Изобретение относится к области информационных технологий, а именно к обработке информационных материалов.
Известные способы и системы модификации информации, в формате электронного документа, можно подразделить на следующие два основных типа:
- текстовые редакторы / процессоры:
1. Лексикон (http://ru.wikipedia.org/wiki/Lexicon - ссылка на источник в глобальной сети «Интернет»);
2. Microsoft Office Word (http://ru.wikipedia.org/wiki/Microsoft Word);
3. Open Office Writer (http://ru.wikipedia.org/wiki/OpenOffice.org Writer);
4. MS Word Pad (http://ru.wikipedia.org/wiki/Rich Text Format).
- языки программирования, встроенные в текстовые процессоры: MS Visual Basic for Application и Open Office Basic (http://ru.wikipedia.org/wiki/VBA).
Основным недостатком текстовых редакторов/процессоров является низкая автоматизация процесса обработки текста. На практике, при возникновении у человека (пользователя ЭВМ) необходимости разделить большой документ на части или изменить формат некоторых его составляющих, весь этот процесс необходимо проводить вручную. К примеру, в документе есть определенное количество предложений, для изменения внешнего вида каждого из них, пользователю необходимо самостоятельно выполнить определенную последовательность операций для каждого из составляющих элементов документа. Время, потраченное на изменение, пропорционально количеству информации в документе.
Языки программирования, встроенные в текстовые редакторы, частично позволяют решить проблему автоматизированной обработки данных, но в тоже время имеют ряд существенных недостатков, делающих невозможным их массовое использование, основными из них являются:
- сложность и трудоемкость написания управляющих команд модификации данных;
- ориентированность на фиксированное логическое содержание документа, набор команд может быть применен только к документу, имеющему заранее известную внутреннюю структуру;
- жесткая привязка к определенному формату документа, не позволяющая использовать имеющийся код для документов в форматах, отличных от базового.
Известен способ управления компонентами сформированного компьютером документа, содержащий этапы, на которых компонуют множество компонентов документа как совокупность отдельных компонентов в контейнер электронного документа, формируют представление связей документа, показывающее как каждый из одного или более компонентов относится к другим компонентам, устанавливают ссылку между какими-либо связанными компонентами упомянутой совокупности отдельных компонентов на основе связи между этими какими-либо связанными компонентами, и после выбора контейнера электронного документа обеспечивают визуальное представление упомянутой совокупности компонентов и обеспечивают визуальное представление того, как каждый компонент упомянутой совокупности компонентов относится к другим компонентам упомянутой совокупности компонентов (Заявка РФ № 2005135951/09, приоритет от 18.11.2005, МПК G06F 7/00, дата публикации заявки: 27.05.2007).
Известен, кроме того, способ идентификации одной или более частей документа, система для осуществления способа и машиночитаемый носитель с записанной на нем программой (Заявка РФ № 2004123222/09 от 27.07.2004, МПК G06K 1/00, дата публикации заявки: 27.01.2006). В известном способе идентифицируют множество визуальных блоков в документе, обнаруживают один или более разделителей между визуальными блоками из упомянутого множества визуальных блоков и строят, основываясь, по меньшей мере частично, на упомянутом множестве визуальных блоков и упомянутых одном или более разделителях, структуру содержимого для документа, причем структура содержимого идентифицирует различные визуальные блоки в качестве различных частей семантического содержимого документа. Система для осуществления способа идентификации средство извлечения визуальных блоков, предназначенное для извлечения визуальных блоков из документа, средство обнаружения визуальных разделителей, предназначенное для приема извлеченных визуальных блоков и обнаружения на основании извлеченных визуальных блоков одного или более визуальных разделителей между извлеченными визуальными блоками, и средство построения структуры содержимого, предназначенное для приема извлеченных визуальных блоков и обнаруженных визуальных разделителей и для использования извлеченных визуальных блоков и обнаруженных визуальных разделителей для построения структуры содержимого для данного документа. Кроме того, известная система дополнительно содержит модуль поиска документов, предназначенный для поиска документов из множества документов на основании, по меньшей мере частично, структуры содержимого, построенной для одного или более из упомянутого множества документов.
Известные технические решения имеют жесткую структуру анализа данных и не имеют возможностей гибкой настройки.
Задачей изобретения является создание способа обработки документов, дающего возможность пользователю оперировать визуальными блоками документа посредствам языка программирования без привязки к содержанию документа или его формату. Такой подход позволяет снять проблему необходимости осуществления повторяющихся операций при модификациях данных в документах большого объема.
Кроме того, задачей изобретения является создание системы, обеспечивающей возможность автоматизации однотипных операций модификации содержимого электронного документа, и машиночитаемого носителя с записанной на нем программой.
Достигаемым при этом техническим результатом является существенное повышение производительности труда пользователя, занимающегося однотипными операциями изменения содержимого электронного документа.
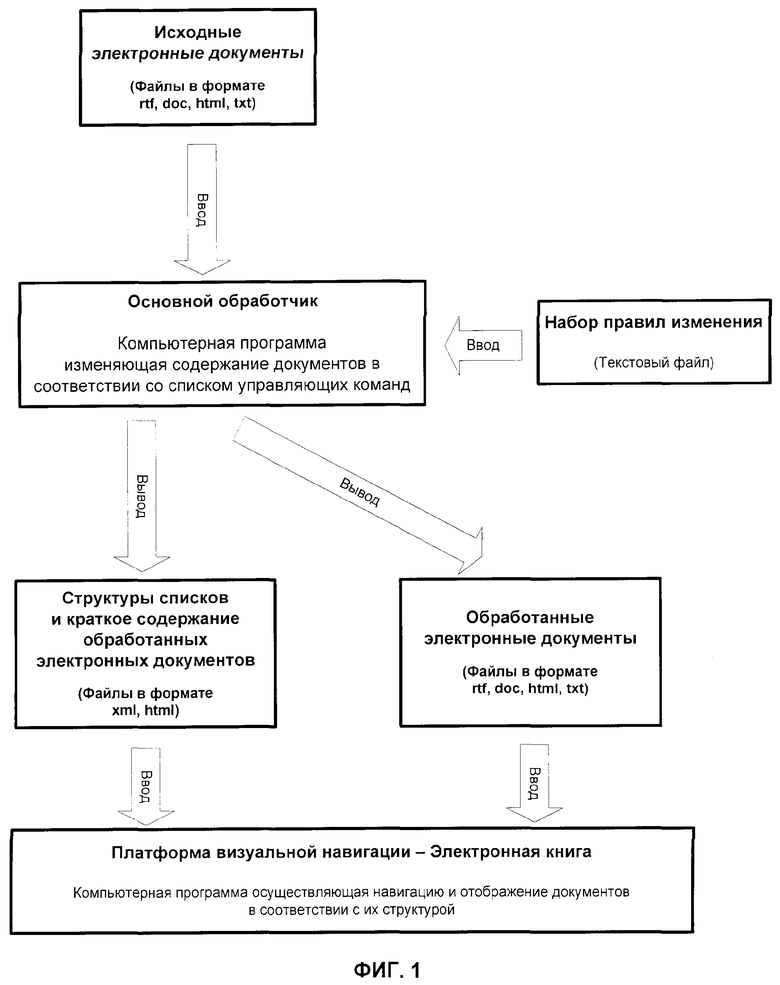
Поставленная задача достигается способом управления данными в сформированном компьютерном документе, содержащим этапы, на которых:
в электронно-вычислительную машину загружают команды, предварительно записанные на машиночитаемом носителе;
запускают процесс анализа команд;
строят список документов, подлежащих обработке;
производят декомпозицию документов во внутренний формат данных системы;
сегментируют загруженные документы на логические блоки;
модифицируют логические блоки;
строят краткое описание содержимого блоков;
производят композицию логических блоков из внутреннего формата во внешний, общедоступный формат хранения данных.
Кроме того, блок записывают в виде файла формата, отличного от формата исходного документа и выводят на устройство печати.
Кроме того, новый документ содержит в себе краткое описание данных, содержащихся в исходных документах.
Кроме того, краткое описание содержимого документов записывают в виде web-страницы со списком ссылок, каждая из которых ссылается на соответствующий исходный документ.
Кроме того, в предлагаемом способе на основе краткой структуры содержимого строят таблицу местоположения отдельных файлов, для каждого файла выделяют ключевые слова, осуществляют поиск выделенных слов в других документах, входящих в краткое описание, все найденные слова в других документах маркируют ссылками на исходный документ.
Кроме того, список блоков объединяют в один общий блок и сохраняют во внешнем формате в виде единого файла.
Кроме того, данные в блоке добавляют, удаляют, заменяют.
Кроме того, изменяют регистр символов, входящих в блок.
Кроме того, визуальное обрамление блока изменяют, добавляют, удаляют.
Кроме того, оформление фоновой заливки и фонового изображения блока добавляют, изменяют, удаляют.
Поставленная задача также достигается тем, что система для осуществления способа управления данными в сформированном компьютерном документе, содержащая компьютер, включающий в себя системный блок, блок памяти программ, подключенные к нему устройства ввода и вывода, устройство отображения, содержит блок памяти исходных документов и блок памяти результирующих документов.
Поставленная задача также достигается тем, что машиночитаемый носитель с записанной на нем программой, предназначенный для непосредственного участия в работе системы для осуществления способа управления, в котором в электронно-вычислительную машину загружают предварительно записанные на машиночитаемом носителе команды, запускают процесс анализа команд, строят список документов, подлежащих обработке, производят декомпозицию документов во внутренний формат данных системы, сегментируют загруженные документы на логические блоки, модифицируют логические блоки, строят краткое описание содержимого блоков и производят композицию логических блоков из внутреннего формата во внешний, общедоступный формат хранения данных.
Реализация заявляемой группы изобретений поясняется чертежами, где на:
фиг.1 представлена укрупненная блок-схема информационной технологии, основанной на предлагаемом способе;
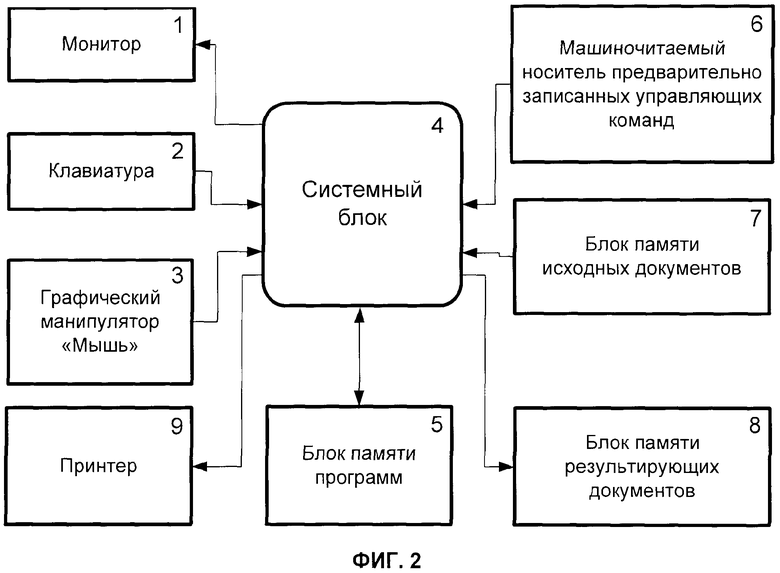
фиг.2 - функциональная схема предлагаемой системы для осуществления способа;
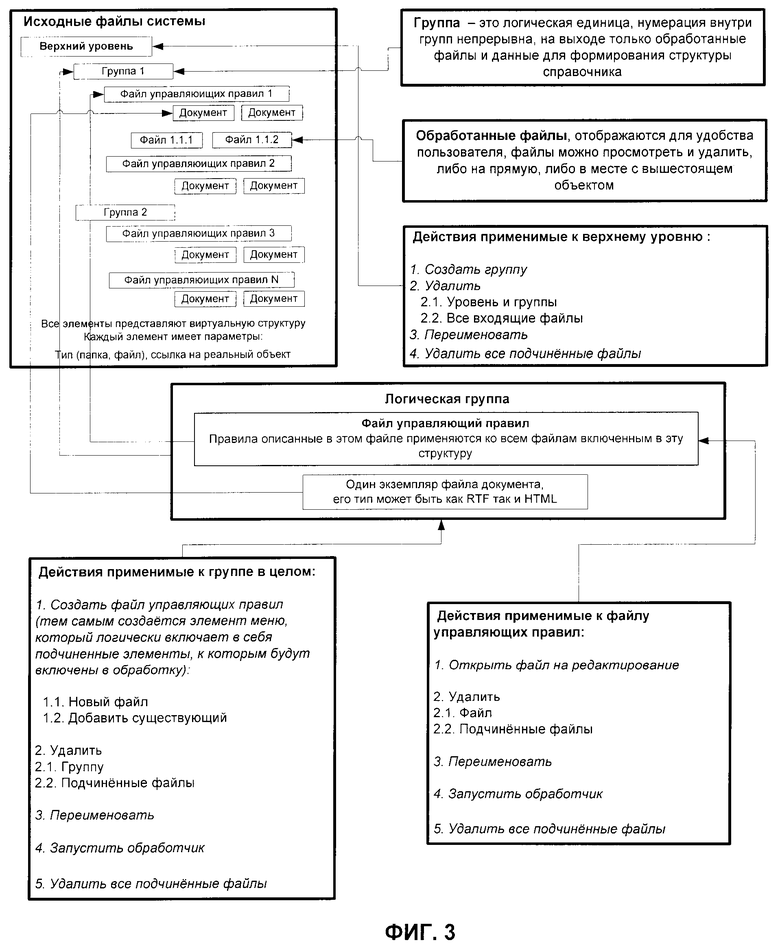
фиг.3 - схематическое изображение процесса управления данными в сформированном компьютерном документе средствами предварительно записанных команд;
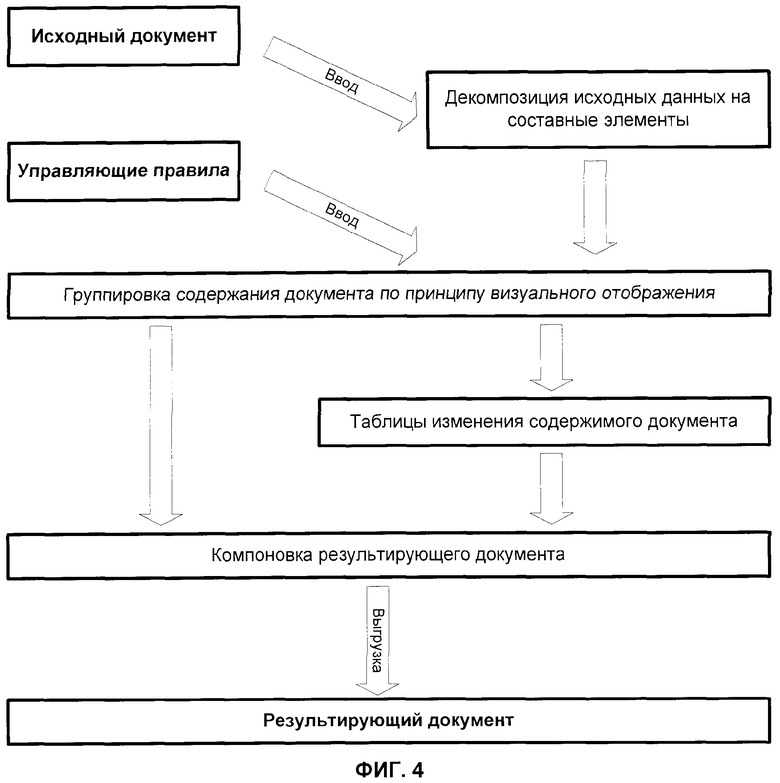
фиг.4 - блок-схема обработчика управляющих правил;
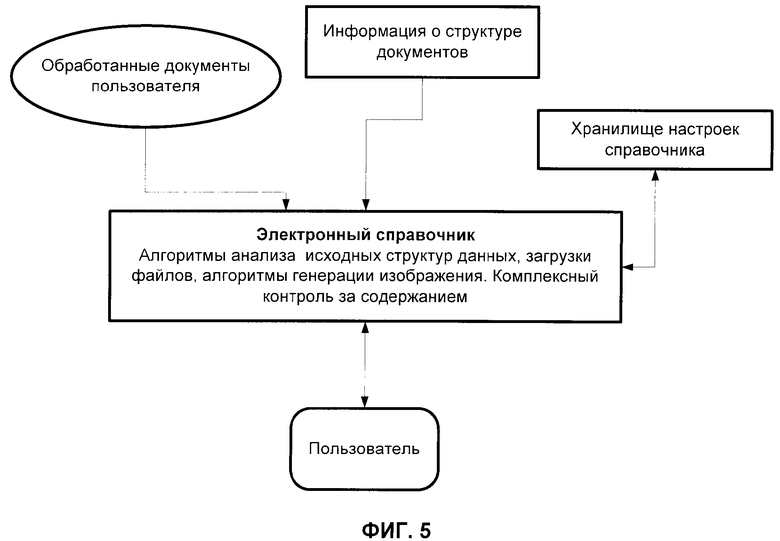
фиг.5 - блок-схема структуры электронного справочника (учебника);
фиг.6 - вариант выполнения пользовательского интерфейса «Выбор базового типа обработки документов»;
фиг.7 - вариант выполнения пользовательского интерфейса «Настройка местоположения результирующих документов»;
фиг.8 - вариант выполнения пользовательского интерфейса «Список исходных документов, участвующих в обработке»;
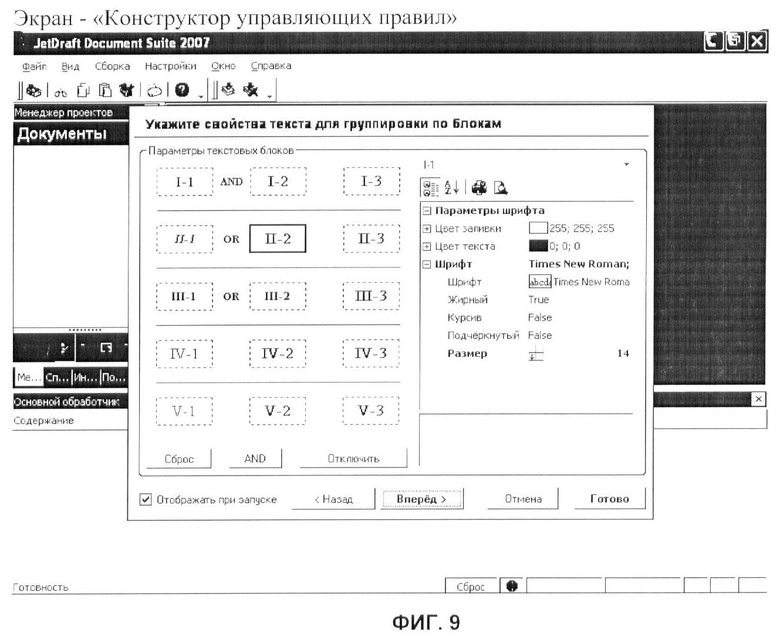
фиг.9 - вариант выполнения пользовательского интерфейса «Конструктор управляющих правил»;
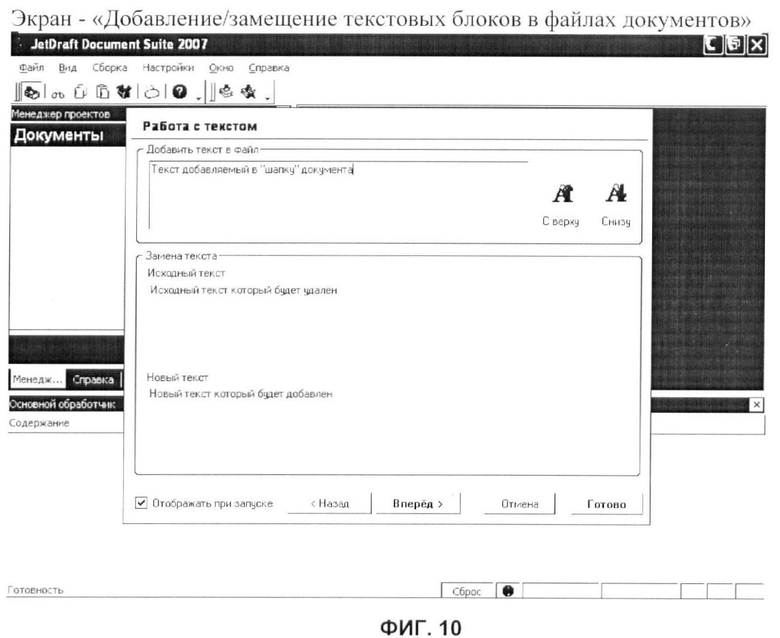
фиг.10 - вариант выполнения пользовательского интерфейса «Добавление/замещение текстовых блоков в файлах документов»;
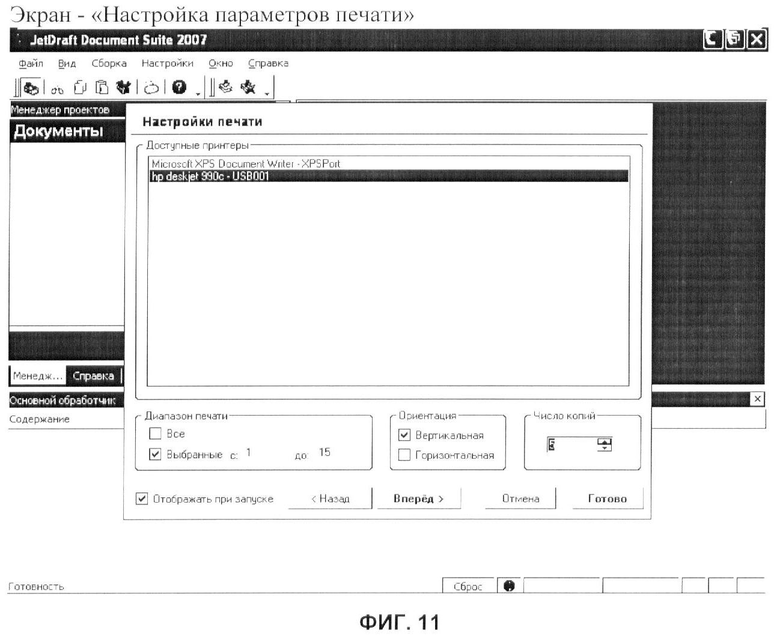
фиг.11 - вариант выполнения пользовательского интерфейса «Настройка параметров печати»;
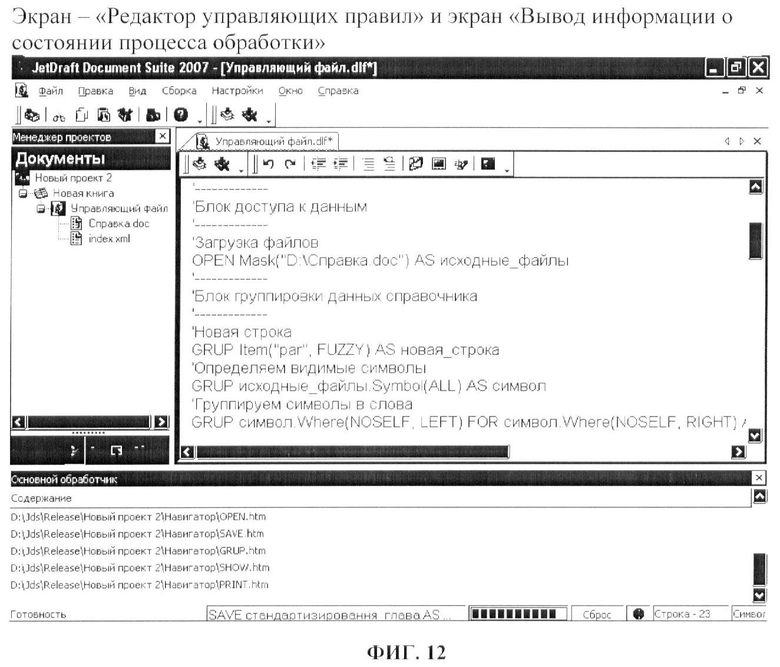
фиг.12 - вариант выполнения пользовательского интерфейса «Редактор управляющих правил» и «Вывод информации о состоянии процесса обработки»;
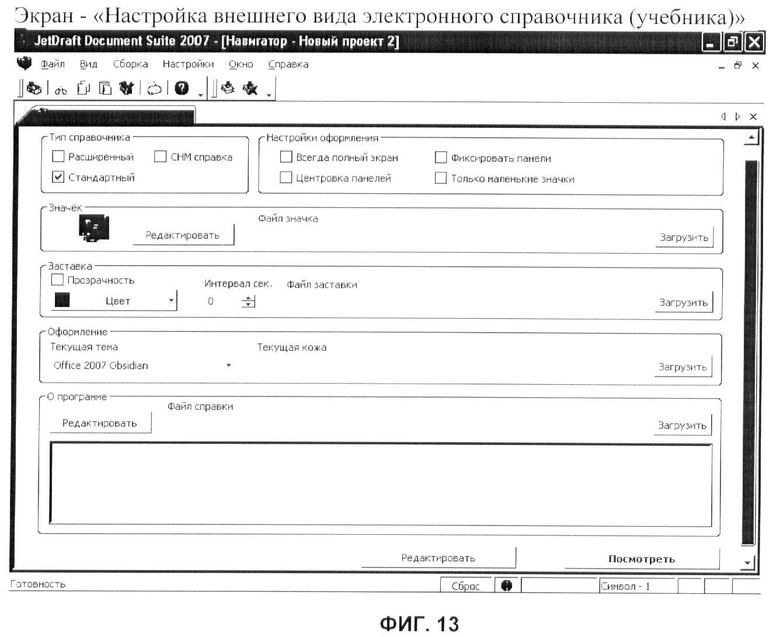
фиг.13 - вариант выполнения пользовательского интерфейса «Настройка внешнего вида электронного справочника (учебника)»;
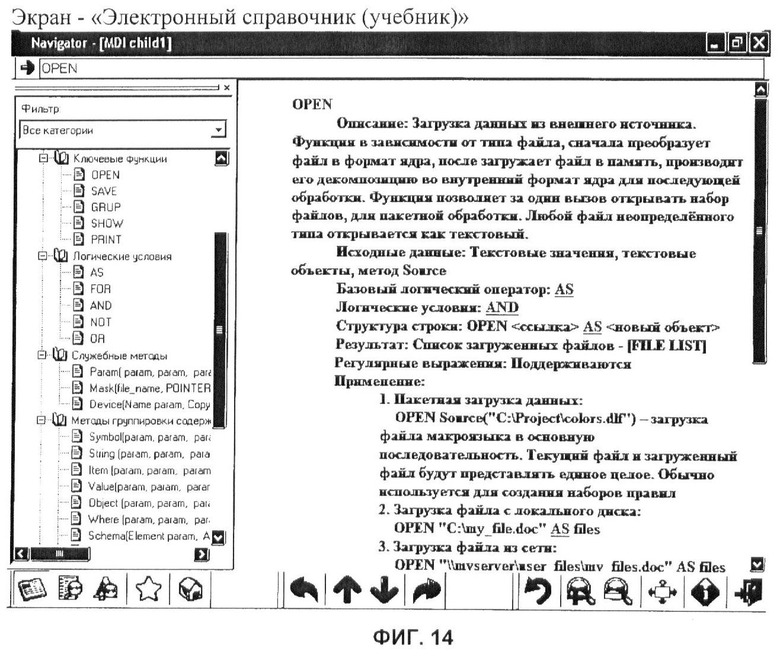
фиг.14 - вариант выполнения пользовательского интерфейса «Электронный справочник (учебник)».
Примерный состав технических средств для осуществления предлагаемого способа, схематически показанный на фиг.2, содержит компьютер, включающий в себя устройство отображения - монитор 1 с устройствами ввода: клавиатурой 2 и графическим манипулятором ("мышью") 3, системный блок 4, блок памяти 5 программ, машиночитаемый носитель 6 предварительно записанных управляющих команд, блок памяти 7 исходных документов, блок памяти 8 результирующих документов и устройство вывода - принтер 9.
Суть изобретения заключается в использовании логических правил управления содержимым документа. Здесь и далее под правилом понимается запись, указывающая системе на необходимость выполнения определенных действий над электронным документом или его частью. Правила универсальны и не имеют привязки к типу операционной системы компьютера, к формату или к внутренней структуре документа.
Структура правила состоит из следующих составных частей: «управляющей функции», «блока основных данных», «логического указателя направления вывода», «результирующего объекта».
Схематично это можно представить в виде записи:
УПРАВЛЯЮЩАЯ ФУНКЦИЯ "блок основных данных" УКАЗАТЕЛЬ НАПРАВЛЕНИЯ ВЫВОДА "результирующий объект".
Управляющая функция определяет базовое назначение правила.
Блок основных данных может содержать: указатель лож/истина, текстовую строку, объект, созданный до места обработки правила, метод с набором параметров, логическое условие группировки.
Логический указатель направления вывода служит для разделения правила на группы исходных и результирующих данных.
Результирующий объект содержит указатели на обработанные данные, с целью их дальнейшего использования в правилах, находящихся ниже в общем процессе обработки.
Основные управляющие функции, используемые в системе:
Открыть - загрузка данных из внешнего источника. Функция в зависимости от типа исходного документа, сначала преобразует файл документа во внутренний формат обработчика, после загружает файл в блок памяти исходных документов и производит его декомпозицию для последующей обработки. Это позволяет за один запуск одновременно анализировать несколько документов;
Сохранить - выгрузка данных в блок памяти результирующих документов;
Группировать - создание нового логического объекта;
Отобразить - вывод наборов данных на основной системный экран;
Печать - вывод данных на устройство печати;
Выполнить - запуск внешнего приложения, находящегося в операционной системе ЭВМ;
Логические условия:
КАК - разделитель правила указывает тип направления вывода данных в правиле;
ОТ - логическое ОТ И ДО. Группирует содержимое текстовых объектов в более крупные блоки. Например, есть предложение, если взять первый и последний символ этого предложения, а затем использовать условие ОТ И ДО, то мы получим указатель на соответствующий диапазон символов в виде S-E, где S - позиция первого символа в предложении, а Е - позиция последнего символа в предложении.
И включает в новый объект элемент только в том случае, если он присутствует в обоих ключевых объектах;
НЕТ обрабатывает списки и включает в новый объект только те элементы, у которых нет совпадений друг с другом;
ИЛИ - из двух списков создает один, при этом в результирующий объект, элементы попадают только один раз, и более в нем не повторяются.
Логически любой текстовый документ система воспринимает как совокупность отдельных блоков.
Обобщенно процесс анализа данных выглядит следующим образом:
- система считывает документ;
- воспринимает отдельные символы;
- используя пробелы, как логические разделители, объединяет символы в слова;
- точки, знаки перехода на новую строку и знаки табуляции воспринимаются как разделители предложений;
- предложения объединяются в абзацы;
- абзацы объединяются в главы;
- главы объединяются в разделы.
На каждом из этих этапов данные представлены в виде логической единицы - блока.
Процесс обработки данных с использованием предлагаемого способа можно разделить на следующие этапы:
в электронно-вычислительную машину загружают предварительно записанные на машиночитаемом носителе команды;
запускают процесс анализа команд;
строят список документов, подлежащих обработке;
производят декомпозицию документов во внутренний формат данных системы;
сегментируют загруженные документы на логические блоки;
модифицируют логические блоки;
строят краткое описание содержимого блоков;
производят композицию логических блоков из внутреннего формата во внешний, общедоступный формат хранения данных.
При необходимости приведенный порядок действий может дополняться:
логический блок записывают в виде файла формата, отличного от формата исходного документа;
логический блок выводят на печать;
новый документ заключает в себе краткое описание данных, содержащихся в исходных документах;
новый документ, содержащий в себе краткое описание данных, записывают в виде web-страницы со списком ссылок, каждая из которых ссылается на соответствующий исходный документ.
На основе структуры содержимого строится таблица расположения отдельных файлов, для каждого файла выделяют ключевые слова, осуществляют поиск выделенных слов в других документах, входящих в краткое описание, все найденные слова в других документах маркируют ссылками на исходный документ.
Список логических блоков объединяют в один общий блок и сохраняют во внешнем формате в виде единого файла.
Добавляют, удаляют, заменяют данные в блоке.
Изменяют регистр символов, входящих в блок.
Изменяют, добавляют, изменяют, удаляют визуальное обрамление блока.
Добавляют, изменяют, удаляют оформление фоновой заливки и фонового изображения блока.
Информационная технология, основанная на предлагаемом способе, включая использование его результатов и предшествующие подготовительные операции, показана в укрупненном виде на фиг.1. Возможный состав технических средств для одного из частных случаев реализации данной технологии изображен на фиг.2. На чертеже приведена примерная система для воплощения изобретения, которая включает в себя универсальную вычислительную систему в виде традиционного компьютера, включающего в себя системный блок 4, блок памяти программ 5, машиночитаемый носитель 6 предварительно записанных управляющих команд, и подключенные к нему устройства ввода - клавиатура 2 и графический манипулятор «Мышь» 3, и устройство отображения 1 (монитор). Для вывода набора данных в печатном виде к системе подключено устройство вывода - принтер 9. При этом система снабжена блоком памяти 7 исходных документов и блоком памяти 8 результирующих документов.
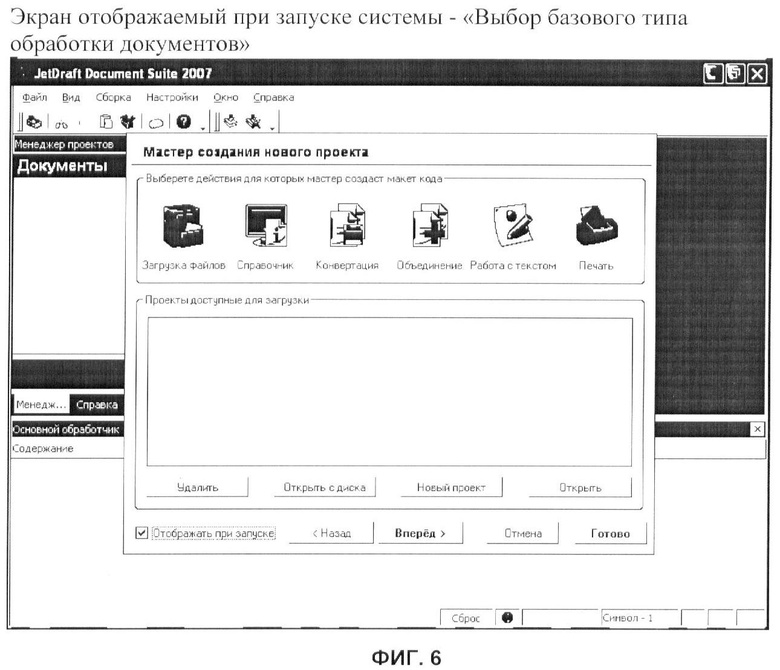
При использовании такого состава технических средств, в процессе запуска приложения (системы) пользователю выводится окно (экран) «Мастер подготовки данных», состоящее из нескольких вложенных окон (экранов):
- выбора базового типа обработки документов - первое (фиг.6):
«Загрузка файлов» - открытие и первичный анализ файлов документа(ов);
«Справочник» - подготовка управляющих команд, с целью создания структуры электронного справочника;
«Конвертация» - изменение формата файла исходного документа(ов) с одного на другой;
«Объединение» - объединение нескольких документов в один общий файл;
«Работа с текстом» - выборочное удаление, добавление, изменение фрагментов текста в документе (max);
«Печать» - вывод на устройство печати, документа(ов).
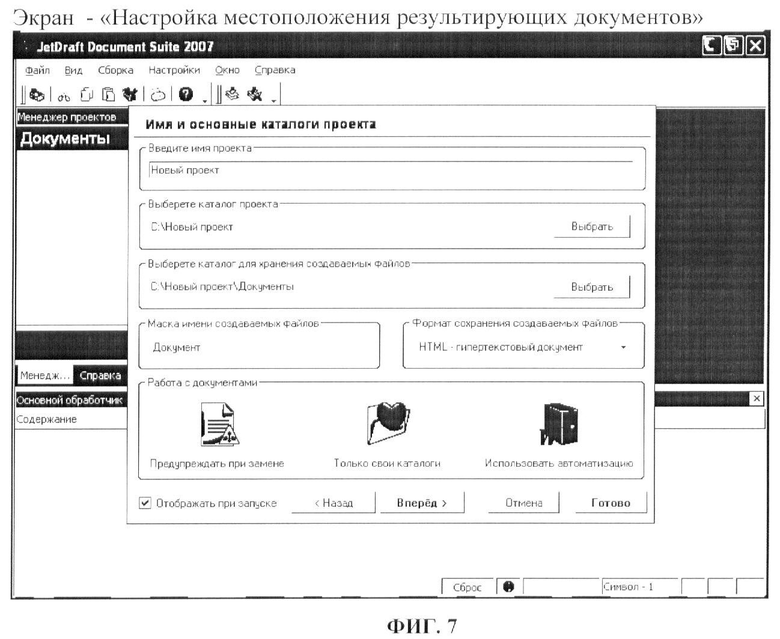
- настройки местоположения результирующих документов (фиг.7);
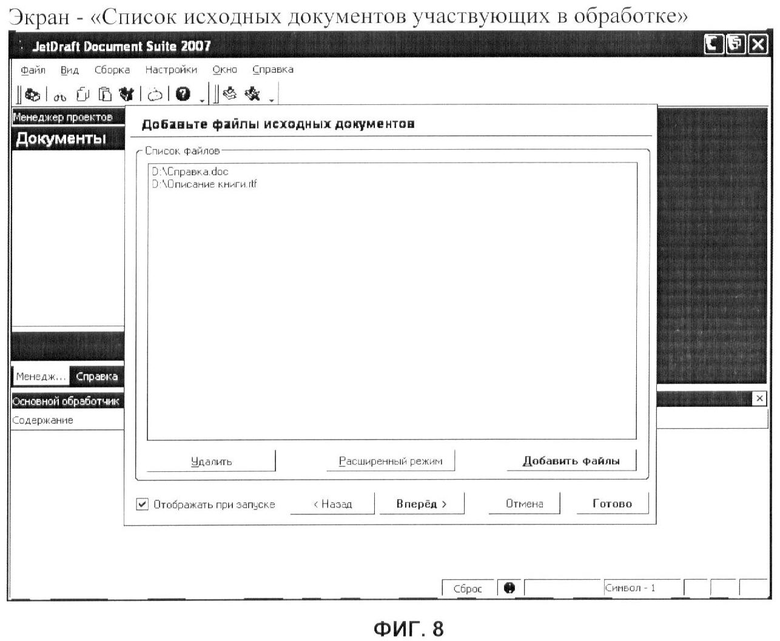
- определения исходных документов, участвующих в обработке (фиг.8);
- конструктор управляющих правил, устанавливающий параметры текстовых блоков, на основе которых будет строить выборка данных из основной последовательности. Каждый из трех блоков должен соответствовать текстовому блоку в документе (фиг.9);
- добавление/замещение текстовых блоков в файлах документов (фиг.10);
- настройка параметров печати (фиг.11).
По завершению работы окна «Мастер подготовки данных» создаются файлы нового проекта, содержащие в себе правила для обработки исходных документов. Далее выводится окно «Редактор управляющих правил» и «Вывод информации о состоянии процесса обработки» и на основе анализа содержимого файлов, созданных мастером, создается дерево проекта со списком документов, подлежащих обработке.
В окне редактора управляющих правил (фиг.12), каждый логический элемент, для удобства восприятия автоматически подсвечивается соответствующим цветом.
Пользователю предоставляется возможность изменить структуру правил в соответствии со своими задачами и личными предпочтениями. Система автоматически отслеживает все изменения, вносимые в структуру правил. На основании этих данных она изменяет список документов, подлежащих обработке, при этом осуществляется контроль правильности логических конструкций и доступность документов, поставленных на обработку (фиг.3).
Центральная часть системы - обработчик управляющих правил, показан на фиг.4.
Пользователь инициирует процесс обработки правил, в ходе которого на экран выводится информация о его текущем состоянии: количество загруженных документов, сформированные текстовые объекты, выгруженные файлы, дополнительная информация по документам.
Выводимая информация представлена в виде отчетов с автоматической группировкой по категориям.
По завершению обработки пользователь продолжает работу с документами средствами сторонних производителей или встроенными средствами системы.
Практическим применением результатов обработки документов заявленным способом является возможность создания на их основе электронного справочника (электронной книги/учебника), с этой целью пользователь открывает окно дополнительных настроек (фиг.13), в соответствии со своими личными предпочтениями изменяет внешнее оформление справочника. Результатом является полноценная электронная книга (фиг.14), содержащая в себе: страницы информации и их список в форме древовидной структуры, возможность перемещения по содержанию, текстовый поиск, возможность добавления закладок. Структура справочника изображена на (фиг.5).
Алгоритм способа управления данными в сформированном компьютерном документе
Шаг 1. Загрузка файла управляющих команд
1.1. Файл управляющих команд загружается с машиночитаемого носителя в память ЭВМ. Посимвольно сравнивается с таблицей системных символов, из файла выделяются базовые управляющие слова и символы разметки кода.
1.2. Управляющие слова сравниваются с массивом ключевых слов, который имеет вид [Код, Логический уровень элемента, Маркер] и содержит в себе следующие типы записей: «присвоение значения переменной», «функция группировки», «зарезервированное слово», «условие добавления», «метод группировки», «метод присвоения», «метод присвоения», «метод группировки (условие или)», «регистр», «значение элемента», «значение регистра».
При совпадении ключевого слова с таблицей осуществляется проверка типа действия:
если код элемента 1, то значит это комментарий, и осуществляется переход на следующую строку;
если код 2, то значит это разделитель и увеличивается переменная счетчика массива на единицу;
если символ новой строки, то переход на новую строку с записью в ячейку массива значения «начало новой строки»;
если у символа нет совпадений, то он записывается во временный массив, в процессе дальнейшей обработки каждый новый символ проходит проверку на совпадение с этой таблицей и с таблицей ключевых слов.
Логический уровень элемента определяется следующим образом:
Уровень 1 определяет элементы, не подчиняющиеся никому.
Уровень 2 - элементы, характеризующие 1-й уровень, например, текстовые переменные, задаваемые пользователем для функции верхнего уровня.
Уровень 3 описывает элементы 2-го уровня.
Уровень 4 конечный, на нем находятся свойства объектов.
Если совпадений с текущей последовательностью не найдено, то значение записывается в конец массива. С целью добавления в массив имен переменных фиксируется число имеющихся команд. В процессе обработки переменная встречается многократно, но в массив заносит только один раз, соответственно каждый элемент массива уникален. По завершению анализа файла все команды представлены в дескрипторной записи вида [Номер, Код связи элемента с основной таблицей].
1.3. Первичная проверка синтаксиса проводится по следующей схеме: последовательно сравниваются логические типы элементов, если первый элемент не равен второму, то далее проверяется второй, не равен ли он третьему, и т.д. Если элемент равен предыдущему, то проверяется, не равен ли его тип нулю и если он равен, то значит присутствуют два начала новой строки, соответственно это неверное правило, при этом удаляются повторяющиеся записи.
Если же тип элементов неравен нулю, то останавливается обработка и записывается адрес ячейки, где произошло совпадение. Далее выводится сообщение об ошибке. По завершению загрузки управляющего файла управление передается процессору обработки данных «Шаг 2».
Шаг 2. Загрузка и первичный анализ файлов документов
1.1.Анализ исходной информации и построение таблицы методов
Внутренний алгоритм системы оптимизирован под работу с файлами формата RTF - Rich Text Format («богатый текстовый формат»). В случае если исходный файл имеет формат отличный от внутреннего, на этапе предварительной обработки система дает указание внешней программе трансформировать тип файла в стандартный формат. Весь процесс загрузки и анализа документов состоит из следующих этапов.
1. Загрузка файла документа в память ЭВМ. При которой документ представляется в виде последовательности блоков, состоящей из трех базовых типов данных: теги (метки в файле/тексте, определяющие границы логического элемента и тип его содержимого), их параметры и текстовую информацию. Этот процесс условно подразделяет на следующие шаги:
построение таблицы методов обработки, в которой функциям будут переданы исходные параметры;
группировка логических элементов, при которой каждый блок будет представлен в виде набора разнородных тегов, внешне соответствующий прежнему объекту, но являющийся новым неделимым объектом.
В соответствии с таблицей тегов файла исходного документа строится матрица свойств файла, при этом для удобства анализа документ разбивается на логические блоки. Разбивка производится по открывающим и закрывающим скобкам, все параметры забираются за один раз. За один проход (с целью экономии времени работы ЭВМ) проводится несколько операций вызова и записи фрагментов данных из памяти программ ЭВМ.
Набор символов проводится к таблице вида: [n, Е, L, Ср, VI]
где n - порядковый номер элемента, Е - номер группы на уровне, L - это уровень нахождения элемента, Ср - код тега (сопоставляется с таблицей тегов), VI - параметр элемента (или текстовое значение элемента).
Каждый символ последовательности сравнивается с таблицей тегов, на этом этапе определяются его свойства. Например: Символ «{»(скобка) означает создание новой ячейки массива. Первый и последний элемент, на одном уровне, открывается и закрывается скобками.
Далее считывается символ «\» (наклонная черта), это символ начала тега, означает, что далее будет идти не число или пробел, а управляющая команда - тег. В процессе анализа считываемые символы записываются в массив, если идущий за тегом числовой символ без пробела, то это параметр тега и он записывается в ячейку текущего тега.
Символ «;» (точка с запятой) закрывает параметры тегов, записываемые в текстовом формате. Параметры, записанные в текстовом формате, сохраняются в отдельную ячейку с форматом тега - параметр 1.
Во временную таблицу автоматически записываются все теги, которые не участвуют в обработке, они необходимы для правильного сохранения обработанного файла в формате, отличного от стандартного.
При записи символа или тега в последовательность, необходимо точно определить значение каждого тега или символа.
Символ последовательности записывается в отдельную ячейку. Если символ не является частью тега, то определяется его регистр. Это экономит такты при сопоставлении данных из таблиц.
Исходный массив не изменяется, при его записи создается новая последовательность.
Каждый тег имеет свой тип, по типу тега определяется, что находится в первом элементе после него. Маркер для каждого уровня один, он хранит одно значение и освобождается после закрывающей скобки.
Типы тегов (тип влияет на параметр тега)
Простой тег (нет параметра, параметр без пробела ноль или число отлично от нуля);
Расширенный тег (нет параметра, параметр без пробела ноль или число отлично от нуля), также сам тег является указателем, что стоит дальше:
по умолчанию, следующий элемент после пробела это текст, если тип единица, то это строковый параметр, если второй тип, то это числовой параметр, если третий тип, то это указатель на двоичную последовательность в исходном массиве.
Если не найдено тегов в группе с последовательностями, отличными от нуля, то после пробела стоит текст.
Указатель текстового символа, если маркер пробела и есть маркер того, что этот объект текст, то теги записываются в массив данных.
Вид оптимизированного массива данных
Код тега, номер уровня, номер блока, тип параметра, ячейка 1, ячейка 2;
если 0, то параметра нет (ячейка 1, ячейка 2 пусты),
если 1, то параметр числовой (ячейка 1 - указатель на ячейку числового массива, ячейка 2 пуста),
если 2, то параметр строковый (ячейка 1 - указатель на ячейку строкового массива, ячейка 2 пуста),
если 3, то параметр бинарная последовательность (ячейки 1 и 2 содержат ссылки на массив адресов последовательностей),
если 4, - текст (ячейка 1 хранит тип символа верхний или нижний регистр).
Для примера: слово «Основной» в этой записи будет выглядит так (где n - код записи):
[n, 0E, 0L, 1, "О"] - предпоследний параметр указывает на регистр, символа (если 0, то символ в обычном регистре, если 1, то в верхнем).
[n, 0E, 0L, 0, "с"]
[n, 0E, 0L, 0, "н"]
[n, 0E, 0L, 0, "o"]
[n, 0E, 0L, 0, "й"]
Шаг 3. Группировка данных в логические объекты
Основной процессор обработки (шаг 2) передает функции адреса параметров, которые предстоит обработать. Все действия находятся в подфункциях (одна и та же функция может выполняться несколько раз). В каждой функции верхнего уровня описывается последовательность выполнения команд.
1. Запускается цикл.
2. Последовательно берется код каждого элемента с единицей и проверяется принадлежность кода к функции.
3. Если значение равно единице, запускается внутренний цикл:
3.1. С текущей позиции до того как ячейка массива станет равной единице, записывается адрес начала и конца группы параметров одной отдельной функции.
3.2. Далее для таблицы вызывается следующая функция, ей передается адрес основной последовательности.
3.3. Завершается текущий цикл.
4. Функция автоматически отбрасывает первое значение т.к. это указатель на ее саму. Тем самым для каждой функции имеется не более трех параметров:
4.1. Здесь известно, что указатель на массив вторичен, он описывает имеющийся диапазон, на базе этого диапазона и строится, основное условие.
4.2. Первый элемент, указатель на диапазон для обработки, второй метод диапазона, третий это условие группировки.
4.3. Оценивается формат выбранного элемента. Параметр указывает, теги какого формата попадают в текущую группу. В соответствии с этим определяются свойства каждого элемента, если элемент текст и если его код равен единице, то значит он попадает под действие текущего правила, соответственно его указатель записывается в общий массив ссылок.
Функция возвращает координаты действия правила в массиве полученных значений, начало и конец диапазона. После получения всех диапазонов условий базовый обработчик проводит окончательную группировку с учетом логических условий «И», «ИЛИ», «НЕТ».
Результатом работы является запись в базовом массиве, где содержится код указателя, а также диапазон значений, на которые он указывает.
Шаг 4. Работа с логическими объектами
Все операции, производимые над логическими блоками, можно разделить на следующие группы.
1. Выделить символ возвращает диапазон всех символов, равных символу, указанному в параметре. Символом является любой отображаемый текстовый объект последовательности. Пример, символами являются: символ табуляции, символ начала новой строки, символ возврата каретки.
2. Получить значение слева/справа возвращает диапазон всех значений, совпадающих с параметром функции и стоящих ближе всего к левой/правой границе группы.
3. Получить/изменить регистр - символа возвращает диапазон символов, имеющих регистр, равный регистру, переданному параметром, или применяет параметр ко всем элементам группы.
4. Получить/изменить шрифт возвращает диапазон всех значений, совпадающих с параметром функции. На первом этапе осуществляется поиск параметра с элементом основного массива и записывается тег, описывающий нужный шрифт, далее последовательно осуществляется поиск всех кодов шрифта, в группу включаются только символьные значения, стоящие от начала тега, до следующего тега с соответствующим форматированием. На втором этапе система применяет параметр функции ко всем значениям диапазона. Для этого осуществляется поиск параметра в основном массиве. Если совпадений не найдено, это значит, что такого шрифта в таблице документа не найдено и необходимо добавить новую запись о шрифте в основной массив. Для правильного применения шрифта к группе удаляются все записи о шрифтах в группе и все записи о шрифтах из выбранного диапазона. Выше по массиву ищется запись о шрифте и заменяется на новое значение.
5. Выгрузить объект создает копию логического объекта в виде файла в блоке памяти результирующих документов. С целью анализа номеров выгружаемых элементов система собирает все параметры логических объектов, при получении команды основного обработчика о наличии маркера границы списка файлов. Создается объект во внешнем хранилище с номером, соответствующим номеру объекта, и осуществляется процесс выгрузки данных.
Уровень вложенности определяется путем анализа полученных данных.
Ключевым элементом списка является элемент, стоящий выше всех в последовательности.
Например: А - это первая команда на сохранение, В - вторая, С - третья,
Каждая команда должна сохранить свой диапазон значений:
An, Bn, Bn, Cn, An, где n - код элемента.
Система считает количество команд и в зависимости от параметров обработки объектов создается различная выходная нумерация файлов с поддержкой вложенной иерархии объектов.
Шаг 5. Индексация выгруженных документов
Соответствующей функции передается диапазон объектов, подлежащих индексации. Имя ключевого файла и индексный код берутся из функции выгрузки логических объектов на шаге 4.
Далее создаются файлы словаря и файлы ссылок:
в файл словаря записываются код документа, ключевые слова;
в файл ссылок, записывается код документа, имя файла, имя исходного файла, кодировка, вес слова, краткая аннотация (название ссылки), порядковый номер в последовательности, глубина вложенности.
На этом процесс обработки документов заканчивается.
Из представленного описания специалисту понятно, что основная часть действий способа управления данными в сформированном компьютерном документе по настоящему изобретению может быть полностью реализована не только в аппаратном, но и в программном виде, поскольку обрабатываемые документы уже оцифрованы и находятся в двоичном представлении.
Эти документы будут обрабатываться процессором компьютера в соответствии с программой, основанной на алгоритме, описанном выше.
В этом случае управляющие команды и программа, соответствующая выполнению вышеприведенного алгоритма функционирования, посредством исполнения которой в компьютере можно реализовать способ по настоящему изобретению, может быть записана на машиночитаемый носитель, предназначенный для непосредственной работы в составе компьютера.
Хотя в описанной здесь системе для осуществления способа применяют магнитный жесткий диск, съемный магнитный диск или съемный оптический диск, для хранения данных могут использоваться и другие типы машиночитаемых носителей данных, в том числе магнитные кассеты, карты флэш-памяти, многоцелевые цифровые диски, картриджи Бернулли, ОЗУ, ПЗУ.
Предлагаемые изобретения могут найти применение для получения разнообразных видов практически полезного результата в различных сферах их использования, в частности, в сфере образования, создание электронных учебников/книг, растравлении акцентов на фрагментах материала с целью его лучшего восприятия; в библиотечном деле с целью сегментирования и управления большим количеством однородных текстовых документов; в сфере разработки программного обеспечения и в сфере защиты авторского права при управлении информацией об авторах, служебной информацией в списках документов; при создании ресурсов всемирной сети Интернет, автоматическая публикация документов; в сфере управления данными с целью преобразования информации из неструктурированного текстового формата в формат со строгой внутренней организацией, в домашнем использовании с целью печати и преобразования формата списков документов.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ДЛЯ ВЫБОРА ЗНАЧИМЫХ ЭЛЕМЕНТОВ СТРАНИЦЫ С НЕЯВНЫМ УКАЗАНИЕМ КООРДИНАТ ДЛЯ ИДЕНТИФИКАЦИИ И ПРОСМОТРА РЕЛЕВАНТНОЙ ИНФОРМАЦИИ | 2015 |
|
RU2708790C2 |
| УНИВЕРСАЛЬНОЕ ПРЕДСТАВЛЕНИЕ ТЕКСТА С ВОЗМОЖНОСТЬЮ ПОДДЕРЖКИ РАЗЛИЧНЫХ ФОРМАТОВ ДОКУМЕНТОВ И ТЕКСТОВАЯ ПОДСИСТЕМА | 2014 |
|
RU2579888C2 |
| ИНТЕЛЛЕКТУАЛЬНАЯ ОБРАБОТКА ЭЛЕКТРОННОГО ДОКУМЕНТА | 2013 |
|
RU2571379C2 |
| Сохранение контента в конвертированных документах | 2014 |
|
RU2648636C2 |
| ПРОГРАММИРУЕМАЯ ОБЪЕКТНАЯ МОДЕЛЬ ДЛЯ ПОДДЕРЖКИ БИБЛИОТЕКИ ПРОСТРАНСТВ ИМЕН ИЛИ СХЕМ В ПРОГРАММНОМ ПРИЛОЖЕНИИ | 2004 |
|
RU2371759C2 |
| СИСТЕМА И СПОСОБ ПОИСКА ДАННЫХ В БАЗЕ ДАННЫХ ГРАФОВ | 2015 |
|
RU2707708C2 |
| РАСШИРЯЕМЫЙ XML-ФОРМАТ И ОБЪЕКТНАЯ МОДЕЛЬ ДЛЯ ДАННЫХ ЛОКАЛИЗАЦИИ | 2006 |
|
RU2419838C2 |
| ИНТЕРФЕЙС ПРОГРАММИРОВАНИЯ ДЛЯ КОМПЬЮТЕРНОЙ ПЛАТФОРМЫ | 2004 |
|
RU2371758C2 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ДАННЫХ ДЛЯ ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ В ТЕКСТЕ | 2019 |
|
RU2755606C2 |
| СПОСОБ УПРАВЛЕНИЯ ДИАЛОГОМ И СИСТЕМА ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА В ПЛАТФОРМЕ ВИРТУАЛЬНЫХ АССИСТЕНТОВ | 2020 |
|
RU2759090C1 |
Изобретение относится к области информационных технологий. Техническим результатом изобретения является существенное повышение производительности труда пользователя, занимающегося однотипными операциями изменения содержимого электронного документа. Технический результат достигается тем, что в способе управления данными в сформированном компьютерном документе в электронно-вычислительную машину загружают предварительно записанные на машиночитаемом носителе команды, запускают процесс анализа команд, строят список документов, подлежащих обработке, приводят содержимое различных видов электронных документов к единому упрощенному виду, анализируют содержимое электронных документов, выделяют совокупности текстовой информации на основе их положения относительно друг друга и визуального представления в конечном документе, разделяют содержимое документов на логические блоки, модифицируют логические блоки, производят объединение измененных логических блоков из упрощенного представления к первоначальному формату электронного документа. 2 н. и 10 з.п. ф-лы, 14 ил.
1. Способ управления данными в сформированном компьютерном документе, содержащий этапы на которых:
в электронно-вычислительную машину на машиночитаемом носителе загружают предварительно записанные команды управления структурой электронного документа;
запускают процесс анализа загруженных команд управления и строят список действий над электронными документами;
строят список документов, подлежащих обработке, на основании информации, содержащейся в предварительно загруженных командах управления;
приводят содержимое различных видов электронных документов к единому, упрощенному виду;
анализируют содержимое электронных документов, выделяют совокупности текстовой информации на основе их положения относительно друг друга и визуального представления в конечном документе, разделяют содержимое документов на логические блоки;
модифицируют логические блоки в соответствии с указаниями, содержащимися в командах управления;
производят объединение измененных логических блоков из упрощенного представления к первоначальному формату электронного документа.
2. Способ по п.1, отличающийся тем, что блок записывают в виде файла формата, отличного от формата исходного документа.
3. Способ по п.1, отличающийся тем, что блок выводят на устройство печати.
4. Способ по п.1, отличающийся тем, что измененный логический блок содержит в себе краткое описание данных, содержащихся в исходных документах.
5. Способ по п.4, отличающийся тем, что краткое описание содержимого документов записывают в виде web-страницы со списком ссылок, каждая из которых ссылается на соответствующий исходный документ.
6. Способ по п.4, отличающийся тем, что на основе краткой структуры содержимого строят таблицу местоположения отдельных файлов, для каждого файла выделяют ключевые слова, осуществляют поиск выделенных слов в других документах, входящих в краткое описание, все найденные слова в других документах маркируют ссылками на исходный документ.
7. Способ по п.1, отличающийся тем, что логические блоки объединяют в один общий логический блок.
8. Способ по п.1, отличающийся тем, что данные в блоке добавляют, удаляют, заменяют.
9. Способ по п.1, отличающийся тем, что изменяют регистр символов, входящих в блок.
10. Способ по п.1, отличающийся тем, что визуальное обрамление блока изменяют, добавляют, удаляют.
11. Способ по п.1, отличающийся тем, что оформление фоновой заливки и фонового изображения блока добавляют, изменяют, удаляют.
12. Машиночитаемый носитель, на который записана программа, при выполнении которой осуществляется способ по любому из пп.1-11.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СПОСОБ ПОИСКА И ВЫБОРКИ ИНФОРМАЦИИ ИЗ РАЗЛИЧНЫХ БАЗ ДАННЫХ | 2006 |
|
RU2305314C1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |

