Область техники
Данное изобретение касается способа и устройства для приема данных.
Уровень техники
Данные разделяют на пакеты данных для их передачи по сети/каналам связи. Сетевой протокол или кодирование обычно используется, чтобы обеспечить механизм коррекции ошибок и тем самым улучшить надежность передачи данных. Например, когда данные передают по Интернету, должен использоваться протокол TCP (Transmission Control Protocol, протокол управления передачей), чтобы обеспечить механизм обнаружения ошибок и повторной передачи и передать данные достоверно, то есть передающему терминалу сообщают, чтобы он повторно передал данные, когда обнаружена потеря пакетов данных.
Однако принимающему терминалу не разрешается возвращать информацию о потере пакетов данных и ошибках передающему терминалу, когда данные передаются в мультимедийных каналах телевизионного вещания, так как для этого используются однонаправленные каналы, и данные передают способом широковещательной/многоадресной передачи "один - многим", так что вышеупомянутый механизм обнаружения ошибок и повторной передачи не может использоваться. В этом случае для пакетов данных перед передачей должно быть выполнено кодирование, использующее прямую коррекцию ошибок (FEC, Forward Error Correction). Типичная прямая коррекция ошибок прикладного уровня включает коды Рида-Соломона (RS), цифровые фонтанные коды и т.п. Поскольку кодирование и декодирование для кода Рида-Соломона имеет высокую сложность, код Рида-Соломона обычно пригоден для ситуаций, в которых длина кода мала. Код с преобразованием Лаби (LT, Luby Transform) и код Raptor являются двумя практическими применимыми цифровыми фонтанными кодами. Коду LT присуще линейное время кодирования и декодирования, что представляет собой существенное улучшение по сравнению с кодом Рида-Соломона, в то время как у кода Raptor более высока эффективность декодирования, поскольку код Raptor использует технику предварительного кодирования. Код Raptor компании Digital Fountain, Inc., используется как службой мультимедийной широковещательной/ многоадресной передачи (MBMS, Multimedia Broadcast/Multicast Service), так и цифровым телевидением (DVB, Digital Video Broadcasting) проекта партнерства 3-го поколения (3GPP, 3rd Generation Partnership Project) как схема кодирования для обеспечения прямой коррекции ошибок.
Если первые К битов кодированного кодового слова совпадают с битами информации, то такой код называют систематическим кодом. Процесс кодирования является процессом формирования N битов длины кода в соответствии с К битами информации, при этом к ним добавляют N-K битов четности, чтобы обеспечить обнаружение и исправление ошибок. Коды LT не поддерживают подход кодирования с использованием систематического кода и, таким образом, код LT не может удовлетворить некоторым практическим требованиям к кодированию с прямой коррекцией ошибок. Код Raptor поддерживает систематический код; однако код Raptor нуждается в отдельном процессе предварительного кодирования, то есть нуждается в матрице предварительного кодирования, и, таким образом, сложность кодирования очень высокая.
Из-за недостатков вышеупомянутых способов кодирования был предложен код с генераторной матрицей низкой плотности (LDGC, Low Density Generator Matrix Code). Код LDGC относится к типу линейных блочных кодов, а ненулевые элементы в его генераторной матрице (матрице кодирования) обычно разреженные. При этом код LDGC является также систематическим кодом.
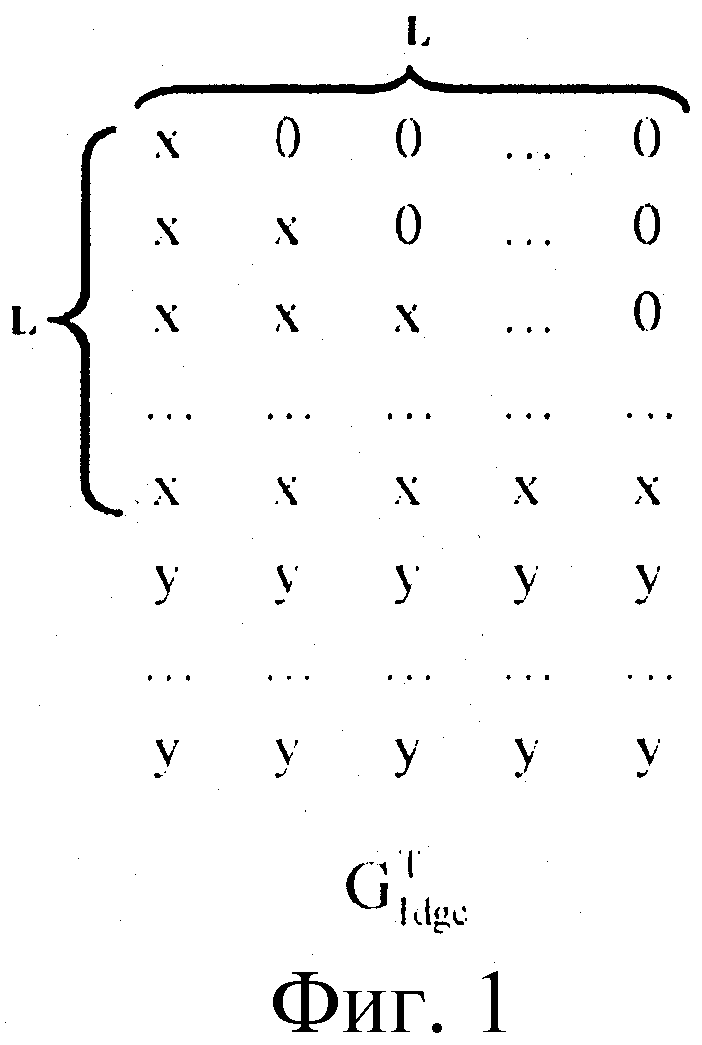
На фиг.1 показана генераторная матрица LDGC. Как показано на фиг.1, квадратная матрица, соответствующая первым L строкам в транспонированной генераторной матрице 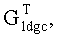 кода LDGC является обычно верхней или нижней треугольной матрицей, обращение которой может быть достигнуто посредством итерации. При этом х и у на фиг.1 могут быть равны 0.
кода LDGC является обычно верхней или нижней треугольной матрицей, обращение которой может быть достигнуто посредством итерации. При этом х и у на фиг.1 могут быть равны 0.
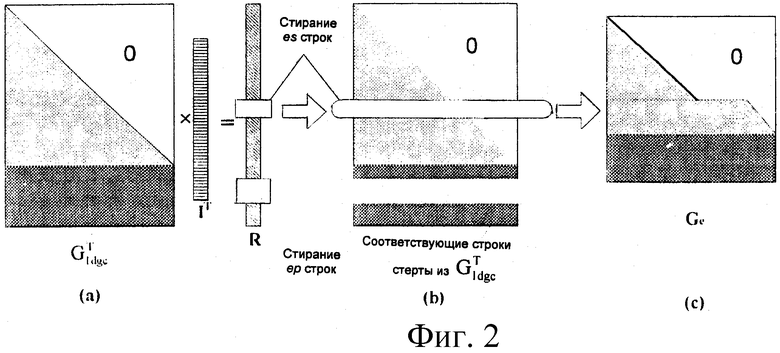
Фиг.2 является иллюстрацией выполнения соответствующего стирания для генераторной матрицы LDGC во время декодирования, согласно состоянию стирания принятых кодовых слов.
Как показано на фиг.2, если при передаче данных возникает ошибка (которую называют "стертыми данными"), то принимающий терминал должен выполнить соответствующую операцию стирания на матрице 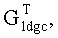 прежде чем использовать
прежде чем использовать 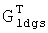 для декодирования. То есть, если предположить, что символы {ri, ri+1,…, ri+x1} и {ri, rj+1,…, rj+х2} в последовательности R (r0, r1……rN-1) длиной N битов стерты каналом, тогда строки {i, i+1,…i+X1} и {j, j+1,…j+X2} в матрице
для декодирования. То есть, если предположить, что символы {ri, ri+1,…, ri+x1} и {ri, rj+1,…, rj+х2} в последовательности R (r0, r1……rN-1) длиной N битов стерты каналом, тогда строки {i, i+1,…i+X1} и {j, j+1,…j+X2} в матрице 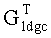 должны также быть стерты, чтобы получить генераторную матрицу Ge со стиранием. Заметим, что матрица Ge является одинаковой для одинаковых состояний ошибок/потери данных.
должны также быть стерты, чтобы получить генераторную матрицу Ge со стиранием. Заметим, что матрица Ge является одинаковой для одинаковых состояний ошибок/потери данных.
Согласно известному уровню техники, когда для передачи данных используются способы кодирования и декодирования с прямой коррекцией ошибок с использованием LDGC и т.п., передающий терминал выполняет кодирование пакетов данных с прямой коррекции ошибок, а принимающий терминал генерирует соответствующую генераторную матрицу Ge со стиранием согласно состоянию передачи каждого пакета данных и декодирует пакеты данных, используя Ge. Эффективность этого способа для приема данных очень низкая. Кроме того, когда в пакете данных слишком много ошибок, декодирование не может быть выполнено, и весь пакет данных должен быть отброшен, поэтому эффективность передачи данных значительно уменьшается, когда условия в сети/канале относительно плохие.
Сущность изобретения
Данное изобретение предлагает способ и устройство для приема данных, обеспечивающие улучшенную эффективность передачи данных и увеличенную скорость обработки данных, декодирования и т.п., чтобы преодолеть недостатки предшествующего уровня техники.
Чтобы решить вышеупомянутую проблему, данное изобретение предлагает способ приема данных, включающий обработку терминалом, принимающим данные, каждого принятого блока файла следующим образом:
А: выполнение декодирования с прямой коррекцией ошибок для Тb декодируемых последовательностей битов блока файла с получением, соответственно, Тb декодированных последовательностей битов информации с длиной К,
при этом i-тая декодируемая последовательность битов образована из i-тых битов каждого нестертого информационного сегмента файла и контрольного сегмента файла блока файла последовательно согласно последовательности информационных сегментов файла и контрольных сегментов файла;
В: объединение К декодированных информационных сегментов файла блока файла последовательно, чтобы генерировать исходные данные файла для блока файла;
при этом m-ный декодированный информационный сегмент файла образован из m-ных битов Тb декодированных последовательностей битов информации в последовательности, соответствующей последовательности упомянутых последовательностей битов информации;
i=1,...., Тb; m=1,…, К; длина информационного сегмента файла и контрольного сегмента файла составляет Тb битов.
Дополнительно, терминал, принимающий данные, получает нестертые информационные сегменты файла и контрольные сегменты файла из пакетов передачи; при этом пакеты передачи включают индексы сегментов файла; и индекс сегмента файла, соответствующий информационному сегменту файла, меньше чем индекс сегмента файла, соответствующий контрольному сегменту файла, в одном и том же блоке файла; и
терминал, принимающий данные, определяет последовательность информационных сегментов файла и контрольных сегментов файла согласно индексам сегментов файла.
Дополнительно, пакеты передачи включают индексы блоков файла;
а способ после завершения обработки блока файла включает следующий шаг:
С: терминал, принимающий данные, объединяет исходные данные файла каждого блока файла последовательно согласно индексам блоков файла, чтобы генерировать исходные данные файла.
Дополнительно, если F/T не является целым числом, то терминал, принимающий данные, удаляет Р битов заполнения из последнего сегмента файла последнего блока файла.
Дополнительно, декодирование с прямой коррекцией ошибок использует алгоритм LDGC, и способ перед выполнением упомянутого декодирования с прямой коррекцией ошибок включает следующий шаг:
А1: терминал, принимающий данные, удаляет соответствующие строки транспонированной генераторной матрицы 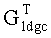 кода LDGC, чтобы генерировать матрицу Ge, согласно индексам сегментов файла стертых информационных сегментов файла и контрольных сегментов файла в блоке файла;
кода LDGC, чтобы генерировать матрицу Ge, согласно индексам сегментов файла стертых информационных сегментов файла и контрольных сегментов файла в блоке файла;
при этом на шаге А упомянутое декодирование с прямой коррекцией ошибок выполняется для декодируемых последовательностей битов с использованием Ge.
Данное изобретение также включает устройство для приема данных, включающее блок приема, блок декодирования и блок объединения данных, при этом:
блок приема используется для вывода Тb декодируемых последовательностей битов блока файла; при этом i-тая декодируемая последовательность битов образована из i-тых битов каждого нестертого информационного сегмента файла и контрольного сегмента файла блока файла последовательно согласно последовательности информационных сегментов файла и контрольных сегментов файла;
блок декодирования используется для выполнения декодирования с прямой коррекцией ошибок для Тb декодируемых последовательностей битов блока файла, выведенных из блока приема, для вывода, соответственно, Тb декодированных последовательностей битов информации с длиной К;
блок объединения данных используется для объединения К декодированных информационных сегментов файла блока файла последовательно, чтобы генерировать исходные данные файла блока файла; при этом m-ный декодированный информационный сегмент файла образован из m-ных битов Тb декодированных последовательностей битов информации в последовательности, соответствующей последовательности упомянутых последовательностей битов информации;
где i=1,...., Tb; m=1,…, K; длина информационного сегмента файла и контрольного сегмента файла составляет Тb битов.
Блок приема получает нестертые информационные сегменты файла и контрольные сегменты файла из пакетов передачи; пакеты передачи включают индексы сегментов файла; и индекс сегмента файла, соответствующий информационному сегменту файла, меньше чем индекс сегмента файла, соответствующий контрольному сегменту файла, в одном и том же блоке файла; и
блок приема определяет последовательность информационных сегментов файла и контрольных сегментов файла согласно индексам сегментов файла.
Дополнительно, пакеты передачи также включают индексы блоков файла;
блок объединения данных также используется для объединения исходных данных файла каждого блока файла последовательно согласно индексам блоков файла, чтобы генерировать исходные данные файла.
Дополнительно, если F/T не является целым числом, то блок объединения данных также используется для того, чтобы удалить Р битов заполнения из последнего сегмента файла последнего блока файла;
при этом P=8×(T×Kt-F); F является полной длиной упомянутых данных в байтах, 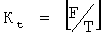 и Т=Тb/8.
и Т=Тb/8.
Дополнительно, декодирование с прямой коррекцией ошибок использует алгоритм LDGC; и
блок декодирования также удаляет соответствующие строки транспонированной генераторной матрицы 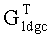 кода LDGC, чтобы генерировать матрицу Ge, согласно индексам сегментов файла стертых информационных сегментов файла и контрольных сегментов файла в блоке файла до выполнения упомянутого декодирования с прямой коррекцией ошибок; и использует Ge, чтобы выполнить упомянутое декодирование с прямой коррекцией ошибок для декодируемых последовательностей битов.
кода LDGC, чтобы генерировать матрицу Ge, согласно индексам сегментов файла стертых информационных сегментов файла и контрольных сегментов файла в блоке файла до выполнения упомянутого декодирования с прямой коррекцией ошибок; и использует Ge, чтобы выполнить упомянутое декодирование с прямой коррекцией ошибок для декодируемых последовательностей битов.
При использовании способа передачи данных и соответствующего способа и устройства для декодирования согласно данному изобретению можно значительно понизить рабочую нагрузку на принимающий терминал; дополнительно, так как потеря единственного пакета данных/информационного сегмента файла не вызывает потери (стирания) большого количества информации кодовых слов в принимающем терминале, показатель успешности декодирования и надежность передачи данных существенно улучшаются.
Краткое описание чертежей
Фиг.1 показывает генераторную матрицу LDGC;
фиг.2 является иллюстрацией выполнения соответствующего стирания для генераторной матрицы LDGC во время декодирования согласно состоянию стирания принятых кодовых слов;
фиг.3 показывает последовательность операций способа передачи данных;.
фиг.4 является иллюстрацией выполнения кодирования с прямой коррекцией ошибок для каждого информационного сегмента файла в блоке файла;
фиг.5 показывает структуру пакета передачи согласно данному изобретению;
фиг.6 показывает последовательность операций способа передачи данных согласно примеру осуществления данного изобретения;
фиг.7 является иллюстрацией построения каждого сегмента файла в блоке файла с использованием способа данного изобретения;
фиг.8 показывает устройство для приема данных согласно примеру осуществления данного изобретения.
Предпочтительные варианты осуществления изобретения
Основная идея данного изобретения состоит в том, что в терминале, передающем данные, осуществляется: разделение данных на информационные сегменты файла с фиксированной длиной, выполнение кодирования с прямой коррекцией ошибок (FEC) для последовательностей битов информации, образованных из битов, находящихся в одной и той же позиции во множестве информационных сегментов файла, чтобы генерировать контрольные сегменты файла, и затем инкапсулирование каждого информационного сегмента файла и контрольного сегмента файла в пакет данных для передачи; а в терминале, принимающем данные, осуществляется: выполнение декодирования последовательностей битов, образованных из битов, находящихся в одной и той же позиции во множестве сегментов файла, чтобы генерировать информационные сегменты файла, и затем объединение информационных сегментов файла последовательно согласно номерам блоков и номерам сегментов информационных сегментов файла, чтобы генерировать исходные данные файла.
Способ передачи данных, использующий вышеописанную идею, и соответствующие способ и устройство для приема данных, будут далее описаны подробно со ссылкой на чертежи и примеры.
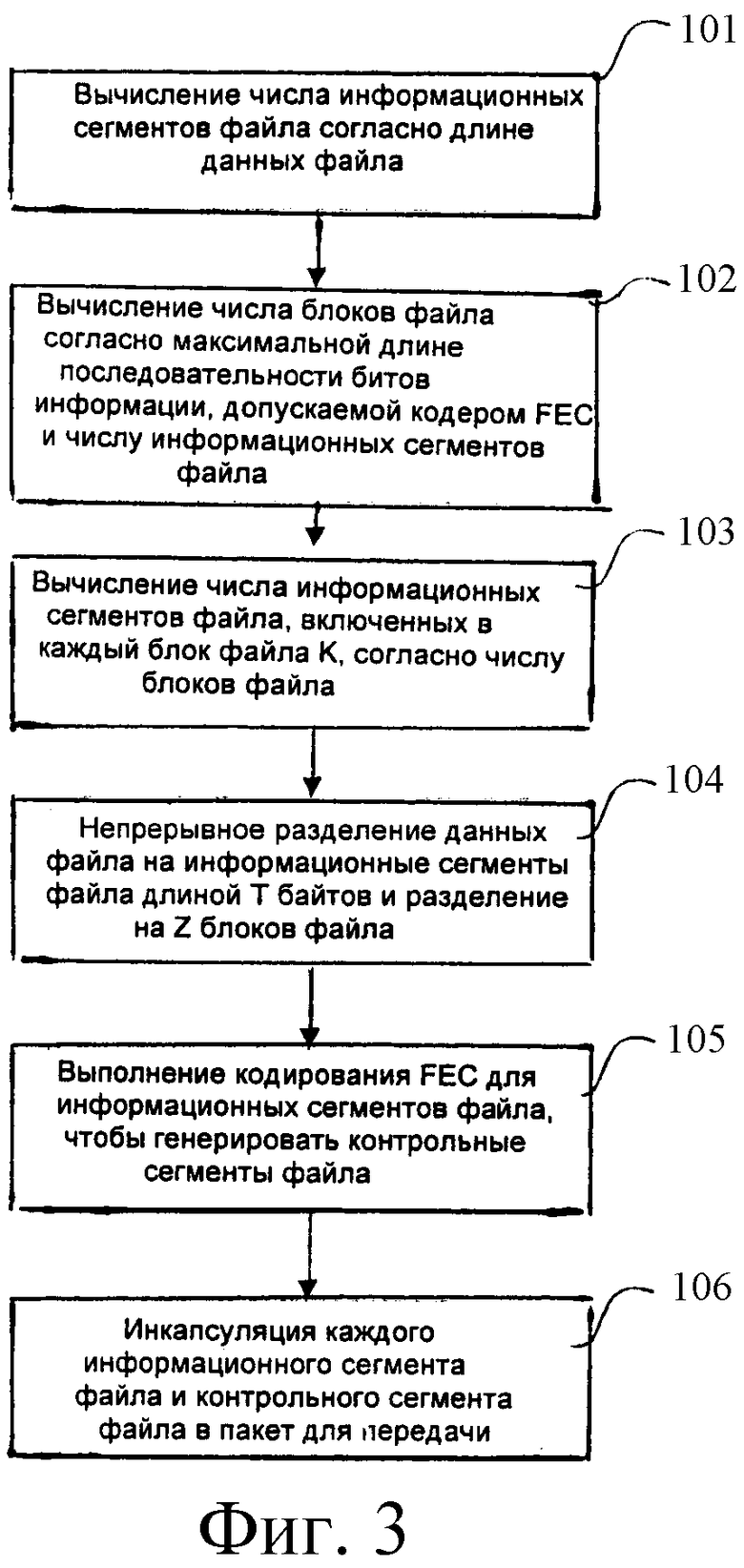
Фиг.3 поясняет последовательность операций способа передачи данных согласно примеру осуществления данного изобретения. Как показано на фиг.3, способ включает следующие шаги.
101: вычисление числа информационных сегментов файла согласно длине данных файла, которые должны быть переданы (они также называются исходными данными файла).
Если длина данных файла составляет F байтов, и длина информационного сегмента файла составляет Т байтов, то данные файла, которые должны быть переданы, разделяют на 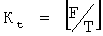 информационных сегментов файла. При этом
информационных сегментов файла. При этом  означает операцию округления до ближайшего большего целого (ceil).
означает операцию округления до ближайшего большего целого (ceil).
Если F/T не является целым числом, то последний информационный сегмент файла должен быть заполнен.
Например, если F=10240000 байтов, и Т=512 байтов, то:
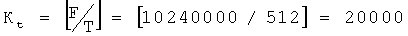 ; то есть данные файла разделяют на 20000 информационных сегментов файла.
; то есть данные файла разделяют на 20000 информационных сегментов файла.
102: вычисление числа блоков файла согласно максимальной длине последовательности битов информации, допускаемой кодером FEC, и числу информационных сегментов файла.
Максимальной длиной последовательности битов информации, допускаемой кодером FEC, является Кmах, и эта величина обычно не больше 8192 битов, тогда число блоков файла 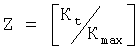 .
.
Согласно вышеприведенному примеру, если Кmах=8000 битов, то число блоков файла, выделенных из данных одного файла, 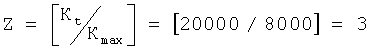 .
.
103: вычисление числа информационных сегментов файла, включенных в каждый блок файла К, согласно числу блоков файла.
Данные файла разделяют на Z=ZL+ZS блоков файла. При этом в первых ZL блоках файла каждый блок файла включает 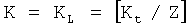 информационных сегмента файла, и их называют длинными блоками файла; а в последних ZS блоках файла каждый блок файла включает
информационных сегмента файла, и их называют длинными блоками файла; а в последних ZS блоках файла каждый блок файла включает 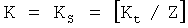 информационных сегмента файла, и их называют короткими блоками файла. При этом
информационных сегмента файла, и их называют короткими блоками файла. При этом  означает операцию округления до ближайшего меньшего целого (floor).
означает операцию округления до ближайшего меньшего целого (floor).
Вышеупомянутые ZL и ZS вычисляют, используя следующие формулы:
Если  , то
, то 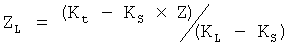 ,
,
если КL=КS, то ZL=Z; ZS=Z-ZL.
Согласно вышеупомянутому примеру, когда Kt=20000:
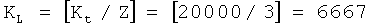 информационных сегментов файла;
информационных сегментов файла;
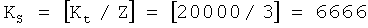 информационных сегментов файла;
информационных сегментов файла;
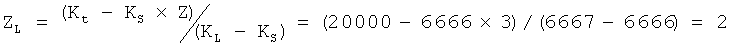 ;
;
ZS=Z-ZL=3-2=1.
Другими словами, каждый из первых двух блоков файла включает 6667 информационных сегментов файла, а последний блок файла включает 6666 информационных сегментов файла.
Основная цель вышеописанного способа назначения информационных сегментов файла состоит в том, чтобы последний блок файла не включал слишком мало информационных сегментов файла. Так как на последующих шагах согласно данному изобретению соответствующее число битов для кодирования извлекают из блока файла согласно числу информационных сегментов файла, включенных в блок файла, то чем меньше будет кодированных кодовых слов, тем хуже эффективность кодирования и декодирования. Поэтому избежать включения в блок файла слишком малого числа информационных сегментов файла означает избежать слишком низкой эффективности кодирования и декодирования.
Конечно, если Kt/Kmax является целым числом (то есть Kt/Z является целым числом), то каждый блок файла включает одно и то же число информационных блоков файла К=Кmах, и нет необходимости дифференцировать длинные и короткие блоки файла.
104: непрерывное разделение данных файла, которые должны быть переданы, на Kt информационных сегментов файла с длиной Т байтов согласно числу информационных сегментов Kt файла, числу Z блоков файла и числу информационных сегментов К файла, включенных в блок файла, полученный посредством вышеописанных вычислений; и группировка каждого информационного сегмента файла последовательно, при разделении информационных сегментов файла на Z блоков файла.
Если Kt/Kmax не является целым числом, то вышеупомянутые Z блоков файла включают ZL длинных блоков файла и ZS коротких блоков файла. Длинные блоки файла включают KL информационных сегментов файла, а короткие блоки файла включают KS информационных сегментов файла.
Дополнительно, в блоке файла также требуется присвоить уникальный индекс сегмента файла (FSI, File Segment Index) для каждого информационного сегмента файла каждого блока файла. При этом FSI является положительным целым числом.
Например, FSI первого информационного сегмента файла определенного блока файла равен 0, FSI второго равен 1 и т.д.
105: выполнение кодирования FEC для последовательностей битов информации, образованных из битов, находящихся в одной и той же позиции каждого информационного сегмента файла в каждом блоке файле, чтобы генерировать последовательности контрольных битов (битов проверки); и размещение каждого бита последовательностей контрольных битов в одной и той же позиции контрольных сегментов файла последовательно;
выполнение кодирования FEC для последовательностей битов информации, образованных из j-ого бита каждого информационного сегмента файла в каждом блоке файла, чтобы генерировать j-ую последовательность контрольных битов, и размещение m-ного бита указанной последовательности контрольных битов в позиции j-ого бита m-ного контрольного сегмента файла блока файла.
Выше j=1,2,...., Tb; m=1,…, M; M является длиной последовательности контрольных битов.
Длина вышеупомянутой последовательности битов информации равна числу К информационных сегментов файла, включенных в блок файла. То есть, что касается длинного блока файла, длина каждой последовательности битов информации составляет KL; что касается короткого блока файла, длина каждой последовательности битов информации составляет KS.
Что касается различных блоков файла, значение М для них также может быть различным, так как длина последовательности битов информации может различаться.
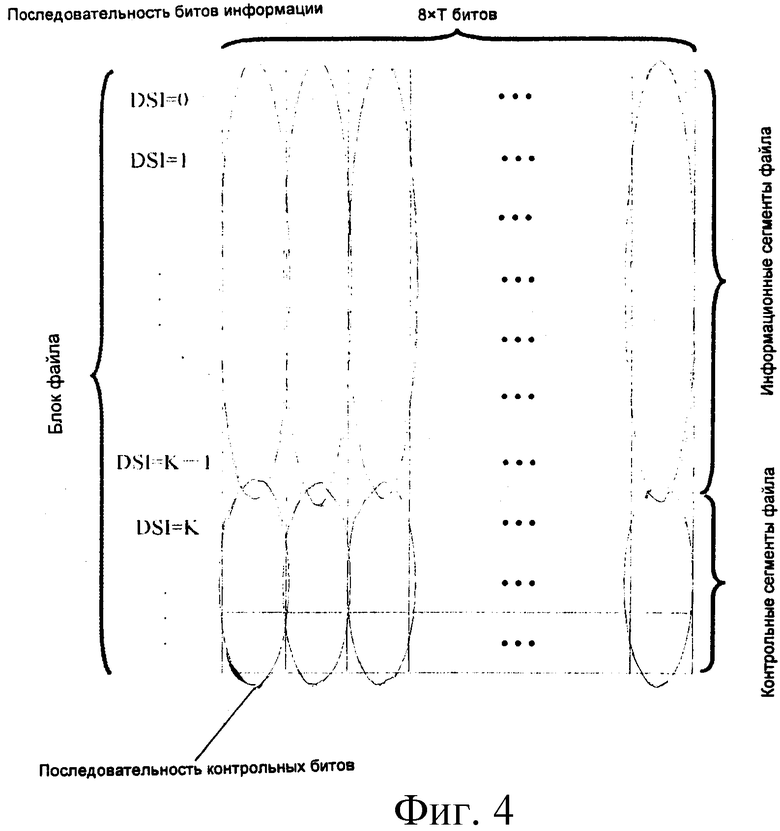
Фиг.4 является иллюстрацией выполнения кодирования FEC для каждого информационного сегмента файла в блоке файла при использовании способа данного изобретения.
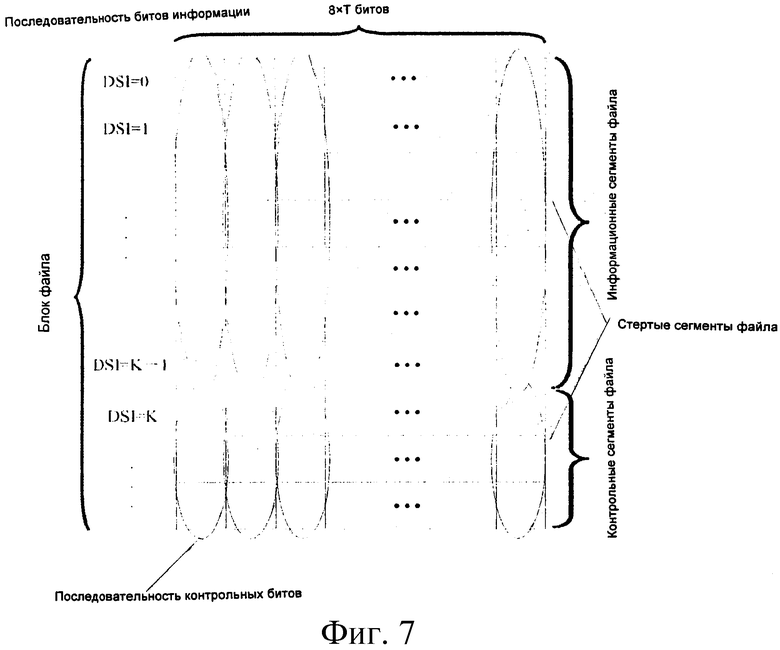
Как показано на фиг.4, блок файла включает множество информационных сегментов файла и контрольных сегментов файла. Каждый информационный сегмент файла включает Тb=8×Т битов, и биты в одной и той же позиции каждого сегмента файла составляют последовательность битов информации; кодирование FEC выполняется для каждой такой последовательности битов информации, чтобы генерировать последовательность контрольных битов.
Следовательно, каждый блок файла включает 8×Т последовательностей битов информации и последовательностей контрольных битов. Длина последовательности битов информации составляет К битов, и если Kt/Kmax не является целым числом, то К=KL или KS; длина последовательности контрольных битов связана с длиной последовательности битов информации и алгоритмом кодирования FEC.
В этом примере алгоритм кодирования FEC использует систематические коды, например LDGC, то есть для последовательности битов информации длиной К битов первые К битов кодового слова, сформированного после кодирования, являются теми же самыми, что и последовательность битов информации, а последовательность, образованная из последующих битов кодового слова, является последовательностью контрольных битов.
Другими словами, одно кодовое слово образовано из одной последовательности битов информации и одной последовательности контрольных битов.
106: инкапсуляция каждого информационного сегмента файла и каждого контрольного сегмента файла в пакет передачи последовательно для передачи после завершения кодирования каждого бита информационных сегментов файла блока файла.
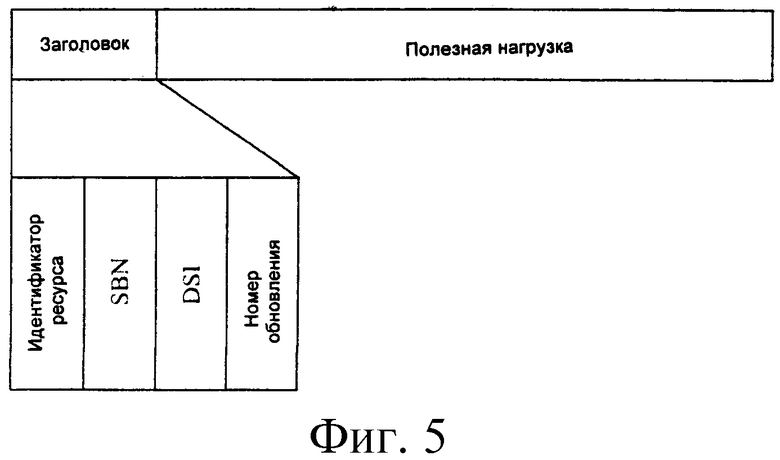
Фиг.5 показывает структуру пакета передачи согласно данному изобретению. Как показано на фиг.5, пакет передачи состоит из двух частей: заголовок (HDR) и полезная нагрузка.
Заголовок включает: идентификатор ресурса, индекс блока файла (FBI, file block index), индекс сегмента файла (FSI, file segment index) и порядковый номер обновления.
Идентификатор ресурса используется, чтобы идентифицировать файл/ресурс, которому принадлежат данные (информационные сегменты файла или контрольные сегменты файла), переданные в пакете передачи.
Индекс блока файла используется, чтобы идентифицировать индекс блока файла данных (информационного сегмента файла или контрольного сегмента файла), переданного в пакете передачи.
Индекс сегмента файла является номером информационного сегмента файла или контрольного сегмента файла, переданного в пакете передачи.
Номер обновления является номером версии файла/ресурса, которому принадлежат данные (информационные сегменты файла или контрольные сегменты файла), переданные в пакете передачи.
Если один пакет передачи включает множество сегментов файла, то поле индекса сегмента файла указывает FSI первого сегмента файла, включенного в пакет передачи.
Имеется два вида пакетов передачи: информационные пакеты передачи и контрольные пакеты передачи.
В полезной нагрузке информационного пакета передачи есть только информационные сегменты файла; в полезной нагрузке контрольного пакета передачи есть только контрольные сегменты файла. Поэтому FSI информационного пакета передачи должен быть меньше, чем К или KL (соответствует длинному блоку файла) или KS (соответствует короткому блоку файла); FSI контрольного пакета передачи должен быть больше или равен К или KL (соответствует длинному блоку файла) или KS (соответствует короткому блоку файла).
Полезная нагрузка каждого пакета передачи может включать G сегментов файла, где значение G определено следующей формулой:
G=min{Р/T, Gmax};
где Р является максимальным размером полезной нагрузки пакета передачи, Gmax является максимальным числом сегментов файла, допускаемых пакетом передачи, и длина сегмента файла составляет Т битов.
Например, Р=512 является максимальным размером полезной нагрузки пакета передачи, Gmax=10 является максимальным числом сегментов файла, допускаемых пакетом передачи. Полезная нагрузка пакета передачи включает G=min{Р/Т, Gmax}=min{1,10}=1 сегмент файла.
Подводя итог, согласно данному изобретению данные файла разделяют на информационные сегменты файла, которые являются одинаковыми по объему, и кодирование FEC выполняют на каждом бите, находящемся в одной и той же позиции информационного сегмента файла, сгруппированного в один и тот же блок файла; поэтому в процессе передачи потеря (стирание) любого информационного сегмента файла влияет только на один бит кодового слова, используемого для декодирования в принимающем терминале; при этом матрица декодирования (например, генераторная матрица LDGC), используемая для декодирования, может выполнять одни и те же операции, такие как стирание строки и обращение матрицы, для 8×Т кодовых слов, что значительно понижает рабочую нагрузку при выполнении декодирования в принимающем терминале. Кроме того, показатель успешности декодированиям надежность передачи данных могут быть значительно увеличены, так как потеря одного информационного сегмента файла не будет вызывать потерю (стирание) большого количества информации кодовых слов в принимающем терминале.
Фиг.6 показывает последовательность операций способа приема данных согласно данному изобретению. Как показано на фиг.6, способ включает следующие шаги:
201: принимающий терминал декапсулирует принятые пакеты передачи (включая информационные пакеты передачи и контрольные пакеты передачи) и получает каждый информационный сегмент файла и контрольный сегмент файла;
Структура инкапсуляции пакета передачи показана на фиг.5, и определенное значение каждого поля было описано выше.
202: упорядочивание нестертых сегментов файла в одном и том же блоке файла (коротко, нестертых сегментов файла) последовательно согласно номерам сегментов, размещение контрольных сегментов файла после информационных сегментов файла, как показано на фиг.7; и, тем временем, выполнение операции стирания для соответствующих строк в матрице 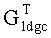 согласно индексам стертых сегментов файла, с получением генераторной матрицы Ge со стиранием.
согласно индексам стертых сегментов файла, с получением генераторной матрицы Ge со стиранием.
Например, имеется N сегментов файла в текущем блоке файла, при этом имеется К информационных сегментов файла, индексы сегментов файла которых равны FSI0, FSl1,…, FSIК-1, соответственно; имеется р (p=N-К) контрольных сегментов файла, индексы сегмента файла которых равны РSIК, FSIК+1,…, FSIN-1, соответственно; и в процессе передачи es информационных сегментов файла были стерты, и номерами этих сегментов являются FSIu+0, FSIu+1,…, FSIu+es-1, соответственно; кроме того, ер контрольных сегментов файла были стерты, и их номерами являются FSIv+0, FSIv+1,…,-FSIv+ep-1, соответственно; тогда сегменты файла упорядочивают последовательно следующим образом:
FSI0, FSI1,…FSIu-1, FSIu+es, FSIu+es+1,…, FSIК, FSIK+1,…FSIv-1, FSIv+ep, FSIv+ep+1,…, FSIN-1.
203: извлечение 1 бита из одной и той же позиции каждого нестертого сегмента файла (включая информационный сегмент файла и контрольный сегмент файла) в одном и том же блоке файла, соответственно, и создание Тb=8×Т последовательностей битов, которые должны быть декодированы, при этом длина каждой последовательности битов, которая должна быть декодирована, равна N-es-ер.
204: выполнение декодирования FEC для каждой последовательности битов, которая должна быть декодирована, с использованием Ge, получение Тb декодированных последовательностей битов информации; и размещение каждого бита декодированных последовательностей битов информации в соответствующей позиции каждого информационного сегмента файла, чтобы сформировать декодированные информационные сегменты файла;
при этом длина декодированной последовательности битов информации равна К, и число декодированных информационных сегментов файла равно К.
Например, последовательность битов, которая должна быть декодирована, образованная из i-того бита каждого нестертого сегмента файла в каждом блоке файла, последовательно (согласно последовательности сегментов файла) декодируется, чтобы генерировать i-тую последовательность битов информации, и m-ный бит последовательности битов информации размещают в i-той позиции бита m-ного информационного сегмента файла декодированного блока файла.
Выше i=1, 2,...., Tb; m=1, 2,…, К; К является Длиной декодированной последовательности битов информации.
205: объединение (то есть объединение данных) декодированных информационных сегментов файла последовательно согласно индексам блока файла и индексам сегмента файла, чтобы сформировать исходные данные файла (то есть данные файла, переданные передающим терминалом).
При выполнении вышеупомянутого объединения предпочтительно упорядочить информационные сегменты файла согласно индексам блока файла, а если индексы блока файла являются одинаковыми, то сегменты упорядочивают согласно индексам сегментов файла.
206: если F/T не является целым числом, и передающим терминалом к файлу были добавлены биты заполнения (то есть биты заполнения в последнем сегменте файла последнего блока файла передаваемого файла), то принимающий терминал удаляет биты заполнения в соответствующих позициях после исходных данных файла.
Число битов заполнения может быть определено следующим способом:
вычисление числа Р битов заполнения согласно длине F данных файла, которые должны быть приняты, в байтах и общему количеству Кt информационных сегментов файла: Р=8×(T×Kt-F); где Т является длиной каждого сегмента файла в байтах.
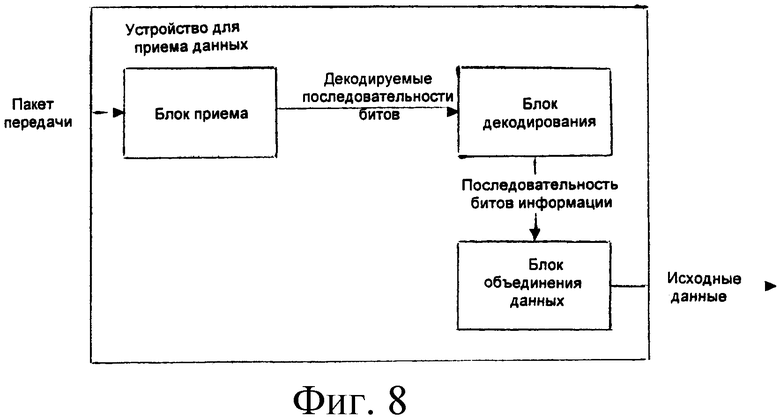
На фиг.8 показано устройство для приема данных согласно примеру осуществления данного изобретения. Как показано на фиг.8, устройство включает: блок приема, блок декодирования и блок объединения данных. При этом:
блок приема используется, чтобы принимать пакеты передачи и получать нестертые информационные сегменты файла и контрольные сегменты файла из пакетов передачи; определять последовательность информационных сегментов файла и контрольных сегментов файла согласно индексам сегментов файла в пакетах передачи; и выводить Tb последовательностей битов, которые должны быть декодированы, блока файла;
при этом i-тая последовательность битов, которая должна быть декодирована, образована из i-тых битов каждого нестертого информационного сегмента файла и контрольного сегмента файла блока файла последовательно согласно последовательности информационных сегментов файла и контрольных сегментов файла; где i=1,...., Тb;
блок декодирования используется для того, чтобы соответственно выполнить декодирование с прямой коррекцией ошибок для Тb декодируемых последовательностей битов, выведенных из блока приема, для вывода Тb декодированных последовательностей битов информации, с длиной К, блока файла.
Вышеупомянутое декодирование с прямой коррекцией ошибок может использовать алгоритм LDGC, при этом блок декодирования также удаляет соответствующие строки транспонированной генераторной матрицы LDGC 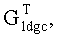 чтобы генерировать Ge, согласно индексам сегментов файла стертых информационных сегментов файла и контрольных сегментов файла в блоке файла до выполнения декодирования с прямой коррекцией ошибок; и декодирование с прямой коррекцией ошибок выполняется для декодируемых битовых последовательностей с использованием Ge.
чтобы генерировать Ge, согласно индексам сегментов файла стертых информационных сегментов файла и контрольных сегментов файла в блоке файла до выполнения декодирования с прямой коррекцией ошибок; и декодирование с прямой коррекцией ошибок выполняется для декодируемых битовых последовательностей с использованием Ge.
Блок объединения данных используется, чтобы извлечь К декодированных информационных сегментов файла последовательно из Тb декодированных последовательностей битов информации блока файла с длиной К и объединить их последовательно, чтобы генерировать исходные данные файла блока файла; дополнительно, блок объединения данных также используется, чтобы объединить исходные данные файла каждого блока файла последовательно согласно индексам блоков файла, чтобы генерировать исходные данные файла.
При этом m-ный декодированный информационный сегмент файла образован из m-ных битов Тb декодированных последовательностей битов информации последовательно, согласно последовательности последовательностей битов информации; где m=1,…, К.
Дополнительно, если F/T не является целым числом, то блок объединения данных также удаляет Р битов заполнения из последнего сегмента файла последнего блока файла;
где P=8×(T×Kt-F); F является полной длиной данных в байтах, 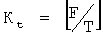 и Т=Тb/8.
и Т=Тb/8.
Промышленная применимость
Рабочую нагрузку на принимающий терминал можно значительно понизить при использовании способа передачи данных и соответствующих способа и устройства декодирования согласно данному изобретению; дополнительно, так как потеря единственного пакета данных/информационного сегмента файла не вызывает потери (стирания) большого объема информации кодовых слов в принимающем терминале, показатель успешности декодирования и надежность передачи данных существенно улучшаются.
Изобретение касается способа и устройства для приема данных. Терминал, принимающий данные, выполняет следующую обработку каждого принятого блока файла: декодирование с прямой коррекцией ошибок для Tb декодируемых последовательностей битов блока файла с получением, соответственно, Tb декодированных последовательностей битов информации с длиной К; при этом i-тая декодируемая последовательность битов образована из i-тых битов каждого нестертого информационного сегмента файла и контрольного сегмента файла блока файла в последовательности, соответствующей последовательности информационных сегментов файла и контрольных сегментов файла; объединение К декодированных информационных сегментов файла блока файла последовательно, чтобы генерировать исходные данные файла блока файла; при этом m-ный декодированный информационный сегмент файла образован из m-ных битов Tb декодированных последовательностей битов информации в последовательности, соответствующей последовательности упомянутых последовательностей битов информации. Технический результат - значительное понижение рабочей нагрузки принимающего терминала при декодировании, существенное улучшение показателя успешности декодирования и надежность передачи данных. 2 н. и 8 з.п. ф-лы, 8 ил.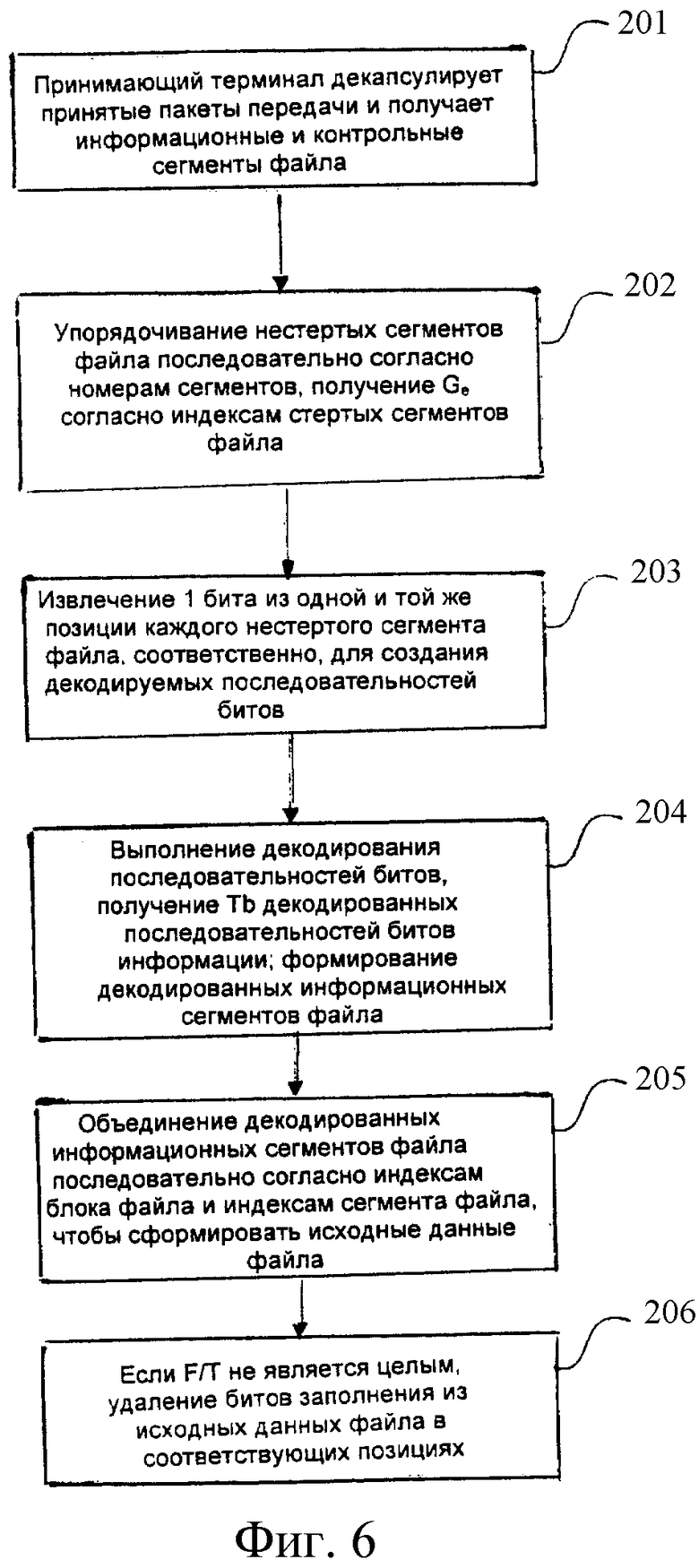
1. Способ приема данных, включающий обработку каждого принятого блока файла в терминале, принимающем данные, следующим образом:
А: выполнение декодирования с прямой коррекцией ошибок для Тb декодируемых последовательностей битов блока файла с получением, соответственно, Тb декодированных последовательностей битов информации с длиной К,
при этом i-я декодируемая последовательность битов образована из i-х битов каждого нестертого информационного сегмента файла и контрольного сегмента файла блока файла последовательно согласно последовательности информационных сегментов файла и контрольных сегментов файла;
В: объединение К декодированных информационных сегментов файла блока файла последовательно, чтобы генерировать исходные данные файла для блока файла;
при этом m-й декодированный информационный сегмент файла образован из m-х битов Тb декодированных последовательностей битов информации в последовательности, соответствующей последовательности упомянутых последовательностей битов информации;
где i=1, …, Тb; m=1, … , К; длина информационного сегмента файла и контрольного сегмента файла составляет Тb битов.
2. Способ по п.1, далее включающий:
получение терминалом, принимающим данные, нестертых информационных сегментов файла и контрольных сегментов файла из пакетов передачи; при этом пакеты передачи включают индексы сегментов файла; и индекс сегмента файла, соответствующий информационному сегменту файла, меньше чем индекс сегмента файла, соответствующий контрольному сегменту файла, в одном и том же блоке файла; и
терминал, принимающий данные, определяет последовательность информационных сегментов файла и контрольных сегментов файла согласно индексам сегментов файла.
3. Способ по п.2, в котором пакеты передачи включают индексы блоков файла,
а способ после завершения обработки блока файла включает следующий шаг:
С: терминал, принимающий данные, объединяет исходные данные файла каждого блока файла в последовательности, соответствующей индексам блоков файла, чтобы генерировать исходные данные файла.
4. Способ по п.1, в котором, если F/T не является целым числом, то способ также включает следующее:
терминал, принимающий данные, удаляет Р битов заполнения из последнего сегмента файла последнего блока файла;
при этом P=8×(T×Kt-F); F является полной длиной упомянутых данных в байтах, 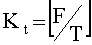 и Т=Тb/8.
и Т=Тb/8.
5. Способ по п.2, в котором декодирование с прямой коррекцией ошибок использует алгоритм кодов с генераторной матрицей низкой плотности (LDGC), и способ перед выполнением упомянутого декодирования с прямой коррекцией ошибок включает следующий шаг:
А1: терминал, принимающий данные, удаляет соответствующие строки транспонированной генераторной матрицы 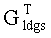 кода LDGC, чтобы генерировать матрицу Ge, согласно индексам сегментов файла стертых информационных сегментов файла и контрольных сегментов файла в блоке файла;
кода LDGC, чтобы генерировать матрицу Ge, согласно индексам сегментов файла стертых информационных сегментов файла и контрольных сегментов файла в блоке файла;
при этом на шаге А упомянутое декодирование с прямой коррекцией ошибок выполняют для декодируемых последовательностей битов с использованием Ge.
6. Устройство для приема данных, включающее блок приема, блок декодирования и блок объединения данных, при этом:
блок приема используется для вывода Тb декодируемых последовательностей битов блока файла; при этом i-я декодируемая последовательность битов образована из i-х битов каждого нестертого информационного сегмента файла и контрольного сегмента файла блока файла последовательно согласно последовательности информационных сегментов файла и контрольных сегментов файла;
блок декодирования используется для выполнения декодирования с прямой коррекцией ошибок для Тb декодируемых последовательностей битов блока файла, выведенных из блока приема, для вывода, соответственно, Тb декодированных последовательностей битов информации с длиной К;
блок объединения данных используется для объединения К декодированных информационных сегментов файла блока файла последовательно, чтобы генерировать исходные данные файла блока файла; при этом m-й декодированный информационный сегмент файла образован из m-х битов Тb декодированных последовательностей битов информации в последовательности, соответствующей последовательности упомянутых последовательностей битов информации;
где i=1, …, Тb; …, m=1, К; длина информационного сегмента файла и контрольного сегмента файла составляет Тb битов.
7. Устройство по п.6, в котором
блок приема получает нестертые информационные сегменты файла и контрольные сегменты файла из пакетов передачи; пакеты передачи включают индексы сегментов файла; и индекс сегмента файла, соответствующий информационному сегменту файла, меньше чем индекс сегмента файла, соответствующий контрольному сегменту файла, в одном и том же блоке файла; и
блок приема определяет последовательность информационных сегментов файла и контрольных сегментов файла согласно индексам сегментов файла.
8. Устройство по п.7, в котором
пакеты передачи также включают индексы блоков файла; и блок объединения данных используется для объединения исходных данных файла каждого блока файла в последовательности, соответствующей индексам блоков файла, чтобы генерировать исходные данные файла.
9. Устройство по п.6, в котором
если F/T не является целым числом, то блок объединения данных также используется для того, чтобы удалить Р битов заполнения из последнего сегмента файла последнего блока файла;
при этом P=8×(T×Kt-F); F является полной длиной упомянутых данных в байтах, и Т=Тb/8.
10. Устройство по п.7, в котором
декодирование с прямой коррекцией ошибок использует алгоритм кодов с генераторной матрицей низкой плотности (LDGC); и
блок декодирования также удаляет соответствующие строки транспонированной генераторной матрицы 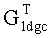 кода LDGC, чтобы
кода LDGC, чтобы
генерировать матрицу Ge, согласно индексам сегментов файла стертых информационных сегментов файла и контрольных сегментов файла в блоке файла до выполнения упомянутого декодирования с прямой коррекцией ошибок; и блок декодирования использует Ge, чтобы выполнить упомянутое декодирование с прямой коррекцией ошибок для декодируемых последовательностей битов.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| CN 101102282 A, 09.01.2008 | |||
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ-ДЕКОДИРОВАНИЯ БЛОКОВЫХ КОДОВ НИЗКОЙ ПЛОТНОСТИ С КОНТРОЛЕМ НА ЧЕТНОСТЬ В СИСТЕМЕ МОБИЛЬНОЙ СВЯЗИ | 2004 |
|
RU2316111C2 |
| EP 1667328 A, 07.06.2006 | |||
| US 7257764 B1, 14.08.2007 | |||
| JP 20308722 A, 20.03.2003. | |||

