Изобретение относится к области электросвязи, а именно к области, связанной с сокращением избыточности передаваемой информации, и может быть использовано для восстановления искаженных сжатых без потерь цифровых данных, сформированных согласно формату Deflate, в информационных системах и системах электросвязи.
Формат архива Deflate разработан Филипом В.Кацом и широко используется на практике, например в протоколе HTTP, форматах PNG, ZIP, GZIP и т.д. и является комбинацией метода словарного сжатия LZ77 (Ziv J., Lempel A., «A Universal Algorithm for Sequential Data Compression», IEEE Transactions on Information Theory, Vol.23, No. 3, pp.337-343.) и кодирования Хаффмана (Huffman, D.A., «A Method for the Construction of Minimum Redundancy Codes», Proceedings of the Institute of Radio Engineers, September 1952, Volume 40, Number 9, pp.1098-1101).
Известен способ сжатия информации (см. Патент США №5051745, опубл. 24.09.1991), заключающийся в том, что кодируемые строки заменяют ссылками на последовательность символов, расположенных в скользящем окне фиксированной длины, хранящем предыдущий текст сообщения, затем полученные ссылки кодируют по методу Хаффмана или Шеннона-Фано.
Основным недостатком данного способа является невозможность извлечения информации при декомпрессии из поврежденных сегментов данных.
Известна спецификация формата архива Deflate (см. Deutsch, P., «Deflate Compressed Data Format Specification version 1.3», Aladdin Enterprises, Network Working Group, May 1996, 16 pages), в которой описан способ компрессии и декомпрессии данных.
Основным недостатком данного способа является невозможность извлечения информации при декомпрессии из поврежденных сегментов данных.
Известно устройство декомпрессии архивов Deflate «Deflate decompressor», осуществляющее декодирование потоков сжатой информации согласно спецификации формата архива Deflate (см. Патент США №8125357 В1, опубл. 22.02.2012).
Основным недостатком данного устройства является невозможность извлечения информации из поврежденных сегментов данных.
Известен также способ восстановления данных из поврежденных архивов (см. Патент США №76033390 В2, опубл. 13.10.2009), заключающийся в том, что из архива, являющегося хранилищем множества сжатых файлов (напр. Zip-архив), осуществляют восстановление файлов, содержащихся в неповрежденной области архива.
Основным недостатком данного способа является невозможность извлечения информации из поврежденных сегментов архива.
Наиболее близким по технической сущности к заявляемому изобретению (прототипом) является способ декомпрессии информации (см. Патент США №7538696 В2, опубл. 26.05.2009), заключающийся в том, что производят считывание сжатых файлов, выделяют сегменты кода LZ77 из входного битового потока посредством их сравнения с заранее заданными кодовыми значениями, вычисляют индекс таблицы поиска по значению сегмента кода LZ77, производят декодирование сегмента кода LZ77 по таблице поиска.
Основным недостатком данного способа является отсутствие процедуры восстановления информации из поврежденных сегментов архива, что приводит к полной или частичной потере информации при декомпрессии архива.
Задачей изобретения является создание способа восстановления искаженных сжатых файлов, позволяющего получить уменьшение потерь информации при декомпрессии искаженных сжатых файлов.
Данная задача решается тем, что способ восстановления искаженных сжатых файлов, заключающийся в том, что производят считывание сжатых файлов, выделяют сегменты кода LZ77 из входного битового потока посредством их сравнения с заранее заданными кодовыми значениями, вычисляют индекс таблицы поиска по значению сегмента кода LZ77, производят декодирование сегмента кода LZ77 по таблице поиска, согласно изобретению,дополнен следующей последовательностью операций:
- после выделения сегментов кода LZ77 из входного битового потока осуществляют поиск ошибок в текущем сегменте кода LZ77;
- производят коррекцию последующих сегментов кода LZ77;
- после декодирования сегмента кода LZ77 формируют контекстную модель декодированных данных;
- определяют местоположение искажения на основе сравнения контекстной модели декодированных данных с заранее заданной общей контекстной моделью данных;
- корректируют искажения декодированных данных.
Перечисленная совокупность существенных признаков позволяет решить задачу изобретения за счет того, что в способе реализована возможность восстановления данных из искаженных сжатых файлов, обеспечивающая минимизацию потерь информации при декомпрессии сжатых файлов за счет использования процедуры коррекции ошибок в сегментах кода LZ77 и контекстной модели декодированной информации.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обусловливающих тот же технический результат, который достигнут в заявляемом способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
«Промышленная применимость» изобретения обусловлена наличием элементной базы, на основе которой могут быть выполнены устройства, реализующие данный способ.
Заявленный способ поясняется чертежами, на которых показано:
фиг.1 - обобщенная блок-схема алгоритма способа восстановления искаженных сжатых файлов;
фиг.2 - сравнение результатов имитационного моделирования для способа-прототипа и предлагаемого способа;
Реализация заявленного способа заключается в следующем (Фиг.1). Перед процедурой считывания сжатых файлов осуществляют ввод информации для формирования общей контекстной модели данных (ОКМД) и формируют ОКМД на основе априорной информации или предположениях о типе данных, которые могут содержаться в архивах, например тексты на различных естественных языках, с целью последующих проверок корректности декомпрессии сжатых данных (блоки 1 и 2). Входной блок сжатых данных записывают в буфер входных данных (БВхД) для последующей декомпрессии (блоки 3, 4 и 5). Процедура декомпрессии осуществляется согласно изобретению-прототипу (блоки 6, 8, 9, 10, 12 и 13) за исключением того, что при несоответствии бит сегмента кода LZ77 (СК LZ77) с одним из заранее заданных значений указатель чтения последовательности бит в БВхД смещается на один бит вправо относительно текущей позиции с целью коррекции последующих сегментов кода LZ77 (блоки 7 и 15). Декодированную (разжатую) информацию записывают в буфер восстановления декодированных данных (БВДД) с целью определения наличия, местоположения и коррекции искажения в декодированных данных (блок 11). На основе информации, содержащейся в БВДД (блок 16), формируют контекстную модель декодированных данных (КМДД) (блок 17). Наличие и местоположение искажения (МНИ) определяют согласно формулам (1) и (2) (блок 18):

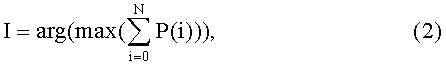
где Р - величина, характеризующая степень схожести контекстов ОКМД и КМДД, ng - количество совпавших контекстов КМДД с контекстами ОКМД и nb - количество не совпавших контекстов КМДД с контекстами ОКМД, i - позиция указателя чтения последовательности символов в БВДД, N - количество символов в БВДД, arg - аргумент функции (arg(f(x))=x), max - максимальное значение функции. Если I=N-1, то искажений в последовательности символов БВДД не обнаружено, содержимое БВДД копируют в буфер выходных данных (БВыхД) и осуществляют вывод информации из БВыхД (блок 25), в противном случае обнаружено искажение на позиции I в БВДД (блоки 19, 20 и 24). Коррекцию искажения осуществляют посредством выполнения следующей последовательности операций (блок 21):
- индексирование символов БВДД по словарю LZ77 (каждому символу, записываемому в БВДД из словаря LZ77, присваивают определенный индекс, который вычисляют по текущему местоположению данного символа в словаре);
- вычисление величины расстояния Евклида D по формуле (3) между каждым контекстом из ОКМД и текущим контекстом КМДД;
- выбор контекста из ОКМД, которому соответствует минимальное расстояние Евклида Dmin,
- замена всех символов в БВДД, соответствующих индексу текущего символа в БВДД, на символы контекста из ОКМД с Dmin.

где D - расстояния Евклида между символами контекста из ОКМД и КМДД, n - количество символов, содержащихся в контексте (порядок контекста), s(1) - символ контекста ОКМД, s(2) - символ контекста КМДД.
Если искажение в последовательности символов БВДД исправить не удалось (блок 22), то последовательность бит в БВхД сдвигают влево на один бит относительно позиции местоположения искажения (блок 23) и процесс декомпрессии осуществляют заново, в противном случае содержимое БВДД копируют в БВыхД (блок 24) и осуществляют вывод информации из БВыхД (блок 25).
Для сравнения предлагаемого способа со способом-прототипом был проведен эксперимент посредством выполнения программы «ArcRecovery» на ЭВМ, построенной согласно приведенному алгоритму в среде программирования «Visual Studio» и в среде моделирования «MatLab». Результаты проведенного эксперимента сформулированы в виде зависимости процентного соотношения декодированной информации от количества битовых ошибок в сжатых данных (Фиг.2), которая показывает, что применение предлагаемого способа дает выигрыш по минимизации потерь информации при равных условиях (одинаковые входные искаженные сжатые файлы) на 10-15% (в зависимости от выбора порядка контекстов ОКМД и КМДД и типа искажения) по сравнению со способом-прототипом.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ДЛЯ УСКОРЕНИЯ ОПЕРАЦИЙ СЖАТИЯ И РАСПАКОВКИ | 2014 |
|
RU2629440C2 |
| УСТРОЙСТВО И СПОСОБ ПРЕДСТАВЛЕНИЯ ТРЕХМЕРНОГО ОБЪЕКТА НА ОСНОВЕ ИЗОБРАЖЕНИЙ С ГЛУБИНОЙ | 2002 |
|
RU2237283C2 |
| ДЕКОДЕР, КОДЕР, КОМПЬЮТЕРНАЯ ПРОГРАММА И СПОСОБ | 2017 |
|
RU2744169C2 |
| СПОСОБ ГЕНЕРИРОВАНИЯ СТРУКТУРЫ УЗЛОВ, ПРЕДНАЗНАЧЕННЫХ ДЛЯ ПРЕДСТАВЛЕНИЯ ТРЕХМЕРНЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ ИЗОБРАЖЕНИЙ С ГЛУБИНОЙ | 2002 |
|
RU2237284C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2019 |
|
RU2755020C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2022 |
|
RU2839276C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2018 |
|
RU2699677C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2018 |
|
RU2758981C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2021 |
|
RU2779898C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2022 |
|
RU2820857C2 |

Изобретение относится к средствам сокращения и восстановления передаваемой информации без потерь цифровых данных, сформированных согласно формату Deflate, в информационных системах и системах электросвязи. Технический результат заключается в уменьшении потерь информации при декомпрессии искаженных сжатых файлов. Благодаря введению процедуры поиска ошибок в текущем сегменте кода и коррекции искажений декодированных данных, основанной на использовании контекстного моделирования информации, появляется возможность восстановления данных из поврежденной области архива, за счет чего потери информации при декомпрессии искаженных сжатых файлов уменьшаются. 2 ил. 
Способ восстановления искаженных сжатых файлов, заключающийся в том, что производят считывание сжатых файлов, выделяют сегменты кода LZ77 из входного битового потока посредством их сравнения с заранее заданными кодовыми значениями, вычисляют индекс таблицы поиска по значению сегмента кода LZ77, производят декодирование сегмента кода LZ77 по таблице поиска, отличающийся тем, что после выделения сегментов кода LZ77 из входного битового потока осуществляют поиск ошибок в текущем сегменте кода LZ77, производят коррекцию последующих сегментов кода LZ77, при этом после декодирования сегмента кода LZ77 формируют контекстную модель декодированных данных, определяют местоположение искажения на основе сравнения контекстной модели декодированных данных с заранее заданной общей контекстной моделью данных, корректируют искажения декодированных данных.
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| US 20100141488A1, 10.06.2010 | |||
| US 20090210437 A1, 20.08.2009 | |||

