ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к автоматической обработке изображений отсканированных документов и других изображений, содержащих текст, а именно к способам и устройствам преобразования изображений документов, содержащих текст на арабском языке, а также текст на других языках, в которых при образовании слов алфавитные символы соединяются вместе в слитную последовательность, в электронные документы.
УРОВЕНЬ ТЕХНИКИ
Уже на протяжении долгого времени для записи и хранения информации используются печатные, машинописные и рукописные документы. Несмотря на современную тенденцию к отказу от бумажного делопроизводства печатные документы продолжают широко использоваться в коммерческих организациях, учреждениях и домах. С развитием современных компьютерных систем создание, хранение, поиск и передача документов в электронном виде превратилась, наряду с непрекращающимся применением печатных документов, в чрезвычайно эффективный и экономически выгодный альтернативный способ записи и хранения информации. Ввиду многочисленных преимуществ современных средств хранения и передачи информации на основе электронных документов с точки зрения как эффективности, так и экономической выгоды, происходит регулярное преобразование печатных документов в электронные с использованием различных способов и устройств, в том числе преобразование печатных документов в цифровые изображения отсканированных документов с использованием электронных оптико-механических сканирующих устройств, цифровых камер и других устройств и систем с последующей автоматической обработкой изображений отсканированных документов для получения электронных документов, закодированных в соответствии с одним или более всевозможных стандартов кодирования электронных документов. В качестве одного примера в настоящее время есть возможность использовать настольный сканер и современные программы оптического распознавания символов (OCR), которые, выполняясь на персональном компьютере, позволяют преобразовывать печатный документ в соответствующий электронный документ, который можно просматривать и редактировать с помощью программы обработки текстов.
Хотя на текущем этапе своего развития современные программы OCR позволяют автоматически преобразовывать в электронные документы сложные печатные документы, содержащие рисунки, рамки, границы строк и другие нетекстовые элементы, а также текстовые символы множества распространенных алфавитных языков, остаются нерешенными проблемы преобразования печатных документов, содержащих текст на арабском языке и текст на других языках, в которых при образовании слов и их фрагментов символы соединяются в слитную последовательность.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Изобретение относится к способам и устройствам преобразования изображений документов, содержащих текст на арабском языке и текст на других языках, в которых символы, соединяясь вместе, образуют слитные слова и фрагменты слов, в соответствующие электронные документы. В одном варианте реализации в рамках способа и устройства обработки изображений документов, к которым относится изобретение, применяются многочисленные методы и средства, позволяющие эффективно осуществлять преобразование изображений документов в электронные документы, которое без их использования было бы трудноосуществимым или практически нецелесообразным. Данные методы и средства включают преобразование морфем и слов изображений текста в параметризованные символы, эффективный поиск аналогичных морфем и слов в электронном хранилище морфем и слов, закодированных в виде непараметризованных символов, и идентификацию потенциальных точек разделения символов и соответствующих путей обхода с использованием аналогичных морфем и слов, найденных в хранилище слов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На Фиг. 1А-В показан печатный документ.
На Фиг. 2 показаны обычный настольный сканер и персональный компьютер, которые используются вместе для преобразования печатных документов в закодированные в цифровом виде электронные документы, которые можно хранить на запоминающих устройствах и (или) в электронной памяти.
На Фиг. 3 показана работа оптических компонентов настольного сканера, изображенного на Фиг. 2.
На Фиг. 4 представлена общая архитектурная схема различных видов компьютеров и других устройств с процессорным управлением.
На Фиг. 5 показано цифровое представление отсканированного документа.
На Фиг. 6 показаны шесть областей изображения отсканированного документа, распознанного в ходе начальной стадии преобразования изображения отсканированного документа, на примере типового документа 100, показанного на Фиг. 1.
На Фиг. 7 показано вращение в горизонтальной плоскости.
На Фиг. 8-10 показан подход к определению исходной ориентации области, содержащей текст.
На Фиг. 11А-С показан один подход к преобразованию изображения документа в электронный документ, применяемый в определенных системах OCR, которые доступны в настоящее время на рынке.
На Фиг. 12 в качестве альтернативы представлен процесс преобразования изображения документа в электронный документ, используемый в различных доступных в настоящее время на рынке способах и устройствах OCR.
На Фиг. 13А-Е в виде блок-схем приведен пример доступных в настоящее время на рынке способов преобразования документов, применяемых в системах OCR.
На Фиг. 14 показан источник добавочных вычислений, потребность в которых возникает в существующих системах OCR.
На Фиг. 15-17 показан один вычислительный подход к идентификации символа на изображении символа и определению его ориентации.
На Фиг. 18-19В показана другая метрика, которая может применяться для распознавания символа на изображении отсканированного документа.
На Фиг. 20А-В показана разновидность классификатора, который может использоваться для формирования гипотез разделения изображения строки текста на последовательность изображений символов.
На Фиг. 21 приведен пример изображения документа, включающего текст на арабском языке.
На Фиг. 22 показаны определенные характеристики текста на языке, напоминающем арабский.
На Фиг. 23 показаны дополнительные свойства текста на языке, напоминающем арабский.
На Фиг. 24 показаны другие дополнительные свойства текста на языке, напоминающем арабский.
На Фиг. 25 показана еще одна дополнительная особенность текста на языке, напоминающем арабский.
На Фиг. 26 показана еще одна дополнительная особенность текста на языке, напоминающем арабский.
На Фиг. 27 показана существенная трудность, связанная с использованием традиционных методов OCR для распознавания символов арабского языка.
На Фиг. 28А-В и 29 показан и обоснован подход, представленный раскрываемыми в настоящей заявке методами OCR, который может найти применение в отношении языков, напоминающих арабский.
На Фиг. 30А-В приведен пример способов OCR, в которых строки текста раскладываются на знаки или символы, к которым относится изобретение и которые особенно применимы в отношении текстов на языке, напоминающем арабский.
На Фиг. 31А-М показано преобразование морфемы или слова, извлеченного из изображения строки текста, в последовательность параметризованных символов.
На Фиг. 32 показано множество объектов, которые могут быть извлечены из текста на языке, напоминающем арабский, в рамках описываемого варианта реализации.
На Фиг. 33 показана простая trie-структура данных.
На Фиг. 34 показаны непараметризованные символы (далее - SFS), используемые для кодирования записей в trie-структуре данных, а также соответствие между параметризованными символами (далее - FSWAP), описанными выше со ссылкой на Фиг. 31А-М и 32, а также непараметризованные символы в одном варианте реализации.
На Фиг. 35 приведено детальное описание преобразования на основе параметров, показанного на Фиг. 34.
На Фиг. 36A-G показано использование trie-структуры, описываемой со ссылкой на Фиг. 33, при идентификации слов словарного состава, аналогичных или идентичных введенному слову.
На Фиг. 37А-В показаны фрагменты таблицы штрафов, используемых при поиске слов и морфем, аналогичных введенной последовательности параметризованных символов, в trie-структуре с записями, закодированными в виде непараметризованных символов.
На Фиг. 38 показаны источники морфем и слов, используемых для создания структуры данных о морфемах и словах, закодированных в виде непараметризованных символов (3022 на Фиг. 30), которые используются для определения потенциальных точек разделения знаков согласно способу и устройству, к которым относится изобретение.
На Фиг. 39A-D приведены блок-схемы, на которых показан один вариант реализации способов и устройств, к которым относится изобретение.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
Изобретение относится к способам и устройствам, использующим способы, которые имеют отношение к оптическому распознаванию символов. В настоящей заявке способы и устройства, к которым она относится, описаны с помощью блок-схем и различных иллюстрированных примеров. Знакомым с современной наукой и технологиями будет понятно, что оптическое распознавание символов предполагает преобразование закодированных в цифровом виде изображений документов в электронные документы и хранение электронных документов на электронных запоминающих устройствах и в подсистемах памяти компьютерных систем. Данные операции предполагают физические изменения в физических компонентах хранения данных. Данные физические изменения, как и все физические изменения в целом, могут быть описаны с помощью переменных термодинамического состояния, в том числе энтальпии и энтропии, и происходят через определенные временные интервалы. Системы оптического распознавания символов, эффективные в смысле меньшего количества производимых вычислений, как правило, обладают меньшим энергопотреблением и временем реакции. Таким образом, оптическое распознавание символов - это «осязаемый» физический процесс с физическими преобразованиями, который можно описать через энергопотребление, изменения в переменных термодинамического состояния и продолжительность действия. Управление физическими процессами, в том числе работой компьютерных систем, обычно описывается с использованием математических выражений и (или) фактического компьютерного кода или псевдокода. Однако данные представления применяются для описания физических процессов, связанных с физическими изменениями в компьютерной системе с управлением машинными командами, а также в других объектах и устройствах, обменивающихся информацией в электронной виде с данной компьютерной системой.
Изобретение относится к способам и устройствам преобразования изображений документов в соответствующие электронные документы, при этом изображения документов содержат текст на арабском языке или текст на других языках, в которых при образовании слов и их частей символы соединяются друг с другом. Различные диалекты арабского и других языков, в которых символы алфавита в составе печатного текста соединяются вместе, так же как буквы соединяются вместе в рукописном английском и русском языках, далее именуются «языки, напоминающие арабский». В рамках нижеследующего обсуждения сначала описываются вопросы, связанные с изображениями отсканированных документов и электронными документами, а затем - методы определения общей ориентации содержащих текст областей изображений отсканированных документов. Во втором подразделе описываются доступные в настоящее время на рынке способы и устройства OCR. В третьем подразделе обсуждаются проблемы преобразования изображений документов, содержащих текст на языке, напоминающем арабский, в электронные документы. Наконец, в четвертом подразделе приводится описание предпочтительных вариантов реализации способов и устройств, к которым относится изобретение.
Изображения отсканированных документов и электронные документы
На Фиг. 1А-В показан печатный документ. На Фиг. 1А показан исходный документ с текстом на японском языке. Печатный документ (100) включает в себя фотографию (102) и пять разных содержащих текст областей (104-108), содержащих японские иероглифы. Это типовой документ, используемый в нижеследующем обсуждении способа и устройств ориентации изображения текста. Текст на японском языке может писаться слева направо в виде горизонтальных строк, так же как пишется текст на английском или русском языке, однако также он может писаться сверху вниз в виде вертикальных столбцов. Например, как видно, область (107) содержит вертикально написанный текст, в то время как фрагмент текста (108) содержит текст, написанный горизонтально. На Фиг. 1В показан перевод на русский язык печатного документа, изображенного на Фиг. 1А.
Печатные документы могут быть преобразованы в закодированные в цифровом виде изображения отсканированных документов различными средствами, в том числе с использованием электронных оптико-механических сканирующих устройств и цифровых камер. На Фиг. 2 показаны обычный настольный сканер и персональный компьютер, которые используются вместе для преобразования печатных документов в закодированные в цифровом виде электронные документы, которые можно хранить на запоминающих устройствах и (или) в электронной памяти. Настольное сканирующее устройство (202) включает в себя прозрачное стекло (204), на которое лицевой стороной вниз помещается документ (206). Запуск сканирования приводит к получению закодированного в цифровом виде изображения отсканированного документа, которое можно передать на персональный компьютер (далее - «ПК») (208) для хранения на запоминающем устройстве. Программа отображения отсканированного документа может вывести закодированное в цифровом виде изображение отсканированного документа на экран (210) устройства отображения ПК (212).
На Фиг. 3 показана работа оптических компонентов настольного сканера, изображенного на Фиг. 2. Оптические компоненты этого CCD-сканера расположены под прозрачным стеклом (204). Фронтально перемещаемый источник яркого света (302) освещает часть сканируемого документа (304), свет от которой отражается вниз. Переизлученный и отраженный свет отражается от фронтально перемещаемого зеркала (306) на неподвижное зеркало (308), которое отражает излучаемый свет на массив CCD-элементов (310), формирующих электрические сигналы пропорционально интенсивности света, падающего на каждый из них. Цветные сканеры могут включать в себя три отдельных ряда или набора CCD-элементов с красным, зеленым и синим фильтрами. Фронтально перемещаемый источник яркого света и зеркало двигаются вместе вдоль документа, в результате чего получается изображение сканируемого документа. Другой тип сканера, использующего другой датчик изображения, называется CIS-сканером. В CIS-сканере подсветка документа осуществляется перемещаемыми светодиодами (LED), при этом отраженный свет светодиодов улавливается набором фотодиодов, который перемещается вместе со светодиодами.
На Фиг. 4 представлена общая архитектурная схема различных видов компьютеров и других устройств с процессорным управлением. Современную компьютерную систему можно описать с помощью высокоуровневой архитектурной схемы, как, например, ПК на Фиг. 2, на которой программы преобразования изображений отсканированных документов и программы оптического распознавания символов хранятся на запоминающих устройствах для передачи на запоминающее устройство и выполнения одним или несколькими процессорами. Запоминающие устройства могут быть представлены различными видами оперативных запоминающих устройств, энергонезависимых запоминающих устройств и различными видами периферийного оборудования для хранения данных, в том числе магнитными дисками, оптическими дисками и твердотельными запоминающими устройствами. Компьютерная система содержит один или несколько центральных процессоров (ЦП) (402-405), один или несколько модулей запоминающих устройств (408), соединенных с ЦП при помощи шины ЦП/память (410) или нескольких шин, первый мост (412), который соединяет шину ЦП/память (410) с дополнительными шинами (414) и (416) или другими средствами высокоскоростного соединения, в том числе несколькими высокоскоростными последовательными линиями связи. Данные шины или последовательные линии, в свою очередь, соединяют ЦП и запоминающее устройство со специализированными процессорами, такими как графический процессор (418), а также с одним или несколькими дополнительными мостами (420), соединенными с высокоскоростными последовательными линиями или с несколькими контроллерами (422-427), такими как контроллер (427), которые предоставляют доступ к различным видам устройств памяти (428), электронным дисплеям, устройствам ввода и другим подобным компонентам, подкомпонентам и вычислительным ресурсам.
На Фиг. 5 показано цифровое представление отсканированного документа. На Фиг. 5 в увеличенном виде (506) показан небольшой круглый фрагмент изображения (502) типового печатного документа (504). На Фиг. 5 также представлен соответствующий фрагмент закодированного в цифровом виде изображения отсканированного документа (508). Закодированный в цифровом виде отсканированный документ включает в себя данные, которые представляют собой двухмерный массив кодировок значений пикселов. В представлении (508) каждая ячейка сетки под символами (например, ячейка (509)) представляет собой квадратную матрицу пикселов. Небольшой фрагмент (510) сетки показан с еще большим увеличением (512) на Фиг. 5, при котором отдельные пиксели представлены в виде элементов матрицы, таких как элемент матрицы (514). При таком уровне увеличения края символов выглядят зазубренными, поскольку пиксель является наименьшим элементом детализации, который можно использовать для излучения или восприятия света определенной яркости. В файле закодированного в цифровом виде отсканированного документа каждый пиксель представлен фиксированным числом битов, при этом кодирование пикселей осуществляется последовательно. Заголовок файла содержит информацию о типе кодировки пикселей, размерах отсканированного изображения и другую информацию, позволяющую программе отображения оцифрованного отсканированного документа получать данные кодирования пикселей и передавать команды устройству отображения или принтеру с целью воспроизведения двухмерного изображения исходного документа по этим кодировкам. Для цифрового кодирования отсканированного изображения документа в виде монохромных изображений с оттенками серого обычно используют 8-битное или 16-битное кодирование пикселей, в то время как при представлении цветного отсканированного изображения может выделяться 24 или более бит для кодирования каждого пикселя, в зависимости от стандарта кодирования цвета. Например, в широко применяемом стандарте RGB для представления интенсивности красного, зеленого и синего цветов используются три 8-битных значения, закодированных с помощью 24-битного значения. Таким образом, оцифрованное отсканированное изображение, по существу, представляет документ аналогично тому, как цифровые фотографии представляют визуальные образы. Каждый закодированный пиксель содержит информацию о яркости света в определенных крошечных областях изображения, а для цветных изображений в нем также содержится информация о цвете. В оцифрованном изображении отсканированного документа отсутствует какая-либо информация о значении закодированных пикселей, например информация, что небольшая двухмерная зона соседних пикселей представляет собой текстовый символ.
Напротив, обычный электронный документ, созданный с помощью текстового редактора, содержит различные виды команд рисования линий, ссылки на представления изображений, такие как закодированные в цифровом виде фотографии и закодированные в цифровом виде текстовые символы. Одним из наиболее часто используемых стандартов для кодирования текстовых символов является стандарт Юникод. В стандарте Юникод обычно применяется 8-разрядный байт для кодирования символов ASCII (американский стандартный код обмена информацией) и 16-разрядные слова для кодирования символов и знаков множества языков, включая японский, китайский и другие неалфавитные текстовые языки. Большая часть вычислительной работы, которую выполняет программа OCR, связана с распознаванием изображений текстовых символов, полученных из оцифрованного изображения отсканированного документа, и с преобразованием изображений символов в соответствующие кодовые комбинации стандарта Юникод. Очевидно, что для хранения текстовых символов стандарта Юникод будет требоваться гораздо меньше места, чем для хранения растровых изображений текстовых символов. Более того, текстовые символы, закодированные по стандарту Юникод, можно редактировать, отображать различными шрифтами и обрабатывать множеством способов, доступных в программах обработки текстов, в то время как закодированные в цифровом виде изображения отсканированного документа можно изменить только с помощью специальных программ редактирования изображений.
На начальной стадии преобразования изображения отсканированного документа в электронный документ печатный документ (например, документ (100), показанный на рисунке 1) анализируется для определения в нем различных областей. Во многих случаях области могут быть логически упорядочены в виде иерархического ациклического дерева, состоящего из корня, представляющего документ как единое целое, промежуточных узлов, представляющих области, содержащие меньшие области, и конечных узлов, представляющих наименьшие области. На Фиг. 6 показаны шесть различных областей типового документа (100), показанного на Фиг. 1, которые были распознаны на начальной стадии преобразования изображения отсканированного документа. В данном случае дерево, представляющее документ, включает в себя корневой узел, соответствующий всему документу в целом, и шесть тупиковых узлов, каждый из которых соответствует одной из идентифицированных областей (602-607). Области можно идентифицировать, применяя ряд различных методов, в том числе различные виды статистического анализа распределения кодировок пикселей или значений пикселей по поверхности изображения. Например, в цветном документе фотографию можно выделить по большему изменению цвета в области фотографии, а также по более частым изменениям значений яркости пикселей по сравнению с областями, содержащими текст.
Как только в рамках начальной стадии анализа будут установлены различные области на изображении отсканированного документа, области, которые с большой вероятностью содержат текст, дополнительно обрабатываются подпрограммами OCR для выявления и преобразования текстовых символов в символы стандарта Юникод или любого другого стандарта кодировки символов. Для того чтобы подпрограммы OCR могли обработать содержащие текст области, определяется исходная ориентация содержащей текст области, благодаря чему в подпрограммах OCR эффективно используются различные способы сопоставления с эталоном для определения текстовых символов. Следует отметить, что изображения в документах могут быть не выровнены должным образом в рамках изображений отсканированного документа из-за погрешности в позиционировании документа на сканере или другом устройстве, формирующем изображение, из-за нестандартной ориентации содержащих текст областей или по другим причинам. В случаях, когда подпрограммы OCR не могут воспринять стандартную ориентацию строк и колонок текста, вычислительная задача сопоставления шаблонов символов с областями изображения отсканированного документа будет намного более сложной и ее выполнение будет намного менее эффективным, так как подпрограммы OCR будут, как правило, пытаться повернуть шаблон символа на угловые интервалы до 360° и при каждом повороте будут пытаться сопоставить данный шаблон символа с потенциальной содержащей текст областью изображения.
Следует пояснить, что исходная ориентация определяется поворотами содержащей текст области в горизонтальной плоскости. На Фиг. 7 показано вращение в горизонтальной плоскости. На Фиг. 7 квадратная область изображения отсканированного документа (702) располагается горизонтально с вертикальной осью вращения (704), проходящей по центру области. При вращении квадратной области по часовой стрелке на 90° получается ориентация (706), показанная на правой стороне Фиг. 7.
Как правило, сразу после выявления содержащей текст области изображение содержащей текст области преобразуется из изображения на основе пикселов в битовую карту в ходе бинаризации, когда каждый пиксель представляется значением бита «0», что указывает на то, что данный пиксель не содержится во фрагменте текстового символа, или значением бита «1», что означает, что данный пиксель содержится в текстовом символе. Таким образом, например, в черно-белой содержащей текст области изображения отсканированного документа, в которой текст напечатан черным цветом на белом фоне, пиксели со значениями менее порогового значения, соответствующего темным областям данного изображения, переводятся в биты со значением «1», тогда как пиксели со значениями, равными или превышающими пороговое значение, соответствующее фону, переводятся в биты со значение «0». Преобразование в значения битов, естественно, имеет произвольный характер, и возможно обратное преобразование, при этом значение «1» означает фон, а значение «0» - символ. Для более эффективного хранения битовая карта может быть подвергнута RLE-компрессии.
На Фиг. 8-10 показан подход к определению исходной ориентации области, содержащей текст. На Фиг. 8 показано формирование гистограммы, соответствующей одной ориентации содержащей текста области. На Фиг. 8 содержащая текст область (802) имеет вертикальную ориентацию. Содержащая текст область разделяется на колонки, разграничиваемые вертикальными линиями, такими как вертикальная линия (804). В каждой колонке подсчитывается количество битов со значением «1» на битовой карте, соответствующей содержащей текст области, которое используется для формирования гистограммы (806), показанной над содержащей текст областью. Колонки в содержащей текст области, не содержащие фрагментов символов или, что то же самое, содержащие только биты со значением «0», не имеют соответствующих колонок в гистограмме, тогда как колонки, содержащие фрагменты символов, соотносятся с колонками в гистограмме высотой, соответствующей пропорции битов в колонке со значением «1». В качестве альтернативы высота колонок гистограммы может масштабироваться с учетом абсолютного количества битов со значением «1» или представлять часть битов в колонке со значением «1» или часть количества битов со значением «1» в колонке в отношении общего количества битов со значением «1» в содержащей текст области.
На Фиг. 9 показаны гистограммы, сформированные для колонок и строк надлежащим образом ориентированной содержащей текст области. На Фиг. 9 содержащая текст область (902) выравнивается по границам страницы, строкам текста, параллельного верхней и нижней части страницы, и колонкам текста, параллельного сторонам страницы. Способ формирования гистограмм, описанный выше со ссылкой на Фиг. 8, был применен ко всей содержащей текст области (902) для формирования гистограмм для вертикальных колонок в содержащей текст области (904) и для горизонтальных строк в содержащей текст области (906). Следует отметить, что гистограммы показаны в виде слитных кривых, пики которых, такие как пик (908) в гистограмме (904) соответствуют центральным фрагментам колонок и строк текста, таких как текстовая колонка (910), которой соответствует пик (908), а впадины, такие как впадина (912), соответствуют колонкам и строкам пробелов между колонками и строками текста, таким как колонка пробела (914) между колонками текста (916) и (918). Сетка стрелок (920) на Фиг. 9 указывает на направление вертикальных и горизонтальных разделов, используемых для формирования гистограммы колонок (904) и гистограммы строк (906).
На Фиг. 10 показана та же содержащая текст область изображения, что показана на Фиг. 9, но с другой угловой ориентацией. В случае содержащей текст области с другой ориентацией (1002) применяется тот же метод, что был описан выше со ссылкой на Фиг. 9, когда гистограммы колонок (1004) и гистограммы строк (1006) формируются с помощью разделов колонок и строк в направлении вертикальных и горизонтальных стрелок (1008). В данном случае гистограммы обычно не имеют объектов и не имеют равноудаленных пиков и впадин, как на гистограммах, показанных на Фиг. 9. Причину этому можно легко понять, рассмотрев вертикальную колонку (1010), показанную на Фиг. 10 пунктирными линиями. Данная вертикальная колонка проходит через текстовые колонки (1012-1015) и колонки пробелов (1016-1020). Почти каждая вертикальная колонка и горизонтальная строка, кроме находящихся на крайних концах гистограмм, проходит как через текст, так и через пробел, в результате чего каждая из вертикальных колонок и горизонтальных строк, как правило, содержит биты со значением «1» и биты со значением «0».
Таким образом, программы оптического распознавания символов (OCR) могут изначально определить ориентацию содержащей текст области путем поворота данной области в пределах 90° и вычисления гистограмм колонок и строк на определенных угловых интервалах, в результате чего получается как минимум одна гребневидная гистограмма, а чаще всего две гребневидные гистограммы, как показано на Фиг. 9, с наилучшими соотношениями пик-впадина. Следует также отметить, что о пробелах между символами в строках и колонках можно судить по пробелам (922) и (924) между пиками в гистограммах колонок и строк.
Доступные в настоящее время на рынке способы и устройства OCR
На Фиг. 11А-С показан один подход к преобразованию изображения документа в электронный документ, применяемый в определенных системах OCR, которые доступны в настоящее время на рынке. Это иерархический по сути подход, который может интерпретироваться и реализовываться рекурсивно, хотя также возможны и нерекурсивные или частично рекурсивные способы определения ориентации. После определения начальной ориентации изображение документа (1102) обрабатывается путем разложения изображения документа на высокоуровневые фрагменты или элементы (1104-1106) изображения документа. В примере, приведенном на Фиг. 11А, изображение документа включает рисунок (1110), первый фрагмент текста (1112) и второй фрагмент текста (1114). Это высокоуровневые элементы изображения документа, которые раскладываются на соответствующие им изображение первого текстового блока (1104), изображение второго текстового блока (1105) и рисунок (1106). В данном случае рисунок является фундаментальным элементов изображения документа и не подлежит дальнейшему разложению. Однако на втором уровне разложения изображение первого текстового блока (1104) раскладывается на отдельные изображения текстовых строк (1116-1120), а изображение второго текстового блока (1105) далее раскладывается на изображения текстовых строк (1122-1123). На последнем уровне каждое изображение текстовой строки, такое как изображение текстовой строки (1123) далее раскладывается на отдельные символы, такие как изображения символов (1126-1134), соответствующие изображению текстовой строки (1123). В определенных вариантах реализации в случае языков, в которых слова образуются путем сочетания знаков алфавита, разложение изображений текстовых строк на изображения символов может включать по крайней мере частичное начальное разложение изображений текстовых строк на изображения слов.
Как показано на Фиг. 11А, определенные способы и устройства OCR сначала раскладывают изображение документа (1102) на изображения символов, такие как изображения символов (1126-1134), а затем конструируют электронный документ, соответствующий изображению документа. Во многих из таких устройств изображение символа является окончательной степенью разложения, выполняемого способами и устройствами OCR в отношении текстовых изображений. Способы и устройства OCR далее применяют множество различных методов преобразования изображений отдельных знаков в соответствующую кодировку данных знаков по стандарту Юникод. Конечно, для получения всевозможных видов кодировок символов могут применяться различные преобразования.
Наконец, как показано на Фиг. 11В, данные способы и устройства OCR формируют электронный документ, соответствующий изображению документа, в обратном иерархическом порядке, начиная с кодировок одинарных символов и нетекстовых элементов нижнего уровня. В случае языков, в которых слова образуются путем сочетания символов алфавита, кодировки символов, такие как кодировка символа (1140), сочетаются в слова, такие как слово (1142). На следующем уровне построения электронного документа слова сочетаются в текстовые строки, такие как текстовая строка (1144), содержащая слово (1142). На еще одном уровне построения электронного документа текстовые строки сочетаются во фрагменты текста, такие как фрагмент текста (1146), содержащий строку текста (1144). Наконец, все из элементов документа высшего уровня, таких как рисунки (1106), фрагмент текста (1148) и фрагмент текста (1150), складываются в электронный документ (1152), соответствующий изображению документа (1102). Электронный документ, как описывалось выше, может содержать Юникод-представления символов или знаков алфавита и различные виды контрольных последовательностей для образования рамок, границ и прочих объектов электронного документа. Таким образом, алфавитный символ (1140), как правило, является закодированным в цифровом виде символом, таким, например, как Юникод-символ, который соответствует изображению символа (1133) на Фиг. 11А. Аналогичным образом, как правило, рисунок (1145) является неким видом сжатого файла изображения, соответствующего рисунку (1106), отсканированного как часть изображения документа. Другими словами, если рассматривать разложение изображения документа на элементы изображения документа как древовидный процесс, как показано на Фиг. 11А, тупиковые узлы дерева преобразуются из отсканированных изображений в надлежащие цифровые кодировки, которые представляют информацию, содержащуюся в отсканированных изображениях, и затем цифровые кодировки собираются воедино в рамках процесса, показанного на Фиг. 11В, для создания закодированного в цифровом виде электронного документа.
На Фиг. 11А-В разложение изображения документа на элементы изображения, преобразование элементов изображения в соответствующие элементы электронного документа и построение электронного документа из элементов электронного документа для простоты показаны через преобразования типа «один ко многим» от элементов более высокого уровня к элементам более низкого уровня и от элементов более низкого уровня к элементам более высокого уровня. На обеих схемах все элементы на данном уровне сочетаются в один элемент более высокого уровня на следующем уровне. Тем не менее, способы и устройства OCR зачастую сталкиваются с множеством разных неоднозначностей и неопределенностей в ходе обработки изображений документов, что на стадии разложения приводит к возникновению нескольких возможных вариантов разложения элемента более высокого уровня на несколько элементов более низкого уровня, а на стадии построения электронного документа множество элементов более низкого уровня могут различным образом сочетаться в элементы более высокого уровня.
На Фиг. 11С показан один пример формирования нескольких гипотез в ходе разложения изображения документа. На Фиг. 11С исходное изображение документа (1102) согласно одной гипотезе, представленной стрелкой (1160), раскладывается на три компонента более низкого уровня (1104-1106), описанных выше со ссылкой на Фиг. 11А. Однако согласно второй гипотезе (1162) изображение текста может, напротив, быть разложено на один фрагмент текста (1164) и рисунок (1106). В данном случае граница между первым фрагментом текста (1112) и вторым фрагментом текста (1114) может быть нечеткой или полностью отсутствовать, в случае чего способам и устройствам OCR может понадобиться провести проверку двух альтернативных гипотез. Возникновение разветвления многовариантных гипотез, как на этапе разложения, так и на этапе построения преобразования изображений документов в электронные документы может привести к буквально тысячам, десяткам тысяч, сотням тысяч, миллионам и более возможных альтернативных вариантов преобразования. В общем, в способах и устройствах OCR для ограничения образования многовариантных гипотез и точного и эффективного перемещения по потенциально громадному множеству вариантов разложения и вариантов построения электронных документов с целью установления единственного наиболее вероятного варианта электронного документа, соответствующего изображению документа, применяются статистическое аргументирование, широкий спектр разных видов метрик и широкий спектр разных видов методов автоматической проверки гипотез.
На Фиг. 12 в качестве альтернативы представлен процесс преобразования изображения документа в электронный документ, используемый в различных доступных в настоящее время на рынке способах и устройствах OCR. Изображение документа (1202) раскладывается на множества элементов изображения высшего уровня (1204) и (1206) через реализацию двух альтернативных гипотез (1208) и (1210), соответственно. На следующем уровне изображения фрагментов текста в ходе первого начального разложения (1204) и данное единственное изображение фрагментов текста в ходе второго начального разложения (1206) раскладываются на изображения текстовых строк в соответствии с тремя гипотезами (1212-1214) по первому варианту разложения высшего уровня (1204) и двумя гипотезами (1216-1217) по второму варианту разложения высшего уровня (1206). Каждый элемент по данным пяти разным вариантам разложения второго уровня далее раскладывается в следующем уровне разложения на отдельные изображения символов согласно нескольким разным гипотезам, что в итоге дает 12 разных вариантов разложения до тупикового узла, таких как разложение до тупикового узла (1218). На второй стадии преобразования изображения документа в электронный документ каждый вариант разложения до тупикового узла преобразуется в эквивалентный вариант разложения на основе элементов электронного документа, а на третьей стадии преобразования изображения документа в электронный документ варианты разложения на основе элементов электронного документа выстраиваются в соответствующий электронный документ, такой как электронный документ (1222), соответствующий варианту разложения до тупикового узла (1218). На Фиг. 12 показано потенциальное множество электронных документов, которые могут быть сформированы через реализацию альтернативных гипотез в процессе преобразования, хотя в реальности в процессе происходит фильтрация различных альтернативных промежуточных, так что окончательный наиболее вероятный вариант электронного документа выбирается из разумного числа альтернатив на финальных этапах построения электронного документа. Другими словами, несмотря на большое потенциальное множество возможных вариантов электронных документов на этапах разложения и построения, происходит фильтрация и отсечение, так что в процессе преобразования фактически осуществляется исследование лишь относительно небольшого подмножества из общего множества вариантов реконструкции электронных документов. На первом уровне разложения на основе элементов электронного документа, на котором последовательность символов собирается в слово, этому слову как последовательности символов и, в свою очередь, фрагменту изображения строки текста, соответствующему этой последовательности символов, по сути, присваивается лексическая идентификация.
На Фиг. 13А-Е в виде блок-схем приведен пример доступных в настоящее время на рынке способов преобразования документов, применяемых в системах OCR. На Фиг. 13А приводится блок-схема подпрограммы «преобразование документа», которая на этапе (1302) получает изображение документа, преобразует изображение документа в электронный документ и возвращает электронный документ на этапе (1304). На этапе (1306) подпрограмма «преобразование документа» устанавливает каждое множество вариантов разложения на ноль, устанавливает переменную numResolutions на 0 и устанавливает переменную bestDocument на ноль. В качестве одного примера варианты разложения, содержащиеся в множестве вариантов разложения, являются тупиковыми узлами дерева разложения, показанного на Фиг. 12. На этапе 1307 подпрограмма «преобразование документа» вызывает подпрограмму «сформировать варианты разложения» для выполнения первой стадии преобразования документа с формированием множества различных вариантов разложения полученного изображения документа, таких как варианты разложения, описанные выше со ссылкой на Фиг. 12, в том числе вариант разложения (1218), непосредственно над горизонтальной пунктирной линией (1220), разделяющей стадию разложения и стадию построения электронного документа. После вызова на этапе (1307) подпрограмма «сформировать варианты разложения» переменные варианты разложения, установленные на ноль на этапе (1306), содержат наиболее вероятные варианты разложения полученного изображения документа или варианты его разложения с наивысшей оценкой. Переменными вариантами разложения, таким образом, является множество вариантов разложения, каждый из которых сам по себе состоит из множества элементов изображения, полученных на стадии первичного разложения в рамках процесса преобразования. Далее в цикле с параметром на этапах (1308-1313) подпрограмма «преобразование документа» создает электронный документ для каждого варианта разложения во множестве, к которому отсылают переменные варианты разложения, и выбирает из созданных электронных документов наилучший или получивший наивысшую оценку. На этапе (1309) вызывается подпрограмма «сформировать электронный документ», которая создает электронный документ из рассматриваемого в текущий момент варианта разложения. Если переменная bestDocument равна нулю, как установлено на этапе (1310), или оценка, соотнесенная с электронным документом, к которому отсылает переменная bestDocument, меньше оценки, соотнесенной с только что сформированным на этапе (1309) электронным документом, как установлено на этапе (1311), переменная bestDocument получает команду отсылать к только что возвращенному электронному документу на этапе (1312). При наличии других подлежащих обработке вариантов разложения, как установлено на этапе (1313), цикл переходит на следующую итерацию. Когда все варианты разложения будут рассмотрены в рамках цикла с параметром, то, если значение переменной bestDocument все еще остается равным нулю, как установлено на этапе (1314), на этапе (1315) возвращается сообщение об ошибке. В противном случае, как описано выше, на этапе (1304) возвращается электронный документ, к которому отсылает переменная bestDocument.
На Фиг. 13В показана блок-схема подпрограммы «сформировать варианты разложения», вызываемой на этапе (1307) на Фиг. 13А. На этапе (1320) подпрограмма «сформировать варианты разложения» получает множество поддоменов sd и индекс конкретного поддомена в составе данного множества поддоменов, подлежащего дальнейшему расширению или разложению. В начале, при первом вызове подпрограммы «сформировать варианты разложения», множество поддоменов - это множество из одного элемента, представляющего собой целое изображение документа. На этапе (1322) подпрограмма «сформировать варианты разложения» вызывает подпрограмму «разложить», которая раскладывает множество поддоменов на множество множеств поддоменов путем разложения индексированного поддомена на поддомены более низкого уровня. Каждое множество поддоменов во множестве множеств поддоменов соотнесено с метрикой или вероятностью, которая указывает на возможность того, что вариант разложения, представленный данным множеством поддоменов, является верным. В рамках цикла с параметром на этапах (1324-1333) рассматривается каждое множество поддоменов s в составе множества множеств поддоменов, возвращенного подпрограммой «разложить». По завершении разложения множества поддоменов s, как установлено на этапе (1325), если количество вариантов разложения меньше максимального желаемого количества вариантов разложения, как установлено на этапе (1326), элементы множества поддоменов s добавляются к следующему свободному варианту разложения во множестве вариантов разложения, а вероятность, соотнесенная с данным множеством поддоменов, на этапе (1327) соотносится с вариантом разложения. Если максимальное количество вариантов разложения достигнуто, но вероятность, соотнесенная с рассматриваемым в текущий момент множеством поддоменов s больше варианта разложения, с которым соотнесена самая низкая вероятность во множестве вариантов разложения, то вариант разложения с самой низкой вероятностью удаляется из множества вариантов разложения для создания свободного варианта разложения, в который на этапе (1327) добавляются элементы множества поддоменов s. Если s разложено не полностью, то для каждого не полностью разложенного элемента в s вызывается подпрограмма «сформировать варианты разложения», при этом аргумент index, указывающий на данный элемент, разворачивает данный элемент в поддомены более низкого уровня в рамках цикла с параметром на этапах (1330-1332).
На Фиг. 13С показана блок-схема подпрограммы «разложить», вызываемой на этапе (3122) на Фиг. 13В. На этапе (1340) подпрограмма «разложить» получает множество поддоменов sd и индекс. На этапе (1342) подпрограмма «разложить» инициализирует множество поддоменов s_set, которое может содержать до sMax множеств поддоменов. На этапе (1342) подпрограмма «разложить» также устанавливает переменную numSets на 0. Затем в рамках цикла с параметром на этапах (1344-1353) каждое из множеств классификаторов используется для установления варианта разложения поддомена, на который указывает аргумент index, с целью создания множества вариантов разложения более низкого уровня, nxt, для множества поддоменов sd. Классификаторы - это подпрограммы, которые разлагают элемент изображения, или поддомен, на первом уровне на поддомены следующего уровня или которые преобразуют элемент изображения документа в элемент электронного документа. Классификаторы, как правило, специфичны для конкретных видов поддоменов изображения на конкретных уровнях разложения. На этапе (1345) инициализируется рассматриваемый далее классификатор и в рамках цикла с предусловием, а на этапах (1346-1352) данный классификатор итерационно вызывается для создания последовательных множеств поддоменов для поддомена множества поддоменов sd, на который указывает index. На этапе (1347) множество поддоменов, nxt, созданное для поддомена, на который указывает index, используется для замены поддомена, на который указывает index, в составе множества поддоменов sd, создавая новое более разложенное множество поддоменов nxtSd. Классификатор соотносит сформированное множество поддоменов с вероятностью, которая затем включается в общую вероятность, соотнесенную с nxtSd. Если количество множеств, хранящихся в s_set, меньше sMax, как установлено на этапе (1348), на этапе (1349) множество поддоменов nextSd добавляется к множеству поддоменов s_set. В противном случае, если вероятность, соотнесенная с nextSd, больше вероятности множества поддоменов с наиболее низкой вероятностью в s_set, как установлено на этапе (1350), то на этапе (1351) данное множество поддоменов с самой низкой вероятностью удаляется из s_set, a nextSd на этапе (1349) добавляется к множеству поддоменов s. Если классификатор может вернуть другое множество поддоменов nxt, как установлено на этапе (1352), обрабатывается следующее множество поддоменов nxt начиная с этапа (1347). В противном случае при наличии дополнительных классификаторов, которые должны быть применены к данному множеству поддоменов sd, как установлено на этапе (1353), поток управления возвращается к этапу (1345) и запускает формирование множеств поддоменов с использованием следующего классификатора. В противном случае множество множеств поддоменов s_set возвращается на этап (1354).
На Фиг. 13D показана блок-схема подпрограммы «инициализировать классификатор», вызываемой на этапе (1345) на Фиг. 13С. Подпрограмма «инициализировать классификатор», показанная на Фиг. 13D, специфичная подпрограмма инициализации классификатора, который формирует возможные точки разделения символов в строке текста. На этапе (1356) подпрограмма «инициализировать классификатор» формирует множество возможных межсимвольных точек в строке текста через вызов подпрограммы, а затем на этапе (1358) формирует возможные пути через межсимвольные точки, как описано ниже со ссылкой на Фиг. 20А-В.
После завершения стадии разложения в рамках процесса преобразования изображения документа, наглядно показанного в виде дерева разложения на Фиг. 12 выше, пунктирная горизонтальная линия (1220), элементы тупикового узла изображения, такие как изображения символов, необходимо преобразовать в соответствующие цифровые кодировки. Это можно сделать с помощью классификаторов трансформации, вызываемых описанной выше подпрограммой «разложить», либо в рамках отдельной стадии процесса преобразования изображения документа в электронный документ. Преобразование изображений символов в Юникод-символы или некую иную цифровую кодировку символов представляет собой существенный этап процесса преобразования изображения документа в электронный документ, который в доступных в настоящее время на рынке системах может быть связан с высокими вычислительными затратами. На Фиг. 13Е показана подпрограмма «идентифицировать символ», которая преобразует изображение символа в символ, закодированный в цифровом виде. На этапе (1360) подпрограмма «идентифицировать символ» получает изображение символа, устанавливает переменную bestMatch на ноль и устанавливает переменную bestScore на ноль. Далее в рамках цикла с параметром на этапах (1362-1370) подпрограмма «идентифицировать символ» рассматривает каждый возможный шаблон символа для языка текста, содержащего изображение символа, с целью идентификации шаблона символа, который точнее всего совпадает с изображением символа. В рамках внутреннего цикла с параметром на этапах (1363-1369) подпрограмма «идентифицировать символ» рассматривает всевозможные варианты масштабирования шаблона символа с целью сопоставления размера шаблона символа с размером полученного изображения символа. В рамках самого внутреннего цикла с параметром на этапах (1364-1368) подпрограмма «идентифицировать символ» рассматривает каждое из различных возможных сочетаний вертикальных и горизонтальных сдвигов масштабированного шаблона символа в отношении изображения символа с целью подгонки шаблона символа к изображению символа. На этапе (1365) подпрограмма «идентифицировать символ» пытается сопоставить изображение символа с шаблоном символа р при рассматриваемом в текущий момент масштабировании s и сдвиге t. Если оценка, полученная в результате операции сопоставления, превышает оценку, содержащуюся в переменной bestScore, как установлено на этапе (1366), то переменная bestScore обновляется с учетом оценки, возвращенной в результате операции сопоставления, которая только что была завершена на этапе (1365), а переменная bestMatch устанавливается на отсылку к рассматриваемому в текущий момент шаблону символа р.
Подпрограмма «идентифицировать символ», так же как и подпрограммы «преобразование документа», «сформировать варианты разложения» и «разложить», и различные классификаторы представляют собой примеры способов и методов преобразования изображения документа в электронный документ. Существует множество различных подходов к реализации способа и устройства преобразования изображения документа в электронный документ, описанных на Фиг. 11А-12.
В случае иероглифических языков, таких как китайский или японский, подпрограмме «идентифицировать символ» может потребоваться рассмотреть десятки тысяч и более различных шаблонов символов. Даже в случае алфавитных языков, таких как английский, подпрограмме «идентифицировать символ» может потребоваться рассмотреть многие тысячи и десятки тысяч шаблонов символов. На Фиг. 14 показан источник добавочных вычислений, потребность в которых возникает в известных системах OCR. На Фиг. 14 изображение символа «R» (1402) сопоставляется подпрограммой «идентифицировать символ» с шаблонами символов, хранящимися для английского языка. Как показано на Фиг. 14, даже для символа «R» может быть большое количество разных шаблонов символов (1404). Однако подпрограмме «идентифицировать символ» необходимо не только попытаться сопоставить изображение символа (1402) с различными шаблонами символов, соответствующими символу «R», но и попытаться сопоставить изображение символа с множеством различных шаблонов символов для всех символов, которые фигурируют в тексте на английском языке, при этом многоточия на каждой стороне блока шаблонов «R» указывают, что для «R», а также для всех прочих букв в верхнем регистре и нижнем регистре, числительных и знаков препинания существует множество дополнительных шаблонов.
На Фиг. 15-17 показан один вычислительный подход к идентификации символа на изображении символа и определению его ориентации. В данном подходе применяется классификатор первого вида, который преобразует элемент изображения в соответствующий элемент электронного документа. На Фиг. 15 японский иероглиф (1502) показан наложенным на прямоугольную сетку (1504). Так же как в области (508) на Фиг. 5, каждый элемент или ячейка сетки представляет собой матрицу элементов-пикселей, в результате чего края символов выглядят сглаженными. В большем увеличении, как и в области (512) на Фиг. 5, края символов будут выглядеть зазубренными. Как было описано выше, данным пикселям присваивается одно из двух значений бита («0» или «1») в зависимости от того, соответствует ли пиксель фрагменту фона или фрагменту символа, соответственно. Часть пикселей в каждой колонке элементов сетки включается в гистограмму (1506), показанную над прямолинейной сеткой (1504). Данная гистограмма представляет собой горизонтальное пространственное распределение пикселей символов в прямолинейной сетке, в которой представлен содержащий один символ фрагмент изображения отсканированного документа. Аналогичным образом гистограмма (1508) показывает пространственное распределение пикселей символов в вертикальном направлении. Гистограмма (1510) связана с гистограммой (1506) зеркальной симметрией, а гистограмма (1512) связана с гистограммой (1508) также по принципу зеркальной симметрии. Данные гистограммы являются подписями или характеристиками для идентификации символа и определения его ориентации.
На Фиг. 16 показана числовая метрика, которую можно вычислить на основе двух из четырех гистограмм, показанных на Фиг. 15. На данной фигуре метрика ориентации, называемая «метрикой гистограммы» или «h-метрикой», вычисляется на основе верхней гистограммы и правой гистограммы ((1506) и (1508)), вычисленных для определенного символа с определенной ориентацией. Каждая гистограмма разделяется на четыре области пунктирными вертикальными линиями, такими как пунктирная вертикальная линия (1602). Каждой области присваивается значение «0» или «1» в зависимости от того, превышает ли колонка гистограммы в заданной области пороговое значение, скажем 0,5. Данные значения битов упорядочены в том же порядке, что и разделы. Таким образом, например, в случае гистограммы (1506) в разделах (1604) и (1606) отсутствуют колонки, превышающие пороговое значение или высоту 0,5, тогда как в разделах (1608) и (1610) есть по крайней мере одна колонка гистограммы, превышающая пороговое значение или высоту 0,5. Таким образом, значения битов, присвоенные разделам, образуют полубайт «0110» (1612). Аналогичное вычисление для правой гистограммы (1508) образует полубайт «0011» (1614). Данные два полубайта можно объединить для получения восьмибитовой h-метрики (1616).
На Фиг. 17 показаны h-метрики, образованные по каждой из четырех ориентаций для асимметричного символа, показанного в нижней строке на Фиг. 14. Каждая ориентация символа показана в колонке (1702), соответствующая восьмибитовая h-метрика показана в колонке (1704), а эквивалентный десятичный номер показан в колонке (1706). Очевидно, что образование h-метрик для каждой из возможных ориентаций символа позволяет легко определять ориентацию символа на изображении отсканированного документа. Аналогичным образом разные символы образуют разные гистограммы и будут иметь разные h-метрики в каждой ориентации по сравнению с h-метриками иероглифа японского языка (1502).
На Фиг. 18-19В показана другая метрика, которая может применяться для распознавания символа на изображении отсканированного документа. Данная метрика может использоваться классификатором второго вида, который преобразует элемент изображения в соответствующий элемент электронного документа. На Фиг. 18 показано представление символа (1802) в трех разных масштабах (1804-1806). Для распознавания определенного символа, а также определения его ориентации, представление может быть наложено на содержащую один символ область изображения отсканированного документа и перемещаться вертикально и горизонтально с целью вычисления поверхности перекрытия (в процентах) представлением символа пикселей символа в содержащей один символ области изображения отсканированного документа в разных положениях. Метрику перекрытия, или о-метрику, можно вывести как максимальное перекрытие представления и пикселей символа в базовой области изображения отсканированного документа во всех из возможных положений. Например, на Фиг. 19А показано несколько разных положений представления в отношении базовой области изображения отсканированного документа, при этом в положении (1902) достигается максимальное перекрытие в размере 60 процентов. Когда такой же процесс выполняется в отношении области изображения отсканированного документа, которая содержит тот же символ с той же ориентацией, что в представлении, достигается максимальное перекрытие в размере 100 процентов (1904). Таким образом, путем вычитания из 1 максимального перекрытия, выраженного как дробь от 0 до 1, получаем дополнительную метрику распознавания и определения ориентации символа, которая может использоваться сама по себе или в сочетании с вышеописанной h-метрикой как для распознавания символа изображения отсканированного документа, так и для определения ориентации символа с маркером ориентации. Значение о-метрики теоретически находится в диапазоне [0, 1], где 0 указывает на точное перекрытие, а 1 означает отсутствие перекрытия, хотя на практике редко удается достичь значения выше 0,95. Как и в случае с h-метрикой, существует множество возможных альтернативных подходов к формированию о-метрики, таких как описанный выше со ссылкой на Фиг. 18-19А. Например, о-метрику можно, как вариант, вычислять как разницу между максимальным перекрытием и средним фактическим перекрытием во всех положениях рассматриваемого представления символов. В число других видов метрик могут входить процентное содержание пикселей символа в содержащей один символ области изображения отсканированного документа и процентное содержание пикселей символа в подобластях содержащей один символ области изображения отсканированного документа. Во многих вариантах реализации для распознавания символа и определения его ориентации могут использоваться десятки и даже сотни разных метрик.
На Фиг. 20А-В показана разновидность классификатора, который может использоваться для формирования гипотез, или вариантов разложения, применительно к разложению изображения строки текста на последовательность изображений символов. Данный третий вид классификаторов разлагает элемент изображения документа на множество элементов изображения документа более низкого уровня. Данный вид классификаторов абстрактно показан на Фиг. 20А-В. В верхней части Фиг. 20А изображение строки текста (2002) представлено в виде заштрихованной накрест горизонтальной полосы. На первом этапе осуществляется идентификация смежных несимвольных битов в битовой карте, содержащей строку текста. Они показаны в виде пробелов (2004-2018). Далее классификатор может рассмотреть все возможные пути, которые ведут от начала строки текста до конца строки текста через идентифицированные пробелы. Например, первый путь, который обходит все идентифицированные пути, показан в отношении разделенной строки текста (2020), где путь состоит из последовательности дуг, таких как дуга (2022). На пути, показанном со ссылкой на строку текста (2020), имеется 15 пробелов (2004-2018) и, следовательно, 15 разных дуг. На другом краю имеется путь одной дуги (2024), показанный в отношении строки текста (2026). Три дополнительных пути показаны в отношении строк текста (2028-2030). Возможные пути представляют собой различные гипотезы о группировке областей изображения строки текста в элементы более высокого уровня.
Во избежание потенциального комбинаторного взрыва, который последует в случае рассмотрения каждой возможной гипотезы, или каждого возможного пути, в качестве отдельного варианта разложения в процессе преобразования изображения документа возможным путям присваиваются общие оценки, и в качестве гипотез отбираются только один или несколько путей с наивысшей оценкой. На Фиг. 20В показан процесс оценки пути. В рамках подхода, показанного на Фиг. 20В, каждая дуга, такая как дуга (2040), соотносится с весом, как, например, вес 0,28 (2042), соотнесенный с дугой (2040). Существует множество способов вычислить вес дуги. В одном примере вес дуги вычисляется (2044) как ширина пробела (2046) в основании строки текста, на которую указывает дуга, умноженная на обратную величину абсолютного значения разницы между интервалом, представленным дугой (2048), и средним интервалом по строке текста, при этом фрагмент текста включает данную строку текста или некий иной элемент изображения более высокого уровня. Данный конкретный расчет веса дуги (2044) предполагает, что чем шире пробел, тем большее вероятность того, что данный пробел представляет границу между символами или словами, и что длины символов или слов находятся в диапазоне средних величин длины. Данный третий тип классификаторов может использоваться в одном случае для разложения строк текста на символы, а в другом для разложения строк текста на слова. Функция взвешивания, позволяющая определить вес дуг, может иметь различные характеристики в зависимости от того, осуществляется ли разложение строки текста на символы или на слова. Окончательная оценка гипотезы, представленной определенным путем, который обходит пробелы, таким как путь, представленный дугами в строке текста (2050) на Фиг. 20В, вычисляется как сумма весов отдельных дуг (2052).
Трудности при обработки текстов на арабском и подобных ему языках
На Фиг. 21 приведен пример изображения документа, включающего текст на арабском языке. В настоящее время доступные на рынке способы и устройства OCR не обеспечивают надежного преобразования изображений документов, содержащих текст на языках, напоминающих арабский. На Фиг. 22 показаны определенные свойства текста на языке, напоминающем арабский. Та же система письма, используемая в различных диалектах арабского языка, также используется в других языках, в том числе персидском, пушту, урду и нескольких тюркских языках. Более того, подобные свойства текста можно обнаружить также в языках деванагари, хинди и корейском языке.
Одно из свойств текста на подобном языке заключается в том, что строки текста читаются справа налево (2204) и сверху вниз (2206). Другое свойство текста на языке, напоминающем арабский, заключается в том, что в нем отдельные символы алфавита соединяются вместе в, как правило, слитные текстовые элементы, которые представляют слова (2208) и (2210). Напротив, в английском, немецком, русском и других алфавитных языках в печати отдельные символы, как правило, отделяются друг от друга межсимвольными интервалами.
На Фиг. 23 показаны дополнительные объекты текста на языке, напоминающем арабский. На Фиг. 23 показаны различные способы, которыми один символ алфавита, «ba», может быть написан в зависимости от того, где в слове встречается символ «ba». Сам по себе символ «ba» пишется с небольшим наклоном в виде нижней части петли или эллипса (2302). Однако при написании в начале слова символ «ba» имеет форму (2304), при написании внутри слова символ «ba» имеет различные представления, как, например, в многосимвольных сочетаниях (2305), а в конце слова символ «ba» пишется в форме, продемонстрированной на примере сочетания символов (2306). На Фиг. 23, представлены многочисленные примеры форм символа «ba» в начале слова, внутри слова и в конце слова (2308-2310).
На Фиг. 24 показаны другие дополнительные свойства текста на языке, напоминающем арабский. Одно дополнительное свойство заключается в том, что для обеспечения в строке текста промежутков различной величины могут быть соединены два символа алфавита с помощью очень длинного удлиняющего штриха (2402). Еще одной дополнительной чертой является то, что текст на языке, напоминающем арабский, как правило, включает большое число различных видов диакритических знаков, таких как диакритические знаки (2404-2407) и (2410-2412). Данные диакритические знаки могут представлять различные гласные буквы, которые обычно не пишутся в виде символов в тексте на языке, напоминающем арабский, могут представлять ударение, а также могут использоваться для других лингвистических целей. Зачастую диакритические знаки являются необязательными и не всегда используются единообразно. Другой дополнительной чертой является то, что, тогда как слова, как правило, образуются путем соединения нескольких символов алфавита вместе, определенные слова также могут включать разрывы в виде межсимвольных промежутков. Таким образом, хотя, как правило, слова представляют собой множества символов алфавита, соединенных вместе с образованием непрерывного метасимвола так же, как в английском языке при написании слов от руки, есть случаи, когда внутри слов встречаются промежутки.
На Фиг. 25 показана еще одна дополнительная особенность текста на языке, напоминающем арабский. В арабском языке существует множество различных лигатур, в которых отдельные символы алфавита или части символов алфавита соединяются вместе, образуя символы, представляющие сочетания основных символов. Данные символы-сочетания могут быть символоподобными подсловами или могут представлять полные слова. На Фиг. 25 показана лигатура (2502), представляющая слово «Аллах». Разные части данной лигатуры показаны с помощью пунктирных кругов и идентифицируются с помощью наименований символов в представлении (2504) лигатуры (2502) в нижней части Фиг. 25.
На Фиг. 26 показана еще одна дополнительная особенность текста на языке, напоминающем арабский. На Фиг. 26 фраза, написанная в первом сценарии (2602), показана в письменном виде при отображении в ряде различных шрифтовых начертаний (2604-2611). Как ясно вытекает из Фиг. 26, с точки зрения сопоставления изображений различные шрифты достаточно сильно друг от друга отличаются.
На Фиг. 27 показана существенная трудность, связанная с использованием традиционных методов OCR для распознавания символов арабского языка. На Фиг. 27 были применены традиционные способы распознавания фрагмента текста (1104) и разложения данного фрагмента текста на строки текста (1116-1120), описанные выше со ссылкой на Фиг. 11А-В. Однако в случае языков, подобных арабскому, как правило, существует значительно больше возможных вариантов разложения строк текста на потенциальные слова, таких как варианты разложения строк на слова (2702-2704), а также намного большее количество возможных вариантов разложения потенциальных слов на знаки, таких как вариант разложения потенциальных слов (2706) на всевозможные множества символов (2708-2714). В результате вычислительная сложность традиционных способов, описанных выше в отношении Фиг. 11А-В, может превышать пределы практической реализуемости при обработке даже в случае мощных современных компьютерных систем. Более того, ввиду большого количества возможных вариантов разложения потенциальных слов на символы, вероятность получения единственного лучшего варианта разложения и соответствующего электронного документа традиционными способами очень мала. Вместо этого традиционные способы, как правило, дают большое количество возможных вариантов электронного документа, которые зачастую неотличимы по показателям качества или вероятности корректности.
Ввиду всех особенностей текста на арабском и других подобных языках, описанных выше со ссылкой на Фиг. 22-25, подход к преобразованию изображения документа, описанный выше со ссылкой на Фиг. 13А-Е, не может эффективно использоваться в отношении документов, содержащих текст на таком языке. Одна из основных причин заключается в слишком большом количестве альтернативных представлений любого заданного символа алфавита для применения всестороннего метода сопоставления шаблонов, показанного на Фиг. 13Е, что делает невозможным применение этого метода по отношению к тексту на арабском языке или на другом языке, обладающем вышеперечисленными особенностями. В качестве еще одного примера ввиду наличия необязательных диакритических знаков и так как большинство гласных букв не пишутся в виде символов алфавита, для определения того, какие символы алфавита явно или неявно содержатся в любой заданной части строки текста, требуется большое количество контекстуальной информации. Рассмотрение такой контекстуальной информации охватывает иерархические уровни разложения и аналогичные иерархические уровни построения электронного документа таким образом, что это сильно осложняет как разложение изображения документа, так и построение электронного документа, а также невероятно повышает вычислительную нагрузку. Третья причина заключается в том, что морфемы и слова в арабском и некоторых похожих языках являются слитными сущностями, а не последовательностями отдельных символов, как в английском или русском. Поэтому для них характерно намного большее количество гипотез, или вариантов разложения, изображения строки текста на изображения символов, чем для языков, в которых слова складываются из отдельных знаков или символов. По всем этим причинам доступные в настоящее время подходы к конвертации содержащих текст элементов изображения документа не обеспечивают надежной конвертации изображений документов, содержащих текст на арабском языке.
Способы и устройства, к которым относится изобретение
На Фиг. 28А-В и 29 показан и обоснован подход, представленный раскрываемыми в настоящей заявке методами OCR, который может найти применение в отношении языков, напоминающих арабский. На Фиг. 28А показано слово арабского языка (2808), небольшие вертикальные строки под которым, такие как вертикальная строка (2804), указывают на положения, в которых традиционные способы OCR, описанные выше со ссылкой на Фиг. 11А-В, распознают потенциальные точки разделения символов. Напротив, на Фиг. 28В с использованием тех же условных обозначений, что были использованы на Фиг. 28А, показаны потенциальные точки разделения символов, сформированные с помощью способов OCR, описываемых ниже. Как нетрудно понять, сравнив Фиг. 28А и Фиг. 28В, количество потенциальных точек разделения (2806), сформированных с помощью традиционных способов OCR, существенно превышает количество потенциальных точек разделения символов (2808), сформированных с помощью способов настоящего изобретения.
На Фиг. 29 показано, почему уменьшение количества потенциальных точек разделения символов повышает эффективность оптического распознавания символов текста на языке, напоминающем арабский. На Фиг. 29 слово, фраза или морфема представлена горизонтальной полосой (2902). На Фиг. 29 для представления потенциальных точек разделения символов используются отрезки вертикальных строк, такие как отрезок вертикальной линии (2904). При отсутствии потенциальных точек разделения символов (2906), как в типовой морфеме, слове или фразе (2902), имеется только один возможный вариант разложения данной морфемы, слова или фразы (2902), или один путь обхода через слово, фразу или морфему в смысле путей, описанных выше со ссылкой на Фиг. 20А-В. На единичный путь обхода указывает стрелка (2908), а количество возможных путей обхода в случае отсутствия потенциальных точек разделения символов равно 20 или 1 (2910 на Фиг. 29). В случае нахождения единичной точки разделения символов (2904) единичная точка разделения (2912) предусматривает два различных пути обхода (2914), первый из которых включает стрелки (2916-2917), а второй включает стрелку (2918). Как можно видеть по увеличению количества точек разделения по направлению вниз в вертикальном направлении на Фиг. 29, количество возможных путей обхода составляет 2n, где n - количество потенциальных точек разделения символов внутри морфемы, слова или фразы. Количество путей обхода, представляющих возможные точки разделения морфемы, слова или фразы на символы, равняется K⋅2n (2920), где 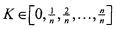 (2922). Постоянная K представляет собой процесс отсечения всех возможных путей обхода, осуществляемый в традиционных устройствах OCR, с целью выделения только путей обхода с достаточной вероятностью высокого значения показателей качества. Таким образом, количество вариантов разложения строк текста на символы увеличивается экспоненциально вместе с количеством потенциальных точек разделения символов, идентифицированных в строке текста. Очевидно, что минимизация количества потенциальных точек разделения может существенно снизить вычислительную нагрузку способа OCR и позволит эффективно выполнять задачу OCR, которая в противном случае была бы трудноосуществимой с вычислительной точки зрения. Тем не менее, одно лишь уменьшение количества потенциальных точек разделения символов не решает проблему вычислительной сложности. Напротив, следует не только сократить количество потенциальных точек разделения, но и обеспечить, чтобы в оставшееся после сокращения множество потенциальных точек разделения символов входили потенциальные точки разделения с наиболее высокой вероятностью представления фактических точек разделения символов. В противном случае вычислительная сложность будет снижаться за счет снижения вероятности корректной конвертации изображения текста в соответствующую кодировку текста. Кроме того, устройство и способ настоящего изобретения позволяют избегать образования необоснованных и непродуктивных путей обхода, как описано ниже.
(2922). Постоянная K представляет собой процесс отсечения всех возможных путей обхода, осуществляемый в традиционных устройствах OCR, с целью выделения только путей обхода с достаточной вероятностью высокого значения показателей качества. Таким образом, количество вариантов разложения строк текста на символы увеличивается экспоненциально вместе с количеством потенциальных точек разделения символов, идентифицированных в строке текста. Очевидно, что минимизация количества потенциальных точек разделения может существенно снизить вычислительную нагрузку способа OCR и позволит эффективно выполнять задачу OCR, которая в противном случае была бы трудноосуществимой с вычислительной точки зрения. Тем не менее, одно лишь уменьшение количества потенциальных точек разделения символов не решает проблему вычислительной сложности. Напротив, следует не только сократить количество потенциальных точек разделения, но и обеспечить, чтобы в оставшееся после сокращения множество потенциальных точек разделения символов входили потенциальные точки разделения с наиболее высокой вероятностью представления фактических точек разделения символов. В противном случае вычислительная сложность будет снижаться за счет снижения вероятности корректной конвертации изображения текста в соответствующую кодировку текста. Кроме того, устройство и способ настоящего изобретения позволяют избегать образования необоснованных и непродуктивных путей обхода, как описано ниже.
На Фиг. 30А-В приведен пример способов OCR, в которых строки текста раскладываются на знаки или символы, и которые особенно применимы в отношении текстов на языке, напоминающем арабский. На Фиг. 30 строка текста на языке, напоминающем арабский, представлена горизонтальной полосой (3002). На первом этапе (3004) срока текста разделяется на морфемы и (или) слова (3006-3010). Данный этап выполняется путем выявления разрывов непрерывности текста, или пробелов, которые пересекают строку текста в вертикальном направлении, как описано выше со ссылкой на Фиг. 20А-В. На втором этапе (3012) каждая морфема или слово в строке текста преобразуется в последовательность параметризованных символов (3014-3019), полученных путем преобразования морфемы или слова (3006). На третьем этапе (3020) каждая последовательность параметризованных символов, соответствующая слову или морфеме, которая была извлечена из строки текста, используется для поиска в структуре данных (3022) и установления одной или более сущностей в структуре данных, идентичных или аналогичных последовательности параметризованных символов. Каждая из структур данных включает указания на точки разделения символов, или точки разделения символов внутри морфемы или внутри слова. На четвертом этапе (3024) из структуры данных извлекаются точки разделения символов, закодированных в каждой из записей, полученных из структуры данных по последовательности параметризованных символов. Например, поиск по структуре данных записей, соответствующих последовательности параметризованных символов (3014-3019), дает две записи - точек разделения символов, представленных отрезками вертикальных линий в горизонтальной полосе (3026) и (3027). Помимо этого также по каждой записи данных записываются указатели пути обхода через изображение морфемы или слова, показанные на Фиг. 30А в виде небольших горизонтальных стрелок, таких как горизонтальная стрелка (3030). Каждый указатель пути обхода имеет хвостовую часть, соответствующую первой точке разделения символов внутри морфемы или внутри слова, и головную часть, или точку, соответствующую второй точке разделения символов внутри морфемы и внутри слова. Как описывается ниже, указатели путей обхода сохраняются во избежание ненужного комбинаторного взрыва возможных путей обхода. На окончательном этапе (3034) точки разделения символов внутри морфемы и внутри слова и указатели путей обхода по каждой последовательности параметризованных символов, в свою очередь, соответствующие извлеченным морфемам или словам, включаются в окончательное множество точек разделения символов внутри морфемы и внутри слова и указателей путей обхода, (3036-3040), по каждой из морфем и (или) слов, полученных на первом этапе (3004). Данные точки разделения символов внутри морфемы и внутри слова и указатели путей обхода, если смотреть на них как единичную последовательность точек разделения символов внутри морфемы и внутри слова и указателей путей обхода (3042), представляют собой множество точек разделения символов внутри морфемы и внутри слова и указателей путей обхода, из которых строятся (с соотнесенными вероятностями) различные возможные пути (в смысле путей, описанных со ссылкой на Фиг. 20А-В), представляющие альтернативные варианты разложения строки текста на символы. Следует отметить, что дублирующие точки разделения символов внутри морфемы и внутри слова и указатели путей обхода в окончательной последовательности точек разделения символов внутри морфемы и внутри слова и указателей путей обхода удаляются, и остаются только уникальные точки разделения символов внутри морфемы и внутри слова и указатели путей обхода.
На Фиг. 30В показано, почему указатели путей обхода накапливаются вместе с точками разделения символов внутри морфемы и внутри слова на этапах (3024) и (3034) на Фиг. 30А. Рассмотрим три различных множества точек разделения символов внутри морфемы и внутри слова и указателей путей обхода (3060-3062), образованных по последовательности параметризованных символов, соответствующей слову или морфеме, на этапе (3024). Если бы происходило накопление только этих точек разделения символов внутри морфемы и внутри слова и указателей путей обхода, показанных в виде отрезков вертикальных линий внутри горизонтальной полосы (3064), то, следовательно, устройству понадобилось бы рассматривать все или большую часть возможных путей обхода, основанных на данных накопленных точках разделения символов внутри морфемы и внутри слова. Все возможные пути обхода включают отрезки путей, такие как отрезок пути (3066), которые фактически не встречаются ни в одной из записей структуры данных, от которых образуются точки разделения символов внутри морфемы и внутри слова и указатели путей обхода (3060-3062). Многие из дополнительных ненаблюдаемых отрезков путей показаны над горизонтальной полосой (3064). Между тем, путем накопления как указателей путей обхода, так и точек разделения символов внутри морфемы и внутри слова можно получить накопленное множество указателей путей обхода, накапливающихся вместе с точками разделения символов внутри морфемы и внутри слова (3070), которые фактически встречаются в записях данных. В целом они представляют собой указатели путей обхода и точки разделения символов внутри морфемы и внутри слова с разумной вероятностью того, что на их основе впоследствии будут сформированы обоснованные гипотезы о последовательности символов или знаков, представленных изображением морфемы или слова.
На Фиг. 31А-М показано преобразование морфемы или слова, извлеченного из изображения строки текста, в последовательность параметризованных символов. Такое преобразование выполняется на этапе (3012), описанном выше со ссылкой на Фиг. 30. Следует отметить, что фраза «параметризованный символ» (FSWAP) относится к множеству символов, определенные члены которого, как правило, соотносятся с параметрами, а некоторые члены которого, как правило, с параметрами не соотносятся. Имеется начальное множество символов, которые сравниваются с членами второго множества непараметризованных символов, при этом каждый такой член называется параметризованным символом (SFS). В некоторых случаях параметризованные символы могут быть идентичными соответствующим непараметризованным символам. В других случаях параметризованные символы могут в зависимости от значения соотнесенных параметров преобразовываться в два или более непараметризованных символа.
На Фиг. 31А показано слово арабского языка (3102). На Фиг. 31В показаны различные метрики, вычисленные в отношении характеристик в текстовом изображении слова (3102), показанного на Фиг. 31А. Сначала слово на Фиг. 31В представляется как имеющее три горизонтальные части: (1) верхнюю часть (3104), (2) основную часть (3106) и (3) нижнюю часть (3108). Основная часть (3106) включает в себя основную часть строки текста, в том числе обычно слитные части строки текста, тогда как верхняя и нижняя части (3104) и (3108) содержат в основном диакритические знаки и расширения объектов, присутствующих в основной части (3106), такие как верхние части вертикальных штрихов, например, вертикальный штрих (3110), а также содержат дополнительные штрихи. Из текста на языке, напоминающем арабский, извлекается некоторое количество разных объектов, что далее подробно описывается ниже. В примере, приведенном на Фиг. 31А-М, один вид объекта, извлеченный из изображения строки текста, называется «пик». Максимальной высотой пика (3112) является высота самого высокого вертикального объекта (3110), при этом относительная высота пика составляет 1.0. Высота пика дополнительных вертикальных объектов, такая как высота пика (3114) вертикального объекта (3116), вычисляется как относительная высота пика по отношению к самому высокому вертикальному объекту (3110). Другим видом объектов, извлекаемых из текста на языке, напоминающем арабский, является петля (3118). Петли характеризуются положением в тексте по отношению к вышеупомянутым основной и нижней частям, а также метрике вещественного качества (3120) с диапазоном [0,0-1,0], которая указывает на качество петли, которое варьируется в диапазоне от 0, что означает, что петля не имеет видимого отверстия и плохо сформирована, до 1, что означает четкую хорошо сформированную петлю с видимым отверстием. Петля (3118) на Фиг. 31В не имеет отверстия. Если бы объект (3124) был распознан как петля, у него бы было отверстие (3126), то есть пустое место, окруженное слитными текстовыми кривыми и строками.
На Фиг. 31С-М объекты последовательно извлекаются из слова (3102), показанного на Фиг. 31А, вместе с числительным, булевыми выражениями и (или) прочими видами параметров, соотнесенных с объектами. На Фиг. 31С-М изображение слова обрабатывается слева направо, однако, как вариант, изображение слова можно обрабатывать справа налево - в направлении, в котором читается и пишется текст на арабском языке. В любом случае, как описывается ниже, образуется последовательность параметризованных символов, представляющих слово, которая упорядочивается в соответствии с объектами слова. На Фиг. 31С показан процесс распознавания первого объекта в слове. Первый объект (3130) является диакритическим знаком в верхней части слова, который преобразуется в верхний диакритический параметризованный символ (3132). Следует отметить, что верхний диакритический параметризованный символ (3132) выбирается для визуального описания процесса извлечения объектов из слова. Параметризованные символы могут, в сущности, быть представлены определенными символами, как на Фиг. 31С-М, однако также могут быть представлены текстовыми строками, целыми числами и в виде прочих представлений.
На Фиг. 31D показано извлечение второго объекта из слова (3102). Второй объект (3134) является или пиком, или петлей и преобразуется в параметризованный символ «пик/петля» (3136). На Фиг. 31Е показано извлечение третьего объекта из слова (3102). Третий объект (3138) является диакритическим знаком в нижней части слова и преобразуется в параметризованный символ «нижний-диакритический» (3140). На Фиг. 31F показано извлечение четвертого объекта из слова (3102). Четвертый объект (3142) является пиком (3144), соотнесенным с относительной высотой пика (3146). На Фиг. 31G показано извлечение пятого объекта из слова (3102). Пятый объект (3148) является диакритическим знаком нижней части и преобразуется в параметризованный символ «нижний-диакритический» (3150). На Фиг. 31Н показано извлечение шестого объекта из слова (3102). Шестой объект (3152) преобразуется в параметризованный символ пика (3154) с относительной высотой пика - 0,49 (3156). На Фиг. 31I показано извлечение седьмого объекта из слова (3102). Седьмой объект (3158) является кривой и преобразуется в параметризованный символ «кратер» (3160). На Фиг. 31J показано извлечение восьмого объекта из слова (3102). Восьмой объект (3162) является вертикальной ориентированной кривой и преобразуется в параметризованный символ «правый-кратер» (3164). Параметризованный символ «правый-кратер» соотносится с параметром положения (3166), указывающим на то, встречается ли параметризованный символ «правый-кратер» в основной части слова или в нижней части слова. Извлечение восьмого объекта наглядно показывает, что извлечение объекта может быть основано на рассмотрении расширенных фрагментов изображения слова, в том числе нескольких объектов. При извлечении каждого параметризованного символа данный процесс не включает последовательное поглощение смежных фрагментов изображения слова; может рассматриваться вплоть до полного изображения слова. На Фиг. 31K показано извлечение девятого объекта из слова (3102). Девятый объект (3168) является петлей и преобразуется в параметризованный символ «петля» (3170), который соотносится с четырьмя разными параметрами (3172) в описываемом варианте реализации. Первый параметр указывает на качество петли (3174), в данном случае 0, так как петля не имеет видимого отверстия. Второй параметр (3178) является параметром положения, указывающим на то, встречается ли петля в основной части слова или в нижней части слова. На Фиг. 31L показано извлечение десятого объекта из слова (3102). Десятый объект (3180) преобразуется в параметризованный символ пика (3182), соотнесенный с относительной высотой пика 1,0 (3184). На Фиг. 31М показано извлечение 11-го объекта из слова (3102). 11 объект (3186) преобразуется в параметризованный символ пика (3188), соотнесенный с относительной высотой пика 1,0 (3190).
На Фиг. 32 показано множество объектов, которые могут быть извлечены из текста на языке, напоминающем арабский, в рамках описываемого варианта реализации. Каждая строка в таблице, такая как строка (3202), представляет один вид параметризованного символа. В первой колонке показан внешний вид объекта в арабском тексте (3204). Во второй колонке показан параметризованный символ, используемый для представления объекта (3206). В третьей колонке (3208) приведено наименование параметризованного символа. В четвертой колонке (3210) перечисляются параметры, соотнесенные с параметризованным символом. В пятой колонке (3212) приводится буквенно-цифровое представление параметризованного символа. Восемь объектов и соответствующие параметризованные символы, показанные на Фиг. 32, представляют собой полное множество объектов и соответствующих параметризованных символов, используемых для оптического распознавания символов в описываемом варианте реализации способов OCR, к которым относится изобретение. Однако согласно альтернативным способам, к которым также относится изобретение, полное множество параметризованных символов может иметь меньшее или большее количество объектов и параметризованных символов, разные объекты и параметризованные символы или разные параметры, соотнесенные с параметризованными символами.
В структуре данных (3022), описанной выше со ссылкой на Фиг. 30, хранятся записи, которые содержат морфемы и слова, закодированные в виде непараметризованных символов. Непараметризованные символы (SFS) связаны с параметризованными символами (FSWAP), описанными выше со ссылкой на Фиг. 31А-М и 32, однако отличаются от них. Как описывается ниже, записи в структуре данных получаются путем преобразования записей словаря арабского или иного похожего языка и прочих источников морфем и слов определенного языка, в котором представлен текст, к которому относятся методы OCR настоящего изобретения. Словарные записи и источники текстовых изображений морфем и слов подвергаются обработке для получения кодировок SFS в рамках процесса, аналогичного процессу извлечения объектов и соответствующих непараметризованных символов из изображений морфем и слов в строках текста, но отличного от него. Данный процесс отличается от процесса, используемого при оптическом распознавании символов текстовых изображений тем, что словарные записи и прочие источники морфем и слов обрабатываются непосредственно в непараметризованные символы, а не в параметризованные символы. Параметризованные символы, как описано выше, могут сопровождаться различными параметрами, такими как качество петли и высота пика. В каком-то смысле данные параметры представляют собой диапазон неоднозначности, которая разрешается при преобразовании параметризованного символа в непараметризованный символ, как описано ниже со ссылкой на Фиг. 34 и 35. Неоднозначность полезна при использовании структуры данных в рамках оптического распознавания символов, позволяя распознавать кодировки непараметризованных символов нескольких аналогичных слов и морфем как возможных потенциальных пар для последовательности параметризованных символов, которые представляют определенное изображение слова или морфемы. Однако при построении структуры данных желательной является прямая кодировка непараметризованных символов по каждой словарной записи и прочим изображениям слов и морфем, извлеченным из источников изображений слов и морфем, так как кодировка непараметризованных символов обеспечивает прямое преобразование в соответствующую запись структуры данных по морфеме или слову, представленному кодировкой непараметризованных символов. В одном варианте реализации для хранения кодировок непараметризованных символов как можно большего количества разных морфем и слов используется trie-структура данных для обеспечения надежной идентификации наиболее вероятных точек разделения символов в строке текста на этапах (3020), (3024) и (3028), описанных со ссылкой на Фиг. 30. Данные вводятся в trie-структуру путем иерархического обхода trie-структуры согласно последовательности непараметризованных символов, в результате чего создаются новые записи, необходимые для того, чтобы можно было обойти весь путь обхода по последовательности непараметризованных символов. Обход заканчивается на узле, в который сохраняется последовательность непараметризованных символов, если данная последовательность непараметризованных символов уже не хранится в данном узле. Как описано ниже, непараметризованные символы включают символы разделения букв, которые не рассматриваются в рамках иерархического обхода, но рассматриваются при сопоставлении одной последовательности непараметризованных символов с другой. Запись trie-структуры, таким образом, включает несколько хранящихся записей с общей последовательностью непараметризованных символов небуквенных разделителей, которые, однако, отличаются друг от друга при использовании символов разделителей букв в рамках сопоставления записей.
На Фиг. 33 показана простая trie-структура данных. В данном примере небольшое множество слов (3302), или словарь, состоит из букв английского языка «а», «b», «с», «d» и «е», которые вместе взятые составляют алфавит (3304). Для хранения данного словаря в древоподобной структуре данных используется trie-структура данных (3306), которая позволяет получать доступ к словам данного словаря в алфавитном порядке, а также обеспечивает простой способ хранения дополнительных слов и распознавание уже сохраненных слов, идентичных или аналогичных введенному. Trie-структура данных имеет пустой корневой узел (3308). Так как по крайней мере одно слово в словаре (3302) начинается с каждой из пяти букв алфавита (3304), второй уровень узлов в trie-структуре (3310) включает пять узлов (3312-3316), соединенных с корнем (3308) дугами, такими как дуга (3318), при этом каждый из них соотнесен с одной из данных букв алфавита. Перемещение по trie-структуре от одного узла на одном уровне до другого узла на следующем, более низком уровне осуществляется через дугу, соотнесенную с буквой, и представляет собой добавление данной буквы в строку букв. Данная строка букв (в корневом узле) пуста и растет по мере обхода trie-структуры вниз по узлам. Всякий раз, когда строка букв, полученная после обхода дуги, представляет одно из слов словаря, узел, достигнутый через данную дугу, включает запись по данному слову. Например, перемещение по trie-структуре от корневого узла (3308) до узла (3312) по дуге (3318) предполагает добавление буквы «а» в изначально пустую строку символов. Полученной в результате перемещения по дуге (3318) строкой символов является строка «а», которая соответствует первому слову в словаре (3302). Таким образом, слово «а» (3320) включено в узел (3312). Строкой символов, полученной в результате перемещения от корневого узла (3308) до узла (3313), является «b». Данная строка символов не соответствует слову в словаре, и поэтому узел (3313) является пустым. В результате обхода trie-структуры от корневого узла (3308) до узла (3312), затем до узла (3322) и, наконец, до узла (3324) по дугам (3318), (3326) и (3328) формируется строка символов «асе», соответствующая второму слову в словаре - соответственно слово «асе» включается в качестве записи в узел (3324). В простом примере, приведенном на Фиг. 33, все слова словаря, кроме слова «а», встречаются в тупиковых узлах trie-структуры. Поиск «сначала вглубь» по trie-структуре дает в результате все слова словаря в алфавитном порядке. Новые слова могут добавляться в словарь (и в trie-структуру), напрямую путем обхода trie-структуры в соответствии с последовательностью символов в слове, при необходимости с добавлением новых дуг и узлов. Следует отметить, что некий заданный внутренний нетупиковый узел, такой как узел (3312), может соответствовать некому слову словаря, тогда как другие внутренние нетупиковые узлы, такие как узел (3313), могут не соответствовать некому слову словаря, вместо этого соответствуя части слова, такому как «b» в случае узла (3313). В типовой trie-структуре данных (3306) внутренние нетупиковые узлы (3312) и (3332) соответствуют словам словаря и обозначаются как таковые прямоугольником с двойными сторонами. В trie-структуре данных, содержащей непараметризованные символы для слов арабского или другого похожего языка, намного большее процентное содержание внутренних нетупиковых узлов соответствует словам и морфемам, чем в типовой trie-структуре (3306).
На Фиг. 34 показаны непараметризованные символы (SFS), используемые для кодирования записей в trie-структуре данных, а также соответствие между параметризованными символами (FSWAP), описанными выше со ссылкой на Фиг. 31А-М и 32, а также непараметризованными в одном варианте реализации. Параметризованные символы, ранее описанные со ссылкой на Фиг. 31А-М и 32, показаны в первом массиве (3402) в верхней части Фиг. 34. Непараметризованные символы показаны во втором массиве (3404) в нижней части Фиг. 34. Соответствие между параметризованными символами в первом массиве (3402) и непараметризованными символами во втором массиве (3404) показано на Фиг. 34 в виде направленных дуг, таких как направленная дуга (3406), которая указывает на взаимно-однозначное соответствие между верхним диакритическим параметризованным символом (3408) и верхним диакритическим непараметризованным символом (3410). В данном случае верхний диакритический параметризованный символ и верхний диакритический непараметризованный символ идентичны. Однако в других случаях параметризованный символ, такой как параметризованный символ (3412), может быть преобразован в два или непараметризованных символов, таких как непараметризованные символы (3414) и (3416). Параметризованный символ пика (3412), другими словами, может соответствовать либо непараметризованному символу с небольшим пиком (3414) или непараметризованному символу с большим пиком (3416). Преобразование управляется параметрами, соотнесенными с параметризованными символами в ходе извлечения объектов и трансформации извлеченных объектов в параметризованные символы, описанные выше со ссылкой на Фиг. 31А-М. Преобразование представлено на Фиг. 34 кругами, отмеченными символом «Р», такими как круг (3418). Как описано выше со ссылкой на Фиг. 31В, 31F, 31Н и 31L-M, пиковые символы соотносятся с относительными значениями высоты. Параметр относительной высоты используется для преобразования пикового символа (3412) либо в непараметризованный символ с небольшим пиком (3414), либо в непараметризованный символ с большим пиком (3416).
На Фиг. 35 приведено детальное описание преобразования на основе параметров, показанного на Фиг. 34. На Фиг. 35 в круг (3502), ранее показанный в виде круга (3418) на Фиг. 34, включается псевдокод. Если относительная высота пика превышает или равняется 0,7 ((3504) на Фиг. 35), параметризованный символ пика (3414) преобразуется в непараметризованный символ с большим пиком (3416), на который указывает пунктирная стрелка (3506). Если относительная высота пика, соотнесенная с параметризованным символом пика (3414) превышает или равняется 0,2 и ниже или равняется 0,6 ((3508) на Фиг. 35), то согласно пунктирной стрелке (3510), параметризованный символ пика (3414) преобразуется в непараметризованный символ с небольшим пиком (3414). Если относительная высота пика менее 0,2 (3512), параметризованный символ пика (3412) отклоняется или отбрасывается. В данном случае вместо преобразования параметризованного символа в непараметризованный символ, параметризованный символ исключается из дальнейшего рассмотрения. Наконец, если относительная высота пика превышает 0,6, но меньше 0,7 (3514), вызывается дополнительная логика (3516), которая устанавливает необходимость преобразования параметризованного символа (3412) в непараметризованный символ с небольшим пиком (3414) или непараметризованный символ с большим пиком (3416). Данная дополнительная логика может включать рассмотрение объектов, смежных с пиковым объектом в слове, из которого извлекаются объекты, рассмотрение различных присутствующих в trie-структуре записей и прочие подобные задачи рассмотрения.
Варианты преобразования на основе параметров (3420) и (3422) относительно непосредственно выводятся из параметров положения, соотнесенных с параметризованными символами левого кратера и правого кратера. В рамках преобразования на основе параметров (3423) рассматривается метрика качества петли и положение петли для отнесения объекта в категорию петли основной части или петли нижней части.
В число непараметризованных символов также входит непараметризованный символ разделителя букв (3412), который обозначает интервалы между знаками или символами арабского или другого похожего языка. Следует отметить, что знаки или символы такого языка не обязательно взаимно-однозначно соответствуют параметризованным или непараметризованным символам. Например, знак или символ арабского или другого похожего языка может состоять из двух или более параметризованных или непараметризованных символов. Разделители букв включаются в записи trie-структуры и соотносятся с координатами относительной длины, что позволяет в рамках способов OCR настоящего изобретения непосредственно получать точки разделения символов в изображениях морфемы или слова масштабно-инвариантным образом.
Хотя trie-структура имеет множество потенциальных сфер применения, одна сфера применения, используемая в способах настоящего изобретения, заключается в идентификации хорошо известных морфем и слов, представленных в виде последовательностей непараметризованных символов, которые соответствуют последовательностям параметризованных символов, извлеченных из текста на арабском или другом похожем языке в ходе разложения строк текста. Данная сфера применения trie-структур далее описывается на простом примере типовой trie-структуры, которая приводится и описывается со ссылкой на Фиг. 33.
На Фиг. 36A-G показано использование trie-структуры, описываемой со ссылкой на Фиг. 33, при идентификации слов словарного состава, аналогичных или идентичных введенному слову. На Фиг. 36А введенное слово «ade» (3602) показано вместе с начальным штрафом обхода, или штрафом, в размере 0 ((3604) на Фиг. 36А). На Фиг. 36В-Е осуществляется исчерпывающий поиск по trie-структуре с целью идентификации введенного слова или слов, аналогичных введенному, в словаре, представленном trie-структурой. Как описывается ниже, неисчерпывающий поиск при использовании с той же целью может быть более эффективным. В ходе поиска осуществляется обход trie-структуры с корректировкой штрафа (3604) в зависимости от соответствия между символами введенного слова и символами, соотнесенными с дугами, по которым осуществляется обход. Существует множество различных возможных видов корректировки штрафа. Штрафы за замену, представленные в таблице (3608), являются числовыми штрафами, соотнесенными с заменой определенного символа в введенном слове на другой символ алфавита в ходе обхода trie-структуры. Например, при поиске слова «ade» в trie-структуре обход дуги (3606) в trie-структуре представляет собой замену буквы «d» в введенном слове «ade» на символ «с». Затем в таблице штрафов за замену (3608) находится штраф, соотнесенный с обходом дуги (3606) в отношении введенного слова «ade», который равняется 4 ((3610) на Фиг. 36А), на что указывает символ введенного слова «d» (3612) и соотнесенный с дугой символ «с» (3614). В примере, показанном на Фиг. 36А, таблица штрафов за замену является диагонально симметричной, таким образом за замену символа «х» в введенном слове на символ «у», соотнесенный с дугой, применяется тот же штраф, что за замену символа «у» в введенном слове на символ «х», соотнесенный с дугой. Однако в фактических сферах применения таблица штрафов за замену может не быть диагонально симметричной. В таблице (3616) показаны дополнительные виды штрафов. Запись в trie-структуре с дополнительным символом в отношении введенного слова получает штраф 20, что отражено в первой строке (3618) таблицы (3616). Если символ во введенном слове не записан в trie-структуре, как показано в строке (3620) в таблице (3616), он также получает штраф 20. Символ во введенном слове, не являющийся знаком алфавита ((3304) на Фиг. 33), получает штраф 15, что отражено в третьей строке (3622) таблицы (3616).
На первом этапе исчерпывающего поиска по trie-структуре, показанном на Фиг. 36В, осуществляется обход trie-структуры от корневого узла (3630) до узлов второго уровня (3632)-(3636). Введенное слово и соотнесенный с ним штраф, полученный в результате обхода каждого из данных пяти дуг, показаны в их соответствии с узлами второго уровня, такими как введенное слово и штраф (3638), соотнесенный с узлом (3632). Так как первым словом введенного слова является «а», обход дуги (3640), соотнесенной с буквой «а», не ведет к увеличению штрафа. Таким образом, штраф, соотнесенный с узлом (3632), остается со значением 0 (3604). Однако обход оставшихся дуг от корневого узла до узлов второго уровня (3642)-(3645) соотносится со штрафом, полученным из таблицы штрафов за замену (3608), так как дуги (3542)-(3645) соотнесены с символами, не являющимися символом «а». На Фиг. 36С исчерпывающий поиск продолжается и состоит в прохождении всех дуг от узлов второго уровня до узлов третьего уровня. Штраф, соотнесенный с узлом третьего уровня (3648), остается на отметке 0 (3650), так как дуги, по которым осуществлялся обход до данного узла, соотнесены со строкой символов «ad», что эквивалентно первым двум символам введенного слова «ade». Штрафы, соотнесенные со всеми прочими узлами третьего уровня, такие как штраф (3652), увеличились согласно штрафам за замену, найденным в таблице штрафов за замену (3608), так как все прочие дуги, исходящие от узлов второго уровня, соотнесены с символам, не являющимися символом «d». На Фиг. 36D показан обход от узлов третьего уровня до узлов четвертого уровня. Наконец, на Фиг. 36Е показан обход от узлов четвертого уровня до узлов пятого уровня, который завершает исчерпывающий поиск по trie-структуре.
На Фиг. 36Е добавлена еще одна таблица (3660), в которой показывается соответствие между записями в trie-структуре, которые соответствуют словам в словаре (3302), и штрафами, соотнесенными с узлами, которые содержат данные записи, полученные в результате вышеописанного обхода trie-структуры в рамках исчерпывающего поиска по trie-структуре. Два слова словаря (3302), расположенные ближе всех к введенному слову «ade», распознаются как первые две записи (3662)-(3663) в таблице (3660) с наименьшими штрафами. Записи сортируются по размеру штрафа в восходящем порядке. Таким образом, исчерпывающий поиск по trie-структуре, при котором осуществляется перемещение по trie-структуре и накопление штрафов в соответствии со штрафами за замену (3608) и дополнительными штрафами в таблице (3616), ведет к упорядочиванию слов словаря, представленного trie-структурой, в нисходящем порядке по схожести с введенным словом. Упорядочивание слов словаря в рамках исчерпывающего поиска зависит от видов штрафов и числовых значений определенных штрафов. Как штрафы за замену, так и прочие виды штрафов можно вывести эмпирическим путем, можно вывести полуаналитическим путем, присваивая штрафы в соответствии с вероятностью замены, опускания и добавления определенных символов, или с использованием различных сочетаний эмпирических и полуэмпирических методов.
Исчерпывающий поиск по trie-структуре, представляющей крупный словарь, как правило, является вычислительно сложной задачей. Ввиду свойств trie-структуры, исчерпывающий поиск, как правило, не требуется для идентификации кандидатов, точнее всего совпадающих с определенным введенным словом. Одним способом сокращения исчерпывающего поиска является остановка дополнительного поиска/перемещения от любого узла, в котором вычисленный размер штрафа превышает определенное пороговое значение. На Фиг. 36F показано первое сокращение исчерпывающего поиска, при котором пороговое значение составляет 10. В данном случае в ходе поиска словарных слов, аналогичных введенному слову «ade» возвращается только три результата (3670), и рассматриваются или обходятся только 17 узлов, заштрихованных на Фиг. 36F, на что указывает утверждение (3672). По сравнению с исчерпывающим поиском рассматривается меньшее количество узлов и возвращается меньшее количество результатов. На Фиг. 36G показан поиск, когда нижний порог равен 6. В данном случае в ходе поиска возвращается еще меньшее количество результатов (3674), и рассматриваются только 11 узлов, заштрихованных на Фиг. 36G, на что указывает утверждение (3676). Таким образом, пороговое значение может использоваться для корректировки процентного содержания узлов, посещенных в ходе поиска словарных слов, идентичных или аналогичных введенному. В небольшой типовой trie-структуре, приведенной на Фиг. 33 и 36A-G для наглядной демонстрации поиска на основе trie-структуры, влияние снижения порога является умеренным, однако в намного более крупных trie-структурах, используемых в различных вариантах реализации устройств OCR, которые могут включать тысячи, десятки тысяч, сотни тысяч и более узлов, снижение порога на 50% может привести к существенному уменьшению количества обходимых узлов. Каждый обход узлов включает выполнение многочисленных команд и операций доступа к многочисленным запоминающим устройствам. Таким образом, неисчерпывающий поиск на основе порога обеспечивает существенное повышение эффективности и снижение циклов исполнения команд и, в конечном счете, потребления энергии.
В рамках способов настоящего изобретения поиск по trie-структуре, заполненной закодированными в виде непараметризованных символов записями, соответствующими морфемам и словам арабского или другого похожего языка и полученными путем анализа различных источников закодированных в цифровом виде морфем и слов арабского языка, осуществляется в форме неисчерпывающего поиска на основе порога, так как описано со ссылкой на Фиг. 36F-G, образом, аналогичным тому, как осуществляется поиск по типовой trie-структуре, показанной на Фиг. 36А-Е. Каждое слово или морфема (3006-3010), идентифицированное в строке текста (3002), трансформируется в последовательность параметризованных символов, а последовательность параметризованных символов затем используется в качестве ввода в неисчерпывающий поиск по trie-структуре, содержащей записи непараметризованных символов. Данный способ и устройства, реализующие способ, таким образом, позволяют получить потенциальные точки разделения символов исходя из фактических точек разделения символов в морфемах и словах, извлеченных из стандартизированных исходных текстов, в том числе словарей. Как описано выше, закодированные в виде непараметризованных символов записи также включают непараметризованные символы разделителей букв с относительными координатами для обеспечения точной идентификации потенциальных точек разделения символов на изображении морфемы или слова. Данный способ обеспечивает как существенное снижение количества образуемых потенциальных точек разделения, так и относительно устойчивую высокую точность, устанавливая наиболее вероятные потенциальные точки разделения. Вместо того чтобы пытаться определить потенциальные точки разделения в слитно отображенных морфемах или словах, применяются фактические хорошо известные точки разделения внутри хорошо известных морфем и слов. Так как trie-структура данных содержит записи, преобразованные из фактических морфем и слов, потенциальные точки разделения имеют высокую вероятность корректности. Неисчерпывающий поиск по trie-структуре морфем и слов, аналогичных последовательности параметризованных символов, извлеченных из введенного изображения морфемы или слова, вычислительно эффективен благодаря сокращению на основе порога и направленному последовательному характеру поиска на основе trie-структуры.
На Фиг. 37А-В показаны части таблицы штрафов, используемых при поиске слов и морфем, аналогичных введенной последовательности параметризованных символов, в trie-структуре с закодированными в виде непараметризованных символов записями. На Фиг. 37А приведена часть таблицы штрафов за несовпадения параметризованных/непараметризованных символов. В первой колонке (3704) показано индексирование непараметризованных символов, а в первой строке (3706) показаны параметризованные символы, извлеченные из строки текста. Используя единичный параметризованный символ и единичный непараметризованный символ из данных первой строки и первой колонки соответственно, можно вычислить штраф, соотнесенный с несовпадением, возникшим при поиске по trie-структуре. Следует отметить, что штраф, соотнесенный с несовпадением между параметризованным символом пика (3708) и непараметризованным символом небольшого пика (3710) либо непараметризованным символом большого пика (3712) вычисляется исходя из относительной высоты объекта пика, соответствующего параметризованного символа пика (3708). Таблица штрафов (3702) также включает штрафы за отсутствие символов, эквивалентные штрафам, показанным в первых двух строках таблицы штрафов (3616) на Фиг. 36А.
На Фиг. 37В приведен фрагмент таблицы штрафов, используемых при поиске слов и морфем, аналогичных введенной последовательности параметризованных символов, по trie-структуре с закодированными в виде непараметризованных символов записями с инверсией пары параметризованных символов. Другими словами, инверсия двух смежных параметризованных символов допускается, однако за инверсию налагается штраф.
На Фиг. 38 показаны источники морфем и слов, используемых для создания структуры данных о морфемах и словах, закодированных в виде непараметризованных символов (3022 на Фиг. 30), которые используются для определения потенциальных точек разделения знаков согласно способу и устройству, к которым относится изобретение. Как описано выше, хранилищем морфем и слов может быть trie-структура данных, которая хранится на устройстве памяти и (или) электронном запоминающем устройстве на компьютерном устройстве. Для создания хранилища слов на основе trie-структуры может использоваться множество различных видов источников, в том числе закодированных в цифровом виде словарей арабского или похожего языка (3802) с извлечением записей слов, их преобразованием в кодировки непараметризованных символов и ввода в trie-структуру данных. Желательным является наличие как можно большего количества примеров таких источников, где текст отображен как можно большим количеством различных шрифтов и стилей письменности данного языка, а также дополнительных примеров различных шрифтов и разновидностей начертания данного языка. Такими источниками, как правило, являются источники, хранящиеся на съемном носителе (3805) или доступные из различных интернет-источников (3806). Морфемы и слова извлекаются из различных источников и преобразуются в последовательности непараметризованных символов, которые вводятся в trie-структуру.
На Фиг. 39A-D приведены блок-схемы, на которых показан один из возможных вариантов реализации способов и устройств, к которым относится изобретение. На Фиг. 39А приведена блок-схема подпрограммы «межсимвольный классификатор» - один возможный вариант реализации способа, описанного выше со ссылкой на Фиг. 30. Данная подпрограмма идентифицирует потенциальные точки разделения символов с высокой вероятностью в слитных морфемах и словах арабского или похожих на арабский языков, а также множество возможных указателей путей обхода. Данная подпрограмма заменяет традиционные способы на этапах (1356)-(1358), показанных на Фиг. 13D, образуя небольшое множество потенциальных точек разделения с высокой вероятностью, как показано на Фиг. 28В, а также обоснованное множество указателей путей обхода, как показано на Фиг. 28А, вместо большого множества необоснованных указателей путей обхода, описанного со ссылкой на Фиг. 30В. Как описано выше, большое множество потенциальных точек разделения и указателей путей обхода, неотличимых друг от друга по степени вероятности или метрикам, может сделать традиционные способы OCR вычислительно неэффективными или трудноосуществимыми, а также неточными или ненадежными.
Подпрограмма «межсимвольный классификатор» на этапе (3902) получает изображение строки текста Intx, инициализирует множество межсимвольных точек разделения sicp, которое может содержать до maxSicp+k элементов, где k - это небольшое число дополнительных элементов во избежание точной проверки границ в типовом варианте реализации, и инициализирует множество указателей путей обхода spp аналогичного размера. Как упоминалось выше, указатель пути обхода может быть представлен парой межсимвольных точек разделения. Множество межсимвольных точек разделения sicp может быть массивом или иным видом структуры данных и может упорядочиваться в восходящем порядке по относительным координатам точек разделения. Множество межсимвольных точек разделения sicp и множество указателей путей обхода spp соответствуют результату (3042), полученному способом, описанным со ссылкой на Фиг. 30. На этапе 3904 локальная переменная total устанавливается на длину строки текста Intx, локальные переменные cuml и rl, совокупная длина и относительная длина обрабатываемой части полученной строки текста, соответственно, обе устанавливаются на значение 0, переменная mum устанавливается на 1, что указывает на количество потенциальных точек разделения, присутствующих в настоящее время в sicp, а начальная точка вводится в sicp. В ходе обработки морфемы и (или) слова извлекаются из введенной строки текста Intx с формированием потенциальных точек разделения и потенциальных указателей путей обхода. Далее в рамках цикла с предусловием (while-loop) на этапах (3906)-(3911) из полученной строки текста по одному извлекаются морфемы и (или) слова и обрабатываются, в результате чего по символам каждой извлеченной морфемы через вызов подпрограммы «обработать морфему» на этапе (3909) формируются потенциальные точки разделения и потенциальные указатели путей обхода. На этапе (3907) из текстовой строки Intx извлекается следующая морфема m, при этом длина изображения извлеченной морфемы сохраняется в локальной переменной Im. Как описано выше со ссылкой на Фиг. 30, морфемы и (или) слова распознаются как слитный текст, отделенный от дополнительного слитного текста в текстовой строке вертикальными пробелами. При вызове подпрограммы «обработать морфему» на этапе (3909) в рамках процесса, описанного выше со ссылкой на Фиг. 30, из морфемы выводятся дополнительные потенциальные точки разделения и указатели путей обхода. На этапе (3910) переменная cuml увеличивается на длину только что извлеченной морфемы cuml, а новая относительная длина для начала следующей извлекаемой морфемы вычисляется как совокупная длина, разделенная на общую длину, или cuml/total. Цикл с предусловием продолжается, пока из полученной строки текста не будут извлечены все морфемы, как установлено на этапе (3911). Содержимое множества sicp и spp, соответствующего множеству возможных точек разделения символов, показано как множество (3036) на Фиг. 30.
На Фиг. 39В показана блок-схема подпрограммы «обработать морфему», вызываемой на этапе (3910) на Фиг. 39А. Подпрограмма «обработать морфему» идентифицирует и регистрирует потенциальные точки разделения морфемы, извлеченной из строки текста на этапе (3907) на Фиг. 39А. На этапе (3914) подпрограмма «обработать морфему» определяет относительную длину морфемы по отношению к общей строке текста, устанавливает локальную переменную range на данную относительную длину, инициализирует множество межсимвольных точек разделения lsicp, которое может содержать до maxLsicp элементов, и инициализирует соответствующее множество указателей путей обхода lpp. На этапе (3916) подпрограмма «обработать морфему» устанавливает локальную переменную maxP - максимальное количество потенциальных точек разделения, которое может быть получено по рассматриваемой в настоящий момент морфеме или слову - на значение, в maxSicp раз превышающее хранящееся в локальной переменной range. Это обеспечивает определение для каждой морфемы максимального числа потенциальных точек разделения исходя из относительной длины морфемы по отношению ко всей строке текста. Кроме того, на этапе (3916) подпрограмма «обработать морфему» устанавливает локальную переменную threshold на начальное значение TSCORE. На этапе (3918) локальная переменная numP - количество потенциальных точек разделения, уже полученных по рассматриваемому в настоящий момент слову или морфеме, устанавливается на 0. На этапе (3920) вызывается подпрограмма «точки морфемы», которая осуществляет поиск записей, аналогичных морфеме, по trie-структуре данных ((3022) на Фиг. 30) по принципу неисчерпывающего поиска, управляемого значением, хранящимся в локальной переменной threshold. Подпрограмма «точки морфем» вызывается с аргументами, включающими указатель на корень trie-структуры, извлеченную морфему m и начальный штраф в размере 0. Если количество потенциальных точек разделения, возвращенное подпрограммой «точки морфем», как установлено на этапе (3922), превышает значение maxP, на этапе (3924) порог уменьшается на соотношение REDUC, и снова вызывается подпрограмма «точки морфемы», которая формирует множество потенциальных точек разделения для данной морфемы. Если количество сформированных точек морфемы является приемлемым, то на этапе (3926) точки разделения морфемы, хранящиеся во множестве Isicp, вводятся во множество sicp, а соответствующие указатели путей обхода вводятся во множество spp с удалением дубликатов. На Фиг. 39В предполагается, что порог может постепенно снижаться до получения приемлемого количества потенциальных точек разделения и что начальное пороговое значение TSCORE является достаточно большим для формирования обоснованно крупного начального множества потенциальных точек разделения. Различные альтернативные подходы могут включать по необходимости изменение порога как в сторону увеличения, так и в сторону уменьшения для получения приемлемого количества потенциальных точек разделения для морфемы.
На Фиг. 39С приведена блок-схема подпрограммы «точки морфем», вызываемой на этапе (3920) на Фиг. 39В. Подпрограмма «точки морфем» осуществляет неисчерпывающий поиск под управлением значения, хранящегося в переменной threshold, с целью найти в trie-структуре закодированные в виде непараметризованных символов записи, аналогичные кодировке символа текущей морфемы m. На этапе (3928) подпрограмма «точки морфем» получает указатель узла, текущую морфему m и данные о штрафе. Подпрограмма «точки морфем» по своей сути является рекурсивной. На этапе (3930) подпрограмма «точки морфем» определяет, превышает ли значение в локальной переменной numP значение, хранящееся в переменной maxP. Если да, то подпрограмма «точки морфемы» выполняет возврат на этапе (3932). Если нет, то на этапе (3934) подпрограмма «точки морфем» определяет, равняется ли теперь длина текущей морфемы m нулю или является ли она пустой. Если нет, то на этапе (3936) вызывается подпрограмма «перемещение» для углубления на один уровень trie-структуры. Если длина текущей морфемы теперь равняется 0, как установлено на этапе (3934), если текущий штраф меньше порога, как установлено на этапе (3936), и если узел, к которому отсылает аргумент nodePtr, содержит закодированную в виде непараметризованного символа морфему или слово, как установлено на этапе (3938), то в рамках цикла с параметром на этапах (3940)-(3944) извлекаются разделители букв в виде непараметризованных символов в закодированной в виде непараметризованных символов морфеме в составе узла trie-структуры, к которому отсылает nodePtr, и вводятся во множество потенциальных точек разделения Isicp, а соответствующие указатели путей обхода вводятся во множество указателей путей обхода Ipp. Если узел, к которому отсылает nodePtr, не содержит морфему, то на этапе (3946) штраф увеличивается на размер штрафа отсутствующего символа, и поток управления переходит на этап (3936), на котором вызывается подпрограмма «перемещение». В рамках цикла с параметром на этапах (3940)-(3944) для каждого рассматриваемого разделителя букв в строке текста вычисляется относительная координата cd (на этапе (3941)), вычисляется соответствующий указатель пути обхода (на этапе (3942)), относительная координата cd вводится во множество Isicp, а следующий вычисленный указатель пути обхода вводится во множество Ipp (на этапе (3943)), после чего numP увеличивается.
На Фиг. 31С показана блок-схема подпрограммы «перемещение», вызываемой на этапе (3936) на Фиг. 39С. На этапе (3947) подпрограмма «перемещение» определяет, является ли nodePtr нулевым указателем. Если nodePtr равен нулю, подпрограмма завершается. На этапе (3948) подпрограмма «перемещение» получает булев аргумент cont и аргумент текущего штрафа penalty. Булев аргумент cont указывает, является ли это первым из двух последовательных вызовов подпрограммы «перемещение». Также на этапе (3948) подпрограмма «перемещение» извлекает из текущей морфемы m следующий объект и преобразует извлеченный объект сначала в параметризованный символ, а затем в непараметризованный символ, как описано выше со ссылкой на Фиг. 31А-М и 34. В рамках цикла с параметром на этапах (3952)-(3962) подпрограмма «перемещение» обходит каждую дугу, исходящую от узла trie-структуры, к которому отсылает переменная nodePtr, и вызывает подпрограмму «точки морфем» (в основном рекурсивно) для узла, достигнутого через дугу от узла trie-структуры, к которому в настоящий момент отсылает переменная nodePtr. Если рассматриваемая в настоящее время дуга соотнесена с непараметризованным символом n, соответствующим объекту, извлеченному из морфемы на этапе (3948), как установлено на этапе (3953), переменная newP устанавливается на значение текущего штрафа на этапе (3955). В противном случае переменная newP устанавливается на значение текущего штрафа плюс значение штрафа за замену символа, выбранного из таблицы штрафов, такой как показанная на Фиг. 37А. На этапе (3956) для продолжения обхода trie-структуры рекурсивно вызывается подпрограмма «точки морфем». Если в рамках текущего обхода был рассмотрен хотя бы один непараметризованный символ, как установлено на этапе (3957), если рассмотренный ранее узел рр - родитель узла, к которому отсылает nodePtr - имеет дугу, соотнесенную с непараметризованным символом n, соединяющим узел рр с узлом ррр, как установлено на этапе (3958), и если дуга, соединяющая узел рр с узлом, к которому отсылает nodePtr, соотнесена с непараметризованным символом n', который не равен n, как установлено на этапе (3959), то переменная newP устанавливается на значение текущего штрафа (на этапе (3955)) плюс значение штрафа за обращение n' в n, полученного из таблицы штрафов, такой как показанная на Фиг. 37В (на этапе (3960)), а на этапе (3961) рекурсивно вызывается подпрограмма «точки морфем». Если есть еще дуги, исходящие от узла trie-структуры, к которому отсылает переменная nodePtr, как установлено на этапе (3962), поток управления возвращается на этап (3952). В противном случае на этапе (3964) снова вызывается подпрограмма «точки морфем» с текущей nodePtr, но с новым штрафом, увеличенным на значение штрафа за отсутствующий символ, который представляет отсутствующие символы в рассматриваемых в дальнейшем записях trie-структуры. Если булева переменная cont является верной, как установлено на этапе (3966), и если рассматриваемая в настоящий момент морфема т не является пустой, как установлено на этапе (3968), то на этапе (3970) снова вызывается, но на этот раз с булевым аргументом FALSE подпрограмма «перемещение» для продолжения поиска с допущением отсутствующего символа в любых рассматриваемых в дальнейшем записях trie-структуры. Подпрограммы «точки морфем» и «перемещение» вместе выполняют рекурсивный неисчерпывающий поиск на основе порогового значения по trie-структуре, как описано выше со ссылкой на Фиг. 36A-G.
В варианте реализации, показанном на Фиг. 39A-D, для ясности и простоты пояснения предполагается, что каждая последовательность непараметризованных символов, хранящихся в trie-структуре данных, является уникальной без учета размещения в ней разделителей букв. Однако может быть так, что существуют разные способы размещения непараметризованных символов разделителей букв в составе последовательности непараметризованных символов, и эти способы соответствуют альтернативным представлениям слова или морфемы или разных слов или морфем. В таком случае каждый узел trie-структуры может включать несколько последовательностей непараметризованных символов, при этом все они содержат ту же последовательность непараметризованных символов небуквенных разделителей, но представляют собой варианты разбиения данной последовательности на символы разными способами. Если узел идентифицируется как соответствующий введенной последовательности параметризованных символов, для введенной последовательности параметризованных символов накапливаются межсимвольные точки разделения и указатели путей обхода по всем непараметризованным символам последовательности.
Хотя настоящее изобретение описывается на примере конкретных вариантов реализации, предполагается, что оно не ограничено только этими вариантами реализации. Специалистам в данной области техники будут очевидны возможные модификации в пределах сущности настоящего изобретения. Например, любые из множества различных параметров реализации и проектирования, в том числе язык программирования, структуры управления, модульная организация, структуры данных и прочие параметры реализации и проектирования, могут варьироваться для получения альтернативных вариантов реализации настоящего изобретения. Как описано выше, несмотря на то что trie-структура данных удобна для идентификации хорошо известных морфем и (или) слов, соответствующих морфеме или слову, идентифицированному в строке текста, в рамках альтернативных вариантов реализации могут использоваться другие виды структур данных с возможностью поиска. Как также описано выше, в одном варианте реализации, который относится к оптическому распознаванию символов в тексте на арабском языке, используются множество параметризованных символов и множество непараметризованных символов, описанные выше со ссылкой на Фиг. 32 и 34, однако в случае как арабского языка, так и других подобных языков могут использоваться альтернативные множества параметризованных и непараметризованных символов. Устройства и способы настоящего изобретения могут быть также применены в отношении слитных рукописных и аналогичных текстов на таких языках, как, среди прочих, английский и русский.
Следует понимать, что представленное выше описание вариантов реализации настоящего изобретения приведено для того, чтобы любой специалист в данной области техники мог воспроизвести или применить настоящее изобретение. Специалистам в данной области техники будут очевидны возможные модификации представленных вариантов реализации, при этом общие принципы, представленные здесь, без отступления от сущности и объема настоящего изобретения могут быть применены в рамках других вариантов реализации. Таким образом, подразумевается, что настоящее изобретение не ограничено представленными здесь вариантами реализации, а напротив, в его объем входят все возможные варианты реализации, соответствующие принципам и новым отличительным признакам настоящего изобретения.


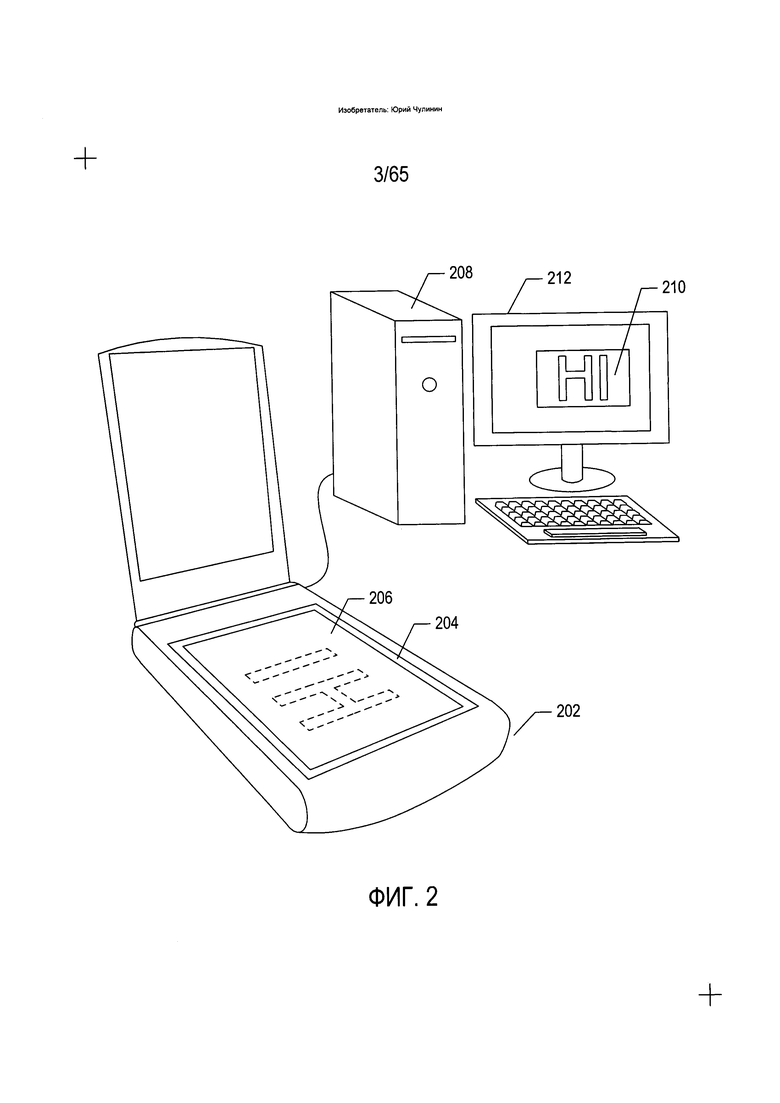
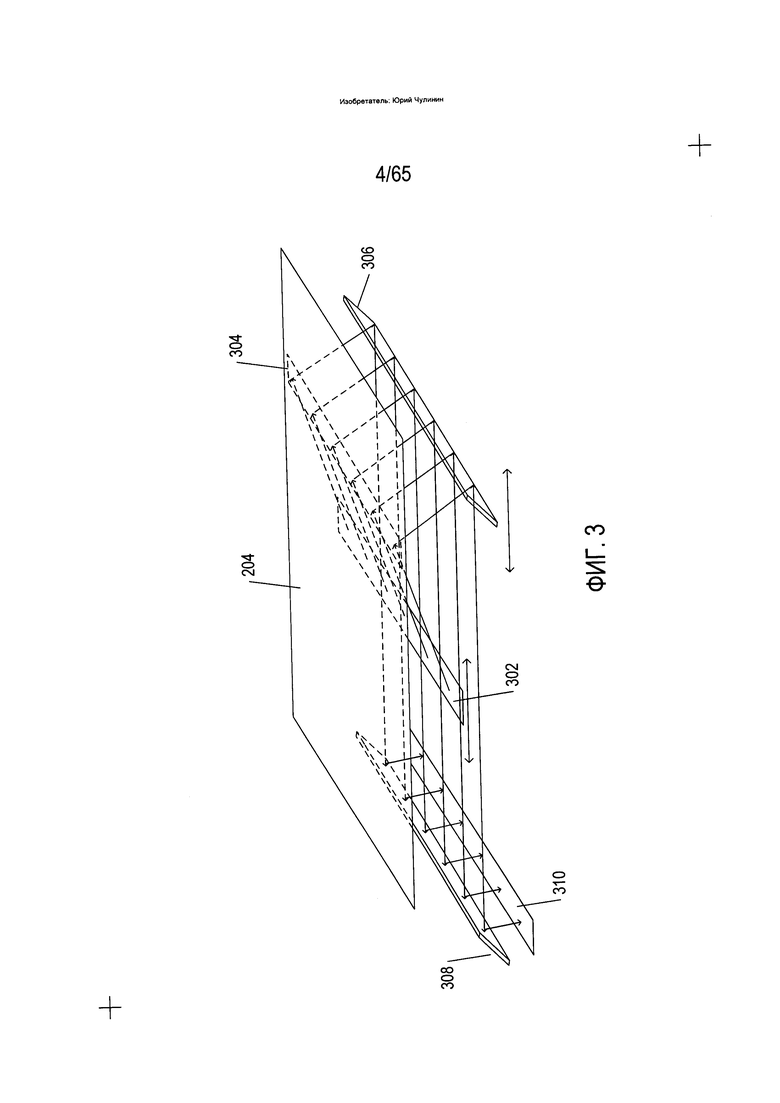
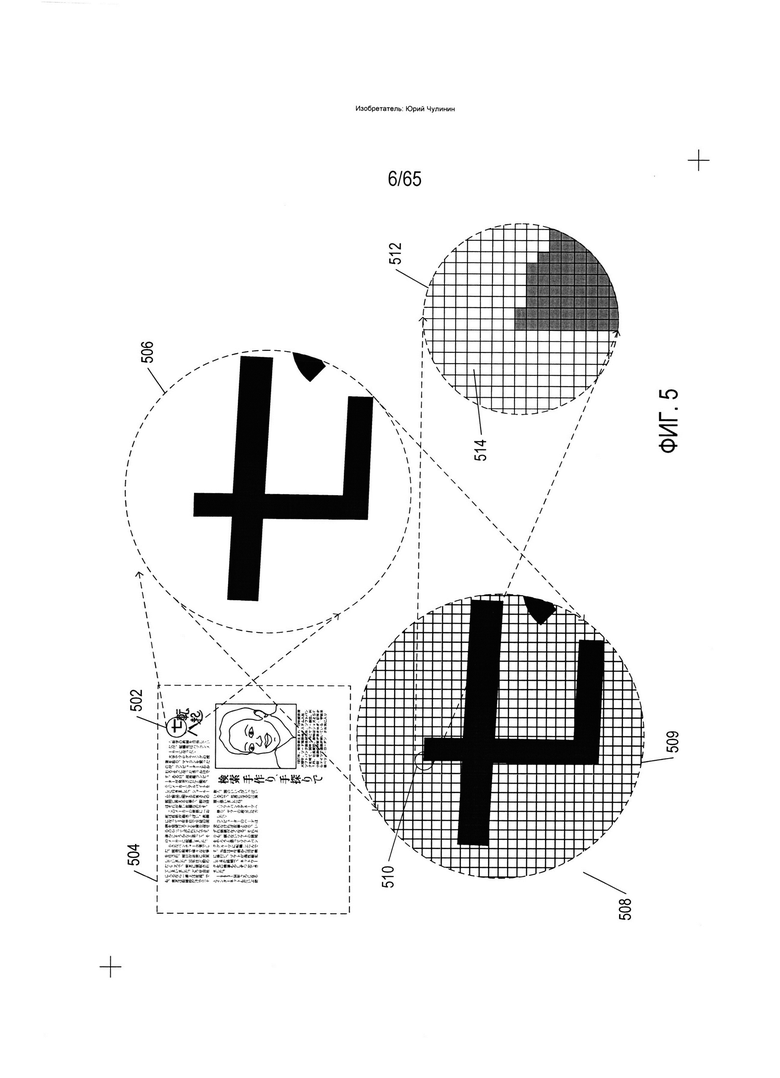

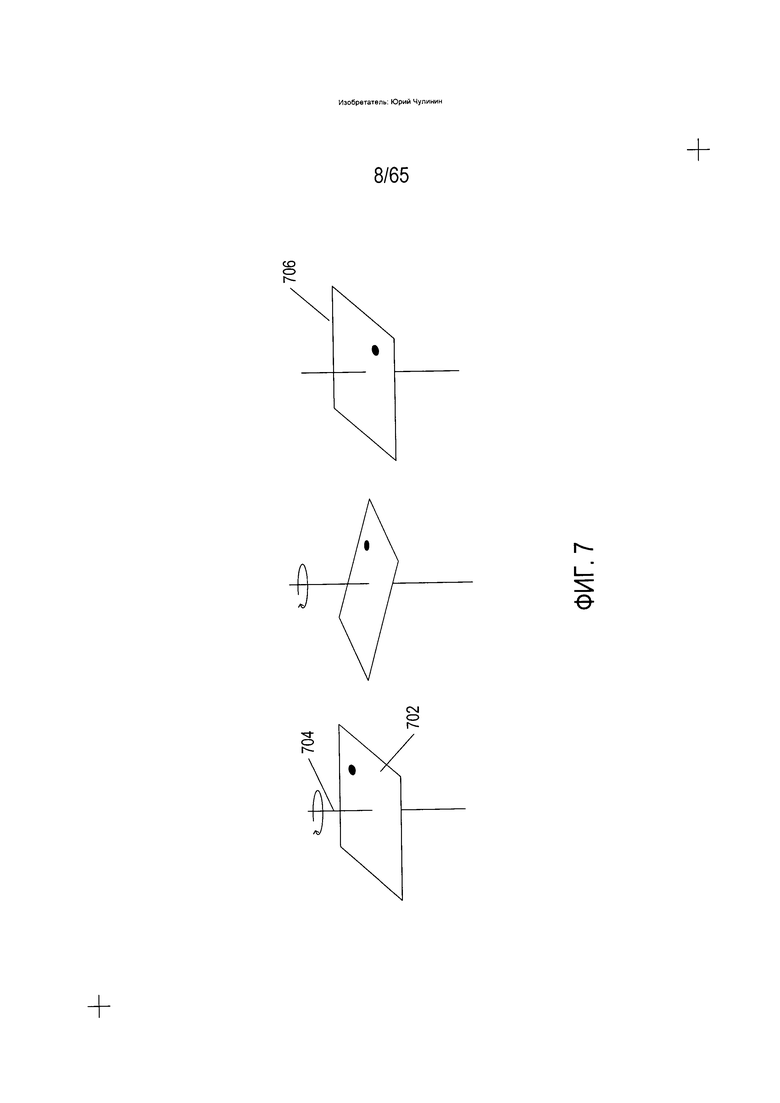
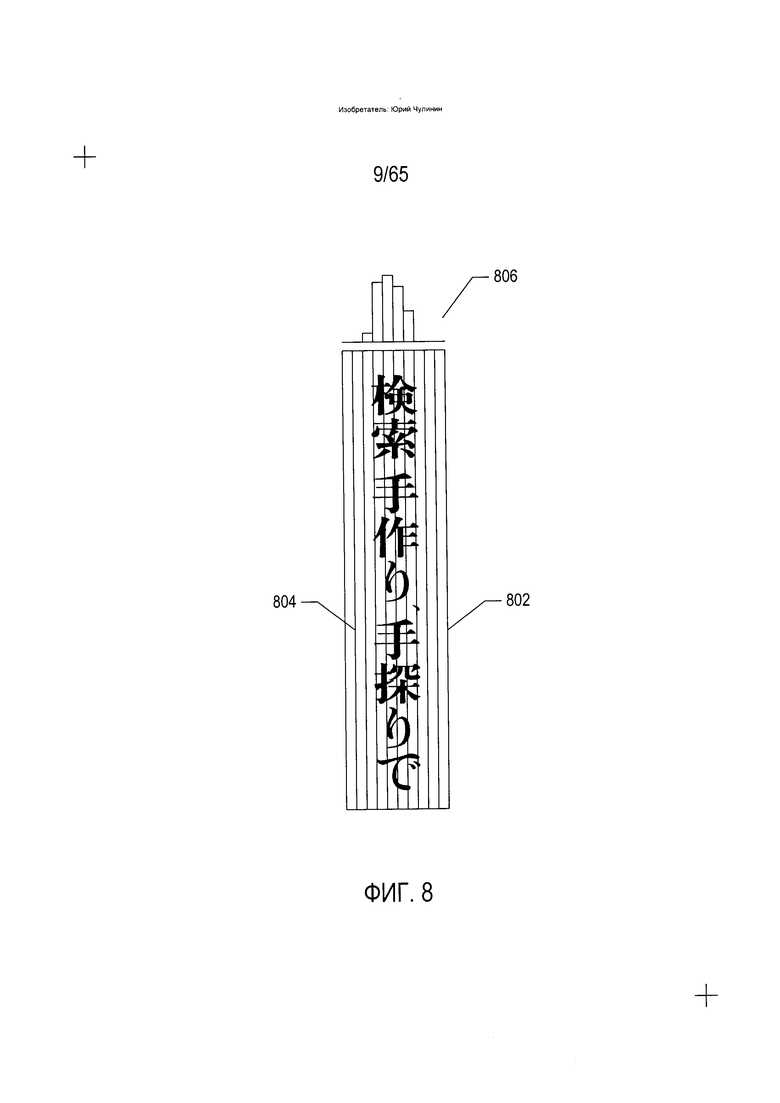
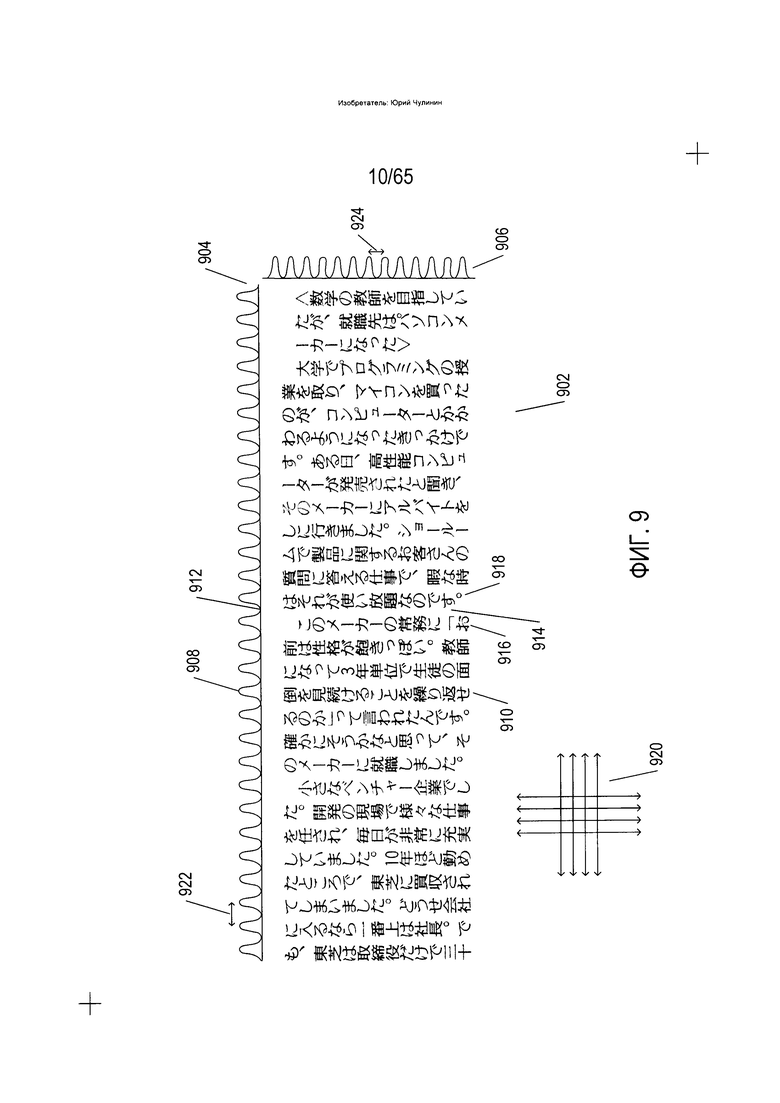
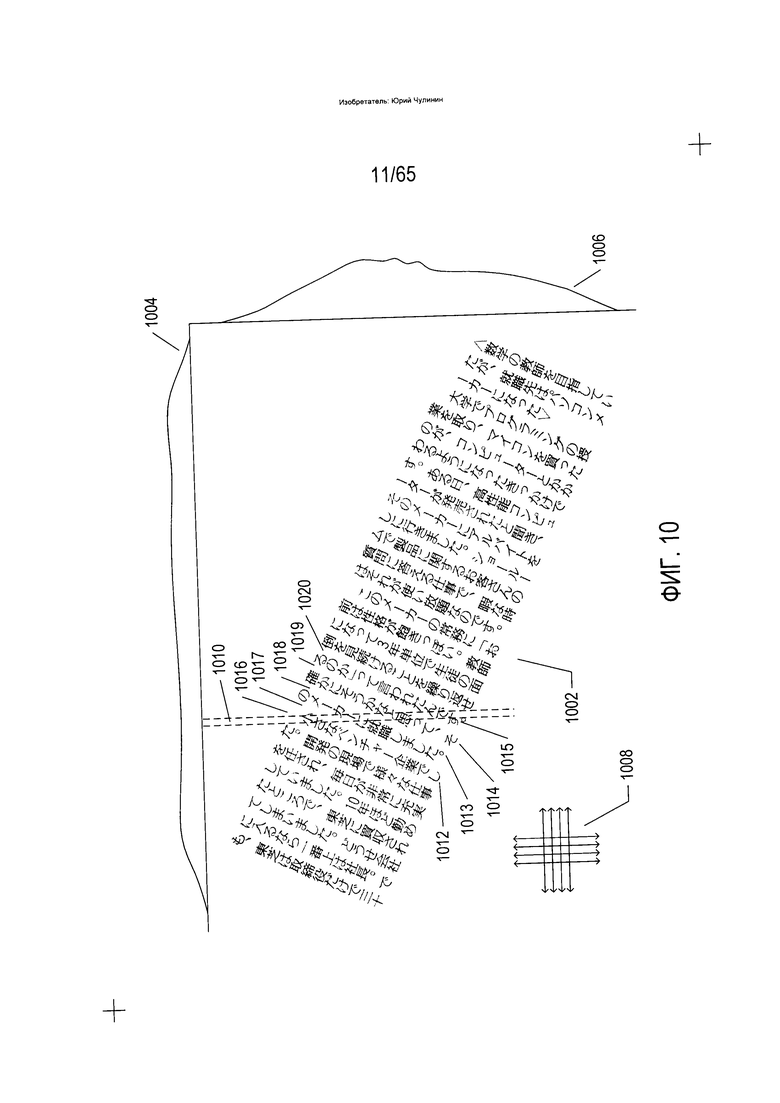
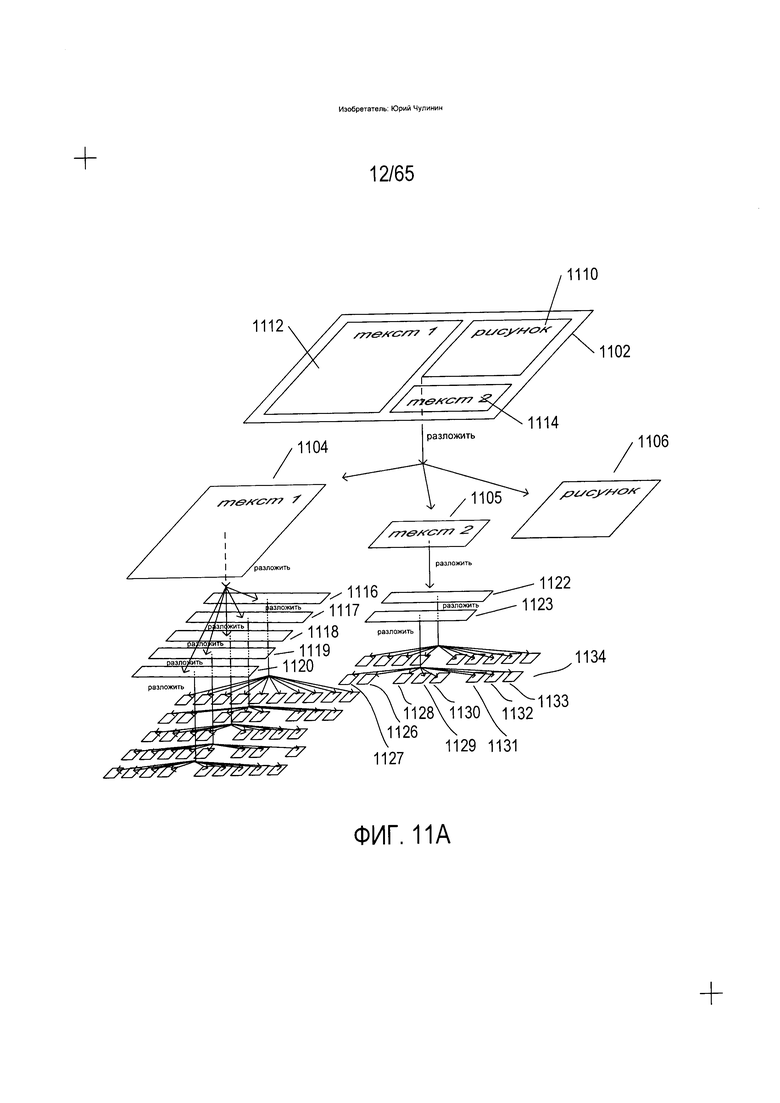
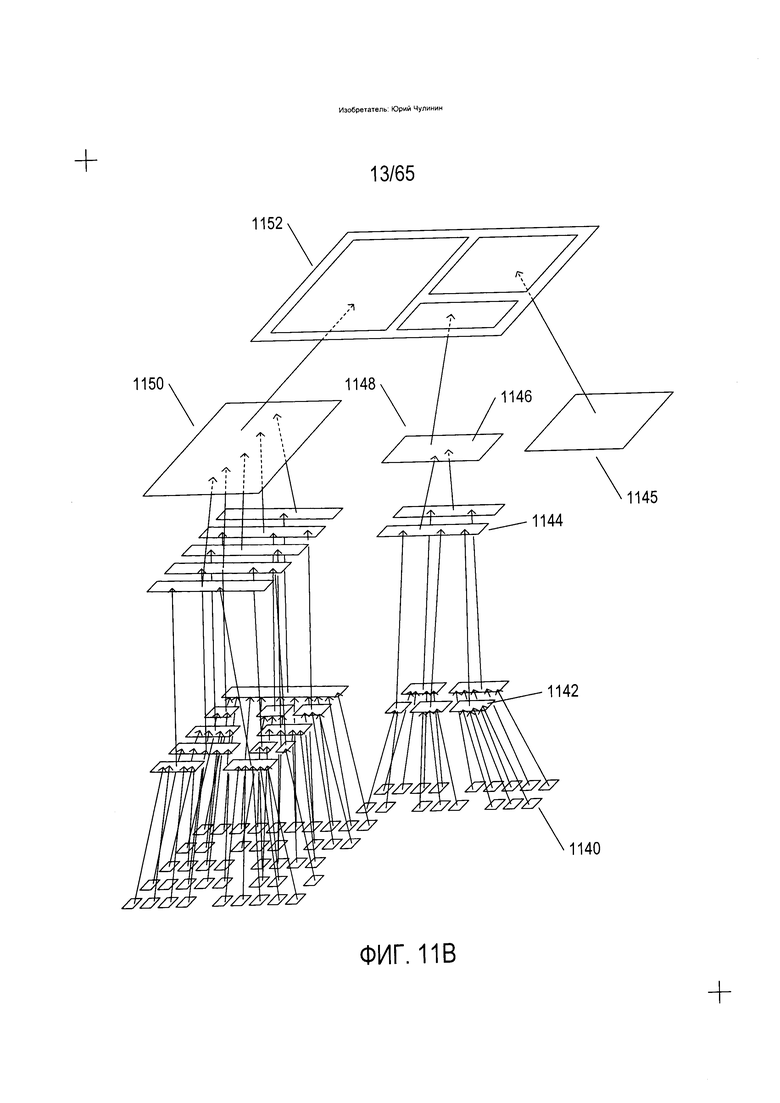
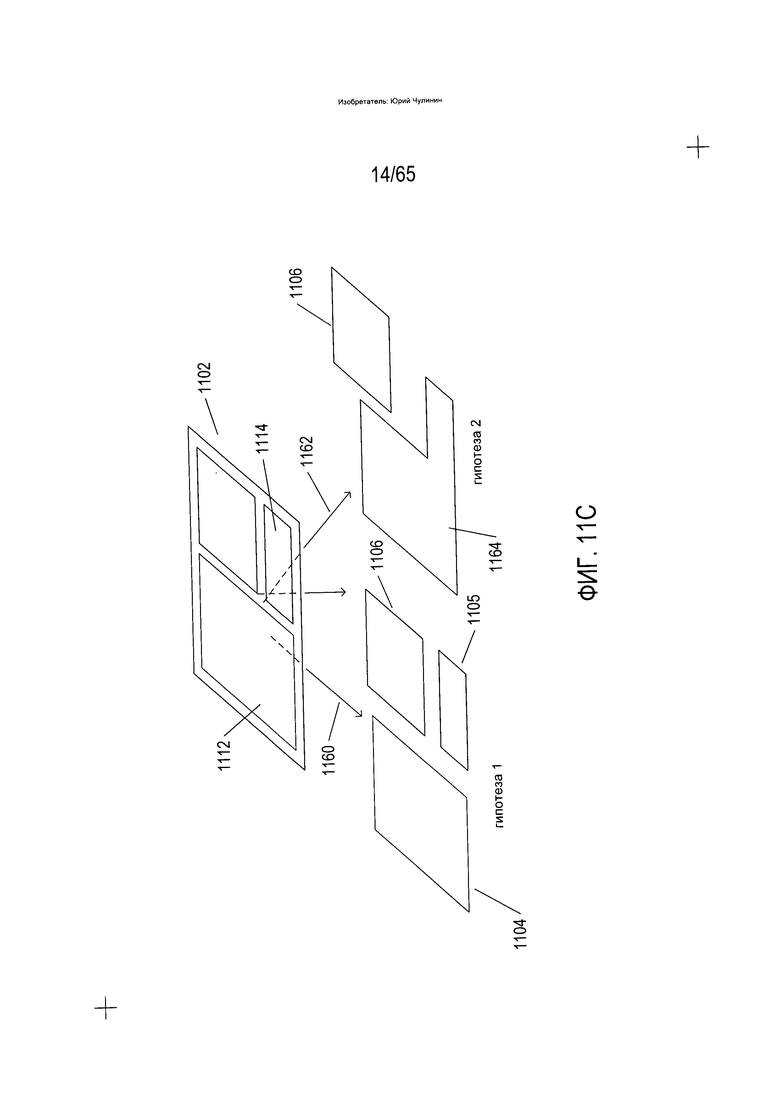
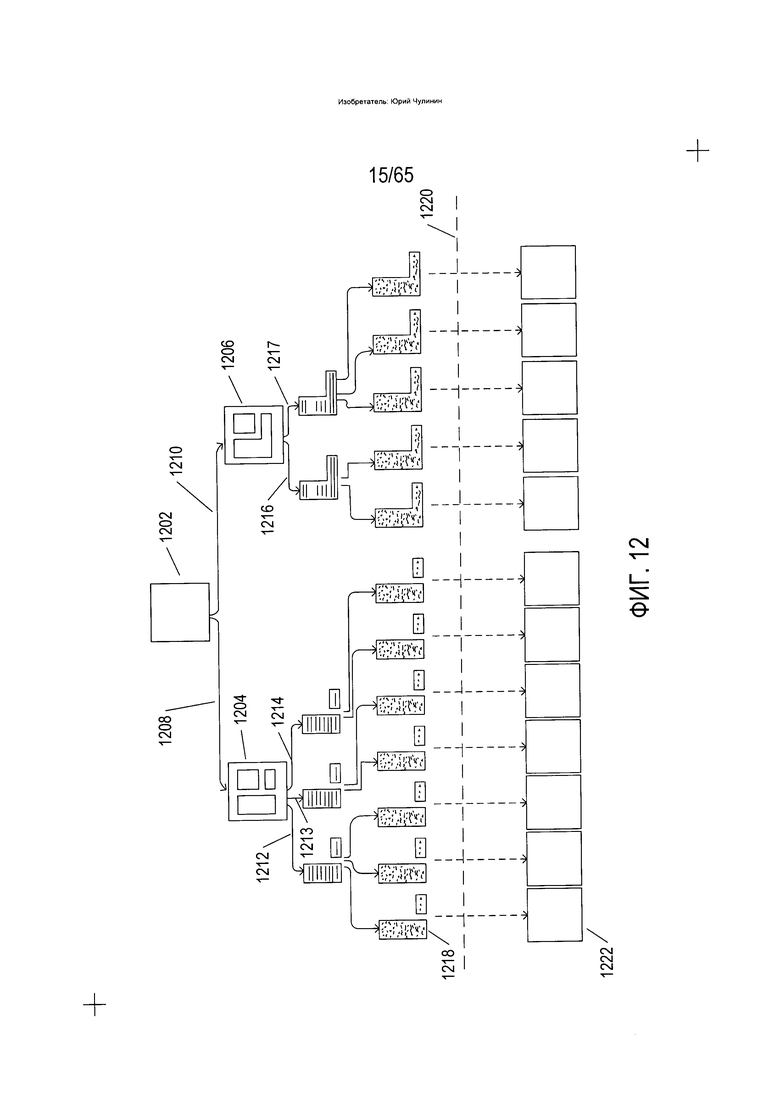
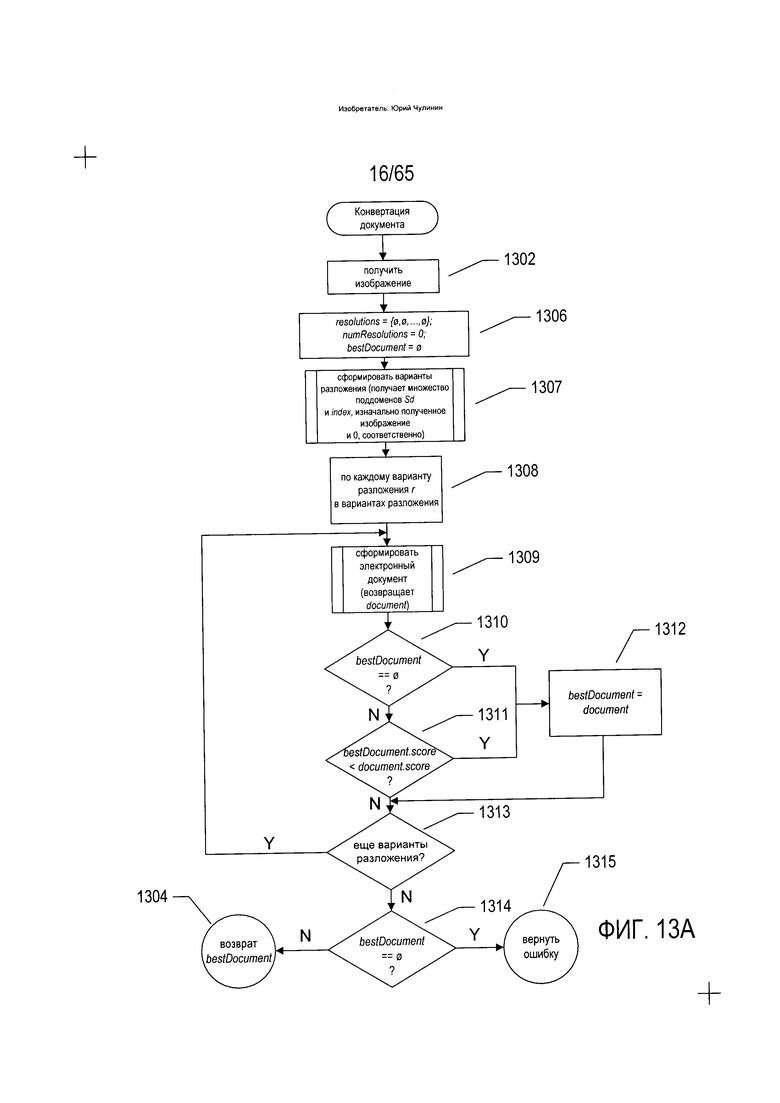
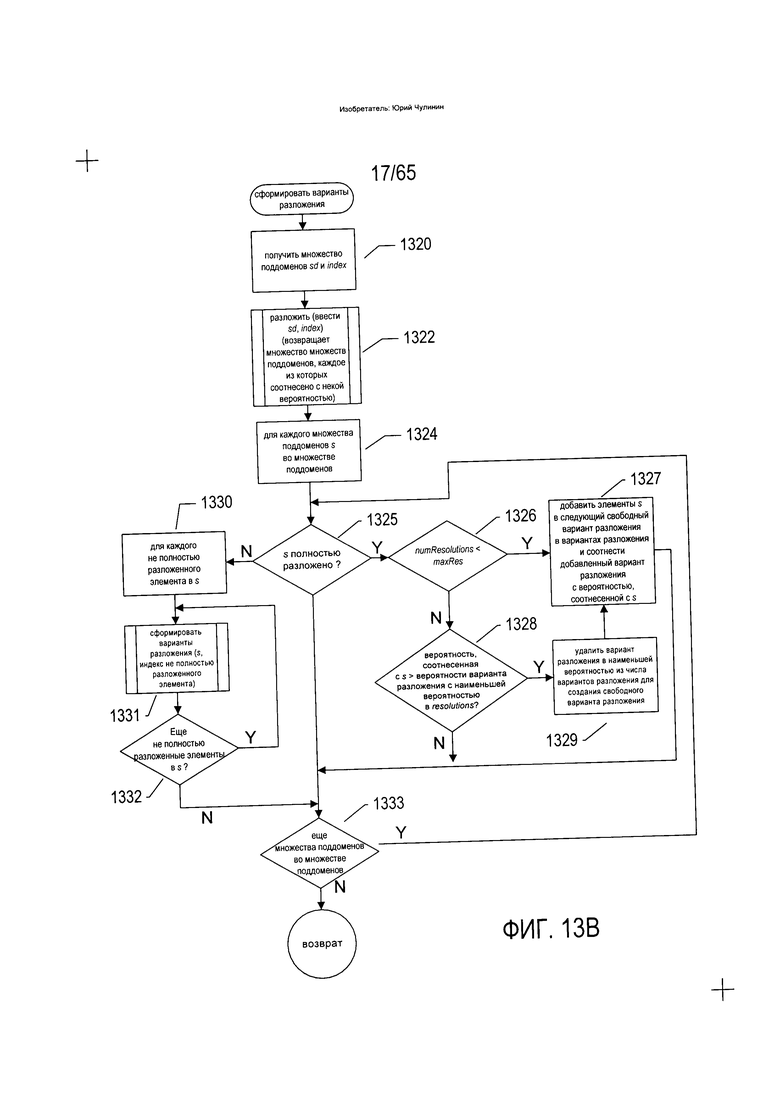
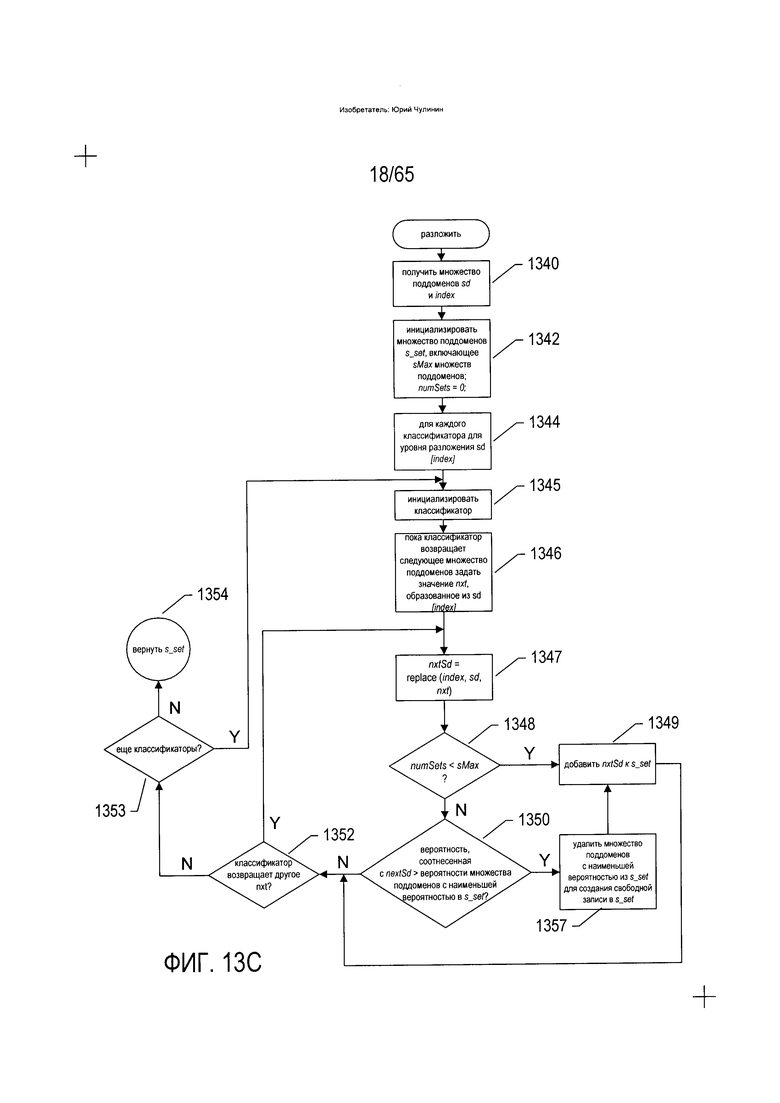
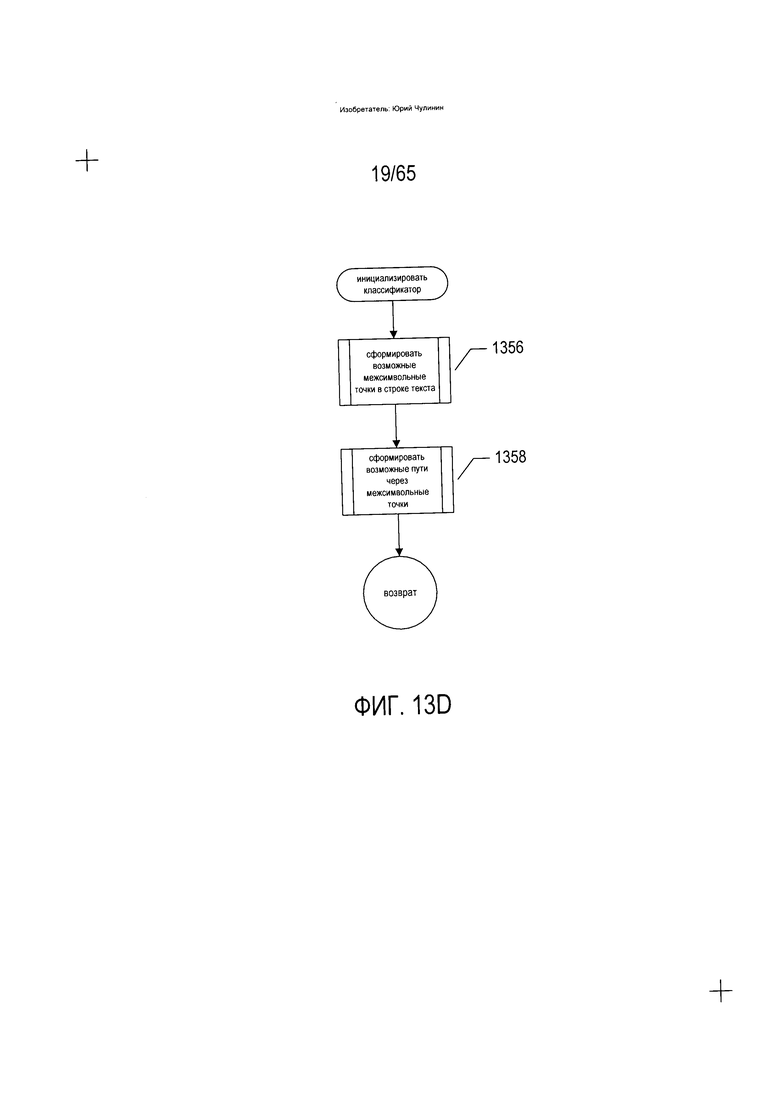
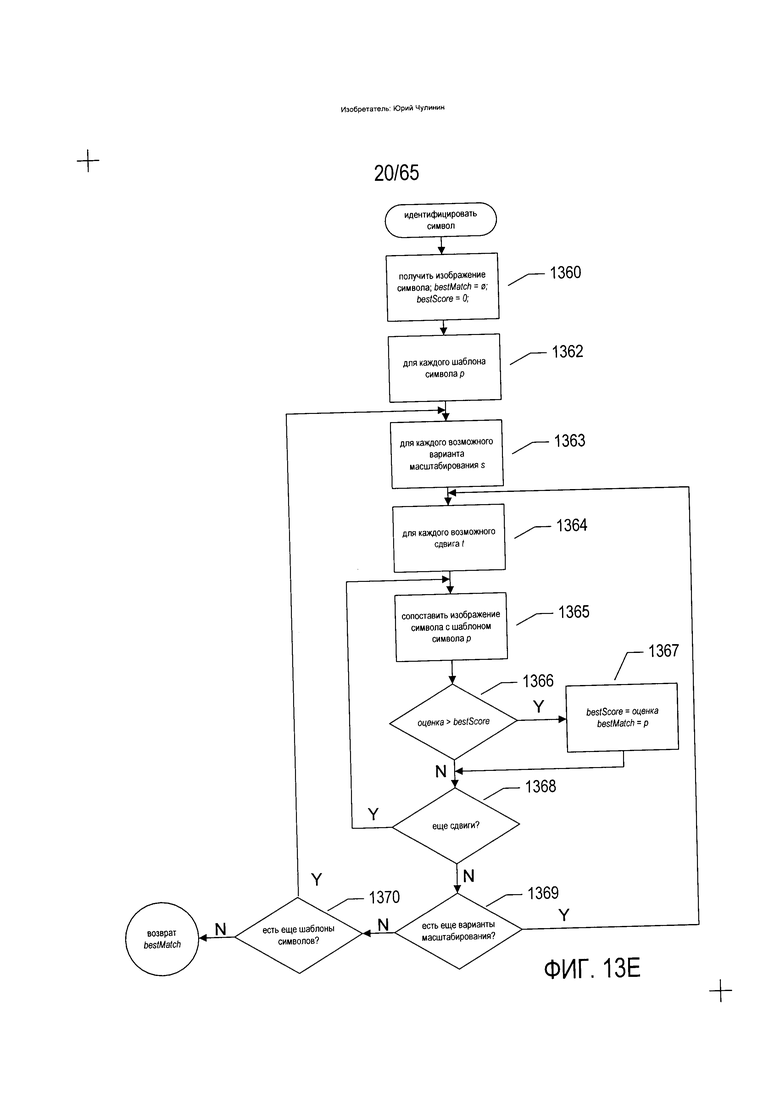
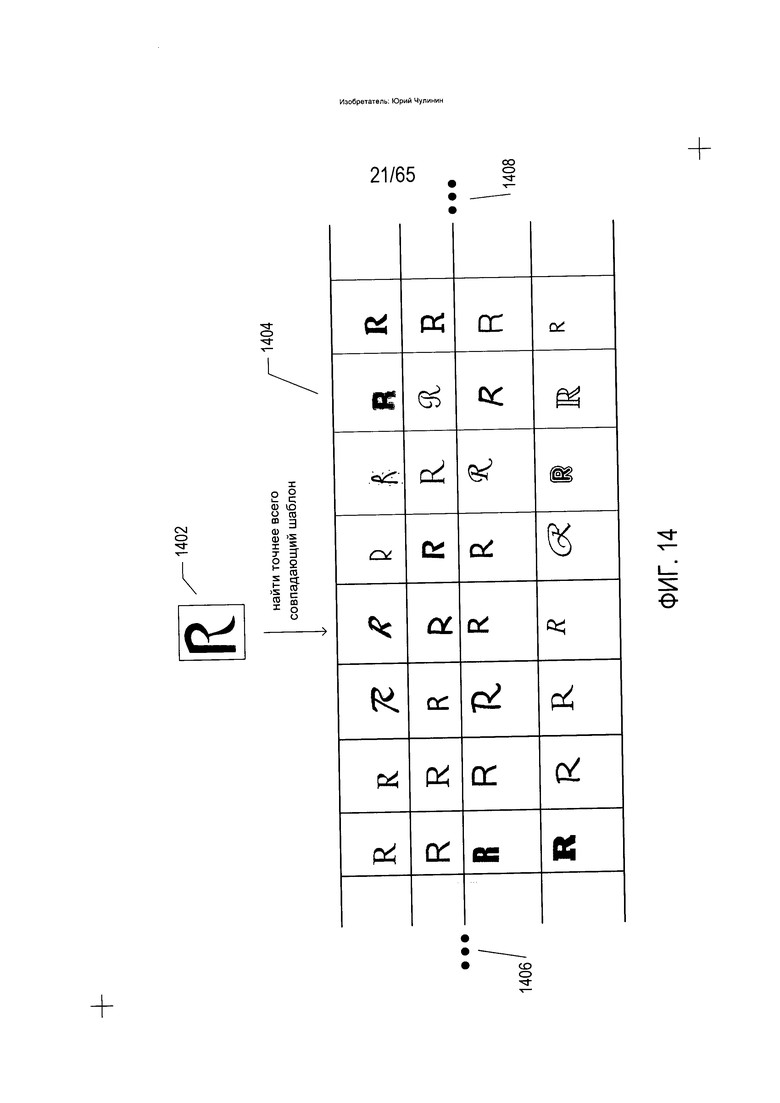
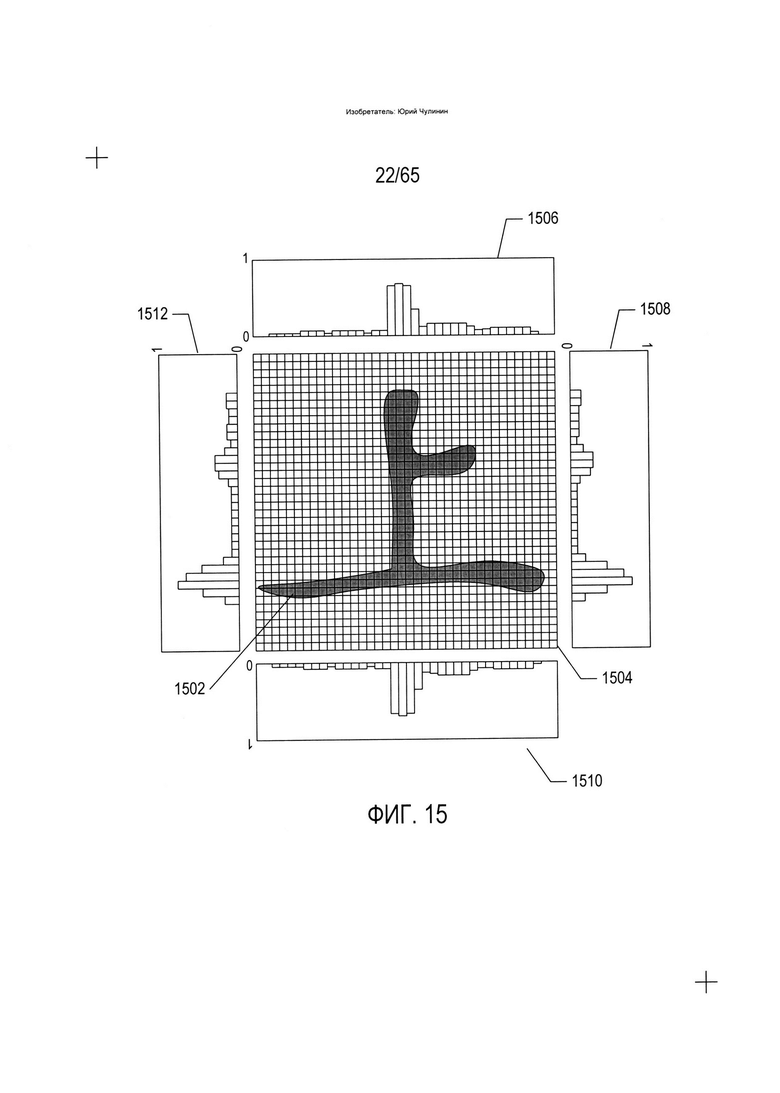
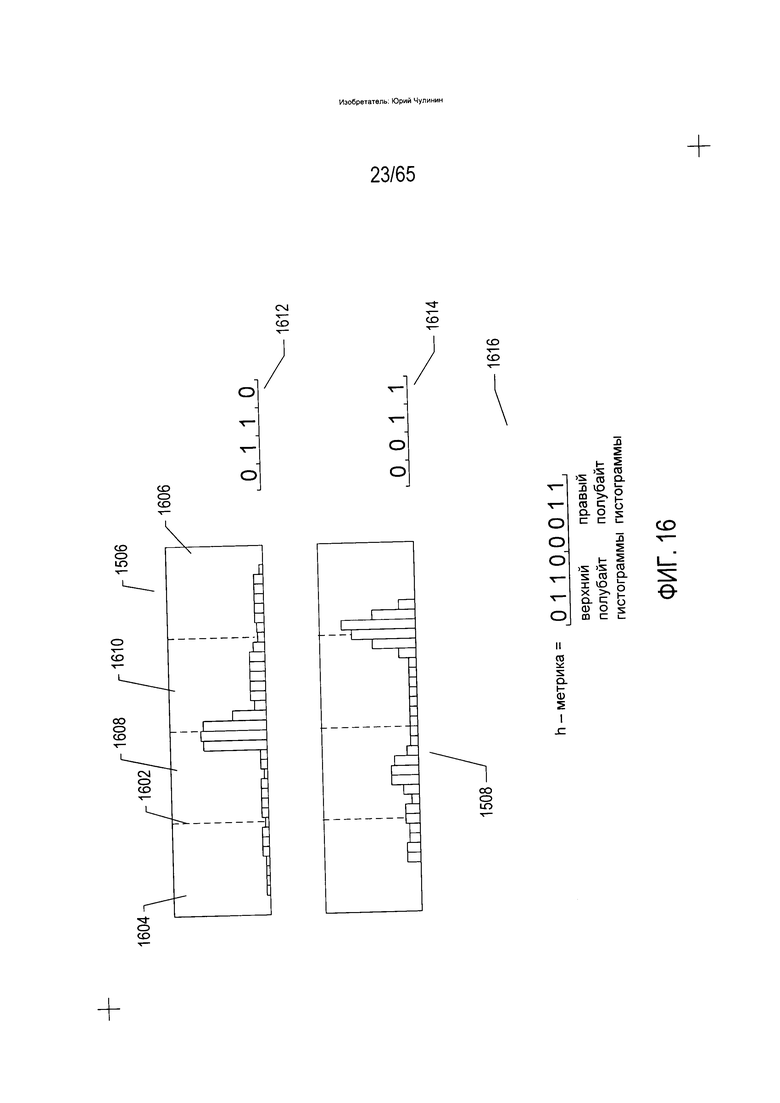
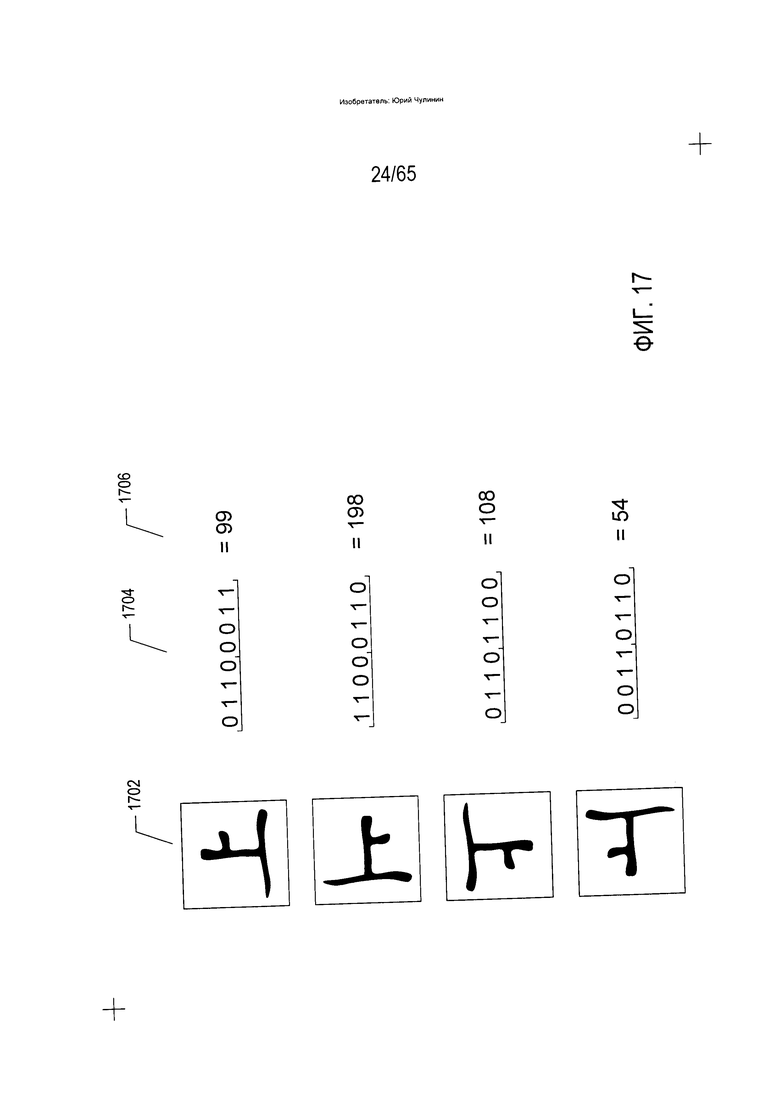
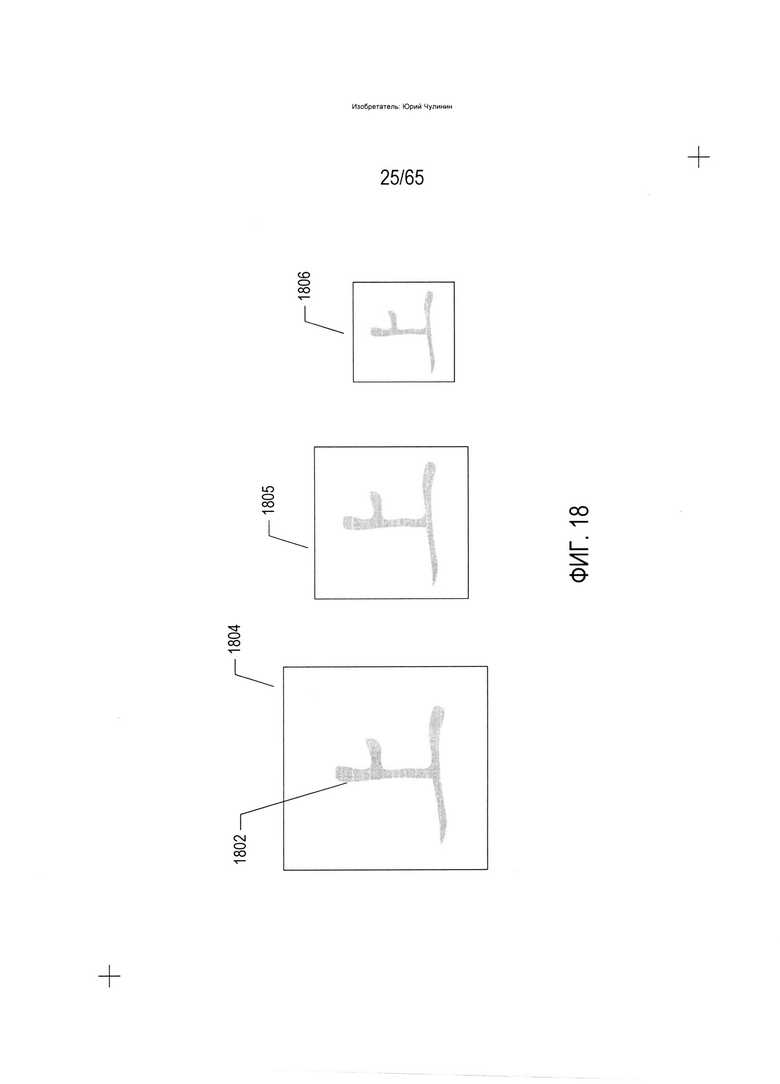
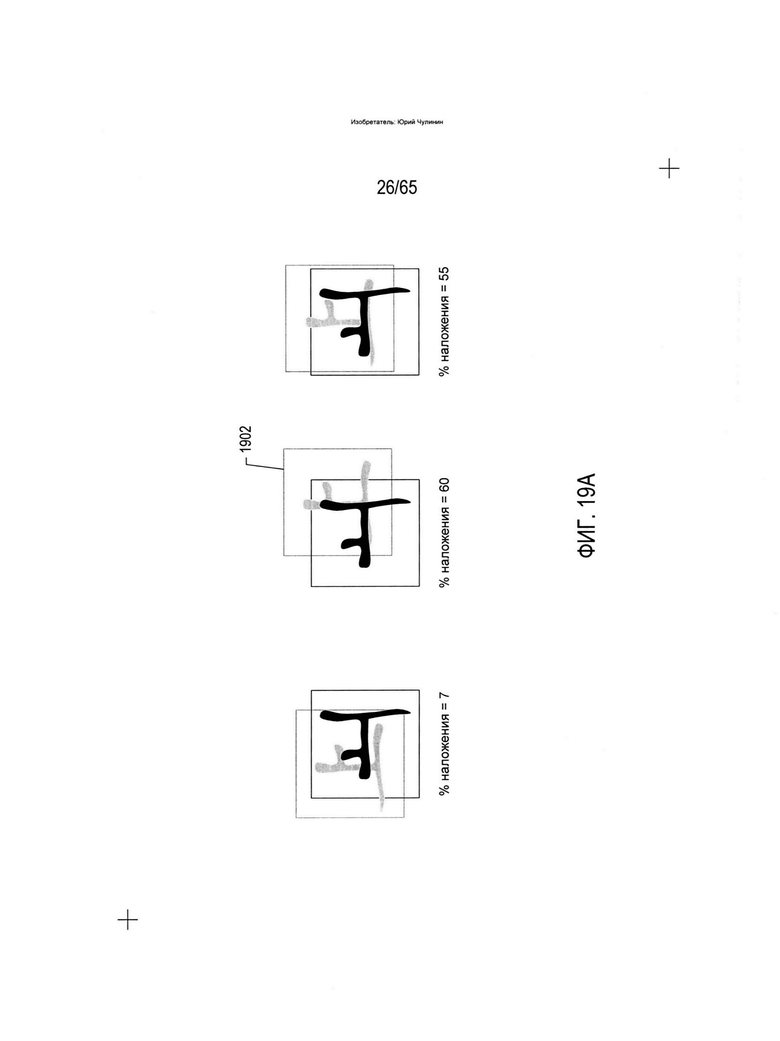
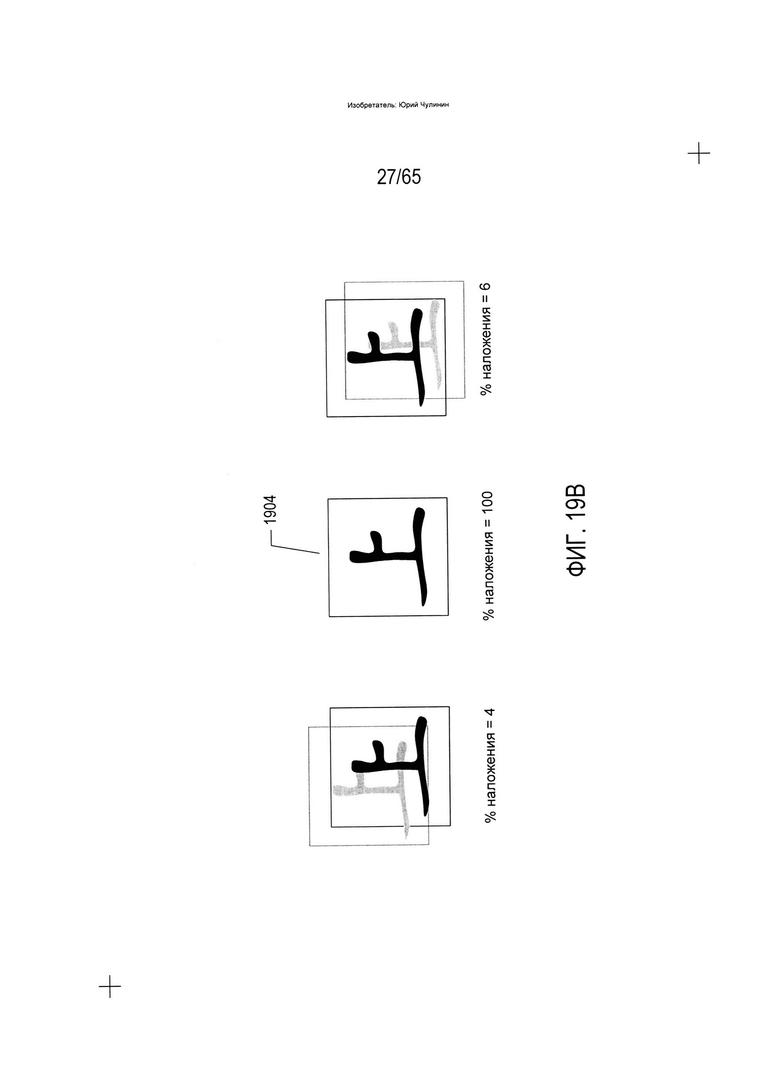
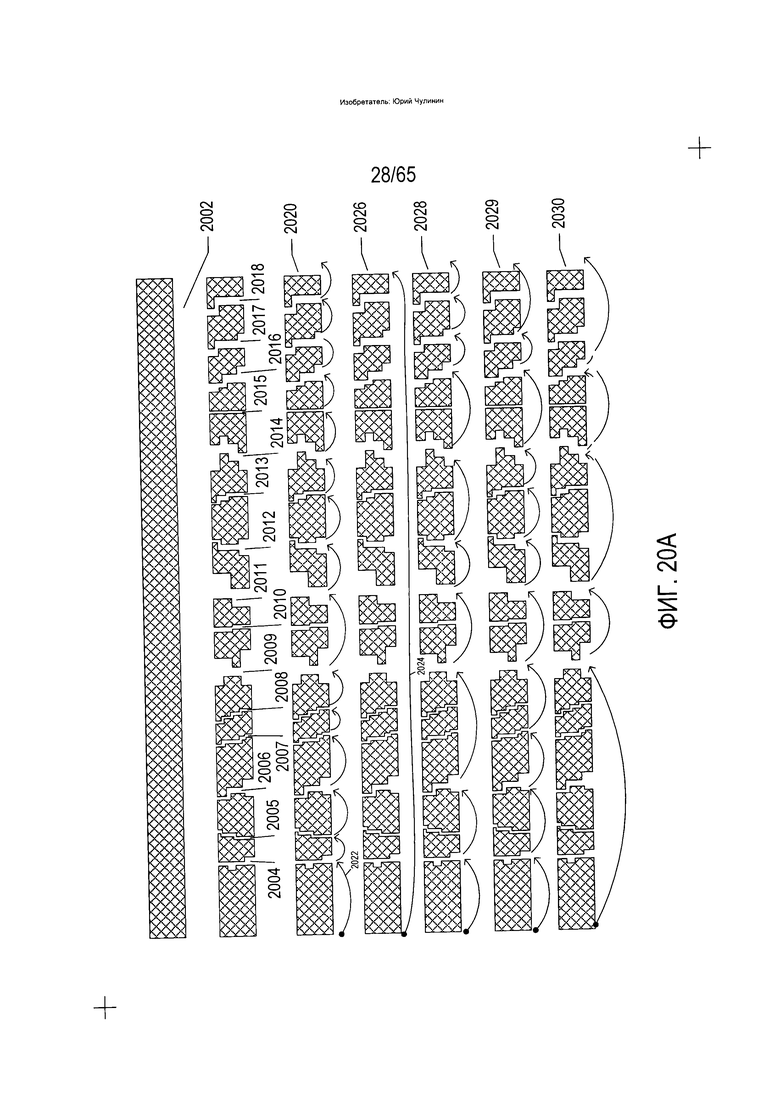
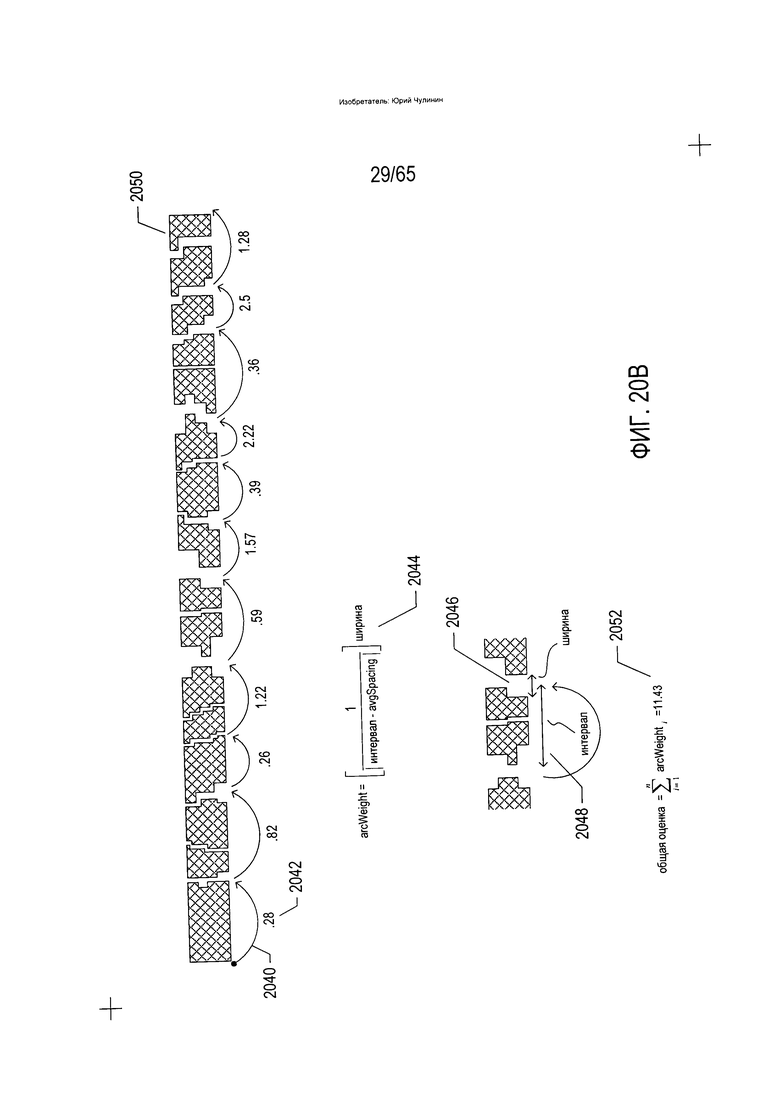

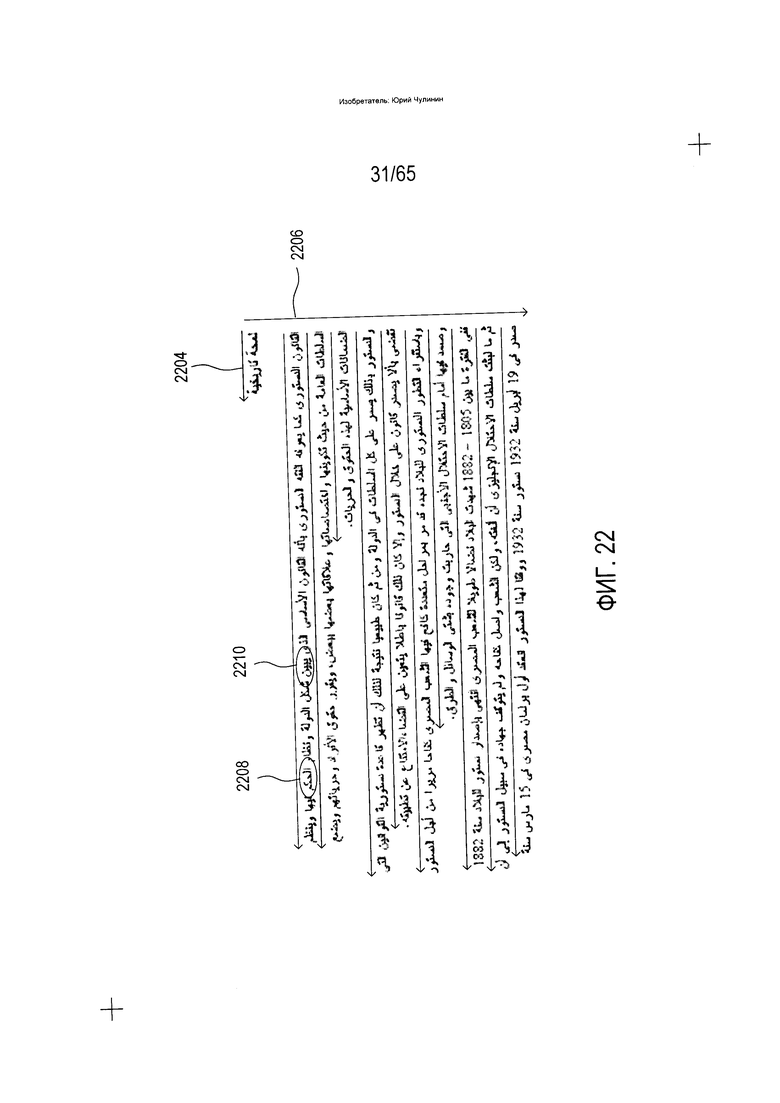
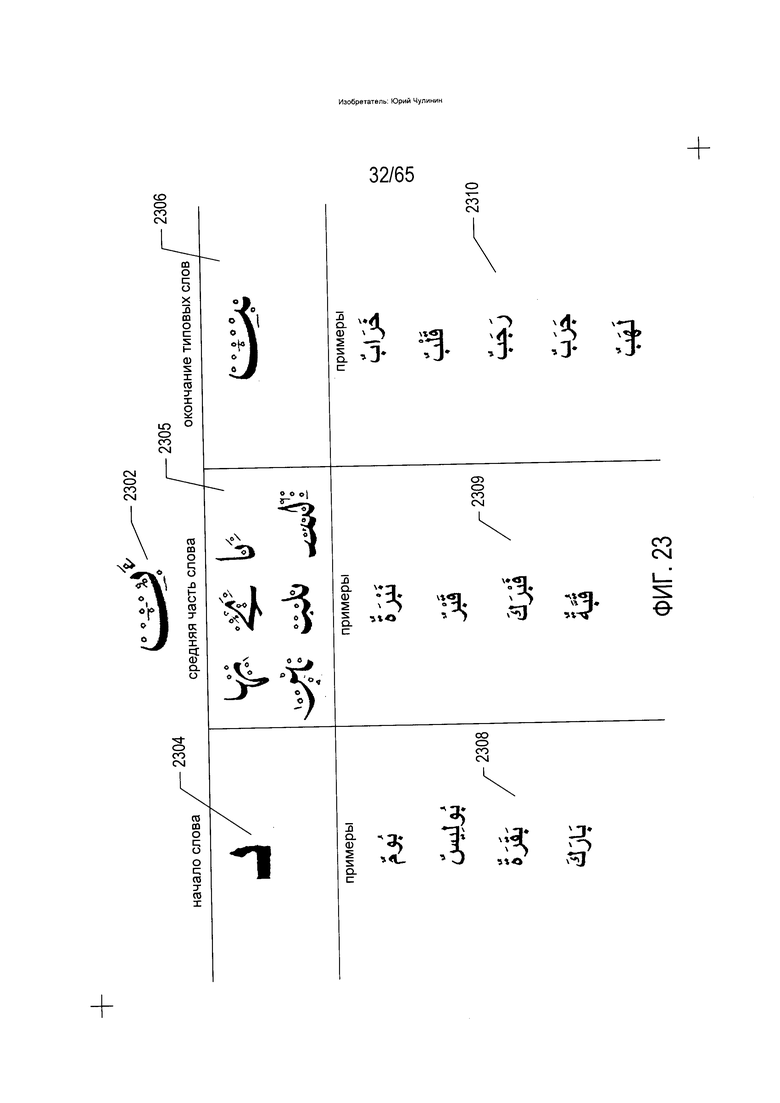

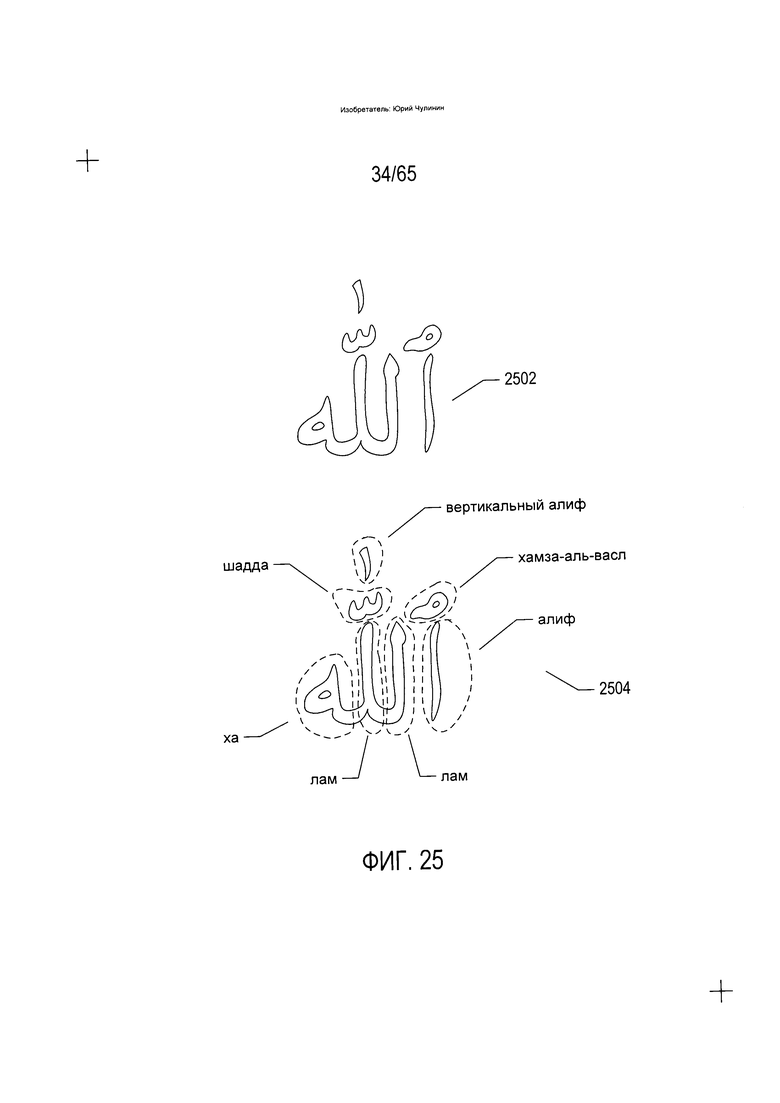

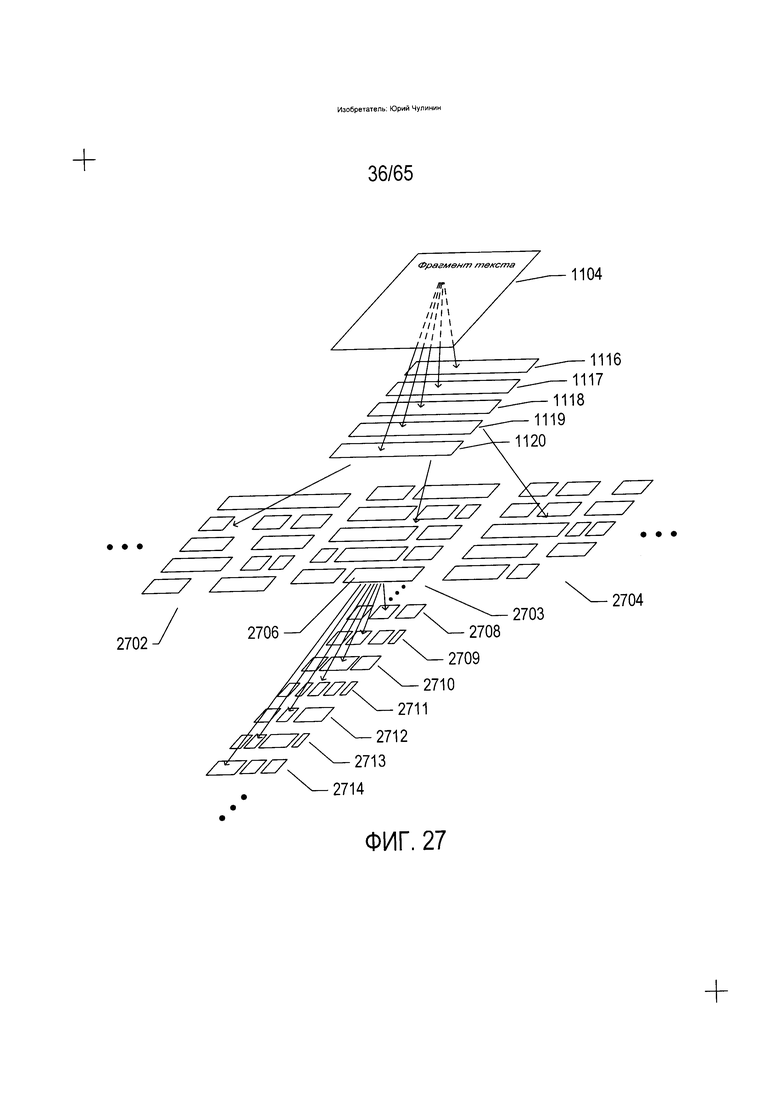
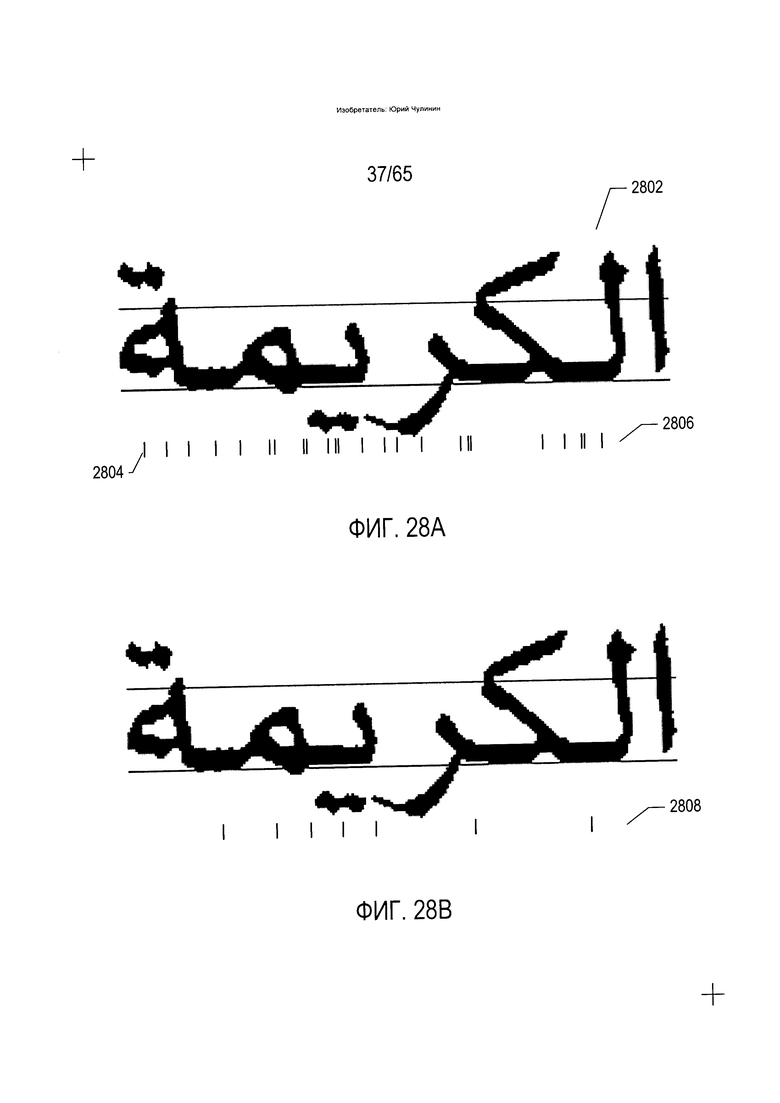
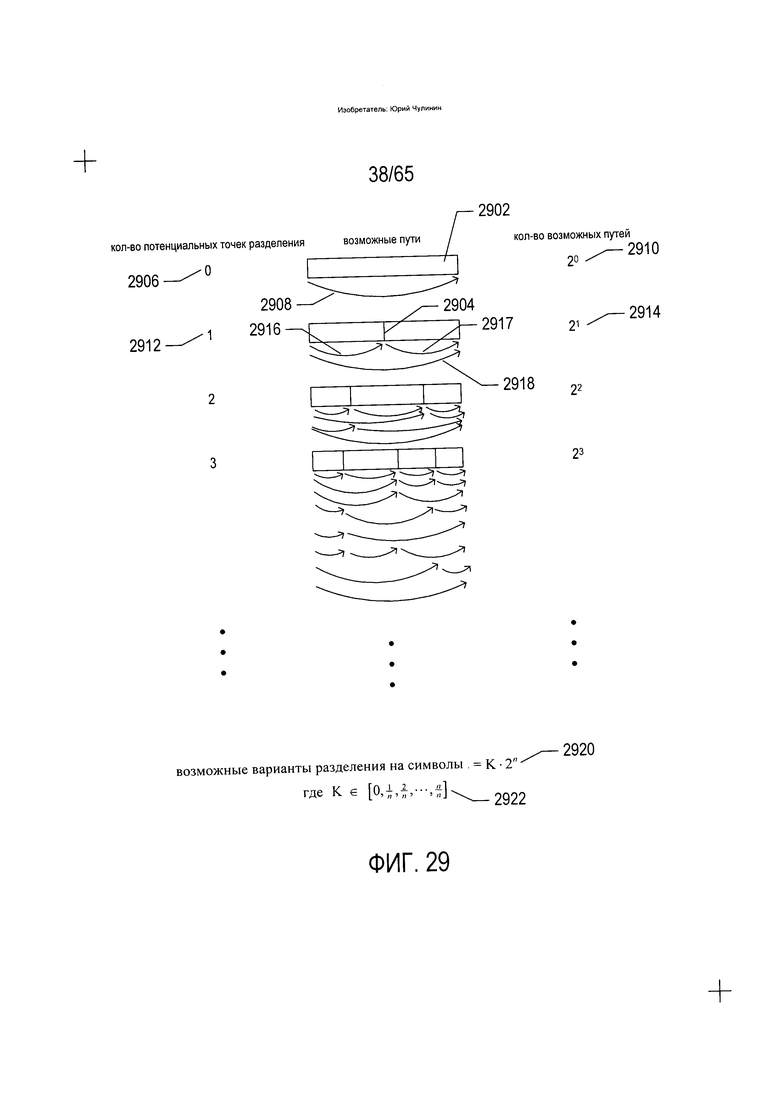
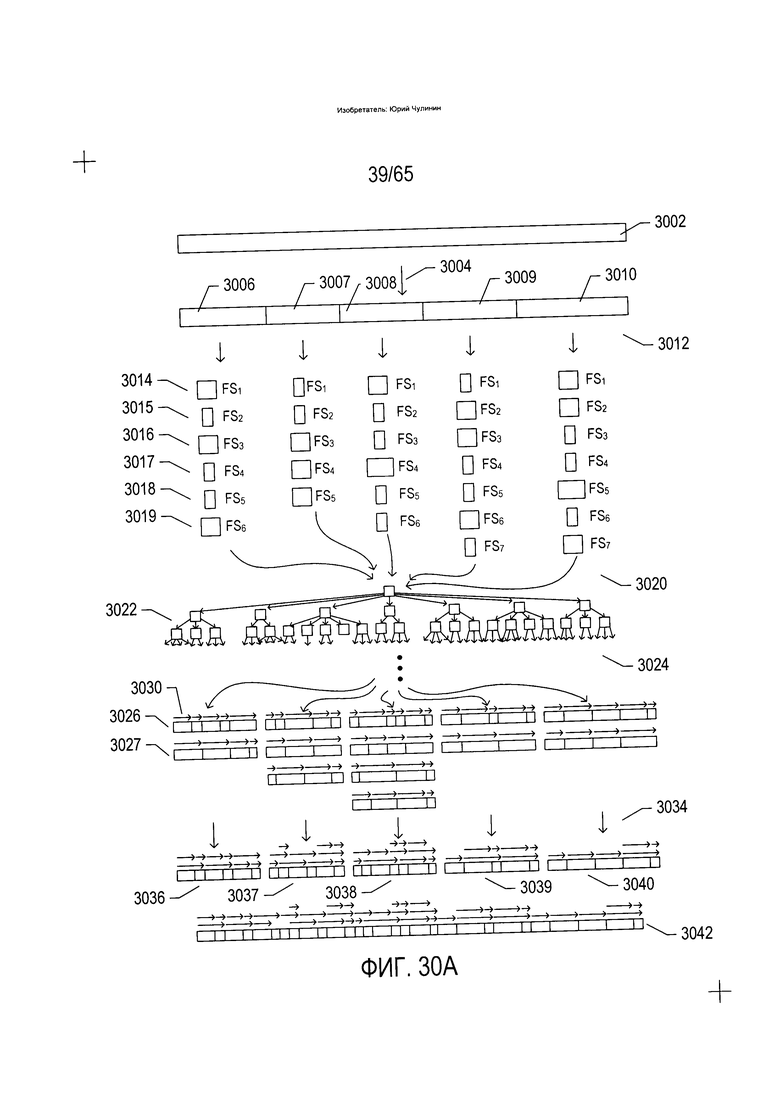
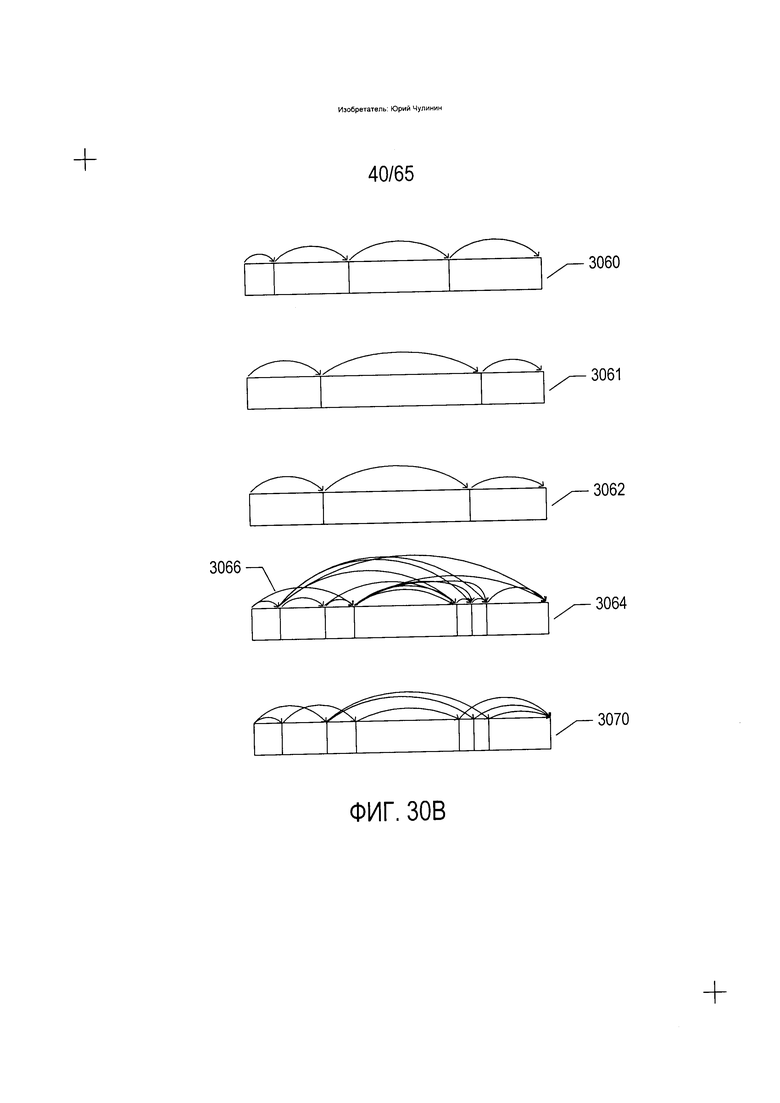
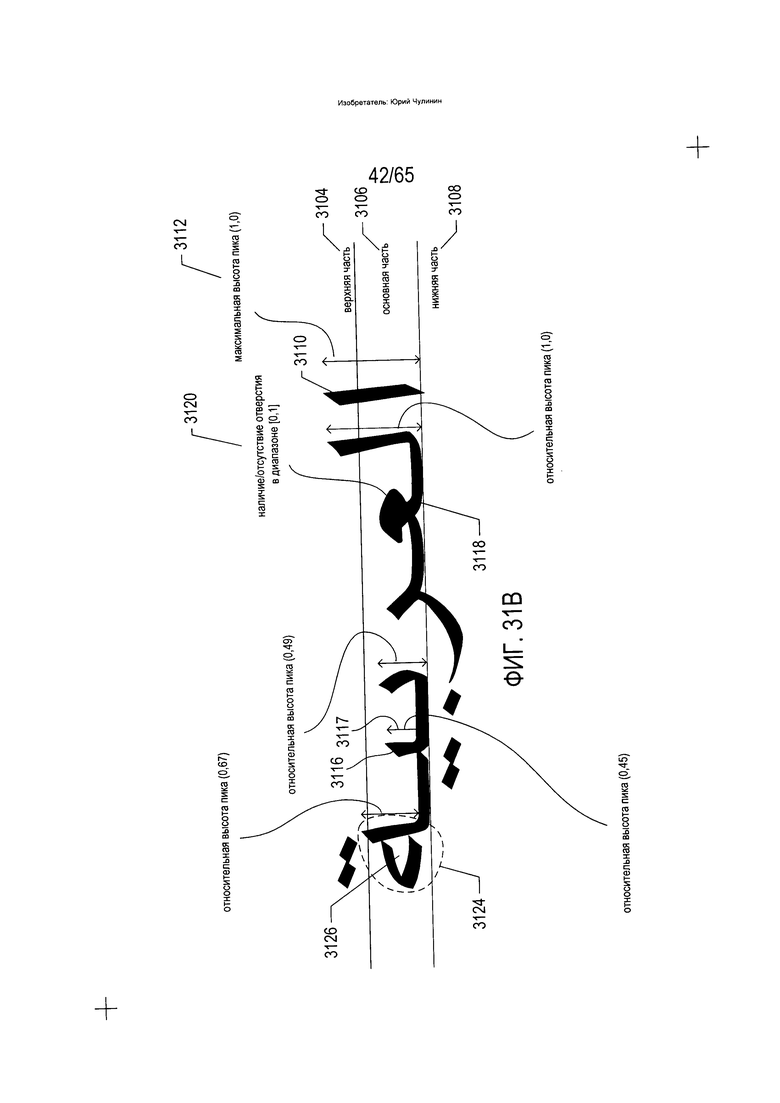



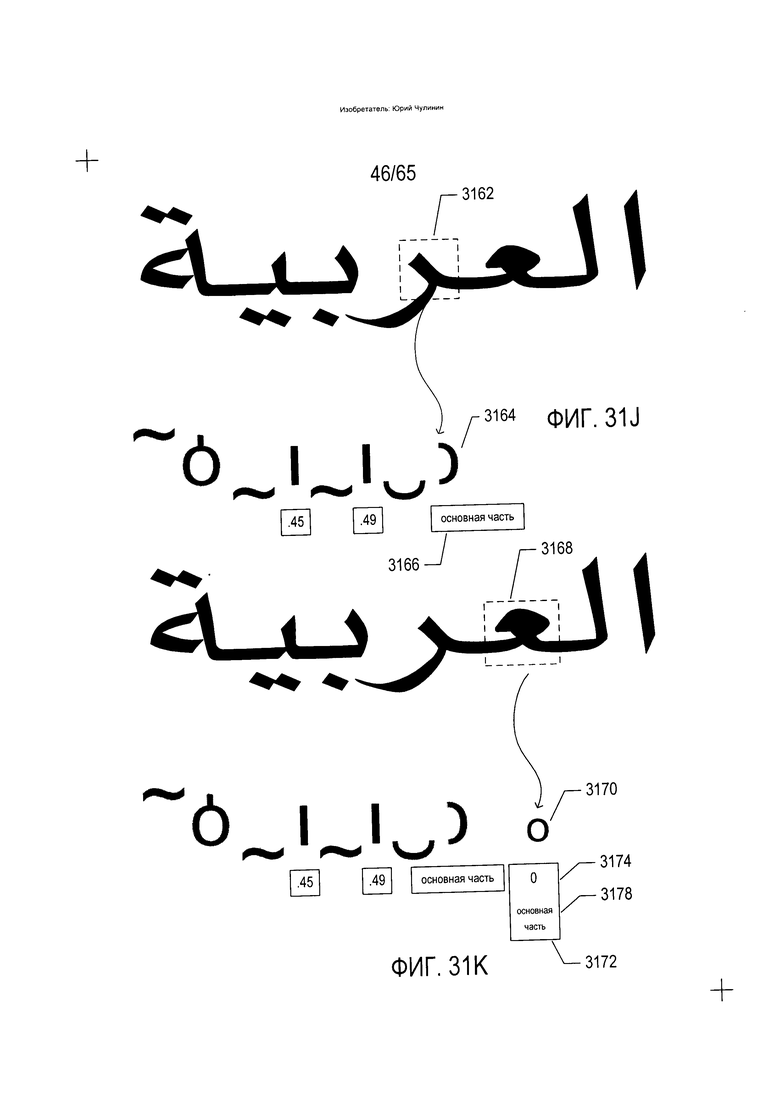
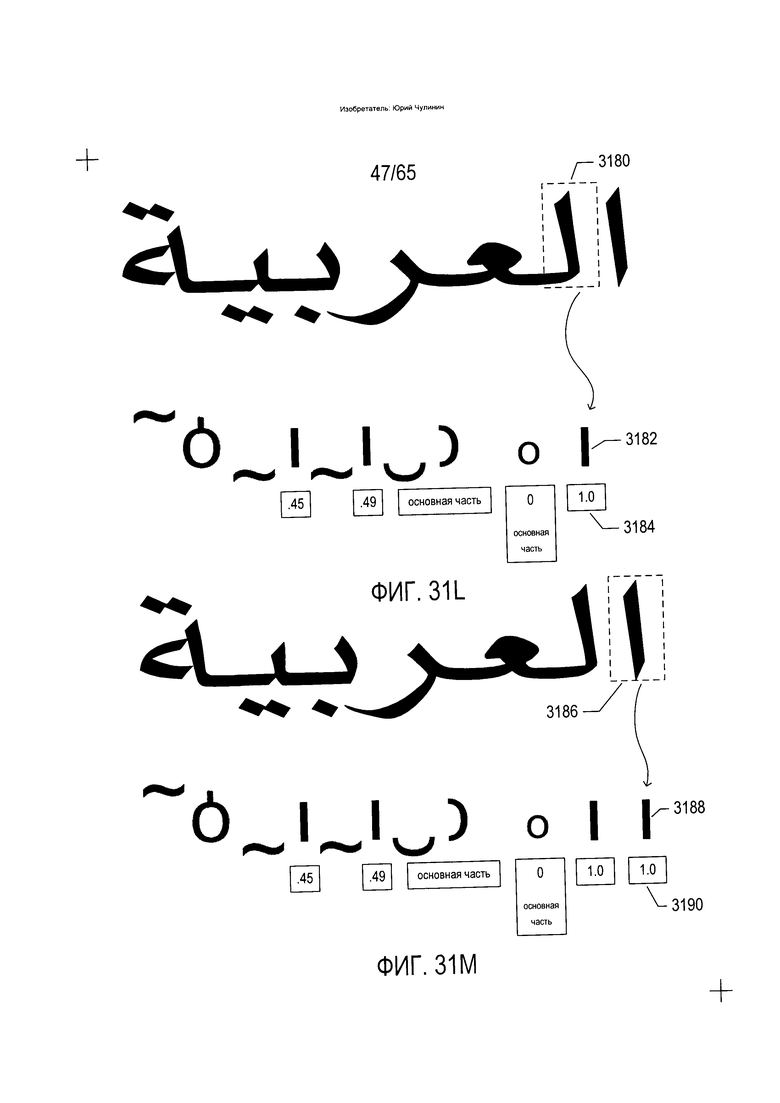
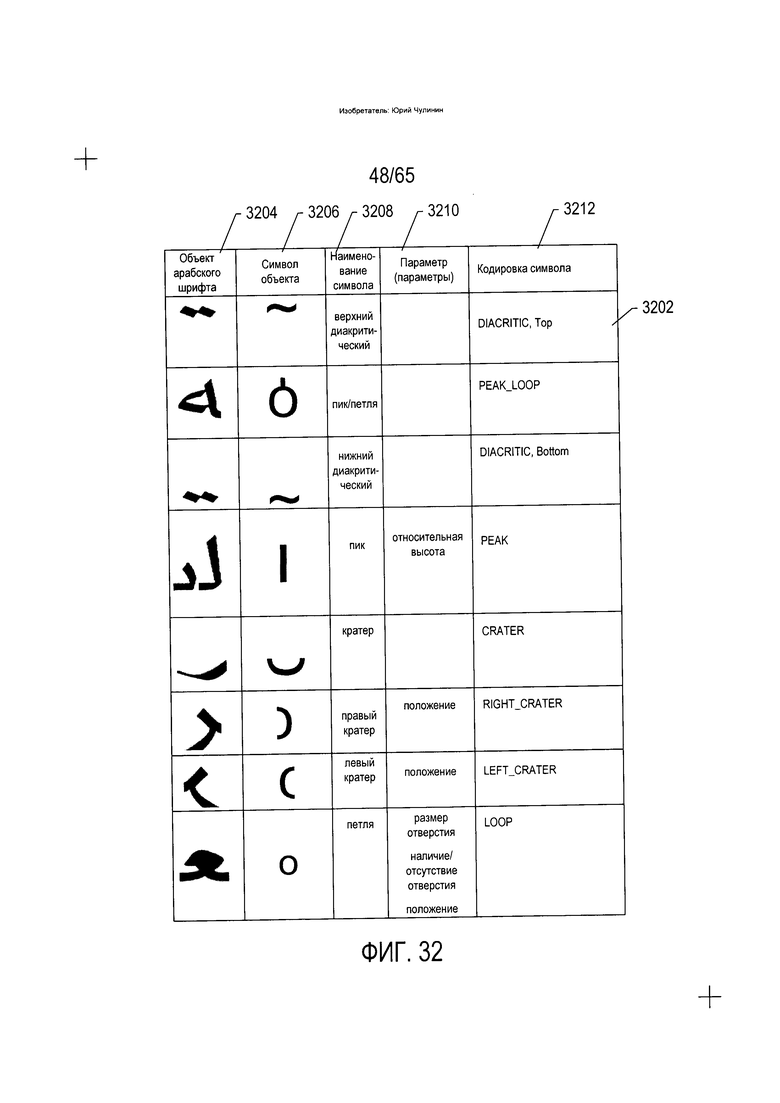
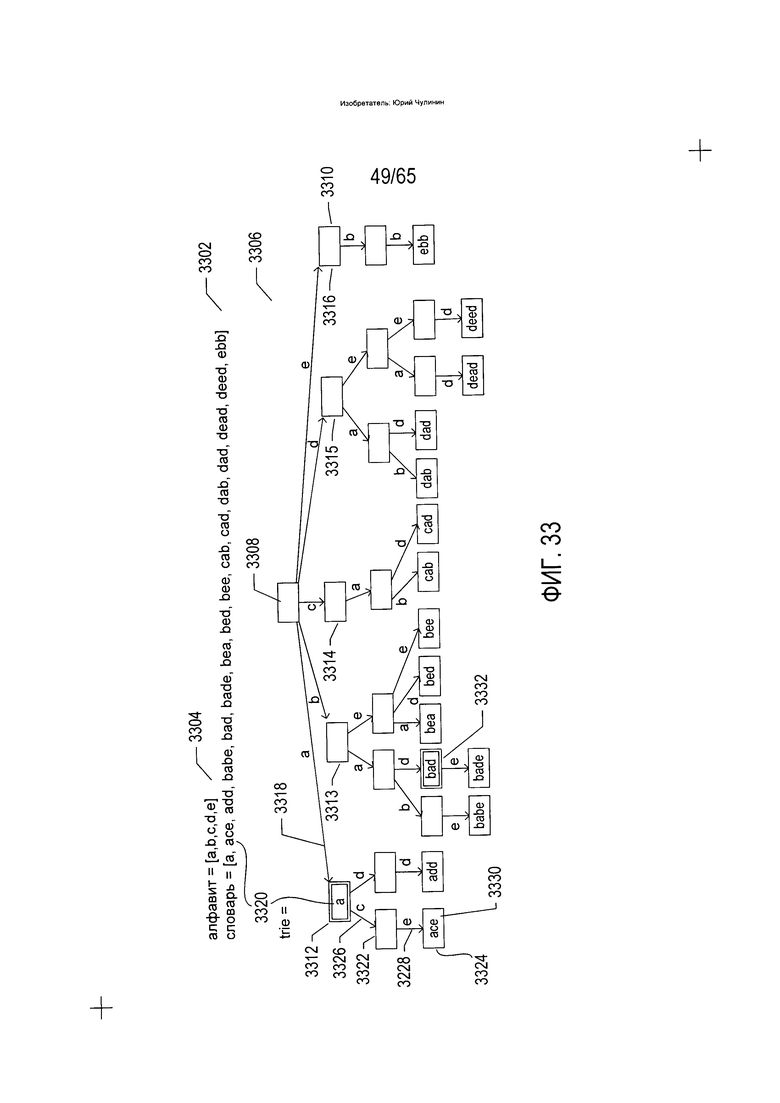
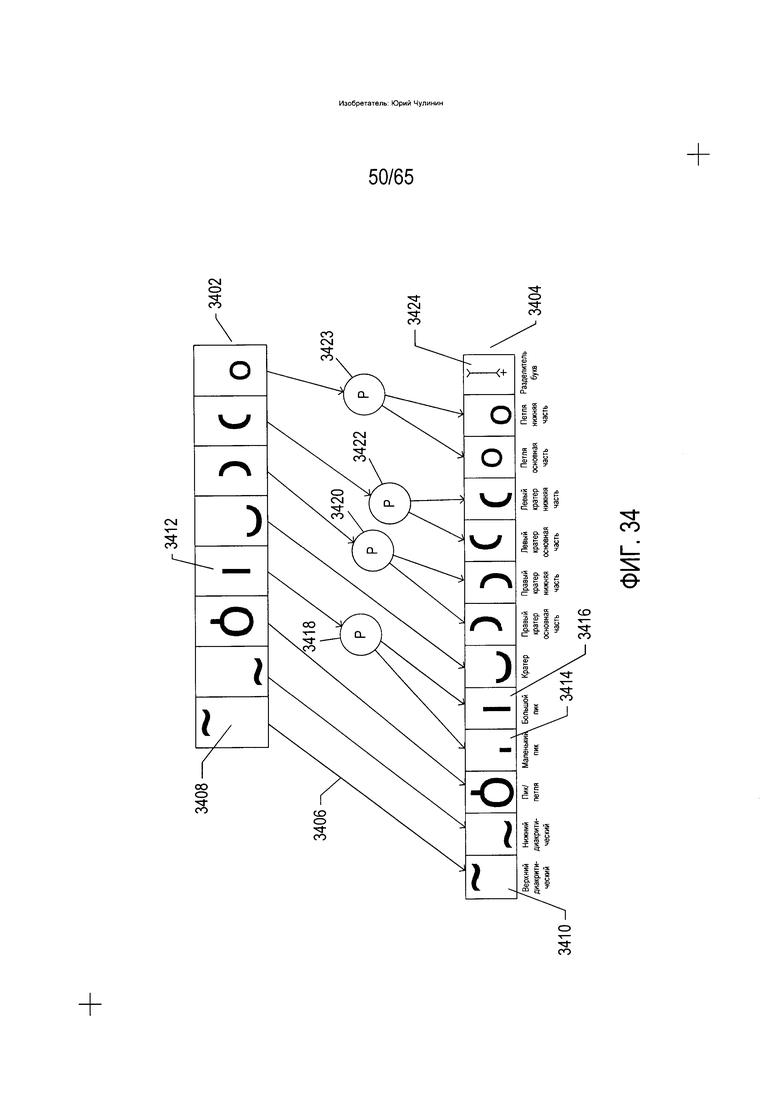
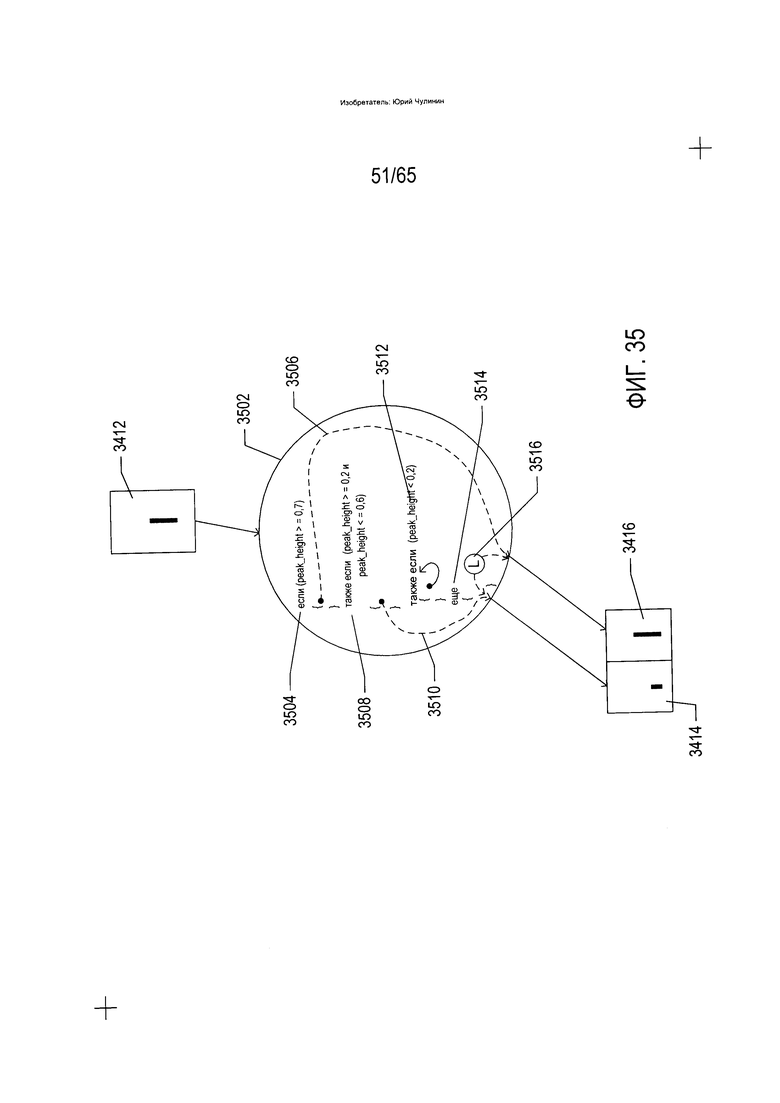
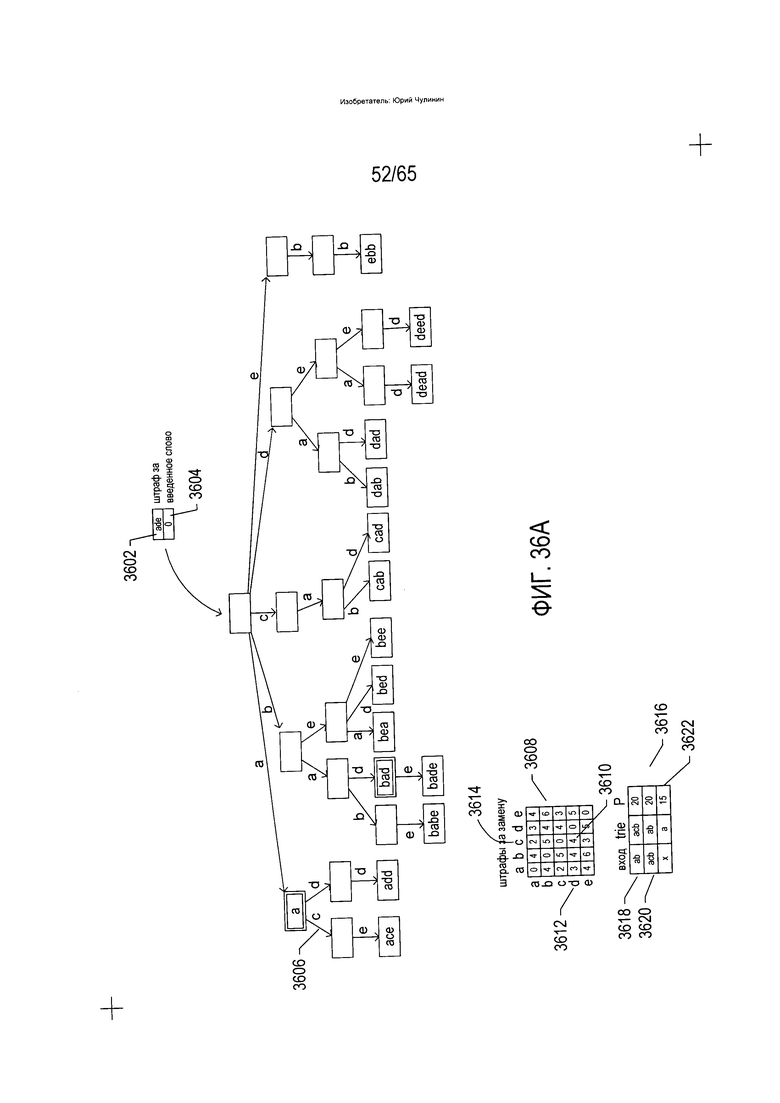
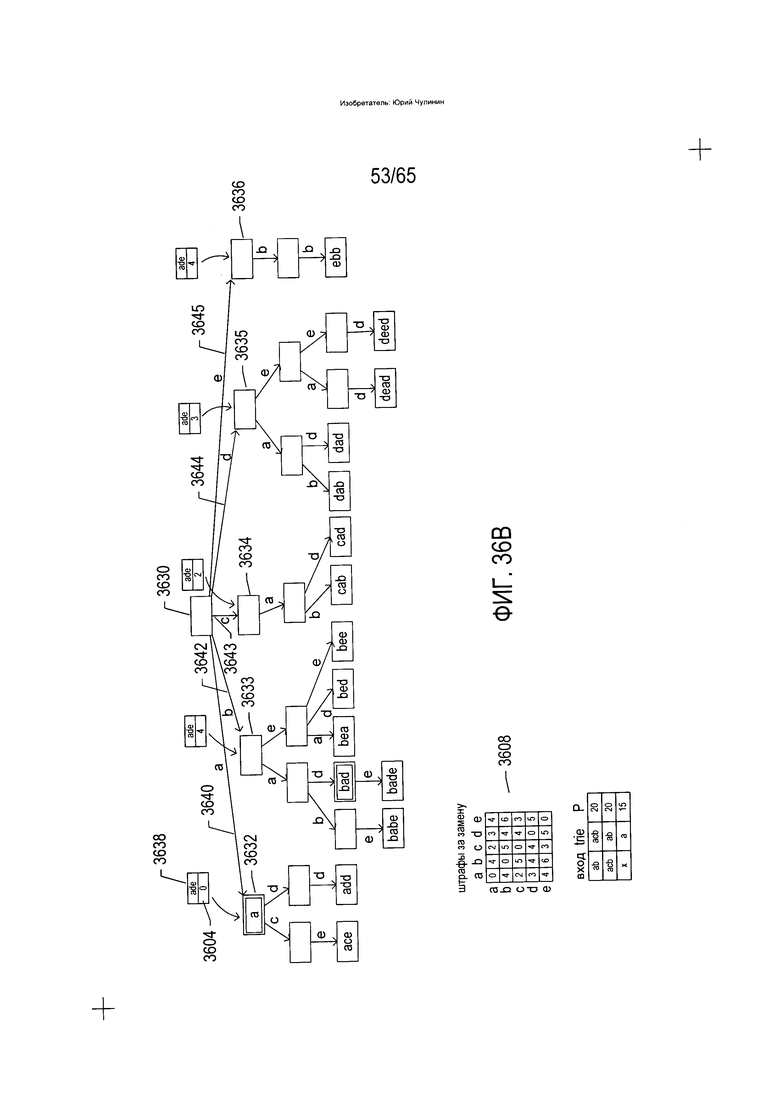
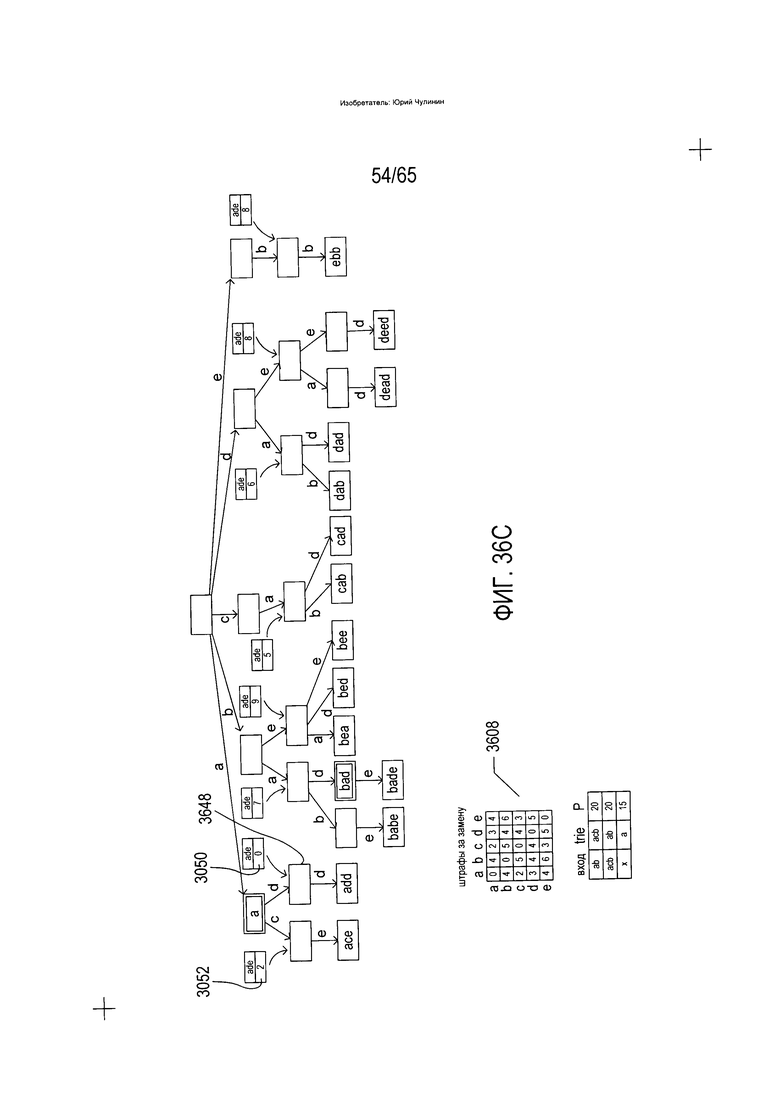
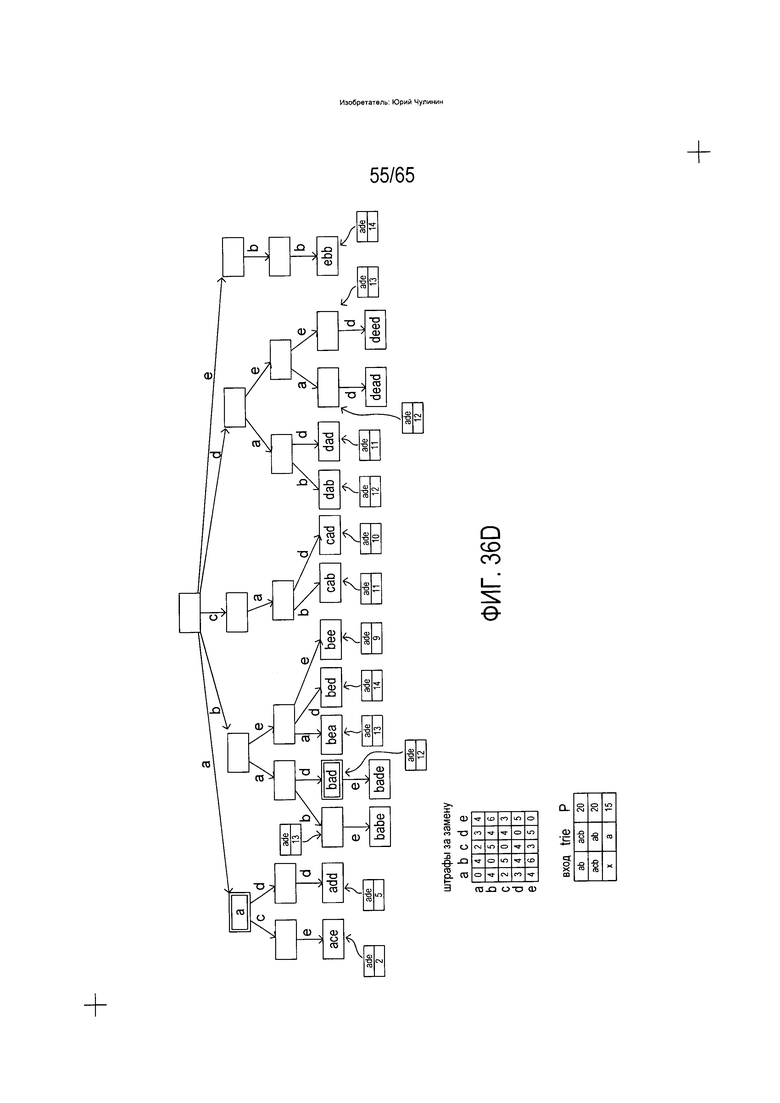
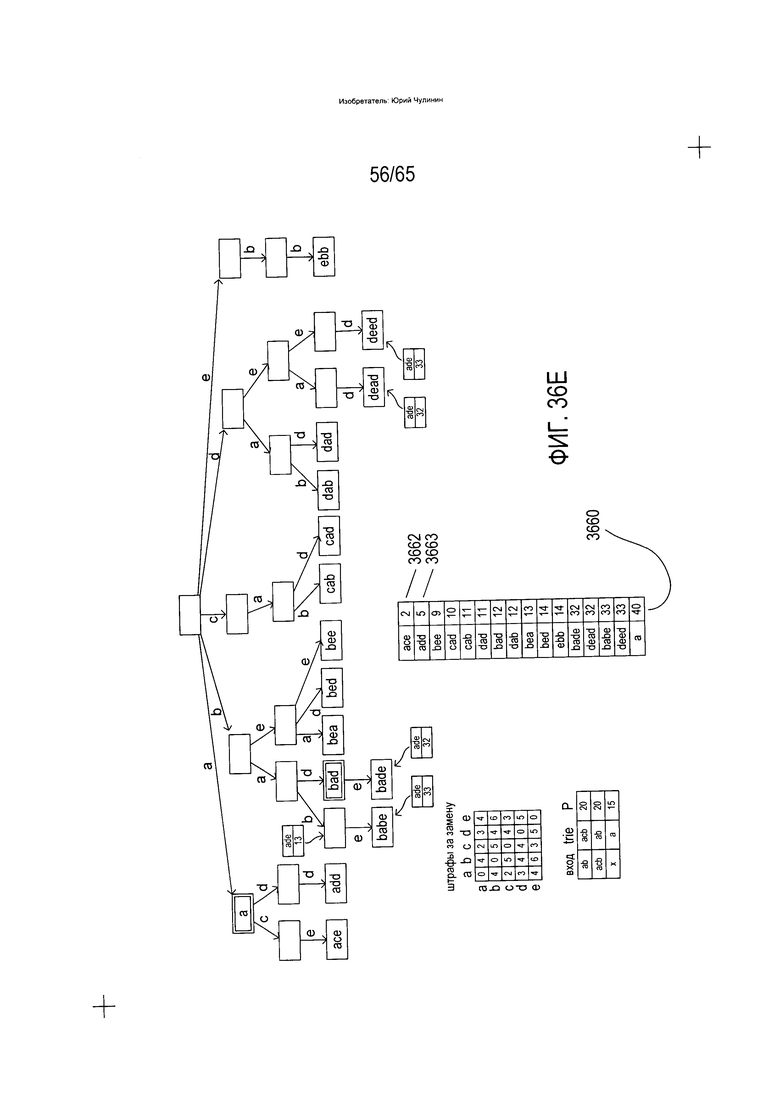
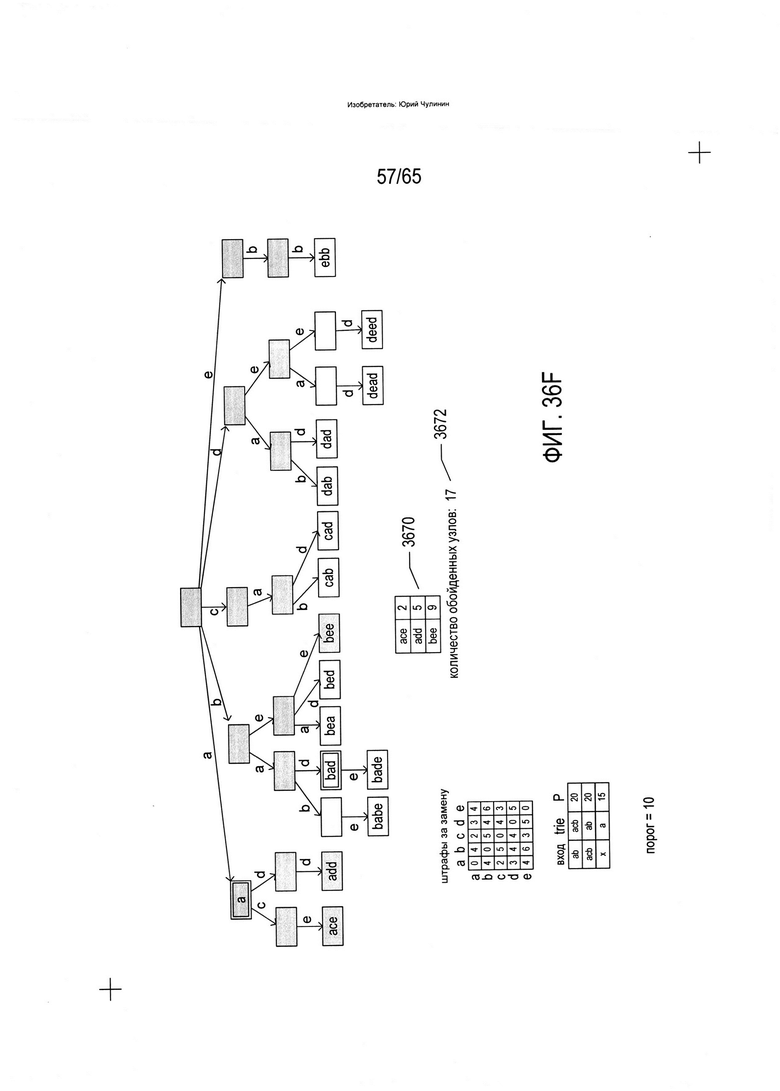
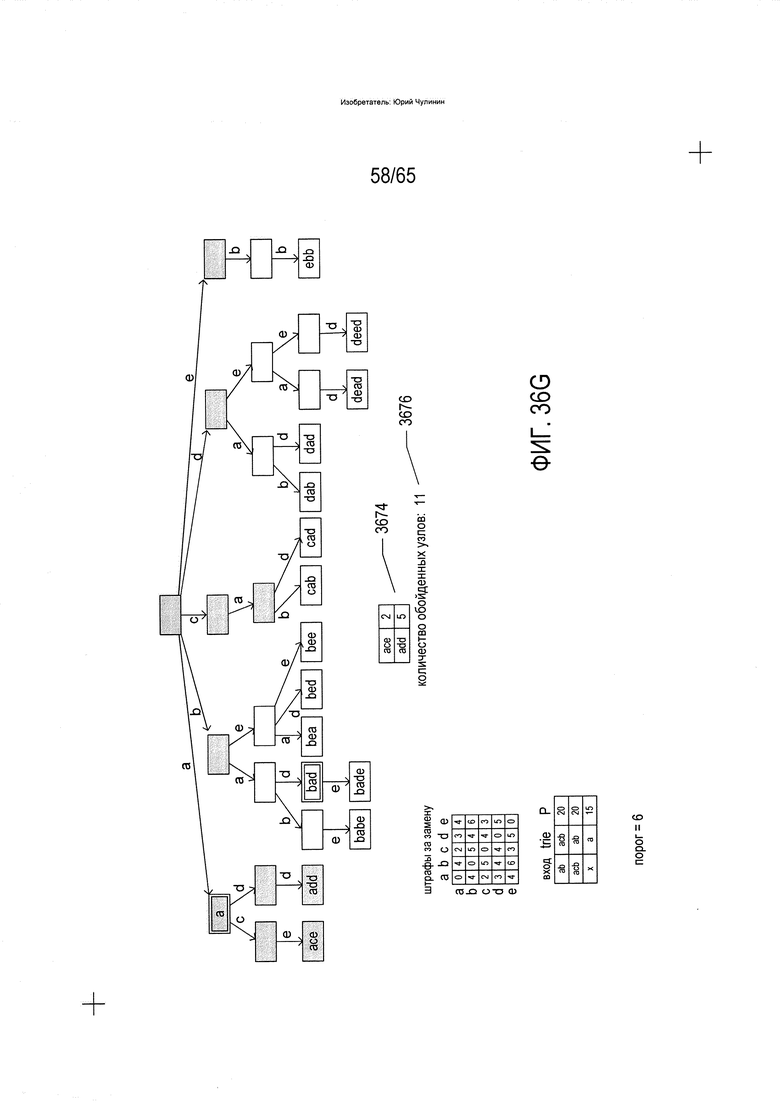
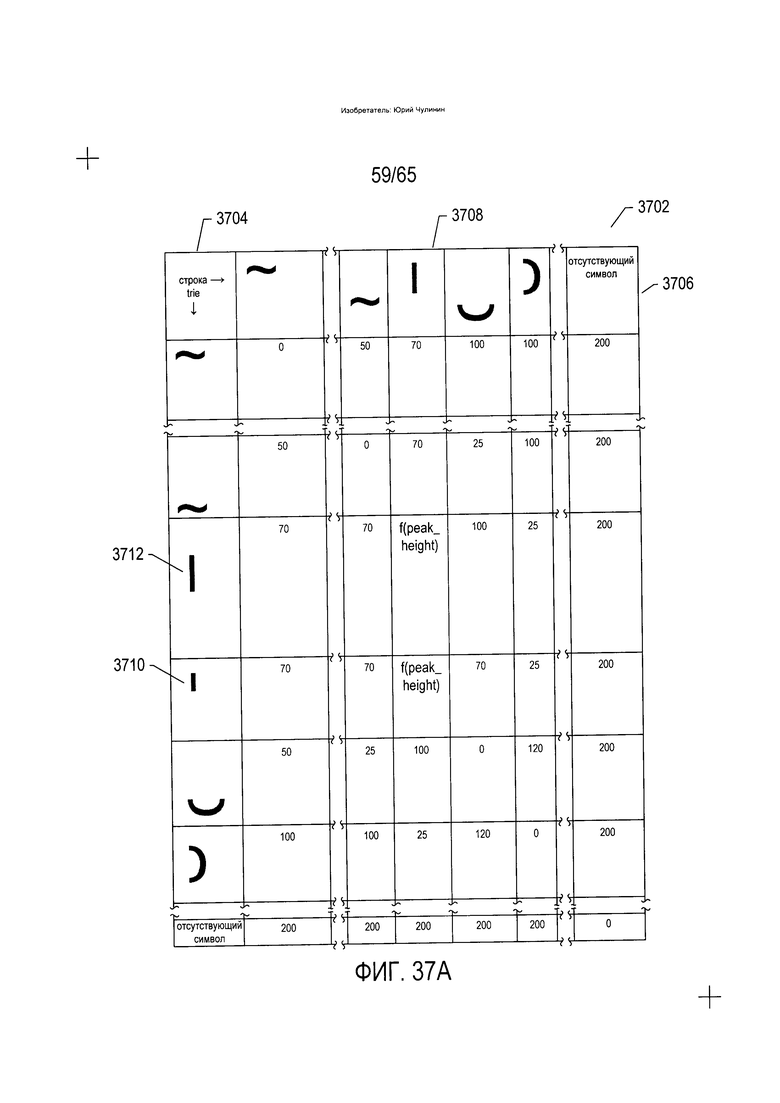
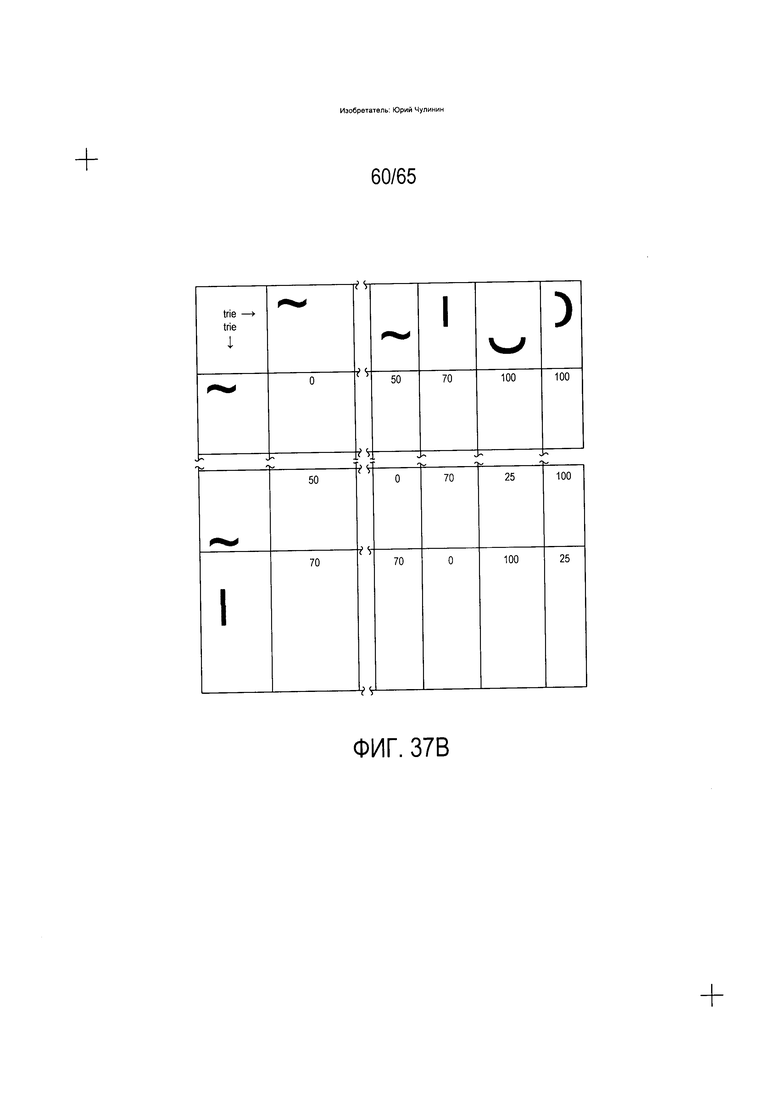
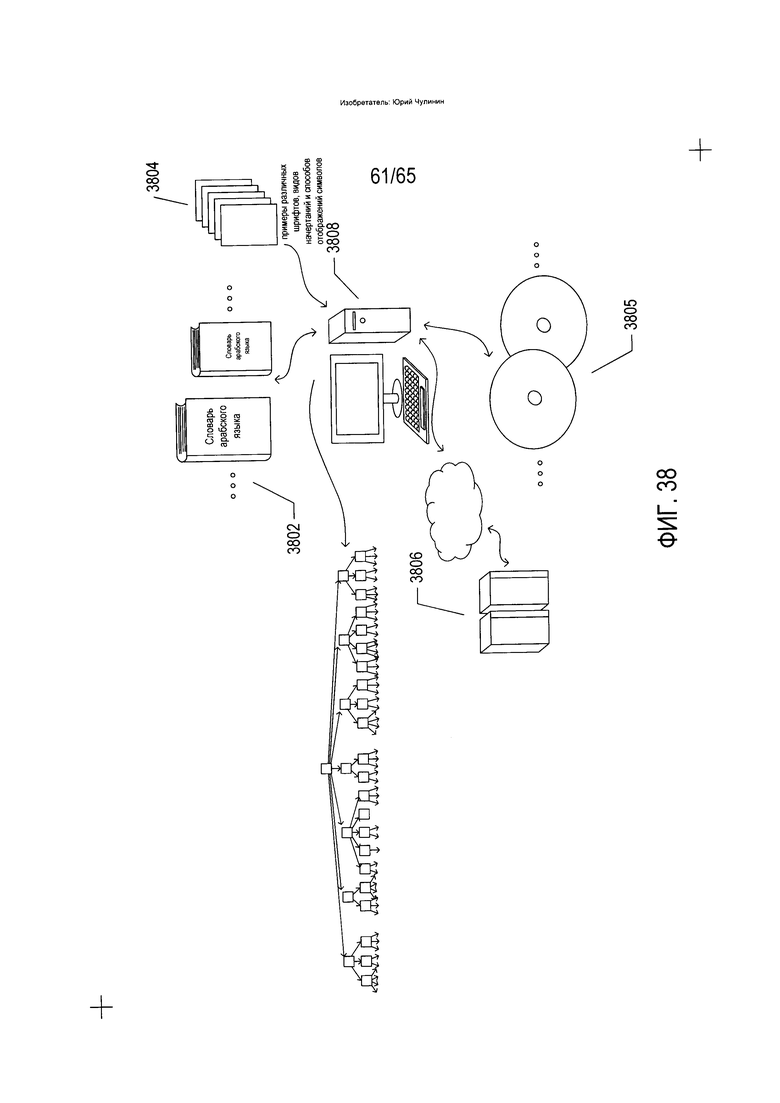
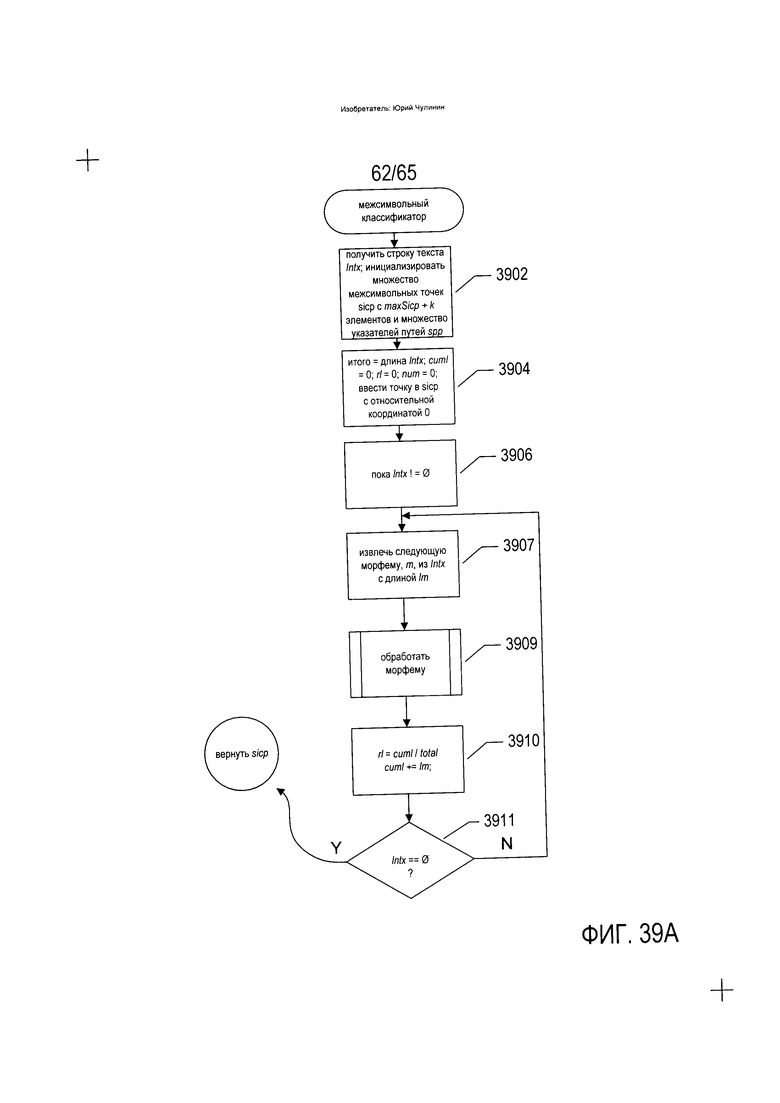
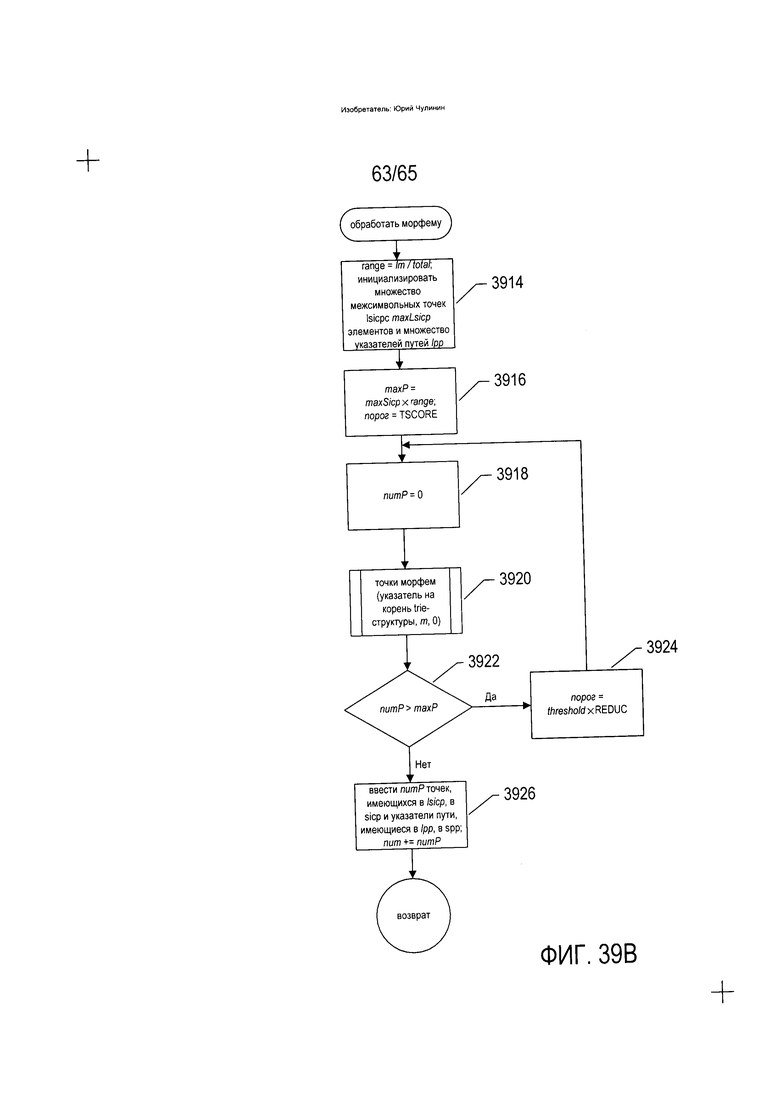
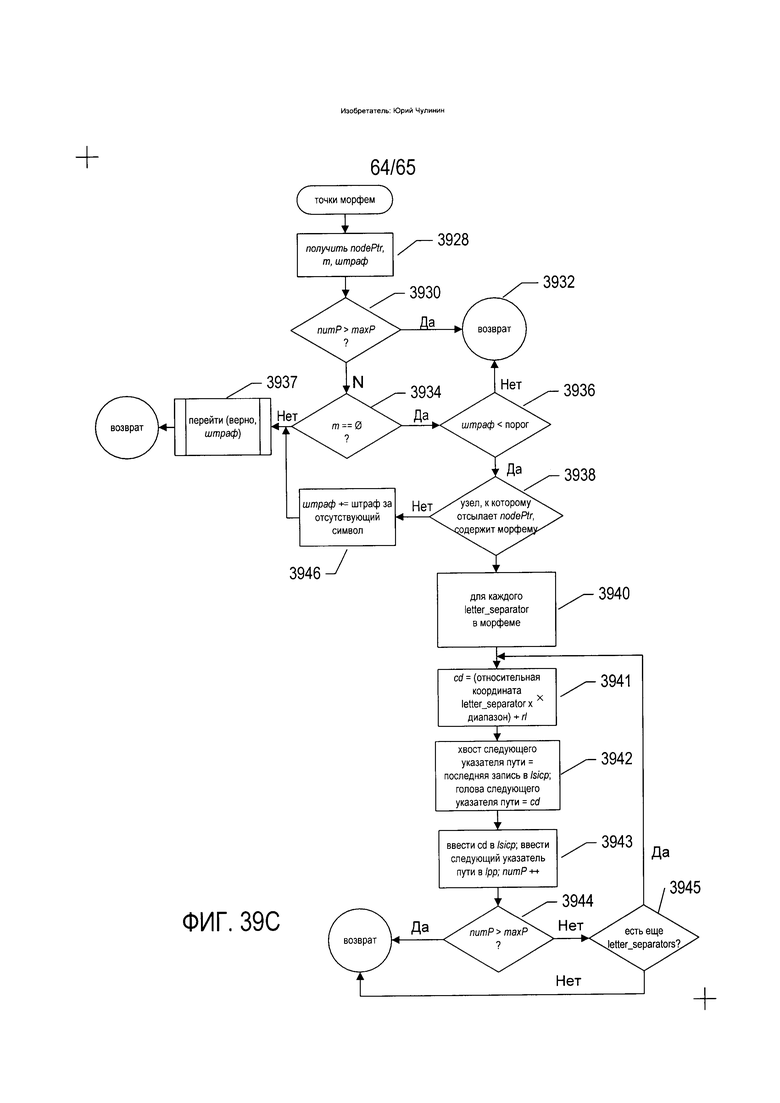
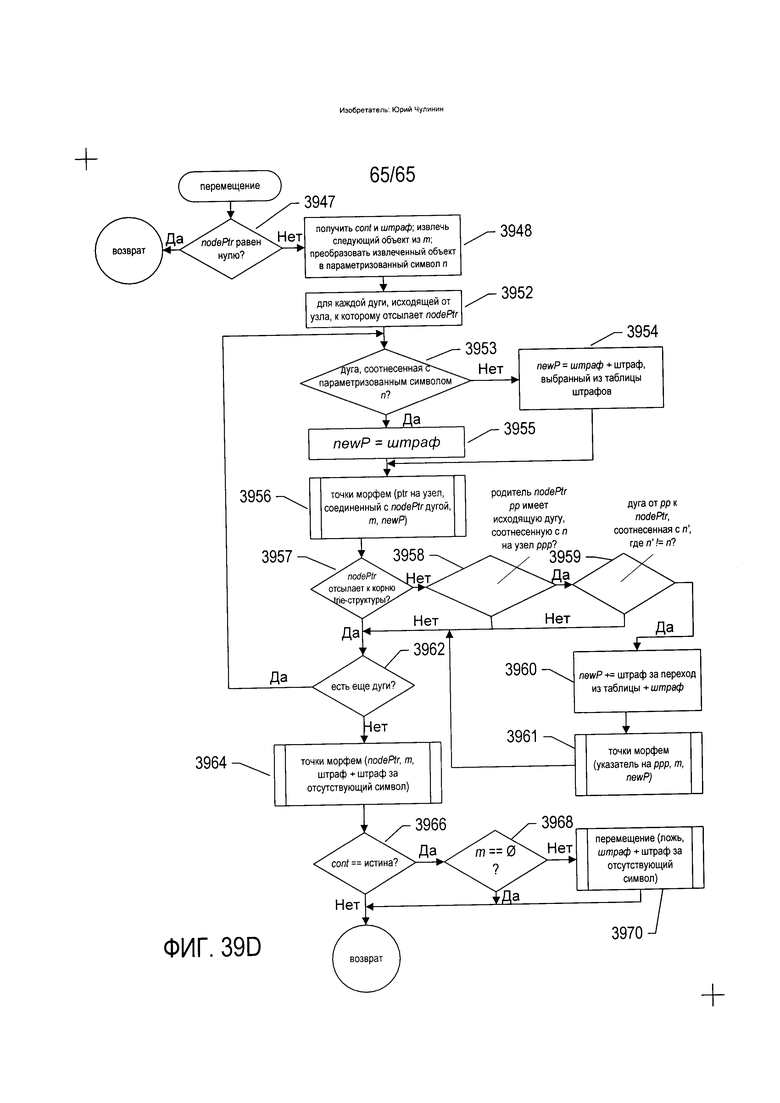
Изобретение относится к способам и устройствам преобразования изображений документов, содержащих текст на арабском языке и текст на других языках, в которых символы, соединяясь вместе, образуют слитные слова и фрагменты слов, в соответствующие электронные документы. Технический результат – повышение достоверности преобразования. Предложены многочисленные методы и средства, позволяющие эффективно осуществлять преобразование изображений документов в электронные документы, которые включают преобразование морфем и слов изображений текста в параметризованные символы, эффективный поиск аналогичных морфем и слов в электронном хранилище морфем и слов, закодированных в виде непараметризованных символов, и идентификацию вероятных точек разделения символов и соответствующих путей перехода с использованием аналогичных морфем и слов, найденных в хранилище слов. 2 н. и 20 з.п. ф-лы, 72 ил.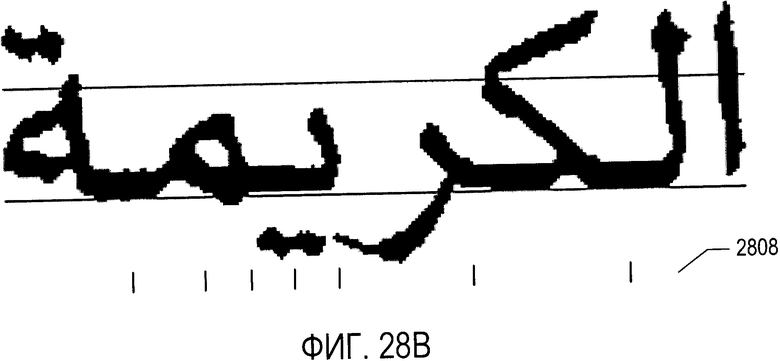
1. Устройство, которое обрабатывает изображение абзаца арабского текста, чтобы породить соответствующий абзац арабского текста, представленный в виде символов общепринятой кодировки, содержащее:
один или несколько процессоров;
одно или несколько запоминающих устройств; и
структуру данных типа «бор» (trie), сохраненную в одном или нескольких запоминающих устройствах, каждое вхождение в которой соответствует морфеме, слову или фразе; и
программу, представленную в виде набора цифровых команд, которая сохранена в одном или нескольких запоминающих устройствах и исполняется одним или несколькими процессорами таким образом, чтобы обеспечить выполнение следующих шагов:
получение изображения абзаца арабского текста,
выделение изображений строк текста на полученном изображении абзаца текста,
выделение частей изображения строки текста, каждая из которых соответствует одной или нескольким морфемам или словам,
для каждой выделенной части изображения
определение одного или нескольких наборов арабских символов, соответствующих возможным способам представления арабского текста выделенной части изображения, включая преобразование выделенной части изображения в последовательность символов, в которой каждый символ соответствует по меньшей мере одному фрагменту текстовой строки на изображении,
сохранение одного или нескольких наборов арабских символов, соответствующих возможным способам представления арабского текста выделенной части изображения, и указанной последовательности символов в одном или нескольких запоминающих устройствах; и
использование одного или нескольких определенных наборов арабских символов и указанной последовательности символов для восстановления электронного текста, соответствующего выделенному изображению строк текста на полученном изображении абзаца текста.
2. Устройство по п. 1, где изображение абзаца текста является цифровым представлением текста, который был отсканирован, сфотографирован цифровым фотоаппаратом, цифровой видеокамерой или получен другим способом, обеспечивающим преобразование изображения текста в цифровой формат, и сохранен в одном или нескольких запоминающих устройствах.
3. Устройство по п. 1, котором указанная последовательность символов является последовательностью параметризованных символов, в которой каждый параметризованный символ может иметь один, два или более параметров или не иметь ни одного и каждый параметризованный символ соответствует таким фрагментам текстовой строки, как одному, двум или большему количеству штрихов, петель, диакритических символов, или другим фрагментам текстовой строки на изображении; и программа дополнительно выполнена с возможностью выполнения таких операций, как:
сохранение последовательности параметризованных символов в одном или нескольких запоминающих устройствах; и
использование последовательности параметризованных символов для определения слов-кандидатов, морфем-кандидатов или слов и морфем-кандидатов, соответствующих выделенной части изображения, которые представлены в виде последовательностей непараметризованных символов в trie-структуре данных.
4. Устройство по п. 1 или 3, в котором указанные морфема, слово или фраза представлены в виде последовательности непараметризованных символов, отличающихся от связанных с ними параметризованных символов.
5. Устройство по п. 4, где параметризованные символы воспроизводят характерные для арабского языка элементы, расположенные в одной из трех основных зон строки, ориентированных вдоль длинной стороны строки:
средней зоне;
верхней зоне; и
нижней зоне.
6. Устройство по п. 5, где в состав параметризованных символов входят:
символ «диакритика в верхней зоне»;
символ «диакритика в нижней зоне»;
символ «петля или пик»;
символ «пик», ассоциированный со значением параметра «высота»;
символ «кратер»;
символ «левый кратер»;
символ «правый кратер»; и
символ «петля».
7. Устройство по п. 4, где в состав непараметризованных символов входят:
непараметризованный символ «диакритика в верхней зоне»;
непараметризованный символ «диакритика в нижней зоне»;
непараметризованный символ «петля или пик»;
непараметризованный символ «малый пик»;
непараметризованный символ «большой пик»;
непараметризованный символ «левый кратер в нижней зоне»;
непараметризованный символ «левый кратер в средней зоне»;
непараметризованный символ «правый кратер в нижней зоне»;
непараметризованный символ «правый кратер в средней зоне»;
непараметризованный символ «кратер в нижней зоне»;
непараметризованный символ «петля в средней зоне»; и
непараметризованный символ «точка разделения символов».
8. Устройство по п. 7, где структура данных типа «бор» содержит:
корневой узел; и
дочерние вершины корневого узла;
где каждая дочерняя вершина связана с родительской вершиной связью, соответствующей непараметризованному символу, который не является «точкой разделения символов», и
каждая дочерняя вершина содержит или соответствует по меньшей мере одной последовательности непараметризованных символов.
9. Устройство по п. 8, где программа, исполняемая одним или несколькими процессорами, использует последовательности параметризованных символов для определения слов-кандидатов, морфем-кандидатов или слов и морфем-кандидатов, соответствующих выделенной части изображения, которые представлены в виде последовательностей непараметризованных символов в структуре данных типа «бор», посредством:
перемещения по иерархической структуре данных в соответствии с последовательностью параметризованных символов для определения в иерархической структуре данных вершин-кандидатов.
10. Устройство по п. 9, где программа, исполняемая одними или несколькими процессорами, перемещается по иерархической структуре данных в соответствии с последовательностью параметризованных символов для определения в иерархической структуре данных вершин-кандидатов посредством выполнения следующих стадий:
установить значение штрафа равным исходной величине, и
рекурсивно перемещаться по иерархической структуре данных в направлении от корневого узла к дочерним вершинам, накапливать текущие штрафы, соответствующие каждой вершине в каждом пути, пройденном по иерархической структуре данных, для определения вершин-кандидатов как вершин, для которых величина накопленного штрафа меньше порогового значения.
11. Устройство по п. 10, где величина текущего штрафа складывается из:
штрафов за подстановку;
штрафов за перемену мест двух соседних параметризованных символов или двух соседних непараметризованных символов;
штрафов за отсутствующий параметризованный символ; и
штрафов за отсутствующий непараметризованный символ.
12. Способ обработки изображения абзаца текста на арабском языке, который позволяет получить соответствующий абзац арабского текста, представленный в виде символов общепринятой кодировки, в устройстве, содержащем один или более процессоров, одно или несколько запоминающих устройств и структуру данных типа «бор», каждое вхождение которой соответствует морфеме, слову или фразе, сохраненную в одном или нескольких запоминающих устройствах, причем способ содержит этапы:
получение изображения абзаца арабского текста;
выделение изображений строк текста на полученном изображении абзаца текста;
выделение частей изображения строки текста, каждая из которых соответствует одной или нескольким морфемам или словам;
для каждой выделенной части изображения:
определение одного или нескольких наборов арабских символов, соответствующих возможным способам представления арабского текста выделенной части изображения, включая преобразование выделенной части изображения в последовательность символов, в которой каждый символ соответствует по меньшей мере одному фрагменту текстовой строки на изображении,
сохранение одного или нескольких наборов арабских символов, соответствующих возможным способам представления арабского текста выделенной части изображения, и указанной последовательности символов в одном или нескольких запоминающих устройствах, и
использование одного или нескольких определенных наборов арабских символов и указанной последовательности символов для восстановления электронного текста, соответствующего выделенному изображению строк текста на полученном изображении абзаца текста.
13. Способ по п. 12, в котором изображение абзаца текста является цифровым представлением текста, который был отсканирован, сфотографирован цифровым фотоаппаратом, цифровой видеокамерой или получен другим способом, обеспечивающим преобразование изображения текста в цифровой формат, и сохранен в одном или нескольких запоминающих устройствах.
14. Способ по п. 12, в котором указанная последовательность символов является последовательностью параметризованных символов, в которой каждый параметризованный символ может иметь один, два или более параметров или не иметь ни одного и каждый параметризованный символ соответствует таким фрагментам текстовой строки, как одному, двум или большему количеству штрихов, петель, диакритических символов, или другим фрагментам текстовой строки на изображении; и дополнительно содержащий этапы, на которых:
сохраняют последовательность параметризованных символов в одном или нескольких запоминающих устройствах; и
используют последовательность параметризованных символов для определения слов-кандидатов, морфем-кандидатов или слов и морфем-кандидатов, соответствующих выделенной части изображения, которые представлены в виде последовательностей непараметризованных символов в структуре данных типа «бор».
15. Способ по п. 12 или 14, в котором указанные морфема, слово или фраза представлены в виде последовательности непараметризованных символов, отличающихся от связанных с ними параметризованных символов.
16. Способ по п. 15, в котором параметризованные символы воспроизводят характерные для арабского языка элементы, расположенные в одной из трех основных зон строки, ориентированных вдоль длинной стороны строки:
средней зоне;
верхней зоне; и
нижней зоне.
17. Способ по п. 15, в котором в состав параметризованных символов входят:
символ «диакритика в верхней зоне»;
символ «диакритика в нижней зоне»;
символ «петля или пик»;
символ «пик», ассоциированный со значением параметра «высота»;
символ «кратер»;
символ «левый кратер»;
символ «правый кратер»; и
символ «петля».
18. Способ по п. 15, в котором в состав непараметризованных символов входят:
непараметризованный символ «диакритика в верхней зоне»;
непараметризованный символ «диакритика в нижней зоне»;
непараметризованный символ «петля или пик»;
непараметризованный символ «малый пик»;
непараметризованный символ «большой пик»;
непараметризованный символ «левый кратер в нижней зоне»;
непараметризованный символ «левый кратер в средней зоне»;
непараметризованный символ «правый кратер в нижней зоне»;
непараметризованный символ «правый кратер в средней зоне»;
непараметризованный символ «кратер в нижней зоне»;
непараметризованный символ «петля в средней зоне»; и
непараметризованный символ «точка разделения символов».
19. Способ по п. 18, в котором структура данных типа «бор» содержит:
корневой узел; и
дочерние вершины корневого узла;
где каждая дочерняя вершина связана с родительской вершиной связью, соответствующей непараметризованному символу, который не является «точкой разделения символов», и
каждая дочерняя вершина содержит или соответствует по меньшей мере одной последовательности непараметризованных символов.
20. Способ по п. 19, в котором программа, исполняемая одним или несколькими процессорами, использует последовательности параметризованных символов для определения слов-кандидатов, морфем-кандидатов или слов и морфем-кандидатов, соответствующих выделенной части изображения, которые представлены в виде последовательностей непараметризованных символов в структуре данных типа «бор», содержит этапы, на которых:
перемещаются по иерархической структуре данных в соответствии с последовательностью параметризованных символов для определения в иерархической структуре данных вершин-кандидатов.
21. Способ по п. 20, в котором программа, исполняемая одними или несколькими процессорами, перемещается по иерархической структуре данных в соответствии с последовательностью параметризованных символов для определения в иерархической структуре данных вершин-кандидатов, содержит этапы, на которых:
устанавливают значение штрафа равным исходной величине, и
рекурсивно перемещаются по иерархической структуре данных в направлении от корневого узла к дочерним вершинам, накапливают текущие штрафы, соответствующие каждой вершине в каждом пути, пройденном по иерархической структуре данных, для определения вершин-кандидатов как вершин, для которых величина накопленного штрафа меньше порогового значения.
22. Способ по п. 21, в котором величина текущего штрафа складывается из:
штрафов за подстановку;
штрафов за перемену мест двух соседних параметризованных символов или двух соседних непараметризованных символов;
штрафов за отсутствующий параметризованный символ; и
штрафов за отсутствующий непараметризованный символ.
| US 5528701 A, 18.06.1996 | |||
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| US 5222160 A, 22.06.1993 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| JP 0057176168 A, 29.10.1982 | |||
| KR 1020060076514 A, 04.07.2006 | |||
| JP 0059165122 A, 18.09.1984 | |||
| СПОСОБ ОБРАБОТКИ ДАННЫХ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ (OCR), ГДЕ ВЫХОДНЫЕ ДАННЫЕ ВКЛЮЧАЮТ В СЕБЯ ИЗОБРАЖЕНИЯ СИМВОЛОВ С НАРУШЕННОЙ ВИДИМОСТЬЮ | 2008 |
|
RU2445699C1 |

