Область техники, к которой относится изобретение
Изобретение в основном относится к видеоанализу и более конкретно к анализу и изучению поведения на основе данных потокового видео.
Уровень техники
Некоторые в настоящее время доступные системы видеонаблюдения имеют простые способности распознавания. Однако многие такие системы наблюдения требуют предварительных знаний (до того как система была разработана) действий и/или объектов, которые система должна быть способна отыскивать. Основной программный код, направленный на конкретные «ненормальные» поведения, должен разрабатываться для создания этих систем наблюдения работоспособными и достаточно функциональными. Другими словами, если системный основной код не включает в себя описания определенных поведений, система будет неспособна распознать такие поведения. Кроме того, для различения поведений часто требуется разработка отдельных программных продуктов. Это делает способности распознавания систем наблюдения трудоемкими и чрезмерно дорогими. Например, мониторинг входов в аэропорт за затаившимися преступниками и идентификация пловцов, которые не перемещаются в бассейне, являются двумя разными ситуациями и поэтому могут требовать разработки двух разных программных продуктов, имеющих свои соответствующие предварительно закодированные «ненормальные» поведения.
Системы наблюдения могут также быть желательными для запоминания обычных сцен и формирования тревоги всякий раз, когда изменения не считаются нормальными изменениями. Однако эти типы систем наблюдения должны предварительно программироваться для узнавания того, какое такое изменение является ненормальным. Кроме того, такие системы не могут точно различать, что на самом деле случилось. Или эти системы определяют, что то, что ранее считалось «нормальным», изменилось. Таким образом, продукты, разработанные таким способом, создаются для определения только ограниченного диапазона заранее определенного типа поведения.
Сущность изобретения
Варианты осуществления настоящего изобретения обеспечивают способ и систему для анализа и изучения поведения на основе полученного потока видеокадров. Объекты, представленные в потоке, определяются на основе анализа видеокадров. Каждый объект может иметь соответствующую поисковую модель, которая используется для отслеживания движений объекта от кадра к кадру. Определяются классы объектов и формируются семантические представления объектов. Семантические представления используются для определения поведений объектов и для изучения поведений, возникающих в среде, показанной получаемыми видеопотоками. Таким образом, система быстро изучает и в реальном времени обычные и необычные поведения для любой среды посредством анализа движений или активностей или отсутствия таковых в среде и идентифицирует и прогнозирует ненормальное и подозрительное поведение на основе того, что было изучено.
Один конкретный вариант осуществления настоящего изобретения включает в себя способ обработки потока видеокадров, регистрирующих события в сцене. Способ включает в себя прием первого кадра потока. Первый кадр включает в себя данные для множества пикселей, включенных в кадр. Способ может, дополнительно, включать в себя идентификацию одной или более групп пикселей в первом кадре. Каждая группа представляет объект в сцене. Способ может еще дополнительно включать в себя формирование поисковой модели, сохраняющей один или более признаков, связанных с каждым идентифицируемым объектом, классификацию каждого объекта, используя изученный классификатор, отслеживание, во втором кадре, каждого объекта, идентифицированного в первом кадре, используя поисковую модель, и передачу первого кадра, второго кадра и классификаций объектов в средство машинного изучения. Способ может еще дополнительно включать в себя формирование, посредством средства машинного изучения, одного или более семантических представлений поведения объекта, находящегося в сцене, из множества кадров. Средство машинного изучения может обычно создаваться для изучения образцов поведения, наблюдаемого в сцене, во множестве кадров и для идентификации появлений образцов поведения в классифицированных объектах.
Краткое описание чертежей
Таким образом, указанные выше признаки, преимущества и объекты настоящего изобретения достигаются и могут быть понятными подробно, при этом более конкретное описание изобретения, которое кратко подытожено выше, может иметь ссылки на варианты, показанные на прилагаемых чертежах.
Однако отметим, что приложенные чертежи только иллюстрируют типичные варианты осуществления этого изобретения и поэтому не рассматриваются как ограничивающие его объем, при этом для изобретения могут допускаться другие равные эффективные варианты осуществления.
Фиг. 1 - высокоуровневая блок-схема система распознавания поведения в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 2 показывает блок-схему способа анализа и изучения поведения на основе потока видеокадров в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 3 показывает модуль заднего и переднего плана средства компьютерного зрения в соответствии с настоящим изобретением.
Фиг. 4 показывает модуль отслеживания интересующих объектов в средстве компьютерного зрения в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 5 показывает модуль оценки/идентификации в средстве компьютерного зрения в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 6 показывает компонент контекстного процессора в средстве компьютерного зрения в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 7 показывает модуль семантического анализа в средстве машинного изучения в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 8 показывает модуль восприятия в средстве машинного изучения в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 9А-9С показывает последовательности видеокадров, в которых система распознавания поведения определяет ненормальное поведение и выдает предупреждение, в соответствии с одним вариантом осуществления настоящего изобретения.
Подробное описание предпочтительных вариантов осуществления
Системы распознавания поведения с машинным обучением, такие варианты осуществления которых, описанные здесь, изучают поведения на основе информации, полученной с течением времени. В контексте настоящего изобретения анализируется информация из видеопотока (т.е. последовательности индивидуальных видеокадров). Описание раскрывает систему распознавания поведения, которая обучается для идентификации и различения между нормальным и ненормальным поведениями в сцене посредством анализа движений и/или активностей (и/или отсутствием таковых) с течением времени. Обычные/необычные поведения заранее не определяются и жестко не кодируются. Взамен система распознавания поведения, описанная здесь, быстро изучает, что является «нормальным» для любой среды, и идентифицирует ненормальное и подозрительное поведение на основе того, чему обучена посредством контроля положения, т.е. анализируя контент записанного видео кадр за кадром.
Далее делаются ссылки на варианты осуществления изобретения. Однако будет понятно, что изобретение не ограничивается какими-либо конкретными описанными вариантами осуществления. Вместо этого любая комбинация следующих признаков и элементов, любая из которых относится к разным вариантам осуществления, предполагается для реализации и осуществления изобретения. Кроме того, в различных вариантах осуществления обеспечиваются разные преимущества по отношению к уровню техники. Однако, хотя варианты осуществления изобретения могут достигать преимущества по отношению к другим возможным решениям и/или по отношению к уровню техники, любое конкретное преимущество, достигаемое любым вариантом осуществления, не ограничивает изобретение. Таким образом, следующие аспекты, признаки, варианты осуществления и преимущества просто иллюстрируют и не рассматриваются как элементы или ограничения, исключенные из приложенной формулы, где точно перечислены в формуле. Аналогично ссылка на «изобретение» не будет ограничивать основную линию любого объекта изобретения, описанного здесь, и не будет рассматриваться в качестве элемента или ограничения, исключенного из приложенной формулы, где точно процитированы в формуле.
Один вариант осуществления реализуется как программный продукт для использования в компьютерной системе. Программа(ы) программного продукта определяет функции вариантов осуществления (включая способ, описанный здесь) и может содержать разные машиночитаемые запоминающие носители. Иллюстративный машиночитаемый запоминающий носитель включает в себя, но не ограничивает: (i) незаписываемый запоминающий носитель (например, постоянная память в компьютере, такая как диски CD-ROM, считываемые дисководом CD-ROM), в котором постоянно хранится информация; (ii) записываемый запоминающий носитель (например, гибкие диски в дискетном дисководе или дисководе жесткого диска), в котором хранится изменяемая информация. Такой машиночитаемый запоминающий носитель, когда несет выполняемые компьютером команды, которые управляют функциями настоящего изобретения, является вариантом осуществления изобретения. Другой носитель включает в себя коммуникационную среду, по которой информация передается на компьютер, такую как через компьютерную или телефонную сеть, включая сети беспроводной передачи. Последний вариант осуществления, в частности, включает в себя передачу информации в или из Интернета и других сетей. Такая коммуникационная среда, когда переносит машиночитаемые команды, которые управляют функциями настоящего изобретения, является вариантом осуществления настоящего изобретения. Машиночитаемый запоминающий носитель и коммуникационная среда широко могут называться здесь в качестве машиночитаемого носителя.
Обычно подпрограмма, выполняемая для реализации вариантов осуществления изобретения, может быть частью операционной системы или конкретного приложения, компонента, программы, модуля, объекта или последовательности команд. Компьютерная программа настоящего изобретения содержит обычно множество команд, которые будут транслироваться собственным компьютером в машиночитаемый формат и, следовательно, машиночитаемые команды. Также программы содержат переменные и структуры данных, которые принадлежат программе или находятся в памяти или в запоминающих устройствах. Кроме того, разные программы, описанные здесь, могут идентифицироваться на основе приложения, для которого они реализуются в конкретных вариантах осуществления изобретения. Однако, будет очевидным, что любые конкретные номенклатуры программ, которые следуют, используются лишь для удобства, и таким образом, изобретение не следует ограничивать использованием только в любом конкретном приложении, идентифицированным и/или подразумеваемым такой номенклатурой.
Варианты осуществления настоящего изобретения обеспечивают систему распознавания поведения и способ анализа, изучения и распознавания поведения. Фиг. 1 является высокоуровневой блок-схемой системы 100 распознавания поведения в соответствии с один вариантом осуществления настоящего изобретения. Как показано, система 100 распознавания поведения включает в себя средство 105 ввода видео, сеть 110, компьютерную систему 115 и устройства 145 ввода и вывода (например, монитор, клавиатура, мышь, принтер и т.п.).
Сеть 110 принимает видеоданные (например, видеопоток(и), видеоизображения или аналогичные) из средства 105 видеоввода. Средством 105 ввода видео может быть видеокамера, VCR, DVR, DVD, компьютер или т.п. Например, средство 105 ввода видео может быть стационарной видеокамерой, расположенной в определенной области (например, станция метро) и постоянно записывающей область и события, возникающие в этом месте. Обычно область, видимая камерой, называется как «сцена». Средство 105 ввода видео может быть сконфигурировано для записи сцены в качестве последовательных индивидуальных видеокадров с конкретной кадровой скоростью (например, 24 кадра в секунду), где каждый кадр включает в себя фиксированное число пикселей (например, 320х240). Каждый пиксель каждого кадра устанавливает цветовое значение (например, значение RGB). Кроме того, видеопоток может форматироваться, используя известные такие форматы, как, например, MPEG2, MJPEG, MPEG4, H.263, H.264 и т.п. Как обсуждается более подробно ниже, система распознавания поведения анализирует эту необработанную информацию для идентификации активности объектов в потоке, классифицирует такие элементы, извлекает множество метаданных в отношении действий и взаимодействия таких элементов и передает эту информацию на средство машинного изучения. В свою очередь средство машинного изучения может быть сконфигурировано для оценки, изучения и запоминания с течением времени. Кроме того, на основе «изучения» средство машинного изучения может идентифицировать определенное поведение в качестве ненормального.
Сеть 110 может использоваться для передачи видеоданных, записанных средством 105 ввода видео, на компьютерную систему 115. В одном варианте осуществления сеть 110 передает принятый поток видеокадров на компьютерную систему 115.
Иллюстративно компьютерная система 115 включает в себя CPU 120, хранилище 125 (например, диск, оптический диск, гибкий диск и т.п.) и память 130, содержащую средство 135 компьютерного зрения и средство 140 машинного изучения. Средство 135 компьютерного зрения может обеспечивать программное приложение, созданное для анализа последовательности видеокадров, полученной средством 105 ввода видео. Например, в одном варианте осуществления средство 135 компьютерного зрения может быть сконфигурировано для анализа видеокадров для идентификации интересующих целей, отслеживать эти интересующие цели, делать вывод о свойствах интересующих целей, классифицировать их по категориям и назначать метки для наблюдаемых данных. В одном варианте осуществления средство 135 компьютерного зрения формирует список атрибутов (таких, как текстура, цвет и т.п.) интересующих классифицируемых объектов и предоставляет список средству 140 машинного изучения. Кроме того, средство компьютерного зрения может предоставлять средству 140 машинного изучения разнообразную информацию о каждом отслеживаемом объекте в сцене (например, кинематические данные, глубины, цвета, данные внешнего вида и т.д.).
Средство 140 машинного изучения получает видеокадры и результаты, сформированные средством 135 компьютерного зрения. Средство 140 машинного изучения анализирует принятые данные, создает семантические представления событий, представленных в видеокадрах, определяет образцы и узнает из них о наблюдаемых поведениях для идентификации нормальных и/или ненормальных событий. Средство 135 компьютерного зрения и средство 140 машинного изучения и их компоненты описываются более подробно ниже. Данные, описывающие любое нормальное/ненормальное поведение/событие, которое было определено, и/или такое поведение/событие, могут предоставляться на устройство 145 вывода для выдачи предупреждения, например предупреждающее сообщение, представленное на экране графического интерфейса GUI.
Обычно средство 135 компьютерного зрения и средство 140 машинного изучения обрабатывают полученные видеоданные в реальном времени. Однако масштабы времени на обработку информации средством 135 компьютерного зрения и средством 140 машинного изучения могут отличаться. Например, в одном варианте осуществления средство 135 компьютерного зрения обрабатывает принятые кадры видеоданных, пока средство машинного изучения обрабатывает принятые данные каждых N кадров. Иными словами, пока средство 135 компьютерного зрения анализирует каждый кадр в реальном времени для получения набора информации о том, что происходит в данном кадре, средство 140 машинного изучения не ограничивается скоростью кадров в реальном времени средства ввода видео.
Отметим, однако, что фиг. 1 показывает лишь одну из возможных структур системы 100 распознавания поведения. Например, хотя средство 105 ввода видео показывается подключенным к компьютерной системе 115 через сеть 110, сеть 110 не всегда присутствует или необходима (например, средство 105 ввода видео может непосредственно подключаться к компьютерной системе 115). Кроме того, в одном варианте осуществления средство 135 компьютерного зрения может реализовываться как часть устройства ввода видео (например, в качестве компонента встроенной программы, прямо зашитой в видеокамеру). В таком случае выходные данные видеокамеры могут предоставляться на средство 140 машинного изучения для анализа.
Фиг. 2 показывает способ 200 анализа и изучения поведения из потока видеокадров в соответствии с одним вариантом осуществления настоящего изобретения. Как показано, способ 200 начинается с этапа 205. На этапе 210 набор видеокадров, полученных от источника ввода видео. На этапе 215 видеокадры могут обрабатываться для минимизации шума видео, нерегулярного или необычного освещения сцены, проблемы, относящиеся к цвету, и так далее. То есть содержание видеокадров может быть усилено для видимого улучшения изображения до обработки компонентами системы распознавания поведения (например, средство 135 компьютерного зрения и средство 140 машинного изучения, описанные выше).
На этапе 220 каждый последующий видеокадр анализируется для идентификации и/или обновления изображения переднего и заднего планов для использования во время последующих этапов способа 200. Обычно изображение заднего плана включает в себя стационарные элементы сцены, фиксированные средством ввода видео (например, пиксели, показывающие платформу станции метро), в то время как изображение переднего плана включает в себя изменяемые элементы, фиксированные средством ввода видео (например, пиксели, показывающие мужчину, движущегося вокруг платформы). Иными словами, изображение заднего плана обеспечивает этап, на котором элементы заднего плана могут вводиться, взаимодействовать друг с другом и удаляться. Изображение заднего плана может включать в себя значение цвета для каждого пикселя в изображении заднего плана. В одном варианте осуществления изображение заднего плана может получаться путем отбора значений цвета для данного пикселя для ряда кадров. Также, если новые кадры принимаются, элементы изображения заднего плана могут изменяться на основе дополнительной информации, включенной в каждый последующий кадр. Обычно, если пиксели являются частью заднего или переднего плана, то могут определяться для каждого кадра в последовательности видеокадров, и элементы переднего плана могут идентифицироваться путем сравнения изображений заднего плана со значениями цветовых пикселей в данном кадре. После того, как пиксели переднего плана идентифицированы, маска может применяться к кадру, эффективно вырезая пиксели, которые являются частью заднего плана, из изображения, оставляя только одно или более пятен пикселей переднего плана в изображении. Например, маска может примеряться к кадру таким образом, чтобы каждый пиксель переднего плана представлялся белым и каждый пиксель заднего плана представлялся черным. В результате черное и белое изображение (представленное в качестве двумерного массива) может предоставляться на последующие элементы системы распознавания поведения. В одном варианте осуществления компьютерная система 115 может обеспечиваться с первоначальными моделями изображения заднего плана для данной сцены.
На этапе 225 изображение переднего плана, связанное с заданным кадром, может анализироваться для идентификации набора пятен (например, группы связанных пикселей) путем сегментации изображения переднего плана на интересующие цели. Другими словами, система может быть сконфигурирована для изоляции разных пятен в изображении переднего плана, где каждое пятно удобно представляет различные объекты переднего плана в кадре (например, машина, мужчина, чемодан и т.п.). Для каждого пятна переднего плана поисковая модель может инициализироваться, когда пятно переднего плана изначально определено. Поисковая модель используется для фиксирования позиции пятна в схеме, идентифицирующей, какие пиксели образуют часть пятна, и хранения различных метаданных, относительно наблюдаемого поведения в пятне от кадра к кадру. Кроме того, поисковая модель может использоваться путем отслеживания модели для прогнозирования, нахождения и отслеживания движений соответствующего объекта от кадра к кадру. Как только последовательные кадры принимаются, поисковая модель обновляется, так как пятно переднего плана продолжает присутствовать в последующих видеокадрах. Такое обновление может периодически выполняться с каждым дополнительным видеокадром, а новая информация, позволяющая уточнять поисковую модель, принимается по мере необходимости или аналогично.
Поисковая модель может реализовываться различными способами. Например, в одном варианте осуществления поисковой моделью может быть модель внешнего вида, созданная для фиксирования ряда признаков о данном объекте переднего плана, включая пиксели, которые являются частью этого объекта переднего плана. Модель внешнего вида данного объекта может затем обновляться на основе пикселей, представляющих этот объект от кадра к кадру. В другом варианте осуществления поисковой моделью может быть минимально ограничивающий прямоугольник для охвата объекта. Хотя вычисление намного быстрее, минимально ограничивающий прямоугольник включает в себя пиксели в качестве части пятна, которые являются, по сути, частью заднего плана. Тем не менее, для некоторых видов анализа этот подход может быть эффективным. Эта поисковая модель описывается ниже более подробно. На этапе 230 поисковая модель используется для отслеживания движений объектов на переднем плане относительно того, как они перемещаются по сцене от кадра к кадру. То есть, после того, как объект идентифицируется в первом кадре, и модель внешнего вида (и/или ограничивающий прямоугольник) формируется для этого объекта, поисковая модель может использоваться для идентификации и отслеживания этого объекта в последующих кадрах на основе модели внешнего вида (и/или ограничивающего прямоугольника) до тех пор, пока объект переднего плана не покинет сцену. Поисковая модель может использоваться для идентификации объекта в видеокадрах после того, как объект, например, изменит положение или позицию. Таким образом, разные типы информации, относящиеся к одному и тому же объекту, определяются (например, кинематические характеристики объекта, ориентация, направление движения и так далее), когда такой объект движется по сцене.
На этапе 235 система распознавания поведения пытается классифицировать пятна переднего плана в качестве одной из классификаций отдельных экземпляров. Например, в одном варианте осуществления система распознавания поведения может быть сконфигурирована для классификации каждого объекта переднего план в качестве одного из «человек», «транспортное средство», «другой» или «неизвестный». Конечно, больше классификаций может использоваться и, кроме того, классификации могут создаваться с учетом потребностей конкретного случая. Например, система распознавания поведения, получающая видеоизображения транспортерной багажной ленты, может классифицировать объекты на ленте по различным видам/размерам багажа. После классификации объекта переднего плана могут быть сделаны дополнительные оценки в отношении такого объекта, например оцениваются поза объекта (например, ориентация, поза и т.д.), местоположение (например, расположение на сцене, представленной видеоизображениями, местоположение относительно других интересующих объектов, и т.д.) и движение (например, траектория, скорость, направление и т.д.). Эта информация может использоваться средством 140 машинного изучения для описания определенных поведений в качестве нормального или ненормального на основе последних наблюдений аналогичных объектов (например, другие объекты, классифицируемые как люди).
На этапе 240 результаты предыдущих этапов (например, результаты отслеживания, данные изображения заднего плана/переднего плана, результаты классификации и т.д.) объединяются и анализируются для создания карты сцены, показанной видеокадрами. В одном варианте осуществления сцена сегментируется на пространственно разделенные области, каждый сегмент определяется набором пикселей. Области сортируются в соответствии с z-глубиной (то есть, какой сегмент ближе и какой сегмент дальше от устройства видеозахвата) и опционально помечается (например, как натуральный, сделанный человеком и т.д.). На этапе 245 создаются семантические представления движений объектов. Иными словами создаются семантические представления движений и/или действий отслеживаемых объектов (например, «автомобиль припаркуется», «автомобиль останавливается», «человек наклоняется», «лицо исчезает» и так далее). На этапе 250 семантические представления анализируются для распознавания образов.
Итоговые семантические представления аннотированы на карте сцены и результаты классификации анализируются на этапе 255. Система распознавания поведения анализирует такие результаты для изучения образцов поведения, обобщает на основе изучения и изучает посредством создания аналогий. Это также позволяет системе распознавания поведения определять и/или изучать, какой вид поведения является нормальным и какой вид поведения является ненормальным. То есть средство машинного изучения может быть сконфигурировано для идентификации распознаваемых образцов, оценки новых поведений для данного объекта, подкрепления или изменения образцов поведения, изученных для данного объекта, и т.д.
На этапе 260 результаты предыдущих шагов опционально анализируются для распознавания поведения. Кроме того, система распознавания поведения может быть сконфигурирована для выполнения определенного действия в ответ на распознавание появления данного события. Например, на основе результатов предыдущих этапов система распознавания поведения может выдавать предупреждение, когда объект переднего плана классифицирован как человек, который занимается необычным поведением. Кроме того, некоторое поведение, которое является «необычным», может основываться на том, что средство изучения «изучило» «нормальное» поведение людей в данной сцене. В одном варианте осуществления предупреждения выдаются только, если ненормальное поведение было определено (например, предупреждение о том, что лицо оставило без присмотра сумку на станции метро). В другом варианте осуществления выдается предупреждение о том, что нормальные события происходят в сцене (например, предупреждение, указывающее, что автомобиль припаркован). Способ заканчивается этапом 275.
Следует отметить, что не является необходимым выполнять все описанные выше этапы в указанном порядке. Кроме того, не все описанные этапы являются необходимыми для работы описанного способа. Какие этапы должны использоваться, в каком порядке этапы должны выполняться и должны ли некоторые этапы повторяться чаще, чем другие этапы, определяется на основе, например, потребностей конкретного пользователя, конкретных качеств наблюдаемой среды и так далее.
Фиг. 3-6 показывают разные компоненты средства 135 компьютерного зрения, показанного на фиг. 1, в соответствии с одним вариантом осуществления настоящего изобретения. В частности, фиг. 3 показывает компоненты модуля 300 переднего и заднего плана. Модуль 300 переднего и заднего плана использует признаки в каждом видеокадре для идентификации, какие пиксели принадлежат изображению заднего плана и какие принадлежат изображению переднего плана. В одном варианте осуществления видеокадры анализируются для классификации каждого пикселя в качестве части изображения заднего плана сцены (и этого кадра) или отображения части изображения переднего плана для этого кадра.
Обычно пиксели, которые не меняют цвет с течением времени, считаются частью изображения заднего плана. Отбирая значение цвета пикселя по времени, присутствие объекта переднего плана в некоторых кадрах может размываться. Кроме того, так как изображение заднего плана может обновляться динамически, то изображение заднего плана может компенсировать изменения в свете и тени. Аналогично пиксели, которые изменяют цвет относительно изображения заднего вида, предполагаются отображающими объект переднего плана. Иными словами, движения объектов переднего плана в сцене определяются на основе разницы между значениями цветов пикселей в последующих видеокадрах. Обычно изображение заднего плана может предусматриваться в качестве видеокадра пикселей, имеющих вырезанные объекты переднего плана. Изображения переднего плана могут предусматриваться в качестве пикселей, которые закрывают задний план. Альтернативно только одно изображение переднего плана может использоваться. Такое изображение переднего плана может представляться в качестве прозрачного видеокадра, который соединяет пиксели переднего плана. Следует отметить, что в то время как два последовательных кадра могут быть достаточными для отслеживания данного объекта переднего плана, сравнение множества последовательных кадров дает более точные результаты при определении изображения заднего плана для данной сцены.
Следует также отметить, что пиксель, первоначально определенный в качестве пикселя заднего плана (в одном кадре), может стать пикселем переднего плана (в другом кадре), и наоборот. Например, если значение цвета пикселя на заднем плане начинает меняться, может быть целесообразным повторно классифицировать его как пиксель переднего плана (например, припаркованный автомобиль в течение длительного периода времени начинает двигаться). Аналогично меняющийся пиксель может стать статическим, поэтому может быть необходимо повторно классифицировать такой пиксель в качестве пикселя заднего плана (например, мусор мог быть принесен на станцию метро для постоянного использования). Однако чтобы избежать ненужных повторных классификаций пикселей и для улучшения интерпретации того, что входит в изображения переднего и заднего планов, в одном варианте осуществления система распознавания поведения может классифицировать пиксели как часть кратковременного заднего плана (STBG), кратковременного переднего плана (STFG), долговременного заднего плана (LTBG) и долговременного переднего план (LTFG). STBG и STFG хранятся в памяти в течение короткого периода времени (например, секунды или меньше), в то время как LTBG и LTFG сохраняются в памяти на длительный период (например, минуты). Определение, сначала, пиксели в качестве STBG/STFG, и затем интерпретирование только квалификаций пикселей в качестве LTBG/LTFG, позволяет более точное определение того, какие пиксели являются частью изображения заднего/переднего плана. Конечно, временные периоды могут регулироваться в зависимости от событий, происходящих в конкретной сцене.
Фиг. 3 показывает компоненты модуля 300 заднего и переднего плана, которые могут использоваться для формирования изображений заднего и переднего плана для видеокадра, в соответствии с одним вариантом осуществления изобретения. Сначала видеокадры принимаются модулем 305 изучения заднего плана. Модуль 300 переднего и заднего плана может обучаться, используя первоначальную последовательность кадров. Обучение позволяет модулю 300 переднего и заднего плана создавать изображение заднего плана сцены, представленной в полученных видеокадрах. Процесс обучения может происходить во время этапа инициализации системы, а именно до того, как определено изображение заднего плана сцены.
Модуль 310 компенсации темной сцены может обрабатывать значения пикселей для компенсации условий слабого или темного освещения части сцены. Кроме того, модуль 310 компенсации темной сцены может быть сконфигурирован для передачи обработанных видеокадров на модуль 315 STFG/STBG и модуль 320 LTBG/LTBG. Модуль 315 STFG/STBG может быть сконфигурирован для определения пикселей STFG и STBG в данном кадре и представления этой информации на модуль 325 старого FG и модуль 335 компенсации подсветки, соответственно. Модуль 320 LTFG/LTBG может быть сконфигурирован для идентификации пикселей LTFG и LTBG и аналогично модулю 315 STFG/STBG, представляют эту информацию на модуль 325 старого FG и модуль 335 компенсации освещенности, соответственно. Модуль 325 старого FG идентифицирует старые пиксели переднего плана и предоставляет результаты на модуль 330 обновления BG. Пиксель может стать «старым», когда определение BG/FG устаревает и нуждается в переоценке. После получения модуль 335 компенсации освещенности может динамически корректировать обработку для изменения освещения (например, осветление/затемнение сцены из-за облаков, затемняющих солнце, или регулирование искусственных источников света), и модуль 310 компенсации темной сцены будет динамически обеспечивать специальную обработку в пределах очень темных областей и/или условий со слабым освещением. Модуль 330 обновления GB обновляет модель изображения заднего плана и передает результаты на модуль 335 компенсации освещения, который, в свою очередь, после обработки всех полученных результатов передает обработанные результаты на модуль LTFG/LTBG.
Таким образом, в совокупности, модуль 300 заднего и переднего плана определяет набор изображений заднего и переднего плана и/или модели переднего и заднего плана для использования другими компонентами системы распознавания поведения. Модели заднего и переднего плана различаются между пикселями, которые являются частью заднего плана сцены (т.е. частью сцены), и пикселями, которые отображают объекты переднего плана (т.е. элементы, выполняющие некоторые действия в сцене). Следует отметить, что хотя в указанном выше описании модуля 300 заднего и переднего плана ссылки делаются только на изображение заднего плана, альтернативно модуль 300 заднего и переднего плана может использовать множество изображений заднего плана (например, сцены кадра изображения могут разделяться на несколько зон заднего плана для более точной идентификации заднего плана).
В одном варианте осуществления модель заднего плана/изображение может включать в себя дополнительную информацию, такую как цвета пикселя. Кроме того, модель заднего плана/изображение обычно включает в себя дополнительные характеристики пикселей, такие как цвет. Однако хранение или сбор такой информации может быть опущены (например, для экономии ресурсов в среде, где известные цвета несущественно улучшают различия между интересующими объектами, например конвейер, транспортирующий объекты в основном одного и того же или аналогичного цвета).
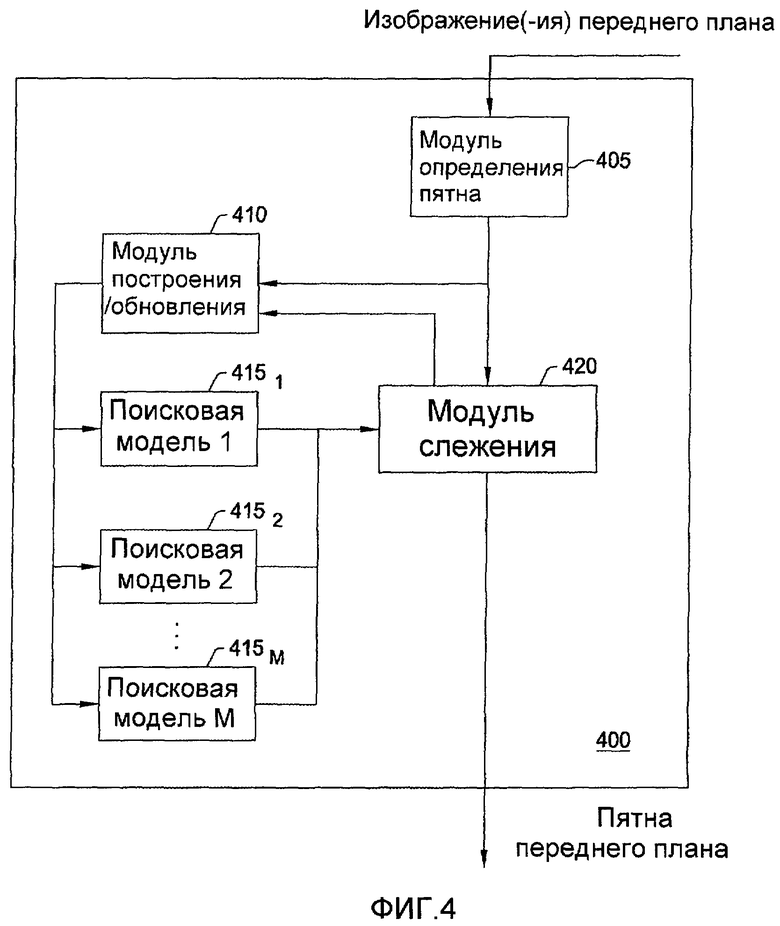
Фиг. 4 показывает модуль 400 объекта переднего плана, созданный для идентификации объектов, отображенных в изображениях переднего плана сцены, в соответствии с одним вариантом осуществления изобретения. В общем модуль 400 объекта переднего плана может быть сконфигурирован для приема изображений переднего плана, созданных модулем 300 заднего и переднего плана для данного кадра, создания/обновления поисковых моделей для изображений переднего плана и попыток отследить движения отображенного объекта в изображениях переднего плана, в которых объект движется по сцене от кадра к кадру.
Как показано на фиг. 4, модуль 400 объекта переднего плана включает в себя модуль 405 обнаружения пятна, модуль 410 создания/обновления, модуль 420 слежения и 1-М поисковые модели, поисковую модель 1 (4151), поисковую модель 2 (4152) - поисковую модель M (415M). В одном варианте осуществления модуль 405 обнаружения пятна может быть сконфигурирован для анализа изображений переднего плана для определения групп соответствующих пикселей, называемых пятнами переднего плана, где каждая такая группа пикселей аналогично представляет четкий объект в сцене. Кроме того, каждому определенному пятну переднего плана назначается идентификационный номер слежения. Пятна переднего плана используются модулем 410 создания/обновления для создания/обновления поисковых моделей 4151-415M, в котором уже существующие поисковые модели были созданы или обновлены для пятен, идентифицированных в предыдущих видео кадрах. В одном варианте осуществления для обновления поисковых моделей 4151 - 415M модуль 410 создания/обновления также использует результаты, сформированные модулем 420 слежения. Если постоянно определяемое пятно не имеет соответствующей поисковой модели, такая поисковая модель строится (создается).
В любой момент модуль 400 объекта переднего плана может включать в себя множество поисковых моделей, каждая представляющая другое пятно переднего плана. Число поисковых моделей может зависеть от того, сколько пятен переднего плана идентифицируется модулем 405 определения пятна в изображении переднего плана. В одном варианте осуществления поисковые модели могут создаваться с прогностическими возможностями в отношении того, что пятно переднего плана может сделать в последующих видеокадрах. Например, поисковые модели, связанные с данным пятном переднего плана, могут включать в себя предполагаемую в дальнейшем позицию (и форму) этого пятна на основе настоящей позиции и кинематические данные. Кроме того, каждая поисковая модель может включать в себя разнообразную информацию, полученную о пятнах данного переднего плана (например, текстуры, цвета, образцы, позиция Z-глубины в сцене, размер, скорость движения, кинематика и т.п.).
Кроме того, различные виды поисковых моделей могут использоваться в соответствии с принципами настоящего изобретения. Как указано, поисковая модель может использоваться модулем 420 слежения для прогнозирования, нахождения и отслеживания движений соответствующего объекта из кадра в кадр. В одном варианте осуществления используется внешний вид модели. Внешний вид модели включает в себя пиксели, используемые для отображения объекта (например, где кадр отображает человека на изображении переднего плана, модель внешнего вида будет включать в себя в основном пиксели контура человека и пиксели внутри контура). В другом варианте осуществления поисковая модель реализуется в виде модели на основе признаков, где модель на основе признаков представляет пиксели внутри прямоугольника, такого как, например, минимально ограничивающего прямоугольника, охватывающего объект (например, где объект является человеком, модель на основе признаков может включать в себя ограничивающий прямоугольник, охватывающий человека). Альтернативно модель на основе признаков может включать в себя множество ограничивающих прямоугольников для данного объекта, такие как прямоугольники минимально возможных размеров, охватывающих различные области этого объекта (например, где кадр отображает человека, модель на основе признака для такого объекта может включать в себя несколько прямоугольников минимального размера, где прямоугольники охватывают различные области человека, такие как руки, ноги, голова и туловище).
Используемые поисковые модели могут зависеть, например, от наблюдаемой среды, предпочтений пользователя системы распознавания поведения и так далее. Например, хотя модель внешнего вида удовлетворительно обеспечивает более точное отслеживание, модель на основе признаков может экономить ресурсы, где, например, формы отслеживаемых интересующих объектов являются простыми (например, ленточный транспортер для багажа).
Как упоминалось выше, модуль 420 слежения использует поисковые модели 415 для отслеживания движений соответствующих объектов, представленных в видеопоследовательности от кадра к кадру, таких как перемещение объекта по сцене. Модуль 420 слежения берет обнаруженное пятно переднего плана текущего видеокадра и ищет поисковую модель предыдущего видеокадра, которая обеспечивает точное соответствие с пятном переднего плана. В одном варианте осуществления для каждого постоянно обнаруживаемого пятна переднего плана модуль 420 слежения ищет поисковую модель 415, у которой относительное пространственное векторное расстояние между поисковой моделью и пятном переднего план абсолютно минимально. Таким образом, модуль 420 слежения может отслеживать местоположение каждого объекта, представленного одной из поисковых моделей 415 от кадра к кадру. В одном варианте осуществления модуль 420 слежения использует кинематическую информацию, полученную на основе предыдущих видеокадров, для оценки положений поисковой модели в текущем видеокадре.
Фиг. 5 показывает модуль 500 оценки/идентификации в средстве компьютера зрения в соответствии с одним вариантом осуществления настоящего изобретения. Обычно модуль 500 оценки/идентификации получает пятна переднего плана и соответствующие поисковые модели и пытается классифицировать объекты в видеокадре, которые представлены пятнами переднего план, в качестве членов известных категорий (классов). В одном варианте осуществления, если интересующий объект был определен, то модуль 500 оценки/идентификации оценивает позу, положение и движение интересующего объекта. Модуль 500 оценки/идентификации обычно обучается на многочисленных положительных и отрицательных примерах, представляющих примеры данного класса. Кроме того, онлайновое обучение может использоваться для динамического обновления классификатора, пока видео анализируется покадрово.
Как показано, модуль 500 оценки/идентификации включает в себя классификатор 505, класс 1 (5101)-класс N (510N) и идентификатор 515. Классификатор 505 пытается классифицировать объект переднего плана в качестве члена одного из классов, класс 1 (5101)-класс N (520N). В случае успеха статические данные (например, размер, цвет и т.п.) и кинематические данные (например, скорость, частота, направление и т.п.), представляющие классифицированный объект, также могут определяться в течение определенного периода времени (например, X раз в кадрах) идентификатором 515. Для каждого определенного объекта модуль 500 оценки/идентификации выдает ряд контекстных событий, содержащих указанные выше статические и кинематические характеристики интересующего объекта, и исследования известных объектов, содержащие статические и кинематические характеристики среднего члена класса определенного объекта.
В одном варианте осуществления система использует четыре классификатора: человек, транспорт, другой и неизвестный. До тех пор, пока класс интересующего объекта не определится, такой объект рассматривается как член класса "неизвестный". Каждый класс содержит позу, статику и кинематические данные о среднем члене класса. В одном варианте осуществления такие данные постоянно обновляются по мере того, как больше интересующих объектов классифицируется и идентифицируется, их поза, статика, кинематические данные определяются и собираются. Следует отметить, что обычно модуль 500 оценки/идентификации обрабатывает информацию в реальном времени на покадровой основе.
Фиг. 6 показывает контекстный процессор 600 в средстве 135 компьютерного зрения, в соответствии с одним вариантом осуществления настоящего изобретения. Обычно контекстный процессор 600 объединяет результаты, полученные от других компонентов средства 135 компьютерного зрения, таких как модуль 300 заднего и переднего планов, модуль 400 объекта переднего плана и модуль 500 оценки/идентификации, для создания карты аннотаций сцены, зафиксированной видеокадрами. В одном варианте осуществления сцена сегментируется на пространственно-разделенные области, которые сортируются в соответствии с z-глубиной сцены, и опционально помечаются как естественно отображающие или сделанные человеком элементы.
Как показано, контекстный процессор 600 может включать в себя средство 605 сегментации области для разделения сцены на мелкие поля (области), средство 610 задания последовательности областей для определения отношений между областями (например, ближе/дальше от устройства захвата видео относительно друг к друга), и картографическое устройство 615 сцены для формирования аннотированной карты. В одном варианте осуществления контекстный процессор 600 использует информацию относительно движений (такую, как траектории) и местоположения отслеживаемых интересующих объектов для формирования аннотированной карты.
Фиг. 7 и 8 показывают различные компоненты средства 140 машинного изучения, показанного на фиг. 1. Конкретно фиг. 7 показывает компоненты модуля 700 семантического анализа и фиг. 8 показывает компоненты модуля 800 восприятия, в соответствии с одним вариантом осуществления настоящего изобретения. Обычно семантический модуль 700 создает семантические представления (например, символические представления) движений и действий отслеживаемых объектов. Семантическое представление обеспечивает формальное описание того, что, как считается, происходит на сцене, на основе движений конкретного отслеживаемого объекта (и, в конечном счете, на основе изменений в значения пиксельных цветов от кадра к кадру). Формальная языковая грамматика (например, существительные и глаголы) используется для описания событий в сцене (например, «парковка автомобиля», «внешний вид человека» и т.п.).
Затем семантические представления анализируются для распознавания образцов, и результаты передаются в модуль 800 восприятия, показанный на фиг. 8. В одном варианте осуществления семантический модуль 700 также создает символьную карту сцены, включая различные аспекты события, происходящие на сцене, такие как символические представления траекторий объектов в сцене. В одном варианте осуществления символьная карта также может включать в себя распределение частот (например, данные о том, как часто и где определенные классы или виды объектов представлены на сцене).
Как показано на фиг. 7, семантический модуль 700 включает в себя сенсорную память 710, модуль (LSA) 715 латентного семантического анализа, модуль 725 примитивных событий, модуль 730 разбиения фазового пространства, модуль (iLSA) 735 инкрементного латентного семантического анализа и модуль 740 формального языка. Сенсорная память 710 получает информацию, обеспеченную для семантического модуля 700, и сохраняет эту информацию для последующего использования модулем 725 примитивных событий и модулем 730 разбиения фазового пространства. В одном варианте осуществления сенсорная память 710 идентифицирует, какая информация должна быть предоставлена для дальнейшего анализа в модуль 725 примитивных событий и модуль 730 разбиения фазового пространства.
Модуль 725 определения примитивных событий может создаваться определением возникновения примитивных событий (например, автомобиль останавливается, меняет направление, исчезает, появляется; человек наклоняется, падает, изменяется и т.п.) в сенсорной памяти 710. Примитивные события, обычно, отражают изменения в кинематических характеристиках отслеживаемых объектов. Таким образом, после того, как объект классифицируется как «автомобиль», модуль 725 определения примитивных событий может оценивать данные в отношении машины для идентификации различных событий поведения, когда они возникают. В одном варианте осуществления примитивные события заранее определяются (например, для конкретной среды, где используется самообучаемая система распознавания поведения). В другом варианте осуществления только некоторые примитивные события заранее определяются (например, парковка, поворот, падение), в то время как другие примитивные события изучаются с течением времени (например, объекты определенного класса можно найти в определенном месте сцены).
Модуль 730 разбиения фазового пространства определяет информацию о геометрическом положении объектов, имеющих скорость, в сцене. Соответственно модуль 725 примитивных событий и модуль 730 разбиения фазового пространства позволяют семантическому модулю 700 анализировать данные двумя различными способами. На основе результатов модуля 725 примитивных событий и модуля 730 разбиения фазового пространства LSA 715 и iLSA 735 создают/обновляют модель сцены, где модель включает в себя интересующие объекты.
LSA 715, обычно, является начальным модулем изучения в семантическом модуле 700. LSA собирает данные в течение периода времени до тех пор, пока LSA 715 формирует результаты с достаточным статистически весом. Иными словами, LSA 715 изучает базовую структуру сцены, в то время как iLSA 735 постепенно обновляет такую структуру. Следует отметить, что iLSA 735 достаточно гибок, чтобы управлять изменениями в образцах поведения, происходящего на сцене. Обучающий модуль 740 формального языка использует данные, сформированные iLSA 735, для создания семантических представлений (символическое представление о том, что происходит в сцене) и передает семантические представления в модуль 800 восприятия для изучения того, что означают созданные семантические представления.
Фиг. 8 показывает модуль восприятия в средстве машинного изучения в соответствии с одним вариантом осуществления изобретения. Модуль 800 восприятия может быть сконфигурирован для обработки результатов, сформированных по меньшей мере некоторыми компонентами компьютерного зрения 135 и средством 140 машинного изучения (например, модулем 500 оценки/идентификации, контекстным процессором 600, семантическим модулем 700 т.д.). Обычно модуль 800 распознавания изучает образы, обобщает на основе изучения и обучается путем создания аналогий.
Как показано на фиг. 8, модуль 800 восприятия может включать в себя ассоциативную память 805 восприятия, планировщик 810, рабочее пространство 815, эпизодическую память 820 и долговременную память 825. Рабочее пространство 815 обеспечивает область памяти, которая отражает, какая информация в настоящее время оценивается средством 140 машинного изучения. А именно рабочее пространство 815 сохраняет элементы данных, которые постоянно имеют «внимание» средства 140 машинного изучения. Как указано ниже, данные в рабочем пространстве 815 могут включать в себя набор результатов восприятия (каждое описывающее событие) и коделеты. Ассоциативная память 805 восприятия собирает данные, переданные на модуль 800 восприятия, и сохраняет такие данные в качестве результатов восприятия. Каждое восприятие может представлять данные, описывающие то, что произошло на видео, такие как примитивное событие. Ассоциативная память 805 восприятия передает результаты восприятия и/или коделеты в рабочее пространство 815.
Коделеты обеспечивают часть исполняемого кода, который описывает и/или следит за отношениями между различными результатами восприятия. Другими словами, коделеты суммируют правила для определения конкретного поведения/события (например, событие парковки), где поведение/событие включает в себя один или более результатов восприятия. Каждый коделет может быть сконфигурирован для приема набора входных результатов восприятия и может обрабатывать их конкретным способом. Например, коделет может принимать набор входных результатов восприятия и оценивать их для определения, возникло ли конкретное событие (например, парковка автомобиля). На примере парковки автомобиля результат восприятия может обновить эпизодическую память 820 информацией о том, какой автомобиль, цвет автомобиля, где припаркован автомобиль и т.д. Кроме того, информация об этом обнаруженном примитивном событии может использоваться для обновления определения примитивного события в долговременной памяти 825. Кроме того, коделеты, распознающие аномалии, используются модулем 800 восприятия. Такие коделеты имеют доступ к результатам восприятия и, если определенные результаты восприятия статистически не коррелируют с ранее накопленными статистическими данными, то может определяться ненормальное событие.
В одном варианте осуществления коделеты полностью заранее записываются. В другом варианте осуществления, по меньшей мере, некоторые коделеты не полностью предварительно записываются, но вместо этого формируются с течением времени. Например, коделет, описывающий нормальное поведение для определенного результата(ов) восприятия, может сам формироваться/модифицироваться на основе накопленных данных, описывающих соответствующие наблюдаемые события.
Планировщик 810 определяет, какой коделет необходимо активировать в любое заданное время. Например, планировщик 810 может пытаться определить соответствие между результатами восприятия, размещенными в рабочем пространстве 815, и коделетами. Когда соответствующий набор входных данных, необходимых для данного коделета (например, набор результатов восприятия), доступен, этот коделет может размещаться в рабочем пространстве 815 и активироваться. Когда доступно множество коделетов для активации, определение, когда и какой коделет активируется, может быть случайным. Однако в одном варианте осуществления определенные коделеты созданы имеющими приоритет над другими (например, коделет, определяющий определенное аномальное поведение). В каждый конкретный момент времени множество коделетов может активироваться планировщиком 810 в рабочем пространстве 815.
Модуль 800 восприятия также использует эпизодическую память 820 и долговременную память 825 для захвата кратковременных и долговременных данных в отношении примитивных событий. Эпизодическая память 820 является кратковременной памятью для хранения последних результатов восприятия. Например, результат восприятия, который был недавно изменен, находится в эпизодической памяти 820. Результаты восприятия помещаются в эпизодическую память 820 из рабочего пространства 815. В то же время рабочее пространство 815 может использовать результаты восприятия, сохраненные в эпизодической памяти 820, для согласования их с соответствующими коделетами.
Обычно, по меньшей мере, некоторые результаты восприятия переходят из эпизодической памяти 820 в долговременную память 825. Однако не каждая часть данных, помещенная в эпизодическую память 820, переходит в долговременную память 825. Некоторые данные исчезают из эпизодической памяти 820 без заполнения долговременной памяти 825 (например, данные, описывающие одноразовое событие, которое не было определено как ненормальное).
В то же время аспекты этого события могут использоваться для пополнения информацией долговременной памяти 825 (например, аспекты того как, где и как долго автомобиль припаркован на автостоянке). Таким образом, долговременная память 825 может использоваться для создания и накопления общих образцов поведения в данной сцене. В одном варианте осуществления образцы поведения, сохраненные в эпизодической памяти 820, и образцы поведения, которые приобрели достаточные статистические веса, помещаются в долговременную память 825 в качестве общих образцов поведения. Однако не все данные, помещенные в долговременную память 825, остаются там. Некоторые данные, в конечном счете, исчезают (например, конкретные детали). Например, если несколько автомобилей разных цветов были припаркованы в одном и том же месте в течение периода времени, общий образец автомобиля, припаркованного в данном конкретном месте, может быть изучен и помещен в долговременную память 825. Однако подробности, касающиеся ранее припаркованных автомобилей, такие как их цвета, будут исчезать из долговременной памяти 825 после некоторого периода времени.
В одном варианте осуществления рабочее пространство 815 использует общие модели поведения, найденные в долговременной памяти 825 для определения событий, происходящих на сцене. После того, как событие было распознано, формируется информация, указывающая, что распознанное событие было определено. Такая информация затем используется для формирования предупреждений. Хотя в одном варианте осуществления выдаются только предупреждения в отношении определенного ненормального поведение (например, нападение), в другом варианте осуществления также выдаются предупреждения, описывающие идентифицированное нормальное поведение (например, припаркованный автомобиль).
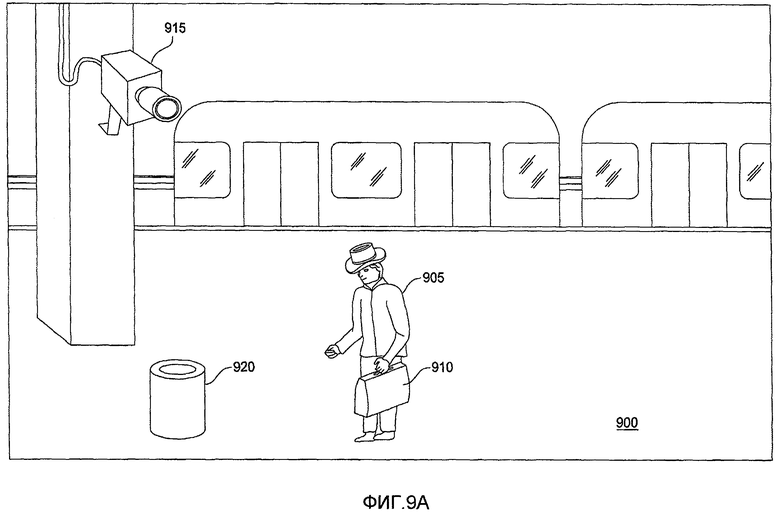
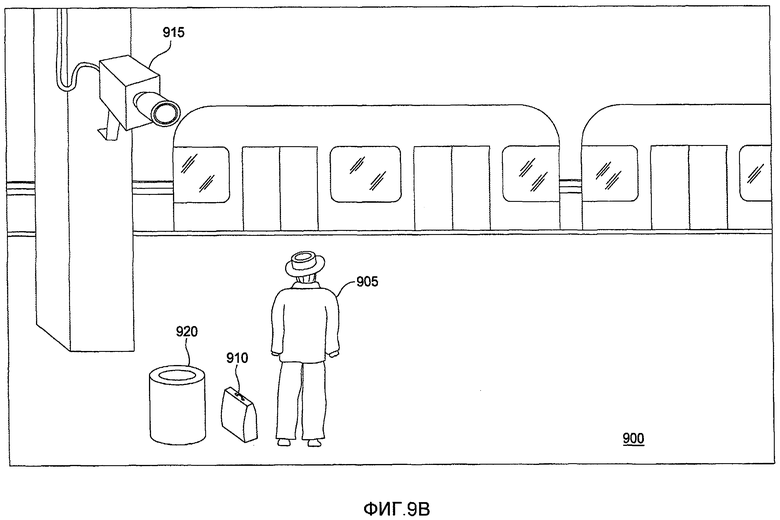
Фиг. 9A-9C показывают сценарий, имеющий место на станции 900 метро, где система распознавания поведения обнаруживает ненормальное поведение и выдает предупреждение, в соответствии с одним вариантом осуществления настоящего изобретения. Как видно, стационарная видеокамера 915 фиксирует события, происходящие на станции 900 метро, и передает видеоизображения, показывающие события, в систему распознавания поведения. Как показано на фиг. 9A-9C, видеокамера 915 фиксирует видеоизображения человека 905, несущего сумку 910, приближающегося к мусорной корзине 920 (фиг. 9A), кладущего сумку 910 на землю рядом с мусорной корзиной 920 (фиг. 9B) и оставляющего сумку 910 позади (фиг. 9C). На основе изучения наблюдаемых людей, входящих на станцию 900 метро, действие оставления «другого» объекта (например, сумки), принесенного другим объектом, классифицируемого как человек, может идентифицироваться как ненормальное, и, соответственно, система распознавания поведения может выдать предупреждение для указания возникновения такого события.
В соответствии с вышеуказанными обсужденными принципами система распознавания поведения интерпретирует пиксели, изображающие стационарную корзину 920 мусора в качестве части изображения заднего плана, без конкретной идентификации корзины 920 мусора в качестве корзины мусора. В противоположность, система распознавания поведения интерпретирует человека 905 и сумку 910 в качестве изображения(й) переднего плана. Первоначально (фиг. 9A) самообучаемая система распознавания поведения может рассматривать человека 905 и сумку 910 как одно пятно переднего плана. Однако, если человек 905 ставит сумку 910 вниз (фиг. 9B-9C), то человек и сумка 910 становятся частями отдельных пятен переднего плана. Хотя в одном варианте осуществления, человек 905 подбирает сумку 910, их соответствующие пятна переднего плана будут объединены в новые пятна переднего плана, в другом варианте осуществления человек 905 и сумка 910 рассматриваются в качестве двух отдельных пятен переднего плана. В еще одном варианте осуществления человек 905 и сумка 910 рассматриваются в качестве отдельных пятен переднего плана с самого начала (фиг. 9A).
Для человека 905 и сумки 910 система распознавания поведения создает и обновляет поисковые модели для отслеживания этих объектов от кадра к кадру. Кроме того, система распознавания поведения классифицирует человека 905 в качестве «человека» и сумку 910 в качестве «другой» (альтернативно как «сумка»), собирает информацию о них и прогнозирует их действия на основе ранее изученного поведения людей и сумок на станции метро. Если оставляемая позади сумка не связана с обычным изученным поведением, система распознавания поведения идентифицирует такое поведение как ненормальное и выдает предупреждение. Альтернативно такое поведение может идентифицироваться как ненормальное, так как система заранее узнала, что ситуация оставления сумки позади указывает на ненормальное поведение.
Хотя вышесказанное направлено на варианты осуществления настоящего изобретения, другие и дополнительные варианты осуществления изобретения могут разрабатываться без отхода от основного его объема, и его объем определяется формулой, которая следует.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОЦЕНКА ТРЕХМЕРНОЙ ТОПОЛОГИИ ДОРОГИ НА ОСНОВЕ ВИДЕОПОСЛЕДОВАТЕЛЬНОСТЕЙ ПОСРЕДСТВОМ ОТСЛЕЖИВАНИЯ ПЕШЕХОДОВ | 2005 |
|
RU2409854C2 |
| СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ И ОТСЛЕЖИВАНИЯ ПАЛЬЦЕВ | 2012 |
|
RU2605370C2 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| УСТРОЙСТВА, СИСТЕМЫ И СПОСОБЫ ВИРТУАЛИЗАЦИИ ЗЕРКАЛА | 2014 |
|
RU2668408C2 |
| СИСТЕМА КАМЕР СТЕРЕОЗРЕНИЯ ДЛЯ ПРЕДОТВРАЩЕНИЯ СТОЛКНОВЕНИЙ ВО ВРЕМЯ НАЗЕМНЫХ ОПЕРАЦИЙ ЛЕТАТЕЛЬНОГО АППАРАТА | 2017 |
|
RU2737562C2 |
| СПОСОБ ПОЛУЧЕНИЯ КАРТЫ ГЛУБИНЫ ИЗОБРАЖЕНИЯ ПОВЫШЕННОГО КАЧЕСТВА | 2011 |
|
RU2587425C2 |
| Способ и устройство для определения направления вращения целевого объекта, считываемый компьютером носитель и электронное устройство | 2018 |
|
RU2754641C2 |
| УЛУЧШЕНИЯ КАЧЕСТВА РАСПОЗНАВАНИЯ ЗА СЧЕТ ПОВЫШЕНИЯ РАЗРЕШЕНИЯ ИЗОБРАЖЕНИЙ | 2013 |
|
RU2538941C1 |
| ФРЕЙМВОРК ПРИЕМА ВИДЕО ДЛЯ ПЛАТФОРМЫ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2720536C1 |
| СПОСОБ ОБНАРУЖЕНИЯ ЧЕЛОВЕЧЕСКИХ ОБЪЕКТОВ В ВИДЕО (ВАРИАНТЫ) | 2013 |
|
RU2635066C2 |







Изобретение относится к видеоанализу и к анализу и изучению поведения на основе данных потокового видео. Техническим результатом является расширение функциональных возможностей распознавания поведения за счет быстрого изучения в реальном времени обычного и необычного поведения для любой среды посредством анализа движений или активностей или отсутствия таковых в среде и идентификации и прогнозирования ненормального и подозрительного поведения на основе того, что было изучено. Объекты, представленные в потоке, определяются на основе анализа видеокадров. Каждый объект может иметь соответствующую поисковую модель, используемую для отслеживания движения объекта от кадра к кадру. Определяются классы объектов и формируются семантические представления объектов. Семантические представления используются для определения поведений объектов и для изучения поведения, возникающего в среде, представленной полученными видеопотоками. 2 н. и 13 з.п. ф-лы, 11 ил.
1. Способ обработки потока видеокадров, регистрирующих события в сцене, содержащий этапы, на которых:
принимают первый кадр потока, при этом первый кадр включает в себя данные для множества пикселей, включенных в этот кадр;
идентифицируют одну или более групп пикселей в первом кадре, при этом каждая группа представляет объект в сцене;
формируют поисковую модель, хранящую один или более признаков, связанных с каждым идентифицированным объектом;
классифицируют каждый из объектов, используя обученный классификатор;
отслеживают во втором кадре каждый из объектов, идентифицированных в первом кадре, используя поисковую модель;
подают первый кадр, второй кадр и классификации объектов в средство машинного обучения; и
формируют средством машинного обучения одно или более семантических представлений поведения, проявляемого объектами в сцене по множеству кадров, при этом средство машинного обучения сконфигурировано изучать шаблоны поведения, наблюдаемые в сцене по множеству кадров, и идентифицировать появления этих шаблонов поведения, проявляемого классифицированными объектами.
2. Способ по п.1, дополнительно содержащий этап, на котором выдают по меньшей мере одно предупреждение, указывающее на возникновение одного из идентифицированных шаблонов поведения со стороны одного из отслеживаемых объектов.
3. Способ п.1, в котором каждая поисковая модель формируется в качестве одной из модели внешнего вида и модели на основе признаков.
4. Способ п.1, в котором этап отслеживания во втором кадре каждого из объектов, идентифицированных в первом кадре, используя поисковую модель, содержит этапы, на которых:
определяют местоположение идентифицированных объектов во втором кадре и
обновляют соответствующую поисковую модель для каждого идентифицированного объекта.
5. Способ п.1, в котором обученный классификатор приспособлен для классификации каждого объекта как одного из человека, автомобиля или другого.
6. Способ по п.1, в котором этап идентификации одной или более групп пикселей в первом кадре содержит этапы, на которых:
идентифицируют по меньшей мере одну группу пикселей, представляющих область переднего плана первого кадра, и по меньшей мере одну группу пикселей, представляющую область заднего плана первого кадра;
сегментируют области переднего плана на пятна переднего плана, при этом каждое пятно переднего плана представляет объект, представленный в первом кадре; и
обновляют изображение заднего плана сцены на основе областей заднего плана, идентифицированных в первом кадре.
7. Способ по п.6, дополнительно содержащий этапы, на которых:
обновляют аннотированную карту сцены, представленной видеопотоком, используя результаты этапов формирования поисковой модели, хранящей один или более признаков, связанных с каждым идентифицированным объектом;
классифицируют каждый из объектов, используя обученный классификатор; и
отслеживают во втором кадре каждый из объектов, идентифицированных в первом кадре, используя поисковую модель, при этом аннотированная карта описывает трехмерную геометрию сцены, включая оцененное трехмерное положение идентифицированных объектов и оцененное трехмерное положение множества объектов, представленных в изображении заднего плана сцены, и при этом этап формирования семантических представлений дополнительно содержит этап, на котором анализируют сформированные семантические представления для распознаваемых шаблонов поведения с использованием латентного семантического анализа.
8. Система для обработки потока видеокадров, регистрирующих события в сцене, содержащая:
источник ввода видео;
процессор и
память, хранящую:
средство компьютерного зрения, при этом средство компьютерного зрения сконфигурировано:
принимать от источника ввода видео первый кадр потока, при этом первый кадр включает в себя данные для множества пикселей, включенных в этот кадр,
идентифицировать одну или более групп пикселей в первом кадре, при этом каждая группа представляет объект в сцене,
формировать поисковую модель, хранящую один или более признаков, связанных с каждым идентифицированным объектом;
классифицировать каждый из объектов, используя обученный классификатор;
отслеживать во втором кадре каждый из объектов, идентифицированных в первом кадре, используя поисковую модель; и
подавать первый кадр, второй кадр и классификации объектов в средство машинного обучения; и
средство машинного обучения, при этом средство машинного обучения сконфигурировано формировать одно или более семантических представлений поведения, проявляемого объектами в сцене по множеству кадров, и дополнительно сконфигурировано изучать шаблоны поведения, наблюдаемого в сцене по множеству кадров, и идентифицировать появления этих шаблонов поведения, проявляемого классифицированными объектами.
9. Система по п.8, в которой средство машинного обучения дополнительно сконфигурировано выдавать по меньшей мере одно предупреждение, указывающее на возникновение одного из идентифицированных шаблонов поведения со стороны одного из отслеживаемых объектов.
10. Система по п.8, в которой каждая поисковая модель формируется как одна из модели внешнего вида и модели на основе признаков.
11. Система по п.8, в которой отслеживание во втором кадре каждого из объектов, идентифицированных в первом кадре, используя поисковую модель, содержит:
определение местоположения идентифицированных объектов во втором кадре и
обновление соответствующей поисковой модели для каждого идентифицированного объекта.
12. Система по п.8, в которой обученный классификатор приспособлен для классификации каждого объекта как одного из человека, автомобиля и другого.
13. Система по п.12, в которой обученный классификатор дополнительно приспособлен для оценки по меньшей мере одного из позы, местоположения и движения для по меньшей мере одного из классифицированных объектов на основе изменений в группе пикселей, представляющих этот объект, по множеству последовательных кадров.
14. Система по п.8, в которой средство компьютерного зрения сконфигурировано для идентификации одной или более групп пикселей в первом кадре посредством выполнения этапов:
идентификации по меньшей мере одной группы пикселей, представляющих область переднего плана первого кадра, и по меньшей мере одной группы пикселей, представляющих область заднего плана первого кадра;
сегментации областей переднего плана на пятна переднего плана, при этом каждое пятно переднего плана представляет объект, представленный в первом кадре; и
обновления изображения заднего плана сцены на основе областей заднего плана, идентифицированных в первом кадре.
15. Система по п.14, в которой средство компьютерного зрения дополнительно сконфигурировано:
обновлять аннотированную карту сцены, представленной видеопотоком, используя результаты этапов формирования поисковой модели, хранящей один или более признаков, связанных с каждым идентифицированным объектом;
классифицировать каждый из объектов, используя обученный классификатор; и
отслеживать во втором кадре каждый из объектов, идентифицированных в первом кадре, используя поисковую модель, при этом аннотированная карта описывает трехмерную геометрию сцены, включая оцененное трехмерное положение идентифицированных объектов и оцененное трехмерное положение множества объектов, представленных в изображении заднего плана сцены, и при этом формирование семантических представлений дополнительно содержит анализ сформированных семантических представлений для распознаваемых шаблонов поведения с использованием латентного семантического анализа.
| US 20060018516 A1, 26.01.2006 | |||
| Установка для нанесения клея на внутреннюю поверхность изделий | 1987 |
|
SU1482735A1 |
| Водоэмульсионная краска | 1983 |
|
SU1162844A1 |
| US 5574845 A, 12.11.1996 | |||
| МЕТОДИКИ МАСШТАБИРУЕМОСТИ НА ОСНОВЕ ИНФОРМАЦИИ СОДЕРЖИМОГО | 2006 |
|
RU2378790C1 |

