Область техники, к которой относится изобретение
Настоящее изобретение относится к обработке изображений неквалифицированным пользователем. В частности, изобретение относится к распознаванию и классификации документов из потока произвольных изображений на основе алгоритмов компьютерного зрения и нейронных сетей.
Уровень техники
Современные смартфоны позволяют быстро делать изображения и сохранять их в большом количестве. Зачастую в количестве гораздо большем, чем пользователь способен рассортировать, обработать. Функциональные возможности таких устройств все время увеличиваются, количество необработанных фотографий растет, пользователю становится практически невозможно найти фотографию, которую он сделал несколько месяцев или год назад.
Отдельная задача заключается в учете фотографий каких-либо документов, или информационных материалов. Необходимость более строгой классификации и извлечения информации из фотографий такого рода очевидна.
Например, чек на товар становится нечитаемым через некоторое время из-за того, что он напечатан на термобумаге, и чтобы избежать ситуаций рекомендуется делать копии чеков, как бумажные, так и электронные, которые можно в любой момент распечатать. Однако из-за большого количества изображений поиск фотографии чека, сделанной больше года назад, представляется трудоемкой, а часто неразрешимой задачей.
Кроме того, вероятность использования копии каждого чека или другого документа или материала невелика, поэтому пользователь не готов самостоятельно вводить различные атрибуты и параметры сфотографированного документа.
В связи с этим возникает необходимость в наличии виртуального помощника на телефоне, реализованного, например, в виде мобильного приложения, который бы самостоятельно, без привлечения пользователя обнаруживал бы документы, определял бы их тип, распознавал текст и другие важные характеристики (QR код и другие).
Такой помощник мог бы не только выделять из потока изображений документы и материалы, но и принимал бы решение за пользователя по ряду полей, обнаруженных в документе: ставил напоминания без его участия по дате окончания действия ОСАГО, заграничного паспорта и другие.
В настоящей момент у пользователя есть набор различных программ и технических средств, которые способны выполнить некоторые из указанных действий. В частности, известно применение нейросетей либо для узнавания образа на изображении, либо для распознавания текста. Однако отсутствует возможность поручить выполнение указаных действий виртуальному помощнику.
Кроме того, технологии классификации и извлечения информации из изображений востребованы не только на смартфоне, но и на других мобильных персональных устройствах, таких как очки дополненной реальности, и, кроме того, на немобильных и не персональных устройствах, таких как корпоративный сканер, камеры CCTV `осуществляющие захват и фиксацию документов.
Раскрытие сущности изобретения
Предметом изобретения является информационная система, обрабатывающая изображение документов. На входе данная информационная система получает изображение в электронном виде, а на выходе – блок информации, содержащий: улучшенное изображение с исправленной геометрией и цветокоррекцией; тип документа, определенный на основе алгоритмов машинного обучения; содержание полей документа, зависящих от определенного ранее типа документа, дополненное информацией из других источников, если это необходимо. Информационная система обладает способностью определять тип документа на основе алгоритмов нейросетей, а также исправлять ошибки распознавания текста за счет каскадной обработки изображения. Данная способность реализована с помощью методики обучения нейросети; в частности, нейросеть самостоятельно выводит формулу, по которой определяет степень схожести анализируемого изображения с документом того или иного типа.
Сущность данного изобретения заключается в использовании каскада технологий распознавания для обеспечения полной автоматизации процесса и автономии от пользователя. Данные технологии являются адаптивными и решения принимается на основе учета множества параметров, включая, но не ограничиваясь:
- общий внешний вид документов того или иного вида;
- способы фотографирования или фиксации в более широком понимании, вида документов того или иного вида;
- текст документа, поддающийся распознаванию;
- штрих-коды, QR коды, другая машиночитаемая информация на документе;
- информация, извлеченная из документов других типов, но принадлежащих тому же пользователю;
- контекст, в котором было сделано изображение, включая предыдущие изображения;
- различные проверочные базы данных, полученных из открытых источников, включая концепцию открытого доступа к государственным данным.
Краткое описание чертежей
Сопроводительные чертежи иллюстрируют принцип работы виртуального помощника и способы обнаружения документов в потоке изображений. На чертежах:
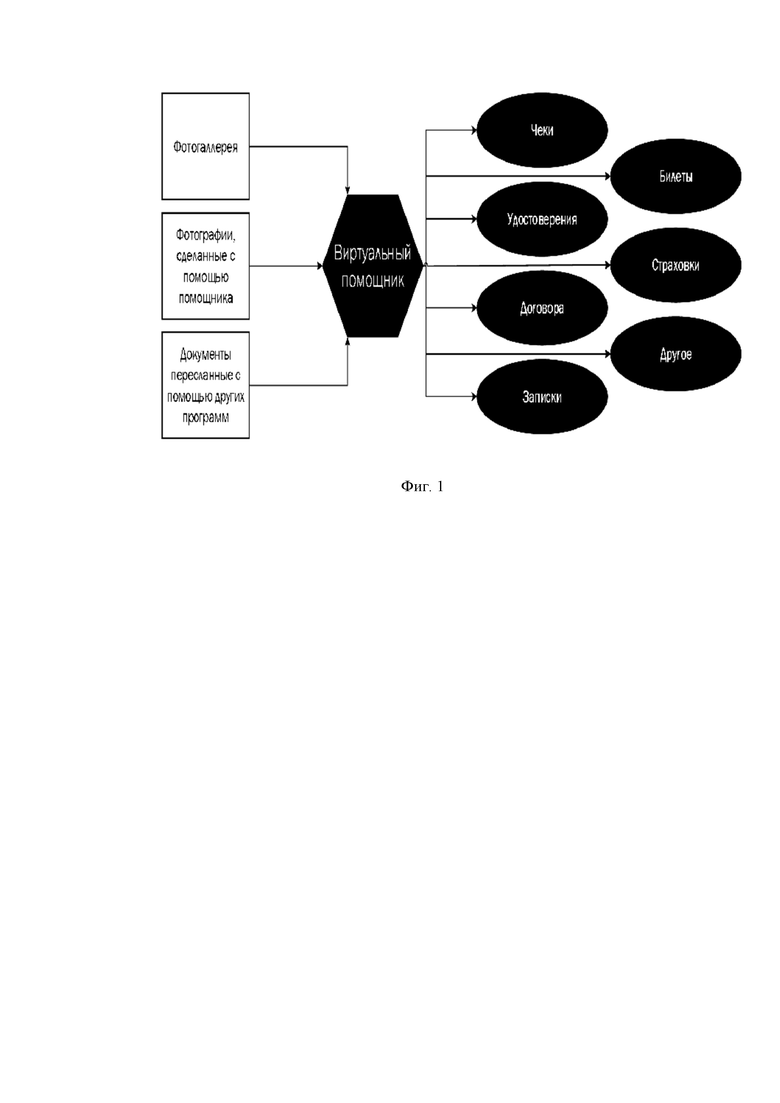
фиг.1 - блок-схема, изображающая виртуального помощника и некоторые примеры источников контекста, которые он может обрабатывать;
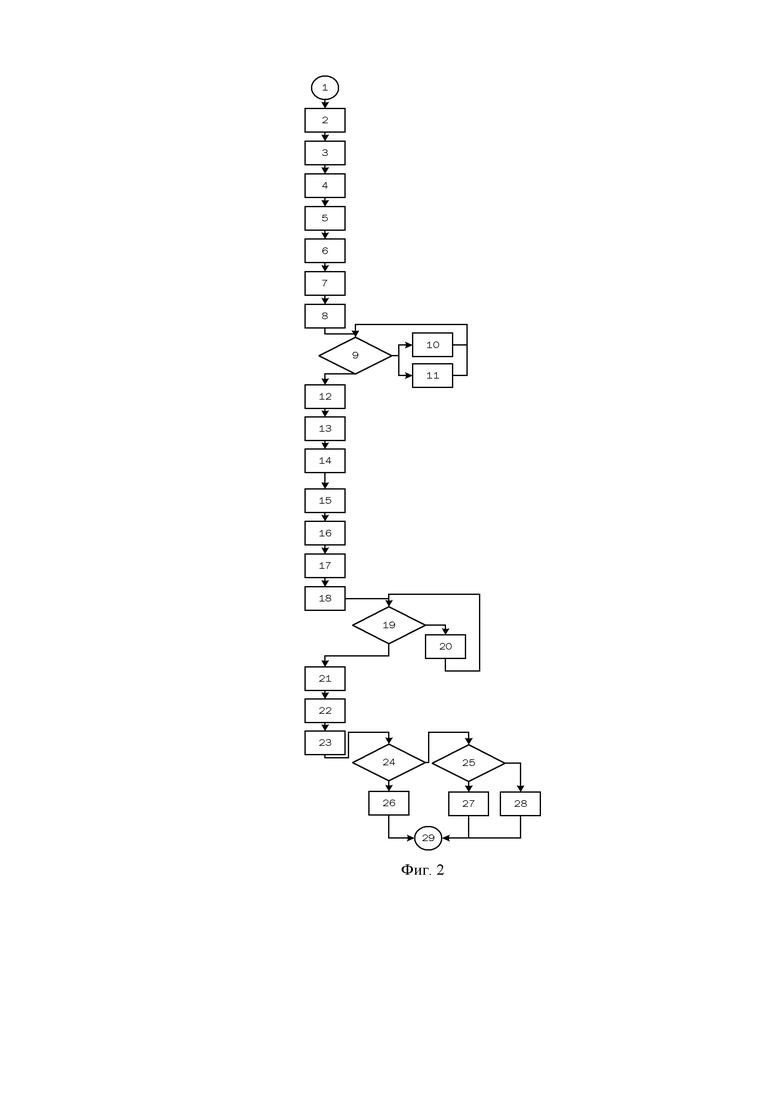
фиг.2 - блок-схема обнаружения и обработки документа;
Осуществление изобретения
Ниже представлены предпочтительные варианты осуществления изобретения.
В одном варианте осуществления заявленное изобретения реализовано на смартфоне в виде виртуального помощника. Общие принципы работы виртуального помощника представлены на фиг. 1.
Виртуальный помощник обрабатывает изображения документов, полученное либо напрямую от пользователя (фотографирование), либо самостоятельно при наличии соответствующего разрешения от пользователя. После произведенной обработки виртуальный помощник классифицирует обработанные изображения по типу содержащегося в них документа (чеки, билеты, договоры, страховые полисы и т. п.).
На фиг. 2 представлен общий алгоритм распознавания типа и параметров документа в одном варианте осуществления изобретения.
Обработка изображения документа начинается на этапе 1.
Вначале выполняется предварительная обработка документа. На этапе 2 производится проверка, что данное изображение не является ранее распознанным документом. В случае, если изображение представляет собой дубликат уже распознанного документа, то документ игнорируется.
Если документ не является дубликатом, то на этапе 3 выполнятся определение границ документа, то есть бумажного листа или другой основы, на котором напечатан/изображен документ. После отсечения изображения за границами основы документа происходит на этапе 4 коррекция геометрии изображения, например, исправление трапециевидных искажений или коррекция ракурса.
На этапе 5 выполняет сохранение начальных ключевых параметров цвета, чтобы на этапе 6 выполнить, при необходимости, выполнить цветокоррекцию, а также оптимизацию контрастности и яркости для обеспечения лучшего распознавания текста. Также производится настройка резкости изображения.
После этого на этапе 7 происходит первичная попытка распознавания текста на изображении и определяется ориентация «верх-низ» (этап 8). На этапе 9 определяется, удалось ли определить верх и низ документа. В случае неудачи в распознавании текста происходит последовательно попытки найти строки текста без попытки прочитать их (этап 10), а также принимается решение о том, является предыдущая обработка документа от того же пользователя схожей по параметрам и какое решение об ориентации документа было принято в результате предыдущей обработки (этап 11). Далее на основе собранной информации происходит поворот документа в соответствии с определенной ориентацией (этап 12).
Затем на этапе 13 сверточная нейронная сеть выполняет первичное распознавание типа документа. Сверточная сеть выставляет степень схожести данного изображения со всеми известными типами документов на основании известного ей заранее типичных образов документов этого типа.
Затем сверточная сеть пытается найти известные ей образы (нетекстовые признаки) на документе, включая изображение лица (этап 14), QR-код или штрихкод (этап 15), герб, логотип (этапе 16) и другую нетекстовую информацию, а также извлечь информацию о координатах и пропорциях такой информации.
На следующем этапе происходит упаковка вся полученной о документе информации и передаче ее рекуррентной нейросети, включая
- «мнение» сверточной сети в виде кортежа с определенными значениями вероятности схожести,
- извлеченный неструктурированный текст, полученный при первичной обработке,
- наличие стоп-слов и их потенциальных модификаций, связанных с низким качеством изображения,
- информация о дате, времени, месте фотографирования,
- информация о ключевых цветовых параметрах изображения
- информация о наличии нетекстовых элементов и их характеристиках
На этапе 17 рекуррентная нейросеть выставляет свои оценки степени похожести документа на документ определенного типа на основе алгоритмов машинного обучения.
На этапе 18 для распознавания документа применяется шаблон, соответствующий типу документа.
На этапе 19 определяется, достаточно ли качество распознанного текста. Если качество недостаточно, то на этапе 20 выполняют поворот документа и проверяют качество распознанного текста еще раз.
На этапе 21 применяется уточненный шаблон для качественного распознавания текста, основанный на типе документа, учитывающий взаимное положение текстовых элементов, их цвет, шрифт и другие особенности. Этот этап, в частности, позволяет отделить шрифт от фонового рисунка, чего было нельзя сделать на предыдущем этапе. Извлеченные блоки текста сохраняются в виде структуры «поле-значение».
Далее для некоторых видов документов происходит обогащение информации, извлеченной из документа (этап 22). Дополнительная информация может быть получена от внешних источников. Так, например, для получения информации о кассовом чеке происходит обращение в «Открытое API ФНС России». Для других документов, например СНИЛС осуществляется сравнение ФИО владельца телефона с ФИО на документе и если отличия заключаются в небольшом количестве символов, причем которые по статистике для данного шрифта относятся к схожим, то ФИО владельца смартфона добавляется как претендент на исправление.
Далее на этапе 22 документ анализируется на предмет того, является ли он многостраничным за счет наличия признаков, характерных для вида документов, таких как номера страниц, связанность текста, наличия одного и того же номера паспорта на изображениях разных страниц паспорта. Для этого анализируются ранее введенные изображения.
Если определено, что изображения относятся к одному и тому же документу, то на этапе 24 выполняется анализ, не является ли это изображение одной и той же страницы документа. Если обнаруживается, что это та же самая страница многостраничного документа, то выбирается страница, у которой лучше произошло распознавание текста и общая резкость изображения выше. Изображения из который был составлен многостраничный документ удаляются (этап 26).
Если обнаружено, что это другая страница многостраничного документа, то на этапе 25 определяется, следует ли создать многостраничных документ или склеить несколько изображений в одно. Например, кассовый чек может быть очень длинным и пользователю требуется сделать несколько фотографий, чтобы целиком его внести. В первом случае к многостраничному документу добавляется новая страница (этап 27), а во втором случае выполняется склейка нескольких изображений в одно.
Свёрточная нейронная сеть CNN обученная использует архитектуру InceptionV3. Эта сеть анализирует изображение и, на основе хранящихся в ней весовых коэффициентов, определяет визуальное сходство текущего изображения с массивом изображений документов того или иного типа. Сеть выдает кортеж, состоящий из скалярных значений вероятностей совпадения изображения. Данные вероятности колеблются от 0% до 100%.
В одном варианте осуществления сверточная нейронная сеть может определять вероятность, что документ принадлежит к определенному типу, по пользуясь следующими значениями параметров, представленными в таблице 1:
Таблица 1
Рекуррентная нейронная сеть (RNN), также базирующаяся на базе TensorFlow Inception, анализирует множество параметров данного изображения, в том числе и решения о визуальном сходстве, принятые нейросетью CNN. На вход данной нейросети поступает набор числовых и строчных значений, в том числе данные, полученные в результате первого прохода модуля распознавания текста. Далее за счет использования многоклассового классификатора (multi-class classifier) и алгоритма мультиномиальной логистической регрессии (multinomial logistic regression algorithm) происходит сравнение с коэффициентами, полученными ранее методикой машинного обучения.
В одном варианте осуществления рекуррентная нейронная сеть определяет вероятностный тип документа по следующей формуле:
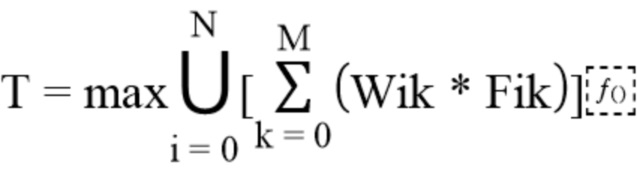 ,
,
где
- T – вероятностное значение приоритетного типа документа
- Max U[] – функция поиска максимума в массиве скалярных значений, каждый из которых представлен суммой N весов.
- Wik*Fik - скалярное значение вероятности для k-того параметра i-того типа документа
- Wik – весовой коэффициент для для k-того параметра i-того типа документа
- Fik – k-тый параметр (фактор) i-того типа документа, представленный функцией свертки соответствующего входного параметра
Пример параметров весовых коэффициентов представлен в таблице 2.
Таблица 2
Пример значений весовых коэффициентов представлен в таблице 3
Таблица 3
В одном варианте осуществления обучение нейронной сети происходит не в режиме реального времени, а в периоды технологического обслуживания. При этом могут выполняться следующие этапы:
- Выполняют первоначальную разметку в базе документов и изображений, в отношении которых в течение работы были жалобы на некорректное распознавание или ряд косвенных параметров выбивается из статистической погрешности.
- Изучают проблемные документы в ручном режиме
- Осуществляют подготовку очищенного набора данных
- Выполняют обучение нейросети на очищенном наборе данных
- Выполняют анализ результатов обучения
- Загружают уточненные коэффициенты в базу данных и переключают поток пользователей на обновленную логику распознавания
Пример применения изобретения
Пользователь запускает приложение на смартфоне и фотографирует кассовые чек средствами, встроенными в приложение. Приложение самостоятельно обрабатывает изображения по способу в соответствии с настоящим изобретением. Если через некоторое время пользователю понадобился данный чек, он может запустить приложение и подать, например, голосовую команду "найти чек на утюг". Приложение выполняет поиск всех кассовых чеков, в которых в качестве товара указан утюг. Пользователь распечатывает чек и прикладывает копию чек, например, к направляемой в магазин претензии. При этом пользователь не выполняет никаких иных действий, кроме фотографирования чека и подачи команды приложению. Всю остальную обработку приложение выполняет самостоятельно.
Настоящее изобретение позволяет надежно распознать и классифицировать документ из потока произвольных изображений.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |
| Способ нейросетевого распознавания рукописных текстовых данных на изображениях | 2024 |
|
RU2837308C1 |
| ИДЕНТИФИКАЦИЯ ПОЛЕЙ НА ИЗОБРАЖЕНИИ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2018 |
|
RU2695489C1 |
| Способ распознавания объектов в системе видеонаблюдения | 2022 |
|
RU2788301C1 |
| РАСПОЗНАВАНИЕ СОБЫТИЙ НА ФОТОГРАФИЯХ С АВТОМАТИЧЕСКИМ ВЫДЕЛЕНИЕМ АЛЬБОМОВ | 2020 |
|
RU2742602C1 |
| Интеллектуальная система выявления и прогнозирования событий на основе нейронных сетей | 2021 |
|
RU2797748C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| ОБУЧАЕМЫЕ ВИЗУАЛЬНЫЕ МАРКЕРЫ И СПОСОБ ИХ ПРОДУЦИРОВАНИЯ | 2016 |
|
RU2665273C2 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
Группа изобретений относится к обработке изображений, в частности к распознаванию типа документа и его содержания из потока произвольных изображений. Техническим результатом является обеспечение корректного распознавания документа и восстановление его содержания из потока изображений даже при наличии неразборчивого текста или его отсутствия на части документа. Способ содержит этапы, на которых извлекают изображение документа с помощью алгоритмов машинного зрения из набора произвольных изображений; определяют предполагаемый тип документа с помощью сверточной нейронной сети на основе извлеченного изображения документа, при этом сверточная сеть выставляет степень схожести изображения документа с известными типами документов на основании заданных образцов документов; определяют тип документа с помощью рекуррентной нейронной сети на основе предполагаемого типа документа, полученного от сверточной нейронной сети, при этом рекуррентная нейронная сеть выставляет оценку степени схожести документа с предполагаемым типом документа на основе алгоритмов машинного обучения; распознают данные, содержащиеся в документе, на основании определенного типа документа; сохраняют распознанные данные. 2 н. и 38 з.п. ф-лы, 2 ил., 3 табл.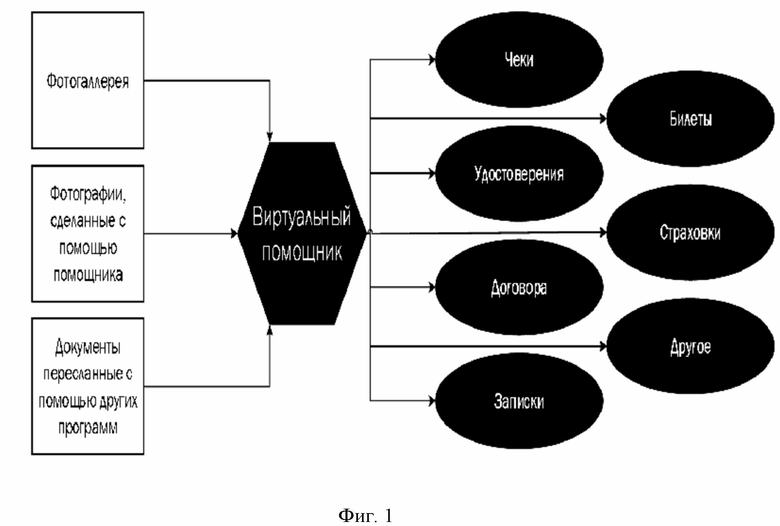
1. Способ распознавания и классификации документов из потока произвольных изображений:
i) извлекают изображение документа с помощью алгоритмов машинного зрения из набора произвольных изображений;
ii) определяют предполагаемый тип документа с помощью сверточной нейронной сети на основе извлеченного изображения документа, при этом сверточная сеть выставляет степень схожести изображения документа с известными типами документов на основании заданных образцов документов;
iii) определяют тип документа с помощью рекуррентной нейронной сети на основе предполагаемого типа документа, полученного от сверточной нейронной сети, при этом рекуррентная нейронная сеть выставляет оценку степени схожести документа с предполагаемым типом документа на основе алгоритмов машинного обучения;
iv) распознают данные, содержащиеся в документе, на основании определенного типа документа;
v) сохраняют распознанные данные.
2. Способ по п. 1, дополнительно содержащий этап, на котором извлекают ключевые нетекстовые признаки документа,
при этом на этапе iii) определяют тип документа дополнительно на основе извлеченных нетекстовых признаков документа.
3. Способ по п. 1, дополнительно содержащий этап, на котором извлекают ключевые текстовые параметры документа,
при этом на этапе iii) определяют тип документа дополнительно на основе извлеченных ключевых текстовых параметров документа.
4. Способ по любому из пп. 1-3, дополнительно содержащий этап, на котором распознают текст, содержащийся в документе, на основе распознанного типа документа и сохраняют распознанный текст.
5. Способ по п. 4, в котором на этапе распознавания текста, содержащегося в документе, на основе распознанного типа документа применяют шаблон, соответствующий типу документа.
6. Способ по любому из пп. 1-3, дополнительно содержащий этап, на котором обогащают распознанные данные дополнительной информацией, извлекаемой из внешних источников на основе распознанных данных.
7. Способ по любому из пп. 1-3, дополнительно содержащий этапы, на которых:
определяют, принадлежат ли распознаваемые данные к распознанному ранее документу, и
в случае, когда определено, что распознаваемые данные принадлежат к распознанному ранее документу, определяют, следует ли создать многостраничный документ или склеить распознаваемые данные с ранее распознанными данными.
8. Способ по п. 7, в котором в случае, когда распознаваемые данные принадлежат к распознанному ранее документу, проверяют, совпадают ли распознаваемые данные с распознанными ранее данными, и,
в случае если распознаваемые данные совпадают с распознанными ранее данными, удаляют распознанные ранее данные или распознаваемые данные.
9. Способ по любому из пп. 1-3, дополнительно содержащий этапы, на которых:
перед этапом определения предполагаемого типа документа сверточной нейронной сетью определяют, не является ли изображение документа уже распознанным изображением документа, и,
в случае если изображение документа является уже распознанным изображением документа, прекращают выполнение способа.
10. Способ по любому из пп. 1-3, дополнительно содержащий этап, на котором;
перед этапом ii) определяют границы документа и выполняют коррекцию геометрии изображения документа.
11. Способ по любому из пп. 1-3, дополнительно содержащий этап, на котором;
перед этапом ii) выполняют коррекцию цвета изображения документа, а также оптимизируют контрастность и яркость изображения для обеспечения лучшего распознавания текста.
12. Способ по любому из пп. 1-3, в котором перед этапом ii) определяют ориентацию документа и, в случае необходимости, выполняют поворот документа.
13. Способ по п. 1, в котором на этапе ii) с помощью сверточной нейронной сети анализируют изображение, определяют на основе хранящихся в ней весовых коэффициентов визуальное сходство текущего изображения с массивом изображений документов различного типа и выдают кортеж, состоящий из скалярных значений вероятностей принадлежности изображения к различным типам документа.
14. Способ по п. 1, в котором на этапе iii) определяют множество параметров изображения документа и с помощью использования многоклассового классификатора (multi-class classifier) и алгоритма мультиномиальной логистической регрессии (multinomial logistic regression algorithm) сравнивают указанные параметры с коэффициентами, полученными в результате машинного обучения.
15. Способ по п. 1, в котором получают набор произвольных изображений, требуемых на этапе i), посредством фотографирования документов.
16. Способ по п. 15, в котором фотографируют документы с помощью камеры смартфона.
17. Способ по п. 15, в котором набор произвольных изображений содержится в банке фотографий, указанном пользователем.
18. Способ по п. 1, в котором этапы выполнения способа выполняют с помощью программного обеспечения.
19. Способ п. 18, в котором программное обеспечение представляет собой мобильное приложение, устанавливаемое на смартфоне.
20. Способ п. 18, в котором программное обеспечение находится в облаке на серверах эксплуатирующей организации.
21. Система для распознавания и классификации документов из потока произвольных изображений, содержащая:
модуль предварительной обработки, выполненный с возможностью извлечения изображения документа с помощью алгоритмов машинного зрения из набора произвольных изображений;
сверточную нейронную сеть, выполненную с возможностью определения предполагаемого типа документа на основе извлеченного изображения документа, при этом сверточная нейронная сеть выполнена с возможностью выставления степени схожести изображения документа с известными типами документов на основании заданных образцов документов;
рекуррентную нейронную сеть, выполненную с возможностью определения типа документа на основе предполагаемого типа документа, полученного от сверточной нейронной сети, при этом рекуррентная нейронная сеть выполнена с возможностью выставления оценки степени схожести документа с предполагаемым типом документа на основе алгоритмов машинного обучения; и
распознавания данных, содержащихся в документе, на основании определенного типа документа;
модуль сохранения, выполненный с возможностью сохранения распознанных данных.
22. Система по п. 21, в которой рекуррентная нейронная сеть выполнена с возможностью извлечения ключевых нетекстовых признаков документа и
определения типа документа дополнительно на основе извлеченных нетекстовых признаков документа.
23. Система по п. 21, в которой рекуррентная нейронная сеть дополнительно выполнена с возможностью распознавания ключевых текстовых параметров документа и
определения типа документа дополнительно на основе распознанных ключевых параметров документа.
24. Способ по любому из пп. 21-23, в которой рекуррентная нейронная сеть выполнена с возможностью распознавания текста, содержащегося в документе, на основе распознанного типа документа, при этом модуль сохранения выполнен с возможностью сохранения распознанного текста.
25. Система по п. 24, в которой рекуррентная нейронная сеть выполнена с возможностью применения шаблона, соответствующего типу документа, при распознавании текста, содержащегося в документе.
26. Система по любому из пп. 21-23, в которой рекуррентная нейронная сеть выполнена с возможностью обогащения распознанных данных дополнительной информацией, извлекаемой из внешних источников на основе распознанных данных.
27. Система по любому из пп. 21-23, в которой рекуррентная нейронная сеть дополнительно выполнена с возможностью:
определения, принадлежат ли распознаваемые данные к распознанному ранее документу, и
в случае, когда определено, что распознаваемые данные принадлежат к распознанному ранее документу, определения, следует ли создать многостраничный документ или склеить распознаваемые данные с ранее распознанными данными.
28. Система по п. 27, в которой рекуррентная нейронная сеть, в случае когда распознаваемые данные принадлежат к распознанному ранее документу, выполнена с возможностью проверки, совпадают ли распознаваемые данные с распознанными ранее данными,
при этом модуль сохранения, в случае если распознаваемые данные совпадают с распознанными ранее данными, выполнен с возможностью удаления распознанных ранее данных или распознаваемых данных.
29. Система по любому из пп. 21-23, в которой модуль предварительной обработки выполнен с возможностью:
определения, не является ли изображение документа уже распознанным изображением документа, и,
в случае если изображение документа является уже распознанным изображением документа, прекращения обработки документа.
30. Система по п. 20, в которой модуль предварительной обработки дополнительно выполнен с возможностью;
определения границ документа и выполнения коррекции геометрии изображения документа.
31. Система по любому из пп. 21-23, в которой модуль предварительной обработки дополнительно выполнен с возможностью выполнения коррекции цвета изображения документа, а также оптимизации контрастности и яркости изображения для обеспечения лучшего распознавания текста.
32. Система по любому из пп. 21-23, в которой модуль предварительной обработки дополнительно выполнен с возможностью определения ориентации документа и, в случае необходимости, выполнения поворота документа.
33. Система по п. 21, в которой сверточная нейронная сеть дополнительно выполнена с возможностью анализа изображения, определения на основе хранящихся в ней весовых коэффициентов визуального сходства текущего изображения с массивом изображений документов различного типа и выдачи кортежа, состоящего из скалярных значений вероятностей принадлежности изображения к различным типам документа.
34. Система по п. 21, в которой рекуррентная нейронная сеть выполнена с возможностью определения множества параметров изображения документа и с помощью использования многоклассового классификатора (multi-class classifier) и алгоритма мультиномиальной логистической регрессии (multinomial logistic regression algorithm) сравнения указанных параметров с коэффициентами, полученными в результате машинного обучения.
35. Система по п. 21, в которой указанный набор произвольных изображений получен посредством фотографирования документов.
36. Система по п. 35, в которой фотографирование документов осуществлено с помощью камеры смартфона.
37. Система по п. 35, в которой набор произвольных изображений содержится в банке фотографий, указанном пользователем.
38. Система по п. 21, в которой модуль предварительной обработки, сверточная нейронная сеть, рекуррентная нейронная сеть и модуль сохранения выполнены в виде программного обеспечения.
39. Система п. 38, в котором программное обеспечение представляет собой мобильное приложение, устанавливаемое на смартфоне.
40. Система п. 38, в котором программное обеспечение находится в облаке на серверах эксплуатирующей организации.
| CN 111079511 A, 28.04.2020 | |||
| CN 109685065 A, 26.04.2019 | |||
| US 10387531 B1, 20.08.2019 | |||
| ОБНАРУЖЕНИЕ ТЕКСТОВЫХ ПОЛЕЙ С ИСПОЛЬЗОВАНИЕМ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2699687C1 |
| СПОСОБЫ И СИСТЕМЫ СЕГМЕНТАЦИИ ДОКУМЕНТА | 2018 |
|
RU2697649C1 |
| СПОСОБ РАЗДЕЛЕНИЯ ТЕКСТОВ И ИЛЛЮСТРАЦИЙ В ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ ДЕСКРИПТОРА СПЕКТРА ДОКУМЕНТА И ДВУХУРОВНЕВОЙ КЛАСТЕРИЗАЦИИ | 2017 |
|
RU2656708C1 |

