Уровень техники
Развитие информационных систем, таких как Интернет, и различных услуг с централизованным управлением для доступа к информационным системам привело к доступности большого объема информации. Поскольку компьютеры становятся все более и более мощными и универсальными, пользователи все больше используют свои компьютеры для большего разнообразия задач. Следствием расширения использования и универсальности компьютеров является увеличивающееся желание со стороны пользователей все более и более полагаться на свои вычислительные устройства, чтобы выполнять свои ежедневные действия. Например, кто-нибудь с доступом к подходящему соединению с Интернет может работать в интерактивном режиме и осуществлять навигацию к информационным страницам (то есть Web-страницам), чтобы собрать информацию, которая является релевантной текущему действию пользователя.
Много служб механизмов поиска, таких как Google и Yahoo!, обеспечивают поиск информации, которая является доступной через Интернет. Эти службы механизма поиска позволяют пользователям искать страницы отображения, например Web-страницы, которые, возможно, представляют интерес для пользователей. После того как пользователь выдает заявку на поиск (то есть запрос), который включает в себя поисковые термины, служба механизма поиска идентифицирует Web-страницы, которые могут относиться к этим поисковым терминам. Чтобы быстро идентифицировать связанные Web-страницы, службы механизма поиска могут поддерживать отображение ключевых слов на Web-страницы. Это отображение может быть выполнено посредством "ползания" (кроулинга) по Web (то есть по "Всемирной паутине"), чтобы идентифицировать ключевые слова каждой Web-страницы. Чтобы «ползать» по сети, служба механизма поиска может использовать список корневых Web-страниц, чтобы идентифицировать все Web-страницы, которые доступны через эти корневые Web-страницы. Ключевые слова любой конкретной Web-страницы могут быть идентифицированы, используя различные известные методы информационного поиска, например идентификации слов заголовка, слов, введенных в метаданные Web-страницы, слов, которые подсвечены, и так далее. Служба механизма поиска может формировать счет релевантности, чтобы указать, насколько релевантной может быть информация Web-страницы поисковому запросу на основании близости каждого совпадения, важности или популярности Web-страницы (например, PageRank в Google), и так далее. Служба механизма поиска затем отображает пользователю ссылки на те Web-страницы в порядке, который основан на ранжировании, определенном их релевантностью.
К сожалению, пользователи информационных систем сталкиваются с проблемой информационной перегрузки. Например, службы механизма поиска часто обеспечивают своего пользователя несоответствующими результатами поиска, таким образом вынуждая пользователя просматривать длинный список Web-страниц, чтобы найти релевантные Web-страницы. Составляющей этой проблемы является постоянное изменение и расширение объема информации и трудности пользователей, с которыми они встречаются при работе с постоянно меняющейся информацией, чтобы обнаружить информацию, которая является заслуживающей доверия и релевантной пользователю.
Сущность изобретения
Обеспечиваются способ и система для ранжирования результатов поиска на основании временной близости к событию, к которому имеют отношение результаты поиска. Система распространения информации ранжирует результаты поиска на основании временного веса, назначенного каждому результату поиска. Временный вес есть индикация важности для пользователя, которая изменяется со временем. Для каждого результата поиска система распространения информации вычисляет временный вес, который основан на временной близости к событию, которое относится к результату поиска. Временный вес может использоваться для повторного ранжирования результатов поиска.
Настоящее описание обеспечивается для представления в упрощенной форме выбора концепций, которые приведены ниже в подробном описании. Этот раздел не предназначен для идентификации ключевых признаков или существенных признаков заявленного объекта изобретения, и при этом не предназначен для использования в качестве помощи в определении объема заявленного объекта изобретения.
Краткое описание чертежей
Фиг. 1 - блок-схема, которая иллюстрирует обработку системы распространения информации согласно некоторым вариантам осуществления.
Фиг. 2 - блок-схема, которая иллюстрирует выбранные компоненты системы распространения информации согласно некоторым вариантам осуществления.
Фиг. 3 - блок - схема последовательности операций, которая иллюстрирует работу компонента профайлера согласно некоторым вариантам осуществления.
Фиг. 4 - блок - схема последовательности операций, которая иллюстрирует работу компонента профайлера по идентификации ключевых терминов согласно некоторым вариантам осуществления.
Фиг. 5 - блок - схема последовательности операций, которая иллюстрирует работу компонента профайлера для формирования запроса согласно некоторым вариантам осуществления.
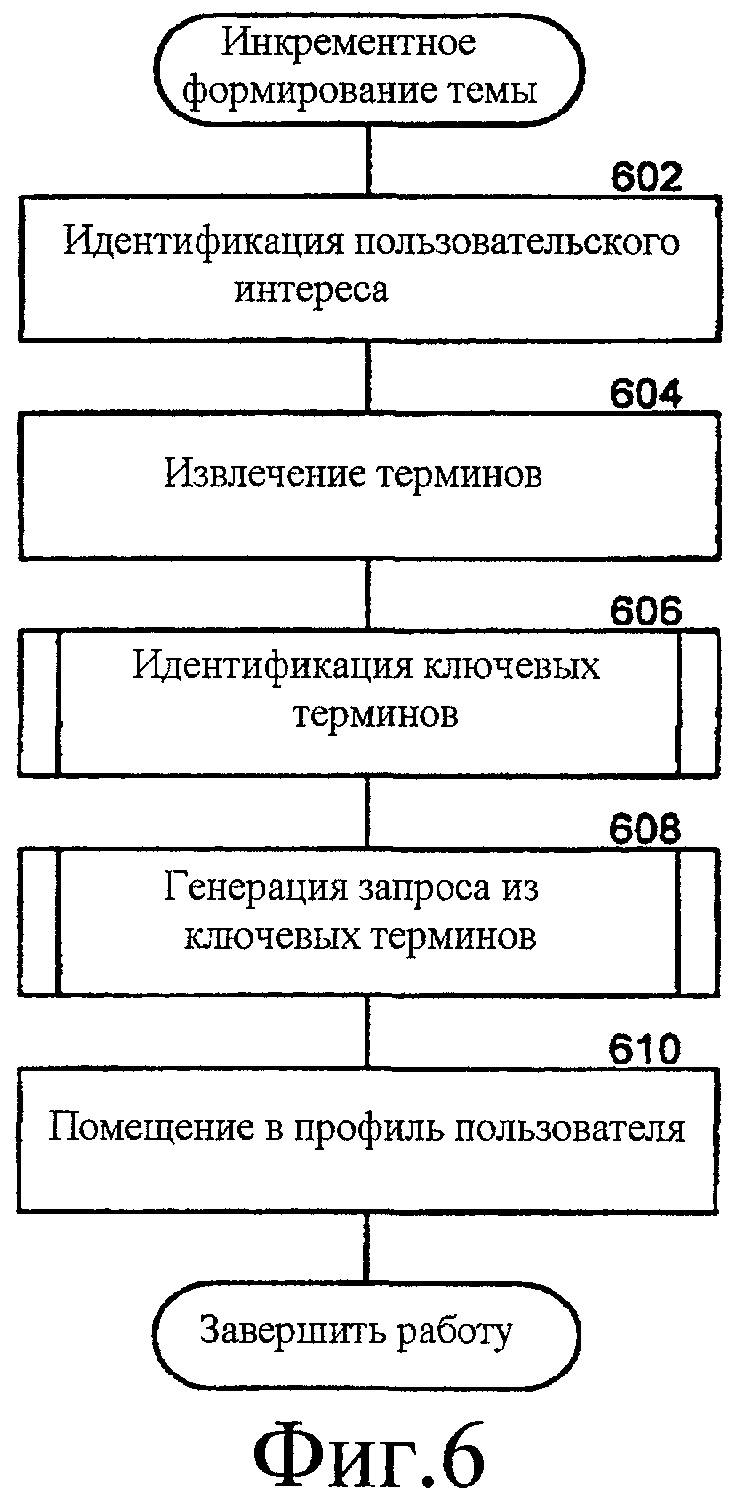
Фиг. 6 - блок - схема последовательности операций, которая иллюстрирует работу компонента профайлера, чтобы с приращением формировать тему, согласно некоторым вариантам осуществления.
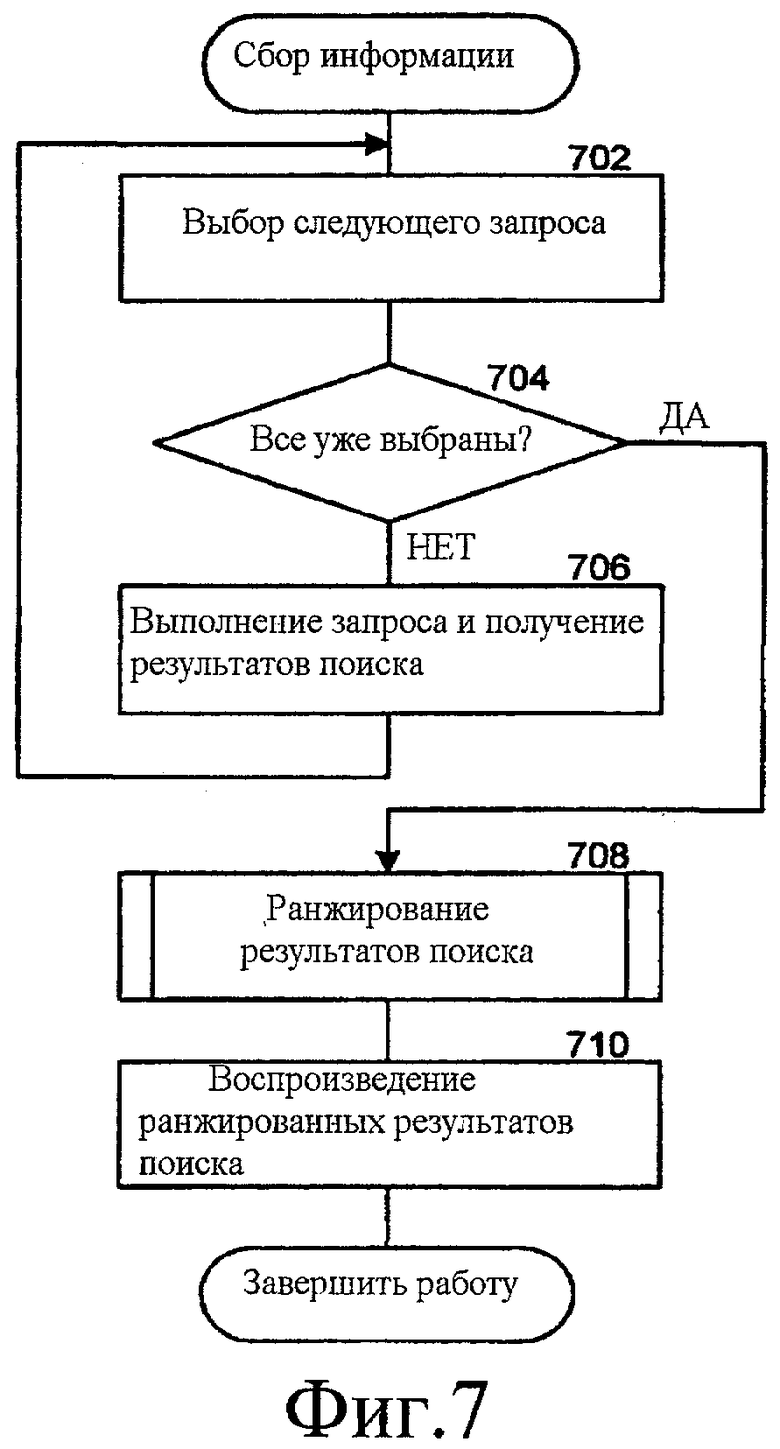
Фиг. 7 - блок - схема последовательности операций, которая иллюстрирует работу компонента сбора информации согласно некоторым вариантам осуществления.
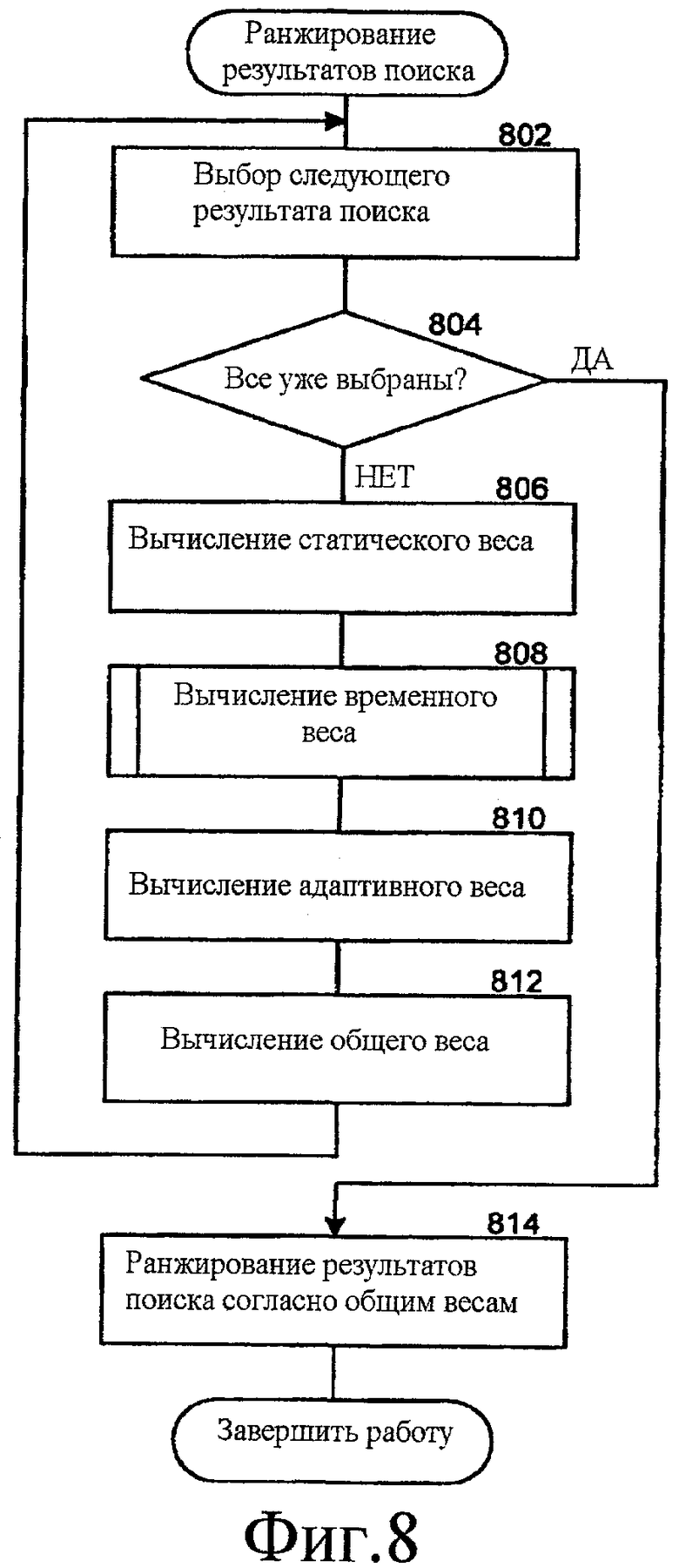
Фиг. 8 - блок - схема последовательности операций, которая иллюстрирует работу компонента ранжирования согласно некоторым вариантам осуществления.
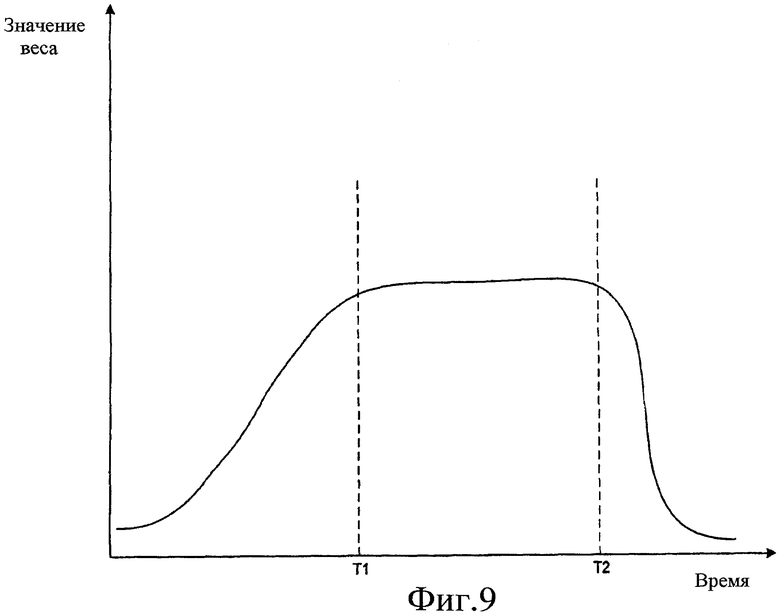
Фиг. 9 - графическое описание значений веса как функции близости к событию согласно некоторым вариантам осуществления.
Фиг. 10 - графическое описание значений веса как функции близости к событию, согласно некоторым вариантам осуществления.
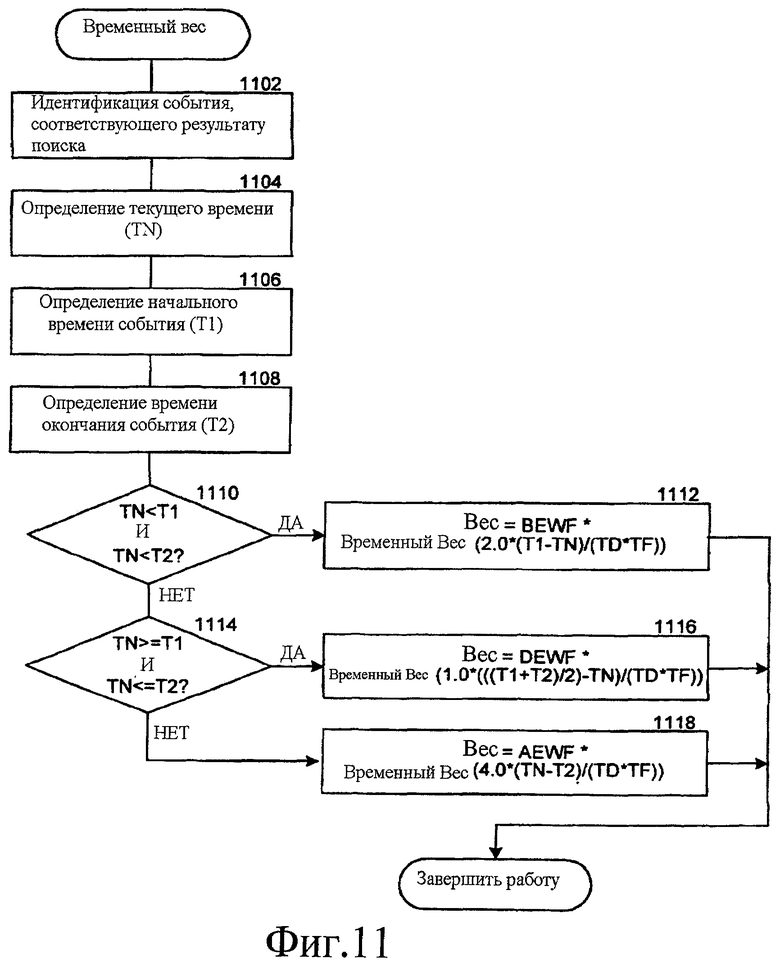
Фиг. 11 - блок - схема последовательности операций, которая иллюстрирует работу компонента ранжирования для вычисления временного веса результата поиска согласно некоторым вариантам осуществления.
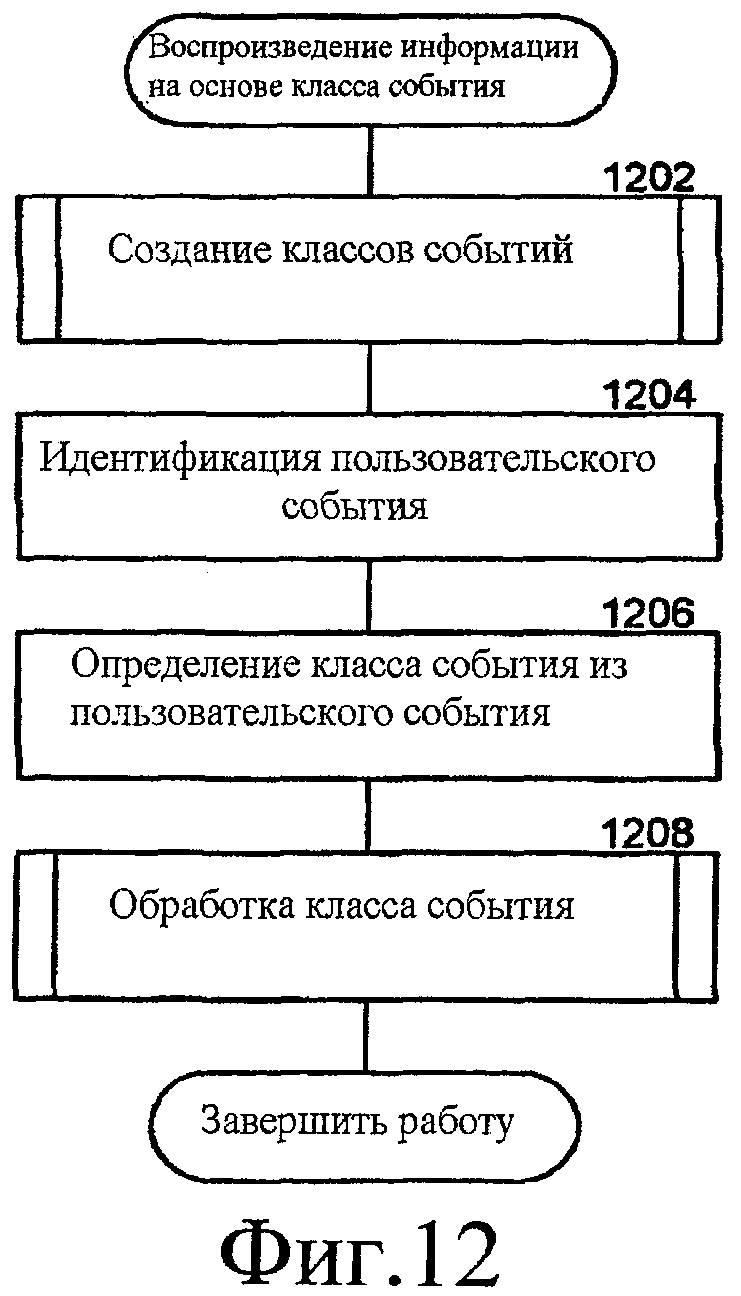
Фиг. 12 - блок - схема последовательности операций, которая иллюстрирует воспроизведение информации на основании класса события, соответствующего пользовательскому событию, согласно некоторым вариантам осуществления.
Фиг. 13 - блок - схема последовательности операций, которая иллюстрирует создание класса события, согласно некоторым вариантам осуществления.
Фиг. 14 - данные примерного листинга, которые иллюстрируют класс события, согласно некоторым вариантам осуществления.
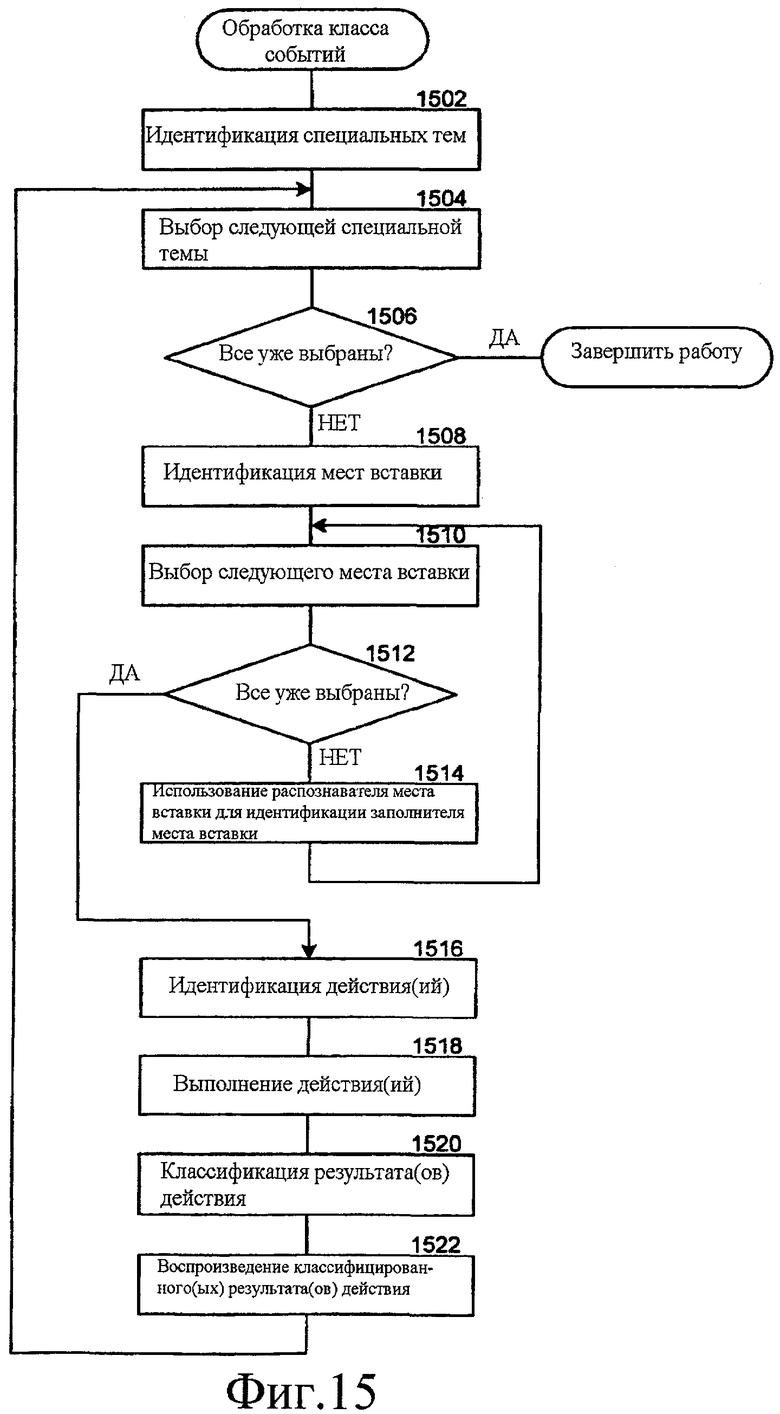
Фиг. 15 - блок - схема последовательности операций, которая иллюстрирует обработку класса события, согласно некоторым вариантам осуществления.
Подробное описание
Обеспечиваются способ и система для адаптивного распространения персонализированной и контекстуально релевантной информации. В некоторых вариантах осуществления система распространения информации идентифицирует интересы пользователя и адаптивно распространяет (передает) пользователю информацию, которая является релевантной интересам пользователя. Интересы пользователя могут быть идентифицированы из информации, полученной из различных источников, например, в качестве примера, записей в календаре пользователя, сообщений электронной почты, информация от использования Всемирной паутины (web), документов, данных планирования ресурсов предприятия (ERP) и т.п. Система распространения информации затем создает профиль для пользователя и включает в этот профиль подробности относительно интересов пользователя. Например, система распространения информации может включать в профиль пользователя информацию относительно: информационных источников для запроса информации для представления пользователю; пользовательских событий (например, собраний, встреч и т.д.), которые анализируются, чтобы определить интересы пользователя; тем, полученных из проанализированных событий; запросов, сформированных для проанализированных событий; языковой модели терминов, которые являются релевантными пользователю; предпочтений пользователя для приема релевантной информации и другой информации, касающейся пользователя. Обычно тема (предмет) может быть определена как любая связная концепция для события. Например, для конференции, которую пользователь намеревается посетить, темы могут включать в себя предмет конференции, представление людей на конференции, людей, посетивших конференцию, место проведения конференции, организации, представленные на конференции, информацию о путешествии для пользователя (например, город начала (путешествия), город назначения, режим путешествия, номера рейсов, бронирования мест в гостинице, резервирование автомобиля на прокат и т.д.), и информацию о погоде. Термины, которые являются релевантными пользователю, могут быть получены из различных источников, используемых для идентификации интересов пользователя. Система распространения информации периодически выполняет запросы в профиле пользователя к соответствующим информационным источникам и получает результаты поиска. Используемый здесь термин "результат поиска" или любой его вариант в общем случае относится к результатам, которые отфильтрованы, используя запрос. Система распространения информации затем ранжирует результаты поиска согласно различным факторам и представляет (воспроизводит) ранжированные результаты поиска пользователю. Система распространения информации получает обратную связь от пользователя относительно представленных результатов поиска и включает информацию обратной связи в профиль пользователя. Система распространения информации может обеспечивать пользовательский интерфейс (ПИ, UI), посредством которого пользователь может просматривать и/или модифицировать подробности интересов пользователя, поддерживаемых в профиле пользователя. Например, пользователь может использовать ПИ, чтобы задать уровень важности и/или релевантности событий, тем, терминов, информационных источников и другой информации, включенной в профиль пользователя. Система распространения информации может также контролировать взаимодействие пользователя с воспроизведенными результатами поиска и делать соответствующие модификации в подробностях (деталях) интересов пользователя, поддерживаемых в профиле пользователя. Система распространения информации может также периодически обновлять профиль пользователя более современными или обновленными подробностями относительно интересов пользователя. Таким образом, система распространения информации через какое-то время становится все более и более чувствительной к потребностям пользователя в информации.
В некоторых вариантах осуществления система распространения информации идентифицирует ключевые термины из терминов, которые являются релевантными пользователю, и генерирует запросы из этих ключевых терминов. Система распространения информации может идентифицировать ключевые термины из терминов, извлеченных из сообщений пользователя, и событий, содержащихся в выбранных папках. В качестве примера система распространения информации может сканировать папки недавней электронной почты пользователя (например, папку почтового ящика для приема сообщений и папку посланных элементов) и извлекать термины из этих папок электронной почты. Система распространения информации может затем идентифицировать сообщения электронной почты в других папках, которые относятся к извлеченным терминам, и извлекать термины из этих связанных сообщений электронной почты. Используя извлеченные термины, система распространения информации создает кластеры терминов, которые являются схожими. Каждый кластер ассоциирован с набором терминов. Система распространения информации затем идентифицирует события, например назначенные встречи пользователя, посредством сканирования записей в приложении ведения календаря, и для каждого события идентифицирует кластеры, ассоциированные с событием. Система распространения информации затем создает одну или более тем для каждого события. Каждая тема может рассматриваться как "контейнер", который содержит информацию, которая является релевантной ее ассоциированному событию, например, название события, продолжительность события и т.д. Система распространения информации идентифицирует ключевые термины в идентифицированных кластерах и генерирует запрос из ключевых терминов. Система распространения информации затем помещает сформированный запрос в тему, которая ассоциирована с событием, и включает эту тему в профиль пользователя.
Система распространения информации может использовать различные способы, чтобы сформировать кластеры терминов. В некоторых вариантах осуществления система распространения информации использует алгоритм К-средних значений. Система распространения информации вводит в алгоритм число K, которое задает требуемое количество кластеров. При первом проходе алгоритм берет первые K терминов в качестве средней точки одного кластера. Средняя точка есть средняя позиция кластера (например, средняя позиция терминов в кластере). Алгоритм затем назначает каждый из оставшихся терминов кластеру с самой близкой средней точкой к этому термину (например, кластеру, где разность между средней точкой и термином минимизирована). При последующих проходах алгоритм повторно вычисляет средние точки кластера на основе предыдущего прохода и затем повторно назначает каждый термин кластеру со средней точкой, которая является самой близкой к этому термину. Алгоритм может быть выполнен для фиксированного количества проходов (например, трех) или до тех пор, пока кластеризация не сойдется на решении. Система распространения информации может использовать любой из ряда известных алгоритмов, включающих в себя оценку максимальной вероятности, спектральную кластеризацию и так далее, чтобы сформировать кластеры терминов.
В некоторых вариантах осуществления система распространения информации идентифицирует ключевые термины в кластере на основании общего веса, назначенного каждому термину. Общий вес термина может быть получен из комбинации веса типа термина и веса релевантности термина. Система распространения информации сначала фильтрует термины, чтобы уменьшить количество терминов, которые могут быть идентифицированы как ключевые термины. Например, система распространения информации может отфильтровывать термины, которые являются унифицированным указателем информационного ресурса (URL), и термины, которые составлены из чисел, чтобы уменьшить количество ключевых терминов-кандидатов. Для каждого из остающихся терминов система распространения информации может вычислять вес типа и вес релевантности. Вес типа - это вес, который назначен термину на основании типа термина. Например, система распространения информации может назначать больший вес типа термину, который является именем, например именем человека, чем термину, который составлен из множества слов. Термину, который составлен из множества слов, может, в свою очередь, быть назначен больший вес типа, чем термину, который является одним словом. Система распространения информации может также назначать различные веса типа термину на основании того, появляется ли термин как часть рассматриваемого текста, как тело текста, как текст контактов или других частей события. Вес релевантности термина - есть мера релевантности термина пользователю и, в частности, интересам пользователя. Одна общая методика для определения релевантности термина пользователю основана на частоте термина и обратной частоте документа (TF*IDF). Частота термина относится к количеству появлений термина в документе, и обратная частота документа относится к обратному значению количества документов, которые содержат этот термин. В этом случае документы обычно относятся к различным информационным источникам, используемым для идентификации интересов пользователя. Система распространения информации может идентифицировать термины, которые являются избыточно представленными, и термины, которые являются недостаточно представленными, в качестве терминов, которые имеют маловероятную релевантность пользователю. Каждому из этих терминов система распространения информации назначает низкий вес релевантности. Каждому из остающихся терминов система распространения информации может назначать вес релевантности, основанный на метрике TF*IDF термина. Система распространения информации может использовать любой из множества других известных методов для определения релевантности термина. Система распространения информации может затем получать общий вес для термина на основании веса типа термина и веса релевантности. Например, общий вес термина может быть получен посредством перемножения веса типа и веса релевантности термина. В некоторых вариантах осуществления общий вес термина может быть получен из веса релевантности термина. Система распространения информации может затем выделять в качестве ключевых терминов термины, чьи общие веса выше заранее определенного порога. Система распространения информации может поддерживать термины и их назначенные веса в профиле пользователя, например, в качестве части языковой модели.
В некоторых вариантах осуществления система распространения информации формирует запрос из ключевых терминов, используя шесть наиболее высоко ранжированных ключевых терминов. Система распространения информации сначала ранжирует ключевые термины на основании общих весов, назначенных ключевым терминам. Система распространения информации затем идентифицирует шесть наиболее высоко ранжированных ключевых терминов и генерирует запрос согласно следующему уравнению:
Запрос = А И B И (C ИЛИ D ИЛИ E ИЛИ F) (1),
где А представляет первый наиболее высоко ранжированный ключевой термин, B представляет второй наиболее высоко ранжированный ключевой термин, C представляет третий наиболее высоко ранжированный ключевой термин, D представляет четвертый наиболее высоко ранжированный ключевой термин, E представляет пятый наиболее высоко ранжированный ключевой термин и F представляет шестой наиболее высоко ранжированный ключевой термин. В случаях, когда имеются менее шести ключевых терминов, система распространения информации может генерировать запрос, используя количество доступных ключевых терминов. Например, если имеются только четыре ключевых термина, система распространения информации может генерировать запрос, опуская пятые и шестые наиболее высоко ранжированные ключевые термины в уравнении (1) выше. Примерами других подходящих запросов, когда имеются менее шести ключевых терминов, включают в себя: Запрос = A; Запрос = А И B; Запрос = А И B И C; Запрос = А И B И (C ИЛИ D); и т.д.
В некоторых вариантах осуществления система распространения информации с приращением (инкрементно) формирует темы, которые могут быть интересны пользователю. Например, пользователь может обеспечивать индикацию, что некоторое событие заслуживает освещения в печати (то есть представляет интерес для пользователя). После приема этой индикации система распространения информации идентифицирует интерес пользователя. Например, система распространения информации может идентифицировать тему из указанного события как представляющую интерес для пользователя. Любая из других тем, которые относятся к указанному случаю, может быть также идентифицирована как интерес пользователя. Система распространения информации затем извлекает термины, которые ассоциированы с этой темой, и из этих терминов идентифицирует ключевые термины. Система распространения информации может идентифицировать ключевые термины на основании общих весов, назначенных терминам, как описано выше. Система распространения информации затем генерирует запрос из ключевых терминов и включает этот запрос в профиль пользователя для выполнения. Система распространения информации может также поддерживать извлеченные термины и их назначенные веса в профиле пользователя, например, в качестве части языковой модели.
Система распространения информации собирает информацию для пользователя через периодические интервалы. На очередном интервале система распространения информации выполняет запросы к информационным источникам, указанным в профиле пользователя, чтобы получить результаты поиска. Информационные источники могут включать в себя MSN Search, MSN News Search и другие информационные источники, которые индексируют блоги, выпуски новостей, Web-страницы, источники документов, web-вещания, видеовещания, аудиовещания и т.д., и которые делают результаты поиска доступными через интерфейс. Система распространения информации затем формирует ранжированный список информационных элементов посредством ранжирования элементов информации, включенных в результаты поиска. Система распространения информации затем воспроизводит ранжированные результаты поиска пользователю. Система распространения информации инициализирует периодические интервалы значениями "по умолчанию", которые могут быть модифицированы пользователем. В некоторых вариантах осуществления система распространения информации собирает информацию, касающуюся событий, которые находятся во временном диапазоне, например диапазоне дат. Например, система распространения информации может инициализировать диапазон дат как одну неделю (например, период из семи дней, начинающийся со дня перед текущим днем (сегодняшним)). В этом случае система распространения информации собирает информацию посредством выполнения запросов, сформированных для тем, соответствующих событиям, которые находятся в пределах этого диапазона дат. В некоторых вариантах осуществления система распространения информации позволяет пользователю инициализировать сбор информации. Например, система распространения информации может обеспечивать ПИ, посредством которого пользователь может определить диапазон дат, представляющий интерес, и запрашивать сбор информации.
В некоторых вариантах осуществления система распространения информации ранжирует результаты поиска на основании общего веса, назначенного каждому результату поиска. Общий вес результата поиска может быть получен из комбинации статического веса результата поиска, адаптивного веса результата поиска и временного веса результата поиска. Статический вес может быть получен из различных коэффициентов взвешивания, таких как важность темы/события для пользователя, важность информационного источника, ранжирование, обеспеченное информационным источником, и релевантность терминов интересам пользователя. Например, статический вес для результата поиска может быть комбинацией важности темы, которая соответствует результату поиска, важности информационного источника, который выдал результат поиска, ранга, обеспеченного информационным источником, который выдал результат поиска, и релевантности терминов в результате поиска интересам пользователя. Релевантность терминов может быть определена, используя языковую модель, включенную в профиль пользователя. Например, косинусная мера подобия может использоваться, чтобы измерить подобие (сходство) терминов в результате поиска с терминами в языковой модели. Адаптивный вес - это вес, который назначен результату поиска на основании предпочтения пользователя и/или обратной связи. Например, пользователь может задать дополнительные информационные источники, из которых нужно извлечь информацию. Пользователь может указывать предпочтительный порядок для информационных источников. Пользователь может также указывать предпочтение некоторого типа результата поиска перед другим типом результата поиска. Система распространения информации может также различать предпочтения пользователя посредством контроля взаимодействия пользователя с информационной системой распространения и, в частности, информации, воспроизведенной информационной системой распространения. Система распространения информации может поддерживать информацию относительно предпочтений и взаимодействий пользователя в профиле пользователя. Временный вес - это вес, который назначен результату поиска на основании близости события, которое соответствует результату поиска. Временное взвешивание дополнительно описано ниже. Система распространения информации может затем получать общий вес для каждого результата поиска на основании статического веса результата поиска, адаптивного веса и временного веса. Например, общий вес результата поиска может быть получен посредством суммирования статического веса, адаптивного веса и временного веса результата поиска. Система распространения информации затем ранжирует результаты поиска согласно их общим весам и воспроизводит ранжированный список результатов поиска. В некоторых вариантах осуществления система распространения информации воспроизводит только заранее определенное количество результатов поиска. Например, система распространения информации может только воспроизводить двадцать наиболее высокоранжированных результатов поиска.
В некоторых вариантах осуществления система распространения информации может оповещать пользователей относительно высокорелевантных результатах поиска. Система распространения информации может оповещать пользователя посредством обеспечения индикации на клиентском вычислительном устройстве пользователя. Например, система распространения информации может вынуждать конкретную иконку или индикатор появляться на ПИ на клиентском вычислительном устройстве пользователя. Система распространения информации может также изменять цвет отображенной иконки или индикатора, чтобы указать присутствие результатов поиска переменной релевантности. Для пользователя, использующего мобильное клиентское вычислительное устройство, такого как смартфон, система распространения информации может посылать пользователю текстовое сообщение, сообщающее пользователю о присутствии релевантных результатов поиска.
Временное ранжирование
Временное ранжирование основано на том понятии, что важность информации изменяется со временем. Например, пользователь может иметь два события, запланированные в календаре пользователя: первое событие о встрече на следующей неделе в Нью-Йорке и второе событие о полете в Нью-Йорк для этой встречи. В некоторый момент времени до встречи важность события встречи будет высока (то есть представляет интерес для пользователя), и любые элементы информации (например, новости), относящиеся к событию встречи, будут также важны. При приближении времени к событию полета событие полета также увеличивается в своей важности, и информационные элементы, относящиеся к событию полета, например информация о задержке рейса, также увеличивается в важности. Как только пользователь выполняет полет и приземляется в Нью-Йорке, событие рейса будет иметь значительно уменьшенную важность для пользователя, и соответствующие элементы информации больше не могут быть интересны пользователю. Как можно видеть из этого примера, события имеют важность для пользователя, и информационные элементы, относящиеся к событиям, также имеют важность для пользователя, но эта важность изменяется во времени и, более конкретно, близости к событиям.
В некоторых вариантах осуществления система распространения информации ранжирует результаты поиска на основании временного веса, назначенного каждому результату поиска. Временный вес есть индикация важности результата поиска для пользователя, которая изменяется со временем. Для каждого результата поиска система распространения информации вычисляет временный вес, который основан на близости события во времени, которое относится к результату поиска. Значение временного веса результата поиска может увеличиваться (например, повышаться) экспоненциально в период времени перед началом соответствующего события. В течение соответствующего события значение временного веса может оставаться относительно постоянным (например, на одном уровне) или может возрастать до пика в момент времени в течение соответствующего события и уменьшаться после него. В период времени после окончания соответствующего события значение временного веса может уменьшаться (например, снижаться) экспоненциально до нуля за очень короткий промежуток времени. Значение временного веса может быть вычислено, используя экспоненциальную функцию следующего вида:
f(t)=k*exp(-m * rti) (2),
где rti представляет временной интервал (например, время с текущего момента времени до начала события), сравненный с длительностью события (например, T2-T1, где T2 - конечное время события и T1 - начальное время события), и k и m - весовые коэффициенты, чьи значения выбирают так, чтобы изменить форму функции, как необходимо. Значения, выбранные для весовых коэффициентов k и m, могут быть различными до, в течение и после события. Значения весовых коэффициентов также могут быть настроены так, чтобы сформировать конкретные временные значения веса для конкретных моментов времени. Например, значения весовых коэффициентов могут быть выбраны так, чтобы сформировать временное значение веса, то есть, например, 1/3 от максимального временного значения веса в момент времени, которым является T2-T1 (то есть продолжительность или длительность события) от T1 (то есть начала события).
В некоторых вариантах осуществления система распространения информации вычисляет временный вес результата поиска, используя следующие уравнения:
если текущее время является временем до начала события, относящегося к результату поиска,
TW=BEWF*TimeWeight(2.0*(T1-TN)/(TD*TF)) (3),
если текущее время является временем в течение события, относящегося к результату поиска,
TW=DEWF*TimeWeight(1.0*(((T1+T2)/2))-TN/(TD*TF)) (4),
если текущее время является временем после конца события, относящегося к результату поиска,
TW = AEWF * TimeWeight (4.0 * (TN-T2)/(TD * TF)) (5),
где TN - текущее время, T1 - время начала события, T2 - время конца события, TD - длительность события во времени, BEWF - весовой коэффициент до события, DEWF - весовой коэффициент в течение события, AEWF - весовой коэффициент после события, TF - весовой коэффициент, и TimeWeight (временный вес) является следующей функцией:
TimeWeight (x)=exp (-1.0 * abs(x)) (6),
где exp представляет экспоненциальную функцию "e", и “abs” представляет функцию абсолютной величины. Значения, назначенные весовым коэффициентам BEWF, DEWF, AEWF и TF, управляют скоростью повышения и скоростью снижения временного веса. В некоторых вариантах осуществления система распространения информации может изменять значения, которые назначены весовым коэффициентам, в зависимости от таких факторов, как продолжительность события, важность события и т.д.
Классы событий
В некоторых вариантах осуществления система распространения информации допускает создание классов событий и распространяет информацию, относящуюся к темам, извлеченным из классов событий. Классы событий обычно могут быть представлены как сценарии, которые определяют темы и действия для получения информации, относящейся к темам. Класс события может быть написан на любом из ряда известных языков описания данных, таком как расширяемый язык разметки (XML), и т.д. Классы событий выполняются, чтобы получить информацию, относящуюся к конкретному классу событий. В некоторых вариантах осуществления система распространения информации может обеспечивать ПИ, посредством которого авторизованный пользователь, такой как администратор системы, может создавать класс события. Чтобы создавать класс события, пользователь может использовать ПИ, чтобы задать распознаватель класса события, набор специальных тем и, для каждой указанной специальной темы, набор слотов (мест вставки), распознаватель слота для каждого слота в наборе слотов и набор действий. Распознаватель класса события позволяет идентифицировать соответствующий класс события. Распознаватель класса события может быть определен в форме эвристики, обычных выражений, шаблонов или других подходящих правил, которые могут быть выполнены, чтобы идентифицировать свой соответствующий класс события. Набор специальных тем определяет релевантные идеи для его соответствующего класса события. Например, специальная тема может быть создана для консультации о путешествии, консультации о погоде, встрече, обеде в ресторане и различных других событий или концепциях событий. Каждый слот (место вставки) является параметром (то есть меткой-заполнителем), который описывает атрибут своей соответствующей специальной темы. Например, чтобы создать специальную тему для консультации о путешествии, пользователь может определить слоты (места вставки) для исходящего города ("FromCity"), города адресата ("ToCity"), одного или более промежуточных городов, авиакомпании-перевозчика, номера рейса, даты и т.п. Чтобы создать специальную тему для встречи, пользователь может определить слоты для предмета встречи, приглашенных на встречу посетителей, представленных компаний и т.п. Распознаватель слота позволяет распознавать или идентифицировать значения или "заполнитель слота" (заполнитель места вставки) для своего соответствующего места вставки. Распознаватель места вставки может быть определен в форме эвристики, регулярных выражений, подпрограмм извлечения информации или других подходящих правил, которые могут быть выполнены, чтобы идентифицировать соответствующий заполнитель места вставки для соответствующего места вставки. Например, распознаватель места вставки для места вставки FromCity в специальной теме консультации о путешествии может задать ограничение или предел, что место вставки FromCity может быть заполнено только названием города, распознанного из стандартного или указанного списка названий городов. Система распространения информации может затем выполнять распознаватель места вставки в отношении набора релевантных элементов календаря, сообщений электронной почты и других информационных источников пользователя, чтобы определить значение для места вставки, ограниченного любым указанным ограничением. Заданные действия вызываются, чтобы получить информацию, соответствующую ее специальной теме. Действие может быть определено как параметризованный URL (то есть URL, имеющий один или более параметров), который должен быть инициализирован и вызван. Для инициализации параметризованного URL система распространения информации сначала определяет значение для каждого из параметров, включенных в URL, и затем заменяет параметры их соответствующими значениями. Действие может быть также задано как URL. В некоторых вариантах осуществления пользователь может задать правила для систематизации (классификации) и извлечения релевантной информации из информации, которая получается посредством выполнения указанных действий.
Чтобы распространять информацию, относящуюся к классу событий, система распространения информации сначала идентифицирует пользовательское событие, которое является интересным пользователю. Система распространения информации может идентифицировать пользовательское событие из профиля пользователя. Система распространения информации затем выполняет определенный распознаватель класса событий, чтобы определить, "вписываться ли” пользовательское событие в один из созданных классов событий. Выполнение определенных распознавателей класса событий может не приводить к идентификации или определению класса событий для пользовательского события. Система распространения информации может позволять пользователю задать класс события для пользовательского события. После определения класса событий для выполнения система распространения информации идентифицирует специальные темы, которые были определены для класса событий, и места вставки, которые были определены для каждой специальной темы. Система распространения информации затем идентифицирует распознаватели места вставки, которые были определены для каждого из мест вставки, и выполняет каждый распознаватель места вставки для различных источников информации пользователя и интересов, таких как сообщения электронной почты пользователя, назначения встреч, элементы календаря и т.д., чтобы идентифицировать заполнитель места вставки для соответствующего места вставки. Система распространения информации также инициализирует любые параметризованные действия посредством идентификации значений заполнителя места вставки и замены этих значений в соответствующих местах. Система распространения информации затем выполняет действия, определенные для этой специальной темы, получает результаты действий и воспроизводит результаты действий пользователю. Например, система распространения информации может инициализировать и вызывать определенные URL и отображать результаты вследствие вызова URL. В некоторых вариантах осуществления система распространения информации может систематизировать результаты действий, чтобы идентифицировать релевантную информацию и воспроизводить релевантную информацию пользователю. В некоторых вариантах осуществления система распространения информации может ранжировать результаты действий и воспроизводить ранжированные результаты действий пользователю.
Фиг. 1 - блок-схема, которая иллюстрирует работу системы распространения информации, согласно некоторым вариантам осуществления. Система распространения информации идентифицирует интересы пользователя, собирает информацию, которая основана на идентифицированных интересах пользователя, ранжирует собранную информацию и воспроизводит ранжированную информацию пользователю. Для каждого пользователя система распространения информации сначала идентифицирует интересы пользователя и определяет общие и специфические для события темы. Интересы пользователя могут быть идентифицированы, используя информацию, полученную из календаря пользователя, сообщений электронной почты, связанных документов и т.д., и темы могут быть определены, используя различные способы кластеризации. Система распространения информации затем автоматически создает профиль для пользователя. Система распространения информации может включать в профиль информацию, такую как источники информации для поиска, чтобы получить информацию для воспроизведения пользователю, события, которые были проанализированы, и темы, которые были сгенерированы, языковую модель, которая расширяется с опытом работы пользователя с информационной системой распространения, а также другую информацию, относящуюся к пользователю. Используя информационные источники и темы, указанные в профиле пользователя, система распространения информации периодически выполняет поиск и сопоставляет результаты поиска, содержащие информацию, которая является потенциально релевантной темам. Система распространения информации затем ранжирует результаты поиска на основании различных факторов, таких как веса темы, ранги, обеспеченные информационными источниками, близость к событиям, и информации обратной связи пользователя. Система распространения информации затем воспроизводит ранжированные результаты поиска пользователю. Система распространения информации затем получает информацию обратной связи пользователя посредством мониторинга взаимодействия пользователя с воспроизведенными результатами поиска и непосредственно распространением информации. Система распространения информации затем включает информацию обратной связи в профиль пользователя. Включая информацию обратной связи в профиль пользователя, система распространения информации способна включить информацию обратной связи в последующие поиски и ранжирование результатов поиска, таким образом становясь все более и более чувствительной к информационным потребностям пользователя.
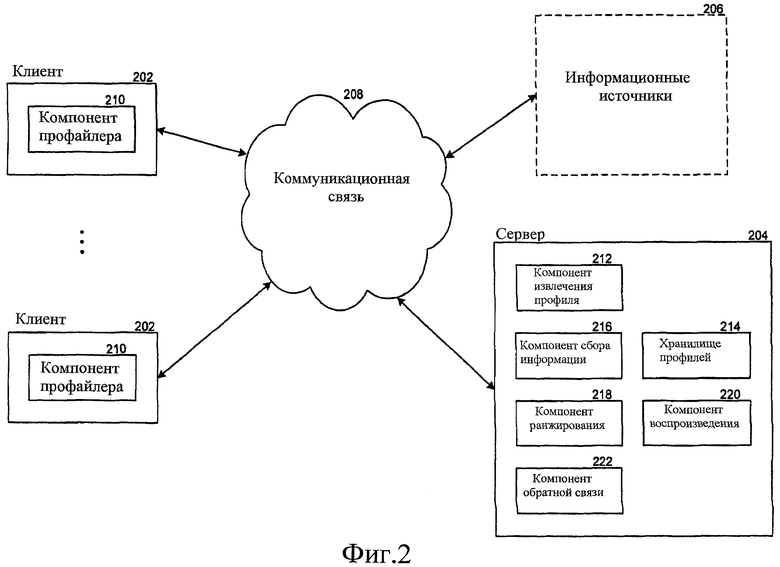
Фиг. 2 - блок-схема, которая иллюстрирует выбранные компоненты системы распространения информации, согласно некоторым вариантам осуществления. Система распространения информации может включать в себя как клиентские компоненты, которые выполняются на вычислительных устройствах пользователя, так и серверные компоненты, которые выполняются на сервере. Как изображено, клиентские устройства 202, сервер 204 и информационные источники 206 каждый подсоединены к линии связи 208. Клиентские устройства соответствуют вычислительным устройствам, используемым пользователями для взаимодействия с информационной системой распространения. Каждое клиентское устройство содержит компонент 210 профайлера. Когда пользователь первоначально регистрируется в информационной системе распространения, вызывается компонент профайлера, чтобы идентифицировать интересы пользователя и автоматически создать профиль для пользователя. Компонент профайлера может затем периодически вызываться, чтобы обновить информацию, касающуюся интересов пользователя, поддерживаемую в профиле пользователя. Компонент профайлера также вызывается, чтобы с приращением генерировать темы, которые могут быть интересны пользователю. Сервер содержит компонент 212 извлечения профиля, хранилище 214 профилей, компонент 216 сбора информации, компонент 218 ранжирования, компонент 220 воспроизведения и компонент 222 обратной связи. Компонент извлечения профиля вызывают, чтобы получить профили пользователя от клиентских устройств. Хранилище профилей содержит профили пользователя. Компонент сбора информации вызывают через периодические интервалы времени, чтобы собрать информацию из соответствующих информационных источников согласно информации, содержащейся в профилях пользователя. Компонент сбора информации обычно ищет информационные источники, используя запросы, указанные в профилях пользователя. Компонент ранжирования вызывают, чтобы ранжировать собранную информацию (например, результаты поиска). Компонент воспроизведения вызывают, чтобы воспроизвести ранжированные результаты поиска соответствующим пользователям. Компонент обратной связи вызывают, чтобы получить информацию обратной связи от пользователя и расширить информацию в профилях пользователя информацией обратной связи пользователя. Хотя и не показано на фиг. 2, клиентские устройства включают в себя компоненты системы распространения информации, чтобы позволить пользователям взаимодействовать с информационной системой распространения, чтобы, например, просматривать и модифицировать содержание пользовательских профилей, принимать уведомления и предупреждения о доступности информации и отображать и просматривать воспроизведенную информацию. Аналогично, сервер также включает в себя компоненты системы распространения информации для определения классов событий и выполнения классов событий.
Вычислительное устройство, на котором система распространения информации реализована, может включать в себя центральный процессор, память, устройства ввода (например, клавиатуру и указательные устройства), устройства вывода (например, устройства отображения) и запоминающие устройства (например, накопители на магнитных дисках). Память и запоминающие устройства являются считываемыми компьютером носителями, которые могут содержать команды, которые реализуют информационную систему распространения. Кроме того, структуры данных и структуры сообщений могут быть сохранены или переданы через среду передачи данных, такую как сигнал в линии связи. Различные линии связи могут использоваться, например Интернет, локальная сеть, глобальная сеть, двухточечная коммутируемая сеть, сеть сотовых телефонов и т.п.
Варианты осуществления системы распространения информации, включающие в себя клиента распространения информации и сервер распространения информации, могут быть реализованы в различных рабочих средах, которые включают в себя персональные компьютеры, серверные компьютеры, карманные или портативные устройства, мультипроцессорные системы, основанные на микропроцессорах системы, программируемую бытовую электронику, цифровые камеры, сетевые персональные компьютеры, миникомпьютеры, универсальные компьютеры, сетевые устройства, распределенные вычислительные среды, которые включают в себя любую из вышеупомянутых систем или устройств, и т.п. Компьютерными системами могут быть сотовые телефоны, персональные цифровые ассистенты, смартфоны, персональные компьютеры, программируемая бытовая электроника, цифровые камеры и так далее.
Система распространения информации может быть описана в общем контексте выполнимых компьютером команд, например программных модулей, выполняемых одним или более компьютерами или другими устройствами. Обычно программные модули включают в себя подпрограммы, программы, объекты, компоненты, структуры данных и так далее, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Как правило, функциональные возможности программных модулей могут быть скомбинированы или распределены так, как требуется в различных вариантах осуществления.
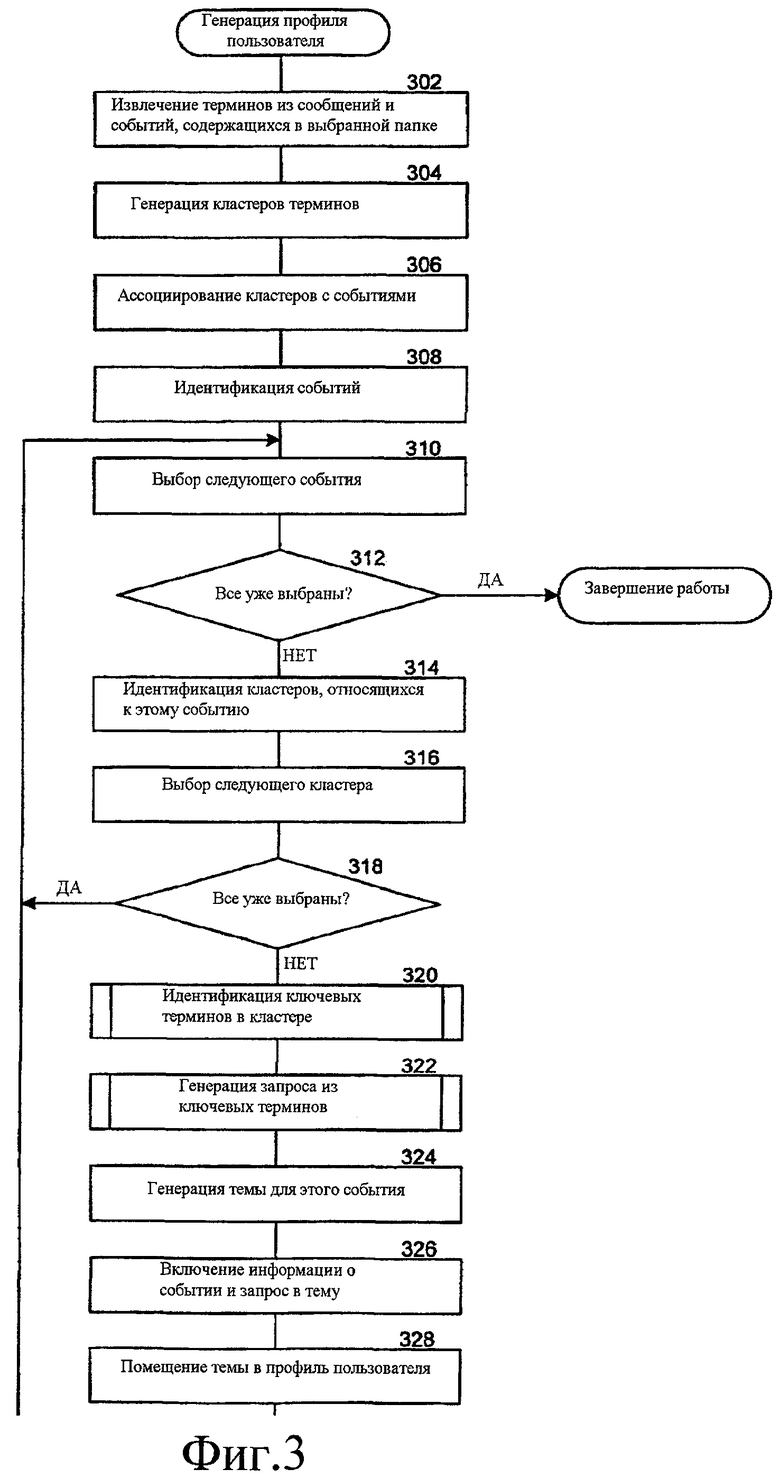
Фиг. 3 - блок-схема последовательности операций, которая иллюстрирует обработку (работу) компонента профайлера, согласно некоторым вариантам осуществления. Компонент профайлера периодически идентифицирует интересы пользователя, чтобы создать или обновить профиль пользователя информацией относительно интересов пользователя. На этапе 302 компонент профайлера извлекает термины из сообщений и событий, содержащихся в выбранных папках, таких как папки электронной почты пользователя. На этапе 304 компонент профайлера генерирует кластеры аналогичных терминов. На этапе 306 компонент профайлера ассоциирует кластеры с событиями. На этапе 308 компонент профайлера идентифицирует пользовательские события, например назначенные встречи пользователя. На этапе 310 компонент профайлера выбирает следующее идентифицированное событие. На этапе 312 принятия решения, если все идентифицированные события уже были выбраны, то компонент профайлера завершает работу, иначе компонент профайлера продолжает работу на этапе 314. На этапе 314 компонент профайлера идентифицирует кластеры, которые относятся к событию. На этапе 316 компонент профайлера выбирает следующий идентифицированный кластер. На этапе 318 принятия решения, если все идентифицированные кластеры уже были выбраны, то компонент профайлера переходит в цикле к этапу 310 для выбора следующего идентифицированного события, иначе компонент профайлера продолжает работу на этапе 320. На этапе 320 компонент профайлера идентифицирует ключевые термины в идентифицированном кластере. На этапе 322 компонент профайлера генерирует запрос из ключевых терминов. На этапе 324 компонент профайлера формирует тему для события и на этапе 326 включает информацию относительно события и сформированного запроса в тему. На этапе 328 компонент профайлера помещает тему в профиль пользователя и затем переходит в цикле к этапу 310, чтобы выбрать следующее идентифицированное событие. Если профиль не существует для пользователя, то компонент профайлера создает профиль для пользователя.
Специалисту понятно, что для этого и других процессов и способов, раскрытых в настоящем описании, функции, выполняемые в процессах и способах, могут быть реализованы в отличающемся порядке. Кроме того, описанные этапы являются только примерными, и некоторые из этапов могут быть необязательными, объединены с меньшим количеством этапов или расширены в дополнительные этапы.
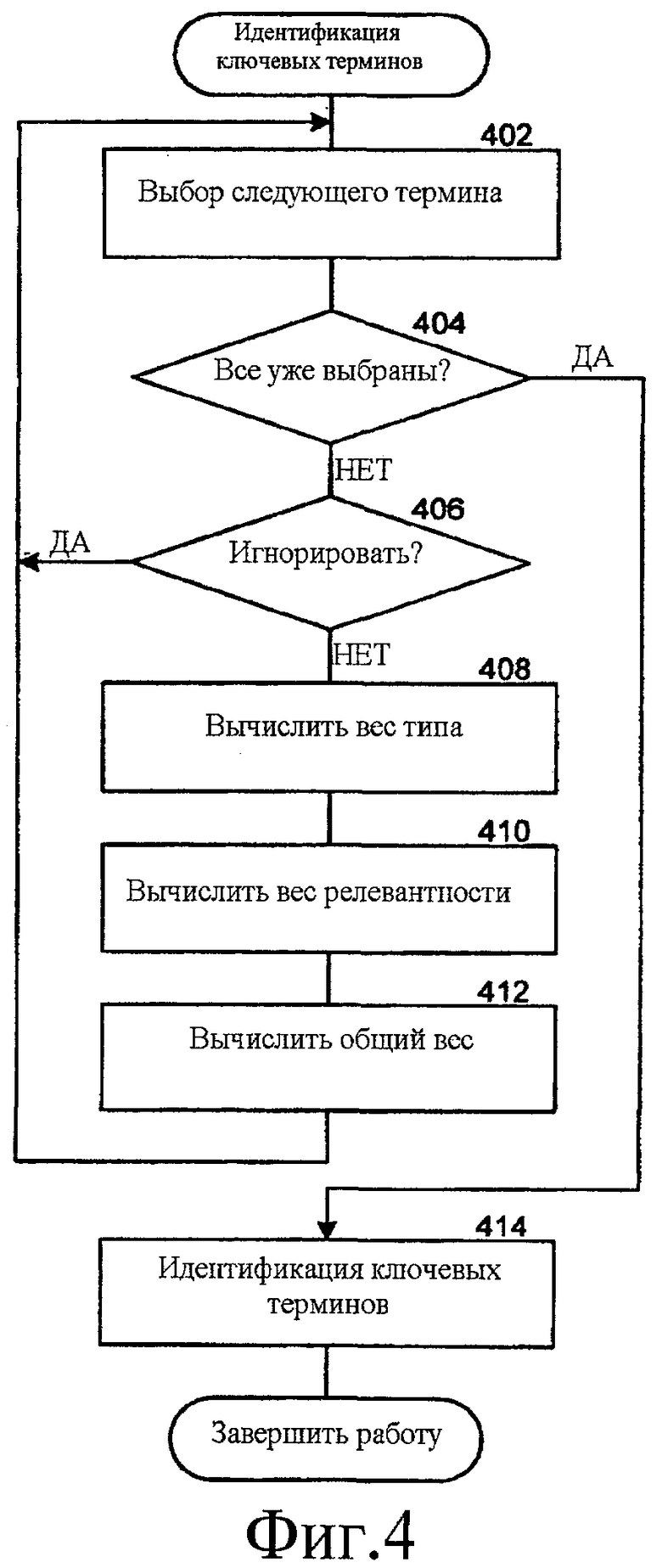
Фиг. 4 - блок-схема последовательности операций, которая иллюстрирует обработку в компоненте профайлера для идентификации ключевых терминов согласно некоторым вариантам осуществления. Например, компонент профайлера может идентифицировать ключевые термины из терминов, которые содержатся в описании события или сообщении электронной почты. Компонент профайлера идентифицирует ключевые термины на основании общего веса, назначенного каждому термину. На этапе 402 компонент профайлера выбирает следующий термин. Компонент профайлера может выбирать термин, используя любое из множества хорошо известных инструментальных средств, таких как система лексического анализа. На этапе 404 принятия решения, если все термины уже были выбраны, то компонент профайлера продолжает работу на этапе 414, иначе компонент профайлера продолжает работу на этапе 406 принятия решения. На этапе 406 принятия решения, если термин должен быть исключен как потенциальный ключевой термин, то компонент профайлера переходит в цикле к этапу 402 для выбора следующего термина, иначе компонент профайлера продолжает работу на этапе 408. На этапе 408 компонент профайлера вычисляет вес типа для термина. На этапе 410 компонент профайлера вычисляет вес релевантности для этого термина. На этапе 412 компонент профайлера вычисляет общий вес на основании веса типа и веса релевантности и назначает общий вес термину, и затем переходит в цикле к этапу 402, чтобы выбрать следующий термин. На этапе 414 компонент профайлера идентифицирует ключевые термины на основании общих весов, назначенных терминам, и завершает работу.
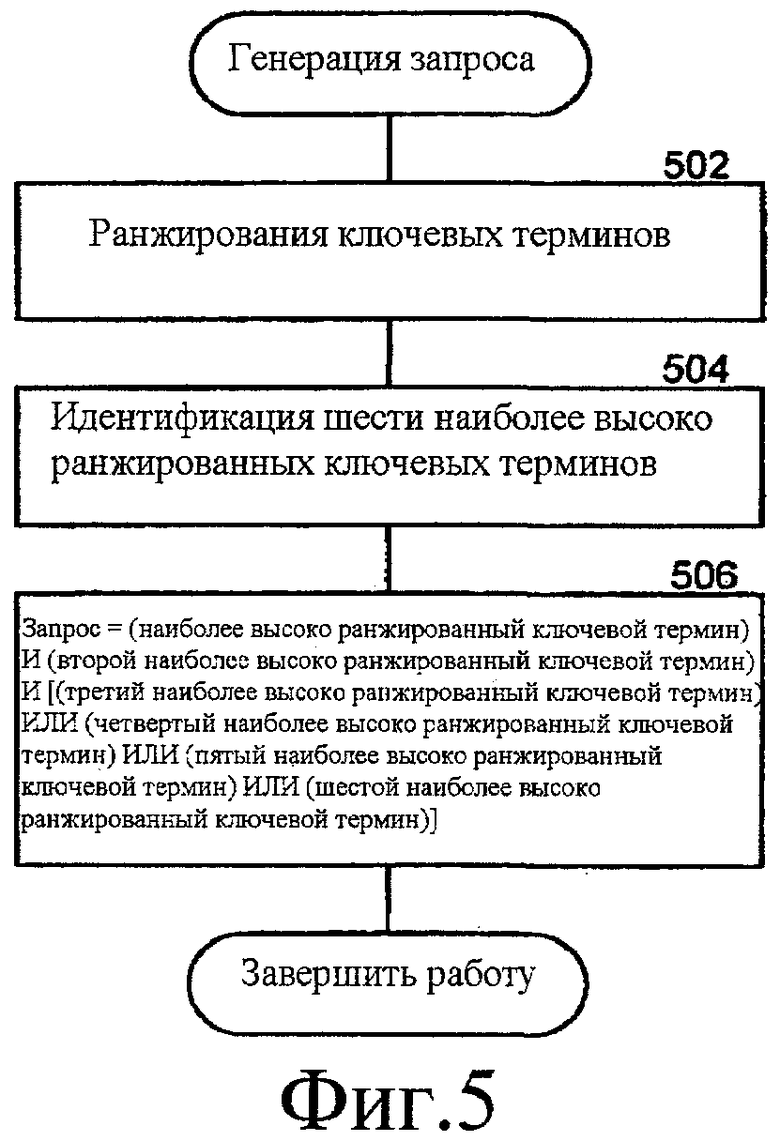
Фиг. 5 - блок-схема последовательности операций, которая иллюстрирует обработку в компоненте профайлера для формирования запроса согласно некоторым вариантам осуществления. Компонент профайлера генерирует запрос из ключевых терминов. На этапе 502 компонент профайлера ранжирует ключевые термины на основании их общих весов. На этапе 504 компонент профайлера идентифицирует шесть ключевых терминов самого высокого ранга. На этапе 506 компонент профайлера генерирует запрос из идентифицированных шести ключевых терминов наивысшего ранга, используя Уравнение 1, и завершает работу. В других вариантах осуществления компонент профайлера может генерировать запрос, используя другое количество ключевых терминов наивысшего ранга.
Фиг. 6 - блок-схема последовательности операций, которая иллюстрирует обработку в компоненте профайлера, чтобы с приращением формировать тему, согласно некоторым вариантам осуществления. Компонент профайлера принимает индикацию, что событие является интересным пользователю. Например, пользователь может задать, что событие заслуживает освещения в печати, и выдает запрос на прием информации, относящейся к указанному событию. На этапе 602 компонент профайлера идентифицирует интерес пользователя, такое как релевантное сообщение или событие. На этапе 604 компонент профайлера извлекает термины, связанные с идентифицированным интересом пользователя. На этапе 606 компонент профайлера идентифицирует ключевые термины из извлеченных терминов. На этапе 608 компонент профайлера формирует запрос из ключевых терминов. На этапе 610 компонент профайлера помещает запрос в профиль пользователя и завершает работу.
Фиг. 7 - блок-схема последовательности операций, которая иллюстрирует обработку в компоненте сбора информации, согласно некоторым вариантам осуществления. Компонент сбора информации периодически собирает информацию для воспроизведения пользователю на основании информации, содержащейся в профиле пользователя. На этапе 702 компонент сбора выбирает следующий запрос из профиля пользователя. На этапе 704 принятия решения, если все запросы уже были выбраны, то компонент сбора продолжает работу на этапе 708, иначе компонент сбора продолжает работу на этапе 706. На этапе 706 компонент сбора выполняет запрос и получает результаты поиска. Компонент сбора может выполнять запрос посредством поиска информационных источников, указанных в профиле пользователя, используя запрос. Вслед за получением результатов поиска для запроса, модуль сбора переходит в цикле на этап 702 для выбора следующего запроса. На этапе 708 компонент сбора ранжирует результаты поиска, которые были получены, выполняя запросы. На этапе 710 компонент сбора воспроизводит ранжированные результаты поиска пользователю и завершает работу.
Фиг. 8 - блок-схема последовательности операций, которая иллюстрирует обработку в компоненте ранжирования, согласно некоторым вариантам осуществления. Компонент ранжирования проходит по результатам поиска (элементам информации, полученным из поиска информационного источника) и ранжирует результаты поиска на основании общего веса, назначенного каждому результату поиска. На этапе 802 компонент ранжирования выбирает следующий результат поиска. На этапе 804 принятия решения, если все результаты поиска уже были выбраны, то компонент ранжирования продолжает работу на этапе 814, иначе компонент ранжирования продолжает работу на этапе 806. На этапе 806 компонент ранжирования вычисляет статический вес для результата поиска. На этапе 808 компонент ранжирования вычисляет временный вес для результата поиска. На этапе 810 компонент ранжирования вычисляет адаптивный вес для результата поиска. На этапе 812 компонент ранжирования вычисляет общий вес на основании статического веса, временного веса и адаптивного веса, назначает общий вес результату поиска и затем переходит в цикле к этапу 802, чтобы выбрать следующий результат поиска. На этапе 814 компонент ранжирования ранжируют результаты поиска на основании общих весов, назначенных результатам поиска, и завершает работу.
Фиг. 9 - графическое описание значений веса как функции близости к событию согласно некоторым вариантам осуществления. График иллюстрирует значение временного веса, которое является важностью элемента информации (то есть результата поиска) для пользователя, относительно времени. Относительная важность элемента информации изменяется по-разному в зависимости от текущего времени. На графике, изображенном на фиг. 9, T1 - запланированное начальное время события, относящееся к элементу информации, и T2 - запланированное конечное время связанного события. В период времени до T1 важность элемента информации для пользователя повышается, например, по экспоненте, как изображено на фиг. 9, но становится более плоской по мере подъема кривой, когда текущее время приближается ближе к T1. В течение события важность элемента информации для пользователя остается относительно постоянной. В течение времени после окончания события важность элемента информации для пользователя быстро понижается, например, по экспоненте как изображено на фиг. 9, так что важность уменьшается до значения нуля за очень короткое время. В некоторых вариантах осуществления, как изображено на фиг. 10, важность элемента информации для пользователя в течение события может повышаться до пика в момент времени в течение события, например во время (T1+T2)/2, и затем уменьшаться к запланированному окончанию события.
Фиг. 11 - блок-схема последовательности операций, которая иллюстрирует обработку в компоненте ранжирования, чтобы вычислить временный вес результата поиска, согласно некоторым вариантам осуществления. На этапе 1102 компонент ранжирования идентифицирует событие, которое соответствует результату поиска. На этапе 1104 компонент ранжирования определяет текущее время (то есть в настоящий момент времени). На этапе 1106 компонент ранжирования определяет время, когда запланировано начало идентифицированного события. На этапе 1108 компонент ранжирования определяет время, когда запланировано окончание идентифицированного события. На этапе 1110 принятия решения, если текущее время является временем до момента времени, когда запланировано начало события, то компонент ранжирования продолжает работу на этапе 1112, иначе компонент ранжирования продолжает работу на этапе 1114 принятия решения. На этапе 1112 компонент ранжирования вычисляет временный вес для результата поиска, используя Уравнение 3, и завершает работу. На этапе 1114 принятия решения, если текущее время есть время между временем, когда запланировано начало события, и временем, когда запланировано окончание события, то компонент ранжирования продолжает работу на этапе 1116, иначе компонент ранжирования продолжает работу на этапе 1118. На этапе 1116 компонент ранжирования вычисляет временный вес для результата поиска, используя Уравнение 4, и завершает работу. На этапе 1118 компонент ранжирования вычисляет временный вес для результата поиска, используя Уравнение 5, и завершает работу.
Фиг. 12 - блок-схема последовательности операций, которая иллюстрирует воспроизведение информации на основании класса события, соответствующего пользовательскому событию, согласно некоторым вариантам осуществления. Система распространения информации создает классы событий и распространяет информацию относительно темы, извлеченной из классов событий. На этапе 1202 компонент системы распространения информации создает классы событий. На этапе 1204 компонент идентифицирует пользовательское событие для обработки. На этапе 1206 компонент определяет класс события, который соответствует идентифицированному пользовательскому событию. На этапе 1208 компонент обрабатывает идентифицированный класс события и завершает работу.
Фиг. 13 - блок-схема последовательности операций, которая иллюстрирует создание класса событий, согласно некоторым вариантам осуществления. Компонент системы распространения информации может создавать класс события в ответ на пользовательский запрос создать класс события и основанный на вводимых данных, обеспеченных пользователем. На этапе 1302 компонент создает распознаватель класса событий для класса событий. На этапе 1304 компонент создает набор специальных тем для класса событий. На этапе 1306 компонент выбирает следующую специальную тему. На этапе 1308 принятия решения, если все специальные темы уже были выбраны, то компонент завершает работу, иначе компонент продолжает работу на этапе 1310. На этапе 1310 компонент создает набор мест вставки для специальной темы. На этапе 1312 компонент создает распознаватель места вставки для каждого из созданных мест вставки. На этапе 1314 компонент создает набор действий для специальной темы. На этапе 1316 компонент создает набор правил для систематизации результатов действий, чтобы извлечь релевантную информацию из результатов действий, и затем переходит в цикле к этапу 1306, чтобы выбрать следующую специальную тему.
Фиг. 14 является примером листинга данных, который иллюстрирует класс события, согласно некоторым вариантам осуществления. Листинг иллюстрирует множество специальных тем, содержащихся в классе события, включая секцию 1402 "Тема советов для путешествия" для специальной темы советов к путешествию. Эта секция темы советов к путешествию содержит секцию 1404 "Места вставки", секцию 1406 "Распознаватель" и секцию 1408 "Действия". Секция места вставки задает места вставки, которые были определены для специальной темы. Например, место вставки "ToCity" (В город) и "ToCountry" (В страну) были определены для темы советов к путешествию. Секция распознавателя задает ограничения на значения мест вставки и то, как определить значения для мест вставки. Секция действий задает действия, которые должны быть предприняты для специальной темы. Например, действия могут быть заданы в форме параметризованных URL, которые должны быть отображены или выполнены. Листинг на фиг. 14 также иллюстрирует другие специальные темы, которые не были иллюстрированы с тем же уровнем подробностей, как советы к специальной теме путешествий. Хотя и не изображено, каждая из этих специальных тем может также содержать секции, подобные тем, что содержатся в специальной теме советов к путешествию.
Фиг. 15 - блок-схема последовательности операций, которая иллюстрирует обработку класса событий, согласно некоторым вариантам осуществления. Компонент системы распространения информации может обрабатывать класс события после идентификации пользовательского события для обработки. На этапе 1502 компонент идентифицирует специальные темы, которые были определены (то есть созданы) для класса событий. На этапе 1504 компонент выбирает следующую определенную специальную тему. На этапе 1506 принятия решения, если все определенные специальные темы уже были выбраны, то компонент завершает работу, иначе компонент продолжает работу на этапе 1508. На этапе 1508 компонент идентифицирует места вставки, которые были заданы для этой специальной темы. На этапе 1510 компонент выбирает следующее определенное место вставки. На этапе 1512 принятия решения, если все определенные места вставки уже были выбраны, то компонент продолжает работу на этапе 1516, иначе компонент продолжает работу на этапе 1514. На этапе 1514 компонент использует распознаватель места вставки для этого места вставки, чтобы идентифицировать заполнитель места вставки (и значение) для этого места вставки, и затем переходит в цикле на этап 1510, чтобы выбрать следующее определенное место вставки. В некоторых вариантах осуществления в случаях, когда компонент не способен идентифицировать заполнитель места вставки, этот компонент может запрашивать пользователя обеспечить заполнитель места вставки. На этапе 1516 компонент идентифицирует действия, которые были определены для специальной темы. На этапе 1518 компонент выполняет эти действия. На этапе 1520 компонент классифицирует результаты действий, например, чтобы идентифицировать релевантную информацию. На этапе 1522 компонент воспроизводит классифицированные результаты действий пользователю, и затем переходит в цикле на этап 1504, чтобы выбрать следующую определенную специальную тему.
Хотя сущность изобретения была описана на языке, специфичном для структурных признаков и/или методологических действий, должно быть понятно, что объект изобретения, определяемый прилагаемой формулой изобретения, необязательно ограничен конкретными признаками или действиями, описанными выше. Скорее, конкретные признаки и действия, описанные выше, раскрыты как примерные формы осуществления формулы изобретения. Соответственно изобретение не ограничено, за исключением прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СБОР ДАННЫХ О ПОЛЬЗОВАТЕЛЬСКОМ ПОВЕДЕНИИ ПРИ ВЕБ-ПОИСКЕ ДЛЯ ПОВЫШЕНИЯ РЕЛЕВАНТНОСТИ ВЕБ-ПОИСКА | 2007 |
|
RU2435212C2 |
| СПОСОБ ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА, СЕРВЕР И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2014 |
|
RU2670494C2 |
| РЕЗЮМИРОВАНИЕ ПОТОКОВ СООБЩЕНИЙ | 2012 |
|
RU2621005C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ РЕЗУЛЬТАТА ПОИСКА ДЛЯ ПОВЫШЕНИЯ УРОВНЯ РАЗНООБРАЗИЯ И ИНФОРМАЦИОННОЙ НАСЫЩЕННОСТИ | 2005 |
|
RU2383922C2 |
| ПОСТРОЕНИЕ И ПРИМЕНЕНИЕ ВЕБ-КАТАЛОГОВ ДЛЯ ФОКУСИРОВАННОГО ПОИСКА | 2005 |
|
RU2382400C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫЧИСЛЕНИЯ ЗНАЧЕНИЯ ВАЖНОСТИ БЛОКА В ДИСПЛЕЙНОЙ СТРАНИЦЕ | 2005 |
|
RU2387004C2 |
| СПОСОБ, СИСТЕМА И КОМПЬЮТЕРНЫЙ ПРОГРАММНЫЙ ПРОДУКТ ДЛЯ ПОИСКА, НАВИГАЦИИ И РАНЖИРОВАНИЯ ДОКУМЕНТОВ В ПЕРСОНАЛЬНОЙ СЕТИ | 2005 |
|
RU2388050C2 |
| ГЕНЕРАЦИЯ ЗАПРОСА С ИСПОЛЬЗОВАНИЕМ КОНФИГУРАЦИИ СРЕДЫ | 2008 |
|
RU2454712C2 |
| ИСПОЛЬЗОВАНИЕ ОБРАТНОЙ СВЯЗИ С ПОЛЬЗОВАТЕЛЕМ ДЛЯ УЛУЧШЕНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2007 |
|
RU2424566C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ПРЕДСТАВЛЕНИЯ ЭЛЕМЕНТА РЕКОМЕНДУЕМОГО СОДЕРЖИМОГО ПОЛЬЗОВАТЕЛЮ | 2017 |
|
RU2699574C2 |



Изобретение относится к системам и способам поиска информации в сети Интернет. Техническим результатом является расширение функциональных возможностей поиска в информационно-поисковой системе благодаря ранжированию результатов поиска на основании временной близости к событию, к которому имеют отношение результаты поиска. Ранжирование заключается в определении временного веса, который является индикацией относительно важности события, изменяющегося со временем, для пользователя. Для каждого результата поиска система распространения информации вычисляет временный вес, который основан на временной близости события, которое относится к результату поиска. Временный вес может использоваться, чтобы заново ранжировать результаты поиска. 3 н. и 17 з.п. ф-лы, 15 ил.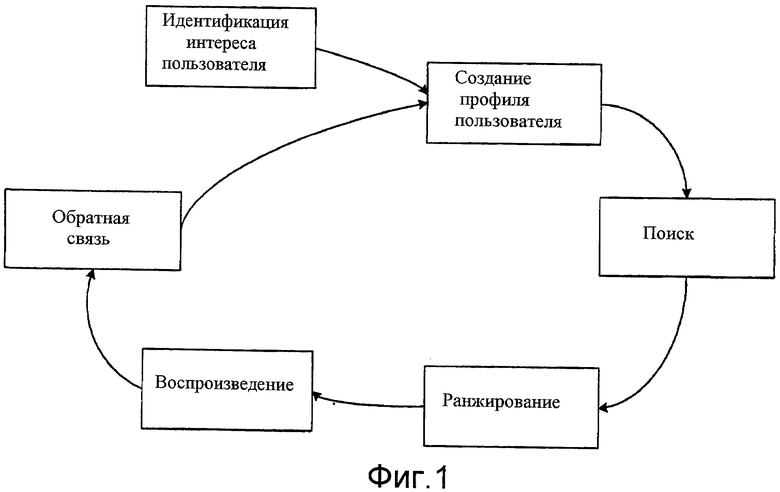
1. Реализованный компьютером способ для вычисления временного веса для результата поиска, причем способ содержит этапы: идентифицируют пользовательское событие (1102), соответствующее результату поиска, причем пользовательское событие имеет начальное время события, время окончания события и длительность события; определяют текущее время (1104); и
определяют временный вес (808) для этого результата поиска на основании временной близости текущего времени к пользовательскому событию.
2. Способ по п.1, в котором временный вес изменяется со временем.
3. Способ по п.1, в котором временный вес увеличивается по мере того, как текущее время приближается к начальному времени события.
4. Способ по п.3, в котором увеличение является экспоненциальным.
5. Способ по п.1, в котором временный вес является постоянным в течение длительности события.
6. Способ по п.1, в котором временный вес в течение длительности события является по меньшей мере временным весом в начальный момент времени события.
7. Способ по п.1, в котором временный вес достигает пика в момент времени в течение длительности события.
8. Способ по п.1, в котором временный вес достигает пика в момент времени на половине длительности события.
9. Способ по п.1, в котором временный вес уменьшается, когда текущее время удаляется от времени окончания события.
10. Способ по п.9, в котором уменьшение является экспоненциальным.
11. Считываемый компьютером носитель, содержащий команды для управления компьютерной системой, чтобы ранжировать во времени результаты поиска, причем способ содержит этапы:
для каждого результата поиска
идентифицируют пользовательское событие (1102), соответствующее результату поиска; и
определяют временный вес для результата поиска (808) на основании временной близости пользовательского события; и
ранжируют результаты поиска на основании временных весов, соответствующих результатам поиска.
12. Считываемый компьютером носитель по п.11, в котором временный вес результата поиска также основан на весовом коэффициенте.
13. Считываемый компьютером носитель по п.12, в котором весовой коэффициент основан на длительности пользовательского события.
14. Считываемый компьютером носитель по п.12, в котором весовой коэффициент основан на важности пользовательского события.
15. Считываемый компьютером носитель по п.12, в котором весовой коэффициент изменяется от момента до пользовательского события, в течение пользовательского события и после пользовательского события.
16. Компьютерная система для вычисления временного веса для результата поиска, содержащая:
компонент, который идентифицирует пользовательское событие (1102), соответствующее результату поиска, причем пользовательское событие имеет начальное время события, время окончания события и длительность события; и
компонент, который определяет временный вес (808) для результата поиска на основании временной близости пользовательского события.
17. Система по п.16, в которой временный вес результата поиска также основан на длительности пользовательского события.
18. Система по п.16, в которой временный вес результата поиска также основан на важности пользовательского события.
19. Система по п.16, в которой временный вес результата поиска увеличивается по экспоненте, когда текущее время приближается к начальному времени пользовательского события.
20. Система по п.16, в которой временный вес результата поиска уменьшается по экспоненте, когда текущее время удаляется от конечного времени пользовательского события.
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ С ПОВЫШЕННОЙ РЕЛЕВАНТНОСТЬЮ | 2003 |
|
RU2236699C1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| ПОСТРОЕНИЕ И ПРИМЕНЕНИЕ ВЕБ-КАТАЛОГОВ ДЛЯ ФОКУСИРОВАННОГО ПОИСКА | 2005 |
|
RU2382400C2 |
| WO 2004066163 A1, 05.08.2004. | |||

