Изобретение относится к области обработки пользовательских данных, полученных из графов онлайновых социальных сетей, с целью интеграции данных различных профилей, принадлежащих одному пользователю. Может быть использовано для построения баз данных пользовательской информации, полученной из различных источников, в частности, для построения расширенного социального графа, содержащего данные о пользователе, полученные из нескольких различных социальных графов. Подобный расширенный социальный граф может быть использован для улучшения качества результатов в ряде задач, таких как поиск информации в Интернете, онлайн-реклама товаров и услуг, построение рекомендаций товаров и услуг пользователям и др.
Рассмотрим основные понятия, необходимые для понимания представленного изобретения:
1. Интеграция данных включает объединение данных, находящихся в различных источниках и предоставление данных пользователям в унифицированном виде. Изобретение обеспечивает интеграцию данных на логическом уровне с целью обеспечения возможности доступа к данным, содержащимся в различных источниках, в терминах единой глобальной схемы, которая описывает их совместное представление с учетом структурных свойств.
2. Социальный граф является цифровым представлением взаимоотношений пользователей онлайновых социальных сетей, которое явно задается различными типами отношений связи между пользователями (например, отношение дружбы, отношение следования и т.д.). Данные пользователя в социальном графе представлены в виде профиля, который представляет собой находящуюся на материальном носителе либо в памяти вычислительной машины совокупность атрибутов (в основном, строковых) в виде пар "имя - значение", которые содержат различную информацию о пользователе (например, имя, пол, адрес, номер телефона и т.д.). Изобретение предназначено для объединения различных социальных графов путем сравнения атрибутов профилей пользователей и интенсивного использования информации, скрытой в связях между профилями.
3. Условные Случайные Поля - это графическая вероятностная модель, в которой в виде ненаправленного графа представлены зависимости между случайными величинами. Узлы графа делятся на два непересекающихся множества - наблюдаемые переменные, которые задаются в качестве входных данных, и скрытые переменные. Ребра графа соответствуют вероятностным взаимосвязям между узлами. Вершинам и ребрам могут быть назначены численные значения, называемые энергиями. Вычисление значений скрытых переменных называется выводом из модели.
4. Машинное обучение - раздел искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться. В представленном изобретении используется разновидность машинного обучения, именуемая обучением с учителем: алгоритм генерирует функцию, которая связывает входные данные с выходными определенным образом (задача классификации). В качестве обучающих данных используются примеры связи входных данных с выходными. В алгоритмах машинного обучения широко используется понятие признака. Признаки - индивидуальные измеримые свойства наблюдаемого феномена, которые используются для создания его численного представления (например, значения метрик строковой похожести для пар атрибутов профилей).
5. Метрики строковой похожести возвращают численное значение похожести пары строк, основываясь на порядке расположения составляющих их символов (например, расстояние Джаро-Винклера [17]).
6. Метрики графовой похожести возвращают численное значение похожести пары узлов графа, основываясь на структуре связей между ними (например, коэффициент Дайса [18]).
Крупнейшим исследованием, посвященным интеграции профилей пользователей социальных сетей, является диссертация Veldman [1]. В ней предлагается множество эвристик, использующих как данные профилей пользователей, так и существующие связи между ними. Результаты подобных исследований также представлены в работах Motoyama et аl [2], Gae-won et al [3], Raad et al [4] и Vozecky et al [5]. В работе [2] авторы сравнивают профили пользователей MySpace и Facebook. В работе [3] авторы делают то же самое с профилями из Twitter и EntityCube. Авторы [4] генерируют синтетические профили пользователей и применяют к ним различные сложные эвристики, стараясь использовать любой потенциально полезный источник данных в социальной сети. В работе [5] профили пользователей Facebook и StudiVZ представлены в виде n-мерных векторов, которые впоследствии сравниваются с помощью различных техник, включая нечеткое сравнение. Авторы также исследуют влияние различных атрибутов профиля на точность результатов сравнения.
Интерес также представляют проекты Foaf-o-matic [6] и Okkam [7], целью которых является интеграция социальных профилей с помощью формальной семантики FOAF (Friend-of-a-friend). Проект Stanford Entity Resolution Framework [8] также предназначен для решения задач, подобных данной. Помимо исходных кодов фреймворка, доступно множество работ, посвященных теоретическим аспектам интеграции данных, таким как масштабируемость, оценка качества и др.
Несмотря на успехи, достигнутые авторами вышеперечисленных работ, в них используется слишком простая модель сравнения профилей, основанная, в основном на попарном сравнении с помощью строковой похожести отдельных атрибутов. Кроме того, существующие связи между профилями учитываются недостаточно либо вообще не берутся во внимание, то же касается особенностей сравниваемых социальных графов.
Наиболее близким к представленному изобретению является способ, предложенный Singla et al [9] для выявления дубликатов в сети цитирования научных работ с помощью модели Условных Случайных Полей. Авторы формулируют задачу в терминах марковской случайной логики и строят модель из фактов и утверждений о сравниваемых объектах, после чего рассчитывают их вероятности. Для оптимизации скорости работы алгоритма авторы производят разбиение модели на пересекающиеся компоненты. Вместе с тем, представленный подход обладает следующими недостатками, препятствующими его использованию для решения рассматриваемой задачи:
- в модели предусмотрено наличие только одного источника данных (граф сети цитирования научных работ);
- узлами модели являются факты и утверждения о сравниваемых объектах, а не сами объекты. В частности, определено два типа узлов: узлы-записи и узлы-атрибуты. Первый тип узлов предназначен для хранения вопроса "Идентичен ли данный объект другому объекту?", тогда как второй тип хранит информацию о похожести атрибутов объектов;
- для сравнения объектов используются только метрики строковой похожести их атрибутов, тогда как метрики графовой похожести не используются.
Настоящее изобретение обладает следующими преимуществами по сравнению с ранее предложенными подходами:
- позволяет упростить представление социального графа в памяти вычислительной машины, поскольку модель Условных Случайных Полей строится на основе одного из сравниваемых графов, при этом узлами модели являются непосредственно профили, а ребрами - связи между ними. Затем рассчитываются энергии связей модели исходя из данных о строковой и графовой похожести профилей, после чего производится поиск оптимального решения в виде конфигурации проекций профилей одной социальной сети на другую;
- с помощью модели Условных Случайных Полей учитывается вся доступная информация о связях между профилями, что позволяет использовать латентную информацию, скрытую в этих связях, для уточнения результатов. Таким образом, способ позволяет производить интеграцию профилей, атрибуты которых содержат лишь незначительное количество полезной информации, что существенно усложняет применение общепринятого подхода, основанного на строковой близости атрибутов;
- адекватность и эффективность различных метрик строковой и графовой близости, а также относительная значимость атрибутов оцениваются с помощью методик машинного обучения на предварительно составленном наборе реальных экспериментальных данных, что позволяет учесть особенности выбранных социальных графов и оптимизировать параметры алгоритма для достижения лучших результатов.
Технический результат использования предлагаемого изобретения состоит в том, что изобретение позволяет ранее неизвестным способом получать список пар профилей пользователей онлайновых социальных сетей, в котором профили в каждой паре содержат информацию об одном и том же пользователе, основываясь только на информации, содержащейся в атрибутах профилей и связях между ними. Также предложен универсальный подход, позволяющий учитывать особенности любой пары социальных графов и оптимизировать параметры метода для получения лучших результатов.
Для лучшего понимания заявленного изобретения далее приводится его подробное описание с соответствующими чертежами.
Фиг.1 представляет собой блок-схему алгоритма работы изобретения
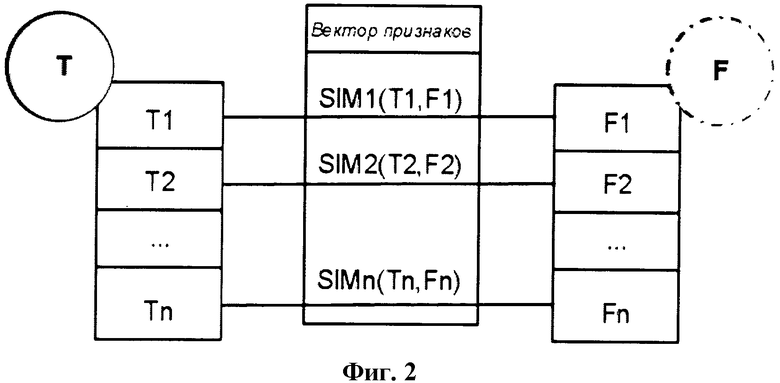
Фиг.2 представляет собой схему расчета значений похожести атрибутов профилей и построение вектора признаков
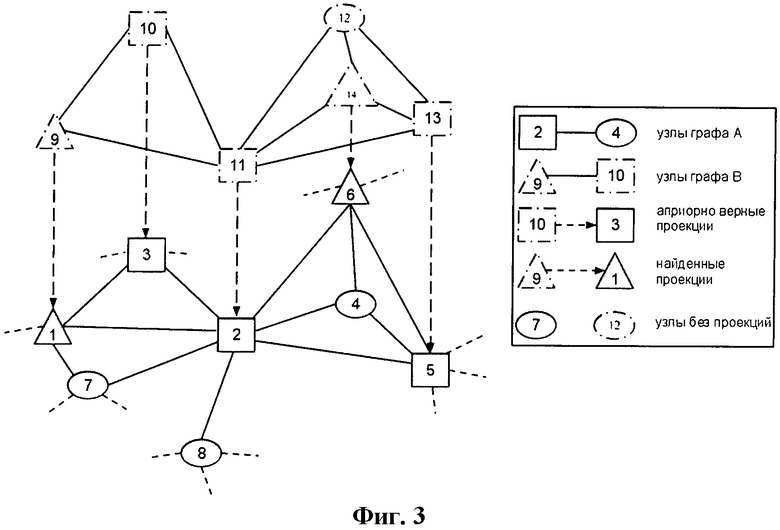
Фиг.3 представляет собой Модель Условных Случайных Полей
Рассмотрим два социальных графа A и B. Для вершины ν∈A соответствующий профиль из графа В будем называть проекцией pr(ν) вершины ν∈A на граф B. Если для вершины ν∈A не определена проекция из B, то ей назначается нейтральная проекция: pr(ν)=N.
Задача интеграции профилей пользователей заключается в определении максимально возможного количества верных проекций (ν, u), ν∈A, u∈A. в терминах модели Условных Случайных Полей проекции pr(ν) для каждого ν∈A являются скрытыми переменными, значение которых нужно установить.
Представленное изобретение основано на следующих основных утверждениях:
- задача определения верной проекции для узла из графа A связана с задачами определения верных проекций для всех смежных узлов из графа A;
- если два узла в графе A связаны, то их проекции в графе B должны иметь как можно более высокое значение графовой похожести.
Предлагаемый способ интеграции профилей пользователей онлайновых социальных сетей содержит алгоритм, включающий в себя ввод всех возможных пар профилей, 19 основных шагов и вывод результата в виде списка пар профилей, в котором каждая пара содержит информацию об одном и том же пользователе, при этом составляющие проекцию профили относятся к разным социальным графам.
Рассмотрим более подробно шаги алгоритма (фиг.1).
Шаг 100. Ввод всех возможных пар профилей.
В сравнении участвуют все возможные пары профилей, поскольку используемый в изобретении алгоритм вывода из модели Условных Случайных Полей дает лучшие результаты при наличии информации об энергиях всех возможных парных комбинаций узлов. Набор профилей из графов A и B со всеми известными связями между ними образуют модель Условных Случайных Полей.
Шаг 101. Выбор следующей пары профилей.
Шаг 102. Расчет значений похожести атрибутов профилей и построение вектора признаков.
Сравнение атрибутов профилей из графов A и B производится с помощью схемы соответствия, которая задает порядок сравнения атрибутов и применяемые метрики похожести (примеры схем соответствия для расчета похожести атрибутов между узлами из различных графов и между двумя узлами графа ν даны в Табл. 1 и Табл. 2 соответственно).
На фиг.2 изображен пример сравнения профилей из Twitter и Facebook. Ti и Fi соответствуют двум сравниваемым атрибутам из профилей Т и F, где i - порядковый номер содержащей данные атрибуты записи в схеме соответствия. К каждой паре атрибутов применяется метрика похожести simi. Значения метрик похожести для всех пар атрибутов составляют вектор признаков, который передается на следующий шаг.
Шаг 103. Расчет энергии пары профилей с помощью алгоритма машинного обучения.
Определим понятия энергий, предварительно определив необходимые переменные.
Граф A используется для построения модели Условных Случайных Полей. Пусть ν и u являются пользователями из графа А, а pr(ν) и pr(u) - их проекциями из графа В.
Тогда энергия узла (унарная энергия) определяется как
Ф(pr(ν)|ν)=α(ν)·(1-profilesimilarity(ν,pr(ν)),
энергия связи (бинарная энергия) определяется как
ψ(pr(ν),pr(u)|ν,u)=β(pr(ν),pr(u))·(1-networksimilarity(pr(ν),pr(u)),
а полная энергия определяется как
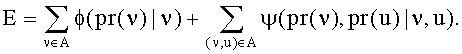
α(ν) и β(pr(ν),pr(u)) являются коэффициентами, регулирующими влияние каждого типа энергий на итоговую модель и результаты работы. Функции profilesimilarity и networksimilarity являются функциями похожести профилей, которые нормированы и увеличиваются с увеличением похожести сравниваемых профилей.
Для расчета унарных и бинарных энергий с целью максимизации точности результатов путем анализа реальных данных используется методика машинного обучения, которая получает на вход набор значений метрик похожести для данной пары профилей в виде вектора признаков и возвращает значение энергии связи данной пары профилей. В качестве методики машинного обучения предусмотрено использование одного из способов:
- Взвешенная линейная комбинация признаков, где веса подбираются при помощи линейной регрессии [15], исходя из того, что унарная энергия для правильных проекций должна быть равна 0, а для неправильных - 1;
- Алгоритм машинного обучения MultiBoostAB [13] над решающими деревьями С 4.5 [14];
- Алгоритм машинного обучения LogitBoost над решающими деревьями М5Р [16].
Перечисленные алгоритмы перед использованием проходят процедуру обучения, т.е. получают на вход множество векторов признаков, полученных при расчете метрик похожести для атрибутов профилей, входящих в состав набора данных, в котором верные проекции заранее заданы вручную. Вектор признаков, используемый для обучения, включает в себя все значения метрик похожести для сравниваемой пары профилей и дополнительное измерение, содержащее значение булевского типа и указывающее, содержат ли данные профили информацию об одном и том же пользователе. Такой набор данных может быть составлен для любой пары социальных графов.
Шаг 104. Является ли данная пара профилей последней? Если НЕТ - переход к шагу 101, если ДА - переход к шагу 105.
Шаг 105. Выбор следующей пары профилей.
Производится последовательный перебор всех возможных пар профилей, в которых один из профилей принадлежит графу A а второй - графу B.
Шаг 106. Расчет похожести пары профилей.
Производится сравнение атрибута выбранной пары профилей, который с наибольшей степенью вероятности однозначно идентифицирует профиль, с помощью метрики строковой похожести.
Шаг 107. Превышает ли значение похожести пары профилей заданное пороговое значение? Если ДА - переход к шагу 108, если НЕТ - переход к шагу 109.
Шаг 108. Добавить пары профилей в список кандидатов.
Шаг 109. Является ли данная пара профилей последней? Если НЕТ - переход к шагу 105, если ДА - переход к шагу 110.
Шаг 110. Выбор наилучших пар профилей из списка кандидатов и составление списка априорно верных проекций.
Для выбора наилучших пар профилей к списку кандидатов применяется алгоритм Куна-Манкреса [19], который производит последовательный перебор всех пар из списка кандидатов и выдает в качестве результата часть из них, выбранных таким образом, чтобы каждый профиль встречался только в одной паре, а профили, составляющие пару, взаимно максимизировали похожесть друг на друга. Результатом является набор априорно верных проекций (пар профилей), которые заносятся в модель с целью улучшения качества результатов.
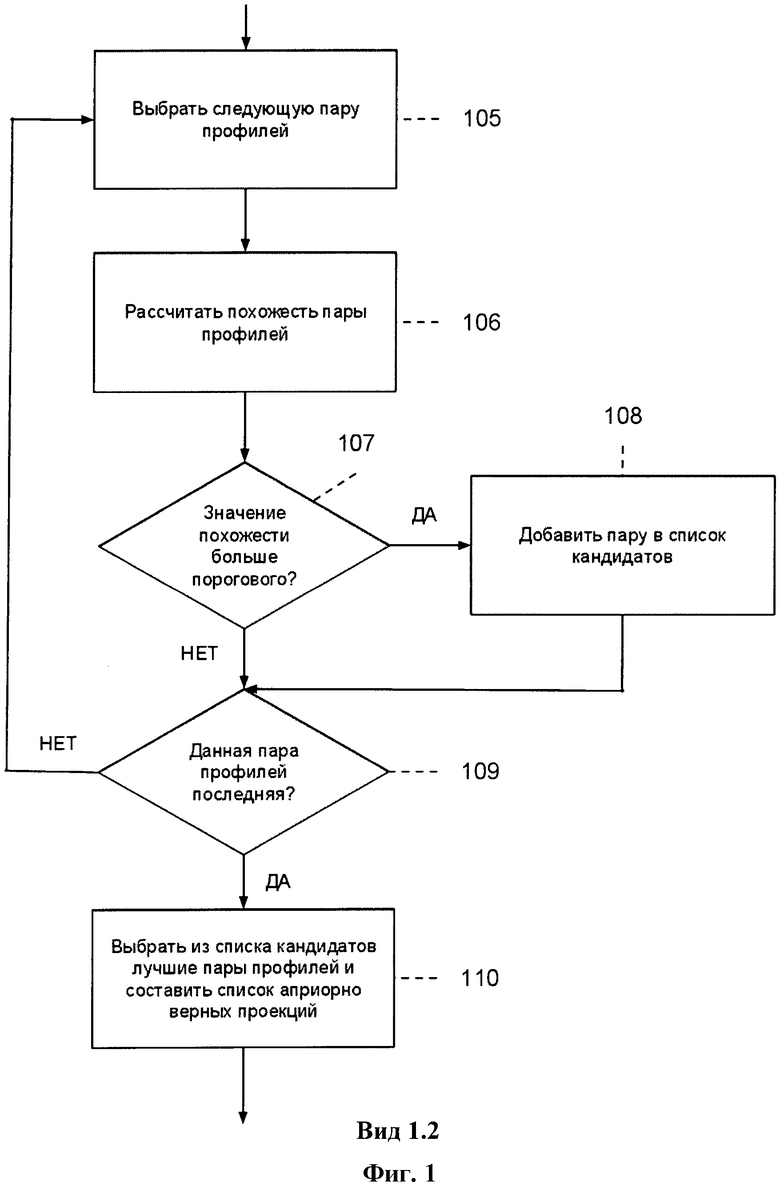
Шаг 111. Разбиение модели на независимые компоненты путем удаления априорно верных проекций.
С целью уменьшения вычислительной сложности алгоритма исходная задача разбивается на подзадачи путем разбиения исходной модели. Это достигается путем удаления найденных априорно верных проекций.
Шаг 112. Выбор следующей компоненты модели.
Шаг 113. Поиск оптимальной конфигурации проекций для выбранной компоненты.
Для решения данной задачи полная энергия модели должна быть минимизирована. Для этого производится вывод из построенной модели Условных Случайных Полей. К задаче вывода сначала применяется квадратичная релаксация [10], затем задача аппроксимируется с применением методов Power Iteration [11] и Singular Value Decomposition [12], после чего решается как задача квадратичного программирования. Результатом данного шага является конфигурация модели (набор проекций), которая минимизирует полную энергию модели и содержит максимальное количество верных проекций профилей.
На фиг.3 схематично изображена модель с набором различных проекций. Узлы графа A изображены непрерывной линией, тогда как узлы графа B - штрихпунктирной линией. Узлы в форме квадратов соответствуют априорно верным проекциям, узлы в форме треугольников являются компонентами проекций, найденных в результате вывода, в то время как для всех остальных узлов подходящих проекций не найдено. Пара узлов, составляющих проекцию, соединена с помощью пунктирной линии.
Шаг 114. Является ли данная компонента модели последней? Если НЕТ - переход к шагу 112, если ДА - переход к шагу 115.
Шаг 115. Объединение результатов для всех компонент модели.
Объединяются списки найденных проекций для всех компонент модели.
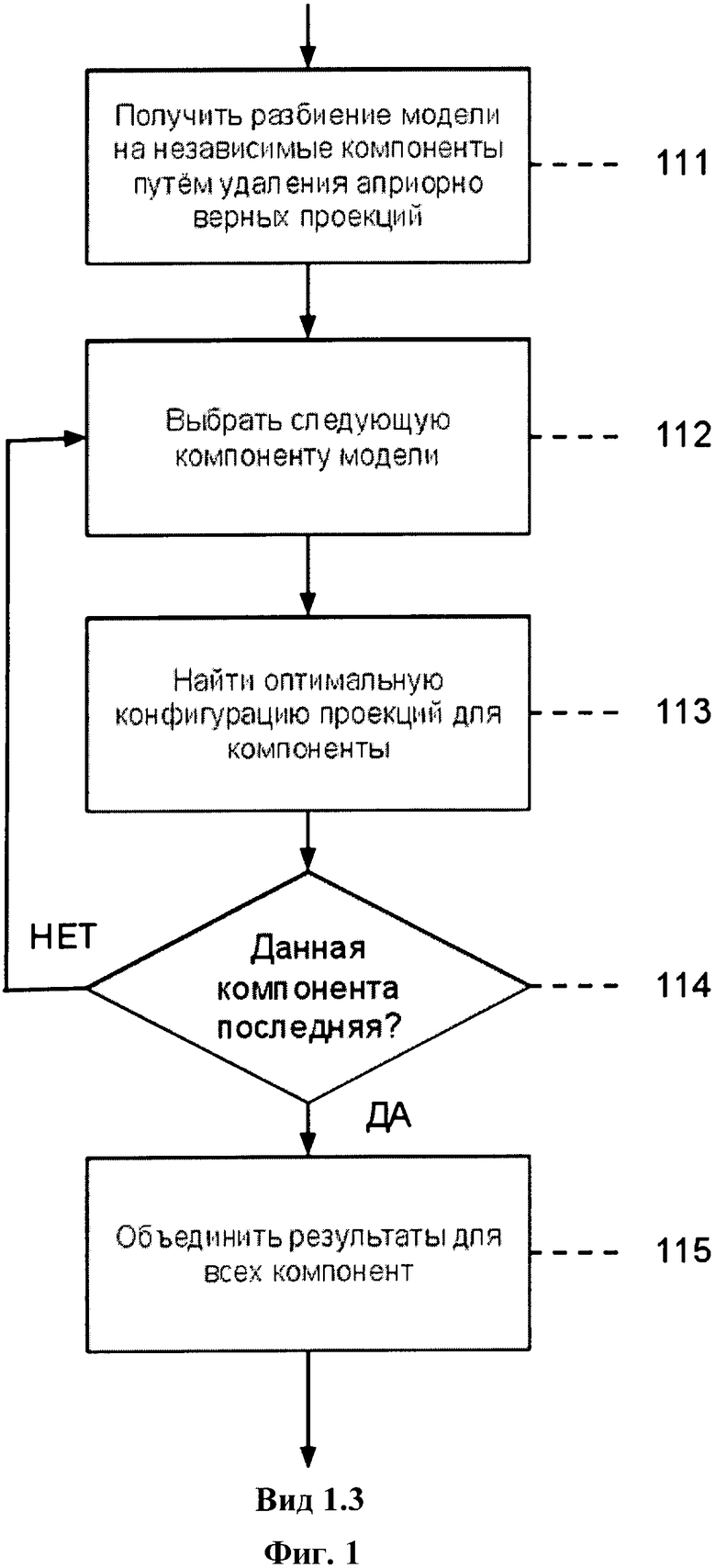
Шаг 116. Выбор следующей проекции.
Шаг 117. Построение вектора признаков для выбранной проекции и перенаправление его классификатору в качестве входных данных.
Для выбранной проекции строится вектор, состоящий из следующих признаков:
- унарная энергия вершины;
- средняя бинарная энергия связи с априорно верными проекциями;
- доля априорно верных проекций в списке вершин, связанных с данной;
- качество набора априорно верных проекций.
Качество набора априорно верных проекций вычисляется как сумма наибольших N весов, назначаемых априорно верным проекциям, связанным с рассматриваемой вершиной, где вес вершины вычисляется как средняя бинарная энергия связи между данной вершиной и другими взвешиваемыми вершинами.
Шаг 118. Является ли выбранная проекция верной?
Для уточнения результатов применяется классификаторный алгоритм машинного обучения (бустинг MultiBoostAB [13] над решающими деревьями С 4.5 [14]). Алгоритм классификации принимает построенный вектор признаков в качестве входных данных и возвращает решение о том, является ли данная вершина корректно спроецированной. В случае, если проекция неверная (решение классификатора не совпадает с решением алгоритма), то переход к шагу 119, в противном случае - переход к шагу 120.
Шаг 119. Удаление выбранной проекции из результатов.
Шаг 120. Является ли данная проекция последней? Если НЕТ - переход к шагу 116, если ДА - переход к шагу 121.
Шаг 121. Вывод списка проекций, в котором каждая проекция содержит информацию об одном и том же пользователе, при этом составляющие проекцию профили относятся к различным социальным графам.
Пример работы
На фиг.3 изображены модели двух социальных графов, где профили представлены узлами, а связи между ними - ребрами. Будем считать, что узлы 1-8 принадлежат графу A (Twitter), а узлы 9-14 принадлежат графу В (Facebook). Все связи между узлами внутри каждого из графов заданы изначально, тогда как связи между узлами разных графов (объединение узлов в пары) являются результатом работы. Граф Twitter с полным набором узлов и ребер используется для построения модели Условных Случайных Полей, а узлы из графа Facebook считаются скрытыми переменными модели. При этом связью в графе Twitter считается отношение взаимного следования (каждый профиль пары следует за другим профилем, т.е. получает уведомления о появлении новой информации в профиле; такое отношение устанавливается путем односторонней активации уведомлений владельцем того профиля, который следует за другим профилем), а в графе Facebook - отношение дружбы (каждый профиль пары дружит с другим профилем; такое отношение устанавливается путем отправки владельцем одного из профилей запроса на установление отношения и получения явного подтверждения запроса).
На шаге 102 рассчитываются значения похожести атрибутов профилей, а также строится вектор признаков. Сравнение атрибутов профилей из графов - A и B производится с помощью схемы соответствия, которая задает порядок сравнения атрибутов и применяемые метрики похожести (примеры схем соответствия для расчета похожести атрибутов между профилями Twitter и Facebook и между профилями Facebook даны в Табл. 1 и Табл. 2 соответственно).
На шаге 103 рассчитываются значения унарных и бинарных энергий.
Для расчета унарных и бинарных энергий используется методика машинного обучения, которая получает на вход вектор признаков и возвращает значение энергии связи данной пары профилей. К примеру, для профилей из Табл.1 вектор признаков выглядит следующим образом:
[0,66; 0,45; 0].
Алгоритм машинного обучения возвращает значение унарной энергии для данной пары профилей, равное 0,52.
На шаге 106 производится попарное сравнение атрибута "Name" всех пар профилей Twitter - Facebook с помощью метрики строкой похожести VMN. Результатом является набор троек вида "номер профиля - номер профиля - значение похожести". Значение порога похожести примем равным 0,51.
На шаге 107 производится сравнение значения метрики строковой похожести с заданным порогом.
На шаге 108 все пары, для которых значение метрики строковой похожести превысило заданный порог, заносятся в список кандидатов.
К примеру, начальный список пар имеет вид:
Тогда список пар-кандидатов будет следующим:
На шаге 110 к списку кандидатов применяется алгоритм Куна-Манкреса для выбора наилучших проекций профилей, взаимно максимизирующих похожесть друг на друга. Результатом является набор априорно верных проекций, которые заносятся в модель:
На фиг.3 априорно верные проекции соответствуют парам узлов в форме квадратов, соединенных пунктирной линией (пары 2-11,3-10 и 5-13). Каждая такая проекция вносит дополнительную полезную информацию в модель и, таким образом, не только помогает уменьшить количество необходимых для получения оптимальной конфигурации вычислений, но и уменьшает вероятность неверных ответов в результатах работы.
На шаге 111 исходная модель разбивается на независимые компоненты путем удаления априорно верных проекций. На рассматриваемом примере после удаления узлов 2, 3 и 5 остаются 3 независимых подграфа (1, 7), (8) и (4). Соответствующие узлы 10, 11 и 13 из графа Facebook также в дальнейшем не рассматриваются и не участвуют в подборе проекций для оставшихся в модели узлов.
На шаге 113 для каждой из образовавшихся независимых компонент модели производится вывод путем применения итеративного алгоритма, перебирающего возможные конфигурации проекций модели и минимизирующего ее полную энергию.
На шаге 115 результаты для всех компонент модели объединяются.
Пример результатов работы данного шага - набор проекций 1-9, 1-12 и 6-14.
На следующих шагах производится уточнение результатов.
На шаге 117 для каждой найденной на шаге 115 проекции составляется вектор признаков, который подается на вход классификатора.
На шаге 118 классификатор принимает решение о верности каждой из проекций. Пусть вектор для проекции 1-9 будет [0,85; 0,5; 0,4; 0,5], а для проекции 1-12 [0,7; 0,6; 0,6; 0,35]. Тогда для проекции 1-9 классификатор дает ответ "истина", а для проекции 1-12 - ответ "ложь".
На шаге 119 проекция 1-12 исключается из результатов работы, поскольку ответ классификатора для данной проекции не совпадает с решением алгоритма.
На шаге 121 выводится список проекций, в котором каждая проекция содержит информацию об одном и том же пользователе, при этом составляющие проекцию профили относятся к разным социальным графам. Окончательный результат работы изобретения на рассматриваемом примере изображен на фиг.3 и содержит 2 проекции: 1-9 и 6-14. Это означает, что вершины 1 и 9 принадлежат различным социальным графам, но при этом содержат информацию об одном и том же пользователе. То же касается вершин 6 и 14.


Изобретение относится к области обработки пользовательских данных, полученных из графов онлайновых социальных сетей, с целью интеграции данных различных профилей, принадлежащих одному пользователю. Техническим результатом является повышение эффективности интеграции профилей пользователей онлайновых социальных сетей. Способ содержит этапы, на которых вводят все возможные пары профилей, строят модель Условных Случайных Полей из всех профилей и связей между ними, для каждой пары профилей рассчитывают значения похожести их атрибутов с помощью метрик строковой и графовой похожести, из полученных значений метрик похожести строят вектор признаков, который передается алгоритму машинного обучения, который осуществляет расчет унарной энергии, либо бинарной энергии, для каждой пары профилей, в которой профили принадлежат различным социальным графам, рассчитывается похожесть профилей, проверяется, превышает ли полученное значение похожести профилей заданное пороговое значение, в случае положительного ответа пара профилей заносится в список кандидатов, из полученного списка кандидатов выбираются априорно верные проекции, модель Условных Случайных Полей разбивается на независимые компоненты, для каждой компоненты модели производится поиск оптимальной конфигурации проекций, производится объединение списков найденных проекций для всех компонент модели. 3 ил., 2 табл.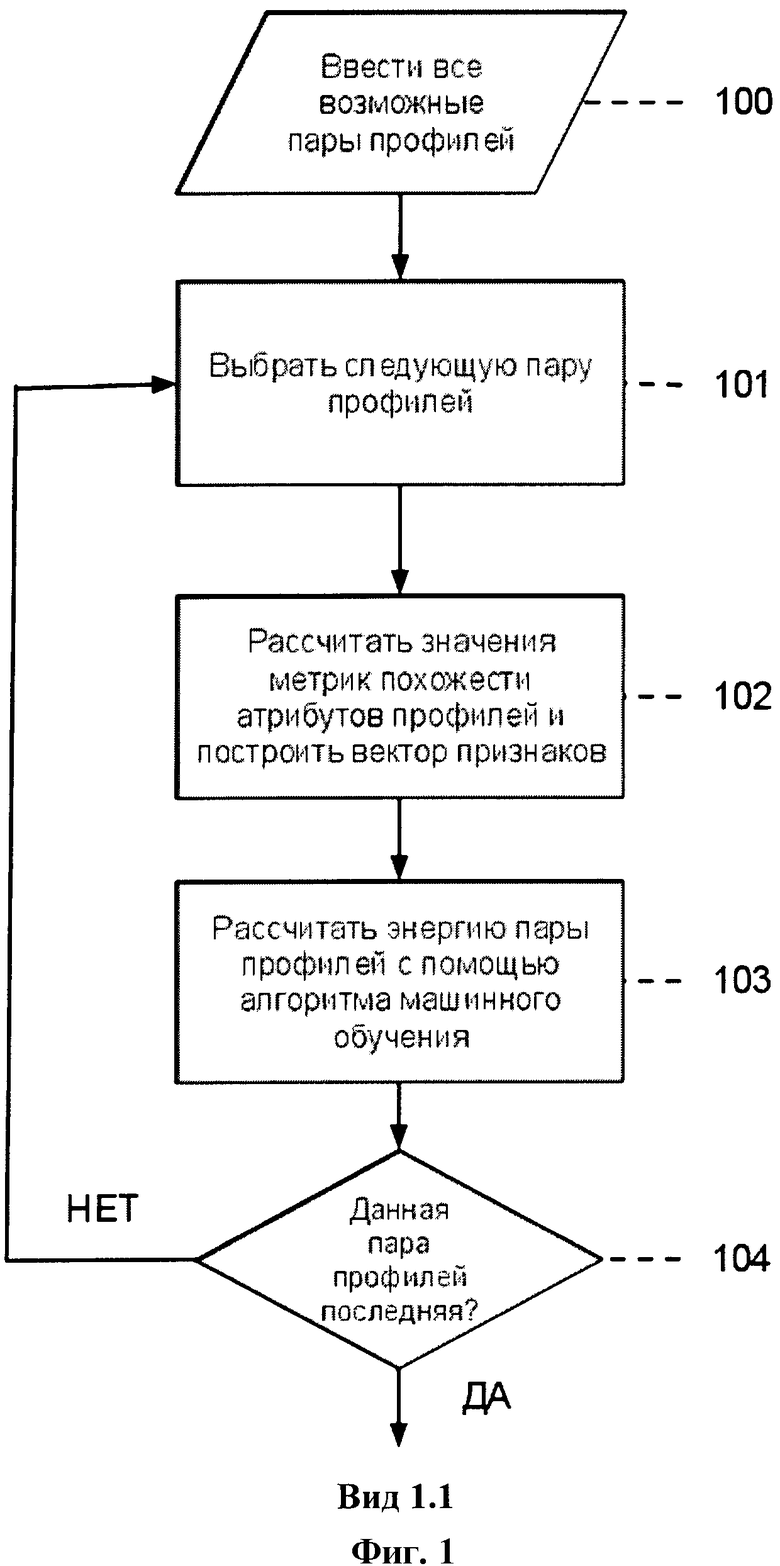
Способ интеграции профилей пользователей онлайновых социальных сетей, отличающийся тем, что вводят все возможные пары профилей, строят модель Условных Случайных Полей из всех профилей и связей между ними, после чего для каждой пары профилей рассчитывают значения похожести их атрибутов с помощью метрик строковой и графовой похожести, основываясь на схемах соответствия для профилей из различных социальных графов, после чего из полученных значений метрик похожести строят вектор признаков, который передается алгоритму машинного обучения, который осуществляет расчет унарной энергии по формуле
Ф(pr(ν)|ν)=α(ν)·(1-profilesimilarity(ν,pr(ν)))
для пары профилей ν и pr(ν), принадлежащих различным социальным графам, либо бинарной энергии по формуле
Ψ(pr(ν),pr(u)|ν,u)=β(pr(ν),pr(u))·(1-networksimilarity(pr(ν),pr(u)))
для пары профилей pr(ν) и pr(u), принадлежащих одному и тому же социальному графу, после чего для каждой пары профилей, в которой профили принадлежат различным социальным графам, рассчитывается похожесть профилей путем применения метрики строковой похожести к атрибуту, который с наибольшей степенью вероятности однозначно идентифицирует профиль, затем проверяется, превышает ли полученное значение похожести профилей заданное пороговое значение, в случае положительного ответа пара профилей заносится в список кандидатов, затем из полученного списка кандидатов выбираются априорно верные проекции путем применения к списку кандидатов алгоритма, который производит последовательный перебор всех пар из списка кандидатов и выдает в качестве результата часть из них, выбранных таким образом, чтобы каждый профиль встречался только в одной паре, а профили, составляющие пару, взаимно максимизировали похожесть друг на друга, затем модель Условных Случайных Полей разбивается на независимые компоненты путем удаления априорно верных проекций, после чего для каждой компоненты модели производится поиск оптимальной конфигурации проекций путем применения итеративного алгоритма, минимизирующего полную энергию модели
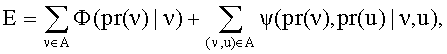
с целью получения максимального количества верных проекций профилей, после чего производится объединение списков найденных проекций для всех компонент модели, затем для каждой найденной проекции строится вектор признаков, который передается классификатору, после чего классификатор определяет, является ли данная проекция верной, в случае отрицательного ответа проекция исключается из результатов, после чего выводят список проекций (пар профилей), каждая из которых содержит информацию об одном и том же пользователе, при этом составляющие проекцию профили относятся к различным социальным графам.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| US 7970912 B2, 28.06.2011 | |||
| US 7680770 B1, 16.03.2010 | |||
| УСТРОЙСТВО ВЫЧИСЛЕНИЯ ПОДОБИЯ И ПРОГРАММА ВЫЧИСЛЕНИЯ ПОДОБИЯ | 2004 |
|
RU2344474C2 |

