Область техники, к которой относится изобретение
Настоящее изобретение относится к области логики обработки информации, микропроцессорам и ассоциированной с ними архитектуре набора команд, которые при выполнении процессором или другой логической схемой обработки информации, выполняют логические, математические или другие функциональные операции.
Уровень техники
Многопроцессорные системы становятся все более и более распространенным явлением. Способ применения многопроцессорных систем включает в себя динамический домен, структурируя вплоть до настольных компьютеров. Для того, чтобы воспользоваться преимуществами многопроцессорных систем, код потока, подлежащий выполнению, может быть разделен посредством планировщиков на различные блоки обработки для внеочередного исполнения. Процесс внеочередного исполнения может выполнять инструкции, так как вход для таких инструкций доступен. Таким образом, инструкция, которая появляется позже в кодовой последовательности, может быть выполнена перед инструкцией, появляющейся ранее в кодовой последовательности.
Краткое описание чертежей
Варианты осуществления проиллюстрированы в качестве примера, и не ограничены на прилагаемых чертежах:
Фиг. 1А показывает блок-схему иллюстративной компьютерной системы, сформированной процессором, который может включать в себя исполнительные блоки для выполнения инструкции, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 1В иллюстрирует систему обработки данных в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 1С иллюстрирует другие варианты осуществления системы обработки данных для выполнения операций сравнения текстовой строки;
Фиг. 2 показывает блок-схему микроархитектуры для процессора, который может включать в себя логические схемы для выполнения инструкции, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 3А иллюстрирует различные представления типа упакованных данных в мультимедийных регистрах, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 3В иллюстрирует возможные форматы хранения данных в регистре, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 3С показывает различные представления типов упакованных данных со знаком и беззнаковые в мультимедийных регистрах, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 3D показывает вариант осуществления формата кодирования операции;
Фиг. 3Е показывает другой возможный формат кодирования операции, имеющий сорок или больше битов, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 3F иллюстрирует еще один возможный формат кодирования операции, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 4А представляет собой блок-схему, иллюстрирующую упорядоченный конвейер и этап переименования регистра, конвейер с изменением последовательности команд, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 4В показывает блок-схему, иллюстрирующую упорядоченную архитектуру ядра и логику переименования регистров, логику с изменением последовательности команд, включенную в состав процессора, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 5А показывает блок-схему процессора, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 5В показывает блок-схему примерной реализации ядра, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 6 показывает блок-схему системы, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 7 показывает блок-схему второй системы, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 8 показывает блок-схему третьей системы в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 9 показывает блок-схему системы-на-кристалле, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 10 показывает процессор, содержащий центральный блок обработки и блок обработки графики, который может выполнять, по меньшей мере, одну инструкцию, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 11 показывает блок-схему, иллюстрирующую разработку IP ядер, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 12 показывает, как инструкция первого типа может быть эмулирована процессором другого типа, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 13 показывает блок-схему, различающую использование конвертора команд программного обеспечения для преобразования двоичных инструкций в наборе источника команды в двоичные инструкции в целевом наборе команд, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 14 представляет собой блок-схему архитектуры набора команд процессора, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 15 представляет собой более подробную блок-схему архитектуры набора команд процессора, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 16 показана блок-схема конвейера для выполнения команд архитектуры набора команд процессора, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 17 показывает блок-схему электронного устройства для использования процессора, в соответствии с вариантами осуществления настоящего изобретения;
Фиг. 18 показывает функциональную блок-схему системы для выполнения инструкции и логику для доступа к памяти в машине с кластерными исполнительными блоками;
Фиг. 19 показывает функциональную блок-схему блоков кэша данных, в соответствии с вариантами осуществления настоящего изобретения; и
Фиг. 20А и 20В являются иллюстрацией способа доступа к памяти в кластерной машине, в соответствии с вариантами осуществления настоящего изобретения.
Осуществление изобретения
Следующее описание описывает инструкции и логику обработки для доступа к памяти в процессоре, виртуальном процессоре, пакете, компьютерной системе или другом устройстве обработки. В одном из вариантов осуществления, такое устройство обработки может включать в себя устройство для обработки в кластерной машине, в которой исполнительные блоки могут быть сгруппированы вместе. В другом варианте осуществления такое устройство обработки может включать в себя кластерную машину широкого исполнения. В последующем описании многочисленные конкретные детали, такие как логическая схема обработки, типы процессоров, микроархитектурные условия, события, механизмы решений и тому подобное изложены для обеспечения более полного понимания вариантов осуществления настоящего изобретения. Следует принять во внимание специалистам в данной области техники, что варианты осуществления могут быть реализованы без таких конкретных деталей. Кроме того, некоторые хорошо известные структуры, схемы и тому подобное не показаны подробно для упрощения описания вариантов осуществления настоящего изобретения.
Несмотря на то, что следующие варианты осуществления описаны со ссылкой на процессор, другие варианты осуществления применимы к другим типам интегральных схем и логических устройств. Подобные способы и идеи вариантов осуществления настоящего изобретения могут быть применены к другим типам схем или полупроводниковым устройствам, которые могут получить выгоду от более высокой пропускной способности конвейерной обработки и улучшенной производительности. Идеи вариантов осуществления настоящего раскрытия применимы к любому процессору или машине, которая выполняет обработку данных. Однако варианты осуществления не ограничены процессорами или машинами, которые выполняют 512-битные, 256-битные, 128-битные, 64-битные, 32-битные или 16-битные операции с данными и могут быть применены к любому процессору и машине, в которой может быть осуществлено манипуляция или управление данными. Кроме того, в последующем описании, приведенные примеры и прилагаемые чертежи показывают различные примеры для целей иллюстрации. Однако эти примеры не следует рассматривать в ограничительном смысле, так как они предназначены только для обеспечения примеров вариантов осуществления настоящего изобретения, а не с целью дать исчерпывающий перечень всех возможных вариантов реализации вариантов осуществления настоящего изобретения.
Несмотря на то, что приведенные ниже примеры описывают процесс обработки команд и распределение в контексте исполнительных блоков и логических схем, другие варианты осуществления настоящего изобретения, могут быть получены путем передачи данных или инструкций, хранящихся на машиночитаемом, материальном носителе, которые, когда выполняются машиной, предписывают машине выполнять функции, в соответствии, по меньшей мере, с одним из вариантов осуществления изобретения. В одном из вариантов осуществления функции, ассоциированные с вариантами осуществления настоящего изобретения, воплощены в машиноисполняемых инструкциях. Инструкции могут быть использованы для вызова процессора общего назначения или процессора специального назначения, которые могут быть запрограммированы инструкциями для выполнения этапов настоящего изобретения. Варианты осуществления настоящего изобретения могут быть представлены в виде компьютерного программного продукта или программного обеспечения, которое может включать в себя машину или компьютерно-считываемый носитель, имеющий сохраненные на нем команды, которые могут быть использованы для программирования компьютера (или других электронных устройств) для выполнения одной или более операций в соответствии с вариантами осуществления настоящего изобретения. Кроме того, этапы осуществления настоящего изобретения могут быть выполнены с помощью специальных компонентов аппаратных средств, которые содержат фиксированные логические функции для выполнения этапов, или любой комбинацией программируемых компьютерных компонентов и аппаратных компонентов с фиксированными функциями.
Инструкции, используемые для программной логики, для выполнения вариантов осуществления настоящего изобретения могут быть сохранены в памяти в системе, такой как DRAM, кэш, флэш-память или другое запоминающее устройство. Кроме того, инструкции могут быть распределены по сети или посредством другого считываемого компьютером носителя информации. Таким образом, машиночитаемый носитель информации может включать в себя любой механизм для хранения или передачи информации в форме, считываемой машиной (например, компьютером), но не ограничиваясь этим, гибкие диски, оптические диски, компакт-диск, компакт-диск постоянной памяти (CD-ROMs) и магнитооптические диски, память только для чтения (ROMs), оперативное запоминающее устройство (RAM), стираемое программируемое постоянное запоминающее устройство (EPROM), электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), магнитные или оптические карты, флэш-память, или материальный машиночитаемый носитель информации, используемый при передаче информации через интернет с помощью электрических, оптических, акустических или других форм распространяющихся сигналов (например, несущие волны, инфракрасные сигналы, цифровые сигналы и т.д.). Соответственно, считываемый компьютером носитель информации может включать в себя любой тип материального машиночитаемого носителя информации, пригодный для хранения или передачи электронных инструкций или информации в форме, считываемой машиной (например, компьютером).
Разработка может осуществляться посредством реализации различных этапов, от создания до компьютерного моделирования и до изготовления. Данные, представляющие конструкцию, могут представлять конструкцию в цифровом виде. Во-первых, как это может быть полезно при моделировании, аппаратные средства могут быть представлены с использованием языка описания аппаратных средств или другого функционального языка описания. Кроме того, модель уровня схемы с логическим и/или транзисторным затвором могут быть изготовлены на некоторых этапах процесса проектирования. Кроме того, конструкции, на каком-то этапе, могут достигать уровня данных, представляющих физическое размещение различных устройств в аппаратной модели. В тех случаях, в которых некоторые способы полупроводникового производства используются, данные, представляющие модель аппаратных средств, могут быть данными, указывающими на наличие или отсутствие различных признаков на различных уровнях маски для масок, используемых для производства интегральных схем. В любом представлении конструкции данные могут быть сохранены в любой форме машиночитаемого носителя. Память или магнитные или оптические запоминающие устройства, такие как диск, может быть машиночитаемым носителем информации для хранения информации, передаваемой с помощью модулированной оптической или электрической волны или иным образом генерироваться для передачи такой информации. При передаче электрической несущей волны с указанием или несущей код или информацию о структуре, при этой осуществляется копирование, буферизация или повторная передача электрического сигнала, может быть сделана новая копия. Таким образом, провайдер связи или сетевой провайдер может хранить на материальном машиночитаемом носителе информации, по меньшей мере, временно, в статье, такой как, информация, закодированная на несущей волне, реализуя способы вариантов осуществления настоящего изобретения.
В современных процессорах могут быть использованы различные исполнительные блоки для обработки и выполнения различных кодов и инструкций. Некоторые инструкции могут быть обработаны быстрее, в то время как другие могут занять несколько тактовых циклов для завершения. Чем выше производительность команд, тем лучше общая производительность процессора. Таким образом, было бы выгодно иметь, на сколько это возможно, больше быстродействующих инструкций. Тем не менее, могут существовать определенные инструкции, которые имеют большую сложность и требуют больше с точки зрения времени выполнения и ресурсов процессора, такие как инструкции с плавающей запятой, операции загрузки/сохранения, перемещение данных и т.д.
Поскольку все больше компьютерных систем используются в интернете, в текстовых и мультимедийных приложениях, была использована дополнительная поддержка процессора в течение долгого времени. В одном варианте осуществления набор инструкций может быть связан с одной или более компьютерных архитектур, включающая в себя типы данных, инструкции, архитектуру регистра, режимы адресации, архитектуру памяти, обработку прерываний и исключений и внешний ввод/вывод (I/O).
В одном варианте осуществления архитектура системы команд (ISA) может быть реализована с помощью одной или более микроархитектур, которые могут включать в себя логику и схемы процессора, используемые для реализации одного или более наборов команд. Соответственно, процессоры с различными микроархитектурами могут совместно использовать, по меньшей мере, часть общего набора инструкций. Например, Intel® Pentium 4 процессоры, процессоры Intel® Core™ и процессоры, изготовленные Advanced Micro Devices, Inc. Саннивейл CA реализовывают почти идентичные версии набора инструкций х86 (с некоторыми расширениями, которые были добавлены в более новые версии), но имеют различные внутренние конструкции. Аналогично, процессоры, разработанные другими компаниями в области разработки процессоров, такие как ARM Holdings, Ltd., MIPS или их лицензиаты или соразработчики, могут совместно использовать, по меньшей мере, часть общего набора команд, но могут включать в себя различные конструкции процессора. Например, та же архитектура регистра ISA может быть реализована по-разному в разных микроархитектурах с использованием новых или хорошо известных технологий, включающие в себя специализированные физические регистры, один или более динамически выделенных физических регистров с использованием механизма переименования регистра (например, использование таблицы псевдонимов регистров (RAT), буфера переупорядочения (ROB) и файла удаления регистра). В одном из вариантов осуществления регистры могут включать в себя один или более регистров, архитектуры регистров, регистровые файлы или другие наборы регистров, которые могут или не могут быть переадресованы с помощью программного обеспечения.
Инструкция может включать в себя один или несколько форматов команд. В одном варианте осуществления формат команд может указывать на различные поля (число битов, расположение битов и т.д.), чтобы указать, среди прочего, какая операция должна быть выполнена, и операнды, на которых будут выполняться эта операция. В дополнительном варианте осуществления, некоторые форматы команд могут быть дополнительно определены с помощью шаблонов команд (или субформаты). Например, шаблоны команд заданного формата команд могут быть определены, чтобы иметь различные подмножества полей формата команды и/или определены, чтобы иметь заданное поле, которое интерпретируется иным образом. В одном варианте осуществления команда может быть выражена с помощью формата команд (и, если определено, в данном одном из шаблонов команд этого формата инструкции) и устанавливает или указывает на операцию и операнды, на которых операция будет работать.
Научные, финансовые, автовекторные общего назначения, RMS (распознавание, анализ и синтез) и визуальные и мультимедийные приложения (например, 2D/3D графика, обработка изображений, сжатие/распаковка видео, алгоритмы распознавания голоса и аудио манипуляции) могут быть обработаны посредством одной и той же операции на большом количестве элементов данных. В одном из вариантов осуществления архитектура с одним потоком команд и несколькими потоками данных (SIMD) относится к типу инструкции, которая вызывает процессор выполнить операции с множеством элементов данных. Технология SIMD может использоваться в процессорах, которые могут логически разделить биты в регистре на ряд с фиксированной величиной или переменной величиной элементов данных, каждое из которых представляет собой отдельное значение. Например, в одном варианте осуществления биты в 64-битовом регистре могут быть организованы как операнд-источника, содержащий четыре отдельных 16-битовых элементов данных, каждый из которых представляет собой отдельное 16-битное значение. Этот тип данных может упоминаться как "упакованный" тип данных, или "вектор" типа данных, и операнды этого типа данных могут упоминаться как операнды упакованных данных или векторные операнды. В одном варианте осуществления элемент упакованных данных или вектор может представлять собой последовательность из элементов упакованных данных, сохраненных в одном регистре, и операнд упакованных данных или вектор операнд может быть исходным или конечным операндом SIMD инструкции (или 'инструкции упакованных данных' или 'инструкции вектора'). В одном варианте осуществления SIMD инструкция определяет одну векторную операцию, выполняемую на двух исходных векторных операндах, чтобы сгенерировать операнд вектора назначения (также называемый как операнд результирующего вектора) одного и того же или разного размера, с тем же или другим числом элементов данных, и в таком же или другом порядке элементов данных.
SIMD технологии, такие как, применяемые процессорами Intel® Core™, имеющие набор команд, включающий в себя х86, ММХ™, потоковые SIMD-расширения (SSE), SSE2, SSE3, инструкции SSE4.1 и SSE4.2, ARM процессоры, такие как ARM Cortex® семейства процессоров, имеющие набор команд, включающий в себя вектор с плавающей точкой (VFP) и/или инструкций NEON, и процессоры MIPS, такие как семейство Loongson процессоров, разработанных Институтом вычислительной техники (ICT) в китайской академии наук, позволили значительное повысить производительность приложений (Core™ и ММХ™ являются зарегистрированными товарными знаками или товарными знаками корпорации Intel в Санта-Клара, штат Калифорния).
В одном из вариантов осуществления выходные и исходные регистры/данные могут быть общими терминами для представления источника и назначения соответствующих данных или операции. В некоторых вариантах осуществления они могут быть реализованы с помощью регистров, памяти или других мест хранения, имеющих другие названия или функции, чем те, которые представлены. Например, в одном варианте осуществления, "DEST1" может быть регистром временного хранения или другой областью хранения данных, в то время, как "SRC1" и "SRC2" могут быть первым и вторым регистром исходного хранения или другой областью памяти и так далее. В других вариантах осуществления, два или более SRC и DEST областей хранения могут соответствовать разным элементам хранения данных в пределах одной области хранения (например, SIMD регистр). В одном из вариантов осуществления один из исходных регистров может также выступать в качестве регистра назначения, например, посредством обратной записи результата операции, выполняемой на первых и вторых исходных данных, на один из двух исходных регистров, служащих в качестве регистров назначения.
На фиг. 1А показана блок-схема иллюстративной компьютерной системы, сформированной процессором, который может включать в себя исполнительные блоки для выполнения инструкции, в соответствии с вариантами осуществления настоящего изобретения. Система 100 может включать в себя компонент, такой как процессор 102, применяя исполнительные блоки, включающие в себя логику для выполнения алгоритмов для обработки данных, в соответствии с настоящим изобретением, например, в варианте осуществления, описанном в данном документе. Система 100 может быть примером систем обработки, основанные на Pentium® III, Pentium® 4, Xeon™, Itanium®, XScale™ и/или микропроцессорам StrongARM™, которые обеспечиваются Intel Corporation Санта-Клара, штат Калифорния, хотя другие системы (включающие в себя персональные компьютеры, имеющие другие микропроцессоры, инженерные рабочие станции, телевизионные приставки и тому подобное) могут быть использованы. В одном варианте осуществления примерная система 100 может использовать версию операционной системы WINDOWS™, предоставляемую Microsoft Corporation в Редмонде, штат Вашингтон, хотя другие операционные системы (UNIX и Linux, например), встроенное программное обеспечение и/или графические пользовательские интерфейсы, также могут использоваться. Таким образом, варианты осуществления настоящего изобретения не ограничены какой-либо конкретной комбинацией схем аппаратного и программного обеспечения.
Варианты осуществления не ограничиваются компьютерными системами. Варианты осуществления настоящего изобретения могут быть использованы и в других устройствах, таких как портативные устройства и встроенные приложения. Некоторые примеры портативных устройств включают в себя сотовые телефоны, устройства интернет протокола, цифровые камеры, персональные цифровые помощники (PDA) и карманные ПК. Встроенные приложения могут включать в себя микроконтроллер, цифровой сигнальный процессор (DSP), систему на кристалле, сетевые компьютеры (NetPC), телеприставки, сетевые концентраторы, переключатели глобальной сети (WAN) или любую другую систему, которая может выполнять одну или более инструкций в соответствии, по меньшей мере, с одним вариантом осуществления.
Компьютерная система 100 может включать в себя процессор 102, который может включать в себя один или более исполнительных блоков 108 для выполнения алгоритма для выполнения, по меньшей мере, одной инструкции, в соответствии с одним из вариантов осуществления настоящего изобретения. Один вариант осуществления изобретения может быть описан в контексте одного настольного процессора или серверной системы, но другие варианты осуществления могут быть включены в состав многопроцессорной системы. Система 100 может быть примером архитектуры системы "хаба". Система 100 может включать в себя процессор 102 для обработки сигналов данных. Процессор 102 может включать в себя микропроцессор со сложным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами очень большой длины (VLIW), процессор, реализующий комбинацию наборов инструкций или любой другой процессор, например, такой как процессор цифровых сигналов, например. В одном варианте осуществления, процессор 102 может быть соединен с шиной 110 процессора, которая может передавать сигналы данных между процессором 102 и другими компонентами в системе 100. Элементы системы 100 могут выполнять обычные функции, которые хорошо известны специалистам в данной области техники.
В одном варианте осуществления, процессор 102 может включать в себя 1-го уровня (LI) внутренний кэш-память 104. В зависимости от архитектуры, процессор 102 может иметь один внутренний кэш или множество уровней внутреннего кэша. В другом варианте осуществления, кэш-память может находиться вне процессора 102. Другие варианты осуществления могут также включать в себя комбинацию внутренних и внешних кэшей в зависимости от конкретной реализации и потребностей. Регистровый файл 106 может хранить различные типы данных в различных регистрах, включающие в себя целочисленные регистры, регистры с плавающей запятой, регистры состояния и регистр указателя инструкций.
Исполнительный блок 108, включающий в себя логику для выполнения целочисленных операций и вычислений с плавающей запятой, также находится в процессоре 102. Процессор 102 также может включать в себя микрокод (UCODE) ROM, которое хранит микрокод для некоторых макрокоманд. В одном варианте осуществления исполнительный блок 108 может включать в себя логику для обработки набора 109 упакованных команд. Включением набора 109 упакованных команд в набор команд процессора 102 общего назначения, а также с соответствующей схемой для выполнения команд, операции, используемые многими мультимедийными приложениями, могут выполняться с использованием упакованных данных в процессоре 102 общего назначения. Таким образом, многие мультимедийные приложения могут быть ускорены и выполняться более эффективно при использовании полной ширины шины данных процессора для выполнения операций с упакованными данными. Это может устранить необходимость передачи более мелких блоков данных по шине передачи данных процессора для выполнения одной или более операций одного элемента данных за один раз.
Варианты осуществления исполнительного блока 108 также могут быть использованы в микроконтроллерах, встроенных процессорах, графических устройствах, DSPs и в других типах логических схем. Система 100 может включать в себя память 120. Память 120 может быть реализована в виде устройства динамической памяти с произвольным доступом (DRAM), устройства статической оперативной памяти (SRAM), устройства флэш-памяти или другого устройства памяти. Память 120 может хранить инструкции и/или данные, представленные сигналами данных, которые могут быть выполнены процессором 102.
Системная логическая микросхема 116 может быть соединена с шиной 110 процессора и памятью 120. Системная логическая микросхема 116 может включать в себя концентратор контроллера памяти (МСН). Процессор 102 может осуществлять связь с МСН 116 через шину 110 процессора. МСН 116 может обеспечить тракт 118 памяти с высокой пропускной способностью к памяти 120 для передачи и хранения данных и для хранения графических команд, данных и текстур. МСН 116 может направлять сигналы данных между процессором 102, памятью 120 и другими компонентами в системе 100 и служит мостом для сигналов данных между шиной 110 процессора, памятью 120 и системой 122 ввода/вывода. В некоторых вариантах осуществления системная логическая микросхема 116 может обеспечивать графический порт для соединения с графическим контроллером 112. МСН 116 может быть соединен с памятью 120 через интерфейс 118 памяти. Графическая карта 112 может быть соединена с МСН 116 через межсоединение 114 быстродействующего графического порта (AGP).
Система 100 может использовать шину 122 интерфейса собственного концентратора для соединения МСН 116 с концентратором 130 I/O контроллера (ICH). В одном варианте осуществления МСН 130 может обеспечить прямое подключение с некоторыми устройствами ввода/вывода через локальную шину ввода/вывода. Локальная шина ввода/вывода может включать в себя высокоскоростную шину ввода/вывода для подключения периферийных устройств к памяти 120, набору микросхем и процессору 102. Примеры могут включать в себя аудио контроллер, концентратор 128 встроенного программного обеспечения (флэш-BIOS), беспроводной приемопередатчик 126, блок 124 хранения данных, унаследованный контроллер ввода/вывода, содержащий пользовательские интерфейсы ввода и клавиатуры, последовательный порт расширения, такой как универсальная последовательная шина (USB) и сетевой контроллер 134. Блок 124 хранения данных может содержать жесткий диск, флоппи-дисковод, CD-ROM, устройство флэш-памяти или другое запоминающее устройство.
В качестве другого варианта осуществления системы, инструкция в соответствии с одним вариантом осуществления, может быть использована с системой на кристалле. Один из вариантов осуществления системы на кристалле включает в себя процессор и память. Память для одной такой системы может включать в себя флэш-память. Флэш-память может быть расположена на том же кристалле, что и процессор, и другие компоненты системы. Кроме того, другие логические блоки, такие как контроллер памяти или графический контроллер также могут быть расположены в системе на кристалле.
Фиг. 1В изображает систему 140 обработки данных, которая реализует принципы вариантов осуществления настоящего изобретения. Как очевидно для специалистов в данной области техники, варианты осуществления, описанные здесь, могут работать с альтернативными системами обработки данных без отхода от сущности и объема вариантов осуществления изобретения.
Компьютерная система 140 содержит процессорное ядро 159 для выполнения, по меньшей мере, одной инструкции, в соответствии с одним вариантом осуществления. В одном из вариантов осуществления процессорное ядро 159 представляет собой блок обработки любого типа архитектуры, включающей в себя, но не ограничиваясь этим, CISC, RISC или VLIW тип архитектуры. Процессорное ядро 159 также может быть изготовлено посредством одного или нескольких технологических процессов, и посредством представления на машиночитаемом носителе информации достаточно подробно, может быть пригодно для облегчения упомянутого производства.
Процессорное ядро 159 содержит исполнительный блок 142, набор регистровых файлов 145 и декодер 114. Процессорное ядро 159 может также включать в себя дополнительные схемы (не показаны), которые могут быть ненужными для понимания вариантов осуществления настоящего изобретения. Исполнительный блок 142 может выполнять инструкции, полученные процессорным ядром 159. В дополнение к выполнению типовых инструкций процессора, исполнительный блок 142 может выполнять инструкции в наборе 143 упакованных команд для выполнения операций над форматами упакованных данных. Набор 143 упакованных команд может включать в себя инструкции для выполнения вариантов осуществления изобретения и других упакованных инструкций. Исполнительный блок 142 может быть соединен с регистровым файлом 145 с помощью внутренней шины. Регистровый файл 145 может представлять собой область хранения на процессорном ядре 159 для хранения информации, в том числе данных. Как упоминалось ранее, следует понимать, что область для хранения может хранить упакованные данные, но это не является критическим. Исполнительный блок 142 может быть соединен с декодером 144. Декодер 144 может декодировать инструкции, полученные процессорным ядром 159 в управляющие сигналы и/или точки входа микрокода. В ответ на эти сигналы управления и/или точек входа микрокода, исполнительный блок 142 выполняет соответствующие операции. В одном варианте осуществления декодер может интерпретировать опкод инструкции, который будет указывать на то, что операция должна выполняться на соответствующих данных, указанных в инструкции.
Процессорное ядро 159 может быть соединено с шиной 141 для связи с различными другими системными устройствами, которые могут включать в себя, но не ограничиваются ими, например, блок 146 управления синхронным динамическим оперативным запоминающим устройством (SDRAM), блок 147 управления статическим оперативным запоминающим устройством (SRAM), интерфейс 148 пакетной флэш-памяти, блок управления 149 картой памяти персонального компьютера международной ассоциации (PCMCIA) / карта памяти (CF), блок управления 150 жидкокристаллическим дисплеем (LCD), контроллер 151 прямого доступа к памяти (DMA) и главный интерфейс 152 альтернативной шины. В одном из вариантов осуществления, система 140 обработки данных также может включать в себя мост 154 ввода/вывода для связи с различными устройствами ввода/вывода через шину 153 ввода/вывода. Такие устройства ввода/вывода могут включать в себя, но не ограничиваются ими, например, универсальный асинхронный приемник/передатчик (UART) 155, универсальную последовательную шину (USB) 156, Bluetooth беспроводного UART 157 и интерфейс 158 расширения ввода/вывода расширения.
Один из вариантов осуществления системы 140 обработки данных обеспечивает для мобильных устройств, сетевой и/или беспроводной связи и процессорного ядра 159, которые могут выполнять SIMD операции, включающую в себя операцию сравнения текстовой строки. Процессорное ядро 159 может быть запрограммировано с помощью различных аудио, видео, изображений и алгоритмов коммуникаций, включающие в себя дискретные преобразования, такие как преобразование Уолша-Адамара, быстрое преобразование Фурье (FFT), дискретное косинусное преобразование (DCT) и их соответствующие обратные преобразования; способы сжатия/распаковки, такие как преобразование цветового пространства, оценка движения кодирования видео или компенсация движения декодирования видео; и функции модуляции/демодуляции (МОДЕМ), такие как импульсно-кодовая модуляция (РСМ).
На фиг. 1С показаны другие варианты осуществления системы обработки данных, которая выполняет SIMD-операции сравнения текстовых строк. В одном из вариантов осуществления, система 160 обработки данных может включать в себя центральный процессор 166, a SIMD сопроцессор 161, кэш-память 167 и систему 168 ввода/вывода. Система 168 ввода/вывода может быть дополнительно соединена с беспроводным интерфейсом 169. SIMD-сопроцессор 161 может выполнять операции, включающие в себя инструкции согласно одному варианту осуществления изобретения. В одном из вариантов осуществления процессорное ядро 170 может быть пригодным для производства посредством одного или нескольких технологических процессов, а также представлено на машинно-читаемом носителе информации достаточно подробно, что может быть пригодным для облегчения изготовления всей или части системы 160 обработки данных, включающей в себя процессорное ядро 170.
В одном из вариантов осуществления, SIMD-сопроцессор 161 содержит исполнительный блок 162 и набор регистровых файлов 164. Один из вариантов основного процессора 165 содержит декодер 165, чтобы распознавать команды из набора 163 инструкций, включающие в себя инструкции, в соответствии с одним вариантом осуществления для исполнения исполнительным блоком 162. В других вариантах осуществления, SIMD-сопроцессор 161 также включает в себя, по меньшей мере, часть декодера 165 для декодирования инструкций набора 163 инструкций. Процессорное ядро 170 может также включать в себя дополнительные схемы (не показаны), которые могут быть излишними для понимания вариантов осуществления настоящего изобретения.
В процессе работы основной процессор 166 выполняет обработку потока данных посредством инструкций, которые управляют операциями обработки данных общего типа, включающую в себя взаимодействие с кэш-памятью 16, и системой 168 ввода/вывода. Находящиеся в потоке инструкции обработки данных могут быть инструкциями SIMD сопроцессора. Декодер 165 основного процессора 166 распознает эти инструкции SIMD-сопроцессора, как тип, который должен быть выполнен посредством подключенного SIMD-сопроцессора 161. Соответственно, основной процессор 166 выдает эти инструкции SIMD сопроцессора (или управляющие сигналы, представляющие инструкции SIMD сопроцессора) на шину 166 сопроцессора. Из шины 166 сопроцессора эти инструкции могут быть приняты любыми присоединенными SIMD сопроцессорами. В этом случае, SIMD-сопроцессор 161 может принимать и исполнять любые принятые инструкции SIMD сопроцессора, предназначенные для него.
Данные могут быть приняты с помощью беспроводного интерфейса 169 для обработки инструкций посредством SIMD сопроцессора. Для одного примера, голосовая связь может быть принята в виде цифрового сигнала, который может быть обработан с помощью инструкций SIMD сопроцессора для генерирования цифровой выборки аудио, характерной для речевой коммуникации. В качестве другого примера, сжатые аудио и/или видео могут быть приняты в виде цифрового потока битов, который может быть обработан с помощью инструкций SIMD сопроцессора для генерирования цифровых выборок аудио и/или видеокадров движения. В одном из вариантов осуществления процессорное ядро 170, главный процессор 166 и SIMD-сопроцессор 161 могут быть интегрированы в единое процессорное ядро 170, содержащее исполнительный блок 162, набор регистровых файлов 164 и декодер 165 для распознавания команд из набора 163 инструкций, включающий в себя инструкции в соответствии с одним вариантом осуществления.
На фиг. 2 представлена блок-схема микроархитектуры для процессора 200, который может включать в себя логические схемы для выполнения инструкции, в соответствии с вариантами осуществления настоящего изобретения. В некоторых вариантах осуществления инструкции в соответствии с одним из вариантов осуществления может быть реализован для работы на элементах данных, имеющих размеры байта, слова, сдвоенного слова, учетверенного слова и т.д., а также типов данных, таких как одинарной и двойной точности целого числа и типов данных с плавающей запятой. В одном варианте осуществления, упорядоченный коммуникационный процессор 201 может реализовать часть процессора 200, который может выбрать инструкции для исполнения и подготавливает инструкции, которые будут использоваться позже в конвейере процессора. Коммуникационный процессор 201 может включать в себя несколько блоков. В одном варианте осуществления, устройство 226 предвыборки инструкций выбирает инструкции из памяти и поставляет инструкции в декодер 228 инструкций, который, в свою очередь, декодирует или интерпретирует инструкции. Например, в одном варианте осуществления декодер декодирует принятую инструкцию в одну или более операций, называемых "микроинструкциями" или "микрооперациями" (также называемые как ор или uops), так что машина может выполнять. В других вариантах осуществления настоящего изобретения декодер выполняет синтаксический разбор инструкции на опкод, соответствующие данные и поля управления, которые могут быть использованы микроархитектурой для выполнения операций в соответствии с одним вариантом осуществления. В одном варианте осуществления, трассовый кэш 230 может собрать декодированные uops в программу упорядоченных последовательностей или трассировать в uops последовательность 234 для исполнения. Когда трассовый кэш 230 наталкивается на сложную инструкцию, ROM 232 микрокода обеспечивает uops, необходимые для завершения операции.
Некоторые инструкции могут быть преобразованы в единую микрооперацию, в то время, как другие требуют нескольких микроопераций для завершения полной операции. В одном варианте осуществления, если более чем четыре микро-ops необходимы для выполнения инструкции, декодер 228 может получить доступ к ROM 232 микрокода для выполнения инструкции. В одном варианте осуществления инструкция может быть декодирована на небольшое число микроопераций для обработки инструкций в декодере 228. В другом варианте осуществления инструкция может быть сохранена в ROM 232 микрокода, где необходимо иметь ряд микроопераций для выполнения операции. Трассовый кэш 230 относится к точке входа программируемой логической матрицы (PLA) для определения корректного указателя микроинструкции для считывания последовательности микрокода для выполнения одной или нескольких инструкций в соответствии с одним вариантом осуществления, из ROM 232 микрокода.
После того, как ROM 232 микрокода заканчивает операцию управления выполнением микрокоманды для инструкции, коммуникационный процессор 201 машины может возобновить выборку микроопераций из трассового кэша 230.
Исполнительный блок 203 с изменением последовательности команд может подготовить инструкции для выполнения. Логическая схема с изменением последовательности команд имеет ряд буферов для сглаживания и переупорядочивания потока инструкций для оптимизации процесса функционирования, при прохождении по конвейеру и являются запланированными для выполнения. Логический распределитель выделяет буферы машины и ресурсы, которые нужны каждой uop для выполнения. Логика переименования регистров переименовывает логические регистры на записях в файле регистров. Распределитель также выделяет запись для каждой uop в одной из двух uop очередей, одну для операций с памятью и одну для операций без памяти, перед планировщиками инструкции: планировщик памяти, быстрый планировщик 202, медленный / общий с плавающей запятой планировщик 204 и планировщик 206 с простой плавающей точкой. Uop планировщики 202, 204, 206 определить, когда uop готова к выполнению, на основе готовности их зависимого входного регистра источников операндов и наличия исполнительных ресурсов uop для завершения свой работы. Быстрый планировщик 202 одного варианта осуществления может планировать на каждую половину основного тактового цикла, в то время как другие планировщики могут только планировать один раз на тактовый цикл основного процессора. Атрибут планировщиков для портов отправки планируют uops для исполнения.
Регистровые файлы 208, 210 могут быть расположены между планировщиками 202, 204, 206 и исполнительные блоки 212, 214, 216, 218, 220, 222, 224 в исполнительном блоке 211. Каждый из регистровых файлов 208, 210 выполняет целочисленную операцию и операцию с плавающей точкой, соответственно. Каждый регистровый файл 208, 210, может включать в себя перепускную сеть, которая может обойти или пересылать только завершенные результаты, которые еще не были записаны в регистровый файл новые зависимые uop. Целочисленный регистровый файл 208 и регистровый файл 210 с плавающей точкой могут обмениваться данными с другими. В одном из вариантов осуществления, целочисленный регистровый файл 208 может быть разделен на два отдельных регистровых файла, один регистровый файл для низкого порядка тридцати двух битных данных, и второй регистровый файл для высокого порядка тридцати двух битных данных. Регистровый файл 210 с плавающей точкой может включать в себя 128-битные записи, так как инструкции с плавающей запятой обычно имеют операнды от 64 до 128 бит в ширину.
Исполнительный блок 211 может содержать исполнительные блоки 212, 214, 216, 218, 220, 222, 224. Исполнительные блоки 212, 214, 216, 218, 220, 222, 224 могут выполнять инструкции. Исполнительный блок 211 может включать в себя регистровые файлы 208, 210, которые хранят целочисленные значения и значения операндов данных с плавающей точкой, микроинструкций для выполнения. В одном варианте осуществления процессор 200 может включать в себя ряд исполнительных блоков: блок формирования адреса (AGU) 212, AGU 214, быстрый ALU 216, быстрый ALU 218, медленный ALU 220, с плавающей точкой ALU 222, блок 224 перемещения с плавающей точкой. В другом варианте воплощении исполнительные блоки 222, 224 с плавающей точкой могут выполнять ММХ, SIMD и SSE или другие операции. В еще одном варианте ALU 222 с плавающей точкой может включать в себя делитель с плавающей точкой 64-бит на 64-бит для выполнения операции деления, излечения квадратного корня и вычет микроопераций. В различных вариантах осуществления инструкции, включающие в себя значение с плавающей точкой, могут быть обработаны посредством аппаратных средств с плавающей точкой. В одном варианте осуществления ALU операции могут быть переданы в высокоскоростные исполнительные блоки ALU 216, 218. Высокоскоростные ALU 216, 218 могут выполнять операции с высокой скоростью с эффективной задержкой в половину тактового цикла. В одном из вариантов осуществления наиболее сложные целочисленные операции обрабатываются медленным ALU 220, так как медленный ALU 220 может включать в себя аппаратное обеспечение для выполнения целочисленных операций для выполнения длиннолатентных операций, таких как умножение, сдвиги, флаг логики и разветвления. Операции загрузки/сохранения памяти могут быть выполнены посредством ALUs 212, 214. В одном варианте осуществления, целочисленные ALUs 216, 218, 220 могут выполнять целочисленные операции на 64-разрядных данных операндов. В других вариантах осуществления ALUs 216, 218, 220 могут быть реализованы для поддержки различных размеров битовых данных, включающие в себя шестнадцати, тридцать двух, 128, 256 и т.д. Аналогично, блоки 222, 224 с плавающей точкой могут быть реализованы для поддержки диапазона операндов, имеющие биты различной ширины. В одном варианте осуществления блоки 222, 224 с плавающей точкой могут работать на 128-битовой ширине упакованных данных операндов в сочетании с SIMD и мультимедийными инструкциями.
В одном из вариантов осуществления, uops планировщики 202, 204, 206, отправляют зависимые операции до того, как родительская загрузка завершит выполнение. Как только микрооперации могут быть спекулятивно запланированы и выполнены в процессоре 200, процессор 200 может также включать в себя логику для обработки выпадения в памяти. Если нагрузка данных выпадает из кэша данных, могут быть зависимые операции, проходящие в конвейере, которые покинули планировщик с временно неправильными данными. Механизм воспроизведения отслеживает и повторно выполняет инструкции, которые используют некорректные данные. Только зависимые операции, возможно, должны быть воспроизведены, и независимые могут быть завершены. Планировщики и механизм воспроизведения одного варианта осуществления процессора также могут быть предназначены для захвата последовательностей инструкций для операций сравнения текстовых строк.
Термин «регистры» может относиться к местам хранения встроенного процессора, которые могут быть использованы в качестве части инструкций для идентификации операндов. Другими словами, регистры могут быть те, которые могут быть пригодны для использования вне процессора (с точки зрения программиста). Тем не менее, в некоторых вариантах осуществления регистры могут не быть ограничены конкретным типом схемы. Скорее всего, регистр может хранить данные, предоставлять данные и выполнять функции, описанные в настоящем документе. Регистры, описанные здесь, могут быть реализованы с помощью схемы в пределах процессора с использованием любого числа различных технологий, таких как выделенные физические регистры, динамически распределяемые физические регистры, используя переименование регистров, комбинации выделенных и динамически выделенных физических регистров и т.д. В одном варианте осуществления целочисленные регистры хранят 32-разрядные целочисленные данные. Регистровый файл одного варианта осуществления также содержит восемь мультимедийных SIMD регистров для упакованных данных. Далее приведено описание регистров, которые могут быть описаны, как регистры данных, предназначенные для хранения упакованных данных, такие как 64-битные ММХ™ регистры (также называемые "мм" регистры в некоторых случаях) в микропроцессорах с поддержкой технологии ММХ от Intel Corporation Санта-Клара, штат Калифорния. Эти ММХ регистры, доступные в обоих формах целочисленные и с плавающей точкой, могут работать с элементами упакованных данных, которые сопровождают SIMD и SSE инструкции. Аналогичным образом, 128-битные ХММ регистры, относящиеся к SSE2, SSE3, SSE4 или неописанные (именуемые обобщенно "SSEx") технологией, могут удерживать такие операнды упакованных данных. В одном варианте осуществления при хранении упакованных данных и целочисленных данных, нет необходимости регистрам различать эти два типа данных. В одном из вариантов осуществления и целочисленные, а также и с плавающей точкой могут содержаться в одном регистровом файле или разных регистровых файлах. Кроме того, в одном варианте осуществления целочисленные данные и данные с плавающей точкой могут быть сохранены в различных регистрах или в тех же регистрах.
В примерах, проиллюстрированных на следующих чертежах, описывается количество операндов данных. Фиг. 3А иллюстрирует различные представления упакованных данных в мультимедийных регистрах в соответствии с вариантами осуществления настоящего изобретения. Фиг. 3А иллюстрирует типы данных для упакованного байта 310, упакованного слова 320 и упакованного двойного слова (DWORD) 330 для 128-битных операндов. Формат 310 упакованного байта в этом примере может иметь длину 128 битов и содержит шестнадцать элементов данных упакованного байта. Байт может быть определен, например, как восемь битов данных. Информация для каждого байтового элемента данных может быть сохранена в бите 7 по бит 0 для байта 0, бит 15 по бит 8 для байта 1, бит 23 по бит 16 для байта 2 и, наконец, бит 120 по бит 127 для байта 15. Таким образом, все доступные биты могут быть использованы в регистре. Такая компоновка для хранения повышает эффективность хранения процессора. А также, посредством доступных шестнадцати элементов данных одна операция теперь может быть выполнена на шестнадцати элементах данных параллельно.
В общем случае, элемент данных может включать в себя отдельный элемент данных, который хранится в одном регистре или в ячейке памяти с другими элементами данных такой же длины. В последовательностях упакованных данных, относящихся к технологии SSEx, число элементов данных, сохраненных в регистре ХММ, может быть 128 бит, деленные на длину в битах отдельного элемента данных. Аналогичным образом, в последовательностях упакованных данных, относящихся к ММХ и SSE технологии, число элементов данных, сохраненных в регистре ММХ, может быть 64 бит, деленным на длину в битах отдельного элемента данных. Хотя типы данных, показанные на фиг. 3А, могут быть 128 битовыми в длину, варианты осуществления настоящего изобретения могут также работать с 64-битными или других размеров операндами. Формат 320 упакованного слова этого примера может быть длиной 128 битов и содержит восемь элементов упакованных данных слова. Каждое упакованное слово содержит шестнадцать битов информации. Формат 330 упакованного двойного слова, показанный на фиг. 3А, может иметь длину 128 битов и содержать четыре элемента упакованных данных двойного слова. Каждый упакованный элемент данных двойного слова содержит тридцать два бита информации. Упакованное учетверенное слово может быть длиной 128 битов и содержит два элемента упакованных данных учетверенного слова.
Фиг. 3В иллюстрирует возможные форматы регистрового хранения данных, в соответствии с вариантами осуществления настоящего изобретения. Каждые упакованные данные могут включать в себя более одного независимого элемента данных. Три формата упакованных данных проиллюстрированы; упакованное полуслово 341, упакованное одно слово 342 и упакованное двойное слово 343. В одном из вариантов осуществления упакованное полуслово 341, упакованное одно слово 342 и упакованное двойное слово содержат элементы данных с фиксированной точкой. В качестве другого варианта осуществления упакованное полуслово 341, упакованное одно слово 342 и упакованное двойное слово 343 могут содержать элементы данных с плавающей точкой. Один вариант осуществления упакованного полуслова 341 может быть 128 битный размер, содержащий восемь элементов 16- битовых данных. Один вариант осуществления упакованного одного слова 342 может иметь длину 128 битов и содержит четыре 32-битовых элемента данных. Один вариант осуществления упакованного двойного слова 343 может быть длиной 128 битов и содержит два элемента 64-битовых данных. Следует принять во внимание, что такие форматы упакованных данных могут быть дополнительно распространены на другие длины регистра, например, до 96-бит, 160 бит, 192 бит, 224 бит, 256-бит или более.
Фиг. 3С иллюстрирует различные типы представлений упакованных данных со знаком и беззнаковые в мультимедийных регистрах в соответствии с вариантами осуществления настоящего изобретения. Представление 344 беззнакового упакованного байта иллюстрирует хранение беззнакового упакованного байта в SIMD регистре. Информация для каждого байтового элемента данных может быть сохранена в бите 7 по бит 0 для байта 0, бит 15 по бит 8 для байта 1, бит 23 по бит 16 для байта 2 и, наконец, бит 120 по бит 127 для байта 15. Таким образом, все доступные биты могут быть использованы в регистре. Такая схема компоновки хранения данных может повысить эффективность хранения процессора. А также, посредством доступных шестнадцати элементов данных, одна операция теперь может быть выполнена на шестнадцати элементах данных параллельным способом. Представление 345 упакованного байта со знаком иллюстрирует хранение упакованного байта со знаком. Обратите внимание, что восьмой бит каждого элемента данных байта может быть знаковым индикатором. Представление 346 беззнакового упакованного слова иллюстрирует, как слово семь по слово ноль может храниться в регистре SIMD. Представление 347 упакованного слова со знаком может быть аналогично представлению 346 беззнакового упакованного слова в регистре. Обратите внимание, что шестнадцатый бит каждого элемента данных слова может быть знаковым индикатором. Представление 348 беззнакового упакованного двойного слова, показывает, как хранятся элементы данных двойного слова. Представление 349 упакованного двойного слова со знаком может быть аналогично представлению 348 беззнакового упакованного двойного слова в регистре. Обратите внимание, что необходимый знак бита может быть тридцать вторым битом каждого элемента данных двойного слова.
На фиг. 3D показан вариант выполнения операции кодирования (кода операции). Кроме того, формат 360 может включать в себя режимы операнда адресации регистра/памяти, соответствующие типу формата опкода, описанный в "Руководстве том 2 IA-32 разработчика архитектуры программного обеспечения Intel: Описание набора основных команд", которое предоставлено Intel Corporation, Санта-Клара, штат Калифорния во Всемирной паутине (WWW) на intel.com/design/litcentr. В одном из вариантов осуществления инструкция может быть закодирована с помощью одного или нескольких из полей 361 и 362. Может быть идентифицировано до двух местоположений операндов на инструкцию, включающие в себя до двух идентификаторов 364 и 365 источника операндов. В одном варианте осуществления идентификатор 366 операнда назначения может быть таким же, как идентификатор 364 операнда источника, в то время как в других вариантах осуществления они могут быть различными. В другом варианте осуществления идентификатор 366 операнда назначения может быть таким же, как идентификатор 365 операнда источника, в то время как в других вариантах они могут быть разными. В одном из вариантов осуществления, один из операндов источника, идентифицированных идентификаторами 364 и 365 операнда источника, могут быть перезаписаны по результатам операции сравнения текстовой строки, тогда как в других вариантах осуществления идентификатор 364 соответствует элементу исходного регистра, и идентификатор 365 соответствует элементу регистра назначения. В одном варианте осуществления идентификаторы 364 и 365 операндов могут идентифицировать 32-битный или 64-битный операнды источника и назначения.
На фиг. 3Е показан другой возможный формат 370 операции кодирования (код операции), имеющий сорок или более битов, в соответствии с вариантами осуществления настоящего изобретения. Формат 370 кода операции соответствует формату 360 кода операции и содержит возможный байт 378 префикса. Инструкция, согласно одному варианту осуществления, может кодироваться одним или несколькими из полей 378, 371 и 372. Могут быть идентифицированы до двух местоположений операндов на инструкцию с помощью идентификаторов 374 и 375 операнда источника и префиксом байта 378. В одном варианте префикс байт 378 может быть использован для идентификации 32-битных или 64-битных операндов источника и назначения. В одном варианте осуществления идентификатор 376 операнда назначения может быть таким же, как идентификатор 374 операнда источника, в то время как в других вариантах осуществления они могут быть различными. В качестве другого варианта осуществления, идентификатор 376 операнда назначения может быть таким же, как идентификатор 375 операнда источника, в то время как в других вариантах осуществления они могут быть различными. В одном варианте осуществления, инструкция работает на одном или нескольких операндах, идентифицированных посредством идентификаторов 374 и 375 операндов, и на одном или более операндах, идентифицированных посредством идентификаторов 374 и 375 операндов, которые могут быть перезаписаны результатами инструкции, в то время как в других вариантах осуществления, операнды, идентифицированные идентификаторами 374 и 375, могут быть записаны на другой элемент данных в другой регистр. Форматы 360 и 370 опкода позволяют записывать в регистр, память в регистр, записывать посредством памяти, записывать посредством регистра, записывать немедленно, записывать посредством получения адресация памяти, указанной в части MOD полей 363 и 373, и возможно масштабированием и смещением байтов.
На фиг. 3F иллюстрируется еще один возможный формат операции кодирования (код операции), в соответствии с вариантами осуществления настоящего изобретения. 64-разрядные арифметические операции архитектуры с одним потоком команд и многими потоками данных (SIMD) могут выполняться с помощью инструкции обработки данных сопроцессора (CDP). Формат 380 операции кодирования (код операции) изображает одну такую CDP инструкцию, имеющую поля 382-389 CDP опкода. Тип инструкции CDP, для другого варианта осуществления, операции может быть закодирован с помощью одного или нескольких из полей 383, 384, 387 и 388. Могут быть идентифицированы вплоть до трех мест операндов на инструкцию, включающие в себя до двух идентификаторов 385 и 390 операнда источника и один идентификатор 386 операнда назначения. Один из вариантов осуществления сопроцессора может работать на восьми, шестнадцати, тридцати двух и 64-битовых значениях. В одном варианте осуществления инструкция может быть выполнена на целочисленных элементах данных. В некоторых вариантах осуществления инструкция может быть выполнена условно, используя поле 381 условия. В некоторых вариантах осуществления размеры данных источника могут быть закодированы с помощью поля 383. В некоторых вариантах осуществления направления ноль (Z), отрицательный (N), нести (С) и переполнение (V) могут быть выполнены на SIMD полях. Для некоторых инструкций тип насыщения может кодироваться полем 384.
На фиг. 4А представлена блок-схема, иллюстрирующая упорядоченный конвейер и этап переименования регистров, конвейер с изменением последовательности команд, в соответствии с вариантами осуществления настоящего изобретения. На фиг. 4В показана блок-схема, иллюстрирующая упорядоченную архитектуру ядра и логику переименования регистров, логику с изменением последовательности команд, которые будут включены в состав процессора, в соответствии с вариантами осуществления настоящего изобретения. Квадраты, очерченные сплошной линией на фиг. 4А, иллюстрируют упорядоченный конвейер, в то время как квадраты, очерченные пунктирной линией, иллюстрируют переименование регистров, конвейер с изменением последовательности команд. Точно так же, квадраты, очерченные сплошной линией на фиг. 4В иллюстрируют упорядоченную архитектуру логики, в то время как квадраты, очерченные пунктирной линией, иллюстрируют логику переименования регистров и логику с изменением последовательности команд.
На фиг. 4А, процессор конвейера 400 может включать в себя этап 402 выборки, этап 404 декодирования длины, этап 406 декодирования, этап 408 выделения, этап 410 переименования, этап 412 планирования (также известный, как отправки или выдачи), этап 414 чтения регистра чтение/память, этап 416 выполнения, этап 418 обратной записи/запись памяти, этап 422 обработки исключений и этап 424 завершения.
На фиг. 4В стрелки обозначают соединения между двумя или более блоками и направление стрелки указывает направление потока данных между этими блоками. Фиг. 4В показывает ядро 490 процессора, включающее в себя коммуникационный процессор 430, соединенный с исполнительным блоком 450, и оба они могут быть соединены с блоком 470 памяти.
Ядро 490 может быть ядром с сокращенным набором команд (RISC), ядром со сложным набором команд (CISC), ядром с очень длинным командным словом (VLIW) или гибридным или альтернативным типом ядра. В одном варианте осуществления ядро 490 может быть ядром специального назначения, таким как, например, сетевым или коммуникационным ядром, устройством сжатия, графическим ядром или тому подобное.
Коммуникационный процессор 430 может включать в себя блок 432 предсказания ветвлений, соединенный с блоком 434 кэш команд. Блок 434 кэш команд может быть соединен с буфером 436 быстрого преобразования адреса (TLB). TLB 436 может быть соединен с блоком 438 выборки инструкций, который соединен с блоком 440 декодирования. Блок 440 декодирования может декодировать инструкции и генерировать в качестве выходной одной или нескольких микроопераций, точки входа микрокода, микрокоманды, другие инструкции или другие управляющие сигналы, которые могут быть декодированы, или иным образом отражать, или могут быть получены из исходных инструкций. Декодер может быть реализован с использованием различных механизмов. Примеры подходящих механизмов включают в себя, но не ограничиваются ими, просмотровые таблицы, аппаратные реализации, программируемые логические матрицы (PLAs), постоянная память микрокода (ROM) и т.п. В одном варианте осуществления блок 434 кэш команд может быть дополнительно соединен с блоком 476 уровня 2 (L2) кэш в блоке 470 памяти. Блок 440 декодирования может быть соединен с блоком 452 переименования/распределителя в исполнительном блоке 450.
Исполнительный блок 450 может включать в себя блок 452 переименования/распределителя, соединенный с блоком 454 удаления и набором из одного или нескольких блоков 456 планировщика. Блоки 456 планировщика представляют любое количество различных планировщиков, включающие в себя резервирование станций, окно центральной инструкции и т.д. Блоки 456 планировщика могут быть соединены с блоками 458 физического регистрового файла. Каждый из блоков 458 физического регистрового файла представляет один или несколько физических регистровых файлов, отличные от тех, которые хранят один или несколько различных типов данных, таких как скалярное целое, скалярное с плавающей точкой, упакованное целое, упакованное с плавающей точкой, вектор целое, вектор с плавающей точкой и т.д., статус (например, указатель команд, т.е. адрес следующей инструкции для выполнения) и т.д. Блоки 458 физического регистрового файла могут быть перекрыты блоком 154 удаления для иллюстрации различных способов, в которых используется переименование регистров и изменение последовательности команд (например, используя один или несколько будущих файлов, буферов переупорядочивания и один или более регистровых файлов удаления, используя один или несколько схем размещения файлов, один или несколько буферов истории; и пул регистров; и т.д.). Как правило, архитектурные регистры могут быть видны вне процессора или с точки зрения программиста. Регистры не могут быть ограничены каким-либо известным конкретным типом схемы. Различные типы регистров могут быть пригодны до тех пор, как они хранят и предоставляют данные, как описано в настоящем документе. Примеры подходящих регистров включают в себя, но не могут быть ограничены, выделенные физические регистры, динамически выделенные физические регистры с использованием переименование регистров, комбинации выделенных и динамически выделенных физических регистров и т.д. Блок 454 удаления и блоки 458 физического регистрового файла могут быть соединены с исполнительными кластерами 460. Исполнительные кластеры 460 могут включать в себя набор из одного или более исполнительных блоков 162 и набор из одного или нескольких блоков 464 доступа к памяти. Исполнительные блоки 462 могут выполнять различные операции (например, сдвиги, сложение, вычитание, умножение) и на различных типах данных (например, скалярное число с плавающей точкой, упакованное целое, упакованное с плавающей точкой, вектор-целое, вектор с плавающей точкой). В то время, как некоторые варианты осуществления могут включать в себя ряд исполнительных блоков, предназначенных для выполнения определенных функций или набора функций, другие варианты осуществления могут включать в себя только один исполнительный блок или несколько исполнительных блоков, которые все выполняют все функции. Блоки 456 планировщика, блоки 458 физического регистрового файла и исполнительные кластеры 460 показаны как, возможно, во множественном числе, потому что некоторые варианты осуществления создают отдельные конвейеры для определенных типов данных/операций (например, конвейер скалярного целого, конвейер скалярного с плавающей точкой/упакованного целого/ упакованного с плавающей точкой/вектор целого/вектор с плавающей точкой и/или конвейер доступа к памяти, что у каждого есть свой собственный блок планировщик, блок физического регистрового файла и/или исполнительный кластер - и в случае отдельного конвейера доступа к памяти, некоторые варианты осуществления могут быть реализованы, в которых только исполнительный кластер этого конвейера имеет блоки 464 доступа к памяти). Следует также понимать, что там, где используются отдельные конвейеры, один или несколько из этих конвейеров может быть с изменением последовательности команд и остальные являются упорядоченными.
Набор блоков 464 доступа к памяти может быть соединен с блоком 470 памяти, который может включать в себя TLB блок 472 данных, соединенный с блоком 474 кэша данных, соединенный с блоком 476 2-го уровня (L2) кэш. В одном примерном варианте осуществления, блоки 464 доступа к памяти могут включать в себя блок нагрузки, блок адреса хранения и блок хранения данных, каждый из которых может быть связан с TLB блоком 472 данных в блоке 470 памяти. Блок 476 L2 кэш может быть соединен с одним или более других уровнях кэш-памяти и, в конечном счете, с основной памятью.
В качестве примера, примерное переименование регистров, архитектура ядра с изменением последовательности команд может реализовать конвейер 400 следующим образом: 1) блок 438 выборки команд может выполнять выборку и этапы 402 и 404 выборки и декодирования длины 402 и 404; 2) блок 440 декодирования может выполнять этап 406 декодирования; 3) блок 452 переименования/распределения может выполнить этап 408 распределения и этап 410 переименования; 4) блоки 456 планировщика могут выполнять этап 412 планирования; 5) блоки 458 физического регистрового файла и блок 470 памяти могут выполнять этап 414 чтения регистра чтения/памяти; исполнительный кластер 460 может выполнять этап 416 выполнения; 6) блок 470 памяти и блоки 458 физического регистрового файла могут выполнять этап 418 обратной записи/записи памяти; 7) различные блоки могут быть вовлечены в выполнение этапа 422 исключения; и 8) блок 454 удаления и блоки 458 физического регистрового файла могут выполнять этап 424 завершения.
Ядро 490 может поддерживать один или более наборов команд (например, набор команд х86 (с некоторыми расширениями, которые были добавлены в более новые версии); MIPS набор инструкций, MIPS Technologies Sunnyvale, СА; набор команд ARM (с возможными дополнительными расширениями, такими как NEON) ARM Holdings Sunnyvale, СА).
Следует понимать, что ядро может поддерживать многопоточный режим передачи данных (выполняя два или более параллельных набора операций или потоков) различными способами. Поддержка многопоточной передачи данных может быть выполнена, например, посредством многопоточной обработки с квантованием времени, одновременной многопоточной обработкой (где одно физическое ядро обеспечивает логическое ядро для каждого из потоков, где физическое ядро одновременно выполняет многопоточный режим) или их комбинации. Такое сочетание может включать в себя, например, выборку с квантованием времени, декодирование и одновременный многопоточный режим, например, в технологии Intel® Hyperthreading.
В то время как переименование регистров может быть описано в контексте выполнения операций с изменением последовательности команд, следует понимать, что переименование регистров может быть использовано в упорядоченной архитектуре. Хотя показанный вариант осуществления процессора может также включать в себя отдельные блоки 434/474 инструкций и кэш данных и совместно использовать блок 476 L2 кэша, другие варианты осуществления могут иметь один внутренний кэш, как для инструкций, так и для данных, таких как, например, уровень 1 (LI) внутренний кэш или множество уровней внутреннего кэша. В некоторых вариантах осуществления система может включать в себя комбинацию внутреннего кэша и внешнего кэша, которая может быть внешним по отношению к ядру и/или процессору. В других вариантах осуществления все из кэша может быть внешним по отношению к ядру и/или процессору.
На фиг. 5А показана блок-схема процессора 500, в соответствии с вариантами осуществления настоящего изобретения. В одном варианте осуществления, процессор 500 может включать в себя многоядерный процессор. Процессор 500 может включать в себя системного агента 510, соединенного с возможностью взаимодействия с одним или более ядер 502. Кроме того, ядра 502 и системный агент 510 могут быть коммуникативно соединены с одним или более кэшей 506. Ядра 502, системный агент 510 и кэш 506 могут быть функционально подсоединены с помощью одного или нескольких блоков 552 управления памятью. Кроме того, ядра 502, системный агент 510 и кэш 506 могут быть коммуникативно соединены с модулем 560 графики с помощью блоков 552 управления памятью.
Процессор 500 может включать в себя любой подходящий механизм для соединения ядер 502, системного агента 510, кэша 506 и модуля 560 графики. В одном варианте осуществления процессор 500 может включать в себя блок 508 кольцевого межсоединения для соединения ядер 502, системного агента 510, кэш 506 и модуля 560 графики. В других вариантах осуществления процессор 500 может включать в себя любое число хорошо известных способов для взаимного соединения таких блоков. Блок 508 кольцевого межсоединения может использовать блоки 552 управления памятью для облегчения взаимосвязи.
Процессор 500 может включать в себя иерархию памяти, содержащую один или несколько уровней кэшей внутри ядер, одно или несколько общих блоков кэша, таких как кэш 506 или внешняя память (не показано), соединенную с набором блоков 552 интегрированного контроллера памяти. Кэш 506 может включать в себя любой подходящий кэш. В одном варианте осуществления кэш 506 может включать в себя один или несколько кэш среднего уровня, такие как 2-го уровня (L2), 3-го уровня (L3), 4-го уровня (L4) или другие уровни кэша, кэш последнего уровня (LLC) и/или их комбинации.
В различных вариантах осуществления одно или более ядер 502 может выполнять многопоточную передачу данных. Системный агент 510 может включать в себя компоненты для координации действий и операционные ядра 502. Блок 510 системного агента может включать в себя, например, блок управления мощностью (PCU). PCU может представлять собой или включать в себя логическую схему и компоненты, необходимые для регулирования состояния питания ядер 502. Системный агент 510 может включать в себя блок 512 отображения для управления одним или несколькими подключенными внешними дисплеями или модулем 560 графики. Системный агент 510 может включать в себя интерфейс 1214 для шины связи для графики. В одном варианте осуществления интерфейс 1214 может быть реализован с помощью PCI Express (PCIe). В еще одном варианте осуществления интерфейс 1214 может быть реализован с помощью шины PCI Express Graphics (PEG). Системный агент 510 может включать в себя прямой медиа-интерфейс (DMI) 516. DMI 516 может обеспечивать связь между различными мостами на материнской плате или другой части компьютерной системы. Системный агент 510 может включать в себя PCIe мост 1218 для обеспечения PCIe связи с другими элементами вычислительной системы. PCIe мост 1218 может быть реализован с помощью контроллера 1220 памяти и логикой 1222 когерентности.
Ядра 502 могут быть реализованы любым подходящим образом. Ядра 502 могут быть гомогенными или гетерогенными с точки зрения архитектуры и/или набора команд. В одном из вариантов осуществления, некоторые из ядер 502 могут быть упорядоченными, в то время как другие могут быть с изменением последовательности команд. В другом варианте осуществления два или более ядер 502 могут выполнять один и тот же набор команд, в то время как другие могут выполнять только подмножество этого набора команд или другого набора команд.
Процессор 500 может включать в себя процессор общего назначения, например, Core™ i3, i5, i7, 2 Duo и Quad, Xeon™, Itanium™, XScale™ или процессор StrongARM™, который может быть предоставлен Intel Corporation, Санта-Клара, Калифорния. Процессор 500 может быть получен из другой компании, такой как ARM Holdings, Ltd, MIPS и т.д. Процессор 500 может быть процессором специального назначения, такие как, например, сетевой или коммуникационный процессор, сжатия, графический процессор, сопроцессор, встроенный процессор или тому подобное. Процессор 500 может быть реализован на одном или более микросхемах. Процессор 500 может быть частью и/или может быть реализован на одной или более подложках с использованием любого из ряда технологических процессов, таких как, например, BiCMOS, CMOS или NMOS.
В одном варианте осуществления заданный один из кэшей 506 может использоваться множество ядер 502. В другом варианте осуществления заданный один кэш 506 может быть выделен одному из ядер 502. Назначение кэшей 506 ядрам 502 может быть обработано с помощью контроллера кэша или другого подходящего механизма. Заданный один из кэшей 506 может быть совместно использован двумя или более ядрами 502 путем осуществления квантования времени заданного кэша 506.
Графический модуль 560 может реализовать интегрированную подсистему обработки графики. В одном варианте осуществления модуль 560 графики может включать в себя графический процессор. Кроме того, графический модуль 560 может включать в себя медиа-блок 565. Медиа-блок 565 может обеспечить кодирование медиа информации и декодирование видео.
На фиг.5 В показана блок-схема примерного варианта реализации ядра 502, в соответствии с вариантами осуществления настоящего изобретения. Ядро 502 может включать в себя магистральный процессор 570, соединенный, с возможностью взаимодействия, с блоком 580 выполнения с изменением последовательности команд. Ядро 502 может быть коммуникативно соединено с другими частями процессора 500 через иерархию 503 кэш-памяти.
Магистральный процессор 570 может быть реализован любым подходящим способом, таким как полностью или частично магистральным процессором 201, как описано выше. В одном из вариантов осуществления, магистральный процессор 570 может осуществлять связь с другими частями процессора 500 через иерархию кэш-памяти 503. В другом варианте осуществления магистральный процессор 570 может извлекать инструкции из частей процессора 500 и подготовить инструкции, которые будут использованы в дальнейшем в процессоре конвейера, поскольку они передаются в блок 580 выполнения с изменением последовательности команд.
Блок 580 выполнения с изменением последовательности команд может быть реализован любым подходящим способом, таким как полностью или частично блока 203 выполнения с изменением последовательности команд, как описано выше. Блок 580 выполнения с изменением последовательности команд может подготовить инструкции, полученные от магистрального процессора 570 для исполнения. Блок 580 выполнения с изменением последовательности может включать в себя модуль 1282 распределения. В одном из вариантов осуществления модуль 1282 распределения может распределять ресурсы процессора 500 или других ресурсов, таких, как регистры или буферы, чтобы выполнить данную инструкцию. Модуль 1282 распределения может выполнить распределение в планировщиках, таких как планировщик памяти, быстрый планировщик, или планировщик с плавающей точкой. Такие планировщики могут быть представлены на фиг 5 В планировщиками 584 ресурсов. Модуль 1282 распределения может быть полностью или частично реализован посредством логики распределения, описанной на фиг. 2. Планировщики 584 ресурсов реализуются, когда инструкция готова к выполнению, на основании готовности заданных источников ресурсов и наличием исполнительных ресурсов, необходимых для выполнения инструкции. Планировщики 584 ресурсов могут быть реализованы, например, планировщиками 202, 204, 206, как описано выше. Планировщики 584 ресурсов могут запланировать выполнение инструкций относительно одного или нескольких ресурсов. В одном варианте осуществления такие ресурсы могут быть внутренними по отношению к ядру 502, и могут быть проиллюстрированы, например, как ресурсы 586. В другом варианте осуществления такие ресурсы могут быть внешними по отношению к ядру 502 и могут быть доступны, например, посредством иерархии 503 кэша. Ресурсы могут включать в себя, например, память, кэш, файлы регистров или регистры. Внутренние ресурсы для ядра 502 могут быть представлены ресурсами 586 на фиг. 5В. По мере необходимости, значения, записываемые или считываемые из ресурсов 586, могут быть согласованы с другими частями процессора 500 с помощью, например, иерархии 503 кэш. Так как инструкции назначены ресурсами, они могут быть помещены в буфер 588 переупорядочивания. Буфер 588 переупорядочивания может отслеживать инструкции, как они выполняются, и может выборочно изменять порядок их выполнения, основываясь на любых подходящих критериях процессора 500. В одном варианте осуществления, буфер 588 переупорядочивания может идентифицировать инструкции или последовательности инструкций, которые могут быть выполнены независимо друг от друга. Такие инструкции или последовательности инструкций могут выполняться параллельно с другими такими инструкциями. Параллельное выполнение в ядре 502 может быть выполнено любым подходящим количеством отдельных исполнительных блоков или виртуальных процессоров. В одном из вариантов осуществления, совместно используемые ресурсы, такие как память, регистры и кэш могут быть доступны для нескольких виртуальных процессоров в пределах данного ядра 502. В других вариантах осуществления, совместно используемые ресурсы могут быть доступны для нескольких объектов обработки в процессоре 500.
Иерархия 503 кэш может быть реализована любым подходящим образом. Например, иерархия 503 кэш может включать в себя один или несколько низших или среднего уровня кэша, например, кэш 572, 574. В одном варианте осуществления иерархия 503 кэш может включать в себя LLC 595, подсоединенной к кэш 572, 574. В другом варианте осуществления LLC 595 может быть реализован в модуле 590, доступном для всех объектов обработки процессора 500. В дополнительном варианте осуществления, модуль 590 может быть реализован в модуле, состоящего из контроллера памяти и кэша 3-го уровня, процессора, поставляемого Intel, Inc. Модуль 590 может включать в себя части или подсистемы процессора 500, необходимые для функционирования ядра 502, но не может быть реализован в ядре 502. Кроме LLC 595, модуль 590 может включать в себя, например, аппаратные интерфейсы, координаторы когерентности памяти, промежуточный процессор межсоединения, конвейер инструкции или контроллер памяти. Доступ к RAM 599 доступный для процессора 500, может быть выполнен с помощью модуля 590 и, более конкретно, LLC 595. Кроме того, другие примеры ядра 502 могут аналогичным образом обеспечить доступ к модулю 590. Координация примеров ядра 502 может быть облегчено частично через модуль 590.
Фиг. 6-8 могут иллюстрируют примерные соответствующие системы, включающие в себя процессор 500, в то время как фиг.9 может иллюстрировать примерную систему на кристалле (SoC), которая может включать в себя один или несколько ядер 502. Другие конструкции системы и варианты реализации, известные в в данной области техники, могут представлять собой ноутбук, настольный компьютер, портативный компьютер, персональный цифровой помощник, рабочую станцию, сервер, сетевые устройства, сетевые концентраторы, коммутаторы, встроенные процессоры, процессоры цифровых сигналов (DSP), графические устройства, игровые устройства, телеприставки, микроконтроллеры, сотовые телефоны, портативные медиа-плееры, карманные устройства и различные другие электронные устройства, которые также могут быть пригодны для применения в данной области техники. В общем, огромное разнообразие систем или электронных устройств, которые включают в себя процессор и/или другую логику, как описано здесь, может в целом подходить для применения.
На фиг. 6 показана блок-схема системы 600, в соответствии с вариантами осуществления настоящего изобретения. Система 600 может включать в себя один или несколько процессоров 610, 615, которые могут быть присоединены к концентратору 620 графического контроллера памяти (GMCH). Возможное использование дополнительных процессоров 615 обозначено на фиг.6 пунктирными линиями.
Каждый процессор 610, 615 может быть какой-то, как описано в варианте осуществления процессора 500. Однако, следует отметить, что встроенная графическая логика и интегрированные блоки управления памятью не могут быть установлены в процессорах 610, 615. На фиг. 6 показано, что GMCH 620 может быть соединен с памятью 640, которая может представлять собой, например, динамическое оперативное запоминающее устройство (DRAM). DRAM может, по меньшей мере, в одном из вариантов осуществления быть ассоциированное с энергонезависимым кэшем.
GMCH 620 может представлять собой набор микросхем или часть набора микросхем. GMCH 620 может обмениваться данными с процессорами 610, 615 и управлять взаимодействием между процессорами 610, 615 и памятью 640. GMCH 620 может также выступать в качестве ускоренного интерфейса шины между процессорами 610, 615 и другими элементами системы 600. В одном варианте осуществления GMCH 620 обменивается данными с процессорами 610, 615 через многоточечную шину, например, системную шину (FSB) 695.
Кроме того, GMCH 620 может быть соединен с устройством 645 отображения (например, дисплей с плоской панелью). В одном варианте осуществления GMCH 620 может включать в себя интегрированный графический ускоритель. GMCH 620 может быть дополнительно соединен с концентратором (ICH) 650 контроллера ввода/вывода (I/O), который может быть использован для соединения различных периферийных устройств с системой 600. Внешнее графическое устройство 660 может включать в себя дискретное графическое устройство, подключенное к ICH 650, вместе с другим периферийным устройством 670.
В других вариантах осуществления дополнительные или другие процессоры могут также устанавливаться в системе 600. Например, дополнительные процессоры 610, 615 могут включать в себя дополнительные процессоры, которые могут быть такими же, как процессор 610, дополнительные процессоры, которые могут быть гетерогенными или асимметричными к процессору 610, ускорители (такие как, например, графический ускоритель или блоки цифровой обработки сигналов (DSP), программируемые пользователем вентильные матрицы или любой другой процессор. Существует множество различий между физическими ресурсами 610, 615, с точки зрения спектра измерения характеристик, включающие в себя архитектурные, микроархитектурные, тепловые, значений энергопотребления характеристик и тому подобное. Эти различия могут эффективно проявляться в виде асимметрии и гетерогенности среди процессоров 610, 615. По меньшей мере, один из вариантов осуществления различных процессоров 610, 615 может быть осуществлен на том же кристалле.
На фиг. 7 показана блок-схема второй системы 700, в соответствии с вариантами осуществления настоящего изобретения. Как показано на фиг. 7, многопроцессорная система 700 может включать в себя систему межсоединений точка-точка и может включать в себя первый процессор 770 и второй процессор 780, соединенный через межсоединение 750 точка-точка. Каждый из процессоров 770 и 780 может представлять собой некоторую версию процессора 500, как один или более процессоров 610, 615.
В то время как на фиг 7 проиллюстрировано два процессора 770, 780, следует понимать, что объем настоящего раскрытия не ограничен таким образом. В других вариантах осуществления один или более дополнительных процессоров могут быть установлены в данном процессоре.
Процессоры 770 и 780 показаны, как включающие в себя блоки 772 и 782 интегрированного контроллера памяти, соответственно. Процессор 770 может также включать в себя, как часть блоков контроллера шины, интерфейсы 776 и 778 точка-точка (Р-Р); аналогичным образом, второй процессор 780 может включать в себя интерфейсы Р-Р 786 и 788. Процессоры 770, 780 могут обмениваться информацией через интерфейс 750 точка-точка (РР) с использованием цепей 778 и 788 Р-Р интерфейса. Как показано на фиг. 7, IMCs 772 и 782 могут соединять процессоры к соответствующим блокам памяти, а именно: к памяти 732 и памяти 734, которые, в одном из вариантов осуществления, могут быть частями основной памяти, локально прикрепляемые к соответствующим процессорам.
Процессоры 770, 780 могут каждый обмениваться информацией с набором микросхем 790 через индивидуальные Р-Р интерфейсы 752, 754 с использованием схем 776, 794, 786, 798 интерфейса точка-точка. В одном варианте осуществления набор микросхем 790 может также обмениваться информацией с высокопроизводительной схемой 738 графики с помощью высокопроизводительного графического интерфейса 739.
Общий кэш (не показан) может быть включен в состав, как процессора, так и использоваться вне обоих процессоров, но соединенные с процессорами через Р-Р межсоединение, таким образом, что любой или оба процессора могут хранить информацию на локальном кэш, так на общем кэше, если а процессор переводится в режим работы пониженного энергопотребления.
Набор микросхем 790 может быть соединен с первой шиной 716 через интерфейс 796. В одном варианте осуществления первая шина 716 может быть шиной межсоединения периферийных компонентов (PCI), шиной, такой как шина PCI Express или другого третьего поколения шиной межсоединения I/O, хотя объем настоящего раскрытия не ограничено таким образом.
Как показано на фиг. 7, различные устройства 714 ввода/вывода могут быть соединены с первой шиной 716, а также с шинным мостом 718, который соединяет первую шину 716 со второй шиной 720. В одном варианте осуществления вторая шина 720 может быть шиной с низким числом выводов (LPC). Различные устройства могут быть соединены со второй шиной 720, в том числе, например, клавиатура и/или мышь 722, устройства 727 связи и блок 728 хранения, такой как диск или другое запоминающее устройство, которое может включать в себя инструкции/код и данные 730, в одном из вариантов осуществления. Кроме того, аудио I/O 724 может быть соединен со второй шиной 720. Следует отметить, что возможны другие архитектуры. Например, вместо архитектуры точка-точка на фиг. 7, система может реализовать многоточечную шину или другую такую архитектуру.
На фиг. 8 показана блок-схема третьей системы 800 в соответствии с вариантами осуществления настоящего изобретения. Как и элементы, показанные на фиг. 7 и 8, они имеют одинаковые ссылочные позиции, и некоторые аспекты, показанные на фиг. 7, были опущены на фиг. 8, для упрощения пояснения других аспектов, проиллюстрированных на фиг.8.
На фиг. 8 показано, что процессоры 870, 880 могут включать в себя встроенную память и логические схемы 872 и 882 управления ввода/вывода ("CL"), соответственно. По меньшей мере, в одном из вариантов осуществления, CL 872, 882 могут включать в себя интегрированные блоки контроллера памяти, такие как описаны выше со ссылкой на фиг. 5 и 7. Кроме того, CL 872, 882 могут также включать в себя логические схемы управления I/O. Фиг. 8 иллюстрирует, что не только память 832, 834 может быть соединена с CL 872, 882, но также и устройства 814 I/O также могут быть соединены с логическими схемами 872 и 882 управления. Унаследованные устройства 815 ввода/вывода могут быть соединены с набором микросхем 890.
На фиг. 9 показана блок-схема SoC 900, в соответствии с вариантами осуществления настоящего изобретения. Одинаковые элементы на фиг. 5 имеют одинаковые ссылочные позиции. Кроме того, квадраты, очерченные пунктирной линией, могут представлять дополнительные функции на более усовершенствованных SoCs. Блоки 902 межсоединения могут быть соединены с: прикладным процессором 910, который может включать в себя набор из одного или более ядер 902A-N и блоки 906 общего кэш; блоком 910 системного агента; интегрированными блоками 914 контроллера шины; блоками 916 контроллера шины; набором из одного или нескольких медиа-процессоров 920, которые могут включать в себя интегрированную графическую логику 908, процессор 924 изображения для обеспечения съемки камерой одиночных фотографий и/или видео, аудио процессор 926 для обеспечения высококачественного воспроизведения аудио, и видеопроцессор 928 для обеспечения высококачественного кодирования/декодирования видео; блок 930 статической памяти с произвольным доступом (SRAM); блок 932 прямого доступа к памяти (DMA); и блок 940 отображения для соединения с одним или более внешними устройствами отображения.
На фиг. 10 показан процессор, содержащий центральный процессор (CPU) и графический процессор (GPU), который может выполнять, по меньшей мере, одну инструкцию, в соответствии с вариантами осуществления настоящего изобретения. В одном варианте осуществления инструкция выполняет операций в соответствии, по меньшей мере, с одним вариантом осуществления, может быть выполнена с помощью CPU. В другом варианте осуществления инструкция может быть выполнена с помощью графического процессора. В еще одном варианте осуществления инструкция может быть выполнена с помощью комбинации операций, выполняемых GPU и CPU. Например, в одном варианте осуществления инструкция, в соответствии с одним вариантом осуществления, может быть получена и декодирована для выполнения на GPU. Тем не менее, одну или несколько операций в пределах декодированной инструкции могут быть выполнены с помощью процессора, и результат возвращается в GPU для окончательного удаления инструкции. С другой стороны, в некоторых вариантах осуществления, процессор может выступать в качестве основного процессора и графического процессора в качестве сопроцессора.
В некоторых вариантах осуществления, инструкции, которые извлекают выгоду из высокопроизводительной параллельной обработки процессоров, могут быть выполнены с помощью графического процессора, в то время как инструкции, которые обрабатываются высокопроизводительными процессорами, которые извлекают выгоду из глубоко конвейерных архитектур, могут быть выполнены с помощью CPU. Например, графика, научные приложения, финансовые приложения и другие параллельные рабочие нагрузки могут быть эффективно обработаны посредством графического процессора, в то время как более последовательные приложения, такие как ядра операционной системы или код приложения, могут обрабатываться более эффективно посредством CPU.
На фиг. 10 процессор 1000 включает в себя процессор 1005, графический процессор 1010, процессор 1015 обработки изображений, видеопроцессор 1020, USB контроллер 1025, UART контроллер 1030, SPI/SDIO контроллер 1035, устройство 1040 отображения, контроллера 1045 интерфейса памяти, MIPI контроллер 1050, флэш-память контроллер 1055, контроллер 1060 удвоенной скорости передачи данных (DDR), подсистема 1065 безопасности и I2 S/I2 С контроллер 1070. Другая логика и схемы могут быть включены в процессор, показанный на фиг. 10, в том числе более процессоров или графических процессоров и другие контроллеры периферийного интерфейса.
Один или более аспектов, по меньшей мере, одного из вариантов осуществления, могут быть реализованы с помощью репрезентативных данных, сохраненных на машиночитаемом носителе, который представляет собой различные логики в процессоре, которые при считывании машиной, вызывают машину построить логику для выполнения способов, описанных в настоящем документе. Такие представления, известные как "IP-ядра» могут храниться на материальном машиночитаемом носителе ("лента") и поставляется различным клиентам или в производственные предприятия для загрузки в процессе изготовления машин, которые, на самом деле, делают логику или процессор. Например, IP-ядра, такие как семейство Cortex™ процессоров, разработанных ARM Holdings, Ltd. и ядра Loongson IP, разработанные Институтом вычислительной техники (ICT) Китайской академии наук, могут быть лицензированы или проданы различным клиентам или лицензиатам, таким как Texas Instruments, Qualcomm, Apple или Samsung и реализованы в процессорах, выпускаемых этими клиентами или лицензиатами.
На фиг. 11 показана блок-схема, иллюстрирующая усовершенствованные IP ядра, в соответствии с вариантами осуществления настоящего изобретения. Модуль 1130 хранения может включать в себя программное обеспечение 1120 моделирования и/или модель 1110 аппаратного или программного обеспечения. В одном варианте осуществления данные, представляющие конструкцию IP-ядра, могут быть обеспечены в модуль 1130 хранения посредством памяти 1140 (например, жесткий диск), проводного соединения (например, интернет) 1150 или беспроводного соединения 1160. Информация IP-ядра генерируется с помощью инструмента моделирования и модели, которая может затем быть передана в производственное предприятие, на котором она может быть изготовлена сторонней организацией для выполнения, по меньшей мере, одной инструкции, в соответствии, по меньшей мере, с одним вариантом осуществления.
В некоторых вариантах осуществления одна или несколько инструкций может соответствовать первому типу или архитектуре (например, х86) и транслирована или эмулирована на процессор другого типа или архитектуры (например, ARM). Инструкция, согласно одному варианту осуществления, может быть выполнена, соответственно, на любом процессоре или типе процессора, включающий в себя ARM, х86, MIPS, GPU или другой тип процессора или архитектуры.
Фиг. 12 иллюстрирует, как инструкция первого типа может быть эмулирована процессором другого типа, в соответствии с вариантами осуществления настоящего изобретения. На фиг. 2 программа 1205 содержит некоторые инструкции, которые могут выполнить ту же самую или, по существу, ту же функцию как инструкция в соответствии с одним из вариантов осуществления. Однако, инструкции программы 1205 могут быть такого типа и/или формата, который отличается от или несовместимыми с процессором 1215, это означает, что инструкции типа в программе 1205 могут не быть в состоянии изначально выполняться процессором 1215. Тем не менее, с помощью логики 1210 эмуляции инструкции программы 1205 могут быть переведены в инструкции, которые могут изначально выполняться процессором 1215. В одном варианте осуществления логика эмуляции может быть воплощена в виде аппаратных средств. В другом варианте осуществления логика эмуляции может быть воплощена на материальном машинно-читаемом носителе информации, содержащий программное обеспечение, чтобы перевести инструкции типа в программе 1205 в тип изначально исполняемом процессором 1215. В других вариантах осуществления логика эмуляции может представлять собой комбинацию фиксированной функции или программируемых аппаратных средств и программы, хранящейся на материальном машиночитаемом носителе. В одном варианте осуществления процессор содержит логику эмуляции, в то время как в других вариантах осуществления логика эмуляции существует вне процессора и может быть предоставлена третьей стороной. В одном варианте осуществления процессор может загрузить логику эмуляции на физический машинно-читаемый носитель информации, содержащий программное обеспечение, посредством выполнения микрокода или аппаратно-программное обеспечения, содержащегося в или ассоциированное с процессором.
На фиг. 13 показана блок-схема, показывающая различия в использовании конвертора команд программного обеспечения для преобразования двоичных инструкций в набор инструкций источника в бинарные инструкции в целевом наборе команд, в соответствии с вариантами осуществления настоящего изобретения.
В показанном варианте осуществления преобразователь инструкции может быть преобразователем инструкции программного обеспечения, хотя преобразователь инструкции может быть реализован в программном обеспечении, программно-аппаратном обеспечении, в аппаратных средствах или в их различных комбинациях. На фиг. 13 показана программа на языке 1302 высокого уровня, которая может быть компилирована с использованием х86 компилятора 1304 для генерации х86 двоичного кода 1306, который может изначально выполняться процессором, по меньшей мере, посредством одного ядра 1316 набора х86 инструкций. Процессор, по меньшей мере, с одним ядром 1316 набора х86 инструкций представляет собой любой процессор, который может, по существу, выполнять те же функции, что и процессор Intel, по меньшей мере, с одним ядром набора х86 инструкций посредством совместимости выполнения или иным образом обрабатывая (1) значительную часть набора инструкций Intel ядра набора х86 инструкций или (2) версий объектного кода приложения или другого программного обеспечения, предназначенного для выполнения на Intel процессоре, по меньшей мере, с одним ядром набора х86 инструкций, чтобы достичь, по существу, одного и того же результата, что и для Intel процессора, по меньшей мере, с одним ядром набора х86 инструкций. х86 компилятор 1304 представляет собой компилятор, который выполнен с возможностью генерировать х86 двоичный код 1306 (например, объектный код), который может с или без дополнительной обработки связи быть выполненным на процессоре, по меньшей мере, с одним ядром 1316 набора х86 инструкций. Точно так же, фиг. 13 показывает программу на языке 1302 высокого уровня, которая может быть компилирована с использованием альтернативного компилятора 1308 набора инструкций для генерирования альтернативного набора инструкций двоичного кода 1310, который может изначально выполняться процессором без, по меньшей мере, одного ядра 1314 набора х86 инструкций (например, процессор с ядрами, который выполняют набор MIPS инструкций MIPS Technologies Саннивейл, штат Калифорния, и/или который выполняют набор ARM инструкций ARM Holdings Саннивейл, Калифорния). Преобразователь 1312 инструкций может быть использован для преобразования х86 двоичного кода 1306 в код, который может изначально выполняться процессором без ядра 1314 набора х86 инструкций. Этот преобразованный код может быть не таким же, как бинарный код 1310 альтернативного набора инструкций; Тем не менее, преобразованный код будет выполнять общую операцию и состоять из инструкций альтернативного набора инструкций. Таким образом, преобразователь 1312 инструкции представляет собой программное обеспечение, программно-аппаратные средства или их комбинацию, что посредством эмуляции, моделирования или любого другого процесса, позволяет процессору или другому электронному устройству, которое не имеет процессора набора х86 инструкций или ядра, для выполнения х86 двоичного кода 1306.
На фиг. 14 показана блок-схема архитектуры 1400 набора инструкций процессора, в соответствии с вариантами осуществления настоящего изобретения. Архитектура 1400 набора инструкций может включать в себя любое подходящее количество или тип компонентов.
Например, архитектура 1400 набора инструкций может включать в себя обработку объектов, таких как одно или более ядер 1406, 1407 и графический процессор 1415. Ядра 1406, 1407 могут быть коммуникативно соединены с остальной частью архитектуры 1400 набора инструкций посредством любого подходящего механизма, например, через шину или кэш. В одном варианте осуществления ядра 1406, 1407 могут быть функционально подсоединены через схему 1408 управления L2 кэш, которая может включать в себя блок 1409 интерфейса с шиной и кэш L2 1410. Ядра 1406, 1407 и графический процессор 1415 могут быть соединены с возможностью взаимодействия друг с другом и с остальной частью архитектуры 1400 набора инструкций посредством межсоединений 1410. В одном варианте осуществления блок 1415 обработки графики может использовать код 1420 видео, определяющий порядок, в котором конкретные видеосигналы будут закодированы и декодированы для вывода.
Архитектура 1400 набора инструкций также может включать в себя любое количество или вид интерфейсов, контроллеров или других механизмов для взаимодействия или установления связи с другими частями электронного устройства или системы. Такие механизмы могут способствовать взаимодействию с, например, периферийными устройствами, устройствами связи, другими процессорами или памятью. В примере, показанном на фиг. 14, архитектура 1400 набора инструкций может включать в себя видеоинтерфейс 1425 жидкокристаллического дисплея (LCD), интерфейс 1430 модуля сопряжения абонентов (SIM), интерфейс 1435 аппаратного загрузчика ROM, контроллер 1440 синхронной динамической памяти с произвольным доступом (SDRAM), флэш-контроллер 1445 и главный блок 1450 последовательного периферийного интерфейса (SPI). LCD видео интерфейс 1425 может обеспечивать вывод видеосигналов, например, из графического процессора 1415 и через, например, интерфейс 1490 процессора для мобильных устройств (MIPI) или мультимедийный интерфейс 1495 высокой четкости (HDMI) в дисплей. Такой дисплей может включать в себя, например, ЖК-дисплей. SIM интерфейс 1430 может предоставлять доступ к или из SIM-карты или устройства. SDRAM контроллер 1440 может обеспечить доступ к или из памяти, такой как SDRAM микросхема или модуль. Флэш-контроллер 1445 может предоставлять доступ к или из памяти, такой как флэш-память или другие примеры RAM. SPI главный блок 1450 может обеспечить доступ к или от коммуникационных модулей, таких как Bluetooth модуль 1470, высокоскоростной 3G модем 1475, модуль 1480 глобальной системы определения местоположения или беспроводной модуль 1485, реализуя стандарт связи, такой как 802.11.
На фиг. 15 представлена более подробная блок-схема архитектуры 1500 набора инструкций процессора, в соответствии с вариантами осуществления настоящего изобретения. Архитектура 1500 инструкций может реализовать один или более аспектов архитектуры 1400 набора инструкций. Более того, архитектура 1500 набора инструкций может иллюстрировать модули и механизмы для выполнения инструкций в процессоре.
Архитектура 1500 инструкций может включать в себя системную память 1540, подсоединенную к одному или более исполнительным объектам 1565. Кроме того, архитектура 1500 инструкций может включать в себя блок кэширования и интерфейс шины, такой как блок 1510, коммуникационно соединенный с исполнительными объектами 1565 и системной памятью 1540. В одном варианте осуществления, загрузка инструкций в исполнительные объекты 1564 может быть выполнена с помощью одного или более этапов исполнения. Такие этапы могут включать в себя, например, этап 1530 предвыборки инструкций, этап 1550 декодирования двойной инструкции, этап 155 переименования регистра, этап 1560 выпуска и этап 1570 обратной записи.
В одном варианте осуществления системная память 1540 может включать в себя указатель 1580 выполненной инструкции. Указатель 1580 выполненной инструкции может хранить значение, идентифицирующее самую последнюю необработанную инструкцию в пределах партии инструкций. Инструкция может храниться в партии инструкций на этапе 1560 выполнения с изменением последовательности команд. Партия инструкций может быть внутри потока, представленного множеством ветвей. Самая поздняя инструкция может соответствовать наименьшему значению РО (порядка программы). РО может включать в себя уникальный номер инструкции. РО может использоваться в порядке выполнения инструкции для обеспечения корректной семантики выполнения кода. РО может быть восстановлен с помощью таких механизмов, как оценка приращения РО, закодированная в инструкции, а не быть абсолютным значением. Такой восстановленный РО может быть известен как RPO. Несмотря на то, что на РО может быть сделана ссылка в данном документе, такой РО может быть использован взаимозаменяемо с RPO. Ветвь может включать в себя последовательность инструкций, данные которых зависят друг от друга. Ветвь может быть выполнена с помощью двоичного преобразователя во время компиляции. Аппаратное исполнение ветви может выполнять инструкции данной ветви в порядке в соответствии с РО различных инструкций. Поток может включать в себя несколько ветвей так, что инструкции различных ветвей могут зависеть друг от друга. РО данной ветви может быть РО самой последней инструкции в ветви, которая еще не была отправлена на исполнение с этапа выдачи. Соответственно, данный поток из нескольких ветвей, каждая ветвь включает в себя инструкции в соответствии с порядком РО указателя 1580 инструкций, может хранить последний, имеющий наименьший номер, РО среди ветвей потока на этапе 1560 выполнения с изменением последовательности команд.
В другом варианте осуществления системная память 1540 может включать в себя указатель 1582 удаления. Указатель 1582 удаления может хранить значение, идентифицирующее РО последней удаленной инструкции. Указатель 1582 удаления может быть установлен, например, посредством блока 454 удаления. Если никакие инструкции не были еще удалены, то указатель 1582 удаления может включать в себя нулевое значение.
Исполнительные объекты 1565 могут включать в себя любое подходящее количество и тип механизмов, с помощью которых процессор может исполнять инструкции. В примере, показанном на фиг. 15, исполнительные объекты 1565 могут включать в себя ALU/блоки 1566 умножения (MUL), ALUs 1567, а также блоки 1568 с плавающей точкой (FPU). В одном варианте осуществления такие объекты могут использовать информацию, содержащуюся в заданном адресе 1569. Исполнительные объекты 1565 в сочетании с выполнением операций на этапах 1530, 1550, 1555, 1560, 1570, могут совместно формировать исполнительный блок.
Блок 1510 может быть реализован любым подходящим способом. В одном варианте осуществления блок 1510 может выполнять управление кэш. В таком варианте осуществления блок 1510, таким образом, может включать в себя кэш 1525. Кэш 1525 может быть реализован, в дополнительном варианте осуществления, как L2 объединенный кэш любого подходящего размера, например, ноль, 128K, 256K, 512K, 1М или 2М байт памяти. В другом дополнительном варианте осуществления кэш 1525 может быть реализован в памяти кода коррекции ошибок. В другом варианте осуществления блок 1510 может выполнять шинное сопряжение с другими частями процессора или электронного устройства. В таком варианте осуществления блок 1510, таким образом, может включать в себя блок 1520 интерфейса с шиной для осуществления связи через межсоединение, внутрипроцессорную шину, межпроцессорную шину или другую коммуникационную шину, порт или линию связи. Блок 1520 интерфейса шины может обеспечить взаимодействие для выполнения, например, генерация адреса памяти и ввода/вывода для передачи данных между исполнительными объектами 1565 и внешними частями системы по отношению к архитектуре 1500 инструкций.
Для дополнительного обеспечения выполнения функций, блок 1520 интерфейса шины может включать в себя блок 1511 управления прерыванием и распределением для генерации прерываний и других коммуникаций с другими частями процессора или электронного устройства. В одном варианте осуществления блок 1520 интерфейса шины может включать в себя блок 1512 управления отслеживанием, который обрабатывает доступ к кэшу и когерентность для нескольких процессорных ядер. В еще одном варианте осуществления, для обеспечения такой функциональности, блок 1512 управления отслеживанием может включать в себя блок переноса кэш-в-кэш, который обрабатывает информацию, передающуюся между различными кэш. В другом дополнительном варианте осуществления блок 1512 управления отслеживанием может включать в себя один или несколько фильтров 1514 отслеживания, предназначенные для контроля когерентности других кэш (не показан), так что контроллер кэш, например, блок 1510, не должен выполнять такой контроль непосредственно. Блок 1510 может включать в себя любое подходящее количество таймеров 1515 для синхронизации действий архитектуры 1500 инструкций. Кроме того, блок 1510 может включать в себя АС порт 1516.
Системная память 1540 может включать в себя любое подходящее количество и тип механизмов для хранения информации для обработки архитектуры 1500 инструкции. В одном варианте осуществления системная память 1504 может включать в себя блок 1530 загрузки для хранения информации, такой как буфер для записи или считывания из памяти или регистров. В другом варианте осуществления системная память 1504 может включать в себя буфер 1545 быстрого преобразования адреса (TLB), который обеспечивает значения адресов поиска между физическими и виртуальными адресами. В еще одном варианте осуществления блок 1520 интерфейса шины может включать в себя блок 1544 управления памятью (MMU) для облегчения доступа к виртуальной памяти. В еще одном варианте осуществления системная память 1504 может включать в себя блок 1543 предвыборки для запроса инструкций из памяти до того, как инструкции действительно необходимы для выполнения, чтобы уменьшить время задержки.
Функционирование архитектуры 1500 инструкции для выполнения инструкции может быть реализовано посредством выполнения различных этапов. Например, с помощью блока 1510 на этапе 1530 предвыборки инструкции может получить доступ к инструкции через блок 1543 предвыборки. Извлекаемые инструкции могут храниться в кэше 1532 инструкции. Этап 1530 предвыборки может обеспечить параметр 1531 для режима быстрой обратной связи, в котором выполняется последовательность инструкций, образуя петлю, которая достаточно мала, чтобы поместиться в пределах заданного кэша. В одном из вариантов осуществления, такой вариант реализации может быть выполнен без необходимости доступа к дополнительным инструкциям, например, из кэш 1532 инструкции. Определение того, что предварительная выборка инструкции может быть выполнена, например, посредством блока 1535 предсказания ветвлений, который может получить доступ к индикации исполнения в глобальной истории 1536, индикациями целевых адресов 1537 или контента стека 1538 возврата, чтобы определить, какая из ветвей 1557 кода будет выполняться далее. Такие ветви могут быть, возможно, в результате предварительно выбраны. Ветви 1557 могут быть получены с помощью других этапов операции, как описано ниже. Этап 1530 предвыборки инструкции может предоставлять инструкции, а также любые предсказания относительно будущих инструкций для этапа декодирования двух инструкции.
Этап 1550 декодирования двух инструкций может перевести принятую инструкцию в инструкции микрокода, которые могут быть выполнены. Этап 1550 декодирования двух инструкций может одновременно декодировать две инструкции за один такт. Кроме того, Этап 1550 декодирования двух инструкций может передавать свои результаты на этап 1555 переименования регистра. Кроме того, этап 1550 декодирования двух инструкций может определять любые полученные ветви после декодирования для последующего исполнения микрокода. Такие результаты могут быть поданы на вход ветвей 1557.
Этап 1555 переименования регистра может перевести ссылки на виртуальные регистры или другие ресурсы на ссылки на физические регистры или ресурсы. Этап 1555 переименования регистра может включать в себя индикации такого отображения в пуле 1556 регистра. Этап 1555 переименования регистра может изменить принятые инструкции и отправить результат на этап 1560 выпуска.
Этап 1560 выпуска может выдавать или отправлять команды в исполнительные объекты 1565. Такая выдача может быть осуществлена с изменением последовательности команд. В одном из вариантов осуществления, множество инструкций могут удерживаться на этапе 1560 выпуска 1560 перед выполнением. Этап 1560 выпуска может включать в себя очередь 1561 инструкций для удержания указанного множества команд. Инструкции могут быть выпущены на этапе 1560 выпуска в конкретный объект 1565 обработки на основании приемлемых критериев, таких как наличие или пригодность ресурсов для выполнения данной инструкции. В одном варианте осуществления этап 1560 выпуска может изменить порядок инструкций в очереди 1561 инструкций таким образом, что первые принятые инструкции не могут быть первыми инструкциями для выполнения. На основании упорядочения очереди 1561 инструкции дополнительная информация разветвления может быть предоставлена ветвям 1557. Этап 1560 выпуска может передать инструкции в исполнительные объекты 1565 для исполнения.
При выполнении, этап 1570 обратной записи может записывать данные в регистры, очереди или другие структуры архитектуры 1500 набора инструкций для передачи информации о завершении данной команды. В зависимости от порядка инструкций, расположенных на этапе 1560 выпуска, операция этапа 1570 обратной записи может дать дополнительные инструкции для выполнения. Выполнение архитектуры 1500 набора инструкций может контролироваться или быть отлажена блоком 1575 трассировки.
На фиг. 16 показана блок-схема исполнительного конвейера 1600 для архитектуры набора инструкций процессора, в соответствии с вариантами осуществления настоящего изобретения. Исполнительный конвейер 1600 может проиллюстрировать работу, например, архитектуры 1500 инструкции, показанной на фиг. 15.
Исполнительный конвейер 1600 может включать в себя любую подходящую комбинацию этапов или операций. На 1605 может быть сделано предсказание ветвей, которые должны быть выполнены далее. В одном варианте осуществления такое предсказание может быть основано на предшествующих выполнениях инструкций и их результатах. На 1610, инструкции, соответствующие предсказанным ветвям исполнения, могут быть загружены в кэш инструкции. На 1615, одна или более таких инструкций в кэше могут быть выбраны для исполнения. На 1620, инструкции, которые были извлечены, могут быть декодированы в микрокод или более конкретный машинный язык. В одном варианте осуществления множество инструкций может быть одновременно декодировано. На 1625, ссылки на регистры или другие ресурсы в пределах декодированных инструкций, могут быть переназначены. Например, ссылки на виртуальные регистры могут быть заменены ссылками на соответствующие физические регистры. На 1630, инструкции могут быть отправлены в очередь на выполнение. На 1640, инструкции могут быть выполнены. Такой порядок выполнения может быть выполнен любым подходящим способом. На 1650, инструкции могут быть выданы в соответствующее исполнительное устройство. Способ, в котором выполняется инструкция, может зависеть от конкретного объекта выполнения. Например, на 1655, ALU может выполнять арифметические функции. ALU может использовать один цикл для своей работы, а также два регистра сдвига. В одном из вариантов осуществления могут быть использованы два ALU и, таким образом, две инструкции могут быть выполнены на 1655. На 1660, осуществляется определение результирующей ветви. Счетчик программы может быть использован для обозначения назначения, к которому будет относиться ветвь. 1660 может быть выполнен в течение одного тактового цикла. На 1665, выполняются арифметические действия с плавающей точкой одним или множеством FPUs. Операции с плавающей точкой могут потребовать несколько циклов для выполнения, например, от двух до десяти циклов. На 1670, может быть выполнена операция умножения и деления. Такие операции могут быть выполнены в четырех тактовых циклах. На 1675, могут быть выполнены операции загрузки и хранения в регистрах или других частях конвейера 1600. Эти операции могут включать в себя загрузку и хранение адресов. Такие операции могут быть выполнены в четырех тактовых циклах. На 1680, операции обратной записи могут быть выполнены в соответствии с требованиями в результате операций 1655-1675.
На фиг. 17 показана блок-схема электронного устройства 1700 для использования процессора 1710, в соответствии с вариантами осуществления настоящего изобретения. Электронное устройство 1700 может включать в себя, например, ноутбук, ультрабук, компьютер, сервер в корпусе, стоечный сервер, лезвийный сервер, ноутбук, настольный компьютер, планшет, мобильное устройство, телефон, встроенный компьютер или любое другое подходящее электронное устройство.
Электронное устройство 1700 может включать в себя процессор 1710, коммуникативно соединенный с любым подходящим количеством или типом компонентов, периферийных устройств, модулей или устройств. Такое соединение может быть осуществлено с помощью любого подходящего типа шины или интерфейса, таких как шины I2 С, системные управляющие шины (SMBus), шины с низким числом выводов (LPC), SPI, шины высокой четкости аудио (HDA), шины для подключения внешних устройств АТ-совместимых компьютерах (SATA), шина USB (версии 1, 2, 3) или шины универсального асинхронного приемника/передатчика (UART).
Такие компоненты могут включать в себя, например, устройство 1724 отображения, сенсорный экран 1725, сенсорную панель 1730, блок 1745 ближней зоны связи (NFC), датчик-концентратор 1740, тепловой датчик 1746, экспресс-набор микросхем (ЕС) 1735, модуль 1738 доверительной платформы (ТРМ), BLOS/прошивки/флэш память 1722, цифровой сигнальный процессор 1760, привод 1720, такой как твердотельный диск (SSD) или жесткий диск (HDD), блок 1750 беспроводной локальной сети (WLAN), блок 1752 Bluetooth, блок 1756 беспроводной глобальной сети (WWAN), система глобального позиционирования (GPS), камеру 1754, такую как USB 3.0 камера или маломощный блок 1715 памяти с удвоенной скоростью передачи данных (LPDDR), реализованный, например, в стандарте LPDDR3. Эти компоненты могут быть каждый реализован любым подходящим способом.
Более того, в различных вариантах осуществления другие компоненты могут быть функционально подсоединены к процессору 1710 через компоненты, рассмотренные выше. Например, акселерометр 1741, датчик 1743 внешней освещенности (ALS), компас 1743 и гироскоп 1744 могут быть коммуникативно соединены с датчиком-концентратор 1740. Тепловой датчик 1739, вентилятор 1737, клавиатура 1746 и сенсорная панель 1730 могут быть коммуникативно соединены с ЕС 1735. Громкоговоритель 1763, наушники 1764 и микрофон 1765 могут быть коммуникативно соединены с аудио блоком 1764, который в свою очередь может быть коммуникативно соединен с DSP 1760. Аудио блок 1764 может включать в себя, например, аудио кодек и усилитель D класса. SIM-карта 1757 может быть подсоединена к WWAN блоку 1756. Компоненты, такие как WLAN блок 1750 и Bluetooth блок 1752, а также WWAN блок 1756 могут быть реализованы в форм-факторе следующего поколения (NGFF).
Варианты осуществления настоящего изобретения включают в себя инструкции и логику для кэш, основанный на спекулятивной векторизации. На фиг. 18 показана функциональная блок-схема системы 1800 для реализации инструкции и логики для доступа к памяти в машине с кластерными исполнительными блоками. Такая машина может включать в себя кластерную машину широкого применения. В одном варианте осуществления система 1800 может обеспечить доступ к памяти для исполнительных блоков с использованием нескольких блоков кэш данных, которые синхронизированы. В еще одном варианте осуществления такая синхронизация может быть выполнена путем синхронизации кэшей данных в пределах нескольких блоков кэша данных. В другом дополнительном варианте осуществления такая синхронизация может быть выполнена путем синхронизации буферов отслеживания в нескольких блоках кэша данных. В еще одном дополнительном варианте осуществления такая синхронизация может быть выполнена путем синхронизации буферов обратной записи в пределах нескольких блоков кэша данных. В еще одном дополнительном варианте осуществления такая синхронизация может быть выполнена путем передачи запросов на заполнение буфера между заполнением буферов в пределах нескольких блоков кэша данных. Такие запросы могут включать в себя операции загрузки, принятые одним таким буфером, который обменивается информацией с другими буферами заполнения.
Система 1800 может выполнять инструкции, такие как поток 1802 инструкций. Система 1800 может сделать выборку, отправить, выполнить и удалить инструкции с изменением последовательности команд. Выполняя процесс исполнения с изменением последовательности команд, система 1800 может выполнять параллелизм на уровне инструкции. Кроме того, система 1800 может обеспечивать кэширование таким образом, что данный исполнительный блок может более быстрого получить доступ к данным, которые ранее были сохранены, определены или выполнены. Такое кэширование может быть установлено посредством множества уровней кэширования.
Система 1800 может быть реализована любым подходящим способом для выполнения кэш, основанного на спекулятивной векторизации. В одном из вариантов осуществления, система 1800 может включать в себя кластерную машину широкого применения (CWEM). CWEM может включать в себя, например, устройство обработки с несколькими исполнительными блоками. В еще одном дополнительном варианте осуществления исполнительные блоки могут выполнять однопоточный код. Чтобы обеспечить исполнение с изменением последовательности команд, система 1800 может включать в себя регистровые файлы для отображения и переименования логических и физических ресурсов. Исполнительные блоки CWEM могут быть распределены по микросхеме или пакету физического кристалла блока обработки. Кроме того, исполнительные блоки могут быть сгруппированы в кластеры. Посредством распределения исполнительных блоков, таким образом, регистровый файл получает доступ, и пропускная способность выполнения может быть улучшена при уменьшении благодаря доступу регистрового файла и пересылки данных. Таким образом, система 1800 может решить задачу по предоставлению доступа к памяти из-за блокирования других инструкций, которые могут находиться в режиме ожидания данных, чтобы выполнить в операцию с изменением последовательности команд, и повысить способность системы 1800 выполнить параллелизм на уровне инструкции.
В одном из вариантов осуществления система 1800 может включать в себя процессор 1802 для приема и выполнения части потока 1804 инструкций. В то время, как конкретные аспекты процессора 1802 проиллюстрированы на фиг. 18, процессор 1802 может включать в себя любой подходящий вид или количество процессоров или устройств обработки или других элементов в их поддержку. Процессор 1802 может быть полностью или частично реализован посредством, или может включать в себя одну или более, CWEMs.
В одном варианте осуществления процессор 1802 может включать в себя ядро, которое может включать в себя исполнительный блок 1816 памяти (MEU) и часть процессора 1820. MEU 1816 может включать в себя элементы для выполнения инструкций. Часть процессора 1820 может включать в себя элементы для поддержки выполнения инструкций. В другом варианте осуществления процессор 1802 может включать в себя любое подходящее число и тип исполнительных блоков 1808, сгруппированных в кластеры 1806. Кластеры 1806 могут быть реализованы в пределах ядра, MEU 1816 или любой другой подходящей части процессора 1802. В одном варианте осуществления исполнительные блоки 108 может включать в себя любую подходящую структуру аппаратных средств для выполнения операции загрузки или хранения контента системы 1800. Такие операции могут быть в или из, например, регистре или ячейке памяти. В другом варианте осуществления кластеры 1806 могут быть реализованы, например, посредством исполнительных кластеров 460.
MEU 1816 может включать в себя любое подходящее количество и тип элементов. В одном варианте осуществления MEU 1816 может включать в себя множество блоков 1804 кэша данных (DCU). Каждый DCU 1804 может быть соединен с возможностью взаимодействия с подходящим количеством кластеров 1806, таких, как один или два кластера 1806. Кроме того, каждый DCU 1804 может быть коммуникативно соединен, по меньшей мере, с одним другим DCU 1804. В еще одном дополнительном варианте осуществления DCUs 1804 могут быть соединены коммуникативно для обеспечения синхронизации подключенных DCUs 1804. DCUs 1804 могут включать в себя LI кэш. MEU 1816 может включать в себя L2 кэш 1810. Хотя показан только один кэш L2 кэш 1810, MEU 1816 может включать в себя любое подходящее количество или вид кэшей. Каждый DCU 1804 может быть коммуникативно соединен с L2 кэш 1810. MEU 1816 или его элементы могут включать в себя интерфейсы для перевода между его элементами и другими элементами системы 1800. Например, интерфейсы могут быть предоставлены для обмена данными между DCUs 1804 и кластерами 1806 или между DCUs 1804 и L2 кэш 1810.
DCUs 1804 могут включать в себя LI кэш, реализованный любым подходящим способом, таким как кэш, реализованный полностью или частично, например, LI внутренним кэш 104. L2 кэш 1810 может быть реализован полностью или частично, например, L2 кэш 476, иерархией 503 кэш, кэш 506, L2 кэш 1410 или кэш 1525.
Часть процессора 1820 может быть реализована любым подходящим образом. Например, часть процессора 1820 может включать в себя L3 кэш 1812 и контроллер 1814 памяти. L2 кэш 1810 может быть подсоединен к L3 кэш 1812. L3 кэш 1812 может быть реализован любым подходящим способом, например, полностью или частично кэшем 506, иерархией кэша 503 или LLC 595. Контроллер 1814 памяти может быть реализован любым подходящим способом для управления операции передач из памяти, например, полностью или частично с помощью МСН 116, блоков 552, CL 872, CL 882 контроллера памяти или интегрированных блоков 914 контроллера памяти.
Схема расположения LI кэшей DCUs 1804, L2 кэш 1810 и L3 кэш может быть расположена в иерархии кэш. Кроме того, несмотря на то, что LI, L2 и L3 конкретно описаны, может быть использовано любое подходящее количество или тип иерархии кэш-памяти. Например, заданное число LI кэшей может быть присвоено индивидуальному L2 кэш, и другое заданное число L2 кэш может быть присвоено индивидуальному L3 кэш. Когда исполнительные блоки 1808 выполняют операцию хранения или загрузки в ячейку памяти, проверка может быть сделана, прежде всего, в LI кэш DCUs 1804, чтобы увидеть, если кэшированная версия местоположения доступна. Если это так, то операция может быть выполнена на локальном кэш. Если нет, то операция попытки может генерировать пропуск, и доступ может быть дополнительно запрошен из кэш более высокого уровня. Предпринятая операция может быть повторена, где значения могут быть возвращены, если значения доступны в таком кэш. В противном случае, еще один пропуск может генерироваться. Эти этапы могут продолжаться до тех пор, пока ни один из кэш не определяется, как содержащий ячейку памяти, о которой идет речь, в которой фактическая ячейка памяти в системе 1800 может быть доступна.
На фиг. 19 показана функциональная блок-схема DCUs 1804 в соответствии с вариантами осуществления настоящего изобретения. Хотя показаны только DCU 1804А и DCU 1804В, аналогичным образом реализованные DCUs, могут быть использованы в системе 1800. В одном варианте осуществления каждый DCU 1804 может быть соединен с возможностью взаимодействия с соответствующим одним или двумя кластерами 1806 через интерфейс 1924 кластера. Кроме того, каждый DCU 1804 может быть подсоединен к L2 кэш 1810 через L2 интерфейс 1922. Кроме того, каждый DCU 1804 может быть соединен с возможностью взаимодействия друг с другом с помощью адресных шин 1940.
DCUs 1804 могут быть реализованы любым подходящим способом для выполнения функций, описанные в настоящем документе. DCUs 1804 могут быть реализованы частично посредством блоков 434, 474 кэш данных. В одном варианте осуществления каждый DCU 1804 может включать в себя кэш (DC) 1926 данных, один или несколько буферов (FB) 1930 заполнения, буфер (WBB) 1928 обратной записи и буфер (SB) 1932 поиска. Кроме того, каждый DCU 1804 может включать в себя мультиплексоры 1936, 1934 для облегчения коммуникации внутри и вне DCU 1804.
DC 1926 может быть реализован любым подходящим способом для выполнения функций, описанные в настоящем документе. В одном варианте осуществления DC 1926 может включать в себя структуру LI кэш данных. DC 1926 может быть реализован в любом подходящем размере. Например, DC 1926 может включать в себя 32 килобайт информации.
WBB 1928 может быть реализован любым подходящим образом для выполнения функций, описанные в настоящем документе. В одном варианте осуществления WBB 1928 может быть реализован, как область хранения в аппаратных средствах. В другом варианте осуществления WBB 1928 может захватить измененные строки кэша, которые исключены, например, из DC 1926. WBB 1928 может хранить такие исключенные измененные строки кэша, пока L2 кэш 1810 не нуждается в них или в состоянии получить их. Такая ситуация может возникнуть, например, когда данные, которые были ранее записаны в DC 1926, до сих пор не переданы в иерархии кэш-памяти, но теперь исключаются из DC 1926.
FB 1930 может быть реализован любым подходящим способом для выполнения функции, описанные в настоящем документе. В одном варианте осуществления FB 1930 может быть реализован в виде аппаратного буфера. FB 1930 может принимать и включать в себя все запросы нагрузки и сохранения, которые генерируют пропуски в попытках получить доступ к DC 1926. FB 1930 может включать в себя запросы, отправленные в L2 кэш 1810 и дополнительные уровни кэш-памяти, такие как L3 кэш 1812, пока запрошенная строка кэша не была возвращена из кэшей более высокого уровня, заполненные в DC 1926.
SB 1932 может быть реализован любым подходящим образом для выполнения функции, описанные в настоящем документе. В одном из вариантов осуществления SB 1928 может быть реализован в виде аппаратного буфера. SB 1928 может хранить строки кэша, найденные в DC 1926, которые находятся в измененном состоянии. Такой вывод может быть сделан, например, благодаря сигналам 1942 отслеживания. Сигналы 1942 отслеживания могут быть доставлены через адресную шину для отслеживания. Сигналы 1942 отслеживания могут быть переданы из L2 кэш 1810 каждому из DCUs 1804 для выполнения проверок в DC 1926, WBB 1928 и FB 1930. Проверки могут быть осуществлены для нахождения строки кэша, которая затребована где-то еще. Первопричина использования сигнала 1942 отслеживания может включать в себя загрузку или хранения в других EUs 1808, возращенные запросы, из-за исключений многоуровневых кэша, операции прямого доступа к памяти или самоанализ благодаря удачному обращению в кэш посредством некэшируемого запроса памяти. Если разыскиваемая строка кэша любой такой операции обнаруживается в DC 1926, то она может быть сохранена в SB 1928 для обратной записи.
Каждый элемент заданного DCU 1804 может быть коммуникативно соединен с другим элементом по любой подходящей линии или шины. Пример шины проиллюстрирован на фиг.19 и может проиллюстрировать различные виды данных, которые передаются между различными элементами DCU 1804. Кроме того, тип шины может быть выбран по информации, которая должна быть передана между соответствующими элементами.
Например, адреса загрузки и сохранения могут быть переданы от EUs 1808 к каждому из DCUs 1804 через адресную шину для загрузки и сохранения. Адреса загрузки и сохранения могут отражать адреса, для которых выполняются операции загрузки и сохранения. В одном варианте осуществления те же самые адреса могут быть отправлены каждому из DCU 1804А, 1804 В. Информация об адресе загрузки и сохранения может быть передана в DC 1926, FB 1930 и WBB 1928. Кроме того, данные, ассоциированные с памятью, могут быть отправлены из EUs 1808 в DCU 1804 через шину данных для данных загрузки и сохранения. В одном варианте осуществления одни и те же данные могут быть отправлены каждому из DCU 1804А, 1804 В. Данные, ассоциированные с памятью, могут быть распределены в DC 1926 и FB 1930.
DC 1926 и FB 1930 может передавать данные в ответ на запросы на загрузку EUs 1808. Данные могут включать в себя всю строку кэша. Данные могут передаваться по шине данных для передачи строки кэша. Выбор того, действительно ли DC 1926 или FB 1930 доставляют данные, может быть определен в соответствии с тем, который из элементов был запрошен, необходимо ли или корректная версия данных. Результаты выбора либо DC 1926, или FB 1930 осуществляются посредством мультиплексора 1936.
DC 1926 может посылать данные строки кэша, которые должны быть записаны обратно в другие кэши, в SB 1932 и WBB 1928. Данные могут быть отправлены через шину данных для передачи строки кэша. Кроме того, FB 1930, SB 1932 и WBB 1928 потенциально могут посылать такие данные обратной записи в L2 кэш 1810. Такие данные могут быть отправлены через шину данных для передачи строки кэша. Выбор данных обратной записи, которые должны быть отправлены, может быть определен в соответствии с тем, которые из элементов запрашиваются, необходимы или имеют правильную версию данных. Результат выбора данных обратной записи направляется в L2 интерфейс 1922 посредством мультиплексора 1934.
Сообщения о внесении данных могут быть отправлены из иерархии кэша через L2 интерфейс 1922 для каждого из DCUs 1804. В одном варианте осуществления одни и те же данные могут быть отправлены каждому из DCUs 1804 одновременно. В другом варианте осуществления сообщение о внесении данных может быть направлено от одного DCU 1804 к другому. Задержки или ожидание могут возникать в такой межблоковой DCU 1804 маршрутизации. Сообщение о внесении данных может включать в себя строки кэша данных, которые могут, в конечном счете, заменить существующие строки кэша в DC 1926. Такие данные могут быть отправлены через шину данных для передачи строки кэша. Сообщение о внесении данных может быть отправлено в FB 1930. В свою очередь, FB 1930 может посылать сообщения о внесении данных, когда это необходимо, синхронизировано или возможно модифицировано, в DC 1926 по шине данных для передач строки кэша.
WBB 1928 может посылать запросы обратной записи в иерархию кэш через L2 интерфейс 1922. Запросы обратной записи могут быть сделаны, когда запрос для DC 1926 вызывает пропуск. Последующие сообщения о внесении данных могут быть направлены в ответ на инструкции загрузки или хранения, которые пропускают в данном кэше; специально для завершения таких сообщений о внесении данных должен быть обеспечен свободный доступ в кэш. Запрос обратной записи сделан для обеспечения таких свободных записей. Данные могут быть отправлены через адресную шину для обработки пропусков кэш.
FB 1930 может посылать требование о замене в DC 1926. Такие запросы могут быть сделаны для инициирования DC 1926 предоставить его контент посредством данных обратной записи или данных исключения. Данные могут быть отправлены через адресную шину для обработки пропусков кэш. Кроме того, FB 1930 может послать запросы на чтение или чтение для владения в иерархию L2 кэш через интерфейс 1922. Запросы могут быть сделаны в ответ на чтение недоступной строки кэш или на попытку выполнить запись в строку кэш. В одном варианте осуществления запрос на владение может привести к аннулированию экземпляров данных кэш в других DCUs 1804. Данные могут быть отправлены через адресную шину для обработки пропусков кэша.
Элементы DCU 1804 могут работать в соответствии с аппаратными часами, общими для всех DCUs 1804. Выбор времени аппаратных часов может быть перенаправлен на каждое DCU 1804. Аппаратные часы могут быть использованы для синхронизации работы каждого DCU 1804 по отношению друг к другу. В одном варианте осуществления контент DC 1926 всех DCUs 1804 может быть идентичен в каждом тактовом цикле. В другом варианте осуществления контент WBB 1928 всех DCUs 1804 может быть идентичен в каждом тактовом цикле. В еще одном варианте осуществления, контент SBs 1932 всех DCUs 1804 может быть идентичен в каждом тактовом цикле. В еще одном варианте осуществления контент FB 1930 различных DCUs 1804 может быть различным для данного тактовый цикл. Такое различие может быть связано с задержкой передач между DCUs 1804.
Синхронизация контента WBB 1928, DC 1926 или SB 1932 может быть выполнено любым подходящим способом. В одном варианте осуществления синхронизация контента WBB 1928, DC 1926 или SB 1932 может быть осуществлена путем реализации той же самой логики, в ответ на различные ситуации в каждом элементе DCUs 1804. Заданные условия или исходные данные могут быть обработаны одинаково и синхронно во всех DCUs 1804. В еще одном варианте осуществления такая идентичная обработка во всех DCUs 1804 может включать в себя одновременное исключение строк кэша данных в каждом соответствующем DC 1926. Исключения строк кэша в DCUs 1804 может произойти, когда каждый DC 1926 заполнен и DCU 1804, возможно, потребуется добавить новую строку кэша. Исключение может освободить место для новой, более полезной строки кэша для доступа EUs 1808. В другом дополнительном варианте каждый DCU 1804 может выполнять один и тот же алгоритм исключения, чтобы определить, какие строки кэша должны быть исключены. Результаты могут быть одинаковыми в каждом DCU 1804, если каждый DCU 1804 был ранее поддержан идентичным контентом в каждом соответствующем DC 1926. В еще одном варианте осуществления сообщения о внесении данных в каждый DC 1926 может обрабатываться одновременно и, таким же образом в каждом DCU 1804. Сообщения о внесении данных сами по себе также могут быть одинаковыми. Сообщения о внесении данных могут быть идентичны благодаря аналогичному процессу создания в соответствующих DCUs 1804 или путем получения одинаковых сообщений о внесении данных из L2 интерфейса 1922 на каждом DCU 1804.
В другом варианте осуществления синхронизация контента WBB 1928, DC 1926 или SB 1932 может быть осуществлена путем одновременного идентичного ввода в DCU 1804. Такие входные данные могут быть получены с помощью любого подходящего источника, такого как иерархии кэша, коммуникативно соединенные с DCU 1804 через L2 интерфейс 1922, или EUs 1808 коммуникативно соединенные через интерфейс 1924 кластера. В еще одном варианте осуществления те же самые инструкции сохранения могут транслироваться из соответствующих EUs 1808 к каждому DCU 1804. Инструкции хранения могут быть идентичными, как и в различных вариантах осуществления, каждый кластер 1808 может включать в себя ту же компоновку EUs 1808. Хранилища могут включать в себя старшие хранилища, которые отражают работу хранилища при удалении инструкции или ресурса. Кроме того, после получения инструкций хранилища, каждый DCU 1804 может обрабатывать инструкции хранилища таким же образом. В еще одном варианте осуществления сообщения о внесении данных могут быть предоставлены для всех DCUs 1804 из иерархии кэша. Каждое такое сообщение о внесении данных, принятое на соответствующем DCUs 1804, может быть обработано таким же образом. В еще одном варианте осуществления идентичные сигналы 1942 отслеживания могут послаться из иерархии L2 кэш через интерфейс 1922 на каждое соответствующее DCU 1804. Как уже говорилось выше, каждый сигнал отслеживания может быть направлен на каждый соответствующий WBB 1928, FB 1930 и DC 1926.
В еще одном варианте осуществления синхронизация контента WBB 1928, DC 1926 или SB 1932 может быть выполнена с помощью одной или нескольких линий 1940 FB синхронизации, коммуникативно соединенные с FBs 1930 соответствующего DCUs 1804. Линии 1940 FB синхронизации могут быть реализованы посредством адресной шины для обработки пропусков кэша. Задержка может произойти во время передачи сообщений через линии 1940 FB синхронизации.
Операции хранения, ассоциированные с удалением, могут транслироваться одновременно каждому соответствующему DCU 1804, в котором каждое хранилище может одновременно обрабатываться таким же образом в каждом соответствующем DCU 1804. Любой подходящий механизм может быть использован для реализации одновременной отправки из каждого набора EUs 1808 или кластера 1806 в соответствующий DCU 1804. В одном варианте осуществления может быть использована очередь отправки глобального хранилища (SDQ). Такая SDQ может быть подсоединена к EUs 1808 или кластерам 1806, чтобы принять хранилища, и может быть функционально подсоединено к каждому DCU 1804 через интерфейс 1924 кластера для отправки таких хранилищ. Отправленные хранилища из SDQ могут быть доставлены каждому DCU с одинаковой задержкой, так что состояние DCU обновляется одновременно. SDQ может осуществить отправку таких хранилищ после определения подходящего количества выпущенных хранилищ. Отправка, таким образом, может включать в себя отправку нескольких хранилищ для DCUs 1804. В другом варианте можно использовать несколько отдельных SDQs. SDQ может поддерживаться на уровне, например, каждого кластера. Каждый из кластеров 1806 может передавать на другие такие SDQs. Трансляция может включать в себя идентификацию количества хранилищ, готовых для SDQ выполняющего трансляцию. Многочисленные отдельные SDQs могут координировать и определять, когда общее количество хранилищ пригодно для отправки. После такого определения, каждый SDQ может посылать свои хранилища всем DCUs 1804.
Как обсуждалось выше, в одном варианте осуществления хранилища всех EUs 1808 и кластеры 1806 могут быть направлены на каждый DC 1926. Любое такое хранилище, которое соответствует существующему значению в DC 1926, может быть записано в DC 1926. Любое такое хранилище, которое пропускает в DC 1926, может быть записано в FB 1930. Так как контент всех DCs 1926 удерживается идентичным, в другом дополнительном варианте осуществления идентичные такие операции могут быть выполнены во всех DCs 1926. Более того, любое хранилище, которое пропускает в DC 1926, может создать запрос на чтение для владения, который будет направлен из FB 1930 в L2 кэш 1810, чтобы извлечь полную строку кэша. Результаты выборки могут быть объединены с данными хранилища, расположенного в FB 1930. В одном варианте осуществления результаты выборки могут транслироваться на все FBs 1930. Кроме того, ожидающее выборки данные хранилища могут быть одинаковыми во всех FBs 1930, так как то же хранилище было написано во всех FBs 1930 при пропуске. После того, как строка кэша была выбрана, а также любые другие выборки для других операций хранилища, которые были пропущены, хранилище может быть глобально проверено посредством записи данных в DC 1926 во всех DCUs 1804. Контент каждого FB 1930 среди различных DCUs 1804 может отличаться до тех пор, пока строка кэша не будет доставлена каждому DCU 1804. Различия могут быть обусловлены задержкам в отправке и приеме данных между DCUs 1804.
Синхронизация FBs 1930 может быть выполнена любым подходящим способом. Как описано выше, строка кэша может потребовать выборку при пропуске в DC 1926. В одном из вариантов осуществления среди всех DCUs 1804 один DCU 1804 может быть ответственным за направление запроса на чтение или запроса на чтение для владения из FBs 1930 в L2 кэш 1810. Ответственный DCU 1804 может быть определен любым подходящим способом. В другом варианте осуществления заданный DCU 1804 может быть определен с помощью хеш-функции, отображения, индекса или иной индикацией на основании физического адреса операции сохранения. В то время, как только один DCU 1804 может направить запрос, в другом варианте осуществления, извлеченной строка кэша может быть транслирована на все FBs 1930. В еще одном варианте осуществления, в то время, как только один DCU 1804 может направить запрос, каждый FB 1930 может удерживать допуск для таких запросов, чтобы точно определить и отслеживать попадания посредством последующих загрузок, которые могут быть в зависимости от извлеченной строки.
Более того, синхронизация FBs 1930 может быть выполнена с использованием адресных шин 1940 для совместного использования контента FB между DCUs 1804. Каждый FB 1930 может включать в себя одни и те же хранилища, сгенерированные кластерами 1806. Таким образом, каждый FB 1930 может одновременно записывать такие хранилища. Тем не менее, в одном варианте осуществления каждый из FB, возможно, не имеет доступа в то же время, что та же операция загрузки. Такая ситуация может возникнуть, например, когда SDQs не хранят запросы на загрузку хранилища, или где та же информация загрузки просто не транслируются из кластеров 1806 во все DCUs. В таком варианте осуществления FB 1930 может, при приеме информации загрузки от соответствующего кластера 1806, записать нагрузку на себя и направить нагрузку на другие FBs 1930 через адресную шину 1940. Каждый FB 1930 запрашивает нагрузку хранилища от своих собственных кластеров 1806 и отслеживает запросы нагрузки, принятые на других FBs 1930. Контент различных FBs 1930 может быть различным при заданном тактовом цикле из-за задержки передачи или времени ожидания для таких запросов нагрузки через адресные шины 1940.
Синхронизация WBBs 1928 может быть выполнена любым подходящим способом. В одном варианте осуществления, когда новая строка кэша записывается сообщениями о внесении данных в DC 1926, одни и те же данные могут быть записаны одновременно на все DCs 1926. В другом варианте осуществления такая же удаленная строка кэша DC 1926 может быть записана одновременно во всех WBBs 1928 с помощью сообщений о внесении данных. При условии обратной записи, в еще одном варианте осуществления, удаленная строка кэша DC 1926 может быть написана из WBB 1928 ответственного DCU 1804 (как определено выше) в L2 кэш 1810. Запись может быть выполнена в следующем тактовом цикле. В еще одном варианте осуществления L2 кэш 1810 может посылать сообщения подтверждения для всех WBBs 1928. Каждый соответствующий WBB 1928 может аннулировать строку кэша сам по себе после приема такого подтверждения.
Синхронизация сигналов 1942 отслеживания из L2 кэша 1812 может быть выполнена любым подходящим способом. В различных вариантах осуществления сигналы 1942 отслеживания могут быть направлены в DC 1926, 1930 FB и WBB 1928. Если запрошенная строка кэша оказывается в модифицированном состоянии в DC 1926, то строка кэша может быть перемещена в буфер 1932 отслеживания. При достижении порогового значения, строка кэша и любая другая собранная информация будет записана обратно через буфер 1932 отслеживания, как выбранная посредством мультиплексора 1934. Ответственный DCU 1804 (как определено выше) может включать в себя буфер 1932 отслеживания, который записывает обратно такие данные. Кроме того, в случае попадания в либо WBB 1928, или в FB 1930, обратна запись будет выполнена таким элементом ответственного DCU 1804. Кроме того, некэшируемая или частичная запись может вызвать FB 1930 выполнить такую обратную запись из ответственного DCU 1804. Ответственный элемент в любом таком случае может быть выбран мультиплексором 1934.
WBB 1928 может быть дополнительно синхронизирован путем выделения эквивалентных записей в соответствующих WBBs 1928 в буфере обратной записи DCUs 1804. В одном из вариантов осуществления такое распределение может быть сделано в тот же тактовый цикл работы процессора. Более того, один экземпляр WBB 1928 может отменить выделение записи сам в себе и другой экземпляр WBB 1928 может выделить эквивалентную запись в себе. В другом варианте осуществления такое распределение и освобождение может быть одновременным.
На фигурах 20А и 20В проиллюстрирован способ 2000 доступа к памяти в кластерной машине, в соответствии с вариантами осуществления настоящего изобретения. Способ 2000 может начаться в любом подходящем месте, и может выполняться в любом подходящем порядке. Например, множество элементов способа 2000 могут реализовываться одновременно на заданном тактовом цикле. Различные секции способа 2000 могут быть выполнены параллельно друг с другом. Кроме того, ветви или решения в способе 2000 могут быть асинхронными. Некоторые элементы способа 2000 могут выполняться одновременно несколькими устройствами, такими как DCUs или его компонентами. DCUs могут быть синхронизированы в соответствии с компонентами, такими как WBBs, FBS, DCs и SBs. При заданном тактовом цикле контент каждого WBB, DC и SB соответствующего DCUs может быть одинаковым. Любое подходящее количество DCUs может быть синхронизировано таким образом. Каждый DCU может быть функционально соединен с одной или двумя кластерами, которые каждый из включает в себя одинаковое число EUs.
На 2003 сигналы отслеживания могут быть отправлены из иерархии кэш-памяти в компоненты всех DCUs. Такие компоненты могут включать в себя DCs, FBS и WBBs всех таких DCUs. Сигналы отслеживания могут направлять запросы о статусе данной строки кэша, которые могут быть найдены в, на или более таких компонентов. На 2005 каждый DCU может определить, были ли найдены какое-либо состояние, основанное на отслеживании, как результат сигналов отслеживания. Если не были обнаружены состояния, основанные на отслеживании, то способ 2000 может перейти к этапу 2010. Если было найдено состояние, основанное на отслеживании, включающее в себя модифицированную строку кэша в DC (или DCs), то способ 2000 может перейти к этапу 2007. Если возникает состояние, основанное на отслеживании, включающее в себя поиск строки кэша в WBB или FB, то способ 2000 может перейти к этапу 2040. На 2007 строка кэша из DCs во все SBs в соответствующих DCUs, то способ 2000 может переходить к этапу 2040. В одном из вариантов осуществления этапы 2003, 2005 и 2007 могут повторяться параллельно с другими элементами способа 2000.
На 2010 операции с памятью в различных EUs и кластерах могут контролироваться. Мониторинг может осуществляться на основе каждого кластера. Такие операции с памятью могут включать в себя различные формы операций хранения и загрузки. В одном из вариантов осуществления 2010 и соответствующие последующие элементы могут быть выполнены параллельно с этапами 2003, 2005 и 2007.
На 2013 может быть определено, выполнена ли операция загрузки или операция сохранения с помощью данного кластера. Если операция загрузки была найдена, то способ 2000 может переходить к этапу 2045. Если операция сохранения было обнаружена, то на этапе 2015 может быть определено, достаточное ли количество хранилищ было принято от всех кластеров. Операция сохранения, определенная на этапе 2010, может быть добавлена в очередь операций сохранения. Такая очередь может быть, например, глобальной и учтенной для хранилищ из всех кластеров или локальной по отношению к очереди, и координировать работу с другими такими очередями. Если требуемое количество хранилищ, сгенерированных различными EUs, достигнуто, то способ 2000 может переходить к 2017. Если требуемое количество хранилищ не было достигнуто, то способ 2000 может переходить к 2037.
На этапе 2017, каждая из собранных операций хранения может быть выдана всем DCUs. На этапе 2020, каждый DCU может определить, находится ли цель данной операции хранения в пределах DC. Если цель операции хранения не находится в DCs, то произошел пропуск. Если пропуск произошел, то способ 2020 может перейти к этапу 2025. Если пропуска не произошло и цель операции хранения доступна в DCs, то способ 2020 может перейти к 2023. Этап 2020 и последующие элементы могут повторяться для каждой переданной операции хранения.
На этапе 2023, операция хранения может быть записана на все DCs. Способ 2000 может перейти к 2037.
На этапе 2025 может быть инициирована обработка пропуска для операции хранения. Операция хранения может быть записана на всех FBs. На 2027 может быть сформирован во всех FBs запрос на чтение для операции хранения, чтобы быть извлеченной из части иерархии кэш, такой как L2. На этапе 2030 FB одного ответственного DCU может выдать запрос на чтение иерархии кэш. Ответственный DCU может быть определен любым подходящим способом, таким как назначение на основе физического адреса операции.
На этапе 2033 данные заполнения могут быть отправлены из иерархии кэш для всех DCUs. Данные заполнения могут быть приняты на соответствующих FBs. В одном из вариантов осуществления иерархия кэша может маршрутизировать данные заполнения в запрашивающее DCU, которое может совместно использовать данные заполнения с каждым других DCUs. В другом варианте осуществления иерархия кэша может маршрутизировать данные заполнения параллельно всем DCUs.
На 2035 старые данные во всех DCs могут быть перемещены, если такие DCs не имеют достаточного свободного места для новых данных заполнения. И перемещенные данные могут быть записаны во все WBBs из DCs. Новые данные заполнения могут быть записаны на все DCs.
На 2037 может быть определено, произошло ли какое-либо условие для обратной записи. Такие условия могут включать в себя, например, потребность в данных, которые были перемещены ранее, но еще не используются совместно с иерархией кэш, запрос некэшируемой памяти, частичная запись, прямой доступ к памяти или запросы в обратном направлении из иерархии кэша. В различных вариантах осуществления такие проверки могут быть выполнены совместно с обработкой на этапе 2005 сигнала отслеживания. Если условие обратной записи произошло, то способ 2000 может переходить к 2040. Если ни одно из условий обратной записи не произошло, то способ 2000 может переходить к 2003, чтобы повторить выполнение способа 2000. В различных вариантах осуществления этапы 2037, 2040 и 2043 могут быть выполнены параллельно с другими элементами способа 2000.
На этапе 2040 WBB, SB, FB ответственного DCU для условия обратной записи могут выполнять обратную запись данных в иерархии кэш. На 2043 может быть принято подтверждение обратной записи. При необходимости, все WBBs могут быть признаны недействительными. Способ 2000 может перейти к 2033 для приема данных заполнения в ответ на запрос обратной записи.
На этапе 2045 операция загрузки может быть определена для отдельного кластера на этапе 2013, и загрузка может быть направлена в ассоциированный индивидуальный DCU. На этапе 2047 может быть определено, имеется ли попадание или пропуск для цели операции загрузки в DC соответствующего DCU. Если есть пропуск, то способ 2000 может перейти к 2053. Если нет пропуска, то способ 2000 может перейти к 2050.
На этапе 2050 операция загрузки может быть выполнена на DC и полученные данные возвращаются в кластер, который сделал запрос на операцию загрузки. Способ 2000 может перейти к 2037.
На этапе 2053 может быть инициирована обработка пропуска для операции загрузки. Операция загрузки может быть записана в FB соответствующего индивидуального DCU, который принял операцию загрузки. На этапе 2055 году операция загрузки может быть передана всем другим FBs в других DCUs. Такая коммуникация может быть осуществлена с помощью специальных адресных линий. В такой связи может быть задержка или ожидание. Задержка может вызвать различные FBs иметь разный контент, пока все FBs не примут операцию загрузки. На этапе 2055 операция загрузки может быть записана на каждом соответствующем FB, при получении, пока все FBs не запишут операцию загрузки. Способ 2000 может перейти к этапу 2030.
Способ 2000 может быть инициирован с помощью любых подходящих критериев. Кроме того, хотя способ 2000 описывает работу конкретных элементов, способ 2000 может быть выполнен с помощью любого подходящего сочетания или типа элементов. Например, способ 2000 может быть реализован с помощью элементов, показанных на фиг. 1-21 или любой другой системы, выполненной с возможностью реализовать способ 2000. По существу, предпочтительный вариант инициализации способа 2000 и порядок элементов, составляющих способ 2000, может зависеть от выбранного варианта реализация. В некоторых вариантах осуществления некоторые элементы могут быть, возможно, опущены, реорганизованы, повторяемы или в использоваться совместно.
Варианты осуществления механизмов, раскрытых в данном документе, могут быть реализованы в аппаратных средствах, программном обеспечении, встроенном программном обеспечении или комбинации таких подходов осуществления. Варианты осуществления изобретения могут быть реализованы в виде компьютерных программ или программного кода, выполняющиеся на программируемых системах, содержащих, по меньшей мере, один процессор, систему хранения информации (включающую в себя энергозависимую и энергонезависимую память и/или элементы хранения), по меньшей мере, одно устройство ввода и, по меньшей мере, одно устройство вывода.
Программный код может быть применен к входным инструкциям для выполнения функций, описанных в данном документе, для генерирования выходной информации. Выходная информация может быть применена к одному или более устройств вывода, известным способом. Для целей данной заявки, система обработки данных может включать в себя любую систему, которая имеет процессор, такой как, например, цифровой сигнальный процессор (DSP), микроконтроллер, специализированную интегральную схему (ASIC) или микропроцессор.
Программный код может быть реализован на процедурном языке высокого уровня или объектно-ориентированном языке программирования для обмена данными с системой обработки. Программный код также может быть реализован на языке ассемблера или машинном языке, при необходимости. На самом деле, механизмы, описанные в данном документе, не ограничены в объеме для любого конкретного языка программирования. В любом случае, язык может быть транслируемым или интерпретируемым языком.
Один или более аспектов, по меньшей мере, одного варианта осуществления, могут быть реализованы с помощью репрезентативных инструкций, хранящихся на машиночитаемом носителе данных, который представляет собой различные логические схемы в процессоре, который при считывании машиной, вызывает машину сформировать логику для выполнения способов, описанных в настоящем документе. Такие представления, известные как «IP-ядра» могут храниться на материальном машиночитаемом носителе информации, и поставляется различным клиентам или производственным предприятиям для загрузки в изготовленные машины, которые на самом деле, формируют логику или процессор.
Такие машиночитаемые носители информации могут включать в себя, без ограничения, непреходящие, материальные компоновки изделий, изготовленных или сформированных с помощью машины или устройства, включающие в себя носители информации, такие как жесткие диски, любой другой тип диска, включающий в себя дискеты, оптические диски, компакт-диски, доступные только для чтения (CD-ROM), компакт-диски с многократной перезаписью данных (CD-RW), магнитооптические диски, полупроводниковые устройства, такие как память только для чтения памяти (ROM), оперативная память (RAM), такая как динамическая оперативная память (DRAM), статическая оперативная память (SRAM), стираемая программируемая постоянная память (EPROM), флэш-память, электрически стираемая программируемая постоянная память (EEPROM), магнитные или оптические карты или любой другой тип носителя информации, подходящий для хранения электронных инструкций.
Соответственно, варианты осуществления изобретения могут также включать в себя невременный материальный машиночитаемый носитель информации, содержащий инструкции или содержащий структурные данные, такие как язык описания аппаратных средств (HDL), который определяет структуры, схемы, устройства, процессоры и/или системные признаки, описанные здесь. Такие варианты осуществления также могут быть отнесены к программным продуктам.
В некоторых случаях, преобразователь инструкции может быть использован для преобразования инструкции из набора инструкций источника в целевой набор инструкций. Например, преобразователь инструкции может переводить (например, с помощью статической двоичной трансляции, динамической двоичной трансляции, включающая в себя динамическую компиляцию), трансформировать, эмулировать или иным образом преобразовывать инструкцию к одной или нескольким другим инструкциям, обрабатываемых ядром. Преобразователь инструкции может быть реализован в программном обеспечении, аппаратных средствах, встроенном программном обеспечении или в их комбинации. Преобразователь инструкции может быть на процессоре, вне процессора или частично на и частично вне процессора.
Таким образом, приведено описание способов выполнения одной или более инструкций, по меньшей мере, посредством одного из вариантов осуществления. В то время, как некоторые примерные варианты осуществления были описаны и показаны на прилагаемых чертежах, следует понимать, что такие варианты осуществления являются только иллюстративными, а не ограничивающими в других вариантах осуществления, и что такие варианты осуществления не ограничивается конкретными конструкциями и механизмами, которые показаны и описаны, поскольку различные другие модификации могут иметь место для специалистов в данной области техники после изучения данного описания. В данной области техники нелегко предвидеть дополнительное совершенствование и развитие, раскрытые варианты осуществления могут быть легко изменены в отношении компоновки и деталей для предоставления возможности использовать на практике технологические достижения, не отступая от принципов настоящего изобретения или объема прилагаемой формулы изобретения.
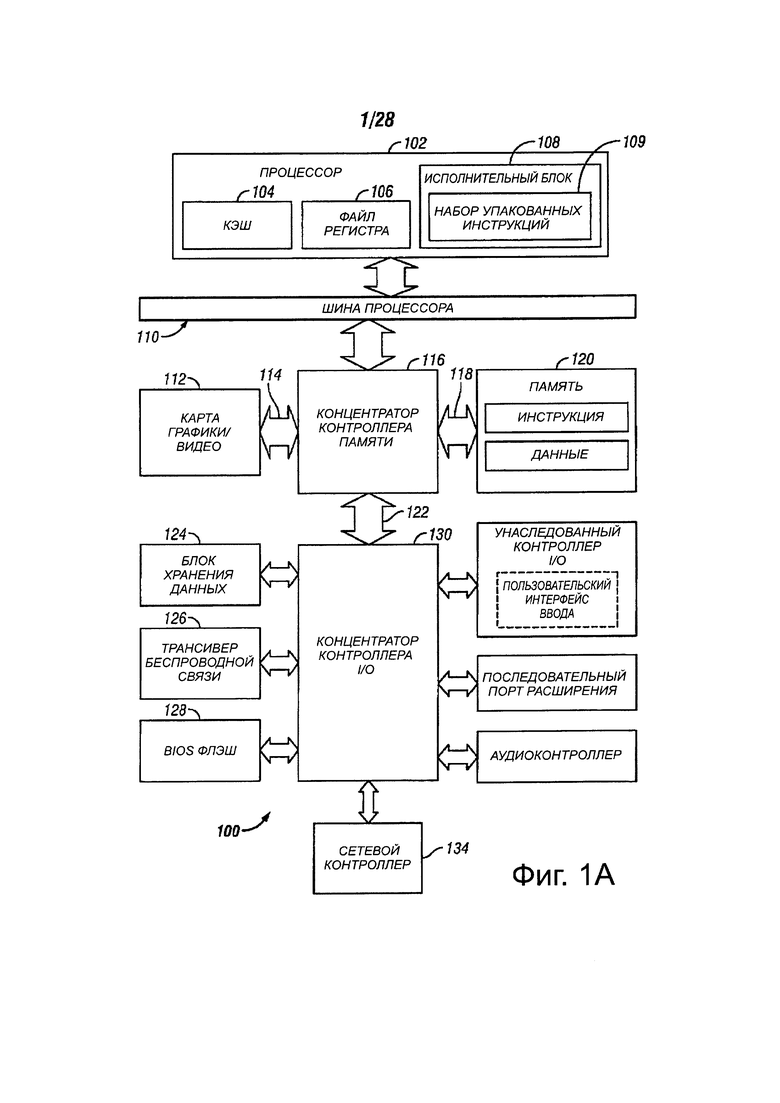
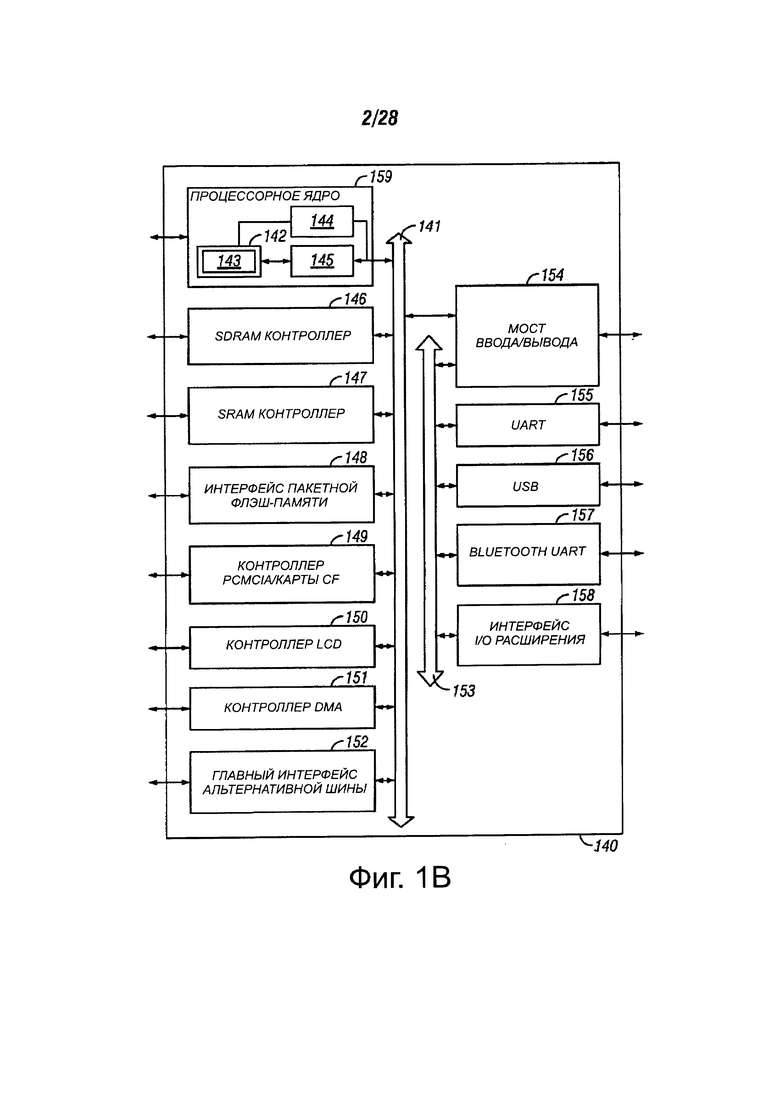
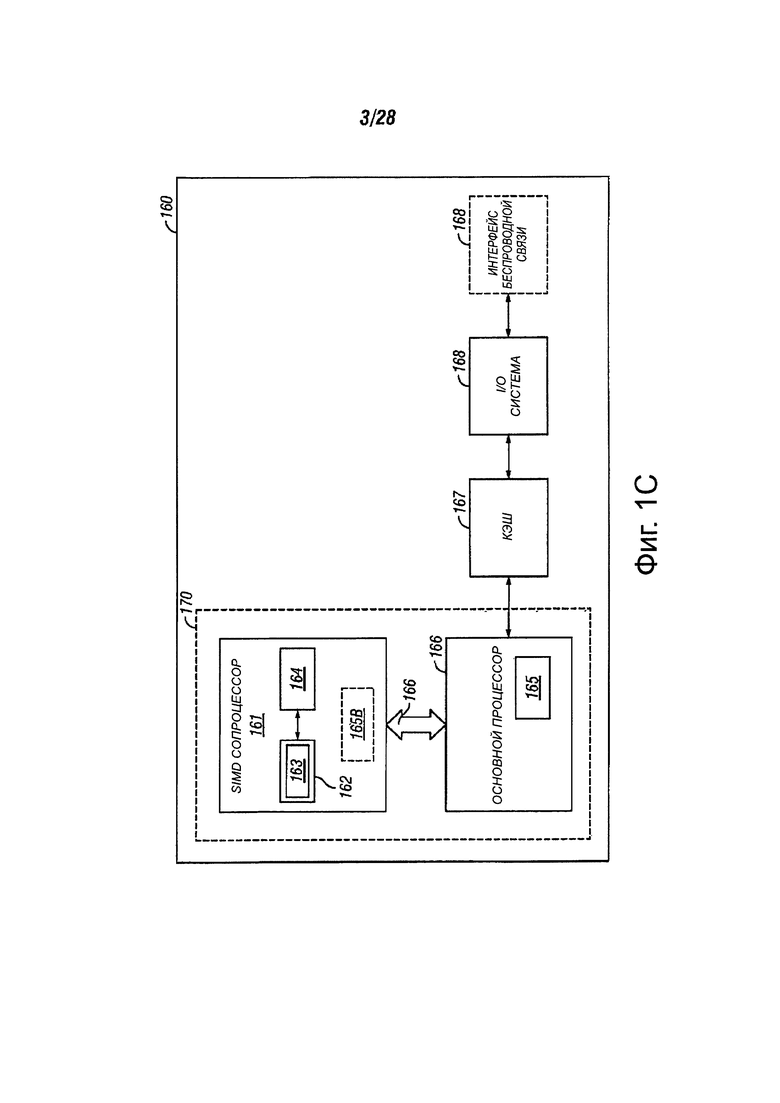
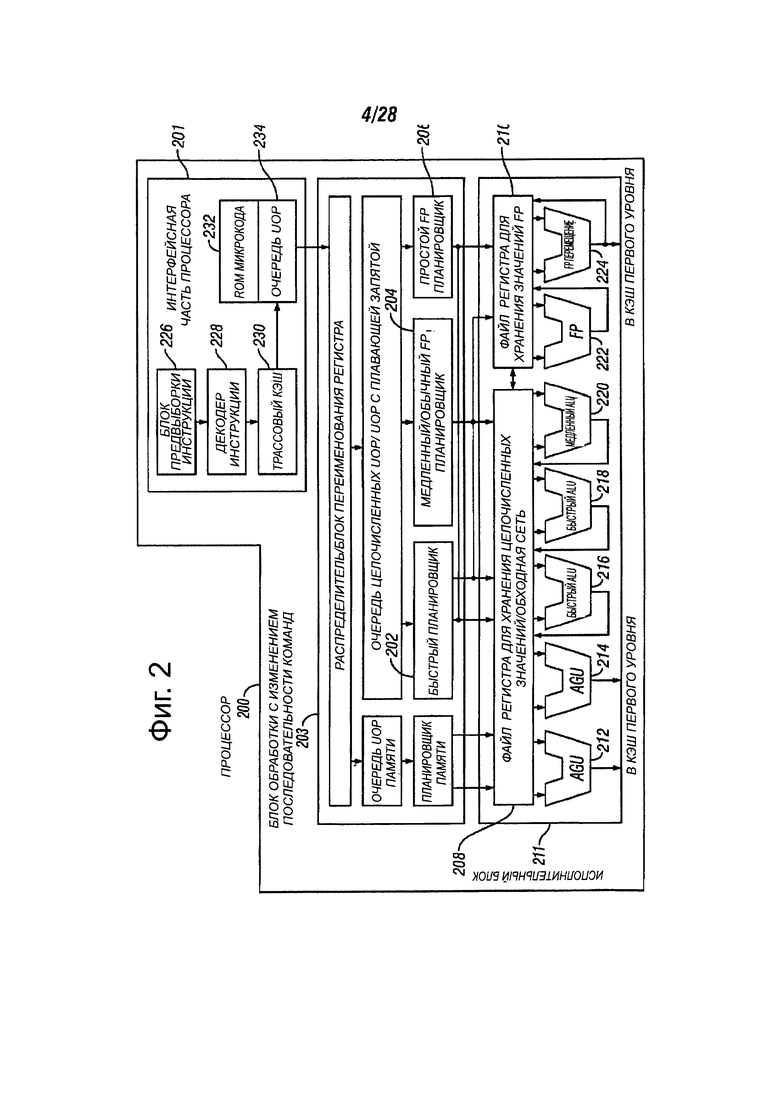
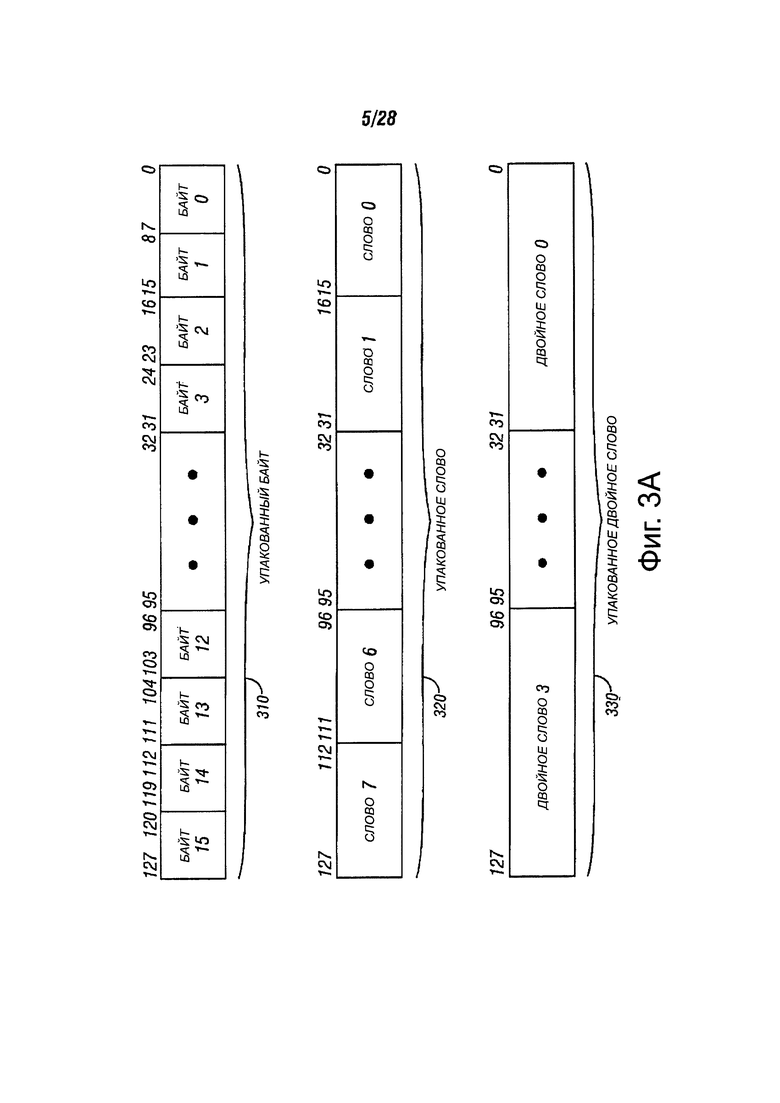
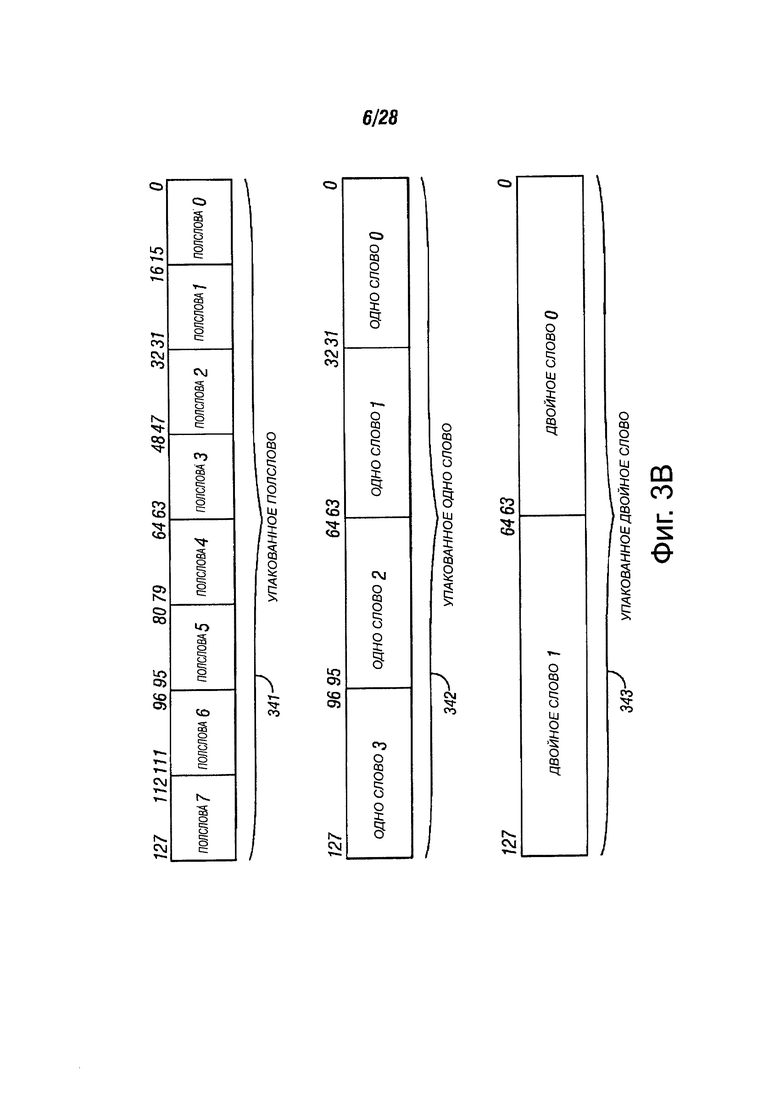
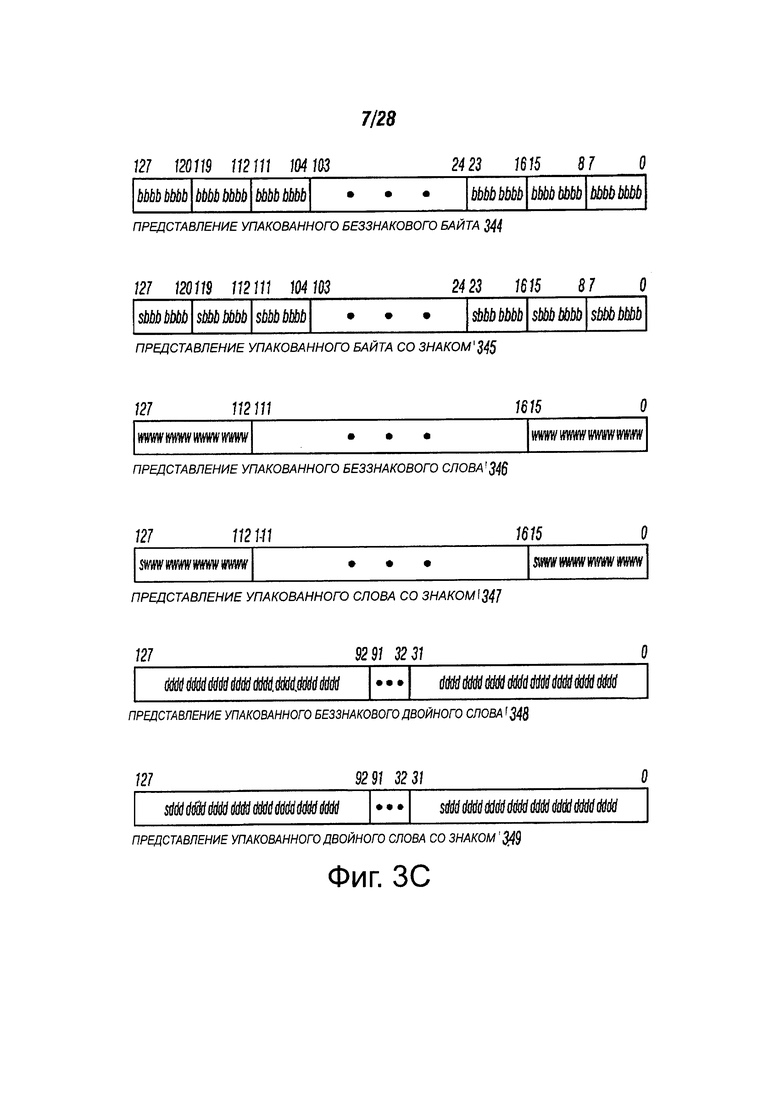
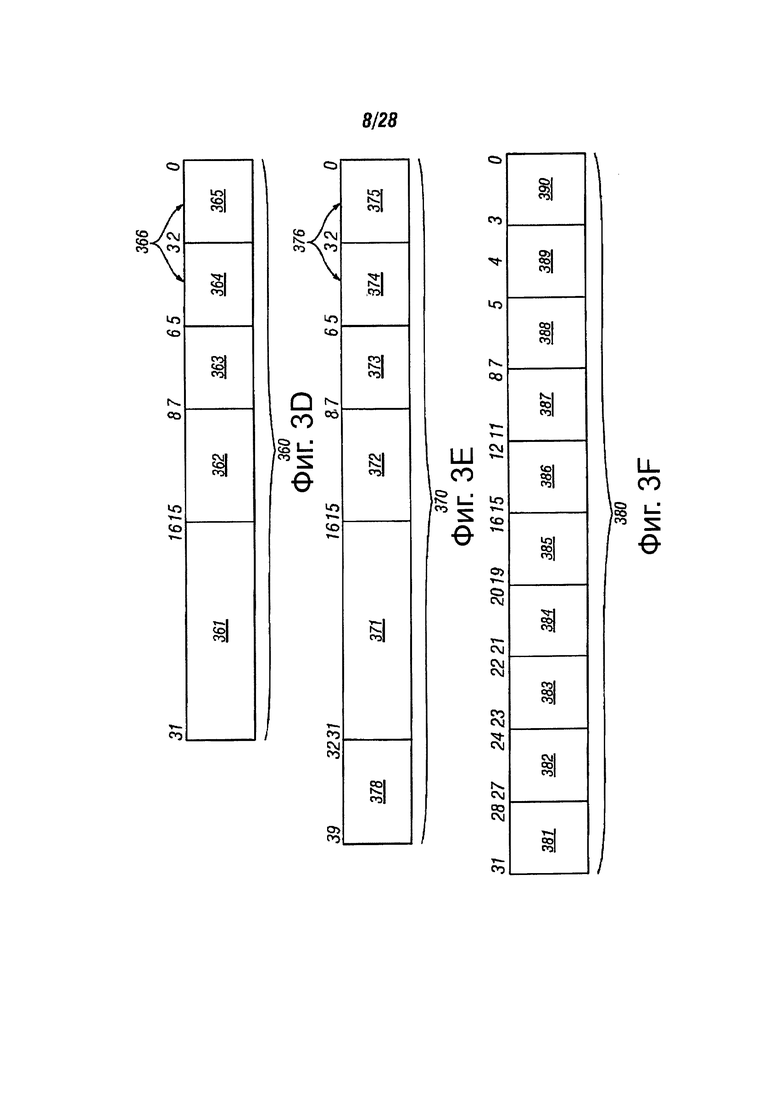
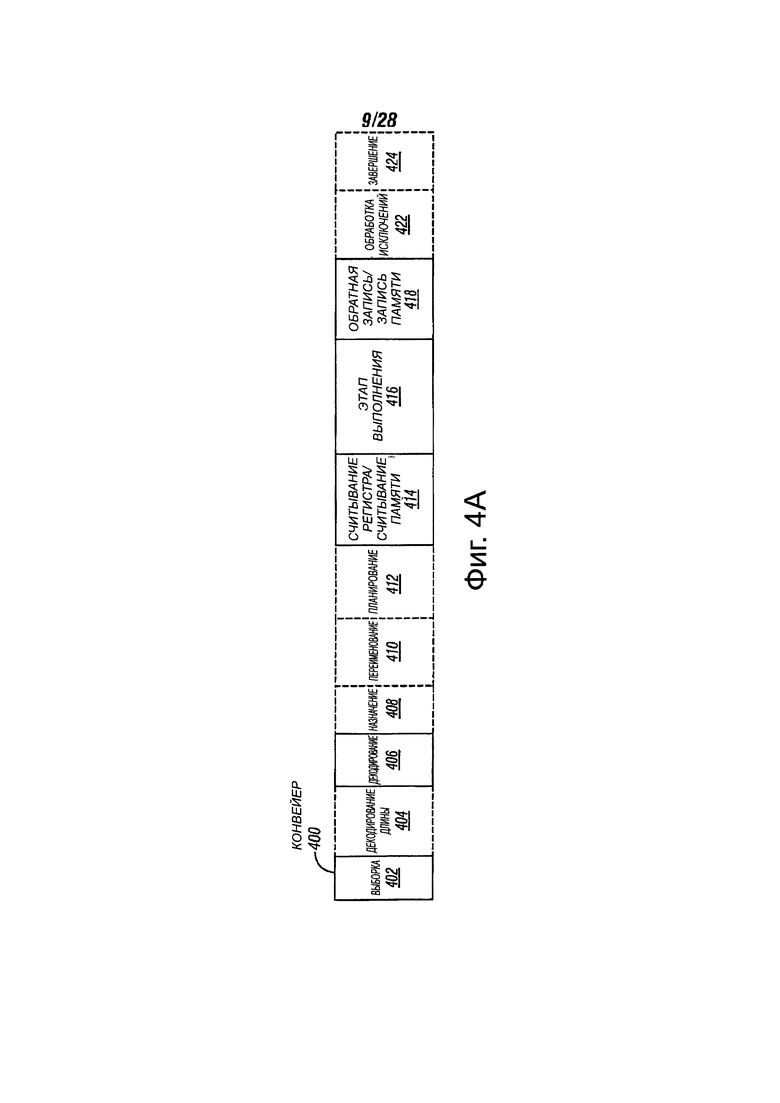
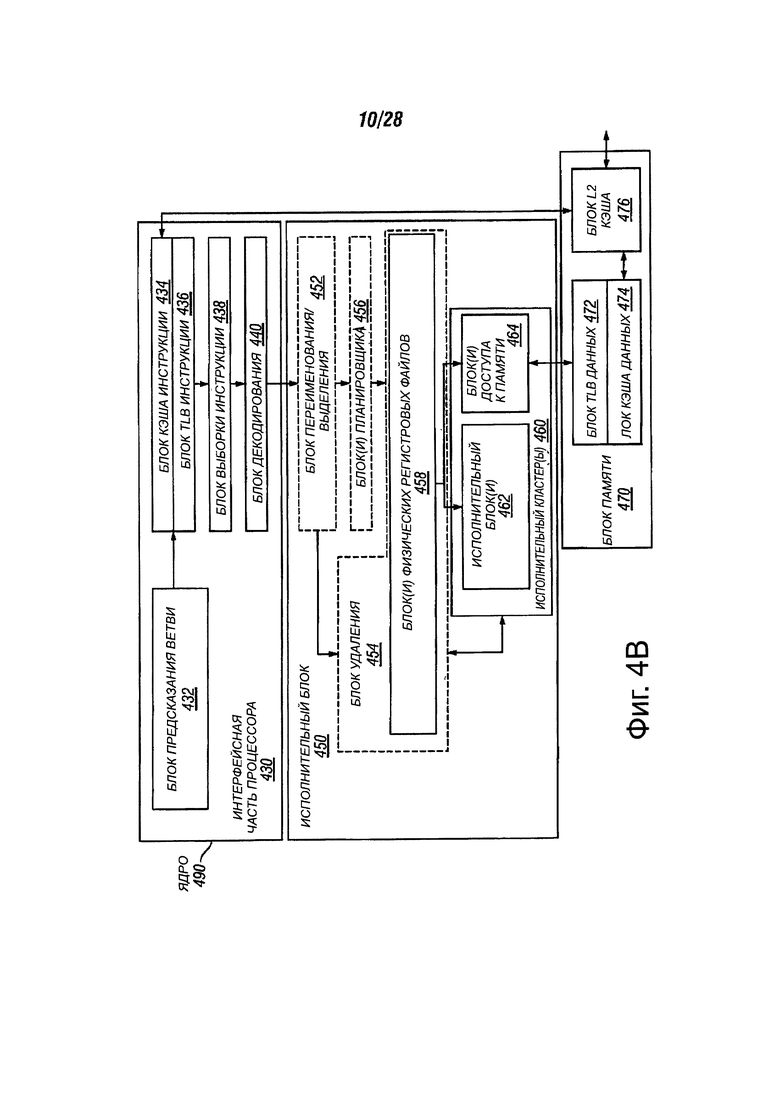
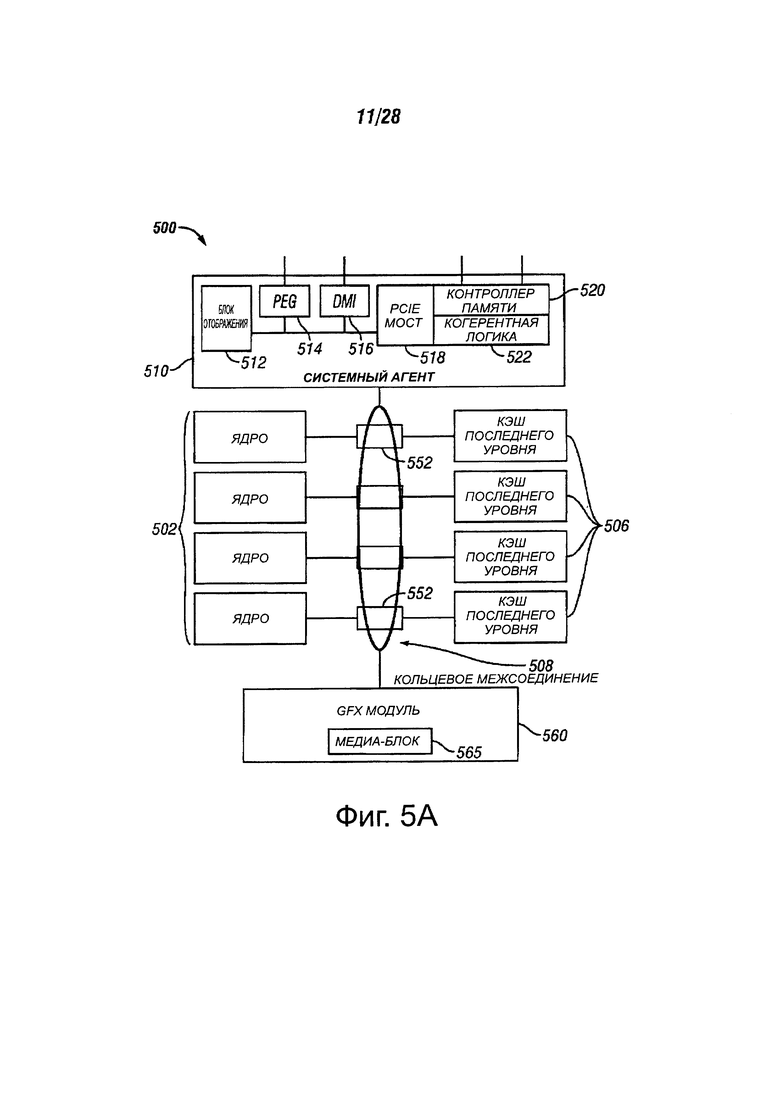
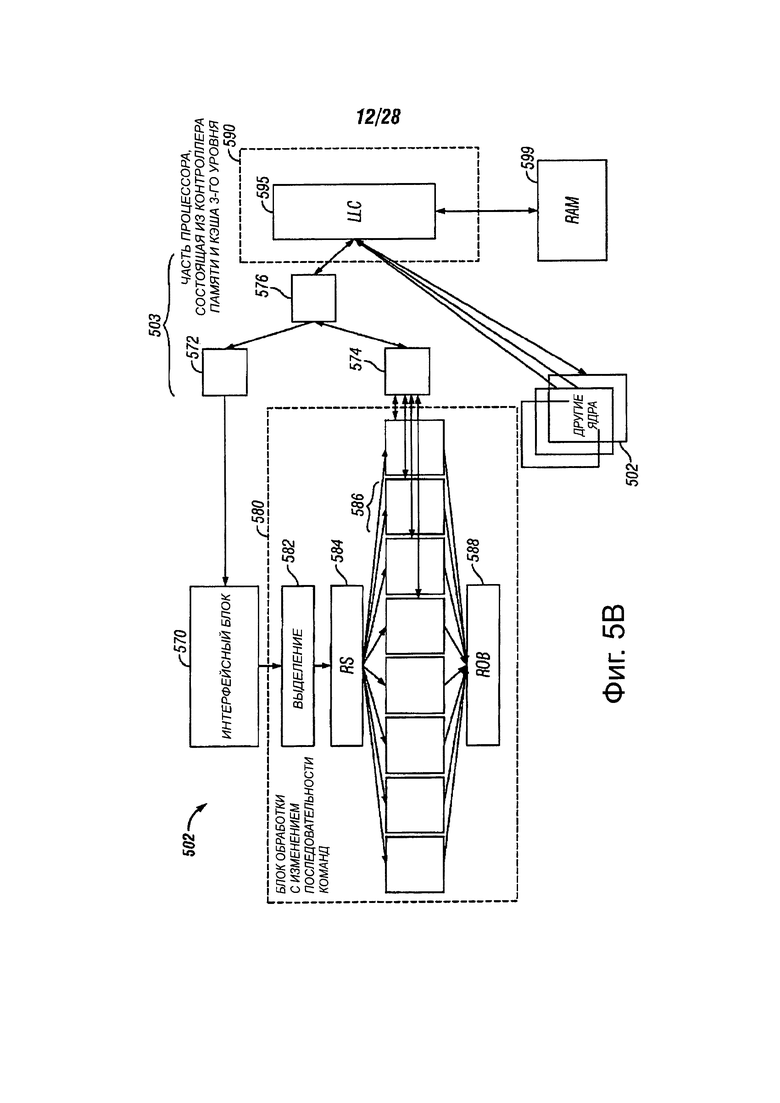
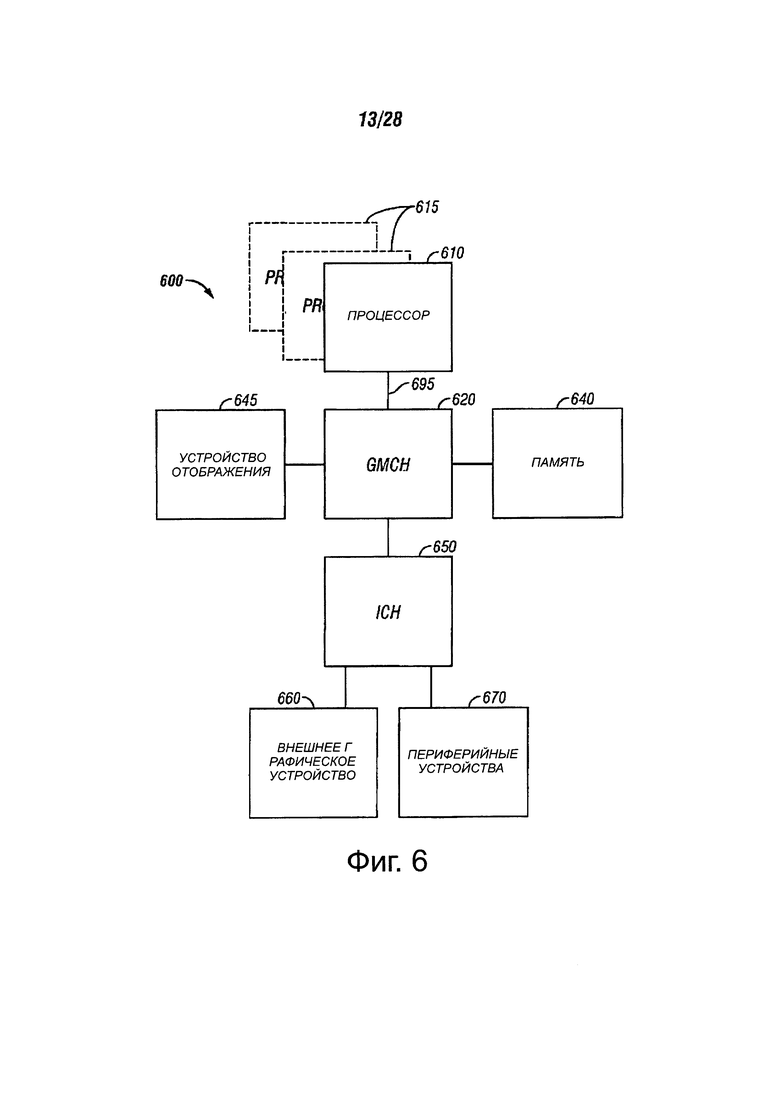
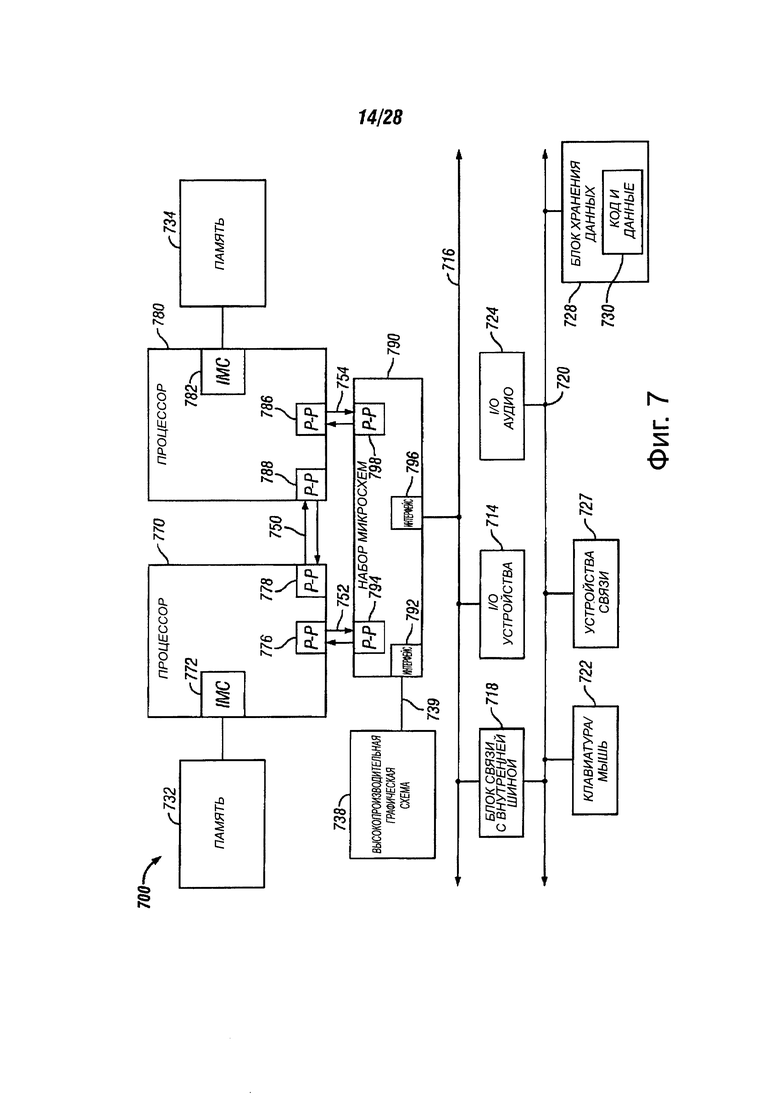
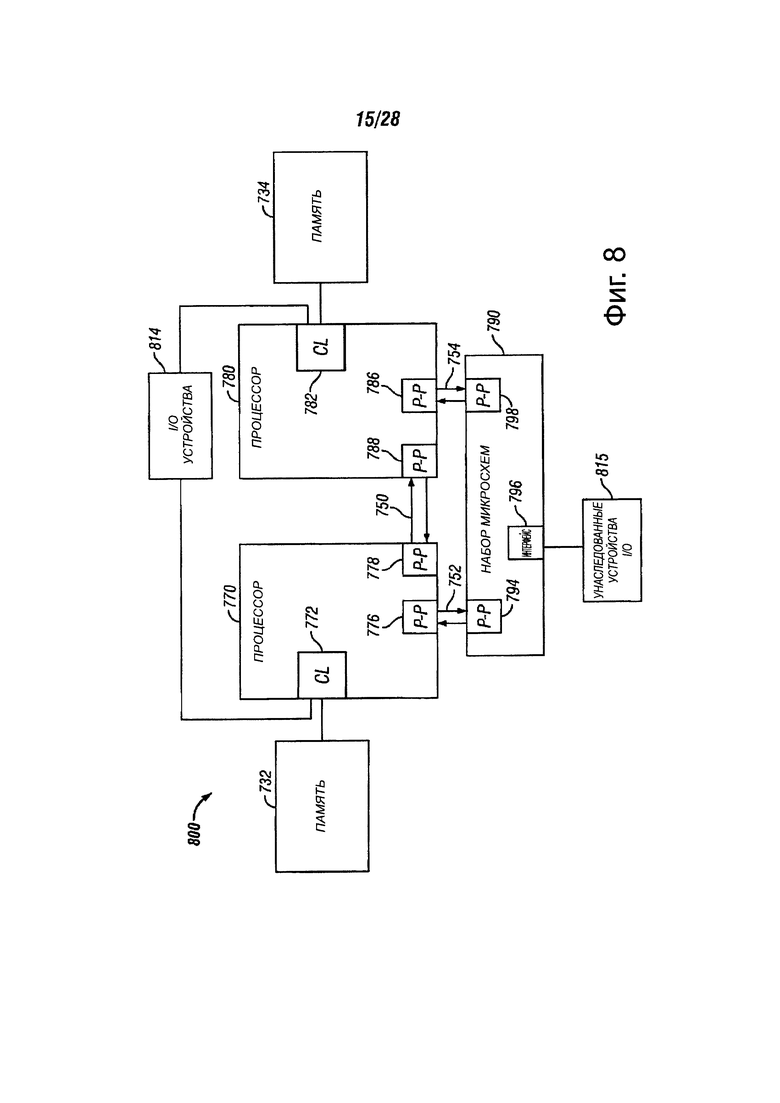
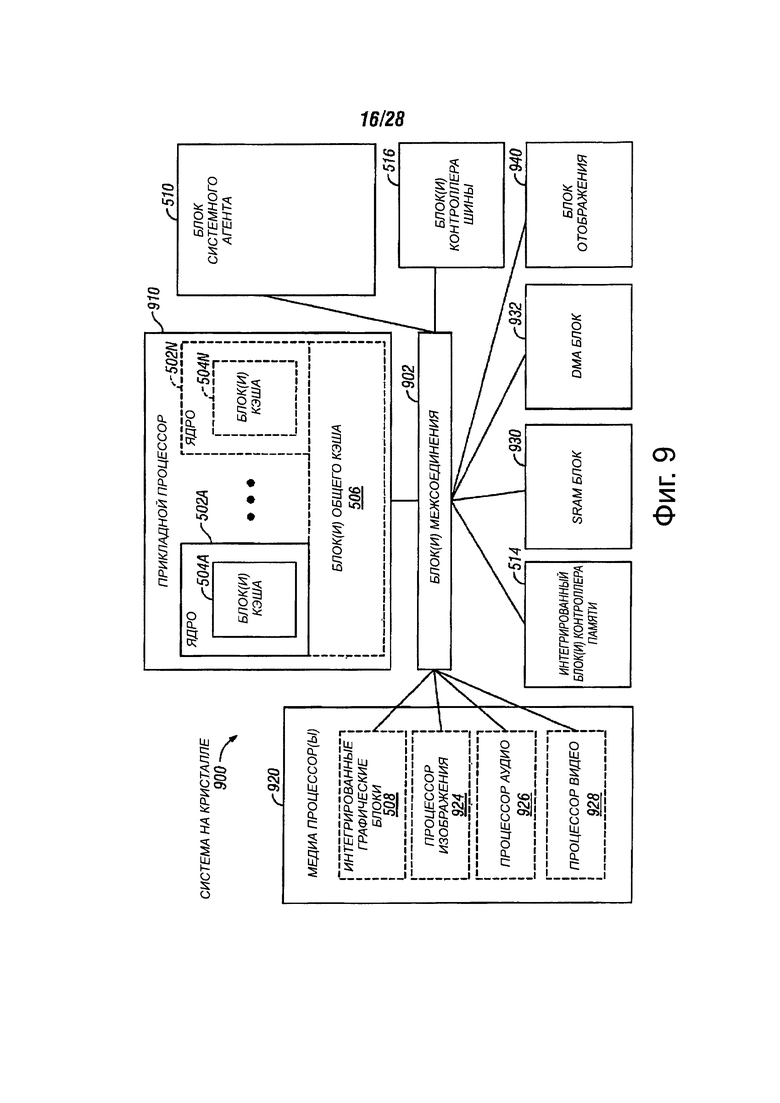
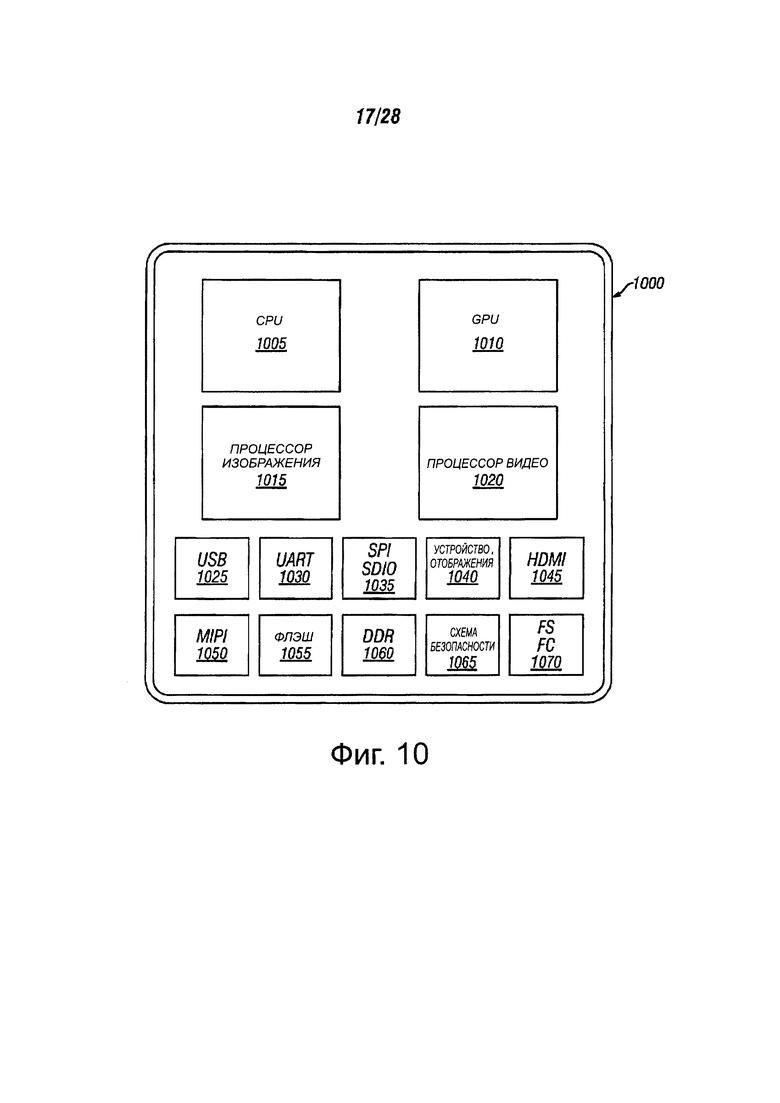
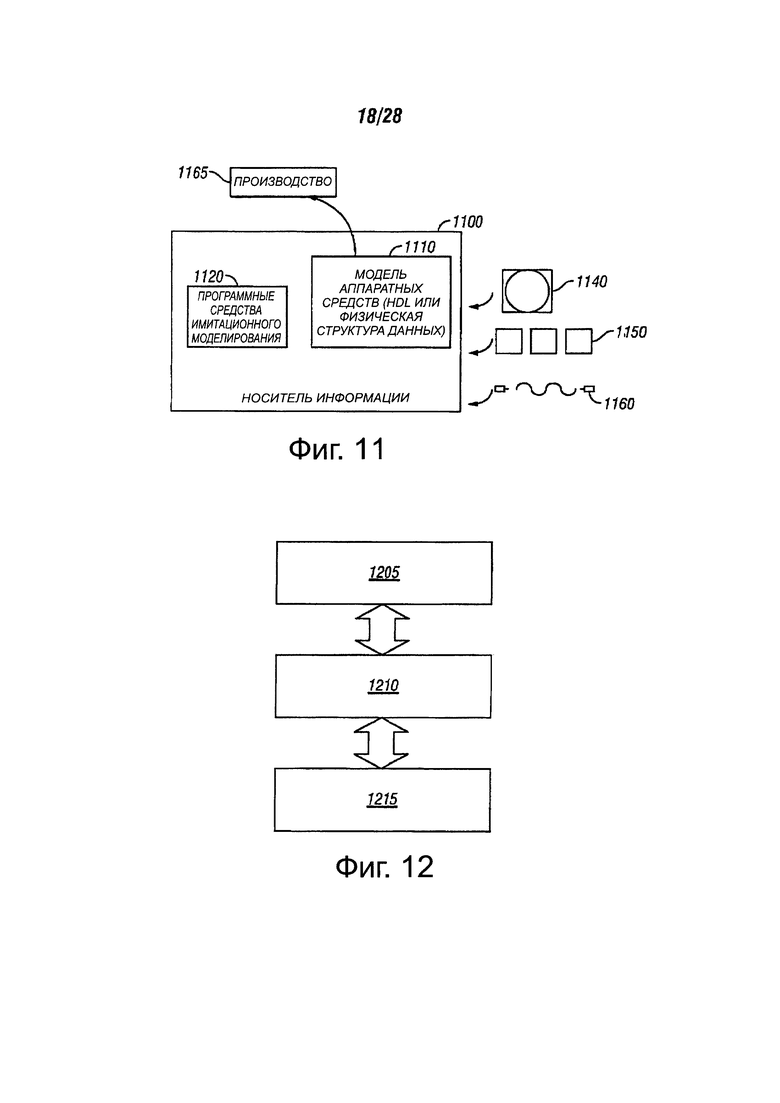
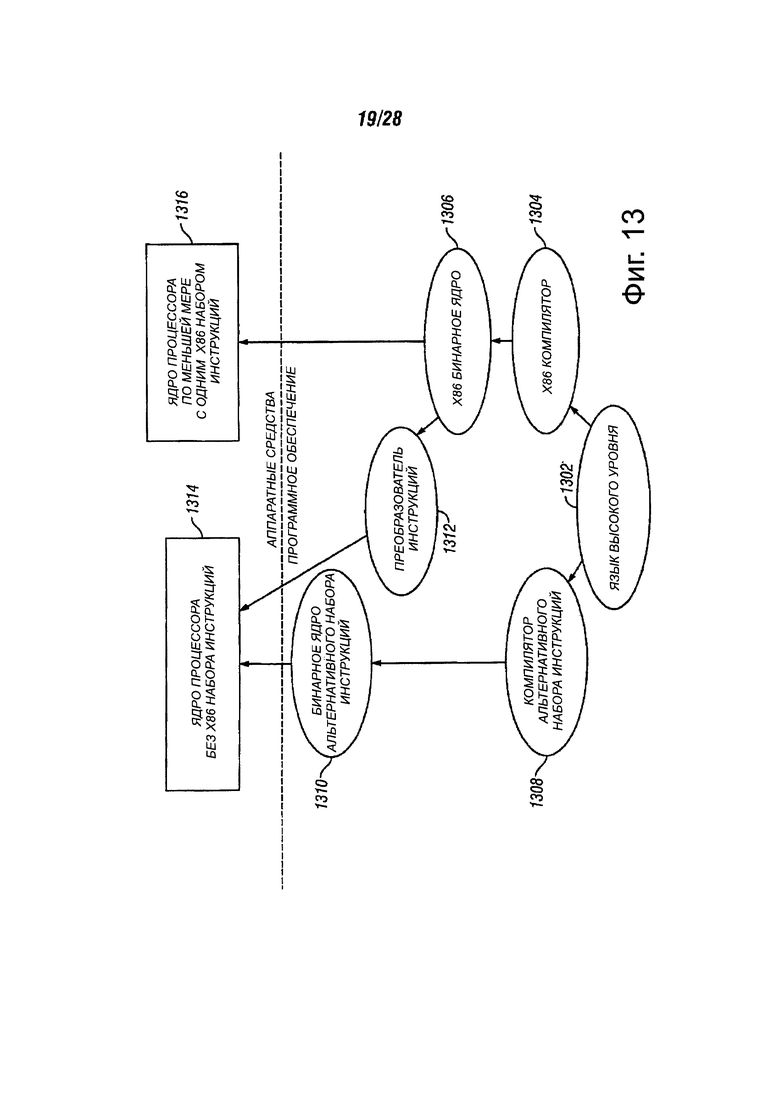
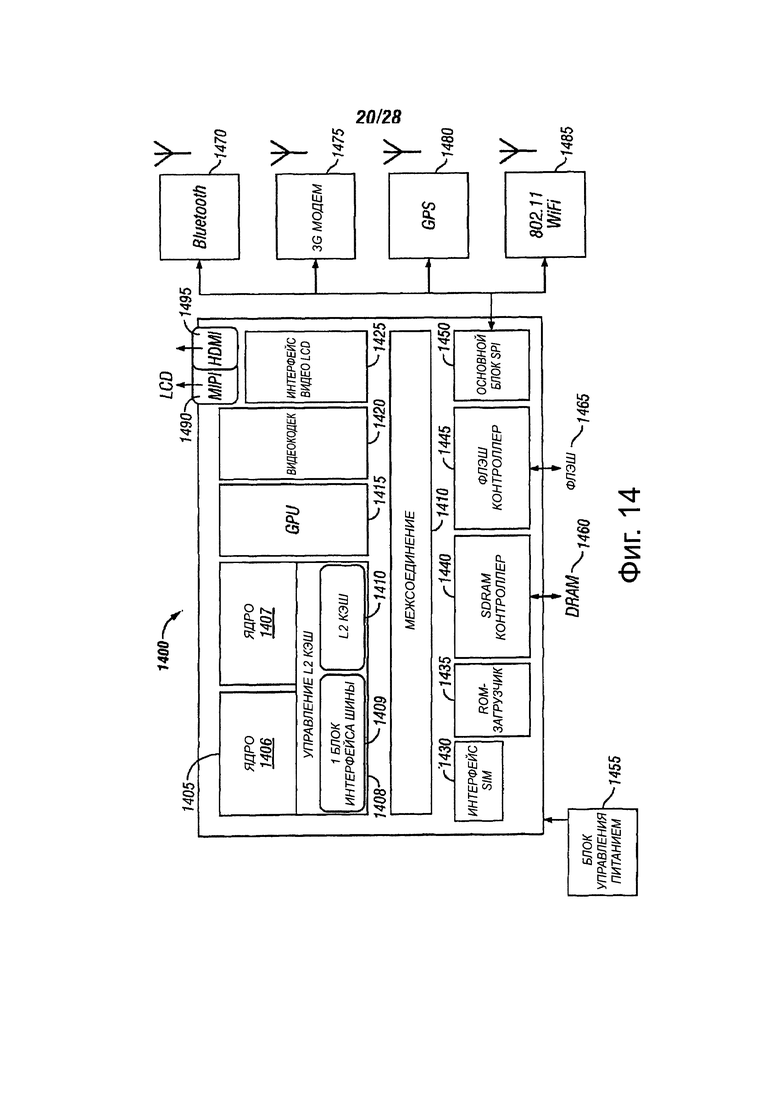
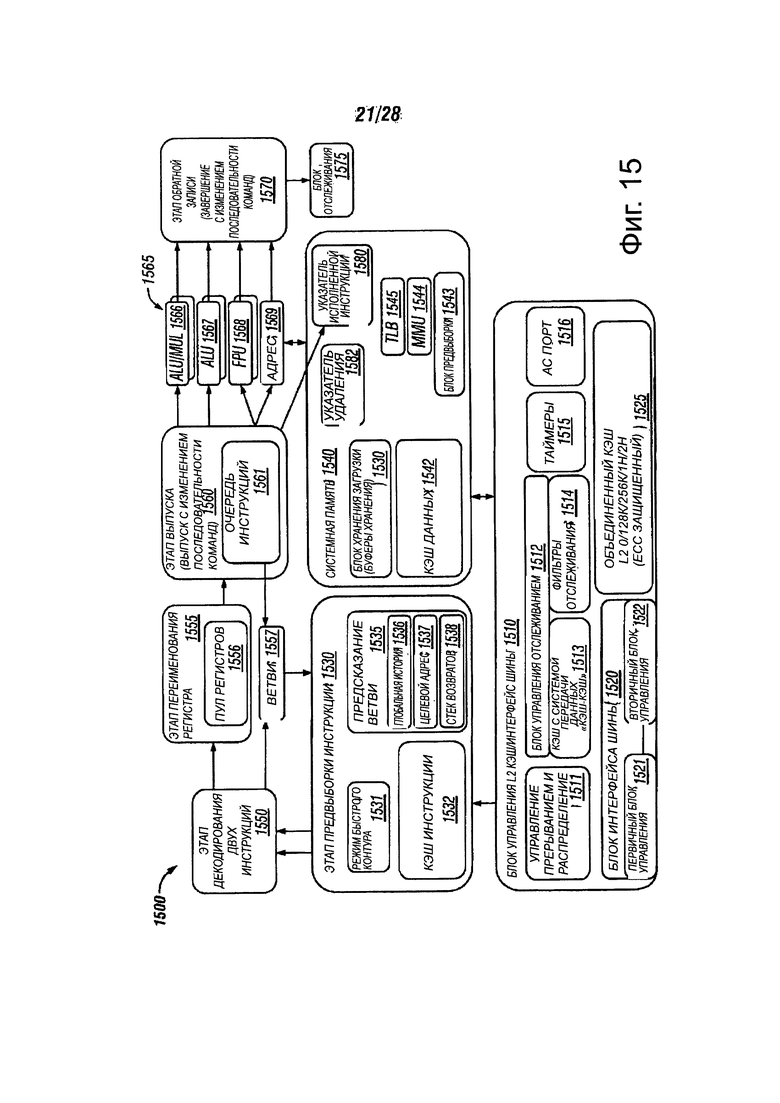
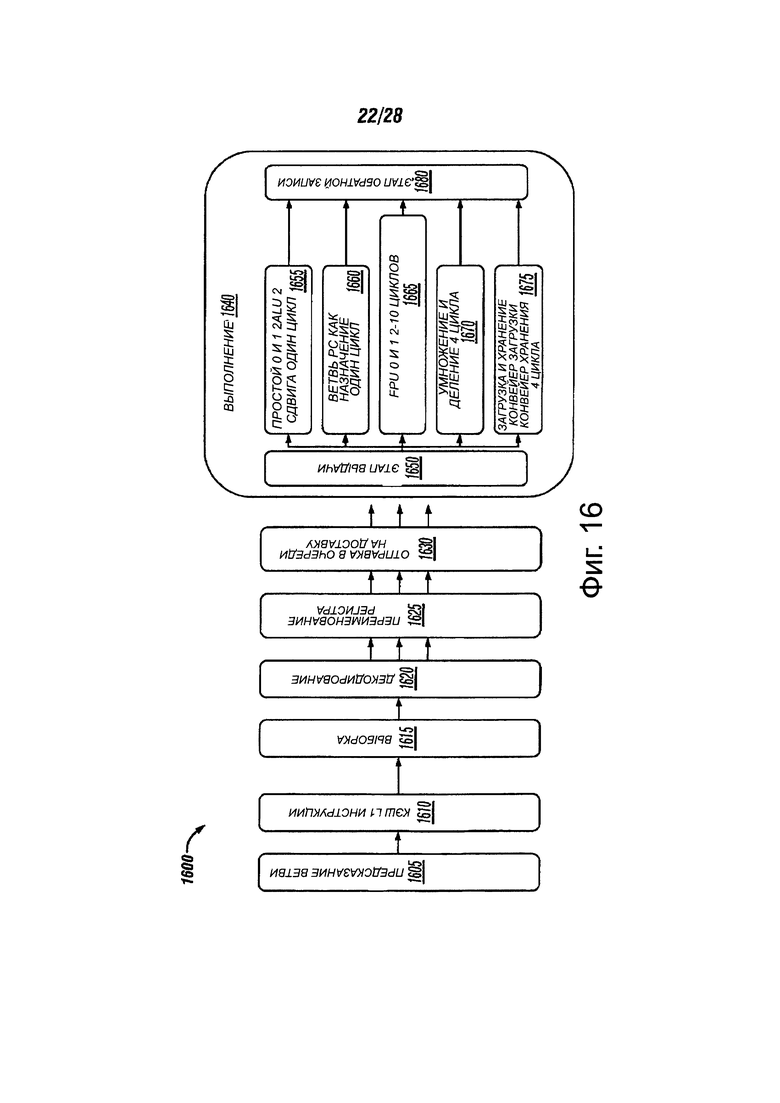
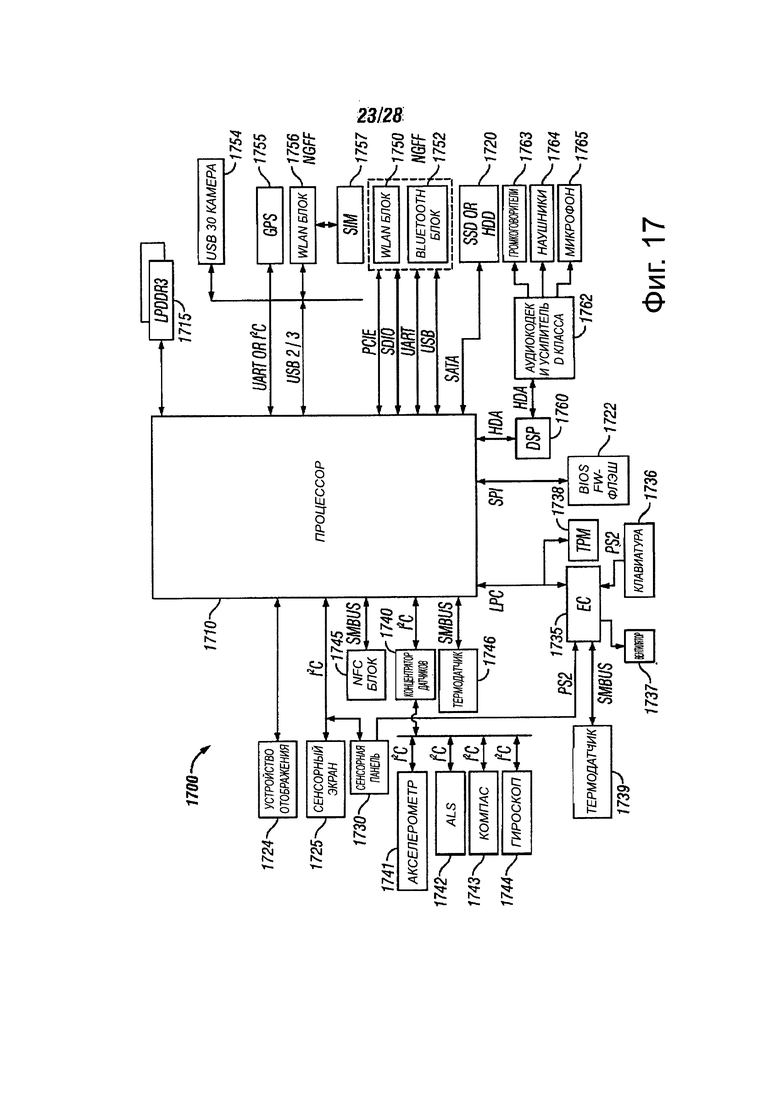
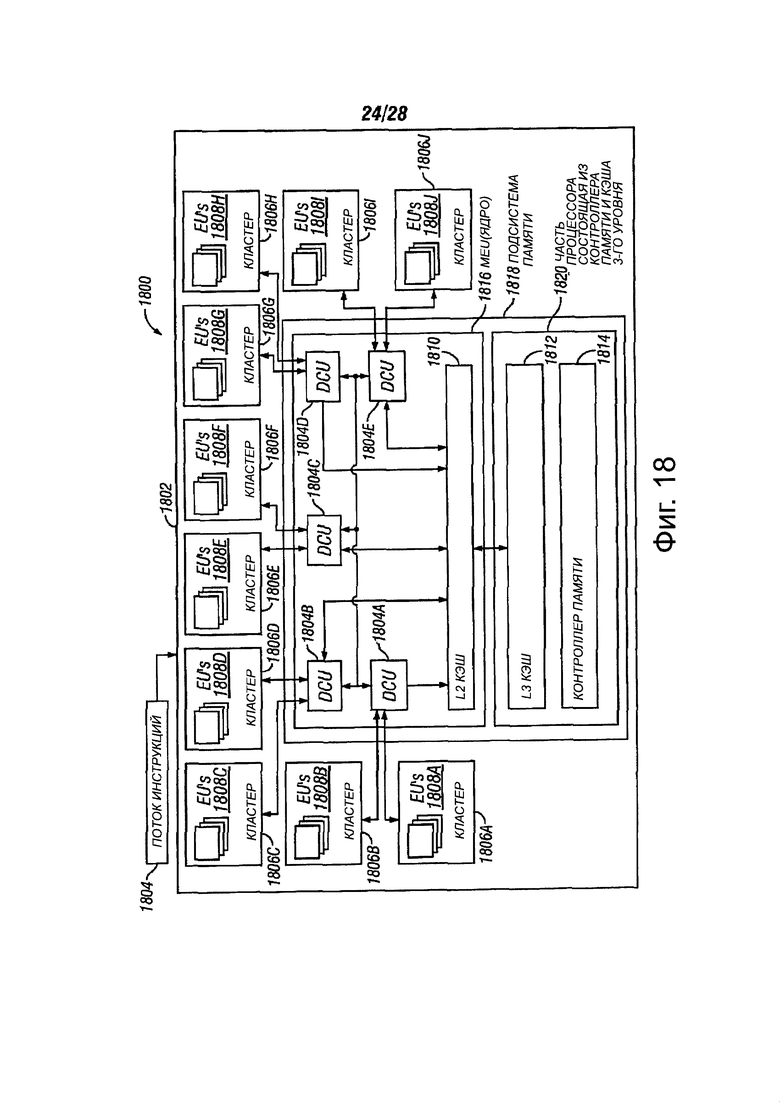
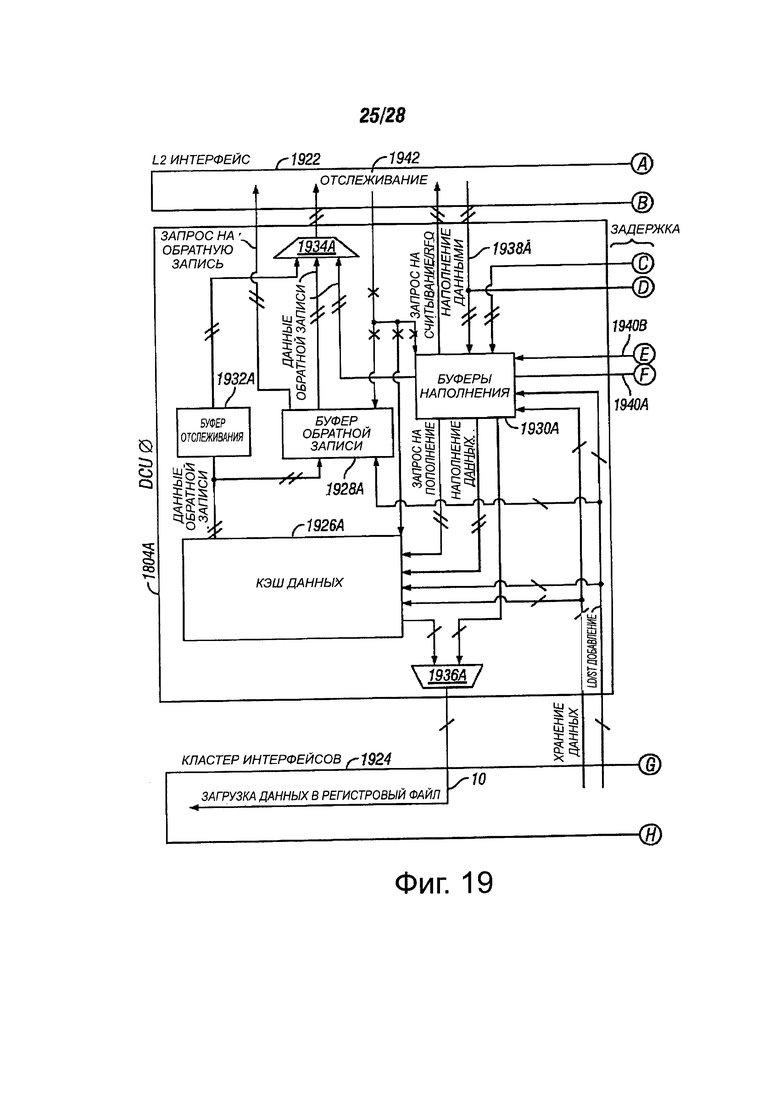
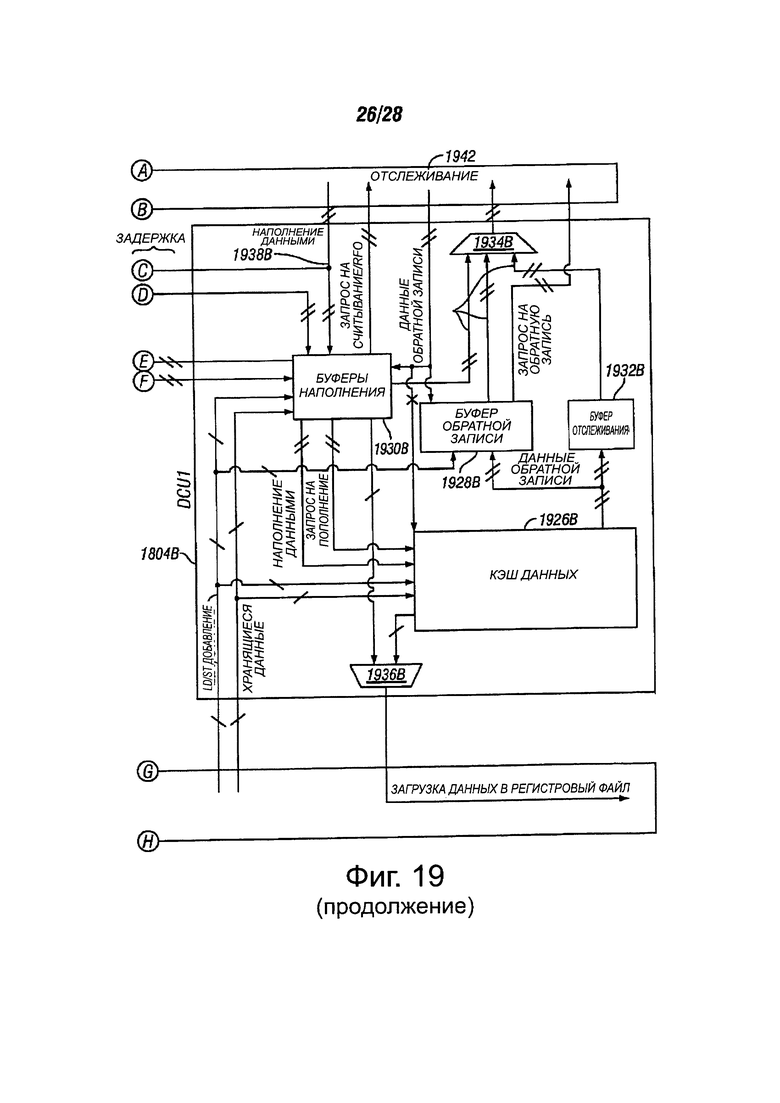
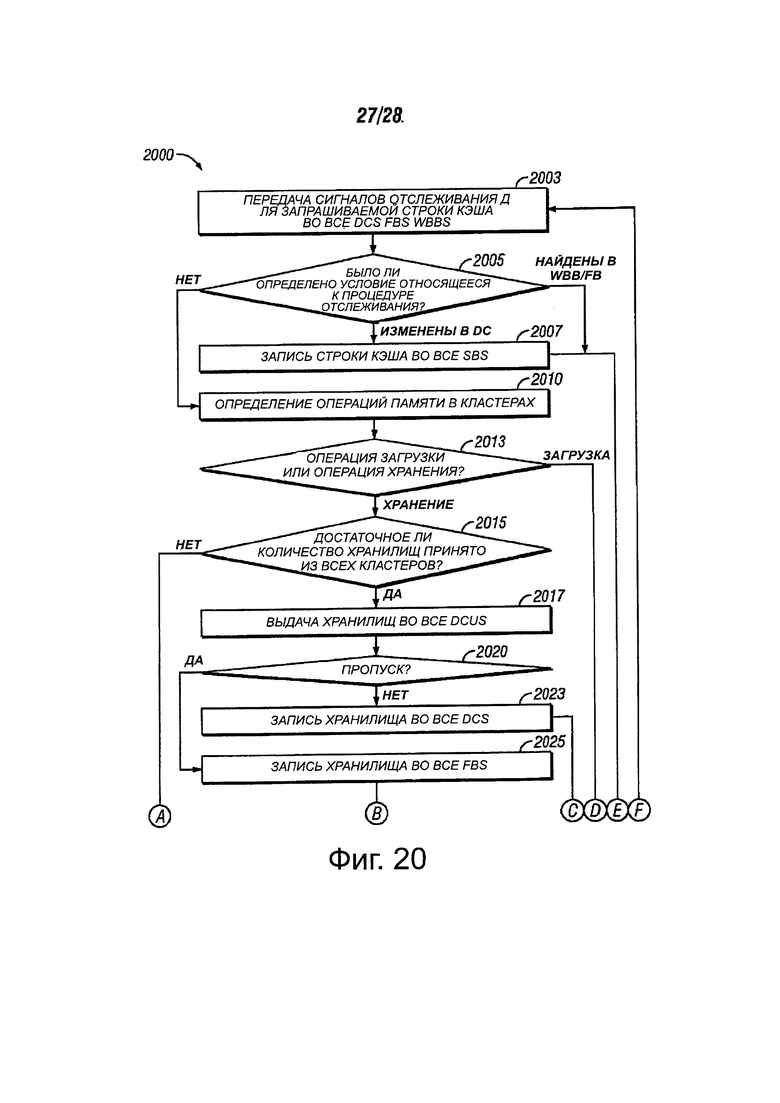
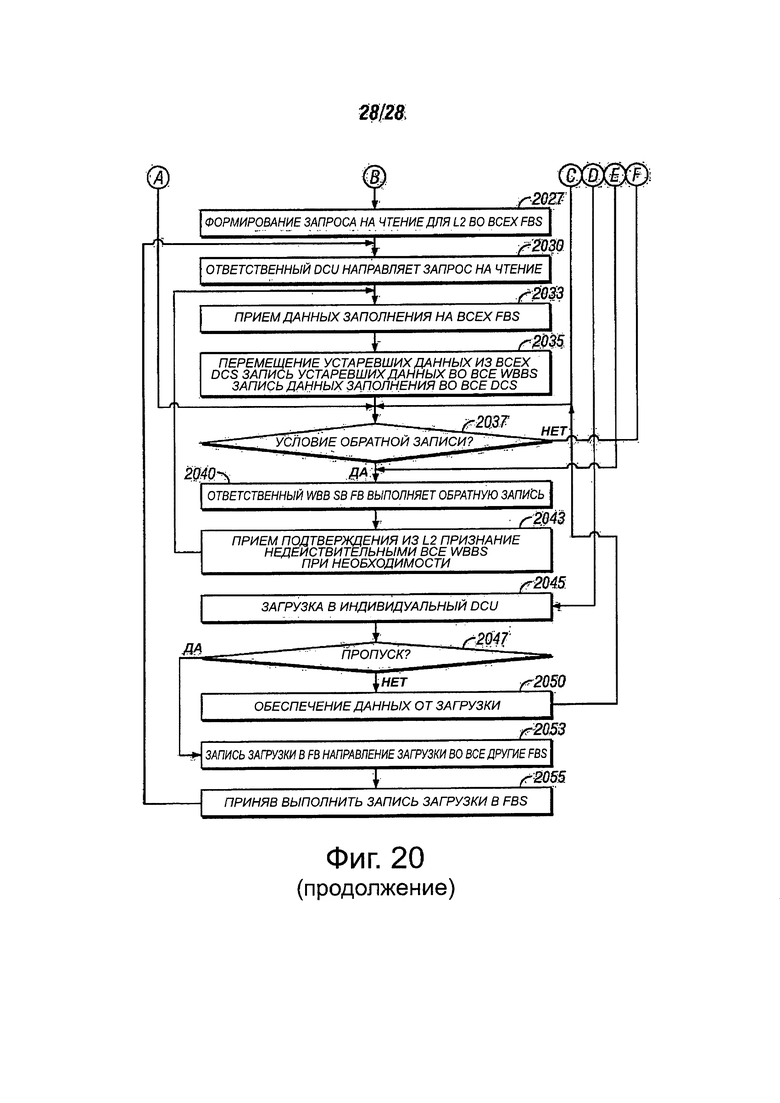
Группа изобретений относится к области логики обработки информации. Техническим результатом является повышение производительности. Процессор включает в себя кэш второго уровня (L2), первый и второй кластер исполнительных блоков и первый и второй блок кэша данных (DCU), соединенные с возможностью связи с соответствующими кластерами исполнительных блоков и L2 кэшем, каждый из DCU включает в себя кэш данных и логику для приема операции памяти из исполнительного блока, ответа на операцию памяти с информацией из кэша данных, когда информация доступна в кэше данных, и извлечения информации из L2 кэша, когда информация не доступна в кэше данных. Процессор дополнительно включает в себя логику для поддержания кэша данных первого DCU равным контенту кэша данных второго DCU на всех тактовых циклах работы процессора. 3 н. и 17 з.п. ф-лы, 31 ил.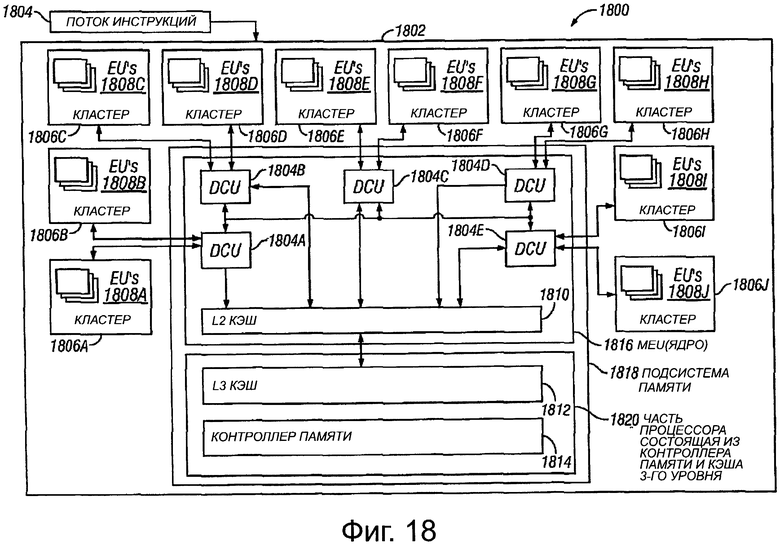
1. Процессор, содержащий:
кэш уровня 2 (L2);
первый кластер исполнительных блоков;
второй кластер исполнительных блоков;
первый блок кэша данных (DCU), соединенный с возможностью связи с первым кластером исполнительных блоков и кэшем L2; и
второй DCU, соединенный с возможностью связи со вторым кластером исполнительных блоков и кэшем L2;
причем:
первый DCU и второй DCU каждый включают в себя:
кэш данных;
первую логику для приема операции с памятью из исполнительного блока;
вторую логику для ответа на операцию с памятью с информацией из кэша данных, когда информация доступна в кэше данных; и
третью логику для извлечения информации из кэша L2,
когда информация недоступна в кэше данных; при этом
процессор дополнительно содержит четвертую логику для поддержания контента кэша данных первого DCU равным контенту кэша данных второго DCU во всех тактовых циклах работы процессора.
2. Процессор по п. 1, в котором:
каждый из первого DCU и второго DCU дополнительно включает в себя буфер обратной записи; а
процессор дополнительно содержит:
пятую логику для выполнения выделения первой записи в буфер обратной записи первого DCU и второй записи в буфер обратной записи второго DCU в том же тактовом цикле работы процессора, причем первая запись и вторая запись эквиваленты друг другу; и
шестую логику для выполнения освобождения третьей записи в буфере обратной записи первого DCU и выделения четвертой записи в буфере обратной записи второго DCU в том же тактовом цикле работы процессора, причем третья запись и четвертая запись эквивалентны друг другу.
3. Процессор по п. 1, в котором:
процессор дополнительно содержит один или более кластеров интерфейсов, соединенных с возможностью связи между первым DCU и первым кластером исполнительных блоков и между вторым DCU и вторым кластером исполнительных блоков; причем
один или более кластеров интерфейсов включают в себя:
пятую логику для сбора операции сохранения из комбинации первого кластера исполнительных блоков и второго кластера исполнительных блоков; и
шестую логику для выдачи операции сохранения в первый DCU и во второй DCU.
4. Процессор по п. 1, в котором каждый из первого DCU и второго DCU дополнительно включают в себя:
пятую логику для выполнения синхронного процесса перемещения из кэша данных; и
шестую логику для выполнения синхронного процесса заполнения в кэш данных.
5. Процессор по п. 1, в котором:
процессор дополнительно содержит кластер интерфейсов, соединенный с возможностью связи между первым DCU и первым кластером исполнительных блоков, причем кластер интерфейсов включает в себя:
пятую логику для сбора операции загрузки из первого кластера исполнительных блоков; и
шестую логику для выдачи операции загрузки в первый DCU; при этом
каждый из первого DCU и второго DCU дополнительно включают в себя буфер заполнения; причем
первый DCU и второй DCU соединены с возможностью связи с шиной; и
первый DCU дополнительно включает в себя:
седьмую логику для идентификации пропуска операции загрузки на кэш данных;
восьмую логику для записи операции загрузки в буфер заполнения на основании пропуска; и
девятую логику для выдачи операции загрузки во второй DCU через шину.
6. Процессор по п. 1, в котором:
каждый из первого DCU и второго DCU дополнительно включают в себя буфер отслеживания; и
процессор дополнительно содержит пятую логику для поддержания контента буфера отслеживания первого DCU равным контенту буфера отслеживания второго DCU для всех тактовых циклов работы процессора.
7. Процессор по п. 1, в котором
процессор дополнительно содержит один или более интерфейсов кэша, соединенных с возможностью связи между первым DCU и кэшем L2 и между вторым DCU и кэшем L2; а
один или более кластеров интерфейсов включают в себя пятую логику для одновременной выдачи запроса отслеживания из кэша L2 в первый DCU и во второй DCU.
8. Способ обработки для доступа к памяти, содержащий выполняемые с помощью процессора этапы, на которых:
принимают операции с памятью из первого кластера исполнительных блоков на первом блоке кэша данных (DCU);
принимают операции с памятью из второго кластера исполнительных блоков на втором DCU;
отвечают на операции с памятью, принятые на первом DCU с информацией из первого кэша данных в первом DCU, когда информация доступна в первом кэше данных;
отвечают на операции с памятью, принятые на втором DCU с информацией из второго кэша данных во втором DCU, когда информация доступна во втором кэше данных;
извлекают информацию из кэша L2, соединенного с возможностью связи с первым DCU и вторым DCU, когда информация недоступна в первом кэше данных и втором кэше данных; и
поддерживают контент кэша данных первого DCU, равным контенту кэша данных второго DCU во всех тактовых циклах работы процессора.
9. Способ по п. 8, дополнительно содержащий этапы, на которых:
выполняют выделение первой записи в буфер обратной записи первого DCU и второй записи в буфер обратной записи второго DCU в одном тактовом цикле работы процессора, причем первая запись и вторая запись эквивалентны друг другу; и
выполняют высвобождение третьей записи в буфере обратной записи первого DCU и выделение четвертой записи в буфер обратной записи второго DCU в одном тактовом цикле работы процессора, причем третья запись и четвертая запись эквивалентны друг другу.
10. Способ по п. 8, дополнительно содержащий этапы, на которых:
собирают операцию сохранения из комбинации первого кластера исполнительных блоков и второго кластера исполнительных блоков; и
выдают операцию сохранения в первый DCU и во второй DCU.
11. Способ по п. 8, дополнительно содержащий этапы, на которых:
осуществляют синхронную обработку эквивалентных перемещений из первого кэша данных и второго кэша данных; и
осуществляют синхронную обработку эквивалентных заполнений в первый кэш данных и во второй кэш данных.
12. Способ по п. 8, дополнительно содержащий этапы, на которых:
собирают операцию загрузки из первого кластера исполнительных блоков;
выдают операцию загрузки в первый DCU;
осуществляют идентификацию пропуска операции загрузки на первом кэше данных;
записывают, на основании пропуска, операцию загрузки в первый буфер заполнения в первом DCU; и
выдают операцию загрузки из первого буфера заполнения во второй буфер заполнения второго DCU через шину.
13. Способ по п. 8, дополнительно содержащий этап, на котором поддерживают контент первого буфера отслеживания первого DCU, равный контенту второго буфера отслеживания второго DCU во всех тактовых циклах работы процессора.
14. Система обработки для доступа к памяти, содержащая:
поток инструкций;
процессор, соединенный с возможностью связи с потоком инструкций и включающий в себя:
первую логику для выполнения потока инструкций;
кэш второго уровня (L2);
первый кластер исполнительных блоков;
второй кластер исполнительных блоков;
первый блок кэша данных (DCU), соединенный с возможностью связи с первым кластером исполнительных блоков и кэшем L2; и
второй DCU, соединенный с возможностью связи со вторым кластером исполнительных блоков и кэшем L2;
причем
первый DCU и второй DCU каждый включают в себя:
кэш данных;
вторую логику для приема операции с памятью из исполнительного блока;
третью логику для ответа на операцию с памятью с информацией из кэша данных, когда информация доступна в кэше данных; и
четвертую логику для извлечения информации из кэша L2, когда информация не доступна в кэше данных; а
процессор дополнительно содержит пятую логику для поддержания контента кэша данных первого DCU равным контенту кэша данных второго DCU во всех тактовых циклах работы процессора.
15. Система по п. 14, в которой:
каждый из первого DCU и второго DCU дополнительно включат в себя буфер обратной записи; а
процессор дополнительно включает в себя:
пятую логику, выполненную с возможностью выделения первой записи в буфер обратной записи первого DCU и второй записи в буфер обратной записи второго DCU в одном тактовом цикле работы процессора, причем первая запись и вторая запись эквиваленты друг другу; и
шестую логику, выполненную с возможностью освобождения третьей записи в буфере обратной записи первого DCU и выделения четвертой записи в буфере обратной записи второго DCU в том же тактовом цикле работы процессора, причем третья запись и четвертая запись эквивалентны друг другу.
16. Система по п. 14, в которой:
процессор дополнительно включает в себя один или более кластеров интерфейсов, соединенных с возможностью связи между первым DCU и первым кластером исполнительных блоков и между вторым DCU и вторым кластером исполнительных блоков; при этом
один или более кластеров интерфейсов включают в себя:
шестую логику для сбора операции сохранения из комбинации первого кластера исполнительных блоков и второго кластера исполнительных блоков; и
седьмую логику для выдачи операции сохранения первому DCU и второму DCU.
17. Система по п. 14, в которой каждый из первого DCU и второго DCU дополнительно включают в себя:
шестую логику, выполненную с возможностью синхронного осуществления процесса перемещения из кэша данных; и
седьмую логику, выполненную с возможностью синхронного осуществления процесса заполнения в кэш данных.
18. Система по п. 14, в которой:
процессор дополнительно включает в себя кластер интерфейсов, соединенный с возможностью связи между первым DCU и первым кластером исполнительных блоков, причем кластер интерфейсов включает в себя:
шестую логику, выполненную с возможностью сбора операции загрузки из первого кластера исполнительных блоков; и
седьмую логику, выполненную с возможностью выдачи операции загрузки первому DCU; при этом
каждый из первого DCU и второго DCU дополнительно включают в себя буфер заполнения; причем
первый DCU и второй DCU соединены с возможностью связи с шиной; а
первый DCU дополнительно включает в себя:
восьмую логику, выполненную с возможностью идентификации пропуска операции загрузки в кэше данных;
девятую логику, выполненную с возможностью записи операции загрузки в буфер заполнения, на основе пропуска; и
десятую логику, выполненную с возможностью выдачи операции загрузки во второй DCU через шину.
19. Система по п. 14, в которой:
каждый из первого DCU и второго DCU дополнительно включают в себя буфер отслеживания; а
процессор дополнительно включает в себя шестую логику, выполненную с возможностью поддержания контента буфера отслеживания первого DCU, равного контенту буфера отслеживания второго DCU во всех тактовых циклах работы процессора.
20. Система по п. 14, в которой
процессор дополнительно включает в себя один или более интерфейсов кэша, соединенных с возможностью связи между первым DCU и кэшем L2 и между вторым DCU и кэшем L2; а
один или более кластеров интерфейсов включают в себя шестую логику, выполненную с возможностью синхронной выдачи запроса на отслеживание из кэша L2 в первый DCU и во второй DCU.
| US 2010274972 A1, 28.10.2010 | |||
| US 2011072213 A1, 24.03.2011 | |||
| US 2008133868 A1, 05.06.2008 | |||
| WO 2013101216 A1, 04.07.2013 | |||
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ УПРЕЖДАЮЩЕГО УПРАВЛЕНИЯ ПАМЯТЬЮ | 2003 |
|
RU2348067C2 |

