ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Изобретение в общем относится к распределенным приложениям и более конкретно к распределенным многомодальным приложениям, осуществленным в среде системы клиент-сервер.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
«Модальность» интерфейса пользователя может быть определена как режим взаимодействия между пользователем и электронным устройством, где взаимодействие осуществляется посредством интерфейса пользователя этого устройства. Модальность интерфейса пользователя может быть осуществлена посредством комбинации аппаратного и программного обеспечения с конкретным типом информации, воспринимаемой человеком (например, информации, воспринимаемой посредством зрения, звука или прикосновения), и/или информации, сформированной человеком (например, информации, сформированной посредством речи или другого физического действия). Например, одним типом модальности интерфейса пользователя является «визуальная модальность», которая может быть осуществлена посредством экрана дисплея и связанного с ним аппаратного и программного обеспечения для формирования визуального отображения на экране дисплея. Визуальная модальность так же может быть осуществлена, используя различные устройства ввода, которые обеспечивают взаимодействия пользователя с визуальным отображением, такие как устройства ввода, которые дают пользователю возможность выбирать информацию, которая визуализируется на визуальном отображении (например, использование механизма прокрутки, сенсорного экрана или кнопок перемещения курсора) для того, чтобы вводить информацию в поля визуального отображения (например, используя цифровую клавиатуру), и/или для того, чтобы изменять фокус визуального отображения от одного поля к другому. Другим типом модальности интерфейса пользователя является «голосовая модальность», которая может быть осуществлена, используя микрофон, громкоговоритель и связанное с ними аппаратное и программное обеспечение, выполненное с возможностью принимать и оцифровывать речь человека, и/или для того, чтобы выводить аудиоинформацию (например, аудиоподсказки или другую аудиоинформацию). Другие типы модальностей интерфейса пользователя включают в себя, например, чтобы назвать всего лишь две, жестикуляционные модальности и перьевые модальности.
В интересах предоставления улучшенной практичности в сравнении с устройствами «одной модальности» электронные устройства могут включать в себя «многомодальный» интерфейс пользователя, который является интерфейсом пользователя, который предоставляет более одной модальности интерфейса пользователя. Например, электронное устройство может предоставлять как визуальную модальность, так и голосовую модальность. Такое устройство может, например, одновременно выдавать визуальную информацию (например, отображаемую информацию) и связанную с ней аудиоинформацию (например, аудиоподсказки), и/или устройство может предоставлять пользователю, по желанию пользователя, возможность вводить информацию посредством речи, цифровой клавиатуры или совместно. В основном, устройство, имеющее многомодальный интерфейс пользователя, обеспечивает улучшенное впечатление пользователя, так как пользователь может выбирать модальность, с помощью которой он или она будет взаимодействовать с устройством. Взаимодействие, используя голосовую модальность, может быть предпочтительным, например, в ситуации, в которой пользователь выбирает взаимодействие со свободными руками, такое как в случае, когда печатание на клавиатуре является слишком трудоемким и/или когда пользователь ослаблен либо постоянно (например, из-за артрита или некоторой другой физической неспособности), либо ситуационно (например, когда пользователь в перчатках и/или когда руки пользователя заняты другими задачами). В противоположность, взаимодействие, используя визуальную модальность, может быть предпочтительным, например, в ситуации, в которой комплексная информация должна быть визуализирована, в случае, когда требуется звуковая конфиденциальность, когда существуют ограничения по шуму и/или когда существуют слуховые ограничения либо постоянные (например, когда у пользователя сложный акцент, недостатки речи и/или ослабленный слух), либо ситуационные (например, когда присутствует значительный фоновый шум или ограничения по шуму).
Многомодальный интерфейс пользователя может быть осуществлен совместно с приложением, которое работает в сетевой среде (например, в среде системы клиент-сервер). В таком случае пользователь взаимодействует с многомодальным интерфейсом пользователя на клиентском устройстве (например, сотовом телефоне или компьютере), а клиентское устройство обменивается информацией с одним или более другими устройствами или платформами (например, сервером) через сеть. В такой сетевой среде были осуществлены две основные технологии для того, чтобы создать элементы системы клиент-сервер, которые поддерживают многомодальный интерфейс пользователя и, более конкретно, элементы системы, которые поддерживают интерфейс пользователя, выполненный с возможностью предоставлять, по меньшей мере, визуальную и голосовую модальность. При использовании «встроенной» технологии, главным образом, все необходимое аппаратное и программное обеспечение, связанное с разнообразными модальностями, включено в само клиентское устройство. Например, клиентское устройство может включать в себя программное и аппаратное обеспечение, выполненные с возможностью выполнять задачи, относящиеся к аудио, такие как обработка речи, распознавание речи и/или синтез речи, среди прочих вещей. В основном, такие задачи, относящиеся к аудио, неизбежно влекут за собой использование специализированных процессоров или механизмов обработки (например, процессоров цифровой обработки сигнала) и существенный объем памяти (например, для хранения таблиц и программного обеспечения, связанного с задачами, относящимися к аудио). Используя «распределенную» технологию, часть обработки, связанной с одной или более модальностями, может быть перенаправлена другому элементу обработки, как например удаленному серверу. Например, когда пользователь говорит, аудиоданные могут отсылаться от клиентского устройства удаленному серверу, а удаленный сервер может выполнять некоторые или все из относящихся к аудио задач и возвращать данные, сообщения об ошибках и/или результаты обработки клиентскому устройству.
Каждая технология имеет свои преимущества и недостатки. Например, преимуществом некоторых традиционных распределенных технологий является то, что некоторые вычислительно напряженные процессы, связанные с многомодальным интерфейсом пользователя (например, задачи, относящиеся к аудио), могут быть выведены за пределы клиентского устройства на другой элемент обработки (например, удаленный сервер), как уже упоминалось. Соответственно, клиентское устройство может не включать в себя специализированные процессоры или механизмы обработки (например, процессоры цифровой обработки сигнала) и дополнительную память для осуществления задач, которые перенаправлены с клиентского устройства. Это означает, что клиентское устройство может быть выполнено более рентабельным образом (например, устройство может быть выполнено в качестве «тонкого» клиента), в сравнении с клиентскими устройствами, которые реализуют встроенные технологии.
Тем не менее, используя традиционные распределенные технологии, состояния различных модальностей должны быть синхронизированы между клиентом и сервером. Согласованной синхронизации между состояниями разнообразных модальностей трудно добиться через сеть. Осуществление многомодального интерфейса пользователя, использующего традиционные распределенные технологии, как правило, выполняется, используя нестандартные протоколы, измененные визуальные и речевые языки разметки приложения и нетрадиционные технологии авторинга (формирования в соответствии с определенным стандартом) контента. Соответственно, такие технологии неохотно принимаются разработчиками приложения.
Что требуется, так это способы многомодального интерфейса пользователя и устройство, которые могут способствовать разработкам тонкого клиента и использованию стандартных протоколов и традиционных технологий авторинга контента. Другие особенности и признаки изобретения станут явными из последующего подробного описания и прилагаемой формулы изобретения, совместно с сопроводительными чертежами и этими предпосылками создания изобретения.
ПЕРЕЧЕНЬ ФИГУР ЧЕРТЕЖЕЙ
Изобретение будет здесь и далее описано совместно со следующими фигурами чертежей, при этом подобные цифровые обозначения указывают подобные элементы, и
Фиг. 1 является упрощенной схемой системы, выполненной с возможностью осуществления распределенных многомодальных приложений, в соответствии с примером варианта осуществления;
Фиг. 2 является логической блок-схемой способа инициирования и проведения сеанса многомодального приложения в соответствии с примером варианта осуществления;
Фиг. 3 является логической блок-схемой способа выполнения синхронизации сеанса многомодального приложения в соответствии с примером варианта осуществления;
Фиг. 4 является примером многомодальной страницы, визуализированной на клиентском устройстве, в соответствии с примером варианта осуществления;
Фиг. 5 является логической блок-схемой способа выполнения процесса обработки события ввода голосовой модальности в соответствии с примером варианта осуществления; и
Фиг.6 является логической блок-схемой способа выполнения процесса обработки события ввода визуальной модальности в соответствии с примером варианта осуществления.
ПОДРОБНОЕ ОПИСАНИЕ
Варианты осуществления включают в себя способы и устройство для осуществления распределенных многомодальных приложений. Эти варианты осуществления могут обеспечить использование стандартных протоколов и традиционных технологий авторинга контента. В добавление, эти варианты осуществления могут быть использованы совместно с устройствами типов «тонкого клиента».
Использованный здесь термин «многомодальный» означает выполненный с возможностью осуществить разнообразные модальности интерфейса пользователя. Термины «распределенное многомодальное приложение», «многомодальное приложение» и «распределенное приложение» могут использоваться взаимозаменяемо для того, чтобы означать приложение программного обеспечения, которое предоставляет многомодальный интерфейс пользователя на клиентском устройстве (например, клиентском устройстве 102, Фиг. 1) и которое включает в себя отдельные компоненты, которые исполняются в раздельных средах исполнения на различных платформах (например, клиентское устройство 102, сервер приложения 104 и/или голосовой сервер 106, Фиг.1).
В варианте осуществления распределенные многомодальные приложения выполнены с возможностью выполняться на системах, имеющих архитектуру систем клиент-сервер (например, система 100, Фиг. 1). Используемые здесь термины «клиент» или «клиентское устройство» могут использоваться взаимозаменяемо для того, чтобы означать объект обработки, электронное устройство или приложение, которое выполнено с возможностью выполнять программное обеспечение, связанное с распределенным многомодальным приложением. В добавление, клиентское устройство выполнено с возможностью получать доступ, через сеть, к одной или более услугам, которые связаны с распределенным многомодальным приложением и которые предоставляются одним или более удаленным серверами.
Термин «сервер» означает обрабатывающий объект, электронное устройство или приложение, которое выполняет услуги для одного или более подсоединенных через сеть клиентов или других серверов в ответ на выданные клиентом или выданные сервером запросы. Термин «сервер приложения» или «AS» означает сервер, выполненный с возможностью инициировать установление соединений управления или данных, связанных с сеансом распределенного многомодального приложения, а также управлять синхронизацией между различными «представлениями», связанными с сеансом приложения. Термин «сервер модальности» означает сервер, приспособленный для браузера, который связан с одной или более модальностями интерфейса пользователя. Термины «голосовой сервер» и «VS» означают сервер модальности, который конкретно выполнен с возможностью исполнять браузер, связанный с голосовой модальностью. Несмотря на то, что описание ниже включает в себя подробные описания систем, в которых голосовой сервер включен для того, чтобы поддерживать голосовую модальность, должно быть понятно, что другие типы серверов модальности, которые поддерживают другие типы модальностей интерфейса пользователя, в добавление или в качестве альтернативы, могут быть включены в систему в других вариантах осуществления (например, жестикуляционная модальность, перьевая модальность и т.д.)
Конкретный пример распределенного многомодального приложения будет использован на протяжении этого описания для того, чтобы способствовать пониманию примера варианта осуществления. Должно быть понятно, что пояснительный пример не должен восприниматься в качестве ограничивающего объем вариантов осуществления только до этого примера. В примере варианта осуществления, распределенное многомодальное приложение выполнено с возможностью поддерживать визуальную модальность и голосовую модальность. Клиентское устройство включает в себя браузер с «возможностью многомодального режима», который выполнен с возможностью интерпретировать машинный код, который предписывает клиентскому устройству визуализировать визуальное отображение, которое включает в себя, по меньшей мере, один элемент отображения, для которого входные данные являются принимаемыми клиентским устройством посредством визуальной модальности и голосовой модальности. В варианте осуществления машинный код включен внутрь и/или на него имеется ссылка со стороны многомодальной страницы, которая, когда интерпретируется, предписывает клиентскому устройству визуализировать разнообразные элементы отображения, взаимодействующие с пользователем (например, поля ввода данных для города, штата, номера улицы и названия улицы).
Используемый здесь термин «интерпретировать» означает интерпретировать и/или исполнять в качестве терминов, понимаемых специалистами в соответствующей области техники. Используемый здесь, термин «машинный код» означает разметку (например, разметку, набранную в стандартном языке обобщенной разметки (SGML), расширяемом языке разметки (XML), языке гипертекстовой разметки (HTML), расширяемом HTML (XHTML), динамическом HTML (DHTML), VoiceXML, тэгами языка речевого приложения (SALT), XHTML+Голос (X+V), масштабируемой векторной графикой (SVG) и/или различными другими языками разметки), сценарии (скрипты) (например, код JavaScript), скомпилированный код (например, скомпилированный C/C++, Java, Lisp, Fortran, Pascal и т.д.) и/или другую информацию, которая может быть легко исполнена или интерпретирована компьютерным процессором (например, клиентским устройством 102, сервером приложения 104 и/или голосовым сервером 106, Фиг. 1).
Снова ссылаясь на пример рассматриваемого здесь многомодального приложения, пользователь клиентского устройства может вводить информацию для элемента отображения, на котором в данный момент «сфокусировано» приложение (например, элемент, который выбран или на котором моргает курсор) и/или может изменять фокус (например, посредством ввода информации для элемента отображения и/или выбора другого элемента отображения). В варианте осуществления, пользователь может вводить информацию для многомодального элемента отображения, используя как визуальную модальность, так и голосовую модальность, по желанию пользователя. Когда, например, пользователь вводит информацию, используя цифровую клавиатуру клиентского устройства, это действие соответствует вводу данных, используя визуальную модальность, и информация будет визуализирована в качестве текста в поле ввода данных, на котором сфокусировано визуальное представление. При вводе информации (например, путем нажатия «ввод» или перемещения курсора), визуальное отображение может быть обновлено для того, чтобы отражать другой фокус.
В качестве альтернативы, пользователь может вводить информацию, используя голосовую модальность (например, пользователь может произнести название города). Когда это происходит, в варианте осуществления, клиентское устройство отсылает аудиоданные, представляющие речь, голосовому серверу. В варианте осуществления аудиоданные могут быть посланы опосредованно через сервер приложения или, в другом варианте осуществления, могут быть посланы непосредственно голосовому серверу. Голосовой сервер выполнен с возможностью непосредственно взаимодействовать с модулем распознавания речи. В варианте осуществления, голосовой сервер дополнительно выполнен с возможностью указывать модулю распознавания речи, к каким ресурсам распознавания речи (например, грамматикам, последовательностям n-символов, статистическим моделям языка или другим ресурсам) модуль распознавания речи должен осуществить доступ для того, чтобы попытаться распознать речь на основе принятых аудиоданных для заданного элемента отображения. Голосовой сервер предоставляет указания на ресурсы распознавания речи для модуля распознавания речи, основанные на интерпретации голосовым браузером речевого диалога, который соответствует машинному коду (например, многомодальной странице), интерпретируемому клиентским устройством.
В варианте осуществления модуль распознавания речи может формировать результат распознавания речи (или ошибку), который голосовой сервер может передавать клиентскому устройству через сервер приложения. Затем клиентское устройство может визуализировать результат распознавания речи в качестве текста в соответствующем поле данных, а фокусы голосового представления и визуального представления могут быть обновлены и синхронизированы, в соответствии с различными вариантами осуществления. Когда фокусы голосового представления и визуального представления синхронизированы, часть речевого диалога, интерпретируемая голосовым браузером, соответствует части машинного кода, интерпретируемой клиентским устройством.
Как будет подробно описано ниже, варианты осуществления включают в себя способы синхронизации визуального представления и голосового представления в свете способности пользователя вводить информацию, используя разнообразные модальности. Это может быть единообразно достигнуто в различных вариантах осуществления, даже несмотря на то что определение фокуса визуального представления поддерживается на клиентском устройстве, а определение фокуса голосового представления поддерживается на сервере голоса. Синхронизация может быть достигнута, используя стандартные протоколы и традиционные технологии авторинга контента, несмотря на новые подходы, тем самым способствуя и поддерживая разработку широкого разнообразия распределенных многомодальных приложений.
Фиг. 1 является упрощенной схемой системы 100, выполненной с возможностью осуществлять распределенные многомодальные приложения в соответствии с примером варианта осуществления. В варианте осуществления система 100 включает в себя множество объектов системы, которые включают в себя, по меньшей мере, одно клиентское устройство 102, сервер 104 приложения (AS), голосовой сервер 106 (VS) и модуль 134 распознавания голоса (SR). Как будет подробно описано ниже, различные синхронные и асинхронные протоколы запроса/ответа поддерживаются объектами системы для того, чтобы поддерживать осуществление сеанса распределенного многомодального приложения внутри системы 100. Используемый здесь термин «сеанс многомодального приложения» может быть определен как экземпляр распределенного многомодального приложения. В варианте осуществления сеанс многомодального приложения включает в себя интерпретацию (например, исполнение и/или интерпретацию) машинного кода (например, машинного кода, связанного с группой из одной или более связанных многомодальных страниц 115) клиентским устройством 102 совместно с интерпретацией группы из одного или более соответствующих речевых диалогов браузером/интерпретатором 132 диалога голосового сервера, исполняемым голосовым сервером 106.
Несмотря на то что проиллюстрировано одно клиентское устройство 102, система 100 может включать в себя множество подобных или отличных клиентских устройств. Например, клиентское устройство 102 может составлять часть электронного устройства, выбранного из группы устройств, которая включает в себя, чтобы назвать некоторые, но не в ограничительном смысле, сотовый телефон, рацию, пейджер, персональный цифровой помощник (PDA), персональное устройство навигации (PND), мобильную компьютерную систему (например, автомобильную или самолетную компьютерную систему), компьютер (например, лэптоп, ноутбук или настольный компьютер) и осуществленный на компьютере телефоном согласно протоколу голоса через интернет (VoIP).
Клиентское устройство 102 включает в себя подсистему обработки и подсистему хранения данных и может быть портативным или стационарным электронным устройством. Для любого типа устройства, клиентское устройство 102 может включать в себя подсистему батареи для того, чтобы предоставлять энергию в случаях, когда для питания клиентского устройства 102 не используется линия электропитания. Клиентское устройство 102 может быть выполнено с возможностью осуществления связи через одну или несколько сетей 108, используя различные проводные и/или беспроводные технологии связи. Соответственно, клиентское устройство 102 может включать в себя какой-либо один или оба из проводного и беспроводного сетевых интерфейсов. Клиентское устройство 102 также может включать в себя многообразие устройств ввода интерфейса пользователя (например, цифровую клавиатуру, клавиши, номеронабиратели, сенсорный экран, микрофон, указывающее устройство (например, мышь или сенсорную панель и стилус) и многообразие устройств вывода интерфейса пользователя (например, экран дисплея, громкоговоритель, разъем аудиовыхода, наушники, наушники-пуговки, устройство с механической вибрацией). В варианте осуществления, устройства интерфейса пользователя, связанные с визуальной модальностью, включают в себя любое одно или более устройств, выбранных из группы устройств, которая включает в себя дисплей, сенсорный экран, цифровую клавиатуру, клавиши, номеронабиратель, указательное устройство и стилус. В варианте осуществления, устройства интерфейса пользователя, связанные с голосовой модальностью, включают в себя любое одно или более устройств, выбранных из группы устройств, которая включает в себя микрофон, громкоговоритель, разъем аудиовыхода, наушники и наушники-пуговки.
В варианте осуществления, клиентское устройство 102 выполнено с возможностью исполнять один или более экземпляров клиентского браузера 112 и/или клиентского приложения 114. В варианте осуществления клиентский браузер 112 выполнен с возможностью обмениваться данными с одним или более серверами (например, сервером 104 приложения и/или голосовым сервером 106) через сеть 108. Более конкретно, клиентский браузер 112 выполнен с возможностью осуществлять доступ к машинному коду (например, многомодальной странице 115) на клиентском устройстве 102 и в дальнейшем интерпретировать этот машинный код. В конкретном варианте осуществления клиентский браузер 112 выполнен с возможностью осуществлять доступ к, по меньшей мере, одной многомодальной странице 115 и интерпретировать машинный код (например, разметку, сценарии и другую информацию) внутри многомодальной страницы 115.
Используемый здесь термин «многомодальная страница» означает набор информации, который представляет, по меньшей мере, один элемент отображения, взаимодействующий с пользователем, который может быть визуально представлен на клиентском устройстве 102 и для которого пользователь может вводить информацию и/или указывать выбор посредством любой из разнообразных модальностей (например, голосовой модальности и визуальной модальности). Многомодальная страница 115 может включать в себя, например, но не в качестве ограничения, web страницу, документ, файл, форму, список или другой тип набора информации. При интерпретации многомодальная страница 115 может предписывать клиентскому устройству 102 визуализировать один или более элементов отображения, взаимодействующих с пользователем. Используемый здесь «элемент отображения, взаимодействующий с пользователем» может включать в себя среди прочего, например, но не в качестве ограничения, поле ввода текста, выбираемый элемент (например, кнопка или кнопка-флажок) и/или интерактивный текст. Вместе с одним или более элементами отображения, взаимодействующими с пользователем, многомодальная страница также может включать в себя другую информацию и/или элементы, например, такие как текстовая информация, изображения (например, неподвижные или анимированные изображения), аудиоинформация, видео, гиперссылки, метаданные и сценарии. Используемый здесь термин «многомодальный элемент отображения» означает элемент отображения, взаимодействующий с пользователем, для которого входные данные могут быть приняты посредством более чем одной модальности интерфейса пользователя.
В варианте осуществления многомодальная страница 115 включает в себя разметку, которая может предписать клиентскому браузеру 112 (или другому программному обеспечению синтаксического анализа) исполнить один или более сценариев, которые являются встроенными или на которые делается ссылка. Сценарий может быть встроен внутри многомодальной страницы 115 или на сценарий может быть сделана ссылка внутри многомодальной страницы 115, а клиентский браузер 112 может осуществлять доступ к сценарию на внешнем источнике (например, сервере) или из локальной памяти (например, из кэша на клиентском устройстве 102).
Как будет подробно описано позже совместно с Фиг. 2-6, сценарий может быть выполнен с возможностью предписывать клиентскому устройству 102 выдавать асинхронные запросы серверу 104 приложения, а этот асинхронный запрос может оставаться ожидающим обработки внутри сервера 104 приложения до тех пор, пока голосовой сервер 106 не уведомит сервер 104 приложения о том, что произошло событие (например, событие распознавания речи или изменение фокуса голосового представления), которое может подтверждать обновление для визуального отображения и/или фокуса визуального представления. В это время сервер 104 приложения будет выдавать ответ на асинхронный запрос. Как будет объяснено более подробно ниже, этот протокол обеспечивает синхронизацию между фокусом визуального представления на клиентском устройстве 102 и фокусом голосового представления на голосовом сервере 106. В варианте осуществления, асинхронные запросы выдаются в качестве асинхронных запросов протокола передачи гипертекста (HTTP), а ответы являются HTTP-ответами. Сценарий может быть выполнен с возможностью предписывать клиентскому устройству 102 выдавать также и синхронные запросы.
Многомодальная страница 115 может быть разработана с использованием технологий AJAX (Асинхронного JavaScript и расширяемого языка разметки (XML)) и соответственно может включать в себя разметку XML и JavaScript, выполненную с возможностью выдавать асинхронные запросы (например, асинхронные HTTP-запросы), названные в предыдущем параграфе, и обрабатывать ответы (например, HTTP-ответы) на эти запросы, в варианте осуществления. В других вариантах осуществления, многомодальная страница 115 может быть разработана, используя другие типы программирования, написания сценариев и/или языков разметки, которые выполнены с возможностью выдавать асинхронные запросы и обрабатывать ответы на эти запросы.
Использованный здесь термин «язык разметки» означает определенный набор синтаксических правил для информации (например, разметки или другого машинного кода), которые являются встроенными внутри набора информации (например, многомодальной страницы 115 или другого машинного кода) и которые указывают программному обеспечению синтаксического анализа (например, клиентскому браузеру 112), среди прочего, структуру, компоновку и/или характеристики элементов отображения (например, текста или другого контента), когда элементы визуализируются на электронном устройстве. Например, но не в качестве ограничения, разметка, связанная с языком разметки, может включать в себя разметку представления, процедурную разметку и/или описательную разметку (также называемую, как «семантическая» разметка). Языки разметки, которые могут быть использованы в различных вариантах осуществления, включают в себя, но не ограничены, SGML, XML, HTML, XHTML, DHTML, VoiceXML, SALT, X+V, SVG и различные другие языки разметки.
Клиентский браузер 112 включает в себя программу программного обеспечения, которая выполнена с возможностью выполнять синтаксический анализ машинного кода (например, разметки) внутри многомодальной страницы (например, многомодальной страницы 115) таким образом, который дает возможность клиентскому устройству 102 визуализировать текст, изображения, видео, музыку и/или другую информацию, представляемую или на которую делается ссылка внутри машинного кода. В различных вариантах осуществления, клиентский браузер 112 может включать в себя, но не ограничивается, HTML/XHTML-браузер, браузер с беспроводным протоколом приложения (WAP), пользовательское приложение и/или коммерчески доступный браузер (например, чтобы назвать некоторые, Internet Explorer, Mozilla Firefox, Safari, Opera и Netscape). В конкретном варианте осуществления, клиентский браузер 112 является XHTML-браузером, который поддерживает технологии программирования AJAX и который также имеет возможности оперирования с аудио. Клиентский браузер 112, в варианте осуществления, является браузером с «возможностью многомодального режима», что означает, что клиентский браузер 112 оборудован механизмом JavaScript и/или его функциональным эквивалентом для интерпретации многомодальной страницы (или другого машинного кода, выполненного с возможностью визуализировать многомодальные элементы отображения), и при этом клиентский браузер 112 выполнен с возможностью поддерживать выдачу асинхронных запросов и взаимодействовать с HTTP-сервером (например, сервером 104 приложения). В добавление, клиентский браузер 112 может рассматриваться в качестве браузера с возможностью многомодального режима, когда клиентский браузер 112 выполнен с возможностью осуществлять доступ к аудиокомпонентам, которые выполнены с возможностью захватывать фрагменты речи пользователя (например, речь пользователя), так что аудиоданные, представляющие эти фрагменты речи, могут быть переданы. В варианте осуществления, аудиокомпоненты также выполнены с возможностью принимать и выдавать (на устройстве аудиовывода) аудионапоминания, принятые из сети через клиентский браузер 112. Аудиокомпоненты доступны в среде программным путем из среды написания сценариев клиентского браузера 112, так что сценарии, которые загружены или к которым осуществляется доступ многомодальной страницей, дают возможность пути аудиоданных быть правильно настроенным, как будет описано более подробно позже.
Клиентское приложение 114 включает в себя компьютерное приложение программного обеспечения не браузерного типа. В варианте осуществления клиентское приложение 114 является кодированным на языке, поддерживаемом браузером (например, SGML, XML, HTML, XHTML, DHTML, Flash, Java или других языках разметки), и является воспринимаемым клиентским браузером 112 для того, чтобы сделать приложение исполняемым. В другом варианте осуществления, клиентское приложение 114 может быть не воспринимаемым клиентским браузером 112 для того, чтобы сделать приложение исполняемым (например, клиентский браузер 112 может быть исключен из системы 100), и клиентское приложение 114 само осуществляет функциональность клиентского браузера 112. Например, клиентское приложение 114 может быть скомпилированной программой, выполненной с возможностью визуализировать многомодальные элементы отображения и может быть запрограммировано с использованием технологии AJAX для того, чтобы добавить голосовую модальность клиентскому устройству 102, как будет описано в дополнительных подробностях ниже. Другими словами в варианте осуществления, в котором клиентское приложение 114 включает в себя функциональность клиентского браузера 112 и клиентский браузер 112 исключен, клиентское приложение 114 может быть приложением с возможностью многомодального режима. Множество различных типов клиентских приложений 114 может быть разработано, включая, чтобы назвать некоторые, например, компоненты приложения, связанные с картографическими приложениями, приложениями навигации и приложениями поиска.
Клиентское устройство 102 может обмениваться данными с сервером 104 приложения через одну или более сетей 108. Сеть 108 может включать в себя, например, сеть с коммутацией пакетов и/или сеть с коммутацией каналов и может, более конкретно, включать в себя одно или более из Интернета, персональной сети (PAN), локальной сети (LAN), глобальной сети (WAN), Широкополосной LAN (WLAN), сети сотовой телефонии, радиосети, сети спутниковой связи, телефонной коммутируемой сети общего пользования (PSTN) и/или любой из многообразия других типов сетей, выполненных с возможностью обмениваться информацией между различными объектами системы. Сеть 108 может быть выполнена с возможностью обмениваться информацией между объектами системы, используя любые из многообразия проводных или беспроводных протоколов связи.
Сервер 104 приложения (AS) выполнен с возможностью выполнять различные AS услуги 118 для клиентского устройства 102. Например, AS услуги 118 могут включать в себя, среди прочего, прием запросов многомодальной страницы от клиентского устройства 102 и предоставление многомодальных страниц клиентскому устройству 102 в ответ на запросы. В варианте осуществления многомодальный контроллер 116 связан с сервером 104 приложения и предоставлен с таким же доменом второго уровня, как и сервер 104 приложения. Многомодальный контроллер 116 выполнен с возможностью обеспечивать синхронизацию между данными и фокусами визуального представления и голосового представления, как будет описано более подробно ниже. Так как многомодальный контроллер 116 и сервер 104 приложения находятся в одном и том же домене второго уровня, в соответствии с традиционной моделью безопасности браузера, многомодальный контроллер 116 может быть целью любых HTTP-запросов, выдаваемых клиентским браузером 112 на основе на интерпретации машинного кода, который находится внутри или на который делается ссылка в многомодальной странице 115, которая была предоставлена клиентскому устройству 102 сервером 104 приложения. Включение многомодального контроллера 116 внутри прямоугольника, соответствующего серверу 106 приложения, не подразумевает, что многомодальный контроллер 116 и сервер 106 приложения (или AS услуги 118) выполняются на одной и той же платформе. В основном сервер 106 приложения (или AS услуги 118) и многомодальный контроллер 116 должны физически и коммуникационно быть объединены таким образом, чтобы придерживаться модели безопасности, налагаемой клиентским браузером 112, в варианте осуществления.
В варианте осуществления AS услуги 118 могут включать в себя прием запросов на многомодальные страницы и речевые диалоги, извлечение многомодальных страниц и речевых диалогов и посылку их запрашивающим объектам. В противоположность, в варианте осуществления, многомодальный контроллер 116 выполнен с возможностью обеспечивать синхронизацию фокусов голосового представления и визуального представления в контексте многомодального сеанса. В добавление, многомодальный контроллер 116 может быть выполнен с возможностью переадресовывать аудиоданные, принятые от клиентского устройства голосовому серверу и наоборот. В альтернативном варианте осуществления, некоторые части или вся функциональность многомодального контроллера 116 может быть осуществлена в AS услугах 118.
Как упомянуто ранее, машинный код, связанный с многомодальными страницами, визуализируемыми на клиентском устройстве 102, выполнен с возможностью выдавать запросы (например, синхронные и/или асинхронные HTTP-запросы) серверу 104 приложения. Некоторые из запросов, направляемых серверу 102 приложения, могут обрабатываться AS услугами 118, а другие запросы, которые более конкретно направлены к многомодальному контроллеру 116, могут обрабатываться многомодальным контроллером 116.
Многомодальный контроллер 116 выполнен с возможностью управлять синхронизацией между данными и фокусом визуального представления, поддерживаемыми клиентским устройством 102, и данными и фокусом голосового представления, поддерживаемыми голосовым сервером 106. По существу, синхронизация фокуса визуального представления и фокуса голосового представления включает в себя предоставление клиентскому устройству 102 и голосовому серверу 106 информации, которая дает возможность интерпретации машинного кода соответствующей многомодальной страницы 115 на клиентском устройстве 102 быть синхронизированной с интерпретацией машинного кода для соответствующего речевого диалога 136 на голосовом сервере 106. Согласно упомянутому другому способу, синхронизация фокуса визуального представления и фокуса голосового представления включает в себя предоставление клиентскому устройству 102 и голосовому серверу 106 информации, которая дает возможность состоянию исполнения визуального представления на клиентском устройстве 102 быть синхронизированным с состоянием исполнения голосового представления на голосовом сервере 106. Синхронизация данных голосового представления и данных визуального представления включает в себя предоставление голосовому серверу данных, соответствующих вводам пользователя, сделанным через визуальную модальность, и предоставление клиентскому устройству данных, соответствующих результатам распознавания речи. Варианты осуществления способов для выполнения этой синхронизации будут описаны более подробно позже.
Голосовой сервер 106 является сервером модальности, который конкретно выполнен с возможностью координировать задачи, относящиеся к обработке речи, с сеансом распределенного многомодального приложения. Как упоминалось ранее, другие типы серверов модальности могут быть включены в систему в другом варианте осуществления. Голосовой сервер 106 выполнен с возможностью исполнять один или более экземпляров VS браузера/интерпретатора диалога 132 (обозначаемого ниже как VS браузер 132) и взаимодействовать со средством 134 распознавания речи.
VS браузер 132 является программой программного обеспечения, которая дает возможность голосовому серверу 106 осуществлять доступ к и интерпретировать речевые диалоги (например, речевой диалог 136), посылать и принимать аудиоданные совместно с интерпретацией речевых диалогов, выдавать асинхронные запросы (например, HTTP-запросы) и принимать и обрабатывать ответы (например, HTTP-ответы) в контексте сеанса многомодального приложения. В различных вариантах осуществления, VS браузер 106 может включать в себя, но не ограничен, пользовательский коммерчески доступный браузер или другое приложение, выполненное с возможностью интерпретировать разметку, связанную с предоставлением голосовой модальности (например, VoiceXML, SALT, X+V и/или другие языки разметки).
Как упомянуто ранее, VS браузер 132 может осуществлять доступ к и интерпретировать речевой диалог 136. Используемый здесь термин «речевой диалог» может быть интерпретирован как означающий набор информации, связанный с обработкой аудиоданных, где часть речевого диалога соответствует элементам отображения, взаимодействующим с пользователем, представленным на многомодальной странице 115. Речевой диалог может включать в себя машинный код, выполненный с возможностью влиять на обработку принятых аудиоданных модулем 134 распознавания речи и/или предоставлять аудиоданные (например, речевые напоминания) в подходящее время, в соответствии с различными вариантами осуществления. Речевой диалог может включать в себя, например, но не в качестве ограничения, web страницу, документ, файл, список или другой тип набора информации. Речевой диалог также может включать в себя другую информацию и/или элементы, такие как, например, текстовую информацию, метаданные, машинный код и сценарии. Несмотря на то, что описанные ниже варианты осуществления включают в себя речевые диалоги, доступ к которым осуществляется (например, они загружаются) через голосовой сервер 106, должно быть понятно, что в других вариантах осуществления речевой диалог может быть выполнен в качестве машинного кода, который постоянно находится на голосовом сервере 106 и в загрузке или доступе к которому нет никакой необходимости.
В варианте осуществления речевой диалог 136 включает в себя машинный код, причем машинный код может включать в себя компилированный код, разметку и/или другую информацию, которая может быть легко интерпретирована голосовым браузером 132. В конкретном варианте осуществления, речевой диалог 136 может включать в себя разметку, которая предписывает VS браузеру 132 осуществлять доступ к и/или исполнять один или более сценариев, которые встроены или на которые делается ссылка (например, код JavaScript). Сценарий может быть встроен внутри речевого диалога 136 или VS браузер может осуществлять доступ к сценарию на внешнем источнике (например, сервере) или из локальной памяти (например, из кэша на голосовом сервере 106). Сценарии могут включать в себя сценарии, выполненные с возможностью предписывать VS браузеру 132 вызывать модуль 134 распознавания речи для того, чтобы, среди прочего, попытаться определить результат распознавания речи на основе принятых аудиоданных, отыскать или сформировать аудионапоминание и/или выдать запросы (например, HTTP-запросы на речевые диалоги или другие типы запросов). В варианте осуществления, речевой диалог 136 может включать в себя разметку (например, VoiceXML, X+V и/или SALT разметку) и JavaScript, выполненные с возможностью выдавать запросы. В других вариантах осуществления речевой диалог 136 может быть разработан с использованием других типов языков программирования, языков написания сценариев и/или языков разметки.
Модуль 134 распознавания речи является приложением программного обеспечения, которое может вызываться VS браузером 132 и которое выполнено с возможностью принимать аудиоданные (например, в сжатом, несжатом, закодированном, не закодированном и декодированном формате) для того, чтобы выполнить алгоритм распознавания речи, используя аудиоданные для того, чтобы попытаться определить результат распознавания речи (например, указание распознанной речи) и вернуть результат распознавания речи или указать, что было определено, что результат отсутствует (например, указать ошибку). Используемый здесь термин «аудиоданные» означает оцифрованное представление речи или других слышимых звуков (в основном «аудио»), где оцифрованное аудиопредставление может включать в себя фрагментированную речь или другие слышимые звуки в сжатом, несжатом, закодированном, не закодированном и/или декодированном формате. Аудиоданные также могут включать в себя указатели на таблицы или другие структуры данных, которые включают в себя аудиоданные, где таблицы могут быть доступными для сервера 102 приложения, голосового сервера 106 и/или клиентского устройства 102. В варианте осуществления, модуль 134 распознавания речи может исполняться совместно с различными ресурсами распознавания речи (например, грамматиками, последовательностями n-символов, статистическими моделями языка и/или другими ресурсами), доступ к которым может быть осуществлен, основываясь на конкретной части речевого диалога 136, который интерпретируется (например, текущий фокус голосового представления).
В варианте осуществления голосовой сервер 106 обменивается данными с сервером 104 приложения через путь 122 связи AS/VS, а модуль 134 распознавания речи обменивается данными с сервером 104 приложения через путь 123 связи AS/SR. Обмены данными между сервером 104 приложения и голосовым сервером 106 могут включать в себя, среди прочего, аудиоданные (например, аудионапоминания), возникающие в голосовом сервере 106 и направленные клиентскому устройству 102, и результаты распознавания речи, определенные модулем 134 распознавания речи. Обмены данными между сервером 104 приложения и модулем 134 распознавания речи могут включать в себя, среди прочего, аудиоданные, принятые сервером 104 приложения от клиентского устройства 102. Голосовой сервер 106 также обменивается данными с многомодальным контроллером 116 через путь связи MMC/VS. Обмены данными между многомодальным контроллером 116 и голосовым сервером 106 могут быть выполнены с использованием протокола управления голосовым браузером (например, стандартный протокол), который позволяет многомодальному контроллеру 116 выдавать команды голосовому серверу 106, относящиеся к тому, какой речевой диалог загрузить, на каком элементе сфокусироваться, и данные, которые должны быть использованы для обновления элементов. В варианте осуществления, многомодальный контроллер 116 по сути преобразует протокол управления голосовым браузером в асинхронные HTTP-запросы, принимаемые клиентским браузером 116, каковые запросы будут подробно описаны позже.
В альтернативном варианте осуществления модуль 134 распознавания речи и клиентское устройство 102 могут непосредственно обмениваться аудиоданными через путь 124 аудиоданных SR/клиент. «Путь аудиоданных SR/клиент» может быть определен как означающий любой один или более путей через сеть 108 (или некоторую другую среду связи), по которым может осуществляться обмен аудиоданными между IP-адресом и/или портом, связанными с модулем 134 распознавания речи, и IP-адресом и/или портом, связанными с клиентским устройством 102. В варианте осуществления, аудиоданные могут потоково передаваться через путь 124 аудиоданных SR/клиент, используя коммуникационный протокол пакетной передачи данных. В качестве альтернативы, обмен аудиоданными может осуществляться через путь 124 аудиоданных SR/клиент, используя способы связи с коммутацией каналов или с переключением между приемом и передачей (РТТ). В варианте осуществления, аудиоданные передаются через путь 124 аудиоданных SR/клиент, используя вариант транспортного протокола реального времени/протокола управления передачей в реальном времени (RTP/RTCP), несмотря на то, что в других вариантах осуществления могут быть осуществлены другие протоколы (например, протокол управления передачей (TCP) или т.п.).
Сервер 104 приложения и голосовой сервер 106 отличаются друг от друга в том, что в этих сервере 104 приложения и голосовом сервере 106 осуществляются разные процессы, и они обмениваются управляющими сообщениями, которые воздействуют на выполнение этих процессов через путь 122 связи AS/VS. В варианте осуществления, сервер 104 приложения и голосовой сервер 106 могут быть осуществлены на физически отличающемся аппаратном обеспечении, которое может, а может и не располагаться совместно. В другом варианте осуществления сервер 104 приложения и голосовой сервер 106 могут быть осуществлены на, по меньшей мере, частично совместно используемом аппаратном обеспечении, несмотря на то, что по-прежнему осуществляется обмен различными сообщениями между этими двумя серверами через путь 122 связи AS/VS, как подробно описано ниже.
Как упомянуто ранее, варианты осуществления изобретения выполнены с возможностью синхронизировать данные и фокус визуального представления и данные и фокус голосового представления, связанные с сеансом распределенного многомодального приложения. Фокус «визуального представления» поддерживается клиентским устройством 102 совместно с интерпретацией многомодальной страницы (например, многомодальной страницы 115), а фокус «голосового представления» поддерживается голосовым сервером 106 совместно с интерпретацией речевого диалога (например, речевого диалога 136), связанного с многомодальной страницей. Термины «визуальное представление» и «фокус визуального представлении» могут быть определены в качестве элемента отображения, соответствующего машинному коду, который включен или к которому имеется доступ внутри многомодальной страницы, которую браузер (например, клиентский браузер 112) интерпретирует в настоящее время или ожидает интерпретации. Например, текущий фокус визуального представления может соответствовать машинному коду, связанному с одним элементом отображения, который выделен, на котором мигает курсор или на котором установлены некоторые другие указания фокуса. Термины «голосовое представление» и «фокус голосового представления» могут быть определены в качестве элемента отображения, соответствующего машинному коду, который включен или к которому имеется доступ внутри речевого диалога, который браузер (например, VS браузер 132) в текущий момент исполняет или ожидает исполнения. Например, текущий фокус голосового представления может соответствовать машинному коду, который предписывает голосовому браузеру 132 ожидать приема аудиоданных в качестве ввода для конкретного элемента отображения, который визуализируется на клиентском устройстве 102.
Варианты осуществления способов для инициирования и проведения сеанса многомодального приложения теперь будут описаны совместно с Фиг. 2-6. Эти варианты осуществления будут описаны в контексте примера особого типа распределенного многомодального приложения для того, чтобы способствовать объяснению и пониманию различных вариантов осуществления. Пример приложения является картографическим приложением, которое включает в себя клиентское приложение, которое выполнено с возможностью предписывать элементам, представленным внутри многомодальной страницы, визуализироваться на клиентском устройстве посредством интерпретации клиентским браузером с поддержкой многомодального режима. В альтернативном варианте осуществления клиентский браузер может быть выполнен с возможностью интерпретировать многомодальную страницу без инициации со стороны клиентского приложения (например, когда пользователь непосредственно инициирует запрос клиентского браузера и предписывает клиентскому браузеру загружать и интерпретировать многомодальную страницу). В еще одном другом альтернативном варианте осуществления клиентское приложение может выполнять некоторые или все из задач клиентского браузера, и/или клиентское приложение может включать в себя некоторую часть или весь машинный код, который иным образом будет включен внутри многомодальной страницы. Соответственно, различные варианты осуществления могут быть выполнены с многомодальной страницей или без нее клиентским приложением или клиентским браузером. Эти варианты осуществления не описываются здесь подробно, несмотря на это должно быть понятно, что они подпадают под объем изобретения.
Пример будет включать в себя клиентское устройство, отображающее многомодальную страницу в виде формы ввода данных, где форма ввода данных включает в себя разнообразные многомодальные элементы отображения. Каждый элемент отображения включает в себя заполняемые поля ввода данных (например, поля ввода данных для города, штата, номера улицы, адреса улицы), в которых пользователь может ввести адресную информацию для целевого местоположения одной или обеих из визуальной модальности и голосовой модальности. После отправки введенной информации система может предоставлять картографическую информацию, которая дает возможность клиентскому устройству отображать карту, которая включает в себя целевое местоположение. Должно быть понятно, что варианты осуществления могут быть использованы также совместно с другими типами распределенных многомодальных приложений (например, среди прочего, поисковых и навигационных приложений).
В приведенном примере разнообразные модальности включают в себя визуальную модальность и голосовую модальность. На клиентском устройстве визуальная модальность может быть выполнена, используя экран дисплея и связанное с ним аппаратное и программное обеспечение для формирования визуальных отображений. Визуальная модальность также может быть осуществлена на клиентском устройстве, используя цифровую клавиатуру и/или одно или более других устройств ввода интерфейса пользователя, которые дают возможность пользователю делать выборы, вводить информацию и/или предпринимать другие действия (например, изменять фокус), посредством взаимодействия с визуальным отображением и/или другими устройствами ввода интерфейса пользователя. Голосовая модальность может быть осуществлена на клиентском устройстве, используя микрофон, громкоговоритель и связанное с ними аппаратное и программное обеспечение, выполненное с возможностью принимать и оцифровывать человеческую речь и/или выводить аудиоинформацию.
В приведенном примере пользователь может взаимодействовать с визуальной модальностью интерфейса пользователя (например, визуальным отображением) путем просмотра визуального отображения и ввода информации в поля визуального отображения, указания выбора или изменения фокуса визуального представления, используя цифровую клавиатуру или другие устройства ввода. В добавление пользователь может взаимодействовать с голосовой модальностью интерфейса пользователя путем прослушивания аудионапоминаний и/или разговаривая для того, чтобы предоставить информацию, связанную с элементами отображения, на которых установлен фокус визуального представления. Должно быть понятно, что в альтернативных вариантах осуществления распределенное многомодальное приложение может быть выполнено с возможностью допускать наборы модальностей, отличные от визуальной модальности и голосовой модальности.
Фиг. 2, которая будет описана ниже, иллюстрирует полный процесс для инициирования и проведения сеанса многомодального приложения в соответствии с вариантом осуществления. Предназначением Фиг. 2 не является ограничение объема изобретения, а наоборот предоставить полный контекст для понимания более подробного описания процесса, проиллюстрированного и описанного совместно с Фиг. 3, 5 и 6.
Фиг. 2 является логической блок-схемой способа инициирования и проведения сеанса многомодального приложения в соответствии с примером варианта осуществления. Способ может начинаться на этапе 202, когда клиентское устройство принимает указание того, что сеанс многомодального приложения должен быть инициирован. В различных вариантах осуществления сеанс многомодального приложения может быть инициирован путем запроса от клиентского приложения (например, клиентской части картографического приложения) и/или клиентским браузером. Например, пользователь клиентского устройства может инициировать экземпляр клиентского приложения, которое выполнено с возможностью визуализировать, либо своими силами, либо совместно с клиентским браузером, визуальное отображение, которое включает в себя, по меньшей мере, один многомодальный элемент отображения, для которого данные могут быть введены, используя визуальную модальность или голосовую модальность. В качестве альтернативы, пользователь может инициировать экземпляр клиентского браузера и может указать клиентскому браузеру требование пользователя, чтобы браузер осуществил доступ к или загрузку многомодальной страницы, которая, когда интерпретируется, предписывает клиентскому устройству визуализировать визуальное отображение. Например, пользователь может предоставлять вводы пользователя для навигации по многомодальной странице.
По получении клиентским устройством указания того, что сеанс многомодального приложения должен быть инициирован, клиентское устройство посылает запрос многомодальной страницы серверу приложения на этапе 204. В варианте осуществления запрос многомодальной страницы является синхронным HTTP-запросом, который включает в себя ссылку (например, унифицированный указатель ресурса или URL) для запрашиваемой страницы. На этапе 206 сервер приложения принимает запрос, извлекает запрошенную многомодальную страницу и посылает многомодальную страницу клиентскому устройству в виде ответа многомодальной страницы (т.е. ответа на запрос многомодальной страницы, посланный клиентским устройством на этапе 204). В варианте осуществления обработка запроса многомодальной страницы выполняется объектом внутри сервера приложения (например, AS услугами 118, Фиг. 1), который предназначен для извлечения и возврата многомодальных (или других) страниц в ответ на клиентские запросы.
На этапе 207 клиентское устройство принимает ответ многомодальной страницы (например, многомодальную страницу) и инициирует интерпретацию разметки и сценариев, которые включены внутри и/или на которые делается ссылка в многомодальной странице. Это включает в себя определение на этапе 208 того, является ли клиентский браузер браузером с поддержкой многомодального режима. Это определение может быть сделано, например, посредством оценки информации конфигурации, принадлежащей клиентскому устройству и/или клиентскому браузеру. Как обсуждалось ранее, клиентский браузер может считаться браузером с поддержкой многомодального режима, когда он выполнен с возможностью захвата и передачи обнаруженных фрагментов речи пользователя (например, речи пользователя), когда он оборудован машиной JavaScript или ее функциональным аналогом для интерпретации многомодальной страницы (или другого машинного кода, выполненного с возможностью визуализировать многомодальные элементы отображения), когда он выполнен с возможностью поддерживать выдачу асинхронных запросов и когда он выполнен с возможностью взаимодействовать с HTTP-сервером (например, сервером 104 приложения, Фиг. 1).
Когда определено, что клиентский браузер не является браузером с поддержкой многомодального режима, тогда клиентское устройство работает в режиме «только визуальной модальности» в блоке 210. В варианте осуществления это включает в себя выполнение клиентским устройством визуализации элементов отображения, представляющих многомодальную страницу, несмотря на то, что клиентское устройство должно ограничивать его интерпретацию многомодальной страницы только теми частями, которые связаны с приемом ввода пользователя через визуальную модальность (например, вводы с цифровой клавиатуры). По существу, те части многомодальной страницы, которые относятся к приему ввода через голосовую модальность, пропускаются клиентским браузером. Дальнейшая обработка в соответствии с традиционными технологиями может происходить после начальной визуализации страницы (например, обработка вводов пользователя через визуальную модальность, изменение фокуса визуальной модальности, навигация на другие страницы и т.д.). В добавление, клиентское устройство может выполнять различные другие процессы, такие как процессы, аналогичные процессам, которые описаны позже в отношении этапов 216, 218, 219, 220 и 24, за исключением того, что эти аналогичные процессы должны исключить этапы, относящиеся к захвату аудио, распознаванию речи, синхронизации данных и фокуса между голосовым представлением и визуальным представлением и другие процессы, относящиеся к голосовой модальности. Так как режим «только визуальной модальности» не является акцентом настоящей заявки, такие операции не рассматриваются здесь подробно.
Когда определено, что клиентский браузер является браузером с поддержкой многомодального режима, сеанс многомодального приложения синхронизируется на этапе 212 посредством взаимодействия между клиентским устройством, сервером приложения (или, более конкретно, с многомодальным контроллером) и голосовым сервером/голосовым браузером, как будет описано более подробно совместно с Фиг. 3. В основном, синхронизация сеанса многомодального приложения включает в себя выполнение клиентским устройством запроса инициирования многомодального сеанса у сервера приложения, где сервер приложения предоставляет речевой диалог, соответствующий многомодальной странице, голосовому серверу, клиентское устройство визуализирует один или более элементов отображения, представленных в многомодальной странице, на визуальном отображении, и клиентское устройство выдает асинхронный запрос события серверу приложения. В варианте осуществления, в котором клиентское устройство и голосовой сервер обмениваются аудиоданными непосредственно (а не посредством сервера приложения), инициирование сеанса многомодального приложения также может включать в себя установление пути аудиоданных (например, пути 124 аудиоданных SR/клиента, Фиг. 1) между клиентским устройством и модулем распознавания речи, по которому будет происходить обмен аудиоданными во время сеанса многомодального приложения. Процесс синхронизации многомодального сеанса будет описан более подробно позже, совместно с описанием Фиг. 3. В варианте осуществления части процесса синхронизации многомодального сеанса, которые выполняются сервером приложения, могут быть выполнены объектом, связанным с сервером приложения (например, многомодальным контроллером 116, Фиг. 1), который предназначен поддерживать синхронизацию между данными и фокусом визуального представления и данными и фокусом голосового представления.
Как будет описано более подробно совместно с Фиг. 5 и 6, во время сеанса многомодального приложения будет осуществляться обмен аудиоданными между клиентским устройством и голосовым сервером, а обмен различными HTTP-запросами и ответами будет осуществляться между клиентским устройством, сервером приложения и голосовым сервером. Среди прочего, различные HTTP-запросы и ответы дают возможность поддерживать синхронизацию между данными и фокусом визуального представления и данными и фокусом голосового представления согласованно по всему многомодальному сеансу.
Обмен аудиоданными и информацией управления осуществляется между различными объектами системы в ответ на события ввода данных, связанные с голосовой модальностью и визуальной модальностью, каковые события упоминаются как «события ввода голосовой модальности» и «события ввода визуальной модальности» соответственно. События ввода голосовой модальности и события ввода визуальной модальности могут воздействовать на данные и фокус голосового представления и/или данные и фокус визуального представления. События ввода голосовой модальности и события ввода визуальной модальности могут происходить в различные моменты времени по мере проведения сеанса многомодального приложения. Как будет описано более подробно совместно с Фиг. 5, когда происходит событие ввода голосовой модальности, выполняется процесс обработки события ввода голосовой модальности на этапе 214. В добавление, как будет описано более подробно совместно с Фиг. 6, когда происходит событие ввода визуальной модальности, выполняется процесс обработки события ввода визуальной модальности на этапе 216. Несмотря на то что этапы 214 и 216 проиллюстрированы как происходящие последовательно, эти процессы могут происходить параллельно или в обратной последовательности, и один из двух или оба процесса могут происходить многократно при проведении сеанса многомодального приложения. В варианте осуществления части процесса обработки ввода голосовой модальности и процесса обработки ввода визуальной модальности, которые выполняются приложением сервера, могут быть выполнены объектом, связанным с сервером приложения (например, многомодальным контроллером 116, Фиг. 1), который предназначен поддерживать синхронизацию между фокусом визуального представления и фокусом голосового представления.
До тех пор пока данные страницы (например, совокупные данные, введенные пользователем для элементов отображения визуализированной страницы) не переданы серверу приложения, как описано этапом 218, процессы обработки событий ввода голосовой модальности и событий ввода визуальной модальности продолжают выполняться, как проиллюстрировано на Фиг. 2. В качестве альтернативы процессы обработки событий ввода голосовой модальности и событий ввода визуальной модальности могут быть прерваны, когда сеанс многомодального приложения иным образом прекращен (например, посредством действий пользователя, отказов связи, превышения лимитов времени ожидания или других событий).
Клиентское устройство может определять на этапе 218, что данные страницы отправлены, когда пользователь указал такую отправку (например, путем выбора опции отправки или нажатия кнопки отправки), когда пользователь ввел данные во все элементы отображения, взаимодействующие с пользователем, и/или когда пользователь ввел данные в последний элемент отображения, взаимодействующий с пользователем в последовательности элементов, визуализированных на визуальном отображении, например. Данные страницы могут быть переданы другими способами, а также в зависимости от конкретного типа многомодальной страницы, визуализированной на клиентском устройстве. Например, несмотря на то что здесь в подробностях описан пример заполняемой формы, многомодальная страница в качестве альтернативы может включать в себя один или более элементов ввода данных с поддержкой речевой модальности, для которых данные могут быть отправлены автоматически по обнаружению фрагмента речи пользователя (например, фрагмента речи пользователя, содержащего указание пользователя на отправку данных). Например, многомодальная страница может быть связана с игрой или отображением графика, в которых пользователь может заставить изменяться перспективы визуального отображения посредством голосовых команд.
Когда клиентское устройство определяет, что данные страницы отправлены, клиентское устройство может послать запрос отправки серверу приложения в варианте осуществления на этапе 219. В варианте осуществления запрос отправки может включать в себя представления некоторых или всех из данных ввода, которые были визуализированы совместно с интерпретацией многомодальной страницы. В варианте осуществления, если разметка внутри в настоящее время интерпретируемой многомодальной страницы указывает, что должна быть загружена новая многомодальная страница, тогда запрос отправки так же может включать в себя ссылку (например, URL) на новую многомодальную страницу. В альтернативном варианте осуществления клиентское устройство может, наоборот, послать ссылки на многомодальную страницу в отдельном запросе многомодальной страницы, а не в запросе отправки. По приему запроса отправки сервер приложения может обработать данные ввода (например, обновить сохраненные значения).
Сеанс многомодального приложения может включать в себя ввод и отправку данных для одной многомодальной страницы или для последовательности многомодальных страниц. Соответственно, на этапе 220 сервер приложения может определять, запросило ли клиентское устройство новую многомодальную страницу (например, когда клиентское устройство предоставило ссылку на многомодальную страницу в запросе отправки или в отдельном запросе). Если нет, то затем, на этапе 222, сервер приложения может закончить многомодальный сеанс и обработка закончится. Если да, то затем, на этапе 224, сервер приложения извлекает новую многомодальную страницу и отправляет новую многомодальную страницу клиентскому устройству в виде ответа отправки. В варианте осуществления извлечение и предоставление новой многомодальной страницы может быть выполнено объектом внутри сервера приложения (например, AS услугами 118, Фиг. 1), который предназначен для извлечения и возврата многомодальных (или других) страниц в ответ на клиентские запросы. В варианте осуществления, после отправки новой многомодальной страницы клиентскому устройству способ может затем повторяться, как изображено на Фиг. 2. Более подробно, клиентское устройство может принять ответ многомодальной страницы с новой многомодальной страницей на этапе 208 (например, «ответ на запрос отправки» является «ответом многомодальной страницы»). Так как клиентское устройство ранее выполнило определение того, является ли клиентский браузер браузером с поддержкой многомодального режима, клиентское устройство может пропустить этот этап и перейти непосредственно к инициированию сеанса многомодального приложения на этапе 214. Как будет ясно из описания к Фиг. 3, некоторые части процесса синхронизации сеанса также могут быть пропущены, если сеанс уже инициирован. Например, сервер приложения может пропустить инициирование многомодального сеанса с голосовым сервером, как будет описано совместно с блоком 304 Фиг. 3.
Фиг. 3 является логической блок-схемой способа выполнения синхронизации сеанса многомодального приложения (например, процесс 214, Фиг. 2) в соответствии с примером варианта осуществления. Способ может начинаться, в варианте осуществления, когда клиентское устройство посылает запрос синхронизации многомодального сеанса серверу приложения, на этапе 302. Запрос синхронизации сеанса многомодального приложения может быть, например, синхронным HTTP-запросом, который указывает серверу приложения, что клиентское устройство является устройством с поддержкой многомодального режима, и что сервер приложения должен приступать к синхронизации многомодального сеанса. В варианте осуществления, запрос синхронизации сеанса многомодального приложения также может включать в себя ссылку (например, URL) для речевого диалога, соответствующего многомодальной странице, интерпретируемой на клиентском устройстве. В добавление, в частности, когда речевой диалог будет первым речевым диалогом, связанным с сеансом многомодального приложения, запрос синхронизации сеанса многомодального приложения может включать в себя информацию аудиосвязи для клиентского устройства. Информация аудиосвязи может включать в себя информацию, которую сервер приложения может использовать во время сеанса многомодального приложения для того, чтобы отправлять аудиоданные клиентскому устройству (например, информацию, описывающую аудиоформат(ы), скорость(и) передачи битов и/или тип(ы) аудио, поддерживаемые клиентским устройством, желательный аудиокодек(и) и/или информацию аудиоадреса, такую как IP-адрес и номер порта клиентского устройства для использования для аудиоданных, посланных клиентскому устройству). В альтернативном варианте осуществления информация аудиосвязи может быть предоставлена в сообщении, отличном от запроса инициирования сеанса многомодального приложения.
На этапе 304 сервер приложения принимает запрос инициирования многомодального сеанса и инициирует многомодальный сеанс с голосовым сервером, за исключением случая, когда он уже сделал это в контексте текущего сеанса многомодального приложения. Это может включать в себя, например, то, что сервер приложения обменивается информацией аудиосвязи с голосовым сервером, которая будет использована для переноса аудиоданных между сервером приложения и голосовым сервером во время сеанса многомодального приложения (например, аудиоформат(ы), скорость(и) передачи битов и/или тип(ы) аудио, поддерживаемые сервером приложения и голосовым сервером, желательный аудиокодек(и) и/или информация аудиоадреса, такая как IP-адрес сервера приложения, IP-адрес голосового сервера и номера портов для использования при обмене аудиоданными).
В альтернативном варианте осуществления, как упоминалось ранее, клиентское устройство и модуль распознавания речи могут обмениваться аудиоданными непосредственно. В таком варианте осуществления, синхронизация сеанса многомодального приложения может включать в себя установление пути аудиоданных между клиентским устройством и модулем распознавания речи (например, пути 124 аудиоданных SR/клиент, Фиг. 1). Несмотря на то, что здесь этот процесс не описан подробно, процесс может включать в себя выполнение обмена между клиентским устройством и модулем распознавания речи информацией о пути аудиоданных через сервер приложения, которая включает в себя информацию, описывающую аудиоформат(ы), скорость(и) передачи битов и/или тип(ы) аудио, поддерживаемые клиентским устройством и модулем распознавания речи, желательный аудиокодек(и) и/или информацию аудиоадреса, такую как IP-адрес клиентского устройства, IP-адрес модуля распознавания речи и номера портов для использования при обмене аудиоданными. Оставшееся описание относится к вариантам осуществления, в которых клиентское устройство и модуль распознавания речи обмениваются аудиоданными посредством сервера приложения. Тем не менее, должно быть понятно, что объем изобретения охватывает альтернативные варианты осуществления, описанные в этом параграфе.
Снова ссылаясь на этап 304, сервер приложения может определять из запроса синхронизации многомодального сеанса ссылку (например, URL) на речевой диалог, соответствующий многомодальной странице, интерпретируемой на клиентском устройстве. В варианте осуществления, сервер приложения может затем извлечь речевой диалог и отправить его голосовому серверу. В альтернативном варианте осуществления, сервер приложения может отправлять ссылку на речевой диалог голосовому серверу. Затем голосовой сервер может сам загрузить или осуществить доступ к речевому диалогу.
Голосовой браузер затем может инициировать интерпретацию речевого диалога. В варианте осуществления это может включать в себя интерпретацию части речевого диалога, которая соответствует многомодальному элементу отображения, на котором клиентское устройство изначально установит свой фокус (например, элемент отображения, на котором будет установлен курсор, когда клиентское устройство инициирует визуализацию многомодальной страницы). Многомодальный элемент отображения, соответствующий части речевого диалога, исполняющейся в настоящее время, указывает текущий фокус голосового представления. Голосовой браузер может инструктировать модуль распознавания речи касаемо того, какие ресурсы распознавания речи (например, грамматики, последовательности n-символов, статистические модели языка или другие ресурсы) он должен использовать для того, чтобы попытаться распознать речь, соответствующую текущему фокусу голосового представления. В добавление, голосовой сервер может информировать сервер приложения о том, что он инициировал интерпретацию речевого диалога. В некоторых случаях, аудионапоминание может быть связано с начальным фокусом голосового представления. Если это так, то затем голосовой сервер может посылать аудиоданные серверу приложения, которые представляют аудионапоминание.
На этапе 306 сервер приложения может посылать ответ синхронизации многомодального сеанса клиентскому устройству (например, ответ на запрос синхронизации многомодального сеанса, который клиентское устройство отправило серверу приложения на этапе 302). Ответ синхронизации многомодального сеанса может указывать клиентскому устройству, что клиентское устройство должно приступить к своей интерпретации многомодальной страницы и визуализации одного или более многомодальных элементов отображения, представленных внутри многомодальной страницы. В добавление, ответ синхронизации многомодального сеанса может включать в себя информацию аудиосвязи, которую клиентское устройство может использовать во время сеанса многомодального приложения для того, чтобы посылать аудиоданные серверу приложения (например, информацию, описывающую аудиоформат(ы), скорость(и) передачи битов и/или тип(ы) аудио, поддерживаемые сервером приложения, желательный аудиокодек(и) и/или информацию аудиоадреса, такую как IP-адрес сервера приложения и номер порта для использования при отправке аудиоданных серверу приложения). В альтернативном варианте осуществления информация аудиосвязи может быть предоставлена в сообщении, отличном от ответа синхронизации сеанса многомодального приложения. Если голосовой сервер предоставляет аудиоданные, соответствующие аудионапоминанию, сервер приложения также может переадресовывать аудиоданные клиентскому устройству.
На этапе 308 клиентское устройство принимает ответ синхронизации многомодального сеанса и интерпретирует ту часть многомодальной страницы, что связана с изначальным отображением одного или более многомодальных элементов отображения на клиентском устройстве. В варианте осуществления, это может включать в себя выполнение клиентским устройством визуализации многомодальных элементов отображения на дисплейном устройстве, связанном с клиентским устройством. Клиентское устройство также может визуализировать курсор или другой указатель начального фокуса визуального представления. Например, клиентское устройство может визуализировать курсор внутри поля ввода данных, связанного с многомодальным элементом отображения. Если сервер приложения переадресовал аудиоданные (например, аудионапоминание) клиентскому устройству, клиентское устройство также может вывести аудиоданные на громкоговоритель или другое устройство аудиовывода, связанное с клиентским устройством.
Фиг. 4 является примером многомодальной страницы, визуализируемой на клиентском устройстве 400, в соответствии с примером варианта осуществления. В проиллюстрированном примере часть визуальной разметки визуализируется в виде четырех многомодальных элементов 401, 402, 403, 404 отображения, каждый из которых включает в себя текстовый ярлык (например, «ГОРОД», «ШТАТ», «НОМЕР УЛИЦЫ» и «НАЗВАНИЕ УЛИЦЫ») и поле ввода данных. В альтернативном варианте осуществления, конкретный многомодальный элемент отображения может быть связан с разнообразными пунктами ввода данных, где модуль распознавания речи может осуществлять доступ к разнообразным ресурсам распознавания речи в попытках сформировать событие(я) распознавания для разнообразных пунктов ввода данных (например, многомодальный элемент отображения может быть связан с «АДРЕСОМ УЛИЦЫ», и соответствующее поле ввода данных может быть заполняемым номером улицы и названием улицы). Начальный фокус визуального представления указывается расположением курсора 405 внутри поля 401 ввода данных. Если аудиоданные, связанные с аудионапоминанием, были посланы клиентскому устройству 400, клиентское устройство 400 может вывести аудиоданные на громкоговоритель 408. Например, начальное аудионапоминание может произнести: «Пожалуйста, введите или назовите название города».
Снова ссылаясь на Фиг. 3, на этапе 310 клиентское устройство посылает асинхронный запрос голосового события (например, асинхронный HTTP-запрос) серверу приложения (например, многомодальному контроллеру 116, Фиг. 1) в варианте осуществления. Запрос голосового события принимается сервером приложения, и между клиентским устройством и сервером приложения устанавливается TCP-соединение. В варианте осуществления, запрос голосового события остается в ожидании на сервере приложения (например, TCP-соединение остается в состоянии существования) до тех пор, пока не происходит «голосовое событие», в момент которого сервер приложения может выдать ответ на запрос голосового события клиентскому устройству. В различных вариантах осуществления, голосовое событие может включать в себя прием сервером приложения указания от голосового сервера о том, что результаты распознавания речи сформированы и/или что фокус голосового представления изменился на новый фокус, прежде чем фокус визуального представления был обновлен на новый фокус. Например, голосовое представление может измениться на новый фокус раньше изменения фокуса для визуального представления, когда произошло событие распознавания речи. Как будет более подробно описано совместно с Фиг. 5, ожидающий запрос голосового события способствует синхронизации между данными и фокусом визуального представления и данными и фокусом голосового представления, когда происходит голосовое событие.
Как будет описано более подробно ниже, клиентское устройство пытается гарантировать, чтобы запрос голосового события ожидал обработки на сервере приложения, главным образом, все время в течение многомодального сеанса для того, чтобы гарантировать, что сервер приложения сможет перехватить и вернуть любые голосовые события клиентскому устройству, которое может произойти спонтанно. В варианте осуществления, клиентское устройство может не отправлять другой асинхронный запрос голосового события серверу приложения до тех пор, пока сервер приложения не выдаст ответ на запрос голосового события на какой-либо ранее отправленный запрос голосового события. Соответственно, только один запрос голосового события (например, одно TCP-соединение) может оставаться в ожидании обработки на сервере приложения в любой заданный момент времени. В альтернативном варианте осуществления, клиентское устройство может отправлять многократные (например, от двух до пяти) асинхронные голосовые события серверу (например, на этапе 310 и/или этапе 514, Фиг. 5) без ожидания ответа на каждое из них, что может привести к множественным ожидающим обработки запросам голосового события на сервере приложения, в течение всей или существенной части сеанса многомодального приложения. В другом альтернативном варианте осуществления клиентское устройство может периодично или время от времени повторно выдавать запрос голосового события для того, чтобы попытаться предотвратить возможность того, что TCP-соединение завершится прежде, чем сервер приложения выдаст ответ. Например, сервер приложения может закончить ожидание запроса голосового события, если он остается в ожидании обработки в течение времени, превышающего период лимита времени, или TCP-соединение может быть завершено по различным другим причинам. В вариантах осуществления, в которых клиентское устройство может обусловить то, что множественные запросы голосового события становятся ожидающими обработки на сервере приложения, сервер приложения может управлять числом запросов голосового события, которым он позволяет оставаться в ожидании обработки, для данного клиентского устройства для того, чтобы управлять загрузкой по обработке, имеющей место на сервере приложения.
После посылки клиентским устройством асинхронного запроса голосового события (или многократных запросов) серверу приложения на этапе 310 способ инициирования сеанса многомодального приложения затем может закончиться. На этой стадии визуальное представление имеет начальный фокус и голосовое представление имеет начальный фокус. Начальные фокусы визуального и голосового представлений должны быть синхронизированы для того, чтобы соответствовать частям многомодальной страницы и речевого диалога, соответственно, которые связаны с приемом ввода пользователя и выполнением распознавания речи для конкретного многомодального элемента отображения. На этой стадии клиентское устройство ожидает ввода пользователя для многомодального элемента отображения через визуальную модальность или голосовую модальность.
Как обсуждалось ранее совместно с этапами 216 и 218 по Фиг. 2, после инициирования сеанса многомодального приложения могут произойти, по меньшей мере, два типа событий, которые могут воздействовать на фокусы голосового представления и визуального представления. Эти типы событий включают в себя событие ввода голосовой модальности и событие ввода визуальной модальности. Событие ввода голосовой модальности происходит, когда вводы пользователя принимаются посредством голосовой модальности. Например, различные события ввода голосовой модальности могут включать в себя, среди прочего, но не ограничены, событие распознавание речи и изменение фокуса голосового представления. В противоположность, событие ввода визуальной модальности происходит, когда вводы пользователя принимаются посредством визуальной модальности. Например, различные события ввода визуальной модальности могут включать в себя, среди прочего, но не ограничены, ввод данных, используя клавиатуру, цифровую клавиатуру или сенсорный экран, и изменение фокуса визуального представления. Фиг. 5 и 6 иллюстрируют варианты осуществления процесса обработки события ввода голосовой модальности и процесса обработки события ввода визуальной модальности, соответственно.
Фиг. 5 является логической блок-схемой способа выполнения процесса обработки события ввода голосовой модальности (например, процесс 216, Фиг. 2) в соответствии с примером варианта осуществления. Способ может начинаться на этапе 502, когда клиентское устройство принимает, посредством его интерфейса пользователя, аудиосигнал, который может представлять фрагмент речи пользователя (например, речь пользователя). Речь пользователя может соответствовать одному элементу отображения (например, речь может быть фрагментом речи «Чикаго», соответствующим элементу 401 отображения, Фиг. 4) или более чем одному элементу отображения (например, речь может быть фрагментом речи «Чикаго, Иллинойс», соответствующим элементам 401 и 402 отображения). По обнаружению фрагмента речи пользователя клиентское устройство может оцифровать и обработать аудиосигнал для того, чтобы сформировать аудиоданные восходящей линии связи, которые представляют фрагмент речи пользователя, и может послать аудиоданные восходящей линии связи на сервер приложения. Используемые здесь «аудиоданные восходящей линии связи» относятся к аудиоданным, посланным от клиентского устройства модулю распознавания речи (например, через сервер приложения), а «аудиоданные нисходящей линии связи» относятся к аудиоданным (например, голосовым напоминаниям), посланным от голосового сервера клиентскому устройству (например, через сервер приложения).
На этапе 504 сервер приложения принимает аудиоданные восходящей линии связи и посылает аудиоданные восходящей линии связи модулю распознавания речи. В варианте осуществления, описанном совместно с этапами 502 и 504, аудиоданные восходящей линии связи посылаются от клиентского устройства модулю распознавания речи через сервер приложения. В альтернативном варианте осуществления, как обсуждалось ранее, аудиоданные восходящей линии связи могут посылаться непосредственно от клиентского устройства модулю распознавания речи (например, по пути 124 аудиоданных SR/клиент, Фиг. 1). В таком варианте осуществления, процессы по этапам 502 и 504 могут быть заменены процессами, в которых клиентское устройство посылает аудиоданные восходящей линии связи модулю распознавания речи.
На этапе 506 модуль распознавания речи принимает аудиоданные восходящей связи и выполняет процесс распознавания речи. В варианте осуществления, процесс распознавания речи выполняется, используя ресурсы распознавания речи, которые были предписаны для использования модулю распознавания речи голосовым браузером (например, на этапе 304, Фиг. 3 или на этапах 610, 620, Фиг.6) в соответствии с текущим состоянием голосового представления. Когда модуль распознавания речи определяет, что аудиоданные восходящей линии связи соответствуют распознаваемой речи, модуль распознавания речи может сформировать результат распознавания на этапе 508 и может послать результат распознавания голосовому браузеру.
Голосовой браузер принимает и обрабатывает результаты распознавания на этапе 510. В варианте осуществления это может включать в себя перевод фокуса визуального представления. Другими словами, так как результат распознавания был сформирован для аудиоданных восходящей линии связи, соответствующих элементу отображения, который был в текущем фокусе визуального представления, голосовой браузер теперь может быть переведен на новый фокус визуального представления, который соответствует другому элементу отображения. Соответственно, голосовой браузер может остановить свою интерпретацию части речевого диалога, связанной с текущим фокусом визуального представления, и может инициировать интерпретацию части речевого диалога, связанной с новым фокусом визуального представления. В варианте осуществления голосовой браузер может посылать серверу приложения информацию обновления, которая может включать в себя результат распознавания (например, данные для элемента отображения) и указание нового фокуса визуального представления.
В варианте осуществления на этапе 512 сервер приложения принимает информацию результата/обновления фокуса и отправляет ответ на запрос голосового события клиентскому устройству. Ответ на запрос голосового события отправляется в качестве ответа на асинхронный запрос голосового события, который был ранее отправлен серверу приложения клиентским устройством и который в текущий момент ожидает обработки на сервере приложения. В варианте осуществления ответ на запрос голосового события может включать в себя результат распознавания и указание нового фокуса голосового представления.
На этапе 514 клиентское устройство принимает ответ на запрос голосового события. Клиентское устройство может затем обновить визуальное представление для того, чтобы отразить результат. Например, клиентское устройство может заполнить элемент отображения, который в текущий момент находится в фокусе визуального представления, текстом, который представляет результат. В добавление, клиентское устройство может обновлять фокус визуального представления для того, чтобы он был синхронизирован с новым фокусом голосового представления. Соответственно, визуальное представление и голосовое представление будут синхронизированными.
В варианте осуществления клиентское устройство отправляет другой асинхронный запрос голосового события (например, асинхронный HTTP-запрос) серверу приложения, как было описано ранее совместно с этапом 310 (Фиг. 3). Запрос голосового события принимается сервером приложения. Предпочтительно, различные синхронные и асинхронные HTTP-запросы будут использовать кэширование соединения, что устранит необходимость разрывать и повторно устанавливать новое TCP-соединение для каждого запроса. Тем не менее, в другом варианте осуществления другое TCP соединение может быть установлено между клиентским устройством и сервером приложения для каждого HTTP-запроса, отправленного клиентским устройством серверу приложения. В варианте осуществления, запрос голосового события будет оставаться в ожидании обработки на сервере приложения до тех пор, пока не произойдет другое голосовое событие. Способ по Фиг. 5 может затем быть закончен.
Фиг. 6 является логической блок-схемой способа выполнения процесса обработки события ввода визуальной модальности (например, процесс 218, Фиг. 2) в соответствии с примером варианта осуществления. В варианте осуществления, способ может начинаться на этапе 602, когда клиентское устройство принимает, посредством своей визуальной модальности, ввод пользователя, который может подтверждать изменение фокуса для визуального представления и/или обновление визуального отображения. Например, пользователь может использовать механизм прокрутки или указания клиентского устройства для того, чтобы выбрать элемент отображения и/или поле ввода данных, которое отличается от того, на котором в текущий момент сфокусировано визуальное представление. В качестве другого примера, пользователь может ввести текст в поле ввода данных, на котором в текущий момент сфокусировано визуальное представление, используя цифровую клавиатуру, например, и может указывать окончание ввода информации в поле данных, как, например, путем нажатия клавиши «ВВОД» (например, клавиши 406 «ВВОД», Фиг.4) или путем предоставления некоторого другого указания.
Когда клиентское устройство принимает ввод пользователя, который подтверждает изменение фокуса визуального представления (без ввода текста), как указано левым ответвлением этапа 604 принятия решения, клиентское устройство может посылать запрос фокуса (например, синхронный HTTP-запрос) серверу приложения на этапе 606. В варианте осуществления запрос фокуса может указывать новый фокус визуального представления. На этапе 608 сервер приложения посылает указание нового фокуса визуального представления голосовому серверу.
На этапе 610 голосовой сервер принимает указание нового фокуса визуального представления. В ответ голосовой браузер может обновить фокус голосового представления для того, чтобы он был синхронизирован с новым фокусом визуального представления. В варианте осуществления это может включать в себя прекращение интерпретации голосовым браузером части голосового диалога, связанного с текущим фокусом голосового представления, и инициирование интерпретации части речевого диалога, связанного с элементом отображения, который является новым фокусом визуального представления. Соответственно, визуальное представление и голосовое представление будут синхронизированы. В добавление голосовой браузер может указывать модулю распознавания речи использовать ресурсы распознавания речи, связанные с новым фокусом голосового представления.
На этапе 612 сервер приложения может посылать ответ на запрос фокуса клиентскому устройству (например, ответ на запрос фокуса, отправленный клиентским устройством серверу приложения на этапе 606). Клиентское устройство принимает ответ на запрос фокуса на этапе 614 и обновляет фокус визуального представления. В варианте осуществления, это может включать в себя прекращение выполнения клиентским браузером своей интерпретации части многомодальной страницы, связанной с текущим элементом отображения и инициирование клиентским браузером интерпретации части многомодальной страницы, связанной с элементом отображения, соответствующим новому фокусу визуального представления. Соответственно, визуальное представление и голосовое представление будут синхронизированы. В добавление, клиентское устройство может обновлять визуальное отображение для того, чтобы отражать новый фокус визуального представления. Например, клиентское устройство может обновлять визуальное отображение так, чтобы включить курсор в блок ввода данных, соответствующий элементу отображения, который является предметом нового фокуса визуального представления. Затем способ может быть закончен.
Ссылаясь обратно на этап 604 принятия решения, когда клиентское устройство принимает ввод текста пользователем, как указано правой ветвью этапа 604 принятия решения, клиентское устройство может послать запрос данных текста (например, синхронный HTTP-запрос) серверу приложения на этапе 616. В варианте осуществления, запрос данных текста может включать в себя представление текста, введенного пользователем. На этапе 618 сервер приложения отправляет представление данных текста голосовому серверу.
На этапе 620 голосовой браузер обновляет (например, сохраняет) представление данных текста и определяет новый фокус голосового представления на основе его интерпретации голосового диалога в свете принятого текста. В ответ, голосовой браузер может затем обновить голосовое представление на новый фокус голосового представления. В варианте осуществления это может включать в себя прекращение интерпретации голосовым браузером части речевого диалога, связанной с текущим фокусом голосового представления, и инициирование интерпретации части речевого диалога, связанной с элементом отображения, который является новым фокусом голосового представления. В добавление, голосовой браузер может предписывать модулю распознавания речи использовать ресурсы распознавания, связанные с новым фокусом голосового представления, и может посылать указание нового фокуса голосового представления серверу приложения.
На этапе 622 сервер приложения может посылать ответ на запрос данных текста клиентскому устройству (например, ответ на запрос текста, посланный клиентским устройством серверу приложения на этапе 616). Ответ данных текста может включать в себя указание нового фокуса голосового представления. Клиентское устройство принимает ответ данных текста на этапе 624 и обновляет фокус визуального представления для того, чтобы синхронизировать с новым фокусом голосового представления. В варианте осуществления это может включать в себя окончание интерпретации клиентским браузером части многомодальной страницы, связанной с текущим элементом отображения, и инициирование интерпретации части многомодальной страницы, связанной с элементом отображения, соответствующим новому фокусу голосового представления. Соответственно, визуальное представление и голосовое представление будут синхронизированы. В добавление, клиентское устройство может обновлять визуальное отображение так, чтобы отражать новый фокус визуального представления. Например, клиентское устройство может обновлять визуальное отображение так, чтобы включить курсор в блок ввода данных, соответствующий элементу отображения, который является предметом нового фокуса визуального представления. Способ затем может быть закончен.
Теперь описаны различные варианты осуществления способов и устройства для осуществления распределенного многомодального приложения. Предшествующее подробное описание, по сути, является просто характерным и не предназначено ограничивать изобретение или заявку и использование изобретения описанными вариантами осуществления. Более того, нет никакого намерения ограничиться какой-либо теорией, представленной в предшествующих предпосылках создания изобретения или подробном описании.
Вариант осуществления включает в себя способ, выполняемый клиентским устройством. Способ включает в себя этап визуализации визуального отображения, которое включает в себя по меньшей мере один многомодальный элемент отображения, для которого ввод данных является принимаемым клиентским устройством посредством визуальной или голосовой модальности, причем фокус визуального представления установлен на первом многомодальном элементе отображения этого по меньшей мере одного многомодального элемента отображения. Способ также включает в себя посылку первого запроса голосового события серверу приложения, где первый запрос голосового события является асинхронным HTTP-запросом, прием аудиосигнала, который может представлять фрагмент речи пользователя, через голосовую модальность, отправку аудиоданных восходящей линии связи, представляющих этот аудиосигнал, модулю распознавания речи, прием ответа на запрос голосового события от сервера приложения в ответ на запрос голосового события и посылку второго запроса голосового события серверу приложения в ответ на прием ответа на запрос голосового события.
Другой вариант осуществления включает в себя способ, выполняемый сервером приложения. Способ включает в себя этапы приема первого запроса голосового события от клиентского устройства, которое визуализировало визуальное отображение, которое включает в себя по меньшей мере один многомодальный элемент отображения, для которого данные ввода являются принимаемыми клиентским устройством посредством визуальной модальности и голосовой модальности, причем первый запрос голосового события является HTTP-запросом. Способ также включает в себя прием результата распознавания речи от голосового сервера, где результат распознавания речи представляет собой результат процесса распознавания речи, выполненного в отношении аудиоданных восходящей линии связи, посланных клиентским устройством модулю распознавания речи, посылку ответа на запрос голосового события клиентскому устройству в ответ на первый запрос голосового события и прием второго запроса голосового события от клиентского устройства в ответ на посылку ответа на запрос голосового события.
Еще один вариант осуществления включает в себя систему, включающую в себя клиентское устройство, выполненное с возможностью визуализировать визуальное отображение, которое включает в себя по меньшей мере один многомодальный элемент отображения, для которого данные ввода являются принимаемыми клиентским устройством посредством визуальной модальности и голосовой модальности, причем фокус визуального представления установлен на первом многомодальном элементе отображения из этого по меньшей мере одного многомодального элемента отображения. Клиентское устройство также выполнено с возможностью посылать первый запрос голосового события серверу приложения, где первый запрос голосового события является асинхронным HTTP-запросом, принимать аудиосигнал, который может представлять фрагмент речи пользователя, через голосовую модальность, посылать аудиоданные восходящей линии связи, представляющие этот аудиосигнал, модулю распознавания речи, принимать ответ на запрос голосового события от сервера приложения в ответ на запрос голосового события и посылать второй запрос голосового события серверу приложения в ответ на прием ответа на запрос голосового события. В варианте осуществления система также включает в себя сервер приложения, который выполнен с возможностью принимать первый запрос голосового события от клиентского устройства, принимать результат распознавания речи от голосового сервера, причем результат распознавания речи представляет собой результат процесса распознавания речи, выполненного в отношении аудиоданных восходящей линии связи, посланных клиентским устройством модулю распознавания речи, посылать ответ на запрос голосового события клиентскому устройству в ответ на первый запрос голосового события и принимать второй запрос голосового события от клиентского устройства в ответ на посылку ответа на запрос голосового события.
Последовательность текста в любом пункте формулы изобретения не предполагает, что этапы процесса должны выполняться во временном или логическом порядке в соответствии с такой последовательностью, если это особо не определено языком формулы изобретения. Более конкретно, этапы процессов по Фиг. 2, 3, 5 и 6 могут чередоваться в любом порядке и/или могут выполняться параллельно без отступления от объема изобретения. В добавление, должно быть понятно, что информация внутри разнообразных отличающихся сообщений (например, запросов и ответов), которые описаны выше как обмениваемые между элементами системы, могут быть объединены вместе в единое сообщение и/или информация внутри конкретного сообщения может быть разделена на множество сообщений. Дополнительно, сообщения могут посылаться элементами системы в последовательностях, отличных от последовательностей, описанных выше. Более того, такие слова как «соединен» или «подключен», использованные в описании отношений между различными элементами, не подразумевают, что между этими элементами должно существовать физическое соединение. Например, два элемента могут быть подсоединены друг к другу физически, электронно, логически или любым другим образом, посредством одного или более дополнительных элементов, без отступления от объема изобретения.
Специалисты в соответствующей области должны понимать, что информация и сигналы могут быть представлены используя любые из многообразия различных техник и технологий. Например, данные, инструкции, команды, информация, сигналы, биты, символы и символы псевдошумовой последовательности, которые возможно упоминались на протяжении описания выше, могут быть представлены напряжениями, несущими, электромагнитными волнами, магнитными полями или частицами, оптическими полями или частицами или любыми их комбинациями.
Специалисты в соответствующей области дополнительно должны оценить, что различные пояснительные логические блоки, модули, схемы и этапы алгоритмов, описанные в отношении раскрытых здесь вариантов осуществления, могут быть осуществлены в качестве электронного аппаратного обеспечения, компьютерного программного обеспечения или их комбинаций. Для того, чтобы очевидно проиллюстрировать это, взаимозаменяемость аппаратного и программного обеспечения, различных пояснительных компонентов, блоков, модулей, схем и этапов были описаны выше в целом с точки зрения их функциональных возможностей. Осуществлена ли такая функциональность в аппаратном или программном обеспечении, зависит от конкретных прикладных и проектных ограничений, наложенных на всю систему. Специалисты могут осуществить желаемую функциональность различными способами для каждого конкретного приложения, но такие решения по реализации не должны интерпретироваться как вызывающие отступление от объема изобретения.
Различные поясняющие логические блоки и модули, описанные в отношении раскрытых здесь вариантов осуществления, могут быть осуществлены или выполнены с помощью процессора общего назначения, цифрового сигнального процессора (DSP), специализированной интегральной микросхемы (ASIC), программируемой вентильной матрицы (FPGA) или другим программируемым логическим устройством, схемой на дискретных компонентах или транзисторной логической схемой, дискретными компонентами аппаратного обеспечения или любой их комбинацией, созданной для того, чтобы выполнять описанные здесь функции. Процессор общего назначения может быть микропроцессором, но, в качестве альтернативы, процессор может быть любым традиционным процессором, контроллером, микроконтроллером или конечным автоматом. Процессор также может быть выполнен в виде комбинации вычислительных устройств, как, например, комбинации DSP и микропроцессора, множеством микропроцессоров, одним или более микропроцессорами совместно с ядром DSP, или любой другой такой конфигурации.
Этапы способа или алгоритма, описанные в отношении раскрытых здесь вариантов осуществления, могут быть реализованы непосредственно в аппаратном обеспечении, в одном или более модулях программного обеспечения, исполняемых процессором, или в комбинации обоих. Модуль программного обеспечения может располагаться в запоминающем устройстве с произвольной выборкой, флэш-памяти, постоянном запоминающем устройстве (ROM), стираемом программируемом ROM (EPROM), электрическом EPROM, регистрах, жестком диске, съемном диске, ROM на компакт-диске (CD-ROM) или любом другом виде носителя данных, известном в технике. Характерный носитель данных подключен к процессору так, что процессор может считывать информацию с и записывать информацию на этот носитель данных. В качестве альтернативы, носитель данных может быть неотъемлемой частью процессора. Процессор и носитель данных могут размещаться на ASIC. ASIC может размещаться в терминале пользователя. В качестве альтернативы, процессор и носитель данных могут располагаться в терминале пользователя как отдельные компоненты.
В то время как, по меньшей мере, один характерный вариант осуществления был представлен в вышеупомянутом подробном описании, должно быть принято во внимание, что существует огромное число вариаций. Также должно быть принято во внимание, что характерный вариант осуществления или характерные варианты осуществления являются всего лишь примерами и не предназначены никаким образом ограничить объем, применимость или конфигурацию изобретения. Наоборот, вышеупомянутое подробное описание предоставит специалисту в соответствующей области подходящий план действий для осуществления характерного варианта осуществления изобретения, и должно быть понятно, что различные изменения могут быть сделаны в функционировании и расположении элементов, описанных в характерном варианте осуществления, без отступления от объема изобретения, определяемого прилагаемой формулой изобретения и ее законными эквивалентами.
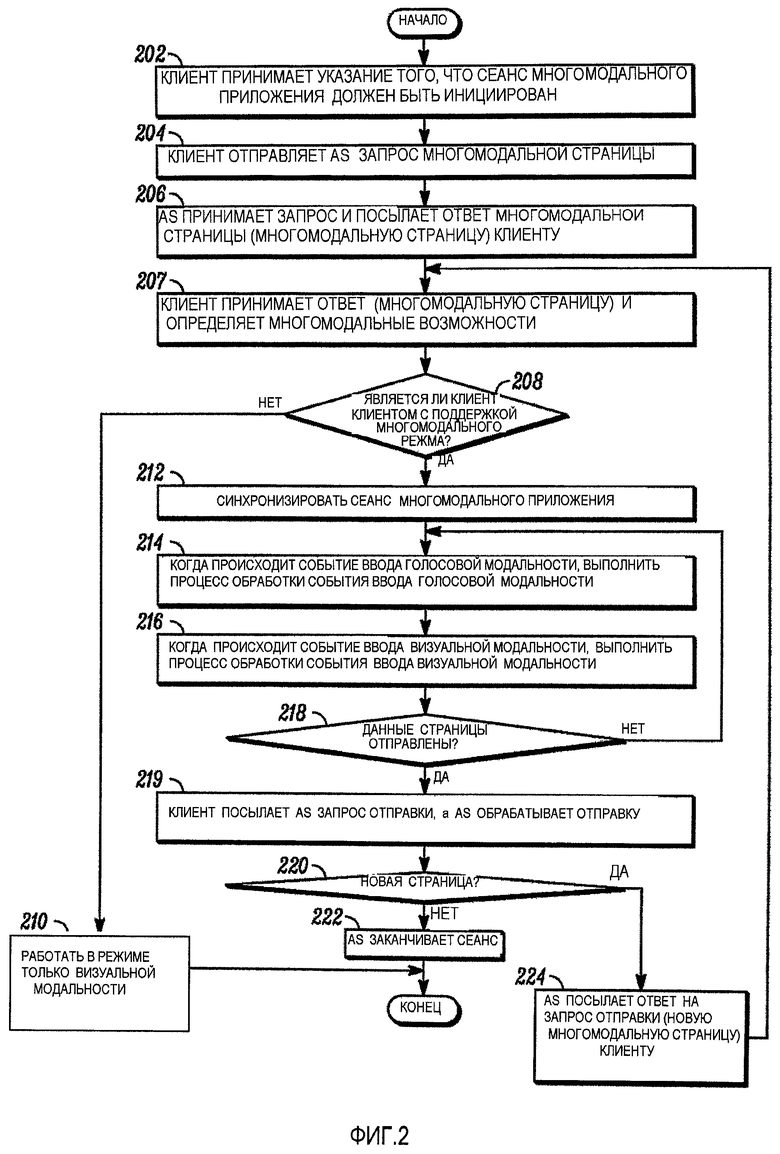
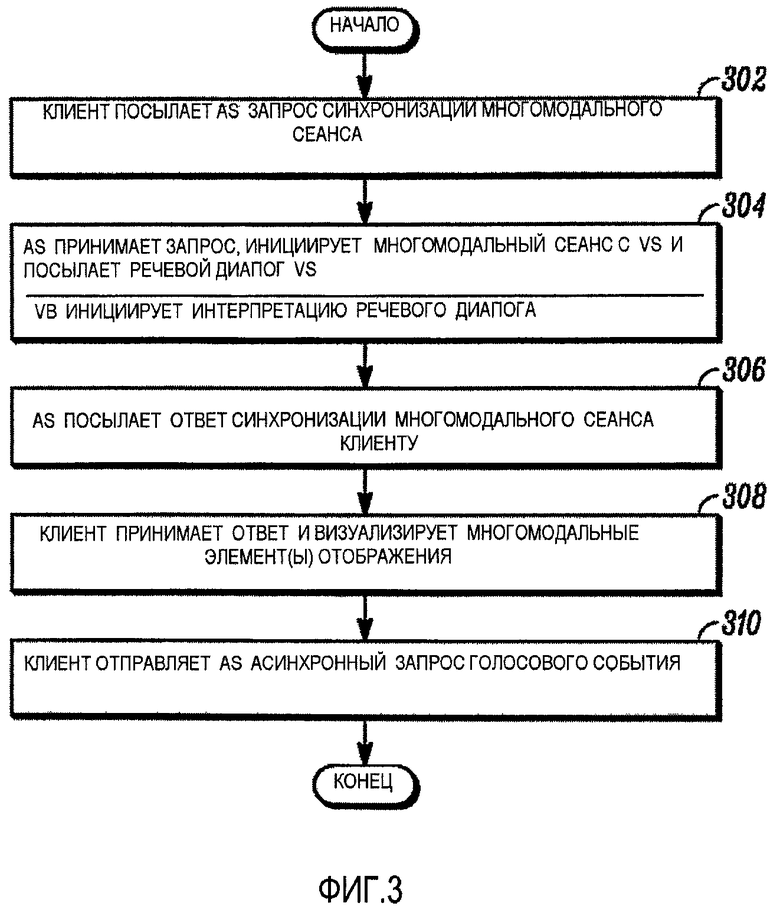
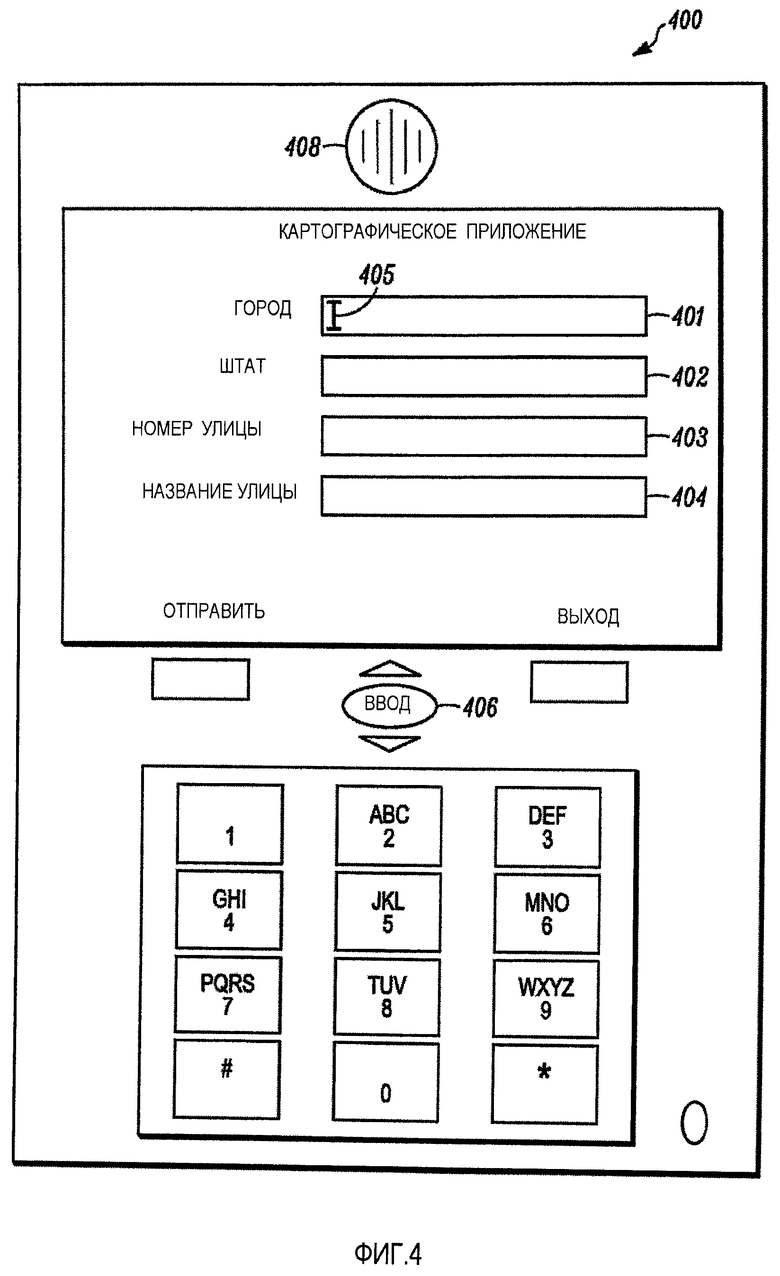
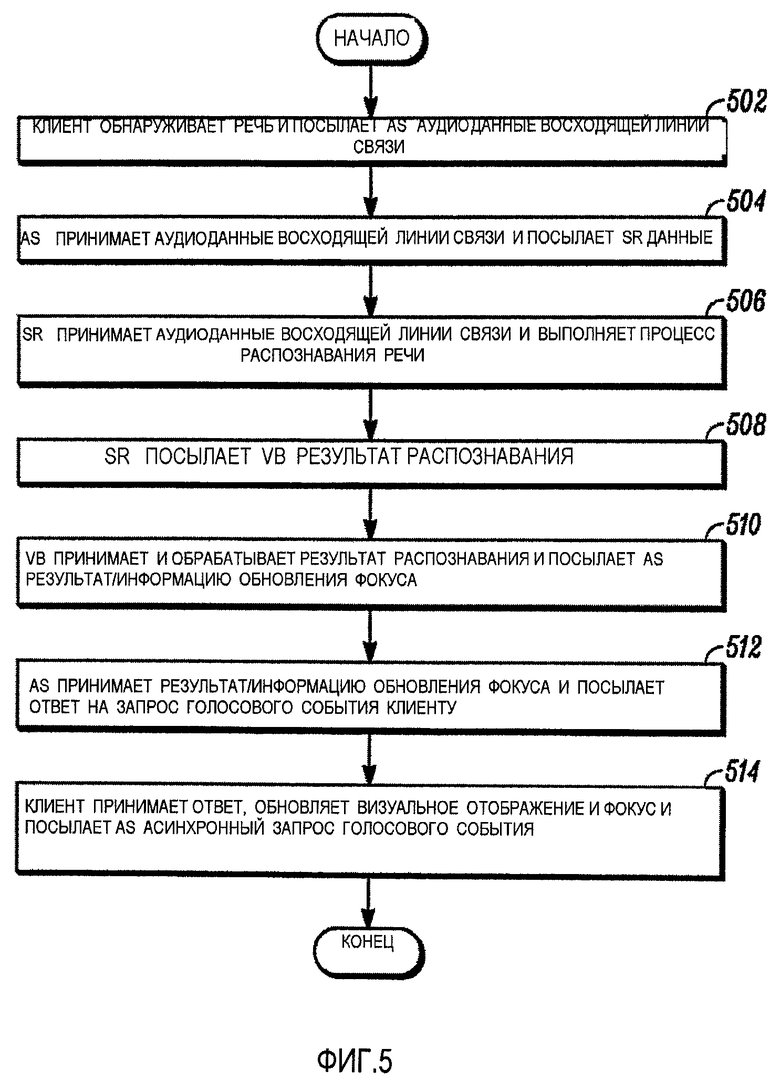
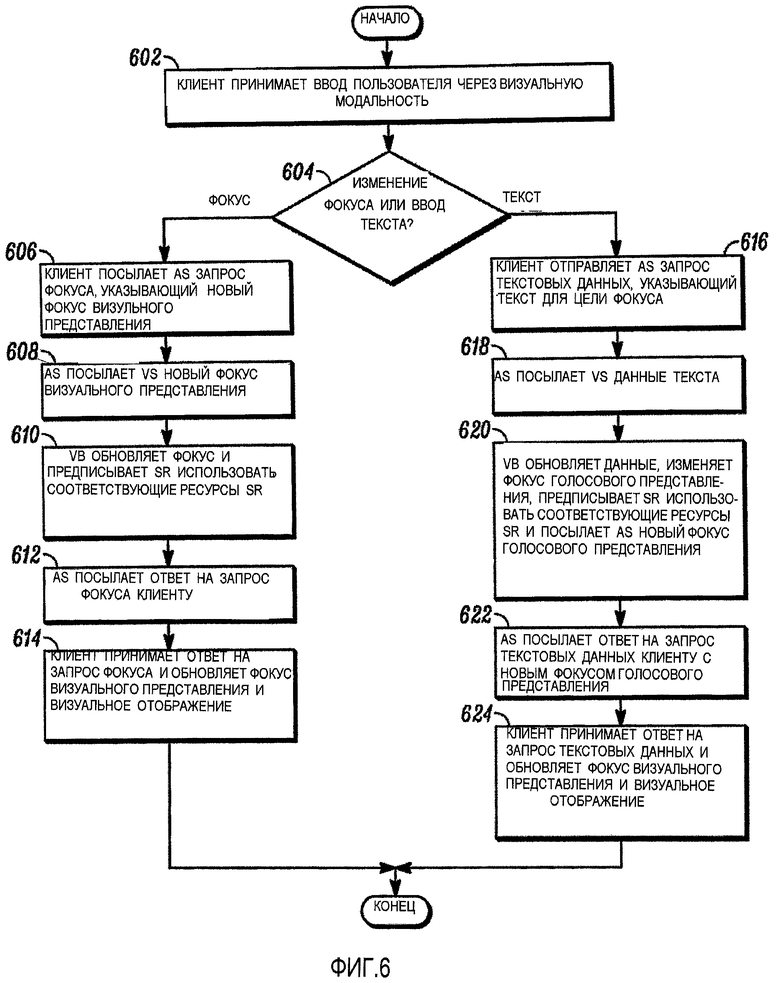
Изобретение относится к средствам для синхронизации данных между визуальным и голосовым представлениями, связанными с распределенными многомодальными приложениями. Технический результат заключается в уменьшении времени нахождения нужного контента. Клиентское устройство визуализирует отображение, которое включает в себя по меньшей мере один многомодальный элемент отображения, для которого данные ввода являются принимаемыми посредством визуальной модальности и голосовой модальности. Когда клиент обнаруживает через голосовую модальность фрагмент речи пользователя, клиент посылает аудиоданные восходящей линии связи, представляющие фрагмент речи, модулю распознавания речи. Сервер приложения принимает результат распознавания речи, сформированный модулем распознавания речи, и посылает ответ на запрос голосового события клиенту. Ответ на запрос голосового события посылается в качестве ответа на асинхронный HTTP-запрос голосового события, посланный ранее клиентом серверу приложения. Затем клиент может послать другой запрос голосового события серверу приложения в ответ на прием ответа на запрос голосового события. 3 н. и 18 з.п. ф-лы, 6 ил.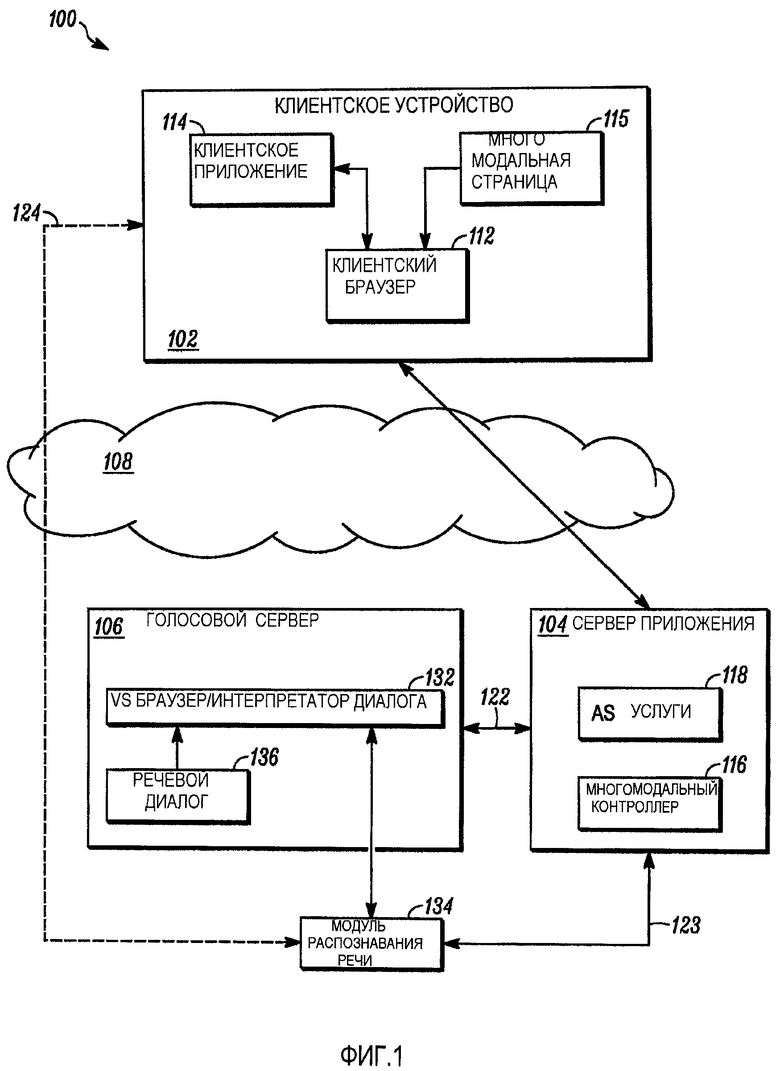
1. Способ осуществления распределенных многомодальных приложений, выполняемый клиентским устройством, при этом способ содержит этапы, на которых
визуализируют визуальное отображение, которое включает в себя по меньшей мере один многомодальный элемент отображения, для которого данные ввода являются принимаемыми клиентским устройством посредством визуальной модальности и голосовой модальности, причем фокус визуального представления установлен на первом многомодальном элементе отображения из этого по меньшей мере одного многомодального элемента отображения;
посылают первый запрос голосового события серверу приложения, при этом первый запрос голосового события является асинхронным запросом по протоколу передачи гипертекста (HTTP);
принимают аудиосигнал, который может представлять фрагмент речи пользователя, через голосовую модальность;
посылают аудиоданные восходящей линии связи, представляющие этот аудиосигнал, модулю распознавания речи и
принимают ответ на запрос голосового события от сервера приложения в ответ на упомянутый запрос голосового события; и
посылают второй запрос голосового события серверу приложения в ответ на прием ответа на запрос голосового события.
2. Способ по п.1, в котором при посылке аудиоданных восходящей линии связи модулю распознавания речи посылают аудиоданные восходящей линии связи серверу приложения для переадресации модулю распознавания речи.
3. Способ по п.1, в котором при посылке аудиоданных восходящей линии связи модулю распознавания речи посылают аудиоданные восходящей линии связи непосредственно модулю распознавания речи.
4. Способ по п.1, дополнительно содержащий этапы, на которых принимают результат распознавания речи и обновляют визуальное отображение так, чтобы отобразить текст, соответствующий результату распознавания речи, в первом многомодальном элементе отображения.
5. Способ по п.1, дополнительно содержащий этапы, на которых
принимают указание нового фокуса голосового представления и
обновляют фокус визуального представления так, чтобы он был синхронизирован с новым фокусом голосового представления.
6. Способ по п.1, дополнительно содержащий этапы, на которых запрашивают многомодальную страницу с сервера приложения, при этом многомодальная страница, при интерпретации, дает возможность клиентскому устройству визуализировать визуальное отображение;
принимают многомодальную страницу от сервера приложения;
определяют, является ли клиентское устройство устройством с поддержкой многомодального режима; и,
если клиентское устройство является устройством с поддержкой многомодального режима, визуализируют визуальное отображение.
7. Способ по п.1, дополнительно содержащий этапы, на которых принимают аудиоданные нисходящей линии связи, причем эти аудиоданные нисходящей линии связи включают в себя аудионапоминание; и
выводят аудионапоминание на устройство аудиовывода клиентского устройства.
8. Способ по п.1, дополнительно содержащий этапы, на которых
принимают ввод пользователя для изменения фокуса визуального представления на второй многомодальный элемент отображения из упомянутого по меньшей мере одного многомодального элемента отображения;
на основе приема ввода пользователя выдают запрос фокуса серверу приложения, указывающий новый фокус визуального представления, соответствующий второму многомодальному элементу отображения;
принимают ответ на запрос фокуса от сервера приложения;
обновляют фокус визуального представления и визуальное отображение в ответ на прием ответа на запрос фокуса так, чтобы указать второй многомодальный элемент отображения в качестве фокуса визуального представления.
9. Способ по п.8, в котором при приеме ввода пользователя
принимают указание того, что пользователь выбрал второй многомодальный элемент отображения, используя устройство указания или прокрутки интерфейса пользователя.
10. Способ по п.8, в котором при приеме ввода пользователя
принимают указание того, что пользователь ввел текст в поле ввода данных для первого многомодального элемента отображения, причем запрос фокуса включает в себя представление этого текста.
11. Способ осуществления распределенных многомодальных приложений, выполняемый сервером приложения, при этом способ содержит этапы, на которых
принимают первый запрос голосового события от клиентского устройства, которое визуализировало визуальное отображение, которое включает в себя по меньшей мере один многомодальный элемент отображения, для которого данные ввода являются принимаемыми клиентским устройством посредством визуальной модальности и голосовой модальности, причем первый запрос голосового события является асинхронным запросом по протоколу передачи гипертекста (HTTP);
принимают результат распознавания речи от голосового сервера, при этом результат распознавания речи представляет собой результат процесса распознавания речи, выполненного в отношении аудиоданных восходящей линии связи, посланных клиентским устройством модулю распознавания речи;
посылают ответ на запрос голосового события клиентскому устройству в ответ на первый запрос голосового события и
принимают второй запрос голосового события от клиентского устройства в ответ на отправку ответа на запрос голосового события.
12. Способ по п.11, дополнительно содержащий этапы, на которых
принимают аудиоданные восходящей линии связи от клиентского устройства и
посылают аудиоданные восходящей линии связи модулю распознавания речи.
13. Способ по п.11, в котором при отправке ответа на запрос голосового события клиентскому устройству
включают результат распознавания речи в ответ на запрос голосового события.
14. Способ по п.11, дополнительно содержащий этапы, на которых
принимают указание нового фокуса голосового представления от голосового сервера и
включают это указание нового фокуса голосового представления в ответ на запрос голосового события.
15. Способ по п.11, дополнительно содержащий этапы, на которых принимают указание нового фокуса визуального представления от клиентского устройства и
посылают это указание нового фокуса визуального представления голосовому серверу.
16. Система для осуществления распределенных многомодальных приложений, содержащая
клиентское устройство, выполненное с возможностью:
визуализировать визуальное отображение, которое включает в себя по меньшей мере один многомодальный элемент отображения, для которого данные ввода являются принимаемыми клиентским устройством посредством визуальной модальности и голосовой модальности, причем фокус визуального представления установлен на первом многомодальным элементе отображения из этого по меньшей мере одного многомодального элемента отображения,
посылать первый запрос голосового события серверу приложения, при этом первый запрос голосового события является асинхронным запросом по протоколу передачи гипертекста (HTTP),
принимать аудиосигнал, который может представлять фрагмент речи пользователя, через голосовую модальность,
посылать аудиоданные восходящей линии связи, представляющие этот аудиосигнал, модулю распознавания речи,
принимать ответ на запрос голосового события от сервера приложения в ответ на упомянутый запрос голосового события и
посылать второй запрос голосового события серверу приложения в ответ на прием ответа на запрос голосового события.
17. Система по п.16, дополнительно содержащая
сервер приложения, при этом сервер приложения выполнен с возможностью:
принимать первый запрос голосового события от клиентского устройства, принимать результат распознавания речи от голосового сервера, при этом результат распознавания речи представляет собой результат процесса распознавания речи, выполненного в отношении аудиоданных восходящей линии связи, посланных клиентским устройством модулю распознавания речи,
посылать ответ на запрос голосового события клиентскому устройству в ответ на первый запрос голосового события и
принимать второй запрос голосового события от клиентского устройства в ответ на посылку ответа на запрос голосового события.
18. Система по п.16, в которой клиентское устройство дополнительно выполнено с возможностью посылать аудиоданные восходящей линии связи серверу приложения для переадресации модулю распознавания речи.
19. Система по п.16, в которой клиентское устройство дополнительно выполнено с возможностью принимать указание нового фокуса голосового представления и обновлять фокус визуального представления так, чтобы он был синхронизирован с новым фокусом голосового представления.
20. Система по п.16, в которой клиентское устройство дополнительно выполнено с возможностью:
принимать ввод пользователя для изменения фокуса визуального представления на второй многомодальный элемент отображения из упомянутого по меньшей мере одного многомодального элемента отображения и на основе приема ввода пользователя выдавать серверу приложения запрос фокуса, указывающий новый фокус визуального представления, соответствующий второму многомодальному элементу отображения, принимать ответ на запрос фокуса от сервера приложения и обновлять фокус визуального представления и визуальное отображение в ответ на прием ответа на запрос фокуса так, чтобы указывать второй многомодальный элемент отображения в качестве фокуса визуального представления.
21. Система по п.16, в которой клиентское устройство является устройством, выбранным из группы устройств, которая включает в себя сотовый телефон, рацию, пейджер, персональный цифровой помощник, персональное устройство навигации, мобильную компьютерную систему, автомобильную компьютерную систему, самолетную компьютерную систему, компьютер, лэптоп, ноутбук, настольный компьютер и реализованный на компьютере телефон согласно протоколу голоса через интернет (VoIP).
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| RU 2006102661 A1, 10.08.2007. | |||

