Область техники
Настоящее изобретение относится, в общем, к кодированию векторов и, в частности, к комбинаторному Факторному Импульсному Кодированию векторов с низкой сложностью.
Уровень техники
Способы кодирования векторных или матричных величин для речи, аудио, изображений, видео и других сигналов хорошо известны. Один такой способ, описанный в патенте США № 6236960 (автор Пенг и др.), который включен в данный документ посредством ссылки, известен как Факторное Импульсное Кодирование (или FPC). FPC может кодировать вектор x i с использованием общего количества M битов, при условии, что
 , (1)
, (1)
и все величины вектора x i вместе имеют такие целые значения, что -m ≤ x i ≤ m, где m является полным количеством импульсов единичной амплитуды, а n является длиной вектора. Общее количество M битов используется, чтобы закодировать N комбинаций максимально эффективным способом так, чтобы следующее выражение, которое описывает теоретически минимальное количество комбинаций, оставалось истинным:
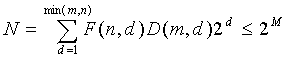 (2)
(2)
В этом неравенстве 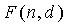 является количеством комбинаций d ненулевых элементов вектора в n положениях и задается как
является количеством комбинаций d ненулевых элементов вектора в n положениях и задается как
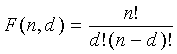 , (3)
, (3)
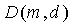 является количеством комбинаций d ненулевых элементов вектора при m полных единичных импульсах и задается как
является количеством комбинаций d ненулевых элементов вектора при m полных единичных импульсах и задается как
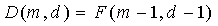 , (4)
, (4)
и 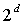 представляет комбинации, требуемые для описания полярности (знака) d ненулевых элементов вектора. Выражение min(m,n) позволяет учесть случай, когда количество импульсов единичной магнитуды превышает длину n вектора. Способ и устройство кодирования и декодирования векторов такой формы полностью были описаны в предшествующем уровне техники. Более того, практическая реализация этого способа кодирования была описана в стандарте 3GPP2 C.S0014-B, где длина вектора n=54 и количество импульсов единичной магнитуды m=7 производят M=35-битное кодовое слово.
представляет комбинации, требуемые для описания полярности (знака) d ненулевых элементов вектора. Выражение min(m,n) позволяет учесть случай, когда количество импульсов единичной магнитуды превышает длину n вектора. Способ и устройство кодирования и декодирования векторов такой формы полностью были описаны в предшествующем уровне техники. Более того, практическая реализация этого способа кодирования была описана в стандарте 3GPP2 C.S0014-B, где длина вектора n=54 и количество импульсов единичной магнитуды m=7 производят M=35-битное кодовое слово.
Несмотря на то, что эти значения n и m не причиняют никакой чрезмерной нагрузки сложности, более высокие значения могут быстро причинить проблемы, особенно в мобильных переносных устройствах, которым нужно сохранять память и вычислительную сложность как можно меньшими. Например, использование этого способа кодирования для некоторых применений (таких как кодирование аудио) могут требовать n=144, m=28, или выше. В таких обстоятельствах затраты, связанные с вычислением комбинаторного выражения 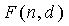 с использованием способов из предшествующего уровня техники, могут быть слишком высоки для практической реализации.
с использованием способов из предшествующего уровня техники, могут быть слишком высоки для практической реализации.
Рассматривая эти затраты более подробно, мы можем переписать Ур.3 как
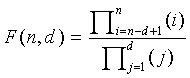 (5)
(5)
Непосредственная реализация проблематична, поскольку 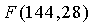 потребует 197 бит точности в числителе и 98 точности в делителе для получения 99-битного частного. Поскольку большинство цифровых сигнальных процессоров (DSP), используемых в сегодняшних переносных устройствах, обычно поддерживают только операции перемножения 16 бит × 16 бит, необходимо будет использовать специальные процедуры умножения/деления с многократной точностью. Такие процедуры требуют последовательности вложенных операций перемножения/накопления, которые обычно требуют порядка k операций перемножения/накопления (MAC), где k является количеством 16-битных сегментов в операнде. Так, исполнение одного 197×16-битного перемножения потребует минимум 13 операций MAC плюс операции сдвига и хранения. Выражение делителя вычисляется похожим способом для получения 98-битного результата. Дополнительно требуется 197/98-битное деление, которое является чрезвычайно сложной операцией, таким образом, вычисление всего отношения факториалов в Ур.5 потребует значительных ресурсов.
потребует 197 бит точности в числителе и 98 точности в делителе для получения 99-битного частного. Поскольку большинство цифровых сигнальных процессоров (DSP), используемых в сегодняшних переносных устройствах, обычно поддерживают только операции перемножения 16 бит × 16 бит, необходимо будет использовать специальные процедуры умножения/деления с многократной точностью. Такие процедуры требуют последовательности вложенных операций перемножения/накопления, которые обычно требуют порядка k операций перемножения/накопления (MAC), где k является количеством 16-битных сегментов в операнде. Так, исполнение одного 197×16-битного перемножения потребует минимум 13 операций MAC плюс операции сдвига и хранения. Выражение делителя вычисляется похожим способом для получения 98-битного результата. Дополнительно требуется 197/98-битное деление, которое является чрезвычайно сложной операцией, таким образом, вычисление всего отношения факториалов в Ур.5 потребует значительных ресурсов.
Для попытки снижения сложности Ур.5 можно переписать для распределения операций деления, чтобы получить следующее:
 (6)
(6)
В этом выражении динамический диапазон операций деления уменьшен, но, к сожалению, нужна повышенная разрядность частного для точного представления деления на 3, 7, 9 и т.д. Чтобы разместить такую структуру, также требуется операция округления для гарантии целого результата. При большом количестве операций деления с высокой точностью такая реализация не решает адекватно проблему сложности для больших m и n, и более того, потенциально может произвести неправильный результат из-за накопленных погрешностей точности.
В еще одной реализации, Ур.5 может быть реорганизовано следующим образом:
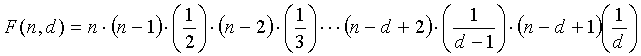 (7)
(7)
Если это выражение оценивать слева направо, результат всегда производить целое значение. Несмотря на то, что этот способ контролирует вопрос точности и динамического диапазона в какой-то степени, большие значения m и n также требуют широкого использования операций перемножения и деления многократной точности.
Наконец, для того чтобы минимизировать вычислительную сложность, возможно предварительно вычислять и сохранять все комбинации факториалов в таблице поиска. Так, все значения 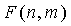 могут быть просто сохранены в матрице n × m и подходящим образом извлечены из памяти с использованием нескольких тактов процессора. Проблема этого подхода, однако, состоит в том, что по мере того, как n и m становятся больше, также растут и требования связанной памяти. Используя предыдущий пример, потребует 144×28×
могут быть просто сохранены в матрице n × m и подходящим образом извлечены из памяти с использованием нескольких тактов процессора. Проблема этого подхода, однако, состоит в том, что по мере того, как n и m становятся больше, также растут и требования связанной памяти. Используя предыдущий пример, потребует 144×28× =52,416 байт для хранения, что неприемлемо для большинства мобильных переносных устройств. Поэтому существует необходимость в способе и устройстве комбинаторного Факторного Импульсного Кодирования векторов с низкой сложностью.
=52,416 байт для хранения, что неприемлемо для большинства мобильных переносных устройств. Поэтому существует необходимость в способе и устройстве комбинаторного Факторного Импульсного Кодирования векторов с низкой сложностью.
Краткое описание чертежей
Фиг.1 - блок-схема кодера.
Фиг.2 иллюстрирует генерацию кодового слова.
Фиг.3 - блок-схема декодера.
Фиг.4 - блок-схема последовательности операций, показывающая работу Генератора Комбинаторной Функции с Фиг.1 и Фиг.3.
Фиг.5 - блок-схема последовательности операций, показывающая работу кодера с Фиг.1.
Фиг.6 - блок-схема последовательности операций, показывающая работу декодера с Фиг.3.
Фиг.7 - блок-схема последовательности операций, показывающая работу схемы комбинаторного кодирования с Фиг.1.
Фиг.8 - блок-схема последовательности операций, показывающая работу схемы комбинаторного декодирования с Фиг.3.
Подробное описание
Для того чтобы удовлетворить вышеупомянутую необходимость, в данном документе представлены способ и устройство комбинаторного Факторного Импульсного Кодирования векторов с низкой сложностью. Во время работы кодера принимается сигнальный вектор (x). Первый операнд (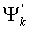 ) многократной точности будет сгенерирован на основании сигнального вектора, который должен быть закодирован. Генерируются операнд мантиссы и операнд экспоненты. Как операнд мантиссы, так и операнд экспоненты представляют второй операнд многократной точности, который основан на сигнальном векторе, который должен быть закодирован. Выбирается часть , которая должна быть модифицирована на основании операнда экспоненты. Часть модифицируется на основании операнда мантиссы для получения модифицированного операнда (
) многократной точности будет сгенерирован на основании сигнального вектора, который должен быть закодирован. Генерируются операнд мантиссы и операнд экспоненты. Как операнд мантиссы, так и операнд экспоненты представляют второй операнд многократной точности, который основан на сигнальном векторе, который должен быть закодирован. Выбирается часть , которая должна быть модифицирована на основании операнда экспоненты. Часть модифицируется на основании операнда мантиссы для получения модифицированного операнда ( ). Наконец, генерируется кодовое слово многократной точности для использования в соответствующем декодере.
). Наконец, генерируется кодовое слово многократной точности для использования в соответствующем декодере.
Настоящее изобретение охватывает способ работы кодера, который кодирует кодовое слово (C) из вектора (x). Способ содержит этапы приема вектора x который должен быть закодирован, генерирования первого операнда () многократной точности на основании x, и генерирования операнда (M) мантиссы и операнда (h) экспоненты. Операнд мантиссы и операнд экспоненты представляют второй операнд ( ) многократной точности, который основывается на сигнальном векторе, который должен быть закодирован. Затем выбирается часть , которая должна быть модифицирована, на основании операнда экспоненты, и часть модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда (). Наконец, генерируется кодовое слово (C) на основании .
) многократной точности, который основывается на сигнальном векторе, который должен быть закодирован. Затем выбирается часть , которая должна быть модифицирована, на основании операнда экспоненты, и часть модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда (). Наконец, генерируется кодовое слово (C) на основании .
Настоящее изобретение дополнительно охватывает кодер, содержащий схему комбинаторного кодирования, выполняющую этапы приема вектора x, который должен быть закодирован, генерирования первого операнда () многократной точности на основании x и генерирования операнда (M) мантиссы и операнда (h) экспоненты. Операнд мантиссы и операнд экспоненты представляют второй операнд () многократной точности, который основан на сигнальном векторе, который должен быть закодирован. Затем выбирается часть , которая должна быть модифицирована, на основании операнда экспоненты, и часть модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда (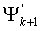 ). Наконец, генерируется кодовое слово (C) на основании .
). Наконец, генерируется кодовое слово (C) на основании .
Настоящее изобретение дополнительно охватывает способ работы декодера, который генерирует вектор (x) из кодового слова (C). Способ содержит этапы приема кодового слова ( ), генерирования первого операнда () многократной точности на основании
), генерирования первого операнда () многократной точности на основании  и генерирования операнда (M) мантиссы и операнда (h) экспоненты. Операнд мантиссы и операнд экспоненты представляют второй операнд () многократной точности, который основан на кодовом слове. Выбирается часть , которая должна быть модифицирована, на основании операнда экспоненты, и часть модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда (). Положение
и генерирования операнда (M) мантиссы и операнда (h) экспоненты. Операнд мантиссы и операнд экспоненты представляют второй операнд () многократной точности, который основан на кодовом слове. Выбирается часть , которая должна быть модифицирована, на основании операнда экспоненты, и часть модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда (). Положение 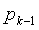 (k-1)-ого ненулевого элемента вектора x декодируется, и вектор (x) генерируется на основании положения .
(k-1)-ого ненулевого элемента вектора x декодируется, и вектор (x) генерируется на основании положения .
Настоящее изобретение дополнительно охватывает декодер, содержащий схему комбинаторного декодирования, выполняющую этапы приема кодового слова (), генерирования первого операнда () многократной точности на основании и генерирования операнда (M) мантиссы и операнда (h) экспоненты. Операнд мантиссы и операнд экспоненты представляют второй операнд () многократной точности, который основан на кодовом слове. Выбирается часть , которая должна быть модифицирована, на основании операнда экспоненты, и часть модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда (). Положение (k-1)-ого ненулевого элемента вектора x декодируется, и вектор (x) генерируется на основании положения .
Обращаясь теперь к чертежам, на которых подобные ссылочные позиции обозначают подобные компоненты, Фиг.1 является блок-схемой кодера 100. Кодер 100 содержит генератор 102 вектора, схему 106 комбинаторного кодирования, генератор 108 комбинаторных функций и другую схему 104 кодирования. Во время работы входной сигнал, который должен быть закодирован, принимается генератором 102 вектора. Как известно из уровня техники, входной сигнал может содержать речь, аудио, изображение, видео, и другие сигналы.
Генератор 102 вектора принимает входной сигнал и создает вектор x i. Генератор 102 вектора может содержать любое количество парадигм кодирования, включая, но не в качестве ограничения, кодирование речи с помощью Линейного Предсказания с Мультикодовым Управлением (CELP), как описано Пенгом и др., кодирование областей преобразования для аудио, изображений и видео, включая способы, основанные на Дискретном Преобразовании Фурье (DFT), Дискретном Косинусном Преобразовании (DCT) и Модифицированном Дискретном Косинусном Преобразовании (MDCT), кодирование вейвлет-преобразований, прямую временную импульсно-кодовую модуляцию (PCM), дифференциальную PCM, адаптивную дифференциальную PCM (ADPCM) или любую из семейства методик кодирования поддиапазонов, которые хорошо известны в уровне техники. Фактически любой сигнальный вектор, имеющий форму, обозначенную выше, может быть эффективно обработан согласно настоящему изобретению.
Схема 106 комбинаторного кодирования принимает вектор x
i и использует Факторное Импульсное Кодирование для получения кодового слова C. Как обсуждалось выше, Факторное Импульсное Кодирование может кодировать вектор x
i с использованием общего количества M бит, при условии, что 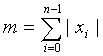 , и все величины вектора x
i вместе имеют такие значения, что -m ≤ x
i
≤ m, где m является полным количеством импульсов единичной амплитуды, а n является длиной вектора. Как обсуждалось выше, более высокие значения n и m могут быстро причинить проблемы, особенно в мобильных переносных устройствах, которым нужно сохранять память и вычислительную сложность как можно меньшими.
, и все величины вектора x
i вместе имеют такие значения, что -m ≤ x
i
≤ m, где m является полным количеством импульсов единичной амплитуды, а n является длиной вектора. Как обсуждалось выше, более высокие значения n и m могут быстро причинить проблемы, особенно в мобильных переносных устройствах, которым нужно сохранять память и вычислительную сложность как можно меньшими.
Чтобы решить этот вопрос, генератор 108 комбинаторных функций использует методику с низкой сложностью для получения 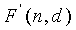 . Схема 106 комбинаторного кодирования затем использует для получения кодового слова C. Схема 106 использует приближения (биты точности) с относительно низкой разрядностью комбинаций факториалов, которые обеспечивают достаточную точность только для того, чтобы сгенерировать правильное кодовое слово. То есть, пока сохраняются конкретные свойства, подходящее приближение функции
. Схема 106 комбинаторного кодирования затем использует для получения кодового слова C. Схема 106 использует приближения (биты точности) с относительно низкой разрядностью комбинаций факториалов, которые обеспечивают достаточную точность только для того, чтобы сгенерировать правильное кодовое слово. То есть, пока сохраняются конкретные свойства, подходящее приближение функции 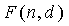 является достаточным для гарантии того, что результирующее кодовое слово однозначно декодируемо. Чтобы описать генерацию функции , сначала выведем функцию
является достаточным для гарантии того, что результирующее кодовое слово однозначно декодируемо. Чтобы описать генерацию функции , сначала выведем функцию 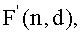 которая является подходящим приближением
которая является подходящим приближением  Первым этапом возьмем логарифм с произвольным основанием a от Ур.5 и выполним обратное преобразование к логарифму по основанию a от реорганизованных членов
Первым этапом возьмем логарифм с произвольным основанием a от Ур.5 и выполним обратное преобразование к логарифму по основанию a от реорганизованных членов
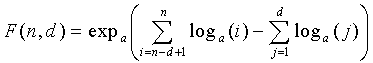 , (8)
, (8)
где функция 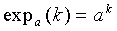 . Далее, определим функции
. Далее, определим функции 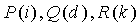 и заменим в Ур.8 таким образом
и заменим в Ур.8 таким образом
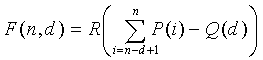 (9)
(9)
где 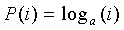 ,
, 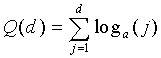 , и
, и 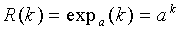 .
.
Однако, согласно предпочтительному варианту настоящего изобретения, нет необходимости в том, чтобы и были эквивалентны для получения однозначно декодируемого кодового слова. Существует только два условия, которые с достаточностью должны выполняться
≥ (10)
и
≥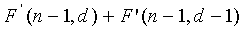 (11)
(11)
Для первого условия ограничение просто говорит о том, что, если <, тогда буду пересекаться кодовые пространства, и следовательно, будет более одного входа, способного генерировать конкретное кодовое слово, таким образом, кодовое слово не будет однозначно декодируемым. Второе условие утверждает, что для заданных n, d «погрешность» должна быть больше или равна, чем сумма членов погрешности, связанной с предыдущим элементом рекурсивной последовательности, описанной Пенгом и др. в патенте США № 6236960. Можно показать, что = истинно только, если комбинаторное выражение в точности является следующим: 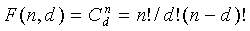 . Однако, несмотря на то, что неравенство Ур.11 является достаточным, нет необходимости в его истинности для всех n и d. Для таких величин может удовлетворять другому неравенству, выводимому из Ур.31 документа Пенга и др. и определяемому как
. Однако, несмотря на то, что неравенство Ур.11 является достаточным, нет необходимости в его истинности для всех n и d. Для таких величин может удовлетворять другому неравенству, выводимому из Ур.31 документа Пенга и др. и определяемому как
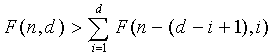 (12)
(12)
В этом случае Ур.11 должно выполняться в строгом смысле для конкретных (m,k),(m≤n),(k≤d), то есть
 >
>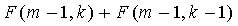 , m≤n, k≤d (13)
, m≤n, k≤d (13)
Возвращаясь к Ур.9, нам требуется сгенерировать путем создания функций 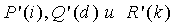 с приближениями низкой сложности для исходных функций так, чтобы
с приближениями низкой сложности для исходных функций так, чтобы
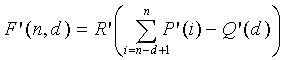 (14)
(14)
и где удовлетворяются условия Ур.10 и 11. Рассматривая 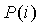 , мы можем аппроксимировать эту функцию так, чтобы
, мы можем аппроксимировать эту функцию так, чтобы 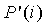 ≥
≥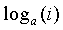 ,
,  . Если мы выберем a=2 и затем ограничим 32-мя битами точности, получившиеся операции можно легко реализовать в переносных мобильных устройствах, поскольку большинство DSP поддерживает однотактовые 32-битные сложения. Поэтому зададим
. Если мы выберем a=2 и затем ограничим 32-мя битами точности, получившиеся операции можно легко реализовать в переносных мобильных устройствах, поскольку большинство DSP поддерживает однотактовые 32-битные сложения. Поэтому зададим
 , (15)
, (15)
где l(i) - коэффициент сдвига, который может изменяться в зависимости от i. В предпочтительном варианте l(i)=l=21, но многие другие варианты значений также возможны. В этом примере коэффициент 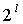 эквивалентен сдвигу на l бит влево, а функция
эквивалентен сдвигу на l бит влево, а функция 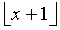 отсекает дробные биты, округляя до следующего наибольшего целого, и, наконец, коэффициент
отсекает дробные биты, округляя до следующего наибольшего целого, и, наконец, коэффициент 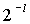 сдвигает результат обратно вправо на l бит. Используя такую методику, функция ≥ для всех i≥1, а также обеспечивает достаточный динамический диапазон и точность с использованием только 32 бит, поскольку 9 бит положительной разрядности в области определения
сдвигает результат обратно вправо на l бит. Используя такую методику, функция ≥ для всех i≥1, а также обеспечивает достаточный динамический диапазон и точность с использованием только 32 бит, поскольку 9 бит положительной разрядности в области определения  могут представлять 512-битное число. Для того чтобы избежать сложности с вычислением этих величин в реальном времени, их можно вычислить предварительно и хранить в таблице с использованием только 144 × 4 байт памяти для примера с . Используя похожую методику аппроксимации
могут представлять 512-битное число. Для того чтобы избежать сложности с вычислением этих величин в реальном времени, их можно вычислить предварительно и хранить в таблице с использованием только 144 × 4 байт памяти для примера с . Используя похожую методику аппроксимации  , получаем
, получаем
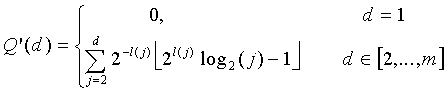 (16)
(16)
где функция  используется из-за вычитания величины из общего количества. Это гарантирует, что
используется из-за вычитания величины из общего количества. Это гарантирует, что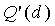 ≤
≤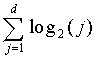 , так что вклад будет гарантировать ≥. Несмотря на то, что l(j) предполагает многие значения в зависимости от m и n, в предпочтительном варианте используется значение l(j)=l=14 для переменного коэффициента сдвига. Как и
, так что вклад будет гарантировать ≥. Несмотря на то, что l(j) предполагает многие значения в зависимости от m и n, в предпочтительном варианте используется значение l(j)=l=14 для переменного коэффициента сдвига. Как и 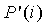 ,
, 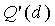 может быть предварительно вычислена и сохранена в таблице с использованием только 28 × 4 байт памяти для примера с . Для определения
может быть предварительно вычислена и сохранена в таблице с использованием только 28 × 4 байт памяти для примера с . Для определения 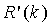 нам необходимо сначала определить k как
нам необходимо сначала определить k как
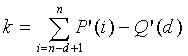 (17)
(17)
При определенных выше и k предпочтительно является 32-битным числом с 8-битным беззнаковым целым компонентом 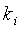 и 24-битным дробным компонентом
и 24-битным дробным компонентом 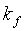 . Используя это, мы можем вывести
. Используя это, мы можем вывести 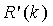 ≥
≥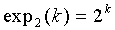 , полагая
, полагая  , и взяв обратное преобразование от логарифма по основанию 2, чтобы получить
, и взяв обратное преобразование от логарифма по основанию 2, чтобы получить 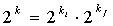 . Затем мы можем использовать разложение в ряд Тейлора для оценки дробного компонента с нужной точностью, представленной как
. Затем мы можем использовать разложение в ряд Тейлора для оценки дробного компонента с нужной точностью, представленной как  , округляя результат с использованием функции округления до наименьшего ближайшего, и затем подходящим образом сдвигая результат для формирования результата с многократной точностью (имеющий только l значащих бит), так что
, округляя результат с использованием функции округления до наименьшего ближайшего, и затем подходящим образом сдвигая результат для формирования результата с многократной точностью (имеющий только l значащих бит), так что
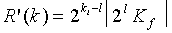 (18)
(18)
где 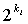 - коэффициент целочисленного сдвига, применяемый к результату разложения в ряд Тейлора. Здесь l является коэффициентом сдвига, используемый аналогично как в Ур.15 и 16 для обеспечения ≥
- коэффициент целочисленного сдвига, применяемый к результату разложения в ряд Тейлора. Здесь l является коэффициентом сдвига, используемый аналогично как в Ур.15 и 16 для обеспечения ≥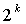 . Однако поскольку не может быть практически предварительно вычислена для эффективной работы в реальном времени, нужна высокая осторожность при задании точных операций, необходимых как в кодере, так и в декодере для гарантии того, что реконструированный сигнальный вектор в точности совпадает с входным сигнальным вектором. Стоит отметить, что может быть получена левым сдвигом
. Однако поскольку не может быть практически предварительно вычислена для эффективной работы в реальном времени, нужна высокая осторожность при задании точных операций, необходимых как в кодере, так и в декодере для гарантии того, что реконструированный сигнальный вектор в точности совпадает с входным сигнальным вектором. Стоит отметить, что может быть получена левым сдвигом 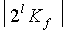 , который может быть точно представлен посредством l бит.
, который может быть точно представлен посредством l бит.
В обсуждении выше функции , и были выбраны так, чтобы отдельная оценка гарантировала, что 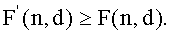 Однако необходимо только, чтобы общий результат удовлетворял этому условию. Например, и могут быть как описано выше, а может быть более близкой к
Однако необходимо только, чтобы общий результат удовлетворял этому условию. Например, и могут быть как описано выше, а может быть более близкой к  функцией, которая может отбрасывать или округлять наименее значащие биты так, чтобы могла быть меньше для некоторых значений k. Это приемлемо, пока такой эффект мал относительно эффекта и , так что свойства Ур.10 и Ур.11 все еще оставались бы истинными.
функцией, которая может отбрасывать или округлять наименее значащие биты так, чтобы могла быть меньше для некоторых значений k. Это приемлемо, пока такой эффект мал относительно эффекта и , так что свойства Ур.10 и Ур.11 все еще оставались бы истинными.
Также любые функции , и могут быть использованы без потери общности, пока свойства Ур.10 и Ур.11 сохраняются. Осторожность должна быть проявлена, однако, в том, что может случиться увеличение битовой скорости, если используется слишком малая точность. Стоит также отметить, что существует характерное соотношение между битовой скоростью и сложностью, и для больших значений m и n увеличение в 1 или 2 бита может быть приемлемым компромиссом за значительное увеличение точности.
Далее будет описано формулирование частичного кодового слова C для положений и магнитуд в схеме 106 комбинаторного кодирования. Пусть 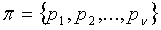 - положения ненулевых импульсов (в возрастающем порядке), а
- положения ненулевых импульсов (в возрастающем порядке), а 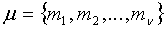 - магнитуды в соответствующих положениях в векторе x. Код для положений импульсов задается как
- магнитуды в соответствующих положениях в векторе x. Код для положений импульсов задается как
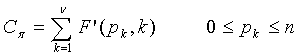 , (19)
, (19)
а код для магнитуд импульсов задается как:
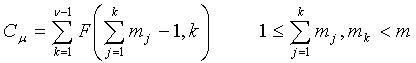 (20)
(20)
Таким образом, формулирование этого кодового слова требует сложения чисел ν и 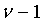 многократной точности. Подобные операции вычитания нужны в декодере. Эти операции также добавляют сложности способу FPC, когда m и n велики. Рассмотрим кодирование/декодирование аудиосигнала в многоуровневой системе кодирования. Эта методика используется для кодирования преобразования остаточного сигнала погрешности на трех уровнях многоуровневой системы. Пусть размер 20мс блока равен n=280 и одинаков для всех уровней. Количество импульсов для кодирования зависит от битовой скорости каждого уровня. Если скорости уровней 8 Кбит/с, 16 Кбит/с или 32 Кбит/с, то им понадобится 160 бит, 320 бит и 640 бит для кодирования 20 мс блока, соответственно. С использованием способа FPC блок длины 280 может быть закодирован с помощью 28, 74, и 230 импульсов для 160 бит, 320 бит и 640 бит на уровень, соответственно. Операции с многократной точностью в уравнениях (19) и (20) выполняются на цифровом сигнальном процессоре, который обычно оперирует 16-битными словами. Таким образом, для формирования 160-битного кодового слова необходимо выполнить операции сложения с 10 словами, а для 640-битного кодового слова операции сложения должны быть выполнены для более чем 40 слов. Каждая операция сложения занимает 4 блока (генерирование переноса разряда, перемещение в массив, сложение с переносом разряда). Следовательно, кодирование/декодирование k-битного кодового слова на p уровнях многоуровневой системы требует
многократной точности. Подобные операции вычитания нужны в декодере. Эти операции также добавляют сложности способу FPC, когда m и n велики. Рассмотрим кодирование/декодирование аудиосигнала в многоуровневой системе кодирования. Эта методика используется для кодирования преобразования остаточного сигнала погрешности на трех уровнях многоуровневой системы. Пусть размер 20мс блока равен n=280 и одинаков для всех уровней. Количество импульсов для кодирования зависит от битовой скорости каждого уровня. Если скорости уровней 8 Кбит/с, 16 Кбит/с или 32 Кбит/с, то им понадобится 160 бит, 320 бит и 640 бит для кодирования 20 мс блока, соответственно. С использованием способа FPC блок длины 280 может быть закодирован с помощью 28, 74, и 230 импульсов для 160 бит, 320 бит и 640 бит на уровень, соответственно. Операции с многократной точностью в уравнениях (19) и (20) выполняются на цифровом сигнальном процессоре, который обычно оперирует 16-битными словами. Таким образом, для формирования 160-битного кодового слова необходимо выполнить операции сложения с 10 словами, а для 640-битного кодового слова операции сложения должны быть выполнены для более чем 40 слов. Каждая операция сложения занимает 4 блока (генерирование переноса разряда, перемещение в массив, сложение с переносом разряда). Следовательно, кодирование/декодирование k-битного кодового слова на p уровнях многоуровневой системы требует 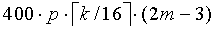 операций/сек. Для разных значений n, m и p сложность операций сложения/вычитания с многократной точностью показана в Таблице 1. В этой таблице WMOPs обозначает взвешенное значение миллионов операций в секунду (Weighted Millions of Operation Per Second).
операций/сек. Для разных значений n, m и p сложность операций сложения/вычитания с многократной точностью показана в Таблице 1. В этой таблице WMOPs обозначает взвешенное значение миллионов операций в секунду (Weighted Millions of Operation Per Second).
Сложность сложения/вычитания в кодировании/декодировании FPC с помощью известного из уровня техники способа
3
3
280
280
16 Кбит/с/320
32 Кбит/с/640
74
230
3,48 WMOPs
22,0 WMOPs
Из Таблицы 1 видно, что, когда битовая скорость удваивается, сложность сложения с многократной точностью возрастает в шесть раз.
Как упоминалось выше, комбинаторная функция заменяется приближенной функцией  , которая задается как
, которая задается как
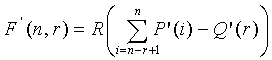 , (21)
, (21)
где
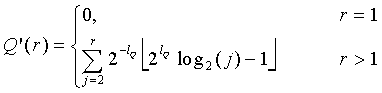 (22)
(22)
и 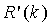 является приближением функции
является приближением функции  , задаваемая как:
, задаваемая как:
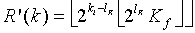 (23)
(23)
где разбито на целый и дробный компоненты k, а 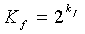 - остаточный член малого порядка разложения в ряд Тейлора дробного компонента k. На основании вышеопределенных функций
- остаточный член малого порядка разложения в ряд Тейлора дробного компонента k. На основании вышеопределенных функций 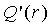 и сначала получается таким образом, что неравенство однозначной декодируемости
и сначала получается таким образом, что неравенство однозначной декодируемости
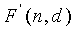 > (24)
> (24)
удовлетворяется для всех n и d.
Возвращаясь к Ур. 19 и 20, замена приближенными функциями 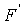 действительных функций F приводит к следующему:
действительных функций F приводит к следующему:
 , (25)
, (25)
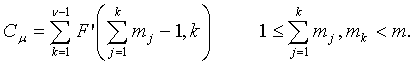 (26)
(26)
Двоичное представление 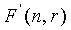 , полученное из Ур. 23, имеет
, полученное из Ур. 23, имеет 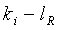 нулей окончания, если
нулей окончания, если 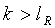 . была получена как число с многократной точностью путем сдвига влево (
. была получена как число с многократной точностью путем сдвига влево ( сдвигов)
сдвигов) 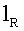 -битного числа. Поскольку замыкающие h бит
-битного числа. Поскольку замыкающие h бит 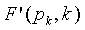 являются нулями, эти замыкающие h бит кодового слова не будут модифицированы, когда мы прибавим к существующей частичной сумме в Ур.25. Чтобы эффективно использовать это свойство, вычисляется в псевдоформате с плавающей запятой, т.е. функция выводит
являются нулями, эти замыкающие h бит кодового слова не будут модифицированы, когда мы прибавим к существующей частичной сумме в Ур.25. Чтобы эффективно использовать это свойство, вычисляется в псевдоформате с плавающей запятой, т.е. функция выводит 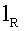 -битную мантиссу (M) и соответствующую неотрицательную экспоненту (h).
-битную мантиссу (M) и соответствующую неотрицательную экспоненту (h). 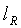 -битная мантисса (M) определяется как
-битная мантисса (M) определяется как
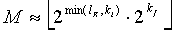 , (27)
, (27)
а экспонента h определяется как
 . (28)
. (28)
Теперь суммирование в Ур.25 и 26 может легко использовать тот факт, что  слова не модифицируются, когда прибавляется к частичной сумме.
слова не модифицируются, когда прибавляется к частичной сумме.
Вышеприведенный способ на самом деле снижает в некоторой степени сложность. Однако перенос разряда, сгенерированный во время операции, возможно придется сохранять до конца кодового слова. Впоследствии мы покажем, что, если 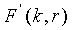 удовлетворяет конкретным условиям, то перенос разряда придется сохранять до намного меньшей части всего кодового слова.
удовлетворяет конкретным условиям, то перенос разряда придется сохранять до намного меньшей части всего кодового слова.
Сначала раскроем, что перенос разряда сохранится на одно дополнительное кодовое слово, если будут складываться (как в Ур.19) в точности комбинаторные функции 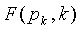 , и суммирование проводится в возрастающим порядком k
, и суммирование проводится в возрастающим порядком k
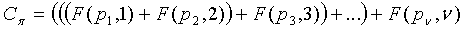 , (29)
, (29)
т.е. частичная сумма  , к которой прибавляется , задается как
, к которой прибавляется , задается как
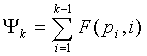 . (30)
. (30)
Можно показать, что операнд с многократной точностью меньше, чем 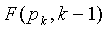 . Максимальное отношение к меньше, чем
. Максимальное отношение к меньше, чем 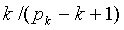 . Это отношение является бесконечностью при
. Это отношение является бесконечностью при 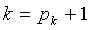 , которое также является максимально возможным значением k. Поскольку
, которое также является максимально возможным значением k. Поскольку 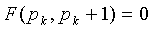 , перенос разряда придется сохранить в этом конкретном случае. Для других значений k это отношение не больше, чем меньшее из n и m. Таким образом
, перенос разряда придется сохранить в этом конкретном случае. Для других значений k это отношение не больше, чем меньшее из n и m. Таким образом
+<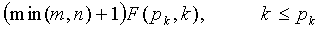 , (31)
, (31)
Поскольку 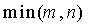 меньше 32768, то вышеприведенное суммирование не приведет к сохранению переноса разряда более, чем на одно дополнительное кодовое слово. Это предполагает, что, если мы используем в точности комбинаторные функции в упорядоченном суммировании (29), то мы получим преимущество сохранения переноса разряда только на одно дополнительное кодовое слово, однако, в точности комбинаторные функции не имеют преимущества замыкающих нулей, и поэтому сложение выполняется по длине .
меньше 32768, то вышеприведенное суммирование не приведет к сохранению переноса разряда более, чем на одно дополнительное кодовое слово. Это предполагает, что, если мы используем в точности комбинаторные функции в упорядоченном суммировании (29), то мы получим преимущество сохранения переноса разряда только на одно дополнительное кодовое слово, однако, в точности комбинаторные функции не имеют преимущества замыкающих нулей, и поэтому сложение выполняется по длине .
Ясно, что нам нужно создать приближенные функции так, чтобы в дополнение к однозначной декодируемости и замыкающим нулям упорядоченное сложение в Ур.29 не требовало сохранения переноса разряда. Можно показать, что частичная сумма (первое кодовое слово с многократной точностью), к которой прибавляется , задается как
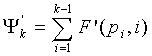 , (32)
, (32)
которая меньше, чем  . Поэтому неравенство
. Поэтому неравенство
 <
<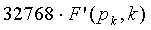 , (33)
, (33)
является достаточным, чтобы при добавлении 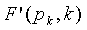 к
к 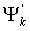 для генерации (модифицированное кодовое слово с многократной точностью),
для генерации (модифицированное кодовое слово с многократной точностью),
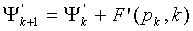 , (34)
, (34)
перенос разряда сохранился только на одно дополнительное кодовое слово. Это было эмпирически определено для , заданной уравнениями 21, 22 и 23. Кроме неравенства однозначной декодируемости нам нужно, чтобы выполнялось неравенство частичных сумм, т.е.
< (35)
Можно показать, что, если неравенство однозначной декодируемости сохраняется для  , тогда
, тогда
< (36)
(36)
Таким образом, достаточно сгенерировать , которая удовлетворяет следующему:
> (37)
Теперь приближенные комбинаторные функции удовлетворяют:
1. неравенству однозначной декодируемости;
2. свойству замыкающих нулей;
3. неравенству частичных сумм.
Поэтому эти функции могут быть использованы в построении факторного упаковывания кодового слова путем модифицирования только очень малого подмножества (только 3 слова из 10, 20 или 30 слов) полного кодового слова многократной точности. Малое подмножество представляется указателем положения, определяемого целыми числами 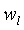 и
и 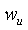 , которые определяют слова в кодовом слове многократной точности, которые будут модифицированы. Указатель положения вычисляется следующим образом:
, которые определяют слова в кодовом слове многократной точности, которые будут модифицированы. Указатель положения вычисляется следующим образом:
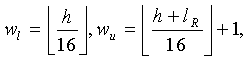 (38)
(38)
где 16 является длиной слова, а 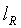 =16 выбирается как длина мантиссы. Слова от до кодового слова (
=16 выбирается как длина мантиссы. Слова от до кодового слова (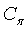 ) многократной точности модифицируются на основании мантиссы M. Заметим, что кодовое слово многократной точности
) многократной точности модифицируются на основании мантиссы M. Заметим, что кодовое слово многократной точности
=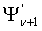 . (39)
. (39)
Декодер использует вычитание из . Используя те же аргументы, как и для суммирования, можно показать, что, если функции 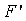 удовлетворяют трем вышеприведенным свойствам, то во время декодирования также только очень малому подмножеству всего кодового слова понадобится модифицирование. В декодере
удовлетворяют трем вышеприведенным свойствам, то во время декодирования также только очень малому подмножеству всего кодового слова понадобится модифицирование. В декодере 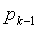 получается как
получается как
 (40)
(40)
Сложность кодирования/декодирования положений и магнитуд с использованием способа, известного из уровня техники, была показана в Таблице 1. (Сложность была показана только для части суммирования и вычитания. Сложность не включает в себя сложность генерирования ). Использование предлагаемого способа для кодирования/декодирования на трех уровнях многоуровневой системы приводит к значительному снижению сложности в сложении/вычитании многократной точности. Соответствующие числа сложности при использовании настоящего изобретения показаны в Таблице 2. Заметим, что улучшение сложности увеличивается, когда используется больше импульсов (более длинный размер кодового слова) в кодировании.
Сложность сложения/вычитания в кодировании/декодировании FPC с помощью настоящего изобретения
3
3
280
280
16 Кбит/с/320
32 Кбит/с/640
74
230
0,53 WMOPs
1,65 WMOPs
Кодирование количества ненулевых положений:
Формат представления -битной мантиссы и экспоненты также имеет преимущества в кодировании количества ненулевых положений. Кодирование количества ненулевых положений ν задается как
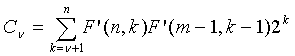 (41)
(41)
Можно легко заметить, что умножение двух приближенных функций может быть более легким в формате мантиссы и экспоненты, чем в формате многократной точности. Основным преимуществом, однако, является то, что когда нам нужно уменьшить сложность, используя представления -битной мантиссы и экспоненты, каждая из функций 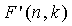 и
и 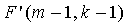 может быть заранее сохранена с использованием только двух слов (произведение их -битных мантисс и сумма их экспонент также могут быть заранее сохранены). Это позволяет более быстрое кодирование ν без каких-либо значительных требований к ROM.
может быть заранее сохранена с использованием только двух слов (произведение их -битных мантисс и сумма их экспонент также могут быть заранее сохранены). Это позволяет более быстрое кодирование ν без каких-либо значительных требований к ROM.
Во время работы кодера 100 схема 106 комбинаторного кодирования будет принимать сигнальный вектор (x), который должен быть закодирован. Первый операнд () многократной точности будет сгенерирован на основании сигнального вектора, который должен быть закодирован. Более конкретно, 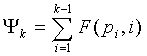 , где
, где 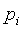 являются положениями ненулевых элементов вектора x. Генерируются операнд мантиссы (
являются положениями ненулевых элементов вектора x. Генерируются операнд мантиссы (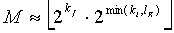 ) и операнд экспоненты (). Как операнд мантиссы, так и операнд экспоненты представляют второй операнд () многократной точности, который основывается на сигнальном векторе, который должен быть закодирован. Схема 106 затем выбирает часть , чтобы модифицировать на основании операнда экспоненты. Как обсуждалось выше, эта часть представляется указателем положения, определяемым целыми числами и , которые определяют слова в кодовом слове многократной точности, которые будут модифицированы. Указатель положения вычисляется как в Ур(38). Еще часть затем модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда () многократной точности как в Ур.(34), и генерируется кодовое слово многократной точности для использования в соответствующем декодере, на основании модифицированного операнда многократной точности, как показано в Ур.39.
) и операнд экспоненты (). Как операнд мантиссы, так и операнд экспоненты представляют второй операнд () многократной точности, который основывается на сигнальном векторе, который должен быть закодирован. Схема 106 затем выбирает часть , чтобы модифицировать на основании операнда экспоненты. Как обсуждалось выше, эта часть представляется указателем положения, определяемым целыми числами и , которые определяют слова в кодовом слове многократной точности, которые будут модифицированы. Указатель положения вычисляется как в Ур(38). Еще часть затем модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда () многократной точности как в Ур.(34), и генерируется кодовое слово многократной точности для использования в соответствующем декодере, на основании модифицированного операнда многократной точности, как показано в Ур.39.
Фиг.2 иллюстрирует один пример генерации кодового слова с помощью вышеприведенной методики. Как описано выше, . Как показано на Фиг.2, только слова 3, 4 и 5 кодового слова многократной точности модифицируются при переходе от к . Конкретными словами, которые выбраны для модифицирования, являются слова от до кодового слова (Cπ) многократной точности, причем и основаны на экспоненте h=50, так что
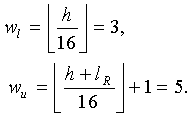
Слово из модифицируется путем прибавления сдвинутых влево 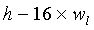 меньших значимых бит мантиссы M. Слова от
меньших значимых бит мантиссы M. Слова от 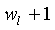 до
до  модифицируются путем прибавления последующих 16 бит мантиссы M. Слово модифицируется путем прибавления только разряда переноса из предыдущего сложения. Заметим, что, поскольку
модифицируются путем прибавления последующих 16 бит мантиссы M. Слово модифицируется путем прибавления только разряда переноса из предыдущего сложения. Заметим, что, поскольку 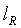 =16, то =
=16, то =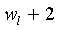 . В случае декодера вместо сложений выполняются вычитания.
. В случае декодера вместо сложений выполняются вычитания.
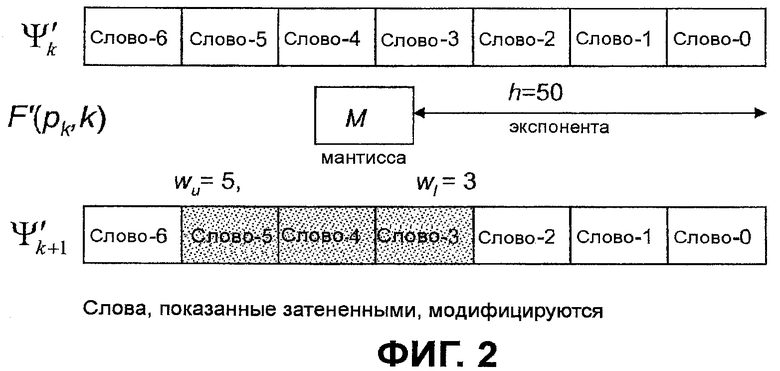
Фиг.3 является блок-схемой декодера 300. Как показано, декодер 300 содержит схему 306 комбинаторного декодирования, схему 310 реконструкции сигнала, другую схему 304 декодирования и генератор 108 комбинаторных функций. Во время работы схемой 306 комбинаторного декодирования принимается комбинаторное кодовое слово. Схема 306 комбинаторного декодирования предоставляет n и d в генератор комбинаторных функций и принимает 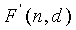 в ответ. Схема 306 декодирования затем создает вектор x
i на основании . Схема 306 работает сходным образом как схема 106, за исключением того, что операции сложения заменены вычитаниями. Другими словами,
в ответ. Схема 306 декодирования затем создает вектор x
i на основании . Схема 306 работает сходным образом как схема 106, за исключением того, что операции сложения заменены вычитаниями. Другими словами, 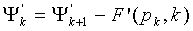 . Вектор x
i передается в схему 310 реконструкции сигнала, где создается выходной сигнал (например, речь, аудио, изображения, видео или другие сигналы) на основании x
i и других параметров от другой схемы 304 декодирования. Более конкретно, другие параметры могут содержать любое количество параметров реконструкции сигнала, связанных с используемой парадигмой кодирования сигналов в конкретном варианте осуществления. Они могут содержать, но не в качестве ограничения, параметры энергии и масштабирования сигнала и параметры спектрального формования и/или фильтра синтезатора. Обычно эти параметры используются для масштабирования энергии и/или спектрального формования реконструированного сигнального вектора x
i таким образом, чтобы воспроизвести окончательный выходной сигнал.
. Вектор x
i передается в схему 310 реконструкции сигнала, где создается выходной сигнал (например, речь, аудио, изображения, видео или другие сигналы) на основании x
i и других параметров от другой схемы 304 декодирования. Более конкретно, другие параметры могут содержать любое количество параметров реконструкции сигнала, связанных с используемой парадигмой кодирования сигналов в конкретном варианте осуществления. Они могут содержать, но не в качестве ограничения, параметры энергии и масштабирования сигнала и параметры спектрального формования и/или фильтра синтезатора. Обычно эти параметры используются для масштабирования энергии и/или спектрального формования реконструированного сигнального вектора x
i таким образом, чтобы воспроизвести окончательный выходной сигнал.
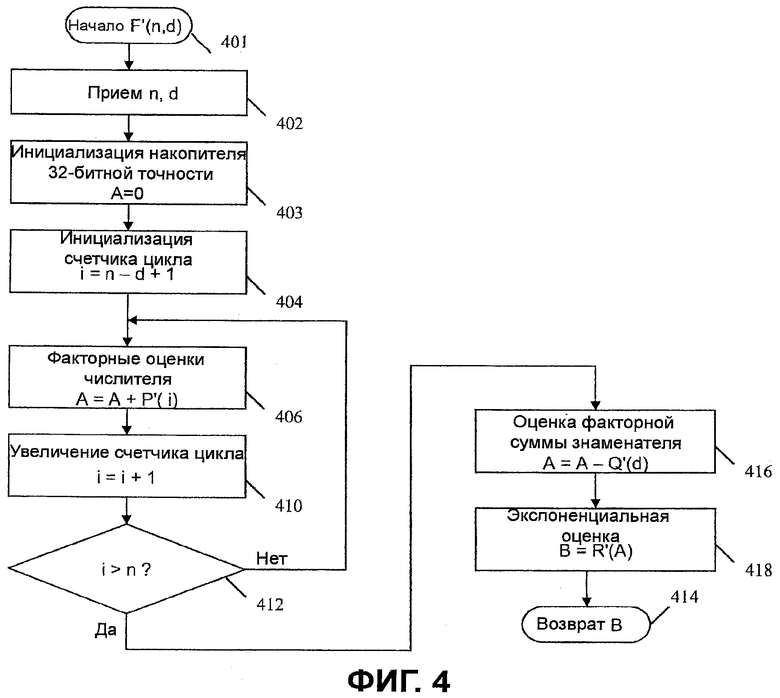
Фиг.4 является блок-схемой последовательности операций, показывающей работу генератора комбинаторных функций с Фиг.1 и Фиг.3. Более конкретно, последовательность операций логической схемы на Фиг.4 показывает те этапы, которые необходимы генератору 108 комбинаторных функций для получения . Последовательность операций логической схемы начинается на этапе 402, где принимаются входные n и d. На этапе 403 накопитель A устанавливается в 0. На этапе 404 счетчик i устанавливается равным n-d+1. На этапе 406 логарифмическое приближение прибавляется к накопителю A. На этапе 410 счетчик i увеличивается на 1. Этапы 406-410 повторяются в цикле, пока счетчик i не превзойдет n. Этап 412 проверяет условие i>n и завершает цикл, когда i превзойдет n. На этой стадии накопитель содержит логарифмическое приближение числителя комбинаторной функции , логарифмическое приближение знаменателя комбинаторной функции вычитается из накопителя на этапе 416 для получения логарифмического приближения комбинаторной функции. На этапе 418 берется экспоненциальное приближение 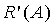 накопителя для генерирования приближения B комбинаторной функции. На этапе 414 B выводится как .
накопителя для генерирования приближения B комбинаторной функции. На этапе 414 B выводится как .
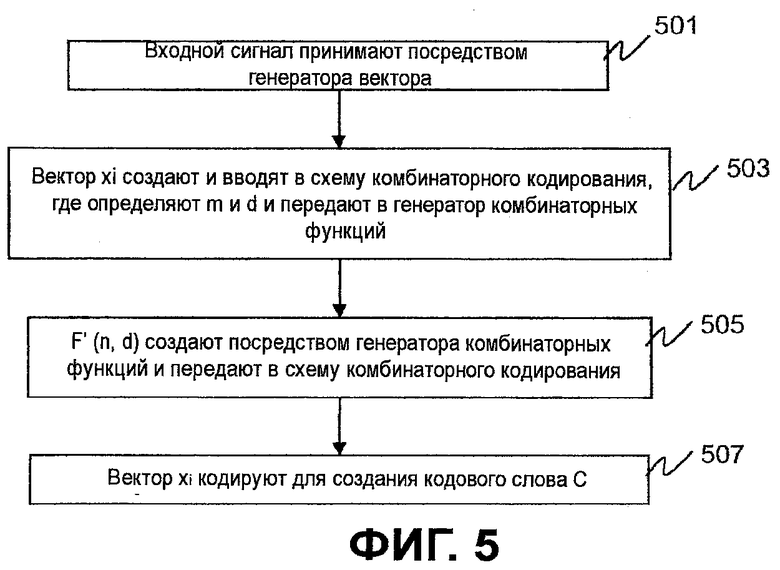
Фиг.5 является блок-схемой последовательности операций, показывающей работу кодера с Фиг.1. Последовательность операций логической схемы начинается на этапе 501, где генератором 102 вектора принимается входной сигнал. Как обсуждалось выше, входной сигнал может содержать речь, аудио, изображение, видео, или другие сигналы. На этапе 503 создается вектор x
i и вводится в схему 106 комбинаторного кодирования, определяются m и d и передаются в генератор 108 комбинаторных функций. Как обсуждалось выше, m является полным количеством импульсов единичной амплитуды (или сумма абсолютных значений совокупно измеренных компонентов x
i) и d является количеством ненулевых элементов x
i. На этапе 505 генератором 108 комбинаторных функций создается и передается в схему 106 комбинаторного кодирования, где вектор x
i кодируется для создания кодового слова C (этап 507). Как обсуждалось выше, создается путем замены функций 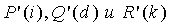 в на приближения низкой сложности исходных функций так, чтобы условия Ур.10 и 11 удовлетворялись.
в на приближения низкой сложности исходных функций так, чтобы условия Ур.10 и 11 удовлетворялись.
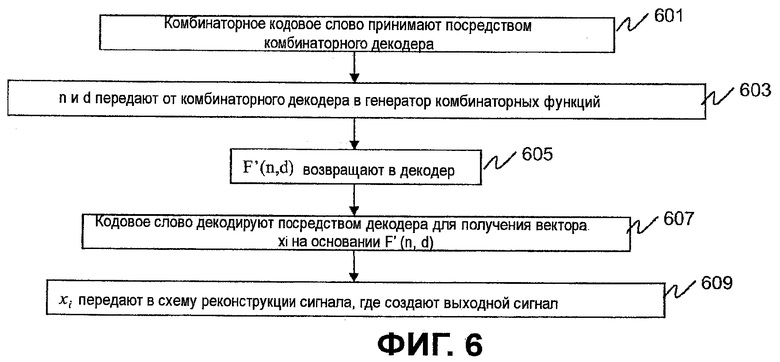
Фиг.6 является блок-схемой последовательности операций, показывающей работу декодера с Фиг.3. Последовательность операций логической схемы начинается на этапе 601, где комбинаторным декодером 306 принимается комбинаторное кодовое слово. На этапе 603 n и d передаются от комбинаторного декодера 306 в генератор 108 комбинаторных функций, и возвращается в комбинаторный декодер 306 (этап 605). Кодовое слово декодируется декодером 306 на основании (этап 607) для получения вектора x
i, а x
i передается схему 310 реконструкции сигнала, где создается выходной сигнал (этап 609).
Фиг.7 является блок-схемой последовательности операций, показывающей работу схемы 106 комбинаторного кодирования. Последовательность операций логической схемы начинается на этапе 701, где принимается сигнальный вектор (x). Первый операнд () многократной точности будет сгенерирован (этап 703) на основании сигнального вектора, который должен быть закодирован. Более конкретно, , где являются положениями ненулевых элементов вектора x. Генерируются (этап 705) операнд мантиссы ( ) и операнд экспоненты (). Как операнд мантиссы, так и операнд экспоненты представляют второй операнд () многократной точности, который основывается на сигнальном векторе, который должен быть закодирован. Схема 106 затем выбирает часть , чтобы модифицировать на основании операнда экспоненты (этап 707). Как обсуждалось выше, эта часть представляется указателем положения, определяемым целыми числами и , которые определяют слова в кодовом слове многократной точности, которые будут модифицированы. Указатель положения вычисляется как в Ур.38. На этапе 709 часть затем модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда () многократной точности как в Ур.34, и на этапе 711 генерируется кодовое слово многократной точности для использования в соответствующем декодере на основании модифицированного операнда многократной точности, как показано в Ур.39.
) и операнд экспоненты (). Как операнд мантиссы, так и операнд экспоненты представляют второй операнд () многократной точности, который основывается на сигнальном векторе, который должен быть закодирован. Схема 106 затем выбирает часть , чтобы модифицировать на основании операнда экспоненты (этап 707). Как обсуждалось выше, эта часть представляется указателем положения, определяемым целыми числами и , которые определяют слова в кодовом слове многократной точности, которые будут модифицированы. Указатель положения вычисляется как в Ур.38. На этапе 709 часть затем модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда () многократной точности как в Ур.34, и на этапе 711 генерируется кодовое слово многократной точности для использования в соответствующем декодере на основании модифицированного операнда многократной точности, как показано в Ур.39.
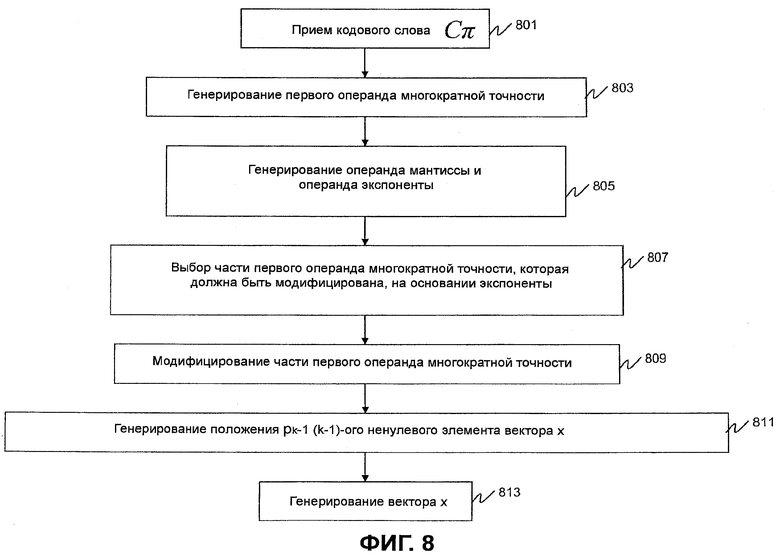
Фиг.8 является блок-схемой последовательности операций, показывающей работу схемы 306 комбинаторного декодирования. Последовательность операций логической схемы начинается на этапе 801, где принимается кодовое слово (Сπ).Первый операнд
(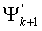 ) многократной точности будет сгенерирован (этап 803) на основании принятого кодового слова. Более конкретно,
) многократной точности будет сгенерирован (этап 803) на основании принятого кодового слова. Более конкретно, 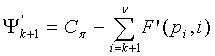 , где являются положениями ненулевых элементов закодированного вектора x. Генерируются (этап 805) операнд мантиссы (
, где являются положениями ненулевых элементов закодированного вектора x. Генерируются (этап 805) операнд мантиссы (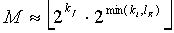 ) и операнд экспоненты
) и операнд экспоненты
(). Как операнд мантиссы, так и операнд экспоненты представляют второй операнд () многократной точности, который основывается на кодовом слове. Как обсуждалось выше, эта часть представляется указателем положения, определяемым целыми числами и , которые определяют слова в кодовом слове многократной точности, которые будут модифицированы. Указатель положения вычисляется как в Ур.38. На этапе 809 часть 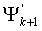 модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда (
модифицируется на основании операнда мантиссы и указателя положения для получения модифицированного операнда ( ) многократной точности как
) многократной точности как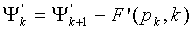 , и на этапе 811 положение (k-1)-го ненулевого элемента вектора x декодируется на основании модифицированного кодового слова многократной точности как в Ур.40. На этапе 813 декодированный вектор (x) генерируется на основании положения .
, и на этапе 811 положение (k-1)-го ненулевого элемента вектора x декодируется на основании модифицированного кодового слова многократной точности как в Ур.40. На этапе 813 декодированный вектор (x) генерируется на основании положения .
Таблица 3 показывает снижение сложности, связанное с настоящим изобретением, по сравнению с уровнем техники. Для разных значений m и n даны связанное число бит M и среднее количество вызовов  за фрейм. Для этих примеров интервал длины фрейма составляет 20 мс, что соответствует скорости 50 фреймов в секунду. Единицей измерения для сравнения сложности является взвешенное значение миллионов операций в секунду, или WMOPS. Была использована компьютерная симуляция для получения оценки сложности, как если бы она была запущена DSP с фиксированной запятой и ограниченной точностью. Для этих примеров при необходимости использовались библиотеки вычислений с многократной точностью, и каждой элементарной команде был назначен подходящий вес. Например, перемножениям и сложениям был назначен вес одной операции, в то время как элементарным трансцендентным операциям и операциям деления был назначен вес 25 операций. По таблице легко заметить, что использование обеспечивает значительное снижение сложности по сравнению с уровнем техники, и что пропорциональное снижение сложности растет с ростом m и n. Показано, что такое снижение сложности так же велико, как два порядка магнитуды для случая с
за фрейм. Для этих примеров интервал длины фрейма составляет 20 мс, что соответствует скорости 50 фреймов в секунду. Единицей измерения для сравнения сложности является взвешенное значение миллионов операций в секунду, или WMOPS. Была использована компьютерная симуляция для получения оценки сложности, как если бы она была запущена DSP с фиксированной запятой и ограниченной точностью. Для этих примеров при необходимости использовались библиотеки вычислений с многократной точностью, и каждой элементарной команде был назначен подходящий вес. Например, перемножениям и сложениям был назначен вес одной операции, в то время как элементарным трансцендентным операциям и операциям деления был назначен вес 25 операций. По таблице легко заметить, что использование обеспечивает значительное снижение сложности по сравнению с уровнем техники, и что пропорциональное снижение сложности растет с ростом m и n. Показано, что такое снижение сложности так же велико, как два порядка магнитуды для случая с 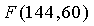 , но будет продолжать расти с дальнейшим ростом m и n. Это происходит в основном за счет роста точности операндов, которая требуется, чтобы разрешать комбинаторные выражения в уровне техники. Эти операции на практике приводят к чрезмерной нагрузке сложности и фактически препятствуют использованию факторного импульсного кодирования в качестве способа кодирования векторов с потенциально большими m и n. Настоящее изобретение решает эти проблемы, требуя только однотактовые операции с низкой точностью вкупе с малым количеством памяти для получения оценок сложных комбинаторных выражений, требуемых для этого типа кодирования.
, но будет продолжать расти с дальнейшим ростом m и n. Это происходит в основном за счет роста точности операндов, которая требуется, чтобы разрешать комбинаторные выражения в уровне техники. Эти операции на практике приводят к чрезмерной нагрузке сложности и фактически препятствуют использованию факторного импульсного кодирования в качестве способа кодирования векторов с потенциально большими m и n. Настоящее изобретение решает эти проблемы, требуя только однотактовые операции с низкой точностью вкупе с малым количеством памяти для получения оценок сложных комбинаторных выражений, требуемых для этого типа кодирования.
Сравнение сложности F(n,m) и F'(n,m)
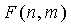 за фрейм уровня техники
за фрейм уровня техники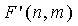 изобретения
изобретения
Последующий текст и уравнения реализуют вышеприведенную методику кодирования и декодирования в спецификации C.P0014-C Проекта Партнерства Третьего Поколения 2 (3GPP2) для Расширенного Кодека с Переменной Скоростью, Речевые Службы Варианты 3, 68 и 70 для Широкополосных Цифровых Систем с Расширением Спектра.
4.13.5 Квантование остаточного линейного спектра MDCT
Коэффициенты MDCT, также называемые остаточным линейным спектром, квантуются тем же способом, что и кодовая факторная книга FCB 4.11.8.3. В общем случае факторное кодирование 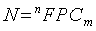 возможных комбинаций может быть достигнуто при условии, что вектор v длины n имеет свойство
возможных комбинаций может быть достигнуто при условии, что вектор v длины n имеет свойство 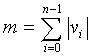 , и все элементы νi целочисленные. То есть, сумма абсолютных значений целочисленных элементов v равна m. В данном случае мы желаем закодировать версию
, и все элементы νi целочисленные. То есть, сумма абсолютных значений целочисленных элементов v равна m. В данном случае мы желаем закодировать версию  с масштабированной энергией, так что
с масштабированной энергией, так что
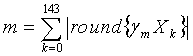 , (4.13.5-1)
, (4.13.5-1)
где 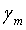 является коэффициентом глобального масштабирования, а диапазон от 0 до 143 соответствует частотам от 0 до 3600 Гц. Для этого случая m может быть для NB или WB входов. Значение , используемое для достижения вышеприведенной задачи, определяется итеративно (для ненулевого
является коэффициентом глобального масштабирования, а диапазон от 0 до 143 соответствует частотам от 0 до 3600 Гц. Для этого случая m может быть для NB или WB входов. Значение , используемое для достижения вышеприведенной задачи, определяется итеративно (для ненулевого  ) согласно следующему псевдокоду:
) согласно следующему псевдокоду:
/*Инициализация*/

/*основной цикл*/
do {
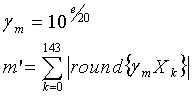
if (m'==m) then break
else if (m'>m and s==+1) then s=-1, 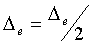
else if (m'<m and s==-1) then s=+1,
end

} while 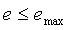 and
and 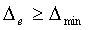
Квантованный остаточный линейный спектр 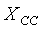 затем вычисляется как
затем вычисляется как
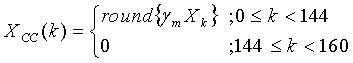 , (4.13.5-2)
, (4.13.5-2)
Если, в редком случае, значения m и m' различны, линейный спектр будет модифицирован путем прибавления или вычитания единичных значений из квантованного линейного спектра . Это гарантирует, что результирующий линейный спектр может быть надежно закодирован с использованием способа факторного кодирования. Выходной индекс, представляющий линейный спектр , обозначается RLSIDX. Этот индекс содержит 131 бит для случая 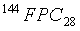 и 114 бит для случая
и 114 бит для случая 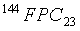 .
.
Для решения вопросов сложности, связанных с кодированием и декодированием вектора , используется приближенная комбинаторная функция 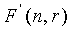 малого порядка вместо стандартного комбинаторного отношения
малого порядка вместо стандартного комбинаторного отношения  . В частности, как кодер, так и декодер используют генератор комбинаторных функций, имеющий свойства
. В частности, как кодер, так и декодер используют генератор комбинаторных функций, имеющий свойства 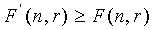 и
и  , которые достаточны для однозначного кодирования/декодирования вектора . Функция задается как
, которые достаточны для однозначного кодирования/декодирования вектора . Функция задается как
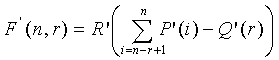 , (4.13.5-3)
, (4.13.5-3)
где 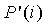 и
и 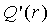 являются 32-битными таблицами поиска, задаваемыми как
являются 32-битными таблицами поиска, задаваемыми как
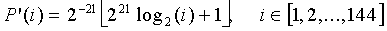 , (4.13.5-4)
, (4.13.5-4)
и
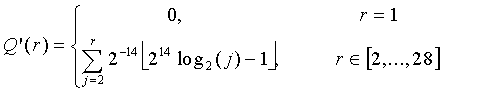 (4.13.5-5)
(4.13.5-5)
и где 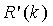 является целочисленным приближением многократной точности функции
является целочисленным приближением многократной точности функции 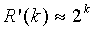 , задаваемой как
, задаваемой как
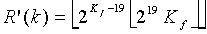 , (4.13.5-6)
, (4.13.5-6)
где разбито на целый и дробный компоненты k, а - остаточный член разложения в ряд Тейлора дробного компонента k. Эти операции значительно снижают сложность, необходимую для вычисления комбинаторных выражений, путем замены операций умножения и деления многократной точности на 32-битные сложения и на приближения 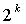 рядом Тейлора низкой сложности с последующей операцией сдвига многократной точности. Все другие компоненты операций кодирования/декодирования те же, что и в 4.11.8.3.
рядом Тейлора низкой сложности с последующей операцией сдвига многократной точности. Все другие компоненты операций кодирования/декодирования те же, что и в 4.11.8.3.
Несмотря на то, что изобретение было описано со ссылкой на конкретный вариант осуществления, специалистам в области техники должно быть понятно, что могут быть сделаны различные модификации в отношении формы и подробностей изобретения без отступления от сущности и объема изобретения. Предполагается, что подобные изменения попадают в объем пунктов следующей формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ КОМБИНАТОРНОГО КОДИРОВАНИЯ МАЛОЙ СЛОЖНОСТИ СИГНАЛОВ | 2009 |
|
RU2471288C2 |
| КОДЕР, ДЕКОДЕР И СООТВЕТСТВУЮЩИЕ СПОСОБЫ С ИСПОЛЬЗОВАНИЕМ КОМПАКТНОГО MV ХРАНИЛИЩА | 2019 |
|
RU2771925C1 |
| КОДЕР, ДЕКОДЕР И СООТВЕТСТВУЮЩИЕ СПОСОБЫ С ИСПОЛЬЗОВАНИЕМ КОМПАКТНОГО MV ХРАНИЛИЩА | 2019 |
|
RU2783385C2 |
| ВЫЧИСЛЕНИЕ ОТНОШЕНИЯ СИГНАЛ-ШУМ КОНВЕРТОРА С УМЕНЬШЕННОЙ СЛОЖНОСТЬЮ | 2013 |
|
RU2610588C2 |
| СПОСОБЫ И УСТРОЙСТВО LDPC-КОДИРОВАНИЯ | 2005 |
|
RU2395902C2 |
| СПОСОБЫ И СИСТЕМЫ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ LDPC КОДОВ | 2016 |
|
RU2716044C1 |
| ОБРАБОТКА ИЗОБРАЖЕНИЙ | 2004 |
|
RU2317587C1 |
| КОДИРОВАНИЕ ПЕРЦЕПЦИОННО-КВАНТОВАННОГО ВИДЕОКОНТЕНТА В МНОГОУРОВНЕВОМ КОДИРОВАНИИ VDR | 2014 |
|
RU2619886C2 |
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ В СКРУЧЕННОМ ПОЛЯРНОМ КОДЕ | 2014 |
|
RU2571587C2 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ ВВЕДЕНИЯ НИЗКОЧАСТОТНЫХ ПРЕДЫСКАЖЕНИЙ В ХОДЕ СЖАТИЯ ЗВУКА НА ОСНОВЕ ACELP/TCX | 2005 |
|
RU2389085C2 |

Изобретение относится к кодированию векторов, в частности к комбинаторному факторному импульсному кодированию векторов с низкой сложностью. Техническим результатом является минимизация вычислительной сложности. Указанный результат достигается тем, что во время работы кодера принимают входной вектор (х). Первый операнд (ψ'k) многократной точности генерируют на основании входного вектора, который должен быть закодирован. Генерируют операнд мантиссы и операнд экспоненты, которые представляют второй операнд многократной точности, основанный на входном векторе, который должен быть закодирован. Далее выбирают часть ψ'k, которая должна быть модифицирована, на основании операнда экспоненты. Часть ψ'k модифицируют на основании операнда мантиссы для получения модифицированного операнда (ψ'k+1) многократной точности. Наконец, генерируют кодовое слово многократной точности на основе модифицированного операнда многократной точности для использования в соответствующем декодере. 4 н. и 5 з.п. ф-лы, 8 ил., 3 табл.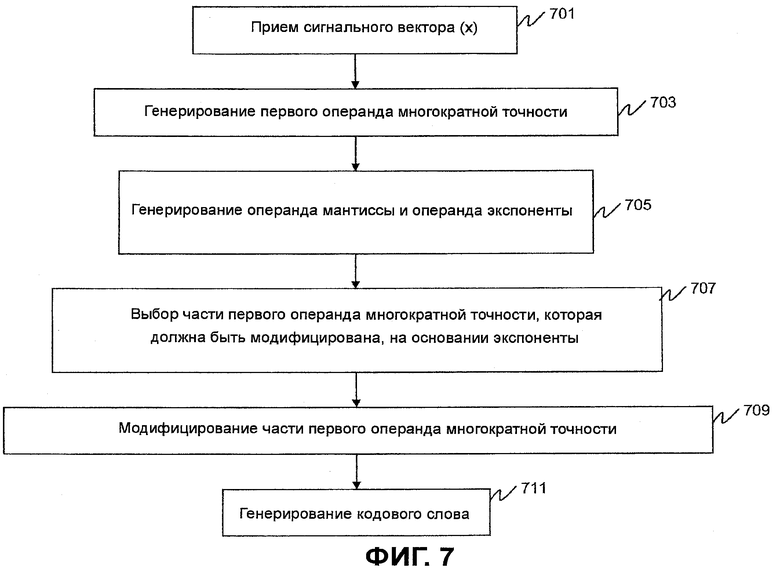
1. Способ работы кодера, который производит кодовое слово (С) из входного вектора (х), причем способ содержит этапы, на которых
принимают входной вектор, который должен быть закодирован;
генерируют первый операнд (Ψ'k) многократной точности на основании входного вектора;
генерируют операнд (М) мантиссы и операнд (h) экспоненты, причем операнд мантиссы и операнд экспоненты представляют второй операнд (F'(pk,k)) многократной точности, который основан на входном векторе, который должен быть закодирован;
выбирают часть первого операнда многократной точности, которая должна быть модифицирована, на основании операнда экспоненты;
модифицируют часть первого операнда многократной точности на основании операнда мантиссы, чтобы произвести модифицированный операнд (Ψ'k+1) многократной точности; и
генерируют кодовое слово (С) на основании модифицированного операнда многократной точности.
2. Способ по п.1, в котором Ψ'k+1, основан на множестве операндов мантиссы и экспоненты, которые представляют F'(pi, i); 1≤i≤k, где pi являются положениями ненулевых элементов входного вектора х.
3. Способ по п.1, в котором 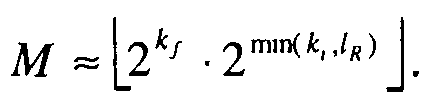
4. Способ по п.1, в котором h является функцией ki.
5. Способ по п.1, в котором часть первого операнда Ψ'k многократной точности, которая должна быть модифицирована, представлена указателем положения, определяемым целыми числами wl и wu.
6. Способ по п.5, в котором
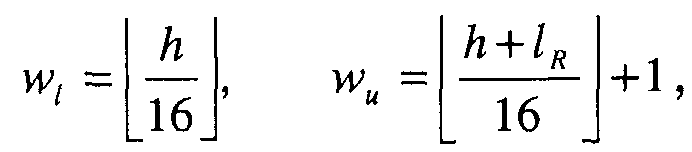
где 16 является длиной слова, а lR является длиной мантиссы.
7. Кодер (100), содержащий
схему (106) комбинаторного кодирования, выполняющую этапы, на которых
принимают сигнальный вектор х, который должен быть закодирован;
генерируют первый операнд (Ψ'k) многократной точности на основании х;
генерируют операнд (М) мантиссы и операнд (h) экспоненты, причем операнд мантиссы и операнд экспоненты представляют второй операнд (F'(pk,k)) многократной точности, который основан на сигнальном векторе, который должен быть закодирован;
выбирают часть Ψ'k, которая должна быть модифицирована, на основании операнда экспоненты;
модифицируют часть Ψ'k на основании операнда мантиссы и указателя положения, чтобы произвести модифицированный операнд (Ψ'k+1) многократной точности; и
генерируют кодовое слово (С) на основании Ψ'k+1.
8. Способ работы декодера, который генерирует вектор (х) из кодового слова (С), причем способ содержит этапы, на которых принимают кодовое слово (Сπ);
генерируют первый операнд (Ψ'k+1) многократной точности на основании Cπ;
генерируют операнд (М) мантиссы и операнд (h) экспоненты, причем операнд мантиссы и операнд экспоненты представляют второй операнд (F'(pk,k)) многократной точности, который основан на кодовом слове;
выбирают часть Ψ'k+1, которая должна быть модифицирована, на основании операнда экспоненты;
модифицируют часть Ψ'k+1 на основании операнда мантиссы и указателя положения, чтобы произвести модифицированный операнд (Ψ'k) многократной точности;
декодируют положение рk-1(k-1)-гo ненулевого элемента вектора х; и
генерируют вектор (х) на основании положения рk-1.
9. Декодер (300), содержащий
схему (306) комбинаторного декодирования, выполняющую этапы, на которых
принимают кодовое слово (Сπ);
генерируют первый операнд (Ψ'k+1) многократной точности на основании Сπ;
генерируют операнд (М) мантиссы и операнд (h) экспоненты, причем операнд мантиссы и операнд экспоненты представляют второй операнд (F'(pk,k)) многократной точности, который основан на кодовом слове;
выбирают часть Ψ'k+1, которая должна быть модифицирована, на основании операнда экспоненты;
модифицируют часть Ψ'k+1, на основании операнда мантиссы и указателя положения, чтобы произвести модифицированный операнд (Ψ'k) многократной точности;
декодируют положение рk-1(k-1)-гo ненулевого элемента вектора х; и генерируют вектор (х) на основании положения pk-1.
| MITTAL U | |||
| и др., Low Complexity Factorial Pulse Coding of MDCT Coefficients using Approximation of Combinatorial Functions, IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2007, 15.04.2007-20.04.2007, c | |||
| РЕЛЬСОВАЯ ПЕДАЛЬ | 1920 |
|
SU289A1 |
| US 5268855 A, 07.12.1993 | |||
| US 5974435 A, 26.10.1999 | |||
| WO 2007012794 A2, 01.02.2007 | |||
| ОПТИЧЕСКИЙ ЦИФРОВОЙ СТРАНИЧНЫЙ УМНОЖИТЕЛЬ С ПЛАВАЮЩЕЙ ТОЧКОЙ | 1998 |
|
RU2137179C1 |

