Изобретение относится к вычислительной технике и касается коммуникационной среды, отличающейся использованием прямой коммутации магистралей PCI Express без преобразования коммуникационного протокола.
Кластеризация - это технология, с помощью которой два или более серверов функционируют как один, представляя собой, с точки зрения пользователя, единый вычислительный ресурс. Главная цель кластеризации - увеличение производительности и (или) отказоустойчивости кластерной системы. Кластерные системы применяются в компаниях, которым нужна надежность и бесперебойная работа бизнес-критичных серверов и приложений.
Вычислительные кластеры, построенные по технологии прямой коммутации каналов PCI Express, могут применяться для решения вычислительно трудоемких задач в областях молекулярной фармакологии, наноэлектроники, в создании энергетических комплексов нового поколения, а также при проведении фундаментальных научных исследований в астрофизике, микробиологии, физике твердого тела, нейроматематике, томографии Земли и в других областях. В первую очередь от кластеров, построенных по базе данной коммуникационной среды, можно ожидать эффективности в расчетах на неструктурных и адаптивных сетках, то есть на задачах, в которых данные сложным образом разбросаны по совокупной памяти системы мелкими порциями, взаимное расположение которых не является регулярным и/или меняется в процессе расчета. Это перспективное, быстро растущее направление в численных методах, известное исключительно высокой трудоемкостью при его реализации на традиционных вычислительных кластерах.
Разработка сети прямой коммутации PCI Express была выполнена американской фирмой OneStopSystems (http://www.onestopsystems.com), но в их разработке отсутствует простой и эффективный способ масштабирования сети без сосредоточенного центрального коммутатора, который присутствует в нашей реализации.
Известен самоформирующийся суперкомпьютер, содержащий множество стоек, на каждой из которых размещен массив разъемов для подключения токопроводящих шин питания стоек к шинам питания плат, и массив плат с размещенными на них микросхемами, причем платы имеют устройства для их закрепления на стойках, а элементы суперкомпьютера соединяются друг с другом с помощью оптоволоконных и электрических шин, при этом имеется компьютер-строитель, один или несколько манипуляторов, управляемых этим компьютером, а также библиотеки охлаждаемых плат, оптоволоконных шин и электрических кабелей в виде наборов этих элементов, установленных в доступных для манипуляторов магазинах (RU №2367125, H05K 7/00, H05K 7/20, G06F 15/18, G06F 1/16, G06F 1/20, опубл. 10.09.2009).
Недостаток данного решения заключается в недостаточном быстродействии.
Известна кластерная система, которая содержит ведущий вычислительный модуль, представляющий собой компьютер с шиной PCIe на своей материнской плате, связанный с коммутатором, выходы которого связаны с ведомыми вычислительными модулями, выполненными с шиной PCIe на своих материнских платах (см. статью «Кластерные системы», выложенную на сайте «IBS Platformix» в сети Интернет в режиме он-лайн по адресу: http://platformix.ru/rus/IT-Infrastructure/components-IT/computing/clusters-sys/index.wbp, обнаружено в мае 2011 г.). Принят в качестве прототипа.
Недостаток данного решения заключается в достаточно большой задержке при передаче данных в сети. Кроме того, конструкция такого суперкомпьютера достаточно сложна и дорога.
Настоящее изобретение направлено на достижение технического результата, заключающегося в повышении скорости передачи данных и уменьшении времени задержки единичной записи данных в «чужую» память на уровне, сравнимом с аналогичными показателями для передачи данных внутри компьютера.
Указанный технический результат достигается тем, что кластерная система содержит ведущий вычислительный модуль, представляющий собой компьютер с шиной PCIe на своей материнской плате, связанный через интерфейсную плату, подключенную к шине PCIe ведущего вычислительного модуля, с коммутатором, выходы которого связаны с ведомыми вычислительными модулями, выполненными с шиной PCIe на своих материнских платах, через интерфейсные платы каждый, подключенные к шине PCIe соответствующего ведомого вычислительного модуля, каждая интерфейсная плата выполнена с двумя портами, один из которых выполнен с возможностью работы в режиме прозрачного порта, а второй - в режиме непрозрачного порта, при этом ведущий вычислительный модуль подключен к прозрачному порту одной интерфейсной платы, которая связана с коммутатором, а ведомые вычислительные модули подключены к непрозрачным портам других интерфейсных плат, которые связаны с коммутатором, коммутатор выполнен с возможностью реализации функции при включении ведомых вычислительных модулей инициализации шины PCIe и подключенных к ней ведомых вычислительных модулей с выделением в непрозрачном порте соответствующей интерфейсной платы адресного пространства для каждого из них в оперативной памяти, и при включении ведущего вычислительного модуля инициализации шины PCIe и подключенного к ней ведущего вычислительного модуля с выделением в прозрачном порте соответствующей интерфейсной платы адресного пространства для них в оперативной памяти, причем коммутатор выполнен с возможностью образования в адресном пространстве шины PCIe ведущего вычислительного модуля диапазона адресов, перекрывающего все окна доступа к ведомым вычислительным модулям, и формирования в каждом непрозрачном порте интерфейсной платы окна с адресом в адресной области в ведущем вычислительном модуле для обеспечения для каждого ведомого вычислительного модуля возможности доступа через адресное пространство к памяти других ведомых вычислительных модулей.
Указанные признаки являются существенными и взаимосвязаны с образованием устойчивой совокупности существенных признаков, достаточной для получения требуемого технического результата.
Настоящее изобретение поясняется конкретными примерами исполнения, которые, однако, не являются единственно возможными, но наглядно демонстрируют возможность достижения требуемого технического результата.
На фиг.1 - топология PCI Express;
фиг.2 - Мульти-Root с применением NT Bridge;
фиг.3 - коммутатор PCI Express с прозрачным и непрозрачным портами;
фиг.4 - общая блок-схема коммуникационной среды;
фиг.5 - общая блок-схема коммутатора;
фиг.6 - блок-схема интерфейсной платы;
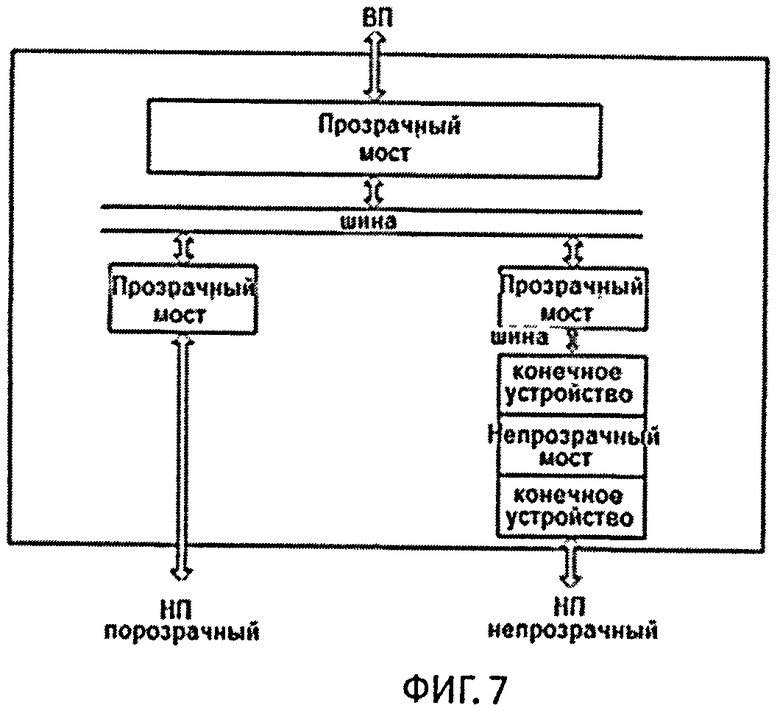
фиг.7 - блок-схема коммутатора PCIe (PCIe Switch) ИП с прозрачным и непрозрачным портами;
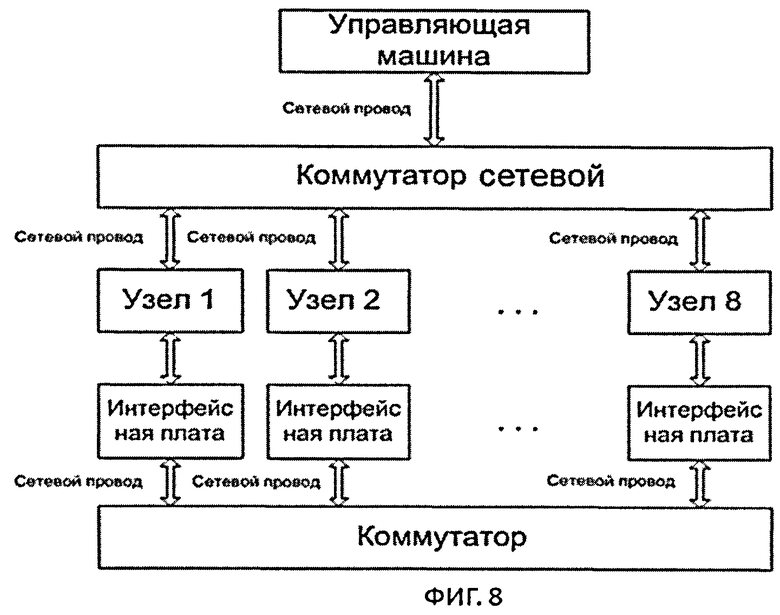
фиг.8 - блок-схема вычислительного кластера ЭВМ МВС-Экспресс.
Согласно настоящему изобретению рассматривается кластерная система, построенная по технологии прямой коммутации каналов PCI Express, которая реализует на аппаратном уровне общее поле памятей большого объема и внешних устройств для всех входящих в кластер узлов. При этом уровни скоростей и задержек при передаче данных в такой сети сравнимы с аналогичными показателями для передачи данных внутри компьютера. Так, время задержки при единичной записи данных в «чужую» память сокращается с 3-6 микросекунд (для современных кластеров) до 200-400 наносекунд. Скорость передачи данных будет лежать в диапазоне от 600 Мбайт до 1,5 Гбайт в секунду в зависимости от ширины применяемых кабелей. Длина пакета данных, на которой достигается пиковая скорость, сократится с нескольких килобайт до десятков байт. Таким образом, возникают предпосылки построения суперкомпьютера с архитектурой, близкой к архитектуре оригинальных западных суперкомпьютеров с общим полем памяти, но с показателями доступности и низкой удельной стоимостью, такими же, как у суперкомпьютеров, построенных на основе кластерных технологий.
Коммуникационная среда кластерной системы основана на стандарте компьютерной шины PCI Express (PCIe) (фиг.1) и имеет древовидную структуру. Корнем дерева является особый узел - Root Complex 1 (с точки зрения шины PCIe), назовем его Ведущим. Листьями дерева являются устройства, подключенные к шине, таковыми здесь являются интерфейсные платы (ИП) всех остальных вычислительных модулей ВМ (назовем - Ведомых), подключенных через коммутатор. Вершины дерева, не являющиеся листьями, представляют собой коммутаторы, т.е. устройства способные принять пакет по некоему входу, проанализировать содержащийся в пакете адрес назначения и в зависимости от того, чему равен этот адрес, выдать пакет в тот или иной выход.
Для более удобного рассмотрения данной коммуникационной среды можно рассмотреть шину PCIe, вкратце описав ее компоненты и общую терминологию.
PCI Express (или PCIe, или PCI-E) - компьютерная шина, использующая программную модель шины PCI и высокопроизводительный физический протокол, основанный на последовательной передаче данных. В отличие от шины PCI, использующей для передачи данных общую шину, PCI Express, в общем случае, является пакетной сетью с топологией типа звезда, устройства PCI Express взаимодействуют между собой через среду, образованную коммутаторами, при этом каждое устройство напрямую связано соединением типа точка-точка с коммутатором.
В стандарте шины PCI Express (PCIe) выделяются три типа устройств. Root Complex I, PCI Switch 2 (PCI коммутатор) и Endpoint 3 (Конечная точка или устройство). Root Complex I - это отдельный процессор подсистемы, который включает отдельный порт или несколько портов PCIe, один или более CPU (Центральных процессоров), объединенных с RAM (Оперативной памятью) и контроллером памяти, а также другими внутренними соединениями и/или мостовыми функциями. Проще говоря. Root Complex - это устройство является точкой соприкосновения трех интерфейсов: шины памяти, PCI Express и процессорной шины.
Маршрутизация PCIe основана на адресации памяти или уникальных номерах устройств (ID), зависящих от типа транзакций. Таким образом, каждое устройство (или функция в устройстве) должно быть идентифицировано уникальным номером на древовидной шине PCIe.
В течение инициализации системы Root Complex выполняет регистрацию для определения различных имеющихся шин, а также устройств, расположенных на каждой шине, к тому же требуется адресное пространство регистров и памяти устройств. Root Complex выделяет номера шин по всем PCIe шинам и конфигурирует номера шин, которые будут использоваться коммутатором PCIe. PCIe ведет себя, как если бы он был мульти PCI-PCI Bridge 4 (Мост) (фиг.1, выносная вставка). Root Complex выделяет и конфигурирует память и адресное пространство портов ввода/вывода для каждого коммутатора PCIe и конечного устройства. Топология PCIe приведена на фиг.1.
Для подключения устройства PCI Express используется двунаправленное последовательное соединение типа точка-точка, называемое lane. Соединение между двумя устройствами PCI Express называется link и состоит из одного (называемого 1х) или нескольких (x2, x4, x8, x12, x16 и x32) двунаправленных последовательных соединений lane. Каждое устройство должно поддерживать соединение х1.
PCI-PCI Bridge (РРВ) 4 - устройство, с помощью которого можно подключать к локальной шине компьютера дополнительные шины. Причем если, например, локальная шина компьютера - PCIe, то к ней можно подключить дополнительно как такую же шину PCIe, так и, например, «старую» шину PCI. Существуют различные типы мостов. Группа PCI Special Iterest Group (PCISIG) в 1994 году разработала основные спецификации архитектур мостов РВВ. Таким образом, выделяются два основных вида мостов: «прозрачный» или «стандартный» и «непрозрачный» или «встроенный» мосты.
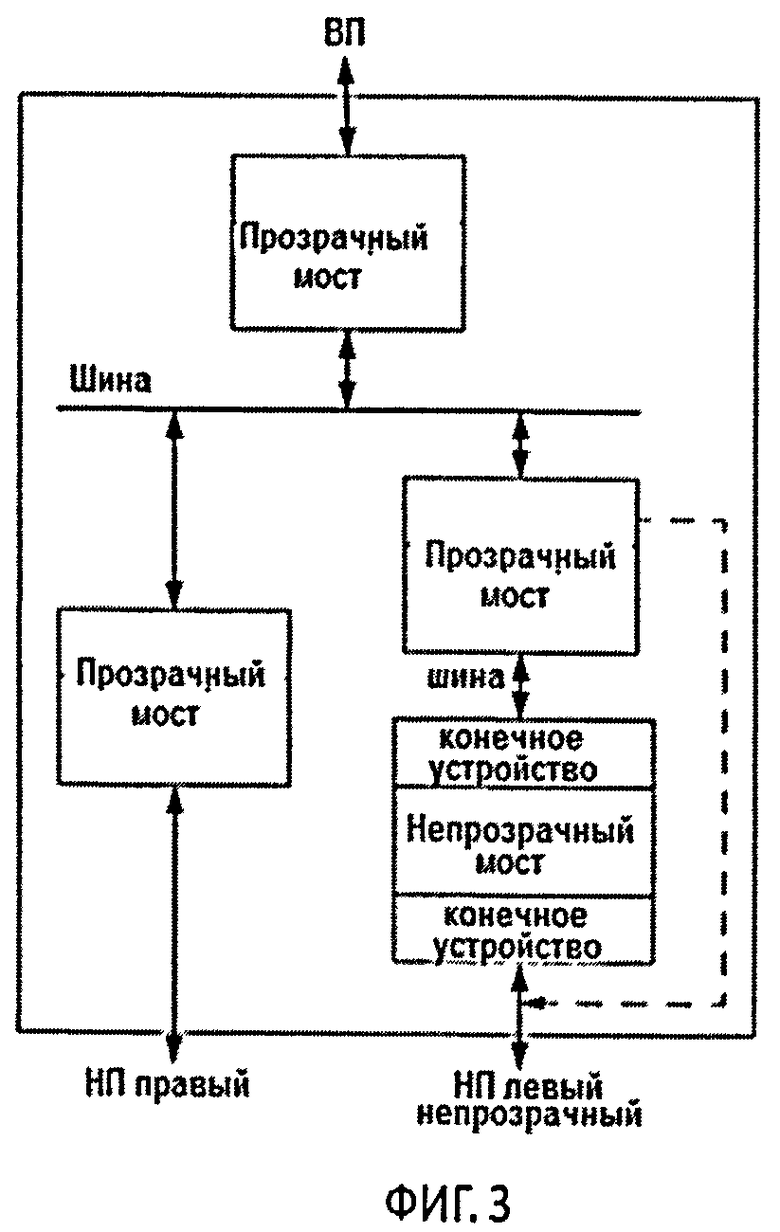
Прозрачный мост (Transparent Bridge или ТВ) при процедуре автоконфигурации проходит стандартную идентификацию на шине PCIe, после чего становится прозрачным по отношению к управляющему процессору, соответственно Root Complex также инициализирует все устройства, которые находятся за этим мостом РРВ. Данный тип РРВ не содержит никаких аппаратных ресурсов, например, устройств прямого доступа к памяти (DMA) или регистров (майлбоксов), которые требовали бы наличия отдельного драйвера устройства, а также не преобразует адреса от одной шины PCIe к другой. Таким образом, коммутатор PCIe, который имеет один порт Upstream и два порта Downstream, состоит из трех прозрачных мостов РРВ 4 и виртуальной шины PCI (фиг.1).
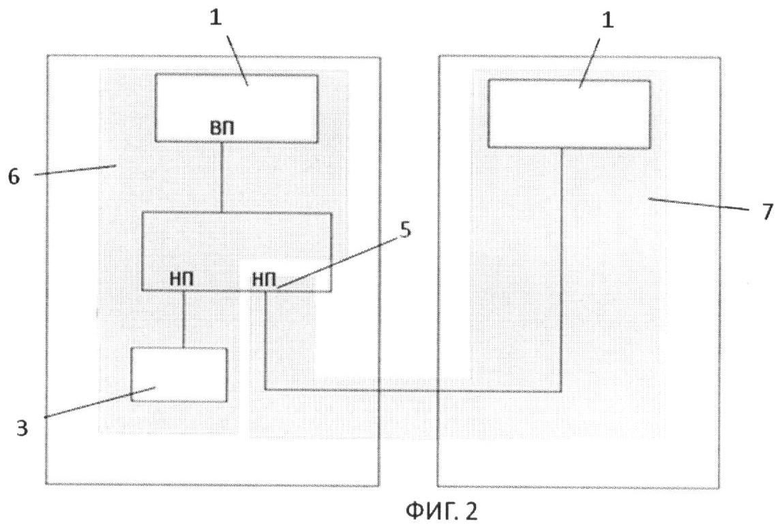
Непрозрачный мост (Not-Transparent Bridge или NTB) - мост, основной задачей которого является разделение областей или, можно выразиться, зон, подверженных сканированию и автоконфигурации локальной или первичной стороной компьютера. При этом конфигурируется непрозрачный мост, устанавливаются адресные окна, определяются трансляция адреса и карты адресных регистров для локальных устройств PCI во встроенных мостах с первичной (локальной) и вторичной (объединительной шины) сторон. Диапазон конфигурации локальных процессоров ограничивается встроенным мостом, и поиск устройств на PCI шине объединительной платы не производится. Таким образом, NTB может решать проблему использования нескольких процессоров (фиг.2).
На фиг.2 изображены Root Complex-1 и Root Complex-2, соединенных между собой по шине PCIe через NTB port 5. Задача NTB port 5 в данном случае заключается в том, чтобы оградить адресное пространство Address Domain-1 (поз.6) от Address Domain-2 (поз.7), таким образом, при автоконфигурации шины Root Complex-1 производит инициализацию локальных PCI устройств до NTB, т.е. он видит NTB как конечное устройство (Endpoint или Internal Endpoint). Root Complex-2, со своей стороны, также инициализирует свои локальные PCI устройства, также до NTB и, соответственно, также видит NTB как конечное устройство (Endpoint или External Endpoint). На фиг.3 приведена более детальная схема PCIe Bridge, где имеются три порта, верхний (Upstream) настроен как ТВ port, нижний левый (Downstream) ТВ port и нижний правый (Downstream) как NTB port.
Использование непрозрачных мостов также позволяет решить проблему конфликтов адресации за счет преобразования адресов. Исходя из фиг.2 рассмотрим пример, в котором Root Complex-1 записывает данные по шине PCIe из своей локальной оперативной памяти в оперативную память Root Complex-2. Основным препятствием при этом является то, что у них разные адресные пространства. PCIe является пакетной сетью, с топологией типа звезда. Следовательно, в заголовке передаваемого пакета нужно указывать идентификационный номер Requester ID (включает в себя идентификаторы шины, устройства и функции), идентификатор типа трафика (Traffic Class), адрес, сведения о маршрутизации и значение, определяющее длину этого пакета или пакета, которым должно ответить запрошенное устройство. Т.к. единственной точкой соприкосновения адресных пространств является NTB, то, соответственно, при передаче пакета из Root Complex-1 в Root Complex-2 в заголовке передаваемого пакета нужно указать адрес, которому соответствует Internal Endpoint (фиг.3). Далее NTB сам преобразовывает адрес и передает пакет в адресное пространство Root Complex-2, где оно доставляется к своей точке назначения.
Более подробное описание NT Bridge можно найти по следующим ссылкам:
1. http://www.google.ru/url?sa=t&source=web&cd=1&ved=0CB0QFjAA&url=http%3A%2F%2Fwww.plxtech.com%2Fpdf%2Ftechnical%2Fexpresslane%2FNTB_Brief_April-05.pdf&rct=j&q=Non-Transporent%20Bridging&ei=IR4sTYq0BsudOsSZpOQK&usg=AFQjCNHQ_gRT2izo9j9ZRHt1vs7BWgtmKw&cad=rja
2. http://www.eetimes.com/electronics-news/4139182/Non-Transparent-Bridging-Makes-PCI-Express-HA-Friendly
3. http://www.design-reuse.com/articles/8408/non-transparent-bridging-allows-multiprocessor-design-with-pci-express.html
4. http://www.google.ru/url?sa=t&source=web&cd=2&ved=0CCYQFjAB&url=http%3A%2F%2Fwww.plxtech.com%2Fpdf%2Ftechnical%2Fexpresslane%2FNontransparentBridging.pdf&rct=j&q=Non-Transporent%20Bridging&ei=IR4sTYq0BsudOsSZpOQK&usg=AFQjCNHOjTiobXgalN_cjMmxs5tIHZaffQ&cad=rja
5. http://www.google.ru/url?sa=t&source=web&cd=5&ved=0CEMQFjAE&url=ftp%3A%2F%2Fdownload.intel.nl%2Fdesign%2Fintarch%2FPAPERS%2F323328.pdf&rct=j&q=Non-Transporent%20Bridging&ei=IR4sTYq0BsudOsSZpOQK&usg=AFQjCNGTjUE-PTFKXLwg9xSW1WTVTXxhRA&cad=rja
Итак, рассмотрев основные компоненты шины PCI Express, можно приступить к описанию коммутационной среды на базе прямой коммутации каналов PCI Express. Данное решение является изобретением.
Общая блок-схема коммуникационной среды (КС) на базе прямой коммутации каналов шины PCIe приведена на фиг.4.
КС состоит из:
- коммутатора 8;
- вычислительных модулей 9 (ВМ);
- интерфейсных плат 10 (ИП), которые подключаются к шине PCIe ВМ;
- сетевых проводов 11 (СП), с помощью которых ИП 10 подключаются к коммутатору 8.
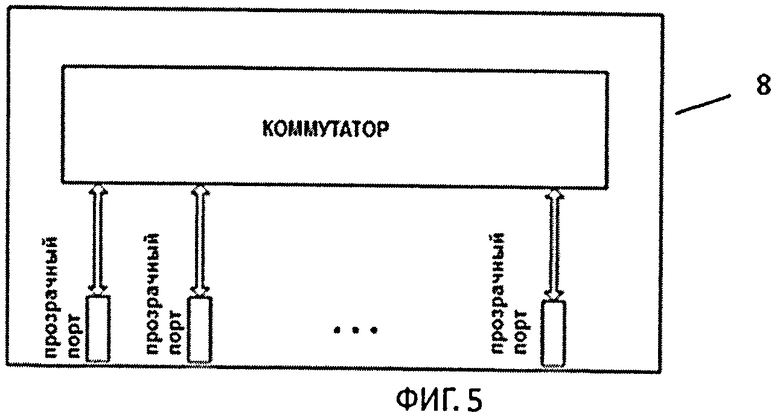
Коммутатор 8 (фиг.5), представляющий собой PCI Switch 2, осуществляет функции пересылки пакетов между ВМ согласно адресу получателя. С логической точки зрения все коммуникации в системе относятся к категории точка-точка и соединяют все устройства напрямую.
ВМ представляет собой компьютер, который имеет на своей материнской плате шину PCIe.
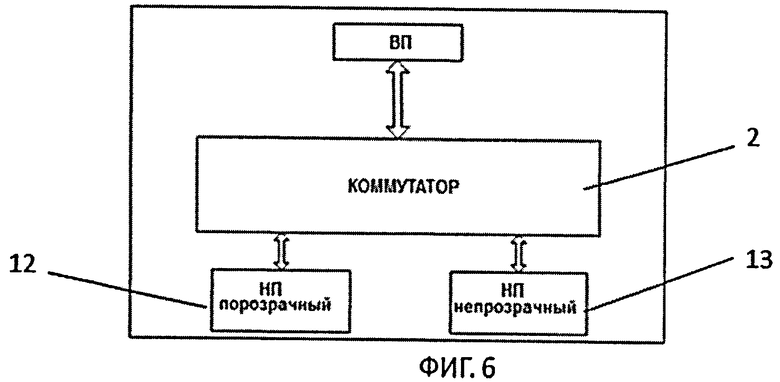
ИП 10 (фиг.6) мультипортовая интерфейсная плата, имеющая два порта, один 12 из которых работает в режиме прозрачного порта, второй 13 в режиме непрозрачного порта. Прозрачный порт используется только для подключения Ведущего (главного Root Complex) к коммутатору. Во всех остальных узлах (Ведомых) для подключения к коммутатору используется непрозрачный порт. Вся логика ИП заложена в коммутаторе PCIe 2 (PCIe Switch на фиг.6). Более подробная блок-схема коммутатора PCIe приведена на фиг.7. Для организации логики, приведенной на фиг.7, используется наша собственная битовая прошивка. Прошивка загружается с помощью программатора. В процессе прошивки в NT-порте настраиваются нужные нам регистры - memory bar, размер которых будет равен размеру локальной порции. Локальная порция - кусок системной памяти по известному фиксированному адресу, который вырезается при загрузке ядра операционной системы (ОС) на ВМ.
В данной КС требуется следующий порядок загрузки узлов: сначала все ведомые, затем коммутатор, последним - ведущий узел.
Включение ведомых ВМ 9: при этом при загрузке BIOS на ВМ 9 происходит инициализация шины PCIe и всех подключенных к ней устройств, а также выделение адресного пространства для них. Далее в процессе загрузки операционная система (ОС) (в качестве ОС используется Linux) выделяет адресное пространство для PCIe шины и устройств в оперативной памяти. Стоит отметить, что Internal Endpoint в NTB ИП (фиг.7) при этом видится ВМ как конечное устройство на своей локальной шине PCIe.
Далее загружается коммутатор путем подачи на него питания. На данном этапе никаких конфигураций или выделений памяти на никаких ВМ не происходит, т.е. просто требуется некоторое время, чтобы коммутатор пришел в работоспособное состояние.
После этого питание подается на ведущий ВМ. Так же, как и в ведомых ВМ, сперва BIOS инициализирует свою шину и устройства на ней, но т.к. ведущий ВМ подключен к коммутатору через прозрачный порт на своей ИП, то он видит как коммутатор, так и External Endpoint (фиг.7) ИП всех ведомых ВМ. Другими словами, Ведущий видит их как конечные устройства на своей локальной шине, и, соответственно, BIOS инициализирует свою шину и устройства, а также адресное пространство для них. Далее ОС выделяет пространство адресов и портов ввода/вывода в своей оперативной памяти. Теперь у ведущего в адресном пространстве шины PCIe появились N-1 (где N - общее число всех ВМ) NT memory bar-ов (extrenal endpoint ИП), каждый из которых размером с локальную порцию. Ведущий может настроить каждый из этих NT портов (окон доступа к ведомым) на адрес локальной порции в соответствующем ведомом узле. Теперь при работе с этим bar-ом ведущий будет попадать в локальную порцию соответствующего ведомого.
У каждого из ведомых в адресном пространстве шины PCIe появился 1 NT memory bar (Internal Endpoint), каждый из которых размером с локальную порцию. Каждый из ведомых может настроить соответствующий NT порт (окно доступа к ведущему) на адрес локальной порции в ведущем.
На этом этапе ведущий видит всех ведомых, каждый ведомый видит ведущего.
Теперь дадим возможность ведомым видеть друг друга. Для этого выберем в адресном пространстве шины PCIe ведущего минимальный naturally aligned диапазон адресов, перекрывающий все окна доступа к ведомым. Назовем его областью перекрестного доступа. Закажем в каждом NT порте еще один NT memory bar (окно перекрестного доступа) размером с эту область и настроим его на адрес этой области в ведущем. Теперь каждый ведомый может через окно перекрестного доступа видеть в области перекрестного доступа любого другого ведомого. При перекрестном доступе данные физически через ведущего не ходят - ведущий предоставил ведомым только адресное пространство, а построенные аппаратно при начальном запуске PCI Express маршрутные таблицы все гонят по кратчайшему пути.
Теперь любой ВМ может осуществлять прямой доступ к памяти всех ведомых ВМ (используемый режим доступа - Master DMA). Также отметим, что за счет использования базового программного обеспечения чтение из чужой памяти осуществляется при помощи программного запроса встречной записи.
Ниже приводится описание примера исполнения кластерной системы ЭВМ МВС-Экспресс с применением данной коммуникационной среды и ЭВМ К-100. На примере блок-схемы ЭВМ МВС-Экспресс (фиг.8) рассмотрим принцип работы коммуникационной среды.
ЭВМ МВС-Экспресс содержит в себе следующее аппаратные средства:
- 8 вычислительных узлов, каждый из которых имеет следующие характеристики:
- Процессор 2 x Opteron 2382; 7 доступных задаче пользователя ядер;
- Оперативная память 16 Gb;
- Диск SATA 320 Gb;
- Сетевая карта Gigibit Ethernet;
- Интерфейсная плата;
- Видеокарта nVidia GeForce 285GTX, 240 GPU;
- Серверный корпус АТХ;
- Управляющая машина:
- Процессор Intel Core2Duo E8400;
- Диск SATA 320Gb;
- DVD
- Корпус АТХ;
- Сетевые карты Gigabit Ethernet;
- Коммутатор Gigabit Ethernet
- Коммутатор PCI Express
Узлы, управляющая машина и коммутаторы размещены в 24U шкафах 600×800.
Коммуникационная среда на базе шины PCI Express (или PCIe), на данной блок-схеме (фиг.8) состоит из Коммутатора PCI Express, Интерфейсных плат, которые вставляются в слот PCI Express в вычислительных узлах и сетевых проводов (стандартные сетевые провода 10 Gb Ethernet) для соединения вычислительных узлов с коммутатором PCI Express. Т.к. данная коммуникационная среда сделана на основе шины PCI Express, имеющей древовидную структуру, то необходимо кого-то назначить корнем этого дерева (или главным Root). Соответственно, один из вычислительных узлов назначается этим корнем, мы его называем Ведущим. Все остальные N-1 узлов - Ведомыми.
Коммутатор PCIe имеет N-1 Downstream портов, к которым подключаются Интерфейсные платы Ведомых узлов и один Upstream порт, к которому подключается Интерфейсная плата Ведущего узла.
Каждая Интерфейсная плата имеет три порта, один из которых настроен как непрозрачный мост (Downstream Not transparent bridge), второй как прозрачный мост (Downstream Transparent bridge), а также порт Upstream. Соответственно, первый слот используется при подключении Ведомых вычислительных узлов к Downstream портам коммутатора PCIe, второй при подключении Ведущего узла к Upstream порту коммутатора PCIe, а третий вставляется в шину PCIe на материнской плате вычислительного узла. Все Интерфейсные платы функционально идентичны, различие состоит лишь в выборе Downstream порта при подключении к коммутатору.
Сетевое подключение для доступа из сетей kiam.ru и internet.
Программное обеспечение
- Операционная система SuSE Linux Enterprise Server 10SP2;
- Система Управления Прохождением Пользовательских Задач (СУППЗ);
- Компиляторы С, Fortran;
- Сервер удаленного доступа по протоколам SSH/SCP.
Основные характеристики коммуникационной сети на базе PCIe:
- скорость: до 700 МБ/с;
- латентность: 1,2 мкс;
- время выдачи слова: ~70 нс;
- время чтения слова: ~2,5 мкс.
Настоящее изобретение промышленно применимо, созданы функционирующие системы, которые опробованы и показали высокие результаты, полностью подтверждающие возможность достижения технического результата.
| название | год | авторы | номер документа |
|---|---|---|---|
| РЕКОНФИГУРИРУЕМАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2017 |
|
RU2677363C1 |
| РЕКОНФИГУРИРУЕМАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2019 |
|
RU2713757C1 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОЗАДАЧНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ | 2021 |
|
RU2780169C1 |
| Высокопроизводительная вычислительная платформа на базе процессоров с разнородной архитектурой | 2016 |
|
RU2635896C1 |
| РЕКОНФИГУРИРУЕМАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА С МНОГОУРОВНЕВОЙ ПОДСИСТЕМОЙ МОНИТОРИНГА И УПРАВЛЕНИЯ | 2018 |
|
RU2699254C1 |
| РЕКОНФИГУРИРУЕМАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2022 |
|
RU2798443C1 |
| АВТОНОМНЫЙ ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ | 2019 |
|
RU2720556C1 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ | 2018 |
|
RU2686004C1 |
| УПРАВЛЕНИЕ РЕСУРСАМИ ДЛЯ ДОМЕНОВ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ ПЕРИФЕРИЙНЫХ КОМПОНЕНТОВ | 2014 |
|
RU2640648C2 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ С ДИНАМИЧЕСКИМ ПЕРЕРАСПРЕДЕЛЕНИЕМ ВЫЧИСЛИТЕЛЬНЫХ РЕСУРСОВ | 2023 |
|
RU2823113C1 |

Изобретение относится к вычислительной технике и касается коммуникационной среды. Технический результат заключается в повышении скорости передачи данных и уменьшении времени задержки единичной записи данных в «чужую» память. Кластерная система содержит ведущий и ведомые вычислительные модули, выполненные с шиной PCIe на своих материнских платах, коммутатор и интерфейсные платы, имеющие по 2 порта каждая - один порт работает в режиме прозрачного порта, а второй - в режиме непрозрачного. Коммутатор выполнен с возможностью образования в адресном пространстве шины PCIe ведущего вычислительного модуля диапазона адресов, перекрывающего все окна доступа к ведомым вычислительным модулям и формирования в каждом непрозрачном порту интерфейсной платы окна с адресом в адресной области в ведущем вычислительном модуле для обеспечения для каждого ведомого вычислительного модуля возможности доступа через адресное пространство к памяти других ведомых вычислительных модулей. 8 ил.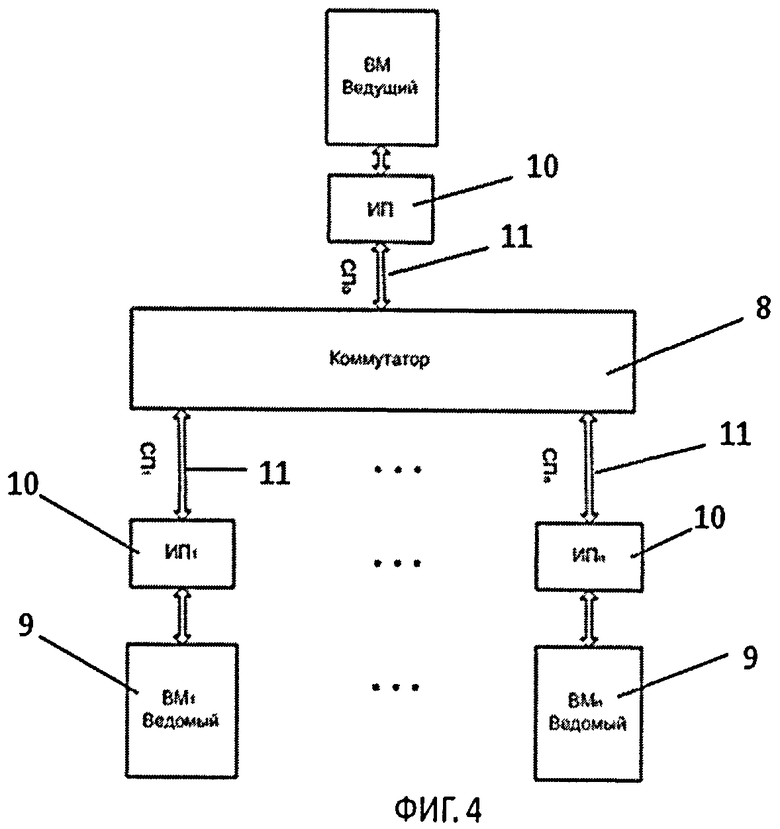
Кластерная система, содержащая ведущий вычислительный модуль, представляющий собой компьютер с шиной PCIe на своей материнской плате, связанный через интерфейсную плату, подключенную к шине PCIe ведущего вычислительного модуля, с коммутатором, выходы которого связаны с ведомыми вычислительными модулями, выполненными с шиной PCIe на своих материнских платах, через интерфейсные платы каждый, подключенные к шине PCIe соответствующего ведомого вычислительного модуля, каждая интерфейсная плата выполнена с двумя портами, один из которых выполнен с возможностью работы в режиме прозрачного порта, а второй - в режиме непрозрачного порта, при этом ведущий вычислительный модуль подключен к прозрачному порту одной интерфейсной платы, которая связана с коммутатором, а ведомые вычислительные модули подключены к непрозрачным портам других интерфейсных плат, которые связаны с коммутатором, коммутатор выполнен с возможностью реализации функции при включении ведомых вычислительных модулей инициализации шины PCIe и подключенных к ней ведомых вычислительных модулей с выделением в непрозрачном порту соответствующей интерфейсной платы адресного пространства для каждого из них в оперативной памяти, и при включении ведущего вычислительного модуля инициализации шины PCIe и подключенного к ней ведущего вычислительного модуля с выделением в прозрачном порту соответствующей интерфейсной платы адресного пространства для них в оперативной памяти, причем коммутатор выполнен с возможностью образования в адресном пространстве шины PCIe ведущего вычислительного модуля диапазон адресов, перекрывающий все окна доступа к ведомым вычислительным модулям, и формирования в каждом непрозрачном порту интерфейсной платы окна с адресом в адресной области в ведущем вычислительном модуле для обеспечения для каждого ведомого вычислительного модуля возможности доступа через адресное пространство к памяти других ведомых вычислительных модулей.
| ВИРТУАЛЬНАЯ МНОГОАДРЕСНАЯ МАРШРУТИЗАЦИЯ ДЛЯ КЛАСТЕРА, ИМЕЮЩЕГО СИНХРОНИЗАЦИЮ СОСТОЯНИЯ | 2005 |
|
RU2388044C2 |
| ОХЛАЖДАЕМАЯ ПЛАТА И САМООРГАНИЗУЮЩИЙСЯ СУПЕРКОМПЬЮТЕР | 2008 |
|
RU2367125C1 |
| УСТРОЙСТВО ОБРАБОТКИ АДРЕСОВ КОММУТАТОРА ЛОКАЛЬНОЙ ВЫЧИСЛИТЕЛЬНОЙ СЕТИ, РАБОТАЮЩЕГО ПО ПРИНЦИПУ ПРОЗРАЧНОГО МОСТА | 2005 |
|
RU2304802C1 |
| US 7676625 B2, 09.03.2010 | |||
| US 7421532 B2, 02.09.2008 | |||
| US 20070234118 A1, 04.10.2007. | |||

