Область изобретения
Настоящее изобретение относится к способу идентификации объектов по их текстовым или иным описаниям и может использоваться, например, в анализе ситуаций, при информационном поиске, в построении поисковых систем, в системах контекстной рекламы и т.п.
Введение
В течение длительного времени таксономии считались полезным средством для классификации объектов. Кроме того, что они дают возможность наименования классов объектов, они также дают возможность определения степени похожести.
В простейшей форме таксономия - это иерархическая группировка отдельных понятий в более общие классы. Два понятия в таксономии имеют общие свойства того уровня группировки, который включает их обоих, а степень того, насколько похожи понятия, зависит от взаимного местоположения классов в иерархии.
Различные авторы, например:
- Ф.Резник, «Исследование информационного контента для оценки семантической похожести в таксономии» («Using information content to evaluate semantic similarity in a taxonomy», Proceedings of the 14th International Joint Conference on Artificial Intelligence, 1995, стр.448-453);
- Ж.By и др., «Глагольная семантика и лексический выбор» («Verb semantics and lexical selection», Proceedings of the 32nd Annual Meeting of the Association for Computational Linguistics, 1994, стр.133-138);
- Д.Лин, «Информационно-теоретическое определение похожести» («An information-theoretic definition of similarity» Proceedings of the 15th International Conference on Machine Learning Proceedings of the 15th International Conference on Machine Learning, 1998, стр.296-304);
- Дж.Райс и др., патентная заявка США номер 20080027929 «Компьютерный метод для поиска похожих объектов с использованием таксономии» («Computer-based method for finding similar objects using a taxonomy»)
разработали способы преобразования интуитивной идеи «похожести» в численную меру, которая может быть использована для измерения «похожести» объектов.
Нахождение похожих объектов по заданному описанию употребляется во многих областях техники. Например, кто-то может хотеть найти патент, похожий на заданный, или объект «похожих» клинических испытаний лекарственных средств. В биоинформатике есть необходимость поиска генетических продуктов (например, белков), похожих на заданный генетический продукт. В каждой из этих областей (и не только в них) для классификации наборов объектов разработаны и используются различные подробные таксономии.
Классификация при помощи таксономии может быть более сложной, чем вышеописанные примеры. Во-первых, часто некоторый класс объектов относится более чем к одному «родительскому» классу (то есть классу, стоящему выше по уровню иерархии). Во-вторых, таксономии часто изменяются с течением времени: образуются новые специализированные группы; содержание старых групп меняется. В-третьих, даже при неизменной таксономии классификация конкретного объекта может меняться при изменении знаний о нем, возможны и разногласия пользователей таксономии о месте в них конкретных объектов.
Проблемы анализа текстов
Имеется ряд проблем, которые должны решаться системами для анализа текстов, в частности:
(а) проблема словоформ - одно и то же слово в русском языке может иметь до 40 различных словоформ, что усложняет поиск;
(б) проблема синонимии - использования разных слов для описания одного и того же явления или идеи. В процессе поиска пользователь по запросу с ключевым словом «врач» может не найти слово «доктор», обозначающее в данном контексте то же самое понятие;
(в) проблема полисемии - одно слово может иметь ряд не связанных друг с другом значений (например, «лук» - растение и «лук» - оружие). В процессе поиска есть большая вероятность нахождения документа не с тем значением слова, которое нужно пользователю.
Также существенным является вопрос определения мер похожести при сравнении документов.
Меры похожести
В литературе описаны три различные группы мер похожести, которые могут быть применены к таксономиям. Первая группа, называемая «мерами похожести терминов», может быть применена для вычисления похожести индивидуальных терминов. Две другие группы мер похожести могут применяться в случае, когда объект обозначается несколькими терминами.
В контексте машинного перевода By и Палмер в вышеуказанной статье, озаглавленной «Глагольная семантика и лексический выбор», описали меру похожести, основанную на глубине таксономии ближайшего общего предка двух терминов относительно таксономической глубины индивидуальных терминов. Чем ближе общий «предок» к терминам, тем больше похожесть. Проблемой этого подхода является то, что одни части таксономии могут быть весьма развиты и содержать значительное число терминов, тогда как в других частях таксономии плотность терминов меньше. Такая разница в «плотностях» терминов делает эту и другие меры похожести, основанные на простом учете количества ребер в графе, недостаточно точными.
Идея использования информационного контента для измерения похожести принадлежит Резнику (см. выше). Используя таксономии проекта WorldNet и оценки частотности слов, полученные из большого массива английских текстов, Резник вычислил семантическую похожесть пар слов путем выделения общего предка с наибольшим информационным контентом. Для слов с несколькими значениями Резник использовал тот смысл, который давал максимальную меру похожести. Используя в качестве стандарта оценки, производимые людьми, Резник обнаружил, что такая мера работает лучше вышеописанных мер, основанных на подсчете числа связей. Мера Резника не может быть использована в случае, когда объект обозначен не одним, а несколькими терминами. Кроме того, эта мера имеет ряд других недостатков. Ее диапазон значений похожести не нормализован, но, что более важно, выбирая родительские узлы с наибольшим информационным содержимым, Резник недооценивает похожесть объектов, фокусируясь только на одном наиболее важном аспекте похожести ценой игнорирования всех остальных.
Лин предоставил аксиоматическое определение похожести и показал, как подход Резника может быть адаптирован для использования в указанной ситуации. Мера похожести Резника была основана исключительно на общности значений слов, тогда как подход Лина принимает в расчет значение разницы смыслов слов для определения нормализованного коэффициента похожести. Лин сравнил свою меру похожести с Резником и Ву-Палмером и обнаружил, что она дает показатели похожести, лучше коррелирующие с человеческими оценками этого критерия, чем их методы. Однако Лин не описал, каким образом его мера похожести может использоваться в случае, когда для описания объекта могут быть применены различные термины.
Мера похожести второй группы описывается в литературе как мера похожести, основанная на числе упоминаний (частоте упоминаний) терминов, являющихся общими в описаниях обоих объектов. Меры этой группы включают в себя Jaccard, Dice и Set Cosine, которые часто используются в системах информационного поиска и отличаются друг от друга способом, которым нормализуется количество общих терминов в описаниях, а также меру, описанную Келлером и др. в статье «Основанные на таксономии мягкие меры похожести в биоинформатике» («Taxonomy-based soft similarity measures in bioinformatics», 2004. Proceedings. 2004 IEEE International Conference on Fuzzy Systems, Volume 1, Issue 25-29 July 2004, стр: 23-29). Все эти меры похожести не берут в расчет структуру таксономии. Любой объект-кандидат, который не имеет в описании общих терминов со сравниваемым объектом, получит нулевой коэффициент похожести, хотя на деле они могут быть весьма сходными.
Третий подход к измерению похожести основывается на мере похожести терминов для определения похожести между индивидуальными терминами, с дальнейшим комбинированием их для получения общего коэффициента похожести. Халкиди и др. в статье «Организация коллекций веб-документов, основанная на семантике связей» («THESUS: Organizing Web document collections based on link semantics», The VLDB Journal - The International Journal on Very Large Data Bases, Vol.12, Issue 4 (November 2003) стр.320-332) описывают меру похожести данного типа для использования в кластеризации интернет-страниц. Используя меру похожести By и Палмера, Халкиди рассматривает каждый термин в исходном и базовом документе по отдельности и находит наиболее похожие термины для каждого из документов. Далее для каждого набора терминов (из исходного и базового документов соответственно) определяются и усредняются коэффициенты похожести. После этого Халкиди комбинирует коэффициенты похожести из двух наборов терминов без учета весовых функций. Поскольку Халкиди также использует меру похожести By и Палмера, использование ее для таксономии, представленных направленными ациклическими графами, не представляется возможным.
Ванг и др. в статье «Генетическое выражение корреляции и генетическая основанная на онтологиях похожесть: оценка качественных взаимоотношений» («Gene expression correlation and gene ontology-based similarity: An assessment of quantitative relationships», Computational Intelligence in Bioinformatics and Computational Biology, 2004. Proceedings of the 2004 IEEE Symposium on CIBCB, 7-8 Oct. 2004, стр.25-31) описывают меру похожести, обходящую проблему, нерешаемую методом Халкиди, путем использования обобщенной формы информационно-теоретической похожести Лина для определения похожести каждой пары терминов.
Необходимо отметить, что Ванг и др. обобщают формулу Лина для использования в таксономии, описываемой направленным ориентированным графом, путем выбора ближайшего общего предка с максимально насыщенным информационным контентом. Их подход отличается от подхода патентной заявки Райе и др. тем, что они применяют меру похожести только к парам терминов и не точно следуют аксиоматическому определению похожести Лина, потому что рассматривают только часть общих значений терминов. Ванг использует отличающуюся от Халкиди функцию для комбинирования коэффициентов подобия пар терминов. Вместо того чтобы усреднять коэффициенты для наиболее близких значений из обоих наборов терминов, они усредняют значения похожести по всем наборам пар терминов.
Все меры похожести в этой третьей группе искусственно разделяют комбинации терминов, для которых уже имеются общие таксономические предки, и те, для которых таковых нет.
Келлер и др. (см. выше) представляют несколько способов определения похожести на базе нечетких мер, основанных на глубине информационного содержимого терминов. Однако эти меры требуют некоторых субъективно-определяемых весовых коэффициентов или решения полиноминальных систем уравнений высокого уровня сложности, что делает использование этих методов неэффективным для больших массивов информации.
Решая задачу поиска «похожих» или «близких» документов, все вышеуказанные способы не решают задачи интерпретации результатов поиска. Например, мы можем измерить точные расстояния между географическими объектами, но при этом не получить никакого представления о положении этих объектов на земной поверхности.
Ключевым отличием метода, используемого в данном изобретении, от вышеописанных методов является то, что он позволяет решать проблемы позиционирования документа или документов в пространстве знаний, не ограничиваясь подсчетом мер похожести пар или групп документов.
Раскрытие изобретения
Определения
Прежде чем перейти к описанию заявленного способа, целесообразно привести определения некоторых понятий, встречающихся в описании и прилагаемой формуле изобретения.
Паттерн - словесные, графические, числовые и прочие компоненты в допустимых формах и модификациях или фраза, включающая микроконтекст.
Микроконтекст - часть паттерна, обладающая самостоятельным значением (например, набору символов может быть присвоено значение "дата", "цена", "ФИО" и т.д.)
Направленный ациклический граф (НАГ) - случай направленного графа, в котором отсутствуют направленные циклы, то есть пути, начинающиеся и кончающиеся в одной и той же вершине.
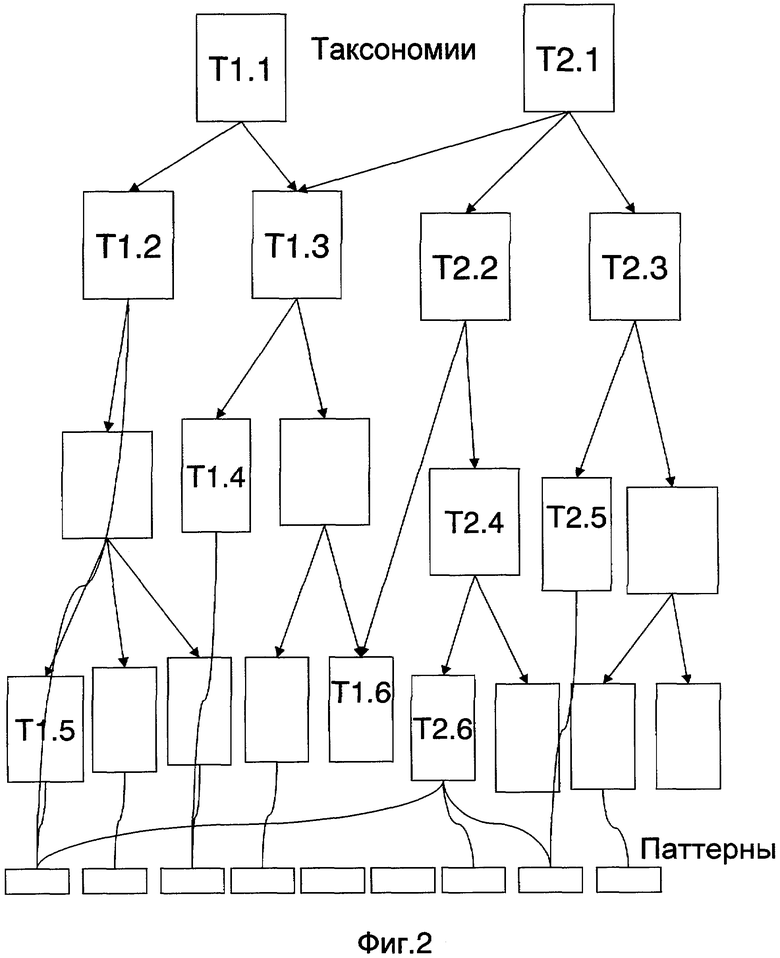
Таксономия - направленный ациклический граф, отражающий иерархию (дерево) понятий в порядке убывания категорий от общего к частному, при этом к каждой категории относится один или несколько паттернов. Узлы графа называются таксонами. Любой таксон, кроме самого верхнего в таксономии, может относиться к одной или нескольким таксономиям.
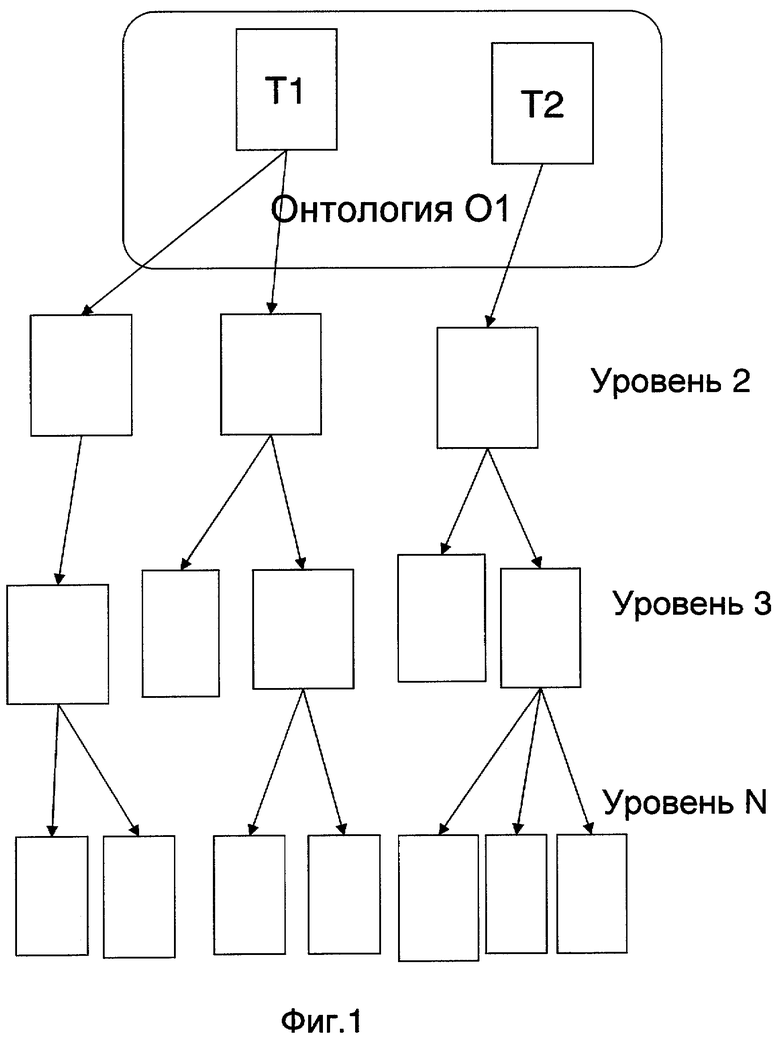
Под Онтологией в настоящей заявке понимается набор таксономии, природа (смысл) которых позволяет сходную интерпретацию и, в частности, может характеризоваться единым коэффициентом значимости (см. фиг.1).
Пространство знаний - совокупность онтологии, описывающих разные предметные области.
Вектор - совокупность наборов значимых категорий, к которым относится рассматриваемый документ, и присвоенных им весов. Каждый документ может быть определен набором векторов.
Категоризатор - это программно-аппаратный механизм, предназначенный для получения описания входного текста в виде набора векторов, позиционирующих входной документ в пространстве знаний. Категоризатор использует априорные знания о связи и иерархии понятий, характерных признаках категорий.
Аналоги
Известен метод «идентификации объектов по их описаниям» (патент РФ №2167450, МПК G06F 17/30, дата публикации 27.12.2000), использующий исключительно статистическую меру похожести, основанную на частоте употребления встречающихся в документе слов. Из-за ограниченности указанных статистических методов остаются нерешенными проблемы полисемии и синонимии в исходных текстах, что существенно снижает качество идентификации по сравнению с предлагаемым изобретением.
Известен метод Латентного Семантического анализа (ЛСА), который может быть использован для целей определения похожести документов (патент США 4839853 «Поиск компьютерной информации с использованием латентных семантических структур» («Computer information retrieval using latent semantic structure», авторы Дирвестер и др., Международная классификация G06F 17/21; G06F 17/30; G06F 15/40). Метод ЛСА использует статистические методы обработки текстов, при которых из массивов текстов извлекается информация о частоте употребления слов и словосочетаний, из которой в свою очередь статистическими методами извлекается информация о «концепциях», дающая возможность последующего определения «похожести» документов. При этом, в отличие от предлагаемого изобретения, метод ЛСА не использует таксономии как основу для вычисления похожести, а опирается только на статистические методы. Например, вес термина обратно пропорционален частотности его упоминания в тексте вне зависимости от тематики документа. Метод ЛСА не позиционирует документы в пространстве знаний.
Описания подходов к построению систематической классификации пространства знаний предложены в книге С.Кордонского «Циклы деятельности и идеальные объекты» (Москва, 2001 г.).
Известен метод поиска документов с использованием таксономии (патент США 6442545 «Term-level text with mining with taxonomies», авторы Фельдман и др., международная классификация G06F 17/30), который не предусматривает возможности вхождения одной и той же категории в разные таксономии, объединение таксономии в онтологии и применение понятие "коэффициента условности" для онтологии.
Известны метод генерации таксономии, описанный в патенте США 6360227 («System and method for generating taxonomies with applications to content-based recommendations», авторы Аггарвал и др., международная классификация G06F 17/30), а также метод создания категоризированных баз документов, описанный в патентной заявке США 20070106662 («Categorized document bases», aвторы Кимброу и др.), рассматривающие похожесть пар записей (документов) в соответствии с заданной таксономией. В отличие от настоящего изобретения они не решают проблему позиционирования документов в пространстве знаний, а относятся только к поиску похожих документов.
Наиболее близкой к предлагаемому способу является представленная Райс и др. патентная заявка США номер 20080027929 «Компьютерный метод для поиска похожих объектов с использованием таксономии» («Computer-based method for finding similar objects using a taxonomy»).
Представленный в настоящей заявке метод отличается от способа Райс и др. тем, что он использует понятие «онтологии» как совокупности таксономии и позволяет учитывать случаи, когда таксон относится к одной или более таксономии, а также использует понятие коэффициента условности, приписываемое таксономии для определения употребимости паттерна при расчете веса категории.
Необходимо отметить, что встречающиеся в реальной жизни документы редко бывают на одну тему. Соответственно документ, как правило, позиционируется в пространстве знаний не одним, а несколькими векторами, каждому из которых может быть присвоен весовой коэффициент.
Как указывалось в вышеупомянутой работе С.Кордонского, позиция наблюдателя определяет степень значимости для него тех или иных аспектов документа и делает бессмысленной попытку определения единственно правильной «главной» темы документа.
Если признать, что для реальных текстов не существует «единственной правильной» и всеобъемлющей онтологии, становится очевидной необходимость создания аппарата позиционирования, ориентированного на получение множественного результата, оставляющего возможность выбора категории, наиболее актуальной в настоящий момент для пользователя системы.
В отличие от настоящего изобретения, все вышеописанные аналоги не рассматривают эту проблему.
Из существующего уровня техники не выявлены объекты, которые содержали бы совокупность указанных выше признаков. Это позволяет считать заявленный способ новым.
Из существующего уровня техники не известна также совокупность признаков, отличных от признаков упомянутого выше наиболее близкого аналога. Это позволяет считать заявленный способ обладающим изобретательским уровнем.
Таким образом, создание механизма позиционирования при наличии множества онтологий, каждая из которых представлена своим набором таксономии, представляется актуальным техническим результатом при создании реально функционирующей системы.
Сутью изобретения является метод позиционирования документов в пространстве знаний, представленном множеством онтологий, которые в свою очередь представлены набором объединяющих паттерны таксономий (см. фиг.2). В отличие от ближайшего аналога (патентная заявка Райс и др.) таксоны используются как обобщение терминов и могут описывать не только наборы релевантных терминов, но и фразы и выражения, рассматриваемые как признаки соответствующих категорий. Так же, как и в рассматриваемом аналоге, один и тот же паттерн может входить в различные категории. В отличие от ближайшего аналога, в данном методе каждая категория может одновременно являться вершиной одного дерева и подкатегорией других деревьев.
В отличие от всех перечисленных методов в данном изобретении таксономии объединяются в онтологии с едиными правилами интерпретации таксонов, а на паттерн могут накладываться дополнительные условия его применения. Например, условный паттерн "финансовый кризис" может входить в дерево категорий, верхние узлы которых обозначены как "Россия", "Германия", "США", но в каждом из трех таксонов будет рассматриваться только при наличии других паттернов, явно принадлежащих этому дереву.
Пространство знаний, онтологии, таксономии и формы их представления в виде направленных ациклических графов или иные не являются предметом настоящего изобретения. Общеизвестный язык RDF (Resource Description Framework) и другие общеизвестные языки описания онтологий и таксономий могут использоваться в качестве входного описания таксономий с последующей трансляцией на язык внутреннего представления категоризатора(310, фиг.3). Возможны и другие варианты входного описания таксономий, подразумевающие создание специальных программных средств-конверторов из языка внешнего представления во внутреннее представление категоризатора.
Краткое описание чертежей
Фиг.1. Диаграмма, показывающая образец онтологии, объединяющей таксономии, представленные в виде направленных ациклических графов.
Фиг.2. Диаграмма, показывающая образец таксономии, представленной в виде направленного ациклического графа, с относящимися к таксонам паттернами.
Фиг.3. Диаграмма, иллюстрирующая вариант осуществления изобретения.
Подробное описание варианта осуществления изобретения
Входной текст 301 (фиг.3) разбивается на предложения 302. Каждое предложение рассматривается на наличие слов и выражений 303, соответствующих паттернам, известным категоризатору 310. На основе паттернов ПH, для которых найдены релевантные слова или выражения в тексте, в имеющихся таксономиях и онтологиях выделяются поддеревья (подграфы) 304, содержащие понятия, соответствующие данному паттерну и всем его родительским понятиям. Найденные паттерны ПH подтверждают гипотезу о принадлежности текста к соответствующим категориям. При этом рассматриваются не только категории, прямо подтвержденные паттернами ПH, но и категории, включающие прямо подтвержденные категории. Поддеревья, состоящие из одного таксона, ведущего к одному понятию, отбрасываются.
Далее в каждом из полученных поддеревьев определяется значение веса каждой категории 305. Вес категории рассчитывается как:
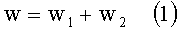
где
w1 - сумма весов всех понятий, напрямую связанных с этой категорией,
w2 - вес всех поддеревьев, относящихся к этому узлу, вычисляемый как
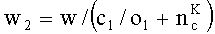 ,
,
где
w - сумма весов всех паттернов ПH, входящих в поддерево,
c1 - число ветвей в поддереве,
o1 - число паттернов в поддереве,
nc - число узлов в поддереве.
Вес паттерна везде равен 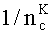 , где
, где
nc - число категорий, с которыми напрямую связан этот паттерн ПH,
К- коэффициент, принимающий значения от 0.3 до 3.
Совокупность векторов, ведущих от верхних категорий таксономии до подтвержденных подкатегорий, отранжированных в порядке весов категорий, показывает позицию данного документа в пространстве знаний.
При этом поддеревья 306, связанные с общей родительской категорией или, при ее отсутствии, верхними подтвержденными категориями, которые имеют значение веса ниже границы отсечения для онтологии, в которую они входят, отбрасываются, то есть признаются малозначимыми.
Значимость категории в таксономии зависит от онтологии и определяется числом отсечения, являющимся характеристикой данной онтологии. В соответствии с набранным весом мы можем определить категории как более или менее значимые для данного документа. При этом в сравнении могут участвовать только категории, принадлежащие таксономиям одной онтологии. Например, рассматривая таксономии "цвет" и "транспортные средства", принадлежащие к разным онтологиям, по-видимому, бессмысленно при поступлении входного текста "красный автомобиль" пытаться определить, является ли данный предмет более красным, чем автомобилем.
В значимые попадают только те категории, которые имеют численное значение веса, превышающее число отсечения, указанное для данной онтологии. Например, текст, содержащий только фрагменты, соответствующие паттернам "Виктор Ющенко", "Юлия Тимошенко", "газовый конфликт", "переговоры с Россией", может породить гипотезы о значимости таксонов: "правительство Украины", "международные экономические отношения", "соглашение о транспортировке газа", "пчеловодство". Гипотеза о том, что в данном документе речь идет о пчеловодах (поскольку В. Ющенко является известным пчеловодом) будет отвергнута, поскольку не находит каких-либо подтверждений другими паттернами документа. То есть "Виктор Ющенко" будет рассматриваться только в контексте его государственной деятельности, а не в контексте его персональных увлечений.
Перед расчетом весовых коэффициентов из рассмотрения исключаются все паттерны, не соответствующие заданным условиям. Так, например, если условием является обязательное подтверждение наличия не менее определенного количества паттернов, подтверждающих данную категорию, то паттерны, не набравшие указанного числа, исключаются из рассмотрения.
Одинаковые по написанию паттерны могут иметь разные специфические атрибуты (как правило, название одной из родительских категорий), указывающие границы действия коэффициента условности 307. Это позволяет указывать разные значения условности для одинаковых по написанию паттернов. Тогда, например, изменение в условности паттерна "шина (автотранспорт)" не будет влиять на значение условности паттерна "шина (травматология)". С помощью условных паттернов, в частности, могут описываться свойства, которые сами по себе не определяют точно объект или явление, а могут принадлежать другим классам объектов или явлений, но в определенных обстоятельствах позволяют сделать выбор нужного объекта. Например, паттерн, соответствующий значению "одно спальное место" или "два спальных места", сам по себе не указывает на то, что речь в документе идет про гостиницу или поезд, или самолет бизнес-класса, но в сочетании с паттернами, определяющими тему "автомобильный транспорт", позволяет сделать вывод, что речь идет не обо всех автомобилях, а только о седельных тягачах или мобильных домах.
В результате для исходного текста определяется набор векторов, указывающих на категории, определяющие контекст данного документа, что и рассматривается как позиция документа в пространстве знаний.
В качестве похожих могут рассматриваться документы, имеющие сходные вектора ("документы об одном и том же"); документ, вектора которого входят как подмножество в набор векторов другого документа (статья про самолет По-2 может входить как подмножество в обширный документ "история авиации СССР").
Все рассмотренные выше действия выполняются с помощью общеизвестных программных операций - сравнений, подсчета повторений, вычисления статистических величин, работы с матрицами и т.п. Конкретный вид соответствующих программ будет определяться конкретным видом аппаратного обеспечения и установленной на нем операционной системы и не является предметом патентных притязаний заявителей.
Таким образом, из приведенного описания видно, что предлагаемое изобретение позволяет идентифицировать (располагать в пространстве знаний) различные объекты с учетом их подобия.
Настоящее изобретение может использоваться в различных областях информационных технологий, например в информационном поиске, оценке ситуаций, контекстной рекламе, может являться основой для построения поисковых систем, которые в отличие от традиционного поиска по образцу сочетают поиск по образцу с "поиском по понятиям", то есть поиском по положению документов в пространстве знаний. Например, при обычном поиске результаты запроса «кризис в России» будут содержать все документы, содержащие слова, упоминаемые в данном запросе, тогда как при использовании алгоритма поиска в пространстве знаний результаты поиска будут релевантны смысловому наполнению запроса. К примеру, "акция массового неповиновения в Дальнегорске" имеет отношение к «кризису в России», но при обычном поиске этот результат не будет получен, поскольку слова «кризис» и «Россия» прямо не упоминаются в документе про «акцию массового неповиновения в Дальнегорске».
Кроме того, данный алгоритм может применяться как средство сопоставления документов в контекстной рекламе; поведенческой рекламе (наличие пространства знаний позволяет вводить понятие "поведение клиента" как историю его перемещений по документам, позиционируемым в данном пространстве, или как историю его перемещений по документам, соответствующим категориям пространства); при привязывании к документу релевантных документов, то есть документов, обладающих аналогичным набором векторов пространства знаний.
Использование настоящего изобретения позволяет получить технический результат, состоящий в увеличении финансовой эффективности систем контекстной рекламы за счет увеличения релевантности демонстрируемых рекламных объявлений; увеличении эффективности систем информационного поиска за счет более точной, релевантной и пертинентной выдачи результатов; улучшении функционирования поисковых систем за счет более четкого таргетирования информации и рекламы.
Приведенные примеры реализации настоящего изобретения служат лишь в качестве иллюстраций и никоим образом не ограничивают объема патентных притязаний, определяемого нижеследующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПОСТРОЕНИЯ СЕМАНТИЧЕСКОЙ МОДЕЛИ ДОКУМЕНТА | 2011 |
|
RU2487403C1 |
| СИСТЕМА И МЕТОД АВТОМАТИЧЕСКОГО СОЗДАНИЯ ШАБЛОНОВ | 2018 |
|
RU2697647C1 |
| ОПРЕДЕЛЕНИЕ СТЕПЕНЕЙ УВЕРЕННОСТИ, СВЯЗАННЫХ СО ЗНАЧЕНИЯМИ АТРИБУТОВ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ | 2016 |
|
RU2640297C2 |
| Построение корпуса сравнимых документов на основе универсальной меры похожести | 2014 |
|
RU2607975C2 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| МНОГОЭТАПНОЕ РАСПОЗНАВАНИЕ ИМЕНОВАННЫХ СУЩНОСТЕЙ В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ МОРФОЛОГИЧЕСКИХ И СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2619193C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ, СОДЕРЖАЩИХ ТЕКСТ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2607976C1 |
| ВОССТАНОВЛЕНИЕ ТЕКСТОВЫХ АННОТАЦИЙ, СВЯЗАННЫХ С ИНФОРМАЦИОННЫМИ ОБЪЕКТАМИ | 2017 |
|
RU2665261C1 |
| СПОСОБ И СИСТЕМА ДЛЯ МАШИННОГО ИЗВЛЕЧЕНИЯ И ИНТЕРПРЕТАЦИИ ТЕКСТОВОЙ ИНФОРМАЦИИ | 2015 |
|
RU2592396C1 |
| Способ формирования математических моделей пациента с использованием технологий искусственного интеллекта | 2017 |
|
RU2720363C2 |
Изобретение относится к идентификации объектов по их текстовым или иным описаниям и может использоваться, например, в анализе ситуаций, при информационном поиске, в построении поисковых систем, в системах контекстной рекламы и т.п. Техническим результатом является повышение эффективности поисковых систем, систем контекстной рекламы и систем поведенческого таргетирования в сети Интернет. Указанный технический результат достигается путем использования способа позиционирования текстов в пространстве знаний. В предлагаемом способе из входных данных выделяют элементы, соответствующие паттернам, входящим в таксоны, образующие таксономии, объединенные в онтологии. Определяют значимые таксоны, которые взвешивают с учетом условий, приписанных паттернам. Составляют набор взвешенных векторов, позиционирующих входной документ в пространстве знаний. При этом для позиционирования используют множество онтологий. При составлении наборов векторов рассматривают только те элементы, которые соответствуют паттернам, входящим в один таксон или в таксоны, имеющие общие родительские таксоны. 2 з.п. ф-лы, 3 ил.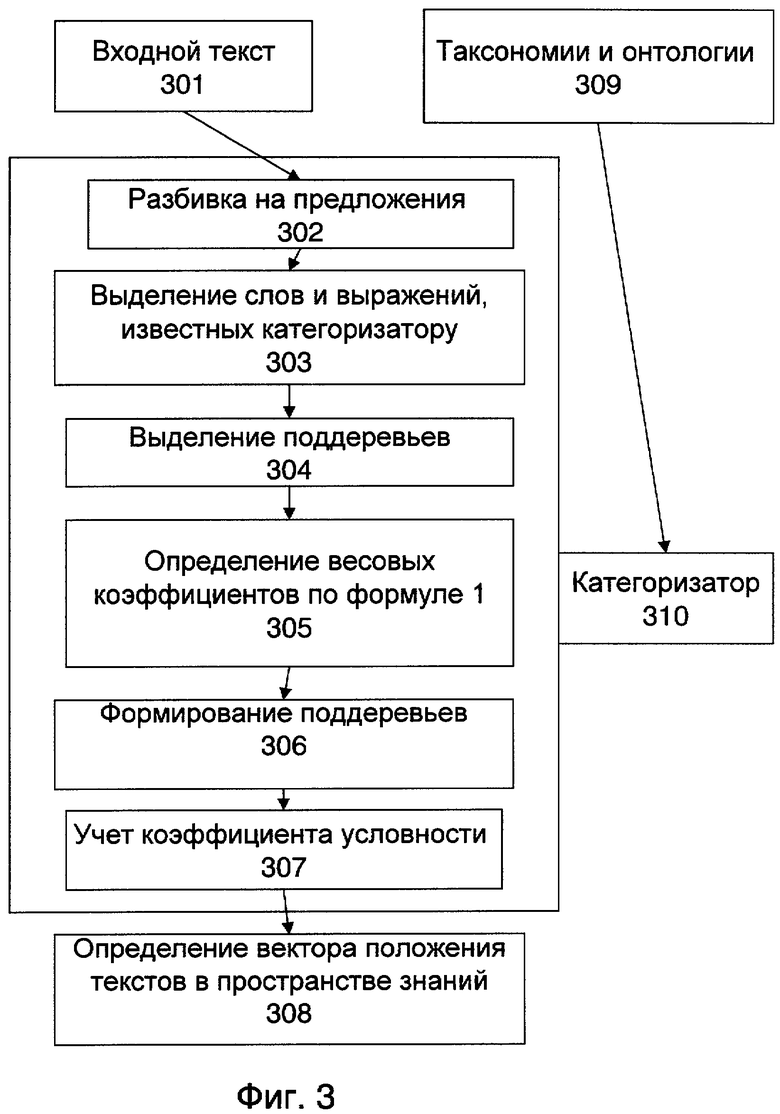
1. Способ позиционирования текстов в пространстве знаний, заключающийся в том, что (а) из входных данных выделяют элементы, соответствующие паттернам, входящим в таксоны, образующие таксономии, объединенные в онтологии; (б) определяют значимые таксоны, которые взвешивают с учетом условий, приписанных паттернам; (в) составляют набор взвешенных векторов, позиционирующих входной документ в пространстве знаний, отличающийся тем, что в нем для позиционирования используют множество онтологии, а также тем, что при составлении наборов векторов рассматривают только те элементы, которые соответствуют паттернам, входящим в один таксон или в таксоны, имеющие общие родительские таксоны.
2. Способ по п.1, отличающийся тем, что все таксоны, кроме верхнего таксона таксономии, могут являться дочерними одновременно для нескольких родительских таксонов.
3. Способ по п.1, отличающийся тем, что использует понятие коэффициента условности как условие, указывающее возможность употребления паттерна только в заданном контексте.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 6360227 B1, 19.03.2002 | |||
| US 6442545 В1, 27.08.2002 | |||
| СПОСОБ ИДЕНТИФИКАЦИИ ОБЪЕКТОВ ПО ИХ ОПИСАНИЯМ | 1999 |
|
RU2167450C2 |
| Химический огнетушитель | 1927 |
|
SU8675A1 |

