Область техники, к которой относится изобретение
Изобретение относится к обработке аудиосигналов. В частности, изобретение относится к измерению воспринимаемой громкости аудиосигнала посредством модификации спектрального представления аудиосигнала как функции от эталонной спектральной формы так, чтобы спектральное представление аудиосигнала более близко соответствовало эталонной спектральной форме, и вычисления воспринимаемой громкости модифицированного спектрального представления аудиосигнала.
Ссылки и включение по ссылке
Определенные способы для объективного измерения воспринимаемой (психоакустической) громкости, используемые для лучшего понимания аспектов настоящего изобретения, описываются в опубликованной международной заявке на патент WO 2004/111994 A2 авторов Alan Jeffrey Seefeldt и другие, опубликованной 23 декабря 2004 года, озаглавленной "Method, Apparatus and Computer Program for Calculating and Adjusting the Perceived Loudness of the Audio Signal", в результирующей заявке на патент США, опубликованной как US 2007/0092089, опубликованной 26 апреля 2007 года, и в статье "A New Objective Measure of Perceived Loudness" авторов Alan Seefeldt и другие, Audio Engineering Society Convention Paper 6236, San Francisco, 28 октября 2004 года. Упомянутые заявки WO 2004/111994 A2 и US 2007/0092089 и упомянутая статья тем самым полностью включаются в данный документ посредством ссылки.
Уровень техники
Существует множество способов для объективного измерения воспринимаемой громкости аудиосигналов. Примеры способов включают в себя A-, B- и C-взвешенные показатели мощности, а также психоакустические модели громкости, такие как описанные в документе "Acoustics - Method for calculating loudness level", ISO 532 (1975), и упомянутых заявках WO 2004/111994 A2 и US 2007/0092089. Взвешенные показатели мощности оперируют посредством взятия входного аудиосигнала, применения известного фильтра, который выделяет более воспринимаемые частоты при одновременном ослаблении менее воспринимаемых частот, и последующего усреднения мощности отфильтрованного сигнала за заранее определенную продолжительность времени. Психоакустические способы типично являются более сложными и ориентированы на то, чтобы оптимизировать моделирование работы человеческого уха. Такие психоакустические способы делят сигнал на полосы частот, которые имитируют частотную характеристику и чувствительность уха, а затем обрабатывают и интегрируют такие полосы частот с учетом психоакустических явлений, таких как частотное и временное маскирование, а также нелинейное восприятие громкости с варьирующейся интенсивностью сигнала. Цель всех таких способов состоит в том, чтобы извлекать численное измерение, которое близко совпадает с субъективным впечатлением от аудиосигнала.
Автор изобретения обнаружил, что описанные объективные измерения громкости не совпадают точно с субъективными впечатлениями для определенных типов аудиосигналов. В упомянутых заявках WO 2004/111994 A2 и US 2007/0092089 такие проблемные сигналы проблемы описываются как "узкополосные", что означает, что большая часть энергии сигнала концентрируется в одной или нескольких небольших частях спектра слышимых звуковых частот. В упомянутых заявках раскрыт способ для того, чтобы обрабатывать такие сигналы, заключающий в себе модификацию традиционной психоакустической модели восприятия громкости, чтобы содержать два вида возрастания функций громкости: один для "широкополосных" сигналов и второй для "узкополосных" сигналов. Заявки WO 2004/111994 A2 и US 2007/0092089 описывают интерполяцию между двумя функциями на основе показателя "узкополосности" сигнала.
Хотя такой способ интерполяции действительно повышает эффективность объективного измерения громкости относительно субъективных впечатлений, автор изобретения с тех пор разработал альтернативную психоакустическую модель восприятия громкости, которая, как он полагает, более оптимально объясняет и разрешает различия между объективными и субъективными измерениями громкости для "узкополосных" проблемных сигналов. Применение этой альтернативной модели к объективному измерению громкости составляет аспект настоящего изобретения.
Краткое описание чертежей
Фиг. 1 показывает упрощенную принципиальную блок-схему аспектов настоящего изобретения.
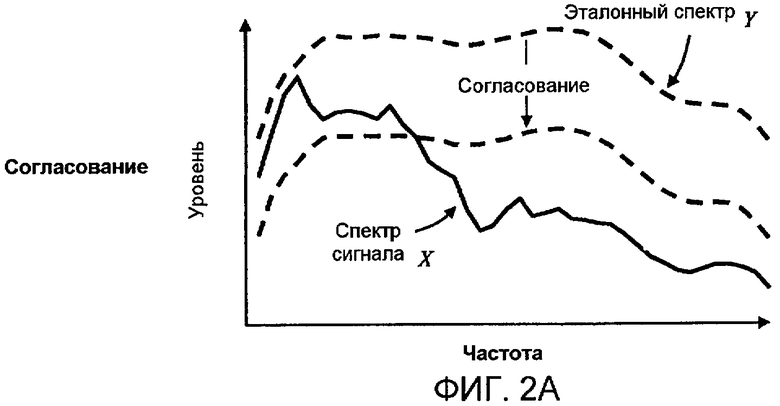
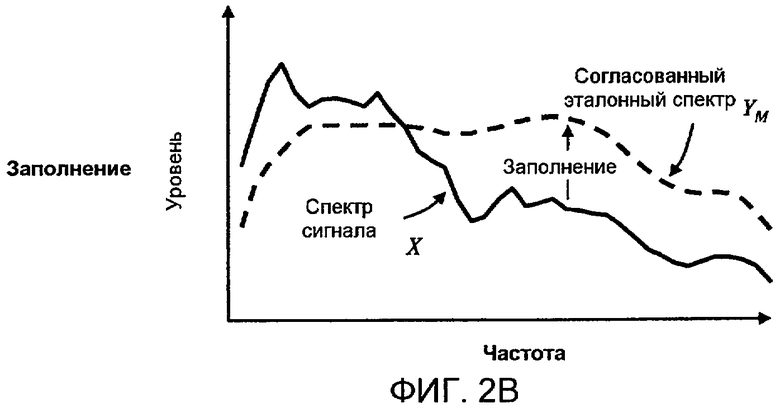
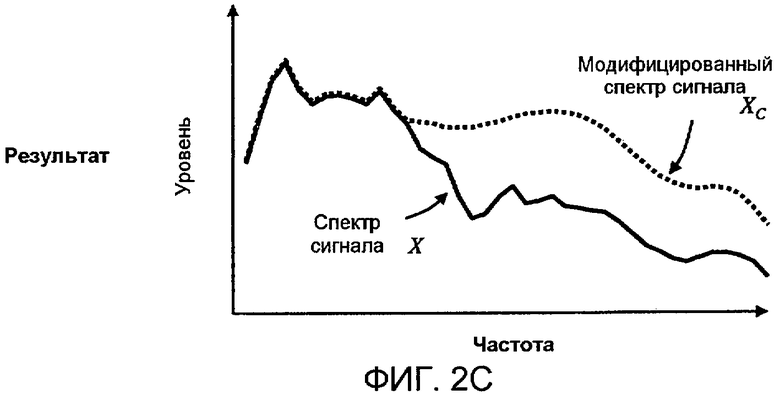
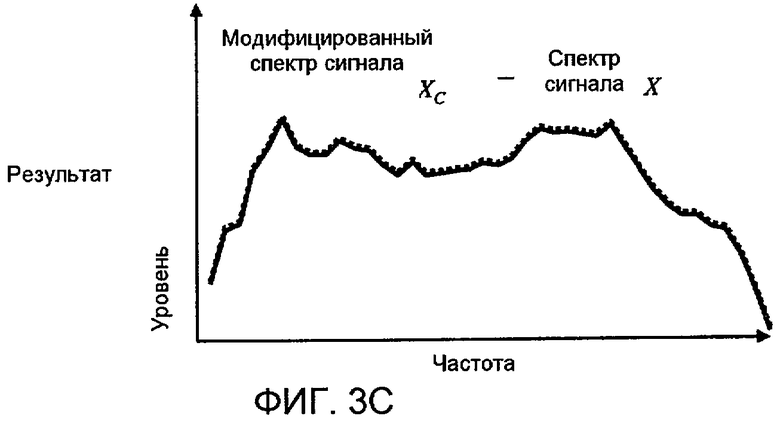
Фиг. 2A, 2B и 2C показывают концептуальным способом пример применения спектральных модификаций в соответствии с аспектами изобретения к идеализированному аудиоспектру, который содержит преимущественно нижние звуковые частоты.
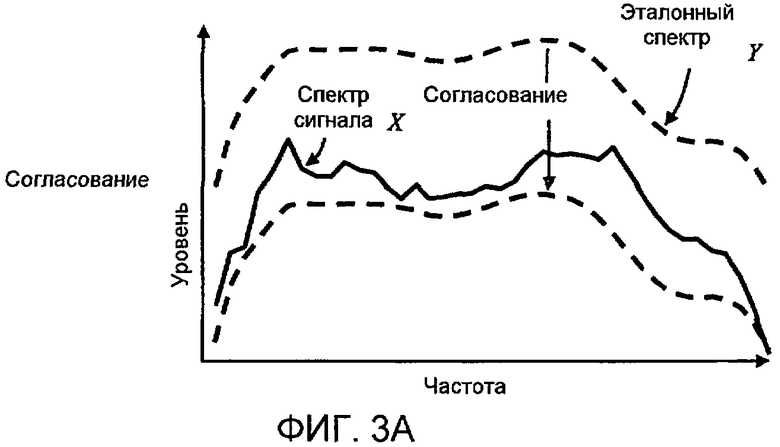
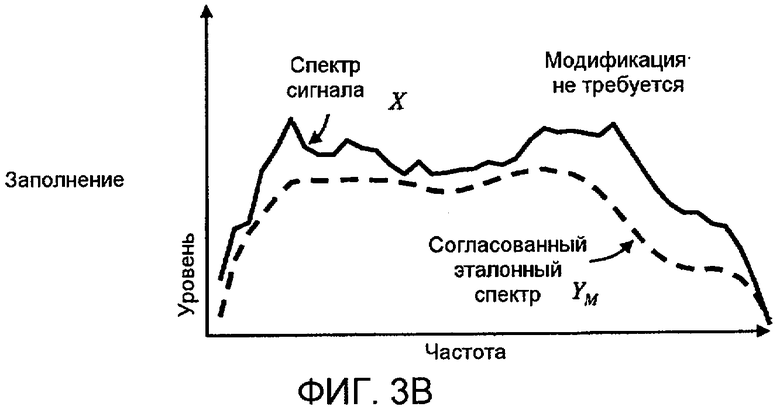
Фиг. 3A, 3B и 3C показывают концептуальным способом пример применения спектральных модификаций в соответствии с аспектами настоящего изобретения к идеализированному аудиоспектру волн, который аналогичен эталонному спектру.
Фиг. 4 показывает набор критических характеристик полосового фильтра, используемых для вычисления сигнала возбуждения в психоакустической модели громкости.
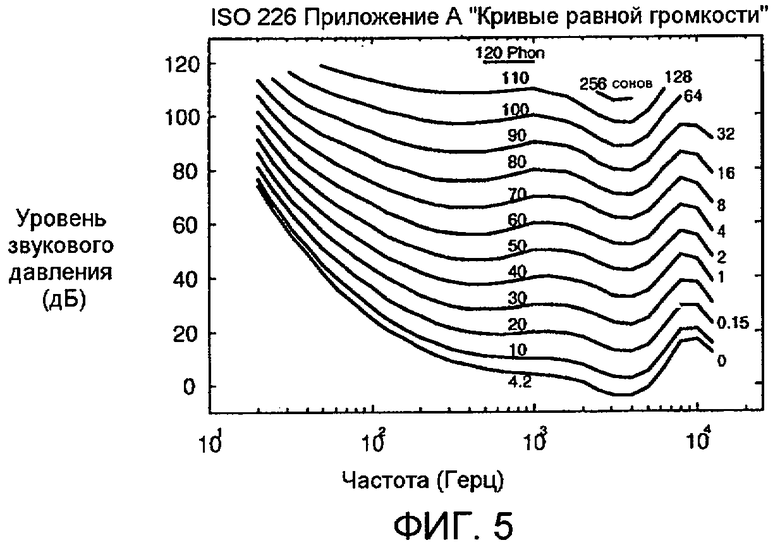
Фиг. 5 показывает кривые равной громкости ISO 226. Горизонтальная шкала - это частота в герцах (логарифмическая шкала по основанию 10), а вертикальная шкала - это уровень звукового давления в децибелах.
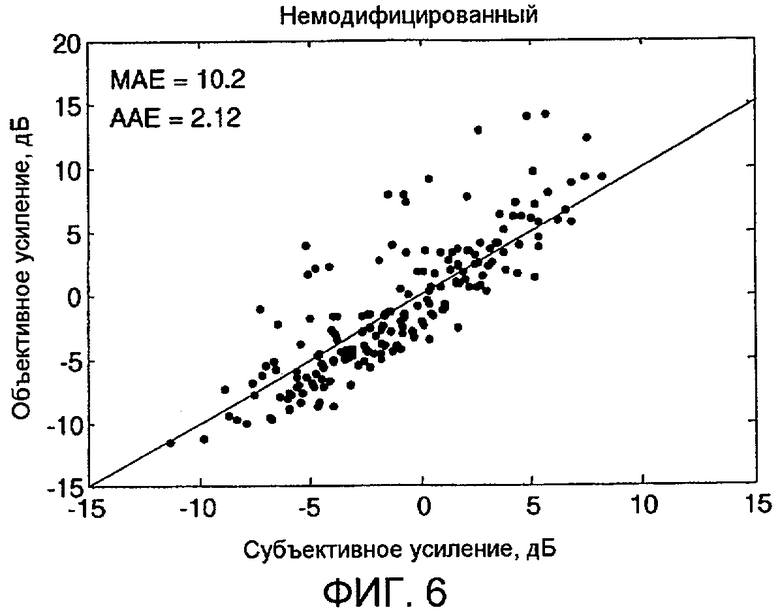
Фиг. 6 является графиком, который сравнивает объективные показатели громкости из немодифицированной психоакустической модели с субъективными показателями громкости для базы данных аудиозаписей.
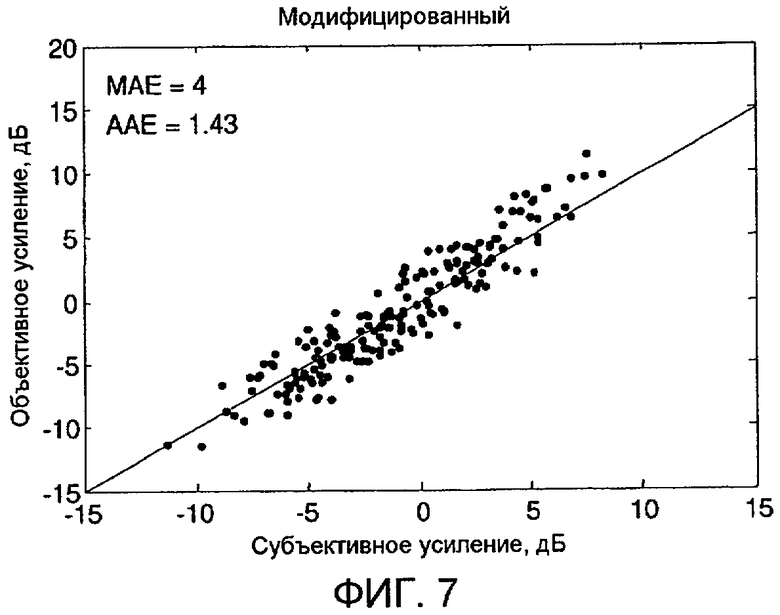
Фиг. 7 является графиком, который сравнивает объективные показатели громкости из психоакустической модели, использующей аспекты настоящего изобретения, с субъективными показателями громкости для одной базы данных аудиозаписей.
Сущность изобретения
Согласно аспектам изобретения способ для измерения воспринимаемой громкости аудиосигнала содержит получение спектрального представления аудиосигнала, модификацию спектрального представления как функции от эталонной спектральной формы так, чтобы спектральное представление аудиосигнала более близко соответствовало эталонной спектральной форме, и вычисление воспринимаемой громкости модифицированного спектрального представления аудиосигнала. Модификация спектрального представления как функции от эталонной спектральной формы может включать в себя минимизацию функции разностей между спектральным представлением и эталонной спектральной формой и задание уровня для эталонной спектральной формы в ответ на минимизацию. Минимизация функции разностей может минимизировать среднее взвешенное разностей между спектральным представлением и эталонной спектральной формой. Минимизация функции разностей дополнительно может включать в себя применение смещения для того, чтобы изменять разности между спектральным представлением и эталонной спектральной формой. Смещение может быть фиксированным смещением. Модификация спектрального представления как функции от эталонной спектральной формы дополнительно может включать в себя взятие максимального уровня спектрального представления аудиосигнала и заданной по уровню эталонной спектральной формы. Спектральное представление аудиосигнала может быть сигналом возбуждения, который аппроксимирует распределение энергии вдоль базилярной мембраны внутреннего уха.
Согласно дополнительным аспектам изобретения способ измерения воспринимаемой громкости аудиосигнала содержит получение представления аудиосигнала, сравнение представления аудиосигнала с эталонным представлением, чтобы определять то, как близко представление аудиосигнала совпадает с эталонным представлением, модификацию, по меньшей мере, части представления аудиосигнала так, чтобы результирующее модифицированное представление аудиосигнала более близко совпадало с эталонным представлением, и определение воспринимаемой громкости аудиосигнала из модифицированного представления аудиосигнала. Модификация, по меньшей мере, части представления аудиосигнала может включать в себя регулирование уровня эталонного представления относительно уровня представления аудиосигнала. Уровень эталонного представления может регулироваться так, чтобы минимизировать функцию разностей между уровнем эталонного представления и уровнем представления аудиосигнала. Модификация, по меньшей мере, части представления аудиосигнала может включать в себя увеличение уровня частей аудиосигнала.
Согласно еще дополнительным аспектам изобретения способ определения воспринимаемой громкости аудиосигнала содержит получение представления аудиосигнала, сравнение спектральной формы представления аудиосигнала с эталонной спектральной формой, регулирование уровня эталонной спектральной формы, чтобы совпадать со спектральной формой представления аудиосигнала так, чтобы разности между спектральной формой представления аудиосигнала и эталонной спектральной формой уменьшались, формирование модифицированной спектральной формы представления аудиосигнала посредством увеличения частей спектральной формы представления аудиосигнала так, чтобы дополнительно улучшать соответствие между спектральной формой представления аудиосигнала и эталонной спектральной формой, и определение воспринимаемой громкости аудиосигнала на основе модифицированной спектральной формы представления аудиосигнала. Регулирование может включать в себя минимизацию функции разностей между спектральной формой представления аудиосигнала и эталонной спектральной формой и задание уровня для эталонной спектральной формы в ответ на минимизацию. Минимизация функции разностей может минимизировать среднее взвешенное разностей между спектральной формой представления аудиосигнала и эталонной спектральной формой. Минимизация функции разностей дополнительно может включать в себя применение смещения, чтобы изменять разности между спектральной формой представления аудиосигнала и эталонной спектральной формой. Смещение может быть фиксированным смещением. Модификация спектрального представления как функции от эталонной спектральной формы дополнительно может включать в себя взятие максимального уровня спектрального представления аудиосигнала и заданной по уровню эталонной спектральной формы.
Согласно дополнительным аспектам и еще дополнительным аспектам настоящего изобретения представление аудиосигнала может быть сигналом возбуждения, который аппроксимирует распределение энергии вдоль базилярной мембраны внутреннего уха.
Другие аспекты изобретения включают в себя устройство, выполняющее любой из вышеизложенных способов, и компьютерную программу, сохраненную на машиночитаемом носителе, для инструктирования компьютеру выполнять любой из вышеизложенных способов.
Лучший вариант осуществления изобретения
В общем смысле, все объективные измерения громкости, упоминаемые ранее (как измерения взвешенной мощности, так и психоакустические модели), могут рассматриваться как интегрирование по частоте некоторого представления спектра аудиосигнала. В случае измерений взвешенной мощности, этот спектр является спектром мощности сигнала, умноженным на спектр мощности выбранного взвешивающего фильтра. В случае психоакустической модели, этот спектр может быть нелинейной функцией мощности в рамках последовательности идущих друг за другом критических полос частот. Как упомянуто выше, выяснилось, что такие объективные показатели громкости предоставляют уменьшенную эффективность для аудиосигналов, обладающих спектром, ранее описанных как "узкополосные".
Вместо интерпретации таких сигналов как узкополосных, автор изобретения создал более простое и более интуитивное пояснение на основе предпосылки, что такие сигналы являются несходными со средней спектральной формой обычных звуков. Можно утверждать, что большинство звуков, встречающихся в повседневной жизни, в частности речь, обладают спектральной формой, которая не расходится слишком значительно со средней "ожидаемой" спектральной формой. Эта средняя спектральная форма показывает общее уменьшение энергии с увеличением частоты, которая пропускается в полосе частот между наименьшими и наибольшими звуковыми частотами. Когда оценивается громкость звука, обладающего спектром, который значительно отклоняется от такой средней спектральной формы, гипотеза автора настоящего изобретения заключается в том, что следует когнитивно "заполнять" до определенной степени те зоны спектра, в которых отсутствует ожидаемая энергия. Общее впечатление громкости затем получается посредством интегрирования по частоте модифицированного спектра, который включает в себя когнитивно "заполненную" спектральную часть, а не фактического спектра сигнала. Например, если прослушивается музыкальное произведение только с игрой на бас-гитаре, в общем, можно ожидать, что другие инструменты в итоге присоединятся к басу и заполнят спектр. Вместо того чтобы определять полную громкость солирующего баса только из его спектра, автор настоящего изобретения полагает, что часть полного восприятия громкости приписывается отсутствующим частотам, которые, как ожидаются, аккомпанируют басу. Аналогия может быть проведена с известным эффектом "отсутствующей основной частоты" в психоакустике. Если слышится последовательность гармонично связанных тонов, но основная частота последовательности отсутствует, последовательность по-прежнему воспринимается как имеющая основной тон, соответствующий отсутствующей основной частоте.
В соответствии с аспектами настоящего изобретения, предположенное выше субъективное явление интегрируется в объективный показатель воспринимаемой громкости. Фиг. 1 иллюстрирует общее представление аспектов изобретения, поскольку оно применяется к любому из уже упомянутых объективных показателей (т.е. как модели взвешенной мощности, так и психоакустические модели). В качестве первого этапа, аудиосигнал x может быть преобразован в спектральное представление X, соразмерное с конкретным используемым объективным показателем громкости. Фиксированный эталонный спектр Y представляет гипотетическую среднюю ожидаемую спектральную форму, поясненную выше. Этот эталонный спектр может быть заранее вычислен, например, посредством усреднения спектров репрезентативной базы данных обычных звуков. В качестве следующего этапа, эталонный спектр Y может "сопоставляться" со спектром сигнала X, чтобы формировать заданный по уровню эталонный спектр Y м . Согласование означает, что Y м формируется как масштабирование уровня Y так, чтобы уровень совпадающего эталонного спектра Y м совмещался с X, при этом совмещение является функцией разности уровня между X и Y м по частоте. Совмещение уровней может включать в себя минимизацию взвешенной или невзвешенной разности между X и Y м по частоте. Такое взвешивание может быть задано любым числом способов, но может быть выбрано так, чтобы частям спектра X, которые в наибольшей степени отклоняются от эталонного спектра Y, присваивались наибольшие веса. Таким образом, самые "необычные" части спектра сигнала X совмещаются ближе всего с Y м . Затем модифицированный спектр сигнала X c формируется посредством модификации X таким образом, чтобы быть ближе к совпадающему эталонному спектру Y м согласно критерию модификации. Как подробно поясняется ниже, эта модификация может принимать форму простого выбора максимума из X и Y м по частоте, который моделирует когнитивное "заполнение", поясненное выше. Наконец, модифицированный спектр сигнала X c может быть обработан согласно выбранному объективному показателю громкости (т.е. некоторому типу интегрирования по частоте), чтобы формировать объективное значение L громкости.
Фиг. 2A-C и 3A-C иллюстрируют соответственно примеры вычисления модифицированных спектров сигнала X c для двух различных первоначальных спектров сигнала X. На фиг. 2A первоначальный спектр сигнала X, представленный посредством сплошной линии, содержит большую часть своей энергии в нижних звуковых частотах. По сравнению с проиллюстрированным эталонным спектром Y, представленным посредством пунктирных линий, форма спектра сигнала X считается "необычной". На фиг. 2A эталонный спектр первоначально показан с произвольным начальным уровнем (верхняя пунктирная линия), при котором он выше спектра сигнала X. Эталонный спектр Y может затем быть уменьшен в масштабе до такого уровня, чтобы совпадать со спектром сигнала X, создавая совпадающий эталонный спектр Y м (нижняя пунктирная линия). Можно отметить, что Y м наиболее близко совпадает с нижними звуковыми частотами X, которые могут рассматриваться "необычной" частью спектра сигнала при сравнении с эталонным спектром. На фиг. 2B, части спектра сигнала X, находящиеся ниже совпадающего эталонного спектра, Y м, задаются равными Y м, тем самым моделируя процесс когнитивного "заполнения". На фиг. 2C можно видеть результат, когда модифицированный спектр сигнала X c , представленный посредством пунктира, равен максимуму из X и Y м по частоте. В этом случае, применение спектральной модификации добавило значительную величину энергии к первоначальному спектру сигнала в верхних частотах. Как результат, громкость, вычисляемая из модифицированного спектра сигнала X c, превышает громкость, которая была бы вычислена из первоначального спектра сигнала X, что является требуемым эффектом.
На фиг. 3A-C спектр сигнала X аналогичен по форме эталонному спектру Y. Как результат, совпадающий эталонный спектр Y м может падать до уровня ниже спектра сигнала X при всех частотах, и модифицированный спектр сигнала X c может быть равным первоначальному спектру сигнала Y. В этом примере модификация не затрагивает никоим образом последующее измерение громкости. Для большей части сигналов их спектры являются достаточно близкими к модифицированному спектру, как на фиг. 3A-C, так что модификация не применяется и поэтому изменение в вычислении громкости не производится. Предпочтительно, только "необычные" спектры, как на фиг. 2A-C, модифицируются.
В упомянутых заявках WO 2004/111994 A2 и US 2007/0092089 авторов Seefeldt и других раскрывается, среди прочего, объективный показатель воспринимаемой громкости на основе психоакустической модели. Предпочтительный вариант осуществления настоящего изобретения может применять описанную спектральную модификацию к такой психоакустической модели. Модель, без модификации, сначала анализируется, а затем представляются сведения по применению модификации.
Из аудиосигнала, x[n], психоакустическая модель сначала вычисляет сигнал возбуждения E[b,t], аппроксимирующий распределение энергии вдоль базилярной мембраны внутреннего уха в критической полосе частот b в течение временного блока t. Это возбуждение может быть вычислено из кратковременного дискретного преобразования Фурье (STDFT) аудиосигнала следующим образом:
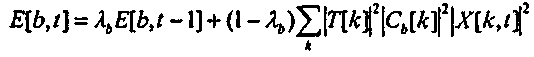 (1)
(1)
где X[k,t] представляет STDFT x[n] во временном блоке t и элементе разрешения k, где k - это индекс элемента разрешения по частоте в преобразовании, T[k] представляет частотную характеристику фильтра, моделирующего передачу аудио через внешнее и среднее ухо, а Cb[k] представляет частотную характеристику базилярной мембраны в местоположении, соответствующем критической полосе частот b. Фиг. 4 иллюстрирует подходящий набор критических характеристик полосового фильтра, в котором сорок полос частот разнесены равномерно вдоль шкалы эквивалентной прямоугольной полосы пропускания (ERB), как задано авторами Moore и Glasberg (B. C. J. Moore, B. Glasberg, T. Baer, "A Model for the Prediction of Thresholds, Loudness and Partial Loudness," Journal of the Audio Engineering Society, Vol. 45, No. 4, апрель 1997 года, стр. 224-240). Каждая форма фильтра описывается посредством округленной экспоненциальной функции, и полосы частот распределяются с использованием разнесения в 1 ERB. Наконец, сглаживающая постоянная времени λb в (1) может быть преимущественно выбрана пропорционально ко времени интегрирования человеческого восприятия громкости в рамках полосы частот b.
Используя кривые равной громкости, такие как проиллюстрированные на фиг. 5, возбуждение в каждой полосе частот преобразуется в уровень возбуждения, который должен формировать такую же громкость при 1 кГц. Конкретная громкость, показатель перцепционной громкости, распределенной по частоте и времени, затем вычисляется из преобразованного возбуждения, E 1KHz [b,t], через сжимающую нелинейность. Одна такая подходящая функция для того, чтобы вычислять конкретную громкость N[b,t], задается следующим образом:
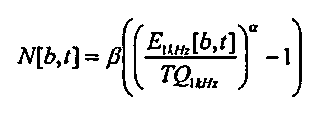 (2)
(2)
где TQ 1KHz - это порог тишины при 1 кГц, а постоянные β и α выбираются так, чтобы совпадать с субъективным впечатлением возрастания громкости для тона в 1 кГц. Хотя выяснилось, что значение 0,24 для β и значение 0,045 для α является подходящим, эти значения не являются критичными. Наконец, полная громкость, L[t], представленная в единицах сона, вычисляется посредством суммирования конкретной громкости по полосам частот
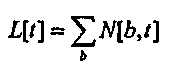 (3)
(3)
В этой психоакустической модели существует два промежуточных спектральных представления аудио до вычисления полной громкости: возбуждение E[b,t] и конкретная громкость N[b,t]. Для настоящего изобретения спектральная модификация может быть применена к ним обоим, но применение модификации к возбуждению, а не к конкретной громкости упрощает вычисления. Это обусловлено тем, что форма возбуждения по частоте является инвариантной к общему уровню аудиосигнала. Это отражается на способе, которым спектры сохраняют неизменную форму при различных уровнях, как показано на фиг. 2A-C и 3A-C. Это не имеет место для конкретной громкости вследствие нелинейности в уравнении 2. Таким образом, примеры, представленные в данном документе, применяют спектральные модификации к спектральному представлению возбуждения.
Продолжая с применением спектральной модификации к возбуждению, предполагается, что фиксированное эталонное возбуждение Y[b] существует. На практике Y[b] может быть создано посредством усреднения возбуждений, вычисленных из базы данных звуков, содержащей большое количество речевых сигналов. Источник спектра эталонного возбуждения Y[b] не является критическим для изобретения. При применении модификации полезно осуществлять операции с представлениями в децибелах возбуждения сигнала E[b,t] и эталонного возбуждения Y[b]
 (4a)
(4a)
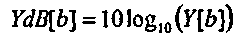 (4b)
(4b)
В качестве первого этапа эталонное возбуждение в децибелах YdB[b] может быть сопоставлено с возбуждением сигнала в децибелах EdB[b,t], чтобы формировать совпадающее эталонное возбуждение в децибелах YdB M [b], где YdB M [b] представляется как масштабирование (или аддитивное смещение при использовании дБ) эталонного возбуждения
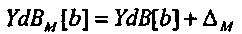 (5)
(5)
Согласующее смещение ΔM вычисляется как функция разности, Δ[b], между EdB[b,t] и YdB[b]
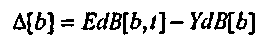 (6)
(6)
Из этого разностного возбуждения, Δ[b], взвешивание, W[b], вычисляется как разностное возбуждение, нормализованное так, чтобы иметь минимум в нуле, и затем возведенное в степень γ
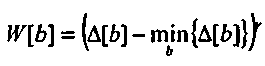 (7)
(7)
На практике задание γ=2 является оптимальным, хотя это значение не является критическим, и другие взвешивания или вообще отказ от взвешивания (т.е. γ=1) может использоваться. Согласующее смещение Δм затем вычисляется как среднее взвешенное разностного возбуждения, Δ[b], плюс допустимое смещение, ΔTol
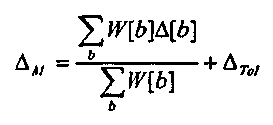 (8)
(8)
Взвешивание в уравнении 7, когда больше единицы, приводит к тому, что части возбуждения сигнала EdB[b,t], наиболее отличающиеся от эталонного возбуждения YdB[b], вносят наибольшую долю в согласующее смещение Δм. Допустимое смещение ΔTol влияет на величину "заполнения", которое происходит, когда применяется модификация. На практике задание ΔTol =-12 дБ является оптимальным, приводя к тому, что большая часть аудиоспектров остается немодифицированной при применении модификации. (На фиг. 3A-C именно это отрицательное значение ΔTol приводит к тому, что совпадающий эталонный спектр полностью падает до уровня ниже, а не соразмерного, относительно спектра сигнала, и поэтому имеет результатом отсутствие регулирования спектра сигнала).
После того как совпадающее эталонное возбуждение вычислено, модификация применяется так, чтобы формировать модифицированное возбуждение сигнала посредством взятия максимума EdB[b,t] и YdB M [b] по полосам частот
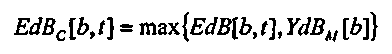 (9)
(9)
Представление в децибелах модифицированного возбуждения затем преобразуется назад в линейное представление
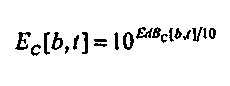 (10)
(10)
Это модифицированное возбуждение сигнала E c [b,t] затем заменяет первоначальное возбуждение сигнала E[b,t] на оставшихся этапах вычисления громкости согласно психоакустической модели (т.е. вычисления конкретной громкости и суммирования конкретной громкости по полосам частот, как задано в уравнениях 2 и 3).
Чтобы продемонстрировать практическую полезность раскрытого изобретения, фиг. 6 и 7 иллюстрируют данные, показывающие то, как немодифицированные и модифицированные психоакустические модели соответственно прогнозируют субъективно оцененную громкость базы данных аудиозаписей. Для каждой тестовой записи в базе данных субъектов попросили регулировать громкость аудио так, чтобы было совпадение с громкостью некоторой фиксированной контрольной записи. Для каждой тестовой записи субъекты могут мгновенно переключаться в обе стороны между тестовой записью и контрольной записью, чтобы определять разность в громкости. Для каждого субъекта конечное отрегулированное увеличение громкости в дБ сохранено для каждой тестовой записи, и эти усиления затем усреднены по многим субъектам, чтобы сформировать субъективные показатели громкости для каждой тестовой записи. Как немодифицированные, так и модифицированные психоакустические модели затем используются для того, чтобы сформировать объективный показатель громкости для каждой из записей в базе данных, и эти объективные показатели сравниваются с субъективными показателями на фиг. 6 и 7. На обоих чертежах горизонтальная ось представляет субъективный показатель в дБ, а вертикальная ось представляет объективный показатель в дБ. Каждая точка на чертеже представляет запись в базе данных, и если объективный показатель идеально совпадает с субъективным показателем, то каждая точка попадает точно на диагональную линию.
Для немодифицированной психоакустической модели на фиг. 6 следует отметить, что большая часть точек данных попадает рядом с диагональной линией, но значительное количество выпадающих значений существует выше линии. Такие выпадающие значения представляют проблемные сигналы, поясненные ранее, и немодифицированная психоакустическая модель оценивает их как слишком тихие в сравнении со средней субъективной оценкой. Для всей базы данных, средняя абсолютная ошибка (AAE) между объективными и субъективными показателями составляет 2,12 дБ, что является довольно низким значением, но максимальная абсолютная ошибка достигает очень высокого значения 10,2 дБ.
Фиг. 7 иллюстрирует те же данные для модифицированной психоакустической модели. Здесь большая часть точек данных на графике остается неизмененной от показанных на фиг. 6, за исключением выпадающих значений, которые были приведены в соответствие с другими точками, кластеризованными вокруг диагонали. По сравнению с немодифицированной психоакустической моделью AAE в некоторой степени снижается до 1,43 дБ, а MAE значительно снижается до 4 дБ. Преимущество раскрытой спектральной модификации ранее выпадающих сигналов становится легко очевидным.
Реализация
Хотя, в принципе, изобретение может быть осуществлено на практике в аналоговой или в цифровой области (или в определенной их комбинации), в практических вариантах осуществления изобретения аудиосигналы представляются посредством выборок в блоках данных и обработка выполняется в цифровой области.
Изобретение может быть реализовано в аппаратных средствах или в программном обеспечении, или в комбинации означенного (к примеру, в программируемых логических матрицах). Если не указано иное, алгоритмы и процессы, включенные как часть изобретения, по сути, не связаны ни с одним конкретным компьютером или другим устройством. В частности, различные машины общего назначения могут использоваться с программами, написанными в соответствии с идеями в данном документе, или может быть более удобным конструировать более специализированное устройство (к примеру, интегральные схемы) для того, чтобы осуществлять требуемые этапы способа. Таким образом, изобретение может быть реализовано в одной или более компьютерных программ, выполняющихся на одной или более программируемых компьютерных систем, каждая из которых содержит, по меньшей мере, один процессор, по меньшей мере, одну систему хранения данных (включающую в себя энергозависимое и энергонезависимое запоминающее устройство и/или запоминающие элементы), по меньшей мере, одно устройство или порт ввода и, по меньшей мере, одно устройство или порт вывода. Программный код применяется к входным данным для того, чтобы выполнять функции, описанные в данном документе, и формировать выходную информацию. Выходная информация применяется к одному или более устройствам вывода известным способом.
Каждая такая программа может быть реализована на любом требуемом машинном языке (включая машинный язык, ассемблер либо высокоуровневые процедурные, логические или объектно-ориентированные языки программирования), чтобы обмениваться данными с компьютерной системой. В любом случае язык может быть компилируемым или интерпретируемым языком.
Каждая такая компьютерная программа предпочтительно сохраняется или загружается на носители или устройства хранения данных (к примеру, полупроводниковые запоминающие устройства или носители либо магнитные или оптические носители), читаемые посредством программируемого компьютера общего или специального назначения, для конфигурирования и работы с компьютером, когда носители или устройства хранения данных считываются посредством компьютерной системы, чтобы выполнять процедуры, описанные в данном документе. Соответствующая изобретению система также может рассматриваться как реализованная в качестве машиночитаемого носителя хранения данных, сконфигурированного с помощью компьютерной программы, при этом носитель хранения данных, сконфигурированный таким образом, предписывает компьютерной системе работать конкретным и заранее заданным способом, чтобы выполнять функции, описанные в данном документе. Описан ряд вариантов осуществления изобретения. Тем не менее, следует понимать, что различные модификации могут быть выполнены без отступления от сущности и объема изобретения. Например, некоторые из этапов, описанных в данном документе, могут быть независимыми от порядка и таким образом могут выполняться в порядке, отличном от описанного.

Изобретение относится к обработке аудиосигналов, в частности к измерению воспринимаемой громкости аудиосигнала. Воспринимаемая громкость аудиосигнала измеряется посредством модификации спектрального представления аудиосигнала как функции от эталонной спектральной формы так, чтобы спектральное представление аудиосигнала более близко соответствовало эталонной спектральной форме, и определения воспринимаемой громкости модифицированного спектрального представления аудиосигнала. Технический результат - повышение эффективности объективного измерения громкости относительно субъективных впечатлений. 3 н. и 7 з.п. ф-лы, 11 ил.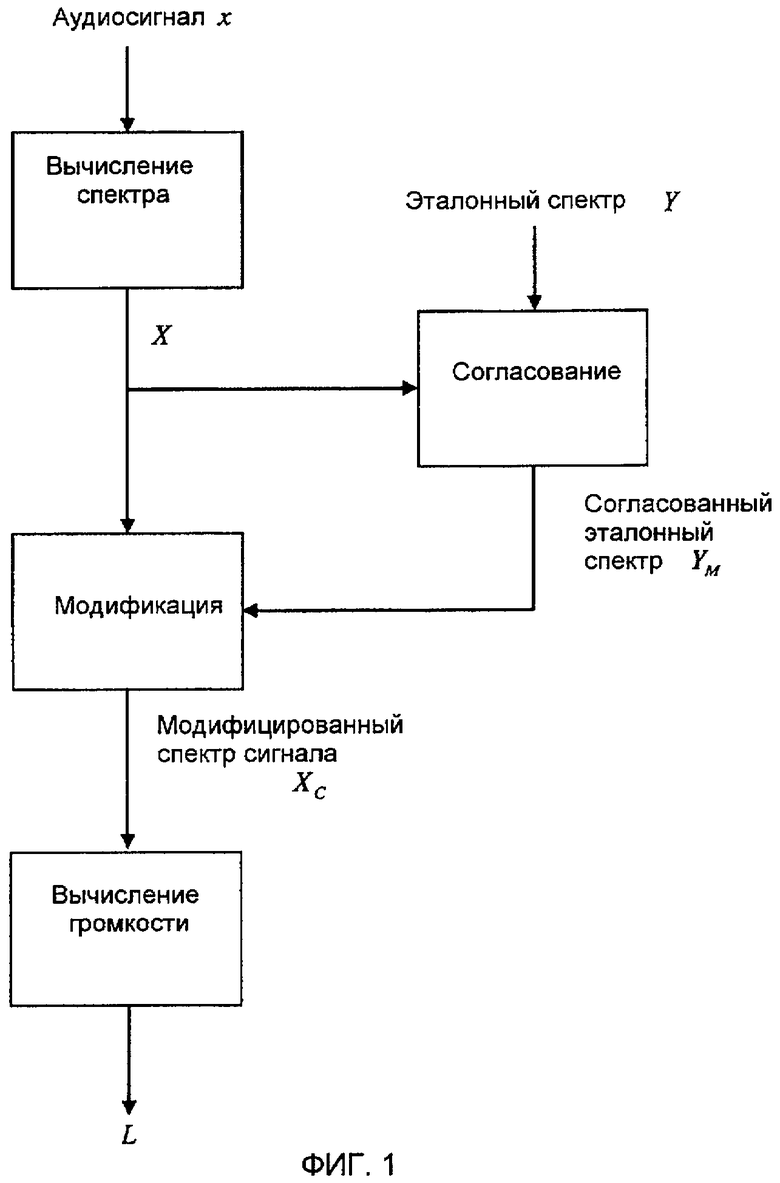
1. Способ для измерения воспринимаемой громкости аудиосигнала, содержащий этапы, на которых:
- получают спектральное представление X аудиосигнала,
- согласуют уровень эталонного спектра Y с уровнем спектрального представления X так, чтобы формировать заданный по уровню эталонный спектр Yм, причем Yм - это масштабирование уровня Y так, чтобы уровень согласованного эталонного спектра совмещался с уровнем спектрального представления X, при этом масштабирование уровня является функцией разности уровней X и Y по частоте, и
- обрабатывают, когда спектральное представление X и заданный по уровню эталонный спектр Yм находятся в пределах допустимого смещения ΔTol друг от друга, спектральное представление X, чтобы формировать показатель воспринимаемой громкости аудиосигнала, при этом
- модифицируют, когда спектральное представление X и заданный по уровню эталонный спектр Yм не находятся в пределах упомянутого допустимого смещения ΔTol друг от друга, спектральное представление X, чтобы формировать модифицированное спектральное представление Хс, которое соответствует заданному по уровню эталонному спектру Yм более близко, чем спектральное представление X;
- обрабатывают модифицированное спектральное представление Хс для формирования измерения воспринимаемой громкости аудиосигнала.
2. Способ по п.1, в котором масштабирование уровня эталонного спектра Y вычисляется как функция от взвешенного или невзвешенного среднего разностей X и Y по частоте.
3. Способ по п.2, в котором масштабирование уровня эталонного спектра Y вычисляется как функция от среднего взвешенного разностей X и Y по частоте и в котором частям спектра X, которые в наибольшей степени отклоняются от эталонного спектра Y, присваиваются большие веса, чем другим частям.
4. Способ по любому из пп.1-3, в котором этап модифицирования упомянутого спектрального представления X так, чтобы формировать модифицированное спектральное представление Хс, когда спектральное представление X и заданный по уровню эталонный спектр Yм не находятся в пределах упомянутого допустимого смещения ΔTol друг от друга, дополнительно включает в себя этап, на котором берут большее из уровня спектрального представления аудиосигнала и заданной по уровню эталонной спектральной формы.
5. Способ по любому из пп.1-3, в котором спектральное представление аудиосигнала - это сигнал возбуждения, который аппроксимирует распределение энергии вдоль базилярной мембраны внутреннего уха.
6. Способ по любому из пп.1-3, в котором упомянутый эталонный спектр Y представляет гипотетическую среднюю ожидаемую спектральную форму.
7. Способ по п.6, в котором упомянутый эталонный спектр Y заранее вычисляется посредством усреднения спектров репрезентативной базы данных обычных звуков.
8. Способ по любому из пп.1-3,7, в котором упомянутый эталонный спектр Y является фиксированным.
9. Система для измерения воспринимаемой громкости аудиосигнала, содержащая средство, выполненное с возможностью осуществления этапов способа по любому из пп.1-8.
10. Машиночитаемый носитель, сохраняющий компьютерную программу, которая, при выполнении посредством компьютера осуществляет способ по любому из пп.1-8.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 2007092089 А1, 2007.04.26 | |||
| ПСИХОАКУСТИЧЕСКИЙ ПРОЦЕССОР | 2004 |
|
RU2279759C2 |
| Способ изоляции поглощающих пластов в скважинах | 1984 |
|
SU1239269A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

