Область техники, к которой относится изобретение
Настоящее изобретение относится к управлению режимом работы устройства радиосвязи. Более конкретно настоящее изобретение относится к способу работы многорежимного устройства радиосвязи в различных системах.
Уровень техники
Устройства радиосвязи, такие как сотовые телефоны, имеют непрерывно растущие возможности обработки и прикладных программных средств для запуска на них. Однако размер устройства создает трудности для использования аппаратных средств пользовательского интерфейса обычно доступных, например, для компьютера. Сотовые телефоны имеют небольшие по размеру клавиатуры и устройства отображения. Однако разработаны способы для использования преимуществ возможности звуковой связи, присущей сотовому телефону. Технология распознавания речи в настоящее время обычно используется в устройствах радиосвязи. Речевой набор в настоящее время является легкодоступным. С появлением служб обработки и передачи данных, включающих в себя использование Интернета, стало очевидно что службы с возможностью поддержки речи могут значительно улучшить функциональность устройств связи. С этой целью был разработан голосовой расширяемый язык разметки (VoiceXML) для содействия службам с возможностью поддержки речи для устройств беспроводной связи. Однако с появлением служб с возможностью поддержки речи, доступных для потребителей, возникли некоторые серьезные проблемы в отношении портативных устройств связи.
В отношении служб с возможностью поддержки речи возникают сложные проблемы при использовании совместно с многорежимными службами. В многорежимных диалогах ввод данных может осуществляться посредством речи, клавиатуры, мыши и других устройств ввода данных, в то время как вывод данных может быть осуществлен через спикеры, устройства отображения и другие устройства вывода данных. Стандартный веб-браузер осуществляет ввод данных через клавиатуру и мышь и вывод данных через устройство отображения. Стандартный голосовой браузер осуществляет ввод данных при помощи речи и вывод данных через аудиоустройство. Многорежимная система требует чтобы два браузера (а возможно и другие) были объединены каким-либо образом. Обычно для этого требуются различные способы, чтобы надлежащим образом синхронизировать приложения, имеющие различные режимы. Некоторые из таких способов описаны в 3 GPP TR22.977, "3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Feasibility study for speech enabled services; (Release 6), v2.0.0 (2002-09).
В случае первого подхода, "толстый клиент с локальными речевыми ресурсами" размещает веб-(визуальный) браузер, голосовой браузер и подчиненные механизмы распознавания речи, и механизмы речевого (текст-в-речь) синтеза на одном и том же устройстве (компьютер, мобильный телефон, телеприставка и т.д.). Такой подход невозможно реализовать на небольших устройствах беспроводной связи вследствие необходимости большого количества программных средств и вычислительной мощности. Второй подход представляет собой "толстый клиент с речевыми ресурсами на основе сервера", где речевые механизмы хранятся в сети, но визуальный браузер и голосовой браузер все еще размещаются в устройстве. Это до некоторой степени более удобно для небольших устройств, чем в первое решение, но все еще очень сложно для реализации на небольших устройствах, таких как мобильные телефоны. Третий подход представляет собой "тонкий клиент", где устройство имеет только визуальный браузер, который должен быть скоординирован с голосовым браузером и речевыми механизмами, размещенными в сети. Такой подход годится для устройств, таких как мобильные телефоны, но при этом требуется синхронизация для поддержки двух скоординированных браузеров, что делает всю систему довольно сложной.
Во всех указанных подходах все еще существует проблема, заключающаяся в том, что решения являются либо непригодными для установления на меньших по размеру устройствах, либо требуют сложной синхронизации.
Следовательно, существует необходимость учета проблем встраивания технологии голосового браузера и многорежимной технологии в устройство беспроводной связи. Это также может быть полезным для предоставления решения, при котором не требуется возможность расширенной обработки в устройстве связи. Это также может быть выгодным для избежания черезмерной сложности устройства связи без значительных дополнительных аппаратных средств или повышения стоимости.
Краткое описание чертежей
На Фиг.1 показана блок-схема первой многорежимной системы связи уровня техники;
На Фиг.2 показана блок-схема второй многорежимной системы связи уровня техники;
На Фиг.3 показана блок-схема третьей многорежимной системы связи уровня техники;
На Фиг.4 показана блок-схема многорежимной системы связи с улучшенным голосовым браузером согласно настоящему изобретению;
На Фиг.5 показана схема последовательности операций, иллюстрирующая этапы многорежимного диалога согласно предпочтительному варианту осуществления настоящего изобретения.
Осуществление изобретения
Настоящее изобретение разделяет приложение голосового браузера на два компонента, а не трактует его как единое целое. Таким образом, количество программного обеспечения в устройстве сильно минимизируется, позволяя запускать многорежимные диалоги на значительно меньших устройствах, чем в других случаях и при меньших затратах. Путем осуществления синхронизации браузера в устройстве устраняется большинство трудностей при решениях известного уровня техники. Дополнительно, имея обычные драйверы для голосового браузера, многорежимное приложение может быть реализовано как обособленная программа, а не приложение браузера. Это усовершенствование в устройстве связи имеет очень низкую стоимость. Взамен добавления вычислительной мощности, которая увеличивает стоимость и увеличивает размер устройства, настоящее изобретение успешно использует существующую вычислительную мощность устройства связи в сочетании с решениями программных средств для голосового браузера, необходимого в многорежимном диалоге.
На Фиг.1 представлена архитектура предшествующего уровня техники, в которой большая часть или вся обработка многорежимной связи осуществляется вне устройства (тонкого) связи. Необходимо понять, что существуют другие соединения, требуемые для правильной работы многорежимного диалога, которые для простоты не показаны. В этом примере показано, что клиентское устройство 10 связи желает получить доступ к многорежимному приложению, находящемуся на сервере 18 приложений. Обычно сервер 18 приложений использует существующий резидентный веб-сервер 20 для связи с Интернетом 16. Многорежимный/голосовой сервер 14 в системе связи, например, провайдера услуг, соединен с Интернетом 16 и производит обслуживание сотовой сети 12, которая, в свою очередь, соединяется с клиентским устройством 10 связи. Веб-сервер предоставляет многорежимный размеченный документ 22, включающий в себя визуальную (XHTML) разметку, и голосовую (VoiceXML) разметку для обеспечения пользователя интерфейсом. Как известно, файл разметки XHTML представляет собой визуальную форму, которая может предоставлять несколько полей для информационного взаимодействия с пользователем. Например, пользователь может навести и кликнуть по полю "кнопки-переключателя" для указания выбора или может напечатать текст в пустом поле для ввода информации. VoiceXML работает совместно с XHTML для обеспечения голосового интерфейса для ввода информации в поля размеченного документа. Например, разметка VoiceXML может определить аудиоприглашение, которое предлагает пользователю выполнить ввод информации в поле. Затем пользователь может что-нибудь сказать (или ввести текст при необходимости), а голосовой браузер VoiceXML может прослушать или преобразовать эту речь и сравнить ее с грамматикой, определенной или указанной при помощи разметки VoiceXML, которая определяет подходящий ответ на приглашение. Разметка VoiceXML может быть связана с любым полем документа, то есть полем фокуса. Работа размеченного документа, в том числе XTML и VoiceXML, уже обеспечена соответствующими стандартами.
Данная сотовая сеть 12 обеспечивает стандартный аудиоввод данных и аудиовывод данных для клиентского устройства 10 через кодек 28, используя аудиопакеты, как определено в RTP или подобных транспортных протоколах, включающих в себя распределенное распознавание речи (DSR), как известно в данной области техники. Сеть 12 также предоставляет канал, который используется для предоставления многорежимной информации в визуальный браузер 26 клиентского устройства. Данная многорежимная информация передается в виде файла 24 XHTML. В этом примере многорежимный/голосовой сервер 14 разделяет и объединяет голосовую (VoiceXML) и визуальную (XHTML) части обмена данными между клиентским устройством 10 и веб-сервером 20. Разделение и объединение требует согласования, которое обеспечивается посредством многорежимной синхронизации голосовой и визуальной частей многорежимного документа 22 таким образом, что клиентское устройство получает и предоставляет многорежимную информацию в виде, согласованном с голосовой частью информации. Клиентское устройство обрабатывает многорежимную информацию 24 при помощи резидентного визуального браузера 26, в то же время обрабатывая информацию аудиопакета при помощи кодека 28, как известно в данной области техники. Раздельная обработка голосовой и визуальной информации может вызвать некоторые проблемы координации, что приводит к необходимости использования локальной блокировки, если это требуется для обеспечения правильной работы для пользователя. Например, пользователь может нажать кнопки, перед тем как фокус поля может быть установлен. Локальная блокировка может зафиксировать экран в то время, пока устанавливается фокус поля. В качестве другого примера, когда представлена форма XHTML на клиентском устройстве и введена голосовая информация, локальное устройство может блокировать экран устройства до момента подтверждения голосовой информации. Блокировка экрана устройства не допускает ввод пользователем текстовой информации в таком же поле формы, что может привести к гонке конфликтующих голосового ввода и ввода текстовой информации в многорежимном/голосовом сервере 14.
Многорежимный/голосовой сервер 14 содержит в себе большую или всю обработку для обмена многорежимной информацией с клиентским устройством 10. Такая обработка управляется менеджером 30 синхронизации. Менеджер 30 синхронизации делит или расщепляет документ 22 на информацию 32 голосового диалога (такой как VoiceXML) и многорежимную информацию (XHTML) и синхронизирует эту информацию, как описано выше. Информация голосового диалога передается в голосовой браузер 34 для взаимодействия с речевыми механизмами 36 на сервере 14 для предоставления соответствующим образом отформатированной аудиоинформации в клиентское устройство 10. К сожалению, для поддержания двух браузеров 26, 34 в согласованном состоянии требуется синхронизация, что делает всю систему довольно сложной, и все еще может требовать наличия локальной блокировки в клиентском устройстве 10. Более того, необходим многорежимный сервер 14 специального назначения, а также специальный протокол для синхронизации браузеров.
Речевой механизм 36 проигрывает аудио и обеспечивает распознавание речи, как известно в данной области техники. Речевые механизмы являются затратными в отношении вычислительных ресурсов и требуют наличия большого оперативного запоминающего устройства (RAM). Такие ресурсы обычно не имеются в наличии в клиентском устройстве, таком как радиотелефон, и поэтому в данном примере используется отдельный многорежимный/голосовой сервер 14. Голосовой браузер 34 является процессором высшего уровня, который обрабатывает диалог, получает соответствующие события документа разметки и управляет речевым механизмом для проигрывания аудиоприглашения и прослушивания голосового ответа. Затем речевые механизмы посылают озвученные ответы в соответствующие поля форм голосового браузера. Голосовой браузер содержит память, хранящую заранее введеный список допустимой грамматики для сопоставления с ответом из речевых механизмов. Например, поле в документе XHTML может требовать ответы "да" или "нет", в качестве единственно подходящих ответов. Речевой механизм может отображать входящий голосовой ввод данных на результат распознавания, который может определять либо распознанное высказывание, допустимое текущей грамматикой (грамматиками), либо код ошибки. Затем результат распознавания может быть передан в голосовой браузер, который затем может обновить свое внутреннее состояние для отображения результата, возможно посредством внесения высказывания в конкретное поле. Голосовой браузер может, в свою очередь, информировать менеджер синхронизации о распознанном результате. В этом случае речевой механизм может попытаться сопоставить голосовой ответ с каждым из ответов "да" или "нет" из своего списка допустимых грамматик и отсылает результат в голосовой браузер, который может определить результат да/нет в подходящем поле и информировать менеджер синхронизации.
Для согласования ответов менеджер 30 синхронизации сообщает веб-браузеру или голосовому браузеру, какое поле в документе задействовано в настоящее время. Другими словами, менеджер синхронизации определяет поле фокуса для браузеров. Хотя это не является синхронизацией в буквальном смысле, результат является таким же. По определению, многорежимный диалог может включать в себя валидный ответ в поле, которое может представлять собой либо аудио, через кодек 28, либо ввод текста, путем ввода с клавитуры, через визуальный браузер 26. Менеджер синхронизации управляет этими событиями для обеспечения скоординированной передачи многорежимной информации.
На Фиг.2 представлена архитектура предшествующего уровня техники, в которой большая часть или вся обработка многорежимной связи осуществляется в устройстве (толстом) связи. Как и прежде, клиентское устройство связи 10 желает получить доступ к многорежимному приложению, находящемуся на сервере 18 приложений, причем сервер 18 приложений использует для связи резидентный веб-сервер 20. Веб-сервер 20 обеспечивает передачу многорежимного размеченного документа 22 непосредственно в клиентское устройство 10 (обычно через сотовую сеть 12, обеспечивающую интернет-соединение через провайдера услуг, например, систему пакетной радиосвязи общего пользования или GPRS). Все многорежимные/голосовые серверные процессы из предыдущего примера теперь являются резидентными в клиентском устройстве 10 и работают так же, как описано выше. К сожалению, (толстое) устройство 10 в настоящее время требует значительного увеличения вычислительной мощности и памяти, что имеет чрезмерно высокую стоимость.
На Фиг.3 представлена архитектура предшествующего уровня техники, в которой некоторая обработка многорежимной связи осуществляется удаленно, для учета ограниченной возможности обработки и ограничений по памяти на устройстве 10 связи. Как и прежде, клиентское устройство 10 связи желает получить доступ к многорежимному приложению, находящемуся на сервере 18 приложений, причем сервер 18 приложений использует для связи резидентный веб-сервер 20. Веб-сервер 20 обеспечивает передачу многорежимного файла 22 непосредственно в клиентское устройство 10 (обычно через сотовую сеть 12, обеспечивающую интернет-соединение через провайдера услуг). Большая часть многорежимных/голосовых серверных процессов из предыдущего 10, и работают так же, как описано выше. Однако теперь удаленный голосовой сервер 38 снабжен речевыми механизмами 36, резидентно установленными на нем. Удаленный голосовой сервер 38 может предоставляться через провайдера услуг или предприятие, как это имеет место в настоящее время. Голосовой браузер 34 связан с речевыми механизмами 36 через заданный протокол управления медиаресурсами (MRCP). К сожалению, (толстое) устройство 10 с удаленными ресурсами все еще требует существенно расширенной вычислительной мощности и памяти, что все еще имеет чрезмерно высокую стоимость. Более того, существует большой объем кодов, передаваемых между голосовым браузером и речевым механизмом, которые могут перегружать сеть и замедлять обмен данными.
В своей простейшей реализации настоящее изобретение представляет собой блок разрешения диалога голосового браузера для системы связи. Блок разрешения голосового браузера включает в себя приложение распознавания речи, содержащее множество элементов взаимодействия приложений, которые представляют собой множество связанных элементов ввода данных пользовательских интерфейсов. Например, если пользователь желает создать новую запись адреса в адресной книге, ему нужно ввести имя и телефонный номер. В этом случае элемент взаимодействия приложений может представлять собой два поля ввода данных, которые являются тесно связанными (т.е. поле имени и поле адреса). Каждый элемент взаимодействия приложений имеет связанные голосовые диалоговые формы, определяющие фрагменты. Например, приложение распознавания речи может быть многорежимным приложением просмотра ресурсов, которое обрабатывает документы приложением просмотра ресурсов, которое обрабатывает документы XHTML+VoiceXML. Каждый документ XHTML+VoiceXML состоит из одного элемента взаимодействия приложений и содержит один или больше форм VoiceXML, связанных с одним или несколькими полями. Каждая форма VoiceXML определяет фрагмент. Драйвер голосового браузера, резидентный на устройстве связи, обеспечивает фрагменты из приложения и генерирует идентификаторы, которые идентифицируют фрагменты. Реализация голосового браузера, резидентного на удаленном голосовом сервере, получает фрагменты от драйвера голосового браузера и загружает множество речевых грамматик, причем последующая введенная речь сопоставляется с этими речевыми грамматиками, связанными с соответствующими идентификаторами, полученными в запросе распознавания речи из драйвера голосового браузера.
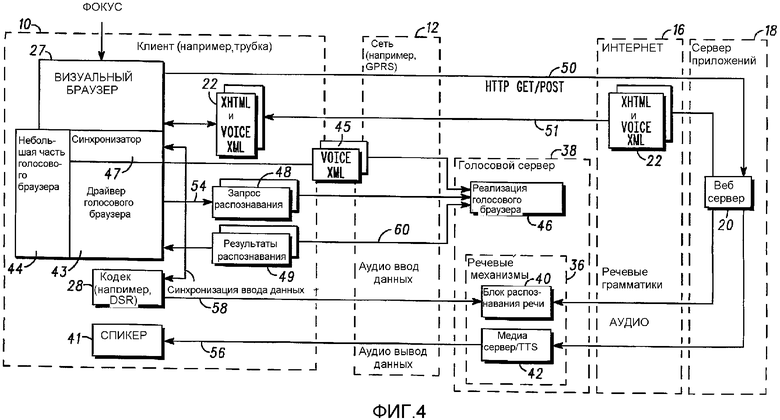
На Фиг.4 представлена практическая конфигурация голосового браузера, использующего блок разрешения голосового браузера для обеспечения многорежимного диалога согласно настоящему изобретению. В данном примере сервер 18 приложений, веб-сервер 20, интернет-соединение 16 и размеченный документ 22 являются такими же, как описано выше, но представлены более подробно для лучшего объяснения настоящего изобретения, причем функциональность голосового браузера отделена. Например, размеченный документ 22 также включает в себя URL, указывающие путь к речевым грамматикам и аудиофайлам. К тому же, речевые механизмы 36 являются такими же, как описано выше, но имеют больше компонентов. Например, речевые механизмы 36 включают в себя блок 40 речевого распознавания для использования с речевыми грамматиками, предоставленными сервером приложений, и медиасервер 42, который может обеспечить аудиоприглашение через аудиоURL или может использовать преобразование текст-в-речь (TTS), как известно в данной области техники.
Один элемент новизны настоящего изобретения заключается в том, что настоящее изобретение делит голосовой браузер на "небольшую часть" 44 голосового браузера на устройстве связи и на "реализацию" 46 голосового браузера на удаленном голосовом сервере 38. В предпочтительном варианте осуществления небольшая часть 44 голосового браузера является разделенной на драйвер 43 голосового браузера, который связан с реализацией 46 голосового браузера и синхронизатором 47, который управляет небольшой частью 44 голосового браузера и визуальным браузером 26. Синхронизатор 47 также не обязательно разрешает или запрещает ввод данных в визуальный браузер 27, основываясь на том, подается ли речевая информация пользователя на кодек 28 или нет (синхронизация ввода данных). Это разделение небольшой части голосового браузера позволяет автономным приложениям выполняться на клиентском устройстве (например, приложения J2ME) быть использованным вместо визуального браузера 27 и/или синхронизатора 47 и к тому же многократно использовать возможности остальной части небольшой части 44 голосового браузера.
Другой элемент новизны настоящего изобретения заключается в том, что визуальный браузер 27 теперь действует на полном размеченном документе, голосовом и аудио, что устраняет необходимость в удаленной синхронизации. В результате синхронизатор 47 может быть реализован значительно меньшим по размеру и более простым, чем менеджер синхронизации предшествующего уровня техники (показанный, как 30 на предыдущих чертежах). Более того, голосовой браузер 43, 46 не использует поля ввода данных и значения, как в предшествующем уровне техники. Вместо этого голосовой браузер работает с выделенными полями. Это помогает упростить реализацию 46 голосового браузера, как будет описано ниже.
На практике, после того как многорежимный размеченный документ 22 доставляется с веб-сервера 20, визуальный браузер посылает его копию на небольшую часть голосового браузера. Визуальный браузер посылает его копию на небольшую часть голосового браузера. Небольшая часть 44 голосового браузера делит или удаляет разметку голосового браузера (например, VoiceXML) из документа, результатом чего является отображаемая разметка (например, XHTML) и разметка голосового браузера (например, VoiceXML). Далее небольшая часть 44 голосового браузера посылает визуальную разметку на визуальный браузер для обработки и отображения на клиентском устройстве, как описано выше. Однако драйвер 43 голосового браузера небольшой части 44 голосового браузера действует на разметке голосового браузера не так, как он действовал в предшествующем уровне техники. В настоящем изобретении драйвер голосового браузера действует на фрагментах размеченного документа. Фрагмент представляет собой одиночную форму VoiceXML (не путать с формой XHTML; хотя она и похожа на форму XHTML, между ними нет взаимно однозначного соответствия) и может рассматриваться, как независимая часть большего документа XHTML+VoiceXML. Форма является только блоком диалога в VoiceXML, чья задача заключается в том, чтобы выдать приглашение пользователю, и обычно занимает одно или несколько полей в данной форме. Одиночное поле ввода данных в форме XHTML может иметь одиночную форму VoiceXML или фрагмент, связанный с ней. Также возможно, если набор тесно связанных форм XHTML ввода данных имеет одну форму VoiceXML, способную заполнять все формы XHTML ввода данных. Драйвер голосового браузера действует на одном выделенном поле или фрагменте размеченного документа за один раз в отличие от голосового браузера предшествующего уровня техники, который работает на целом документе форм и значений.
Кроме того, драйвер голосового браузера использует меньшее количество видов обработки, чем голосовой браузер предшествующего уровня техники, поскольку генерировать формы/фрагменты VoiceXML из документа XHTML+VoiceXML не так сложно, поскольку эти формы/фрагменты уже собраны вместе в разделе заголовка документа. Все что необходимо драйверу голосового браузера сделать, это найти фрагмента/формы, связать с ними однозначные идентификаторы (как будет описано ниже) и инициировать небольшую часть голосового браузера для их упаковки для передачи к реализации голосового браузера. Идентификатор является всего лишь строкой, которая однозначно идентифицирует одиночную форму VoiceXML (где однозначность требуется только в области действия набора фрагментов, передаваемых в реализацию голосового браузера, которые сгенерированы из одиночного многорежимного размеченного документа). Использование фрагментов и идентификаторов понижает объем передачи данных между клиентским устройством 10 и удаленным сервером 38 через сеть 12.
В частности, для выделенного поля существует связанный фрагмент. Следует отметить, что драйвер голосового браузера может управлять одним из двух полей XHTML или VoiceXML. Например, форма XHTML может запросить у пользователя адрес места жительства. В этом случае присутствует текстовое поле для адреса места жительства (номер и улица), другое текстовое поле (необязательно) для номера комнаты, другое текстовое поле для города, всплывающее меню для штата и последнее текстовое поле для почтового индекса. Теперь, с данной XHTML формой может существовать комплект форм VoiceXML, которые работают совместно для заполнения данных полей. Например, одна форма VoiceXML может быть реализована с возможностью заполнения и поля уличного адреса и поля номера комнаты, а другая форма VoiceXML может быть использована для заполнения полей города и штатов и третья форма VoiceXML может заполнять только почтовый индекс. Эти формы определены как фрагменты страницы.
Каждая из этих трех форм VoiceXML может иметь свои собственные уникальные идентификаторы (например, названия форм VoiceXML). Например, эти идентификаторы могут быть названы "улица+комната", "город+штат" и "почтовый индекс" соответственно. Форма "улица+комната" VoiceXML может включать в себя аудиоприглашение, в результате чего пользователь услышит "скажите уличный адрес и номер комнаты" при активации. Здесь также присутствует разрешенная грамматика, которая понимает уличный адрес и необязательно номер комнаты. Форма "город+штат" VoiceXML может включать в себя аудиоприглашение, такое как "скажите название города и штат", и соответствующую для этого грамматику. То же имеет место и для почтового индекса.
Небольшая часть голосового браузера посылает страницу связанных фрагментов 45 VoiceXML в реализацию 46 голосового браузера. Затем, когда небольшой части 44 голосового браузера необходимо прослушивание пользовательских введенных данных, она посылает запрос 48 распознавания к реализации 46 голосового браузера, сообщая имя или идентификатор формы для использования при распознавании. Как описано выше, голосовой сервер 38 содержит речевые грамматики, но в данном варианте осуществления посылаются идентификаторы, которые кодируют реализацию голосового браузера только для просмотра в грамматиках "улица+комната", "город+штат" и "почтовый индекс" для нахождения соответствия с ранее посланными голосовыми фрагментами. Формы VoiceXML могут быть переданы один раз на сервер 38, обработаны и затем занесены в кэш. Последующие запросы могут идентифицировать формы VoiceXML, занесенные в кэш, с помощью их идентификатора. Это устраняет необходимость передачи и обработки разметки VoiceXML при каждом запросе. В результате грамматический поиск упрощается, при этом экономятся вычислительная мощность и время. Когда идентификатор для формы/фрагмента для поля улицы плюс комнаты документа отправляют к реализации голосового браузера, как запрос 48 распознавания, реализация голосового браузера может ввести речевые данные и голосовой браузер 46 может активизировать распознаватель 40 речи с соответствующими грамматиками для поиска соответствия, такого как, например, соответствие с речевыми данными "Main Street". Как только соответствие найдено, реализация голосового браузера передает то, что сказал пользователь в виде текста ("M-a-I-n-s-t-r-e-e-t") драйверу 43 голосового браузера в виде результата 49 распознавания, который аналогичен предшествующему уровню техники. Далее, небольшая часть 44 голосового браузера получает результат и обновляет визуальный браузер 27 для отображения результата. Хотя реализация 46 голосового браузера может быть такой же, как голосовой браузер предшествующего уровня техники с интерфейсом для небольшой части 44 голосового браузера, настоящее изобретение обеспечивает более простую реализацию, поскольку теперь голосовой браузер только обрабатывает небольшие фрагменты простой разметки VoiceXML, для того чтобы не использовать большое количество тегов и параметров в языке VoiceXML.
На практике небольшая часть 44 голосового браузера может посылать к реализации 46 голосового браузера связанные фрагменты 45 для всех полей страницы одновременно. Затем, небольшая часть 44 голосового браузера координирует голосовую часть многорежимного взаимодействия для любого выделенного поля и посылает по мере необходимости идентификаторы 48 запроса распознавания речи в реализацию 46 голосового браузера и получает результаты 49 распознавания в ответном сигнале для данного фрагмента. Является желательным сделать запрос 48 распознавания и результат 49 распознавания основанными на разметке (например, XML), а не использовать низкоуровневый API, такой как MRCP, как используется в предшествующем уровне техники.
Фиг.5 в сочетании с Фиг.4 может быть использована для объяснения взаимодействия многорежимного диалога согласно настоящему изобретению. На Фиг.5 представлено упрощенное взаимодействие между двумя текстовыми полями в размеченном документе, причем одно заполняется через голос (А), а другое заполняется непосредственно как текст (Б). Необходимо понимать, что в многорежимном диалоге может быть использовано множество голосовых полей и текстовых полей. Пользователь инициирует диалог, например, кликая по Интернет адресу. Это инициирует визуальный браузер для отправки HTTP GET/POST запроса 50 на веб-сервер 20 приложений для получения 51 желаемого размеченного документа 22. Документ также содержит URL соответствующих грамматик для документа, которые могут быть загружены на голосовой сервер 38. После получения визуальный браузер 27 запускает и выводит 52 документ на экран клиентского устройства 10. Затем аудио- и визуальный документ передается на небольшую часть 44 голосового браузера, который выделяет голосовые (VoiceXML) разметки из документа. Небольшая часть голосового браузера также идентифицирует формы (фрагменты) VoiceXML разметки и посылает эти фрагменты на голосовой сервер 38. На этой стадии реализация 46 голосового браузера и речевые механизмы 36 голосового сервера 38 необязательно могут выполнять фоновую проверку, является ли документ правильно оформленным или нет, и могут также выполнять предварительную обработку (то есть компиляцию) документа, извлекать/предварительно обрабатывать (то есть компилировать, декодировать/кодировать) внешние речевые грамматики или аудиоприглашения на которые может ссылаться документ, и выполнять синтез текста в речь.
Затем пользователь выделяет поле показанного размеченного документа, определяющего фокус 53. Визуальный браузер 27 получает фокусное изменение, выполняя переход непосредственно к выделенному полю, и передает выделенное поле в небольшую часть 44 голосового браузера. Затем драйвер 43 голосового браузера небольшой части 44 голосового браузера посылает 54 идентификаторы для данного выделенного поля формы, как запрос 48 распознавания голосового сервера 38, который подтверждает прием 55 запроса. На данном этапе голосовой сервер 38 может необязательно пригласить пользователя для ввода речевых данных, посылая 56, одно или более аудиоприглашений пользователю, в виде аудиопакетов 57 транспортного протокола реального времени (RTP). Аудиоданные направляют в спикер 41 аудиоресурса клиентского устройства. Затем пользователь может дать голосовой ответ, нажав кнопку "нажал-и-говори" (РТТ) и посылая речь 58 через кодек 28 аудиоресурса клиентского устройства в голосовой сервер 38. Кодек направляет речь в виде RTP DSR пакетов 59 в речевой механизм голосового сервера, который сопоставляет речь с подходящей грамматикой согласно соответствующему идентификатору для данной формы и поля, и посылает текстовый ответ, представляющий собой результат распознавания в драйвер 43 небольшой части 44 голосового браузера. Небольшая часть голосового браузера взаимодействует с визуальным браузером 27, обновляя экран дисплея устройства и отображая поля и значения.
Пользователь также может выбрать поле отображаемого размеченного документа, определяя фокус 61 для ввода текста. Как и прежде, визуальный браузер 27 принимает изменение фокуса, выполняет переход к полю, получившему фокус, и передает фокус поля небольшой части 44 голосового браузера. Затем драйвер 43 небольшой части 44 голосового браузера выполняет форму 63 для данного поля, получившего фокус, для запроса 48 на распознавание голосового сервера 44, который подтверждает 64 запрос. Исходя из того, что в настоящем описании используется аудиоприглашение (хотя оно может быть использовано, как описано выше), затем пользователь может ответить вводом 65 текста, который непосредственно обновляет карту полей и значений. После передачи данных формы (которые содержатся в карте полей и значений) в веб-сервер 20 визуальный браузер также посылает команду 67 отмены через небольшую часть 44 голосового браузера в голосовой сервер в направлении голосового сервера для остановки прослушивания грамматики. Затем процесс диалога может повториться самостоятельно.
Настоящее изобретение предлагает решение обеспечения многорежимного диалога с ограниченными ресурсами. Настоящее изобретение может применяться для поддержки синхронизированной многорежимной связи. Способ предоставляет процесс, который делит требования обработки для голосового браузера с использованием минимальных требований к процессору и памяти на устройстве связи. Это сопровождается только незначительной модификацией программных средств, причем отсутствует необходимость во внешней синхронизации или специализированном многорежимном сервере.
Хотя настоящее изобретение описано и проиллюстрировано приведенным выше описанием и чертежами, необходимо понять, что данное описание представлено только в виде примера и что специалистами в данной области техники могут быть сделаны многочисленные изменения и модификации без отступления от объема настоящего изобретения. Хотя настоящее изобретение нашло конкретное применение в портативных сотовых телефонах, настоящее изобретение может быть использовано в многорежимном диалоге в любом устройстве связи, включая пейджеры, электронные органайзеры и компьютеры. Приложение изобретения должно быть ограничено только нижеследующей формулой изобретения.



Изобретение относится к управлению режимом работы устройства радиосвязи, более конкретно к способу работы многорежимного устройства радиосвязи в различных системах. Блок разрешения диалога голосового браузера многорежимного диалога использует многорежимный размеченный документ с полями, имеющими основанные на разметке формы, связанные с каждым полем и определяющие фрагменты. Драйвер голосового браузера является резидентным в устройстве связи и предоставляет фрагменты и идентификаторы, которые идентифицируют фрагменты. Реализация голосового браузера является резидентной в удаленном голосовом сервере, и получает фрагменты из драйвера, и загружает множество речевых грамматик. Введенная речь сопоставляется с этими речевыми грамматиками, связанными с соответствующими идентификаторами, полученными в запросе распознавания речи из драйвера голосового браузера. Технический результат - обеспечение многорежимного диалога устройств с ограниченными ресурсами при незначительной модификации программных средств и при отсутствии необходимости во внешней синхронизации. 2 н. и 8 з.п ф-лы, 5 ил.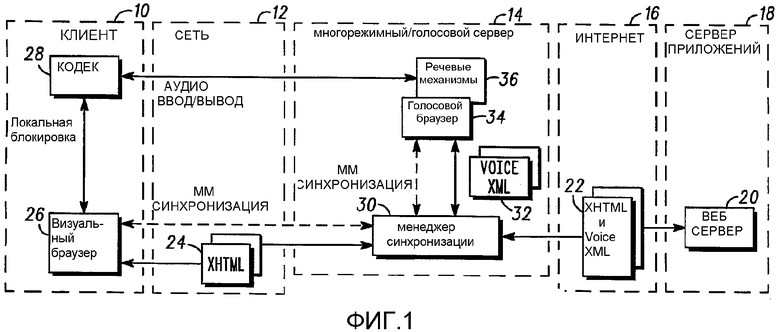
приложение распознавания речи, содержащее множество блоков взаимодействия приложений, причем каждый блок имеет связанные формы голосового диалога, определяющие фрагменты;
драйвер голосового браузера, причем драйвер голосового браузера является резидентным в устройстве связи; при этом драйвер голосового браузера предоставляет фрагменты из приложения и генерирует идентификаторы, которые идентифицируют фрагменты; и
реализацию голосового браузера, резидентную на удаленном голосовом сервере, причем реализация голосового браузера принимает фрагменты из драйвера голосового браузера и загружает множество речевых грамматик, при этом последующая введенная речь сопоставляется с этими речевыми грамматиками, связанными с соответствующими идентификаторами, полученными в запросе распознавания речи из драйвера голосового браузера.
обеспечивают драйвер голосового браузера, резидентный в устройстве связи, и реализацию голосового браузера, содержащую множество речевых грамматик, резидентную в удаленном голосовом сервере;
выполняют приложение распознавания речи, содержащее множество блоков взаимодействия приложений, причем каждый блок имеет связанные формы голосового диалога, определяющие фрагменты;
определяют идентификаторы, связанные с каждым фрагментом; предоставляют фрагменты в реализации голосового браузера;
выполняют фокусирование на поле в одном из блоков взаимодействия приложений;
посылают запрос распознавания речи, включающий в себя идентификатор формы, связанной со сфокусированным полем, из драйвера голосового браузера в реализацию голосового браузера;
вводят и распознают речь;
сопоставляют речь с подходящей речевой грамматикой, связанной с идентификатором; и
получают результаты распознавания речи.
| US 6400806 В1, 04.06.2002 | |||
| СЕТЬ, ОБЕСПЕЧИВАЮЩАЯ ВОЗМОЖНОСТИ ИСПОЛЬЗОВАНИЯ МНОЖЕСТВА ВИДОВ СРЕДСТВ ПЕРЕДАЧИ ИНФОРМАЦИИ | 1994 |
|
RU2127960C1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Устройство для автоматическогоРЕгулиРОВАНия НАгРузКи пАРАллЕльНОРАбОТАющиХ дВигАТЕлЕй | 1975 |
|
SU829995A1 |

