Изобретение относится к компьютерной системе и способу передачи данных в такой компьютерной системе. Изобретение относится прежде всего к обработке данных в системе с доступом к неоднородной памяти (NUMA, от англ. "Non-uniform Memory Access") и, в частности, к системе обработки данных с NUMA и способу передачи данных в такой системе обработки данных с NUMA, в которой запросы на считывание спекулятивно направляются в удаленную память.
В вычислительной технике хорошо известно, что повысить производительность вычислительной, соответственно компьютерной системы можно за счет использования совместной вычислительной мощности нескольких отдельных процессоров при их тандемном соединении. Многопроцессорные компьютерные системы могут быть реализованы на базе самых различных топологий, одни из которых могут быть в большей степени пригодны для решения одних прикладных задач и в меньшей - для решения иных прикладных задач, и наоборот, что определяется требованиями к производительности и программными средствами, используемыми для решения той или иной прикладной задачи. Одной из наиболее распространенных топологий многопроцессорных компьютерных систем является симметричная многопроцессорная (СМП) конфигурация, в которой несколькими процессорами совместно используются общие ресурсы, например системная память и подсистема ввода-вывода, которые обычно связаны с общей системной схемой (шиной) межсоединения. Подобные компьютерные системы называют симметричными, поскольку в компьютерной СМП-системе время задержки при обращении к данным, хранящимся в общей системной памяти, является в оптимальном случае одинаковым для всех процессоров.
Хотя компьютерные СМП-системы и допускают применение в них сравнительно простых методов межпроцессорной связи и совместного использования данных, тем не менее они обладают ограниченной масштабируемостью. Иными словами, производительность типичной компьютерной СМП-системы невозможно повысить только, как это резонно можно было бы предположить, за счет ее масштабирования (т. е. за счет увеличения в ней количества процессоров), поскольку присущие шине, памяти и средствам ввода-вывода ограничения касательно их пропускной способности не позволяют достичь значительных преимуществ и значительного выигрыша в производительности при масштабировании компьютерной СМП-системы сверх зависящих от конкретной реализации пределов, для которых оптимизировано использование таких общих ресурсов. Таким образом, с увеличением масштаба компьютерной системы ее быстродействие из-за присущих самой СМП-топологии ограничений касательно пропускной способности несколько снижается, что проявляется прежде всего при обращении к системной памяти. Помимо этого масштабирование компьютерных СМП-систем связано с дополнительными производственными затратами и тем самым со снижением рентабельности их изготовления. Так, например, несмотря на возможность оптимизировать некоторые компоненты для их использования в однопроцессорных компьютерных системах и небольших компьютерных СМП-системах, такие компоненты обычно оказываются неэффективными при их использовании в больших компьютерных СМП-системах. И наоборот, компоненты, предназначенные для использования в больших компьютерных СМП-системах, оказывается экономически невыгодным применять в небольших системах.
Поэтому для устранения большинства ограничений, присущих компьютерным СМП-системам, за счет некоторого их усложнения была разработана альтернативная топология многопроцессорных компьютерных систем, которая известна как архитектура доступа к неоднородной памяти (NUMA). Типичная компьютерная система с NUMA имеет несколько соединенных между собой узлов, в состав каждого из которых входит один или несколько процессоров и локальная "системная" память. Подобные компьютерные системы называют системами с доступом к неоднородной памяти по той причине, что задержка в доступе к данным, хранящимся в системной памяти локального узла, оказывается для каждого относящегося к такому локальному узлу процессора меньше задержки в доступе к данным, хранящимся в системной памяти удаленного узла. Системы с NUMA могут также подразделяться на некогерентные и кэш-когерентные системы в зависимости от того, поддерживается ли когерентность данных между кэшами различных узлов. Сложность систем с NUMA и с поддержкой когерентности кэшей (CC-NUMA) в значительной степени определяется наличием дополнительных средств передачи данных, которыми требуется оснащать аппаратные средства для поддержания когерентности данных не только между различными уровнями кэш-памяти и системной памятью в каждом отдельном узле, но и между кэшами и модулями системной памяти различных узлов. Однако компьютерные системы с NUMA лишены недостатков, связанных с ограничениями, накладываемыми на масштабируемость традиционных компьютерных СМП-систем, поскольку каждый узел в компьютерной системе с NUMA может быть реализован в виде СМП-системы меньших размеров. Благодаря этому появляется возможность оптимизировать совместно используемые компоненты, входящие в состав каждого узла, для использования лишь несколькими процессорами, тогда как в отношении всей системы в целом удается достичь значительных преимуществ, проявляющихся в увеличении ее производительности за счет параллельной работы процессоров при большем их числе, при одновременном поддержании задержки в доступе к памяти на сравнительно низком уровне.
Основная проблема, влияющая на производительность компьютерных систем с CC-NUMA, связана с задержкой в выполнении операций по передаче данных (т.е. непосредственно самих данных, сообщений, команд, запросов и т.д.) через схему межузлового соединения. Так, в частности, задержка в выполнении операций по считыванию данных, находящихся в удаленной системной памяти, каковые операции являются наиболее распространенным типом операций, выполняемых в компьютерной системе, может в два раза превышать задержку в выполнении операций по считыванию данных, находящихся в локальной системной памяти. Так, например, в заявке ЕР-А-0817072 описана многопроцессорная система с подузлом-контроллером, который управляет взаимодействием между процессорным узлом и остальной частью системы. При инициировании запроса на выполнение той или иной операции в процессорном узле сначала проверяется возможность выполнения этой операции на локальном уровне, и, если такая возможность отсутствует, то требуется использовать удаленный доступ. При этом никакие действия не предпринимаются до тех пор, пока не будет установлено, возможно ли обслужить данный запрос на локальном уровне или нет. Из-за сравнительно большой задержки в выполнении операций считывания через схемы межузлового соединения по сравнению с выполнением операций считывания через схемы локального межсоединения представляется целесообразным сократить задержку в выполнении операций считывания через схемы межузлового соединения. Описанный в заявке ЕР-А-0379771 подход позволяет частично решить эту проблему и сократить время задержки в выполнении соответствующих операций за счет хранения модифицированной копии запрашиваемых данных в кэш-памяти.
В основу настоящего изобретения была положена задача разработать методику, которая позволила бы по меньшей мере частично устранить описанные выше недостатки, присущие известным из уровня техники решениям.
Указанная задача решается согласно изобретению с помощью предлагаемой в нем компьютерной системы, прежде всего компьютерной системы с NUMA, имеющей схему межузлового соединения, а также по меньшей мере локальный процессорный узел и удаленный процессорный узел, каждый из которых связан со схемой межузлового соединения, причем локальный процессорный узел имеет схему локального межсоединения, процессор и системную память, соединенные с этой схемой локального межсоединения, а также контроллер, расположенный между схемой локального межсоединения и схемой межузлового соединения и предназначенный для спекулятивной передачи запроса, полученного от схемы локального межсоединения, в удаленный процессорный узел через схему межузлового соединения, и для обработки ответа на запрос, полученного от удаленного процессорного узла, в соответствии с разрешением запроса в локальном процессорном узле, при этом контроллер локального процессорного узла отбрасывает данные, полученные от удаленного процессорного узла в ответ на запрос, если ответом на этот запрос, получаемым в локальном процессорном узле, является ответ когерентности с указанием на модифицированное или совместное вмешательство.
В такой компьютерной системе удаленный процессорный узел предпочтительно имеет также схему локального межсоединения и контроллер, расположенный между указанными схемой межузлового соединения и схемой локального межсоединения, при этом в ответ на получение спекулятивного запроса этот контроллер удаленного процессорного узла направляет такой спекулятивный запрос в схему локального межсоединения этого удаленного процессорного узла.
Согласно еще одному предпочтительному варианту осуществления изобретения в предлагаемой в нем компьютерной системе имеется также третий процессорный узел, при этом указанный запрос содержит адрес, а контроллер первого процессорного узла по меньшей мере частично на основании содержащегося в запросе адреса выбирает целевой процессорный узел, являющийся получателем спекулятивно переданного запроса.
В соответствии со следующим предпочтительным вариантом выполнения компьютерной системы в удаленном процессорном узле имеется системная память, при этом контроллер локального процессорного узла спекулятивно пересылает запрос в этот удаленный процессорный узел при установлении, что в этом запросе указан адрес, относящийся к указанной системной памяти удаленного процессорного узла.
Помимо этого в предлагаемой в изобретении компьютерной системе контроллер локального процессорного узла предпочтительно направляет полученные от удаленного процессорного узла данные в схему локального межсоединения локального процессорного узла, если ответом на запрос, получаемым в локальном процессорном узле, является ответ когерентности, указывающий на невозможность локального обслуживания этого запроса.
В изобретении предлагается также способ передачи данных в компьютерной системе, прежде всего в компьютерной системе с NUMA, имеющей схему межузлового соединения, связывающую между собой по меньшей мере локальный процессорный узел и удаленный процессорный узел, причем локальный процессорный узел имеет схему локального межсоединения, процессор и системную память, соединенные с этой схемой локального межсоединения, а также контроллер, расположенный между схемой локального межсоединения и схемой межузлового соединения, заключающийся в том, что в удаленный процессорный узел через схему межузлового соединения спекулятивно передают запрос, полученный от схемы локального межсоединения, и при поступлении в локальный процессорный узел от удаленного процессорного узла ответа на указанный запрос этот ответ на запрос обрабатывают в соответствии с разрешением запроса в локальном процессорном узле, причем при такой обработке указанного ответа на запрос отбрасывает данные, полученные от удаленного процессорного узла, если ответом на этот запрос, получаемым в локальном процессорном узле, является ответ когерентности с указанием на модифицированное или совместное вмешательство.
Согласно одному из предпочтительных вариантов осуществления предлагаемого в изобретении способа при получении в удаленном процессорном узле спекулятивного запроса этот спекулятивный запрос направляют в схему локального межсоединения удаленного процессорного узла.
В другом предпочтительном варианте осуществления предлагаемого в изобретении способа компьютерная система имеет также третий процессорный узел, а запрос содержит адрес, при этом по меньшей мере частично на основании содержащегося в запросе адреса выбирают целевой процессорный узел, являющийся получателем спекулятивно переданного запроса.
В соответствии еще с одним предпочтительным вариантом осуществления предлагаемого в изобретении способа в удаленном процессорном узле имеется системная память, при этом при спекулятивной передаче запроса его спекулятивно передают в удаленный процессорный узел при установлении, что в этом запросе указан адрес, относящийся к указанной системной памяти удаленного процессорного узла.
Согласно одному из предпочтительных вариантов осуществления предлагаемого в изобретении способа при обработке ответа полученные от удаленного процессорного узла данные направляют в схему локального межсоединения локального процессорного узла, если ответом на запрос, получаемым в локальном процессорном узле, является ответ когерентности, указывающий на невозможность локального обслуживания этого запроса.
Другие отличительные особенности и преимущества изобретения более подробно рассмотрены ниже на примере одного из вариантов его осуществления со ссылкой на прилагаемые чертежи, на которых показано:
на фиг.1 - схема предлагаемой в изобретении компьютерной системы с NUMA, выполненной по одному из вариантов,
на фиг.2 - подробная структурная схема показанного на фиг.1 узла контроллера,
на фиг.3А и 3Б - логические блок-схемы высокого уровня, совместно иллюстрирующие один из возможных примеров осуществления способа обработки запросов, когда запросы на считывание спекулятивно направляются инициирующим их процессорным узлом в удаленный процессорный узел, и
на фиг.4А-4Г - схемы, иллюстрирующие в качестве примера обработку данных в соответствии со способом, проиллюстрированным на фиг.3А и 3Б.
Общая структура системы
Ниже со ссылкой на прилагаемые чертежи и прежде всего со ссылкой на фиг. 1 рассмотрен один из возможных вариантов выполнения предлагаемой в изобретении компьютерной системы с NUMA. Такая показанная на чертеже система может быть реализована в виде рабочей станции, сервера или универсальной вычислительной машины (мэйнфрейма). Как показано на чертеже, в состав компьютерной системы 6 с NUMA входит несколько (Nm2) процессорных узлов 8а-8n, которые соединены между собой схемой 22 межузлового соединения. В состав каждого из таких процессорных узлов 8а-8n может входить М (М≥0) процессоров 10, схема 16 локального межсоединения и системная память 18, доступ к которой осуществляется через контроллер 17 памяти. Процессоры 10а-10m предпочтительно (но необязательно) являются идентичными процессорами, в качестве которых могут использоваться процессоры серии PowerPCТМ, выпускаемые корпорацией International Business Machines (IBM), Армонк, шт. Нью-Йорк. Помимо таких элементов, как регистры, командная логика и операционные или исполнительные блоки, используемые для выполнения программных команд, которые (элементы) совместно составляют так называемое ядро 12 процессора, каждый из процессоров 10а-10m имеет также реализованную в виде встроенного кэша иерархическую структуру (иерархическую кэш-память), используемую для направления данных в ядро 12 процессора из модулей системной памяти 18. Каждая такая иерархическая кэш-память 14 может включать, например, кэш 1-го уровня (L1) и кэш 2-го уровня (L2), емкость которых составляет 8-32 килобайта (кбайт) и 1-16 мегабайт (Мбайт) соответственно.
Каждый из процессорных узлов 8а-8n имеет также соответствующий контроллер 20 узла, включенный между схемой 16 локального межсоединения и схемой 22 межузлового соединения. Каждый такой контроллер 20 узла служит своего рода локальным агентом для удаленного процессорного узла 8 и выполняет с этой целью по меньшей мере две функции. Во-первых, каждый контроллер 20 узла отслеживает состояние относящейся к нему схемы 16 локального межсоединения и обеспечивает передачу данных от нее в удаленные процессорные узлы 8. Во-вторых, каждый контроллер 20 узла отслеживает наличие передаваемых в схеме 22 межузлового соединения данных и управляет направлением соответствующих данных в схему 16 локального межсоединения. Передачей данных в каждой схеме 16 локального межсоединения управляет арбитр 24. Арбитры 24 регулируют доступ к схеме 16 локального межсоединения на основе сигналов запроса шины, формируемых процессорами 10, а также компилируют ответы когерентности для отслеживаемых операций по передаче данных в схеме 16 локального межсоединения, как это более подробно описано ниже.
Схема 16 локального межсоединения через мост 26 связана с шиной 30 второго уровня, которая может быть реализована, например, в виде локальной шины PCI (от англ. "Peripheral Component Interconnect", "взаимное соединение периферийных компонентов"). Подобный мост 26 с шиной второго уровня позволяет создать тракт передачи данных с малым временем задержки или ожидания, через который процессоры 10 могут непосредственно получать доступ к устройствам 32 ввода-вывода и запоминающим устройствам 34, отображаемым на шинную память и/или пространство адресов ввода-вывода, а также создать высокоскоростной тракт передачи данных, по которому устройства 32 ввода-вывода и запоминающие устройства 34 могут получать доступ к системной памяти 18. Устройства 32 ввода-вывода могут представлять собой, например, дисплей, клавиатуру, графический указатель, а также последовательные и параллельные порты, предназначенные для подсоединения к внешним сетям или отдельно подсоединяемым устройствам. Запоминающие устройства 34 могут представлять собой запоминающие устройства на оптических или магнитных дисках, обеспечивающие энергонезависимое хранение операционной системы и прикладного программного обеспечения.
Организация памяти
В компьютерной системе 6 с NUMA всеми процессорами 10 совместно используется единое пространство адресов физической памяти, т.е. каждый физический адрес относится только к одной ячейке в одном из модулей системной памяти 18. В соответствии с этим все содержимое системной памяти, к которому обычно может получить доступ любой процессор 10 компьютерной системы 6 с NUMA, может рассматриваться как содержимое, распределенное между модулями системной памяти 18. Так, например, согласно одному из возможных вариантов осуществления настоящего изобретения с четырьмя процессорными узлами 8 в компьютерной системе NUMA может использоваться физическое адресное пространство объемом 16 гигабайт (Гбайт), состоящее из области, образующей универсальную память (память общего назначения), и зарезервированной области. Образующая универсальную память область разделена на сегменты по 500 Мбайт, при этом каждому из четырех процессорных узлов 8 выделяется каждый четвертый сегмент. В зарезервированной области, объем которой может составлять приблизительно 2 Гбайта, находятся память хранения данных для управления системой и периферийная память, а также области ввода-вывода, которые по одной распределены между процессорными узлами 8.
В последующем описании процессорный узел 8, в системной памяти 18 которого хранится определенный элемент данных, называется базовым узлом для этого элемента данных, и наоборот, другие процессорные узлы 8а-8n называются удаленными узлами по отношению к такому элементу данных.
Когерентность памяти
Поскольку любой из процессоров 10 компьютерной системы 6 с NUMA может запрашивать, выбирать и модифицировать данные, хранящиеся в каждой системной памяти 18, в такой компьютерной системе 6 с NUMA используется протокол обеспечения когерентности кэшей, позволяющий поддерживать когерентность между кэшами одного и того же процессорного узла и между кэшами различных процессорных узлов. В соответствии с этим компьютерную систему 6 с NUMA следует классифицировать как компьютерную систему с доступом к неоднородной памяти и с поддержкой когерентности кэшей (CC-NUMA). Используемый при этом протокол обеспечения когерентности кэшей зависит от конкретной реализации системы и может представлять собой хорошо известный протокол MESI (от англ. "Modified, Exclusive, Shared, Invalid", "модифицированный (М), монопольный (Е), совместный (S), недействительный (I)") или его разновидность. В последующем предполагается, что для иерархических кэшей 14 и арбитров 24 используется обычный протокол MESI, состояния М, S и I которого распознаются контроллерами 20 узлов, а состояние Е для соблюдения корректности рассматривается ими как объединенное с состоянием М. Иными словами, в контроллерах 20 узлов предполагается, что данные, монопольно хранящиеся в удаленном кэше, были модифицированы вне зависимости от того, действительно ли такие данные были модифицированы или нет.
Архитектура межсоединений
Схемы 16 локального межсоединения и схема 22 межузлового соединения в каждом случае могут быть реализованы на базе любой шинной широковещательной архитектуры, коммутационной широковещательной архитектуры или коммутационной нешироковещательной архитектуры. Однако в предпочтительном варианте предлагается реализовать по меньшей мере схему 22 межузлового соединения в виде схемы коммутационного нешироковещательного межсоединения, для управления которой используется протокол связи 6хх, разработанный корпорацией IBM. Схемы 16 локального межсоединения и схема 22 межузлового соединения позволяют выполнять различные операции раздельно, т.е. это означает, что между адресами и данными, совместно составляющими передаваемую информацию, не существует фиксированной временной зависимости и что упорядочение пакетов данных может происходить отдельно от соответствующих им адресных пакетов. В предпочтительном варианте эффективность работы схем 16 локального межсоединения и схемы 22 межузлового соединения можно также повысить за счет выполнения операций по передаче данных в конвейерном режиме, что позволяет начинать следующую операцию передачи данных еще до поступления в устройство, инициировавшее выполнение предыдущей операции передачи данных, ответов когерентности от каждого получателя данных.
Вне зависимости от типа или типов используемой архитектуры межсоединений для передачи информации между процессорными узлами 8 через схему 22 межузлового соединения и между модулями отслеживания через схемы 16 локального межсоединения используется по меньшей мере три типа "пакетов" (термин "пакет" используется в данном случае для обозначения дискретной единицы информации), а именно адресные пакеты, пакеты данных и пакеты ответов когерентности. В таблицах I и II в обобщенном виде представлена информация о соответствующих полях и приведено их описание для адресных пакетов и пакетов данных соответственно.
Как следует из таблиц I и II, каждый пакет в передаваемой информации маркируется соответствующим тегом, чтобы узел-получатель данных или модуль отслеживания мог определить, к каким передаваемым данным, соответственно к какой операции передачи данных относится каждый пакет. Для специалистов в данной области очевидно, что для регулирования загруженности средств передачи данных, обладающих ограниченными возможностями, можно использовать дополнительную управляющую потоком данных или последовательностью выполнения команд логику и соответствующие управляющие потоком данных или последовательностью выполнения команд сигналы.
В каждом процессорном узле 8 ответы состояния и когерентности передаются между каждым модулем отслеживания и локальным арбитром 24. Сигнальные линии, используемые в схемах 16 локального межсоединения для передачи информации о состоянии и когерентности, представлены ниже в таблице III.
Между ответами состояния и когерентности, передаваемыми по линиям передачи сигналов AResp и AStat в схемах 16 локального межсоединения, и соответствующими пакетами адресов предпочтительно существует фиксированная, но программируемая временная зависимость. Так, например, во втором цикле после приема адресного пакета может потребоваться голосование по сигналам AStatOut, которое позволяет получить предварительную информацию о том, удалось ли каждому модулю отслеживания успешно принять адресный пакет, передаваемый по схеме 16 локального межсоединения. Арбитр 24 компилирует результаты голосования по сигналам AStatOut и затем по истечении фиксированного, но программируемого числа циклов (например, через 1 цикл) выдает результат голосования AStatIn. Возможные результаты голосования AStat приведены ниже в таблице IV.
По завершении периода AStatIn может потребоваться провести через фиксированное, но программируемое число циклов (например, через 2 цикла) голосование по сигналам ARespOut. Арбитр 24 также компилирует результаты голосования по ARespOut для каждого модуля отслеживания и выдает результат голосования ARespIn, предпочтительно во время следующего цикла. Возможные результаты голосования AResp предпочтительно содержат ответы когерентности, указанные ниже в таблице V.
Результат голосования ReRun, который обычно выдается контроллером 20 узла в качестве результата голосования AResp, указывает, что для отслеживаемого запроса выявлено длительное время ожидания и что инициатору запроса будет направлена команда повторить операцию в более поздний момент времени. Таким образом, в отличие от результата голосования Retry, который также может выдаваться в качестве результата голосования AResp, результат голосования ReRun делает ответственным за повторение операции по передаче данных в более поздний момент времени получателя (а не на отправителя) данных, проголосовавшего за ReRun.
Контроллер узла
На фиг. 2 более подробно показана функциональная схема контроллера 20 узла, используемого в компьютерной системе 6 с NUMA, показанной на фиг.1. Как показано на фиг.2, каждый контроллер 20 узла, который включен между схемой 16 локального межсоединения и схемой 22 межузлового соединения, имеет блок 40 приема запросов (БПЗ), блок 42 отправки запросов (БОЗ), блок 44 приема данных (БПД) и блок 46 отправки данных (БОД). БПЗ 40, БОЗ 42, БПД 44 и БОД 46 могут быть реализованы, например, на базе программируемых пользователем вентильных матриц (ППВМ) либо специализированных интегральных схем (СИС). Как указано выше, адресный тракт и тракт передачи данных через контроллер 20 узла являются разветвляющимися, при этом адресные пакеты (и пакеты когерентности) обрабатываются БПЗ 40 и БОЗ 42, а пакеты данных обрабатываются БПД 44 и БОД 46.
БПЗ 40, из названия которого следует, что он предназначен для приема потока запросов, поступающего от схемы 22 межузлового соединения, отвечает за прием адресных пакетов и пакетов когерентности от схемы 22 межузлового соединения, выдачу запросов в схему 16 локального межсоединения и пересылку ответов в БОЗ 42. В состав БПЗ 40 входит мультиплексор 52 ответов, который принимает пакеты от схемы 22 межузлового соединения и передает выбранные пакеты в устройство 54 управления передачей данных по шине (УУПДШ) и в логику 56 обработки ответов когерентности в БОЗ 42. В ответ на получение адресного пакета от мультиплексора 52 ответов главное устройство 54 управления передачей данных по шине может инициировать операцию по передаче данных по его схеме 16 локального межсоединения, тип которой (операции) может совпадать с типом операции по передаче данных, который указан в принятом адресном пакете, или может отличаться от него.
БОЗ 42, который, как следует из его названия, образует канал для передачи потока запросов в схему 22 межузлового соединения, имеет рассчитанный на хранение большого количества записей буфер 60 ожидания, в котором временно хранятся атрибуты еще не завершенных операций по передаче данных, которые передаются в схему 22 межузлового соединения. Подобные атрибуты операций по передаче данных, хранящиеся в виде записи в буфере 60 ожидания, предпочтительно содержат по меньшей мере адрес операции по передаче данных (включая метку), ее тип и число ожидаемых ответов когерентности. Для каждой записи в буфере ожидания предусмотрено соответствующее состояние, которое либо может принимать значение Null, указывающее на возможность удаления соответствующей записи из буфера ожидания, либо может принимать значение ReRun, указывающее, что операция все еще не завершена. Помимо направления адресных пакетов в схему 22 межузлового соединения БОЗ 42 взаимодействует также с БПЗ 40 для обработки запросов на доступ к памяти и выдает команды в БПД 44 и БОД 46 для управления передачей данных между схемой 16 локального межсоединения и схемой 22 межузлового соединения. БОЗ 42 реализует также выбранный протокол когерентности (например, протокол MSI) для схемы 22 межузлового соединения совместно с логикой 56 обработки ответов когерентности и ведет директорию 50 когерентности с использованием логики 58 управления директорией.
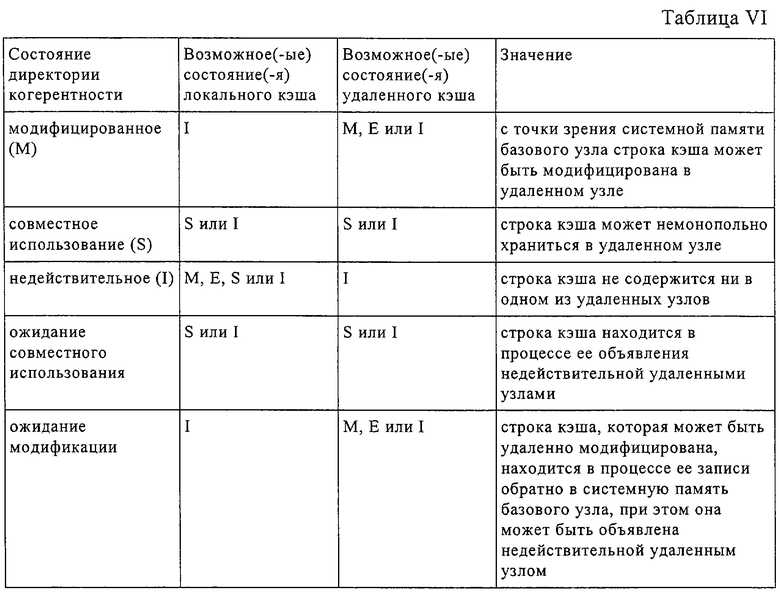
В директории 50 когерентности хранятся указатели адресов данных в системной памяти (например, строки кэша), сверенные с кэшами удаленных узлов, для которых локальный процессорный узел является базовым узлом. Указатели адресов для каждой строки кэша хранятся вместе с идентификаторами каждого удаленного процессорного узла, в котором имеется копия строки кэша, и с состоянием когерентности строки кэша в каждом таком удаленном процессорном узле. Возможные состояния когерентности для записей в директории 50 когерентности приведены в таблице VI.
Как указано в таблице VI, информация о состоянии когерентности строк кэша, содержащихся в удаленных процессорных узлах, является неточной. Подобная неточность обусловлена тем фактом, что строка кэша, содержащаяся в удаленном узле, может перейти из состояния S в I, из Е в I или из Е в М без извещения об этом контроллера 20 базового узла.
Обработка запросов на считывание
На фиг.3А и 3Б приведены две логические блок-схемы высокого уровня, совместно иллюстрирующие один из возможных примеров осуществления способа обработки запросов на считывание в соответствии с настоящим изобретением. Процедура, блок-схема которой показана на фиг.3А, начинается на шаге 70 и затем переходит к шагу 72, на котором процессор 10, например процессор 10а процессорного узла 8а, выдает запрос на считывание в его схему 16 локального межсоединения. Этот запрос на считывание поступает в контроллер 20 узла и в остальные модули отслеживания, связанные со схемой 16 локального межсоединения процессорного узла 8а. В ответ на поступление запроса на считывание модули отслеживания выдают результаты голосования по AStatOut, которые компилируются арбитром 24 для формирования результата голосования AStatIn (шаг 74). Если в запросе на считывание указан адрес в удаленной системной памяти 18, то перед выдачей контроллером 20 узла результата голосования Ack в качестве результата голосования по AStatOut, разрешающего дальнейшую обработку запроса на считывание, контроллер 20 узла выделит в буфере 60 ожидания элемент считывания и элемент записи с очисткой. За счет выделения обоих этих элементов контроллер 20 узла может спекулятивно направить запрос на считывание в базовый узел запрошенной строки кэша и правильно обработать ответ на запрос на считывание независимо от результата последующего голосования AResp в процессорном узле 8а.
Если результатом голосования AStatIn, полученным на шаге 74, является Retry, то на следующем шаге 76 запрос на считывание аннулируется, возможно, выделенные в буфере 60 ожидания элементы освобождаются, и осуществляется возврат к шагу 72, который рассмотрен выше. В этом случае процессор 10а должен повторно выдать запрос на считывание в более поздний момент времени. Если же на шаге 74 результатом голосования AStatIn не является Retry, то осуществляется переход от шага 76 к шагу 78, на котором контроллер 20 узла путем обращения к карте памяти определяет, является ли его процессорный узел 8 базовым узлом для физического адреса, указанного в запросе на считывание. При положительном ответе осуществляется переход к шагу 80, а в противном случае, т.е. если процессорный узел 8 не является базовым узлом для запроса на считывание, происходит переход к шагу 100.
На шаге 80 модули отслеживания процессорного узла 8а проводят голосование по ARespOut, результаты которого компилируются арбитром 24 с получением результата голосования ARespIn. Если директория 50 когерентности указывает на то, что строка кэша, адрес которой указан в запросе на считывание, связана по меньшей мере с одним удаленным процессорным узлом 8, то контроллер 20 узла выдаст в качестве результата голосования результат ReRun, если для обслуживания запроса на считывание требуется связь с удаленным процессорным узлом 8. Так, например, если директория 50 когерентности указывает, что состояние запрошенной строки кэша в удаленном процессорном узле 8 установлено на "модифицированное" ("Modified") 8, то для обслуживания запроса на считывание его потребуется направить в удаленный процессорный узел 8. Аналогичным образом, если директория 50 когерентности указывает, что состояние запрошенной строки кэша в удаленном процессорном узле 8 установлено на "совместное использование" ("Shared"), то для обслуживания запроса на считывание с целью модификации в удаленный процессорный узел 8 потребуется направить команду аннулирования, чтобы сделать недействительной находящуюся в этом удаленном процессорном узле копию или копии запрошенной строки кэша. Если полученным на шаге 82 результатом голосования ARespIn не является ReRun, то осуществляется переход к шагу 90, который описан ниже, а если результатом голосования ARespIn является ReRun, то осуществляется переход к шагу 84.
На шаге 84 контроллер 20 узла через схему 22 межузлового соединения передает соответствующее сообщение в один или несколько удаленных процессорных узлов 8, которые проверили запрошенную строку кэша. Как указано выше, подобное сообщение может представлять собой команду для кэша (например, команду аннулирования) или запрос на считывание. После этого осуществляется переход к шагу 86, выполнение которого циклически продолжается до тех пор, пока в контроллер 20 узла не поступят ответы от каждого из удаленных процессорных узлов 8, в которые на шаге 84 было передано сообщение. После получения соответствующего числа ответов, среди которых может присутствовать копия запрошенной строки кэша, контроллер 20 узла передает в схему 16 локального межсоединения запрос ReRun, который является командой инициировавшему посылку запроса на считывание процессору 10а повторно выдать запрос на считывание. После этого на шаге 88 инициировавший посылку запроса на считывание процессор 10а в ответ на указанный запрос ReRun повторно выдает запрос на считывание в схему 16 локального межсоединения. По истечении периодов AStat и AResp на следующем шаге 90 запрос на считывание обслуживается либо в контроллере 20 локального процессорного узла, направляющем копию запрошенной строки кэша, полученной от удаленного процессорного узла 8, либо другим локальным модулем отслеживания в процессорном узле 8а (например, контроллером 17 памяти или иерархическим кэшем 14), направляющим запрошенную строку кэша. После этого осуществляется переход к шагу 150, на котором выполнение всей процедуры завершается.
Если же на шаге 100 контроллер 20 процессорного узла 8а определит, что процессорный узел 8а не является базовым узлом для запрошенной строки кэша, то этот контроллер 20 узла спекулятивно направляет запрос на считывание в удаленный процессорный узел 8, который является базовым узлом для запрошенной строки кэша. Как показано на фиг.3А, запрос на считывание пересылается контроллером 20 узла по меньшей мере одновременно с периодом ARespIn, предпочтительно сразу же по получении результата голосования AStatIn от арбитра 24 и до начала периода ARespOut. При направлении запроса на считывание состояние элемента считывания в буфере 60 ожидания изменяется на ReRun. Затем на шаге 102 модули отслеживания выдают результаты их голосования по ARespOut, которые компилируются арбитром 24 с получением результата голосования ARespIn. После этого на шаге 110 и на последующих шагах базовый узел выдает ответ на запрос на считывание, который (ответ) обрабатывается контроллером 20 узла в соответствии с результатом голосования ARespIn для запроса на считывание в процессорном узле 8а.
Если результатом голосования ARespIn является Retry, то запрос на считывание по существу аннулируется в процессорном узле 8а. Таким образом, в ответ на получение в качестве результата голосования ARespIn результата Retry состояние элементов считывания и записи, выделенных в буфере 60 ожидания, изменяется на Null. После этого осуществляется переход к шагу 110, от которого далее происходит переход к шагам 112 и 114, на первом из которых контроллер 20 узла ожидает получения запрошенной строки кэша от базового узла, а на втором отбрасывает строку кэша, если состояние элемента считывания в буфере 60 ожидания соответствует состоянию Null. После этого осуществляется переход к шагу 150, на котором выполнение всей процедуры завершается.
Если результатом голосования ARespIn является Modified Intervention ("модифицированное вмешательство"), то запрос на считывание может быть обслужен на локальном уровне в процессорном узле 8а без использования (устаревших) данных от базового узла. Таким образом, в ответ на получение в качестве результата голосования ARespIn результата Modified Intervention ("модифицированное вмешательство") состояние элемента считывания в буфере 60 ожидания изменяется на состояние Null, после чего осуществляется переход к шагу 102, а от него - через шаги 110 и 120 к шагу 122. На этом шаге 122 модуль отслеживания, который во время периода ARespOut выдал результат голосования Modified Intervention ("модифицированное вмешательство"), направляет запрошенную строку кэша в схему 16 локального межсоединения процессорного узла 8а. После этого состояние когерентности запрошенной строки кэша в модуле отслеживания, направившем запрошенную строку кэша, изменяется с Modified ("модифицированное") на Shared ("совместное использование"). В ответ на получение запрошенной строки кэша инициировавший посылку запроса процессор 10а на шаге 124 загружает эту строку кэша в свой иерархический кэш 14. Помимо этого контроллер 20 узла перехватывает запрошенную строку кэша в схеме 16 локального межсоединения и на шаге 126 выдает в базовый узел содержащую строку кэша команду на запись с очисткой с целью обновления системной памяти 18 этого базового узла путем записи в нее модифицированной строки кэша. После этого осуществляется переход к шагу 112, который уже был рассмотрен выше.
Протокол когерентности, используемый в компьютерной системе 6, может дополнительно поддерживать режим совместного вмешательства, т.е. обслуживание запроса на считывание локальным иерархическим кэшем 14, в котором запрошенная строка кэша хранится в состоянии Shared ("совместное использование"). Если режим совместного вмешательства поддерживается протоколом когерентности кэша, используемым в компьютерной системы 6, а результатом голосования ARespIn для выданного запроса является Shared (т.е. "совместное вмешательство", или "Shared Intervention"), то модуль отслеживания, который в качестве результата голосования выдал результат Shared ("совместное использование"), на шаге 132 направляет запрошенную строку кэша в схему 16 локального межсоединения. В ответ на получение запрошенной строки кэша инициировавший посылку запроса процессор 10а на следующем шаге 134 загружает эту запрошенную строку кэша в свой иерархический кэш 14. Поскольку при этом не требуется вносить никаких изменений в системную память 18, состояние элементов считывания и записи, выделенных в буфере 60 ожидания, изменяется на состояние Null, после чего осуществляется переход к шагу 150, на котором выполнение всей процедуры завершается.
Если же результатом голосования ARespIn для запроса в процессорном узле 8а является результат ReRun, то состояние элемента записи в буфере 60 ожидания изменяется на Null, а состояние элемента считывания изменяется на ReRun. После этого от шага 102 последовательно осуществляется переход к выполнению шагов 110, 120 и 130 и после них к шагу 142, на котором контроллер 20 процессорного узла 8а ожидает получения запрошенной строки кэша от базового узла и который выполняется циклически до получения запрошенной строки кэша от базового узла. После получения запрошенной строки кэша от базового узла через схему 22 межузлового соединения контроллер 20 узла на следующем шаге 144 передает эту строку кэша запросившему ее процессору 10а через схему 16 локального межсоединения. После этого на следующем шаге 146 по получении запрошенной строки кэша инициировавший посылку запроса процессор 10а загружает эту запрошенную строку кэша в свой иерархический кэш 14. После этого осуществляется переход к шагу 150, на котором выполнение всей процедуры завершается.
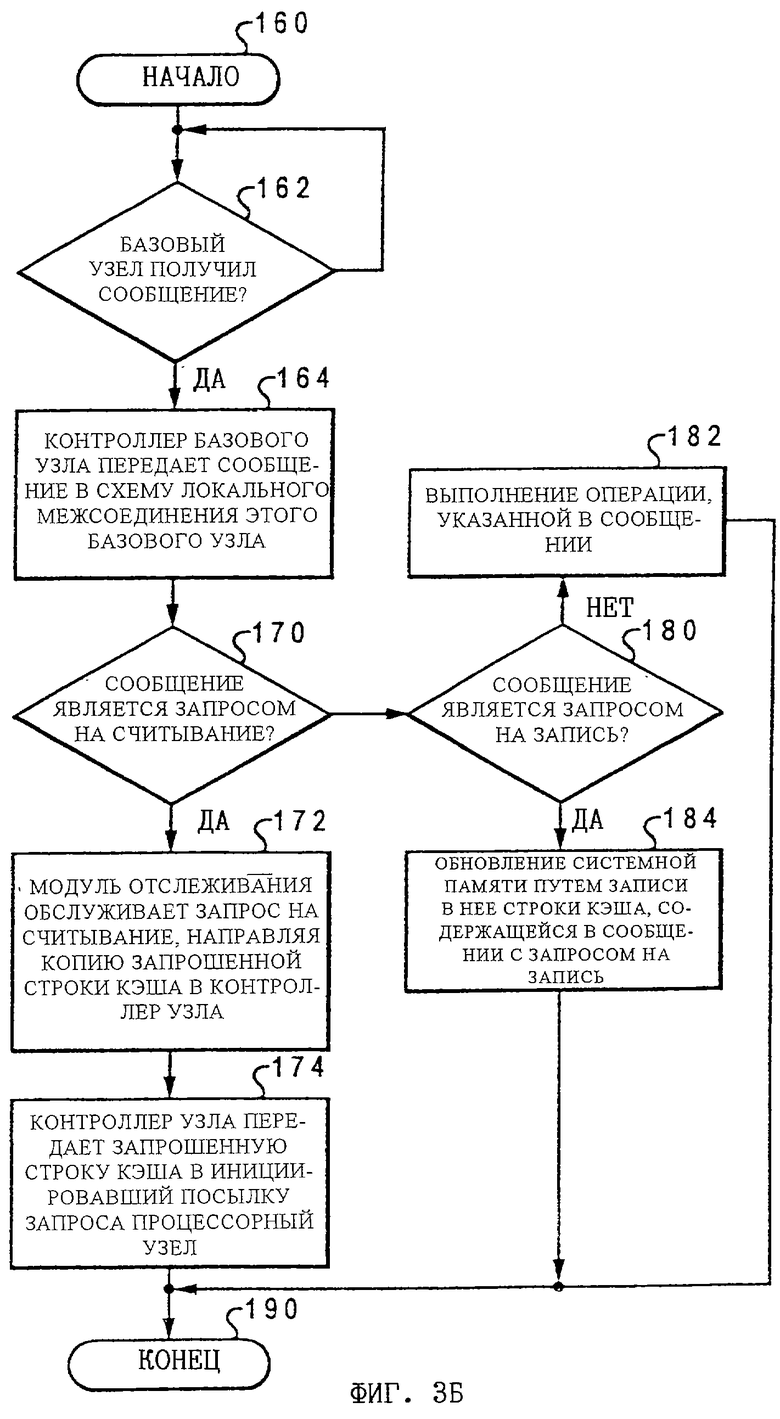
На фиг.3Б показана логическая блок-схема высокого уровня, иллюстрирующая обработку в базовом узле сообщения, полученного от другого процессорного узла. Как показано на чертеже, эта процедура начинается на шаге 160 и затем переходит к шагу 162, на котором проверяется, получил ли базовый узел сообщение от другого процессорного узла через схему 22 межузлового соединения. Если такое сообщение получено не было, то выполнение шага 162 циклически повторяется до тех пор, пока от другого процессорного узла 8 не будет получено какое-либо сообщение. При получении контроллером 20 базового узла сообщения от удаленного процессорного узла 8 осуществляется переход к шагу 164, на котором контроллер 20 базового узла передает принятое на шаге 162 сообщение в схему 16 локального межсоединения этого базового узла. После этого на шаге 170 определяется, является ли полученное сообщение, направленное в схему 16 локального межсоединения, запросом на считывание, и при положительном ответе осуществляется переход к шагу 172, на котором этот запрос на считывание обслуживается модулем отслеживания, который направляет копию запрошенной строки кэша в контроллер 20 базового узла. При получении этой запрошенной строки кэша контроллер 20 узла на следующем шаге 174 передает ее в инициировавший запрос процессорный узел 8 через схему 22 межузлового соединения. После этого осуществляется переход к шагу 190, на котором выполнение всей процедуры завершается.
Если же полученное на шаге 164 сообщение, переданное в схему 16 локального межсоединения базового узла, является запросом на запись (например, запись с очисткой), то после проверки на шаге 170 осуществляется переход к шагу 180, а от него - к шагу 184, на котором контроллером 17 памяти обновляется системная память 18 путем записи в нее строки кэша, содержащейся в сообщении с запросом на запись. После этого осуществляется переход к шагу 190, на котором выполнение всей процедуры завершается. Если же сообщение, переданное в схему 16 локального межсоединения базового узла, не является ни запросом на считывание, ни запросом на запись, то осуществляется переход к шагу 182, на котором базовый узел выполняет определенную(ые) операцию(и), указанную(ые) в сообщении, после чего осуществляется переход к шагу 190, на котором выполнение всей процедуры завершается. В качестве примера таких операций, которые могут выполняться при получении соответствующего сообщения и которые не являются операциями считывания или записи, можно назвать изменение состояний когерентности строк кэша, находящихся в иерархическом кэше 14 базового узла.
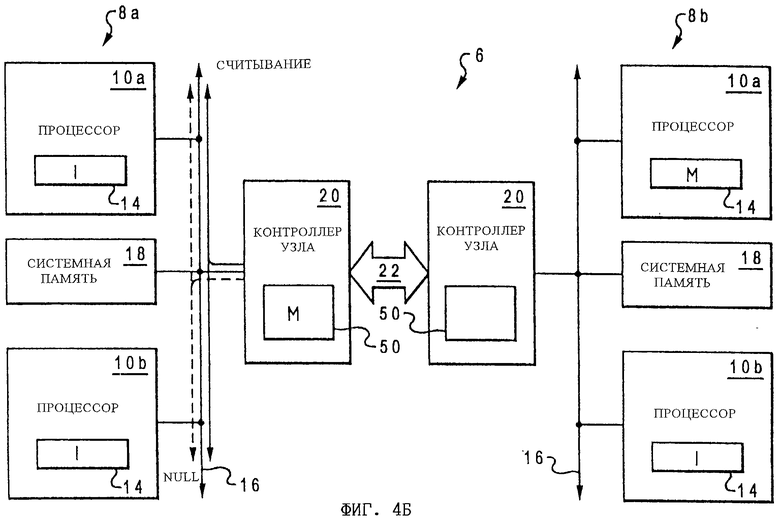
На фиг. 4А-4Г в качестве примера показан один из вариантов выполнения процесса обработки данных в соответствии с настоящим изобретением. В этом варианте процесс обработки данных рассматривается ниже на примере упрощенной модели компьютерной системы 6 с двумя процессорными узлами 8а и 8b, каждый из которых имеет по два процессора 10а и 10b. Состояние когерентности запрошенной строки кэша указывается в иерархическом кэше 14 каждого процессора 10, а также в директории 50 когерентности, относящейся к базовому узлу 8а.
Как показано на фиг.4А, сначала процессор 10b процессорного узла 8b выдает запрос на считывание для строки кэша, состояние которой в иерархическом кэше 14 этого процессора соответствует состоянию Invalid ("недействительное") (т. е. эта строка кэша отсутствует в нем). В ответ на получение этого запроса на считывание контроллер 20 процессорного узла 8b спекулятивно передает запрос на считывание в процессорный узел 8а, который является базовым узлом для строки кэша, указанной в запросе на считывание. После спекулятивного направления запроса на считывание в процессорный узел 8а процессор 10а в течение периода ARespOut голосует за Modified Intervention ("модифицированное вмешательство"), поскольку в его иерархическом кэше 14 запрошенная строка кэша находится в состоянии Modified ("модифицированное"). Арбитр процессорного узла 8b компилирует результаты голосования по ARespOut и в качестве результата голосования ARespIn направляет в каждый модуль отслеживания в процессорном узле 8b результат Modified Intervention ("модифицированное вмешательство").
После этого контроллер 20 процессорного узла 8а, как показано на фиг.4Б, принимает спекулятивно направленный запрос на считывание и выдает этот запрос на считывание в его схему 16 локального межсоединения. Как показано на фиг.4Б, контроллер 20 узла в ответ на указание директорией 50 когерентности, что состояние указанной в запросе на считывание строки кэша установлено в процессорном узле 8b на состояние Modified ("модифицированное"), выдает в течение периода ARespOut результат голосования Null. Контроллер 20 узла, распознающий такое особое условие, разрешает дальнейшую обработку запроса на считывание, как это более подробно описано ниже со ссылкой на фиг.4Г.
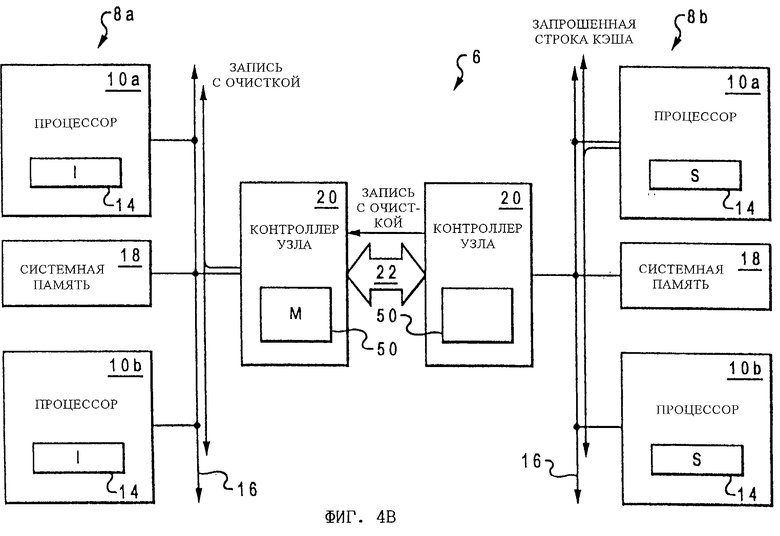
Как показано на фиг.4В, процессор 10а процессорного узла 8b вне зависимости от спекулятивного направления запроса на считывание в процессорный узел 8а (и, возможно, до направления, одновременно с направлением или после направления такого запроса на считывание) направляет в ответ на этот запрос на считывание запрошенную строку кэша в схему 16 локального межсоединения и изменяет состояние когерентности запрошенной строки кэша в своем иерархическом кэше 14 на состояние Shared ("совместное использование"). При обнаружении отслеживаемой запрошенной строки кэша инициировавший посылку запроса процессор 10b загружает эту запрошенную строку кэша в свой иерархический кэш 14 и устанавливает соответствующее состояние когерентности на Shared ("совместное использование"). Помимо этого контроллер 20 процессорного узла 8b перехватывает строку кэша и выдает в процессорный узел 8а сообщение с запросом на запись с очисткой, содержащее модифицированную строку кэша. При получении этого сообщения с запросом на запись с очисткой контроллер 20 процессорного узла 8а направляет это сообщение в системную память 18 через свою схему 16 локального межсоединения 16. После этого соответствующая строка системной памяти 18 базового узла 8а обновляется путем записи в нее модифицированных данных.
Как показано на фиг.4Г, системная память 18 процессорного узла 8а вне зависимости от рассмотренного выше со ссылкой на фиг.4А ее обновления (и, возможно, до такого обновления, одновременно с этим обновлением или после него) направляет в ответ на запрос на считывание, возможно, устаревшую копию запрошенной строки кэша в контроллер 20 процессорного узла 8а через схему 16 локального межсоединения 16. После этого контроллер 20 процессорного узла 8а направляет эту копию запрошенной строки кэша в контроллер 20 процессорного узла 8b, который отбрасывает строку кэша, поскольку в его буфере 60 ожидания запрос на считывание помечен как Null.
Таким образом, в настоящем изобретении предлагается усовершенствованная компьютерная система с NUMA и усовершенствованный способ передачи данных в такой компьютерной системе с NUMA. Согласно изобретению запрос на считывание спекулятивно направляется в удаленный (т.е. базовый) процессорный узел через схему межузлового соединения еще до определения возможности обслуживания запроса на считывание на локальном уровне без вмешательства удаленного процессорного узла. Ответ, выдаваемый удаленным процессорным узлом на спекулятивно направленный запрос на считывание, обрабатывается инициировавшим посылку запроса процессорным узлом в соответствии с локальным ответом когерентности для запроса на считывание. Подобный подход позволяет значительно сократить задержку в выполнении операций по передаче данных или по обмену данных.
В соответствии с приведенным выше описанием в изобретении предлагается компьютерная система с доступом к неоднородной памяти (NUMA), имеющая по меньшей мере локальный процессорный узел и удаленный процессорный узел, каждый из которых связан со схемой межузлового соединения. Локальный процессорный узел имеет схему локального межсоединения, процессор и системную память, соединенные с этой схемой локального межсоединения, а также контроллер, расположенный между схемой локального межсоединения и схемой межузлового соединения. Такой контроллер узла в ответ на запрос на считывание, полученный от схемы локального межсоединения, спекулятивно передает этот запрос на считывание в удаленный процессорный узел через схему межузлового соединения. После этого при получении ответа на запрос на считывание от удаленного процессорного узла указанный контроллер узла обрабатывает этот ответ в соответствии с разрешением запроса на считывание в локальном процессорном узле. Так, например, согласно одному из вариантов процесса обработки данные, содержащиеся в ответе, полученном от удаленного процессорного узла, отбрасываются контроллером узла, если ответом на запрос на считывание, полученным в локальном процессорном узле, является ответ когерентности с указанием на модифицированное вмешательство (Modified Intervention).








Изобретение относится к компьютерным сетям. Техническим результатом является сокращение времени выполнения операций по передаче данных. Для этого схема системы содержит локальный процессорный узел, удаленный процессорный узел, схему межузлового соединения, каждый локальный процессорный узел содержит схему локального межсоединения, процессор, системную память, контроллер, при этом упомянутый контроллер отбрасывает данные, полученные от удаленного процессорного узла в ответ на запрос, если ответом на этот запрос, получаемым в локальном процессорном узле, является ответ когерентности с указанием на модифицированное или совместное вмешательство. Способ включает в себя следующие операции: в удаленный процессорный узел спекулятивно передают запрос, полученный от схемы локального межсоединения, и при поступлении в локальный процессорный узел ответа на указанный запрос этот ответ на запрос обрабатывают в соответствии с разрешением запроса в локальном процессорном узле, причем при такой обработке указанного ответа на запрос отбрасывают данные, полученные от удаленного процессорного узла, если ответом на этот запрос, получаемым в локальном процессорном узле, является ответ когерентности с указанием на модифицированное или совместное вмешательство. 2 с. и 8 з.п. ф-лы, 8 ил., 6 табл.
| Устройство для транспортировки иРАзлиВКи РАСплАВА | 1979 |
|
SU817072A1 |
| Захват автооператора | 1976 |
|
SU608638A1 |
| УСТРОЙСТВО для АВТОМАТИЧЕСКОГО УПРАВЛЕНИ СТВОРКАМИ ВОРОТ И ДВЕРЕЙ | 0 |
|
SU379771A1 |
| ЯКУБАЙТИС Э.А | |||
| Информационно-вычислительные сети | |||
| - М: Финансы и статистика, 1984, с | |||
| Устройство для электрической сигнализации | 1918 |
|
SU16A1 |

