Область техники
Изобретение относится, в целом, к области кодирования и декодирования контента. В частности, изобретение относится к извлечению данных из буфера и загрузки их в буфер.
Предшествующий уровень техники
Мультимедийные приложения на протяжении более десяти лет являются движущей силой развития микропроцессоров. Фактически, большинство обновлений в вычислительной технике за последние годы обусловлено мультимедийными приложениями, главным образом в потребительских сегментах рынка, но также в производственных сегментах в целях развлечения, расширенного образования и связи. Тем не менее, в будущем мультимедийные приложения потребуют еще больших вычислительных возможностей. В результате, использование персональных компьютеров (ПК) завтрашнего дня будет в еще большей степени направлено на аудиовизуальные эффекты, а также будет упрощаться и, что важнее, вычислительная деятельность будет объединяться со связью.
Соответственно, отображение изображений, а также воспроизведение аудио- и видеоинформации становятся все более популярным применением современных вычислительных устройств. К сожалению, объем данных, необходимых для приложений этого типа, постоянно возрастает. В результате, рост вычислительной мощности, памяти и емкости дисков, равно как и пропускной способности сетей, способствовали созданию и использованию более крупных и более качественных изображений, а также более продолжительных и более качественных аудио- и видеозаписей. Однако контент (содержимое), используемый этими приложениями, обычно хранится в сжатом формате для экономии объема памяти и ресурсов канала связи.
В результате, приложения, поддерживающие контент, например, аудио- и видеоданные, реально ограничены в воспроизведении аудио- и видеоданных. Контент, например, аудио- и видеоданные, обычно имеет вид потока, т.е. передаваемый контент воспроизводится по мере поступления. Для обеспечения потокового режима данные сжимают перед передачей, чтобы преодолеть ограничения пропускной способности сети и удовлетворять требованиям воспроизведения. В результате, аудио- и видеоданные должны декодироваться в реальном времени независимо от того, передаются ли они в потоковом режиме по сети или хранятся в локальном устройстве. Кроме того, вычислительные требования возрастают по мере повышения качества аудиосигнала и разрешения видеоизображения и увеличения размера кадра. Таким образом, процесс декомпрессии видеоданных является одним из наиболее потребляющих вычислительные ресурсы в популярных приложениях.
К сожалению, в настоящее время наблюдается рост вычислительных затрат, тогда как пропускная способность и качество обслуживания остаются постоянными. Можно предсказать, что такой дисбаланс будет определять будущее приложений. В результате, постоянно расширяющийся класс новых алгоритмов и приложений нацелен на избавление от вычислительной сложности, достижение повышенного качества аудио-видео, снижение битовых скоростей (передачи битов), создание простых в применении инструментальных средств, и т.д. Соответственно, этот дисбаланс приведет к созданию новых стандартов сжатия, новых алгоритмов обработки и парадигме сквозного приложения, в которых многие операции в разных доменах будут необходимы для обеспечения надлежащей доставки мультимедиа от кодирования и шифрования к передаче, последующей обработке и управлению.
Используемые в настоящее время алгоритмы сжатия, например метод объединенной группы экспертов по фотографии (JPEG) и JPEG 2000 сжатия изображения, а также методы группы экспертов по движущимся изображениям (MPEG), MPEG-1, MPEG-2 and MPEG-4 сжатия аудио- и видеоданных объединяют два подхода. Сначала данные обрабатывают с помощью преобразования, а затем квантуют. Затем осуществляют сжатие путем перемещения воспринимаемых и значимых данных. Это так называемый метод с потерями, поскольку исходные данные не полностью восстанавливаются при декомпрессии. Результаты первого этапа подвергают дальнейшему сжатию методом статистического кодирования. Статистическое кодирование заключается в том, что исходные символы данных (в данном случае квантованные коэффициенты преобразований) заменяют символами, длина которых зависит от частотности исходных символов данных. Наиболее частотные исходные символы данных заменяют короткими символами статистического кода, а наименее частотные заменяют длинными символами статистического кода. Поэтому длина символов статистического кода изменяется с их битовой длиной.
Этапы декодирования изображения выполняются в обратном порядке по отношению к этапам кодирования. Статистическое декодирование предшествует трансформационному декодированию и т.д. К сожалению, при статистическом декодировании имеется мало параллелизма данных по причине зависимостей данных, которые происходят из различных связей символов. Различные архитектурные команды обычно эффективны для операций преобразования, но обычно мало полезны для статистического декодирования. Однако по мере увеличения возможностей архитектурных команд за счет более объемных регистров и новых команд возрастает доля времени, необходимого для статистического декодирования и приложений воспроизведения мультимедиа. Соответственно, усовершенствования в статистическом декодировании отстают от усовершенствований трансформационного декодирования.
Поэтому остается необходимость в преодолении одного или нескольких ограничений в вышеописанном существовании.
Краткое описание чертежей
Иллюстративное и неограничительное описание настоящего изобретения приведено со ссылкой на фигуры прилагаемых чертежей, в которых:
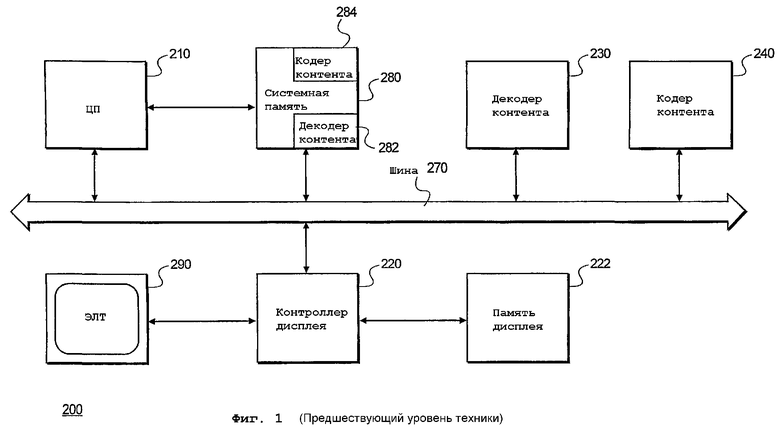
фиг.1 - блок-схема традиционной компьютерной системы, известной из уровня техники, в которой идеи настоящего изобретения могут быть реализованы в одном варианте осуществления настоящего изобретения;
фиг.2 - блок-схема декодера контента, который можно использовать в компьютерной системе, изображенной на фиг.1, согласно варианту осуществления настоящего изобретения;
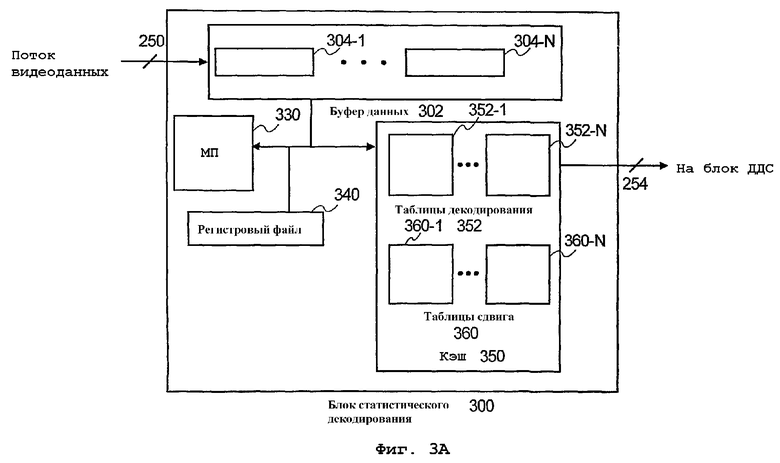
фиг.3А - блок-схема блока статистического декодирования декодера контента, изображенного на фиг.2, согласно еще одному варианту осуществления настоящего изобретения;
фиг.3В - схема конечного устройства (назначения) хранения данных согласно еще одному варианту осуществления настоящего изобретения;
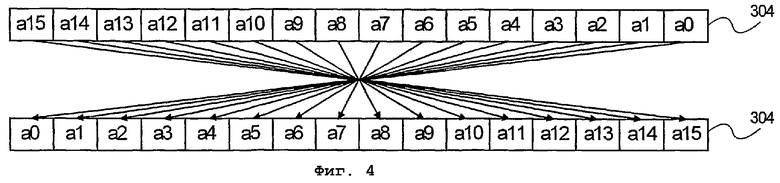
фиг.4 - блок-схема преобразования данных в устройстве хранения данных согласно еще одному варианту осуществления настоящего изобретения;
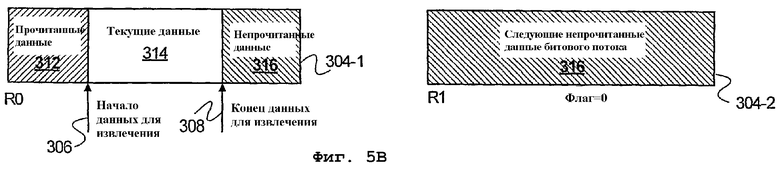
фиг.5А-5D - блок-схема считывания данных из одного или нескольких устройств хранения буфера данных согласно еще одному варианту осуществления настоящего изобретения;
фиг.6 - блок-схема кодера контента, который можно использовать в компьютерной системе, изображенной на фиг.1, согласно еще одному варианту осуществления настоящего изобретения;
фиг.7А и 7В - блок-схема блока статистического кодирования, изображенного на фиг.6, согласно еще одному варианту осуществления настоящего изобретения;
фиг.8 - блок-схема алгоритма способа осуществления доступа к данным в буфере данных согласно варианту осуществления настоящего изобретения;
фиг.9 - блок-схема алгоритма дополнительного способа загрузки данных в буфер данных согласно еще одному варианту осуществления настоящего изобретения;
фиг.10 - блок-схема алгоритма дополнительного способа проверки, распространяются ли запрашиваемые данные на одно или несколько устройств хранения данных в буфере данных согласно еще одному варианту осуществления настоящего изобретения;
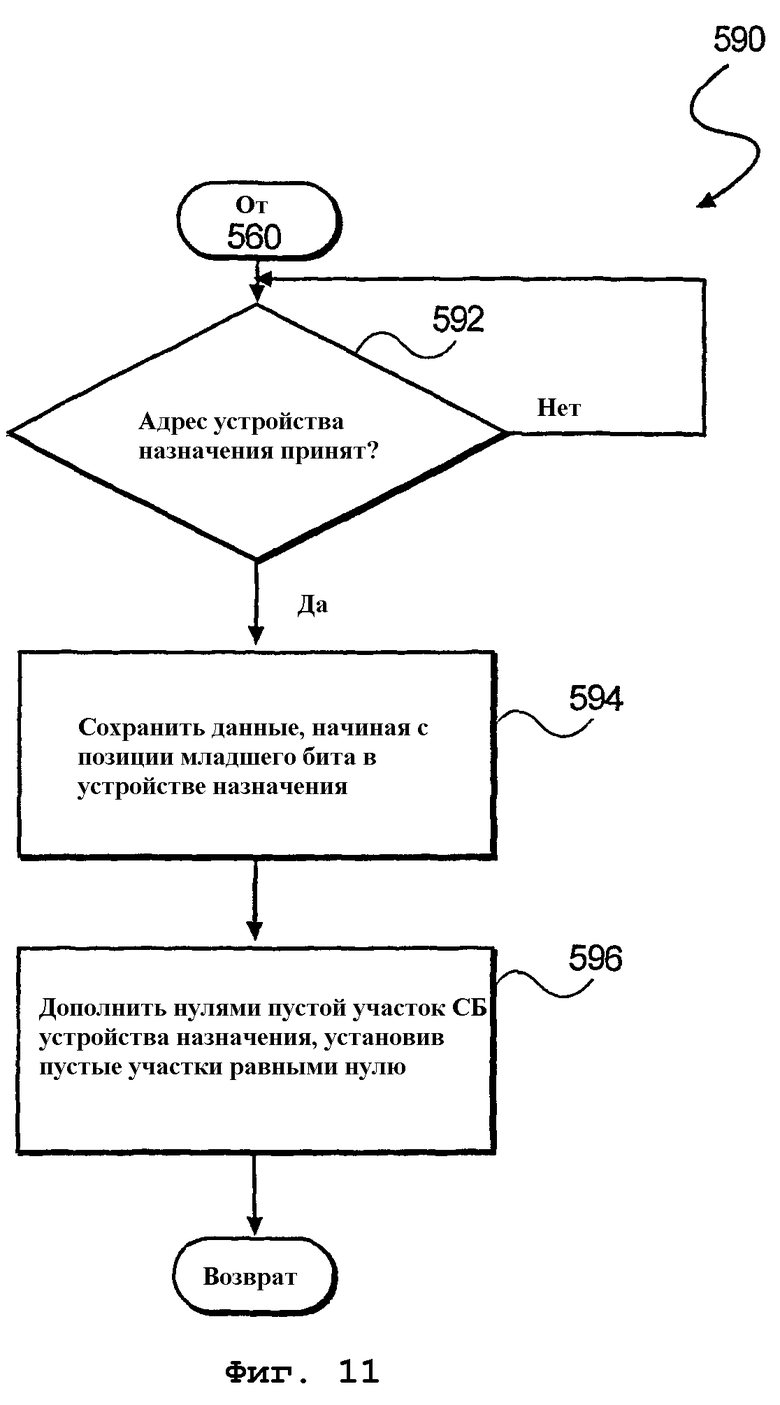
фиг.11 - блок-схема алгоритма дополнительного способа сохранения данных в устройстве назначения хранения данных согласно еще одному варианту осуществления настоящего изобретения;
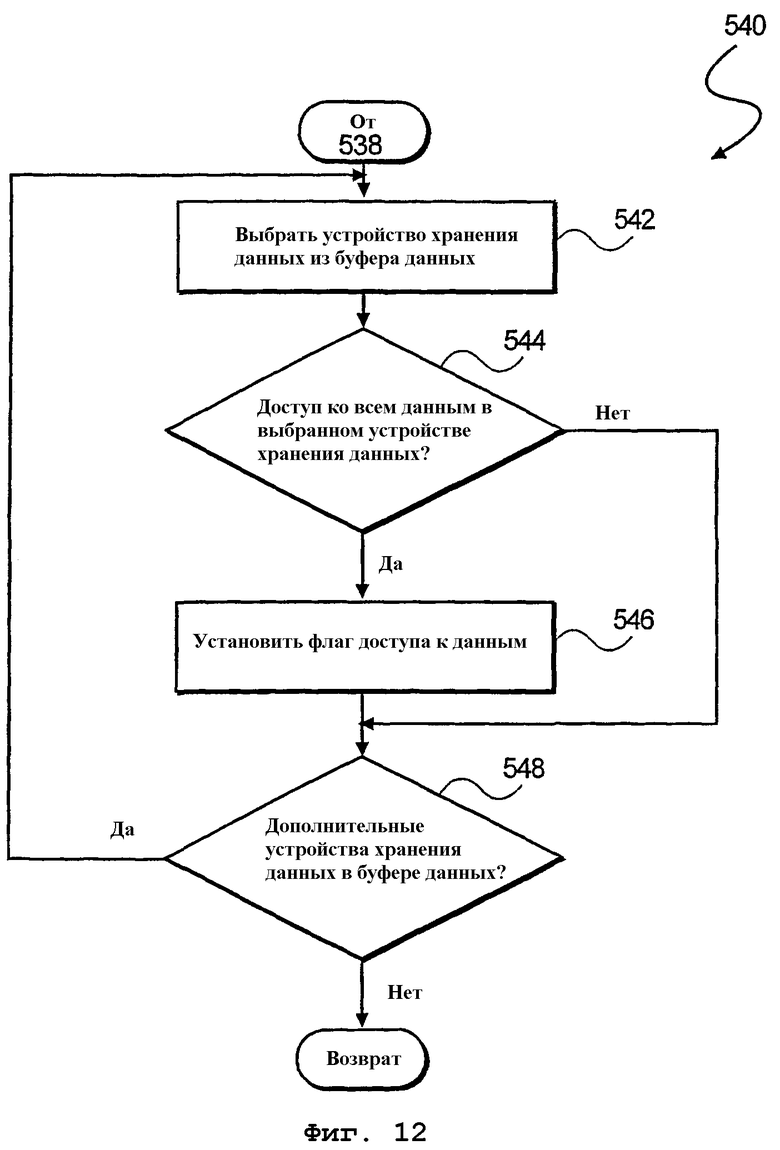
фиг.12 - блок-схема алгоритма дополнительного способа объединения данных, распространяющихся на одно или несколько устройств хранения данных буфера данных согласно иллюстративному варианту осуществления настоящего изобретения;
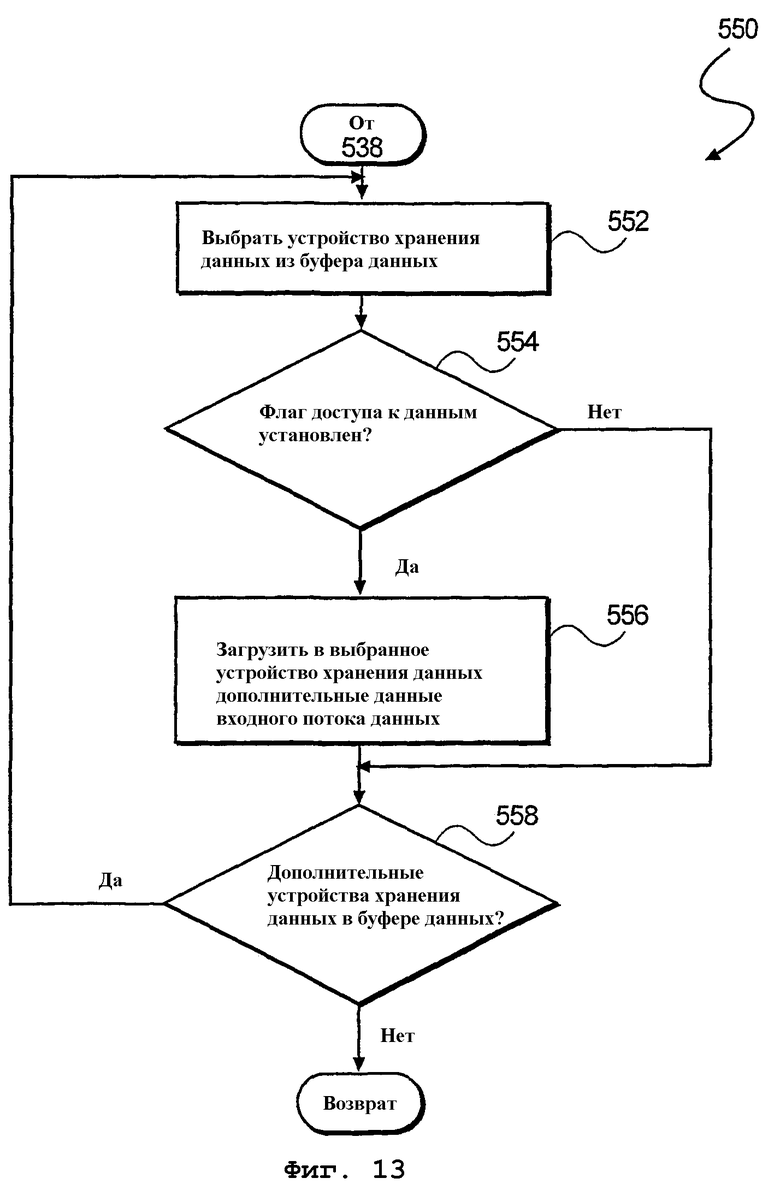
фиг.13 - блок-схема алгоритма дополнительного способа загрузки данных в устройство хранения данных буфера данных при осуществлении доступа ко всем данным в буфере данных согласно еще одному варианту осуществления настоящего изобретения;
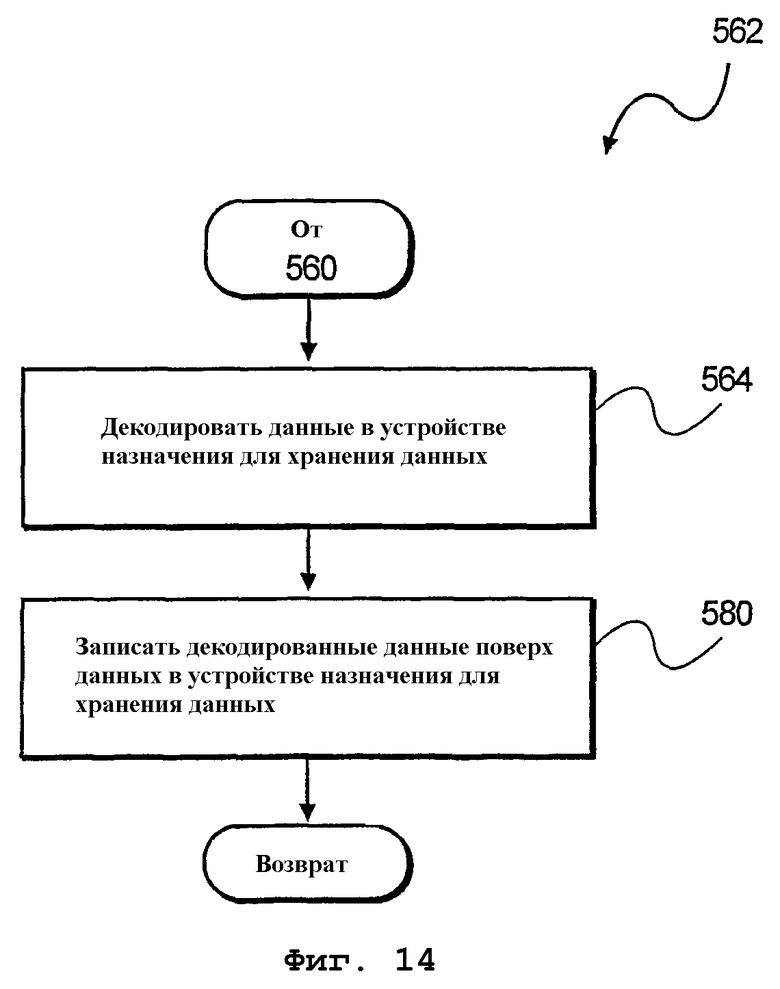
фиг.14 - блок-схема алгоритма дополнительного способа декодирования выбранных данных согласно еще одному варианту осуществления настоящего изобретения;
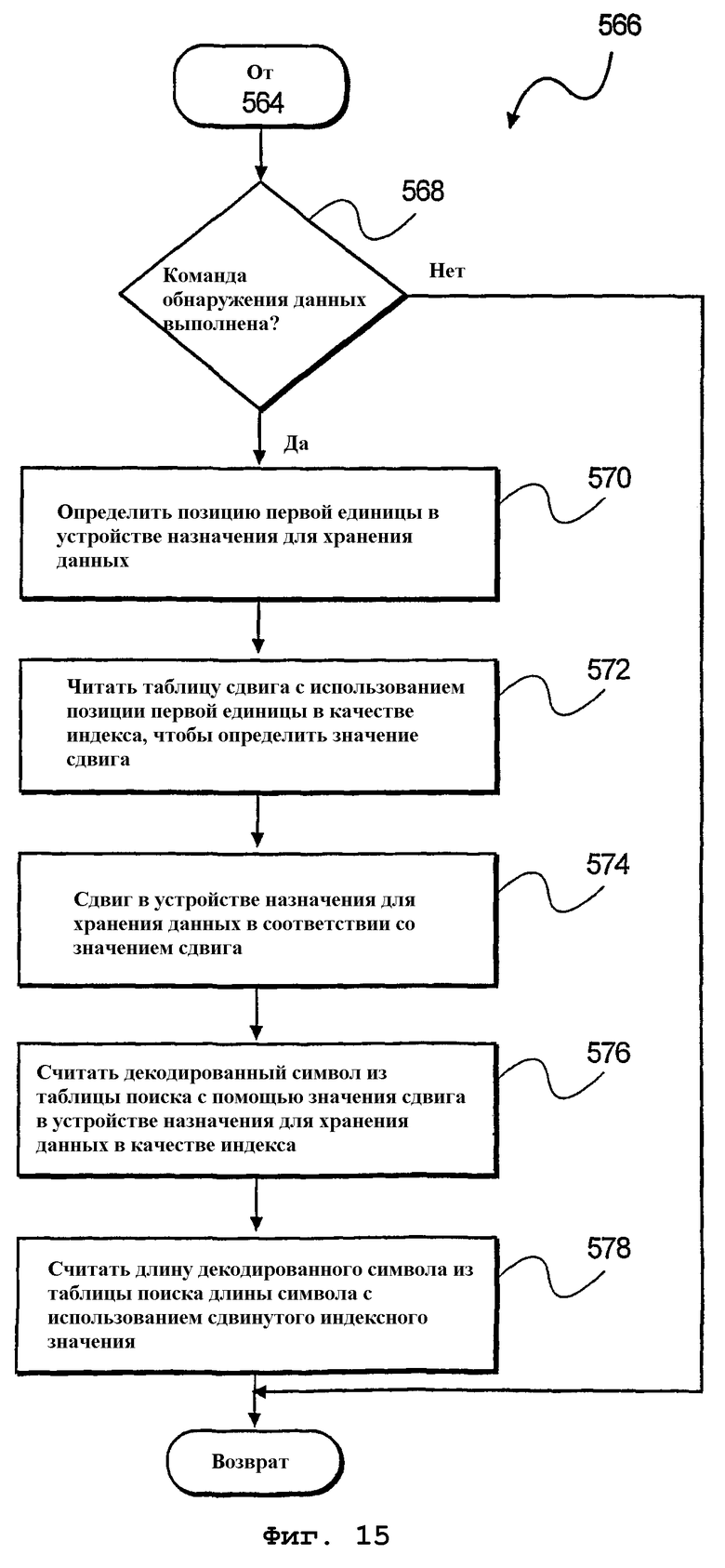
фиг.15 - блок-схема алгоритма декодирования данных в конечном устройстве хранения данных согласно иллюстративному варианту осуществления настоящего изобретения;
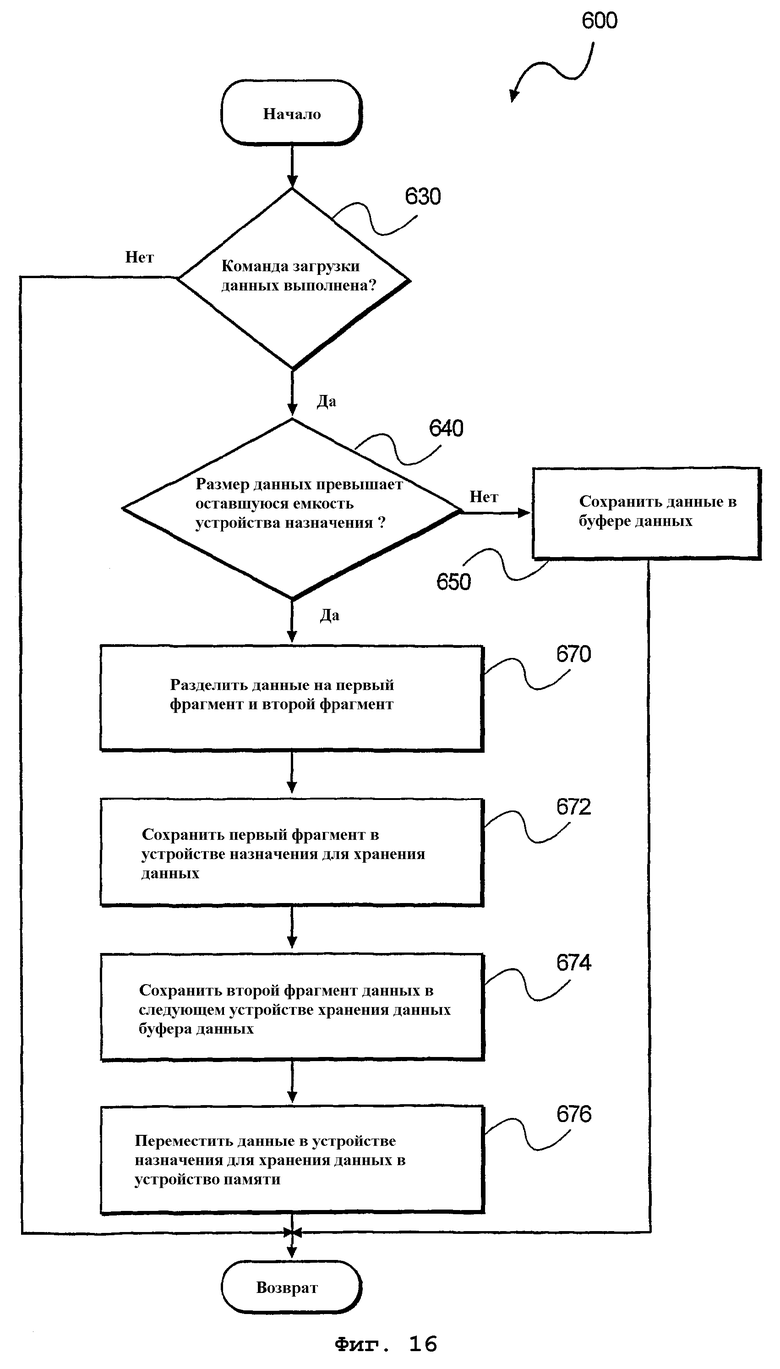
фиг.16 - блок-схема алгоритма способа загрузки данных в буфер данных, который содержит множество устройств хранения данных согласно варианту осуществления настоящего изобретения;
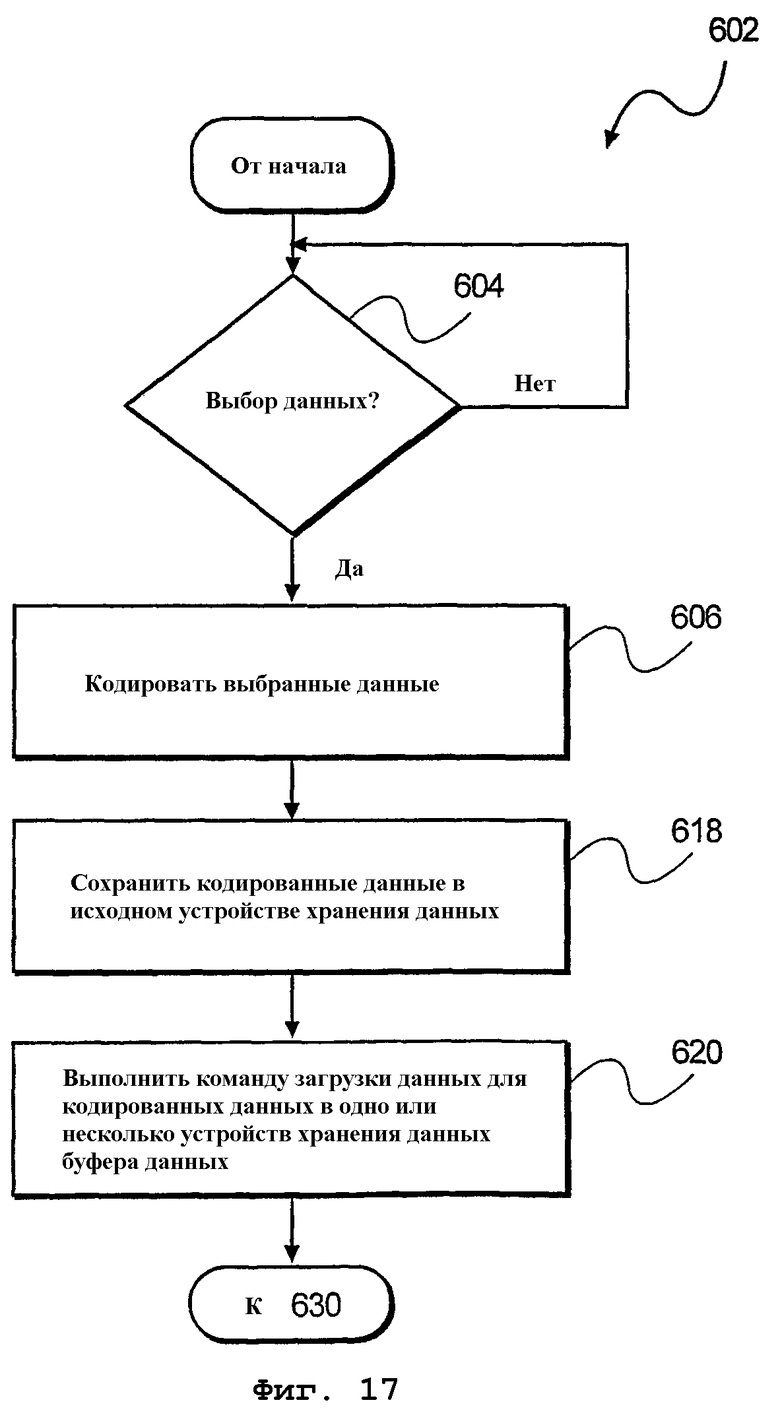
фиг.17 - блок-схема алгоритма кодирования данных перед загрузкой в буфер данных согласно еще одному варианту осуществления настоящего изобретения;
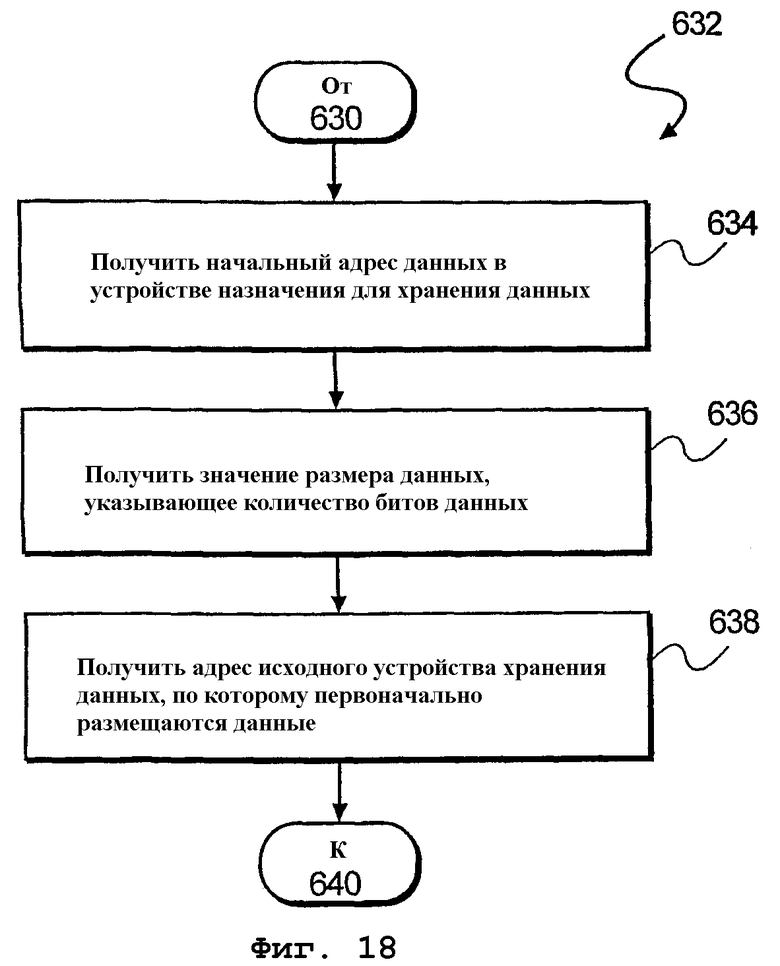
фиг.18 - блок-схема алгоритма дополнительного способа, осуществляемого в ответ на выполнение команды загрузки данных согласно еще одному варианту осуществления настоящего изобретения;
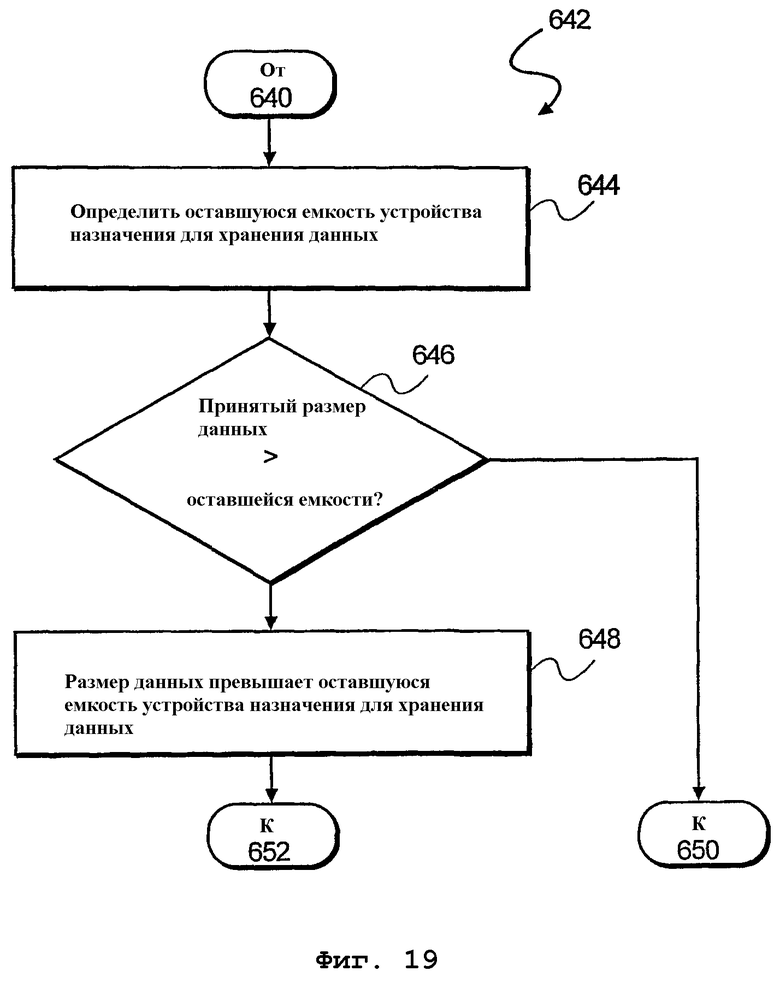
фиг.19 - блок-схема алгоритма дополнительного способа определения, превосходят ли загружаемые данные емкость конечного устройства хранения данных в буфере данных согласно еще одному варианту осуществления настоящего изобретения;
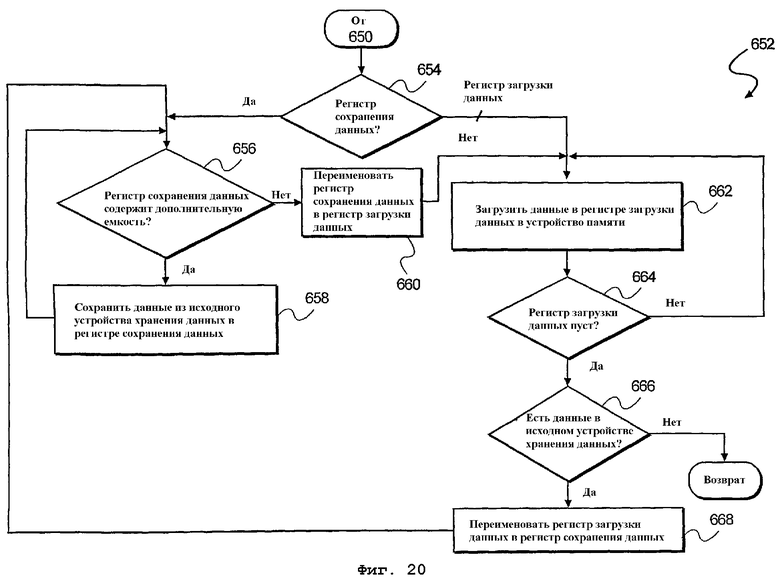
фиг.20 - блок-схема алгоритма способа загрузки данных в буфер данных, который содержит регистр сохранения данных и регистр загрузки данных согласно иллюстративному варианту осуществления настоящего изобретения;
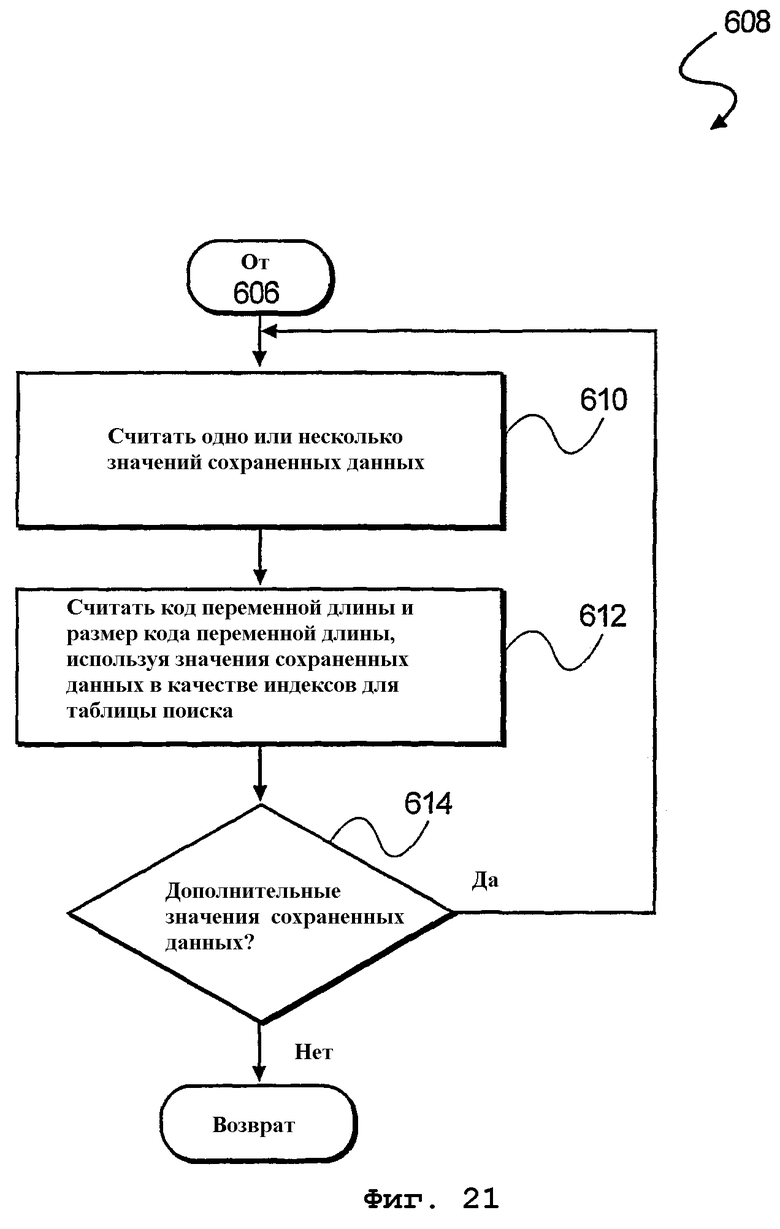
фиг.21 - блок-схема алгоритма дополнительного способа кодирования данных, выбранных из устройства памяти, согласно еще одному варианту осуществления настоящего изобретения.
Подробное описание
Ниже описаны способ и устройство для извлечения данных из буфера и загрузки их в буфер. Способ включает в себя выбор данных из буфера данных с побитовой адресацией в ответ на выполнение команды доступа к данным. Буфер данных, из которого выбираются данные, включает в себя множество устройств хранения данных, одно или несколько из которых первоначально содержит выбранные данные. Соответственно, множество устройств хранения данных образует единое адресное пространство с адресацией на битовом уровне. Когда выбранные данные распространяются от исходного устройства хранения данных на следующее устройство хранения данных буфера данных, фрагмент выбранных данных из исходного устройства хранения данных конкатенируется (объединяется) с оставшимся фрагментом выбранных данных из следующего устройства хранения данных для формирования выбранных данных в качестве непрерывного блока. Наконец, после формирования выбранных данных выбранные данные сохраняются в устройстве назначения для хранения данных.
В нижеследующем описании в целях объяснения многочисленные конкретные подробности изложены для обеспечения исчерпывающего понимания настоящего изобретения. Однако специалисты в данной области поймут, что настоящее изобретение можно осуществлять на практике без некоторых из этих конкретных деталей. Кроме того, в нижеследующем описании приведены примеры, и различные примеры, показанные на прилагаемых чертежах, носят иллюстративный характер. Однако эти примеры не следует рассматривать в ограничительном смысле, поскольку они призваны лишь представлять примеры настоящего изобретения, а не обеспечивать исчерпывающий список всех возможных реализаций настоящего изобретения. В других случаях общеизвестные структуры и устройства показаны в виде блок-схем во избежание увеличения ненужных подробностей настоящего изобретения.
Согласно варианту осуществления способы настоящего изобретения реализованы в виде машинно-выполняемых команд. В соответствии с командами процессор общего или специального назначения, программируемый командами, выполняет этапы настоящего изобретения. Альтернативно, этапы настоящего изобретения могут выполняться конкретными аппаратными компонентами, которые содержат аппаратно-реализованную логику для осуществления способов, или любым сочетанием программируемых компьютерных компонентов и специализированных аппаратных компонентов. Настоящее изобретение можно обеспечить в виде компьютерного программного продукта, который может включать в себя машинный или компьютер-носчитываемый носитель, на котором хранятся команды, которые можно использовать для программирования компьютера (или других электронных устройств или систем) для осуществления процесса, отвечающего настоящему изобретению. Компьютерно-считываемый носитель может включать в себя, но не исключительно, флоппи-диски, оптические диски, компакт-диски, предназначенные только для чтения (CD-ROM) и магнитооптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), стираемые программируемые постоянные запоминающие устройства (СППЗУ), электрически стираемые программируемые постоянные запоминающие устройства (ЭСППЗУ), магнитные или оптические карты, флэш-память и т.п.
СИСТЕМА
Ниже описана изображенная на фиг.1 блок-схема, на которой показаны основные компоненты компьютерной системы 200, в которой можно реализовать формат хранения согласно изобретению. Компьютерная система 200 содержит контроллер 220 дисплея. Контроллер 220 дисплея представляет собой, например, адаптер видеографики (VGA), супер-VGA (SVGA) и т.п. Контроллер 220 дисплея генерирует пиксельные данные для дисплея 290, который представляет собой, например, ЭЛТ, плоско-панельный дисплей и т.п. Пиксельные данные генерируются в соответствии с той или иной частотой обновления дисплея 290 (например, 60 Гц, 72 Гц, 75 Гц и т.д.) и горизонтальным и вертикальным разрешением изображения, формируемого на дисплее (например, 640x480 пикселей, 1024x768 пикселей, 800x600 и т.д.). Контроллер 220 дисплея может генерировать непрерывный поток пиксельных данных на характеристической частоте дисплея 290.
Контроллер 220 дисплея также снабжен памятью 222 дисплея, в которой хранятся пиксельные данные в текстовом, графическом или видео режимах для вывода на дисплей 290. Главный процессор 210 подключен к контроллеру 220 дисплея через шину 270 и обновляет содержимое памяти 222 дисплея при изменении изображения, выводимого на дисплей 290. Шина 270 может представлять собой, например, шину соединения периферийных компонентов (PCI) и т.п. Системная память 280 может быть подключена к главному процессору 210 для сохранения данных.
Аппаратный декодер 230 контента предусмотрен для декодирования видео-, аудиоданных, данных изображения и речевых данных («контента»), например, видеоданных в формате группы экспертов по движущимся изображениям (MPEG). MPEG-видеоданные поступают от источника MPEG-видеоданных (например, с CD-ROM и т.п.). Альтернативно, декодер 230 контента реализован, например, в виде традиционного программного декодера 282, хранящегося в системной памяти 280. Декодированные данные выводятся в системную память 280 или непосредственно в память 222 дисплея.
Компьютерная система 200 дополнительно содержит кодер 240 контента, предназначенный для кодирования данных контента, например, данных изображения, аудио-, видео- и речевых данных, генерируемых компьютерной системой 200. После того как контент закодирован кодером 240 контента, кодированный контент можно сохранить в системной памяти 280 или передать, в том числе в потоковом режиме, посредством ЦП 210 на конечное устройство (устройство назначения), которое не показано. Альтернативно, кодер 240 контента реализован, например, в виде традиционного программного кодера 284, хранящегося в системной памяти 280.
К сожалению, декодер 230 контента, равно как и кодер 240 контента компьютерной системы 200, в незначительной степени использует или совсем не использует параллелизм при вышеописанном статистическом кодировании и декодировании, например, при арифметическом кодировании и декодировании или кодировании и декодировании методом Хаффмана. В действительности, при статистическом кодировании и декодировании имеется мало параллелизма данных по причине зависимостей данных, обусловленных разными длинами символов. Хотя многие команды архитектуры с одним потоком команд и множественными потоками данных (SIMD) очень эффективны для операций преобразования (описанных выше), такие команды мало полезны для статистического кодирования и декодирования.
Кроме того, по мере увеличения возможностей команд SIMD за счет более объемных регистров и новых команд возрастает доля времени, необходимого для статистического декодирования, а также кодирования в приложениях воспроизведения мультимедийной информации. Соответственно, усовершенствования в статистическом декодировании отстают от усовершенствований трансформационного декодирования (декодирования преобразованием). Примеры методов статистического сжатия с помощью символов кода переменной длины включают в себя, но не исключительно, кодирование по Хаффману и арифметическое кодирование. Поэтому специалисту в данной области очевидно, что идеи настоящего изобретения (описанные ниже) можно реализовать как в программных, так и в аппаратных декодерах/кодерах контента.
На фиг.2 изображены компоненты декодера 250 контента, который можно использовать в компьютерной системе 200 согласно первому варианту осуществления настоящего изобретения. В описываемом варианте осуществления битовый поток 252 контента, который представляет собой, например, данные MPEG, данные JPEG и т.п., поступает от источника контента, например, источника данных MPEG, источника данных JPEG и т.п. и может подвергаться декодированию и декомпрессии следующим образом. Хотя конфигурация декодера 250 контента соответствует декодеру MPEG, представленный вариант осуществления носит иллюстративный характер и не подлежит рассмотрению в ограничительном смысле.
Соответственно, декодер 250 контента принимает битовый поток 252 MPEG на блоке 300 статистического декодирования. Однако в отличие от традиционного статистического декодера блок 300 статистического декодирования использует буфер с адресацией на битовом уровне для минимизации времени, необходимого для декодирования принятого битового потока 252, что более подробно описано ниже со ссылкой на фиг.3А. Соответственно, блок 300 статистического декодирования определяет декодированный символ, а также длину декодированного символа для принятого битового потока 252, который поступает на блок 256 декодирования по длинам серий.
Блок 256 ДДС принимает декодированный символ и длину декодированного символа от блока 300 статистического декодирования, чтобы генерировать квантованный блок 258, который поступает на блок обратного квантования (блок ОК) 262. Блок 262 ОК осуществляет обратное квантование квантованного блока 258 для генерации частотного спектра 264 квантованного блока. Затем блок 266 обратного дискретного косинусного преобразования (ОДКП) квантованного блока 268.
Сгенерированный декодированный блок 268 поступает на блок 270 компенсации движения (БКД). Компенсация движения осуществляется на БКД 270 для воссоздания данных 272 MPEG. Наконец, блок 274 преобразования цветов преобразует данные 272 MPEG к цветовому пространству «красный, зеленый, синий» (КЗС) для генерации изображений 280. Однако в отличие от традиционных декодеров контента, например аппаратного декодера 230 или программного декодера 282 контента компьютерной системы 200, изображенной на фиг.1, декодер контента использует блок 300 статистического декодирования, дополнительно описанный со ссылкой на фиг.3А.
Согласно фиг.3А блок 300 статистического декодирования использует буфер 302 данных, который содержит множество устройств 304 (304-1,... 304-N) хранения данных. В одном варианте осуществления буфер 302 данных использует регистры с адресацией на битовом уровне, которые могут включать в себя 128-разрядные регистры MMX. Однако специалистам в данной области очевидно, что устройства хранения данных буфера 302 данных не ограничиваются регистрами и, в общем случае, включают в себя любое устройство хранения данных, способное хранить цифровые данные. Таким образом, принятые данные 250 битового потока загружаются в множество устройств 304 хранения данных буфера 302 данных.
К сожалению, кодированный битовый поток 250 использует кодированные символы переменной длины. Согласно описанному выше, статистическое кодирование заменяет исходные символы данных кодированными символами, длина которых зависит от частотности исходных символов данных, при этом наиболее часто встречающиеся исходные символы данных заменяются короткими символами статистического кода, а наиболее редко встречающиеся заменяются длинными символами статистического кода. Поэтому, чтобы захватить кодированный символ, имеющий переменную длину, нужно выбирать данные из буфера данных.
Следовательно, задержки в захвате кодированных символов переменной длины создают трудности при статистическом кодировании на традиционных декодерах. Поэтому блок 300 статистического декодирования использует буфер с адресацией на битовом уровне, который способен захватывать фрагменты данных, которые распространяются между различными устройствами хранения данных буфера 302 данных, чтобы захватить используемые кодированные символы переменной длины. Для этого блок статистического декодирования может выбрать фрагмент данных в исходном устройстве 304 хранения данных, входящем в состав буфера 302 данных и сохранить фрагмент данных в конечном устройстве 342 (устройстве назначения) для хранения данных, изображенном на фиг.3В, которое может размещаться в регистровом файле 340 блока 300 статистического декодирования.
Соответственно, согласно идеям настоящего изобретения, процессор 330, в ответ на выполнение команды обнаружения данных, может определить позицию первой единицы в устройстве назначения для хранения данных. Определив эту позицию, процессор 330 может, согласно одному варианту осуществления, использовать таблицу 360 сдвига (360-1,..., 360-N) в кэш-памяти 350 блока 300 статистического декодирования. При этом процессор 330 может считывать таблицу 360 сдвига, чтобы получить значение сдвига, используя позицию первой единицы в качестве индекса (указателя). После определения значения сдвига устройство 342 назначения для хранения данных можно, например, подвергнуть сдвигу вправо в соответствии со значением сдвига. После сдвига вправо процессор может считать декодированный символ из таблицы 352 декодирования (352-1,..., 352-N) кэш-памяти 350, чтобы определить декодированный символ на основании значения устройства 342 хранения сдвинутых данных.
Наконец, длина декодированного символа считывается из таблицы 352 декодирования с использованием значения конечного устройства 342 хранения сдвинутых вправо данных. Соответственно, используя буфер с адресацией на битовом уровне, блок статистического декодирования может определять слова или символы кода в устройствах хранения данных с минимальными накладными расходами. Иными словами, в отличие от традиционных статистических декодеров блок 300 статистического декодирования избегает многих проверок, применяемых традиционными статистическими декодерами для определения позиции первой единицы, что часто приводит к существенным задержкам при статистическом декодировании на декодере контента. Кроме того, после определения кодированных символов, согласно одному варианту осуществления, используется указатель, указывающий начальную позицию следующих кодированных символов или кодового слова на основании длины кодового слова.
Возвращаясь к фиг.3А, заметим, что в альтернативном варианте осуществления кэш-память 350 содержит только таблицы 352 декодирования и не использует таблицы 360 сдвига. Соответственно, в описанном варианте осуществления таблицы декодирования могут включать в себя значение уровня или величины, значение длины серии до следующего ненулевого значения и длину кодового слова. Поэтому, когда фрагмент потоковых видеоданных считывается из устройства 304 хранения данных в буфере данных 302, к выбранному фрагменту данных можно применять маску для извлечения данных поиска из выбранного фрагмента данных.
Как таковые таблицы 352 декодирования запрашиваются с использованием данных поиска, пока в одной из таблиц 352 декодирования не обнаружится соответствующий элемент. Согласно одному варианту осуществления, когда битовая длина данных поиска меньше длины кодового слова, таблица кодирования возвращает непригодный (недействительный) ответ. Соответственно, к данным поиска добавляются дополнительные биты и делается новое обращение к таблице 352 декодирования, пока не будет возвращено пригодное значение. Поэтому выбранный фрагмент данных, после определения его положения, декодируется с использованием значения уровня/величины, значения длины серии и значения кодового слова, полученного из таблицы 352 декодирования. Кроме того, после определения кодированных символов, согласно одному варианту осуществления, используется указатель, указывающий начальную позицию следующих кодированных символов или кодового слова на основании длины кодового слова.
На фиг.4 представлено преобразование данных в устройстве 304 хранения данных буфера 302 данных. В показанном примере данные в устройстве 304 хранения данных могут первоначально храниться в порядке «начиная с младших битов». Первоначальное упорядочение данных, в целом, базируется на методологии организации данных в соответствующей вычислительной архитектуре. К сожалению, MPEG, наиболее распространенный видеоформат, организует данные в порядке «начиная со старших битов». В результате декодирование данных MPEG требует преобразования от порядка «начиная с младших битов» к порядку «начиная со старших битов». Альтернативно, данные можно первоначально хранить в порядке «начиная со старших битов», тем самым избегая преобразования.
Следовательно, в устройстве 304 хранения данных производится обращение данных в ответ на выполнение команды преобразования данных. При этом, согласно описываемому варианту осуществления обращение порядка байтов осуществляется посредством одной команды для каждого размера регистра. Однако согласно альтернативному способу обращение порядка байтов осуществляется в 32-разрядных регистрах в единичной команде. Следовательно, 32-битовые слова, байты которых были переставлены в 32-разрядных регистрах, загружаются в более объемные регистры. После загрузки обращение порядка этих 32-разрядных слов производится посредством одной команды.
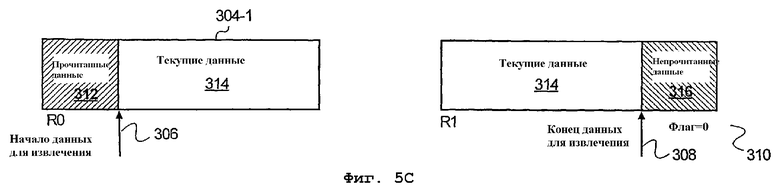
На фиг.5А-5D изображен буфер 302 данных блока 300 статистического кодирования, использующий исходное устройство 304-1 хранения данных (R0) и вспомогательное устройство 304-2 хранения данных (R1). Согласно описанному, различные устройства 304 хранения данных буфера 302 данных обеспечивают адресацию на битовом уровне, что можно использовать для ускорения кодирования и декодирования данных контента. Соответственно, данные битового потока первоначально загружаются в устройство 304-1 хранения данных R0. После заполнения устройства хранения данных R0, данные битового потока сохраняются в устройстве 304-2 хранения данных R1. При этом, в описываемом варианте осуществления, устройства хранения данных R0 и R1 содержат непрочитанные данные битового потока.
На фиг.5В показаны устройства хранения данных R0 и R1 и данные, доступ к которым осуществляется на границах битов. В результате, биты являются единичными элементами, определяющими объем (размер) данных, к которым можно осуществлять доступ в буфере 302 данных. Следовательно, минимальная разность адресов доступа для устройств хранения данных составляет один бит. Соответственно, в описываемом варианте осуществления буфер 302 данных содержит множество регистров с адресацией на битовом уровне. Однако специалистам в данной области очевидно, что в качестве устройств хранения данных с адресацией на битовом уровне можно использовать и другое оборудование, способное сохранять данные.
Следовательно, обеспечивается начальный битовый адрес 306 выбранных текущих данных 314 в устройстве 304-1 хранения данных R0 и на основании количества битов, которые нужно прочитать, можно вычислить концевую позицию 308 запрашиваемых данных. Кроме того, согласно одному варианту осуществления устройства хранения данных содержат флаг 310 для определения, был ли осуществлен доступ к каждому фрагменту данных битового потока в соответствующем устройстве хранения данных. При этом, что касается устройства 304-1 хранения данных R0, устройство 304-1 R0 содержит прочитанные данные 312, текущие данные 314 и непрочитанные данные 316.
На фиг.5С изображен вариант осуществления буфера 302 данных, когда запрашиваемые данные содержатся в нескольких устройствах хранения данных (от R0 на R1). При обнаружении такого случая осуществляется операция слияния регистров. Соответственно, в ответ на выполнение команды слияния регистров текущие данные из устройства хранения данных R0 и текущие данные из устройства хранения данных R1 считываются и копируются в устройство назначения для хранения данных в качестве непрерывного блока. В описываемом варианте осуществления устройство назначения для хранения данных представляет собой регистр, который может содержаться в регистровом файле 340 блока 300 статистического кодирования, изображенного на фиг.3А. Однако устройство назначения для хранения данных может представлять собой оборудование любого типа, способное сохранять цифровые данные.
Согласно альтернативному варианту осуществления, в случае обнаружения расположения данных (в нескольких регистрах), ненужные или прочитанные данные в устройстве хранения данных R0 можно сдвинуть, чтобы освободить место для данных, которые располагаются также в устройстве хранения данных R1. После сдвига непрочитанных данных за пределы устройства хранения данных R0 текущие данные в устройстве хранения данных R1 можно сдвинуть в устройство хранения данных R0. Следовательно, когда текущие данные содержатся в устройстве хранения данных R0, данные можно копировать в устройство назначения для хранения данных в качестве непрерывного модуля (блока). После копирования все данные в устройстве хранения данных R0 являются ненужными прочитанными данными и потому в устройство хранения данных R0 можно загружать свежие данные.
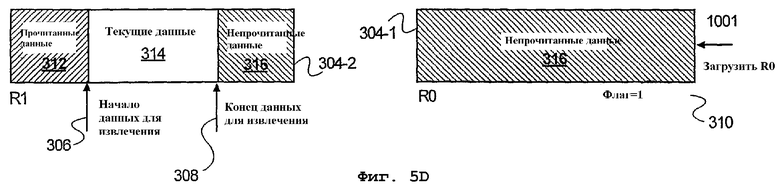
На фиг.5D изображен вариант осуществления, когда буфер 302 данных действует как кольцевой буфер. При этом, когда текущий массив данных выбран из устройства 304-1 хранения данных R0 и устройства 304-2 хранения данных R1, устройство 304-1 хранения данных R0 больше не будет содержать непрочитанных данных. Соответственно, как показано на фиг.5D, доступ ко всем данным в устройстве 304-1 хранения данных R0 был произведен, в результате чего установлен флаг 310. Кроме того в описываемом варианте осуществления, позиция устройства 304-1 хранения данных R0 перемещается к концу буфера 302, чтобы можно было загружать данные в устройство хранения данных R0 из входного потока данных. Следовательно, в описываемом варианте осуществления, буфер данных функционирует как кольцевой буфер. Другими словами, в представленном примере все данные при следующей операции доступа выбираются из устройства 304-1 хранения данных R1.Однако в некоторых вариантах осуществления участки доступа к данным перекрываются, в результате чего доступ к некоторым битам осуществляется более одного раза, тогда как в других случаях доступ к некоторым битам не осуществляется вовсе. При этом, в описываемых вариантах осуществления способ задания адреса нужных данных, к которым нужно осуществить доступ в буфере 302 данных, обеспечивается путем получения первого ИД регистра, который может состоять из типа номера регистра, в котором появляется первый бит, к которому осуществляется доступ. Способ также включает в себя битовый адрес, заданный битовой позицией в регистре, количество битов, к которым нужно произвести доступ, и (в большинстве случаев) второй регистр, в котором находятся некоторые данные, подлежащие доступу, если диапазон битов, подлежащих доступу, выходит за пределы первоначального исходного регистра.
В описываемом варианте осуществления начальная битовая позиция (306) текущих данных и количество битов, подлежащих извлечению, хранятся в двух дополнительных регистрах (не показаны). Однако в альтернативном варианте осуществления спецификация данных, к которым нужно осуществить доступ, обеспечивается приемом адреса 306 первого бита и адреса 308 последнего бита вместо адреса 306 первого бита и количества битов данных, к которым осуществляется доступ. Адрес 308 последнего бита может быть связан с регистром (R1 304-2), в котором хранится последний бит, а может быть связан с первым регистром (R0 304-1), в каковом случае он равен сумме адреса первого бита и количества битов, к которым нужно осуществить доступ. В последнем случае последний адрес 308 может относиться к позиции в другом регистре (R1 304-2), если адрес 308 последнего бита выходит за пределы максимального адреса первого регистра (R0 304-1). В этом случае в буфере фактически имеется единое адресное пространство.
При этом данные, к которым осуществляется доступ, переносятся в конечный регистр 342 (регистр назначения), показанный на фиг.3В. Конечный регистр 342 или устройство 304 хранения данных может быть регистром того же или другого типа по отношению к устройствам 304 хранения данных в буфере 302 данных. Согласно одному варианту осуществления данные, к которым осуществляется доступ, загружаются в самую нижнюю или младшую позицию в регистре (см. фиг.3В). Кроме того, когда запрашивается доступ к данным, требующим команды слияния регистров, данные состыковываются (конкатенируются) так, что в конечное устройство 342 хранения данных загружается непрерывный блок данных.
Во многих случаях данные, к которым осуществляется доступ, из буфера 302 данных не заполняют конечное устройство 342 (устройство назначения) хранения данных. В этих случаях конечное устройство 342 хранения данных дополняется нулями, т.е. биты в конечном регистре 342, которые не являются частью данных, к которым осуществляется доступ, устанавливаются равными нулю. Дополнение нулями конечного устройства 342 хранения данных в одном варианте осуществления осуществляется посредством команды загрузки данных, которая загружает данные из буфера в конечное устройство 342 хранения данных (см. фиг.3В). Кроме того, когда установлен флаг 310, указывающий, что ко всем данным в соответствующем устройстве хранения данных был произведен доступ, флаг сбрасывается, когда выполняется команда загрузки дополнительных данных в буфер данных. При этом процессор не ожидает загрузки данных, чтобы установить флаг.
Однако в альтернативном варианте осуществления определение, что ко всем данным в регистре был произведен доступ, осуществляется путем сравнения наибольшего адреса в регистре (позиции старшего бита в регистре) с суммой адреса (местоположения бита) первого бита 306, к которому осуществлен доступ, и количества битов, подлежащих доступу. Тогда, если эта сумма больше максимального адреса в регистре (позиции СБ), значит ко всем данным из регистра был произведен доступ. Соответственно, в описанном выше варианте осуществления, когда ко всем данным в регистре был произведен доступ, данные из битового потока 252 загружаются в регистр и регистр перемещается в конец буфера, так что доступ ко вновь загруженным данным осуществляется после других данных, уже находящихся в буфере.
Наконец, буфер 302 данных с побитовой адресацией поддерживает программные оптимизации, например, функции цикла и обхода. При этом цикл можно проходить так, что не нужно проверять после декодирования каждого символа, ко всем ли данным в регистре был произведен доступ. Соответственно, количество раз, которое цикл может быть статически обойден, равно битовой длине регистра х (количество регистров в буфере минус один), деленной на максимальное количество битов, доступных в буфере. Например, если длина буфера равна 128 битов и количество регистров в буфере равно двум, это гарантированно будет 128x(2-1), что составляет 128 битов в буфере. Следовательно, если максимально доступно 17 битов, то буфер никогда не выйдет за пределы данных после 128, деленное на 17, что равно 7 запросам. Соответственно, буфер будет «обойден» семь раз.
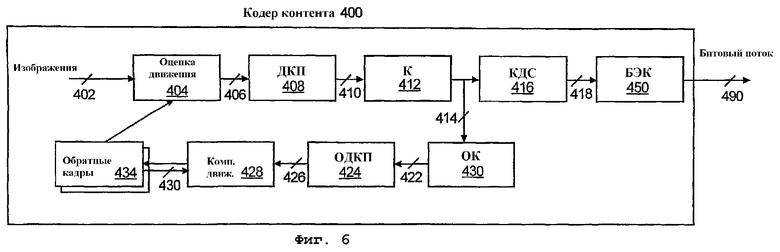
На фиг.6 изображена блок-схема компонентов кодера 400 контента, который можно использовать в компьютерной системе 100 согласно другому варианту осуществления настоящего изобретения. Кодер 400 контента первоначально принимает данные контента 402, например, изображения, аудио- и видеоданные. Соответственно, для каждого блока данных в потоке 402 изображения кодер 400 осуществляет пять этапов для получения кодированного блока. На первом этапе блок 404 оценки движения осуществляет оценку движения, чтобы воспользоваться временными избыточностями среди изображений. Соответственно, блок 406 оценки движения генерирует вектор движения для каждого блока в макроблоке данных 402 контента, который поступает на блок дискретного косинусного преобразования (блок 408 ДКП).
При этом блок 408 ДКП берет исходные блочные данные и осуществляет дискретное косинусное преобразование на блоке, чтобы найти его частотный спектр. Этот частотный спектр 410 поступает на блок квантования 412. Блок квантования 412 обнуляет большое количество малых значений принятого частотного спектра, тем самым уменьшая количество различных значений частоты в частотном спектре. Этот этап квантования является этапом «с потерями» процесса кодирования, и степень квантования задается с использованием как матриц квантования, так и коэффициентов квантования.
После квантования осуществляется кодирование по длинам серий и статистическое кодирование с использованием квантованного блока 414, принятого из блока 412 квантования. Блок кодирования по длинам серий (блок 416 КДС) кодирует ненулевые элементы и количество нулей между ними для дополнительного сжатия данных 402 контента. Наконец, блок 450 статистического кодирования определяет код переменной длины и размер кода переменной длины из принятых данных, кодированных по длинам серий, чтобы генерировать кодированный битовый поток 490. Однако в отличие от традиционных статистических кодеров, блок 450 статистического кодирования использует вышеописанный буфер 480 с адресацией на битовом уровне, чтобы сохранять кодированные символы данных до сохранения кодированных символов данных, например, в устройстве памяти, указанном на фиг.7А и 7В.
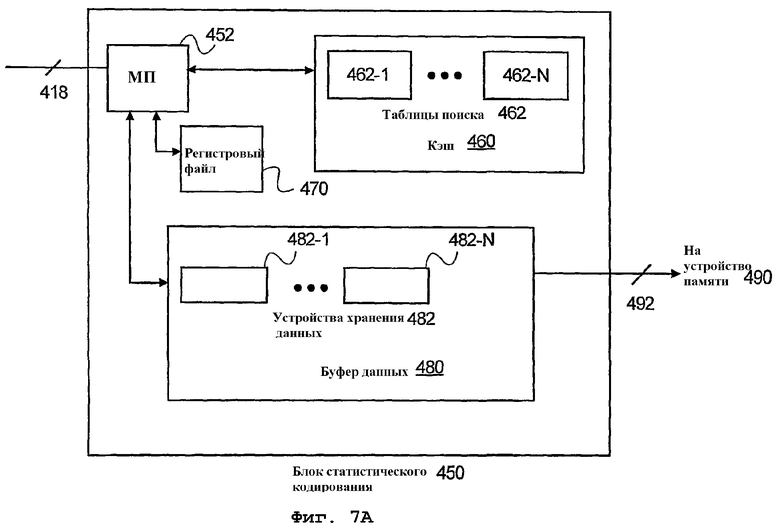
На фиг.7А изображен блок статистического кодирования, соответствующий иллюстративному варианту осуществления настоящего изобретения. Блок 450 статистического кодирования содержит микропроцессор 452, который считывает или принимает значение, подлежащее кодированию. В случае MPEG принимаются два значения, а именно уровень и длина серии, которые подлежат кодированию. С использованием полученных значений процессор применяет таблицу 462 поиска (просмотра), чтобы определить код переменной длины и размер кода переменной длины для принятых данных. При этом когда код переменной длины и размер кода переменной длины определены, блок 450 статистического кодирования может сохранять кодированные символы в буфере 480 данных. При этом кодированные символы сохраняются в устройствах 482 хранения данных (482-1,... 482-N), пока буфер 480 данных не заполнится.
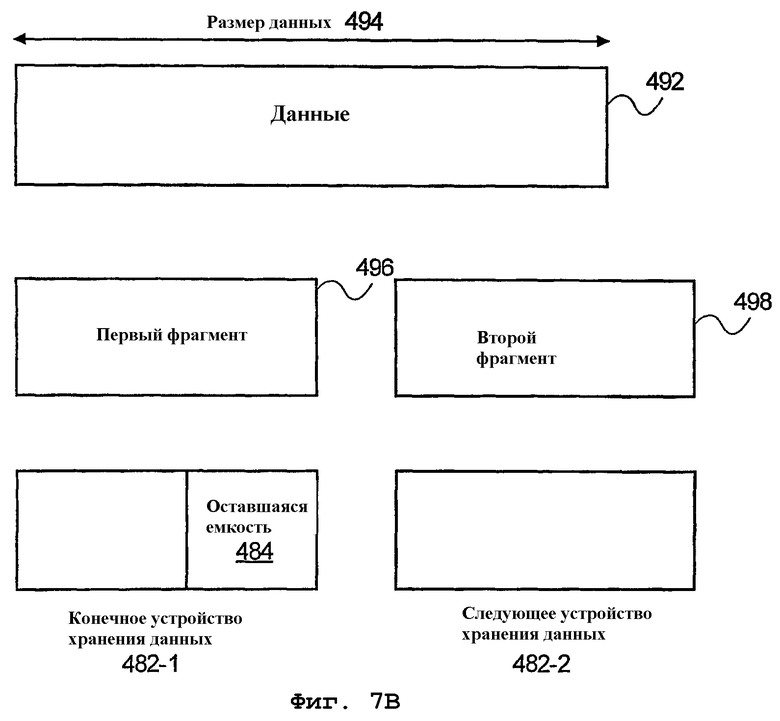
Однако при использовании вышеописанных методов буфер данных, хотя и использует множество устройств хранения данных, содержит единое адресное пространство, так что по завершении сохранения данных 494 в устройстве хранения данных буфера данных дополнительные данные или кодированные символы разделяются на первый фрагмент 496 (сохраняется в 482-1) и второй фрагмент 498 и поступают в следующее устройство 482-2 хранения данных, как показано на фиг.7В. Соответственно, устройства 482 хранения данных используют указатель, который отслеживает следующую битовую позицию, в которой можно сохранить данные. Кроме того, по заполнении устройства хранения данных символы в устройстве хранения данных можно переместить в память и, как описано выше, устройство хранения данных можно «переместить» в конечную позицию в буфере данных, чтобы его можно было использовать для сохранения дополнительных кодированных символов данных в то время, как другие данные записываются в память.
Согласно одному варианту осуществления, регистры 482 в буфере 480 данных поименованы так, что они имеют одну и ту же позицию в буфере. Соответственно, при осуществлении доступа к буферу данных со стороны регистра-назначения, данные в регистре 482-1 сохранения данных буфера 480 данных сохраняются в регистре назначения, в то время как регистр 482-2 загрузки данных загружается из памяти. В случае когда регистр хранения записывает в буфере 480 данных, данные сохраняются в регистре 482-1 сохранения данных буфера 480 данных в то время, как данные в регистре 482-2 загрузки данных загружаются в память. Соответственно, физические регистры попеременно играют роль регистров загрузки и сохранения, чтобы обеспечить непрерывность операций записи или сохранения в буфере данных, например, как изображено на фиг.5D. Теперь опишем процедурные способы реализации идей настоящего изобретения.
ПРИНЦИП РАБОТЫ
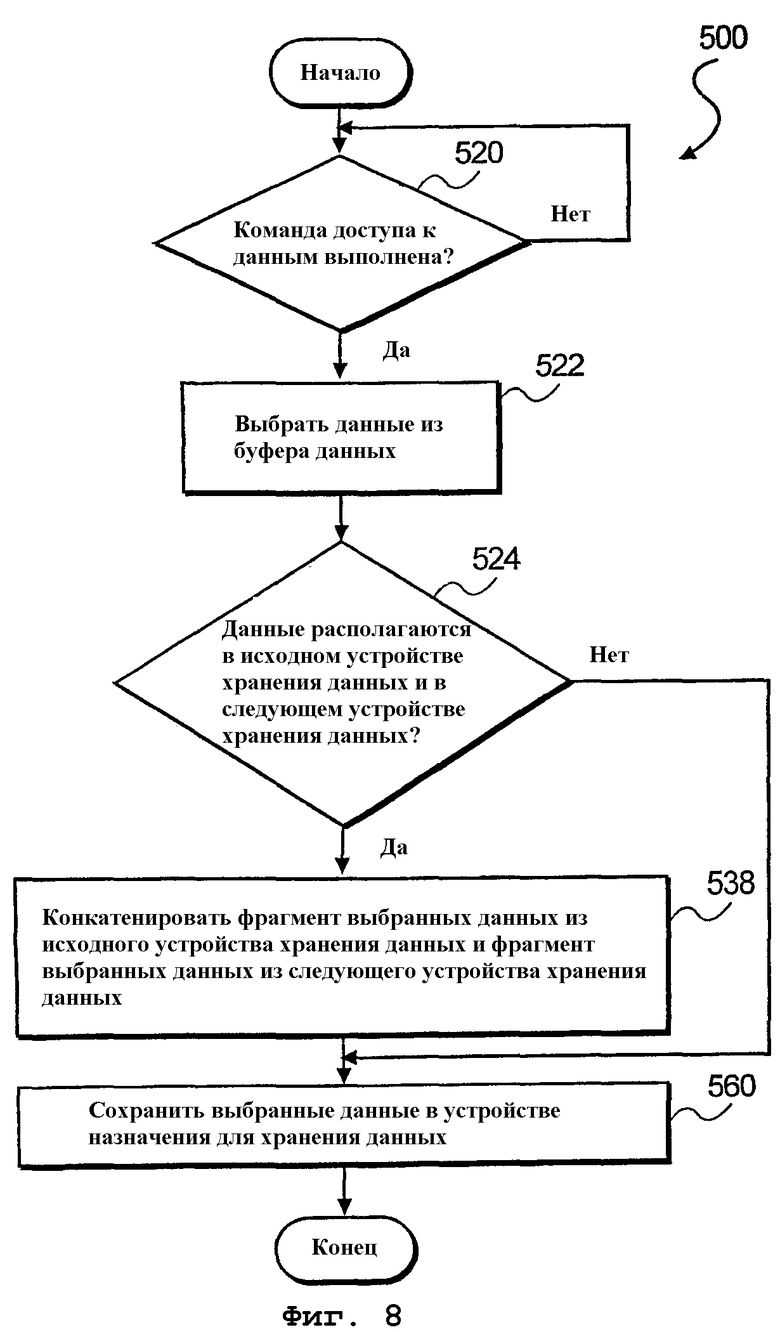
На фиг.8 изображена блок-схема алгоритма способа 500 извлечения данных из буфера 302 с адресацией на битовом уровне, например, изображенного на фиг.3А. На этапе 520 обработки производится определение, была ли выполнена команда доступа к данным. В ответ на выполнение команды доступа к данным производится выбор данных из буфера 302 данных на этапе 522 обработки. Затем на этапе 524 обработки производится определение, распространяются ли (переходят ли) данные от исходного устройства 304-1 хранения данных на следующее устройство 304-2 хранения данных в буфере 302 данных (см. фиг.5С). Если определено распространение данных (расположение в нескольких устройствах), то выполняется этап 538 обработки. В противном случае осуществляется переход к этапу 560 обработки. На этапе 538 обработки фрагмент выбранных данных из исходного устройства 304-1 хранения данных и фрагмент выбранных данных из следующего устройства 304-2 хранения данных конкатенируются для формирования выбранных данных в виде непрерывного блока. Наконец, на этапе 560 обработки выбранные данные сохраняются в устройстве 342 назначения хранения данных.
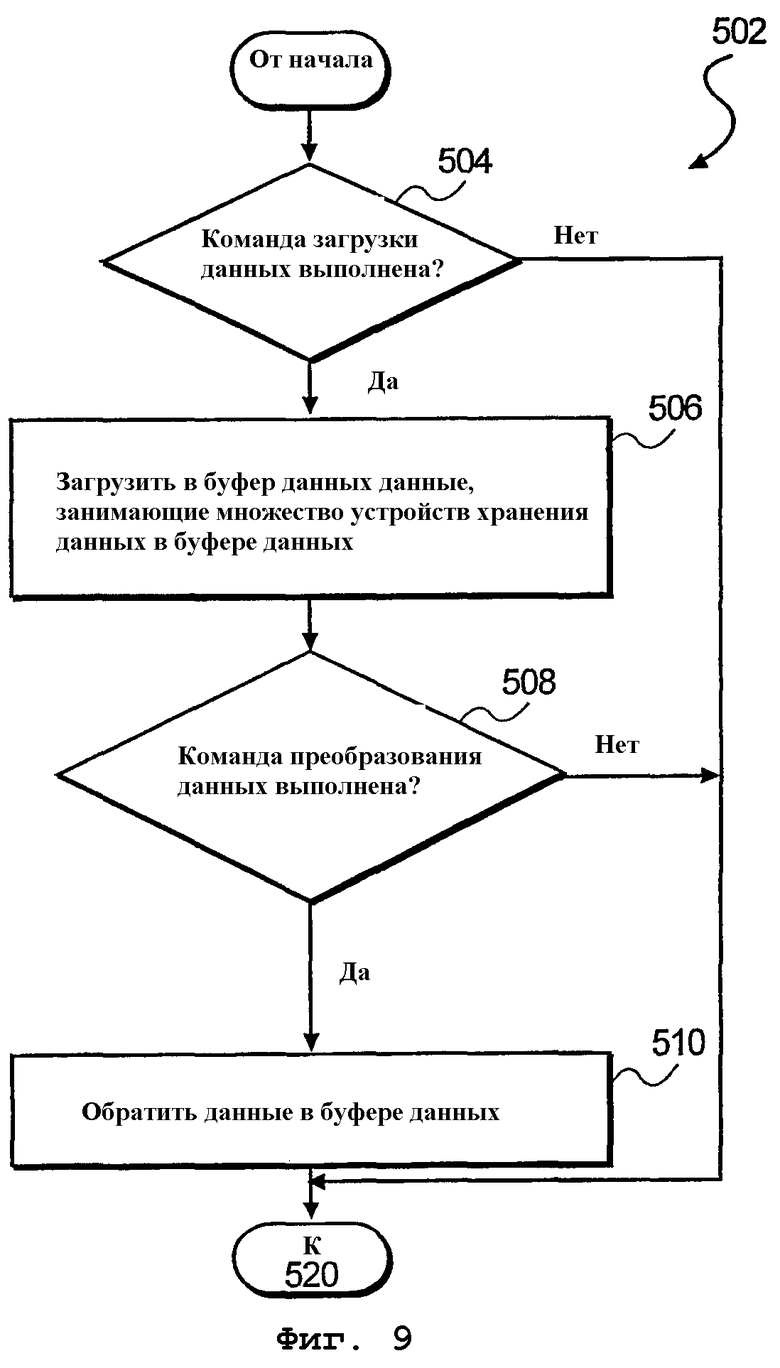
На фиг.9 изображена блок-схема алгоритма дополнительного способа 502 загрузки входного битового потока данных в буфер 502 данных (см. фиг.5А-5D). При этом на этапе 504 обработки производится определение, была ли выполнена команда загрузки данных. В ответ на выполнение команды загрузки данных на этапе 506 обработки данные загружаются в буфер 302 данных, который охватывает множество устройств хранения данных в буфере данных. Соответственно, как описано выше, буфер данных использует множество устройств хранения данных, которые, согласно одному варианту осуществления, представляют собой 128-разрядные регистры. Кроме того, вышеописанная функция слияния регистров позволяет буферу данных действовать как единое адресное пространство, которое позволяет данным занимать один или несколько регистров в буфере данных.
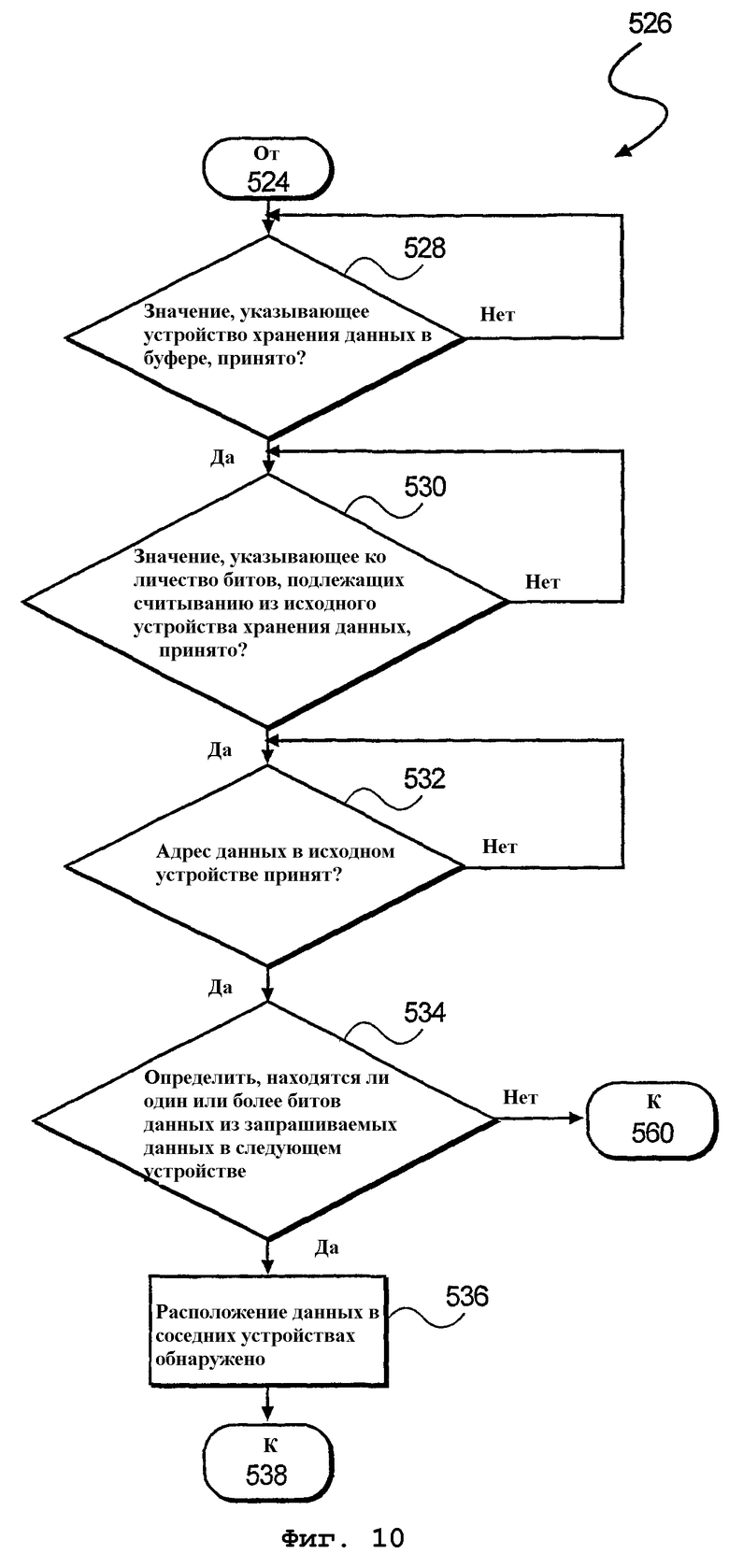
После загрузки буфера данных осуществляется этап 508 обработки. На этапе 508 обработки производится определение, была ли выполнена команда преобразования данных. Соответственно, в ответ на выполнение команды преобразования данных производится обращение порядка данных в устройствах 304 хранения данных буфера данных 302 на этапе 510 обработки (см. фиг.4). По завершении осуществляется переход к этапу 520 обработки, указанному на фиг.8. В описанных выше вариантах осуществления преобразование данных включает в себя преобразование из порядка «начиная с младших битов» к порядку «начиная со старших битов». Однако преобразование данных не ограничивается описанным примером. На фиг.10 изображена блок-схема алгоритма дополнительного способа 526 определения распространения данных (см. фиг.5С). Соответственно, на этапе 528 обработки осуществляется прием значения устройства, указывающего устройство 304-1 хранения данных в буфере 302 данных. После приема на этапе 530 обработки осуществляется прием битового значения, указывающего количество битов, подлежащих считыванию из исходного устройства 304-1 хранения данных. Наконец, на этапе 532 обработки осуществляется прием адреса 306 запрашиваемых данных в исходном устройстве 304-1 хранения данных. Наконец, на этапе 534 обработки производится определение, находятся ли один или более битов запрашиваемых данных 314 в следующем устройстве 304-1 хранения данных в буфере 302 данных.
Согласно описанному выше, методы определения распространения (перехода) данных включают в себя сравнение оставшейся емкости исходного устройства 304-1 хранения данных с принятым битовым значением, указывающим количество битов запрашиваемых данных 314. При этом, если количество битов превышает оставшуюся емкость, значит данные распространяются на (переходят в) следующее устройство хранения данных. Альтернативно, можно принимать начальный адрес 306 запрашиваемых данных и концевой адрес 308 запрашиваемых данных, так что, когда начальный адрес 306 и концевой адрес 308 относятся к разным устройствам хранения данных, регистрируется распространение (расположение в соседних устройствах) данных. В случае обнаружения распространения данных осуществляется переход к этапу 538 обработки, указанному на фиг.8. В противном случае осуществляется переход к этапу 560 обработки, указанному на фиг.8.
На фиг.11 изображена логическая блок-схема дополнительного способа 590 сохранения выбранных данных (см. фиг.3В). При этом на этапе 592 обработки производится прием адреса конечного устройства хранения данных. После приема на этапе 594 обработки данные сохраняются в устройстве 342 назначения для хранения данных, начиная с позиции младшего бита (МБ). Наконец, на этапе 596 осуществляется заполнение нулями пустых участков старших битов (СБ) устройства 342 назначения для хранения данных путем задания пустых участков равными нулю.
На фиг.12 изображена блок-схема алгоритма (последовательности операций) дополнительного способа конкатенации или осуществления слияния регистров данных, которые распространяются на одно или несколько устройств хранения данных (см. фиг.5С). На этапе 542 обработки производится выбор устройства 304-1 хранения данных из буфера 302 данных. На этапе 544 обработки производится определение, ко всем ли данным в выбранном устройстве хранения данных произведен доступ. Согласно одному варианту осуществления это определение опирается на флаг 310 доступа, указанный на фиг.5А-5С. Согласно альтернативному варианту осуществления определение осуществляется путем выяснения, содержатся ли указатель 306 начала данных и указатель 308 конца данных в одном и том же регистре. Если нет, то регистрируется распространение данных. Если ко всем данным в выбранном устройстве хранения данных произведен доступ, на этапе 546 обработки устанавливается флаг доступа к данным. Наконец, на этапе 548 для каждого устройства хранения данных в буфере данных повторяются этапы 542-546.
На фиг.13 показан дополнительный способ 550 загрузки данных в устройство хранения данных буфера данных, когда был осуществлен доступ к данным в устройстве хранения данных (см. фиг.5А-5D). При этом на этапе 552 обработки из буфера 302 данных производится выбор устройства 304-1 хранения данных. Затем на этапе 554 обработки производится определение, установлен ли флаг 310 доступа. Если флаг 310 доступа установлен, то на этапе 556 обработки в выбранное устройство хранения данных загружаются дополнительные данные входного потока данных. Наконец, на этапе 558 обработки для каждого устройства хранения данных в буфере данных повторяются этапы 552-556 обработки.
На фиг.14 изображена блок-схема алгоритма дополнительного способа 562 декодирования данных, сохраненных в конечном устройстве 342 хранения данных (см. фиг.3В). На этапе 564 обработки декодируются данные в устройстве 342 назначения хранения данных. Затем на этапе 580 обработки декодированные данные записываются поверх данных, содержащихся в конечном устройстве хранения данных.
На фиг.15 изображена блок-схема алгоритма дополнительного способа 566 декодирования данных в устройстве назначения хранения данных, осуществляемого на этапе 568 обработки, указанном на фиг.14. На этапе 568 обработки производится определение, выполнена ли команда обнаружения данных. В ответ на выполнение команды обнаружения данных, на этапе 570 обработки производится определение позиции 344 первой единицы в конечном устройстве 342 хранения данных, например, показанном на фиг.3В. Затем на этапе 572 обработки значение сдвига считывается из таблицы 360 сдвига с использованием позиции первой единицы в качестве индекса (указателя) для определения значения сдвига. На этапе 574 обработки производится сдвиг в устройстве 342 назначения хранения данных согласно значению сдвига.
Затем на этапе 576 обработки декодированный символ считывается из таблицы 352 поиска на основании значения сдвига в устройстве назначения хранения данных в качестве индекса (см. фиг.3А). Наконец, на этапе 578 обработки длина декодированного символа считывается из таблицы 352 поиска длины символа также с использованием значения сдвига для устройства хранения данных в качестве индекса. При этом команда обнаружения данных избегает многих традиционных проверок, применяемых традиционными статистическими декодерами для определения позиции первой единицы, которая используется для обнаружения кодового слова в принятом битовом потоке. Поэтому после обнаружения кодового слова используется указатель для отметки начала следующего кодового слова в соответствующем устройстве 304 хранения данных буфера 302 данных.
Альтернативно, как описано выше со ссылкой на фиг.3А, кэш-память может ограничиваться таблицами 353 декодирования, которые содержат значение длины кодового слова, значение уровня/величины и значение длины серии. При этом согласно описываемому варианту осуществления к конечному устройству 342 (устройству назначения) хранения данных применяется маска для определения маскированных/поисковых данных. После определения маскированных данных маскированные данные используются для доступа к таблице 352 декодирования в кэш-памяти 350. Если запрашиваемые данные содержатся в таблице, то значение длины кодового слова, значение уровня/величины и значение длины серии извлекаются из одного элемента данных, считанного из таблицы. В противном случае, если данные не содержатся в таблице, то считанное кодовое слово будет указывать, что данных в таблице нет. При этом процесс повторяется в остальных таблицах кэш-памяти 350, пока не будут обнаружены нужные данные.
На фиг.16 представлен способ 600 сохранения данных в буфере 480 данных с адресацией на битовом уровне, например, изображенном на фиг.7А и 7В. На этапе 630 обработки производится определение, выполнена ли команда загрузки данных. В ответ на выполнение команды загрузки данных на этапе 640 обработки производится определение, превышает ли размер 494 данных 492, подлежащих загрузке, оставшуюся емкость 484 устройства 482-1 назначения для хранения данных в буфере 480 данных. В этом случае выполняется этап 670 обработки.
В противном случае данные загружаются или сохраняются в конечном устройстве 482 хранения данных буфера 480 данных. На этапе 670 обработки данные 494 делятся на первый фрагмент 496 и второй фрагмент 498. После разделения, на этапе 672 обработки первый фрагмент 496 загружается в устройство 482-1 назначения для хранения данных. Затем второй фрагмент данных 498 загружается в следующее устройство хранения данных буфера данных (см. фиг.7В). Наконец, на этапе 676 обработки данные в устройстве 482-1 назначения для хранения данных перемещаются, например, в устройство 490 памяти.
На фиг.17 представлен дополнительный способ 602 кодирования данных до сохранения данных в буфере 480 данных с адресацией на битовом уровне. На этапе 604 обработки осуществляется выбор данных 418 из исходного устройства хранения данных. После выбора на этапе 606 обработки выбранные данные кодируются. Затем, на этапе 618 обработки, кодированные данные сохраняются в исходном устройстве хранения данных. Наконец, на этапе 620 обработки выполняется команда загрузки данных для загрузки кодированных данных в одно или несколько устройств хранения данных в буфере данных. После выполнения осуществляется переход к этапу 630 обработки, указанному на фиг.16.
На фиг.18 изображена блок-схема алгоритма дополнительного способа 632, осуществляемого в ответ на выполнение команды загрузки данных. На этапе 634 обработки осуществляется прием начального адреса данных в устройстве 482 назначения для хранения данных буфера 480 данных. Затем на этапе 636 обработки осуществляется прием значения размера данных, указывающего количество битов данных, подлежащих сохранению в устройстве 482 назначения для хранения данных. Наконец, на этапе 638 обработки осуществляется прием адреса исходного устройства хранения данных, по которому первоначально размещались данные. После приема осуществляется переход к этапу 640 обработки, указанному на фиг.16.
На фиг.19 изображена блок-схема алгоритма дополнительного способа 642 определения, превышает ли размер данных, подлежащих загрузке, оставшуюся емкость устройства 482-1 назначения в буфере 480 данных, указанного на фиг.7В. Соответственно, на этапе 644 обработки определяется оставшаяся емкость 484 текущего устройства 482-1 назначения для хранения данных в буфере 480 данных. Затем на этапе 646 обработки производится определение, превосходит ли принятый размер 494 данных оставшуюся емкость 484. В этом случае выполняется этап 640 обработки. В противном случае происходит переход к этапу 650 обработки, указанному на фиг.16.
На этапе 648 размер 494 данных превышает оставшуюся емкость 484 устройства 482-1 назначения для хранения. Соответственно, данные должны делиться на первый фрагмент 496 и второй фрагмент 498 на этапе 640 обработки, указанном на фиг.16. Разделение осуществляется путем выбора количества битов из принятых данных 492, равного оставшейся емкости 484 устройства 482-1 назначения для хранения данных. Выбранные данные образуют первый фрагмент 496 данных 492, который будет сохранен в конечном устройстве (устройстве назначения) хранения данных. Затем оставшийся фрагмент данных 492 используется как второй фрагмент 498 данных, так что второй фрагмент 498 можно сохранить в следующем устройстве 482-2 хранения данных буфера 480 данных. Соответственно, возможность разделения данных позволяет буферу данных функционировать как единое адресное пространство, так что по заполнении соответствующего устройства хранения данных в буфере данных данные можно записывать в память.
На фиг.20 представлен способ, согласно которому буфер 480 данных, например, изображенный на фиг.3А и фиг.7В, использует регистр 482-1 сохранения данных и регистр 482-2 загрузки данных в качестве множества регистров в буфере 480 данных. Соответственно, в ответ на команду доступа к данным для сохранения данных в буфере 480 данных производится определение, является ли текущий регистр в буфере 480 данных регистром 482-1 хранения данных. Если да, то выполняется этап 656 обработки. На этапе 656 производится определение, содержит ли регистр 482-1 сохранения данных дополнительную емкость. Если регистр 482-1 сохранения данных содержит дополнительную емкость, то выполняется этап 658 обработки.
На этапе 658 обработки данные из исходного устройства хранения данных сохраняются в регистре 482-1 хранения данных. В противном случае регистр 482-1 сохранения данных заполнен и теперь должен функционировать как регистр 482-1 загрузки данных. Согласно описанному здесь регистр 482-2 загрузки данных используется в буфере 480 данных как кольцевой буфер, так что регистр 482-2 загрузки данных полностью заполнен данными и поэтому требует записи данных в память 490. Напротив, регистр сохранения данных - это регистр, который содержит дополнительную емкость и в который загружаются принятые данные в ответ на выполнение команды загрузки данных.
Следовательно, на этапе 660 обработки регистр сохранения данных после заполнения переименовывается в регистр загрузки данных. Затем на этапе 662 обработки данные в регистре загрузки данных сохраняются в устройстве 490 памяти. Затем на этапе 664 обработки производится определение, пуст ли регистр 482-2 загрузки данных. В этом случае этап 662 обработки повторяется до опустошения регистра 482-2 загрузки данных. После опустошения регистра 482-2 загрузки данных выполняется этап 666 обработки. На этапе 666 обработки производится определение, имеются ли дополнительные данные в исходном устройстве хранения данных. При наличии дополнительных данных в исходном устройстве хранения данных регистр 482-2 загрузки данных переименовывается в регистр 482-1 сохранения данных, после чего в него можно загружать дополнительные данные. В противном случае происходит возврат к этапу 650 обработки, указанному на фиг.17, и выполнение способа на этом заканчивается.
Наконец, на фиг.21 изображена блок-схема алгоритма дополнительного способа кодирования выбранных данных, осуществляемого на этапе 606 обработки, указанном на фиг.17. На этапе 610 обработки производится считывание одного или нескольких значений сохраненных данных. Затем на этапе 612 обработки производится считывание символа кода переменной длины и размера кода переменной длины из таблиц поиска символов, указанных на фиг.7А. Специалистам в данной области известно, что кодированные символы и длины генерируются на основании частотности элементов данных в потоке данных. Наконец, на этапе 614 обработки этапы 610 и 612 обработки повторяются для каждого значения сохраненных данных.
АЛЬТЕРНАТИВНЫЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
Выше описаны некоторые аспекты одной реализации буфера данных с адресацией на битовом уровне для обеспечения усовершенствованного статистического кодирования/декодирования. Однако различные реализации буфера с адресацией на битовом уровне обеспечивают многочисленные признаки, включающие, дополняющие, поддерживающие и/или заменяющие вышеописанные признаки. Признаки могут быть реализованы как часть системы обработки изображений или как часть аппаратного/программного кодера/декодера в различных реализациях. Кроме того, в вышеприведенном описании в иллюстративных целях применяется конкретная система понятий для обеспечения ясного понимания изобретения. Однако специалистам в данной области известно, что для практического осуществления изобретения не требуются конкретные детали.
Кроме того, хотя описанный здесь вариант осуществления связан с буфером с адресацией на битовом уровне, специалистам в данной области известно, что идеи настоящего изобретения можно применять и к другим системам. Фактически системы для буферизации операций битового уровня соответствуют идеям настоящего изобретения и не выходят за рамки объема и сущности настоящего изобретения. Описанные выше варианты осуществления были выбраны и описаны для наглядного объяснения принципов изобретения и его практических применений. Эти варианты осуществления были выбраны, чтобы другие специалисты в данной области могли наилучшим образом использовать изобретение и различные варианты осуществления с различными модификациями, пригодными для конкретного использования.
Следует понимать, что хотя в вышеприведенном описании указаны многочисленные характеристики и преимущества различных вариантов осуществления настоящего изобретения совместно с деталями структуры и функциями различных вариантов осуществления изобретения, данное раскрытие носит исключительно иллюстративный характер. В некоторых случаях лишь некоторые модули описаны подробно применительно к одному такому варианту осуществления. Тем не менее, понятно и ожидаемо, что такие модули можно использовать и в других вариантах осуществления изобретения. Изменения допустимы в деталях, особенно касающихся структуры и управления, соответствующих принципам настоящего изобретения, которые в полной мере согласуются с расширительным толкованием терминов, используемых в прилагаемой формуле изобретения.
Настоящее изобретение обеспечивает многочисленные преимущества над известными методами. Настоящее изобретение предусматривает возможность ускорения приложений, которые используют или требуют доступ к битам и интенсивные манипуляции битами. Описанные здесь способы обеспечивают повышенную эффективность и повышенную производительность (скорость) в манипулировании и извлечении данных из регистра, используемого в качестве буфера, тем самым ускоряя статистическое кодирование и декодирование.
Признаки настоящего изобретения обеспечивают преимущества производительности для различных приложений, использующих битовые доступ и манипуляции, например быстрые операции обращения порядка следования байтов, которые облегчают эффективное преобразование «начиная с младших битов» в «начиная со старших битов». Кроме того, буфер данных поддерживает доступ к данным и сохранение данных по границам битов на основании объемов данных, к которым производится доступ, которые сохраняются и измеряются в битах, а не в байтах. Буфер может содержать несколько регистров, которые действуют как кольцевой буфер. При осуществлении доступа к битам из одного регистра данные в другом регистре можно загружать в память. Следовательно, при сохранении последовательности битов в одном регистре данные в другом можно сохранять в памяти.
Последовательность битов, загруженная из буфера данных или сохраненная в буфере данных, может занимать несколько регистров. Наконец, команда определяет позицию первой единицы данных в битовом буфере, к которым осуществляется доступ. Позицию первой единицы можно использовать для определения количества битов для сдвига битов в регистре назначения. Это делается с помощью одной команды и без помощи условных переходов, в отличие от традиционной реализации статистического декодирования. Результирующие данные в конечном регистре используются для доступа к таблице поиска. Битовый буфер может также допускать программную оптимизацию выполнения цикла.
Выше описаны иллюстративные варианты осуществления и наилучший режим, но раскрытые варианты осуществления допускают модификации и вариации, не выходящие за пределы объема изобретения, описанного в нижеследующей формуле изобретения.


Изобретение относится к области кодирования и декодирования контента, в частности к извлечению данных из буфера и загрузки их в буфер. Техническим результатом является повышение скорости загрузки и извлечения данных. Способ заключается в выборе данных из буфера в ответ на выполнение команды доступа к данным, при этом буфер содержит множество устройств хранения данных, образующих единое адресное пространство с адресацией на битовом уровне. Если выбираемые данные содержатся в исходном устройстве хранения данных и в следующем устройстве хранения данных, фрагмент выбранных данных из исходного устройства хранения данных конкатенируется с оставшимся фрагментом выбранных данных из следующего устройства хранения данных для формирования выбранных данных в виде непрерывного блока, выбранные данные сохраняются в устройстве назначения для хранения данных. Способ загрузки данных в буфер заключается в сохранении данных в буфере, причем, если размер данных превышает емкость устройства для хранения данных, делят данные на фрагменты и сохраняют данные в исходном устройстве для хранения и следующем. По завершении сохранения перемещают данные из устройства для хранения в устройство памяти. 5 н. и 30 з.п. ф-лы, 26 ил.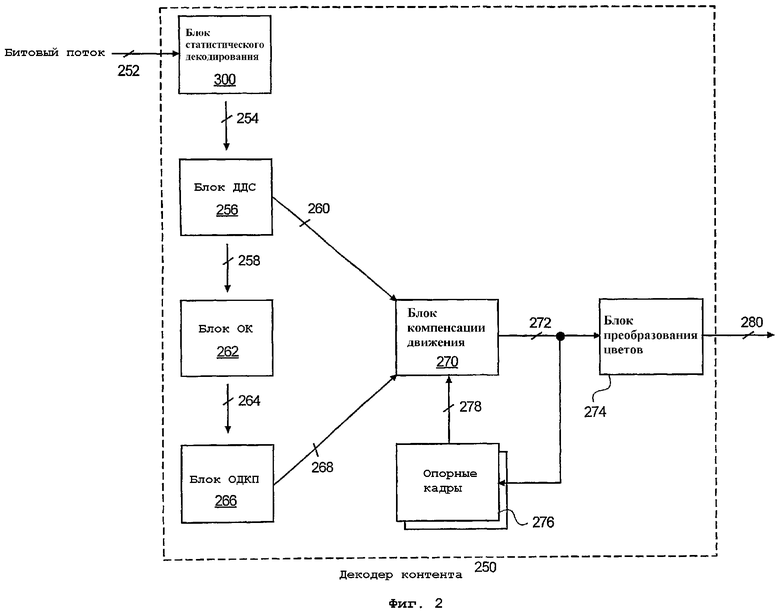
| ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО | 1990 |
|
RU2030785C1 |
| Многоканальное устройство для буферизации данных | 1989 |
|
SU1721600A1 |
| ЕР 0913764 А1, 06.05.1999 | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| US 6195741 A, 27.02.2001. | |||

