Настоящее изобретение относится к разрешению противоречивых выходных данных из системы оптического распознавания символов (OCR) и, в особенности, к способу обработки выходных данных OCR, где выходные данные включают в себя изображения символов, нераспознаваемые из-за перечеркнутого текста или наложенных объектов других типов, ухудшающих процесс оптического распознавания системы OCR.
Системы оптического распознавания символов обеспечивают преобразование растрированных изображений документов в текст в кодах ASCII, что облегчает поиск, замену и переформатирование документов и т.д. в компьютерной системе. Одной из особенностей функциональности OCR является преобразование рукописных и машинописных документов, книг, медицинских журналов и т.д., например, в документы, доступные для поиска в сетях Интернет и Интранет. В целом, качество извлечения информации и поиска документов значительно улучшается в том случае, когда все документы доступны для электронного извлечения и поиска. Например, корпоративная система Интранет может связывать все старые и новые документы предприятия путем всестороннего применения функциональности OCR, являющейся частью сети Интранет (или частью сети Интернет в случае документов, представляющих общественный интерес).
Однако качество функциональности OCR ограничено большой сложностью самой системы OCR. Трудно обеспечить функциональность OCR, которая способна была бы преодолеть любые трудности, встречающиеся при попытках преобразования изображений текста в текст в компьютерных кодах. Одна из таких трудностей связана с зачеркнутым текстом, который часто встречается в документах. Например, для обозначения документа как копии оригинального документа, на странице документа может быть поставлен штамп с текстом «COPY». Иногда такие документы должны быть заверены как правильные копии оригинального документа, что, как правило, осуществляется при помощи дополнительных штампов и, например, подписи лица, которому поручено заверять такие копии.
Обычным эффектом перечеркнутого текста или других объектов, наложенных на символы, является то, что символы в словах скрываются под объектами, предусматриваемыми, как описано выше, штампом или рукописной подписью, что делает затруднительной идентификацию системой OCR символов и слов, включающих в себя эти символы. Обычно система OCR предусматривает выходные данные, в которые включается перечень недостоверно распознаваемых символов. Таким образом, можно идентифицировать перечеркнутые символы и т.д., а их положение на странице с текстом и в словах и т.д., а также возможные альтернативные интерпретации скрытых или частично скрытых символов и т.д. могут сообщаться системой OCR.
Согласно одной из особенностей настоящего изобретения, можно идентифицировать как сами по себе подобные наложенные объекты, так и положение и степень наложения объекта на изображение символа в тексте. Если наложенные объекты идентифицированы, части изображения символа с нарушенной видимостью исключаются из изображения, представляющего символ. Остальные части изображений символов с нарушенной видимостью затем сопоставляются с изображениями из набора эталонных изображений символов согласно настоящему изобретению. Данное сопоставление делает возможной идентификацию, по меньшей мере, одного эталонного изображения, имеющего наибольшее сходство с изображением, содержащим остающиеся части изображения символа с нарушенной видимостью. Если этот способ возвращает только одно изображение символа-кандидата, имеющее сходство, которое превышает заданный пороговый уровень, проблему можно считать решенной. Однако, как правило, существует несколько символов-кандидатов, которые имеют высокую степень сходства между остающимися частями изображения символа с нарушенной видимостью, и эталонными изображениями кандидатов. Поэтому трудность заключается в выборе среди множества изображений символов-кандидатов правильного изображения символа-кандидата, которое является правильной идентификацией символа с нарушенной видимостью.
Согласно примеру осуществления настоящего изобретения, информация, связанная с местоположением и степенью наложения объектов на символ, используется для моделирования наложенного объекта на эталонных изображениях в том же местоположении и с той же степенью наложения, а затем образец символа с нарушенной видимостью сопоставляется с изображениями, смоделированными с фактически наложенным объектом. Например, корреляции между остающимися частями изображений соответствующих образцов символов с нарушенной видимостью с эталонными изображениями возможных символов-кандидатов обеспечивают способ идентификации такого эталонного изображения символа, которое фактически представляет образец символа с нарушенной видимостью и, соответственно, является правильным распознаванием образца символа с нарушенной видимостью.
Согласно другой особенности настоящего изобретения, вероятность выбора правильного изображения символа-кандидата, являющегося правильной идентификацией символа с нарушенной видимостью, из множества символов-кандидатов значительно увеличивается тогда, когда набор изображений символов-кандидатов предусматривается путем использования изображений символов из того же документа, что и идентифицированные системой OCR как символы, идентифицируемые с достоверностью, которая превышает заранее определенный пороговый уровень. Такие изображения символов включают в себя детали изображений символов в том виде, в каком они встречаются в самом документе, в отличие от модельных изображений символов, которые известны в прототипах сравнений с эталоном символа. При моделировании наложенных объектов образца символа с нарушенной видимостью на таких эталонных изображениях, устойчивость корреляции заметно увеличивается.
Фиг.1 - пример штампованной буквы Р, нарушающей видимость части страницы с текстом. Символ Р является частью штампа, включающего в себя текст «COPY».
Фиг.2а - образец символа а с видимостью, нарушенной частично наложенным символом Р по фиг.1.
Фиг.2б - удаление секции с нарушенной видимостью по фиг.2а согласно настоящему изобретению.
Фиг.3а - пример максимальной корреляции между изображением по фиг.2б и эталоном символа a, который показан на фиг.3б.
Фиг.4а - различные категории пикселей в символе с нарушенной видимостью по фиг.2а согласно настоящему изобретению.
Фиг.4б - соответствующие категории пикселей в перечеркнутом эталоне согласно настоящему изобретению.
Согласно одной из особенностей настоящего изобретения, присутствие наложенного объекта, например, штампа, рукописной подписи и т.д., можно идентифицировать, анализируя связанные пиксели на изображениях, которые включают в себя обогащенные текстом области документа. В альтернативном варианте, или в качестве дополнения, выходные данные из системы OCR могут включать в себя идентификации недостоверно распознаваемых символов, их положения на странице и т.д., обеспечивая краткое указание на то, где могут присутствовать подобные трудности. Например, краткое указание на подобную трудность может быть идентифицировано по тому, что в месте, где текстовая строка перечеркнута, будет присутствовать, по меньшей мере один символ, который нельзя распознать, а другие символы со столь же низким качеством будут нераспознаваемыми в текстовых строках над или под текущей строкой. Дополнительное исследование содержимого пикселей в пространстве между текстовыми строками может затем предоставить достоверное указание перечеркнутых символов, например, потому, что в нормальной ситуации эти пространства должны быть пустыми. Например, отслеживание контуров отпечатка при наличии наложенного объекта или отслеживание центровых линий отпечатка при наличии наложенного объекта может предоставить подтверждение присутствия в документе перечеркнутого текста. В других способах может использоваться модель известных отпечатков из штампов, которые, возможно, использовались на страницах документов. Вращая модельное изображение штампа, можно осуществить идентификацию отпечатка на странице. Другим указателем на присутствие перечеркнутого текста может служить размер текста в сравнении с размером наложенного объекта. Дополнительные способы могут предусматривать подтверждение перечеркнутого текста путем следования по кратчайшему расстоянию между символами с нарушенной видимостью на одной из строк текста, находящейся над другой текстовой строкой. Если на этой кратчайшей линии присутствуют отпечатки («включенные» пиксели), они, вероятно, относятся к наложенному объекту на странице, например к штампу. Также возможно использовать для идентификации длинных линий поперек страницы морфологические операторы. Однако в объем настоящего изобретения входит использование любых способов, обеспечивающих идентификацию перечеркнутых символов в изображении текста.
Идентификация перечеркнутого текста приводит в действие поиск изображений символов, фактически включающих в себя перечеркнутые области. Эти символы идентифицируются системой OCR как нераспознаваемые или недостоверно распознаваемые символы. Например, такие символы идентифицируются путем сопоставления сообщаемых символов и их положения на изображении текста с информацией, полученной при идентификации присутствия наложенного отпечатка. Затем эти изображения символов идентифицируются путем снабжения соответствующих символов текста ограничивающими блоками. В результате образцы символов включают в себя три типа возможных изображений перечеркнутых символов: первый тип - полностью перечеркнутые изображения, второй тип - изображения частично перечеркнутых символов, на которых перечеркнутая секция покрывает часть тела символа, третий возможный сценарий - перечеркнутая секция в ограничивающем блоке не пересекает и не касается тела символа, однако проходит через ограничивающий блок, не покрывая ни одной части тела символа. В последнем случае, вероятнее всего, система OCR будет неспособна правильно идентифицировать символ, поскольку избыточные «включенные» пиксели будут ухудшать алгоритм распознавания, используемый системой OCR. Полностью перечеркнутые символы можно достоверно идентифицировать, используя слова, частью которых они являются. Однако слово, которое включает в себя пропущенный символ (или полностью нераспознаваемый символ) будет предусматривать перечень возможных слов-кандидатов. Также существует вероятность маскировки наложенным объектом нескольких символов в словах. Разрешение противоречивых слов представляет собой изобретение другого типа, которое находится за пределами, ограничиваемыми объемом настоящего изобретения. Однако, как бы ни идентифицировался перечеркнутый символ, контроль идентификации, например, с использованием поиска по словарю, находится в пределах, ограничиваемых объемом настоящего изобретения. Если словарь возвращает слово, оно является возможным подтверждением рассматриваемого символа.
Поэтому настоящее изобретение предусматривает достоверное распознавание изображений частично перечеркнутых символов (вышеуказанных второго и третьего типов). Одной из особенностей настоящего изобретения является способность соотнесения частей, или местоположений областей, на изображениях между различными изображениями символов. Как известно специалистам в данной области, общая система отсчета может быть установлена путем использования в качестве точки отсчета, например, угла текстовой страницы, а затем использования упорядоченных пар чисел для отнесения отдельных пикселей, кластеров пикселей, связанных пикселей и т.д., что, однако, требует значительных усилий для преобразования координат при сопоставлении информации, находящей на текстовой странице в различных положениях. Информация местоположения или области об отличительных особенностях изображений символов и (или) о недостоверно распознаваемых символах может быть согласованно соотнесена со всеми изображениям соответствующих отдельных изображений символов в том случае, когда изображения выровнены друг относительно друга так, что максимально возможные доли тел символов находятся один над другим при рассмотрении изображений одно поверх другого. Для достижения такого выравнивания, необходимо вычислить смещения между различными изображениями, например, путем корреляции комбинаций изображений. Согласно примеру осуществления настоящего изобретения, ограничивающие блоки, используемые для разделения перечеркнутых символов с текстовой страницы, можно коррелировать с эталонными изображениями символов, таким образом получая смещение, используемое для выравнивания изображений согласно настоящему изобретению. Выравнивание, предусматриваемое вычислением максимальной корреляции и соответствующим ее размещением между изображениями, делает возможной идентификацию на изображении текстовой страницы областей образцов символов с нарушенной видимостью, которые фактически перечеркнуты относительно самого тела символа. Когда область идентифицирована, в то же положение относительно самого тела символа на эталонных изображениях символов может быть введена аналогичная область, включающая в себя перечеркнутые части. Это обеспечивает возможность изучения того, что остается от эталонных изображений, и сопоставления содержимого этих областей с областями образца символа с нарушенной видимостью, которые включают в себя участки с нарушенной видимостью. Поиск максимальной корреляции предусматривает измерение того, какое из эталонных изображений включает в себя области за пределами секций с нарушенной видимостью, которые в наибольшей степени эквивалентны аналогичным областям на образце с нарушенной видимостью, включающем в себя наложенный объект. Эталонное изображение, имеющее максимальную величину корреляции, является правильным выбором в качестве идентификации образца перечеркнутого символа с нарушенной видимостью.
На фиг.1 показана ситуация, в которой на части страницы проштампована буква Р из слова «COPY». В одном из примеров осуществления настоящего изобретения для иллюстрации примеров особенностей настоящего изобретения используется перечеркнутый символ а, указанный на фиг.1 стрелкой.
На фиг.2а показан символ a, заключенный в ограничивающий блок, отделяющий изображение символа а, которое включает в себя участок с нарушенной видимостью от остального изображения, включающего в себя текст. На фиг.2б показана ситуация, в которой область, включающая в себя участок с нарушенной видимостью, «вырезана», например, путем присвоения всем значением уровня серого пикселей значения фонового цвета (т.е. белого). Согласно одной из особенностей настоящего изобретения, сопоставление изображения с «вырезанным» перечеркнутым участком упрощает сопоставление этого изображения с другими изображениями символов. Изображение по фиг.2б затем используется для сопоставления изображения с другими эталонными изображениями.
После идентификации присутствия отпечатка и нарушения видимости текста, например, отпечатком из штампа, информация о точках, в которых отпечаток пересекает строки текста, может использоваться для идентификации входных и выходных точек отпечатка в ограничивающем блоке образца символа с нарушенной видимостью, поскольку образец символа с нарушенной видимостью фактически извлекается из положения на странице, где отпечаток фактически присутствует. Однако любой способ, предусматривающий идентификацию областей, которые включают в себя наложенный объект, находится в пределах, ограничиваемых объемом настоящего изобретения. Для определения того, что символ с нарушенной видимостью относится к одному из типов, подробно описанных выше, можно использовать размер отпечатка. Если тип символа - первый, процесс завершается, а два других типа наложенных объектов обрабатываются по способу в соответствии с настоящим изобретением.
Согласно примеру осуществления настоящего изобретения, изображение по фиг.2б коррелируют с эталонными изображениями, созданными из изображений символов, которые имеют качество изображения, превышающее заранее определенный пороговый уровень. На фиг.3а показано, как корреляция, идентифицированная путем корреляции изображения по фиг.2б с эталонным изображением по фиг.3б, обеспечивает выравнивание с изображением символа а с нарушенной видимостью внутри выбранного ограничивающего блока, а также как можно идентифицировать области, принадлежащие собственно к символу, и области, принадлежащие к перечеркнутым областям.
Согласно еще одному примеру осуществления настоящего изобретения, размеры тела символа на эталонных изображениях сопоставляются с размером степени наложения объекта в образце символа с нарушенной видимостью. Если размер тела символа на эталонном изображении (отмасштабированном по размеру шрифта в документе) оказывается меньше размера степени наложения участка с нарушенной видимостью, данные эталонные изображения исключаются из дальнейшего использования при поиске правильной идентификации образца символа с нарушенной видимостью, поскольку тела таких эталонных изображений будут полностью скрыты, например, отпечатком, нарушающим видимость изображений символов. Таким образом, можно ограничить количество сопоставлений.
На фиг.4а и 4б показано, как пиксели на изображениях, представляющих эталон, образец с нарушенной видимостью и перечеркнутые участки можно классифицировать как принадлежащие к одной из четырех различных классификаций. Такая классификация лучше всего достигается путем использования порога для эталонных изображений, который обеспечивает максимальную корреляцию образцом с нарушенной видимостью, включающим в себя перечеркнутый участок, а затем - введения идентифицированного перечеркнутого участка в данное эталонное изображение. Поскольку корреляция между изображениями предусматривает смещение, или сдвиг, между изображениями, эти классификации можно идентифицировать на всех изображениях, как показано, соответственно, на фиг.4а и 4б, и визуализировать, присваивая:
1. «включенным» пикселям, не затронутым перечеркнутым участком, - белый символ +;
2. «включенным» пикселям, затронутым перечеркнутым участком, - черный символ о,
3. «выключенным» пикселям, не затронутым перечеркнутым участком, - без визуализации;
4. «выключенным» пикселям, затронутым перечеркнутым участком, - черный символ х.
Существует несколько способов установления того, какое из эталонных изображений имеет максимальное сходство при сопоставлении с изображением символа с нарушенной видимостью. Например, к этим способам относится корреляция изображений после выравнивания соответствующих изображений. Согласно другому примеру осуществления настоящего изобретения, единственными представляющими интерес пикселями являются «включенные» пиксели, как установлено выше в классификации пикселей, заключенных в изображениях, которые обрабатываются системой OCR. Затем можно вычислить степень параллельности между «включенными» пикселями в образце символа с нарушенной видимостью и на эталонном изображении. Пример такой параллельности:
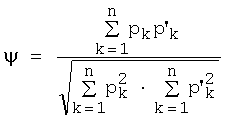
где pk - сдвиг незатронутых «включенных» пикселей в образце символа с нарушенной видимостью, а р'k - незатронутые «включенные» пиксели на эталонном изображении. Параллельность для примера эталона символа а по фиг.1 составляет 0,971, что является максимальным для всех эталонов, идентифицированных в данном документе. Таким образом, достигается правильная классификация.
Согласно одной из особенностей настоящего изобретения, описанные выше стадии способа наилучшим образом выполняются в том случае, когда эталонные изображения являются изображениями символов в том виде, в каком они встречаются в документе, обрабатываемом системой OCR. Эталонные изображения можно идентифицировать как изображения символов, имеющие качество, которое превышает заранее определенный уровень, и (или) как суперпозицию нескольких изображений одно поверх другого, представляющих одно и то же изображение символа и обозначаемую как класс символа.
Согласно одному из примеров осуществления настоящего изобретения, при создании классов символов осуществляются следующие стадии:
I. случайный выбор трех образцов из класса, корреляция всех комбинаций этих образцов и выбор пары коррелированных образцов, имеющей корреляцию, которая превышает заранее заданный пороговый уровень, в качестве исходного пункта для эталона класса данного символа;
II. если ни одна из комбинаций пар, выбранных на стадии I, не обладает корреляцией, превышающей пороговый уровень, - выбор других образцов из класса до получения пары, имеющей корреляцию, которая превышает заранее заданный пороговый уровень;
III. если ни одна из пар образцов, выбранных на стадии II, не имеет корреляции, которая превышает заранее заданный пороговый уровень, данный класс исключается из дальнейшего использования;
IV. для исходной пары, идентифицированной на стадии I или II, - корреляция изображений пары, идентифицирующая смещение между ними, затем - генерирование из изображений выровненного суммарного эталонного изображения, которое используется в качестве исходного эталонного изображения для класса соответствующего символа;
V. для всех остальных образцов в классе - их корреляция с суммарным эталоном (стадия IV) для идентификации смещения между ними и, если корреляция превышает заранее определенный порог, выравнивание изображений перед их сложением с суммарным изображением (стадия IV);
VI. если некоторые выровненные изображения, используемые на стадии V, включают в себя части, выходящие за пределы исходного эталона (стадия IV) - расширение суммарного эталона до нахождения всех образцов внутри ограничивающего блока, определяемого размером медианы ограничивающих блоков подмножества изображений, представляющего большинство изображений.
Согласно другому примеру осуществления настоящего изобретения, накопление выровненных изображений в эталон для класса, представляющего символ, также включает в себя сложение соответствующих значений уровня серого пикселей из соответствующих местоположений на выровненных изображениях так, чтобы перед осуществлением сложения каждое значение уровня серого пикселя было взвешено относительно обратной величины от количества выровненных изображений, накопленных на текущий момент в эталонном изображении для класса.
В некоторых случаях, в наборе эталонов, или классе, согласно настоящему изобретению, некоторые изображения символов пропущены. Это может приводить к ситуации, когда пропущено, например, эталонное изображение. Такие ситуации могут возникать, например, тогда, когда символ действительно редко используется в языке документа. Например, в норвежском языке символ с является редко используемым в отличие от других языков, где с - наиболее часто используемый символ. Типичной ошибочной альтернативой символу с является символ е. Разумно предположить, что для символа е эталон будет присутствовать, а для символа с - нет. Если пропуск символа с идентифицирован, можно предусмотреть синтетическое эталонное изображение на основе уже существующего эталонного изображения символа, который имеет сходство с пропущенным эталонным изображением. Тогда некоторые графические признаки символов, встречающихся в документе, который обрабатываются системой OCR, будут являться частью синтезированного эталонного изображения.
В одном из примеров осуществления, согласно настоящему изобретению, скрытый символ распознается путем осуществления следующих стадий способа, например, реализованных в компьютерной программе, присоединенной или связанной с системой OCR в единую компьютерную систему, или с другой компьютерной системой, присоединенной или связанной с компьютерной программой посредством сети:
Предполагается, что эталоны для существенных классов изображений символов и шрифтов накоплены, ограничивающий блок для скрытого символа (слова) идентифицирован, а также идентифицирована мера местоположения помех относительно ограничивающего блока.
Стадия 1: присвоение помехам на изображении символа репрезентативного фонового уровня (например черный инвертируется в белый или наоборот).
Стадия 2: корреляция с накопленными эталонами.
Стадия 3: сравнение накопленных эталонов с порогом, например, при помощи сравнения с порогом по алгоритму Canny.
Стадия 4: для каждого эталона-кандидата:
1. идентификация наложения загрязняющих помех на сдвинутом эталоне;
2. выбор «включенных» пикселей на эталоне, который не затронут помехами, и применение к этим пикселями и пикселями на сдвиге образцов метрики согласованности в соответствии с максимумами корреляции, используемыми для вычисления метрики согласованности;
3. корреляция сдвинутого эталонного изображения с изображением символа, где помехам (наложению) на обоих изображениях присвоен фоновый уровень, использование общих пикселей в изображении символа и сдвинутом эталонном изображении для нормирования;
4. сохранение максимального значения метрики для эталона;
5. сохранение максимальной корреляции для эталона;
Эталон с максимальным значением является наиболее вероятным символом для скрытого символа. Таким образом, скрытый символ идентифицирован.
Варианты осуществления:
1. Способ для разрешения противоречивых выходных данных из системы Оптического распознавания символов (OCR), где выходные данные включают в себя, по меньшей мере, один образец символа с нарушенной видимостью, которая вызвана, по меньшей мере, одним наложенным объектом в документе, обрабатываемом системой OCR, где способ включает в себя:
а) поиск по выходным данным для идентификации изображений символов, обладающих качеством изображения, которое превышает заранее определенный уровень, и использование этих изображений символов в качестве набора эталонных изображений для символов;
б) идентификация местоположения области участка с нарушенной видимостью, по меньшей мере, на одном образце символа с нарушенной видимостью;
в) использование информации о местоположении и области из образца символа с нарушенной видимостью для нахождения соответствующих областей на эталонных изображениях перед сопоставлением соответствующих эталонных изображений, по меньшей мере, с одним образцом символа с нарушенной видимостью, пренебрежение при сопоставлении содержимым изображения в найденных соответствующих областях, использование эталонного изображения, обладающего наибольшим сходством с изображением символа с нарушенной видимостью в качестве правильной идентификации символа с нарушенной видимостью.
2. Способ по варианту 1, отличающийся тем, что значениям уровней серого пикселей, заключенных в найденной области, скрывающего участка, присваивается значение фонового уровня.
3. Способ по варианту 1, отличающийся тем, что изображение образца символа с нарушенной видимостью и соответствующие эталонные изображения коррелируют для вычисления смещения между соответствующими изображениями, которое используется для выравнивания соответствующих изображений перед их сопоставлением.
4. Способ по варианту 1, отличающийся тем, что изображение образца символа с нарушенной видимостью коррелируют с каждым соответствующим эталонным изображением, перечень эталонных изображений, обеспечивающих корреляцию, которая превышает заранее определенный пороговый уровень, перечисляется как набор эталонных изображений-кандидатов, являющихся возможными правильными идентификациями образца символа с нарушенной видимостью, а затем соответствующие эталонные изображения-кандидаты используются при сопоставлении для получения правильной идентификации образца символа с нарушенной видимостью.
5. Способ по варианту 1, отличающийся тем, что сопоставление изображения образца символа с нарушенной видимостью с соответствующими эталонными изображениями вычисляется как метрика согласованности:
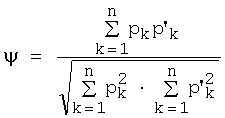
где р'k - значения пикселей на изображении, по меньшей мере, одного образца символа с нарушенной видимостью, принадлежащего к телу собственно символа, но не к фону изображения, а рk - значения соответствующим образом расположенных пикселей на соответствующем выровненном изображении эталонного изображения, принадлежащего к собственно телу эталонного символа, но не к фону изображения.
6. Способ по варианту 1, отличающийся тем, что стадия, предусматривающая эталонный набор, включает в себя сортировку всех сообщаемых идентифицированных символов, превышающих пороговый уровень, в классы, где каждый класс представляет один и тот же идентифицированный символ в эталонном наборе, а затем - осуществление стадий обеспечения изображений для каждого символа или класса в эталонном наборе путем:
I. Случайного выбора трех образцов в классе, корреляции всех комбинаций этих трех образцов, а затем - выбора пары коррелированных образцов, обеспечивающей корреляцию, которая превышает заранее заданный пороговый уровень, в качестве исходного пункта для эталона класса данного символа;
II. Если ни одна из комбинаций пар, выбранных на стадии I, не обладает корреляцией, превышающей пороговый уровень, - выбора других образцов из класса до получения пары, имеющей корреляцию, которая превышает заранее заданный пороговый уровень;
III. Если ни одна из пар образцов, выбранных на стадии II, не имеет корреляции, которая превышает заранее заданный пороговый уровень, - исключения класса из дальнейшего использования;
IV. Для исходной пары, идентифицированной на стадии I или II, - корреляции изображений пары, идентифицирующей смещение между ними, затем - генерирования из изображений выровненного суммарного эталонного изображения, которое используется в качестве исходного эталонного изображения для класса соответствующего символа;
V. Для всех остальных образцов в классе - их корреляции с суммарным эталоном (стадия IV) для идентификации смещения между ними и, если корреляция превышает заранее определенный порог, выравнивания изображений перед их сложением с суммарным изображением (стадия IV);
VI. Если некоторые выровненные изображения, используемые на стадии V, включают в себя части, выходящие за пределы исходного эталона (стадия IV) - расширения суммарного эталона после использования всех образцов.
7. Способ по варианту 6, отличающийся тем, что накопление выровненных изображений в эталоне класса, представляющего символ, также включает в себя сложение соответствующих значений уровней серого пикселей и соответствующих местоположений на выровненных изображениях таким образом, чтобы каждое значение уровня серого пикселя перед осуществлением сложения взвешивалось по обратной величине от количества выровненных изображений, накопленных на текущий момент в эталонном изображении для класса.
8. Способ по варианту 6, отличающийся тем, что в ситуации, когда класс символа пропущен по причине пропуска изображений идентифицированного символа в документе, обрабатываемом системой OCR, пропущенный эталонный класс синтезируется из другого существующего эталонного класса, имеющего сходство с пропущенным эталонным классом.






Изобретение относится к способу для разрешения противоречивых выходных данных из системы оптического распознавания символов (OCR). Технический результат заключается в повышении качества распознавания данных в системе оптического распознавания символов. В способе проводят поиск по выходным данным для идентификации изображений символов, обладающих качеством изображения, которое превышает заранее определенный уровень, и использование этих изображений символов в качестве набора эталонных изображений для символов, идентифицируют местоположение области участка с нарушенной видимостью на образце символа с нарушенной видимостью, используют информацию о местоположении и области из образца символа с нарушенной видимостью для нахождения соответствующих областей на эталонных изображениях перед сопоставлением соответствующих эталонных изображений с образцом символа с нарушенной видимостью, пренебрегая при сопоставлении содержимым изображения в найденных соответствующих областях, и используют эталонное изображение, обладающее наибольшим сходством с изображением символа с нарушенной видимостью в качестве правильной идентификации символа с нарушенной видимостью. 7 з.п. ф-лы, 7 ил.
1. Способ для разрешения противоречивых выходных данных из системы оптического распознавания символов (OCR), отличающийся тем, что выходные данные включают в себя, по меньшей мере, один образец символа с нарушенной видимостью, которая вызвана, по меньшей мере, одним наложенным объектом в документе, обрабатываемом системой OCR, где способ включает в себя:
а) поиск по выходным данным для идентификации изображений символов, обладающих качеством изображения, которое превышает заранее определенный уровень, и использование этих изображений символов в качестве набора эталонных изображений для символов;
б) идентификация местоположения области участка с нарушенной видимостью, по меньшей мере, на одном образце символа с нарушенной видимостью;
в) использование информации о местоположении и области из образца символа с нарушенной видимостью для нахождения соответствующих областей на эталонных изображениях перед сопоставлением соответствующих эталонных изображений, по меньшей мере, с одним образцом символа с нарушенной видимостью, пренебрегая при сопоставлении содержимым изображения в найденных соответствующих областях, и использование эталонного изображения, обладающего наибольшим сходством с изображением символа с нарушенной видимостью в качестве правильной идентификации символа с нарушенной видимостью.
2. Способ по п.1, отличающийся тем, что значениям уровней серого пикселей, заключенных в найденной области, скрывающего участка, присваивают значение фонового уровня.
3. Способ по п.1, отличающийся тем, что изображение образца символа с нарушенной видимостью и соответствующие эталонные изображения коррелируют для вычисления смещения между соответствующими изображениями, которое используют для выравнивания соответствующих изображений перед их сопоставлением.
4. Способ по п.1, отличающийся тем, что изображение образца символа с нарушенной видимостью коррелируют с каждым соответствующим эталонным изображением, перечень эталонных изображений, обеспечивающих корреляцию, которая превышает заранее определенный пороговый уровень, перечисляют как набор эталонных изображений-кандидатов, являющихся возможными правильными идентификациями образца символа с нарушенной видимостью, а затем соответствующие эталонные изображения-кандидаты используют при сопоставлении для получения правильной идентификации образца символа с нарушенной видимостью.
5. Способ по п.1, отличающийся тем, что сопоставление изображения образца символа с нарушенной видимостью с соответствующими эталонными изображениями вычисляют как метрику согласованности:
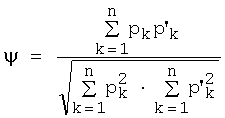
где p'k - значения пикселей на изображении, по меньшей мере, одного образца символа с нарушенной видимостью, принадлежащего к телу собственно символа, но не к фону изображения, pk - значения соответствующим образом расположенных пикселей на соответствующем выровненном изображении эталонного изображения, принадлежащего к собственно телу эталонного символа, но не к фону изображения.
6. Способ по п.1, отличающийся тем, что стадия, предусматривающая эталонный набор, включает в себя сортировку всех сообщаемых идентифицированных символов, превышающих пороговый уровень, в классы, где каждый класс представляет один и тот же идентифицированный символ в эталонном наборе, а затем - осуществляют стадии обеспечения изображений для каждого символа или класса в эталонном наборе путем:
I. случайного выбора трех образцов в классе, корреляции всех комбинаций этих трех образцов, а затем - выбора пары коррелированных образцов, обеспечивающей корреляцию, которая превышает заранее заданный пороговый уровень, в качестве исходного пункта для эталона класса данного символа;
II. выбора других образцов из класса до получения пары, имеющей корреляцию, которая превышает заранее заданный пороговый уровень, если ни одна из комбинаций пар, выбранных на стадии I, не обладает корреляцией, превышающей пороговый уровень;
III. исключения класса из дальнейшего использования, если ни одна из пар образцов, выбранных на стадии II, не имеет корреляции, которая превышает заранее заданный пороговый уровень;
IV. для исходной пары, идентифицированной на стадии I или II, - корреляции изображений пары, идентифицирующей смещение между ними, затем - генерирования из изображений выровненного суммарного эталонного изображения, которое используется в качестве исходного эталонного изображения для класса соответствующего символа;
V. для всех остальных образцов в классе - их корреляции с суммарным эталоном (стадия IV) для идентификации смещения между ними и, если корреляция превышает заранее определенный порог, выравнивания изображений перед их сложением с суммарным изображением (стадия IV);
VI. расширения суммарного эталона после использования всех образцов, если некоторые выровненные изображения, используемые на стадии V, включают в себя части, выходящие за пределы исходного эталона (стадия IV).
7. Способ по п.6, отличающийся тем, что накопление выровненных изображений в эталоне класса, представляющего символ, также включает в себя сложение соответствующих значений уровней серого пикселей и соответствующих местоположений на выровненных изображениях таким образом, чтобы каждое значение уровня серого пикселя перед осуществлением сложения взвешивалось по обратной величине от количества выровненных изображений, накопленных на текущий момент в эталонном изображении для класса.
8. Способ по п.6, отличающийся тем, что в ситуации, когда класс символа пропущен по причине пропуска изображений идентифицированного символа в документе, обрабатываемом системой OCR, пропущенный эталонный класс синтезируют из другого существующего эталонного класса, имеющего сходство с пропущенным эталонным классом.
| US 20020131642 A1, 19.09.2002 | |||
| US 20060056696 A1, 16.03.2006 | |||
| US 5751850 A, 12.05.1998 | |||
| US 5963666 A, 05.10.1999 | |||
| US 5745600 A, 28.04.1998 | |||
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА С ПРИМЕНЕНИЕМ НАСТРАИВАЕМОГО КЛАССИФИКАТОРА | 2002 |
|
RU2234126C2 |

