Изобретение относится к области передачи данных, в частности к пересылке упрощенной информации, содержащей текст, рассчитанной на приемники простой конструкции, и к передаче информации, содержащей текст и иные данные, предназначенной для принимающих устройств с расширенными функциями, причем приемники обоих типов предусматривают считывание потока данных.
В настоящее время существует множество индивидуальных оконечных приемных устройств, способных принимать передаваемую информацию в режиме мобильной связи. Широкий спектр приемных устройств отличается значительным разнообразием их функциональных возможностей и рабочей мощности. Например, портативный компьютер как мобильное устройство приема передаваемой информации имеет очень высокую производительность и мощность благодаря значительным ресурсам процессора и памяти. С другой стороны, мобильный телефон, например, также являющийся средством информационного обеспечения по радиоканалам, имеет очень ограниченные ресурсы производительности и мощности. Небольшой мобильный радиоприемник, не предназначенный для использования в качестве мобильного телефона, а лишь в качестве простого переносного радиоприемника для получения таких сведений, как результаты матчей футбольной лиги или другие спортивные новости, газетные заголовки, прогноз погоды и т.п., имеет еще более ограниченные ресурсы по обработке данных и рабочей мощности при пользовании услугами соответствующей вещательной службы.
Подобные текстовые информационные радиоуслуги, оказываемые с целью простого сбора и дальнейшего использования данных или оперативного радиообмена, получили название "Journaline" ("джорналайн", информационная строка). Такая служба обмена информацией поддерживает очень широкий диапазон типов приемных устройств от экономичных с малоформатным текстовым дисплеем до высокотехнологичных решений с графическим пользовательским интерфейсом и дополнительным тексто-речевым обеспечением.
Пользователь имеет возможность немедленно в интерактивном режиме обрабатывать всю поступающую с радиостанции информацию. В этом отношении такую службу можно сравнить с системой телетекста. Основная информация предоставляется в простом текстовом формате, но при этом обеспечивается возможность дополнительно задействовать более сложную систему графического отображения, включая элементы мультимедиа, такие как изображение или видеоэпизод и другие расширенные функции.
С другой стороны, важно, чтобы поток данных, транслируемый, например, передатчиком цифрового радиовещания, предусматривал обратную совместимость, что означает, что одна и та же информация могла бы быть считана и обработана как простыми, так и более сложными приемными устройствами, или как базовыми приемниками, которые являются простыми приемниками, так и приемниками с расширенными функциями, которые представляют собой более сложные системы радиоприема.
Предметом настоящего изобретения является осуществление концепции формирования потока данных и его обработки одновременно простыми и сложными приемниками, что обеспечивает универсальность процесса передачи и обработки данных, дополняющих текстовую информацию, которые должны одинаково распознаваться как простыми, так и сложными приемными устройствами.
Согласно пунктам формулы изобретения эта задача решена с помощью аппарата, генерирующего поток данных, аппарата, считывающего поток данных, метода генерирования потока данных, метода считывания потока данных и компьютерного программного обеспечения.
Кроме текстовой информации поток данных включает в себя управляющую последовательность начала перехода, обозначающую первые элементы данных, которые должны быть пропущены базовым декодером и считаны расширенным декодером, первый набор элементов данных, управляющую последовательность продолжения перехода, обозначающую второй набор элементов данных, которые вновь должны быть пропущены базовым декодером и считаны расширенным декодером вместе с первым набором элементов данных, затем - второй набор элементов данных и, наконец, при необходимости - текстовую информацию.
Таким образом, обеспечивается, с одной стороны, возможность использовать короткие начальные управляющие последовательности, поскольку число элементов данных, с которым соотносится последовательность начала перехода, может быть, в крайнем случае, равно или меньше максимального числа элементов данных, о которых оповещает начальная последовательность перехода. В тех редких случаях, предусмотренных исключительно для декодеров высшего класса, когда число единиц данных превышает число единиц данных, кодируемых начальной последовательностью перехода, в поток данных далее вводят управляющую последовательность продолжения перехода, задающую число элементов данных, которые должны считываться декодером с расширенными возможностями вместе с первым набором элементов данных. Таким образом, для более коротких блоков данных с меньшим числом единиц данных всегда требуется лишь короткий код управляющей последовательности начала перехода, поскольку такое кодирование не предусматривается для информации произвольной длины, а лишь с ограниченной длиной элементов данных. С другой стороны, гибкость достигается тем, что информация произвольной длины вводится в поток данных сколь угодно частым повторением управляющих последовательностей продолжения перехода и остальных элементов данных после них.
Другими словами, благодаря гибкости потока данных объем вводимой в текст информации для декодера усложненной конструкции не ограничен. Однако это не влияет на длину начальной последовательности перехода, поскольку функция обозначения большой длины вставок данных фактически разделена на несколько последовательностей, а именно на последовательность управления началом перехода и последовательность управления продолжением перехода, позже вводимую в поток данных и, возможно, в очередные начальные последовательности перехода, в то время как для коротких вставок данных, встречающихся относительно часто, требуется лишь очень короткая начальная последовательность перехода. Таким образом, когда декодер усложненной конструкции обнаруживает в потоке данных управляющую последовательность продолжения перехода, он знает, что единицы данных, выделенные с помощью этой последовательности, относятся к первым элементам данных. Для обеспечения большей универсальности используемых потоков данных указатель типа данных размещается среди единиц данных, что определяет тип данных и посредством этого - вид преобразований, применимых к этим данным, содержащимся в элементах данных как первой, так и второй очереди. Указатель типа данных помещается, например, перед первым порядком элементов данных, обозначенным управляющей последовательностью начала перехода, и перед вторым порядком элементов данных, обозначенным управляющей последовательностью продолжения перехода.
Ниже представлено на рассмотрение описание предпочтительных вариантов осуществления изобретения с приложением чертежей.
А именно:
на фиг.1 показана блок-схема аппарата потока данных;
на фиг.2а показана блок-схема базового приемного устройства;
на фиг.2b показана блок-схема приемного устройства с расширенными функциями;
на фиг.3а дана схема потока данных;
на фиг.3b укрупненно показаны управляющая последовательность начала перехода и управляющая последовательность продолжения перехода с точки зрения идентичности структуры;
на фиг.3с схематически показана структура данных, обозначенных последовательностью начала перехода и последовательностью продолжения перехода на фиг.3а или фиг.3b, снабженных указателем типа данных, предназначенных для считывания декодером с расширенными функциями;
на фиг.4а дан пример структуры потока данных без кода продолжения;
на фиг.4b дан пример кодирования с включением кода продолжения;
на фиг.5 представлена блок-схема метода генерирования потока данных;
на фиг.6А представлена блок-схема считывания данных базовым приемным устройством;
на фиг.6В представлена блок-схема считывания данных приемным устройством с расширенными функциями; и
на фиг.7 отображены различные типы данных, маркируемые указателем типа данных, и способы их обработки.
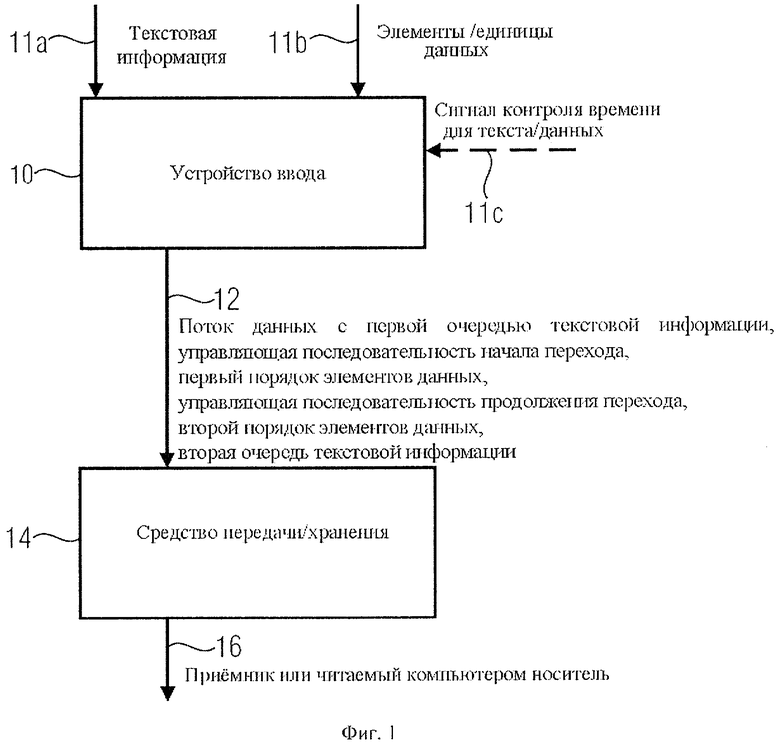
На фиг.1 показан аппарат генерирования потока данных, включающий в себя устройство 10 ввода информации в формируемый для вывода поток данных 12. Поток данных вводят в устройство 14 передачи и/или хранения потока данных для пересылки на приемное устройство или декодер потока данных по каналу передачи в свободном пространстве 16 по типу радиотрансляции. Или же выход 16 устройства 14 передачи или хранения данных соединяют с читаемой компьютером средой хранения информации, например картой памяти, которая подключается непосредственно или находится на другом конце канала связи в составе приемного оборудования, которое или просто сохраняет данные без обработки, или же одновременно накапливает и обрабатывает их. Таким образом, читаемый компьютером накопитель данных может представлять собой плату энергонезависимой памяти внутри приемника или декодера, или твердый диск портативного компьютера, или ОЗУ декодера, которое сохраняет данные при подаче на него питания.
Устройство ввода 10 содержит текстовые данные 11а и элементы данных 11b. Вычисления предпочтительно выполняют в байтах. Следовательно, длина одной единицы данных составляет 8 битов или 1 байт. Такая гранулярность является предпочтительной, поскольку при ней легко обрабатываются как текст, так и данные. В данной ситуации для кодирования текста предпочтительнее используют формат кодирования Юникода UTF-8, в котором каждый стандартный символ ASCII кодируется одним байтом, в то время как, например, умлауты немецкого языка кодируются 2 байтами, а иероглифы китайского языка кодируются 3, 4 или более байтами. Из этого следует, что базовое приемное устройство рассчитано на расшифровку кодировки UTF-8, что может быть выполнено, например, введением таблицы декодирования UTF-8. В зависимости от способа декодирования устройство ввода параллельно получает текстовую информацию и элементы данных. При этом устройство ввода принимает также управляющий сигнал времени 11с, определяющий, в какое время текстовая информация и в какое время элементы данных должны быть введены, например, в последовательный поток данных 12. В другом случае устройство 10 ввода может получить за один прием текстовую информацию и элементы данных в виде потока данных, структурированного надлежащим образом по времени или по последовательности битов.
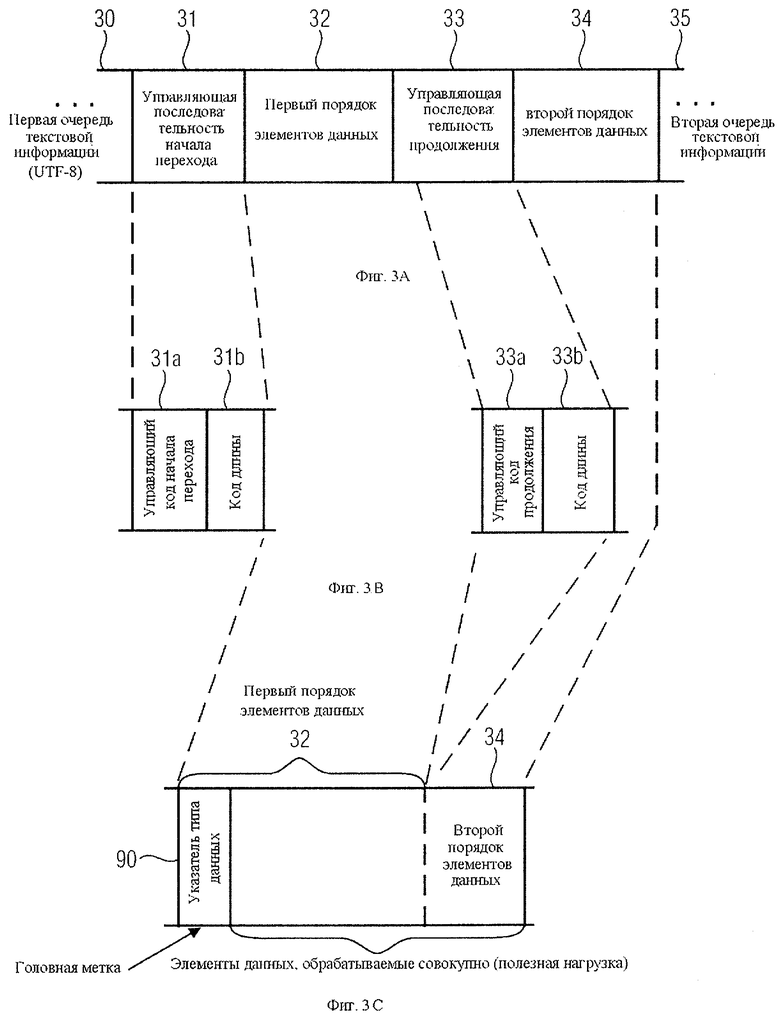
Устройство ввода предназначено для ввода в поток данных текстовой информации. При вводе элементов данных, которые должны быть пропущены простым декодером и считаны или обработаны более сложным декодером, управляющая последовательность начала перехода вводится в поток данных так, как показано, например, на фиг.3а. Управляющая последовательность начала перехода 31 устанавливает первую очередь элементов данных, которая будет пропущена базовым декодером и считана декодером с расширенными функциями. Затем, эта первая очередь единиц данных также вводится в поток данных, что показано на фиг.3а как элемент 32. Если вводимый блок данных содержит большее число единиц данных, чем определено начальной последовательностью перехода, устройство 10 введет управляющую последовательность продолжения перехода 33, определяющую вторую очередь элементов данных, которые будут пропущены базовым декодером, но должны быть считаны декодером более сложной конструкции вместе с первой очередью элементов данных. Затем, эта вторая очередь единиц данных также вводится в поток данных, что показано на фиг.3а как элемент 34.
В случае, если крупный блок данных содержит больше информации, чем может быть задано управляющей последовательностью продолжения перехода, в поток данных записывается следующая управляющая последовательность продолжения перехода, и т.д. до полного введения всех элементов данных, которые должны быть внесены в данную часть текстовой информации для совокупного считывания декодером с расширенными функциями.
После этого устройство ввода 10 на фиг.1, как правило, опять вводит текст, обозначенный, например, на фиг.3а как вторая составляющая текстовых данных 35, завершающая поток данных таким образом, что в нем содержатся первая 30 и вторая 35 составляющие текстовой информации, которые как бы окружают данные, которые будут проигнорированы базовым декодером, причем базовый декодер должен, по меньшей мере, предусматривать способность распознавать управляющую последовательность начала перехода и в особенности - число единиц данных, а также - управляющую последовательность продолжения перехода и, по крайней мере, число содержащихся единиц данных с целью обеспечения правильного пропуска соответствующего числа элементов данных в потоке данных.
На фиг.3b показан пример управляющей последовательности начала перехода 31, которая содержит код начала перехода 31а и код длины последующих элементов данных 31b. Управляющая последовательность продолжения перехода 33 строится аналогично, включая в себя отдельный код продолжения 33а и код длины последующей цепочки данных 33b. Например, все коды 31а, 31b, 33а, 33b имеют длину 1 байт или, соответственно, одну единицу данных каждый, в результате чего 256 элементов данных могут быть закодированы с помощью кода длины. Это означает, что, если длина блока данных превышает 256 единиц данных, код продолжения 33а должен быть вписан или введен в поток данных после первых 256 единиц данных, чтобы закодировать остающиеся элементы блока данных в следующем коде длины 33b.
Если бы единица данных была длиннее, то с помощью кода длины, длина которого, в свою очередь, составляет одну единицу данных, можно было бы закодировать большее количество элементов данных, что в результате дало бы сокращение общего числа кодов продолжения в таком потоке данных. Однако если выбрать код длины, содержащий менее 8 битов, максимальный объем данных, который может быть закодирован с помощью кода длины, соответственно уменьшится, при этом количество кодов продолжения в потоке данных наоборот соответствующим образом увеличится. Как правило, оптимум заключается в том, что каждой определенной средней длине блоков данных соответствует своя определенная длина единиц данных. Слишком длинный код длины снижает эффективность метода, поскольку даже для очень коротких вставок данных в поток данных необходимо вписывать весь длинный код длины полностью. С другой стороны, если код длины будет слишком коротким, внесение кода продолжения потребуется для слишком большого числа блоков данных, что не допустимо, в частности при варианте осуществления на фиг.3b, если более длинный код длины используется с самого начала.
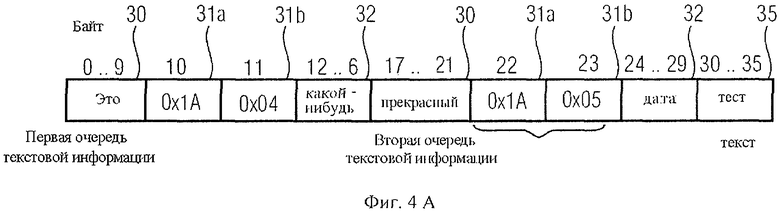
На фиг.4а приведен пример типичного потока данных, дающего в итоге индикацию на дисплее: "This is a great test!" ("Это - прекрасный тест!"), как показано на фиг.4а как элемент 40. В начале соответствующего потока данных помещена первая часть текстовой информации: "This is a " ("Это - "). Для этого требуется 10 байтов, так как один байт необходим для каждого символа и пробела в кодировке UTF-8. Таким образом, первые текстовые данные занимают 10 байтов.
Далее следует вставка данных. Маркером для этого служит код начала перехода 31a, в примере на фиг.4а обозначенный как 1А, находящийся в индексе байта 10 (нулевого), где префикс "0х" указывает на шестнадцатеричное представление. Безусловно, кодом начала перехода может служить любой другой код, отличающийся от кода текста. Иными словами, в примере на фиг.4а код начала перехода 31а длиной 1 байт должен отличаться от кодов, обозначающих символы (цифры, буквы…), которые отображаются на дисплее в кодировке UTF-8. Таким образом, управляющими кодами могут служить, например, управляющие символы UTF-8 или другие фиксированные символы, отличающиеся от текстовых кодов знаков, индицируемых на дисплее.
За кодом начала перехода 31а следует код длины 31b, который указывает продолжительность поля данных, следующего за кодом длины 31b. Поле длины содержит код 4, следовательно, первые элементы данных 32 на фиг.4а состоят из 5 байтов. Причина этого - то, что поле длины подразумевает в своем составе термин "-1", так как нулевое значение длины не имеет смысл.
Затем следует другое текстовое поле, а именно слово "great", занимающее 5 байтов, после чего снова в поле индекса байта 22 внесен код начала перехода 31а, вслед за которым введен код длины 31b со значением 5, поскольку после кода длины в поля индексов байтов 24-29 вписаны 6-байтовые данные. В конце размещен еще один текстовый блок 35 длиной 6 байтов, так как по 1 байту требуется для каждого символа слова "test", и 1 байт занимает восклицательный знак.
Это дает в результате 36-байтовый поток данных, включающий в себя 11 байтов служебных данных в двух различных позициях.
Базовый декодер считывает и отображает информацию, пока не встретит управляющий код начала перехода 31a, который расшифровывает как команду к поиску кода длины, ассоциированного с кодом начала перехода. После этого базовый декодер распознает этот код длины как команду к пропуску элементов данных, заданных управляющим кодом начала перехода и кодом длины, и далее игнорирует их. Затем базовый декодер начинает считывать текстовые данные в полях индексов байтов 17-21 до повторного распознавания управляющего кода начала перехода 31а, после чего будет искать ассоциированный с ним код длины 31b для дальнейшего повторного пропуска указанного в нем количества байтов.
Этим простым способом гарантирована способность базового декодера читать поток данных, предназначенный для более новых или более сложных декодеров с расширенными функциями. Способность базового декодера, не рассчитанного на считывание данных, правильно распознавать управляющую последовательность начала перехода, содержащую код и параметр длины, обеспечивает обратную совместимость оборудования.
При этом декодер с расширенными функциями не только отображает обычный текст и распознает управляющую последовательность начала перехода, содержащуюся в кодах 31а и 31b, но и не игнорирует ассоциированные с ней данные, считывает их и выполняет заложенные в них дополнительные функции, управление которыми может осуществляться через поток данных.
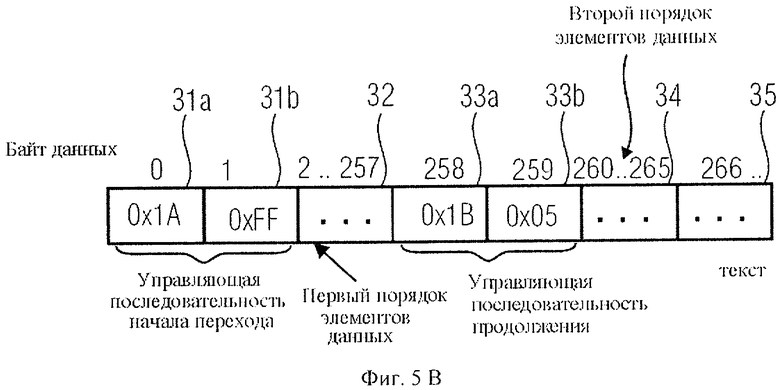
На фиг.4b приведен пример кодирования с введением управляющего кода продолжения, причем длина одного из блоков данных в этом примере составляет более 256 байтов. При введении такого большого блока данных в первую очередь в индекс байта данных 0 вносят управляющую последовательность начала перехода, которая вновь состоит из управляющего кода начала перехода 31а и кода длины последующей цепочки данных 31b.
Однако теперь показатель длины в коде длины 31b представляет собой не любое число, как в поле индекса байта 11 или индекса байта 23, а максимальное, а именно "FF". Затем, после кода длины 31b, в поля индексов байтов 2-257 потока данных вписываются 256 первых единиц данных 32. Поскольку остается еще несколько последующих единиц данных, в совокупности составляющих 262 байта, генератор потока данных определяет, что в поток данных вписаны не все данные. На основании этого генератор данных вводит в поток данных управляющий код продолжения 33а. отличающийся от управляющего кода начала перехода 31а таким образом, что декодер в состоянии определить, что элементы данных, относящиеся к коду продолжения, следующие, например, непосредственно за кодом продолжения, связаны с элементами данных, обработанными или введенными перед управляющим кодом продолжения. В примере на фиг.4b необходимо ввести еще шесть единиц данных, поэтому код длины 33b, следующий за кодом продолжения, задает длину 6 (код 0×05). Следом за этим кодом длины формирование потока данных завершается введением второй очереди единиц данных 34, после чего, начиная с индекса байта 266, как показано на фиг.4b, может следовать, например, обычный текст 35.
Следует отметить, что в зависимости от версии исполнения управляющий код продолжения 33а не обязательно должен отличаться от управляющего кода начала перехода 31а. Это не существенно для базового декодера. Базовый декодер рассчитан только на распознавание управляющего кода начала перехода 31а и управляющего кода продолжения 33а и на корректную расшифровку кода длины последующего ряда элементов данных с целью определения объема данных, которые должны быть пропущены. В данном случае декодер с расширенными функциями должен быть реализован таким образом, чтобы автоматически определять при первом распознавании управляющего кода начала перехода в сочетании с кодом длины, обозначающим максимальную длину, например FF, что последующие элементы данных относятся к элементам данных 32 и, следовательно, должны быть обработаны совокупно. Следовательно, для управляющего кода начала перехода 31а должно быть "включено" то значение, что следующий за ним код длины 31b указывает максимальную длину. Если управляющий код начала перехода 31а и код продолжения 33а имеют одинаковое значение притом, что код длины 31b, стоящий после первого управляющего кода начала перехода 31а, не содержит максимальное значение, то есть FF, декодер распознает код продолжения, следующий за элементами данных, не как управляющий код продолжения, а как новый код перехода, в результате чего данные, идущие за вторым кодом начала перехода, не воспринимаются как продолжение данных, идущих за первым кодом начала перехода, а как новые данные нового блока данных, которые могут быть обработаны иначе. Интерпретация, являются или нет текущие данные продолжением предшествующих данных, имеет особое значение, когда указатель типа данных размещен в каждом блоке данных, состоящем из нескольких единиц данных в определенной позиции, например в начальной, которая считывается, если эти данные не являются продолжением порядка данных, или, если эти данные являются продолжением предшествующих данных, не ожидается декодером и также не считывается, что будет объяснено ниже в контексте фиг.3с.
Далее, что касается фиг.5, на ней представлена примерная последовательность шагов по формированию потока данных, выполняемого генератором потока данных, схема которого дана на фиг.1.
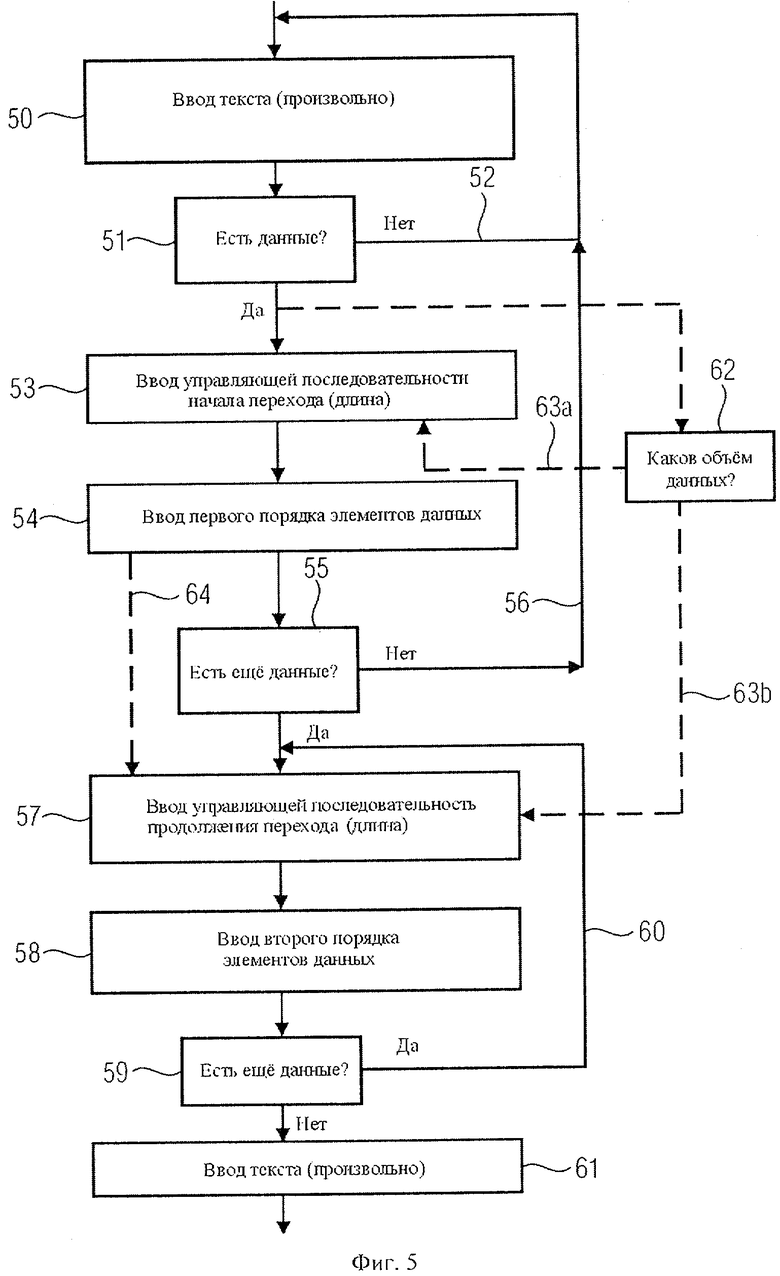
Блок-схема на фиг.5 начинается с шага ввода текста 50. На шаге 51 проверяется, есть ли данные для ввода после введения текста. При ответе "нет" в поток данных вводится следующий текстовый объект, что отображено контуром 52. При ответе "да" устройство ввода 10 вводит управляющую последовательность начала перехода, что показано в рамке шага 53. Управляющая последовательность начала перехода содержит информацию о длине данных, то есть о количестве единиц данных. После введения управляющей последовательности начала перехода в поток данных вводятся первые элементы данных, что показано на шаге 54. На шаге 55 проверяется, все ли данные, относящиеся к блоку данных, введены в поток данных. При ответе "нет", то есть, если данных больше нет, снова вводится текстовый объект или управляющий код, что отображено контуром 56.
Здесь следует отметить, что последовательности управления началом перехода могли стоять перед текстом, после текста или внутри текста. Кроме того, управляющая последовательность начала перехода может находиться перед или после другой управляющей последовательности, причем другая управляющая последовательность может указывать не только на наличие данных. Если же в наличии есть данные, вводится управляющая последовательность продолжения перехода, что показано на шаге 57. В этой последовательности продолжения перехода определяется также длина единиц данных, которые будут введены далее, на шаге 58. На шаге 59 проверяется, есть ли еще данные для ввода. Если данные еще имеются, то есть, если необходимо ввести другие данные из этого блока данных, вновь пишется управляющая последовательность продолжения перехода, что показано на шаге 60. Если же все данные введены полностью, вновь вводится текст, как правило, способом, показанным на шаге 50. Для ясности операция ввода текста после блока данных показана как шаг 61 на фиг.5.
Следует обратить внимание на то, что проверка наличия оставшихся данных на шаге 55 или на шаге 59 не обязательна, если длина вводимых данных задается параллельно или отдельной операцией, как показано на фиг.5 в рамке 62. На шаге 62 определяется, какова длина вводимого блока данных. Исходя из максимального числа единиц данных, которые должны быть закодированы в управляющей последовательности начала перехода, на шаге 52 моментально определяется, сколько потребуется последовательностей продолжения. В версии исполнения, представленной на фиг.4b, на шаге 62 было определено, что в управляющую последовательность начала перехода должна быть введена максимальная длина данных, и что затем будет введена последовательность продолжения, длина которой также определяется, что показано управляющими стрелками 63а и 63b на фиг.5. В подобном случае проверка на шаге 55 или шаге 59 не выполняется, что обозначено пунктирной стрелкой 64. При таком варианте управляющая последовательность начала перехода полностью подготовлена перед вводом элементов данных в поток данных, в то время как в альтернативном варианте значение длины будет введено в управляющую последовательность начала перехода уже после того, как введены элементы данных первой или второй очередности.
Далее в контексте фиг.2а и фиг.2b будут рассмотрены приемные устройства для приема или декодирования потока данных, при этом структура потока данных в основном будет соответствовать схеме, представленной на фиг.3а, включающей в себя текстовые данные, управляющую последовательность начала перехода, ряд элементов данных, затем управляющую последовательность продолжения перехода и следующий за ней очередной ряд элементов данных, после которого могут следовать текстовые данные или очередная управляющая последовательность продолжения перехода.
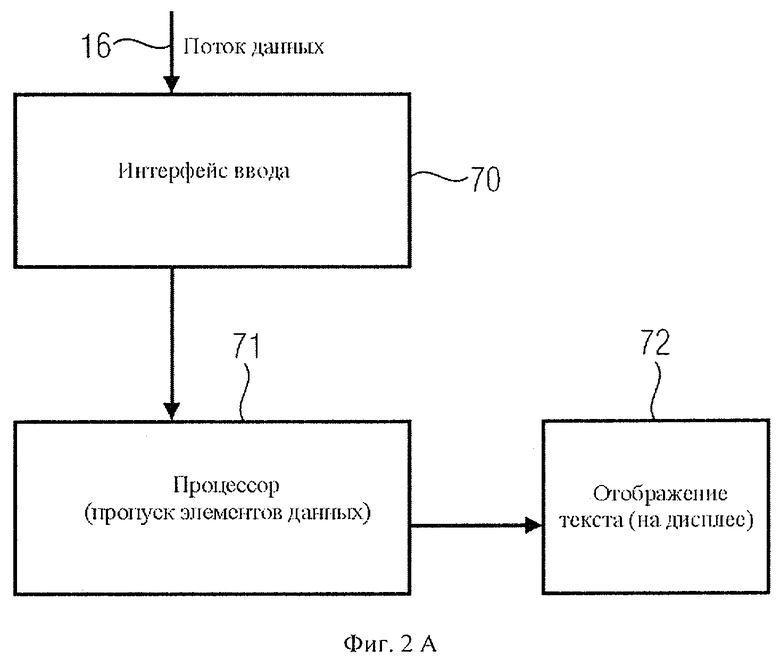
Базовое приемное устройство для чтения потока данных включает в себя интерфейс ввода 70 потока данных 16. Затем поток данных передается на микропроцессор 71, сопряженный с текстовым дисплеем 72, для чтения и визуального отображения текста из потока данных, причем микропроцессор, встретив последовательность начала перехода, определяет длину или количество единиц данных для их пропуска, а также микропроцессор, встретив далее управляющую последовательность продолжения перехода, также пропускает заданное последовательностью продолжения количество единиц данных, как показано в рамке 71 на фиг.2а.
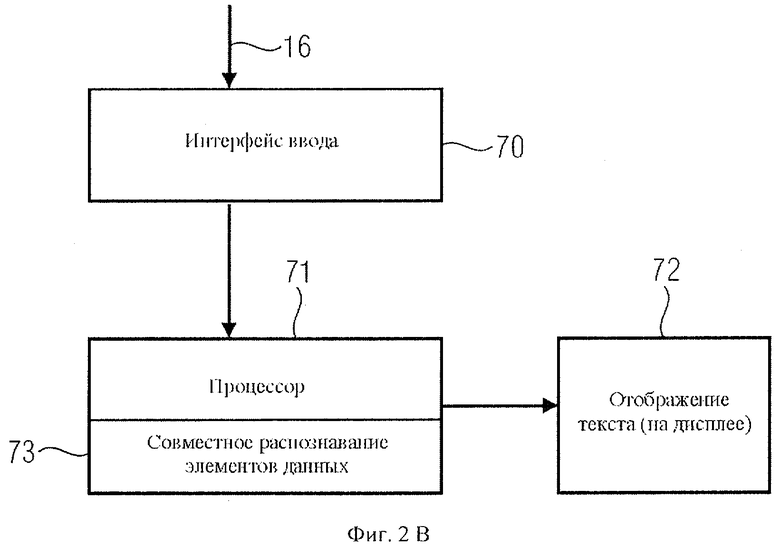
Приемное устройство с расширенными функциями, как показано на фиг.2b, отличается от базового приемного устройства на фиг.2а тем, что в нем дополнительно предусмотрен модуль или микропроцессор 71 с функциями считывания и выполнения единиц данных вместо их пропуска.
В дополнение к текстовому дисплею 72, который в приемном устройстве с расширенными функциями может или будет работать так же, как в базовом приемнике, приемное устройство с расширенными функциями считывает элементы данных, введенные после управляющей последовательности начала перехода и управляющей последовательности продолжения перехода.
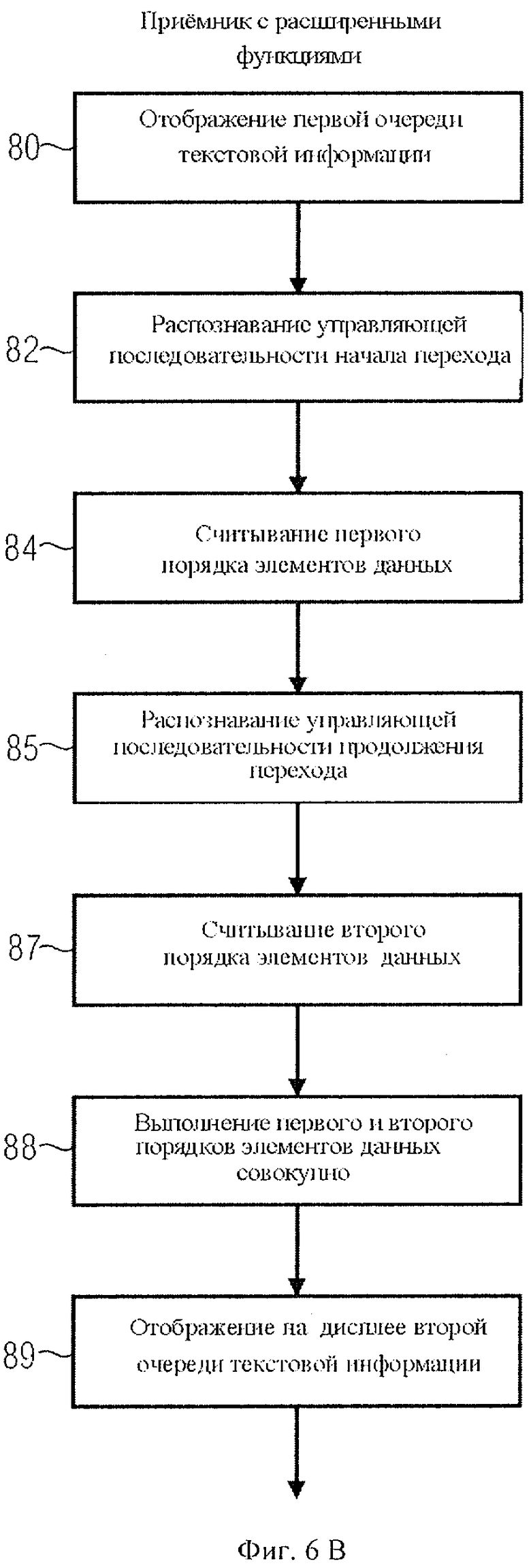
Далее, с помощью фиг.6А и фиг.6В дается сопоставление функциональных возможностей базового приемного устройства, не предусматривающего обработку данных, и приемного устройства с расширенными функциями, предусматривающего обработку данных.
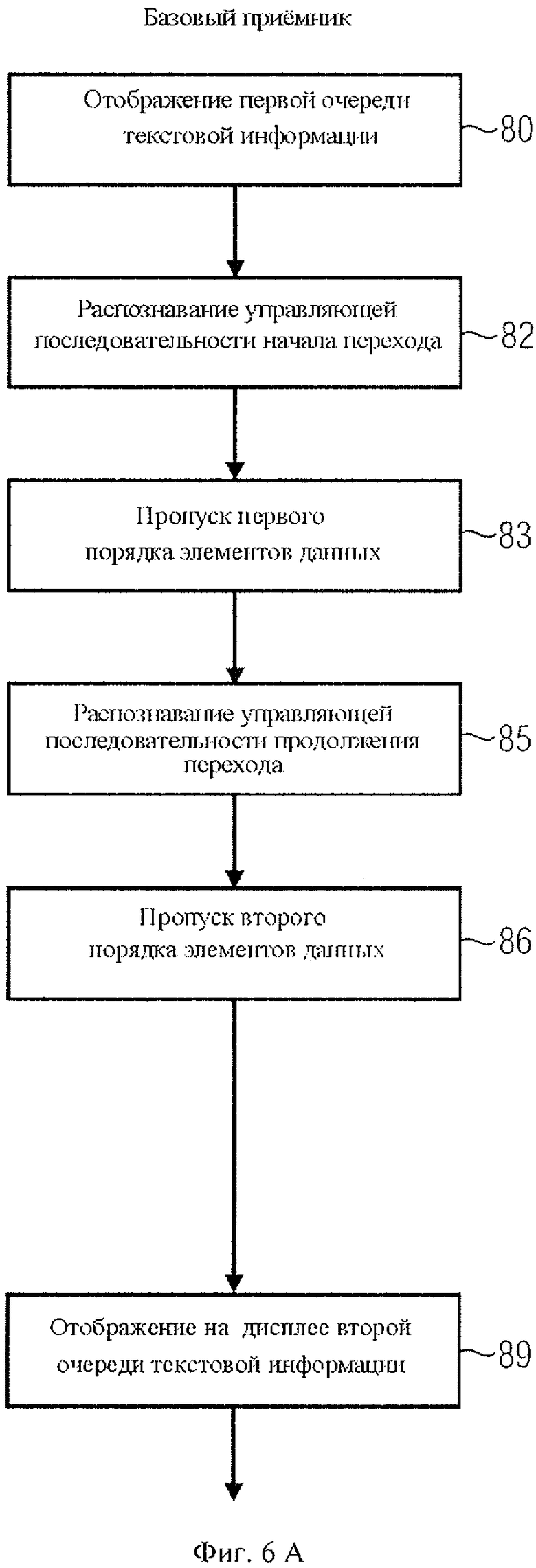
При чтении текста как базовым приемником, так и приемным устройством с расширенными функциями микропроцессор 71 на фиг.2а или фиг.2b обрабатывает текстовые данные, декодирует их, передает на текстовый дисплей 72 для отображения, что показано на шаге 80 на фиг.6А и фиг.6В. Если приемные устройства встречают управляющую последовательность начала перехода, она распознается, что показано на шаге 82. В частности, базовое приемное устройство распознает на шаге 82 количество единиц данных, обозначенных управляющей последовательностью начала перехода, то есть, например, кодом длины 31b на фиг.3b. На шаге 83 базовое приемное устройство пропускает то количество единиц данных, которое определено на шаге 82. Приемное устройство с расширенными функциями, наоборот, на шаге 84 не будет пропускать элементы данных, следующие за управляющей последовательностью начала перехода, а считает их. Поэтому предпочтительнее, если приемное устройство с расширенными функциями тоже получит информацию о длине. Однако если данные закодированы иным способом, чем текст, информация о длине не обязательна.
На шаге 85 как базовый приемник, так и приемное устройство с расширенными функциями распознают управляющую последовательность продолжения перехода, следующую за первой очередью элементов данных 32 на фиг.3а. Здесь базовый приемник главным образом интересует код длины, чтобы определить, сколько данных ему необходимо пропустить на шаге 86. Напротив, приемное устройство с расширенными функциями на шаге 87 не будет пропускать вторую очередь элементов данных, а считает их. Далее, на шаге 88, которого нет у базового приемника, приемное устройство более сложной конструкции задействует свои расширенные функции или модуль 73 на фиг.2b и совокупно выполняет первую и вторую очередь элементов данных. Когда все элементы данных будут обработаны, оба типа приемных устройств - и базовое, и более сложное - на шаге 89 выведут на дисплей вторую часть текстовой информации, то есть данные 35, следующие за потоком данных, как показано на фиг.3а. Однако если второй код длины 33b также обозначает максимальную длину, в этом примере - "FF", приемное устройство с расширенными функциями распознает следующий управляющий код продолжения, считывает очередной код длины, после чего добавляет обозначенные элементы данных к первой и второй очереди единиц данных для их совокупного выполнения.
Ниже, в контексте фиг.3с, более подробно будут описаны функции усовершенствованного приемника на шаге 88, то есть - способ считывания данных, извлеченных после управляющего кода начала перехода и управляющего кода продолжения.
В одном из примеров первый порядок единиц данных заключает в себе указатель типа данных 90 длиной, например, 1 байт. Такой указатель типа данных 90 может находиться только в определенном, например, первом байте первого ряда элементов данных, ссылка на который дается в управляющей последовательности начала перехода 31. Для сравнения, подобный указатель типа данных отсутствует во втором ряду элементов данных 34, который, тем не мене, несет полную информационную, или так называемую "полезную нагрузку", единиц данных, которая реализуется совокупно. При применении указателя типа данных 90 декодер с расширенными функциями расшифровывает данные, стоящие за управляющим кодом продолжения как однотипные с элементами данных первого ряда. Благодаря этому не требуют специальной маркировки элементы данных второй очереди, следующие за управляющим кодом продолжения в потоке данных, который содержит информацию о том, что это - продолжение массива данных, или о том, какой тип представляют элементы данных второй очереди. Вместо этого указатель типа данных, размещенный в первой очереди элементов данных, просто повторяется или запрашивается для второй очереди элементов данных, или же данные, содержащиеся во второй очереди элементов данных, просто добавляются к первой очереди элементов данных, как будто никогда не было их разделения, так, что затем они выполняются или обрабатываются как единое целое.
Преимуществом настоящего изобретения является то, что размерно варьируемый поток данных основывается на общепринятых стандартах. В силу этого объекты могут импортироваться и обрабатываться в формате XML.
Поток данных широко применим в цифровых радиопередающих системах в качестве дополнительного канала передачи данных, обеспечивающего слушателям дополнительные возможности, поскольку они получают оперативный доступ к информации в текстовой форме из любой точки, при этом устройства приема цифрового радиовещания могут быть как простыми, по крайней мере, отображающими текстовую информацию, так и очень сложными и дорогостоящими, предусматривающими любой вид обработки элементов данных первой и второй очереди. Понятно, что недорогие приемники с текстовым дисплеем станут доступными как товар массового спроса и создадут дополнительные удобства и возможности для слушателя. Кроме того, поток данных применим для приемных устройств высокого технического уровня с графическим интерфейсом пользователя и голосовым воспроизведением. Все это легко реализуется даже в недорогих приемниках и просто в эксплуатации, когда пользователю нет необходимости настраивать правильный вид текущих данных. Наоборот, в зависимости от класса приемника, данные удаляются или выполняются полностью автоматически, без участия пользователя.
Кроме того, в некоторых случаях текстовые данные имеют объектно-ориентированное (тематическое) представление, при котором каждый объект представляет собой отдельный независимый блок. Благодаря этому отсутствует необходимость встраивать и поддерживать внутри приемного устройства глобальные структуры данных. Тематические объекты транслируются по принципу карусели данных, а в приемниках применяется кэширование данных. Текстовые данные, которые могут представлять собой, например, составление меню, новости или биржевые сводки, транслируются в виде так называемых объектов NML, где NML (News Service Mark-Up Language) означает "язык разметки информационной службы", которые аналогичны двоичному представлению информации на основе языка XML.
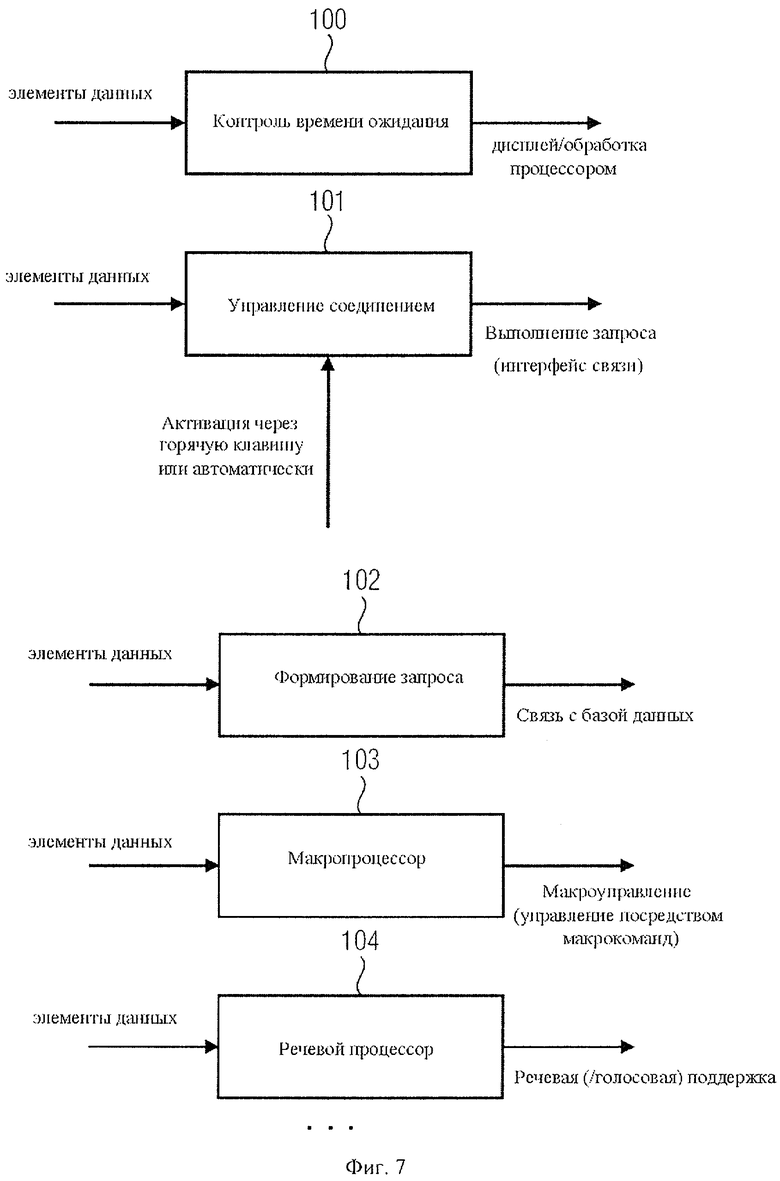
Предпочтительно в качестве начального управляющего кода 31а использовать шестнадцатеричный код 1А, а в качестве управляющего кода продолжения, например, шестнадцатеричный код 1В. Как будет показано ниже, указатель типа данных 90 на фиг.3с может обозначать несколько типов данных. Приведенные ниже значения указателей типа данных являются только примерами. Указатель "00" служит заполнением. Введенные данные содержат байты заполнения в тех случаях, когда это содержимое игнорируется как декодером с расширенными функциями, так и базовым декодером. Другой тип набора данных имеет указатель "01" и обозначает предельное время ожидания. Устанавливается абсолютный период времени ожидания объекта NML. По истечении установленного времени ожидания объект NML больше не отображается. Это представление кода управляющей последовательности необходимо для выборочной маркировки объектов NML. Кроме того, отображается время истечения полного срока службы. Показатель, следующий за индикатором типа данных, отображающий полезную нагрузку из расчета ее начала через 15 минут после 1.1.2000, содержит 24-битовое целое число без знака, что составляет более 450 лет. Указатель типа данных вида "02" обозначает относительное время ожидания. Здесь устанавливается относительный период времени ожидания представления объекта NML. По истечении этого периода объект NML больше не отображается. Время ожидания начинается с момента приема каждого NML-объекта, даже если объект уже хранится в кэш-памяти. Этот код управляющей последовательности служит для выборочной маркировки объектов NML. Показатель продолжительности полезной нагрузки включает в себя количество минут в виде 16-битового целого числа без знака, что составляет более 45 дней. Как правило, данные времени ожидания обрабатываются специальным блоком управления 100 на фиг.7.
Указатель типа данных "03" относится к основной целевой ссылке. Общая целевая ссылка - это тематический объект, задаваемый или активируемый, например, блоком управления соединением 101, в случаях, когда пользователь непосредственно требует выполнение конкретного действия, то есть, когда с помощью "горячей клавиши" отображается или выполняется присвоенная ей функция, чтобы обеспечить пользователю обмен данными. Общие целевые ссылки могут быть заданы для всех типов NML-объектов. Сообщение о наличии доступа по общей целевой ссылке для отображаемого в реальном времени объекта NML поступает тем или иным способом к пользователю, имеющему приемное устройство с расширенными функциями. Данные полезной нагрузки, показанные, например, на фиг.3с, имеют следующий формат: 1 байт обозначает тип соединения, и n байтов указывают адрес связи. Применимы, например, следующие значения типов связи. Если значение типа связи, например “00”, следующие 2 байта являются идентификатором другого объекта NML в той же информационной службе.
Другой байт типа связи, например "01", за которым следует символьная строка унифицированного идентификатора ресурса URI, указывает на различные мультиплексные каналы, службы или сервисные элементы цифрового радиовещания DAB/DRM.
Другой тип соединения, "02", отображает строку символов URL, указывающую адрес или документ в Интернете.
Еще один тип связи, "03", за которым следует номер телефона, отсылает к службе голосового вещания, доступной по телефону. Телефонный номер начинается с международного кода, например "+[международный код страны]".
Как правило, приемные устройства высокого класса предполагают игнорирование неизвестных показателей типа связи.
Следующий указатель типа данных - "FF" - рассматривается, например, как указатель специальных данных, предшествующий данным, относящимся только к определенным моделям приемных устройств с расширенными функциями, которые рассчитаны на считывание таких специализированных данных.
Кроме вышеупомянутых типов управления объектами, элементы данных могут включать в себя типы управления контентом. Указатель типа данных "20", называемый также ключевым словом, маркирует последующее ключевое слово вместе с произвольным описанием ключевого слова. Ключевое слово может быть использовано, например, для образования поискового индекса, ориентированного на приемное устройство, что показано с помощью блока формирования запроса 102 на фиг.7. Раздел данных полезной нагрузки имеет следующий формат. Первым стоит код длины, имеющий длину ключевого слова, где значение, равное длине-1, обозначено целое число без знака. Определяется число визуальных текстовых знаков, следующих за этим разделом, которые должны восприниматься как ключевое слово. Далее следует описание, состоящее из n байтов, в котором как дополнение к ключевому слову может быть проиндексировано и/или отображено для пользователя дополнительное описание.
Другой указатель типа данных, например "21", представляет макроопределение. С использованием макроса, описание текстовых разделов, включая сопутствующие управляющие последовательности, может быть введено несколько раз в любом месте контентного раздела с помощью простой ссылки. Например, с помощью макроса можно описать характеристики речи, которая в дополнение к элементам текста будет сопровождаться видеорядом. Раздел данных имеет формат, в котором в исходном положении идентификатор макроса (от 0 до 255), состоящий из одного байта, устанавливает последующие макроопределения. Далее следует макроопределение из n байтов. Текст (включая управляющие последовательности), который должен подставляться каждый раз, когда упоминается идентификатор этого макроса, входит в состав макроопределения в количестве n байтов. Следует обратить внимание на то, что макросы не обязательно должны использоваться для существенной информации, поскольку приемные устройства могут ее проигнорировать. Еще один указатель типа данных, "22", может служить, например, ссылкой на макрос. Макроопределение, ассоциированное с его идентификатором, подставляется в этой позиции управляющей последовательности для отображения пользователю. Участок данных включает в себя 1-байтовый идентификатор макрокоманды (от 0 до 255), дающий ссылку на макроопределение. Макросы, как правило, обрабатываются макропроцессором 103 на фиг.7.
В состав другой группы типов данных могут входить функции голосовой поддержки. Например, указатель типа данных "А0" определяет стандартный или предварительно установленный язык. Здесь описывается или снабжается ссылкой предварительно установленный язык объекта NML. Участок данных, то есть полезная нагрузка на фиг.3с, содержит языковой код ISO из 3 строчных букв.
Другой тип данных речевой поддержки, обозначенный, например, "А1", составляет языковой раздел. Этот тип данных определяет язык обозначенного отрезка текста или указанной части NML-объекта. Раздел полезной нагрузки имеет следующий формат. Длина текста обозначена одним байтом, величина которого равна величине ряда единиц данных этой длины текста -1, представленной в виде целого числа без знака. Этим устанавливается количество видимых текстовых знаков, для которых задается язык, следующих за этим разделом данных. Затем следует группа из 3 байтов, задающая язык, содержащая языковой код ISO из 3 строчных букв.
Другой тип языковой поддержки индексируется, например, указателем типа данных "А2". Этот тип относится к речевым фонемам и дает описание фонем отрезка текста с использованием международного фонетического алфавита (IPA). Формат раздела полезной нагрузки сначала содержит обозначение длины текста, состоящее из одного байта, значением которого является целое число. Этот байт определяет количество видимых текстовых знаков, которые должны быть описаны фонетически, следующих за этим разделом данных. Затем следует группа из n байтов, содержащая фонемы IPA. Эта группа содержит описание фонем в виде системы обозначений IPA.
Еще один вид данных речевой поддержки, обозначенный, например, указателем типа данных "A3", содержит команду прерывания речи, подаваемую тексто-речевому процессору в позиции управляющей последовательности. Раздел данных содержит 1 байт в виде целого числа без знака, который устанавливает величину речевого периода в 0,1 секунды.
Другой тип речевой поддержки, который может, например, иметь указатель типа данных "А4", определяет символы и, в частности, количество видимых текстовых знаков, следующих после управляющей последовательности, которые должны восприниматься тексто-речевым процессором как единичные символы или цифры, вместо слитных слов или непрерывных чисел. Раздел полезной нагрузки составляет 1 байт, определяющий количество видимых текстовых знаков в виде целого числа без знака, имеющего соответствующее значение.
Следует указать на то, что все упомянутые типы данных, в зависимости от максимального числа, которое может быть отображено кодом длины, могут быть введены в первую очередь единиц данных 32 на фиг.3а или, если количества единиц данных не достаточно для записи всех данных, они могут быть внесены в последующие очереди единиц данных, каждая из которых может начинаться управляющей последовательностью продолжения перехода. Из этого следует, что не обязательно все типы данных, проиндексированные указателем типа данных, должны иметь элементы данных как после управляющей последовательности начала перехода, так и после управляющей последовательности продолжения перехода. Вместо этого короткие типы данных могут содержать лишь данные, не требующие продолжения, поскольку ряд элементов этих данных меньше максимального ряда единиц данных, который может быть обозначен кодом длины 31b.
В зависимости от обстоятельств каждый изобретенный метод может быть осуществлен как в форме аппаратных средств, так и в виде программного обеспечения. Метод может быть реализован на цифровом накопителе данных, в частности на диске или CD с электронно считываемыми управляющими сигналами, совместимыми и поддерживаемыми программируемой компьютерной системой. В силу этого изобретение в целом включает в себя также компьютерный программный продукт с кодом программы, хранящимся на машиночитаемом носителе, благодаря чему изобретенный метод может быть осуществлен путем выполнения программы на компьютере. Иными словами, изобретение может быть реализовано в виде программы для компьютера, имеющей код программы, позволяющий осуществлять метод путем выполнения программы на компьютере.
Реализация аппарата для генерирования потока данных включает в себя последовательный поток данных и устройство ввода 10 в поток данных управляющей последовательности начала перехода 31 после или перед текстовыми данными 30 и управляющей последовательности продолжения перехода 33 после первой очереди 32 элементов данных.
В предпочтительном варианте осуществления аппарата для генерирования устройство ввода 10 вводит в поток данных сначала текстовые данные 30, затем - управляющую последовательность начала перехода 31, затем - первую очередь элементов данных, затем -управляющую последовательность продолжения перехода 33 и затем - вторую очередь элементов данных 34.
В предпочтительный вариант осуществления аппарата для генерирования код длины 31b вводится в поток данных непосредственно после управляющего кода начала перехода 31а, или код длины 33b вводится в поток данных непосредственно после управляющего кода продолжения 33а.
В предпочтительном варианте осуществления аппарата для генерирования код длины 33b, введенный в поток данных после управляющего кода продолжения 33а, и код длины 31b, введенный в поток данных после управляющего кода начала перехода 31а, взяты из одной таблицы кодирования длины.
В предпочтительном варианте осуществления аппарата для генерирования все единицы данных в потоке данных равны, и каждая содержит заданное число битов.
В предпочтительном варианте осуществления аппарата для генерирования заданное число битов в единице данных равняется 8, что составляет 1 байт.
В предпочтительном варианте осуществления аппарата для генерирования поток данных должен быть читаем первым типом базовых приемных устройств и вторым типом приемных устройств с расширенными функциями, при этом устройство ввода 10 должно быть реализовано таким образом, чтобы использовать коды текстовых данных, распознаваемые базовыми приемными устройствами и приемными устройствами с расширенными функциями.
В предпочтительном варианте осуществления аппарата для генерирования управляющий код начала перехода 31а имеет одинаковую длину с управляющим кодом продолжения 33а, входящего в состав управляющей последовательности продолжения перехода 33, причем эта длина равна длине одной единицы данных.
В предпочтительном варианте осуществления аппарата для генерирования код длины используется для кодирования длины контента от 1 до 256 байтов.
В предпочтительном варианте осуществления аппарата для генерирования указатель типа данных 90 не предназначен для считывания базовым декодером, но предназначен для считывания декодером с расширенными функциями.
В предпочтительном варианте осуществления аппарата для генерирования устройство ввода 10 предназначено для ввода после указателя типа данных 90 данных обозначенного в этом указателе типа.
В предпочтительном варианте осуществления аппарата для генерирования устройство ввода 10 предназначено для ввода в поток данных указателя типа данных 90 в первой очереди единиц данных 32 непосредственно после кода длины 31b. входящего в состав управляющей последовательности начала перехода 31.
В предпочтительном варианте осуществления устройство считывания сохраняет поток данных в буфер, и микропроцессор 71 удаляет первый ряд элементов данных 32 и второй ряд элементов данных 34 из буфера, и непрерывно считывает содержимое буфера, или управляет буфером таким образом, что область буфера, где хранятся первый ряд элементов данных 32 и второй ряд элементов данных 34, при чтении буфера пропускаются.
В предпочтительном варианте осуществления устройства считывания первый ряд элементов данных 32 включает в себя указатель типа данных 90, обозначающий тип данных, которые содержатся в первом ряде элементов данных 32 и во втором ряде элементов данных 34, а процессор 71 распознает указатель типа данных 90 и обрабатывает первый 32 и второй 34 ряды элементов данных вместе, исходя из определения указателя типа данных 90.
В предпочтительном варианте осуществления адресатом устройства считывания являются объект в потоке данных, содержащий текстовые данные, мультиплексный канал цифрового радиовещания DAB/DRM, информационная служба или сервисный элемент, адрес в Интернете, документ в Интернете или номер телефона.
В предпочтительном варианте осуществления устройства считывания при распознавании не подлежащего считыванию адресата микропроцессор 71 игнорирует первый ряд элементов данных 32 или второй ряд элементов данных 34.
В предпочтительном варианте осуществления устройства считывания первый ряд элементов данных 32, второй ряд элементов данных 34 или последующие элементы данных содержат указатель типа данных 90, включающий в себя параметры поддержки речи для речевого процессора 73, которые определяют язык текстового раздела, содержат речевые фонемы, обозначают паузы речи или содержат речевые символы, при этом процессор 71 выводит параметры поддержки речи и пересылает их речевому процессору для синтезирования или управления речевым выходом.
В предпочтительном варианте осуществления поток данных сохраняется на читаемом компьютером носителе.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНЦЕПЦИЯ ПЕРЕДАЧИ ПОТОКА УСТРОЙСТВА ДОСТУПА | 2010 |
|
RU2574852C2 |
| АУТЕНТИФИКАЦИЯ ПОТОКОВ ДАННЫХ | 2010 |
|
RU2509424C2 |
| ОБРАБОТКА ДАННЫХ С ИСПОЛЬЗОВАНИЕМ НЕСКОЛЬКИХ НАБОРОВ КОМАНД | 2002 |
|
RU2281547C2 |
| ПРОЦЕССОР ПЕРЕДАТЧИКА ЗВУКОВЫХ СИГНАЛОВ, ПРОЦЕССОР ПРИЕМНИКА ЗВУКОВЫХ СИГНАЛОВ И СВЯЗАННЫЕ С НИМИ СПОСОБЫ И НОСИТЕЛИ ДАННЫХ | 2020 |
|
RU2782730C1 |
| ЗАПИСЬ ПОТОКА МУЛЬТИМЕДИЙНЫХ ДАННЫХ В ТРЕК УКАЗАНИЙ О ПРИЕМЕ КОНТЕЙНЕРНОГО МЕДИАФАЙЛА | 2008 |
|
RU2434277C2 |
| ПРИНЦИП КОДИРОВАНИЯ, ДЕЛАЮЩИЙ ВОЗМОЖНОЙ ПАРАЛЛЕЛЬНУЮ ОБРАБОТКУ, ТРАНСПОРТНЫЙ ДЕМУЛЬТИПЛЕКСОР И БИТОВЫЙ ПОТОК ВИДЕО | 2022 |
|
RU2808541C1 |
| СПОСОБ ГРУППОВОГО КОДИРОВАНИЯ ПОТОКА РАСТРОВЫХ ДАННЫХ | 2004 |
|
RU2350035C2 |
| СТРУКТУРА ДЕКОДЕРА ДЛЯ ОПТИМИЗИРОВАННОГО УПРАВЛЕНИЯ ОБРАБОТКОЙ ОШИБОК В ПОТОКОВОЙ ПЕРЕДАЧЕ МУЛЬТИМЕДИЙНЫХ ДАННЫХ | 2006 |
|
RU2374787C2 |
| СПОСОБ УПРАВЛЕНИЯ ДАННЫМИ В СФОРМИРОВАННОМ КОМПЬЮТЕРНОМ ДОКУМЕНТЕ И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ С ЗАПИСАННОЙ НА НЕМ ПРОГРАММОЙ | 2007 |
|
RU2379748C2 |
| КОНЦЕПЦИЯ ПОТОКА ВИДЕОДАННЫХ | 2013 |
|
RU2720534C2 |
Изобретение относится к области передачи данных, в частности к пересылке упрощенной информации, содержащей текст, рассчитанной на приемники простой конструкции, и к передаче информации, содержащей текст и иные данные, предназначенной для принимающих устройств с расширенными функциями, причем приемники обоих типов предусматривают считывание потока данных. Техническим результатом является обеспечение универсальности процесса передачи и обработки данных, дополняющих текстовую информацию. Способ содержит: ввод текстовых данных в поток данных; ввод в поток данных управляющей последовательности начала перехода, ввод в поток данных первого порядка элементов данных, ввод в поток данных управляющей последовательности продолжения перехода и ввод в поток данных второго порядка элементов данных. 8 н. и 7 з.п. ф-лы, 12 ил.
1. Аппарат генерирования потока данных, включающий в себя устройство ввода (10), предназначенное для ввода в поток данных текстовых данных (30), ввода в поток данных управляющей последовательности начала перехода (31), причем управляющая последовательность начала перехода определяет первый порядок элементов данных, который должен быть пропущен базовым декодером и считан декодером с расширенными функциями, ввода в поток данных первого порядка элементов данных (32), ввода в поток данных управляющей последовательности продолжения перехода (33), причем управляющая последовательность продолжения перехода определяет второй порядок элементов данных, который должен быть пропущен базовым декодером и считан декодером с расширенными функциями вместе с первым порядком элементов данных, и для ввода в поток данных второго порядка элементов данных (34).
2. Аппарат по п.1, в котором управляющая последовательность начала перехода (31) содержит управляющий код начала перехода (31а) и код длины (31b), или в котором управляющая последовательность продолжения перехода (33) содержит управляющий код продолжения (33а) и код длины (33b), причем управляющий код начала перехода (31а) или управляющий код продолжения перехода (33а) отличаются от кодов текста.
3. Аппарат по п.1, в котором устройство (10) предназначено для ввода в поток данных согласованного с управляющей последовательностью начала перехода (31) указателя типа данных (90), который определяет тип данных первого (32) и второго (34) порядка элементов данных в потоке данных.
4. Устройство распознавания текстовых данных (30), содержащихся в потоке данных, управляющей последовательности начала перехода (31), которая определяет первый порядок элементов данных (32), первого порядка элементов данных (32), управляющей последовательности продолжения перехода (33), которая определяет второй порядок элементов данных, и второго порядка элементов данных (34), состоящее из устройства отображения (72) текстовых данных (30) и процессора (71), распознающего управляющую последовательность начала перехода (31) таким образом, что обозначенный в ней первый порядок элементов данных (32) игнорируется, и распознающего управляющую последовательность продолжения перехода (33) таким образом, что обозначенный в ней второй порядок элементов данных (34) игнорируется.
5. Устройство распознавания текстовых данных (30), содержащихся в потоке данных, управляющей последовательности начала перехода (31), которая определяет первый порядок элементов данных (32), первого порядка элементов данных (32), управляющей последовательности продолжения перехода (33), которая определяет второй порядок элементов данных, и второго порядка элементов данных (34), состоящее из устройства отображения (72) текстовых данных (30); процессора (71), распознающего управляющую последовательность начала перехода (31) таким образом, что считывается первый порядок элементов данных (32), распознающего управляющую последовательность продолжения перехода (33) таким образом, что считывается второй порядок элементов данных (34), и обрабатывающий совокупно (73) первый порядок элементов данных (32) и второй порядок элементов данных (34) дополнительно или вместо отображения текстовых данных (30).
6. Устройство по п.5, где первый порядок элементов данных (32) и второй порядок элементов данных (34) определяет адресат контакта и где процессор (71) выполняет соединение с этим адресатом.
7. Устройство по п.5, где первый порядок элементов данных (32), или второй порядок элементов данных (34), или любой последующий порядок элементов данных устанавливает для объекта величину абсолютного или относительного периода ожидания и где процессор (71) путем сопоставления времени ожидания и процессорного времени контролирует время ожидания (100) так, чтобы отображение текстовой информации и расширенного мультимедийного контента не выходило за рамки времени ожидания, установленного по процессорному времени.
8. Устройство по п.5, где первый порядок элементов данных (32) и второй порядок элементов данных (34) или любые последующие элементы данных задают текстовые знаки, которые должны распознаваться как ключевые слова, и где процессор (71) содержит устройство формирования поискового запроса (102) к базе данных аппарата с целью выполнения декодирования по ключевому слову.
9. Устройство по п.5, где первый порядок элементов данных (32), или второй порядок элементов данных (34), или любые последующие элементы данных содержат макросы и где процессор (71) осуществляет функции макропроцессора (103), выполняя команды макроопределений.
10. Устройство по п.5, где первый порядок элементов данных (32), второй порядок элементов данных (34) или любой последующий порядок элементов данных содержит указатель типа данных (90), который представляет описание речи, при этом процессор (71) содержит речевой процессор (73, 104), управляемый элементами данных для настройки выходных параметров речи.
11. Способ генерирования потока данных, включающий в себя ввод текстовых данных (30) в поток данных; ввод в поток данных управляющей последовательности начала перехода (31), при этом управляющая последовательность начала перехода определяет первый порядок элементов данных, которые должны быть пропущены базовым декодером и считаны декодером с расширенными функциями, ввод в поток данных первого порядка элементов данных (32), ввод в поток данных управляющей последовательности продолжения перехода (33), при этом управляющая последовательность продолжения перехода определяет второй порядок элементов данных, которые должны быть пропущены базовым декодером и считаны декодером с расширенными функциями вместе с первым порядком элементов данных; и ввод в поток данных второго порядка элементов данных (34).
12. Способ чтения потока данных с распознаванием текстовой информации (30), управляющей последовательности начала перехода (31), которая определяет первый порядок элементов данных (32), первого порядка элементов данных (32), управляющей последовательности продолжения перехода (33), которая определяет второй порядок элементов данных, и второго порядка элементов данных (34), включающий в себя отображение (72) текстовой информации (30); распознавание управляющей последовательности начала перехода (31) таким образом, что первый порядок элементов данных определяется этой управляющей последовательностью; пропуск первого порядка элементов данных после распознавания управляющей последовательности начала перехода; распознавание управляющей последовательности продолжения перехода (33) таким образом, что второй порядок элементов данных (34) определяется этой управляющей последовательностью, пропуск второго порядка элементов данных (34) после распознавания управляющей последовательности продолжения перехода.
13. Способ чтения потока данных с распознаванием текстовой информации (30), управляющей последовательности начала перехода (31), которая определяет первый порядок элементов данных (32), первого порядка элементов данных (32), управляющей последовательности продолжения перехода (33), которая определяет второй порядок элементов данных, и второго порядка элементов данных (34), включающий в себя распознавание управляющей последовательности начала перехода (31) с определением первого порядка элементов данных (32), считывание первого порядка элементов данных после распознавания управляющей последовательности начала перехода; распознавание управляющей последовательности продолжения перехода (33) с определением второго порядка элементов данных (34); считывание второго порядка элементов данных после распознавания управляющей последовательности продолжения перехода и совместная обработка (73) первого (32) и второго (34) порядков элементов данных в дополнение к или вместо текстовых данных (30).
14. Машиночитаемый носитель информации с записанным кодом программы, обеспечивающий при выполнении на компьютере осуществление метода по пп.11, или 12, или 13 формулы изобретения.
15. Машиночитаемый носитель информации, с сохраненным на нем потоком данных, содержащим текстовую информацию (30), управляющую последовательность начала перехода (31), которая определяет первый порядок элементов данных (32), первый порядок элементов данных (32), управляющую последовательность продолжения перехода (33), которая определяет второй порядок элементов данных, и второй порядок элементов данных (34).
| RU 2005110957 А, 10.09.2005 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| RU 2005141133 А, 10.05.2006 | |||
| US 2003039193 A1, 27.02.2003. | |||

