Область техники
Изобретение относится к способу осуществления машинной оценки качества передачи аудиосигналов, в особенности речевых сигналов, при этом в некотором частотном диапазоне определяются спектры подлежащего передаче сигнала источника и переданного сигнала приема.
Уровень техники
Оценка качества передачи речевых каналов приобретает все большее значение с ростом распространения и с расширением территорий использования мобильных радиотелефонных систем. Стремятся создать способ, обеспечивающий объективность оценки (т.е. независимость от оценки конкретного лица) и возможность его автоматической реализации.
Высококачественная передача речи по каналу связи в стандартизованной полосе 0,3-3,4 кГц обеспечивает разборчивость речи порядка 98%. Однако введение цифровых мобильных сетей с кодированием речи в оконечных устройствах может существенно ухудшить разборчивость речи. Определение количественной характеристики ухудшения представляет в общем случае известные трудности.
Качество речи представляет собой неопределенное понятие по сравнению, например, с частотой следования (скоростью передачи) битов, эхо-сигналом или уровнем громкости. Так как степень удовлетворения пользователей можно непосредственно измерить качеством передаваемой речи, способы кодирования должны выбираться и оцениваться в отношении их качества речи. Для оценки способа кодирования речи обычно осуществляют очень трудоемкие тесты на прослушивание. Результаты, получаемые при этом, едва ли могут быть воспроизведены, и зависят от мотивации слушателей, принимающих участие в тестах. Поэтому стремятся найти инструментальную замену, которая позволяет измерить с помощью соответствующих процедур физических измерений признаки качества речи, которые максимальным образом коррелируют с субъективным образом получаемыми результатами (средним баллом оценки - СБО).
Из ЕР 0644674 А2 известен способ оценки качества передачи на участке речевого канала, позволяющий осуществить автоматическую оценку, которая в значительной степени коррелирует с восприятием слушателя. Т.е. система может проводить оценку качества передачи и при этом подходить к оценке с определенной меркой, подобной той, которая применяется опытным участником тестов. Основная идея состоит в применении нейронной сети. Она обучается с использованием образцов речи. В конечном счете, производится интегральная оценка качества. При этом не выясняют причины потери качества.
Современные способы кодирования речи осуществляют компрессию данных и используют очень низкие скорости передачи битов. Поэтому простые известные способы объективной оценки, как, например, определение отношения сигнал/шум, оказываются неэффективными.
Сущность изобретения
Задача изобретения состоит в создании способа упомянутого выше типа, который обеспечивает получение объективной оценки (предсказание качества речи) с учетом слухового процесса человека.
Решение этой задачи определяется признаками, приведенными в пункте 1 формулы изобретения. Согласно изобретению, для оценки качества передачи определяется значение спектрального подобия, которое основывается на расчете ковариации спектров сигнала источника и сигнала приема и делении ковариации на стандартные отклонения обоих названных спектров.
Тесты с использованием ряда проверенных образцов речи и соответствующего суждения, получаемого в результате прослушивания, показали, что на основе соответствующего изобретению способа может быть достигнута очень высокая корреляция со значениями, полученными в результате прослушивания. По сравнению с методом, базирующимся на использовании нейронной сети, предлагаемый способ имеет следующие преимущества:
- снижение потребностей в памяти и центральном процессорном блоке. Это важно для реализации в режиме реального времени;
- отсутствие трудоемкого процесса обучения системы при введении нового образца речи;
- отсутствие субоптимального имманентного для системы эталона. Наилучшее качество речи, которое может быть измерено по такой мерке, соответствует наилучшему качеству образца речи.
Предпочтительным образом, спектральное значение подобия взвешивается коэффициентом, который в зависимости от отношения энергий спектров сигнала приема к сигналу источника значение подобия снижает сильнее в том случае, когда энергия сигнала приема больше, чем энергия сигнала источника, по сравнению с тем случаем, когда энергия сигнала приема меньше, чем энергия сигнала источника. Таким путем дополнительные сигнальные составляющие в сигнале приема взвешиваются негативно более сильно, чем отсутствующие сигнальные составляющие.
В соответствии с особенно предпочтительным вариантом осуществления весовой коэффициент также зависит от энергии сигнала приема. Для каждого любого соотношения энергий спектров сигнала приема и сигнала источника справедливо то, что значение подобия снижается тем сильнее, чем выше энергия сигнала приема. Тем самым регулируется влияние помехи в сигнале приема на значение подобия в зависимости от энергии сигнала приема. Для этого определены два окна (интервала) уровней: одно ниже предварительно заданного порога, а другое выше этого порога. Предпочтительно выше упомянутого порога определено несколько, в частности, три окна уровней. В зависимости от окна уровней, в котором находится сигнал приема, осуществляется снижение значения подобия. Чем выше уровень, тем сильнее снижение.
В принципе изобретение может использоваться для любых аудиосигналов. Если аудиосигналы содержат неактивные фазы (интервалы), что является типичным для речевых сигналов, целесообразно проводить оценку качества отдельно для активных и неактивных фаз. Фрагменты сигнала, энергия которых превосходит предварительно заданный порог, соотносят с активными фазами, а остальные фрагменты квалифицируются как паузы (неактивные фазы).
Для неактивных фаз (например, пауз речи) может применяться функция качества, которая в зависимости от энергии пауз спадает дегрессивно:

Здесь А - соответственно выбранная константа, Emax - максимально возможное значение энергии пауз.
Общее качество передачи (т.е. собственно качество передачи) получается из взвешенной линейной комбинации качества активной и неактивной фазы. При этом весовые коэффициенты зависят от доли активной фазы в полном сигнале, а именно нелинейным образом, с преобладанием активной фазы. При доле, например, 50% качество активной фазы может составлять порядка 90%.
Паузы и соответственно помехи в паузах также отделяются и учитываются в меньшей степени, чем активные фазы сигнала. При этом исходят из того, что в паузах по существу не передается информация, но, несмотря на это, учитываются воспринимаемые как неприятные помехи в паузах.
В соответствии с особенно предпочтительным вариантом осуществления изобретения определяются временные отсчеты сигнала источника и сигнала приема в блоках данных, которые перекрываются друг с другом на интервал от нескольких миллисекунд до нескольких десятков миллисекунд (например, 16 мс). Такое перекрытие имитирует, по меньшей мере частично, временное маскирование, внутренне присущее органам слуха человека.
В значительной степени реалистичная имитация временного маскирования получается в том случае, когда дополнительно, после преобразования в частотную область, к спектру текущего блока данных аддитивно добавляется ослабленный спектр предыдущего блока данных. Спектральные компоненты при этом взвешиваются предпочтительно различным образом. Низкочастотные компоненты предыдущего блока данных взвешиваются сильнее, чем высокочастотные.
Целесообразно, перед осуществлением временного маскирования предпринять компрессию спектральных составляющих. Если в частотном диапазоне возникает одновременно множество частот, то в слуховой системе возникает сверхреакция, т.е. полный уровень громкости воспринимается как более высокий, чем уровень громкости суммы отдельных частотных составляющих. В конечном счете, это означает компрессию составляющих.
Дополнительной мерой достижения хорошей корреляции между результатами оценки согласно соответствующему изобретению способу и субъективным восприятием человека является свертка спектра блока данных с асимметричной “функцией размывания”. Эта математическая операция применяется как к сигналу источника, так и к сигналу приема перед определением подобия.
Функция размывания на графике зависимости частоты от громкости предпочтительно представляет собой треугольную функцию, левый фронт которой круче, чем правый.
Перед сверткой спектры могут дополнительно расширяться за счет возведения в степень со значением ε>1 (например, ε=4/3). Тем самым имитируется функция громкости, характерная для органа слуха человека.
В последующем детальном описании и в формуле изобретения охарактеризованы другие предпочтительные формы выполнения и комбинации признаков изобретения.
Краткое описание чертежей
Изобретение поясняется на примерах осуществления, иллюстрируемых чертежами, на которых представлено следующее:
фиг.1 - обобщенная блок-схема, поясняющая принцип обработки;
фиг.2 - блок-схема отдельных этапов способа для осуществления оценки качества;
фиг.3 - пример окна Хэмминга;
фиг.4 - представление функции взвешивания для вычисления преобразования частоты в звук;
фиг.5 - представление частотной характеристики телефонного фильтра;
фиг.6 - представление кривых одинаковой силы звука для плоского звукового поля (Ln - сила звука, N - громкость);
фиг.7 - схематичное представление временного маскирования;
фиг.8 - представление функции громкости (в единицах громкости - сон) для уровня звука (в единицах уровня громкости звука - фон) тонального сигнала частоты 1 кГц;
фиг.9 - представление функции размывания;
фиг.10 - графическое представление коэффициента речи в функции речевых составляющих сигнала источника;
фиг.11 - графическое представление качества на интервале паузы в функции речевой энергии на интервале паузы;
фиг.12 - графическое представление постоянной усиления в функции отношения энергий;
фиг.13 - графическое представление весовых коэффициентов для реализации временного маскирования в зависимости от частотных составляющих.
На чертежах одинаковые элементы обозначены одинаковыми ссылочными позициями.
Варианты осуществления изобретения
Ниже конкретный пример осуществления поясняется со ссылками на чертежи.
Фиг.1 иллюстрирует принцип обработки. В качестве сигнала x(i) источника используется выборка речевого сигнала. Он обрабатывается устройством 1 речевого кодирования или соответственно передается и переводится в сигнал y(i) приема (кодированный речевой сигнал). Указанные сигналы представлены в цифровой форме. Частота дискретизации составляет, например, 8 кГц, а цифровое квантование соответствует 16 битам. Формат данных предпочтительно соответствует импульсно-кодовой модуляции (ИКМ) (без сжатия).
Сигнал источника и сигнал приема отдельно подвергаются обработке на этапах предварительной обработки 2 и психоакустического моделирования 3. Производится вычисление 4 степени различия, при котором оценивается подобие сигналов. И в заключение осуществляется вычисление 5 СБО, чтобы получить результат, сопоставимый с субъективной оценкой человека.
Фиг.2 поясняет процессы, детально описанные ниже. Сигнал источника и сигнал приема подвергаются одинаковой процедуре обработки. Ради простоты процедура представлена на чертеже однократно. Однако должно быть ясно, что оба сигнала обрабатываются отдельно вплоть до получения меры их различия.
Сигнал источника основан на фрагменте речи, выбранном таким образом, чтобы его статистика частоты (повторяемости) звуков произносимой речи по возможности точно соответствовала произносимой речи. Для исключения контекстного слушания применяют бессмысленные слоги, так называемые логатомы. Выборка речи должна иметь по возможности постоянный уровень речи.
Длительность выборки речи находится в пределах от 3 до 8 секунд (в типовом случае 5 секунд).
Подготовка сигнала состоит в следующем. На первом этапе сигнал источника вводится в виде вектора x(i), а сигнал приема - в виде вектора y(i). Оба сигнала должны быть синхронизированы по времени и по уровню. Затем исключается составляющая постоянного тока путем вычитания из каждого значения выборки среднего значения:

Затем сигналы нормируются общим среднеквадратичным уровнем, поэтому постоянный коэффициент усиления в сигнале не учитывается:
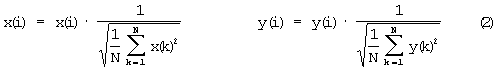
Затем осуществляется формирование блоков (кадров) данных: оба сигнала подразделяются на сегменты длиной 32 мс (256 значений выборок при частоте дискретизации 8 кГц). Эти блоки данных используются в качестве блоков обработки данных на всех последующих этапах обработки. Перекрытие блоков данных предпочтительно составляет 50% (128 значений выборок).
Затем осуществляется обработка с использованием окна Хэмминга 5 (см. фиг.2). На первом этапе обработки блоки данных подвергаются временному взвешиванию. Генерируется так называемое окно Хэмминга (фиг.3), на которое умножаются значения сигнала блока данных.

Задачей обработки с использованием окна является преобразование неограниченного во времени сигнала в ограниченный во времени сигнал путем умножения неограниченного во времени сигнала на функцию окна, которая вне определенной области отсутствует (равна нулю).
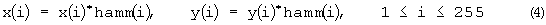
Сигнал х(i) источника во временной области затем преобразуется в частотную область посредством дискретного преобразования Фурье (фиг.2, ДПФ 7). Для дискретной во времени последовательности значений x(i), где i=0, 1, 2,..., N-1, полученной в результате обработки с использованием окна, комплексное преобразование Фурье C(j) для сигнала x(i) источника и периода N имеет вид:

Те же самые этапы осуществляются для кодированного сигнала или соответственно сигнала у(i) приема:

На следующем этапе вычисляется модуль спектра (фиг.2, формирование модуля 8). Индексом х всегда обозначается сигнал источника, а индексом у -сигнал приема:

Затем производится разбиение на критические полосы частот (фиг.2, Барк-преобразование 9).
Здесь вводится модифицированная модель (см. E. Zwicker, Psychoakustik, 1982). Базилярная мембрана в человеческом ухе делит частотный спектр на критические группы частот. Эти группы частот играют важную роль в восприятии силы звука. При низких частотах группы частот имеют постоянную ширину полосы 100 Гц, на частотах выше 500 Гц она возрастает пропорционально частоте (составляет порядка 20% от соответствующей средней частоты). Это приближенно соответствует приближенно свойствам органа слуха человека, который также обрабатывает сигналы в полосах частот, во всяком случае эти полосы являются переменными, т.е. их средняя частота подстраивается на соответствующий источник звука.
Таблица 1 показывает взаимосвязь между высотой z звука, частотой f, шириной ΔF группы частот, а также индексом быстрого преобразования.
Фурье (БПФ). Индексы БПФ соответствуют разрешению БПФ 256. Для последующего расчета представляет интерес только ширина полосы 100-4000 Гц.

Примененные здесь окна представляют упрощение. Все группы частот имеют ширину ΔZ(z)=1 барк. Шкала звуков z в единицах измерения [барк] рассчитывается согласно следующей формуле:
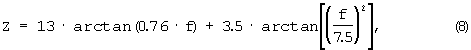
Причем f выражена в [кГц], a Z - в [барк].
Разница в звуках в 1 барк соответствует примерно расстоянию 1,3 мм на базилярной мембране (150 клеток волоса). Собственно преобразование частоты в звук может осуществляться просто по следующей формуле:

где If[j] - индекс первой выборки, a I1[j] - индекс последней выборки на шкале частоты в герцах для j-ой полосы; Δfj обозначает ширину полосы для j-ой полосы в герцах; g(f) - функция взвешивания (фиг.5). Так как дискретное преобразование Фурье выдает только значения спектра в дискретных позициях (частоты), то границы полосы также совпадают с такой частотой. Значения на границах полос в каждом соседнем окне взвешиваются только наполовину. Границы полос соответствуют значениям N*8000/256 Гц.
N=3, 6, 9, 13, 16, 20, 25, 29, 35, 41, 47, 55, 65, 74, 86, 101, 118.
Для ширины полосы, соответствующей телефонии и составляющей от 0,3 до 3,4 кГц, используются 17 значений на шкале звука. Из полученных в результате 128 значений БПФ первые 2, относящиеся к диапазону частот от 0 Гц до 94 Гц, и последние 10, которые относятся к диапазону частот от 3700 Гц до 4000 Гц, отбрасываются.
Оба сигнала затем фильтруются с помощью фильтра, частотная характеристика которого соответствует кривой колебаний напряженности поля при приеме соответствующего телефонного аппарата (фиг.2, фильтрация 10 в полосе частот телефонных сигналов):

где Filt[j] - частотный отклик в j-ой полосе частотной характеристики телефонного аппарата (определяется согласно Рекомендации ITU-T, Приложение D/P.830).
На фиг.5 значения (в логарифмическом масштабе) такого фильтра представлены графически.
Дополнительно можно вычислить кривые в единицах измерения уровня громкости - фон (фиг.2, вычисление кривых в единицах измерения уровня громкости - фон - этап 11). К этому необходимо добавить следующее:
в качестве силы звука для любого звука принимается уровень тонального сигнала частоты 1 кГц, который при фронтальном падении в форме плоской волны на испытуемого вызывает то же восприятие силы звука, что и измеряемый звук (см. E. Zwicker, Psychoakustik, 1982). Таким образом, можно говорить о кривых одинаковой силы звука для различных частот. Эти кривые представлены на фиг.6.
Из фиг.6 можно видеть, что, например, тональный сигнал на частоте 100 Гц при пороговой силе звука 3 фон имеет уровень звука 25 дБ. Тот же тональный сигнал, но при уровне силы звука 40 фон, имеет уровень звука 50 дБ. Можно также видеть, что, например, для тонального сигнала 100 Гц уровень звука 30 дБ должен быть мощнее, чем для тонального сигнала 4 кГц, чтобы оба эти тональные сигналы могли вырабатывать одинаковую громкость, воспринимаемую ухом. Приближение в соответствующей изобретению модели обеспечивается тем, что сигналы Рх и Ру умножаются на комплементарную (дополняющую) функцию.
Так как орган слуха человека при одновременном приходе множества спектральных составляющих в одной полосе обеспечивает сверхреакцию, т.е. воспринимает суммарную силу звука как большую, чем линейная сумма отдельных значений силы звука, отдельные спектральные составляющие подвергаются компрессии (сжимаются). Конкретная сжатая громкость имеет единицу измерения 1 сон. Для обеспечения преобразования “фон-сон” (этап 12 на фиг.2) в предлагаемом случае возбуждение, выраженное в [барк], сжимается с использованием показателя степени α=0,3:
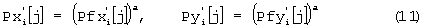
Важным аспектом предпочтительного варианта осуществления является моделирование временного перекрытия.
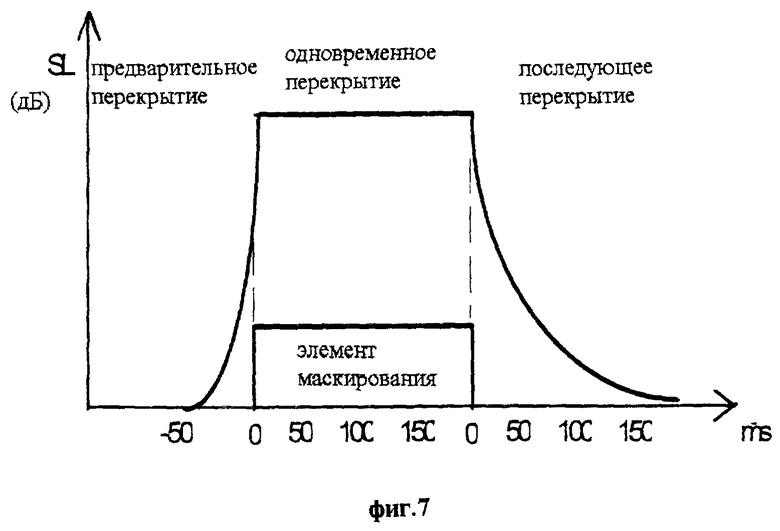
Орган слуха человека не способен различить два коротких тестовых звука, приходящих непосредственно один за другим. Зависящие от времени процессы показаны на фиг.7. Элемент маскирования длительностью 200 мс накрывает короткий импульс тонального сигнала. Момент времени, где начинается элемент маскирования, обозначен как 0. Влево время отрицательно. Вторая временная шкала начинается там, где кончается элемент маскирования. Можно видеть три временных области. Предварительное наложение имеет место перед включением элемента маскирования. Непосредственно после него осуществляется одновременное наложение, и по окончании элемента маскирования имеет место последующее наложение. Для последующего наложения имеется логическое объяснение (послезвучание). Предварительное наложение происходит уже перед включением элемента маскирования. Слуховые восприятия не возникают немедленно. Необходима некоторая обработка для выработки восприятия. Громкому звуку присуща быстрая обработка, а тихому звуку на уровне порога слышимости - более длительное время обработки. Предварительное наложение продолжается около 20 мс, а последующее наложение 100 мс. Таким образом, последующее наложение имеет доминирующее влияние. Последующее наложение зависит от длительности элемента маскирования и спектра накрываемого звука.
Грубое приближение временного наложения достигается уже посредством перекрытия блоков данных при предварительной обработке сигналов. При длительности блока данных 32 мс (256 значений выборок при частоте дискретизации 8 кГц) время перекрытия составляет 16 мс (50%). Этого достаточно для средних и высоких частот. Для низких частот это наложение намного длительнее (более 120 мс). Оно реализуется путем добавления ослабленного спектра предыдущего блока данных (см. этап 15 временного наложения на фиг.2). При этом ослабление различно в каждой полосе частот:

где coeff(j) - весовые коэффициенты, которые рассчитываются по формуле:

Где Framelength - длительность блока данных в дискретных значениях, например, 256; NrOfBarks - число барк-значений внутри блока данных (например, в данном случае 17); Fc - частота дискретизации; η=0,001.
Весовые коэффициенты для реализации временного маскирования в зависимости от частотных составляющих приведены для примера на фиг.13. Очевидно, что весовые коэффициенты снижаются с возрастанием барк-индекса (т.е. с возрастанием частоты).
Временное наложение реализуется в данном случае как последующее наложение. Предварительным наложением в данном контексте можно пренебречь.
На последующем этапе обработки спектры сигналов “размываются” (этап 13 размытия частоты на фиг.2). Основой этого является то, что человеческое ухо не способно четко различить две частотные составляющие, расположенные рядом. Степень размытия по частоте зависит от соответствующих частот, их амплитуд и других факторов.
Величину восприятия органа слуха определяет громкость. Она определяет, во сколько раз измеряемый звук громче или тише, чем стандартный звук. Найденная таким образом величина восприятия определяется как относительная громкость. В качестве стандартного звука используется уровень звука тонального сигнала частоты 1 кГц. С тональным сигналом частоты 1 кГц с уровнем 40 дБ соотнесена громкость 1 сон. В вышеупомянутом источнике (E. Zwicker, Psychoakustik, 1982) приведено следующее определение функции громкости:
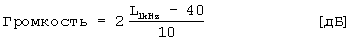
На фиг.8 показана функция громкости в единицах измерения [сон] для тонального сигнала частоты 1 кГц в качестве функции уровня звука в единицах измерения [фон].
В рамках представленного примера осуществления эта функция громкости приближенно описывается следующим образом:

где ε=4/3
Спектр на данном этапе расширяется (см. этап 14 преобразования функции громкости на фиг.2).
Полученный таким образом спектр подвергается свертке с дискретной последовательностью коэффициентов (функция свертки). Результат соответствует размыванию спектра по оси частот. Свертка двух последовательностей х и у соответствует относительно сложной свертке последовательностей во временной области или умножению их преобразований Фурье. Во временной области справедлива формула:

где m - длина последовательности х, n - длина последовательности у. Результат с имеет длину k=m+n+1, j=max(1, k+1-n): min (k,m).
В частотной области:

где FFT - быстрое преобразование Фурье (БПФ).
Вместо х в данном примере используется сигнал Рх”’ и Ру”’ длины 17 (m=17), а вместо у используется функция размытия Λ длины 9 (n=9). Тем самым результат имеет длительность 17+9-1=25(k=25).

Λ(•) - функция размытия, форма которой представлена на фиг.6. Она является асимметричной. Левый фронт возрастает от значения громкости -30 для частотной составляющей 1 до значения громкости 0 для частотной составляющей 4. После этого она спадает снова прямолинейно до значения громкости -30 для частотной составляющей 9. Функция размытия является, следовательно, асимметричной треугольной функцией.
Психоакустическое моделирование 3 (см. фиг.1) на этом заканчивается. Далее следует расчет качества.
Степень различия между взвешенными спектрами сигнала источника и сигнала приема рассчитывается следующим образом:

где Qsp - степень различия на интервале речи (активная фаза речи) и Qpa-степень различия на интервале паузы (неактивная фаза речи); ηsp - коэффициент речи, ηра - коэффициент паузы.
Сначала проводится анализ сигнала источника с целью нахождения сигнальной последовательности, где речь находится в активной фазе. При этом формируется так называемый энергетический профиль Enprofile согласно формуле:

Здесь SPEECH_THR определяет пороговое значение, ниже которого речь неактивна. Оно определяется чаще всего как + 10 дБ к максимальной динамике аналого-цифровых преобразователей. При 16-битовом разрешении SPEECH_THR=-96,3+10=-86,3 дБ. В последовательности SPEECH_THR=-80 дБ.
Качество обратно пропорционально подобию Qтот сигнала источника и сигнала приема. QTOT=1 означает, что сигнал источника и сигнал приема полностью одинаковы. Для QTOT=0 эти два сигнала совершенно непохожи один на другой. Коэффициент речи ηsp вычисляется по следующей формуле:

где μ=1,01 и Psp - составляющая речи.
Как показывает фиг.10, влияние речевой последовательности больше (коэффициент речи больше), если речевая составляющая больше. Так, при μ=1,01 и Psp=0,5 (50%) этот коэффициент ηsp=0,91. Таким образом, влияние речевой последовательности в сигнале соответствует 91%, а последовательности пауз - только 9% (100-91). При μ=1,07 влияние речевой последовательности меньше (80%).
После этого вычисляется коэффициент пауз:

Качество на интервале пауз вычисляется не таким же путем, как качество на интервале речи.
Qpa является функцией энергии сигнала на интервале пауз. Если эта энергия возрастает, то значение Qpa меньше (что соответствует ухудшению качества):
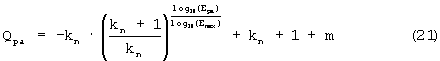
kn является предварительно определенной константой и имеет в данном случае значение 0,01. Ера - среднеквадратичная энергия сигнала на интервале пауз для сигнала приема. Только если эта энергия больше, чем среднеквадратичная энергия сигнала на интервале пауз в сигнале источника, это оказывает влияние на значение Qpa. Таким образом, Ера=mах(Е refpa, Ера). Наименьшее значение Ера равно 2. Еmах - максимальная среднеквадратичная энергия сигнала при заданном цифровом разрешении (для 16-битового разрешения Еmах=32768). Значение m в формуле (21) представляет собой корректирующий коэффициент для Ера=2, так что тогда Qра=1. Этот корректирующий коэффициент вычисляется следующим образом:
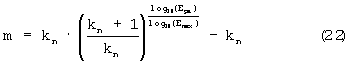
При Еmах=32768, Emin=2 и kn=0,01 значение для m равно 0,003602. По существу база kn*(kn+1)/kn может приниматься в качестве соответственно выбранной константы А.
На фиг.11 представлена взаимосвязь между среднеквадратичной энергией сигнала на интервале пауз и Qpa.
Качество на интервале речи определяется через степень различия между спектрами сигнала источника и сигнала приема.
Сначала определяются четыре окна уровней. Окно №1 определено от -96,3 дБ до -70 дБ, окно №2 от -70 дБ до -46 дБ, окно №3 от -46 дБ до -26 дБ и окно №4 от -26 дБ до 0 дБ. Сигналы, уровни которых находятся в первом окне, интерпретируются как пауза и при оценке Qsp не принимаются во внимание. Путем подразделения на четыре окна обеспечивается множественное разрешение. Подобные процессы происходят в органе слуха человека. Таким образом, влиянием помех в сигнале можно управлять в зависимости от их энергии. Окно №4, которое соответствует максимальной энергии, взвешивается максимальным образом.
Степень различия между спектрами сигнала источника и сигнала приема на интервале речи для k-го блока данных и i-го окна уровней, т.е. Qsp(i,k) вычисляется следующим образом:

где Ex(k) - спектр сигнала источника и Ey(k) - спектр сигнала приема в k-ом блоке данных. Параметром n обозначено спектральное разрешение блока данных. Величина n соответствует числу барк-значений во временном блоке данных (например, 17). Усредненный спектр в k-ом блоке данных обозначен как E(k). Параметр Gi,k представляет собой константу усиления, которая зависит от блока данных и от окна и значение которой зависит от отношения энергий Ру/Рх.
Графическое представление значений Gi,k в функции отношения энергий приведено на фиг.12.
Если этот коэффициент усиления равен 1 (энергия сигнала приема равна энергии сигнала источника), то и Gi,k=1.
Если энергия в сигнале приема равна энергии в сигнале источника, то Gi,k=1. Это не оказывает влияния на Qsp. Все другие значения приводят к меньшим значениям Gi,k или соответственно Qsp, что соответствует большей степени различия относительно сигнала источника (качество сигнала приема меньше). Если энергия сигнала приема больше, чем энергия сигнала источника, т.е.  то константа усиления ведет себя в соответствии со следующим равенством:
то константа усиления ведет себя в соответствии со следующим равенством:

Если это отношение энергий  , то справедливо следующее равенство:
, то справедливо следующее равенство:

Значения для εHI и εLO. Для отдельных окон уровней приведены в табл.2:

Описанная выше константа усиления обеспечивает, чтобы дополнительное содержание в сигнале приема сильнее увеличивало степень различия, чем отсутствие содержания.
Из формулы (23) очевидно, что числитель соответствует функции ковариации, а знаменатель - произведению двух стандартных отклонений. Также для k-го блока данных и для i-го окна уровней степень различия равна:

Значения θ и γSD, приведенные в таблице 2, необходимы для каждого окна уровней, чтобы отдельные значения Qsp(i,k) преобразовать в единственную меру различия Qsp.
В зависимости от содержимого сигнала получают три вектора Qsp(i), длины которых могут быть различными. В первом приближении вычисляется среднее значение для соответствующего i-го окна уровней:

Здесь N - длина вектора Qsp(i) или соответственно число блоков данных для соответствующего i-го окна речи.
После этого вычисляется стандартное отклонение SDi вектора Qsp(i):

SD описывает распределение помехи в кодированном сигнале. Для импульсных шумов значение SD относительно велико, для равномерно распределенных шумов оно, напротив, мало. Также и орган слуха человека воспринимает импульсные помехи сильнее. Типичным примером могут служить аналоговые сети передачи речевых сигналов, как, например, AMPS (Усовершенствованная мобильная телефонная система).
Тем самым влияние качества распределения сигнала реализуется следующим образом:
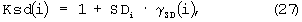
причем определяется, что
Ksd(i)=1, для Ksd(i)>1 и
Ksd(i)=0, для Ksd(i)<0
и, наконец,

Вычисление качества интервала речи Qsp производится в виде взвешенной суммы отдельных значений качества для каждого окна согласно выражению:

Весовые коэффициенты Ui определяются соотношением

Причем ηsp представляет собой коэффициент речи согласно формуле (19), а pi соответствует взвешенной степени принадлежности сигнала к i-ому окну и вычисляется в соответствии со следующими равенствами:

где Ni - число блоков данных речевого сигнала в i-ом окне, Nsp - общее число блоков данных речевого сигнала и сумма всех θ всегда равна 1:
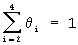
Т.е. чем больше частное  или θi, тем большее значение имеет помеха в соответствующем блоке данных речевого сигнала.
или θi, тем большее значение имеет помеха в соответствующем блоке данных речевого сигнала.
Разумеется, для константы усиления, не зависящей от уровня сигнала, значения для εHI, εLO, θ и γSD могут выбираться одинаковыми для каждого окна.
На фиг.2 соответствующий этап обработки представлен как этап 16 вычисления степени различия. Этап 17 вычисления качества определяет значение QTOT (формула 18).
И, наконец, осуществляется этап 5 вычисления среднего балла оценки (СБО). Это преобразование необходимо, чтобы значение QTOT представить на истинной шкале качества. Шкала качества с единицами измерения СБО определена в документе ITU Т Р.800 “Способ субъективного определения качества передачи”, 08/96. Проводится статистически соответствующее число измерений. Затем все измеренные значения представляются в виде отдельных точек на диаграмме. Затем через все точки проводится кривая тренда в форме полинома второго порядка:

где MOS означает СБО.
Это значение, называемое “объективным СБО”, соответствует теперь заданному значению СБО. В наилучшем случае оба значения равны.
Описанный способ может быть реализован с использованием специализированных аппаратных средств и/или программного обеспечения. Формулы могут программироваться без каких-либо затруднений. Обработка сигнала источника проводится заранее, и накапливаются только результаты обработки психоакустического моделирования. Сигнал приема может, например, обрабатываться в режиме реального времени. Для осуществления вычислений степени различия спектров следует обратиться к соответствующим запомненным значениям сигнала источника.
Соответствующий изобретению способ тестировался с использованием различных выборок речи при различных условиях. Длительность выборки варьировалась в пределах от 4 до 16 секунд.
Тестировались следующие передачи речевых сигналов в реальной сети:
- нормальное соединение стандарта ISDN (Цифровая сеть с комплексными услугами);
- передачи GSM-FR (протокол ретрансляции кадров в системе стандарта GSM (Глобальная сеть мобильной связи) <-> ISDN и самостоятельно GSN-FR;
- различные передачи посредством устройств DCME (оборудование мультиплексирования для цифровых линий) с кодерами, использующими адаптивную дифференциальную импульсно-кодовую модуляцию (АДИКМ) или линейное прогнозирование с кодовым возбуждением с низкой задержкой (G.728).
Все соединения управлялись с различными уровнями речевого сигнала.
При моделировании:
- кодек множественного доступа с кодовым разделением каналов (МДКР) стандарта (IS-95) с различными частотами ошибок в битах;
- Кодек множественного доступа с временным разделением каналов (МДВР) (стандартов IS-54 и IS-641) с включенным эхо-компенсатором;
- аддитивные шумы фона и различные частотные характеристики.
Каждый тест состоит из ряда оцениваемых речевых выборок и относящейся к нему субъективной оценки, получаемой на слух (СБО). Полученная корреляция между результатами способа, соответствующего изобретению, и значениями, полученными при оценке на слух, была весьма высокой.
В заключение следует отметить, что посредством
- моделирования временного перекрытия,
- моделирования частотного перекрытия,
- описанной модели вычисления степени различия,
- моделирования степени различия на интервале пауз и
- моделирования влияния отношения энергий на качество
создана система оценки, имеющая разностороннее применение и очень хорошую корреляцию с субъективным восприятием.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ МАШИННОЙ ОЦЕНКИ КАЧЕСТВА ПЕРЕДАЧИ РЕЧИ | 2010 |
|
RU2435232C1 |
| СПОСОБ ОСУЩЕСТВЛЕНИЯ МАШИННОЙ ОЦЕНКИ КАЧЕСТВА ЗВУКОВЫХ СИГНАЛОВ | 2005 |
|
RU2312405C2 |
| СПОСОБ ПОВЫШЕНИЯ РАЗБОРЧИВОСТИ И ИНФОРМАТИВНОСТИ ЗВУКОВЫХ СИГНАЛОВ В ШУМОВОЙ ОБСТАНОВКЕ | 2014 |
|
RU2589298C1 |
| ПСИХОАКУСТИЧЕСКАЯ МОДЕЛЬ ДЛЯ АУДИООБРАБОТКИ | 2020 |
|
RU2826044C1 |
| УСТРОЙСТВО, СПОСОБ ИЛИ КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ГЕНЕРАЦИИ АУДИОСИГНАЛА С РАСШИРЕННОЙ ПОЛОСОЙ С ИСПОЛЬЗОВАНИЕМ ПРОЦЕССОРА НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2745298C1 |
| СПОСОБ ПЕРЕОЗВУЧИВАНИЯ АУДИОМАТЕРИАЛОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2012 |
|
RU2510954C2 |
| МЕТОДЫ УЛУЧШЕНИЯ ДИАЛОГОВ | 2007 |
|
RU2408164C1 |
| СПОСОБ И УСТРОЙСТВО ВОКОДИРОВАНИЯ ПЕРЕМЕННОЙ СКОРОСТИ ПРИ ПОНИЖЕННОЙ СКОРОСТИ КОДИРОВАНИЯ | 1995 |
|
RU2146394C1 |
| УСТРОЙСТВА И СПОСОБЫ ДЛЯ ОБРАБОТКИ АУДИО СИГНАЛА С ЦЕЛЬЮ ПОВЫШЕНИЯ РАЗБОРЧИВОСТИ РЕЧИ, ИСПОЛЬЗУЯ ФУНКЦИЮ ВЫДЕЛЕНИЯ НУЖНЫХ ХАРАКТЕРИСТИК | 2009 |
|
RU2507608C2 |
| УСТРОЙСТВО ДЛЯ ПОСТОБРАБОТКИ ЗВУКОВОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ ВЫЯВЛЕНИЯ МЕСТА ВСПЛЕСКА | 2018 |
|
RU2734781C1 |











Изобретение относится к машинной оценке качества передачи аудиосигналов. Его использование позволяет получить технический результат в виде получения объективной оценки (предсказания) качества речи с учетом слухового процесса человека. Сигнал источника (например, речевая выборка) обрабатывается или соответственно передается с помощью устройства речевого кодирования и преобразуется в сигнал приема (кодированный речевой сигнал). Сигналы источника и приема подвергаются отдельно предварительной обработке и психоакустическому моделированию. Затем осуществляется вычисление степени различия, посредством которой оценивается подобие сигналов. И, наконец, проводится вычисление среднего балла оценки, чтобы получить результат, сопоставимый с субъективной оценкой человека. Технический результат достигается благодаря тому, что для оценки качества передачи определяется значение спектрального подобия, при этом ковариацию спектров сигнала источника и принимаемого сигнала делят на произведение стандартного отклонения обоих спектров. 10 з.п. ф-лы, 13 ил., 2 табл.


где Ера - энергия сигнала на интервале пауз; Emax - максимальная энергия сигнала на интервале пауз.
| Способ оценки качества канала передачи речевого сигнала | 1986 |
|
SU1322486A1 |

