Область техники, к которой относится изобретение
Настоящая технология относится к области поисковых систем в целом и конкретно к системе и способу персонализации агрегированных результатов поиска на странице результатов поиска.
Уровень техники
Различные глобальные или локальные сети связи (Интернет, Всемирная Паутина, локальные сети и подобные им) предлагают пользователю большой объем информации. Информация включает в себя контекстуальные разделы, такие как, новости и текущие события, карты, информацию о компаниях, финансовую информацию и ресурсы, информацию о траффике, игры и информацию развлекательного характера. Пользователи используют множество клиентских устройств (настольный компьютер, портативный компьютер, ноутбук, смартфон, планшеты и подобные им) для получения доступа к богатому информационному контенту (например, изображениям, аудио- и видеофайлам, анимированным изображениям и прочему мультимедийному контенту подобных сетей).
В общем случае, пользователь может получить доступ к ресурсу сети связи двумя основными способами. Данный пользователь может получить доступ к конкретному ресурсу напрямую, введя адрес ресурса (обычно URL или Единый указатель ресурса, например www.webpage.com), или же выбрав ссылку в электронном сообщении или на другом веб-ресурсе. В другом случае пользователь может воспользоваться поисковой системы для поиска желаемого ресурса. Последнее особенно подходит для тех случаев, когда пользователю известна интересующая его тематика, но неизвестен конкретный адрес интересующего ресурса.
Существуют многочисленные поисковые системы, доступные пользователю. Некоторые из них являются поисковыми системами общего назначения (например, Yandex™, Google™, Yahoo™, и т.д.). Другие являются вертикальными поисковыми системами - т.е. поисковыми системами, связанными с конкретной темой поиска - например, поисковая система Momondo™, связанная с поиском авиарейсов.
Вне зависимости от того, какая используется поисковая система, она обычно выполнена с возможностью получения поискового запроса от пользователя, выполнения поиска и вывода пользователю ранжированной страницы с результатами поиска (известную как страница результатов поиска или SERP). Были проделаны различные попытки улучшить страницы результатов поиска (SERP), который бы позволил пользователю проще и быстрее оценивать результаты поиска.
В дополнение к общему интернет-поиску или веб-поиску поисковые системы часто предоставляют доступ к специальным сервисам или вертикальным доменам, что позволяет пользователю получать результаты конкретного типа (например, видео, изображения и так далее) или относящиеся к конкретному домену (например, новости, погода и так далее). В некоторых случаях, результаты поиска по вертикальным доменам могут быть интегрированы в общую страницу результатов поиска (SEPR). Способ широко использовался в последние годы ведущими коммерческими поисковыми системами и называется агрегированным поиском. Агрегированный поиск может предоставлять пользователю возможность получать релевантные результаты конкретного типа непосредственно на странице результатов поиска (SERP).
Одной из наиболее важных проблем, касающихся агрегированного поиска является проблема поиска вертикалей, соответствующих запросу пользователя, и удобное размещение их результатов на странице результатов поиска (SERP). Данная проблема была рассмотрена с помощью модели машинного обучения, основанной на характеристиках, которые должны способствовать определению релевантности вертикального домена запросу. Примерами подобных характеристик являются: данные запроса (например, использование текста запроса для определения релевантности вертикального домена); данные от вертикали (например, использование свойств коллекции проиндексированных документов, принадлежащих вертикальному домену); данные о переходах и показах (например, использование истории поискового поведения пользователя, включая в себя переходы, выбор и так далее); сетевые данные (например, использование характеристик, полученных от общих сетевых результатов поиска, например, релевантность текста, величина переходов и показов сетевых документов и так далее).
В патентной заявке США No. US 2013/0067364 раскрыты способы и системы упрощения представления результатов поиска, по разному выделяющихся, причем размер результата поиска корректируется в соответствии с определением того, что степень выделения результата поиска должна быть модифицирована. Отображение результатов поиска с различными степенями выделения помогает в привлечении внимания пользователя к тем результатам поиска, которые могут быть более интересными или более релевантными. Таким образом, пользователь может быстрее идентифицировать или выбирать информацию, которая наиболее релевантна или интересна пользователю. Например, результат поиска отображается в большем размере или выделен сильнее по сравнению с другими результатами поиска, чтобы быть более привлекательным для пользователя.
Раскрытие изобретения
Задачей предлагаемой технологии является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники.
Предлагаются способы и системы персонализации агрегированных результатов поиска. В одном из вариантов осуществления персональная релевантность общего домена и результатов поиска вертикального домена определяется для конкретного пользователя и используется для агрегации результатов поиска на странице результатов поика (SERP). В некоторых вариантах осуществления результаты различающихся поисков, т.е. от различных вертикальных доменов объединяются. В некоторых вариантах осуществления персональная релевантность результатов поиска для конкретного пользователя определяется с помощью информации, полученной из истории пользовательских поисков. В одном не ограничивающем примере, который будет подробно описан далее, машинообучаемая функция ранжирования персонализованной вертикали, которая заметно улучшает используемый механизм ранжирования вертикалей, основана по меньшей мере на одной из трех классов персонализированных характеристик.
Одним из объектов настоящего решения является способ предоставления страницы результатов поиска (SERP) пользователю в ответ на поисковый запрос, причем страница результатов поиска (SERP) включает в себя первый результат общего поиска (т.е. результат поиска в общем домене) и первый результат вертикального поиска (т.е. результат поиска в вертикальном домене). Способ выполняется на сервере. Способ включает в себя оценку параметра предпочтительной агрегации для конкретного пользователя, этот параметр создается в зависимости по меньшей мере от одной характеристики истории поиска пользователя; ранжирование первого результата общего поиска и первого результата вертикального поиска по отношению друг к другу в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать порядок ранжирования результатов поиска; и инициирование отображения электронным устройством, связанным с пользователем, ранжированного порядка результатов поиска в рамках страницы результатов поиска (SERP).
В некоторых вариантах осуществления страница результатов поиска (SERP) включает в себя второй результат вертикального поиска; первый результат общего поиска, первый результат вертикального поиска и второй результат вертикального поиска, которые ранжированы по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать порядок ранжирования результатов поиска; и инициирование отображения электронным устройством, связанным с пользователем (используемым пользователем), ранжированного порядка результатов поиска в рамках страницы результатов поиска (SERP).
В некоторых вариантах осуществления, первый и второй результаты вертикального поиска ранжируют совместно по отношению к результату общего поиска, и отображают в виде блока на странице результатов поиска (SERP). В других вариантах осуществления, первый результат вертикального поиска и второй результат вертикального поиска ранжируются и отображаются по отдельности на странице результатов поиска (SERP).
В некоторых вариантах осуществления, первый результат вертикального поиска и второй результат вертикального поиска создаются при поиске на одном и то же вертикальном домене. Другими словами, первый результат вертикального поиска создается при поиске по первому вертикальному домену, второй результат вертикального поиска создается при поиске по второму вертикальному домену, причем первый вертикальный домен и второй вертикальный домен являются одним и тем же доменом. В других вариантах осуществления, первый результат вертикального поиска и второй результат вертикального поиска получают при поиске по различным вертикальным доменам, другими словами, первый вертикальный домен и второй вертикальный домен не являются одним и тем же доменом.
В некоторых вариантах осуществления страница результатов поиска (SERP) включает в себя второй результат общего поиска; первый результат общего поиска, первый результат вертикального поиска, второй результат вертикального поиска и второй результат общего поиска ранжированы по отношению друг к другу в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать порядок ранжирования результатов поиска; и инициирование отображения электронным устройством, связанным с пользователем, ранжированного порядка результатов поиска в рамках страницы результатов поиска (SERP).
В некоторых вариантах осуществления первый результат общего поиска ранжирован в зависимости от параметра общего доменного ранжирования до (перед) ранжирования в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя. В некоторых вариантах осуществления первый результат вертикального поиска ранжирован в зависимости от параметра вертикального доменного ранжирования до ранжирования в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя.
В некоторых вариантах осуществления первый результат общего поиска и второй результат общего поиска ранжированы в зависимости от параметра общего доменного ранжирования до ранжирования в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя. В некоторых вариантах первый результат вертикального поиска и второй результат вертикального поиска ранжированы в зависимости от параметра вертикального доменного ранжирования до ранжирования в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя.
В некоторых вариантах осуществления представленные здесь способы дополнительно включают в себя этап определения того, что первый результат общего поиска, первый результат вертикального поиска, второй результат вертикального поиска и/или второй результат общего поиска являются релевантными по отношению к поисковому запросу пользователя, до этапа ранжирования результатов поиска в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
В некоторых вариантах осуществления любой из: параметра общего доменного ранжирования и параметра вертикального доменного ранжирования включает в себя атрибут ранжирования для конкретного пользователя, т.е. атрибут общего ранжирования для конкретного пользователя и/или атрибут вертикального ранжирования для конкретного пользователя соответственно. Атрибут общего ранжирования для конкретного пользователя и атрибут вертикального ранжирования для конкретного пользователя основаны по меньшей мере на одной характеристике истории поиска пользователя. В некоторых вариантах по меньшей мере одна характеристика истории поиска пользователя, на которой основан атрибут общего ранжирования для конкретного пользователя и/или атрибут вертикального ранжирования для конкретного пользователя, является той же самой, что по меньшей мере одна характеристика истории поиска пользователя, на которой основан параметр предпочтительной агрегации для конкретного пользователя. В других вариантах осуществления по меньшей мере одна характеристика истории поиска пользователя, на которой основан атрибут общего ранжирования для конкретного пользователя и/или атрибут вертикального ранжирования для конкретного пользователя, отличается от по меньшей мере одной характеристики истории поиска пользователя, на которой основан параметр предпочтительной агрегации для конкретного пользователя.
В некоторых вариантах осуществления по меньшей мере одна характеристика истории поиска пользователя включает в себя по меньшей мере одно из: прошлые пользовательские предпочтения относительно агрегированного общего содержимого и вертикального содержимого, а также общего содержимого отдельно и вертикального содержимого отдельно; прошлые пользовательские предпочтения относительно получения результатов от конкретного вертикального домена; и пользовательские цели, касающиеся поискового запроса. Пользовательские цели могут включать в себя, например, желание увидеть содержимое вертикали (т.е. содержимое вертикального домена или содержимое, идентифицированное при поиске по вертикальному домену). Не ограничивающим примером конкретных типов содержимого вертикалей может являться видео, изображения, коммерческое содержимое, музыка, погода, географические данные, текст, словарные статьи, события, новости и реклама.
В некоторых вариантах осуществления по меньшей мере одна характеристика истории поиска пользователя включает в себя по меньшей мере одно из: соотношение числа переходов и показов; число раз, когда результат поиска был выбран за конкретный период времени; время ожидания после нажатия; и был ли переход к результату последним действием пользователя в предыдущей сессии пользователя.
В некоторых вариантах осуществления, по меньшей мере одна характеристика истории поиска пользователя включает в себя любое из: данные о запросе; сетевые данные; и данные из поискового лога.
В некоторых вариантах по меньшей мере одна характеристика истории поиска пользователя включает в себя любое из: требования к агрегированному поиску; конкретные предпочтения к вертикалям; и способность переходить по вертикалям.
В некоторых вариантах осуществления параметр предпочтительной агрегации для конкретного пользователя создается с помощью алгоритма градиентного бустинга дерева решений (Gradient Boosted Decision Tree-based). В некоторых вариантах осуществления параметр предпочтительной агрегации для конкретного пользователя создается с помощью алгоритма машинного обучения. Параметр предпочтительной агрегации для конкретного пользователя может быть создан до момента во времени, когда пользователь подтвердил поисковый запрос; в момент времени, когда пользователь подтвердил поисковый запрос (одновременно); или после момента времени, когда пользователь подтвердил поисковый запрос.
В некоторых вариантах оценка параметра предпочтительной агрегации для конкретного пользователя включает в себя получение доступа к логу, который включает по меньшей мере одну характеристику истории поисков пользователя. Лог может сохраняться и быть связан с входными учетными данными пользователя.
Другим объектом настоящего решения является сервер, выполненный с возможностью предоставлять страницу результатов поиска (SERP) пользователю в ответ на поисковый запрос, сервер обладает постоянным машиночитаемым носителем информации, который хранит выполняемые компьютером инструкции (машиночитаемые коды), которые при выполнении инициируют осуществление сервером следующих этапов: оценки параметра предпочтительной агрегации для конкретного пользователя, причем параметр предпочтительной агрегации для конкретного пользователя создается в зависимости от по меньшей мере одной характеристики истории поиска пользователя; ранжирования первого результата общего поиска и первого результата вертикального поиска по отношению друг к другу в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать ранжированный порядок результатов поиска; и инициирования отображения электронным устройством, связанным с пользователем, результатов поиска в ранжированном порядке на странице результатов поиска (SERP) в ответ на поисковый запрос.
Еще одним объектом настоящего решения является постоянный машиночитаемый носитель информации, который хранит выполняемые компьютером инструкции (машиночитаемые коды), которые при выполнении инициируют осуществление по меньшей мере одним процессором: представление страницы результатов поиска (SERP) пользователю в ответ на поисковый запрос, причем представление страницы результатов поиска включает в себя: оценку параметра предпочтительной агрегации для конкретного пользователя, причем параметр предпочтительной агрегации для конкретного пользователя создается в зависимости от по меньшей мере одной характеристики истории поиска пользователя; ранжирование первого результата общего поиска и первого результата вертикального поиска по отношению друг к другу в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать ранжированный порядок результатов поиска; и инициирование отображения электронным устройством, связанным с пользователем, результатов поиска в ранжированном порядке на странице результатов поиска (SERP).
В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным. В контексте настоящего описания использование выражения «сервер» не означает, что каждая задача (например, полученные инструкции или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
В контексте настоящего описания «электронное устройство, связанное с пользователем» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим для решения соответствующей задачи. Таким образом, примерами электронных устройств, связанных с пользователем (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как электронное устройство, связанное с пользователем, в настоящем контексте, может вести себя как сервер по отношению к другим связанным с пользователем электронным устройствам. Использование выражения «электронное устройство, связанное с пользователем» не исключает возможности использования множества электронных устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
В контексте настоящего описания «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, которое выполняет процесс, который сохраняет или использует информацию, хранящуюся в базе данных, или же она может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
В контексте настоящего описания «информация» включает в себя любую информацию, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
В контексте настоящего описания «используемый компьютером носитель компьютерной информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
В контексте настоящего описания термин ʺрезультат поискаʺ подразумевает под собой компонент на странице результатов поиска (т.е. SERP), который отображается в ответ на поисковый запрос пользователя. Исключительно в качестве примера, компонентом может являться, например, веб-результат, мгновенный ответ, релевантный результат поиска, рекламное объявление, вкладку и тому подобное. В одном из вариантов осуществления технологии, результатом поиска может быть веб-результат, мгновенный ответ, релевантный результат поиска, рекламное объявление, вкладку и тому подобное. Дополнительно или альтернативно, результатом поиска может являться набор компонентов, отображаемых в виде группы рядом друг с другом на странице результатов поиска. Например, результатом поиска может быть группа изображений, которые расположены рядом друг с другом и появляются на странице результатов поиска вместе. Например, на Фиг. 1 представлен результат 106 вертикального поиска, представляющий собой группу изображений, расположенных вплотную друг к другу, которые включают в себя изображение 122, изображение 124 и изображение 126.
В контексте настоящего описания термин ʺзапросʺ подразумевает собой любой тип запроса, включая один или несколько поисковых терминов, которые могут быть отправлены поисковой системе (или нескольким поисковым системам) для идентификации результатов поиска и/или их компонентов в зависимости от поискового(ых) термина(ов), который(е) содержится(атся) в запросе. Результаты поиска или их компоненты, которые можно идентифицировать по наличию запросов в структуре данных, представляют собой результаты, полученные в ответ на запросы. Например, результат поиска может быть веб-ресузльатом, мгновенным ответом и т.д.
В контексте настоящего описания термин ʺблокʺ подразумевает под собой короткую последовательность сетевых (общих) или вертикальных результатов, которые представлены на странице результатов поиска (SERP) в сгруппированном виде. Блоки могут быть сгруппированы вертикально (например, новости) или горизонтально (например, изображения) на странице результатов поиска (SERP).
В контексте настоящего описания термин ʺобщий доменʺ подразумевает под собой контент общего вида, например, индексированный Интернет контент или сетевой контент. Например, общий поисковый домен не ограничен поиском по конкретной категории результатов, а способен предоставлять все результаты, наиболее подходящие запросу. Такой общий (не зависимый от категорий) поиск с помощью поисковой системы может выдавать результаты, включающие в себя не конкретизированный по категориям цифровой контент, а также конкретизированный по категориям контент, например, изображения, видео, новости, магазины, блоги, книги, места, дискуссии, рецепты, патенты, акции, хроники и т.д. и прочий цифровой контент, который относится к конкретному типу цифрового контента. Примером поиска по общему домену может являться поиск по Глобальной сети (WWW). Поиск по общему домену дает ʺрезультат общего поискаʺ. Подобные результаты общего поиска также называются ʺсетевые результатыʺ, ʺрезультаты сетевого поискаʺ, ʺосновные сетевые результатыʺ и ʺобщие сетевые результатыʺ. Обычно сетевой результат включает в себя ссылку на веб-сайт и фрагмент, отображающий содержание этого веб-сайта. Пользователь может выбирать ссылку на сетевой результат для того, чтобы перейти к веб-странице, связанной с поисковым запросом пользователя.
В контексте настоящего описания термин ʺвертикальный доменʺ подразумевает собой наличие информационного домена, содержащего конкретизированный контент, например, контент одного типа (например, тип медиа, жанр контента, тема и т.д.). Вертикальный домен, таким образом, включает в себя конкретную подгруппу из большого набора данных, например, конкретную подгруппу сетевых данных. Например, вертикальный домен может включать в себя конкретную информацию, например, новости, изображения, видео, местные предприятия, предметы на продажу, прогноз погоды и так далее. Поиск по вертикальному домену дает ʺрезультат вертикального поискаʺ. Подобные результаты вертикального поиска также упоминаются здесь как ʺвертикалиʺ и ʺвертикальные результатыʺ.
В контексте настоящего описания выражение ʺагрегированный результат поискаʺ подразумевает собой интегрирование результатов общего (например, сетевого) поиска и результатов вертикального поиска в пределах страницы результатов поиска. Например, результаты вертикального поиска могут быть интегрированы в результаты общего (например, сетевого) поиска в пределах страницы результатов поиска или же наоборот - т.е. результаты общего поиска могут быть интегрированы с результатами вертикального поиска в пределах страницы результатов поиска.
В контексте настоящего описания выражения ʺпараметр предпочтительной агрегации для конкретного пользователяʺ подразумевает собой наличие инструмента ранжирования, который основан по меньшей мере на одной характеристики истории поисков пользователя, и используется для ранжирования агрегированных результатов поиска. В общем случае, история поисков пользователя предоставляет данные или информацию из истории (также называемую здесь как ʺхарактеристики), относящуюся к запросу, конечному результату поиска или его компоненту. Эти характеристики истории поисков пользователя могут описывать или характеризовать запрос, результат поиска и/или влияние или взаимодействие пользователя с ними. Пользовательское влияние или взаимодействие в общем случае подразумевает влияние или взаимодействие (например, выбор, нажатие и т.д.) с результатом поиска. Таким образом, характеристика истории поисков пользователя может представлять собой, например, количество раз, когда результат поиска был представлен (например, за определенный период времени), положение или позиция результата поиска, количество раз, когда результат поиска был выбран или когда пользователь нажал на него (например, за определенный период времени), соотношение числа переходов и показов, количество раз, когда результат поиска был выбран в конкретной позиции или конкретном размере на странице результатов поиска (SERP) (например, за определенный период времени), обозначение или классификация цели запроса (т.е. включает ли в себя запрос конкретную цель, например, видео, изображение, коммерческую цель и так далее). Следует отметить, что подобные характеристики истории поисков пользователя могут обновляться или изменяться по ходу того, как собираются исторические данные. Соответственно, чем больше данных отслеживается и анализируется, тем более свежие данные могут быть использованы для создания новых или измененных характеристик истории поисков пользователя.
В некоторых вариантах осуществления результаты поиска (т.е. результаты общего поиска и результаты вертикального поиска) ранжированы относительно друг друга в соответствии с параметром предпочтительной агрегации для конкретного пользователя, который оценивается с использованием по меньшей мере одной характеристики истории поисков пользователя. Параметр предпочтительной агрегации для конкретного пользователя может быть основан на любой характеристики или комбинации характеристик истории поисков пользователя, как описано выше, например, соотношении числа переходов и показов в логах запросов, истории переходов, поисковой истории и тому подобного. Таким образом, характеристики могут быть анализированы для того, чтобы определить, какие именно результаты поиска или их компоненты должны располагаться на странице результатов поиска в соответствии с пользовательскими нуждами или предпочтениями. Результаты поиска, которые максимально релевантны по отношению к конкретному запросу, обычно обладают наиболее высоким рангом, т.е. рангом, который каким-либо образом указывает на высокий приоритет или предпочтение.
В некоторых вариантах осуществления результаты общего поиска сначала ранжируются в зависимости от параметра общего доменного ранжирования, до агрегирования их с результатами вертикального поиска и последующего ранжирования в соответствии с параметром агрегации конкретного пользователя. В контексте настоящего описания выражение ʺпараметр общего доменного ранжированияʺ подразумевает собой инструмент ранжирования, который используется для ранжирования результатов общего поиска. Многие подобные инструменты ранжирования известны и, следует иметь в виду, что любые подобные инструменты могут быть использованы в предлагаемых здесь способах и системах. В одном варианте параметр общего доменного ранжирования основан на или включает в себя по меньшей мере один атрибут общего ранжирования для конкретного пользователя. Используемое здесь выражение ʺатрибут общего ранжирования для конкретного пользователяʺ подразумевает собой любую характеристику или комбинацию характеристик истории поисков пользователя относящихся к результатам общего поиска, таких, например, как соотношение числа переходов и показов в логах запросов, истории переходов, поисковой истории и тому подобного, которые могут быть анализированы для того, чтобы определить то, где следует расположить результаты общего поиска или их компоненты на странице результатов общего поиска в соответствии с потребностями и предпочтениями пользователя.
Аналогично, в некоторых вариантах осуществления результаты вертикального поиска сначала ранжируются в зависимости от параметра вертикального доменного ранжирования, до агрегирования их с результатами общего поиска и последующего ранжирования в соответствии с параметром агрегации конкретного пользователя. В контексте настоящего описания выражение ʺпараметр вертикального доменного ранжированияʺ подразумевает собой инструмент ранжирования, который используется для ранжирования результатов вертикального поиска. Многие подобные инструменты ранжирования известны и, следует иметь в виду, что любые подобные инструменты могут быть использованы в предлагаемых здесь способах и системах. В одном варианте осуществления параметр вертикального доменного ранжирования основан на или включает в себя по меньшей мере один признак вертикального ранжирования для конкретного пользователя. Используемое здесь выражение ʺпризнак вертикального ранжирования для конкретного пользователяʺ подразумевает собой любую характеристику или комбинацию характеристик истории поисков пользователя, относящихся к результатам вертикального поиска, таких, например, как соотношение числа переходов и показов в логах запросов, истории переходов, поисковой истории и тому подобного, которые могут быть анализированы для того, чтобы определить то, где следует расположить результаты вертикального поиска или их компоненты на странице результатов вертикального поиска в соответствии с потребностями и предпочтениями пользователя.
В контексте настоящего описания слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной связи между этими существительными. Так, например, следует иметь в виду, что использование терминов ʺпервый серверʺ и ʺтретий серверʺ не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий ʺвторой серверʺ обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание ʺпервогоʺ элемента и ʺвторогоʺ элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, ʺпервыйʺ сервер и ʺвторойʺ сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
Каждый вариант осуществления включает по меньшей мере одну из вышеупомянутых целей и/или объектов.
Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы.
Краткое описание чертежей
Для лучшего понимания, а также других аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
На Фиг. 1 представлен снимок 100 экрана, на котором представлена страница результатов поиска (SERP), реализованная в соответствии с известными методиками, причем на странице результатов поиска (SERP) представлены агрегированные результаты вертикального поиска (видео, изображения) и результаты общего поиска.
На Фиг. 2 представлен график, показывающий изменение средней точности (MAP) в виде функции от адаптированной энтропии кликов.
На Фиг. 3 представлен график, показывающий распределение изменения средней точности (MAP) для уникальных запросов, упорядоченных по изменению средней точности.
На Фиг. 4 представлен график, показывающий распределение изменения средней точности (MAP) для пользователей, упорядоченных по изменению средней точности.
На Фиг. 5 представлен график, показывающий изменение средней точности (MAP) для групп пользователей.
На Фиг. 6 представлена принципиальная схема способа 600, выполненного в соответствии с вариантами осуществления.
На Фиг. 7 представлена принципиальная схема способа 700, выполненного в соответствии с вариантами осуществления.
На Фиг. 8 представлена принципиальная схема способа 800, выполненного в соответствии с вариантами осуществления.
На Фиг. 9 представлена принципиальная схема системы 900, выполненной в соответствии с вариантами осуществления.
Осуществление изобретения
Таким образом, все последующее описание представлено только как описание иллюстративного примера. Это описание не предназначено для определения объема правовой охраны. Некоторые полезные примеры модификаций способов и систем также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что описанные здесь способы и системы представляют собой в некоторых конкретных проявлениях вариант осуществления настоящей технологии, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления могут обладать гораздо большей сложностью.
На Фиг. 9 представлена принципиальная схема системы 900, выполненной в соответствии с вариантами осуществления, не ограничивающими объем правовой охраны. Важно иметь в виду, что нижеследующее описание системы 900 представляет собой описание иллюстративных вариантов осуществления. Система 900 включает в себя сеть 902 передачи данных. Сеть 902 передачи данных обычно связана со множеством электронных устройств, связанных соответственно со множеством пользователей. Первое электронное устройство 904 и второе электронное устройство 906 представлены на чертеже для целей иллюстрации. Первое электронное устройство 904 связано с первым пользователем 908. Второе электронное устройство 906 связано со вторым пользователем 910. Следует отметить, что тот факт, что клиентские устройства связаны с конкретными пользователями, не предполагает и не подразумевает какого-либо конкретного режима работы.
Сеть 902 передачи данных также связана с сервером 912. Сервер 912 может осуществлять поиск, ранжировать результаты поиска, агрегировать результаты поиска, инициировать отображение электронным устройствами, связанными с пользователями, страницы результаты поиска и т.д. В некоторых вариантах осуществления, сервер 912 может хранить информацию и данные (например, в базе 914 данных), например, истории поисков пользователя и их характеристик, параметры предпочтительной агрегации для конкретного пользователя и т.д.
Важно иметь в виду, что варианты осуществления электронных устройств 904, 906 сети 902 передачи данных и сервера 912 даны исключительно в иллюстрационных целях. Таким образом, специалистам в данной области техники будут ясны подробности других конкретных вариантов исполнения данных элементов.
Варианты осуществления сервера 912 никак конкретно не ограничены. Например, сервер 912 может быть реализован как один сервер или множество серверов. Сервер 912 может быть реализован как обычный компьютерный сервер или на любом подходящем аппаратном и/или прикладном программном, и/или системном программном обеспечении или их комбинации. Сервер 912 способен получать запросы (например, от электронного устройства 904, связанного с пользователем 908) через сеть (например, сеть 902 передачи данных), и передавать эти запросы или инициировать передачу этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным. В контексте настоящего описания использование выражения «сервер» не означает, что каждая задача (например, полученные инструкции или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
Варианты осуществления электронных устройств 904 и 906, связанных с пользователями 908, 910, никак конкретно не ограничены. Например, пользователи 908, 910 могут работать в различных обстоятельствах, в которых каждый из них выполняет различные роли и обладает различными обязанностями. Эти различные роли могут относиться к профессиональным или личным занятиям пользователя - например, сотрудник, подрядчик, заказчик, поставщик или член семьи. В рамках этих различных контекстов пользователь может использовать различные электронные устройства (например, настольные компьютеры, портативные компьютеры, персональные компьютеры, мобильные телефоны, планшеты и т.д.) или электронные устройства, использующие возможность удаленной обработки данных (например, если приложения расположены на веб-сайте или виртуальной машине, размещенной в центре обработке данных). Различные вычислительные среды могут быть установлены на электронных устройствах с возможностью локальной обработки данных (например, различные операционные системы, виртуальные среды программного обеспечения, Сетевые приложения, родные приложения, контейнеры, BIOS/APIs, и т.д.) для взаимодействия с сервером. Пользователи используют множество электронных устройств (настольные компьютеры, портативные компьютеры, ноутбуки, смартфоны, планшеты и тому подобное) для получения доступа к сетевому контенту (например, изображениям, аудио- и видеофайлам, анимированным изображениям и прочему мультимедийному контенту). Электронное устройство 904, 906 включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для выполнения поиска. В общем случае, пользователь 908, 910 может получать доступ к вычислительным службам на сервере вне зависимости от используемых заранее определенных систем аппаратного/программного обеспечения и сетей передачи данных.
В общем случае, пользователь 908, 910 выполняет поиск, выполняя поисковый запрос с помощью поисковой системы. Выполнение поиска никак конкретно не ограничено. В одном примере пользователь может получать доступ к веб-сайту, связанному с поисковой системой для выполнения поискового запроса. Например, поисковая система может быть вызвана при вводе URL (Единого Указателя Ресурсов), связанного с поисковой системой Yandex www.vandex.ru. Важно иметь в виду, что поисковый запрос может быть сделан и поиск может быть осуществлен с помощью любой другой коммерчески доступной или собственной поисковой системы. В некоторых вариантах осуществления поисковый запрос может быть создан с помощью браузерного приложения на портативном устройстве (например, беспроводном устройстве связи). Для тех случаев (но не только), когда электронное устройство 904, 906, связанное с пользователем, является портативным устройством, таким как, например, Samsung™ Galaxy™ Sill, электронное устройство 904, 906 может использовать приложение Яндекс браузер. Важно иметь в виду, что любое другое коммерчески доступное или собственное браузерное приложение может быть использовано для реализации вариантов осуществления.
В некоторых вариантах осуществления настоящей электронное устройство 904, 906, связанное с пользователем 908, 910, соединено с сетью 902 передачи данных, например, через линию передачи данных (не показана). В некоторых вариантах осуществления сеть 902 связи может представлять собой Интернет. В других вариантах осуществления сеть 902 передачи данных может быть реализована иначе: в виде глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии передачи данных не ограничена, и будет зависеть от того, как реализовано электронное устройство 904, 906. В качестве примера, когда электронное устройство 904, 906 представляет собой беспроводное устройство связи (например, смартфон), линия 102 передачи данных представляет собой беспроводную сеть связи (например, среди прочего, линия связи сети 3G, 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где электронное устройство 904, 906 представляет собой портативный компьютер, линия передачи данных может быть как беспроводной (беспроводной Интернет WiFi®, Bluetooth® и т.п) так и проводной (соединение в зависимости от сети Ethernet). Специалисты в данной области техники поймут, что данные варианты осуществления представлены только в качестве примеров и возможны другие варианты осуществления деталей электронного устройства, линии передачи данных и сети передачи данных.
В некоторых вариантах осуществления, сервер 912 также соединен с сетью 902 передачи данных. Как обсуждалось выше, сервер 912 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящей технологии, сервер 912 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Сервер 912 может быть реализован на любом подходящем аппаратном и/или прикладном программном, и/или системном программном обеспечении или их комбинации. В некоторых вариантах осуществления технологии сервер 912 является одиночным сервером. В других вариантах осуществления, функциональность сервера 912 может быть разделена, и может выполняться с помощью нескольких серверов.
Сервер 912 соединен коммуникационно (или иным образом имеет доступ) с базой 914 данных. Основной задачей базы 914 данных является хранение информации и данных, например, характеристик историй пользователя 908, 910, параметров предпочтительной агрегации для конкретного пользователя 908, 910 и так далее. Варианты осуществления базы 914 данных не ограничены. Следует иметь в виду, что может быть использовано любое подходящее аппаратное обеспечение для хранения данных. В некоторых вариантах база 914 данных может быть смежной с сервером 912, т.е. они необязательно представляют с собой отдельные части аппаратного обеспечения, как показано на фигурах, однако и такой вариант тоже возможен.
Пример агрегированного результата поиска показан на Фиг. 1, где представлен снимок 100 экрана, на котором показана страница результатов поиска (SERP), созданная коммерческой поисковой системой в ответ на запрос ʺmetallicaʺ, и реализованная в соответствии с известными способами. В представленном варианте страница результатов поиска (SERP) отображает агрегированные результаты поиска, включая в себя первый результат 104 вертикального поиска (состоящий из трех изображений 116, 118 и 120, которые являются кадрами из видео), созданный при поиске по первому вертикальному домену 112; второй результат 106 вертикального поиска (состоящий из трех изображений 122, 124 и 126), созданный при поиске по второму вертикальному домену 114; первый результат 102 общего поиска; второй результат 108 общего поиска; и третий результат 110 общего поиска. Первый результат 102 общего поиска и третий результат 110 общего поиска включают краткую информацию 130 и 128 соответственно. Второй результат 108 общего поиска включает в себя отрывок 132, который позволяет пользователю предварительно просматривать содержимое второго результата 108 общего поиска.
На Фиг. 6 представлена принципиальная схема способа 600, выполненного в соответствии с вариантами осуществления. Способ 600 может выполняться на сервере 912.
Этап 602 - оценка параметра предпочтительной агрегации для конкретного пользователя
Способ 600 начинается на этапе 602, на котором сервер 912 оценивает параметр предпочтительной агрегации для конкретного пользователя в отношении пользователя 908, 910, который ввел поисковый запрос, причем параметр предпочтительной агрегации для конкретного пользователя был создан в зависимости от по меньшей мере одной характеристики истории поисков пользователя.
В некоторых вариантах осуществления по меньшей мере одна характеристика истории поисков пользователя является истерическими данными или информацией, относящейся к предыдущим запросам, введенным пользователем 908, 910, или результатом поиска или его компонентом, таким как, например описание, или характеристика запроса или результата поиска; и влияние или взаимодействие пользователя с ними. Пользовательское влияние или взаимодействие в общем случае подразумевает влияние или взаимодействие (например, выбор, нажатие и т.д.) с результатом поиска. Таким образом, характеристика истории поисков пользователя может представлять собой количество раз, когда результат поиска был представлен (например, за определенный период времени), положение или позиция результата поиска, количество раз, когда результат поиска был выбран или когда пользователь нажал на него (например, за определенный период времени), соотношение числа (количества) переходов и показов, количество раз, когда результат поиска был выбран в конкретной позиции или конкретном размере на странице результатов поиска (SERP) (например, за определенный период времени), обозначение или классификация цели запроса (те включает ли в себя запрос конкретную цель, например, видео, изображение, коммерческую цель и так далее). Следует отметить, что подобные характеристики истории поисков пользователя могут обновляться или изменяться по ходу того, как собираются исторические данные. Соответственно, чем больше данных отслеживается и анализируется, тем более свежие данные могут быть использованы для создания новых или измененных характеристик истории поисков пользователя.
В некоторых вариантах осуществления по меньшей мере одна характеристика истории поиска пользователя представляет собой любое из: данные о запросе, сетевые данные; и данные из поискового лога. В некоторых вариантах осуществления, которые представлены здесь только ради примера, эти характеристики могут быть оценены следующим образом.
Сначала происходит построение базового, независимого от пользователя, вектора характеристик φВ(q, r). Первый элемент вектора φВ(q, r) - I(r), таким образом, способ обучения всегда будет информирован о типе результата (т.е. является ли он веб-реузльтатом, изображением, новостным результатом и т.д.). Недоступные характеристики для конкретного типа результата будут приниматься равными нулю, и, соответственно, первый элемент φВ(q, r) идентифицирует следующие ситуации.
Далее, для оценки данных запроса, в базовый набор характеристик включают булеву переменную, идентифицирующую тот факт, является ли запрос навигационным. Для каждой вертикали Vj также создается униграммная вертикальная языковая модель Lj. Каждая модель создается в зависимости от запросов, для которых был выбран результат из вертикали Vj за время ожидания, превышающее, например, 30 секунд. Следует иметь в виду, что могут быть использованы различные величины времени ожидания, например, 10 секунд, 20 секунд, 30 секунд, 40 секунд, 50 секунд, 1 минута, 2 минуты, 3 минуты и т.д. В случае если r является вертикальным результатом, и I(r)=j, вероятность запроса Lj может быть добавлена к вектору характеристик φВ(q, r). В случае, когда r является результатом общего поиска, ноль может быть добавлен к φВ(q, r).
Для того, чтобы оценить вертикальные данные и сетевые данные, в некоторых вариантах осуществления, первой характеристикой может являться позиция результата в оригинальном ранжировании. Величина релевантности результата, вычисляемая в алгоритме оригинального ранжирования только для сетевых результатов, также может быть использована в качестве характеристики. Следует отметить, что в данном примере, базовых набор характеристик φВ(q, r) включается в себя характеристики, необходимые для создания не персонализированной версии величины вертикальной релевантности.
Для оценки данных поискового лога, в некоторых вариантах осуществления технологии могут быть использованы характеристики, связанные с количеством кликов, например:
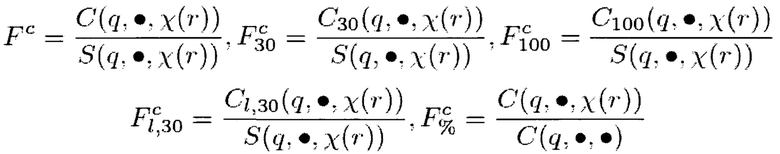
где:
C(q, u, r) - число кликов пользователя u на конкретный результат r для запроса q;
S(q, u, r) - число раз, когда результат r был показан пользователю и при запросе q;
 - указывает на сумму всех величин для указанной переменной за наблюдаемый период времени (например, C(, u, r)
- указывает на сумму всех величин для указанной переменной за наблюдаемый период времени (например, C(, u, r) 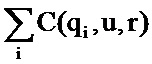
X(r) равно ri, если I(ri) равно нулю, и X(r) равно VI(ri), если I(ri) не равно нулю;
I(ri) равно j, если ri является результатом вертикального поиска, и I(ri) равно нулю, если ri является результатом общего поиска;
FC является характеристикой истории поисков пользователя, представляющей собой отношение числа кликов к числу раз, когда результат был показан, с указывает на тот факт, что эта характеристика относится к истории поисков пользователя;
C30 представляет собой число кликов за время ожидания более 30 секунд; C100 представляет собой число кликов за время ожидания более 100 секунд; CI,30 представляет собой число кликов, которые являлись последними кликами на результаты поиска и обладают временем ожидания более 30 секунд; и
r представляет собой результат общего поиска и результат вертикального поиска.
В общем, в данном случае, если r представляет собой результат вертикального поиска, то X(r) относится к блоку результатов вертикального поиска в том же вертикальном домене V (V используется здесь для обозначения вертикального домена). Поэтому следует иметь в виду, что X(r) является результатом общего поиска ri в том случае, где r является результатом общего поиска, и X(ri) является вертикальным доменом, к которому принадлежит ri, в том случае, если r является результатом вертикального поиска. В том случае, когда X(r) представляет собой Vj, подобные характеристики предоставляют информацию о кликах на вертикальные результаты поиска, и могут считаться характеристиками данных вертикали. Когда I(r) равно нулю, это означает, что r не является результатом вертикального поиска, и X(r) равно r.
В некоторых вариантах осуществления характеристика истории поиска пользователя является любой из следующих характеристик, относящихся к вертикали: требования к агрегированному поиску; конкретные предпочтения к вертикалям; и способность переходить по вертикалям.
В одном примере ʺтребования к агрегированному поискуʺ описывают то, заинтересован ли пользователь 908, 910 в агрегированных результатах поиска в целом, или предпочитает им общие веб-результаты. В общем случае, результаты вертикального поиска представлены отдельно от результатов общего веб-поиска, что может повлиять на пользовательский опыт. Требования к агрегированному поиску могут отражать отношение пользователя к подобному представлению результатов поиска. В некоторых вариантах осуществления характеристики, описывающие агрегированный поиск, могут быть представлены следующим образом:
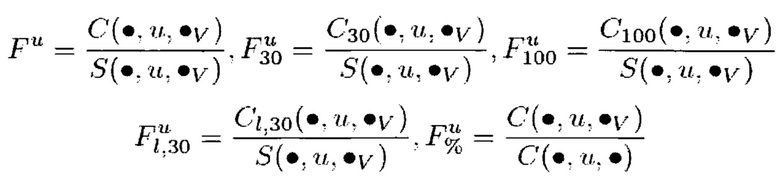
где:
C(q, u, v) - число кликов пользователя u на конкретный вертикальный результат v для запроса q;
S(q, u, v) - число раз, когда вертикальный результат v был показан пользователю u при запросе q;
указывает на сумму всех величин для указанной переменной за наблюдаемый период времени (например, C(, u, r) v представляет собой сумму всех результатов вертикального поиска во всех вертикальных доменах);
Fu является характеристикой истории поисков пользователя, представляющей собой отношение числа кликов к числу раз, когда вертикальный результат был показан, u указывает на тот факт, что эта характеристика относится к требованиям пользователя к агрегированному поиску; и
C30 представляет собой число кликов за время ожидания более 30 секунд; C100 представляет собой число кликов за время ожидания более 100 секунд; CI,30 представляет собой число кликов, которые являлись последними кликами на результаты поиска и обладают временем ожидания более 30 секунд.
В одном варианте осуществления вектор Fu пяти характеристик обозначен как φa(u).
Необходимо иметь в виду, что Fu% представляет собой соотношение числа кликов на сумму всех результатов вертикального поиска (v) к числу кликов на сумму всех результатов поиска (результаты общего поиска + результаты вертикального поиска). Таким образом, он представляет собой желание пользователя выбрать результат вертикального поиска, в виде процентов из всех результатов поиска (общих + вертикальных).
В варианте осуществления ʺконкретные предпочтения к вертикалямʺ описывают желание пользователя получать результаты конкретного типа для всех поисковых запросов. Эта характеристика может коррелировать с интересами пользователя и, может помочь устранить неоднозначность некоторых запросов для конкретного пользователя. Например, характеристика этого типа может выражать разницу между пользовательской униграммной языковой моделью (например, построенной на запросах, введенных пользователем за наблюдаемый период времени) и языковой моделью для вертикали результата. Эта разница может быть вычислена с помощью расстояния Кульбака-Лейблера,
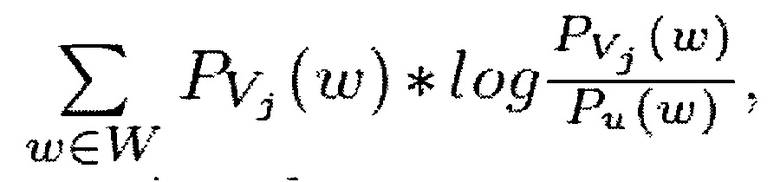
где Vj=X(ri). Если I(ri) равно нулю, то эта характеристика принимается равной нулю.
Здесь Vj представляет собой все результаты вертикального поиска в конкретном вертикальном домене, т.е. в вертикальном домене j. Таким образом, сумма всех результатов вертикального поиска в вертикальном домене обозначается Vj,,где j=1, …, N.
В другом варианте осуществления ʺконкретные предпочтения к вертикалямʺ могут быть выяснены при использовании информации о кликах. Например, в одном варианте осуществления информация о кликах может быть выяснена с помощью следующего набор характеристик:
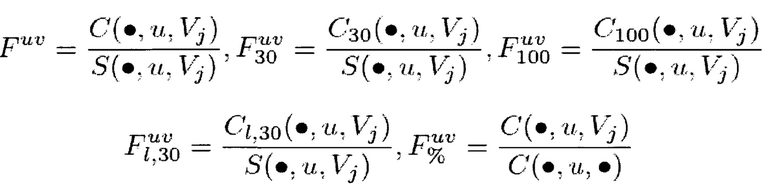
где:
C(q, u, Vj) представляет собой число кликов пользователя u на результаты поиска в вертикальном домене Vj для запроса q; и j является I(ri) (другими словами, ri является конкретным результатом i в рамках вертикального домена j, где i и j равны 1, …, N);
S(q, u, Vj) - число раз, когда результат вертикального поиска в вертикальном домене Vj был показан пользователю u при запросе q;
указывает на сумму всех величин для указанной переменной за наблюдаемый период времени (например, С(, u, r)
Fuv является характеристикой истории поисков пользователя, представляющей собой отношение числа кликов к числу раз, когда вертикальный результат был показан, uv указывает на тот факт, что эта характеристика относится к конкретным предпочтениям пользователя относительно вертикалей; и
C30 представляет собой число кликов за время ожидания более 30 секунд; C100 представляет собой число кликов за время ожидания более 100 секунд; CI,30 представляет собой число кликов, которые являлись последними кликами на результаты поиска и обладают временем ожидания более 30 секунд.
В одном варианте осуществления, вектор Fuv этих характеристик обозначен как φc(u, r). Если j равно 0, то пользователь предпочитает видеть результаты общего поиска, и эти характеристики не будут использоваться.
В варианте осуществления ʺспособность переходить по вертикалямʺ относится к тому факту, что для некоторых запросов желания пользователя могут не совпадать с его/ее общими предпочтениями. Например, для конкретного запроса результаты из новостной вертикали или вертикали погоды могут быть более релевантными, чем результаты из вертикали изображений, для пользователей 908, 910, живущих в Амстердаме, и вводящих запрос ʺАмстердамʺ, вне зависимости от того, что обычно пользователь предпочитает видеть изображения. В другом варианте осуществления характеристики, связанные с количеством кликов, которые отражают это свойство, могут быть описаны следующим образом:
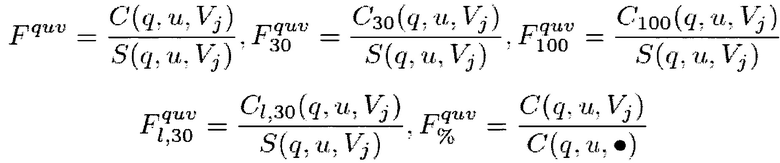
где:
C(q, u, Vj) представляет собой число кликов пользователя u по результатам вертикального поиска в вертикальном домене Vj для запроса q; и j явялется I(ri), как было указано выше;
S(q, u, Vj) - число раз, когда результат вертикального поиска в вертикальном домене Vj был показан пользователю u при запросе q;
указывает на сумму всех величин для указанной переменной за наблюдаемый период времени (например, C(, u, r)
Fquv является характеристикой истории поисков пользователя, представляющей собой отношение числа кликов к числу раз, когда вертикальный результат был показан, quv указывает на тот факт, что эта характеристика относится к конкретным предпочтениям пользователя относительно вертикалей, связанным со способностью переходить по вертикалям; и
C30 представляет собой число кликов за время ожидания более 30 секунд; C100 представляет собой число кликов за время ожидания более 100 секунд; CI,30 представляет собой число кликов, которые являлись последними кликами на результаты поиска и обладают временем ожидания более 30 секунд.
В одном варианте осуществления технологии, вектор Fquv этих характеристик обозначен как φn(q, u, r).
В некоторых вариантах осуществления, абсолютные величины соответствующих кликов и показов (количество показанных раз) могут быть добавлены к каждому из вышеупомянутых векторов характеристик (конкретнее, S(, r, v) и C(, u, ), φa(u), и так далее); это отражает уровень активности пользователя в отношении результатов вертикального поиска.
Как отмечалось выше, векторы характеристик для ʺтребований к агрегированному поискʺ, ʺконкретным предпочтениям к вертикалямʺ и "способности переходить по вертикалям" относятся только к результатам вертикального поиска. Таким образом, если I(ri) равняется нулю (другими словами, все результаты поиска являются результатам общего поиска, а результаты вертикального поиска отсутствуют), все элементы этих трех векторов характеристик равняются нулю.
В некоторых вариантах осуществления по меньшей мере одна характеристика истории поиска пользователя представляет собой по меньшей мере одно из: прошлые пользовательские предпочтения относительно агрегированного общего содержимого и вертикального содержимого, а также общего содержимого отдельно и вертикального содержимого отдельно; прошлые пользовательские предпочтения относительно получения результатов от конкретного вертикального домена; и пользовательские цели, касающиеся поискового запроса. Пользовательские цели могу включать себя, например, конкретные типы содержимого вертикалей, такого как - видео, изображения, коммерческое содержимое, музыка, погода, географические данные, текст, словарные статьи, события, новости и/или реклама.
В некоторых вариантах осуществления по меньшей мере одна характеристика истории поиска пользователя представляет собой по меньшей мере одно из: соотношение числа переходов и показов; число раз, когда результат поиска был выбран за конкретный период времени; время ожидания после нажатия; и был ли переход к результату последним действием пользователя в предыдущей сессии пользователя.
Возвращаясь к этапу 602 способа 600, параметр предпочтительной агрегации для конкретного пользователя был создан в зависимости от по меньшей мере одной характеристики истории поисков пользователя. В некоторых вариантах осуществления параметр предпочтительной агрегации для конкретного пользователя был создан до введения запроса пользователем 908, 910. В подобных вариантах осуществления параметр предпочтительной агрегации для конкретного пользователя может храниться в базе 914 данных и может быть получен сервером 912 на этапе оценки. В других вариантах осуществления параметр предпочтительной агрегации для конкретного пользователя был создан одновременно с введением запроса пользователем 908, 910. В некоторых других вариантах параметр предпочтительной агрегации для конкретного пользователя был создан после ввода запроса пользователем 908, 910. Следует иметь в виду, что тот момент, когда параметр предпочтительной агрегации для конкретного пользователя создается, конкретно никак не связан с тем моментом, когда был введен конкретный поисковый запрос. В некоторых вариантах параметр предпочтительной агрегации для конкретного пользователя создается и сохраняется, например, в базе 914 данных, таким образом, чтобы быть полученным при необходимости из базы 914 данных сервером 912 на этапе оценки.
Способ или алгоритм, используемый для создания параметра предпочтительной агрегации для конкретного пользователя, никак конкретно не ограничен. В некоторых вариантах осуществления параметр предпочтительной агрегации для конкретного пользователя создается с помощью алгоритма градиентного бустинга дерева решений (Gradient Boosted Decision Tree-based). В некоторых вариантах параметр предпочтительной агрегации для конкретного пользователя создается с помощью алгоритма машинного обучения. В некоторых вариантах параметр предпочтительной агрегации для конкретного пользователя создается при получении доступа логу (не показан) в базе 914 данных, который включает в себя по меньшей мере одну характеристику истории поисков пользователя. Лог может сохраняться, например, в связи со входными учетными данными пользователя в базе 914 данных. Варианты осуществления лога никак конкретно не ограничены.
Специалисты в области техники оценят тот факт, что характеристики истории поисков пользователя, например запись о предыдущих активностях пользователя, или профиль пользователя 908, 910, может быть создана в зависимости от предыдущей истории поисков пользователя 908, 910, определенной в зависимости от, например, cookies (куки) или другой цифровой информации, хранящейся на электронном устройстве 904, 906, с помощью которого пользователь выполняет поиск, или на сервере 912 (например, в базе 914 данных). В некоторых вариантах пользователь 908, 910 также может быть зарегистрирован с помощью поисковой системы, которая сохраняет историю поисков пользователя. В некоторых вариантах характеристики история поисков пользователя хранится в базе 914 данных, например, лог активности пользователя или история поисков, может быть основана на предыдущей истории поисков пользователя 908, 910, созданных за время текущего сеанса поиска. Например, если пользователь 908, 910 выполняет первый поиск, а затем выполняет второй поиск, связанный с первым поиском в зависимости от результатов первого поиска, то результаты, которые создаются поисковой системой для второго поиска, могут быть основаны на характеристиках первого поиска, выполненного пользователем 908, 910.
Этап 604 - ранжирование первого результата общего поиска и первого результата вертикального поиска по отношению друг к другу в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать ранжированный порядок результатов поиска, способ выполняет на сервере
Возвращаясь к способу 600, первый результат 102 общего поиска и первый результат 104 вертикального поиска ранжированы относительно друг друга в зависимости от по меньшей мере параметра предпочтительной агрегации для конкретного пользователя.
Ранжирование относится в основном к определению порядка, позиций и расположения результатов поиска и/или их компонентов по отношению друг к другу. Результат поиска, наиболее релевантный по отношению к конкретному запросу, обычно обладает более высоким рангом. Более высокий ранг применяется для указания ранга, который значительнее или каким-либо образом обладает более высоким приоритетом или более предпочтителен. Ранжирование может быть основано на любых данных, таких как, например, соотношение числа переходов и показов в логах запросов, история пользователя, цель запроса, признаки результатов (например, тип или категория результата поиска), и их комбинация. Ранжирование используется для определения того, где конкретно должны быть расположены результаты поиска и их компоненты в рамках страницы результатов поиска. Специалистам в данной области техники будет понятно, что ранжирование может быть или не быть персонализированным или относящимся к конкретному пользователю, т.е. может быть основано на персональной информации пользователя, например, характеристиках истории поисков пользователя.
Специалистам в данной области техники будет понятно, что возможны различные способы ранжирования/персонализации результатов поиска. В качестве примера, некоторые способы ранжирования результатов в соответствии с их релевантностью основаны на всех или некоторых из следующих критериев: (i) насколько популярен данный поисковый запрос или ответ на него; (ii) сколько результатов выдается на поисковый запрос; (iii) содержит ли поисковый запрос какие-либо ключевые термины (например, «изображения», «видео», «погода» и т.п.), (iv) насколько часто конкретный поисковый запрос содержит ключевые термины при вводе его другими пользователями; и (v) насколько часто другие пользователи при выполнении аналогичного поиска выбирали конкретный ресурс или конкретные результаты вертикального поиска, когда результаты были представлены на стандартной SERP. Следует иметь в виду, что любые подобные способы ранжирования и/или персонализации могут быть использованы в дополнение или в комбинации с ранжированием в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
Например, в некоторых вариантах результаты общего поиска могут быть ранжированы с помощью известных способов ранжирования до ранжирования в зависимости от параметра предпочтительной агрегации для конкретного пользователя. Таким образом, в некоторых вариантах осуществления результаты общего поиска ранжированы в зависимости от параметра общего доменного ранжирования до ранжирования, известном в данной области техники, до ранжирования в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
Аналогично, в некоторых вариантах результаты вертикального поиска ранжированы с помощью известных способов ранжирования для вертикалей до ранжирования в зависимости от параметра предпочтительной агрегации для конкретного пользователя. Таким образом, в некоторых результаты вертикального поиска ранжированы в зависимости от параметра вертикального доменного ранжирования до ранжирования, известном в данной области техники, до ранжирования в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
Специалисты в данной области техники оценят тот факт, что результаты общего поиска, полученные от поисковой системы, обычно ранжированы с помощью известных способов ранжирования, например, одного или нескольких алгоритмов общего ранжирования, многие из которых известны в данной области техники, до получения или отображения результатов поиска. Аналогично, результаты вертикального поиска, полученные от поисковой системы, обычно ранжированы с помощью известных способов ранжирования, например, одного или нескольких алгоритмов вертикального ранжирования до получения или отображения результатов поиска. Таким образом, следует иметь в виду, что в некоторых вариантах осуществления первый результат общего поиска и второй результат общего поиска были ранжированы относительно друг друга с помощью известных способов ранжирования, и первый результат вертикального поиска и второй результат вертикального поиска ранжированы относительно друг друга с помощью известных способов ранжирования, до ранжирования в зависимости от параметра предпочтительной агрегации для конкретного пользователя. Например, на Фиг. 1 первый результат 102 общего поиска обладает рангом выше, чем второй результат 108 общего поиска, который обладает рангом выше, чем третий результат 110 общего поиска; эти ранги являются результатом ранжирования результатов общего поиска с помощью алгоритма общего ранжирования до агрегации результатов общего и вертикального поиска и ранжирования их относительно друг друга в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
Такие предварительные ранжирования могут быть (или не быть) персонализированными, т.е. могут быть (или не быть) основаны на признаке ранжирования для конкретного пользователя. В некоторых вариантах подобные предварительные ранжирования результатов общего поиска и/или вертикального поиска основаны на известных способах общего ранжирования, не связанных с конкретным пользователем. В других вариантах предварительные ранжирования результатов общего поиска и/или вертикального поиска связаны с конкретным пользователем, т.е. основаны на признаках общего или вертикального ранжирования для конкретного пользователя. Признаки ранжирования для конкретного пользователя основаны на персональной информации пользователя, такой как характеристики истории поисков пользователя, как описано выше, и обеспечивают персонализированное ранжирование. Множество уровней персонализированного ранжирования может быть внедрено в способы и системы настоящей технологии, например, результаты общего поиска и/или вертикального поиска могут быть сначала ранжированы в соответствии с признаками ранжирования для конкретного пользователя до агрегирования и ранжирования результатов общего и вертикального поиска с помощью параметра предпочтительной агрегации для конкретного пользователя.
В некоторых вариантах осуществления, в которых используются признаки общего и вертикального ранжирования для конкретного пользователя, они могут быть основаны на одной и той же характеристике или наборе характеристик истории поисков пользователя. В других вариантах, в которых используются признаки общего и вертикального ранжирования для конкретного пользователя, они могут быть основаны на различных характеристиках или наборе характеристик истории поисков пользователя. В других вариантах, в которых используются признаки общего и вертикального ранжирования для конкретного пользователя, они могут быть основаны на перекрывающемся наборе характеристик истории поисков пользователя, т.е. они могут быть основаны на некоторых, но не всех одинаковых характеристиках.
Аналогично, в некоторых вариантах параметр предпочтительной агрегации для конкретного пользователя может быть основан на той же характеристике или наборе характеристик истории поисков пользователя, который использован для создания признаков общего и/или вертикального ранжирования для конкретного пользователя. В других вариантах другая характеристика или набор характеристик истории поисков пользователя может быть использован для создания параметра предпочтительной агрегации для конкретного пользователя и признаков общего и/или вертикального ранжирования для конкретного пользователя. В других вариантах параметр предпочтительной агрегации для конкретного пользователя и признаки общего и/или вертикального ранжирования для конкретного пользователям могут быть созданы в зависимости от перекрывающегося набора характеристик истории поисков пользователя, т.е. они могут быть основаны на некоторых, но не всех одинаковых характеристиках.
В некоторых вариантах осуществления способ 600 дополнительно включает в себя этап определения того, что первый результат общего поиска и второй результат вертикального поиска релевантны поисковому запросу пользователя, до ранжирования их по отношению друг к другу.
Способ 600 выполняется на сервере 912. Как упоминалось выше, варианты осуществления сервера 912 никак конкретно не ограничены. Например, сервер 912 может быть реализован как один сервер или множество серверов.
Этап 606 - инициирование отображения электронным устройством, связанным с пользователем, результатов поиска в ранжированном порядке на странице результатов поиска (SERP) в ответ на поисковый запрос
Далее способ 600 переходит к выполнению этапа 606, на котором электронное устройство 904, 906, связанное с пользователем 908, 910 отображает в ранжированном порядке результаты поиска на странице результатов поиска. Электронное устройство 904, 906, связанное с пользователем 908, 910, коммуникативно соединено с сервером 912 таким образом, что страница результатов поиска (SERP), отображаемая на электронном устройстве 904, 906 в ответ на ввод пользователем 908, 910 поискового запроса.
На этапе 606 страница результатов поиска (SERP), отображаемая на электронном устройстве 904, 906 в ответ на ввод пользователем 908, 910 поискового запроса, отображает результаты поиска в ранжированном порядке, созданном при ранжировании на этапе 604. В примере, показанном на Фиг. 1, представлен снимок экрана со страницей результатов поиска (SERP), отображающей результаты, агрегированные в соответствии с настоящим решением. Страница результатов поиска (SERP) на Фиг. 1 отображает первый результат 104 вертикального поиска, обладающий изображениями 116, 118 и 120, за которым следует первый результат 102 общего поиска, второй результат 108 общего поиска, третий результат 110 общего поиска, и, наконец, второй результат 106 вертикального поиска, обладающий изображениями 122, 124 и 126. На этой странице результатов поиска (SERP) первый результат 104 вертикального поиска обладает наиболее высоким рангом и, соответственно, отображается на странице первым. Результаты 102, 108, 110 обладают более низким рангом, чем первый результат 104 вертикального поиска, и более высоким, чем второй результат 106 вертикального поиска, поэтому они показаны в середине, между двумя результатам 104 и 106 вертикального поиска.
Первый результат 102 общего поиска обладает более высоким рангом, чем второй результат 108 общего поиска, который обладает более высоким рангом, чем третий результат 110 общего поиска; результаты общего поиска отображаются в соответствии с этим порядком сверху вниз на странице результатов поиска (SERP).
В примере, показанном на Фиг. 1, три результата 102, 108 и 110 общего поиска отображаются вместе одним блогом, между двумя результатами 104, 106 вертикального поиска. Тем не менее, возможны другие варианты в зависимости от параметра предпочтительной агрегации для конкретного пользователя. Например, первый результат 104 вертикального поиска и второй результат 106 вертикального поиска ранжируются и отображаются по отдельности на странице результатов поиска (SERP), как показано на Фиг. 1, или могут быть ранжированы вместе и отображаться в виде блока (не показан) на странице результатов поиска (SERP). В другом примере первый результат 102 общего поиска может быть ранжирован выше, чем первый результат 104 вертикального поиска, и может отображаться вверху страницы результатов поиска (SERP) (не показано). Специалистам в данной области техники будет ясно, что возможны многие другие перестановки.
Также следует иметь в виду, что само расположение результатов поиска никак конкретно не ограничено. Например, результаты поиска могут быть расположены вертикально, горизонтально, в виде сети или какой-либо комбинации всех этих способов. Отображение результатов поиска на странице результатов поиска (SERP) может варьироваться в зависимости от типа электронного устройства 904, 906, связанного с пользователем 908, 910. Например, экран настольного компьютера может обладать большим размером, чем экран ноутбука, нетбука или планшета, которые могут, в свою очередь, обладать большим экраном, чем небольшие электронные устройства, например, мобильные телефоны. Размеры экрана могут оказывать влияние на число результатов поиска, отображаемых на странице результатов поиска (SERP) пользователю 908, 910, а также на число ссылок, фрагментов (например, фрагмент 132), или на количество отображаемой краткой информации (например, краткая информация 128, 130). В некоторых вариантах позиции результатов 102, 104, 106, 108, 110 поиска на странице результатов поиска (SERP) может соответствовать рангу результатов поиска на странице результатов поиска (SERP). Тем не менее, в некоторых вариантах ранг может быть отображен в каких-то признаках, отличных от позиции, например, в выделении, размере, цвете и т.д. на странице результатов поиска (SERP).
На Фиг. 7 представлена принципиальная схема способа 700, выполненного в соответствии с вариантами осуществления настоящего решения. Способ 700 может выполняться на сервере 912.
Этап 702 - оценка параметра предпочтительной агрегации для конкретного пользователя
Аналогично способу 600, способ 700 начинается на этапе 702, на котором сервер 912 оценивает параметр предпочтительной агрегации для конкретного пользователя, который был создан в зависимости по меньшей мере от одной характеристики истории поисков пользователя 908, 910, который ввел поисковый запрос. Способ 700 дополнительно включает в себя результат вертикального поиска.
Этапы 704 и 706 - ранжирование первого результата общего поиска, первого результата вертикального поиска и второго результата вертикального поиска по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать порядок ранжирования результатов поиска и инициировать отображение электронным устройством, связанным с пользователем, ранжированного порядка результатов поиска на странице результатов поиска (SERP).
Способ 700 продолжается на этапах 704 и 706, где первый результат 102 общего поиска и первый результат 104 вертикального поиска и второй результат 106 вертикального поиска ранжированы по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать порядок ранжирования результатов поиска, в котором результаты поиска отображаются на странице результатов поиска (SERP). В представленном на Фиг. 1 примере, первый результат 104 вертикального поиска и второй результат 106 вертикального поиска идентифицируются при поиске на двух различных вертикальных доменах. Первый результат 104 вертикального поиска идентифицируется при поиске в первом вертикальном домене 112 (видео), а второй результат 106 вертикального поиска идентифицируется при поиске во втором вертикальном домене 114 (изображения). В некоторых других вариантах первый результат вертикального поиска и второй результат вертикального поиска могут быть идентифицированы при поиске на одном и то же вертикальном домене (не показан). Следует иметь в виду, что в том случае, где на странице результатов поиска (SERP) отображается более одного результата вертикального поиска, эти результаты могут поступать от различных вертикальных доменов. Далее, два результата вертикального поиска, идентифицированные как принадлежащие к одному вертикальному домену, могут отображаться отдельно на странице результатов поиска (SERP) или могут располагаться вместе на странице результатов поиска (SERP) - в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
В некоторых вариантах способ 700 дополнительно включает в себя этап определения того, что первый результат общего поиска, первый результат вертикального поиска и второй результат вертикального поиска релевантны для поискового запроса пользователя, до ранжирования их по отношению друг к другу.
На Фиг. 8 представлена принципиальная схема способа 800, выполненного в соответствии с вариантами осуществления настоящего решения. Способ 800 может выполняться на сервере 912.
Этап 802 - оценка параметра предпочтительной агрегации для конкретного пользователя
Аналогично способу 700, способ 800 начинается на этапе 802, на котором сервер 912 оценивает параметр предпочтительной агрегации для конкретного пользователя, который был создан в зависимости по меньшей мере от одной характеристики истории поисков пользователя, который ввел поисковый запрос. Способ 800 дополнительно включает в себя результат общего поиска.
Этапы 804 и 806 - ранжирование первого результата общего поиска, первого результата вертикального поиска, второго результата вертикального поиска и второго результата общего поиска по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать порядок ранжирования результатов поиска и инициировать отображение электронным устройством, связанным с пользователем, ранжированного порядка результатов поиска на странице результатов поиска (SERP).
Способ 800 продолжается на этапах 804 и 806, где первый результат 102 общего поиска и первый результат 104 вертикального поиска, второй результат 108 вертикального поиска и второй результат 108 общего поиска ранжированы по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать порядок ранжирования результатов поиска, в котором результаты поиска отображаются на странице результатов поиска (SERP). В примере, представленном на Фиг. 1, первый результат 102 общего поиска и второй результат 108 общего поиска отображаются вместе, причем первый результат 102 общего поиска обладает рангом выше, чем второй результат 108 общего поиска, и, соответственно, отображается выше, чем второй результат 108 общего поиска на странице результатов поиска (SERP). В некоторых других вариантах первый результат общего поиска и второй результат общего поиска могут отображаться отдельно на странице результатов поиска (SERP), поскольку они могут быть ранжированы отдельно. Например, результат вертикального поиска может обладать рангом, находящимся между рангами первого результата общего поиска и второго результата общего поиска (не показано). В другом альтернативном варианте осуществления, второй результат общего поиска может обладать более высоким рангом, чем результат общего поиска (не показано). Следует иметь в виду, что возможны многие подобные перестановки, которые будут зависеть от параметра предпочтительной агрегации для конкретного пользователя и соответствующего созданного порядка ранжирования результатов поиска.
В некоторых вариантах способ 800 дополнительно включает в себя этап определения, что первый результат общего поиска, первый результат вертикального поиска, второй результат вертикального поиска и второй результат общего поиска релевантны для поискового запроса пользователя, до ранжирования их по отношению друг к другу.
Настоящее описание не предназначено для установки границ реализации конкретных описанных здесь вариантов осуществления, которые предназначены только для целей иллюстрации различных аспектов. Специалистам в данной области техники будет ясно, что возможны многие другие модификации и вариации. Специалистам в данной области техники будут очевидны функционально эквивалентные способы и системы, которые дополняют уже описанные в рамках настоящего описания. В иллюстративном варианте осуществления любые описанные здесь операции, процессы и т.п. могут быть реализованы как машиночитаемые инструкции, хранящиеся на постоянном машиночитаемом носителе. Машиночитаемые инструкции могут выполняться процессором мобильного элемента, сетевого элемента и/или любого другого вычислительного устройства, инициируя выполнение описанных здесь способов.
В дополнение к вариантам осуществления предусмотрен сервер 912, выполненный с возможностью отображать страницу результатов поиска (SERP) пользователю 908, 910 в ответ на поисковый запрос, причем сервер 912 обладает постоянным машиночитаемым носителем информации, который хранит выполняемые компьютером инструкции, выполнение которых настраивает сервер, выполненный с возможностью выполнять этапы способов, описанных здесь.
Примеры
Если не указано иное, или на иное четко указывает контекст, все использованные здесь технические и научные термины обладают тем же смыслом, что будет ясен специалисту, обладающему знанием области, к которой принадлежит настоящее изобретение. Следует иметь в виду, что любые методы и материалы, аналогичные или эквивалентные тем, что описаны здесь, могут быть использованы для реализации или тестирования изобретения.
В обсуждаемых здесь примерах, персонализация агрегированных результатов поиска демонтрируется в ответ на поисковый запрос ʺmetallicaʺ. Сначала персонализация ранжирования вертикалей была выполнена в соответствии с описанной методологией. Оригинальный алгоритм ранжирования дал 10 результатов и некоторое число вертикальных результатов, которые вставлены между ними. Следует отметить, что вертикальный результат иногда может быть представлен в виде блока документов конкретного типа, обладающих наивысшим рангом, как представлено на Фиг. 1, где результат 104 вертикального поиска включает в себя блок из трех изображений 116, 118 и 120. Для того, чтобы избежать неоднозначности, термин ʺвертикальный результатʺ обозначает блок, состоящий по меньшей мере из одного вертикального компонента.
Оригинальные страницы результатов удовлетворяют следующим ограничениям: во-первых, может быть не более одного вертикального результата, внедренного в каждую вертикаль. Во-вторых, вертикальные результаты могут быть добавлены только в четыре слота: над первым сетевым результатов; между третьим и четвертым результатами; между шестым и седьмым результатами; и после десятого сетевого результата. На Фиг. 1 представлена верхняя часть страницы результатов поиска (SERP), удовлетворяющая этим ограничениям.
В некоторых экспериментах результаты поиска могут быть агрегированы в любом порядке, даже нарушая вышеописанные ограничения, если это необходимо. Рассматриваются только запросы, для которых представлен по меньшей мере один вертикальный результат, в позициях с 11 по 14 были агрегированны только разнородные результаты. Для экспериментальных целей также был разработан следующий набор вертикалей: Изображения, Видео, Музыка, Новости, Словари, События и Погода. Следует иметь в виду, что используемый здесь подход представлен только для иллюстративных целей, и может быть применен к любому другому набору вертикальных доменов.
Для исполнения функции агрегации был построен мультипространственный вектор характеристик φ(q, u, r,) для каждого результата ri, соответствующего запросу q, введеному пользователем u. Отметим, что результат ri может представлять собой либо сетевой результат или вертикальный результат для любого вертикального домена. Если результат релевантен для пользователя, то вектор, помечается 1, в противном случае - 0. Далее был использован точечный подход к обучению модели ранжирования и всех результатов для агрегирования в соответствии с расчетной моделью.
В следующих секциях будет описано построение векторов характеристик для различных экспериментальных настроек, но, сначала, будут введены используемые обозначения.
Далее используются следующие обозначения: Каждая рассматриваемая вертикаль обозначена Vj, j=1, …, N. Для каждого результата ri существует функция индикатор I(ri), которая выводит j, если ri является результатом от вертикали Vj (например, вертикальным результатом), и 0, если это результат поиска по общему домену (например, общим результатом, например общим сетевым результатом). X(ri) является формальной функцией, которая выводит ri, если I(ri)=0, и VI(ri) в остальных случаях. C(q, u, r) представляет собой число кликов пользователя u на конкретный результат r (конкретный результат r является результатом поиска для вертикального домена или общего домена) для запроса q. C30(q, u, r) и C100(q, u, r) являются счетчиками числа кликов за время ожидания более 30 и 100 секунд соответственно. CI,30(q, u, r) представляет собой число кликов, которые являются последними кликами по результатам соответствующего поискового запроса q и обладают временем ожидания более 30 секунд. Для ясности обозначим, что С(, u, r) и  , r) или C(q, , ) могут быть обозначены аналогичным образом. Далее, C(q, u, Vj) обозначает сумму кликов пользователя u на все результаты от вертикали Vj, представленные для запроса q за наблюдаемый период времени. Поскольку эти результаты могут фактически отличать в различные моменты, эта величина обозначается как ʺклики по вертикалиʺ. C(q, u, v) обозначает сумму C(q; u; Vj) для всех вертикалей.
, r) или C(q, , ) могут быть обозначены аналогичным образом. Далее, C(q, u, Vj) обозначает сумму кликов пользователя u на все результаты от вертикали Vj, представленные для запроса q за наблюдаемый период времени. Поскольку эти результаты могут фактически отличать в различные моменты, эта величина обозначается как ʺклики по вертикалиʺ. C(q, u, v) обозначает сумму C(q; u; Vj) для всех вертикалей.
Число раз, когда любой результат r был показан пользователю u, который ввел запрос q, обозначено как S(q, u, r). Считается, что результат ʺбыл показанʺ в одном из следующих случаев: 1) если результат был помещен на первую позицию; 2) если по нему был совершен клик; или 3) если клик был совершен по документу, расположенному ниже. В соответствии с определениями, указанными выше, легко перейти к определению таких величин как S(q, u, v), S(q, u, ) и т.д. Аналогичные обозначения были описаны.
Теперь будут описаны базовые характеристики. Сначала будет описано построение вектора φВ(q, r) базовых характеристик, не зависящих от пользователя. Первый элемент вектора φВ(q, r) - I(r), таким образом, способ обучения всегда проинформирован о типе результата (т.е. является ли он результатом поиска от общего домена (например, всемирной паутины) или результатом поиска от вертикального домена (например, изображений или новостей). Недоступные характеристики для конкретного типа результата будут приниматься равными нулю; соответственно, первый элемент φВ(q, r) указывает на подобные ситуации.
Для того, чтобы построить конкурентную базовую линию, реализуются следующие характеристики, представляющие те, что хорошо известны в данной области техники.
Данные о запросе. Как было описано, в базовый набор характеристик включают булеву переменную, идентифицирующую тот факт, является ли запрос навигационным. Для каждой вертикали Vj также создается униграммная вертикальная языковая модель Lj. Каждая модель создается в зависимости от запросов, для которых по результату из вертикали Vj были совершены клики за время ожидания более 30 секунд, которое является точным и широко используемым индикатором релевантности результата. Итак, если вертикальный результат представляет собой r, и I(r)=j, добавляется вероятность запроса Lj к вектору характеристик φВ(q, r). Если r является результатом от общего домена (например, общим сетевым результатом), то ноль добавляется φВ(q, r) (и алгоритм машинного обучения информируется о типе результата с помощью первой координаты φВ(q, r)). Тексты запросов более предпочтительны, чем тексты документов для построения наших моделей, поскольку некоторые вертикальные домены работают с нетекстовым содержимым, и с ними следует обращаться соответственно. Другой причиной является тот факт, что построенные таким образом модели обладают аналогичной семантикой по отношению к ключевым характеристикам и, таким образом, обеспечивают функции агрегации еще и таким типом сигнала. Длина запроса также добавлена в качестве характеристики.
Вертикальные данные и Общие данные. Первой характеристикой этого типа является позиция результата в оригинальном ранжировании. Величина релевантности результата, вычисляемая в алгоритме оригинального ранжирования только для сетевых результатов, также используется в качестве характеристики. Отметим, что базовый набор характеристик включает в себя характеристики, необходимые для создания не персонализированной версии величины вертикальной релевантности, таким образом, для целей правильного сравнения персонализированного и не персонализированного подходов релевантность вертикалей была явно рассчитана, а не получена каким-либо иным путем.
Данные поискового лога. Следующие используемые характеристики являются пятью характеристиками, связанными с количеством кликов:
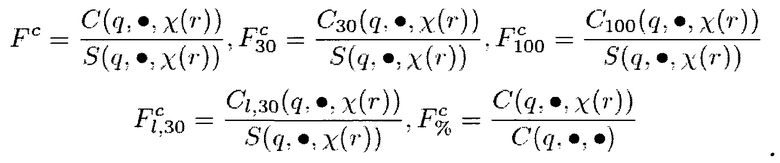
Следует отметить, что аналогичные характеристики уже были использованы в оригинальном алгоритме ранжирования поисковой системы, но мы явно добавляем их к φВ(q, r) для того, чтобы подчеркнуть эффект описанного здесь персонализированного подхода. Если X(r) является Vj, эти характеристики предоставляют информацию о числе кликов по результатам вертикального поиска.
Характеристики персонализации. Предусмотрено три класса характеристик персонализации, относящихся к вертикальным доменам (также называемых ʺотносящиеся к вертикалямʺ): 1) Требования к агрегированному поиску; 2) Конкретные предпочтения к вертикалям; и 3) Способность переходить по вертикалям. Эти характеристики персонализации подробнее будут описаны ниже.
1. Требования к агрегированному поиску. Этот набор характеристик описывает то, заинтересован ли пользователь в целом в агрегированных результатах поиска или предпочитает им общие сетевые результаты. Вертикальные результаты часто обладают внешним видом, который отличается от общих сетевых результатов, что может влиять на пользовательский опыт. Этот набор характеристик предназначен для отображения пользовательского отношения к подобным переменам. В данном примере мы исходили из информации об истории кликов. Конкретнее - набор характеристик выглядит следующим образом:
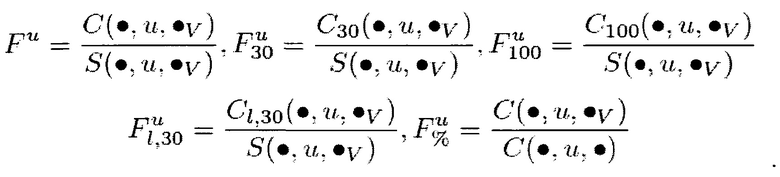
Вектор этих пяти характеристик обозначается φа(u).
2. Конкретные предпочтения к вертикалям. Этот набор свойств описывает желание пользователя получать результаты конкретного типа на все запросы. Предполагается, что это коррелирует с интересами пользователя. Далее, добавление характеристик подобного типа к профилю персонализации пользователя может помочь избежать неоднозначности некоторых запросов для конкретного пользователя.
Первая характеристика этого класса подчеркивает разницу между униграммной языковой моделью пользователя (построенной на запросах, введенных пользователем за наблюдаемый период времени) и языковой моделью для результатов вертикального поиска (описанных ранее в разделе, озаглавленном ʺБазовые характеристикиʺ). Разница была высчитана в виде расстояния Кульбака-Лейблера 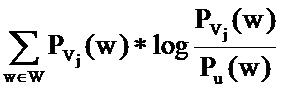
Вышеприведенную мотивацию пользователя можно выразить и другим образом - используя информацию о кликах. Для этой цели предлагается следующий набор характеристик:
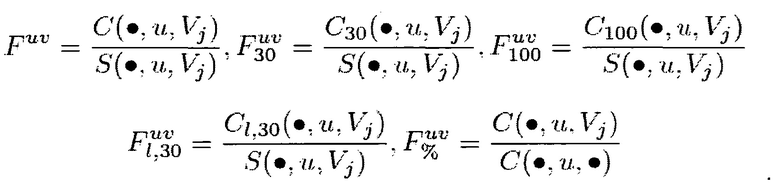
Здесь j=I(ri). Вектор этих шести характеристик обозначается φc(u, ri).
3. Способность переходить по вертикалям. С другой стороны, потребности пользователя в некоторых конкретных запросах могут не совпадать с его/ее обычными предпочтениями. Например, результаты из новостной вертикали или вертикали погоды могут быть более релевантными, чем результаты из вертикали изображений, для пользователя, живущего в Амстердаме, и вводящего запрос ʺАмстердамʺ, вне зависимости от того, что обычно этот пользователь предпочитает изображения. Характеристики, связанные с количеством кликов, которые должны отображать это предположение рассчитываются следующим образом:
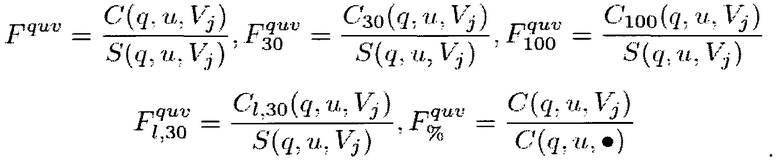
Опять же, здесь j=I(ri), и вектор этих пяти характеристик обозначается φn(q, u, ri).
Мы добавляем абсолютные значения, соответствующие кликам и показам, к каждому из этих векторов характеристик (то есть, S(, u, v) и C(, u, ) к φа(u) и так далее). Таким образом, предлагаемые модели получают информацию об уровне пользовательской активности по отношению к результатам вертикального поиска, которая может обладать полезными сигналами для алгоритма обучения. Другой причиной добавления этих характеристик является тот факт, что остальные характеристики становятся более надежными при более высоких значениях характеристик активности. Таким образом, предоставление подобной информации алгоритму обучения является полезным для всего процесса обучения.
Отметим, что эти характеристики имеют смысл только для результатов вертикального поиска. Поэтому если I(ri)=0, то все элементы этих трех векторов характеристик будут равняться нулю.
Функции агрегации. Мы тренировали несколько функций агрегации, которые различаются в наборах характеристик, где они были использованы. Для тренировки моделей был использован алгоритм градиентного бустинга дерева решений (GBDT), выполненный с возможностью минимизировать среднеквадратичную ошибку (MSE). Алгоритмы градиентного бустинга дерева решений известны в данной области техники и были использованы ранее. Следует иметь в виду, что могут быть использованы многие другие алгоритмы, и выбора алгоритма не является важным для этих экспериментов. В представленных здесь вариантах осуществления технологии был использован алгоритм в зависимости от дерева решений, поскольку преследовалась цель создать чувствительные к вертикалям функции ранжирования, и использовать некоторые характеристики только в том случае, если они доступны для конкретного типа результата (например, некоторые характеристики персонализации не доступны для результатов общего поиска). Предполагается, что любой другой подходящий алгоритм в зависимости от дерева решений будет давать те же результаты.
Были использованы те же параметры обучения алгоритма (диапазон уменьшения, размер деревьев), что и для тренировки функции выполнения ранжирования одной из крупных коммерчески доступных поисковых систем.
Функция базового ранжирования RВ была тренирована в соответствии с вышеописанной схемой с помощью вектора характеристик φВ(q, r). Этот вектор характеристик включает в себя позицию результата в оригинальном ранжировании, которая представляет собой производственный рейтинг одного из крупных поисковых систем. С другой стороны он включает в себя представление набора характеристик, которые упоминались выше (данные запроса, вертикальные данные, данные о соотношении числа переходов и показов и сетевые данные). Таким образом, этот набор характеристик предоставляет очень конкурентоспособную базовую линию.
Чтобы оценить потенциал персонализации для улучшения представления агрегированных результатов поиска, и чтобы оценить сильные стороны различных классов характеристик персонализации, были тренированы еще четыре функции ранжирования. Функция Racn была тренирована на конкатенации векторов характеристик φВ, φа, φc, φn. Функция Rac была тренирована на конкатенации векторов характеристик φВ, φа, φс, Ran - на векторах φВ, φа, φn и Rcn - на векторах φВ, φс, φn.
Набор данных и протокол эксперимента. Для выполнения экспериментов были собраны данные о пользовательских сессиях из поисковых логов крупной коммерческой поисковой системы. Для каждого запроса эти логи содержат: сам запрос, верхние результаты, выведенные поисковой системой в ответ на запрос, и информацию о кликах по результатам. Каждому пользователю этой поисковой системы был назначен специальный анонимный идентификатор пользователя (UID) в виде cookie (куки), который также хранится в логах и позволяет идентифицировать действия, выполняемые различными пользователями. Предлагаемый набор данных состоит из восьминедельной выборки пользовательских сессии, сохраненных за май и июнь 2012 года. Учитываются только те результаты поиска, в которые включен по меньшей мере один результат вертикального поиска. Следует иметь в виду, что могут быть использованы многие другие поисковые системы, и выбор поисковой системы не является важным для этих экспериментов. Предполагается, что любая другая подходящая поисковая система будет давать те же результаты.
Поскольку в данном случае была предпринята попытка оценить персонализированные характеристики, не представляется возможным использовать мнения экспертов. Вместо этого была получена информация о релевантности результатов из поисковых логов. Результат считается релевантным для конкретного поискового запроса, если по нему был совершен клик за время ожидания более 30 секунд, или в том случае, если клик по этому результату являлся последним действием пользователя за эту сессию. В противном случае, представленные результаты считаются нерелевантными.
Для того чтобы построить тренировочные и тестовые наборы были использованы сессии седьмой и восьмой недель наблюдений соответственно. Наборы данных были отобраны таким образом для того, чтобы избежать ситуации, в которой модели были бы протестированы на сессиях за тот же период времени, который был использован для обучения, что могло бы исказить результаты. Для обоих наборов данных рассматриваются только запросы, для которых по меньшей мере один результат обладает позитивной оценкой и для которых результат вертикального поиска был показан в соответствии с термином ʺбыл показанʺ, представленном выше. Для создания характеристики поисковых логов (как персонализированных, так и не персонализированных) для тренировки были использованы сессии недель 1-6, а для текстового набора были использованы сессии недель 2-7, таким образом, одно и то же количество информации будет использовано для тренировки и тестирования.
Последняя группа пользователей состоит из тех пользователей, которые увидели результат в какой-либо вертикали по меньшей мере 5 раз за оба периода сбора характеристик (недели 1-6 и недели 2-7). Следует отметить, что пользователи не отбирались по степени из активности за тестовый период, поскольку это также могло бы исказить полученные результаты. Подобная фильтрация оставляет примерно 30 миллионов различных пользователей. Оба набора - тренировочный и тестовый - состоят примерно из 100 миллионов запросов, около 70% из которых были введены пользователями из рассматриваемой группы пользователей. Были случайно выбраны 10% собранных профилей из этой группы пользователей для целей настоящих экспериментов. С учетом случайности выборки это подмножество отражает характеристики пользовательских профилей в группе в целом. Таким образом, конечная группа пользователей состоит примерно из 3 миллионов пользователей, и тренировочный и тестовый наборы включают в себя результаты поиска примерно для 7 миллионов запросов.
Все функции ранжирования были тренированы и оценены одним и тем же способом с помощью конкретного для пользователя типа пятикратной перекрестной проверки, которая происходила следующим образом: Конечная группа профилей пользователя была разделена на 5 подгрупп. По ходу каждой перекрестной проверки четыре подгруппы профилей пользователей были использованы для тренировки, а оставшаяся - для тестирования. Для тренировки модели были использованы сессии из тренировочного набора (неделя 7), которые относятся к пользователям из четырем обучающим подгруппам. После этого модель была протестирована на сессия из тестового набора данных (неделя 8), которые относятся к пользователям из проверочной подгруппы. Эта процедура была проделана пять раз таким образом, чтобы каждая из подгрупп была использована в качестве группы проверки. Такая перекрестная проверка дает уверенность в том, что полученные результаты не были искажены в отношении пользователей, использованных для обучения.
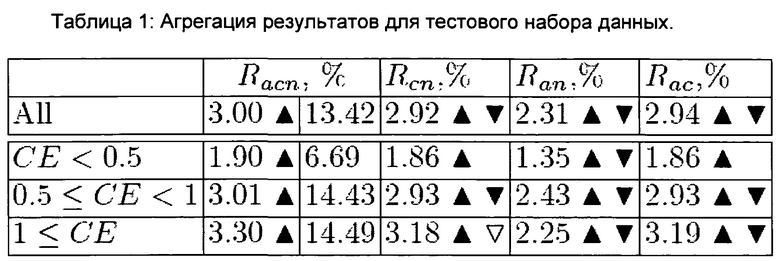
Результаты
Качество агрегации было рассчитано с помощью средней точности агрегированных документов для запросов из каждой тестовой подгруппы (средняя точность - MAP), которое затем было усреднено по подгруппам. Относительные улучшения персонализированных алгоритмов по сравнению с базовым ранжированием представлены в таблице 1 в соответствии с предыдущими исследованиями.
Также было оценены результаты работы моделей на нескольких подмножествам потоковых запросов, и было выяснено, что изменения в энтропии клика для запроса четко коррелируют с выгодой, которая может быть получена при персонализации ранжирования документов, относящихся к этому запросу. Термин ʺэнтропияʺ широко используется в данной области техники и относится к средней неопределенности случайной переменной. Средняя энтропия клика была адаптирована под нужды агрегированного поиска, т.е. вероятность клика для каждого конкретного результата не была использована. Вместо этого были использованы агрегированные вероятности кликов по всем результатам общего поиска и агрегированные вероятности кликов по каждому результату вертикального поиска Более строго:
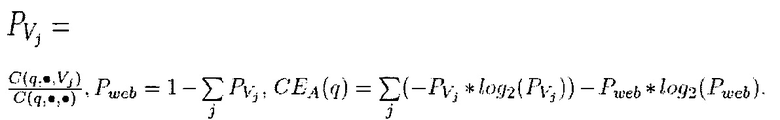
Общие показатели: Общие результаты для всех моделей представлены в таблице 1. В заголовке столбца указана конкретная использованная модель. Символ  означает 99% (p-значение<0.01) уровня статистической значимости для улучшения по сравнению с базовой линией в соответствии с непараметрическим статистическим тестом Уилкоксона для каждой из пяти тестовых подгрупп. Символ
означает 99% (p-значение<0.01) уровня статистической значимости для улучшения по сравнению с базовой линией в соответствии с непараметрическим статистическим тестом Уилкоксона для каждой из пяти тестовых подгрупп. Символ  означает, что соответствующая модель работает значительно хуже, чем модель Racn на каждой подгруппе с p-значением <0.01.
означает, что соответствующая модель работает значительно хуже, чем модель Racn на каждой подгруппе с p-значением <0.01.  то же самое для p-значения <0.05.
то же самое для p-значения <0.05.
Правая часть столбца Rgcn отображает улучшения для запросов, в которых средняя точности (MAP) ранжирования, полученная с помощью базовой модели Rb и персонализированной Racn модели, различаются. Подобные запросы составляют примерно 29% потока запросов в каждой тестовой подгруппе. Средняя точность (MAP) выросла на 18% для потока - таким образом, ранжирование было улучшено для 62% запросов с помощью применения агрегации.
Из этой таблицы видно, что для всех четырех персонализированных моделей было улучшено качество ранжирования.
В следующих разделах представлен более подробный анализ работы модели Racn, зависящей от запроса, пользователя или вертикали.
Анализ уровня запроса. Сначала рассматривается зависимость влияния персонального подхода от изменения в энтропии клика более подробно (тем не менее, общие результаты персонализированных моделей для запросов с известной энтропией клика всегда превышают средние значения). На Фиг. 2 представлены улучшения средней точности (MAP) в виде функции адаптированной энтропии клика (см. выше определение ʺадаптированной энтропии кликаʺ в начале раздела ʺРезультатыʺ). Этот график демонстрирует, что общий рост энтропии приводит к увеличению эффекта персонализации для ранжирования результатов вертикального поиска. Позитивный эффект наблюдается даже для тех запросов, энтропия которых невелика, и, несмотря на снижение улучшения средней точности (MAP) слева от 1, средний рост средней точности (MAP) в диапазоне 0,5-1 превосходит расчетное значение интервала [0, 0.5], как показано в Табл.1.
Как упоминалось выше, агрегация влияет на 29% потока запросов в каждой тестовой подгруппе, которая состоит примерно из 1,2 миллиона запросов. С другой стороны, каждый тестовая подгруппа состоит примерно из 680,000 уникальных запросов. Доля уникальных запросов, попадающих под влияние агрегации, составляла 32%, 61% из которых был позитивно агрегирован. Следует отметить, что те же запросы, введенные другими пользователями, могут быть агрегированы другим образом или не агрегированы вовсе. Уникальный запрос считается обработанным, если ранжирования моделей Rb и Racb отличаются для любых данных в наборе данных. На Фиг. 3 показано выполнение средней агрегации персонализированной модели для уникальных запросов (введенных по меньшей мере 5 раз) между 5 и 95 процентилями примера подобных запросов, сортированных по росту средней точности (MAP). Появления запроса были подсчитаны за восемь недель наблюдений.
Анализ уровня пользователя. Другим ценным аспектом анализа персонализированных моделей является их влияние на отдельных пользователей. Поскольку трехмиллионная группа пользователей была разделена на 5 неперекрывающихся подгрупп, каждая из которых состоит примерно из 600,000 пользователей. Тем не менее, соответствующая часть тестового набора данных содержит запросы, введенным примерно 450,000 пользователей, поскольку не всех наблюдаемых пользователи были активны в течение восьми недель наблюдений. На сессии примерно у 54% этих пользователей влияет предлагаемая агрегация, и для 64% из них персонализированная агрегация обладает позитивным эффектом. На Фиг. 4 представлено распределение роста средней точности (MAP) для доли пользователей между 5 и 95 процентилями примера пользователей, которые ввели по меньшей мере 5 запросов в течение восьмой недели.
Для обнаружения классов пользователей, которые различаются при персонализации, пользователей разделяют на группы в зависимости от числа раз, когда каждому пользователю были показаны результаты поиска по вертикальному домену за наблюдаемый период времени. Таким образом, если пользователю результаты поиска по вертикальному домену были показаны k раз, то этот пользователь записывается в группу, пронумерованную [(k-5)/5]. Выбираются верхние из подобных групп по критерию числа записанных пользователей. Средние изменения средней точности (MAP) внутри группы представлены на Фиг. 5 в виде функции от номера группы. Несмотря на то, что средняя точность в каждой группе возрастает, можно наблюдать тот факт, что величина этого роста сильно зависит от номера группы, и, таким образом, от числа раз, когда пользователю была показана какая-либо вертикаль. Важно отметить, что это число было рассчитано за наблюдаемый период времени сбора данных, так что оно может быть использовано в процессе обучения, то есть, при тренировке различных моделей для пользователей с различными уровнями активности в отношении агрегированного поиска.
Анализ страницы результатов поиска (SERP). Следующим направлением анализа является зависимость эффекта персонализации от вертикалей, представленных на странице результатов поиска (SERP). Сначала измеряется то, как изменяет персонализированная агрегация порядок вертикальных результатов, если страница результатов поиска (SERP) содержит по меньшей мере два из них. С этой целью рассчитывается средняя точность только с учетом вертикальных результатов, полученный результат показывается 1,24% роста (p-значение <0.01 для каждой подгруппы). Также изучалась зависимость роста средней точности от числа представленных на странице результатов поиска (SERP) вертикалей, были получены следующие результаты: для 1 представленного вертикального результата (75% запросов) средняя точность выросла на 2,72%, для 2 представленных вертикалей (22% запросов) средняя точность выросла на 3,80%; для 3 представленных вертикальных результатов рост составил 4,31% (2,5% запросов), и для 4 результатов рост составил 3,43% (примерно 0,5% запросов). Все перемены были существенны при p-значении <0.01 для каждой из 5 подгрупп. Также изучалось то, какие вертикали получают больше выгоды от персонализированного подхода, и было выяснено, что для вертикалей Видео и Погоды выгода была наибольшей (5,35% и 8,2%), а для вертикалей Словари и События существенные улучшения не были достигнуты.
Модификации и улучшения вышеописанных вариантов осуществления будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего решения ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА | 2015 |
|
RU2640639C2 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2015 |
|
RU2632148C2 |
| СПОСОБ (ВАРИАНТЫ) И СЕРВЕР РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ НА ОСНОВЕ ПАРАМЕТРА ПОЛЕЗНОСТИ | 2015 |
|
RU2632138C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ АНОМАЛЬНЫХ ПОСЕЩЕНИЙ ВЕБ-САЙТОВ | 2019 |
|
RU2775824C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ПОДСКАЗОК ПО РАСШИРЕНИЮ ПОИСКОВЫХ ЗАПРОСОВ В ПОИСКОВОЙ СИСТЕМЕ | 2019 |
|
RU2744111C2 |
| Способ и система для рекомендации свежих саджестов поисковых запросов в поисковой системе | 2018 |
|
RU2692045C1 |
| СЕРВЕР ДЛЯ ОПРЕДЕЛЕНИЯ ПОИСКОВОЙ ВЫДАЧИ НА ПОИСКОВЫЙ ЗАПРОС И ЭЛЕКТРОННОЕ УСТРОЙСТВО | 2013 |
|
RU2583739C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| СПОСОБ И СЕРВЕР ОБРАБОТКИ ПОИСКОВОГО ПРЕДЛОЖЕНИЯ | 2015 |
|
RU2609079C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
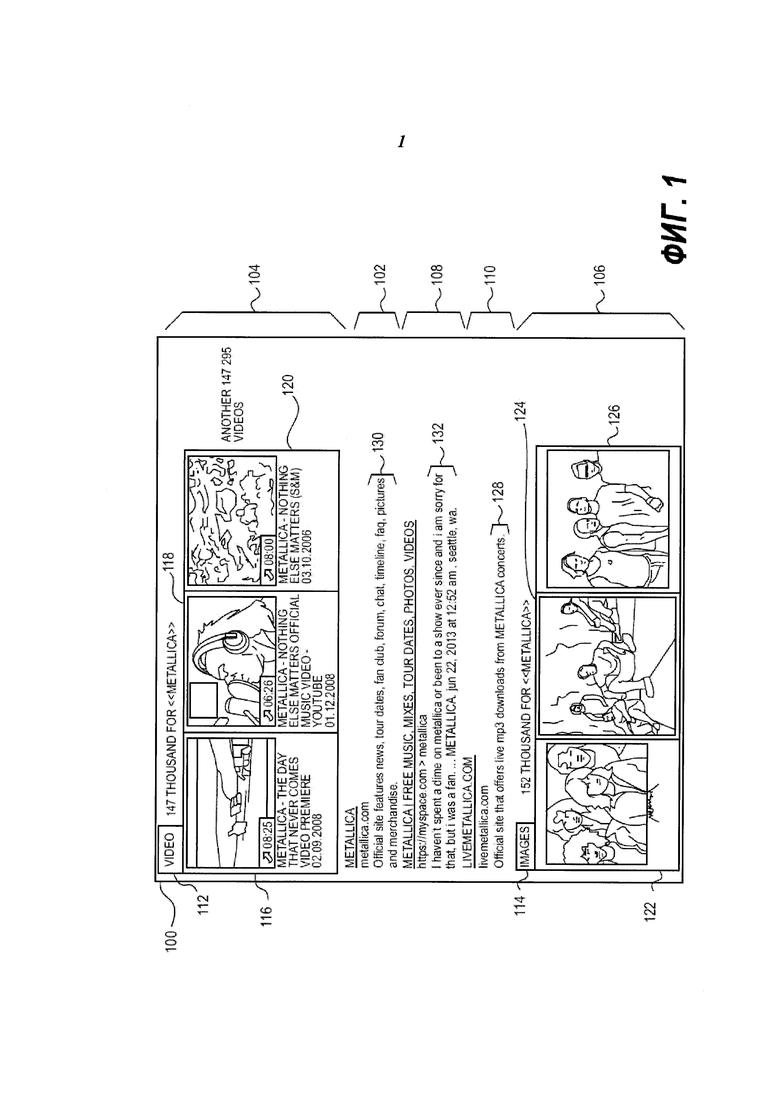
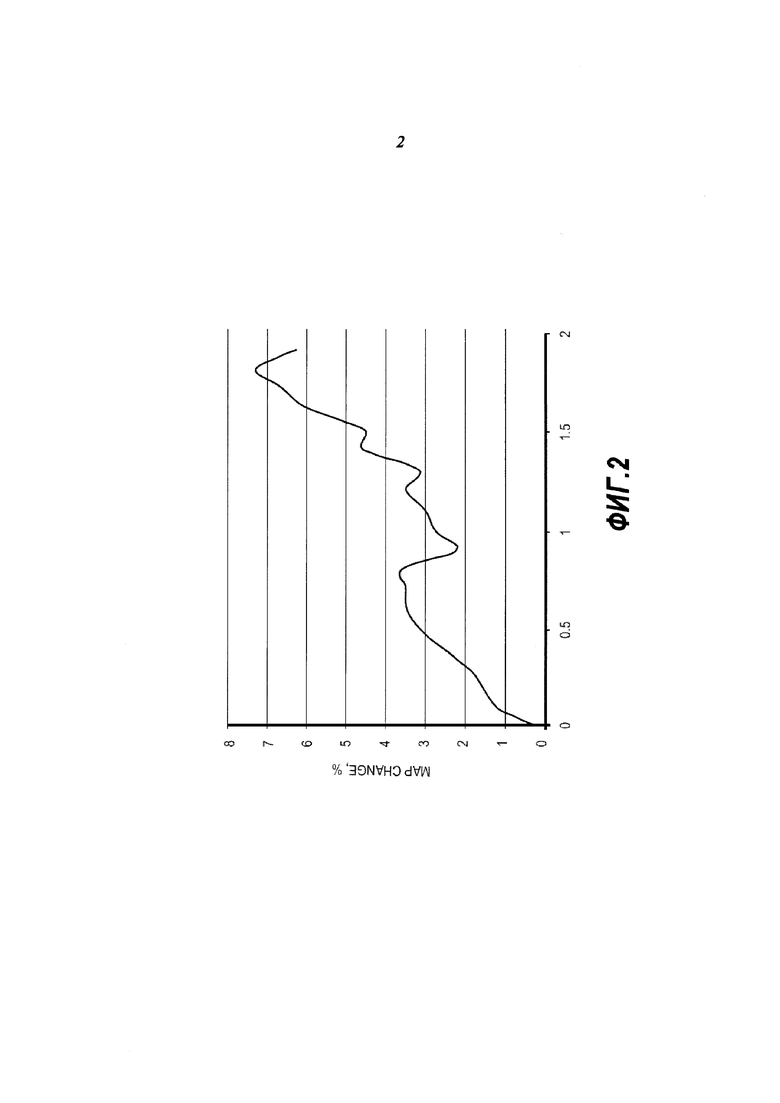
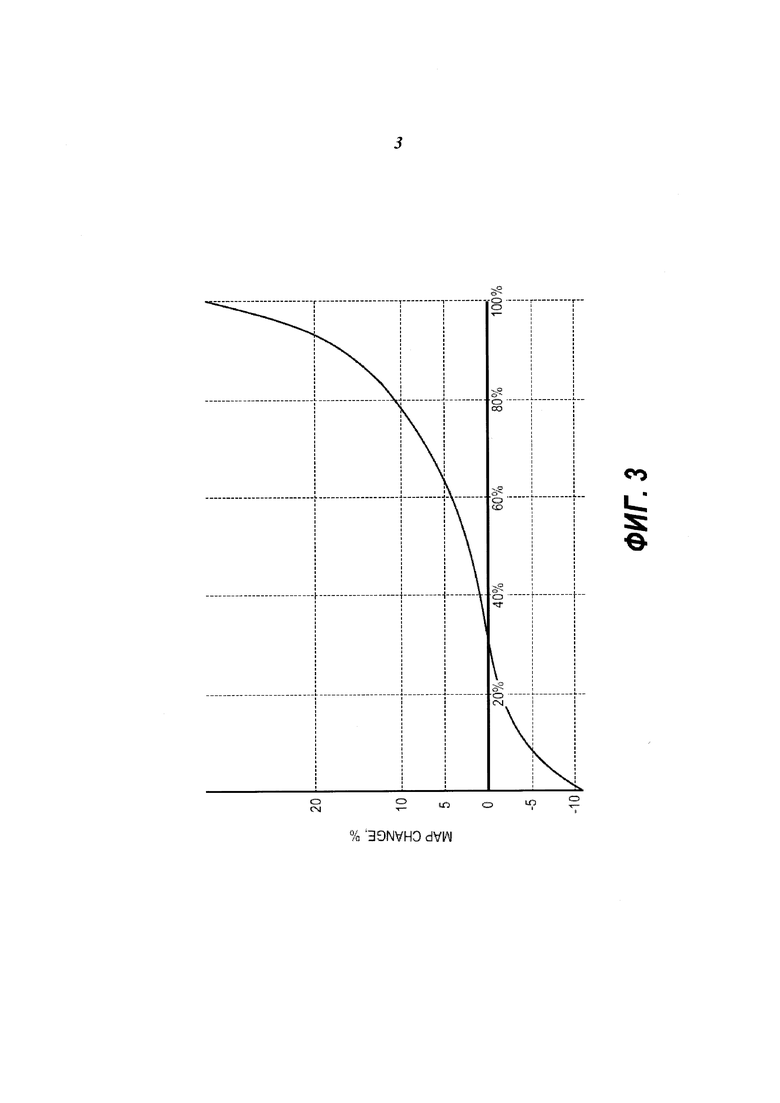
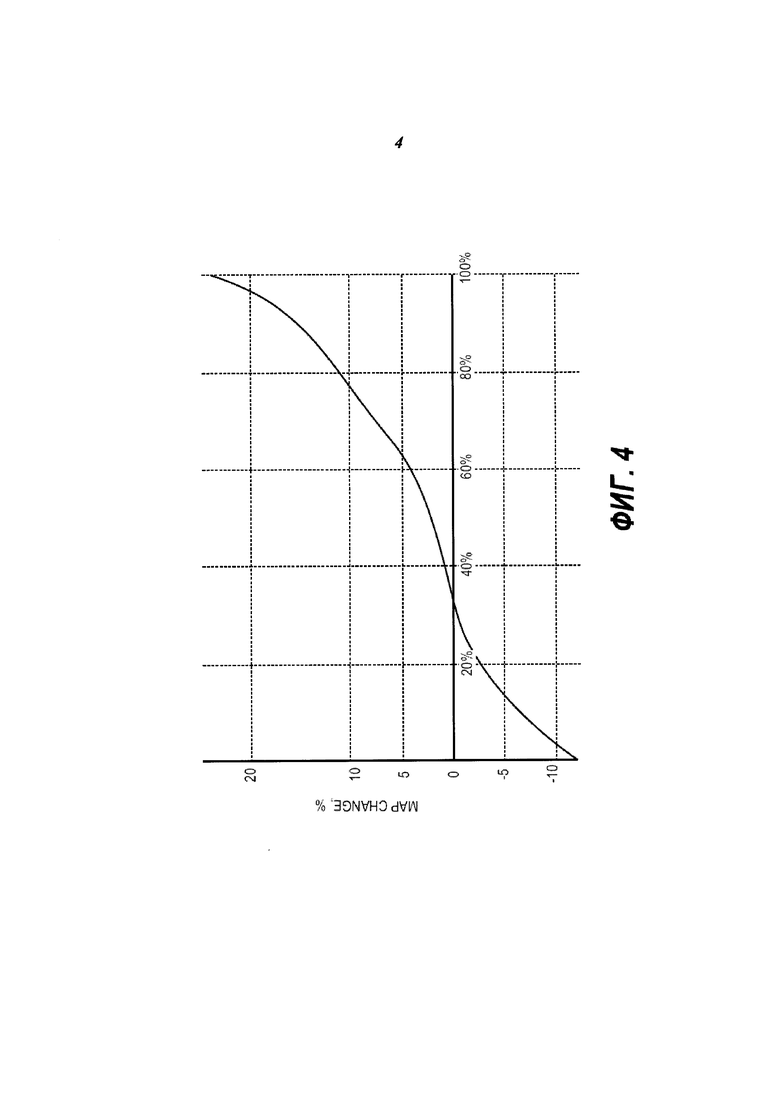
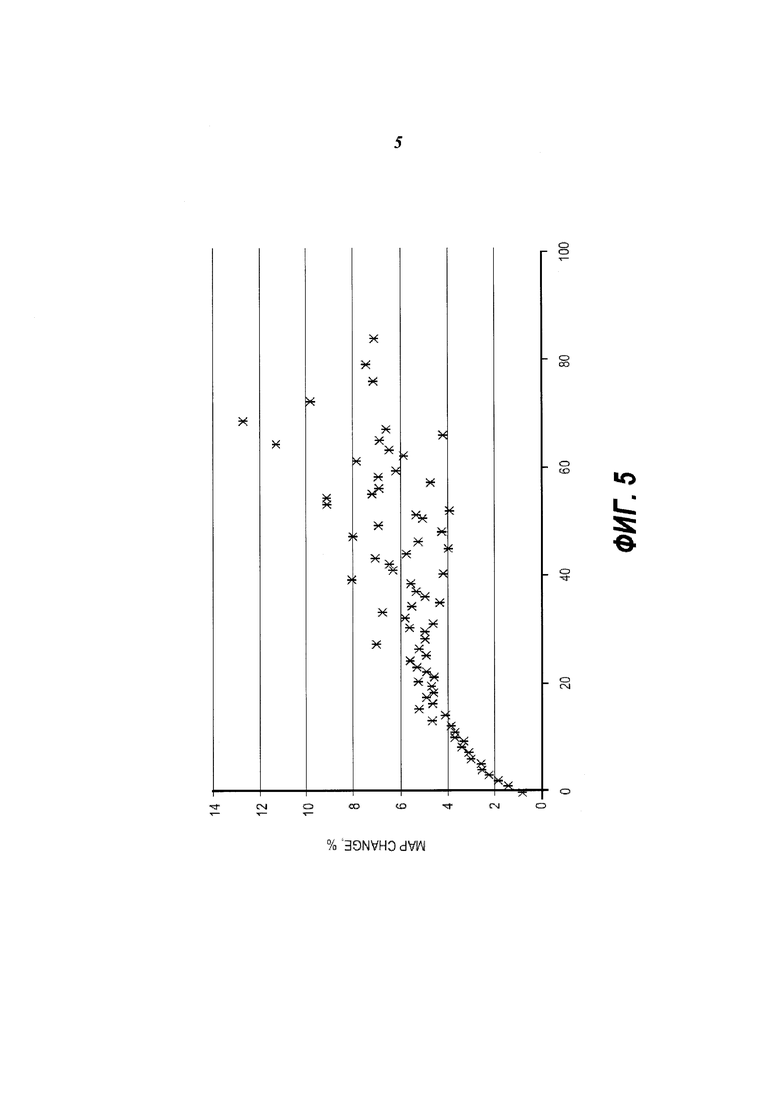
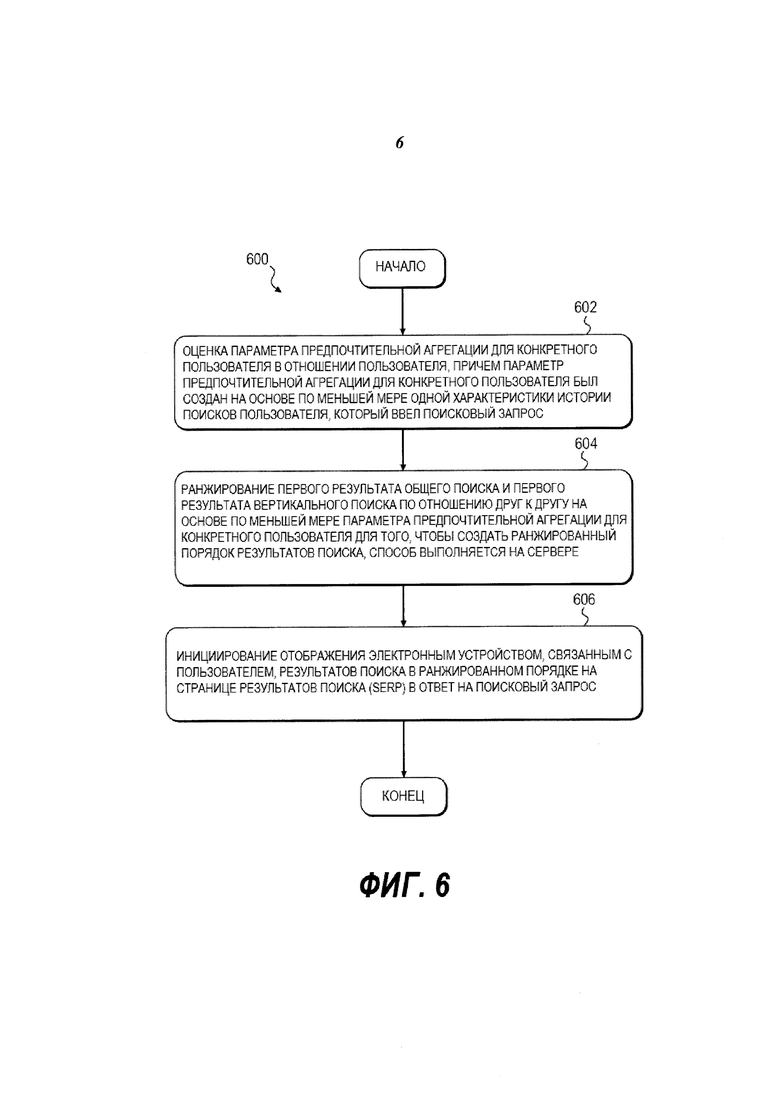
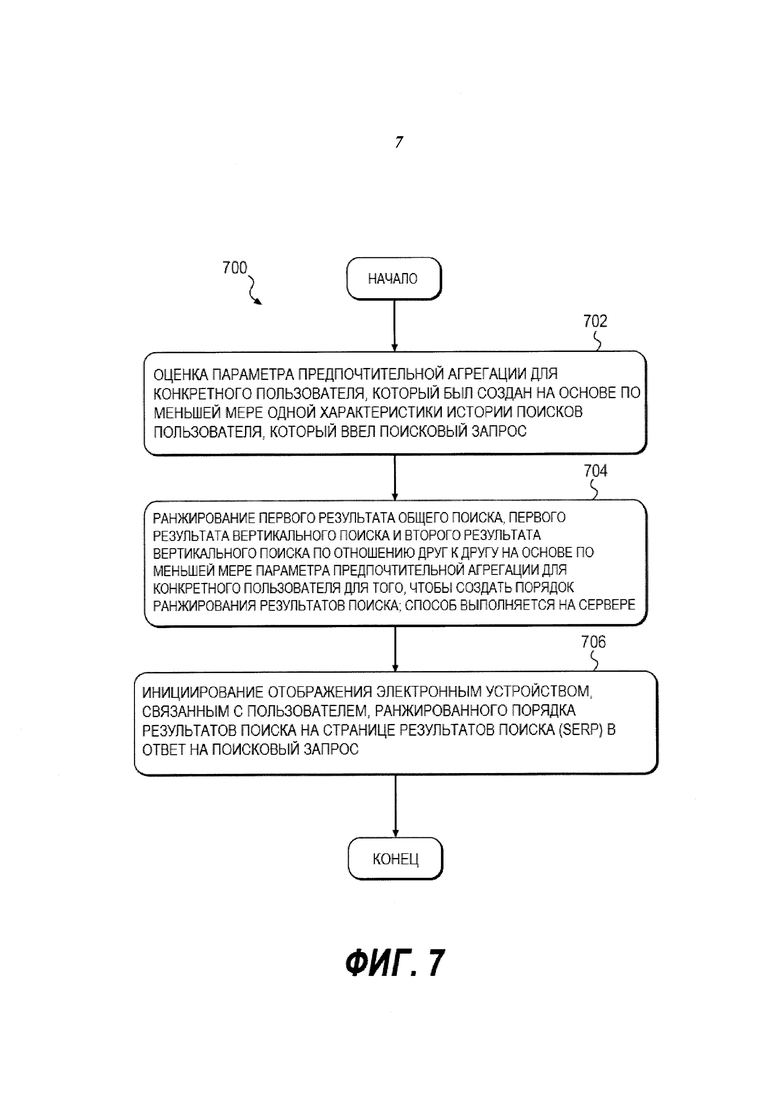
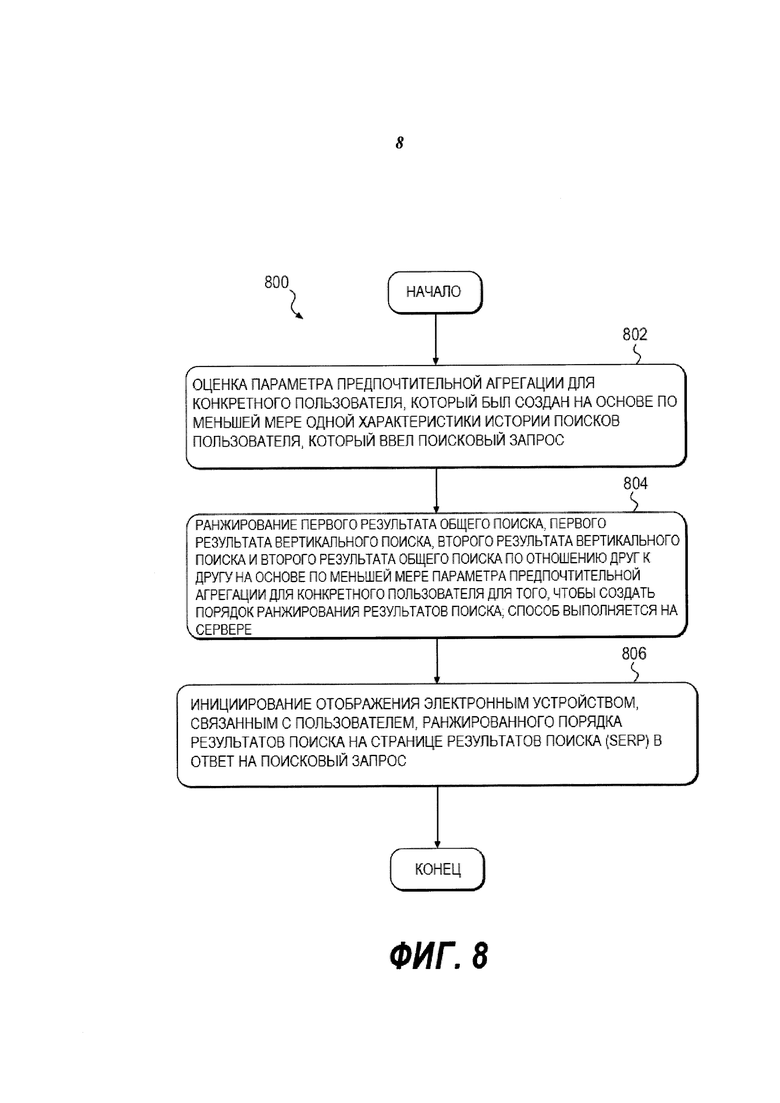
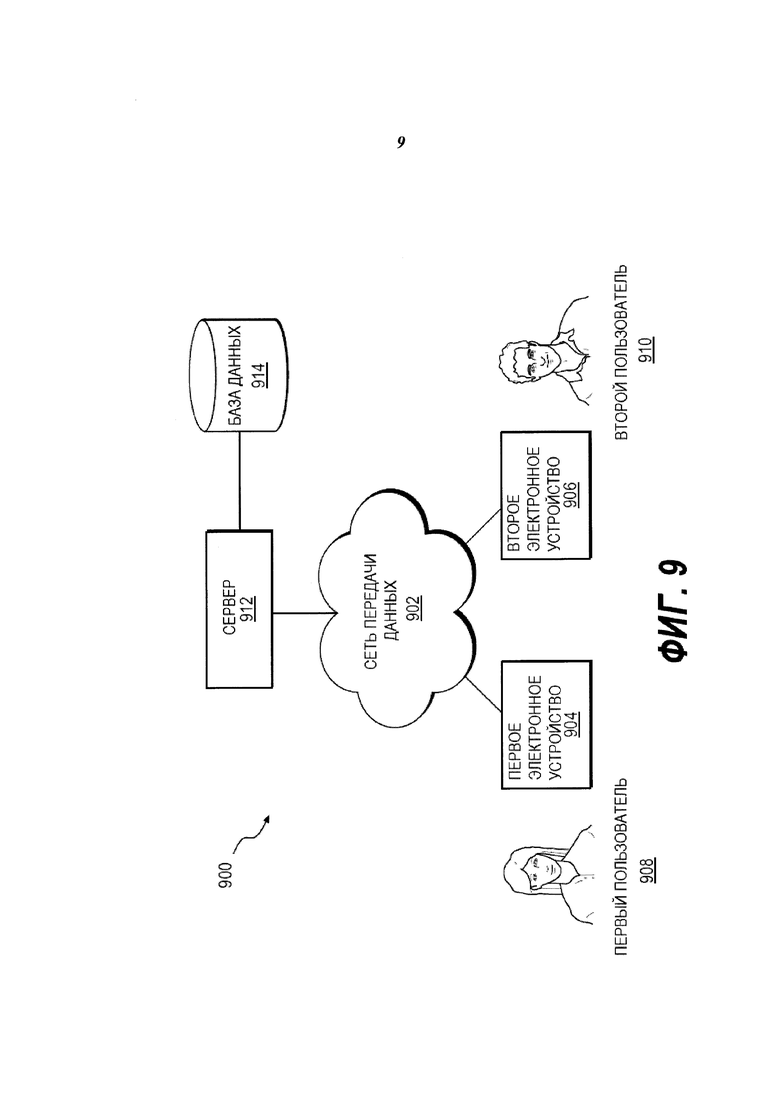
Изобретение относится к средствам обработки поискового запроса. Техническим результатом является персонализация агрегированных результатов поиска. Способ выполняется сервером. Способ включает в себя оценку параметра предпочтительной агрегации для конкретного пользователя, в зависимости от по меньшей мере прошлых пользовательских предпочтений относительно агрегированного общего и вертикального содержимого; ранжирование первого результата общего поиска и первого результата вертикального поиска по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя для того, чтобы создать порядок ранжирования результатов поиска; и инициирование отображения электронным устройством, связанным с пользователем, ранжированного порядка результатов поиска в рамках страницы результатов поиска (SERP). 3 н. и 33 з.п. ф-лы, 9 ил., 1 табл.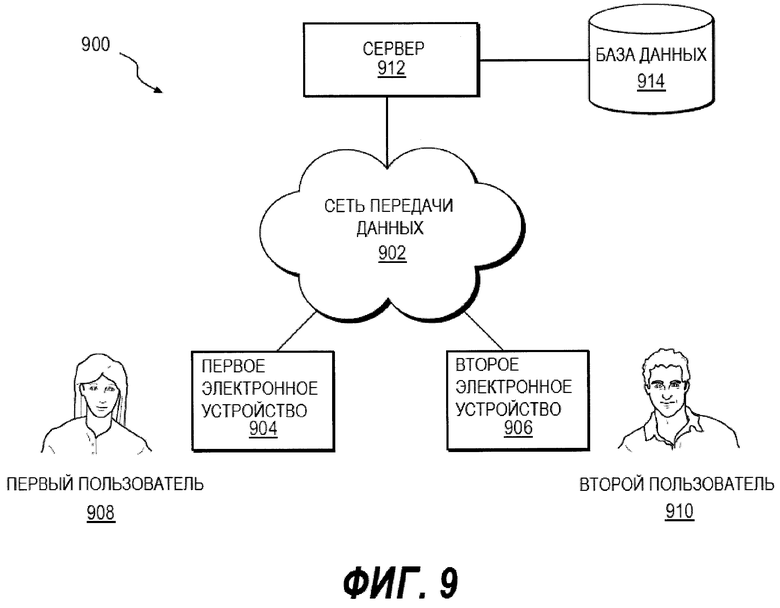
1. Способ обработки поискового запроса, включающий:
оценку параметра предпочтительной агрегации для конкретного пользователя в зависимости по меньшей мере от прошлых пользовательских предпочтений относительно агрегированного общего и вертикального содержимого;
ранжирование первого результата общего поиска и первого результата вертикального поиска по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя; и
формирование с учетом ранжира страницы результатов поиска (SERP), содержащей первый результат общего поиска и первый результат вертикального поиска.
2. Способ по п. 1, в котором получают второй результат вертикального поиска; а первый результат общего поиска, первый результат вертикального поиска и второй результат вертикального поиска ранжируют по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации.
3. Способ по п. 2, в котором первый и второй результаты вертикального поиска ранжируют вместе по отношению к первому результату общего поиска и отображают в виде блока на странице результатов поиска (SERP).
4. Способ по п. 2, в котором первый и второй результаты вертикального поиска ранжируют по отношению к первому результату общего поиска и отображают по отдельности на странице результатов поиска (SERP).
5. Способ по любому из пп. 2-4, в котором:
первый результат общего поиска, первый результат вертикального поиска, второй результат вертикального поиска и второй результат общего поиска ранжируют по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя.
6. Способ по п. 1, в котором первый результат общего поиска ранжируют в зависимости от параметра общего доменного ранжирования перед ранжированием в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
7. Способ по любому из пп. 1-4 или 6, в котором первый результат вертикального поиска ранжируют в зависимости от параметра общего доменного ранжирования перед ранжированием в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
8. Способ по п. 5, в котором первый и второй результаты общего поиска ранжируют в зависимости от параметра общего доменного ранжирования перед ранжированием в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
9. Способ по п. 5, в котором первый и второй результаты вертикального поиска ранжируют в зависимости от параметра вертикального доменного ранжирования перед ранжированием в зависимости от параметра предпочтительной агрегации для конкретного пользователя.
10. Способ по любому из пп. 8-9, в котором выбирают параметр общего доменного ранжирования в зависимости от признака общего ранжирования для конкретного пользователя.
11. Способ по любому из пп. 8-9, в котором выбирают параметр вертикального доменного ранжирования в зависимости от признака вертикального ранжирования для конкретного пользователя.
12. Способ по п. 10, в котором выбирают признак общего ранжирования для конкретного пользователя в зависимости от указанной характеристики истории поиска пользователя.
13. Способ по п. 11, в котором выбирают признак вертикального ранжирования для конкретного пользователя в зависимости от указанной характеристики истории поиска пользователя.
14. Способ по п. 1, в котором оценку параметра предпочтительной агрегации для конкретного пользователя дополнительно осуществляют в зависимости по меньшей мере от отдельно общего содержимого и отдельно вертикального содержимого и/или прошлых пользовательских предпочтений относительно получения результатов от конкретного вертикального домена и/или пользовательских целей, касающихся поискового запроса.
15. Способ по п. 1, в котором оценку параметра предпочтительной агрегации для конкретного пользователя дополнительно осуществляют в зависимости по меньшей мере от соотношения числа переходов и показов, и/или количества выборов результата поиска за конкретный период времени, и/или времени ожидания после нажатия, и/или перехода к результату, являющегося последним действием пользователя в предыдущей сессии пользователя.
16. Способ по п. 14, в котором формируют страницу результатов поиска (SERP) с определенным типом вертикального содержимого.
17. Способ по п. 16, в котором в качестве типа содержимого вертикалей используют видео, изображения, коммерческое содержимое, музыку, погоду, географические данные, текст, словарные статьи, события, новости и/или рекламу.
18. Способ по п. 1, в котором оценку параметра предпочтительной агрегации для конкретного пользователя дополнительно осуществляют в зависимости по меньшей мере от данных о запросе, или сетевых данных, или данных из поискового лога.
19. Способ по п. 1, в котором оценку параметра предпочтительной агрегации для конкретного пользователя дополнительно осуществляют в зависимости по меньшей мере от требования к агрегированному поиску или предпочтения к вертикали или возможности перехода по вертикалям.
20. Способ по п. 1, в котором параметр предпочтительной агрегации для конкретного пользователя выбирают посредством алгоритма градиентного бустинга дерева решений.
21. Способ п. 1, в котором параметр предпочтительной агрегации для конкретного пользователя выбирают посредством алгоритма машинного обучения.
22. Способ по п. 1, в котором выбирают параметр предпочтительной агрегации для конкретного пользователя перед подтверждением поискового запроса.
23. Способ по п. 22, в котором оценку параметра предпочтительной агрегации для конкретного пользователя дополнительно осуществляют посредством получения ранее созданного параметра предпочтительной агрегации для конкретного пользователя.
24. Способ по п. 1, в котором получают параметр предпочтительной агрегации для конкретного пользователя одновременно с подтверждением пользователем поискового запроса.
25. Способ по п. 1, в котором получают параметр предпочтительной агрегации для конкретного пользователя после подтверждения пользователем поискового запроса.
26. Способ по п. 1, в котором получение параметра предпочтительной агрегации для конкретного пользователя дополнительно осуществляют посредством доступа к журналу, содержащему по меньшей мере одну характеристику истории поисков пользователя.
27. Способ по п. 26, в котором хранят упомянутый журнал со связью с учетными данными пользователя.
28. Способ по п. 2, в котором получают первый и второй результаты вертикального поиска при поиске по вертикальному домену.
29. Способ по п. 2, в котором получают первый результат вертикального поиска при поиске по первому вертикальному домену, получают второй результат вертикального поиска при поиске по второму вертикальному домену, причем выбирают первый вертикальный домен и второй вертикальный домен различными.
30. Способ по п. 1, который включает определение релевантности поисковому запросу первого результата общего поиска и второго результата вертикального поиска до ранжирования.
31. Сервер для обработки поискового запроса, включающий постоянный машиночитаемый носитель информации, содержащий машиночитаемые коды, и выполненный с возможностью осуществления способа по п. 1.
32. Сервер по п. 31, в котором страница результатов поиска содержит второй результат вертикального поиска; и первый результат общего поиска, первый результат вертикального поиска и второй результат вертикального поиска ранжированы по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя.
33. Сервер по п. 32, в котором страница результатов поиска (SERP) содержит второй результат вертикального поиска; и первый результат общего поиска и вертикального поиска, второй результат вертикального поиска и общего поиска ранжированы по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя.
34. Постоянный машиночитаемый носитель информации для обработки поискового запроса, содержащий машиночитаемые коды, выполненные с возможностью осуществления способа по п. 1.
35. Машиночитаемый носитель по п. 34, в котором страница результатов поиска содержит второй результат вертикального поиска; и первый результат общего поиска, первый результат вертикального поиска и второй результат вертикального поиска ранжированы по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя.
36. Машиночитаемый носитель по п. 35, в котором страница результатов поиска (SERP) содержит второй результат вертикального поиска; первый результат общего поиска и вертикального поиска, второй результат вертикального поиска и общего поиска ранжированы по отношению друг к другу в зависимости по меньшей мере от параметра предпочтительной агрегации для конкретного пользователя.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Электромеханический полосовой фильтр | 1957 |
|
SU110847A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |

