Предлагаемое изобретение относится к вычислительной технике и может найти применение при создании активных устройств локальных вычислительных сетей.
Коммутаторы используют два основных алгоритма маршрутизации: алгоритм прозрачного моста либо алгоритм маршрутизации от источника [1].
В алгоритме маршрутизации от источника полная информация о маршруте сообщения хранится в самом сообщении. Эта информация используется коммутаторами непосредственно как команда коммутации сообщения с входного порта на определенный выходной порт или группу выходных портов. Весь маршрут определен еще при начале передачи сообщения и задается передающей станцией.
Коммутаторы, работающие по принципу прозрачного моста, незаметны для конечных станций в сети. Конечные станции при использовании коммутаторов, работающих по принципу прозрачных мостов, работают точно так же, как и в случае их отсутствия, то есть не предпринимают никаких дополнительных действий, чтобы сообщение прошло через коммутатор. Коммутатор, работающий по принципу прозрачного моста, самостоятельно строит специальную адресную таблицу, на основании которой он решает, на какие порты передавать пришедшее сообщение. Коммутатор, работающий по принципу прозрачного моста, строит свою адресную таблицу на основании пассивного наблюдения за графиком, циркулирующим в подключенных к его портам сегментах. При этом коммутатор, работающий по принципу прозрачного порта, учитывает адреса источников сообщений, поступающих на порты коммутатора. По адресу источника сообщения коммутатор делает вывод о принадлежности станции с этим адресом сегменту сети, с которого пришло данное сообщение. Каждый порт коммутатора работает как конечная станция своего сегмента за одним исключением - порт коммутатора не имеет своего адреса. Порт коммутатора работает в неразборчивом режиме захвата сообщений, когда все поступающие на порт сообщения запоминаются в буферной памяти. С помощью такого режима коммутатор следит за всем графиком, передаваемым в присоединенных к нему сегментах, и использует проходящие через него сообщения для изучения состава сети.
Обучение вновь пришедшим адресам может производиться различными способами.
Самый прямой способ - занесение в очередную ячейку нового адреса. Но такое заполнение будет неупорядоченным, и поиск такого адреса в адресной таблице будет требовать больших вычислительных затрат.
Наиболее часто употребляемый способ - это использование специальных хэш-функций. Хэш-функция отображает широкое поле адреса станции в сети в узкое поле адреса ячейки в адресной таблице, где этот адрес станции хранится. Количество адресов, которые могут иметь конечные станции в сети, как правило, значительно превышает количество адресов, которые может сохранить в своей адресной таблице коммутатор, работающий по принципу прозрачного моста. Поэтому не исключены коллизии, когда разным адресам станций в сети соответствует одна и та же ячейка адресной таблицы. Для избавления от коллизий используются дополнительные механизмы, например каждому значению хэш-функции сопоставляется несколько ячеек адресной таблицы.
Кроме использования хэш-функций можно применять также метод упорядоченного заполнения адресной таблицы по возрастанию адресов конечных станций в сети или по убыванию. При приходе нового адреса производится переупорядочивание адресной таблицы. Поиск адреса в таблице может вестись методом двоичного поиска. Метод двоичного поиска заключается в следующем. В упорядоченном наборе данных выбирается некоторое произвольное данное и производится сравнение этого данного с искомым. Адрес выбранного данного запоминается. Если выбранное данное меньше искомого, то запомненный адрес делится пополам. По полученному адресу извлекается данное и вновь сравнивается с искомым. Если оно больше искомого, то к текущему адресу прибавляется половина расстояния от этого адреса до адреса предыдущего сравниваемого данного. По найденному адресу вновь извлекается данное и сравнивается с искомым. Так продолжается до тех пор, пока не будет найдено искомое данное либо пока расстояние между данными, участвующих в двух очередных сравнениях, не станет равным единице, что будет говорить о том, что искомого данного в упорядоченном наборе данных нет. Максимальное время, затрачиваемое на поиск ячейки в адресной таблице, при использовании алгоритма двоичного поиска растет логарифмически по основанию два от количества заполненных ячеек в адресной таблице.
Наиболее близким к предлагаемому устройству является устройство обработки адресов, применяемое фирмой Allayer в своих коммутаторах локальной вычислительной сети, работающего по принципу прозрачного моста, имеющее в своем составе таблицу адресов, блок реализации хэш-функции первого типа и блок управления [2]. В качестве хэш-функций в устройстве обработки адресов фирмы Allayer используются алгоритмы вычисления циклических полиномов [3], подобные вычислению циклического избыточного кода CRC (Cycle Redundancy Code - циклический избыточный код), который вычисляется по всему полю сетевого адреса. Каждому значению хэш-функции в адресной таблице соответствует несколько ячеек. После вычисления значения хэш-функции устройство проводит выборку ячейки из адресной таблицы, расположенной по адресу, равному значению хэш-функции. Сравнив сетевой адрес, находящийся в ячейке с сетевым адресом, ячейку с которым необходимо найти, устройство определяет, правильно ли найдена ячейка или произошла коллизия. В случае, если искомый сетевой адрес и найденный сетевой адрес не совпадают, устройство приходит к выводу, что произошла коллизия и необходимо проверить следующую ячейку, соответствующую тому же значению хэш-функции. Для каждого значения хэш-функции таких ячеек может быть 8 во внутренней адресной таблице, 4 в адресной таблице, использующей внешнюю память, и до 7 ячеек, разделяемых всеми значениями хэш-функции. Минимальная гарантированная выборка сетевых адресов при наихудшем разрешении по хэш-функциям, когда все адреса выборки приводят к одному и тому же значению хэш-функции, содержит 15 элементов, что составляет очень малую часть от общего размера адресной таблицы (от 1024 ячеек и выше). Время, затрачиваемое, на поиск сетевых адресов, приводящих к одинаковому значению хэш-функции, растет линейно по мере увеличения количества таких адресов, хранящихся в адресной таблице.
Задача изобретения состоит в повышении быстродействия и надежности обработки адресов в коммутаторах, работающих по принципу прозрачного моста и в которых бы для произвольных наборов адресов обработка адресов проводилась бы быстро, при этом существовало бы минимальное гарантированное количество адресов, которые сохранялись бы в адресной таблице при наихудшей выборке этих адресов в смысле хэш-функции, и это минимально гарантированное количество адресов было бы сопоставимо с размерами адресной таблицы, и максимальное время на поиск сетевых адресов при росте заполненности адресной таблицы возрастало бы медленнее, чем линейно.
Техническим результатом является обеспечение использования хэш-функций в сочетании с алгоритмом упорядоченного заполнения и двоичного поиска.
Предлагаемое устройство обработки адресов коммутатора локальной вычислительной сети, работающего по принципу прозрачного моста, использует одновременно механизм хэширования и механизм упорядоченного заполнения и двоичного поиска.
Предлагаемое устройство поясняется чертежом, на котором приведена функциональная схема устройства обработки адресов коммутатора локальной вычислительной сети, работающего по принципу прозрачного моста.
Устройство содержит следующие функциональные блоки:
· Адресная таблица 1, состоящая из:
- Физической страницы памяти 2, состоящей из области хэш-функции первого типа;
- Физической страницы памяти 3, состоящей из
- Области хэш-функции второго типа 4,
- Области упорядоченного заполнения и двоичного поиска 5,
· Блок реализации хэш-функции первого типа 6;
· Блок реализации хэш-функции второго типа 7;
· Блок реализации операции упорядоченного заполнения и двоичного поиска 8;
· Очередь заданий на блок реализации операции упорядоченного заполнения и двоичного поиска 9;
· Блок у правления 10.
Первая физическая страница памяти 2 связана с блоком реализации хэш-функции первого типа 6, вторая физическая страница памяти 3 состоит из двух областей, первая область 4 второй физической страницы памяти 3 связана с блоком реализации хэш-функции второго типа 7, вторая область 5 второй физической страницы памяти 3 связана с блоком упорядоченного заполнения и двоичного поиска 8, очередь заданий 9 связана с блоком реализации операции упорядоченного заполнения и двоичного поиска 8, при этом таблица адресов 1, блоки реализации хэш-функции первого 6 и второго 7 типов, очередь заданий 9 и блок реализации операции упорядоченного заполнения и двоичного поиска 8 связаны с блоком управления 10.
Принцип работы устройства обработки адресов коммутатора локальной вычислительной сети, работающего по принципу прозрачного моста, состоит в следующем.
Адресная таблица 1 коммутатора физически разделена на две страницы равного размера 2 и 3. Заполнение первой страницы 2 и поиск адресов в этой странице адресной таблицы 1 производятся с использованием хэш-функции первого типа. Хэш-функция первого типа использует аппаратную реализацию алгоритма вычисления циклического избыточного кода (CRC - Cycle Redundancy Code), который производит отображение широкого поля адреса станции в сети (например, 48-разрядного) в узкое поле адреса ячейки в адресной таблице (например, 10-разрядное). Вторая физическая страница 3 разделена логически на две части 4 и 5. Заполнение первой половины 4 второй страницы 3 и поиск адресов в этой части таблицы производятся с использованием хэш-функции второго типа. Хэш-функция второго типа использует аппаратную реализацию алгоритма вычисления циклического избыточного кода, который производит отображение широкого поля адреса станции в сети (например, 48-разрядного) в узкое поле адреса ячейки в адресной таблице (например, 9-разрядное). Хэш-функция второго типа отличается от хэш-функции первого типа тем, что она использует другой порождающий многочлен, и разрядность результата на ее выходе на один разряд меньше разрядности результата на выходе первой хэш-функции. Заполнение второй половины 5 второй страницы 3 адресной таблицы 1 производится упорядоченно по возрастанию адресов станций. Адреса станций в этой части таблицы ищутся методом двоичного поиска. Соответствующие операции реализованы в блоке упорядоченного заполнения и двоичного поиска 8.
Блок управления 10 реализует управление доступом к адресной таблице 1 со стороны блоков реализации хэш-функций первого 6 и второго 7 типов и блока упорядоченного заполнения и двоичного поиска 8, синхронизует работу блоков реализации хэш-функции первого 6 и второго 7 типов, а также блока упорядоченного заполнения и двоичного поиска 8 и очереди заданий 9. Также блок управления 10 обрабатывает входящие запросы от внешних устройств на обучение либо поиск адреса в адресной таблице 1 и выдает внешним устройствам результаты обработки запроса. Блок управления 10 может быть реализован на машине конечных автоматов либо на микропроцессорном ядре.
Использование двух хэш-функций позволяет более равномерно отображать адреса станций в сети в адреса ячеек адресной таблицы 1. Обращение к этим областям выполняется за один машинный такт.
Использование области последовательного заполнения и двоичного поиска позволяет коммутатору работать с некоторым минимальным гарантированным количеством станций в сети даже в случае, когда все эти станции обладают наихудшей по отношению к обеим хэш-функциям выборкой адресов. Наихудшая выборка адресов в данном случае - это такая выборка адресов, при которой все члены выборки приводят к одинаковым значениям обеих хэш-функций, т.е. вызывают коллизии. Обращение к области упорядоченного заполнения и двоичного поиска выполняется медленнее, чем это происходит при использовании хэш-функций. В данном случае время обращения растет линейно при заполнении таблицы и логарифмически при поиске адресов в таблице. Поэтому, чтобы не блокировать работу устройств, с которых поступает адресная информация на устройство обработки адресов коммутатора, запросы к этой области памяти поступают через буферную очередь заданий, выполненную, например, по принципу первым пришел - первым вышел (FIFO - first input, first output).
Обе хэш-функции используются одновременно, и если произошла коллизия по одной хэш-функции, то управление передается второй хэш-функции, если же произошла коллизия и по второй хэш-функции, то управление передается через очередь заданий в блок реализации операции упорядоченного заполнения и двоичного поиска 8. Управление работой устройства обработки адресов коммутатора локальной вычислительной сети осуществляется блоком управления 10.
Преимущество предлагаемого устройства в том, что оно позволяет производить быстрый поиск адресов станций в адресной таблице и быстрое заполнение адресной таблицы для случайных наборов адресов станций и гарантирует возможность работы коммутатора с фиксированным минимальным количеством адресов станций в случае наихудшей выборки этих адресов в смысле хэш-функций. Минимальное гарантированное количество адресов станций сопоставимо с размером всей адресной таблицы и равно четверти размера адресной таблицы. Для наихудшей выборки адресов в смысле хэш-функций обработка адресов производится медленней, чем для любой иной произвольной выборки. Максимальное время, затрачиваемое на поиск сетевых адресов, хранящихся в области упорядоченного заполнения и двоичного поиска, растет лишь логарифмически по основанию два по отношению к количеству сетевых адресов, хранящихся в этой области адресной таблицы.
Источники информации
1. Олифер В.Г., Олифер Н. А. Компьютерные сети. Принципы, технологии, протоколы. - СПб.: питер, 2001. - 672 с.: ил.
2. Understanding Address Hashing. Application Note AN002. Revision 1. Allayer Communications. August 2000. (www.allayer.com/pdf/an002.pdf)
3. Акритас А. Основы компьютерной алгебры с приложениями. Пер. с англ. Панкратьева Е.В. Изд-во "Мир". Москва, 1994.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОРГАНИЗАЦИИ ТАБЛИЦЫ ФИЛЬТРАЦИИ МЕЖСЕТЕВОГО КОММУТАТОРА И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2013 |
|
RU2538323C1 |
| СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ НА ОСНОВЕ ПОТОКА ДАННЫХ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2005 |
|
RU2281546C1 |
| СПОСОБ И УСТРОЙСТВО ГИБРИДНОЙ КОММУТАЦИИ РАСПРЕДЕЛЕННОЙ МНОГОУРОВНЕВОЙ ТЕЛЕКОММУНИКАЦИОННОЙ СИСТЕМЫ, БЛОК КОММУТАЦИИ И ГЕНЕРАТОР ИСКУССТВЕННОГО ТРАФИКА | 2014 |
|
RU2542906C1 |
| КЛАСТЕРНАЯ СИСТЕМА С ПРЯМОЙ КОММУТАЦИЕЙ КАНАЛОВ | 2011 |
|
RU2461055C1 |
| УСТРОЙСТВО ДЛЯ ПРИЕМА И ПЕРЕДАЧИ ДАННЫХ С ВОЗМОЖНОСТЬЮ ОСУЩЕСТВЛЕНИЯ ВЗАИМОДЕЙСТВИЯ С OpenFlow КОНТРОЛЛЕРОМ | 2014 |
|
RU2584471C1 |
| ТРАНСЛЯЦИЯ АДРЕСОВ ВВОДА-ВЫВОДА В АДРЕСА ЯЧЕЕК ПАМЯТИ | 2010 |
|
RU2547705C2 |
| ПАКЕТНЫЙ КОММУТАТОР, ПАМЯТЬ N ПОРТОВ И СИСТЕМА ДЛЯ КОММУТАЦИИ ПАКЕТОВ (ВАРИАНТЫ) | 1992 |
|
RU2115254C1 |
| Программируемые устройства для обработки запросов передачи данных памяти | 2016 |
|
RU2690751C2 |
| ИСПОЛЬЗОВАНИЕ АУТЕНТИФИЦИРОВАННЫХ МАНИФЕСТОВ ДЛЯ ОБЕСПЕЧЕНИЯ ВНЕШНЕЙ СЕРТИФИКАЦИИ МНОГОПРОЦЕССОРНЫХ ПЛАТФОРМ | 2014 |
|
RU2599340C2 |
| УСТРОЙСТВО МОНИТОРИНГА ИНФОРМАЦИОННОГО ТРАФИКА | 2020 |
|
RU2740534C1 |
Предлагаемое изобретение относится к вычислительной технике и может найти применение при создании активных устройств локальных вычислительных сетей. Техническим результатом является обеспечение возможности использование хэш-функций в сочетании с алгоритмом упорядоченного заполнения и двоичного поиска, повышение быстродействия и надежности обработки адресов в коммутаторах. Указанный результат достигается за счет того, что устройство имеет в своем составе таблицу адресов, блок реализации хэш-функций первого и второго типа, блок реализации операции упорядоченного заполнения и двоичного поиска и блок управления. Таблица адресов разделена на две независимые физические страницы памяти. Очередь заданий связана с блоком реализации операции упорядоченного заполнения и двоичного поиска. Таблица адресов, блоки реализации хэш-функций первого и второго типов, очередь заданий и блок реализации операции упорядоченного заполнения и двоичного поиска связаны с блоком управления. 1 ил.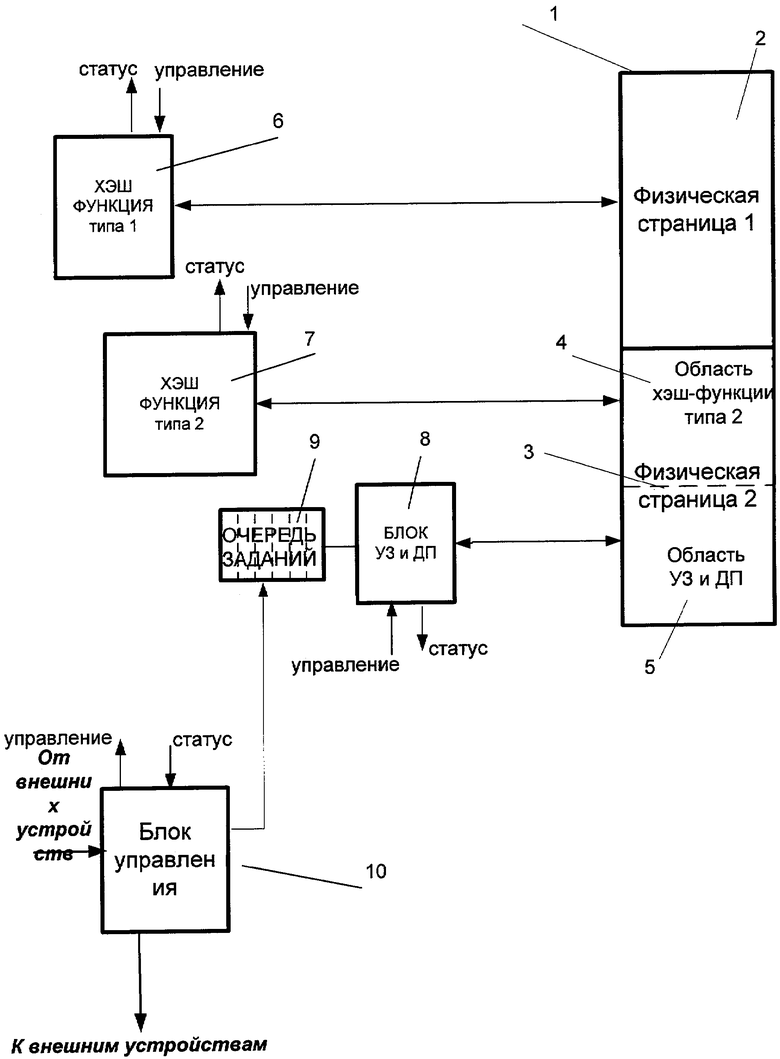
Устройство обработки адресов коммутатора локальной вычислительной сети, работающего по принципу прозрачного моста, имеющее в своем составе таблицу адресов, блок реализации хэш-функции первого типа, отличающееся тем, что оно снабжено блоком реализации хэш-функции второго типа, блоком реализации операции упорядоченного заполнения таблицы адресов и двоичного поиска адреса и очередью заданий на блок реализации операции упорядоченного заполнения таблицы адресов и двоичного поиска адреса, а также блоком управления, предназначенным для синхронизации работы блоков реализации хэш-функции первого и второго типов, и блока реализации операции упорядоченного заполнения таблицы адресов и двоичного поиска адреса, а также для обработки входящих запросов от внешних устройств и выдачи внешним устройствам результатов обработки запросов, при этом, таблица адресов разделена на две независимые физические страницы памяти, первая физическая страница памяти связана с блоком реализации хэш-функции первого типа, вторая физическая страница памяти состоит из двух областей, первая область второй физической страницы памяти связана с блоком реализации хэш-функции второго типа, вторая область второй физической страницы памяти связана с блоком реализации операции упорядоченного заполнения таблицы адресов и двоичного поиска адреса, очередь заданий связана с блоком реализации операции упорядоченного заполнения адресов и двоичного поиска адреса.
| RU 2001126897 А, 20.07.2003 | |||
| US 6804767 В1, 12.10.2004 | |||
| JP 2004326772 A, 18.11.2004 | |||
| RU 2001126895 A, 20.07.2003. |

