Уровень техники
Общеизвестны способы кодирования векторных или матричных величин для речевых сигналов, аудиосигналов, сигналов изображения, видеосигналов и других сигналов. Один такой способ, описанный в патенте США 6236960, Peng et al (который включен в данный документ по ссылке), известен как факториальное импульсное кодирование (или FPC). FPC может кодировать вектор xi, используя в сумме M битов, с учетом того, что:

и все значения вектора xi представляют собой целочисленные значения, так что
-m≤xi≤m, где m представляет собой суммарное количество импульсов единичной амплитуды, и n представляет собой длину вектора. Суммарные M битов используются для кодирования N комбинаций максимально эффективным образом, так что сохраняется справедливость следующего выражения, которое описывает теоретически минимальное количество комбинаций:
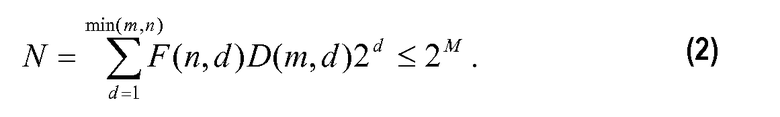
Для этого уравнения F(n,d) представляют собой количество комбинаций d ненулевых векторных элементов по n положениям, определяемым посредством:

D(m,d) представляет собой количество комбинаций d ненулевых векторных элементов при заданных m суммарных единичных импульсах, определяемых посредством:

и 2d представляет комбинации, необходимые для описания полярности (знака) d ненулевых векторных элементов. Член min(m,n) учитывает случай, когда количество импульсов m единичной величины превышает длину n вектора. Способ и устройство кодирования и декодирования векторов этого вида были полностью описаны в известном уровне техники. Кроме того, практическая реализация данного способа кодирования была описана в стандарте C.S0014-B Проекта 2 партнерства по созданию системы третьего поколения (3GPP2), где длина вектора n=54, и количество импульсов единичной величины m=7 создает кодовое слово из M=35 битов.
Хотя эти значения n и m не вызывают какой-либо чрезмерной нагрузки из-за сложности, большие значения могут быстро вызвать проблемы, особенно в мобильных карманных устройствах, в которых необходимо поддерживать объем памяти и сложность вычислений минимально возможными. Например, использование данного способа кодирования для некоторых применений (таких как аудиокодирование) может потребовать n=144 и m=28 или выше. При таких условиях затраты, связанные с выведением комбинаторного выражения F(n,d), используя способы известного уровня техники, могут быть слишком высокие для практической реализации.
Рассматривая эти затраты более подробно, можно переписать уравнение 3 как:

Непосредственная реализация является проблематичной, так как F(144, 28) потребует 197 битов точности в числителе и 98 битов точности в знаменателе для получения 99-битового частного. Так как большинство процессоров цифровой обработки сигналов (DSP), используемых в современных карманных устройствах, обычно поддерживают только операции умножения 16 бит × 16 бит, необходимо применять специальные подпрограммы умножения/деления с многократно увеличенной точностью. Такие подпрограммы требуют последовательности вложенных операций умножения/накопления, которые обычно требуют порядка k операций умножения/накопления (MAC), где k представляет собой количество 16-битовых сегментов в операнде. Для 197-битового операнда 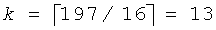 . Поэтому выполнение одного 197×16-битового умножения потребует минимум 13 операций MAC плюс операции сдвига и сохранения. Член знаменателя вычисляется подобным образом для получения 98-битового результата. Кроме того, требуется 197/98-битовое деление, которое представляет собой очень сложную операцию, таким образом, вычисление всего факториального отношения в уравнении 5 потребовало бы значительных ресурсов.
. Поэтому выполнение одного 197×16-битового умножения потребует минимум 13 операций MAC плюс операции сдвига и сохранения. Член знаменателя вычисляется подобным образом для получения 98-битового результата. Кроме того, требуется 197/98-битовое деление, которое представляет собой очень сложную операцию, таким образом, вычисление всего факториального отношения в уравнении 5 потребовало бы значительных ресурсов.
В попытке уменьшить сложность уравнение 5 можно переписать для распределения операций деления для получения следующего:
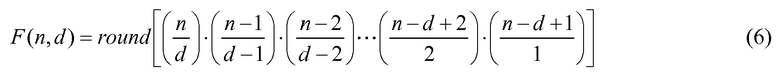
В данном выражении уменьшается динамический диапазон операций деления, но, к сожалению, необходимо повышенное разрешение частного, чтобы точно представить деление на 3, 7, 9 и т.д. Чтобы приспособить эту структуру, также необходима операция округления, чтобы гарантировать целочисленный результат. При заданном большом количестве операций деления с высокой точностью эта реализация не решает надлежащим образом проблему сложности для больших m и n и дополнительно имеет потенциальную возможность получения неправильного результата из-за накопленных ошибок точности.
В еще другой реализации уравнение 5 может быть переупорядочено следующим образом:
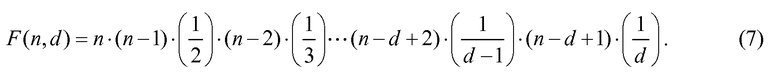
Если это выражение оценивается слева направо, то результат всегда создает целочисленное значение. Хотя этот способ контролирует вопрос точности и динамического диапазона в некоторой степени, большие значения m и n все же требуют интенсивного использования операций умножения и деления с многократно увеличенной точностью.
Наконец, чтобы минимизировать сложность вычислений, может быть возможным выполнять предварительное вычисление и сохранение всех факториальных комбинаций в таблице соответствия. Таким образом, все значения F(n,m) могут быть просто сохранены в матрице размера n×m и соответствующим образом извлечены из памяти, используя всего несколько циклов процессора. Проблема с данным подходом, однако, заключается в том, что когда n и m становятся большими, таким же становится связанное с ними требование к памяти. Ссылаясь на предыдущий пример, F(144, 28) потребует 144 × 28 × 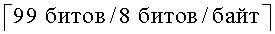 =52416 байтов памяти, что является чрезмерным для большинства мобильных карманных устройств. Поэтому существует потребность в способе и устройстве для комбинаторного факториального импульсного кодирования малой сложности векторов.
=52416 байтов памяти, что является чрезмерным для большинства мобильных карманных устройств. Поэтому существует потребность в способе и устройстве для комбинаторного факториального импульсного кодирования малой сложности векторов.
Краткое описание чертежей
Признаки изобретения, которые, как считается, являются новыми, подробно изложены в прилагаемой формуле изобретения. Само изобретение, однако, как в отношении организации, так и способа работы, вместе с его целями и преимуществами, лучше всего может быть понято посредством ссылки на последующее подробное описание изобретения, которое описывает некоторые примерные варианты осуществления изобретения, рассматриваемые вместе с прилагаемыми чертежами, на которых:
фиг.1 представляет собой блок-схему кодера.
Фиг.2 представляет собой блок-схему декодера.
Фиг.3 представляет собой блок-схему последовательности операций, изображающую работу генератора комбинаторной функции по фиг.1 и фиг.3.
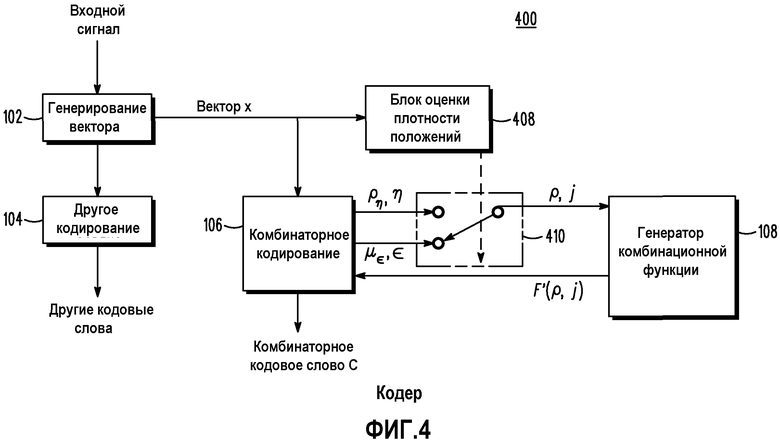
Фиг.4 представляет собой блок-схему кодера согласно различным вариантам осуществления.
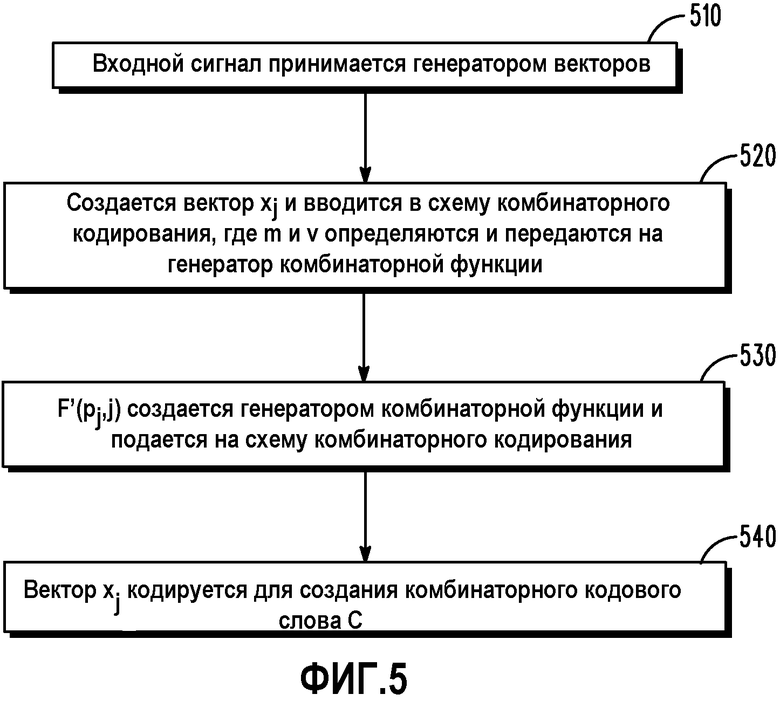
Фиг.5 представляет собой блок-схему последовательности операций, изображающую работу кодера согласно различным вариантам осуществления.
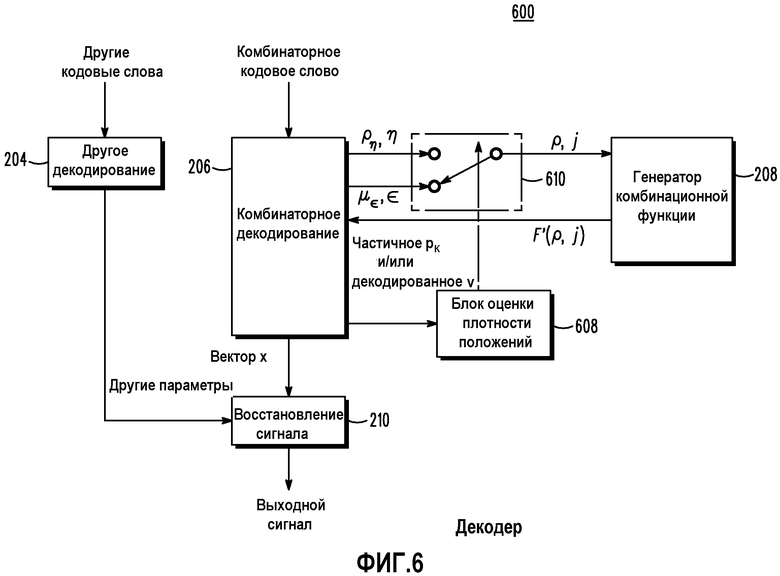
Фиг.6 представляет собой блок-схему декодера согласно различным вариантам осуществления.
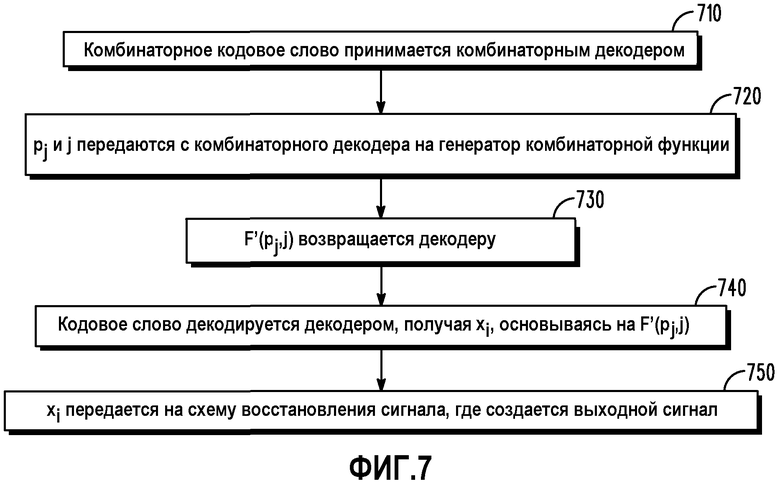
Фиг.7 представляет собой блок-схему последовательности операций, изображающую работу декодера согласно различным вариантам осуществления.
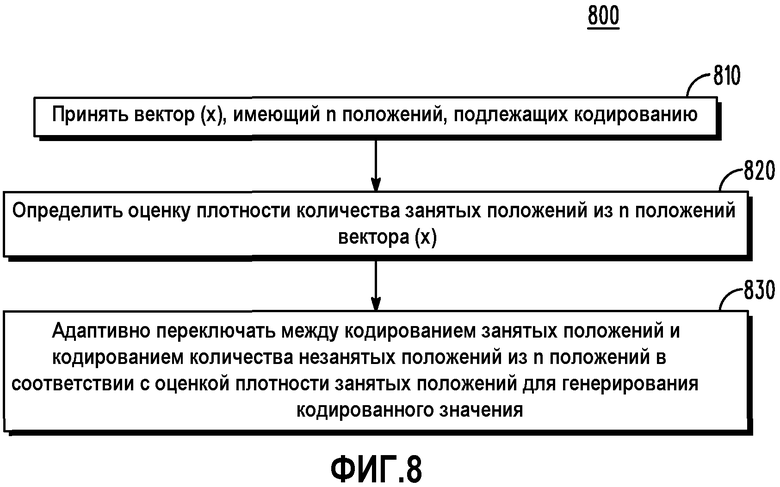
Фиг.8 представляет собой блок-схему последовательности операций, изображающую работу кодера, использующего оценку плотности, согласно различным вариантам осуществления.
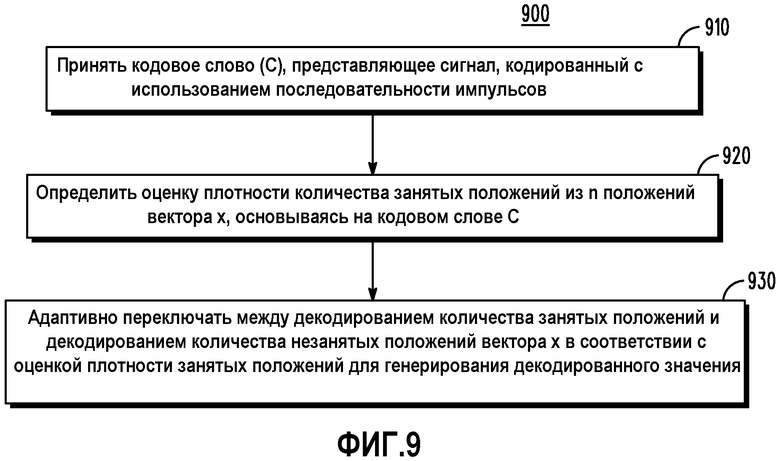
Фиг.9 представляет собой блок-схему последовательности операций, изображающую работу декодера, использующего оценку плотности, согласно различным вариантам осуществления.
Фиг.10 представляет собой блок-схему последовательности операций, изображающую работу кодера относительно порогового значения согласно различным вариантам осуществления.
Фиг.11 представляет собой блок-схему последовательности операций, изображающую работу декодера относительно порогового значения согласно различным вариантам осуществления.
Специалист в данной области техники понимает, что элементы на фигурах изображены для простоты и ясности и необязательно, чтобы они были нарисованы в масштабе. Например, размеры некоторых элементов на фигурах могут быть увеличены относительно других элементов, чтобы способствовать улучшению понимания вариантов осуществления настоящего изобретения.
Подробное описание
Хотя данное изобретение допускает наличие варианта осуществления во многих разных видах, на чертежах показаны и в данном документе подробно описываются конкретные варианты осуществления, понимая, что настоящее раскрытие должно рассматриваться как пример принципов изобретения и не предполагается, что оно ограничивает изобретение конкретными изображенными и описанными вариантами осуществления. В описании ниже подобные позиции используются для описания таких же, подобных или соответствующих деталей на нескольких видах чертежей.
В данном документе относительные термины, такие как первый и второй, верхний и нижний и т.п., могут использоваться исключительно для различения одного объекта или действия от другого объекта или действия, не требуя или подразумевая обязательно какой-либо фактической такой зависимости или порядка между такими объектами или действиями. Термины «содержит», «содержащий» или любой другой их вариант, как предполагается, охватывают неисключительное включение, так что процесс, способ, предмет или устройство, которое содержит список элементов, не включает в себя только эти элементы, но может включать в себя другие элементы, не перечисленные в явной форме или присущие такому процессу, способу, предмету или устройству. Элемент, которому предшествует «содержит …» не исключает, без дополнительных ограничений, наличие дополнительных идентичных элементов в процессе, способе, предмете или устройстве, которые содержат элемент.
Ссылка в данном документе на «один вариант осуществления», «некоторые варианты осуществления», «вариант осуществления» или подобные термины означает, что конкретный признак, структура или характеристика, описанные в связи с вариантом осуществления, включен в по меньшей мере один вариант осуществления настоящего изобретения. Таким образом, необязательно, что все появления таких фраз или в различных местах в данном описании изобретения ссылаются на один и тот же вариант осуществления. Кроме того, конкретные признаки, структуры или характеристики могут объединяться без ограничения любым подходящим образом в одном или нескольких вариантах осуществления.
Термин «или», как он используется в данном документе, должен интерпретироваться как включающий или означающий любое одно или любое сочетание. Поэтому «А, В или С» означает «любое из следующего: А; В; С; А и В; А и С; В и С; А, В и С». Исключение для этого определения имеет место только тогда, когда сочетание элементов, функций, этапов или действий является некоторым образом в своей основе взаимно исключающим.
Настоящее изобретение относится, в основном, к кодированию векторов и, в частности, к комбинационному факториальному импульсному кодированию векторов.
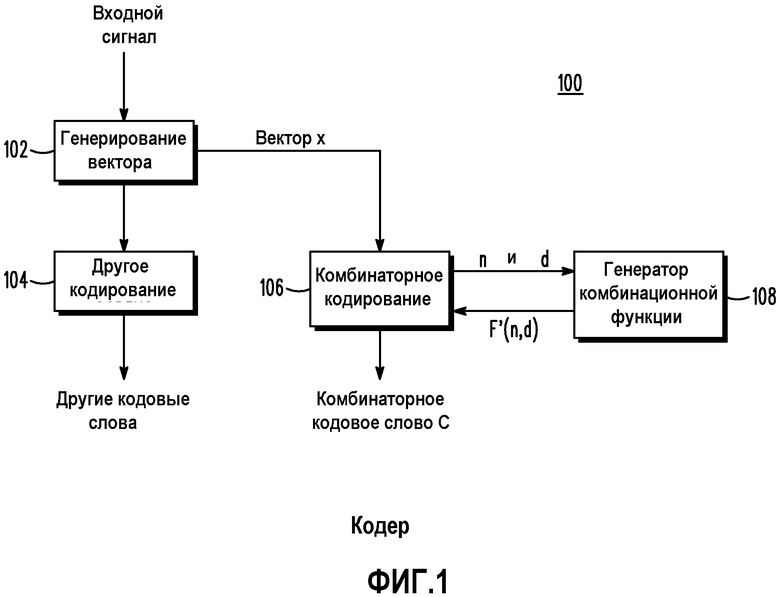
Как показано на чертежах, на которых подобные позиции обозначают подобные компоненты, фиг.1 представляет собой блок-схему кодера 100. Кодер 100 содержит генератор 102 векторов, схему (кодер) 106 комбинационного кодирования, генератор 108 комбинационных функций и схему 104 другого кодирования. Во время работы входной сигнал, подлежащий кодированию, принимается генератором 102 векторов. Как известно в технике, входной сигнал может содержать такие сигналы, как речевой сигнал, аудиосигнал, сигнал изображения, видеосигнал и другие сигналы.
Генератор 102 векторов принимает входной сигнал и создает вектор xi. Генератор 102 векторов может содержать любое количество парадигм кодирования, включая, но не ограничиваясь ими, кодирование речи CELP (линейное предсказание с кодовым возбуждением), описанное Peng et al, кодирование в области преобразования для аудио, изображений и видео, включая способы, основанные на дискретном преобразовании Фурье (DFT), дискретном косинусном преобразовании (DCT) и модифицированном дискретном косинусном преобразовании (MDCT), кодирование с вейвлет-преобразованием, прямую импульсно-кодовую модуляцию (PCM) во временной области, дифференциальную PCM, адаптивную дифференциальную PCM (ADPCM) или любой один из семейства методов полосного кодирования, которые общеизвестны в технике. Фактически, любой вектор сигнала вида, приведенного выше, может быть выгодно обработан согласно некоторым вариантам осуществления настоящего изобретения.
Схема 106 комбинаторного кодирования принимает вектор xi и использует факториальное импульсное кодирование для получения кодового слова C. Как описано выше, факториальное импульсное кодирование может кодировать вектор xi, используя в сумме M битов, при условии, что 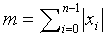 , и все значения вектора xi являются целочисленными, так что -m≤xi≤m, где m представляет собой суммарное количество единичных импульсов амплитуды, и n представляет собой длину вектора. Как описано выше, большие значения m и n могут быстро вызывать проблемы, особенно в мобильных карманных устройствах, в которых необходимо поддерживать объем памяти и сложность вычислений максимально низкими.
, и все значения вектора xi являются целочисленными, так что -m≤xi≤m, где m представляет собой суммарное количество единичных импульсов амплитуды, и n представляет собой длину вектора. Как описано выше, большие значения m и n могут быстро вызывать проблемы, особенно в мобильных карманных устройствах, в которых необходимо поддерживать объем памяти и сложность вычислений максимально низкими.
Чтобы решить этот вопрос, генератор 108 комбинаторных функций использует метод малой сложности для получения F'(n,d). Схема 106 комбинаторного кодирования затем использует F'(n,d) для получения кодового слова C. Схема 108 использует аппроксимации с относительно низким разрешением (биты точности) факториальных комбинаций F'(n,d), которые обеспечивают только необходимую точность для возможности генерирования достоверного кодового слова. Т.е. пока сохраняются некоторые свойства, подходящая аппроксимация функции F(n,d) достаточна для того, чтобы гарантировать, что результирующее кодовое слово является однозначно декодируемым.
Чтобы описать генерирование F'(n,d), сначала выводят функцию F'(n,d), которая представляет собой подходящую аппроксимацию F(n,d). Первым этапом является взятие логарифма по произвольному основанию a в уравнении 5 и взятие антилогарифма по основанию a переупорядоченных членов:
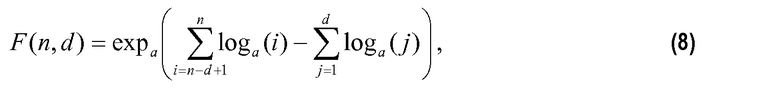
где функция expa(k)=ak. Затем определяют функции P(i), Q(d) и R(k) и подставляют в уравнение 8, так что:

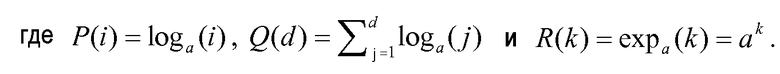
Однако согласно примерному варианту осуществления настоящего изобретения не является необходимым, чтобы F(n,d) и F'(n,d) были эквивалентными по порядку, чтобы результирующее кодовое слово являлось однозначно декодируемым. Существует только два условия, которые достаточны для того, чтобы они были справедливыми:

и
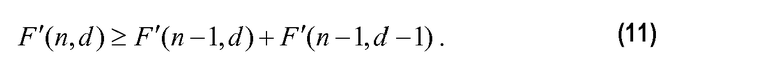
Для первого условия ограничение просто определяет, что если F'(n,d)<F(n,d), тогда будет перекрытие кодовых пространств, и, впоследствии, будет более одного входа, способного генерировать конкретное кодовое слово; таким образом, кодовое слово не является однозначно декодируемым. Второе условие определяет, что «ошибка» для данного n, d должна быть больше или равна сумме слагаемых ошибки, связанных с предыдущим элементом рекурсивной зависимости, описанной у Peng et.al в патенте США 6236960. Может быть показано, что F(n,d)=F(n-1,d)+F(n-1,d-1), которое верно только тогда, когда комбинаторное выражение точно равно F(n,d)=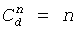 !/d!(n-d)!. Однако, когда неравенство в уравнении 11 является достаточным, оно может необязательно быть верным для всех значений n и d. Для таких значений F(n,d) может удовлетворять другому неравенству, выведенному из уравнения 31 у Peng et al. и определяется:
!/d!(n-d)!. Однако, когда неравенство в уравнении 11 является достаточным, оно может необязательно быть верным для всех значений n и d. Для таких значений F(n,d) может удовлетворять другому неравенству, выведенному из уравнения 31 у Peng et al. и определяется:
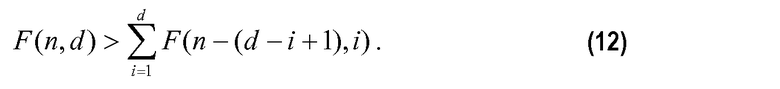
В данном случае, уравнение 11 должно выполняться со строгим неравенством для некоторых (m,k), (m≤n), (k≤d), т.е.:
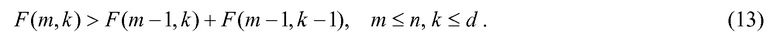
Возвращаясь обратно к уравнению 9, изобретатели теперь хотят сгенерировать F'(n,d) посредством создания функций P'(i), Q'(d) и R'(k) с аппроксимацией малой сложности исходных функций, так что:

и где выполняются условия, приведенные в уравнениях 10 и 11. Рассматривая P(i), можно аппроксимировать функцию, так что P'(i)≥loga(i), 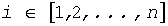 . Если выбрать a=2 и затем ограничить P'(i) до 32 битов точности, то легко реализовать результирующие операции на карманном мобильном устройстве, так как большинство DSP поддерживают 32-битовые сложения с одним циклом. Поэтому изобретатели определяют:
. Если выбрать a=2 и затем ограничить P'(i) до 32 битов точности, то легко реализовать результирующие операции на карманном мобильном устройстве, так как большинство DSP поддерживают 32-битовые сложения с одним циклом. Поэтому изобретатели определяют:
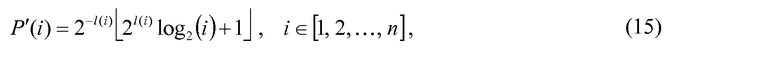
где l(i) представляет собой коэффициент сдвига, который может изменяться как функция i. В предпочтительном варианте осуществления l(i)=l=21, но возможны многие другие множества значений. Для данного примера коэффициент 2l эквивалентен сдвигу l битов влево, посредством чего функция округления до ближайшего меньшего целого 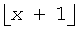 удаляет дробные биты, в тоже время округляя до следующего наибольшего целого числа, и, наконец, коэффициент 2-l сдвигает результаты обратно вправо на l битов. Используя данную методологию, функция P'(i)≥log2(i) для всех i≥1 и также обеспечивает достаточный динамический диапазон и точность, используя только 32 бита, так как 9 битов положительного целочисленного разрешения в области log2 могут представлять 512-битовое число. Чтобы избежать сложности вычислений этих значений в реальном времени, они могут вычисляться предварительно и сохраняться в таблице, используя 144 × 4 битов памяти для примера F(144, 28). Используя подобную методологию для аппроксимации Q(d), изобретатели получают:
удаляет дробные биты, в тоже время округляя до следующего наибольшего целого числа, и, наконец, коэффициент 2-l сдвигает результаты обратно вправо на l битов. Используя данную методологию, функция P'(i)≥log2(i) для всех i≥1 и также обеспечивает достаточный динамический диапазон и точность, используя только 32 бита, так как 9 битов положительного целочисленного разрешения в области log2 могут представлять 512-битовое число. Чтобы избежать сложности вычислений этих значений в реальном времени, они могут вычисляться предварительно и сохраняться в таблице, используя 144 × 4 битов памяти для примера F(144, 28). Используя подобную методологию для аппроксимации Q(d), изобретатели получают:
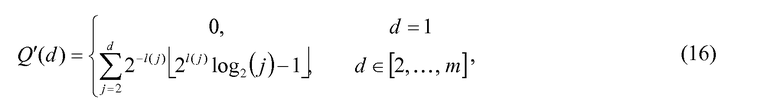
где функция округления до ближайшего меньшего целого 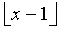 используется из-за вычитания величины из общего. Это гарантирует, что Q'(d)
используется из-за вычитания величины из общего. Это гарантирует, что Q'(d)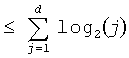 , так что вклад Q'(d) будет гарантировать F'(n,d)≥F(n,d). Хотя l(j) может принимать многие значения в зависимости от конфигурации m и n, предпочтительный вариант осуществления использует значение l(j)=l=14 для переменного коэффициента сдвига. Подобно P'(i), Q'(d) может вычисляться предварительно и сохраняться в таблице, используя только 28×4 байтов памяти для примера F(144, 28). Для определения R'(k) необходимо сначала определить k следующим образом:
, так что вклад Q'(d) будет гарантировать F'(n,d)≥F(n,d). Хотя l(j) может принимать многие значения в зависимости от конфигурации m и n, предпочтительный вариант осуществления использует значение l(j)=l=14 для переменного коэффициента сдвига. Подобно P'(i), Q'(d) может вычисляться предварительно и сохраняться в таблице, используя только 28×4 байтов памяти для примера F(144, 28). Для определения R'(k) необходимо сначала определить k следующим образом:

С P'(i) и Q'(d), определенными выше, k представляет собой предпочтительно 32-битовое число с 8-битовой целочисленной составляющей ki без знака и 24-битовой дробной составляющей kf. Используя это, можно вывести R'(k)≥exp2(k)=2k, принимая k=ki+kf, и затем беря антилогарифм по основанию 2 для получения 2k=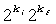 . Затем можно использовать разложение в ряд Тейлора для оценки дробной составляющей до требуемой точности, представленной
. Затем можно использовать разложение в ряд Тейлора для оценки дробной составляющей до требуемой точности, представленной 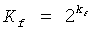 , округляя результат, используя функцию округления до ближайшего большего целого, и затем сдвигая соответствующим образом результат для формирования результата с многократно увеличенной точностью (только с l старшими битами), так что:
, округляя результат, используя функцию округления до ближайшего большего целого, и затем сдвигая соответствующим образом результат для формирования результата с многократно увеличенной точностью (только с l старшими битами), так что:

где 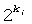 представляет собой целочисленный коэффициент сдвига, применяемый к результату разложения в ряд Тейлора. В данном случае, l представляет собой коэффициент сдвига, используемый подобно уравнениям 15 и 16, чтобы гарантировать R'(k)≥2k. Однако, так как R'(k) практически не может быть вычислена предварительно для эффективной работы в реальном времени, необходимо очень внимательно относится к заданию точных операций, необходимых как в кодере, так и в декодере для обеспечения того, чтобы восстановленный вектор сигнала точно соответствовал вектору входного сигнала. Отметьте, что R'(k) может быть получен в результате сдвига влево
представляет собой целочисленный коэффициент сдвига, применяемый к результату разложения в ряд Тейлора. В данном случае, l представляет собой коэффициент сдвига, используемый подобно уравнениям 15 и 16, чтобы гарантировать R'(k)≥2k. Однако, так как R'(k) практически не может быть вычислена предварительно для эффективной работы в реальном времени, необходимо очень внимательно относится к заданию точных операций, необходимых как в кодере, так и в декодере для обеспечения того, чтобы восстановленный вектор сигнала точно соответствовал вектору входного сигнала. Отметьте, что R'(k) может быть получен в результате сдвига влево 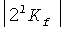 , который может быть точно представлен l битами.
, который может быть точно представлен l битами.
В вышеприведенном описании функции P'(i), Q'(d) и R'(k) были выбраны так, что каждая индивидуальная оценка функции гарантирует, что результирующее F'(n,d)≥F(n,d). Однако необходимо только, чтобы совокупное влияние удовлетворяло данному условию. Например, P'(i) и Q'(d) могут быть такими, которые описаны выше, но R'(k) может быть более обычной функцией R'(k)≈2k, которая может обрезать или округлять самые младшие биты, так что R'(k) может быть меньше, чем 2k для некоторых значений k. Это допустимо, пока данное влияние является незначительным относительно влияния P'(i) и Q'(d), поэтому свойства в уравнениях 10 и 11 все же сохраняются действительными.
Также любая функция P'(i), Q'(d) и R'(k) может использоваться без потери общности, пока выполняются свойства уравнений 10 и 11. Необходимо быть внимательным, однако, что повышение скорости передачи битов может происходить, если используется слишком малая точность. Также необходимо отметить, что существует присущий компромисс между скоростью передачи битов и сложностью, и для больших значений m и n увеличение на 1 или 2 бита может быть приемлемым компромиссом для существенного снижения сложности.
Теперь описывается формулировка частичного кодового слова C для положения и величин в схеме 106 комбинаторного кодирования. Пусть π={p1, p2, …, pv} будут положениями ненулевых импульсов (в возрастающем порядке) и µ={m1, m2, …, mv} величинами в соответствующих положениях у вектора x. Код для положений импульса определяется:
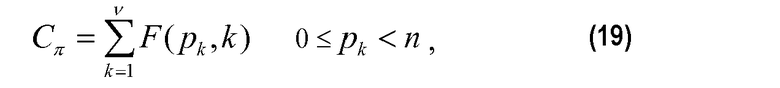
и код для величин импульса определяется:
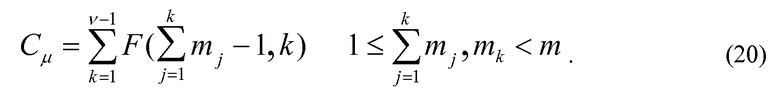
Таким образом, формулировка этого кодового слова требует сложение v и v-1 чисел с многократно увеличенной точностью. Подобные операции вычитания необходимы в декодере. Эти операции также добавляют сложность способу FPC, когда m и n большие. Рассмотрим кодирование/декодирование аудиосигнала для системы многоуровневого встроенного кодирования. Этот метод используется для кодирования преобразования сигнала остаточной ошибки на трех уровнях многоуровневой системы. Пусть размер 20-мс блока равен n=280 и одинаков для всех уровней. Количество импульсов для кодирования зависит от скорости передачи битов каждого уровня. Если каждый уровень составляет 8 кбит/с, 16 кбит/с или 32 кбит/с, тогда они требуют 160 битов, 320 битов и 640 битов для кодирования 20-мс блока соответственно. Используя метод FPC, блок длиной 280 может кодироваться с использованием 28, 74 и 230 импульсов для 160 битов, 320 битов и 640 битов на уровень соответственно. Операции с многократно увеличенной точностью в уравнениях 19 и 20 выполняются на процессоре цифровой обработки сигналов, который обычно работает с 16-битовыми словами. Таким образом, для образования 160-битового кодового слова операции сложения необходимы для выполнения свыше 10 слов, и для 640-битового кодового слова операция сложения должна выполняться по 40 словам. Каждая операция сложения занимает 4 единицы (генерирование переноса, перемещение в массив, сложение с учетом разряда переноса). Следовательно, кодирование/декодирование k-битового кодового слова на p-уровнях многоуровневой системы требует 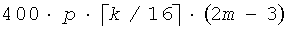 операций/с. Для различных значений n, m и p сложность операций сложения/вычитания с многократно увеличенной сложностью показана в таблице 1. В этой таблице WMOPS обозначает взвешенный миллион операций в секунду.
операций/с. Для различных значений n, m и p сложность операций сложения/вычитания с многократно увеличенной сложностью показана в таблице 1. В этой таблице WMOPS обозначает взвешенный миллион операций в секунду.
Сложность сложения/вычитания при кодировании/декодировании FPC, используя способ известного уровня техники
Из таблицы 1 отмечаем, что, если скорость передачи битов удваивается, сложность сложения с многократно увеличенной точностью повышается в шесть раз.
Как упомянуто выше, комбинаторная функция заменяется аппроксимирующей функцией F'(n,r), которая определяется следующим образом:

где
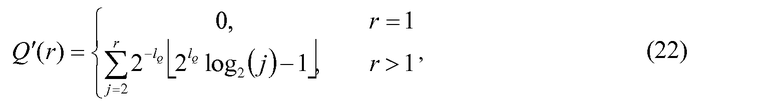
и R'(k) представляет собой аппроксимацию функции R'(k)≈2k, заданной как:

где k=ki+kf разбивается на целочисленную и дробную составляющие k, и представляет собой разложение в ряд Тейлора с низким разрешением дробной составляющей k. Основываясь на вышеприведенных предварительно определенных функциях Q'(r) и R'(k), сначала получают P'(i), так что однозначно определяемое неравенство декодируемости
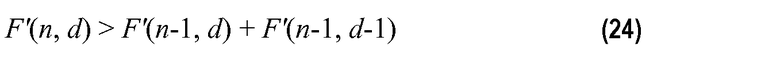
выполняется для всех значений n и d.
Возвращаясь обратно к уравнениям 19 и 20, замена аппроксимирующих функций F' вместо фактических функций F дает:
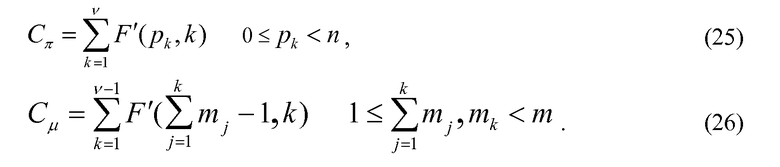
Кодирование количества ненулевых положений:
Формат lR-битового представления мантиссы и порядка также имеет преимущества при кодировании нескольких ненулевых положений. Кодирование количества ненулевых положений v определяется посредством:
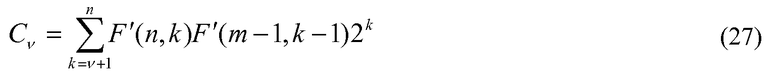
Можно легко видеть, что умножение двух аппроксимирующих функций может быть существенно более легким в формате мантиссы и порядка, чем в формате с многократно увеличенной точностью. Основное преимущество, однако, заключается в том, что когда изобретатели хотят уменьшить сложность, тогда используя lR-битовое представление мантиссы и порядка, каждая из F'(n,k) и F'(m-1,k-1) может быть предварительно сохранена с использованием только двух слов (произведение их lR-битовой мантиссы и суммы их порядка также может быть предварительно сохранено). Это позволяет быстрее выполнять кодирование v без какого-либо существенного требуемого объема постоянного запоминающего устройства (ROM).
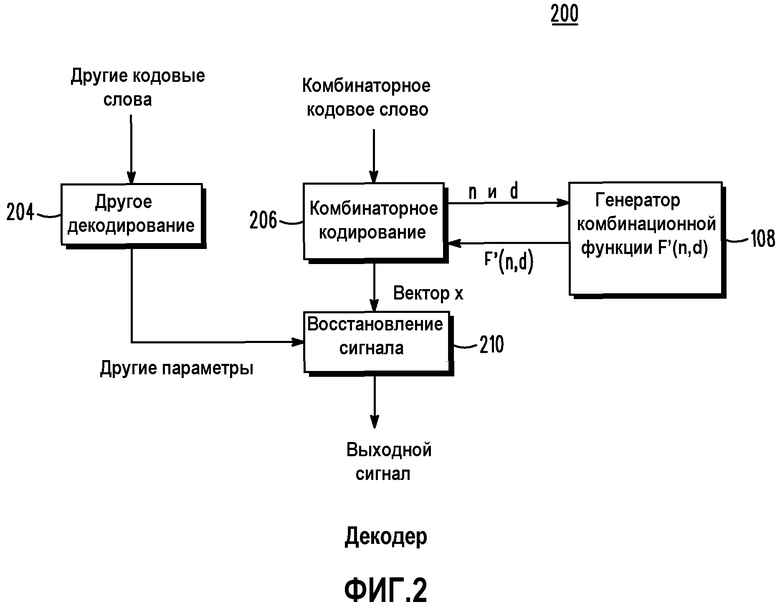
Фиг.2 представляет собой блок-схему декодера 200. Как показано, декодер 200 содержит схему 206 комбинаторного декодирования, схему 210 восстановления сигнала, схему 204 другого декодирования и генератор 108 комбинаторной функции. Во время работы комбинаторное кодовое слово принимается схемой 206 комбинаторного декодирования. Схема 206 комбинаторного декодирования подает n и d на генератор комбинаторной функции и принимает в ответ F'(n,d). Схема 302 декодирования затем создает вектор xi, основанный на F'(n,d). Схема 206 работает аналогично схеме 106 за исключением того, что вычитание заменяется операциями сложения. Другими словами, 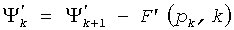 . Вектор xi подается на схему 210 восстановления сигнала, где выходной сигнал (например, речевой сигнал, аудиосигнал, сигнал изображения, видеосигнал или другие сигналы) создается на основе xi и других параметров от схемы 204 другого декодирования. Более конкретно, другие параметры могут включать в себя любое количество параметров восстановления сигнала, связанных с парадигмой кодирования сигнала, используемой в конкретном варианте осуществления. Они могут включать в себя, но не ограничиваются ими, параметры масштабирования сигнала и энергии и параметры формирования спектра и/или синтезирующего фильтра. Обычно эти параметры используются для масштабирования энергии и/или спектральной формы вектора xi восстановленного сигнала таким образом, чтобы воспроизводить окончательный выходной сигнал.
. Вектор xi подается на схему 210 восстановления сигнала, где выходной сигнал (например, речевой сигнал, аудиосигнал, сигнал изображения, видеосигнал или другие сигналы) создается на основе xi и других параметров от схемы 204 другого декодирования. Более конкретно, другие параметры могут включать в себя любое количество параметров восстановления сигнала, связанных с парадигмой кодирования сигнала, используемой в конкретном варианте осуществления. Они могут включать в себя, но не ограничиваются ими, параметры масштабирования сигнала и энергии и параметры формирования спектра и/или синтезирующего фильтра. Обычно эти параметры используются для масштабирования энергии и/или спектральной формы вектора xi восстановленного сигнала таким образом, чтобы воспроизводить окончательный выходной сигнал.
Фиг.3 представляет собой блок-схему последовательности операций, изображающую работу генератора комбинаторной функции по фиг.1 и фиг.3. Более конкретно, логическая последовательность 300 операций на фиг.3 изображает эти этапы генератора 108 комбинаторной функции для получения F'(n,d). Логическая последовательность операций начинается в позиции 301, 302, где принимаются входные величины n и d. В позиции 303 накопитель A устанавливается в 0. В позиции 304 счетчик i устанавливается равным n-d+1. В позиции 306 логарифмическая аппроксимация P'(i) добавляется в накопитель A. В позиции 310 счетчик i получает приращение 1. Позиции 306 и 310 повторяются в цикле до тех пор, пока содержимое счетчика i не станет больше n. В позиции 312 проверяется i>n и завершается цикл, когда i становится больше n. На этом этапе накопитель содержит логарифмическую аппроксимацию числителя комбинаторной функции F(n,d). Логарифмическая аппроксимация знаменателя комбинаторной функции Q'(d) вычитается из содержимого накопителя в позиции 316, и получается логарифмическая аппроксимация комбинаторной функции. В позиции 318 берется экспоненциальная аппроксимация R'(A) содержимого накопителя для генерирования аппроксимации B комбинаторной функции. В позиции 314 B выводится в качестве F'(n,d).
Хотя использование комбинаторного вычисления с уменьшенной сложностью, описанного выше, служит для значительного снижения сложности, вычисление этих функций все же вносит существенный вклад в сложность способов кодирования и декодирования. Чтобы решить этот вопрос, некоторые варианты осуществления настоящего изобретения обеспечивают адаптивное переключение между способами кодирования и декодирования положений импульсов и/или величин импульсов, чтобы уменьшить количество моментов времени, когда должно выполняться вычисление комбинаторной функции.
Возвращаясь снова к уравнениям 19 и 20, а также к их соответствующим уравнениям 25 и 26 реализации с уменьшенной сложностью, отмечается, что процесс кодирования в уравнении 19 и уравнение 25 требуют v вычислений комбинаторных функций F и F' соответственно. Аналогично, уравнения 20 и 26 требуют v-1 вычислений этих функций. Декодирование положений импульсов и величины импульса является итеративным, и, следовательно, количество моментов времени, когда вычисляются эти функции, обычно значительно больше. В декодере количество вычислений этих функций увеличивается линейно с количеством ненулевых положений или занятых положений v. Чтобы уменьшить сложность кодирования/декодирования положений импульса и/или величин импульса, некоторые альтернативные варианты осуществления изобретения обеспечивают способ кодирования и декодирования положения импульса и/или величин импульса, который требует меньшего количества вычислений этих комбинаторных функций. В этих альтернативных вариантах осуществления изобретатели предлагают модифицировать уравнения 19 и 20 и посредством расширения модифицировать уравнения 25 и 26, чтобы селективно кодировать незанятые положения.
Рассмотрим сначала уравнение 20 и соответствующее уравнение 26 с уменьшенной сложностью. Если определим

тогда уравнение 20 можно переписать следующим образом:
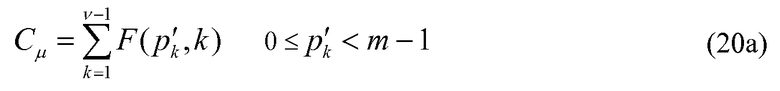
И уравнение 26 можно переписать следующим образом:
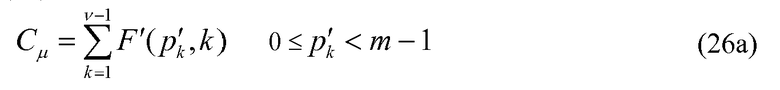
Отметьте, что уравнения 20а и 26а подобны по структуре уравнениям 19 и 25 соответственно, причем pk заменено на p'k, n заменено на m-1, и занятые положения v заменены на v-1, т.е. кодирование величин импульса может рассматриваться как кодирование положения v-1 импульсов, размещенных в m-1 расположениях, где занятые положения идентифицируются посредством p'k. Фактически, кодирование величин импульса может рассматриваться как величины mj занятых импульсов, преобразуемых для генерирования псевдоположений, определенных членами pj и uj. Таким образом, любое изменение в способе кодирования положений импульса легко может быть расширено на кодирование величин импульса, и наоборот.
Согласно некоторым альтернативным вариантам осуществления изобретатели тогда предполагают оптимизацию кодирования величин импульса и/или положений импульса для уменьшения количества требуемых вычислений комбинаторных функций. Перед кодированием/декодированием положений импульса v кодируется/декодируется (уравнение 27). Следовательно, если удвоенное количество ненулевых положений больше количества расположений, т.е. 2·v>n, тогда количество незанятых положений u1, u2, …, uv меньше количества занятых положений v. Таким образом, в таких случаях кодирование/декодирование незанятых положений с использованием уравнения, подобного уравнению 19 (или 25), будет приводить к меньшему количеству вычислений комбинаторных функций и, следовательно, будет иметь меньшую сложность. Чтобы проиллюстрировать это математически, определим сначала uk в качестве незанятых положений, и U пусть будет множеством незанятых положений, т.е.
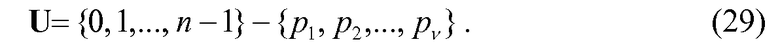
Отметим, что размер U равен n-v. Теперь, когда 2·v>n, код для положения теперь вычисляется как:
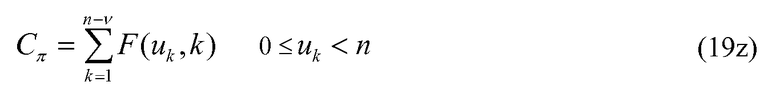
или
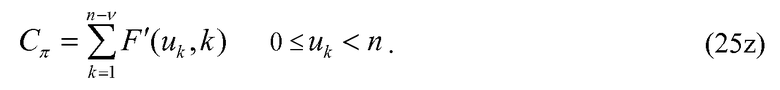
Аналогично для кодирования величин, если 2·(v-1)>(m-1), тогда
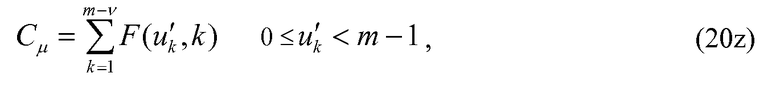
или
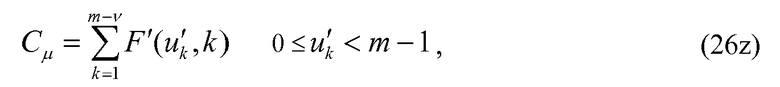
где u'k принадлежит множеству U', определенному как
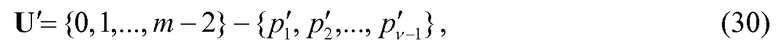
и p'k являются теми, которые определены в уравнении 28.
Изобретатели теперь оценивают то, как предлагаемый способ селективного кодирования незанятых положений может уменьшить сложность посредством применения предлагаемого метода при кодировании 27 импульсов в 280 расположениях, т.е. n=280 и m=27. Так как 2·m<n, то может не требоваться предлагаемый подход кодирования для генерирования кода для положений (Cπ) импульса. Однако для кодирования величины импульса предлагаемый метод может выгодно использоваться.
Оказывается, что без использования предлагаемого метода сложность наихудшего случая алгоритма кодирования/декодирования (когда используются комбинаторные функции малой сложности) в данном конкретном примере наблюдается тогда, когда количество ненулевых положений (v) находится между 25 и 27, т.е. между m и m-2. Когда v=25, тогда использование уравнения 26 потребует 24 вычисления комбинаторной функции для кодирования и несколько больше для декодирования. Использование предлагаемого метода (уравнение 26z) в такой ситуации потребует вычисление комбинаторной функции только дважды в кодере и значительно меньшее количество раз в декодере при сравнении с другими методами декодирования.
Согласно предлагаемому методу кодирования/декодирования, согласующемуся с вариантами осуществления настоящего изобретения, сложность наихудшего случая в данном примере тогда, когда v близко к m/2. В данном случае кодирование и декодирование количества ненулевых положений v, используя уравнение 27, вносит существенный вклад в сложность. Сохранение параметров (запоминание 54 слов требуется в данном примере), как описано в разделе «Кодирование количества ненулевых положений», дополнительно уменьшает сложность.
Таблица ниже показывает снижение сложности, когда предлагаемый способ кодирования незанятых положений используется для кодирования 27 импульсов в 280 расположениях, и кодирование выполняется 2 раза в 20-мс кадре. Таблица также показывает преимущество, получаемое от сохранения параметров, используемых при вычислении кода для количества ненулевых положений (уравнение 27). Из таблицы изобретатели заключают, что селективное кодирование незанятых положений, приводящее к снижению сложности на 0,6 WMOP (с 3,59 до 2,9), и, если также сохраняются параметры, используемые в уравнении 27, тогда уменьшение составляет 0,75 WMOP (с 3,59 до 2,75).
Процесс декодирования является обратным процессу кодирования и включает в себя сначала декодирование количества ненулевых положений (v), основываясь на принятом кодовом слове С. Различные способы, например способ, описанный у Peng et al и у Mittal et al (патент США 6662154), для кодирования/декодирования количества ненулевых положений, могут применяться для этой цели. Кодовые слова Сπ для положения и Cµ для величин извлекаются на основе кодового слова C и v. Положение p1, p2,…, pv декодируется на основе кодового слова Сπ. Величины m1, m2, …, mv декодируются на основе кодового слова Cµ. Теперь декодируется кодированный сигнал:

Метод, описанный в данном документе, уменьшения количества вычислений комбинаторной функции посредством переключения между кодированием занятых и незанятых положений, может дополнительно быть усовершенствован улучшенной аппроксимирующей комбинаторной функцией, как описано ниже. Она основывается на признании того факта, что декодер имеет значительную сложность, вызванную необходимостью декодера многократно находить наибольшее значение pk, так что F'(pk,k) меньше числа Ck с многократно увеличенной точностью. Декодер итеративно получает такое значение pk. Эти итерации могут потребовать нескольких вычислений комбинаторных функций F', которые добавляют сложность в процесс декодирования.
Чтобы дополнительно уменьшить сложность аппроксимирующей комбинаторной функции в уравнении 21 вместо предварительного сохранения P'(i), частичное суммирование P'(i), такое как:

и теперь уравнение 21 может быть эквивалентно вычислено как:
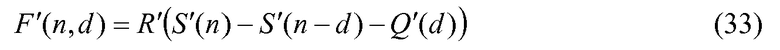
Даже если использование аппроксимирующих комбинаторных функций значительно уменьшило сложность, вычисление этих функций все же образует одну из главных долей сложности декодирования. Один способ снижения количества вычислений комбинаторной функции посредством переключения между кодированием занятого положения и незанятого положения недавно был описан в отдельном раскрытии. Даже с этими улучшениями декодер имеет существенную сложность. Это потому, что декодеру необходимо многократно находить наибольшее значение pk, так что F'(pk,k) меньше числа Ck с многократно увеличенной точностью. Декодер итеративно получает такое значение pk. Эти итерации могут потребовать нескольких вычислений комбинаторных функций, которые добавляют сложность процессу декодирования.
При признании того факта, что существует потребность в способе кодирования, где декодеру не нужно выполнять итерацию для получения pk, представлена улучшенная комбинаторная функция, в которой декодеру не нужно выполнять итерацию для получения pk. Если уравнение 33 используется для определения F'(pk,k), тогда может быть невыполнимым получение такого решения без итераций.
Изобретатели переопределили аппроксимирующую комбинаторную функцию следующим образом:
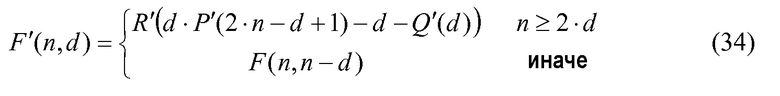
где
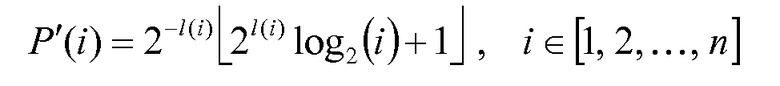
представляет собой логарифм i до l(i)=16 десятичных разрядов, и Q″(d)=Q'(d)+d вычисляется предварительно и сохраняется, так что F'(n,d), определенная в уравнении 34, удовлетворяет однозначно определяемому неравенству 24 декодируемости.
При Q'(d), определенном в уравнении 16 в качестве аппроксимирующего логарифма (основание 2) d!, F'(n,d), определенная в уравнении 34, представляет собой аппроксимацию фактической комбинаторной функции, определенной в уравнении 3 и уравнении 5. Возвращаясь обратно к уравнению 5, числитель, как можно считать, представляет собой d-ую степень среднего геометрического: n, n-1, n-2, …, n-d+1. Среднее арифметическое этих чисел равно 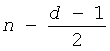 . Если аппроксимировать среднее геометрическое со средним арифметическим, то аппроксимация уравнения 5 может быть записана как:
. Если аппроксимировать среднее геометрическое со средним арифметическим, то аппроксимация уравнения 5 может быть записана как:
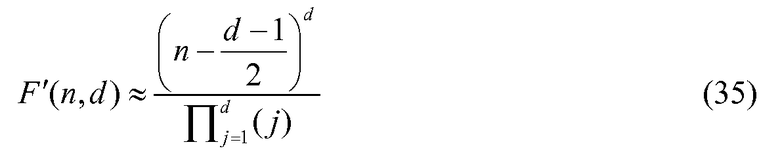
Если взять логарифм (основание 2) уравнения 34 и использовать подход, подобный подходу, использованному при получении уравнения 21, то получим
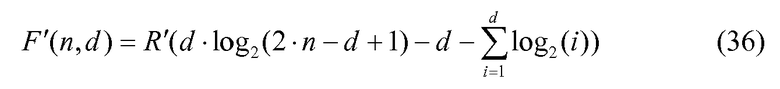
Таким образом,
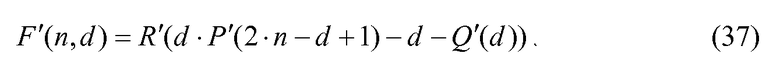
где P'(n)≈log2(n), 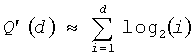 , R(k)≈2k. Ряд Тейлора малой сложности используется для генерирования R'(k). Способ генерирования R'(k) описывается при обсуждении после уравнения 18 выше.
, R(k)≈2k. Ряд Тейлора малой сложности используется для генерирования R'(k). Способ генерирования R'(k) описывается при обсуждении после уравнения 18 выше.
Как используется в данном документе и в прилагаемой формуле изобретения, многочисленные факториальные комбинации, т.е. комбинаторная функция F или аппроксимирующие факториальные комбинации F', обозначенные, в основном, в F', могут использоваться без отступления от сущности и объема различных предложенных вариантов осуществления. Как описано выше, эти комбинаторные функции могут включать в себя, но не ограничиваются ими, следующие уравнения:
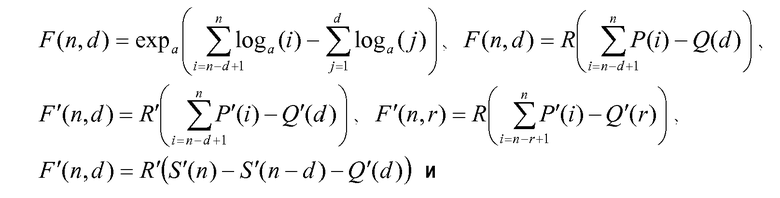
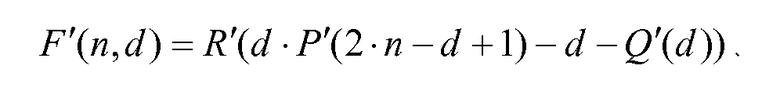
Адаптивное переключение между способами кодирования и декодирования положений импульса и/или величин импульса для уменьшения количества раз, когда должно выполняться вычисление комбинаторной функции, может быть лучше понято в результате ссылки на чертежи. Ссылаясь теперь на фиг.4, на ней изображена блок-схема 400 кодера. Как можно видеть, этот кодер, хотя в некоторой степени подобный кодеру на фиг.1, имеет переключатель 410, который управляется информацией о плотности, подаваемой блоком 408 оценки плотности положений, как показано. Целевой вектор x вводится в блок 408 оценки плотности положений, который выводит плотность в виде суммарного количества занятых положений (v) и в виде количества занятых положений, которые еще должны кодироваться (η), и возможного количества расположений этих занятых положений (ρ). Блок 106 комбинаторного кодирования может генерировать и выводить как занятое положение (pk), так и незанятое положение (uk) на переключатель 410. Какое из этих двух, (pk) или (uk), которое должно быть подано на генератор 108 комбинаторной функции от переключателя 410, определяется переключателем 410. Переключатель может пропускать незанятое положение (uk) на 108, если количество ненулевых положений больше некоторого заданного значения. Переключатель также может пропускать незанятое положение (uk), если отношение количества занятых положений, которые еще должны кодироваться, к возможному количеству расположений этих занятых положений, больше заданного значения.
Фиг.5 представляет собой блок-схему последовательности операций, изображающую упрощенное представление работы кодера по фиг.4. Логическая последовательность операций начинается в позиции 510, где входной сигнал принимается генератором 102 векторов. Как описано выше, входной сигнал может содержать речевой сигнал, аудиосигнал, сигнал изображения, видеосигнал или другие сигналы. В позиции 520 создается вектор xi и вводится в схему 106 комбинаторного кодирования, где m и v определяются и подаются на генератор 108 комбинаторной функции. Как описано выше, m представляет собой суммарное количество импульсов единичной амплитуды (или сумму абсолютных значений целочисленных составляющих xi), и v представляет собой количество ненулевых элементов xi. В позиции 530 F'(pj,j) создается генератором 108 комбинаторной функции и подается на схему 106 комбинаторного кодирования, где вектор xi кодируется для создания комбинаторного кодового слова C в позиции 540. Как описано выше, F'(pj,j) создается посредством замены функций P(i), Q(j) и R(k) в F(pj,j) аппроксимациями малой сложности исходных функций, так что удовлетворяются условия, приведенные в уравнениях 10 и 11.
Ссылаясь теперь на фиг.6, на ней изображена блок-схема 600 декодера, соответствующая некоторым вариантам осуществления. Декодер 600 работает противоположно кодеру 400. Как показано, декодер 600 содержит схему 206 комбинаторного декодирования, схему 210 восстановления сигнала, схему 204 другого кодирования, генератор 208 комбинаторной функции, переключатель 610 и блок 608 оценки плотности положений. Во время работы комбинаторное кодовое слово принимается схемой 206 комбинаторного декодирования. Схема 206 комбинаторного декодирования подает n и d на генератор комбинаторной функции и принимает в ответ F'(n,d). Схема 302 декодирования затем создает вектор xi, основанный на F'(n,d). Схема 206 работает аналогично схеме 106 за исключением того, что вычитание заменяет операции сложения. Другими словами, 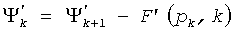 . Вектор xi подается на схему 210 восстановления сигнала, где создается выходной сигнал (например, речевой сигнал, аудиосигнал, сигнал изображения, видеосигнал или другие сигналы), основываясь на xi и других параметрах от схемы 204 другого декодирования. Более конкретно, другие параметры могут включать в себя любое количество параметров восстановления сигнала, связанных с парадигмой кодирования сигнала, используемой в конкретном варианте осуществления. Они могут включать в себя, но не ограничиваются ими, параметры масштабирования и энергии сигнала и параметры формирования спектра и/или синтезирующего фильтра. Обычно эти параметры используются для масштабирования энергии и/или формы спектра вектора xi восстановленного сигнала таким образом, чтобы воспроизвести окончательный выходной сигнал.
. Вектор xi подается на схему 210 восстановления сигнала, где создается выходной сигнал (например, речевой сигнал, аудиосигнал, сигнал изображения, видеосигнал или другие сигналы), основываясь на xi и других параметрах от схемы 204 другого декодирования. Более конкретно, другие параметры могут включать в себя любое количество параметров восстановления сигнала, связанных с парадигмой кодирования сигнала, используемой в конкретном варианте осуществления. Они могут включать в себя, но не ограничиваются ими, параметры масштабирования и энергии сигнала и параметры формирования спектра и/или синтезирующего фильтра. Обычно эти параметры используются для масштабирования энергии и/или формы спектра вектора xi восстановленного сигнала таким образом, чтобы воспроизвести окончательный выходной сигнал.
Фиг.7 представляет собой блок-схему последовательности операций, изображающую упрощенное представление работы декодера по фиг.6. Логическая последовательность операций начинается в позиции 710, где комбинаторное кодовое слово принимается комбинаторным декодером 206. В позиции 720 pj и j передаются от комбинаторного декодера 206 на генератор 208 комбинаторной функции, и F(pj,j) возвращается на декодер 206 в позиции 730. Кодовое слово декодируется декодером 206, основываясь на F(pj,j) в позиции 740 для получения вектора xi, и xi подается на схему 210 восстановления сигнала, где в позиции 750 создается выходной сигнал.
Можно видеть, что предлагаемый способ кодирования «незанятого положения» в различных вариантах осуществления применяется при кодировании как положений, так и величины. Однако специалисту в данной области техники понятно, что данный способ может применяться для кодирования любых из этих параметров. Аналогично, декодер работает противоположно кодеру. В то время как декодер известного уровня техники всегда декодирует положение (pk) и (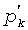 ), декодер, соответствующий вариантам осуществления настоящего изобретения, может декодировать незанятые положения (uk), когда 2·v>n, или может декодировать
), декодер, соответствующий вариантам осуществления настоящего изобретения, может декодировать незанятые положения (uk), когда 2·v>n, или может декодировать  , когда 2·(v-1)>m-1. После декодирования uk и декодер может преобразовать их в pk, и mk.
, когда 2·(v-1)>m-1. После декодирования uk и декодер может преобразовать их в pk, и mk.
Начиная с простого обзора кодирования в соответствии с некоторыми вариантами осуществления настоящего изобретения рассмотрим следующую последовательность операций:
принимается сигнал, кодированный с использованием последовательности импульсов;
определяется количество положений (v) ненулевых импульсов, и может генерироваться код Cv для v, используя уравнение 27 (отметьте, что это дополнительный этап, и кодовое слово (С), конечно, может аппроксимироваться кодами Сπ и Cµ);
определяются положения ненулевых импульсов p1, p2, …, pv; если 2·v≤n, тогда генерировать код Сπ для положения, используя уравнение 25, в противном случае генерировать код Сπ для положения, используя уравнение 25z;
определяются величины m1, m2, …, mv ненулевых импульсов; если 2·(v-1)≤m-1, тогда генерировать код Cµ для величины, используя уравнение 26, в противном случае генерировать код Cµ для величины, используя уравнение 26z;
объединить коды Cv, Сπ и Cµ и образовать кодовое слово (С).
Может быть рассмотрена упрощенная последовательность операций для декодирования в соответствии с некоторыми вариантами осуществления:
принять кодовое слово (С), представляющее сигнал, кодированный с использованием последовательности импульсов;
определить количество положений (v) ненулевых импульсов, в которых v равно наибольшему значению, так что Cv в уравнении 21 не больше С. (Отметим снова, что декодирование может происходить без явного определения Cv в уравнении 21.);
извлечь кодовое слово Сπ и Cµ, основываясь на кодовом слове С и количестве ненулевых положений (v);
если 2·v≤n, тогда декодировать занятые положения p1, p2, …, pv, основываясь на Сπ; в противном случае, декодировать незанятые положения u1, u2,…, uv и вычислить занятые положения из незанятых положений;
если 2·(v-1)≤m-1, тогда декодировать p'1, p'2, …, p'v-1, основываясь на Cµ; в противном случае декодировать u'1, u'2, …, u'v-1. Получить m1, m2, …, mv величины ненулевых положений, основываясь на p'1, p'2, …, p'v-1 или u'1, u'2, …, u'v-1; и
декодировать кодированный сигнал, используя уравнение 31, основываясь на декодированном ненулевом положении и декодированных величинах ненулевых положений.
Ниже дополнительно рассматриваются эти упрощенные последовательности операций.
Ссылаясь теперь на фиг.8, последовательность 800 операций иллюстрирует процесс кодирования работы кодера согласно некоторым вариантам осуществления настоящего изобретения и может рассматриваться с точки зрения адаптивного переключения между кодированием занятых и незанятых положений вектора как функция оценки плотности. В блоке 810 принимается вектор (x), имеющий n положений, подлежащих кодированию. В блоке 820 определяется оценка плотности множества занятых положений из n положений вектора (х). В блоке 830 происходит адаптивное переключение между кодированием множества занятых положений и кодированием множества незанятых положений из n положений в соответствии с оценкой плотности множества занятых положений для генерирования кодированного значения. Оценка плотности положения определяется количеством множества незанятых положений относительно количества множества занятых положений, и поэтому адаптивное переключение между кодированием множества занятых положений и кодированием множества незанятых положений дополнительно содержит кодирование множества незанятых положений, когда количество множества незанятых положений меньше порогового значения; и кодирование множества занятых положений, когда количество множества незанятых положений не меньше порога. Пороговое значение может рассматриваться равным количеству множества занятых положений, такому как n/2. Кодовое слово (С) генерируется из множества кодовых значений, причем каждое значение определяется на множестве положений из n положений вектора (х).
Ссылаясь теперь на фиг.9, последовательность 900 операций иллюстрирует процесс декодирования работы декодера согласно некоторым вариантам осуществления настоящего изобретения. В блоке 910 принимается кодовое слово (С), представляющее сигнал, кодированный с использованием последовательности импульсов. В блоке 920 определяется оценка плотности множества занятых положений из n положений вектора (х), основываясь на кодовом слове С. В блоке 930 выполняется адаптивное переключение между декодированием множества занятых положений и декодированием множества незанятых положений вектора х в соответствии с оценкой плотности множества занятых положений для генерирования декодированного значения. Оценка плотности положения может определяться количеством множества незанятых положений относительно количества множества занятых положений, и адаптивное переключение между декодированием множества занятых положений и декодированием множества незанятых положений может дополнительно содержать: декодирование множества незанятых положений для генерирования множества декодированных незанятых положений и генерирование множества декодированных занятых положений из множества декодированных незанятых положений, когда количество множества незанятых положений меньше порогового значения; и декодирование множества занятых положений, когда количество множества незанятых положений не больше порога. Пороговое значение может представлять собой количество множества занятых положений. Вектор (х) генерируется соответствующим образом из декодированного значения в данном случае. Оно может дополнительно осуществляться посредством извлечения кода Cµ и кода Сπ из кодового слова (С), основываясь на количестве множества занятых положений v вектора х.
Сформулировав несколько по-другому, последовательности 1000 и 1100 операций на фиг.10 и 11 соответственно иллюстрируют использование оценки плотности, но с точки зрения рассмотрения непосредственно количества незанятых положений относительно порога, такого как количество занятых положений. Последовательность 1000 операций на фиг.10 иллюстрирует способ работы кодера, который действует для кодирования кодового слова (С) из вектора (х). В блоке 1010 принимается вектор (х), имеющий n положений, подлежащих кодированию. Блок 1020 принятия решения запрашивает, меньше ли порога количество множества незанятых положений из n положений вектора (х). Если ДА, тогда в блоке 1030 определяются значения множества незанятых положений из n положений вектора (х) и генерируется кодовое слово (С) из значений множества незанятых положений. Если НЕТ, тогда в блоке 1040 определяются значения множества занятых положений, и генерируется кодовое слово (С) из значений множества занятых положений.
Для кодирования величин импульса в примерном варианте осуществления, в котором количество множества незанятых положений из n положений вектора (х) меньше порога, равного (m-1)/2, определение значений множества незанятых положений может дополнительно содержать: определение множества величин m1, m2, …, mv импульса из множества занятых положений; генерирование множества незанятых положений 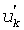 импульса, основываясь на множестве величин импульса; и кодирование множества величин, когда 2·(v-1)>m-1, посредством кодирования положения m-v незанятых положений импульса, расположенных в m-1 расположениях, для генерирования кода Cµ для множества величин импульса. Кодирование множества величин импульса множества незанятых положений тогда может дополнительно содержать: генерирование кода Cµ для множества величин в соответствии с
импульса, основываясь на множестве величин импульса; и кодирование множества величин, когда 2·(v-1)>m-1, посредством кодирования положения m-v незанятых положений импульса, расположенных в m-1 расположениях, для генерирования кода Cµ для множества величин импульса. Кодирование множества величин импульса множества незанятых положений тогда может дополнительно содержать: генерирование кода Cµ для множества величин в соответствии с 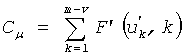
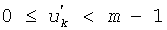 , где
, где 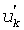 принадлежит множеству U', определенному как U'={0,1,…,m-2}-{p'1, p'2, …, p'v-1} и
принадлежит множеству U', определенному как U'={0,1,…,m-2}-{p'1, p'2, …, p'v-1} и 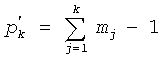 .
.
Кодовое слово (С) в данном случае может, по меньшей мере частично, определяться кодом Cµ множества величин импульса.
Продолжая с примерным вариантом осуществления, в котором количество множества незанятых положений из n положений вектора (х) меньше порога, также может необязательно выполняться кодирование множества положений импульса из множества незанятых положений для генерирования кода Сπ для множества незанятых положений. Код Сπ для множества незанятых положений генерируется в соответствии с 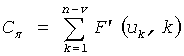 0≤uk<n.
0≤uk<n.
Кроме того, кодирование множества положений импульса множества занятых положений для генерирования кода Сπ для множества занятых положений может выполняться в соответствии с 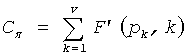 0≤pk<n. Само собой разумеется, что в таких случаях кодовое слово (С), по меньшей мере частично, определяется кодами Сπ и Cµ.
0≤pk<n. Само собой разумеется, что в таких случаях кодовое слово (С), по меньшей мере частично, определяется кодами Сπ и Cµ.
Хотя было описано, что может выполняться кодирование как величины, так и положения, и кодирование положения может выполняться в комбинации с кодированием величины, эти два типа кодирования могут выполняться отдельно или в комбинации. Например, в случае, в котором желательно выполнить только кодирование положения, рассмотрим следующее. Определение множества положений p1, p2, …, pv ненулевого импульса в векторе х может содержать: селективное кодирование множества незанятых положений для генерирования кода Сπ для множества незанятых положений в соответствии с 0≤uk<n. И наоборот, если выполняется только кодирование величины, и где количество множества незанятых положений из n положений вектора (х) не меньше порога, равного (m-1)/2, определение значений множества занятых положений и генерирование кодового слова (С) из значений множества занятых положений может дополнительно содержать: определение множества величин m1, m2, …, mv импульса множества занятых положений, когда 2·(v-1)≤m-1 для генерирования кода Cµ для величин импульса в соответствии с 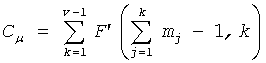

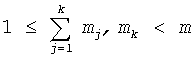 ; и генерирование кодового слова С из по меньшей мере кода Cµ.
; и генерирование кодового слова С из по меньшей мере кода Cµ.
В этих случаях, однако, если количество множества незанятых положений из n положений вектора (х) не меньше порога, способ включает в себя определение значений множества занятых положений и генерирование кодового слова (С) из значений множества занятых положений и в случае кодирования положения дополнительно содержит: кодирование множества положений p1, p2, …, pv импульса множества занятых положений для генерирования кода Сπ в соответствии с 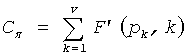 0≤pk<n.
0≤pk<n.
Ссылаясь обратно на фиг.4, работа кодера 400 содержит следующее схемы 106 комбинаторного кодирования: прием вектора (х), имеющего n положений, подлежащих кодированию; определение оценки плотности множества занятых положений из n положений вектора (х); и адаптивное переключение между кодированием множества занятых положений и кодированием множества незанятых положений из n положений в соответствии с оценкой плотности множества занятых положений для генерирования кодированного значения. Как ранее предложено, оценка плотности положения может определяться количеством множества незанятых положений относительно количества множества занятых положений и адаптивным переключением между кодированием множества занятых положений и кодированием множества незанятых положений, выполняемым схемой комбинаторного кодирования. Это кодирование дополнительно содержит: кодирование множества незанятых положений, когда количество множества незанятых положений меньше порогового значения; и кодирование множества занятых положений, когда количество множества незанятых положений не меньше порога. Как дополнительно описано, определение оценки плотности и адаптивное переключение между кодированием множества занятых положений и кодированием множества незанятых положений, основываясь на оценке плотности, может выполняться динамически на множестве положений из n положений вектора (х).
Последовательность 1100 операций на фиг.11 иллюстрирует способ работы декодера, который действует для генерирования вектора (х) из принятого кодового слова (С). В блоке 1110 принимается кодовое слово (С), представляющее сигнал, кодированный с использованием последовательности импульсов. В блоке 1120 принятия решения выполняется запрос, является ли количество множества незанятых положений из n положений вектора (х) меньше порога. Если ДА, тогда в блоке 1130 декодируется множество незанятых положений из n положений вектора (х) и множество занятых положений, основываясь на декодированном множестве незанятых положений. В блоке 1140 генерируется множество декодированных значений занятых положений из множества незанятых положений, и вектор (х) генерируется из множества декодированных значений незанятых и занятых положений. Если НЕТ, тогда последовательность операций переходит на блок 1150, где декодируется множество занятых положений.
Можно понять, что код Cµ и код Сπ могут извлекаться из кодового слова (С), основываясь на количестве множества занятых положений v вектора х.
При условии, при котором количество множества незанятых положений из n положений вектора (х) меньше порога, декодирование величины может дополнительно содержать: декодирование множества незанятых положений импульса; декодирование множества величин m1, m2, …, mv импульса множества занятых положений из извлеченного кода Cµ и множества декодированных незанятых положений импульса; и декодирование кодового слова (С), используя декодированное множество величин m1, m2, …, mv импульса множества занятых положений для генерирования вектора (х) в соответствии с 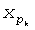 =mksk.
=mksk.
Аналогично, если количество множества незанятых положений из n положений вектора (х) меньше порога, декодирование положения может содержать: декодирование множества незанятых положений uk импульса; генерирование множества декодированных занятых положений импульса из множества декодированных незанятых положений uk импульса; и декодирование кодового слова (С), используя декодированные незанятые положения импульса и декодированные занятые положения импульса для генерирования вектора (х).
Ссылаясь снова на фиг.6, работа декодера 600 содержит следующее схемы 206 комбинаторного декодирования: прием кодового слова (С), представляющего сигнал, кодированный с использованием последовательности импульсов; определение оценки плотности множества занятых положений из n положений вектора (х), основываясь на кодовом слове С; и адаптивное переключение между декодированием множества занятых положений и декодированием множества незанятых положений вектора х в соответствии с оценкой плотности множества занятых положений для генерирования декодированного значения. Снова, как описано выше, оценка плотности положения может определяться количеством множества незанятых положений относительно количества множества занятых положений, и адаптивное переключение между декодированием множества занятых положений и декодированием множества незанятых положений, выполняемым схемой комбинаторного декодирования, дополнительно содержит: декодирование множества незанятых положений для генерирования множества декодированных незанятых положений и генерирование множества декодированных занятых положений из множества декодированных незанятых положений, когда количество множества незанятых положений меньше порогового значения; и декодирование множества занятых положений, когда количество множества незанятых положений не меньше порога. Как описано ниже, определение оценки плотности и адаптивное переключение между декодированием множества занятых положений и декодированием множества незанятых положений, основываясь на оценке плотности, могут выполняться динамически на множестве положений из n положений вектора (х).
Как ранее упомянуто, переключение между режимами кодирования или декодирования может происходить динамически на более чем одном расположении как функция оценки плотности в различных расположениях.
Согласно различным вариантам осуществления настоящего изобретения кодировать ли занятые положения или кодировать ли незанятое положение основывается на средней плотности, которая определяется как отношение занятых положений к количеству расположений. В предыдущем разделе изобретатели показали способ, в котором решение принимается только один раз, и один и тот же подход, т.е. или кодирование занятых положений, или кодирование незанятого положения принимается для всех положений. Так как распределение занятых положений может быть неравномерным по всем расположениям, плотность также является неравномерной. Следовательно, может быть целесообразным выполнять переключение принятия решения на кодирование занятых или незанятых положений, основываясь на плотности в различных случаях. Изобретатели иллюстрируют это на примере. Они рассматривают случай, когда из n=27 расположений 16 положений являются занятыми. Занятыми положениями являются 0, 7, 9, 10, 12, 13, 15, 16, 17, 18, 19, 20, 21, 22, 24 и 25. В способе известного уровня техники эти занятые положения непосредственно кодируются с использованием уравнения 26, и, как описано выше, количество занятых положений больше n/2, незанятые положения 1, 2, 3, 4, 5, 6, 8, 11, 14, 23 и 26 кодируются с использованием уравнения 26z. Отметьте, что кодер известного уровня техники требовал 16 вычислений комбинаторной функции, тогда как кодер в настоящем изобретении требует 11 вычислений комбинаторной функции F или F' в данном примере. Рассматривая занятые и незанятые положения, можно видеть, что кодирование с использованием занятого положения до первых 5 положений импульса, т.е. положения 0, 7, 9, 10 и 12, и затем кодирование незанятых положений, т.е. положений 14, 23 и 26, уменьшает до 8 вычислений комбинаторных функций в кодере. Однако декодеру необходимо знать, какой способ используется для кодирования и где происходит переключение с одного способа на другой способ. Так как декодер начинает декодирование с самого старшего положения до самого младшего положения, самое старшее положение кодируется на основе количества занятых положений. Затем оценивается плотность занятых положений, и, если плотность меньше 0,5, тогда кодируется следующее занятое положение, в противном случае кодируется следующее незанятое положение.
Для иллюстрации этого изобретатели снова рассматривают вышеприведенный пример. Так как начальная плотность занятых положений больше 0,5, самое старшее незанятое положение 26 кодируется как F'(26,11). Теперь оценка плотности занятых положений составляет 16 положений в 26 расположениях, которая также больше 0,5, и, следовательно, следующее незанятое положение 23 кодируется как F'(23,10). Теперь можно сделать вывод (даже на декодере), что положения 24 и 25 были заняты. Плотность занятых положений теперь становится 14 занятых положений в 23 расположениях, которая все еще больше 0,5, и, следовательно, следующее незанятое положение 14 кодируется как F'(14,9). Легко можно оценить, что плотность остального занятого положения составляет 6 импульсов в 14 расположениях, которая меньше 0,5. Теперь следующее занятое положение 13 кодируется как F'(13,6). Теперь плотность занятых положений оценивается как 5 импульсов в 13 расположениях, которая меньше 0,5, и, следовательно, кодируется следующее во времени занятое положение, т.е. положение 12 кодируется как F'(12,5). Теперь имеется 4 занятых положения в 12 расположениях, и, следовательно, снова занятое положение кодируется как F'(10,4). Используя эти же аргументы, следующие три занятых положения кодируются как F'(9,3), F'(7,2) и F'(0,1). Таким образом, кодовое слово
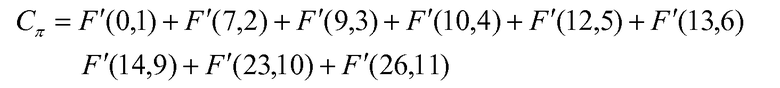
требует девять вычислений комбинаторных функций в данном примере.
ДИНАМИЧЕСКОЕ ПЕРЕКЛЮЧЕНИЕ - КОДЕР
В отношении динамического переключения между методологиями кодирования в одном или нескольких позиционных расположениях такое переключение может представлять собой функцию оценки плотности, определенной на одном или нескольких расположениях. Таким образом, определение оценки плотности и адаптивное переключение между кодированием множества занятых положений и кодированием множества незанятых положений, основываясь на оценке плотности, выполняется динамически на множестве положений из n положений вектора (х). Определяются занятые положения p1, p2, …, pv и незанятые положения u1, u2, …, uv из n положений вектора (х). Для положений pk из n положений:
а. если 2·v>n, кодирование самых старших незанятых положений как F'(un-v,v), но, если 2·v≤n, тогда кодирование самого старшего незанятого положения как F'(pv,v), причем последнее кодированное положение (ρ) устанавливается на pv или un-v;
b. вычисление количества занятых положений (η) и количества незанятых положений (ε), которое меньше последнего кодированного положения (ρ);
с. если 2·η≤ρ, тогда получение максимального занятого положения pk менее ρ и кодирование положения как F'(pk,η), причем последним кодированным положением является ρ=pk;
d. если 2·η>ρ, тогда получение максимального незанятого положения uk менее ρ и кодирование положения как F'(uk,ε), причем последним кодированным положением является ρ=uk;
e. повторение b, c и d до тех пор, пока η или ε не будет равно 0.
Коды положения, сгенерированные в d и e, могут суммироваться для генерирования кода Сπ положения.
В случае кодирования величины, определяется множество величин m1, m2, …, mv импульса множества занятых положений. Затем также определяются занятые положения p'1, p'2, …, p'v-1, и незанятые положения u'1, u'2, …, u'm-v из n положений вектора (х), основываясь на множестве величин m1, m2, …, mv импульса. Для положений p'k из n положений:
а. если 2·(v-1)>m-1, кодирование самых старших незанятых положений как F'(u'm-v,v-1), но если 2·(v-1)≤m-1, тогда кодирование самого старшего незанятого положения как F'(p'v,v-1), причем последнее кодированное положение (ρ') устанавливается на p'v или u'm-v;
b. вычисление количества занятых положений (η') и количества незанятых положений (ε'), которые меньше последнего кодированного положения (ρ');
с. если 2·η'≤ρ', тогда получение максимального занятого положения p'k меньшего ρ' и кодирование положения как F'(p'k,η'), причем последним кодированным положением является ρ'=p'k;
d. если 2·η'>ρ', тогда получение максимального незанятого положения u'k меньшего ρ' и кодирование положения как F'(u'k,ε'), причем последним кодированным положением является ρ'=u'k;
e. повторение b, c и d до тех пор, пока η' или ε' не будет равно 0.
Коды положения, сгенерированные в d и e, суммируются для генерирования кода Cµ положения.
ДИНАМИЧЕСКОЕ ПЕРЕКЛЮЧЕНИЕ - ДЕКОДЕР
В отношении динамического переключения во время декодирования определяется оценка плотности, и адаптивное переключение между декодированием множества занятых положений и декодированием множества незанятых положений, основываясь на оценке плотности, динамически выполняется на множестве положений из n положений вектора (х). Для декодирования положения переключение содержит для положений pk из n положений:
а. если 2·v>n, декодирование самых старших незанятых положений как F'(un-v,v) из кода Сπ, но если 2·v≤n, тогда декодирование самого старшего занятого положения как F'(pv,v), причем последнее декодированное положение (ρ) устанавливается на pv или un-v;
b. вычисление количества занятых положений (η) и количества незанятых положений (ε), которые меньше последнего декодированного положения (ρ);
с. если 2·η≤ρ, тогда получение максимального занятого положения pk меньшего ρ и декодирование положения как F'(pk,η), причем последним декодированным положением является ρ=pk;
d. если 2·η>ρ, тогда получение максимального незанятого положения uk меньшего ρ и декодирование положения как F'(uk,ε), причем последним декодированным положением является ρ=uk;
e. повторение b, c и d до тех пор, пока η или ε не будет равно 0.
Декодируется множество занятых положений из максимальных занятых положений pk и максимальных незанятых положений uk, сгенерированных в a, b, c, d и e.
В отношении декодирования величины определяется множество величин m1, m2, …, mv импульса множества занятых положений. Также определяются занятые положения p'1, p'2, …, p'v-1, и незанятые положения u'1, u'2, …, u'm-v из n положений вектора (х), основываясь на множестве величин m1, m2, …, mv импульса. И для положений p'k из n положений:
а. если 2·(v-1)>m-1, декодирование самых старших незанятых положений как F'(u'm-v,v-1) из кода Cµ, но если 2·(v-1)≤m-1, тогда декодирование самого старшего незанятого положения как F'(p'v,v-1), причем последнее декодированное положение (ρ') устанавливается на p'v или u'm-v;
b. вычисление количества занятых положений (η') и количества незанятых положений (ε'), которые меньше последнего декодированного положения (ρ');
с. если 2·η'≤ρ', тогда получение максимального занятого положения p'k меньшего ρ' и декодирование положения как F'(p'k,η'), причем последним декодированным положением является ρ'=p'k;
d. если 2·η'>ρ', тогда получение максимального незанятого положения u'k меньшего ρ' и декодирование положения как F'(u'k,ε'), причем последним декодированным положением является ρ'=u'k;
e. повторение b, c и d до тех пор, пока η' или ε' не будет равно 0.
Декодируется множество занятых положений из максимальных занятых положений pk и максимальных незанятых положений uk, сгенерированных в a, b, c, d и e.
В вышеприведенном описании изобретения были описаны конкретные варианты осуществления настоящего изобретения. Однако специалист в данной области техники оценит, что могут быть сделаны различные модификации и изменения без отступления от объема настоящего изобретения, изложенного в формуле изобретения ниже. Следовательно, описание изобретения и фигуры должны рассматриваться в иллюстративном, а не ограничительном смысле, и все такие модификации, как предполагается, включены в объем настоящего изобретения. Достоинства, преимущества, решения проблем и любой элемент(ы), которые могут вызвать то, что любое достоинство, преимущество или решение происходит или становится более отчетливым, не должны толковаться в качестве критических, необходимых или существенных признаков или элементов любого или всех пунктов формулы изобретения. Изобретение определяется исключительно прилагаемой формулой изобретения, включающей в себя любые исправления, сделанные во время рассмотрения данной заявки и всех эквивалентов заявленных пунктов формулы изобретения.


Изобретение относится к способам кодирования векторных или матричных величин для речевых сигналов, аудиосигналов, сигналов изображения, видеосигналов и других сигналов, в частности к способам для кодирования и декодирования положения импульса и/или величин импульса, которые адаптивно переключаются между кодированием положения импульсов, имеющих ненулевое значение, и кодированием положения импульсов, имеющих нулевое значение. Техническим результатом является обеспечение способа и устройства для комбинаторного факториального импульсного кодирования малой сложности векторов. Указанный результат достигается тем, что способ работы кодера, который кодирует кодовое слово (С) из вектора (х), включает прием вектора (х), имеющего n положений, подлежащих кодированию; определение оценки плотности множества занятых положений из n положений вектора (х); и адаптивное переключение между кодированием этого множества занятых положений и кодированием множества незанятых положений из n положений в соответствии с оценкой плотности упомянутого множества занятых положений для генерирования кодированного значения для кодового слова. При этом кодированное значение содержит упомянутую оценку плотности для использования соответствующим декодером. 4 н. и 6 з.п. ф-лы, 2 табл., 11 ил., 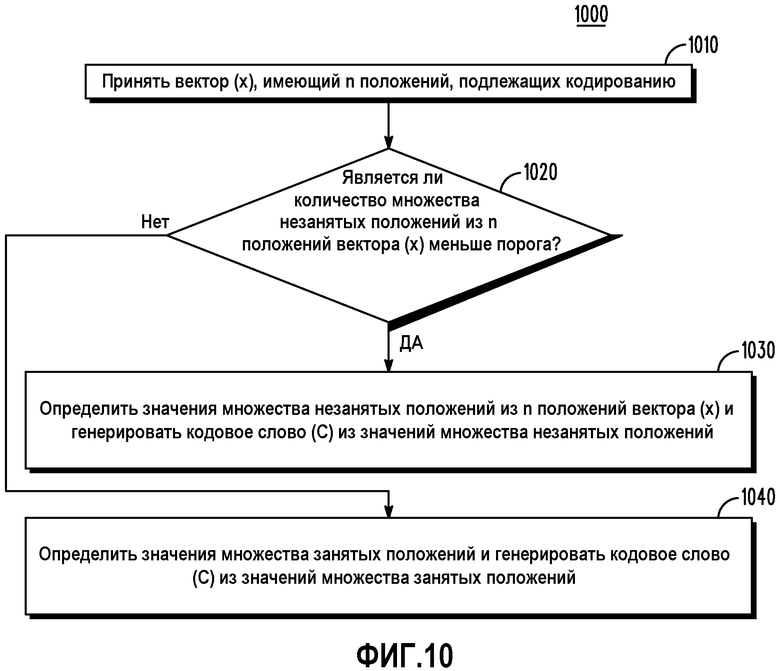
1. Способ работы кодера, который кодирует кодовое слово (С) из вектора (х), содержащий:
прием вектора (х), имеющего n положений, подлежащих кодированию;
определение оценки плотности множества занятых положений из n положений вектора (х); и
адаптивное переключение между кодированием этого множества занятых положений и кодированием множества незанятых положений из n положений в соответствии с оценкой плотности упомянутого множества занятых положений для генерирования кодированного значения для кодового слова, причем это кодированное значение содержит упомянутую оценку плотности для использования соответствующим декодером.
2. Способ по п.1, в котором определение оценки плотности и адаптивное переключение между кодированием множества занятых положений и кодированием множества незанятых положений на основе оценки плотности динамически выполняется на множестве положений из n положений вектора (х).
3. Способ по п.1, в котором оценка плотности положения определяется количеством множества незанятых положений относительно количества множества занятых положений, и при адаптивном переключении между кодированием множества занятых положений и кодированием множества незанятых положений:
если количество множества незанятых положений из n положений вектора (х) меньше порога, определяют значения множества незанятых положений из n положений вектора (х) и генерируют кодовое слово (С) из значений множества незанятых положений, и
в противном случае, если количество множества незанятых положений вектора (х) не меньше порога, определяют значения множества занятых положений и генерируют кодовое слово (С) из значений множества занятых положений.
4. Кодер, содержащий:
схему комбинаторного кодирования, выполненную с возможностью:
приема вектора (х), имеющего n положений, подлежащих кодированию;
определения оценки плотности множества занятых положений из n положений вектора (х);
адаптивного переключения между кодированием этого множества занятых положений и кодированием множества незанятых положений из n положений в соответствии с оценкой плотности упомянутого множества занятых положений для генерирования кодированного значения для кодового слова, причем это кодированное значение содержит упомянутую оценку плотности для использования соответствующим декодером.
5. Кодер по п.4, в котором оценка плотности положения определяется количеством множества незанятых положений относительно количества множества занятых положений, и адаптивное переключение между кодированием множества занятых положений и кодированием множества незанятых положений, выполняемое схемой комбинаторного кодирования, дополнительно содержит:
кодирование множества незанятых положений, когда количество множества незанятых положений меньше порогового значения; и
кодирование множества занятых положений, когда количество множества незанятых положений не меньше порога.
6. Кодер по п.4, в котором определение оценки плотности и адаптивное переключение между кодированием множества занятых положений и кодированием множества незанятых положений на основе оценки плотности динамически выполняется на множестве положений из n положений вектора (х).
7. Способ работы декодера, который генерирует вектор (х) из кодового слова (С), содержащий:
прием кодового слова (С), представляющего сигнал, кодированный с использованием последовательности импульсов;
определение оценки плотности множества занятых положений из n положений вектора (х) на основе кодового слова С; и
адаптивное переключение между декодированием этого множества занятых положений и декодированием множества незанятых положений вектора (х) в соответствии с оценкой плотности упомянутого множества занятых положений для генерирования декодированного значения.
8. Способ по п.7, в котором определение оценки плотности и адаптивное переключение между декодированием множества занятых положений и декодированием множества незанятых положений на основе оценки плотности динамически выполняется на множестве положений из n положений вектора (х).
9. Способ по п.8, в котором оценка плотности положения определяется количеством множества незанятых положений относительно количества множества занятых положений и при адаптивном переключении между декодированием множества занятых положений и декодированием множества незанятых положений:
если количество множества незанятых положений из n положений вектора (х) меньше порога, декодируют множество незанятых положений из n положений вектора (х) и декодируют множество занятых положений на основе декодированного множества незанятых положений;
генерируют множество декодированных значений занятых положений из множества незанятых положений и генерируют вектор (х) из множества декодированных значений незанятых и занятых положений, и
в противном случае, если количество множества незанятых положений вектора (х) не меньше порога, декодируют множество занятых положений.
10. Декодер, содержащий: схему комбинаторного декодирования, выполненную с возможностью:
приема кодового слова (С), представляющего сигнал, кодированный с использованием последовательности импульсов;
определение оценки плотности множества занятых положений из n положений вектора (х) на основе кодового слова (С); и
адаптивного переключения между декодированием множества занятых положений и декодированием множества незанятых положений вектора (х) в соответствии с оценкой плотности множества занятых положений для генерирования декодированного значения.
| MARKAS Т | |||
| и др | |||
| Multispectral image compression algorithms, Data Compression Conference, 30.03.1993 - 02.04.1993, c.391-400 | |||
| JP 10282997 A, 23.10.1998 | |||
| WO 00/16501 A1, 23.03.2000 | |||
| US 4464714 A, 07.08.1984 | |||
| СПОСОБ И УСТРОЙСТВО ОСУЩЕСТВЛЕНИЯ ПОИСКА В СПРАВОЧНИКЕ КОДОВ ДЛЯ КОДИРОВАНИЯ ЗВУКОВОГО СИГНАЛА И СИСТЕМА СОТОВОЙ СВЯЗИ | 1996 |
|
RU2142166C1 |

