Изобретение относится к автоматике и вычислительной технике и может быть использовано для предварительной обработки сообщений графического формата (СГФ). Предлагаемый способ позволяет выявить контентное содержание растрового изображения.
В настоящее время известны различные способы распознавания сообщений и обработки информации. В частности, в качестве аналогов можно назвать следующие способы.
1. Дерягин Д.Г., Сапроненко В.М. Способ распознавания текстовой информации из векторно-растрового изображения. Патент РФ №2309456, G06K 9/36, 2007 // Изобретения. - М.: ФИПС, 2007.
2. Чанде С., Сааринен П. Обработка информации. Патент РФ №2387007, G06K 9/00, 2010 // Изобретения. - М.: ФИПС, 2010.
3. Лысенко В.Л. Способ распознавания кодированных изображений. Патент РФ №2126552, G06K 9/00, 1999 // Изобретения. - М.: ФИПС, 1999.
В качестве прототипа при разработке предлагаемого способа распознавания контентного содержания СГФ использован «Способ распознавания текстовой информации из векторно-растрового изображения» Патент РФ №2309456, G06K 9/36, 2007. В прототипе для решения задачи выявляют текстовые объекты и извлекают информацию о визуальном оформлении документа.
В прототипе в рамках предварительной обработки (перед распознаванием символов) используя атрибуты форматирования файла, имеющиеся в файле растрового изображения, выполняют следующие операции.
1) Выполняют разбиение изображения до получения областей (фрагментов), содержащих неразрывный логически связанный текст наибольшего размера. Для этого изображение разбивают на области, предположительно содержащие текст, и затем анализируют соседние области на возможность их объединения в более крупные фрагменты.
2) Выполняют разбиение текстовых объектов на отдельные символы и группы символов по предполагаемым местам размещения пробелов или других неидентифицируемых символов, анализ и составление (объединение, сборка) групп символов в строки. Для разбиения на отдельные символы и группы символов выполняют преобразование абсолютных координат символов в группы, разделенные пробелами и увеличенными межсимвольными промежутками.
3) Выполняют обработку и анализ растровых объектов для выявления изображения текста в нетекстовых объектах, анализ для выявления векторных объектов, отличных от разделителей, в том числе выходящих за пределы объекта.
Недостаток прототипа состоит в его применимости для извлечения только текстовой информации и информации о форматировании документа.
Технический результат предлагаемого способа состоит в расширении возможностей по распознаванию контентного содержания изображений, которые заключаются в возможности выявлять сообщения графических форматов, содержащие рисунки, баннеры, чертежи, диаграммы, тексты, таблицы и графические интерпретации кодов (контентное содержание), а также в ускорении процесса обработки за счет исключения процедур разбиения изображения на связанные тексты и поиска предполагаемых мест расположения пробелов и неидентифицируемых символов.
Известный способ (прототип) не позволяет достичь заявленного технического результата.
Основу предлагаемого способа распознавания контентного содержания растрового изображения составляют теоретические предпосылки в виде выявленных статистических свойств, присущих структуре сообщений графических форматов с различным содержанием (контентом). С учетом этого способ включает в себя два основных этапа (фиг.1).
На первом этапе реализации способа определяют (оценивают) объем растра изображения, содержащегося в СГФ, и отсеивают сообщения, принадлежащие к элементам Web-дизайна (баннеры). На втором этапе оценивают значение признаков, характеризующих энтропию сообщений графических форматов и принимают решение о контентном содержании сообщения.
Предлагаемый способ позволяет разделять сообщения графических форматов на следующие классы:
- сообщения графических форматов, содержащих художественные изображения (фотографии, рисунки), - гипотеза W1;
- сообщения графических форматов, содержащих изображения с малой динамикой структурных связей в растре (комиксы, чертежи, диаграммы, схемы), - гипотеза W2;
- сообщения графических форматов, содержащих изображения с большой динамикой структурных связей в растре (тексты, таблицы, карты), - гипотеза W3;
- сообщения графических форматов, содержащих неструктурированные изображения с большой динамикой связей в растре (графические коды, шифры, изображения с поврежденным растром), - гипотеза W4;
- сообщения графических форматов, содержащие изображения с малым расширением (баннеры, иконки, элементы Web-дизайна и т.д.), - гипотеза W5.
Сущность способа состоит в реализации совокупности следующих процедур.
Этап 1. Первый этап обработки СГФ предназначен для выявления сообщений с малым объемом растра и их обработки. На первом этапе выполняют следующие процедуры.
1) Принятый графический файл S(i) декодируют в сообщение графического формата S[m,n,h].
2) Сообщение графического формата преобразуют в двумерный массив размером m×n элементов, описывающий структуру растра изображения, при этом:
- если массив является трехмерным (h=3), то СГФ преобразуют в цветоразностную систему YCrCb и для расчета информативного признака используют двумерный массив Y[m,n];
- если массив является одномерным (параметр h=1), то для расчета информативного признака используют двумерный массив S[m,n,1].
3) Определяют объем растра изображения VS=mn и полученное значение объема растра VS сравнивают с пороговым значением VP, при этом:
- если полученное значение объема растра VS удовлетворяет неравенству VS<VP, то принимают решение в пользу гипотезы W5;
- если полученное значение объема растра VS удовлетворяет условию VS≥VP, то принимают решение о принадлежности СГФ к одной из гипотез W1, W2, W3 или W4 и исходные данные поступают для расчета значения информативного признака.
В рамках предлагаемого способа в качестве порогового значения объема растра предлагается величина VP≈40000, которая определяется на основе анализа многочисленных СГФ в реальных каналах передачи данных.
Этап 2. На втором этапе производится вычисление и оценивание результирующего информативного признака, по значениям которого СГФ разделяется на указанные классы. На втором этапе выполняют следующие процедуры.
1) Рассчитывают значение результирующего информативного признака 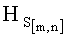 характеризующего контентное содержание СГФ.
характеризующего контентное содержание СГФ.
Для вычисления результирующего информативного признака при распознавании контента СГФ предлагается многоуровневая схема преобразований структурных признаков объекта с целью получения значений, характеризующих энтропию СГФ.
В рамках решения задачи оценивания контентного содержания сообщений графических форматов первичными признаками, доступными субъекту непосредственно или с помощью специальных средств наблюдения, являются элементы структуры растра вида

которые объединяют в две подгруппы признаков первого уровня и образуют упорядоченные множества векторов 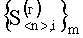 , i=1(1)m и
, i=1(1)m и 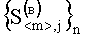 , j=1(1)n. С признаками первого уровня производят операцию расчета построчного (постолбцового) коэффициента корреляции между соседними векторами из множеств
, j=1(1)n. С признаками первого уровня производят операцию расчета построчного (постолбцового) коэффициента корреляции между соседними векторами из множеств 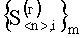 , i=1(1)m и
, i=1(1)m и 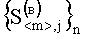 , j=1(1)n, в результате чего образуются признаки второго уровня в виде коэффициента корреляции:
, j=1(1)n, в результате чего образуются признаки второго уровня в виде коэффициента корреляции:
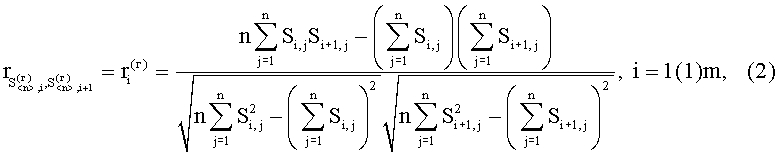
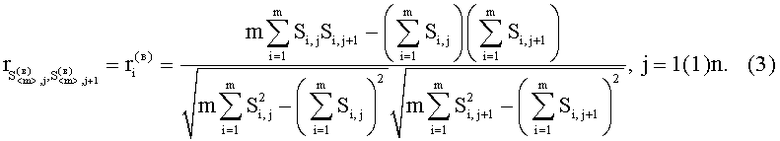
Признаки второго уровня представляют собой элементы векторов 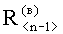 и
и 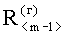 , в которых содержатся результаты расчета построчных (постолбцовых) коэффициентов корреляции. Над признаками второго уровня производят операцию вычисления отклонений элементов векторов
, в которых содержатся результаты расчета построчных (постолбцовых) коэффициентов корреляции. Над признаками второго уровня производят операцию вычисления отклонений элементов векторов 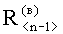 и
и 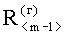 коэффициентов корреляций от значений линейных трендов
коэффициентов корреляций от значений линейных трендов 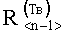 и
и 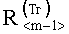 :
:
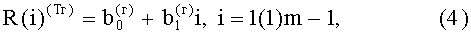
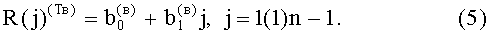
В результате вычисления отклонений формируются признаки третьего уровня в виде:
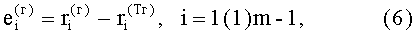
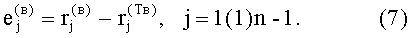
Признаки третьего уровня представляют собой значения элементов векторов 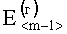 и
и 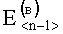 , которые характеризуют нелинейные отношения элементов структуры растра изображения. При этом чем больше динамика изменения значений соседних элементов векторов
, которые характеризуют нелинейные отношения элементов структуры растра изображения. При этом чем больше динамика изменения значений соседних элементов векторов 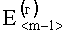 и
и 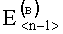 , тем больше динамика (хаотичность) нелинейных связей в структуре растра изображения, т.е. тем больше энтропия СГФ. Вычислительные процедуры на третьем уровне обеспечивают расчет величины, характеризующей зависимость (динамику) между элементами векторов
, тем больше динамика (хаотичность) нелинейных связей в структуре растра изображения, т.е. тем больше энтропия СГФ. Вычислительные процедуры на третьем уровне обеспечивают расчет величины, характеризующей зависимость (динамику) между элементами векторов 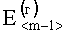 и
и 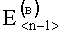 , которая представляет собой среднее значение разности соседних элементов в массивах
, которая представляет собой среднее значение разности соседних элементов в массивах 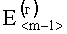 и
и 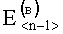 :
:
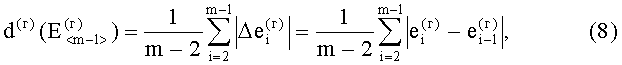
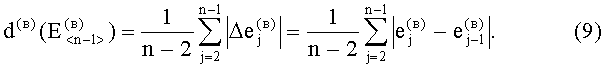
В результате вычислений по формулам (8) и (9) образуются признаки четвертого уровня, которые определяют числовые значения составляющих d(г)(Е<m-1>) и d(в)(Е<n-1>) результирующего информативного признака оценивания контентной информации СГФ.
На четвертом уровне вычисляют значение результирующего информативного признака 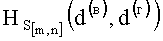 по выражению вида
по выражению вида
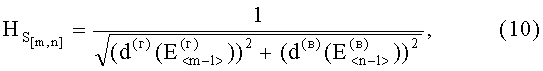
и разделяют изображений в соответствии с их контентным содержанием.
Таким образом, вычисление результирующего информативного признака для разделения изображений с различным контентным содержанием осуществляют с помощью сложной четырехуровневой системы преобразований структурных признаков исходного СГФ. В результате преобразований признаковое пространство сокращается в (m·n-1) раз, что существенно уменьшает размеры признаковых описаний.
2) Полученное значение информативного признака 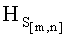 сравнивают с пороговыми значениями Hp1, Hp2 и Hp3 (исследуют значение информативного признака
сравнивают с пороговыми значениями Hp1, Hp2 и Hp3 (исследуют значение информативного признака 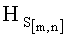 ), при этом:
), при этом:
- если полученное значение результирующего информативного признака 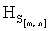 удовлетворяет условию
удовлетворяет условию 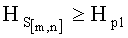 , то принимают решение в пользу гипотезы W1;
, то принимают решение в пользу гипотезы W1;
- если полученное значение результирующего информативного признака 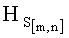 удовлетворяет условию
удовлетворяет условию 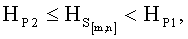 то принимают решение в пользу гипотезы W2;
то принимают решение в пользу гипотезы W2;
- если полученное значение результирующего информативного признака 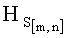 удовлетворяет условию
удовлетворяет условию  то принимают решение в пользу гипотезы W3;
то принимают решение в пользу гипотезы W3;
- если полученное значение результирующего информативного признака 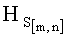 удовлетворяет условию
удовлетворяет условию 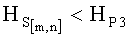 , то принимают решение в пользу гипотезы W4.
, то принимают решение в пользу гипотезы W4.
Для определения численного значения порогов принятия решения Hp1, Hp2 и Hp3 требуется оценить статистические характеристики (законы распределения) величины 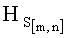 для каждого класса СГФ. В силу того что генеральная совокупность СГФ (множество различных СГФ) бесконечна, оценивание законов распределения и числовых характеристик необходимо осуществлять на основе выборочного метода.
для каждого класса СГФ. В силу того что генеральная совокупность СГФ (множество различных СГФ) бесконечна, оценивание законов распределения и числовых характеристик необходимо осуществлять на основе выборочного метода.
Для проведения выборочных наблюдений важно правильно установить требуемый объем выборки NTp, который в значительной степени определяет необходимые при этом временные, трудовые и стоимостные затраты. Для определения объема выборки необходимо задать надежность (доверительную вероятность β) и точность (доверительный интервал ε) оценок.
Для построения статистической плотности распределения вероятностей 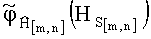 необходимо провести серию из NТрφ испытаний по схеме Бернулли (независимых и однородных). Задав максимальную вероятностную погрешность статистической оценки плотности распределения ε и доверительную вероятность β, количество проводимых испытаний NТрφ можно оценить по формуле
необходимо провести серию из NТрφ испытаний по схеме Бернулли (независимых и однородных). Задав максимальную вероятностную погрешность статистической оценки плотности распределения ε и доверительную вероятность β, количество проводимых испытаний NТрφ можно оценить по формуле

где Ф(tβ)=β.
Количество испытаний, вычисленное по формуле (11) при максимальной вероятной погрешности ε=1% и доверительной вероятности β=0,95, принимает значение NТрφ=9600.
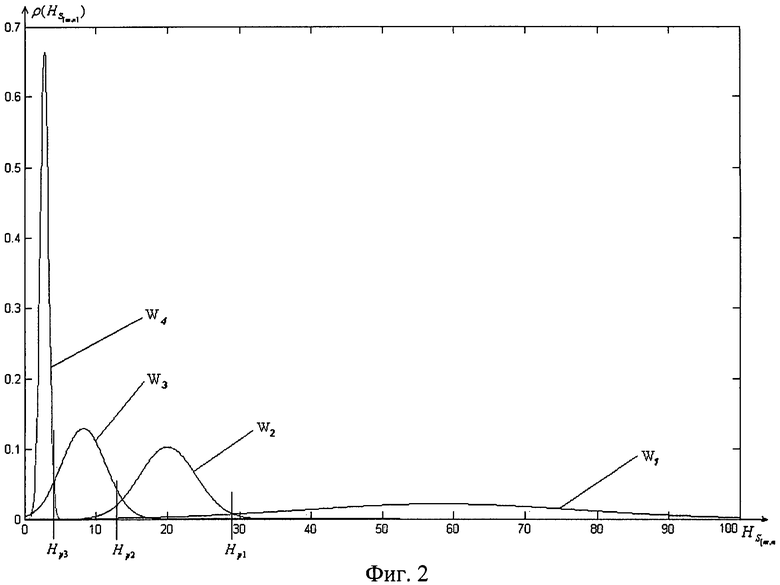
В результате исследований результирующего информативного признака методом статистических испытаний доказана возможность его описания в виде нормальных законов распределения с соответствующими оценками математического ожидания и дисперсии 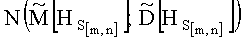 (фиг.2) для четырех классов изображений, содержащих различную контентную информацию (табл. 1).
(фиг.2) для четырех классов изображений, содержащих различную контентную информацию (табл. 1).
В связи с отсутствием априорных вероятностей появления объектов рассматриваемых классов в канале связи, а также матрицы потерь от неправильных решений для обоснования пороговых значений целесообразно использовать критерий Неймана-Пирсона. Результаты вычисления пороговых значений представлены в таблице 1.
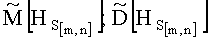
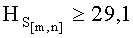
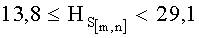
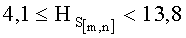
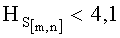
Разработанный способ позволяет осуществлять предварительное распознавание контентного содержания СГФ и основан на различиях статистических свойств структурных связей между элементами растра изображений.
Предложенный способ позволяет повысить уровень автоматизации действий по контролю за контентным содержанием сообщений, передаваемых в графическом виде, а также составляет основу для построения системы анализа и отбора сообщений графических форматов путем реализации модели отбора и методики обработки СГФ в условиях их априорной семантической неопределенности.
Изобретение относится к автоматике и вычислительной технике и может быть использовано для предварительной обработки сообщений графического формата (СГФ). Технический результат состоит в расширении возможностей по распознаванию, которые заключаются в возможности выявлять изображения, содержащие рисунки, баннеры, чертежи, диаграммы, тексты, таблицы и графические интерпретации кодов; а также в ускорении процесса обработки. Способ распознавания контентного содержания сообщения графического формата основан на последовательности операций, в результате которых декодируют сообщение с целью формирования растра изображения, оценивают объем растра изображения (произведение размеров изображения), вычисляют значение информативного признака, характеризующего неопределенность в структуре растра изображения. Предложенный способ позволяет повысить уровень автоматизации действий по контролю за контентным содержанием сообщений, передаваемых в графическом виде, а также составляет основу для построения системы анализа и отбора сообщений графических форматов путем реализации модели отбора и методики обработки СГФ в условиях их априорной семантической неопределенности. 2 ил., 1 табл.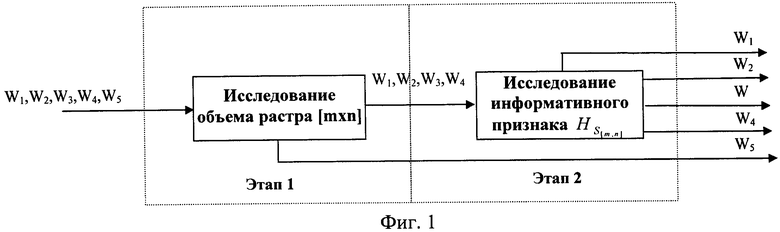
Способ распознавания контентного содержания сообщения графического формата, включающий операцию декодирования графического файла с целью формирования растра изображения, отличающийся тем, что выполняют операции по преобразованию структурных признаков изображения, вычисляют объем растра изображения, построчные и постолбцовые коэффициенты корреляции в растре изображения, отклонения значений коэффициентов корреляции от линейного тренда, среднее значение разности соседних элементов в массивах, результирующий информативный признак, характеризующий энтропию сообщений графических форматов, разделяют изображения на классы по следующим видам контентного содержания сообщений графических форматов: изображения баннеров, «иконок», элементов Web-дизайна, художественные изображения (фотографии, рисунки), структурированные изображения с малой динамикой (комиксы, чертежи, диаграммы, схемы), структурированные с большой динамикой (тексты, таблицы, карты), неструктурированные с большой динамикой (коды, ошибки).
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ ИЗ ВЕКТОРНО-РАСТРОВОГО ИЗОБРАЖЕНИЯ | 2005 |
|
RU2309456C2 |
| СПОСОБ ОБНАРУЖЕНИЯ ТЕКСТА В РАСТРОВОМ ИЗОБРАЖЕНИИ (ВАРИАНТЫ) И СПОСОБ ВЫЯВЛЕНИЯ СПАМА, СОДЕРЖАЩЕГО РАСТРОВЫЕ ИЗОБРАЖЕНИЯ | 2007 |
|
RU2363047C1 |
| Устройство для формирования информативных признаков при распознавании изображений | 1987 |
|
SU1559358A1 |
| СПОСОБ РАСПОЗНАВАНИЯ КОДИРОВАННЫХ ИЗОБРАЖЕНИЙ | 1995 |
|
RU2126552C1 |
| Вибросверлильное устройство | 1973 |
|
SU457547A1 |

