Изобретение относится к области оптического распознавания символов и, в частности, к методам распознавания печатного текста из растрового изображения, полученного любым способом.
Известен способ распознавания текстовой информации, при котором растровое изображение разбивается на области (блоки), предположительно содержащие изображения печатных символов текста, с последующим сопоставлением изображения в блоках с эталонным описанием изображения, содержащимся в одном или нескольких специальных признаковых (или растровых) классификаторах.
Такой способ реализуется в способе распознавания информации по патенту США №5680479, 21.10.1997.
Известен способ распознавания текстовой информации, при котором набор изображений символов, составляющих слово, прошедших через классификатор, вместе с набором возможных вариантов символов направляются на анализ в алгоритм контекстного анализа. В результате контекстного анализа число возможных вариантов букв снижается до одного варианта.
Такой способ реализуется в способе распознавания информации по патенту США №5933531, 03.08.1999.
Техническим результатом изобретения является повышение качества распознавания текста, увеличение быстродействия, снижение требований к компьютерным ресурсам.
Это достигается тем, что в системе организуют растровый классификатор, настраиваемый в процессе распознавания и, следовательно, более приспособленный к параметрам текущего текста и имеющий меньшее время обращения. Настройка растрового классификатора осуществляют по результатам обработки в предварительно настроенном признаковом классификаторе и в алгоритме контекстного анализа.
Реализация этого способа позволяет существенно повысить качество распознавания текста, быстродействие распознавания, уменьшить чувствительность к ошибкам омнифонтового классификатора, снизить требований к компьютерным ресурсам.
Известны способы распознавания символов печатного текста, использующие для увеличения быстродействия классификаторы с ограниченным набором шрифтов (напр., патент США №5509092, 16.04.1996).
Недостатком этих способов является ограниченность разновидностей текста имеющимся набором шрифтов, что сильно сужает область применения способа.
Известен способ распознавания символов печатного текста, использующий многошрифтовой (омнифонтовый) классификатор (патент США №5805747, 08.09.1998).
Недостатком способа является значительное время обращения к омнифонтовому классификатору, а также значительные требуемые компьютерные ресурсы.
Известен способ, использующий для распознавания динамически настраиваемый растровый классификатор как основной инструмент для распознавания, и омнифонтовый предварительно настроенный классификатор для настройки (патент США №6038342, 14.03.2000).
Недостатком способа является чувствительность к ошибкам омнифонтового классификатора.
Известен способ, использующий для распознавания вместе с омнифонтовым классификатором алгоритм контекстного анализа (патент США №6028970, 22.02.2000)
Недостатком способа является снижение быстродействия работы.
Известны способы настройки классификаторов на работу с разными типами и размерами шрифтов (напр., патенты США №5675710, 07.10.1997; №5818963, 06.10.1998; Японии JP 2001215987, 10.08.2001).
Недостатком способов является низкое быстродействие и недостаточная надежность распознавания.
Указанные недостатки значительно ограничивают возможности использования известных способов для распознавания текстовой информации.
Известные методы непригодны для достижения заявленного технического результата.
Предлагаемый способ отличается тем, что для распознавания символов печатного текста из растрового изображения используется настраиваемый растровый классификатор совместно с алгоритмом контекстного анализа как основной инструмент для распознавания, и омнифонтовый предварительно настроенный классификатор совместно с алгоритмом контекстного анализа - как вспомогательный инструмент распознавания, а также для настройки растрового классификатора.
Растровый классификатор сравнивает распознаваемое изображение с хранящимися эталонными изображениями.
Эталонное изображение получают усреднением изображений, используемых при настройке - каждый элемент усредненного изображения хранит среднюю интенсивность элементов изображений, используемых при настройке.
В качестве меры совпадения используют взвешенную сумму разностей интенсивности пикселей сравниваемых изображений. С каждым эталонным изображением связывают уровень его надежности, корректируемый в процессе настройки.
Уровень надежности может быть выражен через число сеансов настройки изображения.
Эталонные изображения с надежностью ниже предварительно установленного уровня не участвуют в распознавании.
Результатом распознавания растрового изображения в классификаторах является одна или несколько пар значений символов вместе с соответствующей вероятностью правильного распознавания.
В случае, если вероятность правильного распознавания слова ниже предварительно заданного уровня, слово помечается для повторного распознавания. Процесс настройки включает следующие шаги.
Для каждого распознанного символа проверяется наличие похожих среди эталонных изображений.
Если такого изображения нет, создается новое эталонное изображение.
Если среди эталонных изображений есть похожее, эталонное изображение дополнительно настраивают. При этом корректируют усредненное изображение и степень надежности. Величина, на которую увеличивается надежность, зависит от оценки, которое слово получило в процессе контекстного анализа, и может составлять 25-50%.
Поэтому, чтобы эталонное изображение достигло достаточно высокого уровня надежности распознавания, оно должно пройти 2-4 сеанса настройки.
Если изображение было распознано настраиваемым классификатором, но контекстный анализ отверг этот вариант, степень надежности эталонного изображения уменьшают. При уменьшении надежности до предварительно заданного минимального уровня эталонное изображение удаляют из классификатора.
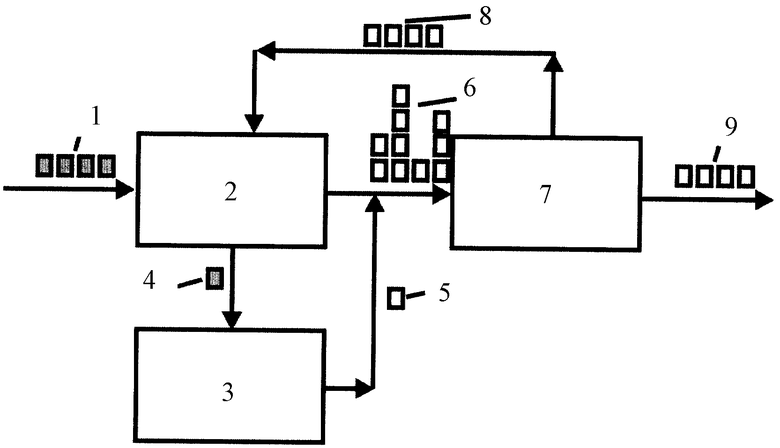
Сущность предложения иллюстрируется чертежом.
Группа графических блоков 1 с изображениями букв, предположительно составляющих слово, последовательно направляется в настраиваемый классификатор 2 для распознавания. Нераспознанные символы 4 или символы с надежностью точного распознавания ниже предварительно заданного уровня, направляются в предварительно настроенный омнифонтовый классификатор 3, результат работы которого - распознанный символ 5. Результатом работы классификатора являются один или несколько возможных вариантов символов для каждого блока с изображением буквы 6.
После обработки в классификаторе (классификаторах) набор вариантов символов 6, предположительно составляющий слово, направляется на обработку алгоритмом контекстного анализа 7. Результатом контекстной обработки является значительно суженный - обычно до 1 варианта - набор возможных вариантов слова 9. Результаты контекстной обработки в виде набора распознанных символов вместе с уровнями надежности каждого символа 8 направляются в настраиваемый классификатор 2 для пополнения и корректировки его информации.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЧЕСКОГО ОПРЕДЕЛЕНИЯ ЯЗЫКА РАСПОЗНАВАЕМОГО ТЕКСТА ПРИ МНОГОЯЗЫЧНОМ РАСПОЗНАВАНИИ | 2002 |
|
RU2251737C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ЗНАКОВ | 2008 |
|
RU2390843C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЗАЧЕРКНУТЫХ СИМВОЛОВ ПРИ РАСПОЗНАВАНИИ РУКОПИСНОГО ТЕКСТА | 2002 |
|
RU2251736C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО РУКОПИСНОМУ ТЕКСТУ | 2014 |
|
RU2553094C1 |
| НЕПОЛНЫЕ ЭТАЛОНЫ | 2013 |
|
RU2641452C2 |
| СПОСОБ ВЫЯВЛЕНИЯ НЕОБХОДИМОСТИ ОБУЧЕНИЯ ЭТАЛОНА ПРИ ВЕРИФИКАЦИИ РАСПОЗНАННОГО ТЕКСТА | 2014 |
|
RU2641225C2 |
| ЗАКОДИРОВАННЫЕ КОДОВЫМИ КОМБИНАЦИЯМИ СЛОВАРИ | 2006 |
|
RU2421809C2 |
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА | 2014 |
|
RU2571545C1 |
| СПОСОБЫ И СИСТЕМЫ АВТОМАТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ С ИСПОЛЬЗОВАНИЕМ ДЕРЕВА РЕШЕНИЙ | 2015 |
|
RU2598300C2 |
| СПОСОБ МНОГОЭТАПНОГО АНАЛИЗА ИНФОРМАЦИИ РАСТРОВОГО ИЗОБРАЖЕНИЯ | 2002 |
|
RU2234734C1 |
Изобретение относится к способам распознавания печатного текста из растрового изображения. Его применение позволяет получить технический результат в виде повышения качества распознавания текста, увеличения быстродействия и снижения требований к системным ресурсам. Этот результат достигается благодаря тому, что способ включает в себя, в частности, следующие этапы: изображение поступает в настраиваемый классификатор; в случае, если настраиваемый классификатор не может распознать символ, для распознавания используют предварительно настроенный классификатор; после обработки классификатором результаты распознавания направляют на контекстный анализ; результаты контекстного анализа направляют для настройки настраиваемого классификатора. При этом ненастраиваемый классификатор совместно с алгоритмом контекстного анализа применяют для настройки настраиваемого классификатора, который, вместе с алгоритмом для контекстного анализа, применяют как основной инструмент распознавания, а ненастраиваемый классификатор применяют как вспомогательный инструмент распознавания. 9 з.п. ф-лы, 1 ил.
| СПОСОБ АДАПТИВНОГО РАСПОЗНАВАНИЯ ИНФОРМАЦИОННЫХ ОБРАЗОВ И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1999 |
|
RU2160467C1 |
| US 6038342 А, 14.03.2000 | |||
| US 6028970 А, 22.02.2000 | |||
| Походная разборная печь для варки пищи и печения хлеба | 1920 |
|
SU11A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |

