ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение, в целом, относится к вычислительным системам, а более конкретно - к системам и способам оптического распознавания символов с использованием комбинации моделей нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
[002] Искусственные нейронные сети - это вычислительные системы, моделирующие биологические нейронные сети. Такие системы обучены решать различные задачи на готовых примерах. Чаще всего они используются в приложениях, которые сложно решить с помощью традиционного компьютерного алгоритма.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] Варианты осуществления настоящего изобретения описывают систему и способ оптического распознавания символов рукописного текста с использованием моделей нейронных сетей. В одном варианте осуществления система получает изображение, изображающее текст. Система выделяет множество признаков из изображения с помощью блока выделения признаков. Система применяет первый декодер к множеству признаков для генерации первого промежуточного вывода. Система применяет второй декодер к множеству признаков для генерации второго промежуточного вывода, при этом блок выделения признаков является общим для первого и второго декодеров. Система определяет значение первой метрики качества для первого промежуточного вывода и значение второй метрики качества для второго промежуточного вывода на основе языковой модели. Система определяет, что значение первой метрики качества больше, чем значение второй метрики качества. В ответ на определение того, что значение первой метрики качества больше, чем значение второй метрики качества, система выбирает первый промежуточный вывод для представления текстов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[004] Настоящее изобретение проиллюстрировано в виде примера, а не в виде ограничения, и его можно более полно понять с помощью ссылки на следующее подробное описание при рассмотрении в комплексе с чертежами, на которых:
[005] На Фиг. 1 изображена схема системы высокого уровня для архитектуры системы в соответствии с одним или более вариантами реализации настоящего изобретения.
[006] На Фиг. 2 изображен пример блок-схемы модуля распознавания текста в соответствии с одним или более вариантами реализации настоящего изобретения.
[007] Фиг. 3A-3B иллюстрируют блок-схемы гибридных декодеров CTC-attention (CTC-внимание) в соответствии с одним или более вариантами реализации настоящего изобретения.
[008] Фиг. 4 иллюстрирует пример блок-схемы декодера на основе коннекционной временной классификации (CTC, Connectionist temporal classification) в соответствии с одним или более вариантами реализации настоящего изобретения.
[009] Фиг. 5 иллюстрирует пример блок-схемы декодера на основе механизма внимания в соответствии с одним или более вариантами реализации настоящего изобретения.
[0010] Фиг. 6 иллюстрирует пример блок-схемы гибридного декодера CTC-attention в соответствии с одним или более вариантами реализации настоящего изобретения.
[0011] На Фиг. 7 изображена блок-схема способа оптического распознавания символов в соответствии с одним или более вариантами реализации настоящего изобретения.
[0012] На Фиг. 8 изображена блок-схема иллюстрации компьютерной системы в соответствии с одним или более вариантами реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0013] Оптическое распознавание символов может включать в себя обработку входного изображения для выделения набора признаков, которые представляют входное изображение, и обработку выделенных признаков декодером (представленным обучаемой моделью), которая выдает строку текста, представленную на изображении. В некоторых вариантах реализации обучаемая модель может быть представлена нейронной сетью.
[0014] Нейронная сеть представляет собой вычислительную модель, имитирующую набор связанных компонентов, называемых искусственными нейронами (по аналогии с аксонами в биологическом мозге). Каждое соединение (синапс) между нейронами может передавать сигнал другому нейрону. Принимающий (постсинаптический) нейрон может обрабатывать сигнал, а затем передавать его нижестоящим нейронам. Нейроны могут иметь состояние, обычно выражаемое действительными числами от 0 до 1. Нейроны и синапсы также могут иметь вес, который изменяется по мере обучения, что может увеличивать или уменьшать силу сигнала, который они посылают следующим нейронам. Кроме того, они могут иметь пороговую функцию, поэтому дальше будет передаваться только сигнал, который выше (или ниже) этого порогового значения.
[0015] Нейроны могут быть организованы слоями. Разные слои могут выполнять разные типы преобразований на своих входах. Сигналы перемещаются от первого (входного) слоя к последнему (выходному) слою через несколько скрытых слоев, таких как многослойный персептрон.
[0016] Нейронные сети могут применяться для реализации моделей глубокого обучения. Глубокое обучение - это набор алгоритмов машинного обучения, которые пытаются смоделировать высокоуровневые абстракции данных с помощью архитектур, состоящих из множества нелинейных преобразований, другими словами, выявить «скрытые признаки».
[0017] Рекуррентные нейронные сети (RNN, Recurrent Neural Network) - это тип нейронной сети с циклическими соединениями между ее блоками. Эти циклы создают концепцию «внутренней памяти» для сети. Соединения между ее блоками образуют направленную последовательность. Внутренняя память RNN позволяет обрабатывать последовательности произвольной длины для генерации соответствующих выходных последовательностей переменной длины.
[0018] RNN может использоваться для обработки серии событий во времени или последовательных пространственных цепочек. В отличие от многослойных персептронов, рекуррентные сети могут использовать свою внутреннюю память для обработки последовательностей произвольной длины. Поэтому сети RNN применимы в задачах, где что-то полностью разделено на такие сегменты, как распознавание рукописного текста или распознавание речи. Для рекуррентных сетей было предложено множество различных архитектурных решений, от простых до сложных. В последнее время наибольшее распространение получили сети с долговременно-кратковременной памятью (LSTM).
[0019] Модель сверточной нейронной сети (CNN) может использоваться для задач распознавания образов. Подход сверточных нейронных сетей заключается в чередовании сверточных слоев (слоев свертки) и слоев понижающей дискретизации (понижающе-дискретизирующих слоев или объединяющих слоев). Структура сети является однонаправленной (без обратной связи) и существенно многослойной. Для обучения используются стандартные способы, чаще всего используется способ обратного распространения ошибки, и для конкретных задач могут быть выбраны различные функции активации нейронов (передаточная функция). Архитектура CNN отличается наличием операции свертки, суть которой заключается в том, что каждый фрагмент изображения перемножается на матрицу свертки (ядро) элемент за элементом, а результат суммируется и записывается в одну и ту же позицию выходного изображения.
[0020] Как отмечалось в данном документе выше, входное изображение может быть обработано для выделения набора признаков, которые представляют входное изображение. Затем выделенные признаки можно обработать декодером распознавания текста, представленным обучаемой моделью, которая выдает строку текста, содержащуюся на изображении.
[0021] LSTM и CNN могут использоваться в качестве строительных блоков для конструкций декодеров распознавания текста. В некоторых вариантах реализации декодер распознавания текста может быть реализован с помощью декодера на основе коннекционной временной классификации (CTC), который включает в себя строительные блоки CNN, LSTM и функцию потерь CTC, как дополнительно описано ниже.
[0022] В других вариантах реализации декодер распознавания текста может быть реализован с помощью кодера-декодера на основе механизма внимания, который включает в себя строительные блоки CNN, LSTM (кодер) и LSTM (декодер), как дополнительно описано ниже. Два декодера спроектированы по-разному, что приводит к разным гипотезам (предположениям) для распознавания текста.
[0023] Преимущественно использование обоих декодеров одновременно может повысить общее качество распознавания текста. Качество может повышаться, потому что эти декодеры могут генерировать разные результаты при одних и тех же входных данных (потому что эти декодеры разные и имеют разную компоновку строительных блоков), и лучший результат может выбираться для повышения качества распознавания текста. Совместное использование различных строительных блоков этих декодеров может дополнительно снизить требования к обработке для выполнения двух декодеров.
[0024] Различные аспекты упомянутых выше способов и систем подробно описаны в настоящем документе ниже в качестве примеров, а не в виде ограничения.
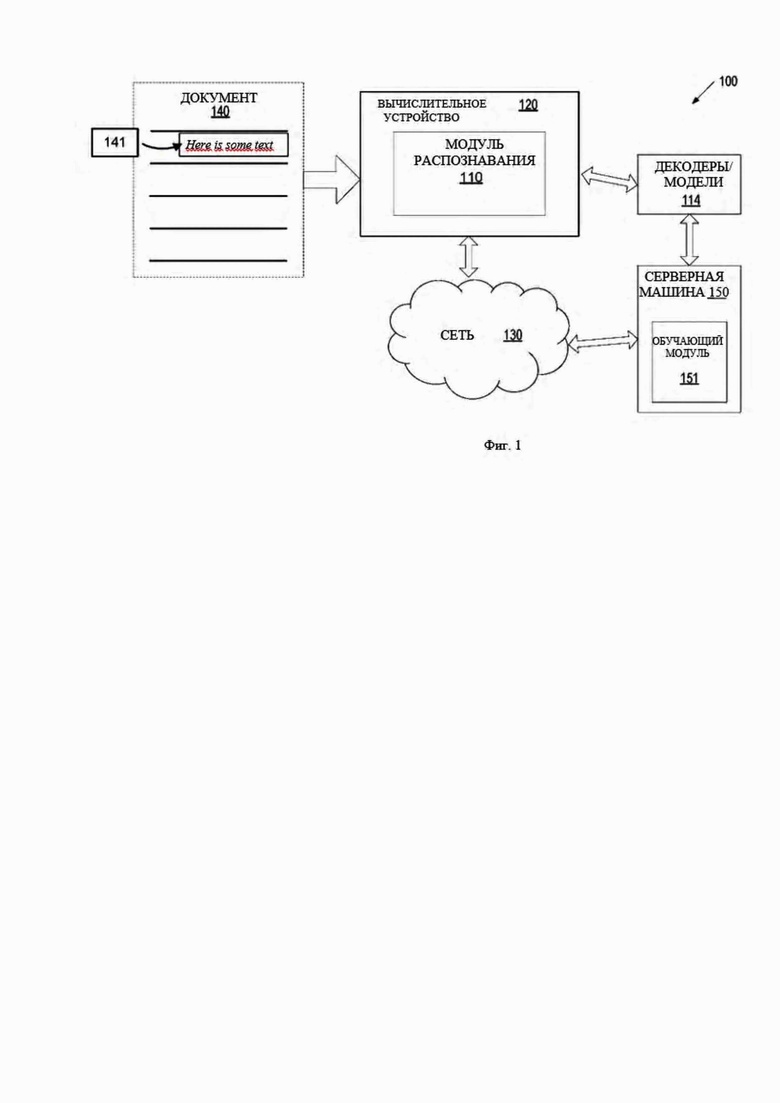
[0025] Фиг. 1 изображает схему системы высокого уровня для архитектуры системы в соответствии с одним или более вариантами реализации настоящего изобретения. Системная архитектура 100 включает в себя вычислительное устройство 120 и серверную машину 150, подключенную к сети 130. Сеть 130 может быть общедоступной сетью (например, Интернет), частной сетью (например, локальной вычислительной сетью (ЛВС) или глобальной вычислительной сетью (ГВС)) или их комбинацией.
[0026] Вычислительное устройство 120 может выполнять распознавание символов с использованием обучаемых классификаторов (таких как нейронная сеть) для эффективного распознавания текстов, включая одно или более предложений. Распознанное предложение может включать одно или более слов. Распознанное слово может включать один или более знаков (символов).
[0027] Вычислительное устройство 120 может быть настольным компьютером, ноутбуком, смартфоном, планшетом, сервером, сканером или любым подходящим вычислительным устройством, способным выполнять описанные в данном документе способы. Вычислительное устройство 120 может принимать документ 140, включающий письменный текст. Следует отметить, что можно получить напечатанный или рукописный текст на любом языке. Документ 140 может включать одно или более предложений, каждое из которых содержит одно или более слов, каждое из которых содержит один или более символов.
[0028] Документ 140 может быть получен, например, путем сканирования документа 140 или фотографирования документа 140. Таким образом, можно получить изображение 141 для текста, включая предложения, слова и символы, включенные в документ 140. Кроме того, в случаях, когда вычислительное устройство 120 является сервером, клиентское устройство, подключенное к серверу через сеть 130, может загружать цифровую копию документа 140 на сервер. В случаях, когда вычислительное устройство 120 является клиентским устройством, подключенным к серверу через сеть 130, клиентское устройство может загружать документ 140 с сервера.
[0029] Изображение текста 141 может использоваться для обучения набора моделей машинного обучения или может быть новым документом, для которого требуется распознавание. Соответственно, на предварительных этапах обработки изображение 141 для текста, включенное в документ 140, может быть подготовлено для обучения набора моделей машинного обучения или последующего распознавания. Например, в изображении 141 для текста текстовые строки можно выбирать вручную или автоматически, отмечать символы, нормализовать, масштабировать и/или преобразовывать текстовые строки в двоичную форму.
[0030] Кроме того, во время предварительной обработки текст в изображении 141, полученном из документа 140, можно разделить на фрагменты (например, слова) текста. Как показано, строка автоматически разделяется на фрагменты текста на промежутках определенного цвета (например, белого), ширина которых превышает пороговое значение (например, 10) пикселей. Выбор строк текста в изображении текста может повысить скорость обработки при распознавании текста путем одновременной обработки более коротких строк текста, например вместо одной длинной строки текста. Предварительно обработанные и откалиброванные изображения 141 для текста могут использоваться для обучения набора моделей машинного обучения или могут быть предоставлены в качестве входных данных для набора обучаемых моделей машинного обучения с целью определения наиболее вероятного текста.
[0031] Вычислительное устройство 120 может включать в себя модуль распознавания текста 110. Модуль распознавания текста 110 может быть программным модулем, исполняемым одним либо более универсальными и/или специализированными аппаратными устройствами. Модуль распознавания текста 110 может включать в себя команды, хранящиеся на одном или более материальном машиночитаемом носителе вычислительного устройства 120 и исполняемые одним или более устройством обработки вычислительного устройства 120. В любом варианте реализации модуль распознавания текста 110 может использовать обучаемые декодеры или модели 114 машинного обучения, которые обучены и используются для распознавания одной или более строки символов/символов из текста на изображении 141. Модуль распознавания текста 110 также может предварительно обрабатывать любые полученные изображения перед использованием изображений для обучения или получения вывода на основе одного из декодеров/моделей 114. В некоторых случаях декодеры/модели 114 могут быть частью модуля распознавания текста 110 или могут быть доступны на другой машине (например, серверной машине 150) с помощью модуля распознавания текста 110. На основе выходных данных обучаемых декодеров/моделей 114 машинного обучения модуль распознавания текста 110 может выделять одно или более предсказанных предложений из текста в изображении 141.
[0032] Серверная машина 150 может быть установленным в стойку сервером, компьютером-маршрутизатором, персональным компьютером, портативным цифровым помощником, мобильным телефоном, ноутбуком, планшетом, камерой, видеокамерой, нетбуком, настольным компьютером, медиацентром или любой комбинацией вышеперечисленного. Серверная машина 150 может включать в себя обучающий модуль 151. Декодеры/модели 114 машинного обучения могут относиться к модельным артефактам, которые создаются обучающим модулем 151 с использованием обучающих данных, включающим в себя обучающие входные данные и соответствующие целевые выходные данные (правильные ответы для соответствующих обучающих входных данных). Обучающий модуль 151 может находить образы в обучающих данных, которые отображают обучающие входные данные для целевых выходных данных (предсказанного ответа), и предоставлять декодеры/модели 114 машинного обучения, которые фиксируют эти образы.
[0033] На Фиг. 2 изображен пример блок-схемы модуля распознавания текста в соответствии с одним или более вариантами реализации настоящего изобретения. Модуль распознавания текста 110 может быть программным модулем, работающим на вычислительном устройстве 120 на Фиг. 1. В одном варианте осуществления модуль распознавания текста 110 может включать в себя модуль приемника изображения 101, модуль выделения признаков 102, модуль декодирования 103, модуль определения метрик качества 104, модуль выбора метрик качества 105 и модуль вывода 106. Один или более модулей 101-106 или их комбинация могут быть реализованы одним или более программными модулями, работающими на одном или более аппаратных устройствах.
[0034] Модуль приемника изображения 101 может принимать изображение документа для оптического распознавания символов (OCR). Изображение может быть файлом документа или файлом рисунка с видимым текстом. Изображение может быть получено из различных средств массовой информации (таких как печатные или рукописные бумажные документы, баннеры, плакаты, знаки, рекламные щиты и/или другие физические объекты с видимым текстом на одной или более их поверхностях). В одном варианте осуществления модуль приемника изображения 101 может предварительно обработать изображение, применив одно или более преобразований изображения к изображению, например бинаризацию, масштабирование размера, кадрирование, преобразования цвета и т.д., чтобы подготовить изображение к оптическому распознаванию символов. В другом варианте осуществления предварительная обработка может сегментировать изображение на фрагменты изображения (изображения с видимыми словами) для дальнейшей обработки.
[0035] Модуль выделения признаков 102 может выделять один или более признаков из изображения. Признаки могут быть индивидуальными измеримыми свойствами или характеристиками воспринимаемого визуального аспекта изображения. В одном варианте осуществления модуль выделения признаков 102 включает в себя блок выделения признаков на основе правил или сверточную нейронную сеть для выделения признаков. Модуль декодирования 103 может декодировать выделенные признаки с помощью двух или более декодеров (таких как декодер на основе CTC или механизма внимания), декодеров для выделения и декодирования выходных символов из признаков. Модуль определения метрик качества 104 может назначать значение метрики качества выходным символам конкретного декодера. Модуль выбора метрик качества 105 может сравнивать значения метрик качества среди выходных символов двух или более декодеров и выбирать выходные символы с наивысшим значением метрики качества. Модуль вывода 106 может выводить выбранные наборы символов. Хотя модули 101-106 показаны отдельно, некоторые из модулей 101-106 или их функциональные возможности могут быть объединены.
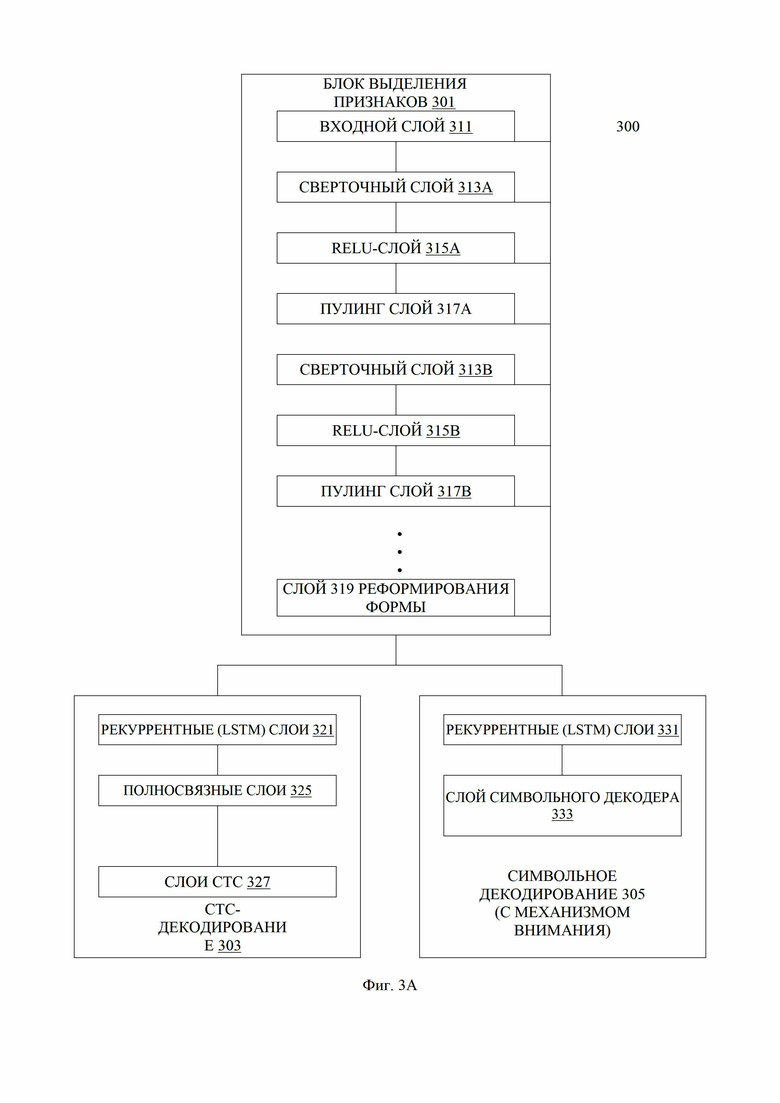
[0036] Фиг. 3A иллюстрирует блок-схему гибридного декодера с одним или более вариантами реализации настоящего изобретения. Декодер 300 может быть единственным гибридным декодером, который может декодировать текст в изображении и выводить символы, представляющие текст. Декодер 300 может быть обучен серверной машиной 150 и предоставлен вычислительному устройству 120 для использования вычислительным устройством 120. Например, декодер 300 может быть одним из декодеров/моделей 114 на Фиг. 1. В одном варианте осуществления декодер 300 включает в себя блок выделения признаков 301, декодер коннекционной временной классификации (CTC-декодер) 303 и символьный декодер 305. Блок выделения признаков может выделять признаки из входного изображения с текстом. Признак можно закодировать, и CTC-декодер 303 может декодировать закодированное изображение на основе CTC-декодирования, как дополнительно описано ниже. Блок выделения признаков 301 может включать в себя модель CNN, используемую для выделения признаков из входного изображения. Выделенные признаки могут быть числовыми векторами, которые представляют текстовые шаблоны, обнаруженные во входном изображении. Символьный декодер (с механизмом внимания) 305 может декодировать входное изображение с текстом, основываясь на декодировании словесных символов с помощью механизма внимания, как дополнительно описано ниже.
[0037] Что касается Фиг. 3A, в одном варианте осуществления блок 301 выделения признаков можно реализовать при помощи сверточной нейронной сети с последовательностью слоев разных типов, таких как сверточные слои, объединяющие слои, слои блока линейной ректификации (ReLU) и полносвязные слои, каждый из которых может выполнять определенную операцию оптического распознавания символов. Как показано, блок 301 выделения признаков может включать в себя входной слой 311, один или более сверточных слоев 313A-313B, ReLU-слоев 315A-315B, объединяющих слоев 317A-317B и слой 319 реформирования формы (или выходной слой) 319.
[0038] В некоторых вариантах осуществления входное изображение может приниматься входным слоем 311 и впоследствии обрабатываться с помощью последовательности слоев блока 301 выделения признаков. Каждый из сверточных слоев может выполнять операцию свертки, которая может включать обработку каждого пикселя входного изображения одним или более фильтрами (матрицами свертки) и запись результата в соответствующую позицию выходного массива. Один или более фильтров свертки могут быть спроектированы для обнаружения определенного признака изображения путем обработки входного изображения и получения соответствующей карты признаков.
[0039] Выходные данные сверточного слоя (например, сверточного слоя 313A) могут подаваться на уровень ReLU (например, ReLU-уровень 315A), который может применять нелинейное преобразование (например, функцию активации) для обработки выходных данных сверточного слоя. Выходные данные ReLU-уровня 315A могут подаваться на объединяющий уровень 317A, который может выполнять операцию понижающей дискретизации или субдискретизации для уменьшения разрешения и размера карты признаков. Выходные данные объединяющего слоя 317A могут подаваться на сверточный слой 313B.
[0040] Обработка изображения с помощью блока 301 выделения признаков может итеративно применять каждый последующий слой, пока каждый слой не выполнит свою соответствующую операцию. Как схематично проиллюстрировано на Фиг. 3A, блок 301 выделения признаков может включать в себя чередующиеся сверточные слои и объединяющие слои. Эти чередующиеся слои могут позволить создать несколько карт признаков разного размера. Каждая из карт признаков может соответствовать одному из множества признаков входного изображения, которые могут использоваться для выполнения оптического распознавания символов.
[0041] В некоторых вариантах осуществления объединяющий слой 317B, который можно представить полносвязным слоем блока 301 выделения признаков, может создавать вектор признаков, характерный для признаков исходного изображения, который можно рассматривать как представление изображение в многомерном пространстве признаков изображения.
[0042] Вектор признаков может подаваться на слой 319 способный реформировать выход в определенную форму. Слой 319 реформирования формы может применять матричное преобразование к вектору признаков, чтобы сгладить вектор признаков в массив признаков для декодирования CTC и/или словесных символов. Отметим, что различные альтернативные варианты реализации блока 301 выделения признаков могут включать в себя любое подходящее количество сверточных слоев, слоев ReLU, слоев объединения и/или любых других слоев. Кроме того, для улучшения обучения и уменьшения вероятности переобучения могут применяться слои пакетной нормализации и выпадения соответственно.
[0043] Что касается Фиг. 3A, в одном варианте осуществления CTC-декодирование 303 включает в себя рекуррентные слои 321, полносвязный слой 325 и слой CTC 327. Рекуррентные слои 321 могут включать в себя один или более управляемых рекуррентных блоков (GRU) или сетей долговременно-кратковременной памяти (LSTM) или других разновидностей RNN. В некоторых вариантах осуществления рекуррентные слои 321 могут быть однонаправленными или двунаправленными. В одном варианте осуществления после рекуррентных слоев 321 наносится один или более полносвязных слоев 325. Полносвязные слои 325 могут включать в себя слой многопеременной логистической функции (softmax). Полносвязные слои 325 могут выводить сигнал на один или более слоев СТС 327, которые включают в себя декодер СТС или функцию потерь СТС. Слои СТС 327 затем генерируют первый декодированный выходной сигнал, например первую гипотезу выходных символов для входного изображения.
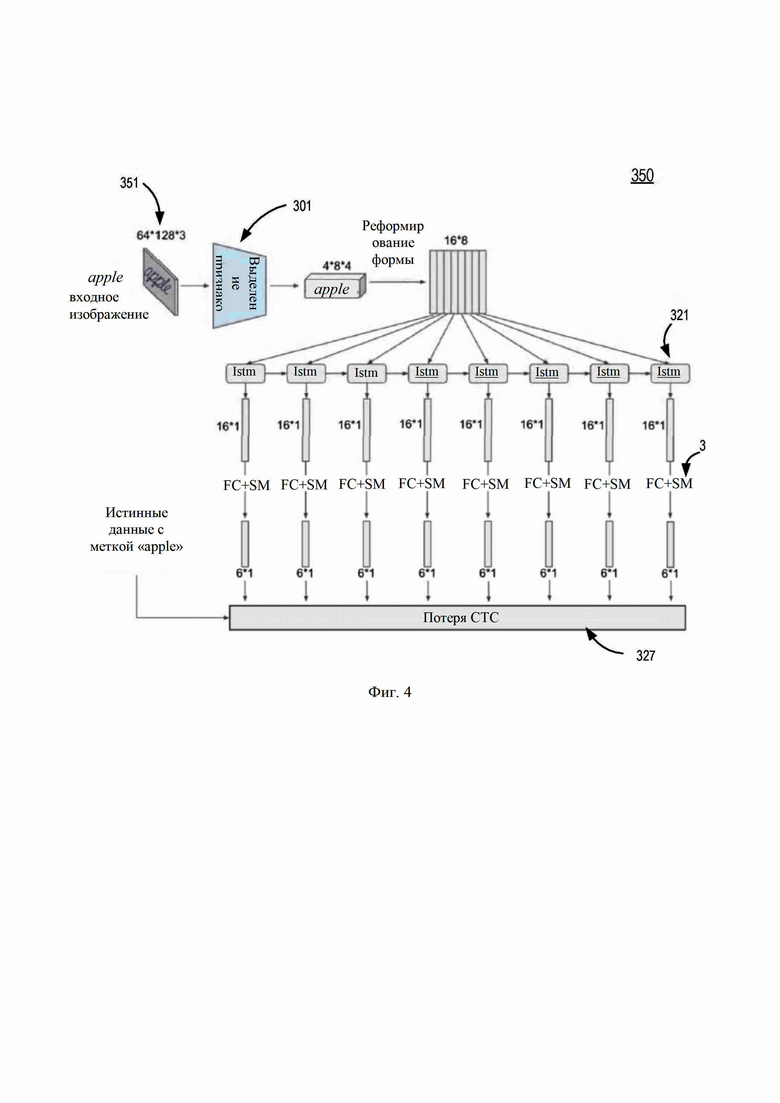
[0044] Коннекционная временная классификация (CTC) представляет собой тип выходных данных нейронной сети и связанную функцию оценки для обучения рекуррентных нейронных сетей (RNN), таких как сети LTSM, решению задач последовательности, где количество пространственных наблюдений является переменным. CTC относится к выходным данным и оценке и не зависит от исходной структуры нейронной сети. То есть функцию потерь CTC можно обучить с помощью любых типов нейронных сетей. Обученную функцию потерь CTC можно затем использовать для декодирования карт признаков с целью получения текста, содержащегося в соответствующем изображении.
[0045] Для CTC входные данные могут быть последовательностью наблюдений (или пространственными интервалами), а выходные данные могут быть последовательностью символов, которая может включать в себя пустые выходные данные так, что один выходной символ соответствует одному наблюдению. Распознавание отдельного выходного символа, по сути, классифицирует случай наблюдения как класс (символ) из набора классов (символов). Например, для распознавания слова, состоящего из любых 26 знаков (символов) алфавита, символы CTC могут быть предварительно определены как 26 символов для 26 знаков алфавита плюс пробел «-», что в сумме составляет 27 символов. Пробелы удаляются при декодировании. Цель пробела состоит в решении задачи изменчивости пространственных интервалов. То есть кодирование CTC не зависит от времени, и, поскольку конкретный символ алфавита может распознаваться в нескольких пространственных наблюдениях, выходные данные могут содержать повторение конкретного символа. В процессе декодирования выполняется алгоритм декодирования CTC для удаления любых повторений символов, например «aa» ->«a», «aabbc» ->«abc», в то время как пробелы эффективно сохраняют предполагаемое повторение символов, например «to-o» ->«too». Пример нейронной сети, основанной на функции потерь CTC, показан на Фиг. 4.
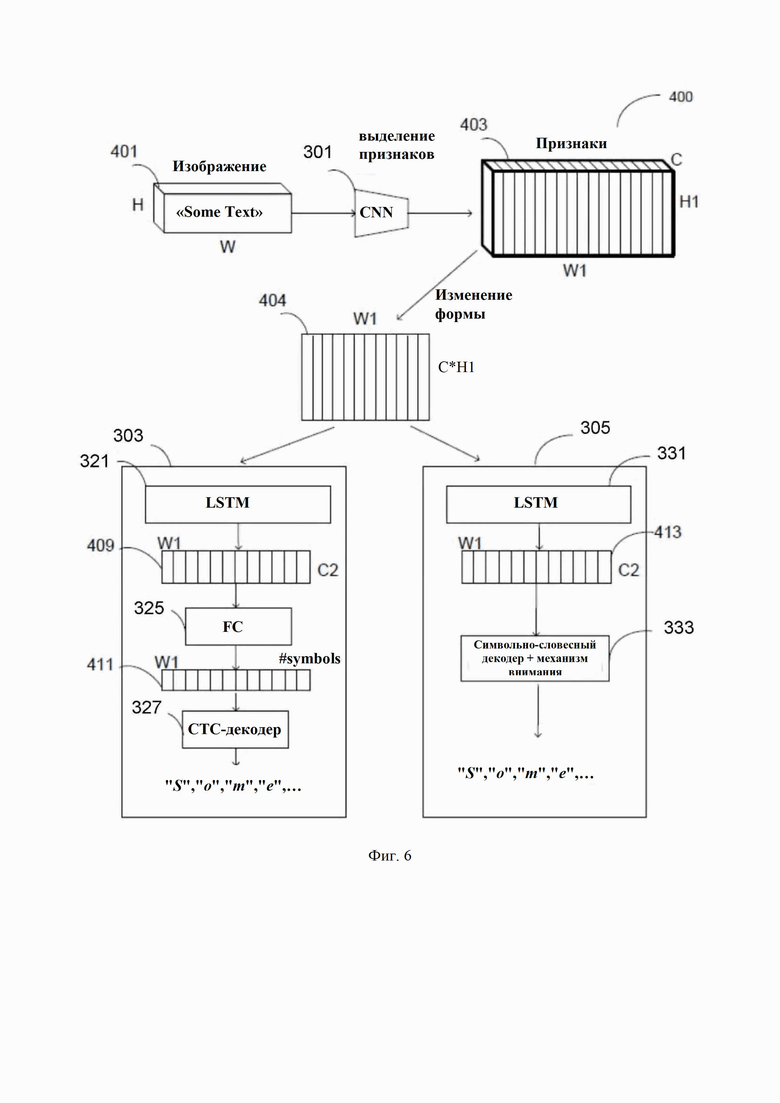
[0046] Что касается Фиг. 3A, в одном варианте осуществления символьное декодирование 305 включает в себя рекуррентные слои 331 и слой символьного декодера 333. В одном варианте осуществления рекуррентные слои 331 могут включать в себя одну или более сеть GRU или LSTM или другие варианты RNN. В одном варианте осуществления рекуррентные слои 331 могут иметь аналогичные компоненты, но отличные от рекуррентных слоев 321 обученные веса. Слой символьного декодера 333 может включать в себя слой декодера слов с механизмом внимания (attention). Механизм внимания - это способ указать сети, на какие наблюдения следует обратить больше внимания. Например, слой c механизмом внимания может идентифицировать факторы на основе обучающего образца, которые уменьшают сетевую ошибку. Идентификация этих факторов (или узлов входа в слой с механизмом внимания) может выполняться во время обучения посредством прямого и обратного распространения. Пример структуры нейронной сети на основе механизма внимании для задач распознавания показан на Фиг. 5.
[0047] Фиг. 3B иллюстрирует блок-схему гибридного декодера с одним или более вариантами реализации настоящего изобретения. Декодер 310 может быть аналогичен декодеру 300, но рекуррентные (LSTM) слои 321 являются совместно используемыми или общими для слоев CTC-декодирования 307 и символьного декодирования 309, например выход рекуррентных слоев 321 служит входами для слоев как CTC-декодирования 307, так и символьного декодирования 309. В одном варианте осуществления рекуррентные (LSTM) слои 321 включают в себя слои LSTM. Здесь рекуррентные слои 321 по отношению к декодеру CTC представляют собой кодер CTC, который не зависит от времени. Рекуррентные слои 321 могут, согласно схеме словесного предсказания кодера-декодера, действовать как кодер по отношению к символьному декодеру. Комбинированный рекуррентный слой 321 может быть обучен выполнять двойные функции: функцию кодера CTC и функцию кодера для словесного предсказания кодера-декодера. Рекуррентные слои 321, общие для обоих декодеров, могут сократить операции обработки и требования к памяти, поскольку генерируется только один набор выходных данных кодирования.
[0048] Фиг. 4 иллюстрирует пример блок-схемы декодера на основе коннекционной временной классификации (CTC) в соответствии с одним или более вариантами реализации настоящего изобретения. Декодер 350 может представлять комбинацию блока выделения признаков 301 и CTC-декодирования 303 на Фиг. 3A. В одном варианте осуществления декодер 350 принимает входное изображение 351 с текстом «apple» для OCR. Входное изображение может иметь размеры 64×128×3, например 64 на 128 пикселей с 3 цветовыми каналами. Входное изображение подается в блок выделения признаков 301 для извлечения карт признаков из входного изображения через различные сверточные, ReLU и объединяющие слои (например, слои понижения дискретизации). Выход блока выделения признаков 301 здесь предоставляет карту признаков 4×8×4. Форму карты признаков 4×8×4 можно изменить с помощью слоя изменения формы (не показан) до размера 16×8. Карта признаков 16×8 (8 пространственных наблюдений) предоставляется для рекуррентных (LSTM) слоев 321 (кодирования CTC), чтобы создать 8 выходных карт признаков размером 16×1. Размер 16×1 ограничен гиперпараметрами блоков LSTM, например, размером и однонаправленностью или двунаправленностью. Двунаправленные блоки LSTM являются расширением однонаправленных блоков LSTM, которые могут улучшить производительность модели в задачах классификации последовательностей. В этом примере текущий блок LSTM 321 принимает входное пространственное наблюдение и создает выходную карту признаков и состояние сети (внутреннюю память). Состояние сети используется в качестве входа следующим блоком LSTM 321. 8 выходных карт признаков с размерами 16×1 могут проходить через один или более полносвязных слоев (с softmax) 325 для генерации 8 выходов с размерами 6×1. Здесь каждый выход 6×1 представляет выходной символ. Примером последовательности выходных символов может быть «aap-plee», где каждый символ соответствует одному из 8 пространственных наблюдений. Затем слой потерь CTC 327 декодирует и преобразует символы в выход. В этом примере повторяющиеся символы «aa» и «ee» могут появляться в выходе кодирования, так как первые два пространственных наблюдения могли вывести «a», а последние два - «e». Затем слой потерь CTC 327 применяет алгоритм CTC-декодирования к выходной последовательности слоев 325, сначала удаляя повторяющиеся символы, а затем удаляя любые пробелы в последовательности, то есть «aap-plee» ->«ap-ple» ->«apple». Хотя Фиг. 4 иллюстрирует пример сети с восемь наблюдениями для слоя LSTM или повторяющегося слоя 321, возможно любое количество наблюдений LSTM. Обратите внимание, что количество наблюдений должно быть больше, чем длина предсказанной последовательности символов. Обратите внимание, что размеры изображения/признака и символы «apple» в этом примере предназначены только для иллюстративных целей, и различные варианты реализации могут включать в себя разные размеры изображения/признака и тексты изображений.
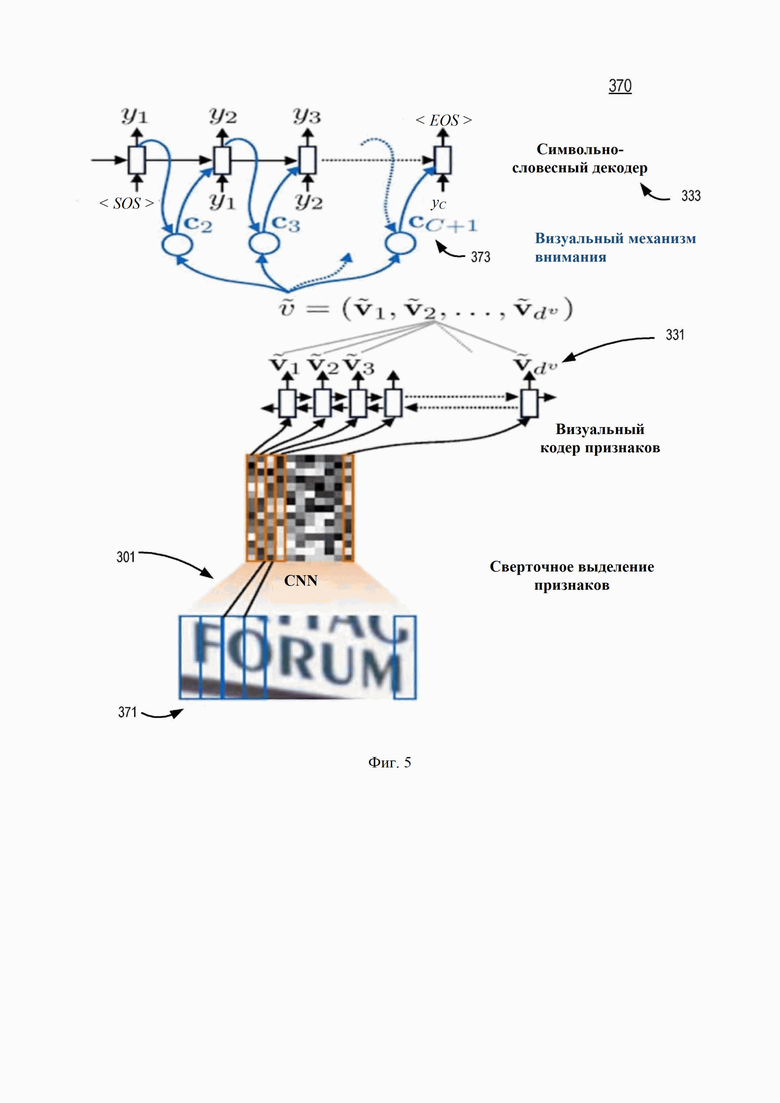
[0049] Фиг. 5 иллюстрирует пример блок-схемы декодера на основе механизма внимания в соответствии с одним или более вариантами реализации настоящего изобретения. Декодер 370 может представлять блок выделения признаков 301 и символьное декодирование 305 на Фиг. 3A. Декодер 370 может использовать схему кодера-декодера с механизмом вниманием, где один или более рекуррентных слоев (таких как рекуррентные слои 331 на Фиг. 3A) используются в качестве компонента кодера, а один или более рекуррентных слоев (таких как слой символьного декодера 333 на Фиг. 3A) используются в качестве компонента декодера схемы кодера-декодера. Что касается Фиг. 5, в одном варианте осуществления декодер 370 принимает входное изображение 371 с текстом forum для OCR. Входное изображение предоставляется в блок выделения признаков 301 для извлечения карт признаков из входного изображения через различные сверточные, ReLU и объединяющие слои (например, слои понижения дискретизации). Выходы карт признаков подаются на рекуррентный слой 331, например кодер визуальных признаков, для кодирования карт признаков в промежуточное представление, например последовательность  . Затем промежуточное представление декодируется в выходные символы у. Нужно учитывать, что есть два специальных символа: начало последовательности (SOS) и конец последовательности (EOS) в выходных символах, которые обозначают начало и конец выходных символов соответственно. EOS решает проблему, состоящую в том, что выходная последовательность символов может иметь длину, отличную от длины наблюдений в рекуррентных слоях. В одном варианте осуществления слой символьного декодера 333 включает в себя один или более рекуррентных слоев (например, LSTM) для выполнения декодирования. Слой символьного декодера 333 может быть однонаправленным или двунаправленным. В одном варианте осуществления выходной символ декодируется на основе ввода из соответствующего промежуточного представления. В другом варианте осуществления в символьный декодер входит механизм внимания. Здесь выходной символ декодируется на основе контекста множества промежуточных представлений. Например, логический вывод входного изображения может дать промежуточное представление, например последовательность . При каждом пространственном наблюдении слой символьного декодирования может выбирать одно или несколько наиболее интересных входных наблюдений на основе последних выходных данных. В одном варианте осуществления контекстный вектор 373 генерируется для представления механизма внимания. То есть контекстный вектор 373 представляет, какая часть промежуточного представления наиболее интересна для декодера при наблюдении. В одном варианте осуществления контекстный вектор включает в себя двоичный вектор для каждого наблюдения, например процесс декодирования определяет, какое из промежуточных представлений следует учитывать. В одном варианте осуществления контекст включает в себя взвешенный вектор для каждого наблюдения, например процесс декодирования определяет, какой вес какого из промежуточных представлений следует учитывать.
. Затем промежуточное представление декодируется в выходные символы у. Нужно учитывать, что есть два специальных символа: начало последовательности (SOS) и конец последовательности (EOS) в выходных символах, которые обозначают начало и конец выходных символов соответственно. EOS решает проблему, состоящую в том, что выходная последовательность символов может иметь длину, отличную от длины наблюдений в рекуррентных слоях. В одном варианте осуществления слой символьного декодера 333 включает в себя один или более рекуррентных слоев (например, LSTM) для выполнения декодирования. Слой символьного декодера 333 может быть однонаправленным или двунаправленным. В одном варианте осуществления выходной символ декодируется на основе ввода из соответствующего промежуточного представления. В другом варианте осуществления в символьный декодер входит механизм внимания. Здесь выходной символ декодируется на основе контекста множества промежуточных представлений. Например, логический вывод входного изображения может дать промежуточное представление, например последовательность . При каждом пространственном наблюдении слой символьного декодирования может выбирать одно или несколько наиболее интересных входных наблюдений на основе последних выходных данных. В одном варианте осуществления контекстный вектор 373 генерируется для представления механизма внимания. То есть контекстный вектор 373 представляет, какая часть промежуточного представления наиболее интересна для декодера при наблюдении. В одном варианте осуществления контекстный вектор включает в себя двоичный вектор для каждого наблюдения, например процесс декодирования определяет, какое из промежуточных представлений следует учитывать. В одном варианте осуществления контекст включает в себя взвешенный вектор для каждого наблюдения, например процесс декодирования определяет, какой вес какого из промежуточных представлений следует учитывать.
[0050] Фиг. 6 иллюстрирует пример блок-схемы гибридного декодера типа «механизм внимания - CTC» в соответствии с одним или более вариантами реализации настоящего изобретения. Декодер 400 может представлять декодер 300 на Фиг. 3A. Что касается Фиг. 6, декодер 400 может быть гибридным декодером типа «механизм внимания - CTC», снабженным CTC-декодированием и символьным декодированием с механизмом внимания, который использует общий блок выделения признаков CNN, например общий для CTC-декодирования и символьного декодирования. В одном варианте осуществления декодер 400 принимает входное изображение 401 с текстом «Some text» для OCR. Изображение 401 может быть предварительно обработано до размеров H×W, где H - высота, а W - ширина изображения 401. Изображение 401 можно передавать через CNN 301 для выделения признаков, чтобы сгенерировать массив признаков (карту признаков) 403 с размерами H1×W1×C, где H1 - это высота, W1 - ширина, а C - канал для признаков 403. Форма выделенных признаков 403 изменена на признаки 404 с размерами W1 на C×H1. Здесь преобразование изменения формы может свести трехмерную карту признаков в двухмерную карту признаков. Затем карта признаков 404 предоставляется как для CTC-декодирования 303, так и для символьного декодирования 305. Что касается CTC-декодирования 303, карта признаков 404 предоставляется одному или более слоям LSTM 321 для генерации промежуточных представлений 409 с размерами W1×C2. Обратите внимание, что значение C2 привязано только к гиперпараметрам LSTM (размеру и направленности). Например, если используется двунаправленный слой LSTM 321 с размером 100, то C2=2×100=200. Если используется однонаправленный слой LSTM 321 с размером 128, то C2=1×128=128. Если доступны все пространственные наблюдения входной последовательности, как в данном примере, двунаправленные LSTM включают в себя два обучаемых блока LSTM вместо одного блока LSTM. Первый LSTM обучается с использованием начальной входной последовательности, а второй LSTM обучается с использованием перевернутой копии входной последовательности. Это может предоставить сети дополнительный контекст и ускорить сеанс обучения.
[0051] Промежуточные представления 409 предоставляются полносвязным слоям 325. Полносвязный слой 325 выполняет еще одну операцию свертки путем умножения промежуточных представлений 409 на матрицу обучаемых весов (не показана). В одном варианте осуществления выходом может быть слой softmax 411, который выводит вероятность выполнения одного из действий из набора всех возможных действий. Недостатком такой архитектуры является сложность реализации выбора сразу нескольких одновременных действий. В другом варианте осуществления слой softmax 411 представляет собой последовательность векторов W1 (или матрицу со столбцами W1), и каждый столбец содержит набор вероятностей, соответствующий набору символов. В одном варианте осуществления набор вероятностей в столбце нормализован, то есть сумма вероятностей для столбца равна 1. Набор символов с размером=«#symbols» включает все допустимые символы распознавания текста, например буквы, числа, разделители и т.д. плюс специальный символ «-», называемый пробелом, который будет использоваться декодером CTC 327. Слой softmax 411 с размерами W на #symbols проходит через декодер CTC 327 для генерации первого набора выходных знаков (символов), представляющих текст во входном изображении 401. Следует отметить, что CTC-декодер 412 выполняет алгоритм декодирования CTC, который удаляет повторяющиеся символы, за которыми следуют пробелы «-», если они есть.
[0052] Что касается символьного декодирования 305, карты признаков 404 предоставляются одному или более слоям LSTM 331 для генерации промежуточных представлений 413 с размерами W1×C2. При символьном декодировании на основе механизма внимания используется другой специальный символ: EOS в промежуточных представлениях 413, который указывает конец последовательности. Таким образом, слои LSTM 331 могут генерировать последовательность с индикатором EOS. Промежуточные представления 413 предоставляются символьному декодеру с механизмом внимания 333, и алгоритм символьного декодирования применяется для генерации второго набора выходных символов/знаков, представляющих текст во входном изображении 401. Здесь алгоритм декодирования символов для символьного декодирования 333 определяет местоположение символа EOS и удаляет все символы после символа EOS.
[0053] В одном варианте осуществления все первые наборы выходных символов и вторые наборы символов проходят через языковую модель (не показана) для определения первой и второй метрики качества для первого и второго набора выходных символов соответственно. Значение метрики качества относится к ранжированию того, насколько отполирована последовательность выходных символов/знаков. Если значение первой метрики качества больше, чем значение второй метрики качества, первый набор выходных символов определяется как выход гибридного декодера 400, и наоборот. В одном варианте осуществления языковая модель включает в себя основанную на правилах модель, базирующуюся на словаре, морфологической модели перегиба, синтаксической модели, или статистике совместимости букв и/или слов, или их комбинации. Значение метрики качества можно определить на основе механизма подсчета сопоставленных выходов для одной или более из этих основанных на правилах моделей. Например, для модели словаря, если первый набор выходных символов (первое слово) совпадает с поиском по словарю, значение метрики качества для первого набора выходных символов пошагово увеличивается на 1. Аналогично, если второй набор выходных символов (второе слово) совпадает с поиском по словарю, значение метрики качества для второго набора выходных символов пошагово увеличивается на 1. В другом примере модель, основанная на статистике совместимости букв, может использовать таблицу совместимости символов, которая указывает, совместимы ли соседние символы. С учетом конкретного символа таблица совместимости символов может указывать, какие соседние символы встречаются часто, например совместимые и соседние символы. Для каждого набора выходных символов каждый символ и его соседи в наборе ищутся в таблице совместимости символов на предмет совпадения. Если совпадение существует, значение метрики качества для набора пошагово увеличивается на 1.
[0054] В другом варианте осуществления языковая модель включает в себя обучаемую модель рекуррентной нейронной сети (RNN) (не показана). В другом варианте осуществления модель RNN включает в себя механизм самовнимания, как описано выше (не показано). Здесь модель RNN можно обучить предоставлять значение метрики качества для набора символов на основе правильности написания слова, представленного набором символов. Например, модель RNN можно обучить классификации текста для разбивки последовательности символов на два класса: слова с правильным написанием и слова с неправильным написанием. Обучающие образцы для первого класса могут использовать словарь и отмечены как первый класс. Обучающие образцы для второго класса могут включать случайно сгенерированные слова, которых нет в словаре, и отмечены как второй класс. Обученная RNN может вывести значение метрики качества на основании вероятности выведенного класса, например значение метрики качества может быть вероятностью того, что слово принадлежит первому классу. Механизм самовнимания может быть аналогичен механизму внимания для декодера 333.
[0055] Что касается Фиг. 1, вышеописанные декодеры могут быть обучены серверной машиной 150. Обучающий модуль 151 серверной машины 150 можно сконфигурировать для обучения любого из декодеров на рис. 3А-6. В одном варианте осуществления, как показано на Фиг. 3A, гибридный декодер типа «механизм внимания - CTC» 300 можно обучать как единое целое. Например, модуль 151 может обучать CTC-декодированию 303 с использованием функции потерь CTC (как показано на Фиг. 4) на основе алгоритма прямого и обратного хода CTC. Модуль 151 может одновременно тренировать символьное декодирование 305 с использованием прямого и обратного распространения. Здесь входные изображения и метки подготавливаются оператором для обучения, например входное изображение с «apple» и двумя отдельными выходами «aap-plee» и «<sos>apple<eos>» для CTC-декодирования 303 и символьного декодирования 305 соответственно могут быть предоставлены как наземные контрольные данные для обучения декодера 300. Здесь <sos> представляет начало последовательности, а<eos> - конец последовательности.
[0056] Например, обучающий модуль 151 может настроить ряд сверточных слоев для блока выделения признаков и ряд слоев LSTM для рекуррентных слоев. Обучающий модуль 151 может инициализировать случайное значение для всех параметров сети декодера. Обучающий модуль 151 может вычислить прямой проход, например передать обучающий экземпляр через сеть и получить все вероятности символов для каждого наблюдения. Для декодирования CTC обучающий модуль 151 может построить таблицу (для всех возможных путей по каждой возможной последовательности промежуточного представления) для представления конкретных последовательностей символов по каждому наблюдению. Обучающий модуль 151 может вычислять прямые и обратные переменные CTC для таблицы и определять ошибку расхождения для вероятности каждого символа при каждом наблюдении на основе прямых и обратных переменных CTC. На основе ошибки расхождения обучающий модуль 151 может обновить один или более весов на слоях LSTM и CNN.
[0057] В другом варианте осуществления модуль 151 может обучать часть CTC-декодера, входящую в гибридный декодер типа «механизм внимания - CTC» 300, отдельно от части символьного декодера с механизмом внимания, входящей в гибридный декодер типа «механизм внимания - CTC» 300. Например, часть CTC-декодера 300 (блок выделения признаков 301 и CTC-декодирование 303) может быть обучена первой. После определения весов модуль 151 обучает символьное декодирование 305, чтобы определять веса слоев при символьном декодировании 305.
[0058] Что касается Фиг. 3B, в одном варианте осуществления гибридный декодер 310 типа «механизм внимания - CTC» может быть обучен как единое целое модулем 151. В другом варианте осуществления модуль 151 может отдельно обучать гибридный декодер 300 типа «механизм внимания - CTC». То есть сначала обучается часть CTC-декодера 300 (блок выделения признаков 301 и CTC-декодирование 303), после чего символьное декодирование 309. После обучения декодера обучаемый декодер может предоставляться модулю распознавания текста для вывода, например модулю распознавания текста 110 на Фиг. 1.
[0059] Фиг. 7 изображает блок-схему способа оптического распознавания символов в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 700 может выполняться посредством логики обработки, которая может включать в себя аппаратное обеспечение (например, устройство обработки, схему, специализированную логику, программируемую логику, микрокод, аппаратное обеспечение устройства, интегральную схему и т.д.), программное обеспечение (например, команды, запускаемые или выполняемые на устройстве обработки) или их комбинацию. В некоторых вариантах осуществления способ 700 выполняется модулем распознавания текста, показанным на Фиг. 1. Хотя и показано в определенной последовательности или порядке, если не указано иное, порядок процессов может быть изменен. Таким образом, проиллюстрированные варианты осуществления следует считать только примерами, и проиллюстрированные процессы могут выполняться в другом порядке, при этом некоторые процессы могут выполняться параллельно. Кроме того, в различных вариантах осуществления можно исключить один или несколько процессов. Таким образом, не все процессы требуются в каждом варианте осуществления. Возможны другие потоки процессов.
[0060] На шаге 701 логика обработки принимает изображение с текстом. На шаге 703 логика обработки выделяет множество признаков из изображения, используя блок выделения признаков. Блок выделения признаков может быть обучаемой моделью CNN, обученной выделять признаки изображения. Признаки изображения могут быть характеристиками записи на изображении, которые могут использоваться для распознавания образов или классификации машинного обучения. На шаге 705 логика обработки применяет первый декодер к множеству признаков для генерации первого промежуточного вывода. Первый промежуточный вывод может быть первой гипотезой/предположением для последовательности воспринимаемых символов на изображении. На шаге 707 логика обработки применяет второй декодер к множеству признаков для генерации второго промежуточного вывода, при котором блок выделения признаков является общим для первого и второго декодеров. Второй промежуточный вывод может быть второй гипотезой/предположением для последовательности воспринимаемых символов на изображении. На шаге 709 система определяет значение первой метрики качества для первого промежуточного вывода и значение второй метрики качества для второго промежуточного вывода на основе языковой модели. Языковая модель может быть моделью словаря, моделью совместимости символов и т.д. На шаге 711 в ответ на определение того, что значение первой метрики качества больше, чем значение второй метрики качества, логика обработки выбирает первый промежуточный вывод для представления текстов.
[0061] В одном варианте осуществления первый декодер включает в себя декодер коннекционной временной классификации, а второй декодер включает в себя символьный декодер с механизмом внимания. В одном варианте осуществления первый декодер включает в себя первый компонент долговременно-кратковременной памяти, а символьный декодер с механизмом внимания включает в себя второй компонент долговременно-кратковременной памяти. В одном варианте осуществления первый и второй декодеры включают в себя компонент долговременно-кратковременной памяти, общий для первого и второго декодеров. В одном варианте осуществления первый и второй декодеры обучаются одновременно с функцией потерь коннекционной временной классификации (CTC) и механизмом внимания соответственно.
[0062] В одном варианте осуществления языковая модель включает в себя словарь, морфологическую модель перегиба, синтаксическую модель или модель статистической совместимости букв или слов. В одном варианте осуществления языковая модель включает в себя модель рекуррентной нейронной сети с механизмом самовнимания.
[0063] Фиг. 8 изображает пример вычислительной системы 800, которая может выполнять один или более способов, описанных в данном документе. В одном примере вычислительная система 800 может соответствовать вычислительному устройству 120, способному выполнять модуль распознавания текста 110 на Фиг. 1, или серверной машине 150, способной выполнять обучающий модуль 151 на Фиг. 1. Вычислительная система может подключаться (например, в сети) к другим вычислительным системам с помощью ЛВС, интрасети, экстрасети или Интернета. Вычислительная система может работать в качестве сервера в сетевой среде клиент-сервер. Вычислительная система может быть персональным компьютером (ПК), планшетом, телеприставкой (STB), персональным цифровым помощником (PDA), мобильным телефоном, камерой, видеокамерой или любым устройством, способным выполнять набор команд (последовательных или иных), определяющих действия, которые должны выполняться этим устройством. Кроме того, хотя проиллюстрирована только одна вычислительная система, термин «компьютер» также следует понимать как включающий любую совокупность компьютеров, которые индивидуально или совместно выполняют набор (или несколько наборов) команд для выполнения одного или нескольких из обсуждаемых в данном документе способов.
[0064] Пример вычислительной системы 800 включает в себя устройство обработки 802, основное ЗУ 804 (например, постоянное ЗУ (ПЗУ), флеш-память, динамическое ЗУ с произвольной выборкой (ДЗУПВ), такое как синхронное ДЗУПВ (СДЗУПВ)), статическое ЗУ 806 (например, флеш-память, статическое ЗУ с произвольной выборкой (СЗУВП)) и устройство хранения данных 816, которые связываются друг с другом через шину 808.
[0065] Устройство обработки 802 представляет одно или более устройств обработки общего назначения, таких как микропроцессор, центральный процессор и т.п. В частности, устройство обработки 802 может быть микропроцессором с полным набором команд (CISC), микропроцессором с сокращенным набором команд (RISC), микропроцессором со сверхдлинным командным словом (VLIW) или процессором, реализующим другие наборы команд, или процессорами, реализующими комбинацию наборов команд. Устройство обработки 802 также может быть представлено одним или более устройствами обработки специального назначения, такими как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), цифровой сигнальный процессор (DSP), сетевой процессор и т.п. Устройство обработки 802 создано с возможностью выполнять команды 826 для реализации операций и шагов, описанных в данном документе.
[0066] Вычислительная система 800 может дополнительно включать в себя сетевое интерфейсное устройство 822. Вычислительная система 800 также может включать в себя видеоконтрольное устройство 810 (например, жидкокристаллический дисплей (ЖКД) или электронно-лучевую трубку (ЭЛТ)), буквенно-цифровой устройство ввода 812 (например, клавиатуру), устройство управления курсором 814 (например, мышь) и устройство генерации сигнала 820 (например, динамик). В одном иллюстративном примере видеоконтрольное устройство 810, буквенно-цифровое устройство ввода 812 и устройство управления курсором 814 могут быть объединены в один компонент или устройство (например, сенсорный ЖК-экран).
[0067] Устройство хранения данных 816 может включать в себя машиночитаемый носитель 824, на котором хранятся команды 826 (например, соответствующие способу, показанному на Фиг. 7 и т.д.), воплощающие одну или несколько методологий или функций, описанных в данном документе. Команды 826 могут также находиться полностью или по меньшей мере частично в основном ЗУ 804 и/или в устройстве обработки 802 во время их исполнения вычислительной системой 800, основным ЗУ 804 и устройством обработки 802, также составляющими машиночитаемый носитель. Команды 826 могут дополнительно передаваться или приниматься по сети через сетевое интерфейсное устройство 822.
[0068] В то время как машиночитаемый носитель данных 824 показан в иллюстративных примерах как единственный носитель, термин «машиночитаемый носитель данных» следует понимать как включающий один носитель или несколько носителей (например, централизованную или распределенную базу данных и/или связанные кеши и серверы), в которых хранятся один или несколько наборов команд. Термин «машиночитаемый носитель данных» также должен включать любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной и который заставляет машину выполнять одну или несколько методологий настоящего изобретения. Термин «машиночитаемый носитель данных» следует соответственно понимать как включающий твердотельные запоминающие устройства, оптические носители и магнитные носители.
[0069] Хотя операции способов в данном документе показаны и описаны в определенном порядке, порядок операций каждого способа может быть изменен так, чтобы определенные операции могли выполняться в обратном порядке, или так, чтобы определенная операция по крайней мере частично могла выполняться одновременно с другими операциями. В некоторых вариантах реализации команды или подоперации отдельных операций могут быть прерывистыми и/или чередующимися.
[0070] Следует понимать, что приведенное выше описание служит для иллюстрации, а не ограничения. Многие другие варианты реализации будут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Следовательно, объем настоящего изобретения должен определяться ссылкой на прилагаемую формулу изобретения вместе с полным объемом эквивалентов, на которые такая формула изобретения имеет право.
[0071] В приведенном выше описании изложены многочисленные подробности. Однако для специалиста в данной области техники будет очевидно, что аспекты настоящего изобретения могут быть реализованы на практике без этих конкретных деталей. В некоторых случаях хорошо известные конструкции и устройства показаны в форме блок-схемы, а не в подробностях, чтобы не затруднять понимание настоящего изобретения.
[0072] Некоторые части подробных описаний выше представлены в терминах алгоритмов и символических представлений операций с битами данных в памяти компьютера. Эти алгоритмические описания и представления являются средствами, используемыми специалистами в области обработки данных, чтобы наиболее эффективно передать суть своей работы другим специалистам в данной области техники. Алгоритм здесь и в целом задуман как самосогласованная последовательность шагов, ведущих к желаемому результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно сохранять, передавать, комбинировать, сравнивать и иным образом использовать. Иногда оказывается удобным, в основном по причинам обычного использования, называть эти сигналы битами, значениями, элементами, знаками, символами, терминами, числами и т.п.
[0073] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и представляют собой просто удобные обозначения, применяемые к этим величинам. Если специально не указано иное, как очевидно из следующего обсуждения, следует понимать, что во всем описании обсуждения с использованием таких терминов, как «получение», «определение», «выбор», «сохранение», «анализ» и т.п., относятся к действию и процессам вычислительной системы или аналогичного электронного вычислительного устройства, которое обрабатывает и преобразует данные, представленные в виде физических (электронных) величин в регистрах и памяти вычислительной системы, в другие данные, аналогично представленные в виде физических величин в памяти или регистрах вычислительной системы или других подобных устройств хранения, передачи или отображения информации.
[0074] Настоящее изобретение также относится к устройству для выполнения операций в данном документе. Это устройство может быть специально сконструировано для требуемых целей или может содержать компьютер общего назначения, выборочно активируемый или реконфигурируемый компьютерной программой, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, таком как, помимо прочего, диск любого типа, включая дискеты, оптические диски, компакт-диски и магнито-оптические диски, постоянные ЗУ (ПЗУ), оперативные ЗУ (ОЗУ), ЭППЗУ, ЭСППЗУ, магнитные или оптические платы или любой тип носителя, подходящий для хранения электронных команд, каждая из которых подключена к системной шине компьютера.
[0075] Алгоритмы и дисплеи, представленные в данном документе, по своей сути не связаны с каким-либо конкретным компьютером или другим устройством. Различные системы общего назначения могут использоваться с программами в соответствии с изложенными идеями, или может оказаться удобным сконструировать более специализированное устройство для выполнения требуемых методических шагов. Требуемая структура для множества этих систем будет отображаться, как указано в описании. Кроме того, аспекты настоящего изобретения не описаны посредством ссылки на какой-либо конкретный язык программирования. Будет принято во внимание, что для реализации идей настоящего изобретения, как описано в данном документе, можно использовать множество языков программирования.
[0076] Варианты реализации настоящего изобретения могут быть предоставлены в виде компьютерного программного продукта или программного обеспечения, которое может включать в себя машиночитаемый носитель для хранения команд, использующихся для программирования компьютерной системы (или других электронных устройств) с целью выполнения процесса в соответствии с настоящим изобретением. Машиночитаемый носитель включает в себя любой механизм для хранения или передачи информации в форме, читаемой машиной (например, компьютером). Например, машиночитаемый (т.е. считываемый компьютером) носитель включает в себя машиночитаемый (например, компьютером) носитель данных (например, постоянное ЗУ (ПЗУ), оперативное ЗУ (ОЗУ), носители данных на магнитных дисках, оптические носители данных, устройства флеш-памяти и т.д.).
[0077] Любой вариант реализации или конструкция, описанные в настоящем документе как «пример», не должны обязательно рассматриваться как предпочтительные или преимущественные по сравнению с другими вариантами реализации или конструкциями. Скорее, использование слов «пример» или «примерный» предназначено для конкретного представления понятий. Используемый в этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». То есть если иное не указано или не ясно из контекста, «X включает A или B» означает любую из естественных включающих перестановок. То есть если X включает A; X включает B; или X включает в себя как A, так и B, тогда «X включает A или B» удовлетворяется в любом из вышеупомянутых случаев. Кроме того, артикли «a» и «an», использованные в англоязычной версии этой заявки и прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Более того, использование терминов «вариант осуществления», «один вариант осуществления», «вариант реализации» или «один вариант реализации» не предназначено для обозначения одного и того же варианта осуществления или реализации, если они не описаны как таковые. Кроме того, используемые здесь термины «первый», «второй», «третий», «четвертый» и т.д. означают метки, позволяющие различать различные элементы, и необязательно могут иметь порядковое значение в соответствии с их числовым обозначением.



Изобретение относится к способу и системе распознавания текста. Технический результат заключается в повышении эффективности и точности распознавания текста. В способе выполняют получение вычислительной системой изображения с текстом; выделение с помощью блока выделения признаков множества признаков из изображения; применение первого декодера к множеству признаков для генерации первого промежуточного вывода, причем промежуточный вывод представляет собой гипотезу последовательности символов текста; применение второго декодера к множеству признаков для генерации второго промежуточного вывода, где блок выделения признаков является общим для первого и второго декодеров; определение на основе языковой модели значения первой метрики качества для первого промежуточного вывода и значения второй метрики качества для второго промежуточного вывода; и в ответ на определение того, что значение первой метрики качества больше, чем значение второй метрики качества, выбор первого промежуточного вывода для представления текста. 3 н. и 17 з.п. ф-лы, 9 ил.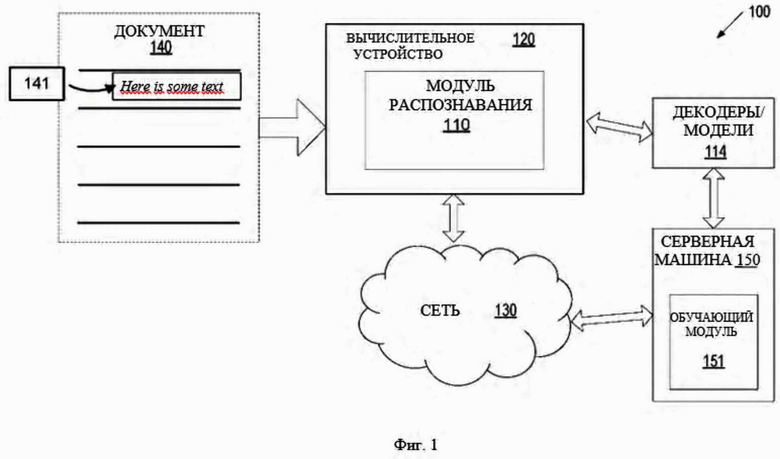
1. Способ распознавания текста, включающий:
получение вычислительной системой изображения с текстом;
выделение с помощью блока выделения признаков множества признаков из изображения;
применение первого декодера к множеству признаков для генерации первого промежуточного вывода, причем промежуточный вывод представляет собой гипотезу последовательности символов текста;
применение второго декодера к множеству признаков для генерации второго промежуточного вывода, где блок выделения признаков является общим для первого и второго декодеров;
определение на основе языковой модели значения первой метрики качества для первого промежуточного вывода и значения второй метрики качества для второго промежуточного вывода; и
в ответ на определение того, что значение первой метрики качества больше, чем значение второй метрики качества, выбор первого промежуточного вывода для представления текста.
2. Способ по п. 1, в котором первый декодер включает в себя декодер коннекционной временной классификации (СТС), а второй декодер включает в себя символьный декодер с механизмом внимания.
3. Способ по п. 2, в котором первый декодер включает в себя первый компонент долговременно-кратковременной памяти, а символьный декодер с механизмом внимания включает в себя второй компонент долговременно-кратковременной памяти.
4. Способ по п. 3, в котором первый компонент долговременно-кратковременной памяти является двунаправленным.
5. Способ по п. 2, в котором первый и второй декодеры включают в себя компонент долговременно-кратковременной памяти, общий для первого и второго декодеров.
6. Способ по п. 1, в котором языковая модель включает в себя по меньшей мере одно из следующего: словарь, морфологическую модель перегиба, синтаксическую модель или модель статистической совместимости букв или слов.
7. Способ по п. 1, в котором языковая модель включает в себя модель рекуррентной нейронной сети.
8. Система для распознавания текста, включающая:
запоминающее устройство;
процессор, связанный с запоминающим устройством, выполненный с возможностью:
получать изображение с текстом;
выделять с помощью блока выделения признаков множество признаков из изображения;
применять первый декодер к множеству признаков для генерации первого промежуточного вывода, причем промежуточный вывод представляет собой гипотезу последовательности символов текста;
применять второй декодер к множеству признаков для генерации второго промежуточного вывода, где блок выделения признаков является общим для первого и второго декодеров;
определять на основе языковой модели значение первой метрики качества для первого промежуточного вывода и значение второй метрики качества для второго промежуточного вывода; и
в ответ на определение того, что значение первой метрики качества больше, чем значение второй метрики качества, выбирать первый промежуточный вывод для представления текста.
9. Система по п. 8, в которой первый декодер включает в себя декодер коннекционной временной классификации (СТС), а второй декодер включает в себя символьный декодер с механизмом внимания.
10. Система по п. 9, в которой первый декодер включает в себя первый компонент долговременно-кратковременной памяти, а символьный декодер с механизмом внимания включает в себя второй компонент долговременно-кратковременной памяти.
11. Система по п. 10, в которой первый компонент долговременно-кратковременной памяти является двунаправленным.
12. Система по п. 9, в которой первый и второй декодеры включают в себя компонент долговременно-кратковременной памяти, общий для первого и второго декодеров.
13. Система по п. 8, в которой языковая модель включает в себя по меньшей мере одно из следующего: словарь, морфологическую модель перегиба, синтаксическую модель или модель статистической совместимости букв или слов.
14. Система по п. 8, в которой языковая модель включает в себя модель рекуррентной нейронной сети.
15. Постоянный машиночитаемый носитель данных, содержащий исполняемые команды, которые при выполнении вычислительной системой побуждают ее:
получать изображение с текстом;
выделять с помощью блока выделения признаков множество признаков из изображения;
применять первый декодер к множеству признаков для генерации первого промежуточного вывода, причем промежуточный вывод представляет собой гипотезу последовательности символов текста;
применять второй декодер к множеству признаков для генерации второго промежуточного вывода, где блок выделения признаков является общим для первого и второго декодеров;
определять на основе языковой модели значение первой метрики качества для первого промежуточного вывода и значение второй метрики качества для второго промежуточного вывода; и
в ответ на определение того, что значение первой метрики качества больше, чем значение второй метрики качества, выбирать первый промежуточный вывод для представления текста.
16. Носитель данных по п. 15, в котором первый декодер включает в себя декодер коннекционной временной классификации (СТС), а второй декодер включает в себя символьный декодер с механизмом внимания.
17. Носитель данных по п. 16, в котором первый декодер включает в себя первый компонент долговременно-кратковременной памяти, а символьный декодер с механизмом внимания включает в себя второй компонент долговременно-кратковременной памяти.
18. Носитель данных по п. 17, в котором первый компонент долговременно-кратковременной памяти является двунаправленным.
19. Носитель данных по п. 16, в котором первый и второй декодеры включают в себя компонент долговременно-кратковременной памяти, общий для первого и второго декодеров.
20. Носитель данных по п. 15, в котором языковая модель включает в себя по меньшей мере одно из следующего: словарь, морфологическую модель перегиба, синтаксическую модель или модель статистической совместимости букв или слов.
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |
| US 10671878 B1, 02.06.2020 | |||
| CN 109993040 A, 09.07.2019 | |||
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| US 10445569 B1, 15.10.2019 | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| CN 111967470 A, 20.11.2020. | |||

