Настоящее изобретение относится в целом к когерентности кэша в многопроцессорных вычислительных системах и, в частности, к кэшу запросов отслеживания для фильтрации запросов отслеживания.
Многие современные программы, реализованные программно, написаны с предположением, что у исполняющего их компьютера очень большое (в идеальном случае, неограниченное) количество быстродействующей памяти. Большинство современных процессоров моделируют это идеальное условие с использованием иерархии типов памяти с разными скоростными и стоимостными характеристиками. Типы памяти в иерархии постепенно изменяются от очень быстрых и очень дорогих на верхнем уровне до более медленных, но более экономичных типов запоминающих устройств на более низких уровнях. Из-за пространственных и временных характеристик локализации большинства программ команды и данные, исполняемые в любой данный момент времени, и те, которые находятся в адресном пространстве рядом с ними, по статистике, вероятно, должны потребоваться в самом ближайшем будущем и могут преимущественно сохраняться на верхних, высокоскоростных иерархических уровнях, где к ним можно быстро получить доступ.
Типичная иерархия памяти может содержать массив очень быстрых регистров общего назначения (GPR) в ядре процессора на верхнем уровне. Регистры процессора могут поддерживаться одной или несколькими кэш-памятями, известными в данной области техники как кэши первого уровня или кэши L1. Кэши L1 могут быть сформированы как массивы памяти на одной интегральной схеме с ядром процессора с обеспечением возможности очень быстрого доступа, но с ограничением по размеру кэша L1. В зависимости от реализации процессор может включать в себя один или несколько внутрисхемных или внесхемных кэшей второго уровня или кэшей L2. Кэши L2 часто реализуют в SRAM для малого времени доступа и во избежание ухудшающих производительность требований обновления DRAM. Поскольку ограничений на размер кэша L2 меньше, то кэши L2 могут быть в несколько раз больше размера кэшей L1, и в многопроцессорных системах один кэш L2 может находиться под двумя или несколькими кэшами L1. Высокоэффективные вычислительные процессоры могут иметь дополнительные уровни кэша (например, L3). Под всеми кэшами находится оперативная память, обычно реализуемая в DRAM или SDRAM для максимальной плотности и, следовательно, самой низкой стоимости каждого бита.
Кэш-памяти в иерархии памяти улучшают производительность с обеспечением очень быстрого доступа к небольшому количеству данных и с уменьшением ширины полосы передачи данных между одним или несколькими процессорами и оперативной памятью. Кэши содержат копии данных, хранящихся в оперативной памяти, и изменения в кэшируемых данных должны быть отражены в оперативной памяти. В общем в данной области техники для передачи записей кэша в оперативную память разработаны два подхода: со сквозной записью и с обратным копированием. В кэше со сквозной записью, когда процессор записывает модифицированные данные в свой кэш L1, он дополнительно (и немедленно) записывает эти модифицированные данные в кэш более низкого уровня и/или в оперативную память. В схеме с обратным копированием процессор может записать модифицированные данные в кэш L1 и отложить обновление изменений в памяти более низкого уровня до более позднего времени. Например, запись может быть задержана до тех пор, пока элемент кэша не будет заменен при обработке промаха кэша, протокол когерентности кэша запросит это, или под управлением программного обеспечения.
В дополнение к предположению о больших количествах быстродействующей памяти современные программы, реализованные программно, исполняются в концептуально смежном и в значительной степени эксклюзивном виртуальном адресном пространстве. Соответственно каждая программа предполагает, что она обладает эксклюзивным (правом) использования всех ресурсов памяти, со специальными исключительными ситуациями для явно разделяемого пространства памяти. Современные процессоры, вместе со сложными программными средствами операционной системы, моделируют это условие посредством отображения виртуальных адресов (используемых программами) в физические адреса (которые адресуют фактические аппаратные средства, например, кэши и оперативную память). Отображение и трансляция виртуальных адресов в физические известны как управление памятью. Управление памятью распределяет ресурсы процессорам и программам, определяет политики управления кэшем, обеспечивает безопасность, обеспечивает защиту данных, улучшает надежность и обеспечивает другие функциональные возможности посредством назначения атрибутов сегментам оперативной памяти, называемым страницами. Многие разные атрибуты могут определяться и назначаться на постраничной основе, например супервизор/пользователь, чтение-запись/только чтение, эксклюзивный/разделяемый, команда/данные, кэш со сквозной записью/с обратным копированием и многие другие. После перевода виртуальных адресов в физические адреса данные приобретают атрибуты, определенные для физической страницы.
Одним подходом к управлению многопроцессорными системами является распределение отдельного «потока» исполнения программы или задачи каждому процессору. В этом случае каждому потоку распределяется эксклюзивная память, из которой он может считывать и в которую он может записывать, не заботясь о состоянии памяти, распределенной любому другому потоку. Однако связанные потоки часто используют совместно некоторые данные, и, соответственно, каждому распределяется одна или несколько общих страниц, имеющих атрибут «разделяемая». Обновления разделяемой памяти должны быть видны всем процессорам, совместно использующим ее, при этом встает вопрос о когерентности кэша. Соответственно разделяемые данные также могут иметь атрибут (указывающий на) необходимость «сквозной записи» кэша L1 в кэш L2 (если кэш L2 поддерживает кэш L1 всех процессоров, совместно использующих страницу) или в оперативную память. Кроме того, для извещения других процессоров о том, что разделяемые данные изменились (и, следовательно, их собственная L1-кэшируемая копия, если таковая вообще имеется, больше не является достоверной), процессор, выполняющий запись, выдает запрос во все процессоры, совместно использующие данные, на аннулирование соответствующей строки в его кэше L1. Межпроцессорные операции по когерентности кэша, в общем, в этом документе называются запросами отслеживания, и запрос на аннулирование строки кэша L1 называется в этом документе запросом отслеживания с аннулированием или просто отслеживанием с аннулированием. Запросы отслеживания с аннулированием возникают, конечно, (и) в сценариях, отличных от описанного выше.
После приема запроса отслеживания с аннулированием процессор должен аннулировать соответствующую строку в своем кэше L1. При следующей попытке считывания данных произойдет промах кэша L1, что обеспечит считывание процессором обновленной версии из разделяемого кэша L2 или оперативной памяти. Обработка отслеживания с аннулированием, однако, подвергается штрафу по мере потребления ею циклов обработки, которые иначе использовались бы для обслуживания загрузок и сохранений в принимающем процессоре. Кроме того, при отслеживании с аннулированием может потребоваться, чтобы конвейер загрузки/сохранения достиг состояния, где известно, что риски сбоя данных, которые усложнены отслеживанием, были разрешены с остановкой конвейера и дальнейшим ухудшением производительности.
Известны различные способы в данной области техники, которые сокращают количество циклов останова процессора, вызываемых процессором, который отслеживают. В одном таком способе поддерживается дублированная копия массива тегов L1 для обращений отслеживания. Когда принято отслеживание с аннулированием, выполняется поиск в дублированном массиве тегов. Если при этом поиске произошел промах, то нет необходимости аннулировать соответствующий элемент в кэше L1, и избегают штрафа, связанного с обработкой отслеживания с аннулированием. Однако это решение подвергается большому штрафу в кремниевой области, так как весь тег для каждого кэша L1 должен быть дублирован с увеличением минимальной площади кристалла, а также потребляемой мощности. Кроме того, процессор должен обновлять две копии тега каждый раз, когда кэш L1 обновляется.
Другим известным способом сокращения количества запросов отслеживания с аннулированием, которые процессор должен обрабатывать, является формирование «группы устройств отслеживания» из процессоров, которые потенциально могут совместно использовать память. После обновления кэша L1 с разделяемыми данными (со сквозной записью в память более низкого уровня) процессор посылает запрос отслеживания с аннулированием только в те процессоры, которые находятся в его группе устройств отслеживания. Группы устройств отслеживания можно определять и поддерживать программными средствами, например, на уровне страницы или глобально. Несмотря на то, что этот способ сокращает глобальное количество запросов отслеживания с аннулированием в системе, он, тем не менее, требует, чтобы каждый процессор в каждой группе устройств отслеживания обрабатывал запрос отслеживания с аннулированием для каждой записи разделяемых данных любым другим процессором в группе.
Еще одним известным способом сокращения количества запросов отслеживания с аннулированием является сбор данных для сохранения. Вместо немедленного исполнения каждой команды на сохранение посредством записи небольших количеств данных в кэш L1 процессор может включать в себя буфер накопления или блок регистров для сбора данных для сохранения. Когда происходит сбор строки кэша, полустроки или другой удобной величины данных или когда имеет место сохранение в строку кэша или полустроку, отличную от той, которую собирают, собранные данные для сохранения записываются в кэш L1 все вместе. Это сокращает количество операций записи в кэш L1 и, следовательно, количество запросов отслеживания с аннулированием, которые должны быть отправлены в другой процессор. Этот способ требует дополнительной внутрикристалльной памяти для буфера накопления или буферов накопления и может плохо работать, когда операции на сохранение не ограничены до такой степени, что они охватываются буферами накопления.
Еще одним известным способом является фильтрация запросов отслеживания с аннулированием в кэше L2 посредством полного включения кэша L1 в кэш L2. В этом случае процессор, записывающий разделяемые данные, выполняет поиск в кэше L2 другого процессора до отслеживания другого процессора. Если произошел промах при поиске L2, то нет никакой необходимости отслеживать кэш L1 другого процессора, и в другом процессоре не ухудшается производительность обработки запроса отслеживания с аннулированием. С использованием кэш-памяти L2 для дублирования одного или нескольких кэшей L1 этот способ уменьшает общий фактический размер кэша. Кроме того, этот способ неэффективен, если два или большее количество процессоров, поддерживаемых одним кэшем L2, совместно используют данные и, следовательно, должны отслеживать друг друга.
Сущность изобретения
Согласно одному или нескольким вариантам осуществления, описанным и заявленным в этом документе, один или несколько кэшей запросов отслеживания поддерживают записи запросов отслеживания. После записи данных, имеющих атрибут «разделяемые», процессор выполняет поиск в кэше запросов отслеживания. Если при поиске произошел промах, то процессор размещает элемент в кэше запросов отслеживания и направляет запрос отслеживания (например, отслеживания с аннулированием) в один или несколько процессоров. Если при поиске в кэше запросов отслеживания произошло попадание, то процессор подавляет запрос отслеживания. Когда процессор считывает разделяемые данные, он также выполняет поиск запроса в кэше отслеживания и аннулирует совпадающий элемент в случае попадания.
Один вариант осуществления относится к способу выдачи запроса отслеживания кэша данных в целевой процессор, имеющий кэш данных, посредством субъекта отслеживания. Поиск в кэше запросов отслеживания выполняется в ответ на операцию сохранения данных, и запрос отслеживания кэша данных подавляется в ответ на попадание.
Другой вариант осуществления относится к вычислительной системе. Система включает в себя память и первый процессор, имеющий кэш данных. Система также включает в себя субъект отслеживания, функционирующий для направления запроса отслеживания кэша данных в первый процессор после записи в память данных, имеющих предопределенный атрибут. Система также включает в себя, по меньшей мере, один кэш запросов отслеживания, содержащий, по меньшей мере, один элемент, причем каждый достоверный элемент указывает на предшествующий запрос отслеживания кэша данных. Субъект отслеживания также функционирует для выполнения поиска в кэше запросов отслеживания до направления запроса отслеживания кэша данных в первый процессор и подавления запроса отслеживания кэша данных в ответ на попадание.
Краткое описание чертежей
Фиг.1 - функциональная блок-схема разделяемого кэша запросов отслеживания в многопроцессорной вычислительной системе.
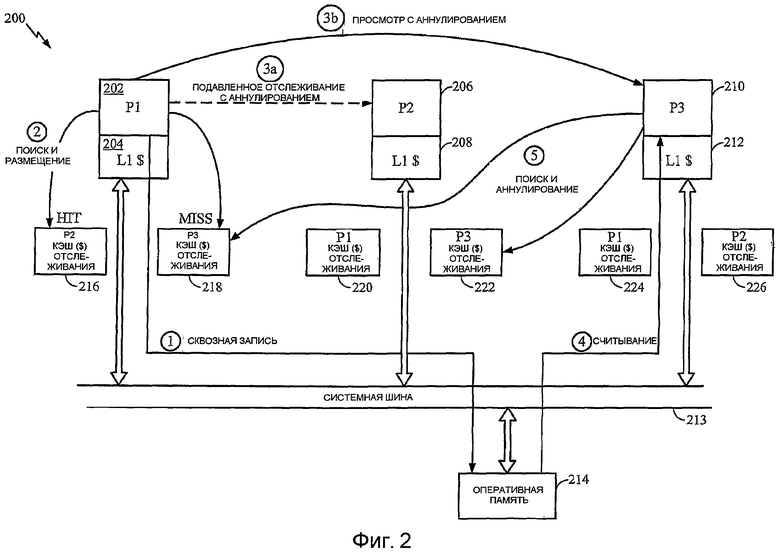
Фиг.2 - функциональная блок-схема множества специальных кэшей запросов отслеживания для каждого процессора в многопроцессорной вычислительной системе.
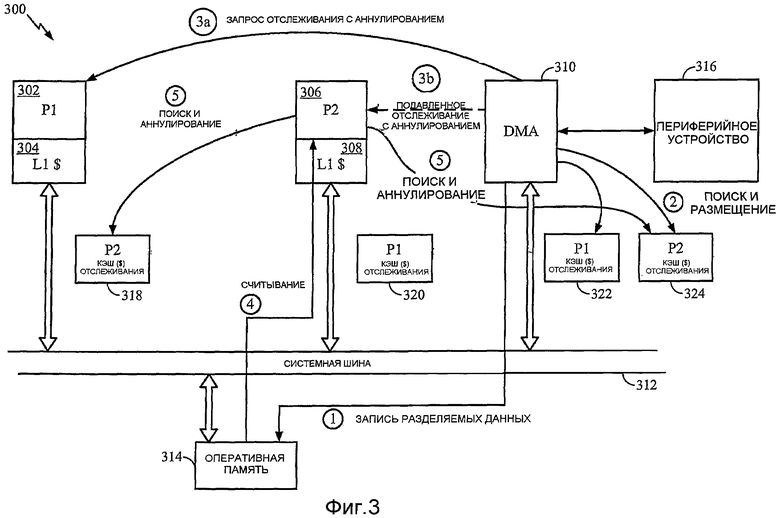
Фиг.3 - функциональная блок-схема многопроцессорной вычислительной системы, включающей в себя непроцессорный субъект отслеживания.
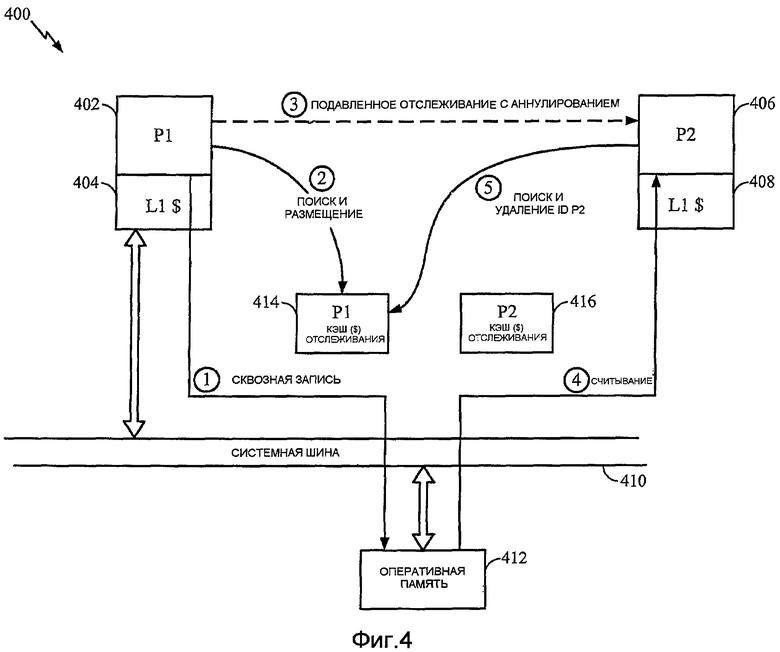
Фиг.4 - функциональная блок-схема одного кэша запросов отслеживания, связанного с каждым процессором в многопроцессорной вычислительной системе.
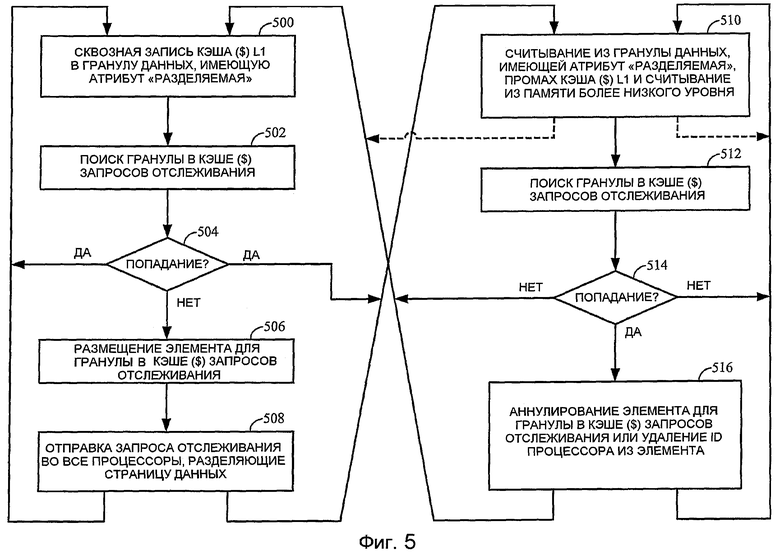
Фиг.5 - блок-схема способа выдачи запроса отслеживания.
Подробное описание
На фиг.1 изображена многопроцессорная вычислительная система, обозначенная в целом позицией 100. Компьютер 100 включает в себя первый процессор 102 (обозначенный P1) и связанный с ним кэш 104 L1. Компьютер 100 дополнительно включает в себя второй процессор 106 (обозначенный P2) и связанный с ним кэш 108 L1. Оба кэша L1 поддерживаются разделяемым кэшем 110 L2, который передает данные по системной шине 112 в оперативную память 114 и из нее. Процессоры 102, 106 могут включать в себя специализированные кэши команд (не изображены) или могут кэшировать и данные, и команды в кэшах L1 и L2. Являются ли кэши 104, 108, 110 специализированными кэшами данных или унифицированными кэшами команда/данные не оказывает влияния на описание вариантов осуществления в этом документе, функционирование которых относится к кэшируемым данным. Как используется в этом документе, операция «кэша данных», например запрос отслеживания кэша данных, одинаково относится и к операции, направленной на специализированный кэш данных, и к операции, направленной на данные, хранящиеся в унифицированном кэше.
Выполнение программ, реализованных программно, на процессорах P1 и P2 в значительной степени является независимым, и их виртуальные адреса отображаются в соответствующие эксклюзивные страницы физической памяти. Однако программы, на самом деле, совместно используют некоторые данные, и, по меньшей мере, некоторые адреса отображаются в страницу разделяемой памяти. Для обеспечения того, чтобы кэш 104, 108 L1 каждого процессора содержал последние разделяемые данные, у разделяемой страницы существует дополнительный атрибут сквозной записи L1. Соответственно в любое время, когда P1 или P2 обновляют адрес разделяемой памяти, кэш 110 L2, а также кэш 104, 108 L1 процессора обновляются. Кроме того, выполняющий обновление процессор 102, 106 посылает запрос отслеживания с аннулированием в другой процессор 102, 106 для возможного аннулирования соответствующей строки в кэше 104, 108 L1 другого процессора. Это вызывает ухудшение производительности в принимающем процессоре 102, 106, как объяснялось выше.
Кэш 116 запросов отслеживания кэширует предыдущие запросы отслеживания с аннулированием и может устранять лишние просмотры с аннулированием с улучшением общей производительности. На фиг.1 схематически изображен этот процесс. На этапе 1 процессор P1 записывает данные в ячейку памяти, имеющую атрибут «разделяемая». Как используется в этом документе, термин «гранула» относится к наименьшему кэшируемому кванту данных в компьютерной системе 100. В большинстве случаев гранула является наименьшим размером строки кэша L1 (некоторые кэши L2 имеют сегментированные строки и могут сохранять несколько гранул в строке). Когерентность кэша поддерживается на основе гранулы. Атрибут «разделяемый» (или в качестве альтернативы, отдельный атрибут сквозной записи) страницы памяти, содержащей гранулу, обеспечивает запись (процессором) P1 его данных в кэш 110 L2, а также в его собственный кэш 104 L1.
На этапе 2 процессор P1 выполняет поиск в кэше 116 запросов отслеживания. Если при поиске в кэше 116 запросов отслеживания произошел промах, то процессор P1 размещает элемент в кэше 116 запросов отслеживания для (поиска) гранулы, связанной с данными сохранения (процессора) P1, и посылает запрос отслеживания с аннулированием в процессор P2 для аннулирования любой соответствующей строки (или гранулы) в кэше 108 L1 (процессора) P2 (этап 3). Если процессор P2 впоследствии будет считывать эту гранулу, то она будет отсутствовать в его кэше 108 L1 с обеспечением обращения к кэшу 110 L2, и в P2 будет возвращена последняя версия данных.
Если процессор P1 впоследствии обновляет идентичную гранулу разделяемых данных, то он снова выполнит сквозную запись в кэш 110 L2 (этап 1). P1 также выполнит поиск в кэше 116 запросов отслеживания (этап 2). На этот раз при поиске в кэше 116 запросов отслеживания произойдет попадание. В ответ процессор P1 подавляет запрос отслеживания с аннулированием в процессор P2 (этап 3 не исполняется). Присутствие элемента в кэше 116 запросов отслеживания, соответствующего грануле, в которую он записывает, обеспечивает процессору P1 то, что предыдущий запрос отслеживания с аннулированием уже аннулировал соответствующую строку в кэше 108 L1 (процессора) P2, и любое считывание гранулы (процессором) P2 обеспечит обращение к кэшу 110 L2. Соответственно запрос отслеживания с аннулированием не является необходимым для когерентности кэша и может безопасно подавляться.
Однако процессор P2 может считывать данные из идентичной гранулы в кэше 110 L2 - и изменять свое соответствующее состояние строки кэша L1 на достоверное - после того, как процессор P1 разместит элемент в кэше 116 запросов отслеживания. В этом случае процессор P1 не должен подавлять запрос отслеживания с аннулированием в процессор P2, если P1 будет записывать новое значение в гранулу, так как (в результате) этого остались бы разные значения в кэше L2 и кэше L1 процессора P2. Для «обеспечения возможности» отслеживаниям с аннулированием, выдаваемым процессором P1, достигать процессора P2 (то есть не быть подавленными), после считывания гранулы на этапе 4, процессор P2 выполняет поиск по грануле в кэше 116 запросов отслеживания на этапе 5. Если в результате этого поиска произойдет попадание, то процессор P2 аннулирует совпадающий элемент кэша запросов отслеживания. Когда процессор P1 впоследствии будет записывать в гранулу, он выдаст новый запрос отслеживания с аннулированием в процессор P2 (при промахе кэша 116 запросов отслеживания). Следовательно, два кэша 104, 108 L1 поддерживают когерентность для записей процессора P1 и считываний процессора P2, причем процессор P1 выдает минимальное количество запросов отслеживания с аннулированием, требуемых для этого.
С другой стороны, если процессор P2 записывает разделяемую гранулу, то он также должен осуществить сквозную запись в кэш 110 L2. При выполнении поиска в кэше 116 запросов отслеживания, однако, может произойти попадание в элемент, который был размещен ранее, когда процессор P1 записывал гранулу. В этом случае (в результате) подавления запроса отслеживания с аннулированием в процессор P1 в кэше 104 L1 P1 осталось бы старое значение, что привело бы к некогерентности кэшей 104, 108 L1. Соответственно в одном варианте осуществления после размещения элемента кэша 116 запросов отслеживания процессор 102, 106, выполняющий сквозную запись в кэш 110 L2, включает идентификатор в этот элемент. После последующих записей процессор 102, 106 должен подавлять запрос отслеживания с аннулированием, только если совпадающий элемент в кэше 116 запросов отслеживания включает в себя идентификатор этого процессора. Аналогично при выполнении поиска в кэше 116 запросов отслеживания после чтения упомянутой гранулы процессор 102, 106 должен аннулировать совпадающий элемент, только если он включает в себя идентификатор другого процессора. В одном варианте осуществления каждый элемент кэша 116 включает в себя идентификационный флажок для каждого процессора в системе, который может совместно использовать данные, и процессоры просматривают и устанавливают или очищают идентификационные флажки, как требуется, после попадания кэша.
Кэш 116 запросов отслеживания может допускать любую организацию кэша или степень связанности, известные в данной области техники. Кэш 116 запросов отслеживания может также принимать любую стратегию замены элемента кэша, известную в данной области техники. Кэш 116 запросов отслеживания предлагает преимущества в производительности, если процессор 102, 106, записывающий разделяемые данные, получает попадание кэша 116 запросов отслеживания и подавляет запросы отслеживания с аннулированием в один или несколько других процессоров 102, 106. Однако если достоверный элемент кэша 116 запросов отслеживания заменяется из-за количества достоверных элементов, превышающего допустимое пространство кэша 116, то никакая ошибочная операция или некогерентность кэша - в худшем случае не приведут к тому, что последующий запрос отслеживания с аннулированием может быть выдан в процессор 102, 106, для которого соответствующая строка кэша L1 уже является недостоверной.
В одном или нескольких вариантах осуществления теги к элементам кэша 116 запросов отслеживания формируются из самых старших битов адреса гранулы и бита достоверности, аналогично тегам в кэшах 104, 108 L1. В одном варианте осуществления «строка», или данные, хранящиеся в элементе кэша 116 запросов отслеживания, являются просто уникальным идентификатором процессора 102, 106, который разместил элемент (то есть процессора 102, 106, выдающего запрос отслеживания с аннулированием), который может, например, содержать идентификационный флажок для каждого процессора в системе 100, который может совместно использовать данные. В другом варианте осуществления идентификатор процессора-источника может сам быть включен в тег, поэтому процессор 102, 106 будет при поиске получать попадание кэша только в свои собственные элементы согласно сохранению разделяемых данных. В этом случае кэшем 116 запросов отслеживания является просто структура ассоциативной памяти (CAM), указывающая попадание или промах, при этом соответствующий элемент RAM не хранит данные. Заметим, что при выполнении поиска в кэше 116 запросов отслеживания согласно загрузке разделяемых данных должны использоваться идентификаторы других процессоров.
В другом варианте осуществления идентификатор процессора-источника может быть опущен, и в каждом элементе кэша 116 запросов отслеживания сохраняется идентификатор каждого целевого процессора, то есть каждого процессора 102, 106, которому послан запрос отслеживания с аннулированием. Идентификация может содержать идентификационный флажок для каждого процессора в системе 100, который может совместно использовать данные. В этом варианте осуществления, после записи в гранулу разделяемых данных, процессор 102, 106, получающий попадание кэша 116 запросов отслеживания, просматривает идентификационные флажки и подавляет запрос отслеживания с аннулированием в каждый процессор, идентификационный флажок которого установлен. Процессор 102, 106 посылает запрос отслеживания с аннулированием в каждый другой процессор, идентификационный флажок которого сброшен в совпадающем элементе, и затем устанавливает флажок(ки) целевых процессоров. После считывания гранулы разделяемых данных процессор 102, 106, получающий попадание кэша 116 запросов отслеживания, сбрасывает свой собственный идентификационный флажок вместо аннулирования всего элемента - очистка пути для запросов отслеживания с аннулированием, которые должны быть направлены в него, но все еще блокированы для отправки в другие процессоры, соответствующая строка кэша которых остается недостоверной.
Другой вариант осуществления описан со ссылкой на фиг.2, на которой изображена компьютерная система 200, включающая в себя процессор P1 202, имеющий кэш 204 L1, процессор P2 206, имеющий кэш 208 L1, и процессор P3 210, имеющий кэш 212 L1. Каждый кэш 204, 208, 212 L1 соединен через системную шину 213 с оперативной памятью 214. Заметим, что, как очевидно из фиг.2, никакой вариант осуществления здесь не требует и не зависит от присутствия или отсутствия кэша L2 или любого другого аспекта иерархии памяти. С каждым процессором 202, 206, 210 связан кэш 216, 218, 220, 222, 224, 226 запросов отслеживания, предназначенный для каждого другого процессора 202, 206, 210 (имеющего кэш данных) в системе 200, который может обращаться к разделяемым данным. Например, с процессором P1 связан кэш 216 запросов отслеживания, предназначенный для процессора P2, и кэш 218 запросов отслеживания, предназначенный для процессора P3. Аналогично (с) процессором P2 связаны кэши 220, 222 запросов отслеживания, предназначенные для процессоров P1 и P3, соответственно. Наконец, кэши 224, 226 запросов отслеживания, соответственно предназначенные для процессоров P1 и P2, связаны с процессором P3. В одном варианте осуществления кэши 216, 218, 220, 222, 224, 226 запросов отслеживания являются только структурами CAM и не включают в себя строки данных.
На фиг.2 схематически изображена работа кэшей запросов отслеживания с характерной последовательностью этапов. На этапе 1 процессор P1 записывает в гранулу разделяемых данных. Атрибуты данных обеспечивают сквозную запись из кэша 204 L1 P1 в память 214. Процессор P1 выполняет поиск в обоих связанных с ним кэшах запросов отслеживания, то есть и в кэше 216 запросов отслеживания, предназначенном для процессора P2, и в кэше 218 запросов отслеживания, предназначенном для процессора P3, на этапе 2. В этом примере происходит попадание кэша 216 запросов отслеживания P2, указывающее, что P1 ранее посылал запрос отслеживания с аннулированием в P2, элемент кэша запросов отслеживания которого не был аннулирован или перезаписан новым размещением. Это означает, что соответствующая строка в кэше 208 L2 P2 была (и остается) недостоверной, и процессор P1 подавляет запрос отслеживания с аннулированием в процессор P2, как обозначено пунктирной линией на этапе 3a.
В этом примере при поиске происходит промах кэша 218 запросов отслеживания, связанного с P1 и предназначенного для P3. В ответ процессор P1 размещает элемент для гранулы в кэше 218 запросов отслеживания P3 и выдает запрос отслеживания с аннулированием в процессор P3 на этапе 3b. Это отслеживание с аннулированием аннулирует соответствующую строку в кэше L1 (процессора) P3 и обеспечивает переход P3 в оперативную память при его следующем считывании из гранулы для извлечения последних данных (которые обновлены посредством записи (процессора) P1).
Впоследствии, как обозначено на этапе 4, процессор P3 считывает из гранулы данных. При чтении происходит промах его собственного кэша 212 L1 (поскольку эта строка была аннулирована отслеживанием с аннулированием (процессора) P1), и осуществляется выборка гранулы из оперативной памяти 214. На этапе 5 процессор P3 выполняет поиск во всех кэшах запросов отслеживания, предназначенных для него, то есть и в кэше 218 запросов отслеживания (процессора) P1, предназначенного для P3, и в кэше 222 запросов отслеживания (процессора) P2, который также предназначен для P3. Если происходит попадание любого (или обоих) кэшей 218, 222, то процессор P3 аннулирует совпадающий элемент для предотвращения подавления запросов отслеживания с аннулированием в P3 соответствующим процессором P1 или P2, если или процессор P1 или P2 записывают новое значение в гранулу разделяемых данных.
Обобщение этого конкретного примера, например, в варианте осуществления, изображенном на фиг.2, где с каждым процессором связан отдельный кэш запросов отслеживания, предназначенный для каждого другого процессора, совместно использующего данные, процессор, записывающий в гранулу разделяемых данных, выполняет поиск в каждом кэше запросов отслеживания, связанном с процессором, выполняющим запись. Для каждого, который получает промах, процессор размещает элемент в кэше запросов отслеживания и посылает запрос отслеживания с аннулированием в процессор, для которого предназначен кэш запросов отслеживания с промахом. Процессор подавляет запросы отслеживания с аннулированием в любой процессор, для которого произошло попадание кэша, предназначенного для него. После считывания гранулы разделяемых данных процессор выполняет поиск во всех кэшах запросов отслеживания, предназначенных для него (и связанных с другими процессорами), и аннулирует любые совпадающие элементы. Следовательно, кэши 204, 208, 212 L1 поддерживают когерентность для данных, имеющих атрибут «разделяемый».
Несмотря на то, что варианты осуществления настоящего изобретения описаны в этом документе в отношении процессоров, каждый из которых имеет кэш L1, в протоколе когерентности кэша могут участвовать другие схемы или логические/функциональные объекты в пределах компьютерной системы 100. На фиг.3 изображен вариант осуществления, аналогичный варианту осуществления по фиг.2, причем в протоколе когерентности кэша участвует непроцессорный субъект отслеживания. Система 300 включает в себя процессор P1 302, имеющий кэш 304 L1, и процессор P2 306, имеющий кэш 308 L1.
Система дополнительно включает в себя контроллер 310 прямого доступа к памяти (DMA). Также известный в данной области техники DMA-контроллер 310 является схемой, функционирующей для перемещения блоков данных из источника (памяти или периферийного устройства) в адресат (память или периферийное устройство) независимо от процессора. В системе 300 процессоры 302, 306 и DMA-контроллер 310 обращаются к оперативной памяти 314 через системную шину 312. Кроме того, DMA-контроллер 310 может считывать и записывать данные непосредственно из порта данных на периферийном устройстве 316. Если DMA-контроллер 310 запрограммирован процессором для записи в разделяемую память, то он должен участвовать в протоколе когерентности кэша для обеспечения когерентности кэшей 304, 308 данных L1.
Так как DMA-контроллер 310 участвует в протоколе когерентности кэша, то он является субъектом отслеживания. Как используется в этом документе, термин «субъект отслеживания» относится к любому субъекту системы, который может выдавать запросы отслеживания в соответствии с протоколом когерентности кэша. В частности, процессор, имеющий кэш данных, является одним типом субъекта отслеживания, но термин «субъект отслеживания» охватывает субъекты системы, отличные от процессоров, имеющих кэши данных. Примеры субъектов отслеживания, кроме процессоров 302, 306 и DMA-контроллера 310, включают в себя математический или графический сопроцессор, механизм компрессии/декомпрессии, например, кодер/декодер MPEG, или любой другой контроллер системной шины, который может обращаться к разделяемым данным в памяти 314.
С каждым субъектом отслеживания 302, 306, 310 связан кэш запросов отслеживания, предназначенный для каждого процессора (имеющего кэш данных), с которым субъект отслеживания может совместно использовать данные. В частности, кэш 318 запросов отслеживания связан с процессором P1 и предназначен для процессора P2. Аналогично кэш 320 запросов отслеживания связан с процессором P2 и предназначен для процессора P1. С DMA-контроллером 310 связаны два кэша запросов отслеживания: кэш 322 запросов отслеживания, предназначенный для процессора P1, и кэш 324 запросов отслеживания, предназначенный для процессора P2.
Процесс когерентности кэша изображен схематически на фиг.3. DMA-контроллер 310 записывает в гранулу разделяемых данных, (находящуюся) в оперативной памяти 314 (этап 1). Так как любой или оба процессора P1 и P2 могут содержать эту гранулу данных в своем кэше 304, 308 L1, то DMA-контроллер 310 обычно посылает запрос отслеживания с аннулированием в каждый процессор P1, P2. Во-первых, однако, DMA-контроллер 310 выполняет поиск в обоих связанных с ним кэшах запросах отслеживания (этап 2), то есть в кэше 322, предназначенном для процессора P1, и в кэше 324, предназначенном для процессора P2. В этом примере при поиске в кэше 322, предназначенном для процессора P1, происходит промах, и при поиске в кэше 324, предназначенном для процессора P2, происходит попадание. В ответ на промах DMA-контроллер 310 посылает запрос отслеживания с аннулированием в процессор P1 (этап 3a) и размещает элемент для гранулы данных в кэше 322 запросов отслеживания, предназначенном для процессора P1. В ответ на попадание DMA-контроллер 310 подавляет запрос отслеживания с аннулированием, который иначе был бы отправлен процессору P2 (этап 3b).
Впоследствии процессор P2 считывает из гранулы разделяемых данных, (находящейся) в памяти 314 (этап 4). Для обеспечения запросов отслеживания с аннулированием, направляемых к нему из всех субъектов отслеживания, процессор P2 выполняет поиск в каждом кэше 318, 324, связанном с другим субъектом отслеживания и предназначенном для процессора P2 (то есть для него). В частности, процессор P2 выполняет кэш-поиск в кэше 318 запросов отслеживания, связанном с процессором P1 и предназначенном для процессора P2, и аннулирует любой совпадающий элемент в случае попадания кэша. Аналогично процессор P2 выполняет кэш-поиск в кэше 324 запросов отслеживания, связанном с DMA-контроллером 310 и предназначенном для процессора P2, и аннулирует любой совпадающий элемент в случае попадания кэша. В этом варианте осуществления кэши 318, 320, 322, 324 запросов отслеживания являются чисто структурами CAM и не требуют идентификационных флажков процессора в элементах кэша.
Заметим, что никакой субъект отслеживания 302, 306, 310 не связал с собой никакой кэш запросов отслеживания, предназначенный для DMA-контроллера 310. Так как у DMA-контроллера 310 нет кэша данных, то нет необходимости, чтобы другой субъект отслеживания направлял запрос отслеживания с аннулированием в DMA-контроллер 310 для аннулирования строки кэша. Кроме того, заметим, что несмотря на то, что DMA-контроллер 310 участвует в протоколе когерентности кэша посредством выдачи запросов отслеживания с аннулированием после записи разделяемых данных в память 314, после считывания из гранулы разделяемых данных, DMA-контроллер 310 не выполняет никакой поиск в кэше запросов отслеживания с целью аннулирования совпадающего элемента. И опять же это происходит из-за того, что у DMA-контроллера 310 отсутствует какой-либо кэш, в котором он должен обеспечить возможность другому субъекту отслеживания аннулировать строку кэша после записи в разделяемые данные.
Еще один вариант осуществления описан согласно фиг.4, на которой изображена компьютерная система 400, включающая в себя два процессора: P1 402, имеющий кэш 404 L1, и P2 406, имеющий кэш 408 L1. Процессоры P1 и P2 соединены через системную шину 410 с оперативной памятью 412. Один кэш 414 запросов отслеживания связан с процессором P1, и отдельный кэш 416 запросов отслеживания связан с процессором P2. Каждый элемент в каждом кэше 414, 416 запросов отслеживания включает в себя флажок или поле, идентифицирующие другой процессор, в который связанный процессор может направлять запрос отслеживания. Например, элементы в кэше 414 запросов отслеживания включают в себя идентификационные флажки для процессора P2, а также любых других процессоров (не изображены) в системе 400, с которыми P1 может совместно использовать данные.
Функционирование этого варианта осуществления изображено схематически на фиг.4. После записи в гранулу данных, имеющую атрибут «разделяемая», процессор P1 получает промах своего кэша 404 L1 и выполняет сквозную запись в оперативную память 412 (этап 1). Процессор P1 выполняет кэш-поиск в кэше 414 запросов отслеживания, связанном с ним (этап 2). В ответ на попадание процессор P1 просматривает идентификационные флажки процессора в совпадающем элементе. Процессор P1 подавляет отправку запроса отслеживания в любой процессор, с которым он совместно использует данные, и идентификационный флажок которого в совпадающем элементе установлен (например, P2, как изображено пунктирной линией на этапе 3). Если идентификационный флажок процессора сброшен и процессор P1 совместно использует гранулу данных с указанным процессором, то процессор P1 отправляет запрос отслеживания в этот процессор и устанавливает идентификационный флажок целевого процессора в совпадающем элементе кэша 414 запросов отслеживания. Если при поиске в кэше 414 запросов отслеживания происходит промах, то процессор P1 размещает элемент и устанавливает идентификационный флажок для каждого процессора, которому он отправляет запрос отслеживания с аннулированием.
Когда любой другой процессор выполняет загрузку из гранулы разделяемых данных, получает промах в своем кэше L1 и осуществляет выборку данных из оперативной памяти, он выполняет кэш-поиски в кэшах 414, 416 запросов отслеживания, связанных с каждым процессором, с которым он совместно использует упомянутую гранулу данных. Например, процессор P2 считывает из памяти данные из гранулы, которую он совместно использует с P1 (этап 4). P2 выполняет поиск в кэше 414 запросов отслеживания P1 (этап 5) и просматривает любой совпадающий элемент. Если идентификационный флажок (процессора) P2 установлен в совпадающем элементе, то процессор P2 сбрасывает свой собственный идентификационный флажок (но не идентификационный флажок любого другого процессора), обеспечивая возможность процессору P1 посылать запросы отслеживания с аннулированием в P2, если P1 впоследствии записывает в гранулу разделяемых данных. Совпадающий элемент, в котором идентификационный флажок (процессора) P2 сброшен, обрабатывается как промах кэша 414 (P2 не предпринимает никаких действий).
В общем в варианте осуществления, изображенном на фиг.4, где каждый процессор имеет один связанный с ним кэш запросов отслеживания, каждый процессор выполняет поиск только в связанном с ним кэше запросов отслеживания после записи разделяемых данных, размещает элемент кэша, в случае необходимости, и устанавливает идентификационный флажок каждого процессора, которому он отправляет запрос отслеживания. После считывания разделяемых данных каждый процессор выполняет поиск в кэше запросов отслеживания, связанном с каждым другим процессором, с которым он совместно использует данные, и сбрасывает свой собственный идентификационный флажок в любом совпадающем элементе.
На фиг.5 изображен способ выдачи запроса отслеживания кэша данных согласно одному или нескольким вариантам осуществления. Один аспект способа «начинается» с того, что субъект отслеживания записывает в гранулу данных, имеющую атрибут «разделяемая», на этапе 500. Если субъект отслеживания является процессором, то атрибут (например, разделяемый и/или со сквозной записью) обеспечивает сквозную запись кэша L1 на более низкий уровень иерархии памяти. Субъект отслеживания выполняет поиск по грануле разделяемых данных в одном или нескольких кэшах запросов отслеживания, связанных с ним, на этапе 502. Если происходит попадание в гранулу разделяемых данных в кэше запросов отслеживания на этапе 504 (и, в некоторых вариантах осуществления, идентификационный флажок для процессора, с которым он совместно использует данные, установлен в совпадающем элементе кэша), то субъект отслеживания подавляет запрос отслеживания кэша данных для одного или нескольких процессоров и продолжает (функционирование). Согласно фиг.5 он может «продолжать» с последующей записью другой гранулы разделяемых данных на этапе 500, считыванием гранулы разделяемых данных, на этапе 510, или выполнением некоторой другой задачи, не относящейся к этому способу. Если гранула разделяемых данных отсутствует в кэше запросов отслеживания (или, в некоторых вариантах осуществления, происходит попадание в нее, но идентификационный флажок целевого процессора сброшен), то субъект отслеживания размещает элемент для гранулы в кэше запросов отслеживания на этапе 506 (или устанавливает идентификационный флажок целевого процессора) и отправляет запрос отслеживания кэша данных в процессор, разделяющий данные, на этапе 508 и продолжает (функционирование).
Другой аспект способа «начинается», когда субъект отслеживания считывает из гранулы данных, имеющей атрибут «разделяемая». Если субъект отслеживания является процессором, то он получает промах в своем кэше L1 и осуществляет выборку гранулы разделяемых данных с более низкого уровня иерархии памяти на этапе 510. Процессор выполняет поиск по грануле в одном или нескольких кэшах запросов отслеживания, предназначенных для него (или элементы которых включают в себя идентификационный флажок для него), на этапе 512. Если при поиске в кэше запросов отслеживания происходит промах на этапе 514 (или, в некоторых вариантах осуществления, при поиске происходит попадание, но идентификационный флажок процессора в совпадающем элементе сброшен), то процессор продолжает (функционирование). Если при поиске в кэше запросов отслеживания происходит попадание на этапе 514 (и, в некоторых вариантах осуществления, идентификационный флажок процессора в совпадающем элементе установлен), то процессор аннулирует совпадающий элемент на этапе 516 (или, в некоторых вариантах осуществления, сбрасывает свой идентификационный флажок) и затем продолжает (функционирование).
Если субъект отслеживания не является процессором с кэшем L1, например, DMA-контроллер, то нет необходимости обращаться к кэшу запросов отслеживания для проверки и аннулирования элемента (или сброса его идентификационного флажка) после считывания из гранулы данных. Так как гранула не кэшируется, то нет необходимости очищать путь для другого субъекта отслеживания для аннулирования или какого-либо другого изменения состояния кэша строки кэша, когда другой объект записывает в гранулу. В этом случае способ продолжается после считывания из гранулы на этапе 510, как обозначено пунктирными стрелками на фиг.5. Другими словами, способ отличается в отношении считывания разделяемых данных в зависимости от того, является ли субъект отслеживания, выполняющий считывание, процессором, имеющим кэш данных, или нет.
Согласно одному или нескольким вариантам осуществления, описанным в этом документе, производительность в многопроцессорных вычислительных системах улучшена посредством уклонения от ухудшений производительности, связанных с выполнением лишних запросов отслеживания, с поддержанием когерентности кэша L1 для данных, имеющих атрибут «разделяемый». В различных вариантах осуществления эта улучшенная производительность достигается при существенном снижении стоимости кремниевой области, по сравнению с подходом дублирования тегов, известным в данной области техники. Кэш запросов отслеживания совместим с вариантами осуществления, использующими другие известные способы подавления запроса отслеживания, например процессоры в пределах определенной программными средствами группы устройств отслеживания, и для процессоров, поддерживаемых идентичным кэшем L2, который полностью включает кэши L1, и обеспечивает преимущества улучшенной производительности для них. Кэш запросов отслеживания совместим со сбором данных для сохранения, и в таком варианте осуществления может быть меньшего размера из-за меньшего количества операций сохранения, выполняемых процессором.
Несмотря на то, что вышеизложенное обсуждение было представлено в терминах кэша L1 со сквозной записью и подавления запросов отслеживания с аннулированием, специалистам в данной области техники будет понятно, что другие алгоритмы записи в кэш и сопутствующие протоколы отслеживания могут преимущественно использовать соответствующие изобретению оборудование, схемы и способы, описанные и заявленные в этом документе. Например, в протоколе кэша MESI (Модифицированная, Эксклюзивная, Разделяемая, Недостоверная) запрос отслеживания может указать процессору изменить состояние строки кэша с Эксклюзивная на Разделяемая.
Настоящее изобретение может, конечно, быть выполнено способами, отличными от тех, которые специально изложены в этом документе, не отступая от существенных признаков изобретения. Настоящие варианты осуществления должны рассматриваться во всех отношениях как иллюстративные, а не ограничительные, и подразумевается, что все изменения в пределах значения и диапазона эквивалентности прилагаемой формулы изобретения охвачены ею.
Изобретение относится к вычислительной технике, а именно к когерентности кэша в многопроцессорных вычислительных системах, в частности к кэшу запросов отслеживания для фильтрация запросов отслеживания. Техническим результатом является сокращение количества запросов отслеживания с аннулированием, которые должен обрабатывать процессор, тем самым сокращая количество циклов останова процессора, вызываемых процессором, который отслеживает. Вычислительная система содержит память, первый процессор, имеющий кэш данных, субъект отслеживания и, по меньшей мере, один кэш запросов отслеживания. Способ описывает работу данной системы. 3 н. и 38 з.п. ф-лы, 5 ил.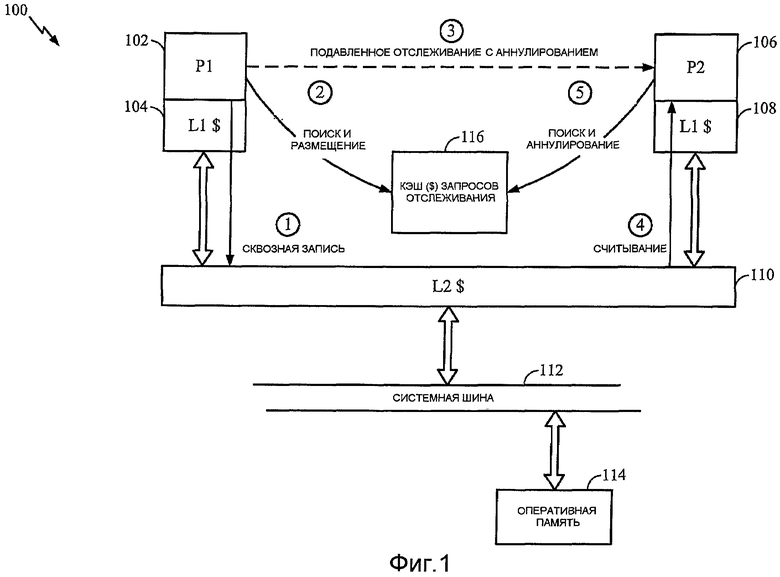
1. Способ фильтрации запроса отслеживания кэша данных в целевой процессор, имеющий кэш данных, посредством субъекта отслеживания, содержащий этапы, на которых: выполняют, до направления запроса отслеживания кэша данных в целевой процессор, поиск в кэше запросов отслеживания в ответ на операцию сохранения данных и отправляют запрос отслеживания кэша данных в целевой процессор, только если поиск в кэше запросов отслеживания завершается промахом, в противном случае, в ответ на попадание, подавляют запрос отслеживания кэша данных.
2. Способ по п.1, в котором при подавлении запроса отслеживания кэша данных в ответ на попадание запрос отслеживания кэша данных подавляют в ответ на идентификацию субъекта отслеживания в совпадающем элементе кэша.
3. Способ по п.1, в котором при подавлении запроса отслеживания кэша данных в ответ на попадание запрос отслеживания кэша данных подавляют в ответ на идентификацию целевого процессора в совпадающем элементе кэша.
4. Способ по п.1, дополнительно содержащий этап, на котором размещают элемент в кэше запросов отслеживания в ответ на промах.
5. Способ по п.4, в котором при размещении элемента в кэше запросов отслеживания в элемент кэша запросов отслеживания включают идентификацию субъекта отслеживания.
6. Способ по п.4, в котором при размещении элемента в кэше запросов отслеживания в элемент кэша запросов отслеживания включают идентификацию целевого процессора.
7. Способ по п.1, дополнительно содержащий этап, на котором устанавливают идентификацию целевого процессора в совпадающем элементе кэша, в котором идентификация целевого процессора не установлена.
8. Способ по п.1, в котором субъект отслеживания является процессором, имеющим кэш данных, при этом способ дополнительно содержит этап, на котором выполняют поиск в кэше запросов отслеживания в ответ на операцию загрузки данных.
9. Способ по п.8, дополнительно содержащий этап, на котором, в ответ на попадание, аннулируют совпадающий элемента кэша запросов отслеживания.
10. Способ по п.8, дополнительно содержащий этап, на котором, в ответ на попадание, удаляют идентификацию процессора из совпадающего элемента кэша.
11. Способ по п.1, в котором поиск в кэше запросов отслеживания выполняют только для операций сохранения данных в отношении данных, имеющих предопределенный атрибут.
12. Способ по п.11, в котором предопределенный атрибут является таким, что данные являются совместно используемыми.
13. Способ по п.1, в котором запрос отслеживания кэша данных приспособлен для изменения состояния строки кэша в кэше данных целевого процессора.
14. Способ по п.13, в котором запрос отслеживания кэша данных является запросом отслеживания с аннулированием, приспособленным для аннулирования строки из кэша данных целевого процессора.
15. Вычислительная система, содержащая: память, первый процессор, имеющий кэш данных, субъект отслеживания, выполненный с возможностью направлять запрос отслеживания кэша данных в первый процессор после записи в память данных, имеющих предопределенный атрибут; и по меньшей мере, один кэш запросов отслеживания, содержащий, по меньшей мере, один элемент, причем каждый достоверный элемент указывает на предшествующий запрос отслеживания кэша данных, причем субъект отслеживания дополнительно выполнен с возможностью осуществлять поиск в кэше запросов отслеживания до направления запроса отслеживания кэша данных в первый процессор и отправлять запрос отслеживания кэша данных в первый процессор, только если поиск в кэше запросов отслеживания завершается промахом, в противном случае, в ответ на попадание, подавлять запрос отслеживания кэша данных.
16. Система по п.15, в которой субъект отслеживания дополнительно выполнен с возможностью размещать новый элемент в кэше запросов отслеживания в ответ на промах.
17. Система по п.15, в которой субъект отслеживания дополнительно выполнен с возможностью подавлять запрос отслеживания кэша данных в ответ на идентификацию субъекта отслеживания в совпадающем элементе кэша.
18. Система по п.15, в которой субъект отслеживания дополнительно выполнен с возможностью подавлять запрос отслеживания кэша данных в ответ на идентификацию первого процессора в совпадающем элементе кэша.
19. Система по п.18, в которой субъект отслеживания дополнительно выполнен с возможностью устанавливать идентификацию первого процессора в совпадающем элементе, в котором идентификация первого процессора не установлена.
20. Система по п.15, в которой первый процессор дополнительно выполнен с возможностью осуществлять поиск в кэше запросов отслеживания после считывания из памяти данных, имеющих предопределенный атрибут, и изменять совпадающий элемент кэша запросов отслеживания в ответ на попадание.
21. Система по п.20, в которой предопределенный атрибут указывает на совместно используемые данные.
22. Система по п.21, в которой первый процессор выполнен с возможностью аннулировать совпадающий элемент кэша запросов отслеживания.
23. Система по п.21, в которой первый процессор выполнен с возможностью сброса в совпадающем элементе кэша запросов отслеживания своей идентификации.
24. Система по п.15, в которой упомянутый, по меньшей мере, один кэш запросов отслеживания содержит один кэш запросов отслеживания, в котором и первый процессор, и субъект отслеживания выполняют поиски после записи в память данных, имеющих предопределенный атрибут.
25. Система по п.15, в которой упомянутый, по меньшей мере, один кэш запросов отслеживания содержит: первый кэш запросов отслеживания, в котором первый процессор выполнен с возможностью осуществлять поиск после записи в память данных, имеющих предопределенный атрибут, и второй кэш запросов отслеживания, в котором субъект отслеживания выполнен с возможностью осуществлять поиски после записи в память данных, имеющих предопределенный атрибут.
26. Система по п.25, в которой первый процессор дополнительно выполнен с возможностью осуществлять поиски во втором кэше запросов отслеживания после считывания из памяти данных, имеющих предопределенный атрибут.
27. Система по п.25, дополнительно содержащая: второй процессор, имеющий кэш данных, и третий кэш запросов отслеживания, в котором субъект отслеживания выполнен с возможностью осуществлять поиски после записи в память данных, имеющих предопределенный атрибут.
28. Вычислительная система для фильтрации запроса отслеживания кэша данных в целевой процессор, имеющий кэш данных, посредством субъекта отслеживания, содержащая: средство для выполнения, до направления запроса отслеживания кэша данных в целевой процессор, поиска в кэше запросов отслеживания в ответ на операцию сохранения данных; и средство для отправки запроса отслеживания кэша данных в целевой процессор, только если поиск в кэше запросов отслеживания завершается промахом, в противном случае, в ответ на попадание, для подавления запроса отслеживания кэша данных.
29. Система по п.28, в которой средство для подавления запроса отслеживания кэша данных в ответ на попадание дополнительно содержит средство для подавления запроса отслеживания кэша данных в ответ на идентификацию субъекта отслеживания в совпадающем элементе кэша.
30. Система по п.28, в которой средство для подавления запроса отслеживания кэша данных в ответ на попадание дополнительно содержит средство для подавления запроса отслеживания кэша данных в ответ на идентификацию целевого процессора в совпадающем элементе кэша.
31. Система по п.28, дополнительно содержащая средство для размещения элемента в кэше запросов отслеживания в ответ на промах.
32. Система по п.31, в которой средство для размещения элемента в кэше запросов отслеживания содержит средство для включения в элемент кэша запросов отслеживания идентификации субъекта отслеживания.
33. Система по п.31, в которой средство для размещения элемента в кэше запросов отслеживания содержит средство для включения в элемент кэша запросов отслеживания идентификации целевого процессора.
34. Система по п.28, дополнительно содержащая средство для установки идентификации целевого процессора в совпадающем элементе кэша, в котором идентификации целевого процессора не установлена.
35. Система по п.28, в которой субъект отслеживания является процессором, имеющим кэш данных, при этом система дополнительно содержит средство для выполнения поиска в кэше запросов отслеживания в ответ на операцию загрузки данных.
36. Система по п.35, дополнительно содержащая средство для аннулирования, в ответ на попадание, совпадающего элемента кэша запросов отслеживания.
37. Система по п.35, дополнительно содержащая средство для удаления, в ответ на попадание, идентификации процессора из совпадающего элемента кэша.
38. Система по п.28, в которой средство для поиска в кэше запросов отслеживания предназначено только для операций сохранения данных в отношении данных, имеющих предопределенный атрибут.
39. Система по п.38, в которой предопределенный атрибут является таким, что данные являются совместно используемыми.
40. Система по п.28, в которой запрос отслеживания кэша данных приспособлен для изменения состояния строки кэша в кэше данных целевого процессора.
41. Система по п.40, в которой запрос отслеживания кэша данных является запросом отслеживания с аннулированием, приспособленным для аннулирования строки из кэша данных целевого процессора.
| US 5745732 A, 28.04.1998 | |||
| US 6516368 B1, 04.02.2003 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ ФИЛЬТРАЦИИ МЕЖПРОЦЕССОРНЫХ ЗАПРОСОВ В МНОГОПРОЦЕССОРНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМАХ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2001 |
|
RU2189630C1 |

