Область техники, к которой относится изобретение
В теории информации сжатие данных или исходное кодирование является процессом кодирования информации, использующим меньше битов, чем использовало бы незакодированное представление посредством использования определенных схем кодирования. Например, текст мог быть закодирован с меньшим количеством битов, если можно было принять соглашение, что слово "compression" является закодированным как "comp.". Одним традиционным примером сжатия, с которым знакомы много пользователей компьютера, является формат файла "ZIP", который, обеспечивая сжатие, действует как архиватор, хранящий большое количество файлов в единственном выходном файле.
Как и в любой передаче данных, сжатая передача данных работает, только когда и отправитель, и получатель информации понимают схему кодирования. Например, текст имеет смысл, только если получатель понимает, что он предназначен, чтобы быть интерпретированным как символы, представляющие английский язык. Точно так же сжатые данные могут только быть поняты, если способ декодирования известен получателю.
Сжатие полезно, потому что оно помогает уменьшать потребление дорогих ресурсов, таких как память или полоса пропускания передачи. На нижней стороне сжатые данные должны быть распакованы, чтобы быть просмотренными (или услышанными). Эта дополнительная обработка распаковки может быть вредной для некоторых приложений. Например, схема сжатия видео может потребовать дорогих аппаратных средств для видео, чтобы оно было достаточно быстро распаковано для просмотра, так как оно распаковывается (опция полного распаковывания видео перед просмотром может быть неудобна и требует места в памяти для распакованного видео). Поэтому схемы сжатия данных вовлекают компромиссы среди различных факторов, включая память, степень сжатия, количество введенного искажения (используя схему сжатия с потерями) и вычислительные ресурсы, требуемые для сжатия и распаковывания данных.
Сущность изобретения
Сущность изобретения предоставлена, чтобы ввести выбор понятий в упрощенной форме, которые описаны далее в подробном описании. Сущность изобретения не предназначена, чтобы идентифицировать главные признаки или существенные признаки заявленного объекта изобретения. И при этом сущность изобретения не используется, чтобы ограничить объем заявленного объекта изобретения.
Могут быть предоставлены сжатие данных и распознавание ключевого слова. Первый проход может пройти текстовую строку, сгенерировать термины и вычислить хеш значение для каждого сгенерированного термина. Для каждого хеш значения может быть создан хеш сегмент, в котором может поддерживаться ассоциированный счет происшествий. Хеш сегменты могут быть сортированы счетом происшествия и несколько наивысших сегментов могут храниться. Как только наивысшие сегменты известны, второй проход может пройти текстовую строку, сгенерировать термины, вычислить хеш значение для каждого термина. Если хеш значения для терминов подходят хеш значениям тех, которые хранятся в сегменте, тогда термин может считаться частым термином. Следовательно, термин может быть добавлен в словарь вместе с соответствующим счетом частоты. Затем словарь может быть проверен для удаления терминов, которые могут быть не частыми, но появились в виду хеш противоречий.
Как предшествующее общее описание, так и последующее подробное описание обеспечивают примеры и являются только объяснительными. Соответственно, предшествующее общее описание и последующее подробное описание не должны восприниматься как ограничительные. Далее, признаки или изменения могут быть предоставлены в дополнение к только что сформулированным. Например, варианты осуществления могут быть направлены к различным комбинациям признаков и подкомбинациям, описанным в подробном описании.
Краткое описание чертежей
Сопроводительные чертежи, которые включены в и составляют часть этого раскрытия, иллюстрируют различные варианты осуществления настоящего изобретения. На чертежах:
фиг.1 является блок-схемой действующей среды;
фиг.2 является блок-схемой способа распознания текста;
фиг.3 является блок-схемой первого прохода;
фиг.4 является блок-схемой второго прохода;
фиг.5 иллюстрирует алгоритм; и
фиг.6 является блок-схемой системы, включающей в себя вычислительное устройство.
Подробное описание
Последующее подробное описание ссылается на сопроводительные чертежи. Везде, где это представляется возможным, одинаковые ссылочные номера используются в чертежах и в последующем описании, чтобы ссылаться к тем же самым или подобным элементам. В то время как варианты осуществления изобретения могут быть описаны, возможны модификации, адаптации и другие варианты осуществления. Например, замены, добавления или модификации могут быть сделаны к элементам, иллюстрированным на чертежах, и способы, описанные здесь, могут быть изменены заменой, переупорядочиванием или добавлением этапов к раскрытым способам. Соответственно, следующее подробное описание не ограничивает изобретение. Вместо этого надлежащий объем изобретения определен приложенной формулой изобретения.
Совместимый с вариантами осуществления изобретения двухпроходный хеш основанный алгоритм может использоваться для того, чтобы обнаружить частые термины в документе (например, текстовой строке). Кроме того, можно управлять соотношением качества памяти к памяти к времени выполнения. Варианты осуществления изобретения могут найти, например, самые частые 100 ключевых слов наряду со своим счетом в документе размером 1,68 мегабайт с 1%-ым ошибочным коэффициентом непопаданий, за 1,5 секунды, сохраняя память до 3 КБит.
Алгоритм, описанный ниже, например, может обнаружить частые ключевые слова в текстовой строке. Рассмотрим текстовую строку, содержащую следующий текст: "I went to the market but the market was closed." Варианты осуществления изобретения могут обнаружить, что "market" и “the” могут быть частыми терминами, которые могут быть квалифицированны как ключевые слова. Однако варианты осуществления изобретения могут также использоваться в целях сжатия. Рассмотрим текстовую строку, содержащую следующий текст: "abracadabra, abrasive brats!". Варианты осуществления изобретения могут обнаружить, что "bra" является частым термином, который желательно сжать. Независимо, цель вариантов осуществления изобретения может состоять в том, чтобы обнаружить частые повторные термины. Другая цель может состоять в том, чтобы произвести обзор документа, подсветить важные термины, сжать данные документа, найти чрезмерные грамматические повторения и т.д. Другими словами, варианты осуществления изобретения могут найти частые термины в текстовой строке, если они являются ключевыми словами, или даже подстроки в строках. Кроме того, варианты осуществления изобретения могут определить, сколько раз каждый частый термин появляется в текстовой строке и могут управлять использованием памяти, временем выполнения и влиять на качество.
Традиционные алгоритмы сжатия созданы для целей сжать-и-хранить. Таким образом, традиционные системы могут сделать поиски дорогими или иногда невозможными без полного распаковывания. Совместимый с вариантами осуществления изобретения, вышеупомянутый двухпроходный хеш основанный алгоритм может осуществить легкое сжатие, делая возможными быстрые поиски. Рассмотрим в качестве примера следующий сценарий. У нас может быть длинный список учетных записей/контактов:
- John Doe
- John Wayne
- Wayne Smith
-...
Когда пользователь впечатывает какой-либо текст (назовем это вводом), мы можем быстро идентифицировать учетные записи/контакты и высветить их.
ZIP может быть использован для сжатия списка. В то время как список можно весьма эффективно сжать, может не получиться возможность выполнить быстрый поиск. Ввиду того что ZIP сжатие может быть адаптивным, мы можем не надеяться на сжатие ввода и поиска подходящих байтов в сжатом списке. Распаковывание списка для сравнения с вводом может также сделать недостижимой главную цель.
Если упомянутый выше двухпроходный хеш основанный алгоритм запущен для поиска наиболее частых двух символов (например, также взвешивая длину строки и стоимость кодирования для поиска "наилучших" двух символов для сжатия), мы можем закончить компактным списком после легкого сжатия:
- $1=John
- $2=Wayne
- $1 Doe
- $1 $2
- $2 Smith
-...
Ввиду того что мы можем управлять тем, сколько символов кодировать, мы можем заменять эти символы в вводе и сравнивать.
Далее показан другой пример с XML. Например, мы можем иметь большой XML документ, содержащий:
<Greetings>
<Word id="Welcome">English</Word> <Word id="Bonjour">French</Word>
<Word id="Danke">German</Word>
...
</Greetings>
Мы можем хотеть иметь возможность использовать меньше памяти, для сохранения XML документа, но при этом иметь возможность использовать запросы Xpath для поисков: Xpath = Greetings/Word[@id="Welcome"].
Мы можем использовать ZIP, чтобы сжать документ XML. XPath, возможно, может не работать (потому что мы сжали байты, но больше не документ XML.) Теперь, если мы выполняем вышеупомянутый двухпроходный хеш основанный алгоритм, чтобы найти самые частые два символа (например, избегая кодирования определенных узлов XML, или атрибуты могут использоваться для поиска "наилучших" двух символов для сжатия). Мы можем закончить с компактным документом XML после легкого сжатия:
$1 =Greetings
$2=Word
<$1 >
<$2 id="Welcome">English<$2>
<$2 id="Bonjour">French<$2>
<$2 id="Danke">German<$2>
…
</$1 >
Теперь мы можем продолжать запуск запросов Xpath: XPath = $1/$2[@id="Welcome"]
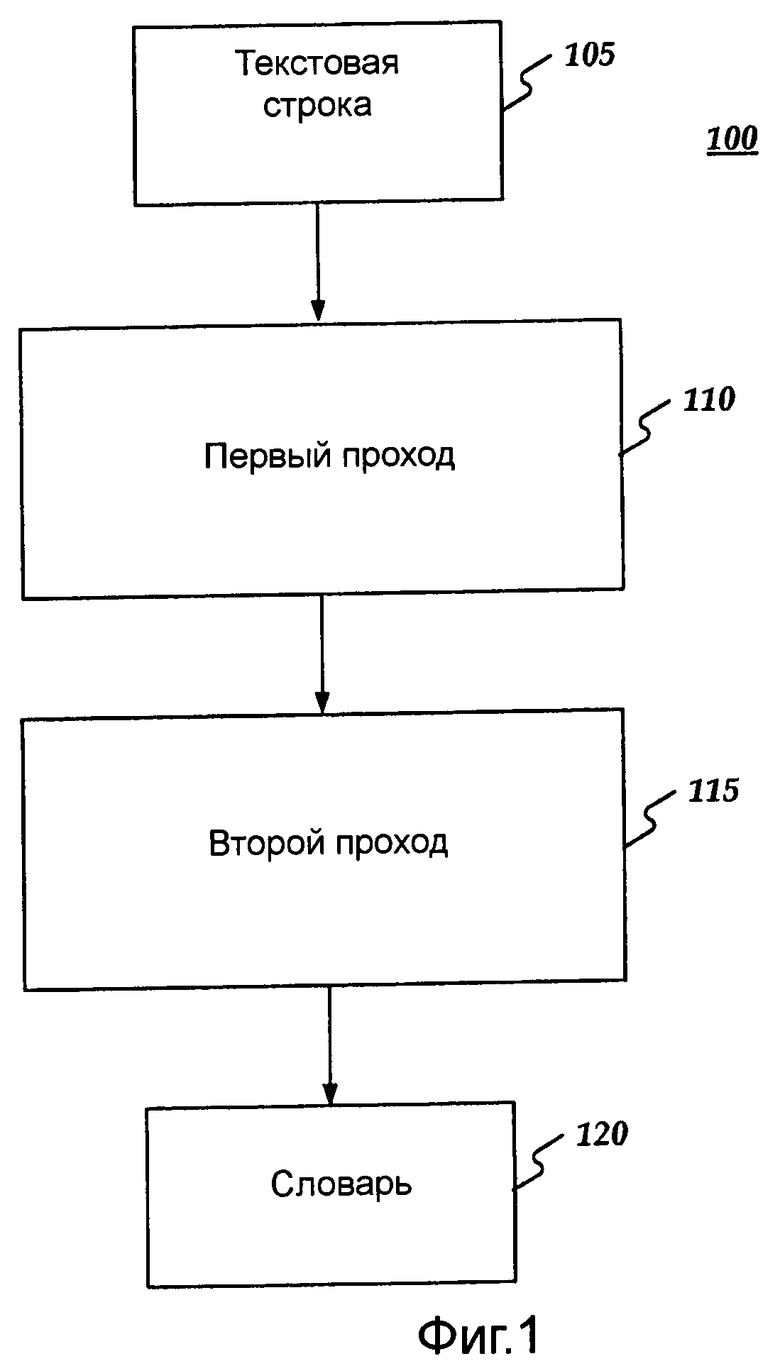
Фиг.1 показывает систему 100 распознавания, совместимую с вариантами осуществления изобретения. Как показано на Фиг.1, текстовая строка 105 может управляться первым проходом 110 и вторым проходом 115, чтобы создать словарь 120. Например, первый проход 110 может проходить текстовую строку 105, генерировать термины и вычислить хеш значение для каждого сгенерированного термина. Для каждого хеш значения может быть создан хеш сегмент, в котором ассоциированный счет происшествия может быть поддержан. Хеш сегменты могут быть сортированы счетом происшествия, и несколько наивысших хеш сегментов могут быть сохранены. Как только наивысшие хеш сегменты известны, второй проход 115 может пройти текстовую строку 105 еще раз, генерировать термины и снова вычислить хеш значение для каждого термина. Если хеш значения терминов соответствуют хеш значениям одного из сохраненных сегментов, то может существовать хорошая вероятность того, что термин является частым термином. Следовательно, термин может быть добавлен к словарю 120 наряду с соответствующим счетом частоты. Затем словарь 120 может быть проверен, чтобы удалить термины, которые, возможно, не являются частыми, но казались такими в виду хеш противоречий. Затем, термины в словаре 120 могут быть ранжированы, сокращены и фильтрованы. Пример алгоритма 500 для осуществления вышеупомянутого двухпроходного процесса показан на Фиг.5.
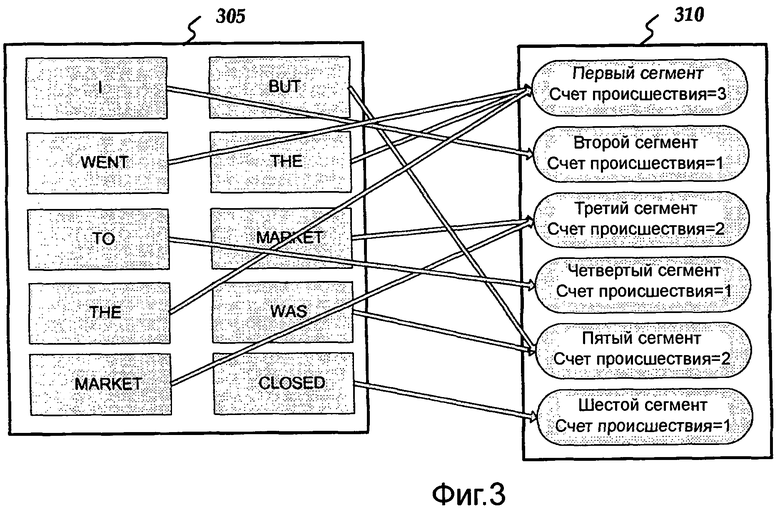
Фиг.2 является блок-схемой, устанавливающей основные этапы, вовлеченные в способ 200, совместимый с вариантом осуществления изобретения для распознавания текста. Способ 200 может быть осуществлен с использованием вычислительного устройства 600, как описано более подробно ниже относительно Фиг.6. Варианты осуществления этапов способа 200 будут описаны более подробно ниже. Способ 200 может начаться в начальном блоке 205 и перейти на этап 210, где вычислительное устройство 600 может генерировать множество сгенерированных терминов, использованных в текстовой строке 105. Например, первый проход 110 может проанализировать текстовую строку 105, включающую в себя "I went to the market but the market was closed." Этот анализ может генерировать множество сгенерированных терминов 305, включающих в себя "I", "went", "to", "the", “market” "but", "the", "market", "was" и "closed", как показано на Фиг.3.
Совместимые с вариантами осуществления изобретения термины префикс/суффикс могут быть сгенерированы, например, в целях сжатия данных. Например, термин "abra" мог генерировать термины префикс/суффикс, такие как: "abra", "bra", "ra", "abr" и т.д. Однако, если нахождение частых ключевых слов в текстовой строке 105 является целью, может не быть никакой потребности генерировать префиксы/суффиксы, скорее могут быть сгенерированы индивидуальные строки от текстовой строки 105.
От этапа 210, где вычислительное устройство 600 генерирует множество сгенерированных терминов 305, используемых в текстовой строке 105, способ 200 может продвинуться к этапу 220, в котором вычислительное устройство 600 может вычислить множество хеш значений из множества сгенерированных терминов 305. Алгоритм хеш строки может использоваться, чтобы генерировать хеш, как показано ниже.
private static int GetHash(string input)
{
int hash = 0;
for (int i = 0; i < input. Length; i++)
{
hash = (hash << 5) + hash + input[i];
}
return hash;
}
Идеальная хеш функция может использоваться, чтобы избежать "противоречий". Противоречия состоят в том, что два различных термина могут привести к тому же самому хеш значению. Совершенная хеш функция набора S является хеш функцией, которая может отобразить различные ключи (элементы) в S к различным числам. Совершенная хеш функция со значениями в диапазоне размера несколько постоянных раз ряд элементов в S может использоваться для эффективного поиска, помещая ключи в хеш таблицу согласно значениям идеальной хеш функции.
Идеальная хеш функция для определенного набора S, который может быть оценен в постоянное время и со значениями в маленьком диапазоне, может быть найдена рандомизированным алгоритмом во многих операциях, который пропорционален размеру S. Минимальный размер описания идеальной хеш функции может зависеть от диапазона ее функциональных значений: чем меньше диапазон, тем больше пространства требуется. Любые идеальные хеш функции, подходящие для использования с хеш таблицей, могут потребовать, по меньшей мере, число битов, которое пропорционально размеру S. Многие варианты осуществления могут потребовать количество битов, которые пропорциональны n log(n), где n является размером S. Это может означать, что пространство для сохранения совершенной хеш-функции может быть сопоставимым пространству для сохранения набора.
Использование идеальной хеш функции может быть лучшим вариантом в ситуациях, когда имеется большой набор, часто не обновляемый, и имеется много поисков в нем. Эффективные решения для выполнения обновления известны как идеальное динамическое хеширование, но эти способы достаточно сложны для осуществления. Простой альтернативой идеального хеширования, которая также позволяет динамические обновления, может также являться "cuckoo хеширование" (cuckoo hashing). Более того, может быть использован минимальный идеальный хеш. Минимальная идеальная хеш функция может быть идеальной хеш функцией, которая преобразовывает n ключи в n последовательные целые числа, обычно [0..n-1] или [1..n]. Более формальный способ объяснения следующий: допустим j и k будут элементами некого набора K. F является минимальной идеальной хеш функцией iff F(j)=F(k), откуда следует что j=k, и существует целое число а, такое что диапазон F является a..a+|K|-1. Минимальная идеальная хеш функция F может быть сохраняющей порядок, если для каких-нибудь клавиш j и k j<k, откуда следует, что F(j)<F(k). Не отрицая вышесказанное, различные алгоритмы, основанные на теории графов/вероятности, могут использоваться, чтобы генерировать идеальные хеш функции (например, CHM минимальный идеальный алгоритм хеширования). Это может, однако, потребовать первого начального прохода (например, маркированный Pass0 в алгоритме 500, показанном на Фиг.5), чье время выполнения может расти линейно с размером ввода.
Как только вычислительное устройство 600 вычисляет множество хеш значений от множества сгенерированных терминов на этапе 220, способ 200 может перейти к этапу 230, на котором вычислительное устройство 600 может создать множество хеш сегментов, соответствующих множеству хеш значений. Например, первый проход 110 может создать множество хеш сегментов 310. Как показано на Фиг.3, множество хеш сегментов может содержать первый сегмент, второй сегмент, третий сегмент, четвертый сегмент, пятый сегмент и шестой сегмент.
После того как вычислительное устройство 600 создает множество хеш сегментов 310 на этапе 230, способ 200 может перейти к этапу 240, на котором вычислительное устройство 600 может поддержать множество значений счета происшествий, соответствующих множеству хеш сегментов 310. Каждый из множества значений счета происшествий может соответственно указывать число раз, которое каждый из множества сгенерированных терминов (например, множества сгенерированных терминов 305) происходит в текстовой строке 105, имеющей хеш значение, которое соответствует множеству соответствующих хеш сегментов значений счета происшествий. Например, как показано на Фиг.3, первый проход 110 может сканировать текстовую строку 105 и вычислить хеш сгенерированных терминов 305. Два случая "market" в сгенерированных терминах 305 могут хешироваться в третий сегмент, приводя к счету происшествий 2 для третьего сегмента. Кроме того, два случая "the" в сгенерированных терминах 305 могут хешироваться в первый сегмент. Однако, "went" может также хешироваться к первому сегменту из-за противоречий, приводящим к счету происшествий 3 для первого сегмента. В любом случае, обнаружение большего количества случаев того же самого термина во множестве сгенерированных терминов может укрепить счет конкретного хеш сегмента.
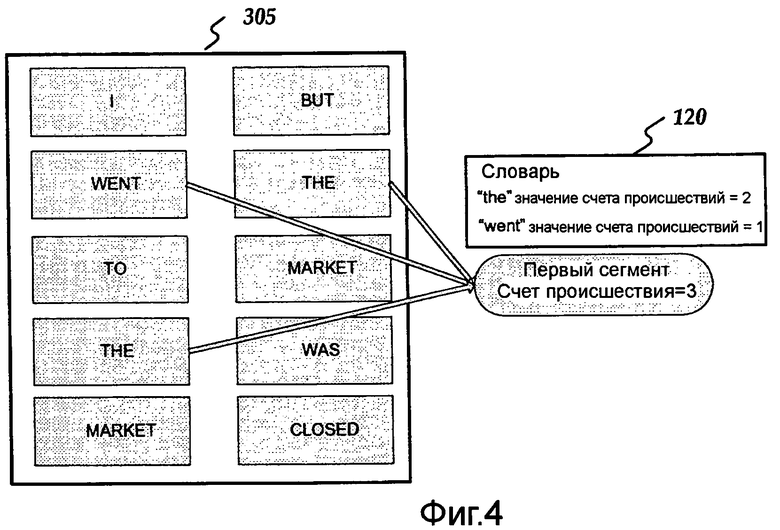
От этапа 240, на котором вычислительное устройство 600 поддерживает множество значений счета происшествий, способ 200 может перейти на этап 250, на котором вычислительное устройство 600 может сбросить те из множества хеш сегментов, которые имеют соответствующие значения счета происшествий меньше, чем первое предопределенное значение. Например, первое предопределенное значение может включать в себя "3". Следовательно, в примере Фиг.3 второй сегмент, третий сегмент, четвертый сегмент, пятый сегмент и шестой сегмент могут быть сброшены, так как каждый из этих хеш сегментов имеет счет происшествий меньше «3», приведенный к примеру, показанному на Фиг.4. В то время как пример на Фиг.4 показывает только один сохраненный хеш сегмент, наивысшие N хеш сегменты, или все хеш сегменты со счетом, больше, чем определенный порог (например, первое предопределенное значение) может быть сохранен. Другими словами, наивысшие N сегменты, имеющие самые высокие значения счета происшествия, могут быть сохранены, не только сегменты, значения счета происшествий которых больше, чем X, например.
Как только вычислительное устройство 600 сбросит сегменты из множества хеш сегментов на этапе 250, способ 200 может перейти на этап 260, на котором вычислительное устройство 600 может добавить термины словаря к словарю 120. Термины словаря могут включать в себя те из множества сгенерированных терминов, которые имеют соответствующие хеш значения, соответствующие любому из множества хеш значений, соответствующих оставшемуся множеству хеш сегментов. Словарь 120 может также включать в себя множество значений счета частоты, соответственно указывающих число раз, которое каждый из терминов словаря произошел в текстовой строке 104. Например, как показано на Фиг.4, второй проход 115, может повторно сканировать текстовую строку 105 и вычислить хеш сгенерированных терминов. Если хеш совпадает с тем из сохраненного сегмента (например, первого сегмента), то термин может быть добавлен в словарь 120 наряду с соответствующим значением счета частоты. Иначе термин может быть сброшен. Как показано на Фиг. 4, словарь 120 может содержать термины «the» (значение счета частоты = 2) и "went" (значение счета частоты = 1). Если текстовая строка 105 была больше, второй проход 115, возможно, мог произвести намного более высокое значение счета частоты для «the» и меньшее значение счета частоты для "went".
Совместимый с вариантами осуществления изобретения второй проход 115, может удалить искажение из-за противоречий и ранжировать термины в словаре 120. Например, "went" хешировался к тому же самому сегменту, как и «the». Однако конечный счет, полученный во время второго прохода 115, может показать, что "went" не настолько частый и может быть удален из словаря 120. Соответственно, противоречия могут быть исправлены.
Кроме того, термины словаря могут быть ранжированы, с использованием функции оценки, которая зависит от цели (например, сжатие данных, обнаружение ключевого слова и т.д.). Например, если целью является сжатие данных, то ранг может быть назначен частому термину словаря на основе его строковой длины, умноженной на его значение счета частоты минус стоимость кодирования этой информации (то есть "выгода" сжатия частого термина словаря). В другом примере, если цель состоит в том, чтобы найти ключевые слова в текстовой строке, то ранг можно назначить частым термином словаря, на основе их значения. Например, на английском языке, частый термин «the» не может быть ранжирован высоко, потому что он обработан как искажение. Соответственно, процессы ранжирования могут различаться в зависимости от цели. Как только вычислительное устройство 600 добавляет термины словаря словарю на этапе 260, способ 200 может затем закончиться на этапе 270.
Вариант осуществления, совместимый с изобретением, может включать в себя систему распознавания текста. Система может включать в себя хранилище памяти и блок обработки, соединенный с хранилищем памяти. Блок обработки может быть выполнен с возможностью генерирования множества сгенерированных терминов, используемых в текстовой строке, вычисления множества хеш значений от множества сгенерированных терминов и создания множества хеш сегментов, соответствующих множеству хеш значений. Кроме того, блок обработки может быть выполнен с возможностью поддержания множества значений счета происшествий, соответствующих множеству хеш сегментов. Каждое множество значений счета происшествий может соответственно указать число раз, которое каждый из множества сгенерированных терминов произошел в текстовой строке, имеющей хеш значение, которое соответствует множеству соответствующих хеш сегментов значений счета происшествия. Кроме того, блок обработки может быть выполнен с возможностью сброса тех из множества хеш сегментов, которые имеют соответствующие значения счета вхождения меньше, чем первое предопределенное значение. Кроме того, блок обработки может быть выполнен с возможностью добавления терминов словаря к словарю. Термины словаря могут включать в себя те из множества сгенерированных терминов, которые имеют соответствующие хеш значения, соответствующие любому из множества хеш значений, соответствующих оставшемуся множеству хеш сегментов. Словарь может включать в себя множество значений счета частоты, соответственно указывающих число раз, которое каждый из терминов словаря произошел в текстовой строке.
Другой вариант осуществления, совместимый с изобретением, может содержать систему распознания текста. Система может содержать хранилище памяти и блок обработки, соединенный с хранилищем памяти. Блок обработки может быть выполнен с возможностью создания множества хеш сегментов, соответствующих множеству хеш значений, соответствующих множеству сгенерированных терминов в текстовой строке, причем, по меньшей мере, часть множества сгенерированных терминов содержит подстроки. Кроме того, блок обработки может быть выполнен с возможностью поддержания множества значений счета происшествий, соответствующих множеству хеш сегментов. Каждый из множества значений счета происшествий может соответственно указать число раз, которое те из множества сгенерированных терминов происходят в текстовой строке, имеющей хеш значение, которое соответствует множеству соответствующего хеш сегмента значений счета происшествий. Кроме того, блок обработки может быть выполнен с возможностью сброса тех из множества хеш сегментов, которые имеют соответствующие значения счета происшествий меньше, чем первое предопределенное значение. Кроме того, блок обработки может быть выполнен с возможностью добавления терминов словаря словарю. Термины словаря могут содержать те из множества сгенерированных терминов, которые имеют соответствующие хеш значения, соответствующие любому из множества хеш значений, соответствующих оставшемуся множеству хеш сегментов. Словарь может включать в себя множество значений счета частоты, соответственно указывающих число раз, которое каждый из терминов словаря произошел в текстовой строке. Кроме того, блок обработки может быть выполнен с возможностью ранжирования терминов словаря с использованием функции оценки, сконфигурированной с возможностью сжатия данных, причем термины словаря могут быть ранжированы на основе множества соответствующих индексов, соответствующих каждому из терминов словаря. Каждый из множества индексов может, соответственно, включать в себя значение счета частоты каждого соответствующего термина словаря, умноженного на длину каждого соответствующего термина словаря.
Еще один вариант осуществления, совместимый с изобретением, может включать в себя систему распознавания текста. Система может содержать хранилище памяти и блок обработки, соединенный с хранилищем памяти. Блок обработки может быть выполненным с возможностью создания множества хеш сегментов, соответствующих множеству хеш значений, соответствующих множеству сгенерированных терминов в текстовой строке, причем каждый из множества сгенерированных терминов включает в себя индивидуальные строки. Кроме того, блок обработки может быть выполненным с возможностью поддержания множества значений счета происшествий, соответствующих множеству хеш сегментов. Каждое из множества значений счета происшествий может соответственно указывать число раз, которое термины из множества сгенерированных терминов происходят в текстовой строке, имеющие хеш значения, которые соответствуют множеству соответствующих хеш сегментов значений счета происшествий. Кроме того, блок обработки может быть выполненным с возможностью сброса тех из множества хеш сегментов, имеющих соответствующие значения счета происшествий меньше, чем первое предопределенное значение, и с возможностью добавления терминов словаря словарю. Термины словаря могут содержать те из множества сгенерированных терминов, которые имеют соответствующие хеш значения, соответствующие любому из множества хеш значений, соответствующих оставшемуся множеству хеш сегментов. Словарь может включать в себя множество значений счета частоты, соответственно указывающих число раз, которое каждый из терминов словаря произошел в текстовой строке. Кроме того, блок обработки может быть выполнен с возможностью ранжирования терминов словаря с использованием функции оценки, конфигурированной для распознавания ключевого слова, причем термины словаря ранжированы на основе их соответствующих значений счета частоты.
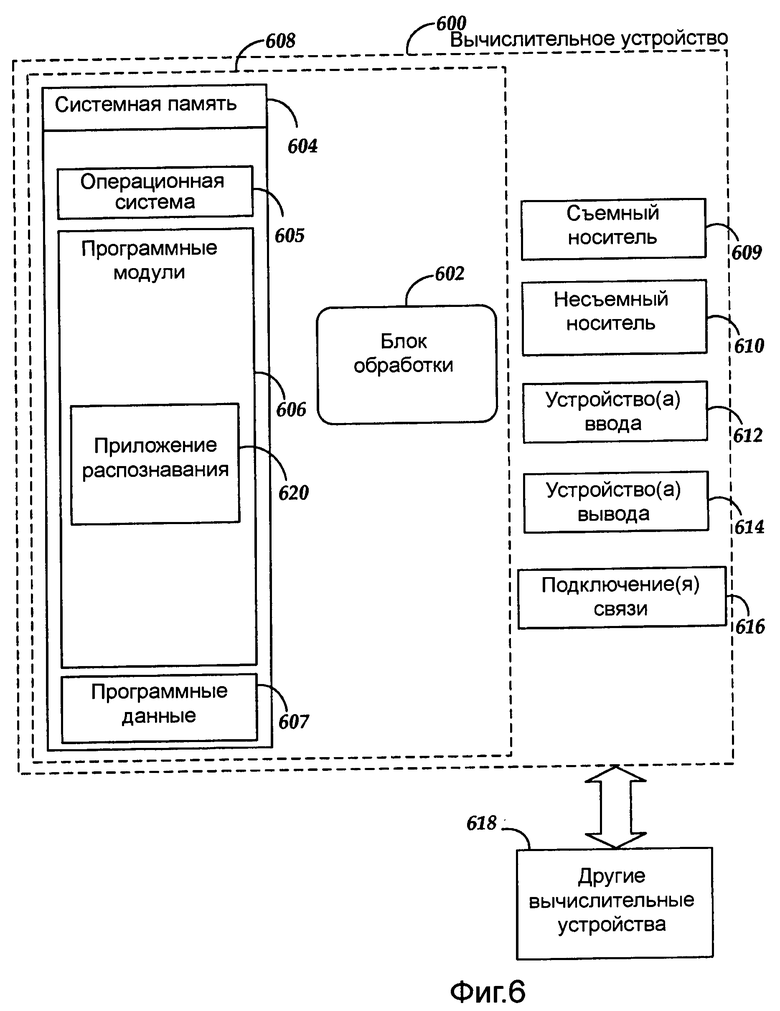
Фиг.6 является блок-схемой системы, включающей в себя вычислительное устройство 600. Совместимое с вариантом осуществления изобретения вышеупомянутое хранилище памяти и блок обработки могут быть осуществлены в вычислительном устройстве, таком как вычислительное устройство 600 на Фиг.6. Любая подходящая комбинация аппаратных средств, программного обеспечения или встроенного программного обеспечения может использоваться, чтобы осуществить хранилище памяти и блок обработки. Например, хранилище памяти и блок обработки могут быть осуществлены с вычислительным устройством 600 или любым из других вычислительных устройств 618, в комбинации с вычислительным устройством 600. Вышеупомянутая система, устройство и процессоры являются примерами, и другие системы, устройства и процессоры могут включать в себя вышеупомянутые хранилище памяти и блок обработки, совместимый с вариантами осуществления изобретения. Кроме того, вычислительное устройство 600 может включать в себя рабочую среду для системы 100, как описано выше. Система 100 может работать в других средах и не ограничена вычислительным устройством 600.
В отношении Фиг.6 система, совместимая с вариантом осуществления изобретения, может включать в себя вычислительное устройство, такое как вычислительное устройство 600. В базовой конфигурации вычислительное устройство 600 может включать в себя, по меньшей мере, один блок 602 обработки и системную память 604. В зависимости от конфигурации и типа вычислительного устройства системная память 604 может включать в себя, но не ограничиваясь, энергозависимую память (например, оперативная память (RAM)), энергонезависимую память (например, постоянное запоминающее устройство (ROM)), флэш-память или их комбинации. Системная память 604 может включать в себя операционную систему 605, один или более модулей 606 программирования и может включать в себя программные данные 607. Операционная система 605, например, может быть подходящей для того, чтобы управлять работой вычислительного устройства 600. В одном варианте осуществления программные модули 606 могут включать в себя, например, приложение 620 распознавания. Кроме того, варианты осуществления изобретения могут быть осуществлены вместе с графической библиотекой, другими операционными системами или любой другой прикладной программой и не ограничены никаким специфическим приложением или системой. Эта базовая конфигурация показана на Фиг.6 компонентами в пределах пунктирной линии 608.
Вычислительное устройство 600 может иметь дополнительные признаки или функциональные возможности. Например, вычислительное устройство 600 может также включать в себя дополнительные устройства хранения данных (съемные и/или несъемные), такие как, например, магнитные диски, оптические диски или лента. Такая дополнительная память иллюстрирована на Фиг.6 съемным носителем 609 и несъемным носителем 610. Компьютерные носители данных могут включать в себя энергозависимые и энергонезависимые, съемные и несъемные носители, осуществленные любым способом или технологией хранения информации, такими как читаемые компьютером команды, структуры данных, программные модули или другие данные. Системная память 604, съемный носитель 609 и несъемный носитель 610 являются всеми компьютерными примерами носителей данных (то есть хранилищем памяти). Компьютерные носители данных могут включать в себя, но не ограничиваясь, RAM, ROM, электрически стираемое постоянное запоминающее устройство (СППЗУ; EEPROM), флэш-память или другую технологию памяти, CD-ROM, цифровые универсальные диски (DVD) или другую оптическую память, магнитные кассеты, магнитную ленту, магнитную память на диске или другие магнитные запоминающие устройства, или какой либо другой носитель, который может использоваться, чтобы хранить информацию, и к которому может обратиться вычислительное устройство 600. Любые такие компьютерные носители данных могут быть частью устройства 600. У вычислительного устройства 600 может также быть устройство(а) 612 ввода данных, такое как клавиатура, мышь, перо, звуковое устройство ввода данных, сенсорное устройство ввода данных и т.д. Устройство(а) 614 вывода, такое как дисплей, динамики, принтер и т.д., также может быть включено. Вышеупомянутые устройства являются примерами, могут быть использованы и другие.
Вычислительное устройство 600 может также содержать подключение 616 связи, которое может позволить устройству 600 передавать данные с другими вычислительными устройствами 618, например как по сети в распределенной вычислительной среде, например intranet или Интернет. Подключение 616 связи является одним примером среды связи. Среда связи типично может воплощаться читаемыми компьютером командами, структурами данных, программными модулями или другими данными в модулированном сигнале данных, таком как несущая или другой транспортный механизм, и включает в себя любые среды доставки информации. Термин "модулированный сигнал данных" может описать сигнал, у которого есть один или более наборов характеристик или измененный таким образом, чтобы закодировать информацию в сигнале. Для примера, а не ограничения, среды связи могут включать в себя проводные среды, такие как проводная сеть или кабельное соединение, и беспроводные среды, такие как звуковые, радиочастотные (RF), инфракрасные и другие беспроводные носители. Термин читаемые компьютером носители, использованный здесь, может включать в себя как носитель данных, так и среды связи.
Как указано выше, некоторое количество программных модулей и файлов данных могут быть сохранены в системной памяти 604, содержащей операционную систему 605. При исполнении на блоке 602 обработки, программные модули 606 (например, приложение 620 распознания) могут выполнить процессы, включающие в себя, например, один или несколько этапов способа 200, как описано выше. Вышеупомянутый процесс является примером, и блок 602 обработки может выполнять другие процессы. Другие программные модули, которые могут использоваться в соответствии с вариантами осуществления настоящего изобретения, могут включать в себя приложения контактов и электронной почты, приложения обработки текста, приложения электронной таблицы, приложения базы данных, приложения презентации слайдов, чертежные приложения или автоматизированные прикладные программы и т.д.
Вообще, совместимые с вариантами осуществления изобретения программные модули могут включать в себя подпрограммы, программы, компоненты, структуры данных и другие типы структур, которые могут выполнять специфические задачи или которые могут осуществлять специфические абстрактные типы данных. Кроме того, варианты осуществления изобретения могут быть осуществлены с другими конфигурациями компьютерной системы, включающими в себя карманные устройства, многопроцессорные системы, программируемую бытовую электронику, основанную на микропроцессорах, миникомпьютеры, универсальные компьютеры и т.п. Варианты осуществления изобретения могут также быть осуществлены в распределенных вычислительных средах, в которых задачи выполнены удаленными устройствами обработки, которые связаны через сеть связи. В распределенной вычислительной среде программные модули могут быть расположены и в локальных, и в удаленных запоминающих устройствах хранения.
Кроме того, варианты осуществления изобретения могут быть осуществлены в электрическом контуре, включающем в себя дискретные электронные элементы, пакованные или интегрированные электронные чипы, содержащие логические шлюзы, контур, использующий микропроцессор, или на единственном чипе, содержащем электронные элементы или микропроцессоры. Варианты осуществления изобретения могут также быть осуществлены, используя другие технологии, способные к выполнению логических операций, таких как, например, И, ИЛИ и НЕ, включая, но не ограничиваясь, механическими, оптическими, жидкими и квантовыми технологиями. Кроме того, варианты осуществления изобретения могут быть осуществлены в пределах универсального компьютера или в любых других контурах или системах.
Варианты осуществления изобретения, например, могут быть осуществлены как компьютерный процесс (способ), вычислительная система или изделие, такое как компьютерный программный продукт или читаемые компьютером носители. Компьютерный программный продукт может быть компьютерным носителем данных, читаемым компьютерной системой и кодирующим компьютерную программу команд для исполнения компьютерного процесса. Компьютерный программный продукт может также быть размноженным сигналом на несущей, читаемой вычислительной системой и кодирующей компьютерную программу команд для того, чтобы исполнить компьютерный процесс. Соответственно, настоящее изобретение может быть воплощено в аппаратных средствах и/или в программном обеспечении (включая встроенное программное обеспечение, резидентское программное обеспечение, микрокод и т.д.). Другими словами, варианты осуществления настоящего изобретения могут принять форму компьютерного программного продукта на используемом компьютером или читаемом компьютером носителе данных, имеющем используемый компьютером или читаемый компьютером код программы, воплощенный в носителе для использования системой или вместе с системой исполнения команды. Используемая компьютером или читаемая компьютером среда может быть любой средой, которая может содержать, хранить, сообщать, размножать или транспортировать программу для использования или в соединении с системой исполнения команды, прибором или устройством.
Используемая компьютером или читаемая компьютером среда может быть, например, но не ограничена, электронным, магнитным, оптическим, электромагнитным, инфракрасным прибором, устройством, или полупроводниковой системой, или средой распространения. Более определенные примеры читаемых компьютером носителей (неисчерпывающий список), читаемая компьютером среда может включать следующее: электрическое соединение, имеющее один или несколько проводов, переносную компьютерную дискету, оперативную память (RAM), постоянное запоминающее устройство (ROM), стираемое программируемое постоянное запоминающее устройство (EPROM или флэш-память), оптическое стекловолокно и переносное постоянное запоминающее устройство компакт-диска (CD-ROM). Важно отметить, что используемый компьютером или читаемый компьютером носитель может даже быть бумагой или другим подходящим носителем, на котором напечатана программа, поскольку программа может быть захвачена с помощью электроники через, например, оптическое сканирование бумаги или другого носителя, затем компилирована, интерпретируема или иначе обработана подходящим способом, в случае необходимости, и затем сохранена в машинной памяти.
Варианты осуществления настоящего изобретения, например, описаны выше в отношении блок-схем и/или оперативных иллюстраций способов, систем и компьютерных программных продуктов в соответствии с вариантами осуществления изобретения. Функции/действия, отмеченные в блоках, могут произойти вне порядка, показанного в любой блок-схеме. Например, два блока, которые показаны последовательно, могут фактически быть выполнены по существу одновременно, или блоки могут иногда выполняться в обратном порядке, в зависимости от вовлеченных функциональных возможностей/действий.
В то время как определенные варианты осуществления изобретения были описаны, могут существовать другие варианты осуществления. Кроме того, хотя варианты осуществления настоящего изобретения были описаны как ассоциативно связанные с данными, хранящимися в памяти и других носителях данных, данные могут также храниться на или читаться с других типов читаемых компьютером носителей, таких как устройства внешней памяти, как жесткие диски, гибкие диски или CD-ROM, несущие из Интернета, или другие формы RAM или ROM. Дополнительно, этапы раскрытых способов могут быть изменены любым образом, включая переупорядочивание этапов и/или вставку, или удаление этапов, не отступая от изобретения.
Все права, включая авторские права в коде, включенном здесь, наделяются в и собственность Заявителя. Заявитель сохраняет и резервирует все права в коде, включенном здесь, и предоставляет разрешение воспроизвести материал только совместно с воспроизводством полученного патента и ни для какой другой цели.
В то время как описание включает в себя примеры, объем притязаний изобретения обозначен последующей формулой изобретения. Кроме того, в то время как описание было написано на языке, определенном для структурных особенностей и/или методологических действий, формула изобретения не ограничена признаками или действиями, описанными выше. Скорее определенные признаки и действия, описанные выше, раскрыты как пример для варианта осуществления изобретения.

Изобретение относится к сжатию данных. Техническим результатом является уменьшение объема памяти, требуемой для хранения данных, и уменьшение времени восстановления сжатых данных. В способе распознавания текста сначала генерируют множество терминов, используемых в текстовой строке, и вычисляют множество хеш значений из множества генерированных терминов. Для каждого хеш значения может быть создан хеш сегмент, в котором может поддерживаться ассоциированный счет происшествий. Хеш сегменты могут быть сортированы счетом происшествия и несколько наивысших сегментов могут храниться. Как только упомянутые наивысшие сегменты известны, второй проход может пройти текстовую строку, сгенерировать термины, вычислить хеш значение для каждого термина. Если хеш значения для терминов подходят хеш значениям тех, которые хранятся в сегменте, тогда термин может считаться частым термином. Следовательно, термин может быть добавлен в словарь вместе с соответствующим счетом частоты. Затем словарь может быть проверен для удаления терминов, которые могут быть не частыми, но появились в виду хеш противоречий. 3 н. и 17 з.п. ф-лы, 6 ил.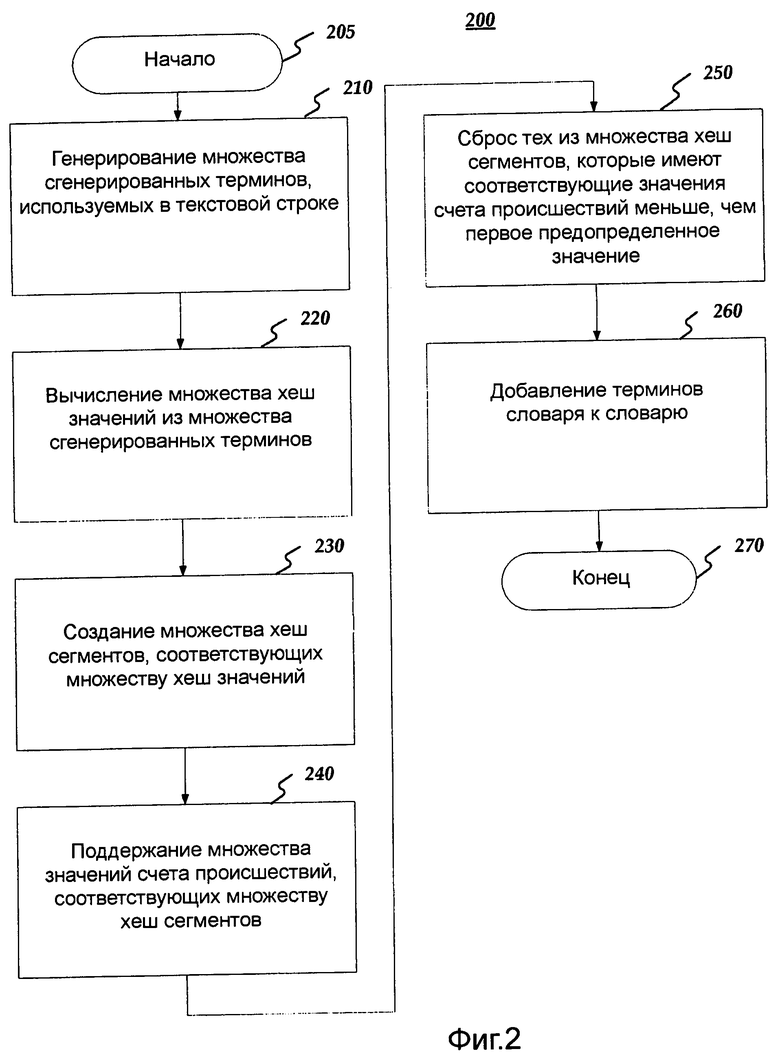
1. Способ распознавания текста, содержащий этапы на которых:
генерируют множество сгенерированных терминов (305), используемых в текстовой строке (105);
вычисляют множество хеш значений из множества генерированных терминов (305);
создают множество хеш сегментов (310), соответствующих множеству хеш значений;
поддерживают множество значений счета происшествий, соответствующих множеству хеш сегментов (310), причем каждое из множества значений счета происшествий соответственно указывает число раз, которое каждый из множества генерированных терминов (305) происходит в текстовой строке (105), имеющей хеш значение, которое соответствует множеству хеш сегментов значений счета происшествий;
сбрасывают те из множества хеш сегментов (310), которые имеют соответствующие значения счета происшествий меньше, чем первое предопределенное значение; и
добавляют термины словаря в словарь (120), термины словаря содержат те из множества сгенерированных терминов (305), имеющие соответствующие хеш значения, соответствующие любому из множества хеш значений, соответствующих оставшемуся множеству хеш сегментов (310), причем словарь (120) включает в себя множество значений счета частоты, соответствующе указывающих число раз, которое каждый из терминов словаря произошел в текстовой строке (105).
2. Способ по п.1, дополнительно содержащий этап, на котором ранжируют термины словаря.
3. Способ по п.1, дополнительно содержащий этап, на котором ранжируют термины словаря с использованием функции оценки.
4. Способ по п.1, дополнительно содержащий этап, на котором ранжируют термины словаря с использованием функции оценки, сконфигурированной для сжатия данных.
5. Способ по п.1, дополнительно содержащий этап, на котором ранжируют термины словаря с использованием функции оценки, сконфигурированной для сжатия данных, в котором термины словаря ранжируют на основе множества соответствующих индексов, соответствующих каждому термину словаря, причем каждый из множества индексов соответствующе содержит значение счета частоты каждого соответствующего термина словаря, умноженного на длину каждого соответствующего термина словаря.
6. Способ по п.1, дополнительно содержащий этап, на котором ранжируют термины словаря с использованием функции оценки, сконфигурированной для распознавания ключевого слова.
7. Способ по п.1, дополнительно содержащий этап, на котором ранжируют термины словаря с использованием функции оценки, сконфигурированной для распознавания ключевого слова, в котором термины словаря ранжируют на основе соответствующих значений счета частоты.
8. Способ по п.1, дополнительно содержащий этап, на котором используют словарь (120) для определения того, какой из сгенерированных терминов (305) сжать в текстовой строке (105).
9. Способ по п.1, дополнительно содержащий этап, на котором используют словарь (120) для определения того, какие из сгенерированных терминов (305) характеризовать как ключевые слова.
10. Способ по п.1, дополнительно содержащий этап, на котором удаляют термины словаря из словаря (120), имеющие соответствующие значения счета частоты меньше, чем второе предопределенное значение.
11. Способ по п.1, в котором этап, на котором генерируют множество сгенерированных терминов (305), используемых в текстовой строке (105), заключается в том, что генерируют множество сгенерированных терминов (305), используемых в текстовой строке (105), причем каждый из множества сгенерированных терминов (305) содержит индивидуальные строки.
12. Способ по п.1, в котором этап, на котором генерируют множество сгенерированных терминов (305), используемых в текстовой строке (105), заключается в том, что генерируют множество сгенерированных терминов (305), используемых в текстовой строке (105), причем, по меньшей мере, часть множества сгенерированных терминов (305) содержит подстроки.
13. Способ по п.1, в котором этап, на котором вычисляют множество хеш значений из множества сгенерированных терминов (305), заключается в том, что вычисляют множество хеш значений на основе идеального хеш алгоритма.
14. Компьютерочитаемый носитель, хранящий набор команд, которые, будучи исполненными, выполняют способ распознавания текста, причем способ, исполняемый набором команд, содержит этапы, на которых:
создают множество хеш сегментов (310) соответствующих множеству хеш значений, соответствующих множеству сгенерированных терминов (305) в текстовой строке (105), причем, по меньшей мере, часть множества сгенерированных терминов (305) содержит подстроки;
поддерживают множество значений счета происшествий, соответствующих множеству хеш сегментов (310), причем каждое из множества значений счета происшествий соответственно указывает число раз, которое каждый из множества генерированных терминов (305) происходит в текстовой строке (105), имеющей хеш значение, которое соответствует множеству хеш сегментов значений счета происшествий;
сбрасывают те из множества хеш сегментов (310), которые имеют соответствующие значения счета происшествий меньше, чем первое предопределенное значение;
добавляют термины словаря в словарь (120), термины словаря содержат те из множества сгенерированных терминов (305), имеющие соответствующие хеш значения, соответствующие любому из множества хеш значений, соответствующих оставшемуся множеству хеш сегментов (310), причем словарь (120) включает в себя множество значений счета частоты, соответствующе указывающих число раз, которое каждый из терминов словаря произошел в текстовой строке (105), и
ранжируют термины словаря с использованием функции оценки, сконфигурированной для сжатия данных, причем термины словаря ранжируют на основе множества соответствующих индексов, соответствующих каждому термину словаря, причем каждый из множества индексов соответственно содержит значение счета частоты каждого соответствующего термина словаря, умноженного на длину каждого соответствующего термина словаря.
15. Компьютерочитаемый носитель по п.14, дополнительно содержащий этап, на котором используют словарь (120) для определения того, какой из сгенерированных терминов (305) сжать в текстовой строке (105).
16. Компьютерочитаемый носитель по п.14, дополнительно содержащий этап, на котором удаляют термины словаря из словаря (120), которые имеют соответствующие значения счета частоты меньше, чем второе предопределенное значение.
17. Компьютерочитаемый носитель по п.14, дополнительно содержащий этап, на котором вычисляют множество хеш значений на основе идеального хеш алгоритма.
18. Система распознания текста, содержащая:
хранилище памяти и
блок обработки, соединенный с хранилищем памяти, причем блок обработки выполнен с возможностью:
создания множества хеш сегментов (310), соответствующих множеству хеш значений, соответствующих множеству сгенерированных терминов (305) в текстовой строке (105), причем каждый из множества сгенерированных терминов (305) содержит индивидуальные строки;
поддержания множества значений счета происшествий, соответствующего множеству хеш сегментов (310), причем каждое из множества значений счета происшествий соответственно указывает число раз, которое каждый из множества генерированных терминов (305) происходит в текстовой строке (105), имеющей хеш значение, которое соответствует множеству хеш сегментов значений счета происшествий;
сброса тех из множества хеш сегментов (310), которые имеют соответствующие значения счета происшествий меньше, чем первое предопределенное значение;
добавления терминов словаря в словарь (120), термины словаря содержат те из множества сгенерированных терминов (305), имеющие соответствующие хеш значения, соответствующие любому из множества хеш значений, соответствующих оставшемуся множеству хеш сегментов (310), причем словарь (120) включает в себя множество значений счета частоты, соответствующе указывающих число раз, которое каждый из терминов словаря произошел в текстовой строке (105), и
ранжирования терминов словаря с использованием функции оценки, сконфигурированной для распознавания ключевого слова, причем термины словаря ранжируют на основе их соответствующих значений счета частоты.
19. Система по п.18, в которой блок обработки дополнительно выполнен с возможностью удаления терминов словаря из словаря (120), которые имеют соответствующие значения счета частоты меньше, чем второе предопределенное значение.
20. Система по п.18, в которой блок обработки дополнительно выполнен с возможностью вычисления множества хеш значений на основе идеального алгоритма.
| JP 2007094838 А, 12.04.2007 | |||
| KR 1020040011769 А, 11.02.2004 | |||
| US 7031910 В2, 18.04.2006 | |||
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В ПОЛИТЕМАТИЧЕСКИХ МАССИВАХ НЕСТРУКТУРИРОВАННЫХ ТЕКСТОВ | 2004 |
|
RU2266560C1 |
| RU 2004108667 А, 27.09.2005. | |||

