Настоящее изобретение относится к разрешению противоречивых выходных данных из системы оптического распознавания символов (OCR) и, в особенности, к способу обработки выходных данных OCR, где выходные данные включают в себя более одной альтернативы распознавания изображения символа.
Системы оптического распознавания символов обеспечивают трансформацию растрированных изображений документов в текст в кодах ASCII, что облегчает поиск, замену и переформатирование документов и т.д. в компьютерной системе. Одной из особенностей функциональности OCR является преобразование рукописных и машинописных документов, книг, медицинских журналов и т.д., например, в документы, доступные для поиска в сетях Интернет и Интранет. В целом, качество извлечения информации и поиска документов значительно улучшается в том случае, когда все документы доступны для электронного извлечения и поиска. Например, корпоративная система Интранет может связывать все старые и новые документы предприятия путем всестороннего применения функциональности OCR, являющейся частью сети Интранет (или частью сети Интернет в случае документов, представляющих общественный интерес).
Однако качество функциональности OCR ограничено большой сложностью системы OCR. Трудно обеспечить функциональность OCR, которая способна преодолеть любые трудности, встречающиеся при попытках преобразования изображений текста в текст в компьютерных кодах. Одним из примеров таких часто возникающих трудностей является неспособность системы OCR правильно различать символы тогда, когда их изображения в тексте кажутся эквивалентными. Например, символ с может быть легко интерпретирован как е и наоборот в случае, когда отличительные детали смазаны по причине грязи или старения и т.д. страницы, включающей эти символы. Эти трудности обычно идентифицируются программой OCR, поскольку система OCR может устанавливать, например, вероятность (или оценочное значение) для достоверного распознавания конкретного символа. Например, в случае, когда два или более символов имеют вероятность, позволяющую считать их, в значительной степени, равновероятными кандидатами для идентификации изображения символа, эти альтернативные символы-кандидаты вносятся, например, в список, являющийся частью выходных данных OCR, вместе со списком соответствующих слов, включающих в себя недостоверно распознаваемые символы, идентифицированные системой OCR. Иногда несколько символов могут быть недостоверно распознаны в одном и том же слове, что увеличивает сложность идентификации правильных символов-кандидатов и, таким образом, самих этих слов.
Согласно особенности настоящего изобретения, неопределенности, связанные с выбором правильных символов-кандидатов среди нескольких символов-кандидатов, можно разрешить, изучая различия в графическом виде, фактически встречающемся на изображениях символов-кандидатов в том виде, как они присутствуют в документе, включающем в себя эти символы, и использование этих идентифицированных графически различных видов для идентификации особенностей различий, присутствующих на изображении недостоверно распознаваемого символа. Ключевой пункт данной особенности настоящего изобретения заключается в том, что идентифицируется не графический вид различий между символами-кандидатами как таковой. Важная особенность настоящего изобретения заключается в идентификации на изображениях символов-кандидатов местоположений областей, которые включают в себя отличительные особенности. Используя информацию о местоположении области, обладающей отличительной особенностью, то же местоположение, или область, можно идентифицировать и в недостоверно распознаваемом символе. Сопоставляя одни и те же местоположения, или области, на изображениях символов-кандидатов и изображении недостоверно распознаваемого символа, можно принять решение о том, какой из символов-кандидатов из всех символов-кандидатов является правильной идентификацией недостоверно распознаваемого символа.
Согласно другой особенности настоящего изобретения, информация местоположения, или области, об отличительных особенностях изображений символов-кандидатов и недостоверно распознаваемых символов может последовательно сравниваться по всем изображениям соответствующих отдельных изображений символов, если изображения выровнены друг относительно друга таким образом, чтобы максимально возможные части самих символов располагались поверх друг друга при их рассмотрении расположенными один поверх другого. Для достижения такого выравнивания можно рассчитать смещения между различными изображениями, например, путем корреляции сочетаний изображений.
Согласно примеру осуществления настоящего изобретения, способ включает в себя стадии идентификации достоверно распознаваемых изображений символов в растрированном документе, которые используются для создания эталонного набора изображений символов, встречающихся в растрированном документе. Все изображения, идентифицированные для одного и того же символа, складываются пиксель к пикселю и взвешиваются по всем используемым изображениям, образуя класс для данного символа. Изображения различных классов используются в качестве эталонных изображений на различных стадиях настоящего изобретения. В случае, когда сообщается о том, что образец изображения символа содержит несколько, например, по меньшей мере, два, альтернативных символа-кандидата на выбор для правильной идентификации, образец изображения символа правильно выбирается и идентифицируется среди символов-кандидатов на стадиях, которые включают в себя сопоставление изображений символов-кандидатов с набором эталонных изображений, что позволяет установить, какое из эталонных изображений с наибольшей вероятностью представляет недостоверно распознаваемый символ.
Фиг.1а, 1б - примеры эталонов символов i и l.
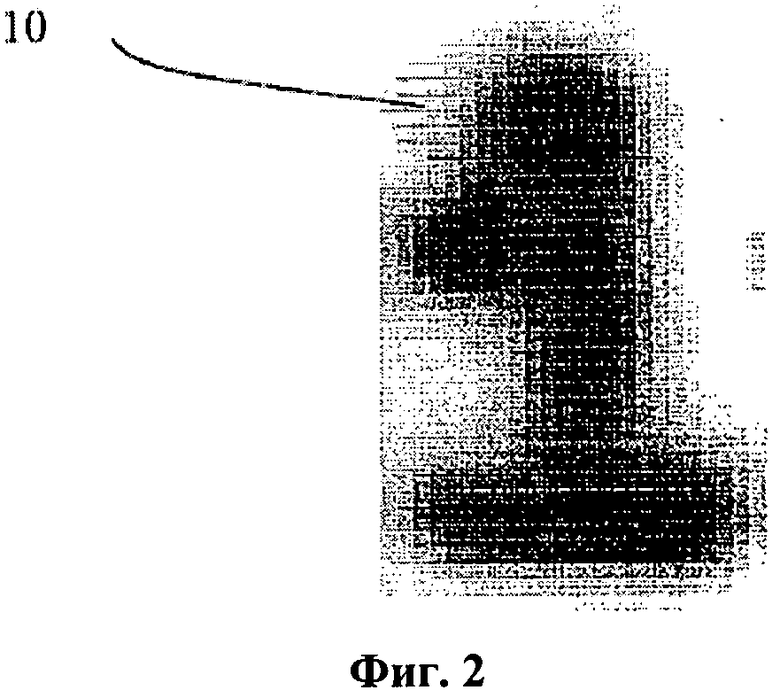
Фиг.2 - смещение между эталонами по фиг.1.
Фиг.3 - пример матрицы разностей согласно настоящему изобретению.
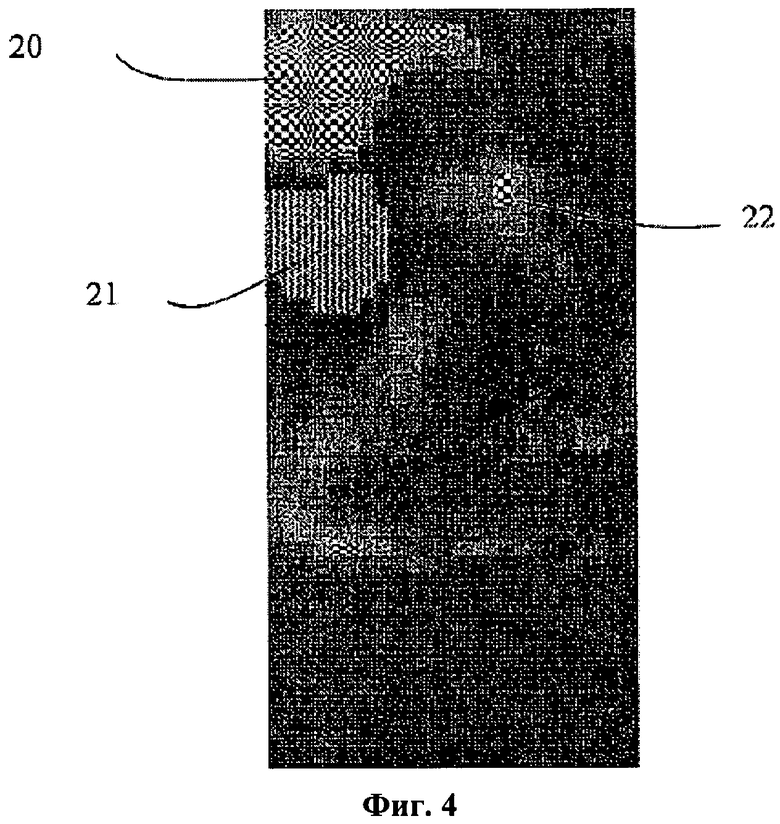
Фиг.4 - положительные и отрицательные области в матрице по фиг.3.
Фиг.5 - пример корреляции выбранных образцов символов с эталоном по фиг.1.
Фиг.6 - различающиеся области по фиг.5.
Фиг.7 - пример корреляции выбранных образцов символов с другим эталоном по фиг.1.
Фиг.8 - различающиеся области по фиг.7.
Фиг.9 - матрица разностей соответствующих символов с и е.
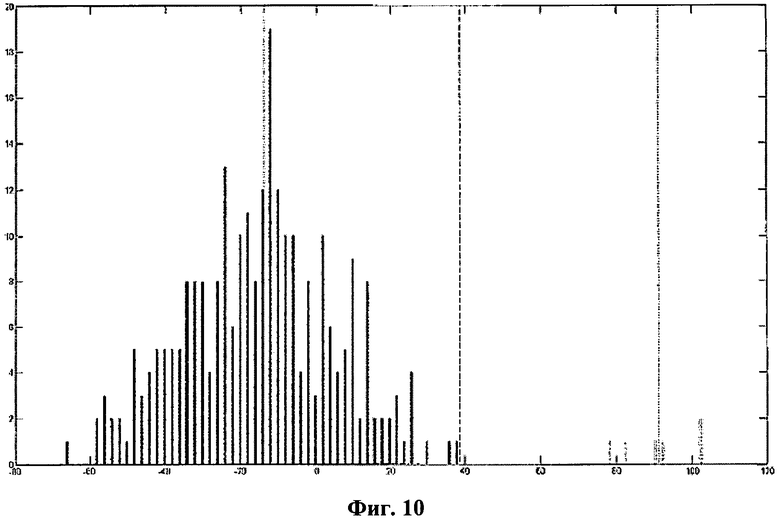
Фиг.10 - пример использования медианы для обозначения областей по фиг.9 как областей с положительными или отрицательными значениями.
Фиг.11 - пример масштабированного изображения символа и коррекции масштабирования.
Фиг.12 - корреляция между эталоном изображения символа и изображениями по фиг.11.
Фиг.13 - пример изображения символа, содержащего систематическую погрешность в отпечатке символа.
Фиг.14 - различающиеся области по фиг.13.
Фиг.15 - пример шума на изображении символа.
Фиг.16 - изображение гистограммы взаимной корреляции по фиг.15.
Фиг.17 - другой пример шума на изображениях символа.
Фиг.18 - пример использования теоретического знания для идентификации положительных и отрицательных областей в матрице разностей согласно настоящему изобретению.
Настоящее изобретение будет подробно описано с отсылкой к примеру осуществления изобретения, который включает в себя недостоверно распознаваемые символы с изображений, соответственно, представляющих символы i и l. Согласно особенности настоящего изобретения, эталоны символов идентифицируются в самом текущем документе, обрабатываемом системой OCR. Таким образом, все характерные особенности символов, фактически присутствующие в документе, являются частью представляющих символы эталонов. На фиг.1а и 1б приведены примеры эталонов, которые идентифицируются процессом OCR как символы, распознаваемые с достоверностью, превышающей предварительно установленный пороговый уровень, и идентифицированные как изображения, представляющие символы i и l соответственно.
Растрированное кодированное изображение символа включает в себя пиксели в растровой матрице, где коды уровня "серого" пикселей представлены в виде ячеек матрицы. Пример изображения символа может включать в себя только белый и черный цвета. Белые части фона представляют бумагу, а черные - графические отпечатки символов на бумаге. Однако, как известно специалистам в данной области, реальные изображения символов могут включать в себя все уровни серого, которые возможно представить в динамическом диапазоне, предусматриваемом форматом пикселя, а прямые линии редко визуализируются как прямые линии - скорее, при рассмотрении на уровне пикселей, они визуализируются как мозаичная головоломка из пикселей. Поэтому способы обработки изображений требуют изучения отдельных пикселей, кластеров пикселей, связанных пикселей и т.д., а также возможности сопоставления частей изображений, например изображений символов, идентифицированных на странице. Поэтому для отнесения различных частей изображения на странице документа необходима система координат. Можно использовать систему координат с началом координат, определяемым углом страницы документа. Однако обработка изображений включает в себя, например, сопоставление изображения символа из одного местоположения на странице с другим изображением другого символа в другом местоположении на странице, что может потребовать огромного количества преобразований упорядоченных пар чисел, относящихся ко всем отличающимся пикселям, группам пикселей, связанным пикселям и т.д. Кроме того, как бы ни извлекалось изображение символа из изображения страницы документа, вокруг графического отпечатка, представляющего символ, необходимо в обязательном порядке предусматривать ограничивающий параллелепипед. Таким образом, трудность заключается в способности отнесения пикселей символа внутри отдельного ограничивающего параллелепипеда, а затем соотнесения с пикселями, расположенными в той же ячейке другого ограничивающего параллелепипеда, заключающего внутри себя отпечаток другого символа.
Согласно примеру осуществления настоящего изобретения, установление взаимно соотносящихся местоположений пикселей в различных ограничивающих параллелепипедах предусматривается способом, который включает в себя корреляцию изображений, ограниченных соответствующими ограничивающими параллелепипедами, и вычисление смещений между изображениями на основе этой корреляции. Различные изображения могут затем выравниваться друг относительно друга в степени, предусматриваемой вычисленными смещениями, способами, которые известны специалистам в данной области.
Пример способа обработки противоречивых выходных данных согласно настоящему изобретению включает в себя корреляцию экземпляра выбранного образца изображения недостоверно распознаваемого символа с изображениями из набора эталонов, полученного из встречающихся в документе изображений символов, которые распознаются с доверительным уровнем, превышающим заданный пороговый уровень. Целью этой корреляции является идентификация эталонного изображения, имеющего наибольшее сходство с выбранным образцом символа. Например, идентифицируются, соответственно, два изображения символов i и l (фиг.1). Эти два изображения затем коррелируют для идентификации первого смещения между изображениями. На фиг.2 показано выравнивание этих изображений с использованием установленного смещения (или отклонения) между изображениями. На фиг.2 черными линиями показаны все пиксели, которые «включены» на изображении, приведенном на фиг.1б. Выравнивание можно проиллюстрировать как размещение одного изображения поверх другого. Важной особенностью способа смещений и выравниваний согласно настоящему изобретению является та, что местоположение конкретной части одного из изображений можно отнести к частям, находящимся в том же местоположении на другом выровненном изображении. Таким образом, можно идентифицировать области, которые отличаются друг от друга в соответствующих изображениях символов. Например, сопоставление изображения символа i с изображением символа l значительно облегчается, если ножки двух символов располагаются непосредственно одна поверх другой. В этом случае легко идентифицировать часть каждого символа, отличающуюся от второго символа, как по соотнесению наборов пикселей или связанных пикселей, так и по отдельным соотносимым пикселям. На фиг.2 показана визуализированная сплошными черными линиями отличающаяся область 10 в верхнем левом углу выровненного изображения. Смещение представляет собой упорядоченную пару чисел, где, например, первое число представляет собой смещение в вертикальном направлении, а второе число - смещение в горизонтальном направлении относительно ограничивающего параллелепипеда. В примере на фиг.2 смещение имеет значение (0, -1), что указывает на отсутствие смещения в вертикальном направлении и на смещение на один пиксель в горизонтальном направлении.
После выравнивания, например, двух изображений ограничивающие параллелепипеды, связанные с каждым из двух соответствующих изображений, могут не совпадать. Совпадать могут только общие части (например, ножка, как обсуждалось выше). В этом случае, пользуясь способами, известными специалистам в данной области, можно создать общий ограничивающий параллелепипед вокруг выровненных изображений.
Согласно примеру осуществления настоящего изобретения, различия между изображениями, представляющими символы-кандидаты, можно идентифицировать, преобразовывая выровненные изображения, например выровненные изображения на фиг.2, в матрицу разностей. Каждый элемент матрицы разностей создается путем вычитания значений пикселей (значений уровней серого) в соответствующих местоположениях из выровненных изображений и размещения вычтенных значений в соответствующим образом расположенные элементы матрицы. На фиг.3 показано вычитание изображений, представляющих эталоны для i и l, путем вычитания i из l (l-i).
Как видно, большинство пикселей в матрице на фиг.3 близки к нулю, и только области, в которых эталоны обладают существенно различным видом, имеют большие положительные или отрицательные значения соответствующих элементов матрицы. На фиг.4 показаны области по фиг.3: положительная область 20, указывающая на преобладание в ней символа l, и отрицательная область 21, указывающая на преобладание в ней символа i (в указанном порядке вычитания, т.е. l-i). При измененном порядке вычитания матрица разностей будет выглядеть иначе.
Для идентификации местоположений различий между изображениями, однако, может использоваться любой способ. Согласно примеру осуществления настоящего изобретения, для идентификации различий между символами-кандидатами используются эталонные изображения, представляющие символы-кандидаты. Затем местоположения областей, включающих в себя отличительные особенности, идентифицируются в выбранном образце символа, который распознается недостоверно. Затем для идентификации эталонного изображения, включающего в себя особенности, представленные в этих областях, изучается содержимое таких областей в выбранном образце символа. Таким образом, эта идентификация является правильной идентификацией выбранного образца символа. Примером осуществления настоящего изобретения являются следующие стадии способа изобретения.
Способ разрешает сомнения относительно противоречивых выходных данных системы оптического распознавания символов (OCR), где выходные данные включают в себя растровые изображения символов, которые встречаются на изображении текстового документа, обрабатываемого системой OCR, и где первое подмножество выходных данных представляет собой изображения символов, которые распознаются со степенью достоверности, превышающей заранее определенный уровень, а также где выходные данные включают в себя второе подмножество символов, которое включает в себя, по меньшей мере, изображение первого символа-кандидата и изображение второго символа, которые идентифицированы как, в значительной степени, равновероятные идентификации одного и того же экземпляра выбранного образца символа из текстового документа, обрабатываемого системой OCR, где способ включает в себя следующие стадии:
а) поиск в первом подмножестве выходных данных, идентификация изображений символов, которые имеют качество изображения, превышающее заранее определенный уровень, и использование этих изображений символов в качестве набора эталонных изображений для символов;
б) сопоставление изображения первого символа-кандидата и изображения второго символа-кандидата с каждым из соответствующих эталонных изображений, идентификация первого эталонного изображения, представляющего изображение первого символа-кандидата, и второго эталонного изображения, представляющего изображение второго символа-кандидата;
в) сопоставление первого эталонного изображения со вторым эталонным изображением, идентификация первого смещения между этими изображениями и выравнивание первого эталонного изображения и второго эталонного изображения в соответствии с первым смещением;
г) идентификация местоположений областей, которые включают в себя особенности, отличающие первое эталонное изображение от второго эталонного изображения, на выровненных изображениях, выражение информации о местоположении областей относительно выровненных изображений;
д) сопоставление изображения выбранного образца символа с первым эталонным изображением и вторым эталонным изображением, идентификация второго смещения и выравнивание изображения выбранного образца символа с первым эталонным изображением и вторым эталонным изображением в соответствии со вторым смещением;
е) использование информации о местоположениях из стадии г) для идентификации соответствующих областей на выровненном изображении выбранного образца символа, сопоставление содержимого изображений областей с установленным местоположением путем вычисления средних значений пикселей, которые включают в себя области с установленным местоположением на изображении выбранного образца символа, и вычитание этих соответствующих средних значений, где результат вычитания совместно с фактически выбранным эталонным изображением, использованным для идентификации второго смещения, предоставляет критерий для выбора первого или второго символа-кандидата в качестве идентифицированного символа для выбранного образца символа.
Дополнительные стадии в другом примере осуществления настоящего изобретения включают в себя стадии способа выбора правильного эталонного изображения:
- если при использовании первого эталонного изображения для идентификации второго смещения результат вычитания вычисленных средних значений превышает первый пороговый уровень, то это означает, что первое эталонное изображение является правильной идентификацией выбранного образца символа, в то время как отрицательный результат вычитания средних значений, лежащий ниже второго порогового уровня, означает, что правильной идентификацией выбранного образца символа является второе эталонное изображение, а если результат вычитания средних значений представляет собой значение, лежащее между первым и вторым пороговыми уровнями, то это означает, что ни первое, ни второе эталонное изображение нельзя выбрать окончательно.
В другом примере осуществления изобретения:
- если при использовании второго эталонного изображения для идентификации второго смещения результат вычитания вычисленных средних значений превышает первый пороговый уровень, то это означает, что второе эталонное изображение является правильной идентификацией выбранного образца символа, в то время как отрицательный результат вычитания средних значений, лежащий ниже второго порогового уровня, означает, что правильной идентификацией выбранного образца символа является первое эталонное изображение, а если результат вычитания средних значений представляет собой значение, лежащее между первым и вторым пороговыми уровнями, то это означает, что ни первое, ни второе эталонное изображение нельзя выбрать окончательно.
В данном описании отсылка к областям с положительным значением и областям с отрицательным значением при отсылке к матрице разностей осуществляется в том смысле, что соответствующие положительные области и отрицательные области демонстрируют, соответственно, преобладание или незначительность различия между изображениями в этих областях в зависимости от порядка вычитания изображений символа-кандидата. Для получения возможности осуществить выбор на фактической стадии выбора правильного символа-кандидата принимается во внимание порядок вычитания. Поэтому при любой отсылке и (или) упоминании областей с положительным или отрицательным значением для правильной интерпретации необходимо принимать во внимание порядок вычитания.
В способе, описанном выше, области с положительным значением и отрицательные области предоставляют информацию о местоположениях, в которых проявляются различия между изображениями символов-кандидатов. Важной особенностью настоящего изобретения является та, что различие проявляется в данной фактической области. Область может не предоставлять точную информацию о контуре графического проявления различия по причине шума и неточного порога изображений документов и т.д. Однако путем, например, корреляции пикселей, ограниченных областью, которая связана с местоположением различий, со сходными областями на изображениях символов-кандидатов, можно отыскать пиксели, составляющие графическую особенность, представляющую различие. Поэтому, согласно настоящему изобретению, информация о местоположении является достаточной для установления степени сходства между областями на соответствующих изображениях, например, путем корреляции по способам, известным специалистам в данной области.
Однако, согласно другой особенности настоящего изобретения, измерение сходства между соответствующими областями можно улучшить, отфильтровывая области с положительным значением и области с отрицательным значением. Это подразумевает фильтрацию уровней серого внутри соответствующих областей, предусматривающую удаление зашумленных уровней серого. На дальнейших стадиях согласно настоящему изобретению контуры областей также могут меняться, например, с использованием теоретического знания о символах на изображении, предусматривая, таким образом, область, которая имеет контур, более точно представляющий графическое проявление различия. Примеры осуществления изобретения, использующие эти особенности настоящего изобретения, будут раскрыты ниже.
Согласно примеру осуществления настоящего изобретения, указанные положительные и отрицательные области можно лучше анализировать, если эти области отфильтрованы с использованием порогового уровня для фильтрации значений пикселей в различающихся областях. Например, на фиг.4 показана результирующая матрица пикселей, которые выбраны только в том случае, если они имеют значения уровня серого выше 25% максимального значения, идентифицированного в положительных областях, а также те, значения которых лежат ниже 25% минимального значения. Области 20, изображенные на фиг.4 при помощи образов «оп-арт», представляют собой остаточные положительные области, а область 21, изображенная «елочкой», представляет остаточную отрицательную область после фильтрации матрицы разностей, представленной на фиг.3. Как показано на фиг.4 при помощи области 22, изображенной в шахматном виде, также могут присутствовать небольшие «островки» областей, представляющих положительные области. Эти небольшие области можно удалить при помощи дополнительной фильтрации, удаляющей области, не превышающие заданный пороговый уровень. Таким образом, области, обозначаемые 22, удаляются.
Дальнейшие стадии согласно настоящему изобретению включают в себя идентификацию второго смещения между изображениями выбранного образца символа и одного из символов-кандидатов. Выбранный образец символа можно выровнять с выбранным символом-кандидатом. На фиг.5 показаны два различных выбранных образца символа, наложенные на эталонное изображение символа i. Второе смещение составляет (-2, 2) для левого изображения и (0, 1) - для правого.
При выравнивании изображения выбранного образца символа с одним из символов-кандидатов, для идентификации одинаковых положений на изображении образца символа, используется информация о местоположениях из матрицы разностей. На фиг.6 черными и белыми горизонтальными полосами показаны, соответственно, положительные и отрицательные области. В данном примере осуществления настоящего изобретения средние значения пикселей (значения уровня серого) вычисляются для каждой соответствующей идентифицированной положительной или отрицательной области. Разница между средними затем используется для идентификации символа-кандидата, являющегося правильным выбором для недостоверно распознаваемого символа.
В таблице I приведены примеры результирующих средних значений из соответствующих положительных и отрицательных областей.
Таблица II иллюстрирует примеры средних значений для случая, когда выбранный образец символа коррелирует с другим символом-кандидатом, что продемонстрировано на фиг.7 и 8 соответственно. Выбор символа-кандидата основан на обратном отслеживании образца символа, который коррелирует с выбранным символом-кандидатом. Если используется первый символ-кандидат, положительная разность средних указывает на то, что первый символ-кандидат им является. Отрицательный результат вычитания указывает на то, что им является другой символ-кандидат.
Согласно другим особенностям настоящего изобретения, альтернативные варианты осуществления настоящего изобретения включают в себя стадии перенормировки областей с положительными и отрицательными значениями в матрице разностей. Для каждой соответствующей области перенормировочный множитель может отличаться. Перенормировка обеспечивает арифметическое согласование различных изображений.
Согласно другим примерам осуществления настоящего изобретения, к изображениям символов возможно применение различных технологий фильтрации, например, для повышения качества графических деталей, снижения шума и т.д. Например, содержимое матрицы разностей можно отфильтровать с использованием пороговых значений уровня серого, превышающих или лежащих ниже порогового уровня, удаляя лишние детали. Кроме того, может применяться известный специалистам в данной области оператор морфологии отверстий.
Другая особенность настоящего изобретения заключается в том, что многие символы-кандидаты могут сообщаться системой OCR как, в значительной степени, эквивалентные кандидаты для недостоверно распознаваемого символа. Согласно примеру осуществления настоящего изобретения формируется вероятная пара символов-кандидатов. Например, если система OCR сообщает о трех символах кандидатах K1, K2 и K3, возможно формирование следующих пар: K1 и K2, K1 и K3, K2 и K3, K2 и K1, K2 и K3, K3 и K1, K3 и K2, которые представляют все возможные комбинации K1, K2 и K3 и могут использоваться для проверки соответствия результата сопоставления, например, K1 и K2, или сопоставления K2 и K1, которое должно давать аналогичный результат. Другими примерами возможных пар могут выступать K1 и K2, K1 и K3, а также K2 и K3. При выполнении способа согласно настоящему изобретению K1 и K2 обрабатывается как первый символ-кандидат, а K2 - как второй символ-кандидат. Способ осуществляется еще раз для K1 и K3 в качестве первого и второго символов-кандидатов соответственно. Затем обрабатываются K2 и K3, и т.д. После обработки всех возможных пар можно получить три возможных результата. Правильным выбором является выбор символа-кандидата, который представляет собой результат нескольких пар комбинаций. В другом примере осуществления изобретения выбор правильного символа-кандидата основан на идентификации пары символов-кандидатов, имеющей наибольшую корреляцию с выбранным образцом символа, а затем выбор результата испытания для данной конкретной пары в качестве правильного выбора для выбранного образца символа. В другом примере вариантов осуществления настоящего изобретения, все символы-кандидаты, сообщаемые системой OCR, коррелируют с выбранным образцом символа. В случае, если корреляция падает ниже заранее установленного порогового уровня, символ-кандидат исключается из рассмотрения согласно настоящему изобретению.
Согласно еще одной особенности настоящего изобретения, эталонные изображения могут улучшать эффективность настоящего изобретения, если изображения символов сгруппировать в классы символов. Например, система OCR может сообщать о многих образцах изображения одного и того же символа, которые непременно распознаются ниже заданного порогового уровня. Тогда все эти изображения одного и того же символа складываются путем сложения уровней серого каждого пикселя соответствующего изображения символа после выравнивания, а сумма взвешивается по количеству складываемых изображений. Данная особенность настоящего изобретения увеличивает графическое качество соответствующих изображений эталонных символов, во-первых, потому, что они являются изображениями реальных изображений, встречающихся в документе, и, во-вторых, путем усреднения компонент шума путем сложения и взвешивания значений пикселей способами, известными специалистам в данной области.
Согласно примеру осуществления настоящего изобретения, для создания классов символов осуществляются следующие стадии:
I. случайный выбор трех образцов в классе, корреляция всех комбинаций этих трех образцов, а затем выбор в качестве исходной позиции для эталона класса данного символа коррелированных образцов, имеющих корреляцию, которая превышает заранее установленный пороговый уровень;
II. в случае, если ни одна из выбранных на стадии I комбинаций не обладает корреляцией, превышающей пороговый уровень, отбор других образцов в классе до тех пор, пока полученная пара не будет иметь корреляцию, превышающую пороговый уровень;
III. в случае, если ни одна из выбранных на стадии II комбинаций не обладает корреляцией, превышающей пороговый уровень, исключение данного класса из дальнейшего использования;
IV. для исходной пары, идентифицированной на стадии I или II, корреляция изображений пары и идентификация смещения между ними для генерирования выровненного суммарного эталонного изображения из изображений, использованных в качестве исходных эталонных изображений для данного класса символа;
V. для всех остальных образцов в классе - корреляция с суммарным эталонным изображением на стадии IV для идентификации смещения между ними и, если корреляция превышает заранее установленный порог, выравнивание изображений перед сложением выровненных изображений с суммарным изображением на стадии IV;
VI. если некоторые из выровненных изображений, используемых на стадии V, включают в себя части изображения, выходящие за пределы исходного эталона (стадия IV), - расширение суммарного шаблона после того, как все используемые изображения оказываются находящимися внутри ограничивающего параллелепипеда, определяемого как средний размер ограничивающих параллелепипедов подмножества изображений, представляющего большинство изображений.
Согласно еще одному примеру осуществления настоящего изобретения, обозначение или вычисление соответствующих положительных и отрицательных областей матрицы разностей включает в себя в качестве критерия обозначения идентификации медианы усредненных различающихся областей классов, представляющих символы-кандидаты. Например, при значении медианы 38 отличающаяся область должна быть обозначена как положительная область, если усредненное значение отличающейся области образца символа не превышает 38, иначе - нуль.
На фиг.9 показан пример символов с и е, где левое изображение иллюстрирует матрицу разностей, полученную путем вычитания значений пикселей из с и е в порядке с-е, а второе изображение иллюстрирует матрицу разностей, полученную путем вычитания значений пикселей из с и е в порядке е-с. В примере осуществления настоящего изобретения такие вычитания осуществляются со всеми, или, по меньшей мере, большей частью изображений класса, где классы представляют собой, например, с и е из этого примера. На фиг.10 показано, как на гистограмме распределяются усредненные значения разностей для некоторых экземпляров изображений с и е. Высота столбца (по вертикальной оси) представляет собой количество образцов члена класса, имеющих усредненное значение разности, указанное вдоль нижней линии (горизонтальной оси). Все усредненные значения разностей на диаграмме, указывающие на символ с, находятся в светло-серых цветах, в то время как все усредненные значения разностей, указывающие на изображение символа е, находятся в темно-сером цвете. Значения всех светло-серых и темно-серых столбцов группируются по отдельности, и затем вычисляется значение медианы для этих значений, которое находится в положении числа 38 на горизонтальной оси и используется в качестве границы, определяющей отнесение областей к областям с положительными и отрицательными значениями в матрице разностей перед ее использованием на стадиях настоящего изобретения, где осуществляется отбор правильных образцов символов как правильного выбора для выбранного образца символа.
На фиг.11 показана трудность другого типа, создающая затруднения при идентификации изображений текста. Например, при сканировании книжной страницы на планшетном сканере изображения символов, находящиеся поблизости от переплета, оказываются искривленными, и при преобразовании системой OCR в растровое изображение масштабирование символов отличается в зависимости от расположения их отпечатков на странице. Аналогичные трудности возникают при фотографировании страницы. Изображение 11а на фиг.11 представляет эталон символа е, а 11б - изображение неправильно масштабированного символа е. Это может создавать трудности при осуществлении различных стадий осуществления настоящего изобретения, включающих в себя корреляции. На фиг.12а приведено изображение по фиг.11б, наложенное поверх эталонного изображения (фиг.11а). Максимальное значение корреляции в этом примере составляет 0,878. Однако эталоны предоставляют возможность оценки ширины и высоты символов, встречающихся в документе. Например, совместно с высотой символа может использоваться медиана всех пикселей, представляющих наложение в классе («включенные» пиксели, составляющие тело символа). Эта информация может затем использоваться для коррекции масштабирования символа, например, изображения на фиг.11б, давая скорректированное изображение, показанное на фиг.11в. Коррекция может осуществляться, например, путем подгонки максимально возможного количества пикселей неправильно масштабированного символа под соответствующие положения в скорректированном изображении с использованием известных специалистам в данной области морфологических операций. На фиг.12б показана результирующая корреляция между эталоном (фиг.11а) и изображением на фиг.11в. Максимальная корреляция составляет для скорректированного изображения 0,945, что является существенным улучшением корреляции.
Согласно другой особенности настоящего изобретения, сходным образом может обрабатываться вращение символов. В одном из примеров осуществления настоящего изобретения перед корреляцией повернутого экземпляра изображения с эталонными изображениями осуществляются способы поиска и проб со случайно выбранными углами вращения. Угол вращения, дающий наибольшую корреляцию, является правильным углом вращения, который можно сохранить и использовать во вращении других изображений, имеющих вероятность вращения изображения символа.
На фиг.13 показана трудность другого типа, которая может быть преодолена посредством вариантов осуществления настоящего изобретения. В данном примере в изображениях символа е присутствует систематическая погрешность. Верхняя часть е всегда заполнена, что может являться результатом неисправности, например, в пишущей машинке. На фиг.13а показано эталонное изображение такого символа е, на фиг.13б показано эталонное изображение символа о из того же документа. На фиг.13в показана матрица разностей этих эталонов. На фиг.14 показаны различающиеся области, где белым пунктиром показаны области преобладания е, а черным пунктиром - области преобладания о. В данном случае для установления преобладания е используется неожиданная расширенная область, что является результатом отсутствия систематической погрешности в погрешности на изображении, представляющем символ.
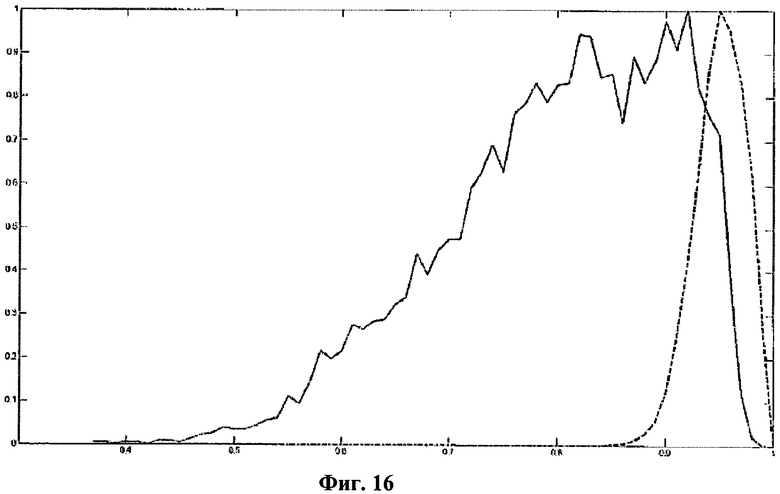
На фиг.15 показан пример трудности, связанной с шумом на изображениях символов. На фиг.15 приведены два изображения символа О, не содержащие шума, и два изображения, включающие в себя шум. На фиг.16 показана взаимная корреляция между символами О данного примера с символами О другого документа, включающими в себя низкий уровень шума. Гистограмма на фиг.16 иллюстрирует распределение, ожидаемое для взаимной корреляции зашумленных изображений символов, показанное сплошной линией, в то время как символы с низким уровнем шума дают значительно меньшее распределение, показанное пунктирной линией. Фиг.16 нормирована таким образом, чтобы максимальное значение корреляции составляло 1.
Распределение взаимных корреляций дает метрику уровня шума, которая может служить в качестве показания для решения об осуществлении каких-либо действий для принятия во внимание шума, присутствующего на эталонных изображениях или в классах символов. На фиг.17 показан пример, где символы е (фиг.17а) и о (фиг.17б) дают матрицу разностей (фиг.17в), которая включает в себя различающиеся области, возникающие по причине шума. Согласно одной из особенностей настоящего изобретения, для улучшения качества информации, предусматриваемой в матрице разностей, используется теоретическое знание. В данном примере осуществления изобретения решение заключается в оформлении части различия, происходящей от символа е, для четкого указания на характерные особенности символов е и о таким образом, чтобы для осуществления выбора правильного символа-кандидата для выбранного образца символа можно было бы использовать матрицу разностей согласно настоящему изобретению. Используемым очевидным теоретическим знанием является топологическая особенность, отделяющая е от о - горизонтальная линия в центре символа е.
Согласно примеру осуществления настоящего изобретения, можно использовать следующие стадии:
1. Идентификация положительных областей в середине символа е.
2. Оценка высоты этих областей (ширина штриха горизонтальной линии).
3. Оценка средней ширины штриха левой и правой стороны символа е.
4. Генерирование линии с оцененной шириной от левого внешнего контура с добавлением оцененной ширины штриха справа.
5. Идентификация отрицательной области, ближайшей к правой части положительной области и находящейся под этой положительной областью.
6. Пренебрежение всеми остальными положительными и отрицательными областями.
Результат этой манипуляции предусматривает изображение, показанное на фиг.18. Преобладание е находится внутри ограничивающего черного прямоугольника.
В некоторых случаях в эталонном наборе или классе согласно настоящему изобретению присутствуют пропуски изображений символов, что может привести к ситуации, когда, например, только один символ-кандидат имеет эталонное изображение. Такие ситуации могут возникать, например, тогда, когда символ действительно редко используется в языке документа. Например, в норвежском языке редко используемым является символ с, в отличие от других языков, где символ с является наиболее часто используемым. Типичной ошибочной альтернативой символу с является символ е. Разумно предположить, что для символа е в наличии будет эталон, однако с высокой вероятностью для символа с эталона в наличии не будет. При идентификации недостающего эталона возможно создание синтетического эталонного изображения на основе уже имеющегося эталонного изображения, которое имеет сходство с недостающим эталонным изображением. Таким образом, некоторые графические атрибуты символов, встречающихся в документе, обрабатываемом системой OCR, будут частью синтезированного эталонного изображения.

























Изобретение относится к вычислительной технике. Технический результат заключается в сокращении неопределенностей, связанных с выбором правильных символов-кандидатов среди нескольких символов-кандидатов. Способ разрешения противоречивых выходных данных из системы оптического распознавания символов (OCR), обеспечивающей преобразование растровых документов в текст в компьютерных кодах в качестве выходных данных. Выходные данные системы OCR включают в себя, по меньшей мере, первый и второй символы, входящие в список вероятных кандидатов для экземпляра одного и того же выбранного образца символа из растрового документа. Разрешение противоречивых выходных данных осуществляется путем выполнения стадий, на которых идентифицируются местоположения различий в графическом виде между символами-кандидатами, а информация о местоположениях используется для идентификации соответствующих положений в выбранном образце символа. На основе метода корреляции информация о местоположении используется для выбора правильного символа-кандидата в качестве идентификации выбранного образца символа. 19 з.п. ф-лы, 31 ил., 2 табл.
1. Способ разрешения противоречивых выходных данных из системы оптического распознавания символов (OCR), отличающийся тем, что выходные данные включают в себя растровые изображения символов в том виде, как они встречаются в изображении текстового документа, обрабатываемого системой OCR, где первое подмножество выходных данных представляет собой изображения символов, распознаваемых со степенью достоверности, которая превышает заранее заданный уровень, где выходные данные также включают в себя второе подмножество символов, включающее в себя, по меньшей мере, изображения первого символа-кандидата и второго символа-кандидата, которые идентифицированы как в значительной степени эквивалентные вероятные идентификации одного и того же экземпляра выбранного образца символа из текстового документа, обрабатываемого системой OCR, где способ включает в себя следующие стадии:
а) поиск в первом подмножестве выходных данных, идентификация изображений символов, которые имеют качество изображения, превышающее заранее заданный уровень, и использование этих изображений символов в качестве набора эталонных изображений символов;
б) сопоставление изображения первого символа-кандидата и изображения второго символа-кандидата с каждым из соответствующих эталонных изображений, идентификация первого эталонного изображения, представляющего изображение первого символа-кандидата, и второго эталонного изображения, представляющего изображение второго символа-кандидата соответственно;
в) сопоставление первого эталонного изображения со вторым эталонным изображением, идентификация первого смещения между этими изображениями и выравнивание первого эталонного изображения относительно второго эталонного изображения в соответствии с первым смещением;
г) идентификация на выровненных изображениях местоположений областей, которые включают в себя особенности, отличающие первое эталонное изображение от второго эталонного изображения, выражение информации о местоположениях этих областей относительно выровненных изображений;
д) сопоставление изображения выбранного образца символа с первым эталонным изображением и вторым эталонным изображением, идентификация второго смещения, выравнивание изображения выбранного образца символа с первым эталонным изображением и вторым эталонным изображением в соответствии со вторым смещением;
е) использование информации о местоположениях из стадии г) для идентификации соответствующих областей на выровненном изображении выбранного образца символа и последующее сопоставление содержимого изображения в областях с установленным местоположением путем вычисления средних значений пикселей, которые заключаются в областях выбранного образца символа с установленным местоположением, последующее вычитание этих соответствующих средних значений, где результат вычитания совместно с фактически выбранным эталонным изображением, использованным при идентификации второго смещения, предоставляет критерий выбора первого символа-кандидата или второго символа-кандидата в качестве идентифицированного символа для выбранного образца символа.
2. Способ по п.1, отличающийся тем, что идентификация эталонного изображения как правильной идентификации выбранного образца символа также включает в себя:
в случае, если для идентификации второго смещения используется первое эталонное изображение, и если результат вычитания вычисленных средних значений превышает первый заранее определенный пороговый уровень, первое эталонное изображение является правильной идентификацией выбранного образца символа; в случае, если отрицательный результат вычитания средних значений находится ниже второго порогового уровня, правильной идентификацией выбранного образца символа является второе эталонное изображение; в случае, если результат вычитания средних значений имеет значение, лежащее между первым и вторым пороговыми уровнями, ни первое, ни второе эталонное изображение нельзя выбрать окончательно.
3. Способ по п.1, отличающийся тем, что идентификация эталонного изображения как правильной идентификации выбранного образца символа также включает в себя:
в случае, если для идентификации второго смещения используется второе эталонное изображение, и если результат вычитания вычисленных средних значений превышает первый заранее определенный пороговый уровень, второе эталонное изображение является правильной идентификацией выбранного образца символа; в случае, если отрицательный результат вычитания средних значений находится ниже второго порогового уровня, правильной идентификацией выбранного образца символа является первое эталонное изображение; в случае, если результат вычитания средних значений имеет значение, лежащее между первым и вторым пороговыми уровнями, ни первое, ни второе эталонное изображение нельзя выбрать окончательно.
4. Способ по п.1, отличающийся тем, что второе подмножество выходных данных включает в себя множество изображений символов-кандидатов, и способ также включает в себя следующие стадии:
ж) составление возможных комбинаций пар соответствующих членов второго подмножества выходных данных, а затем использование членов каждой составленной пары изображений символов-кандидатов как изображения первого символа-кандидата и изображения второго символа кандидата соответственно, по одной паре за раз на стадиях а)-е);
з) стадия е) также включает в себя запись результатов всех сопоставлений изображений, а затем выбор эталонного изображения из составленной пары изображений символов-кандидатов, обеспечивающей наибольшую степень согласованности, которая превышает заранее определенный уровень, в качестве правильной идентификации для выбранного образца символа.
5. Способ по п.1, отличающийся тем, что стадии, которые включают в себя сопоставление изображений, предусматривают корреляцию значений пикселей на соответствующих сопоставляемых изображениях и использование максимальных значений корреляции для идентификации как первого, так и второго смещения, соответственно, для идентификации эталонных изображений и сопоставления содержимого изображений в областях на соответствующих выровненных изображениях.
6. Способ по п.1, отличающийся тем, что стадия идентификации местоположений областей, которые включают в себя особенности, отличающие первое эталонное изображение от второго эталонного изображения, включает в себя генерирование матрицы разностей путем вычитания значений пикселей из первого выровненного эталонного изображения и второго выровненного эталонного изображения, где значения пикселей расположены в местоположениях, соответствующих положениям ячеек матрицы, а затем идентификацию в матрице разностей областей с положительным значением, превышающим заранее определенный пороговый уровень, и областей с отрицательным значением, лежащим ниже другого заранее определенного порогового уровня, а также исключение остальных областей, как и областей, включающих в себя отличительные особенности.
7. Способ по п.6, отличающийся тем, что при идентификации первого эталонного изображения или второго эталонного изображения как правильной идентификации выбранного образца символа используется порядок вычитания между первым эталонным изображением и вторым эталонным изображением.
8. Способ по п.7, отличающийся тем, что область с положительным значением указывает на преобладание первого эталонного изображения в области с положительным значением в том случае, если второе эталонное изображение вычитается из первого эталонного изображения, а область с положительным значением указывает на преобладание второго эталонного изображения в области с положительным значением в том случае, если первое эталонное изображение вычитается из второго эталонного изображения.
9. Способ по п.6, отличающийся тем, что также включает в себя перенормировку всех абсолютных значений в матрице разностей так, чтобы абсолютные значения находились в интервале от нуля до единицы.
10. Способ по п.9, отличающийся тем, что также включает в себя использование отдельных перенормировочных множителей для областей с положительными значениями и областей с отрицательными значениями соответственно.
11. Способ по п.6, отличающийся тем, что также включает в себя использование пороговых уровней для фильтрации содержимого ячеек матрицы разностей соответственно с низким пороговым уровнем и высоким пороговым уровнем, а затем сопоставления растровых выходов при каждом использовании соответствующих пороговых уровней на одном и том же растровом изображении, хранящемся в матрице разностей, с последующим удалением связанных пикселей, которые занимают области меньшие, чем заранее определенный предел, перед идентификацией в матрице разностей местоположений областей с положительным и отрицательным значениями.
12. Способ по п.9, отличающийся тем, что также включает в себя использование оператора морфологии отверстий на растровых выходах при использовании соответственно низкого и высокого пороговых уровней.
13. Способ по п.1, отличающийся тем, что стадия идентификации второго смещения включает в себя корреляцию изображения образца символа со всеми эталонными изображениями в эталонном наборе, а также использование для получения второго смещения эталонного изображения с максимальной корреляцией с изображением образца символа.
14. Способ по п.1, отличающийся тем, что стадия идентификации правильного эталонного изображения как идентификации для выбранного образца символа включает в себя использование эталона для первого символа-кандидата, а затем осуществление остальных стадий способа для данного выбора, осуществление тех же стадий с эталоном второго символа-кандидата, контроль одинакового выхода результатов сопоставлений при применении соответственно первого и второго эталонных изображений и использование эталонного изображения, дающего такой же результат сопоставлений как правильной идентификации выбранного образца символа.
15. Способ по п.14, отличающийся тем, что в ситуации, когда использование двух соответствующих эталонных изображений приводит к одному результату сопоставления, окончательному для одного из двух эталонных изображений, а второе эталонное изображение приводит к неокончательному результату, ситуация дополнительно включает в себя стадию выбора эталонного изображения, обеспечивающего окончательный результат как правильно идентифицированного эталонного изображения для выбранного образца символа.
16. Способ по п.1, отличающийся тем, что стадия а) включает в себя сортировку всех сообщаемых идентифицированных символов первого подмножества, превышающих заранее определенный пороговый уровень, в классы, где каждый класс представляет один и тот же идентифицированный символ, а затем осуществление следующих стадий:
I. случайный выбор трех образцов в классе, корреляция всех комбинаций этих трех образцов, а затем выбор пары коррелированных образцов, обеспечивающих корреляцию, которая превышает заранее определенный пороговый уровень, в качестве исходного пункта для эталона данного класса символа;
II. если ни одна из комбинаций пар, выбранных на стадии I, не обеспечивает корреляции, превышающей пороговый уровень, выбор других образцов в классе до получения пары, имеющей корреляцию, которая превышает заранее определенный пороговый уровень;
III. если оказывается, что ни одна из комбинаций пар, выбранных на стадии II, не имеет корреляции, которая превышает заранее определенный пороговый уровень, класс исключается из дальнейшего использования;
IV. для исходной пары, идентифицированной на стадии I или II, - корреляция изображений пары и идентификация смещения между ними перед генерированием выровненного суммарного эталонного изображения из изображений, используемых в качестве исходных эталонных изображений для соответствующего класса символа;
V. для всех остальных образцов в классе - корреляция с суммарным эталоном (стадия IV) для идентификации смещения между ними и, если корреляция превышает заранее заданный порог, выравнивание изображений перед добавлением выровненных изображений к суммарному изображению (стадия IV);
VI. если некоторые выровненные изображения на стадии V включают в себя части изображения, которые выходят за пределы исходного изображения (стадия IV), - расширение суммарного эталона после использования всех образцов.
17. Способ по п.16, отличающийся тем, что суммирование выровненных изображений в эталон для класса, представляющего символ, также включает в себя сложение соответствующих значений уровня серого пикселей из соответствующих местоположений на выровненных изображениях таким образом, чтобы каждое значение уровня серого пикселя взвешивалось по обратному количеству текущих суммированных выровненных изображений на эталонном изображении для класса перед осуществлением сложения.
18. Способ по п.6, отличающийся тем, что использование эталонных классов по п.16 также включает в себя использование всех изображений-членов эталонного класса для областей с положительными и отрицательными значениями путем вычитания значений пикселей соответствующих членов первого эталонного класса из соответствующих членов второго эталонного класса, а также использование средних значений этих вычитаний в качестве результата вычитаний в матрице разностей.
19. Способ по п.1, отличающийся тем, что использование матрицы разностей по п.6 также включает в себя использование теоретического знания для манипулирования контурами идентифицированных областей с положительным и отрицательным значениями.
20. Способ по п.16, отличающийся тем, что в ситуации, когда класс символа отсутствует из-за отсутствия изображений идентифицированного символа в документе, обрабатываемом системой OCR, недостающий эталонный класс синтезируется из другого существующего эталонного класса, сходного с недостающим эталонным классом.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 6111984 A, 29.08.2000 | |||
| US 6701016 B1, 02.03.2004 | |||
| Устройство для механического съема листовых материалов с рам с кулачковыми зажимами | 1973 |
|
SU745952A1 |
| EP 1818857 A2, 15.08.2007 | |||
| Приспособление к трепальной машине для заправки холста на скалку | 1938 |
|
SU63571A1 |

