данное устройство содержит интерфейс 110 приема. Интерфейс приема конфигурируется для приема множества кадров, причем интерфейс 110 приема конфигурируется для приема первого кадра из множества кадров, указанный первый кадр содержит первую часть звукового сигнала, указанная первая часть звукового сигнала представлена в первой области. Кроме того, интерфейс 110 приема конфигурируется для приема второго кадра из множества кадров, указанный второй кадр содержит вторую часть звукового сигнала.
Кроме того, устройство содержит блок 120 преобразования для преобразования второй части звукового сигнала или значения сигнала, извлеченного из второй части звукового сигнала, из второй области в область отслеживания для получения информации второй части сигнала, причем вторая область отличается от первой области, причем область отслеживания отличается от второй области, и причем область отслеживания равна или отличается от первой области.
К тому же устройство содержит блок 130 отслеживания уровня шума, причем блок отслеживания уровня шума конфигурируется для приема информации первой части сигнала, представленной в области отслеживания, причем информация первой части сигнала зависит от первой части звукового сигнала, причем блок отслеживания уровня шума конфигурируется для приема второй части сигнала, представленной в области отслеживания, и причем блок отслеживания уровня шума конфигурируется для определения информации уровня шума в зависимости от информации первой части сигнала, представленной в области отслеживания, и в зависимости от информации второй части сигнала, представленной в области отслеживания.
Кроме того, устройство содержит блок восстановления для восстановления третьей части звукового сигнала в зависимости от информации уровня шума, если третий кадр из множества кадров не принимается с помощью интерфейса приема, но он поврежден.
По отношению к первой и/или второй части звукового сигнала, например, первая и/или вторая часть звукового сигнала могут, например, подаваться в один или большее количество процессоров (не показаны) для генерации одного или большего количества сигналов громкоговорителя для одного или большего количества громкоговорителей, так, чтобы принятая звуковая информация, содержащаяся в первой и/или второй частях звукового сигнала, могла воспроизводиться.
Кроме того, однако, первая и вторая части звукового сигнала также используются для маскирования, например, в случае, если последующие кадры не достигают приемника или в случае, когда последующие кадры являются ошибочными.
Среди прочего, настоящее изобретение основано на обнаружении, что отслеживание уровня шума должно проводиться в общей области, в данной работе называемой «областью отслеживания». Область отслеживания, может, например, быть областью возбуждения, например, областью, в которой сигнал представлен с помощью LPC (LPC=коэффициент линейного предсказания) или с помощью ISP (ISP=спектральная пара иммитанса), как описано в R-WB и AMR-WB+ (см. [3GP12a], [3GP12b], [3GP09a], [3GP09b], [3GP09c]). У отслеживания уровня шума в одной области есть среди прочего преимущество, что предотвращает эффект наложения спектров, когда сигнал переключается между первым представлением в первой области и вторым представлением во второй области (например, когда представление сигнала переключается от ACELP к TCX или наоборот).
По отношению к блоку 120 преобразования, преобразуемым является или непосредственно вторая часть звукового сигнала, или сигнал, извлеченный из второй части звукового сигнала (например, вторая часть звукового сигнала обработана для получения извлекаемого сигнала), или значение, извлеченное из второй части звукового сигнала (например, вторая часть звукового сигнала обработана для получения извлекаемого значения).
По отношению к первой части звукового сигнала, в некоторых вариантах осуществления первая часть звукового сигнала может обрабатываться и/или преобразовываться в область отслеживания.
В других вариантах осуществления, однако, первая часть звукового сигнала может быть уже представлена в области отслеживания.
В некоторых вариантах осуществления информация первой части сигнала идентична первой части звукового сигнала. В других вариантах осуществления информация первой части сигнала является, например, объединенным значением, зависящим от первой части звукового сигнала.
Далее сначала более подробно рассматривают плавное изменение к уровню комфортного шума.
Описанный подход плавного изменения может, например, воплощаться в версии с низкой задержкой xHE-AAC [NMR+12] (xHE-AAC=расширенное высокоэффективное AAC), которая имеет возможность бесшовного переключения между кодированием ACELP (речь) и MDCT (музыка/шум) на покадровой основе.
По отношению к обычному отслеживанию уровня в области отслеживания, например, в области возбуждения для применения постепенного плавного изменения к соответствующему уровню комфортного шума во время потери пакета, такой уровень комфортного шума должен идентифицироваться во время обычного процесса декодирования. Может, например, приниматься, что уровень шума, аналогичный фоновому шуму, является самым удобным. Таким образом уровень фонового шума может извлекаться и постоянно обновляться во время обычного декодирования.
Настоящее изобретение основано на обнаружении, что когда имеют переключаемый основной кодек (например, ACELP и TCX), отслеживание общего уровня фонового шума независимо от выбранного основного кодера является особенно подходящим.
Фиг. 6 изображает отслеживание уровня фонового шума согласно предпочтительному варианту осуществления в декодере во время безошибочного режима работы, например, во время обычного декодирования.
Само отслеживание может, например, выполняться, используя подход статистической информации о минимумах (см. [Mar01]).
Этот отслеживаемый уровень фонового шума можно, например, рассматривать в качестве упомянутой выше информации уровня шума.
Например, статистическая информация о минимумах оценки шума, представленная в документе: «Rainer Martin, Noise power spectral density estimation based on optimal smoothing and minimum statistics, IEEE Transactions on Speech and Audio Processing 9 (2001 ), no. 5, 504-512» [Mar01], может использоваться для отслеживания уровня фонового шума.
Соответственно, в некоторых вариантах осуществления блок 130 отслеживания уровня шума конфигурируется для определения информации уровня шума с помощью применения подхода статистической информации о минимумах, например, используя статистическую информацию о минимумах оценки шума [Mar01].
Впоследствии описаны некоторые особенности и подробности этого подхода отслеживания.
Рассматривая отслеживание уровня, предполагается, что фон является шумоподобным. Следовательно, предпочтительно выполнять отслеживания уровня в области возбуждения, чтобы избежать отслеживания приоритетных тональных компонент, которые выведены с помощью LPC. Например, заполнение шумом ACELP может также использовать уровень фонового шума в области возбуждения. При отслеживании в области возбуждения только одно единственное отслеживание уровня фонового шума может служить двум целям, что экономит вычислительную сложность. В предпочтительном варианте осуществления отслеживание выполняется в области возбуждения ACELP.
Фиг. 7 показывает извлечение усиления синтеза LPC и компенсации предыскажений согласно варианту осуществления.
Рассматривая извлечение уровня, извлечение уровня может, например, проводиться или в области времени, или в области возбуждения, или в любой другой подходящей области. Если области для извлечения уровня и отслеживания уровня отличаются, то может быть необходима, например, компенсация усиления.
В предпочтительном варианте осуществления извлечение уровня для ACELP выполняется в области возбуждения. Следовательно, никакая компенсация усиления не требуется.
Для TCX компенсация усиления может, например, быть необходима для корректировки извлеченного уровня к области возбуждения ACELP.
В предпочтительном варианте осуществления извлечение уровня для TCX происходит во временной области. Управляемая компенсация усиления находится для этого подхода: усиление, представленное с помощью синтеза LPC и компенсации предыскажений, извлекается, как показано на фиг. 7, и извлеченный уровень делится на это усиление.
Альтернативно, извлечение уровня для TCX может выполняться в области возбуждения TCX. Однако, компенсацию усиления между областью возбуждения TCX и областью возбуждения ACELP считают слишком сложной.
Таким образом, возвращаясь к фиг. 1a, в некоторых вариантах осуществления первая часть звукового сигнала представлена во временной области в качестве первой области. Блок 120 преобразования конфигурируется для преобразования второй части звукового сигнала или значения, извлеченного из второй части звукового сигнала, из области возбуждения, являющейся второй областью, во временную область, являющуюся областью отслеживания. В таких вариантах осуществления блок 130 отслеживания уровня шума конфигурируется для приема информации первой части сигнала, представленной во временной области в качестве области отслеживания. Кроме того, блок 130 отслеживания уровня шума конфигурируется для приема второй части сигнала, представленной во временной области в качестве области отслеживания.
В других вариантах осуществления первая часть звукового сигнала представлена в области возбуждения в качестве первой области. Блок 120 преобразования конфигурируется для преобразования второй части звукового сигнала или значения, извлеченного из второй части звукового сигнала, из временной области, являющей второй областью, в область возбуждения, являющуюся областью отслеживания. В таких вариантах осуществления блок 130 отслеживания уровня шума конфигурируется для приема информации первой части сигнала, представленной в области возбуждения в качестве области отслеживания. Кроме того, блок 130 отслеживания уровня шума конфигурируется для приема второй части сигнала, представленной в области возбуждения в качестве области отслеживания.
В варианте осуществления первая часть звукового сигнала может, например, быть представлена в области возбуждения в качестве первой области, причем блок 130 отслеживания уровня шума может, например, конфигурироваться для приема информации первой части сигнала, причем указанная информация первой части сигнала представлена в области FFT, будучи областью отслеживания, и причем указанная информация первой части сигнала зависит от указанной первой части звукового сигнала, представленной в области возбуждения, причем блок 120 преобразования может, например, конфигурироваться для преобразования второй части звукового сигнала или значения, извлеченного из второй части звукового сигнала, из временной области, являющейся второй областью, в область FFT, являющуюся областью отслеживания, и причем блок 130 отслеживания уровня шума может, например, конфигурироваться для приема второй части звукового сигнала, представленной в области FFT.
Фиг. 1b показывает устройство согласно другому варианту осуществления. На фиг. 1b блок 120 преобразования из фиг. 1a является первым блоком 120 преобразования, и блок восстановления 140 из фиг. 1a является первым блоком 140 восстановления. Устройство дополнительно содержит второй блок 121 преобразования и второй блок 141 восстановления.
Второй блок 121 преобразования конфигурируется для преобразования информации уровня шума из области отслеживания во вторую область, если четвертый кадр из множества кадров не принимается с помощью интерфейса приема или если указанный четвертый кадр принимается с помощью интерфейса приема, но он поврежден.
Кроме того, второй блок 141 восстановления конфигурируется для восстановления четвертой части звукового сигнала в зависимости от информации уровня шума, представленной во второй области, если указанный четвертый кадр из множества кадров не принимается с помощью интерфейса приема или если указанный четвертый кадр принимается с помощью интерфейса приема, но он поврежден.
Фиг. 1c показывает устройство для декодирования звукового сигнала согласно другому варианту осуществления. Устройство дополнительно содержит первый блок 150 объединения для определения первого объединенного значения в зависимости от первой части звукового сигнала. Кроме того, устройство на фиг. 1c дополнительно содержит второй блок 160 объединения для определения второго объединенного значения в качестве значения, извлеченного из второй части звукового сигнала в зависимости от второй части звукового сигнала. В варианте осуществления на фиг. 1c блок 130 отслеживания уровня шума конфигурируется для приема первого объединенного значения в качестве информации первой части сигнала, представленной в области отслеживания, причем блок 130 отслеживания уровня шума конфигурируется для приема второго объединенного значения в качестве информации второй части сигнала, представленной в области отслеживания. Блок 130 отслеживания уровня шума конфигурируется для определения информации уровня шума в зависимости от первого объединенного значения, представленного в области отслеживания, и в зависимости от второго объединенного значения, представленного в области отслеживания.
В варианте осуществления первый блок 150 объединения конфигурируется для определения первого объединенного значения таким образом, чтобы первое объединенное значение указывало среднеквадратическое значение первой части звукового сигнала или сигнала, извлеченного из первой части звукового сигнала. Кроме того, второй блок 160 объединения конфигурируется для определения второго объединенного значения таким образом, чтобы второе объединенное значение указывало среднеквадратическое значение второй части звукового сигнала или сигнала, извлеченного из второй части звукового сигнала.
Фиг. 6 показывает устройство для декодирования звукового сигнала согласно дополнительному варианту осуществления.
На фиг. 6 блок 630 отслеживания уровня фона воплощает блок 130 отслеживания уровня шума согласно фиг. 1a.
Кроме того, на фиг. 6 блок 650 RMS (RMS=среднеквадратическое значение) является первым блоком объединения, и блок 660 RMS является вторым блоком объединения.
Согласно некоторым вариантам осуществления (первый) блок 120 преобразования на фиг. 1a, фиг. 1b и фиг. 1c конфигурируется для преобразования значения, извлеченного из второй части звукового сигнала, из второй области в область отслеживания с помощью применения значения усиления (x) к значению, извлеченному из второй части звукового сигнала, например, с помощью деления значения, извлеченного из второй части звукового сигнала, на значение усиления (x). В других вариантах осуществления может, например, выполняться умножение на значение усиления.
В некоторых вариантах осуществления значение усиления (x) может, например, указывать усиление, представленное с помощью синтеза кодирования с линейным предсказанием, или значение усиления (x) может, например, указывать усиление, представленное с помощью синтеза кодирования с линейным предсказанием и компенсации предыскажений.
На фиг. 6 блок 622 обеспечивает значение (x), которое указывает усиление, представленное с помощью синтеза кодирования с линейным предсказанием и компенсации предыскажений. Блок 622 затем делит значение, обеспеченное с помощью второго блока 660 объединения, которое является значением, извлеченным из второй части звукового сигнала, на обеспеченное значение усиления (x) (например, или с помощью деления на x, или с помощью умножения на значение 1/x). Таким образом блок 620 на фиг. 6, который содержит блоки 621 и 622, воплощает первый блок преобразования на фиг. 1a, фиг. 1b или фиг. 1c.
Устройство на фиг. 6 принимает первый кадр с первой частью звукового сигнала, являющейся вокализованным возбуждением и/или невокализованным возбуждением и представленной в области отслеживания, на фиг. 6 (ACELP) – в области LPC. Первая часть звукового сигнала подается в блок 671 синтеза LPC и компенсации предыскажений для обработки для получения выводимой во временной области первой части звукового сигнала. Кроме того, первая часть звукового сигнала подается в модуль 650 RMS для получения первого значения, указывающего среднеквадратического значения первой части звукового сигнала. Это первое значение (первое RMS значение) представлено в области отслеживания. Первое RMS значение, представленное в области отслеживания, затем подается в блок 630 отслеживания уровня шума.
Кроме того, устройство на фиг. 6 принимает второй кадр со второй частью звукового сигнала, содержащей спектр MDCT и представленной в области MDCT. Заполнение шумом проводится с помощью модуля 681 заполнения шумом, формирование шума в частотной области проводится с помощью модуля 682 формирования шума в частотной области, преобразование во временную область проводится с помощью модуля 683 iMDCT/OLA (OLA=перекрытие с суммированием), и долгосрочное предсказание проводится с помощью блока 684 долгосрочного предсказания. Блок долгосрочного предсказания может, например, содержать буфер задержки (не показан на фиг. 6).
Сигнал, извлеченный из второй части звукового сигнала, затем подается в модуль 660 RMS для получения второго значения, указывающего среднеквадратическое значение того сигнала, который извлекается из второй части звукового сигнала. Это второе значение (второе RMS значение) все еще представлено во временной области. Блок 620 затем преобразовывает второе RMS значение из временной области в область отслеживания, в данном случае (ACELP) в область LPC. Второе RMS значение, представленное в области отслеживания, затем подается в блок 630 отслеживания уровня шума.
В вариантах осуществления отслеживание уровня проводится в области возбуждения, но плавное изменение TCX проводится во временной области.
Принимая во внимание, что во время обычного декодирования отслеживается уровень фонового шума, он может, например, использоваться во время потери пакета в качестве индикатора соответствующего уровня комфортного шума, к которому последний принятый сигнал равномерно плавно изменяется в соответствии с уровнем.
Извлечение уровня для отслеживания и применение плавного изменения уровня в общем случае независимы друг от друга и могут выполняться в различных областях. В предпочтительном варианте осуществления применение уровня выполняется в тех же самых областях, в которых выполняется извлечение уровня, что приводит к тем же самым преимуществам, что для ACELP никакая компенсация усиления не нужна, и что для TCX необходима компенсация обратного усиления, как для извлечения уровня (см. фиг. 6), и следовательно, одинаковое извлечение усиления может использоваться, как показано на фиг. 7.
В последующем описана компенсация влияния высокочастотного фильтра на усиление синтеза LPC согласно вариантам осуществления.
Фиг. 8 изображает этот подход. В частности, фиг. 8 показывает применение уровня комфортного шума во время потери пакета.
На фиг. 8, блок 643 фильтра высокочастотного усиления, блок 644 умножения, блок 645 плавного изменения, блок 646 высокочастотного фильтра, блок 647 плавного изменения и блок 648 объединения вместе формируют первый блок восстановления.
Кроме того, на фиг. 8 блок 631 предоставления уровня фона предоставляет информацию уровня шума. Например, блок 631 предоставления уровня фона может в равной степени воплощаться в качестве блока 630 отслеживания фонового уровня на фиг. 6.
К тому же на фиг. 8 блок 649 усиления синтеза LPC и компенсации предыскажений и блок 641 умножения вместе формируют второй блок 640 преобразования.
Кроме того, на фиг. 8 блок 642 плавного изменения представляет второй блок восстановления.
В варианте осуществления на фиг. 8 плавное изменение вокализованного и невокализованного возбуждения выполняется отдельно: вокализованное возбуждение плавно изменяется к нулю, а невокализованное возбуждение плавно изменяется к уровню комфортного шума. Фиг. 8 к тому же изображает высокочастотный фильтр, который вводится в цепочку сигнала невокализованного возбуждения для устранения низкочастотных компонент для всех случаев кроме тех случаев, когда сигнал классифицирован как невокализованный.
Что касается модели влияния высокочастотного фильтра, уровень после синтеза LPC и компенсации предыскажений вычисляется один раз с высокочастотным фильтром и один раз без него. Впоследствии соотношение этих двух уровней извлекается и используется для изменения применяемого уровня фона.
Это показано на фиг. 9. В частности, фиг. 9 изображает компенсацию усовершенствованного высокочастотного усиления во время маскирования ACELP согласно варианту осуществления.
Вместо текущего сигнала возбуждения только простой импульс используется в качестве вводимой информации для этого вычисления. Это обеспечивает уменьшенную сложность, поскольку импульсная характеристика затухает быстро и таким образом извлечение RMS может выполняться на более коротком цикле. Практически, только один субкадр используется вместо целого кадра.
Согласно варианту осуществления блок 130 отслеживания уровня шума конфигурируется для определения уровня комфортного шума в качестве информации уровня шума. Блок 140 восстановления конфигурируется для восстановления третьей части звукового сигнала в зависимости от информации уровня шума, если указанный третий кадр из множества кадров не принимается с помощью интерфейса 110 приема или если указанный третий кадр принимается с помощью интерфейса 110 приема, но он поврежден.
Согласно варианту осуществления блок 130 отслеживания уровня шума конфигурируется для определения уровня комфортного шума в качестве информации уровня шума. Блок 140 восстановления конфигурируется для восстановления третьей части звукового сигнала в зависимости от информации уровня шума, если указанный третий кадр из множества кадров не принимается с помощью интерфейса 110 приема или если указанный третий кадр принимается с помощью интерфейса 110 приема, но он поврежден.
В варианте осуществления блок 130 отслеживания уровня шума конфигурируется для определения уровня комфортного шума в качестве информации уровня шума, извлеченной из спектра уровня шума, причем указанный спектр уровня шума получается с помощью применения подхода статистической информации о минимумах. Блок 140 восстановления конфигурируется для восстановления третьей части звукового сигнала в зависимости от множества коэффициентов линейного предсказания, если указанный третий кадр из множества кадров не принимается с помощью интерфейса 110 приема или если указанный третий кадр принимается с помощью интерфейса 110 приема, но он поврежден.
В варианте осуществления (первый и/или второй) блок 140, 141 восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала в зависимости от информации уровня шума и в зависимости от первой части звукового сигнала, если указанный третий (четвертый) кадр из множества кадров не принимается с помощью интерфейса 110 приема или если указанный третий (четвертый) кадр принимается с помощью интерфейса 110 приема, но он поврежден.
Согласно варианту осуществления (первый и/или второй) блок 140, 141 восстановления может, например, конфигурироваться для восстановления третьей (или четвертой) части звукового сигнала с помощью ослабления или усиления первой части звукового сигнала.
Фиг. 14 показывает устройство для декодирования звукового сигнала. Устройство содержит интерфейс 110 приема, причем интерфейс 110 приема конфигурируется для приема первого кадра, содержащего первую часть звукового сигнала, и причем интерфейс 110 приема конфигурируется для приема второго кадра, содержащего вторую часть звукового сигнала.
Кроме того, устройство содержит блок 130 отслеживания уровня шума, причем блок 130 отслеживания уровня шума конфигурируется для определения информации уровня шума в зависимости по меньшей мере от одной из первой части звукового сигнала и второй части звукового сигнала (это означает: в зависимости от первой части звукового сигнала и/или второй части звукового сигнала), причем информация уровня шума представлена в области отслеживания.
К тому же устройство содержит первый блок 140 восстановления для восстановления в первой области восстановления третьей части звукового сигнала в зависимости от информации уровня шума, если третий кадр из множества кадров не принимается с помощью интерфейса 110 приема или если указанный третий кадр принимается с помощью интерфейса 110 приема, но он поврежден, причем первая область восстановления отличается или равна области отслеживания.
Кроме того, устройство содержит блок 121 преобразования для преобразования информации уровня шума из области отслеживания во вторую область восстановления, если четвертый кадр из множества кадров не принимается с помощью интерфейса 110 приема или если указанный четвертый кадр принимается с помощью интерфейса 110 приема, но он поврежден, причем вторая область восстановления отличается от области отслеживания, и причем вторая область восстановления отличается от первой области восстановления.
К тому же устройство содержит второй блок 141 восстановления для восстановления во второй области восстановления четвертой части звукового сигнала в зависимости от информации уровня шума, представленной во второй области восстановления, если указанный четвертый кадр из множества кадров не принимается с помощью интерфейса 110 приема или если указанный четвертый кадр принимается с помощью интерфейса 110 приема, но он поврежден.
Согласно некоторым вариантам осуществления область отслеживания может, например, быть временной областью, спектральной областью, областью FFT, областью MDCT или областью возбуждения. Первая область восстановления может, например, быть временной областью, спектральной областью, областью FFT, областью MDCT или областью возбуждения. Вторая область восстановления может, например, быть временной областью, спектральной областью, областью FFT, областью MDCT или областью возбуждения.
В варианте осуществления область отслеживания может, например, быть областью FFT, первая область восстановления может, например, быть временной областью, а вторая область восстановления может, например, быть областью возбуждения.
В другом варианте осуществления область отслеживания может, например, быть временной областью, первая область восстановления может, например, быть временной областью, а вторая область восстановления может, например, быть областью возбуждения.
Согласно варианту осуществления указанная первая часть звукового сигнала может, например, быть представлена в первой входной области, и указанная вторая часть звукового сигнала может, например, быть представлена во второй входной области. Блок преобразования может, например, быть вторым блоком преобразования. Устройство может, например, дополнительно содержать первый блок преобразования для преобразования второй части звукового сигнала или значения или сигнала, извлеченного из второй части звукового сигнала, из второй входной области в область отслеживания для получения информации второй части сигнала. Блок отслеживания уровня шума может, например, конфигурироваться для приема информации первой части сигнала, представленной в области отслеживания, причем информация первой части сигнала зависит от первой части звукового сигнала, причем блок отслеживания уровня шума конфигурируется для приема второй части сигнала, представленной в области отслеживания, и причем блок отслеживания уровня шума конфигурируется для определения информации уровня шума в зависимости от информации первой части сигнала, представленной в области отслеживания, и в зависимости от информации второй части сигнала, представленной в области отслеживания.
Согласно варианту осуществления первая входная область может, например, быть областью возбуждения, а вторая входная область может, например, быть областью MDCT.
В другом варианте осуществления первая входная область может, например, быть областью MDCT, и причем вторая входная область может, например, быть областью MDCT.
Если, например, сигнал представлен во временной области, то он может, например, быть представлен с помощью выборок сигнала во временной области. Или, например, если сигнал представлен в спектральной области, то он может, например, быть представлен спектральными выборками из спектра сигнала.
В варианте осуществления область отслеживания может, например, быть областью FFT, первая область восстановления может, например, быть временной областью, а вторая область восстановления может, например, быть областью возбуждения.
В другом варианте осуществления область отслеживания может, например, быть временной областью, первая область восстановления может, например, быть временной областью, а вторая область восстановления может, например, быть областью возбуждения.
В некоторых вариантах осуществления блоки, показанные на фиг. 14, могут, например, конфигурироваться, как описано для фиг. 1a, 1b, 1c и 1d.
Рассматривая конкретные варианты осуществления, например, в режиме с низкой скоростью устройство согласно варианту осуществления может, например, принимать в качестве вводимой информации кадры ACELP, которые представлены в области возбуждения, и которые затем преобразовываются во временную область через синтез LPC. Кроме того, в режиме с низкой скоростью устройство согласно варианту осуществления может, например, принимать в качестве вводимой информации кадры TCX, которые представлены в области MDCT, и которые затем преобразовываются во временную область через обратное MDCT.
Отслеживание затем проводится в FFT-области, причем сигнал FFT извлекается из сигнала во временной области с помощью проведения FFT (быстрого преобразования Фурье). Отслеживание может, например, проводиться с помощью проведения подхода статистической информации о минимумах, отдельно для всех спектральных линий, для получения спектра комфортного шума.
Маскирование затем проводится с помощью проведения извлечения уровня, основываясь на спектре комфортного шума. Извлечение уровня проводится, основываясь на спектре комфортного шума. Преобразование уровня во временную область проводится для FD TCX PLC. Плавное изменение проводится во временной области. Извлечение уровня в области возбуждения проводится для PLC ACELP и для TD PLC TCX (как для ACELP). Затем проводится плавное изменение в области возбуждения.
Следующий список обобщает это:
низкая скорость:
• ввод:
o acelp (область возбуждения -> временная область, через синтез lpc)
o tcx (область mdct -> временная область, через обратное MDCT)
• отслеживание:
o fft-область, извлеченная из временной области через FFT
o статистическая информация о минимумах, отдельно для всех спектральных линий -> спектр комфортного шума
• маскирование:
o извлечение уровня, основываясь на комфортном спектре
o преобразование уровня во временную область для
■ FD TCX PLC
-> плавное изменение во временной области
o преобразование уровня в область возбуждения для
■ ACELP PLC
■ TD TCX PLC (как для ACELP)
-> плавное изменение в области возбуждения
Например, в режиме с высокой скоростью можно, например, принимать кадры TCX в качестве вводимой информации, которые представлены в области MDCT, и которые затем преобразовываются во временную область через обратное MDCT.
Отслеживание может затем проводиться во временной области. Отслеживание может, например, проводиться с помощью проведения подхода статистическая информация о минимумах, основываясь на уровне энергии для получения уровня комфортного шума.
Для маскирования для FD TCX PLC уровень может использоваться «как есть», и может проводиться только плавное изменение во временной области. Для TD TCX PLC (как для ACELP) проводится преобразование уровня в область возбуждения и плавное изменение в области возбуждения.
Следующий список обобщает это:
высокая скорость:
• ввод:
o tcx (область mdct -> временная область через обратное MDCT)
• отслеживание:
o во временной области
o статистическая информация о минимумах на уровне энергии -> уровень комфортного шума
• маскирование:
o использование уровня «как есть»
■ FD TCX PLC
-> плавное изменение во временной области
o преобразование уровня в область возбуждения для
■ TD TCX PLC (как для ACELP)
-> плавное изменение в области возбуждения
Область FFT и область MDCT обе являются спектральными областями, тогда как область возбуждения является некоторой временной областью.
Согласно варианту осуществления первый блок 140 восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала с помощью проведения первого плавного изменения к шумоподобному спектру. Второй блок 141 восстановления может, например, конфигурироваться для восстановления четвертой части звукового сигнала с помощью проведения второго плавного изменения к шумоподобному спектру и/или второго плавного изменения усиления LTP. Кроме того, первый блок 140 восстановления и второй блок 141 восстановления могут, например, конфигурироваться для проведения первого плавного изменения и второго плавного изменения к шумоподобному спектру и/или второго плавного изменения усиления LTP с той же самой скоростью плавного изменения.
Теперь рассматривают адаптивное формирование спектра комфортного шума.
Для достижения адаптивного формирования к комфортному шуму во время потери пачки пакетов, в качестве первого этапа может проводиться обнаружение соответствующих коэффициентов LPC, которые представляют фоновый шум. Эти коэффициенты LPC могут быть извлекаться во время активной речи, используя подход статистической информации о минимумах для поиска спектра фонового шума и затем для вычисления из него коэффициентов LPC при использовании произвольного алгоритма для извлечения LPC, известного от литературы. Некоторые варианты осуществления, например, могут непосредственно преобразовывать спектр фонового шума в представление, которое может использоваться непосредственно для FDNS в области MDCT.
Плавное изменение к комфортному шум может выполняться в области ISF (также может применяться в области LSF; LSF - частота спектральных линий):
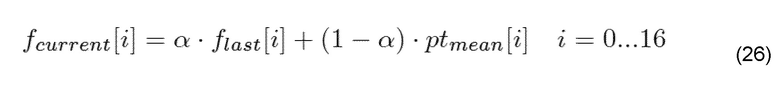
устанавливая ptmean в соответствующие коэффициенты LP, описывающие комфортный шум.
Рассматривая вышеописанное адаптивное формирование спектра комфортного шума более общий вариант осуществления показан с помощью фиг. 11.
Фиг. 11 показывает устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала согласно варианту осуществления.
Устройство содержит интерфейс 1110 приема для приема одного или большего количества кадров, генератор 1120 коэффициентов и средство 1130 восстановления сигнала.
Генератор 1120 коэффициентов конфигурируется для определения, если текущий кадр из одного или большего количества кадров принимается с помощью интерфейса 1110 приема и если текущий кадр, принимаемый с помощью интерфейса 1110 приема, не поврежден/ошибочен, одного или большего количества коэффициентов первого звукового сигнала, содержащихся в текущем кадре, причем указанный один или большее количество коэффициентов первого звукового сигнала указывают характеристику кодированного звукового сигнала, и одного или большего количества коэффициентов шума, указывающих фоновый шум кодированного звукового сигнала. Кроме того, генератор 1120 коэффициентов конфигурируется для генерации одного или большего количества коэффициентов второго звукового сигнала, в зависимости от одного или большего количества коэффициентов первого звукового сигнала и в зависимости от одного или большего количества коэффициентов шума, если текущий кадр не принимается с помощью интерфейса 1110 приема или если текущий кадр, принимаемый с помощью интерфейса 1110 приема, поврежден/ошибочен.
Средство 1130 восстановления звукового сигнала конфигурируется для восстановления первой части восстановленного звукового сигнала в зависимости от одного или большего количества коэффициентов первого звукового сигнала, если текущий кадр принимается с помощью интерфейса 110 приема и если текущий кадр, принимаемый с помощью интерфейса 1110 приема, не поврежден. Кроме того, средство 1130 восстановления звукового сигнала конфигурируется для восстановления второй части восстановленного звукового сигнала в зависимости от одного или большего количества коэффициентов второго звукового сигнала, если текущий кадр не принимается с помощью интерфейса 1110 приема или если текущий кадр, принимаемый с помощью интерфейса 1110 приема, поврежден.
Определение фонового шума хорошо известно в предшествующем уровне техники (см., например, [Mar01]: Rainer Martin, Noise power spectral density estimation based on optimal smoothing and minimum statistics, IEEE Transactions on Speech and Audio Processing 9 (2001 ), no. 5, 504 -512), и в варианте осуществления устройство действует соответствующим образом.
В некоторых вариантах осуществления один или большее количество коэффициентов первого звукового сигнала могут, например, быть одним или большим количеством коэффициентов фильтра линейного предсказания кодированного звукового сигнала. В некоторых вариантах осуществления один или большее количество коэффициентов первого звукового сигнала могут, например, быть одним или большим количеством коэффициентов фильтра линейного предсказания кодированного звукового сигнала.
В уровне техники хорошо известно, как восстановить звуковой сигнал, например, речевой сигнал, из коэффициентов фильтра линейного предсказания или из спектральных пар иммитанса (см., например, [3GP09c]: Speech codec speech processing functions; adaptive multi-rate - wideband (AMRWB) speech codec; transcoding functions, 3GPP TS 26.190, 3rd Generation Partnership Project, 2009), и в варианте осуществления средство восстановления сигнала действует соответствующим образом.
Согласно варианту осуществления один или большее количество коэффициентов шума могут, например, быть одним или большим количеством коэффициентов фильтра линейного предсказания, указывающих фоновый шум кодированного звукового сигнала. В варианте осуществления один или большее количество коэффициентов фильтра линейного предсказания могут, например, представлять форму спектра фонового шума.
В варианте осуществления генератор 1120 коэффициентов может, например, конфигурироваться для определения одной или большего количества вторых частей звукового сигнала таким образом, чтобы одна или большее количество вторых частей звукового сигнала были одним или большим количеством коэффициентов фильтра линейного предсказания восстановленного звукового сигнала, или таким образом, чтобы один или большее количество коэффициентов первого звукового сигнала были одной или большим количеством спектральных пар иммитанса восстановленного звукового сигнала.
Согласно варианту осуществления генератор 1120 коэффициентов может, например, конфигурироваться для генерации одного или большего количества коэффициентов второго звукового сигнала, применяя формулу:
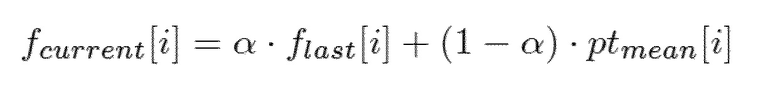
в которой fcurrent[i] обозначает один из одного или большего количества коэффициентов второго звукового сигнала, в которой flast[i] обозначает один из одного или большего количества коэффициентов первого звукового сигнала, в которой ptmean[i] является одним из одного или большего количества коэффициентов шума, в которой α является действительным числом, причем 0 ≤ α ≤ 1, и в которой i является индексом.
Согласно варианту осуществления flast[i] обозначает коэффициент фильтра линейного предсказания кодированного звукового сигнала, и причем fcurrent[i] обозначает коэффициент фильтра линейного предсказания восстановленного звукового сигнала.
В варианте осуществления ptmean[i] может, например, быть коэффициентом фильтра линейного предсказания, указывающим фоновый шум кодированного звукового сигнала.
Согласно варианту осуществления генератор 1120 коэффициентов может, например, конфигурироваться для генерации по меньшей мере 10 вторых коэффициентов звукового сигнала в качестве одного или большего количества коэффициентов второго звукового сигнала.
В варианте осуществления генератор 1120 коэффициентов может, например, конфигурироваться для определения, если текущий кадр из одного или большего количества кадров принимается с помощью интерфейса 1110 приема и если текущий кадр, принимаемый с помощью интерфейса 1110 приема, не поврежден, одного или большее количество коэффициентов шума с помощью определения спектра шума кодированного звукового сигнала.
В последующем рассматривают плавное изменения спектра MDCT к белому шуму перед применением FDNS.
Вместо случайной модификации знака элемента MDCT (скремблирования знака) весь спектр заполняют белым шумом, сформированным, используя FDNS. Чтобы избежать мгновенного изменения в характеристиках спектра, применяется плавный переход между скремблированием знака и заполнением шумом. Плавный переход может реализовываться следующим образом:

где:
cum_damping - (абсолютный) коэффициент ослабления - он уменьшается от кадра к кадру, начиная с 1 и уменьшаясь к 0
x_old - спектр последнего принятого кадра
random_sign возвращает 1 или -1
noise содержит случайный вектор (белый шум), который масштабируется таким образом, чтобы его среднеквадратическое значение (RMS) было аналогично последнему хорошему спектру.
Элемент random_sign()*old_x[i] характеризует процесс скремблирования знака для рандомизации фазы и таким образом - чтобы избежать повторений гармоник.
Впоследствии, другая нормализация уровня энергии может выполняться после плавного перехода для обеспечения, чтобы энергия суммирования не отклонялась из-за корреляции двух векторов.
Согласно вариантам осуществления первый блок 140 восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала в зависимости от информации уровня шума и в зависимости от первой части звукового сигнала. В конкретном варианте осуществления первый блок 140 восстановления может, например, конфигурироваться для восстановления третьей части звукового сигнала с помощью ослабления или усиления первой части звукового сигнала.
В некоторых вариантах осуществления второй блок 141 восстановления может, например, конфигурироваться для восстановления четвертой части звукового сигнала в зависимости от информации уровня шума и в зависимости от второй части звукового сигнала. В конкретном варианте осуществления второй блок 141 восстановления может, например, конфигурироваться для восстановления четвертой части звукового сигнала с помощью ослабления или усиления второй части звукового сигнала.
Рассматривая вышеописанное плавное изменение спектра MDCT к белому шуму перед применением FDNS, более общий вариант осуществления показан на фиг. 12.
Фиг. 12 показывает устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала согласно варианту осуществления.
Устройство содержит интерфейс 1210 приема для приема одного или большего количества кадров, содержащих информацию о множестве выборок звукового сигнала из спектра звукового сигнала для кодированного звукового сигнала, и процессор 1220 для генерации восстановленного звукового сигнала.
Процессор 1220 конфигурируется для генерации восстановленного звукового сигнала с помощью плавного изменения модифицированного спектра к целевому спектру, если текущий кадр не принимается с помощью интерфейса 1210 приема или если текущий кадр принимается с помощью интерфейса 1210 приема, но он поврежден, причем модифицированный спектр содержит множество модифицированных выборок сигнала, причем для каждой из модифицированных выборок сигнала из модифицированного спектра абсолютная величина указанной модифицированной выборки сигнала равна абсолютной величине одной из выборок звукового сигнала из спектра звукового сигнала.
Кроме того, процессор 1220 конфигурируется для того, чтобы не выполнять плавное изменение модифицированного спектра к целевому спектру, если текущий кадр из одного или большего количества кадров принимается с помощью интерфейса 1210 приема и если текущий кадр, принимаемый с помощью интерфейса 1210 приема, не поврежден.
Согласно варианту осуществления целевой спектр является шумоподобным спектром.
В варианте осуществления шумоподобный спектр представляет белый шум.
Согласно варианту осуществления шумоподобный спектр имеет конкретную форму.
В варианте осуществления форма шумоподобного спектра зависит от спектра звукового сигнала ранее принятого сигнала.
Согласно варианту осуществления шумоподобный спектр формируется в зависимости от формы спектра звукового сигнала.
В варианте осуществления процессор 1220 использует коэффициент наклона для формирования шумоподобного спектра.
Согласно варианту осуществления процессор 1220 использует формулу
shaped_noise[i]=noise * power (tilt_factor, i/N)
в которой N обозначает количество выборок,
в которой i является индексом,
в которой 0 <= i < N при tilt_factor > 0,
в которой power является степенной функцией.
Если tilt_factor меньше 1, то это означает ослабление при увеличении i. Если tilt_factor больше 1, то это означает усиление при увеличении i.
Согласно другому варианту осуществления процессор 1220 может использовать формулу
shaped_noise[i]=noise * (1+i/(N-1) * (tilt_factor-1))
в которой N обозначает количество выборок,
в которой i является индексом,
в которой 0 <= i < N при tilt_factor > 0.
Согласно варианту осуществления процессор 1220 конфигурируется для генерации модифицированного спектра с помощью изменения знака одной или большего количества выборок звукового сигнала из спектра звукового сигнала, если текущий кадр не принимается с помощью интерфейса 1210 приема или если текущий кадр, принимаемый с помощью интерфейса 1210 приема, поврежден.
В варианте осуществления каждая из выборок звукового сигнала из спектра звукового сигнала представлена действительным числом, а не мнимым числом.
Согласно варианту осуществления выборки звукового сигнала из спектра звукового сигнала представлены в области модифицированного дискретного косинусного преобразования.
В другом варианте осуществления выборки звукового сигнала из спектра звукового сигнала представлены в области модифицированного дискретного синусного преобразования.
Согласно варианту осуществления процессор 1220 конфигурируется для генерации модифицированного спектра с помощью использования функции случайного знака, которая случайно или псевдослучайно выводит или первое, или второе значение.
В варианте осуществления процессор 1220 конфигурируется для плавного изменения модифицированного спектра к целевому спектру с помощью последовательного уменьшения коэффициента ослабления.
Согласно варианту осуществления процессор 1220 конфигурируется для плавного изменения модифицированного спектра к целевому спектру с помощью последовательного увеличения коэффициента ослабления.
В варианте осуществления, если текущий кадр не принимается с помощью интерфейса 1210 приема или если текущий кадр, принимаемый с помощью интерфейса 1210 приема, поврежден, то процессор 1220 конфигурируется для генерации восстановленного звукового сигнала, используя формулу:
x[i]=(1-cum_damping) * noise[i]+cum_damping * random_sign() * x_old[i]
в которой i является индексом, в которой x[i] обозначает выборку восстановленного звукового сигнала, в которой cum_damping является коэффициентом ослабления, в которой x_old[i] обозначает одну из выборок звукового сигнала из спектра звукового сигнала для кодированного звукового сигнала, в которой random_sign() возвращает 1 или -1, и в которой noise является случайным вектором, указывающим целевой спектр.
Некоторые варианты осуществления продолжают операцию TCX LTP. В этих вариантах осуществления операция TCX LTP продолжается во время маскирования с параметрами LTP (отставание LTP и усиление LTP), извлеченными из последнего хорошего кадра.
Операции LTP могут быть получены в итоге следующим образом:
- Заполняют буфер задержки LTP, основываясь на ранее извлеченном выходном сигнале.
- Основываясь на отставании LTP: выбирают соответствующую часть сигнала из буфера задержки LTP, которая используется в качестве коэффициента LTP для формирования текущего сигнала.
- Повторно масштабируют этот вклад LTP, используя усиление LTP.
- Складывают этот повторно масштабированный вклад LTP с входным сигналом LTP для генерации выходного сигнала LTP.
Разные подходы можно рассматривать по отношению ко времени, когда выполняется обновление буфера задержки LTP:
В качестве первой операции LTP в кадре n используют выход от последнего кадра n-1. Он обновляет буфер задержки LTP в кадре n для использования во время LTP-обработки в кадре n.
В качестве последней операции LTP в кадре n используют выход от текущего кадра n. Он обновляет буфер задержки LTP в кадре n для использования во время LTP-обработки в кадре n+1.
В последующем рассматривают разъединение цикла обратной связи TCX LTP.
Разъединение цикла обратной связи TCX LTP предотвращает введение дополнительного шума (являющегося результатом замены шумом, относящимся к входному сигналу LPT) во время каждого цикла обратной связи декодера LTP, который находится в режиме маскирования.
Фиг. 10 показывает это разъединение. В частности, фиг. 10 изображает разъединение цикла обратной связи LTP во время маскирования (bfi=1).
Фиг. 10 показывает буфер 1020 задержки, блок 1030 выбора выборок и процессор 1040 выборок (процессор 1040 выборок обозначен пунктирной линией).
По отношению ко времени, когда выполняется обновление буфера 1020 задержки LTP, некоторые варианты осуществления действуют следующим образом:
- Для обычной операции: для обновления буфера 1020 задержки LTP, когда первая операция LTP может быть предпочтительной, так как суммированный выходной сигнал обычно сохраняется постоянно. С этим подходом выделенный буфер может не использоваться.
- Для разъединенной операции: для обновления буфера 1020 задержки LTP, когда последняя операция LTP может быть предпочтительной, так как вклад LTP в сигнал обычно сохраняется только временно. С этим подходом временный сигнал вклада LTP сохраняется. В зависимости от воплощения этот буфер вклада LTP может вполне быть сделан постоянным.
Предполагая, что последний подход используется в любом случае (обычное функционирование и маскирование), варианты осуществления могут, например, реализовывать следующее:
- Во время обычного функционирования: выходной сигнал во временной области декодера LTP после его суммирования с входным сигналом LTP используется для подачи в буфер задержки LTP.
- Во время маскирования: выходной сигнал во временной области декодера LTP до его суммирования с входным сигналом LTP используется для подачи в буфер задержки LTP.
Некоторые варианты осуществления плавно изменяют усиление TCX LTP к нулю. В таком варианте осуществления усиление TCX LTP может, например, плавно изменяться к нулю с некоторым адаптируемым к сигналу коэффициентом плавного изменения. Это может, например, выполняться итерационно, например, согласно следующему псевдокоду:
gain=gain_past * damping;
[...]
gain_past=gain;
где:
gain является усилением декодера TCX LTP, применяемым в текущем кадре;
gain_past является усилением декодера TCX LTP, применяемым в предыдущем кадре;
damping является (относительным) коэффициентом плавного изменения.
Фиг. 1d показывает устройство согласно дополнительному варианту осуществления, причем данное устройство дополнительно содержит блок 170 долгосрочного предсказания, содержащий буфер 180 задержки. Блок 170 долгосрочного предсказания конфигурируется для генерации обработанного сигнала в зависимости от второй части звукового сигнала, в зависимости от вводимой в буфер задержки информации, сохраняемой в буфере 180 задержки, и в зависимости от усиления долгосрочного предсказания. Кроме того, блок долгосрочного предсказания конфигурируется для плавного изменения усиления долгосрочного предсказания к нулю, если указанный третий кадр из множества кадров не принимается с помощью интерфейса 110 приема или если указанный третий кадр принимается с помощью интерфейса 110 приема, но он поврежден.
В других вариантах осуществления (не показаны) блок долгосрочного предсказания может, например, конфигурироваться для генерации обработанного сигнала в зависимости от первой части звукового сигнала, в зависимости от вводимой в буфер задержки информации, сохраняемой в буфере задержки, и в зависимости от усиления долгосрочного предсказания.
На фиг. 1d первый блок 140 восстановления может, например, генерировать третью часть звукового сигнала, также зависящую от обработанного сигнала.
В варианте осуществления блок 170 долгосрочного предсказания может, например, конфигурироваться для плавного изменения усиления долгосрочного предсказания к нулю, причем скорость, с которой усиление долгосрочного предсказания плавно изменяется к нулю, зависит от коэффициента плавного изменения.
Альтернативно или дополнительно, блок 170 долгосрочного предсказания может, например, конфигурироваться для обновления вводимой в буфер 180 задержки информации с помощью сохранения сгенерированного обработанного сигнала в буфере 180 задержки, если указанный третий кадр из множества кадров не принимается с помощью интерфейса 110 приема или если указанный третий кадр принимается с помощью интерфейса 110 приема, но он поврежден.
Рассматривая вышеописанное использование TCX LTP, более общий вариант осуществления показан на фиг. 13.
Фиг. 13 показывает устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала.
Устройство содержит интерфейс 1310 приема для приема множества кадров, буфер 1320 задержки для сохранения выборок звукового сигнала из декодированного звукового сигнала, блок 1330 выбора выборок для выбора множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере 1320 задержки, и процессор 1340 выборок для обработки выбранных выборок звукового сигнала для получения восстановленных выборок звукового сигнала из восстановленного звукового сигнала.
Блок 1330 выбора выборок конфигурируется для выбора, если текущий кадр принимается с помощью интерфейса 1310 приема и если текущий кадр, принимаемый с помощью интерфейса 1310 приема, не поврежден, множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере 1320 задержки, в зависимости от информации отставания основного тона, содержащейся в текущем кадре. Кроме того, блок 1330 выбора выборок конфигурируется для выбора, если текущий кадр не принимается с помощью интерфейса 1310 приема или если текущий кадр, принимаемый с помощью интерфейса 1310 приема, поврежден, множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере 1320 задержки, в зависимости от информации отставания основного тона, содержащейся в другом кадре, принятом ранее с помощью интерфейса 1310 приема.
Согласно варианту осуществления процессор 1340 выборок может, например, конфигурироваться для получения восстановленных выборок звукового сигнала, если текущий кадр принимается с помощью интерфейса 1310 приема и если текущий кадр, принимаемый с помощью интерфейса 1310 приема, не поврежден, с помощью повторного масштабирования выбранных выборок звукового сигнала в зависимости от информации усиления, содержащейся в текущем кадре. Кроме того, блок 1330 выбора выборок может, например, конфигурироваться для получения восстановленных выборок звукового сигнала, если текущий кадр не принимается с помощью интерфейса 1310 приема или если текущий кадр, принимаемый с помощью интерфейса 1310 приема, поврежден, с помощью повторного масштабирования выбранных выборок звукового сигнала в зависимости от информации усиления, содержащейся в указанном другом кадре, принятом ранее с помощью интерфейса 1310 приема.
В варианте осуществления процессор 1340 выборок может, например, конфигурироваться для получения восстановленных выборок звукового сигнала, если текущий кадр принимается с помощью интерфейса 1310 приема и если текущий кадр, принимаемый с помощью интерфейса 1310 приема, не поврежден, с помощью умножения выбранных выборок звукового сигнала и значения, зависящего от информации усиления, содержащейся в текущем кадре. Кроме того, блок 1330 выбора выборок конфигурируется для получения восстановленных выборок звукового сигнала, если текущий кадр не принимается с помощью интерфейса 1310 приема или если текущий кадр, принимаемый с помощью интерфейса 1310 приема, поврежден, с помощью умножения выбранных выборок звукового сигнала и значения, зависящего от информации усиления, содержащейся в указанном другом кадре, принятом ранее с помощью интерфейса 1310 приема.
Согласно варианту осуществления процессор 1340 выборок может, например, конфигурироваться для сохранения восстановленных выборок звукового сигнала в буфере 1320 задержки.
В варианте осуществления процессор 1340 выборок может, например, конфигурироваться для сохранения восстановленных выборок звукового сигнала в буфере 1320 задержки перед тем, как дополнительный кадр будет принят с помощью интерфейса 1310 приема.
Согласно варианту осуществления процессор 1340 выборок может, например, конфигурироваться для сохранения восстановленных выборок звукового сигнала в буфере 1320 задержки после того, как дополнительный кадр будет принят с помощью интерфейса 1310 приема.
В варианте осуществления процессор 1340 выборок может, например, конфигурироваться для повторного масштабирования выбранных выборок звукового сигнала в зависимости от информации усиления для получения повторно масштабированных выборок звукового сигнала и объединения повторно масштабированных выборок звукового сигнала с входными выборками звукового сигнала для получения обработанных выборок звукового сигнала.
Согласно варианту осуществления процессор 1340 выборок может, например, конфигурироваться для сохранения обработанных выборок звукового сигнала с помощью указания комбинации повторно масштабированных выборок звукового сигнала и входных выборок звукового сигнала в буфере 1320 задержки и не выполнения сохранения повторно масштабированных выборок звукового сигнала в буфере 1320 задержки, если текущий кадр принимается с помощью интерфейса 1310 приема и если текущий кадр, принимаемый с помощью интерфейса 1310 приема, не поврежден. Кроме того, процессор 1340 выборок конфигурируется для сохранения повторно масштабированных выборок звукового сигнала в буфере 1320 задержки и не выполнения сохранения обработанных выборок звукового сигнала в буфере 1320 задержки, если текущий кадр не принимается с помощью интерфейса 1310 приема или если текущий кадр, принимаемый с помощью интерфейса 1310 приема, поврежден.
Согласно другому варианту осуществления процессор выборок 340 может, например, конфигурироваться для сохранения обработанных выборок звукового сигнала в буфере 1320 задержки, если текущий кадр не принимается с помощью интерфейса 1310 приема или если текущий кадр, принимаемый с помощью интерфейса 1310 приема, поврежден.
В варианте осуществления блок 1330 выбора выборок может, например, конфигурироваться для получения восстановленных выборок звукового сигнала с помощью повторного масштабирования выбранных выборок звукового сигнала в зависимости от модифицированного усиления, причем модифицированное усиление определяется согласно формуле:
gain=gain_past * damping;
в которой gain является модифицированным усилением, в которой блок 1330 выбора выборок может, например, конфигурироваться для установки gain_past в gain после того, как значение gain вычислено, и в которой damping является действительным числом.
Согласно варианту осуществления блок 1330 выбора выборок может, например, конфигурироваться для вычисления модифицированного усиления.
В варианте осуществления damping может, например, определяться согласно: 0 < damping < 1.
Согласно варианту осуществления модифицированное усиление gain может, например, устанавливаться в нуль, если по меньшей мере предопределенное количество кадров не принято с помощью интерфейса 1310 приема после того, как кадр последний раз был принят с помощью интерфейса 1310 приема.
В последующем рассматривают скорость плавного изменения. Существуют несколько модулей маскирования, которые применяют конкретный вид плавного изменения. Хотя скорость этого плавного изменения может по-разному выбираться в этих модулях, выгодно использовать одинаковую скорость плавного изменения для всех модулей маскирования для одного ядра (ACELP или TCX). Например:
Для ACELP одинаковая скорость плавного изменения должна использоваться, в частности, для сигнала адаптивной кодовой книги (с помощью изменения усиления) и/или для сигнала инновационной кодовой книги (с помощью изменения усиления).
Также, для TCX одинаковая скорость плавного изменения должна использоваться, в частности для сигнала во временной области, и/или для усиления LTP (плавного изменения к нулю), и/или для взвешивания LPC (плавного изменения к единице), и/или для коэффициентов LP (плавного изменения к форме спектра фона), и/или для плавного перехода к белому шуму.
Может дополнительно быть предпочтительно также использовать одинаковую скорость плавного изменения для ACELP и TCX, но из-за различной природы ядер, можно также выбирать использование различных скоростей плавного изменения.
Эта скорость плавного изменения может быть статической, но предпочтительно она адаптируется к характеристикам сигнала. Например, скорость плавного изменения может, например, зависеть от коэффициента стабильности LPC (TCX) и/или от классификации, и/или от количества последовательно потерянных кадров.
Скорость плавного изменения может, например, определяться в зависимости от коэффициента ослабления, который может задаваться абсолютно или относительно, и который может также изменяться во времени во время конкретного плавного изменения.
В вариантах осуществления та же самая скорость плавного изменения используется для плавного изменения усиления LTP, как и для плавного изменения белого шума.
Обеспечены устройство, способ и компьютерная программа для генерации сигнала комфортного шума, который описан выше.
Хотя некоторые аспекты описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или особенности этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или особенности соответствующего устройства.
Изобретенный разбираемый сигнал может сохраняться на цифровом носителе данных или может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, такой как Интернет.
В зависимости от конкретных требований реализации варианты осуществления изобретения могут воплощаться в оборудовании или в программном обеспечении. Воплощение может выполняться, используя цифровой носитель данных, например гибкий диск, DVD (цифровой универсальный диск), CD (компакт-диск), ПЗУ (постоянное запоминающее устройство), ППЗУ (программируемое ПЗУ), СППЗУ (стираемое программируемое ПЗУ), ЭСППЗУ (электрически стираемое программируемое ПЗУ) или флэш-память, имеющий сохраненные на нем считываемые помощью электроники управляющие сигналы, которые взаимодействуют (или имеют возможность взаимодействия) с программируемой компьютерной системой таким образом, чтобы выполнялся соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат не являющийся временным носитель информации, имеющий считываемые с помощью электроники управляющие сигналы, которые имеют возможность взаимодействия с программируемой компьютерной системой таким образом, чтобы выполнялся один из способов, описанных в данной работе.
В общем случае варианты осуществления настоящего изобретения могут реализовываться в качестве компьютерного программного продукта с кодом программы, данный код программы работает для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Код программы может, например, сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в данной работе, сохраненную на машиночитаемом носителе.
Другими словами, вариантом осуществления изобретенного способа поэтому является компьютерная программа, имеющая код программы для выполнения одного из способов, описанных в данной работе, когда данная компьютерная программа выполняется на компьютере.
Дополнительным вариантом осуществления изобретенных способов поэтому является носитель информации (или цифровой носитель данных, или считываемый компьютером носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в данной работе.
Дополнительным вариантом осуществления изобретенного способа поэтому является поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в данной работе. Поток данных или последовательность сигналов могут, например, конфигурироваться для перемещения через соединение передачи данных, например через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, конфигурируемое или настроенное для выполнения одного из способов, описанных в данной работе.
Дополнительный вариант осуществления содержит компьютер, на котором установлена компьютерная программа для выполнения одного из способов, описанных в данной работе.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей способов, описанных в данной работе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может совместно работать с микропроцессором для выполнения одного из способов, описанных в данной работе. В общем случае способы предпочтительно выполняются с помощью какого-либо аппаратного устройства.
Вышеописанные варианты осуществления являются просто иллюстративными для принципов настоящего изобретения. Подразумевается, что модификации и разновидности структур и подробностей, описанные в данной работе, будут очевидны для специалистов. Поэтому намерением является ограничение только с помощью объема последующей формулы изобретения, а не конкретными подробностями, представленными посредством описания и объяснения вариантов осуществления в данной работе.
ССЫЛКИ
[3GP09a] 3GPP; Technical Specification Group Services and System Aspects, Extended adaptive multi-rate - wideband (AMR-WB+) codec, 3GPP TS 26.290, 3rd Generation Partnership Project, 2009.
[3GP09b] Extended adaptive multi-rate - wideband (AMR-WB+) codec; floating-point ANSI-C code, 3GPP TS 26.304, 3rd Generation Partnership Project, 2009.
[3GP09c] Speech codec speech processing functions; adaptive multi-rate - wideband (AMRWB) speech codec; transcoding functions, 3GPP TS 26.190, 3rd Generation Partnership Project, 2009.
[3GP12a] Adaptive multi-rate (AMR) speech codec; error concealment of lost frames (release 11), 3GPP TS 26.091, 3rd Generation Partnership Project, Sep 2012.
[3GP12b] Adaptive multi-rate (AMR) speech codec; transcoding functions (release 11), 3GPP TS 26.090, 3rd Generation Partnership Project, Sep 2012. [3GP12c], ANSI-C code for the adaptive multi-rate - wideband (AMR-WB) speech codec, 3GPP TS 26.173, 3rd Generation Partnership Project, Sep 2012.
[3GP12d] ANSI-C code for the floating-point adaptive multi-rate (AMR) speech codec (release11), 3GPP TS 26.104, 3rd Generation Partnership Project, Sep 2012.
[3GP12e] General audio codec audio processing functions; Enhanced aacPlus general audio codec; additional decoder tools (release 11), 3GPP TS 26.402, 3rd Generation Partnership Project, Sep 2012.
[3GP12f] Speech codec speech processing functions; adaptive multi-rate - wideband (amr-wb)speech codec; ansi-c code, 3GPP TS 26.204, 3rd Generation Partnership Project, 2012.
[3GP12g] Speech codec speech processing functions; adaptive multi-rate - wideband (AMR-WB) speech codec; error concealment of erroneous or lost frames, 3GPP TS 26.191, 3rdGeneration Partnership Project, Sep 2012.
[BJH06] I. Batina, J. Jensen, and R. Heusdens, Noise power spectrum estimation for speechenhancement using an autoregressive model for speech power spectrum dynamics, in Proc.IEEE Int. Conf. Acoust., Speech, Signal Process. 3 (2006), 1064–1067.
[BP06] A. Borowicz and A. Petrovsky, Minima controlled noise estimation for klt-based speechenhancement, CD-ROM, 2006, Italy, Florence.
[Coh03] I. Cohen, Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging, IEEE Trans. Speech Audio Process. 11 (2003), no. 5, 466–475.
[CPK08] Choong Sang Cho, Nam In Park, and Hong Kook Kim, A packet loss concealment algorithm robust to burst packet loss for celp-type speech coders, Tech. report, KoreaEnectronics Technology Institute, Gwang Institute of Science and Technology, 2008, The 23rd International Technical Conference on Circuits/Systems, Computers and Communications(ITC-CSCC 2008).
[Dob95] G. Doblinger, Computationally efficient speech enhancement by spectral minima trackingin subbands, in Proc. Eurospeech (1995), 1513–1516.
[EBU10] EBU/ETSI JTC Broadcast, Digital audio broadcasting (DAB); transport of advancedaudio coding (AAC) audio, ETSI TS 102 563, European Broadcasting Union, May 2010.
[EBU12] Digital radio mondiale (DRM); system specification, ETSI ES 201 980, ETSI,Jun 2012.
[EH08] Jan S. Erkelens and Richards Heusdens, Tracking of Nonstationary Noise Based onData-Driven Recursive Noise Power Estimation, Audio, Speech, and Language Processing,IEEE Transactions on 16 (2008), no. 6, 1112 –1123.
[EM84] Y. Ephraim and D. Malah, Speech enhancement using a minimum mean-square errors hort-time spectral amplitude estimator, IEEE Trans. Acoustics, Speech and Signal Processing32 (1984), no. 6, 1109–1121.
[EM85] Speech enhancement using a minimum mean-square error log-spectral amplitudeestimator, IEEE Trans. Acoustics, Speech and Signal Processing 33 (1985), 443–445.
[Gan05] S. Gannot, Speech enhancement: Application of the kalman filter in the estimate-maximize(em framework), Springer, 2005.
[HE95] H. G. Hirsch and C. Ehrlicher, Noise estimation techniques for robust speech recognition,Proc. IEEE Int. Conf. Acoustics, Speech, Signal Processing, no. pp. 153-156, IEEE, 1995.
[HHJ10] Richard C. Hendriks, Richard Heusdens, and Jesper Jensen, MMSE based noise PSD tracking with low complexity, Acoustics Speech and Signal Processing (ICASSP), 2010IEEE International Conference on, Mar 2010, pp. 4266 –4269.
[HJH08] Richard C. Hendriks, Jesper Jensen, and Richard Heusdens, Noise tracking using dftdomain subspace decompositions, IEEE Trans. Audio, Speech, Lang. Process. 16 (2008),no. 3, 541–553.
[IET12] IETF, Definition of the Opus Audio Codec, Tech. Report RFC 6716, Internet EngineeringTask Force, Sep 2012.
[ISO09] ISO/IEC JTC1/SC29/WG11, Information technology – coding of audio-visual objects– part 3: Audio, ISO/IEC IS 14496-3, International Organization for Standardization,2009.
[ITU03] ITU-T, Wideband coding of speech at around 16 kbit/s using adaptive multi-rate wideband(amr-wb), Recommendation ITU-T G.722.2, Telecommunication Standardization Sectorof ITU, Jul 2003.
[ITU05] Low-complexity coding at 24 and 32 kbit/s for hands-free operation in systemswith low frame loss, Recommendation ITU-T G.722.1, Telecommunication StandardizationSector of ITU, May 2005.
[ITU06a] G.722 Appendix III:A high-complexity algorithm for packet loss concealment for G.722, ITU-T Recommendation, ITU-T, Nov 2006.
[ITU06b] G.729.1: G.729-based embedded variable bit-rate coder: An 8-32 kbit/s scalablewideband coder bitstream interoperable with g.729, Recommendation ITU-T G.729.1,Telecommunication Standardization Sector of ITU, May 2006.
[ITU07] G.722 Appendix IV: A low-complexity algorithm for packet loss concealmentwith G.722, ITU-T Recommendation, ITU-T, Aug 2007.
[ITU08a] G.718: Frame error robust narrow-band and wideband embedded variable bit-ratecoding of speech and audio from 8-32 kbit/s, Recommendation ITU-T G.718, TelecommunicationStandardization Sector of ITU, Jun 2008.
[ITU08b] G.719: Low-complexity, full-band audio coding for high-quality, conversationalapplications, Recommendation ITU-T G.719, Telecommunication Standardization Sectorof ITU, Jun 2008.
[ITU12] G.729: Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excitedlinear prediction (cs-acelp), Recommendation ITU-T G.729, TelecommunicationStandardization Sector of ITU, June 2012.
[LS01] Pierre Lauber and Ralph Sperschneider, Error concealment for compressed digital audio, Audio Engineering Society Convention 111, no. 5460, Sep 2001.
[Mar01] Rainer Martin, Noise power spectral density estimation based on optimal smoothing and minimum statistics, IEEE Transactions on Speech and Audio Processing 9 (2001), no. 5,504 –512.
[Mar03] Statistical methods for the enhancement of noisy speech, InternationalWorkshopon Acoustic Echo and Noise Control (IWAENC2003), Technical University of Braunschweig,Sep 2003.
[MC99] R. Martin and R. Cox, New speech enhancement techniques for low bit rate speech coding,in Proc. IEEE Workshop on Speech Coding (1999), 165–167.
[MCA99] D. Malah, R. V. Cox, and A. J. Accardi, Tracking speech-presence uncertainty to improvespeech enhancement in nonstationary noise environments, Proc. IEEE Int. Conf. onAcoustics Speech and Signal Processing (1999), 789–792.
[MEP01] Nikolaus Meine, Bernd Edler, and Heiko Purnhagen, Error protection and concealmentfor HILN MPEG-4 parametric audio coding, Audio Engineering Society Convention 110,no. 5300, May 2001.
[MPC89] Y. Mahieux, J.-P. Petit, and A. Charbonnier, Transform coding of audio signals usingcorrelation between successive transform blocks, Acoustics, Speech, and Signal Processing,1989. ICASSP-89., 1989 International Conference on, 1989, pp. 2021–2024 vol.3.
[NMR+12] Max Neuendorf, Markus Multrus, Nikolaus Rettelbach, Guillaume Fuchs, Julien Robilliard,Jérémie Lecomte, Stephan Wilde, Stefan Bayer, Sascha Disch, Christian Helmrich,Roch Lefebvre, Philippe Gournay, Bruno Bessette, Jimmy Lapierre, KristopferKjörling, Heiko Purnhagen, Lars Villemoes, Werner Oomen, Erik Schuijers, Kei Kikuiri,Toru Chinen, Takeshi Norimatsu, Chong Kok Seng, Eunmi Oh, Miyoung Kim, SchuylerQuackenbush, and Berndhard Grill, MPEG Unified Speech and Audio Coding - The ISO/ MPEG Standard for High-Efficiency Audio Coding of all Content Types, ConventionPaper 8654, AES, April 2012, Presented at the 132nd Convention Budapest, Hungary.
[PKJ+11] Nam In Park, Hong Kook Kim, Min A Jung, Seong Ro Lee, and Seung Ho Choi, Burstpacket loss concealment using multiple codebooks and comfort noise for celp-type speechcoders in wireless sensor networks, Sensors 11 (2011), 5323–5336.
[QD03] Schuyler Quackenbush and Peter F. Driessen, Error mitigation in MPEG-4 audio packetcommunication systems, Audio Engineering Society Convention 115, no. 5981, Oct 2003.
[RL06] S. Rangachari and P. C. Loizou, A noise-estimation algorithm for highly non-stationaryenvironments, Speech Commun. 48 (2006), 220–231.
[SFB00] V. Stahl, A. Fischer, and R. Bippus, Quantile based noise estimation for spectral subtractionand wiener filtering, in Proc. IEEE Int. Conf. Acoust., Speech and Signal Process.(2000), 1875–1878.
[SS98] J. Sohn and W. Sung, A voice activity detector employing soft decision based noisespectrum adaptation, Proc. IEEE Int. Conf. Acoustics, Speech, Signal Processing, no.pp. 365-368, IEEE, 1998.
[Yu09] Rongshan Yu, A low-complexity noise estimation algorithm based on smoothing of noisepower estimation and estimation bias correction, Acoustics, Speech and Signal Processing, 2009. ICASSP 2009. IEEE International Conference on, Apr 2009, pp. 4421–4424.
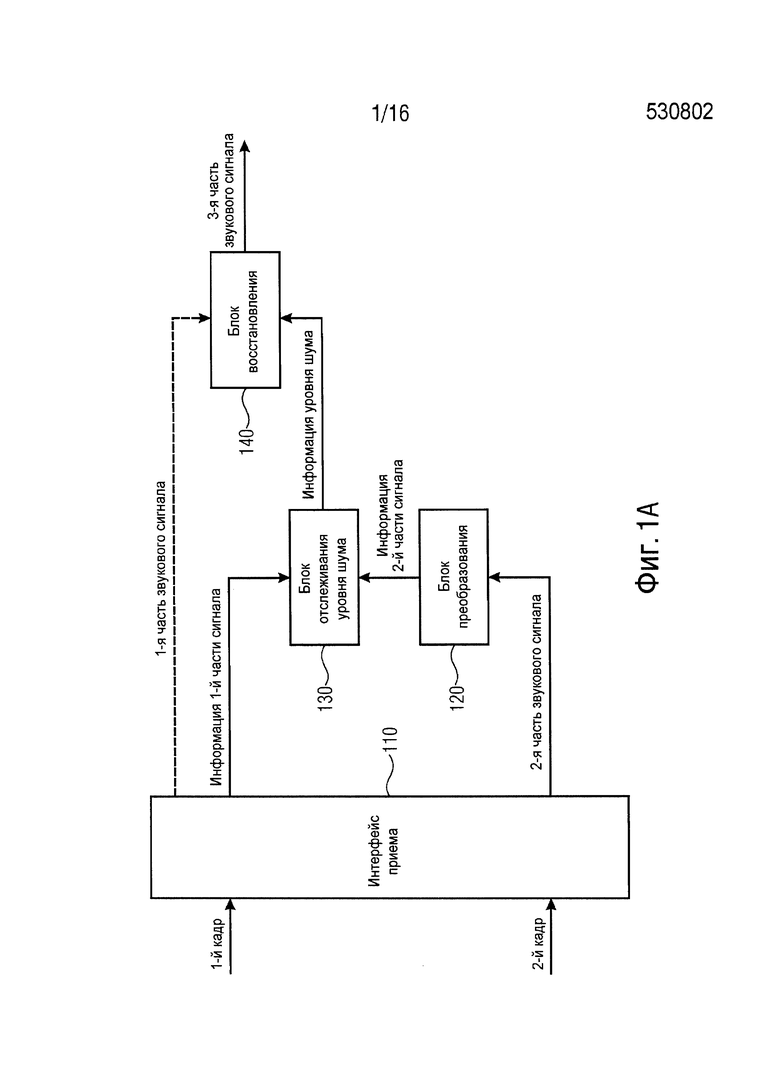
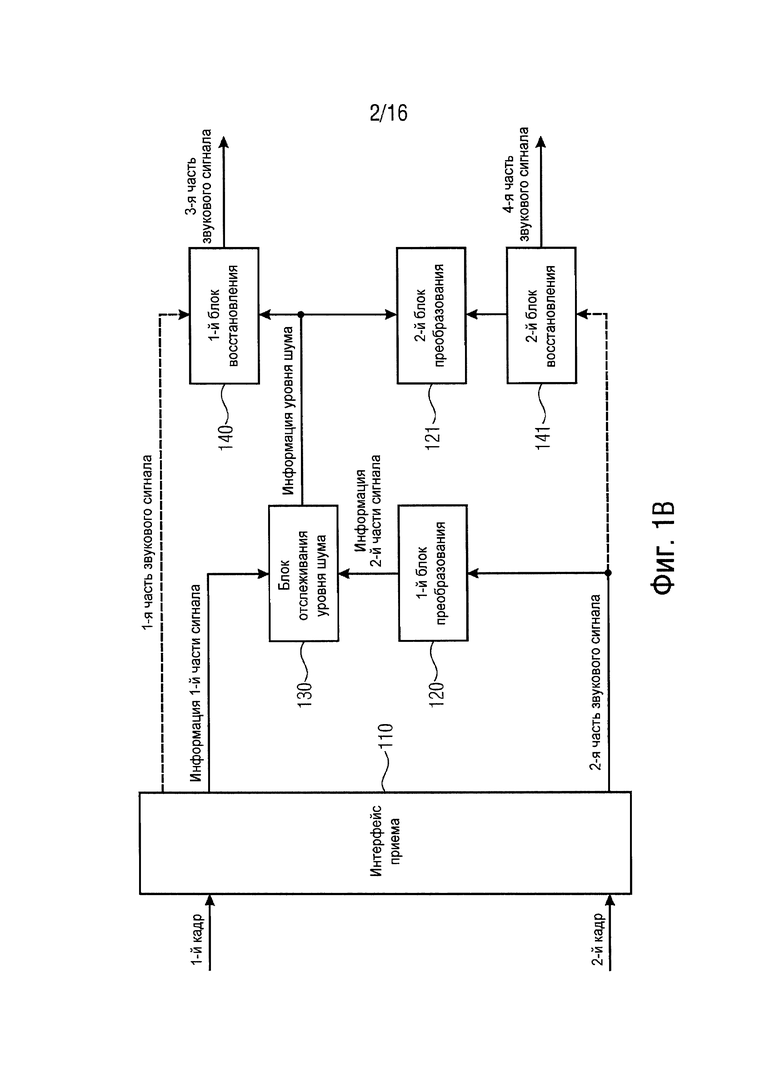
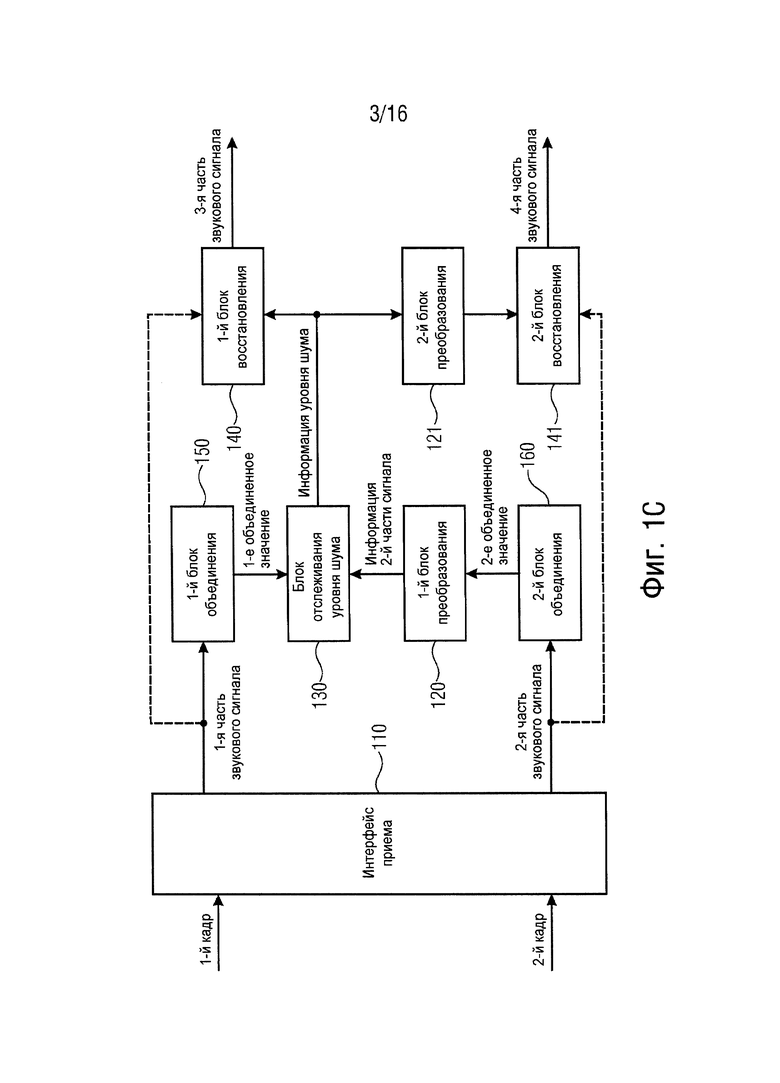
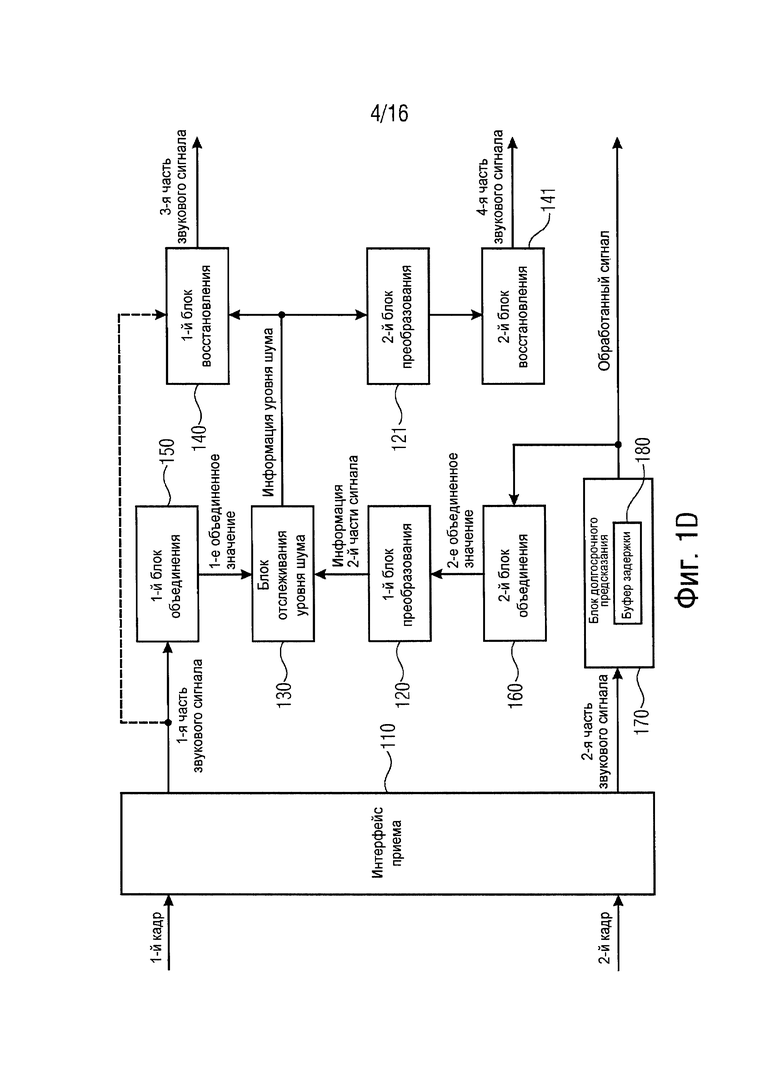
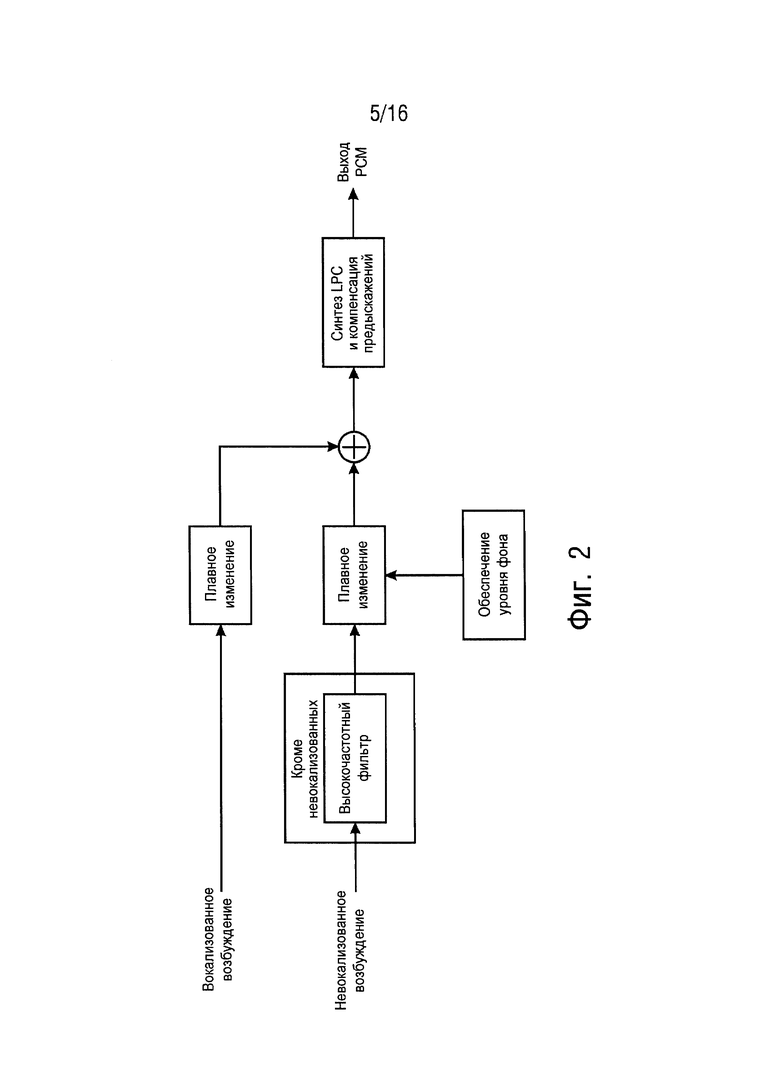
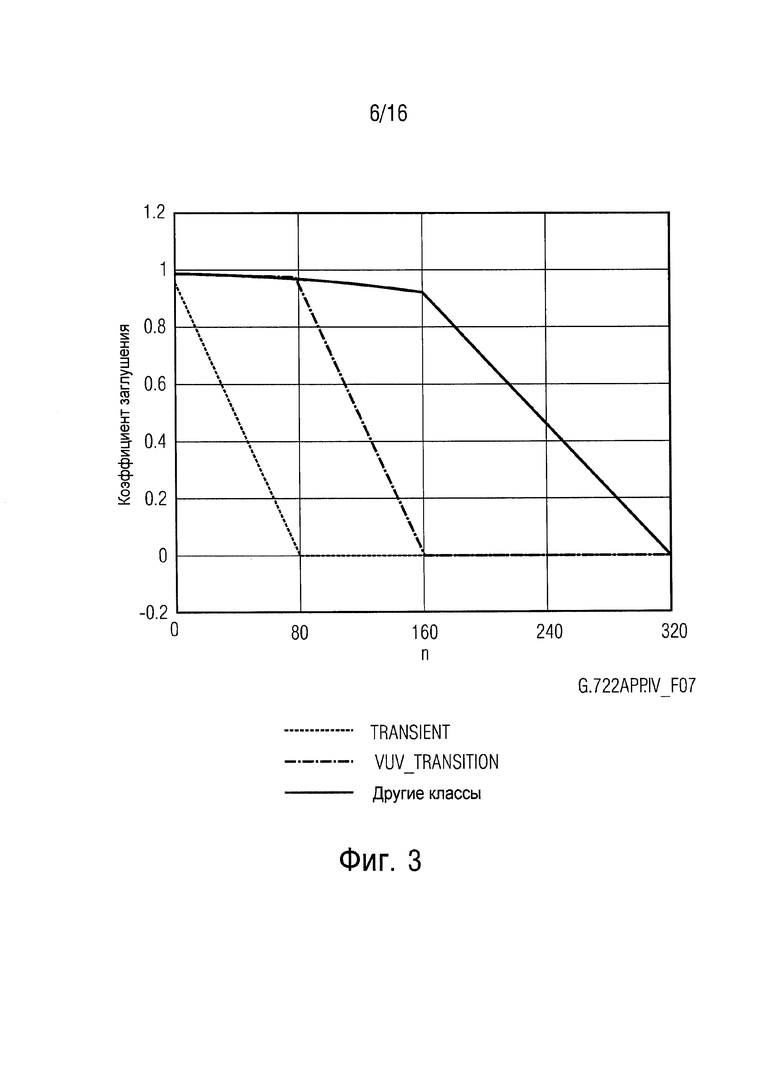
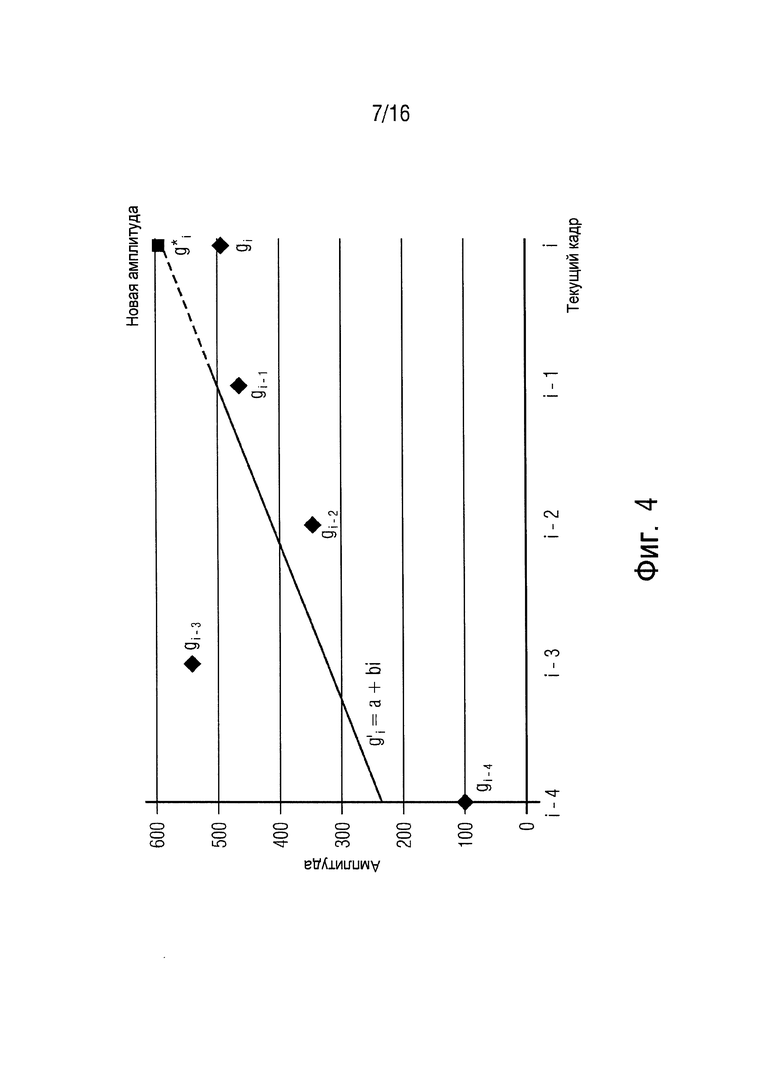

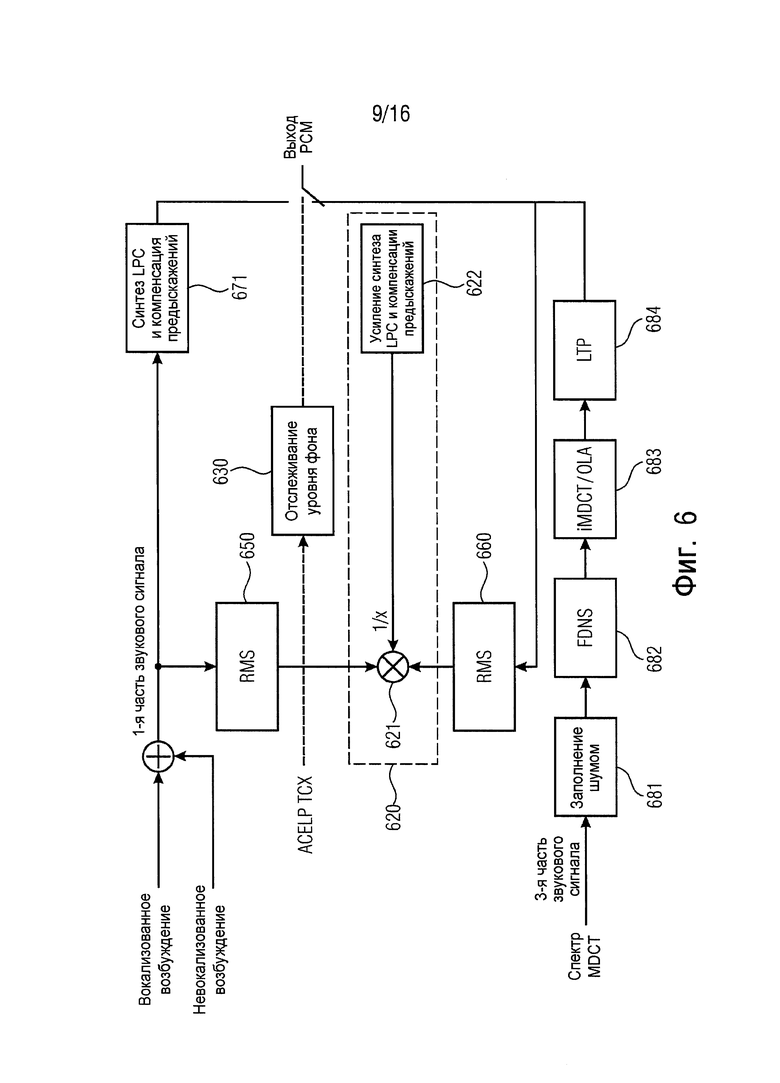
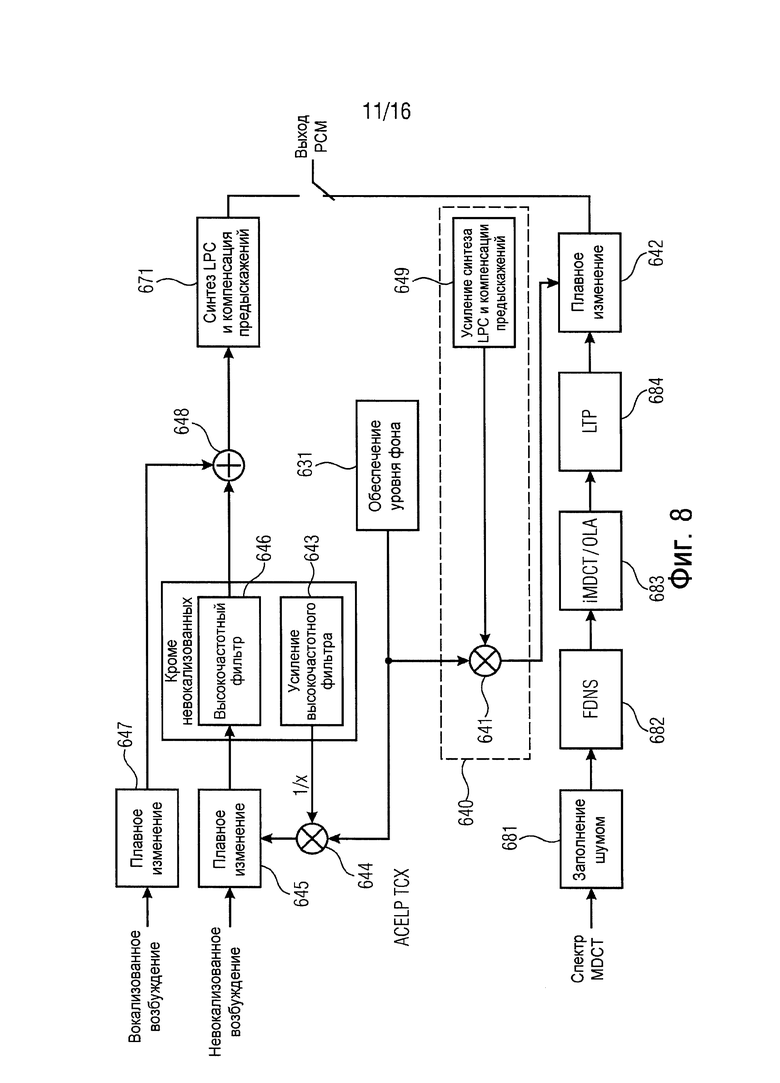
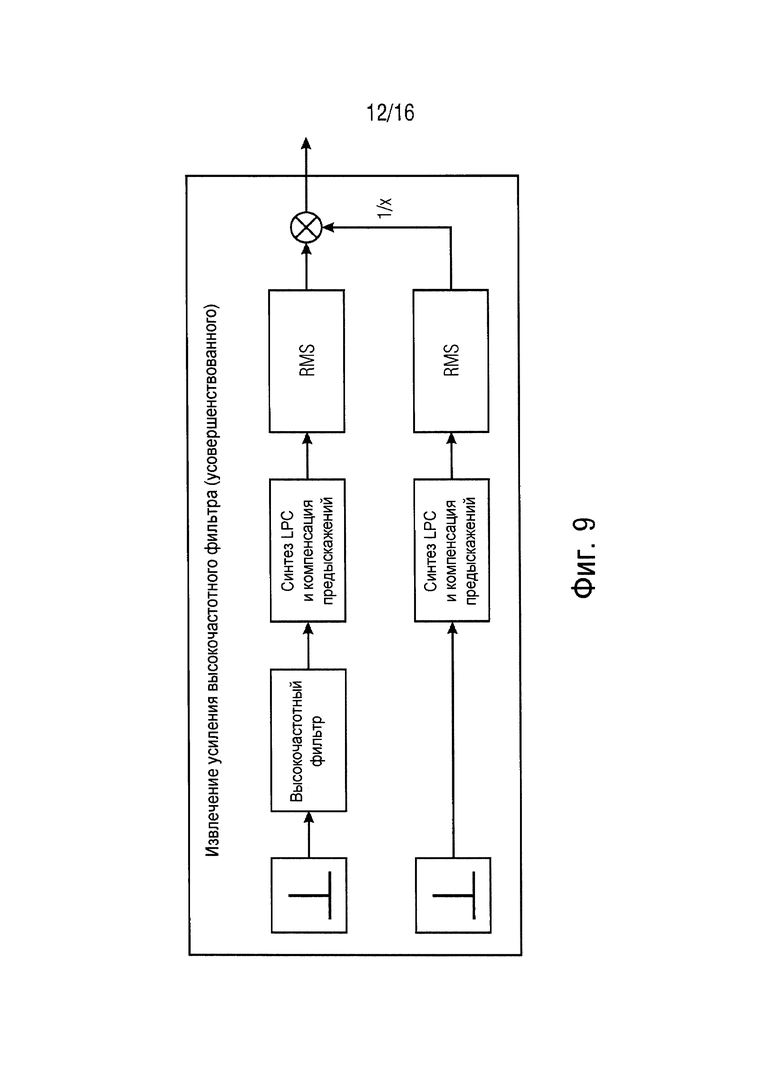
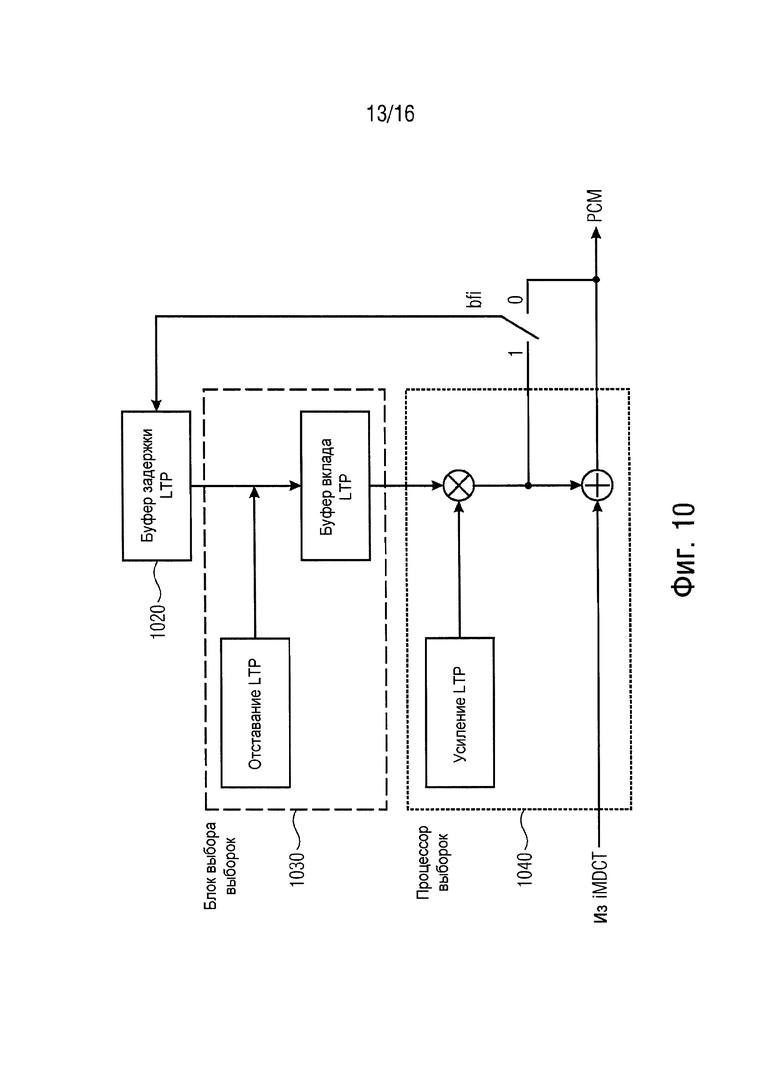
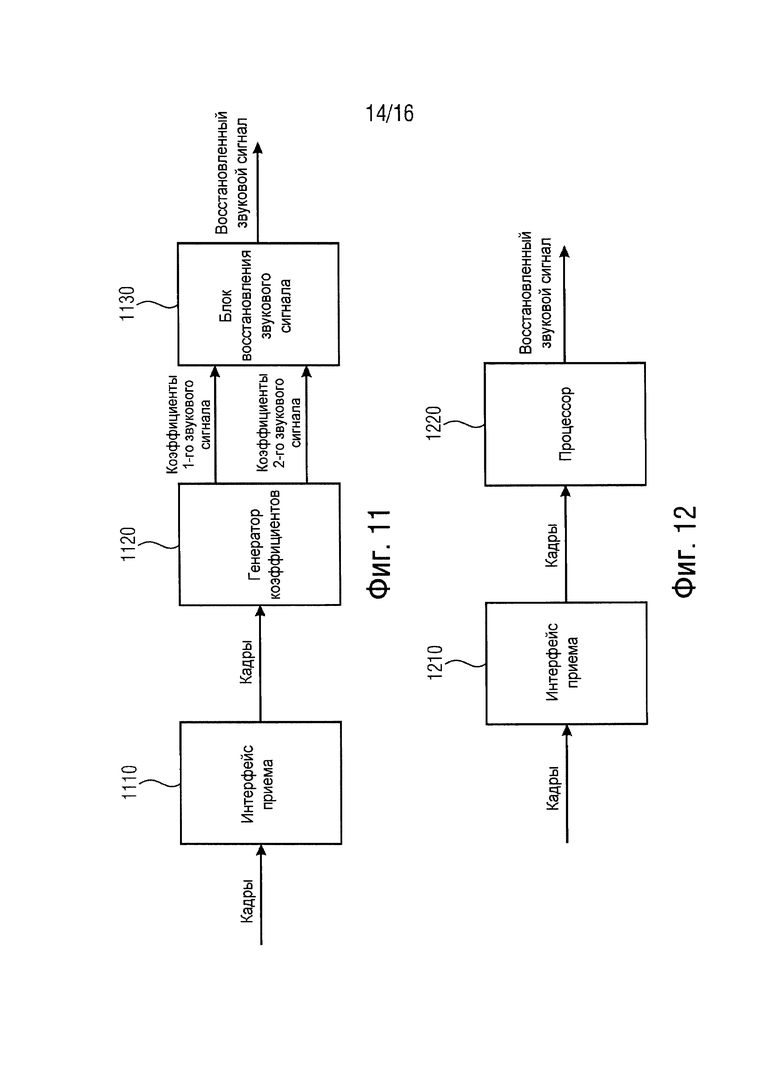
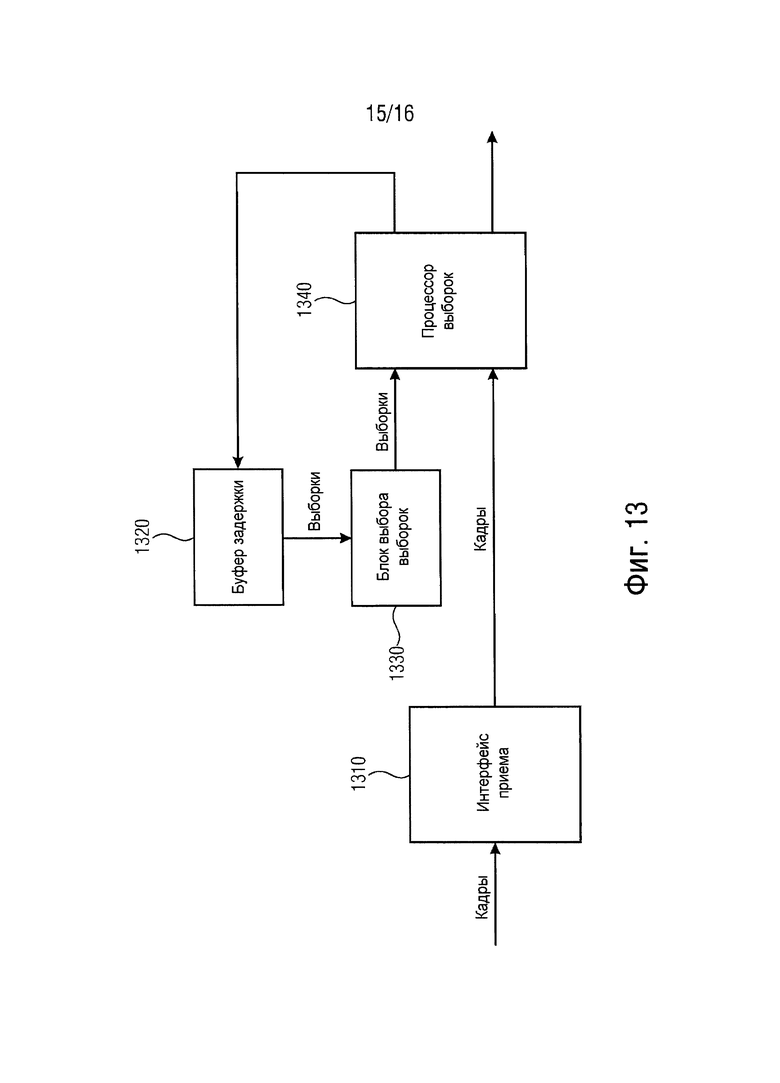
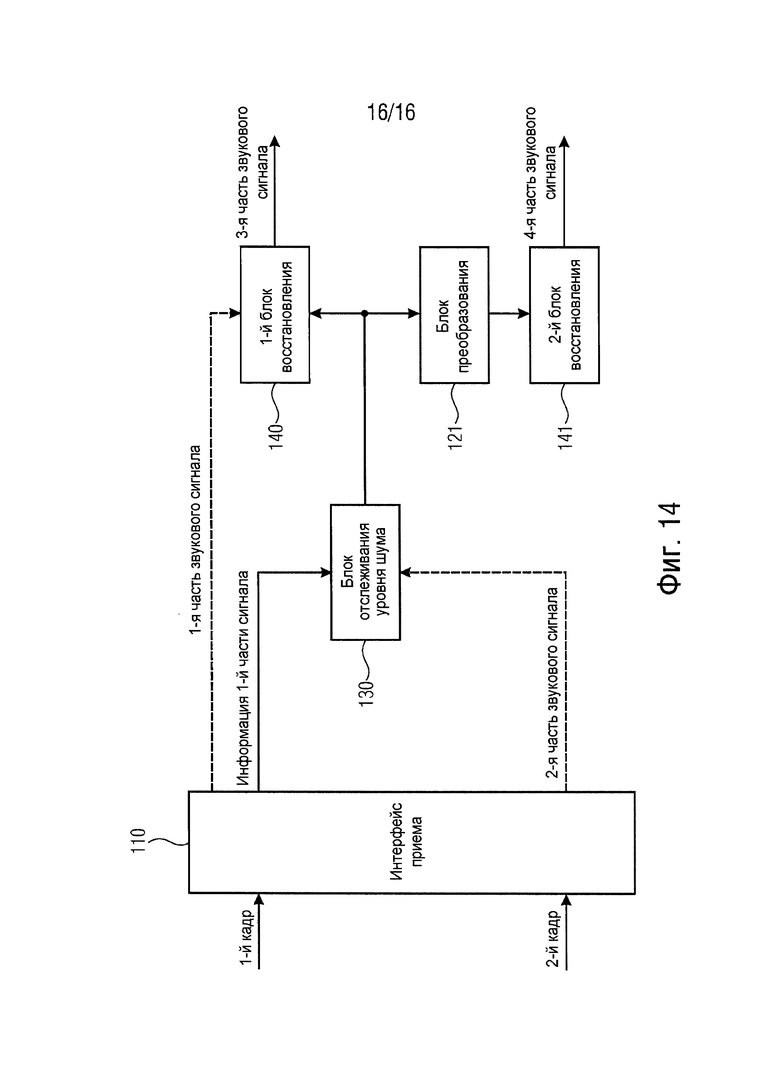
Изобретение относится к кодированию и декодированию звуковых сигналов. Технический результат – повышение точности восстановления звуковых сигналов. Устройство содержит интерфейс приема для приема множества кадров, буфер задержки для хранения выборок звукового сигнала, блок выбора выборок для выбора множества выбранных выборок звукового сигнала и процессор выборок для обработки выбранных выборок звукового сигнала для получения восстановленных выборок звукового сигнала из восстановленного звукового сигнала. Блок выбора выборок конфигурируется для выбора, если текущий кадр принимается с помощью интерфейса приема и если текущий кадр не поврежден, множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере задержки, в зависимости от информации отставания основного тона, содержащейся в текущем кадре. Кроме того, блок выбора выборок конфигурируется для выбора, если текущий кадр не принимается с помощью интерфейса приема или если текущий кадр поврежден, множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере задержки, в зависимости от информации отставания основного тона, содержащейся в другом кадре, принятом ранее с помощью интерфейса приема. 3 н. и 10 з.п. ф-лы, 17 ил., 2 табл.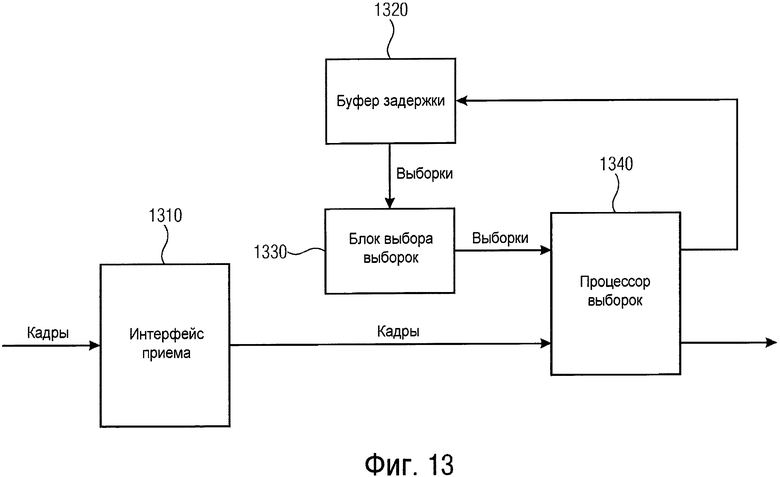
1. Устройство для декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала, причем данное устройство конфигурируется для приема множества кадров и причем данное устройство содержит:
модуль (683) обратного модифицированного дискретного косинусного преобразования для декодирования множества кадров с помощью проведения обратного модифицированного дискретного косинусного преобразования для получения выборок звукового сигнала для декодированного звукового сигнала, и
блок (684) долгосрочного предсказания для проведения долгосрочного предсказания, содержащий:
буфер (1020) задержки для хранения выборок звукового сигнала для декодированного звукового сигнала,
блок (1030) выбора выборок для выбора множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере (1020) задержки, и
процессор (1040) выборок для обработки выбранных выборок звукового сигнала для получения восстановленных выборок звукового сигнала для восстановленного звукового сигнала,
причем блок (1030) выбора выборок конфигурируется для выбора, если текущий кадр принимается с помощью данного устройства и если текущий кадр, принимаемый с помощью данного устройства, не поврежден, множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере (1020) задержки, в зависимости от информации отставания основного тона, содержащейся в текущем кадре, и
причем блок (1030) выбора выборок конфигурируется для выбора, если текущий кадр не принимается с помощью данного устройства или если текущий кадр, принимаемый с помощью данного устройства, поврежден, множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере (1020) задержки, в зависимости от информации отставания основного тона, содержащейся в другом кадре, принятом ранее с помощью данного устройства,
причем блок (1030) выбора выборок конфигурируется для получения восстановленных выборок звукового сигнала с помощью повторного масштабирования выбранных выборок звукового сигнала в зависимости от модифицированного усиления, причем модифицированное усиление определяется согласно формуле:
gain=gain_past * damping;
в которой gain является модифицированным усилением,
в которой блок (1030) выбора выборок конфигурируется для установки gain_past в значение gain после того, как вычислено значение gain, и
в которой damping является действительной величиной при 0 ≤ damping ≤ 1.
2. Устройство по п. 1,
в котором процессор (1040) выборок конфигурируется для получения восстановленных выборок звукового сигнала, если текущий кадр принимается с помощью данного устройства и если текущий кадр, принимаемый с помощью данного устройства, не поврежден, с помощью повторного масштабирования выбранных выборок звукового сигнала в зависимости от информации усиления, содержащейся в текущем кадре, и
в котором блок (1030) выбора выборок конфигурируется для получения восстановленных выборок звукового сигнала, если текущий кадр не принимается с помощью данного устройства или если текущий кадр, принимаемый с помощью данного устройства, поврежден, с помощью повторного масштабирования выбранных выборок звукового сигнала в зависимости от информации усиления, содержащейся в указанном другом кадре, принятом ранее с помощью данного устройства.
3. Устройство по п. 2,
в котором процессор (1040) выборок конфигурируется для получения восстановленных выборок звукового сигнала, если текущий кадр принимается с помощью данного устройства и если текущий кадр, принимаемый с помощью данного устройства, не поврежден, с помощью умножения выбранных выборок звукового сигнала и значения, зависящего от информации усиления, содержащейся в текущем кадре, и
в котором блок (1030) выбора выборок конфигурируется для получения восстановленных выборок звукового сигнала, если текущий кадр не принимается с помощью данного устройства или если текущий кадр, принимаемый с помощью данного устройства, поврежден, с помощью умножения выбранных выборок звукового сигнала и значения, зависящего от информации усиления, содержащейся в указанном другом кадре, принятом ранее с помощью данного устройства.
4. Устройство по п. 1, в котором процессор (1040) выборок конфигурируется для сохранения восстановленных выборок звукового сигнала в буфере (1020) задержки.
5. Устройство по п. 4, в котором процессор (1040) выборок конфигурируется для сохранения восстановленных выборок звукового сигнала в буфере (1020) задержки перед тем, как дополнительный кадр принимается с помощью данного устройства.
6. Устройство по п. 4, в котором процессор (1040) выборок конфигурируется для сохранения восстановленных выборок звукового сигнала в буфере (1020) задержки после того, как дополнительный кадр принимается с помощью данного устройства.
7. Устройство по п. 1, в котором процессор (1040) выборок конфигурируется для повторного масштабирования выбранных выборок звукового сигнала в зависимости от информации усиления для получения повторно масштабированных выборок звукового сигнала и объединения повторно масштабированных выборок звукового сигнала с входными выборками звукового сигнала для получения обработанных выборок звукового сигнала.
8. Устройство по п. 7,
в котором процессор (1040) выборок конфигурируется для сохранения обработанных выборок звукового сигнала, указывая комбинацию повторно масштабированных выборок звукового сигнала и вводимых выборок звукового сигнала, в буфере (1020) задержки и не выполнения сохранения повторно масштабированных выборок звукового сигнала в буфере (1020) задержки, если текущий кадр принимается с помощью данного устройства и если текущий кадр, принимаемый с помощью данного устройства, не поврежден, и
в котором процессор (1040) выборок конфигурируется для сохранения повторно масштабированных выборок звукового сигнала в буфере (1020) задержки и не выполнения сохранения обработанных выборок звукового сигнала в буфере (1020) задержки, если текущий кадр не принимается с помощью данного устройства или если текущий кадр, принимаемый с помощью данного устройства, поврежден.
9. Устройство по п. 7, в котором процессор (1040) выборок конфигурируется для сохранения обработанных выборок звукового сигнала в буфере (1020) задержки, если текущий кадр не принимается с помощью данного устройства или если текущий кадр, принимаемый с помощью данного устройства, поврежден.
10. Устройство по п. 1, в котором блок (1030) выбора выборок конфигурируется для вычисления модифицированного усиления
11. Устройство по п. 1, в котором модифицированное усиление gain устанавливается в ноль, если по меньшей мере предопределенное количество кадров не было принято с помощью данного устройства после того, как последний кадр был принят с помощью данного устройства.
12. Способ декодирования кодированного звукового сигнала для получения восстановленного звукового сигнала, причем данный способ содержит этапы, на которых:
принимают множество кадров,
декодируют множество кадров с помощью проведения обратного модифицированного дискретного косинусного преобразования для получения выборок звукового сигнала из декодированного звукового сигнала,
проводят долгосрочное предсказание с помощью
сохранения выборок звукового сигнала для декодированного звукового сигнала,
выбора множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере (1020) задержки, и
обработки выбранных выборок звукового сигнала для получения восстановленных выборок звукового сигнала из восстановленного звукового сигнала,
причем если текущий кадр принимается и если текущий принимаемый кадр не поврежден, то этап выбора множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере (1020) задержки, проводится в зависимости от информации отставания основного тона, содержащейся в текущем кадре, и
причем если текущий кадр не принимается или если текущий принимаемый кадр поврежден, то этап выбора множества выбранных выборок звукового сигнала из выборок звукового сигнала, сохраненных в буфере (1020) задержки, проводится в зависимости от информации отставания основного тона, содержащейся в другом кадре, принятом ранее,
причем способ содержит этап повторного масштабирования выбранных выборок звукового сигнала в зависимости от модифицированного усиления, причем модифицированное усиление определяется согласно формуле:
gain=gain_past * damping;
в которой gain является модифицированным усилением,
в которой gain_past устанавливается в gain после того, как вычислено значение gain, и
в которой damping является действительной величиной при 0 ≤ damping ≤ 1.
13. Машиночитаемый носитель, содержащий компьютерную программу для реализации способа по п. 12, когда она выполняется на компьютере или процессоре обработки сигналов.
| Регулятор скорости | 1990 |
|
SU1775717A1 |
| КЛЕЙ | 1991 |
|
RU2026330C1 |
| СПОСОБ И УСТРОЙСТВО МАСШТАБИРУЕМОГО КОДИРОВАНИЯ-ДЕКОДИРОВАНИЯ СТЕРЕОФОНИЧЕСКОГО ЗВУКОВОГО СИГНАЛА (ВАРИАНТЫ) | 1998 |
|
RU2197776C2 |
| ДЕКОДИРОВАНИЕ КОДИРОВАННЫХ С ПРЕДСКАЗАНИЕМ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ АДАПТАЦИИ БУФЕРА | 2007 |
|
RU2408089C9 |
| СПОСОБ И УСТРОЙСТВО ЭФФЕКТИВНОЙ МАСКИРОВКИ СТИРАНИЯ КАДРОВ В РЕЧЕВЫХ КОДЕКАХ | 2006 |
|
RU2419891C2 |
| СХЕМА АУДИОКОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ С ПЕРЕКЛЮЧЕНИЕМ БАЙПАС | 2009 |
|
RU2483364C2 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 6384438 B1, 24.06.2003 | |||
| US 7630890 B2, 08.12.2009 | |||
| US 8255213 B2, 28.08.2012. | |||

