ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
В общем плане настоящее изобретение относится к системам связи, а более конкретно к кодированию речевых и звуковых сигналов в подобных системах связи.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Сжатие цифровых речевых и звуковых сигналов хорошо известно. Сжатие обычно требуется для эффективной передачи сигналов по каналу связи или для хранения сжатых сигналов на цифровом устройстве хранения данных, таком как устройство твердотельной памяти или жесткий магнитный диск компьютера. Хотя существует много технологий сжатия (или "кодирования"), один способ, известный как Линейное Предсказание с Мультикодовым Управлением (CELP), являющийся одним из семейства алгоритмов кодирования "анализ-посредством-синтеза", остается очень популярным для цифрового кодирования речи. Анализ-посредством-синтеза в общем относится к процессу кодирования, в котором множество параметров цифровой модели используют для синтезирования набора возможных сигналов, которые сравнивают с входным сигналом и анализируют на предмет искажения. Набор параметров, который производит наименьшее искажение, затем либо передают, либо сохраняют и в конечном итоге используют для воссоздания оценки оригинального входного сигнала. CELP является определенным способом анализа-посредством-синтеза, в котором используют один или несколько словарей кодов, каждый из которых, по существу, содержит наборы кодовых векторов, извлекаемых из данного словаря кодов в соответствии с индексом словаря кодов.
В современных кодерах CELP существует проблема с поддержкой высококачественного воспроизведения речи и звука при довольно низкой информационной скорости. Это особенно верно для музыки и других общих звуковых сигналов, которые не очень хорошо вписываются в модель речи CELP. В этом случае несоответствие модели может вызвать серьезное снижение качества звука, что может быть неприемлемо для конечного пользователя оборудования, в котором применены подобные способы. Таким образом, остается необходимость в улучшении качества работы речевых кодеров типа CELP на низких расходах битов (битрейтах), особенно для музыки и других неречевых видов входных сигналов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На фиг.1 показана функциональная схема встроенной системы сжатия речи/звука по предшествующему уровню техники.
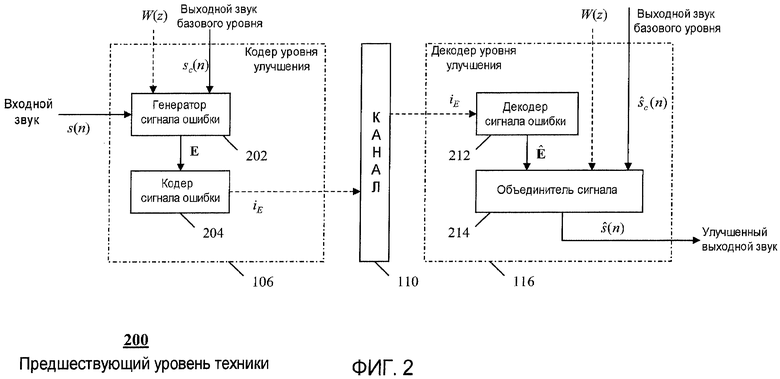
На фиг.2 показан более подробный пример кодера уровня улучшения по предшествующему уровню техники, показанному на фиг.1.
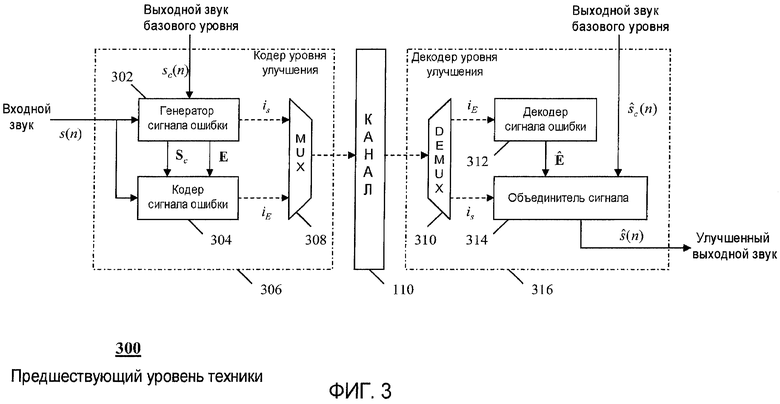
На фиг.3 показан более подробный пример кодера уровня улучшения по предшествующему уровню техники, показанному на фиг.1.
На фиг.4 показана функциональная схема кодера и декодера уровня улучшения.
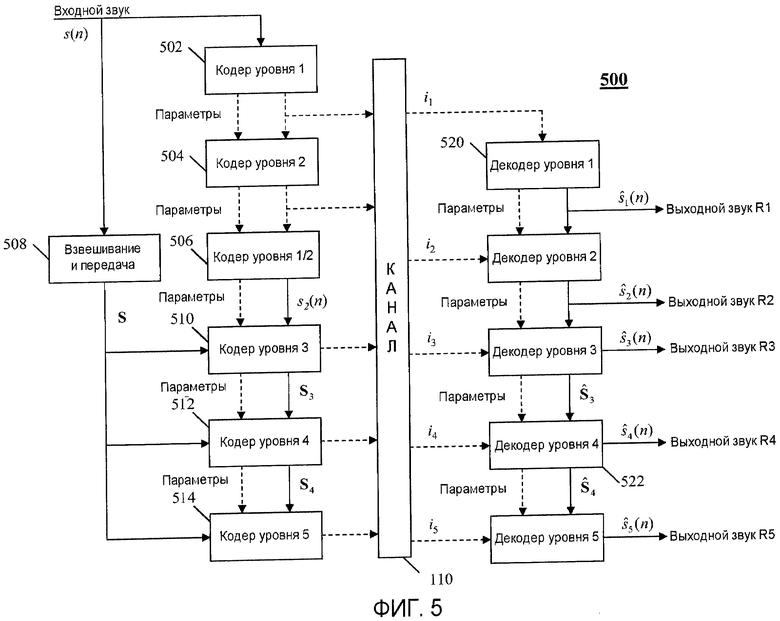
На фиг.5 показана функциональная схема многоуровневой встроенной системы кодирования.
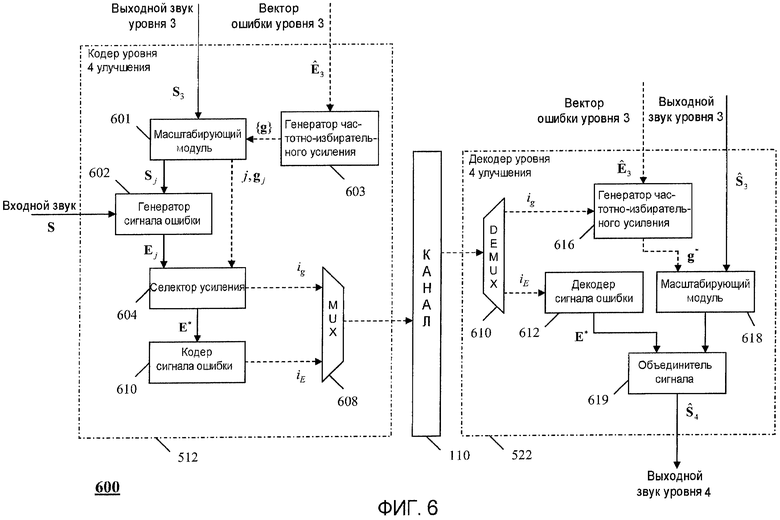
На фиг.6 показана функциональная схема кодера и декодера уровня 4.
На фиг.7 показана блок-схема, демонстрирующая работу кодера, показанная на фиг.4 и фиг.6.
ПОДРОБНОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
С целью удовлетворения вышеупомянутой необходимости в настоящем документе описаны способ и устройство для формирования уровня улучшения в системе кодирования звука. Во время работы подлежащий кодированию входной сигнал принимают и кодируют для получения кодированного звукового сигнала. Данный кодированный звуковой сигнал затем масштабируют с помощью множества значений усиления для получения масштабированных кодированных звуковых сигналов, каждый из которых имеет относящееся к нему значение усиления, и определяют множество значений ошибки, существующих между входным сигналом и каждым из множества масштабированных кодированных звуковых сигналов. Затем выбирают значение усиления, относящееся к масштабированному кодированному звуковому сигналу, дающему в результате низкое значение ошибки, существующей между входным сигналом и данным масштабированным кодированным звуковым сигналом. Наконец, данное низкое значение ошибки передают вместе с данным значением усиления как часть уровня улучшения по отношению к данному кодированному звуковому сигналу.
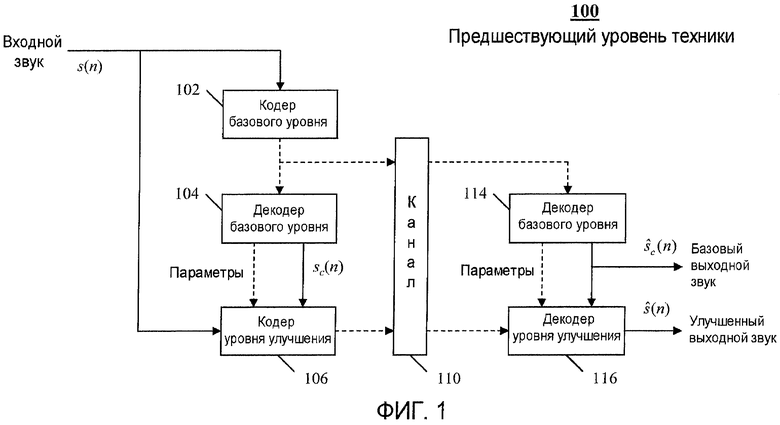
На фиг.1 показана встроенная система сжатия голоса/звука по предшествующему уровню техники. Входящий звук s(n) сначала обрабатывается кодером 102 базового уровня, который в этих целях может использовать алгоритм кодирования речи типа CELP. Кодированный битовый поток передают в канал 110, а также вводят в местный декодер 104 базового уровня, где формируется восстановленный звуковой сигнал s c(n) базового уровня. Затем кодер 116 уровня улучшения используется для кодирования дополнительной информации на основе некоторого сравнения сигналов s(n) и s c(n) и при желании может использовать параметры от декодера 104 базового уровня. Как и декодер 104 базового уровня, декодер 114 базового уровня преобразует параметры битового потока базового уровня в звуковой сигнал ŝ c(n) базового уровня. Затем для получения улучшенного выходного звукового сигнала ŝ(n) декодер 115 уровня улучшения использует битовый поток уровня улучшения из канала 110 и сигнал ŝ c(n).
Основным преимуществом подобных встроенных систем кодирования является то, что конкретный канал 110 может быть не способен постоянно поддерживать требования по полосе пропускания, связанные с алгоритмами кодирования звука высокого качества. Тем не менее встроенный кодер позволяет принимать неполный битовый поток из канала 110 для формирования, например, только базового звукового вывода, когда битовый поток уровня улучшения потерян или поврежден. Однако существует компромисс в качестве между встроенными и невстроенными кодерами, а также между различными целями оптимизации встроенного кодирования. То есть более высококачественное кодирование уровня улучшения может помочь достичь лучшего баланса между базовым уровнем и уровнем улучшения, а также уменьшить общую информационную скорость для лучших характеристик передачи (например, снижения перегрузки), что может вызвать более низкую частоту появления ошибочных пакетов для уровней улучшения.
Более подробный пример кодера 106 уровня улучшения по предшествующему уровню техники показан на фиг.2. Здесь генератор 202 сигнала ошибки состоит из сигнала взвешенной разности, который преобразуется в область MDCT (модифицированное дискретное косинусное преобразование) для обработки кодером 204 сигнала ошибки. Сигнал E ошибки задается как:
E=MDCT{W(s-s c)}, (1)
где W является перцепционной матрицей весовых коэффициентов, основанной на коэффициентах A(z) фильтра LP (линейного предсказания) из декодера 104 базового уровня, s является вектором (то есть кадром) отсчетов из входящего звукового сигнала s(n), а s c является соответствующим вектором отсчетов из декодера 104 базового уровня. Пример процесса MDCT описан в рекомендации ITU-T G.729.1. Сигнал E ошибки затем обрабатывается кодером 204 сигнала ошибки для получения кодового слова i E, которое затем передается в канал 110. В данном примере важно отметить, что кодер 106 сигнала представляет только один сигнал E ошибки и выводит одно соответствующее кодовое слово i E. Причина этого станет понятна позднее.
Затем декодер 116 уровня улучшения принимает кодированный битовый поток из канала 110 и соответственным образом демультиплексирует данный битовый поток для получения кодового слова i E. Декодер 212 сигнала ошибки использует кодовое слово i E для восстановления сигнала Ê ошибки уровня улучшения, который затем объединяют с выходным звуковым сигналом ŝ c(n) базового уровня для получения улучшенного выходного звукового сигнала ŝ(n) согласно нижеследующей формуле:
ŝ=s c+W -1 MDCT-1{Ê} (2)
где MDCT-1 является обратным MDCT (включая перекрытие с суммированием), а W -1 является обратной перцепционной матрицей весовых коэффициентов.
Другой пример кодера уровня улучшения показан на фиг.3. Здесь формирование сигнала E ошибки генератором 302 сигнала ошибки предусматривает адаптивное предварительное масштабирование, в котором выполняются некоторые изменения в звуковом выводе s c(n) базового уровня. Этот процесс приводит к формированию некоторого числа битов, которые показаны в кодере 106 уровня улучшения как кодовое слово i s.
Дополнительно, кодер 106 уровня улучшения демонстрирует входной звуковой сигнал s(n) и преобразованный выходной звук S c базового уровня, вводимый в кодер 304 сигнала ошибки. Эти сигналы используются для создания психоакустической модели для усовершенствования кодирования сигнала E ошибки уровня улучшения. Затем кодовые слова i s и i E мультиплексируются посредством мультиплексора (MUX) 308 и затем посылаются в канал 110 для последующего декодирования декодером 116 уровня улучшения. Кодированный битовый поток принимается демультипликатором 310, который разделяет данный битовый поток на компоненты i s и i E. Затем кодовое слово i E используется декодером 312 сигнала ошибки для восстановления сигнала Ê ошибки уровня улучшения. Объединитель 314 сигналов некоторым способом масштабирует сигнал ŝ c(n), используя масштабирующие биты i s, а затем объединяет результат с сигналом Ê ошибки уровня улучшения для получения улучшенного выходного звукового сигнала ŝ(n).
На фиг.4 показан первый вариант осуществления настоящего изобретения. На этой фигуре показан кодер 406 уровня улучшения, принимающий выходной сигнал s c(n) посредством масштабирующего модуля 401. Заранее заданный набор усилений {g} используется для получения множества масштабированных выходных сигналов {S} базового уровня, где g j и S j являются j-ми вариантами соответствующих наборов. В масштабирующем модуле 401 согласно первому варианту осуществления обрабатывают сигнал s c(n) в области (MDCT) как:
S j=G j×MDCT{Ws c}; 0≤j<M (3)
где W может быть некоторой перцепционной матрицей весовых коэффициентов, s c является вектором отсчетов из декодера 104 базового уровня, MDCT является операцией, хорошо известной в данной области техники, а G j может быть матрицей усилений, образуемой посредством возможного вектора g j усиления, и где M является числом возможных векторов усиления. По первому варианту осуществления G j использует вектор g j как диагональ и нули во всех остальных позициях (то есть диагональную матрицу), несмотря на многие существующие возможности. Например, G j может быть ленточной матрицей или даже простой скалярной величиной, умноженной на единичную матрицу I. В качестве альтернативы, могут быть некоторые выгоды от оставления сигнала S j во временной области или могут быть некоторые случаи, когда выгодно преобразовать звук в другую область, такую как область дискретного преобразования Фурье (DFT). В данной области техники хорошо известно много подобных преобразований. В этих случаях масштабирующий модуль может выводить соответствующий S j на основании соответствующей векторной области.
Но в любом случае, основной причиной масштабирования выходного звука базового уровня является компенсация несоответствия модели (или некоторого другого недостатка кодирования), могущего вызвать значительную разницу между входным сигналом и кодеком базового уровня. Например, если входной звуковой сигнал в первую очередь является музыкальным сигналом, а кодек базового уровня основан на голосовой модели, то тогда выход базового уровня может содержать существенно искаженные характеристики сигнала, в каковом случае с точки зрения качества звучания является выгодным выборочно уменьшить энергию компонентов этого сигнала перед применением дополнительного кодирования данного сигнального компонента посредством одного или нескольких уровней улучшения.
Возможный вектор S j масштабированного усилением звука базового уровня и входящий звук s(n) затем можно использовать как ввод в генератор 402 сигнала ошибки. По предпочтительному варианту осуществления настоящего изобретения входящий звуковой сигнал s(n) конвертируют в вектор S таким образом, что S и S j являются соответственно сонаправленными. То есть вектор s, представляющий s(n), сонаправлен во времени (по фазе) с s c, и по предпочтительному варианту осуществления можно применить соответствующие операции:
E j=MDCT{Ws}-S j; 0≤j<M (4)
Данное выражение производит множество векторов E j сигнала ошибки, которые представляют собой взвешенную разность между входным звуком и масштабированным по усилению выходным звуком базового уровня в спектральной области MDCT. По другим вариантам осуществления, в которых рассматриваются другие области, вышеприведенное выражение можно изменить на основании соответствующей области обработки.
Затем для оценки множества векторов E j сигнала ошибок в соответствии с первым вариантом осуществления настоящего изобретения используют селектор 404 усиления для получения оптимального вектора E *, оптимального параметра g * усиления и впоследствии соответствующего индекса усиления i g. Селектор 404 усиления может использовать множество способов для определения оптимальных параметров, E * и g *, которые могут включать в себя способы с обратной связью (например, минимизация показателя искажения), способы без обратной связи (например, эвристическая классификация, оценка рабочих характеристик модели и так далее) или сочетания и тех и других способов. По предпочтительному варианту осуществления можно использовать смещенный показатель искажения, который задан как разность смещенной энергии между оригинальным вектором S звукового сигнала и составным восстановленным вектором сигнала:
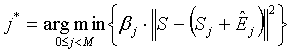 (5)
(5)
где Ê j может быть количественной оценкой вектора E j, а β j может быть составляющей смещения, используемой для добавления решения о выборе индекса j * ошибки перцепционно оптимального усиления. Примерный способ для векторного квантования вектора сигнала дан в патентной заявке США номер 11/531122, озаглавленной "APPARATUS AND METHOD FOR LOW COMPLEXITY COMBINATORIAL CODING OF SIGNALS", хотя возможны и многие другие способы. Признав, что E j=S-S j, уравнение (5) можно переписать как:
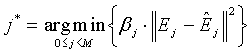 (6)
(6)
В данном выражении член 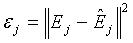 представляет собой энергию разности между неквантованным и квантованным сигналами ошибки. Для ясности эту величину можно назвать "остаточной энергией", и она может в дальнейшем быть использована для оценки "критерия выбора усиления", по которому выбирают оптимальный параметр g
* усиления. Один такой критерий выбора усиления дан в уравнении (6), хотя многие возможны.
представляет собой энергию разности между неквантованным и квантованным сигналами ошибки. Для ясности эту величину можно назвать "остаточной энергией", и она может в дальнейшем быть использована для оценки "критерия выбора усиления", по которому выбирают оптимальный параметр g
* усиления. Один такой критерий выбора усиления дан в уравнении (6), хотя многие возможны.
Необходимость в составляющей β j смещения может возникнуть в том случае, когда функция W взвешивания ошибки в уравнениях (3) и (4) не может в достаточной мере произвести одинаково ощутимые искажения вокруг вектора Ê j. Например, хотя функцию W взвешивания ошибки можно использовать для попытки "отбелить" спектр ошибки до некоторой степени, могут существовать определенные преимущества в придании большего веса низким частотам из-за восприятия искажения человеческим ухом. В результате увеличения веса ошибок в низких частотах, высокочастотные сигналы могут быть недомоделированными уровнем улучшения. В этих случаях может быть прямая выгода от смещения показателя искажения к значениям g j, которые не ослабляют высокочастотные компоненты S j, так чтобы недомоделирование высоких частот не вызывало неприятные или ненатуральные звуковые артефакты в конечном восстановленном звуковом сигнале. Одним подобным примером будет случай глухого голосового сигнала. В этом случае входящий звук обычно состоит из шумоподобных сигналов средней и высокой частоты, производимых турбулентным потоком воздуха из человеческого рта. Вполне возможно, что кодер базового уровня не закодирует этот вид колебательного сигнала напрямую, а может использовать шумовую модель для формирования сходного по звучанию звукового сигнала. Это может привести к, в целом, низкой корреляции между входящим звуковым сигналом и выходным звуковым сигналом базового уровня. Однако в этом варианте осуществления вектор E j сигнала ошибки основан на разности между входным звуковым сигналом и выходным звуковым сигналом базового уровня. Поскольку эти сигналы могут не быть коррелированы очень хорошо, энергия сигнала E j ошибки не обязательно будет ниже, чем или входящий звук, или выходящий звук базового уровня. В этом случае минимизация ошибки в уравнении (6) может привести к тому, что масштабирование по усилению получится слишком агрессивным, что может вызвать потенциально слышимые артефакты.
В другом случае показатели β j смещения могут основываться на других сигнальных характеристиках входного звукового сигнала и/или выходного звукового сигнала базового уровня. Например, отношение пикового значения к среднему спектру сигнала может дать представление о коэффициенте гармоник этого сигнала. Такие сигналы, как речь и некоторые виды музыки, могут иметь высокий коэффициент гармоник и, таким образом, высокое отношение пикового значения к среднему. Однако музыкальный сигнал, обработанный посредством голосового кодека, может привести к низкому качеству из-за несоответствия модели кодирования, и в результате спектр выходного сигнала базового уровня может иметь сниженное отношение пикового значения к среднему при сравнении со спектром входного сигнала. В этом случае может оказаться выгодным уменьшить величину смещения в процессе минимизации для того, чтобы позволить отмасштабировать усилению выходной звук уровня ядра до меньшей энергии, позволив, таким образом, кодированию базового уровня улучшения иметь более выраженный эффект по отношению к составному выходному звуку. Наоборот, некоторые виды голосовых или музыкальных входных сигналов могут показывать более низкие отношения пиковых значений к среднему, в каковом случае эти сигналы могут восприниматься как более шумные и могут, таким образом, получить выгоду от меньшего масштабирования выходного звука базового уровня посредством увеличения смещения ошибки. Примером функции для генерирования показателей смещения для β j является:
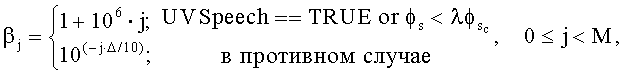 (7)
(7)
где λ может быть некоторым пороговым значением, а отношение пиковой величины к средней для вектора 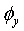 можно задать как:
можно задать как:
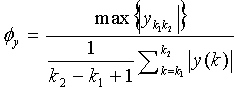 (8)
(8)
и где 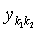 является таким вектором поднабора из y(k), что
является таким вектором поднабора из y(k), что 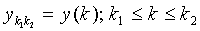 .
.
После того как из уравнения (6) определен оптимальный индекс j * усиления, генерируется соответствующее кодовое слово ig и оптимальный вектор E * ошибки посылается в кодер 410 сигнала ошибки, где E * кодируют в вид, пригодный для мультиплексирования (посредством MUX 408), с другими кодовыми словами и передают для использования на соответствующий декодер. По предпочтительному варианту осуществления кодер 408 сигнала ошибки использует факториальное импульсное кодирование (FPC). Данный способ выгоден с точки зрения сложности обработки, поскольку процесс перебора, связанный с кодированием вектора E *, независим от процесса формирования вектора, используемого для формирования Ê j.
Декодер 416 уровня улучшения реверсирует эти процессы для получения улучшенного выходного звука ŝ(n). Более конкретно, декодер 416 принимает i g и i E, при этом i E посылают в декодер 412 сигнала ошибки, где из кодового слова получают оптимальный вектор E * ошибки. Данный оптимальный вектор E * ошибки передается в объединитель 414 сигналов, где принятый ŝ(n) изменяют согласно уравнению (2) для получения ŝ(n).
Второй вариант осуществления настоящего изобретения включает в себя многоуровневую встроенную систему кодирования, показанную на фиг.5. Как можно здесь видеть, в данном примере есть пять встроенных уровней. Уровни 1 и 2 могут оба основываться на голосовом кодеке, а уровни 3, 4 и 5 могут быть уровнями улучшения MDCT. Таким образом, кодеры 502 и 503 могут использовать голосовые кодеки для формирования и вывода кодированного входного сигнала s(n). Кодеры 510, 512 и 514 содержат кодеры уровня улучшения, каждый из которых выводит отличающиеся улучшения по отношению к кодированному сигналу. Подобно предыдущему варианту осуществления, вектор сигнала ошибки для уровня 3 (кодером 510) можно задать как:
E 3=S-S 2, (9)
где S=MDCT{Ws} является взвешенным преобразованным входным сигналом, а S=MDCT{Ws 2} является взвешенным преобразованным сигналом, сгенерированным декодером 506 уровня 1/2. По данному варианту осуществления уровень 3 может являться уровнем квантования низкой скорости, и, соответственно, для кодирования соответствующего квантованного сигнала Ê 3=Q{E 3} ошибки может понадобиться относительно мало битов. Для обеспечения хорошего качества в соответствии с этими ограничениями можно квантовать только часть коэффициентов в E 3. Положения кодируемых коэффициентов могут быть постоянными или могут изменяться, но если допустимо их изменение, то для определения этих положений может потребоваться посылка декодеру дополнительной информации. Если, например, диапазон кодируемых положений начинается с k s и заканчивается на k e, где 0≤k s<k e<N, то тогда вектор квантованного сигнала Ê 3 ошибки может содержать ненулевые значения только в пределах этого диапазона и нули за пределами этого диапазона. Информация о положении и диапазоне также может быть неявной, в зависимости от используемого способа кодирования. Например, в кодировании звука хорошо известно, что полоса частот может считаться важной в плане восприятия и что кодирование вектора сигнала можно сфокусировать на этих частотах. В этих условиях кодируемый диапазон может изменяться и может не охватывать непрерывный набор частот. Но, во всяком случае, после квантования сигнала составной кодированный выходной спектр можно построить как:
S 3=Ê 3+S 2 (10)
что затем используется как вход для кодера 512 уровня 4.
Кодер 512 уровня 4 подобен кодеру 406 уровня улучшения по предыдущему варианту осуществления. Используя возможный вектор g j усиления, соответствующий вектор ошибки можно описать как:
E 4(j)=S-G j S 3 (11)
где G j может быть матрицей усилений с вектором g j в качестве диагонального компонента. Однако в текущем варианте осуществления вектор g j усиления может иметь отношение к вектору Ê 3 квантованного сигнала ошибки следующим образом. Поскольку вектор Ê 3 квантованного сигнала ошибки может быть ограничен в частотном диапазоне, например, начиная с положения k s вектора и заканчивая положением k e вектора, предполагается, что выходной сигнал S 3 уровня 3 будет закодирован в данном диапазоне весьма точно. Следовательно, в соответствии с настоящим изобретением вектор g j усиления корректируется на основании кодируемых положений k s и k e вектора сигнала ошибки уровня 3. Точнее говоря, для сохранения целостности сигнала в этих местах соответствующие отдельные элементы усиления можно задать как постоянную величину α. То есть:
 (12)
(12)
где обычно 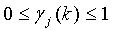 , а
, а 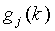 является k-м положением j-го возможного вектора. По предпочтительному варианту осуществления значение данной константы равно единице (α=1), однако возможны многие значения. Дополнительно, частотный диапазон может охватывать несколько начальных и конечных положений. То есть уравнение (12) можно сегментировать на несплошные диапазоны изменяемых усилений, которые основываются на некоторой функции от сигнала Ê
3 ошибки, и в более общем виде может быть переписано как:
является k-м положением j-го возможного вектора. По предпочтительному варианту осуществления значение данной константы равно единице (α=1), однако возможны многие значения. Дополнительно, частотный диапазон может охватывать несколько начальных и конечных положений. То есть уравнение (12) можно сегментировать на несплошные диапазоны изменяемых усилений, которые основываются на некоторой функции от сигнала Ê
3 ошибки, и в более общем виде может быть переписано как:
 (13)
(13)
В данном примере для создания 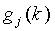 , когда соответствующие положения в предварительно квантованном сигнале Ê
3 ошибки ненулевые, используется постоянное усиление α, а когда соответствующие положения в Ê
3 нулевые, используется функция усиления
, когда соответствующие положения в предварительно квантованном сигнале Ê
3 ошибки ненулевые, используется постоянное усиление α, а когда соответствующие положения в Ê
3 нулевые, используется функция усиления 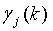 . Некоторую возможную функцию усиления можно задать как:
. Некоторую возможную функцию усиления можно задать как:
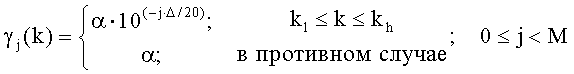 (14)
(14)
где Δ является размером шага (например, Δ≈2,2 дБ), α является константой, M является числом вариантов (например, M=4, что можно представить, используя только 2 бита), а k l и k h являются соответственно отсечками низких и высоких частот, после которых может происходить уменьшение усиления. Введение параметров k l и k h полезно в системах, в которых масштабирование желательно только в определенном диапазоне частот. Например, в данном варианте осуществления высокие частоты могут быть ненадлежащим образом смоделированными базовым уровнем, таким образом, энергия в полосе высоких частот может быть характерным образом ниже, чем во входном звуковом сигнале. В этом случае польза от масштабирования выходного сигнала уровня 3 в этой области может быть мала или вообще отсутствовать, поскольку в результате может возрасти общая энергия ошибки.
Обобщая, множество вероятных векторов g j усиления основывается на некоторой функции кодированных элементов предварительно кодированного вектора сигнала, в данном случае Ê 3. Это можно выразить в общем виде как:
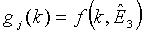 (15)
(15)
Соответствующие действия декодера показаны на правой стороне фиг.5. По мере того как принимаются различные уровни кодированных битовых потоков (от i 1 до i 5), по иерархии уровней улучшения строятся более высококачественные выходные сигналы относительно декодера базового уровня (уровня 1). То есть для данного конкретного варианта осуществления поскольку первые два уровня содержат кодирование по речевой модели во временной области (например, CELP), а оставшиеся три уровня содержат кодирование в области преобразования (например, MDCT), тогда конечный вывод для системы ŝ(n) создается согласно нижеследующему:
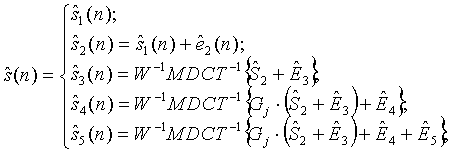 (16)
(16)
где ê 2(n) является сигналом уровня 2 временной области уровня улучшения, а Ŝ 2=MDCT{Ws 2} является взвешенным вектором MDCT, соответствующим звуковому выводу ŝ 2(n) уровня 2. В данном выражении общий выходной сигнал ŝ(n) можно определить из наивысшего уровня последовательных уровней битовых потоков, которые принимаются. В данном варианте осуществления предполагается, что более низкие уровни имеют более высокую вероятность быть правильно принятыми из канала, и, следовательно, наборы кодовых слов {i 1}, {i 1 i 2}, {i 1 i 2 i 3} и так далее определяют подлежащий уровень при декодировании уровня улучшения в уравнении (16).
На фиг.6 показана блок-схема, демонстрирующая кодер 512 и декодер 522 уровня 4. Кодер и декодер, показанные на фиг.6, аналогичны показанным на фиг.4, за исключением того, что значение усиления, используемое масштабирующими модулями 601 и 618, получается посредством частотно-избирательных генераторов 603 и 616 усиления соответственно. Во время работы звуковой вывод S 3 уровня 3 является выводом из кодера уровня 3 и принимается масштабирующим модулем 601. Дополнительно, вектор Ê 3 ошибки уровня 3 является выводом кодера 510 уровня 3 и принимается частотно-избирательным генератором 603 усиления. Как уже обсуждалось, поскольку вектор Ê 3 квантованного сигнала ошибки может быть ограничен в частотном диапазоне, вектор g j усиления корректируется на основании, например, положений k s и k e, как показано в уравнении 12, или более общего выражения в уравнении (13).
Масштабированный звук S j является выводом из масштабирующего модуля 601 и принимается генератором 602 сигнала ошибки. Как обсуждалось выше, генератор 602 сигнала ошибки принимает входной звуковой сигнал S и определяет значение E j ошибки для каждого масштабирующего вектора, используемого масштабирующим модулем 601. Эти векторы ошибки подаются в схему 604 выбора усиления вместе со значениями усиления, использованными для определения векторов ошибки, и конкретной ошибкой E *, основывающейся на оптимальной величине g * усиления. Кодовое слово (i g), представляющее оптимальное усиление g * и являющееся выводом из селектора 604 усиления, вместе с оптимальным вектором E * ошибки передается в кодер 610, где определяют и выводят кодовое слово i E. Как i g, так и i E выводят в мультиплексор 608 и передают через канал 110 в декодер 522 уровня 4.
Во время работы декодера 522 уровня 4 i g и i E принимают и демультиплексируют. Кодовое слово усиления i g и вектор Ê 3 ошибки уровня 3 используют как ввод в частотно-избирательный генератор 616 усиления для получения вектора g * усиления по соответствующему способу кодера 512. Затем для получения восстановленного звукового вывода Ŝ 4 вектор g * усиления применяют к вектору Ŝ 3 восстановленного звука в масштабирующем модуле 618, вывод из которого затем объединяют с вектором E * ошибки уровня 4 уровня улучшения, который получен из декодера 612 сигнала ошибки посредством декодирования кодового слова iE.
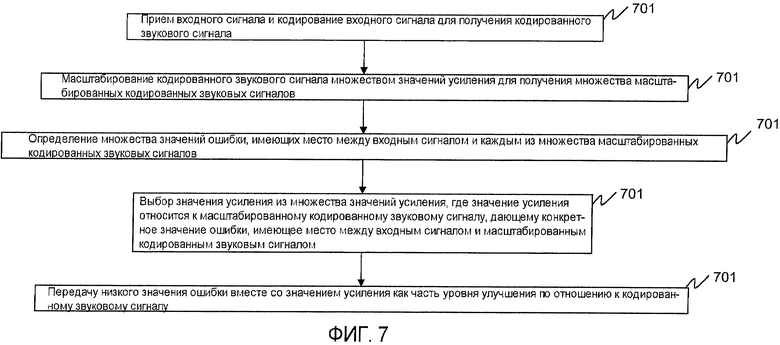
На фиг.7 показана блок-схема, демонстрирующая работу кодера в соответствии с первым и вторым вариантами осуществления настоящего изобретения. Как было описано выше, оба варианта осуществления задействуют уровень улучшения, масштабирующий кодированный звук множеством значений масштабирования, а затем выбирающий значение масштабирования, приводящее к наименьшей ошибке. При этом по второму варианту осуществления настоящего изобретения для формирования значений усиления применяется частотно-избирательный генератор 603 усиления.
Логическая блок-схема начинается этапом 701, на котором кодер базового уровня принимает подлежащий кодированию входной сигнал и кодирует данный сигнал для получения кодированного звукового сигнала. Кодер 406 уровня улучшения принимает кодированный звуковой сигнал (s c(n)) и модуль 401 масштабирования масштабирует этот кодированный звуковой сигнал множеством значений усиления для получения множества масштабированных кодированных звуковых сигналов, каждый из которых имеет соответствующее ему значение усиления (этап 703). На этапе 705 генератор 402 сигнала ошибки определяет множество значений ошибки, имеющих место между входным сигналом и каждым из множества масштабированных кодированных звуковых сигналов. Затем селектор 404 усиления выбирает значение усиления из данного множества значений усилений (этап 707). Как было описано выше, значение усиления (g *) связано с масштабированным кодированным звуковым сигналом, вызывающим наименьшее значение (E *) ошибки, имеющее место между входным сигналом и масштабированным кодированным звуковым сигналом. Наконец, на этапе 709 передатчик 418 передает данное низкое значение (E *) ошибки вместе с величиной (g *) усиления как часть уровня улучшения по отношению к кодированному звуковому сигналу. Специалисты в данной области техники признают, что и E *, и g * были закодированы должным образом перед передачей.
Как было описано выше, на принимающей стороне кодированный звуковой сигнал будет принят вместе с уровнем улучшения. Уровень улучшения является улучшением данного кодированного звукового сигнала, содержащим значение (g *) усиления и сигнал ошибки (E * ), относящийся к данному значению усиления.
Хотя данное изобретение было, в частности, показано и описано со ссылкой на конкретные варианты осуществления, специалисты в данной области техники поймут, что в них можно сделать различные изменения в форме и деталях, не выходя за рамки объема данного изобретения. Например, хотя вышеописанные технологии описаны относительно передачи и приема по каналу телекоммуникационной системы, данную технологию можно применить в равной степени к системе, использующей систему сжатия сигнала с целью уменьшения потребностей в средствах хранения на цифровом устройстве хранения данных, таком как твердотельное устройство хранения данных или компьютерный жесткий магнитный диск. Предполагается, что такие изменения подпадают под объем, определяемый нижеследующей формулой изобретения.
Изобретение относится к кодированию речевых и звуковых сигналов в системах связи. Техническим результатом является улучшение качества работы речевых кодеров типа CELP на низких скоростях передачи данных. Указанный результат достигается тем, что в способе встроенного кодирования сигнала встроенным звуковым кодером принимают входной сигнал, подлежащий кодированию; кодируют входной сигнал посредством первого уровня встроенного звукового кодера; получают восстановленный звуковой сигнал первого уровня из кодированного входного сигнала. Посредством второго уровня встроенного звукового кодера масштабируют восстановленный звуковой сигнал первого уровня множеством значений усиления для получения множества масштабированных восстановленных звуковых сигналов, причем данные множество значений усиления зависят от восстановленного звукового сигнала первого уровня и, кроме того, каждый из данного множества масштабированных восстановленных звуковых сигналов имеет относящееся к нему значение усиления, определяют множество значений ошибки на основе входного сигнала и каждого из упомянутого множества масштабированных восстановленных звуковых сигналов и выбирают значение усиления из упомянутого множества значений усиления на основе упомянутого множества значений ошибки. Посредством встроенного звукового кодера передают или сохраняют данное значение усиления как часть уровня улучшения по отношению к кодированному звуковому сигналу. 5 н. и 8 з.п. ф-лы, 7 ил.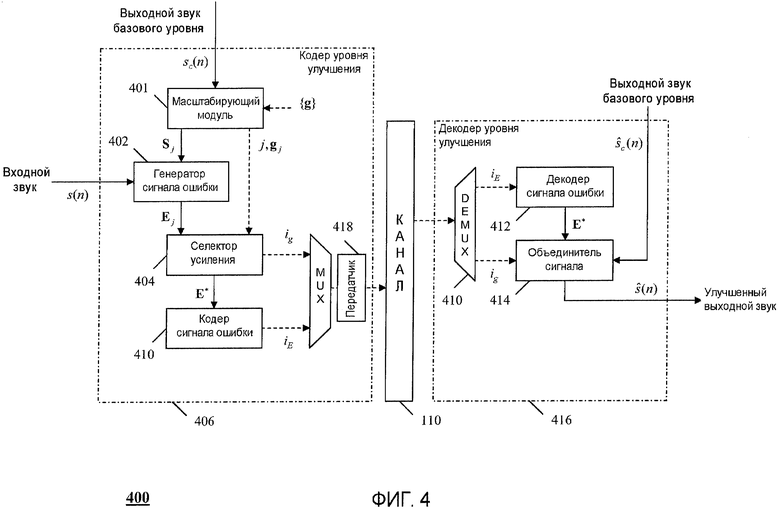
1. Способ встроенного кодирования сигнала встроенным звуковым кодером, содержащий этапы, на которых:
посредством встроенного звукового кодера принимают входной сигнал, подлежащий кодированию;
посредством первого уровня встроенного звукового кодера кодируют входной сигнал;
получают восстановленный звуковой сигнал первого уровня из кодированного входного сигнала;
посредством второго уровня встроенного звукового кодера масштабируют восстановленный звуковой сигнал первого уровня множеством значений усиления для получения множества масштабированных восстановленных звуковых сигналов, причем данное множество значений усиления зависят от восстановленного звукового сигнала первого уровня и, кроме того, каждый из данного множества масштабированных восстановленных звуковых сигналов имеет относящееся к нему значение усиления;
посредством второго уровня встроенного звукового кодера определяют множество значений ошибки на основе входного сигнала и каждого из упомянутого множества масштабированных восстановленных звуковых сигналов;
посредством второго уровня встроенного звукового кодера выбирают значение усиления из упомянутого множества значений усиления на основе упомянутого множества значений ошибки; и
посредством встроенного звукового кодера передают или сохраняют данное значение усиления как часть уровня улучшения по отношению к кодированному звуковому сигналу.
2. Способ по п.1, в котором упомянутое множество значений усиления содержит частотно-избирательные значения усиления.
3. Способ по п.1, в котором первый уровень встроенного звукового кодера содержит кодер на основе линейного предсказания с мультикодовым управлением (CELP).
4. Способ приема встроенным звуковым декодером кодированного звукового сигнала и уровня улучшения по отношению к этому кодированному звуковому сигналу, содержащий этапы, на которых:
посредством первого уровня встроенного звукового декодера принимают кодированный звуковой сигнал; и
посредством второго уровня встроенного звукового декодера принимают уровень улучшения по отношению к этому кодированному звуковому сигналу, причем уровень улучшения по отношению к кодированному звуковому сигналу содержит значение усиления и сигнал ошибки, относящийся к этому значению усиления, где значение усиления выбрано передатчиком из множества значений усиления, причем значение усиления относится к масштабированному восстановленному звуковому сигналу, дающему конкретное значение ошибки, имеющее место между звуковым сигналом и масштабированным восстановленным звуковым сигналом; и
посредством встроенного звукового декодера улучшают кодированный звуковой сигнал на основе упомянутых значения усиления и значения ошибки.
5. Способ по п.4, в котором упомянутое значение усиления содержит частотно-избирательное значение усиления.
6. Способ по п.5, в котором частотно-избирательные значения усиления есть

где, в общем, 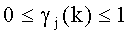 , а
, а 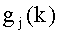 - усиление k-го положения j-го возможного вектора.
- усиление k-го положения j-го возможного вектора.
7. Способ по п.5, в котором первый уровень встроенного звукового декодера содержит декодер на основе линейного предсказания с мультикодовым управлением (CELP).
8. Способ по п.5, в котором встроенный звуковой декодер содержит третий уровень, при этом третий уровень расположен между первым уровнем и вторым уровнем, и при этом третий уровень выдает вектор ошибки частотной области.
9. Устройство для встроенного кодирования сигнала, содержащее:
встроенный звуковой кодер, принимающий входной сигнал, подлежащий кодированию, при этом встроенный звуковой кодер содержит:
первый уровень встроенного звукового кодера, кодирующий входной сигнал;
местный декодер, получающий восстановленный звуковой сигнал первого уровня из кодированного входного сигнала;
второй уровень встроенного звукового кодера, масштабирующий восстановленный звуковой сигнал первого уровня множеством значений усиления для получения множества масштабированных восстановленных звуковых сигналов, причем данное множество значений усиления зависят от восстановленного звукового сигнала первого уровня и, кроме того, каждый из данного множества масштабированных восстановленных звуковых сигналов имеет относящееся к нему значение усиления,
при этом второй уровень встроенного звукового кодера определяет множество значений ошибки, имеющих место между входным сигналом и каждым из упомянутого множества масштабированных восстановленных звуковых сигналов,
при этом второй уровень встроенного звукового кодера выбирает значение усиления из упомянутого множества значений усиления, где это значение усиления выбирается на основе упомянутого множества значений ошибки, имеющих место между входным сигналом и масштабированным восстановленным звуковым сигналом; и
передатчик, передающий выбранное значение усиления как часть уровня улучшения по отношению к кодированному звуковому сигналу.
10. Устройство по п.9, в котором упомянутое множество значений усиления содержат частотно-избирательные значения усиления.
11. Устройство по п.10, в котором частотно-избирательные значения усилений есть

где, в общем, 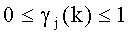 , а
, а 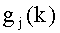 - усиление k-го положения j-го возможного вектора.
- усиление k-го положения j-го возможного вектора.
12. Устройство для формирования улучшенного звукового сигнала, содержащее:
первый уровень встроенного декодера, принимающий кодированный звуковой сигнал; и
второй уровень встроенного декодера, принимающий уровень улучшения по отношению к кодированному звуковому сигналу и формирующий улучшенный звуковой сигнал, причем уровень улучшения по отношению к кодированному звуковому сигналу содержит значение усиления и сигнал ошибки, относящийся к этому значению усиления, при этом значение усиления выбрано кодером из множества значений усиления, причем значение усиления относится к масштабированному восстановленному звуковому сигналу, дающему конкретное значение ошибки, имеющее место между входным звуковым сигналом и масштабированным восстановленным звуковым сигналом.
13. Устройство для вывода улучшенного восстановленного звукового сигнала, содержащее:
первый уровень встроенного декодера, принимающий кодовые слова для получения восстановленного звукового сигнала; и
второй уровень встроенного декодера, принимающий кодовые слова для уровня улучшения по отношению к кодированному звуковому сигналу и выводящий улучшенный восстановленный звуковой сигнал, где уровень улучшения по отношению к восстановленному звуковому сигналу содержит частотно-избирательное значение усиления и сигнал ошибки, относящийся к этому значению усиления, причем частотно-избирательное значение усиления основывается на восстановленном звуковом сигнале и, кроме того, частотно-избирательное значение усиления выбирается из множества значений усиления на основе множества значений ошибки.
| RAMPRASHAD S.A | |||
| Embedded coding using a mixed speech and audio coding paradigm, International Journal of Speech Technology, т.2, №4, 05.1999, с.359-372 | |||
| KOVESI В | |||
| A scalable speech and audio coding scheme with continuous bitrate flexibility, Acoustics, Speech, and Signal Processing, Proceedings (ICASSP '04) | |||
| IEEE International Conference, |

