ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее техническое решение относится к области вычислительной техники, в частности к области информационной безопасности, а именно к способу и вычислительному устройству для кластеризации фишинговых веб-ресурсов на основе изображения визуального контента, с целью дальнейшей атрибуции фишинговых веб-сайтов, зеркал, заблокированных и/или запрещенных веб-сайтов.
УРОВЕНЬ ТЕХНИКИ
[0002] Одним из самых широко распространенных видов вредоносных веб-ресурсов является фишинговые сайты. Их главная цель - получать конфиденциальные данные пользователей для совершения мошеннических действий.
[0003] Принцип работы фишинговых сайтов заключается в копировании или подражании существующим сервисам каких-либо брендов, например, банков, платежных систем, электронной почты, социальных сетей, торговых марок, для добровольного получения конфиденциальных данных от пользователя (логин, пароль, почта, ФИО, номер документа, идентифицирующего личность, данные платежных карт, и т.д.).
[0004] В качестве примера, но не ограничиваясь им, это может быть поддельный сайт дистанционного банковского обслуживания (ДБО), на котором пользователя побуждают различными психологическими приемами ввести регистрационные данные и/или сообщить дополнительную конфиденциальную информацию. После чего полученная информация используется мошенниками для кражи денежных средств пользователя или иных противоправных действий.
[0005] Стоит отметить, что имитация реальных сервисов может осуществляться также с целью заработка на рекламе, отображения недостоверной или запрещенной информации, а также в случае зеркала официального ресурса в целях незаконного распространения авторского или запрещенного контента. Все описанные действия могут нанести репутационный вред владельцам исходных веб-ресурсов или предоставлять незаконный доступ к нежелательному контенту.
[0006] Технологии распространения фитинга позволяют создавать множество однотипных сайтов с помощью так называемых фишинговых наборов, что усложняет их своевременное выявление и блокировку.
[0007] Фишинговый набор (англ. Phishing Kit) - это архивный файл, содержащий скрипты, необходимые для создания и работы фишингового сайта. Такой инструмент позволяет злоумышленникам, не обладающим глубокими навыками программирования, быстро разворачивать сотни фишинговых страниц, часто используя их как «зеркала» друг друга. При блокировке одного такого сайта - мошенник активирует другой, при блокировке этого - следующий и так далее. Таким образом, фишинг-кит позволяет атакующим быстро возобновлять работу вредоносных ресурсов, обеспечивая собственную неуязвимость. Этим объясняется интерес к ним со стороны специалистов по кибербезопасности. Детектирование фишинговых наборов позволяет не только находить сотни и даже тысячи фишинговых страниц, но и, что более важно, может служить отправной точкой расследований с целью идентификации их разработчиков и привлечения их к ответственности.
[0008] Стоит отметить, что для привлечения покупателей разработчики фишинговых наборов используют в них известные бренды с большой аудиторией, что в теории должно облегчить реализацию мошеннических схем для будущих владельцев таких наборов. В 2020 году наиболее часто использующимися в фишинговых наборах брендами были Amazon, Google, Instagram, Office 365 и PayPal, а на топ-3 интернет-площадок для торговли фишинговыми наборами был представлен Exploit, OGUsers и Crimenetwork.
[0009] В простейшем случае идентификация фишинговых веб-ресурсов происходит на основе сравнения URL-адреса с базами данных скомпрометированных URL-адресов. Более сложные способы могут быть основаны на анализе структурных элементов страницы.
[0010] Из патента США №8856937 (опубл. 07.10.2014) известен способ и система для определения вредоносных веб-ресурсов. Этот известный способ включает создание и пополнение базы данных веб-ресурсов, содержащей легитимные веб-ресурсы, подозрительные веб-ресурсы и вредоносные веб-ресурсы. Классификация веб-ресурсов осуществляется на основе сравнения скриншотов веб-ресурсов с легитимными и фишинговыми веб-ресурсами, содержащимися в базе данных.
[0011] В патенте CN 101826105 В (опубл. 05.02.2019) описан метод обнаружения фишинговых страниц, основанный на сопоставлении элементов веб-страниц, а именно вычисления оптимального соответствия графов для поиска совпадающих пар функций среди различных сигнатур веб страниц. Метод также характеризуется определением внутренних весов признаков текста, характеристик изображения путем определения относительных весов среди сходства текста, и изображений при вычислении сходства веб-страниц с использованием анализа логарифмической регрессии.
[0012] Для ускорения процесса определения вредоносных веб-ресурсов, которое может быть осуществлено с использованием, например, систем и способов, раскрытых в приведенных выше документах из уровня техники, могут быть образованы кластеры веб-ресурсов, содержащие выборочную совокупность веб-ресурсов, которые в дальнейшем анализируют для выявления среди них, например, веб-ресурсов, вовлеченных в фишинг.
[0013] В патентах US 10200381 В2 (опубл. 05.02.2019) и US 8381292 В1 (опубл. 19.02.2013) раскрываются методы защиты бренда от фишинга на основе сравнения профилей потенциально фишингового ресурса с базовыми (искомыми) шаблонами веб-страниц брендов.
[0014] Один из недостатков известных устройств и способов для кластеризации веб-ресурсов, например, раскрытых в источнике US 2015/0067839 (опубл. 05.03.2015), состоит в чрезмерном количестве анализируемых подозрительных веб-ресурсов, содержащихся в полученных кластерах, что в свою очередь обуславливает чрезмерные трудоемкость и/или ресурсоемкость проверки всех этих подозрительных веб-ресурсов в полученных кластерах для выявления среди них веб-ресурсов, являющихся копиями оригинальных веб-ресурсов или содержащих по меньшей мере некоторые элементы содержимого оригинального веб-ресурса, с обеспечением их последующего анализа на вовлеченность в фишинговую деятельность.
[0015] Подготовка целевых кластеров веб-ресурсов, в которых веб-ресурсы с высокой долей вероятности являются копиями оригинального веб-ресурса и вовлечены, например, в фишинговую деятельность, является важным аспектом для улучшения скорости и точности определения вредоносных веб-ресурсов. На максимально точную подготовку целевых кластеров веб-ресурсов и направлены многие известные технические решения, однако, как было отмечено выше, эти известные технические решения обладают рядом недостатков и требуют улучшения.
[0016] Также в уровне технике известно решение RU 2676247 С1 (опубл. 26.12.2018), которое выбрано в качестве прототипа, решающее проблему автоматизированной фильтрации массива подозрительных веб-ресурсов для выявления по существу всех фишинговых веб-ресурсов, дублирующих по меньшей мере часть контента с конкретного оригинального веб-ресурса, благодаря возможности создания базы данных, содержащей только предполагаемые фишинговые веб-ресурсы, каждый из которых в дальнейшем может быть автоматически и/или вручную проанализирован на причастность к совершению вредоносных действий, связанных с фишингом. Автоматизированная фильтрация всего массива выявленных подозрительных веб-ресурсов в свою очередь позволяет существенно сократить вычислительные ресурсы компьютерного устройства и его ресурсы памяти, необходимые на выявление причастности анализируемых веб-ресурсов к совершению вредоносных действий, связанных с фишингом, благодаря тому, что анализу подвергается не весь массив подозрительных веб-ресурсов, а только ограниченная совокупность веб-ресурсов, ассоциированных с оригинальным веб-ресурсом и имеющая с высокой степенью вероятности отношение к фишингу ввиду дублирования контента оригинального веб-ресурса, являющегося легитимным.
[0017] Однако, указанное решение направлено на кластеризацию на основе элементов, извлеченных во время сбора со страницы, в отличии от данного решения, в котором элементы извлекаются с изображения веб-ресурса, что позволяет повысить точность подхода, так как у разных фишинговых страниц, использующих разные бренды может быть один и тот же скрипт (JavaScript), или одна и та же иконка, или одни и те же сигнатуры в HTML коде. Преимущество состоит в том, что анализируется уже отрендеренный контент, то есть контент получаемый после выполнения браузером шагов по преобразованию HTML, CSS и JavaScript в визуальное изображение, а не данные кода. Такой подход приводит к уменьшению частоты ложных срабатываний.
[0018] Таким образом, в дальнейшем необходимо совершенствовании устройств и способов для кластеризации веб-ресурсов, в частности для подготовки таких кластеров веб-ресурсов, которые бы снижали трудоемкость и/или ресурсоемкость их последующей проверки на причастность, например, к фишингу, посредством использования усовершенствованных технологии компьютерного зрения в совокупности с усовершенствованным алгоритмом кластеризации.
[0019] Следовательно, настоящее техническое решение создано для преодоления по меньшей мере одного обозначенного выше недостатка известных устройств и способов для кластеризации контента фишинговых веб-ресурсов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0020] Технической проблемой, на решение которой направлено заявленное решение, является создание способа и вычислительного устройства для кластеризации фишинговых веб-ресурсов на основе изображения визуального контента. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах изобретения.
[0021] Технический результат заключается в повышение точности кластеризации фишинговых веб-ресурсов на основе изображения визуального контента.
[0022] Заявленный результат достигается за счет осуществления способа кластеризации фишинговых веб-ресурсов на основе изображения визуального контента, выполняемый на компьютерном устройстве, содержащем по меньшей мере процессор и память, при этом способ содержит этапы, на которых:
получают указания на множество фишинговых веб-ресурсов;
извлекают по меньшей мере одно изображение визуального контента каждого из множества веб-ресурсов;
обрабатывают содержимое каждого изображения визуального контента, связанного с одним из множества веб-ресурсов, при этом
выделяют контуры элементов на каждом изображении визуального контента фишингового веб-ресурса;
осуществляют фильтрацию выявленных контуров на каждом изображении визуального контента путем удаления одинаковых контуров;
на основе попарного сравнения выявленных контуров и контуров кластеров производят объединение веб-ресурса, связанного со сравниваемыми контурами с кластером,
причем если значение сходства преодолевает пороговое значение,
в противоположном случае создают новый кластер для веб-ресурса;
сохраняют указания на веб-ресурсы, ассоциированные с соответствующими контурами содержимого из множества указанных кластеров, в базе данных.
[0023] В частном варианте реализации описываемого способа множество веб-ресурсов включает, по меньшей мере, два веб-ресурса.
[0024] В частном варианте реализации описываемого способа для получения указаний на множество веб-ресурсов предварительно выполняют сканирование сети.
[0025] В частном варианте реализации описываемого способа указания на множество веб-ресурсов получают, по меньшей мере, частично от внешнего источника по сети передачи данных.
[0026] В частном варианте реализации описываемого способа указания на множество веб-ресурсов получают из предварительно сформированной базы данных веб-ресурсов.
[0027] В частном варианте реализации описываемого способа выделяют по меньшей мере следующие контуры элементов, содержащихся на изображении визуального контента: логотипов, очертаний букв, отдельных слов, картинок, форм.
[0028] В частном варианте реализации описываемого способа для выделения контуров используют по меньшей мере следующие методы: детектор границ Кэнни и алгоритм поиска контуров.
[0029] В частном варианте реализации описываемого способа при обработке содержимого каждого полученного изображения визуального контента дополнительно производят удаление мелких, наклонных и вытянутых контуров.
[0030] В частном варианте реализации описываемого способа производят фильтрацию выявленных контуров на каждом изображении визуального контента путем удаления одинаковых контуров, причем
если сравниваемые контуры по высоте и/или ширине отличаются больше, чем на два пикселя, то считают их разными
[0031] В частном варианте реализации описываемого способа производят фильтрацию выявленных контуров на каждом изображении визуального контента путем удаления одинаковых контуров, причем
если сравниваемые контуры по высоте и/или ширине отличаются на два пикселя или меньше, то
контуры накладывают друг на друга, и
вычисляют попиксельную разность изображений,
причем для полученного разностного изображения вычисляют оценку похожести в диапазоне от 0, где изображения одинаковы до 100 - изображения полностью противоположны,
причем оценка похожести (Р) вычисляется как среднее арифметическое значений пикселей, то есть сумма значений пикселей, деленная на количество пикселей изображения, причем вычисляемое для значений, взятых из всех трех каналов RGB:

где Ri, Gi, Bi - значение i-го пикселя в каналах R, G и В соответственно, а N - общее количество пикселей изображения,
причем контуры, оценка похожести которых не превышает 7 удаляются.
[0032] В частном варианте реализации описываемого способа дополнительно для каждого контура, выявленного на изображении визуального контента рассчитывают инвариантные визуальные хеш-функции
[0033] В частном варианте реализации описываемого способа если при сравнении с изображениями кластеров обнаружено менее трех похожих контуров на изображении визуального контента фишингового веб-ресурса, то выводят сообщение о не информативности, причем в данном случае новое изображение визуального контента в кластер не добавляется, а если в кластере менее двух изображений, то кластер удаляется;
если при сравнение обнаружено от трех до пяти похожих контуров, то для добавления изображения визуального контента фишингового веб-ресурса в определенный кластер необходимо полное совпадение всех контуров кластера;
если при сравнение обнаружено от пяти до десяти похожих контуров, то для добавления изображения визуального контента фишингового веб-ресурса в определенный кластер необходимо совпадение половины контуров с контурами кластера,
если при сравнение обнаружено от десяти до пятнадцати похожих контуров, то для добавления изображения визуального контента фишингового веб-ресурса в определенный кластер необходимо совпадение четверти контуров кластера,
если при сравнение обнаружено от пятнадцати похожих контуров, то для добавления изображения визуального контента фишингового веб-ресурса в определенный кластер необходимо совпадение по меньшей мере пятой части контуров кластера.
[0034] В частном варианте реализации описываемого способа при отнесении изображения визуального контента фишингового веб-ресурса к нескольким кластерам, его добавление происходит в кластер с наибольшим числом совпадений контуров.
[0035] В частном варианте реализации описываемого способа дополнительно после кластеризации каждого из множества изображений визуального контента фишинговых веб-ресурсов удаляют кластеры, в которых содержится менее трех изображений.
[0036] В частном варианте реализации описываемого способа изображения, которые содержались в удаленных кластерах заносят в специальный список и временно считаются мусорными.
[0037] В частном варианте реализации описываемого способа дополнительно на основе каждого изображения визуального контента, содержащегося в списке, создают матрицу смежности, в которой на пересечении расположено число совпадающих контуров, для выявления списка пар похожих контуров по размерам.
[0038] В частном варианте реализации описываемого способа дополнительно для определения ассоциированности по меньшей мере двух изображения визуального контента веб-ресурсов в матрице смежности изменяют значение на 0, если число совпадающих по размерам контуров, менее заданного порога, или на 1, если число совпадений контуров больше порога.
[0039] В частном варианте реализации описываемого способа производят вычисление сильно связных компонентов графа, в которых находится более двух изображений и создают новый кластер для каждой из выявленных компонент.
[0040] Заявленный результат также достигается за счет реализации вычислительного устройства для кластеризации фишингового контента, содержащее память для хранения машиночитаемых инструкций и по меньшей мере один вычислительный процессор, выполненный с возможностью исполнения машиночитаемых инструкций для обеспечения осуществления способа кластеризации фишингового контента.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0041] Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
[0042] Фиг. 1 иллюстрирует упрощенное схематическое представление одной из неограничивающих реализаций системы для осуществления настоящего технического решения.
[0043] Фиг. 2 иллюстрирует одну из неограничивающих реализаций представления информации о ресурсах веб-страницы в базе данных ресурсов.
[0044] Фиг. 3 иллюстрирует блок-схему последовательности операций согласно аспекту настоящего способа кластеризации фишинговых веб-ресурсов на основе изображения визуального контента.
[0045] Фиг. 4 иллюстрирует неограничивающий пример первого веб-ресурса.
[0046] Фиг. 5 иллюстрирует неограничивающий пример второго веб-ресурса.
[0047] Фиг. 6 иллюстрирует неограничивающий пример третьего веб-ресурса.
[0048] Фиг. 7 иллюстрирует упрощенное схематическое представление одной из неограничивающих реализаций компьютерного устройства для осуществления настоящего технического решения.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0049] В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
[0050] Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
[0051] Отметим, что в контексте настоящего описания, если специально не указано иное, термин «элемент содержимого» или «контент» относится к любым данным, которые могут быть представлены (визуально, в аудио формате или как-либо иначе), которые может содержать веб-ресурс. Таким образом, элементом содержимого для целей настоящего технического решения может являться, в частности, шрифт, элемент меню, шаблон веб-ресурса, форма для заполнения, написанный текст, изображение, часть изображения, графика, анимация, видео, музыка, запись голоса и так далее, а также любая их комбинация. В частности, контентом также являются и любые другие ресурсы, которые могут быть переданы по протоколам http/https.
[0052] Дополнительно настоящее описание раскрывает термин изображение визуального контента веб-ресурса, под которым понимается скриншот (screenshot - «снимок экрана»), то есть изображение, полученное вычислительным устройством и показывающее в точности то, что видит пользователь на экране монитора или другого визуального устройства вывода.
[0053] Контуры (боксы) - выделенные на изображении визуального контента, то есть на скриншоте, прямоугольные элементы, например, кнопки, поля ввода, логотипы компаний, титульные надписи и т.п.
[0054] Кластеры - группы изображений визуального контента (скришотов), сформированные на основе совпадения выявленных на них уникальных контуров (боксов), для конкретного фишингового набора. С каждым кластером также ассоциирован, например, хранится в базе данных с указанием на определенный кластер, набор ссылок (указаний) на фишинговые страницы, соответствующие изображениям визуального контента, и имеющие между собой много общего (например, направленные на одну конкретную компанию или похожие между собой по лендингу).
[0055] В контексте настоящего описания, если четко не указано иное, «указатель» или «указание» информационного элемента может представлять собой сам информационный элемент или указатель, отсылку, ссылку или другой косвенный способ, позволяющий получателю указания найти сеть, память, базу данных или другой машиночитаемый носитель, из которого может быть извлечен информационный элемент. Например, указатель веб-ресурса может включать в себя сам файл или набор файлов веб-ресурса, или же он может являться универсальным указателем ресурса (например, URL, таким как www.webpage.com), идентифицирующим веб-ресурс по отношению к конкретной сети (в частности, Интернет), или он может какими-либо другими средствами передавать получателю указание на сетевую папку, адрес памяти, таблицу в базе данных или другое место, в котором можно получить доступ к веб-ресурсу или отдельным его элементам содержания. Как будет понятно специалистам в данной области техники, степень точности, необходимая для такого указания, зависит от степени первичного понимания того, как должна быть интерпретирована информация, которой обмениваются получатель и отправитель указателя. Например, если до передачи данных между отправителем и получателем понятно, что указатель информационного элемента принимает вид универсального указателя ресурса URL, передача указателя, ссылки на данный веб-ресурс - это все, что необходимо для эффективной передачи веб-ресурса получателю, несмотря на то, что сам по себе информационный элемент (например, веб-ресурс или отдельный его элемент содержания) не передавался между отправителем и получателем указания.
[0056] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый веб-ресурс" и "третий веб-ресурс" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) веб-ресурсов в множестве веб-ресурсов, равно как и их использование (само по себе) не предполагает, что некий "второй веб-ресурс" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[0057] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
[0058] На Фиг. 1 представлено упрощенное схематическое представление одной из неограничивающих реализаций системы кластеризации фишингового контента 100 для осуществления настоящего технического решения.
[0059] В некоторых неограничивающих вариантах реализации настоящего технического решения система 100, обеспечивающая реализацию способа, может включать в себя сеть 110 передачи данных, по крайней мере одно вычислительное устройство 120 для определения вредоносных веб-ресурсов, и базу данных 130.
[0060] Система 100 может также включать в себя по меньшей мере один поисковый сервер 140, имеющий доступ к базе данных веб-ресурсов 130.
[0061] В еще одном неограничивающем варианте реализации настоящего изобретения система 100 может включать дополнительно активное сетевое оборудование (не показано) и клиентское устройство (не показано).
[0062] В качестве сети 110 передачи данных может выступать, например, сеть Интернет или любая другая вычислительная сеть.
[0063] Вычислительное устройство 120 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения устройство 120 может представлять собой сервер Dell™ PowerEdge™, или может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию.
[0064] Варианты возможного осуществления вычислительного устройства 120 хорошо известны. Таким образом, достаточно отметить, что устройство 120 включает в себя, среди прочего, интерфейс сетевой передачи данных (например, модем, сетевую карту и тому подобное) для двусторонней связи по сети передачи данных (не изображена); и процессор 121, связанный с интерфейсом сетевой передачи данных, причем процессор 121 выполнен с возможностью выполнять различные алгоритмы, включая те, что описаны ниже. С этой целью процессор 121 может иметь доступ к машиночитаемым инструкциям, хранящимся на машиночитаемом носителе (не показан), выполнение которых инициирует реализацию процессором 121 различных процедур, описанных здесь далее.
[0065] В некоторых вариантах осуществления настоящего технического решения вычислительное устройство 120 включает в себя по меньшей мере одну базу данных 122, которая выполнена с возможностью хранить по меньшей мере часть указаний на элементы содержимого, элементов содержимого, группы элементов содержимого, и указание на веб-ресурсы, ассоциированные с соответствующим элементом содержимого или группой элементов содержимого. Так, в качестве примера, веб-ресурс, на котором имеются все элементы содержимого из группы элементов содержимого, является ассоциированным с данной группой элементов содержимого.
[0066] Стоит отметить, что база 122 данных может быть реализована как часть вычислительного устройства 120 или иным способом быть доступна вычислительному устройству 120.
[0067] Возможен вариант осуществления системы 100, согласно которому вычислительное устройство 120 включает в себя машиночитаемый носитель (не показан), на котором могут быть предварительно сохранены машиночитаемые инструкции и/или база данных 122. Альтернативно или дополнительно устройство 120 может иметь доступ к машиночитаемым инструкциям и/или базе данных 122, расположенных на ином оборудовании. То, как именно реализован доступ процессора 121 вычислительного устройства 120 к машиночитаемым инструкциям и базе данных 122 не является ограничивающим условием настоящего технического решения.
[0068] Процессор 121 выполнен с возможностью получения указаний на множество веб-ресурсов. Например, в качестве неограничивающего примера получение указаний на множество веб-ресурсов может представлять собой получение списка единых указателей ресурсов (URL). Дополнительно стоит отметить, что источники указаний на множество веб-ресурсов могут быть различными.
[0069] Возможен вариант осуществления настоящего технического решения, в котором процессор 121 выполнен с возможностью получения указания на множество веб-ресурсов по меньшей мере частично от внешнего источника по сети передачи данных 110. Например, внешний источник может представлять собой поисковый сервер 140 имеющий доступ к базе данных веб-ресурсов 130 и/или сервер сбора данных о вредоносных веб-ресурсах (не показан), и т.д. Причем вычислительное устройство 120 может иметь доступ к базе данных веб-ресурсов 130 по сети передачи данных 110. Альтернативно или дополнительно внешний источник может представлять собой веб-ресурс, включающий указания на множестве веб-ресурсов (например, проверенная база данных фишинговых веб-ресурсов, как Google Safe Browsing (GSB), OpenPhish (OP). Стоит отметить что, как именно и по какому принципу сгруппированы указания на веб-ресурсы на внешнем источнике, в частности, в базе данных веб-ресурсов 130 не является ограничивающим условием.
[0070] Варианты осуществления поискового сервера 140 хорошо известны. Таким образом, достаточно отметить, что поисковый сервер 140 включает в себя, среди прочего, интерфейс сетевой передачи данных (например, модем, сетевую карту и тому подобное) для двусторонней связи по сети передачи данных 110; и процессор (не показан), связанный с интерфейсом сетевой передачи данных, причем процессор выполнен с возможностью осуществлять поиск веб-ресурсов в сети передачи данных 110 и их сохранение в базе данных 130. С этой целью процессор поискового сервера может иметь доступ к соответствующим машиночитаемым инструкциям, хранящимся на машиночитаемом носителе (не показан).
[0071] Так, процесс заполнения и сохранения базы данных веб-ресурсов 130 в общем случае известен как сбор данных (или кроулинг, от англ. "crawling"), причем поисковый сервер 140 выполнен с возможностью просматривать различные веб-ресурсы, доступные по сети 110 передачи данных, и сохранять их в базе данных веб-ресурсов 130 по одному или нескольким предварительно заданным параметрам. В качестве примера, но не ограничения поисковый сервер 140 может выполнять сканирование сети передачи данных 110 и сохранять все новые и обновленные веб-ресурсы и таким образом собрать полную базу веб-ресурсов сети передачи данных 130, и/или собирать веб-ресурсы, например, включающие определенные ключевые слова на одном или нескольких языках. Поскольку вредоносные веб-ресурсы (в частности фишинговые веб-сайты) обычно пытаются имитировать сайты банков, платежных систем и сервисов электронной почты, то ключевыми словами могут быть, например, но не ограничиваясь ими: «банк», «кредит», «карта», т.д. Поиск также может осуществляться по доменным именам, и/или другим параметрам. Найденные и отобранные указания на веб-ресурсы сохраняются в базе данных веб-ресурсов 130, после чего могут быть получены процессором вычислительного устройства 120 по сети передачи данных 110 от поискового сервера 140.
[0072] Кроме того, поисковый сервер 140 выполнен с возможностью исследования по меньшей мере части элементов содержимого каждого веб-ресурса из множества веб-ресурсов. Элементы содержимого веб-ресурса могут представляют собой файлы элементов содержимого и/или хеш-суммы файлов элементов содержимого (например, хеш-суммы, вычисленные по алгоритму sha256). Формат файлов элементов содержимого никак конкретно не ограничен и будет зависеть от типа конкретного элемента содержимого. Например, для случая, когда элемент содержимого представляет собой изображение, файл может быть представлен, в частности, в одном из следующих форматов: "jpg", "jpeg", "png", "bmp", "gif и т.д. Для случая, когда элемент содержимого представляет собой текст, файл может быть представлен, в частности, в одном из следующих форматов: "txt", "doc", "html" и др. Для случая, когда элемент содержимого представляет собой шрифт, файл может быть представлен, в частности, в одном из следующих форматов: "woff", "ttf, "eot", "svg" и т.д. Для случая, когда элемент содержимого представляет собой скрипт, файл может быть представлен, в частности, в одном из следующих форматов: "asp", "aspx", "php", "jsp", "cgi" и т.д. Для случая, когда элемент содержимого представляет собой анимацию или видео, файл может быть представлен, в частности, в одном из следующих форматов: "flv", "swf, "avi", "mp4", "mov" и т.д. Для случая, когда элемент содержимого представляет собой каскадную таблицу стилей, файл может быть представлен, в частности, в формате "ess". Указанный перечень возможных элементов содержимого и форматов, в которых они могут быть представлены, не является ограничивающим условием настоящего технического решения.
[0073] Извлечение элементов, а также создание изображений визуального контента (скриншотов) найденных веб-ресурсов может выполняться процессором поискового сервера 140 с помощью специально написанных сценариев и/или скриптов для браузеров.
[0074] Кроме того, стоит отметить, что еще в одном неограничивающем варианте осуществления настоящей технологии описанную функцию по созданию изображений визуального контента может осуществлять вычислительное устройство 120.
[0075] В одном из частных вариантов исполнения настоящей технологии изображение визуального контента (скриншот) может быть получен посредством использования инструмента для автоматизации действий веб-браузера Selenium WebDriver с помощью метода <.save_screenshot(filename)> или <.get_screenshot_as_file(filename)> и сохранен в базе данных 122.
[0076] Альтернативно возможен вариант осуществления настоящего технического решения, в котором процессор 121 вычислительного устройства 120 выполнен с возможностью получения указания на множество веб-ресурсов напрямую из предварительно сформированной базы данных веб-ресурсов 130. Причем предварительно сформированная база данных веб-ресурсов 130 может быть доступна вычислительному устройству 120 по сети.
[0077] Возможен вариант осуществления настоящего технического решения, в котором процессор 121 выполнен с возможностью выполнять сканирование сети 110 для получения указаний на множество веб-ресурсов и таким образом вычислительное устройство 120 может выполнять описанные выше функции поискового сервера 140. Например, сканирование сети может быть выполнено по IP-адресам веб-ресурсов, доменным именам, ключевым словам и другим параметрам.
[0078] Процессор 121 вычислительного устройства 120 выполнен с возможностью обрабатывать полученные элементы, а также изображения визуального контента веб-ресурсов для кластеризации фишингового контента, а также выполнять их группирование, на основе определенных пороговых значений сходства.
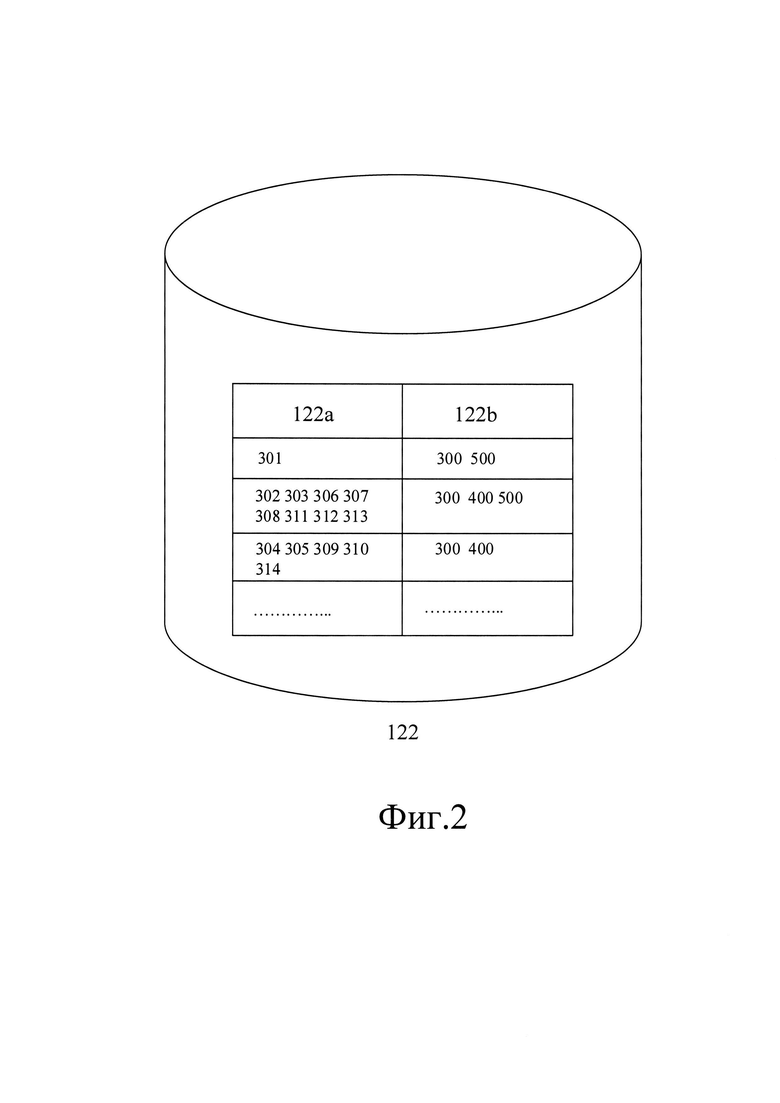
[0079] Со ссылкой на Фиг. 2 показан иллюстративный пример базы данных 122, содержащей данные о контурах элементов содержимого (122а) и веб-ресурсах (122b), ассоциированных с соответствующими контурами элементов содержимого.
[0080] В показанном примере базы данных 122 представлен кластер из ассоциированных веб-ресурсов 300, 400, 500, на основе выявленных боксов элементов 302, 303, 306, 307, 308, 311, 312, 313.
[0081] Стоит отметить, что количество и качество наполнения базы данных 122 никак не ограничено, приведенные примеры боксов элементов содержимого и ассоциированных с ними веб-ресурсов служит лишь для целей обеспечения понимания настоящего технического решения и не является ограничивающим. Очевидно, что наполнение базы данных 122 может обладать гораздо большей сложностью.
[0082] Далее со ссылкой на фиг. 3 будет подробнее рассмотрен заявляемый способ кластеризации фишинговых веб-ресурсов на основе изображения визуального контента, который выполняется в соответствии с неограничивающими вариантами осуществления настоящего технического решения (200).
[0083] Способ 200 может быть выполнен на вычислительном устройстве 120 и, конкретнее, его процессором 121 в соответствии с неограничивающим вариантом реализации системы 100, представленной на фиг. 1. Также со ссылкой на, Фиг. 4, Фиг. 5 и Фиг. 6 рассмотрим иллюстративный пример осуществления способа.
[0084] На Фиг. 4 представлен пример изображения виртуального контента применительно к веб-ресурсу 300, включающего множество выделенных контуров 301-314. При этом, контуры 302-306 представляют собой элемент кнопки для перенаправления с этого ресурса на какой-либо сторонний ресурс, контуры элементов 301, 307-311 представляют собой логотипы брендов, контуры 312-313 - знаки, а 314 - выделенная прямоугольная область, содержащая остальные элементы.
[0085] На Фиг. 5 представлен пример изображения виртуального контента второго веб-ресурса 400, включающий множество элементы содержимого. При этом некоторые контуры элементов содержимого, а именно 302-314, имеются также в первом веб-ресурсе 300 и описаны выше. Дополнительно веб-ресурс 400 имеет элементы 401, 402, 403.
[0086] На Фиг. 6 представлен пример третьего веб-ресурса 500, включающий элементы содержимого, в частности, 301,302, 303, 306, 307, 308, 311,312, 313, 501. Элементы содержимого 302, 303, 306, 307, 308, 311 312, 313, которые имеются также в первом и втором веб-ресурсе, а также 301, ассоциирующийся только с первым веб-ресурсом, были описаны выше. Элемент содержимого 501 представляет собой строку, на которой расположены кнопки перехода на сторонние веб-ресурсы.
[0087] В контексте настоящего технического решения количество и виды различных элементов содержимого не являются ограничивающим условием. Веб-ресурсы на фиг. 4 фиг. 5 и фиг. 6 представлены лишь в качестве иллюстративных примеров, очевидно, что настоящее техническое решение может быть также применено для любых других веб-ресурсов, обладающих большим или меньшим количеством элементов содержимого, причем типы элементов содержимого и само содержимое могут повторяться или не повторяться в рамках одного и того же веб-ресурса. Часть элементов содержимого, имеющихся на представленных иллюстративных примерах веб-ресурсов не пронумерованы.
[0088] Фиг. 3 содержит последовательности операций согласно аспекту настоящего способа (200) кластеризации фишинговых веб-ресурсов на основе изображения визуального контента, который будет раскрыт подробнее ниже.
ШАГ 210 ПОЛУЧАЮТ УКАЗАНИЯ НА МНОЖЕСТВО ФИШИНГОВЫХ ВЕБ-РЕСУРСОВ
[0089] Соответственно способ 200 начинается на этапе 210, где вычислительное устройство 120 получает указания на по меньшей мере один веб-ресурс, содержащий фишинговый контент.
[0090] Указания на множество веб-ресурсов могут представлять собой как сами веб-ресурсы, так, например, и ссылки на веб-ресурсы, URL, доступные по сети передачи данных 110 или иной сети (не показана), вычислительному устройству 120.
[0091] С учетом неограничивающего иллюстративного примера вычислительное устройство 120 на этапе 210 получает указания на множество из трех веб-ресурсов 300, 400 и 500 от внешнего источника - поискового сервера 140 из базы данных веб-ресурсов 130. Стоит отметить, что веб-ресурсы 300, 400 и 500 были предварительно найдены поисковым сервером 140 и сохранены в базе данных веб-ресурсов 130. Также указания на множество веб-ресурсов могли быть получены по меньшей мере частично из предварительно сформированной базы данных веб-ресурсов 130, причем возможен дополнительный вариант осуществления способа 200, в котором вычислительное устройство 120 может получать указания на множество веб-ресурсов напрямую из базы данных веб-ресурсов 130.
[0092] Дополнительно возможен вариант осуществления способа 200, в котором для получения указаний на множество веб-ресурсов вычислительное устройство 120 выполняет сканирование сети передачи данных 110. Сканирование сети передачи данных 110 может выполняться вычислительным устройством 120 аналогично поисковому серверу 140, как было описано выше или иначе с помощью доступного ПО, способного производить поиск по заданным параметрам в сети.
[0093] Возможен вариант осуществления способа 200, в котором на этапе 210 получают множество веб-ресурсов из по меньшей мере двух различных источников. Например, указания на веб-ресурсы 300 и 500 получают от поискового сервера 140 из базы данных веб-ресурсов 130, а веб-ресурс 400 получают из иного внешнего источника (не показан, например, из специальной внешней базы данных фишинговых веб-ресурсов) по сети передачи данных 110.
[0094] Также возможен дополнительный вариант осуществления способа 200, в котором полученное URL указание ведет к папке с файлами (например, js, ess, image и т.д), а не соответствует привычному отображению веб-страниц, тогда система 100 по сети 110 подключается к внешнему сервису (не показано), например, к 'scan-open-dir', который выполняет исследование всех найденных по указанному адресу папок, а также возвращает результат назад в систему 100, которая с помощью специально написанных парсеров обрабатывает данную информацию и распределяет ее в базе данных 122.
[0095] Способ 200 далее переходит выполнению этапа 220.
ШАГ 220 ИЗВЛЕКАЮТ ПО МЕНЬШЕЙ МЕРЕ ОДНО ИЗОБРАЖЕНИЕ ВИЗУАЛЬНОГО КОНТЕНТА КАЖДОГО ИЗ МНОЖЕСТВА ВЕБ-РЕСУРСОВ.
[0096] Шаг 220 - извлечение по меньшей мере одного изображения визуального контента каждого из множества веб-ресурсов.
[0097] В неограничивающих вариантах осуществления настоящего изобретения изображение визуального контента может быть сделано поисковым сервером 140 и сохранено в базе данных 130 или же сделано посредством процессора 121 вычислительного устройства 120 и сохранено в базе данных 122 любым хорошо известным методом.
[0098] В частности, для иллюстративного примера, к таким методам можно отнести использование виртуальных браузеров (например, Селениум). В настройках виртуального браузера устанавливается расширение, выполняется очистка кеша, переход на веб-ресурс, после чего автоматически в указанном месте сохраняются изображения визуального контента содержимого данного веб-ресурса. Кроме того, для тех же целей может использоваться любое доступное ПО, скрипт, написанный на любом языке программирования и способный интерпретироваться системой для получения искомого изображения визуального контента.
[0099] Далее после этапа извлечения изображения визуального контента способ переходит на этап 230.
ШАГ 230 ОБРАБАТЫВАЮТ СОДЕРЖИМОЕ КАЖДОГО ИЗВЛЕЧЕННОГО ИЗОБРАЖЕНИЯ ВИЗУАЛЬНОГО КОНТЕНТА, СВЯЗАННОГО С ОДНИМ ИЗ МНОЖЕСТВА ВЕБ-РЕСУРСОВ.
[0100] На данном этапе обрабатывают содержимое каждого извлеченного изображения визуального контента, связанного с одним из множества веб-ресурсов.
[0101] При этом данный этап в предпочтительном варианте осуществления описываемой в данном документе технологии включает себя по меньшей мере следующие подэтапы:
выделения контуров элементов на каждом изображении визуального контента фишингового веб-ресурса;
осуществления фильтрации выявленных контуров на каждом изображении визуального контента путем удаления одинаковых контуров.
[0102] На этом этапе происходит выделение контуров по меньшей мере следующих элементов содержимого изображения визуального контента: логотипов, очертаний букв, отдельных слов, картинок, форм. Это может выполняться с помощью детектора границ Кэнни и алгоритма поиска контуров.
[0103] Стоит отметить, что контуры на изображении визуального контента - это такие кривые на изображении, вдоль которых происходит резкое изменение яркости, цветности или других параметров изображения. Поэтому целями преобразования изображения в набор кривых являются: выделение существенных характеристик изображения и сокращение объема информации для последующего анализа.
[0104] Соответственно в процессе выделения контуров с помощью детектора границ Кэнни выполняются по меньшей мере следующие шаги:
убирают шум и лишние детали из изображения визуального контента посредством применения фильтра Гаусса, вычисляют первые производные (магнитуд и направлений) функции интенсивности пикселей по горизонтальному и вертикальному направлениям посредством применения оператора Собеля,
отбирают пиксели, которые потенциально принадлежат ребру с использованием процедуры non-maximum suppression, причем пиксели, которым соответствуют вектора производных по направлениям, являющиеся локальными максимумами, считаются потенциальными кандидатами на принадлежность ребру;
и проводят двойное отсечение, то есть выделяют "сильные" и "слабые" ребра, где пиксели, интенсивность которых превышает максимальный порог, считают пикселями, принадлежащими "сильным" ребрам. Принимается, что пиксели с интенсивностью, входящей в интервал от минимального до максимального порогового значения, принадлежат "слабым" ребрам. Пиксели, интенсивность которых меньше минимального порога, отбрасывают, исключают из дальнейшего рассмотрения. Результирующие ребра содержат пиксели всех "сильных" ребер и те пиксели "слабых" ребер, чья окрестность содержит хотя бы один пиксель "сильных" ребер.
[0105] Стоит отметить, что далее дополнительно применяется алгоритм обнаружения контуров на изображении визуального контента. В настоящем техническом решении использование определенного алгоритма для выявления границ на изображении не является ограничивающим моментом, поэтому возможно использование любого известного метода. В качестве примера, но не ограничиваясь им, к таким методам можно отнести: оператор Кирша, оператор Робинса, алгоритмы Марр-Хильдрет (Marr-Hildreth) и Харриса, а также его модификации: Ши-Томаса, Харриса-Лапласа и др.
[0106] После выделения контуров дополнительно производят очистку (удаление) мелких, наклонных и сильно вытянутых контуров. Стоит отметить в качестве примера, но не ограничиваясь им, что мелкими могут считаться контуры, которые меньше 350 пикселей, а сильно вытянутыми считаются те, у которых ширина или высота менее 10 пикселей. Наклонными контурами считаются такие, границы которых не параллельны сторонам изображения визуального контента.
[0107] Критерии очистки могут быть предварительно заданы экспертом либо созданы автоматически на основе статистических данных об использовании элементов содержимого во множестве веб-ресурсов. Например, при превышении предварительно заданного порогового значения количества веб-ресурсов, ассоциированных с данным элементом содержимого, он может считаться стандартным элементом содержимого. Пороговое значение может задаваться вручную оператором, либо выбираться с помощью различных автоматизированных алгоритмов, в том числе на основе машинного обучения.
[0108] В предпочтительном варианте осуществления настоящей технологии процессор 121 вычислительного устройства 120 производит попарное сравнение схожих контуров, при этом:
если сравниваемые контуры по высоте и/или ширине отличаются больше, чем на 2 пикселя, то их считают разными;
если сравниваемые контуры по высоте и/или ширине отличаются на 2 пикселя или меньше, то накладывают контуры друг на друга и вычисляют попиксельную разность изображений контуров, а для полученного изображения вычисляется оценка похожести в диапазоне от 0, когда изображения одинаковы, до 100, когда изображения совершенно различны,
при этом контуры, оценка похожести которых не превышает 7, удаляют.
[0109] В соответствии с описанным выше, оценка похожести (Р) вычисляется как среднее арифметическое значений пикселей (1), то есть сумма значений пикселей, деленная на количество пикселей изображения, причем вычисляемое для значений, взятых из всех трех каналов RGB:

где Ri, Gi, Bi - значение i-ro пикселя в каналах R, G и В соответственно, а N - общее количество пикселей изображения.
[0110] Стоит отметить, что в одном из вариантов осуществления настоящей технологии для каждого контура, выявленного на изображении визуального контента, используют инвариантные к масштабированию визуальные хеш-функции. Инвариантное к масштабированию хеширование полезно, когда, например, один и тот же визуальный контент отображается в разных масштабах на разном оборудовании устройства и операционных системах. Сами эти хеш-функции могут быть любыми общеизвестными.
[0111] В одном из альтернативных вариантов реализации возможно применение метода удаления схожих контуров, в котором:
если сравниваемые контуры по высоте или ширине отличаются более, чем на 2 пикселя, то их считают разными;
если один из контуров больше другого, то последовательно сравнивают 9 всевозможных расположений меньшего контура в большем, вычисляют разность между наложенными друг на друга контурами, вычисляют для разности оценку похожести (1), и при этом удаляют контуры, разность которых не превышает установленного порога.
[0112] Стоит отметить, что при выполнении альтернативного варианта реализации настоящей технологии может быть получено и менее 9 расположений одного контура в другом контуре, в зависимости от разницы по одной из координат.
[0113] В альтернативном варианте реализации настоящего технического решения, в случае, когда один из контуров больше другого, принимают разницу по ширине за дельту (delta), и производят поиск по меньшей мере одного расположения для получения попиксельной разности изображений со смещениями: 0,  delta относительно левого верхнего угла. Такие же действия могут быть выполнены и в случае, когда контуры различаются по высоте.
delta относительно левого верхнего угла. Такие же действия могут быть выполнены и в случае, когда контуры различаются по высоте.
[0114] В иллюстративном варианте реализации настоящего технического решения, в случае, когда первый контур больше по ширине, а второй по высоте, производят выравнивание контуров по ширине, применяя по меньшей мере следующие варианты смещения: 0, delta относительно левого верхнего угла и далее сравнивают их так, что первый контур лежит внутри другого. Соответственно, максимальная разница по высоте/ширине может быть 2 пикселя, поэтому рассматривают смещения, например, в 0, 1 и 2 пикселя, при этом контур, который больше по ширине/высоте обрезают по соответствующему размеру меньшего контура, то есть если разница между контурами была 2 пикселя по ширине, то большой контур обрезают тремя способами: справа 2 пикселя; слева и справа по 1 пикселю; и слева 2 пикселя. Далее при сравнении полученных контуров вычисляется оценка похожести (1), и если контуры похожи, один из них удаляется. Причем в данном случае если в любом из 9 наложений оценка окажется меньше порога, то контуры считают похожими.
[0115] Далее способ переходит к выполнению этапа 240.
ШАГ 240 ПОПАРНО СРАВНИВАЮТ ВЫЯВЛЕННЫЕ КОНТУРЫ И КОНТУРЫ КЛАСТЕРОВ, И В ОТВЕТ НА ТО, ЧТО ОЦЕНКА ПОХОЖЕСТИ ПРЕОДОЛЕЛА ПОРОГОВОЕ ЗНАЧЕНИЕ, ПРОИЗВОДЯТ ОБЪЕДИНЕНИЕ ИЗОБРАЖЕНИЯ ВИЗУАЛЬНОГО КОНТЕНТА, СОДЕРЖАЩЕГО СРАВНИВАЕМЫЕ КОНТУРЫ, С КЛАСТЕРОМ, В ПРОТИВОПОЛОЖНОМ СЛУЧАЕ СОЗДАЮТ ДЛЯ ДАННОГО ИЗОБРАЖЕНИЯ ВИЗУАЛЬНОГО КОНТЕНТА НОВЫЙ КЛАСТЕР.
[0116] На этапе 240 производят попарное сравнение выявленных контуров и контуров, принадлежащих кластерам, и при превышении оценкой похожести (1) порогового значения, добавляют изображение визуального контента в кластер; если оценка не превышает порога, то создают для данного изображения визуального контента новый кластер.
[0117] В неограничивающих вариантах осуществления настоящей технологии кластерами являются сформированные группы изображений, соотнесенных с веб-ресурсами, на основе схожести выявленных уникальных контуров (боксов).
[0118] В неограничивающих вариантах структура кластера представляет собой по меньшей мере совокупность: непосредственно изображений визуального контента, соотнесенного с указателем на него, а также выявленных контуров на изображении, при этом дополнительно для каждого контура в кластере запоминают время последнего его совпадения и число последующих несовпадений при добавлении нового изображения в кластер.
[0119] В качестве иллюстративного примера, как уже было указано ранее после добавления первого изображения визуального контента 300 в кластер, все контуры, выделенные на нем, становятся контурами кластера. Далее при добавлении изображения визуального контента 400, контуры 302, 303, …314 совпадают с контурами, выявленными на изображении 300 и им в соответствие ставится время их совпадения. Контуру 301 ставится в соответствие число 1, которое показывает, что этот контур не совпал при добавлении нового изображения в кластер один раз, а контуры 401, 402, 403 добавляются к контурам кластера. Далее при добавлении изображения визуального контента 500 в этот кластер, контурам 301, 302, 303, 306, 307, 308, 311, 312, 313 ставится в соответствие новое время их совпадения, а для контуров 304, 305, 309, 310, 314, 401, 402, 403 счетчик несовпадений увеличивается на единицу; притом контур 501 добавляется к контурам кластера.
[0120] В соответствии с настоящим техническим решением после попарного последовательного сравнения изображений визуального контента в случае преодоления порогового значения контур добавляется в кластер, при этом в описываемом случае добавляют все новые контуры, соответствующие изображению визуального контента, ассоциированного с кластером в базу данных 122. Совпадением при этом считается превышение оценкой похожести Р (1) заранее заданного порогового значения.
[0121] В качестве примера, но не ограничиваясь им со ссылкой на фиг. 3, 4, 5 способ 200 начинает свою работу с обработки первого изображения визуального контента, представленного на фиг. 3, далее, как было указано выше, указанное изображение обрабатывают, выявляя на нем контуры. После чего попарно сравнивают выявленные контуры с контурами кластеров (в описываемый момент контуры кластеров в базе данных 122 отсутствуют и их счетчик установлен в 0) и создают новый кластер, содержащий изображение визуального контента, представленное на фиг 3, так как оценка похожести Р (1) ни в одном из случаев не преодолевает порогового значения сходства. При этом созданный кластер содержит изображение визуального контента, указатель на него, а также все контуры, выявленные на изображении, а именно 301, 302…312. После способ переходит к кластеризации второго изображения визуального контента, представленного на фиг. 4. При этом стоит заметить, что данное изображение визуального контента имеет одинаковые контуры с кластером, сформированным ранее на основе обработки первого изображения визуального контента (302…313). Количество совпадающих контуров веб-ресурса 400 и контуров кластера, созданного на основе изображения визуального контента веб-ресурса 300, превышает допустимый порог, а значит изображение веб-ресурса 400 добавляется в кластер, при этом контуры 401, 402, выявленные только для веб-ресурса 400, добавляются к контурам кластера.
[0122] Возможен вариант осуществления настоящего технического решения, в котором процессор 121 выполнен с возможностью в многопоточном режиме обрабатывать каждый контур, а именно находить в базе данных 122 все контуры, разница размеров с которыми не превышает заданного числа пикселей, например, двух пикселей по ширине и/или высоте, и формировать из них множество похожих контуров.
[0123] Соответственно, в вариантах осуществления описываемой технологии, формируют по меньшей мере две таблицы в базе данных 122, при этом первая таблица включает в себя информацию о количестве изображений, на которых был обнаружен каждый из контуров, выявленных на изображениях визуального контента, каждому из имеющихся кластеров, а вторая таблица -об общем количестве контуров, входящих в каждый кластер. На основании сведений, содержащихся в сформированных таблицах, отсеивают (удаляют) кластеры, в которых общее число совпадающих контуров составляет менее 85% от числа контуров изображения визуального контента, ассоциированных с ним. При этом в случае, если после процедуры отсеивания для дальнейшей проверки остается свыше пятнадцати кластеров, то из них отбирают пятнадцать кластеров с наибольшим числом совпадений.
[0124] Ниже будут приведены примерные варианты указанных выше таблиц, а именно таблица 1, которая включает себя информацию о принадлежности каждого из выявленных контуров каждому из кластеров, и таблица 2, содержащая сведения об общем числе контуров в каждом кластере. Стоит дополнительно отметить, что конкретные данные в таблицах 1 и 2, приведены исключительно с целью иллюстрации, вместо этих данных могут быть любые другие численные величины, полученные при выполнении способа 200, в том числе таблицы могут содержать другие количества строк и столбцов.


[0125] В варианте осуществления настоящего технического решения далее в многопоточном режиме дополнительно сравнивают контуры каждого кластера, хранящиеся в базе данных 122, и контуры анализируемого изображения визуального контента, при этом объединяя совпавшие контуры и выделяя все кластеры, в которых были совпавшие контуры в соответствии с таблицей 1.
[0126] Кроме того, на данном этапе для добавления изображения визуального контента в кластер выполняют сравнение в многопоточном режиме каждого из выявленных на изображении контуров с каждым из контуров, присутствующих в разных кластерах.
[0127] В возможных вариантах осуществления настоящего способа вычисление порога для добавления изображения визуального контента в кластер (или объединения нескольких кластеров) происходит следующим образом:
находят (min), минимальное количество контуров в объединяемых объектах, то есть наименьшее из двух чисел: число, соответствующее количеству контуров на изображении визуального контента и число, соответствующее количеству контуров в данном кластере,
если min≤2, то вычислительное устройство 120 может выводить предупреждение о не информативности изображения, причем в данном случае новое изображение визуального контента в кластер не добавляется;
2<min<5, то для добавления изображения визуального контента в определенный кластер необходимо совпадение всех контуров на изображении и контуров в кластере;
5≤min≤10, то для добавления изображения визуального контента в определенный кластер необходимо совпадение по меньшей мере 50% от min контуров на изображении и контуров в кластере,
10<min≤15, то для добавления изображения визуального контента в определенный кластер необходимо совпадение по меньшей мере 25% от min контуров на изображении и контуров в кластере,
min>15, то для добавления изображения визуального контента в определенный кластер необходимо совпадение по меньшей мере 20% от min контуров на изображении и контуров в кластере.
[0128] [0128] Стоит отметить, что кластер создается только из изображений визуального контента, на которых выявлено по меньшей мере три контура.
[0129] В вариантах осуществления настоящего решения, возможно отнесение изображения визуального контента к нескольким кластерам, при этом его добавляют в кластер с наибольшим числом совпадений контуров. Кроме того, в данном варианте происходит проверка на возможность объединения выявленных кластеров.
[0130] Стоит отметить, что в возможных вариантах осуществления настоящего технического решения, этапы объединения кластеров аналогичны этапам добавления изображения визуального контента веб-ресурса в кластер, при одном отличии, что попарно сравнивают между собой контуры двух кластеров и в случае преодоления порога объединяют кластеры. Соответственно, все контуры первого кластера сравниваются со всеми контурами второго, при этом для каждого контура может быть только одно совпадение, то есть, если контур первого кластера совпал с контуром второго кластера, то эти контуры при дальнейших сравнениях не рассматриваются.
[0131] Способ 200 переходит к выполнению этапа 250.
ШАГ 250 СОХРАНЯЮТ УКАЗАНИЯ НА ВЕБ-РЕСУРСЫ, ИЗОБРАЖЕНИЯ ВИЗУАЛЬНОГО КОНТЕНТА КОТОРЫХ ОКАЗАЛИСЬ ПРИНАДЛЕЖАЩИМИ ОДНОМУ КЛАСТЕРУ, В БАЗЕ ДАННЫХ.
[0132] Далее сохраняют указания на веб-ресурсы, изображения визуального контента которых в ходе вышеописанного анализа оказались принадлежащими к одному кластеру, в базе данных 122 вычислительного устройства 120. Иными словами, на данном этапе сохраняют в базе данных информацию о том, какие именно веб-ресурсы принадлежат к одному и тому же подмножеству предположительно фишинговых веб-ресурсов.
[0133] В дополнительном варианте осуществления выявленные и сохраненные в базе данных кластеры могут затем передаваться на внешние устройства (не показаны на чертежах) с целью дальнейшей атрибуции фишинговых веб-ресурсов, зеркал веб-ресурсов, заблокированных или запрещенных веб-сайтов.
[0134] Стоит отметить, что в дополнительном варианте реализации настоящей технологии после кластеризации всех изображений визуального контента удаляют кластеры, в которых оказалось менее установленного числа изображений, например, для лучшего понимания, менее трех изображений визуального контента. Такие изображения заносятся в специальный список, сохраненный в базе данных 122, и временно считают «мусорными», неинформативными.
[0135] Далее, по меньшей мере один раз в определенный промежуток времени, устанавливаемый в системе 100, получают список от 1 до N всех оставшихся «мусорных» изображений визуального контента и соответствующих им контуров для фильтрации неинформативных изображений веб-ресурсов.
[0136] После проведения фильтрации для оставшиеся изображений визуального контента в списке от 1 до N, в базе данных создают дополнительную матрицу, в которой как в строках, так и в столбцах представлены оставшиеся «мусорные» изображения от 1 до N, а на пересечении строк и столбцов проставлено количество совпадающих для них контуров. Созданная матрица смежности используется для выявления устройством 120 списка уникальных пар похожих по размерам контуров, сопоставленных с изображениями.
[0137] В таблице 3 приведен неограничивающий пример построения дополнительной матрицы, пример который представлен в таблице 3. Стоит также отметить, что конкретные данные в таблице 3, приведены исключительно с целью иллюстрации, вместо этих данных могут быть любые другие численные величины, полученные при выполнении способа 200, в том числе матрица может содержать другие количества строк и столбцов.
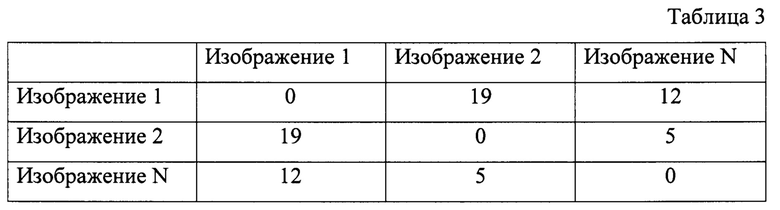
[0138] В неограничивающем варианте осуществления настоящей технологии после выявления устройством 120 списка похожих по размерам контуров в несколько потоков сравнивают содержащиеся в списке контуры и оставляют только наиболее похожие пары контуров. При этом информацию о пересечении контуров заносят в матрицу, хранящуюся в базе данных 122 для тех изображений визуального контента, к которым эти контуры относятся.
[0139] При этом для каждой уникальной пары изображений, содержащейся в списке, например, со ссылкой на таблицу 3, для изображения 1 и изображения 2, накладывают контуры друг на друга для выявления количества похожих пар контуров и, если в некой паре контуров контуры оказываются похожи друг на друга, то в изначально созданной матрице, где все заполнено 0, число в соответствующей ячейке увеличивают на 1. В данном примере, как можно видеть из таблицы 3, для данной пары изображений было найдено 19 похожих пар контуров.
[0140] Далее для подтверждения ассоциированности пар веб-ресурсов на основе пар их изображений визуального контента построчно проверяют матрицу, при этом преобразуя ее в матрицу смежности. В том случае, если количество контуров, совпавших у каждой пары изображений, превышает заранее заданный порог, в соответствующей ячейке матрицы проставляют единицу. Если количество совпавших контуров оказывается меньше заданного порога, в соответствующей ячейке проставляют ноль. Неограничивающий пример преобразованной матрицы смежности, показанной ранее в таблице 3, и обработанной данным способом при значении порога 10, показан в таблице 4.

[0141] В неограничивающих вариантах осуществления настоящей технологии далее производят вычисление сильно связных компонентов матрицы смежности. По сути, на данном шаге строят максимально связанный подграф, в котором любая вершина достижима из любой другой вершины графа. Собственно, методы вычисления сильно связанных компонент матрицы смежности широко известны в теории графов; при этом для реализации настоящей технологии может быть использован любой из этих методов.
[0142] В неограничивающем варианте осуществления настоящей технологии, для определения сильно связанных компонент используют алгоритм Тарьяна с модификациями Нуутила или нерекурсивный алгоритм Тарьяна.
[0143] Каждый такой построенный подграф образует новый кластер изображений визуального контента. Дополнительно стоит отметить, что построенный из «мусорных» изображений визуального контента кластер добавляется к построенным ранее кластерам как равнозначный. При этом изображения визуального контента, которые остались в списке «мусорных» изображений остаются там до тех пор, пока не войдут в один из новых кластеров, составленных из «мусорных» изображений.
[0144] На Фиг. 7 далее будет представлена общая схема вычислительного устройства (700), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
[0145] В общем случае устройство (700) содержит такие компоненты, как: один или более процессоров (701), по меньшей мере одну память (702), средство хранения данных (703), интерфейсы ввода/вывода (704), средство В/В (705), средства сетевого взаимодействия (706).
[0146] Процессор (701) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (700) или функциональности одного или более его компонентов. Процессор (701) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (702).
[0147] Память (702), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемую функциональность.
[0148] Средство хранения данных (703) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п.
[0149] Интерфейсы (704) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, Fire Wire и т.п. Выбор интерфейсов (704) зависит от конкретного исполнения устройства (700), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
[0150] В качестве средств В/В данных (705) могут использоваться клавиатура, джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
[0151] Средства сетевого взаимодействия (706) выбираются из устройств, обеспечивающих прием и передачу данных по сети, например, Ethernet-карта, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (705) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[0152] Компоненты устройства (700) сопряжены посредством общей шины передачи данных (710).
[0153] В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
[0154] Заявленный способ кластеризации фишингового контента обеспечивает повышение точности кластеризации множества веб-ресурсов на группы, что позволяет затем осуществлять оперативную проверку каждой из сохраненных групп экспертом и выявлять группы фишинговых сайтов, например, созданных посредством фишинговых наборов, выявлять зеркала и копии заблокированных и выявленных ранее вредоносных веб-ресурсов, определять авторов фишингового набора или владельца/ев фишингового веб-ресурса. При этом существенно снижается нагрузка на эксперта в процессе определения вредоносных веб-ресурсов.
[0155] Модификации и улучшения вышеописанных вариантов осуществления настоящего технического решения будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ КЛАСТЕРИЗАЦИИ ВЕБ-РЕСУРСОВ | 2018 |
|
RU2676247C1 |
| Способ и система для идентификации кластеров аффилированных веб-сайтов | 2020 |
|
RU2740856C1 |
| Способ блокировки сетевых соединений | 2018 |
|
RU2728506C2 |
| Способ блокировки сетевых соединений с ресурсами из запрещенных категорий | 2018 |
|
RU2702080C1 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ И ОРГАНИЗАЦИИ КЭША ВЕБ-БРАУЗЕРА ДЛЯ ОБЕСПЕЧЕНИЯ АВТОНОМНОГО ПРОСМОТРА | 2014 |
|
RU2608668C2 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ И ОРГАНИЗАЦИИ КЭША ВЕБ-БРАУЗЕРА | 2014 |
|
RU2629448C2 |
| СИСТЕМА И СПОСОБ СБОРА ИНФОРМАЦИИ ДЛЯ ОБНАРУЖЕНИЯ ФИШИНГА | 2016 |
|
RU2671991C2 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ФИШИНГОВЫХ ВЕБ-СТРАНИЦ | 2016 |
|
RU2637477C1 |
| ОПТИМИЗИРОВАННЫЙ ПРОЦЕСС ВОСПРОИЗВЕДЕНИЯ БРАУЗЕРА | 2014 |
|
RU2638726C1 |
| АННОТАЦИЯ ПОСРЕДСТВОМ ПОИСКА | 2007 |
|
RU2439686C2 |






Изобретение относится к вычислительной технике. Технический результат заключается в повышении точности кластеризации фишинговых веб-ресурсов. Предложен способ кластеризации фишинговых веб-ресурсов на основе изображения визуального контента, выполняемый на компьютерном устройстве, содержащем по меньшей мере процессор и память, и содержащий этапы, на которых: получают указания на множество фишинговых веб-ресурсов; извлекают изображение визуального контента каждого из множества веб-ресурсов; обрабатывают содержимое каждого изображения визуального контента, связанного с одним из множества веб-ресурсов, при этом выделяют контуры элементов на каждом изображении визуального контента фишингового веб-ресурса; осуществляют фильтрацию выявленных контуров на каждом изображении визуального контента путем удаления одинаковых контуров; на основе попарного сравнения выявленных контуров и контуров кластеров производят объединение веб-ресурса, связанного со сравниваемыми контурами с кластером; сохраняют указания на веб-ресурсы, ассоциированные с соответствующими контурами содержимого из множества указанных кластеров, в базе данных. 2 н. и 17 з.п. ф-лы, 7 ил.
1. Способ кластеризации фишинговых веб-ресурсов на основе изображения визуального контента, выполняемый на компьютерном устройстве, содержащем по меньшей мере процессор и память, при этом способ содержит этапы, на которых:
получают указания на множество фишинговых веб-ресурсов;
извлекают по меньшей мере одно изображение визуального контента каждого из множества веб-ресурсов;
обрабатывают содержимое каждого изображения визуального контента, связанного с одним из множества веб-ресурсов, при этом
выделяют контуры элементов на каждом изображении визуального контента фишингового веб-ресурса;
осуществляют фильтрацию выявленных контуров на каждом изображении визуального контента путем удаления одинаковых контуров;
на основе попарного сравнения выявленных контуров и контуров кластеров производят объединение веб-ресурса, связанного со сравниваемыми контурами, с кластером,
причем если значение сходства преодолевает пороговое значение, то объединяют изображение визуального контента, содержащего сравниваемые контуры, с кластером,
в противоположном случае создают новый кластер для веб-ресурса;
сохраняют указания на веб-ресурсы, ассоциированные с соответствующими контурами содержимого из множества указанных кластеров, в базе данных.
2. Способ по п. 1, в котором множество веб-ресурсов включает по меньшей мере два веб-ресурса.
3. Способ по п. 1, в котором для получения указаний на множество веб-ресурсов предварительно выполняют сканирование сети.
4. Способ по п. 1, в котором указания на множество веб-ресурсов получают по меньшей мере частично от внешнего источника по сети передачи данных.
5. Способ по п. 1, в котором указания на множество веб-ресурсов получают из предварительно сформированной базы данных веб-ресурсов.
6. Способ по п. 1, в котором выделяют по меньшей мере следующие контуры элементов, содержащихся на изображении визуального контента: логотипов, очертаний букв, отдельных слов, картинок, форм.
7. Способ по п. 1, в котором для выделения контуров используют по меньшей мере следующие методы: детектор границ Кэнни и алгоритм поиска контуров.
8. Способ по п. 1, в котором при обработке содержимого каждого полученного изображения визуального контента дополнительно производят удаление мелких, наклонных и вытянутых контуров.
9. Способ по п. 1, в котором производят фильтрацию выявленных контуров на каждом изображении визуального контента путем удаления одинаковых контуров, причем
если сравниваемые контуры по высоте и/или ширине отличаются больше чем на два пикселя, то считают их разными.
10. Способ по п. 1, в котором производят фильтрацию выявленных контуров на каждом изображении визуального контента путем удаления одинаковых контуров, причем
если сравниваемые контуры по высоте и/или ширине отличаются на два пикселя или меньше, то
контуры накладывают друг на друга и вычисляют попиксельную разность изображений,
причем для полученного разностного изображения вычисляют оценку похожести в диапазоне от 0, где изображения одинаковы, до 100 - изображения полностью противоположны,
причем оценка похожести (Р) вычисляется как среднее арифметическое значений пикселей, то есть сумма значений пикселей, деленная на количество пикселей изображения, причем вычисляемое для значений, взятых из всех трех каналов RGB:

где Ri, Gi, Bi - значения i-го пикселя в каналах R, G и В соответственно,
а N - общее количество пикселей изображения,
причем контуры, оценка похожести которых не превышает 7, удаляются.
11. Способ по п. 1, в котором дополнительно для каждого контура, выявленного на изображении визуального контента, рассчитывают инвариантные визуальные хеш-функции.
12. Способ по п. 1, в котором если при сравнении с изображениями кластеров обнаружено менее трех похожих контуров на изображении визуального контента фишингового веб-ресурса, то выводят сообщение о неинформативности, причем в данном случае новое изображение визуального контента в кластер не добавляется, а если в кластере менее двух изображений, то кластер удаляется;
если при сравнении обнаружено от трех до пяти похожих контуров, то для добавления изображения визуального контента фишингового веб-ресурса в определенный кластер необходимо полное совпадение всех контуров кластера;
если при сравнении обнаружено от пяти до десяти похожих контуров, то для добавления изображения визуального контента фишингового веб-ресурса в определенный кластер необходимо совпадение половины контуров с контурами кластера,
если при сравнении обнаружено от десяти до пятнадцати похожих контуров, то для добавления изображения визуального контента фишингового веб-ресурса в определенный кластер необходимо совпадение четверти контуров кластера,
если при сравнении обнаружено от пятнадцати похожих контуров, то для добавления изображения визуального контента фишингового веб-ресурса в определенный кластер необходимо совпадение по меньшей мере пятой части контуров кластера.
13. Способ по п. 1, в котором при отнесении изображения визуального контента фишингового веб-ресурса к нескольким кластерам его добавление происходит в кластер с наибольшим числом совпадений контуров.
14. Способ по п. 1, в котором дополнительно после кластеризации каждого из множества изображений визуального контента фишинговых веб-ресурсов удаляют кластеры, в которых содержится менее трех изображений.
15. Способ по п. 14, в котором дополнительно изображения, которые содержались в удаленных кластерах, заносят в специальный список и временно считают мусорными.
16. Способ по п. 15, в котором дополнительно на основе каждого изображения визуального контента, содержащегося в списке, создают матрицу смежности, в которой на пересечении расположено число совпадающих контуров, для выявления списка пар похожих контуров по размерам.
17. Способ по п. 16, в котором дополнительно для определения ассоциированности по меньшей мере двух изображений визуального контента веб-ресурсов в матрице смежности изменяют значение на 0, если число совпадающих по размерам контуров менее заданного порога, или на 1, если число совпадений контуров больше порога.
18. Способ по п. 17, в котором производят вычисление сильно связных компонентов графа, в которых находится более двух изображений, и создают новый кластер для каждой из выявленных компонент.
19. Вычислительное устройство для кластеризации фишингового контента, содержащее память для хранения машиночитаемых инструкций и по меньшей мере один вычислительный процессор, выполненный с возможностью исполнения машиночитаемых инструкций для обеспечения осуществления способа кластеризации фишингового контента по любому из пп. 1-18.
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ФИШИНГОВЫХ ВЕБ-СТРАНИЦ | 2016 |
|
RU2637477C1 |

