ПРИТЯЗАНИЕ НА ПРИОРИТЕТ ПО ЗАКОНУ 35 В СВОДЕ
ЗАКОНОВ США, §119
Настоящая Заявка на патент притязает на приоритет предварительной заявки № 61/041.212, озаглавленной «Storing LLRs in Interleaved Form to Reduce Hardware Memory», поданной 31 марта 2008 года и переуступленной правопреемнику по настоящей заявке.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится, в основном, к устройству и способам декодирования в системе беспроводной связи. В частности, настоящее изобретение относится к хранению информации о логарифмических отношениях правдоподобия в перемеженном виде.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Системы беспроводной связи широко применяются для передачи различных видов коммуникационного контента, такого как голос, данные и т.д. Это могут быть системы с многостанционным доступом, способные обеспечивать связь с множеством пользователей путем коллективного использования доступных системных ресурсов (например, полосы пропускания и мощности передатчика). К примерам таких систем с многостанционным доступом относятся системы Многостанционного доступа с кодовым разделением каналов (CDMA), системы Многостанционного доступа с временным разделением каналов (TDMA), системы Многостанционного доступа с частотным разделением каналов (FDMA), системы 3GPP LTE и системы Множественного доступа с ортогональным частотным разделением (OFDMA).
Как правило, беспроводная система многостанционного доступа может одновременно обеспечивать связь для множества беспроводных терминалов. Каждый терминал осуществляет связь с одной или более базовыми станциями путем передач по прямой и обратной линиям связи. Прямая линия связи (или нисходящая линия связи) относится к линии связи от базовых станций к терминалам (например, к мобильной станции), а обратная линия связи (или восходящая линия связи) относится к линии связи от терминалов к базовым станциям. Такая линия связи может быть установлена через систему одним входом/одним выходом (SISO), множеством входов/одним выходом (MISO) или множеством входов/множеством выходов (MIMO).
В системе MIMO для передачи данных используется множество (N T) передающих антенн и множество (N R) приемных антенн. Канал MIMO, образуемый N T передающими и N R приемными антеннами, может быть разделен на N S независимых каналов, которые называются также пространственными каналами, где N S ≤ min {N T, N R}. Каждый из N S независимых каналов соответствует некоторому измерению. При использовании дополнительного числа измерений, создаваемых множеством передающих и приемных антенн, система MIMO может обеспечить улучшенные характеристики (например, более высокую пропускную способность и/или более высокую надежность). Например, система MIMO может поддерживать системы Дуплексной связи с временным разделением (TDD) и Дуплексной связи с частотным разделением (FDD). В системе TDD передачи по прямой и обратной линиям связи осуществляются в одной и той же области частот, вследствие чего принцип взаимности позволяет установить отличие прямой линии связи от обратной. Это позволяет точке доступа получить усиление при формировании диаграммы направленности по прямой линии связи, когда в точке доступа имеется множество антенн.
Системы беспроводной связи подвержены различным нарушениям канала и мешающим шумам, вносимым на некотором участке беспроводной линии связи. Такие искажения приводят к ошибкам в данных, обрабатываемых приемником. В целом, имеются две основные категории защиты от ошибок, применимые к системам беспроводной связи: обнаружение ошибок и исправление ошибок. Методы обнаружения ошибок, такие как автоматический запрос на повторение (ARQ), с целью обнаружения ошибок обычно добавляют множество избыточных битов к передаваемому информационному кадру. При обнаружении ошибки приемник, как правило, отправляет назад передатчику сообщение об обнаружении ошибки для запроса на повторную передачу того же передаваемого информационного кадра. Методы исправления ошибок, такие как прямое исправление ошибок (FEC), напротив, с целью исправления ошибок, как правило, структурированным образом добавляют больше избыточных битов к передаваемому информационному кадру. Исправление ошибок позволяет приемнику как обнаруживать, так и исправлять принятые ошибки без обратной связи и повторной передачи. В зависимости от характеристик ошибок канала и пропускной способности в сопоставлении с требованиями к времени запаздывания предпочтение может быть отдано обнаружению ошибок либо исправлению ошибок.
В опубликованных заявках на патент Соединенных Штатов US 2007/011593 A1 и US 2006/133533 A1 описаны примеры существующей конструкции приемника, формирующего последовательность значений логарифмического отношения правдоподобия (LLR) путем демодуляции принятого сигнала, сформированного путем модуляции последовательности перемеженных кодированных битов. Значения LLR сохраняются в памяти, а затем подвергаются обращенному перемежению и декодированию.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В примерах осуществления настоящего изобретения технические проблемы, связанные с вышеупомянутой существующей конструкцией приемника, решаются за счет обеспечения сокращения сложностей, связанных с хранением значений LLR. Принятую передачу множества перемеженных кодовых слов обрабатывают. В данной передаче не хватает по меньшей мере одного бита кодового слова по меньшей мере одного из кодовых слов. Получают значения LLR для упомянутого множества перемеженных кодовых слов. Эти значения LLR сохраняются в памяти без сохранения дополнения нулями для упомянутого по меньшей мере одного бита кодового слова. Упомянутые перемеженные кодовые слова подвергаются обращенному перемежению после того, как значения LLR сохранены в памяти. Обращенное перемежение обеспечивает дополнение нулями для упомянутого по меньшей мере одного бита кодового слова.
Следует понимать, что другие аспекты будут ясны специалистам из нижеследующего подробного описания, в котором в качестве примеров показаны и описаны различные варианты осуществления. Чертежи и подробное описание следует рассматривать как имеющие иллюстративный характер, а не ограничительный.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 - блок схема, иллюстрирующая пример беспроводной системы связи множественного доступа.
Фиг.2 - блок схема, иллюстрирующая пример беспроводной системы связи MIMO.
Фиг.3 - блок схема, иллюстрирующая пример процессора передаваемых данных для кодирования с гибридным автоматическим запросом на повторную передачу данных (HARQ).
Фиг.4 - блок схема, иллюстрирующая более детальный пример процессора передаваемых данных для кодирования HARQ.
На Фиг.5 приведен пример гибридной операции ARQ.
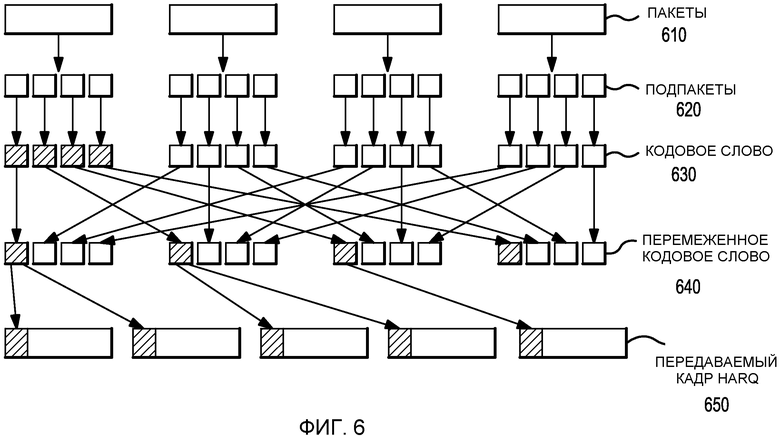
На Фиг.6 приведен пример схемы передачи в соответствии с настоящим изобретением.
На Фиг.7 приведен пример алгоритмической диаграммы сохранения значений логарифмического отношения правдоподобия (LLR) в перемеженном виде.
На Фиг.8 приведен пример устройства, содержащего процессор, осуществляющий связь с памятью для реализации процессов для сохранения значений логарифмического отношения правдоподобия (LLR) в перемеженном виде.
На Фиг.9 приведен пример устройства, подходящего для сохранения значений логарифмического отношения правдоподобия (LLR) в перемеженном виде.
ПОДРОБНОЕ ОПИСАНИЕ
Изложенное ниже подробное описание применительно к прилагаемым чертежам предполагает описание различных аспектов настоящего изобретения и не предполагает изложения только тех аспектов, в соответствии с которыми настоящее изобретение может быть практически осуществлено. Каждый аспект, описанный в настоящем изобретении, изложен лишь в качестве примера или иллюстрации настоящего изобретения и не должен рассматриваться как предпочтительный или выгодный по сравнению с другими аспектами осуществления. Подробное описание включает в себя конкретные детали с целью обеспечения глубокого понимания настоящего изобретения. Однако специалистам будет ясно, что настоящее изобретение может быть практически осуществлено без этих конкретных деталей. В ряде примеров хорошо известные структуры и устройства показаны в виде блок-схем, чтобы избежать затруднения понимания принципов настоящего изобретения. Аббревиатуры и прочая описательная терминология могут использоваться лишь для удобства и ясности и не ограничивают объем настоящего изобретения.
Несмотря на то, что для простоты объяснения методики показаны и описаны в виде последовательностей действий, следует понимать, что данные методики не ограничиваются порядком выполнения действий, поскольку ряд действий, в соответствии с одним или более аспектами, может выполняться в другом порядке и/или одновременно с другими действиями, показанными и описанными в настоящем изобретении. Например, специалистам будет ясно, что методика альтернативно может быть изложена в виде последовательности взаимосвязанных состояний или событий, например, на диаграмме состояний. Кроме того, не все изображенные действия могут потребоваться для осуществления методики в соответствии с одним или более аспектами.
Описанные здесь методики могут использоваться в различных системах беспроводной связи, таких как системы Многостанционного доступа с кодовым разделением каналов (CDMA), системы Многостанционного доступа с временным разделением каналов (TDMA), системы Многостанционного доступа с частотным разделением каналов (FDMA), системы Множественного доступа с ортогональным частотным разделением каналов (OFDMA), системы FDMA с передачей на одной несущей (SC-FDMA) и т.д. Термины «системы» и «сети» часто используются на равных основаниях. В системе CDMA может быть реализована технология радиосвязи, такая как универсальный Наземный Радио доступ (UTRA), cdma2000 и др. UTRA включает в себя Широкополосный CDMA (W-CDMA) и Низкую частоту следования элементарных посылок (LCR). Cdma2000 распространяется на стандарты IS-2000, IS-95 и IS-856. В системе TDMA может быть реализована технология радиосвязи, такая как Глобальная система мобильной связи (GSM). В системе OFDMA может быть реализована технология радиосвязи, такая как Развитой UTRA (E-UTRA), IEEE 802.11, IEEE 802.16, IEEE 802.20, Flash-OFDM® и др. UTRA, E-UTRA и GSM входят в Универсальную систему мобильной связи (UMTS). Долгосрочное развитие (LTE) - это перспективный вариант UMTS, в котором используется E-UTRA. UTRA, E-UTRA, GSM, UMTS и LTE описаны в документах от организации, называющейся «Проект партнерства третьего поколения» (3GPP). Система cdma2000 описана в документах от организации, называющейся «Проект партнерства третьего поколения 2» (3GPP2). Указанные различные технологии и стандарты радиосвязи известны.
Кроме того, еще одним методом беспроводной связи является Многостанционный доступ с частотным разделением каналов и передачей на одной несущей (SC-FDMA), в котором используются модуляция на одной несущей и коррекция в частотной области. Система SC-FDMA может иметь те же характеристики и общую сложность, что и система OFDMA. Сигнал SC-FDMA имеет более низкое отношение пиковой и средней мощностей (PAPR) из-за присущей ему структуры с одной несущей. SC-FDMA привлекает к себе огромное внимание, особенно в восходящей линии связи, для которой более низкая величина PAPR дает значительные преимущества мобильному терминалу с точки зрения эффективности в плане передаваемой мощности. Использование метода SC-FDMA - это в настоящее время рабочая гипотеза для схемы множественного доступа в восходящей линии связи в Долгосрочном развитии (LTE) 3GPP или в системе Развитой UTRA. Все рассмотренные выше методы и стандарты связи могут использоваться описанными здесь информационно-ориентированными алгоритмами мультиплексирования.
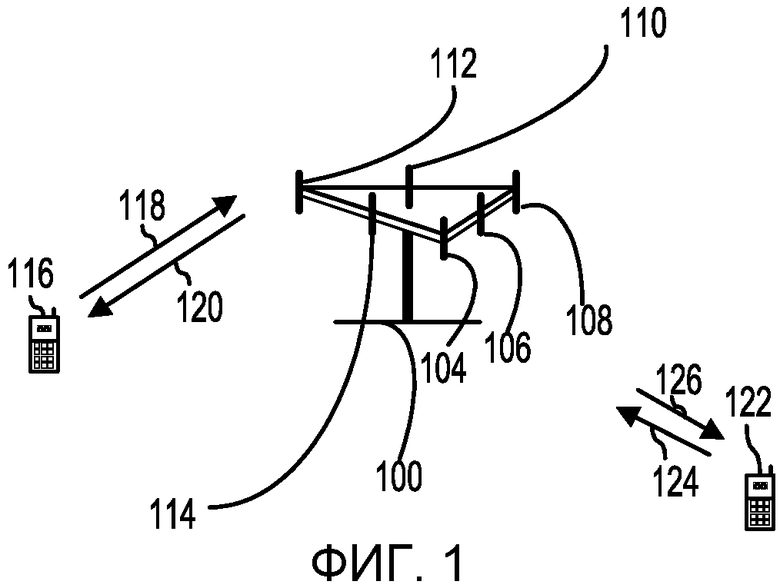
Фиг.1 - это блок-схема, иллюстрирующая пример беспроводной системы связи множественного доступа. Как показано на Фиг.1, точка доступа 100 (АР) содержит множество групп антенн, при этом одна из них содержит 104 и 106, другая содержит 108 и 110, а дополнительная содержит 112 и 114. На Фиг.1 для каждой группы антенн показаны только две антенны, однако в каждой группе антенн может использоваться большее или меньшее число антенн. Терминал доступа 116 (АТ) осуществляет связь с антеннами 112 и 114, причем антенны 112 и 114 передают информацию на терминал доступа 116 по прямой линии связи 120 и принимают информацию с терминала доступа 116 по обратной линии связи 118. Терминал доступа 122 осуществляет связь с антеннами 106 и 108, причем антенны 106 и 108 передают информацию на терминал доступа 122 по прямой линии связи 126 и принимают информацию с терминала доступа 122 по обратной линии связи 124. В системе FDD каналы связи 118, 120, 124 и 126 могут использовать для связи другую частоту. Например, прямая линия связи 120 может использовать частоту, отличающуюся от используемой обратной линией связи 118. Каждая группа антенн и/или зона, в которой с помощью них предполагается осуществлять связь, часто называется сектором точки доступа. В одном из примеров каждая из групп антенн предназначена для связи с терминалами доступа в секторе зоны, обслуживаемой точкой доступа 100.
При осуществлении связи по прямым линиям связи 120 и 126 передающие антенны точки доступа 100 используют формирование диаграммы направленности с целью улучшения отношения сигнал-шум прямых линий связи для различных терминалов доступа 116 и 124. Кроме того, точка доступа, использующая формирование диаграммы направленности для осуществления передачи на терминалы доступа, беспорядочно разбросанные по ее зоне обслуживания, создает меньше помех для терминалов доступа в соседних сотах, чем точка доступа, осуществляющая передачу на все свои терминалы доступа через единственную антенну. Точкой доступа может быть стационарная станция. Точка доступа может также называться узлом доступа, базовой станцией, узлом В или каким-либо иным подобным известным термином. Терминал доступа может также называться мобильной станцией, абонентской аппаратурой, устройством беспроводной связи или каким-либо иным подобным известным термином.
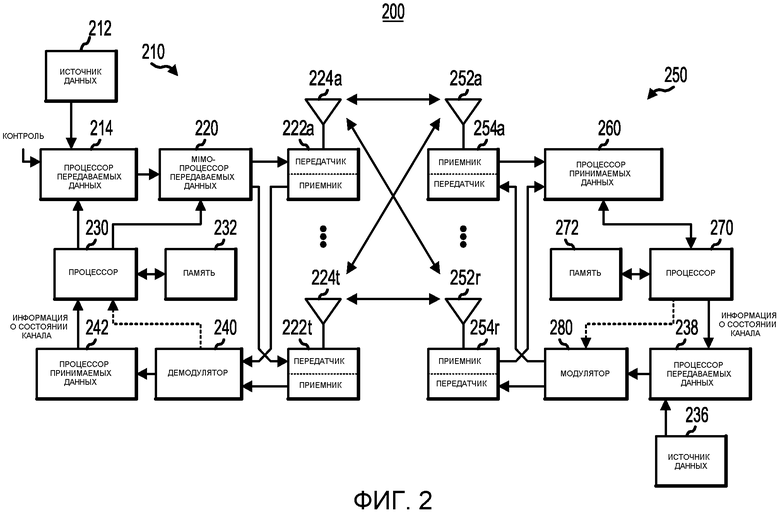
Фиг.2 - это блок-схема, иллюстрирующая пример системы беспроводной связи MIMO. На Фиг.2 изображена передающая система 210 (известная также как точка доступа) и приемная система 250 (известная также как терминал доступа) в системе MIMO 200. В передающей системе 210 данные трафика по ряду информационных потоков передаются с источника данных 212 на процессор передаваемых данных 214. В одном из примеров каждый информационный поток передается через соответствующую передающую антенну. Процессор передаваемых данных 214 осуществляет форматирование, кодирование и перемежение данных трафика для каждого информационного потока на основе специальной схемы кодирования, выбранной для этого информационного потока для обеспечения кодированной информации.
Кодированная информация по каждому информационному потоку может быть мультиплексирована с контрольной информацией с использованием методов OFDM. Контрольная информация - это, как правило, известная комбинация данных, которая обрабатывается известным способом и может использоваться в приемной системе для оценки характеристики канала. Затем мультиплексированная контрольная и кодированная информация по каждому информационному потоку модулируется (т.е. отображается на символы) на основе конкретного способа модуляции (например, двухпозиционной фазовой манипуляции (BPSK), квадратурной фазовой манипуляции (QPSK), многократной фазовой манипуляции (M-PSK) или многоуровневой квадратурной амплитудной модуляции (M-QAM)), выбираемого для этого информационного потока с целью обеспечения символов модуляции. Скорость передачи, кодирование и модуляция данных для каждого информационного потока могут определяться командами, исполняемыми процессором 230.
Затем символы модуляции по всем информационным потокам передаются на MIMO-процессор 220 передаваемых данных, который может далее обрабатывать символы модуляции (например, для OFDM). Затем MIMO-процессор 220 передаваемых данных передает N T потоков символов модуляции на N T передатчиков 222а-222t. В одном из примеров, MIMO-процессор 220 передаваемых данных применяет весовые коэффициенты формирования диаграммы направленности к символам информационных потоков и к антенне, с которой осуществляется передача символа. Каждый из передатчиков 222а-222t принимает и обрабатывает соответствующий поток символов для передачи одного или более аналоговых сигналов, а затем нормирует (например, усиливает, фильтрует и преобразует с повышением частоты) эти аналоговые сигналы для получения модулированного сигнала, подходящего для передачи по каналу MIMO. Затем N T модулированных сигналов с передатчиков 222а-222t передаются с N T антенн 224а-224t соответственно.
В приемной системе 250 переданные модулированные сигналы принимаются N R антеннами 252а-252r, а принятый сигнал с каждой из антенн 252а-252r передается на соответствующий приемник 254а-254r. Каждый из приемников 254а-254r приводит к требуемому виду (например, фильтрует, усиливает и преобразует с понижением частоты) соответствующий принятый сигнал, оцифровывает приведенный к требуемому виду сигнал для получения выборок, а затем обрабатывает эти выборки для получения соответствующего «принятого» потока символов.
Далее процессор 260 принимаемых данных принимает и обрабатывает N R принятых потоков символов с N R приемников 254а-254r на основе метода обработки конкретного процессора для получения N T «обнаруженных» потоков символов. Затем процессор принимаемых данных 260 осуществляет демодуляцию, обращенное перемежение и декодирование каждого обнаруженного потока символов для восстановления данных трафика для этого информационного потока. Обработка с помощью процессора 260 принимаемых данных является дополняющей обработку, выполняемую MIMO-процессором 220 передаваемых данных и процессором 214 передаваемых данных в передающей системе 210. Процессор 270 периодически определяет, какую матрицу предварительного кодирования использовать (обсуждается ниже). Процессор 270 формирует сообщение обратной линии связи, содержащее блок индекса матрицы и блок значения ранга.
Сообщение обратной линии связи может содержать различного рода информацию о линии связи и/или принятом информационном потоке. Затем сообщение обратной линии связи обрабатывается процессором 238 передаваемых данных, который также принимает данные трафика по ряду информационных потоков с источника данных 236, модулируется модулятором 280, приводится к требуемому виду передатчиками 254а-254r и передается назад в передающую систему 210.
В передающей системе 210 модулированные сигналы с приемной системы 250 принимаются антеннами 224а-224t, приводятся к требуемому виду приемниками 222а-222t, демодулируются демодулятором 240 и обрабатываются процессором 242 принимаемых данных для извлечения сообщения обратной линии связи, переданного приемной системой 250. Затем процессор 230 определяет, какую матрицу предварительного кодирования использовать для определения весовых коэффициентов формирования диаграммы направленности, после чего процессор 230 обрабатывает извлеченное сообщение. Специалисту в данной области техники должно быть ясно, что приемопередатчики 222а-222t называются передатчиками в прямой линии связи и приемниками в обратной линии связи. Аналогичным образом, специалисту в данной области техники должно быть ясно, что приемопередатчики 254а-254r называются приемниками в прямой линии связи и передатчиками в обратной линии связи.
Как указано выше, в зависимости от характеристик ошибок канала и пропускной способности в сопоставлении с требованиями к времени запаздывания системы предпочтение может быть отдано обнаружению ошибок или исправлению ошибок. Гибридный ARQ (HARQ) - это третья категория защиты от ошибок, которая сочетает в себе как особенности обнаружения ошибок, так и особенности исправления ошибок в попытке достичь преимуществ обоих методов. В одном из примеров HARQ, первая передача передаваемого информационного кадра может содержать только биты обнаружения ошибок. Если приемник устанавливает, что информационный кадр принят без ошибок, получение сообщения подтверждается, и повторная передача не требуется. Однако если приемник с использованием битов обнаружения ошибок устанавливает, что информационный кадр принят ошибочно, то сообщение об обнаружении ошибок передается назад на передатчик, который осуществляет вторую передачу передаваемого информационного кадра вместе с дополнительными битами исправления ошибок. Далее, если приемник без использования дополнительных битов обнаружения ошибок устанавливает, что информационный кадр вновь принят ошибочно, еще одно сообщение об обнаружении ошибок передается на передатчик, который осуществляет третью передачу передаваемого информационного кадра вместе с отдельным набором битов исправления ошибок. Как правило, повторные передачи HARQ могут повторяться для одного и того же передаваемого информационного кадра до тех пор, пока он не будет принят без ошибок вплоть до заранее заданного максимального числа повторных передач, в зависимости от того, что наступит раньше.
В одном из примеров в Ультра-мобильной широкополосной (UMB) системе для Канала передачи данных прямой линии связи (FLDCH) входящие пакеты Управления доступом к среде (МАС) сначала делятся на подпакеты, длина которых равна или менее, например, 4 кбит. Затем эти подпакеты поступают в модуль турбо/сверточного кодирования с прямым исправлением ошибок для кодирования, перемежения и повтора. Выходной поток двоичных битов для каждого подпакета, называемый кодовым словом, может быть, например, в 5 раз длиннее, чем подпакет из-за служебных данных прямого исправления ошибок. Затем кодовое слово передается во множестве посылок HARQ с повтором в случае необходимости. Передачи HARQ, как правило, разделены некоторым периодом времени. Например, в HARQ8 кодовое слово передается раз в 8 кадров. Для каждого переданного кадра передаются только отдельные биты всего кодового слова. В существующей конструкции все кодированное кодовое слово сохраняется в памяти. Общая требуемая память будет, по меньшей мере, в 5 раз больше суммы длин всех поступающих пакетов МАС. Например, в прямой линии связи UMB, в предположении наихудших величин (т.е. наивысшего формата пакетов для всех блоков (128)), 4 уровней и глубины перемежения HARQ 8 кадров, существующая конструкция требует около 25 Мбит внутрикристальной памяти.
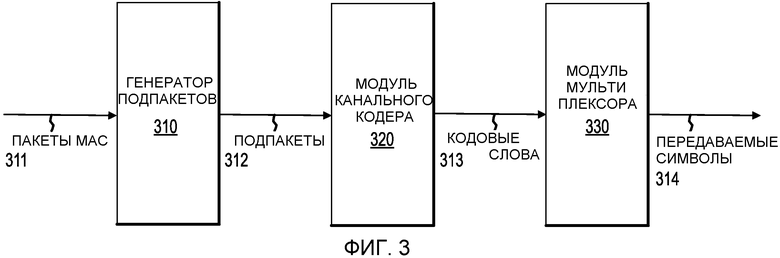
Фиг.3 - это блок схема, иллюстрирующая пример процессора передаваемых данных для кодирования HARQ. Процессор 300 передаваемых данных собирает и зашифровывает пакеты МАС 311. Генератор 310 подпакетов принимает пакеты МАС 311 на своем входе и преобразует их в подпакеты 312, которые имеют длину менее, например, 4 кбит. Модуль 320 канального кодера принимает подпакеты 312 и формирует на выходе кодовые слова 313. Модуль 330 мультиплексора принимает кодовые слова 313 на входе и формирует передаваемые символы 314 с конкретным распределением ресурсов в конкретной передаче HARQ. В одном из вариантов осуществления процессор 300 передаваемых данных создает таблицу перемежения подпакетов и ведет историю HARQ вместе с модулем 330 мультиплексора.
Фиг.4 - это блок схема, иллюстрирующая более детальный пример процессора передаваемых данных для кодирования HARQ. Входное сообщение 401 принимается и разбивается на множество подпакетов разделителем 410 сообщений. В одном варианте осуществления длина каждого подпакета ограничена величиной не более 4096 бит. Затем каждый подпакет передается в модуль вставки 420 циклического избыточного кода (CRC), в котором биты обнаружения ошибок формируются и присоединяются к каждому подпакету. В одном варианте осуществления биты обнаружения ошибок вычисляются в виде 24-битового кода CRC. Далее кодер 430 формирует кодированные подпакеты для исправления ошибок. В одном варианте осуществления кодер 430 является турбо-кодером. В другом варианте осуществления кодер 430 является сверточным кодером. Далее канальный перемежитель 440 перемежает (т.е. перетасовывает) кодированные подпакеты для обеспечения способности к восстановлению после пакетных ошибок. Модуль 450 повтора последовательностей и скремблер 460 данных выполняют дополнительную обработку сигналов по перемеженным кодированным подпакетам. Наконец, средство 470 мультиплексирования и отображения на символы модуляции объединяет скремблированные подпакеты и выдает выходные символы модуляции 471.
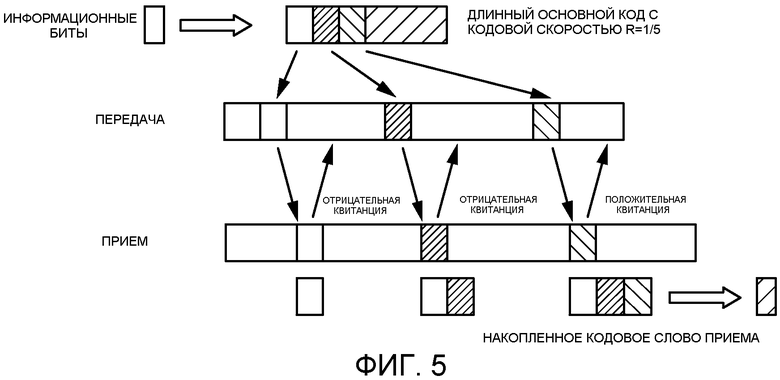
На Фиг.5 приведен пример гибридной операции ARQ. В одном примере кодовое слово состоит из длинного основного кода с кодовой скоростью R=1/5. В одном варианте осуществления передатчик постепенно передает биты четности для обнаружения ошибок и/или исправления ошибок в каждой передаче. В одном примере для UMB может быть отправлено до шести посылок. Повторение используется, когда число переданных битов превышает длину блока основного кодового слова. В одном варианте осуществления модуль канального кодера 320 не запоминает полное основное кодовое слово по всем передачам. Вместо этого модуль канального кодера 320 сохраняет входную информацию модуля канального кодера по всем передачам и запускает модуль канального кодера 320 для каждой передачи, ведя историю действий по всем передачам.
В одном варианте осуществления в присутствии Гибридного ARQ кодовое слово не всегда передается во всей полноте после перемежения. В приемнике отношение правдоподобия (LR) вычисляется по каждому принятому кодовому слову после демодуляции для принятия решений в отношении битов. Отношение правдоподобия (LR) - это отношение величин максимальной вероятности результата для двух различных гипотез. Оно используется в качестве статистического критерия для осуществления выбора одной из двух различных гипотез исходя из этого отношения. В одном примере отношение правдоподобия (LR) вычисляется приемником с мягким принятием решения в виде отношения апостериорной вероятности для бита одного состояния выхода, например, единицы, к апостериорной вероятности для бита другого состояния выхода, например, нуля. Логарифмическое отношение правдоподобия (LLR) определяется как логарифм отношения правдоподобия (LR) и используется для удобства вычислений. Например, умножение и деление при вычислении отношения правдоподобия (LR) преобразуется в суммирование и вычитание при вычислении логарифмического отношения правдоподобия (LLR).
В приемнике значения LLR для еще не переданных битов кодового слова считаются нулевыми. Эти нули дополняют значения LLR, соответствующие переданным битам кодового слова, а затем подвергаются обращенному перемежению. Однако после обращенного перемежения вставленные ранее нули оказываются разбросанными по всему кодовому слову. Кроме того, если перемеженные значения LLR сохраняются в памяти, это потребует обнуления значений LLR для участков, соответствующих еще не переданным битам. При мягком объединении принятые значения LLR должны суммироваться с ранее принятыми значениями LLR. Если кодовое слово хранится в перемеженном виде, это потребует беспорядочного считывания данных, а после мягкого объединения записи случайным образом в аппаратной памяти. Перед обращенным перемежением вставленные нули занимают смежные участки. При запоминании значений LLR перед обращенным перемежением требования к средней аппаратной памяти сохраняются за счет запоминания только уже принятых значений LLR и автоматического предположения о том, что остальные значения являются нулевыми. Кроме того, благодаря этому исключается необходимость в обнулении участков, соответствующих этим значениям LLR. Поскольку значения LLR запоминаются до обращенного перемежения, во время мягкого объединения число считываний из памяти сокращается и адресация памяти упрощается.
В одном аспекте, размер кодового слова находится в широком диапазоне (например, от 128 бит до 20 кбит) и из-за HARQ имеет переменное время существования (например, от 1 физического кадра до 48 физических кадров). Поэтому определение объема памяти LLR для наихудшего случая может оказаться невозможным. Использование связных списков и динамическое распределение памяти позволяет оптимизировать использование памяти. Предположим, что память LLR разбивается на узлы, каждый из которых может быть выделен и освобожден независимо. Такие узлы имеют одинаковый размер, причем их размер является программируемым. Эти узлы изначально располагаются в так называемом связном списке свободных узлов. Каждое кодовое слово связано с уникальным связным списком, в котором узлы выделяются по мере необходимости из связного списка свободных узлов. Такое динамическое распределение позволяет выделять память только по требованию, тем самым, оптимизируя использование памяти. В конце времени существования кодового слова (например, ввиду завершения пользователем или успешного декодирования) узлы, выделенные в связном списке, возвращаются в связной список свободных узлов.
В Ультра-мобильной широкополосной (UMB) системе передача данных осуществляется пакетами на физическом уровне. Каждый пакет потенциально содержит более одного подпакета. Каждый подпакет представляет собой кодовое слово, которое закодировано и перемежено в передатчике и должно быть подвергнуто обращенному перемежению и декодированию в приемнике. Кодовое слово - это последовательность битов длиной n. В приемнике каждый бит из кодированной последовательности соответствует логарифмическому отношению правдоподобия (LLR). В одном примере LLR имеет значение 6 бит. Такие кодовые слова обычно передаются через множество физических кадров (например, для использования гибридного ARQ). Как правило, кодовое слово не передается в своей полноте в любой из этих посылок, и только часть его передается в любой передаче HARQ. Такие значения LLR должны сохраняться в памяти до, например, завершения пользователем или успешного декодирования.
В передатчике кодированное кодовое слово перемежается. Перемеженные фрагменты последовательности передаются в последовательных передачах HARQ. Передается некоторая часть перемеженной последовательности. В соответствии с каждым битом в этой переданной части приемник вычисляет значение LLR. Значение LLR, соответствующее битам, которые еще не были переданы, устанавливается нулевым. В UMB, если кодовое слово передается полностью и имеется возможность передачи, то перемеженное кодовое слово передается повторно с самого начала. Вычисление LLR для этих повторно переданных битов включает в себя считывание значения LLR из памяти, суммирование вычисленного LLR для текущей передачи и запоминание этого значения.
Перед выполнением процесса декодирования эти значения LLR отображаются соответственным образом на переданное кодовое слово. Данная операция фактически обращает операцию перемежения и известна как обращенное перемежение.
Запоминание значений LLR после обращенного перемежения (как это выполняется традиционно) имеет следующие недостатки:
1. Нули, которые вставлены в качестве дополнения к значениям LLR, соответствующим еще не переданным битам кодового слова, разбросаны по всему кодовому слову.
2. Это требует обнуления значений LLR для памяти, выделенной кодовому слову при инициализации.
3. Запись значений LLR в память требует беспорядочной записи, поскольку принятые значения LLR разбросаны по всему кодовому слову.
4. Во время выполнения операции считывания, модификации и записи (RMW) принятые значения LLR должны суммироваться с ранее принятыми значениями LLR. Это требует беспорядочного считывания данных, а, после мягкого объединения беспорядочной записи в запоминающем устройстве.
Запоминание значений LLR перед обращенным перемежением и перенос обращенного перемежителя в декодер позволяют преодолеть вышеупомянутые недостатки по следующим причинам:
1. Вставляемые нули вставляются перед значениями LLR, соответствующими принятым битам, и являются смежными. Поэтому операция дополнения нулями может выполняться в обращенном перемежителе путем прохода по длине принятых значений LLR как параметру. Благодаря запоминанию значений LLR перед перемежением существует экономия средней аппаратной памяти за счет запоминания только уже принятых значений LLR и автоматического предположения о том, что остальные значения являются нулевыми.
2. В результате отсутствует необходимость в обнулении значений LLR при инициализации.
3. В перемеженном кодовом слове значения LLR вычисляются для смежных битов, и поэтому запись осуществляется в непрерывном порядке.
4. Во время выполнения операции считывания, модификации и записи (RMW) число считываний из памяти сокращается и адресация памяти упрощается, поскольку считывание из памяти и запись в памяти осуществляются непрерывно.
В системе UMB размер кодового слова (т.е. длина n) находится в широком диапазоне, например, от 128 бит до 20 кбит, и имеет переменное время существования, например, от 1 физического кадра до 48 физических кадров. Статистическое выделение места для кодового слова в памяти LLR предполагало бы выделение максимального размера для каждого кодового слова на время существования кодового слова, что имеет следующие недостатки:
1. Кодовому слову, меньшему максимального размера, выделяется дополнительное место, которое не используется.
2. Фрагменты кодового слова принимаются во множестве посылок HARQ, а участки памяти, уже выделенные на доли еще не переданных кодовых слов, не используются.
В одном аспекте для устранения вышеупомянутых недостатков используется статистическое мультиплексирование путем динамического распределения памяти по мере необходимости. В сущности, это есть разделение (т.е. не физическое разделение) памяти LLR на узлы. За каждым кодовым словом закрепляется некоторое количество узлов, и значения LLR каждого кодового слова запоминаются в этих узлах. Каждое кодовое слово отслеживает эти узлы через связный список. Эти узлы закрепляются только по мере необходимости, тем самым, устраняя вышеупомянутые недостатки. Узлы могут выделяться и высвобождаться независимо. В одном примере узлы имеют одинаковый размер, а их размер является программируемым. Эти узлы изначально располагаются в связном списке свободных узлов.
Каждое кодовое слово связано с уникальным связным списком, в котором узлы выделяются по мере необходимости из связного списка свободных узлов. Такое динамическое распределение позволяет выделять память только по требованию, тем самым, оптимизируя использование памяти. В конце времени существования кодового слова (например, ввиду завершения пользователем или успешного декодирования) узлы, выделенные в связном списке, возвращаются в связный список свободных узлов.
На Фиг.6 приведен пример схемы передачи в соответствии с настоящим изобретением. Передаваемые пакеты 610 сначала организуются в передатчике. Затем пакеты разбиваются на подпакеты 620. Каждый подпакет отправляется на кодер для формирования кодовых слов 630. Кодовые слова 630 далее отправляются на перемежитель для обеспечения способности к восстановлению после пакетных ошибок и формирования перемеженных кодовых слов 640. Затем перемеженные кодовые слова 640 разбиваются на более мелкие части и отправляются в отдельных передаваемых кадрах HARQ 650. Таким образом, принятые кадры HARQ содержат несмежные части принятых кодовых слов ввиду перемежения и формата передачи HARQ.
На Фиг.7 приведен пример алгоритмической диаграммы сохранения значений логарифмического отношения правдоподобия (LLR) в перемеженном виде. На этапе 710 осуществляется прием множества перемеженных кодовых слов. В одном аспекте после приема перемеженных кодовых слов множество перемеженных кодовых слов демодулируется. В одном примере демодуляция основана на одном из следующего: двухпозиционная фазовая манипуляция (BPSK), квадратурная фазовая манипуляция (QPSK), многократная фазовая манипуляция (MPSK) или квадратурная амплитудная модуляция (QAM). В одном аспекте, кодовыми словами являются блочные коды, сверточные коды, турбокоды или каскадные коды.
После этапа 710 на этапе 720 формируется, по меньшей мере, одно логарифмическое отношение правдоподобия (LLR) для множества перемеженных кодовых слов. В одном примере, по меньшей мере, одно значение LLR формируется после демодуляции множества перемеженных кодовых слов. В одном варианте осуществления помимо использования перемеженных кодовых слов для получения, по меньшей мере, одного значения LLR, используется также модель ошибок канала связи. Специалистам известно построение модели ошибок с использованием математического анализа, эмпирических измерений и/или имитации т.д. В одном примере модель ошибок моделирует ошибки в битах с учетом полного пути распространения (т.е. начиная с передатчика, через передачу по каналу связи, и заканчивая приемником).
После этапа 720 на этапе 730 осуществляется сохранение, по меньшей мере, одного значения LLR в памяти. В одном варианте осуществления память является элементом приемника, осуществляющим этап запоминания. В одном примере памятью является оперативное запоминающее устройство (RAM). После этапа 730 на этапе 740 осуществляется обращенное перемежение множества перемеженных кодовых слов после сохранения в памяти, по меньшей мере, одного значения LLR. После этапа 740 на этапе 750 осуществляется принятие решения в отношении битов для перемеженных кодовых слов с использованием хранящегося в памяти, по меньшей мере, одного значения LLR. В одном примере принятием решения в отношении битов является мягкое принятие решения. В одном варианте осуществления выполнение этапов приведенной на Фиг.7 алгоритмической диаграммы снижает требования к памяти.
В одном аспекте, приемник выполняет один или более этап с этапа 710 по этап 750. В одном примере, приемник используется для запоминания значений логарифмического отношения правдоподобия (LLR) в обращенном перемежителе для обращенного перемежения множества перемеженных кодовых слов после сохранения в памяти, по меньшей мере, одного значения LLR; а декодер используется для принятия решения в отношении битов для прошедших обращенное перемежение кодовых слов с использованием хранящегося в памяти, по меньшей мере, одного значения LLR.
Специалисту в данной области техники будет понятно, что при осуществлении настоящего изобретения этапы, описанные в примере приведенной на Фиг.7 алгоритмической диаграммы, можно поменять местами.
Кроме того, специалистам ясно, что различные иллюстративные элементы, логические блоки, модули, цепи и/или этапы алгоритмов, описанные в связи с описанными здесь примерами, могут быть реализованы в виде электронного оборудования, аппаратно реализованного программного обеспечения (firmware), компьютерного программного обеспечения или их комбинаций. Для того чтобы ясно проиллюстрировать взаимозаменяемость оборудования, аппаратно реализованного программного обеспечения и компьютерного программного обеспечения, различные иллюстративные элементы, блоки, модули, цепи и/или этапы алгоритмов описаны выше в общих чертах с точки зрения их функциональных возможностей. Реализуются ли эти функциональные возможности в виде оборудования, аппаратно реализованного программного обеспечения или компьютерного программного обеспечения, зависит от конкретного применения и конструктивных ограничений, налагаемых на систему в целом. Специалисты в данной области при осуществлении настоящего изобретения могут реализовать описанные функциональные возможности различными способами.
Например, касательно аппаратной реализации, блоки обработки могут быть реализованы в одной или более специализированных интегральных схемах (ASIC), цифровых сигнальных процессорах (DSP), устройствах цифровой обработки сигналов (DSPD), программируемых логических устройствах (PLD), программируемых пользователем вентильных матрицах (FPGA), процессорах, контроллерах, микроконтроллерах, микропроцессорах, прочих электронных блоках, предназначенных для выполнения описанных в настоящем документе функций, либо их комбинации. Касательно программного обеспечения, реализация может быть осуществлена с помощью модулей (например, процедур, функций и т.д.), выполняющих описанные в настоящем документе функции. Содержащиеся в программах коды могут храниться в блоках памяти и исполняться процессором. Кроме того, различные иллюстративные структурные диаграммы, логические блоки, модули и/или этапы алгоритмов, описанные в настоящем документе, могут быть также запрограммированы в виде машиночитаемых команд, записанных на любом известном машиночитаемом носителе или реализованных в любом известном программном продукте.
В одном или более примерах описанные в настоящем документе этапы или функции могут быть реализованы в оборудовании, компьютерном программном обеспечении, аппаратно реализованном программном обеспечении или в любой их комбинации. При реализации а компьютерном программном обеспечении эти функции могут храниться или передаваться в виде одной или более команд или кодов, записанных на машиночитаемом носителе. Машиночитаемый носитель включает в себя как компьютерные носители информации, так и среды передачи данных, обеспечивающие перенос компьютерной программы из одного места в другое. Носителями информации могут быть любые доступные носители, доступ к которым может быть осуществлен с компьютера. В качестве примеров, а не ограничений можно назвать оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), компакт-диск (CD-ROM), либо иной накопитель на оптических дисках, накопитель на магнитных дисках или иное магнитное запоминающее устройство, либо любой другой носитель, который может использоваться для переноса или хранения требуемого кода программы в виде команд или структур данных и доступ к которому может быть осуществлен с компьютера. Кроме того, любое соединение, строго говоря, является машиночитаемым носителем информации. Например, если программное обеспечение передается с Web-сайта, сервера или из иного удаленного источника с помощью коаксиального кабеля, волоконно-оптического кабеля, витой пары, цифровой абонентской линии (DSL), либо с помощью беспроводных технологий, таких как инфракрасная, радиочастотная и микроволновая, то коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL или беспроводные технологии, такие как инфракрасная, радиочастотная и микроволновая, входят в определение носителя. Используемый в настоящем документе термин «диск» включает компакт-диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD), гибкий магнитный диск и диск blue ray, при этом в одних дисках воспроизведение данных осуществляется магнитным способом, а в других дисках воспроизведение данных осуществляется оптическим способом с помощью лазеров. Комбинации вышеупомянутых носителей также должны подпадать под определение машиночитаемого носителя.
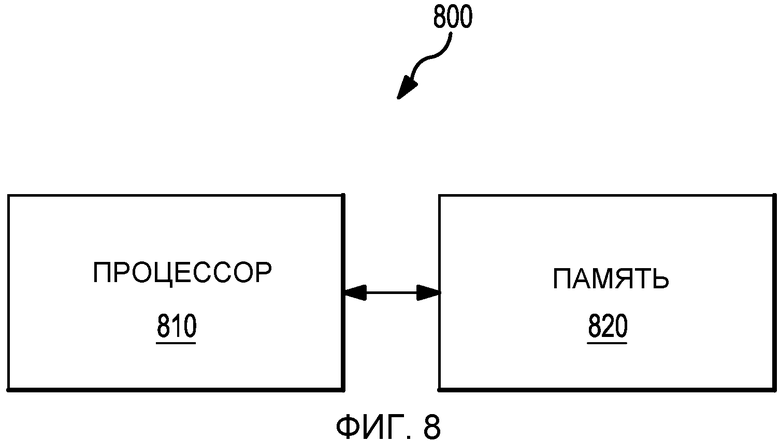
В одном примере иллюстративные элементы, структурные диаграммы, логические блоки, модули и/или этапы алгоритмов, описанные в настоящем документе, реализуются или исполняются с помощью одного или более процессоров. В одном варианте осуществления процессор связан с памятью, которая хранит данные, метаданные, команды программ и т.д. для исполнения процессором с целью реализации или осуществления различных структурных диаграмм, логических блоков и/или модулей, описанных в настоящем документе. На Фиг.8 изображен пример устройства 800, содержащего процессор 810, который осуществляет обмен информацией с памятью 820 для выполнения процесса запоминания логарифмических отношений правдоподобия (LLR) в перемеженном виде. В одном примере устройство 800 используется для реализации алгоритма, изображенного на Фиг.7. В одном варианте осуществления память 820 расположена внутри процессора 810. В другом варианте осуществления память 820 расположена вне процессора 810. В одном варианте осуществления процессор 810 содержит схему для реализации или осуществления различных структурных диаграмм, логических блоков и/или модулей, описанных в настоящем документе.
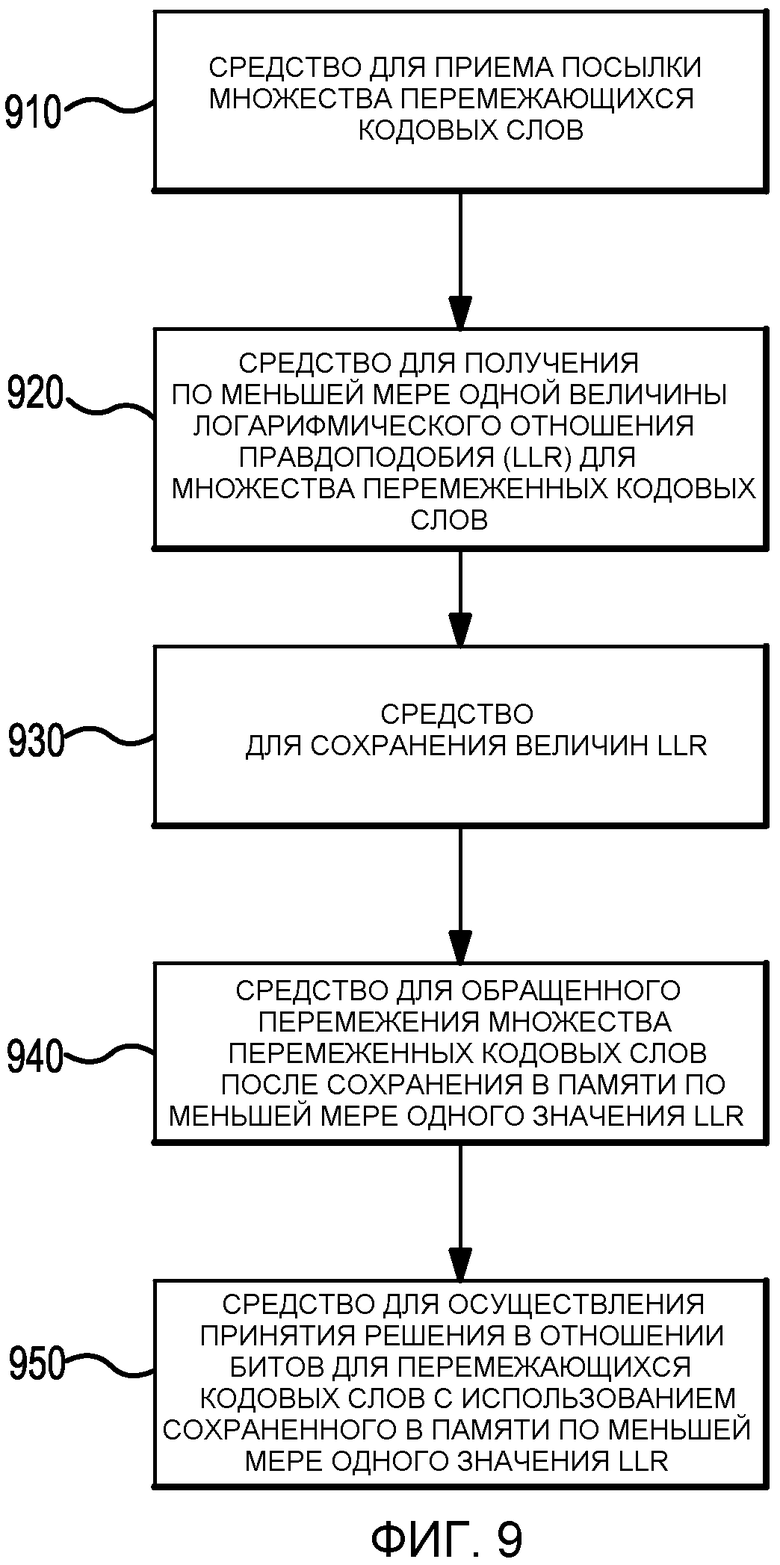
На Фиг.9 приведен пример устройства, подходящего для сохранения значений логарифмического отношения правдоподобия (LLR) в перемеженном виде. В одном варианте осуществления устройство 900 реализуется, по меньшей мере, одним процессором, содержащим один или более модулей, которые сконфигурированы для хранения значений логарифмического отношения правдоподобия (LLR) в перемеженном виде, как описано в настоящем документе в блоках 910, 920, 930, 940 и 950. Например, каждый модуль содержит оборудование, компьютерное программное обеспечение, аппаратно реализованное программное обеспечение или любую их комбинацию. В одном варианте осуществления устройство 900 реализуется, по меньшей мере, одной памятью, которая осуществляет обмен информацией, по меньшей мере, с одним процессором.
Предыдущее описание раскрытых вариантов осуществления представлено для того, чтобы любой специалист мог осуществить или использовать настоящее изобретение. Специалистам будут понятны различные изменения данных вариантов осуществления, а определенные здесь основные принципы могут быть применены к другим вариантам осуществления.

Изобретение относится к вычислительной технике. Технический результат заключается в сокращении числа считываний из памяти и упрощении адресации памяти за счет того, что считывание из памяти и запись в памяти осуществляются непрерывно. Способ сохранения логарифмических отношений правдоподобия в перемеженном виде, в котором принимают передачу множества перемеженных кодовых слов, причем в данной передаче не хватает по меньшей мере одного бита кодового слова в по меньшей мере в одном из этих кодовых слов; получают значения логарифмического отношения правдоподобия (LLR) для упомянутого множества перемеженных кодовых слов; сохраняют значения LLR в памяти; выполняют обращенное перемежение упомянутого множества перемеженных кодовых слов после сохранения в памяти значений LLR; и выполняют принятие решения в отношении битов для прошедших обращенное перемежение кодовых слов с использованием сохраненных значений LLR; причем при упомянутом сохранении сохраняют значения LLR без обеспечения заполнения нулями для упомянутого по меньшей мере одного бита кодового слова; и при упомянутом обращенном перемежении обеспечивают заполнение нулями для упомянутого по меньшей мере одного бита кодового слова. 3 н. и 20 з.п. ф-лы, 9 ил.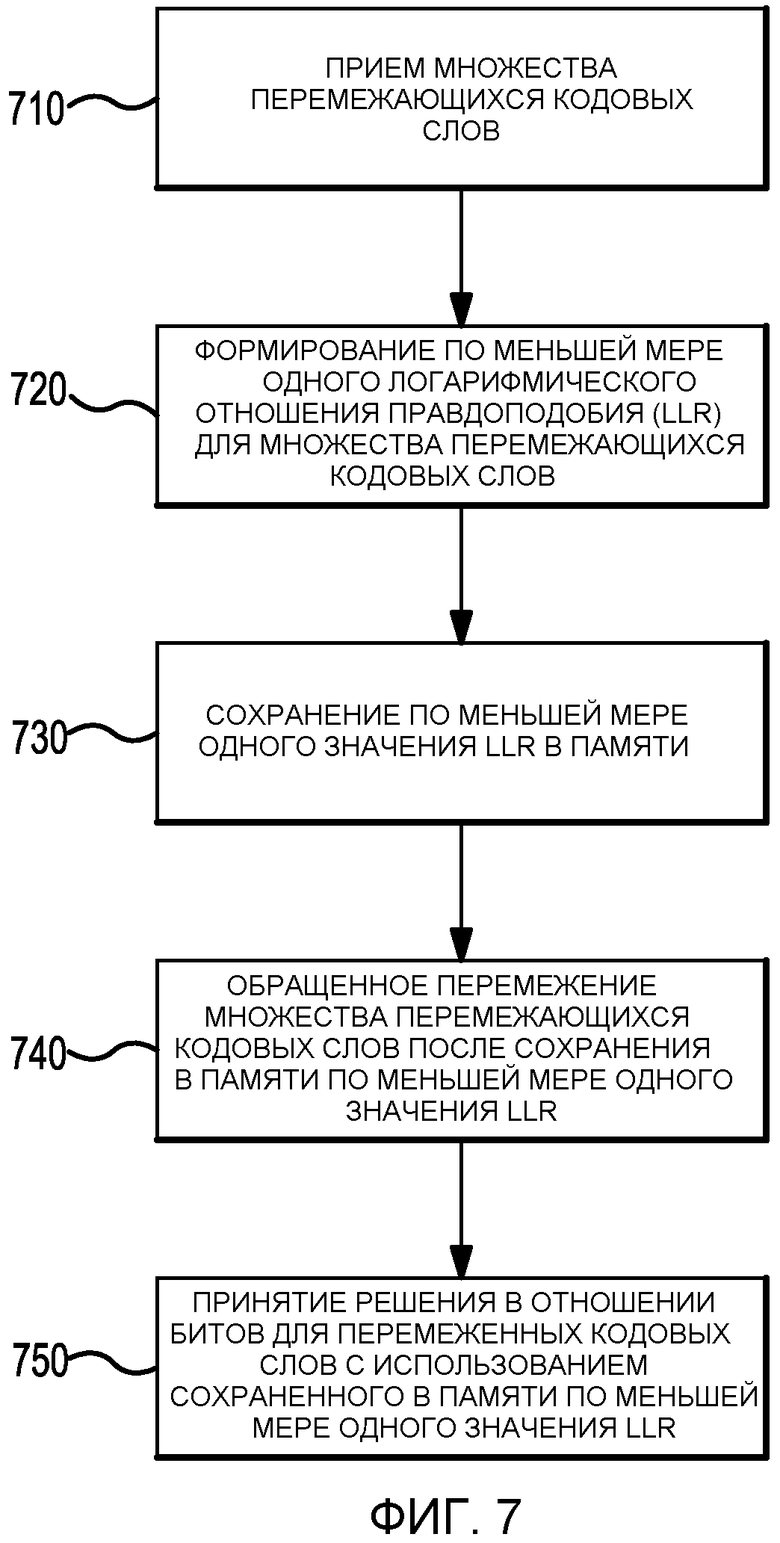
1. Способ сохранения логарифмических отношений правдоподобия в перемеженном виде, включающий в себя этапы, на которых принимают передачу множества перемеженных кодовых слов (710), причем в данной передаче не хватает по меньшей мере одного бита кодового слова в по меньшей мере в одном из этих кодовых слов; получают значения логарифмического отношения правдоподобия (LLR) для упомянутого множества перемеженных кодовых слов (720); сохраняют значения логарифмического отношения правдоподобия (LLR) в памяти (730); выполняют обращенное перемежение упомянутого множества перемеженных кодовых слов после сохранения в памяти значений LLR (740); и выполняют принятие решения в отношении битов для прошедших обращенное перемежение кодовых слов с использованием сохраненных значений LLR (750), отличающийся тем, что:
при упомянутом сохранении (730) сохраняют значения LLR без обеспечения заполнения нулями для упомянутого по меньшей мере одного бита кодового слова; и
при упомянутом обращенном перемежении (740) обеспечивают заполнение нулями для упомянутого по меньшей мере одного бита кодового слова.
2. Способ по п.1, в котором при упомянутом получении (720) демодулируют упомянутое множество перемеженных кодовых слов.
3. Способ по п.2, в котором упомянутая демодуляция (720) основана на одном из следующего: двухпозиционная фазовая манипуляция (BPSK), квадратурная фазовая манипуляция (QPSK), многократная фазовая манипуляция (MPSK) и квадратурная амплитудная модуляция (QAM).
4. Способ по п.3, в котором при упомянутом получении (720) используют модель ошибок канала связи для получения значений LLR.
5. Способ по п.4, в котором при упомянутом получении (720) выполняют построение модели ошибок на основе по меньшей мере одного из следующего: математический анализ, эмпирические измерения и имитация.
6. Способ по п.1, в котором при упомянутом сохранении (730) сохраняют значения LLR в памяти, которая также хранит команды для процессора (810).
7. Способ по п.1, в котором при упомянутом сохранении (730) сохраняют значения LLR в оперативном запоминающем устройстве (RAM).
8. Способ по п.1, в котором при упомянутом принятии решения в отношении битов (750) выполняют мягкое принятие решения.
9. Устройство для сохранения логарифмических отношений правдоподобия (LLR) в перемеженном виде, содержащее: средство для приема передачи множества перемеженных кодовых слов (910), причем в данной передаче не хватает по меньшей мере одного бита кодового слова в по меньшей мере одном из этих кодовых слов; средство для получения значений логарифмического отношения правдоподобия (LLR) для упомянутого множества перемеженных кодовых слов (920); средство для сохранения значений LLR (930); средство для обращенного перемежения упомянутого множества перемеженных кодовых слов после сохранения значений LLR (940); и средство для осуществления принятия решения в отношении битов для прошедших обращенное перемежение кодовых слов с использованием сохраненных значений LLR (950), отличающееся тем, что:
упомянутое средство для сохранения (930) включает в себя средство для сохранения значений LLR без обеспечения заполнения нулями для упомянутого по меньшей мере одного бита кодового слова; и
упомянутое средство для обращенного перемежения (940) включает в себя средство для обеспечения заполнения нулями для упомянутого по меньшей мере одного бита кодового слова.
10. Устройство по п.9, в котором упомянутое средство для получения (920) включает в себя средство для демодуляции упомянутого множества перемеженных кодовых слов.
11. Устройство по п.10, в котором демодуляция (920) основана на одном из следующего: двухпозиционная фазовая манипуляция (BPSK), квадратурная фазовая манипуляция (QPSK), многократная фазовая манипуляция (MPSK) и квадратурная амплитудная модуляция (QAM).
12. Устройство по п.9, в котором упомянутое средство для получения (920) включает в себя средство для использования модели ошибок канала связи для получения значений LLR.
13. Устройство по п.12, в котором упомянутое средство для получения (920) включает в себя средство для построения модели ошибок на основе по меньшей мере одного из следующего: математический анализ, эмпирические измерения и имитация.
14. Устройство по п.9, в котором упомянутое средство для осуществления принятия решения в отношении битов (950) содержит средство для осуществления мягкого принятия решения.
15. Устройство по п.9, в котором упомянутое средство для приема (910) содержит антенну, при этом упомянутое средство для получения (920) содержит демодулятор, причем упомянутое средство для сохранения (930) содержит память, при этом упомянутое средство для обращенного перемежения (940) содержит обращенный перемежитель, и при этом упомянутое средство для осуществления (950) содержит декодер.
16. Устройство по п.15, в котором демодулятор из состава упомянутого средства для получения (920) сконфигурирован для демодуляции упомянутого множества перемеженных кодовых слов.
17. Устройство по п.16, в котором демодуляция (920) основана на одном из следующего: двухпозиционная фазовая манипуляция (BPSK), квадратурная фазовая манипуляция (QPSK), многократная фазовая манипуляция (MPSK) и квадратурная амплитудная модуляция (QAM).
18. Устройство по п.15, в котором демодулятор из состава упомянутого средства для получения (920) сконфигурирован для использования модели ошибок канала связи для получения значений LLR.
19. Устройство по п.18, в котором модель ошибок, используемая упомянутым средством для получения (920), основана на по меньшей мере одном из следующего: математический анализ, эмпирические измерения и имитация.
20. Устройство по п.15, в котором память из состава упомянутого средства для сохранения (930) является оперативным запоминающим устройством (RAM).
21. Устройство по п.20, в котором принятием решения принятия решения в отношении битов, выполняемым упомянутым средством для осуществления (950), является мягкое принятие решения.
22. Устройство по п.15, в котором принятием решения в отношении битов, выполняемое упомянутым средством для осуществления (950), является мягкое принятие решения.
23. Машиночитаемый носитель информации, имеющий хранящийся на нем код программы, который при исполнении по меньшей мере одним процессором (810) предписывает этому по меньшей мере одному процессору осуществлять все этапы способа по любому одному из пп.1-8.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| EP 1858187 A1, 21.11.2007 | |||
| ИЕРАРХИЧЕСКОЕ КОДИРОВАНИЕ С ИСПОЛЬЗОВАНИЕМ МНОЖЕСТВА АНТЕНН В СИСТЕМЕ РАДИОСВЯЗИ | 2004 |
|
RU2316900C1 |
| Штатив для рентгеновских трубок | 1926 |
|
SU6093A1 |

