Изобретения относятся к области биохимии, биофармакологии, биотехнологии, генной инженерии, а также практического программирования вложенных физико-биохимических процессов и технологий, а именно к способам кодирования всех видов информации (текстовых файлов, изображений, звуковых файлов) с использованием ДНК, РНК и аминокислотных последовательностей для последующего ее хранения, обработки, приема/передачи.
Известен способ кодирования текстовой информации на основе ДНК (патент № US 6,312,911, МПК C12Q 1/68, G06N 3/12, 2001 г.), который заключается в кодировании текста сообщения в последовательности ДНК и последующим извлечением сообщения с помощью молекулярно-генетической системы, каждый элемент которой состоит из трех различных азотистых оснований ДНК и представляет один алфавитно-цифровой символ. Так как ДНК имеет 4 основания (А - аденин, Т - тимин, С - цитозин, G - гуанин), то максимальное триплетное представление известной молекулярно-генетической системы будет в виде 64 уникальных символов, соответствующих числу сочетаний четырех азотистых оснований.
Известен способ кодирования всех видов информации (текстовых файлов, изображений или звуковых файлов) по патенту № US 2005/0053968 (МПК G06F 19/00, C12Q 1/68, G06N 3/12, G01N 33/48, G11B 20/00, G01N 33/50, G11C 13/02, 2005 г.) с использованием молекулярно-генетической системы, состоящей из различных сочетаний четырех азотистых оснований ДНК (G, А, С, Т), при этом каждое сочетание представляет собой уникальный символ. С помощью известного способа производят синтетическую ДНК-молекулу, которая включает в себя цифровую информацию и ключ шифрования. Синтетическую ДНК встраивают в ДНК носитель для хранения. В случае, когда количество ДНК является слишком большим, то информация может быть раздроблена на несколько сегментов. Способ, описанный в патенте, способен восстанавливать фрагментированные сегменты ДНК путем сопоставления праймера одного из сегментов с хвостовым праймером на одном из последующих сегментов.
Известные способы имеют ограниченную область действия, поскольку не могут быть использованы для эффективного кодирования большого объема информации и имеют низкую помехоустойчивость кодирования.
Из уровня техники известно избыточное кодирование цифровой информации помехоустойчивым кодом, заключающееся в том, что с целью повышения помехоустойчивости к информационным битам добавляется к проверочных бит, позволяющих обнаружить и (или) исправить возникающие в декодере из-за канала связи ошибки в информации. Известный способ помехоустойчивого кодирования с использованием проверочных бит описан, например, в патенте РФ №2408979 (МПК Н03М 13/19, 2011 г.).
Наиболее близким по технической сущности к заявляемому способу является способ кодирования информации, согласно которому массив кодируемой информации разделяют на дискретные элементы (символы), каждому выделенному символу ставят в соответствие, по крайней мере, один триплет, выстраивают уникальную ДНК-последовательность, которую разбивают на множество перекрывающихся ДНК-сегментов. Ко множеству ДНК-сегментов добавляют соответствующую индексирующую информацию, состоящую из i - информационных бит, представляя тем самым кодируемую информацию в машиночитаемую последовательность в двоичной форме счисления. (Патент № US 61/654,295, МПК G06F 19/00, 2013 г.).
Недостатком данного способа является сравнительно высокая его избыточность, поскольку для кодирования необходимо достаточно большое количество триплетов, что может привести к снижению эффективности кодирования и возникновению ошибок при кодировании, а также низкая информационная емкость, приходящая на каждое азотистое основание, которая приблизительно равна 1.83 битам.
Высокая емкость ДНК для хранения информации является в настоящее время предметом изучения свойств ДНК в целях использования в качестве носителя информации. Молекулы ДНК обеспечивают высокую плотность хранящейся информации, они долговечны и способны хранить информацию многие сотни лет в определенных для этого условиях (т.е. холодная, сухая и темная среда). С позиции теории обеспечения помехоустойчивости в технике цифровой связи и передачи дискретных сигналов генетическая информация обладает природной помехоустойчивостью. Однако остается нерешенной проблема, которая возникает при использовании известных способов кодирования и декодирования информации, - это искажение в процессе кодирования исходной информации из-за различных внешних факторов: дефекты синтеза ДНК, деградацию молекул ДНК во времени и ошибок построения последовательности. Поэтому, несмотря на предшествующие разработки, все еще существует необходимость в систематическом изучении и классифицировании всех специфических взаимодействий между последовательностями из смешанных азотистых оснований с целью определения условий эффективного и быстрого кодирования без помех большого объема информации.
При создании изобретений решалась задача сохранения больших информационных массивов без потерь данных с использованием минимального объема элементов материального носителя.
Технический результат, который будет получен при осуществлении предлагаемого решения, является повышение эффективности помехоустойчивого кодирования и декодирования информации за счет увеличения объема передачи и приема информации при уменьшении количества используемых для кодирования и декодирования элементов.
Указанный технический результат достигается способом кодирования информации, в котором массив кодируемой информации разделяют на логически законченные фрагменты, каждому из которых ставят в соответствие, по крайней мере, один элемент используемой для кодирования молекулярно-генетической системы; ко множеству элементов системы добавляют соответствующую индексирующую информацию, состоящую из i-информационных бит; к каждой кодовой комбинации информационных бит добавляют комбинацию из k-контрольных бит, определяемую в зависимости от комбинации i-информационных бит; при этом, согласно изобретению, каждую i+k битовую информацию в двоичной форме счисления записывают в виде мультиплета, состоящего из n-числа азотистых оснований или соответствующих им аминокислот и являющегося элементом молекулярно-генетической системы, состоящей из основы, выполненной в виде матрицы из четырех азотистых оснований 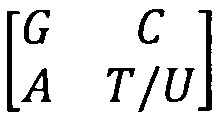 , сгруппированных по количеству водородных связей, и по количеству конденсированных колец, содержащихся в структурах молекул азотистых оснований, которую предварительно формируют путем многократного тензорного возведения в квадрат каждой матрицы предыдущего поколения для образования матрицы следующего поколения; при этом бинарные индексы системы, формирующие i-информационные биты, соответствуют выбранной характеристике азотистых оснований, вместе с кодируемой информацией записывают значение n, от которого зависит размер используемой для кодирования матрицы, а также информацию о выбранном способе трансформации матрицы в последовательность и порядок ее прочтения.
, сгруппированных по количеству водородных связей, и по количеству конденсированных колец, содержащихся в структурах молекул азотистых оснований, которую предварительно формируют путем многократного тензорного возведения в квадрат каждой матрицы предыдущего поколения для образования матрицы следующего поколения; при этом бинарные индексы системы, формирующие i-информационные биты, соответствуют выбранной характеристике азотистых оснований, вместе с кодируемой информацией записывают значение n, от которого зависит размер используемой для кодирования матрицы, а также информацию о выбранном способе трансформации матрицы в последовательность и порядок ее прочтения.
При этом, согласно изобретению, кодируемую информацию выстраивают в машиночитаемую последовательность в двоичной форме исчисления, включающую бинарные индексы для каждого мультиплета.
При этом, согласно изобретению, кодируемую информацию выстраивают в последовательность азотистых оснований.
При этом, согласно изобретению, к каждой кодовой комбинации i-информационных бит добавляют комбинацию из m-управляющих бит, определяемую в зависимости от комбинации i и k бит.
При этом, согласно изобретению, по положению каждого мультиплета в матрице молекулярно-генетической системы оценивают рецессивный или доминантный признак соответствующего ему логически законченного фрагмента.
При этом, согласно изобретению, последовательность азотистых оснований разбивают на логически законченные фрагменты, в которых также закодирована информация о начале и конце информационного отрывка.
При этом, согласно изобретению, кодируемую информацию выстраивают в последовательность азотистых оснований для кодирования на уровне ДНК.
При этом, согласно изобретению, кодируемую информацию выстраивают в последовательность азотистых оснований для кодирования на уровне РНК.
При этом, согласно изобретению, кодируемую информацию выстраивают в последовательность аминокислот.
При этом, согласно изобретению, кодируемую информацию выстраивают в последовательность азотистых оснований для кодирования на уровне белков.
При этом, согласно изобретению, молекулярно-генетическая система имеет линейное матричное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет квадратичное матричное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет прямоугольное матричное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет круговое матричное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет объемное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет вид структурного дерева графов.
При этом, согласно изобретению, бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для ДНК.
При этом, согласно изобретению, бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для РНК.
При этом, согласно изобретению, бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для аминокислот.
При этом, согласно изобретению, бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований, формирующих рецессивные и доминантные признаки на генном уровне.
При этом, согласно изобретению, синтетическую ДНК, сформированную из полученной последовательности азотистых оснований, содержащей кодируемую информацию, встраивают в носитель для хранения.
При этом, согласно изобретению, синтетическую ДНК, сформированную из полученной последовательности азотистых оснований, содержащей кодируемую информацию, встраивают в носитель для логико-математических вычислений.
Указанный технический результат достигается способом декодирования информации, в котором машиночитаемую последовательность разбивают на части, состоящие из логически законченных фрагментов декодируемой информации, включающих комбинации из i-информационных бит и k-контрольных бит, ставя в соответствие каждому логически законченному фрагменту, по крайней мере, один мультиплет, состоящий из n-числа азотистых оснований или соответствующих им аминокислот и являющийся элементом используемой для декодирования молекулярно-генетической системы, при этом, согласно изобретению, молекулярно-генетическая система состоит из основы, выполненной в виде матрицы из четырех азотистых оснований 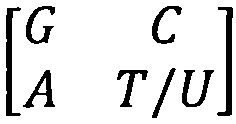 , сгруппированных по количеству водородных связей, и по количеству конденсированных колец, содержащихся в структурах молекул азотистых оснований, которую предварительно формируют путем многократного тензорного возведения в квадрат каждой матрицы предыдущего поколения для образования матрицы следующего поколения; при этом бинарные индексы системы, формирующие i-информационные биты, соответствуют выбранной характеристике азотистых оснований, а индексы, формирующие k-контрольные биты, определяют в зависимости от комбинации i-информационных бит.
, сгруппированных по количеству водородных связей, и по количеству конденсированных колец, содержащихся в структурах молекул азотистых оснований, которую предварительно формируют путем многократного тензорного возведения в квадрат каждой матрицы предыдущего поколения для образования матрицы следующего поколения; при этом бинарные индексы системы, формирующие i-информационные биты, соответствуют выбранной характеристике азотистых оснований, а индексы, формирующие k-контрольные биты, определяют в зависимости от комбинации i-информационных бит.
При этом, согласно изобретению, дискретные части машиночитаемой последовательности, состоящие из логически законченных фрагментов декодируемой информации, включают комбинации из m-управляющих бит, при этом индексы, формирующие m управляющие биты, определяют в зависимости от комбинации i-информационных бит.
При этом, согласно изобретению, по положению каждого мультиплета в матрице молекулярно-генетической системы оценивают рецессивный или доминантный признак соответствующего ему логически законченного фрагмента.
При этом, согласно изобретению, молекулярно-генетическая система имеет линейное матричное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет квадратичное матричное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет прямоугольное матричное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет круговое матричное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет объемное представление.
При этом, согласно изобретению, молекулярно-генетическая система имеет вид структурного дерева графов.
При этом, согласно изобретению, бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для ДНК.
При этом, согласно изобретению, бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для РНК.
При этом, согласно изобретению, бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для аминокислот.
При этом, согласно изобретению, бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований, формирующих рецессивные и доминантные признаки на генном уровне.
В молекулярной биологии центральная догма - это поток информации от ДНК через РНК от нуклеиновых кислот на белок. Переход генетической информации от ДНК к РНК и от РНК к аминокислотам, формирующим белковые комплексы, является универсальным для всех без исключения клеточных организмов, лежит в основе биосинтеза макромолекул. ДНК, РНК, аминокислоты и белки относятся к линейным полимерам, то есть каждый входящий в их состав мономер соединяется, как, правило, с двумя другими мономерами. Последовательность мономеров кодирует информацию, правила передачи которой описываются центральной догмой.
Воспроизводство молекул ДНК и синтеза молекул РНК осуществляется способом, при котором одна нить ДНК служит матрицей (образцом) для построения дочерней молекулы (матричный синтез). Такой способ обеспечивает копирование наследственной информации и реализацию ее в процессе аминокислотного (белкового) синтеза. Направление потока информации включает три типа матричных синтезов: синтез ДНК - репликация, синтез РНК - транскрипция, синтез белка - трансляция. Кроме того, существует матричный синтез, исправляющий ошибки в структуре ДНК (РНК), вариант ограниченной репликации (репарация), который восстанавливает первоначальную структуру ДНК (РНК). Матричная природа синтеза нуклеиновых кислот и белков обеспечивает высокую точность воспроизведения информации.
В настоящее время особое значение в техническом развитии имеет познание принципов помехоустойчивости генетического кода в связи проблемой обеспечения помехоустойчивости информационных систем. В случае кодирования с помощью последовательностей азотистых оснований ДНК (РНК), а также аминокислот, кодируемая информация будет представлять собой сложнейшую бинарную комбинацию, которая определяется расположением мультиплетов в системе. Декодирование такого представления информации требует сложного математического подхода. Используемая для кодирования и декодирования иерархическая система позволяет определить стабильность каждого мультиплета, общую его структуру молекул и многие другие параметры.
Молекулы белков, нуклеиновых кислот (ДНК, РНК) и полисахаридов, формирующие ткани, органы, внутриклеточный каркас (цитоскелет) и внеклеточный матрикс, мембранные каналы, рецепторы, а также молекулярные машины для синтеза, упаковки и утилизации белков и нуклеиновых кислот, относятся к биологическим нанообъектам. Размер белковых молекул колеблется от 1 до 1000 нм. Диаметр спирали ДНК составляет 2 нм, а ее длина может достигать нескольких сантиметров. Белковые комплексы, формирующие нити цитоскелета, имеют толщину 7-25 нм при длине до нескольких микрон. Указанная особенность позволяет сохранять большие объемы информации с использованием сравнительно небольшого объема материального носителя.
Набор четырех азотистых оснований обычно считается элементарным алфавитом генетического кода. Генетическая информация, передаваемая молекулами наследственности (ДНК и РНК), определяет первичное строение белков живого организма. Каждый кодируемый белок представляет собой цепь из 20-22 видов аминокислот. Последовательность аминокислот в белковой цепи определяется последовательностью триплетов (трехбуквенных «слов»). Триплетом (или кодоном) представляет собой комбинацию из трех последовательно расположенных азотистых оснований, расположенных на нити ДНК (или РНК).
Информация в компьютерах обычно хранится в виде матриц, а ее обработка в компьютерах ведется с помощью матриц унитарных 27 преобразований, прежде всего нормированных матриц Адамара, выступающих в роли логических устройств, которые выполняют различные действия при получении различных условий.
Предложенные к защите изобретения позволяют обнаружить структурные особенности генетического кода на базе математики матриц, построенного в виде предложенной молекулярно-генетической системы, представляющей собой иерархическую систему элементов генетического кода. При этом закономерности в предложенной системе, прослеживаемые по различным характеристикам азотистых оснований для ДНК, РНК, а также аминокислот, обеспечивают помехоустойчивость предложенной системы с точки зрения матрично-математических методов теории дискретных сигналов и цифровой техники. Причем данные закономерности прослеживаются также и на нижестоящих (атомарном и субатомарном) и вышестоящих (белковом, генном) уровнях. Кроме того, в данном подходе структуризации отсутствует необходимое различение ДНК и РНК уровней. Кроме того, структурирование возможно как с мажорными, так и с минорными азотистыми основаниями.
Кроме того, в используемой для кодирования/декодирования молекулярно-генетической системе прослеживается стройная и хорошо моделируемая математически фрактальная взаимосвязь на следующих уровнях:
ДНК ⎯ РНК ⎯ Аминокислоты ⎯ Белки ⎯ Генетические признаки
При этом на каждом структурном уровне рассмотрения молекулярно-генетической системы можно выявить четкие математические зависимости при подсчете атомарных и субатомарных составляющих азотистых оснований.
При этом, на структурном уровне имеется возможность цветового анализа молекулярно-генетической системы: черно-белая, построенная на основе индексирующей информации (1 - черный, 0 - белый), и цветные: фрактальная цветовая схема и схема, организованная по длине волн видимого спектра.
При этом, помимо квадратичной и круговой схем построения молекулярно-генетической системы, определяется линейное представление, прямоугольное представление, объемное (кубическое) представление и представление в виде дерева графов.
Заявленные изобретения поясняются иллюстрирующими материалами, где:
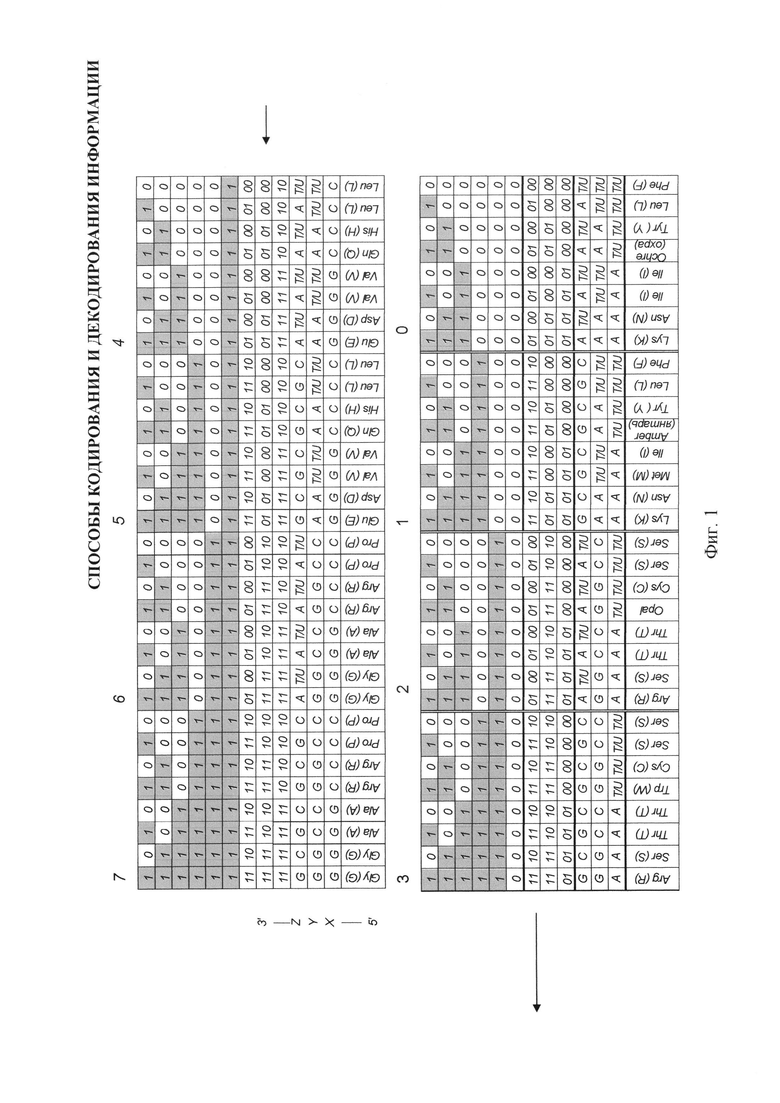
- на фиг. 1 изображено линейное матричное представление используемой для кодирования матрицы, сформированной из 64-х триплетов, для ДНК, РНК и аминокислот с соответствующей каждому элементу матрицы бинарной индексирующей информацией;
- на фиг. 2 - квадратичное матричное представление триплетной матрицы для ДНК, РНК и аминокислот;
- на фиг. 3 - прямоугольное матричное представление триплетной матрицы для ДНК, РНК и аминокислот;
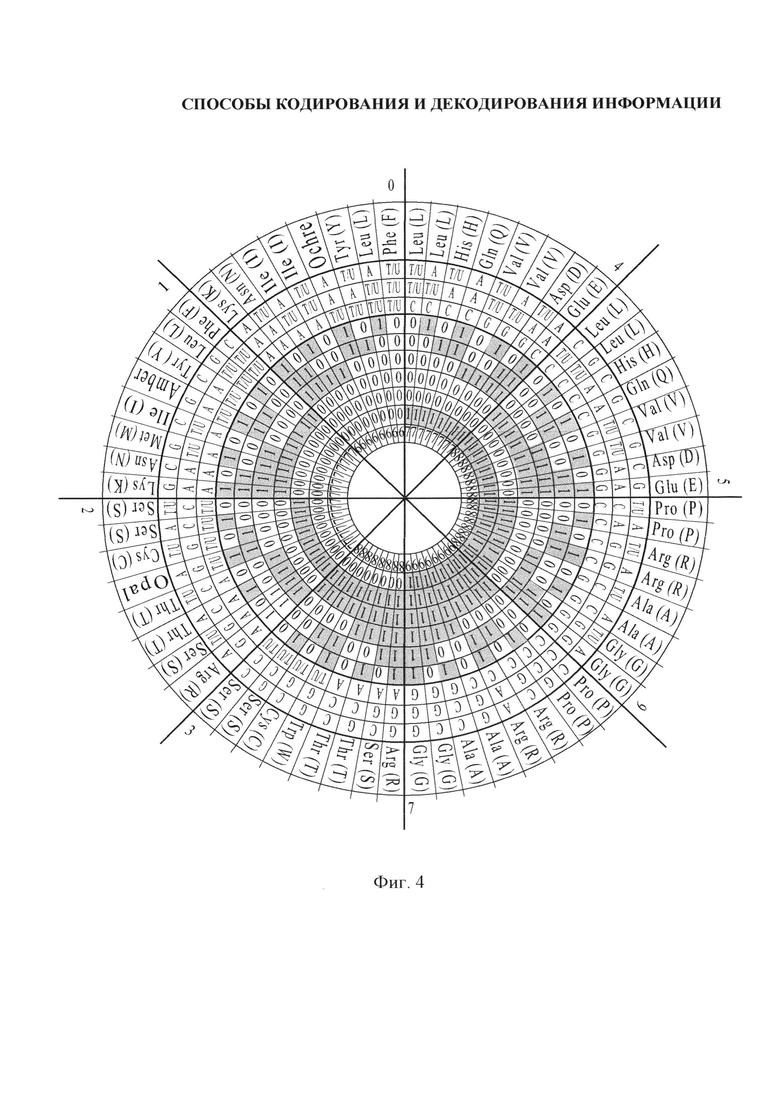
- на фиг. 4 - круговое представление триплетной матрицы для ДНК, РНК и аминокислот;
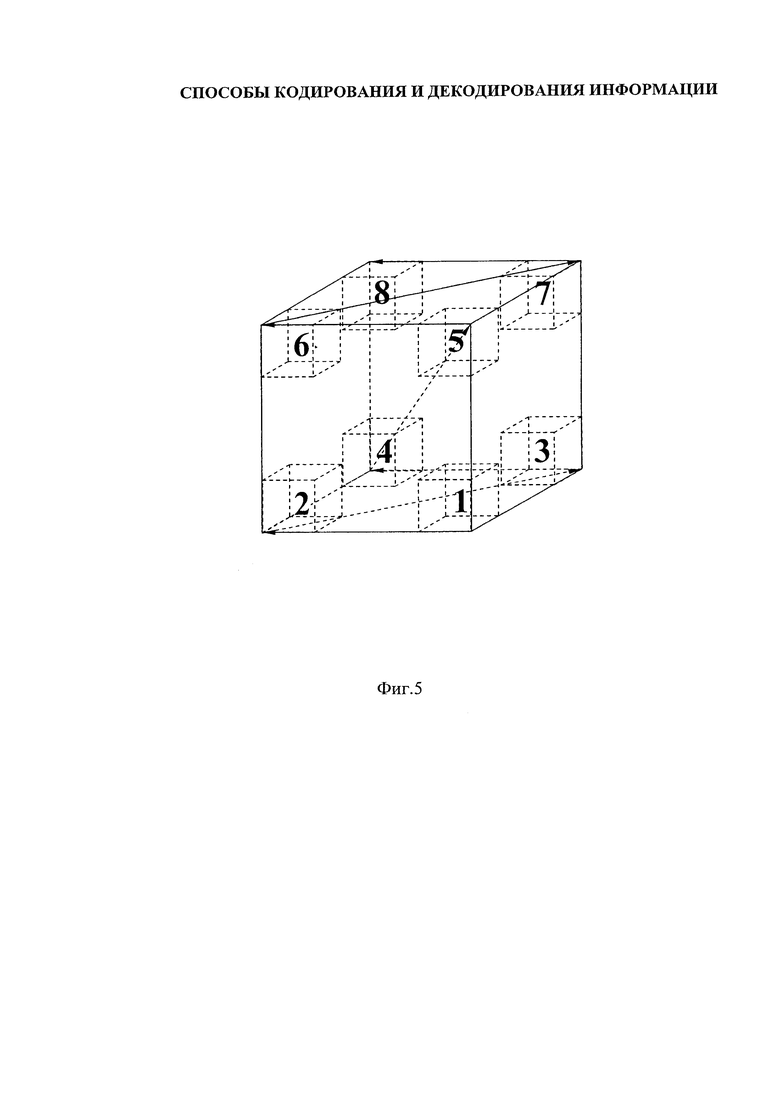
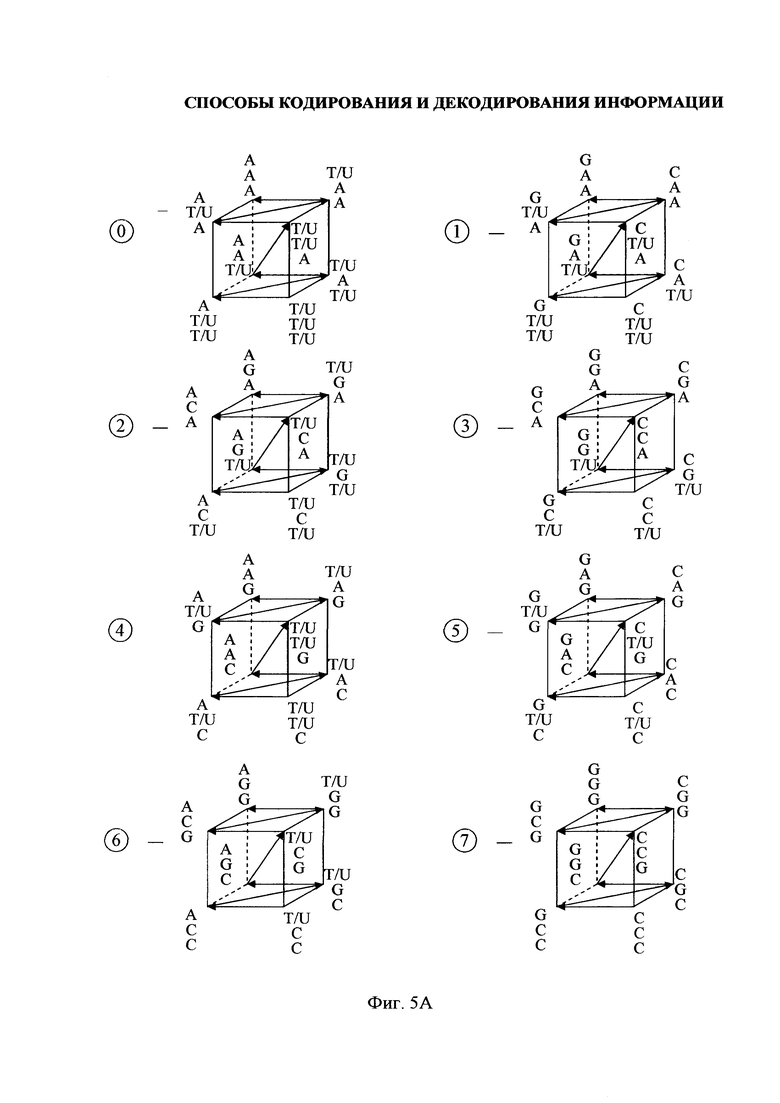
- на фиг. 5, 5А - объемное (кубическое) представление триплетной матрицы для ДНК/РНК;
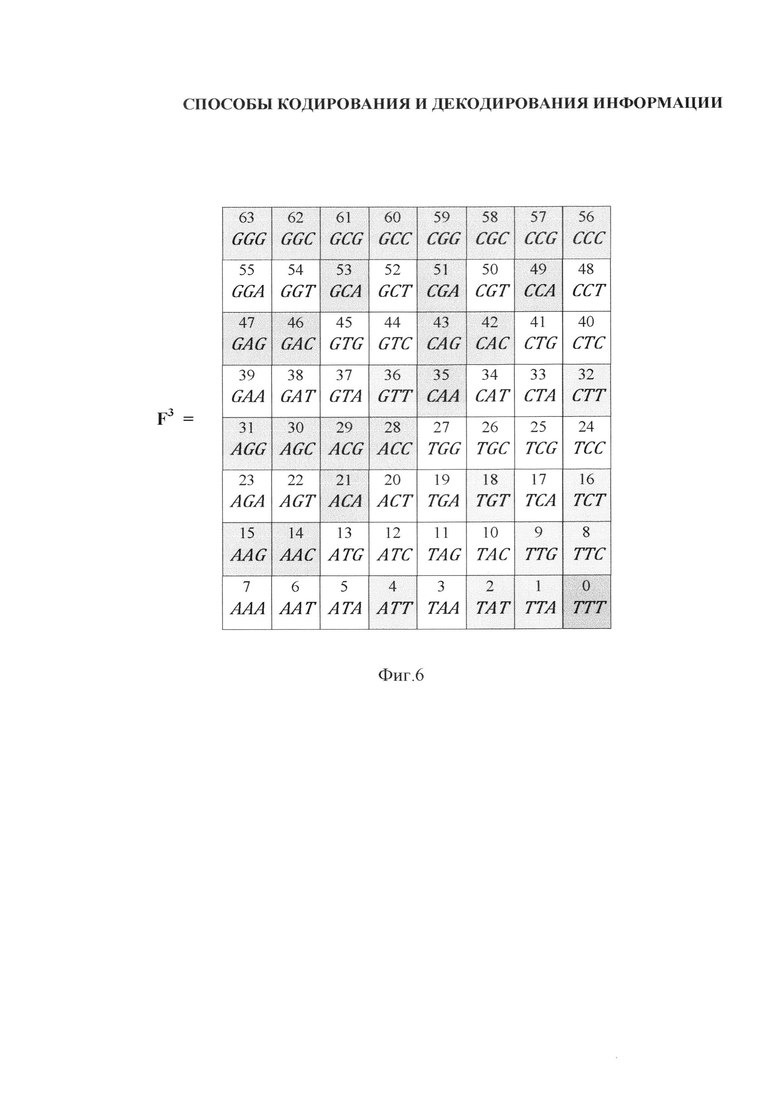
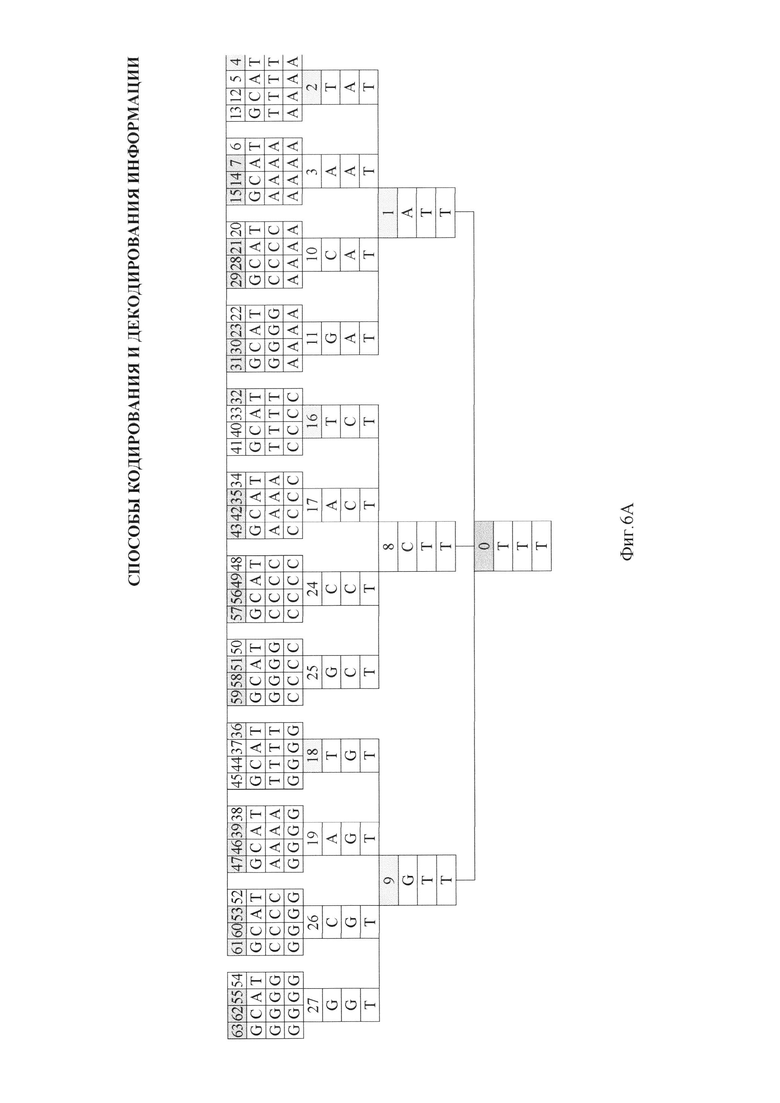
- на фиг. 6, 6А - представление триплетной матрицы для ДНК в виде структурного дерева графов;
- на фиг. 7 - изменение количества водородных связей в линейном представлении триплетной матрицы для ДНК;
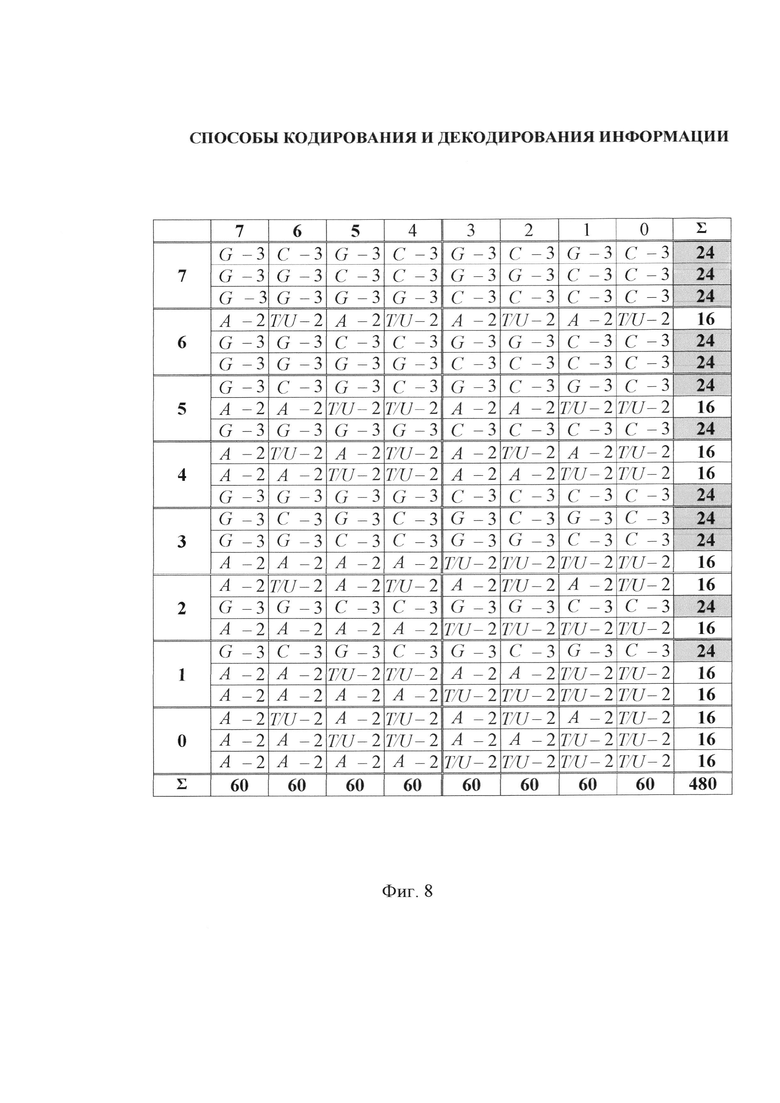
- на фиг. 8 - изменение количества водородных связей в квадратичном представлении триплетной матрицы для ДНК/РНК;
- на фиг. 9 - изменение суммарного количества атомов углерода (С), водорода (Н), азота (N), и кислорода (О) для каждого азотистого основания в линейном представлении триплетной матрицы для ДНК;
- на фиг. 10 - изменение суммарного количества атомов углерода (С) для каждого азотистого основания ДНК в линейном представлении триплетной матрицы;
- на фиг. 11 - изменение суммарного количества атомов углерода (С) для каждого азотистого основания РНК в линейном представлении триплетной матрицы;
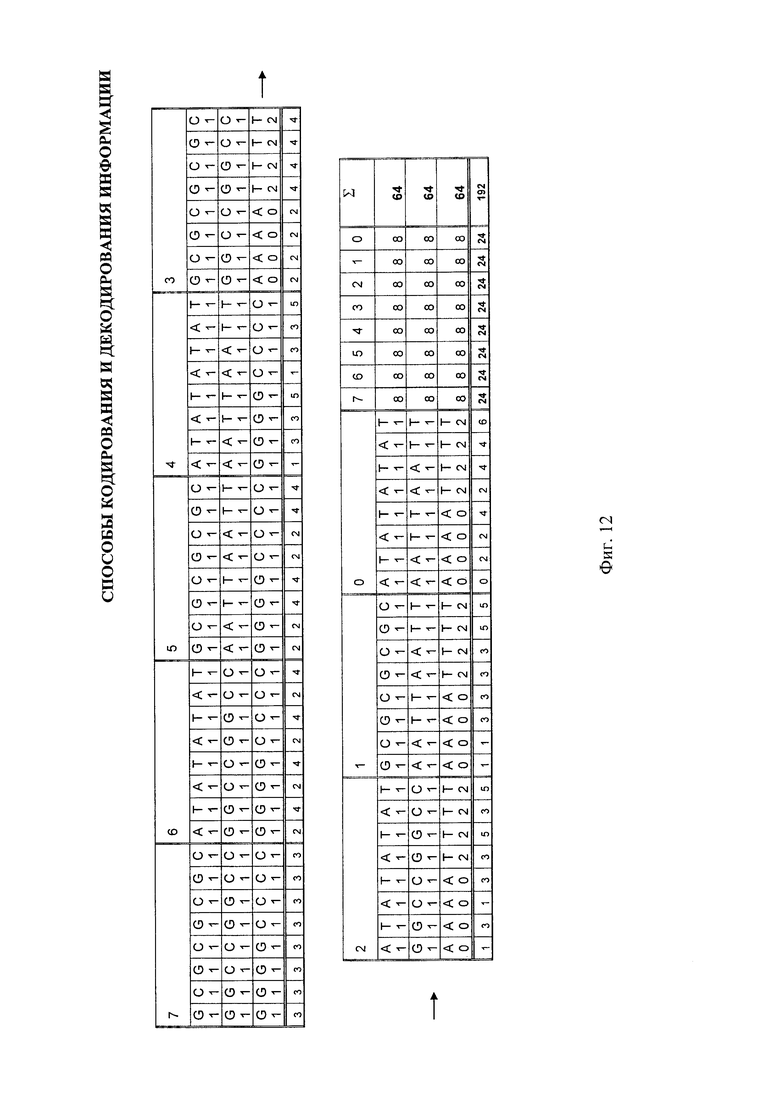
- на фиг. 12 - значение суммарного количества атомов кислорода (О) для каждого азотистого основания ДНК в линейном представлении триплетной матрицы;
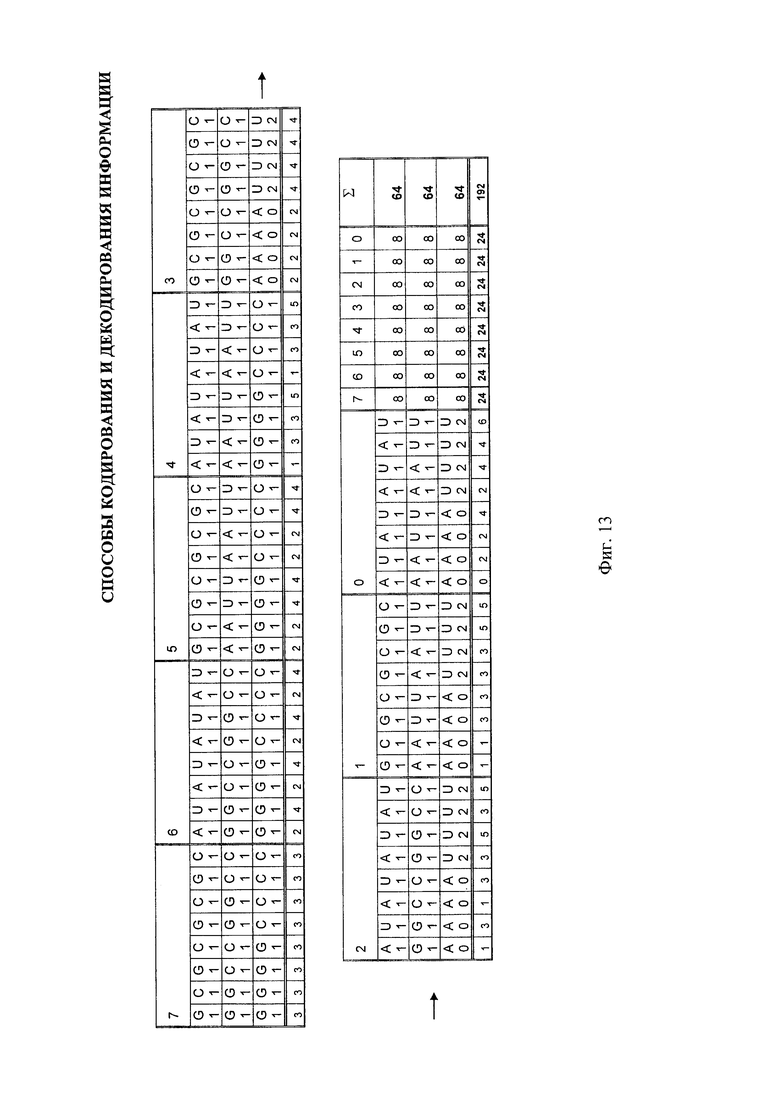
- на фиг. 13 - значение суммарного количества атомов кислорода (О) для каждого азотистого основания РНК в линейном представлении триплетной матрицы;
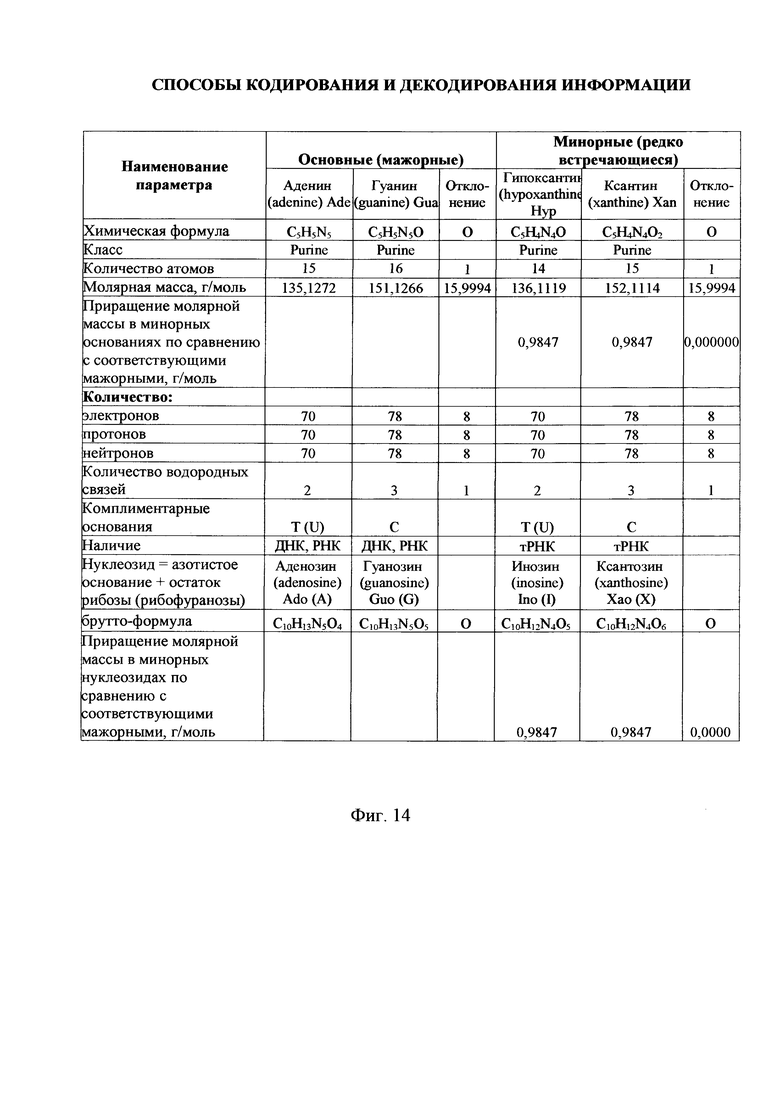
- на фиг. 14 - сравнительный анализ мажорных и минорных азотистых оснований для ДНК и РНК;
- на фиг. 15 - таблица соотношений информационных (переменных) и контрольных (результирующих) значений логической операции сложение по модулю 2 в виде 64 триплетов ДНК (РНК);
- на фиг. 16 - таблица соотношений значений результирующих векторов и их триплетная интерпретация;
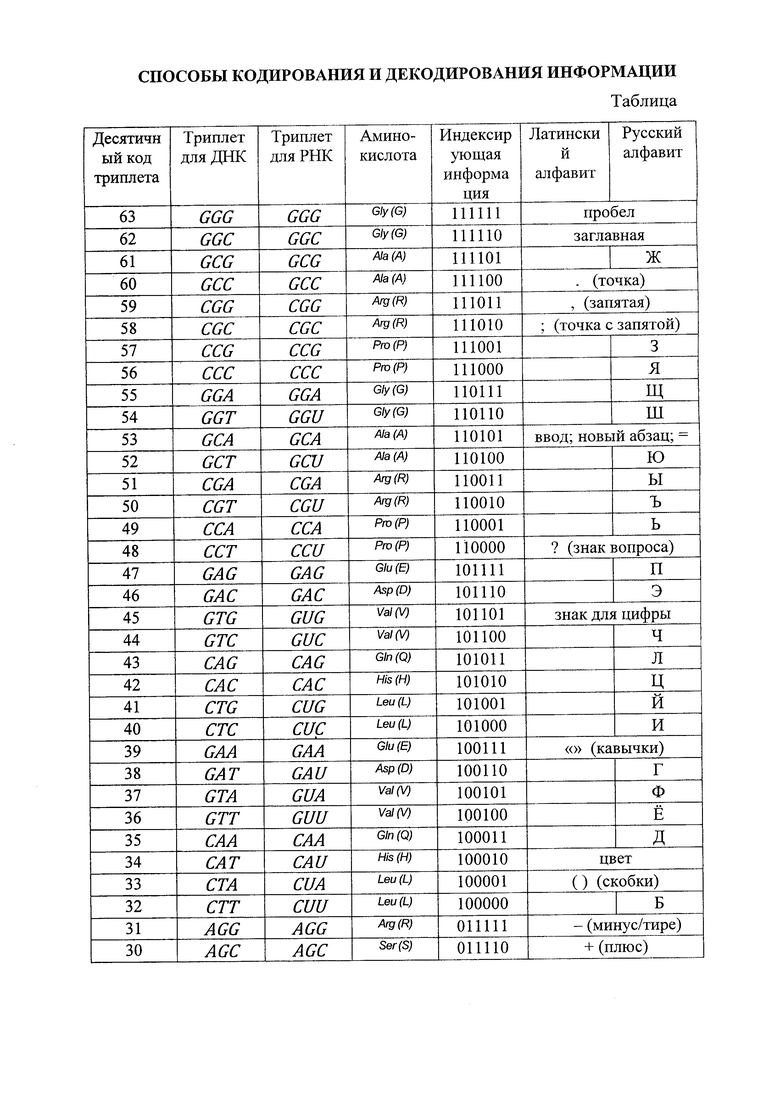
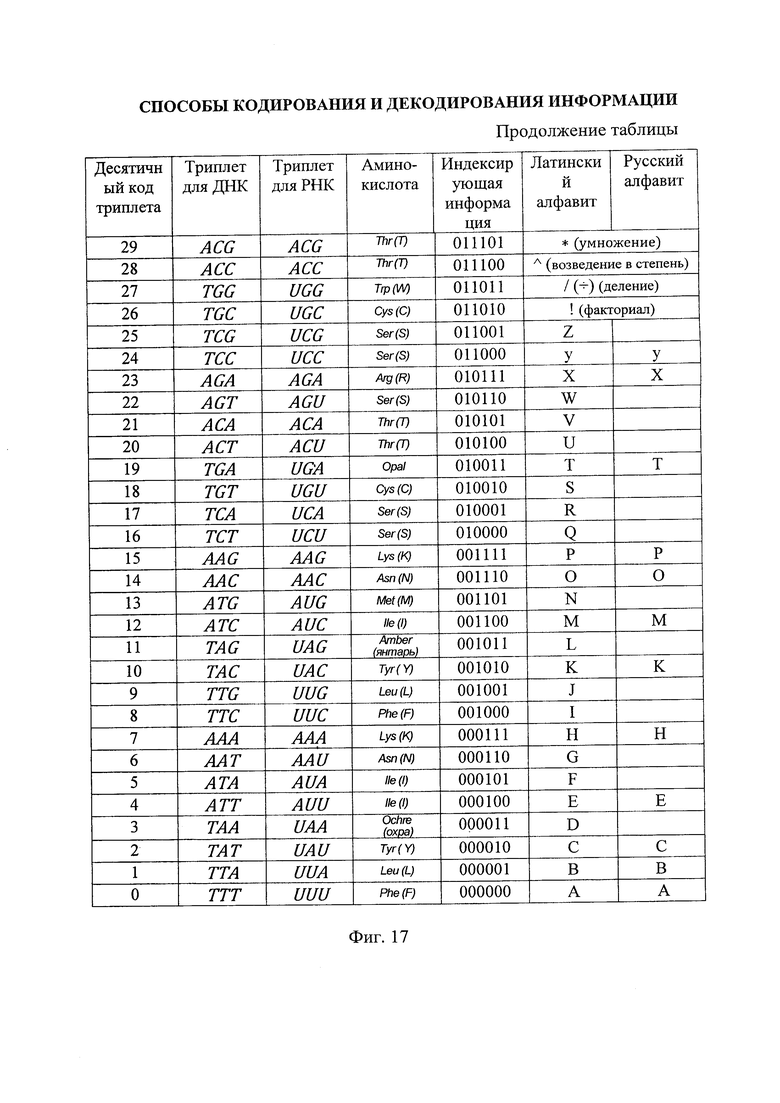
- на фиг. 17 - алфавит, составленный на основе молекулярно-генетической системы триплетов.
На практике могут быть разновидности цифровой, текстовой, символьной, графической и смешанной информации. Сущность изобретений заключается в преобразовании любого вида информации в последовательность кодовых комбинаций, состоящих из i - информационных бит с добавлением к каждой кодовой комбинации информационных бит для возможности восстановлении информации по кодовым комбинациям k - контрольных бит, комбинацию которых определяют в зависимости от комбинации i - информационных бит. При этом комбинацию из k - контрольных бит выбирают в соответствии с числовыми представлениями, которые либо совпадают с полной ортогональной системой функций Уолша, применяемой в помехоустойчивом кодировании для обработки дискретных сигналов, либо имеют константное значение.
Массив кодируемой информации разделяют на логически законченные фрагменты (символьный ряд, визуальный ряд, звуковой ряд, ряд биологических последовательностей на генетическом уровне, соматическом уровне), каждому из которых ставят в соответствие, по крайней мере, один элемент молекулярно-генетической системы, состоящий из n-числа азотистых оснований. Ко множеству элементов системы добавляют индексирующую информацию из i - информационный бит, соответствующую выбранной характеристике азотистых оснований для ДНК, РНК или аминокислот. На основании индексирующей информации формируют кодовую проверочную комбинацию из k - контрольных бит, например, комбинацию значений булевой функции сложения переменных значений по модулю 2, числовые представления которой совпадают с полной ортогональной системой функций Уолша. [И.В.Агафонова «Криптографические свойства нелинейных булевых функций», 2007 г., http://dha.spb.ru/PDF/cryptoBOOLEAN.pdf]. Например, количество соответствующих азотистых оснований для одного дискретного элемента кодируемой информации может быть равно 6-ти (X, Y, Z - кодовая комбинация элемента; X'Y'Z' - кодовая комбинация проверки). Используя Z-кодирование, кодируемую информацию представляют в виде машиночитаемой последовательности в двоичной (дискретной) форме счисления либо в виде уникальной нуклеотидной последовательности их n-числа мультиплетов. Вместе с кодируемой информацией записывают значение n и информацию о выбранном способе трансформации матрицы в последовательность. Благодаря фрактальности предложенной для кодирования молекулярно-генетической системы мультиплетная последовательность может быть выстроена для РНК, ДНК, аминокислот, белков.
ДНК и РНК включают в себя нуклеотиды, которые состоят из сахара, фосфатной группы и азотсодержащих оснований: цитозина (С), аденина (А), гуанина (G), тимина (T) для ДНК и урацила (U) для РНК. При этом азотсодержащие основания представляют собой специфические конструкции с особыми биохимическими характеристиками. Поскольку структура сахаро-фосфатного остова остается неизменной, характеристики пяти мажорных азотсодержащих оснований определяют положение нуклеотидов при построении основы молекулярно-генетической системы элементов, которая выполнена в виде квадратной матрицы F1 размера 2×2.
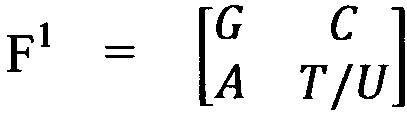 , где T/U означает использование при построении системы тимина (для ДНК) или урацила (для РНК).
, где T/U означает использование при построении системы тимина (для ДНК) или урацила (для РНК).
Основа из четырех азотсодержащих оснований для ДНК и четырех азотсодержащих оснований для РНК является носителем содержательной симметричной системы различительно-объединяющих признаков, которая разбивает четыре азотсодержащих основания различными способами на пары, эквивалентные по одному из этих признаков. Для ДНК основа (F1) выстраивается с тимином (Т), для РНК - с урацилом (U).
Термин «молекулярно-генетическая система», используемый в данном контексте, означает комплекс структур и механизмов передачи наследственной информации (генетического материала), характерных для данного вида. [Арефьев В.А., Лисовенко Л.А. Англо-русский толковый словарь генетических терминов. 1995. 407 с.]. При этом система есть объект, целостность которого обеспечивается совокупностью связей и отношений между группами элементов, объединенных развернутыми в пространстве и во времени структурами.
Обоснование данного построения состоит в следующем.
Двойная спираль обычной ДНК состоит из двух взаимно перевитых полинуклеотидных цепей, азотистые основания которых попарно соединены водородными связями. Жесткость пространственной конфигурации ДНК в основном обеспечивается большим количеством водородных связей между противолежащими основаниями цепей, так что против аденина (А) одной цепи всегда находится тимин (Т) другой, против гуанина (G) - цитозин (С), поэтому одна нить по расположению азотистых оснований комплементарная (дополнительная) к другой нити. Аденин (А) одной цепи связан с тимином (Т) другой, а гуанин (G) с цитозином (С). РНК представляет собой одноцепочную молекулу, построенную таким же образом, как и одна из цепей ДНК. Нуклеотиды РНК похожи на нуклеотиды ДНК, хотя и не тождественны им. Три азотистых основания совершенно такие же, как в ДНК: аденин (А), гуанин (G) и цитозин (С). Однако вместо тимина (Т) в РНК присутствует близкое ему по строению азотистое основание - урацил (U).
В представленной основе (F1) азотсодержащие основания построчно сгруппированы по количеству водородных связей: в первой строке матрицы - комплементарная пара с сильной водородной связью G - С, имеющая три водородные связи, во второй строке - комплементарная пара со слабой водородной связью А - Т(для ДНК)/и(для РНК), имеющая две водородные связи.
Во-вторых, особенность азотистых оснований заключается в том, что ни подразделяются на два типа: пуриновые - аденин (А), гуанин (G) и пиримидиновые - цитозин (С), тимин (Т) и урацил (U). Основу структуры молекул пуриновых и пиримидиновых оснований составляют два ароматических гетероциклических соединения - пиримидин и пурин. Молекула пурина состоит из двух конденсированных колец, а молекула пиримидина - из одного кольца. Следовательно, в представленной основе (F1) азотсодержащие основания по столбцам сгруппированы по количеству конденсированных колец: в первом столбце матрицы - пуриновые основания, имеющие большее число колец в молекулярном строении, во втором столбце - пиримидиновые основания, имеющие меньшее число колец.
Таким образом, получаем основу (F1) системы элементов, в которой азотистые основания разбиты на пары соответствующие их основным характеристикам: по горизонтали: в первой строке элементы с тремя водородными связями, а во второй - элементы с двумя водородными связями, а по вертикали в первом столбце пуриновые основания, во втором - пиримидиновые основания.
В этом разбиении на эквивалентные пары по конкретному признаку каждому азотистому основанию может быть добавлен индекс бинарной оппозиции: например, единицы - в случае сильного проявления признака, и нуля - в случае слабого его проявления. В случае разбиения на бинарные индексы, основанные на биохимических характеристиках азотсодержащих оснований, элементная основа (F1) иллюстрируется следующим образом: 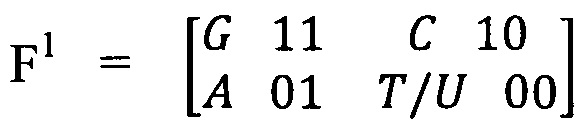
Размещение азотистых оснований в элементной основе и наглядно поясняет, что по первому признаку эквивалентными являются горизонтальные пары оснований G=C (три водородные связи, сильная позиция, соответствующая цифре 1) и A=T/U (две водородные связи, слабая позиция, цифра 0), по второму признаку - вертикальные пары G=A (два кольца в молекуле, сильная позиция, соответствующая цифре 1), C=T/U (одно кольцо в молекуле, слабая позиция, соответствующая цифре 0).
Молекулярно-генетическая система для кодирования сформирована путем тензорного (кронекеровского) произведения основы на саму себя. Так, например, матрица следующего поколения F2 для ДНК размером 4×4 будет выглядеть следующим образом:
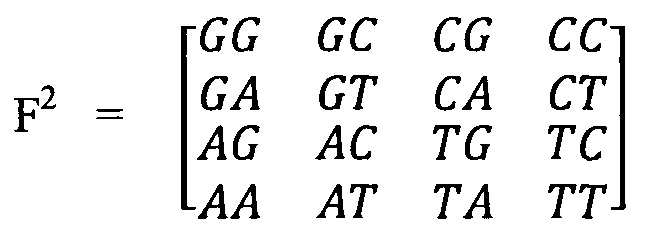
А матрица поколения F3 для ДНК размером 8×8 будет выглядеть:

Количество элементов матрицы обосновано количеством сочетаний триплетов из четырех азотистых оснований. Каждый из триплетов имеет свою индивидуальность, поскольку он выступает в качестве собственного значения матрицы и ему соответствует его собственный вектор этой матрицы. Например, каждый из трех триплетов ААС, АСА и САА завязан на свой собственный вектор, а потому в данном отношении эти триплеты существенно различны.
Таким образом, молекулярно-генетическая система сформирована в результате бесконечного количества повторов Fn=F ⊗ Fn-1, где каждый квадрант матрицы F(n) полностью воспроизводит матрицу F(n-1) предыдущего поколения или предыдущей степени. Матрица каждого нового поколения содержит в себе в скрытом виде информацию обо всех предыдущих поколениях (о матрицах всех предыдущих степенях). А самая большая мультиплетная матрица F(∞) матрица содержит информацию обо всех матрицах с более короткими мультиплетами. С возрастанием матричного порядка увеличивается количество сочетаний азотсодержащих оснований, которые определяют множество уникальных элементов структурированной системы, которое может быть бесконечным. Следовательно, с помощью предлагаемой системы элементов можно принимать, передавать, хранить и воспроизводить большой объем информации.
Чтобы иметь возможность обрабатывать информацию техническими средствами, та же система может быть сформирована в двоичной системе исчисления - из индексных значений по столбцам и строкам своих наборов, исходя из сочетаний пуриново-пиримидиновых оснований и количества водородных связей.
Например, в триплетной матрице для ДНК каждый триплет в двоичной системе будет представлен в виде гексаграмм, содержащих, например, 1 байт информации - по 6 бит в каждом байте:
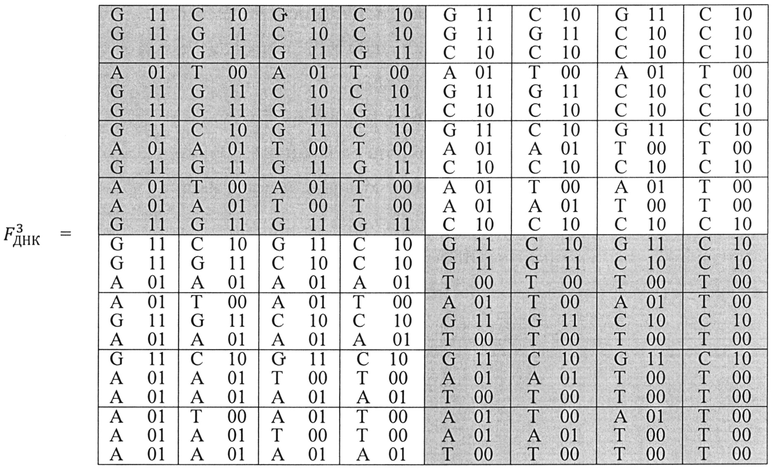
Причем, построение каждого триплета в двоичной системе осуществляется с его нижнего азотистого основания, поскольку нижнее основание является элементом первоначальной матрицы F1 размером 2×2, путем сочетания двоичного кода сначала по характеристике «количество водородных связей», а потом - по характеристике «пурин-пиримидин». К нижнему основанию крепится 5'-конец, в верхнем основании - 3'-конец. Замечено также, что движение электронов, также как и считывание идет снизу вверх - от 5' -Р04 (-) к 3' -ОН(+) концу.
Кроме того, описанная система элементов формирует признак: - «доминантный»/«рецессивный», что важно для передачи информации. На уровне ДНК и РНК доминантным (стабильным) является такое азотистое основание, которое присутствует как в ДНК, так и в РНК, а именно: G, С, А. Вместе с тем, рецессивным (изменяемым) является такое азотистое основание, которое встречается только или в ДНК (Т), или только в РНК (U). Среди четырех азотистых оснований тимин (Т) противопоставлен природой трем другим основаниям, поскольку при переходе от ДНК к РНК тимин (Т) заменяется другим азотистым основанием - урацилом (U) и является рецессивным. Поэтому с учетом указанного признака, представленная молекулярно-генетическая система подобна решетке Пеннета (1906 г.) для полигибридного скрещивания организмов, которая представляет законы Менделя наследования признаков при полигибридном скрещивании, подтверждающие наличие природного многоканального помехоустойчивого кодирования информации о наследовании в каждом организме. Эти решетки - графический метод определения генотипа по сочетанию мужских и женских гамет при скрещивании, предложенный английским биологом Р. Пеннетом (R. Punnett). Только в решетках Пеннета вместо собственных значений матриц и их комбинаций фигурируют аналогичные комбинации доминантных и рецессивных аллелей генов от родительских репродуктивных клеток - гамет. При этом в случае передачи информации доминирующие признаки кодируются более устойчивыми (стабильными) азотсодержащими основаниями.
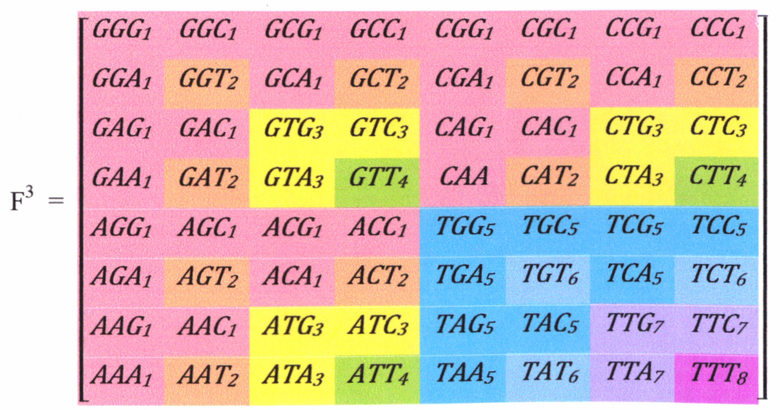
Каждый триплет отмечен определенным цветом в зависимости от степени устойчивости азотсодержащих оснований: красным цветом (нижний индекс - 1) те триплеты, в которых только стабильные основания, не меняющиеся и для ДНК и для РНК; оранжевым цветом (нижний индекс - 2) триплеты, в которых только верхнее (дочернее) основание будет меняться, два нижних останутся стабильными; желтым цветом (нижний индекс - 3) те триплеты, у которых будет меняться среднее основания при стабильных нижнем и верхнем; зеленым цветом (нижний индекс - 4) триплеты, у которых только нижнее основание стабильно, а верхнее и среднее меняются; голубым цветом (нижний индекс - 5) те триплеты, у которых меняется нижнее (материнское) основание, при стабильных верхнем и среднем; синим цветом (нижний индекс - 6) триплеты с изменяемыми нижним и верхнем основаниями при стабильном среднем основании; фиолетовым (нижний индекс - 7) триплеты с нижним и средним изменяемым основанием и стабильным верхнем основанием; пурпурным (нижний индекс - 8) - со всеми изменяемыми основаниями.
Построенная решетка Пеннета визуально повторяет ковер Серпинского и иллюстрирует фрактальное построение элементов молекулярно-генетической системы, совпадающей с частью себя самой. Иными словами представленная система имеет ту же структуру, что и ее части. При этом матрица Серпинского продуцирует матрицу Адамара, определяющую признаки помехоустойчивого кодирования. Следовательно, элементные характеристики на всех жизненных уровнях определяют уникальность каждого элемента молекулярно-генетической системы, принцип построения которой обусловлен, например, функцией Уолша, активно применяемой для помехоустойчивого кодирования информации.
Использование фракталов - матриц, каждая часть которой отображает целое, - позволяет сформировать молекулярно-генетическую систему на различных жизненных уровнях, используя в качестве элементов матрицы помимо азотистых оснований атомы, субатомы, аминокислоты, белки, которые в свою очередь формируют (ткани, органы, строительный материал).
Информация от ДНК к РНК передается транспортной последовательностью азотсодержащих оснований, построенной по принципу их комплементарности относительно друг друга.
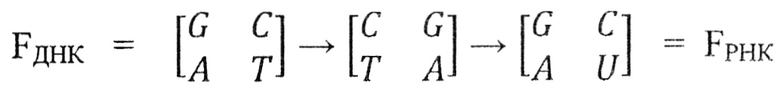
При многократном повторении операции Fn=F ⊗ Fn-1 над матрицей азотистых оснований для РНК получаем идентичную по построению систему элементов, в которой основание тимин (Т) заменено на урацил (U) - также являющийся пиримидиновым основанием с двумя водородными связями:
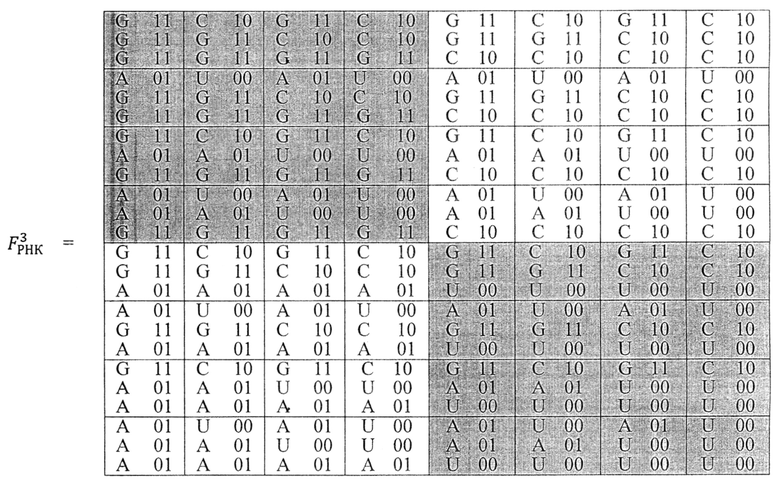
Следовательно, двоичная система триплетов ДНК, представленная в виде гексаграмм, будет идентична для системы триплетов РНК.
Аналогичным образом информация от РНК передается транспортной последовательностью азотсодержащих оснований TPНК к аминокислотам, формирующим белки. Триплетная матрица 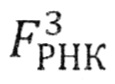 для РНК (как и все последующие матрицы размером, кратным 3) позволяет выстроить структурную систему для аминокислот
для РНК (как и все последующие матрицы размером, кратным 3) позволяет выстроить структурную систему для аминокислот 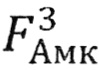 , ставя в соответствие каждому триплету (кодону) определенную аминокислоту согласно существующей классификационной таблице аминокислот (https://ru.wikipedia.org/wiki/Генетический код). 64 кодонам соответствует 20 аминокислот: Ala - аланин, Arg - аргинин, Asn - аспарагин. Asp - аспарагиновая кислота, Cys - цистеин, Gln - глутамин, Glu - глутаминовая кислота, Gly - глицин, His - гистидин, Ilе - изолейцин, Leu - лейцин, Lys - лизин, Met - метионин, Phe - фенилаланин, Pro - пролин, Ser - серии, Thr - треонин, Trp - триптофан, Туr -тирозин, Val - валин.
, ставя в соответствие каждому триплету (кодону) определенную аминокислоту согласно существующей классификационной таблице аминокислот (https://ru.wikipedia.org/wiki/Генетический код). 64 кодонам соответствует 20 аминокислот: Ala - аланин, Arg - аргинин, Asn - аспарагин. Asp - аспарагиновая кислота, Cys - цистеин, Gln - глутамин, Glu - глутаминовая кислота, Gly - глицин, His - гистидин, Ilе - изолейцин, Leu - лейцин, Lys - лизин, Met - метионин, Phe - фенилаланин, Pro - пролин, Ser - серии, Thr - треонин, Trp - триптофан, Туr -тирозин, Val - валин.
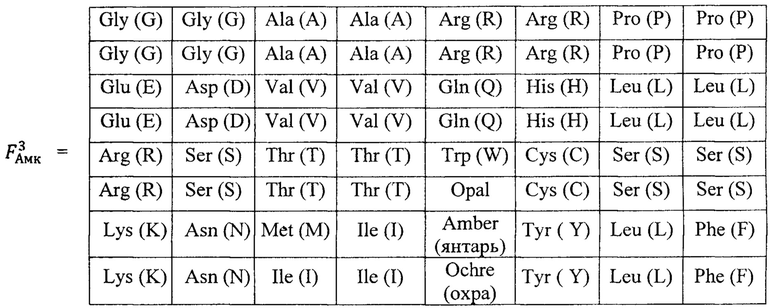
Возможно использование не только стандартного генетического кода, но и известных вариаций последнего, с добавлением 21-й (Селеноцистеин) и 22-й (пирролизин) аминокислот. Последовательность кодонов в гене определяет последовательность аминокислот в полипептидной цепи белка, кодируемого этим геном.
Построенная согласно описанному правилу любая матрица с различными собственными мультиплетными значениями трансформируется последовательность (линейное представление) с помощью известных способов кодирования элементов. Если в иерархической структуре данных каждый элемент хранит указатели на его предыдущее поколение, то при линейном представлении такие указатели не используются. Среди способов кодирования наиболее распространенными и эффективными является применение кривой Лебега (Z-кривой) и применение кривой Гильберта. Достоинством кривой Гильберта является ее непрерывность - соседние элементы расположены последовательно. Преимуществом Z-кривой является простота и скорость вычисления, поэтому она чаще применяется на практике. Для кодирования элементов с использованием Z-кривой используется код Мортона, который для Z-кривой вычисляется смещением и смешиванием бит двоичного представления каждой из координат.
На фиг. 1 в качестве одного из возможных примеров осуществления изобретений с использованием молекулярно-генетической системы изображена триплетная матрица для ДНК/РНК и аминокислот с соответствующей каждому элементу матрицы бинарной индексирующей информацией, которая для триплетной системы состоит из 64-х уникальных гексограмм, расположение каждой из которых обусловлено характеристиками азотистых оснований ДНК/РНК. Для лучшего восприятия структуры системы кодирования 64 элемента матрицы разбиты на восемь октетов, нумерация которых начинается с менее устойчивых элементов системы. Матрица изображена в линейном представлении, при котором каждый из восьми октетов расположены последовательно друг за другом с восьмого по первый октет.
В используемой для кодирования информации системе прослеживаются числовые представления, применяемые в кодовой комбинации контрольных бит, которые либо совпадают с полной ортогональной системой функций Уолша, применяемой в помехоустойчивом кодировании для обработки дискретных сигналов, либо имеют константное значение, применяемое для проведения проверок правильного построения системы. В зависимости от применения описываемых способов кодирования/декодирования информации могут быть использованы различные структурные матричные представления, в которых выполняется основное свойство матриц Адамара: FFT=n1, где F - матрица из n элементов -1 и +1. Причем описанные выше числовые представления и свойство матриц Адамара выполняются в различных структурных представлениях триплетной системы:
1) при квадратичном матричном представлении триплетной матрицы для ДНК, РНК и аминокислот (фиг. 2);
2) при прямоугольном матричном представлении триплетной матрицы для ДНК, РНК и аминокислот (фиг. 3);
3) при круговом матричном представлении триплетной матрицы для ДНК, РНК и аминокислот (фиг. 4);
4) при объемном (кубическом) представлении триплетной матрицы для ДНК/РНК (фиг. 5, 5А);
5) при представлении триплетной матрицы для ДНК в виде структурного дерева графов (фиг. 6, 6А). Причем, в данном примере числовые обозначения азотистых оснований в десятичной системе счисления от 0 до 63 формируются в ходе стандартного преобразования из двоичной системы счисления.
Могут быть также цветовые и звуковые представления, применяемые кодирования соответственно изображения и звукового ряда.
Например, в линейном представлении F3 количество водородных связей для каждого из 64-х триплетов изменяется от 9 до 6 с уменьшением по направлению к первому октету матрицы (фиг. 7), причем в одном октете количество водородных одинаковое у всех триплетов. Значения суммированных водородных связей построчно для каждого октета либо 24, либо 16 и совпадают с ортогональной системой функций Уолша. Общее количество построчно просуммированных водородных связей одинаковое и равно 160.
В квадратичном представлении F3 количество водородных связей для каждого из 64-х триплетов также изменяется от 9 до 6 с уменьшением по направлению к первому октету матрицы (фиг. 8). При этом значения суммированных водородных связей построчно для каждого октета либо 24, либо 16 также совпадают с ортогональной системой функций Уолша. Общее количество просуммированных по столбцам водородных связей одинаковое и равно 60. В круговом представлении F3 количество водородных связей для двух триплетов, размещенных на противоположных сегментах круга в сумме одинаковое и равно 15-ти (фиг. 4). Например, 9-ть водородных связей у триплетов 8-го октета в сумме с 6-ю водородными связями у триплетов противоположного 1-го октета дадут значение 15-ть.
У каждого азотистого основания разное количество атомов, в том числе количество атомов углерода (С), количества атомов водорода (Н), количества атомов азота (N), количества атомов кислорода (О):
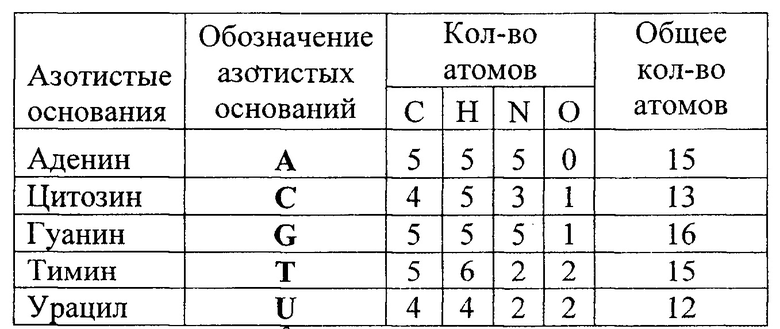
Триплетная система F3 исходя из количества атомов обладает закономерностями, приведенными на фиг. 9. При построчном суммировании количество атомов углерода (С), водорода (Н), азота (N), и кислорода (О) каждого октета либо 116, либо 120 и совпадает с ортогональной системой функций Уолша. При этом общее количество построчно просуммированных атомов углерода (С), водорода (Н), азота (N), и кислорода (О) одинаковое и равно 944.
При рассмотрении суммарного количество атомов углерода (С) для ДНК (фиг. 10) в линейном представлении триплетной матрицы значения атомов при построчном суммировании либо 36 било 40 и совпадают с ортогональной системой функций Уолша. Вместе с тем при рассмотрении суммарного количества атомов углерода (С) для РНК (фиг. 11) в линейном представлении триплетной матрицы значения атомов при построчном суммировании одинаковые и равны 36.
При рассмотрении суммарного количество атомов кислорода (О) для ДНК (фиг. 12) и для РНК (фиг. 13) в линейном представлении триплетной матрицы значения атомов при построчном суммировании одинаковые как для ДНК, так и для РНК, и равны 8.
Аналогичным образом можно проследить закономерности в выстроенной системе в различных ее представлениях по следующим характеристикам:
1. Величины электронной и протонной плотности в атомах азотистых оснований в целом и в частности: в атомах азотистых оснований у углерода (С), у водорода (Н), у азота (N) и у кислорода (О);
2. Величины нейтронной плотности в атомах азотистых оснований, в том числе в атомах азотистых оснований у углерода (С), у водорода (Н), у азота (N) и у кислорода (О);
3. Значения разности между протонной и нейтронной плотностью в атомах азотистых оснований, в том числе в атомах азотистых оснований у углерода (С), у водорода (Н), у азота (N) и у кислорода (О);
4. «Заряда» азотистых оснований («+1» - «aMino»; «-1» - «Keto»). У каждого элемента системы свой электрический заряд «aMino» - (положительный заряд) или «Keto» - (отрицательный заряд). У аденина и цитозина положительный заряд «aMino», а у гуанина, титозина и урацила - отрицательный заряд «Keto»;
5. Молекулярной плотности в атомах азотистых оснований, в том числе в атомах азотистых оснований у углерода (С), у водорода (Н), у азота (N) и у кислорода (О);
6. Плотности кварков в протонах атомов азотистых оснований, в том числе в протонах атомов азотистых оснований у углерода (С), у водорода (Н), у азота (N) и у кислорода (О);
7. Плотности кварков в нейтронах атомов азотистых оснований, в том числе в нейтронах атомов азотистых оснований у углерода (С), у водорода (Н), у азота (N) и у кислорода (О);
8. Плотности кварков в протонах и нейтронах атомов азотистых оснований, в том числе в протонах и нейтронах атомов азотистых оснований у углерода (С), у водорода (Н), у азота (N) и у кислорода (О);
9. Плотности электронной валентной зоны в атомах азотистых оснований.
Таким образом, при использовании дополнительно, по крайней мере, одной из вышеперечисленных характеристик также получают числовые представления, которые совпадают с функцией Уолша, которые можно использовать для проверочных кодовых комбинаций. В результате комбинации азотистых оснований согласно их характеристикам получаем структурную систему уникальных (неповторяющихся) элементов, дающую характеристику всей системы. Логическая структура подтверждается раскрытыми выше особенностями.
В настоящем примере используются мажорные (часто встречающиеся) азотистые основания, но в практической реализации возможно использовать и минорные (редко встречающиеся) азотистые основания. При этом каждое минорное основание, соответствующее определенному мажорному основанию, обладают аналогичными характеристиками, применяемыми для построения молекулярно-генетической системы. Следовательно, использование минорных оснований структурное построение молекулярно-генетической системы не нарушится. Сравнительный пример мажоров и миноров приведен на фиг. 14. При совместном использовании и мажорных и минорных оснований информационная мощность молекулярно-генетической системы возрастет.
В настоящее время общепринятым является обозначение позиции нуклеотидов в кодонах на 5'-3' цепи ДНК через X, Y и Z, где X - «приставка», Y - «корень», a Z - «окончание». Таким образом, триплет на этой цепи будет выглядеть следующим образом:
5'-X-Y-Z-3'.
В свою очередь, комплиментарный вышеприведенной записи триплет на 3'-5' цепи будет иметь запись:
3'-Z-Y-X-5'.
Триплет можно представить в виде суммы трех векторов:
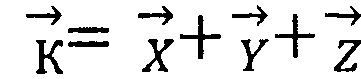 , где
, где
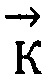 - вектор физико-биохимической системы «триплет» (кодон);
- вектор физико-биохимической системы «триплет» (кодон);
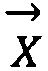 - первый элемент физико-биохимической системы «триплет» (азотистое основание), представленный в форме единичного вектора «приставка»;
- первый элемент физико-биохимической системы «триплет» (азотистое основание), представленный в форме единичного вектора «приставка»;
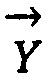 - второй элемент физико-биохимической системы «триплет» (азотистое основание), представленный в форме единичного вектора «корень»;
- второй элемент физико-биохимической системы «триплет» (азотистое основание), представленный в форме единичного вектора «корень»;
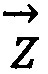 - третий элемент физико-биохимической системы «триплет» (азотистое основание), представленный в форме единичного вектора «окончание»;
- третий элемент физико-биохимической системы «триплет» (азотистое основание), представленный в форме единичного вектора «окончание»;
m - порядковый номер триплета (или его элементов) на 5'-3' цепи;
n - общее количество триплетов на 5'-3' цепи.
В свою очередь каждый единичный элемент векторного «триплета» можно разложить на составляющие его, элементы и записать в комплексном виде:
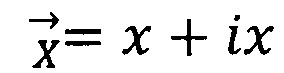 , где
, где
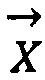 - первый элемент физико-биохимической системы «триплет» (азотистое основание), представленный в форме единичного вектора «приставка»;
- первый элемент физико-биохимической системы «триплет» (азотистое основание), представленный в форме единичного вектора «приставка»;
х - действительная часть комплексного числа, соответствующая оси Нb (оси водородных связей);
i - мнимая единица для элемента «приставка»;
ix - мнимая часть комплексного числа, соответствующая оси РР (оси класса азотистого основания).
Множество единичных векторов можно представить на единичной окружности комплексной плоскости. Аналогичным образом представляются элементы триплета типа Y («корень») и типа Z («окончание»).
Таким образом, появляется возможность записать триплет на т-позиции, представленный выражением:
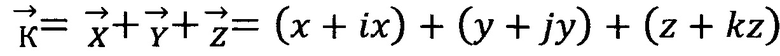 , где
, где
i, j, k - мнимые единицы со следующим свойством:
в матричной форме
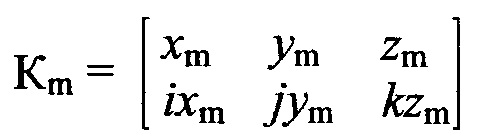
В силу того, что количество размещений с повторениями из n по k рассчитывается по формуле: 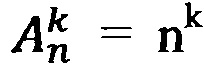 , то три азотистых основания, собранных в триплет, формируют 64 различных кодона, что эквивалентно логарифмической записи: log464=3.
, то три азотистых основания, собранных в триплет, формируют 64 различных кодона, что эквивалентно логарифмической записи: log464=3.
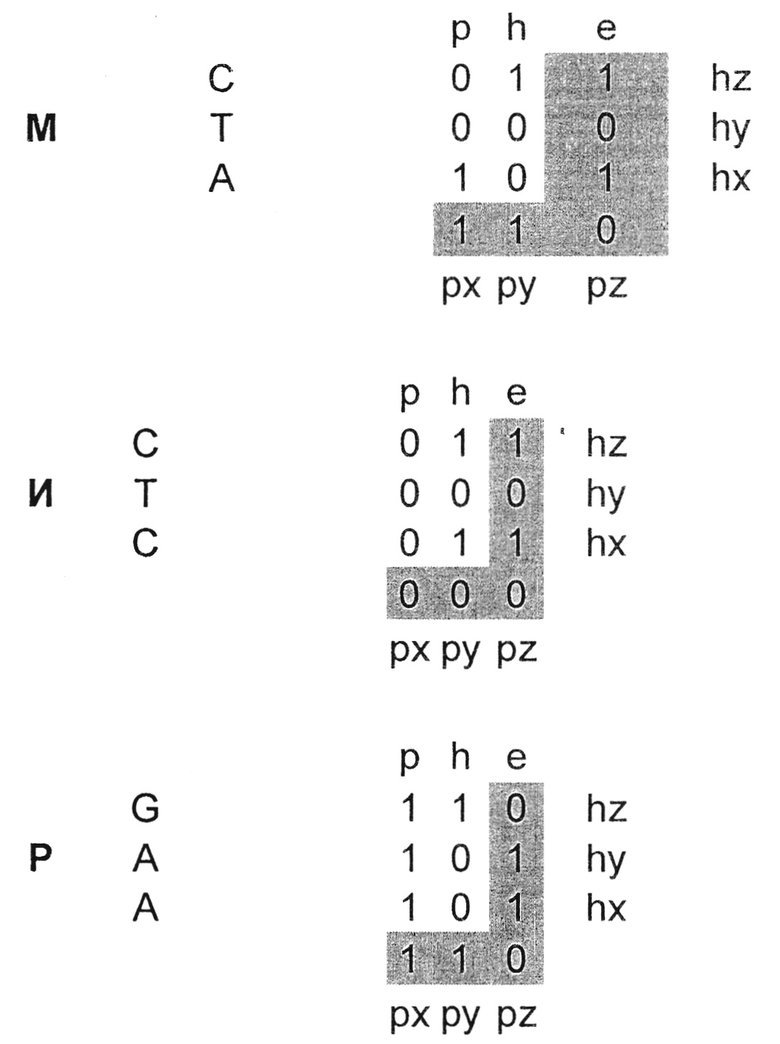
Пример 1. Реализация в описанном выше способе кодирования для записи контрольных бит логической операции «сложение по модулю» (ab), при которой для бинарного сложения по модулю применяется правило: результат равен «0», если оба операнда (а) и (b) различны, во всех остальных случаях результат равен «1»:

Для тернарного сложения (X, Y, Z) по модулю 2 применяется правило: результат равен «0», если нет операндов, равных «1», либо их четное количество, в остальных случаях результат равен «0»:

Данный способ записи основывается на разложении мажорных азотистых оснований (А, С, G, Т, U), а также их минорных аналогов на три бита:
- бит «р» класса азотистого основания (пурин или пиримидин);
- бит «h» количества водородных связей у азотистого основания (2 или 3);
- бит «е» группы азотистого основания (aMino или Keto).
При этом первые два информационных бита («р» - пурины или пиримидины и «h» - количество водородных связей) выступают в качестве переменных значений, а третий контрольный бит «е» - в виде результата логической операции.
В приведенной ниже таблице приведено соответствие битовых значений азотистых оснований для реализации способа записи логических элементов, где «р» - класс пурин или пиримидин, «h» - количество водородных связей 2 или 3, «е» - группа Keto или aMino.
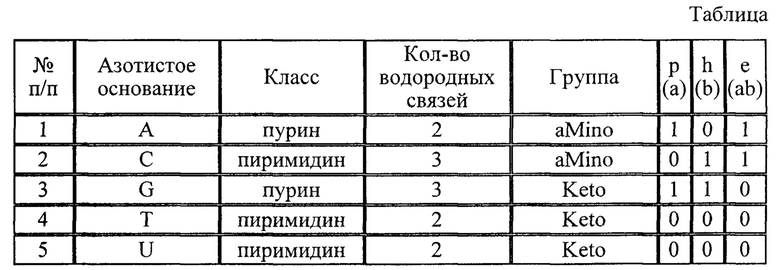
Как видно из таблицы, с помощью одного азотистого основания возможно записать 3 бита информации (два информационных бит и один контрольный бит), причем при использовании записи логических элементов в виде триплетов (кодонов) одновременно реализуется бинарное и тернарное сложение по модулю 2.

Следовательно, в приведенном примере с помощью одного азотистого основания возможно записать 9 бит информации (6 информационных бит переменных значений и 3 контрольных (результирующих) бита).
При сопоставлении (фиг. 15) общего количества значений булевой функции для результирующего триплетного вектора е (∑x∑y∑z), которое равно 8 (от 000 до 111) и общего количества значений для результирующего триплетного вектора XYZ (∑p∑h∑∑), равного 4 (000; 011; 101; 110), получаем общее количество побитовых значений в триплетной записи азотистых оснований, которое равно 16 (фиг. 16).
В силу того, что получается всего 16 различных комбинаций для 64 триплетов, то имеется возможность «уплотнить» запись 16 наборов не триплетами, а дуплетами (см. таблицу 2а и 2б).


В результате данной операции мы высвобождаем одно место под азотистое основание в триплете (Таблица 3) и можем использовать его в качестве управляющего значения одного из четырех состояний: G (11); С (01); А (10) и Т (00).
Например,
G (11) - символ, выделенный жирным шрифтом,
С (01) - символ, выделенный наклонным (курсивным) шрифтом,
А (10) - символ, выделенный подчеркнутым шрифтом,
Т (00) - обычный символ.
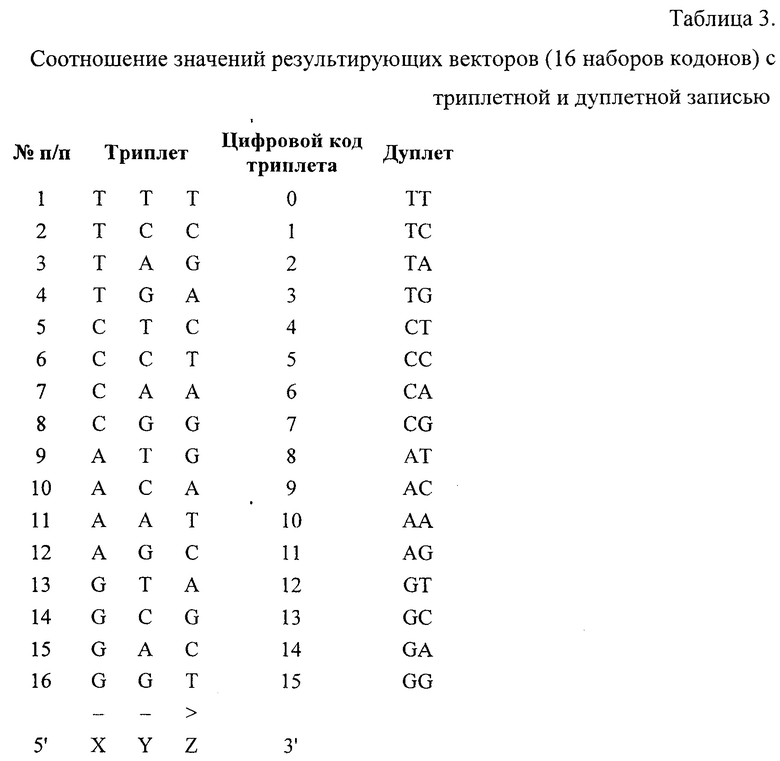
Пример 2 Кодирование слова «МИР» (без проверки на ошибки)
На фиг. 17 указаны соответствия триплетного кода ДНК (РНК) символьным значениям латинского и русского алфавита. Запись осуществляется по направлению от 5'-конца к 3'-концу. В приведенном примере одному логическому элементу соответствуют три азотистых основания.
Кодовую комбинацию можно отображать в различных вариантах:
1) линейном:
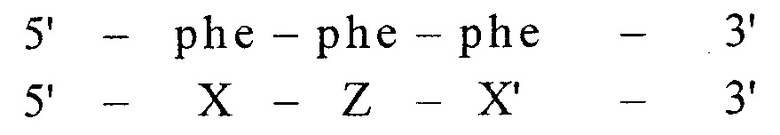
2) блочном (вертикальном):
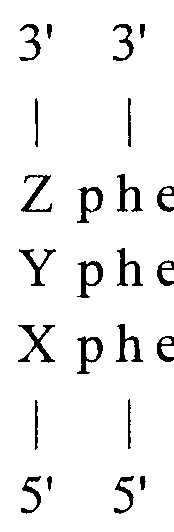
3) блочном (горизонтальном):
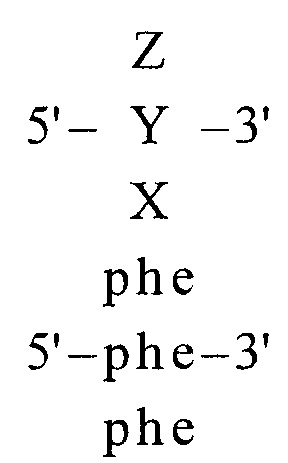
Слово «МИР» разбивают на логические элементы «М», «И», «Р». Каждому элементу присваивают уникальный символ алфавита, составленного на основе молекулярно-генетической системы триплетов (фиг. 17), построенной по вышеописанному принципу. К каждому символу ставят в соответствие элемент системы с добавлением индексирующей информации.
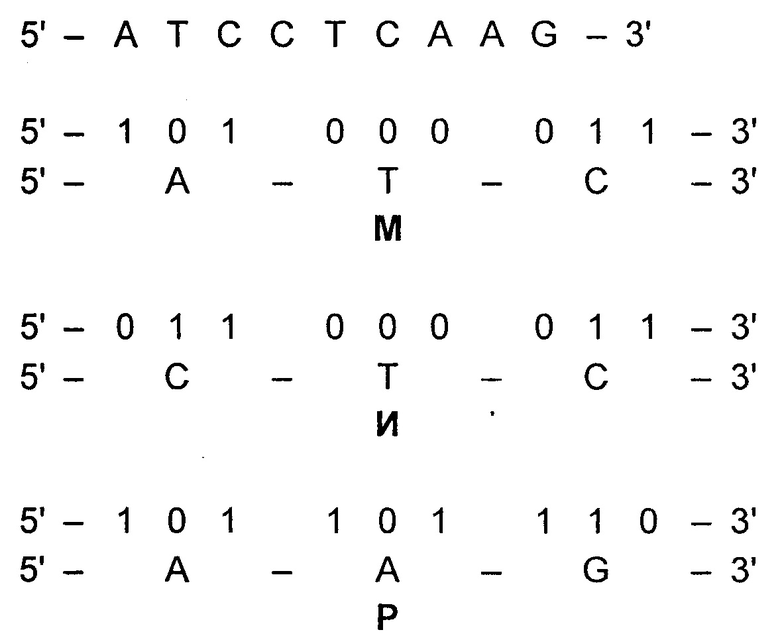
Затем определяют кодовую комбинацию исходя из значений функции сложения по модулю 2:
Поскольку запись символов с использованием азотистых оснований не предполагает проверку на ошибки, то фактически на каждое азотистое основание приходится 2 бита информации. Таким образом, на слово «МИР», приходится 9 азотистых оснований или 18 бит.
Пример 3 Кодирование слова «МИР» с проверкой на ошибки. Как и в предыдущем примере, запись осуществляется по направлению от 5'-конца к 3'-концу. При этом в приведенном примере одному логическому элементу соответствуют шесть азотистых оснований (X, Y, Z, X', Y', Z'): 3 азотистых оснований (X, Y, Z) предназначены для записи информации, а другие 3 азотистых оснований (Х', Y', Z') предназначены для записи контрольного (проверочного) кода.
Для того, чтобы была возможность проверки правильности прочтения записи, пользуются данными, приведенными на фиг. 16, где указаны значения результирующих векторов и их триплетная интерпретация из 16 наборов кодонов.
Таким образом, кодирование информации строится по следующему алгоритму:
1. Массив кодируемой информации разбивают на логически законченные фрагменты: в данном примере слово разделено на буквы.
2. Каждому фрагменту ставят в соответствие триплетный код ДНК (РНК) 5'-XYZ-3' согласно фиг. 17 и располагают кодовые комбинации информационных бит (переменных значений, кодирующих ту или иную характеристику азотистого основания) в виде матрицы.
3. К каждой кодовой комбинации информационных бит добавляют контрольных бит, являющиеся результирующими значениями для бинарного сложения по модулю 2 кодовых комбинаций информационных бит, для тернарного сложения по модулю 2 кодовых комбинаций информационных бит, а также сумму сумм (проверку проверок).
4. Ставят в соответствие контрольным битам триплет 5'-X'Y'Z'-3' (фиг. 16), и формируют последовательность контрольных бит бинарного, тернарного сложения и итоговой проверки (суммы сумм).
5. Формируют итоговую запись символа из шести азотистых оснований, состоящую из основного (5'-XYZ-3') и вспомогательного триплетов (5'-X'Y'Z'-3'):

Чтобы показать помехоустойчивость предлагаемого способа, позволяющего минимизировать потерю информационных данных из-за появления ошибок, используют методы обнаружения ошибок. Один из наиболее популярных методов обнаружения ошибок, является метод проверки на четность, который выполняется по строкам и по столбцам сформированной на основе кодовых комбинаций информационных бит матрицы - пример 4. Если четное число единиц, то добавляют «0», если нечетное - то «1». Завершают проверкой на четность проверки по строкам и столбцам вместе.
Если во всех проверках получился «0», то комбинация верна. При наличии ошибки в результате проверки обнаружится «1». На пересечении строки и столбца, в которых в результате проверки обнаружилась «1», находится ошибочный разряд.
Слово «МИР» закодировано с возможностью проверки на ошибки, представляя в виде последовательности:
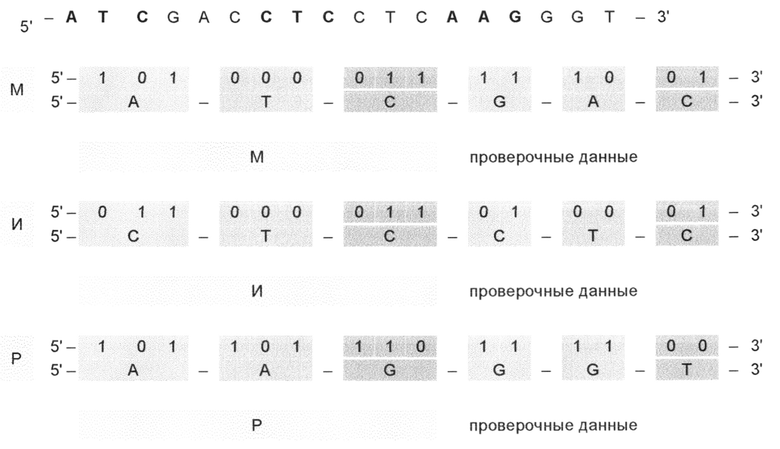
Матрица информационных и контрольных бит, а также матрица проверки на четность выглядят следующим образом:


В примере 4 показан способ записи символов с использованием азотистых оснований (с 4 состояниями символа и проверкой на ошибки на основе матричного кода). Одному логическому элементу соответствуют шесть азотистых оснований (X, Y, Z, X', Y', Z'), содержащих 15 бит информации, в том числе: 3 азотистых оснований (X, Y, Z) предназначены для записи информации содержат 9 бит, 2 азотистых оснований (X', Y'), содержащих 4 бит информации, предназначены для записи проверочного кода, и одно азотистое основание (Z'), содержащее 2 бита, предназначено для управляющего кода.
В данном примере плотность записываемой информации: 15 бит / 6 азотистых оснований составляет 2,5 бита на одно азотистое основание.
Кодовую информацию и алгоритм проверки формируют так же, как показано на примере 3. Особенностью данного примера является формирование проверочных значений не триплетным, а дуплетным кодом (фиг. 16). В результате этого высвобождается одно азотистое основание (Z') на управляющий код, используемый для вспомогательной информации.
Например, управляющий код, приходящийся на азотистое основание (Z') может быть как и в примере 1 в виде следующей кодировки:
G (11) - символ, выделенный жирным шрифтом
С (01) - символ, выделенный наклонным (курсивным) шрифтом
А (10) - символ, выделенный подчеркнутым шрифтом
Т (00) - обычный символ в тексте

Таким образом, слово «МИР» может быть закодировано с возможностью проверки на ошибки, а также с возможностью представления этого слова определенным шрифтом (в нашем примере - курсивом).
Слово: « МИР »

Кодируемую описанным способом информацию записывают, в том числе разбивая ее на короткие фрагменты ДНК, в которых также закодирована информация о начале и конце информационного отрывка. При этом один нуклеотид на одном уровне количество водородных связей и основания кодирует, по меньшей мере, два бита данных. При записи информации блоки синтезируются из отдельных нуклеотидов при помощи струйного ДНК-принтера. Для записи определенной информации синтезируют необходимые фрагменты ДНК, которые предварительно размножают и распознают при помощи устройства секвенирования, например Illumina HiSeq. Наличие адреса у каждого блока позволяет хранить информацию в виде смеси из коротких последовательностей нуклеотидов, а не единой цепочки ДНК. Такой способ позволяет хранить практически неограниченный объем информации. Для чтения синтезированных фрагментов ДНК могут быть использованы известные технологии секвенирования и специальное программное оборудование для перевода генетического кода обратно в двоичный файл на основе предложенной молекулярно-генетической системы.
Для декодирования информации также используется описанная выше молекулярно-генетическая система. При декодировании машиночитаемую последовательность разбивают на равные части, состоящие из i+k+m-числа нулей и единиц, являющиеся индексами логически законченных фрагментов декодируемой информации, состоящих из i-информационных бит, k-контрольных бит и m-управляющих бит. Затем каждой части ставят в соответствие мультиплет, состоящий из n-числа азотистых оснований и являющийся элементом молекулярно-генетической системы, определяя тем самым последовательность из логически законченных фрагментов декодируемой информации.
Таким образом, при использовании предлагаемого к защите способа кодирования и декодирования информации с использованием молекулярно-генетической системы в виде квадратных матриц, структурированных на характеристиках азотистых оснований нуклеотидов, достигается заявленный технический результат - оперирование без искажения и изменения большим объемом информации, а также в обеспечении возможности кодирования и декодирования цифрового сигнала для помехоустойчивой передачи информации программными средствами.
| название | год | авторы | номер документа |
|---|---|---|---|
| РНК-РЕПЛИКОН ДЛЯ УНИВЕРСАЛЬНОЙ И ЭФФЕКТИВНОЙ ГЕННОЙ ЭКСПРЕССИИ | 2017 |
|
RU2748892C2 |
| Способ кодирования цифровой информации в виде многомерного нанобар-кода | 2020 |
|
RU2777708C2 |
| БИНАРНЫЙ ФОРМАТ ДЛЯ ЭКЗЕМПЛЯРОВ MPEG-7 | 2001 |
|
RU2285354C2 |
| ЭНХАНСЕР ПАЛОЧКОВИДНОГО ВИРУСА САХАРНОГО ТРОСТНИКА (SCBV) И ЕГО ПРИМЕНЕНИЕ В ФУНКЦИОНАЛЬНОЙ ГЕНОМИКЕ РАСТЕНИЙ | 2013 |
|
RU2639517C2 |
| ТРИПЛЕТНЫЙ АНТИГЕН TREPONEMA PALLIDUM | 2012 |
|
RU2588656C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2761066C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2804029C2 |
| Способ генерации информационного штрихкода из данных, подлежащих кодированию, устройство для его реализации и код, полученный данным способом | 2024 |
|
RU2833411C1 |
| СПОСОБ ПОМЕХОУСТОЙЧИВОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЦИФРОВЫХ ДАННЫХ | 2015 |
|
RU2585977C1 |
| ОСНОВАННОЕ НА СТРУКТУРЕ ПРОГНОЗНОЕ МОДЕЛИРОВАНИЕ | 2014 |
|
RU2694321C2 |








Изобретение относится к области кодирования/декодирования информации. Технический результат - повышение эффективности помехоустойчивого кодирования/декодирования информации за счет увеличения объема передачи/приема информации при уменьшении количества используемых элементов. При выполнении способа кодирования информации массив кодируемой информации разделяют на логически законченные фрагменты, каждому из которых ставят в соответствие элемент используемой для кодирования молекулярно-генетической системы; ко множеству элементов системы добавляют соответствующую индексирующую информацию, состоящую из i-информационных бит; к каждой кодовой комбинации информационных бит добавляют комбинацию из k-контрольных бит, определяемую в зависимости от комбинации i-информационных бит; каждую i+k битовую информацию в двоичной форме счисления записывают в виде мультиплета, состоящего из n-числа азотистых оснований или соответствующих им аминокислот и являющегося элементом молекулярно-генетической системы, вместе с кодируемой информацией записывают значение n, от которого зависит размер используемой для кодирования матрицы, а также информацию о выбранном способе трансформации матрицы и порядок ее прочтения. 2 н. и 33 з.п. ф-лы, 17 ил., 4 табл.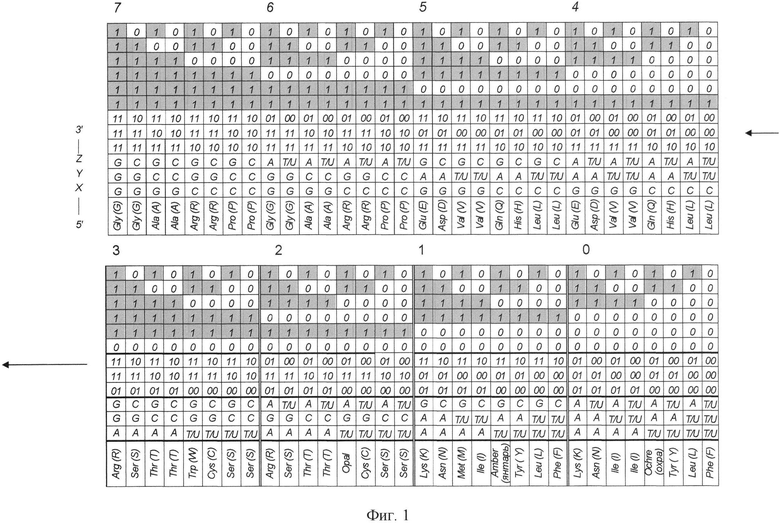
1. Способ кодирования информации, согласно которому:
массив кодируемой информации разделяют на логически законченные фрагменты, каждому из которых ставят в соответствие, по крайней мере, один элемент используемой для кодирования молекулярно-генетической системы;
ко множеству элементов системы добавляют соответствующую индексирующую информацию, состоящую из i-информационных бит;
к каждой кодовой комбинации информационных бит добавляют комбинацию из k-контрольных бит, определяемую в зависимости от комбинации i-информационных бит; отличающийся тем, что:
каждую i+k битовую информацию в двоичной форме счисления записывают в виде мультиплета, состоящего из n-числа азотистых оснований или соответствующих им аминокислот и являющегося элементом молекулярно-генетической системы,
состоящей из основы, выполненной в виде матрицы из четырех азотистых оснований 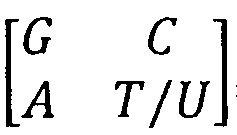 , сгруппированных по количеству водородных связей и по количеству конденсированных колец, содержащихся в структурах молекул азотистых оснований,
, сгруппированных по количеству водородных связей и по количеству конденсированных колец, содержащихся в структурах молекул азотистых оснований,
которую предварительно формируют путем многократного тензорного возведения в квадрат каждой матрицы предыдущего поколения для образования матрицы следующего поколения;
при этом бинарные индексы системы, формирующие i-информационные биты, соответствуют выбранной характеристике азотистых оснований,
вместе с кодируемой информацией записывают значение n, от которого зависит размер используемой для кодирования матрицы, а также информацию о выбранном способе трансформации матрицы в последовательность и порядок ее прочтения.
2. Способ кодирования по п. 1, отличающийся тем, что кодируемую информацию выстраивают в машиночитаемую последовательность в двоичной форме исчисления, включающую бинарные индексы для каждого мультиплета.
3. Способ кодирования по п. 1, отличающийся тем, что кодируемую информацию выстраивают в последовательность азотистых оснований.
4. Способ кодирования по п. 1, отличающийся тем, что к каждой кодовой комбинации i-информационных бит добавляют комбинацию из m-управляющих бит, определяемую в зависимости от комбинации i и k бит.
5. Способ кодирования по п. 1, отличающийся тем, что по положению каждого мультиплета в матрице молекулярно-генетической системы оценивают рецессивный или доминантный признак соответствующего ему логически законченного фрагмента.
6. Способ кодирования по п. 1, отличающийся тем, что последовательность азотистых оснований разбивают на законченные фрагменты, в которых также закодирована информация о начале и конце информационного отрывка.
7. Способ кодирования по п. 3, отличающийся тем, что кодируемую информацию выстраивают в последовательность азотистых оснований для кодирования на уровне ДНК.
8. Способ кодирования по п. 3, отличающийся тем, что кодируемую информацию выстраивают в последовательность азотистых оснований для кодирования на уровне РНК.
9. Способ кодирования по п. 3, отличающийся тем, что кодируемую информацию выстраивают в последовательность аминокислот.
10. Способ кодирования по п. 3, отличающийся тем, что кодируемую информацию выстраивают в последовательность азотистых оснований для кодирования на уровне белков.
11. Способ кодирования по п. 1, отличающийся тем, что молекулярно-генетическая система имеет линейное матричное представление.
12. Способ кодирования по п. 1, отличающийся тем, что молекулярно-генетическая система имеет квадратичное матричное представление.
13. Способ кодирования по п. 1, отличающийся тем, что молекулярно-генетическая система имеет прямоугольное матричное представление.
14. Способ кодирования по п. 1, отличающийся тем, что молекулярно-генетическая система имеет круговое матричное представление.
15. Способ кодирования по п. 1, отличающийся тем, что молекулярно-генетическая система имеет объемное представление.
16. Способ кодирования по п. 1, отличающийся тем, что молекулярно-генетическая система имеет вид структурного дерева графов.
17. Способ кодирования по п. 1, отличающийся тем, что бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для ДНК.
18. Способ кодирования по п. 1, отличающийся тем, что бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для РНК.
19. Способ кодирования по п. 1 или 18, отличающийся тем, что бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для аминокислот.
20. Способ кодирования по п. 1, отличающийся тем, что бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований, формирующих рецессивные и доминантные признаки на генном уровне.
21. Способ кодирования по п. 1, отличающийся тем, что синтетическую ДНК, сформированную из полученной последовательности азотистых оснований, содержащей кодируемую информацию, встраивают в носитель для хранения.
22. Способ кодирования по п. 1, отличающийся тем, что синтетическую ДНК, сформированную из полученной последовательности азотистых оснований, содержащей кодируемую информацию, встраивают в носитель для логико-математических вычислений.
23. Способ декодирования информации, согласно которому:
машиночитаемую последовательность разбивают на части, состоящие из логически законченных фрагментов декодируемой информации, включающих комбинации из i-информационных бит и k-контрольных бит, ставя в соответствие каждому логически законченному фрагменту, по крайней мере, один мультиплет, состоящий из n-числа азотистых оснований или соответствующих им аминокислот и являющийся элементом используемой для декодирования молекулярно-генетической системы, отличающийся тем, что:
молекулярно-генетическая система состоит из основы, выполненной в виде матрицы из четырех азотистых оснований 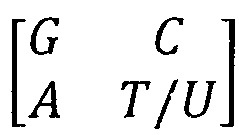 , сгруппированных по количеству водородных связей и по количеству конденсированных колец, содержащихся в структурах молекул азотистых оснований,
, сгруппированных по количеству водородных связей и по количеству конденсированных колец, содержащихся в структурах молекул азотистых оснований,
которую предварительно формируют путем многократного тензорного возведения в квадрат каждой матрицы предыдущего поколения для образования матрицы следующего поколения;
при этом бинарные индексы системы, формирующие i-информационные биты, соответствуют выбранной характеристике азотистых оснований, а индексы, формирующие k-контрольные биты, определяют в зависимости от комбинации i-информационных бит.
24. Способ декодирования по п. 23, отличающийся тем, что дискретные части машиночитаемой последовательности, состоящие из логически законченных фрагментов декодируемой информации, включают комбинации из m-управляющих бит, при этом индексы, формирующие m-управляющие биты, определяют в зависимости от комбинации i-информационных бит.
25. Способ декодирования по п. 23, отличающийся тем, что по положению каждого мультиплета в матрице молекулярно-генетической системы оценивают рецессивный или доминантный признак соответствующего ему логически законченного фрагмента.
26. Способ декодирования по п. 23, отличающийся тем, что молекулярно-генетическая система имеет линейное матричное представление.
27. Способ декодирования по п. 23, отличающийся тем, что молекулярно-генетическая система имеет квадратичное матричное представление.
28. Способ декодирования по п. 23, отличающийся тем, что молекулярно-генетическая система имеет прямоугольное матричное представление.
29. Способ декодирования по п. 23, отличающийся тем, что молекулярно-генетическая система имеет круговое матричное представление.
30. Способ декодирования по п. 23, отличающийся тем, что молекулярно-генетическая система имеет объемное представление.
31. Способ декодирования по п. 23, отличающийся тем, что молекулярно-генетическая система имеет вид структурного дерева графов.
32. Способ декодирования по п. 23, отличающийся тем, что бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для ДНК.
33. Способ декодирования по п. 23, отличающийся тем, что бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для РНК.
34. Способ декодирования по п. 23 или 33, отличающийся тем, что бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований для аминокислот.
35. Способ декодирования по п. 23, отличающийся тем, что бинарные индексы молекулярно-генетической системы соответствуют выбранной характеристике азотистых оснований, формирующих рецессивные и доминантные признаки на генном уровне.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 6312911 B1, 06.11.2001 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| CN 105022935 A, 04.11.2015 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ С ИСПРАВЛЕНИЕМ ОШИБОК | 2007 |
|
RU2408979C2 |

